Copyright 1997-2007 MySQL AB
This documentation is NOT distributed under a GPL license. Use of this documentation is subject to the following terms: You may create a printed copy of this documentation solely for your own personal use. Conversion to other formats is allowed as long as the actual content is not altered or edited in any way. You shall not publish or distribute this documentation in any form or on any media, except if you distribute the documentation in a manner similar to how MySQL disseminates it (that is, electronically for download on a Web site with the software) or on a CD-ROM or similar medium, provided however that the documentation is disseminated together with the software on the same medium. Any other use, such as any dissemination of printed copies or use of this documentation, in whole or in part, in another publication, requires the prior written consent from an authorized representative of MySQL AB. MySQL AB reserves any and all rights to this documentation not expressly granted above.
Please email <docs@mysql.com> for more information.
Abstract
This is the MySQL Reference Manual. It documents MySQL 5.0 through 5.0.42.
This manual is for MySQL Enterprise Server, our commercial offering, and for MySQL Community Server. Sections that do not apply for MySQL Enterprise Server users are marked:
This section does not apply to MySQL Enterprise Server users.
Sections that do not apply to MySQL Community Server users are marked:
This section does not apply to MySQL Community Server users.
Document generated on: 2007-06-12 (revision: 6767)
Table of Contents
- Preface
- 1. General Information
- 1.1. About This Manual
- 1.2. Conventions Used in This Manual
- 1.3. Overview of MySQL AB
- 1.4. Overview of the MySQL Database Management System
- 1.5. Overview of the MaxDB Database Management System
- 1.6. MySQL Development Roadmap
- 1.7. MySQL Information Sources
- 1.8. How to Report Bugs or Problems
- 1.9. MySQL Standards Compliance
- 2. Installing and Upgrading MySQL
- 2.1. MySQL Installation Overview
- 2.2. Determining your current MySQL version
- 2.3. Installing MySQL Enterprise
- 2.4. Installing MySQL Community Server
- 2.4.1. Overview of MySQL Community Server Installation
- 2.4.2. Operating Systems Supported by MySQL Community Server
- 2.4.3. Choosing Which MySQL Distribution to Install
- 2.4.4. How to Get MySQL
- 2.4.5. Verifying Package Integrity Using MD5 Checksums or
GnuPG - 2.4.6. Installation Layouts
- 2.4.7. Standard MySQL Installation Using a Binary Distribution
- 2.4.8. Installing MySQL on Windows
- 2.4.9. Installing MySQL from RPM Packages on Linux
- 2.4.10. Installing MySQL on Mac OS X
- 2.4.11. Installing MySQL on Solaris
- 2.4.12. Installing MySQL on NetWare
- 2.4.13. Installing MySQL from
tar.gzPackages on Other Unix-Like Systems - 2.4.14. MySQL Installation Using a Source Distribution
- 2.4.15. Post-Installation Setup and Testing
- 2.4.16. Upgrading MySQL
- 2.4.17. Downgrading MySQL
- 2.4.18. Operating System-Specific Notes
- 2.4.19. Environment Variables
- 2.4.20. Perl Installation Notes
- 3. Tutorial
- 3.1. Connecting to and Disconnecting from the Server
- 3.2. Entering Queries
- 3.3. Creating and Using a Database
- 3.4. Getting Information About Databases and Tables
- 3.5. Using mysql in Batch Mode
- 3.6. Examples of Common Queries
- 3.6.1. The Maximum Value for a Column
- 3.6.2. The Row Holding the Maximum of a Certain Column
- 3.6.3. Maximum of Column per Group
- 3.6.4. The Rows Holding the Group-wise Maximum of a Certain Field
- 3.6.5. Using User-Defined Variables
- 3.6.6. Using Foreign Keys
- 3.6.7. Searching on Two Keys
- 3.6.8. Calculating Visits Per Day
- 3.6.9. Using
AUTO_INCREMENT
- 3.7. Queries from the Twin Project
- 3.8. Using MySQL with Apache
- 4. Using MySQL Programs
- 5. Database Administration
- 5.1. Overview of Server-Side Programs
- 5.2. mysqld — The MySQL Server
- 5.3. MySQL Server Startup Programs
- 5.4. mysqlmanager — The MySQL Instance Manager
- 5.4.1. MySQL Instance Manager Command Options
- 5.4.2. MySQL Instance Manager Configuration Files
- 5.4.3. Starting the MySQL Server with MySQL Instance Manager
- 5.4.4. Instance Manager User and Password Management
- 5.4.5. MySQL Server Instance Status Monitoring
- 5.4.6. Connecting to MySQL Instance Manager
- 5.4.7. MySQL Instance Manager Commands
- 5.5. Installation-Related Programs
- 5.5.1. comp_err — Compile MySQL Error Message File
- 5.5.2. make_win_bin_dist — Package MySQL Distribution as ZIP Archive
- 5.5.3. make_win_src_distribution — Create Source Distribution for Windows
- 5.5.4. mysql_fix_privilege_tables — Upgrade MySQL System Tables
- 5.5.5. mysql_install_db — MySQL Data Directory Initialization Script
- 5.5.6. mysql_secure_installation — Improve MySQL Installation Security
- 5.5.7. mysql_tzinfo_to_sql — Load the Time Zone Tables
- 5.5.8. mysql_upgrade — Check Tables for MySQL Upgrade
- 5.6. General Security Issues
- 5.7. The MySQL Access Privilege System
- 5.7.1. What the Privilege System Does
- 5.7.2. How the Privilege System Works
- 5.7.3. Privileges Provided by MySQL
- 5.7.4. Connecting to the MySQL Server
- 5.7.5. Access Control, Stage 1: Connection Verification
- 5.7.6. Access Control, Stage 2: Request Verification
- 5.7.7. When Privilege Changes Take Effect
- 5.7.8. Causes of
Access deniedErrors - 5.7.9. Password Hashing as of MySQL 4.1
- 5.8. MySQL User Account Management
- 5.9. Backup and Recovery
- 5.10. MySQL Localization and International Usage
- 5.10.1. The Character Set Used for Data and Sorting
- 5.10.2. Setting the Error Message Language
- 5.10.3. Adding a New Character Set
- 5.10.4. The Character Definition Arrays
- 5.10.5. String Collating Support
- 5.10.6. Multi-Byte Character Support
- 5.10.7. Problems With Character Sets
- 5.10.8. MySQL Server Time Zone Support
- 5.10.9. MySQL Server Locale Support
- 5.11. MySQL Server Logs
- 5.12. Running Multiple MySQL Servers on the Same Machine
- 5.13. The MySQL Query Cache
- 6. Replication
- 6.1. Introduction to Replication
- 6.2. Replication Implementation Overview
- 6.3. Replication Implementation Details
- 6.4. How to Set Up Replication
- 6.5. Replication Compatibility Between MySQL Versions
- 6.6. Upgrading a Replication Setup
- 6.7. Replication Features and Known Problems
- 6.8. Replication Startup Options
- 6.9. How Servers Evaluate Replication Rules
- 6.10. Replication FAQ
- 6.11. Troubleshooting Replication
- 6.12. How to Report Replication Bugs or Problems
- 6.13. Auto-Increment in Multiple-Master Replication
- 7. Optimization
- 7.1. Optimization Overview
- 7.2. Optimizing
SELECTand Other Statements - 7.2.1. Optimizing Queries with
EXPLAIN - 7.2.2. Estimating Query Performance
- 7.2.3. Speed of
SELECTQueries - 7.2.4.
WHEREClause Optimization - 7.2.5. Range Optimization
- 7.2.6. Index Merge Optimization
- 7.2.7.
IS NULLOptimization - 7.2.8.
LEFT JOINandRIGHT JOINOptimization - 7.2.9. Nested Join Optimization
- 7.2.10. Outer Join Simplification
- 7.2.11.
ORDER BYOptimization - 7.2.12.
GROUP BYOptimization - 7.2.13.
DISTINCTOptimization - 7.2.14. Optimizing
IN/=ANYSubqueries - 7.2.15.
LIMITOptimization - 7.2.16. How to Avoid Table Scans
- 7.2.17. Speed of
INSERTStatements - 7.2.18. Speed of
UPDATEStatements - 7.2.19. Speed of
DELETEStatements - 7.2.20. Other Optimization Tips
- 7.2.1. Optimizing Queries with
- 7.3. Locking Issues
- 7.4. Optimizing Database Structure
- 7.4.1. Design Choices
- 7.4.2. Make Your Data as Small as Possible
- 7.4.3. Column Indexes
- 7.4.4. Multiple-Column Indexes
- 7.4.5. How MySQL Uses Indexes
- 7.4.6. The
MyISAMKey Cache - 7.4.7.
MyISAMIndex Statistics Collection - 7.4.8. How MySQL Opens and Closes Tables
- 7.4.9. Drawbacks to Creating Many Tables in the Same Database
- 7.5. Optimizing the MySQL Server
- 7.6. Disk Issues
- 8. Client and Utility Programs
- 8.1. Overview of Client and Utility Programs
- 8.2. innochecksum — Offline InnoDB File Checksum Utility
- 8.3. my_print_defaults — Display Options from Option Files
- 8.4. myisam_ftdump — Display Full-Text Index information
- 8.5. myisamchk — MyISAM Table-Maintenance Utility
- 8.6. myisamlog — Display MyISAM Log File Contents
- 8.7. myisampack — Generate Compressed, Read-Only MyISAM Tables
- 8.8. mysql — The MySQL Command-Line Tool
- 8.9. mysqlaccess — Client for Checking Access Privileges
- 8.10. mysqladmin — Client for Administering a MySQL Server
- 8.11. mysqlbinlog — Utility for Processing Binary Log Files
- 8.12. mysqlcheck — A Table Maintenance and Repair Program
- 8.13. mysqldump — A Database Backup Program
- 8.14. mysqlhotcopy — A Database Backup Program
- 8.15. mysqlimport — A Data Import Program
- 8.16. mysqlmanagerc — Internal Test-Suite Program
- 8.17. mysqlmanager-pwgen — Internal Test-Suite Program
- 8.18. mysqlshow — Display Database, Table, and Column Information
- 8.19. mysql_convert_table_format — Convert Tables to Use a Given Storage Engine
- 8.20. mysql_explain_log — Use EXPLAIN on Statements in Query Log
- 8.21. mysql_find_rows — Extract Queries from Update Log
- 8.22. mysql_fix_extensions — Make Table Filename Extensions Lowercase
- 8.23. mysql_setpermission — Interactively Set Permissions in Grant Tables
- 8.24. mysql_tableinfo — Generate Database Metadata
- 8.25. mysql_waitpid — Kill Process and Wait for Its Termination
- 8.26. mysql_zap — Kill Processes That Match a Pattern
- 8.27. perror — Explain Error Codes
- 8.28. replace — A String-Replacement Utility
- 8.29. resolveip — Resolve Hostname to IP Address or Vice Versa
- 8.30. resolve_stack_dump — Resolve Numeric Stack Trace Dump to Symbols
- 9. Language Structure
- 10. Character Set Support
- 10.1. Character Sets and Collations in General
- 10.2. Character Sets and Collations in MySQL
- 10.3. Specifying Character Sets and Collations
- 10.3.1. Server Character Set and Collation
- 10.3.2. Database Character Set and Collation
- 10.3.3. Table Character Set and Collation
- 10.3.4. Column Character Set and Collation
- 10.3.5. Character String Literal Character Set and Collation
- 10.3.6. National Character Set
- 10.3.7. Examples of Character Set and Collation Assignment
- 10.3.8. Compatibility with Other DBMSs
- 10.4. Connection Character Sets and Collations
- 10.5. Collation Issues
- 10.6. Operations Affected by Character Set Support
- 10.7. Unicode Support
- 10.8. UTF-8 for Metadata
- 10.9. Column Character Set Conversion
- 10.10. Character Sets and Collations That MySQL Supports
- 11. Data Types
- 12. Functions and Operators
- 12.1. Operator and Function Reference
- 12.2. Operators
- 12.3. Control Flow Functions
- 12.4. String Functions
- 12.5. Numeric Functions
- 12.6. Date and Time Functions
- 12.7. What Calendar Is Used By MySQL?
- 12.8. Full-Text Search Functions
- 12.9. Cast Functions and Operators
- 12.10. Other Functions
- 12.11. Functions and Modifiers for Use with
GROUP BYClauses
- 13. SQL Statement Syntax
- 14. Storage Engines
- 14.1. The
MyISAMStorage Engine - 14.2. The
InnoDBStorage Engine - 14.2.1.
InnoDBOverview - 14.2.2.
InnoDBContact Information - 14.2.3.
InnoDBConfiguration - 14.2.4.
InnoDBStartup Options and System Variables - 14.2.5. Creating the
InnoDBTablespace - 14.2.6. Creating and Using
InnoDBTables - 14.2.7. Adding and Removing
InnoDBData and Log Files - 14.2.8. Backing Up and Recovering an
InnoDBDatabase - 14.2.9. Moving an
InnoDBDatabase to Another Machine - 14.2.10.
InnoDBTransaction Model and Locking - 14.2.11.
InnoDBPerformance Tuning Tips - 14.2.12. Implementation of Multi-Versioning
- 14.2.13.
InnoDBTable and Index Structures - 14.2.14.
InnoDBFile Space Management and Disk I/O - 14.2.15.
InnoDBError Handling - 14.2.16. Restrictions on
InnoDBTables - 14.2.17.
InnoDBTroubleshooting
- 14.2.1.
- 14.3. The
MERGEStorage Engine - 14.4. The
MEMORY(HEAP) Storage Engine - 14.5. The
BDB(BerkeleyDB) Storage Engine - 14.6. The
EXAMPLEStorage Engine - 14.7. The
FEDERATEDStorage Engine - 14.8. The
ARCHIVEStorage Engine - 14.9. The
CSVStorage Engine - 14.10. The
BLACKHOLEStorage Engine
- 14.1. The
- 15. MySQL Cluster
- 15.1. MySQL Cluster Overview
- 15.2. Basic MySQL Cluster Concepts
- 15.3. Simple Multi-Computer How-To
- 15.4. MySQL Cluster Configuration
- 15.5. Upgrading and Downgrading MySQL Cluster
- 15.6. Process Management in MySQL Cluster
- 15.7. Management of MySQL Cluster
- 15.8. On-line Backup of MySQL Cluster
- 15.9. Cluster Utility Programs
- 15.9.1. ndb_config — Extract NDB Configuration Information
- 15.9.2. ndb_cpcd — Automate Testing for NDB Development
- 15.9.3. ndb_delete_all — Delete All Rows from NDB Table
- 15.9.4. ndb_desc — Describe NDB Tables
- 15.9.5. ndb_drop_index — Drop Index from NDB Table
- 15.9.6. ndb_drop_table — Drop NDB Table
- 15.9.7. ndb_error_reporter — NDB Error-Reporting Utility
- 15.9.8. ndb_print_backup_file — Print NDB Backup File Contents
- 15.9.9. ndb_print_schema_file — Print NDB Schema File Contents
- 15.9.10. ndb_print_sys_file — Print NDB System File Contents
- 15.9.11. ndb_select_all — Print Rows from NDB Table
- 15.9.12. ndb_select_count — Print Row Counts for NDB Tables
- 15.9.13. ndb_show_tables — Display List of NDB Tables
- 15.9.14. ndb_size.pl — NDBCluster Size Requirement Estimator
- 15.9.15. ndb_waiter — Wait for Cluster to Reach a Given Status
- 15.10. Using High-Speed Interconnects with MySQL Cluster
- 15.11. Known Limitations of MySQL Cluster
- 15.11.1. Non-Compliance In SQL Syntax
- 15.11.2. Limits and Differences from Standard MySQL Limits
- 15.11.3. Limits Relating to Transaction Handling
- 15.11.4. Error Handling
- 15.11.5. Limits Associated with Database Objects
- 15.11.6. Unsupported Or Missing Features
- 15.11.7. Limitations Relating to Performance
- 15.11.8. Issues Exclusive to MySQL Cluster
- 15.11.9. Limitations Relating to Multiple Cluster Nodes
- 15.11.10. Previous MySQL Cluster Issues Resolved in MySQL 5.1
- 15.12. MySQL Cluster Development Roadmap
- 15.13. MySQL Cluster Glossary
- 16. Spatial Extensions
- 16.1. Introduction to MySQL Spatial Support
- 16.2. The OpenGIS Geometry Model
- 16.2.1. The Geometry Class Hierarchy
- 16.2.2. Class
Geometry - 16.2.3. Class
Point - 16.2.4. Class
Curve - 16.2.5. Class
LineString - 16.2.6. Class
Surface - 16.2.7. Class
Polygon - 16.2.8. Class
GeometryCollection - 16.2.9. Class
MultiPoint - 16.2.10. Class
MultiCurve - 16.2.11. Class
MultiLineString - 16.2.12. Class
MultiSurface - 16.2.13. Class
MultiPolygon
- 16.3. Supported Spatial Data Formats
- 16.4. Creating a Spatially Enabled MySQL Database
- 16.5. Analyzing Spatial Information
- 16.5.1. Geometry Format Conversion Functions
- 16.5.2.
GeometryFunctions - 16.5.3. Functions That Create New Geometries from Existing Ones
- 16.5.4. Functions for Testing Spatial Relations Between Geometric Objects
- 16.5.5. Relations on Geometry Minimal Bounding Rectangles (MBRs)
- 16.5.6. Functions That Test Spatial Relationships Between Geometries
- 16.6. Optimizing Spatial Analysis
- 16.7. MySQL Conformance and Compatibility
- 17. Stored Procedures and Functions
- 17.1. Stored Routines and the Grant Tables
- 17.2. Stored Routine Syntax
- 17.2.1.
CREATE PROCEDUREandCREATE FUNCTIONSyntax - 17.2.2.
ALTER PROCEDUREandALTER FUNCTIONSyntax - 17.2.3.
DROP PROCEDUREandDROP FUNCTIONSyntax - 17.2.4.
CALLStatement Syntax - 17.2.5.
BEGIN ... ENDCompound Statement Syntax - 17.2.6.
DECLAREStatement Syntax - 17.2.7. Variables in Stored Routines
- 17.2.8. Conditions and Handlers
- 17.2.9. Cursors
- 17.2.10. Flow Control Constructs
- 17.2.1.
- 17.3. Stored Procedures, Functions, Triggers, and
LAST_INSERT_ID() - 17.4. Binary Logging of Stored Routines and Triggers
- 18. Triggers
- 19. Views
- 20. The
INFORMATION_SCHEMADatabase - 20.1. The
INFORMATION_SCHEMA SCHEMATATable - 20.2. The
INFORMATION_SCHEMA TABLESTable - 20.3. The
INFORMATION_SCHEMA COLUMNSTable - 20.4. The
INFORMATION_SCHEMA STATISTICSTable - 20.5. The
INFORMATION_SCHEMA USER_PRIVILEGESTable - 20.6. The
INFORMATION_SCHEMA SCHEMA_PRIVILEGESTable - 20.7. The
INFORMATION_SCHEMA TABLE_PRIVILEGESTable - 20.8. The
INFORMATION_SCHEMA COLUMN_PRIVILEGESTable - 20.9. The
INFORMATION_SCHEMA CHARACTER_SETSTable - 20.10. The
INFORMATION_SCHEMA COLLATIONSTable - 20.11. The
INFORMATION_SCHEMA COLLATION_CHARACTER_SET_APPLICABILITYTable - 20.12. The
INFORMATION_SCHEMA TABLE_CONSTRAINTSTable - 20.13. The
INFORMATION_SCHEMA KEY_COLUMN_USAGETable - 20.14. The
INFORMATION_SCHEMA ROUTINESTable - 20.15. The
INFORMATION_SCHEMA VIEWSTable - 20.16. The
INFORMATION_SCHEMA TRIGGERSTable - 20.17. The
INFORMATION_SCHEMA PROFILINGTable - 20.18. Other
INFORMATION_SCHEMATables - 20.19. Extensions to
SHOWStatements
- 20.1. The
- 21. Precision Math
- 22. APIs and Libraries
- 22.1. libmysqld, the Embedded MySQL Server Library
- 22.2. MySQL C API
- 22.2.1. C API Data types
- 22.2.2. C API Function Overview
- 22.2.3. C API Function Descriptions
- 22.2.4. C API Prepared Statements
- 22.2.5. C API Prepared Statement Data types
- 22.2.6. C API Prepared Statement Function Overview
- 22.2.7. C API Prepared Statement Function Descriptions
- 22.2.8. C API Prepared statement problems
- 22.2.9. C API Handling of Multiple Statement Execution
- 22.2.10. C API Handling of Date and Time Values
- 22.2.11. C API Threaded Function Descriptions
- 22.2.12. C API Embedded Server Function Descriptions
- 22.2.13. Controlling Automatic Reconnect Behavior
- 22.2.14. Common Questions and Problems When Using the C API
- 22.2.15. Building Client Programs
- 22.2.16. How to Make a Threaded Client
- 22.3. MySQL PHP API
- 22.4. MySQL Perl API
- 22.5. MySQL C++ API
- 22.6. MySQL Python API
- 22.7. MySQL Tcl API
- 22.8. MySQL Eiffel Wrapper
- 22.9. MySQL Program Development Utilities
- 23. Connectors
- 24. Extending MySQL
- A. MySQL 5.0 Frequently Asked Questions
- A.1. MySQL 5.0 FAQ — General
- A.2. MySQL 5.0 FAQ — Storage Engines
- A.3. MySQL 5.0 FAQ — Server SQL Mode
- A.4. MySQL 5.0 FAQ — Stored Procedures
- A.5. MySQL 5.0 FAQ — Triggers
- A.6. MySQL 5.0 FAQ — Views
- A.7. MySQL 5.0 FAQ —
INFORMATION_SCHEMA - A.8. MySQL 5.0 FAQ — Migration
- A.9. MySQL 5.0 FAQ — Security
- A.10. MySQL 5.0 FAQ — MySQL Cluster
- A.11. MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- A.12. MySQL 5.0 FAQ — Connectors & APIs
- A.13. MySQL 5.0 FAQ — Replication
- A.14. MySQL 5.0 FAQ — MySQL, DRBD, and Heartbeat
- A.14.1. Distributed Replicated Block Device
- A.14.2. Linux Heartbeat
- A.14.3. DRBD Architecture
- A.14.4. DRBD and MySQL Replication
- A.14.5. DRBD and File Systems
- A.14.6. DRBD and LVM
- A.14.7. DRBD and Virtualization
- A.14.8. DRBD and Security
- A.14.9. DRBD and System Requirements
- A.14.10. DBRD and Support and Consulting
- B. Errors, Error Codes, and Common Problems
- C. MySQL Enterprise Release Notes
- C.1. MySQL Enterprise 5.0 Release Notes
- C.1.1. Changes in MySQL Enterprise 5.0.44 (Not yet released)
- C.1.2. Release Notes for MySQL Enterprise 5.0.42 (23 May 2007)
- C.1.3. Release Notes for MySQL Enterprise 5.0.40 (17 April 2007)
- C.1.4. Release Notes for MySQL Enterprise 5.0.38 (20 March 2007 released)
- C.1.5. Release Notes for MySQL Enterprise 5.0.36sp1 (12 April 2007)
- C.1.6. Release Notes for MySQL Enterprise 5.0.36 (20 February 2007)
- C.1.7. Release Notes for MySQL Enterprise 5.0.34 (17 January 2007)
- C.1.8. Release Notes for MySQL Enterprise 5.0.32 (20 December 2006)
- C.1.9. Release Notes for MySQL Enterprise 5.0.30sp1 (19 January 2007)
- C.1.10. Release Notes for MySQL Enterprise 5.0.30 (14 November 2006)
- C.1.11. Release Notes for MySQL Enterprise 5.0.28 (24 October 2006)
- D. MySQL Community Server Enhancements and Release Notes
- E. MySQL Change History
- E.1. Changes in release 5.0.x (Production)
- E.1.1. Changes for release 5.0.27 and up
- E.1.2. Changes in release 5.0.26 (03 October 2006)
- E.1.3. Changes in release 5.0.25 (15 September 2006)
- E.1.4. Changes in release 5.0.24a (25 August 2006)
- E.1.5. Changes in release 5.0.24 (27 July 2006)
- E.1.6. Changes in release 5.0.23 (Not released)
- E.1.7. Changes in release 5.0.22 (24 May 2006)
- E.1.8. Changes in release 5.0.21 (02 May 2006)
- E.1.9. Changes in release 5.0.20a (18 April 2006)
- E.1.10. Changes in release 5.0.20 (31 March 2006)
- E.1.11. Changes in release 5.0.19 (04 March 2006)
- E.1.12. Changes in release 5.0.18 (21 December 2005)
- E.1.13. Changes in release 5.0.17 (14 December 2005)
- E.1.14. Changes in release 5.0.16 (10 November 2005)
- E.1.15. Changes in release 5.0.15 (19 October 2005: Production)
- E.1.16. Changes in release 5.0.14 (Not released)
- E.1.17. Changes in release 5.0.13 (22 September 2005: Release Candidate)
- E.1.18. Changes in release 5.0.12 (02 September 2005)
- E.1.19. Changes in release 5.0.11 (06 August 2005)
- E.1.20. Changes in release 5.0.10 (27 July 2005)
- E.1.21. Changes in release 5.0.9 (15 July 2005)
- E.1.22. Changes in release 5.0.8 (Not released)
- E.1.23. Changes in release 5.0.7 (10 June 2005)
- E.1.24. Changes in release 5.0.6 (26 May 2005)
- E.1.25. Changes in release 5.0.5 (Not released)
- E.1.26. Changes in release 5.0.4 (16 April 2005)
- E.1.27. Changes in release 5.0.3 (23 March 2005: Beta)
- E.1.28. Changes in release 5.0.2 (01 December 2004)
- E.1.29. Changes in release 5.0.1 (27 July 2004)
- E.1.30. Changes in release 5.0.0 (22 December 2003: Alpha)
- E.2. Changes in MySQL Cluster
- E.2.1. Changes in MySQL Cluster-5.0.7 (10 June 2005)
- E.2.2. Changes in MySQL Cluster-5.0.6 (26 May 2005)
- E.2.3. Changes in MySQL Cluster-5.0.5 (Not released)
- E.2.4. Changes in MySQL Cluster-5.0.4 (16 April 2005)
- E.2.5. Changes in MySQL Cluster-5.0.3 (23 March 2005: Beta)
- E.2.6. Changes in MySQL Cluster-5.0.1 (27 July 2004)
- E.2.7. Changes in MySQL Cluster-4.1.13 (15 July 2005)
- E.2.8. Changes in MySQL Cluster-4.1.12 (13 May 2005)
- E.2.9. Changes in MySQL Cluster-4.1.11 (01 April 2005)
- E.2.10. Changes in MySQL Cluster-4.1.10 (12 February 2005)
- E.2.11. Changes in MySQL Cluster-4.1.9 (13 January 2005)
- E.2.12. Changes in MySQL Cluster-4.1.8 (14 December 2004)
- E.2.13. Changes in MySQL Cluster-4.1.7 (23 October 2004)
- E.2.14. Changes in MySQL Cluster-4.1.6 (10 October 2004)
- E.2.15. Changes in MySQL Cluster-4.1.5 (16 September 2004)
- E.2.16. Changes in MySQL Cluster-4.1.4 (31 August 2004)
- E.2.17. Changes in MySQL Cluster-4.1.3 (28 June 2004)
- E.3. MySQL Connector/ODBC (MyODBC) Change History
- E.3.1. Changes in Connector/ODBC 5.0.12 (Not yet released)
- E.3.2. Changes in Connector/ODBC 5.0.11 (31 January 2007)
- E.3.3. Changes in Connector/ODBC 5.0.10 (14 December 2006)
- E.3.4. Changes in Connector/ODBC 5.0.9 (22 November 2006)
- E.3.5. Changes in Connector/ODBC 5.0.8 (17 November 2006)
- E.3.6. Changes in Connector/ODBC 5.0.7 (08 November 2006)
- E.3.7. Changes in Connector/ODBC 5.0.6 (03 November 2006)
- E.3.8. Changes in Connector/ODBC 5.0.5 (17 October 2006)
- E.3.9. Changes in Connector/ODBC 5.0.3 (Connector/ODBC 5.0 Alpha 3) (20 June 2006)
- E.3.10. Changes in Connector/ODBC 5.0.2 (Never released)
- E.3.11. Changes in Connector/ODBC 5.0.1 (Connector/ODBC 5.0 Alpha 2) (05 June 2006)
- E.3.12. Changes in Connector/ODBC 3.51.16 (Not yet released)
- E.3.13. Changes in Connector/ODBC 3.51.15 (7 May 2007)
- E.3.14. Changes in Connector/ODBC 3.51.14 (08 March 2007)
- E.3.15. Changes in Connector/ODBC 3.51.13 (Never released)
- E.3.16. Changes in Connector/ODBC 3.51.12
- E.3.17. Changes in Connector/ODBC 3.51.11
- E.4. Connector/NET Change History
- E.4.1. Changes in MySQL Connector/NET Version 5.1.2 (Not yet released)
- E.4.2. Changes in MySQL Connector/NET Version 5.1.1 (23 May 2007)
- E.4.3. Changes in MySQL Connector/NET Version 5.1.0 (01 May 2007)
- E.4.4. Changes in MySQL Connector/NET Version 5.0.8 (Not yet released)
- E.4.5. Changes in MySQL Connector/NET Version 5.0.7 (18 May 2007)
- E.4.6. Changes in MySQL Connector/NET Version 5.0.6 (22 March 2007)
- E.4.7. Changes in MySQL Connector/NET Version 5.0.5 (07 March 2007)
- E.4.8. Changes in MySQL Connector/NET Version 5.0.4 (Not released)
- E.4.9. Changes in MySQL Connector/NET Version 5.0.3 (05 January 2007)
- E.4.10. Changes in MySQL Connector/NET Version 5.0.2 (06 November 2006)
- E.4.11. Changes in MySQL Connector/NET Version 5.0.1 (01 October 2006)
- E.4.12. Changes in MySQL Connector/NET Version 5.0.0 (08 August 2006)
- E.4.13. Changes in MySQL Connector/NET Version 1.0.10 (Not yet released)
- E.4.14. Changes in MySQL Connector/NET Version 1.0.9 (02 February 2007
- E.4.15. Changes in MySQL Connector/NET Version 1.0.8 (20 October 2006)
- E.4.16. Changes in MySQL Connector/NET Version 1.0.7 (21 November 2005)
- E.4.17. Changes in MySQL Connector/NET Version 1.0.6 (03 October 2005)
- E.4.18. Changes in MySQL Connector/NET Version 1.0.5 (29 August 2005)
- E.4.19. Changes in MySQL Connector/NET Version 1.0.4 (20 January 2005)
- E.4.20. Changes in MySQL Connector/NET Version 1.0.3-gamma (12 October 2004)
- E.4.21. Changes in MySQL Connector/NET Version 1.0.2-gamma (15 November 2004)
- E.4.22. Changes in MySQL Connector/NET Version 1.0.1-beta2 (27 October 2004)
- E.4.23. Changes in MySQL Connector/NET Version 1.0.0 (01 September 2004)
- E.4.24. Changes in MySQL Connector/NET Version 0.9.0 (30 August 2004)
- E.4.25. Changes in MySQL Connector/NET Version 0.76
- E.4.26. Changes in MySQL Connector/NET Version 0.75
- E.4.27. Changes in MySQL Connector/NET Version 0.74
- E.4.28. Changes in MySQL Connector/NET Version 0.71
- E.4.29. Changes in MySQL Connector/NET Version 0.70
- E.4.30. Changes in MySQL Connector/NET Version 0.68
- E.4.31. Changes in MySQL Connector/NET Version 0.65
- E.4.32. Changes in MySQL Connector/NET Version 0.60
- E.4.33. Changes in MySQL Connector/NET Version 0.50
- E.5. MySQL Visual Studio Plugin Change History
- E.6. MySQL Connector/J Change History
- E.6.1. Changes in MySQL Connector/J 5.1.x
- E.6.2. Changes in MySQL Connector/J 5.0.x
- E.6.3. Changes in MySQL Connector/J 3.1.x
- E.6.4. Changes in MySQL Connector/J 3.0.x
- E.6.5. Changes in MySQL Connector/J 2.0.x
- E.6.6. Changes in MySQL Connector/J 1.2b (04 July 1999)
- E.6.7. Changes in MySQL Connector/J 1.2.x and lower
- E.7. MySQL Connector/MXJ Change History
- E.7.1. Changes in MySQL Connector/MXJ 5.0.6 (04 May 2007)
- E.7.2. Changes in MySQL Connector/MXJ 5.0.5 (14 March 2007)
- E.7.3. Changes in MySQL Connector/MXJ 5.0.4 (28 January 2007)
- E.7.4. Changes in MySQL Connector/MXJ 5.0.3 (24 June 2006)
- E.7.5. Changes in MySQL Connector/MXJ 5.0.2 (15 June 2006)
- E.7.6. Changes in MySQL Connector/MXJ 5.0.1 (Never released)
- E.7.7. Changes in MySQL Connector/MXJ 5.0.0 (09 December 2005)
- F. Limits and Restrictions
- G. Credits
- Index
List of Figures
List of Tables
List of Examples
- 23.1. Obtaining a connection from the
DriverManager - 23.2. Using java.sql.Statement to execute a
SELECTquery - 23.3. Stored Procedures
- 23.4. Using
Connection.prepareCall() - 23.5. Registering output parameters
- 23.6. Setting
CallableStatementinput parameters - 23.7. Retrieving results and output parameter values
- 23.8. Retrieving
AUTO_INCREMENTcolumn values usingStatement.getGeneratedKeys() - 23.9. Retrieving
AUTO_INCREMENTcolumn values usingSELECT LAST_INSERT_ID() - 23.10. Retrieving
AUTO_INCREMENTcolumn values inUpdatable ResultSets - 23.11. Using a connection pool with a J2EE application server
- 23.12. Example of transaction with retry logic
This is the Reference Manual for the MySQL Database System, version
5.0, through release 5.0.42. It is not
intended for use with older versions of the MySQL software due to
the many functional and other differences between MySQL
5.0 and previous versions. If you are using a version
4.1 release of the MySQL software, please refer to the
MySQL 3.23, 4.0, 4.1 Reference Manual,
which covers the 3.23, 4.0, and 4.1 series of MySQL software
releases. Differences between minor versions of MySQL
5.0 are noted in the present text with reference to
release numbers (5.0.x).
Table of Contents
- 1.1. About This Manual
- 1.2. Conventions Used in This Manual
- 1.3. Overview of MySQL AB
- 1.4. Overview of the MySQL Database Management System
- 1.5. Overview of the MaxDB Database Management System
- 1.6. MySQL Development Roadmap
- 1.7. MySQL Information Sources
- 1.8. How to Report Bugs or Problems
- 1.9. MySQL Standards Compliance
The MySQL® software delivers a very fast, multi-threaded, multi-user, and robust SQL (Structured Query Language) database server. MySQL Server is intended for mission-critical, heavy-load production systems as well as for embedding into mass-deployed software. MySQL is a registered trademark of MySQL AB.
The MySQL software is Dual Licensed. Users can choose to use the MySQL software as an Open Source product under the terms of the GNU General Public License (http://www.fsf.org/licenses/) or can purchase a standard commercial license from MySQL AB. See http://www.mysql.com/company/legal/licensing/ for more information on our licensing policies.
The following list describes some sections of particular interest in this manual:
For a discussion about the capabilities of the MySQL Database Server, see Section 1.4.3, “The Main Features of MySQL”.
For future plans, see Section 1.6, “MySQL Development Roadmap”.
For installation instructions, see Chapter 2, Installing and Upgrading MySQL. For information about upgrading MySQL, see Section 2.4.16, “Upgrading MySQL”.
For a tutorial introduction to the MySQL Database Server, see Chapter 3, Tutorial.
For information about configuring and administering MySQL Server, see Chapter 5, Database Administration.
For information about setting up replication servers, see Chapter 6, Replication.
For answers to a number of questions that are often asked concerning the MySQL Database Server and its capabilities, see Appendix A, MySQL 5.0 Frequently Asked Questions.
For a list of currently known bugs and misfeatures, see Section B.1.8, “Known Issues in MySQL”.
For a list of all the contributors to this project, see Appendix G, Credits.
For a history of new features and bugfixes, see Appendix E, MySQL Change History.
For tips on porting the MySQL Database Software to new architectures or operating systems, see MySQL Internals: Porting.
For benchmarking information, see the
sql-benchbenchmarking directory in your MySQL distribution.
Important:
To report errors (often called “bugs”), please use the instructions at Section 1.8, “How to Report Bugs or Problems”.
If you have found a sensitive security bug in MySQL Server, please
let us know immediately by sending an email message to
<security@mysql.com>.
This is the Reference Manual for the MySQL Database System,
version 5.0, through release 5.0.42. It is
not intended for use with older versions of the MySQL software due
to the many functional and other differences between MySQL
5.0 and previous versions. If you are using a version
4.1 release of the MySQL software, please refer to
the
MySQL 3.23, 4.0, 4.1 Reference Manual,
which covers the 3.23, 4.0, and 4.1 series of MySQL software
releases. Differences between minor versions of MySQL
5.0 are noted in the present text with reference to
release numbers (5.0.x).
Because this manual serves as a reference, it does not provide general instruction on SQL or relational database concepts. It also does not teach you how to use your operating system or command-line interpreter.
The MySQL Database Software is under constant development, and the Reference Manual is updated frequently as well. The most recent version of the manual is available online in searchable form at http://dev.mysql.com/doc/. Other formats also are available there, including HTML, PDF, and Windows CHM versions.
The Reference Manual source files are written in DocBook XML format. The HTML version and other formats are produced automatically, primarily using the DocBook XSL stylesheets. For information about DocBook, see http://docbook.org/
The DocBook XML sources of this manual are available from http://dev.mysql.com/tech-resources/sources.html. You can check out a copy of the documentation repository with this command:
svn checkout http://svn.mysql.com/svnpublic/mysqldoc/
If you have questions about using MySQL, you can ask them using
our mailing lists or forums. See Section 1.7.1, “MySQL Mailing Lists”,
and Section 1.7.2, “MySQL Community Support at the MySQL Forums”. If you have suggestions concerning
additions or corrections to the manual itself, please send them to
the documentation team at <docs@mysql.com>.
This manual was originally written by David Axmark and Michael “Monty” Widenius. It is maintained by the MySQL Documentation Team, consisting of Paul DuBois, Stefan Hinz, Jon Stephens, Martin MC Brown, and Peter Lavin. For the many other contributors, see Appendix G, Credits.
The copyright to this manual is owned by the Swedish company MySQL AB. MySQL® and the MySQL logo are registered trademarks of MySQL AB. Other trademarks and registered trademarks referred to in this manual are the property of their respective owners, and are used for identification purposes only.
This manual uses certain typographical conventions:
Text in this styleis used for SQL statements; database, table, and column names; program listings and source code; and environment variables. Example: “To reload the grant tables, use theFLUSH PRIVILEGESstatement.”Text in this styleindicates input that you type in examples.Text in this style indicates the names of executable programs and scripts, examples being mysql (the MySQL command line client program) and mysqld (the MySQL server executable).
Text in this styleis used for variable input for which you should substitute a value of your own choosing.Filenames and directory names are written like this: “The global
my.cnffile is located in the/etcdirectory.”Character sequences are written like this: “To specify a wildcard, use the ‘
%’ character.”Text in this style is used for emphasis.
Text in this style is used in table headings and to convey especially strong emphasis.
When commands are shown that are meant to be executed from within a
particular program, the prompt shown preceding the command indicates
which command to use. For example, shell>
indicates a command that you execute from your login shell, and
mysql> indicates a statement that you execute
from the mysql client program:
shell>type a shell command heremysql>type a mysql statement here
The “shell” is your command interpreter. On Unix, this is typically a program such as sh, csh, or bash. On Windows, the equivalent program is command.com or cmd.exe, typically run in a console window.
When you enter a command or statement shown in an example, do not type the prompt shown in the example.
Database, table, and column names must often be substituted into
statements. To indicate that such substitution is necessary, this
manual uses db_name,
tbl_name, and
col_name. For example, you might see a
statement like this:
mysql> SELECT col_name FROM db_name.tbl_name;
This means that if you were to enter a similar statement, you would supply your own database, table, and column names, perhaps like this:
mysql> SELECT author_name FROM biblio_db.author_list;
SQL keywords are not case sensitive and may be written in any lettercase. This manual uses uppercase.
In syntax descriptions, square brackets
(‘[’ and
‘]’) indicate optional words or
clauses. For example, in the following statement, IF
EXISTS is optional:
DROP TABLE [IF EXISTS] tbl_name
When a syntax element consists of a number of alternatives, the
alternatives are separated by vertical bars
(‘|’). When one member from a set of
choices may be chosen, the alternatives are
listed within square brackets (‘[’
and ‘]’):
TRIM([[BOTH | LEADING | TRAILING] [remstr] FROM]str)
When one member from a set of choices must be
chosen, the alternatives are listed within braces
(‘{’ and
‘}’):
{DESCRIBE | DESC} tbl_name [col_name | wild]
An ellipsis (...) indicates the omission of a
section of a statement, typically to provide a shorter version of
more complex syntax. For example, INSERT ...
SELECT is shorthand for the form of
INSERT statement that is followed by a
SELECT statement.
An ellipsis can also indicate that the preceding syntax element of a
statement may be repeated. In the following example, multiple
reset_option values may be given, with
each of those after the first preceded by commas:
RESETreset_option[,reset_option] ...
Commands for setting shell variables are shown using Bourne shell
syntax. For example, the sequence to set the CC
environment variable and run the configure
command looks like this in Bourne shell syntax:
shell> CC=gcc ./configure
If you are using csh or tcsh, you must issue commands somewhat differently:
shell>setenv CC gccshell>./configure
MySQL AB is the company of the MySQL founders and main developers. MySQL AB was originally established in Sweden by David Axmark, Allan Larsson, and Michael “Monty” Widenius.
We are dedicated to developing the MySQL database software and promoting it to new users. MySQL AB owns the copyright to the MySQL source code, the MySQL logo and (registered) trademark, and this manual. See Section 1.4, “Overview of the MySQL Database Management System”.
The MySQL core values show our dedication to MySQL and Open Source.
These core values direct how MySQL AB works with the MySQL server software:
To be the best and the most widely used database in the world
To be available and affordable by all
To be easy to use
To be continuously improved while remaining fast and safe
To be fun to use and improve
To be free from bugs
These are the core values of the company MySQL AB and its employees:
We subscribe to the Open Source philosophy and support the Open Source community
We aim to be good citizens
We prefer partners that share our values and mindset
We answer email and provide support
We are a virtual company, networking with others
We work against software patents
The MySQL Web site (http://www.mysql.com/) provides the latest information about MySQL and MySQL AB.
By the way, the “AB” part of the company name is the acronym for the Swedish “aktiebolag,” or “stock company.” It translates to “MySQL, Inc.” In fact, MySQL, Inc. and MySQL GmbH are examples of MySQL AB subsidiaries. They are located in the United States and Germany, respectively.
MySQL, the most popular Open Source SQL database management system, is developed, distributed, and supported by MySQL AB. MySQL AB is a commercial company, founded by the MySQL developers. It is a second generation Open Source company that unites Open Source values and methodology with a successful business model.
The MySQL Web site (http://www.mysql.com/) provides the latest information about MySQL software and MySQL AB.
MySQL is a database management system.
A database is a structured collection of data. It may be anything from a simple shopping list to a picture gallery or the vast amounts of information in a corporate network. To add, access, and process data stored in a computer database, you need a database management system such as MySQL Server. Since computers are very good at handling large amounts of data, database management systems play a central role in computing, as standalone utilities, or as parts of other applications.
MySQL is a relational database management system.
A relational database stores data in separate tables rather than putting all the data in one big storeroom. This adds speed and flexibility. The SQL part of “MySQL” stands for “Structured Query Language.” SQL is the most common standardized language used to access databases and is defined by the ANSI/ISO SQL Standard. The SQL standard has been evolving since 1986 and several versions exist. In this manual, “SQL-92” refers to the standard released in 1992, “SQL:1999” refers to the standard released in 1999, and “SQL:2003” refers to the current version of the standard. We use the phrase “the SQL standard” to mean the current version of the SQL Standard at any time.
MySQL software is Open Source.
Open Source means that it is possible for anyone to use and modify the software. Anybody can download the MySQL software from the Internet and use it without paying anything. If you wish, you may study the source code and change it to suit your needs. The MySQL software uses the GPL (GNU General Public License), http://www.fsf.org/licenses/, to define what you may and may not do with the software in different situations. If you feel uncomfortable with the GPL or need to embed MySQL code into a commercial application, you can buy a commercially licensed version from us. See the MySQL Licensing Overview for more information (http://www.mysql.com/company/legal/licensing/).
The MySQL Database Server is very fast, reliable, and easy to use.
If that is what you are looking for, you should give it a try. MySQL Server also has a practical set of features developed in close cooperation with our users. You can find a performance comparison of MySQL Server with other database managers on our benchmark page. See Section 7.1.4, “The MySQL Benchmark Suite”.
MySQL Server was originally developed to handle large databases much faster than existing solutions and has been successfully used in highly demanding production environments for several years. Although under constant development, MySQL Server today offers a rich and useful set of functions. Its connectivity, speed, and security make MySQL Server highly suited for accessing databases on the Internet.
MySQL Server works in client/server or embedded systems.
The MySQL Database Software is a client/server system that consists of a multi-threaded SQL server that supports different backends, several different client programs and libraries, administrative tools, and a wide range of application programming interfaces (APIs).
We also provide MySQL Server as an embedded multi-threaded library that you can link into your application to get a smaller, faster, easier-to-manage standalone product.
A large amount of contributed MySQL software is available.
It is very likely that your favorite application or language supports the MySQL Database Server.
The official way to pronounce “MySQL” is “My Ess Que Ell” (not “my sequel”), but we don't mind if you pronounce it as “my sequel” or in some other localized way.
We started out with the intention of using the
mSQL database system to connect to our tables
using our own fast low-level (ISAM) routines. However, after some
testing, we came to the conclusion that mSQL
was not fast enough or flexible enough for our needs. This
resulted in a new SQL interface to our database but with almost
the same API interface as mSQL. This API was
designed to allow third-party code that was written for use with
mSQL to be ported easily for use with MySQL.
The derivation of the name MySQL is not clear. Our base directory and a large number of our libraries and tools have had the prefix “my” for well over 10 years. However, co-founder Monty Widenius's daughter is also named My. Which of the two gave its name to MySQL is still a mystery, even for us.
The name of the MySQL Dolphin (our logo) is “Sakila,” which was chosen by the founders of MySQL AB from a huge list of names suggested by users in our “Name the Dolphin” contest. The winning name was submitted by Ambrose Twebaze, an Open Source software developer from Swaziland, Africa. According to Ambrose, the feminine name Sakila has its roots in SiSwati, the local language of Swaziland. Sakila is also the name of a town in Arusha, Tanzania, near Ambrose's country of origin, Uganda.
This section describes some of the important characteristics of the MySQL Database Software. See also Section 1.6, “MySQL Development Roadmap”, for more information about current and upcoming features. In most respects, it applies to all versions of MySQL. For information about features as they are introduced into MySQL on a series-specific basis, see “In a Nutshell” section of the appropriate Manual:
MySQL 4.0 and 4.1: MySQL 4.0 in a Nutshell, and MySQL 4.1 in a Nutshell
MySQL 5.0: Section 1.6.1, “What's New in MySQL 5.0”
MySQL 5.1: What's New in MySQL 5.1
Internals and Portability:
Written in C and C++.
Tested with a broad range of different compilers.
Works on many different platforms. See Section 2.4.2, “Operating Systems Supported by MySQL Community Server”.
Uses GNU Automake, Autoconf, and Libtool for portability.
The MySQL Server design is multi-layered with independent modules.
Fully multi-threaded using kernel threads. It can easily use multiple CPUs if they are available.
Provides transactional and non-transactional storage engines.
Uses very fast B-tree disk tables (
MyISAM) with index compression.Relatively easy to add other storage engines. This is useful if you want to provide an SQL interface for an in-house database.
A very fast thread-based memory allocation system.
Very fast joins using an optimized one-sweep multi-join.
In-memory hash tables, which are used as temporary tables.
SQL functions are implemented using a highly optimized class library and should be as fast as possible. Usually there is no memory allocation at all after query initialization.
The MySQL code is tested with Purify (a commercial memory leakage detector) as well as with Valgrind, a GPL tool (http://developer.kde.org/~sewardj/).
The server is available as a separate program for use in a client/server networked environment. It is also available as a library that can be embedded (linked) into standalone applications. Such applications can be used in isolation or in environments where no network is available.
Data Types:
Many data types: signed/unsigned integers 1, 2, 3, 4, and 8 bytes long,
FLOAT,DOUBLE,CHAR,VARCHAR,TEXT,BLOB,DATE,TIME,DATETIME,TIMESTAMP,YEAR,SET,ENUM, and OpenGIS spatial types. See Chapter 11, Data Types.Fixed-length and variable-length records.
Statements and Functions:
Full operator and function support in the
SELECTlist andWHEREclause of queries. For example:mysql>
SELECT CONCAT(first_name, ' ', last_name)->FROM citizen->WHERE income/dependents > 10000 AND age > 30;Full support for SQL
GROUP BYandORDER BYclauses. Support for group functions (COUNT(),COUNT(DISTINCT ...),AVG(),STD(),SUM(),MAX(),MIN(), andGROUP_CONCAT()).Support for
LEFT OUTER JOINandRIGHT OUTER JOINwith both standard SQL and ODBC syntax.Support for aliases on tables and columns as required by standard SQL.
DELETE,INSERT,REPLACE, andUPDATEreturn the number of rows that were changed (affected). It is possible to return the number of rows matched instead by setting a flag when connecting to the server.The MySQL-specific
SHOWstatement can be used to retrieve information about databases, storage engines, tables, and indexes. MySQL 5.0 adds support for theINFORMATION_SCHEMAdatabase, implemented according to standard SQL.The
EXPLAINstatement can be used to determine how the optimizer resolves a query.Function names do not clash with table or column names. For example,
ABSis a valid column name. The only restriction is that for a function call, no spaces are allowed between the function name and the ‘(’ that follows it. See Section 9.3, “Reserved Words”.You can refer to tables from different databases in the same statement.
Security:
A privilege and password system that is very flexible and secure, and that allows host-based verification.
Passwords are secure because all password traffic is encrypted when you connect to a server.
Scalability and Limits:
Handles large databases. We use MySQL Server with databases that contain 50 million records. We also know of users who use MySQL Server with 60,000 tables and about 5,000,000,000 rows.
Up to 64 indexes per table are allowed (32 before MySQL 4.1.2). Each index may consist of 1 to 16 columns or parts of columns. The maximum index width is 1000 bytes (767 for
InnoDB); before MySQL 4.1.2, the limit is 500 bytes. An index may use a prefix of a column forCHAR,VARCHAR,BLOB, orTEXTcolumn types.
Connectivity:
Clients can connect to MySQL Server using several protocols:
Clients can connect using TCP/IP sockets on any platform.
On Windows systems in the NT family (NT, 2000, XP, 2003, or Vista), clients can connect using named pipes if the server is started with the
--enable-named-pipeoption. In MySQL 4.1 and higher, Windows servers also support shared-memory connections if started with the--shared-memoryoption. Clients can connect through shared memory by using the--protocol=memoryoption.On Unix systems, clients can connect using Unix domain socket files.
MySQL client programs can be written in many languages. A client library written in C is available for clients written in C or C++, or for any language that provides C bindings.
APIs for C, C++, Eiffel, Java, Perl, PHP, Python, Ruby, and Tcl are available, allowing MySQL clients to be written in many languages. See Chapter 22, APIs and Libraries.
The Connector/ODBC (MyODBC) interface provides MySQL support for client programs that use ODBC (Open Database Connectivity) connections. For example, you can use MS Access to connect to your MySQL server. Clients can be run on Windows or Unix. MyODBC source is available. All ODBC 2.5 functions are supported, as are many others. See Chapter 23, Connectors.
The Connector/J interface provides MySQL support for Java client programs that use JDBC connections. Clients can be run on Windows or Unix. Connector/J source is available. See Chapter 23, Connectors.
MySQL Connector/NET enables developers to easily create .NET applications that require secure, high-performance data connectivity with MySQL. It implements the required ADO.NET interfaces and integrates into ADO.NET aware tools. Developers can build applications using their choice of .NET languages. MySQL Connector/NET is a fully managed ADO.NET driver written in 100% pure C#. See Chapter 23, Connectors.
Localization:
The server can provide error messages to clients in many languages. See Section 5.10.2, “Setting the Error Message Language”.
Full support for several different character sets, including
latin1(cp1252),german,big5,ujis, and more. For example, the Scandinavian characters ‘å’, ‘ä’ and ‘ö’ are allowed in table and column names. Unicode support is available as of MySQL 4.1.All data is saved in the chosen character set.
Sorting and comparisons are done according to the chosen character set and collation (using
latin1and Swedish collation by default). It is possible to change this when the MySQL server is started. To see an example of very advanced sorting, look at the Czech sorting code. MySQL Server supports many different character sets that can be specified at compile time and runtime.As of MySQL 4.1, the server time zone can be changed dynamically, and individual clients can specify their own time zone. Section 5.10.8, “MySQL Server Time Zone Support”.
MySQL Enterprise For assistance in getting optimal performance from your MySQL server subscribe to MySQL Enterprise. For more information see http://www.mysql.com/products/enterprise/.
Clients and Tools:
MySQL AB provides several client and utility programs. These include both command-line programs such as mysqldump and mysqladmin, and graphical programs such as MySQL Administrator and MySQL Query Browser.
MySQL Server has built-in support for SQL statements to check, optimize, and repair tables. These statements are available from the command line through the mysqlcheck client. MySQL also includes myisamchk, a very fast command-line utility for performing these operations on
MyISAMtables. See Chapter 8, Client and Utility Programs.MySQL programs can be invoked with the
--helpor-?option to obtain online assistance.
MaxDB is a heavy-duty enterprise database. The database management system is SAP-certified.
MaxDB is the new name of a database management system formerly called SAP DB. In 2003 SAP AG and MySQL AB joined a partnership and re-branded the database system to MaxDB. The development of MaxDB has continued since then as it was done before—through the SAP developer team.
MySQL AB cooperates closely with the MaxDB team at SAP around delivering improvements to the MaxDB product. Joint efforts include development of new native drivers to enable more efficient usage of MaxDB in the Open Source community, and improvement of documentation to expand the MaxDB user base. Interoperability features between MySQL and MaxDB database also are seen as important. For example, the new MaxDB Synchronization Manager supports data synchronization from MaxDB to MySQL.
The MaxDB database management system does not share a common code-base with the MySQL database management system. The MaxDB and MySQL database management systems are independent products provided by MySQL AB.
MySQL AB offers a complete portfolio of Professional Services for MaxDB.
MaxDB is an ANSI SQL-92 (entry level) compliant relational database management system (RDBMS) from SAP AG, that is delivered by MySQL AB as well. MaxDB fulfills the needs for enterprise usage: safety, scalability, high concurrency, and performance. It runs on all major operating systems. Over the years it has proven able to run SAP R/3 and terabytes of data in 24×7 operation.
The database development started in 1977 as a research project at the Technical University of Berlin. In the early 1980s it became a database product that subsequently was owned by Nixdorf, Siemens Nixdorf, Software AG, and today by SAP AG. Along the way, it has been named VDN, Reflex, Supra 2, DDB/4, Entire SQL-DB-Server, and ADABAS D. In 1997, SAP took over the software from Software AG and renamed it to SAP DB. Since October 2000, SAP DB sources additionally were released as Open Source under the GNU General Public License (see GNU General Public License).
In 2003, SAP AG and MySQL AB formed a partnership and re-branded the database system to MaxDB.
The history of MaxDB goes back to SAP DB, SAP AG's DBMS. That is, MaxDB is a re-branded and enhanced version of SAP DB. For many years, MaxDB has been used for small, medium, and large installations of the mySAP Business Suite and other demanding SQL applications requiring an enterprise-class DBMS with regard to the number of users, the transactional workload, and the size of the database.
SAP DB was meant to provide an alternative to third-party database systems such as Oracle, Microsoft SQL Server, and DB2 by IBM. In October 2000, SAP AG released SAP DB under the GNU GPL license (see GNU General Public License), thus making it Open Source software.
Today, MaxDB is used in about 3,500 SAP customer installations worldwide. Moreover, the majority of all DBMS installations on Unix and Linux within SAP’s IT department rely on MaxDB. MaxDB is tuned toward heavy-duty online transaction processing (OLTP) with several thousand users and database sizes ranging from several hundred GB to multiple TB.
In 2003, SAP and MySQL concluded a partnership and development cooperation agreement. As a result, SAP's database system SAP DB has been delivered under the name of MaxDB by MySQL since the release of version 7.5 (November 2003).
Version 7.5 of MaxDB is a direct advancement of the SAP DB 7.4 code base. Therefore, the MaxDB software version 7.5 can be used as a direct upgrade of previous SAP DB versions starting 7.2.04 and higher.
The former SAP DB development team at SAP AG is responsible, now as before, for developing and supporting MaxDB. MySQL AB cooperates closely with the MaxDB team at SAP around delivering improvements to the MaxDB product, see Section 1.5, “Overview of the MaxDB Database Management System”. Both SAP AG and MySQL AB handle the sale and distribution of MaxDB. The advancement of MaxDB and the MySQL Server leverages synergies that benefit both product lines.
MaxDB is subjected to SAP AG's complete quality assurance process before it is shipped with SAP solutions or provided as a download from the MySQL site.
MaxDB is a heavy-duty, SAP-certified Open Source database for OLTP and OLAP usage which offers high reliability, availability, scalability, and a very comprehensive feature set. It is targeted for large mySAP Business Suite environments and other applications that require maximum enterprise-level database functionality and complements the MySQL database server.
MaxDB operates as a client/server product. It was developed to meet the needs of installations in OLTP and Data Warehouse/OLAP/Decision Support scenarios and offers these benefits:
Easy configuration and administration: GUI-based Installation Manager and Database Manager as single administration tools for DBMS operations
Around-the-clock operation, no planned downtimes, no permanent attendance required: Automatic space management, no need for reorganizations
Sophisticated backup and restore capabilities: Online and incremental backups, recovery wizard to guide you through the recovery scenario
Supports large number of users, database sizes in the terabytes, and demanding workloads: Proven reliability, performance, and scalability
High availability: Cluster support, standby configuration, hot standby configuration
MaxDB can be used under the same licenses available for the other products distributed by MySQL AB. Thus, MaxDB is available under the GNU General Public License, and a commercial license. For more information on licensing, see http://www.mysql.com/company/legal/licensing/.
MySQL AB offers MaxDB technical support to non-SAP customers. MaxDB support is available on various levels (Basic, Silver, and Gold), which expand from unlimited email/web-support to 24×7 phone support for business critical systems.
MySQL AB also offers Licenses and Support for MaxDB when used with SAP Applications, like SAP NetWeaver and mySAP Business Suite. For more information on licenses and support for your needs, please contact MySQL AB. (See http://www.mysql.com/company/contact/.)
Consulting and training services are available. MySQL gives classes on MaxDB at regular intervals. See http://www.mysql.com/training/ for a list of classes.
MaxDB is MySQL AB's SAP-certified database. The MaxDB database server complements the MySQL AB product portfolio. Some MaxDB features are not available on the MySQL database management server and vice versa.
The following list summarizes the main differences between MaxDB and MySQL; it is not complete.
MaxDB runs as a client/server system. MySQL can run as a client/server system or as an embedded system.
MaxDB might not run on all platforms supported by MySQL.
MaxDB uses a proprietary network protocol for client/server communication. MySQL uses either TCP/IP (with or without SSL encryption), sockets (under Unix-like systems), or named pipes or shared memory (under Windows NT-family systems).
MaxDB supports stored procedures and functions. MySQL 5.0 and up also supports stored procedures and functions. MaxDB supports programming of triggers through an SQL extension. MySQL 5.0 supports triggers. MaxDB contains a debugger for stored procedure languages, can cascade nested triggers, and supports multiple triggers per action and row.
MaxDB is distributed with user interfaces that are text-based, graphical, or Web-based. MySQL is distributed with text-based user interfaces only; graphical user interfaces such as MySQL Query Browser or MySQL Administrator are shipped separately from the main distributions. Web-based user interfaces for MySQL are offered by third parties.
MaxDB supports a number of programming interfaces that also are supported by MySQL. For developing with MaxDB, the MaxDB ODBC Driver, SQL Database Connectivity (SQLDBC), JDBC Driver, Perl and Python modules and a MaxDB PHP extension, which provides access to MySQL MaxDB databases using PHP, are available. Third Party Programming Interfaces: Support for OLE DB, ADO, DAO, RDO and .NET through ODBC. MaxDB supports embedded SQL with C/C++.
MaxDB includes administrative features that MySQL does not have: job scheduling by time (included in MySQL as of 5.1), event, and alert, and sending messages to a database administrator on alert thresholds. (MySQL has scheduling support starting with version 5.1.6.)
MaxDB and MySQL are independent database management servers. The interoperation of the systems is possible in a way that the systems can exchange their data. To exchange data between MaxDB and MySQL, you can use the import and export tools of the systems or the MaxDB Synchronization Manager. The import and export tools can be used to transfer data in an infrequent, manual fashion. The MaxDB Synchronization Manager offers faster, automatic data transfer capabilities.
The MaxDB Loader can be used to export data and object
definitions. The Loader can export data using MaxDB internal,
binary formats and text formats (CSV). Data exported from MaxDB in
text formats can be imported into MySQL using the
mysqlimport client program. To export MySQL
data, you can use either mysqldump to create
INSERT statements or SELECT ... INTO
OUTFILE to create a text file (CSV). Use the MaxDB
Loader to import the data files generated by MySQL.
Object definitions can be exchanged between the systems using
MaxDB Loader and the MySQL tool mysqldump. As
the SQL dialects of both systems differ slightly and MaxDB has
features currently not supported by MySQL like SQL constraints, we
recommend to hand-tune the definition files. The
mysqldump tool offers an option
--compatible=maxdb to produce output that is
compatible with MaxDB to make porting easier.
The MaxDB Synchronization Manager is available as part of MaxDB 7.6. The Synchronization Manager supports creation of asynchronous replication scenarios between several MaxDB instances. However, interoperability features also are planned, so that the Synchronization Manager supports replication to and from a MySQL server.
The main page for MaxDB information is http://www.mysql.com/products/maxdb, which provides details about the features of the MaxDB database management systems and has pointers to available documentation.
The MySQL Reference Manual does not contain any MaxDB documentation other than the introduction given in this section. MaxDB has its own documentation, which is called the MaxDB library and is available at http://dev.mysql.com/doc/maxdb/index.html.
MySQL AB runs a community mailing list on MaxDB; see http://lists.mysql.com/maxdb. The list shows a vivid community discussion. Many of the core developers contribute to it. Product announcements are sent to the list.
A Web forum on MaxDB is available at http://forums.mysql.com/. The forum focuses on MaxDB questions not related to SAP applications.
This section describes the general MySQL development roadmap, including major features implemented in or planned for various MySQL releases. The following sections provide information for each release series.
The current production release series is MySQL 5.0, which was declared stable for production use as of MySQL 5.0.15, released in October 2005. The previous production release series was MySQL 4.1, which was declared stable for production use as of MySQL 4.1.7, released in October 2004. “Production status” means that future 5.0 and 4.1 development is limited only to bugfixes. For the older MySQL 4.0 and 3.23 series, only critical bugfixes are made.
Active MySQL development currently is taking place in the MySQL 5.0 and 5.1 release series, and new features are being added only to the latter.
Before upgrading from one release series to the next, please see the notes in Section 2.4.16, “Upgrading MySQL”.
The most requested features and the versions in which they were implemented or are scheduled for implementation are summarized in the following table:
| Feature | MySQL Series |
| Unions | 4.0 |
| Subqueries | 4.1 |
| R-trees | 4.1 (for the MyISAM storage engine) |
| Stored procedures | 5.0 |
| Views | 5.0 |
| Cursors | 5.0 |
| XA transactions | 5.0 |
| Triggers | 5.0 and 5.1 |
| Event scheduler | 5.1 |
| Partitioning | 5.1 |
| Pluggable storage engine API | 5.1 |
| Plugin API | 5.1 |
| Row-based replication | 5.1 |
| Server log tables | 5.1 |
| Foreign keys | 5.2 (implemented in 3.23 for InnoDB) |
The following features are implemented in MySQL 5.0.
BITData Type: Can be used to store numbers in binary notation. See Section 11.1.1, “Overview of Numeric Types”.Cursors: Elementary support for server-side cursors. For information about using cursors within stored routines, see Section 17.2.9, “Cursors”. For information about using cursors from within the C API, see Section 22.2.7.3, “
mysql_stmt_attr_set()”.Information Schema: The introduction of the
INFORMATION_SCHEMAdatabase in MySQL 5.0 provided a standards-compliant means for accessing the MySQL Server's metadata; that is, data about the databases (schemas) on the server and the objects which they contain. See Chapter 20, TheINFORMATION_SCHEMADatabase.Instance Manager: Can be used to start and stop the MySQL Server, even from a remote host. See Section 5.4, “mysqlmanager — The MySQL Instance Manager”.
Precision Math: MySQL 5.0 introduced stricter criteria for acceptance or rejection of data, and implemented a new library for fixed-point arithmetic. These contributed to a much higher degree of accuracy for mathematical operations and greater control over invalid values. See Chapter 21, Precision Math.
Storage Engines: Storage engines added in MySQL 5.0 include
ARCHIVEandFEDERATED. See Section 14.8, “TheARCHIVEStorage Engine”, and Section 14.7, “TheFEDERATEDStorage Engine”.Stored Routines: Support for named stored procedures and stored functions was implemented in MySQL 5.0. See Chapter 17, Stored Procedures and Functions.
Strict Mode and Standard Error Handling: MySQL 5.0 added a strict mode where by it follows standard SQL in a number of ways in which it did not previously. Support for standard SQLSTATE error messages was also implemented. See Section 5.2.6, “SQL Modes”.
Triggers: MySQL 5.0 added limited support for triggers. See Chapter 18, Triggers, and Section 1.9.5.4, “Stored Routines and Triggers”.
VARCHARData Type: The maximum effective length of aVARCHARcolumn was increased to 65,535 bytes, and stripping of trailing whitespace was eliminated. (The actual maximum length of aVARCHARis determined by the maximum row size and the character set you use. The maximum effective column length is subject to a row size of 65,532 bytes.) See Section 11.4, “String Types”.Views: MySQL 5.0 added support for named, updatable views. See Chapter 19, Views, and Section 1.9.5.6, “Views”.
XA Transactions: See Section 13.4.7, “XA Transactions”.
MySQL Enterprise For assistance in maximizing your usage of the many new features of MySQL, subscribe to MySQL Enterprise. For more information see http://www.mysql.com/products/enterprise/advisors.html.
Performance enhancements: A number of improvements were made in MySQL 5.0 to improve the speed of certain types of queries and in the handling of certain types. These include:
MySQL 5.0 introduces a new “greedy” optimizer which can greatly reduce the time required to arrive at a query execution plan. This is particularly noticeable where several tables are to be joined and no good join keys can otherwise be found. Without the greedy optimizer, the complexity of the search for an execution plan is calculated as
N!Nis the number of tables to be joined. The greedy optimizer reduces this toN!/(D-1)!Dis the depth of the search. Although the greedy optimizer does not guarantee the best possible of all execution plans (this is currently being worked on), it can reduce the time spent arriving at an execution plan for a join involving a great many tables — 30, 40, or more — by a factor of as much as 1,000. This should eliminate most if not all situations where users thought that the optimizer had hung when trying to perform joins across many tables.Use of the Index Merge method to obtain better optimization of
ANDandORrelations over different keys. (Previously, these were optimized only where both relations in theWHEREclause involved the same key.) This also applies to other one-to-one comparison operators (>,<, and so on), including=and theINoperator. This means that MySQL can use multiple indexes in retrieving results for conditions such asWHERE key1 > 4 OR key2 < 7and even combinations of conditions such asWHERE (key1 > 4 OR key2 < 7) AND (key3 >= 10 OR key4 = 1). See Section 7.2.6, “Index Merge Optimization”.A new equality detector finds and optimizes “hidden” equalities in joins. For example, a
WHEREclause such ast1.c1=t2.c2 AND t2.c2=t3.c3 AND t1.c1 < 5
implies these other conditions
t1.c1=t3.c3 AND t2.c2 < 5 AND t3.c3 < 5
These optimizations can be applied with any combination of
ANDandORoperators. See Section 7.2.9, “Nested Join Optimization”, and Section 7.2.10, “Outer Join Simplification”.Optimization of
NOT INandNOT BETWEENrelations, reducing or eliminating table scans for queries making use of them by mean of range analysis. The performance of MySQL with regard to these relations now matches its performance with regard toINandBETWEEN.The
VARCHARdata type as implemented in MySQL 5.0 is more efficient than in previous versions, due to the elimination of the old (and nonstandard) removal of trailing spaces during retrieval.The addition of a true
BITcolumn type; this type is much more efficient for storage and retrieval of Boolean values than the workarounds required in MySQL in versions previous to 5.0.Performance Improvements in the
InnoDBStorage Engine:New compact storage format which can save up to 20% of the disk space required in previous MySQL/
InnoDBversions.Faster recovery from a failed or aborted
ALTER TABLE.Faster implementation of
TRUNCATE.
Performance Improvements in the
NDBClusterStorage Engine:Faster handling of queries that use
INandBETWEEN.Condition pushdown: In cases involving the comparison of an unindexed column with a constant, this condition is “pushed down” to the cluster where it is evaluated in all partitions simultaneously, eliminating the need to send non-matching records over the network. This can make such queries 10 to 100 times faster than in MySQL 4.1 Cluster.
See Section 7.2.1, “Optimizing Queries with
EXPLAIN”, for more information.
(See Chapter 15, MySQL Cluster.)
For those wishing to take a look at the bleeding edge of MySQL development, we make our BitKeeper repository for MySQL publicly available. See Section 2.4.14.3, “Installing from the Development Source Tree”.
This section lists sources of additional information that you may find helpful, such as the MySQL mailing lists and user forums, and Internet Relay Chat.
This section introduces the MySQL mailing lists and provides guidelines as to how the lists should be used. When you subscribe to a mailing list, you receive all postings to the list as email messages. You can also send your own questions and answers to the list.
To subscribe to or unsubscribe from any of the mailing lists described in this section, visit http://lists.mysql.com/. For most of them, you can select the regular version of the list where you get individual messages, or a digest version where you get one large message per day.
Please do not send messages about subscribing or unsubscribing to any of the mailing lists, because such messages are distributed automatically to thousands of other users.
Your local site may have many subscribers to a MySQL mailing list.
If so, the site may have a local mailing list, so that messages
sent from lists.mysql.com to your site are
propagated to the local list. In such cases, please contact your
system administrator to be added to or dropped from the local
MySQL list.
If you wish to have traffic for a mailing list go to a separate
mailbox in your mail program, set up a filter based on the message
headers. You can use either the List-ID: or
Delivered-To: headers to identify list
messages.
The MySQL mailing lists are as follows:
announceThis list is for announcements of new versions of MySQL and related programs. This is a low-volume list to which all MySQL users should subscribe.
mysqlThis is the main list for general MySQL discussion. Please note that some topics are better discussed on the more-specialized lists. If you post to the wrong list, you may not get an answer.
bugsThis list is for people who want to stay informed about issues reported since the last release of MySQL or who want to be actively involved in the process of bug hunting and fixing. See Section 1.8, “How to Report Bugs or Problems”.
internalsThis list is for people who work on the MySQL code. This is also the forum for discussions on MySQL development and for posting patches.
mysqldocThis list is for people who work on the MySQL documentation: people from MySQL AB, translators, and other community members.
benchmarksThis list is for anyone interested in performance issues. Discussions concentrate on database performance (not limited to MySQL), but also include broader categories such as performance of the kernel, filesystem, disk system, and so on.
packagersThis list is for discussions on packaging and distributing MySQL. This is the forum used by distribution maintainers to exchange ideas on packaging MySQL and on ensuring that MySQL looks and feels as similar as possible on all supported platforms and operating systems.
javaThis list is for discussions about the MySQL server and Java. It is mostly used to discuss JDBC drivers such as MySQL Connector/J.
win32This list is for all topics concerning the MySQL software on Microsoft operating systems, such as Windows 9x, Me, NT, 2000, XP, and 2003.
myodbcThis list is for all topics concerning connecting to the MySQL server with ODBC.
gui-toolsThis list is for all topics concerning MySQL graphical user interface tools such as
MySQL AdministratorandMySQL Query Browser.clusterThis list is for discussion of MySQL Cluster.
dotnetThis list is for discussion of the MySQL server and the .NET platform. It is mostly related to MySQL Connector/Net.
plusplusThis list is for all topics concerning programming with the C++ API for MySQL.
perlThis list is for all topics concerning Perl support for MySQL with
DBD::mysql.
If you're unable to get an answer to your questions from a MySQL mailing list or forum, one option is to purchase support from MySQL AB. This puts you in direct contact with MySQL developers.
The following table shows some MySQL mailing lists in languages other than English. These lists are not operated by MySQL AB.
<mysql-france-subscribe@yahoogroups.com>A French mailing list.
A Korean mailing list. To subscribe, email
subscribe mysql your@email.addressto this list.<mysql-de-request@lists.4t2.com>A German mailing list. To subscribe, email
subscribe mysql-de your@email.addressto this list. You can find information about this mailing list at http://www.4t2.com/mysql/.<mysql-br-request@listas.linkway.com.br>A Portuguese mailing list. To subscribe, email
subscribe mysql-br your@email.addressto this list.A Spanish mailing list. To subscribe, email
subscribe mysql your@email.addressto this list.
Please don't post mail messages from your browser with HTML mode turned on. Many users don't read mail with a browser.
When you answer a question sent to a mailing list, if you consider your answer to have broad interest, you may want to post it to the list instead of replying directly to the individual who asked. Try to make your answer general enough that people other than the original poster may benefit from it. When you post to the list, please make sure that your answer is not a duplication of a previous answer.
Try to summarize the essential part of the question in your reply. Don't feel obliged to quote the entire original message.
When answers are sent to you individually and not to the mailing list, it is considered good etiquette to summarize the answers and send the summary to the mailing list so that others may have the benefit of responses you received that helped you solve your problem.
The forums at http://forums.mysql.com are an important community resource. Many forums are available, grouped into these general categories:
Migration
MySQL Usage
MySQL Connectors
Programming Languages
Tools
3rd-Party Applications
Storage Engines
MySQL Technology
SQL Standards
Business
In addition to the various MySQL mailing lists and forums, you can find experienced community people on Internet Relay Chat (IRC). These are the best networks/channels currently known to us:
freenode (see http://www.freenode.net/ for servers)
#mysqlis primarily for MySQL questions, but other database and general SQL questions are welcome. Questions about PHP, Perl, or C in combination with MySQL are also common.
If you are looking for IRC client software to connect to an IRC
network, take a look at xChat
(http://www.xchat.org/). X-Chat (GPL licensed) is
available for Unix as well as for Windows platforms (a free
Windows build of X-Chat is available at
http://www.silverex.org/download/).
MySQL AB offers technical support in the form of MySQL Enterprise. For organizations that rely on the MySQL DBMS for business-critical production applications, MySQL Enterprise is a commercial subscription offering which includes:
MySQL Enterprise Server
MySQL Network Monitoring and Advisory Services
Monthly Rapid Updates and Quarterly Service Packs
MySQL Knowledge Base
24x7 Technical and Consultative Support
MySQL Enterprise is available in multiple tiers, giving you the flexibility to choose the level of service that best matches your needs. For more information see MySQL Enterprise.
Before posting a bug report about a problem, please try to verify that it is a bug and that it has not been reported already:
Start by searching the MySQL online manual at http://dev.mysql.com/doc/. We try to keep the manual up to date by updating it frequently with solutions to newly found problems. The change history (http://dev.mysql.com/doc/mysql/en/news.html) can be particularly useful since it is quite possible that a newer version contains a solution to your problem.
If you get a parse error for a SQL statement, please check your syntax closely. If you can't find something wrong with it, it's extremely likely that your current version of MySQL Server doesn't support the syntax you are using. If you are using the current version and the manual doesn't cover the syntax that you are using, MySQL Server doesn't support your statement. In this case, your options are to implement the syntax yourself or email
<licensing@mysql.com>and ask for an offer to implement it.If the manual covers the syntax you are using, but you have an older version of MySQL Server, you should check the MySQL change history to see when the syntax was implemented. In this case, you have the option of upgrading to a newer version of MySQL Server.
For solutions to some common problems, see Section B.1, “Problems and Common Errors”.
Search the bugs database at http://bugs.mysql.com/ to see whether the bug has been reported and fixed.
Search the MySQL mailing list archives at http://lists.mysql.com/. See Section 1.7.1, “MySQL Mailing Lists”.
You can also use http://www.mysql.com/search/ to search all the Web pages (including the manual) that are located at the MySQL AB Web site.
If you can't find an answer in the manual, the bugs database, or the mailing list archives, check with your local MySQL expert. If you still can't find an answer to your question, please use the following guidelines for reporting the bug.
The normal way to report bugs is to visit http://bugs.mysql.com/, which is the address for our bugs database. This database is public and can be browsed and searched by anyone. If you log in to the system, you can enter new reports. If you have no Web access, you can generate a bug report by using the mysqlbug script described at the end of this section.
Bugs posted in the bugs database at http://bugs.mysql.com/ that are corrected for a given release are noted in the change history.
If you have found a sensitive security bug in MySQL, you can send
email to <security@mysql.com>.
To discuss problems with other users, you can use one of the MySQL mailing lists. Section 1.7.1, “MySQL Mailing Lists”.
Writing a good bug report takes patience, but doing it right the first time saves time both for us and for yourself. A good bug report, containing a full test case for the bug, makes it very likely that we will fix the bug in the next release. This section helps you write your report correctly so that you don't waste your time doing things that may not help us much or at all. Please read this section carefully and make sure that all the information described here is included in your report.
Preferably, you should test the problem using the latest production
or development version of MySQL Server before posting. Anyone should
be able to repeat the bug by just using mysql test <
script_file on your test case or by running the shell or
Perl script that you include in the bug report. Any bug that we are
able to repeat has a high chance of being fixed in the next MySQL
release.
It is most helpful when a good description of the problem is included in the bug report. That is, give a good example of everything you did that led to the problem and describe, in exact detail, the problem itself. The best reports are those that include a full example showing how to reproduce the bug or problem. See MySQL Internals: Porting.
Remember that it is possible for us to respond to a report containing too much information, but not to one containing too little. People often omit facts because they think they know the cause of a problem and assume that some details don't matter. A good principle to follow is that if you are in doubt about stating something, state it. It is faster and less troublesome to write a couple more lines in your report than to wait longer for the answer if we must ask you to provide information that was missing from the initial report.
The most common errors made in bug reports are (a) not including the version number of the MySQL distribution that you use, and (b) not fully describing the platform on which the MySQL server is installed (including the platform type and version number). These are highly relevant pieces of information, and in 99 cases out of 100, the bug report is useless without them. Very often we get questions like, “Why doesn't this work for me?” Then we find that the feature requested wasn't implemented in that MySQL version, or that a bug described in a report has been fixed in newer MySQL versions. Errors often are platform-dependent. In such cases, it is next to impossible for us to fix anything without knowing the operating system and the version number of the platform.
If you compiled MySQL from source, remember also to provide information about your compiler if it is related to the problem. Often people find bugs in compilers and think the problem is MySQL-related. Most compilers are under development all the time and become better version by version. To determine whether your problem depends on your compiler, we need to know what compiler you used. Note that every compiling problem should be regarded as a bug and reported accordingly.
If a program produces an error message, it is very important to include the message in your report. If we try to search for something from the archives, it is better that the error message reported exactly matches the one that the program produces. (Even the lettercase should be observed.) It is best to copy and paste the entire error message into your report. You should never try to reproduce the message from memory.
If you have a problem with Connector/ODBC (MyODBC), please try to generate a trace file and send it with your report. See the MyODBC section of Chapter 23, Connectors.
If your report includes long query output lines from test cases that
you run with the mysql command-line tool, you can
make the output more readable by using the
--vertical option or the \G
statement terminator. The EXPLAIN SELECT example
later in this section demonstrates the use of \G.
Please include the following information in your report:
The version number of the MySQL distribution you are using (for example, MySQL 5.0.19). You can find out which version you are running by executing mysqladmin version. The mysqladmin program can be found in the
bindirectory under your MySQL installation directory.The manufacturer and model of the machine on which you experience the problem.
The operating system name and version. If you work with Windows, you can usually get the name and version number by double-clicking your My Computer icon and pulling down the “Help/About Windows” menu. For most Unix-like operating systems, you can get this information by executing the command
uname -a.Sometimes the amount of memory (real and virtual) is relevant. If in doubt, include these values.
If you are using a source distribution of the MySQL software, include the name and version number of the compiler that you used. If you have a binary distribution, include the distribution name.
If the problem occurs during compilation, include the exact error messages and also a few lines of context around the offending code in the file where the error occurs.
If mysqld died, you should also report the statement that crashed mysqld. You can usually get this information by running mysqld with query logging enabled, and then looking in the log after mysqld crashes. See MySQL Internals: Porting.
If a database table is related to the problem, include the output from the
SHOW CREATE TABLEstatement in the bug report. This is a very easy way to get the definition of any table in a database. The information helps us create a situation matching the one that you have experienced.db_name.tbl_nameThe SQL mode in effect when the problem occurred can be significant, so please report the value of the
sql_modesystem variable. For stored procedure, stored function, and trigger objects, the relevantsql_modevalue is the one in effect when the object was created. For a stored procedure or function, theSHOW CREATE PROCEDUREorSHOW CREATE FUNCTIONstatement shows the relevant SQL mode, or you can queryINFORMATION_SCHEMAfor the information:SELECT ROUTINE_SCHEMA, ROUTINE_NAME, SQL_MODE FROM INFORMATION_SCHEMA.ROUTINES;
For triggers, you can use this statement:
SELECT EVENT_OBJECT_SCHEMA, EVENT_OBJECT_TABLE, TRIGGER_NAME, SQL_MODE FROM INFORMATION_SCHEMA.TRIGGERS;
For performance-related bugs or problems with
SELECTstatements, you should always include the output ofEXPLAIN SELECT ..., and at least the number of rows that theSELECTstatement produces. You should also include the output fromSHOW CREATE TABLEfor each table that is involved. The more information you provide about your situation, the more likely it is that someone can help you.tbl_nameThe following is an example of a very good bug report. The statements are run using the mysql command-line tool. Note the use of the
\Gstatement terminator for statements that would otherwise provide very long output lines that are difficult to read.mysql>
SHOW VARIABLES;mysql>SHOW COLUMNS FROM ...\G<output from SHOW COLUMNS>mysql>EXPLAIN SELECT ...\G<output from EXPLAIN>mysql>FLUSH STATUS;mysql>SELECT ...;<A short version of the output from SELECT, including the time taken to run the query>mysql>SHOW STATUS;<output from SHOW STATUS>If a bug or problem occurs while running mysqld, try to provide an input script that reproduces the anomaly. This script should include any necessary source files. The more closely the script can reproduce your situation, the better. If you can make a reproducible test case, you should upload it to be attached to the bug report.
If you can't provide a script, you should at least include the output from mysqladmin variables extended-status processlist in your report to provide some information on how your system is performing.
If you can't produce a test case with only a few rows, or if the test table is too big to be included in the bug report (more than 10 rows), you should dump your tables using mysqldump and create a
READMEfile that describes your problem. Create a compressed archive of your files using tar and gzip or zip, and use FTP to transfer the archive to ftp://ftp.mysql.com/pub/mysql/upload/. Then enter the problem into our bugs database at http://bugs.mysql.com/.If you believe that the MySQL server produces a strange result from a statement, include not only the result, but also your opinion of what the result should be, and an explanation describing the basis for your opinion.
When you provide an example of the problem, it's better to use the table names, variable names, and so forth that exist in your actual situation than to come up with new names. The problem could be related to the name of a table or variable. These cases are rare, perhaps, but it is better to be safe than sorry. After all, it should be easier for you to provide an example that uses your actual situation, and it is by all means better for us. If you have data that you don't want to be visible to others in the bug report, you can use FTP to transfer it to ftp://ftp.mysql.com/pub/mysql/upload/. If the information is really top secret and you don't want to show it even to us, go ahead and provide an example using other names, but please regard this as the last choice.
Include all the options given to the relevant programs, if possible. For example, indicate the options that you use when you start the mysqld server, as well as the options that you use to run any MySQL client programs. The options to programs such as mysqld and mysql, and to the configure script, are often key to resolving problems and are very relevant. It is never a bad idea to include them. If your problem involves a program written in a language such as Perl or PHP, please include the language processor's version number, as well as the version for any modules that the program uses. For example, if you have a Perl script that uses the
DBIandDBD::mysqlmodules, include the version numbers for Perl,DBI, andDBD::mysql.If your question is related to the privilege system, please include the output of mysqlaccess, the output of mysqladmin reload, and all the error messages you get when trying to connect. When you test your privileges, you should first run mysqlaccess. After this, execute mysqladmin reload version and try to connect with the program that gives you trouble. mysqlaccess can be found in the
bindirectory under your MySQL installation directory.If you have a patch for a bug, do include it. But don't assume that the patch is all we need, or that we can use it, if you don't provide some necessary information such as test cases showing the bug that your patch fixes. We might find problems with your patch or we might not understand it at all. If so, we can't use it.
If we can't verify the exact purpose of the patch, we won't use it. Test cases help us here. Show that the patch handles all the situations that may occur. If we find a borderline case (even a rare one) where the patch won't work, it may be useless.
Guesses about what the bug is, why it occurs, or what it depends on are usually wrong. Even the MySQL team can't guess such things without first using a debugger to determine the real cause of a bug.
Indicate in your bug report that you have checked the reference manual and mail archive so that others know you have tried to solve the problem yourself.
If the problem is that your data appears corrupt or you get errors when you access a particular table, you should first check your tables and then try to repair them with
CHECK TABLEandREPAIR TABLEor with myisamchk. See Chapter 5, Database Administration.If you are running Windows, please verify the value of
lower_case_table_namesusing theSHOW VARIABLES LIKE 'lower_case_table_names'command. This variable affects how the server handles lettercase of database and table names. Its effect for a given value should be as described in Section 9.2.2, “Identifier Case Sensitivity”.If you often get corrupted tables, you should try to find out when and why this happens. In this case, the error log in the MySQL data directory may contain some information about what happened. (This is the file with the
.errsuffix in the name.) See Section 5.11.1, “The Error Log”. Please include any relevant information from this file in your bug report. Normally mysqld should never crash a table if nothing killed it in the middle of an update. If you can find the cause of mysqld dying, it's much easier for us to provide you with a fix for the problem. See Section B.1.1, “How to Determine What Is Causing a Problem”.If possible, download and install the most recent version of MySQL Server and check whether it solves your problem. All versions of the MySQL software are thoroughly tested and should work without problems. We believe in making everything as backward-compatible as possible, and you should be able to switch MySQL versions without difficulty. See Section 2.4.3, “Choosing Which MySQL Distribution to Install”.
If you have no Web access and cannot report a bug by visiting
http://bugs.mysql.com/, you can use the
mysqlbug script to generate a bug report (or a
report about any problem). mysqlbug helps you
generate a report by determining much of the following information
automatically, but if something important is missing, please include
it with your message. mysqlbug can be found in
the scripts directory (source distribution) and
in the bin directory under your MySQL
installation directory (binary distribution).
This section describes how MySQL relates to the ANSI/ISO SQL standards. MySQL Server has many extensions to the SQL standard, and here you can find out what they are and how to use them. You can also find information about functionality missing from MySQL Server, and how to work around some of the differences.
The SQL standard has been evolving since 1986 and several versions exist. In this manual, “SQL-92” refers to the standard released in 1992, “SQL:1999” refers to the standard released in 1999, and “SQL:2003” refers to the current version of the standard. We use the phrase “the SQL standard” or “standard SQL” to mean the current version of the SQL Standard at any time.
One of our main goals with the product is to continue to work
toward compliance with the SQL standard, but without sacrificing
speed or reliability. We are not afraid to add extensions to SQL
or support for non-SQL features if this greatly increases the
usability of MySQL Server for a large segment of our user base.
The HANDLER interface is an example of this
strategy. See Section 13.2.3, “HANDLER Syntax”.
We continue to support transactional and non-transactional databases to satisfy both mission-critical 24/7 usage and heavy Web or logging usage.
MySQL Server was originally designed to work with medium-sized databases (10-100 million rows, or about 100MB per table) on small computer systems. Today MySQL Server handles terabyte-sized databases, but the code can also be compiled in a reduced version suitable for hand-held and embedded devices. The compact design of the MySQL server makes development in both directions possible without any conflicts in the source tree.
Currently, we are not targeting real-time support, although MySQL replication capabilities offer significant functionality.
MySQL supports high-availability database clustering using the
NDBCluster storage engine. See
Chapter 15, MySQL Cluster.
XML support is to be implemented in a future version of the database server.
Our aim is to support the full ANSI/ISO SQL standard, but without making concessions to speed and quality of the code.
ODBC levels 0-3.51.
The MySQL server can operate in different SQL modes, and can apply these modes differentially for different clients. This capability enables each application to tailor the server's operating mode to its own requirements.
SQL modes control aspects of server operation such as what SQL syntax MySQL should support and what kind of data validation checks it should perform. This makes it easier to use MySQL in different environments and to use MySQL together with other database servers.
You can set the default SQL mode by starting
mysqld with the
--sql-mode="
option. You can also change the mode at runtime by setting the
mode_value"sql_mode system variable with a SET
[SESSION|GLOBAL]
sql_mode='
statement.
mode_value'
For more information on setting the SQL mode, see Section 5.2.6, “SQL Modes”.
You can tell mysqld to run in ANSI mode with
the --ansi startup option. Running the server
in ANSI mode is the same as starting it with the following
options:
--transaction-isolation=SERIALIZABLE --sql-mode=ANSI
You can achieve the same effect at runtime by executing these two statements:
SET GLOBAL TRANSACTION ISOLATION LEVEL SERIALIZABLE; SET GLOBAL sql_mode = 'ANSI';
You can see that setting the sql_mode system
variable to 'ANSI' enables all SQL mode
options that are relevant for ANSI mode as follows:
mysql>SET GLOBAL sql_mode='ANSI';mysql>SELECT @@global.sql_mode;-> 'REAL_AS_FLOAT,PIPES_AS_CONCAT,ANSI_QUOTES,IGNORE_SPACE,ANSI'
Note that running the server in ANSI mode with
--ansi is not quite the same as setting the SQL
mode to 'ANSI'. The --ansi
option affects the SQL mode and also sets the transaction
isolation level. Setting the SQL mode to
'ANSI' has no effect on the isolation level.
See Section 5.2.2, “Command Options”, and Section 1.9.2, “Selecting SQL Modes”.
MySQL Server supports some extensions that you probably won't find in other SQL DBMSs. Be warned that if you use them, your code won't be portable to other SQL servers. In some cases, you can write code that includes MySQL extensions, but is still portable, by using comments of the following form:
/*! MySQL-specific code */
In this case, MySQL Server parses and executes the code within
the comment as it would any other SQL statement, but other SQL
servers will ignore the extensions. For example, MySQL Server
recognizes the STRAIGHT_JOIN keyword in the
following statement, but other servers will not:
SELECT /*! STRAIGHT_JOIN */ col1 FROM table1,table2 WHERE ...
If you add a version number after the
‘!’ character, the syntax within
the comment is executed only if the MySQL version is greater
than or equal to the specified version number. The
TEMPORARY keyword in the following comment is
executed only by servers from MySQL 3.23.02 or higher:
CREATE /*!32302 TEMPORARY */ TABLE t (a INT);
The following descriptions list MySQL extensions, organized by category.
Organization of data on disk
MySQL Server maps each database to a directory under the MySQL data directory, and maps tables within a database to filenames in the database directory. This has a few implications:
Database and table names are case sensitive in MySQL Server on operating systems that have case-sensitive filenames (such as most Unix systems). See Section 9.2.2, “Identifier Case Sensitivity”.
You can use standard system commands to back up, rename, move, delete, and copy tables that are managed by the
MyISAMstorage engine. For example, it is possible to rename aMyISAMtable by renaming the.MYD,.MYI, and.frmfiles to which the table corresponds. (Nevertheless, it is preferable to useRENAME TABLEorALTER TABLE ... RENAMEand let the server rename the files.)
Database and table names cannot contain pathname separator characters (‘
/’, ‘\’).General language syntax
By default, strings can be enclosed by either ‘
"’ or ‘'’, not just by ‘'’. (If theANSI_QUOTESSQL mode is enabled, strings can be enclosed only by ‘'’ and the server interprets strings enclosed by ‘"’ as identifiers.)‘
\’ is the escape character in strings.In SQL statements, you can access tables from different databases with the
db_name.tbl_namesyntax. Some SQL servers provide the same functionality but call thisUser space. MySQL Server doesn't support tablespaces such as used in statements like this:CREATE TABLE ralph.my_table ... IN my_tablespace.
SQL statement syntax
The
ANALYZE TABLE,CHECK TABLE,OPTIMIZE TABLE, andREPAIR TABLEstatements.The
CREATE DATABASE,DROP DATABASE, andALTER DATABASEstatements. See Section 13.1.3, “CREATE DATABASESyntax”, Section 13.1.6, “DROP DATABASESyntax”, and Section 13.1.1, “ALTER DATABASESyntax”.The
DOstatement.EXPLAIN SELECTto obtain a description of how tables are processed by the query optimizer.The
FLUSHandRESETstatements.The
SETstatement. See Section 13.5.3, “SETSyntax”.The
SHOWstatement. See Section 13.5.4, “SHOWSyntax”. As of MySQL 5.0, the information produced by many of the MySQL-specificSHOWstatements can be obtained in more standard fashion by usingSELECTto queryINFORMATION_SCHEMA. See Chapter 20, TheINFORMATION_SCHEMADatabase.Use of
LOAD DATA INFILE. In many cases, this syntax is compatible with Oracle'sLOAD DATA INFILE. See Section 13.2.5, “LOAD DATA INFILESyntax”.Use of
RENAME TABLE. See Section 13.1.9, “RENAME TABLESyntax”.Use of
REPLACEinstead ofDELETEplusINSERT. See Section 13.2.6, “REPLACESyntax”.Use of
CHANGE,col_nameDROP, orcol_nameDROP INDEX,IGNOREorRENAMEinALTER TABLEstatements. Use of multipleADD,ALTER,DROP, orCHANGEclauses in anALTER TABLEstatement. See Section 13.1.2, “ALTER TABLESyntax”.Use of index names, indexes on a prefix of a column, and use of
INDEXorKEYinCREATE TABLEstatements. See Section 13.1.5, “CREATE TABLESyntax”.Use of
TEMPORARYorIF NOT EXISTSwithCREATE TABLE.Use of
IF EXISTSwithDROP TABLEandDROP DATABASE.The capability of dropping multiple tables with a single
DROP TABLEstatement.The
ORDER BYandLIMITclauses of theUPDATEandDELETEstatements.INSERT INTOsyntax.tbl_nameSETcol_name= ...The
DELAYEDclause of theINSERTandREPLACEstatements.The
LOW_PRIORITYclause of theINSERT,REPLACE,DELETE, andUPDATEstatements.Use of
INTO OUTFILEorINTO DUMPFILEinSELECTstatements. See Section 13.2.7, “SELECTSyntax”.Options such as
STRAIGHT_JOINorSQL_SMALL_RESULTinSELECTstatements.You don't need to name all selected columns in the
GROUP BYclause. This gives better performance for some very specific, but quite normal queries. See Section 12.11, “Functions and Modifiers for Use withGROUP BYClauses”.You can specify
ASCandDESCwithGROUP BY, not just withORDER BY.The ability to set variables in a statement with the
:=assignment operator:mysql>
SELECT @a:=SUM(total),@b:=COUNT(*),@a/@b AS avg->FROM test_table;mysql>SELECT @t1:=(@t2:=1)+@t3:=4,@t1,@t2,@t3;
Data types
The
MEDIUMINT,SET, andENUMdata types, and the variousBLOBandTEXTdata types.The
AUTO_INCREMENT,BINARY,NULL,UNSIGNED, andZEROFILLdata type attributes.
Functions and operators
To make it easier for users who migrate from other SQL environments, MySQL Server supports aliases for many functions. For example, all string functions support both standard SQL syntax and ODBC syntax.
MySQL Server understands the
||and&&operators to mean logical OR and AND, as in the C programming language. In MySQL Server,||andORare synonyms, as are&&andAND. Because of this nice syntax, MySQL Server doesn't support the standard SQL||operator for string concatenation; useCONCAT()instead. BecauseCONCAT()takes any number of arguments, it's easy to convert use of the||operator to MySQL Server.Use of
COUNT(DISTINCTwherevalue_list)value_listhas more than one element.String comparisons are case-insensitive by default, with sort ordering determined by the collation of the current character set, which is
latin1(cp1252 West European) by default. If you don't like this, you should declare your columns with theBINARYattribute or use theBINARYcast, which causes comparisons to be done using the underlying character code values rather then a lexical ordering.The
%operator is a synonym forMOD(). That is,N%MMOD(.N,M)%is supported for C programmers and for compatibility with PostgreSQL.The
=,<>,<=,<,>=,>,<<,>>,<=>,AND,OR, orLIKEoperators may be used in expressions in the output column list (to the left of theFROM) inSELECTstatements. For example:mysql>
SELECT col1=1 AND col2=2 FROM my_table;The
LAST_INSERT_ID()function returns the most recentAUTO_INCREMENTvalue. See Section 12.10.3, “Information Functions”.LIKEis allowed on numeric values.The
REGEXPandNOT REGEXPextended regular expression operators.CONCAT()orCHAR()with one argument or more than two arguments. (In MySQL Server, these functions can take a variable number of arguments.)The
BIT_COUNT(),CASE,ELT(),FROM_DAYS(),FORMAT(),IF(),PASSWORD(),ENCRYPT(),MD5(),ENCODE(),DECODE(),PERIOD_ADD(),PERIOD_DIFF(),TO_DAYS(), andWEEKDAY()functions.Use of
TRIM()to trim substrings. Standard SQL supports removal of single characters only.The
GROUP BYfunctionsSTD(),BIT_OR(),BIT_AND(),BIT_XOR(), andGROUP_CONCAT(). See Section 12.11, “Functions and Modifiers for Use withGROUP BYClauses”.
For a prioritized list indicating when new extensions are added to MySQL Server, you should consult the online MySQL development roadmap at http://dev.mysql.com/doc/mysql/en/roadmap.html.
We try to make MySQL Server follow the ANSI SQL standard and the ODBC SQL standard, but MySQL Server performs operations differently in some cases:
For
VARCHARcolumns, trailing spaces are removed when the value is stored. (This is fixed in MySQL 5.0.3). See Section B.1.8, “Known Issues in MySQL”.In some cases,
CHARcolumns are silently converted toVARCHARcolumns when you define a table or alter its structure. (This no longer occurs as of MySQL 5.0.3). See Section 13.1.5.1, “Silent Column Specification Changes”.There are several differences between the MySQL and standard SQL privilege systems. For example, in MySQL, privileges for a table are not automatically revoked when you delete a table. You must explicitly issue a
REVOKEstatement to revoke privileges for a table. For more information, see Section 13.5.1.5, “REVOKESyntax”.The
CAST()function does not support cast toREALorBIGINT. See Section 12.9, “Cast Functions and Operators”.Standard SQL requires that a
HAVINGclause in aSELECTstatement be able to refer to columns in theGROUP BYclause. This cannot be done before MySQL 5.0.2.
MySQL 4.1 and up supports subqueries and derived tables. A
“subquery” is a SELECT
statement nested within another statement. A “derived
table” (an unnamed view) is a subquery in the
FROM clause of another statement. See
Section 13.2.8, “Subquery Syntax”.
For MySQL versions older than 4.1, most subqueries can be rewritten using joins or other methods. See Section 13.2.8.11, “Rewriting Subqueries as Joins for Earlier MySQL Versions”, for examples that show how to do this.
MySQL Server doesn't support the SELECT ... INTO
TABLE Sybase SQL extension. Instead, MySQL Server
supports the INSERT INTO ... SELECT
standard SQL syntax, which is basically the same thing. See
Section 13.2.4.1, “INSERT ... SELECT Syntax”. For example:
INSERT INTO tbl_temp2 (fld_id)
SELECT tbl_temp1.fld_order_id
FROM tbl_temp1 WHERE tbl_temp1.fld_order_id > 100;
Alternatively, you can use SELECT ... INTO
OUTFILE or CREATE TABLE ...
SELECT.
As of MySQL 5.0, you can use SELECT ...
INTO with user-defined variables. The same syntax
can also be used inside stored routines using cursors and
local variables. See Section 17.2.7.3, “SELECT ... INTO Statement”.
MySQL Server (version 3.23-max and all versions 4.0 and above)
supports transactions with the InnoDB and
BDB transactional storage engines.
InnoDB provides full
ACID compliance. See
Chapter 14, Storage Engines. For information about
InnoDB differences from standard SQL with
regard to treatment of transaction errors, see
Section 14.2.15, “InnoDB Error Handling”.
The other non-transactional storage engines in MySQL Server
(such as MyISAM) follow a different
paradigm for data integrity called “atomic
operations.” In transactional terms,
MyISAM tables effectively always operate in
AUTOCOMMIT=1 mode. Atomic operations often
offer comparable integrity with higher performance.
Because MySQL Server supports both paradigms, you can decide whether your applications are best served by the speed of atomic operations or the use of transactional features. This choice can be made on a per-table basis.
MySQL Enterprise For expert advice on choosing and tuning storage engines, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
As noted, the trade-off for transactional versus
non-transactional storage engines lies mostly in performance.
Transactional tables have significantly higher memory and disk
space requirements, and more CPU overhead. On the other hand,
transactional storage engines such as
InnoDB also offer many significant
features. MySQL Server's modular design allows the concurrent
use of different storage engines to suit different
requirements and deliver optimum performance in all
situations.
But how do you use the features of MySQL Server to maintain
rigorous integrity even with the non-transactional
MyISAM tables, and how do these features
compare with the transactional storage engines?
If your applications are written in a way that is dependent on being able to call
ROLLBACKrather thanCOMMITin critical situations, transactions are more convenient. Transactions also ensure that unfinished updates or corrupting activities are not committed to the database; the server is given the opportunity to do an automatic rollback and your database is saved.If you use non-transactional tables, MySQL Server in almost all cases allows you to resolve potential problems by including simple checks before updates and by running simple scripts that check the databases for inconsistencies and automatically repair or warn if such an inconsistency occurs. Note that just by using the MySQL log or even adding one extra log, you can normally fix tables perfectly with no data integrity loss.
More often than not, critical transactional updates can be rewritten to be atomic. Generally speaking, all integrity problems that transactions solve can be done with
LOCK TABLESor atomic updates, ensuring that there are no automatic aborts from the server, which is a common problem with transactional database systems.To be safe with MySQL Server, regardless of whether you use transactional tables, you only need to have backups and have binary logging turned on. When that is true, you can recover from any situation that you could with any other transactional database system. It is always good to have backups, regardless of which database system you use.
The transactional paradigm has its benefits and its drawbacks. Many users and application developers depend on the ease with which they can code around problems where an abort appears to be necessary, or is necessary. However, even if you are new to the atomic operations paradigm, or more familiar with transactions, do consider the speed benefit that non-transactional tables can offer on the order of three to five times the speed of the fastest and most optimally tuned transactional tables.
In situations where integrity is of highest importance, MySQL
Server offers transaction-level reliability and integrity even
for non-transactional tables. If you lock tables with
LOCK TABLES, all updates stall until
integrity checks are made. If you obtain a READ
LOCAL lock (as opposed to a write lock) for a table
that allows concurrent inserts at the end of the table, reads
are allowed, as are inserts by other clients. The newly
inserted records are not be seen by the client that has the
read lock until it releases the lock. With INSERT
DELAYED, you can write inserts that go into a local
queue until the locks are released, without having the client
wait for the insert to complete. See
Section 7.3.3, “Concurrent Inserts”, and
Section 13.2.4.2, “INSERT DELAYED Syntax”.
“Atomic,” in the sense that we mean it, is nothing magical. It only means that you can be sure that while each specific update is running, no other user can interfere with it, and there can never be an automatic rollback (which can happen with transactional tables if you are not very careful). MySQL Server also guarantees that there are no dirty reads.
Following are some techniques for working with non-transactional tables:
Loops that need transactions normally can be coded with the help of
LOCK TABLES, and you don't need cursors to update records on the fly.To avoid using
ROLLBACK, you can employ the following strategy:Use
LOCK TABLESto lock all the tables you want to access.Test the conditions that must be true before performing the update.
Update if the conditions are satisfied.
Use
UNLOCK TABLESto release your locks.
This is usually a much faster method than using transactions with possible rollbacks, although not always. The only situation this solution doesn't handle is when someone kills the threads in the middle of an update. In that case, all locks are released but some of the updates may not have been executed.
You can also use functions to update records in a single operation. You can get a very efficient application by using the following techniques:
Modify columns relative to their current value.
Update only those columns that actually have changed.
For example, when we are updating customer information, we update only the customer data that has changed and test only that none of the changed data, or data that depends on the changed data, has changed compared to the original row. The test for changed data is done with the
WHEREclause in theUPDATEstatement. If the record wasn't updated, we give the client a message: “Some of the data you have changed has been changed by another user.” Then we show the old row versus the new row in a window so that the user can decide which version of the customer record to use.This gives us something that is similar to column locking but is actually even better because we only update some of the columns, using values that are relative to their current values. This means that typical
UPDATEstatements look something like these:UPDATE tablename SET pay_back=pay_back+125; UPDATE customer SET customer_date='current_date', address='new address', phone='new phone', money_owed_to_us=money_owed_to_us-125 WHERE customer_id=id AND address='old address' AND phone='old phone';This is very efficient and works even if another client has changed the values in the
pay_backormoney_owed_to_uscolumns.In many cases, users have wanted
LOCK TABLESorROLLBACKfor the purpose of managing unique identifiers. This can be handled much more efficiently without locking or rolling back by using anAUTO_INCREMENTcolumn and either theLAST_INSERT_ID()SQL function or themysql_insert_id()C API function. See Section 12.10.3, “Information Functions”, and Section 22.2.3.37, “mysql_insert_id()”.You can generally code around the need for row-level locking. Some situations really do need it, and
InnoDBtables support row-level locking. Otherwise, withMyISAMtables, you can use a flag column in the table and do something like the following:UPDATE
tbl_nameSET row_flag=1 WHERE id=ID;MySQL returns
1for the number of affected rows if the row was found androw_flagwasn't1in the original row. You can think of this as though MySQL Server changed the preceding statement to:UPDATE
tbl_nameSET row_flag=1 WHERE id=ID AND row_flag <> 1;
Stored procedures and functions are implemented beginning with MySQL 5.0. See Chapter 17, Stored Procedures and Functions.
Basic trigger functionality is implemented beginning with MySQL 5.0.2, with further development planned for MySQL 5.1. See Chapter 18, Triggers.
In MySQL Server 3.23.44 and up, the InnoDB
storage engine supports checking of foreign key constraints,
including CASCADE, ON
DELETE, and ON UPDATE. See
Section 14.2.6.4, “FOREIGN KEY Constraints”.
For storage engines other than InnoDB,
MySQL Server parses the FOREIGN KEY syntax
in CREATE TABLE statements, but does not
use or store it. In the future, the implementation will be
extended to store this information in the table specification
file so that it may be retrieved by
mysqldump and ODBC. At a later stage,
foreign key constraints will be implemented for
MyISAM tables as well.
Foreign key enforcement offers several benefits to database developers:
Assuming proper design of the relationships, foreign key constraints make it more difficult for a programmer to introduce an inconsistency into the database.
Centralized checking of constraints by the database server makes it unnecessary to perform these checks on the application side. This eliminates the possibility that different applications may not all check the constraints in the same way.
Using cascading updates and deletes can simplify the application code.
Properly designed foreign key rules aid in documenting relationships between tables.
Do keep in mind that these benefits come at the cost of additional overhead for the database server to perform the necessary checks. Additional checking by the server affects performance, which for some applications may be sufficiently undesirable as to be avoided if possible. (Some major commercial applications have coded the foreign key logic at the application level for this reason.)
MySQL gives database developers the choice of which approach
to use. If you don't need foreign keys and want to avoid the
overhead associated with enforcing referential integrity, you
can choose another storage engine instead, such as
MyISAM. (For example, the
MyISAM storage engine offers very fast
performance for applications that perform only
INSERT and SELECT
operations. In this case, the table has no holes in the middle
and the inserts can be performed concurrently with retrievals.
See Section 7.3.3, “Concurrent Inserts”.)
If you choose not to take advantage of referential integrity checks, keep the following considerations in mind:
In the absence of server-side foreign key relationship checking, the application itself must handle relationship issues. For example, it must take care to insert rows into tables in the proper order, and to avoid creating orphaned child records. It must also be able to recover from errors that occur in the middle of multiple-record insert operations.
If
ON DELETEis the only referential integrity capability an application needs, you can achieve a similar effect as of MySQL Server 4.0 by using multiple-tableDELETEstatements to delete rows from many tables with a single statement. See Section 13.2.1, “DELETESyntax”.A workaround for the lack of
ON DELETEis to add the appropriateDELETEstatements to your application when you delete records from a table that has a foreign key. In practice, this is often as quick as using foreign keys and is more portable.
Be aware that the use of foreign keys can sometimes lead to problems:
Foreign key support addresses many referential integrity issues, but it is still necessary to design key relationships carefully to avoid circular rules or incorrect combinations of cascading deletes.
It is not uncommon for a DBA to create a topology of relationships that makes it difficult to restore individual tables from a backup. (MySQL alleviates this difficulty by allowing you to temporarily disable foreign key checks when reloading a table that depends on other tables. See Section 14.2.6.4, “
FOREIGN KEYConstraints”. As of MySQL 4.1.1, mysqldump generates dump files that take advantage of this capability automatically when they are reloaded.)
Note that foreign keys in SQL are used to check and enforce
referential integrity, not to join tables. If you want to get
results from multiple tables from a SELECT
statement, you do this by performing a join between them:
SELECT * FROM t1 INNER JOIN t2 ON t1.id = t2.id;
See Section 13.2.7.1, “JOIN Syntax”, and
Section 3.6.6, “Using Foreign Keys”.
The FOREIGN KEY syntax without ON
DELETE ... is often used by ODBC applications to
produce automatic WHERE clauses.
Views (including updatable views) are implemented beginning with MySQL Server 5.0.1. See Chapter 19, Views.
Views are useful for allowing users to access a set of relations (tables) as if it were a single table, and limiting their access to just that. Views can also be used to restrict access to rows (a subset of a particular table). For access control to columns, you can also use the sophisticated privilege system in MySQL Server. See Section 5.7, “The MySQL Access Privilege System”.
In designing an implementation of views, our ambitious goal, as much as is possible within the confines of SQL, has been full compliance with “Codd's Rule #6” for relational database systems: “All views that are theoretically updatable, should in practice also be updatable.”
Standard SQL uses the C syntax /* this is a comment
*/ for comments, and MySQL Server supports this
syntax as well. MySQL also support extensions to this syntax
that allow MySQL-specific SQL to be embedded in the comment,
as described in Section 9.5, “Comment Syntax”.
Standard SQL uses ‘--’ as a
start-comment sequence. MySQL Server uses
‘#’ as the start comment
character. MySQL Server 3.23.3 and up also supports a variant
of the ‘--’ comment style. That
is, the ‘--’ start-comment
sequence must be followed by a space (or by a control
character such as a newline). The space is required to prevent
problems with automatically generated SQL queries that use
constructs such as the following, where we automatically
insert the value of the payment for
payment:
UPDATE account SET credit=credit-payment
Consider about what happens if payment has
a negative value such as -1:
UPDATE account SET credit=credit--1
credit--1 is a legal expression in SQL, but
‘--’ is interpreted as the
start of a comment, part of the expression is discarded. The
result is a statement that has a completely different meaning
than intended:
UPDATE account SET credit=credit
The statement produces no change in value at all. This
illustrates that allowing comments to start with
‘--’ can have serious
consequences.
Using our implementation requires a space following the
‘--’ in order for it to be
recognized as a start-comment sequence in MySQL Server 3.23.3
and newer. Therefore, credit--1 is safe to
use.
Another safe feature is that the mysql
command-line client ignores lines that start with
‘--’.
The following information is relevant only if you are running a MySQL version earlier than 3.23.3:
If you have an SQL script in a text file that contains
‘--’ comments, you should use
the replace utility as follows to convert
the comments to use ‘#’
characters before executing the script:
shell>replace " --" " #" < text-file-with-funny-comments.sql \| mysqldb_name
That is safer than executing the script in the usual way:
shell> mysql db_name < text-file-with-funny-comments.sql
You can also edit the script file “in place” to
change the ‘--’ comments to
‘#’ comments:
shell> replace " --" " #" -- text-file-with-funny-comments.sql
Change them back with this command:
shell> replace " #" " --" -- text-file-with-funny-comments.sql
MySQL allows you to work both with transactional tables that allow rollback and with non-transactional tables that do not. Because of this, constraint handling is a bit different in MySQL than in other DBMSs. We must handle the case when you have inserted or updated a lot of rows in a non-transactional table for which changes cannot be rolled back when an error occurs.
The basic philosophy is that MySQL Server tries to produce an error for anything that it can detect while parsing a statement to be executed, and tries to recover from any errors that occur while executing the statement. We do this in most cases, but not yet for all.
The options MySQL has when an error occurs are to stop the statement in the middle or to recover as well as possible from the problem and continue. By default, the server follows the latter course. This means, for example, that the server may coerce illegal values to the closest legal values.
Beginning with MySQL 5.0.2, several SQL mode options are available to provide greater control over handling of bad data values and whether to continue statement execution or abort when errors occur. Using these options, you can configure MySQL Server to act in a more traditional fashion that is like other DBMSs that reject improper input. The SQL mode can be set globally at server startup to affect all clients. Individual clients can set the SQL mode at runtime, which enables each client to select the behavior most appropriate for its requirements. See Section 5.2.6, “SQL Modes”.
MySQL Enterprise To be alerted when there is no form of server-enforced data integrity, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
The following sections describe how MySQL Server handles different types of constraints.
Normally, an error occurs when you try to
INSERT or UPDATE a row
that causes a primary key, unique key, or foreign key
violation. If you are using a transactional storage engine
such as InnoDB, MySQL automatically rolls
back the statement. If you are using a non-transactional
storage engine, MySQL stops processing the statement at the
row for which the error occurred and leaves any remaining rows
unprocessed.
If you want to ignore such key violations, MySQL supports an
IGNORE keyword for
INSERT and UPDATE. In
this case, MySQL ignores any key violations and continues
processing with the next row. See Section 13.2.4, “INSERT Syntax”,
and Section 13.2.10, “UPDATE Syntax”.
You can get information about the number of rows actually
inserted or updated with the mysql_info() C
API function. You can also use the SHOW
WARNINGS statement. See
Section 22.2.3.35, “mysql_info()”, and
Section 13.5.4.28, “SHOW WARNINGS Syntax”.
Currently, only InnoDB tables support
foreign keys. See
Section 14.2.6.4, “FOREIGN KEY Constraints”. Foreign key
support in MyISAM tables is scheduled for
implementation in MySQL 5.2. See Section 1.6, “MySQL Development Roadmap”.
Before MySQL 5.0.2, MySQL is forgiving of illegal or improper data values and coerces them to legal values for data entry. In MySQL 5.0.2 and up, that remains the default behavior, but you can change the server SQL mode to select more traditional treatment of bad values such that the server rejects them and aborts the statement in which they occur. Section 5.2.6, “SQL Modes”.
This section describes the default (forgiving) behavior of MySQL, as well as the strict SQL mode and how it differs.
If you are not using strict mode, then whenever you insert an
“incorrect” value into a column, such as a
NULL into a NOT NULL
column or a too-large numeric value into a numeric column,
MySQL sets the column to the “best possible
value” instead of producing an error: The following
rules describe in more detail how this works:
If you try to store an out of range value into a numeric column, MySQL Server instead stores zero, the smallest possible value, or the largest possible value, whichever is closest to the invalid value.
For strings, MySQL stores either the empty string or as much of the string as can be stored in the column.
If you try to store a string that doesn't start with a number into a numeric column, MySQL Server stores 0.
Invalid values for
ENUMandSETcolumns ae handled as described in Section 1.9.6.3, “ENUMandSETConstraints”.MySQL allows you to store certain incorrect date values into
DATEandDATETIMEcolumns (such as'2000-02-31'or'2000-02-00'). The idea is that it's not the job of the SQL server to validate dates. If MySQL can store a date value and retrieve exactly the same value, MySQL stores it as given. If the date is totally wrong (outside the server's ability to store it), the special “zero” date value'0000-00-00'is stored in the column instead.If you try to store
NULLinto a column that doesn't takeNULLvalues, an error occurs for single-rowINSERTstatements. For multiple-rowINSERTstatements or forINSERT INTO ... SELECTstatements, MySQL Server stores the implicit default value for the column data type. In general, this is0for numeric types, the empty string ('') for string types, and the “zero” value for date and time types. Implicit default values are discussed in Section 11.1.4, “Data Type Default Values”.If an
INSERTstatement specifies no value for a column, MySQL inserts its default value if the column definition includes an explicitDEFAULTclause. If the definition has no suchDEFAULTclause, MySQL inserts the implicit default value for the column data type.
The reason for using the preceding rules in non-strict mode is that we can't check these conditions until the statement has begun executing. We can't just roll back if we encounter a problem after updating a few rows, because the storage engine may not support rollback. The option of terminating the statement is not that good; in this case, the update would be “half done,” which is probably the worst possible scenario. In this case, it's better to “do the best you can” and then continue as if nothing happened.
In MySQL 5.0.2 and up, you can select stricter treatment of
input values by using the
STRICT_TRANS_TABLES or
STRICT_ALL_TABLES SQL modes:
SET sql_mode = 'STRICT_TRANS_TABLES'; SET sql_mode = 'STRICT_ALL_TABLES';
STRICT_TRANS_TABLES enables strict mode for
transactional storage engines, and also to some extent for
non-transactional engines. It works like this:
For transactional storage engines, bad data values occurring anywhere in a statement cause the statement to abort and roll back.
For non-transactional storage engines, a statement aborts if the error occurs in the first row to be inserted or updated. (When the error occurs in the first row, the statement can be aborted to leave the table unchanged, just as for a transactional table.) Errors in rows after the first do not abort the statement, because the table has already been changed by the first row. Instead, bad data values are adjusted and result in warnings rather than errors. In other words, with
STRICT_TRANS_TABLES, a wrong value causes MySQL to roll back all updates done so far, if that can be done without changing the table. But once the table has been changed, further errors result in adjustments and warnings.
For even stricter checking, enable
STRICT_ALL_TABLES. This is the same as
STRICT_TRANS_TABLES except that for
non-transactional storage engines, errors abort the statement
even for bad data in rows following the first row. This means
that if an error occurs partway through a multiple-row insert
or update for a non-transactional table, a partial update
results. Earlier rows are inserted or updated, but those from
the point of the error on are not. To avoid this for
non-transactional tables, either use single-row statements or
else use STRICT_TRANS_TABLES if conversion
warnings rather than errors are acceptable. To avoid problems
in the first place, do not use MySQL to check column content.
It is safest (and often faster) to let the application ensure
that it passes only legal values to the database.
With either of the strict mode options, you can cause errors
to be treated as warnings by using INSERT
IGNORE or UPDATE IGNORE rather
than INSERT or UPDATE
without IGNORE.
ENUM and SET columns
provide an efficient way to define columns that can contain
only a given set of values. See Section 11.4.4, “The ENUM Type”, and
Section 11.4.5, “The SET Type”. However, before MySQL 5.0.2,
ENUM and SET columns do
not provide true constraints on entry of invalid data:
ENUMcolumns always have a default value. If you specify no default value, then it isNULLfor columns that can haveNULL, otherwise it is the first enumeration value in the column definition.If you insert an incorrect value into an
ENUMcolumn or if you force a value into anENUMcolumn withIGNORE, it is set to the reserved enumeration value of0, which is displayed as an empty string in string context.If you insert an incorrect value into a
SETcolumn, the incorrect value is ignored. For example, if the column can contain the values'a','b', and'c', an attempt to assign'a,x,b,y'results in a value of'a,b'.
As of MySQL 5.0.2, you can configure the server to use strict
SQL mode. See Section 5.2.6, “SQL Modes”. With strict
mode enabled, the definition of a ENUM or
SET column does act as a constraint on
values entered into the column. An error occurs for values
that do not satisfy these conditions:
An
ENUMvalue must be one of those listed in the column definition, or the internal numeric equivalent thereof. The value cannot be the error value (that is, 0 or the empty string). For a column defined asENUM('a','b','c'), values such as'','d', or'ax'are illegal and are rejected.A
SETvalue must be the empty string or a value consisting only of the values listed in the column definition separated by commas. For a column defined asSET('a','b','c'), values such as'd'or'a,b,c,d'are illegal and are rejected.
Errors for invalid values can be suppressed in strict mode if
you use INSERT IGNORE or UPDATE
IGNORE. In this case, a warning is generated rather
than an error. For ENUM, the value is
inserted as the error member (0). For
SET, the value is inserted as given except
that any invalid substrings are deleted. For example,
'a,x,b,y' results in a value of
'a,b'.
Table of Contents
- 2.1. MySQL Installation Overview
- 2.2. Determining your current MySQL version
- 2.3. Installing MySQL Enterprise
- 2.4. Installing MySQL Community Server
- 2.4.1. Overview of MySQL Community Server Installation
- 2.4.2. Operating Systems Supported by MySQL Community Server
- 2.4.3. Choosing Which MySQL Distribution to Install
- 2.4.4. How to Get MySQL
- 2.4.5. Verifying Package Integrity Using MD5 Checksums or
GnuPG - 2.4.6. Installation Layouts
- 2.4.7. Standard MySQL Installation Using a Binary Distribution
- 2.4.8. Installing MySQL on Windows
- 2.4.9. Installing MySQL from RPM Packages on Linux
- 2.4.10. Installing MySQL on Mac OS X
- 2.4.11. Installing MySQL on Solaris
- 2.4.12. Installing MySQL on NetWare
- 2.4.13. Installing MySQL from
tar.gzPackages on Other Unix-Like Systems - 2.4.14. MySQL Installation Using a Source Distribution
- 2.4.15. Post-Installation Setup and Testing
- 2.4.16. Upgrading MySQL
- 2.4.17. Downgrading MySQL
- 2.4.18. Operating System-Specific Notes
- 2.4.19. Environment Variables
- 2.4.20. Perl Installation Notes
This chapter describes how to obtain and install MySQL. You can choose to install MySQL Enterprise or MySQL Community Server:
MySQL Enterprise is MySQL AB's commercial offering for modern enterprise businesses. It includes MySQL Enterprise Server and the services provided by MySQL Network. To install MySQL Enterprise, see Section 2.3, “Installing MySQL Enterprise”.
MySQL Community Server is for users who are comfortable configuring and administering MySQL by themselves. To install MySQL Community Server, see Section 2.4, “Installing MySQL Community Server”.
If you plan to upgrade an existing version of MySQL to a newer version rather than install MySQL for the first time, see Section 2.4.16, “Upgrading MySQL”, for information about upgrade procedures and about issues that you should consider before upgrading.
If you are interested in migrating to MySQL from another database system, you may wish to read Section A.8, “MySQL 5.0 FAQ — Migration”, which contains answers to some common questions concerning migration issues.
To determine the version and release of your currently installed MySQL installation, there are a number of options.
Using a command client (
mysql), the server version of the MySQL server that you are connected to will be shown once you are connected. The server version information will includecommunityorenterpriseaccordingly.For example, here is the output from a MySQL Community Server edition installed on Linux:
Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 6 Server version: 5.0.27-standard MySQL Community Edition - Standard (GPL) Type 'help;' or '\h' for help. Type '\c' to clear the buffer. mysql>
Below is the output from MySQL Enterprise Server on Windows:
Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 2 Server version: 5.0.28-enterprise-gpl-nt MySQL Enterprise Server (GPL) Type 'help;' or '\h' for help. Type '\c' to clear the buffer. mysql>
You may also determine the version information using the version variables. Both the version and version_comment variables contain version information for the server you are connected to. Use the
SHOW VARIABLESstatement to obtain the information you want. For example:mysql> show variables like "%version%"; +-------------------------+------------------------------------------+ | Variable_name | Value | +-------------------------+------------------------------------------+ | protocol_version | 10 | | version | 5.0.27-standard | | version_comment | MySQL Community Edition - Standard (GPL) | | version_compile_machine | i686 | | version_compile_os | pc-linux-gnu | +-------------------------+------------------------------------------+ 5 rows in set (0.04 sec) mysql>
The
STATUScommand will display the version and version comment information. For example:mysql> status; -------------- ./client/mysql Ver 14.12 Distrib 5.0.29, for pc-linux-gnu (i686) using readline 5.0 Connection id: 8 Current database: Current user: mc@localhost SSL: Not in use Current pager: /usr/bin/less Using outfile: '' Using delimiter: ; Server version: 5.0.27-standard MySQL Community Edition - Standard (GPL) Protocol version: 10 Connection: Localhost via UNIX socket Server characterset: latin1 Db characterset: latin1 Client characterset: latin1 Conn. characterset: latin1 UNIX socket: /tmp/mysql.sock Uptime: 1 day 3 hours 58 min 43 sec Threads: 2 Questions: 17 Slow queries: 0 Opens: 11 Flush tables: 1 Open tables: 6 Queries per second avg: 0.000 --------------
MySQL Administrator will show the server version within the Server Information tab. Only the value of the
versioninformation is shown.
This section does not apply to MySQL Community Server users.
This section contains information about the components, installation and initial configuration requirements for installing MySQL Enterprise.
This section does not apply to MySQL Community Server users.
To obtain MySQL Enterprise, visit http://www.mysql.com/products/enterprise/. The platforms that are officially supported for MySQL Enterprise are listed at http://www.mysql.com/support/supportedplatforms.html.
To install MySQL Enterprise, you should install the main distribution plus the latest available service pack or hot-fix. You only need to install the latest service pack or hot-fix – this will include all updates since the previous main distribution release. For platforms that do not have a MySQL Enterprise Server installer, use the Community Server instructions (see Section 2.4, “Installing MySQL Community Server”).
This section does not apply to MySQL Community Server users.
Enterprise Server releases will be created for the following packages from the MySQL 5.0 tree:
mysql-enterprise: Released under a commercial license and includes the following storage engines:MyISAM,MEMORY,MERGE,InnoDB,ARCHIVE,BLACKHOLE,EXAMPLE,FEDERATED.mysql-enterprise-gpl: Same asmysql-enterprise, but released under the GPL.mysql-cluster:mysql-enterpriseplus MySQL Cluster (NDB).mysql-classic: Released under a commercial license, does not includeInnoDB.mysql-community: Same asmysql-enterprise-gpl, but available for the community, and released every 6 months.
To satisfy different user requirements, we provide several servers. mysqld is an optimized server that is a smaller, faster binary. mysqld-debug is compiled with debugging support but is otherwise configured identically to the non-debug server.
Each of these servers is compiled from the same source distribution, though with different configuration options. All native MySQL clients can connect to servers from either MySQL version.
This section does not apply to MySQL Community Server users.
Installers for MySQL Enterprise are available for the Windows and Mac OS X. For other platforms, you will need to use the TAR, Zip or native package format (RPM, Solaris PKG) pafiles to perform the installation.
This section does not apply to MySQL Community Server users.
The Enterprise MySQL Server installer installs the MySQL server and the MySQL Server Configuration Wizard, and enables you to run the configuration wizard to set up and configure your server before use.
To start the installation process:
Download the
mysql-enterprisefile and extract theVERSION-win32.zipSetup.exefile. You should double-click on this file to start the installation process.The opening screen provides an overview of what the installer will achieve. Click to continue.
Choose your installation type. The Typical installation installs the main server and associated components, but does not include the developer libraries. The Complete installation installs everything. The Custom installation enables you to select which components are installed. Choose your installation and click to continue.
If you have selected the custom installation, you need to choose which components are installed. Click to continute.
The installation choices you have made will be summarized for you. If you have made a mistake, you can click to choose an alternate installation type. If you are ready to continue, choose .
You can optionally set up your a connection to your MySQL.com account by entering your login details, or you can create a new account, or you can skip the MySQL.com signup.
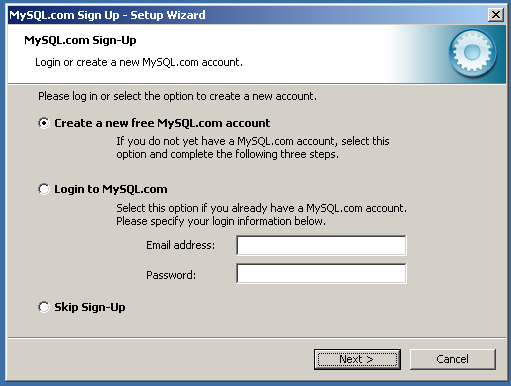
The installation should proceed, installing the components you have selected. Once the installation has completed, you will get the opportunity to start the MySQL Instance Configuration Wizard. Untick the box if you do not want to run the wizard at this time. Click to complete the installation. If you have opted to run the wizard, then it will be started once the installer has completed.
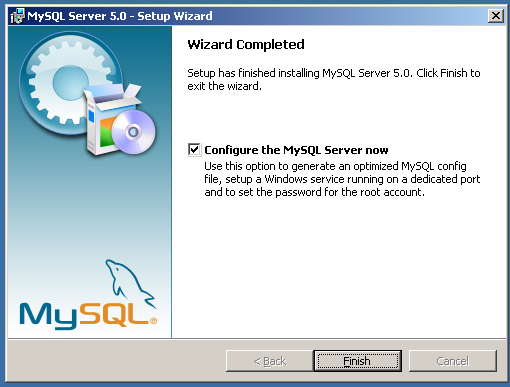
If you selected to run the MySQL Configuration Wizard, see Section 2.3.3.2, “MySQL Server Configuration Wizard”.
The MySQL Server Configuration Wizard helps automate the process of
configuring your server. It creates a custom MySQL configuration
file (my.ini or my.cnf) by
asking you a series of questions and then applying your responses to
a template to generate the configuration file that is tuned to your
installation.
The MySQL Server Configuration Wizard is included with the MySQL 5.0 server. For Community Server users, the MySQL Server Configuration Wizard is available only for Windows. For Enterprise Server users, the MySQL Server Configuration Wizard is included as part of the standard Enterprise Installer.
The MySQL Server Configuration Wizard is to a large extent the result of feedback that MySQL AB has received from many users over a period of several years. However, if you find that it lacks some feature important to you, please report it in our bugs database using the instructions given in Section 1.8, “How to Report Bugs or Problems”.
The MySQL Server Configuration Wizard is normally started as part of the installation process. You should only need to run the MySQL Server Configuration Wizard again when you need to change the configuration parameters of your server.
You can launch the MySQL Configuration Wizard by clicking the entry in the section of the Windows menu.
Alternatively, you can navigate to the bin
directory of your MySQL installation and launch the
MySQLInstanceConfig.exe file directly.
The MySQL Server Configuration Wizard places the
my.ini file in the installation directory
for the MySQL server. This helps associate configuration files
with particular server instances.
To ensure that the MySQL server knows where to look for the
my.ini file, an argument similar to this is
passed to the MySQL server as part of the service installation:
--defaults-file="C:\Program Files\MySQL\MySQL Server 5.0\my.ini"
Here, C:\Program Files\MySQL\MySQL Server
5.0 is replaced with the installation
path to the MySQL Server. The --defaults-file
option instructs the MySQL server to read the specified file for
configuration options when it starts.
Apart from making changes to the my.ini
file by running the MySQL Server Configuration Wizard again, you
can modify it by opening it with a text editor and making any
necessary changes. You can also modify the server configuration
with the
MySQL
Administrator utility. For more information about server
configuration, see Section 5.2.2, “Command Options”.
MySQL clients and utilities such as the mysql
and mysqldump command-line clients are not
able to locate the my.ini file located in
the server installation directory. To configure the client and
utility applications, create a new my.ini
file in the Windows installation directory (for example,
C:\WINDOWS).
Under Windows Server 2003, Windows Server 2000 and Windows XP,
MySQL Server Configuration Wizard will configure MySQL to work
as a Windows service. To start and stop MySQL you use the
Services application that is supplied as
part of the Windows Administrator Tools.
This section does not apply to MySQL Community Server users.
To start the MySQL Configuration Wizard on Linux, you must run
the mysqlsetup command. You must be running
an X Windows System server for the MySQL Server Configuration
Wizard.
To display the MySQL Server Configuration Wizard interface on a
different machine, set the value of the
DISPLAY variable on the command line:
shell>
DISPLAY=remote:0.0 mysqlsetup
The MySQL Server Configuration Wizard places the
my.cnf file in the
/etc directory.
This configuration file is automatically used when
mysqld is started. The standard MySQL server
initialization script, typically located within
/etc/init.d/mysql, will also use this file
automatically.
Apart from making changes to the my.ini
file by running the MySQL Server Configuration Wizard again, you
can modify it by opening it with a text editor and making any
necessary changes. You can also modify the server configuration
with the
MySQL
Administrator utility. For more information about server
configuration, see Section 5.2.2, “Command Options”.
If the MySQL Server Configuration Wizard detects an existing configuration file, you have the option of either reconfiguring your existing server, or removing the server instance by deleting the configuration file and stopping and removing the MySQL service.
To reconfigure an existing server, choose the option and click the button. Any existing configuration file is not overwritten, but renamed (within the same directory) using a timestamp (Windows) or sequential number (Linux). To remove the existing server instance, choose the option and click the button.
If you choose the
option, you advance to a confirmation window. Click the
button. The MySQL Server
Configuration Wizard stops and removes the MySQL service, and then
deletes the configuration file. The server installation and its
data folder are not removed.
If you choose the option, you advance to the dialog where you can choose the type of installation that you wish to configure.
When you start the MySQL Server Configuration Wizard for a new MySQL installation, or choose the option for an existing installation, you advance to the dialog.
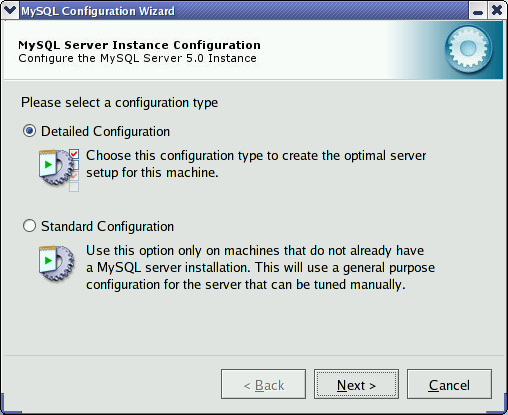
There are two configuration types available: and . The option is intended for new users who want to get started with MySQL quickly without having to make many decisions about server configuration. The option is intended for advanced users who want more fine-grained control over server configuration.
If you are new to MySQL and need a server configured as a single-user developer machine, the should suit your needs. Choosing the option causes the MySQL Configuration Wizard to set all configuration options automatically with the exception of and .
The sets options that may be incompatible with systems where there are existing MySQL installations. If you have an existing MySQL installation on your system in addition to the installation you wish to configure, the option is recommended.
To complete the , please refer to the sections on and in Section 2.3.3.2.10, “The Service Options Dialog”, and Section 2.3.3.2.11, “The Security Options Dialog”, respectively.
There are three different server types available to choose from. The server type that you choose affects the decisions that the MySQL Server Configuration Wizard makes with regard to memory, disk, and processor usage.
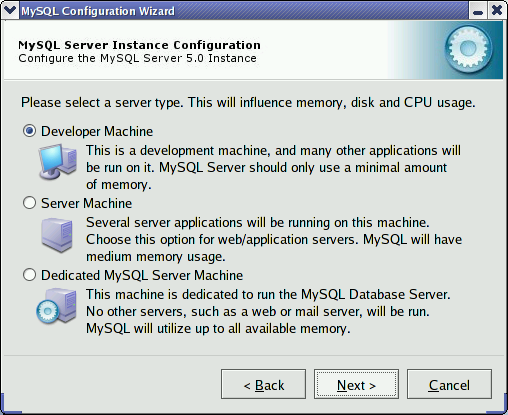
: Choose this option for a typical desktop workstation where MySQL is intended only for personal use. It is assumed that many other desktop applications are running. The MySQL server is configured to use minimal system resources.
: Choose this option for a server machine where the MySQL server is running alongside other server applications such as FTP, email, and Web servers. The MySQL server is configured to use a moderate portion of the system resources.
: Choose this option for a server machine that is intended to run only the MySQL server. It is assumed that no other applications are running. The MySQL server is configured to use all available system resources.
Note
By selecting one of the preconfigured configurations, the values
and settings of various options in your
my.cnf or my.ini will
be altered accordingly. The default values and options as
described in the reference manual may therefore be different to
the options and values that were created during the execution of
the configuration wizard.
The dialog allows you to
indicate the storage engines that you expect to use when creating
MySQL tables. The option you choose determines whether the
InnoDB storage engine is available and what
percentage of the server resources are available to
InnoDB.
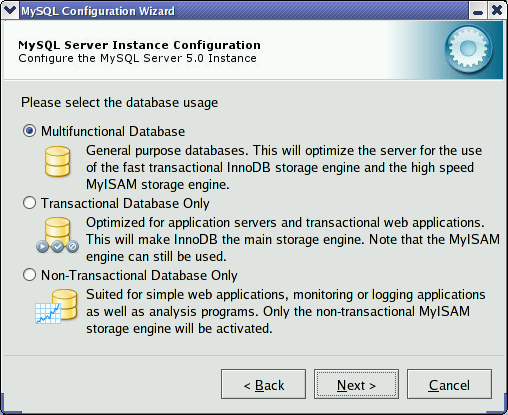
: This option enables both the
InnoDBandMyISAMstorage engines and divides resources evenly between the two. This option is recommended for users who use both storage engines on a regular basis.: This option enables both the
InnoDBandMyISAMstorage engines, but dedicates most server resources to theInnoDBstorage engine. This option is recommended for users who useInnoDBalmost exclusively and make only minimal use ofMyISAM.: This option disables the
InnoDBstorage engine completely and dedicates all server resources to theMyISAMstorage engine. This option is recommended for users who do not useInnoDB.
Some users may want to locate the InnoDB
tablespace files in a different location than the MySQL server
data directory. Placing the tablespace files in a separate
location can be desirable if your system has a higher capacity or
higher performance storage device available, such as a RAID
storage system.
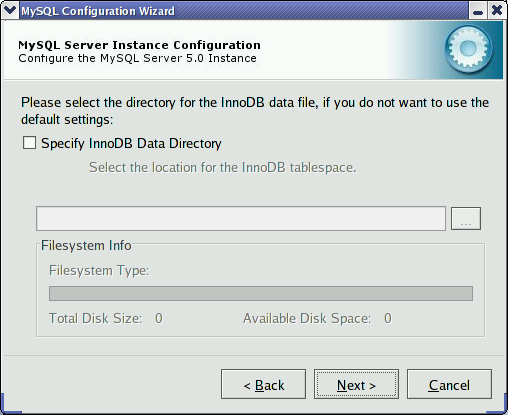
To change the default location for the InnoDB
tablespace files, choose a new drive from the drop-down list of
drive letters and choose a new path from the drop-down list of
paths. To create a custom path, click the
button.
If you are modifying the configuration of an existing server, you must click the button before you change the path. In this situation you must move the existing tablespace files to the new location manually before starting the server.
To prevent the server from running out of resources, it is important to limit the number of concurrent connections to the MySQL server that can be established. The dialog allows you to choose the expected usage of your server, and sets the limit for concurrent connections accordingly. It is also possible to set the concurrent connection limit manually.
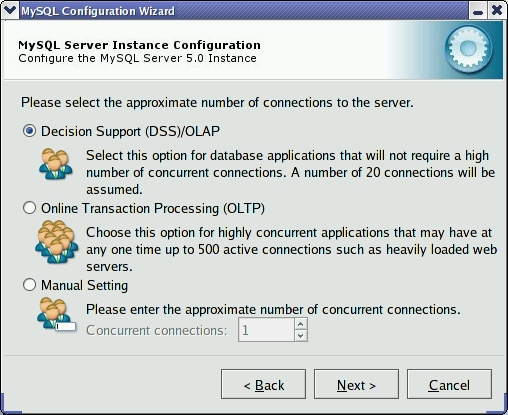
: Choose this option if your server does not require a large number of concurrent connections. The maximum number of connections is set at 100, with an average of 20 concurrent connections assumed.
: Choose this option if your server requires a large number of concurrent connections. The maximum number of connections is set at 500.
: Choose this option to set the maximum number of concurrent connections to the server manually. Choose the number of concurrent connections from the drop-down box provided, or enter the maximum number of connections into the drop-down box if the number you desire is not listed.
Use the dialog to enable or disable TCP/IP networking and to configure the port number that is used to connect to the MySQL server.
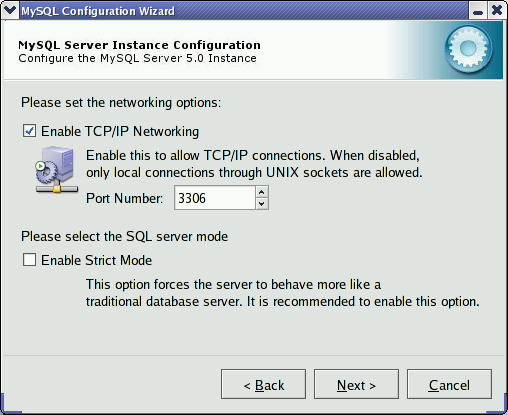
TCP/IP networking is enabled by default. To disable TCP/IP networking, uncheck the box next to the option.
Port 3306 is used by default. To change the port used to access MySQL, choose a new port number from the drop-down box or type a new port number directly into the drop-down box. If the port number you choose is in use, you are prompted to confirm your choice of port number.
Set the to either enable or disable strict mode. Enabling strict mode (default) makes MySQL behave more like other database management systems. If you run applications that rely on MySQL's old “forgiving” behavior, make sure to either adapt those applications or to disable strict mode. For more information about strict mode, see Section 5.2.6, “SQL Modes”.
The MySQL server supports multiple character sets and it is possible to set a default server character set that is applied to all tables, columns, and databases unless overridden. Use the dialog to change the default character set of the MySQL server.
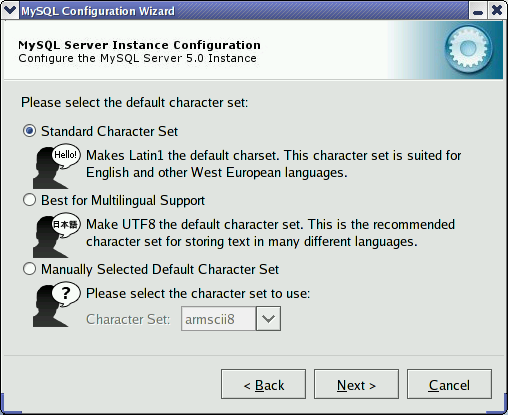
: Choose this option if you want to use
latin1as the default server character set.latin1is used for English and many Western European languages.: Choose this option if you want to use
utf8as the default server character set. This is a Unicode character set that can store characters from many different languages.: Choose this option if you want to pick the server's default character set manually. Choose the desired character set from the provided drop-down list.
This section does not apply to MySQL Community Server users.
On Windows platforms, the MySQL server can be installed as a Windows service. When installed this way, the MySQL server can be started automatically during system startup, and even restarted automatically by Windows in the event of a service failure.
The MySQL Server Configuration Wizard installs the MySQL server as
a service by default, using the service name
MySQL. If you do not wish to install the
service, uncheck the box next to the option. You can change the service
name by picking a new service name from the drop-down box provided
or by entering a new service name into the drop-down box.
To install the MySQL server as a service but not have it started automatically at startup, uncheck the box next to the option.
It is strongly recommended that you set a
root password for your MySQL server,
and the MySQL Server Configuration Wizard requires by default that
you do so. If you do not wish to set a root
password, uncheck the box next to the option.
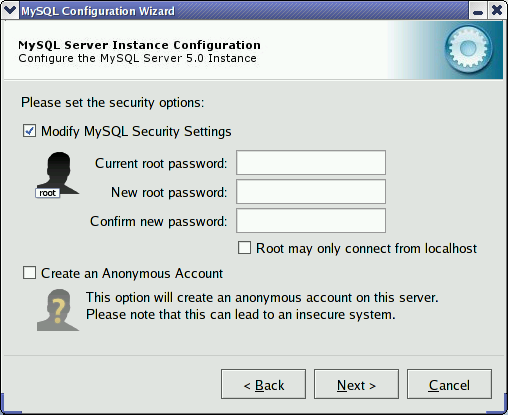
To set the root password, enter the desired
password into both the and
boxes. If you are reconfiguring an existing server, you need to
enter the existing root password into the
box.
To prevent root logins from across the network,
check the box next to the option. This increases the security of
your root account.
To create an anonymous user account, check the box next to the option. Creating an anonymous account can decrease server security and cause login and permission difficulties. For this reason, it is not recommended.
The final dialog in the MySQL Server Configuration Wizard is the . To start the configuration process, click the button. To return to a previous dialog, click the button. To exit the MySQL Server Configuration Wizard without configuring the server, click the button.
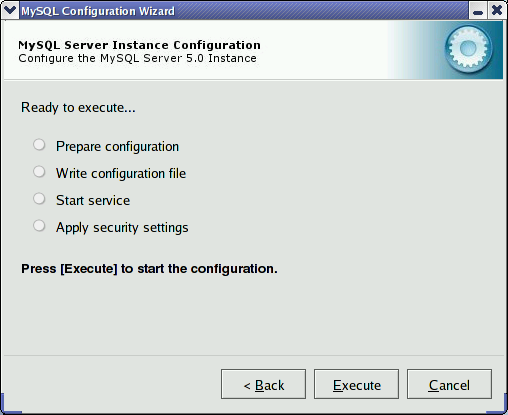
After you click the button, the MySQL Server Configuration Wizard performs a series of tasks and displays the progress onscreen as the tasks are performed.
The MySQL Server Configuration Wizard first determines
configuration file options based on your choices using a template
prepared by MySQL AB developers and engineers. This template is
named my-template.ini and is located in your
server installation directory.
The MySQL Configuration Wizard then writes these options to the corresponding configuration file.
If you chose to create a service for the MySQL server, the MySQL Server Configuration Wizard creates and starts the service. If you are reconfiguring an existing service, the MySQL Server Configuration Wizard restarts the service to apply your configuration changes.
If you chose to set a root password, the MySQL
Configuration Wizard connects to the server, sets your new
root password, and applies any other security
settings you may have selected.
After the MySQL Server Configuration Wizard has completed its tasks, it displays a summary. Click the button to exit the MySQL Server Configuration Wizard.
This section does not apply to MySQL Community Server users.
When upgrading to MySQL Enterprise from Community Server you need only follow the installation process to install and upgrade the packages to the latest version provided by MySQL Enterprise. You will also need to install the latest MySQL Enterprise Service Pack and any outstanding MySQL Hot-fix packs.
Be aware, however, that you must take into account any of the changes when moving between major releases. You should also check the release notes (see Appendix C, MySQL Enterprise Release Notes) for details on major changes between revisions of MySQL Enterprise Server. For details of changes in other packages in MySQL Enterprise, see Appendix E, MySQL Change History.
You should also review the notes and advice contained within Section 2.4.16, “Upgrading MySQL”.
This section does not apply to MySQL Community Server users.
You can uninstall MySQL Enterprise using the standard tools according to your operating system.
Note
When uninstalling, any data files created are not removed. You will need to separately remove these files to completely remove MySQL from your system.
To uninstall MySQL Enterprise on Windows you should use the Add or Remove Programs utility located within the Control Panel.
Packages within MySQL Enterprise must be removed individually. You may also use this option to remove packages that you no longer want or use.
Any data you created while MySQL Enterprise was installed will not be removed. You will need to separately delete this information.
To uninstall MySQL Enterprise on a Linux operating system that uses the RPM package format, you must remove each of the packages that were installed by the MySQL Enterprise Installer individually.
To do this, first obtain a list of the installed packages:
shell> rpm -q -a|grep -i mysql mysql-docs-en-5.0.26-1 MySQL-server-standard-5.0.26-0.rhel4 mysql-connector-j-5.0.3-1 MySQL-devel-standard-5.0.26-0.rhel4 mysql-query-browser-5.0r4-1rhel4 mysql-connector-odbc-3.51.12-1 MySQL-client-standard-5.0.26-0.rhel4 mysql-administrator-5.0r4-1rhel4 mysql-gui-tools-5.0r4-1rhel4 mysql-setup-wizard-1.0-1 mysql-connector-net-1.0.7-1
You can remove these packages individually, or all together automatically, like this:
shell> rpm -q -a|grep -i mysql|xargs rpm --erase
- 2.4.1. Overview of MySQL Community Server Installation
- 2.4.2. Operating Systems Supported by MySQL Community Server
- 2.4.3. Choosing Which MySQL Distribution to Install
- 2.4.4. How to Get MySQL
- 2.4.5. Verifying Package Integrity Using MD5 Checksums or
GnuPG - 2.4.6. Installation Layouts
- 2.4.7. Standard MySQL Installation Using a Binary Distribution
- 2.4.8. Installing MySQL on Windows
- 2.4.9. Installing MySQL from RPM Packages on Linux
- 2.4.10. Installing MySQL on Mac OS X
- 2.4.11. Installing MySQL on Solaris
- 2.4.12. Installing MySQL on NetWare
- 2.4.13. Installing MySQL from
tar.gzPackages on Other Unix-Like Systems - 2.4.14. MySQL Installation Using a Source Distribution
- 2.4.15. Post-Installation Setup and Testing
- 2.4.16. Upgrading MySQL
- 2.4.17. Downgrading MySQL
- 2.4.18. Operating System-Specific Notes
- 2.4.19. Environment Variables
- 2.4.20. Perl Installation Notes
Determine whether MySQL runs and is supported on your platform. Please note that not all platforms are equally suitable for running MySQL, and that not all platforms on which MySQL is known to run are officially supported by MySQL AB. For a list of platforms on which MySQL Community Server runs, see Section 2.4.2, “Operating Systems Supported by MySQL Community Server”.
Choose which distribution to install. Several versions of MySQL are available, and most are available in several distribution formats. You can choose from prepackaged distributions containing binary (precompiled) programs or source code. When in doubt, use a binary distribution. We also provide public access to our current source tree for those who want to see our most recent developments and help us test new code. To determine which version and type of distribution you should use, see Section 2.4.3, “Choosing Which MySQL Distribution to Install”.
Download the distribution that you want to install. For instructions, see Section 2.4.4, “How to Get MySQL”. To verify the integrity of the distribution, use the instructions in Section 2.4.5, “Verifying Package Integrity Using MD5 Checksums or
GnuPG”.Install the distribution. To install MySQL from a binary distribution, use the instructions in Section 2.4.7, “Standard MySQL Installation Using a Binary Distribution”. To install MySQL from a source distribution or from the current development source tree, use the instructions in Section 2.4.14, “MySQL Installation Using a Source Distribution”.
If you encounter installation difficulties, see Section 2.4.18, “Operating System-Specific Notes”, for information on solving problems for particular platforms.
Perform any necessary post-installation setup. After installing MySQL, read Section 2.4.15, “Post-Installation Setup and Testing”. This section contains important information about making sure the MySQL server is working properly. It also describes how to secure the initial MySQL user accounts, which have no passwords until you assign passwords. The section applies whether you install MySQL using a binary or source distribution.
If you want to run the MySQL benchmark scripts, Perl support for MySQL must be available. See Section 2.4.20, “Perl Installation Notes”.
The immediately following sections contain the information necessary to choose, download, and verify your distribution. The instructions in later sections of the chapter describe how to install the distribution that you choose. For binary distributions, see the instructions at Section 2.4.7, “Standard MySQL Installation Using a Binary Distribution”. To build MySQL from source, use the instructions at Section 2.4.14, “MySQL Installation Using a Source Distribution”.
This section does not apply to MySQL Enterprise Server users.
This section lists the operating systems on which MySQL Community Server is known to run.
Important: MySQL AB does not necessarily provide official support for all the platforms listed in this section. For information about those platforms which MySQL AB officially supports, see MySQL Server Supported Platforms on the MySQL Web site.
We use GNU Autoconf, so it is possible to port MySQL to all modern systems that have a C++ compiler and a working implementation of POSIX threads. (Thread support is needed for the server. To compile only the client code, the only requirement is a C++ compiler.)
MySQL has been reported to compile successfully on the following combinations of operating system and thread package.
AIX 4.x, 5.x with native threads. See Section 2.4.18.5.3, “IBM-AIX notes”.
Amiga.
FreeBSD 5.x and up with native threads.
HP-UX 11.x with the native threads. See Section 2.4.18.5.2, “HP-UX Version 11.x Notes”.
Linux, builds on all fairly recent Linux distributions with
glibc2.3. See Section 2.4.18.1, “Linux Notes”.Mac OS X. See Section 2.4.18.2, “Mac OS X Notes”.
NetBSD 1.3/1.4 Intel and NetBSD 1.3 Alpha. See Section 2.4.18.4.2, “NetBSD Notes”.
Novell NetWare 6.0 and 6.5. See Section 2.4.12, “Installing MySQL on NetWare”.
OpenBSD 2.5 and with native threads. OpenBSD earlier than 2.5 with the MIT-pthreads package. See Section 2.4.18.4.3, “OpenBSD 2.5 Notes”.
SCO OpenServer 5.0.X with a recent port of the FSU Pthreads package. See Section 2.4.18.5.8, “SCO UNIX and OpenServer 5.0.x Notes”.
SCO Openserver 6.0.x. See Section 2.4.18.5.9, “SCO OpenServer 6.0.x Notes”.
SCO UnixWare 7.1.x. See Section 2.4.18.5.10, “SCO UnixWare 7.1.x and OpenUNIX 8.0.0 Notes”.
SGI Irix 6.x with native threads. See Section 2.4.18.5.7, “SGI Irix Notes”.
Solaris 2.5 and above with native threads on SPARC and x86. See Section 2.4.18.3, “Solaris Notes”.
Tru64 Unix. See Section 2.4.18.5.5, “Alpha-DEC-UNIX Notes (Tru64)”.
Windows 2000, XP, and Windows Server 2003. See Section 2.4.8, “Installing MySQL on Windows”.
MySQL has also been known to run on other systems in the past. See Section 2.4.18, “Operating System-Specific Notes”. Some porting effort might be required for current versions of MySQL on these systems.
Not all platforms are equally well suited for running MySQL. How well a certain platform is suited for a high-load mission-critical MySQL server is determined by the following factors:
General stability of the thread library. A platform may have an excellent reputation otherwise, but MySQL is only as stable as the thread library it calls, even if everything else is perfect.
The capability of the kernel and the thread library to take advantage of symmetric multi-processor (SMP) systems. In other words, when a process creates a thread, it should be possible for that thread to run on a CPU different from the original process.
The capability of the kernel and the thread library to run many threads that acquire and release a mutex over a short critical region frequently without excessive context switches. If the implementation of
pthread_mutex_lock()is too anxious to yield CPU time, this hurts MySQL tremendously. If this issue is not taken care of, adding extra CPUs actually makes MySQL slower.General filesystem stability and performance.
If your tables are large, performance is affected by the ability of the filesystem to deal with large files at all and to deal with them efficiently.
Our level of expertise here at MySQL AB with the platform. If we know a platform well, we enable platform-specific optimizations and fixes at compile time. We can also provide advice on configuring your system optimally for MySQL.
The amount of testing we have done internally for similar configurations.
The number of users that have run MySQL successfully on the platform in similar configurations. If this number is high, the likelihood of encountering platform-specific surprises is much smaller.
This section does not apply to MySQL Enterprise Server users.
When preparing to install MySQL, you should decide which version to use. MySQL development occurs in several release series, and you can pick the one that best fits your needs. After deciding which version to install, you can choose a distribution format. Releases are available in binary or source format.
This section does not apply to MySQL Enterprise Server users.
The first decision to make is whether you want to use a production (stable) release or a development release. In the MySQL development process, multiple release series co-exist, each at a different stage of maturity:
MySQL 5.1 is the current development release series.
MySQL 5.0 is the current stable (production-quality) release series. New releases are issued for bugfixes only; no new features are being added that could effect stability.
MySQL 4.1 is the previous stable (production-quality) release series. New releases are issued for critical bugfixes and security fixes. No significant new features are to be added to this series.
MySQL 4.0 and 3.23 are the old stable (production-quality) release series. These versions are now retired, so new releases are issued only to fix extremely critical bugs (primarily security issues).
We do not believe in a complete code freeze because this prevents us from making bugfixes and other fixes that must be done. By “somewhat frozen” we mean that we may add small things that should not affect anything that currently works in a production release. Naturally, relevant bugfixes from an earlier series propagate to later series.
Normally, if you are beginning to use MySQL for the first time or trying to port it to some system for which there is no binary distribution, we recommend going with the production release series. Currently, this is MySQL 5.0. All MySQL releases, even those from development series, are checked with the MySQL benchmarks and an extensive test suite before being issued.
If you are running an older system and want to upgrade, but do not want to take the chance of having a non-seamless upgrade, you should upgrade to the latest version in the same release series you are using (where only the last part of the version number is newer than yours). We have tried to fix only fatal bugs and make only small, relatively “safe” changes to that version.
If you want to use new features not present in the production release series, you can use a version from a development series. Note that development releases are not as stable as production releases.
If you want to use the very latest sources containing all current patches and bugfixes, you can use one of our BitKeeper repositories. These are not “releases” as such, but are available as previews of the code on which future releases are to be based.
The MySQL naming scheme uses release names that consist of three numbers and a suffix; for example, mysql-5.0.12-beta. The numbers within the release name are interpreted as follows:
The first number (5) is the major version and describes the file format. All MySQL 5 releases have the same file format.
The second number (0) is the release level. Taken together, the major version and release level constitute the release series number.
The third number (12) is the version number within the release series. This is incremented for each new release. Usually you want the latest version for the series you have chosen.
For each minor update, the last number in the version string is incremented. When there are major new features or minor incompatibilities with previous versions, the second number in the version string is incremented. When the file format changes, the first number is increased.
Release names also include a suffix to indicates the stability level of the release. Releases within a series progress through a set of suffixes to indicate how the stability level improves. The possible suffixes are:
alpha indicates that the release is for preview purposes only. Known bugs should be documented in the News section (see Appendix E, MySQL Change History). Most alpha releases implement new commands and extensions. Active development that may involve major code changes can occur in an alpha release. However, we do conduct testing before issuing a release.
beta indicates that the release is appropriate for use with new development. Within beta releases, the features and compatibility should remain consistent. However, beta releases may contain numerous and major unaddressed bugs.
All APIs, externally visible structures, and columns for SQL statements will not change during future beta, release candidate, or production releases.
rc indicates a Release Candidate. Release candidates are believed to be stable, having passed all of MySQL's internal testing, and with all known fatal runtime bugs fixed. However, the release has not been in widespread use long enough to know for sure that all bugs have been identified. Only minor fixes are added. (A release candidate is what formerly was known as a gamma release.)
If there is no suffix, it indicates that the release is a General Availability (GA) or Production release. GA releases are stable, having successfully passed through all earlier release stages and are believed to be reliable, free of serious bugs, and suitable for use in production systems. Only critical bugfixes are applied to the release.
MySQL uses a naming scheme that is slightly different from most other products. In general, it is usually safe to use any version that has been out for a couple of weeks without being replaced by a new version within the same release series.
All releases of MySQL are run through our standard tests and benchmarks to ensure that they are relatively safe to use. Because the standard tests are extended over time to check for all previously found bugs, the test suite keeps getting better.
All releases have been tested at least with these tools:
An internal test suite
The
mysql-testdirectory contains an extensive set of test cases. We run these tests for every server binary. See Section 24.1.2, “MySQL Test Suite”, for more information about this test suite.The MySQL benchmark suite
This suite runs a range of common queries. It is also a test to determine whether the latest batch of optimizations actually made the code faster. See Section 7.1.4, “The MySQL Benchmark Suite”.
The
crash-metestThis test tries to determine what features the database supports and what its capabilities and limitations are. See Section 7.1.4, “The MySQL Benchmark Suite”.
We also test the newest MySQL version in our internal production environment, on at least one machine. We have more than 100GB of data to work with.
This section does not apply to MySQL Enterprise Server users.
After choosing which version of MySQL to install, you should decide whether to use a binary distribution or a source distribution. In most cases, you should probably use a binary distribution, if one exists for your platform. Binary distributions are available in native format for many platforms, such as RPM files for Linux or PKG package installers for Mac OS X or Solaris. Distributions also are available as Zip archives or compressed tar files.
Reasons to choose a binary distribution include the following:
Binary distributions generally are easier to install than source distributions.
To satisfy different user requirements, we provide several servers in binary distributions. mysqld is an optimized server that is a smaller, faster binary. mysqld-debug is compiled with debugging support.
Each of these servers is compiled from the same source distribution, though with different configuration options. All native MySQL clients can connect to servers from either MySQL version.
Under some circumstances, you may be better off installing MySQL from a source distribution:
You want to install MySQL at some explicit location. The standard binary distributions are ready to run at any installation location, but you might require even more flexibility to place MySQL components where you want.
You want to configure mysqld to ensure that features are available that might not be included in the standard binary distributions. Here is a list of the most common extra options that you may want to use to ensure feature availability:
--with-berkeley-db(not available on all platforms)--with-libwrap--with-named-z-libs(this is done for some of the binaries)--with-debug[=full]
You want to configure mysqld without some features that are included in the standard binary distributions. For example, distributions normally are compiled with support for all character sets. If you want a smaller MySQL server, you can recompile it with support for only the character sets you need.
You have a special compiler (such as
pgcc) or want to use compiler options that are better optimized for your processor. Binary distributions are compiled with options that should work on a variety of processors from the same processor family.You want to use the latest sources from one of the BitKeeper repositories to have access to all current bugfixes. For example, if you have found a bug and reported it to the MySQL development team, the bugfix is committed to the source repository and you can access it there. The bugfix does not appear in a release until a release actually is issued.
You want to read (or modify) the C and C++ code that makes up MySQL. For this purpose, you should get a source distribution, because the source code is always the ultimate manual.
Source distributions contain more tests and examples than binary distributions.
MySQL is evolving quite rapidly and we want to share new developments with other MySQL users. We try to produce a new release whenever we have new and useful features that others also seem to have a need for.
We also try to help users who request features that are easy to implement. We take note of what our licensed users want, and we especially take note of what our support customers want and try to help them in this regard.
No one is required to download a new release. The News section helps you determine whether the new release has something you really want. See Appendix E, MySQL Change History.
We use the following policy when updating MySQL:
Enterprise Server releases are meant to appear every 18 months, supplemented by quarterly service packs and monthly rapid updates. Community Server releases are meant to appear 2–3 times per year.
Releases are issued within each series. Enterprise Server releases are numbered using even numbers (for example, 5.0.20). Community Server releases are numbered using odd numbers (for example, 5.0.21).
Binary distributions for some platforms are made by us for major releases. Other people may make binary distributions for other systems, but probably less frequently.
We make fixes available as soon as we have identified and corrected small or non-critical but annoying bugs. The fixes are available in source form immediately from our public BitKeeper repositories, and are included in the next release.
If by any chance a security vulnerability or critical bug is found in a release, our policy is to fix it in a new release as soon as possible. (We would like other companies to do this, too!)
This section does not apply to MySQL Enterprise Server users.
We put considerable time and effort into making our releases bug-free. Our policy is never to release a version of MySQL intended for production use that has any known fatal, repeatable bugs.
We have documented all open problems, bugs, and issues that are dependent on design decisions. See Section B.1.8, “Known Issues in MySQL”.
Our aim is to fix everything that is fixable without making a stable MySQL version less stable. In certain cases, this means we can fix an issue in the development versions, but not in the stable (production) version. Naturally, we document such issues so that users are aware of them.
Here is a description of our build process:
We monitor bugs from our customer support list, the bugs database at http://bugs.mysql.com/, and the MySQL external mailing lists.
All reported bugs for live versions are entered into the bugs database.
When we fix a bug, we always try to make a test case for it and include it into our test system to ensure that the bug can never recur without being detected. (About 90% of all fixed bugs have test cases.)
We create test cases for each new feature that we add to MySQL.
Before we start to build a new MySQL release, we ensure that all reported repeatable bugs for that MySQL version (3.23.x, 4.0.x, 4.1.x, 5.0.x, 5.1.x, and so on) are fixed. If something is impossible to fix due to some internal design decision in MySQL, we document this in the manual. See Section B.1.8, “Known Issues in MySQL”.
We do a build on all platforms for which we support binaries and run our test suite and benchmark suite on all of them.
We do not publish a binary for a platform for which the test or benchmark suite fails. If the problem is due to a general error in the source, we fix it and do the build plus tests on all systems again from scratch.
The build and test process takes a week. If we receive a report regarding a fatal bug during this process (for example, one that causes a core dump), we fix the problem and restart the build process.
After publishing the binaries on http://dev.mysql.com/, we send out an announcement message to the
mysqlandannouncemailing lists. See Section 1.7.1, “MySQL Mailing Lists”. The announcement message contains a list of all changes to the release and any known problems with the release. The Known Problems section in the release notes has been needed for only a handful of releases.To quickly give our users access to the latest MySQL features, we try to produce a new MySQL release every 4-8 weeks. Source code snapshots are built daily and are available at http://downloads.mysql.com/snapshots.php.
If, despite our best efforts, we receive any bug reports after a release is issued that a critical problem exists for the build on a specific platform, we fix it at once and build a new
'a'release for that platform. Thanks to our large user base, problems are found and resolved very quickly.Our track record for making stable releases is quite good. In the last 150 releases, we had to do a new build for fewer than 10 of them. In three of these cases, the bug was a faulty
glibclibrary on one of our build machines that took us a long time to track down.
This section does not apply to MySQL Enterprise Server users.
As a service of MySQL AB, we provide a set of binary distributions of MySQL that are compiled on systems at our site or on systems where supporters of MySQL kindly have given us access to their machines.
In addition to the binaries provided in platform-specific
package formats, we offer binary distributions for a number of
platforms in the form of compressed tar files
(.tar.gz files). See
Section 2.4.7, “Standard MySQL Installation Using a Binary Distribution”.
The RPM distributions for MySQL 5.0 releases that we make available through our Web site are generated by MySQL AB.
For Windows distributions, see Section 2.4.8, “Installing MySQL on Windows”.
These distributions are generated using the script
Build-tools/Do-compile, which compiles the
source code and creates the binary tar.gz
archive using
scripts/make_binary_distribution.
These binaries are configured and built with the following
compilers and options. This information can also be obtained by
looking at the variables COMP_ENV_INFO and
CONFIGURE_LINE inside the script
bin/mysqlbug of every binary
tar file distribution.
Anyone who has more optimal options for any of the following
configure commands can mail them to the MySQL
internals mailing list. See
Section 1.7.1, “MySQL Mailing Lists”.
If you want to compile a debug version of MySQL, you should add
--with-debug or
--with-debug=full to the following
configure commands and remove any
-fomit-frame-pointer options.
The following binaries are built on MySQL AB development systems:
Linux 2.4.xx x86 with gcc 2.95.3:
CFLAGS="-O2 -mcpu=pentiumpro" CXX=gcc CXXFLAGS="-O2 -mcpu=pentiumpro -felide-constructors" ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --enable-assembler --disable-shared --with-client-ldflags=-all-static --with-mysqld-ldflags=-all-static
Linux 2.4.x x86 with icc (Intel C++ Compiler 8.1 or later releases):
CC=icc CXX=icpc CFLAGS="-O3 -unroll2 -ip -mp -no-gcc -restrict" CXXFLAGS="-O3 -unroll2 -ip -mp -no-gcc -restrict" ./configure --prefix=/usr/local/mysql --localstatedir=/usr/local/mysql/data --libexecdir=/usr/local/mysql/bin --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --enable-assembler --disable-shared --with-client-ldflags=-all-static --with-mysqld-ldflags=-all-static --with-embedded-server --with-innodb
Note that versions 8.1 and newer of the Intel compiler have separate drivers for 'pure' C (
icc) and C++ (icpc); if you use icc version 8.0 or older for building MySQL, you will need to setCXX=icc.Linux 2.4.xx Intel Itanium 2 with ecc (Intel C++ Itanium Compiler 7.0):
CC=ecc CFLAGS="-O2 -tpp2 -ip -nolib_inline" CXX=ecc CXXFLAGS="-O2 -tpp2 -ip -nolib_inline" ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile
Linux 2.4.xx Intel Itanium with ecc (Intel C++ Itanium Compiler 7.0):
CC=ecc CFLAGS=-tpp1 CXX=ecc CXXFLAGS=-tpp1 ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile
Linux 2.4.xx alpha with
ccc(Compaq C V6.2-505 / Compaq C++ V6.3-006):CC=ccc CFLAGS="-fast -arch generic" CXX=cxx CXXFLAGS="-fast -arch generic -noexceptions -nortti" ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --with-mysqld-ldflags=-non_shared --with-client-ldflags=-non_shared --disable-shared
Linux 2.x.xx ppc with gcc 2.95.4:
CC=gcc CFLAGS="-O3 -fno-omit-frame-pointer" CXX=gcc CXXFLAGS="-O3 -fno-omit-frame-pointer -felide-constructors -fno-exceptions -fno-rtti" ./configure --prefix=/usr/local/mysql --localstatedir=/usr/local/mysql/data --libexecdir=/usr/local/mysql/bin --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --disable-shared --with-embedded-server --with-innodb
Linux 2.4.xx s390 with gcc 2.95.3:
CFLAGS="-O2" CXX=gcc CXXFLAGS="-O2 -felide-constructors" ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --disable-shared --with-client-ldflags=-all-static --with-mysqld-ldflags=-all-static
Linux 2.4.xx x86_64 (AMD64) with gcc 3.2.1:
CXX=gcc ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --disable-shared
Sun Solaris 8 x86 with gcc 3.2.3:
CC=gcc CFLAGS="-O3 -fno-omit-frame-pointer" CXX=gcc CXXFLAGS="-O3 -fno-omit-frame-pointer -felide-constructors -fno-exceptions -fno-rtti" ./configure --prefix=/usr/local/mysql --localstatedir=/usr/local/mysql/data --libexecdir=/usr/local/mysql/bin --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --disable-shared --with-innodb
Sun Solaris 8 SPARC with gcc 3.2:
CC=gcc CFLAGS="-O3 -fno-omit-frame-pointer" CXX=gcc CXXFLAGS="-O3 -fno-omit-frame-pointer -felide-constructors -fno-exceptions -fno-rtti" ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --enable-assembler --with-named-z-libs=no --with-named-curses-libs=-lcurses --disable-shared
Sun Solaris 8 SPARC 64-bit with gcc 3.2:
CC=gcc CFLAGS="-O3 -m64 -fno-omit-frame-pointer" CXX=gcc CXXFLAGS="-O3 -m64 -fno-omit-frame-pointer -felide-constructors -fno-exceptions -fno-rtti" ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --with-named-z-libs=no --with-named-curses-libs=-lcurses --disable-shared
Sun Solaris 9 SPARC with gcc 2.95.3:
CC=gcc CFLAGS="-O3 -fno-omit-frame-pointer" CXX=gcc CXXFLAGS="-O3 -fno-omit-frame-pointer -felide-constructors -fno-exceptions -fno-rtti" ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --enable-assembler --with-named-curses-libs=-lcurses --disable-shared
Sun Solaris 9 SPARC with
cc-5.0(Sun Forte 5.0):CC=cc-5.0 CXX=CC ASFLAGS="-xarch=v9" CFLAGS="-Xa -xstrconst -mt -D_FORTEC_ -xarch=v9" CXXFLAGS="-noex -mt -D_FORTEC_ -xarch=v9" ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --enable-assembler --with-named-z-libs=no --enable-thread-safe-client --disable-shared
IBM AIX 4.3.2 ppc with gcc 3.2.3:
CFLAGS="-O2 -mcpu=powerpc -Wa,-many " CXX=gcc CXXFLAGS="-O2 -mcpu=powerpc -Wa,-many -felide-constructors -fno-exceptions -fno-rtti" ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --with-named-z-libs=no --disable-shared
IBM AIX 4.3.3 ppc with
xlC_r(IBM Visual Age C/C++ 6.0):CC=xlc_r CFLAGS="-ma -O2 -qstrict -qoptimize=2 -qmaxmem=8192" CXX=xlC_r CXXFLAGS ="-ma -O2 -qstrict -qoptimize=2 -qmaxmem=8192" ./configure --prefix=/usr/local/mysql --localstatedir=/usr/local/mysql/data --libexecdir=/usr/local/mysql/bin --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --with-named-z-libs=no --disable-shared --with-innodb
IBM AIX 5.1.0 ppc with gcc 3.3:
CFLAGS="-O2 -mcpu=powerpc -Wa,-many" CXX=gcc CXXFLAGS="-O2 -mcpu=powerpc -Wa,-many -felide-constructors -fno-exceptions -fno-rtti" ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --with-named-z-libs=no --disable-shared
IBM AIX 5.2.0 ppc with
xlC_r(IBM Visual Age C/C++ 6.0):CC=xlc_r CFLAGS="-ma -O2 -qstrict -qoptimize=2 -qmaxmem=8192" CXX=xlC_r CXXFLAGS="-ma -O2 -qstrict -qoptimize=2 -qmaxmem=8192" ./configure --prefix=/usr/local/mysql --localstatedir=/usr/local/mysql/data --libexecdir=/usr/local/mysql/bin --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --with-named-z-libs=no --disable-shared --with-embedded-server --with-innodb
HP-UX 10.20 pa-risc1.1 with gcc 3.1:
CFLAGS="-DHPUX -I/opt/dce/include -O3 -fPIC" CXX=gcc CXXFLAGS="-DHPUX -I/opt/dce /include -felide-constructors -fno-exceptions -fno-rtti -O3 -fPIC" ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --with-pthread --with-named-thread-libs=-ldce --with-lib-ccflags=-fPIC --disable-shared
HP-UX 11.00 pa-risc with
aCC(HP ANSI C++ B3910B A.03.50):CC=cc CXX=aCC CFLAGS=+DAportable CXXFLAGS=+DAportable ./configure --prefix=/usr/local/mysql --localstatedir=/usr/local/mysql/data --libexecdir=/usr/local/mysql/bin --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --disable-shared --with-embedded-server --with-innodb
HP-UX 11.11 pa-risc2.0 64bit with
aCC(HP ANSI C++ B3910B A.03.33):CC=cc CXX=aCC CFLAGS=+DD64 CXXFLAGS=+DD64 ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --disable-shared
HP-UX 11.11 pa-risc2.0 32bit with
aCC(HP ANSI C++ B3910B A.03.33):CC=cc CXX=aCC CFLAGS="+DAportable" CXXFLAGS="+DAportable" ./configure --prefix=/usr/local/mysql --localstatedir=/usr/local/mysql/data --libexecdir=/usr/local/mysql/bin --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --disable-shared --with-innodb
HP-UX 11.22 ia64 64bit with
aCC(HP aC++/ANSI C B3910B A.05.50):CC=cc CXX=aCC CFLAGS="+DD64 +DSitanium2" CXXFLAGS="+DD64 +DSitanium2" ./configure --prefix=/usr/local/mysql --localstatedir=/usr/local/mysql/data --libexecdir=/usr/local/mysql/bin --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --disable-shared --with-embedded-server --with-innodb
Apple Mac OS X 10.2 powerpc with gcc 3.1:
CC=gcc CFLAGS="-O3 -fno-omit-frame-pointer" CXX=gcc CXXFLAGS="-O3 -fno-omit-frame-pointer -felide-constructors -fno-exceptions -fno-rtti" ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --disable-shared
FreeBSD 4.7 i386 with gcc 2.95.4:
CFLAGS=-DHAVE_BROKEN_REALPATH ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --enable-assembler --with-named-z-libs=not-used --disable-shared
FreeBSD 4.7 i386 using LinuxThreads with gcc 2.95.4:
CFLAGS="-DHAVE_BROKEN_REALPATH -D__USE_UNIX98 -D_REENTRANT -D_THREAD_SAFE -I/usr/local/include/pthread/linuxthreads" CXXFLAGS="-DHAVE_BROKEN_REALPATH -D__USE_UNIX98 -D_REENTRANT -D_THREAD_SAFE -I/usr/local/include/pthread/linuxthreads" ./configure --prefix=/usr/local/mysql --localstatedir=/usr/local/mysql/data --libexecdir=/usr/local/mysql/bin --enable-thread-safe-client --enable-local-infile --enable-assembler --with-named-thread-libs="-DHAVE_GLIBC2_STYLE_GETHOSTBYNAME_R -D_THREAD_SAFE -I /usr/local/include/pthread/linuxthreads -L/usr/local/lib -llthread -llgcc_r" --disable-shared --with-embedded-server --with-innodb
QNX Neutrino 6.2.1 i386 with gcc 2.95.3qnx-nto 20010315:
CC=gcc CFLAGS="-O3 -fno-omit-frame-pointer" CXX=gcc CXXFLAGS="-O3 -fno-omit-frame-pointer -felide-constructors -fno-exceptions -fno-rtti" ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --disable-shared
The following binaries are built on third-party systems kindly provided to MySQL AB by other users. These are provided only as a courtesy; MySQL AB does not have full control over these systems, so we can provide only limited support for the binaries built on them.
SCO Unix 3.2v5.0.7 i386 with gcc 2.95.3:
CFLAGS="-O3 -mpentium" LDFLAGS=-static CXX=gcc CXXFLAGS="-O3 -mpentium -felide-constructors" ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --with-named-z-libs=no --enable-thread-safe-client --disable-shared
SCO UnixWare 7.1.4 i386 with CC 3.2:
CC=cc CFLAGS="-O" CXX=CC ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --with-named-z-libs=no --enable-thread-safe-client --disable-shared --with-readline
SCO OpenServer 6.0.0 i386 with CC 3.2:
CC=cc CFLAGS="-O" CXX=CC ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --with-named-z-libs=no --enable-thread-safe-client --disable-shared --with-readline
Compaq Tru64 OSF/1 V5.1 732 alpha with
cc/cxx(Compaq C V6.3-029i / DIGITAL C++ V6.1-027):CC="cc -pthread" CFLAGS="-O4 -ansi_alias -ansi_args -fast -inline speed -speculate all" CXX="cxx -pthread" CXXFLAGS="-O4 -ansi_alias -fast -inline speed -speculate all -noexceptions -nortti" ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --with-named-thread-libs="-lpthread -lmach -lexc -lc" --disable-shared --with-mysqld-ldflags=-all-static
SGI Irix 6.5 IP32 with gcc 3.0.1:
CC=gcc CFLAGS="-O3 -fno-omit-frame-pointer" CXXFLAGS="-O3 -fno-omit-frame-pointer -felide-constructors -fno-exceptions -fno-rtti" ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --disable-shared
FreeBSD/sparc64 5.0 with gcc 3.2.1:
CFLAGS=-DHAVE_BROKEN_REALPATH ./configure --prefix=/usr/local/mysql --localstatedir=/usr/local/mysql/data --libexecdir=/usr/local/mysql/bin --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --disable-shared --with-innodb
The following compile options have been used for binary packages that MySQL AB provided in the past. These binaries no longer are being updated, but the compile options are listed here for reference purposes.
Linux 2.2.xx SPARC with egcs 1.1.2:
CC=gcc CFLAGS="-O3 -fno-omit-frame-pointer" CXX=gcc CXXFLAGS="-O3 -fno-omit-frame-pointer -felide-constructors -fno-exceptions -fno-rtti" ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex --enable-thread-safe-client --enable-local-infile --enable-assembler --disable-shared
Linux 2.2.x with x686 with gcc 2.95.2:
CFLAGS="-O3 -mpentiumpro" CXX=gcc CXXFLAGS="-O3 -mpentiumpro -felide-constructors -fno-exceptions -fno-rtti" ./configure --prefix=/usr/local/mysql --enable-assembler --with-mysqld-ldflags=-all-static --disable-shared --with-extra-charsets=complex
SunOS 4.1.4 2 sun4c with gcc 2.7.2.1:
CC=gcc CXX=gcc CXXFLAGS="-O3 -felide-constructors" ./configure --prefix=/usr/local/mysql --disable-shared --with-extra-charsets=complex --enable-assembler
SunOS 5.5.1 (and above) sun4u with egcs 1.0.3a or 2.90.27 or gcc 2.95.2 and newer:
CC=gcc CFLAGS="-O3" CXX=gcc CXXFLAGS="-O3 -felide-constructors -fno-exceptions -fno-rtti" ./configure --prefix=/usr/local/mysql --with-low-memory --with-extra-charsets=complex --enable-assembler
SunOS 5.6 i86pc with gcc 2.8.1:
CC=gcc CXX=gcc CXXFLAGS=-O3 ./configure --prefix=/usr/local/mysql --with-low-memory --with-extra-charsets=complex
BSDI BSD/OS 3.1 i386 with gcc 2.7.2.1:
CC=gcc CXX=gcc CXXFLAGS=-O ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex
BSDI BSD/OS 2.1 i386 with gcc 2.7.2:
CC=gcc CXX=gcc CXXFLAGS=-O3 ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex
AIX 4.2 with gcc 2.7.2.2:
CC=gcc CXX=gcc CXXFLAGS=-O3 ./configure --prefix=/usr/local/mysql --with-extra-charsets=complex
This section does not apply to MySQL Enterprise Server users.
Check our downloads page at http://dev.mysql.com/downloads/ for information about the current version of MySQL and for downloading instructions. For a complete up-to-date list of MySQL download mirror sites, see http://dev.mysql.com/downloads/mirrors.html. You can also find information there about becoming a MySQL mirror site and how to report a bad or out-of-date mirror.
Our main mirror is located at http://mirrors.sunsite.dk/mysql/.
This section does not apply to MySQL Enterprise Server users.
After you have downloaded the MySQL package that suits your needs and before you attempt to install it, you should make sure that it is intact and has not been tampered with. MySQL AB offers three means of integrity checking:
MD5 checksums
Cryptographic signatures using
GnuPG, the GNU Privacy GuardFor RPM packages, the built-in RPM integrity verification mechanism
The following sections describe how to use these methods.
If you notice that the MD5 checksum or GPG signatures do not
match, first try to download the respective package one more time,
perhaps from another mirror site. If you repeatedly cannot
successfully verify the integrity of the package, please notify us
about such incidents, including the full package name and the
download site you have been using, at
<webmaster@mysql.com> or
<build@mysql.com>. Do not report downloading problems
using the bug-reporting system.
This section does not apply to MySQL Enterprise Server users.
After you have downloaded a MySQL package, you should make sure
that its MD5 checksum matches the one provided on the MySQL
download pages. Each package has an individual checksum that you
can verify with the following command, where
package_name is the name of the
package you downloaded:
shell> md5sum package_name
Example:
shell> md5sum mysql-standard-5.0.42-linux-i686.tar.gz
aaab65abbec64d5e907dcd41b8699945 mysql-standard-5.0.42-linux-i686.tar.gz
You should verify that the resulting checksum (the string of hexadecimal digits) matches the one displayed on the download page immediately below the respective package.
Note: Make sure to verify the
checksum of the archive file (for example,
the .zip or .tar.gz
file) and not of the files that are contained inside of the
archive.
Note that not all operating systems support the
md5sum command. On some, it is simply called
md5, and others do not ship it at all. On
Linux, it is part of the GNU Text
Utilities package, which is available for a wide
range of platforms. You can download the source code from
http://www.gnu.org/software/textutils/ as well.
If you have OpenSSL installed, you can use the command
openssl md5
package_name instead. A
Windows implementation of the md5 command
line utility is available from
http://www.fourmilab.ch/md5/.
winMd5Sum is a graphical MD5 checking tool
that can be obtained from
http://www.nullriver.com/index/products/winmd5sum.
This section does not apply to MySQL Enterprise Server users.
Another method of verifying the integrity and authenticity of a package is to use cryptographic signatures. This is more reliable than using MD5 checksums, but requires more work.
At MySQL AB, we sign MySQL downloadable packages with GnuPG (GNU Privacy Guard). GnuPG is an Open Source alternative to the well-known Pretty Good Privacy (PGP) by Phil Zimmermann. See http://www.gnupg.org/ for more information about GnuPG and how to obtain and install it on your system. Most Linux distributions ship with GnuPG installed by default. For more information about GnuPG, see http://www.openpgp.org/.
To verify the signature for a specific package, you first need
to obtain a copy of MySQL AB's public GPG build key, which you
can download from http://www.keyserver.net/. The
key that you want to obtain is named
build@mysql.com. Alternatively, you can cut
and paste the key directly from the following text:
Key ID:
pub 1024D/5072E1F5 2003-02-03
MySQL Package signing key (www.mysql.com) <build@mysql.com>
Fingerprint: A4A9 4068 76FC BD3C 4567 70C8 8C71 8D3B 5072 E1F5
Public Key (ASCII-armored):
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (GNU/Linux)
Comment: For info see http://www.gnupg.org
mQGiBD4+owwRBAC14GIfUfCyEDSIePvEW3SAFUdJBtoQHH/nJKZyQT7h9bPlUWC3
RODjQReyCITRrdwyrKUGku2FmeVGwn2u2WmDMNABLnpprWPkBdCk96+OmSLN9brZ
fw2vOUgCmYv2hW0hyDHuvYlQA/BThQoADgj8AW6/0Lo7V1W9/8VuHP0gQwCgvzV3
BqOxRznNCRCRxAuAuVztHRcEAJooQK1+iSiunZMYD1WufeXfshc57S/+yeJkegNW
hxwR9pRWVArNYJdDRT+rf2RUe3vpquKNQU/hnEIUHJRQqYHo8gTxvxXNQc7fJYLV
K2HtkrPbP72vwsEKMYhhr0eKCbtLGfls9krjJ6sBgACyP/Vb7hiPwxh6rDZ7ITnE
kYpXBACmWpP8NJTkamEnPCia2ZoOHODANwpUkP43I7jsDmgtobZX9qnrAXw+uNDI
QJEXM6FSbi0LLtZciNlYsafwAPEOMDKpMqAK6IyisNtPvaLd8lH0bPAnWqcyefep
rv0sxxqUEMcM3o7wwgfN83POkDasDbs3pjwPhxvhz6//62zQJ7Q7TXlTUUwgUGFj
a2FnZSBzaWduaW5nIGtleSAod3d3Lm15c3FsLmNvbSkgPGJ1aWxkQG15c3FsLmNv
bT6IXQQTEQIAHQUCPj6jDAUJCWYBgAULBwoDBAMVAwIDFgIBAheAAAoJEIxxjTtQ
cuH1cY4AnilUwTXn8MatQOiG0a/bPxrvK/gCAJ4oinSNZRYTnblChwFaazt7PF3q
zIhMBBMRAgAMBQI+PqPRBYMJZgC7AAoJEElQ4SqycpHyJOEAn1mxHijft00bKXvu
cSo/pECUmppiAJ41M9MRVj5VcdH/KN/KjRtW6tHFPYhMBBMRAgAMBQI+QoIDBYMJ
YiKJAAoJELb1zU3GuiQ/lpEAoIhpp6BozKI8p6eaabzF5MlJH58pAKCu/ROofK8J
Eg2aLos+5zEYrB/LsrkCDQQ+PqMdEAgA7+GJfxbMdY4wslPnjH9rF4N2qfWsEN/l
xaZoJYc3a6M02WCnHl6ahT2/tBK2w1QI4YFteR47gCvtgb6O1JHffOo2HfLmRDRi
Rjd1DTCHqeyX7CHhcghj/dNRlW2Z0l5QFEcmV9U0Vhp3aFfWC4Ujfs3LU+hkAWzE
7zaD5cH9J7yv/6xuZVw411x0h4UqsTcWMu0iM1BzELqX1DY7LwoPEb/O9Rkbf4fm
Le11EzIaCa4PqARXQZc4dhSinMt6K3X4BrRsKTfozBu74F47D8Ilbf5vSYHbuE5p
/1oIDznkg/p8kW+3FxuWrycciqFTcNz215yyX39LXFnlLzKUb/F5GwADBQf+Lwqq
a8CGrRfsOAJxim63CHfty5mUc5rUSnTslGYEIOCR1BeQauyPZbPDsDD9MZ1ZaSaf
anFvwFG6Llx9xkU7tzq+vKLoWkm4u5xf3vn55VjnSd1aQ9eQnUcXiL4cnBGoTbOW
I39EcyzgslzBdC++MPjcQTcA7p6JUVsP6oAB3FQWg54tuUo0Ec8bsM8b3Ev42Lmu
QT5NdKHGwHsXTPtl0klk4bQk4OajHsiy1BMahpT27jWjJlMiJc+IWJ0mghkKHt92
6s/ymfdf5HkdQ1cyvsz5tryVI3Fx78XeSYfQvuuwqp2H139pXGEkg0n6KdUOetdZ
Whe70YGNPw1yjWJT1IhMBBgRAgAMBQI+PqMdBQkJZgGAAAoJEIxxjTtQcuH17p4A
n3r1QpVC9yhnW2cSAjq+kr72GX0eAJ4295kl6NxYEuFApmr1+0uUq/SlsQ==
=YJkx
-----END PGP PUBLIC KEY BLOCK-----
To import the build key into your personal public GPG keyring,
use gpg --import. For example, if you have
saved the key in a file named
mysql_pubkey.asc, the import command looks
like this:
shell> gpg --import mysql_pubkey.asc
After you have downloaded and imported the public build key,
download your desired MySQL package and the corresponding
signature, which also is available from the download page. The
signature file has the same name as the distribution file with
an .asc extension. For example:
| Distribution file | mysql-standard-5.0.42-linux-i686.tar.gz |
| Signature file | mysql-standard-5.0.42-linux-i686.tar.gz.asc |
Make sure that both files are stored in the same directory and then run the following command to verify the signature for the distribution file:
shell> gpg --verify package_name.asc
Example:
shell> gpg --verify mysql-standard-5.0.42-linux-i686.tar.gz.asc
gpg: Signature made Tue 12 Jul 2005 23:35:41 EST using DSA key ID 5072E1F5
gpg: Good signature from "MySQL Package signing key (www.mysql.com) <build@mysql.com>"
The Good signature message indicates that
everything is all right. You can ignore any insecure
memory warning you might obtain.
See the GPG documentation for more information on how to work with public keys.
This section does not apply to MySQL Enterprise Server users.
For RPM packages, there is no separate signature. RPM packages have a built-in GPG signature and MD5 checksum. You can verify a package by running the following command:
shell> rpm --checksig package_name.rpm
Example:
shell> rpm --checksig MySQL-server-5.0.42-0.glibc23.i386.rpm
MySQL-server-5.0.42-0.glibc23.i386.rpm: md5 gpg OK
Note: If you are using RPM 4.1
and it complains about (GPG) NOT OK (MISSING KEYS:
GPG#5072e1f5), even though you have imported the MySQL
public build key into your own GPG keyring, you need to import
the key into the RPM keyring first. RPM 4.1 no longer uses your
personal GPG keyring (or GPG itself). Rather, it maintains its
own keyring because it is a system-wide application and a user's
GPG public keyring is a user-specific file. To import the MySQL
public key into the RPM keyring, first obtain the key as
described in Section 2.4.5.2, “Signature Checking Using GnuPG”. Then use
rpm --import to import the key. For example,
if you have saved the public key in a file named
mysql_pubkey.asc, import it using this
command:
shell> rpm --import mysql_pubkey.asc
If you need to obtain the MySQL public key, see
Section 2.4.5.2, “Signature Checking Using GnuPG”.
This section describes the default layout of the directories created by installing binary or source distributions provided by MySQL AB. A distribution provided by another vendor might use a layout different from those shown here.
For MySQL 5.0 on Windows, the default installation
directory is C:\Program Files\MySQL\MySQL Server
5.0. (Some Windows users prefer to install
in C:\mysql, the directory that formerly was
used as the default. However, the layout of the subdirectories
remains the same.) The installation directory has the following
subdirectories:
| Directory | Contents of Directory |
bin | Client programs and the mysqld server |
data | Log files, databases |
Docs | Manual in CHM format |
examples | Example programs and scripts |
include | Include (header) files |
lib | Libraries |
scripts | Utility scripts |
share | Error message files |
Installations created from MySQL AB's Linux RPM distributions result in files under the following system directories:
| Directory | Contents of Directory |
/usr/bin | Client programs and scripts |
/usr/sbin | The mysqld server |
/var/lib/mysql | Log files, databases |
/usr/share/info | Manual in Info format |
/usr/share/man | Unix manual pages |
/usr/include/mysql | Include (header) files |
/usr/lib/mysql | Libraries |
/usr/share/mysql | Error message and character set files |
/usr/share/sql-bench | Benchmarks |
On Unix, a tar file binary distribution is
installed by unpacking it at the installation location you choose
(typically /usr/local/mysql) and creates the
following directories in that location:
| Directory | Contents of Directory |
bin | Client programs and the mysqld server |
data | Log files, databases |
docs | Manual in Info format |
man | Unix manual pages |
include | Include (header) files |
lib | Libraries |
scripts | mysql_install_db |
share/mysql | Error message files |
sql-bench | Benchmarks |
A source distribution is installed after you configure and compile
it. By default, the installation step installs files under
/usr/local, in the following subdirectories:
| Directory | Contents of Directory |
bin | Client programs and scripts |
include/mysql | Include (header) files |
Docs | Manual in Info, CHM formats |
man | Unix manual pages |
lib/mysql | Libraries |
libexec | The mysqld server |
share/mysql | Error message files |
sql-bench | Benchmarks and crash-me test |
var | Databases and log files |
Within its installation directory, the layout of a source installation differs from that of a binary installation in the following ways:
The mysqld server is installed in the
libexecdirectory rather than in thebindirectory.The data directory is
varrather thandata.mysql_install_db is installed in the
bindirectory rather than in thescriptsdirectory.The header file and library directories are
include/mysqlandlib/mysqlrather thanincludeandlib.
You can create your own binary installation from a compiled source
distribution by executing the
scripts/make_binary_distribution script from
the top directory of the source distribution.
This section does not apply to MySQL Enterprise Server users.
The next several sections cover the installation of MySQL on
platforms where we offer packages using the native packaging
format of the respective platform. (This is also known as
performing a “binary install.”) However, binary
distributions of MySQL are available for many other platforms as
well. See Section 2.4.13, “Installing MySQL from tar.gz Packages on Other
Unix-Like Systems”, for generic
installation instructions for these packages that apply to all
platforms.
See Section 2.4, “Installing MySQL Community Server”, for more information on what other binary distributions are available and how to obtain them.
- 2.4.8.1. Choosing An Installation Package
- 2.4.8.2. Installing MySQL with the Automated Installer
- 2.4.8.3. Using the MySQL Installation Wizard
- 2.4.8.4. MySQL Windows Configuration Wizard
- 2.4.8.5. Installing MySQL from a Noinstall Zip Archive
- 2.4.8.6. Extracting the Install Archive
- 2.4.8.7. Creating an Option File
- 2.4.8.8. Selecting a MySQL Server Type
- 2.4.8.9. Starting the Server for the First Time
- 2.4.8.10. Starting MySQL from the Windows Command Line
- 2.4.8.11. Starting MySQL as a Windows Service
- 2.4.8.12. Testing The MySQL Installation
- 2.4.8.13. Troubleshooting a MySQL Installation Under Windows
- 2.4.8.14. Upgrading MySQL on Windows
- 2.4.8.15. MySQL on Windows Compared to MySQL on Unix
This section does not apply to MySQL Enterprise Server users.
A native Windows distribution of MySQL has been available from MySQL AB since version 3.21 and represents a sizable percentage of the daily downloads of MySQL. This section describes the process for installing MySQL on Windows.
Note: If you are upgrading MySQL from an existing installation older than MySQL 4.1.5, you must first perform the procedure described in Section 2.4.8.14, “Upgrading MySQL on Windows”.
To run MySQL on Windows, you need the following:
A 32-bit Windows operating system such as 2000, XP, or Windows Server 2003.
A Windows operating system permits you to run the MySQL server as a service. See Section 2.4.8.11, “Starting MySQL as a Windows Service”.
Generally, you should install MySQL on Windows using an account that has administrator rights. Otherwise, you may encounter problems with certain operations such as editing the
PATHenvironment variable or accessing the Service Control Manager.TCP/IP protocol support.
Enough space on the hard drive to unpack, install, and create the databases in accordance with your requirements (generally a minimum of 200 megabytes is recommended.)
There may also be other requirements, depending on how you plan to use MySQL:
If you plan to connect to the MySQL server via ODBC, you need a Connector/ODBC driver. See Chapter 23, Connectors.
If you need tables with a size larger than 4GB, install MySQL on an NTFS or newer filesystem. Don't forget to use
MAX_ROWSandAVG_ROW_LENGTHwhen you create tables. See Section 13.1.5, “CREATE TABLESyntax”.
MySQL for Windows is available in several distribution formats:
Binary distributions are available that contain a setup program that installs everything you need so that you can start the server immediately. Another binary distribution format contains an archive that you simply unpack in the installation location and then configure yourself. For details, see Section 2.4.8.1, “Choosing An Installation Package”.
The source distribution contains all the code and support files for building the executables using the Visual Studio compiler system.
Generally speaking, you should use a binary distribution that includes an installer. It is simpler to use than the others, and you need no additional tools to get MySQL up and running. The installer for the Windows version of MySQL, combined with a GUI Configuration Wizard, automatically installs MySQL, creates an option file, starts the server, and secures the default user accounts.
The following section describes how to install MySQL on Windows using a binary distribution. To use an installation package that does not include an installer, follow the procedure described in Section 2.4.8.5, “Installing MySQL from a Noinstall Zip Archive”. To install using a source distribution, see Section 2.4.14.6, “Installing MySQL from Source on Windows”.
MySQL distributions for Windows can be downloaded from http://dev.mysql.com/downloads/. See Section 2.4.4, “How to Get MySQL”.
This section does not apply to MySQL Enterprise Server users.
For MySQL 5.0, there are three installation packages to choose from when installing MySQL on Windows:
The Essentials Package: This package has a filename similar to
mysql-essential-5.0.42-win32.msiand contains the minimum set of files needed to install MySQL on Windows, including the Configuration Wizard. This package does not include optional components such as the embedded server and benchmark suite.The Complete Package: This package has a filename similar to
mysql-5.0.42-win32.zipand contains all files needed for a complete Windows installation, including the Configuration Wizard. This package includes optional components such as the embedded server and benchmark suite.The Noinstall Archive: This package has a filename similar to
mysql-noinstall-5.0.42-win32.zipand contains all the files found in the Complete install package, with the exception of the Configuration Wizard. This package does not include an automated installer, and must be manually installed and configured.
The Essentials package is recommended for most users. It is
provided as an .msi file for use with the
Windows Installer. The Complete and Noinstall distributions are
packaged as Zip archives. To use them, you must have a tool that
can unpack .zip files.
Your choice of install package affects the installation process you must follow. If you choose to install either the Essentials or Complete install packages, see Section 2.4.8.2, “Installing MySQL with the Automated Installer”. If you choose to install MySQL from the Noinstall archive, see Section 2.4.8.5, “Installing MySQL from a Noinstall Zip Archive”.
New MySQL users can use the MySQL Installation Wizard and MySQL Configuration Wizard to install MySQL on Windows. These are designed to install and configure MySQL in such a way that new users can immediately get started using MySQL.
The MySQL Installation Wizard and MySQL Configuration Wizard are available in the Essentials and Complete install packages. They are recommended for most standard MySQL installations. Exceptions include users who need to install multiple instances of MySQL on a single server host and advanced users who want complete control of server configuration.
MySQL Installation Wizard is an installer for the MySQL server that uses the latest installer technologies for Microsoft Windows. The MySQL Installation Wizard, in combination with the MySQL Configuration Wizard, allows a user to install and configure a MySQL server that is ready for use immediately after installation.
The MySQL Installation Wizard is the standard installer for all MySQL server distributions, version 4.1.5 and higher. Users of previous versions of MySQL need to shut down and remove their existing MySQL installations manually before installing MySQL with the MySQL Installation Wizard. See Section 2.4.8.3.7, “Upgrading MySQL with the Installation Wizard”, for more information on upgrading from a previous version.
Microsoft has included an improved version of their Microsoft Windows Installer (MSI) in the recent versions of Windows. MSI has become the de-facto standard for application installations on Windows 2000, Windows XP, and Windows Server 2003. The MySQL Installation Wizard makes use of this technology to provide a smoother and more flexible installation process.
The Microsoft Windows Installer Engine was updated with the release of Windows XP; those using a previous version of Windows can reference this Microsoft Knowledge Base article for information on upgrading to the latest version of the Windows Installer Engine.
In addition, Microsoft has introduced the WiX (Windows Installer XML) toolkit recently. This is the first highly acknowledged Open Source project from Microsoft. We have switched to WiX because it is an Open Source project and it allows us to handle the complete Windows installation process in a flexible manner using scripts.
Improving the MySQL Installation Wizard depends on the support and feedback of users like you. If you find that the MySQL Installation Wizard is lacking some feature important to you, or if you discover a bug, please report it in our bugs database using the instructions given in Section 1.8, “How to Report Bugs or Problems”.
This section does not apply to MySQL Enterprise Server users.
The MySQL installation packages can be downloaded from http://dev.mysql.com/downloads/. If the package you download is contained within a Zip archive, you need to extract the archive first.
The process for starting the wizard depends on the contents of
the installation package you download. If there is a
setup.exe file present, double-click it
to start the installation process. If there is an
.msi file present, double-click it to
start the installation process.
This section does not apply to MySQL Enterprise Server users.
There are three installation types available: Typical, Complete, and Custom.
The Typical installation type installs the MySQL server, the mysql command-line client, and the command-line utilities. The command-line clients and utilities include mysqldump, myisamchk, and several other tools to help you manage the MySQL server.
The Complete installation type installs all components included in the installation package. The full installation package includes components such as the embedded server library, the benchmark suite, support scripts, and documentation.
The Custom installation type gives you complete control over which packages you wish to install and the installation path that is used. See Section 2.4.8.3.4, “The Custom Install Dialog”, for more information on performing a custom install.
If you choose the Typical or Complete installation types and click the button, you advance to the confirmation screen to verify your choices and begin the installation. If you choose the Custom installation type and click the button, you advance to the custom installation dialog, described in Section 2.4.8.3.4, “The Custom Install Dialog”.
This section does not apply to MySQL Enterprise Server users.
If you wish to change the installation path or the specific components that are installed by the MySQL Installation Wizard, choose the Custom installation type.
A tree view on the left side of the custom install dialog lists all available components. Components that are not installed have a red X icon; components that are installed have a gray icon. To change whether a component is installed, click on that component's icon and choose a new option from the drop-down list that appears.
You can change the default installation path by clicking the button to the right of the displayed installation path.
After choosing your installation components and installation path, click the button to advance to the confirmation dialog.
This section does not apply to MySQL Enterprise Server users.
Once you choose an installation type and optionally choose your installation components, you advance to the confirmation dialog. Your installation type and installation path are displayed for you to review.
To install MySQL if you are satisfied with your settings, click the button. To change your settings, click the button. To exit the MySQL Installation Wizard without installing MySQL, click the button.
After installation is complete, you have the option of registering with the MySQL web site. Registration gives you access to post in the MySQL forums at forums.mysql.com, along with the ability to report bugs at bugs.mysql.com and to subscribe to our newsletter. The final screen of the installer provides a summary of the installation and gives you the option to launch the MySQL Configuration Wizard, which you can use to create a configuration file, install the MySQL service, and configure security settings.
This section does not apply to MySQL Enterprise Server users.
Once you click the button, the MySQL Installation Wizard begins the installation process and makes certain changes to your system which are described in the sections that follow.
Changes to the Registry
The MySQL Installation Wizard creates one Windows registry key
in a typical install situation, located in
HKEY_LOCAL_MACHINE\SOFTWARE\MySQL AB.
The MySQL Installation Wizard creates a key named after the
major version of the server that is being installed, such as
MySQL Server 5.0. It contains
two string values, Location and
Version. The Location
string contains the path to the installation directory. In a
default installation it contains C:\Program
Files\MySQL\MySQL Server 5.0\. The
Version string contains the release number.
For example, for an installation of MySQL Server
5.0.42, the key contains a value of
5.0.42.
These registry keys are used to help external tools identify
the installed location of the MySQL server, preventing a
complete scan of the hard-disk to determine the installation
path of the MySQL server. The registry keys are not required
to run the server, and if you install MySQL using the
noinstall Zip archive, the registry keys
are not created.
Changes to the Start Menu
The MySQL Installation Wizard creates a new entry in the Windows menu under a common MySQL menu heading named after the major version of MySQL that you have installed. For example, if you install MySQL 5.0, the MySQL Installation Wizard creates a section in the menu.
The following entries are created within the new menu section:
: This is a shortcut to the mysql command-line client and is configured to connect as the
rootuser. The shortcut prompts for arootuser password when you connect.: This is a shortcut to the MySQL Configuration Wizard. Use this shortcut to configure a newly installed server, or to reconfigure an existing server.
: This is a link to the MySQL server documentation that is stored locally in the MySQL server installation directory. This option is not available when the MySQL server is installed using the Essentials installation package.
Changes to the File System
The MySQL Installation Wizard by default installs the MySQL
5.0 server to C:\, where
Program
Files\MySQL\MySQL Server
5.0Program Files is the default
location for applications in your system, and
5.0 is the major
version of your MySQL server. This is the recommended location
for the MySQL server, replacing the former default location
C:\mysql.
By default, all MySQL applications are stored in a common
directory at C:\, where
Program
Files\MySQLProgram Files is the default
location for applications in your Windows installation. A
typical MySQL installation on a developer machine might look
like this:
C:\Program Files\MySQL\MySQL Server 5.0 C:\Program Files\MySQL\MySQL Administrator 1.0 C:\Program Files\MySQL\MySQL Query Browser 1.0
This approach makes it easier to manage and maintain all MySQL applications installed on a particular system.
This section does not apply to MySQL Enterprise Server users.
The MySQL Installation Wizard can perform server upgrades automatically using the upgrade capabilities of MSI. That means you do not need to remove a previous installation manually before installing a new release. The installer automatically shuts down and removes the previous MySQL service before installing the new version.
Automatic upgrades are available only when upgrading between installations that have the same major and minor version numbers. For example, you can upgrade automatically from MySQL 4.1.5 to MySQL 4.1.6, but not from MySQL 4.1 to MySQL 5.0.
For instructions on using the MySQL Configuration Wizard for Wizard to configure your MySQL server, see Section 2.3.3.2, “MySQL Server Configuration Wizard”.
This section does not apply to MySQL Enterprise Server users.
Users who are installing from the Noinstall package can use the instructions in this section to manually install MySQL. The process for installing MySQL from a Zip archive is as follows:
Extract the archive to the desired install directory
Create an option file
Choose a MySQL server type
Start the MySQL server
Secure the default user accounts
This process is described in the sections that follow.
This section does not apply to MySQL Enterprise Server users.
To install MySQL manually, do the following:
If you are upgrading from a previous version please refer to Section 2.4.8.14, “Upgrading MySQL on Windows”, before beginning the upgrade process.
Make sure that you are logged in as a user with administrator privileges.
Choose an installation location. Traditionally, the MySQL server is installed in
C:\mysql. The MySQL Installation Wizard installs MySQL underC:\Program Files\MySQL. If you do not install MySQL atC:\mysql, you must specify the path to the install directory during startup or in an option file. See Section 2.4.8.7, “Creating an Option File”.Extract the install archive to the chosen installation location using your preferred Zip archive tool. Some tools may extract the archive to a folder within your chosen installation location. If this occurs, you can move the contents of the subfolder into the chosen installation location.
If you need to specify startup options when you run the server, you can indicate them on the command line or place them in an option file. For options that are used every time the server starts, you may find it most convenient to use an option file to specify your MySQL configuration. This is particularly true under the following circumstances:
The installation or data directory locations are different from the default locations (
C:\Program Files\MySQL\MySQL Server 5.0andC:\Program Files\MySQL\MySQL Server 5.0\data).You need to tune the server settings.
When the MySQL server starts on Windows, it looks for options in
two files: the my.ini file in the Windows
directory, and the C:\my.cnf file. The
Windows directory typically is named something like
C:\WINDOWS. You can determine its exact
location from the value of the WINDIR
environment variable using the following command:
C:\> echo %WINDIR%
MySQL looks for options first in the my.ini
file, and then in the my.cnf file. However,
to avoid confusion, it's best if you use only one file. If your
PC uses a boot loader where C: is not the
boot drive, your only option is to use the
my.ini file. Whichever option file you use,
it must be a plain text file.
You can also make use of the example option files included with your MySQL distribution; see Section 4.3.2.1, “Preconfigured Option Files”.
An option file can be created and modified with any text editor,
such as Notepad. For example, if MySQL is installed in
E:\mysql and the data directory is in
E:\mydata\data, you can create an option
file containing a [mysqld] section to specify
values for the basedir and
datadir parameters:
[mysqld] # set basedir to your installation path basedir=E:/mysql # set datadir to the location of your data directory datadir=E:/mydata/data
Note that Windows pathnames are specified in option files using (forward) slashes rather than backslashes. If you do use backslashes, you must double them:
[mysqld] # set basedir to your installation path basedir=E:\\mysql # set datadir to the location of your data directory datadir=E:\\mydata\\data
On Windows, the MySQL installer places the data directory
directly under the directory where you install MySQL. If you
would like to use a data directory in a different location, you
should copy the entire contents of the data
directory to the new location. For example, if MySQL is
installed in C:\Program Files\MySQL\MySQL Server
5.0, the data directory is by default in
C:\Program Files\MySQL\MySQL Server
5.0\data. If you want to use
E:\mydata as the data directory instead,
you must do two things:
Move the entire
datadirectory and all of its contents fromC:\Program Files\MySQL\MySQL Server 5.0\datatoE:\mydata.Use a
--datadiroption to specify the new data directory location each time you start the server.
This section does not apply to MySQL Enterprise Server users.
The following table shows the available servers for Windows in MySQL 5.0.
| Binary | Description |
| mysqld-nt | Optimized binary with named-pipe support |
| mysqld | Optimized binary without named-pipe support |
| mysqld-debug | Like mysqld-nt, but compiled with full debugging and automatic memory allocation checking |
All of the preceding binaries are optimized for modern Intel processors, but should work on any Intel i386-class or higher processor.
Each of the servers in a distribution support the same set of
storage engines. The SHOW ENGINES statement
displays which engines a given server supports.
All Windows MySQL 5.0 servers have support for symbolic linking of database directories.
MySQL supports TCP/IP on all Windows platforms. The
mysqld-nt and mysql-debug
servers support named pipes. However, the default is to use
TCP/IP regardless of platform. (Named pipes are slower than
TCP/IP in many Windows configurations.)
Use of named pipes is subject to these conditions:
Named pipes are enabled only if you start the server with the
--enable-named-pipeoption. It is necessary to use this option explicitly because some users have experienced problems with shutting down the MySQL server when named pipes were used.Named-pipe connections are allowed only by the mysqld-nt and mysqld-debug servers.
Note: Most of the examples in this manual use mysqld as the server name. If you choose to use a different server, such as mysqld-nt, make the appropriate substitutions in the commands that are shown in the examples.
This section gives a general overview of starting the MySQL server. The following sections provide more specific information for starting the MySQL server from the command line or as a Windows service.
The information here applies primarily if you installed MySQL
using the Noinstall version, or if you wish
to configure and test MySQL manually rather than with the GUI
tools.
The examples in these sections assume that MySQL is installed
under the default location of C:\Program
Files\MySQL\MySQL Server 5.0. Adjust the
pathnames shown in the examples if you have MySQL installed in a
different location.
Clients have two options. They can use TCP/IP, or they can use a named pipe if the server supports named-pipe connections.
MySQL for Windows also supports shared-memory connections if the
server is started with the --shared-memory
option. Clients can connect through shared memory by using the
--protocol=memory option.
For information about which server binary to run, see Section 2.4.8.8, “Selecting a MySQL Server Type”.
Testing is best done from a command prompt in a console window (or “DOS window”). In this way you can have the server display status messages in the window where they are easy to see. If something is wrong with your configuration, these messages make it easier for you to identify and fix any problems.
To start the server, enter this command:
C:\> "C:\Program Files\MySQL\MySQL Server 5.0\bin\mysqld" --console
For a server that includes InnoDB support,
you should see the messages similar to those following as it
starts (the pathnames and sizes may differ):
InnoDB: The first specified datafile c:\ibdata\ibdata1 did not exist: InnoDB: a new database to be created! InnoDB: Setting file c:\ibdata\ibdata1 size to 209715200 InnoDB: Database physically writes the file full: wait... InnoDB: Log file c:\iblogs\ib_logfile0 did not exist: new to be created InnoDB: Setting log file c:\iblogs\ib_logfile0 size to 31457280 InnoDB: Log file c:\iblogs\ib_logfile1 did not exist: new to be created InnoDB: Setting log file c:\iblogs\ib_logfile1 size to 31457280 InnoDB: Log file c:\iblogs\ib_logfile2 did not exist: new to be created InnoDB: Setting log file c:\iblogs\ib_logfile2 size to 31457280 InnoDB: Doublewrite buffer not found: creating new InnoDB: Doublewrite buffer created InnoDB: creating foreign key constraint system tables InnoDB: foreign key constraint system tables created 011024 10:58:25 InnoDB: Started
When the server finishes its startup sequence, you should see something like this, which indicates that the server is ready to service client connections:
mysqld: ready for connections Version: '5.0.42' socket: '' port: 3306
The server continues to write to the console any further diagnostic output it produces. You can open a new console window in which to run client programs.
If you omit the --console option, the server
writes diagnostic output to the error log in the data directory
(C:\Program Files\MySQL\MySQL Server
5.0\data by default). The error log is
the file with the .err extension.
Note: The accounts that are listed in the MySQL grant tables initially have no passwords. After starting the server, you should set up passwords for them using the instructions in Section 2.4.15, “Post-Installation Setup and Testing”.
The MySQL server can be started manually from the command line. This can be done on any version of Windows.
To start the mysqld server from the command line, you should start a console window (or “DOS window”) and enter this command:
C:\> "C:\Program Files\MySQL\MySQL Server 5.0\bin\mysqld"
The path to mysqld may vary depending on the install location of MySQL on your system.
You can stop the MySQL server by executing this command:
C:\> "C:\Program Files\MySQL\MySQL Server 5.0\bin\mysqladmin" -u root shutdown
Note: If the MySQL
root user account has a password, you need to
invoke mysqladmin with the
-p option and supply the password when
prompted.
This command invokes the MySQL administrative utility
mysqladmin to connect to the server and tell
it to shut down. The command connects as the MySQL
root user, which is the default
administrative account in the MySQL grant system. Note that
users in the MySQL grant system are wholly independent from any
login users under Windows.
If mysqld doesn't start, check the error log
to see whether the server wrote any messages there to indicate
the cause of the problem. The error log is located in the
C:\Program Files\MySQL\MySQL Server
5.0\data directory. It is the file with
a suffix of .err. You can also try to start
the server as mysqld --console; in this case,
you may get some useful information on the screen that may help
solve the problem.
The last option is to start mysqld with the
--standalone and --debug
options. In this case, mysqld writes a log
file C:\mysqld.trace that should contain
the reason why mysqld doesn't start. See
MySQL
Internals: Porting.
Use mysqld --verbose --help to display all the options that mysqld understands.
On Windows, the recommended way to run MySQL is to install it as a Windows service, whereby MySQL starts and stops automatically when Windows starts and stops. A MySQL server installed as a service can also be controlled from the command line using NET commands, or with the graphical Services utility.
The Services utility (the Windows Service Control Manager) can be found in the Windows Control Panel (under on Windows 2000, XP, and Server 2003). To avoid conflicts, it is advisable to close the Services utility while performing server installation or removal operations from the command line.
Before installing MySQL as a Windows service, you should first stop the current server if it is running by using the following command:
C:\> "C:\Program Files\MySQL\MySQL Server 5.0\bin\mysqladmin" -u root shutdown
Note: If the MySQL
root user account has a password, you need to
invoke mysqladmin with the
-p option and supply the password when
prompted.
This command invokes the MySQL administrative utility
mysqladmin to connect to the server and tell
it to shut down. The command connects as the MySQL
root user, which is the default
administrative account in the MySQL grant system. Note that
users in the MySQL grant system are wholly independent from any
login users under Windows.
Install the server as a service using this command:
C:\> "C:\Program Files\MySQL\MySQL Server 5.0\bin\mysqld" --install
The service-installation command does not start the server. Instructions for that are given later in this section.
To make it easier to invoke MySQL programs, you can add the
pathname of the MySQL bin directory to your
Windows system PATH environment variable:
On the Windows desktop, right-click on the My Computer icon, and select
Next select the tab from the menu that appears, and click the button.
Under System Variables, select , and then click the button. The dialogue should appear.
Place your cursor at the end of the text appearing in the space marked Variable Value. (Use the End key to ensure that your cursor is positioned at the very end of the text in this space.) Then enter the complete pathname of your MySQL
bindirectory (for example,C:\Program Files\MySQL\MySQL Server 5.0\bin), Note that there should be a semicolon separating this path from any values present in this field. Dismiss this dialogue, and each dialogue in turn, by clicking until all of the dialogues that were opened have been dismissed. You should now be able to invoke any MySQL executable program by typing its name at the DOS prompt from any directory on the system, without having to supply the path. This includes the servers, the mysql client, and all MySQL command-line utilities such as mysqladmin and mysqldump.You should not add the MySQL
bindirectory to your WindowsPATHif you are running multiple MySQL servers on the same machine.
Warning: You must exercise
great care when editing your system PATH by
hand; accidental deletion or modification of any portion of the
existing PATH value can leave you with a
malfunctioning or even unusable system.
The following additional arguments can be used in MySQL 5.0 when installing the service:
You can specify a service name immediately following the
--installoption. The default service name isMySQL.If a service name is given, it can be followed by a single option. By convention, this should be
--defaults-file=to specify the name of an option file from which the server should read options when it starts.file_nameIt is possible to use a single option other than
--defaults-file, but this is discouraged.--defaults-fileis more flexible because it enables you to specify multiple startup options for the server by placing them in the named option file. Also, in MySQL 5.0, use of an option different from--defaults-fileis not supported until 5.0.3.As of MySQL 5.0.1, you can also specify a
--local-serviceoption following the service name. This causes the server to run using theLocalServiceWindows account that has limited system privileges. This account is available only for Windows XP or newer. If both--defaults-fileand--local-serviceare given following the service name, they can be in any order.
For a MySQL server that is installed as a Windows service, the following rules determine the service name and option files that the server uses:
If the service-installation command specifies no service name or the default service name (
MySQL) following the--installoption, the server uses the a service name ofMySQLand reads options from the[mysqld]group in the standard option files.If the service-installation command specifies a service name other than
MySQLfollowing the--installoption, the server uses that service name. It reads options from the group that has the same name as the service, and reads options from the standard option files.The server also reads options from the
[mysqld]group from the standard option files. This allows you to use the[mysqld]group for options that should be used by all MySQL services, and an option group with the same name as a service for use by the server installed with that service name.If the service-installation command specifies a
--defaults-fileoption after the service name, the server reads options only from the[mysqld]group of the named file and ignores the standard option files.
As a more complex example, consider the following command:
C:\>"C:\Program Files\MySQL\MySQL Server 5.0\bin\mysqld"--install MySQL --defaults-file=C:\my-opts.cnf
Here, the default service name (MySQL) is
given after the --install option. If no
--defaults-file option had been given, this
command would have the effect of causing the server to read the
[mysqld] group from the standard option
files. However, because the --defaults-file
option is present, the server reads options from the
[mysqld] option group, and only from the
named file.
You can also specify options as Start parameters in the Windows Services utility before you start the MySQL service.
Once a MySQL server has been installed as a service, Windows starts the service automatically whenever Windows starts. The service also can be started immediately from the Services utility, or by using a NET START MySQL command. The NET command is not case sensitive.
When run as a service, mysqld has no access
to a console window, so no messages can be seen there. If
mysqld does not start, check the error log to
see whether the server wrote any messages there to indicate the
cause of the problem. The error log is located in the MySQL data
directory (for example, C:\Program Files\MySQL\MySQL
Server 5.0\data). It is the file with a
suffix of .err.
When a MySQL server has been installed as a service, and the
service is running, Windows stops the service automatically when
Windows shuts down. The server also can be stopped manually by
using the Services utility, the NET
STOP MySQL command, or the mysqladmin
shutdown command.
You also have the choice of installing the server as a manual
service if you do not wish for the service to be started
automatically during the boot process. To do this, use the
--install-manual option rather than the
--install option:
C:\> "C:\Program Files\MySQL\MySQL Server 5.0\bin\mysqld" --install-manual
To remove a server that is installed as a service, first stop it
if it is running by executing NET STOP MySQL.
Then use the --remove option to remove it:
C:\> "C:\Program Files\MySQL\MySQL Server 5.0\bin\mysqld" --remove
If mysqld is not running as a service, you can start it from the command line. For instructions, see Section 2.4.8.10, “Starting MySQL from the Windows Command Line”.
Please see Section 2.4.8.13, “Troubleshooting a MySQL Installation Under Windows”, if you encounter difficulties during installation.
You can test whether the MySQL server is working by executing any of the following commands:
C:\>"C:\Program Files\MySQL\MySQL Server 5.0\bin\mysqlshow"C:\>"C:\Program Files\MySQL\MySQL Server 5.0\bin\mysqlshow" -u root mysqlC:\>"C:\Program Files\MySQL\MySQL Server 5.0\bin\mysqladmin" version status procC:\>"C:\Program Files\MySQL\MySQL Server 5.0\bin\mysql" test
If mysqld is slow to respond to TCP/IP
connections from client programs, there is probably a problem
with your DNS. In this case, start mysqld
with the --skip-name-resolve option and use
only localhost and IP numbers in the
Host column of the MySQL grant tables.
You can force a MySQL client to use a named-pipe connection
rather than TCP/IP by specifying the --pipe or
--protocol=PIPE option, or by specifying
. (period) as the host name. Use the
--socket option to specify the name of the pipe
if you do not want to use the default pipe name.
Note that if you have set a password for the
root account, deleted the anonymous account,
or created a new user account, then you must use the appropriate
-u and -p options with the
commands shown above in order to connect with the MySQL Server.
See Section 5.7.4, “Connecting to the MySQL Server”.
For more information about mysqlshow, see Section 8.18, “mysqlshow — Display Database, Table, and Column Information”.
When installing and running MySQL for the first time, you may encounter certain errors that prevent the MySQL server from starting. The purpose of this section is to help you diagnose and correct some of these errors.
Your first resource when troubleshooting server issues is the
error log. The MySQL server uses the error log to record
information relevant to the error that prevents the server from
starting. The error log is located in the data directory
specified in your my.ini file. The default
data directory location is C:\Program
Files\MySQL\MySQL Server 5.0\data. See
Section 5.11.1, “The Error Log”.
Another source of information regarding possible errors is the console messages displayed when the MySQL service is starting. Use the NET START MySQL command from the command line after installing mysqld as a service to see any error messages regarding the starting of the MySQL server as a service. See Section 2.4.8.11, “Starting MySQL as a Windows Service”.
The following examples show other common error messages you may encounter when installing MySQL and starting the server for the first time:
If the MySQL server cannot find the
mysqlprivileges database or other critical files, you may see these messsages:System error 1067 has occurred. Fatal error: Can't open privilege tables: Table 'mysql.host' doesn't exist
These messages often occur when the MySQL base or data directories are installed in different locations than the default locations (
C:\Program Files\MySQL\MySQL Server 5.0andC:\Program Files\MySQL\MySQL Server 5.0\data, respectively).This situation may occur when MySQL is upgraded and installed to a new location, but the configuration file is not updated to reflect the new location. In addition, there may be old and new configuration files that conflict. Be sure to delete or rename any old configuration files when upgrading MySQL.
If you have installed MySQL to a directory other than
C:\Program Files\MySQL\MySQL Server 5.0, you need to ensure that the MySQL server is aware of this through the use of a configuration (my.ini) file. Themy.inifile needs to be located in your Windows directory, typicallyC:\WINDOWS. You can determine its exact location from the value of theWINDIRenvironment variable by issuing the following command from the command prompt:C:\>
echo %WINDIR%An option file can be created and modified with any text editor, such as Notepad. For example, if MySQL is installed in
E:\mysqland the data directory isD:\MySQLdata, you can create the option file and set up a[mysqld]section to specify values for thebasediranddatadirparameters:[mysqld] # set basedir to your installation path basedir=E:/mysql # set datadir to the location of your data directory datadir=D:/MySQLdata
Note that Windows pathnames are specified in option files using (forward) slashes rather than backslashes. If you do use backslashes, you must double them:
[mysqld] # set basedir to your installation path basedir=C:\\Program Files\\MySQL\\MySQL Server 5.0 # set datadir to the location of your data directory datadir=D:\\MySQLdata
MySQL Enterprise For expert advice on the start-up options appropriate to your circumstances, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see, http://www.mysql.com/products/enterprise/advisors.html.
If you change the
datadirvalue in your MySQL configuration file, you must move the contents of the existing MySQL data directory before restarting the MySQL server.If you reinstall or upgrade MySQL without first stopping and removing the existing MySQL service and install MySQL using the MySQL Configuration Wizard, you may see this error:
Error: Cannot create Windows service for MySql. Error: 0
This occurs when the Configuration Wizard tries to install the service and finds an existing service with the same name.
One solution to this problem is to choose a service name other than
mysqlwhen using the configuration wizard. This allows the new service to be installed correctly, but leaves the outdated service in place. Although this is harmless, it is best to remove old services that are no longer in use.To permanently remove the old
mysqlservice, execute the following command as a user with administrative privileges, on the command-line:C:\>
sc delete mysql[SC] DeleteService SUCCESSIf the
scutility is not available for your version of Windows, download thedelsrvutility from http://www.microsoft.com/windows2000/techinfo/reskit/tools/existing/delsrv-o.asp and use thedelsrv mysqlsyntax.
This section does not apply to MySQL Enterprise Server users.
This section lists some of the steps you should take when upgrading MySQL on Windows.
Review Section 2.4.16, “Upgrading MySQL”, for additional information on upgrading MySQL that is not specific to Windows.
You should always back up your current MySQL installation before performing an upgrade. See Section 5.9.1, “Database Backups”.
Download the latest Windows distribution of MySQL from http://dev.mysql.com/downloads/.
Before upgrading MySQL, you must stop the server. If the server is installed as a service, stop the service with the following command from the command prompt:
C:\>
NET STOP MySQLIf you are not running the MySQL server as a service, use the following command to stop it:
C:\>
"C:\Program Files\MySQL\MySQL Server 5.0\bin\mysqladmin" -u root shutdownNote: If the MySQL
rootuser account has a password, you need to invoke mysqladmin with the-poption and supply the password when prompted.When upgrading to MySQL 5.0 from a version previous to 4.1.5, or when upgrading from a version of MySQL installed from a Zip archive to a version of MySQL installed with the MySQL Installation Wizard, you must manually remove the previous installation and MySQL service (if the server is installed as a service).
To remove the MySQL service, use the following command:
C:\>
C:\mysql\bin\mysqld --removeIf you do not remove the existing service, the MySQL Installation Wizard may fail to properly install the new MySQL service.
If you are using the MySQL Installation Wizard, start the wizard as described in Section 2.4.8.3, “Using the MySQL Installation Wizard”.
If you are installing MySQL from a Zip archive, extract the archive. You may either overwrite your existing MySQL installation (usually located at
C:\mysql), or install it into a different directory, such asC:\mysql5. Overwriting the existing installation is recommended.If you were running MySQL as a Windows service and you had to remove the service earlier in this procedure, reinstall the service. (See Section 2.4.8.11, “Starting MySQL as a Windows Service”.)
Restart the server. For example, use NET START MySQL if you run MySQL as a service, or invoke mysqld directly otherwise.
If you encounter errors, see Section 2.4.8.13, “Troubleshooting a MySQL Installation Under Windows”.
MySQL for Windows has proven itself to be very stable. The Windows version of MySQL has the same features as the corresponding Unix version, with the following exceptions:
Limited number of ports
Windows systems have about 4,000 ports available for client connections, and after a connection on a port closes, it takes two to four minutes before the port can be reused. In situations where clients connect to and disconnect from the server at a high rate, it is possible for all available ports to be used up before closed ports become available again. If this happens, the MySQL server appears to be unresponsive even though it is running. Note that ports may be used by other applications running on the machine as well, in which case the number of ports available to MySQL is lower.
For more information about this problem, see http://support.microsoft.com/default.aspx?scid=kb;en-us;196271.
Concurrent reads
MySQL depends on the
pread()andpwrite()system calls to be able to mixINSERTandSELECT. Currently, we use mutexes to emulatepread()andpwrite(). We intend to replace the file level interface with a virtual interface in the future so that we can use thereadfile()/writefile()interface to get more speed. The current implementation limits the number of open files that MySQL 5.0 can use to 2,048, which means that you cannot run as many concurrent threads on Windows as on Unix.Blocking read
MySQL uses a blocking read for each connection. That has the following implications if named-pipe connections are enabled:
A connection is not disconnected automatically after eight hours, as happens with the Unix version of MySQL.
If a connection hangs, it is not possible to break it without killing MySQL.
mysqladmin kill does not work on a sleeping connection.
mysqladmin shutdown cannot abort as long as there are sleeping connections.
We plan to fix this problem in the future.
ALTER TABLEWhile you are executing an
ALTER TABLEstatement, the table is locked from being used by other threads. This has to do with the fact that on Windows, you can't delete a file that is in use by another thread. In the future, we may find some way to work around this problem.DROP TABLEDROP TABLEon a table that is in use by aMERGEtable does not work on Windows because theMERGEhandler does the table mapping hidden from the upper layer of MySQL. Because Windows does not allow dropping files that are open, you first must flush allMERGEtables (withFLUSH TABLES) or drop theMERGEtable before dropping the table.DATA DIRECTORYandINDEX DIRECTORYThe
DATA DIRECTORYandINDEX DIRECTORYoptions forCREATE TABLEare ignored on Windows, because Windows doesn't support symbolic links. These options also are ignored on systems that have a non-functionalrealpath()call.DROP DATABASEYou cannot drop a database that is in use by some thread.
Case-insensitive names
Filenames are not case sensitive on Windows, so MySQL database and table names are also not case sensitive on Windows. The only restriction is that database and table names must be specified using the same case throughout a given statement. See Section 9.2.2, “Identifier Case Sensitivity”.
The ‘
\’ pathname separator characterPathname components in Windows are separated by the ‘
\’ character, which is also the escape character in MySQL. If you are usingLOAD DATA INFILEorSELECT ... INTO OUTFILE, use Unix-style filenames with ‘/’ characters:mysql>
LOAD DATA INFILE 'C:/tmp/skr.txt' INTO TABLE skr;mysql>SELECT * INTO OUTFILE 'C:/tmp/skr.txt' FROM skr;Alternatively, you must double the ‘
\’ character:mysql>
LOAD DATA INFILE 'C:\\tmp\\skr.txt' INTO TABLE skr;mysql>SELECT * INTO OUTFILE 'C:\\tmp\\skr.txt' FROM skr;Problems with pipes
Pipes do not work reliably from the Windows command-line prompt. If the pipe includes the character
^Z/CHAR(24), Windows thinks that it has encountered end-of-file and aborts the program.This is mainly a problem when you try to apply a binary log as follows:
C:\>
mysqlbinlogbinary_log_file| mysql --user=rootIf you have a problem applying the log and suspect that it is because of a
^Z/CHAR(24)character, you can use the following workaround:C:\>
mysqlbinlogC:\>binary_log_file--result-file=/tmp/bin.sqlmysql --user=root --execute "source /tmp/bin.sql"The latter command also can be used to reliably read in any SQL file that may contain binary data.
Access denied for usererrorIf MySQL cannot resolve your hostname properly, you may get the following error when you attempt to run a MySQL client program to connect to a server running on the same machine:
Access denied for user '
some_user'@'unknown' to database 'mysql'To fix this problem, you should create a file named
\windows\hostscontaining the following information:127.0.0.1 localhost
Here are some open issues for anyone who might want to help us improve MySQL on Windows:
Add macros to use the faster thread-safe increment/decrement methods provided by Windows.
The recommended way to install MySQL on RPM-based Linux
distributions is by using the RPM packages. The RPMs provided by
MySQL AB to the community should work on all versions of Linux
that support RPM packages and use glibc 2.3.
MySQL AB also provides RPMs with binaries that are statically
linked to a patched version of glibc 2.2, but
only for the x86 (32-bit) architecture. To obtain RPM packages,
see Section 2.4.4, “How to Get MySQL”.
For non-RPM Linux distributions, you can install MySQL using a
.tar.gz package. See
Section 2.4.13, “Installing MySQL from tar.gz Packages on Other
Unix-Like Systems”.
MySQL AB does provide some platform-specific RPMs; the difference between a platform-specific RPM and a generic RPM is that a platform-specific RPM is built on the targeted platform and is linked dynamically whereas a generic RPM is linked statically with LinuxThreads.
Note
RPM distributions of MySQL often are provided by other vendors. Be aware that they may differ in features and capabilities from those built by MySQL AB, and that the instructions in this manual do not necessarily apply to installing them. The vendor's instructions should be consulted instead.
If you have problems with an RPM file (for example, if you receive
the error Sorry, the host
'), see Section 2.4.18.1.2, “Linux Binary Distribution Notes”.
xxxx' could not be looked
up
In most cases, you need to install only the
MySQL-server and
MySQL-client packages to get a functional MySQL
installation. The other packages are not required for a standard
installation.
If you get a dependency failure when trying to install MySQL
packages (for example, error: removing these packages
would break dependencies: libmysqlclient.so.10 is needed by
...), you should also install the
MySQL-shared-compat package, which includes
both the shared libraries for backward compatibility
(libmysqlclient.so.12 for MySQL 4.0 and
libmysqlclient.so.10 for MySQL 3.23).
Some Linux distributions still ship with MySQL 3.23 and they
usually link applications dynamically to save disk space. If these
shared libraries are in a separate package (for example,
MySQL-shared), it is sufficient to simply leave
this package installed and just upgrade the MySQL server and
client packages (which are statically linked and do not depend on
the shared libraries). For distributions that include the shared
libraries in the same package as the MySQL server (for example,
Red Hat Linux), you could either install our 3.23
MySQL-shared RPM, or use the
MySQL-shared-compat package instead. (Do not
install both.)
The RPM packages shown in the following list are available. The
names shown here use a suffix of
.glibc23.i386.rpm, but particular packages
can have different suffixes, as described later. Packages that
have community in the names are Community
Server builds, available from MySQL 5.0.27 on.
MySQL-server-,VERSION.glibc23.i386.rpmMySQL-server-community-VERSION.glibc23.i386.rpmThe MySQL server. You need this unless you only want to connect to a MySQL server running on another machine.
MySQL-client-,VERSION.glibc23.i386.rpmMySQL-client-community-VERSION.glibc23.i386.rpmThe standard MySQL client programs. You probably always want to install this package.
MySQL-bench-VERSION.glibc23.i386.rpmTests and benchmarks. Requires Perl and the
DBIandDBD::mysqlmodules.MySQL-devel-,VERSION.glibc23.i386.rpmMySQL-devel-community-VERSION.glibc23.i386.rpmThe libraries and include files that are needed if you want to compile other MySQL clients, such as the Perl modules.
MySQL-debuginfo-,VERSION.glibc23.i386.rpmMySQL-community-debuginfo-VERSION.glibc23.i386.rpmThis package contains debugging information.
debuginfoRPMs are never needed to use MySQL software; this is true both for the server and for client programs. However, they contain additional information that might be needed by a debugger to analyze a crash.MySQL-shared-,VERSION.glibc23.i386.rpmMySQL-shared-community-VERSION.glibc23.i386.rpmThis package contains the shared libraries (
libmysqlclient.so*) that certain languages and applications need to dynamically load and use MySQL. It contains single-threaded and thread-safe libraries. If you install this package, do not install theMySQL-shared-compatpackage.MySQL-shared-compat-VERSION.glibc23.i386.rpmThis package includes the shared libraries for MySQL 3.23, 4.0, 4.1, and 5.0. It contains single-threaded and thread-safe libraries. Install this package instead of
MySQL-sharedif you have applications installed that are dynamically linked against older versions of MySQL but you want to upgrade to the current version without breaking the library dependencies.MySQL-clustermanagement-community,VERSION.glibc23.i386.rpmMySQL-clusterstorage-community,VERSION.glibc23.i386.rpmMySQL-clustertools-community,VERSION.glibc23.i386.rpmMySQL-clusterextra-communityVERSION.glibc23.i386.rpmPackages that contain additional files for MySQL Cluster installations. These are platform-specific RPMs, in contrast to the platform-independent
ndb-RPMs.xxxMySQL-ndb-management-,VERSION.glibc23.i386.rpmMySQL-ndb-storage-,VERSION.glibc23.i386.rpmMySQL-ndb-tools-,VERSION.glibc23.i386.rpmMySQL-ndb-extra-VERSION.glibc23.i386.rpmPackages that contain additional files for MySQL Cluster installations. These are platform-independent RPMs, in contrast to the platform-specific
clusterRPMs.xxx-communityMySQL-test-community-VERSION.glibc23.i386.rpmThis package includes the MySQL test suite.
MySQL-VERSION.src.rpmThis contains the source code for all of the previous packages. It can also be used to rebuild the RPMs on other architectures (for example, Alpha or SPARC).
The suffix of RPM package names (following the
VERSION value) has the following
syntax:
[.PLATFORM].CPU.rpm
The PLATFORM and
CPU values indicate the type of system
for which the package is built.
PLATFORM, if present, indicates the
platform, and CPU indicates the
processor type or family.
If the PLATFORM value is missing (for
example,
MySQL-server-),
the package is statically linked against a version of
VERSION.i386.rpmglibc 2.2 that has been patched to handle
larger numbers of threads with larger stack sizes than the stock
library.
If PLATFORM is present, the package is
dynamically linked against glibc 2.3 and the
PLATFORM value indicates
whether the
package is platform independent or intended for a specific
platform:
glibc23 | Platform independent, should run on any Linux distribution that supports
glibc 2.3 |
rhel3, rhel4 | Red Hat Enterprise Linux 3 or 4 |
sles9, sles10 | SuSE Linux Enterprise Server 9 or 10 |
The CPU value indicates the processor
type or family for which the package is built:
i386 | x86 processor, 386 and up |
i586 | x86 processor, Pentium and up |
x86_64 | 64-bit x86 processor |
ia64 | Itanium (IA-64) processor |
To see all files in an RPM package (for example, a
MySQL-server RPM), run a command like this:
shell> rpm -qpl MySQL-server-VERSION.glibc23.i386.rpm
To perform a standard minimal installation, install the server and client RPMs:
shell>rpm -i MySQL-server-shell>VERSION.glibc23.i386.rpmrpm -i MySQL-client-VERSION.glibc23.i386.rpm
To install only the client programs, install just the client RPM:
shell> rpm -i MySQL-client-VERSION.glibc23.i386.rpm
RPM provides a feature to verify the integrity and authenticity of
packages before installing them. If you would like to learn more
about this feature, see
Section 2.4.5, “Verifying Package Integrity Using MD5 Checksums or
GnuPG”.
The server RPM places data under the
/var/lib/mysql directory. The RPM also
creates a login account for a user named mysql
(if one does not exist) to use for running the MySQL server, and
creates the appropriate entries in
/etc/init.d/ to start the server
automatically at boot time. (This means that if you have performed
a previous installation and have made changes to its startup
script, you may want to make a copy of the script so that you
don't lose it when you install a newer RPM.) See
Section 2.4.15.2.2, “Starting and Stopping MySQL Automatically”, for more information on how
MySQL can be started automatically on system startup.
If you want to install the MySQL RPM on older Linux distributions
that do not support initialization scripts in
/etc/init.d (directly or via a symlink), you
should create a symbolic link that points to the location where
your initialization scripts actually are installed. For example,
if that location is /etc/rc.d/init.d, use
these commands before installing the RPM to create
/etc/init.d as a symbolic link that points
there:
shell>cd /etcshell>ln -s rc.d/init.d .
However, all current major Linux distributions should support the
new directory layout that uses /etc/init.d,
because it is required for LSB (Linux Standard Base) compliance.
If the RPM files that you install include
MySQL-server, the mysqld
server should be up and running after installation. You should be
able to start using MySQL.
If something goes wrong, you can find more information in the
binary installation section. See
Section 2.4.13, “Installing MySQL from tar.gz Packages on Other
Unix-Like Systems”.
Note: The accounts that are listed in the MySQL grant tables initially have no passwords. After starting the server, you should set up passwords for them using the instructions in Section 2.4.15, “Post-Installation Setup and Testing”.
You can install MySQL on Mac OS X 10.3.x (“Panther”) or newer using a Mac OS X binary package in PKG format instead of the binary tarball distribution. Please note that older versions of Mac OS X (for example, 10.1.x or 10.2.x) are not supported by this package.
The package is located inside a disk image
(.dmg) file that you first need to mount by
double-clicking its icon in the Finder. It should then mount the
image and display its contents.
To obtain MySQL, see Section 2.4.4, “How to Get MySQL”.
Note: Before proceeding with the installation, be sure to shut down all running MySQL server instances by either using the MySQL Manager Application (on Mac OS X Server) or via mysqladmin shutdown on the command line.
To actually install the MySQL PKG file, double-click on the package icon. This launches the Mac OS X Package Installer, which guides you through the installation of MySQL.
Due to a bug in the Mac OS X package installer, you may see this error message in the destination disk selection dialog:
You cannot install this software on this disk. (null)
If this error occurs, simply click the Go Back
button once to return to the previous screen. Then click
Continue to advance to the destination disk
selection again, and you should be able to choose the destination
disk correctly. We have reported this bug to Apple and it is
investigating this problem.
The Mac OS X PKG of MySQL installs itself into
/usr/local/mysql-
and also installs a symbolic link,
VERSION/usr/local/mysql, that points to the new
location. If a directory named
/usr/local/mysql exists, it is renamed to
/usr/local/mysql.bak first. Additionally, the
installer creates the grant tables in the mysql
database by executing mysql_install_db.
The installation layout is similar to that of a
tar file binary distribution; all MySQL
binaries are located in the directory
/usr/local/mysql/bin. The MySQL socket file
is created as /tmp/mysql.sock by default. See
Section 2.4.6, “Installation Layouts”.
MySQL installation requires a Mac OS X user account named
mysql. A user account with this name should
exist by default on Mac OS X 10.2 and up.
If you are running Mac OS X Server, a version of MySQL should already be installed. The following table shows the versions of MySQL that ship with Mac OS X Server versions.
| Mac OS X Server Version | MySQL Version |
| 10.2-10.2.2 | 3.23.51 |
| 10.2.3-10.2.6 | 3.23.53 |
| 10.3 | 4.0.14 |
| 10.3.2 | 4.0.16 |
| 10.4.0 | 4.1.10a |
This manual section covers the installation of the official MySQL Mac OS X PKG only. Make sure to read Apple's help information about installing MySQL: Run the “Help View” application, select “Mac OS X Server” help, do a search for “MySQL,” and read the item entitled “Installing MySQL.”
For preinstalled versions of MySQL on Mac OS X Server, note especially that you should start mysqld with safe_mysqld instead of mysqld_safe if MySQL is older than version 4.0.
If you previously used Marc Liyanage's MySQL packages for Mac OS X from http://www.entropy.ch, you can simply follow the update instructions for packages using the binary installation layout as given on his pages.
If you are upgrading from Marc's 3.23.x versions or from the Mac OS X Server version of MySQL to the official MySQL PKG, you also need to convert the existing MySQL privilege tables to the current format, because some new security privileges have been added. See Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.
If you want MySQL to start automatically during system startup, you also need to install the MySQL Startup Item. It is part of the Mac OS X installation disk images as a separate installation package. Simply double-click the MySQLStartupItem.pkg icon and follow the instructions to install it. The Startup Item need be installed only once. There is no need to install it each time you upgrade the MySQL package later.
The Startup Item for MySQL is installed into
/Library/StartupItems/MySQLCOM. (Before MySQL
4.1.2, the location was
/Library/StartupItems/MySQL, but that
collided with the MySQL Startup Item installed by Mac OS X
Server.) Startup Item installation adds a variable
MYSQLCOM=-YES- to the system configuration file
/etc/hostconfig. If you want to disable the
automatic startup of MySQL, simply change this variable to
MYSQLCOM=-NO-.
On Mac OS X Server, the default MySQL installation uses the
variable MYSQL in the
/etc/hostconfig file. The MySQL AB Startup
Item installer disables this variable by setting it to
MYSQL=-NO-. This avoids boot time conflicts
with the MYSQLCOM variable used by the MySQL AB
Startup Item. However, it does not shut down a running MySQL
server. You should do that yourself.
After the installation, you can start up MySQL by running the following commands in a terminal window. You must have administrator privileges to perform this task.
If you have installed the Startup Item, use this command:
shell>sudo /Library/StartupItems/MySQLCOM/MySQLCOM start(Enter your password, if necessary)(Press Control-D or enter "exit" to exit the shell)
If you don't use the Startup Item, enter the following command sequence:
shell>cd /usr/local/mysqlshell>sudo ./bin/mysqld_safe(Enter your password, if necessary)(Press Control-Z)shell>bg(Press Control-D or enter "exit" to exit the shell)
You should be able to connect to the MySQL server, for example, by
running /usr/local/mysql/bin/mysql.
Note: The accounts that are listed in the MySQL grant tables initially have no passwords. After starting the server, you should set up passwords for them using the instructions in Section 2.4.15, “Post-Installation Setup and Testing”.
You might want to add aliases to your shell's resource file to make it easier to access commonly used programs such as mysql and mysqladmin from the command line. The syntax for bash is:
alias mysql=/usr/local/mysql/bin/mysql alias mysqladmin=/usr/local/mysql/bin/mysqladmin
For tcsh, use:
alias mysql /usr/local/mysql/bin/mysql alias mysqladmin /usr/local/mysql/bin/mysqladmin
Even better, add /usr/local/mysql/bin to your
PATH environment variable. For example, add the
following line to your $HOME/.bashrc file if
your shell is bash:
PATH=${PATH}:/usr/local/mysql/bin
Add the following line to your $HOME/.tcshrc
file if your shell is tcsh:
setenv PATH ${PATH}:/usr/local/mysql/bin
If no .bashrc or .tcshrc
file exists in your home directory, create it with a text editor.
If you are upgrading an existing installation, note that installing a new MySQL PKG does not remove the directory of an older installation. Unfortunately, the Mac OS X Installer does not yet offer the functionality required to properly upgrade previously installed packages.
To use your existing databases with the new installation, you'll
need to copy the contents of the old data directory to the new
data directory. Make sure that neither the old server nor the new
one is running when you do this. After you have copied over the
MySQL database files from the previous installation and have
successfully started the new server, you should consider removing
the old installation files to save disk space. Additionally, you
should also remove older versions of the Package Receipt
directories located in
/Library/Receipts/mysql-.
VERSION.pkg
If you install MySQL using a binary tarball distribution on Solaris, you may run into trouble even before you get the MySQL distribution unpacked, as the Solaris tar cannot handle long filenames. This means that you may see errors when you try to unpack MySQL.
If this occurs, you must use GNU tar (gtar) to unpack the distribution. You can find a precompiled copy for Solaris at http://dev.mysql.com/downloads/os-solaris.html.
You can install MySQL on Solaris using a binary package in PKG
format instead of the binary tarball distribution. Before
installing using the binary PKG format, you should create the
mysql user and group, for example:
groupadd mysql useradd -g mysql mysql
Some basic PKG-handling commands follow:
To add a package:
pkgadd -d
package_name.pkgTo remove a package:
pkgrm
package_nameTo get a full list of installed packages:
pkginfo
To get detailed information for a package:
pkginfo -l
package_nameTo list the files belonging to a package:
pkgchk -v
package_nameTo get packaging information for an arbitrary file:
pkgchk -l -p
file_name
For additional information about installing MySQL on Solaris, see Section 2.4.18.3, “Solaris Notes”.
This section does not apply to MySQL Enterprise Server users.
Porting MySQL to NetWare was an effort spearheaded by Novell. Novell customers should be pleased to note that NetWare 6.5 ships with bundled MySQL binaries, complete with an automatic commercial use license for all servers running that version of NetWare.
MySQL for NetWare is compiled using a combination of Metrowerks CodeWarrior for NetWare and special cross-compilation versions of the GNU autotools.
The latest binary packages for NetWare can be obtained at http://dev.mysql.com/downloads/. See Section 2.4.4, “How to Get MySQL”.
To host MySQL, the NetWare server must meet these requirements:
The latest Support Pack of NetWare 6.5 must be installed.
The system must meet Novell's minimum requirements to run the respective version of NetWare.
MySQL data and the program binaries must be installed on an NSS volume; traditional volumes are not supported.
To install MySQL for NetWare, use the following procedure:
If you are upgrading from a prior installation, stop the MySQL server. This is done from the server console, using the following command:
SERVER: mysqladmin -u root shutdown
Note: If the MySQL
rootuser account has a password, you need to invoke mysqladmin with the-poption and supply the password when prompted.Log on to the target server from a client machine with access to the location where you are installing MySQL.
Extract the binary package Zip file onto the server. Be sure to allow the paths in the Zip file to be used. It is safe to simply extract the file to
SYS:\.If you are upgrading from a prior installation, you may need to copy the data directory (for example,
SYS:MYSQL\DATA), as well asmy.cnf, if you have customized it. You can then delete the old copy of MySQL.You might want to rename the directory to something more consistent and easy to use. The examples in this manual use
SYS:MYSQLto refer to the installation directory.Note that MySQL installation on NetWare does not detect if a version of MySQL is already installed outside the NetWare release. Therefore, if you have installed the latest MySQL version from the Web (for example, MySQL 4.1 or later) in
SYS:\MYSQL, you must rename the folder before upgrading the NetWare server; otherwise, files inSYS:\MySQLare overwritten by the MySQL version present in NetWare Support Pack.At the server console, add a search path for the directory containing the MySQL NLMs. For example:
SERVER: SEARCH ADD SYS:MYSQL\BIN
Initialize the data directory and the grant tables, if necessary, by executing mysql_install_db at the server console.
Start the MySQL server using mysqld_safe at the server console.
To finish the installation, you should also add the following commands to
autoexec.ncf. For example, if your MySQL installation is inSYS:MYSQLand you want MySQL to start automatically, you could add these lines:#Starts the MySQL 5.0.x database server SEARCH ADD SYS:MYSQL\BIN MYSQLD_SAFE
If you are running MySQL on NetWare 6.0, we strongly suggest that you use the
--skip-external-lockingoption on the command line:#Starts the MySQL 5.0.x database server SEARCH ADD SYS:MYSQL\BIN MYSQLD_SAFE --skip-external-locking
It is also necessary to use
CHECK TABLEandREPAIR TABLEinstead of myisamchk, because myisamchk makes use of external locking. External locking is known to have problems on NetWare 6.0; the problem has been eliminated in NetWare 6.5. Note that the use of MySQL on Netware 6.0 is not officially supported.mysqld_safe on NetWare provides a screen presence. When you unload (shut down) the mysqld_safe NLM, the screen does not go away by default. Instead, it prompts for user input:
*<NLM has terminated; Press any key to close the screen>*
If you want NetWare to close the screen automatically instead, use the
--autocloseoption to mysqld_safe. For example:#Starts the MySQL 5.0.x database server SEARCH ADD SYS:MYSQL\BIN MYSQLD_SAFE --autoclose
The behavior of mysqld_safe on NetWare is described further in Section 5.3.1, “mysqld_safe — MySQL Server Startup Script”.
When installing MySQL, either for the first time or upgrading from a previous version, download and install the latest and appropriate Perl module and PHP extensions for NetWare:
If there was an existing installation of MySQL on the NetWare
server, be sure to check for existing MySQL startup commands in
autoexec.ncf, and edit or delete them as
necessary.
Note: The accounts that are listed in the MySQL grant tables initially have no passwords. After starting the server, you should set up passwords for them using the instructions in Section 2.4.15, “Post-Installation Setup and Testing”.
This section does not apply to MySQL Enterprise Server users.
This section covers the installation of MySQL binary distributions
that are provided for various platforms in the form of compressed
tar files (files with a
.tar.gz extension). See
Section 2.4.3.5, “MySQL Binaries Compiled by MySQL AB”, for a detailed list.
To obtain MySQL, see Section 2.4.4, “How to Get MySQL”.
MySQL tar file binary distributions have names
of the form
mysql-,
where VERSION-OS.tar.gzVERSION5.0.42), and
OS indicates the type of operating
system for which the distribution is intended (for example,
pc-linux-i686).
In addition to these generic packages, we also offer binaries in platform-specific package formats for selected platforms. See Section 2.4.7, “Standard MySQL Installation Using a Binary Distribution”, for more information on how to install these.
You need the following tools to install a MySQL tar file binary distribution:
GNU
gunzipto uncompress the distribution.A reasonable tar to unpack the distribution. GNU tar is known to work. Some operating systems come with a preinstalled version of tar that is known to have problems. For example, Mac OS X tar and Sun tar are known to have problems with long filenames. On Mac OS X, you can use the preinstalled gnutar program. On other systems with a deficient tar, you should install GNU tar first.
If you run into problems and need to file a bug report, please use the instructions in Section 1.8, “How to Report Bugs or Problems”.
The basic commands that you must execute to install and use a MySQL binary distribution are:
shell>groupadd mysqlshell>useradd -g mysql mysqlshell>cd /usr/localshell>gunzip <shell>/path/to/mysql-VERSION-OS.tar.gz | tar xvf -ln -sshell>full-path-to-mysql-VERSION-OSmysqlcd mysqlshell>chown -R mysql .shell>chgrp -R mysql .shell>scripts/mysql_install_db --user=mysqlshell>chown -R root .shell>chown -R mysql datashell>bin/mysqld_safe --user=mysql &
Note: This procedure does not set up any passwords for MySQL accounts. After following the procedure, proceed to Section 2.4.15, “Post-Installation Setup and Testing”.
A more detailed version of the preceding description for installing a binary distribution follows:
Add a login user and group for mysqld to run as:
shell>
groupadd mysqlshell>useradd -g mysql mysqlThese commands add the
mysqlgroup and themysqluser. The syntax for useradd and groupadd may differ slightly on different versions of Unix, or they may have different names such as adduser and addgroup.You might want to call the user and group something else instead of
mysql. If so, substitute the appropriate name in the following steps.Pick the directory under which you want to unpack the distribution and change location into it. In the following example, we unpack the distribution under
/usr/local. (The instructions, therefore, assume that you have permission to create files and directories in/usr/local. If that directory is protected, you must perform the installation asroot.)shell>
cd /usr/localObtain a distribution file using the instructions in Section 2.4.4, “How to Get MySQL”. For a given release, binary distributions for all platforms are built from the same MySQL source distribution.
Unpack the distribution, which creates the installation directory. Then create a symbolic link to that directory:
shell>
gunzip <shell>/path/to/mysql-VERSION-OS.tar.gz | tar xvf -ln -sfull-path-to-mysql-VERSION-OSmysqlThe tar command creates a directory named
mysql-. TheVERSION-OSlncommand makes a symbolic link to that directory. This lets you refer more easily to the installation directory as/usr/local/mysql.With GNU tar, no separate invocation of
gunzipis necessary. You can replace the first line with the following alternative command to uncompress and extract the distribution:shell>
tar zxvf/path/to/mysql-VERSION-OS.tar.gzChange location into the installation directory:
shell>
cd mysqlYou will find several files and subdirectories in the
mysqldirectory. The most important for installation purposes are thebinandscriptssubdirectories:The
bindirectory contains client programs and the server. You should add the full pathname of this directory to yourPATHenvironment variable so that your shell finds the MySQL programs properly. See Section 2.4.19, “Environment Variables”.The
scriptsdirectory contains the mysql_install_db script used to initialize themysqldatabase containing the grant tables that store the server access permissions.
Ensure that the distribution contents are accessible to
mysql. If you unpacked the distribution asmysql, no further action is required. If you unpacked the distribution asroot, its contents will be owned byroot. Change its ownership tomysqlby executing the following commands asrootin the installation directory:shell>
chown -R mysql .shell>chgrp -R mysql .The first command changes the owner attribute of the files to the
mysqluser. The second changes the group attribute to themysqlgroup.If you have not installed MySQL before, you must create the MySQL data directory and initialize the grant tables:
shell>
scripts/mysql_install_db --user=mysqlIf you run the command as
root, include the--useroption as shown. If you run the command while logged in as that user, you can omit the--useroption.The command should create the data directory and its contents with
mysqlas the owner.After creating or updating the grant tables, you need to restart the server manually.
Most of the MySQL installation can be owned by
rootif you like. The exception is that the data directory must be owned bymysql. To accomplish this, run the following commands asrootin the installation directory:shell>
chown -R root .shell>chown -R mysql dataIf you want MySQL to start automatically when you boot your machine, you can copy
support-files/mysql.serverto the location where your system has its startup files. More information can be found in thesupport-files/mysql.serverscript itself and in Section 2.4.15.2.2, “Starting and Stopping MySQL Automatically”.You can set up new accounts using the bin/mysql_setpermission script if you install the
DBIandDBD::mysqlPerl modules. See Section 8.23, “mysql_setpermission — Interactively Set Permissions in Grant Tables”. For Perl module installation instructions, see Section 2.4.20, “Perl Installation Notes”.If you would like to use mysqlaccess and have the MySQL distribution in some non-standard location, you must change the location where mysqlaccess expects to find the mysql client. Edit the
bin/mysqlaccessscript at approximately line 18. Search for a line that looks like this:$MYSQL = '/usr/local/bin/mysql'; # path to mysql executable
Change the path to reflect the location where mysql actually is stored on your system. If you do not do this, a
Broken pipeerror will occur when you run mysqlaccess.
After everything has been unpacked and installed, you should test your distribution. To start the MySQL server, use the following command:
shell> bin/mysqld_safe --user=mysql &
If you run the command as root, you must use
the --user option as shown. The value of the
option is the name of the login account that you created in the
first step to use for running the server. If you run the command
while logged in as mysql, you can omit the
--user option.
If the command fails immediately and prints mysqld
ended, you can find some information in the
host_name.err
More information about mysqld_safe is given in Section 5.3.1, “mysqld_safe — MySQL Server Startup Script”.
Note: The accounts that are listed in the MySQL grant tables initially have no passwords. After starting the server, you should set up passwords for them using the instructions in Section 2.4.15, “Post-Installation Setup and Testing”.
This section does not apply to MySQL Enterprise Server users.
Before you proceed with an installation from source, first check whether our binary is available for your platform and whether it works for you. We put a great deal of effort into ensuring that our binaries are built with the best possible options.
To obtain a source distribution for MySQL, Section 2.4.4, “How to Get MySQL”. If you want to build MySQL from source on Windows, see Section 2.4.14.6, “Installing MySQL from Source on Windows”.
MySQL source distributions are provided as compressed
tar archives and have names of the form
mysql-,
where VERSION.tar.gzVERSION is a number like
5.0.42.
You need the following tools to build and install MySQL from source:
GNU
gunzipto uncompress the distribution.A reasonable tar to unpack the distribution. GNU tar is known to work. Some operating systems come with a preinstalled version of tar that is known to have problems. For example, the tar provided with early versions of Mac OS X tar, SunOS 4.x and Solaris 8 and earlier are known to have problems with long filenames. On Mac OS X, you can use the preinstalled gnutar program. On other systems with a deficient tar, you should install GNU tar first.
A working ANSI C++ compiler. gcc 2.95.2 or later, egcs 1.0.2 or later or egcs 2.91.66, SGI C++, and SunPro C++ are some of the compilers that are known to work.
libg++is not needed when using gcc. gcc 2.7.x has a bug that makes it impossible to compile some perfectly legal C++ files, such assql/sql_base.cc. If you have only gcc 2.7.x, you must upgrade your gcc to be able to compile MySQL. gcc 2.8.1 is also known to have problems on some platforms, so it should be avoided if a new compiler exists for the platform.gcc 2.95.2 or later is recommended when compiling MySQL 3.23.x.
A good make program. GNU make is always recommended and is sometimes required. If you have problems, we recommend GNU make 3.75 or newer.
If you are using a version of gcc recent enough
to understand the -fno-exceptions option, it is
very important that you use this option.
Otherwise, you may compile a binary that crashes randomly. We also
recommend that you use -felide-constructors and
-fno-rtti along with
-fno-exceptions. When in doubt, do the following:
CFLAGS="-O3" CXX=gcc CXXFLAGS="-O3 -felide-constructors \
-fno-exceptions -fno-rtti" ./configure \
--prefix=/usr/local/mysql --enable-assembler \
--with-mysqld-ldflags=-all-static
On most systems, this gives you a fast and stable binary.
If you run into problems and need to file a bug report, please use the instructions in Section 1.8, “How to Report Bugs or Problems”.
This section does not apply to MySQL Enterprise Server users.
The basic commands that you must execute to install a MySQL source distribution are:
shell>groupadd mysqlshell>useradd -g mysql mysqlshell>gunzip < mysql-shell>VERSION.tar.gz | tar -xvf -cd mysql-shell>VERSION./configure --prefix=/usr/local/mysqlshell>makeshell>make installshell>cp support-files/my-medium.cnf /etc/my.cnfshell>cd /usr/local/mysqlshell>chown -R mysql .shell>chgrp -R mysql .shell>bin/mysql_install_db --user=mysqlshell>chown -R root .shell>chown -R mysql varshell>bin/mysqld_safe --user=mysql &
If you start from a source RPM, do the following:
shell> rpmbuild --rebuild --clean MySQL-VERSION.src.rpm
This makes a binary RPM that you can install. For older versions of RPM, you may have to replace the command rpmbuild with rpm instead.
Note: This procedure does not set up any passwords for MySQL accounts. After following the procedure, proceed to Section 2.4.15, “Post-Installation Setup and Testing”, for post-installation setup and testing.
A more detailed version of the preceding description for installing MySQL from a source distribution follows:
Add a login user and group for mysqld to run as:
shell>
groupadd mysqlshell>useradd -g mysql mysqlThese commands add the
mysqlgroup and themysqluser. The syntax for useradd and groupadd may differ slightly on different versions of Unix, or they may have different names such as adduser and addgroup.You might want to call the user and group something else instead of
mysql. If so, substitute the appropriate name in the following steps.Perform the following steps as the
mysqluser, except as noted.Pick the directory under which you want to unpack the distribution and change location into it.
Obtain a distribution file using the instructions in Section 2.4.4, “How to Get MySQL”.
Unpack the distribution into the current directory:
shell>
gunzip </path/to/mysql-VERSION.tar.gz | tar xvf -This command creates a directory named
mysql-.VERSIONWith GNU tar, no separate invocation of
gunzipis necessary. You can use the following alternative command to uncompress and extract the distribution:shell>
tar zxvf/path/to/mysql-VERSION-OS.tar.gzChange location into the top-level directory of the unpacked distribution:
shell>
cd mysql-VERSIONNote that currently you must configure and build MySQL from this top-level directory. You cannot build it in a different directory.
Configure the release and compile everything:
shell>
./configure --prefix=/usr/local/mysqlshell>makeWhen you run configure, you might want to specify other options. Run ./configure --help for a list of options. Section 2.4.14.2, “Typical configure Options”, discusses some of the more useful options.
If configure fails and you are going to send mail to a MySQL mailing list to ask for assistance, please include any lines from
config.logthat you think can help solve the problem. Also include the last couple of lines of output from configure. To file a bug report, please use the instructions in Section 1.8, “How to Report Bugs or Problems”.If the compile fails, see Section 2.4.14.4, “Dealing with Problems Compiling MySQL”, for help.
Install the distribution:
shell>
make installYou might need to run this command as
root.If you want to set up an option file, use one of those present in the
support-filesdirectory as a template. For example:shell>
cp support-files/my-medium.cnf /etc/my.cnfYou might need to run this command as
root.If you want to configure support for
InnoDBtables, you should edit the/etc/my.cnffile, remove the#character before the option lines that start withinnodb_..., and modify the option values to be what you want. See Section 4.3.2, “Using Option Files”, and Section 14.2.3, “InnoDBConfiguration”.Change location into the installation directory:
shell>
cd /usr/local/mysqlIf you ran the make install command as
root, the installed files will be owned byroot. Ensure that the installation is accessible tomysqlby executing the following commands asrootin the installation directory:shell>
chown -R mysql .shell>chgrp -R mysql .The first command changes the owner attribute of the files to the
mysqluser. The second changes the group attribute to themysqlgroup.If you have not installed MySQL before, you must create the MySQL data directory and initialize the grant tables:
shell>
bin/mysql_install_db --user=mysqlIf you run the command as
root, include the--useroption as shown. If you run the command while logged in asmysql, you can omit the--useroption.The command should create the data directory and its contents with
mysqlas the owner.After using mysql_install_db to create the grant tables for MySQL, you must restart the server manually. The mysqld_safe command to do this is shown in a later step.
Most of the MySQL installation can be owned by
rootif you like. The exception is that the data directory must be owned bymysql. To accomplish this, run the following commands asrootin the installation directory:shell>
chown -R root .shell>chown -R mysql varIf you want MySQL to start automatically when you boot your machine, you can copy
support-files/mysql.serverto the location where your system has its startup files. More information can be found in thesupport-files/mysql.serverscript itself; see also Section 2.4.15.2.2, “Starting and Stopping MySQL Automatically”.You can set up new accounts using the bin/mysql_setpermission script if you install the
DBIandDBD::mysqlPerl modules. See Section 8.23, “mysql_setpermission — Interactively Set Permissions in Grant Tables”. For Perl module installation instructions, see Section 2.4.20, “Perl Installation Notes”.
After everything has been installed, you should test your distribution. To start the MySQL server, use the following command:
shell> /usr/local/mysql/bin/mysqld_safe --user=mysql &
If you run the command as root, you should
use the --user option as shown. The value of
the option is the name of the login account that you created in
the first step to use for running the server. If you run the
command while logged in as that user, you can omit the
--user option.
If the command fails immediately and prints mysqld
ended, you can find some information in the
host_name.err
More information about mysqld_safe is given in Section 5.3.1, “mysqld_safe — MySQL Server Startup Script”.
Note: The accounts that are listed in the MySQL grant tables initially have no passwords. After starting the server, you should set up passwords for them using the instructions in Section 2.4.15, “Post-Installation Setup and Testing”.
This section does not apply to MySQL Enterprise Server users.
The configure script gives you a great deal of control over how you configure a MySQL source distribution. Typically you do this using options on the configure command line. You can also affect configure using certain environment variables. See Section 2.4.19, “Environment Variables”. For a full list of options supported by configure, run this command:
shell> ./configure --help
Some of the configure options available are described here:
To compile just the MySQL client libraries and client programs and not the server, use the
--without-serveroption:shell>
./configure --without-serverIf you have no C++ compiler, some client programs such as mysql cannot be compiled because they require C++.. In this case, you can remove the code in configure that tests for the C++ compiler and then run ./configure with the
--without-serveroption. The compile step should still try to build all clients, but you can ignore any warnings about files such asmysql.cc. (If make stops, try make -k to tell it to continue with the rest of the build even if errors occur.)If you want to build the embedded MySQL library (
libmysqld.a), use the--with-embedded-serveroption.If you don't want your log files and database directories located under
/usr/local/var, use a configure command something like one of these:shell>
./configure --prefix=/usr/local/mysqlshell>./configure --prefix=/usr/local \--localstatedir=/usr/local/mysql/dataThe first command changes the installation prefix so that everything is installed under
/usr/local/mysqlrather than the default of/usr/local. The second command preserves the default installation prefix, but overrides the default location for database directories (normally/usr/local/var) and changes it to/usr/local/mysql/data.You can also specify the installation directory and data directory locations at server startup time by using the
--basedirand--datadiroptions. These can be given on the command line or in an MySQL option file, although it is more common to use an option file. See Section 4.3.2, “Using Option Files”.If you are using Unix and you want the MySQL socket file location to be somewhere other than the default location (normally in the directory
/tmpor/var/run), use a configure command like this:shell>
./configure \--with-unix-socket-path=/usr/local/mysql/tmp/mysql.sockThe socket filename must be an absolute pathname. You can also change the location of
mysql.sockat server startup by using a MySQL option file. See Section B.1.4.5, “How to Protect or Change the MySQL Unix Socket File”.If you want to compile statically linked programs (for example, to make a binary distribution, to get better performance, or to work around problems with some Red Hat Linux distributions), run configure like this:
shell>
./configure --with-client-ldflags=-all-static \--with-mysqld-ldflags=-all-staticIf you are using gcc and don't have
libg++orlibstdc++installed, you can tell configure to use gcc as your C++ compiler:shell>
CC=gcc CXX=gcc ./configureWhen you use gcc as your C++ compiler, it does not attempt to link in
libg++orlibstdc++. This may be a good thing to do even if you have those libraries installed. Some versions of them have caused strange problems for MySQL users in the past.The following list indicates some compilers and environment variable settings that are commonly used with each one.
gcc 2.7.2:
CC=gcc CXX=gcc CXXFLAGS="-O3 -felide-constructors"
egcs 1.0.3a:
CC=gcc CXX=gcc CXXFLAGS="-O3 -felide-constructors \ -fno-exceptions -fno-rtti"
gcc 2.95.2:
CFLAGS="-O3 -mpentiumpro" CXX=gcc CXXFLAGS="-O3 -mpentiumpro \ -felide-constructors -fno-exceptions -fno-rtti"
pgcc2.90.29 or newer:CFLAGS="-O3 -mpentiumpro -mstack-align-double" CXX=gcc \ CXXFLAGS="-O3 -mpentiumpro -mstack-align-double \ -felide-constructors -fno-exceptions -fno-rtti"
In most cases, you can get a reasonably optimized MySQL binary by using the options from the preceding list and adding the following options to the configure line:
--prefix=/usr/local/mysql --enable-assembler \ --with-mysqld-ldflags=-all-static
The full configure line would, in other words, be something like the following for all recent gcc versions:
CFLAGS="-O3 -mpentiumpro" CXX=gcc CXXFLAGS="-O3 -mpentiumpro \ -felide-constructors -fno-exceptions -fno-rtti" ./configure \ --prefix=/usr/local/mysql --enable-assembler \ --with-mysqld-ldflags=-all-static
The binaries we provide on the MySQL Web site at http://dev.mysql.com/downloads/ are all compiled with full optimization and should be perfect for most users. See Section 2.4.3.5, “MySQL Binaries Compiled by MySQL AB”. There are some configuration settings you can tweak to build an even faster binary, but these are only for advanced users. See Section 7.5.4, “How Compiling and Linking Affects the Speed of MySQL”.
If the build fails and produces errors about your compiler or linker not being able to create the shared library
libmysqlclient.so.(whereNNis a version number), you can work around this problem by giving the--disable-sharedoption to configure. In this case, configure does not build a sharedlibmysqlclient.so.library.NBy default, MySQL uses the
latin1(cp1252 West European) character set. To change the default set, use the--with-charsetoption:shell>
./configure --with-charset=CHARSETCHARSETmay be one ofbinary,armscii8,ascii,big5,cp1250,cp1251,cp1256,cp1257,cp850,cp852,cp866,cp932,dec8,eucjpms,euckr,gb2312,gbk,geostd8,greek,hebrew,hp8,keybcs2,koi8r,koi8u,latin1,latin2,latin5,latin7,macce,macroman,sjis,swe7,tis620,ucs2,ujis,utf8. See Section 5.10.1, “The Character Set Used for Data and Sorting”. (Additional character sets might be available. Check the output from ./configure --help for the current list.)The default collation may also be specified. MySQL uses the
latin1_swedish_cicollation by default. To change this, use the--with-collationoption:shell>
./configure --with-collation=COLLATIONTo change both the character set and the collation, use both the
--with-charsetand--with-collationoptions. The collation must be a legal collation for the character set. (Use theSHOW COLLATIONstatement to determine which collations are available for each character set.)Warning: If you change character sets after having created any tables, you must run myisamchk -r -q --set-collation=
collation_nameon everyMyISAMtable. Your indexes may be sorted incorrectly otherwise. This can happen if you install MySQL, create some tables, and then reconfigure MySQL to use a different character set and reinstall it.With the configure option
--with-extra-charsets=, you can define which additional character sets should be compiled into the server.LISTLISTis one of the following:A list of character set names separated by spaces
complexto include all character sets that can't be dynamically loadedallto include all character sets into the binaries
Clients that want to convert characters between the server and the client should use the
SET NAMESstatement. See Section 13.5.3, “SETSyntax”, and Section 10.4, “Connection Character Sets and Collations”.To configure MySQL with debugging code, use the
--with-debugoption:shell>
./configure --with-debugThis causes a safe memory allocator to be included that can find some errors and that provides output about what is happening. See MySQL Internals: Porting.
As of MySQL 5.0.25, using
--with-debugto configure MySQL with debugging support enables you to use the--debug="d,parser_debug"option when you start the server. This causes the Bison parser that is used to process SQL statements to dump a parser trace to the server's standard error output. Typically, this output is written to the error log.If your client programs are using threads, you must compile a thread-safe version of the MySQL client library with the
--enable-thread-safe-clientconfigure option. This creates alibmysqlclient_rlibrary with which you should link your threaded applications. See Section 22.2.16, “How to Make a Threaded Client”.It is possible to build MySQL 5.0 with large table support using the
--with-big-tablesoption, beginning with MySQL 5.0.4.This option causes the variables that store table row counts to be declared as
unsigned long longrather thanunsigned long. This enables tables to hold up to approximately 1.844E+19 ((232)2) rows rather than 232 (~4.295E+09) rows. Previously it was necessary to pass-DBIG_TABLESto the compiler manually in order to enable this feature.Run configure with the
--disable-grant-optionsoption to cause the the--bootstrap,--skip-grant-tables, and--init-fileoptions for mysqld to be disabled. For Windows, the configure.js script recognizes theDISABLE_GRANT_OPTIONSflag, which has the same effect. The capability is available as of MySQL 5.0.34.See Section 2.4.18, “Operating System-Specific Notes”, for options that pertain to particular operating systems.
See Section 5.8.7.2, “Using SSL Connections”, for options that pertain to configuring MySQL to support secure (encrypted) connections.
This section does not apply to MySQL Enterprise Server users.
Caution: You should read this section only if you are interested in helping us test our new code. If you just want to get MySQL up and running on your system, you should use a standard release distribution (either a binary or source distribution).
To obtain our most recent development source tree, first
download and install the BitKeeper free client if you do not
have it. The client can be obtained from
http://www.bitmover.com/bk-client2.0.shar. Note
that you will need gcc and
make to build the BitKeeper free client, and
patch and tar to use the
BitKeeper free client. Note that old
1.1 versions of the BitKeeper free client will not
work!
To install the BitKeeper client on Unix, use these commands:
shell>/bin/sh bk-client2.0.sharshell>cd bk-client2.0shell>make
If you get a cc: command not found error,
invoke this command before running make:
shell> make CC=gcc
The step above will create the utility bkf, which is the free BitKeeper client.
To install the BitKeeper client on Windows, use these instructions:
Download and install Cygwin from http://cygwin.com.
Make sure patch, tar, gcc and make have been installed under Cygwin. You can test this by issuing which
gccfor each command. If a required tool is not installed, run Cygwin's package manager, select the required tools and install them.For the installation of the BitKeeper free client, use the same installations as given for Unix-like systems above.
For more information on bkf, use:
shell> bkf --help
After you have installed the BitKeeper client, you can access the MySQL development source tree:
Change location to the directory you want to work from, and then use the following command to make a local copy of the MySQL 5.0 branch:
shell>
bkf clone bk://mysql.bkbits.net/mysql-5.0 mysql-5.0In the preceding example, the source tree is set up in the
mysql-5.0/subdirectory of your current directory.The initial download of the source tree may take a while, depending on the speed of your connection. Please be patient.
You need GNU make, autoconf 2.58 (or newer), automake 1.8.1, libtool 1.5, and m4 to run the next set of commands. Even though many operating systems come with their own implementation of make, chances are high that the compilation fails with strange error messages. Therefore, it is highly recommended that you use GNU make (sometimes named gmake) instead.
Fortunately, a large number of operating systems ship with the GNU toolchain preinstalled or supply installable packages of these. In any case, they can also be downloaded from the following locations:
To configure MySQL 5.0, you also need GNU bison. You should use the latest version of bison where possible. Version 1.75 and version 2.1 are known to work. There have been reported problems with bison 1.875. If you experience problems, upgrade to a later, rather than earlier, version. Versions of bison older than 1.75 may report this error:
sql_yacc.yy:#####: fatal error: maximum table size (32767) exceeded
Note: The maximum table size is not actually exceeded; the error is caused by bugs in older versions of bison.
The following example shows the typical commands required to configure a source tree. The first
cdcommand changes location into the top-level directory of the tree; replacemysql-5.0with the appropriate directory name.shell>
cd mysql-5.0shell>(cd bdb/dist; sh s_all)shell>(cd innobase; autoreconf --force --install)shell>autoreconf --force --installshell>./configure # Add your favorite options hereshell>makeOr you can use BUILD/autorun.sh as a shortcut for the following sequence of commands:
shell>
aclocal; autoheadershell>libtoolize --automake --forceshell>automake --force --add-missing; autoconfshell>(cd innobase; aclocal; autoheader; autoconf; automake)shell>(cd bdb/dist; sh s_all)The command lines that change directory into the
innobaseandbdb/distdirectories are used to configure theInnoDBand Berkeley DB (BDB) storage engines. You can omit these command lines if you to not requireInnoDBorBDBsupport.If you get some strange errors during this stage, verify that you really have libtool installed.
A collection of our standard configuration scripts is located in the
BUILD/subdirectory. You may find it more convenient to use theBUILD/compile-pentium-debugscript than the preceding set of shell commands. To compile on a different architecture, modify the script by removing flags that are Pentium-specific.When the build is done, run make install. Be careful with this on a production machine; the command may overwrite your live release installation. If you have another installation of MySQL, we recommend that you run ./configure with different values for the
--prefix,--with-tcp-port, and--unix-socket-pathoptions than those used for your production server.Play hard with your new installation and try to make the new features crash. Start by running make test. See Section 24.1.2, “MySQL Test Suite”.
If you have gotten to the make stage, but the distribution does not compile, please enter the problem into our bugs database using the instructions given in Section 1.8, “How to Report Bugs or Problems”. If you have installed the latest versions of the required GNU tools, and they crash trying to process our configuration files, please report that also. However, if you execute
aclocaland get acommand not founderror or a similar problem, do not report it. Instead, make sure that all the necessary tools are installed and that yourPATHvariable is set correctly so that your shell can find them.After initially copying the repository with bkf to obtain the source tree, you should use pull option to periodically update your local copy. To do this any time after you have set up the repository, use this command:
shell>
bkf pullYou can examine the changeset comments for the tree by using the
changesoption to bkf:shell> bkf changes
To get a list of the changes that would be applied with the next
bkf pull:shell> bkf changes -R
To obtain a patch file for a specific changeset (
CSETID), use:shell> bkf changes -vvr
CSETIDIf you see diffs or code that you have a question about, do not hesitate to send email to the MySQL Internals mailing list. (See Section 1.7.1, “MySQL Mailing Lists”.) Also, if you think you have a better idea on how to do something, send an email message to the list with your proposed patch.
You can also browse changesets, comments, and source code online. To browse this information for MySQL 5.0, go to http://mysql.bkbits.net:8080/mysql-5.0.
This section does not apply to MySQL Enterprise Server users.
All MySQL programs compile cleanly for us with no warnings on Solaris or Linux using gcc. On other systems, warnings may occur due to differences in system include files. See Section 2.4.14.5, “MIT-pthreads Notes”, for warnings that may occur when using MIT-pthreads. For other problems, check the following list.
The solution to many problems involves reconfiguring. If you do need to reconfigure, take note of the following:
If configure is run after it has previously been run, it may use information that was gathered during its previous invocation. This information is stored in
config.cache. When configure starts up, it looks for that file and reads its contents if it exists, on the assumption that the information is still correct. That assumption is invalid when you reconfigure.Each time you run configure, you must run make again to recompile. However, you may want to remove old object files from previous builds first because they were compiled using different configuration options.
To prevent old configuration information or object files from being used, run these commands before re-running configure:
shell>rm config.cacheshell>make clean
Alternatively, you can run make distclean.
The following list describes some of the problems when compiling MySQL that have been found to occur most often:
If you get errors such as the ones shown here when compiling
sql_yacc.cc, you probably have run out of memory or swap space:Internal compiler error: program cc1plus got fatal signal 11 Out of virtual memory Virtual memory exhausted
The problem is that gcc requires a huge amount of memory to compile
sql_yacc.ccwith inline functions. Try running configure with the--with-low-memoryoption:shell>
./configure --with-low-memoryThis option causes
-fno-inlineto be added to the compile line if you are using gcc and-O0if you are using something else. You should try the--with-low-memoryoption even if you have so much memory and swap space that you think you can't possibly have run out. This problem has been observed to occur even on systems with generous hardware configurations, and the--with-low-memoryoption usually fixes it.By default, configure picks c++ as the compiler name and GNU c++ links with
-lg++. If you are using gcc, that behavior can cause problems during configuration such as this:configure: error: installation or configuration problem: C++ compiler cannot create executables.
You might also observe problems during compilation related to g++,
libg++, orlibstdc++.One cause of these problems is that you may not have g++, or you may have g++ but not
libg++, orlibstdc++. Take a look at theconfig.logfile. It should contain the exact reason why your C++ compiler didn't work. To work around these problems, you can use gcc as your C++ compiler. Try setting the environment variableCXXto"gcc -O3". For example:shell>
CXX="gcc -O3" ./configureThis works because gcc compiles C++ source files as well as g++ does, but does not link in
libg++orlibstdc++by default.Another way to fix these problems is to install g++,
libg++, andlibstdc++. However, we recommend that you not uselibg++orlibstdc++with MySQL because this only increases the binary size of mysqld without providing any benefits. Some versions of these libraries have also caused strange problems for MySQL users in the past.If your compile fails with errors such as any of the following, you must upgrade your version of make to GNU make:
making all in mit-pthreads make: Fatal error in reader: Makefile, line 18: Badly formed macro assignment
Or:
make: file `Makefile' line 18: Must be a separator (:
Or:
pthread.h: No such file or directory
Solaris and FreeBSD are known to have troublesome make programs.
GNU make 3.75 is known to work.
If you want to define flags to be used by your C or C++ compilers, do so by adding the flags to the
CFLAGSandCXXFLAGSenvironment variables. You can also specify the compiler names this way usingCCandCXX. For example:shell>
CC=gccshell>CFLAGS=-O3shell>CXX=gccshell>CXXFLAGS=-O3shell>export CC CFLAGS CXX CXXFLAGSSee Section 2.4.3.5, “MySQL Binaries Compiled by MySQL AB”, for a list of flag definitions that have been found to be useful on various systems.
If you get errors such as those shown here when compiling mysqld, configure did not correctly detect the type of the last argument to
accept(),getsockname(), orgetpeername():cxx: Error: mysqld.cc, line 645: In this statement, the referenced type of the pointer value ''length'' is ''unsigned long'', which is not compatible with ''int''. new_sock = accept(sock, (struct sockaddr *)&cAddr, &length);To fix this, edit the
config.hfile (which is generated by configure). Look for these lines:/* Define as the base type of the last arg to accept */ #define SOCKET_SIZE_TYPE XXX
Change
XXXtosize_torint, depending on your operating system. (You must do this each time you run configure because configure regeneratesconfig.h.)The
sql_yacc.ccfile is generated fromsql_yacc.yy. Normally, the build process does not need to createsql_yacc.ccbecause MySQL comes with a pre-generated copy. However, if you do need to re-create it, you might encounter this error:"sql_yacc.yy", line
xxxfatal: default action causes potential...This is a sign that your version of yacc is deficient. You probably need to install bison (the GNU version of yacc) and use that instead.
On Debian Linux 3.0, you need to install
gawkinstead of the defaultmawkif you want to compile MySQL with Berkeley DB support.If you need to debug mysqld or a MySQL client, run configure with the
--with-debugoption, and then recompile and link your clients with the new client library. See MySQL Internals: Porting.If you get a compilation error on Linux (for example, SuSE Linux 8.1 or Red Hat Linux 7.3) similar to the following one, you probably do not have g++ installed:
libmysql.c:1329: warning: passing arg 5 of `gethostbyname_r' from incompatible pointer type libmysql.c:1329: too few arguments to function `gethostbyname_r' libmysql.c:1329: warning: assignment makes pointer from integer without a cast make[2]: *** [libmysql.lo] Error 1
By default, the configure script attempts to determine the correct number of arguments by using g++ (the GNU C++ compiler). This test yields incorrect results if g++ is not installed. There are two ways to work around this problem:
Make sure that the GNU C++ g++ is installed. On some Linux distributions, the required package is called
gpp; on others, it is named gcc-c++.Use gcc as your C++ compiler by setting the
CXXenvironment variable to gcc:export CXX="gcc"
You must run configure again after making either of those changes.
This section does not apply to MySQL Enterprise Server users.
This section describes some of the issues involved in using MIT-pthreads.
On Linux, you should not use MIT-pthreads. Use the installed LinuxThreads implementation instead. See Section 2.4.18.1, “Linux Notes”.
If your system does not provide native thread support, you should build MySQL using the MIT-pthreads package. This includes older FreeBSD systems, SunOS 4.x, Solaris 2.4 and earlier, and some others. See Section 2.4.2, “Operating Systems Supported by MySQL Community Server”.
MIT-pthreads is not part of the MySQL 5.0 source distribution. If you require this package, you need to download it separately from http://dev.mysql.com/Downloads/Contrib/pthreads-1_60_beta6-mysql.tar.gz
After downloading, extract this source archive into the top
level of the MySQL source directory. It creates a new
subdirectory named mit-pthreads.
On most systems, you can force MIT-pthreads to be used by running configure with the
--with-mit-threadsoption:shell>
./configure --with-mit-threadsBuilding in a non-source directory is not supported when using MIT-pthreads because we want to minimize our changes to this code.
The checks that determine whether to use MIT-pthreads occur only during the part of the configuration process that deals with the server code. If you have configured the distribution using
--without-serverto build only the client code, clients do not know whether MIT-pthreads is being used and use Unix socket file connections by default. Because Unix socket files do not work under MIT-pthreads on some platforms, this means you need to use-hor--hostwith a value other thanlocalhostwhen you run client programs.When MySQL is compiled using MIT-pthreads, system locking is disabled by default for performance reasons. You can tell the server to use system locking with the
--external-lockingoption. This is needed only if you want to be able to run two MySQL servers against the same data files, but that is not recommended, anyway.Sometimes the pthread
bind()command fails to bind to a socket without any error message (at least on Solaris). The result is that all connections to the server fail. For example:shell>
mysqladmin versionmysqladmin: connect to server at '' failed; error: 'Can't connect to mysql server on localhost (146)'The solution to this problem is to kill the mysqld server and restart it. This has happened to us only when we have forcibly stopped the server and restarted it immediately.
With MIT-pthreads, the
sleep()system call isn't interruptible withSIGINT(break). This is noticeable only when you run mysqladmin --sleep. You must wait for thesleep()call to terminate before the interrupt is served and the process stops.When linking, you might receive warning messages like these (at least on Solaris); they can be ignored:
ld: warning: symbol `_iob' has differing sizes: (file /my/local/pthreads/lib/libpthread.a(findfp.o) value=0x4; file /usr/lib/libc.so value=0x140); /my/local/pthreads/lib/libpthread.a(findfp.o) definition taken ld: warning: symbol `__iob' has differing sizes: (file /my/local/pthreads/lib/libpthread.a(findfp.o) value=0x4; file /usr/lib/libc.so value=0x140); /my/local/pthreads/lib/libpthread.a(findfp.o) definition takenSome other warnings also can be ignored:
implicit declaration of function `int strtoll(...)' implicit declaration of function `int strtoul(...)'
We have not been able to make
readlinework with MIT-pthreads. (This is not necessary, but may be of interest to some.)
This section does not apply to MySQL Enterprise Server users.
These instructions describe how to build binaries from source for MySQL 5.0 on Windows. Instructions are provided for building binaries from a standard source distribution or from the BitKeeper tree that contains the latest development source.
Note: The instructions here are strictly for users who want to test MySQL on Microsoft Windows from the latest source distribution or from the BitKeeper tree. For production use, MySQL AB does not advise using a MySQL server built by yourself from source. Normally, it is best to use precompiled binary distributions of MySQL that are built specifically for optimal performance on Windows by MySQL AB. Instructions for installing binary distributions are available in Section 2.4.8, “Installing MySQL on Windows”.
To build MySQL on Windows from source, you must satisfy the following system, compiler, and resource requirements:
Windows 2000, Windows XP, or newer version. Windows Vista is not supported until Microsoft certifies Visual Studio 2005 on Vista.
CMake, which can be downloaded from http://www.cmake.org. After installing, modify your path to include the
cmakebinary.Microsoft Visual C++ 2005 Express Edition, Visual Studio .Net 2003 (7.1), or Visual Studio 2005 (8.0) compiler system.
If you are using Visual C++ 2005 Express Edition, you must also install an appropriate Platform SDK. More information and links to downloads for various Windows platforms is available from http://msdn.microsoft.com/platformsdk/.
If you are compiling from a BitKeeper tree or making changes to the parser, you need
bisonfor Windows, which can be downloaded from http://gnuwin32.sourceforge.net/packages/bison.htm. Download the package labeled “Complete package, excluding sources”. After installing the package, modify your path to include the bison binary and ensure that this binary is accessible from Visual Studio.Cygwin might be necessary if you want to run the test script or package the compiled binaries and support files into a Zip archive. (Cygwin is needed only to test or package the distribution, not to build it.) Cygwin is available from http://cygwin.com.
3GB to 5GB of disk space.
The exact system requirements can be found here: http://msdn.microsoft.com/vstudio/Previous/2003/sysreqs/default.aspx and http://msdn.microsoft.com/vstudio/products/sysreqs/default.aspx
You also need a MySQL source distribution for Windows, which can be obtained two ways:
Obtain a Windows source distribution packaged by MySQL AB for the particular version of MySQL in which you are interested. These are available from http://dev.mysql.com/downloads/.
Package a source distribution yourself from the latest BitKeeper developer source tree. If you plan to do this, and you are not using the CMake build method, you must create the package on a Unix system and then transfer it to your Windows system. (Some of the configuration and build steps require tools that work only on Unix.) Thus, if you are not using CMake, the BitKeeper approach requires:
A system running Unix, or a Unix-like system such as Linux.
BitKeeper installed on that system. See Section 2.4.14.3, “Installing from the Development Source Tree”, for instructions how to download and install BitKeeper.
If you are using a Windows source distribution, you can go directly to Section 2.4.14.6.1, “Building MySQL from Source Using CMake and Visual Studio”, or Section 2.4.14.6.2, “Building MySQL from Source Using VC++”. To build from the BitKeeper tree without CMake, proceed to Section 2.4.14.6.4, “Creating a Windows Source Package from the Latest Development Source”.
If you find something not working as expected, or you have
suggestions about ways to improve the current build process on
Windows, please send a message to the win32
mailing list. See Section 1.7.1, “MySQL Mailing Lists”.
This section does not apply to MySQL Enterprise Server users.
Follow this procedure to build MySQL:
If you are installing from a packaged source distribution, create a work directory (for example,
C:\workdir), and unpack the source distribution there using WinZip or another Windows tool that can read.zipfiles. This directory is the work directory in the following instructions.If you are installing from a BitKeeper tree, the root directory of that tree is the work directory in the following instructions.
Using a command shell, navigate to the work directory and run the following command:
C:\workdir>
win\configureoptionsThese options are available:
WITH_INNOBASE_STORAGE_ENGINE: Enable theInnoDBstorage engine.WITH_PARTITION_STORAGE_ENGINE: Enable user-defined partitioning.WITH_ARCHIVE_STORAGE_ENGINE: Enable theARCHIVEstorage engine.WITH_BLACKHOLE_STORAGE_ENGINE: Enable theBLACKHOLEstorage engine.WITH_EXAMPLE_STORAGE_ENGINE: Enable theEXAMPLEstorage engine.WITH_FEDERATED_STORAGE_ENGINE: Enable theFEDERATEDstorage engine.__NT__: Enable support for named pipes.MYSQL_SERVER_SUFFIX=: Server suffix, default none.suffixCOMPILATION_COMMENT=: Server comment, default "Source distribution".commentMYSQL_TCP_PORT=: Server port, default 3306.portDISABLE_GRANT_OPTIONS: Disables the the--bootstrap,--skip-grant-tables, and--init-fileoptions for mysqld. This option is available as of MySQL 5.0.36.
For example (type the command on one line):
C:\workdir>
win\configure WITH_INNOBASE_STORAGE_ENGINEWITH_PARTITION_STORAGE_ENGINE MYSQL_SERVER_SUFFIX=-proFrom the work directory, execute the
win\build-vs8.batorwin\build-vs71.batfile, depending on the version of Visual Studio you have installed. The script invokes CMake, which generates themysql.slnsolution file.You can also use
win\build-vs8_x64.batto build the 64-bit version of MySQL. However, you cannot build the 64-bit version with Visual Studio Express Edition. You must use Visual Studio 2005 (8.0) or higher.From the work directory, open the generated
mysql.slnfile with Visual Studio and select the proper configuration using the menu. The menu provides , , , options. Then select > to build the solution.Remember the configuration that you use in this step. It is important later when you run the test script because that script needs to know which configuration you used.
Test the server. The server built using the preceding instructions expects that the MySQL base directory and data directory are
C:\mysqlandC:\mysql\databy default. If you want to test your server using the source tree root directory and its data directory as the base directory and data directory, you need to tell the server their pathnames. You can either do this on the command line with the--basedirand--datadiroptions, or by placing appropriate options in an option file. (See Section 4.3.2, “Using Option Files”.) If you have an existing data directory elsewhere that you want to use, you can specify its pathname instead.When the server is running in standalone fashion or as a service based on your configuration, try to connect to it from the mysql interactive command-line utility.
You can also run the standard test script, mysql-test-run.pl. This script is written in Perl, so you'll need either Cygwin or ActiveState Perl to run it. You may also need to install the modules required by the script. To run the test script, change location into the
mysql-testdirectory under the work directory, set theMTR_VS_CONFIGenvironment variable to the configuration you selected earlier (or use the--vs-configoption), and invoke mysql-test-run.pl. For example (using Cygwin and the bash shell):shell>
cd mysql-testshell>export MTS_VS_CONFIG=debugshell>./mysqltest-run.pl --force --timershell>./mysqltest-run.pl --force --timer --ps-protocol
When you are satisfied that the programs you have built are
working correctly, stop the server. Now you can install the
distribution. One way to do this is to use the
make_win_bin_dist script in the
scripts directory of the MySQL source
distribution (see Section 5.5.2, “make_win_bin_dist — Package MySQL Distribution as ZIP Archive”). This
is a shell script, so you must have Cygwin installed if you
want to use it. It creates a Zip archive of the built
executables and support files that you can unpack in the
location at which you want to install MySQL.
It is also possible to install MySQL by copying directories and files directly:
Create the directories where you want to install MySQL. For example, to install into
C:\mysql, use these commands:C:\>
mkdir C:\mysqlC:\>mkdir C:\mysql\binC:\>mkdir C:\mysql\dataC:\>mkdir C:\mysql\shareC:\>mkdir C:\mysql\scriptsIf you want to compile other clients and link them to MySQL, you should also create several additional directories:
C:\>
mkdir C:\mysql\includeC:\>mkdir C:\mysql\libC:\>mkdir C:\mysql\lib\debugC:\>mkdir C:\mysql\lib\optIf you want to benchmark MySQL, create this directory:
C:\>
mkdir C:\mysql\sql-benchBenchmarking requires Perl support. See Section 2.4.20, “Perl Installation Notes”.
From the work directory, copy into the
C:\mysqldirectory the following directories:C:\>
cd \workdirC:\workdir>copy client_release\*.exe C:\mysql\binC:\workdir>copy client_debug\mysqld.exe C:\mysql\bin\mysqld-debug.exeC:\workdir>xcopy scripts\*.* C:\mysql\scripts /EC:\workdir>xcopy share\*.* C:\mysql\share /EIf you want to compile other clients and link them to MySQL, you should also copy several libraries and header files:
C:\workdir>
copy lib_debug\mysqlclient.lib C:\mysql\lib\debugC:\workdir>copy lib_debug\libmysql.* C:\mysql\lib\debugC:\workdir>copy lib_debug\zlib.* C:\mysql\lib\debugC:\workdir>copy lib_release\mysqlclient.lib C:\mysql\lib\optC:\workdir>copy lib_release\libmysql.* C:\mysql\lib\optC:\workdir>copy lib_release\zlib.* C:\mysql\lib\optC:\workdir>copy include\*.h C:\mysql\includeC:\workdir>copy libmysql\libmysql.def C:\mysql\includeIf you want to benchmark MySQL, you should also do this:
C:\workdir>
xcopy sql-bench\*.* C:\mysql\bench /E
After installation, set up and start the server in the same way as for binary Windows distributions. See Section 2.4.8, “Installing MySQL on Windows”.
This section does not apply to MySQL Enterprise Server users.
Note: VC++ workspace files for MySQL 4.1 and above are compatible with Microsoft Visual Studio 7.1 and tested by MySQL AB staff before each release.
Follow this procedure to build MySQL:
Create a work directory (for example,
C:\workdir).Unpack the source distribution in the aforementioned directory using WinZip or another Windows tool that can read
.zipfiles.Start Visual Studio .Net 2003 (7.1).
From the menu, select .
Open the
mysql.slnsolution you find in the work directory.From the menu, select .
In the pop-up menu, select the configuration to use. You likely want to use one of (normal server), (more engines and features), or configuration.
From the menu, select .
Debug versions of the programs and libraries are placed in the
client_debugandlib_debugdirectories. Release versions of the programs and libraries are placed in theclient_releaseandlib_releasedirectories.Test the server. The server built using the preceding instructions expects that the MySQL base directory and data directory are
C:\mysqlandC:\mysql\databy default. If you want to test your server using the source tree root directory and its data directory as the base directory and data directory, you need to tell the server their pathnames. You can either do this on the command line with the--basedirand--datadiroptions, or by placing appropriate options in an option file. (See Section 4.3.2, “Using Option Files”.) If you have an existing data directory elsewhere that you want to use, you can specify its pathname instead.Start your server from the
client_releaseorclient_debugdirectory, depending on which server you built or want to use. The general server startup instructions are in Section 2.4.8, “Installing MySQL on Windows”. You must adapt the instructions appropriately if you want to use a different base directory or data directory.When the server is running in standalone fashion or as a service based on your configuration, try to connect to it from the mysql interactive command-line utility that exists in your
client_releaseorclient_debugdirectory.
When you are satisfied that the programs you have built are working correctly, stop the server. Then install MySQL using the instructions at the end of Section 2.4.14.6.1, “Building MySQL from Source Using CMake and Visual Studio”.
After installation, set up and start the server in the same way as for binary Windows distributions. See Section 2.4.8, “Installing MySQL on Windows”.
This section does not apply to MySQL Enterprise Server users.
You can compile the MySQL Windows source with Borland C++ 5.02. (The Windows source includes only projects for Microsoft VC++, for Borland C++ you have to do the project files yourself.)
One known problem with Borland C++ is that it uses a different
structure alignment than VC++. This means that you run into
problems if you try to use the default
libmysql.dll libraries (that were compiled
using VC++) with Borland C++. To avoid this problem, only call
mysql_init() with NULL
as an argument, not a pre-allocated MYSQL
structure.
This section does not apply to MySQL Enterprise Server users.
To create a Windows source package from the current BitKeeper source tree, use the instructions here. This procedure must be performed on a system running a Unix or Unix-like operating system because some of the configuration and build steps require tools that work only on Unix. For example, the following procedure is known to work well on Linux.
Copy the BitKeeper source tree for MySQL 5.0. For instructions on how to do this, see Section 2.4.14.3, “Installing from the Development Source Tree”.
Configure and build the distribution so that you have a server binary to work with. One way to do this is to run the following command in the top-level directory of your source tree:
shell>
./BUILD/compile-pentium-maxAfter making sure that the build process completed successfully, run the following utility script from top-level directory of your source tree:
shell>
./scripts/make_win_src_distributionThis script creates a Windows source package to be used on your Windows system. You can supply different options to the script based on your needs. See Section 5.5.3, “make_win_src_distribution — Create Source Distribution for Windows”, for a list of allowable options.
By default, make_win_src_distribution creates a Zip-format archive with the name
mysql-, whereVERSION-win-src.zipVERSIONrepresents the version of your MySQL source tree.Copy or upload the Windows source package that you have just created to your Windows machine. To compile it, use the instructions in Section 2.4.14.6.2, “Building MySQL from Source Using VC++”.
This section does not apply to MySQL Enterprise Server users.
In your source files, you should include
my_global.h before
mysql.h:
#include <my_global.h> #include <mysql.h>
my_global.h includes any other files needed
for Windows compatibility (such as
windows.h) if you compile your program on
Windows.
You can either link your code with the dynamic
libmysql.lib library, which is just a
wrapper to load in libmysql.dll on demand,
or link with the static mysqlclient.lib
library.
The MySQL client libraries are compiled as threaded libraries, so you should also compile your code to be multi-threaded.
After installing MySQL, there are some issues that you should address. For example, on Unix, you should initialize the data directory and create the MySQL grant tables. On all platforms, an important security concern is that the initial accounts in the grant tables have no passwords. You should assign passwords to prevent unauthorized access to the MySQL server. Optionally, you can create time zone tables to enable recognition of named time zones.
The following sections include post-installation procedures that are specific to Windows systems and to Unix systems. Another section, Section 2.4.15.2.3, “Starting and Troubleshooting the MySQL Server”, applies to all platforms; it describes what to do if you have trouble getting the server to start. Section 2.4.15.3, “Securing the Initial MySQL Accounts”, also applies to all platforms. You should follow its instructions to make sure that you have properly protected your MySQL accounts by assigning passwords to them.
When you are ready to create additional user accounts, you can find information on the MySQL access control system and account management in Section 5.7, “The MySQL Access Privilege System”, and Section 5.8, “MySQL User Account Management”.
On Windows, the data directory and the grant tables do not have
to be created. MySQL Windows distributions include the grant
tables with a set of preinitialized accounts in the
mysql database under the data directory. It
is unnecessary to run the mysql_install_db
script that is used on Unix. Regarding passwords, if you
installed MySQL using the Windows Installation Wizard, you may
have already assigned passwords to the accounts. (See
Section 2.4.8.3, “Using the MySQL Installation Wizard”.) Otherwise, use the
password-assignment procedure given in
Section 2.4.15.3, “Securing the Initial MySQL Accounts”.
Before setting up passwords, you might want to try running some client programs to make sure that you can connect to the server and that it is operating properly. Make sure that the server is running (see Section 2.4.8.9, “Starting the Server for the First Time”), and then issue the following commands to verify that you can retrieve information from the server. The output should be similar to what is shown here:
C:\>C:\mysql\bin\mysqlshow+-----------+ | Databases | +-----------+ | mysql | | test | +-----------+ C:\>C:\mysql\bin\mysqlshow mysqlDatabase: mysql +---------------------------+ | Tables | +---------------------------+ | columns_priv | | db | | func | | help_category | | help_keyword | | help_relation | | help_topic | | host | | proc | | procs_priv | | tables_priv | | time_zone | | time_zone_leap_second | | time_zone_name | | time_zone_transition | | time_zone_transition_type | | user | +---------------------------+ C:\>C:\mysql\bin\mysql -e "SELECT Host,Db,User FROM db" mysql+------+-------+------+ | host | db | user | +------+-------+------+ | % | test% | | +------+-------+------+
If you are running a version of Windows that supports services and you want the MySQL server to run automatically when Windows starts, see Section 2.4.8.11, “Starting MySQL as a Windows Service”.
After installing MySQL on Unix, you need to initialize the grant tables, start the server, and make sure that the server works satisfactorily. You may also wish to arrange for the server to be started and stopped automatically when your system starts and stops. You should also assign passwords to the accounts in the grant tables.
On Unix, the grant tables are set up by the mysql_install_db program. For some installation methods, this program is run for you automatically:
If you install MySQL on Linux using RPM distributions, the server RPM runs mysql_install_db.
If you install MySQL on Mac OS X using a PKG distribution, the installer runs mysql_install_db.
Otherwise, you will need to run mysql_install_db yourself.
The following procedure describes how to initialize the grant tables (if that has not previously been done) and then start the server. It also suggests some commands that you can use to test whether the server is accessible and working properly. For information about starting and stopping the server automatically, see Section 2.4.15.2.2, “Starting and Stopping MySQL Automatically”.
After you complete the procedure and have the server running, you should assign passwords to the accounts created by mysql_install_db. Instructions for doing so are given in Section 2.4.15.3, “Securing the Initial MySQL Accounts”.
In the examples shown here, the server runs under the user ID of
the mysql login account. This assumes that
such an account exists. Either create the account if it does not
exist, or substitute the name of a different existing login
account that you plan to use for running the server.
Change location into the top-level directory of your MySQL installation, represented here by
BASEDIR:shell>
cdBASEDIRBASEDIRis likely to be something like/usr/local/mysqlor/usr/local. The following steps assume that you are located in this directory.If necessary, run the mysql_install_db program to set up the initial MySQL grant tables containing the privileges that determine how users are allowed to connect to the server. You'll need to do this if you used a distribution type for which the installation procedure doesn't run the program for you.
Typically, mysql_install_db needs to be run only the first time you install MySQL, so you can skip this step if you are upgrading an existing installation, However, mysql_install_db does not overwrite any existing privilege tables, so it should be safe to run in any circumstances.
To initialize the grant tables, use one of the following commands, depending on whether mysql_install_db is located in the
binorscriptsdirectory:shell>
bin/mysql_install_db --user=mysqlshell>scripts/mysql_install_db --user=mysqlThe mysql_install_db script creates the server's data directory. Under the data directory, it creates directories for the
mysqldatabase that holds all database privileges and thetestdatabase that you can use to test MySQL. The script also creates privilege table entries forrootand anonymous-user accounts. The accounts have no passwords initially. A description of their initial privileges is given in Section 2.4.15.3, “Securing the Initial MySQL Accounts”. Briefly, these privileges allow the MySQLrootuser to do anything, and allow anybody to create or use databases with a name oftestor starting withtest_.It is important to make sure that the database directories and files are owned by the
mysqllogin account so that the server has read and write access to them when you run it later. To ensure this, the--useroption should be used as shown if you run mysql_install_db asroot. Otherwise, you should execute the script while logged in asmysql, in which case you can omit the--useroption from the command.mysql_install_db creates several tables in the
mysqldatabase, includinguser,db,host,tables_priv,columns_priv,func, and others. See Section 5.7, “The MySQL Access Privilege System”, for a complete listing and description of these tables.If you don't want to have the
testdatabase, you can remove it with mysqladmin -u root drop test after starting the server.If you have trouble with mysql_install_db at this point, see Section 2.4.15.2.1, “Problems Running mysql_install_db”.
Start the MySQL server:
shell>
bin/mysqld_safe --user=mysql &It is important that the MySQL server be run using an unprivileged (non-
root) login account. To ensure this, the--useroption should be used as shown if you runmysql_safeas systemroot. Otherwise, you should execute the script while logged in to the system asmysql, in which case you can omit the--useroption from the command.Further instructions for running MySQL as an unprivileged user are given in Section 5.6.5, “How to Run MySQL as a Normal User”.
If you neglected to create the grant tables before proceeding to this step, the following message appears in the error log file when you start the server:
mysqld: Can't find file: 'host.frm'
If you have other problems starting the server, see Section 2.4.15.2.3, “Starting and Troubleshooting the MySQL Server”.
Use mysqladmin to verify that the server is running. The following commands provide simple tests to check whether the server is up and responding to connections:
shell>
bin/mysqladmin versionshell>bin/mysqladmin variablesThe output from mysqladmin version varies slightly depending on your platform and version of MySQL, but should be similar to that shown here:
shell>
bin/mysqladmin versionmysqladmin Ver 14.12 Distrib 5.0.42, for pc-linux-gnu on i686 Copyright (C) 2000 MySQL AB & MySQL Finland AB & TCX DataKonsult AB This software comes with ABSOLUTELY NO WARRANTY. This is free software, and you are welcome to modify and redistribute it under the GPL license Server version 5.0.42 Protocol version 10 Connection Localhost via UNIX socket UNIX socket /var/lib/mysql/mysql.sock Uptime: 14 days 5 hours 5 min 21 sec Threads: 1 Questions: 366 Slow queries: 0 Opens: 0 Flush tables: 1 Open tables: 19 Queries per second avg: 0.000To see what else you can do with mysqladmin, invoke it with the
--helpoption.Verify that you can shut down the server:
shell>
bin/mysqladmin -u root shutdownVerify that you can start the server again. Do this by using mysqld_safe or by invoking mysqld directly. For example:
shell>
bin/mysqld_safe --user=mysql --log &If mysqld_safe fails, see Section 2.4.15.2.3, “Starting and Troubleshooting the MySQL Server”.
Run some simple tests to verify that you can retrieve information from the server. The output should be similar to what is shown here:
shell>
bin/mysqlshow+-----------+ | Databases | +-----------+ | mysql | | test | +-----------+ shell>bin/mysqlshow mysqlDatabase: mysql +---------------------------+ | Tables | +---------------------------+ | columns_priv | | db | | func | | help_category | | help_keyword | | help_relation | | help_topic | | host | | proc | | procs_priv | | tables_priv | | time_zone | | time_zone_leap_second | | time_zone_name | | time_zone_transition | | time_zone_transition_type | | user | +---------------------------+ shell>bin/mysql -e "SELECT Host,Db,User FROM db" mysql+------+--------+------+ | host | db | user | +------+--------+------+ | % | test | | | % | test_% | | +------+--------+------+There is a benchmark suite in the
sql-benchdirectory (under the MySQL installation directory) that you can use to compare how MySQL performs on different platforms. The benchmark suite is written in Perl. It requires the Perl DBI module that provides a database-independent interface to the various databases, and some other additional Perl modules:DBI DBD::mysql Data::Dumper Data::ShowTable
These modules can be obtained from CPAN (http://www.cpan.org/). See also Section 2.4.20.1, “Installing Perl on Unix”.
The
sql-bench/Resultsdirectory contains the results from many runs against different databases and platforms. To run all tests, execute these commands:shell>
cd sql-benchshell>perl run-all-testsIf you don't have the
sql-benchdirectory, you probably installed MySQL using RPM files other than the source RPM. (The source RPM includes thesql-benchbenchmark directory.) In this case, you must first install the benchmark suite before you can use it. There are separate benchmark RPM files namedmysql-bench-that contain benchmark code and data.VERSION.i386.rpmIf you have a source distribution, there are also tests in its
testssubdirectory that you can run. For example, to runauto_increment.tst, execute this command from the top-level directory of your source distribution:shell>
mysql -vvf test < ./tests/auto_increment.tstThe expected result of the test can be found in the
./tests/auto_increment.resfile.At this point, you should have the server running. However, none of the initial MySQL accounts have a password, so you should assign passwords using the instructions found in Section 2.4.15.3, “Securing the Initial MySQL Accounts”.
The MySQL 5.0 installation procedure creates time
zone tables in the mysql database. However,
you must populate the tables manually using the instructions in
Section 5.10.8, “MySQL Server Time Zone Support”.
This section does not apply to MySQL Enterprise Server users.
The purpose of the mysql_install_db script is to generate new MySQL privilege tables. It does not overwrite existing MySQL privilege tables, and it does not affect any other data.
If you want to re-create your privilege tables, first stop the
mysqld server if it's running. Then rename
the mysql directory under the data
directory to save it, and then run
mysql_install_db. Suppose that your current
directory is the MySQL installation directory and that
mysql_install_db is located in the
bin directory and the data directory is
named data. To rename the
mysql database and re-run
mysql_install_db, use these commands.
shell>mv data/mysql data/mysql.oldshell>bin/mysql_install_db --user=mysql
When you run mysql_install_db, you might encounter the following problems:
mysql_install_db fails to install the grant tables
You may find that mysql_install_db fails to install the grant tables and terminates after displaying the following messages:
Starting mysqld daemon with databases from XXXXXX mysqld ended
In this case, you should examine the error log file very carefully. The log should be located in the directory
XXXXXXnamed by the error message and should indicate why mysqld didn't start. If you do not understand what happened, include the log when you post a bug report. See Section 1.8, “How to Report Bugs or Problems”.There is a mysqld process running
This indicates that the server is running, in which case the grant tables have probably been created already. If so, there is no need to run mysql_install_db at all because it needs to be run only once (when you install MySQL the first time).
Installing a second mysqld server does not work when one server is running
This can happen when you have an existing MySQL installation, but want to put a new installation in a different location. For example, you might have a production installation, but you want to create a second installation for testing purposes. Generally the problem that occurs when you try to run a second server is that it tries to use a network interface that is in use by the first server. In this case, you should see one of the following error messages:
Can't start server: Bind on TCP/IP port: Address already in use Can't start server: Bind on unix socket...
For instructions on setting up multiple servers, see Section 5.12, “Running Multiple MySQL Servers on the Same Machine”.
You do not have write access to the
/tmpdirectoryIf you do not have write access to create temporary files or a Unix socket file in the default location (the
/tmpdirectory), an error occurs when you run mysql_install_db or the mysqld server.You can specify different locations for the temporary directory and Unix socket file by executing these commands prior to starting mysql_install_db or mysqld, where
some_tmp_diris the full pathname to some directory for which you have write permission:shell>
TMPDIR=/shell>some_tmp_dir/MYSQL_UNIX_PORT=/shell>some_tmp_dir/mysql.sockexport TMPDIR MYSQL_UNIX_PORTThen you should be able to run mysql_install_db and start the server with these commands:
shell>
bin/mysql_install_db --user=mysqlshell>bin/mysqld_safe --user=mysql &If mysql_install_db is located in the
scriptsdirectory, modify the first command toscripts/mysql_install_db.See Section B.1.4.5, “How to Protect or Change the MySQL Unix Socket File”, and Section 2.4.19, “Environment Variables”.
There are some alternatives to running the mysql_install_db script provided in the MySQL distribution:
If you want the initial privileges to be different from the standard defaults, you can modify mysql_install_db before you run it. However, it is preferable to use
GRANTandREVOKEto change the privileges after the grant tables have been set up. In other words, you can run mysql_install_db, and then usemysql -u root mysqlto connect to the server as the MySQLrootuser so that you can issue the necessaryGRANTandREVOKEstatements.If you want to install MySQL on several machines with the same privileges, you can put the
GRANTandREVOKEstatements in a file and execute the file as a script usingmysqlafter running mysql_install_db. For example:shell>
bin/mysql_install_db --user=mysqlshell>bin/mysql -u root < your_script_fileBy doing this, you can avoid having to issue the statements manually on each machine.
It is possible to re-create the grant tables completely after they have previously been created. You might want to do this if you're just learning how to use
GRANTandREVOKEand have made so many modifications after running mysql_install_db that you want to wipe out the tables and start over.To re-create the grant tables, remove all the
.frm,.MYI, and.MYDfiles in themysqldatabase directory. Then run the mysql_install_db script again.You can start mysqld manually using the
--skip-grant-tablesoption and add the privilege information yourself using mysql:shell>
bin/mysqld_safe --user=mysql --skip-grant-tables &shell>bin/mysql mysqlFrom mysql, manually execute the SQL commands contained in mysql_install_db. Make sure that you run mysqladmin flush-privileges or mysqladmin reload afterward to tell the server to reload the grant tables.
Note that by not using mysql_install_db, you not only have to populate the grant tables manually, you also have to create them first.
Generally, you start the mysqld server in one of these ways:
By invoking mysqld directly. This works on any platform.
By running the MySQL server as a Windows service. The service can be set to start the server automatically when Windows starts, or as a manual service that you start on request. For instructions, see Section 2.4.8.11, “Starting MySQL as a Windows Service”.
By invoking mysqld_safe, which tries to determine the proper options for mysqld and then runs it with those options. This script is used on Unix and Unix-like systems. See Section 5.3.1, “mysqld_safe — MySQL Server Startup Script”.
By invoking mysql.server. This script is used primarily at system startup and shutdown on systems that use System V-style run directories, where it usually is installed under the name
mysql. The mysql.server script starts the server by invoking mysqld_safe. See Section 5.3.2, “mysql.server — MySQL Server Startup Script”.On Mac OS X, you can install a separate MySQL Startup Item package to enable the automatic startup of MySQL on system startup. The Startup Item starts the server by invoking mysql.server. See Section 2.4.10, “Installing MySQL on Mac OS X”, for details.
The mysqld_safe and mysql.server scripts and the Mac OS X Startup Item can be used to start the server manually, or automatically at system startup time. mysql.server and the Startup Item also can be used to stop the server.
To start or stop the server manually using the
mysql.server script, invoke it with
start or stop arguments:
shell>mysql.server startshell>mysql.server stop
Before mysql.server starts the server, it
changes location to the MySQL installation directory, and then
invokes mysqld_safe. If you want the server
to run as some specific user, add an appropriate
user option to the
[mysqld] group of the
/etc/my.cnf option file, as shown later
in this section. (It is possible that you will need to edit
mysql.server if you've installed a binary
distribution of MySQL in a non-standard location. Modify it to
cd into the proper directory before it runs
mysqld_safe. If you do this, your modified
version of mysql.server may be overwritten
if you upgrade MySQL in the future, so you should make a copy
of your edited version that you can reinstall.)
mysql.server stop stops the server by sending a signal to it. You can also stop the server manually by executing mysqladmin shutdown.
To start and stop MySQL automatically on your server, you need
to add start and stop commands to the appropriate places in
your /etc/rc* files.
If you use the Linux server RPM package
(MySQL-server-),
the mysql.server script is installed in the
VERSION.rpm/etc/init.d directory with the name
mysql. You need not install it manually.
See Section 2.4.9, “Installing MySQL from RPM Packages on Linux”, for more information on the
Linux RPM packages.
Some vendors provide RPM packages that install a startup script under a different name such as mysqld.
If you install MySQL from a source distribution or using a
binary distribution format that does not install
mysql.server automatically, you can install
it manually. The script can be found in the
support-files directory under the MySQL
installation directory or in a MySQL source tree.
To install mysql.server manually, copy it
to the /etc/init.d directory with the
name mysql, and then make it executable. Do
this by changing location into the appropriate directory where
mysql.server is located and executing these
commands:
shell>cp mysql.server /etc/init.d/mysqlshell>chmod +x /etc/init.d/mysql
Older Red Hat systems use the
/etc/rc.d/init.d directory rather than
/etc/init.d. Adjust the preceding
commands accordingly. Alternatively, first create
/etc/init.d as a symbolic link that
points to /etc/rc.d/init.d:
shell>cd /etcshell>ln -s rc.d/init.d .
After installing the script, the commands needed to activate
it to run at system startup depend on your operating system.
On Linux, you can use chkconfig:
shell> chkconfig --add mysql
On some Linux systems, the following command also seems to be necessary to fully enable the mysql script:
shell> chkconfig --level 345 mysql on
On FreeBSD, startup scripts generally should go in
/usr/local/etc/rc.d/. The
rc(8) manual page states that scripts in
this directory are executed only if their basename matches the
*.sh shell filename pattern. Any other
files or directories present within the directory are silently
ignored. In other words, on FreeBSD, you should install the
mysql.server script as
/usr/local/etc/rc.d/mysql.server.sh to
enable automatic startup.
As an alternative to the preceding setup, some operating
systems also use /etc/rc.local or
/etc/init.d/boot.local to start
additional services on startup. To start up MySQL using this
method, you could append a command like the one following to
the appropriate startup file:
/bin/sh -c 'cd /usr/local/mysql; ./bin/mysqld_safe --user=mysql &'
For other systems, consult your operating system documentation to see how to install startup scripts.
You can add options for mysql.server in a
global /etc/my.cnf file. A typical
/etc/my.cnf file might look like this:
[mysqld] datadir=/usr/local/mysql/var socket=/var/tmp/mysql.sock port=3306 user=mysql [mysql.server] basedir=/usr/local/mysql
The mysql.server script understands the
following options: basedir,
datadir, and pid-file.
If specified, they must be placed in an
option file, not on the command line.
mysql.server understands only
start and stop as
command-line arguments.
The following table shows which option groups the server and each startup script read from option files:
| Script | Option Groups |
| mysqld | [mysqld], [server],
[mysqld- |
| mysqld_safe | [mysqld], [server],
[mysqld_safe] |
| mysql.server | [mysqld], [mysql.server],
[server] |
[mysqld-
means that groups with names like
major_version][mysqld-4.1] and
[mysqld-5.0] are read by
servers having versions 4.1.x,
5.0.x, and so forth. This feature can be used to
specify options that can be read only by servers within a
given release series.
For backward compatibility, mysql.server
also reads the [mysql_server] group and
mysqld_safe also reads the
[safe_mysqld] group. However, you should
update your option files to use the
[mysql.server] and
[mysqld_safe] groups instead when using
MySQL 5.0.
This section provides troubleshooting suggestions for problems starting the server on Unix. If you are using Windows, see Section 2.4.8.13, “Troubleshooting a MySQL Installation Under Windows”.
If you have problems starting the server, here are some things to try:
Check the error log to see why the server does not start.
Specify any special options needed by the storage engines you are using.
Make sure that the server knows where to find the data directory.
Make sure that the server can access the data directory. The ownership and permissions of the data directory and its contents must be set such that the server can read and modify them.
Verify that the network interfaces the server wants to use are available.
Some storage engines have options that control their behavior.
You can create a my.cnf file and specify
startup options for the engines that you plan to use. If you
are going to use storage engines that support transactional
tables (InnoDB, BDB,
NDB), be sure that you have them configured
the way you want before starting the server:
MySQL Enterprise For expert advice on start-up options appropriate to your circumstances, subscribe to The MySQL Network Monitoring and Advisory Service. For more information see, http://www.mysql.com/products/enterprise/advisors.html.
If you are using
InnoDBtables, see Section 14.2.3, “InnoDBConfiguration”.If you are using
BDB(Berkeley DB) tables, see Section 14.5.3, “BDBStartup Options”.If you are using MySQL Cluster, see Section 15.4, “MySQL Cluster Configuration”.
Storage engines will use default option values if you specify none, but it is recommended that you review the available options and specify explicit values for those for which the defaults are not appropriate for your installation.
When the mysqld server starts, it changes location to the data directory. This is where it expects to find databases and where it expects to write log files. The server also writes the pid (process ID) file in the data directory.
The data directory location is hardwired in when the server is
compiled. This is where the server looks for the data
directory by default. If the data directory is located
somewhere else on your system, the server will not work
properly. You can determine what the default path settings are
by invoking mysqld with the
--verbose and --help
options.
If the default locations don't match the MySQL installation layout on your system, you can override them by specifying options to mysqld or mysqld_safe on the command line or in an option file.
To specify the location of the data directory explicitly, use
the --datadir option. However, normally you
can tell mysqld the location of the base
directory under which MySQL is installed and it looks for the
data directory there. You can do this with the
--basedir option.
To check the effect of specifying path options, invoke
mysqld with those options followed by the
--verbose and --help
options. For example, if you change location into the
directory where mysqld is installed and
then run the following command, it shows the effect of
starting the server with a base directory of
/usr/local:
shell> ./mysqld --basedir=/usr/local --verbose --help
You can specify other options such as
--datadir as well, but
--verbose and --help must be
the last options.
Once you determine the path settings you want, start the
server without --verbose and
--help.
If mysqld is currently running, you can find out what path settings it is using by executing this command:
shell> mysqladmin variables
Or:
shell> mysqladmin -h host_name variables
host_name is the name of the MySQL
server host.
If you get Errcode 13 (which means
Permission denied) when starting
mysqld, this means that the privileges of
the data directory or its contents do not allow the server
access. In this case, you change the permissions for the
involved files and directories so that the server has the
right to use them. You can also start the server as
root, but this raises security issues and
should be avoided.
On Unix, change location into the data directory and check the
ownership of the data directory and its contents to make sure
the server has access. For example, if the data directory is
/usr/local/mysql/var, use this command:
shell> ls -la /usr/local/mysql/var
If the data directory or its files or subdirectories are not
owned by the login account that you use for running the
server, change their ownership to that account. If the account
is named mysql, use these commands:
shell>chown -R mysql /usr/local/mysql/varshell>chgrp -R mysql /usr/local/mysql/var
If the server fails to start up correctly, check the error
log. Log files are located in the data directory (typically
C:\Program Files\MySQL\MySQL Server
5.0\data on Windows,
/usr/local/mysql/data for a Unix binary
distribution, and /usr/local/var for a
Unix source distribution). Look in the data directory for
files with names of the form
host_name.errhost_name.loghost_name is the name of your
server host. Then examine the last few lines of these files.
On Unix, you can use tail to display them:
shell>tailshell>host_name.errtailhost_name.log
The error log should contain information that indicates why the server couldn't start. For example, you might see something like this in the log:
000729 14:50:10 bdb: Recovery function for LSN 1 27595 failed 000729 14:50:10 bdb: warning: ./test/t1.db: No such file or directory 000729 14:50:10 Can't init databases
This means that you did not start mysqld
with the --bdb-no-recover option and Berkeley
DB found something wrong with its own log files when it tried
to recover your databases. To be able to continue, you should
move the old Berkeley DB log files from the database directory
to some other place, where you can later examine them. The
BDB log files are named in sequence
beginning with log.0000000001, where the
number increases over time.
If you are running mysqld with
BDB table support and
mysqld dumps core at startup, this could be
due to problems with the BDB recovery log.
In this case, you can try starting mysqld
with --bdb-no-recover. If that helps, you
should remove all BDB log files from the
data directory and try starting mysqld
again without the --bdb-no-recover option.
If either of the following errors occur, it means that some other program (perhaps another mysqld server) is using the TCP/IP port or Unix socket file that mysqld is trying to use:
Can't start server: Bind on TCP/IP port: Address already in use Can't start server: Bind on unix socket...
Use ps to determine whether you have another mysqld server running. If so, shut down the server before starting mysqld again. (If another server is running, and you really want to run multiple servers, you can find information about how to do so in Section 5.12, “Running Multiple MySQL Servers on the Same Machine”.)
If no other server is running, try to execute the command
telnet . (The
default MySQL port number is 3306.) Then press Enter a couple
of times. If you don't get an error message like
your_host_name
tcp_ip_port_numbertelnet: Unable to connect to remote host: Connection
refused, some other program is using the TCP/IP port
that mysqld is trying to use. You'll need
to track down what program this is and disable it, or else
tell mysqld to listen to a different port
with the --port option. In this case, you'll
also need to specify the port number for client programs when
connecting to the server via TCP/IP.
Another reason the port might be inaccessible is that you have a firewall running that blocks connections to it. If so, modify the firewall settings to allow access to the port.
If the server starts but you can't connect to it, you should
make sure that you have an entry in
/etc/hosts that looks like this:
127.0.0.1 localhost
This problem occurs only on systems that do not have a working thread library and for which MySQL must be configured to use MIT-pthreads.
If you cannot get mysqld to start, you can
try to make a trace file to find the problem by using the
--debug option. See
MySQL
Internals: Porting.
Part of the MySQL installation process is to set up the
mysql database that contains the grant
tables:
Windows distributions contain preinitialized grant tables that are installed automatically.
On Unix, the grant tables are populated by the mysql_install_db program. Some installation methods run this program for you. Others require that you execute it manually. For details, see Section 2.4.15.2, “Unix Post-Installation Procedures”.
The grant tables define the initial MySQL user accounts and their access privileges. These accounts are set up as follows:
Accounts with the username
rootare created. These are superuser accounts that can do anything. The initialrootaccount passwords are empty, so anyone can connect to the MySQL server asroot— without a password — and be granted all privileges.On Windows, one
rootaccount is created; this account allows connecting from the local host only. The Windows installer will optionally create an account allowing for connections from any host only if the user selects the Enable root access from remote machines option during installation.On Unix, both
rootaccounts are for connections from the local host. Connections must be made from the local host by specifying a hostname oflocalhostfor one of the accounts, or the actual hostname or IP number for the other.
Two anonymous-user accounts are created, each with an empty username. The anonymous accounts have no password, so anyone can use them to connect to the MySQL server.
On Windows, one anonymous account is for connections from the local host. It has no global privileges. (Before MySQL 5.1.16, it has all global privileges, just like the
rootaccounts.) The other is for connections from any host and has all privileges for thetestdatabase and for other databases with names that start withtest.On Unix, both anonymous accounts are for connections from the local host. Connections must be made from the local host by specifying a hostname of
localhostfor one of the accounts, or the actual hostname or IP number for the other. These accounts have all privileges for thetestdatabase and for other databases with names that start withtest_.
As noted, none of the initial accounts have passwords. This means that your MySQL installation is unprotected until you do something about it:
If you want to prevent clients from connecting as anonymous users without a password, you should either assign a password to each anonymous account or else remove the accounts.
You should assign a password to each MySQL
rootaccount.
The following instructions describe how to set up passwords for
the initial MySQL accounts, first for the anonymous accounts and
then for the root accounts. Replace
“newpwd” in the examples
with the actual password that you want to use. The instructions
also cover how to remove the anonymous accounts, should you
prefer not to allow anonymous access at all.
You might want to defer setting the passwords until later, so that you don't need to specify them while you perform additional setup or testing. However, be sure to set them before using your installation for production purposes.
Anonymous Account Password Assignment
To assign passwords to the anonymous accounts, connect to the
server as root and then use either
SET PASSWORD or UPDATE. In
either case, be sure to encrypt the password using the
PASSWORD() function.
To use SET PASSWORD on Windows, do this:
shell>mysql -u rootmysql>SET PASSWORD FOR ''@'localhost' = PASSWORD('mysql>newpwd');SET PASSWORD FOR ''@'%' = PASSWORD('newpwd');
To use SET PASSWORD on Unix, do this:
shell>mysql -u rootmysql>SET PASSWORD FOR ''@'localhost' = PASSWORD('mysql>newpwd');SET PASSWORD FOR ''@'host_name' = PASSWORD('newpwd');
In the second SET PASSWORD statement, replace
host_name with the name of the server
host. This is the name that is specified in the
Host column of the
non-localhost record for
root in the user table. If
you don't know what hostname this is, issue the following
statement before using SET PASSWORD:
mysql> SELECT Host, User FROM mysql.user;
Look for the record that has root in the
User column and something other than
localhost in the Host
column. Then use that Host value in the
second SET PASSWORD statement.
The other way to assign passwords to the anonymous accounts is
by using UPDATE to modify the
user table directly. Connect to the server as
root and issue an UPDATE
statement that assigns a value to the
Password column of the appropriate
user table records. The procedure is the same
for Windows and Unix. The following UPDATE
statement assigns a password to both anonymous accounts at once:
shell>mysql -u rootmysql>UPDATE mysql.user SET Password = PASSWORD('->newpwd')WHERE User = '';mysql>FLUSH PRIVILEGES;
After you update the passwords in the user
table directly using UPDATE, you must tell
the server to re-read the grant tables with FLUSH
PRIVILEGES. Otherwise, the change goes unnoticed until
you restart the server.
Anonymous Account Removal
If you prefer to remove the anonymous accounts instead, do so as follows:
shell>mysql -u rootmysql>DELETE FROM mysql.user WHERE User = '';mysql>FLUSH PRIVILEGES;
The DELETE statement applies both to Windows
and to Unix. On Windows, if you want to remove only the
anonymous account that has the same privileges as
root, do this instead:
shell>mysql -u rootmysql>DELETE FROM mysql.user WHERE Host='localhost' AND User='';mysql>FLUSH PRIVILEGES;
That account allows anonymous access but has full privileges, so removing it improves security.
root Account Password
Assignment
You can assign passwords to the root accounts
in several ways. The following discussion demonstrates three
methods:
Use the
SET PASSWORDstatementUse the mysqladmin command-line client program
Use the
UPDATEstatement
To assign passwords using SET PASSWORD,
connect to the server as root and issue two
SET PASSWORD statements. Be sure to encrypt
the password using the PASSWORD() function.
For Windows, do this:
shell>mysql -u rootmysql>SET PASSWORD FOR 'root'@'localhost' = PASSWORD('mysql>newpwd');SET PASSWORD FOR 'root'@'%' = PASSWORD('newpwd');
For Unix, do this:
shell>mysql -u rootmysql>SET PASSWORD FOR 'root'@'localhost' = PASSWORD('mysql>newpwd');SET PASSWORD FOR 'root'@'host_name' = PASSWORD('newpwd');
In the second SET PASSWORD statement, replace
host_name with the name of the server
host. This is the same hostname that you used when you assigned
the anonymous account passwords.
To assign passwords to the root accounts
using mysqladmin, execute the following
commands:
shell>mysqladmin -u root password "shell>newpwd"mysqladmin -u root -hhost_namepassword "newpwd"
These commands apply both to Windows and to Unix. In the second
command, replace host_name with the
name of the server host. The double quotes around the password
are not always necessary, but you should use them if the
password contains spaces or other characters that are special to
your command interpreter.
You can also use UPDATE to modify the
user table directly. The following
UPDATE statement assigns a password to both
root accounts at once:
shell>mysql -u rootmysql>UPDATE mysql.user SET Password = PASSWORD('->newpwd')WHERE User = 'root';mysql>FLUSH PRIVILEGES;
The UPDATE statement applies both to Windows
and to Unix.
After the passwords have been set, you must supply the appropriate password whenever you connect to the server. For example, if you want to use mysqladmin to shut down the server, you can do so using this command:
shell>mysqladmin -u root -p shutdownEnter password:(enter root password here)
Note: If you forget your
root password after setting it up,
Section B.1.4.1, “How to Reset the Root Password”, covers the procedure
for resetting it.
To set up additional accounts, you can use the
GRANT statement. For instructions, see
Section 5.8.2, “Adding New User Accounts to MySQL”.
As a general rule, we recommend that when upgrading from one release series to another, you should go to the next series rather than skipping a series. For example, if you currently are running MySQL 3.23 and wish to upgrade to a newer series, upgrade to MySQL 4.0 rather than to 4.1 or 5.0.
The following items form a checklist of things that you should do whenever you perform an upgrade:
Before upgrading from MySQL 4.1 to 5.0, read Section 2.4.16.2, “Upgrading from MySQL 4.1 to 5.0”) as well as Appendix E, MySQL Change History. These provide information about features that are new in MySQL 5.0 or differ from those found in MySQL 4.1. If you wish to upgrade from a release series previous to MySQL 4.1, you should upgrade to each successive release series in turn until you have reached MySQL 4.1, and then proceed with the upgrade to MySQL 5.0. For information on upgrading from MySQL 4.1 or earlier releases, see the MySQL 3.23, 4.0, 4.1 Reference Manual.
Before you perform an upgrade, back up your databases, including the
mysqldatabase that contains the grant tables.Some releases of MySQL introduce incompatible changes to tables. (Our aim is to avoid these changes, but occasionally they are necessary to correct problems that would be worse than an incompatibility between releases.) Some releases of MySQL introduce changes to the structure of the grant tables to add new privileges or features.
To avoid problems due to such changes, after you upgrade to a new version of MySQL, you should run mysql_upgrade to check your tables (and repair them if necessary), and to update your grant tables to make sure that they have the current structure so that you can take advantage of any new capabilities. See Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.
If you are running MySQL Server on Windows, see Section 2.4.8.14, “Upgrading MySQL on Windows”.
If you are using replication, see Section 6.6, “Upgrading a Replication Setup”, for information on upgrading your replication setup.
MySQL 5.0.27 is the last version in MySQL 5.0 for which MySQL-Max binary distributions are provided, except for RPM distributions. For RPMs, MySQL 5.0.37 is the last release. After these versions, the features previously included in the mysqld-max server are included in mysqld.
If you previously installed a MySQL-Max distribution that includes a server named mysqld-max, and then upgrade later to a non-Max version of MySQL, mysqld_safe still attempts to run the old mysqld-max server. If you perform such an upgrade, you should remove the old mysqld-max server manually to ensure that mysqld_safe runs the new mysqld server.
If you have created a user-defined function (UDF) with a given name and upgrade MySQL to a version that implements a new built-in function with the same name, the UDF becomes inaccessible. To correct this, use
DROP FUNCTIONto drop the UDF, and then useCREATE FUNCTIONto re-create the UDF with a different non-conflicting name. If a new version of MySQL implements a built-in function with the same name as an existing stored function, you have two choices: Rename the stored function to use a non-conflicting name, or change calls to the function so that they use a database qualifier (that is, usedb_name.func_name()
You can always move the MySQL format files and data files between
different versions on the same architecture as long as you stay
within versions for the same release series of MySQL. If you
change the character set when running MySQL, you must run
myisamchk -r -q
--set-collation=collation_name
on all MyISAM tables. Otherwise, your indexes
may not be ordered correctly, because changing the character set
may also change the sort order.
If you are cautious about using new versions, you can always rename your old mysqld before installing a newer one. For example, if you are using MySQL 4.1.13 and want to upgrade to 5.0.10, rename your current server from mysqld to mysqld-4.1.13. If your new mysqld then does something unexpected, you can simply shut it down and restart with your old mysqld.
If, after an upgrade, you experience problems with recompiled
client programs, such as Commands out of sync
or unexpected core dumps, you probably have used old header or
library files when compiling your programs. In this case, you
should check the date for your mysql.h file
and libmysqlclient.a library to verify that
they are from the new MySQL distribution. If not, recompile your
programs with the new headers and libraries.
If problems occur, such as that the new mysqld
server does not start or that you cannot connect without a
password, verify that you do not have an old
my.cnf file from your previous installation.
You can check this with the --print-defaults
option (for example, mysqld --print-defaults).
If this command displays anything other than the program name, you
have an active my.cnf file that affects
server or client operation.
It is a good idea to rebuild and reinstall the Perl
DBD::mysql module whenever you install a new
release of MySQL. The same applies to other MySQL interfaces as
well, such as the PHP mysql extension and the
Python MySQLdb module.
This section does not apply to MySQL Enterprise Server users.
When upgrading a 5.0 installation to 5.0.10 or above note that it is necessary to upgrade your grant tables. Otherwise, creating stored procedures and functions might not work. The procedure for doing this is described in Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.
Note: It is good practice to back up your data before installing any new version of software. Although MySQL works very hard to ensure a high level of quality, you should protect your data by making a backup. MySQL recommends that you dump and reload your tables from any previous version to upgrade to 5.0.
In general, you should do the following when upgrading from MySQL 4.1 from 5.0:
Check the items in Section 2.4.16, “Upgrading MySQL”, to see whether any of them might affect your applications.
Check the items in the change lists found later in this section to see whether any of them might affect your applications. Note particularly any that are marked Incompatible change. These result in incompatibilities with earlier versions of MySQL, and may require your attention before you upgrade.
Some releases of MySQL introduce incompatible changes to tables. (Our aim is to avoid these changes, but occasionally they are necessary to correct problems that would be worse than an incompatibility between releases.) Some releases of MySQL introduce changes to the structure of the grant tables to add new privileges or features.
To avoid problems due to such changes, after you upgrade to a new version of MySQL, you should check your tables (and repair them if necessary), and update your grant tables to make sure that they have the current structure so that you can take advantage of any new capabilities. See Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.
Read the MySQL 5.0 change history to see what significant new features you can use in 5.0. See Section E.1, “Changes in release 5.0.x (Production)”.
If you are running MySQL Server on Windows, see Section 2.4.8.14, “Upgrading MySQL on Windows”.
MySQL 5.0 adds support for stored procedures. This support requires the
mysql.proctable. To create this table, you should run the mysql_upgrade program as described in Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.MySQL 5.0 adds support for views. This support requires extra privilege columns in the
mysql.userandmysql.dbtables. To create these columns, you should run the mysql_upgrade program as described in Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.If you are using replication, see Section 6.6, “Upgrading a Replication Setup”, for information on upgrading your replication setup.
Several visible behaviors have changed between MySQL 4.1 and MySQL 5.0 to make MySQL more compatible with standard SQL. These changes may affect your applications.
The following lists describe changes that may affect applications and that you should watch out for when upgrading to MySQL 5.0.
Server Changes:
Incompatible change: The indexing order for end-space in
TEXTcolumns forInnoDBandMyISAMtables has changed. Starting from 5.0.3,TEXTindexes are compared as space-padded at the end (just as MySQL sortsCHAR,VARCHARandTEXTfields). If you have a index on aTEXTcolumn, you should runCHECK TABLEon it. If the check reports errors, rebuild the indexes: Dump and reload the table if it is anInnoDBtable, or runOPTIMIZE TABLEorREPAIR TABLEif it is aMyISAMtable.Incompatible change. For
BINARYcolumns, the pad value and how it is handled has changed as of MySQL 5.0.15. The pad value for inserts now is0x00rather than space, and there is no stripping of the pad value for retrievals. For details, see Section 11.4.2, “TheBINARYandVARBINARYTypes”.Incompatible change: As of MySQL 5.0.3, the server by default no longer loads user-defined functions (UDFs) unless they have at least one auxiliary symbol (for example, an
xxx_initorxxx_deinitsymbol) defined in addition to the main function symbol. This behavior can be overridden with the--allow-suspicious-udfsoption. See Section 24.2.4.6, “User-Defined Function Security Precautions”.Incompatible change: Previously, a lock wait timeout caused
InnoDBto roll back the entire current transaction. As of MySQL 5.0.13, it rolls back only the most recent SQL statement.Incompatible change: For
ENUMcolumns that had enumeration values containing commas, the commas were mapped to 0xff internally. However, this rendered the commas indistinguishable from true 0xff characters in the values. This no longer occurs. However, the fix requires that you dump and reload any tables that haveENUMcolumns containing true 0xff in their values: Dump the tables using mysqldump with the current server before upgrading from a version of MySQL 5.0 older than 5.0.36 to version 5.0.36 or newer.Incompatible change: The update log has been removed in MySQL 5.0. If you had enabled it previously, you should enable the binary log instead.
Incompatible change: Support for the
ISAMstorage engine has been removed in MySQL 5.0. If you have anyISAMtables, you should convert them before upgrading. For example, to convert anISAMtable to use theMyISAMstorage engine, use this statement:ALTER TABLE
tbl_nameENGINE = MyISAM;Use a similar statement for every
ISAMtable in each of your databases.Incompatible change: Support for
RAIDoptions inMyISAMtables has been removed in MySQL 5.0. If you have tables that use these options, you should convert them before upgrading. One way to do this is to dump them with mysqldump, edit the dump file to remove theRAIDoptions in theCREATE TABLEstatements, and reload the dump file. Another possibility is to useCREATE TABLEto create a new table from thenew_tbl... SELECTraid_tblRAIDtable. However, theCREATE TABLEpart of the statement must contain sufficient information to re-create column attributes as well as indexes, or column attributes may be lost and indexes will not appear in the new table. See Section 13.1.5, “CREATE TABLESyntax”.The
.MYDfiles forRAIDtables in a given database are stored under the database directory in subdirectories that have names consisting of two hex digits in the range from00toff. After converting all tables that useRAIDoptions, theseRAID-related subdirectories still will exist but can be removed. Verify that they are empty, and then remove them manually. (If they are not empty, there is someRAIDtable that has not been converted.)As of MySQL 5.0.25, the
lc_time_namessystem variable specifies the locale that controls the language used to display day and month names and abbreviations. This variable affects the output from theDATE_FORMAT(),DAYNAME()andMONTHNAME()functions. See Section 5.10.9, “MySQL Server Locale Support”.In MySQL 5.0.6, binary logging of stored routines and triggers was changed. This change has implications for security, replication, and data recovery, as discussed in Section 17.4, “Binary Logging of Stored Routines and Triggers”.
As of MySQL 5.0.28, mysqld_safe no longer implicitly invokes mysqld-max if it exists. Instead, it invokes mysqld unless a
--mysqldor--mysqld-versionoption is given to specify another server explicitly. If you previously relied on the implicit invocation of mysqld-max, you should use an appropriate option now.
SQL Changes:
Incompatible change: Beginning with MySQL 5.0.12, natural joins and joins with
USING, including outer join variants, are processed according to the SQL:2003 standard. The changes include elimination of redundant output columns forNATURALjoins and joins specified with aUSINGclause and proper ordering of output columns. The precedence of the comma operator also now is lower compared toJOIN,LEFT JOIN, and so forth.These changes make MySQL more compliant with standard SQL. However, they can result in different output columns for some joins. Also, some queries that appeared to work correctly prior to 5.0.12 must be rewritten to comply with the standard. For details about the scope of the changes and examples that show what query rewrites are necessary, see Section 13.2.7.1, “
JOINSyntax”.Incompatible change: The namespace for triggers has changed in MySQL 5.0.10. Previously, trigger names had to be unique per table. Now they must be unique within the schema (database). An implication of this change is that
DROP TRIGGERsyntax now uses a schema name instead of a table name (schema name is optional and, if omitted, the current schema will be used).When upgrading from a previous version of MySQL 5 to MySQL 5.0.10 or newer, you must drop all triggers and re-create them or
DROP TRIGGERwill not work after the upgrade. Here is a suggested procedure for doing this:Upgrade to MySQL 5.0.10 or later to be able to access trigger information in the
INFORMATION_SCHEMA.TRIGGERStable. (It should work even for pre-5.0.10 triggers.)Dump all trigger definitions using the following
SELECTstatement:SELECT CONCAT('CREATE TRIGGER ', t.TRIGGER_SCHEMA, '.', t.TRIGGER_NAME, ' ', t.ACTION_TIMING, ' ', t.EVENT_MANIPULATION, ' ON ', t.EVENT_OBJECT_SCHEMA, '.', t.EVENT_OBJECT_TABLE, ' FOR EACH ROW ', t.ACTION_STATEMENT, '//' ) INTO OUTFILE '/tmp/triggers.sql' FROM INFORMATION_SCHEMA.TRIGGERS AS t;The statement uses
INTO OUTFILE, so you must have theFILEprivilege. The file will be created on the server host. Use a different filename if you like. To be 100% safe, inspect the trigger definitions in thetriggers.sqlfile, and perhaps make a backup of the file.Stop the server and drop all triggers by removing all
.TRGfiles in your database directories. Change location to your data directory and issue this command:shell>
rm */*.TRGStart the server and re-create all triggers using the
triggers.sqlfile. For the file created earlier, use these commands in the mysql program:mysql>
delimiter // ;mysql>source /tmp/triggers.sql //Use the
SHOW TRIGGERSstatement to check that all triggers were created successfully.
Incompatible change: As of MySQL 5.0.15, the
CHAR()function returns a binary string rather than a string in the connection character set. An optionalUSINGclause may be used to produce a result in a specific character set instead. Also, arguments larger than 256 produce multiple characters. They are no longer interpreted modulo 256 to produce a single character each. These changes may cause some incompatibilities:charset_nameCHAR(ORD('A')) = 'a'is no longer true:mysql>
SELECT CHAR(ORD('A')) = 'a';+----------------------+ | CHAR(ORD('A')) = 'a' | +----------------------+ | 0 | +----------------------+To perform a case-insensitive comparison, you can produce a result string in a non-binary character set by adding a
USINGclause or converting the result:mysql>
SELECT CHAR(ORD('A') USING latin1) = 'a';+-----------------------------------+ | CHAR(ORD('A') USING latin1) = 'a' | +-----------------------------------+ | 1 | +-----------------------------------+ mysql>SELECT CONVERT(CHAR(ORD('A')) USING latin1) = 'a';+--------------------------------------------+ | CONVERT(CHAR(ORD('A')) USING latin1) = 'a' | +--------------------------------------------+ | 1 | +--------------------------------------------+CREATE TABLE ... SELECT CHAR(...)produces aVARBINARYcolumn, not aVARCHARcolumn. To produce aVARCHARcolumn, useUSINGorCONVERT()as just described to convert theCHAR()result into a non-binary character set.Previously, the following statements inserted the value
0x00410041('AA'as aucs2string) into the table:CREATE TABLE t (ucs2_column CHAR(2) CHARACTER SET ucs2); INSERT INTO t VALUES (CHAR(0x41,0x41));
As of MySQL 5.0.15, the statements insert a single
ucs2character with value0x4141.
Incompatible change: By default, integer subtraction involving an unsigned value should produce an unsigned result. Tracking of the “unsignedness” of an expression was improved in MySQL 5.0.13. This means that, in some cases where an unsigned subtraction would have resulted in a signed integer, it now results in an unsigned integer. One context in which this difference manifests itself is when a subtraction involving an unsigned operand would be negative.
Suppose that
iis aTINYINT UNSIGNEDcolumn and has a value of 0. The server evaluates the following expression using 64-bit unsigned integer arithmetic with the following result:mysql>
SELECT i - 1 FROM t;+----------------------+ | i - 1 | +----------------------+ | 18446744073709551615 | +----------------------+If the expression is used in an
UPDATE t SET i = i - 1statement, the expression is evaluated and the result assigned toiaccording to the usual rules for handling values outside the column range or 0 to 255. That is, the value is clipped to the nearest endpoint of the range. However, the result is version-specific:Before MySQL 5.0.13, the expression is evaluated but is treated as the equivalent 64-bit signed value (–1) for the assignment. The value of –1 is clipped to the nearest endpoint of the column range, resulting in a value of 0:
mysql>
UPDATE t SET i = i - 1; SELECT i FROM t;+------+ | i | +------+ | 0 | +------+As of MySQL 5.0.13, the expression is evaluated and retains its unsigned attribute for the assignment. The value of 18446744073709551615 is clipped to the nearest endpoint of the column range, resulting in a value of 255:
mysql>
UPDATE t SET i = i - 1; SELECT i FROM t;+------+ | i | +------+ | 255 | +------+
To get the older behavior, use
CAST()to convert the expression result to a signed value:UPDATE t SET i = CAST(i - 1 AS SIGNED);
Alternatively, set the
NO_UNSIGNED_SUBTRACTIONSQL mode. However, this will affect all integer subtractions involving unsigned values.Incompatible change: Before MySQL 5.0.13,
NOW()andSYSDATE()return the same value (the time at which the statement in which the function occurs begins executing). As of MySQL 5.0.13,SYSDATE()returns the time at which it it executes, which can differ from the value returned byNOW(). For information about the implications for binary logging and replication, see the description forSYSDATE()in Section 12.6, “Date and Time Functions” and forSET TIMESTAMPin Section 13.5.3, “SETSyntax”. To restore the former behavior forSYSDATE()and cause it to be an alias forNOW(), start the server with the--sysdate-is-nowoption (available as of MySQL 5.0.20).Incompatible change: Before MySQL 5.0.13,
GREATEST(andx,NULL)LEAST(returnx,NULL)xwhenxis a non-NULLvalue. As of 5.0.3, both functions returnNULLif any argument isNULL, the same as Oracle. This change can cause problems for applications that rely on the old behavior.Incompatible change: Before MySQL 4.1.13/5.0.8, conversion of
DATETIMEvalues to numeric form by adding zero produced a result inYYYYMMDDHHMMSSformat. The result ofDATETIME+0is now inYYYYMMDDHHMMSS.000000format.Incompatible change: In MySQL 4.1.12/5.0.6, the behavior of
LOAD DATA INFILEandSELECT ... INTO OUTFILEhas changed when theFIELDS TERMINATED BYandFIELDS ENCLOSED BYvalues both are empty. Formerly, a column was read or written the display width of the column. For example,INT(4)was read or written using a field with a width of 4. Now columns are read and written using a field width wide enough to hold all values in the field. However, data files written before this change was made might not be reloaded correctly withLOAD DATA INFILEfor MySQL 4.1.12/5.0.6 and up. This change also affects data files read by mysqlimport and written by mysqldump --tab, which useLOAD DATA INFILEandSELECT ... INTO OUTFILE. For more information, see Section 13.2.5, “LOAD DATA INFILESyntax”.Incompatible change: The implementation of
DECIMALhas changed in MySQL 5.0.3. You should make your applications aware of this change. For information about this change, and about possible incompatibilities with old applications, see Chapter 21, Precision Math.DECIMALcolumns are stored in a more efficient format. To convert a table to use the newDECIMALtype, you should do anALTER TABLEon it. (TheALTER TABLEalso will change the table'sVARCHARcolumns to use the newVARCHARdata type properties, described in a separate item.)A consequence of the change in handling of the
DECIMALandNUMERICfixed-point data types is that the server is more strict to follow standard SQL. For example, a data type ofDECIMAL(3,1)stores a maximum value of 99.9. Before MySQL 5.0.3, the server allowed larger numbers to be stored. That is, it stored a value such as 100.0 as 100.0. As of MySQL 5.0.3, the server clips 100.0 to the maximum allowable value of 99.9. If you have tables that were created before MySQL 5.0.3 and that contain floating-point data not strictly legal for the data type, you should alter the data types of those columns. For example:ALTER TABLE
tbl_nameMODIFYcol_nameDECIMAL(4,1);The behavior used by the server for
DECIMALcolumns in a table depends on the version of MySQL used to create the table. If your server is from MySQL 5.0.3 or higher, but you haveDECIMALcolumns in tables that were created before 5.0.3, the old behavior still applies to those columns. To convert the tables to the newerDECIMALformat, dump them with mysqldump and reload them.Incompatible change: MySQL 5.0.3 and up uses precision math when calculating with
DECIMALand integer columns (64 decimal digits) and for rounding exact-value numbers. Rounding behavior is well-defined, not dependent on the implementation of the underlying C library. However, this might result in incompatibilities for applications that rely on the old behavior. (For example, inserting .5 into anINTcolumn results in 1 as of MySQL 5.0.3, but might be 0 in older versions.) For more information about rounding behavior, see Section 21.4, “Rounding Behavior”, and Section 21.5, “Precision Math Examples”.Incompatible change:
MyISAMandInnoDBtables created withDECIMALcolumns in MySQL 5.0.3 to 5.0.5 will appear corrupt after an upgrade to MySQL 5.0.6. (The same incompatibility will occur for these tables created in MySQL 5.0.6 after a downgrade to MySQL 5.0.3 to 5.0.5.) If you have such tables, check and repair them with mysql_upgrade after upgrading. See Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.Incompatible change: For user-defined functions, exact-value decimal arguments such as
1.3orDECIMALcolumn values were passed asREAL_RESULTvalues prior to MySQL 5.0.3. As of 5.0.3, they are passed as strings with a type ofDECIMAL_RESULT. If you upgrade to 5.0.3 and find that your UDF now receives string values, use the initialization function to coerce the arguments to numbers as described in Section 24.2.4.3, “UDF Argument Processing”.Incompatible change: Before MySQL 5.0.2,
SHOW STATUSreturned global status values. The default as of 5.0.2 is to return session values, which is incompatible with previous versions. To issue aSHOW STATUSstatement that will retrieve global status values for all versions of MySQL, write it like this:SHOW /*!50002 GLOBAL */ STATUS;
Incompatible change: User variables are not case sensitive in MySQL 5.0. In MySQL 4.1,
SET @x = 0; SET @X = 1; SELECT @x;created two variables and returned0. In MySQL 5.0, it creates one variable and returns1. Replication setups that rely on the old behavior may be affected by this change.Some keywords are reserved in MySQL 5.0 that were not reserved in MySQL 4.1. See Section 9.3, “Reserved Words”.
The
LOAD DATA FROM MASTERandLOAD TABLE FROM MASTERstatements are deprecated. See Section 13.6.2.2, “LOAD DATA FROM MASTERSyntax”, for recommended alternatives.As of MySQL 5.0.3, trailing spaces no longer are removed from values stored in
VARCHARandVARBINARYcolumns. The maximum lengths forVARCHARandVARBINARYcolumns in MySQL 5.0.3 and later are 65,535 characters and 65,535 bytes, respectively.When a binary upgrade (filesystem-level copy of data files) to MySQL 5.0 is performed for a table with a
VARBINARYcolumn, the column is space-padded to the full allowable width of the column. This causes values inVARBINARYcolumns that do not occupy the full width of the column to include extra trailing spaces after the upgrade, which means that the data in the column is different.In addition, new rows inserted into a table upgraded in this way will be space padded to the full width of the column.
This issue can be resolved as follows:
For each table containing
VARBINARYcolumns, execute the statementALTER TABLE
table_nameENGINE=engine_name;where
table_nameis the name of the table andengine_nameis the name of the storage engine currently used bytable_name. In other words, if the table namedmytableuses theMyISAMstorage engine, then you would use this statement:ALTER TABLE mytable ENGINE=MYISAM;
This rebuilds the table so that it uses the 5.0
VARBINARYformat.Then you must remove all trailing spaces from any
VARBINARYcolumn values. For eachVARBINARYcolumnvarbinary_column, you should perform the following statement (wheretable_nameis the name of the table containing theVARBINARYcolumn):UPDATE
table_nameSETvarbinary_column= RTRIM(varbinary_column);This is necessary and safe because trailing spaces are stripped before 5.0.3, meaning that any trailing spaces are erroneous.
This problem does not occur (and thus these two steps are not required) for tables upgraded using the recommended procedure of dumping tables prior to the upgrade and reloading them afterwards.
Note: If you create a table with new
VARCHARorVARBINARYcolumns in MySQL 5.0.3 or later, the table will not be usable if you downgrade to a version older than 5.0.3. Dump the table with mysqldump before downgrading and reload it after downgrading.Comparisons made between
FLOATorDOUBLEvalues that happened to work in MySQL 4.1 may not do so in 5.0. Values of these types are imprecise in all MySQL versions, and you are strongly advised to avoid such comparisons asWHERE, regardless of the MySQL version you are using. See Section B.1.5.8, “Problems with Floating-Point Comparisons”.col_name=some_doubleAs of MySQL 5.0.3,
BITis a separate data type, not a synonym forTINYINT(1). See Section 11.1.1, “Overview of Numeric Types”.MySQL 5.0.2 adds several SQL modes that allow stricter control over rejecting records that have invalid or missing values. See Section 5.2.6, “SQL Modes”, and Section 1.9.6.2, “Constraints on Invalid Data”. If you want to enable this control but continue to use MySQL's capability for storing incorrect dates such as
'2004-02-31', you should start the server with--sql_mode="TRADITIONAL,ALLOW_INVALID_DATES".As of MySQL 5.0.2, the
SCHEMAandSCHEMASkeywords are accepted as synonyms forDATABASEandDATABASES, respectively. (While “schemata” is grammatically correct and even appears in some MySQL 5.0 system database and table names, it cannot be used as a keyword.)As of MySQL 5.0.25,
TIMESTAMPcolumns that areNOT NULLnow are reported that way bySHOW COLUMNSandINFORMATION_SCHEMA, rather than asNULL.
C API Changes:
Incompatible change: Because the MySQL 5.0 server has a new implementation of the
DECIMALdata type, a problem may occur if the server is used by older clients that still are linked against MySQL 4.1 client libraries. If a client uses the binary client/server protocol to execute prepared statements that generate result sets containing numeric values, an error will be raised:'Using unsupported buffer type: 246'This error occurs because the 4.1 client libraries do not support the new
MYSQL_TYPE_NEWDECIMALtype value added in 5.0. There is no way to disable the newDECIMALdata type on the server side. You can avoid the problem by relinking the application with the client libraries from MySQL 5.0.Incompatible change: The
ER_WARN_DATA_TRUNCATEDwarning symbol was renamed toWARN_DATA_TRUNCATEDin MySQL 5.0.3.The
reconnectflag in theMYSQLstructure is set to 0 bymysql_real_connect(). Only those client programs which did not explicitly set this flag to 0 or 1 aftermysql_real_connect()experience a change. Having automatic reconnection enabled by default was considered too dangerous (due to the fact that table locks, temporary tables, user variables, and session variables are lost after reconnection).
You can copy the .frm,
.MYI, and .MYD files
for MyISAM tables between different
architectures that support the same floating-point format.
(MySQL takes care of any byte-swapping issues.) See
Section 14.1, “The MyISAM Storage Engine”.
In cases where you need to transfer databases between different architectures, you can use mysqldump to create a file containing SQL statements. You can then transfer the file to the other machine and feed it as input to the mysql client.
Use mysqldump --help to see what options are available. If you are moving the data to a newer version of MySQL, you should use mysqldump --opt to take advantage of any optimizations that result in a dump file that is smaller and can be processed more quickly.
The easiest (although not the fastest) way to move a database between two machines is to run the following commands on the machine on which the database is located:
shell>mysqladmin -h 'shell>other_hostname' createdb_namemysqldump --optdb_name| mysql -h 'other_hostname'db_name
If you want to copy a database from a remote machine over a slow network, you can use these commands:
shell>mysqladmin createshell>db_namemysqldump -h 'other_hostname' --opt --compressdb_name| mysqldb_name
You can also store the dump in a file, transfer the file to the target machine, and then load the file into the database there. For example, you can dump a database to a compressed file on the source machine like this:
shell> mysqldump --quick db_name | gzip > db_name.gz
Transfer the file containing the database contents to the target machine and run these commands there:
shell>mysqladmin createshell>db_namegunzip <db_name.gz | mysqldb_name
You can also use mysqldump and
mysqlimport to transfer the database. For
large tables, this is much faster than simply using
mysqldump. In the following commands,
DUMPDIR represents the full pathname
of the directory you use to store the output from
mysqldump.
First, create the directory for the output files and dump the database:
shell>mkdirshell>DUMPDIRmysqldump --tab=DUMPDIRdb_name
Then transfer the files in the
DUMPDIR directory to some
corresponding directory on the target machine and load the files
into MySQL there:
shell>mysqladmin createshell>db_name# create databasecatshell>DUMPDIR/*.sql | mysqldb_name# create tables in databasemysqlimportdb_nameDUMPDIR/*.txt # load data into tables
Do not forget to copy the mysql database
because that is where the grant tables are stored. You might
have to run commands as the MySQL root user
on the new machine until you have the mysql
database in place.
After you import the mysql database on the
new machine, execute mysqladmin
flush-privileges so that the server reloads the grant
table information.
This section does not apply to MySQL Enterprise Server users.
This section describes what you should do to downgrade to an older MySQL version in the unlikely case that the previous version worked better than the new one.
If you are downgrading within the same release series (for example, from 4.1.13 to 4.1.12) the general rule is that you just have to install the new binaries on top of the old ones. There is no need to do anything with the databases. As always, however, it is always a good idea to make a backup.
The following items form a checklist of things you should do whenever you perform a downgrade:
Read the upgrading section for the release series from which you are downgrading to be sure that it does not have any features you really need. Section 2.4.16, “Upgrading MySQL”.
If there is a downgrading section for that version, you should read that as well.
In most cases, you can move the MySQL format files and data files between different versions on the same architecture as long as you stay within versions for the same release series of MySQL.
If you downgrade from one release series to another, there may be
incompatibilities in table storage formats. In this case, you can
use mysqldump to dump your tables before
downgrading. After downgrading, reload the dump file using
mysql or mysqlimport to
re-create your tables. For examples, see
Section 2.4.16.3, “Copying MySQL Databases to Another Machine”.
The normal symptom of a downward-incompatible table format change when you downgrade is that you can't open tables. In that case, use the following procedure:
Stop the older MySQL server that you are downgrading to.
Restart the newer MySQL server you are downgrading from.
Dump any tables that were inaccessible to the older server by using mysqldump to create a dump file.
Stop the newer MySQL server and restart the older one.
Reload the dump file into the older server. Your tables should be accessible.
This section does not apply to MySQL Enterprise Server users.
MySQL 4.1 does not support stored routines or triggers. If your
databases contain stored routines or triggers, prevent them from
being dumped when you use mysqldump by using
the --skip-routines and
--skip-triggers options. (See
Section 8.13, “mysqldump — A Database Backup Program”.)
MySQL 4.1 does not support views. If your databases contain
views, remove them with DROP VIEW before
using mysqldump. (See
Section 19.3, “DROP VIEW Syntax”.)
After downgrading from MySQL 5.0, you may see the following
information in the mysql.err file:
Incorrect information in file: './mysql/user.frm'
In this case, you can do the following:
Start MySQL 5.0.4 (or newer).
Run mysql_fix_privilege_tables, which will change the
mysql.usertable to a format that both MySQL 4.1 and 5.0 can use.Stop the MySQL server.
Start MySQL 4.1.
If the preceding procedure fails, you should be able to do the following instead:
Start MySQL 5.0.4 (or newer).
Run mysqldump --opt --add-drop-table mysql > /tmp/mysql.dump.
Stop the MySQL server.
Start MySQL 4.1 with the
--skip-grantoption.Run mysql mysql < /tmp/mysql.dump.
Run mysqladmin flush-privileges.
This section discusses issues that have been found to occur on Linux. The first few subsections describe general operating system-related issues, problems that can occur when using binary or source distributions, and post-installation issues. The remaining subsections discuss problems that occur with Linux on specific platforms.
Note that most of these problems occur on older versions of Linux. If you are running a recent version, you may see none of them.
MySQL needs at least Linux version 2.0.
Warning: We have seen some strange problems with Linux 2.2.14 and MySQL on SMP systems. We also have reports from some MySQL users that they have encountered serious stability problems using MySQL with kernel 2.2.14. If you are using this kernel, you should upgrade to 2.2.19 (or newer) or to a 2.4 kernel. If you have a multiple-CPU box, you should seriously consider using 2.4 because it gives you a significant speed boost. Your system should be more stable.
When using LinuxThreads, you should see a minimum of three mysqld processes running. These are in fact threads. There is one thread for the LinuxThreads manager, one thread to handle connections, and one thread to handle alarms and signals.
The Linux-Intel binary and RPM releases of MySQL are configured for the highest possible speed. We are always trying to use the fastest stable compiler available.
The binary release is linked with -static,
which means you do not normally need to worry about which
version of the system libraries you have. You need not install
LinuxThreads, either. A program linked with
-static is slightly larger than a dynamically
linked program, but also slightly faster (3-5%). However, one
problem with a statically linked program is that you can't use
user-defined functions (UDFs). If you are going to write or
use UDFs (this is something for C or C++ programmers only),
you must compile MySQL yourself using dynamic linking.
A known issue with binary distributions is that on older Linux
systems that use libc (such as Red Hat 4.x
or Slackware), you get some (non-fatal) issues with hostname
resolution. If your system uses libc rather
than glibc2, you probably will encounter
some difficulties with hostname resolution and
getpwnam(). This happens because
glibc (unfortunately) depends on some
external libraries to implement hostname resolution and
getpwent(), even when compiled with
-static. These problems manifest themselves
in two ways:
You may see the following error message when you run mysql_install_db:
Sorry, the host '
xxxx' could not be looked upYou can deal with this by executing mysql_install_db --force, which does not execute the resolveip test in mysql_install_db. The downside is that you cannot use hostnames in the grant tables: except for
localhost, you must use IP numbers instead. If you are using an old version of MySQL that does not support--force, you must manually remove theresolveiptest inmysql_installusing a text editor.You also may see the following error when you try to run mysqld with the
--useroption:getpwnam: No such file or directory
To work around this problem, start mysqld by using the
sucommand rather than by specifying the--useroption. This causes the system itself to change the user ID of the mysqld process so that mysqld need not do so.
Another solution, which solves both problems, is not to use a
binary distribution. Obtain a MySQL source distribution (in
RPM or tar.gz format) and install that
instead.
On some Linux 2.2 versions, you may get the error
Resource temporarily unavailable when
clients make a great many new connections to a
mysqld server over TCP/IP. The problem is
that Linux has a delay between the time that you close a
TCP/IP socket and the time that the system actually frees it.
There is room for only a finite number of TCP/IP slots, so you
encounter the resource-unavailable error if clients attempt
too many new TCP/IP connections over a short period of time.
For example, you may see the error when you run the MySQL
test-connect benchmark over TCP/IP.
We have inquired about this problem a few times on different Linux mailing lists but have never been able to find a suitable resolution. The only known “fix” is for clients to use persistent connections, or, if you are running the database server and clients on the same machine, to use Unix socket file connections rather than TCP/IP connections.
This section does not apply to MySQL Enterprise Server users.
The following notes regarding glibc apply
only to the situation when you build MySQL yourself. If you
are running Linux on an x86 machine, in most cases it is much
better for you to use our binary. We link our binaries against
the best patched version of glibc we can
find and with the best compiler options, in an attempt to make
it suitable for a high-load server. For a typical user, even
for setups with a lot of concurrent connections or tables
exceeding the 2GB limit, our binary is the best choice in most
cases. After reading the following text, if you are in doubt
about what to do, try our binary first to determine whether it
meets your needs. If you discover that it is not good enough,
you may want to try your own build. In that case, we would
appreciate a note about it so that we can build a better
binary next time.
MySQL uses LinuxThreads on Linux. If you are using an old
Linux version that doesn't have glibc2, you
must install LinuxThreads before trying to compile MySQL. You
can obtain LinuxThreads from
http://dev.mysql.com/downloads/os-linux.html.
Note that glibc versions before and
including version 2.1.1 have a fatal bug in
pthread_mutex_timedwait() handling, which
is used when INSERT DELAYED statements are
issued. We recommend that you not use INSERT
DELAYED before upgrading glibc.
Note that Linux kernel and the LinuxThread library can by default handle a maximum of 1,024 threads. If you plan to have more than 1,000 concurrent connections, you need to make some changes to LinuxThreads, as follows:
Increase
PTHREAD_THREADS_MAXinsysdeps/unix/sysv/linux/bits/local_lim.hto 4096 and decreaseSTACK_SIZEinlinuxthreads/internals.hto 256KB. The paths are relative to the root ofglibc. (Note that MySQL is not stable with 600-1000 connections ifSTACK_SIZEis the default of 2MB.)Recompile LinuxThreads to produce a new
libpthread.alibrary, and relink MySQL against it.
There is another issue that greatly hurts MySQL performance,
especially on SMP systems. The mutex implementation in
LinuxThreads in glibc 2.1 is very poor for
programs with many threads that hold the mutex only for a
short time. This produces a paradoxical result: If you link
MySQL against an unmodified LinuxThreads, removing processors
from an SMP actually improves MySQL performance in many cases.
We have made a patch available for glibc
2.1.3 to correct this behavior
(http://dev.mysql.com/Downloads/Linux/linuxthreads-2.1-patch).
With glibc 2.2.2, MySQL uses the adaptive
mutex, which is much better than even the patched one in
glibc 2.1.3. Be warned, however, that under
some conditions, the current mutex code in
glibc 2.2.2 overspins, which hurts MySQL
performance. The likelihood that this condition occurs can be
reduced by re-nicing the mysqld process to
the highest priority. We have also been able to correct the
overspin behavior with a patch, available at
http://dev.mysql.com/Downloads/Linux/linuxthreads-2.2.2.patch.
It combines the correction of overspin, maximum number of
threads, and stack spacing all in one. You need to apply it in
the linuxthreads directory with
patch -p0
</tmp/linuxthreads-2.2.2.patch. We hope it is
included in some form in future releases of
glibc 2.2. In any case, if you link against
glibc 2.2.2, you still need to correct
STACK_SIZE and
PTHREAD_THREADS_MAX. We hope that the
defaults is corrected to some more acceptable values for
high-load MySQL setup in the future, so that the commands
needed to produce your own build can be reduced to
./configure; make; make install.
We recommend that you use these patches to build a special
static version of libpthread.a and use it
only for statically linking against MySQL. We know that these
patches are safe for MySQL and significantly improve its
performance, but we cannot say anything about their effects on
other applications. If you link other applications that
require LinuxThreads against the patched static version of the
library, or build a patched shared version and install it on
your system, you do so at your own risk.
If you experience any strange problems during the installation of MySQL, or with some common utilities hanging, it is very likely that they are either library or compiler related. If this is the case, using our binary resolves them.
If you link your own MySQL client programs, you may see the following error at runtime:
ld.so.1: fatal: libmysqlclient.so.#: open failed: No such file or directory
This problem can be avoided by one of the following methods:
If you are using the Fujitsu compiler
(fcc/FCC), you may have some problems
compiling MySQL because the Linux header files are very
gcc oriented. The following
configure line should work with
fcc/FCC:
CC=fcc CFLAGS="-O -K fast -K lib -K omitfp -Kpreex -D_GNU_SOURCE \
-DCONST=const -DNO_STRTOLL_PROTO" \
CXX=FCC CXXFLAGS="-O -K fast -K lib \
-K omitfp -K preex --no_exceptions --no_rtti -D_GNU_SOURCE \
-DCONST=const -Dalloca=__builtin_alloca -DNO_STRTOLL_PROTO \
'-D_EXTERN_INLINE=static __inline'" \
./configure \
--prefix=/usr/local/mysql --enable-assembler \
--with-mysqld-ldflags=-all-static --disable-shared \
--with-low-memory
mysql.server can be found in the
support-files directory under the MySQL
installation directory or in a MySQL source tree. You can
install it as /etc/init.d/mysql for
automatic MySQL startup and shutdown. See
Section 2.4.15.2.2, “Starting and Stopping MySQL Automatically”.
If MySQL cannot open enough files or connections, it may be that you have not configured Linux to handle enough files.
In Linux 2.2 and onward, you can check the number of allocated file handles as follows:
shell>cat /proc/sys/fs/file-maxshell>cat /proc/sys/fs/dquot-maxshell>cat /proc/sys/fs/super-max
If you have more than 16MB of memory, you should add something
like the following to your init scripts (for example,
/etc/init.d/boot.local on SuSE Linux):
echo 65536 > /proc/sys/fs/file-max echo 8192 > /proc/sys/fs/dquot-max echo 1024 > /proc/sys/fs/super-max
You can also run the echo commands from the
command line as root, but these settings
are lost the next time your computer restarts.
Alternatively, you can set these parameters on startup by
using the sysctl tool, which is used by
many Linux distributions (including SuSE Linux 8.0 and later).
Put the following values into a file named
/etc/sysctl.conf:
# Increase some values for MySQL fs.file-max = 65536 fs.dquot-max = 8192 fs.super-max = 1024
You should also add the following to
/etc/my.cnf:
[mysqld_safe] open-files-limit=8192
This should allow the server a limit of 8,192 for the combined number of connections and open files.
The STACK_SIZE constant in LinuxThreads
controls the spacing of thread stacks in the address space. It
needs to be large enough so that there is plenty of room for
each individual thread stack, but small enough to keep the
stack of some threads from running into the global
mysqld data. Unfortunately, as we have
experimentally discovered, the Linux implementation of
mmap() successfully unmaps a mapped region
if you ask it to map out an address currently in use, zeroing
out the data on the entire page instead of returning an error.
So, the safety of mysqld or any other
threaded application depends on the “gentlemanly”
behavior of the code that creates threads. The user must take
measures to make sure that the number of running threads at
any given time is sufficiently low for thread stacks to stay
away from the global heap. With mysqld, you
should enforce this behavior by setting a reasonable value for
the max_connections variable.
If you build MySQL yourself, you can patch LinuxThreads for
better stack use. See Section 2.4.18.1.3, “Linux Source Distribution Notes”. If
you do not want to patch LinuxThreads, you should set
max_connections to a value no higher than
500. It should be even less if you have a large key buffer,
large heap tables, or some other things that make
mysqld allocate a lot of memory, or if you
are running a 2.2 kernel with a 2GB patch. If you are using
our binary or RPM version, you can safely set
max_connections at 1500, assuming no large
key buffer or heap tables with lots of data. The more you
reduce STACK_SIZE in LinuxThreads the more
threads you can safely create. We recommend values between
128KB and 256KB.
If you use a lot of concurrent connections, you may suffer from a “feature” in the 2.2 kernel that attempts to prevent fork bomb attacks by penalizing a process for forking or cloning a child. This causes MySQL not to scale well as you increase the number of concurrent clients. On single-CPU systems, we have seen this manifest as very slow thread creation; it may take a long time to connect to MySQL (as long as one minute), and it may take just as long to shut it down. On multiple-CPU systems, we have observed a gradual drop in query speed as the number of clients increases. In the process of trying to find a solution, we have received a kernel patch from one of our users who claimed it helped for his site. This patch is available at http://dev.mysql.com/Downloads/Patches/linux-fork.patch. We have done rather extensive testing of this patch on both development and production systems. It has significantly improved MySQL performance without causing any problems and we recommend it to our users who still run high-load servers on 2.2 kernels.
This issue has been fixed in the 2.4 kernel, so if you are not satisfied with the current performance of your system, rather than patching your 2.2 kernel, it might be easier to upgrade to 2.4. On SMP systems, upgrading also gives you a nice SMP boost in addition to fixing the fairness bug.
We have tested MySQL on the 2.4 kernel on a two-CPU machine and found MySQL scales much better. There was virtually no slowdown on query throughput all the way up to 1,000 clients, and the MySQL scaling factor (computed as the ratio of maximum throughput to the throughput for one client) was 180%. We have observed similar results on a four-CPU system: Virtually no slowdown as the number of clients was increased up to 1,000, and a 300% scaling factor. Based on these results, for a high-load SMP server using a 2.2 kernel, we definitely recommend upgrading to the 2.4 kernel at this point.
We have discovered that it is essential to run the
mysqld process with the highest possible
priority on the 2.4 kernel to achieve maximum performance.
This can be done by adding a renice -20 $$
command to mysqld_safe. In our testing on a
four-CPU machine, increasing the priority resulted in a 60%
throughput increase with 400 clients.
We are currently also trying to collect more information on
how well MySQL performs with a 2.4 kernel on four-way and
eight-way systems. If you have access such a system and have
done some benchmarks, please send an email message to
<benchmarks@mysql.com> with the results. We will
review them for inclusion in the manual.
If you see a dead mysqld server process with ps, this usually means that you have found a bug in MySQL or you have a corrupted table. See Section B.1.4.2, “What to Do If MySQL Keeps Crashing”.
To get a core dump on Linux if mysqld dies
with a SIGSEGV signal, you can start
mysqld with the
--core-file option. Note that you also
probably need to raise the core file size by adding
ulimit -c 1000000 to
mysqld_safe or starting
mysqld_safe with
--core-file-size=1000000. See
Section 5.3.1, “mysqld_safe — MySQL Server Startup Script”.
MySQL requires libc 5.4.12 or newer. It is
known to work with libc 5.4.46.
glibc 2.0.6 and later should also work.
There have been some problems with the
glibc RPMs from Red Hat, so if you have
problems, check whether there are any updates. The
glibc 2.0.7-19 and 2.0.7-29 RPMs are known
to work.
If you are using Red Hat 8.0 or a new glibc
2.2.x library, you may see mysqld die in
gethostbyaddr(). This happens because the
new glibc library requires a stack size
greater than 128KB for this call. To fix the problem, start
mysqld with the
--thread-stack=192K option. (Use -O
thread_stack=192K before MySQL 4.) This stack size is
the default on MySQL 4.0.10 and above, so you should not see
the problem.
If you are using gcc 3.0 and above to
compile MySQL, you must install the
libstdc++v3 library before compiling MySQL;
if you don't do this, you get an error about a missing
__cxa_pure_virtual symbol during linking.
On some older Linux distributions, configure may produce an error like this:
Syntax error in sched.h. Change _P to __P in the /usr/include/sched.h file. See the Installation chapter in the Reference Manual.
Just do what the error message says. Add an extra underscore
to the _P macro name that has only one
underscore, and then try again.
You may get some warnings when compiling. Those shown here can be ignored:
mysqld.cc -o objs-thread/mysqld.o mysqld.cc: In function `void init_signals()': mysqld.cc:315: warning: assignment of negative value `-1' to `long unsigned int' mysqld.cc: In function `void * signal_hand(void *)': mysqld.cc:346: warning: assignment of negative value `-1' to `long unsigned int'
If mysqld always dumps core when it starts,
the problem may be that you have an old
/lib/libc.a. Try renaming it, and then
remove sql/mysqld and do a new
make install and try again. This problem
has been reported on some Slackware installations.
If you get the following error when linking
mysqld, it means that your
libg++.a is not installed correctly:
/usr/lib/libc.a(putc.o): In function `_IO_putc': putc.o(.text+0x0): multiple definition of `_IO_putc'
You can avoid using libg++.a by running
configure like this:
shell> CXX=gcc ./configure
In some implementations, readdir_r() is
broken. The symptom is that the SHOW
DATABASES statement always returns an empty set.
This can be fixed by removing
HAVE_READDIR_R from
config.h after configuring and before
compiling.
We have tested MySQL 5.0 on Alpha with our benchmarks and test suite, and it appears to work well.
We currently build the MySQL binary packages on SuSE Linux 7.0 for AXP, kernel 2.4.4-SMP, Compaq C compiler (V6.2-505) and Compaq C++ compiler (V6.3-006) on a Compaq DS20 machine with an Alpha EV6 processor.
You can find the preceding compilers at http://www.support.compaq.com/alpha-tools/. By using these compilers rather than gcc, we get about 9-14% better MySQL performance.
For MySQL on Alpha, we use the -arch generic
flag to our compile options, which ensures that the binary
runs on all Alpha processors. We also compile statically to
avoid library problems. The configure
command looks like this:
CC=ccc CFLAGS="-fast -arch generic" CXX=cxx \
CXXFLAGS="-fast -arch generic -noexceptions -nortti" \
./configure --prefix=/usr/local/mysql --disable-shared \
--with-extra-charsets=complex --enable-thread-safe-client \
--with-mysqld-ldflags=-non_shared --with-client-ldflags=-non_shared
If you want to use egcs, the following configure line worked for us:
CFLAGS="-O3 -fomit-frame-pointer" CXX=gcc \
CXXFLAGS="-O3 -fomit-frame-pointer -felide-constructors \
-fno-exceptions -fno-rtti" \
./configure --prefix=/usr/local/mysql --disable-shared
Some known problems when running MySQL on Linux-Alpha:
Debugging threaded applications like MySQL does not work with
gdb 4.18. You should use gdb 5.1 instead.If you try linking mysqld statically when using gcc, the resulting image dumps core at startup time. In other words, do not use
--with-mysqld-ldflags=-all-staticwith gcc.
MySQL should work on MkLinux with the newest
glibc package (tested with
glibc 2.0.7).
To get MySQL to work on Qube2 (Linux Mips), you need the
newest glibc libraries.
glibc-2.0.7-29C2 is known to work. You must
also use the egcs C++ compiler
(egcs 1.0.2-9, gcc
2.95.2 or newer).
To get MySQL to compile on Linux IA-64, we use the following configure command for building with gcc 2.96:
CC=gcc \
CFLAGS="-O3 -fno-omit-frame-pointer" \
CXX=gcc \
CXXFLAGS="-O3 -fno-omit-frame-pointer -felide-constructors \
-fno-exceptions -fno-rtti" \
./configure --prefix=/usr/local/mysql \
"--with-comment=Official MySQL binary" \
--with-extra-charsets=complex
On IA-64, the MySQL client binaries use shared libraries. This
means that if you install our binary distribution at a
location other than /usr/local/mysql, you
need to add the path of the directory where you have
libmysqlclient.so installed either to the
/etc/ld.so.conf file or to the value of
your LD_LIBRARY_PATH environment variable.
See Section B.1.3.1, “Problems Linking to the MySQL Client Library”.
RHEL4 comes with SELinux, which supports tighter access
control for processes. If SELinux is enabled
(SELINUX in
/etc/selinux/config is set to
enforcing, SELINUXTYPE
is set to either targeted or
strict), you might encounter problems
installing MySQL AB RPM packages.
Red Hat has an update that solves this. It involves an update of the “security policy” specification to handle the install structure of the RPMs provided by MySQL AB. For further information, see https://bugzilla.redhat.com/bugzilla/show_bug.cgi?id=167551 and http://rhn.redhat.com/errata/RHBA-2006-0049.html.
On Mac OS X, tar cannot handle long
filenames. If you need to unpack a .tar.gz
distribution, use gnutar instead.
MySQL should work without major problems on Mac OS X 10.x (Darwin).
Known issues:
If you have problems with performance under heavy load, try using the
--skip-thread-priorityoption to mysqld. This runs all threads with the same priority. On Mac OS X, this gives better performance, at least until Apple fixes its thread scheduler.The connection times (
wait_timeout,interactive_timeoutandnet_read_timeout) values are not honored.This is probably a signal handling problem in the thread library where the signal doesn't break a pending read and we hope that a future update to the thread libraries will fix this.
Our binary for Mac OS X is compiled on Darwin 6.3 with the following configure line:
CC=gcc CFLAGS="-O3 -fno-omit-frame-pointer" CXX=gcc \
CXXFLAGS="-O3 -fno-omit-frame-pointer -felide-constructors \
-fno-exceptions -fno-rtti" \
./configure --prefix=/usr/local/mysql \
--with-extra-charsets=complex --enable-thread-safe-client \
--enable-local-infile --disable-shared
For current versions of Mac OS X Server, no operating system changes are necessary before compiling MySQL. Compiling for the Server platform is the same as for the client version of Mac OS X.
For older versions (Mac OS X Server 1.2, a.k.a. Rhapsody), you must first install a pthread package before trying to configure MySQL.
For information about installing MySQL on Solaris using PKG distributions, see Section 2.4.11, “Installing MySQL on Solaris”.
On Solaris, you may run into trouble even before you get the MySQL distribution unpacked, as the Solaris tar cannot handle long filenames. This means that you may see errors when you try to unpack MySQL.
If this occurs, you must use GNU tar (gtar) to unpack the distribution. You can find a precompiled copy for Solaris at http://dev.mysql.com/downloads/os-solaris.html.
Sun native threads work only on Solaris 2.5 and higher. For Solaris 2.4 and earlier, MySQL automatically uses MIT-pthreads. See Section 2.4.14.5, “MIT-pthreads Notes”.
If you get the following error from configure, it means that you have something wrong with your compiler installation:
checking for restartable system calls... configure: error can not run test programs while cross compiling
In this case, you should upgrade your compiler to a newer
version. You may also be able to solve this problem by inserting
the following row into the config.cache
file:
ac_cv_sys_restartable_syscalls=${ac_cv_sys_restartable_syscalls='no'}
If you are using Solaris on a SPARC, the recommended compiler is gcc 2.95.2 or 3.2. You can find this at http://gcc.gnu.org/. Note that egcs 1.1.1 and gcc 2.8.1 do not work reliably on SPARC.
The recommended configure line when using gcc 2.95.2 is:
CC=gcc CFLAGS="-O3" \
CXX=gcc CXXFLAGS="-O3 -felide-constructors -fno-exceptions -fno-rtti" \
./configure --prefix=/usr/local/mysql --with-low-memory \
--enable-assembler
If you have an UltraSPARC system, you can get 4% better
performance by adding -mcpu=v8
-Wa,-xarch=v8plusa to the CFLAGS and
CXXFLAGS environment variables.
If you have Sun's Forte 5.0 (or newer) compiler, you can run configure like this:
CC=cc CFLAGS="-Xa -fast -native -xstrconst -mt" \ CXX=CC CXXFLAGS="-noex -mt" \ ./configure --prefix=/usr/local/mysql --enable-assembler
To create a 64-bit binary with Sun's Forte compiler, use the following configuration options:
CC=cc CFLAGS="-Xa -fast -native -xstrconst -mt -xarch=v9" \ CXX=CC CXXFLAGS="-noex -mt -xarch=v9" ASFLAGS="-xarch=v9" \ ./configure --prefix=/usr/local/mysql --enable-assembler
To create a 64-bit Solaris binary using gcc,
add -m64 to CFLAGS and
CXXFLAGS and remove
--enable-assembler from the
configure line.
In the MySQL benchmarks, we obtained a 4% speed increase on
UltraSPARC when using Forte 5.0 in 32-bit mode, as compared to
using gcc 3.2 with the -mcpu
flag.
If you create a 64-bit mysqld binary, it is 4% slower than the 32-bit binary, but can handle more threads and memory.
When using Solaris 10 for x86_64, you should mount any
filesystems on which you intend to store
InnoDB files with the
forcedirectio option. (By default mounting is
done without this option.) Failing to do so will cause a
significant drop in performance when using the
InnoDB storage engine on this platform.
If you get a problem with fdatasync or
sched_yield, you can fix this by adding
LIBS=-lrt to the configure
line
For compilers older than WorkShop 5.3, you might have to edit the configure script. Change this line:
#if !defined(__STDC__) || __STDC__ != 1
To this:
#if !defined(__STDC__)
If you turn on __STDC__ with the
-Xc option, the Sun compiler can't compile with
the Solaris pthread.h header file. This is
a Sun bug (broken compiler or broken include file).
If mysqld issues the following error message
when you run it, you have tried to compile MySQL with the Sun
compiler without enabling the -mt multi-thread
option:
libc internal error: _rmutex_unlock: rmutex not held
Add -mt to CFLAGS and
CXXFLAGS and recompile.
If you are using the SFW version of gcc
(which comes with Solaris 8), you must add
/opt/sfw/lib to the environment variable
LD_LIBRARY_PATH before running
configure.
If you are using the gcc available from
sunfreeware.com, you may have many problems.
To avoid this, you should recompile gcc and
GNU binutils on the machine where you are
running them.
If you get the following error when compiling MySQL with gcc, it means that your gcc is not configured for your version of Solaris:
shell> gcc -O3 -g -O2 -DDBUG_OFF -o thr_alarm ...
./thr_alarm.c: In function `signal_hand':
./thr_alarm.c:556: too many arguments to function `sigwait'
The proper thing to do in this case is to get the newest version of gcc and compile it with your current gcc compiler. At least for Solaris 2.5, almost all binary versions of gcc have old, unusable include files that break all programs that use threads, and possibly other programs as well.
Solaris does not provide static versions of all system libraries
(libpthreads and libdl),
so you cannot compile MySQL with --static. If
you try to do so, you get one of the following errors:
ld: fatal: library -ldl: not found undefined reference to `dlopen' cannot find -lrt
If you link your own MySQL client programs, you may see the following error at runtime:
ld.so.1: fatal: libmysqlclient.so.#: open failed: No such file or directory
This problem can be avoided by one of the following methods:
If you have problems with configure trying to
link with -lz when you don't have
zlib installed, you have two options:
If you want to be able to use the compressed communication protocol, you need to get and install
zlibfromftp.gnu.org.Run configure with the
--with-named-z-libs=nooption when building MySQL.
If you are using gcc and have problems with
loading user-defined functions (UDFs) into MySQL, try adding
-lgcc to the link line for the UDF.
If you would like MySQL to start automatically, you can copy
support-files/mysql.server to
/etc/init.d and create a symbolic link to
it named /etc/rc3.d/S99mysql.server.
If too many processes try to connect very rapidly to mysqld, you should see this error in the MySQL log:
Error in accept: Protocol error
You might try starting the server with the
--back_log=50 option as a workaround for this.
(Use -O back_log=50 before MySQL 4.)
Solaris doesn't support core files for
setuid() applications, so you can't get a
core file from mysqld if you are using the
--user option.
Normally, you can use a Solaris 2.6 binary on Solaris 2.7 and 2.8. Most of the Solaris 2.6 issues also apply for Solaris 2.7 and 2.8.
MySQL should be able to detect new versions of Solaris automatically and enable workarounds for the following problems.
Solaris 2.7 / 2.8 has some bugs in the include files. You may see the following error when you use gcc:
/usr/include/widec.h:42: warning: `getwc' redefined /usr/include/wchar.h:326: warning: this is the location of the previous definition
If this occurs, you can fix the problem by copying
/usr/include/widec.h to
.../lib/gcc-lib/os/gcc-version/include and
changing line 41 from this:
#if !defined(lint) && !defined(__lint)
To this:
#if !defined(lint) && !defined(__lint) && !defined(getwc)
Alternatively, you can edit
/usr/include/widec.h directly. Either
way, after you make the fix, you should remove
config.cache and run
configure again.
If you get the following errors when you run
make, it's because
configure didn't detect the
curses.h file (probably because of the
error in /usr/include/widec.h):
In file included from mysql.cc:50: /usr/include/term.h:1060: syntax error before `,' /usr/include/term.h:1081: syntax error before `;'
The solution to this problem is to do one of the following:
Configure with
CFLAGS=-DHAVE_CURSES_H CXXFLAGS=-DHAVE_CURSES_H ./configure.Edit
/usr/include/widec.has indicated in the preceding discussion and re-run configure.Remove the
#define HAVE_TERMline from theconfig.hfile and run make again.
If your linker cannot find -lz when linking
client programs, the problem is probably that your
libz.so file is installed in
/usr/local/lib. You can fix this problem
by one of the following methods:
Add
/usr/local/libtoLD_LIBRARY_PATH.Add a link to
libz.sofrom/lib.If you are using Solaris 8, you can install the optional
zlibfrom your Solaris 8 CD distribution.Run configure with the
--with-named-z-libs=nooption when building MySQL.
On Solaris 8 on x86, mysqld dumps core if
you remove the debug symbols using strip.
If you are using gcc or egcs on Solaris x86 and you experience problems with core dumps under load, you should use the following configure command:
CC=gcc CFLAGS="-O3 -fomit-frame-pointer -DHAVE_CURSES_H" \
CXX=gcc \
CXXFLAGS="-O3 -fomit-frame-pointer -felide-constructors \
-fno-exceptions -fno-rtti -DHAVE_CURSES_H" \
./configure --prefix=/usr/local/mysql
This avoids problems with the libstdc++
library and with C++ exceptions.
If this doesn't help, you should compile a debug version and run it with a trace file or under gdb. See MySQL Internals: Porting.
This section provides information about using MySQL on variants of BSD Unix.
FreeBSD 4.x or newer is recommended for running MySQL, because
the thread package is much more integrated. To get a secure
and stable system, you should use only FreeBSD kernels that
are marked -RELEASE.
The easiest (and preferred) way to install MySQL is to use the
mysql-server and
mysql-client ports available at
http://www.freebsd.org/. Using these ports
gives you the following benefits:
A working MySQL with all optimizations enabled that are known to work on your version of FreeBSD.
Automatic configuration and build.
Startup scripts installed in
/usr/local/etc/rc.d.The ability to use
pkg_info -Lto see which files are installed.The ability to use
pkg_deleteto remove MySQL if you no longer want it on your machine.
It is recommended you use MIT-pthreads on FreeBSD 2.x, and native threads on FreeBSD 3 and up. It is possible to run with native threads on some late 2.2.x versions, but you may encounter problems shutting down mysqld.
Unfortunately, certain function calls on FreeBSD are not yet
fully thread-safe. Most notably, this includes the
gethostbyname() function, which is used by
MySQL to convert hostnames into IP addresses. Under certain
circumstances, the mysqld process suddenly
causes 100% CPU load and is unresponsive. If you encounter
this problem, try to start MySQL using the
--skip-name-resolve option.
Alternatively, you can link MySQL on FreeBSD 4.x against the LinuxThreads library, which avoids a few of the problems that the native FreeBSD thread implementation has. For a very good comparison of LinuxThreads versus native threads, see Jeremy Zawodny's article FreeBSD or Linux for your MySQL Server? at http://jeremy.zawodny.com/blog/archives/000697.html.
Known problem when using LinuxThreads on FreeBSD is:
The connection times (
wait_timeout,interactive_timeoutandnet_read_timeout) values are not honored. The symptom is that persistent connections can hang for a very long time without getting closed down and that a 'kill' for a thread will not take affect until the thread does it a new commandThis is probably a signal handling problem in the thread library where the signal doesn't break a pending read. This is supposed to be fixed in FreeBSD 5.0
The MySQL build process requires GNU make (gmake) to work. If GNU make is not available, you must install it first before compiling MySQL.
The recommended way to compile and install MySQL on FreeBSD with gcc (2.95.2 and up) is:
CC=gcc CFLAGS="-O2 -fno-strength-reduce" \
CXX=gcc CXXFLAGS="-O2 -fno-rtti -fno-exceptions \
-felide-constructors -fno-strength-reduce" \
./configure --prefix=/usr/local/mysql --enable-assembler
gmake
gmake install
cd /usr/local/mysql
bin/mysql_install_db --user=mysql
bin/mysqld_safe &
If you notice that configure uses MIT-pthreads, you should read the MIT-pthreads notes. See Section 2.4.14.5, “MIT-pthreads Notes”.
If you get an error from make install that
it can't find /usr/include/pthreads,
configure didn't detect that you need
MIT-pthreads. To fix this problem, remove
config.cache, and then re-run
configure with the
--with-mit-threads option.
Be sure that your name resolver setup is correct. Otherwise,
you may experience resolver delays or failures when connecting
to mysqld. Also make sure that the
localhost entry in the
/etc/hosts file is correct. The file
should start with a line similar to this:
127.0.0.1 localhost localhost.your.domain
FreeBSD is known to have a very low default file handle limit.
See Section B.1.2.17, “'File' Not Found and
Similar Errors”. Start the
server by using the --open-files-limit option
for mysqld_safe, or raise the limits for
the mysqld user in
/etc/login.conf and rebuild it with
cap_mkdb /etc/login.conf. Also be sure that
you set the appropriate class for this user in the password
file if you are not using the default (use chpass
mysqld-user-name). See
Section 5.3.1, “mysqld_safe — MySQL Server Startup Script”.
FreeBSD limits the size of a process to 512MB, even if you have much more RAM available on the system. So you may get an error such as this:
Out of memory (Needed 16391 bytes)
In current versions of FreeBSD (at least 4.x and greater), you
may increase this limit by adding the following entries to the
/boot/loader.conf file and rebooting the
machine (these are not settings that can be changed at run
time with the sysctl command):
kern.maxdsiz="1073741824" # 1GB kern.dfldsiz="1073741824" # 1GB kern.maxssiz="134217728" # 128MB
For older versions of FreeBSD, you must recompile your kernel
to change the maximum data segment size for a process. In this
case, you should look at the MAXDSIZ option
in the LINT config file for more
information.
If you get problems with the current date in MySQL, setting
the TZ variable should help. See
Section 2.4.19, “Environment Variables”.
To compile on NetBSD, you need GNU make.
Otherwise, the build process fails when
make tries to run lint
on C++ files.
On OpenBSD 2.5, you can compile MySQL with native threads with the following options:
CFLAGS=-pthread CXXFLAGS=-pthread ./configure --with-mit-threads=no
If you get the following error when compiling MySQL, your ulimit value for virtual memory is too low:
item_func.h: In method `Item_func_ge::Item_func_ge(const Item_func_ge &)': item_func.h:28: virtual memory exhausted make[2]: *** [item_func.o] Error 1
Try using ulimit -v 80000 and run make again. If this doesn't work and you are using bash, try switching to csh or sh; some BSDI users have reported problems with bash and ulimit.
If you are using gcc, you may also use have
to use the --with-low-memory flag for
configure to be able to compile
sql_yacc.cc.
If you get problems with the current date in MySQL, setting
the TZ variable should help. See
Section 2.4.19, “Environment Variables”.
Upgrade to BSD/OS 3.1. If that is not possible, install BSDIpatch M300-038.
Use the following command when configuring MySQL:
env CXX=shlicc++ CC=shlicc2 \
./configure \
--prefix=/usr/local/mysql \
--localstatedir=/var/mysql \
--without-perl \
--with-unix-socket-path=/var/mysql/mysql.sock
The following is also known to work:
env CC=gcc CXX=gcc CXXFLAGS=-O3 \
./configure \
--prefix=/usr/local/mysql \
--with-unix-socket-path=/var/mysql/mysql.sock
You can change the directory locations if you wish, or just use the defaults by not specifying any locations.
If you have problems with performance under heavy load, try
using the --skip-thread-priority option to
mysqld. This runs all threads with the same
priority. On BSDI 3.1, this gives better performance, at least
until BSDI fixes its thread scheduler.
If you get the error virtual memory
exhausted while compiling, you should try using
ulimit -v 80000 and running
make again. If this doesn't work and you
are using bash, try switching to
csh or sh; some BSDI
users have reported problems with bash and
ulimit.
BSDI 4.x has some thread-related bugs. If you want to use MySQL on this, you should install all thread-related patches. At least M400-023 should be installed.
On some BSDI 4.x systems, you may get problems with shared
libraries. The symptom is that you can't execute any client
programs, for example, mysqladmin. In this
case, you need to reconfigure not to use shared libraries with
the --disable-shared option to configure.
Some customers have had problems on BSDI 4.0.1 that the mysqld binary after a while can't open tables. This occurs because some library/system-related bug causes mysqld to change current directory without having asked for that to happen.
The fix is to either upgrade MySQL to at least version 3.23.34
or, after running configure, remove the
line #define HAVE_REALPATH from
config.h before running
make.
Note that this means that you can't symbolically link a database directories to another database directory or symbolic link a table to another database on BSDI. (Making a symbolic link to another disk is okay).
This section does not apply to MySQL Enterprise Server users.
There are a couple of small problems when compiling MySQL on HP-UX. We recommend that you use gcc instead of the HP-UX native compiler, because gcc produces better code.
We recommend using gcc 2.95 on HP-UX. Don't
use high optimization flags (such as -O6)
because they may not be safe on HP-UX.
The following configure line should work with gcc 2.95:
CFLAGS="-I/opt/dce/include -fpic" \
CXXFLAGS="-I/opt/dce/include -felide-constructors -fno-exceptions \
-fno-rtti" \
CXX=gcc \
./configure --with-pthread \
--with-named-thread-libs='-ldce' \
--prefix=/usr/local/mysql --disable-shared
The following configure line should work with gcc 3.1:
CFLAGS="-DHPUX -I/opt/dce/include -O3 -fPIC" CXX=gcc \
CXXFLAGS="-DHPUX -I/opt/dce/include -felide-constructors \
-fno-exceptions -fno-rtti -O3 -fPIC" \
./configure --prefix=/usr/local/mysql \
--with-extra-charsets=complex --enable-thread-safe-client \
--enable-local-infile --with-pthread \
--with-named-thread-libs=-ldce --with-lib-ccflags=-fPIC
--disable-shared
Because of some critical bugs in the standard HP-UX libraries, you should install the following patches before trying to run MySQL on HP-UX 11.0:
PHKL_22840 Streams cumulative PHNE_22397 ARPA cumulative
This solves the problem of getting
EWOULDBLOCK from recv()
and EBADF from accept()
in threaded applications.
If you are using gcc 2.95.1 on an unpatched HP-UX 11.x system, you may get the following error:
In file included from /usr/include/unistd.h:11,
from ../include/global.h:125,
from mysql_priv.h:15,
from item.cc:19:
/usr/include/sys/unistd.h:184: declaration of C function ...
/usr/include/sys/pthread.h:440: previous declaration ...
In file included from item.h:306,
from mysql_priv.h:158,
from item.cc:19:
The problem is that HP-UX does not define
pthreads_atfork() consistently. It has
conflicting prototypes in
/usr/include/sys/unistd.h:184 and
/usr/include/sys/pthread.h:440.
One solution is to copy
/usr/include/sys/unistd.h into
mysql/include and edit
unistd.h and change it to match the
definition in pthread.h. Look for this
line:
extern int pthread_atfork(void (*prepare)(), void (*parent)(),
void (*child)());
Change it to look like this:
extern int pthread_atfork(void (*prepare)(void), void (*parent)(void),
void (*child)(void));
After making the change, the following configure line should work:
CFLAGS="-fomit-frame-pointer -O3 -fpic" CXX=gcc \ CXXFLAGS="-felide-constructors -fno-exceptions -fno-rtti -O3" \ ./configure --prefix=/usr/local/mysql --disable-shared
If you are using HP-UX compiler, you can use the following command (which has been tested with cc B.11.11.04):
CC=cc CXX=aCC CFLAGS=+DD64 CXXFLAGS=+DD64 ./configure \
--with-extra-character-set=complex
You can ignore any errors of the following type:
aCC: warning 901: unknown option: `-3': use +help for online documentation
If you get the following error from configure, verify that you don't have the path to the K&R compiler before the path to the HP-UX C and C++ compiler:
checking for cc option to accept ANSI C... no configure: error: MySQL requires an ANSI C compiler (and a C++ compiler). Try gcc. See the Installation chapter in the Reference Manual.
Another reason for not being able to compile is that you
didn't define the +DD64 flags as just
described.
Another possibility for HP-UX 11 is to use the MySQL binaries provided at http://dev.mysql.com/downloads/, which we have built and tested ourselves. We have also received reports that the HP-UX 10.20 binaries supplied by MySQL can be run successfully on HP-UX 11. If you encounter problems, you should be sure to check your HP-UX patch level.
Automatic detection of xlC is missing from
Autoconf, so a number of variables need to be set before
running configure. The following example
uses the IBM compiler:
export CC="xlc_r -ma -O3 -qstrict -qoptimize=3 -qmaxmem=8192 "
export CXX="xlC_r -ma -O3 -qstrict -qoptimize=3 -qmaxmem=8192"
export CFLAGS="-I /usr/local/include"
export LDFLAGS="-L /usr/local/lib"
export CPPFLAGS=$CFLAGS
export CXXFLAGS=$CFLAGS
./configure --prefix=/usr/local \
--localstatedir=/var/mysql \
--sbindir='/usr/local/bin' \
--libexecdir='/usr/local/bin' \
--enable-thread-safe-client \
--enable-large-files
The preceding options are used to compile the MySQL distribution that can be found at http://www-frec.bull.com/.
If you change the -O3 to -O2
in the preceding configure line, you must
also remove the -qstrict option. This is a
limitation in the IBM C compiler.
If you are using gcc or
egcs to compile MySQL, you
must use the
-fno-exceptions flag, because the exception
handling in gcc/egcs is
not thread-safe! (This is tested with egcs
1.1.) There are also some known problems with IBM's assembler
that may cause it to generate bad code when used with
gcc.
We recommend the following configure line with egcs and gcc 2.95 on AIX:
CC="gcc -pipe -mcpu=power -Wa,-many" \ CXX="gcc -pipe -mcpu=power -Wa,-many" \ CXXFLAGS="-felide-constructors -fno-exceptions -fno-rtti" \ ./configure --prefix=/usr/local/mysql --with-low-memory
The -Wa,-many option is necessary for the
compile to be successful. IBM is aware of this problem but is
in no hurry to fix it because of the workaround that is
available. We don't know if the
-fno-exceptions is required with
gcc 2.95, but because MySQL doesn't use
exceptions and the option generates faster code, we recommend
that you should always use it with egcs /
gcc.
If you get a problem with assembler code, try changing the
-mcpu= option
to match your CPU. Typically xxxpower2,
power, or powerpc may
need to be used. Alternatively, you might need to use
604 or 604e. We are not
positive but suspect that power would
likely be safe most of the time, even on a power2 machine.
If you don't know what your CPU is, execute a uname
-m command. It produces a string that looks like
000514676700, with a format of
xxyyyyyymmss where xx
and ss are always 00,
yyyyyy is a unique system ID and
mm is the ID of the CPU Planar. A chart of
these values can be found at
http://www16.boulder.ibm.com/pseries/en_US/cmds/aixcmds5/uname.htm.
This gives you a machine type and a machine model you can use to determine what type of CPU you have.
If you have problems with signals (MySQL dies unexpectedly under high load), you may have found an OS bug with threads and signals. In this case, you can tell MySQL not to use signals by configuring as follows:
CFLAGS=-DDONT_USE_THR_ALARM CXX=gcc \
CXXFLAGS="-felide-constructors -fno-exceptions -fno-rtti \
-DDONT_USE_THR_ALARM" \
./configure --prefix=/usr/local/mysql --with-debug \
--with-low-memory
This doesn't affect the performance of MySQL, but has the side effect that you can't kill clients that are “sleeping” on a connection with mysqladmin kill or mysqladmin shutdown. Instead, the client dies when it issues its next command.
On some versions of AIX, linking with
libbind.a makes
getservbyname() dump core. This is an AIX
bug and should be reported to IBM.
For AIX 4.2.1 and gcc, you have to make the following changes.
After configuring, edit config.h and
include/my_config.h and change the line
that says this:
#define HAVE_SNPRINTF 1
to this:
#undef HAVE_SNPRINTF
And finally, in mysqld.cc, you need to
add a prototype for initgroups().
#ifdef _AIX41 extern "C" int initgroups(const char *,int); #endif
If you need to allocate a lot of memory to the mysqld process, it's not enough to just use ulimit -d unlimited. You may also have to modify mysqld_safe to add a line something like this:
export LDR_CNTRL='MAXDATA=0x80000000'
You can find more information about using a lot of memory at http://publib16.boulder.ibm.com/pseries/en_US/aixprggd/genprogc/lrg_prg_support.htm.
Users of AIX 4.3 should use gmake instead of the make utility included with AIX.
As of AIX 4.1, the C compiler has been unbundled from AIX as a separate product. We recommend using gcc 3.3.2, which can be obtained here: ftp://ftp.software.ibm.com/aix/freeSoftware/aixtoolbox/RPMS/ppc/gcc/
The steps for compiling MySQL on AIX with
gcc 3.3.2 are similar to those for using
gcc 2.95 (in particular, the need to edit
config.h and
my_config.h after running
configure). However, before running
configure, you should also patch the
curses.h file as follows:
/opt/freeware/lib/gcc-lib/powerpc-ibm-aix5.2.0.0/3.3.2/include/curses.h.ORIG
Mon Dec 26 02:17:28 2005
--- /opt/freeware/lib/gcc-lib/powerpc-ibm-aix5.2.0.0/3.3.2/include/curses.h
Mon Dec 26 02:40:13 2005
***************
*** 2023,2029 ****
#endif /* _AIX32_CURSES */
! #if defined(__USE_FIXED_PROTOTYPES__) || defined(__cplusplus) || defined
(__STRICT_ANSI__)
extern int delwin (WINDOW *);
extern int endwin (void);
extern int getcurx (WINDOW *);
--- 2023,2029 ----
#endif /* _AIX32_CURSES */
! #if 0 && (defined(__USE_FIXED_PROTOTYPES__) || defined(__cplusplus)
|| defined
(__STRICT_ANSI__))
extern int delwin (WINDOW *);
extern int endwin (void);
extern int getcurx (WINDOW *);
This section does not apply to MySQL Enterprise Server users.
On SunOS 4, MIT-pthreads is needed to compile MySQL. This in turn means you need GNU make.
Some SunOS 4 systems have problems with dynamic libraries and libtool. You can use the following configure line to avoid this problem:
./configure --disable-shared --with-mysqld-ldflags=-all-static
When compiling readline, you may get
warnings about duplicate defines. These can be ignored.
When compiling mysqld, there are some
implicit declaration of function warnings.
These can be ignored.
This section does not apply to MySQL Enterprise Server users.
If you are using egcs 1.1.2 on Digital Unix, you should upgrade to gcc 2.95.2, because egcs on DEC has some serious bugs!
When compiling threaded programs under Digital Unix, the
documentation recommends using the -pthread
option for cc and cxx
and the -lmach -lexc libraries (in addition
to -lpthread). You should run
configure something like this:
CC="cc -pthread" CXX="cxx -pthread -O" \ ./configure --with-named-thread-libs="-lpthread -lmach -lexc -lc"
When compiling mysqld, you may see a couple of warnings like this:
mysqld.cc: In function void handle_connections()': mysqld.cc:626: passing long unsigned int *' as argument 3 of accept(int,sockadddr *, int *)'
You can safely ignore these warnings. They occur because configure can detect only errors, not warnings.
If you start the server directly from the command line, you
may have problems with it dying when you log out. (When you
log out, your outstanding processes receive a
SIGHUP signal.) If so, try starting the
server like this:
nohup mysqld [options] &
nohup causes the command following it to
ignore any SIGHUP signal sent from the
terminal. Alternatively, start the server by running
mysqld_safe, which invokes
mysqld using nohup for
you. See Section 5.3.1, “mysqld_safe — MySQL Server Startup Script”.
If you get a problem when compiling
mysys/get_opt.c, just remove the
#define _NO_PROTO line from the start of
that file.
If you are using Compaq's CC compiler, the following configure line should work:
CC="cc -pthread"
CFLAGS="-O4 -ansi_alias -ansi_args -fast -inline speed \
-speculate all -arch host"
CXX="cxx -pthread"
CXXFLAGS="-O4 -ansi_alias -ansi_args -fast -inline speed \
-speculate all -arch host -noexceptions -nortti"
export CC CFLAGS CXX CXXFLAGS
./configure \
--prefix=/usr/local/mysql \
--with-low-memory \
--enable-large-files \
--enable-shared=yes \
--with-named-thread-libs="-lpthread -lmach -lexc -lc"
gnumake
If you get a problem with libtool when compiling with shared libraries as just shown, when linking mysql, you should be able to get around this by issuing these commands:
cd mysql
/bin/sh ../libtool --mode=link cxx -pthread -O3 -DDBUG_OFF \
-O4 -ansi_alias -ansi_args -fast -inline speed \
-speculate all \ -arch host -DUNDEF_HAVE_GETHOSTBYNAME_R \
-o mysql mysql.o readline.o sql_string.o completion_hash.o \
../readline/libreadline.a -lcurses \
../libmysql/.libs/libmysqlclient.so -lm
cd ..
gnumake
gnumake install
scripts/mysql_install_db
This section does not apply to MySQL Enterprise Server users.
If you have problems compiling and have DEC CC and gcc installed, try running configure like this:
CC=cc CFLAGS=-O CXX=gcc CXXFLAGS=-O3 \ ./configure --prefix=/usr/local/mysql
If you get problems with the c_asm.h
file, you can create and use a 'dummy'
c_asm.h file with:
touch include/c_asm.h CC=gcc CFLAGS=-I./include \ CXX=gcc CXXFLAGS=-O3 \ ./configure --prefix=/usr/local/mysql
Note that the following problems with the ld program can be fixed by downloading the latest DEC (Compaq) patch kit from: http://ftp.support.compaq.com/public/unix/.
On OSF/1 V4.0D and compiler "DEC C V5.6-071 on Digital Unix
V4.0 (Rev. 878)," the compiler had some strange behavior
(undefined asm symbols).
/bin/ld also appears to be broken (problems
with _exit undefined errors occurring while
linking mysqld). On this system, we have
managed to compile MySQL with the following
configure line, after replacing
/bin/ld with the version from OSF 4.0C:
CC=gcc CXX=gcc CXXFLAGS=-O3 ./configure --prefix=/usr/local/mysql
With the Digital compiler "C++ V6.1-029," the following should work:
CC=cc -pthread
CFLAGS=-O4 -ansi_alias -ansi_args -fast -inline speed \
-speculate all -arch host
CXX=cxx -pthread
CXXFLAGS=-O4 -ansi_alias -ansi_args -fast -inline speed \
-speculate all -arch host -noexceptions -nortti
export CC CFLAGS CXX CXXFLAGS
./configure --prefix=/usr/mysql/mysql \
--with-mysqld-ldflags=-all-static --disable-shared \
--with-named-thread-libs="-lmach -lexc -lc"
In some versions of OSF/1, the alloca()
function is broken. Fix this by removing the line in
config.h that defines
'HAVE_ALLOCA'.
The alloca() function also may have an
incorrect prototype in
/usr/include/alloca.h. This warning
resulting from this can be ignored.
configure uses the following thread
libraries automatically:
--with-named-thread-libs="-lpthread -lmach -lexc
-lc".
When using gcc, you can also try running configure like this:
CFLAGS=-D_PTHREAD_USE_D4 CXX=gcc CXXFLAGS=-O3 ./configure ...
If you have problems with signals (MySQL dies unexpectedly under high load), you may have found an OS bug with threads and signals. In this case, you can tell MySQL not to use signals by configuring with:
CFLAGS=-DDONT_USE_THR_ALARM \ CXXFLAGS=-DDONT_USE_THR_ALARM \ ./configure ...
This does not affect the performance of MySQL, but has the side effect that you can't kill clients that are “sleeping” on a connection with mysqladmin kill or mysqladmin shutdown. Instead, the client dies when it issues its next command.
With gcc 2.95.2, you may encounter the following compile error:
sql_acl.cc:1456: Internal compiler error in `scan_region', at except.c:2566 Please submit a full bug report.
To fix this, you should change to the sql
directory and do a cut-and-paste of the last
gcc line, but change -O3
to -O0 (or add -O0
immediately after gcc if you don't have any
-O option on your compile line). After this
is done, you can just change back to the top-level directory
and run make again.
This section does not apply to MySQL Enterprise Server users.
As of MySQL 5.0, we don't provide binaries for Irix any more.
If you are using Irix 6.5.3 or newer,
mysqld is able to create threads only if
you run it as a user that has CAP_SCHED_MGT
privileges (such as root) or give the
mysqld server this privilege with the
following shell command:
chcap "CAP_SCHED_MGT+epi" /opt/mysql/libexec/mysqld
You may have to undefine some symbols in
config.h after running
configure and before compiling.
In some Irix implementations, the alloca()
function is broken. If the mysqld server
dies on some SELECT statements, remove the
lines from config.h that define
HAVE_ALLOC and
HAVE_ALLOCA_H. If mysqladmin
create doesn't work, remove the line from
config.h that defines
HAVE_READDIR_R. You may have to remove the
HAVE_TERM_H line as well.
SGI recommends that you install all the patches on this page as a set: http://support.sgi.com/surfzone/patches/patchset/6.2_indigo.rps.html
At the very minimum, you should install the latest kernel
rollup, the latest rld rollup, and the
latest libc rollup.
You definitely need all the POSIX patches on this page, for pthreads support:
http://support.sgi.com/surfzone/patches/patchset/6.2_posix.rps.html
If you get the something like the following error when
compiling mysql.cc:
"/usr/include/curses.h", line 82: error(1084): invalid combination of type
Type the following in the top-level directory of your MySQL source tree:
extra/replace bool curses_bool < /usr/include/curses.h > include/curses.h make
There have also been reports of scheduling problems. If only one thread is running, performance is slow. Avoid this by starting another client. This may lead to a two-to-tenfold increase in execution speed thereafter for the other thread. This is a poorly understood problem with Irix threads; you may have to improvise to find solutions until this can be fixed.
If you are compiling with gcc, you can use the following configure command:
CC=gcc CXX=gcc CXXFLAGS=-O3 \
./configure --prefix=/usr/local/mysql --enable-thread-safe-client \
--with-named-thread-libs=-lpthread
On Irix 6.5.11 with native Irix C and C++ compilers ver. 7.3.1.2, the following is reported to work
CC=cc CXX=CC CFLAGS='-O3 -n32 -TARG:platform=IP22 -I/usr/local/include \
-L/usr/local/lib' CXXFLAGS='-O3 -n32 -TARG:platform=IP22 \
-I/usr/local/include -L/usr/local/lib' \
./configure --prefix=/usr/local/mysql --with-innodb --with-berkeley-db \
--with-libwrap=/usr/local \
--with-named-curses-libs=/usr/local/lib/libncurses.a
The current port is tested only on
sco3.2v5.0.5,
sco3.2v5.0.6, and
sco3.2v5.0.7 systems. There has also been
progress on a port to sco3.2v4.2. Open
Server 5.0.8 (Legend) has native threads and allows files
greater than 2GB. The current maximum file size is 2GB.
We have been able to compile MySQL with the following configure command on OpenServer with gcc 2.95.3.
CC=gcc CFLAGS="-D_FILE_OFFSET_BITS=64 -O3" \
CXX=gcc CXXFLAGS="-D_FILE_OFFSET_BITS=64 -O3" \
./configure --prefix=/usr/local/mysql \
--enable-thread-safe-client --with-innodb \
--with-openssl --with-vio --with-extra-charsets=complex
gcc is available at ftp://ftp.sco.com/pub/openserver5/opensrc/gnutools-5.0.7Kj.
This development system requires the OpenServer Execution
Environment Supplement oss646B on OpenServer 5.0.6 and oss656B
and The OpenSource libraries found in gwxlibs. All OpenSource
tools are in the opensrc directory. They
are available at
ftp://ftp.sco.com/pub/openserver5/opensrc/.
We recommend using the latest production release of MySQL.
SCO provides operating system patches at ftp://ftp.sco.com/pub/openserver5 for OpenServer 5.0.[0-6] and ftp://ftp.sco.com/pub/openserverv5/507 for OpenServer 5.0.7.
SCO provides information about security fixes at ftp://ftp.sco.com/pub/security/OpenServer for OpenServer 5.0.x.
The maximum file size on an OpenSever 5.0.x system is 2GB.
The total memory which can be allocated for streams buffers, clists, and lock records cannot exceed 60MB on OpenServer 5.0.x.
Streams buffers are allocated in units of 4096 byte pages, clists are 70 bytes each, and lock records are 64 bytes each, so:
(NSTRPAGES × 4096) + (NCLIST × 70) + (MAX_FLCKREC × 64) <= 62914560
Follow this procedure to configure the Database Services option. If you are unsure whether an application requires this, see the documentation provided with the application.
Log in as
root.Enable the SUDS driver by editing the
/etc/conf/sdevice.d/sudsfile. Change theNin the second field to aY.Use mkdev aio or the Hardware/Kernel Manager to enable support for asynchronous I/O and relink the kernel. To allow users to lock down memory for use with this type of I/O, update the aiomemlock(F) file. This file should be updated to include the names of users that can use AIO and the maximum amounts of memory they can lock down.
Many applications use setuid binaries so that you need to specify only a single user. See the documentation provided with the application to determine whether this is the case for your application.
After you complete this process, reboot the system to create a new kernel incorporating these changes.
By default, the entries in
/etc/conf/cf.d/mtune are set as follows:
Value Default Min Max ----- ------- --- --- NBUF 0 24 450000 NHBUF 0 32 524288 NMPBUF 0 12 512 MAX_INODE 0 100 64000 MAX_FILE 0 100 64000 CTBUFSIZE 128 0 256 MAX_PROC 0 50 16000 MAX_REGION 0 500 160000 NCLIST 170 120 16640 MAXUP 100 15 16000 NOFILES 110 60 11000 NHINODE 128 64 8192 NAUTOUP 10 0 60 NGROUPS 8 0 128 BDFLUSHR 30 1 300 MAX_FLCKREC 0 50 16000 PUTBUFSZ 8000 2000 20000 MAXSLICE 100 25 100 ULIMIT 4194303 2048 4194303 * Streams Parameters NSTREAM 64 1 32768 NSTRPUSH 9 9 9 NMUXLINK 192 1 4096 STRMSGSZ 16384 4096 524288 STRCTLSZ 1024 1024 1024 STRMAXBLK 524288 4096 524288 NSTRPAGES 500 0 8000 STRSPLITFRAC 80 50 100 NLOG 3 3 3 NUMSP 64 1 256 NUMTIM 16 1 8192 NUMTRW 16 1 8192 * Semaphore Parameters SEMMAP 10 10 8192 SEMMNI 10 10 8192 SEMMNS 60 60 8192 SEMMNU 30 10 8192 SEMMSL 25 25 150 SEMOPM 10 10 1024 SEMUME 10 10 25 SEMVMX 32767 32767 32767 SEMAEM 16384 16384 16384 * Shared Memory Parameters SHMMAX 524288 131072 2147483647 SHMMIN 1 1 1 SHMMNI 100 100 2000 FILE 0 100 64000 NMOUNT 0 4 256 NPROC 0 50 16000 NREGION 0 500 160000
We recommend setting these values as follows:
NOFILESshould be 4096 or 2048.MAXUPshould be 2048.
To make changes to the kernel, use the idtune
name parameter command.
idtune modifies the
/etc/conf/cf.d/stune file for you. For
example, to change SEMMS to
200, execute this command as
root:
# /etc/conf/bin/idtune SEMMNS 200
Then rebuild and reboot the kernel by issuing this command:
# /etc/conf/bin/idbuild -B && init 6
We recommend tuning the system, but the proper parameter values to use depend on the number of users accessing the application or database and size the of the database (that is, the used buffer pool). The following kernel parameters can be set with idtune:
SHMMAX(recommended setting: 128MB) andSHMSEG(recommended setting: 15). These parameters have an influence on the MySQL database engine to create user buffer pools.NOFILESandMAXUPshould be set to at least 2048.MAXPROCshould be set to at least 3000/4000 (depends on number of users) or more.We also recommend using the following formulas to calculate values for
SEMMSL,SEMMNS, andSEMMNU:SEMMSL = 13
13 is what has been found to be the best for both Progress and MySQL.
SEMMNS = SEMMSL ×
number of db servers to be run on the systemSet
SEMMNSto the value ofSEMMSLmultiplied by the number of database servers (maximum) that you are running on the system at one time.SEMMNU = SEMMNS
Set the value of
SEMMNUto equal the value ofSEMMNS. You could probably set this to 75% ofSEMMNS, but this is a conservative estimate.
You need to at least install the SCO OpenServer Linker and Application Development Libraries or the OpenServer Development System to use gcc. You cannot use the GCC Dev system without installing one of these.
You should get the FSU Pthreads package and install it first. This can be found at http://moss.csc.ncsu.edu/~mueller/ftp/pub/PART/pthreads.tar.gz. You can also get a precompiled package from ftp://ftp.zenez.com/pub/zenez/prgms/FSU-threads-3.14.tar.gz.
FSU Pthreads can be compiled with SCO Unix 4.2 with tcpip, or
using OpenServer 3.0 or Open Desktop 3.0 (OS 3.0 ODT 3.0) with
the SCO Development System installed using a good port of GCC
2.5.x. For ODT or OS 3.0, you need a good port of GCC 2.5.x.
There are a lot of problems without a good port. The port for
this product requires the SCO Unix Development system. Without
it, you are missing the libraries and the linker that is
needed. You also need
SCO-3.2v4.2-includes.tar.gz. This file
contains the changes to the SCO Development include files that
are needed to get MySQL to build. You need to replace the
existing system include files with these modified header
files. They can be obtained from
ftp://ftp.zenez.com/pub/zenez/prgms/SCO-3.2v4.2-includes.tar.gz.
To build FSU Pthreads on your system, all you should need to
do is run GNU make. The
Makefile in FSU-threads-3.14.tar.gz is
set up to make FSU-threads.
You can run ./configure in the
threads/src directory and select the SCO
OpenServer option. This command copies
Makefile.SCO5 to
Makefile. Then run
make.
To install in the default /usr/include
directory, log in as root, and then
cd to the thread/src
directory and run make install.
Remember that you must use GNU make to build MySQL.
Note: If you don't start
mysqld_safe as root, you
should get only the default 110 open files per process.
mysqld writes a note about this in the log
file.
With SCO 3.2V4.2, you should use FSU Pthreads version 3.14 or newer. The following configure command should work:
CFLAGS="-D_XOPEN_XPG4" CXX=gcc CXXFLAGS="-D_XOPEN_XPG4" \
./configure \
--prefix=/usr/local/mysql \
--with-named-thread-libs="-lgthreads -lsocket -lgen -lgthreads" \
--with-named-curses-libs="-lcurses"
You may have problems with some include files. In this case, you can find new SCO-specific include files at ftp://ftp.zenez.com/pub/zenez/prgms/SCO-3.2v4.2-includes.tar.gz.
You should unpack this file in the
include directory of your MySQL source
tree.
SCO development notes:
MySQL should automatically detect FSU Pthreads and link mysqld with
-lgthreads -lsocket -lgthreads.The SCO development libraries are re-entrant in FSU Pthreads. SCO claims that its library functions are re-entrant, so they must be re-entrant with FSU Pthreads. FSU Pthreads on OpenServer tries to use the SCO scheme to make re-entrant libraries.
FSU Pthreads (at least the version at ftp://ftp.zenez.com) comes linked with GNU
malloc. If you encounter problems with memory usage, make sure thatgmalloc.ois included inlibgthreads.aandlibgthreads.so.In FSU Pthreads, the following system calls are pthreads-aware:
read(),write(),getmsg(),connect(),accept(),select(), andwait().The CSSA-2001-SCO.35.2 (the patch is listed in custom as erg711905-dscr_remap security patch (version 2.0.0)) breaks FSU threads and makes mysqld unstable. You have to remove this one if you want to run mysqld on an OpenServer 5.0.6 machine.
If you use SCO OpenServer 5, you may need to recompile FSU pthreads with
-DDRAFT7inCFLAGS. Otherwise,InnoDBmay hang at a mysqld startup.SCO provides operating system patches at ftp://ftp.sco.com/pub/openserver5 for OpenServer 5.0.x.
SCO provides security fixes and
libsocket.so.2at ftp://ftp.sco.com/pub/security/OpenServer and ftp://ftp.sco.com/pub/security/sse for OpenServer 5.0.x.Pre-OSR506 security fixes. Also, the
telnetdfix at ftp://stage.caldera.com/pub/security/openserver/ or ftp://stage.caldera.com/pub/security/openserver/CSSA-2001-SCO.10/ as bothlibsocket.so.2andlibresolv.so.1with instructions for installing on pre-OSR506 systems.It's probably a good idea to install these patches before trying to compile/use MySQL.
Beginning with Legend/OpenServer 6.0.0, there are native threads and no 2GB file size limit.
OpenServer 6 includes these key improvements:
Larger file support up to 1 TB
Multiprocessor support increased from 4 to 32 processors
Increased memory support up to 64GB
Extending the power of UnixWare into OpenServer 6
Dramatic performance improvement
OpenServer 6.0.0 commands are organized as follows:
/binis for commands that behave exactly the same as on OpenServer 5.0.x./u95/binis for commands that have better standards conformance, for example Large File System (LFS) support./udk/binis for commands that behave the same as on UnixWare 7.1.4. The default is for the LFS support.
The following is a guide to setting PATH on
OpenServer 6. If the user wants the traditional OpenServer
5.0.x then PATH should be
/bin first. If the user wants LFS
support, the path should be
/u95/bin:/bin. If the user wants UnixWare
7 support first, the path would be
/udk/bin:/u95/bin:/bin:.
We recommend using the latest production release of MySQL. Should you choose to use an older release of MySQL on OpenServer 6.0.x, you must use a version of MySQL at least as recent as 3.22.13 to get fixes for some portability and OS problems.
MySQL distribution files with names of the following form are
tar archives of media are tar archives of
media images suitable for installation with the SCO Software
Manager (/etc/custom) on SCO OpenServer
6:
mysql-PRODUCT-5.0.42-sco-osr6-i686.VOLS.tar
A distribution where PRODUCT is
pro-cert is the Commercially licensed MySQL
Pro Certified server. A distribution where
PRODUCT is
pro-gpl-cert is the MySQL Pro Certified
server licensed under the terms of the General Public License
(GPL).
Select whichever distribution you wish to install and, after download, extract the tar archive into an empty directory. For example:
shell>mkdir /tmp/mysql-proshell>cd /tmp/mysql-proshell>tar xf /tmp/mysql-pro-cert-5.0.42-sco-osr6-i686.VOLS.tar
Prior to installation, back up your data in accordance with the procedures outlined in Section 2.4.16, “Upgrading MySQL”.
Remove any previously installed pkgadd version of MySQL:
shell> pkginfo mysql 2>&1 > /dev/null && pkgrm mysql
Install MySQL Pro from media images using the SCO Software Manager:
shell> /etc/custom -p SCO:MySQL -i -z /tmp/mysql-pro
Alternatively, the SCO Software Manager can be displayed
graphically by clicking on the Software
Manager icon on the desktop, selecting
Software -> Install New, selecting the
host, selecting Media Images for the Media
Device, and entering /tmp/mysql-pro as
the Image Directory.
After installation, run mkdev mysql as the
root user to configure your newly installed
MySQL Pro Certified server.
Note: The installation
procedure for VOLS packages does not create the
mysql user and group that the package uses
by default. You should either create the
mysql user and group, or else select a
different user and group using an option in mkdev
mysql.
If you wish to configure your MySQL Pro server to interface with the Apache Web server via PHP, download and install the PHP update from SCO at ftp://ftp.sco.com/pub/updates/OpenServer/SCOSA-2006.17/.
We have been able to compile MySQL with the following configure command on OpenServer 6.0.x:
CC=cc CFLAGS="-D_FILE_OFFSET_BITS=64 -O3" \
CXX=CC CXXFLAGS="-D_FILE_OFFSET_BITS=64 -O3" \
./configure --prefix=/usr/local/mysql \
--enable-thread-safe-client --with-berkeley-db \
--with-extra-charsets=complex \
--build=i686-unknown-sysv5SCO_SV6.0.0
If you use gcc, you must use gcc 2.95.3 or newer.
CC=gcc CXX=g++ ... ./configure ...
The version of Berkeley DB that comes with either UnixWare
7.1.4 or OpenServer 6.0.0 is not used when building MySQL.
MySQL instead uses its own version of Berkeley DB. The
configure command needs to build both a
static and a dynamic library in
src_directory/bdb/build_unix/BDB
version. The workaround is as follows.
Configure as normal for MySQL.
cd bdb/build_unix/cp -p Makefile Makefile.savUse same options and run ../dist/configure.
Run gmake.
cp -p Makefile.sav MakefileChange location to the top source directory and run gmake.
This allows both the shared and dynamic libraries to be made and work.
SCO provides OpenServer 6 operating system patches at ftp://ftp.sco.com/pub/openserver6.
SCO provides information about security fixes at ftp://ftp.sco.com/pub/security/OpenServer.
By default, the maximum file size on a OpenServer 6.0.0 system is 1TB. Some operating system utilities have a limitation of 2GB. The maximum possible file size on UnixWare 7 is 1TB with VXFS or HTFS.
OpenServer 6 can be configured for large file support (file sizes greater than 2GB) by tuning the UNIX kernel.
By default, the entries in
/etc/conf/cf.d/mtune are set as follows:
Value Default Min Max ----- ------- --- --- SVMMLIM 0x9000000 0x1000000 0x7FFFFFFF HVMMLIM 0x9000000 0x1000000 0x7FFFFFFF
To make changes to the kernel, use the idtune
name parameter command.
idtune modifies the
/etc/conf/cf.d/stune file for you. We
recommend setting the kernel values by executing the following
commands as root:
#/etc/conf/bin/idtune SDATLIM 0x7FFFFFFF#/etc/conf/bin/idtune HDATLIM 0x7FFFFFFF#/etc/conf/bin/idtune SVMMLIM 0x7FFFFFFF#/etc/conf/bin/idtune HVMMLIM 0x7FFFFFFF#/etc/conf/bin/idtune SFNOLIM 2048#/etc/conf/bin/idtune HFNOLIM 2048
Then rebuild and reboot the kernel by issuing this command:
# /etc/conf/bin/idbuild -B && init 6
We recommend tuning the system, but the proper parameter values to use depend on the number of users accessing the application or database and size the of the database (that is, the used buffer pool). The following kernel parameters can be set with idtune:
SHMMAX(recommended setting: 128MB) andSHMSEG(recommended setting: 15). These parameters have an influence on the MySQL database engine to create user buffer pools.SFNOLIMandHFNOLIMshould be at maximum 2048.NPROCshould be set to at least 3000/4000 (depends on number of users).We also recommend using the following formulas to calculate values for
SEMMSL,SEMMNS, andSEMMNU:SEMMSL = 13
13 is what has been found to be the best for both Progress and MySQL.
SEMMNS = SEMMSL ×
number of db servers to be run on the systemSet
SEMMNSto the value ofSEMMSLmultiplied by the number of database servers (maximum) that you are running on the system at one time.SEMMNU = SEMMNS
Set the value of
SEMMNUto equal the value ofSEMMNS. You could probably set this to 75% ofSEMMNS, but this is a conservative estimate.
We recommend using the latest production release of MySQL. Should you choose to use an older release of MySQL on UnixWare 7.1.x, you must use a version of MySQL at least as recent as 3.22.13 to get fixes for some portability and OS problems.
We have been able to compile MySQL with the following configure command on UnixWare 7.1.x:
CC="cc" CFLAGS="-I/usr/local/include" \
CXX="CC" CXXFLAGS="-I/usr/local/include" \
./configure --prefix=/usr/local/mysql \
--enable-thread-safe-client --with-berkeley-db=./bdb \
--with-innodb --with-openssl --with-extra-charsets=complex
If you want to use gcc, you must use gcc 2.95.3 or newer.
CC=gcc CXX=g++ ... ./configure ...
The version of Berkeley DB that comes with either UnixWare
7.1.4 or OpenServer 6.0.0 is not used when building MySQL.
MySQL instead uses its own version of Berkeley DB. The
configure command needs to build both a
static and a dynamic library in
src_directory/bdb/build_unix/BDB
version. The workaround is as follows.
Configure as normal for MySQL.
cd bdb/build_unix/cp -p Makefile Makefile.savUse same options and run ../dist/configure.
Run gmake.
cp -p Makefile.sav MakefileChange to top source directory and run gmake.
This allows both the shared and dynamic libraries to be made and work.
SCO provides operating system patches at ftp://ftp.sco.com/pub/unixware7 for UnixWare 7.1.1, ftp://ftp.sco.com/pub/unixware7/713/ for UnixWare 7.1.3, ftp://ftp.sco.com/pub/unixware7/714/ for UnixWare 7.1.4, and ftp://ftp.sco.com/pub/openunix8 for OpenUNIX 8.0.0.
SCO provides information about security fixes at ftp://ftp.sco.com/pub/security/OpenUNIX for OpenUNIX and ftp://ftp.sco.com/pub/security/UnixWare for UnixWare.
The UnixWare 7 file size limit is 1 TB with VXFS. Some OS utilities have a limitation of 2GB.
On UnixWare 7.1.4 you do not need to do anything to get large file support, but to enable large file support on prior versions of UnixWare 7.1.x, run fsadm.
#fsadm -Fvxfs -o largefiles /#fsadm /* Note #ulimit unlimited#/etc/conf/bin/idtune SFSZLIM 0x7FFFFFFF** Note #/etc/conf/bin/idtune HFSZLIM 0x7FFFFFFF** Note #/etc/conf/bin/idbuild -B* This should report "largefiles". ** 0x7FFFFFFF represents infinity for these values.
Reboot the system using shutdown.
By default, the entries in
/etc/conf/cf.d/mtune are set as follows:
Value Default Min Max ----- ------- --- --- SVMMLIM 0x9000000 0x1000000 0x7FFFFFFF HVMMLIM 0x9000000 0x1000000 0x7FFFFFFF
To make changes to the kernel, use the idtune
name parameter command.
idtune modifies the
/etc/conf/cf.d/stune file for you. We
recommend setting the kernel values by executing the following
commands as root:
#/etc/conf/bin/idtune SDATLIM 0x7FFFFFFF#/etc/conf/bin/idtune HDATLIM 0x7FFFFFFF#/etc/conf/bin/idtune SVMMLIM 0x7FFFFFFF#/etc/conf/bin/idtune HVMMLIM 0x7FFFFFFF#/etc/conf/bin/idtune SFNOLIM 2048#/etc/conf/bin/idtune HFNOLIM 2048
Then rebuild and reboot the kernel by issuing this command:
# /etc/conf/bin/idbuild -B && init 6
We recommend tuning the system, but the proper parameter values to use depend on the number of users accessing the application or database and size the of the database (that is, the used buffer pool). The following kernel parameters can be set with idtune:
SHMMAX(recommended setting: 128MB) andSHMSEG(recommended setting: 15). These parameters have an influence on the MySQL database engine to create user buffer pools.SFNOLIMandHFNOLIMshould be at maximum 2048.NPROCshould be set to at least 3000/4000 (depends on number of users).We also recommend using the following formulas to calculate values for
SEMMSL,SEMMNS, andSEMMNU:SEMMSL = 13
13 is what has been found to be the best for both Progress and MySQL.
SEMMNS = SEMMSL ×
number of db servers to be run on the systemSet
SEMMNSto the value ofSEMMSLmultiplied by the number of database servers (maximum) that you are running on the system at one time.SEMMNU = SEMMNS
Set the value of
SEMMNUto equal the value ofSEMMNS. You could probably set this to 75% ofSEMMNS, but this is a conservative estimate.
This section does not apply to MySQL Enterprise Server users.
MySQL uses quite a few open files. Because of this, you should
add something like the following to your
CONFIG.SYS file:
SET EMXOPT=-c -n -h1024
If you do not do this, you may encounter the following error:
File 'xxxx' not found (Errcode: 24)
When using MySQL with OS/2 Warp 3, FixPack 29 or above is required. With OS/2 Warp 4, FixPack 4 or above is required. This is a requirement of the Pthreads library. MySQL must be installed on a partition with a type that supports long filenames, such as HPFS, FAT32, and so on.
The INSTALL.CMD script must be run from OS/2's own CMD.EXE and may not work with replacement shells such as 4OS2.EXE.
The scripts/mysql-install-db script has
been renamed. It is called install.cmd and
is a REXX script, which sets up the default MySQL security
settings and creates the WorkPlace Shell icons for MySQL.
Dynamic module support is compiled in but not fully tested. Dynamic modules should be compiled using the Pthreads runtime library.
gcc -Zdll -Zmt -Zcrtdll=pthrdrtl -I../include -I../regex -I.. \
-o example udf_example.c -L../lib -lmysqlclient udf_example.def
mv example.dll example.udf
Note: Due to limitations in
OS/2, UDF module name stems must not exceed eight characters.
Modules are stored in the /mysql2/udf
directory; the safe-mysqld.cmd script puts
this directory in the BEGINLIBPATH
environment variable. When using UDF modules, specified
extensions are ignored---it is assumed to be
.udf. For example, in Unix, the shared
module might be named example.so and you
would load a function from it like this:
mysql> CREATE FUNCTION metaphon RETURNS STRING SONAME 'example.so';
In OS/2, the module would be named
example.udf, but you would not specify the
module extension:
mysql> CREATE FUNCTION metaphon RETURNS STRING SONAME 'example';
This section lists all the environment variables that are used directly or indirectly by MySQL. Most of these can also be found in other places in this manual.
Note that any options on the command line take precedence over values specified in option files and environment variables, and values in option files take precedence over values in environment variables.
In many cases, it is preferable to use an option file instead of environment variables to modify the behavior of MySQL. See Section 4.3.2, “Using Option Files”.
| Variable | Description |
CXX | The name of your C++ compiler (for running configure). |
CC | The name of your C compiler (for running configure). |
CFLAGS | Flags for your C compiler (for running configure). |
CXXFLAGS | Flags for your C++ compiler (for running configure). |
DBI_USER | The default username for Perl DBI. |
DBI_TRACE | Trace options for Perl DBI. |
HOME | The default path for the mysql history file is
$HOME/.mysql_history. |
LD_RUN_PATH | Used to specify the location of libmysqlclient.so. |
MYSQL_DEBUG | Debug trace options when debugging. |
MYSQL_GROUP_SUFFIX | Option group suffix value (like specifying
--defaults-group-suffix). |
MYSQL_HISTFILE | The path to the mysql history file. If this variable
is set, its value overrides the default for
$HOME/.mysql_history. |
MYSQL_HOME | The path to the directory in which the server-specific
my.cnf file resides (as of MySQL
5.0.3). |
MYSQL_HOST | The default hostname used by the mysql command-line client. |
MYSQL_PS1 | The command prompt to use in the mysql command-line client. |
MYSQL_PWD | The default password when connecting to mysqld. Note that using this is insecure. See Section 5.8.6, “Keeping Your Password Secure”. |
MYSQL_TCP_PORT | The default TCP/IP port number. |
MYSQL_UNIX_PORT | The default Unix socket filename; used for connections to
localhost. |
PATH | Used by the shell to find MySQL programs. |
TMPDIR | The directory where temporary files are created. |
TZ | This should be set to your local time zone. See Section B.1.4.6, “Time Zone Problems”. |
UMASK_DIR | The user-directory creation mask when creating directories. Note that
this is ANDed with
UMASK. |
UMASK | The user-file creation mask when creating files. |
USER | The default username on Windows and NetWare used when connecting to mysqld. |
Perl support for MySQL is provided by means of the
DBI/DBD client interface.
The interface requires Perl 5.6.1 or later. It does not
work if you have an older version of Perl.
If you want to use transactions with Perl DBI, you need to have
DBD::mysql version 1.2216 or newer.
DBD::mysql 2.9003 or newer is recommended.
If you are using the MySQL 4.1 or newer client library, you must
use DBD::mysql 2.9003 or newer.
Perl support is not included with MySQL distributions. You can obtain the necessary modules from http://search.cpan.org for Unix, or by using the ActiveState ppm program on Windows. The following sections describe how to do this.
Perl support for MySQL must be installed if you want to run the MySQL benchmark scripts. See Section 7.1.4, “The MySQL Benchmark Suite”.
MySQL Perl support requires that you have installed MySQL client programming support (libraries and header files). Most installation methods install the necessary files. However, if you installed MySQL from RPM files on Linux, be sure that you've installed the developer RPM. The client programs are in the client RPM, but client programming support is in the developer RPM.
If you want to install Perl support, the files you need can be obtained from the CPAN (Comprehensive Perl Archive Network) at http://search.cpan.org.
The easiest way to install Perl modules on Unix is to use the
CPAN module. For example:
shell>perl -MCPAN -e shellcpan>install DBIcpan>install DBD::mysql
The DBD::mysql installation runs a number of
tests. These tests attempt to connect to the local MySQL server
using the default username and password. (The default username
is your login name on Unix, and ODBC on
Windows. The default password is “no password.”) If
you cannot connect to the server with those values (for example,
if your account has a password), the tests fail. You can use
force install DBD::mysql to ignore the failed
tests.
DBI requires the
Data::Dumper module. It may be installed; if
not, you should install it before installing
DBI.
It is also possible to download the module distributions in the form of compressed tar archives and build the modules manually. For example, to unpack and build a DBI distribution, use a procedure such as this:
Unpack the distribution into the current directory:
shell>
gunzip < DBI-VERSION.tar.gz | tar xvf -This command creates a directory named
DBI-.VERSIONChange location into the top-level directory of the unpacked distribution:
shell>
cd DBI-VERSIONBuild the distribution and compile everything:
shell>
perl Makefile.PLshell>makeshell>make testshell>make install
The make test command is important because it
verifies that the module is working. Note that when you run that
command during the DBD::mysql installation to
exercise the interface code, the MySQL server must be running or
the test fails.
It is a good idea to rebuild and reinstall the
DBD::mysql distribution whenever you install
a new release of MySQL, particularly if you notice symptoms such
as that all your DBI scripts fail after you
upgrade MySQL.
If you do not have access rights to install Perl modules in the system directory or if you want to install local Perl modules, the following reference may be useful: http://servers.digitaldaze.com/extensions/perl/modules.html#modules
Look under the heading “Installing New Modules that Require Locally Installed Modules.”
On Windows, you should do the following to install the MySQL
DBD module with ActiveState Perl:
Get ActiveState Perl from http://www.activestate.com/Products/ActivePerl/ and install it.
Open a console window (a “DOS window”).
If necessary, set the
HTTP_proxyvariable. For example, you might try a setting like this:set HTTP_proxy=my.proxy.com:3128
Start the PPM program:
C:\>
C:\perl\bin\ppm.plIf you have not previously done so, install
DBI:ppm> install DBI
If this succeeds, run the following command:
ppm>
install DBD-mysql
This procedure should work with ActiveState Perl 5.6 or newer.
If you cannot get the procedure to work, you should install the MyODBC driver instead and connect to the MySQL server through ODBC:
use DBI;
$dbh= DBI->connect("DBI:ODBC:$dsn",$user,$password) ||
die "Got error $DBI::errstr when connecting to $dsn\n";
If Perl reports that it cannot find the
../mysql/mysql.so module, the problem is
probably that Perl cannot locate the
libmysqlclient.so shared library. You
should be able to fix this problem by one of the following
methods:
Compile the
DBD::mysqldistribution withperl Makefile.PL -static -configrather thanperl Makefile.PL.Copy
libmysqlclient.soto the directory where your other shared libraries are located (probably/usr/libor/lib).Modify the
-Loptions used to compileDBD::mysqlto reflect the actual location oflibmysqlclient.so.On Linux, you can add the pathname of the directory where
libmysqlclient.sois located to the/etc/ld.so.conffile.Add the pathname of the directory where
libmysqlclient.sois located to theLD_RUN_PATHenvironment variable. Some systems useLD_LIBRARY_PATHinstead.
Note that you may also need to modify the -L
options if there are other libraries that the linker fails to
find. For example, if the linker cannot find
libc because it is in
/lib and the link command specifies
-L/usr/lib, change the -L
option to -L/lib or add -L/lib
to the existing link command.
If you get the following errors from
DBD::mysql, you are probably using
gcc (or using an old binary compiled with
gcc):
/usr/bin/perl: can't resolve symbol '__moddi3' /usr/bin/perl: can't resolve symbol '__divdi3'
Add -L/usr/lib/gcc-lib/... -lgcc to the link
command when the mysql.so library gets
built (check the output from make for
mysql.so when you compile the Perl client).
The -L option should specify the pathname of
the directory where libgcc.a is located on
your system.
Another cause of this problem may be that Perl and MySQL are not both compiled with gcc. In this case, you can solve the mismatch by compiling both with gcc.
You may see the following error from
DBD::mysql when you run the tests:
t/00base............install_driver(mysql) failed: Can't load '../blib/arch/auto/DBD/mysql/mysql.so' for module DBD::mysql: ../blib/arch/auto/DBD/mysql/mysql.so: undefined symbol: uncompress at /usr/lib/perl5/5.00503/i586-linux/DynaLoader.pm line 169.
This means that you need to include the -lz
compression library on the link line. That can be done by
changing the following line in the file
lib/DBD/mysql/Install.pm:
$sysliblist .= " -lm";
Change that line to:
$sysliblist .= " -lm -lz";
After this, you must run make realclean and then proceed with the installation from the beginning.
If you want to install DBI on SCO, you have to edit the
Makefile in
DBI-xxx and each subdirectory. Note
that the following assumes gcc 2.95.2 or
newer:
OLD: NEW: CC = cc CC = gcc CCCDLFLAGS = -KPIC -W1,-Bexport CCCDLFLAGS = -fpic CCDLFLAGS = -wl,-Bexport CCDLFLAGS = LD = ld LD = gcc -G -fpic LDDLFLAGS = -G -L/usr/local/lib LDDLFLAGS = -L/usr/local/lib LDFLAGS = -belf -L/usr/local/lib LDFLAGS = -L/usr/local/lib LD = ld LD = gcc -G -fpic OPTIMISE = -Od OPTIMISE = -O1 OLD: CCCFLAGS = -belf -dy -w0 -U M_XENIX -DPERL_SCO5 -I/usr/local/include NEW: CCFLAGS = -U M_XENIX -DPERL_SCO5 -I/usr/local/include
These changes are necessary because the Perl dynaloader does not
load the DBI modules if they were compiled
with icc or cc.
If you want to use the Perl module on a system that does not
support dynamic linking (such as SCO), you can generate a static
version of Perl that includes DBI and
DBD::mysql. The way this works is that you
generate a version of Perl with the DBI code
linked in and install it on top of your current Perl. Then you
use that to build a version of Perl that additionally has the
DBD code linked in, and install that.
On SCO, you must have the following environment variables set:
LD_LIBRARY_PATH=/lib:/usr/lib:/usr/local/lib:/usr/progressive/lib
Or:
LD_LIBRARY_PATH=/usr/lib:/lib:/usr/local/lib:/usr/ccs/lib:\
/usr/progressive/lib:/usr/skunk/lib
LIBPATH=/usr/lib:/lib:/usr/local/lib:/usr/ccs/lib:\
/usr/progressive/lib:/usr/skunk/lib
MANPATH=scohelp:/usr/man:/usr/local1/man:/usr/local/man:\
/usr/skunk/man:
First, create a Perl that includes a statically linked
DBI module by running these commands in the
directory where your DBI distribution is
located:
shell>perl Makefile.PL -static -configshell>makeshell>make installshell>make perl
Then you must install the new Perl. The output of make perl indicates the exact make command you need to execute to perform the installation. On SCO, this is make -f Makefile.aperl inst_perl MAP_TARGET=perl.
Next, use the just-created Perl to create another Perl that also
includes a statically linked DBD::mysql by
running these commands in the directory where your
DBD::mysql distribution is located:
shell>perl Makefile.PL -static -configshell>makeshell>make installshell>make perl
Finally, you should install this new Perl. Again, the output of make perl indicates the command to use.
Table of Contents
- 3.1. Connecting to and Disconnecting from the Server
- 3.2. Entering Queries
- 3.3. Creating and Using a Database
- 3.4. Getting Information About Databases and Tables
- 3.5. Using mysql in Batch Mode
- 3.6. Examples of Common Queries
- 3.6.1. The Maximum Value for a Column
- 3.6.2. The Row Holding the Maximum of a Certain Column
- 3.6.3. Maximum of Column per Group
- 3.6.4. The Rows Holding the Group-wise Maximum of a Certain Field
- 3.6.5. Using User-Defined Variables
- 3.6.6. Using Foreign Keys
- 3.6.7. Searching on Two Keys
- 3.6.8. Calculating Visits Per Day
- 3.6.9. Using
AUTO_INCREMENT
- 3.7. Queries from the Twin Project
- 3.8. Using MySQL with Apache
This chapter provides a tutorial introduction to MySQL by showing how to use the mysql client program to create and use a simple database. mysql (sometimes referred to as the “terminal monitor” or just “monitor”) is an interactive program that allows you to connect to a MySQL server, run queries, and view the results. mysql may also be used in batch mode: you place your queries in a file beforehand, then tell mysql to execute the contents of the file. Both ways of using mysql are covered here.
To see a list of options provided by mysql,
invoke it with the --help option:
shell> mysql --help
This chapter assumes that mysql is installed on your machine and that a MySQL server is available to which you can connect. If this is not true, contact your MySQL administrator. (If you are the administrator, you need to consult the relevant portions of this manual, such as Chapter 5, Database Administration.)
This chapter describes the entire process of setting up and using a database. If you are interested only in accessing an existing database, you may want to skip over the sections that describe how to create the database and the tables it contains.
Because this chapter is tutorial in nature, many details are necessarily omitted. Consult the relevant sections of the manual for more information on the topics covered here.
To connect to the server, you will usually need to provide a MySQL user name when you invoke mysql and, most likely, a password. If the server runs on a machine other than the one where you log in, you will also need to specify a host name. Contact your administrator to find out what connection parameters you should use to connect (that is, what host, user name, and password to use). Once you know the proper parameters, you should be able to connect like this:
shell>mysql -hEnter password:host-uuser-p********
host and user represent the
host name where your MySQL server is running and the user name of
your MySQL account. Substitute appropriate values for your setup.
The ******** represents your password; enter it
when mysql displays the Enter
password: prompt.
If that works, you should see some introductory information
followed by a mysql> prompt:
shell>mysql -hEnter password:host-uuser-p********Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 25338 to server version: 5.0.42-standard Type 'help;' or '\h' for help. Type '\c' to clear the buffer. mysql>
The mysql> prompt tells you that
mysql is ready for you to enter commands.
If you are logging in on the same machine that MySQL is running on, you can omit the host, and simply use the following:
shell> mysql -u user -p
If, when you attempt to log in, you get an error message such as ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2), it means that that MySQL server daemon (Unix) or service (Windows) is not running. Consult the administrator or see the section of Chapter 2, Installing and Upgrading MySQL that is appropriate to your operating system.
For help with other problems often encountered when trying to log in, see Section B.1.2, “Common Errors When Using MySQL Programs”.
Some MySQL installations allow users to connect as the anonymous (unnamed) user to the server running on the local host. If this is the case on your machine, you should be able to connect to that server by invoking mysql without any options:
shell> mysql
After you have connected successfully, you can disconnect any time
by typing QUIT (or \q) at
the mysql> prompt:
mysql> QUIT
Bye
On Unix, you can also disconnect by pressing Control-D.
Most examples in the following sections assume that you are
connected to the server. They indicate this by the
mysql> prompt.
Make sure that you are connected to the server, as discussed in the previous section. Doing so does not in itself select any database to work with, but that's okay. At this point, it's more important to find out a little about how to issue queries than to jump right in creating tables, loading data into them, and retrieving data from them. This section describes the basic principles of entering commands, using several queries you can try out to familiarize yourself with how mysql works.
Here's a simple command that asks the server to tell you its
version number and the current date. Type it in as shown here
following the mysql> prompt and press Enter:
mysql> SELECT VERSION(), CURRENT_DATE;
+----------------+--------------+
| VERSION() | CURRENT_DATE |
+----------------+--------------+
| 5.0.7-beta-Max | 2005-07-11 |
+----------------+--------------+
1 row in set (0.01 sec)
mysql>
This query illustrates several things about mysql:
A command normally consists of an SQL statement followed by a semicolon. (There are some exceptions where a semicolon may be omitted.
QUIT, mentioned earlier, is one of them. We'll get to others later.)When you issue a command, mysql sends it to the server for execution and displays the results, then prints another
mysql>prompt to indicate that it is ready for another command.mysql displays query output in tabular form (rows and columns). The first row contains labels for the columns. The rows following are the query results. Normally, column labels are the names of the columns you fetch from database tables. If you're retrieving the value of an expression rather than a table column (as in the example just shown), mysql labels the column using the expression itself.
mysql shows how many rows were returned and how long the query took to execute, which gives you a rough idea of server performance. These values are imprecise because they represent wall clock time (not CPU or machine time), and because they are affected by factors such as server load and network latency. (For brevity, the “rows in set” line is sometimes not shown in the remaining examples in this chapter.)
Keywords may be entered in any lettercase. The following queries are equivalent:
mysql>SELECT VERSION(), CURRENT_DATE;mysql>select version(), current_date;mysql>SeLeCt vErSiOn(), current_DATE;
Here's another query. It demonstrates that you can use mysql as a simple calculator:
mysql> SELECT SIN(PI()/4), (4+1)*5;
+------------------+---------+
| SIN(PI()/4) | (4+1)*5 |
+------------------+---------+
| 0.70710678118655 | 25 |
+------------------+---------+
1 row in set (0.02 sec)
The queries shown thus far have been relatively short, single-line statements. You can even enter multiple statements on a single line. Just end each one with a semicolon:
mysql> SELECT VERSION(); SELECT NOW();
+----------------+
| VERSION() |
+----------------+
| 5.0.7-beta-Max |
+----------------+
1 row in set (0.00 sec)
+---------------------+
| NOW() |
+---------------------+
| 2005-07-11 17:59:36 |
+---------------------+
1 row in set (0.00 sec)
A command need not be given all on a single line, so lengthy commands that require several lines are not a problem. mysql determines where your statement ends by looking for the terminating semicolon, not by looking for the end of the input line. (In other words, mysql accepts free-format input: it collects input lines but does not execute them until it sees the semicolon.)
Here's a simple multiple-line statement:
mysql>SELECT->USER()->,->CURRENT_DATE;+---------------+--------------+ | USER() | CURRENT_DATE | +---------------+--------------+ | jon@localhost | 2005-07-11 | +---------------+--------------+
In this example, notice how the prompt changes from
mysql> to -> after you
enter the first line of a multiple-line query. This is how
mysql indicates that it has not yet seen a
complete statement and is waiting for the rest. The prompt is your
friend, because it provides valuable feedback. If you use that
feedback, you can always be aware of what mysql
is waiting for.
If you decide you do not want to execute a command that you are in
the process of entering, cancel it by typing
\c:
mysql>SELECT->USER()->\cmysql>
Here, too, notice the prompt. It switches back to
mysql> after you type \c,
providing feedback to indicate that mysql is
ready for a new command.
The following table shows each of the prompts you may see and summarizes what they mean about the state that mysql is in:
| Prompt | Meaning |
mysql> | Ready for new command. |
-> | Waiting for next line of multiple-line command. |
'> | Waiting for next line, waiting for completion of a string that began
with a single quote (‘'’). |
"> | Waiting for next line, waiting for completion of a string that began
with a double quote (‘"’). |
`> | Waiting for next line, waiting for completion of an identifier that
began with a backtick
(‘`’). |
/*> | Waiting for next line, waiting for completion of a comment that began
with /*. |
In the MySQL 5.0 series, the /*> prompt was
implemented in MySQL 5.0.6.
Multiple-line statements commonly occur by accident when you intend to issue a command on a single line, but forget the terminating semicolon. In this case, mysql waits for more input:
mysql> SELECT USER()
->
If this happens to you (you think you've entered a statement but
the only response is a -> prompt), most
likely mysql is waiting for the semicolon. If
you don't notice what the prompt is telling you, you might sit
there for a while before realizing what you need to do. Enter a
semicolon to complete the statement, and mysql
executes it:
mysql>SELECT USER()->;+---------------+ | USER() | +---------------+ | jon@localhost | +---------------+
The '> and "> prompts
occur during string collection (another way of saying that MySQL
is waiting for completion of a string). In MySQL, you can write
strings surrounded by either ‘'’ or
‘"’ characters (for example,
'hello' or "goodbye"), and
mysql lets you enter strings that span multiple
lines. When you see a '> or
"> prompt, it means that you have entered a
line containing a string that begins with a
‘'’ or
‘"’ quote character, but have not
yet entered the matching quote that terminates the string. This
often indicates that you have inadvertently left out a quote
character. For example:
mysql> SELECT * FROM my_table WHERE name = 'Smith AND age < 30;
'>
If you enter this SELECT statement, then press
Enter and wait for the result, nothing happens.
Instead of wondering why this query takes so long, notice the clue
provided by the '> prompt. It tells you that
mysql expects to see the rest of an
unterminated string. (Do you see the error in the statement? The
string 'Smith is missing the second single
quote mark.)
At this point, what do you do? The simplest thing is to cancel the
command. However, you cannot just type \c in
this case, because mysql interprets it as part
of the string that it is collecting. Instead, enter the closing
quote character (so mysql knows you've finished
the string), then type \c:
mysql>SELECT * FROM my_table WHERE name = 'Smith AND age < 30;'>'\cmysql>
The prompt changes back to mysql>,
indicating that mysql is ready for a new
command.
The `> prompt is similar to the
'> and "> prompts, but
indicates that you have begun but not completed a backtick-quoted
identifier.
It is important to know what the '>,
">, and `> prompts
signify, because if you mistakenly enter an unterminated string,
any further lines you type appear to be ignored by
mysql — including a line containing
QUIT. This can be quite confusing, especially
if you do not know that you need to supply the terminating quote
before you can cancel the current command.
Once you know how to enter commands, you are ready to access a database.
Suppose that you have several pets in your home (your menagerie) and you would like to keep track of various types of information about them. You can do so by creating tables to hold your data and loading them with the desired information. Then you can answer different sorts of questions about your animals by retrieving data from the tables. This section shows you how to:
Create a database
Create a table
Load data into the table
Retrieve data from the table in various ways
Use multiple tables
The menagerie database is simple (deliberately), but it is not difficult to think of real-world situations in which a similar type of database might be used. For example, a database like this could be used by a farmer to keep track of livestock, or by a veterinarian to keep track of patient records. A menagerie distribution containing some of the queries and sample data used in the following sections can be obtained from the MySQL Web site. It is available in both compressed tar file and Zip formats at http://dev.mysql.com/doc/.
Use the SHOW statement to find out what
databases currently exist on the server:
mysql> SHOW DATABASES;
+----------+
| Database |
+----------+
| mysql |
| test |
| tmp |
+----------+
The mysql database describes user access
privileges. The test database often is
available as a workspace for users to try things out.
The list of databases displayed by the statement may be different
on your machine; SHOW DATABASES does not show
databases that you have no privileges for if you do not have the
SHOW DATABASES privilege. See
Section 13.5.4.8, “SHOW DATABASES Syntax”.
If the test database exists, try to access it:
mysql> USE test
Database changed
Note that USE, like QUIT,
does not require a semicolon. (You can terminate such statements
with a semicolon if you like; it does no harm.) The
USE statement is special in another way, too:
it must be given on a single line.
You can use the test database (if you have
access to it) for the examples that follow, but anything you
create in that database can be removed by anyone else with access
to it. For this reason, you should probably ask your MySQL
administrator for permission to use a database of your own.
Suppose that you want to call yours menagerie.
The administrator needs to execute a command like this:
mysql> GRANT ALL ON menagerie.* TO 'your_mysql_name'@'your_client_host';
where your_mysql_name is the MySQL user name
assigned to you and your_client_host is the
host from which you connect to the server.
If the administrator creates your database for you when setting up your permissions, you can begin using it. Otherwise, you need to create it yourself:
mysql> CREATE DATABASE menagerie;
Under Unix, database names are case sensitive (unlike SQL
keywords), so you must always refer to your database as
menagerie, not as
Menagerie, MENAGERIE, or
some other variant. This is also true for table names. (Under
Windows, this restriction does not apply, although you must
refer to databases and tables using the same lettercase
throughout a given query. However, for a variety of reasons, our
recommended best practice is always to use the same lettercase
that was used when the database was created.)
Note: If you get an error such as ERROR 1044 (42000): Access denied for user 'monty'@'localhost' to database 'menagerie' when attempting to create a database, this means that your user account does not have the necessary privileges to do so. Discuss this with the administrator or see Section 5.7, “The MySQL Access Privilege System”.
Creating a database does not select it for use; you must do that
explicitly. To make menagerie the current
database, use this command:
mysql> USE menagerie;
Database changed
Your database needs to be created only once, but you must select
it for use each time you begin a mysql
session. You can do this by issuing a USE
statement as shown in the example. Alternatively, you can select
the database on the command line when you invoke
mysql. Just specify its name after any
connection parameters that you might need to provide. For
example:
shell>mysql -hEnter password:host-uuser-p menagerie********
Note that menagerie in the command just shown
is not your password. If you
want to supply your password on the command line after the
-p option, you must do so with no intervening
space (for example, as -pmypassword,
not as -p mypassword).
However, putting your password on the command line is not
recommended, because doing so exposes it to snooping by other
users logged in on your machine.
Creating the database is the easy part, but at this point it's
empty, as SHOW TABLES tells you:
mysql> SHOW TABLES;
Empty set (0.00 sec)
The harder part is deciding what the structure of your database should be: what tables you need and what columns should be in each of them.
You want a table that contains a record for each of your pets.
This can be called the pet table, and it
should contain, as a bare minimum, each animal's name. Because
the name by itself is not very interesting, the table should
contain other information. For example, if more than one person
in your family keeps pets, you might want to list each animal's
owner. You might also want to record some basic descriptive
information such as species and sex.
How about age? That might be of interest, but it's not a good thing to store in a database. Age changes as time passes, which means you'd have to update your records often. Instead, it's better to store a fixed value such as date of birth. Then, whenever you need age, you can calculate it as the difference between the current date and the birth date. MySQL provides functions for doing date arithmetic, so this is not difficult. Storing birth date rather than age has other advantages, too:
You can use the database for tasks such as generating reminders for upcoming pet birthdays. (If you think this type of query is somewhat silly, note that it is the same question you might ask in the context of a business database to identify clients to whom you need to send out birthday greetings in the current week or month, for that computer-assisted personal touch.)
You can calculate age in relation to dates other than the current date. For example, if you store death date in the database, you can easily calculate how old a pet was when it died.
You can probably think of other types of information that would
be useful in the pet table, but the ones
identified so far are sufficient: name, owner, species, sex,
birth, and death.
Use a CREATE TABLE statement to specify the
layout of your table:
mysql>CREATE TABLE pet (name VARCHAR(20), owner VARCHAR(20),->species VARCHAR(20), sex CHAR(1), birth DATE, death DATE);
VARCHAR is a good choice for the
name, owner, and
species columns because the column values
vary in length. The lengths in those column definitions need not
all be the same, and need not be 20. You can
normally pick any length from 1 to
65535, whatever seems most reasonable to you.
(Note: Prior to MySQL 5.0.3,
the upper limit was 255.) If you make a poor choice and it turns
out later that you need a longer field, MySQL provides an
ALTER TABLE statement.
Several types of values can be chosen to represent sex in animal
records, such as 'm' and
'f', or perhaps 'male' and
'female'. It is simplest to use the single
characters 'm' and 'f'.
The use of the DATE data type for the
birth and death columns is
a fairly obvious choice.
Once you have created a table, SHOW TABLES
should produce some output:
mysql> SHOW TABLES;
+---------------------+
| Tables in menagerie |
+---------------------+
| pet |
+---------------------+
To verify that your table was created the way you expected, use
a DESCRIBE statement:
mysql> DESCRIBE pet;
+---------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+-------+
| name | varchar(20) | YES | | NULL | |
| owner | varchar(20) | YES | | NULL | |
| species | varchar(20) | YES | | NULL | |
| sex | char(1) | YES | | NULL | |
| birth | date | YES | | NULL | |
| death | date | YES | | NULL | |
+---------+-------------+------+-----+---------+-------+
You can use DESCRIBE any time, for example,
if you forget the names of the columns in your table or what
types they have.
For more information about MySQL data types, see Chapter 11, Data Types.
After creating your table, you need to populate it. The
LOAD DATA and INSERT
statements are useful for this.
Suppose that your pet records can be described as shown here.
(Observe that MySQL expects dates in
'YYYY-MM-DD' format; this may be different
from what you are used to.)
| name | owner | species | sex | birth | death |
| Fluffy | Harold | cat | f | 1993-02-04 | |
| Claws | Gwen | cat | m | 1994-03-17 | |
| Buffy | Harold | dog | f | 1989-05-13 | |
| Fang | Benny | dog | m | 1990-08-27 | |
| Bowser | Diane | dog | m | 1979-08-31 | 1995-07-29 |
| Chirpy | Gwen | bird | f | 1998-09-11 | |
| Whistler | Gwen | bird | 1997-12-09 | ||
| Slim | Benny | snake | m | 1996-04-29 |
Because you are beginning with an empty table, an easy way to populate it is to create a text file containing a row for each of your animals, then load the contents of the file into the table with a single statement.
You could create a text file pet.txt
containing one record per line, with values separated by tabs,
and given in the order in which the columns were listed in the
CREATE TABLE statement. For missing values
(such as unknown sexes or death dates for animals that are still
living), you can use NULL values. To
represent these in your text file, use \N
(backslash, capital-N). For example, the record for Whistler the
bird would look like this (where the whitespace between values
is a single tab character):
Whistler Gwen bird \N 1997-12-09 \N
To load the text file pet.txt into the
pet table, use this command:
mysql> LOAD DATA LOCAL INFILE '/path/pet.txt' INTO TABLE pet;
Note that if you created the file on Windows with an editor that
uses \r\n as a line terminator, you should
use:
mysql>LOAD DATA LOCAL INFILE '/path/pet.txt' INTO TABLE pet->LINES TERMINATED BY '\r\n';
(On an Apple machine running OS X, you would likely want to use
LINES TERMINATED BY '\r'.)
You can specify the column value separator and end of line
marker explicitly in the LOAD DATA statement
if you wish, but the defaults are tab and linefeed. These are
sufficient for the statement to read the file
pet.txt properly.
If the statement fails, it is likely that your MySQL
installation does not have local file capability enabled by
default. See Section 5.6.4, “Security Issues with LOAD DATA LOCAL”, for information
on how to change this.
When you want to add new records one at a time, the
INSERT statement is useful. In its simplest
form, you supply values for each column, in the order in which
the columns were listed in the CREATE TABLE
statement. Suppose that Diane gets a new hamster named
“Puffball.” You could add a new record using an
INSERT statement like this:
mysql>INSERT INTO pet->VALUES ('Puffball','Diane','hamster','f','1999-03-30',NULL);
Note that string and date values are specified as quoted strings
here. Also, with INSERT, you can insert
NULL directly to represent a missing value.
You do not use \N like you do with
LOAD DATA.
From this example, you should be able to see that there would be
a lot more typing involved to load your records initially using
several INSERT statements rather than a
single LOAD DATA statement.
The SELECT statement is used to pull
information from a table. The general form of the statement is:
SELECTwhat_to_selectFROMwhich_tableWHEREconditions_to_satisfy;
what_to_select indicates what you
want to see. This can be a list of columns, or
* to indicate “all columns.”
which_table indicates the table from
which you want to retrieve data. The WHERE
clause is optional. If it is present,
conditions_to_satisfy specifies one
or more conditions that rows must satisfy to qualify for
retrieval.
The simplest form of SELECT retrieves
everything from a table:
mysql> SELECT * FROM pet;
+----------+--------+---------+------+------------+------------+
| name | owner | species | sex | birth | death |
+----------+--------+---------+------+------------+------------+
| Fluffy | Harold | cat | f | 1993-02-04 | NULL |
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
| Fang | Benny | dog | m | 1990-08-27 | NULL |
| Bowser | Diane | dog | m | 1979-08-31 | 1995-07-29 |
| Chirpy | Gwen | bird | f | 1998-09-11 | NULL |
| Whistler | Gwen | bird | NULL | 1997-12-09 | NULL |
| Slim | Benny | snake | m | 1996-04-29 | NULL |
| Puffball | Diane | hamster | f | 1999-03-30 | NULL |
+----------+--------+---------+------+------------+------------+
This form of SELECT is useful if you want
to review your entire table, for example, after you've just
loaded it with your initial dataset. For example, you may
happen to think that the birth date for Bowser doesn't seem
quite right. Consulting your original pedigree papers, you
find that the correct birth year should be 1989, not 1979.
There are at least two ways to fix this:
Edit the file
pet.txtto correct the error, then empty the table and reload it usingDELETEandLOAD DATA:mysql>
DELETE FROM pet;mysql>LOAD DATA LOCAL INFILE 'pet.txt' INTO TABLE pet;However, if you do this, you must also re-enter the record for Puffball.
Fix only the erroneous record with an
UPDATEstatement:mysql>
UPDATE pet SET birth = '1989-08-31' WHERE name = 'Bowser';The
UPDATEchanges only the record in question and does not require you to reload the table.
As shown in the preceding section, it is easy to retrieve an
entire table. Just omit the WHERE clause
from the SELECT statement. But typically
you don't want to see the entire table, particularly when it
becomes large. Instead, you're usually more interested in
answering a particular question, in which case you specify
some constraints on the information you want. Let's look at
some selection queries in terms of questions about your pets
that they answer.
You can select only particular rows from your table. For example, if you want to verify the change that you made to Bowser's birth date, select Bowser's record like this:
mysql> SELECT * FROM pet WHERE name = 'Bowser';
+--------+-------+---------+------+------------+------------+
| name | owner | species | sex | birth | death |
+--------+-------+---------+------+------------+------------+
| Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 |
+--------+-------+---------+------+------------+------------+
The output confirms that the year is correctly recorded as 1989, not 1979.
String comparisons normally are case-insensitive, so you can
specify the name as 'bowser',
'BOWSER', and so forth. The query result is
the same.
You can specify conditions on any column, not just
name. For example, if you want to know
which animals were born during or after 1998, test the
birth column:
mysql> SELECT * FROM pet WHERE birth >= '1998-1-1';
+----------+-------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+----------+-------+---------+------+------------+-------+
| Chirpy | Gwen | bird | f | 1998-09-11 | NULL |
| Puffball | Diane | hamster | f | 1999-03-30 | NULL |
+----------+-------+---------+------+------------+-------+
You can combine conditions, for example, to locate female dogs:
mysql> SELECT * FROM pet WHERE species = 'dog' AND sex = 'f';
+-------+--------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+-------+--------+---------+------+------------+-------+
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+-------+--------+---------+------+------------+-------+
The preceding query uses the AND logical
operator. There is also an OR operator:
mysql> SELECT * FROM pet WHERE species = 'snake' OR species = 'bird';
+----------+-------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+----------+-------+---------+------+------------+-------+
| Chirpy | Gwen | bird | f | 1998-09-11 | NULL |
| Whistler | Gwen | bird | NULL | 1997-12-09 | NULL |
| Slim | Benny | snake | m | 1996-04-29 | NULL |
+----------+-------+---------+------+------------+-------+
AND and OR may be
intermixed, although AND has higher
precedence than OR. If you use both
operators, it is a good idea to use parentheses to indicate
explicitly how conditions should be grouped:
mysql>SELECT * FROM pet WHERE (species = 'cat' AND sex = 'm')->OR (species = 'dog' AND sex = 'f');+-------+--------+---------+------+------------+-------+ | name | owner | species | sex | birth | death | +-------+--------+---------+------+------------+-------+ | Claws | Gwen | cat | m | 1994-03-17 | NULL | | Buffy | Harold | dog | f | 1989-05-13 | NULL | +-------+--------+---------+------+------------+-------+
If you do not want to see entire rows from your table, just
name the columns in which you are interested, separated by
commas. For example, if you want to know when your animals
were born, select the name and
birth columns:
mysql> SELECT name, birth FROM pet;
+----------+------------+
| name | birth |
+----------+------------+
| Fluffy | 1993-02-04 |
| Claws | 1994-03-17 |
| Buffy | 1989-05-13 |
| Fang | 1990-08-27 |
| Bowser | 1989-08-31 |
| Chirpy | 1998-09-11 |
| Whistler | 1997-12-09 |
| Slim | 1996-04-29 |
| Puffball | 1999-03-30 |
+----------+------------+
To find out who owns pets, use this query:
mysql> SELECT owner FROM pet;
+--------+
| owner |
+--------+
| Harold |
| Gwen |
| Harold |
| Benny |
| Diane |
| Gwen |
| Gwen |
| Benny |
| Diane |
+--------+
Notice that the query simply retrieves the
owner column from each record, and some of
them appear more than once. To minimize the output, retrieve
each unique output record just once by adding the keyword
DISTINCT:
mysql> SELECT DISTINCT owner FROM pet;
+--------+
| owner |
+--------+
| Benny |
| Diane |
| Gwen |
| Harold |
+--------+
You can use a WHERE clause to combine row
selection with column selection. For example, to get birth
dates for dogs and cats only, use this query:
mysql>SELECT name, species, birth FROM pet->WHERE species = 'dog' OR species = 'cat';+--------+---------+------------+ | name | species | birth | +--------+---------+------------+ | Fluffy | cat | 1993-02-04 | | Claws | cat | 1994-03-17 | | Buffy | dog | 1989-05-13 | | Fang | dog | 1990-08-27 | | Bowser | dog | 1989-08-31 | +--------+---------+------------+
You may have noticed in the preceding examples that the result
rows are displayed in no particular order. It's often easier
to examine query output when the rows are sorted in some
meaningful way. To sort a result, use an ORDER
BY clause.
Here are animal birthdays, sorted by date:
mysql> SELECT name, birth FROM pet ORDER BY birth;
+----------+------------+
| name | birth |
+----------+------------+
| Buffy | 1989-05-13 |
| Bowser | 1989-08-31 |
| Fang | 1990-08-27 |
| Fluffy | 1993-02-04 |
| Claws | 1994-03-17 |
| Slim | 1996-04-29 |
| Whistler | 1997-12-09 |
| Chirpy | 1998-09-11 |
| Puffball | 1999-03-30 |
+----------+------------+
On character type columns, sorting — like all other
comparison operations — is normally performed in a
case-insensitive fashion. This means that the order is
undefined for columns that are identical except for their
case. You can force a case-sensitive sort for a column by
using BINARY like so: ORDER BY
BINARY .
col_name
The default sort order is ascending, with smallest values
first. To sort in reverse (descending) order, add the
DESC keyword to the name of the column you
are sorting by:
mysql> SELECT name, birth FROM pet ORDER BY birth DESC;
+----------+------------+
| name | birth |
+----------+------------+
| Puffball | 1999-03-30 |
| Chirpy | 1998-09-11 |
| Whistler | 1997-12-09 |
| Slim | 1996-04-29 |
| Claws | 1994-03-17 |
| Fluffy | 1993-02-04 |
| Fang | 1990-08-27 |
| Bowser | 1989-08-31 |
| Buffy | 1989-05-13 |
+----------+------------+
You can sort on multiple columns, and you can sort different columns in different directions. For example, to sort by type of animal in ascending order, then by birth date within animal type in descending order (youngest animals first), use the following query:
mysql>SELECT name, species, birth FROM pet->ORDER BY species, birth DESC;+----------+---------+------------+ | name | species | birth | +----------+---------+------------+ | Chirpy | bird | 1998-09-11 | | Whistler | bird | 1997-12-09 | | Claws | cat | 1994-03-17 | | Fluffy | cat | 1993-02-04 | | Fang | dog | 1990-08-27 | | Bowser | dog | 1989-08-31 | | Buffy | dog | 1989-05-13 | | Puffball | hamster | 1999-03-30 | | Slim | snake | 1996-04-29 | +----------+---------+------------+
Note that the DESC keyword applies only to
the column name immediately preceding it
(birth); it does not affect the
species column sort order.
MySQL provides several functions that you can use to perform calculations on dates, for example, to calculate ages or extract parts of dates.
To determine how many years old each of your pets is, compute the difference in the year part of the current date and the birth date, then subtract one if the current date occurs earlier in the calendar year than the birth date. The following query shows, for each pet, the birth date, the current date, and the age in years.
mysql>SELECT name, birth, CURDATE(),->(YEAR(CURDATE())-YEAR(birth))->- (RIGHT(CURDATE(),5)<RIGHT(birth,5))->AS age->FROM pet;+----------+------------+------------+------+ | name | birth | CURDATE() | age | +----------+------------+------------+------+ | Fluffy | 1993-02-04 | 2003-08-19 | 10 | | Claws | 1994-03-17 | 2003-08-19 | 9 | | Buffy | 1989-05-13 | 2003-08-19 | 14 | | Fang | 1990-08-27 | 2003-08-19 | 12 | | Bowser | 1989-08-31 | 2003-08-19 | 13 | | Chirpy | 1998-09-11 | 2003-08-19 | 4 | | Whistler | 1997-12-09 | 2003-08-19 | 5 | | Slim | 1996-04-29 | 2003-08-19 | 7 | | Puffball | 1999-03-30 | 2003-08-19 | 4 | +----------+------------+------------+------+
Here, YEAR() pulls out the year part of a
date and RIGHT() pulls off the rightmost
five characters that represent the MM-DD
(calendar year) part of the date. The part of the expression
that compares the MM-DD values evaluates to
1 or 0, which adjusts the year difference down a year if
CURDATE() occurs earlier in the year than
birth. The full expression is somewhat
ungainly, so an alias
(age) is used to make the output column
label more meaningful.
The query works, but the result could be scanned more easily
if the rows were presented in some order. This can be done by
adding an ORDER BY name clause to sort the
output by name:
mysql>SELECT name, birth, CURDATE(),->(YEAR(CURDATE())-YEAR(birth))->- (RIGHT(CURDATE(),5)<RIGHT(birth,5))->AS age->FROM pet ORDER BY name;+----------+------------+------------+------+ | name | birth | CURDATE() | age | +----------+------------+------------+------+ | Bowser | 1989-08-31 | 2003-08-19 | 13 | | Buffy | 1989-05-13 | 2003-08-19 | 14 | | Chirpy | 1998-09-11 | 2003-08-19 | 4 | | Claws | 1994-03-17 | 2003-08-19 | 9 | | Fang | 1990-08-27 | 2003-08-19 | 12 | | Fluffy | 1993-02-04 | 2003-08-19 | 10 | | Puffball | 1999-03-30 | 2003-08-19 | 4 | | Slim | 1996-04-29 | 2003-08-19 | 7 | | Whistler | 1997-12-09 | 2003-08-19 | 5 | +----------+------------+------------+------+
To sort the output by age rather than
name, just use a different ORDER
BY clause:
mysql>SELECT name, birth, CURDATE(),->(YEAR(CURDATE())-YEAR(birth))->- (RIGHT(CURDATE(),5)<RIGHT(birth,5))->AS age->FROM pet ORDER BY age;+----------+------------+------------+------+ | name | birth | CURDATE() | age | +----------+------------+------------+------+ | Chirpy | 1998-09-11 | 2003-08-19 | 4 | | Puffball | 1999-03-30 | 2003-08-19 | 4 | | Whistler | 1997-12-09 | 2003-08-19 | 5 | | Slim | 1996-04-29 | 2003-08-19 | 7 | | Claws | 1994-03-17 | 2003-08-19 | 9 | | Fluffy | 1993-02-04 | 2003-08-19 | 10 | | Fang | 1990-08-27 | 2003-08-19 | 12 | | Bowser | 1989-08-31 | 2003-08-19 | 13 | | Buffy | 1989-05-13 | 2003-08-19 | 14 | +----------+------------+------------+------+
A similar query can be used to determine age at death for
animals that have died. You determine which animals these are
by checking whether the death value is
NULL. Then, for those with
non-NULL values, compute the difference
between the death and
birth values:
mysql>SELECT name, birth, death,->(YEAR(death)-YEAR(birth)) - (RIGHT(death,5)<RIGHT(birth,5))->AS age->FROM pet WHERE death IS NOT NULL ORDER BY age;+--------+------------+------------+------+ | name | birth | death | age | +--------+------------+------------+------+ | Bowser | 1989-08-31 | 1995-07-29 | 5 | +--------+------------+------------+------+
The query uses death IS NOT NULL rather
than death <> NULL because
NULL is a special value that cannot be
compared using the usual comparison operators. This is
discussed later. See Section 3.3.4.6, “Working with NULL Values”.
What if you want to know which animals have birthdays next
month? For this type of calculation, year and day are
irrelevant; you simply want to extract the month part of the
birth column. MySQL provides several
functions for extracting parts of dates, such as
YEAR(), MONTH(), and
DAYOFMONTH(). MONTH() is
the appropriate function here. To see how it works, run a
simple query that displays the value of both
birth and MONTH(birth):
mysql> SELECT name, birth, MONTH(birth) FROM pet;
+----------+------------+--------------+
| name | birth | MONTH(birth) |
+----------+------------+--------------+
| Fluffy | 1993-02-04 | 2 |
| Claws | 1994-03-17 | 3 |
| Buffy | 1989-05-13 | 5 |
| Fang | 1990-08-27 | 8 |
| Bowser | 1989-08-31 | 8 |
| Chirpy | 1998-09-11 | 9 |
| Whistler | 1997-12-09 | 12 |
| Slim | 1996-04-29 | 4 |
| Puffball | 1999-03-30 | 3 |
+----------+------------+--------------+
Finding animals with birthdays in the upcoming month is also
simple. Suppose that the current month is April. Then the
month value is 4 and you can look for
animals born in May (month 5) like this:
mysql> SELECT name, birth FROM pet WHERE MONTH(birth) = 5;
+-------+------------+
| name | birth |
+-------+------------+
| Buffy | 1989-05-13 |
+-------+------------+
There is a small complication if the current month is
December. You cannot merely add one to the month number
(12) and look for animals born in month
13, because there is no such month.
Instead, you look for animals born in January (month
1).
You can write the query so that it works no matter what the
current month is, so that you do not have to use the number
for a particular month. DATE_ADD() allows
you to add a time interval to a given date. If you add a month
to the value of CURDATE(), then extract the
month part with MONTH(), the result
produces the month in which to look for birthdays:
mysql>SELECT name, birth FROM pet->WHERE MONTH(birth) = MONTH(DATE_ADD(CURDATE(),INTERVAL 1 MONTH));
A different way to accomplish the same task is to add
1 to get the next month after the current
one after using the modulo function (MOD)
to wrap the month value to 0 if it is
currently 12:
mysql>SELECT name, birth FROM pet->WHERE MONTH(birth) = MOD(MONTH(CURDATE()), 12) + 1;
Note that MONTH returns a number between
1 and 12. And
MOD(something,12) returns a number between
0 and 11. So the
addition has to be after the MOD(),
otherwise we would go from November (11) to
January (1).
The NULL value can be surprising until you
get used to it. Conceptually, NULL means
“a missing unknown value” and it is treated
somewhat differently from other values. To test for
NULL, you cannot use the arithmetic
comparison operators such as =,
<, or <>. To
demonstrate this for yourself, try the following query:
mysql> SELECT 1 = NULL, 1 <> NULL, 1 < NULL, 1 > NULL;
+----------+-----------+----------+----------+
| 1 = NULL | 1 <> NULL | 1 < NULL | 1 > NULL |
+----------+-----------+----------+----------+
| NULL | NULL | NULL | NULL |
+----------+-----------+----------+----------+
Clearly you get no meaningful results from these comparisons.
Use the IS NULL and IS NOT
NULL operators instead:
mysql> SELECT 1 IS NULL, 1 IS NOT NULL;
+-----------+---------------+
| 1 IS NULL | 1 IS NOT NULL |
+-----------+---------------+
| 0 | 1 |
+-----------+---------------+
Note that in MySQL, 0 or
NULL means false and anything else means
true. The default truth value from a boolean operation is
1.
This special treatment of NULL is why, in
the previous section, it was necessary to determine which
animals are no longer alive using death IS NOT
NULL instead of death <>
NULL.
Two NULL values are regarded as equal in a
GROUP BY.
When doing an ORDER BY,
NULL values are presented first if you do
ORDER BY ... ASC and last if you do
ORDER BY ... DESC.
A common error when working with NULL is to
assume that it is not possible to insert a zero or an empty
string into a column defined as NOT NULL,
but this is not the case. These are in fact values, whereas
NULL means “not having a
value.” You can test this easily enough by using
IS [NOT]
NULL as shown:
mysql> SELECT 0 IS NULL, 0 IS NOT NULL, '' IS NULL, '' IS NOT NULL;
+-----------+---------------+------------+----------------+
| 0 IS NULL | 0 IS NOT NULL | '' IS NULL | '' IS NOT NULL |
+-----------+---------------+------------+----------------+
| 0 | 1 | 0 | 1 |
+-----------+---------------+------------+----------------+
Thus it is entirely possible to insert a zero or empty string
into a NOT NULL column, as these are in
fact NOT NULL. See
Section B.1.5.3, “Problems with NULL Values”.
MySQL provides standard SQL pattern matching as well as a form of pattern matching based on extended regular expressions similar to those used by Unix utilities such as vi, grep, and sed.
SQL pattern matching allows you to use
‘_’ to match any single
character and ‘%’ to match an
arbitrary number of characters (including zero characters). In
MySQL, SQL patterns are case-insensitive by default. Some
examples are shown here. Note that you do not use
= or <> when you
use SQL patterns; use the LIKE or
NOT LIKE comparison operators instead.
To find names beginning with
‘b’:
mysql> SELECT * FROM pet WHERE name LIKE 'b%';
+--------+--------+---------+------+------------+------------+
| name | owner | species | sex | birth | death |
+--------+--------+---------+------+------------+------------+
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
| Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 |
+--------+--------+---------+------+------------+------------+
To find names ending with ‘fy’:
mysql> SELECT * FROM pet WHERE name LIKE '%fy';
+--------+--------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+--------+--------+---------+------+------------+-------+
| Fluffy | Harold | cat | f | 1993-02-04 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+--------+--------+---------+------+------------+-------+
To find names containing a ‘w’:
mysql> SELECT * FROM pet WHERE name LIKE '%w%';
+----------+-------+---------+------+------------+------------+
| name | owner | species | sex | birth | death |
+----------+-------+---------+------+------------+------------+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 |
| Whistler | Gwen | bird | NULL | 1997-12-09 | NULL |
+----------+-------+---------+------+------------+------------+
To find names containing exactly five characters, use five
instances of the ‘_’ pattern
character:
mysql> SELECT * FROM pet WHERE name LIKE '_____';
+-------+--------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+-------+--------+---------+------+------------+-------+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+-------+--------+---------+------+------------+-------+
The other type of pattern matching provided by MySQL uses
extended regular expressions. When you test for a match for
this type of pattern, use the REGEXP and
NOT REGEXP operators (or
RLIKE and NOT RLIKE,
which are synonyms).
Some characteristics of extended regular expressions are:
‘
.’ matches any single character.A character class ‘
[...]’ matches any character within the brackets. For example, ‘[abc]’ matches ‘a’, ‘b’, or ‘c’. To name a range of characters, use a dash. ‘[a-z]’ matches any letter, whereas ‘[0-9]’ matches any digit.‘
*’ matches zero or more instances of the thing preceding it. For example, ‘x*’ matches any number of ‘x’ characters, ‘[0-9]*’ matches any number of digits, and ‘.*’ matches any number of anything.A
REGEXPpattern match succeeds if the pattern matches anywhere in the value being tested. (This differs from aLIKEpattern match, which succeeds only if the pattern matches the entire value.)To anchor a pattern so that it must match the beginning or end of the value being tested, use ‘
^’ at the beginning or ‘$’ at the end of the pattern.
To demonstrate how extended regular expressions work, the
LIKE queries shown previously are rewritten
here to use REGEXP.
To find names beginning with
‘b’, use
‘^’ to match the beginning of
the name:
mysql> SELECT * FROM pet WHERE name REGEXP '^b';
+--------+--------+---------+------+------------+------------+
| name | owner | species | sex | birth | death |
+--------+--------+---------+------+------------+------------+
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
| Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 |
+--------+--------+---------+------+------------+------------+
If you really want to force a REGEXP
comparison to be case sensitive, use the
BINARY keyword to make one of the strings a
binary string. This query matches only lowercase
‘b’ at the beginning of a name:
mysql> SELECT * FROM pet WHERE name REGEXP BINARY '^b';
To find names ending with ‘fy’,
use ‘$’ to match the end of the
name:
mysql> SELECT * FROM pet WHERE name REGEXP 'fy$';
+--------+--------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+--------+--------+---------+------+------------+-------+
| Fluffy | Harold | cat | f | 1993-02-04 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+--------+--------+---------+------+------------+-------+
To find names containing a ‘w’,
use this query:
mysql> SELECT * FROM pet WHERE name REGEXP 'w';
+----------+-------+---------+------+------------+------------+
| name | owner | species | sex | birth | death |
+----------+-------+---------+------+------------+------------+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 |
| Whistler | Gwen | bird | NULL | 1997-12-09 | NULL |
+----------+-------+---------+------+------------+------------+
Because a regular expression pattern matches if it occurs anywhere in the value, it is not necessary in the previous query to put a wildcard on either side of the pattern to get it to match the entire value like it would be if you used an SQL pattern.
To find names containing exactly five characters, use
‘^’ and
‘$’ to match the beginning and
end of the name, and five instances of
‘.’ in between:
mysql> SELECT * FROM pet WHERE name REGEXP '^.....$';
+-------+--------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+-------+--------+---------+------+------------+-------+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+-------+--------+---------+------+------------+-------+
You could also write the previous query using the
{
(“repeat-n}n-times”)
operator:
mysql> SELECT * FROM pet WHERE name REGEXP '^.{5}$';
+-------+--------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+-------+--------+---------+------+------------+-------+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+-------+--------+---------+------+------------+-------+
Section 12.4.2, “Regular Expressions”, provides more information about the syntax for regular expressions.
Databases are often used to answer the question, “How often does a certain type of data occur in a table?” For example, you might want to know how many pets you have, or how many pets each owner has, or you might want to perform various kinds of census operations on your animals.
Counting the total number of animals you have is the same
question as “How many rows are in the
pet table?” because there is one
record per pet. COUNT(*) counts the number
of rows, so the query to count your animals looks like this:
mysql> SELECT COUNT(*) FROM pet;
+----------+
| COUNT(*) |
+----------+
| 9 |
+----------+
Earlier, you retrieved the names of the people who owned pets.
You can use COUNT() if you want to find out
how many pets each owner has:
mysql> SELECT owner, COUNT(*) FROM pet GROUP BY owner;
+--------+----------+
| owner | COUNT(*) |
+--------+----------+
| Benny | 2 |
| Diane | 2 |
| Gwen | 3 |
| Harold | 2 |
+--------+----------+
Note the use of GROUP BY to group all
records for each owner. Without it, all you
get is an error message:
mysql> SELECT owner, COUNT(*) FROM pet;
ERROR 1140 (42000): Mixing of GROUP columns (MIN(),MAX(),COUNT(),...)
with no GROUP columns is illegal if there is no GROUP BY clause
COUNT() and GROUP BY are
useful for characterizing your data in various ways. The
following examples show different ways to perform animal
census operations.
Number of animals per species:
mysql> SELECT species, COUNT(*) FROM pet GROUP BY species;
+---------+----------+
| species | COUNT(*) |
+---------+----------+
| bird | 2 |
| cat | 2 |
| dog | 3 |
| hamster | 1 |
| snake | 1 |
+---------+----------+
Number of animals per sex:
mysql> SELECT sex, COUNT(*) FROM pet GROUP BY sex;
+------+----------+
| sex | COUNT(*) |
+------+----------+
| NULL | 1 |
| f | 4 |
| m | 4 |
+------+----------+
(In this output, NULL indicates that the
sex is unknown.)
Number of animals per combination of species and sex:
mysql> SELECT species, sex, COUNT(*) FROM pet GROUP BY species, sex;
+---------+------+----------+
| species | sex | COUNT(*) |
+---------+------+----------+
| bird | NULL | 1 |
| bird | f | 1 |
| cat | f | 1 |
| cat | m | 1 |
| dog | f | 1 |
| dog | m | 2 |
| hamster | f | 1 |
| snake | m | 1 |
+---------+------+----------+
You need not retrieve an entire table when you use
COUNT(). For example, the previous query,
when performed just on dogs and cats, looks like this:
mysql>SELECT species, sex, COUNT(*) FROM pet->WHERE species = 'dog' OR species = 'cat'->GROUP BY species, sex;+---------+------+----------+ | species | sex | COUNT(*) | +---------+------+----------+ | cat | f | 1 | | cat | m | 1 | | dog | f | 1 | | dog | m | 2 | +---------+------+----------+
Or, if you wanted the number of animals per sex only for animals whose sex is known:
mysql>SELECT species, sex, COUNT(*) FROM pet->WHERE sex IS NOT NULL->GROUP BY species, sex;+---------+------+----------+ | species | sex | COUNT(*) | +---------+------+----------+ | bird | f | 1 | | cat | f | 1 | | cat | m | 1 | | dog | f | 1 | | dog | m | 2 | | hamster | f | 1 | | snake | m | 1 | +---------+------+----------+
The pet table keeps track of which pets you
have. If you want to record other information about them, such
as events in their lives like visits to the vet or when
litters are born, you need another table. What should this
table look like? It needs:
To contain the pet name so that you know which animal each event pertains to.
A date so that you know when the event occurred.
A field to describe the event.
An event type field, if you want to be able to categorize events.
Given these considerations, the CREATE
TABLE statement for the event
table might look like this:
mysql>CREATE TABLE event (name VARCHAR(20), date DATE,->type VARCHAR(15), remark VARCHAR(255));
As with the pet table, it's easiest to load
the initial records by creating a tab-delimited text file
containing the information:
| name | date | type | remark |
| Fluffy | 1995-05-15 | litter | 4 kittens, 3 female, 1 male |
| Buffy | 1993-06-23 | litter | 5 puppies, 2 female, 3 male |
| Buffy | 1994-06-19 | litter | 3 puppies, 3 female |
| Chirpy | 1999-03-21 | vet | needed beak straightened |
| Slim | 1997-08-03 | vet | broken rib |
| Bowser | 1991-10-12 | kennel | |
| Fang | 1991-10-12 | kennel | |
| Fang | 1998-08-28 | birthday | Gave him a new chew toy |
| Claws | 1998-03-17 | birthday | Gave him a new flea collar |
| Whistler | 1998-12-09 | birthday | First birthday |
Load the records like this:
mysql> LOAD DATA LOCAL INFILE 'event.txt' INTO TABLE event;
Based on what you have learned from the queries that you have
run on the pet table, you should be able to
perform retrievals on the records in the
event table; the principles are the same.
But when is the event table by itself
insufficient to answer questions you might ask?
Suppose that you want to find out the ages at which each pet
had its litters. We saw earlier how to calculate ages from two
dates. The litter date of the mother is in the
event table, but to calculate her age on
that date you need her birth date, which is stored in the
pet table. This means the query requires
both tables:
mysql>SELECT pet.name,->(YEAR(date)-YEAR(birth)) - (RIGHT(date,5)<RIGHT(birth,5)) AS age,->remark->FROM pet INNER JOIN event->ON pet.name = event.name->WHERE event.type = 'litter';+--------+------+-----------------------------+ | name | age | remark | +--------+------+-----------------------------+ | Fluffy | 2 | 4 kittens, 3 female, 1 male | | Buffy | 4 | 5 puppies, 2 female, 3 male | | Buffy | 5 | 3 puppies, 3 female | +--------+------+-----------------------------+
There are several things to note about this query:
The
FROMclause joins two tables because the query needs to pull information from both of them.When combining (joining) information from multiple tables, you need to specify how records in one table can be matched to records in the other. This is easy because they both have a
namecolumn. The query usesONclause to match up records in the two tables based on thenamevalues.The query uses an
INNER JOINto combine the tables. AnINNER JOINallows for rows from either table to appear in the result if and only if both tables meet the conditions specified in theONclause. In this example, theONclause specifies that thenamecolumn in thepettable must match thenamecolumn in theeventtable. If a name appears in one table but not the other, the row will not appear in the result because the condition in theONclause fails.Because the
namecolumn occurs in both tables, you must be specific about which table you mean when referring to the column. This is done by prepending the table name to the column name.
You need not have two different tables to perform a join.
Sometimes it is useful to join a table to itself, if you want
to compare records in a table to other records in that same
table. For example, to find breeding pairs among your pets,
you can join the pet table with itself to
produce candidate pairs of males and females of like species:
mysql>SELECT p1.name, p1.sex, p2.name, p2.sex, p1.species->FROM pet AS p1 INNER JOIN pet AS p2->ON p1.species = p2.species AND p1.sex = 'f' AND p2.sex = 'm';+--------+------+--------+------+---------+ | name | sex | name | sex | species | +--------+------+--------+------+---------+ | Fluffy | f | Claws | m | cat | | Buffy | f | Fang | m | dog | | Buffy | f | Bowser | m | dog | +--------+------+--------+------+---------+
In this query, we specify aliases for the table name to refer to the columns and keep straight which instance of the table each column reference is associated with.
What if you forget the name of a database or table, or what the structure of a given table is (for example, what its columns are called)? MySQL addresses this problem through several statements that provide information about the databases and tables it supports.
You have previously seen SHOW DATABASES, which
lists the databases managed by the server. To find out which
database is currently selected, use the
DATABASE() function:
mysql> SELECT DATABASE();
+------------+
| DATABASE() |
+------------+
| menagerie |
+------------+
If you have not yet selected any database, the result is
NULL.
To find out what tables the default database contains (for example, when you are not sure about the name of a table), use this command:
mysql> SHOW TABLES;
+---------------------+
| Tables_in_menagerie |
+---------------------+
| event |
| pet |
+---------------------+
The name of the column in the output produced by this statement is
always
Tables_in_,
where db_namedb_name is the name of the
database. See Section 13.5.4.25, “SHOW TABLES Syntax”, for more information.
If you want to find out about the structure of a table, the
DESCRIBE command is useful; it displays
information about each of a table's columns:
mysql> DESCRIBE pet;
+---------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+-------+
| name | varchar(20) | YES | | NULL | |
| owner | varchar(20) | YES | | NULL | |
| species | varchar(20) | YES | | NULL | |
| sex | char(1) | YES | | NULL | |
| birth | date | YES | | NULL | |
| death | date | YES | | NULL | |
+---------+-------------+------+-----+---------+-------+
Field indicates the column name,
Type is the data type for the column,
NULL indicates whether the column can contain
NULL values, Key indicates
whether the column is indexed, and Default
specifies the column's default value. Extra
displays special information about columns; for example, if a
column was created with the AUTO_INCREMENT
option, this is shown here.
DESC is a short form of
DESCRIBE. See Section 13.3.1, “DESCRIBE Syntax”, for
more information.
You can obtain the CREATE TABLE statement
necessary to create an existing table using the SHOW
CREATE TABLE statement. See
Section 13.5.4.6, “SHOW CREATE TABLE Syntax”.
If you have indexes on a table, SHOW INDEX FROM
produces information
about them. See Section 13.5.4.13, “tbl_nameSHOW INDEX Syntax”, for more about this
statement.
In the previous sections, you used mysql interactively to enter queries and view the results. You can also run mysql in batch mode. To do this, put the commands you want to run in a file, then tell mysql to read its input from the file:
shell> mysql < batch-file
If you are running mysql under Windows and have some special characters in the file that cause problems, you can do this:
C:\> mysql -e "source batch-file"
If you need to specify connection parameters on the command line, the command might look like this:
shell>mysql -hEnter password:host-uuser-p <batch-file********
When you use mysql this way, you are creating a script file, then executing the script.
If you want the script to continue even if some of the statements
in it produce errors, you should use the --force
command-line option.
Why use a script? Here are a few reasons:
If you run a query repeatedly (say, every day or every week), making it a script allows you to avoid retyping it each time you execute it.
You can generate new queries from existing ones that are similar by copying and editing script files.
Batch mode can also be useful while you're developing a query, particularly for multiple-line commands or multiple-statement sequences of commands. If you make a mistake, you don't have to retype everything. Just edit your script to correct the error, then tell mysql to execute it again.
If you have a query that produces a lot of output, you can run the output through a pager rather than watching it scroll off the top of your screen:
shell>
mysql <batch-file| moreYou can catch the output in a file for further processing:
shell>
mysql <batch-file> mysql.outYou can distribute your script to other people so that they can also run the commands.
Some situations do not allow for interactive use, for example, when you run a query from a cron job. In this case, you must use batch mode.
The default output format is different (more concise) when you run
mysql in batch mode than when you use it
interactively. For example, the output of SELECT DISTINCT
species FROM pet looks like this when
mysql is run interactively:
+---------+ | species | +---------+ | bird | | cat | | dog | | hamster | | snake | +---------+
In batch mode, the output looks like this instead:
species bird cat dog hamster snake
If you want to get the interactive output format in batch mode,
use mysql -t. To echo to the output the
commands that are executed, use mysql -vvv.
You can also use scripts from the mysql prompt
by using the source command or
\. command:
mysql>sourcemysql>filename;\.filename
See Section 8.8.4, “Executing SQL Statements from a Text File”, for more information.
- 3.6.1. The Maximum Value for a Column
- 3.6.2. The Row Holding the Maximum of a Certain Column
- 3.6.3. Maximum of Column per Group
- 3.6.4. The Rows Holding the Group-wise Maximum of a Certain Field
- 3.6.5. Using User-Defined Variables
- 3.6.6. Using Foreign Keys
- 3.6.7. Searching on Two Keys
- 3.6.8. Calculating Visits Per Day
- 3.6.9. Using
AUTO_INCREMENT
Here are examples of how to solve some common problems with MySQL.
Some of the examples use the table shop to hold
the price of each article (item number) for certain traders
(dealers). Supposing that each trader has a single fixed price per
article, then (article,
dealer) is a primary key for the records.
Start the command-line tool mysql and select a database:
shell> mysql your-database-name
(In most MySQL installations, you can use the database named
test).
You can create and populate the example table with these statements:
CREATE TABLE shop (
article INT(4) UNSIGNED ZEROFILL DEFAULT '0000' NOT NULL,
dealer CHAR(20) DEFAULT '' NOT NULL,
price DOUBLE(16,2) DEFAULT '0.00' NOT NULL,
PRIMARY KEY(article, dealer));
INSERT INTO shop VALUES
(1,'A',3.45),(1,'B',3.99),(2,'A',10.99),(3,'B',1.45),
(3,'C',1.69),(3,'D',1.25),(4,'D',19.95);
After issuing the statements, the table should have the following contents:
SELECT * FROM shop; +---------+--------+-------+ | article | dealer | price | +---------+--------+-------+ | 0001 | A | 3.45 | | 0001 | B | 3.99 | | 0002 | A | 10.99 | | 0003 | B | 1.45 | | 0003 | C | 1.69 | | 0003 | D | 1.25 | | 0004 | D | 19.95 | +---------+--------+-------+
“What's the highest item number?”
SELECT MAX(article) AS article FROM shop; +---------+ | article | +---------+ | 4 | +---------+
Task: Find the number, dealer, and price of the most expensive article.
This is easily done with a subquery:
SELECT article, dealer, price FROM shop WHERE price=(SELECT MAX(price) FROM shop);
Another solution is to sort all rows descending by price and get
only the first row using the MySQL-specific
LIMIT clause:
SELECT article, dealer, price FROM shop ORDER BY price DESC LIMIT 1;
Note: If there were several
most expensive articles, each with a price of 19.95, the
LIMIT solution would show only one of them.
Task: Find the highest price per article.
SELECT article, MAX(price) AS price FROM shop GROUP BY article +---------+-------+ | article | price | +---------+-------+ | 0001 | 3.99 | | 0002 | 10.99 | | 0003 | 1.69 | | 0004 | 19.95 | +---------+-------+
Task: For each article, find the dealer or dealers with the most expensive price.
This problem can be solved with a subquery like this one:
SELECT article, dealer, price
FROM shop s1
WHERE price=(SELECT MAX(s2.price)
FROM shop s2
WHERE s1.article = s2.article);
+---------+--------+-------+
| article | dealer | price |
+---------+--------+-------+
| 0001 | B | 3.99 |
| 0002 | A | 10.99 |
| 0003 | C | 1.69 |
| 0004 | D | 19.95 |
+---------+--------+-------+
The preceding example uses a correlated subquery, which can be
inefficient (see Section 13.2.8.7, “Correlated Subqueries”). Other
possibilities for solving the problem are to use a uncorrelated
subquery in the FROM clause or a
LEFT JOIN:
SELECT s1.article, dealer, s1.price FROM shop s1 JOIN ( SELECT article, MAX(price) AS price FROM shop GROUP BY article) AS s2 ON s1.article = s2.article AND s1.price = s2.price; SELECT s1.article, s1.dealer, s1.price FROM shop s1 LEFT JOIN shop s2 ON s1.article = s2.article AND s1.price < s2.price WHERE s2.article IS NULL;
The LEFT JOIN works on the basis that when
s1.price is at its maximum value, there is no
s2.price with a greater value and the
s2 rows values will be
NULL. See Section 13.2.7.1, “JOIN Syntax”.
You can employ MySQL user variables to remember results without having to store them in temporary variables in the client. (See Section 9.4, “User-Defined Variables”.)
For example, to find the articles with the highest and lowest price you can do this:
mysql>SELECT @min_price:=MIN(price),@max_price:=MAX(price) FROM shop;mysql>SELECT * FROM shop WHERE price=@min_price OR price=@max_price;+---------+--------+-------+ | article | dealer | price | +---------+--------+-------+ | 0003 | D | 1.25 | | 0004 | D | 19.95 | +---------+--------+-------+
In MySQL, InnoDB tables support checking of
foreign key constraints. See Section 14.2, “The InnoDB Storage Engine”, and
Section 1.9.5.5, “Foreign Keys”.
A foreign key constraint is not required merely to join two
tables. For storage engines other than
InnoDB, it is possible when defining a column
to use a REFERENCES
clause, which has no actual effect, and serves only as
a memo or comment to you that the column which you are currently
defining is intended to refer to a column in another
table. It is extremely important to realize when
using this syntax that:
tbl_name(col_name)
MySQL does not perform any sort of
CHECKto make sure thatcol_nameactually exists intbl_name(or even thattbl_nameitself exists).MySQL does not perform any sort of action on
tbl_namesuch as deleting rows in response to actions taken on rows in the table which you are defining; in other words, this syntax induces noON DELETEorON UPDATEbehavior whatsoever. (Although you can write anON DELETEorON UPDATEclause as part of theREFERENCESclause, it is also ignored.)This syntax creates a column; it does not create any sort of index or key.
This syntax will cause an error if used in trying to define an
InnoDBtable.
You can use a column so created as a join column, as shown here:
CREATE TABLE person (
id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
name CHAR(60) NOT NULL,
PRIMARY KEY (id)
);
CREATE TABLE shirt (
id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
style ENUM('t-shirt', 'polo', 'dress') NOT NULL,
color ENUM('red', 'blue', 'orange', 'white', 'black') NOT NULL,
owner SMALLINT UNSIGNED NOT NULL REFERENCES person(id),
PRIMARY KEY (id)
);
INSERT INTO person VALUES (NULL, 'Antonio Paz');
SELECT @last := LAST_INSERT_ID();
INSERT INTO shirt VALUES
(NULL, 'polo', 'blue', @last),
(NULL, 'dress', 'white', @last),
(NULL, 't-shirt', 'blue', @last);
INSERT INTO person VALUES (NULL, 'Lilliana Angelovska');
SELECT @last := LAST_INSERT_ID();
INSERT INTO shirt VALUES
(NULL, 'dress', 'orange', @last),
(NULL, 'polo', 'red', @last),
(NULL, 'dress', 'blue', @last),
(NULL, 't-shirt', 'white', @last);
SELECT * FROM person;
+----+---------------------+
| id | name |
+----+---------------------+
| 1 | Antonio Paz |
| 2 | Lilliana Angelovska |
+----+---------------------+
SELECT * FROM shirt;
+----+---------+--------+-------+
| id | style | color | owner |
+----+---------+--------+-------+
| 1 | polo | blue | 1 |
| 2 | dress | white | 1 |
| 3 | t-shirt | blue | 1 |
| 4 | dress | orange | 2 |
| 5 | polo | red | 2 |
| 6 | dress | blue | 2 |
| 7 | t-shirt | white | 2 |
+----+---------+--------+-------+
SELECT s.* FROM person p INNER JOIN shirt s
ON s.owner = p.id
WHERE p.name LIKE 'Lilliana%'
AND s.color <> 'white';
+----+-------+--------+-------+
| id | style | color | owner |
+----+-------+--------+-------+
| 4 | dress | orange | 2 |
| 5 | polo | red | 2 |
| 6 | dress | blue | 2 |
+----+-------+--------+-------+
When used in this fashion, the REFERENCES
clause is not displayed in the output of SHOW CREATE
TABLE or DESCRIBE:
SHOW CREATE TABLE shirt\G
*************************** 1. row ***************************
Table: shirt
Create Table: CREATE TABLE `shirt` (
`id` smallint(5) unsigned NOT NULL auto_increment,
`style` enum('t-shirt','polo','dress') NOT NULL,
`color` enum('red','blue','orange','white','black') NOT NULL,
`owner` smallint(5) unsigned NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1
The use of REFERENCES in this way as a
comment or “reminder” in a column definition works
with both MyISAM and
BerkeleyDB tables.
An OR using a single key is well optimized,
as is the handling of AND.
The one tricky case is that of searching on two different keys
combined with OR:
SELECT field1_index, field2_index FROM test_table WHERE field1_index = '1' OR field2_index = '1'
This case is optimized from MySQL 5.0.0. See Section 7.2.6, “Index Merge Optimization”.
You can also solve the problem efficiently by using a
UNION that combines the output of two
separate SELECT statements. See
Section 13.2.7.3, “UNION Syntax”.
Each SELECT searches only one key and can be
optimized:
SELECT field1_index, field2_index
FROM test_table WHERE field1_index = '1'
UNION
SELECT field1_index, field2_index
FROM test_table WHERE field2_index = '1';
The following example shows how you can use the bit group functions to calculate the number of days per month a user has visited a Web page.
CREATE TABLE t1 (year YEAR(4), month INT(2) UNSIGNED ZEROFILL,
day INT(2) UNSIGNED ZEROFILL);
INSERT INTO t1 VALUES(2000,1,1),(2000,1,20),(2000,1,30),(2000,2,2),
(2000,2,23),(2000,2,23);
The example table contains year-month-day values representing visits by users to the page. To determine how many different days in each month these visits occur, use this query:
SELECT year,month,BIT_COUNT(BIT_OR(1<<day)) AS days FROM t1
GROUP BY year,month;
Which returns:
+------+-------+------+ | year | month | days | +------+-------+------+ | 2000 | 01 | 3 | | 2000 | 02 | 2 | +------+-------+------+
The query calculates how many different days appear in the table for each year/month combination, with automatic removal of duplicate entries.
The AUTO_INCREMENT attribute can be used to
generate a unique identity for new rows:
CREATE TABLE animals (
id MEDIUMINT NOT NULL AUTO_INCREMENT,
name CHAR(30) NOT NULL,
PRIMARY KEY (id)
);
INSERT INTO animals (name) VALUES
('dog'),('cat'),('penguin'),
('lax'),('whale'),('ostrich');
SELECT * FROM animals;
Which returns:
+----+---------+ | id | name | +----+---------+ | 1 | dog | | 2 | cat | | 3 | penguin | | 4 | lax | | 5 | whale | | 6 | ostrich | +----+---------+
You can retrieve the most recent
AUTO_INCREMENT value with the
LAST_INSERT_ID() SQL function or the
mysql_insert_id() C API function. These
functions are connection-specific, so their return values are
not affected by another connection which is also performing
inserts.
Note: For a multiple-row
insert, LAST_INSERT_ID() and
mysql_insert_id() actually return the
AUTO_INCREMENT key from the
first of the inserted rows. This allows
multiple-row inserts to be reproduced correctly on other servers
in a replication setup.
For MyISAM and BDB tables
you can specify AUTO_INCREMENT on a secondary
column in a multiple-column index. In this case, the generated
value for the AUTO_INCREMENT column is
calculated as
MAX(. This
is useful when you want to put data into ordered groups.
auto_increment_column) +
1 WHERE
prefix=given-prefix
CREATE TABLE animals (
grp ENUM('fish','mammal','bird') NOT NULL,
id MEDIUMINT NOT NULL AUTO_INCREMENT,
name CHAR(30) NOT NULL,
PRIMARY KEY (grp,id)
);
INSERT INTO animals (grp,name) VALUES
('mammal','dog'),('mammal','cat'),
('bird','penguin'),('fish','lax'),('mammal','whale'),
('bird','ostrich');
SELECT * FROM animals ORDER BY grp,id;
Which returns:
+--------+----+---------+ | grp | id | name | +--------+----+---------+ | fish | 1 | lax | | mammal | 1 | dog | | mammal | 2 | cat | | mammal | 3 | whale | | bird | 1 | penguin | | bird | 2 | ostrich | +--------+----+---------+
Note that in this case (when the
AUTO_INCREMENT column is part of a
multiple-column index), AUTO_INCREMENT values
are reused if you delete the row with the biggest
AUTO_INCREMENT value in any group. This
happens even for MyISAM tables, for which
AUTO_INCREMENT values normally are not
reused.
If the AUTO_INCREMENT column is part of
multiple indexes, MySQL will generate sequence values using the
index that begins with the AUTO_INCREMENT
column, if there is one. For example, if the
animals table contained indexes
PRIMARY KEY (grp, id) and INDEX
(id), MySQL would ignore the PRIMARY
KEY for generating sequence values. As a result, the
table would contain a single sequence, not a sequence per
grp value.
To start with an AUTO_INCREMENT value other
than 1, you can set that value with CREATE
TABLE or ALTER TABLE, like this:
mysql> ALTER TABLE tbl AUTO_INCREMENT = 100;
More information about AUTO_INCREMENT is
available here:
How to assign the
AUTO_INCREMENTattribute to a column: Section 13.1.5, “CREATE TABLESyntax”, and Section 13.1.2, “ALTER TABLESyntax”.How
AUTO_INCREMENTbehaves depending on the SQL mode: Section 5.2.6, “SQL Modes”.Find the row that contains the most recent AUTO_INCREMENT value: Section 12.2.3, “Comparison Functions and Operators”.
Set the
AUTO_INCREMENTvalue to be used: Section 13.5.3, “SETSyntax”.AUTO_INCREMENTand replication: Section 6.7, “Replication Features and Known Problems”.Server-system variables related to
AUTO_INCREMENT(auto_increment_incrementandauto_increment_offset) that can be used for replication: Section 5.2.3, “System Variables”.
At Analytikerna and Lentus, we have been doing the systems and field work for a big research project. This project is a collaboration between the Institute of Environmental Medicine at Karolinska Institutet Stockholm and the Section on Clinical Research in Aging and Psychology at the University of Southern California.
The project involves a screening part where all twins in Sweden older than 65 years are interviewed by telephone. Twins who meet certain criteria are passed on to the next stage. In this latter stage, twins who want to participate are visited by a doctor/nurse team. Some of the examinations include physical and neuropsychological examination, laboratory testing, neuroimaging, psychological status assessment, and family history collection. In addition, data are collected on medical and environmental risk factors.
More information about Twin studies can be found at: http://www.mep.ki.se/twinreg/index_en.html
The latter part of the project is administered with a Web interface written using Perl and MySQL.
Each night all data from the interviews is moved into a MySQL database.
The following query is used to determine who goes into the second part of the project:
SELECT
CONCAT(p1.id, p1.tvab) + 0 AS tvid,
CONCAT(p1.christian_name, ' ', p1.surname) AS Name,
p1.postal_code AS Code,
p1.city AS City,
pg.abrev AS Area,
IF(td.participation = 'Aborted', 'A', ' ') AS A,
p1.dead AS dead1,
l.event AS event1,
td.suspect AS tsuspect1,
id.suspect AS isuspect1,
td.severe AS tsevere1,
id.severe AS isevere1,
p2.dead AS dead2,
l2.event AS event2,
h2.nurse AS nurse2,
h2.doctor AS doctor2,
td2.suspect AS tsuspect2,
id2.suspect AS isuspect2,
td2.severe AS tsevere2,
id2.severe AS isevere2,
l.finish_date
FROM
twin_project AS tp
/* For Twin 1 */
LEFT JOIN twin_data AS td ON tp.id = td.id
AND tp.tvab = td.tvab
LEFT JOIN informant_data AS id ON tp.id = id.id
AND tp.tvab = id.tvab
LEFT JOIN harmony AS h ON tp.id = h.id
AND tp.tvab = h.tvab
LEFT JOIN lentus AS l ON tp.id = l.id
AND tp.tvab = l.tvab
/* For Twin 2 */
LEFT JOIN twin_data AS td2 ON p2.id = td2.id
AND p2.tvab = td2.tvab
LEFT JOIN informant_data AS id2 ON p2.id = id2.id
AND p2.tvab = id2.tvab
LEFT JOIN harmony AS h2 ON p2.id = h2.id
AND p2.tvab = h2.tvab
LEFT JOIN lentus AS l2 ON p2.id = l2.id
AND p2.tvab = l2.tvab,
person_data AS p1,
person_data AS p2,
postal_groups AS pg
WHERE
/* p1 gets main twin and p2 gets his/her twin. */
/* ptvab is a field inverted from tvab */
p1.id = tp.id AND p1.tvab = tp.tvab AND
p2.id = p1.id AND p2.ptvab = p1.tvab AND
/* Just the screening survey */
tp.survey_no = 5 AND
/* Skip if partner died before 65 but allow emigration (dead=9) */
(p2.dead = 0 OR p2.dead = 9 OR
(p2.dead = 1 AND
(p2.death_date = 0 OR
(((TO_DAYS(p2.death_date) - TO_DAYS(p2.birthday)) / 365)
>= 65))))
AND
(
/* Twin is suspect */
(td.future_contact = 'Yes' AND td.suspect = 2) OR
/* Twin is suspect - Informant is Blessed */
(td.future_contact = 'Yes' AND td.suspect = 1
AND id.suspect = 1) OR
/* No twin - Informant is Blessed */
(ISNULL(td.suspect) AND id.suspect = 1
AND id.future_contact = 'Yes') OR
/* Twin broken off - Informant is Blessed */
(td.participation = 'Aborted'
AND id.suspect = 1 AND id.future_contact = 'Yes') OR
/* Twin broken off - No inform - Have partner */
(td.participation = 'Aborted' AND ISNULL(id.suspect)
AND p2.dead = 0))
AND
l.event = 'Finished'
/* Get at area code */
AND SUBSTRING(p1.postal_code, 1, 2) = pg.code
/* Not already distributed */
AND (h.nurse IS NULL OR h.nurse=00 OR h.doctor=00)
/* Has not refused or been aborted */
AND NOT (h.status = 'Refused' OR h.status = 'Aborted'
OR h.status = 'Died' OR h.status = 'Other')
ORDER BY
tvid;
Some explanations:
CONCAT(p1.id, p1.tvab) + 0 AS tvidWe want to sort on the concatenated
idandtvabin numerical order. Adding0to the result causes MySQL to treat the result as a number.column
idThis identifies a pair of twins. It is a key in all tables.
column
tvabThis identifies a twin in a pair. It has a value of
1or2.column
ptvabThis is an inverse of
tvab. Whentvabis1this is2, and vice versa. It exists to save typing and to make it easier for MySQL to optimize the query.
This query demonstrates, among other things, how to do lookups
on a table from the same table with a join
(p1 and p2). In the
example, this is used to check whether a twin's partner died
before the age of 65. If so, the row is not returned.
All of the above exist in all tables with twin-related
information. We have a key on both id,tvab
(all tables), and id,ptvab
(person_data) to make queries faster.
On our production machine (A 200MHz UltraSPARC), this query returns about 150-200 rows and takes less than one second.
The current number of records in the tables used in the query:
| Table | Rows |
person_data | 71074 |
lentus | 5291 |
twin_project | 5286 |
twin_data | 2012 |
informant_data | 663 |
harmony | 381 |
postal_groups | 100 |
Each interview ends with a status code called
event. The query shown here is used to
display a table over all twin pairs combined by event. This
indicates in how many pairs both twins are finished, in how many
pairs one twin is finished and the other refused, and so on.
SELECT
t1.event,
t2.event,
COUNT(*)
FROM
lentus AS t1,
lentus AS t2,
twin_project AS tp
WHERE
/* We are looking at one pair at a time */
t1.id = tp.id
AND t1.tvab=tp.tvab
AND t1.id = t2.id
/* Just the screening survey */
AND tp.survey_no = 5
/* This makes each pair only appear once */
AND t1.tvab='1' AND t2.tvab='2'
GROUP BY
t1.event, t2.event;
There are programs that let you authenticate your users from a MySQL database and also let you write your log files into a MySQL table.
You can change the Apache logging format to be easily readable by MySQL by putting the following into the Apache configuration file:
LogFormat \
"\"%h\",%{%Y%m%d%H%M%S}t,%>s,\"%b\",\"%{Content-Type}o\", \
\"%U\",\"%{Referer}i\",\"%{User-Agent}i\""
To load a log file in that format into MySQL, you can use a statement something like this:
LOAD DATA INFILE '/local/access_log' INTO TABLEtbl_nameFIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' ESCAPED BY '\\'
The named table should be created to have columns that correspond
to those that the LogFormat line writes to the
log file.
Table of Contents
This chapter provides a brief overview of the command-line programs provided by MySQL AB and discusses the general syntax for specifying options when you run these programs. Most programs have options that are specific to their own operation, but the option syntax is similar for all of them. Later chapters provide more detailed descriptions of individual programs, including which options they recognize.
MySQL AB also provides three GUI client programs for use with MySQL Server:
MySQL Administrator: This tool is used for administering MySQL servers, databases, tables, and user accounts.
MySQL Query Browser: This graphical tool is provided by MySQL AB for creating, executing, and optimizing queries on MySQL databases.
MySQL Migration Toolkit: This tool helps you migrate schemas and data from other relational database management systems for use with MySQL.
These GUI programs each have their own manuals that you can access at http://dev.mysql.com/doc/.
MySQL AB provides several types of programs:
The MySQL server and server startup scripts:
mysqld is the MySQL server.
mysqld_safe, mysql.server, and mysqld_multi are server startup scripts.
mysql_install_db initializes the data directory and the initial databases.
MySQL Instance Manager monitors and manages MySQL Server instances.
Chapter 5, Database Administration, discusses these programs further
Client programs that access the server:
mysql is a command-line client for executing SQL statements interactively or in batch mode.
mysqladmin is an administrative client.
mysqlcheck performs table maintenance operations.
mysqldump and mysqlhotcopy make database backups.
mysqlimport imports data files.
mysqlshow displays information about databases and tables.
Chapter 8, Client and Utility Programs, discusses these programs further
Utility programs that operate independently of the server:
myisamchk performs table maintenance operations.
myisampack produces compressed, read-only tables.
mysqlbinlog is a tool for processing binary log files.
perror displays the meaning of error codes.
Chapter 8, Client and Utility Programs, discusses these programs further
Most MySQL distributions include all of these programs, except for those programs that are platform-specific. (For example, the server startup scripts are not used on Windows.) The exception is that RPM distributions are more specialized. There is one RPM for the server, another for client programs, and so forth. If you appear to be missing one or more programs, see Chapter 2, Installing and Upgrading MySQL, for information on types of distributions and what they contain. It may be that you have a distribution that does not include all programs and you need to install something else.
To invoke a MySQL program from the command line (that is, from
your shell or command prompt), enter the program name followed by
any options or other arguments needed to instruct the program what
you want it to do. The following commands show some sample program
invocations. “shell>”
represents the prompt for your command interpreter; it is not part
of what you type. The particular prompt you see depends on your
command interpreter. Typical prompts are $ for
sh or bash,
% for csh or
tcsh, and C:\> for the
Windows command.com or
cmd.exe command interpreters.
shell>mysql -u root testshell>mysqladmin extended-status variablesshell>mysqlshow --helpshell>mysqldump --user=root personnel
Arguments that begin with a single or double dash
(‘-’,
‘--’) are option arguments. Options
typically specify the type of connection a program should make to
the server or affect its operational mode. Option syntax is
described in Section 4.3, “Specifying Program Options”.
Non-option arguments (arguments with no leading dash) provide
additional information to the program. For example, the
mysql program interprets the first non-option
argument as a database name, so the command mysql -u root
test indicates that you want to use the
test database.
Later sections that describe individual programs indicate which options a program understands and describe the meaning of any additional non-option arguments.
Some options are common to a number of programs. The most common
of these are the --host (or -h),
--user (or -u), and
--password (or -p) options that
specify connection parameters. They indicate the host where the
MySQL server is running, and the username and password of your
MySQL account. All MySQL client programs understand these options;
they allow you to specify which server to connect to and the
account to use on that server.
Other connection options are --port (or
-P) to specify a TCP/IP port number and
--socket (or -S) to specify a
Unix socket file on Unix (or named pipe name on Windows).
The default hostname is localhost. For client
programs on Unix, the hostname localhost is
special. It causes the client to connect to the MySQL server
through a Unix socket file. This occurs even if a
--port or -P option is given to
specify a port number. To ensure that the client makes a TCP/IP
connection to the local server, use --host or
-h to specify a hostname value of
127.0.0.1, or the IP address or name of the
local server. You can also specify the connection protocol
explicitly, even for localhost, by using the
--protocol=tcp option.
On Windows, the hostname . causes the client to
connect to the local server using a named pipe, if the server has
named-pipe connections enabled. If named-pipe connections are not
enabled, an error occurs.
You may find it necessary to invoke MySQL programs using the
pathname to the bin directory in which they
are installed. This is likely to be the case if you get a
“program not found” error whenever you attempt to run
a MySQL program from any directory other than the
bin directory. To make it more convenient to
use MySQL, you can add the pathname of the
bin directory to your PATH
environment variable setting. That enables you to run a program by
typing only its name, not its entire pathname. For example, if
mysql is installed in
/usr/local/mysql/bin, you'll be able to run
it by invoking it as mysql; it will not be
necessary to invoke it as
/usr/local/mysql/bin/mysql.
Consult the documentation for your command interpreter for
instructions on setting your PATH variable. The
syntax for setting environment variables is interpreter-specific.
(Some information is given in
Section 4.3.3, “Using Environment Variables to Specify Options”.)
There are several ways to specify options for MySQL programs:
List the options on the command line following the program name. This is most common for options that apply to a specific invocation of the program.
List the options in an option file that the program reads when it starts. This is common for options that you want the program to use each time it runs.
List the options in environment variables. This method is useful for options that you want to apply each time the program runs. In practice, option files are used more commonly for this purpose. However, Section 5.12.2, “Running Multiple Servers on Unix”, discusses one situation in which environment variables can be very helpful. It describes a handy technique that uses such variables to specify the TCP/IP port number and Unix socket file for both the server and client programs.
MySQL programs determine which options are given first by examining environment variables, then by reading option files, and then by checking the command line. This means that environment variables have the lowest precedence and command-line options the highest.
Because options are processed in order, if an option is specified
multiple times, the last occurrence takes precedence. The
following command causes mysql to connect to
the server running on localhost:
shell> mysql -h example.com -h localhost
If conflicting or related options are given, later options take precedence over earlier options. The following command runs mysql in “no column names” mode:
shell> mysql --column-names --skip-column-names
An option can be specified by writing it in full or as any
unambiguous prefix. For example, the --compress
option can be given to mysqldump as
--compr, but not as --comp
because that is ambiguous:
shell> mysqldump --comp
mysqldump: ambiguous option '--comp' (compatible, compress)
Be aware that the use of option prefixes can cause problems in the event that new options are implemented for a program. A prefix that is unambigious now might become ambiguous in the future.
You can take advantage of the way that MySQL programs process options by specifying default values for a program's options in an option file. That enables you to avoid typing them each time you run the program, but also allows you to override the defaults if necessary by using command-line options.
Program options specified on the command line follow these rules:
Options are given after the command name.
An option argument begins with one dash or two dashes, depending on whether it has a short name or a long name. Many options have both forms. For example,
-?and--helpare the short and long forms of the option that instructs a MySQL program to display its help message.Option names are case sensitive.
-vand-Vare both legal and have different meanings. (They are the corresponding short forms of the--verboseand--versionoptions.)Some options take a value following the option name. For example,
-h localhostor--host=localhostindicate the MySQL server host to a client program. The option value tells the program the name of the host where the MySQL server is running.For a long option that takes a value, separate the option name and the value by an ‘
=’ sign. For a short option that takes a value, the option value can immediately follow the option letter, or there can be a space between:-hlocalhostand-h localhostare equivalent. An exception to this rule is the option for specifying your MySQL password. This option can be given in long form as--password=or aspass_val--password. In the latter case (with no password value given), the program prompts you for the password. The password option also may be given in short form as-por aspass_val-p. However, for the short form, if the password value is given, it must follow the option letter with no intervening space. The reason for this is that if a space follows the option letter, the program has no way to tell whether a following argument is supposed to be the password value or some other kind of argument. Consequently, the following two commands have two completely different meanings:shell>
mysql -ptestshell>mysql -p testThe first command instructs mysql to use a password value of
test, but specifies no default database. The second instructs mysql to prompt for the password value and to usetestas the default database.
Some options control behavior that can be turned on or off. For
example, the mysql client supports a
--column-names option that determines whether
or not to display a row of column names at the beginning of
query results. By default, this option is enabled. However, you
may want to disable it in some instances, such as when sending
the output of mysql into another program that
expects to see only data and not an initial header line.
To disable column names, you can specify the option using any of these forms:
--disable-column-names --skip-column-names --column-names=0
The --disable and --skip
prefixes and the =0 suffix all have the same
effect: They turn the option off.
The “enabled” form of the option may be specified in any of these ways:
--column-names --enable-column-names --column-names=1
If an option is prefixed by --loose, a program
does not exit with an error if it does not recognize the option,
but instead issues only a warning:
shell> mysql --loose-no-such-option
mysql: WARNING: unknown option '--no-such-option'
The --loose prefix can be useful when you run
programs from multiple installations of MySQL on the same
machine and list options in an option file, An option that may
not be recognized by all versions of a program can be given
using the --loose prefix (or
loose in an option file). Versions of the
program that recognize the option process it normally, and
versions that do not recognize it issue a warning and ignore it.
Another option that may occasionally be useful with
mysql is the --execute or
-e option, which can be used to pass SQL
statements to the server. When this option is used,
mysql executes the statements and exits. The
statements must be enclosed by quotation marks. For example, you
can use the following command to obtain a list of user accounts:
shell>mysql -u root -p --execute="SELECT User, Host FROM user" mysqlEnter password:******+------+-----------+ | User | Host | +------+-----------+ | | gigan | | root | gigan | | | localhost | | jon | localhost | | root | localhost | +------+-----------+ shell>
Note that the long form (--execute) is followed
by an equals sign (=).
If you wish to use quoted values within a statement, you will either need to escape the inner quotes, or use a different type of quotes within the statement from those used to quote the statement itself. The capabilities of your command processor dictate your choices for whether you can use single or double quotation marks and the syntax for escaping quote characters. For example, if your command processor supports quoting with single or double quotes, you can double quotes around the statement, and single quotes for any quoted values within the statement.
In the preceding example, the name of the
mysql database was passed as a separate
argument. However, the same statement could have been executed
using this command, which specifies no default database:
mysql> mysql -u root -p --execute="SELECT User, Host FROM mysql.user"
Multiple SQL statements may be passed on the command line, separated by semicolons:
shell>mysql -u root -p -e "SELECT VERSION();SELECT NOW()"Enter password:******+------------+ | VERSION() | +------------+ | 5.0.19-log | +------------+ +---------------------+ | NOW() | +---------------------+ | 2006-01-05 21:19:04 | +---------------------+
The --execute or -e option may
also be used to pass commands in an analogous fashion to the
ndb_mgm management client for MySQL Cluster.
See Section 15.3.6, “Safe Shutdown and Restart”, for
an example.
Most MySQL programs can read startup options from option files (also sometimes called configuration files). Option files provide a convenient way to specify commonly used options so that they need not be entered on the command line each time you run a program. For the MySQL server, MySQL provides a number of preconfigured option files.
To determine whether a program reads option files, invoke it
with the --help option
(--verbose and --help for
mysqld). If the program reads option files,
the help message indicates which files it looks for and which
option groups it recognizes.
Note: Option files used with MySQL Cluster programs are covered in Section 15.4, “MySQL Cluster Configuration”.
On Windows, MySQL programs read startup options from the following files:
| Filename | Purpose |
| Global options |
C:\my.cnf | Global options |
| Global Options |
defaults-extra-file | The file specified with
--defaults-extra-file=,
if any |
WINDIR represents the location of
your Windows directory. This is commonly
C:\WINDOWS. You can determine its exact
location from the value of the WINDIR
environment variable using the following command:
C:\> echo %WINDIR%
INSTALLDIR represents the
installation directory of MySQL. This is typically
C:\ where
PROGRAMDIR\MySQL\MySQL
5.0 ServerPROGRAMDIR represents the programs
directory (usually Program Files on
English-language versions of Windows), when MySQL
5.0 has been installed using the installation and
configuration wizards. See
Section 2.3.3.2.1.1, “The MySQL Server Configuration Wizard on Windows”.
On Unix, MySQL programs read startup options from the following files:
| Filename | Purpose |
/etc/my.cnf | Global options |
$MYSQL_HOME/my.cnf | Server-specific options |
defaults-extra-file | The file specified with
--defaults-extra-file=,
if any |
~/.my.cnf | User-specific options |
MYSQL_HOME is an environment variable
containing the path to the directory in which the
server-specific my.cnf file resides. (This
was DATADIR prior to MySQL version
5.0.3.)
If MYSQL_HOME is not set and you start the
server using the mysqld_safe program,
mysqld_safe attempts to set
MYSQL_HOME as follows:
Let
BASEDIRandDATADIRrepresent the pathnames of the MySQL base directory and data directory, respectively.If there is a
my.cnffile inDATADIRbut not inBASEDIR, mysqld_safe setsMYSQL_HOMEtoDATADIR.Otherwise, if
MYSQL_HOMEis not set and there is nomy.cnffile inDATADIR, mysqld_safe setsMYSQL_HOMEtoBASEDIR.
In MySQL 5.0, use of
DATADIR as the location for
my.cnf is deprecated.
BASEDIR is a better location.
Typically, DATADIR is
/usr/local/mysql/data for a binary
installation or /usr/local/var for a source
installation. Note that this is the data directory location that
was specified at configuration time, not the one specified with
the --datadir option when
mysqld starts. Use of
--datadir at runtime has no effect on where the
server looks for option files, because it looks for them before
processing any options.
MySQL looks for option files in the order just described and reads any that exist. If an option file that you want to use does not exist, create it with a plain text editor.
If multiple instances of a given option are found, the last
instance takes precedence. There is one exception: For
mysqld, the first
instance of the --user option is used as a
security precaution, to prevent a user specified in an option
file from being overridden on the command line.
Note: On Unix platforms, MySQL ignores configuration files that are world-writable. This is intentional, and acts as a security measure.
Any long option that may be given on the command line when
running a MySQL program can be given in an option file as well.
To get the list of available options for a program, run it with
the --help option.
The syntax for specifying options in an option file is similar
to command-line syntax, except that you omit the leading two
dashes. For example, --quick or
--host=localhost on the command line should be
specified as quick or
host=localhost in an option file. To specify
an option of the form
--loose- in
an option file, write it as
opt_nameloose-.
opt_name
Empty lines in option files are ignored. Non-empty lines can take any of the following forms:
#,comment;commentComment lines start with ‘
#’ or ‘;’. A ‘#’ comment can start in the middle of a line as well.[group]groupis the name of the program or group for which you want to set options. After a group line, any option-setting lines apply to the named group until the end of the option file or another group line is given.opt_nameThis is equivalent to
--on the command line.opt_nameopt_name=valueThis is equivalent to
--on the command line. In an option file, you can have spaces around the ‘opt_name=value=’ character, something that is not true on the command line. You can enclose the value within single quotes or double quotes, which is useful if the value contains a ‘#’ comment character or whitespace.
For options that take a numeric value, the value can be given
with a suffix of K, M, or
G (either uppercase or lowercase) to indicate
a multiplier of 1024, 10242 or
10243. For example, the following
command tells mysqladmin to ping the server
1024 times, sleeping 10 seconds between each ping:
mysql> mysqladmin --count=1K --sleep=10 ping
Leading and trailing blanks are automatically deleted from
option names and values. You may use the escape sequences
‘\b’,
‘\t’,
‘\n’,
‘\r’,
‘\\’, and
‘\s’ in option values to
represent the backspace, tab, newline, carriage return,
backslash, and space characters.
Because the ‘\\’ escape sequence
represents a single backslash, you must write each
‘\’ as
‘\\’. Alternatively, you can
specify the value using ‘/’
rather than ‘\’ as the pathname
separator.
If an option group name is the same as a program name, options
in the group apply specifically to that program. For example,
the [mysqld] and [mysql]
groups apply to the mysqld server and the
mysql client program, respectively.
The [client] option group is read by all
client programs (but not by
mysqld). This allows you to specify options
that apply to all clients. For example,
[client] is the perfect group to use to
specify the password that you use to connect to the server. (But
make sure that the option file is readable and writable only by
yourself, so that other people cannot find out your password.)
Be sure not to put an option in the [client]
group unless it is recognized by all client
programs that you use. Programs that do not understand the
option quit after displaying an error message if you try to run
them.
Here is a typical global option file:
[client] port=3306 socket=/tmp/mysql.sock [mysqld] port=3306 socket=/tmp/mysql.sock key_buffer_size=16M max_allowed_packet=8M [mysqldump] quick
The preceding option file uses
var_name=valuekey_buffer_size and
max_allowed_packet variables.
Here is a typical user option file:
[client] # The following password will be sent to all standard MySQL clients password="my_password" [mysql] no-auto-rehash connect_timeout=2 [mysqlhotcopy] interactive-timeout
If you want to create option groups that should be read by
mysqld servers from a specific MySQL release
series only, you can do this by using groups with names of
[mysqld-4.1],
[mysqld-5.0], and so forth. The
following group indicates that the --new option
should be used only by MySQL servers with 5.0.x
version numbers:
[mysqld-5.0] new
Beginning with MySQL 5.0.4, it is possible to use
!include directives in option files to
include other option files and !includedir to
search specific directories for option files. For example, to
include the /home/mydir/myopt.cnf file, use
the following directive:
!include /home/mydir/myopt.cnf
To search the /home/mydir directory and
read option files found there, use this directive:
!includedir /home/mydir
There is no guarantee about the order in which the option files in the directory will be read.
Note: Currently, any files to
be found and included using the !includedir
directive on Unix operating systems must
have filenames ending in .cnf. On Windows,
this directive checks for files with the
.ini or .cnf
extension.
Write the contents of an included option file like any other
option file. That is, it should contain groups of options, each
preceded by a
[ line that
indicates the program to which the options apply.
group]
While an included file is being processed, only those options in
groups that the current program is looking for are used. Other
groups are ignored. Suppose that a my.cnf
file contains this line:
!include /home/mydir/myopt.cnf
And suppose that /home/mydir/myopt.cnf
looks like this:
[mysqladmin] force [mysqld] key_buffer_size=16M
If my.cnf is processed by
mysqld, only the [mysqld]
group in /home/mydir/myopt.cnf is used. If
the file is processed by mysqladmin, only the
[mysqldamin] group is used. If the file is
processed by any other program, no options in
/home/mydir/myopt.cnf are used.
The !includedir directive is processed
similarly except that all option files in the named directory
are read.
If you have a source distribution, you can find sample option
files named
my- in
the xxxx.cnfsupport-files directory. If you have a
binary distribution, look in the
support-files directory under your MySQL
installation directory. On Windows, the sample option files may
be located in the MySQL installation directory (see earlier in
this section or Chapter 2, Installing and Upgrading MySQL, if you do not know
where this is). Currently, there are sample option files for
small, medium, large, and very large systems. To experiment with
one of these files, copy it to C:\my.cnf on
Windows or to .my.cnf in your home
directory on Unix.
Note: On Windows, the
.cnf or .ini option
file extension might not be displayed.
Most MySQL programs that support option files handle the
following options. They affect option-file handling, so they
must be given on the command line and not in an option file. To
work properly, each of these options must immediately follow the
command name, with the exception that
--print-defaults may be used immediately after
--defaults-file or
--defaults-extra-file. Also, you should avoid
the use of the ‘~’ shell
metacharacter when specifying filenames because it might not be
interpreted as you expect.
Don't read any option files.
Print the program name and all options that it gets from option files.
Use only the given option file.
file_nameis the full pathname to the file. If the file does not exist or is otherwise inaccessible, the program will exit with an error.--defaults-extra-file=file_nameRead this option file after the global option file but (on Unix) before the user option file.
file_nameis the full pathname to the file. As of MySQL 5.0.6, if the file does not exist or is otherwise inaccessible, the program will exit with an error.If this option is given, the program reads not only its usual option groups, but also groups with the usual names and a suffix of
str. For example, the mysql client normally reads the[client]and[mysql]groups. If the--default-group-suffix=_otheroption is given, mysql also reads the[client_other]and[mysql_other]groups. This option was added in MySQL 5.0.10.
In shell scripts, you can use the
my_print_defaults program to parse option
files and see what options would be used by a given program. The
following example shows the output that
my_print_defaults might produce when asked to
show the options found in the [client] and
[mysql] groups:
shell> my_print_defaults client mysql
--port=3306
--socket=/tmp/mysql.sock
--no-auto-rehash
Note for developers: Option file handling is implemented in the C client library simply by processing all options in the appropriate group or groups before any command-line arguments. This works well for programs that use the last instance of an option that is specified multiple times. If you have a C or C++ program that handles multiply specified options this way but that doesn't read option files, you need add only two lines to give it that capability. Check the source code of any of the standard MySQL clients to see how to do this.
Several other language interfaces to MySQL are based on the C client library, and some of them provide a way to access option file contents. These include Perl and Python. For details, see the documentation for your preferred interface.
MySQL provides a number of preconfigured option files that can
be used as a basis for tuning the MySQL server. Look in your
installation directory for files such as
my-small.cnf,
my-medium.cnf,
my-large.cnf, and
my-huge.cnf, which you can rename and
copy to the appropriate location for use as a base
configuration file. Regarding names and appropriate location,
see the general information provided in
Section 4.3.2, “Using Option Files”. On Windows, those files have a
.ini rather than a
.cnf extension.
To specify an option using an environment variable, set the
variable using the syntax appropriate for your command
processor. For example, on Windows or NetWare, you can set the
USER variable to specify your MySQL account
name. To do so, use this syntax:
SET USER=your_name
The syntax on Unix depends on your shell. Suppose that you want
to specify the TCP/IP port number using the
MYSQL_TCP_PORT variable. Typical syntax (such
as for sh, bash,
zsh, and so on) is as follows:
MYSQL_TCP_PORT=3306 export MYSQL_TCP_PORT
The first command sets the variable, and the
export command exports the variable to the
shell environment so that its value becomes accessible to MySQL
and other processes.
For csh and tcsh, use setenv to make the shell variable available to the environment:
setenv MYSQL_TCP_PORT 3306
The commands to set environment variables can be executed at
your command prompt to take effect immediately, but the settings
persist only until you log out. To have the settings take effect
each time you log in, place the appropriate command or commands
in a startup file that your command interpreter reads each time
it starts. Typical startup files are
AUTOEXEC.BAT for Windows,
.bash_profile for bash,
or .tcshrc for tcsh.
Consult the documentation for your command interpreter for
specific details.
Section 2.4.19, “Environment Variables”, lists all environment variables that affect MySQL program operation.
Many MySQL programs have internal variables that can be set at
runtime. Program variables are set the same way as any other
long option that takes a value. For example,
mysql has a
max_allowed_packet variable that controls the
maximum size of its communication buffer. To set the
max_allowed_packet variable for
mysql to a value of 16MB, use either of the
following commands:
shell>mysql --max_allowed_packet=16777216shell>mysql --max_allowed_packet=16M
The first command specifies the value in bytes. The second
specifies the value in megabytes. For variables that take a
numeric value, the value can be given with a suffix of
K, M, or
G (either uppercase or lowercase) to indicate
a multiplier of 1024, 10242 or
10243. (For example, when used to set
max_allowed_packet, the suffixes indicate
units of kilobytes, megabytes, or gigabytes.)
In an option file, variable settings are given without the leading dashes:
[mysql] max_allowed_packet=16777216
Or:
[mysql] max_allowed_packet=16M
If you like, underscores in a variable name can be specified as dashes. The following option groups are equivalent. Both set the size of the server's key buffer to 512MB:
[mysqld] key_buffer_size=512M [mysqld] key-buffer-size=512M
Note: Before MySQL 4.0.2, the
only syntax for setting program variables was
--set-variable=
(or
option=valueset-variable=
in option files). This syntax still is recognized, but is
deprecated as of MySQL 4.0.2.
option=value
Many server system variables can also be set at runtime. For details, see Section 5.2.4.2, “Dynamic System Variables”.
Table of Contents
- 5.1. Overview of Server-Side Programs
- 5.2. mysqld — The MySQL Server
- 5.3. MySQL Server Startup Programs
- 5.4. mysqlmanager — The MySQL Instance Manager
- 5.4.1. MySQL Instance Manager Command Options
- 5.4.2. MySQL Instance Manager Configuration Files
- 5.4.3. Starting the MySQL Server with MySQL Instance Manager
- 5.4.4. Instance Manager User and Password Management
- 5.4.5. MySQL Server Instance Status Monitoring
- 5.4.6. Connecting to MySQL Instance Manager
- 5.4.7. MySQL Instance Manager Commands
- 5.5. Installation-Related Programs
- 5.5.1. comp_err — Compile MySQL Error Message File
- 5.5.2. make_win_bin_dist — Package MySQL Distribution as ZIP Archive
- 5.5.3. make_win_src_distribution — Create Source Distribution for Windows
- 5.5.4. mysql_fix_privilege_tables — Upgrade MySQL System Tables
- 5.5.5. mysql_install_db — MySQL Data Directory Initialization Script
- 5.5.6. mysql_secure_installation — Improve MySQL Installation Security
- 5.5.7. mysql_tzinfo_to_sql — Load the Time Zone Tables
- 5.5.8. mysql_upgrade — Check Tables for MySQL Upgrade
- 5.6. General Security Issues
- 5.7. The MySQL Access Privilege System
- 5.7.1. What the Privilege System Does
- 5.7.2. How the Privilege System Works
- 5.7.3. Privileges Provided by MySQL
- 5.7.4. Connecting to the MySQL Server
- 5.7.5. Access Control, Stage 1: Connection Verification
- 5.7.6. Access Control, Stage 2: Request Verification
- 5.7.7. When Privilege Changes Take Effect
- 5.7.8. Causes of
Access deniedErrors - 5.7.9. Password Hashing as of MySQL 4.1
- 5.8. MySQL User Account Management
- 5.9. Backup and Recovery
- 5.10. MySQL Localization and International Usage
- 5.10.1. The Character Set Used for Data and Sorting
- 5.10.2. Setting the Error Message Language
- 5.10.3. Adding a New Character Set
- 5.10.4. The Character Definition Arrays
- 5.10.5. String Collating Support
- 5.10.6. Multi-Byte Character Support
- 5.10.7. Problems With Character Sets
- 5.10.8. MySQL Server Time Zone Support
- 5.10.9. MySQL Server Locale Support
- 5.11. MySQL Server Logs
- 5.12. Running Multiple MySQL Servers on the Same Machine
- 5.13. The MySQL Query Cache
This chapter covers topics that deal with administering a MySQL installation:
Configuring the server
Managing user accounts
Performing backups
The server log files
The query cache
The MySQL server, mysqld, is the main program that does most of the work in a MySQL installation. The server is accompanied by several related scripts that perform setup operations when you install MySQL or that assist you in starting and stopping the server. This section provides an overview of the server and related programs. The following sections provide more detailed information about each of these programs.
Each MySQL program takes many different options. Most programs
provide a --help option that you can use to get a
description of the program's different options. For example, try
mysqld --help.
You can override default option values for MySQL programs by specifying options on the command line or in an option file. Section 4.3, “Specifying Program Options”.
The following list briefly describes the MySQL server and server-related programs:
The SQL daemon (that is, the MySQL server). To use client programs, mysqld must be running, because clients gain access to databases by connecting to the server. See Section 5.2, “mysqld — The MySQL Server”.
A server startup script. mysqld_safe attempts to start mysqld. See Section 5.3.1, “mysqld_safe — MySQL Server Startup Script”.
A server startup script. This script is used on systems that use System V-style run directories containing scripts that start system services for particular run levels. It invokes mysqld_safe to start the MySQL server. See Section 5.3.2, “mysql.server — MySQL Server Startup Script”.
A server startup script that can start or stop multiple servers installed on the system. See Section 5.3.3, “mysqld_multi — Manage Multiple MySQL Servers”. As of MySQL 5.0.3 (Unix-like systems) or 5.0.13 (Windows), an alternative to mysqld_multi is
mysqlmanager, the MySQL Instance Manager. See Section 5.4, “mysqlmanager — The MySQL Instance Manager”.The MySQL Instance Manager, a program for monitoring and managing MySQL servers. See Section 5.4, “mysqlmanager — The MySQL Instance Manager”.
There are several other programs that are related to MySQL installation or upgrading:
This program is used during the MySQL build/installation process. It compiles error message files from the error source files. See Section 5.5.1, “comp_err — Compile MySQL Error Message File”.
This program makes a binary release of a compiled MySQL. This could be sent by FTP to
/pub/mysql/upload/onftp.mysql.comfor the convenience of other MySQL users.This program is used on Windows. It packages a MySQL distribution for installation after the source distribution has been built. See Section 5.5.2, “make_win_bin_dist — Package MySQL Distribution as ZIP Archive”.
This program is used after a MySQL upgrade operation. It updates the grant tables with any changes that have been made in newer versions of MySQL. See Section 5.5.4, “mysql_fix_privilege_tables — Upgrade MySQL System Tables”.
Note: As of MySQL 5.0.19, this program has been superseded by mysql_upgrade.
This script creates the MySQL database and initializes the grant tables with default privileges. It is usually executed only once, when first installing MySQL on a system. See Section 2.4.15.2, “Unix Post-Installation Procedures”, and Section 5.5.5, “mysql_install_db — MySQL Data Directory Initialization Script”.
This program enables you to improve the security of your MySQL installation. SQL. See Section 5.5.6, “mysql_secure_installation — Improve MySQL Installation Security”.
This program loads the time zone tables in the
mysqldatabase using the contents of the host system zoneinfo database (the set of files describing time zones). SQL. See Section 5.5.7, “mysql_tzinfo_to_sql — Load the Time Zone Tables”.This program is used after a MySQL upgrade operation. It checks tables for incompatibilities and repairs them if necessary, and updates the grant tables with any changes that have been made in newer versions of MySQL. See Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.
This program is used on Unix or Unix-like systems to create a MySQL source distribution that can be compiled on Windows. See Section 2.4.14.6.4, “Creating a Windows Source Package from the Latest Development Source”, and Section 5.5.3, “make_win_src_distribution — Create Source Distribution for Windows”.
mysqld is the MySQL server. The following discussion covers these MySQL server configuration topics:
Startup options that the server supports
Server system variables
Server status variables
How to set the server SQL mode
The server shutdown process
Note: Not all storage engines
are supported by all MySQL server binaries and configurations.
To find out how to determine which storage engines are
supported by your MySQL server installation, see
Section 13.5.4.10, “SHOW ENGINES Syntax”.
The following table provides a list of all the command line
options, server and status variables applicable within
mysqld.
The table lists command line options (Cmd-line), options valid in configuration files (Option file), server system variables (Server Var), and status variables (Status var) in one unified list, with notification of where each option/variable is valid. If a server option set on the command line or in an option file differs from the name of the corresponding server system or status variable, the variable name is noted immediately below the corresponding option. For status variables, the scope of the variable is shown (Scope) as either global, session, or both. Please see the corresponding sections for details on setting and using the options and variables. Where appropriate, a direct link to further information on the item as available.
Note
This table is part of an ongoing process to expand and simplify the information provided on these elements. Further improvements to the table, and corresponding descriptions will be applied over the coming months.
| Name | Cmd-line | Option file | Server Var | Status Var | Var Scope | Dynamic |
|---|---|---|---|---|---|---|
| abort-slave-event-count | Y | Y | ||||
| Aborted_clients | Y | both | no | |||
| Aborted_connects | Y | both | no | |||
| allow-suspicious-udfs | Y | Y | ||||
| ansi | Y | Y | ||||
| auto-increment-increment | Y | Y | both | no | ||
| - Variable: auto_increment_increment | Y | both | no | |||
| auto-increment-offset | Y | Y | both | no | ||
| - Variable: auto_increment_offset | Y | both | no | |||
| autocommit | Y | Y | Y | session | yes | |
| automatic_sp_privileges | Y | Y | Y | both | no | |
| back_log | Y | Y | Y | both | no | |
| basedir | Y | Y | Y | both | no | |
| bdb | Y | Y | both | no | ||
| - Variable: have_bdb | Y | both | no | |||
| bdb-home | Y | Y | no | |||
| - Variable: bdb_home | Y | no | ||||
| bdb-lock-detect | Y | Y | ||||
| bdb-logdir | Y | Y | no | |||
| - Variable: bdb_logdir | Y | no | ||||
| bdb-no-recover | Y | Y | ||||
| bdb-shared-data | Y | Y | no | |||
| - Variable: bdb_shared_data | Y | no | ||||
| bdb-tmpdir | Y | Y | no | |||
| - Variable: bdb_tmpdir | Y | no | ||||
| bdb_cache_size | Y | Y | Y | no | ||
| bdb_lock_max | Y | Y | Y | no | ||
| bdb_log_buffer_size | Y | Y | Y | no | ||
| bdb_max_lock | Y | Y | Y | no | ||
| big-tables | Y | Y | yes | |||
| - Variable: big_tables | Y | yes | ||||
| bind-address | Y | Y | ||||
| binlog-do-db | Y | Y | ||||
| binlog-ignore-db | Y | Y | ||||
| Binlog_cache_disk_use | Y | both | no | |||
| binlog_cache_size | Y | Y | Y | both | yes | |
| Binlog_cache_use | Y | both | no | |||
| bootstrap | Y | Y | ||||
| bulk_insert_buffer_size | Y | Y | Y | both | yes | |
| Bytes_received | Y | both | no | |||
| Bytes_sent | Y | both | no | |||
| character-set-client-handshake | Y | |||||
| character-set-filesystem | Y | Y | both | no | ||
| - Variable: character_set_filesystem | Y | both | no | |||
| character-set-server | Y | Y | both | yes | ||
| - Variable: character_set_server | Y | both | yes | |||
| character-sets-dir | Y | Y | both | no | ||
| - Variable: character_sets_dir | Y | both | no | |||
| character_set_client | Y | both | yes | |||
| character_set_connection | Y | both | yes | |||
| character_set_database | Y | both | yes | |||
| character_set_results | Y | both | yes | |||
| character_set_system | Y | both | yes | |||
| chroot | Y | Y | ||||
| collation_connection | Y | Y | Y | both | yes | |
| collation_database | Y | Y | Y | both | yes | |
| collation_server | Y | Y | Y | both | yes | |
| Com_admin_commands | Y | both | no | |||
| Com_alter_db | Y | both | no | |||
| Com_alter_event | Y | both | no | |||
| Com_alter_table | Y | both | no | |||
| Com_analyze | Y | both | no | |||
| Com_backup_table | Y | both | no | |||
| Com_begin | Y | both | no | |||
| Com_change_db | Y | both | no | |||
| Com_change_master | Y | both | no | |||
| Com_check | Y | both | no | |||
| Com_checksum | Y | both | no | |||
| Com_commit | Y | both | no | |||
| Com_create_db | Y | both | no | |||
| Com_create_event | Y | both | no | |||
| Com_create_function | Y | both | no | |||
| Com_create_index | Y | both | no | |||
| Com_create_table | Y | both | no | |||
| Com_create_user | Y | both | no | |||
| Com_dealloc_sql | Y | both | no | |||
| Com_delete | Y | both | no | |||
| Com_delete_multi | Y | both | no | |||
| Com_do | Y | both | no | |||
| Com_drop_db | Y | both | no | |||
| Com_drop_event | Y | both | no | |||
| Com_drop_function | Y | both | no | |||
| Com_drop_index | Y | both | no | |||
| Com_drop_table | Y | both | no | |||
| Com_drop_user | Y | both | no | |||
| Com_execute_sql | Y | both | no | |||
| Com_flush | Y | both | no | |||
| Com_grant | Y | both | no | |||
| Com_ha_close | Y | both | no | |||
| Com_ha_open | Y | both | no | |||
| Com_ha_read | Y | both | no | |||
| Com_help | Y | both | no | |||
| Com_insert | Y | both | no | |||
| Com_insert_select | Y | both | no | |||
| Com_kill | Y | both | no | |||
| Com_load | Y | both | no | |||
| Com_lock_tables | Y | both | no | |||
| Com_optimize | Y | both | no | |||
| Com_preload_keys | Y | both | no | |||
| Com_prepare_sql | Y | both | no | |||
| Com_purge | Y | both | no | |||
| Com_purge_before_date | Y | both | no | |||
| Com_rename_table | Y | both | no | |||
| Com_repair | Y | both | no | |||
| Com_replace | Y | both | no | |||
| Com_replace_select | Y | both | no | |||
| Com_reset | Y | both | no | |||
| Com_restore_table | Y | both | no | |||
| Com_revoke | Y | both | no | |||
| Com_revoke_all | Y | both | no | |||
| Com_rollback | Y | both | no | |||
| Com_savepoint | Y | both | no | |||
| Com_select | Y | both | no | |||
| Com_set_option | Y | both | no | |||
| Com_show_binlog_events | Y | both | no | |||
| Com_show_binlogs | Y | both | no | |||
| Com_show_charsets | Y | both | no | |||
| Com_show_collations | Y | both | no | |||
| Com_show_column_types | Y | both | no | |||
| Com_show_create_db | Y | both | no | |||
| Com_show_create_event | Y | both | no | |||
| Com_show_create_table | Y | both | no | |||
| Com_show_databases | Y | both | no | |||
| Com_show_engine_logs | Y | both | no | |||
| Com_show_engine_mutex | Y | both | no | |||
| Com_show_engine_status | Y | both | no | |||
| Com_show_errors | Y | both | no | |||
| Com_show_events | Y | both | no | |||
| Com_show_fields | Y | both | no | |||
| Com_show_grants | Y | both | no | |||
| Com_show_keys | Y | both | no | |||
| Com_show_master_status | Y | both | no | |||
| Com_show_new_master | Y | both | no | |||
| Com_show_open_tables | Y | both | no | |||
| Com_show_plugins | Y | both | no | |||
| Com_show_privileges | Y | both | no | |||
| Com_show_processlist | Y | both | no | |||
| Com_show_slave_hosts | Y | both | no | |||
| Com_show_slave_status | Y | both | no | |||
| Com_show_status | Y | both | no | |||
| Com_show_storage_engines | Y | both | no | |||
| Com_show_tables | Y | both | no | |||
| Com_show_triggers | Y | both | no | |||
| Com_show_variables | Y | both | no | |||
| Com_show_warnings | Y | both | no | |||
| Com_slave_start | Y | both | no | |||
| Com_slave_stop | Y | both | no | |||
| Com_stmt_close | Y | both | no | |||
| Com_stmt_execute | Y | both | no | |||
| Com_stmt_fetch | Y | both | no | |||
| Com_stmt_prepare | Y | both | no | |||
| Com_stmt_reset | Y | both | no | |||
| Com_stmt_send_long_data | Y | both | no | |||
| Com_truncate | Y | both | no | |||
| Com_unlock_tables | Y | both | no | |||
| Com_update | Y | both | no | |||
| Com_update_multi | Y | both | no | |||
| Com_xa_commit | Y | both | no | |||
| Com_xa_end | Y | both | no | |||
| Com_xa_prepare | Y | both | no | |||
| Com_xa_recover | Y | both | no | |||
| Com_xa_rollback | Y | both | no | |||
| Com_xa_start | Y | both | no | |||
| completion_type | Y | Y | Y | both | yes | |
| Compression | Y | both | no | |||
| concurrent-insert | Y | Y | both | yes | ||
| - Variable: concurrent_insert | Y | both | yes | |||
| connect_timeout | Y | Y | Y | both | yes | |
| Connections | Y | both | no | |||
| console | Y | Y | ||||
| core-file | Y | Y | ||||
| Created_tmp_disk_tables | Y | both | no | |||
| Created_tmp_files | Y | both | no | |||
| Created_tmp_tables | Y | both | no | |||
| datadir | Y | Y | Y | both | no | |
| date_format | Y | Y | both | yes | ||
| datetime_format | Y | Y | both | yes | ||
| debug | Y | Y | ||||
| default-character-set | Y | Y | ||||
| default-storage-engine | Y | Y | ||||
| default-table-type | Y | Y | ||||
| default-time-zone | Y | Y | ||||
| - Variable: time_zone | ||||||
| default_week_format | Y | Y | Y | both | yes | |
| defaults-extra-file | Y | |||||
| defaults-file | Y | |||||
| defaults-group-suffix | Y | |||||
| delay-key-write | Y | Y | both | yes | ||
| - Variable: delay_key_write | Y | both | yes | |||
| Delayed_errors | Y | both | no | |||
| delayed_insert_limit | Y | Y | Y | both | yes | |
| Delayed_insert_threads | Y | both | no | |||
| delayed_insert_timeout | Y | Y | Y | both | yes | |
| delayed_queue_size | Y | Y | Y | both | yes | |
| Delayed_writes | Y | both | no | |||
| des-key-file | Y | Y | Y | no | ||
| disconnect-slave-event-count | Y | Y | ||||
| div_precision_increment | Y | Y | Y | both | yes | |
| enable-locking | Y | |||||
| enable-pstack | Y | Y | ||||
| engine-condition-pushdown | Y | Y | both | yes | ||
| - Variable: engine_condition_pushdown | Y | both | yes | |||
| error_count | Y | session | yes | |||
| exit-info | Y | Y | ||||
| expire_logs_days | Y | Y | Y | both | yes | |
| external-locking | Y | Y | ||||
| flush | Y | Y | Y | both | yes | |
| Flush_commands | Y | both | no | |||
| flush_time | Y | Y | Y | both | yes | |
| foreign_key_checks | Y | Y | session | yes | ||
| ft_boolean_syntax | Y | Y | Y | both | yes | |
| ft_max_word_len | Y | Y | Y | both | yes | |
| ft_min_word_len | Y | Y | Y | global | yes | |
| ft_query_expansion_limit | Y | Y | Y | both | yes | |
| ft_stopword_file | Y | Y | Y | both | yes | |
| gdb | Y | Y | ||||
| group_concat_max_len | Y | Y | Y | both | yes | |
| Handler_commit | Y | both | no | |||
| Handler_delete | Y | both | no | |||
| Handler_discover | Y | both | no | |||
| Handler_prepare | Y | both | no | |||
| Handler_read_first | Y | both | no | |||
| Handler_read_key | Y | both | no | |||
| Handler_read_next | Y | both | no | |||
| Handler_read_prev | Y | both | no | |||
| Handler_read_rnd | Y | both | no | |||
| Handler_read_rnd_next | Y | both | no | |||
| Handler_rollback | Y | both | no | |||
| Handler_savepoint | Y | both | no | |||
| Handler_savepoint_rollback | Y | both | no | |||
| Handler_update | Y | both | no | |||
| Handler_write | Y | both | no | |||
| have_archive | Y | both | no | |||
| have_blackhole_engine | Y | both | no | |||
| have_compress | Y | both | no | |||
| have_crypt | Y | both | no | |||
| have_csv | Y | both | no | |||
| have_example_engine | Y | both | no | |||
| have_federated_engine | Y | both | no | |||
| have_geometry | Y | both | no | |||
| have_innodb | Y | both | no | |||
| have_isam | Y | both | no | |||
| have_merge_engine | Y | both | no | |||
| have_ndbcluster | Y | both | no | |||
| have_openssl | Y | both | no | |||
| have_query_cache | Y | both | no | |||
| have_raid | Y | both | no | |||
| have_rtree_keys | Y | both | no | |||
| have_symlink | Y | both | no | |||
| help | Y | |||||
| hostname | Y | global | no | |||
| identity | Y | Y | Y | session | yes | |
| init-file | Y | Y | both | no | ||
| - Variable: init_file | Y | both | no | |||
| init_connect | Y | Y | Y | both | no | |
| init_slave | Y | Y | Y | both | no | |
| innodb | Y | Y | ||||
| innodb-doublewrite | Y | Y | both | no | ||
| - Variable: innodb_doublewrite | Y | both | no | |||
| innodb-safe-binlog | Y | Y | ||||
| innodb_additional_mem_pool_size | Y | Y | Y | both | no | |
| innodb_autoextend_increment | Y | Y | Y | both | yes | |
| innodb_buffer_pool_awe_mem_mb | Y | Y | Y | both | no | |
| Innodb_buffer_pool_pages_data | Y | both | no | |||
| Innodb_buffer_pool_pages_dirty | Y | both | no | |||
| Innodb_buffer_pool_pages_flushed | Y | both | no | |||
| Innodb_buffer_pool_pages_free | Y | both | no | |||
| Innodb_buffer_pool_pages_latched | Y | both | no | |||
| Innodb_buffer_pool_pages_misc | Y | both | no | |||
| Innodb_buffer_pool_pages_total | Y | both | no | |||
| Innodb_buffer_pool_read_ahead_rnd | Y | both | no | |||
| Innodb_buffer_pool_read_ahead_seq | Y | both | no | |||
| Innodb_buffer_pool_read_requests | Y | both | no | |||
| Innodb_buffer_pool_reads | Y | both | no | |||
| innodb_buffer_pool_size | Y | Y | Y | both | no | |
| Innodb_buffer_pool_wait_free | Y | both | no | |||
| Innodb_buffer_pool_write_requests | Y | both | no | |||
| innodb_checksums | Y | Y | Y | both | yes | |
| innodb_commit_concurrency | Y | Y | Y | both | yes | |
| innodb_concurrency_tickets | Y | Y | Y | both | yes | |
| innodb_data_file_path | Y | Y | Y | both | no | |
| Innodb_data_fsyncs | Y | both | no | |||
| innodb_data_home_dir | Y | Y | Y | both | no | |
| Innodb_data_pending_fsyncs | Y | both | no | |||
| Innodb_data_pending_reads | Y | both | no | |||
| Innodb_data_pending_writes | Y | both | no | |||
| Innodb_data_read | Y | both | no | |||
| Innodb_data_reads | Y | both | no | |||
| Innodb_data_writes | Y | both | no | |||
| Innodb_data_written | Y | both | no | |||
| Innodb_dblwr_pages_written | Y | both | no | |||
| Innodb_dblwr_writes | Y | both | no | |||
| innodb_fast_shutdown | Y | Y | Y | both | no | |
| innodb_file_io_threads | Y | Y | Y | both | no | |
| innodb_file_per_table | Y | Y | Y | both | no | |
| innodb_flush_log_at_trx_commit | Y | Y | Y | both | no | |
| innodb_flush_method | Y | Y | Y | both | no | |
| innodb_force_recovery | Y | Y | Y | both | no | |
| innodb_lock_wait_timeout | Y | Y | Y | both | no | |
| innodb_locks_unsafe_for_binlog | Y | Y | Y | both | no | |
| innodb_log_arch_dir | Y | Y | Y | both | no | |
| innodb_log_archive | Y | Y | Y | both | no | |
| innodb_log_buffer_size | Y | Y | Y | both | no | |
| innodb_log_file_size | Y | Y | Y | both | no | |
| innodb_log_files_in_group | Y | Y | Y | both | no | |
| innodb_log_group_home_dir | Y | Y | Y | both | no | |
| Innodb_log_waits | Y | both | no | |||
| Innodb_log_write_requests | Y | both | no | |||
| Innodb_log_writes | Y | both | no | |||
| innodb_max_dirty_pages_pct | Y | Y | Y | both | yes | |
| innodb_max_purge_lag | Y | Y | Y | both | yes | |
| innodb_mirrored_log_groups | Y | Y | Y | both | no | |
| innodb_open_files | Y | Y | Y | both | no | |
| Innodb_os_log_fsyncs | Y | both | no | |||
| Innodb_os_log_pending_fsyncs | Y | both | no | |||
| Innodb_os_log_pending_writes | Y | both | no | |||
| Innodb_os_log_written | Y | both | no | |||
| Innodb_page_size | Y | both | no | |||
| Innodb_pages_created | Y | both | no | |||
| Innodb_pages_read | Y | both | no | |||
| Innodb_pages_written | Y | both | no | |||
| innodb_rollback_on_timeout | Y | Y | Y | no | ||
| Innodb_row_lock_current_waits | Y | both | no | |||
| Innodb_row_lock_time | Y | both | no | |||
| Innodb_row_lock_time_avg | Y | both | no | |||
| Innodb_row_lock_time_max | Y | both | no | |||
| Innodb_row_lock_waits | Y | both | no | |||
| Innodb_rows_deleted | Y | both | no | |||
| Innodb_rows_inserted | Y | both | no | |||
| Innodb_rows_read | Y | both | no | |||
| Innodb_rows_updated | Y | both | no | |||
| innodb_status_file | Y | Y | Y | no | ||
| innodb_support_xa | Y | Y | Y | both | yes | |
| innodb_sync_spin_loops | Y | Y | Y | both | yes | |
| innodb_table_locks | Y | Y | Y | both | yes | |
| innodb_thread_concurrency | Y | Y | Y | both | yes | |
| innodb_thread_sleep_delay | Y | Y | Y | both | yes | |
| insert_id | Y | Y | Y | session | yes | |
| interactive_timeout | Y | Y | Y | both | yes | |
| join_buffer_size | Y | Y | Y | both | yes | |
| Key_blocks_not_flushed | Y | both | no | |||
| Key_blocks_unused | Y | both | no | |||
| Key_blocks_used | Y | both | no | |||
| key_buffer_size | Y | Y | Y | both | yes | |
| key_cache_age_threshold | Y | Y | Y | both | no | |
| key_cache_block_size | Y | Y | Y | both | no | |
| key_cache_division_limit | Y | Y | Y | both | no | |
| Key_read_requests | Y | both | no | |||
| Key_reads | Y | both | no | |||
| Key_write_requests | Y | both | no | |||
| Key_writes | Y | both | no | |||
| language | Y | Y | Y | both | no | |
| large-pages | Y | Y | both | no | ||
| - Variable: large_pages | Y | both | no | |||
| large_files_support | Y | both | no | |||
| last_insert_id | Y | Y | Y | session | yes | |
| Last_query_cost | Y | session | no | |||
| lc_time_names | Y | both | yes | |||
| license | Y | both | no | |||
| local-infile | Y | Y | global | yes | ||
| - Variable: local_infile | Y | global | yes | |||
| log | Y | Y | Y | both | no | |
| log-bin | Y | Y | both | no | ||
| - Variable: log_bin | Y | both | no | |||
| log-bin-index | Y | Y | Y | no | ||
| log-bin-trust-function-creators | Y | Y | yes | |||
| - Variable: log_bin_trust_function_creators | Y | yes | ||||
| log-bin-trust-routine-creators | Y | Y | both | no | ||
| - Variable: log_bin_trust_routine_creators | Y | both | no | |||
| log-error | Y | Y | both | no | ||
| - Variable: log_error | Y | both | no | |||
| log-isam | Y | Y | Y | no | ||
| log-queries-not-using-indexes | Y | Y | both | yes | ||
| - Variable: log_queries_not_using_indexes | Y | both | yes | |||
| log-short-format | Y | Y | ||||
| log-slave-updates | Y | Y | both | no | ||
| - Variable: log_slave_updates | Y | both | no | |||
| log-slow-admin-statements | Y | Y | ||||
| log-slow-queries | Y | Y | both | no | ||
| - Variable: log_slow_queries | Y | both | no | |||
| log-tc | Y | Y | ||||
| log-tc-size | Y | Y | ||||
| log-warnings | Y | Y | both | yes | ||
| - Variable: log_warnings | Y | both | yes | |||
| long_query_time | Y | Y | Y | both | yes | |
| low-priority-updates | Y | Y | yes | |||
| - Variable: low_priority_updates | Y | yes | ||||
| lower_case_table_names | Y | Y | Y | no | ||
| master-connect-retry | Y | Y | ||||
| master-host | Y | Y | ||||
| master-info-file | Y | Y | ||||
| master-password | Y | Y | ||||
| master-port | Y | Y | ||||
| master-retry-count | Y | Y | ||||
| master-ssl | Y | Y | ||||
| master-ssl-ca | Y | Y | ||||
| master-ssl-capath | Y | Y | ||||
| master-ssl-cert | Y | Y | ||||
| master-ssl-cipher | Y | Y | ||||
| master-ssl-key | Y | Y | ||||
| master-user | Y | Y | ||||
| max-binlog-dump-events | Y | Y | ||||
| max_allowed_packet | Y | Y | Y | both | yes | |
| max_binlog_cache_size | Y | Y | Y | global | yes | |
| max_binlog_size | Y | Y | Y | global | yes | |
| max_connect_errors | Y | Y | Y | global | yes | |
| max_connections | Y | Y | Y | global | yes | |
| max_delayed_threads | Y | Y | Y | global | yes | |
| max_error_count | Y | Y | Y | both | yes | |
| max_heap_table_size | Y | Y | Y | both | yes | |
| max_insert_delayed_threads | Y | global | yes | |||
| max_join_size | Y | Y | Y | both | yes | |
| max_length_for_sort_data | Y | Y | Y | yes | ||
| max_prepared_stmt_count | Y | Y | Y | global | yes | |
| max_relay_log_size | Y | Y | Y | global | yes | |
| max_seeks_for_key | Y | Y | Y | both | yes | |
| max_sort_length | Y | Y | Y | both | yes | |
| max_sp_recursion_depth | Y | Y | Y | yes | ||
| max_tmp_tables | Y | Y | Y | both | yes | |
| Max_used_connections | Y | both | no | |||
| max_user_connections | Y | Y | Y | both | yes | |
| max_write_lock_count | Y | Y | Y | global | yes | |
| maximum-query_cache_size | Y | Y | no | |||
| memlock | Y | Y | both | no | ||
| - Variable: locked_in_memory | Y | both | no | |||
| merge | Y | Y | Y | no | ||
| multi_range_count | Y | Y | Y | both | yes | |
| multi_read_range | Y | Y | Y | both | yes | |
| myisam-recover | Y | Y | Y | no | ||
| myisam_block_size | Y | Y | Y | yes | ||
| myisam_data_pointer_size | Y | Y | Y | global | yes | |
| myisam_max_extra_sort_file_size | Y | Y | Y | yes | ||
| myisam_max_sort_file_size | Y | Y | Y | both | yes | |
| myisam_repair_threads | Y | Y | Y | both | yes | |
| myisam_sort_buffer_size | Y | Y | Y | both | yes | |
| myisam_stats_method | Y | Y | Y | both | yes | |
| named_pipe | Y | Y | ||||
| ndb_autoincrement_prefetch_sz | Y | yes | ||||
| ndb_cache_check_time | Y | Y | yes | |||
| Ndb_cluster_node_id | Y | both | no | |||
| Ndb_config_from_host | Y | both | no | |||
| Ndb_config_from_port | Y | both | no | |||
| ndb_force_send | Y | Y | Y | yes | ||
| ndb_index_stat_cache_entries | Y | Y | ||||
| ndb_index_stat_enable | Y | Y | ||||
| ndb_index_stat_update_freq | Y | Y | ||||
| ndb_optimized_node_selection | Y | Y | ||||
| ndb_report_thresh_binlog_epoch_slip | Y | Y | ||||
| ndb_report_thresh_binlog_mem_usage | Y | Y | ||||
| ndb_use_exact_count | Y | yes | ||||
| ndb_use_transactions | Y | Y | ||||
| ndbcluster | Y | Y | Y | yes | ||
| net_buffer_length | Y | Y | Y | both | yes | |
| net_read_timeout | Y | Y | Y | both | yes | |
| net_retry_count | Y | Y | Y | both | yes | |
| net_write_timeout | Y | Y | Y | both | yes | |
| new | Y | Y | Y | no | ||
| no-defaults | Y | |||||
| Not_flushed_delayed_rows | Y | both | no | |||
| old-passwords | Y | Y | yes | |||
| - Variable: old_passwords | Y | yes | ||||
| old-protocol | Y | Y | ||||
| old-style-user-limits | Y | Y | Y | no | ||
| Open_files | Y | both | no | |||
| open_files_limit | Y | Y | Y | no | ||
| Open_streams | Y | both | no | |||
| Open_tables | Y | both | no | |||
| Opened_tables | Y | both | no | |||
| optimizer_prune_level | Y | Y | Y | both | yes | |
| optimizer_search_depth | Y | Y | Y | both | yes | |
| pid-file | Y | Y | Y | no | ||
| port | Y | Y | Y | no | ||
| port-open-timeout | Y | Y | ||||
| preload_buffer_size | Y | Y | Y | both | yes | |
| prepared_stmt_count | Y | Y | both | no | ||
| print-defaults | Y | |||||
| profiling | Y | session | yes | |||
| profiling_history_size | Y | session | yes | |||
| protocol_version | Y | both | no | |||
| Qcache_free_blocks | Y | both | no | |||
| Qcache_free_memory | Y | both | no | |||
| Qcache_hits | Y | both | no | |||
| Qcache_inserts | Y | both | no | |||
| Qcache_lowmem_prunes | Y | both | no | |||
| Qcache_not_cached | Y | both | no | |||
| Qcache_queries_in_cache | Y | both | no | |||
| Qcache_total_blocks | Y | both | no | |||
| query_alloc_block_size | Y | Y | Y | both | yes | |
| query_cache_limit | Y | Y | Y | both | yes | |
| query_cache_min_res_unit | Y | Y | Y | both | yes | |
| query_cache_size | Y | Y | Y | both | yes | |
| query_cache_type | Y | Y | Y | both | yes | |
| query_cache_wlock_invalidate | Y | Y | Y | both | yes | |
| query_prealloc_size | Y | Y | Y | both | yes | |
| Questions | Y | both | no | |||
| range_alloc_block_size | Y | Y | Y | both | yes | |
| read_buffer_size | Y | Y | Y | both | yes | |
| read_only | Y | Y | Y | both | yes | |
| read_rnd_buffer_size | Y | Y | Y | both | yes | |
| relay-log | Y | Y | Y | no | ||
| relay-log-index | Y | Y | ||||
| relay-log-info-file | Y | Y | ||||
| relay_log_purge | Y | Y | Y | both | no | |
| relay_log_space_limit | Y | Y | Y | both | no | |
| replicate-do-db | Y | Y | ||||
| replicate-do-table | Y | Y | ||||
| replicate-ignore-db | Y | Y | ||||
| replicate-ignore-table | Y | Y | ||||
| replicate-rewrite-db | Y | Y | ||||
| replicate-same-server-id | Y | Y | ||||
| replicate-wild-do-table | Y | Y | ||||
| replicate-wild-ignore-table | Y | Y | ||||
| report-host | Y | Y | ||||
| report-password | Y | Y | Y | no | ||
| report-port | Y | Y | ||||
| report-user | Y | Y | ||||
| rpl_recovery_rank | Y | both | yes | |||
| Rpl_status | Y | both | no | |||
| safe-mode | Y | Y | ||||
| safe-user-create | Y | Y | ||||
| safemalloc-mem-limit | Y | Y | ||||
| secure-auth | Y | Y | both | yes | ||
| - Variable: secure_auth | Y | both | yes | |||
| secure-file-priv | Y | Y | global | no | ||
| - Variable: secure_file_priv | Y | global | no | |||
| Select_full_join | Y | both | no | |||
| Select_full_range_join | Y | both | no | |||
| Select_range | Y | both | no | |||
| Select_range_check | Y | both | no | |||
| Select_scan | Y | both | no | |||
| server-id | Y | Y | both | yes | ||
| - Variable: server_id | Y | both | yes | |||
| set-variable | Y | Y | ||||
| shared-memory-base-name | Y | Y | ||||
| shared_memory | Y | Y | ||||
| show-slave-auth-info | Y | Y | ||||
| skip-automatic_sp_privileges | Y | Y | ||||
| skip-bdb | Y | Y | ||||
| - Variable: skip_bdb | ||||||
| skip-character-set-client-handshake | Y | Y | ||||
| skip-concurrent-insert | Y | Y | ||||
| - Variable: skip-concurrent_insert | ||||||
| skip-external-locking | Y | Y | both | no | ||
| - Variable: skip_external_locking | Y | both | no | |||
| skip-grant-tables | Y | Y | ||||
| skip-host-cache | Y | Y | ||||
| skip-innodb | Y | Y | ||||
| skip-innodb-checksums | Y | Y | ||||
| skip-locking | Y | Y | ||||
| skip-log-warnings | Y | Y | no | |||
| skip-merge | Y | Y | Y | no | ||
| skip-name-resolve | Y | Y | ||||
| skip-networking | Y | Y | both | no | ||
| - Variable: skip_networking | Y | both | no | |||
| skip-new | Y | Y | ||||
| skip-safemalloc | Y | Y | ||||
| skip-show-database | Y | Y | both | no | ||
| - Variable: skip_show_database | Y | both | no | |||
| skip-slave-start | Y | Y | ||||
| skip-ssl | Y | Y | ||||
| skip-stack-trace | Y | Y | ||||
| skip-symbolic-links | Y | |||||
| skip-symlink | Y | Y | ||||
| skip-sync-bdb-logs | Y | Y | ||||
| skip-thread-priority | Y | Y | ||||
| slave-load-tmpdir | Y | Y | both | no | ||
| - Variable: slave_load_tmpdir | Y | both | no | |||
| slave-net-timeout | Y | Y | global | yes | ||
| - Variable: slave_net_timeout | Y | global | yes | |||
| slave-skip-errors | Y | Y | both | no | ||
| - Variable: slave_skip_errors | Y | both | no | |||
| slave_compressed_protocol | Y | Y | Y | both | no | |
| Slave_open_temp_tables | Y | both | no | |||
| Slave_retried_transactions | Y | both | no | |||
| Slave_running | Y | both | no | |||
| slave_transaction_retries | Y | Y | Y | both | yes | |
| Slow_launch_threads | Y | both | no | |||
| slow_launch_time | Y | Y | Y | both | yes | |
| Slow_queries | Y | both | no | |||
| socket | Y | Y | Y | both | no | |
| sort_buffer_size | Y | Y | Y | both | yes | |
| Sort_merge_passes | Y | both | no | |||
| Sort_range | Y | both | no | |||
| Sort_rows | Y | both | no | |||
| Sort_scan | Y | both | no | |||
| sporadic-binlog-dump-fail | Y | Y | ||||
| sql-mode | Y | Y | both | yes | ||
| - Variable: sql_mode | Y | both | yes | |||
| sql_auto_is_null | Y | Y | Y | session | no | |
| sql_big_selects | Y | Y | Y | both | yes | |
| sql_big_tables | Y | session | yes | |||
| sql_buffer_result | Y | Y | Y | session | yes | |
| sql_log_bin | Y | Y | Y | session | yes | |
| sql_log_off | Y | Y | Y | session | yes | |
| sql_log_update | Y | Y | Y | session | yes | |
| sql_low_priority_updates | Y | both | yes | |||
| sql_max_join_size | Y | both | yes | |||
| sql_notes | Y | Y | Y | both | yes | |
| sql_quote_show_create | Y | Y | Y | session | yes | |
| sql_safe_updates | Y | Y | Y | session | yes | |
| sql_select_limit | Y | Y | Y | session | yes | |
| sql_slave_skip_counter | Y | global | yes | |||
| sql_warnings | Y | Y | Y | both | yes | |
| ssl | Y | Y | Y | no | ||
| ssl-ca | Y | Y | both | no | ||
| - Variable: ssl_ca | Y | both | no | |||
| ssl-capath | Y | Y | both | no | ||
| - Variable: ssl_capath | Y | both | no | |||
| ssl-cert | Y | Y | both | no | ||
| - Variable: ssl_cert | Y | both | no | |||
| ssl-cipher | Y | Y | both | no | ||
| - Variable: ssl_cipher | Y | both | no | |||
| ssl-key | Y | Y | both | no | ||
| - Variable: ssl_key | Y | both | no | |||
| ssl-verify-server-cert | Y | Y | ||||
| standalone | Y | Y | ||||
| storage_engine | Y | both | no | |||
| symbolic-links | Y | Y | ||||
| sync-bdb-logs | Y | Y | Y | no | ||
| sync-binlog | Y | Y | both | yes | ||
| - Variable: sync_binlog | Y | both | yes | |||
| sync-frm | Y | Y | both | yes | ||
| - Variable: sync_frm | Y | both | yes | |||
| sysdate-is-now | Y | Y | ||||
| system_time_zone | Y | both | no | |||
| table_cache | Y | Y | Y | both | yes | |
| table_lock_wait_timeout | Y | Y | Y | both | yes | |
| Table_locks_immediate | Y | both | no | |||
| Table_locks_waited | Y | both | no | |||
| table_open_cache | Y | Y | global | yes | ||
| table_type | Y | both | yes | |||
| tc-heuristic-recover | Y | Y | ||||
| Tc_log_max_pages_used | Y | both | no | |||
| Tc_log_page_size | Y | both | no | |||
| Tc_log_page_waits | Y | both | no | |||
| temp-pool | Y | Y | ||||
| thread_cache_size | Y | Y | Y | both | yes | |
| thread_concurrency | Y | Y | Y | no | ||
| thread_stack | Y | Y | Y | both | no | |
| Threads_cached | Y | both | no | |||
| Threads_connected | Y | both | no | |||
| Threads_created | Y | both | no | |||
| Threads_running | Y | both | no | |||
| time_format | Y | Y | Y | both | no | |
| timed_mutexes | Y | Y | Y | no | ||
| timestamp | Y | Y | Y | session | yes | |
| tmp_table_size | Y | Y | Y | both | yes | |
| tmpdir | Y | Y | Y | both | no | |
| transaction-isolation | Y | Y | ||||
| transaction_alloc_block_size | Y | Y | Y | both | yes | |
| transaction_prealloc_size | Y | Y | Y | both | yes | |
| tx_isolation | Y | both | yes | |||
| unique_checks | Y | Y | Y | session | yes | |
| updatable_views_with_limit | Y | Y | Y | both | no | |
| Uptime | Y | both | no | |||
| Uptime_since_flush_status | Y | both | no | |||
| user | Y | Y | ||||
| verbose | Y | |||||
| version | Y | Y | both | no | ||
| version_comment | Y | both | no | |||
| version_compile_machine | Y | both | no | |||
| version_compile_os | Y | both | no | |||
| wait_timeout | Y | Y | Y | both | yes | |
| warning_count | Y | session | yes | |||
| warnings | Y | Y |
When you start the mysqld server, you can specify program options using any of the methods described in Section 4.3, “Specifying Program Options”. The most common methods are to provide options in an option file or on the command line. However, in most cases it is desirable to make sure that the server uses the same options each time it runs. The best way to ensure this is to list them in an option file. See Section 4.3.2, “Using Option Files”.
MySQL Enterprise For expert advice on setting command options, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
mysqld reads options from the
[mysqld] and [server]
groups. mysqld_safe reads options from the
[mysqld], [server],
[mysqld_safe], and
[safe_mysqld] groups.
mysql.server reads options from the
[mysqld] and
[mysql.server] groups.
An embedded MySQL server usually reads options from the
[server], [embedded],
and
[
groups, where xxxxx_SERVER]xxxxx is the name of
the application into which the server is embedded.
mysqld accepts many command options. For a brief summary, execute mysqld --help. To see the full list, use mysqld --verbose --help.
The following list shows some of the most common server options. Additional options are described in other sections:
Options that affect security: See Section 5.6.3, “Security-Related mysqld Options”.
SSL-related options: See Section 5.8.7.3, “SSL Command Options”.
Binary log control options: See Section 5.11.3, “The Binary Log”.
Replication-related options: See Section 6.8, “Replication Startup Options”.
Options specific to particular storage engines: See Section 14.1.1, “
MyISAMStartup Options”, Section 14.5.3, “BDBStartup Options”, Section 14.2.4, “InnoDBStartup Options and System Variables”, and Section 15.6.5.1, “MySQL Cluster-Related Command Options for mysqld”.
You can also set the values of server system variables by using variable names as options, as described later in this section.
Display a short help message and exit. Use both the
--verboseand--helpoptions to see the full message.This option is used internally by the MySQL test suite for replication testing and debugging.
This option controls whether user-defined functions that have only an
xxxsymbol for the main function can be loaded. By default, the option is off and only UDFs that have at least one auxiliary symbol can be loaded; this prevents attempts at loading functions from shared object files other than those containing legitimate UDFs. This option was added in version 5.0.3. See Section 24.2.4.6, “User-Defined Function Security Precautions”.Use standard (ANSI) SQL syntax instead of MySQL syntax. For more precise control over the server SQL mode, use the
--sql-modeoption instead. See Section 1.9.3, “Running MySQL in ANSI Mode”, and Section 5.2.6, “SQL Modes”.The path to the MySQL installation directory. All paths are usually resolved relative to this directory.
Allow large result sets by saving all temporary sets in files. This option prevents most “table full” errors, but also slows down queries for which in-memory tables would suffice. Since MySQL 3.23.2, the server is able to handle large result sets automatically by using memory for small temporary tables and switching to disk tables where necessary.
The IP address to bind to.
This option is used by the mysql_install_db script to create the MySQL privilege tables without having to start a full MySQL server.
This option is unavailable if MySQL was configured with the
--disable-grant-optionsoption. See Section 2.4.14.2, “Typical configure Options”.The directory where character sets are installed. See Section 5.10.1, “The Character Set Used for Data and Sorting”.
--character-set-client-handshakeDon't ignore character set information sent by the client. To ignore client information and use the default server character set, use
--skip-character-set-client-handshake; this makes MySQL behave like MySQL 4.0.--character-set-filesystem=charset_nameThe filesystem character set. This option sets the
character_set_filesystemsystem variable. It was added in MySQL 5.0.19.--character-set-server=,charset_name-Ccharset_nameUse
charset_nameas the default server character set. See Section 5.10.1, “The Character Set Used for Data and Sorting”. If you use this option to specify a non-default character set, you should also use--collation-serverto specify the collation.Put the mysqld server in a closed environment during startup by using the
chroot()system call. This is a recommended security measure. Note that use of this option somewhat limitsLOAD DATA INFILEandSELECT ... INTO OUTFILE.--collation-server=collation_nameUse
collation_nameas the default server collation. See Section 5.10.1, “The Character Set Used for Data and Sorting”.(Windows only.) Write error log messages to
stderrandstdouteven if--log-erroris specified. mysqld does not close the console window if this option is used.Write a core file if mysqld dies. For some systems, you must also specify the
--core-file-sizeoption to mysqld_safe. See Section 5.3.1, “mysqld_safe — MySQL Server Startup Script”. Note that on some systems, such as Solaris, you do not get a core file if you are also using the--useroption.The path to the data directory.
--debug[=,debug_options]-# [debug_options]If MySQL is configured with
--with-debug, you can use this option to get a trace file of what mysqld is doing. Thedebug_optionsstring often is'd:t:o,. The default isfile_name''d:t:i:o,mysqld.trace'. See MySQL Internals: Porting.As of MySQL 5.0.25, using
--with-debugto configure MySQL with debugging support enables you to use the--debug="d,parser_debug"option when you start the server. This causes the Bison parser that is used to process SQL statements to dump a parser trace to the server's standard error output. Typically, this output is written to the error log.--default-character-set=(DEPRECATED)charset_nameUse
charset_nameas the default character set. This option is deprecated in favor of--character-set-server. See Section 5.10.1, “The Character Set Used for Data and Sorting”.--default-collation=collation_nameUse
collation_nameas the default collation. This option is deprecated in favor of--collation-server. See Section 5.10.1, “The Character Set Used for Data and Sorting”.Set the default storage engine (table type) for tables. See Chapter 14, Storage Engines.
This option is a synonym for
--default-storage-engine.Set the default server time zone. This option sets the global
time_zonesystem variable. If this option is not given, the default time zone is the same as the system time zone (given by the value of thesystem_time_zonesystem variable.--delay-key-write[={OFF|ON|ALL}]Specify how to use delayed key writes. Delayed key writing causes key buffers not to be flushed between writes for
MyISAMtables.OFFdisables delayed key writes.ONenables delayed key writes for those tables that were created with theDELAY_KEY_WRITEoption.ALLdelays key writes for allMyISAMtables. See Section 7.5.2, “Tuning Server Parameters”, and Section 14.1.1, “MyISAMStartup Options”.Note: If you set this variable to
ALL, you should not useMyISAMtables from within another program (such as another MySQL server or myisamchk) when the tables are in use. Doing so leads to index corruption.Read the default DES keys from this file. These keys are used by the
DES_ENCRYPT()andDES_DECRYPT()functions.--disconnect-slave-event-countThis option is used internally by the MySQL test suite for replication testing and debugging.
Enable support for named pipes. This option can be used only with the mysqld-nt and mysqld-debug servers that support named-pipe connections.
--exit-info[=,flags]-T [flags]This is a bit mask of different flags that you can use for debugging the mysqld server. Do not use this option unless you know exactly what it does!
Enable external locking (system locking), which is disabled by default as of MySQL 4.0. Note that if you use this option on a system on which
lockddoes not fully work (such as Linux), it is easy for mysqld to deadlock. This option previously was named--enable-locking.For more information about external locking, including conditions under which it can and cannot be used, see Section 7.3.4, “External Locking”.
Flush (synchronize) all changes to disk after each SQL statement. Normally, MySQL does a write of all changes to disk only after each SQL statement and lets the operating system handle the synchronizing to disk. See Section B.1.4.2, “What to Do If MySQL Keeps Crashing”.
Print a symbolic stack trace on failure.
Install an interrupt handler for
SIGINT(needed to stop mysqld with^Cto set breakpoints) and disable stack tracing and core file handling. See MySQL Internals: Porting.Read SQL statements from this file at startup. Each statement must be on a single line and should not include comments.
This option is unavailable if MySQL was configured with the
--disable-grant-optionsoption. See Section 2.4.14.2, “Typical configure Options”.Adds consistency guarantees between the content of
InnoDBtables and the binary log. See Section 5.11.3, “The Binary Log”. This option was removed in MySQL 5.0.3, having been made obsolete by the introduction of XA transaction support.--innodb-xxxThe
InnoDBoptions are listed in Section 14.2.4, “InnoDBStartup Options and System Variables”.--language=lang_name, -Llang_nameReturn client error messages in the given language.
lang_namecan be given as the language name or as the full pathname to the directory where the language files are installed. See Section 5.10.2, “Setting the Error Message Language”.Some hardware/operating system architectures support memory pages greater than the default (usually 4KB). The actual implementation of this support depends on the underlying hardware and OS. Applications that perform a lot of memory accesses may obtain performance improvements by using large pages due to reduced Translation Lookaside Buffer (TLB) misses.
Currently, MySQL supports only the Linux implementation of large pages support (which is called HugeTLB in Linux). We have plans to extend this support to FreeBSD, Solaris and possibly other platforms.
Before large pages can be used on Linux, it is necessary to configure the HugeTLB memory pool. For reference, consult the
hugetlbpage.txtfile in the Linux kernel source.This option is disabled by default. It was added in MySQL 5.0.3.
--log[=,file_name]-l [file_name]Log connections and SQL statements received from clients to this file. See Section 5.11.2, “The General Query Log”. If you omit the filename, MySQL uses
host_name.logEnable binary logging. The server logs all statements that change data to the binary log, which is used for backup and replication. See Section 5.11.3, “The Binary Log”.
The option value, if given, is the basename for the log sequence. The server creates binary log files in sequence by adding a numeric suffix to the basename. It is recommended that you specify a basename (see Section B.1.8.1, “Open Issues in MySQL”, for the reason). Otherwise, MySQL uses
host_name-binThe index file for binary log filenames. See Section 5.11.3, “The Binary Log”. If you omit the filename, and if you didn't specify one with
--log-bin, MySQL useshost_name-bin.index--log-bin-trust-function-creators[={0|1}]With no argument or an argument of 1, this option sets the
log_bin_trust_function_creatorssystem variable to 1. With an argument of 0, this option sets the system variable to 0.log_bin_trust_function_creatorsaffects how MySQL enforces restrictions on stored function creation. See Section 17.4, “Binary Logging of Stored Routines and Triggers”.This option was added in MySQL 5.0.16.
--log-bin-trust-routine-creators[={0|1}]This is the old name for
--log-bin-trust-function-creators. Before MySQL 5.0.16, it also applies to stored procedures, not just stored functions and sets thelog_bin_trust_routine_creatorssystem variable. As of 5.0.16, this option is deprecated. It is recognized for backward compatibility but its use results in a warning.This option was added in MySQL 5.0.6.
Log errors and startup messages to this file. See Section 5.11.1, “The Error Log”. If you omit the filename, MySQL uses
host_name.err.err.Log all
MyISAMchanges to this file (used only when debuggingMyISAM).--log-long-format(DEPRECATED)Log extra information to the update log, binary update log, and slow query log, if they have been activated. For example, the username and timestamp are logged for all queries. This option is deprecated, as it now represents the default logging behavior. (See the description for
--log-short-format.) The--log-queries-not-using-indexesoption is available for the purpose of logging queries that do not use indexes to the slow query log.--log-queries-not-using-indexesIf you are using this option with
--log-slow-queries, queries that do not use indexes are logged to the slow query log. See Section 5.11.4, “The Slow Query Log”.Log less information to the update log, binary update log, and slow query log, if they have been activated. For example, the username and timestamp are not logged for queries.
Log slow administrative statements such as
OPTIMIZE TABLE,ANALYZE TABLE, andALTER TABLEto the slow query log.--log-slow-queries[=file_name]Log all queries that have taken more than
long_query_timeseconds to execute to this file. See Section 5.11.4, “The Slow Query Log”. See the descriptions of the--log-long-formatand--log-short-formatoptions for details.The name of the memory-mapped transaction coordinator log file (for XA transactions that affect multiple storage engines when the binary log is disabled). The default name is
tc.log. The file is created under the data directory if not given as a full pathname. Currently, this option is unused. Added in MySQL 5.0.3.The size in bytes of the memory-mapped transaction coordinator log. The default size is 24KB. Added in MySQL 5.0.3.
--log-warnings[=,level]-W [level]Print out warnings such as
Aborted connection...to the error log. Enabling this option is recommended, for example, if you use replication (you get more information about what is happening, such as messages about network failures and reconnections). This option is enabled (1) by default, and the defaultlevelvalue if omitted is 1. To disable this option, use--log-warnings=0. Aborted connections are not logged to the error log unless the value is greater than 1. See Section B.1.2.10, “Communication Errors and Aborted Connections”.Give table-modifying operations (
INSERT,REPLACE,DELETE,UPDATE) lower priority than selects. This can also be done via{INSERT | REPLACE | DELETE | UPDATE} LOW_PRIORITY ...to lower the priority of only one query, or bySET LOW_PRIORITY_UPDATES=1to change the priority in one thread. This affects only storage engines that use only table-level locking (MyISAM,MEMORY,MERGE). See Section 7.3.2, “Table Locking Issues”.This option is used internally by the MySQL test suite for replication testing and debugging.
Lock the mysqld process in memory. This works on systems such as Solaris that support the
mlockall()system call. This might help if you have a problem where the operating system is causing mysqld to swap on disk. Note that use of this option requires that you run the server asroot, which is normally not a good idea for security reasons. See Section 5.6.5, “How to Run MySQL as a Normal User”.--myisam-recover[=option[,option]...]]Set the
MyISAMstorage engine recovery mode. The option value is any combination of the values ofDEFAULT,BACKUP,FORCE, orQUICK. If you specify multiple values, separate them by commas. You can also use a value of""to disable this option. If this option is used, each time mysqld opens aMyISAMtable, it checks whether the table is marked as crashed or wasn't closed properly. (The last option works only if you are running with external locking disabled.) If this is the case, mysqld runs a check on the table. If the table was corrupted, mysqld attempts to repair it.The following options affect how the repair works:
Option Description DEFAULTThe same as not giving any option to --myisam-recover.BACKUPIf the data file was changed during recovery, save a backup of the tbl_name.MYDtbl_name-datetime.BAKFORCERun recovery even if we would lose more than one row from the .MYDfile.QUICKDon't check the rows in the table if there aren't any delete blocks. Before the server automatically repairs a table, it writes a note about the repair to the error log. If you want to be able to recover from most problems without user intervention, you should use the options
BACKUP,FORCE. This forces a repair of a table even if some rows would be deleted, but it keeps the old data file as a backup so that you can later examine what happened.--ndb-connectstring=connect_stringWhen using the
NDBstorage engine, it is possible to point out the management server that distributes the cluster configuration by setting the connect string option. See Section 15.4.4.2, “The Cluster Connectstring”, for syntax.If the binary includes support for the
NDB Clusterstorage engine, this option enables the engine, which is disabled by default. See Chapter 15, MySQL Cluster.Force the server to generate short (pre-4.1) password hashes for new passwords. This is useful for compatibility when the server must support older client programs. See Section 5.7.9, “Password Hashing as of MySQL 4.1”.
Only use one thread (for debugging under Linux). This option is available only if the server is built with debugging enabled. See MySQL Internals: Porting.
Change the number of file descriptors available to mysqld. If this option is not set or is set to 0, mysqld uses the value to reserve file descriptors with
setrlimit(). If the value is 0, mysqld reservesmax_connections×5ormax_connections + table_open_cache×2files (whichever is larger). You should try increasing this value if mysqld gives you the errorToo many open files.The pathname of the process ID file. This file is used by other programs such as mysqld_safe to determine the server's process ID.
The port number to use when listening for TCP/IP connections. The port number must be 1024 or higher unless the server is started by the
rootsystem user.On some systems, when the server is stopped, the TCP/IP port might not become available immediately. If the server is restarted quickly afterward, its attempt to reopen the port can fail. This option indicates how many seconds the server should wait for the TCP/IP port to become free if it cannot be opened. The default is not to wait. This option was added in MySQL 5.0.19.
Skip some optimization stages.
If this option is enabled, a user cannot create new MySQL users by using the
GRANTstatement unless the user has theINSERTprivilege for themysql.usertable or any column in the table. If you want a user to have the ability to create new users that have those privileges that the user has the right to grant, you should grant the user the following privilege:GRANT INSERT(user) ON mysql.user TO '
user_name'@'host_name';This ensures that the user cannot change any privilege columns directly, but has to use the
GRANTstatement to give privileges to other users.Disallow authentication by clients that attempt to use accounts that have old (pre-4.1) passwords.
This option limits the effect of the
LOAD_FILE()function and theLOAD DATAandSELECT ... INTO OUTFILEstatements to work only with files in the specified directory.This option was added in MySQL 5.0.38.
Enable shared-memory connections by local clients. This option is available only on Windows.
--shared-memory-base-name=nameThe name of shared memory to use for shared-memory connections. This option is available only on Windows. The default name is
MYSQL. The name is case sensitive.Disable the
BDBstorage engine. This saves memory and might speed up some operations. Do not use this option if you requireBDBtables.Turn off the ability to select and insert at the same time on
MyISAMtables. (This is to be used only if you think you have found a bug in this feature.) See Section 7.3.3, “Concurrent Inserts”.Do not use external locking (system locking). For more information about external locking, including conditions under which it can and cannot be used, see Section 7.3.4, “External Locking”.
External locking has been disabled by default since MySQL 4.0.
This option causes the server not to use the privilege system at all, which gives anyone with access to the server unrestricted access to all databases. You can cause a running server to start using the grant tables again by executing mysqladmin flush-privileges or mysqladmin reload command from a system shell, or by issuing a MySQL
FLUSH PRIVILEGESstatement after connecting to the server. This option also suppresses loading of user-defined functions (UDFs).This option is unavailable if MySQL was configured with the
--disable-grant-optionsoption. See Section 2.4.14.2, “Typical configure Options”.Do not use the internal hostname cache for faster name-to-IP resolution. Instead, query the DNS server every time a client connects. See Section 7.5.7, “How MySQL Uses DNS”.
Disable the
InnoDBstorage engine. This saves memory and disk space and might speed up some operations. Do not use this option if you requireInnoDBtables.Disable the
MERGEstorage engine. This option was added in MySQL 5.0.24. It can be used if the following behavior is undesirable: If a user has access toMyISAMtablet, that user can create aMERGEtablemthat accessest. However, if the user's privileges ontare subsequently revoked, the user can continue to accesstby doing so throughm.Do not resolve hostnames when checking client connections. Use only IP numbers. If you use this option, all
Hostcolumn values in the grant tables must be IP numbers orlocalhost. See Section 7.5.7, “How MySQL Uses DNS”.Disable the
NDB Clusterstorage engine. This is the default for binaries that were built withNDB Clusterstorage engine support; the server allocates memory and other resources for this storage engine only if the--ndbclusteroption is given explicitly. See Section 15.4.3, “Quick Test Setup of MySQL Cluster”, for an example of usage.Don't listen for TCP/IP connections at all. All interaction with mysqld must be made via named pipes or shared memory (on Windows) or Unix socket files (on Unix). This option is highly recommended for systems where only local clients are allowed. See Section 7.5.7, “How MySQL Uses DNS”.
This option is used internally by the MySQL test suite for replication testing and debugging.
Options that begin with
--sslspecify whether to allow clients to connect via SSL and indicate where to find SSL keys and certificates. See Section 5.8.7.3, “SSL Command Options”.Instructs the MySQL server not to run as a service.
--symbolic-links,--skip-symbolic-linksEnable or disable symbolic link support. This option has different effects on Windows and Unix:
On Windows, enabling symbolic links allows you to establish a symbolic link to a database directory by creating a
db_name.symOn Unix, enabling symbolic links means that you can link a
MyISAMindex file or data file to another directory with theINDEX DIRECTORYorDATA DIRECTORYoptions of theCREATE TABLEstatement. If you delete or rename the table, the files that its symbolic links point to also are deleted or renamed. See Section 7.6.1.2, “Using Symbolic Links for Tables on Unix”.
If MySQL is configured with
--with-debug=full, all MySQL programs check for memory overruns during each memory allocation and memory freeing operation. This checking is very slow, so for the server you can avoid it when you don't need it by using the--skip-safemallocoption.With this option, the
SHOW DATABASESstatement is allowed only to users who have theSHOW DATABASESprivilege, and the statement displays all database names. Without this option,SHOW DATABASESis allowed to all users, but displays each database name only if the user has theSHOW DATABASESprivilege or some privilege for the database. Note that any global privilege is considered a privilege for the database.Don't write stack traces. This option is useful when you are running mysqld under a debugger. On some systems, you also must use this option to get a core file. See MySQL Internals: Porting.
Disable using thread priorities for faster response time.
On Unix, this option specifies the Unix socket file to use when listening for local connections. The default value is
/tmp/mysql.sock. On Windows, the option specifies the pipe name to use when listening for local connections that use a named pipe. The default value isMySQL(not case sensitive).--sql-mode=value[,value[,value...]]Set the SQL mode. See Section 5.2.6, “SQL Modes”.
As of MySQL 5.0.13,
SYSDATE()by default returns the time at which it executes, not the time at which the statement in which it occurs begins executing. This differs from the behavior ofNOW(). This option causesSYSDATE()to be an alias forNOW(). For information about the implications for binary logging and replication, see the description forSYSDATE()in Section 12.6, “Date and Time Functions” and forSET TIMESTAMPin Section 13.5.3, “SETSyntax”.This option was added in MySQL 5.0.20.
--tc-heuristic-recover={COMMIT|ROLLBACK}The type of decision to use in the heuristic recovery process. Currently, this option is unused. Added in MySQL 5.0.3.
This option causes most temporary files created by the server to use a small set of names, rather than a unique name for each new file. This works around a problem in the Linux kernel dealing with creating many new files with different names. With the old behavior, Linux seems to “leak” memory, because it is being allocated to the directory entry cache rather than to the disk cache.
Sets the default transaction isolation level. The
levelvalue can beREAD-UNCOMMITTED,READ-COMMITTED,REPEATABLE-READ, orSERIALIZABLE. See Section 13.4.6, “SET TRANSACTIONSyntax”.The path of the directory to use for creating temporary files. It might be useful if your default
/tmpdirectory resides on a partition that is too small to hold temporary tables. This option accepts several paths that are used in round-robin fashion. Paths should be separated by colon characters (‘:’) on Unix and semicolon characters (‘;’) on Windows, NetWare, and OS/2. If the MySQL server is acting as a replication slave, you should not set--tmpdirto point to a directory on a memory-based filesystem or to a directory that is cleared when the server host restarts. For more information about the storage location of temporary files, see Section B.1.4.4, “Where MySQL Stores Temporary Files”. A replication slave needs some of its temporary files to survive a machine restart so that it can replicate temporary tables orLOAD DATA INFILEoperations. If files in the temporary file directory are lost when the server restarts, replication fails.--user={,user_name|user_id}-u {user_name|user_id}Run the mysqld server as the user having the name
user_nameor the numeric user IDuser_id. (“User” in this context refers to a system login account, not a MySQL user listed in the grant tables.)This option is mandatory when starting mysqld as
root. The server changes its user ID during its startup sequence, causing it to run as that particular user rather than asroot. See Section 5.6.1, “General Security Guidelines”.To avoid a possible security hole where a user adds a
--user=rootoption to amy.cnffile (thus causing the server to run asroot), mysqld uses only the first--useroption specified and produces a warning if there are multiple--useroptions. Options in/etc/my.cnfand$MYSQL_HOME/my.cnfare processed before command-line options, so it is recommended that you put a--useroption in/etc/my.cnfand specify a value other thanroot. The option in/etc/my.cnfis found before any other--useroptions, which ensures that the server runs as a user other thanroot, and that a warning results if any other--useroption is found.Display version information and exit.
You can assign a value to a server system variable by using an
option of the form
--.
For example, var_name=value--key_buffer_size=32M sets the
key_buffer_size variable to a value of
32MB.
Note that when you assign a value to a variable, MySQL might automatically correct the value to stay within a given range, or adjust the value to the closest allowable value if only certain values are allowed.
If you want to restrict the maximum value to which a variable
can be set at runtime with SET, you can
define this by using the
--maximum-
command-line option.
var_name=value
It is also possible to set variables by using
--set-variable=
or var_name=value-O
syntax. This syntax is deprecated.
var_name=value
You can change the values of most system variables for a
running server with the SET statement. See
Section 13.5.3, “SET Syntax”.
Section 5.2.3, “System Variables”, provides a full description for all variables, and additional information for setting them at server startup and runtime. Section 7.5.2, “Tuning Server Parameters”, includes information on optimizing the server by tuning system variables.
The mysql server maintains many system
variables that indicate how it is configured. Each system
variable has a default value. System variables can be set at
server startup using options on the command line or in an
option file. Most of them can be changed dynamically while the
server is running by means of the SET
statement, which enables you to modify operation of the server
without having to stop and restart it. You can refer to system
variable values in expressions.
There are several ways to see the names and values of system variables:
To see the values that a server will use based on its compiled-in defaults and any option files that it reads, use this command:
mysqld --verbose --help
To see the values that a server will use based on its compiled-in defaults, ignoring the settings in any option files, use this command:
mysqld --no-defaults --verbose --help
To see the current values used by a running server, use the
SHOW VARIABLESstatement.
This section provides a description of each system variable. Variables with no version indicated are present in all MySQL 5.0 releases. For historical information concerning their implementation, please see MySQL 3.23, 4.0, 4.1 Reference Manual.
For additional system variable information, see these sections:
Section 5.2.4, “Using System Variables”, discusses the syntax for setting and displaying system variable values.
Section 5.2.4.2, “Dynamic System Variables”, lists the variables that can be set at runtime.
Information on tuning system variables can be found in Section 7.5.2, “Tuning Server Parameters”.
Section 14.2.4, “
InnoDBStartup Options and System Variables”, listsInnoDBsystem variables.
Note: Some of the following variable
descriptions refer to “enabling” or
“disabling” a variable. These variables can be
enabled with the SET statement by setting
them to ON or 1, or
disabled by setting them to OFF or
0. However, to set such a variable on the
command line or in an option file, you must set it to
1 or 0; setting it to
ON or OFF will not work.
For example, on the command line,
--delay_key_write=1 works but
--delay_key_write=ON does not.
Values for buffer sizes, lengths, and stack sizes are given in bytes unless otherwise specified.
auto_increment_incrementandauto_increment_offsetare intended for use with master-to-master replication, and can be used to control the operation ofAUTO_INCREMENTcolumns. Both variables can be set globally or locally, and each can assume an integer value between 1 and 65,535 inclusive. Setting the value of either of these two variables to 0 causes its value to be set to 1 instead. Attempting to set the value of either of these two variables to an integer greater than 65,535 or less than 0 causes its value to be set to 65,535 instead. Attempting to set the value ofauto_increment_incrementorauto_increment_offsetto a non-integer value gives rise to an error, and the actual value of the variable remains unchanged.These two variables affect
AUTO_INCREMENTcolumn behavior as follows:auto_increment_incrementcontrols the interval between successive column values. For example:mysql>
SHOW VARIABLES LIKE 'auto_inc%';+--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 1 | | auto_increment_offset | 1 | +--------------------------+-------+ 2 rows in set (0.00 sec) mysql>CREATE TABLE autoinc1->(col INT NOT NULL AUTO_INCREMENT PRIMARY KEY);Query OK, 0 rows affected (0.04 sec) mysql>SET @@auto_increment_increment=10;Query OK, 0 rows affected (0.00 sec) mysql>SHOW VARIABLES LIKE 'auto_inc%';+--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 10 | | auto_increment_offset | 1 | +--------------------------+-------+ 2 rows in set (0.01 sec) mysql>INSERT INTO autoinc1 VALUES (NULL), (NULL), (NULL), (NULL);Query OK, 4 rows affected (0.00 sec) Records: 4 Duplicates: 0 Warnings: 0 mysql>SELECT col FROM autoinc1;+-----+ | col | +-----+ | 1 | | 11 | | 21 | | 31 | +-----+ 4 rows in set (0.00 sec)(Note how
SHOW VARIABLESis used here to obtain the current values for these variables.)auto_increment_offsetdetermines the starting point for theAUTO_INCREMENTcolumn value. Consider the following, assuming that these statements are executed during the same session as the example given in the description forauto_increment_increment:mysql>
SET @@auto_increment_offset=5;Query OK, 0 rows affected (0.00 sec) mysql>SHOW VARIABLES LIKE 'auto_inc%';+--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 10 | | auto_increment_offset | 5 | +--------------------------+-------+ 2 rows in set (0.00 sec) mysql>CREATE TABLE autoinc2->(col INT NOT NULL AUTO_INCREMENT PRIMARY KEY);Query OK, 0 rows affected (0.06 sec) mysql>INSERT INTO autoinc2 VALUES (NULL), (NULL), (NULL), (NULL);Query OK, 4 rows affected (0.00 sec) Records: 4 Duplicates: 0 Warnings: 0 mysql>SELECT col FROM autoinc2;+-----+ | col | +-----+ | 5 | | 15 | | 25 | | 35 | +-----+ 4 rows in set (0.02 sec)If the value of
auto_increment_offsetis greater than that ofauto_increment_increment, the value ofauto_increment_offsetis ignored.
Should one or both of these variables be changed and then new rows inserted into a table containing an
AUTO_INCREMENTcolumn, the results may seem counterintuitive because the series ofAUTO_INCREMENTvalues is calculated without regard to any values already present in the column, and the next value inserted is the least value in the series that is greater than the maximum existing value in theAUTO_INCREMENTcolumn. In other words, the series is calculated like so:auto_increment_offset +N× auto_increment_incrementwhere
Nis a positive integer value in the series [1, 2, 3, ...]. For example:mysql>
SHOW VARIABLES LIKE 'auto_inc%';+--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 10 | | auto_increment_offset | 5 | +--------------------------+-------+ 2 rows in set (0.00 sec) mysql>SELECT col FROM autoinc1;+-----+ | col | +-----+ | 1 | | 11 | | 21 | | 31 | +-----+ 4 rows in set (0.00 sec) mysql>INSERT INTO autoinc1 VALUES (NULL), (NULL), (NULL), (NULL);Query OK, 4 rows affected (0.00 sec) Records: 4 Duplicates: 0 Warnings: 0 mysql>SELECT col FROM autoinc1;+-----+ | col | +-----+ | 1 | | 11 | | 21 | | 31 | | 35 | | 45 | | 55 | | 65 | +-----+ 8 rows in set (0.00 sec)The values shown for
auto_increment_incrementandauto_increment_offsetgenerate the series 5 +N× 10, that is, [5, 15, 25, 35, 45, ...]. The greatest value present in thecolcolumn prior to theINSERTis 31, and the next available value in theAUTO_INCREMENTseries is 35, so the inserted values forcolbegin at that point and the results are as shown for theSELECTquery.It is important to remember that it is not possible to confine the effects of these two variables to a single table, and thus they do not take the place of the sequences offered by some other database management systems; these variables control the behavior of all
AUTO_INCREMENTcolumns in all tables on the MySQL server. If one of these variables is set globally, its effects persist until the global value is changed or overridden by setting them locally, or until mysqld is restarted. If set locally, the new value affectsAUTO_INCREMENTcolumns for all tables into which new rows are inserted by the current user for the duration of the session, unless the values are changed during that session.The
auto_increment_incrementvariable was added in MySQL 5.0.2. Its default value is 1. See Section 6.13, “Auto-Increment in Multiple-Master Replication”.This variable was introduced in MySQL 5.0.2. Its default value is 1. For particulars, see the description for
auto_increment_increment.When this variable has a value of 1 (the default), the server automatically grants the
EXECUTEandALTER ROUTINEprivileges to the creator of a stored routine, if the user cannot already execute and alter or drop the routine. (TheALTER ROUTINEprivileges is required to drop the routine.) The server also automatically drops those privileges when the creator drops the routine. Ifautomatic_sp_privilegesis 0, the server does not automatically add and drop these privileges. This variable was added in MySQL 5.0.3.The number of outstanding connection requests MySQL can have. This comes into play when the main MySQL thread gets very many connection requests in a very short time. It then takes some time (although very little) for the main thread to check the connection and start a new thread. The
back_logvalue indicates how many requests can be stacked during this short time before MySQL momentarily stops answering new requests. You need to increase this only if you expect a large number of connections in a short period of time.In other words, this value is the size of the listen queue for incoming TCP/IP connections. Your operating system has its own limit on the size of this queue. The manual page for the Unix
listen()system call should have more details. Check your OS documentation for the maximum value for this variable.back_logcannot be set higher than your operating system limit.basedirThe MySQL installation base directory. This variable can be set with the
--basediroption.The size of the buffer that is allocated for caching indexes and rows for
BDBtables. If you don't useBDBtables, you should start mysqld with--skip-bdbto not allocate memory for this cache.The base directory for
BDBtables. This should be assigned the same value as thedatadirvariable.The size of the buffer that is allocated for caching indexes and rows for
BDBtables. If you don't useBDBtables, you should set this to 0 or start mysqld with--skip-bdbto not allocate memory for this cache.The directory where the
BDBstorage engine writes its log files. This variable can be set with the--bdb-logdiroption.The maximum number of locks that can be active for a
BDBtable (10,000 by default). You should increase this value if errors such as the following occur when you perform long transactions or when mysqld has to examine many rows to calculate a query:bdb: Lock table is out of available locks Got error 12 from ...
This is
ONif you are using--bdb-shared-datato start Berkeley DB in multi-process mode. (Do not useDB_PRIVATEwhen initializing Berkeley DB.)The
BDBtemporary file directory.The size of the cache to hold the SQL statements for the binary log during a transaction. A binary log cache is allocated for each client if the server supports any transactional storage engines and if the server has the binary log enabled (
--log-binoption). If you often use large, multiple-statement transactions, you can increase this cache size to get more performance. TheBinlog_cache_useandBinlog_cache_disk_usestatus variables can be useful for tuning the size of this variable. See Section 5.11.3, “The Binary Log”.MySQL Enterprise For recommendations on the optimum setting for
binlog_cache_sizesubscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.MyISAMuses a special tree-like cache to make bulk inserts faster forINSERT ... SELECT,INSERT ... VALUES (...), (...), ..., andLOAD DATA INFILEwhen adding data to non-empty tables. This variable limits the size of the cache tree in bytes per thread. Setting it to 0 disables this optimization. The default value is 8MB.The character set for statements that arrive from the client.
The character set used for literals that do not have a character set introducer and for number-to-string conversion.
The character set used by the default database. The server sets this variable whenever the default database changes. If there is no default database, the variable has the same value as
character_set_server.The filesystem character set. This variable is used to interpret string literals that refer to filenames, such as in the
LOAD DATA INFILEandSELECT ... INTO OUTFILEstatements and theLOAD_FILE()function. Such filenames are converted fromcharacter_set_clienttocharacter_set_filesystembefore the file opening attempt occurs. The default value isbinary, which means that no conversion occurs. For systems on which multi-byte filenames are allowed, a different value may be more appropriate. For example, if the system represents filenames using UTF-8, setcharacter_set_filesystemto'utf8'. This variable was added in MySQL 5.0.19.The character set used for returning query results to the client.
The server's default character set.
The character set used by the server for storing identifiers. The value is always
utf8.The directory where character sets are installed.
The collation of the connection character set.
The collation used by the default database. The server sets this variable whenever the default database changes. If there is no default database, the variable has the same value as
collation_server.The server's default collation.
The transaction completion type:
If the value is 0 (the default),
COMMITandROLLBACKare unaffected.If the value is 1,
COMMITandROLLBACKare equivalent toCOMMIT AND CHAINandROLLBACK AND CHAIN, respectively. (A new transaction starts immediately with the same isolation level as the just-terminated transaction.)If the value is 2,
COMMITandROLLBACKare equivalent toCOMMIT RELEASEandROLLBACK RELEASE, respectively. (The server disconnects after terminating the transaction.)
This variable was added in MySQL 5.0.3
If 1 (the default), MySQL allows
INSERTandSELECTstatements to run concurrently forMyISAMtables that have no free blocks in the middle of the data file. You can turn this option off by starting mysqld with--safeor--skip-new.In MySQL 5.0.6, this variable was changed to take three integer values:
Value Description 0 Off 1 (Default) Enables concurrent insert for MyISAMtables that don't have holes2 Enables concurrent inserts for all MyISAMtables, even those that have holes. For a table with a hole, new rows are inserted at the end of the table if it is in use by another thread. Otherwise, MySQL acquires a normal write lock and inserts the row into the hole.See also Section 7.3.3, “Concurrent Inserts”.
The number of seconds that the mysqld server waits for a connect packet before responding with
Bad handshake.datadirThe MySQL data directory. This variable can be set with the
--datadiroption.This variable is not implemented.
This variable is not implemented.
The default mode value to use for the
WEEK()function. See Section 12.6, “Date and Time Functions”.This option applies only to
MyISAMtables. It can have one of the following values to affect handling of theDELAY_KEY_WRITEtable option that can be used inCREATE TABLEstatements.Option Description OFFDELAY_KEY_WRITEis ignored.ONMySQL honors any DELAY_KEY_WRITEoption specified inCREATE TABLEstatements. This is the default value.ALLAll new opened tables are treated as if they were created with the DELAY_KEY_WRITEoption enabled.If
DELAY_KEY_WRITEis enabled for a table, the key buffer is not flushed for the table on every index update, but only when the table is closed. This speeds up writes on keys a lot, but if you use this feature, you should add automatic checking of allMyISAMtables by starting the server with the--myisam-recoveroption (for example,--myisam-recover=BACKUP,FORCE). See Section 5.2.2, “Command Options”, and Section 14.1.1, “MyISAMStartup Options”.Note that if you enable external locking with
--external-locking, there is no protection against index corruption for tables that use delayed key writes.After inserting
delayed_insert_limitdelayed rows, theINSERT DELAYEDhandler thread checks whether there are anySELECTstatements pending. If so, it allows them to execute before continuing to insert delayed rows.How many seconds an
INSERT DELAYEDhandler thread should wait forINSERTstatements before terminating.This is a per-table limit on the number of rows to queue when handling
INSERT DELAYEDstatements. If the queue becomes full, any client that issues anINSERT DELAYEDstatement waits until there is room in the queue again.This variable indicates the number of digits of precision by which to increase the result of division operations performed with the
/operator. The default value is 4. The minimum and maximum values are 0 and 30, respectively. The following example illustrates the effect of increasing the default value.mysql>
SELECT 1/7;+--------+ | 1/7 | +--------+ | 0.1429 | +--------+ mysql>SET div_precision_increment = 12;mysql>SELECT 1/7;+----------------+ | 1/7 | +----------------+ | 0.142857142857 | +----------------+This variable was added in MySQL 5.0.6.
This variable applies to NDB. By default it is 0 (
OFF): If you execute a query such asSELECT * FROM t WHERE mycol = 42, wheremycolis a non-indexed column, the query is executed as a full table scan on every NDB node. Each node sends every row to the MySQL server, which applies theWHEREcondition. Ifengine_condition_pushdownis set to 1 (ON), the condition is “pushed down” to the storage engine and sent to the NDB nodes. Each node uses the condition to perform the scan, and only sends back to the MySQL server the rows that match the condition.This variable was added in MySQL 5.0.3. Before that, the default
NDBbehavior is the same as for a value ofOFF.The number of days for automatic binary log removal. The default is 0, which means “no automatic removal.” Possible removals happen at startup and at binary log rotation.
flushIf
ON, the server flushes (synchronizes) all changes to disk after each SQL statement. Normally, MySQL does a write of all changes to disk only after each SQL statement and lets the operating system handle the synchronizing to disk. See Section B.1.4.2, “What to Do If MySQL Keeps Crashing”. This variable is set toONif you start mysqld with the--flushoption.If this is set to a non-zero value, all tables are closed every
flush_timeseconds to free up resources and synchronize unflushed data to disk. We recommend that this option be used only on systems with minimal resources.The list of operators supported by boolean full-text searches performed using
IN BOOLEAN MODE. See Section 12.8.1, “Boolean Full-Text Searches”.The default variable value is
'+ -><()~*:""&|'. The rules for changing the value are as follows:Operator function is determined by position within the string.
The replacement value must be 14 characters.
Each character must be an ASCII non-alphanumeric character.
Either the first or second character must be a space.
No duplicates are allowed except the phrase quoting operators in positions 11 and 12. These two characters are not required to be the same, but they are the only two that may be.
Positions 10, 13, and 14 (which by default are set to ‘
:’, ‘&’, and ‘|’) are reserved for future extensions.
The maximum length of the word to be included in a
FULLTEXTindex.Note:
FULLTEXTindexes must be rebuilt after changing this variable. UseREPAIR TABLE.tbl_nameQUICKThe minimum length of the word to be included in a
FULLTEXTindex.Note:
FULLTEXTindexes must be rebuilt after changing this variable. UseREPAIR TABLE.tbl_nameQUICKThe number of top matches to use for full-text searches performed using
WITH QUERY EXPANSION.The file from which to read the list of stopwords for full-text searches. All the words from the file are used; comments are not honored. By default, a built-in list of stopwords is used (as defined in the
myisam/ft_static.cfile). Setting this variable to the empty string ('') disables stopword filtering.Note:
FULLTEXTindexes must be rebuilt after changing this variable or the contents of the stopword file. UseREPAIR TABLE.tbl_nameQUICKThe maximum allowed result length for the
GROUP_CONCAT()function. The default is 1024.YESif mysqld supportsARCHIVEtables,NOif not.YESif mysqld supportsBDBtables.DISABLEDif--skip-bdbis used.YESif mysqld supportsBLACKHOLEtables,NOif not.YESif thezlibcompression library is available to the server,NOif not. If not, theCOMPRESS()andUNCOMPRESS()functions cannot be used.YESif thecrypt()system call is available to the server,NOif not. If not, theENCRYPT()function cannot be used.YESif mysqld supportsCSVtables,NOif not.YESif mysqld supportsEXAMPLEtables,NOif not.YESif mysqld supportsFEDERATEDtables,NOif not. This variable was added in MySQL 5.0.3.YESif the server supports spatial data types,NOif not.YESif mysqld supportsInnoDBtables.DISABLEDif--skip-innodbis used.In MySQL 5.0, this variable appears only for reasons of backward compatibility. It is always
NObecauseISAMtables are no longer supported.YESif mysqld supportsMERGEtables.DISABLEDif--skip-mergeis used. This variable was added in MySQL 5.0.24.YESif mysqld supportsNDB Clustertables.DISABLEDif--skip-ndbclusteris used.YESif mysqld supports SSL connections,NOif not.YESif mysqld supports the query cache,NOif not.In MySQL 5.0, this variable appears only for reasons of backward compatibility. It is always
NObecauseRAIDtables are no longer supported.YESifRTREEindexes are available,NOif not. (These are used for spatial indexes inMyISAMtables.)YESif symbolic link support is enabled,NOif not. This is required on Unix for support of theDATA DIRECTORYandINDEX DIRECTORYtable options, and on Windows for support of data directory symlinks.The server sets this variable to the server hostname at startup. This variable was added in MySQL 5.0.38.
A string to be executed by the server for each client that connects. The string consists of one or more SQL statements. To specify multiple statements, separate them by semicolon characters. For example, each client begins by default with autocommit mode enabled. There is no global system variable to specify that autocommit should be disabled by default, but
init_connectcan be used to achieve the same effect:SET GLOBAL init_connect='SET AUTOCOMMIT=0';
This variable can also be set on the command line or in an option file. To set the variable as just shown using an option file, include these lines:
[mysqld] init_connect='SET AUTOCOMMIT=0'
Note that the content of
init_connectis not executed for users that have theSUPERprivilege. This is done so that an erroneous value forinit_connectdoes not prevent all clients from connecting. For example, the value might contain a statement that has a syntax error, thus causing client connections to fail. Not executinginit_connectfor users that have theSUPERprivilege enables them to open a connection and fix theinit_connectvalue.The name of the file specified with the
--init-fileoption when you start the server. This should be a file containing SQL statements that you want the server to execute when it starts. Each statement must be on a single line and should not include comments.Note that the
--init-fileoption is unavailable if MySQL was configured with the--disable-grant-optionsoption. See Section 2.4.14.2, “Typical configure Options”.This variable is similar to
init_connect, but is a string to be executed by a slave server each time the SQL thread starts. The format of the string is the same as for theinit_connectvariable.innodb_xxxInnoDBsystem variables are listed in Section 14.2.4, “InnoDBStartup Options and System Variables”.The number of seconds the server waits for activity on an interactive connection before closing it. An interactive client is defined as a client that uses the
CLIENT_INTERACTIVEoption tomysql_real_connect(). See alsowait_timeout.The size of the buffer that is used for joins that do not use indexes and thus perform full table scans. Normally, the best way to get fast joins is to add indexes. Increase the value of
join_buffer_sizeto get a faster full join when adding indexes is not possible. One join buffer is allocated for each full join between two tables. For a complex join between several tables for which indexes are not used, multiple join buffers might be necessary.Index blocks for
MyISAMtables are buffered and are shared by all threads.key_buffer_sizeis the size of the buffer used for index blocks. The key buffer is also known as the key cache.The maximum allowable setting for
key_buffer_sizeis 4GB. The effective maximum size might be less, depending on your available physical RAM and per-process RAM limits imposed by your operating system or hardware platform.Increase the value to get better index handling (for all reads and multiple writes) to as much as you can afford. Using a value that is 25% of total memory on a machine that mainly runs MySQL is quite common. However, if you make the value too large (for example, more than 50% of your total memory) your system might start to page and become extremely slow. MySQL relies on the operating system to perform filesystem caching for data reads, so you must leave some room for the filesystem cache. Consider also the memory requirements of other storage engines.
For even more speed when writing many rows at the same time, use
LOCK TABLES. See Section 7.2.17, “Speed ofINSERTStatements”.You can check the performance of the key buffer by issuing a
SHOW STATUSstatement and examining theKey_read_requests,Key_reads,Key_write_requests, andKey_writesstatus variables. (See Section 13.5.4, “SHOWSyntax”.) TheKey_reads/Key_read_requestsratio should normally be less than 0.01. TheKey_writes/Key_write_requestsratio is usually near 1 if you are using mostly updates and deletes, but might be much smaller if you tend to do updates that affect many rows at the same time or if you are using theDELAY_KEY_WRITEtable option.The fraction of the key buffer in use can be determined using
key_buffer_sizein conjunction with theKey_blocks_unusedstatus variable and the buffer block size, which is available from thekey_cache_block_sizesystem variable:1 - ((Key_blocks_unused × key_cache_block_size) / key_buffer_size)
This value is an approximation because some space in the key buffer may be allocated internally for administrative structures.
It is possible to create multiple
MyISAMkey caches. The size limit of 4GB applies to each cache individually, not as a group. See Section 7.4.6, “TheMyISAMKey Cache”.This value controls the demotion of buffers from the hot sub-chain of a key cache to the warm sub-chain. Lower values cause demotion to happen more quickly. The minimum value is 100. The default value is 300. See Section 7.4.6, “The
MyISAMKey Cache”.The size in bytes of blocks in the key cache. The default value is 1024. See Section 7.4.6, “The
MyISAMKey Cache”.The division point between the hot and warm sub-chains of the key cache buffer chain. The value is the percentage of the buffer chain to use for the warm sub-chain. Allowable values range from 1 to 100. The default value is 100. See Section 7.4.6, “The
MyISAMKey Cache”.languageThe language used for error messages.
Whether mysqld was compiled with options for large file support.
large_pagesWhether large page support is enabled. This variable was added in MySQL 5.0.3.
This variable specifies the locale that controls the language used to display day and month names and abbreviations. This variable affects the output from the
DATE_FORMAT(),DAYNAME()andMONTHNAME()functions. Locale names are POSIX-style values such as'ja_JP'or'pt_BR'. The default value is'en_US'regardless of your system's locale setting. For further information, see Section 5.10.9, “MySQL Server Locale Support”. This variable was added in MySQL 5.0.25.The type of license the server has.
Whether
LOCALis supported forLOAD DATA INFILEstatements. See Section 5.6.4, “Security Issues withLOAD DATA LOCAL”.Whether mysqld was locked in memory with
--memlock.logWhether logging of all statements to the general query log is enabled. See Section 5.11.2, “The General Query Log”.
Whether the binary log is enabled. See Section 5.11.3, “The Binary Log”.
log_bin_trust_function_creatorsThis variable applies when binary logging is enabled. It controls whether stored function creators can be trusted not to create stored functions that will cause unsafe events to be written to the binary log. If set to 0 (the default), users are not allowed to create or alter stored functions unless they have the
SUPERprivilege in addition to theCREATE ROUTINEorALTER ROUTINEprivilege. A setting of 0 also enforces the restriction that a function must be declared with theDETERMINISTICcharacteristic, or with theREADS SQL DATAorNO SQLcharacteristic. If the variable is set to 1, MySQL does not enforce these restrictions on stored function creation. See Section 17.4, “Binary Logging of Stored Routines and Triggers”.This variable was added in MySQL 5.0.16.
log_bin_trust_routine_creatorsThis is the old name for
log_bin_trust_function_creators. Before MySQL 5.0.16, it also applies to stored procedures, not just stored functions. As of 5.0.16, this variable is deprecated. It is recognized for backward compatibility but its use results in a warning.This variable was added in MySQL 5.0.6.
The location of the error log.
Whether queries that do not use indexes are logged to the slow query log. See Section 5.11.4, “The Slow Query Log”. This variable was added in MySQL 5.0.23.
Whether updates received by a slave server from a master server should be logged to the slave's own binary log. Binary logging must be enabled on the slave for this variable to have any effect. See Section 6.8, “Replication Startup Options”.
Whether slow queries should be logged. “Slow” is determined by the value of the
long_query_timevariable. See Section 5.11.4, “The Slow Query Log”.Whether to produce additional warning messages. It is enabled (1) by default and can be disabled by setting it to 0. Aborted connections are not logged to the error log unless the value is greater than 1.
If a query takes longer than this many seconds, the server increments the
Slow_queriesstatus variable. If you are using the--log-slow-queriesoption, the query is logged to the slow query log file. This value is measured in real time, not CPU time, so a query that is under the threshold on a lightly loaded system might be above the threshold on a heavily loaded one. The minimum value is 1. The default is 10. See Section 5.11.4, “The Slow Query Log”.If set to
1, allINSERT,UPDATE,DELETE, andLOCK TABLE WRITEstatements wait until there is no pendingSELECTorLOCK TABLE READon the affected table. This affects only storage engines that use only table-level locking (MyISAM,MEMORY,MERGE). This variable previously was namedsql_low_priority_updates.This variable describes the case sensitivity of filenames on the filesystem where the data directory is located.
OFFmeans filenames are case sensitive,ONmeans they are not case sensitive.If set to 1, table names are stored in lowercase on disk and table name comparisons are not case sensitive. If set to 2 table names are stored as given but compared in lowercase. This option also applies to database names and table aliases. See Section 9.2.2, “Identifier Case Sensitivity”.
If you are using
InnoDBtables, you should set this variable to 1 on all platforms to force names to be converted to lowercase.You should not set this variable to 0 if you are running MySQL on a system that does not have case-sensitive filenames (such as Windows or Mac OS X). If this variable is not set at startup and the filesystem on which the data directory is located does not have case-sensitive filenames, MySQL automatically sets
lower_case_table_namesto 2.The maximum size of one packet or any generated/intermediate string.
The packet message buffer is initialized to
net_buffer_lengthbytes, but can grow up tomax_allowed_packetbytes when needed. This value by default is small, to catch large (possibly incorrect) packets.You must increase this value if you are using large
BLOBcolumns or long strings. It should be as big as the largestBLOByou want to use. The protocol limit formax_allowed_packetis 1GB.If a multiple-statement transaction requires more than this many bytes of memory, the server generates a
Multi-statement transaction required more than 'max_binlog_cache_size' bytes of storageerror. The minimum value is 4096, the maximum and default values are 4GB.If a write to the binary log causes the current log file size to exceed the value of this variable, the server rotates the binary logs (closes the current file and opens the next one). You cannot set this variable to more than 1GB or to less than 4096 bytes. The default value is 1GB.
A transaction is written in one chunk to the binary log, so it is never split between several binary logs. Therefore, if you have big transactions, you might see binary logs larger than
max_binlog_size.If
max_relay_log_sizeis 0, the value ofmax_binlog_sizeapplies to relay logs as well.If there are more than this number of interrupted connections from a host, that host is blocked from further connections. You can unblock blocked hosts with the
FLUSH HOSTSstatement.The number of simultaneous client connections allowed. By default, this is 100. See Section B.1.2.6, “
Too many connections”, for more information.MySQL Enterprise For notification that the maximum number of connections is getting dangerously high and for advice on setting the optimum value for
max_connectionssubscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.Increasing this value increases the number of file descriptors that mysqld requires. See Section 7.4.8, “How MySQL Opens and Closes Tables”, for comments on file descriptor limits.
Do not start more than this number of threads to handle
INSERT DELAYEDstatements. If you try to insert data into a new table after allINSERT DELAYEDthreads are in use, the row is inserted as if theDELAYEDattribute wasn't specified. If you set this to 0, MySQL never creates a thread to handleDELAYEDrows; in effect, this disablesDELAYEDentirely.The maximum number of error, warning, and note messages to be stored for display by the
SHOW ERRORSandSHOW WARNINGSstatements.This variable sets the maximum size to which
MEMORYtables are allowed to grow. The value of the variable is used to calculateMEMORYtableMAX_ROWSvalues. Setting this variable has no effect on any existingMEMORYtable, unless the table is re-created with a statement such asCREATE TABLEor altered withALTER TABLEorTRUNCATE TABLE.MySQL Enterprise Subscribers to the MySQL Network Monitoring and Advisory Service receive recommendations for the optimum setting for
max_heap_table_size. For more information see http://www.mysql.com/products/enterprise/advisors.html.This variable is a synonym for
max_delayed_threads.Do not allow
SELECTstatements that probably need to examine more thanmax_join_sizerows (for single-table statements) or row combinations (for multiple-table statements) or that are likely to do more thanmax_join_sizedisk seeks. By setting this value, you can catchSELECTstatements where keys are not used properly and that would probably take a long time. Set it if your users tend to perform joins that lack aWHEREclause, that take a long time, or that return millions of rows.Setting this variable to a value other than
DEFAULTresets the value ofSQL_BIG_SELECTSto0. If you set theSQL_BIG_SELECTSvalue again, themax_join_sizevariable is ignored.If a query result is in the query cache, no result size check is performed, because the result has previously been computed and it does not burden the server to send it to the client.
This variable previously was named
sql_max_join_size.The cutoff on the size of index values that determines which
filesortalgorithm to use. See Section 7.2.11, “ORDER BYOptimization”.This variable limits the total number of prepared statements in the server. It can be used in environments where there is the potential for denial-of-service attacks based on running the server out of memory by preparing huge numbers of statements. The default value is 16,382. The allowable range of values is from 0 to 1 million. If the value is set lower than the current number of prepared statements, existing statements are not affected and can be used, but no new statements can be prepared until the current number drops below the limit. This variable was added in MySQL 5.0.21.
If a write by a replication slave to its relay log causes the current log file size to exceed the value of this variable, the slave rotates the relay logs (closes the current file and opens the next one). If
max_relay_log_sizeis 0, the server usesmax_binlog_sizefor both the binary log and the relay log. Ifmax_relay_log_sizeis greater than 0, it constrains the size of the relay log, which enables you to have different sizes for the two logs. You must setmax_relay_log_sizeto between 4096 bytes and 1GB (inclusive), or to 0. The default value is 0. See Section 6.3, “Replication Implementation Details”.Limit the assumed maximum number of seeks when looking up rows based on a key. The MySQL optimizer assumes that no more than this number of key seeks are required when searching for matching rows in a table by scanning an index, regardless of the actual cardinality of the index (see Section 13.5.4.13, “
SHOW INDEXSyntax”). By setting this to a low value (say, 100), you can force MySQL to prefer indexes instead of table scans.The number of bytes to use when sorting
BLOBorTEXTvalues. Only the firstmax_sort_lengthbytes of each value are used; the rest are ignored.The number of times that a stored procedure may call itself. The default value for this option is 0, which completely disallows recursion in stored procedures. The maximum value is 255.
This variable can be set globally and per session.
The maximum number of temporary tables a client can keep open at the same time. (This option does not yet do anything.)
The maximum number of simultaneous connections allowed to any given MySQL account. A value of 0 means “no limit.”
Before MySQL 5.0.3, this variable has only global scope. Beginning with MySQL 5.0.3, it also has a read-only session scope. The session variable has the same value as the global variable unless the current account has a non-zero
MAX_USER_CONNECTIONSresource limit. In that case, the session value reflects the account limit.After this many write locks, allow some pending read lock requests to be processed in between.
The maximum number of ranges to send to a table handler at once during range selects. The default value is 256. Sending multiple ranges to a handler at once can improve the performance of certain selects dramatically. This especially true for the NDB Cluster table handler, which needs to send the range requests to all nodes. Sending a batch of those requests at once reduces the communication costs significantly. This variable was added in MySQL 5.0.3.
The block size to be used for
MyISAMindex pages.The default pointer size in bytes, to be used by
CREATE TABLEforMyISAMtables when noMAX_ROWSoption is specified. This variable cannot be less than 2 or larger than 7. The default value is 6 (4 before MySQL 5.0.6). This variable was added in MySQL 4.1.2. See Section B.1.2.11, “The table is full”.myisam_max_extra_sort_file_size(DEPRECATED)If the temporary file used for fast
MyISAMindex creation would be larger than using the key cache by the amount specified here, prefer the key cache method. This is mainly used to force long character keys in large tables to use the slower key cache method to create the index. The value is given in bytes.Note: This variable was removed in MySQL 5.0.6.
The maximum size of the temporary file that MySQL is allowed to use while re-creating a
MyISAMindex (duringREPAIR TABLE,ALTER TABLE, orLOAD DATA INFILE). If the file size would be larger than this value, the index is created using the key cache instead, which is slower. The value is given in bytes.The default value is 2GB. If
MyISAMindex files exceed this size and disk space is available, increasing the value may help performance.The value of the
--myisam-recoveroption. See Section 5.2.2, “Command Options”.If this value is greater than 1,
MyISAMtable indexes are created in parallel (each index in its own thread) during theRepair by sortingprocess. The default value is 1.Note: Multi-threaded repair is still beta-quality code.
The size of the buffer that is allocated when sorting
MyISAMindexes during aREPAIR TABLEor when creating indexes withCREATE INDEXorALTER TABLE.How the server treats
NULLvalues when collecting statistics about the distribution of index values forMyISAMtables. This variable has two possible values,nulls_equalandnulls_unequal. Fornulls_equal, allNULLindex values are considered equal and form a single value group that has a size equal to the number ofNULLvalues. Fornulls_unequal,NULLvalues are considered unequal, and eachNULLforms a distinct value group of size 1.The method that is used for generating table statistics influences how the optimizer chooses indexes for query execution, as described in Section 7.4.7, “
MyISAMIndex Statistics Collection”.This variable was added in MySQL 5.0.14. For older versions, the statistics collection method is equivalent to
nulls_equal.Specifies the maximum number of ranges to send to a storage engine during range selects. The default value is 256. Sending multiple ranges to an engine is a feature that can improve the performance of certain selects dramatically, particularly for
NDBCLUSTER. This engine needs to send the range requests to all nodes, and sending many of those requests at once reduces the communication costs significantly. This variable was added in MySQL 5.0.3.(Windows only.) Indicates whether the server supports connections over named pipes.
Determines the probability of gaps in an autoincremented column. Set to
1to minimize this. Set to a high value for optimization — makes inserts faster, but decreases the likelihood that consecutive autoincrement numbers will be used in a batch of inserts. Default value:32. Mimimum value:1.The number of milliseconds to wait before checking the
NDBquery cache. Setting this to0(the default and minimum value) means that theNDBquery cache will be checked for validation on every query.The recommended maximum value for this variable is
1000, which means that the query cache is checked once per second. A larger value means theNDBquery cache is less often checked and invalidated due to updates on a different mysqld. It is generally not desirable to set this to a value greater than2000.Forces sending of buffers to
NDBimmediately, without waiting for other threads. Defaults toON.Sets the granularity of the statistics by determining the number of starting and ending keys to store in the statistics memory cache. Zero means no caching takes place; in this case, the data nodes are always queried directly. Default value:
32.Use
NDBindex statistics in query optimization. Defaults toON.How often to query data nodes instead of the statistics cache. For example, a value of
20(the default) means to direct every 20th query to the data nodes.Causes an SQL node to contact the nearest data node in the cluster. Enabled by default. Set to
0orOFFto disable, in which case the SQL node attempts to contact data nodes in succession.ndb_report_thresh_binlog_epoch_slipThis is a threshold on the number of epochs to be behind before reporting binlog status. For example, a value of
3(the default) means that if the difference between which epoch has been received from the storage nodes and which epoch has been applied to the binlog is 3 or more, a status message will be sent to the cluster log.ndb_report_thresh_binlog_mem_usageThis is a threshold on the percentage of free memory remaining before reporting binlog status. For example, a value of
10(the default) means that if the amount of available memory for receiving binlog data from the data nodes falls below 10%, a status message will be sent to the cluster log.Forces
NDBto use a count of records duringSELECT COUNT(*)query planning to speed up this type of query. The default value isON. For faster queries overall, disable this feature by setting the value ofndb_use_exact_counttoOFF.You can disable
NDBtransaction support by setting this variable's values toOFF(not recommended). The default isON.Each client thread is associated with a connection buffer and result buffer. Both begin with a size given by
net_buffer_lengthbut are dynamically enlarged up tomax_allowed_packetbytes as needed. The result buffer shrinks tonet_buffer_lengthafter each SQL statement.This variable should not normally be changed, but if you have very little memory, you can set it to the expected length of statements sent by clients. If statements exceed this length, the connection buffer is automatically enlarged. The maximum value to which
net_buffer_lengthcan be set is 1MB.The number of seconds to wait for more data from a connection before aborting the read. This timeout applies only to TCP/IP connections, not to connections made via Unix socket files, named pipes, or shared memory. When the server is reading from the client,
net_read_timeoutis the timeout value controlling when to abort. When the server is writing to the client,net_write_timeoutis the timeout value controlling when to abort. See alsoslave_net_timeout.If a read on a communication port is interrupted, retry this many times before giving up. This value should be set quite high on FreeBSD because internal interrupts are sent to all threads.
The number of seconds to wait for a block to be written to a connection before aborting the write. This timeout applies only to TCP/IP connections, not to connections made via Unix socket files, named pipes, or shared memory. See also
net_read_timeout.This variable was used in MySQL 4.0 to turn on some 4.1 behaviors, and is retained for backward compatibility. In MySQL 5.0, its value is always
OFF.Whether the server should use pre-4.1-style passwords for MySQL user accounts. See Section B.1.2.3, “
Client does not support authentication protocol”.This is not a variable, but it can be used when setting some variables. It is described in Section 13.5.3, “
SETSyntax”.The number of files that the operating system allows mysqld to open. This is the real value allowed by the system and might be different from the value you gave using the
--open-files-limitoption to mysqld or mysqld_safe. The value is 0 on systems where MySQL can't change the number of open files.Controls the heuristics applied during query optimization to prune less-promising partial plans from the optimizer search space. A value of 0 disables heuristics so that the optimizer performs an exhaustive search. A value of 1 causes the optimizer to prune plans based on the number of rows retrieved by intermediate plans. This variable was added in MySQL 5.0.1.
The maximum depth of search performed by the query optimizer. Values larger than the number of relations in a query result in better query plans, but take longer to generate an execution plan for a query. Values smaller than the number of relations in a query return an execution plan quicker, but the resulting plan may be far from being optimal. If set to 0, the system automatically picks a reasonable value. If set to the maximum number of tables used in a query plus 2, the optimizer switches to the algorithm used in MySQL 5.0.0 (and previous versions) for performing searches. This variable was added in MySQL 5.0.1.
The pathname of the process ID (PID) file. This variable can be set with the
--pid-fileoption.portThe number of the port on which the server listens for TCP/IP connections. This variable can be set with the
--portoption.The size of the buffer that is allocated when preloading indexes.
The current number of prepared statements. (The maximum number of statements is given by the
max_prepared_stmt_countsystem variable.) This variable was added in MySQL 5.0.21. In MySQL 5.0.32, it was converted to the globalPrepared_stmt_countstatus variable.The version of the client/server protocol used by the MySQL server.
The allocation size of memory blocks that are allocated for objects created during statement parsing and execution. If you have problems with memory fragmentation, it might help to increase this a bit.
Don't cache results that are larger than this number of bytes. The default value is 1MB.
The minimum size (in bytes) for blocks allocated by the query cache. The default value is 4096 (4KB). Tuning information for this variable is given in Section 5.13.3, “Query Cache Configuration”.
The amount of memory allocated for caching query results. The default value is 0, which disables the query cache. The allowable values are multiples of 1024; other values are rounded down to the nearest multiple. Note that
query_cache_sizebytes of memory are allocated even ifquery_cache_typeis set to 0. See Section 5.13.3, “Query Cache Configuration”, for more information.Set the query cache type. Setting the
GLOBALvalue sets the type for all clients that connect thereafter. Individual clients can set theSESSIONvalue to affect their own use of the query cache. Possible values are shown in the following table:Option Description 0orOFFDon't cache results in or retrieve results from the query cache. Note that this does not deallocate the query cache buffer. To do that, you should set query_cache_sizeto 0.1orONCache all query results except for those that begin with SELECT SQL_NO_CACHE.2orDEMANDCache results only for queries that begin with SELECT SQL_CACHE.This variable defaults to
ON.Normally, when one client acquires a
WRITElock on aMyISAMtable, other clients are not blocked from issuing statements that read from the table if the query results are present in the query cache. Setting this variable to 1 causes acquisition of aWRITElock for a table to invalidate any queries in the query cache that refer to the table. This forces other clients that attempt to access the table to wait while the lock is in effect.The size of the persistent buffer used for statement parsing and execution. This buffer is not freed between statements. If you are running complex queries, a larger
query_prealloc_sizevalue might be helpful in improving performance, because it can reduce the need for the server to perform memory allocation during query execution operations.The size of blocks that are allocated when doing range optimization.
Each thread that does a sequential scan allocates a buffer of this size (in bytes) for each table it scans. If you do many sequential scans, you might want to increase this value, which defaults to 131072.
read_buffer_sizeandread_rnd_buffer_sizeare not specific to any storage engine and apply in a general manner for optimization. See Section 7.5.5, “How MySQL Uses Memory”, for example.When this variable is set to
ON, the server allows no updates except from users that have theSUPERprivilege or (on a slave server) from updates performed by slave threads. On a slave server, this can be useful to ensure that the slave accepts updates only from its master server and not from clients. As of MySQL 5.0.16, this variable does not apply toTEMPORARYtables.read_onlyexists only as aGLOBALvariable, so changes to its value require theSUPERprivilege. Changes toread_onlyon a master server are not replicated to slave servers. The value can be set on a slave server independent of the setting on the master.When reading rows in sorted order following a key-sorting operation, the rows are read through this buffer to avoid disk seeks. Setting the variable to a large value can improve
ORDER BYperformance by a lot. However, this is a buffer allocated for each client, so you should not set the global variable to a large value. Instead, change the session variable only from within those clients that need to run large queries.read_buffer_sizeandread_rnd_buffer_sizeare not specific to any storage engine and apply in a general manner for optimization. See Section 7.5.5, “How MySQL Uses Memory”, for example.Disables or enables automatic purging of relay log files as soon as they are not needed any more. The default value is 1 (
ON).This variable is unused.
If the MySQL server has been started with the
--secure-authoption, it blocks connections from all accounts that have passwords stored in the old (pre-4.1) format. In that case, the value of this variable isON, otherwise it isOFF.You should enable this option if you want to prevent all use of passwords employing the old format (and hence insecure communication over the network).
Server startup fails with an error if this option is enabled and the privilege tables are in pre-4.1 format. See Section B.1.2.3, “
Client does not support authentication protocol”.By default, this variable is empty. If set to the name of a directory, it limits the effect of the
LOAD_FILE()function and theLOAD DATAandSELECT ... INTO OUTFILEstatements to work only with files in that directory.This variable was added in MySQL 5.0.38.
The server ID. This value is set by the
--server-idoption. It is used for replication to enable master and slave servers to identify themselves uniquely.(Windows only.) Whether the server allows shared-memory connections.
(Windows only.) The name of shared memory to use for shared-memory connections. This is useful when running multiple MySQL instances on a single physical machine. The default name is
MYSQL. The name is case sensitive.This is
OFFif mysqld uses external locking,ONif external locking is disabled.skip_networkingThis is
ONif the server allows only local (non-TCP/IP) connections. On Unix, local connections use a Unix socket file. On Windows, local connections use a named pipe or shared memory. On NetWare, only TCP/IP connections are supported, so do not set this variable toON. This variable can be set toONwith the--skip-networkingoption.This prevents people from using the
SHOW DATABASESstatement if they do not have theSHOW DATABASESprivilege. This can improve security if you have concerns about users being able to see databases belonging to other users. Its effect depends on theSHOW DATABASESprivilege: If the variable value isON, theSHOW DATABASESstatement is allowed only to users who have theSHOW DATABASESprivilege, and the statement displays all database names. If the value isOFF,SHOW DATABASESis allowed to all users, but displays the names of only those databases for which the user has theSHOW DATABASESor other privilege.Whether to use compression of the slave/master protocol if both the slave and the master support it.
The name of the directory where the slave creates temporary files for replicating
LOAD DATA INFILEstatements.The number of seconds to wait for more data from a master/slave connection before aborting the read. This timeout applies only to TCP/IP connections, not to connections made via Unix socket files, named pipes, or shared memory.
slave_skip_errorsThe replication errors that the slave should skip (ignore).
If a replication slave SQL thread fails to execute a transaction because of an
InnoDBdeadlock or exceededInnoDB'sinnodb_lock_wait_timeoutor NDBCluster'sTransactionDeadlockDetectionTimeoutorTransactionInactiveTimeout, it automatically retriesslave_transaction_retriestimes before stopping with an error. The default priot to MySQL 4.0.3 is 0. You must explicitly set the value greater than 0 to enable the “retry” behavior, which is probably a good idea. In MySQL 5.0.3 or newer, the default is 10.If creating a thread takes longer than this many seconds, the server increments the
Slow_launch_threadsstatus variable.socketOn Unix platforms, this variable is the name of the socket file that is used for local client connections. The default is
/tmp/mysql.sock. (For some distribution formats, the directory might be different, such as/var/lib/mysqlfor RPMs.)On Windows, this variable is the name of the named pipe that is used for local client connections. The default value is
MySQL(not case sensitive).Each thread that needs to do a sort allocates a buffer of this size. Increase this value for faster
ORDER BYorGROUP BYoperations. See Section B.1.4.4, “Where MySQL Stores Temporary Files”.The current server SQL mode, which can be set dynamically. See Section 5.2.6, “SQL Modes”.
The number of events from the master that a slave server should skip. See Section 13.6.2.6, “
SET GLOBAL SQL_SLAVE_SKIP_COUNTERSyntax”.The path to a file with a list of trusted SSL CAs. This variable was added in MySQL 5.0.23.
The path to a directory that contains trusted SSL CA certificates in PEM format. This variable was added in MySQL 5.0.23.
The name of the SSL certificate file to use for establishing a secure connection. This variable was added in MySQL 5.0.23.
A list of allowable ciphers to use for SSL encryption. The cipher list has the same format as the
openssl cipherscommand. This variable was added in MySQL 5.0.23.The name of the SSL key file to use for establishing a secure connection. This variable was added in MySQL 5.0.23.
The default storage engine (table type). To set the storage engine at server startup, use the
--default-storage-engineoption. See Section 5.2.2, “Command Options”.If the value of this variable is positive, the MySQL server synchronizes its binary log to disk (using
fdatasync()) after everysync_binlogwrites to the binary log. Note that there is one write to the binary log per statement if autocommit is enabled, and one write per transaction otherwise. The default value is 0, which does no synchronizing to disk. A value of 1 is the safest choice, because in the event of a crash you lose at most one statement or transaction from the binary log. However, it is also the slowest choice (unless the disk has a battery-backed cache, which makes synchronization very fast).If the value of
sync_binlogis 0 (the default), no extra flushing is done. The server relies on the operating system to flush the file contents occasionaly as for any other file.If this variable is set to 1, when any non-temporary table is created its
.frmfile is synchronized to disk (usingfdatasync()). This is slower but safer in case of a crash. The default is 1.The server system time zone. When the server begins executing, it inherits a time zone setting from the machine defaults, possibly modified by the environment of the account used for running the server or the startup script. The value is used to set
system_time_zone. Typically the time zone is specified by theTZenvironment variable. It also can be specified using the--timezoneoption of the mysqld_safe script.The
system_time_zonevariable differs fromtime_zone. Although they might have the same value, the latter variable is used to initialize the time zone for each client that connects. See Section 5.10.8, “MySQL Server Time Zone Support”.The number of open tables for all threads. Increasing this value increases the number of file descriptors that mysqld requires. You can check whether you need to increase the table cache by checking the
Opened_tablesstatus variable. See Section 5.2.5, “Status Variables”. If the value ofOpened_tablesis large and you don't doFLUSH TABLESoften (which just forces all tables to be closed and reopened), then you should increase the value of thetable_cachevariable. For more information about the table cache, see Section 7.4.8, “How MySQL Opens and Closes Tables”.Specifies a wait timeout for table-level locks, in seconds. The default timeout is 50 seconds. The timeout is active only if the connection has open cursors. This variable can also be set globally at runtime (you need the
SUPERprivilege to do this). It's available as of MySQL 5.0.10.This variable is a synonym for
storage_engine. In MySQL 5.0,storage_engineis the preferred name.How many threads the server should cache for reuse. When a client disconnects, the client's threads are put in the cache if there are fewer than
thread_cache_sizethreads there. Requests for threads are satisfied by reusing threads taken from the cache if possible, and only when the cache is empty is a new thread created. This variable can be increased to improve performance if you have a lot of new connections. (Normally, this doesn't provide a notable performance improvement if you have a good thread implementation.) By examining the difference between theConnectionsandThreads_createdstatus variables, you can see how efficient the thread cache is. For details, see Section 5.2.5, “Status Variables”.On Solaris, mysqld calls
thr_setconcurrency()with this value. This function enables applications to give the threads system a hint about the desired number of threads that should be run at the same time.The stack size for each thread. Many of the limits detected by the
crash-metest are dependent on this value. The default is large enough for normal operation. See Section 7.1.4, “The MySQL Benchmark Suite”. The default is 192KB.This variable is not implemented.
The current time zone. This variable is used to initialize the time zone for each client that connects. By default, the initial value of this is
'SYSTEM'(which means, “use the value ofsystem_time_zone”). The value can be specified explicitly at server startup with the--default-time-zoneoption. See Section 5.10.8, “MySQL Server Time Zone Support”.This variable controls whether
InnoDBmutexes are timed. If this variable is set to 0 orOFF(the default), mutex timing is disabled. If the variable is set to 1 orON, mutex timing is enabled. With timing enabled, theos_wait_timesvalue in the output fromSHOW ENGINE INNODB MUTEXindicates the amount of time (in ms) spent in operating system waits. Otherwise, the value is 0. This variable was added in MySQL 5.0.3.The maximum size of in-memory temporary tables. (The actual limit is determined as the smaller of
max_heap_table_sizeandtmp_table_size.) If an in-memory temporary table exceeds the limit, MySQL automatically converts it to an on-diskMyISAMtable. Increase the value oftmp_table_size(andmax_heap_table_sizeif necessary) if you do many advancedGROUP BYqueries and you have lots of memory.tmpdirThe directory used for temporary files and temporary tables. This variable can be set to a list of several paths that are used in round-robin fashion. Paths should be separated by colon characters (‘
:’) on Unix and semicolon characters (‘;’) on Windows, NetWare, and OS/2.The multiple-directory feature can be used to spread the load between several physical disks. If the MySQL server is acting as a replication slave, you should not set
tmpdirto point to a directory on a memory-based filesystem or to a directory that is cleared when the server host restarts. A replication slave needs some of its temporary files to survive a machine restart so that it can replicate temporary tables orLOAD DATA INFILEoperations. If files in the temporary file directory are lost when the server restarts, replication fails. However, if you are using MySQL 4.0.0 or later, you can set the slave's temporary directory using theslave_load_tmpdirvariable. In that case, the slave won't use the generaltmpdirvalue and you can settmpdirto a non-permanent location.The amount in bytes by which to increase a per-transaction memory pool which needs memory. See the description of
transaction_prealloc_size.There is a per-transaction memory pool from which various transaction-related allocations take memory. The initial size of the pool in bytes is
transaction_prealloc_size. For every allocation that cannot be satisfied from the pool because it has insufficient memory available, the pool is increased bytransaction_alloc_block_sizebytes. When the transaction ends, the pool is truncated totransaction_prealloc_sizebytes.By making
transaction_prealloc_sizesufficiently large to contain all statements within a single transaction, you can avoid manymalloc()calls.The default transaction isolation level. Defaults to
REPEATABLE-READ.This variable is set by the
SET TRANSACTION ISOLATION LEVELstatement. See Section 13.4.6, “SET TRANSACTIONSyntax”. If you settx_isolationdirectly to an isolation level name that contains a space, the name should be enclosed within quotes, with the space replaced by a dash. For example:SET tx_isolation = 'READ-COMMITTED';
This variable controls whether updates to a view can be made when the view does not contain all columns of the primary key defined in the underlying table, if the update statement contains a
LIMITclause. (Such updates often are generated by GUI tools.) An update is anUPDATEorDELETEstatement. Primary key here means aPRIMARY KEY, or aUNIQUEindex in which no column can containNULL.The variable can have two values:
1orYES: Issue a warning only (not an error message). This is the default value.0orNO: Prohibit the update.
This variable was added in MySQL 5.0.2.
versionThe version number for the server.
Starting with MySQL 5.0.24, the version number will also indicate whether the server is a standard release (Community) or Enterprise release (for example,
5.0.28-enterprise-gpl-nt).The
BDBstorage engine version.The configure script has a
--with-commentoption that allows a comment to be specified when building MySQL. This variable contains the value of that comment.For precompiled binaries, this variable will hold the server version and license information. Starting with MySQL 5.0.24,
version_commentwill include the full server type and license. For community users this will appear asMySQL Community Edition - Standard (GPL). For Enterprise users, the version might be displayed asMySQL Enterprise Server (GPL). The corresponding license for your MySQL binary is shown in parentheses. For server compiled from source, the default value will be the same as that for Community releases.The type of machine or architecture on which MySQL was built.
The type of operating system on which MySQL was built.
The number of seconds the server waits for activity on a non-interactive connection before closing it. This timeout applies only to TCP/IP and Unix socket file connections, not to connections made via named pipes, or shared memory.
On thread startup, the session
wait_timeoutvalue is initialized from the globalwait_timeoutvalue or from the globalinteractive_timeoutvalue, depending on the type of client (as defined by theCLIENT_INTERACTIVEconnect option tomysql_real_connect()). See alsointeractive_timeout.
MySQL Enterprise Expert use of server system variables is part of the service offered by the MySQL Network Monitoring and Advisory Service. To subscribe see http://www.mysql.com/products/enterprise/advisors.html.
The mysql server maintains many system
variables that indicate how it is configured.
Section 5.2.3, “System Variables”, describes the
meaning of these variables. Each system variable has a default
value. System variables can be set at server startup using
options on the command line or in an option file. Most of them
can be changed dynamically while the server is running by
means of the SET statement, which enables
you to modify operation of the server without having to stop
and restart it. You can refer to system variable values in
expressions.
The server maintains two kinds of system variables. Global variables affect the overall operation of the server. Session variables affect its operation for individual client connections. A given system variable can have both a global and a session value. Global and session system variables are related as follows:
When the server starts, it initializes all global variables to their default values. These defaults can be changed by options specified on the command line or in an option file. (See Section 4.3, “Specifying Program Options”.)
The server also maintains a set of session variables for each client that connects. The client's session variables are initialized at connect time using the current values of the corresponding global variables. For example, the client's SQL mode is controlled by the session
sql_modevalue, which is initialized when the client connects to the value of the globalsql_modevalue.
System variable values can be set globally at server startup
by using options on the command line or in an option file.
When you use a startup option to set a variable that takes a
numeric value, the value can be given with a suffix of
K, M, or
G (either uppercase or lowercase) to
indicate a multiplier of 1024,
10242 or
10243; that is, units of kilobytes,
megabytes, or gigabytes, respectively. Thus, the following
command starts the server with a query cache size of 16
megabytes and a maximum packet size of one gigabyte:
mysqld --query_cache_size=16M --max_allowed_packet=1G
Within an option file, those variables are set like this:
[mysqld] query_cache_size=16M max_allowed_packet=1G
The lettercase of suffix letters does not matter;
16M and 16m are
equivalent, as are 1G and
1g.
If you want to restrict the maximum value to which a system
variable can be set at runtime with the SET
statement, you can specify this maximum by using an option of
the form
--maximum-
at server startup. For example, to prevent the value of
var_name=valuequery_cache_size from being increased to
more than 32MB at runtime, use the option
--maximum-query_cache_size=32M.
Many system variables are dynamic and can be changed while the
server runs by using the SET statement. For
a list, see Section 5.2.4.2, “Dynamic System Variables”. To
change a system variable with SET, refer to
it as var_name, optionally preceded
by a modifier:
To indicate explicitly that a variable is a global variable, precede its name by
GLOBALor@@global.. TheSUPERprivilege is required to set global variables.To indicate explicitly that a variable is a session variable, precede its name by
SESSION,@@session., or@@. Setting a session variable requires no special privilege, but a client can change only its own session variables, not those of any other client.LOCALand@@local.are synonyms forSESSIONand@@session..If no modifier is present,
SETchanges the session variable.
A SET statement can contain multiple
variable assignments, separated by commas. If you set several
system variables, the most recent GLOBAL or
SESSION modifier in the statement is used
for following variables that have no modifier specified.
Examples:
SET sort_buffer_size=10000; SET @@local.sort_buffer_size=10000; SET GLOBAL sort_buffer_size=1000000, SESSION sort_buffer_size=1000000; SET @@sort_buffer_size=1000000; SET @@global.sort_buffer_size=1000000, @@local.sort_buffer_size=1000000;
When you assign a value to a system variable with
SET, you cannot use suffix letters in the
value (as can be done with startup options). However, the
value can take the form of an expression:
SET sort_buffer_size = 10 * 1024 * 1024;
The @@
syntax for system variables is supported for compatibility
with some other database systems.
var_name
If you change a session system variable, the value remains in effect until your session ends or until you change the variable to a different value. The change is not visible to other clients.
If you change a global system variable, the value is
remembered and used for new connections until the server
restarts. (To make a global system variable setting permanent,
you should set it in an option file.) The change is visible to
any client that accesses that global variable. However, the
change affects the corresponding session variable only for
clients that connect after the change. The global variable
change does not affect the session variable for any client
that is currently connected (not even that of the client that
issues the SET GLOBAL statement).
To prevent incorrect usage, MySQL produces an error if you use
SET GLOBAL with a variable that can only be
used with SET SESSION or if you do not
specify GLOBAL (or
@@global.) when setting a global variable.
To set a SESSION variable to the
GLOBAL value or a GLOBAL
value to the compiled-in MySQL default value, use the
DEFAULT keyword. For example, the following
two statements are identical in setting the session value of
max_join_size to the global value:
SET max_join_size=DEFAULT; SET @@session.max_join_size=@@global.max_join_size;
Not all system variables can be set to
DEFAULT. In such cases, use of
DEFAULT results in an error.
You can refer to the values of specific global or sesson
system variables in expressions by using one of the
@@-modifiers. For example, you can retrieve
values in a SELECT statement like this:
SELECT @@global.sql_mode, @@session.sql_mode, @@sql_mode;
When you refer to a system variable in an expression as
@@ (that
is, when you do not specify var_name@@global. or
@@session.), MySQL returns the session
value if it exists and the global value otherwise. (This
differs from SET
@@, which always
refers to the session value.)
var_name =
value
Note: Some system variables can be
enabled with the SET statement by setting
them to ON or 1, or
disabled by setting them to OFF or
0. However, to set such a variable on the
command line or in an option file, you must set it to
1 or 0; setting it to
ON or OFF will not work.
For example, on the command line,
--delay_key_write=1 works but
--delay_key_write=ON does not.
To display system variable names and values, use the
SHOW VARIABLES statement:
mysql> SHOW VARIABLES;
+--------+--------------------------------------------------------------+
| Variable_name | Value |
+--------+--------------------------------------------------------------+
| auto_increment_increment | 1 |
| auto_increment_offset | 1 |
| automatic_sp_privileges | ON |
| back_log | 50 |
| basedir | / |
| bdb_cache_size | 8388600 |
| bdb_home | /var/lib/mysql/ |
| bdb_log_buffer_size | 32768 |
| bdb_logdir | |
| bdb_max_lock | 10000 |
| bdb_shared_data | OFF |
| bdb_tmpdir | /tmp/ |
| binlog_cache_size | 32768 |
| bulk_insert_buffer_size | 8388608 |
| character_set_client | latin1 |
| character_set_connection | latin1 |
| character_set_database | latin1 |
| character_set_results | latin1 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
| collation_connection | latin1_swedish_ci |
| collation_database | latin1_swedish_ci |
| collation_server | latin1_swedish_ci |
...
| innodb_additional_mem_pool_size | 1048576 |
| innodb_autoextend_increment | 8 |
| innodb_buffer_pool_awe_mem_mb | 0 |
| innodb_buffer_pool_size | 8388608 |
| innodb_checksums | ON |
| innodb_commit_concurrency | 0 |
| innodb_concurrency_tickets | 500 |
| innodb_data_file_path | ibdata1:10M:autoextend |
| innodb_data_home_dir | |
...
| version | 5.0.19 |
| version_comment | MySQL Community Edition - (GPL) |
| version_compile_machine | i686 |
| version_compile_os | pc-linux-gnu |
| wait_timeout | 28800 |
+--------+--------------------------------------------------------------+
With a LIKE clause, the statement displays
only those variables that match the pattern. To obtain a
specific variable name, use a LIKE clause
as shown:
SHOW VARIABLES LIKE 'max_join_size'; SHOW SESSION VARIABLES LIKE 'max_join_size';
To get a list of variables whose name match a pattern, use the
‘%’ wildcard character in a
LIKE clause:
SHOW VARIABLES LIKE '%size%'; SHOW GLOBAL VARIABLES LIKE '%size%';
Wildcard characters can be used in any position within the
pattern to be matched. Strictly speaking, because
‘_’ is a wildcard that matches
any single character, you should escape it as
‘\_’ to match it literally. In
practice, this is rarely necessary.
For SHOW VARIABLES, if you specify neither
GLOBAL nor SESSION,
MySQL returns SESSION values.
The reason for requiring the GLOBAL keyword
when setting GLOBAL-only variables but not
when retrieving them is to prevent problems in the future. If
we were to remove a SESSION variable that
has the same name as a GLOBAL variable, a
client with the SUPER privilege might
accidentally change the GLOBAL variable
rather than just the SESSION variable for
its own connection. If we add a SESSION
variable with the same name as a GLOBAL
variable, a client that intends to change the
GLOBAL variable might find only its own
SESSION variable changed.
A structured variable differs from a regular system variable in two respects:
Its value is a structure with components that specify server parameters considered to be closely related.
There might be several instances of a given type of structured variable. Each one has a different name and refers to a different resource maintained by the server.
MySQL 5.0 supports one structured variable type, which specifies parameters governing the operation of key caches. A key cache structured variable has these components:
key_buffer_sizekey_cache_block_sizekey_cache_division_limitkey_cache_age_threshold
This section describes the syntax for referring to
structured variables. Key cache variables are used for
syntax examples, but specific details about how key caches
operate are found elsewhere, in
Section 7.4.6, “The MyISAM Key Cache”.
To refer to a component of a structured variable instance,
you can use a compound name in
instance_name.component_name
format. Examples:
hot_cache.key_buffer_size hot_cache.key_cache_block_size cold_cache.key_cache_block_size
For each structured system variable, an instance with the
name of default is always predefined. If
you refer to a component of a structured variable without
any instance name, the default instance
is used. Thus, default.key_buffer_size
and key_buffer_size both refer to the
same system variable.
Structured variable instances and components follow these naming rules:
For a given type of structured variable, each instance must have a name that is unique within variables of that type. However, instance names need not be unique across structured variable types. For example, each structured variable has an instance named
default, sodefaultis not unique across variable types.The names of the components of each structured variable type must be unique across all system variable names. If this were not true (that is, if two different types of structured variables could share component member names), it would not be clear which default structured variable to use for references to member names that are not qualified by an instance name.
If a structured variable instance name is not legal as an unquoted identifier, refer to it as a quoted identifier using backticks. For example,
hot-cacheis not legal, but`hot-cache`is.global,session, andlocalare not legal instance names. This avoids a conflict with notation such as@@global.for referring to non-structured system variables.var_name
Currently, the first two rules have no possibility of being violated because the only structured variable type is the one for key caches. These rules will assume greater significance if some other type of structured variable is created in the future.
With one exception, you can refer to structured variable components using compound names in any context where simple variable names can occur. For example, you can assign a value to a structured variable using a command-line option:
shell> mysqld --hot_cache.key_buffer_size=64K
In an option file, use this syntax:
[mysqld] hot_cache.key_buffer_size=64K
If you start the server with this option, it creates a key
cache named hot_cache with a size of 64KB
in addition to the default key cache that has a default size
of 8MB.
Suppose that you start the server as follows:
shell>mysqld --key_buffer_size=256K \--extra_cache.key_buffer_size=128K \--extra_cache.key_cache_block_size=2048
In this case, the server sets the size of the default key
cache to 256KB. (You could also have written
--default.key_buffer_size=256K.) In
addition, the server creates a second key cache named
extra_cache that has a size of 128KB,
with the size of block buffers for caching table index
blocks set to 2048 bytes.
The following example starts the server with three different key caches having sizes in a 3:1:1 ratio:
shell>mysqld --key_buffer_size=6M \--hot_cache.key_buffer_size=2M \--cold_cache.key_buffer_size=2M
Structured variable values may be set and retrieved at
runtime as well. For example, to set a key cache named
hot_cache to a size of 10MB, use either
of these statements:
mysql>SET GLOBAL hot_cache.key_buffer_size = 10*1024*1024;mysql>SET @@global.hot_cache.key_buffer_size = 10*1024*1024;
To retrieve the cache size, do this:
mysql> SELECT @@global.hot_cache.key_buffer_size;
However, the following statement does not work. The variable
is not interpreted as a compound name, but as a simple
string for a LIKE pattern-matching
operation:
mysql> SHOW GLOBAL VARIABLES LIKE 'hot_cache.key_buffer_size';
This is the exception to being able to use structured variable names anywhere a simple variable name may occur.
Many server system variables are dynamic and can be set at
runtime using SET GLOBAL or SET
SESSION. You can also obtain their values using
SELECT. See
Section 5.2.4, “Using System Variables”.
The following table shows the full list of all dynamic
system variables. The last column indicates for each
variable whether GLOBAL or
SESSION (or both) apply. The table also
lists session options that can be set with the
SET statement.
Section 13.5.3, “SET Syntax”, discusses these options.
Variables that have a type of “string” take a
string value. Variables that have a type of
“numeric” take a numeric value. Variables that
have a type of “boolean” can be set to 0, 1,
ON or OFF. (If you set
them on the command line or in an option file, use the
numeric values.) Variables that are marked as
“enumeration” normally should be set to one of
the available values for the variable, but can also be set
to the number that corresponds to the desired enumeration
value. For enumerated system variables, the first
enumeration value corresponds to 0. This differs from
ENUM columns, for which the first
enumeration value corresponds to 1.
| Variable Name | Value Type | Type |
autocommit | boolean | SESSION |
automatic_sp_privileges | boolean | GLOBAL |
big_tables | boolean | SESSION |
binlog_cache_size | numeric | GLOBAL |
bulk_insert_buffer_size | numeric | GLOBAL | SESSION |
character_set_client | string | GLOBAL | SESSION |
character_set_connection | string | GLOBAL | SESSION
|
character_set_filesystem | string | GLOBAL | SESSION |
character_set_results | string | GLOBAL | SESSION |
character_set_server | string | GLOBAL | SESSION |
collation_connection | string | GLOBAL | SESSION |
collation_server | string | GLOBAL | SESSION |
completion_type | numeric | GLOBAL | SESSION |
concurrent_insert | numeric | GLOBAL |
connect_timeout | numeric | GLOBAL |
default_week_format | numeric | GLOBAL | SESSION |
delay_key_write | OFF | ON | ALL | GLOBAL |
delayed_insert_limit | numeric | GLOBAL |
delayed_insert_timeout | numeric | GLOBAL |
delayed_queue_size | numeric | GLOBAL |
div_precision_increment | numeric | GLOBAL | SESSION |
engine_condition_pushdown | boolean | GLOBAL | SESSION |
error_count | numeric | SESSION |
expire_logs_days | numeric | GLOBAL |
flush | boolean | GLOBAL |
flush_time | numeric | GLOBAL |
foreign_key_checks | boolean | SESSION |
ft_boolean_syntax | string | GLOBAL |
group_concat_max_len | numeric | GLOBAL | SESSION |
identity | numeric | SESSION |
innodb_autoextend_increment | numeric | GLOBAL |
innodb_commit_concurrency | numeric | GLOBAL |
innodb_concurrency_tickets | numeric | GLOBAL |
innodb_max_dirty_pages_pct | numeric | GLOBAL |
innodb_max_purge_lag | numeric | GLOBAL |
innodb_support_xa | boolean | GLOBAL | SESSION |
innodb_sync_spin_loops | numeric | GLOBAL |
innodb_table_locks | boolean | GLOBAL | SESSION |
innodb_thread_concurrency | numeric | GLOBAL |
innodb_thread_sleep_delay | numeric | GLOBAL |
insert_id | numeric | SESSION |
interactive_timeout | numeric | GLOBAL | SESSION |
join_buffer_size | numeric | GLOBAL | SESSION |
key_buffer_size | numeric | GLOBAL |
last_insert_id | numeric | SESSION |
lc_time_names | string | GLOBAL | SESSION |
local_infile | boolean | GLOBAL |
log_queries_not_using_indexes | boolean | GLOBAL |
log_warnings | numeric | GLOBAL |
long_query_time | numeric | GLOBAL | SESSION |
low_priority_updates | boolean | GLOBAL | SESSION |
max_allowed_packet | numeric | GLOBAL | SESSION |
max_binlog_cache_size | numeric | GLOBAL |
max_binlog_size | numeric | GLOBAL |
max_connect_errors | numeric | GLOBAL |
max_connections | numeric | GLOBAL |
max_delayed_threads | numeric | GLOBAL |
max_error_count | numeric | GLOBAL | SESSION |
max_heap_table_size | numeric | GLOBAL | SESSION |
max_insert_delayed_threads | numeric | GLOBAL |
max_join_size | numeric | GLOBAL | SESSION |
max_prepared_stmt_count | numeric | GLOBAL |
max_relay_log_size | numeric | GLOBAL |
max_seeks_for_key | numeric | GLOBAL | SESSION |
max_sort_length | numeric | GLOBAL | SESSION |
max_tmp_tables | numeric | GLOBAL | SESSION |
max_user_connections | numeric | GLOBAL |
max_write_lock_count | numeric | GLOBAL |
multi_range_count | numeric | GLOBAL | SESSION |
myisam_data_pointer_size | numeric | GLOBAL |
log_bin_trust_function_creators | boolean | GLOBAL |
myisam_max_sort_file_size | numeric | GLOBAL | SESSION |
myisam_repair_threads | numeric | GLOBAL | SESSION |
myisam_sort_buffer_size | numeric | GLOBAL | SESSION |
myisam_stats_method | enum | GLOBAL | SESSION |
net_buffer_length | numeric | GLOBAL | SESSION |
net_read_timeout | numeric | GLOBAL | SESSION |
net_retry_count | numeric | GLOBAL | SESSION |
net_write_timeout | numeric | GLOBAL | SESSION |
old_passwords | numeric | GLOBAL | SESSION |
optimizer_prune_level | numeric | GLOBAL | SESSION |
optimizer_search_depth | numeric | GLOBAL | SESSION |
preload_buffer_size | numeric | GLOBAL | SESSION |
profiling | boolean | SESSION |
profiling_history_size | numeric | SESSION |
query_alloc_block_size | numeric | GLOBAL | SESSION |
query_cache_limit | numeric | GLOBAL |
query_cache_size | numeric | GLOBAL |
query_cache_type | enumeration | GLOBAL | SESSION |
query_cache_wlock_invalidate | boolean | GLOBAL | SESSION |
query_prealloc_size | numeric | GLOBAL | SESSION |
range_alloc_block_size | numeric | GLOBAL | SESSION |
read_buffer_size | numeric | GLOBAL | SESSION |
read_only | numeric | GLOBAL |
read_rnd_buffer_size | numeric | GLOBAL | SESSION |
rpl_recovery_rank | numeric | GLOBAL |
safe_show_database | boolean | GLOBAL |
secure_auth | boolean | GLOBAL |
server_id | numeric | GLOBAL |
slave_compressed_protocol | boolean | GLOBAL |
slave_net_timeout | numeric | GLOBAL |
slave_transaction_retries | numeric | GLOBAL |
slow_launch_time | numeric | GLOBAL |
sort_buffer_size | numeric | GLOBAL | SESSION |
sql_auto_is_null | boolean | SESSION |
sql_big_selects | boolean | SESSION |
sql_big_tables | boolean | SESSION |
sql_buffer_result | boolean | SESSION |
sql_log_bin | boolean | SESSION |
sql_log_off | boolean | SESSION |
sql_log_update | boolean | SESSION |
sql_low_priority_updates | boolean | GLOBAL | SESSION |
sql_max_join_size | numeric | GLOBAL | SESSION |
sql_mode | enumeration | GLOBAL | SESSION |
sql_notes | boolean | SESSION |
sql_quote_show_create | boolean | SESSION |
sql_safe_updates | boolean | SESSION |
sql_select_limit | numeric | SESSION |
sql_slave_skip_counter | numeric | GLOBAL |
updatable_views_with_limit | enumeration | GLOBAL | SESSION |
sql_warnings | boolean | SESSION |
sync_binlog | numeric | GLOBAL |
sync_frm | boolean | GLOBAL |
storage_engine | enumeration | GLOBAL | SESSION |
table_cache | numeric | GLOBAL |
table_type | enumeration | GLOBAL | SESSION |
thread_cache_size | numeric | GLOBAL |
time_zone | string | GLOBAL | SESSION |
timestamp | boolean | SESSION |
tmp_table_size | enumeration | GLOBAL | SESSION |
transaction_alloc_block_size | numeric | GLOBAL | SESSION |
transaction_prealloc_size | numeric | GLOBAL | SESSION |
tx_isolation | enumeration | GLOBAL | SESSION |
unique_checks | boolean | SESSION |
wait_timeout | numeric | GLOBAL | SESSION |
warning_count | numeric | SESSION |
MySQL Enterprise Improper configuration of system variables can adversely affect performance and security. The MySQL Network Monitoring and Advisory Service continually monitors system variables and provides expert advice about appropriate settings. For more information see http://www.mysql.com/products/enterprise/advisors.html.
The server maintains many status variables that provide
information about its operation. You can view these variables
and their values by using the SHOW [GLOBAL]
STATUS statement. The optional
GLOBAL keyword aggregates the values over
all connections.
mysql> SHOW GLOBAL STATUS;
+-----------------------------------+------------+
| Variable_name | Value |
+-----------------------------------+------------+
| Aborted_clients | 0 |
| Aborted_connects | 0 |
| Bytes_received | 155372598 |
| Bytes_sent | 1176560426 |
...
| Connections | 30023 |
| Created_tmp_disk_tables | 0 |
| Created_tmp_files | 3 |
| Created_tmp_tables | 2 |
...
| Threads_created | 217 |
| Threads_running | 88 |
| Uptime | 1389872 |
+-----------------------------------+------------+
Note: Before MySQL 5.0.2,
SHOW STATUS returned global status values.
Because the default as of 5.0.2 is to return session values,
this is incompatible with previous versions. To issue a
SHOW STATUS statement that will retrieve
global status values for all versions of MySQL, write it like
this:
SHOW /*!50002 GLOBAL */ STATUS;
Many status variables are reset to 0 by the FLUSH
STATUS statement.
MySQL Enterprise For expert advice on using status variables, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
The status variables have the following meanings. Variables with no version indicated were already present prior to MySQL 5.0. For information regarding their implementation history, see MySQL 3.23, 4.0, 4.1 Reference Manual.
The number of connections that were aborted because the client died without closing the connection properly. See Section B.1.2.10, “Communication Errors and Aborted Connections”.
The number of failed attempts to connect to the MySQL server. See Section B.1.2.10, “Communication Errors and Aborted Connections”.
The number of transactions that used the temporary binary log cache but that exceeded the value of
binlog_cache_sizeand used a temporary file to store statements from the transaction.The number of transactions that used the temporary binary log cache.
The number of bytes received from all clients.
The number of bytes sent to all clients.
The
Com_statement counter variables indicate the number of times eachxxxxxxstatement has been executed. There is one status variable for each type of statement. For example,Com_deleteandCom_insertcountDELETEandINSERTstatements, respectively. However, if a query result is returned from query cache, the server increments theQcache_hitsstatus variable, notCom_select. See Section 5.13.4, “Query Cache Status and Maintenance”.All of the
Com_stmt_variables are increased even if a prepared statement argument is unknown or an error occurred during execution. In other words, their values correspond to the number of requests issued, not to the number of requests successfully completed.xxxThe
Com_stmt_status variables were added in 5.0.8:xxxCom_stmt_prepareCom_stmt_executeCom_stmt_fetchCom_stmt_send_long_dataCom_stmt_resetCom_stmt_close
Those variables stand for prepared statement commands. Their names refer to the
COM_command set used in the network layer. In other words, their values increase whenever prepared statement API calls such as mysql_stmt_prepare(), mysql_stmt_execute(), and so forth are executed. However,xxxCom_stmt_prepare,Com_stmt_executeandCom_stmt_closealso increase forPREPARE,EXECUTE, orDEALLOCATE PREPARE, respectively. Additionally, the values of the older (available since MySQL 4.1.3) statement counter variablesCom_prepare_sql,Com_execute_sql, andCom_dealloc_sqlincrease for thePREPARE,EXECUTE, andDEALLOCATE PREPAREstatements.Com_stmt_fetchstands for the total number of network round-trips issued when fetching from cursors.Whether the client connection uses compression in the client/server protocol. Added in MySQL 5.0.16.
The number of connection attempts (successful or not) to the MySQL server.
The number of temporary tables on disk created automatically by the server while executing statements.
How many temporary files mysqld has created.
The number of in-memory temporary tables created automatically by the server while executing statements. If
Created_tmp_disk_tablesis large, you may want to increase thetmp_table_sizevalue to cause temporary tables to be memory-based instead of disk-based.The number of rows written with
INSERT DELAYEDfor which some error occurred (probablyduplicate key).The number of
INSERT DELAYEDhandler threads in use.The number of
INSERT DELAYEDrows written.The number of executed
FLUSHstatements.The number of internal
COMMITstatements.The number of times that rows have been deleted from tables.
The MySQL server can ask the
NDB Clusterstorage engine if it knows about a table with a given name. This is called discovery.Handler_discoverindicates the number of times that tables have been discovered via this mechanism.A counter for the prepare phase of two-phase commit operations. Added in MySQL 5.0.3.
The number of times the first entry was read from an index. If this value is high, it suggests that the server is doing a lot of full index scans; for example,
SELECT col1 FROM foo, assuming thatcol1is indexed.The number of requests to read a row based on a key. If this value is high, it is a good indication that your tables are properly indexed for your queries.
The number of requests to read the next row in key order. This value is incremented if you are querying an index column with a range constraint or if you are doing an index scan.
The number of requests to read the previous row in key order. This read method is mainly used to optimize
ORDER BY ... DESC.The number of requests to read a row based on a fixed position. This value is high if you are doing a lot of queries that require sorting of the result. You probably have a lot of queries that require MySQL to scan entire tables or you have joins that don't use keys properly.
The number of requests to read the next row in the data file. This value is high if you are doing a lot of table scans. Generally this suggests that your tables are not properly indexed or that your queries are not written to take advantage of the indexes you have.
The number of requests for a storage engine to perform a rollback operation.
The number of requests for a storage engine to place a savepoint. Added in MySQL 5.0.3.
The number of requests for a storage engine to roll back to a savepoint. Added in MySQL 5.0.3.
The number of requests to update a row in a table.
The number of requests to insert a row in a table.
The number of pages containing data (dirty or clean). Added in MySQL 5.0.2.
Innodb_buffer_pool_pages_dirtyThe number of pages currently dirty. Added in MySQL 5.0.2.
Innodb_buffer_pool_pages_flushedThe number of buffer pool page-flush requests. Added in MySQL 5.0.2.
The number of free pages. Added in MySQL 5.0.2.
Innodb_buffer_pool_pages_latchedThe number of latched pages in
InnoDBbuffer pool. These are pages currently being read or written or that cannot be flushed or removed for some other reason. Added in MySQL 5.0.2.The number of pages that are busy because they have been allocated for administrative overhead such as row locks or the adaptive hash index. This value can also be calculated as
Innodb_buffer_pool_pages_total–Innodb_buffer_pool_pages_free–Innodb_buffer_pool_pages_data. Added in MySQL 5.0.2.Innodb_buffer_pool_pages_totalThe total size of buffer pool, in pages. Added in MySQL 5.0.2.
Innodb_buffer_pool_read_ahead_rndThe number of “random” read-aheads initiated by
InnoDB. This happens when a query scans a large portion of a table but in random order. Added in MySQL 5.0.2.Innodb_buffer_pool_read_ahead_seqThe number of sequential read-aheads initiated by
InnoDB. This happens whenInnoDBdoes a sequential full table scan. Added in MySQL 5.0.2.Innodb_buffer_pool_read_requestsThe number of logical read requests
InnoDBhas done. Added in MySQL 5.0.2.The number of logical reads that
InnoDBcould not satisfy from the buffer pool and had to do a single-page read. Added in MySQL 5.0.2.Normally, writes to the
InnoDBbuffer pool happen in the background. However, if it is necessary to read or create a page and no clean pages are available, it is also necessary to wait for pages to be flushed first. This counter counts instances of these waits. If the buffer pool size has been set properly, this value should be small. Added in MySQL 5.0.2.Innodb_buffer_pool_write_requestsThe number writes done to the
InnoDBbuffer pool. Added in MySQL 5.0.2.The number of
fsync()operations so far. Added in MySQL 5.0.2.The current number of pending
fsync()operations. Added in MySQL 5.0.2.The current number of pending reads. Added in MySQL 5.0.2.
The current number of pending writes. Added in MySQL 5.0.2.
The amount of data read so far, in bytes. Added in MySQL 5.0.2.
The total number of data reads. Added in MySQL 5.0.2.
The total number of data writes. Added in MySQL 5.0.2.
The amount of data written so far, in bytes. Added in MySQL 5.0.2.
Innodb_dblwr_writes,Innodb_dblwr_pages_writtenThe number of doublewrite operations that have been performed and the number of pages that have been written for this purpose. Added in MySQL 5.0.2. See Section 14.2.14.1, “
InnoDBDisk I/O”.The number of times that the log buffer was too small and a wait was required for it to be flushed before continuing. Added in MySQL 5.0.2.
The number of log write requests. Added in MySQL 5.0.2.
The number of physical writes to the log file. Added in MySQL 5.0.2.
The number of
fsync()writes done to the log file. Added in MySQL 5.0.2.The number of pending log file
fsync()operations. Added in MySQL 5.0.2.The number of pending log file writes. Added in MySQL 5.0.2.
The number of bytes written to the log file. Added in MySQL 5.0.2.
The compiled-in
InnoDBpage size (default 16KB). Many values are counted in pages; the page size allows them to be easily converted to bytes. Added in MySQL 5.0.2.The number of pages created. Added in MySQL 5.0.2.
The number of pages read. Added in MySQL 5.0.2.
The number of pages written. Added in MySQL 5.0.2.
The number of row locks currently being waited for. Added in MySQL 5.0.3.
The total time spent in acquiring row locks, in milliseconds. Added in MySQL 5.0.3.
The average time to acquire a row lock, in milliseconds. Added in MySQL 5.0.3.
The maximum time to acquire a row lock, in milliseconds. Added in MySQL 5.0.3.
The number of times a row lock had to be waited for. Added in MySQL 5.0.3.
The number of rows deleted from
InnoDBtables. Added in MySQL 5.0.2.The number of rows inserted into
InnoDBtables. Added in MySQL 5.0.2.The number of rows read from
InnoDBtables. Added in MySQL 5.0.2.The number of rows updated in
InnoDBtables. Added in MySQL 5.0.2.The number of key blocks in the key cache that have changed but have not yet been flushed to disk.
The number of unused blocks in the key cache. You can use this value to determine how much of the key cache is in use; see the discussion of
key_buffer_sizein Section 5.2.3, “System Variables”.The number of used blocks in the key cache. This value is a high-water mark that indicates the maximum number of blocks that have ever been in use at one time.
The number of requests to read a key block from the cache.
The number of physical reads of a key block from disk. If
Key_readsis large, then yourkey_buffer_sizevalue is probably too small. The cache miss rate can be calculated asKey_reads/Key_read_requests.The number of requests to write a key block to the cache.
The number of physical writes of a key block to disk.
The total cost of the last compiled query as computed by the query optimizer. This is useful for comparing the cost of different query plans for the same query. The default value of 0 means that no query has been compiled yet. This variable was added in MySQL 5.0.1, with a default value of -1. In MySQL 5.0.7, the default was changed to 0; also in version 5.0.7, the scope of
Last_query_costwas changed to session rather than global.Prior to MySQL 5.0.16, this variable was not updated for queries served from the query cache.
The maximum number of connections that have been in use simultaneously since the server started.
If the server is acting as a MySQL Cluster node, then the value of this variable its node ID in the cluster.
If the server is not part of a MySQL Cluster, then the value of this variable is 0.
If the server is part of a MySQL Cluster, the value of this variable is the hostname or IP address of the Cluster management server from which it gets its configuration data.
If the server is not part of a MySQL Cluster, then the value of this variable is an empty string.
Prior to MySQL 5.0.23, this variable was named
Ndb_connected_host.If the server is part of a MySQL Cluster, the value of this variable is the number of the port through which it is connected to the Cluster management server from which it gets its configuration data.
If the server is not part of a MySQL Cluster, then the value of this variable is 0.
Prior to MySQL 5.0.23, this variable was named
Ndb_connected_port.If the server is part of a MySQL Cluster, the value of this variable is the number of data nodes in the cluster.
If the server is not part of a MySQL Cluster, then the value of this variable is 0.
Prior to MySQL 5.0.29, this variable was named
Ndb_number_of_storage_nodes.The number of rows waiting to be written in
INSERT DELAYqueues.The number of files that are open.
The number of streams that are open (used mainly for logging).
The number of tables that are open.
The number of tables that have been opened. If
Opened_tablesis big, yourtable_cachevalue is probably too small.The current number of prepared statements. (The maximum number of statements is given by the
max_prepared_stmt_countsystem variable.) This variable was added in MySQL 5.0.32.The number of free memory blocks in the query cache.
The amount of free memory for the query cache.
The number of query cache hits.
The number of queries added to the query cache.
The number of queries that were deleted from the query cache because of low memory.
The number of non-cached queries (not cacheable, or not cached due to the
query_cache_typesetting).The number of queries registered in the query cache.
The total number of blocks in the query cache.
The number of statements that clients have sent to the server.
The status of fail-safe replication (not yet implemented).
The number of joins that perform table scans because they do not use indexes. If this value is not 0, you should carefully check the indexes of your tables.
The number of joins that used a range search on a reference table.
The number of joins that used ranges on the first table. This is normally not a critical issue even if the value is quite large.
The number of joins without keys that check for key usage after each row. If this is not 0, you should carefully check the indexes of your tables.
The number of joins that did a full scan of the first table.
The number of temporary tables that the slave SQL thread currently has open.
This is
ONif this server is a slave that is connected to a master.The total number of times since startup that the replication slave SQL thread has retried transactions. This variable was added in version 5.0.4.
The number of threads that have taken more than
slow_launch_timeseconds to create.The number of queries that have taken more than
long_query_timeseconds. See Section 5.11.4, “The Slow Query Log”.The number of merge passes that the sort algorithm has had to do. If this value is large, you should consider increasing the value of the
sort_buffer_sizesystem variable.The number of sorts that were done using ranges.
The number of sorted rows.
The number of sorts that were done by scanning the table.
Ssl_xxxVariables used for SSL connections.
The number of times that a table lock was acquired immediately.
The number of times that a table lock could not be acquired immediately and a wait was needed. If this is high and you have performance problems, you should first optimize your queries, and then either split your table or tables or use replication.
For the memory-mapped implementation of the log that is used by mysqld when it acts as the transaction coordinator for recovery of internal XA transactions, this variable indicates the largest number of pages used for the log since the server started. If the product of
Tc_log_max_pages_usedandTc_log_page_sizeis always significantly less than the log size, the size is larger than necessary and can be reduced. (The size is set by the--log-tc-sizeoption. Currently, this variable is unused: It is unneeded for binary log-based recovery, and the memory-mapped recovery log method is not used unless the number of storage engines capable of two-phase commit is greater than one. (InnoDBis the only applicable engine.) Added in MySQL 5.0.3.The page size used for the memory-mapped implementation of the XA recovery log. The default value is determined using
getpagesize(). Currently, this variable is unused for the same reasons as described forTc_log_max_pages_used. Added in MySQL 5.0.3.For the memory-mapped implementation of the recovery log, this variable increments each time the server was not able to commit a transaction and had to wait for a free page in the log. If this value is large, you might want to increase the log size (with the
--log-tc-sizeoption). For binary log-based recovery, this variable increments each time the binary log cannot be closed because there are two-phase commits in progress. (The close operation waits until all such transactions are finished.) Added in MySQL 5.0.3.The number of threads in the thread cache.
The number of currently open connections.
The number of threads created to handle connections. If
Threads_createdis big, you may want to increase thethread_cache_sizevalue. The cache miss rate can be calculated asThreads_created/Connections.The number of threads that are not sleeping.
The number of seconds that the server has been up.
The MySQL server can operate in different SQL modes, and can apply these modes differently for different clients. This capability enables each application to tailor the server's operating mode to its own requirements.
For answers to some questions that are often asked about server SQL modes in MySQL, see Section A.3, “MySQL 5.0 FAQ — Server SQL Mode”.
Modes define what SQL syntax MySQL should support and what kind of data validation checks it should perform. This makes it easier to use MySQL in different environments and to use MySQL together with other database servers.
You can set the default SQL mode by starting
mysqld with the
--sql-mode="
option, or by using
modes"sql-mode="
in modes"my.cnf (Unix operating systems) or
my.ini (Windows).
modes is a list of different modes
separated by comma (“,”)
characters. The default value is empty (no modes set). The
modes value also can be empty
(--sql-mode="" on the command line, or
sql-mode="" in my.cnf on
Unix systems or in my.ini on Windows) if
you want to clear it explicitly.
You can change the SQL mode at runtime by using a SET
[GLOBAL|SESSION]
sql_mode='
statement to set the modes'sql_mode system value.
Setting the GLOBAL variable requires the
SUPER privilege and affects the operation
of all clients that connect from that time on. Setting the
SESSION variable affects only the current
client. Any client can change its own session
sql_mode value at any time.
You can retrieve the current global or session
sql_mode value with the following
statements:
SELECT @@global.sql_mode; SELECT @@session.sql_mode;
The most important sql_mode values are
probably these:
This mode changes syntax and behavior to conform more closely to standard SQL.
If a value could not be inserted as given into a transactional table, abort the statement. For a non-transactional table, abort the statement if the value occurs in a single-row statement or the first row of a multiple-row statement. More detail is given later in this section. (Implemented in MySQL 5.0.2)
Make MySQL behave like a “traditional” SQL database system. A simple description of this mode is “give an error instead of a warning” when inserting an incorrect value into a column. Note: The
INSERT/UPDATEaborts as soon as the error is noticed. This may not be what you want if you are using a non-transactional storage engine, because data changes made prior to the error may not be rolled back, resulting in a “partially done” update. (Added in MySQL 5.0.2)
When this manual refers to “strict mode,” it
means a mode where at least one of
STRICT_TRANS_TABLES or
STRICT_ALL_TABLES is enabled.
The following list describes all supported modes:
Don't do full checking of dates. Check only that the month is in the range from 1 to 12 and the day is in the range from 1 to 31. This is very convenient for Web applications where you obtain year, month, and day in three different fields and you want to store exactly what the user inserted (without date validation). This mode applies to
DATEandDATETIMEcolumns. It does not applyTIMESTAMPcolumns, which always require a valid date.This mode is implemented in MySQL 5.0.2. Before 5.0.2, this was the default MySQL date-handling mode. As of 5.0.2, the server requires that month and day values be legal, and not merely in the range 1 to 12 and 1 to 31, respectively. With strict mode disabled, invalid dates such as
'2004-04-31'are converted to'0000-00-00'and a warning is generated. With strict mode enabled, invalid dates generate an error. To allow such dates, enableALLOW_INVALID_DATES.Treat ‘
"’ as an identifier quote character (like the ‘`’ quote character) and not as a string quote character. You can still use ‘`’ to quote identifiers with this mode enabled. WithANSI_QUOTESenabled, you cannot use double quotes to quote literal strings, because it is interpreted as an identifier.Produce an error in strict mode (otherwise a warning) when a division by zero (or
MOD(X,0)) occurs during anINSERTorUPDATE. If this mode is not enabled, MySQL instead returnsNULLfor divisions by zero. ForINSERT IGNOREorUPDATE IGNORE, MySQL generates a warning for divisions by zero, but the result of the operation isNULL. (Implemented in MySQL 5.0.2)From MySQL 5.0.2 on, the precedence of the
NOToperator is such that expressions such asNOT a BETWEEN b AND care parsed asNOT (a BETWEEN b AND c). Before MySQL 5.0.2, the expression is parsed as(NOT a) BETWEEN b AND c. The old higher-precedence behavior can be obtained by enabling theHIGH_NOT_PRECEDENCESQL mode. (Added in MySQL 5.0.2)mysql>
SET sql_mode = '';mysql>SELECT NOT 1 BETWEEN -5 AND 5;-> 0 mysql>SET sql_mode = 'HIGH_NOT_PRECEDENCE';mysql>SELECT NOT 1 BETWEEN -5 AND 5;-> 1Allow spaces between a function name and the ‘
(’ character. This causes built-in function names to be treated as reserved words. As a result, identifiers that are the same as function names must be quoted as described in Section 9.2, “Database, Table, Index, Column, and Alias Names”. For example, because there is aCOUNT()function, the use ofcountas a table name in the following statement causes an error:mysql>
CREATE TABLE count (i INT);ERROR 1064 (42000): You have an error in your SQL syntaxThe table name should be quoted:
mysql>
CREATE TABLE `count` (i INT);Query OK, 0 rows affected (0.00 sec)The
IGNORE_SPACESQL mode applies to built-in functions, not to user-defined functions or stored functions. It is always allowable to have spaces after a UDF or stored function name, regardless of whetherIGNORE_SPACEis enabled.For further discussion of
IGNORE_SPACE, see Section 9.2.3, “Function Name Parsing and Resolution”.Prevent the
GRANTstatement from automatically creating new users if it would otherwise do so, unless a non-empty password also is specified. (Added in MySQL 5.0.2)NO_AUTO_VALUE_ON_ZEROaffects handling ofAUTO_INCREMENTcolumns. Normally, you generate the next sequence number for the column by inserting eitherNULLor0into it.NO_AUTO_VALUE_ON_ZEROsuppresses this behavior for0so that onlyNULLgenerates the next sequence number.This mode can be useful if
0has been stored in a table'sAUTO_INCREMENTcolumn. (Storing0is not a recommended practice, by the way.) For example, if you dump the table with mysqldump and then reload it, MySQL normally generates new sequence numbers when it encounters the0values, resulting in a table with contents different from the one that was dumped. EnablingNO_AUTO_VALUE_ON_ZERObefore reloading the dump file solves this problem. mysqldump now automatically includes in its output a statement that enablesNO_AUTO_VALUE_ON_ZERO, to avoid this problem.Disable the use of the backslash character (‘
\’) as an escape character within strings. With this mode enabled, backslash becomes an ordinary character like any other. (Implemented in MySQL 5.0.1)When creating a table, ignore all
INDEX DIRECTORYandDATA DIRECTORYdirectives. This option is useful on slave replication servers.NO_ENGINE_SUBSTITUTIONControl automatic substitution of the default storage engine when a statement such as
CREATE TABLEorALTER TABLEspecifies a storage engine that is disabled or not compiled in. (Implemented in MySQL 5.0.8)With
NO_ENGINE_SUBSTITUTIONdisabled, the default engine is used and a warning occurs if the desired engine is known but disabled or not compiled in. If the desired engine is invalid (not a known engine name), an error occurs and the table is not created or altered.With
NO_ENGINE_SUBSTITUTIONenabled, an error occurs and the table is not created or altered if the desired engine is unavailable for any reason (whether disabled or invalid).Do not print MySQL-specific column options in the output of
SHOW CREATE TABLE. This mode is used by mysqldump in portability mode.Do not print MySQL-specific index options in the output of
SHOW CREATE TABLE. This mode is used by mysqldump in portability mode.Do not print MySQL-specific table options (such as
ENGINE) in the output ofSHOW CREATE TABLE. This mode is used by mysqldump in portability mode.In integer subtraction operations, do not mark the result as
UNSIGNEDif one of the operands is unsigned. In other words, the result of a subtraction is always signed whenever this mode is in effect, even if one of the operands is unsigned. For example, compare the type of columnc2in tablet1with that of columnc2in tablet2:mysql>
SET SQL_MODE='';mysql>CREATE TABLE test (c1 BIGINT UNSIGNED NOT NULL);mysql>CREATE TABLE t1 SELECT c1 - 1 AS c2 FROM test;mysql>DESCRIBE t1;+-------+---------------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------------------+------+-----+---------+-------+ | c2 | bigint(21) unsigned | | | 0 | | +-------+---------------------+------+-----+---------+-------+ mysql>SET SQL_MODE='NO_UNSIGNED_SUBTRACTION';mysql>CREATE TABLE t2 SELECT c1 - 1 AS c2 FROM test;mysql>DESCRIBE t2;+-------+------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+------------+------+-----+---------+-------+ | c2 | bigint(21) | | | 0 | | +-------+------------+------+-----+---------+-------+Note that this means that
BIGINT UNSIGNEDis not 100% usable in all contexts. See Section 12.9, “Cast Functions and Operators”.mysql>
SET SQL_MODE = '';mysql>SELECT CAST(0 AS UNSIGNED) - 1;+-------------------------+ | CAST(0 AS UNSIGNED) - 1 | +-------------------------+ | 18446744073709551615 | +-------------------------+ mysql>SET SQL_MODE = 'NO_UNSIGNED_SUBTRACTION';mysql>SELECT CAST(0 AS UNSIGNED) - 1;+-------------------------+ | CAST(0 AS UNSIGNED) - 1 | +-------------------------+ | -1 | +-------------------------+In strict mode, don't allow
'0000-00-00'as a valid date. You can still insert zero dates with theIGNOREoption. When not in strict mode, the date is accepted but a warning is generated. (Added in MySQL 5.0.2)In strict mode, don't accept dates where the month or day part is 0. If used with the
IGNOREoption, MySQL inserts a'0000-00-00'date for any such date. When not in strict mode, the date is accepted but a warning is generated. (Added in MySQL 5.0.2)Do not allow queries for which the
SELECTlist refers to non-aggregated columns that are not named in theGROUP BYclause. The following query is invalid with this mode enabled becauseaddressis not named in theGROUP BYclause:SELECT name, address, MAX(age) FROM t GROUP BY name;
As of MySQL 5.0.23, this mode also restricts references to non-aggregated columns in the
HAVINGclause that are not named in theGROUP BYclause.Treat
||as a string concatenation operator (same asCONCAT()) rather than as a synonym forOR.Treat
REALas a synonym forFLOAT. By default, MySQL treatsREALas a synonym forDOUBLE.Enable strict mode for all storage engines. Invalid data values are rejected. Additional detail follows. (Added in MySQL 5.0.2)
Enable strict mode for transactional storage engines, and when possible for non-transactional storage engines. Additional details follow. (Implemented in MySQL 5.0.2)
Strict mode controls how MySQL handles input values that are
invalid or missing. A value can be invalid for several
reasons. For example, it might have the wrong data type for
the column, or it might be out of range. A value is missing
when a new row to be inserted does not contain a value for a
non-NULL column that has no explicit
DEFAULT clause in its definition. (For a
NULL column, NULL is
inserted if the value is missing.)
For transactional tables, an error occurs for invalid or
missing values in a statement when either of the
STRICT_ALL_TABLES or
STRICT_TRANS_TABLES modes are enabled. The
statement is aborted and rolled back.
For non-transactional tables, the behavior is the same for either mode, if the bad value occurs in the first row to be inserted or updated. The statement is aborted and the table remains unchanged. If the statement inserts or modifies multiple rows and the bad value occurs in the second or later row, the result depends on which strict option is enabled:
For
STRICT_ALL_TABLES, MySQL returns an error and ignores the rest of the rows. However, in this case, the earlier rows still have been inserted or updated. This means that you might get a partial update, which might not be what you want. To avoid this, it's best to use single-row statements because these can be aborted without changing the table.For
STRICT_TRANS_TABLES, MySQL converts an invalid value to the closest valid value for the column and insert the adjusted value. If a value is missing, MySQL inserts the implicit default value for the column data type. In either case, MySQL generates a warning rather than an error and continues processing the statement. Implicit defaults are described in Section 11.1.4, “Data Type Default Values”.
Strict mode disallows invalid date values such as
'2004-04-31'. It does not disallow dates
with zero parts such as '2004-04-00' or
“zero” dates. To disallow these as well, enable
the NO_ZERO_IN_DATE and
NO_ZERO_DATE SQL modes in addition to
strict mode.
If you are not using strict mode (that is, neither
STRICT_TRANS_TABLES nor
STRICT_ALL_TABLES is enabled), MySQL
inserts adjusted values for invalid or missing values and
produces warnings. In strict mode, you can produce this
behavior by using INSERT IGNORE or
UPDATE IGNORE. See
Section 13.5.4.28, “SHOW WARNINGS Syntax”.
The following special modes are provided as shorthand for
combinations of mode values from the preceding list. All are
available in MySQL 5.0 beginning with version
5.0.0, except for TRADITIONAL, which was
implemented in MySQL 5.0.2.
The descriptions include all mode values that are available in the most recent version of MySQL. For older versions, a combination mode does not include individual mode values that are not available except in newer versions.
Equivalent to
REAL_AS_FLOAT,PIPES_AS_CONCAT,ANSI_QUOTES,IGNORE_SPACE. Before MySQL 5.0.3,ANSIalso includesONLY_FULL_GROUP_BY.As of MySQL 5.0.40,
ANSImode also causes the server to return an error for queries where a set functionSwith an outer referenceS(outer_ref)SELECT * FROM t1 WHERE t1.a IN (SELECT MAX(t1.b) FROM t2 WHERE ...);
Here,
MAX(t1.b)cannot aggregated in the outer query because it appears in theWHEREclause of that query. Standard SQL requires an error in this situation. IfANSImode is not enabled, the server treatsS(outer_ref)S(const)Equivalent to
PIPES_AS_CONCAT,ANSI_QUOTES,IGNORE_SPACE,NO_KEY_OPTIONS,NO_TABLE_OPTIONS,NO_FIELD_OPTIONS.Equivalent to
PIPES_AS_CONCAT,ANSI_QUOTES,IGNORE_SPACE,NO_KEY_OPTIONS,NO_TABLE_OPTIONS,NO_FIELD_OPTIONS,NO_AUTO_CREATE_USER.Equivalent to
PIPES_AS_CONCAT,ANSI_QUOTES,IGNORE_SPACE,NO_KEY_OPTIONS,NO_TABLE_OPTIONS,NO_FIELD_OPTIONS.Equivalent to
NO_FIELD_OPTIONS,HIGH_NOT_PRECEDENCE.Equivalent to
NO_FIELD_OPTIONS,HIGH_NOT_PRECEDENCE.Equivalent to
PIPES_AS_CONCAT,ANSI_QUOTES,IGNORE_SPACE,NO_KEY_OPTIONS,NO_TABLE_OPTIONS,NO_FIELD_OPTIONS,NO_AUTO_CREATE_USER.Equivalent to
PIPES_AS_CONCAT,ANSI_QUOTES,IGNORE_SPACE,NO_KEY_OPTIONS,NO_TABLE_OPTIONS,NO_FIELD_OPTIONS.Equivalent to
STRICT_TRANS_TABLES,STRICT_ALL_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER.
The server shutdown process takes place as follows:
The shutdown process is initiated.
Server shutdown can be initiated several ways. For example, a user with the
SHUTDOWNprivilege can execute a mysqladmin shutdown command. mysqladmin can be used on any platform supported by MySQL. Other operating system-specific shutdown initiation methods are possible as well: The server shuts down on Unix when it receives aSIGTERMsignal. A server running as a service on Windows shuts down when the services manager tells it to.The server creates a shutdown thread if necessary.
Depending on how shutdown was initiated, the server might create a thread to handle the shutdown process. If shutdown was requested by a client, a shutdown thread is created. If shutdown is the result of receiving a
SIGTERMsignal, the signal thread might handle shutdown itself, or it might create a separate thread to do so. If the server tries to create a shutdown thread and cannot (for example, if memory is exhausted), it issues a diagnostic message that appears in the error log:Error: Can't create thread to kill server
The server stops accepting new connections.
To prevent new activity from being initiated during shutdown, the server stops accepting new client connections. It does this by closing the network connections to which it normally listens for connections: the TCP/IP port, the Unix socket file, the Windows named pipe, and shared memory on Windows.
The server terminates current activity.
For each thread that is associated with a client connection, the connection to the client is broken and the thread is marked as killed. Threads die when they notice that they are so marked. Threads for idle connections die quickly. Threads that currently are processing statements check their state periodically and take longer to die. For additional information about thread termination, see Section 13.5.5.3, “
KILLSyntax”, in particular for the instructions about killedREPAIR TABLEorOPTIMIZE TABLEoperations onMyISAMtables.For threads that have an open transaction, the transaction is rolled back. Note that if a thread is updating a non-transactional table, an operation such as a multiple-row
UPDATEorINSERTmay leave the table partially updated, because the operation can terminate before completion.If the server is a master replication server, threads associated with currently connected slaves are treated like other client threads. That is, each one is marked as killed and exits when it next checks its state.
If the server is a slave replication server, the I/O and SQL threads, if active, are stopped before client threads are marked as killed. The SQL thread is allowed to finish its current statement (to avoid causing replication problems), and then stops. If the SQL thread was in the middle of a transaction at this point, the transaction is rolled back.
Storage engines are shut down or closed.
At this stage, the table cache is flushed and all open tables are closed.
Each storage engine performs any actions necessary for tables that it manages. For example,
MyISAMflushes any pending index writes for a table.InnoDBflushes its buffer pool to disk (starting from 5.0.5: unlessinnodb_fast_shutdownis 2), writes the current LSN to the tablespace, and terminates its own internal threads.The server exits.
MySQL Server supports a HELP statement that
returns online information from the MySQL Reference manual
(see Section 13.3.2, “HELP Syntax”). The proper operation of this
statement requires that the help tables in the
mysql database be initialized with help
topic information, which is done by processing the contents of
the fill_help_tables.sql script.
For a MySQL binary distribution on Unix, help table setup occurs when you run mysql_install_db. For an RPM distribution on Linux or binary distribution on Windows, help table setup occurs as part of the MySQL installation process.
For a MySQL source distribution, you can find the
fill_help_tables.sql file in the
scripts directory. To load the file
manually, make sure that you have initialized the
mysql database by running
mysql_install_db, and then process the file
with the mysql client as follows:
shell> mysql -u root mysql < fill_help_tables.sql
If you are working with BitKeeper and a MySQL development
source tree, the tree doesn't contain
fill_help_tables.sql. You can download
the proper file for your version of MySQL from
http://dev.mysql.com/doc/. After downloading and
uncompressing the file, process it with
mysql as just described.
This section describes several programs that are used to start mysqld, the MySQL server.
mysqld_safe is the recommended way to start a mysqld server on Unix and NetWare. mysqld_safe adds some safety features such as restarting the server when an error occurs and logging runtime information to an error log file. NetWare-specific behaviors are listed later in this section.
Note: To preserve backward compatibility with older versions of MySQL, MySQL binary distributions still include safe_mysqld as a symbolic link to mysqld_safe. However, you should not rely on this because it is removed as of MySQL 5.1.
By default, mysqld_safe before MySQL 5.0.27 tries to start an executable named mysqld-max if it exists, and mysqld otherwise. Be aware of the implications of this behavior:
On Linux, the
MySQL-MaxRPM relies on this mysqld_safe behavior. The RPM installs an executable named mysqld-max, which causes mysqld_safe to automatically use that executable rather than mysqld from that point on.If you install a MySQL-Max distribution that includes a server named mysqld-max, and then upgrade later to a non-Max version of MySQL, mysqld_safe will still attempt to run the old mysqld-max server. If you perform such an upgrade, you should manually remove the old mysqld-max server to ensure that mysqld_safe runs the new mysqld server.
To override the default behavior and specify explicitly the
name of the server you want to run, specify a
--mysqld or
--mysqld-version option to
mysqld_safe. You can also use
--ledir to indicate the directory where
mysqld_safe should look for the server.
Many of the options to mysqld_safe are the same as the options to mysqld. See Section 5.2.2, “Command Options”.
All options specified to mysqld_safe on
the command line are passed to mysqld. If
you want to use any options that are specific to
mysqld_safe and that
mysqld doesn't support, do not specify
them on the command line. Instead, list them in the
[mysqld_safe] group of an option file.
See Section 4.3.2, “Using Option Files”.
mysqld_safe reads all options from the
[mysqld], [server],
and [mysqld_safe] sections in option
files. For backward compatibility, it also reads
[safe_mysqld] sections, although you
should rename such sections to
[mysqld_safe] in MySQL 5.0
installations.
mysqld_safe supports the following options:
Display a help message and exit. (Added in MySQL 5.0.3)
(NetWare only) On NetWare, mysqld_safe provides a screen presence. When you unload (shut down) the mysqld_safe NLM, the screen does not by default go away. Instead, it prompts for user input:
*<NLM has terminated; Press any key to close the screen>*
If you want NetWare to close the screen automatically instead, use the
--autocloseoption to mysqld_safe.The path to the MySQL installation directory.
The size of the core file that mysqld should be able to create. The option value is passed to ulimit -c.
The path to the data directory.
The name of an option file to be read in addition to the usual option files. This must be the first option on the command line if it is used. As of MySQL 5.0.6, if the file does not exist or is otherwise inaccessible, the server will exit with an error.
The name of an option file to be read instead of the usual option files. This must be the first option on the command line if it is used.
If mysqld_safe cannot find the server, use this option to indicate the pathname to the directory where the server is located.
Write the error log to the given file. See Section 5.11.1, “The Error Log”.
The name of the server program (in the
ledirdirectory) that you want to start. This option is needed if you use the MySQL binary distribution but have the data directory outside of the binary distribution. If mysqld_safe cannot find the server, use the--lediroption to indicate the pathname to the directory where the server is located.This option is similar to the
--mysqldoption, but you specify only the suffix for the server program name. The basename is assumed to be mysqld. For example, if you use--mysqld-version=debug, mysqld_safe starts the mysqld-debug program in theledirdirectory. If the argument to--mysqld-versionis empty, mysqld_safe uses mysqld in theledirdirectory.Use the
niceprogram to set the server's scheduling priority to the given value.Do not read any option files. This must be the first option on the command line if it is used.
The number of files that mysqld should be able to open. The option value is passed to ulimit -n. Note that you need to start mysqld_safe as
rootfor this to work properly!The pathname of the process ID file.
The port number that the server should use when listening for TCP/IP connections. The port number must be 1024 or higher unless the server is started by the
rootsystem user.The Unix socket file that the server should use when listening for local connections.
Set the
TZtime zone environment variable to the given option value. Consult your operating system documentation for legal time zone specification formats.Run the mysqld server as the user having the name
user_nameor the numeric user IDuser_id. (“User” in this context refers to a system login account, not a MySQL user listed in the grant tables.)
If you execute mysqld_safe with the
--defaults-file or
--defaults-extra-option option to name an
option file, the option must be the first one given on the
command line or the option file will not be used. For
example, this command will not use the named option file:
mysql> mysqld_safe --port=port_num --defaults-file=file_name
Instead, use the following command:
mysql> mysqld_safe --defaults-file=file_name --port=port_num
The mysqld_safe script is written so that it normally can start a server that was installed from either a source or a binary distribution of MySQL, even though these types of distributions typically install the server in slightly different locations. (See Section 2.4.6, “Installation Layouts”.) mysqld_safe expects one of the following conditions to be true:
The server and databases can be found relative to the working directory (the directory from which mysqld_safe is invoked). For binary distributions, mysqld_safe looks under its working directory for
binanddatadirectories. For source distributions, it looks forlibexecandvardirectories. This condition should be met if you execute mysqld_safe from your MySQL installation directory (for example,/usr/local/mysqlfor a binary distribution).If the server and databases cannot be found relative to the working directory, mysqld_safe attempts to locate them by absolute pathnames. Typical locations are
/usr/local/libexecand/usr/local/var. The actual locations are determined from the values configured into the distribution at the time it was built. They should be correct if MySQL is installed in the location specified at configuration time.
Because mysqld_safe tries to find the server and databases relative to its own working directory, you can install a binary distribution of MySQL anywhere, as long as you run mysqld_safe from the MySQL installation directory:
shell>cdshell>mysql_installation_directorybin/mysqld_safe &
If mysqld_safe fails, even when invoked
from the MySQL installation directory, you can specify the
--ledir and --datadir
options to indicate the directories in which the server and
databases are located on your system.
Normally, you should not edit the
mysqld_safe script. Instead, configure
mysqld_safe by using command-line options
or options in the [mysqld_safe] section
of a my.cnf option file. In rare cases,
it might be necessary to edit mysqld_safe
to get it to start the server properly. However, if you do
this, your modified version of
mysqld_safe might be overwritten if you
upgrade MySQL in the future, so you should make a copy of
your edited version that you can reinstall.
On NetWare, mysqld_safe is a NetWare Loadable Module (NLM) that is ported from the original Unix shell script. It starts the server as follows:
Runs a number of system and option checks.
Runs a check on
MyISAMtables.Provides a screen presence for the MySQL server.
Starts mysqld, monitors it, and restarts it if it terminates in error.
Sends error messages from mysqld to the
host_name.errSends mysqld_safe screen output to the
host_name.safe
MySQL distributions on Unix include a script named mysql.server. It can be used on systems such as Linux and Solaris that use System V-style run directories to start and stop system services. It is also used by the Mac OS X Startup Item for MySQL.
mysql.server can be found in the
support-files directory under your
MySQL installation directory or in a MySQL source
distribution.
If you use the Linux server RPM package
(MySQL-server-),
the mysql.server script will be installed
in the VERSION.rpm/etc/init.d directory with the
name mysql. You need not install it
manually. See Section 2.4.9, “Installing MySQL from RPM Packages on Linux”, for more
information on the Linux RPM packages.
Some vendors provide RPM packages that install a startup script under a different name such as mysqld.
If you install MySQL from a source distribution or using a binary distribution format that does not install mysql.server automatically, you can install it manually. Instructions are provided in Section 2.4.15.2.2, “Starting and Stopping MySQL Automatically”.
mysql.server reads options from the
[mysql.server] and
[mysqld] sections of option files. For
backward compatibility, it also reads
[mysql_server] sections, although you
should rename such sections to
[mysql.server] when using MySQL
5.0.
mysqld_multi is designed to manage several mysqld processes that listen for connections on different Unix socket files and TCP/IP ports. It can start or stop servers, or report their current status. The MySQL Instance Manager is an alternative means of managing multiple servers (see Section 5.4, “mysqlmanager — The MySQL Instance Manager”).
mysqld_multi searches for groups named
[mysqld in
N]my.cnf (or in the file named by the
--config-file option).
N can be any positive integer.
This number is referred to in the following discussion as
the option group number, or GNR.
Group numbers distinguish option groups from one another and
are used as arguments to mysqld_multi to
specify which servers you want to start, stop, or obtain a
status report for. Options listed in these groups are the
same that you would use in the [mysqld]
group used for starting mysqld. (See, for
example, Section 2.4.15.2.2, “Starting and Stopping MySQL Automatically”.) However, when
using multiple servers, it is necessary that each one use
its own value for options such as the Unix socket file and
TCP/IP port number. For more information on which options
must be unique per server in a multiple-server environment,
see Section 5.12, “Running Multiple MySQL Servers on the Same Machine”.
To invoke mysqld_multi, use the following syntax:
shell> mysqld_multi [options] {start|stop|report} [GNR[,GNR] ...]
start, stop, and
report indicate which operation to
perform. You can perform the designated operation for a
single server or multiple servers, depending on the
GNR list that follows the option
name. If there is no list, mysqld_multi
performs the operation for all servers in the option file.
Each GNR value represents an
option group number or range of group numbers. The value
should be the number at the end of the group name in the
option file. For example, the GNR
for a group named [mysqld17] is
17. To specify a range of numbers,
separate the first and last numbers by a dash. The
GNR value
10-13 represents groups
[mysqld10] through
[mysqld13]. Multiple groups or group
ranges can be specified on the command line, separated by
commas. There must be no whitespace characters (spaces or
tabs) in the GNR list; anything
after a whitespace character is ignored.
This command starts a single server using option group
[mysqld17]:
shell> mysqld_multi start 17
This command stops several servers, using option groups
[mysqld8] and
[mysqld10] through
[mysqld13]:
shell> mysqld_multi stop 8,10-13
For an example of how you might set up an option file, use this command:
shell> mysqld_multi --example
mysqld_multi supports the following options:
Display a help message and exit.
Specify the name of an alternative option file. This affects where mysqld_multi looks for
[mysqldoption groups. Without this option, all options are read from the usualN]my.cnffile. The option does not affect where mysqld_multi reads its own options, which are always taken from the[mysqld_multi]group in the usualmy.cnffile.Display a sample option file.
Specify the name of the log file. If the file exists, log output is appended to it.
The mysqladmin binary to be used to stop servers.
The mysqld binary to be used. Note that you can specify mysqld_safe as the value for this option also. If you use mysqld_safe to start the server, you can include the
mysqldorlediroptions in the corresponding[mysqldoption group. These options indicate the name of the server that mysqld_safe should start and the pathname of the directory where the server is located. (See the descriptions for these options in Section 5.3.1, “mysqld_safe — MySQL Server Startup Script”.) Example:N][mysqld38] mysqld = mysqld-debug ledir = /opt/local/mysql/libexec
Print log information to
stdoutrather than to the log file. By default, output goes to the log file.The password of the MySQL account to use when invoking mysqladmin. Note that the password value is not optional for this option, unlike for other MySQL programs.
Silent mode; disable warnings.
Connect to each MySQL server via the TCP/IP port instead of the Unix socket file. (If a socket file is missing, the server might still be running, but accessible only via the TCP/IP port.) By default, connections are made using the Unix socket file. This option affects
stopandreportoperations.The username of the MySQL account to use when invoking mysqladmin.
Be more verbose.
Display version information and exit.
Some notes about mysqld_multi:
Most important: Before using mysqld_multi be sure that you understand the meanings of the options that are passed to the mysqld servers and why you would want to have separate mysqld processes. Beware of the dangers of using multiple mysqld servers with the same data directory. Use separate data directories, unless you know what you are doing. Starting multiple servers with the same data directory does not give you extra performance in a threaded system. See Section 5.12, “Running Multiple MySQL Servers on the Same Machine”.
Important: Make sure that the data directory for each server is fully accessible to the Unix account that the specific mysqld process is started as. Do not use the Unix
rootaccount for this, unless you know what you are doing. See Section 5.6.5, “How to Run MySQL as a Normal User”.Make sure that the MySQL account used for stopping the mysqld servers (with the mysqladmin program) has the same username and password for each server. Also, make sure that the account has the
SHUTDOWNprivilege. If the servers that you want to manage have different usernames or passwords for the administrative accounts, you might want to create an account on each server that has the same username and password. For example, you might set up a commonmulti_adminaccount by executing the following commands for each server:shell>
mysql -u root -S /tmp/mysql.sock -pEnter password: mysql>GRANT SHUTDOWN ON *.*->TO 'multi_admin'@'localhost' IDENTIFIED BY 'multipass';See Section 5.7.2, “How the Privilege System Works”. You have to do this for each mysqld server. Change the connection parameters appropriately when connecting to each one. Note that the hostname part of the account name must allow you to connect as
multi_adminfrom the host where you want to run mysqld_multi.The Unix socket file and the TCP/IP port number must be different for every mysqld.
The
--pid-fileoption is very important if you are using mysqld_safe to start mysqld (for example,--mysqld=mysqld_safe) Every mysqld should have its own process ID file. The advantage of using mysqld_safe instead of mysqld is that mysqld_safe monitors its mysqld process and restarts it if the process terminates due to a signal sent usingkill -9or for other reasons, such as a segmentation fault. Please note that the mysqld_safe script might require that you start it from a certain place. This means that you might have to change location to a certain directory before running mysqld_multi. If you have problems starting, please see the mysqld_safe script. Check especially the lines:---------------------------------------------------------------- MY_PWD=`pwd` # Check if we are starting this relative (for the binary release) if test -d $MY_PWD/data/mysql -a -f ./share/mysql/english/errmsg.sys -a \ -x ./bin/mysqld ----------------------------------------------------------------
The test performed by these lines should be successful, or you might encounter problems. See Section 5.3.1, “mysqld_safe — MySQL Server Startup Script”.
You might want to use the
--useroption for mysqld, but to do this you need to run the mysqld_multi script as the Unixrootuser. Having the option in the option file doesn't matter; you just get a warning if you are not the superuser and the mysqld processes are started under your own Unix account.
The following example shows how you might set up an option
file for use with mysqld_multi. The order
in which the mysqld programs are started
or stopped depends on the order in which they appear in the
option file. Group numbers need not form an unbroken
sequence. The first and fifth
[mysqld
groups were intentionally omitted from the example to
illustrate that you can have “gaps” in the
option file. This gives you more flexibility.
N]
# This file should probably be in your home dir (~/.my.cnf) # or /etc/my.cnf # Version 2.1 by Jani Tolonen [mysqld_multi] mysqld = /usr/local/bin/mysqld_safe mysqladmin = /usr/local/bin/mysqladmin user = multi_admin password = multipass [mysqld2] socket = /tmp/mysql.sock2 port = 3307 pid-file = /usr/local/mysql/var2/hostname.pid2 datadir = /usr/local/mysql/var2 language = /usr/local/share/mysql/english user = john [mysqld3] socket = /tmp/mysql.sock3 port = 3308 pid-file = /usr/local/mysql/var3/hostname.pid3 datadir = /usr/local/mysql/var3 language = /usr/local/share/mysql/swedish user = monty [mysqld4] socket = /tmp/mysql.sock4 port = 3309 pid-file = /usr/local/mysql/var4/hostname.pid4 datadir = /usr/local/mysql/var4 language = /usr/local/share/mysql/estonia user = tonu [mysqld6] socket = /tmp/mysql.sock6 port = 3311 pid-file = /usr/local/mysql/var6/hostname.pid6 datadir = /usr/local/mysql/var6 language = /usr/local/share/mysql/japanese user = jani
- 5.4.1. MySQL Instance Manager Command Options
- 5.4.2. MySQL Instance Manager Configuration Files
- 5.4.3. Starting the MySQL Server with MySQL Instance Manager
- 5.4.4. Instance Manager User and Password Management
- 5.4.5. MySQL Server Instance Status Monitoring
- 5.4.6. Connecting to MySQL Instance Manager
- 5.4.7. MySQL Instance Manager Commands
mysqlmanager is the MySQL Instance Manager (IM). This program monitors and manages MySQL Database Server instances. MySQL Instance Manager is available for Unix-like operating systems, and also on Windows as of MySQL 5.0.13. It runs as a daemon that listens on a TCP/IP port. On Unix, it also listens on a Unix socket file.
MySQL Instance Manager is included in MySQL distributions from
version 5.0.3, and can be used in place of the
mysqld_safe script to start and stop one or
more instances of MySQL Server. Because Instance Manager can
manage multiple server instances, it can also be used in place
of the mysqld_multi script. Instance
Manager offers these capabilities:
Instance Manager can start and stop instances, and report on the status of instances.
Server instances can be treated as guarded or unguarded:
When Instance Manager starts, it starts each guarded instance. If the instance crashes, Instance Manager detects this and restarts it. When Instance Manager stops, it stops the instance.
A nonguarded instance is not started when Instance Manager starts or monitored by it. If the instance crashes after being started, Instance Manager does not restart it. When Instance Manager exits, it does not stop the instance if it is running.
Instances are guarded by default. An instance can be designated as nonguarded by including the
nonguardedoption in the configuration file.Instance Manager provides an interactive interface for configuring instances, so that the need to edit the configuration file manually is reduced or eliminated.
Instance Manager provides remote instance management. That is, it runs on the host where you want to control MySQL Server instances, but you can connect to it from a remote host to perform instance-management operations.
The following sections describe MySQL Instance Manager operation in more detail.
The MySQL Instance Manager supports a number of command
options. For a brief listing, invoke
mysqlmanager with the
--help option. Options may be given on the
command line or in the Instance Manager configuration file. On
Windows, the standard configuration file is
my.ini in the directory where Instance
Manager is installed. On Unix, the standard file is
/etc/my.cnf. To specify a different
configuration file, start Instance Manager with the
--defaults-file option.
mysqlmanager supports the following options:
Display a help message and exit.
The file in which the angel process records its process ID when mysqlmanager runs in daemon mode (that is, when the
--run-as-serviceoption is given). The default filename ismysqlmanager.angel.pid.If the
--angel-pid-fileoption is not given, the default angel PID file has the same name as the PID file except that any PID file extension is replaced with an extension of.angel.pid. (For example,mysqlmanager.pidbecomesmysqlmanager.angel.pid.)This option was added in MySQL 5.0.23.
The IP address to bind to.
The pathname of the MySQL Server binary. This pathname is used for all server instance sections in the configuration file for which no
mysqld-pathoption is present. The default value of this option is the compiled-in pathname, which depends on how the MySQL distribution was configured. Example:--default-mysqld-path=/usr/sbin/mysqldRead Instance Manager and MySQL Server settings from the given file. All configuration changes made by the Instance Manager will be written to this file. This must be the first option on the command line if it is used, and the file must exist.
If this option is not given, Instance Manager uses its standard configuration file. On Windows, the standard file is
my.iniin the directory where Instance Manager is installed. On Unix, the standard file is/etc/my.cnf.On Windows, install Instance Manager as a Windows service. The service name is
MySQL Manager. This option was added in MySQL 5.0.11.The path to the Instance Manager log file. This option has no effect unless the --run-as-service option is also given. If the filename specified for the option is a relative name, the log file is created under the directory from which Instance Manager is started. To ensure that the file is created in a specific directory, specify it as a full pathname.
If
--run-as-serviceis given without--log, the log file ismysqlmanager.login the data directory.If
--run-as-serviceis not given, log messages go to the standard output. To capture log output, you can redirect Instance Manager output to a file:mysqlmanager > im.log
The interval in seconds for monitoring server instances. The default value is 20 seconds. Instance Manager tries to connect to each monitored (guarded) instance using the non-existing
MySQL_Instance_Manageruser account to check whether it is alive/not hanging. If the result of the connection attempt indicates that the instance is unavailable, Instance Manager performs several attempts to restart the instance.Normally, the
MySQL_Instance_Manageraccount does not exist, so the connection attempts by Instance Manager cause the monitored instance to produce messages in its general query log similar to the following:Access denied for user 'MySQL_Instance_M'@'localhost' (using password: YES)
The
nonguardedoption in the appropriate server instance section disables monitoring for a particular instance. If the instance dies after being started, Instance Manager will not restart it. Instance Manager tries to connect to a nonguarded instance only when you request the instance's status (for example, with theSHOW INSTANCESstatus.See Section 5.4.5, “MySQL Server Instance Status Monitoring”, for more information.
Prepare an entry for the password file, print it to the standard output, and exit. You can redirect the output from Instance Manager to a file to save the entry in the file.
The name of the file where the Instance Manager looks for users and passwords. On Windows, the default is
mysqlmanager.passwdin the directory where Instance Manager is installed. On Unix, the default file is/etc/mysqlmanager.passwd.The process ID file to use. On Windows, the default file is
mysqlmanager.pidin the directory where Instance Manager is installed. On Unix, the default ismysqlmanager.pidin the data directory.The port number to use when listening for TCP/IP connections from clients. The default port number (assigned by IANA) is 2273.
Print the current defaults and exit. This must be the first option on the command line if it is used.
On Windows, removes Instance Manager as a Windows service. This assumes that Instance Manager has been run with
--installpreviously. This option was added in MySQL 5.0.11.On Unix, daemonize and start an angel process. The angel process monitors Instance Manager and restarts it if it crashes. (The angel process itself is simple and unlikely to crash.)
On Unix, the socket file to use for incoming connections. The default file is named
/tmp/mysqlmanager.sock. This option has no meaning on Windows.This option is used on Windows to run Instance Manager in standalone mode. You should specify it when you start Instance Manager from the command line. This option was added in MySQL 5.0.13.
On Unix, the username of the system account to use for starting and running mysqlmanager. This option generates a warning and has no effect unless you start mysqlmanager as
root(so that it can change its effective user ID), or as the named user. It is recommended that you configure mysqlmanager to run using the same account used to run the mysqld server. (“User” in this context refers to a system login account, not a MySQL user listed in the grant tables.)Display version information and exit.
The number of seconds to wait for activity on an incoming connection before closing it. The default is 28800 seconds (8 hours).
This option was added in MySQL 5.0.19. Before that, the timeout is 30 seconds and cannot be changed.
Instance Manager uses its standard configuration file unless
it is started with a --defaults-file option
that specifies a different file. On Windows, the standard file
is my.ini in the directory where Instance
Manager is installed. On Unix, the standard file is
/etc/my.cnf. (Prior to MySQL 5.0.10, the
MySQL Instance Manager read the same configuration files as
the MySQL Server, including /etc/my.cnf,
~/.my.cnf, and so forth.)
Instance Manager reads options for itself from the
[manager] section of the configuration
file, and options for server instances from
[mysqld] or
[mysqld
sections. The N][manager] section contains
any of the options listed in
Section 5.4.1, “MySQL Instance Manager Command Options”, except for
those specified as having to be given as the first option on
the command line. Here is a sample
[manager] section:
# MySQL Instance Manager options section [manager] default-mysqld-path = /usr/local/mysql/libexec/mysqld socket=/tmp/manager.sock pid-file=/tmp/manager.pid password-file = /home/cps/.mysqlmanager.passwd monitoring-interval = 2 port = 1999 bind-address = 192.168.1.5
Each [mysqld] or
[mysqld
instance section specifies options given by Instance Manager
to a server instance at startup. These are mainly common MySQL
Server options (see Section 5.2.2, “Command Options”). In
addition, a
N][mysqld
section can contain the options in the following list, which
are specific to Instance Manager. These options are
interpreted by Instance Manager itself; it does not pass them
to the server when it attempts to start that server.
N]
Warning
The Instance Manager-specific options must not be used in a
[mysqld] section. If a server is started
without using Instance Manager, it will not recognize these
options and will fail to start properly.
mysqld-path =pathThe pathname of the mysqld server binary to use for the server instance.
nonguardedThis option disables Instance Manager monitoring functionality for the server instance. By default, an instance is guarded: At Instance Manager start time, it starts the instance. It also monitors the instance status and attempts to restart it if it fails. At Instance Manager exit time, it stops the instance. None of these things happen for nonguarded instances.
shutdown-delay =secondsThe number of seconds Instance Manager should wait for the server instance to shut down. The default value is 35 seconds. After the delay expires, Instance Manager assumes that the instance is hanging and attempts to terminate it. If you use
InnoDBwith large tables, you should increase this value.
Here are some sample instance sections:
[mysqld1] mysqld-path=/usr/local/mysql/libexec/mysqld socket=/tmp/mysql.sock port=3307 server_id=1 skip-stack-trace core-file skip-bdb log-bin log-error log=mylog log-slow-queries [mysqld2] nonguarded port=3308 server_id=2 mysqld-path= /home/cps/mysql/trees/mysql-5.0/sql/mysqld socket = /tmp/mysql.sock5 pid-file = /tmp/hostname.pid5 datadir= /home/cps/mysql_data/data_dir1 language=/home/cps/mysql/trees/mysql-5.0/sql/share/english log-bin log=/tmp/fordel.log
This section discusses how Instance Manager starts server instances when it starts. However, before you start Instance Manager, you should set up a password file for it. Otherwise, you will not be able to connect to Instance Manager to control it after it starts. For details about creating Instance Manager accounts, see Section 5.4.4, “Instance Manager User and Password Management”.
On Unix, the mysqld MySQL database server
normally is started with the mysql.server
script, which usually resides in the
/etc/init.d/ directory. In MySQL 5.0.3,
this script invokes mysqlmanager (the MySQL
Instance Manager binary) to start MySQL. (In prior versions of
MySQL the mysqld_safe script is used for
this purpose.) Starting from MySQL 5.0.4, the behavior of the
startup script was changed again to incorporate both setup
schemes. In version 5.0.4, the startup script uses the old
scheme (invoking mysqld_safe) by default,
but one can set the use_mysqld_safe
variable in the script to 0 (zero) to use
the MySQL Instance Manager to start a server.
Starting with MySQL 5.0.19, you can use Instance Manager if
you modify the my.cnf configuration file
by adding use-manager to the
[mysql.server] section:
[mysql.server] use-manager
When Instance Manager starts, it reads its configuration file
if it exists to find server instance sections and prepare a
list of instances. Instance sections have names of the form
[mysqld] or
[mysqld, where
N]N is an unsigned integer (for
example, [mysqld1],
[mysqld2], and so forth).
After preparing the list of instances, Instance Manager starts
the guarded instances in the list. If there are no instances,
Instance Manager creates an instance named
mysqld and attempts to start it with
default (compiled-in) configuration values. This means that
the Instance Manager cannot find the mysqld
program if it is not installed in the default location.
(Section 2.4.6, “Installation Layouts”, describes default
locations for components of MySQL distributions.) If you have
installed the MySQL server in a non-standard location, you
should create the Instance Manager configuration file.
Instance Manager also stops all guarded server instances when it shuts down.
The allowable options for
[mysqld server
instance sections are described in
Section 5.4.2, “MySQL Instance Manager Configuration Files”. In
these sections, you can use a special
N]mysqld-path=
option that is recognized only by Instance Manager. Use this
option to let Instance Manager know where the
mysqld binary resides. If there are
multiple instances, it may also be necessary to set other
options such as path-to-mysqld-binarydatadir and
port, to ensure that each instance has a
different data directory and TCP/IP port number.
Section 5.12, “Running Multiple MySQL Servers on the Same Machine”, discusses the
configuration values that must differ for each instance when
you run multiple instance on the same machine.
Warning
The [mysqld] instance section, if it
exists, must not contain any Instance Manager-specific
options.
The typical Unix startup/shutdown cycle for a MySQL server with the MySQL Instance Manager enabled is as follows:
The /etc/init.d/mysql script starts MySQL Instance Manager.
Instance Manager starts the guarded server instances and monitors them.
If a server instance fails, Instance Manager restarts it.
If Instance Manager is shut down (for example, with the /etc/init.d/mysql stop command), it shuts down all server instances.
The Instance Manager stores its user information in a password
file. On Windows, the default is
mysqlmanager.passwd in the directory
where Instance Manager is installed. On Unix, the default file
is /etc/mysqlmanager.passwd. To specify a
different location for the password file, use the
--password-file option.
If the password file does not exist or contains no password entries, you cannot connect to the Instance Manager.
Note
Any Instance Manager process that is running to monitor server instances does not notice changes to the password file. You must stop it and restart it after making password entry changes.
Entries in the password file have the following format, where the two fields are the account username and encrypted password, separated by a colon:
petr:*35110DC9B4D8140F5DE667E28C72DD2597B5C848
Instance Manager password encryption is the same as that used by MySQL Server. It is a one-way operation; no means are provided for decrypting encrypted passwords.
Instance Manager accounts differ somewhat from MySQL Server accounts:
MySQL Server accounts are associated with a hostname, username, and password (see Section 5.8.1, “MySQL Usernames and Passwords”).
Instance Manager accounts are associated with a username and password only.
This means that a client can connect to Instance Manager with
a given username from any host. To limit connections so that
clients can connect only from the local host, start Instance
Manager with the --bind-address=127.0.0.1
option so that it listens only to the local network interface.
Remote clients will not be able to connect. Local clients can
connect like this:
shell> mysql -h 127.0.0.1 -P 2273
To generate a new entry, invoke Instance Manager with the
--passwd option and append the output to
the /etc/mysqlmanager.passwd file. Here
is an example:
shell>mysqlmanager --passwd >> /etc/mysqlmanager.passwdCreating record for new user. Enter user name:mikeEnter password:mikepassRe-type password:mikepass
At the prompts, enter the username and password for the new Instance Manager user. You must enter the password twice. It does not echo to the screen, so double entry guards against entering a different password than you intend (if the two passwords do not match, no entry is generated).
The preceding command causes the following line to be added to
/etc/mysqlmanager.passwd:
mike:*BBF1F551DD9DD96A01E66EC7DDC073911BAD17BA
To monitor the status of each guarded server instance, the
MySQL Instance Manager attempts to connect to the instance at
regular intervals using the
MySQL_Instance_Manager@localhost user
account with a password of
check_connection.
You are not required to create this account for MySQL Server; in fact, it is expected that it will not exist. Instance Manager can tell that a server is operational if the server accepts the connection attempt but refuses access for the account by returning a login error. However, these failed connection attempts are logged by the server to its general query log (see Section 5.11.2, “The General Query Log”).
Instance Manager also attempts a connection to nonguarded
server instances when you use the SHOW
INSTANCES or SHOW INSTANCE STATUS
command. This is the only status monitoring done for
nonguarded instances.
Instance Manager knows if a server instance fails at startup because it receives a status from the attempt. For an instance that starts but later crashes, Instance Manager receives a signal because it is the parent process of the instance.
After you set up a password file for the MySQL Instance Manager and Instance Manager is running, you can connect to it. The MySQL client-server protocol is used to communicate with the Instance Manager. For example, you can connect to it using the standard mysql client program:
shell> mysql --port=2273 --host=im.example.org --user=mysql --password
Instance Manager supports the version of the MySQL client-server protocol used by the client tools and libraries distributed with MySQL 4.1 or later, so other programs that use the MySQL C API also can connect to it.
After you connect to MySQL Instance Manager, you can issue commands. The following general principles apply to Instance Manager command execution:
Commands that take an instance name fail if the name is not a valid instance name.
Commands that take an instance name fail if the instance does not exist.
Instance Manager maintains information about instance configuration in an internal (in-memory) cache. Initially, this information comes from the configuration file if it exists, but some commands change the configuration of an instance. Commands that modify the configuration file fail if the file does not exist or is not accessible to Instance Manager.
On Windows, the standard file is
my.iniin the directory where Instance Manager is installed. On Unix, the standard configuration file is/etc/my.cnf. To specify a different configuration file, start Instance Manager with the--defaults-fileoption.If a
[mysqld]instance section exists in the configuration file, it must not contain any Instance Manager-specific options (see Section 5.4.2, “MySQL Instance Manager Configuration Files”). Therefore, you must not add any of these options if you change the configuration for an instance namedmysqld.
The following list describes the commands that Instance Manager accepts, with examples.
START INSTANCEinstance_nameThis command attempts to start an offline instance. The command is asynchronous; it does not wait for the instance to start.
mysql>
START INSTANCE mysqld4;Query OK, 0 rows affected (0,00 sec)STOP INSTANCEinstance_nameThis command attempts to stop an instance. The command is synchronous; it waits for the instance to stop.
mysql>
STOP INSTANCE mysqld4;Query OK, 0 rows affected (0,00 sec)SHOW INSTANCESShows the names and status of all loaded instances.
mysql>
SHOW INSTANCES;+---------------+---------+ | instance_name | status | +---------------+---------+ | mysqld3 | offline | | mysqld4 | online | | mysqld2 | offline | +---------------+---------+SHOW INSTANCE STATUSinstance_nameShows status and version information for an instance.
mysql>
SHOW INSTANCE STATUS mysqld3;+---------------+--------+---------+ | instance_name | status | version | +---------------+--------+---------+ | mysqld3 | online | unknown | +---------------+--------+---------+SHOW INSTANCE OPTIONSinstance_nameShows the options used by an instance.
mysql>
SHOW INSTANCE OPTIONS mysqld3;+---------------+---------------------------------------------------+ | option_name | value | +---------------+---------------------------------------------------+ | instance_name | mysqld3 | | mysqld-path | /home/cps/mysql/trees/mysql-4.1/sql/mysqld | | port | 3309 | | socket | /tmp/mysql.sock3 | | pid-file | hostname.pid3 | | datadir | /home/cps/mysql_data/data_dir1/ | | language | /home/cps/mysql/trees/mysql-4.1/sql/share/english | +---------------+---------------------------------------------------+SHOWinstance_nameLOG FILESThe command lists all log files used by the instance. The result set contains the path to the log file and the log file size. If no log file path is specified in the instance section of the configuration file (for example,
log=/var/mysql.log), the Instance Manager tries to guess its placement. If Instance Manager is unable to guess the log file placement you should specify the log file location explicitly by using a log option in the appropriate instance section of the configuration file.mysql>
SHOW mysqld LOG FILES;+-------------+------------------------------------+----------+ | Logfile | Path | Filesize | +-------------+------------------------------------+----------+ | ERROR LOG | /home/cps/var/mysql/owlet.err | 9186 | | GENERAL LOG | /home/cps/var/mysql/owlet.log | 471503 | | SLOW LOG | /home/cps/var/mysql/owlet-slow.log | 4463 | +-------------+------------------------------------+----------+Log options are described in Section 5.2.2, “Command Options”.
SHOWinstance_nameLOG {ERROR | SLOW | GENERAL}size[,offset_from_end]This command retrieves a portion of the specified log file. Because most users are interested in the latest log messages, the
sizeparameter defines the number of bytes to retrieve from the end of the log. To retrieve data from the middle of the log file, specify the optionaloffset_from_endparameter. The following example retrieves 21 bytes of data, starting 23 bytes before the end of the log file and ending 2 bytes before the end:mysql>
SHOW mysqld LOG GENERAL 21, 2;+---------------------+ | Log | +---------------------+ | using password: YES | +---------------------+SETinstance_name.option_name[=option_value]This command edits the specified instance's configuration section to change or add instance options. The option is added to the section is it is not already present. Otherwise, the new setting replaces the existing one.
mysql>
SET mysqld2.port=3322;Query OK, 0 rows affected (0.00 sec)Changes made to the configuration file do not take effect until the MySQL server is restarted. In addition, these changes are not stored in the instance manager's local cache of instance settings until a
FLUSH INSTANCEScommand is executed.UNSETinstance_name.option_nameThis command removes an option from an instance's configuration section.
mysql>
UNSET mysqld2.port;Query OK, 0 rows affected (0.00 sec)Changes made to the configuration file do not take effect until the MySQL server is restarted. In addition, these changes are not stored in the instance manager's local cache of instance settings until a
FLUSH INSTANCEScommand is executed.FLUSH INSTANCESThis command forces Instance Manager reread the configuration file and to refresh internal structures. This command should be performed after editing the configuration file. The command does not restart instances.
mysql>
FLUSH INSTANCES;Query OK, 0 rows affected (0.04 sec)FLUSH INSTANCESis deprecated and will be removed in MySQL 5.2.
- 5.5.1. comp_err — Compile MySQL Error Message File
- 5.5.2. make_win_bin_dist — Package MySQL Distribution as ZIP Archive
- 5.5.3. make_win_src_distribution — Create Source Distribution for Windows
- 5.5.4. mysql_fix_privilege_tables — Upgrade MySQL System Tables
- 5.5.5. mysql_install_db — MySQL Data Directory Initialization Script
- 5.5.6. mysql_secure_installation — Improve MySQL Installation Security
- 5.5.7. mysql_tzinfo_to_sql — Load the Time Zone Tables
- 5.5.8. mysql_upgrade — Check Tables for MySQL Upgrade
The programs in this section are used when installing or upgrading MySQL.
comp_err creates the
errmsg.sys file that is used by
mysqld to determine the error messages to
display for different error codes.
comp_err normally is run automatically
when MySQL is built. It compiles the
errmsg.sys file from the plaintext file
located at sql/share/errmsg.txt in
MySQL source distributions.
comp_err also generates
mysqld_error.h,
mysqld_ername.h, and
sql_state.h header files.
For more information about how error messages are defined, see the MySQL Internals Manual.
Invoke comp_err like this:
shell> comp_err [options]
comp_err understands the options described in the following list.
Display a help message and exit.
The character set directory. The default is
../sql/share/charsets.--debug=debug_options, -#debug_optionsWrite a debugging log. The
debug_optionsstring often is'd:t:O,. The default isfile_name''d:t:O,/tmp/comp_err.trace'.Print some debugging information when the program exits.
--header_file=file_name, -Hfile_nameThe name of the error header file. The default is
mysqld_error.h.--in_file=file_name, -Ffile_nameThe name of the input file. The default is
../sql/share/errmsg.txt.--name_file=file_name, -Nfile_nameThe name of the error name file. The default is
mysqld_ername.h.The name of the output base directory. The default is
../sql/share/.--out_file=file_name, -Ofile_nameThe name of the output file. The default is
errmsg.sys.--statefile=file_name, -Sfile_nameThe name for the SQLSTATE header file. The default is
sql_state.h.Display version information and exit.
This script is used on Windows after building a MySQL distribution from source to create executable programs. It packages the binaries and support files into a ZIP archive that can be unpacked at the location where you want to install MySQL.
make_win_bin_dist is a shell script, so you must have Cygwin installed to use it.
This program's use is subject to change. Currently, you invoke it as follows from the root directory of your source distribution:
shell> make_win_bin_dist [options] package_basename [copy_def ...]
The package_basename argument
provides the basename for the resulting ZIP archive. This
name will be the name of the directory that results from
unpacking the archive.
Because you might want to include files of directories from
other builds, you can instruct this script do copy them in
for you, via copy_def arguments,
which of which is of the form
relative_dest_name=source_name.
Example:
bin/mysqld-max.exe=../my-max-build/sql/release/mysqld.exe
If you specify a directory, the entire directory will be copied.
make_win_bin_dist understands the following options:
Pack the debug binaries and produce an error if they were not built.
Pack the embedded server and produce an error if it was not built. The default is to pack it if it was built.
Add a suffix to the basename of the mysql binary. For example, a suffix of
-abcproduces a binary named mysqld-abc.exe.Don't pack the debug binaries even if they were built.
Don't pack the embedded server even if it was built.
Use this option when the target for this build was
Debug, and you just want to replace the normal binaries with debug versions (that is, do not use separatedebugdirectories).
make_win_src_distribution creates a Windows source package to be used on Windows systems. It is used after you configure and build the source distribution on a Unix or Unix-like system so that you have a server binary to work with. (See the instructions at Section 2.4.14.6.4, “Creating a Windows Source Package from the Latest Development Source”.)
Invoke make_win_src_distribution like this from the top-level directory of a MySQL source distribution:
shell> make_win_src_distribution [options]
make_win_src_distribution understands the following options:
--helpDisplay a help message and exit.
--debugPrint information about script operations; do not create a package.
--tmpSpecify the temporary location.
--suffixThe suffix name for the package.
--dirnameDirectory name to copy files (intermediate).
--silentDo not print verbose list of files processed.
--tarCreate a
tar.gzpackage instead of a.zippackage.By default, make_win_src_distribution creates a Zip-format archive with the name
mysql-, whereVERSION-win-src.zipVERSIONrepresents the version of your MySQL source tree.
Some releases of MySQL introduce changes to the structure of
the system tables in the mysql database
to add new privileges or support new features. When you
update to a new version of MySQL, you should update your
system tables as well to make sure that their structure is
up to date. Otherwise, there might be capabilities that you
cannot take advantage of. First, make a backup of your
mysql database, and then use the
following procedure.
Note: As of MySQL 5.0.19, mysql_fix_privilege_tables is superseded by mysql_upgrade, which should be used instead. See Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.
On Unix or Unix-like systems, update the system tables by running the mysql_fix_privilege_tables script:
shell> mysql_fix_privilege_tables
You must run this script while the server is running. It
attempts to connect to the server running on the local host
as root. If your root
account requires a password, indicate the password on the
command line like this:
shell> mysql_fix_privilege_tables --password=root_password
The mysql_fix_privilege_tables script
performs any actions necessary to convert your system tables
to the current format. You might see some Duplicate
column name warnings as it runs; you can ignore
them.
After running the script, stop the server and restart it.
On Windows systems, MySQL distributions include a
mysql_fix_privilege_tables.sql SQL
script that you can run using the mysql
client. For example, if your MySQL installation is located
at C:\Program Files\MySQL\MySQL Server
5.0, the commands look like this:
C:\>cd "C:\Program Files\MySQL\MySQL Server 5.0"C:\>bin\mysql -u root -p mysqlmysql>SOURCE scripts/mysql_fix_privilege_tables.sql
The mysql command will prompt you for the
root password; enter it when prompted.
If your installation is located in some other directory, adjust the pathnames appropriately.
As with the Unix procedure, you might see some
Duplicate column name warnings as
mysql processes the statements in the
mysql_fix_privilege_tables.sql script;
you can ignore them.
After running the script, stop the server and restart it.
mysql_install_db initializes the MySQL
data directory and creates the system tables that it
contains, if they do not exist. Because the MySQL server,
mysqld, needs to access the data
directory when it runs later, you should either run
mysql_install_db from the same account
that will be used for running mysqld or
run it as root and use the
--user option to indicate the username that
mysqld will run as.
To invoke mysql_install_db, use the following syntax:
shell> mysql_install_db [options]
mysql_install_db needs to invoke
mysqld with the
--bootstrap and
--skip-grant-tables options (see
Section 2.4.14.2, “Typical configure Options”). If MySQL was
configured with the --disable-grant-options
option, --bootstrap and
--skip-grant-tables will be disabled. To
handle this, set the MYSQLD_BOOTSTRAP
environment variable to the full pathname of a server that
has all options enabled. mysql_install_db
will use that server.
mysql_install_db supports the following options:
--basedir=pathThe path to the MySQL installation directory.
--forceCauses mysql_install_db to run even if DNS does not work. In that case, grant table entries that normally use hostnames will use IP addresses.
--datadir=,path--ldata=pathThe path to the MySQL data directory.
--rpmFor internal use. This option is used by RPM files during the MySQL installation process.
--skip-name-resolveUse IP addresses rather than hostnames when creating grant table entries. This option can be useful if your DNS does not work.
--srcdir=pathFor internal use. The directory under which mysql_install_db looks for support files such as the error message file and the file for populating the help tables. This option was added in MySQL 5.0.32.
--user=user_nameThe login username to use for running mysqld. Files and directories created by mysqld will be owned by this user. You must be
rootto use this option. By default, mysqld runs using your current login name and files and directories that it creates will be owned by you.--verboseVerbose mode. Print more information about what the program does.
--windowsFor internal use. This option is used for creating Windows distributions.
This program enables you to improve the security of your MySQL installation in the following ways:
You can set a password for
rootaccounts.You can remove
rootaccounts that are accessible from outside the local host.You can remove anonymous-user accounts.
You can remove the
testdatabase, which by default can be accessed by anonymous users.
Invoke mysql_secure_installation without arguments:
shell> mysql_secure_installation
The script will prompt you to determine which actions to perform.
The mysql_tzinfo_to_sql program loads the
time zone tables in the mysql database.
It is used on systems that have a
zoneinfo database (the set of files
describing time zones). Examples of such systems are Linux,
FreeBSD, Sun Solaris, and Mac OS X. One likely location for
these files is the /usr/share/zoneinfo
directory. If your system does not have a zoneinfo database,
you can use the downloadable package described in
Section 5.10.8, “MySQL Server Time Zone Support”.
mysql_tzinfo_to_sql can be invoked several ways:
shell>mysql_tzinfo_to_sqlshell>tz_dirmysql_tzinfo_to_sqlshell>tz_file tz_namemysql_tzinfo_to_sql --leaptz_file
For the first invocation syntax, pass the zoneinfo directory pathname to mysql_tzinfo_to_sql and send the output into the mysql program. For example:
shell> mysql_tzinfo_to_sql /usr/share/zoneinfo | mysql -u root mysql
mysql_tzinfo_to_sql reads your system's time zone files and generates SQL statements from them. mysql processes those statements to load the time zone tables.
The second syntax causes
mysql_tzinfo_to_sql to load a single time
zone file tz_file that
corresponds to a time zone name
tz_name:
shell> mysql_tzinfo_to_sql tz_file tz_name | mysql -u root mysql
If your time zone needs to account for leap seconds, invoke
mysql_tzinfo_to_sql using the third
syntax, which initializes the leap second information.
tz_file is the name of your time
zone file:
shell> mysql_tzinfo_to_sql --leap tz_file | mysql -u root mysql
mysql_upgrade should be executed each time you upgrade MySQL. It checks all tables in all databases for incompatibilities with the current version of MySQL Server. If a table is found to have a possible incompatibility, it is checked. If any problems are found, the table is repaired. mysql_upgrade also upgrades the system tables so that you can take advantage of new privileges or capabilities that might have been added.
All checked and repaired tables are marked with the current MySQL version number. This ensures that next time you run mysql_upgrade with the same version of the server, it can tell whether there is any need to check or repair the table again.
mysql_upgrade also saves the MySQL
version number in a file named
mysql_upgrade.info in the data
directory. This is used to quickly check if all tables have
been checked for this release so that table-checking can be
skipped. To ignore this file, use the
--force option.
To check and repair tables and to upgrade the system tables, mysql_upgrade executes the following commands:
mysqlcheck --check-upgrade --all-databases --auto-repair mysql_fix_privilege_tables
mysql_upgrade supersedes the older mysql_fix_privilege_tables script. In MySQL 5.0.19, mysql_upgrade was added as a shell script and worked only for Unix systems. As of MySQL 5.0.25, mysql_upgrade is an executable binary and is available on all systems. On systems older than those supporting mysql_upgrade, you can execute the mysqlcheck command manually, and then upgrade your system tables as described in Section 5.5.4, “mysql_fix_privilege_tables — Upgrade MySQL System Tables”.
For details about what is checked, see the description of
the FOR UPGRADE option of the
CHECK TABLE statement (see
Section 13.5.2.3, “CHECK TABLE Syntax”).
To use mysql_upgrade, make sure that the server is running, and then invoke it like this:
shell> mysql_upgrade [options]
mysql_upgrade reads options from the
command line and from the [mysql_upgrade]
group in option files. It supports the following options:
Display a short help message and exit.
The path to the MySQL installation directory.
The path to the data directory.
Force execution of mysqlcheck even if mysql_upgrade has already been executed for the current version of MySQL. (In other words, this option causes the
mysql_upgrade.infofile to be ignored.)--user=,user_name-uuser_nameThe MySQL username to use when connecting to the server. The default username is
root.Verbose mode. Print more information about what the program does.
Other options are passed to mysqlcheck
and to mysql_fix_privilege_tables. For
example, it might be necessary to specify the
--password[=
option.
password]
This section describes some general security issues to be aware of and what you can do to make your MySQL installation more secure against attack or misuse. For information specifically about the access control system that MySQL uses for setting up user accounts and checking database access, see Section 5.7, “The MySQL Access Privilege System”.
For answers to some questions that are often asked about MySQL Server security issues, see Section A.9, “MySQL 5.0 FAQ — Security”.
Anyone using MySQL on a computer connected to the Internet should read this section to avoid the most common security mistakes.
In discussing security, we emphasize the necessity of fully protecting the entire server host (not just the MySQL server) against all types of applicable attacks: eavesdropping, altering, playback, and denial of service. We do not cover all aspects of availability and fault tolerance here.
MySQL uses security based on Access Control Lists (ACLs) for all connections, queries, and other operations that users can attempt to perform. There is also support for SSL-encrypted connections between MySQL clients and servers. Many of the concepts discussed here are not specific to MySQL at all; the same general ideas apply to almost all applications.
When running MySQL, follow these guidelines whenever possible:
Do not ever give anyone (except MySQL
rootaccounts) access to theusertable in themysqldatabase! This is critical.Learn the MySQL access privilege system. The
GRANTandREVOKEstatements are used for controlling access to MySQL. Do not grant more privileges than necessary. Never grant privileges to all hosts.Checklist:
Try
mysql -u root. If you are able to connect successfully to the server without being asked for a password, anyone can connect to your MySQL server as the MySQLrootuser with full privileges! Review the MySQL installation instructions, paying particular attention to the information about setting arootpassword. See Section 2.4.15.3, “Securing the Initial MySQL Accounts”.Use the
SHOW GRANTSstatement to check which accounts have access to what. Then use theREVOKEstatement to remove those privileges that are not necessary.
Do not store any plain-text passwords in your database. If your computer becomes compromised, the intruder can take the full list of passwords and use them. Instead, use
MD5(),SHA1(), or some other one-way hashing function and store the hash value.Do not choose passwords from dictionaries. Special programs exist to break passwords. Even passwords like “xfish98” are very bad. Much better is “duag98” which contains the same word “fish” but typed one key to the left on a standard QWERTY keyboard. Another method is to use a password that is taken from the first characters of each word in a sentence (for example, “Mary had a little lamb” results in a password of “Mhall”). The password is easy to remember and type, but difficult to guess for someone who does not know the sentence.
Invest in a firewall. This protects you from at least 50% of all types of exploits in any software. Put MySQL behind the firewall or in a demilitarized zone (DMZ).
Checklist:
Try to scan your ports from the Internet using a tool such as
nmap. MySQL uses port 3306 by default. This port should not be accessible from untrusted hosts. Another simple way to check whether or not your MySQL port is open is to try the following command from some remote machine, whereserver_hostis the hostname or IP number of the host on which your MySQL server runs:shell>
telnetserver_host3306If you get a connection and some garbage characters, the port is open, and should be closed on your firewall or router, unless you really have a good reason to keep it open. If telnet hangs or the connection is refused, the port is blocked, which is how you want it to be.
Do not trust any data entered by users of your applications. They can try to trick your code by entering special or escaped character sequences in Web forms, URLs, or whatever application you have built. Be sure that your application remains secure if a user enters something like “
; DROP DATABASE mysql;”. This is an extreme example, but large security leaks and data loss might occur as a result of hackers using similar techniques, if you do not prepare for them.A common mistake is to protect only string data values. Remember to check numeric data as well. If an application generates a query such as
SELECT * FROM table WHERE ID=234when a user enters the value234, the user can enter the value234 OR 1=1to cause the application to generate the querySELECT * FROM table WHERE ID=234 OR 1=1. As a result, the server retrieves every row in the table. This exposes every row and causes excessive server load. The simplest way to protect from this type of attack is to use single quotes around the numeric constants:SELECT * FROM table WHERE ID='234'. If the user enters extra information, it all becomes part of the string. In a numeric context, MySQL automatically converts this string to a number and strips any trailing non-numeric characters from it.Sometimes people think that if a database contains only publicly available data, it need not be protected. This is incorrect. Even if it is allowable to display any row in the database, you should still protect against denial of service attacks (for example, those that are based on the technique in the preceding paragraph that causes the server to waste resources). Otherwise, your server becomes unresponsive to legitimate users.
Checklist:
Try to enter single and double quote marks (‘
'’ and ‘"’) in all of your Web forms. If you get any kind of MySQL error, investigate the problem right away.Try to modify dynamic URLs by adding
%22(‘"’),%23(‘#’), and%27(‘'’) to them.Try to modify data types in dynamic URLs from numeric to character types using the characters shown in the previous examples. Your application should be safe against these and similar attacks.
Try to enter characters, spaces, and special symbols rather than numbers in numeric fields. Your application should remove them before passing them to MySQL or else generate an error. Passing unchecked values to MySQL is very dangerous!
Check the size of data before passing it to MySQL.
Have your application connect to the database using a username different from the one you use for administrative purposes. Do not give your applications any access privileges they do not need.
Many application programming interfaces provide a means of escaping special characters in data values. Properly used, this prevents application users from entering values that cause the application to generate statements that have a different effect than you intend:
MySQL C API: Use the
mysql_real_escape_string()API call.MySQL++: Use the
escapeandquotemodifiers for query streams.PHP: Use the
mysql_real_escape_string()function (available as of PHP 4.3.0, prior to that PHP version usemysql_escape_string(), and prior to PHP 4.0.3, useaddslashes()). Note that onlymysql_real_escape_string()is character set-aware; the other functions can be “bypassed” when using (invalid) multi-byte character sets. In PHP 5, you can use themysqliextension, which supports the improved MySQL authentication protocol and passwords, as well as prepared statements with placeholders.Perl DBI: Use placeholders or the
quote()method.Ruby DBI: Use placeholders or the
quote()method.Java JDBC: Use a
PreparedStatementobject and placeholders.
Other programming interfaces might have similar capabilities.
Do not transmit plain (unencrypted) data over the Internet. This information is accessible to everyone who has the time and ability to intercept it and use it for their own purposes. Instead, use an encrypted protocol such as SSL or SSH. MySQL supports internal SSL connections as of version 4.0. Another technique is to use SSH port-forwarding to create an encrypted (and compressed) tunnel for the communication.
Learn to use the tcpdump and strings utilities. In most cases, you can check whether MySQL data streams are unencrypted by issuing a command like the following:
shell>
tcpdump -l -i eth0 -w - src or dst port 3306 | strings(This works under Linux and should work with small modifications under other systems.) Warning: If you do not see plaintext data, this doesn't always mean that the information actually is encrypted. If you need high security, you should consult with a security expert.
When you connect to a MySQL server, you should use a password. The password is not transmitted in clear text over the connection. Password handling during the client connection sequence was upgraded in MySQL 4.1.1 to be very secure. If you are still using pre-4.1.1-style passwords, the encryption algorithm is not as strong as the newer algorithm. With some effort, a clever attacker who can sniff the traffic between the client and the server can crack the password. (See Section 5.7.9, “Password Hashing as of MySQL 4.1”, for a discussion of the different password handling methods.)
MySQL Enterprise The MySQL Network Monitoring and Advisory Service enforces best practices for maximizing the security of your servers. For more information see http://www.mysql.com/products/enterprise/advisors.html.
All other information is transferred as text, and can be read by anyone who is able to watch the connection. If the connection between the client and the server goes through an untrusted network, and you are concerned about this, you can use the compressed protocol to make traffic much more difficult to decipher. You can also use MySQL's internal SSL support to make the connection even more secure. See Section 5.8.7, “Using Secure Connections”. Alternatively, use SSH to get an encrypted TCP/IP connection between a MySQL server and a MySQL client. You can find an Open Source SSH client at http://www.openssh.org/, and a commercial SSH client at http://www.ssh.com/.
To make a MySQL system secure, you should strongly consider the following suggestions:
Require all MySQL accounts to have a password. A client program does not necessarily know the identity of the person running it. It is common for client/server applications that the user can specify any username to the client program. For example, anyone can use the mysql program to connect as any other person simply by invoking it as
mysql -uifother_userdb_nameother_userhas no password. If all accounts have a password, connecting using another user's account becomes much more difficult.For a discussion of methods for setting passwords, see Section 5.8.5, “Assigning Account Passwords”.
Never run the MySQL server as the Unix
rootuser. This is extremely dangerous, because any user with theFILEprivilege is able to cause the server to create files asroot(for example,~root/.bashrc). To prevent this, mysqld refuses to run asrootunless that is specified explicitly using the--user=rootoption.mysqld can (and should) be run as an ordinary, unprivileged user instead. You can create a separate Unix account named
mysqlto make everything even more secure. Use this account only for administering MySQL. To start mysqld as a different Unix user, add auseroption that specifies the username in the[mysqld]group of themy.cnfoption file where you specify server options. For example:[mysqld] user=mysql
This causes the server to start as the designated user whether you start it manually or by using mysqld_safe or mysql.server. For more details, see Section 5.6.5, “How to Run MySQL as a Normal User”.
Running mysqld as a Unix user other than
rootdoes not mean that you need to change therootusername in theusertable. Usernames for MySQL accounts have nothing to do with usernames for Unix accounts.Do not allow the use of symlinks to tables. (This capability can be disabled with the
--skip-symbolic-linksoption.) This is especially important if you run mysqld asroot, because anyone that has write access to the server's data directory then could delete any file in the system! See Section 7.6.1.2, “Using Symbolic Links for Tables on Unix”.Make sure that the only Unix user with read or write privileges in the database directories is the user that mysqld runs as.
Do not grant the
PROCESSorSUPERprivilege to non-administrative users. The output of mysqladmin processlist andSHOW PROCESSLISTshows the text of any statements currently being executed, so any user who is allowed to see the server process list might be able to see statements issued by other users such asUPDATE user SET password=PASSWORD('not_secure').mysqld reserves an extra connection for users who have the
SUPERprivilege, so that a MySQLrootuser can log in and check server activity even if all normal connections are in use.The
SUPERprivilege can be used to terminate client connections, change server operation by changing the value of system variables, and control replication servers.Do not grant the
FILEprivilege to non-administrative users. Any user that has this privilege can write a file anywhere in the filesystem with the privileges of the mysqld daemon. To make this a bit safer, files generated withSELECT ... INTO OUTFILEdo not overwrite existing files and are writable by everyone.The
FILEprivilege may also be used to read any file that is world-readable or accessible to the Unix user that the server runs as. With this privilege, you can read any file into a database table. This could be abused, for example, by usingLOAD DATAto load/etc/passwdinto a table, which then can be displayed withSELECT.If you do not trust your DNS, you should use IP numbers rather than hostnames in the grant tables. In any case, you should be very careful about creating grant table entries using hostname values that contain wildcards.
If you want to restrict the number of connections allowed to a single account, you can do so by setting the
max_user_connectionsvariable in mysqld. TheGRANTstatement also supports resource control options for limiting the extent of server use allowed to an account. See Section 13.5.1.3, “GRANTSyntax”.Options that begin with
--sslspecify whether to allow clients to connect via SSL and indicate where to find SSL keys and certificates. See Section 5.8.7.3, “SSL Command Options”.
The following mysqld options affect security:
This option controls whether user-defined functions that have only an
xxxsymbol for the main function can be loaded. By default, the option is off and only UDFs that have at least one auxiliary symbol can be loaded; this prevents attempts at loading functions from shared object files other than those containing legitimate UDFs. For MySQL 5.0, this option was added in MySQL 5.0.3. See Section 24.2.4.6, “User-Defined Function Security Precautions”.If you start the server with
--local-infile=0, clients cannot useLOCALinLOAD DATAstatements. See Section 5.6.4, “Security Issues withLOAD DATA LOCAL”.Force the server to generate short (pre-4.1) password hashes for new passwords. This is useful for compatibility when the server must support older client programs. See Section 5.7.9, “Password Hashing as of MySQL 4.1”.
MySQL Enterprise The MySQL Network Monitoring and Advisory Service offers advice on the security implications of using this option. For subscription information see http://www.mysql.com/products/enterprise/advisors.html.
--safe-show-database(OBSOLETE)In previous versions of MySQL, this option caused the
SHOW DATABASESstatement to display the names of only those databases for which the user had some kind of privilege. In MySQL 5.0, this option is no longer available as this is now the default behavior, and there is aSHOW DATABASESprivilege that can be used to control access to database names on a per-account basis. See Section 13.5.1.3, “GRANTSyntax”.If this option is enabled, a user cannot create new MySQL users by using the
GRANTstatement unless the user has theINSERTprivilege for themysql.usertable or any column in the table. If you want a user to have the ability to create new users that have those privileges that the user has the right to grant, you should grant the user the following privilege:GRANT INSERT(user) ON mysql.user TO '
user_name'@'host_name';This ensures that the user cannot change any privilege columns directly, but has to use the
GRANTstatement to give privileges to other users.Disallow authentication for accounts that have old (pre-4.1) passwords.
The mysql client also has a
--secure-authoption, which prevents connections to a server if the server requires a password in old format for the client account.This option limits the effect of the
LOAD_FILE()function and theLOAD DATAandSELECT ... INTO OUTFILEstatements to work only with files in the specified directory.This option was added in MySQL 5.0.38.
This option causes the server not to use the privilege system at all. This gives anyone with access to the server unrestricted access to all databases. You can cause a running server to start using the grant tables again by executing mysqladmin flush-privileges or mysqladmin reload command from a system shell, or by issuing a MySQL
FLUSH PRIVILEGESstatement. This option also suppresses loading of user-defined functions (UDFs).Hostnames are not resolved. All
Hostcolumn values in the grant tables must be IP numbers orlocalhost.Do not allow TCP/IP connections over the network. All connections to mysqld must be made via Unix socket files.
With this option, the
SHOW DATABASESstatement is allowed only to users who have theSHOW DATABASESprivilege, and the statement displays all database names. Without this option,SHOW DATABASESis allowed to all users, but displays each database name only if the user has theSHOW DATABASESprivilege or some privilege for the database. Note that any global privilege is a privilege for the database.
The LOAD DATA statement can load a file that
is located on the server host, or it can load a file that is
located on the client host when the LOCAL
keyword is specified.
There are two potential security issues with supporting the
LOCAL version of LOAD DATA
statements:
The transfer of the file from the client host to the server host is initiated by the MySQL server. In theory, a patched server could be built that would tell the client program to transfer a file of the server's choosing rather than the file named by the client in the
LOAD DATAstatement. Such a server could access any file on the client host to which the client user has read access.In a Web environment where the clients are connecting from a Web server, a user could use
LOAD DATA LOCALto read any files that the Web server process has read access to (assuming that a user could run any command against the SQL server). In this environment, the client with respect to the MySQL server actually is the Web server, not the remote program being run by the user who connects to the Web server.
To deal with these problems, we changed how LOAD DATA
LOCAL is handled as of MySQL 3.23.49 and MySQL 4.0.2
(4.0.13 on Windows):
By default, all MySQL clients and libraries in binary distributions are compiled with the
--enable-local-infileoption, to be compatible with MySQL 3.23.48 and before.If you build MySQL from source but do not invoke configure with the
--enable-local-infileoption,LOAD DATA LOCALcannot be used by any client unless it is written explicitly to invokemysql_options(... MYSQL_OPT_LOCAL_INFILE, 0). See Section 22.2.3.49, “mysql_options()”.You can disable all
LOAD DATA LOCALcommands from the server side by starting mysqld with the--local-infile=0option.For the mysql command-line client,
LOAD DATA LOCALcan be enabled by specifying the--local-infile[=1]option, or disabled with the--local-infile=0option. Similarly, for mysqlimport, the--localor-Loption enables local data file loading. In any case, successful use of a local loading operation requires that the server is enabled to allow it.If you use
LOAD DATA LOCALin Perl scripts or other programs that read the[client]group from option files, you can add thelocal-infile=1option to that group. However, to keep this from causing problems for programs that do not understandlocal-infile, specify it using theloose-prefix:[client] loose-local-infile=1
If
LOAD DATA LOCAL INFILEis disabled, either in the server or the client, a client that attempts to issue such a statement receives the following error message:ERROR 1148: The used command is not allowed with this MySQL version
MySQL Enterprise
Security advisors notify subscribers to the MySQL Network
Monitoring and Advisory Service whenever a server is started
with the --local-infile option enabled. For
more information see
http://www.mysql.com/products/enterprise/advisors.html.
On Windows, you can run the server as a Windows service using a normal user account.
On Unix, the MySQL server mysqld can be
started and run by any user. However, you should avoid running
the server as the Unix root user for security
reasons. To change mysqld to run as a normal
unprivileged Unix user user_name, you
must do the following:
Stop the server if it's running (use mysqladmin shutdown).
Change the database directories and files so that
user_namehas privileges to read and write files in them (you might need to do this as the Unixrootuser):shell>
chown -Ruser_name/path/to/mysql/datadirIf you do not do this, the server will not be able to access databases or tables when it runs as
user_name.If directories or files within the MySQL data directory are symbolic links, you'll also need to follow those links and change the directories and files they point to.
chown -Rmight not follow symbolic links for you.Start the server as user
user_name. If you are using MySQL 3.22 or later, another alternative is to start mysqld as the Unixrootuser and use the--user=option. mysqld starts up, then switches to run as the Unix useruser_nameuser_namebefore accepting any connections.To start the server as the given user automatically at system startup time, specify the username by adding a
useroption to the[mysqld]group of the/etc/my.cnfoption file or themy.cnfoption file in the server's data directory. For example:[mysqld] user=
user_name
If your Unix machine itself isn't secured, you should assign
passwords to the MySQL root accounts in the
grant tables. Otherwise, any user with a login account on that
machine can run the mysql client with a
--user=root option and perform any operation.
(It is a good idea to assign passwords to MySQL accounts in any
case, but especially so when other login accounts exist on the
server host.) See Section 2.4.15, “Post-Installation Setup and Testing”.
- 5.7.1. What the Privilege System Does
- 5.7.2. How the Privilege System Works
- 5.7.3. Privileges Provided by MySQL
- 5.7.4. Connecting to the MySQL Server
- 5.7.5. Access Control, Stage 1: Connection Verification
- 5.7.6. Access Control, Stage 2: Request Verification
- 5.7.7. When Privilege Changes Take Effect
- 5.7.8. Causes of
Access deniedErrors - 5.7.9. Password Hashing as of MySQL 4.1
MySQL has an advanced but non-standard security and privilege system. The following discussion describes how it works.
The primary function of the MySQL privilege system is to
authenticate a user who connects from a given host and to
associate that user with privileges on a database such as
SELECT, INSERT,
UPDATE, and DELETE.
Additional functionality includes the ability to have anonymous
users and to grant privileges for MySQL-specific functions such
as LOAD DATA INFILE and administrative
operations.
The MySQL privilege system ensures that all users may perform only the operations allowed to them. As a user, when you connect to a MySQL server, your identity is determined by the host from which you connect and the username you specify. When you issue requests after connecting, the system grants privileges according to your identity and what you want to do.
MySQL considers both your hostname and username in identifying
you because there is little reason to assume that a given
username belongs to the same person everywhere on the Internet.
For example, the user joe who connects from
office.example.com need not be the same
person as the user joe who connects from
home.example.com. MySQL handles this by
allowing you to distinguish users on different hosts that happen
to have the same name: You can grant one set of privileges for
connections by joe from
office.example.com, and a different set of
privileges for connections by joe from
home.example.com.
MySQL access control involves two stages when you run a client program that connects to the server:
Stage 1: The server checks whether it should allow you to connect.
Stage 2: Assuming that you can connect, the server checks each statement you issue to determine whether you have sufficient privileges to perform it. For example, if you try to select rows from a table in a database or drop a table from the database, the server verifies that you have the
SELECTprivilege for the table or theDROPprivilege for the database.
If your privileges are changed (either by yourself or someone else) while you are connected, those changes do not necessarily take effect immediately for the next statement that you issue. See Section 5.7.7, “When Privilege Changes Take Effect”, for details.
The server stores privilege information in the grant tables of
the mysql database (that is, in the database
named mysql). The MySQL server reads the
contents of these tables into memory when it starts and re-reads
them under the circumstances indicated in
Section 5.7.7, “When Privilege Changes Take Effect”. Access-control decisions
are based on the in-memory copies of the grant tables.
Normally, you manipulate the contents of the grant tables
indirectly by using statements such as GRANT
and REVOKE to set up accounts and control the
privileges available to each one. See
Section 13.5.1, “Account Management Statements”. The discussion here
describes the underlying structure of the grant tables and how
the server uses their contents when interacting with clients.
The server uses the user,
db, and host tables in the
mysql database at both stages of access
control. The columns in the user and
db tables are shown here. The
host table is similar to the
db table but has a specialized use as
described in Section 5.7.6, “Access Control, Stage 2: Request Verification”.
| Table Name | user | db |
| Scope columns | Host | Host |
User | Db | |
Password | User | |
| Privilege columns | Select_priv | Select_priv |
Insert_priv | Insert_priv | |
Update_priv | Update_priv | |
Delete_priv | Delete_priv | |
Index_priv | Index_priv | |
Alter_priv | Alter_priv | |
Create_priv | Create_priv | |
Drop_priv | Drop_priv | |
Grant_priv | Grant_priv | |
Create_view_priv | Create_view_priv | |
Show_view_priv | Show_view_priv | |
Create_routine_priv | Create_routine_priv | |
Alter_routine_priv | Alter_routine_priv | |
Execute_priv | Execute_priv | |
Create_tmp_table_priv | Create_tmp_table_priv | |
Lock_tables_priv | Lock_tables_priv | |
References_priv | References_priv | |
Reload_priv | ||
Shutdown_priv | ||
Process_priv | ||
File_priv | ||
Show_db_priv | ||
Super_priv | ||
Repl_slave_priv | ||
Repl_client_priv | ||
Create_user_priv | ||
| Security columns | ssl_type | |
ssl_cipher | ||
x509_issuer | ||
x509_subject | ||
| Resource control columns | max_questions | |
max_updates | ||
max_connections | ||
max_user_connections |
Execute_priv was present in MySQL 5.0.0, but
did not become operational until MySQL 5.0.3.
The Create_view_priv and
Show_view_priv columns were added in MySQL
5.0.1.
The Create_routine_priv,
Alter_routine_priv, and
max_user_connections columns were added in
MySQL 5.0.3.
During the second stage of access control, the server performs
request verification to make sure that each client has
sufficient privileges for each request that it issues. In
addition to the user, db,
and host grant tables, the server may also
consult the tables_priv and
columns_priv tables for requests that involve
tables. The tables_priv and
columns_priv tables provide finer privilege
control at the table and column levels. They have the following
columns:
| Table Name | tables_priv | columns_priv |
| Scope columns | Host | Host |
Db | Db | |
User | User | |
Table_name | Table_name | |
Column_name | ||
| Privilege columns | Table_priv | Column_priv |
Column_priv | ||
| Other columns | Timestamp | Timestamp |
Grantor |
The Timestamp and Grantor
columns currently are unused and are discussed no further here.
For verification of requests that involve stored routines, the
server may consult the procs_priv table. This
table has the following columns:
| Table Name | procs_priv |
| Scope columns | Host |
Db | |
User | |
Routine_name | |
Routine_type | |
| Privilege columns | Proc_priv |
| Other columns | Timestamp |
Grantor |
The procs_priv table exists as of MySQL
5.0.3. The Routine_type column was added in
MySQL 5.0.6. It is an ENUM column with values
of 'FUNCTION' or
'PROCEDURE' to indicate the type of routine
the row refers to. This column allows privileges to be granted
separately for a function and a procedure with the same name.
The Timestamp and Grantor
columns currently are unused and are discussed no further here.
Each grant table contains scope columns and privilege columns:
Scope columns determine the scope of each row (entry) in the tables; that is, the context in which the row applies. For example, a
usertable row withHostandUservalues of'thomas.loc.gov'and'bob'would be used for authenticating connections made to the server from the hostthomas.loc.govby a client that specifies a username ofbob. Similarly, adbtable row withHost,User, andDbcolumn values of'thomas.loc.gov','bob'and'reports'would be used whenbobconnects from the hostthomas.loc.govto access thereportsdatabase. Thetables_privandcolumns_privtables contain scope columns indicating tables or table/column combinations to which each row applies. Theprocs_privscope columns indicate the stored routine to which each row applies.Privilege columns indicate which privileges are granted by a table row; that is, what operations can be performed. The server combines the information in the various grant tables to form a complete description of a user's privileges. Section 5.7.6, “Access Control, Stage 2: Request Verification”, describes the rules that are used to do this.
Scope columns contain strings. They are declared as shown here; the default value for each is the empty string:
| Column Name | Type |
Host | CHAR(60) |
User | CHAR(16) |
Password | CHAR(16) |
Db | CHAR(64) |
Table_name | CHAR(64) |
Column_name | CHAR(64) |
Routine_name | CHAR(64) |
For access-checking purposes, comparisons of
Host values are case-insensitive.
User, Password,
Db, and Table_name values
are case sensitive. Column_name and
Routine_name values are case insensitive.
In the user, db, and
host tables, each privilege is listed in a
separate column that is declared as ENUM('N','Y')
DEFAULT 'N'. In other words, each privilege can be
disabled or enabled, with the default being disabled.
In the tables_priv,
columns_priv, and
procs_priv tables, the privilege columns are
declared as SET columns. Values in these
columns can contain any combination of the privileges controlled
by the table:
| Table Name | Column Name | Possible Set Elements |
tables_priv | Table_priv | 'Select', 'Insert', 'Update', 'Delete', 'Create', 'Drop',
'Grant', 'References', 'Index', 'Alter', 'Create View',
'Show view' |
tables_priv | Column_priv | 'Select', 'Insert', 'Update', 'References' |
columns_priv | Column_priv | 'Select', 'Insert', 'Update', 'References' |
procs_priv | Proc_priv | 'Execute', 'Alter Routine', 'Grant' |
Briefly, the server uses the grant tables in the following manner:
The
usertable scope columns determine whether to reject or allow incoming connections. For allowed connections, any privileges granted in theusertable indicate the user's global (superuser) privileges. Any privilege granted in this table applies to all databases on the server.Note: Because any global privilege is considered a privilege for all databases, any global privilege enables a user to see all database names with
SHOW DATABASESor by examining theSCHEMATAtable ofINFORMATION_SCHEMA.The
dbtable scope columns determine which users can access which databases from which hosts. The privilege columns determine which operations are allowed. A privilege granted at the database level applies to the database and to all its tables.The
hosttable is used in conjunction with thedbtable when you want a givendbtable row to apply to several hosts. For example, if you want a user to be able to use a database from several hosts in your network, leave theHostvalue empty in the user'sdbtable row, then populate thehosttable with a row for each of those hosts. This mechanism is described more detail in Section 5.7.6, “Access Control, Stage 2: Request Verification”.Note: The
hosttable must be modified directly with statements such asINSERT,UPDATE, andDELETE. It is not affected by statements such asGRANTandREVOKEthat modify the grant tables indirectly. Most MySQL installations need not use this table at all.The
tables_privandcolumns_privtables are similar to thedbtable, but are more fine-grained: They apply at the table and column levels rather than at the database level. A privilege granted at the table level applies to the table and to all its columns. A privilege granted at the column level applies only to a specific column.The
procs_privtable applies to stored routines. A privilege granted at the routine level applies only to a single routine.
Administrative privileges (such as RELOAD or
SHUTDOWN) are specified only in the
user table. The reason for this is that
administrative operations are operations on the server itself
and are not database-specific, so there is no reason to list
these privileges in the other grant tables. In fact, to
determine whether you can perform an administrative operation,
the server need consult only the user table.
The FILE privilege also is specified only in
the user table. It is not an administrative
privilege as such, but your ability to read or write files on
the server host is independent of the database you are
accessing.
The mysqld server reads the contents of the
grant tables into memory when it starts. You can tell it to
re-read the tables by issuing a FLUSH
PRIVILEGES statement or executing a
mysqladmin flush-privileges or
mysqladmin reload command. Changes to the
grant tables take effect as indicated in
Section 5.7.7, “When Privilege Changes Take Effect”.
When you modify the contents of the grant tables, it is a good
idea to make sure that your changes set up privileges the way
you want. To check the privileges for a given account, use the
SHOW GRANTS statement. (See
Section 13.5.4.12, “SHOW GRANTS Syntax”.) For example, to determine the
privileges that are granted to an account with
Host and User values of
pc84.example.com and bob,
issue this statement:
SHOW GRANTS FOR 'bob'@'pc84.example.com';
For additional help in diagnosing privilege-related problems,
see Section 5.7.8, “Causes of Access denied Errors”. For general advice on
security issues, see Section 5.6, “General Security Issues”.
Information about account privileges is stored in the
user, db,
host, tables_priv,
columns_priv, and
procs_priv tables in the
mysql database. The MySQL server reads the
contents of these tables into memory when it starts and re-reads
them under the circumstances indicated in
Section 5.7.7, “When Privilege Changes Take Effect”. Access-control decisions
are based on the in-memory copies of the grant tables.
The names used in the GRANT and
REVOKE statements to refer to privileges are
shown in the following table, along with the column name
associated with each privilege in the grant tables and the
context in which the privilege applies. Further information
about the meaning of each privilege may be found at
Section 13.5.1.3, “GRANT Syntax”.
| Privilege | Column | Context |
CREATE | Create_priv | databases, tables, or indexes |
DROP | Drop_priv | databases or tables |
GRANT OPTION | Grant_priv | databases, tables, or stored routines |
REFERENCES | References_priv | databases or tables |
ALTER | Alter_priv | tables |
DELETE | Delete_priv | tables |
INDEX | Index_priv | tables |
INSERT | Insert_priv | tables |
SELECT | Select_priv | tables |
UPDATE | Update_priv | tables |
CREATE VIEW | Create_view_priv | views |
SHOW VIEW | Show_view_priv | views |
ALTER ROUTINE | Alter_routine_priv | stored routines |
CREATE ROUTINE | Create_routine_priv | stored routines |
EXECUTE | Execute_priv | stored routines |
FILE | File_priv | file access on server host |
CREATE TEMPORARY TABLES | Create_tmp_table_priv | server administration |
LOCK TABLES | Lock_tables_priv | server administration |
CREATE USER | Create_user_priv | server administration |
PROCESS | Process_priv | server administration |
RELOAD | Reload_priv | server administration |
REPLICATION CLIENT | Repl_client_priv | server administration |
REPLICATION SLAVE | Repl_slave_priv | server administration |
SHOW DATABASES | Show_db_priv | server administration |
SHUTDOWN | Shutdown_priv | server administration |
SUPER | Super_priv | server administration |
Some releases of MySQL introduce changes to the structure of the grant tables to add new privileges or features. Whenever you update to a new version of MySQL, you should update your grant tables to make sure that they have the current structure so that you can take advantage of any new capabilities. See Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.
CREATE VIEW and SHOW VIEW
were added in MySQL 5.0.1. CREATE USER,
CREATE ROUTINE, and ALTER
ROUTINE were added in MySQL 5.0.3. Although
EXECUTE was present in MySQL 5.0.0, it did
not become operational until MySQL 5.0.3.
To create or alter stored routines if binary logging is enabled,
you may also need the SUPER privilege, as
described in Section 17.4, “Binary Logging of Stored Routines and Triggers”.
The CREATE and DROP
privileges allow you to create new databases and tables, or to
drop (remove) existing databases and tables. If you
grant the DROP privilege for the
mysql database to a user, that user can drop
the database in which the MySQL access privileges are
stored.
The SELECT, INSERT,
UPDATE, and DELETE
privileges allow you to perform operations on rows in existing
tables in a database. INSERT is also required
for the ANALYZE TABLE, OPTIMIZE
TABLE, and REPAIR TABLE
table-maintenance statements.
SELECT statements require the
SELECT privilege only if they actually
retrieve rows from a table. Some SELECT
statements do not access tables and can be executed without
permission for any database. For example, you can use the
mysql client as a simple calculator to
evaluate expressions that make no reference to tables:
SELECT 1+1; SELECT PI()*2;
The INDEX privilege enables you to create or
drop (remove) indexes. INDEX applies to
existing tables. If you have the CREATE
privilege for a table, you can include index definitions in the
CREATE TABLE statement.
The ALTER privilege enables you to use
ALTER TABLE to change the structure of or
rename tables.
MySQL Enterprise
In some circumstances the ALTER privilege
is entirely unnecessary — on slaves where there are no
non-replicated tables, for instance. The MySQL Network
Monitoring and Advisory Service notifies subscribers when
accounts have inappropriate privileges. For more information
see http://www.mysql.com/products/enterprise/advisors.html.
The CREATE ROUTINE privilege is needed for
creating stored routines (functions and procedures).
ALTER ROUTINE privilege is needed for
altering or dropping stored routines, and
EXECUTE is needed for executing stored
routines.
The GRANT privilege enables you to give to
other users those privileges that you yourself possess. It can
be used for databases, tables, and stored routines.
The FILE privilege gives you permission to
read and write files on the server host using the LOAD
DATA INFILE and SELECT ... INTO
OUTFILE statements. A user who has the
FILE privilege can read any file on the
server host that is either world-readable or readable by the
MySQL server. (This implies the user can read any file in any
database directory, because the server can access any of those
files.) The FILE privilege also enables the
user to create new files in any directory where the MySQL server
has write access. As a security measure, the server will not
overwrite existing files.
The remaining privileges are used for administrative operations. Many of them can be performed by using the mysqladmin program or by issuing SQL statements. The following table shows which mysqladmin commands each administrative privilege enables you to execute:
| Privilege | Commands Permitted to Privilege Holders |
RELOAD | flush-hosts, flush-logs,
flush-privileges,
flush-status,
flush-tables,
flush-threads,
refresh, reload |
SHUTDOWN | shutdown |
PROCESS | processlist |
SUPER | kill |
The reload command tells the server to
re-read the grant tables into memory.
flush-privileges is a synonym for
reload. The refresh
command closes and reopens the log files and flushes all tables.
The other
flush- commands
perform functions similar to xxxrefresh, but are
more specific and may be preferable in some instances. For
example, if you want to flush just the log files,
flush-logs is a better choice than
refresh.
The shutdown command shuts down the server.
There is no corresponding SQL statement.
The processlist command displays information
about the threads executing within the server (that is,
information about the statements being executed by clients). The
kill command terminates server threads. You
can always display or kill your own threads, but you need the
PROCESS privilege to display threads
initiated by other users and the SUPER
privilege to kill them. See Section 13.5.5.3, “KILL Syntax”.
The CREATE TEMPORARY TABLES privilege enables
the use of the keyword TEMPORARY in
CREATE TABLE statements.
The LOCK TABLES privilege enables the use of
explicit LOCK TABLES statements to lock
tables for which you have the SELECT
privilege. This includes the use of write locks, which prevents
anyone else from reading the locked table.
The REPLICATION CLIENT privilege enables the
use of SHOW MASTER STATUS and SHOW
SLAVE STATUS.
The REPLICATION SLAVE privilege should be
granted to accounts that are used by slave servers to connect to
the current server as their master. Without this privilege, the
slave cannot request updates that have been made to databases on
the master server.
The SHOW DATABASES privilege allows the
account to see database names by issuing the SHOW
DATABASE statement. Accounts that do not have this
privilege see only databases for which they have some
privileges, and cannot use the statement at all if the server
was started with the --skip-show-database
option. Note that any global privilege is a
privilege for the database.
It is a good idea to grant to an account only those privileges
that it needs. You should exercise particular caution in
granting the FILE and administrative
privileges:
The
FILEprivilege can be abused to read into a database table any files that the MySQL server can read on the server host. This includes all world-readable files and files in the server's data directory. The table can then be accessed usingSELECTto transfer its contents to the client host.The
GRANTprivilege enables users to give their privileges to other users. Two users that have different privileges and with theGRANTprivilege are able to combine privileges.The
ALTERprivilege may be used to subvert the privilege system by renaming tables.The
SHUTDOWNprivilege can be abused to deny service to other users entirely by terminating the server.The
PROCESSprivilege can be used to view the plain text of currently executing statements, including statements that set or change passwords.The
SUPERprivilege can be used to terminate other clients or change how the server operates.Privileges granted for the
mysqldatabase itself can be used to change passwords and other access privilege information. Passwords are stored encrypted, so a malicious user cannot simply read them to know the plain text password. However, a user with write access to theusertablePasswordcolumn can change an account's password, and then connect to the MySQL server using that account.MySQL Enterprise Accounts with unnecessary global privileges constitute a security risk. Subscribers to the MySQL Network Monitoring and Advisory Service are automatically alerted to the existence of such accounts. For detailed information see http://www.mysql.com/products/enterprise/advisors.html.
There are some things that you cannot do with the MySQL privilege system:
You cannot explicitly specify that a given user should be denied access. That is, you cannot explicitly match a user and then refuse the connection.
You cannot specify that a user has privileges to create or drop tables in a database but not to create or drop the database itself.
A password applies globally to an account. You cannot associate a password with a specific object such as a database, table, or routine.
MySQL client programs generally expect you to specify certain connection parameters when you want to access a MySQL server:
The name of the host where the MySQL server is running
Your username
Your password
For example, the mysql client can be started
as follows from a command-line prompt (indicated here by
shell>):
shell> mysql -h host_name -u user_name -pyour_pass
Alternative forms of the -h,
-u, and -p options are
--host=,
host_name--user=,
and
user_name--password=.
Note that there is no space between
your_pass-p or --password= and the
password following it.
If you use a -p or --password
option but do not specify the password value, the client program
prompts you to enter the password. The password is not displayed
as you enter it. This is more secure than giving the password on
the command line. Any user on your system may be able to see a
password specified on the command line by executing a command
such as ps auxw. See
Section 5.8.6, “Keeping Your Password Secure”.
MySQL client programs use default values for any connection parameter option that you do not specify:
The default hostname is
localhost.The default username is
ODBCon Windows and your Unix login name on Unix.No password is supplied if neither
-pnor--passwordis given.
Thus, for a Unix user with a login name of
joe, all of the following commands are
equivalent:
shell>mysql -h localhost -u joeshell>mysql -h localhostshell>mysql -u joeshell>mysql
Other MySQL clients behave similarly.
You can specify different default values to be used when you make a connection so that you need not enter them on the command line each time you invoke a client program. This can be done in a couple of ways:
You can specify connection parameters in the
[client]section of an option file. The relevant section of the file might look like this:[client] host=
host_nameuser=user_namepassword=your_passSection 4.3.2, “Using Option Files”, discusses option files further.
You can specify some connection parameters using environment variables. The host can be specified for mysql using
MYSQL_HOST. The MySQL username can be specified usingUSER(this is for Windows and NetWare only). The password can be specified usingMYSQL_PWD, although this is insecure; see Section 5.8.6, “Keeping Your Password Secure”. For a list of variables, see Section 2.4.19, “Environment Variables”.
When you attempt to connect to a MySQL server, the server accepts or rejects the connection based on your identity and whether you can verify your identity by supplying the correct password. If not, the server denies access to you completely. Otherwise, the server accepts the connection, and then enters Stage 2 and waits for requests.
Your identity is based on two pieces of information:
The client host from which you connect
Your MySQL username
Identity checking is performed using the three
user table scope columns
(Host, User, and
Password). The server accepts the connection
only if the Host and User
columns in some user table row match the
client hostname and username and the client supplies the
password specified in that row.
Host values in the user
table may be specified as follows:
A
Hostvalue may be a hostname or an IP number, or'localhost'to indicate the local host.You can use the wildcard characters ‘
%’ and ‘_’ inHostcolumn values. These have the same meaning as for pattern-matching operations performed with theLIKEoperator. For example, aHostvalue of'%'matches any hostname, whereas a value of'%.mysql.com'matches any host in themysql.comdomain.MySQL Enterprise An overly broad host specifier such as ‘
%’ constitutes a security risk. The MySQL Network Monitoring and Advisory Service provides safeguards against this kind of vulnerability. For more information see http://www.mysql.com/products/enterprise/advisors.html.For
Hostvalues specified as IP numbers, you can specify a netmask indicating how many address bits to use for the network number. For example:GRANT ALL PRIVILEGES ON db.* TO david@'192.58.197.0/255.255.255.0';
This allows
davidto connect from any client host having an IP numberclient_ipfor which the following condition is true:client_ip & netmask = host_ip
That is, for the
GRANTstatement just shown:client_ip & 255.255.255.0 = 192.58.197.0
IP numbers that satisfy this condition and can connect to the MySQL server are those in the range from
192.58.197.0to192.58.197.255.Note: The netmask can only be used to tell the server to use 8, 16, 24, or 32 bits of the address. Examples:
192.0.0.0/255.0.0.0: anything on the 192 class A network192.168.0.0/255.255.0.0: anything on the 192.168 class B network192.168.1.0/255.255.255.0: anything on the 192.168.1 class C network192.168.1.1: only this specific IP
The following netmask (28 bits) will not work:
192.168.0.1/255.255.255.240
A blank
Hostvalue in adbtable row means that its privileges should be combined with those in the row in thehosttable that matches the client hostname. The privileges are combined using an AND (intersection) operation, not OR (union). Section 5.7.6, “Access Control, Stage 2: Request Verification”, discusses use of thehosttable further.A blank
Hostvalue in the other grant tables is the same as'%'.
Because you can use IP wildcard values in the
Host column (for example,
'144.155.166.%' to match every host on a
subnet), someone could try to exploit this capability by naming
a host 144.155.166.somewhere.com. To foil
such attempts, MySQL disallows matching on hostnames that start
with digits and a dot. Thus, if you have a host named something
like 1.2.foo.com, its name never matches the
Host column of the grant tables. An IP
wildcard value can match only IP numbers, not hostnames.
In the User column, wildcard characters are
not allowed, but you can specify a blank value, which matches
any name. If the user table row that matches
an incoming connection has a blank username, the user is
considered to be an anonymous user with no name, not a user with
the name that the client actually specified. This means that a
blank username is used for all further access checking for the
duration of the connection (that is, during Stage 2).
The Password column can be blank. This is not
a wildcard and does not mean that any password matches. It means
that the user must connect without specifying a password.
Non-blank Password values in the
user table represent encrypted passwords.
MySQL does not store passwords in plaintext form for anyone to
see. Rather, the password supplied by a user who is attempting
to connect is encrypted (using the PASSWORD()
function). The encrypted password then is used during the
connection process when checking whether the password is
correct. (This is done without the encrypted password ever
traveling over the connection.) From MySQL's point of view, the
encrypted password is the real password, so
you should never give anyone access to it. In particular,
do not give non-administrative users read access to
tables in the mysql database.
MySQL 5.0 employs the stronger authentication
method (first implemented in MySQL 4.1) that has better password
protection during the connection process than in earlier
versions. It is secure even if TCP/IP packets are sniffed or the
mysql database is captured.
Section 5.7.9, “Password Hashing as of MySQL 4.1”, discusses password
encryption further.
The following table shows how various combinations of
Host and User values in
the user table apply to incoming connections.
Host Value | User Value | Allowable Connections |
'thomas.loc.gov' | 'fred' | fred, connecting from
thomas.loc.gov |
'thomas.loc.gov' | '' | Any user, connecting from thomas.loc.gov |
'%' | 'fred' | fred, connecting from any host |
'%' | '' | Any user, connecting from any host |
'%.loc.gov' | 'fred' | fred, connecting from any host in the
loc.gov domain |
'x.y.%' | 'fred' | fred, connecting from x.y.net,
x.y.com, x.y.edu,
and so on (this is probably not useful) |
'144.155.166.177' | 'fred' | fred, connecting from the host with IP address
144.155.166.177 |
'144.155.166.%' | 'fred' | fred, connecting from any host in the
144.155.166 class C subnet |
'144.155.166.0/255.255.255.0' | 'fred' | Same as previous example |
It is possible for the client hostname and username of an
incoming connection to match more than one row in the
user table. The preceding set of examples
demonstrates this: Several of the entries shown match a
connection from thomas.loc.gov by
fred.
When multiple matches are possible, the server must determine which of them to use. It resolves this issue as follows:
Whenever the server reads the
usertable into memory, it sorts the rows.When a client attempts to connect, the server looks through the rows in sorted order.
The server uses the first row that matches the client hostname and username.
To see how this works, suppose that the user
table looks like this:
+-----------+----------+- | Host | User | ... +-----------+----------+- | % | root | ... | % | jeffrey | ... | localhost | root | ... | localhost | | ... +-----------+----------+-
When the server reads the table into memory, it orders the rows
with the most-specific Host values first.
Literal hostnames and IP numbers are the most specific. The
pattern '%' means “any host” and
is least specific. Rows with the same Host
value are ordered with the most-specific User
values first (a blank User value means
“any user” and is least specific). For the
user table just shown, the result after
sorting looks like this:
+-----------+----------+- | Host | User | ... +-----------+----------+- | localhost | root | ... | localhost | | ... | % | jeffrey | ... | % | root | ... +-----------+----------+-
When a client attempts to connect, the server looks through the
sorted rows and uses the first match found. For a connection
from localhost by jeffrey,
two of the rows from the table match: the one with
Host and User values of
'localhost' and '', and
the one with values of '%' and
'jeffrey'. The 'localhost'
row appears first in sorted order, so that is the one the server
uses.
Here is another example. Suppose that the
user table looks like this:
+----------------+----------+- | Host | User | ... +----------------+----------+- | % | jeffrey | ... | thomas.loc.gov | | ... +----------------+----------+-
The sorted table looks like this:
+----------------+----------+- | Host | User | ... +----------------+----------+- | thomas.loc.gov | | ... | % | jeffrey | ... +----------------+----------+-
A connection by jeffrey from
thomas.loc.gov is matched by the first row,
whereas a connection by jeffrey from
whitehouse.gov is matched by the second.
It is a common misconception to think that, for a given
username, all rows that explicitly name that user are used first
when the server attempts to find a match for the connection.
This is simply not true. The previous example illustrates this,
where a connection from thomas.loc.gov by
jeffrey is first matched not by the row
containing 'jeffrey' as the
User column value, but by the row with no
username. As a result, jeffrey is
authenticated as an anonymous user, even though he specified a
username when connecting.
If you are able to connect to the server, but your privileges
are not what you expect, you probably are being authenticated as
some other account. To find out what account the server used to
authenticate you, use the CURRENT_USER()
function. (See Section 12.10.3, “Information Functions”.) It
returns a value in
user_name@host_nameUser and
Host values from the matching
user table row. Suppose that
jeffrey connects and issues the following
query:
mysql> SELECT CURRENT_USER();
+----------------+
| CURRENT_USER() |
+----------------+
| @localhost |
+----------------+
The result shown here indicates that the matching
user table row had a blank
User column value. In other words, the server
is treating jeffrey as an anonymous user.
Another thing you can do to diagnose authentication problems is
to print out the user table and sort it by
hand to see where the first match is being made.
After you establish a connection, the server enters Stage 2 of
access control. For each request that you issue via that
connection, the server determines what operation you want to
perform, then checks whether you have sufficient privileges to
do so. This is where the privilege columns in the grant tables
come into play. These privileges can come from any of the
user, db,
host, tables_priv,
columns_priv, or
procs_priv tables. (You may find it helpful
to refer to Section 5.7.2, “How the Privilege System Works”, which lists the
columns present in each of the grant tables.)
The user table grants privileges that are
assigned to you on a global basis and that apply no matter what
the default database is. For example, if the
user table grants you the
DELETE privilege, you can delete rows from
any table in any database on the server host! In other words,
user table privileges are superuser
privileges. It is wise to grant privileges in the
user table only to superusers such as
database administrators. For other users, you should leave all
privileges in the user table set to
'N' and grant privileges at more specific
levels only. You can grant privileges for particular databases,
tables, columns, or routines.
The db and host tables
grant database-specific privileges. Values in the scope columns
of these tables can take the following forms:
The wildcard characters ‘
%’ and ‘_’ can be used in theHostandDbcolumns of either table. These have the same meaning as for pattern-matching operations performed with theLIKEoperator. If you want to use either character literally when granting privileges, you must escape it with a backslash. For example, to include the underscore character (‘_’) as part of a database name, specify it as ‘\_’ in theGRANTstatement.A
'%'Hostvalue in thedbtable means “any host.” A blankHostvalue in thedbtable means “consult thehosttable for further information” (a process that is described later in this section).A
'%'or blankHostvalue in thehosttable means “any host.”A
'%'or blankDbvalue in either table means “any database.”A blank
Uservalue in either table matches the anonymous user.
The server reads the db and
host tables into memory and sorts them at the
same time that it reads the user table. The
server sorts the db table based on the
Host, Db, and
User scope columns, and sorts the
host table based on the
Host and Db scope columns.
As with the user table, sorting puts the
most-specific values first and least-specific values last, and
when the server looks for matching entries, it uses the first
match that it finds.
The tables_priv
columns_priv, and
procs_priv tables grant table-specific,
column-specific, and routine-specific privileges. Values in the
scope columns of these tables can take the following forms:
The wildcard characters ‘
%’ and ‘_’ can be used in theHostcolumn. These have the same meaning as for pattern-matching operations performed with theLIKEoperator.A
'%'or blankHostvalue means “any host.”The
Db,Table_name, andColumn_namecolumns cannot contain wildcards or be blank.
The server sorts the tables_priv,
columns_priv, and
procs_priv tables based on the
Host, Db, and
User columns. This is similar to
db table sorting, but simpler because only
the Host column can contain wildcards.
The server uses the sorted tables to verify each request that it
receives. For requests that require administrative privileges
such as SHUTDOWN or
RELOAD, the server checks only the
user table row because that is the only table
that specifies administrative privileges. The server grants
access if the row allows the requested operation and denies
access otherwise. For example, if you want to execute
mysqladmin shutdown but your
user table row doesn't grant the
SHUTDOWN privilege to you, the server denies
access without even checking the db or
host tables. (They contain no
Shutdown_priv column, so there is no need to
do so.)
For database-related requests (INSERT,
UPDATE, and so on), the server first checks
the user's global (superuser) privileges by looking in the
user table row. If the row allows the
requested operation, access is granted. If the global privileges
in the user table are insufficient, the
server determines the user's database-specific privileges by
checking the db and host
tables:
The server looks in the
dbtable for a match on theHost,Db, andUsercolumns. TheHostandUsercolumns are matched to the connecting user's hostname and MySQL username. TheDbcolumn is matched to the database that the user wants to access. If there is no row for theHostandUser, access is denied.If there is a matching
dbtable row and itsHostcolumn is not blank, that row defines the user's database-specific privileges.If the matching
dbtable row'sHostcolumn is blank, it signifies that thehosttable enumerates which hosts should be allowed access to the database. In this case, a further lookup is done in thehosttable to find a match on theHostandDbcolumns. If nohosttable row matches, access is denied. If there is a match, the user's database-specific privileges are computed as the intersection (not the union!) of the privileges in thedbandhosttable entries; that is, the privileges that are'Y'in both entries. (This way you can grant general privileges in thedbtable row and then selectively restrict them on a host-by-host basis using thehosttable entries.)
After determining the database-specific privileges granted by
the db and host table
entries, the server adds them to the global privileges granted
by the user table. If the result allows the
requested operation, access is granted. Otherwise, the server
successively checks the user's table and column privileges in
the tables_priv and
columns_priv tables, adds those to the user's
privileges, and allows or denies access based on the result. For
stored routine operations, the server uses the
procs_priv table rather than
tables_priv and
columns_priv.
Expressed in boolean terms, the preceding description of how a user's privileges are calculated may be summarized like this:
global privileges OR (database privileges AND host privileges) OR table privileges OR column privileges OR routine privileges
It may not be apparent why, if the global
user row privileges are initially found to be
insufficient for the requested operation, the server adds those
privileges to the database, table, and column privileges later.
The reason is that a request might require more than one type of
privilege. For example, if you execute an INSERT INTO
... SELECT statement, you need both the
INSERT and the SELECT
privileges. Your privileges might be such that the
user table row grants one privilege and the
db table row grants the other. In this case,
you have the necessary privileges to perform the request, but
the server cannot tell that from either table by itself; the
privileges granted by the entries in both tables must be
combined.
The host table is not affected by the
GRANT or REVOKE
statements, so it is unused in most MySQL installations. If you
modify it directly, you can use it for some specialized
purposes, such as to maintain a list of secure servers. For
example, at TcX, the host table contains a
list of all machines on the local network. These are granted all
privileges.
You can also use the host table to indicate
hosts that are not secure. Suppose that you
have a machine public.your.domain that is
located in a public area that you do not consider secure. You
can allow access to all hosts on your network except that
machine by using host table entries like
this:
+--------------------+----+- | Host | Db | ... +--------------------+----+- | public.your.domain | % | ... (all privileges set to 'N') | %.your.domain | % | ... (all privileges set to 'Y') +--------------------+----+-
Naturally, you should always test your changes to the grant
tables (for example, by using SHOW GRANTS) to
make sure that your access privileges are actually set up the
way you think they are.
When mysqld starts, it reads all grant table contents into memory. The in-memory tables become effective for access control at that point.
When the server reloads the grant tables, privileges for existing client connections are affected as follows:
Table and column privilege changes take effect with the client's next request.
Database privilege changes take effect at the next
USEstatement.db_nameNote: Client applications may cache the database name; thus, this effect may not be visible to them without actually changing to a different database or executing a
FLUSH PRIVILEGESstatement.Changes to global privileges and passwords take effect the next time the client connects.
If you modify the grant tables indirectly using statements such
as GRANT, REVOKE, or
SET PASSWORD, the server notices these
changes and loads the grant tables into memory again
immediately.
If you modify the grant tables directly using statements such as
INSERT, UPDATE, or
DELETE, your changes have no effect on
privilege checking until you either restart the server or tell
it to reload the tables. To reload the grant tables manually,
issue a FLUSH PRIVILEGES statement or execute
a mysqladmin flush-privileges or
mysqladmin reload command.
If you change the grant tables directly but forget to reload them, your changes have no effect until you restart the server. This may leave you wondering why your changes do not seem to make any difference!
If you encounter problems when you try to connect to the MySQL server, the following items describe some courses of action you can take to correct the problem.
Make sure that the server is running. If it is not running, you cannot connect to it. For example, if you attempt to connect to the server and see a message such as one of those following, one cause might be that the server is not running:
shell>
mysqlERROR 2003: Can't connect to MySQL server on 'host_name' (111) shell>mysqlERROR 2002: Can't connect to local MySQL server through socket '/tmp/mysql.sock' (111)It might also be that the server is running, but you are trying to connect using a TCP/IP port, named pipe, or Unix socket file different from the one on which the server is listening. To correct this when you invoke a client program, specify a
--portoption to indicate the proper port number, or a--socketoption to indicate the proper named pipe or Unix socket file. To find out where the socket file is, you can use this command:shell>
netstat -ln | grep mysqlThe grant tables must be properly set up so that the server can use them for access control. For some distribution types (such as binary distributions on Windows, or RPM distributions on Linux), the installation process initializes the
mysqldatabase containing the grant tables. For distributions that do not do this, you must initialize the grant tables manually by running the mysql_install_db script. For details, see Section 2.4.15.2, “Unix Post-Installation Procedures”.One way to determine whether you need to initialize the grant tables is to look for a
mysqldirectory under the data directory. (The data directory normally is nameddataorvarand is located under your MySQL installation directory.) Make sure that you have a file nameduser.MYDin themysqldatabase directory. If you do not, execute the mysql_install_db script. After running this script and starting the server, test the initial privileges by executing this command:shell>
mysql -u root testThe server should let you connect without error.
After a fresh installation, you should connect to the server and set up your users and their access permissions:
shell>
mysql -u root mysqlThe server should let you connect because the MySQL
rootuser has no password initially. That is also a security risk, so setting the password for therootaccounts is something you should do while you're setting up your other MySQL accounts. For instructions on setting the initial passwords, see Section 2.4.15.3, “Securing the Initial MySQL Accounts”.MySQL Enterprise The MySQL Network Monitoring and Advisory Service enforces security-related best practices. For example, subscribers are alerted whenever there is any account without a password. For more information see http://www.mysql.com/products/enterprise/advisors.html.
If you have updated an existing MySQL installation to a newer version, did you run the mysql_upgrade script? If not, do so. The structure of the grant tables changes occasionally when new capabilities are added, so after an upgrade you should always make sure that your tables have the current structure. For instructions, see Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.
If a client program receives the following error message when it tries to connect, it means that the server expects passwords in a newer format than the client is capable of generating:
shell>
mysqlClient does not support authentication protocol requested by server; consider upgrading MySQL clientFor information on how to deal with this, see Section 5.7.9, “Password Hashing as of MySQL 4.1”, and Section B.1.2.3, “
Client does not support authentication protocol”.If you try to connect as
rootand get the following error, it means that you do not have a row in theusertable with aUsercolumn value of'root'and that mysqld cannot resolve the hostname for your client:Access denied for user ''@'unknown' to database mysql
In this case, you must restart the server with the
--skip-grant-tablesoption and edit your/etc/hostsfile or\windows\hostsfile to add an entry for your host.Remember that client programs use connection parameters specified in option files or environment variables. If a client program seems to be sending incorrect default connection parameters when you have not specified them on the command line, check your environment and any applicable option files. For example, if you get
Access deniedwhen you run a client without any options, make sure that you have not specified an old password in any of your option files!You can suppress the use of option files by a client program by invoking it with the
--no-defaultsoption. For example:shell>
mysqladmin --no-defaults -u root versionThe option files that clients use are listed in Section 4.3.2, “Using Option Files”. Environment variables are listed in Section 2.4.19, “Environment Variables”.
If you get the following error, it means that you are using an incorrect
rootpassword:shell>
mysqladmin -u root -pAccess denied for user 'root'@'localhost' (using password: YES)xxxxverIf the preceding error occurs even when you have not specified a password, it means that you have an incorrect password listed in some option file. Try the
--no-defaultsoption as described in the previous item.For information on changing passwords, see Section 5.8.5, “Assigning Account Passwords”.
If you have lost or forgotten the
rootpassword, you can restart mysqld with--skip-grant-tablesto change the password. See Section B.1.4.1, “How to Reset the Root Password”.If you change a password by using
SET PASSWORD,INSERT, orUPDATE, you must encrypt the password using thePASSWORD()function. If you do not usePASSWORD()for these statements, the password will not work. For example, the following statement sets a password, but fails to encrypt it, so the user is not able to connect afterward:SET PASSWORD FOR 'abe'@'
host_name' = 'eagle';Instead, set the password like this:
SET PASSWORD FOR 'abe'@'
host_name' = PASSWORD('eagle');The
PASSWORD()function is unnecessary when you specify a password using theGRANTor (beginning with MySQL 5.0.2)CREATE USERstatements, or the mysqladmin password command. Each of those automatically usesPASSWORD()to encrypt the password. See Section 5.8.5, “Assigning Account Passwords”, and Section 13.5.1.1, “CREATE USERSyntax”.localhostis a synonym for your local hostname, and is also the default host to which clients try to connect if you specify no host explicitly.To avoid this problem on such systems, you can use a
--host=127.0.0.1option to name the server host explicitly. This will make a TCP/IP connection to the local mysqld server. You can also use TCP/IP by specifying a--hostoption that uses the actual hostname of the local host. In this case, the hostname must be specified in ausertable row on the server host, even though you are running the client program on the same host as the server.If you get an
Access deniederror when trying to connect to the database withmysql -u, you may have a problem with theuser_nameusertable. Check this by executingmysql -u root mysqland issuing this SQL statement:SELECT * FROM user;
The result should include a row with the
HostandUsercolumns matching your computer's hostname and your MySQL username.The
Access deniederror message tells you who you are trying to log in as, the client host from which you are trying to connect, and whether you were using a password. Normally, you should have one row in theusertable that exactly matches the hostname and username that were given in the error message. For example, if you get an error message that containsusing password: NO, it means that you tried to log in without a password.If the following error occurs when you try to connect from a host other than the one on which the MySQL server is running, it means that there is no row in the
usertable with aHostvalue that matches the client host:Host ... is not allowed to connect to this MySQL server
You can fix this by setting up an account for the combination of client hostname and username that you are using when trying to connect.
If you do not know the IP number or hostname of the machine from which you are connecting, you should put a row with
'%'as theHostcolumn value in theusertable. After trying to connect from the client machine, use aSELECT USER()query to see how you really did connect. (Then change the'%'in theusertable row to the actual hostname that shows up in the log. Otherwise, your system is left insecure because it allows connections from any host for the given username.)On Linux, another reason that this error might occur is that you are using a binary MySQL version that is compiled with a different version of the
glibclibrary than the one you are using. In this case, you should either upgrade your operating system orglibc, or download a source distribution of MySQL version and compile it yourself. A source RPM is normally trivial to compile and install, so this is not a big problem.If you specify a hostname when trying to connect, but get an error message where the hostname is not shown or is an IP number, it means that the MySQL server got an error when trying to resolve the IP number of the client host to a name:
shell>
mysqladmin -u root -pAccess denied for user 'root'@'' (using password: YES)xxxx-hsome_hostnameverThis indicates a DNS problem. To fix it, execute mysqladmin flush-hosts to reset the internal DNS hostname cache. See Section 7.5.7, “How MySQL Uses DNS”.
Some permanent solutions are:
Determine what is wrong with your DNS server and fix it.
Specify IP numbers rather than hostnames in the MySQL grant tables.
Put an entry for the client machine name in
/etc/hostsor\windows\hosts.Start mysqld with the
--skip-name-resolveoption.Start mysqld with the
--skip-host-cacheoption.On Unix, if you are running the server and the client on the same machine, connect to
localhost. Unix connections tolocalhostuse a Unix socket file rather than TCP/IP.On Windows, if you are running the server and the client on the same machine and the server supports named pipe connections, connect to the hostname
.(period). Connections to.use a named pipe rather than TCP/IP.
If
mysql -u root testworks butmysql -hresults inyour_hostname-u root testAccess denied(whereyour_hostnameis the actual hostname of the local host), you may not have the correct name for your host in theusertable. A common problem here is that theHostvalue in theusertable row specifies an unqualified hostname, but your system's name resolution routines return a fully qualified domain name (or vice versa). For example, if you have an entry with host'tcx'in theusertable, but your DNS tells MySQL that your hostname is'tcx.subnet.se', the entry does not work. Try adding an entry to theusertable that contains the IP number of your host as theHostcolumn value. (Alternatively, you could add an entry to theusertable with aHostvalue that contains a wildcard; for example,'tcx.%'. However, use of hostnames ending with ‘%’ is insecure and is not recommended!)If
mysql -uworks butuser_nametestmysql -udoes not, you have not granted database access foruser_nameother_db_nameother_db_nameto the given user.If
mysql -uworks when executed on the server host, butuser_namemysql -hdoes not work when executed on a remote client host, you have not enabled access to the server for the given username from the remote host.host_name-uuser_nameIf you cannot figure out why you get
Access denied, remove from theusertable all entries that haveHostvalues containing wildcards (entries that contain ‘%’ or ‘_’). A very common error is to insert a new entry withHost='%'andUser=', thinking that this allows you to specifysome_user'localhostto connect from the same machine. The reason that this does not work is that the default privileges include an entry withHost='localhost'andUser=''. Because that entry has aHostvalue'localhost'that is more specific than'%', it is used in preference to the new entry when connecting fromlocalhost! The correct procedure is to insert a second entry withHost='localhost'andUser=', or to delete the entry withsome_user'Host='localhost'andUser=''. After deleting the entry, remember to issue aFLUSH PRIVILEGESstatement to reload the grant tables.If you get the following error, you may have a problem with the
dborhosttable:Access to database denied
If the entry selected from the
dbtable has an empty value in theHostcolumn, make sure that there are one or more corresponding entries in thehosttable specifying which hosts thedbtable entry applies to.If you are able to connect to the MySQL server, but get an
Access deniedmessage whenever you issue aSELECT ... INTO OUTFILEorLOAD DATA INFILEstatement, your entry in theusertable does not have theFILEprivilege enabled.If you change the grant tables directly (for example, by using
INSERT,UPDATE, orDELETEstatements) and your changes seem to be ignored, remember that you must execute aFLUSH PRIVILEGESstatement or a mysqladmin flush-privileges command to cause the server to re-read the privilege tables. Otherwise, your changes have no effect until the next time the server is restarted. Remember that after you change therootpassword with anUPDATEcommand, you won't need to specify the new password until after you flush the privileges, because the server won't know you've changed the password yet!If your privileges seem to have changed in the middle of a session, it may be that a MySQL administrator has changed them. Reloading the grant tables affects new client connections, but it also affects existing connections as indicated in Section 5.7.7, “When Privilege Changes Take Effect”.
If you have access problems with a Perl, PHP, Python, or ODBC program, try to connect to the server with
mysql -uoruser_namedb_namemysql -u. If you are able to connect using the mysql client, the problem lies with your program, not with the access privileges. (There is no space betweenuser_name-pyour_passdb_name-pand the password; you can also use the--password=syntax to specify the password. If you use theyour_pass-p--passwordoption with no password value, MySQL prompts you for the password.)For testing, start the mysqld server with the
--skip-grant-tablesoption. Then you can change the MySQL grant tables and use the mysqlaccess script to check whether your modifications have the desired effect. When you are satisfied with your changes, execute mysqladmin flush-privileges to tell the mysqld server to start using the new grant tables. (Reloading the grant tables overrides the--skip-grant-tablesoption. This enables you to tell the server to begin using the grant tables again without stopping and restarting it.)If everything else fails, start the mysqld server with a debugging option (for example,
--debug=d,general,query). This prints host and user information about attempted connections, as well as information about each command issued. See MySQL Internals: Porting.If you have any other problems with the MySQL grant tables and feel you must post the problem to the mailing list, always provide a dump of the MySQL grant tables. You can dump the tables with the mysqldump mysql command. To file a bug report, see the instructions at Section 1.8, “How to Report Bugs or Problems”. In some cases, you may need to restart mysqld with
--skip-grant-tablesto run mysqldump.
MySQL user accounts are listed in the user
table of the mysql database. Each MySQL
account is assigned a password, although what is stored in the
Password column of the
user table is not the plaintext version of
the password, but a hash value computed from it. Password hash
values are computed by the PASSWORD()
function.
MySQL uses passwords in two phases of client/server communication:
When a client attempts to connect to the server, there is an initial authentication step in which the client must present a password that has a hash value matching the hash value stored in the
usertable for the account that the client wants to use.After the client connects, it can (if it has sufficient privileges) set or change the password hashes for accounts listed in the
usertable. The client can do this by using thePASSWORD()function to generate a password hash, or by using theGRANTorSET PASSWORDstatements.
In other words, the server uses hash values
during authentication when a client first attempts to connect.
The server generates hash values if a
connected client invokes the PASSWORD()
function or uses a GRANT or SET
PASSWORD statement to set or change a password.
The password hashing mechanism was updated in MySQL 4.1 to provide better security and to reduce the risk of passwords being intercepted. However, this new mechanism is understood only by MySQL 4.1 (and newer) servers and clients, which can result in some compatibility problems. A 4.1 or newer client can connect to a pre-4.1 server, because the client understands both the old and new password hashing mechanisms. However, a pre-4.1 client that attempts to connect to a 4.1 or newer server may run into difficulties. For example, a 3.23 mysql client that attempts to connect to a 5.0 server may fail with the following error message:
shell> mysql -h localhost -u root
Client does not support authentication protocol requested
by server; consider upgrading MySQL client
Another common example of this phenomenon occurs for attempts to
use the older PHP mysql extension after
upgrading to MySQL 4.1 or newer. (See
Section 22.3.1, “Common Problems with MySQL and PHP”.)
The following discussion describes the differences between the
old and new password mechanisms, and what you should do if you
upgrade your server but need to maintain backward compatibility
with pre-4.1 clients. Additional information can be found in
Section B.1.2.3, “Client does not support authentication protocol”. This information is of particular
importance to PHP programmers migrating MySQL databases from
version 4.0 or lower to version 4.1 or higher.
Note: This discussion contrasts 4.1 behavior with pre-4.1 behavior, but the 4.1 behavior described here actually begins with 4.1.1. MySQL 4.1.0 is an “odd” release because it has a slightly different mechanism than that implemented in 4.1.1 and up. Differences between 4.1.0 and more recent versions are described further in MySQL 3.23, 4.0, 4.1 Reference Manual.
Prior to MySQL 4.1, password hashes computed by the
PASSWORD() function are 16 bytes long. Such
hashes look like this:
mysql> SELECT PASSWORD('mypass');
+--------------------+
| PASSWORD('mypass') |
+--------------------+
| 6f8c114b58f2ce9e |
+--------------------+
The Password column of the
user table (in which these hashes are stored)
also is 16 bytes long before MySQL 4.1.
As of MySQL 4.1, the PASSWORD() function has
been modified to produce a longer 41-byte hash value:
mysql> SELECT PASSWORD('mypass');
+-------------------------------------------+
| PASSWORD('mypass') |
+-------------------------------------------+
| *6C8989366EAF75BB670AD8EA7A7FC1176A95CEF4 |
+-------------------------------------------+
Accordingly, the Password column in the
user table also must be 41 bytes long to
store these values:
If you perform a new installation of MySQL 5.0, the
Passwordcolumn is made 41 bytes long automatically.Upgrading from MySQL 4.1 (4.1.1 or later in the 4.1 series) to MySQL 5.0 should not give rise to any issues in this regard because both versions use the same password hashing mechanism. If you wish to upgrade an older release of MySQL to version 5.0, you should upgrade to version 4.1 first, then upgrade the 4.1 installation to 5.0.
A widened Password column can store password
hashes in both the old and new formats. The format of any given
password hash value can be determined two ways:
The obvious difference is the length (16 bytes versus 41 bytes).
A second difference is that password hashes in the new format always begin with a ‘
*’ character, whereas passwords in the old format never do.
The longer password hash format has better cryptographic properties, and client authentication based on long hashes is more secure than that based on the older short hashes.
The differences between short and long password hashes are relevant both for how the server uses passwords during authentication and for how it generates password hashes for connected clients that perform password-changing operations.
The way in which the server uses password hashes during
authentication is affected by the width of the
Password column:
If the column is short, only short-hash authentication is used.
If the column is long, it can hold either short or long hashes, and the server can use either format:
Pre-4.1 clients can connect, although because they know only about the old hashing mechanism, they can authenticate only using accounts that have short hashes.
4.1 and later clients can authenticate using accounts that have short or long hashes.
Even for short-hash accounts, the authentication process is actually a bit more secure for 4.1 and later clients than for older clients. In terms of security, the gradient from least to most secure is:
Pre-4.1 client authenticating with short password hash
4.1 or later client authenticating with short password hash
4.1 or later client authenticating with long password hash
The way in which the server generates password hashes for
connected clients is affected by the width of the
Password column and by the
--old-passwords option. A 4.1 or later server
generates long hashes only if certain conditions are met: The
Password column must be wide enough to hold
long values and the --old-passwords option must
not be given. These conditions apply as follows:
The
Passwordcolumn must be wide enough to hold long hashes (41 bytes). If the column has not been updated and still has the pre-4.1 width of 16 bytes, the server notices that long hashes cannot fit into it and generates only short hashes when a client performs password-changing operations usingPASSWORD(),GRANT, orSET PASSWORD. This is the behavior that occurs if you have upgraded to 4.1 but have not yet run the mysql_fix_privilege_tables script to widen thePasswordcolumn.If the
Passwordcolumn is wide, it can store either short or long password hashes. In this case,PASSWORD(),GRANT, andSET PASSWORDgenerate long hashes unless the server was started with the--old-passwordsoption. That option forces the server to generate short password hashes instead.
The purpose of the --old-passwords option is to
enable you to maintain backward compatibility with pre-4.1
clients under circumstances where the server would otherwise
generate long password hashes. The option doesn't affect
authentication (4.1 and later clients can still use accounts
that have long password hashes), but it does prevent creation of
a long password hash in the user table as the
result of a password-changing operation. Were that to occur, the
account no longer could be used by pre-4.1 clients. Without the
--old-passwords option, the following
undesirable scenario is possible:
An old client connects to an account that has a short password hash.
The client changes its own password. Without
--old-passwords, this results in the account having a long password hash.The next time the old client attempts to connect to the account, it cannot, because the account has a long password hash that requires the new hashing mechanism during authentication. (Once an account has a long password hash in the user table, only 4.1 and later clients can authenticate for it, because pre-4.1 clients do not understand long hashes.)
This scenario illustrates that, if you must support older
pre-4.1 clients, it is dangerous to run a 4.1 or newer server
without using the --old-passwords option. By
running the server with --old-passwords,
password-changing operations do not generate long password
hashes and thus do not cause accounts to become inaccessible to
older clients. (Those clients cannot inadvertently lock
themselves out by changing their password and ending up with a
long password hash.)
The downside of the --old-passwords option is
that any passwords you create or change use short hashes, even
for 4.1 clients. Thus, you lose the additional security provided
by long password hashes. If you want to create an account that
has a long hash (for example, for use by 4.1 clients), you must
do so while running the server without
--old-passwords.
The following scenarios are possible for running a 4.1 or later server:
Scenario 1: Short
Password column in user table:
Only short hashes can be stored in the
Passwordcolumn.The server uses only short hashes during client authentication.
For connected clients, password hash-generating operations involving
PASSWORD(),GRANT, orSET PASSWORDuse short hashes exclusively. Any change to an account's password results in that account having a short password hash.The
--old-passwordsoption can be used but is superfluous because with a shortPasswordcolumn, the server generates only short password hashes anyway.
Scenario 2: Long
Password column; server not started with
--old-passwords option:
Short or long hashes can be stored in the
Passwordcolumn.4.1 and later clients can authenticate using accounts that have short or long hashes.
Pre-4.1 clients can authenticate only using accounts that have short hashes.
For connected clients, password hash-generating operations involving
PASSWORD(),GRANT, orSET PASSWORDuse long hashes exclusively. A change to an account's password results in that account having a long password hash.
As indicated earlier, a danger in this scenario is that it is
possible for accounts that have a short password hash to become
inaccessible to pre-4.1 clients. A change to such an account's
password made via GRANT,
PASSWORD(), or SET
PASSWORD results in the account being given a long
password hash. From that point on, no pre-4.1 client can
authenticate to that account until the client upgrades to 4.1.
To deal with this problem, you can change a password in a
special way. For example, normally you use SET
PASSWORD as follows to change an account password:
SET PASSWORD FOR 'some_user'@'some_host' = PASSWORD('mypass');
To change the password but create a short hash, use the
OLD_PASSWORD() function instead:
SET PASSWORD FOR 'some_user'@'some_host' = OLD_PASSWORD('mypass');
OLD_PASSWORD() is useful for situations in
which you explicitly want to generate a short hash.
Scenario 3: Long
Password column; 4.1 or newer server started
with --old-passwords option:
Short or long hashes can be stored in the
Passwordcolumn.4.1 and later clients can authenticate for accounts that have short or long hashes (but note that it is possible to create long hashes only when the server is started without
--old-passwords).Pre-4.1 clients can authenticate only for accounts that have short hashes.
For connected clients, password hash-generating operations involving
PASSWORD(),GRANT, orSET PASSWORDuse short hashes exclusively. Any change to an account's password results in that account having a short password hash.
In this scenario, you cannot create accounts that have long
password hashes, because the --old-passwords
option prevents generation of long hashes. Also, if you create
an account with a long hash before using the
--old-passwords option, changing the account's
password while --old-passwords is in effect
results in the account being given a short password, causing it
to lose the security benefits of a longer hash.
The disadvantages for these scenarios may be summarized as follows:
In scenario 1, you cannot take advantage of longer hashes that provide more secure authentication.
In scenario 2, accounts with short hashes become inaccessible to
pre-4.1 clients if you change their passwords without explicitly
using OLD_PASSWORD().
In scenario 3, --old-passwords prevents
accounts with short hashes from becoming inaccessible, but
password-changing operations cause accounts with long hashes to
revert to short hashes, and you cannot change them back to long
hashes while --old-passwords is in effect.
An upgrade to MySQL version 4.1 or later can cause
compatibility issues for applications that use
PASSWORD() to generate passwords for their
own purposes. Applications really should not do this, because
PASSWORD() should be used only to manage
passwords for MySQL accounts. But some applications use
PASSWORD() for their own purposes anyway.
If you upgrade to 4.1 or later from a pre-4.1 version of MySQL
and run the server under conditions where it generates long
password hashes, an application using
PASSWORD() for its own passwords breaks.
The recommended course of action in such cases is to modify
the application to use another function, such as
SHA1() or MD5(), to
produce hashed values. If that is not possible, you can use
the OLD_PASSWORD() function, which is
provided for generate short hashes in the old format. However,
you should note that OLD_PASSWORD() may one
day no longer be supported.
If the server is running under circumstances where it
generates short hashes, OLD_PASSWORD() is
available but is equivalent to PASSWORD().
PHP programmers migrating their MySQL databases from version 4.0 or lower to version 4.1 or higher should see Section 22.3, “MySQL PHP API”.
This section describes how to set up accounts for clients of your MySQL server. It discusses the following topics:
The meaning of account names and passwords as used in MySQL and how that compares to names and passwords used by your operating system
How to set up new accounts and remove existing accounts
How to change passwords
Guidelines for using passwords securely
How to use secure connections with SSL
A MySQL account is defined in terms of a username and the client host or hosts from which the user can connect to the server. The account also has a password. There are several distinctions between the way usernames and passwords are used by MySQL and the way they are used by your operating system:
Usernames, as used by MySQL for authentication purposes, have nothing to do with usernames (login names) as used by Windows or Unix. On Unix, most MySQL clients by default try to log in using the current Unix username as the MySQL username, but that is for convenience only. The default can be overridden easily, because client programs allow any username to be specified with a
-uor--useroption. Because this means that anyone can attempt to connect to the server using any username, you cannot make a database secure in any way unless all MySQL accounts have passwords. Anyone who specifies a username for an account that has no password is able to connect successfully to the server.MySQL usernames can be up to 16 characters long. This limit is hard-coded in the MySQL servers and clients, and trying to circumvent it by modifying the definitions of the tables in the
mysqldatabase does not work.Note: You should never alter any of the tables in the
mysqldatabase in any manner whatsoever except by means of the procedure prescribed by MySQL AB that is described in Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”. Attempting to redefine MySQL's system tables in any other fashion results in undefined (and unsupported!) behavior.Operating system usernames are completely unrelated to MySQL usernames and may even be of a different maximum length. For example, Unix usernames typically are limited to eight characters.
MySQL passwords have nothing to do with passwords for logging in to your operating system. There is no necessary connection between the password you use to log in to a Windows or Unix machine and the password you use to access the MySQL server on that machine.
MySQL encrypts passwords using its own algorithm. This encryption is different from that used during the Unix login process. MySQL password encryption is the same as that implemented by the
PASSWORD()SQL function. Unix password encryption is the same as that implemented by theENCRYPT()SQL function. See the descriptions of thePASSWORD()andENCRYPT()functions in Section 12.10.2, “Encryption and Compression Functions”. From version 4.1 on, MySQL employs a stronger authentication method that has better password protection during the connection process than in earlier versions. It is secure even if TCP/IP packets are sniffed or themysqldatabase is captured. (In earlier versions, even though passwords are stored in encrypted form in theusertable, knowledge of the encrypted password value could be used to connect to the MySQL server.)
When you install MySQL, the grant tables are populated with an
initial set of accounts. These accounts have names and access
privileges that are described in
Section 2.4.15.3, “Securing the Initial MySQL Accounts”, which also discusses how
to assign passwords to them. Thereafter, you normally set up,
modify, and remove MySQL accounts using statements such as
GRANT and REVOKE. See
Section 13.5.1, “Account Management Statements”.
When you connect to a MySQL server with a command-line client, you should specify the username and password for the account that you want to use:
shell> mysql --user=monty --password=guess db_name
If you prefer short options, the command looks like this:
shell> mysql -u monty -pguess db_name
There must be no space between the
-p option and the following password value. See
Section 5.7.4, “Connecting to the MySQL Server”.
The preceding commands include the password value on the command
line, which can be a security risk. See
Section 5.8.6, “Keeping Your Password Secure”. To avoid this problem,
specify the --password or -p
option without any following password value:
shell>mysql --user=monty --passwordshell>db_namemysql -u monty -pdb_name
When the password option has no password value, the client
program prints a prompt and waits for you to enter the password.
(In these examples, db_name is
not interpreted as a password because it is
separated from the preceding password option by a space.)
On some systems, the library routine that MySQL uses to prompt for a password automatically limits the password to eight characters. That is a problem with the system library, not with MySQL. Internally, MySQL doesn't have any limit for the length of the password. To work around the problem, change your MySQL password to a value that is eight or fewer characters long, or put your password in an option file.
You can create MySQL accounts in two ways:
By using statements intended for creating accounts, such as
CREATE USERorGRANTBy manipulating the MySQL grant tables directly with statements such as
INSERT,UPDATE, orDELETE
The preferred method is to use account-creation statements
because they are more concise and less error-prone.
CREATE USER and GRANT are
described in Section 13.5.1.1, “CREATE USER Syntax”, and
Section 13.5.1.3, “GRANT Syntax”.
Another option for creating accounts is to use one of several
available third-party programs that offer capabilities for MySQL
account administration. phpMyAdmin is one
such program.
The following examples show how to use the
mysql client program to set up new users.
These examples assume that privileges are set up according to
the defaults described in Section 2.4.15.3, “Securing the Initial MySQL Accounts”.
This means that to make changes, you must connect to the MySQL
server as the MySQL root user, and the
root account must have the
INSERT privilege for the
mysql database and the
RELOAD administrative privilege.
As noted in the examples where appropriate, some of the
statements will fail if you have the server's SQL mode has been
set to enable certain restrictions. In particular, strict mode
(STRICT_TRANS_TABLES,
STRICT_ALL_TABLES) and
NO_AUTO_CREATE_USER will prevent the server
from accepting some of the statements. Workarounds are indicated
for these cases. For more information about SQL modes and their
effect on grant table manipulation, see
Section 5.2.6, “SQL Modes”, and Section 13.5.1.3, “GRANT Syntax”.
First, use the mysql program to connect to
the server as the MySQL root user:
shell> mysql --user=root mysql
If you have assigned a password to the root
account, you'll also need to supply a
--password or -p option for
this mysql command and also for those later
in this section.
After connecting to the server as root, you
can add new accounts. The following statements use
GRANT to set up four new accounts:
mysql>GRANT ALL PRIVILEGES ON *.* TO 'monty'@'localhost'->IDENTIFIED BY 'some_pass' WITH GRANT OPTION;mysql>GRANT ALL PRIVILEGES ON *.* TO 'monty'@'%'->IDENTIFIED BY 'some_pass' WITH GRANT OPTION;mysql>GRANT RELOAD,PROCESS ON *.* TO 'admin'@'localhost';mysql>GRANT USAGE ON *.* TO 'dummy'@'localhost';
The accounts created by these GRANT
statements have the following properties:
Two of the accounts have a username of
montyand a password ofsome_pass. Both accounts are superuser accounts with full privileges to do anything. One account ('monty'@'localhost') can be used only when connecting from the local host. The other ('monty'@'%') can be used to connect from any other host. Note that it is necessary to have both accounts formontyto be able to connect from anywhere asmonty. Without thelocalhostaccount, the anonymous-user account forlocalhostthat is created by mysql_install_db would take precedence whenmontyconnects from the local host. As a result,montywould be treated as an anonymous user. The reason for this is that the anonymous-user account has a more specificHostcolumn value than the'monty'@'%'account and thus comes earlier in theusertable sort order. (usertable sorting is discussed in Section 5.7.5, “Access Control, Stage 1: Connection Verification”.)One account has a username of
adminand no password. This account can be used only by connecting from the local host. It is granted theRELOADandPROCESSadministrative privileges. These privileges allow theadminuser to execute the mysqladmin reload, mysqladmin refresh, and mysqladmin flush-xxxcommands, as well as mysqladmin processlist . No privileges are granted for accessing any databases. You could add such privileges later by issuing additionalGRANTstatements.One account has a username of
dummyand no password. This account can be used only by connecting from the local host. No privileges are granted. TheUSAGEprivilege in theGRANTstatement enables you to create an account without giving it any privileges. It has the effect of setting all the global privileges to'N'. It is assumed that you will grant specific privileges to the account later.The statements that create accounts with no password will fail if the
NO_AUTO_CREATE_USERSQL mode is enabled. To deal with this, use anIDENTIFIED BYclause that specifies a non-empty password.
As an alternative to GRANT, you can create
the same accounts directly by issuing INSERT
statements and then telling the server to reload the grant
tables using FLUSH PRIVILEGES:
shell>mysql --user=root mysqlmysql>INSERT INTO user->VALUES('localhost','monty',PASSWORD('some_pass'),->'Y','Y','Y','Y','Y','Y','Y','Y','Y','Y','Y','Y','Y','Y');mysql>INSERT INTO user->VALUES('%','monty',PASSWORD('some_pass'),->'Y','Y','Y','Y','Y','Y','Y','Y','Y','Y','Y','Y','Y',->'Y','Y','Y','Y','Y','Y','Y','Y','Y','Y','Y','Y','Y',->'','','','',0,0,0,0);mysql>INSERT INTO user SET Host='localhost',User='admin',->Reload_priv='Y', Process_priv='Y';mysql>INSERT INTO user (Host,User,Password)->VALUES('localhost','dummy','');mysql>FLUSH PRIVILEGES;
The reason for using FLUSH PRIVILEGES when
you create accounts with INSERT is to tell
the server to re-read the grant tables. Otherwise, the changes
go unnoticed until you restart the server. With
GRANT, FLUSH PRIVILEGES is
unnecessary.
The reason for using the PASSWORD() function
with INSERT is to encrypt the password. The
GRANT statement encrypts the password for
you, so PASSWORD() is unnecessary.
The 'Y' values enable privileges for the
accounts. Depending on your MySQL version, you may have to use a
different number of 'Y' values in the first
two INSERT statements. For the
admin account, you may also employ the more
readable extended INSERT syntax using
SET.
In the INSERT statement for the
dummy account, only the
Host, User, and
Password columns in the
user table row are assigned values. None of
the privilege columns are set explicitly, so MySQL assigns them
all the default value of 'N'. This is
equivalent to what GRANT USAGE does.
If strict SQL mode is enabled, all columns that have no default
value must have a value specified. In this case,
INSERT statements must explicitly specify
values for the ssl_cipher,
x509_issuer, and
x509_subject columns.
Note that to set up a superuser account, it is necessary only to
create a user table entry with the privilege
columns set to 'Y'. user
table privileges are global, so no entries in any of the other
grant tables are needed.
The next examples create three accounts and give them access to
specific databases. Each of them has a username of
custom and password of
obscure.
To create the accounts with GRANT, use the
following statements:
shell>mysql --user=root mysqlmysql>GRANT SELECT,INSERT,UPDATE,DELETE,CREATE,DROP->ON bankaccount.*->TO 'custom'@'localhost'->IDENTIFIED BY 'obscure';mysql>GRANT SELECT,INSERT,UPDATE,DELETE,CREATE,DROP->ON expenses.*->TO 'custom'@'whitehouse.gov'->IDENTIFIED BY 'obscure';mysql>GRANT SELECT,INSERT,UPDATE,DELETE,CREATE,DROP->ON customer.*->TO 'custom'@'server.domain'->IDENTIFIED BY 'obscure';
The three accounts can be used as follows:
The first account can access the
bankaccountdatabase, but only from the local host.The second account can access the
expensesdatabase, but only from the hostwhitehouse.gov.The third account can access the
customerdatabase, but only from the hostserver.domain.
To set up the custom accounts without
GRANT, use INSERT
statements as follows to modify the grant tables directly:
shell>mysql --user=root mysqlmysql>INSERT INTO user (Host,User,Password)->VALUES('localhost','custom',PASSWORD('obscure'));mysql>INSERT INTO user (Host,User,Password)->VALUES('whitehouse.gov','custom',PASSWORD('obscure'));mysql>INSERT INTO user (Host,User,Password)->VALUES('server.domain','custom',PASSWORD('obscure'));mysql>INSERT INTO db->(Host,Db,User,Select_priv,Insert_priv,->Update_priv,Delete_priv,Create_priv,Drop_priv)->VALUES('localhost','bankaccount','custom',->'Y','Y','Y','Y','Y','Y');mysql>INSERT INTO db->(Host,Db,User,Select_priv,Insert_priv,->Update_priv,Delete_priv,Create_priv,Drop_priv)->VALUES('whitehouse.gov','expenses','custom',->'Y','Y','Y','Y','Y','Y');mysql>INSERT INTO db->(Host,Db,User,Select_priv,Insert_priv,->Update_priv,Delete_priv,Create_priv,Drop_priv)->VALUES('server.domain','customer','custom',->'Y','Y','Y','Y','Y','Y');mysql>FLUSH PRIVILEGES;
The first three INSERT statements add
user table entries that allow the user
custom to connect from the various hosts with
the given password, but grant no global privileges (all
privileges are set to the default value of
'N'). The next three
INSERT statements add db
table entries that grant privileges to custom
for the bankaccount,
expenses, and customer
databases, but only when accessed from the proper hosts. As
usual when you modify the grant tables directly, you must tell
the server to reload them with FLUSH
PRIVILEGES so that the privilege changes take effect.
If you want to give a specific user access from all machines in
a given domain (for example, mydomain.com),
you can issue a GRANT statement that uses the
‘%’ wildcard character in the
host part of the account name:
mysql>GRANT ...->ON *.*->TO 'myname'@'%.mydomain.com'->IDENTIFIED BY 'mypass';
To do the same thing by modifying the grant tables directly, do this:
mysql>INSERT INTO user (Host,User,Password,...)->VALUES('%.mydomain.com','myname',PASSWORD('mypass'),...);mysql>FLUSH PRIVILEGES;
To remove an account, use the DROP USER
statement, which is described in Section 13.5.1.2, “DROP USER Syntax”.
One means of limiting use of MySQL server resources is to set
the max_user_connections system variable to a
non-zero value. However, this method is strictly global, and
does not allow for management of individual accounts. In
addition, it limits only the number of simultaneous connections
made using a single account, and not what a client can do once
connected. Both types of control are of interest to many MySQL
administrators, particularly those working for Internet Service
Providers.
In MySQL 5.0, you can limit the following server resources for individual accounts:
The number of queries that an account can issue per hour
The number of updates that an account can issue per hour
The number of times an account can connect to the server per hour
Any statement that a client can issue counts against the query limit. Only statements that modify databases or tables count against the update limit.
From MySQL 5.0.3 on, it is also possible to limit the number of simultaneous connections to the server on a per-account basis.
An account in this context is a single row in the
user table. Each account is uniquely
identified by its User and
Host column values.
As a prerequisite for using this feature, the
user table in the mysql
database must contain the resource-related columns. Resource
limits are stored in the max_questions,
max_updates,
max_connections, and
max_user_connections columns. If your
user table doesn't have these columns, it
must be upgraded; see Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.
To set resource limits with a GRANT
statement, use a WITH clause that names each
resource to be limited and a per-hour count indicating the limit
value. For example, to create a new account that can access the
customer database, but only in a limited
fashion, issue this statement:
mysql>GRANT ALL ON customer.* TO 'francis'@'localhost'->IDENTIFIED BY 'frank'->WITH MAX_QUERIES_PER_HOUR 20->MAX_UPDATES_PER_HOUR 10->MAX_CONNECTIONS_PER_HOUR 5->MAX_USER_CONNECTIONS 2;
The limit types need not all be named in the
WITH clause, but those named can be present
in any order. The value for each per-hour limit should be an
integer representing a count per hour. If the
GRANT statement has no
WITH clause, the limits are each set to the
default value of zero (that is, no limit). For
MAX_USER_CONNECTIONS, the limit is an integer
indicating the maximum number of simultaneous connections the
account can make at any one time. If the limit is set to the
default value of zero, the
max_user_connections system variable
determines the number of simultaneous connections for the
account.
To set or change limits for an existing account, use a
GRANT USAGE statement at the global level
(ON *.*). The following statement changes the
query limit for francis to 100:
mysql>GRANT USAGE ON *.* TO 'francis'@'localhost'->WITH MAX_QUERIES_PER_HOUR 100;
This statement leaves the account's existing privileges unchanged and modifies only the limit values specified.
To remove an existing limit, set its value to zero. For example,
to remove the limit on how many times per hour
francis can connect, use this statement:
mysql>GRANT USAGE ON *.* TO 'francis'@'localhost'->WITH MAX_CONNECTIONS_PER_HOUR 0;
Resource-use counting takes place when any account has a non-zero limit placed on its use of any of the resources.
As the server runs, it counts the number of times each account uses resources. If an account reaches its limit on number of connections within the last hour, further connections for the account are rejected until that hour is up. Similarly, if the account reaches its limit on the number of queries or updates, further queries or updates are rejected until the hour is up. In all such cases, an appropriate error message is issued.
Resource counting is done per account, not per client. For example, if your account has a query limit of 50, you cannot increase your limit to 100 by making two simultaneous client connections to the server. Queries issued on both connections are counted together.
Queries for which results are served from the query cache do not
count against the MAX_QUERIES_PER_HOUR limit.
The current per-hour resource-use counts can be reset globally for all accounts, or individually for a given account:
To reset the current counts to zero for all accounts, issue a
FLUSH USER_RESOURCESstatement. The counts also can be reset by reloading the grant tables (for example, with aFLUSH PRIVILEGESstatement or a mysqladmin reload command).The counts for an individual account can be set to zero by re-granting it any of its limits. To do this, use
GRANT USAGEas described earlier and specify a limit value equal to the value that the account currently has.
Counter resets do not affect the
MAX_USER_CONNECTIONS limit.
All counts begin at zero when the server starts; counts are not carried over through a restart.
Passwords may be assigned from the command line by using the mysqladmin command:
shell> mysqladmin -u user_name -h host_name password "newpwd"
The account for which this command resets the password is the
one with a user table row that matches
user_name in the
User column and the client host
from which you connect in the
Host column.
Another way to assign a password to an account is to issue a
SET PASSWORD statement:
mysql> SET PASSWORD FOR 'jeffrey'@'%' = PASSWORD('biscuit');
Only users such as root that have update
access to the mysql database can change the
password for other users. If you are not connected as an
anonymous user, you can change your own password by omitting the
FOR clause:
mysql> SET PASSWORD = PASSWORD('biscuit');
You can also use a GRANT USAGE statement at
the global level (ON *.*) to assign a
password to an account without affecting the account's current
privileges:
mysql> GRANT USAGE ON *.* TO 'jeffrey'@'%' IDENTIFIED BY 'biscuit';
Although it is generally preferable to assign passwords using
one of the preceding methods, you can also do so by modifying
the user table directly:
To establish a password when creating a new account, provide a value for the
Passwordcolumn:shell>
mysql -u root mysqlmysql>INSERT INTO user (Host,User,Password)->VALUES('%','jeffrey',PASSWORD('biscuit'));mysql>FLUSH PRIVILEGES;To change the password for an existing account, use
UPDATEto set thePasswordcolumn value:shell>
mysql -u root mysqlmysql>UPDATE user SET Password = PASSWORD('bagel')->WHERE Host = '%' AND User = 'francis';mysql>FLUSH PRIVILEGES;
When you assign an account a non-empty password using
SET PASSWORD, INSERT, or
UPDATE, you must use the
PASSWORD() function to encrypt it.
PASSWORD() is necessary because the
user table stores passwords in encrypted
form, not as plaintext. If you forget that fact, you are likely
to set passwords like this:
shell>mysql -u root mysqlmysql>INSERT INTO user (Host,User,Password)->VALUES('%','jeffrey','biscuit');mysql>FLUSH PRIVILEGES;
The result is that the literal value
'biscuit' is stored as the password in the
user table, not the encrypted value. When
jeffrey attempts to connect to the server
using this password, the value is encrypted and compared to the
value stored in the user table. However, the
stored value is the literal string 'biscuit',
so the comparison fails and the server rejects the connection:
shell> mysql -u jeffrey -pbiscuit test
Access denied
If you assign passwords using the GRANT ... IDENTIFIED
BY statement or the mysqladmin
password command, they both take care of encrypting
the password for you. In these cases, using
PASSWORD() function is unnecessary.
Note:
PASSWORD() encryption is different from Unix
password encryption. See Section 5.8.1, “MySQL Usernames and Passwords”.
On an administrative level, you should never grant access to the
user grant table to any non-administrative
accounts.
When you run a client program to connect to the MySQL server, it is inadvisable to specify your password in a way that exposes it to discovery by other users. The methods you can use to specify your password when you run client programs are listed here, along with an assessment of the risks of each method:
Use a
-poryour_pass--password=option on the command line. For example:your_passshell>
mysql -u francis -pfrankdb_nameThis is convenient but insecure, because your password becomes visible to system status programs such as ps that may be invoked by other users to display command lines. MySQL clients typically overwrite the command-line password argument with zeros during their initialization sequence. However, there is still a brief interval during which the value is visible. On some systems this strategy is ineffective, anyway, and the password remains visible to ps. (SystemV Unix systems and perhaps others are subject to this problem.)
Use the
-por--passwordoption with no password value specified. In this case, the client program solicits the password from the terminal:shell>
mysql -u francis -pEnter password: ********db_nameThe ‘
*’ characters indicate where you enter your password. The password is not displayed as you enter it.It is more secure to enter your password this way than to specify it on the command line because it is not visible to other users. However, this method of entering a password is suitable only for programs that you run interactively. If you want to invoke a client from a script that runs non-interactively, there is no opportunity to enter the password from the terminal. On some systems, you may even find that the first line of your script is read and interpreted (incorrectly) as your password.
Store your password in an option file. For example, on Unix you can list your password in the
[client]section of the.my.cnffile in your home directory:[client] password=your_pass
If you store your password in
.my.cnf, the file should not be accessible to anyone but yourself. To ensure this, set the file access mode to400or600. For example:shell>
chmod 600 .my.cnfSection 4.3.2, “Using Option Files”, discusses option files in more detail.
Store your password in the
MYSQL_PWDenvironment variable. This method of specifying your MySQL password must be considered extremely insecure and should not be used. Some versions of ps include an option to display the environment of running processes. If you setMYSQL_PWD, your password is exposed to any other user who runs ps. Even on systems without such a version of ps, it is unwise to assume that there are no other methods by which users can examine process environments. See Section 2.4.19, “Environment Variables”.
All in all, the safest methods are to have the client program prompt for the password or to specify the password in a properly protected option file.
MySQL supports secure (encrypted) connections between MySQL
clients and the server using the Secure Sockets Layer (SSL)
protocol. This section discusses how to use SSL connections. It
also describes a way to set up SSH on Windows. For information
on how to require users to use SSL connections, see the
discussion of the REQUIRE clause of the
GRANT statement in Section 13.5.1.3, “GRANT Syntax”.
The standard configuration of MySQL is intended to be as fast as possible, so encrypted connections are not used by default. Doing so would make the client/server protocol much slower. Encrypting data is a CPU-intensive operation that requires the computer to do additional work and can delay other MySQL tasks. For applications that require the security provided by encrypted connections, the extra computation is warranted.
MySQL allows encryption to be enabled on a per-connection basis. You can choose a normal unencrypted connection or a secure encrypted SSL connection according the requirements of individual applications.
Secure connections are based on the OpenSSL API and are available through the MySQL C API. Replication uses the C API, so secure connections can be used between master and slave servers.
To understand how MySQL uses SSL, it is necessary to explain some basic SSL and X509 concepts. People who are familiar with these can skip this part of the discussion.
By default, MySQL uses unencrypted connections between the
client and the server. This means that someone with access to
the network could watch all your traffic and look at the data
being sent or received. They could even change the data while
it is in transit between client and server. To improve
security a little, you can compress client/server traffic by
using the --compress option when invoking
client programs. However, this does not foil a determined
attacker.
When you need to move information over a network in a secure fashion, an unencrypted connection is unacceptable. Encryption is the way to make any kind of data unreadable. In fact, today's practice requires many additional security elements from encryption algorithms. They should resist many kind of known attacks such as changing the order of encrypted messages or replaying data twice.
SSL is a protocol that uses different encryption algorithms to ensure that data received over a public network can be trusted. It has mechanisms to detect any data change, loss, or replay. SSL also incorporates algorithms that provide identity verification using the X509 standard.
X509 makes it possible to identify someone on the Internet. It is most commonly used in e-commerce applications. In basic terms, there should be some company called a “Certificate Authority” (or CA) that assigns electronic certificates to anyone who needs them. Certificates rely on asymmetric encryption algorithms that have two encryption keys (a public key and a secret key). A certificate owner can show the certificate to another party as proof of identity. A certificate consists of its owner's public key. Any data encrypted with this public key can be decrypted only using the corresponding secret key, which is held by the owner of the certificate.
If you need more information about SSL, X509, or encryption, use your favorite Internet search engine to search for the keywords in which you are interested.
To use SSL connections between the MySQL server and client programs, your system must support either OpenSSL or yaSSL and your version of MySQL must be built with SSL support.
To make it easier to use secure connections, MySQL is bundled with yaSSL as of MySQL 5.0.10. (MySQL and yaSSL employ the same licensing model, whereas OpenSSL uses an Apache-style license.) yaSSL support initially was available only for a few platforms, but now it is available on all platforms supported by MySQL AB.
To get secure connections to work with MySQL and SSL, you must do the following:
If you are not using a binary (precompiled) version of MySQL that has been built with SSL support, and you are going to use OpenSSL rather than the bundled yaSSL library, install OpenSSL if it has not already been installed. We have tested MySQL with OpenSSL 0.9.6. To obtain OpenSSL, visit http://www.openssl.org.
If you are not using a binary (precompiled) version of MySQL that has been built with SSL support, configure a MySQL source distribution to use SSL. When you configure MySQL, invoke the configure script with the appropriate option to select the SSL library that you want to use.
For yaSSL:
shell>
./configure --with-yasslFor OpenSSL:
shell>
./configure --with-opensslBefore MySQL 5.0, it was also neccessary to use
--with-vio, but that option is no longer required.Note that yaSSL support on Unix platforms requires that either
/dev/urandomor/dev/randombe available to retrieve true random numbers. For additional information (especially regarding yaSSL on Solaris versions prior to 2.8 and HP-UX), see Bug#13164.Make sure that you have upgraded your grant tables to include the SSL-related columns in the
mysql.usertable. This is necessary if your grant tables date from a version of MySQL older than 4.0. The upgrade procedure is described in Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.To check whether a server binary is compiled with SSL support, invoke it with the
--ssloption. An error will occur if the server does not support SSL:shell>
mysqld --ssl --help060525 14:18:52 [ERROR] mysqld: unknown option '--ssl'To check whether a running mysqld server supports SSL, examine the value of the
have_opensslsystem variable:mysql>
SHOW VARIABLES LIKE 'have_openssl';+---------------+-------+ | Variable_name | Value | +---------------+-------+ | have_openssl | YES | +---------------+-------+If the value is
YES, the server supports SSL connections. If the value isDISABLED, the server supports SSL connections but was not started with the appropriate--ssl-options (described later in this section). If the value isxxxYES, the server supports SSL connections.
To enable SSL connections, the proper SSL-related command options must be used (see Section 5.8.7.3, “SSL Command Options”).
To start the MySQL server so that it allows clients to connect via SSL, use the options that identify the key and certificate files the server needs when establishing a secure connection:
shell>mysqld --ssl-ca=cacert.pem\--ssl-cert=server-cert.pem\--ssl-key=server-key.pem
--ssl-caidentifies the Certificate Authority (CA) certificate.--ssl-certidentifies the server public key. This can be sent to the client and authenticated against the CA certificate that it has.--ssl-keyidentifies the server private key.
To establish a secure connection to a MySQL server with SSL
support, the options that a client must specify depend on the
SSL requirements of the user account that the client uses.
(See the discussion of the REQUIRE clause
in Section 13.5.1.3, “GRANT Syntax”.)
If the account has no special SSL requirements or was created
using a GRANT statement that includes the
REQUIRE SSL option, a client can connect
securely by using just the --ssl-ca option:
shell> mysql --ssl-ca=cacert.pem
To require that a client certificate also be specified, create
the account using the REQUIRE X509 option.
Then the client must also specify the proper client key and
certificate files or the server will reject the connection:
shell>mysql --ssl-ca=cacert.pem\--ssl-cert=client-cert.pem\--ssl-key=client-key.pem
In other words, the options are similar to those used for the server. Note that the Certificate Authority certificate has to be the same.
A client can determine whether the current connection with the
server uses SSL by checking the value of the
Ssl_cipher status variable. The value of
Ssl_cipher is non-empty if SSL is used, and
empty otherwise. For example:
mysql> SHOW STATUS LIKE 'Ssl_cipher';
+---------------+--------------------+
| Variable_name | Value |
+---------------+--------------------+
| Ssl_cipher | DHE-RSA-AES256-SHA |
+---------------+--------------------+
For the mysql client, you can use the
STATUS or \s command and
check the SSL line:
mysql> \s
...
SSL: Not in use
...
Or:
mysql> \s
...
SSL: Cipher in use is DHE-RSA-AES256-SHA
...
To establish a secure connection from within an application
program, use the mysql_ssl_set() C API
function to set the appropriate certificate options before
calling mysql_real_connect(). See
Section 22.2.3.67, “mysql_ssl_set()”. After the connection is
established, you can use
mysql_get_ssl_cipher() to determine whether
SSL is in use. A non-NULL return value
indicates a secure connection and names the SSL cipher used
for encryption. A NULL return value
indicates that SSL is not being used. See
Section 22.2.3.33, “mysql_get_ssl_cipher()”.
The following list describes options that are used for
specifying the use of SSL, certificate files, and key files.
They can be given on the command line or in an option file.
These options are not available unless MySQL has been built
with SSL support. See Section 5.8.7.2, “Using SSL Connections”.
(There are also --master-ssl* options that
can be used for setting up a secure connection from a slave
replication server to a master server; see
Section 6.8, “Replication Startup Options”.)
For the server, this option specifies that the server allows SSL connections. For a client program, it allows the client to connect to the server using SSL. This option is not sufficient in itself to cause an SSL connection to be used. You must also specify the
--ssl-caoption, and possibly the--ssl-certand--ssl-keyoptions.This option is more often used in its opposite form to override any other SSL options and indicate that SSL should not be used. To do this, specify the option as
--skip-sslor--ssl=0.Note that use of
--ssldoes not require an SSL connection. For example, if the server or client is compiled without SSL support, a normal unencrypted connection is used.The secure way to require use of an SSL connection is to create an account on the server that includes a
REQUIRE SSLclause in theGRANTstatement. Then use that account to connect to the server, where both the server and the client have SSL support enabled.The
REQUIREclause allows other SSL-related restrictions as well. The description ofREQUIREin Section 13.5.1.3, “GRANTSyntax”, provides additional detail about which SSL command options may or must be specified by clients that connect using accounts that are created using the variousREQUIREoptions.The path to a file that contains a list of trusted SSL CAs.
The path to a directory that contains trusted SSL CA certificates in PEM format.
The name of the SSL certificate file to use for establishing a secure connection.
A list of allowable ciphers to use for SSL encryption.
cipher_listhas the same format as theopenssl cipherscommand.Example:
--ssl-cipher=ALL:-AES:-EXPThe name of the SSL key file to use for establishing a secure connection.
This option is available for client programs. It causes the server's Common Name value in its certificate to be verified against the hostname used when connecting to the server, and the connection is rejected if there is a mismatch. This feature can be used to prevent man-in-the-middle attacks. Verification is disabled by default. This option was added in MySQL 5.0.23.
As of MySQL 5.0.40, if you use SSL when establishing a client
connection, you can tell the client not to authenticate the
server certificate by specifying neither
--ssl-ca nor --ssl-capath.
The server still verifies the client according to any
applicable requirements established via
GRANT statements for the client, and it
still uses any
--ssl-ca/--ssl-capath values
that were passed to server at startup time.
This section demonstrates how to set up SSL certificate and key files for use by MySQL servers and clients. The first example shows a simplified procedure such as you might use from the command line. The second shows a script that contains more detail. Both examples use the openssl command that is part of OpenSSL.
The following example shows a set of commands to create MySQL server and client certificate and key files. You will need to respond to several prompts by the openssl commands. For testing, you can press Enter to all prompts. For production use, you should provide non-empty responses.
# Create clean environment shell>rm -rf newcertsshell>mkdir newcerts && cd newcerts# Create CA certificate shell>openssl genrsa 2048 > ca-key.pemshell>openssl req -new -x509 -nodes -days 1000 \-key ca-key.pem > ca-cert.pem# Create server certificate shell>openssl req -newkey rsa:2048 -days 1000 \-nodes -keyout server-key.pem > server-req.pemshell>openssl x509 -req -in server-req.pem -days 1000 \-CA ca-cert.pem -CAkey ca-key.pem -set_serial 01 > server-cert.pem# Create client certificate shell>openssl req -newkey rsa:2048 -days 1000 \-nodes -keyout client-key.pem > client-req.pemshell>openssl x509 -req -in client-req.pem -days 1000 \-CA ca-cert.pem -CAkey ca-key.pem -set_serial 01 > client-cert.pem
Here is an example script that shows how to set up SSL certificates for MySQL:
DIR=`pwd`/openssl
PRIV=$DIR/private
mkdir $DIR $PRIV $DIR/newcerts
cp /usr/share/ssl/openssl.cnf $DIR
replace ./demoCA $DIR -- $DIR/openssl.cnf
# Create necessary files: $database, $serial and $new_certs_dir
# directory (optional)
touch $DIR/index.txt
echo "01" > $DIR/serial
#
# Generation of Certificate Authority(CA)
#
openssl req -new -x509 -keyout $PRIV/cakey.pem -out $DIR/cacert.pem \
-config $DIR/openssl.cnf
# Sample output:
# Using configuration from /home/monty/openssl/openssl.cnf
# Generating a 1024 bit RSA private key
# ................++++++
# .........++++++
# writing new private key to '/home/monty/openssl/private/cakey.pem'
# Enter PEM pass phrase:
# Verifying password - Enter PEM pass phrase:
# -----
# You are about to be asked to enter information that will be
# incorporated into your certificate request.
# What you are about to enter is what is called a Distinguished Name
# or a DN.
# There are quite a few fields but you can leave some blank
# For some fields there will be a default value,
# If you enter '.', the field will be left blank.
# -----
# Country Name (2 letter code) [AU]:FI
# State or Province Name (full name) [Some-State]:.
# Locality Name (eg, city) []:
# Organization Name (eg, company) [Internet Widgits Pty Ltd]:MySQL AB
# Organizational Unit Name (eg, section) []:
# Common Name (eg, YOUR name) []:MySQL admin
# Email Address []:
#
# Create server request and key
#
openssl req -new -keyout $DIR/server-key.pem -out \
$DIR/server-req.pem -days 3600 -config $DIR/openssl.cnf
# Sample output:
# Using configuration from /home/monty/openssl/openssl.cnf
# Generating a 1024 bit RSA private key
# ..++++++
# ..........++++++
# writing new private key to '/home/monty/openssl/server-key.pem'
# Enter PEM pass phrase:
# Verifying password - Enter PEM pass phrase:
# -----
# You are about to be asked to enter information that will be
# incorporated into your certificate request.
# What you are about to enter is what is called a Distinguished Name
# or a DN.
# There are quite a few fields but you can leave some blank
# For some fields there will be a default value,
# If you enter '.', the field will be left blank.
# -----
# Country Name (2 letter code) [AU]:FI
# State or Province Name (full name) [Some-State]:.
# Locality Name (eg, city) []:
# Organization Name (eg, company) [Internet Widgits Pty Ltd]:MySQL AB
# Organizational Unit Name (eg, section) []:
# Common Name (eg, YOUR name) []:MySQL server
# Email Address []:
#
# Please enter the following 'extra' attributes
# to be sent with your certificate request
# A challenge password []:
# An optional company name []:
#
# Remove the passphrase from the key (optional)
#
openssl rsa -in $DIR/server-key.pem -out $DIR/server-key.pem
#
# Sign server cert
#
openssl ca -policy policy_anything -out $DIR/server-cert.pem \
-config $DIR/openssl.cnf -infiles $DIR/server-req.pem
# Sample output:
# Using configuration from /home/monty/openssl/openssl.cnf
# Enter PEM pass phrase:
# Check that the request matches the signature
# Signature ok
# The Subjects Distinguished Name is as follows
# countryName :PRINTABLE:'FI'
# organizationName :PRINTABLE:'MySQL AB'
# commonName :PRINTABLE:'MySQL admin'
# Certificate is to be certified until Sep 13 14:22:46 2003 GMT
# (365 days)
# Sign the certificate? [y/n]:y
#
#
# 1 out of 1 certificate requests certified, commit? [y/n]y
# Write out database with 1 new entries
# Data Base Updated
#
# Create client request and key
#
openssl req -new -keyout $DIR/client-key.pem -out \
$DIR/client-req.pem -days 3600 -config $DIR/openssl.cnf
# Sample output:
# Using configuration from /home/monty/openssl/openssl.cnf
# Generating a 1024 bit RSA private key
# .....................................++++++
# .............................................++++++
# writing new private key to '/home/monty/openssl/client-key.pem'
# Enter PEM pass phrase:
# Verifying password - Enter PEM pass phrase:
# -----
# You are about to be asked to enter information that will be
# incorporated into your certificate request.
# What you are about to enter is what is called a Distinguished Name
# or a DN.
# There are quite a few fields but you can leave some blank
# For some fields there will be a default value,
# If you enter '.', the field will be left blank.
# -----
# Country Name (2 letter code) [AU]:FI
# State or Province Name (full name) [Some-State]:.
# Locality Name (eg, city) []:
# Organization Name (eg, company) [Internet Widgits Pty Ltd]:MySQL AB
# Organizational Unit Name (eg, section) []:
# Common Name (eg, YOUR name) []:MySQL user
# Email Address []:
#
# Please enter the following 'extra' attributes
# to be sent with your certificate request
# A challenge password []:
# An optional company name []:
#
# Remove a passphrase from the key (optional)
#
openssl rsa -in $DIR/client-key.pem -out $DIR/client-key.pem
#
# Sign client cert
#
openssl ca -policy policy_anything -out $DIR/client-cert.pem \
-config $DIR/openssl.cnf -infiles $DIR/client-req.pem
# Sample output:
# Using configuration from /home/monty/openssl/openssl.cnf
# Enter PEM pass phrase:
# Check that the request matches the signature
# Signature ok
# The Subjects Distinguished Name is as follows
# countryName :PRINTABLE:'FI'
# organizationName :PRINTABLE:'MySQL AB'
# commonName :PRINTABLE:'MySQL user'
# Certificate is to be certified until Sep 13 16:45:17 2003 GMT
# (365 days)
# Sign the certificate? [y/n]:y
#
#
# 1 out of 1 certificate requests certified, commit? [y/n]y
# Write out database with 1 new entries
# Data Base Updated
#
# Create a my.cnf file that you can use to test the certificates
#
cnf=""
cnf="$cnf [client]"
cnf="$cnf ssl-ca=$DIR/cacert.pem"
cnf="$cnf ssl-cert=$DIR/client-cert.pem"
cnf="$cnf ssl-key=$DIR/client-key.pem"
cnf="$cnf [mysqld]"
cnf="$cnf ssl-ca=$DIR/cacert.pem"
cnf="$cnf ssl-cert=$DIR/server-cert.pem"
cnf="$cnf ssl-key=$DIR/server-key.pem"
echo $cnf | replace " " '
' > $DIR/my.cnf
To test SSL connections, start the server as follows, where
$DIR is the pathname to the directory where
the sample my.cnf option file is located:
shell> mysqld --defaults-file=$DIR/my.cnf &
Then invoke a client program using the same option file:
shell> mysql --defaults-file=$DIR/my.cnf
If you have a MySQL source distribution, you can also test
your setup by modifying the preceding
my.cnf file to refer to the demonstration
certificate and key files in the SSL
directory of the distribution.
Here is a note that describes how to get a secure connection
to a remote MySQL server with SSH (by David Carlson
<dcarlson@mplcomm.com>):
Install an SSH client on your Windows machine. As a user, the best non-free one I have found is from
SecureCRTfrom http://www.vandyke.com/. Another option isf-securefrom http://www.f-secure.com/. You can also find some free ones onGoogleat http://directory.google.com/Top/Computers/Security/Products_and_Tools/Cryptography/SSH/Clients/Windows/.Start your Windows SSH client. Set
Host_Name =. Setyourmysqlserver_URL_or_IPuserid=to log in to your server. Thisyour_useriduseridvalue might not be the same as the username of your MySQL account.Set up port forwarding. Either do a remote forward (Set
local_port: 3306,remote_host:,yourmysqlservername_or_ipremote_port: 3306) or a local forward (Setport: 3306,host: localhost,remote port: 3306).Save everything, otherwise you will have to redo it the next time.
Log in to your server with the SSH session you just created.
On your Windows machine, start some ODBC application (such as Access).
Create a new file in Windows and link to MySQL using the ODBC driver the same way you normally do, except type in
localhostfor the MySQL host server, notyourmysqlservername.
At this point, you should have an ODBC connection to MySQL, encrypted using SSH.
This section discusses how to make database backups (full and
incremental) and how to perform table maintenance. The syntax of
the SQL statements described here is given in
Chapter 13, SQL Statement Syntax. Much of the information here
pertains primarily to MyISAM tables. Additional
information about InnoDB backup procedures is
given in Section 14.2.8, “Backing Up and Recovering an InnoDB Database”.
Because MySQL tables are stored as files, it is easy to do a
backup. To get a consistent backup, do a LOCK
TABLES on the relevant tables, followed by
FLUSH TABLES for the tables. See
Section 13.4.5, “LOCK TABLES and UNLOCK TABLES
Syntax”, and Section 13.5.5.2, “FLUSH Syntax”. You
need only a read lock; this allows other clients to continue to
query the tables while you are making a copy of the files in the
database directory. The FLUSH TABLES
statement is needed to ensure that the all active index pages
are written to disk before you start the backup.
To make an SQL-level backup of a table, you can use
SELECT INTO ... OUTFILE. For this statement,
the output file cannot already exist because allowing files to
be overwritten would constitute a security risk. See
Section 13.2.7, “SELECT Syntax”.
Another technique for backing up a database is to use the mysqldump program or the mysqlhotcopy script. See Section 8.13, “mysqldump — A Database Backup Program”, and Section 8.14, “mysqlhotcopy — A Database Backup Program”.
Create a full backup of your database:
shell>
mysqldump --tab=/path/to/some/dir--optdb_nameOr:
shell>
mysqlhotcopydb_name/path/to/some/dirYou can also create a binary backup simply by copying all table files (
*.frm,*.MYD, and*.MYIfiles), as long as the server isn't updating anything. The mysqlhotcopy script uses this method. (But note that these methods do not work if your database containsInnoDBtables.InnoDBdoes not store table contents in database directories, and mysqlhotcopy works only forMyISAMtables.)Stop mysqld if it is running, then start it with the
--log-bin[=option. See Section 5.11.3, “The Binary Log”. The binary log files provide you with the information you need to replicate changes to the database that are made subsequent to the point at which you executed mysqldump.file_name]
For InnoDB tables, it is possible to perform
an online backup that takes no locks on tables; see
Section 8.13, “mysqldump — A Database Backup Program”.
MySQL supports incremental backups: You need to start the server
with the --log-bin option to enable binary
logging; see Section 5.11.3, “The Binary Log”. At the moment you
want to make an incremental backup (containing all changes that
happened since the last full or incremental backup), you should
rotate the binary log by using FLUSH LOGS.
This done, you need to copy to the backup location all binary
logs which range from the one of the moment of the last full or
incremental backup to the last but one. These binary logs are
the incremental backup; at restore time, you apply them as
explained further below. The next time you do a full backup, you
should also rotate the binary log using FLUSH
LOGS, mysqldump --flush-logs, or
mysqlhotcopy --flushlog. See
Section 8.13, “mysqldump — A Database Backup Program”, and Section 8.14, “mysqlhotcopy — A Database Backup Program”.
If your MySQL server is a slave replication server, then
regardless of the backup method you choose, you should also back
up the master.info and
relay-log.info files when you back up your
slave's data. These files are always needed to resume
replication after you restore the slave's data. If your slave is
subject to replicating LOAD DATA INFILE
commands, you should also back up any
SQL_LOAD-* files that may exist in the
directory specified by the --slave-load-tmpdir
option. (This location defaults to the value of the
tmpdir variable if not specified.) The slave
needs these files to resume replication of any interrupted
LOAD DATA INFILE operations.
MySQL Enterprise The MySQL Network Monitoring and Advisory Service provides numerous advisors that issue immediate warnings should replication issues arise. For more information see http://www.mysql.com/products/enterprise/advisors.html.
If you have to restore MyISAM tables, try to
recover them using REPAIR TABLE or
myisamchk -r first. That should work in 99.9%
of all cases. If myisamchk fails, try the
following procedure. Note that it works only if you have enabled
binary logging by starting MySQL with the
--log-bin option.
Restore the original mysqldump backup, or binary backup.
Execute the following command to re-run the updates in the binary logs:
shell>
mysqlbinlog binlog.[0-9]* | mysqlIn some cases, you may want to re-run only certain binary logs, from certain positions (usually you want to re-run all binary logs from the date of the restored backup, excepting possibly some incorrect statements). See Section 8.11, “mysqlbinlog — Utility for Processing Binary Log Files”, for more information on the mysqlbinlog utility and how to use it.
You can also make selective backups of individual files:
To dump the table, use
SELECT * INTO OUTFILE '.file_name' FROMtbl_nameTo reload the table, use
LOAD DATA INFILE '. To avoid duplicate rows, the table must have afile_name' REPLACE ...PRIMARY KEYor aUNIQUEindex. TheREPLACEkeyword causes old rows to be replaced with new ones when a new row duplicates an old row on a unique key value.
If you have performance problems with your server while making backups, one strategy that can help is to set up replication and perform backups on the slave rather than on the master. See Section 6.1, “Introduction to Replication”.
If you are using a Veritas filesystem, you can make a backup like this:
From a client program, execute
FLUSH TABLES WITH READ LOCK.From another shell, execute
mount vxfs snapshot.From the first client, execute
UNLOCK TABLES.Copy files from the snapshot.
Unmount the snapshot.
This section discusses a procedure for performing backups that allows you to recover data after several types of crashes:
Operating system crash
Power failure
Filesystem crash
Hardware problem (hard drive, motherboard, and so forth)
The example commands do not include options such as
--user and --password for the
mysqldump and mysql
programs. You should include such options as necessary so that
the MySQL server allows you to connect to it.
We assume that data is stored in the InnoDB
storage engine, which has support for transactions and automatic
crash recovery. We also assume that the MySQL server is under
load at the time of the crash. If it were not, no recovery would
ever be needed.
For cases of operating system crashes or power failures, we can
assume that MySQL's disk data is available after a restart. The
InnoDB data files might not contain
consistent data due to the crash, but InnoDB
reads its logs and finds in them the list of pending committed
and non-committed transactions that have not been flushed to the
data files. InnoDB automatically rolls back
those transactions that were not committed, and flushes to its
data files those that were committed. Information about this
recovery process is conveyed to the user through the MySQL error
log. The following is an example log excerpt:
InnoDB: Database was not shut down normally. InnoDB: Starting recovery from log files... InnoDB: Starting log scan based on checkpoint at InnoDB: log sequence number 0 13674004 InnoDB: Doing recovery: scanned up to log sequence number 0 13739520 InnoDB: Doing recovery: scanned up to log sequence number 0 13805056 InnoDB: Doing recovery: scanned up to log sequence number 0 13870592 InnoDB: Doing recovery: scanned up to log sequence number 0 13936128 ... InnoDB: Doing recovery: scanned up to log sequence number 0 20555264 InnoDB: Doing recovery: scanned up to log sequence number 0 20620800 InnoDB: Doing recovery: scanned up to log sequence number 0 20664692 InnoDB: 1 uncommitted transaction(s) which must be rolled back InnoDB: Starting rollback of uncommitted transactions InnoDB: Rolling back trx no 16745 InnoDB: Rolling back of trx no 16745 completed InnoDB: Rollback of uncommitted transactions completed InnoDB: Starting an apply batch of log records to the database... InnoDB: Apply batch completed InnoDB: Started mysqld: ready for connections
For the cases of filesystem crashes or hardware problems, we can assume that the MySQL disk data is not available after a restart. This means that MySQL fails to start successfully because some blocks of disk data are no longer readable. In this case, it is necessary to reformat the disk, install a new one, or otherwise correct the underlying problem. Then it is necessary to recover our MySQL data from backups, which means that we must already have made backups. To make sure that is the case, we should design a backup policy.
We all know that backups must be scheduled periodically. A
full backups (a snapshot of the data at a point in time) can
be done in MySQL with several tools. For example,
InnoDB Hot Backup provides online
non-blocking physical backup of the InnoDB
data files, and mysqldump provides online
logical backup. This discussion uses
mysqldump.
MySQL Enterprise For expert advice on backups and replication, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
Assume that we make a backup on Sunday at 1 p.m., when load is
low. The following command makes a full backup of all our
InnoDB tables in all databases:
shell> mysqldump --single-transaction --all-databases > backup_sunday_1_PM.sql
This is an online, non-blocking backup that does not disturb
the reads and writes on the tables. We assumed earlier that
our tables are InnoDB tables, so
--single-transaction uses a consistent read
and guarantees that data seen by mysqldump
does not change. (Changes made by other clients to
InnoDB tables are not seen by the
mysqldump process.) If we do also have
other types of tables, we must assume that they are not
changed during the backup. For example, for the
MyISAM tables in the
mysql database, we must assume that no
administrative changes are being made to MySQL accounts during
the backup.
The resulting .sql file produced by
mysqldump contains a set of SQL
INSERT statements that can be used to
reload the dumped tables at a later time.
Full backups are necessary, but they are not always convenient. They produce large backup files and take time to generate. They are not optimal in the sense that each successive full backup includes all data, even that part that has not changed since the previous full backup. After we have made the initial full backup, it is more efficient to make incremental backups. They are smaller and take less time to produce. The tradeoff is that, at recovery time, you cannot restore your data just by reloading the full backup. You must also process the incremental backups to recover the incremental changes.
To make incremental backups, we need to save the incremental
changes. The MySQL server should always be started with the
--log-bin option so that it stores these
changes in a file while it updates data. This option enables
binary logging, so that the server writes each SQL statement
that updates data into a file called a MySQL binary log.
Looking at the data directory of a MySQL server that was
started with the --log-bin option and that
has been running for some days, we find these MySQL binary log
files:
-rw-rw---- 1 guilhem guilhem 1277324 Nov 10 23:59 gbichot2-bin.000001 -rw-rw---- 1 guilhem guilhem 4 Nov 10 23:59 gbichot2-bin.000002 -rw-rw---- 1 guilhem guilhem 79 Nov 11 11:06 gbichot2-bin.000003 -rw-rw---- 1 guilhem guilhem 508 Nov 11 11:08 gbichot2-bin.000004 -rw-rw---- 1 guilhem guilhem 220047446 Nov 12 16:47 gbichot2-bin.000005 -rw-rw---- 1 guilhem guilhem 998412 Nov 14 10:08 gbichot2-bin.000006 -rw-rw---- 1 guilhem guilhem 361 Nov 14 10:07 gbichot2-bin.index
Each time it restarts, the MySQL server creates a new binary
log file using the next number in the sequence. While the
server is running, you can also tell it to close the current
binary log file and begin a new one manually by issuing a
FLUSH LOGS SQL statement or with a
mysqladmin flush-logs command.
mysqldump also has an option to flush the
logs. The .index file in the data directory
contains the list of all MySQL binary logs in the directory.
This file is used for replication.
The MySQL binary logs are important for recovery because they form the set of incremental backups. If you make sure to flush the logs when you make your full backup, then any binary log files created afterward contain all the data changes made since the backup. Let's modify the previous mysqldump command a bit so that it flushes the MySQL binary logs at the moment of the full backup, and so that the dump file contains the name of the new current binary log:
shell>mysqldump --single-transaction --flush-logs --master-data=2 \--all-databases > backup_sunday_1_PM.sql
After executing this command, the data directory contains a
new binary log file, gbichot2-bin.000007.
The resulting .sql file includes these
lines:
-- Position to start replication or point-in-time recovery from -- CHANGE MASTER TO MASTER_LOG_FILE='gbichot2-bin.000007',MASTER_LOG_POS=4;
Because the mysqldump command made a full backup, those lines mean two things:
The
.sqlfile contains all changes made before any changes written to thegbichot2-bin.000007binary log file or newer.All data changes logged after the backup are not present in the
.sql, but are present in thegbichot2-bin.000007binary log file or newer.
On Monday at 1 p.m., we can create an incremental backup by
flushing the logs to begin a new binary log file. For example,
executing a mysqladmin flush-logs command
creates gbichot2-bin.000008. All changes
between the Sunday 1 p.m. full backup and Monday 1 p.m. will
be in the gbichot2-bin.000007 file. This
incremental backup is important, so it is a good idea to copy
it to a safe place. (For example, back it up on tape or DVD,
or copy it to another machine.) On Tuesday at 1 p.m., execute
another mysqladmin flush-logs command. All
changes between Monday 1 p.m. and Tuesday 1 p.m. will be in
the gbichot2-bin.000008 file (which also
should be copied somewhere safe).
The MySQL binary logs take up disk space. To free up space, purge them from time to time. One way to do this is by deleting the binary logs that are no longer needed, such as when we make a full backup:
shell>mysqldump --single-transaction --flush-logs --master-data=2 \--all-databases --delete-master-logs > backup_sunday_1_PM.sql
Note: Deleting the MySQL
binary logs with mysqldump
--delete-master-logs can be dangerous if your server
is a replication master server, because slave servers might
not yet fully have processed the contents of the binary log.
The description for the PURGE MASTER LOGS
statement explains what should be verified before deleting the
MySQL binary logs. See Section 13.6.1.1, “PURGE MASTER LOGS Syntax”.
Now, suppose that we have a catastrophic crash on Wednesday at 8 a.m. that requires recovery from backups. To recover, first we restore the last full backup we have (the one from Sunday 1 p.m.). The full backup file is just a set of SQL statements, so restoring it is very easy:
shell> mysql < backup_sunday_1_PM.sql
At this point, the data is restored to its state as of Sunday
1 p.m.. To restore the changes made since then, we must use
the incremental backups; that is, the
gbichot2-bin.000007 and
gbichot2-bin.000008 binary log files.
Fetch the files if necessary from where they were backed up,
and then process their contents like this:
shell> mysqlbinlog gbichot2-bin.000007 gbichot2-bin.000008 | mysql
We now have recovered the data to its state as of Tuesday 1
p.m., but still are missing the changes from that date to the
date of the crash. To not lose them, we would have needed to
have the MySQL server store its MySQL binary logs into a safe
location (RAID disks, SAN, ...) different from the place where
it stores its data files, so that these logs were not on the
destroyed disk. (That is, we can start the server with a
--log-bin option that specifies a location on
a different physical device from the one on which the data
directory resides. That way, the logs are safe even if the
device containing the directory is lost.) If we had done this,
we would have the gbichot2-bin.000009
file at hand, and we could apply it using
mysqlbinlog and mysql to
restore the most recent data changes with no loss up to the
moment of the crash.
In case of an operating system crash or power failure,
InnoDB itself does all the job of
recovering data. But to make sure that you can sleep well,
observe the following guidelines:
Always run the MySQL server with the
--log-binoption, or even--log-bin=, where the log file name is located on some safe media different from the drive on which the data directory is located. If you have such safe media, this technique can also be good for disk load balancing (which results in a performance improvement).log_nameMake periodic full backups, using the mysqldump command shown earlier in Section 5.9.2.1, “Backup Policy”, that makes an online, non-blocking backup.
Make periodic incremental backups by flushing the logs with
FLUSH LOGSor mysqladmin flush-logs.
If a MySQL server was started with the
--log-bin option to enable binary logging, you
can use the mysqlbinlog utility to recover
data from the binary log files, starting from a specified point
in time (for example, since your last backup) until the present
or another specified point in time. For information on enabling
the binary log and using mysqlbinlog, see
Section 5.11.3, “The Binary Log”, and Section 8.11, “mysqlbinlog — Utility for Processing Binary Log Files”.
MySQL Enterprise For maximum data recovery, MySQL Network Monitoring and Advisory Service advises subscribers to synchronize to disk at each write. For more information see http://www.mysql.com/products/enterprise/advisors.html.
To restore data from a binary log, you must know the location
and name of the current binary log file. By default, the server
creates binary log files in the data directory, but a pathname
can be specified with the --log-bin option to
place the files in a different location. Typically the option is
given in an option file (that is, my.cnf or
my.ini, depending on your system). It can
also be given on the command line when the server is started. To
determine the name of the current binary log file, issue the
following statement:
mysql> SHOW BINLOG EVENTS\G
If you prefer, you can execute the following command from the command line instead:
shell> mysql -u root -p -E -e "SHOW BINLOG EVENTS"
Enter the root password for your server when
mysql prompts you for it.
To indicate the start and end times for recovery, specify the
--start-date and --stop-date
options for mysqlbinlog, in
DATETIME format. As an example, suppose
that exactly at 10:00 a.m. on April 20, 2005 an SQL statement
was executed that deleted a large table. To restore the table
and data, you could restore the previous night's backup, and
then execute the following command:
shell>mysqlbinlog --stop-date="2005-04-20 9:59:59" \/var/log/mysql/bin.123456 | mysql -u root -p
This command recovers all of the data up until the date and
time given by the --stop-date option. If you
did not detect the erroneous SQL statement that was entered
until hours later, you will probably also want to recover the
activity that occurred afterward. Based on this, you could run
mysqlbinlog again with a start date and
time, like so:
shell>mysqlbinlog --start-date="2005-04-20 10:01:00" \/var/log/mysql/bin.123456 | mysql -u root -p
In this command, the SQL statements logged from 10:01 a.m. on will be re-executed. The combination of restoring of the previous night's dump file and the two mysqlbinlog commands restores everything up until one second before 10:00 a.m. and everything from 10:01 a.m. on. You should examine the log to be sure of the exact times to specify for the commands. To display the log file contents without executing them, use this command:
shell> mysqlbinlog /var/log/mysql/bin.123456 > /tmp/mysql_restore.sql
Then open the file with a text editor to examine it.
Instead of specifying dates and times, the
--start-position and
--stop-position options for
mysqlbinlog can be used for specifying log
positions. They work the same as the start and stop date
options, except that you specify log position numbers rather
than dates. Using positions may enable you to be more precise
about which part of the log to recover, especially if many
transactions occurred around the same time as a damaging SQL
statement. To determine the position numbers, run
mysqlbinlog for a range of times near the
time when the unwanted transaction was executed, but redirect
the results to a text file for examination. This can be done
like so:
shell>mysqlbinlog --start-date="2005-04-20 9:55:00" \--stop-date="2005-04-20 10:05:00" \/var/log/mysql/bin.123456 > /tmp/mysql_restore.sql
This command creates a small text file in the
/tmp directory that contains the SQL
statements around the time that the deleterious SQL statement
was executed. Open this file with a text editor and look for
the statement that you don't want to repeat. Determine the
positions in the binary log for stopping and resuming the
recovery and make note of them. Positions are labeled as
log_pos followed by a number. After
restoring the previous backup file, use the position numbers
to process the binary log file. For example, you would use
commands something like these:
shell>mysqlbinlog --stop-position="368312" /var/log/mysql/bin.123456 \| mysql -u root -pshell>mysqlbinlog --start-position="368315" /var/log/mysql/bin.123456 \| mysql -u root -p
The first command recovers all the transactions up until the
stop position given. The second command recovers all
transactions from the starting position given until the end of
the binary log. Because the output of
mysqlbinlog includes SET
TIMESTAMP statements before each SQL statement
recorded, the recovered data and related MySQL logs will
reflect the original times at which the transactions were
executed.
This section discusses how to use myisamchk
to check or repair MyISAM tables (tables that
have .MYD and .MYI
files for storing data and indexes). For general
myisamchk background, see
Section 8.5, “myisamchk — MyISAM Table-Maintenance Utility”.
You can use myisamchk to get information about your database tables or to check, repair, or optimize them. The following sections describe how to perform these operations and how to set up a table maintenance schedule.
Even though table repair with myisamchk is quite secure, it is always a good idea to make a backup before doing a repair or any maintenance operation that could make a lot of changes to a table.
myisamchk operations that affect indexes can
cause FULLTEXT indexes to be rebuilt with
full-text parameters that are incompatible with the values used
by the MySQL server. To avoid this problem, follow the
guidelines in Section 8.5.1, “myisamchk General Options”.
In many cases, you may find it simpler to do
MyISAM table maintenance using the SQL
statements that perform operations that
myisamchk can do:
To check or repair
MyISAMtables, useCHECK TABLEorREPAIR TABLE.To optimize
MyISAMtables, useOPTIMIZE TABLE.To analyze
MyISAMtables, useANALYZE TABLE.
These statements can be used directly or by means of the
mysqlcheck client program. One advantage of
these statements over myisamchk is that the
server does all the work. With myisamchk, you
must make sure that the server does not use the tables at the
same time so that there is no unwanted interaction between
myisamchk and the server. See
Section 13.5.2.1, “ANALYZE TABLE Syntax”, Section 13.5.2.3, “CHECK TABLE Syntax”,
Section 13.5.2.5, “OPTIMIZE TABLE Syntax”, and
Section 13.5.2.6, “REPAIR TABLE Syntax”.
This section describes how to check for and deal with data corruption in MySQL databases. If your tables become corrupted frequently, you should try to find the reason why. See Section B.1.4.2, “What to Do If MySQL Keeps Crashing”.
For an explanation of how MyISAM tables can
become corrupted, see Section 14.1.4, “MyISAM Table Problems”.
If you run mysqld with external locking disabled (which is the default as of MySQL 4.0), you cannot reliably use myisamchk to check a table when mysqld is using the same table. If you can be certain that no one will access the tables through mysqld while you run myisamchk, you only have to execute mysqladmin flush-tables before you start checking the tables. If you cannot guarantee this, you must stop mysqld while you check the tables. If you run myisamchk to check tables that mysqld is updating at the same time, you may get a warning that a table is corrupt even when it is not.
If the server is run with external locking enabled, you can use myisamchk to check tables at any time. In this case, if the server tries to update a table that myisamchk is using, the server will wait for myisamchk to finish before it continues.
If you use myisamchk to repair or optimize tables, you must always ensure that the mysqld server is not using the table (this also applies if external locking is disabled). If you don't stop mysqld, you should at least do a mysqladmin flush-tables before you run myisamchk. Your tables may become corrupted if the server and myisamchk access the tables simultaneously.
When performing crash recovery, it is important to understand
that each MyISAM table
tbl_name in a database corresponds
to three files in the database directory:
| File | Purpose |
| Definition (format) file |
| Data file |
| Index file |
Each of these three file types is subject to corruption in various ways, but problems occur most often in data files and index files.
myisamchk works by creating a copy of the
.MYD data file row by row. It ends the
repair stage by removing the old .MYD
file and renaming the new file to the original file name. If
you use --quick, myisamchk
does not create a temporary .MYD file,
but instead assumes that the .MYD file is
correct and generates only a new index file without touching
the .MYD file. This is safe, because
myisamchk automatically detects whether the
.MYD file is corrupt and aborts the
repair if it is. You can also specify the
--quick option twice to
myisamchk. In this case,
myisamchk does not abort on some errors
(such as duplicate-key errors) but instead tries to resolve
them by modifying the .MYD file. Normally
the use of two --quick options is useful only
if you have too little free disk space to perform a normal
repair. In this case, you should at least make a backup of the
table before running myisamchk.
To check a MyISAM table, use the following
commands:
myisamchktbl_nameThis finds 99.99% of all errors. What it cannot find is corruption that involves only the data file (which is very unusual). If you want to check a table, you should normally run myisamchk without options or with the
-s(silent) option.myisamchk -mtbl_nameThis finds 99.999% of all errors. It first checks all index entries for errors and then reads through all rows. It calculates a checksum for all key values in the rows and verifies that the checksum matches the checksum for the keys in the index tree.
myisamchk -etbl_nameThis does a complete and thorough check of all data (
-emeans “extended check”). It does a check-read of every key for each row to verify that they indeed point to the correct row. This may take a long time for a large table that has many indexes. Normally, myisamchk stops after the first error it finds. If you want to obtain more information, you can add the-v(verbose) option. This causes myisamchk to keep going, up through a maximum of 20 errors.myisamchk -e -itbl_nameThis is like the previous command, but the
-ioption tells myisamchk to print additional statistical information.
In most cases, a simple myisamchk command with no arguments other than the table name is sufficient to check a table.
The discussion in this section describes how to use
myisamchk on MyISAM
tables (extensions .MYI and
.MYD).
You can also (and should, if possible) use the CHECK
TABLE and REPAIR TABLE statements
to check and repair MyISAM tables. See
Section 13.5.2.3, “CHECK TABLE Syntax”, and
Section 13.5.2.6, “REPAIR TABLE Syntax”.
Symptoms of corrupted tables include queries that abort unexpectedly and observable errors such as these:
tbl_name.frmCan't find file
tbl_name.MYInnn)Unexpected end of file
Record file is crashed
Got error
nnnfrom table handler
To get more information about the error, run
perror nnn,
where nnn is the error number. The
following example shows how to use perror
to find the meanings for the most common error numbers that
indicate a problem with a table:
shell> perror 126 127 132 134 135 136 141 144 145
MySQL error code 126 = Index file is crashed
MySQL error code 127 = Record-file is crashed
MySQL error code 132 = Old database file
MySQL error code 134 = Record was already deleted (or record file crashed)
MySQL error code 135 = No more room in record file
MySQL error code 136 = No more room in index file
MySQL error code 141 = Duplicate unique key or constraint on write or update
MySQL error code 144 = Table is crashed and last repair failed
MySQL error code 145 = Table was marked as crashed and should be repaired
Note that error 135 (no more room in record file) and error
136 (no more room in index file) are not errors that can be
fixed by a simple repair. In this case, you must use
ALTER TABLE to increase the
MAX_ROWS and
AVG_ROW_LENGTH table option values:
ALTER TABLEtbl_nameMAX_ROWS=xxxAVG_ROW_LENGTH=yyy;
If you do not know the current table option values, use
SHOW CREATE TABLE.
For the other errors, you must repair your tables. myisamchk can usually detect and fix most problems that occur.
The repair process involves up to four stages, described here. Before you begin, you should change location to the database directory and check the permissions of the table files. On Unix, make sure that they are readable by the user that mysqld runs as (and to you, because you need to access the files you are checking). If it turns out you need to modify files, they must also be writable by you.
This section is for the cases where a table check fails (such
as those described in Section 5.9.4.2, “How to Check MyISAM Tables for Errors”), or you want to
use the extended features that myisamchk
provides.
The options that you can use for table maintenance with myisamchk are described in Section 8.5, “myisamchk — MyISAM Table-Maintenance Utility”.
If you are going to repair a table from the command line, you must first stop the mysqld server. Note that when you do mysqladmin shutdown on a remote server, the mysqld server is still alive for a while after mysqladmin returns, until all statement-processing has stopped and all index changes have been flushed to disk.
Stage 1: Checking your tables
Run myisamchk *.MYI or myisamchk
-e *.MYI if you have more time. Use the
-s (silent) option to suppress unnecessary
information.
If the mysqld server is stopped, you should
use the --update-state option to tell
myisamchk to mark the table as
“checked.”
You have to repair only those tables for which myisamchk announces an error. For such tables, proceed to Stage 2.
If you get unexpected errors when checking (such as
out of memory errors), or if
myisamchk crashes, go to Stage 3.
Stage 2: Easy safe repair
First, try myisamchk -r -q
tbl_name (-r
-q means “quick recovery mode”). This
attempts to repair the index file without touching the data
file. If the data file contains everything that it should and
the delete links point at the correct locations within the
data file, this should work, and the table is fixed. Start
repairing the next table. Otherwise, use the following
procedure:
Make a backup of the data file before continuing.
Use myisamchk -r
tbl_name(-rmeans “recovery mode”). This removes incorrect rows and deleted rows from the data file and reconstructs the index file.If the preceding step fails, use myisamchk --safe-recover
tbl_name. Safe recovery mode uses an old recovery method that handles a few cases that regular recovery mode does not (but is slower).
Note: If you want a repair operation to go much faster, you
should set the values of the
sort_buffer_size and
key_buffer_size variables each to about 25%
of your available memory when running
myisamchk.
If you get unexpected errors when repairing (such as
out of memory errors), or if
myisamchk crashes, go to Stage 3.
Stage 3: Difficult repair
You should reach this stage only if the first 16KB block in the index file is destroyed or contains incorrect information, or if the index file is missing. In this case, it is necessary to create a new index file. Do so as follows:
Move the data file to a safe place.
Use the table description file to create new (empty) data and index files:
shell>
mysqlmysql>db_nameSET AUTOCOMMIT=1;mysql>TRUNCATE TABLEmysql>tbl_name;quitCopy the old data file back onto the newly created data file. (Do not just move the old file back onto the new file. You want to retain a copy in case something goes wrong.)
Go back to Stage 2. myisamchk -r -q should work. (This should not be an endless loop.)
You can also use the REPAIR TABLE
SQL
statement, which performs the whole procedure automatically.
There is also no possibility of unwanted interaction between a
utility and the server, because the server does all the work
when you use tbl_name USE_FRMREPAIR TABLE. See
Section 13.5.2.6, “REPAIR TABLE Syntax”.
Stage 4: Very difficult repair
You should reach this stage only if the
.frm description file has also crashed.
That should never happen, because the description file is not
changed after the table is created:
Restore the description file from a backup and go back to Stage 3. You can also restore the index file and go back to Stage 2. In the latter case, you should start with myisamchk -r.
If you do not have a backup but know exactly how the table was created, create a copy of the table in another database. Remove the new data file, and then move the
.frmdescription and.MYIindex files from the other database to your crashed database. This gives you new description and index files, but leaves the.MYDdata file alone. Go back to Stage 2 and attempt to reconstruct the index file.
To coalesce fragmented rows and eliminate wasted space that results from deleting or updating rows, run myisamchk in recovery mode:
shell> myisamchk -r tbl_name
You can optimize a table in the same way by using the
OPTIMIZE TABLE SQL statement.
OPTIMIZE TABLE does a table repair and a
key analysis, and also sorts the index tree so that key
lookups are faster. There is also no possibility of unwanted
interaction between a utility and the server, because the
server does all the work when you use OPTIMIZE
TABLE. See Section 13.5.2.5, “OPTIMIZE TABLE Syntax”.
myisamchk has a number of other options that you can use to improve the performance of a table:
--analyze,-a--sort-index,-S--sort-records=,index_num-Rindex_num
For a full description of all available options, see Section 8.5, “myisamchk — MyISAM Table-Maintenance Utility”.
To obtain a description of a table or statistics about it, use the commands shown here. We explain some of the information in more detail later.
myisamchk -d
tbl_nameRuns myisamchk in “describe mode” to produce a description of your table. If you start the MySQL server with external locking disabled, myisamchk may report an error for a table that is updated while it runs. However, because myisamchk does not change the table in describe mode, there is no risk of destroying data.
myisamchk -d -v
tbl_nameAdding
-vruns myisamchk in verbose mode so that it produces more information about what it is doing.myisamchk -eis
tbl_nameShows only the most important information from a table. This operation is slow because it must read the entire table.
myisamchk -eiv
tbl_nameThis is like
-eis, but tells you what is being done.
The tbl_name argument can be either
the name of a MyISAM table or the name of
its index file, as described in Section 8.5, “myisamchk — MyISAM Table-Maintenance Utility”.
Multiple tbl_name arguments can be
given.
Sample output for some of these commands follows. They are based on a table with these data and index file sizes:
-rw-rw-r-- 1 monty tcx 317235748 Jan 12 17:30 company.MYD -rw-rw-r-- 1 davida tcx 96482304 Jan 12 18:35 company.MYI
Example of myisamchk -d output:
MyISAM file: company.MYI
Record format: Fixed length
Data records: 1403698 Deleted blocks: 0
Recordlength: 226
table description:
Key Start Len Index Type
1 2 8 unique double
2 15 10 multip. text packed stripped
3 219 8 multip. double
4 63 10 multip. text packed stripped
5 167 2 multip. unsigned short
6 177 4 multip. unsigned long
7 155 4 multip. text
8 138 4 multip. unsigned long
9 177 4 multip. unsigned long
193 1 text
Example of myisamchk -d -v output:
MyISAM file: company
Record format: Fixed length
File-version: 1
Creation time: 1999-10-30 12:12:51
Recover time: 1999-10-31 19:13:01
Status: checked
Data records: 1403698 Deleted blocks: 0
Datafile parts: 1403698 Deleted data: 0
Datafile pointer (bytes): 3 Keyfile pointer (bytes): 3
Max datafile length: 3791650815 Max keyfile length: 4294967294
Recordlength: 226
table description:
Key Start Len Index Type Rec/key Root Blocksize
1 2 8 unique double 1 15845376 1024
2 15 10 multip. text packed stripped 2 25062400 1024
3 219 8 multip. double 73 40907776 1024
4 63 10 multip. text packed stripped 5 48097280 1024
5 167 2 multip. unsigned short 4840 55200768 1024
6 177 4 multip. unsigned long 1346 65145856 1024
7 155 4 multip. text 4995 75090944 1024
8 138 4 multip. unsigned long 87 85036032 1024
9 177 4 multip. unsigned long 178 96481280 1024
193 1 text
Example of myisamchk -eis output:
Checking MyISAM file: company Key: 1: Keyblocks used: 97% Packed: 0% Max levels: 4 Key: 2: Keyblocks used: 98% Packed: 50% Max levels: 4 Key: 3: Keyblocks used: 97% Packed: 0% Max levels: 4 Key: 4: Keyblocks used: 99% Packed: 60% Max levels: 3 Key: 5: Keyblocks used: 99% Packed: 0% Max levels: 3 Key: 6: Keyblocks used: 99% Packed: 0% Max levels: 3 Key: 7: Keyblocks used: 99% Packed: 0% Max levels: 3 Key: 8: Keyblocks used: 99% Packed: 0% Max levels: 3 Key: 9: Keyblocks used: 98% Packed: 0% Max levels: 4 Total: Keyblocks used: 98% Packed: 17% Records: 1403698 M.recordlength: 226 Packed: 0% Recordspace used: 100% Empty space: 0% Blocks/Record: 1.00 Record blocks: 1403698 Delete blocks: 0 Recorddata: 317235748 Deleted data: 0 Lost space: 0 Linkdata: 0 User time 1626.51, System time 232.36 Maximum resident set size 0, Integral resident set size 0 Non physical pagefaults 0, Physical pagefaults 627, Swaps 0 Blocks in 0 out 0, Messages in 0 out 0, Signals 0 Voluntary context switches 639, Involuntary context switches 28966
Example of myisamchk -eiv output:
Checking MyISAM file: company
Data records: 1403698 Deleted blocks: 0
- check file-size
- check delete-chain
block_size 1024:
index 1:
index 2:
index 3:
index 4:
index 5:
index 6:
index 7:
index 8:
index 9:
No recordlinks
- check index reference
- check data record references index: 1
Key: 1: Keyblocks used: 97% Packed: 0% Max levels: 4
- check data record references index: 2
Key: 2: Keyblocks used: 98% Packed: 50% Max levels: 4
- check data record references index: 3
Key: 3: Keyblocks used: 97% Packed: 0% Max levels: 4
- check data record references index: 4
Key: 4: Keyblocks used: 99% Packed: 60% Max levels: 3
- check data record references index: 5
Key: 5: Keyblocks used: 99% Packed: 0% Max levels: 3
- check data record references index: 6
Key: 6: Keyblocks used: 99% Packed: 0% Max levels: 3
- check data record references index: 7
Key: 7: Keyblocks used: 99% Packed: 0% Max levels: 3
- check data record references index: 8
Key: 8: Keyblocks used: 99% Packed: 0% Max levels: 3
- check data record references index: 9
Key: 9: Keyblocks used: 98% Packed: 0% Max levels: 4
Total: Keyblocks used: 9% Packed: 17%
- check records and index references
*** LOTS OF ROW NUMBERS DELETED ***
Records: 1403698 M.recordlength: 226 Packed: 0%
Recordspace used: 100% Empty space: 0% Blocks/Record: 1.00
Record blocks: 1403698 Delete blocks: 0
Recorddata: 317235748 Deleted data: 0
Lost space: 0 Linkdata: 0
User time 1639.63, System time 251.61
Maximum resident set size 0, Integral resident set size 0
Non physical pagefaults 0, Physical pagefaults 10580, Swaps 0
Blocks in 4 out 0, Messages in 0 out 0, Signals 0
Voluntary context switches 10604, Involuntary context switches 122798
Explanations for the types of information myisamchk produces are given here. “Keyfile” refers to the index file. “Record” and “row” are synonymous.
MyISAM fileName of the
MyISAM(index) file.File-versionVersion of
MyISAMformat. Currently always 2.Creation timeWhen the data file was created.
Recover timeWhen the index/data file was last reconstructed.
Data recordsHow many rows are in the table.
Deleted blocksHow many deleted blocks still have reserved space. You can optimize your table to minimize this space. See Section 5.9.4.4, “Table Optimization”.
Datafile partsFor dynamic-row format, this indicates how many data blocks there are. For an optimized table without fragmented rows, this is the same as
Data records.Deleted dataHow many bytes of unreclaimed deleted data there are. You can optimize your table to minimize this space. See Section 5.9.4.4, “Table Optimization”.
Datafile pointerThe size of the data file pointer, in bytes. It is usually 2, 3, 4, or 5 bytes. Most tables manage with 2 bytes, but this cannot be controlled from MySQL yet. For fixed tables, this is a row address. For dynamic tables, this is a byte address.
Keyfile pointerThe size of the index file pointer, in bytes. It is usually 1, 2, or 3 bytes. Most tables manage with 2 bytes, but this is calculated automatically by MySQL. It is always a block address.
Max datafile lengthHow long the table data file can become, in bytes.
Max keyfile lengthHow long the table index file can become, in bytes.
RecordlengthHow much space each row takes, in bytes.
Record formatThe format used to store table rows. The preceding examples use
Fixed length. Other possible values areCompressedandPacked.table descriptionA list of all keys in the table. For each key, myisamchk displays some low-level information:
KeyThis key's number.
StartWhere in the row this portion of the index starts.
LenHow long this portion of the index is. For packed numbers, this should always be the full length of the column. For strings, it may be shorter than the full length of the indexed column, because you can index a prefix of a string column.
IndexWhether a key value can exist multiple times in the index. Possible values are
uniqueormultip.(multiple).TypeWhat data type this portion of the index has. This is a
MyISAMdata type with the possible valuespacked,stripped, orempty.RootAddress of the root index block.
BlocksizeThe size of each index block. By default this is 1024, but the value may be changed at compile time when MySQL is built from source.
Rec/keyThis is a statistical value used by the optimizer. It tells how many rows there are per value for this index. A unique index always has a value of 1. This may be updated after a table is loaded (or greatly changed) with myisamchk -a. If this is not updated at all, a default value of 30 is given.
For the table shown in the examples, there are two
table descriptionlines for the ninth index. This indicates that it is a multiple-part index with two parts.Keyblocks usedWhat percentage of the keyblocks are used. When a table has just been reorganized with myisamchk, as for the table in the examples, the values are very high (very near the theoretical maximum).
PackedMySQL tries to pack key values that have a common suffix. This can only be used for indexes on
CHARandVARCHARcolumns. For long indexed strings that have similar leftmost parts, this can significantly reduce the space used. In the third of the preceding examples, the fourth key is 10 characters long and a 60% reduction in space is achieved.Max levelsHow deep the B-tree for this key is. Large tables with long key values get high values.
RecordsHow many rows are in the table.
M.recordlengthThe average row length. This is the exact row length for tables with fixed-length rows, because all rows have the same length.
PackedMySQL strips spaces from the end of strings. The
Packedvalue indicates the percentage of savings achieved by doing this.Recordspace usedWhat percentage of the data file is used.
Empty spaceWhat percentage of the data file is unused.
Blocks/RecordAverage number of blocks per row (that is, how many links a fragmented row is composed of). This is always 1.0 for fixed-format tables. This value should stay as close to 1.0 as possible. If it gets too large, you can reorganize the table. See Section 5.9.4.4, “Table Optimization”.
RecordblocksHow many blocks (links) are used. For fixed-format tables, this is the same as the number of rows.
DeleteblocksHow many blocks (links) are deleted.
RecorddataHow many bytes in the data file are used.
Deleted dataHow many bytes in the data file are deleted (unused).
Lost spaceIf a row is updated to a shorter length, some space is lost. This is the sum of all such losses, in bytes.
LinkdataWhen the dynamic table format is used, row fragments are linked with pointers (4 to 7 bytes each).
Linkdatais the sum of the amount of storage used by all such pointers.
If a table has been compressed with myisampack, myisamchk -d prints additional information about each table column. See Section 8.7, “myisampack — Generate Compressed, Read-Only MyISAM Tables”, for an example of this information and a description of what it means.
It is a good idea to perform table checks on a regular basis
rather than waiting for problems to occur. One way to check
and repair MyISAM tables is with the
CHECK TABLE and REPAIR
TABLE statements. See Section 13.5.2.3, “CHECK TABLE Syntax”,
and Section 13.5.2.6, “REPAIR TABLE Syntax”.
Another way to check tables is to use
myisamchk. For maintenance purposes, you
can use myisamchk -s. The
-s option (short for
--silent) causes myisamchk
to run in silent mode, printing messages only when errors
occur.
It is also a good idea to enable automatic
MyISAM table checking. For example,
whenever the machine has done a restart in the middle of an
update, you usually need to check each table that could have
been affected before it is used further. (These are
“expected crashed tables.”) To check
MyISAM tables automatically, start the
server with the --myisam-recover option. See
Section 5.2.2, “Command Options”.
You should also check your tables regularly during normal
system operation. At MySQL AB, we run a
cron job to check all our important tables
once a week, using a line like this in a
crontab file:
35 0 * * 0/path/to/myisamchk--fast --silent/path/to/datadir/*/*.MYI
This prints out information about crashed tables so that we can examine and repair them when needed.
Because we have not had any unexpectedly crashed tables (tables that become corrupted for reasons other than hardware trouble) for several years, once a week is more than sufficient for us.
We recommend that to start with, you execute myisamchk -s each night on all tables that have been updated during the last 24 hours, until you come to trust MySQL as much as we do.
Normally, MySQL tables need little maintenance. If you are
performing many updates to MyISAM tables
with dynamic-sized rows (tables with
VARCHAR, BLOB, or
TEXT columns) or have tables with many
deleted rows you may want to defragment/reclaim space from the
tables from time to time. You can do this by using
OPTIMIZE TABLE on the tables in question.
Alternatively, if you can stop the mysqld
server for a while, change location into the data directory
and use this command while the server is stopped:
shell> myisamchk -r -s --sort-index --sort_buffer_size=16M */*.MYI
- 5.10.1. The Character Set Used for Data and Sorting
- 5.10.2. Setting the Error Message Language
- 5.10.3. Adding a New Character Set
- 5.10.4. The Character Definition Arrays
- 5.10.5. String Collating Support
- 5.10.6. Multi-Byte Character Support
- 5.10.7. Problems With Character Sets
- 5.10.8. MySQL Server Time Zone Support
- 5.10.9. MySQL Server Locale Support
This section describes how to configure the server to use different character sets. It also discusses how to set the server's time zone and enable per-connection time zone support.
By default, MySQL uses the latin1 (cp1252
West European) character set and the
latin1_swedish_ci collation that sorts
according to Swedish/Finnish rules. These defaults are suitable
for the United States and most of Western Europe.
All MySQL binary distributions are compiled with
--with-extra-charsets=complex. This adds code
to all standard programs that enables them to handle
latin1 and all multi-byte character sets
within the binary. Other character sets are loaded from a
character-set definition file when needed.
The character set determines what characters are allowed in
identifiers. The collation determines how strings are sorted by
the ORDER BY and GROUP BY
clauses of the SELECT statement.
You can change the default server character set and collation
with the --character-set-server and
--collation-server options when you start the
server. The collation must be a legal collation for the default
character set. (Use the SHOW COLLATION
statement to determine which collations are available for each
character set.) See Section 5.2.2, “Command Options”.
The character sets available depend on the
--with-charset=
and
charset_name--with-extra-charsets= options to
configure, and the character set
configuration files listed in
list-of-charsets
| complex | all | noneSHAREDIR/charsets/Index
If you change the character set when running MySQL, that may
also change the sort order. Consequently, you must run
myisamchk -r -q
--set-collation=collation_name
on all MyISAM tables, or your indexes may not
be ordered correctly.
When a client connects to a MySQL server, the server indicates to the client what the server's default character set is. The client switches to this character set for this connection.
You should use mysql_real_escape_string()
when escaping strings for an SQL query.
mysql_real_escape_string() is identical to
the old mysql_escape_string() function,
except that it takes the MYSQL connection
handle as the first parameter so that the appropriate character
set can be taken into account when escaping characters.
If the client is compiled with paths that differ from where the
server is installed and the user who configured MySQL didn't
include all character sets in the MySQL binary, you must tell
the client where it can find the additional character sets it
needs if the server runs with a different character set from the
client. You can do this by specifying a
--character-sets-dir option to indicate the
path to the directory in which the dynamic MySQL character sets
are stored. For example, you can put the following in an option
file:
[client] character-sets-dir=/usr/local/mysql/share/mysql/charsets
You can force the client to use specific character set as follows:
[client]
default-character-set=charset_name
This is normally unnecessary, however.
In MySQL 5.0, character set and collation are
specified separately. This means that if you want German sort
order, you should select the latin1
character set and either the
latin1_german1_ci or
latin1_german2_ci collation. For example,
to start the server with the
latin1_german1_ci collation, use the
--character-set-server=latin1 and
--collation-server=latin1_german1_ci options.
For information on the differences between these two collations, see Section 10.10.2, “West European Character Sets”.
By default, mysqld produces error messages in English, but they can also be displayed in any of these other languages: Czech, Danish, Dutch, Estonian, French, German, Greek, Hungarian, Italian, Japanese, Korean, Norwegian, Norwegian-ny, Polish, Portuguese, Romanian, Russian, Slovak, Spanish, or Swedish.
To start mysqld with a particular language
for error messages, use the --language or
-L option. The option value can be a language
name or the full path to the error message file. For example:
shell> mysqld --language=swedish
Or:
shell> mysqld --language=/usr/local/share/swedish
The language name should be specified in lowercase.
By default, the language files are located in the
share/
directory under the MySQL base directory.
LANGUAGE
You can also change the content of the error messages produced by the server. Details can be found in the MySQL Internals manual, available at http://forge.mysql.com/wiki/MySQL_Internals_Error_Messages. If you upgrade to a newer version of MySQL after changing the error messages, remember to repeat your changes after the upgrade.
This section discusses the procedure for adding a new character set to MySQL. You must have a MySQL source distribution to use these instructions. To choose the proper procedure, determine whether the character set is simple or complex:
If the character set does not need to use special string collating routines for sorting and does not need multi-byte character support, it is simple.
If it needs either of those features, it is complex.
For example, latin1 and
danish are simple character sets, whereas
big5 and czech are complex
character sets.
In the following instructions, the name of the character set is
represented by MYSET.
For a simple character set, do the following:
Add
MYSETto the end of thesql/share/charsets/Indexfile. Assign a unique number to it.Create the file
sql/share/charsets/. (You can use a copy ofMYSET.confsql/share/charsets/latin1.confas the basis for this file.)The syntax for the file is very simple:
Comments start with a ‘
#’ character and continue to the end of the line.Words are separated by arbitrary amounts of whitespace.
When defining the character set, every word must be a number in hexadecimal format.
The
ctypearray takes up the first 257 words. Theto_lower[],to_upper[]andsort_order[]arrays take up 256 words each after that.
Add the character set name to the
CHARSETS_AVAILABLEandCOMPILED_CHARSETSlists inconfigure.in.Reconfigure, recompile, and test.
For a complex character set, do the following:
Create the file
strings/ctype-in the MySQL source distribution.MYSET.cAdd
MYSETto the end of thesql/share/charsets/Indexfile. Assign a unique number to it.Look at one of the existing
ctype-*.cfiles (such asstrings/ctype-big5.c) to see what needs to be defined. Note that the arrays in your file must have names likectype_,MYSETto_lower_, and so on. These correspond to the arrays for a simple character set. See Section 5.10.4, “The Character Definition Arrays”.MYSETNear the top of the file, place a special comment like this:
/* * This comment is parsed by configure to create ctype.c, * so don't change it unless you know what you are doing. * * .configure. number_
MYSET=MYNUMBER* .configure. strxfrm_multiply_MYSET=N* .configure. mbmaxlen_MYSET=N*/The configure program uses this comment to include the character set into the MySQL library automatically.
The
strxfrm_multiplyandmbmaxlenlines are explained in the following sections. You need include them only if you need the string collating functions or the multi-byte character set functions, respectively.You should then create some of the following functions:
my_strncoll_MYSET()my_strcoll_MYSET()my_strxfrm_MYSET()my_like_range_MYSET()
Add the character set name to the
CHARSETS_AVAILABLEandCOMPILED_CHARSETSlists inconfigure.in.Reconfigure, recompile, and test.
The sql/share/charsets/README file includes
additional instructions.
If you want to have the character set included in the MySQL
distribution, mail a patch to the MySQL
internals mailing list. See
Section 1.7.1, “MySQL Mailing Lists”.
to_lower[] and to_upper[]
are simple arrays that hold the lowercase and uppercase
characters corresponding to each member of the character set.
For example:
to_lower['A'] should contain 'a' to_upper['a'] should contain 'A'
sort_order[] is a map indicating how
characters should be ordered for comparison and sorting
purposes. Quite often (but not for all character sets) this is
the same as to_upper[], which means that
sorting is case-insensitive. MySQL sorts characters based on the
values of sort_order[] elements. For more
complicated sorting rules, see the discussion of string
collating in Section 5.10.5, “String Collating Support”.
ctype[] is an array of bit values, with one
element for one character. (Note that
to_lower[], to_upper[],
and sort_order[] are indexed by character
value, but ctype[] is indexed by character
value + 1. This is an old legacy convention for handling
EOF.)
You can find the following bitmask definitions in
m_ctype.h:
#define _U 01 /* Uppercase */ #define _L 02 /* Lowercase */ #define _N 04 /* Numeral (digit) */ #define _S 010 /* Spacing character */ #define _P 020 /* Punctuation */ #define _C 040 /* Control character */ #define _B 0100 /* Blank */ #define _X 0200 /* heXadecimal digit */
The ctype[] entry for each character should
be the union of the applicable bitmask values that describe the
character. For example, 'A' is an uppercase
character (_U) as well as a hexadecimal digit
(_X), so ctype['A'+1]
should contain the value:
_U + _X = 01 + 0200 = 0201
If the sorting rules for your language are too complex to be
handled with the simple sort_order[] table,
you need to use the string collating functions.
The best documentation for this is the existing character sets.
Look at the big5, czech,
gbk, sjis, and
tis160 character sets for examples.
You must specify the
strxfrm_multiply_
value in the special comment at the top of the file.
MYSET=NN should be set to the maximum ratio
the strings may grow during
my_strxfrm_
(it must be a positive integer).
MYSET
If you want to add support for a new character set that includes multi-byte characters, you need to use the multi-byte character functions.
The best documentation for this is the existing character sets.
Look at the euc_kr,
gb2312, gbk,
sjis, and ujis character
sets for examples. These are implemented in the
ctype-
files in the charset_name.cstrings directory.
You must specify the
mbmaxlen_
value in the special comment at the top of the source file.
MYSET=NN should be set to the size in bytes
of the largest character in the set.
If you try to use a character set that is not compiled into your binary, you might run into the following problems:
Your program uses an incorrect path to determine where the character sets are stored. (Default
/usr/local/mysql/share/mysql/charsets). This can be fixed by using the--character-sets-diroption when you run the program in question.The character set is a multi-byte character set that cannot be loaded dynamically. In this case, you must recompile the program with support for the character set.
The character set is a dynamic character set, but you do not have a configure file for it. In this case, you should install the configure file for the character set from a new MySQL distribution.
If your
Indexfile does not contain the name for the character set, your program displays the following error message:ERROR 1105: File '/usr/local/share/mysql/charsets/?.conf' not found (Errcode: 2)
In this case, you should either get a new
Indexfile or manually add the name of any missing character sets to the current file.
For MyISAM tables, you can check the
character set name and number for a table with
myisamchk -dvv
tbl_name.
The MySQL server maintains several time zone settings:
The system time zone. When the server starts, it attempts to determine the time zone of the host machine and uses it to set the
system_time_zonesystem variable. The value does not change thereafter.You can set the system time zone for MySQL Server at startup with the
--timezone=option to mysqld_safe. You can also set it by setting thetimezone_nameTZenvironment variable before you start mysqld. The allowable values for--timezoneorTZare system-dependent. Consult your operating system documentation to see what values are acceptable.The server's current time zone. The global
time_zonesystem variable indicates the time zone the server currently is operating in. The initial value fortime_zoneis'SYSTEM', which indicates that the server time zone is the same as the system time zone.The initial global server time zone value can be specified explicitly at startup with the
--default-time-zone=option on the command line, or you can use the following line in an option file:timezonedefault-time-zone='
timezone'If you have the
SUPERprivilege, you can set the global server time zone value at runtime with this statement:mysql>
SET GLOBAL time_zone =timezone;Per-connection time zones. Each client that connects has its own time zone setting, given by the session
time_zonevariable. Initially, the session variable takes its value from the globaltime_zonevariable, but the client can change its own time zone with this statement:mysql>
SET time_zone =timezone;
The current session time zone setting affects display and
storage of time values that are zone-sensitive. This includes
the values displayed by functions such as
NOW() or CURTIME(), and
values stored in and retrieved from TIMESTAMP
columns. Values for TIMESTAMP columns are
converted from the current time zone to UTC for storage, and
from UTC to the current time zone for retrieval. The current
time zone setting does not affect values displayed by functions
such as UTC_TIMESTAMP() or values in
DATE, TIME, or
DATETIME columns.
The current values of the global and client-specific time zones can be retrieved like this:
mysql> SELECT @@global.time_zone, @@session.time_zone;
timezone values can be given in
several formats, none of which are case sensitive:
The value
'SYSTEM'indicates that the time zone should be the same as the system time zone.The value can be given as a string indicating an offset from UTC, such as
'+10:00'or'-6:00'.The value can be given as a named time zone, such as
'Europe/Helsinki','US/Eastern', or'MET'. Named time zones can be used only if the time zone information tables in themysqldatabase have been created and populated.
The MySQL installation procedure creates the time zone tables in
the mysql database, but does not load them.
You must do so manually using the following instructions. (If
you are upgrading to MySQL 4.1.3 or later from an earlier
version, you can create the tables by upgrading your
mysql database. Use the instructions in
Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”. After creating the tables, you
can load them.)
Note
Loading the time zone information is not necessarily a one-time operation because the information changes occasionally. For example, the rules for Daylight Saving Time in the United States, Mexico, and parts of Canada changed in 2007. When such changes occur, applications that use the old rules become out of date and you may find it necessary to reload the time zone tables to keep the information used by your MySQL server current. See the notes at the end of this section.
If your system has its own zoneinfo
database (the set of files describing time zones), you should
use the mysql_tzinfo_to_sql program for
filling the time zone tables. Examples of such systems are
Linux, FreeBSD, Sun Solaris, and Mac OS X. One likely location
for these files is the /usr/share/zoneinfo
directory. If your system does not have a zoneinfo database, you
can use the downloadable package described later in this
section.
The mysql_tzinfo_to_sql program is used to load the time zone tables. On the command line, pass the zoneinfo directory pathname to mysql_tzinfo_to_sql and send the output into the mysql program. For example:
shell> mysql_tzinfo_to_sql /usr/share/zoneinfo | mysql -u root mysql
mysql_tzinfo_to_sql reads your system's time zone files and generates SQL statements from them. mysql processes those statements to load the time zone tables.
mysql_tzinfo_to_sql also can be used to load a single time zone file or to generate leap second information:
To load a single time zone file
tz_filethat corresponds to a time zone nametz_name, invoke mysql_tzinfo_to_sql like this:shell>
mysql_tzinfo_to_sqltz_filetz_name| mysql -u root mysqlWith this approach, you must execute a separate command to load the time zone file for each named zone that the server needs to know about.
If your time zone needs to account for leap seconds, initialize the leap second information like this, where
tz_fileis the name of your time zone file:shell>
mysql_tzinfo_to_sql --leaptz_file| mysql -u root mysql
If your system is one that has no zoneinfo database (for example, Windows or HP-UX), you can use the package of pre-built time zone tables that is available for download at the MySQL Developer Zone:
http://dev.mysql.com/downloads/timezones.html
This time zone package contains .frm,
.MYD, and .MYI files
for the MyISAM time zone tables. These tables
should be part of the mysql database, so you
should place the files in the mysql
subdirectory of your MySQL server's data directory. The server
should be stopped while you do this and restarted afterward.
Warning: Do not use the downloadable package if your system has a zoneinfo database. Use the mysql_tzinfo_to_sql utility instead. Otherwise, you may cause a difference in datetime handling between MySQL and other applications on your system.
For information about time zone settings in replication setup, please see Section 6.7, “Replication Features and Known Problems”.
Staying Current with Time Zone Changes
As mentioned earlier, when the time zone rules change, applications that use the old rules become out of date. To stay current, it is necessary to make sure that your system uses current time zone information is used. For MySQL, there are two factors to consider in staying current:
The operating system time affects the value that the MySQL server uses for times if its time zone is set to
SYSTEM. Make sure that your operating system is using the latest time zone information. For most operating systems, the latest update or service pack prepares your system for the time changes. Check the Web site for your operating system vendor for an update that addresses the time changes.If you replace the system's
/etc/localtimetimezone file with a verion that uses rules differing from those in effect at mysqld startup, you should restart mysqld so that it uses the updated rules. Otherwise, mysqld might not notice when the system changes its time.If you use named time zones with MySQL, make sure that the time zone tables in the
mysqldatabase are up to date. If your system has its own zoneinfo database, you should reload the MySQL time zone tables whenever the zoneinfo database is updated, using the instructions given earlier in this section. For systems that do not have their own zoneinfo database, check the MySQL Developer Zone for updates. When a new update is available, download it and use it to replace your current time zone tables. mysqld caches time zone information that it looks up, so after replacing the time zone tables, you should restart mysqld to make sure that it does not continue to serve outdated time zone data.
If you are uncertain whether named time zones are available, for use either as the server's time zone setting or by clients that set their own time zone, check whether your time zone tables are empty. The following query determines whether the table that contains time zone names has any rows:
mysql> SELECT COUNT(*) FROM mysql.time_zone_name;
+----------+
| COUNT(*) |
+----------+
| 0 |
+----------+
A count of zero indicates that the table is empty. In this case, no one can be using named time zones, and you don't need to update the tables. A count greater than zero indicates that the table is not empty and that its contents are available to be used for named time zone support. In this case, you should be sure to reload your time zone tables so that anyone who uses named time zones will get correct query results.
To check whether your MySQL installation is updated properly for a change in Daylight Saving Time rules, use a test like the one following. The example uses values that are appropriate for the 2007 DST 1-hour change that occurs in the United States on March 11 at 2 a.m.
The test uses these two queries:
SELECT CONVERT_TZ('2007-03-11 2:00:00','US/Eastern','US/Central');
SELECT CONVERT_TZ('2007-03-11 3:00:00','US/Eastern','US/Central');
The two time values indicate the times at which the DST change occurs, and the use of named time zones requires that the time zone tables be used. The desired result is that both queries return the same result (the input time, converted to the equivalent value in the 'US/Central' time zone).
Before updating the time zone tables, you would see an incorrect result like this:
mysql>SELECT CONVERT_TZ('2007-03-11 2:00:00','US/Eastern','US/Central');+------------------------------------------------------------+ | CONVERT_TZ('2007-03-11 2:00:00','US/Eastern','US/Central') | +------------------------------------------------------------+ | 2007-03-11 01:00:00 | +------------------------------------------------------------+ mysql>SELECT CONVERT_TZ('2007-03-11 3:00:00','US/Eastern','US/Central');+------------------------------------------------------------+ | CONVERT_TZ('2007-03-11 3:00:00','US/Eastern','US/Central') | +------------------------------------------------------------+ | 2007-03-11 02:00:00 | +------------------------------------------------------------+
After updating the tables, you should see the correct result:
mysql>SELECT CONVERT_TZ('2007-03-11 2:00:00','US/Eastern','US/Central');+------------------------------------------------------------+ | CONVERT_TZ('2007-03-11 2:00:00','US/Eastern','US/Central') | +------------------------------------------------------------+ | 2007-03-11 01:00:00 | +------------------------------------------------------------+ mysql>SELECT CONVERT_TZ('2007-03-11 3:00:00','US/Eastern','US/Central');+------------------------------------------------------------+ | CONVERT_TZ('2007-03-11 3:00:00','US/Eastern','US/Central') | +------------------------------------------------------------+ | 2007-03-11 01:00:00 | +------------------------------------------------------------+
Beginning with MySQL 5.0.25, the locale indicated by the
lc_time_names system variable controls the
language used to display day and month names and abbreviations.
This variable affects the output from the
DATE_FORMAT(), DAYNAME()
and MONTHNAME() functions.
Locale names are POSIX-style values such as
'ja_JP' or 'pt_BR'. The
default value is 'en_US' regardless of your
system's locale setting, but any client can examine or set its
lc_time_names value as shown in the following
example:
mysql>SET NAMES 'utf8';Query OK, 0 rows affected (0.09 sec) mysql>SELECT @@lc_time_names;+-----------------+ | @@lc_time_names | +-----------------+ | en_US | +-----------------+ 1 row in set (0.00 sec) mysql>SELECT DAYNAME('2010-01-01'), MONTHNAME('2010-01-01');+-----------------------+-------------------------+ | DAYNAME('2010-01-01') | MONTHNAME('2010-01-01') | +-----------------------+-------------------------+ | Friday | January | +-----------------------+-------------------------+ 1 row in set (0.00 sec) mysql>SELECT DATE_FORMAT('2010-01-01','%W %a %M %b');+-----------------------------------------+ | DATE_FORMAT('2010-01-01','%W %a %M %b') | +-----------------------------------------+ | Friday Fri January Jan | +-----------------------------------------+ 1 row in set (0.00 sec) mysql>SET lc_time_names = 'es_MX';Query OK, 0 rows affected (0.00 sec) mysql>SELECT @@lc_time_names;+-----------------+ | @@lc_time_names | +-----------------+ | es_MX | +-----------------+ 1 row in set (0.00 sec) mysql>SELECT DAYNAME('2010-01-01'), MONTHNAME('2010-01-01');+-----------------------+-------------------------+ | DAYNAME('2010-01-01') | MONTHNAME('2010-01-01') | +-----------------------+-------------------------+ | viernes | enero | +-----------------------+-------------------------+ 1 row in set (0.00 sec) mysql>SELECT DATE_FORMAT('2010-01-01','%W %a %M %b');+-----------------------------------------+ | DATE_FORMAT('2010-01-01','%W %a %M %b') | +-----------------------------------------+ | viernes vie enero ene | +-----------------------------------------+ 1 row in set (0.00 sec)
The day or month name for each of the affected functions is
converted from utf8 to the character set
indicated by the character_set_connection
system variable.
lc_time_names may be set to any of the
following locale values:
ar_AE: Arabic - United Arab Emirates | ar_BH: Arabic - Bahrain |
ar_DZ: Arabic - Algeria | ar_EG: Arabic - Egypt |
ar_IN: Arabic - Iran | ar_IQ: Arabic - Iraq |
ar_JO: Arabic - Jordan | ar_KW: Arabic - Kuwait |
ar_LB: Arabic - Lebanon | ar_LY: Arabic - Libya |
ar_MA: Arabic - Morocco | ar_OM: Arabic - Oman |
ar_QA: Arabic - Qatar | ar_SA: Arabic - Saudi Arabia |
ar_SD: Arabic - Sudan | ar_SY: Arabic - Syria |
ar_TN: Arabic - Tunisia | ar_YE: Arabic - Yemen |
be_BY: Belarusian - Belarus | bg_BG: Bulgarian - Bulgaria |
ca_ES: Catalan - Catalan | cs_CZ: Czech - Czech Republic |
da_DK: Danish - Denmark | de_AT: German - Austria |
de_BE: German - Belgium | de_CH: German - Switzerland |
de_DE: German - Germany | de_LU: German - Luxembourg |
EE: Estonian - Estonia | en_AU: English - Australia |
en_CA: English - Canada | en_GB: English - United Kingdom |
en_IN: English - India | en_NZ: English - New Zealand |
en_PH: English - Philippines | en_US: English - United States |
en_ZA: English - South Africa | en_ZW: English - Zimbabwe |
es_AR: Spanish - Argentina | es_BO: Spanish - Bolivia |
es_CL: Spanish - Chile | es_CO: Spanish - Columbia |
es_CR: Spanish - Costa Rica | es_DO: Spanish - Dominican Republic |
es_EC: Spanish - Ecuador | es_ES: Spanish - Spain |
es_GT: Spanish - Guatemala | es_HN: Spanish - Honduras |
es_MX: Spanish - Mexico | es_NI: Spanish - Nicaragua |
es_PA: Spanish - Panama | es_PE: Spanish - Peru |
es_PR: Spanish - Puerto Rico | es_PY: Spanish - Paraguay |
es_SV: Spanish - El Salvador | es_US: Spanish - United States |
es_UY: Spanish - Uruguay | es_VE: Spanish - Venezuela |
eu_ES: Basque - Basque | fi_FI: Finnish - Finland |
fo_FO: Faroese - Faroe Islands | fr_BE: French - Belgium |
fr_CA: French - Canada | fr_CH: French - Switzerland |
fr_FR: French - France | fr_LU: French - Luxembourg |
gl_ES: Galician - Galician | gu_IN: Gujarati - India |
he_IL: Hebrew - Israel | hi_IN: Hindi - India |
hr_HR: Croatian - Croatia | hu_HU: Hungarian - Hungary |
id_ID: Indonesian - Indonesia | is_IS: Icelandic - Iceland |
it_CH: Italian - Switzerland | it_IT: Italian - Italy |
ja_JP: Japanese - Japan | ko_KR: Korean - Korea |
lt_LT: Lithuanian - Lithuania | lv_LV: Latvian - Latvia |
mk_MK: Macedonian - FYROM | mn_MN: Mongolia - Mongolian |
ms_MY: Malay - Malaysia | nb_NO: Norwegian(Bokml) - Norway |
nl_BE: Dutch - Belgium | nl_NL: Dutch - The Netherlands |
no_NO: Norwegian - Norway | pl_PL: Polish - Poland |
pt_BR: Portugese - Brazil | pt_PT: Portugese - Portugal |
ro_RO: Romanian - Romania | ru_RU: Russian - Russia |
ru_UA: Russian - Ukraine | sk_SK: Slovak - Slovakia |
sl_SI: Slovenian - Slovenia | sq_AL: Albanian - Albania |
sr_YU: Serbian - Yugoslavia | sv_FI: Swedish - Finland |
sv_SE: Swedish - Sweden | ta_IN: Tamil - India |
te_IN: Telugu - India | th_TH: Thai - Thailand |
tr_TR: Turkish - Turkey | uk_UA: Ukrainian - Ukraine |
ur_PK: Urdu - Pakistan | vi_VN: Vietnamese - Vietnam |
zh_CN: Chinese - Peoples Republic of China | zh_HK: Chinese - Hong Kong SAR |
zh_TW: Chinese - Taiwan |
lc_time_names currently does not affect the
STR_TO_DATE() or
GET_FORMAT() function.
MySQL has several different logs that can help you find out what is going on inside mysqld:
| Log Type | Information Written to Log |
| The error log | Problems encountered starting, running, or stopping mysqld |
| The general query log | Established client connections and statements received from clients |
| The binary log | All statements that change data (also used for replication) |
| The slow query log | All queries that took more than long_query_time
seconds to execute or didn't use indexes |
By default, all log files are created in the
mysqld data directory. You can force
mysqld to close and reopen the log files (or in
some cases switch to a new log) by flushing the logs. Log flushing
occurs when you issue a FLUSH LOGS statement or
execute mysqladmin flush-logs or
mysqladmin refresh. See
Section 13.5.5.2, “FLUSH Syntax”, and Section 8.10, “mysqladmin — Client for Administering a MySQL Server”.
If you are using MySQL replication capabilities, slave replication servers maintain additional log files called relay logs. Chapter 6, Replication, discusses relay log contents and configuration.
MySQL Enterprise The MySQL Network Monitoring and Advisory Service provides a number of advisors specifically related to the various log files. For more information see http://www.mysql.com/products/enterprise/advisors.html.
The error log file contains information indicating when mysqld was started and stopped and also any critical errors that occur while the server is running. If mysqld notices a table that needs to be automatically checked or repaired, it writes a message to the error log.
On some operating systems, the error log contains a stack trace if mysqld dies. The trace can be used to determine where mysqld died. See MySQL Internals: Porting.
If mysqld_safe is used to start
mysqld and mysqld dies
unexpectedly, mysqld_safe notices that it
needs to restart mysqld and writes a
restarted mysqld message to the error log.
You can specify where mysqld stores the error
log file with the
--log-error[=
option. If no file_name]file_name value is
given, mysqld uses the name
host_name.errFLUSH LOGS, the error log is renamed with the
suffix -old and mysqld
creates a new empty log file. (No renaming occurs if the
--log-error option was not given.)
If you do not specify --log-error, or (on
Windows) if you use the --console option,
errors are written to stderr, the standard
error output. Usually this is your terminal.
On Windows, error output is always written to the
.err file if --console is
not given.
The --log-warnings option or
log_warnings system variable can be used to
control warning logging to the error log. The default value is
enabled (1). Warning logging can be disabled using a value of 0.
Aborted connections are not logged to the error log unless the
value is greater than 1. See
Section B.1.2.10, “Communication Errors and Aborted Connections”.
The general query log is a general record of what mysqld is doing. The server writes information to this log when clients connect or disconnect, and it logs each SQL statement received from clients. The general query log can be very useful when you suspect an error in a client and want to know exactly what the client sent to mysqld.
mysqld writes statements to the query log in the order that it receives them, which might differ from the order in which they are executed. This logging order contrasts to the binary log, for which statements are written after they are executed but before any locks are released. (Also, the query log contains all statements, whereas the binary log does not contain statements that only select data.)
To enable the general query log, start mysqld
with the
--log[= or
file_name]-l [
option.
file_name]
If no file_name value is given for
--log or -l, the default name
is host_name.log
Server restarts and log flushing do not cause a new general query log file to be generated (although flushing closes and reopens it). On Unix, you can rename the file and create a new one by using the following commands:
shell>mvshell>host_name.loghost_name-old.logmysqladmin flush-logsshell>cpshell>host_name-old.logbackup-directoryrmhost_name-old.log
On Windows, you cannot rename the log file while the server has it open. You must stop the server and rename the file, and then restart the server to create a new log file.
The binary log contains all statements that update data or
potentially could have updated it (for example, a
DELETE which matched no rows). Statements are
stored in the form of “events” that describe the
modifications. The binary log also contains information about
how long each statement took that updated data.
Note: The binary log has replaced the old update log, which is no longer available as of MySQL 5.0. The binary log contains all information that is available in the update log in a more efficient format and in a manner that is transaction-safe. If you are using transactions, you must use the MySQL binary log for backups instead of the old update log.
The binary log is not used for statements such as
SELECT or SHOW that do not
modify data. If you want to log all statements (for example, to
identify a problem query), use the general query log. See
Section 5.11.2, “The General Query Log”.
The primary purpose of the binary log is to be able to update databases during a restore operation as fully as possible, because the binary log contains all updates done after a backup was made. The binary log is also used on master replication servers as a record of the statements to be sent to slave servers. See Chapter 6, Replication.
MySQL Enterprise The binary log can also be used to track significant DDL events. Analyzing the binary log in this way is an integral part of the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
Running the server with the binary log enabled makes performance about 1% slower. However, the benefits of the binary log for restore operations and in allowing you to set up replication generally outweigh this minor performance decrement.
When started with the
--log-bin[=
option, mysqld writes a log file containing
all SQL commands that update data. If no
base_name]base_name value is given, the default
name is the name of the host machine followed by
-bin. If the basename is given, but not as an
absolute pathname, the server writes the file in the data
directory. It is recommended that you specify a basename; see
Section B.1.8.1, “Open Issues in MySQL”, for the reason.
If you supply an extension in the log name (for example,
--log-bin=),
the extension is silently removed and ignored.
base_name.extension
mysqld appends a numeric extension to the
binary log basename. The number increases each time the server
creates a new log file, thus creating an ordered series of
files. The server creates a new binary log file each time it
starts or flushes the logs. The server also creates a new binary
log file automatically when the current log's size reaches
max_binlog_size. A binary log file may become
larger than max_binlog_size if you are using
large transactions because a transaction is written to the file
in one piece, never split between files.
To keep track of which binary log files have been used,
mysqld also creates a binary log index file
that contains the names of all used binary log files. By default
this has the same basename as the binary log file, with the
extension '.index'. You can change the name
of the binary log index file with the
--log-bin-index[=
option. You should not manually edit this file while
mysqld is running; doing so would confuse
mysqld.
file_name]
Replication slave servers by default do not write to their own
binary log any statements that are received from the replication
master. To cause these statements to be logged, start the slave
with the --log-slave-updates option.
Writes to the binary log file and binary log index file are
handled in the same way as writes to MyISAM
tables. See Section B.1.4.3, “How MySQL Handles a Full Disk”.
You can delete all binary log files with the RESET
MASTER statement, or a subset of them with
PURGE MASTER LOGS. See
Section 13.5.5.5, “RESET Syntax”, and
Section 13.6.1.1, “PURGE MASTER LOGS Syntax”.
The binary log format has some known limitations that can affect recovery from backups. See Section 6.7, “Replication Features and Known Problems”.
Binary logging for stored routines and triggers is done as described in Section 17.4, “Binary Logging of Stored Routines and Triggers”.
You can use the following options to mysqld to affect what is logged to the binary log. See also the discussion that follows this option list.
If you are using replication, the options described here affect which statements are sent by a master server to its slaves. There are also options for slave servers that control which statements received from the master to execute or ignore. For details, see Section 6.8, “Replication Startup Options”.
Tell the server to restrict binary logging to updates for which the default database is
db_name(that is, the database selected byUSE). All other databases that are not explicitly mentioned are ignored. If you use this option, you should ensure that you do updates only in the default database.There is an exception to this for
CREATE DATABASE,ALTER DATABASE, andDROP DATABASEstatements. The server uses the database named in the statement (not the default database) to decide whether it should log the statement.An example of what does not work as you might expect: If the server is started with
binlog-do-db=sales, and you runUSE prices; UPDATE sales.january SET amount=amount+1000;, this statement is not written into the binary log.To log multiple databases, use multiple options, specifying the option once for each database.
Tell the server to suppress binary logging of updates for which the default database is
db_name(that is, the database selected byUSE). If you use this option, you should ensure that you do updates only in the default database.As with the
--binlog-do-dboption, there is an exception for theCREATE DATABASE,ALTER DATABASE, andDROP DATABASEstatements. The server uses the database named in the statement (not the default database) to decide whether it should log the statement.An example of what does not work as you might expect: If the server is started with
binlog-ignore-db=sales, and you runUSE prices; UPDATE sales.january SET amount=amount+1000;, this statement is written into the binary log.To ignore multiple databases, use multiple options, specifying the option once for each database.
The server evaluates the options for logging or ignoring updates
to the binary log according to the following rules. As described
previously, there is an exception for the CREATE
DATABASE, ALTER DATABASE, and
DROP DATABASE statements. In those cases, the
database being created, altered, or dropped
replaces the default database in the following rules:
Are there
--binlog-do-dbor--binlog-ignore-dbrules?No: Write the statement to the binary log and exit.
Yes: Go to the next step.
There are some rules (
--binlog-do-db,--binlog-ignore-db, or both). Is there a default database (has any database been selected byUSE?)?No: Do not write the statement, and exit.
Yes: Go to the next step.
There is a default database. Are there some
--binlog-do-dbrules?Yes: Does the default database match any of the
--binlog-do-dbrules?Yes: Write the statement and exit.
No: Do not write the statement, and exit.
No: Go to the next step.
There are some
--binlog-ignore-dbrules. Does the default database match any of the--binlog-ignore-dbrules?Yes: Do not write the statement, and exit.
No: Write the query and exit.
For example, a slave running with only
--binlog-do-db=sales does not write to the
binary log any statement for which the default database is
different from sales (in other words,
--binlog-do-db can sometimes mean “ignore
other databases”).
If you are using replication, you should not delete old binary
log files until you are sure that no slave still needs to use
them. For example, if your slaves never run more than three days
behind, once a day you can execute mysqladmin
flush-logs on the master and then remove any logs that
are more than three days old. You can remove the files manually,
but it is preferable to use PURGE MASTER
LOGS, which also safely updates the binary log index
file for you (and which can take a date argument). See
Section 13.6.1.1, “PURGE MASTER LOGS Syntax”.
A client that has the SUPER privilege can
disable binary logging of its own statements by using a
SET SQL_LOG_BIN=0 statement. See
Section 13.5.3, “SET Syntax”.
You can display the contents of binary log files with the mysqlbinlog utility. This can be useful when you want to reprocess statements in the log. For example, you can update a MySQL server from the binary log as follows:
shell> mysqlbinlog log_file | mysql -h server_name
See Section 8.11, “mysqlbinlog — Utility for Processing Binary Log Files”, for more information on the mysqlbinlog utility and how to use it. mysqlbinlog also can be used with relay log files because they are written using the same format as binary log files.
Binary logging is done immediately after a statement completes but before any locks are released or any commit is done. This ensures that the log is logged in execution order.
Updates to non-transactional tables are stored in the binary log
immediately after execution. Within an uncommitted transaction,
all updates (UPDATE,
DELETE, or INSERT) that
change transactional tables such as BDB or
InnoDB tables are cached until a
COMMIT statement is received by the server.
At that point, mysqld writes the entire
transaction to the binary log before the
COMMIT is executed. When the thread that
handles the transaction starts, it allocates a buffer of
binlog_cache_size to buffer statements. If a
statement is bigger than this, the thread opens a temporary file
to store the transaction. The temporary file is deleted when the
thread ends.
Modifications to non-transactional tables cannot be rolled back.
If a transaction that is rolled back includes modifications to
non-transactional tables, the entire transaction is logged with
a ROLLBACK statement at the end to ensure
that the modifications to those tables are replicated.
The Binlog_cache_use status variable shows
the number of transactions that used this buffer (and possibly a
temporary file) for storing statements. The
Binlog_cache_disk_use status variable shows
how many of those transactions actually had to use a temporary
file. These two variables can be used for tuning
binlog_cache_size to a large enough value
that avoids the use of temporary files.
The max_binlog_cache_size system variable
(default 4GB, which is also the maximum) can be used to restrict
the total size used to cache a multiple-statement transaction.
If a transaction is larger than this many bytes, it fails and
rolls back. The minimum value is 4096.
If you are using the binary log, concurrent inserts are
converted to normal inserts for CREATE ...
SELECT or INSERT ... SELECT
statement. This is done to ensure that you can re-create an
exact copy of your tables by applying the log during a backup
operation.
Note that the binary log format is different in MySQL 5.0 from previous versions of MySQL, due to enhancements in replication. See Section 6.5, “Replication Compatibility Between MySQL Versions”.
By default, the binary log is not synchronized to disk at each
write. So if the operating system or machine (not only the MySQL
server) crashes, there is a chance that the last statements of
the binary log are lost. To prevent this, you can make the
binary log be synchronized to disk after every
N writes to the binary log, with the
sync_binlog system variable. See
Section 5.2.3, “System Variables”. 1 is the safest value
for sync_binlog, but also the slowest. Even
with sync_binlog set to 1, there is still the
chance of an inconsistency between the table content and binary
log content in case of a crash. For example, if you are using
InnoDB tables and the MySQL server processes
a COMMIT statement, it writes the whole
transaction to the binary log and then commits this transaction
into InnoDB. If the server crashes between
those two operations, the transaction is rolled back by
InnoDB at restart but still exists in the
binary log. This problem can be solved with the
--innodb-safe-binlog option, which adds
consistency between the content of InnoDB
tables and the binary log. (Note:
--innodb-safe-binlog is unneeded as of MySQL
5.0; it was made obsolete by the introduction of XA transaction
support.)
For this option to provide a greater degree of safety, the MySQL
server should also be configured to synchronize the binary log
and the InnoDB logs to disk at every
transaction. The InnoDB logs are synchronized
by default, and sync_binlog=1 can be used to
synchronize the binary log. The effect of this option is that at
restart after a crash, after doing a rollback of transactions,
the MySQL server cuts rolled back InnoDB
transactions from the binary log. This ensures that the binary
log reflects the exact data of InnoDB tables,
and so, that the slave remains in synchrony with the master (not
receiving a statement which has been rolled back).
Note that --innodb-safe-binlog can be used even
if the MySQL server updates other storage engines than
InnoDB. Only statements and transactions that
affect InnoDB tables are subject to removal
from the binary log at InnoDB's crash
recovery. If the MySQL server discovers at crash recovery that
the binary log is shorter than it should have been, it lacks at
least one successfully committed InnoDB
transaction. This should not happen if
sync_binlog=1 and the disk/filesystem do an
actual sync when they are requested to (some don't), so the
server prints an error message The binary log
<name> is shorter than its expected size. In
this case, this binary log is not correct and replication should
be restarted from a fresh snapshot of the master's data.
The slow query log consists of all SQL statements that took more
than long_query_time seconds to execute. The
time to acquire the initial table locks is not counted as
execution time. mysqld writes a statement to
the slow query log after it has been executed and after all
locks have been released, so log order might be different from
execution order. The minimum and default values of
long_query_time are 1 and 10, respectively.
To enable the slow query log, start mysqld
with the
--log-slow-queries[=
option.
file_name]
If no file_name value is given for
--log-slow-queries, the default name is
host_name-slow.log
The slow query log can be used to find queries that take a long time to execute and are therefore candidates for optimization. However, examining a long slow query log can become a difficult task. To make this easier, you can process the slow query log using the mysqldumpslow command to summarize the queries that appear in the log. Use mysqldumpslow --help to see the options that this command supports.
In MySQL 5.0, queries that do not use indexes are
logged in the slow query log if the
--log-queries-not-using-indexes option is
specified. See Section 5.2.2, “Command Options”.
MySQL Enterprise Excessive table scans are indicative of missing or poorly optimized indexes. Using an advisor specifically designed for the task, the MySQL Network Monitoring and Advisory Service can identify such problems and offer advice on resolution. For more information see http://www.mysql.com/products/enterprise/advisors.html.
In MySQL 5.0, the
--log-slow-admin-statements server option
enables you to request logging of slow administrative statements
such as OPTIMIZE TABLE, ANALYZE
TABLE, and ALTER TABLE to the slow
query log.
Queries handled by the query cache are not added to the slow query log, nor are queries that would not benefit from the presence of an index because the table has zero rows or one row.
MySQL Server can create a number of different log files that make it easy to see what is going on. See Section 5.11, “MySQL Server Logs”. However, you must clean up these files regularly to ensure that the logs do not take up too much disk space.
When using MySQL with logging enabled, you may want to back up and remove old log files from time to time and tell MySQL to start logging to new files. See Section 5.9.1, “Database Backups”.
On a Linux (Red Hat) installation, you can use the
mysql-log-rotate script for this. If you
installed MySQL from an RPM distribution, this script should
have been installed automatically. You should be careful with
this script if you are using the binary log for replication. You
should not remove binary logs until you are certain that their
contents have been processed by all slaves.
On other systems, you must install a short script yourself that you start from cron (or its equivalent) for handling log files.
For the binary log, you can set the
expire_logs_days system variable to expire
binary log files automatically after a given number of days (see
Section 5.2.3, “System Variables”). If you are using
replication, you should set the variable no lower than the
maximum number of days your slaves might lag behind the master.
You can force MySQL to start using new log files by issuing a
FLUSH LOGS statement or executing
mysqladmin flush-logs or mysqladmin
refresh. See Section 13.5.5.2, “FLUSH Syntax”, and
Section 8.10, “mysqladmin — Client for Administering a MySQL Server”.
A log flushing operation does the following:
If general query logging (
--log) or slow query logging (--log-slow-queries) to a log file is enabled, the server closes and reopens the general query log file or slow query log file.If binary logging (
--log-bin) is used, the server closes the current log file and opens a new log file with the next sequence number.If the server was given an error log filename with the
--log-erroroption, it renames the error log with the suffix-oldand creates a new empty error log file.
The server creates a new binary log file when you flush the
logs. However, it just closes and reopens the general and slow
query log files. To cause new files to be created on Unix,
rename the current logs before flushing them. At flush time, the
server will open new logs with the original names. For example,
if the general and slow query logs are named
mysql.log and
mysql-slow.log, you can use a series of
commands like this:
shell>cdshell>mysql-data-directorymv mysql.log mysql.oldshell>mv mysql-slow.log mysql-slow.oldshell>mysqladmin flush-logs
At this point, you can make a backup of
mysql.old and
mysql-slow.log and then remove them from
disk.
On Windows, you cannot rename log files while the server has them open. You must stop the server and rename them, and then restart the server to create new logs.
The session sql_log_off variable can be set
to ON or OFF to disable or
enable general query logging for the current connection.
In some cases, you might want to run multiple mysqld servers on the same machine. You might want to test a new MySQL release while leaving your existing production setup undisturbed. Or you might want to give different users access to different mysqld servers that they manage themselves. (For example, you might be an Internet Service Provider that wants to provide independent MySQL installations for different customers.)
To run multiple servers on a single machine, each server must have unique values for several operating parameters. These can be set on the command line or in option files. See Section 4.3, “Specifying Program Options”.
At least the following options must be different for each server:
--port=port_num--portcontrols the port number for TCP/IP connections.--socket=path--socketcontrols the Unix socket file path on Unix and the name of the named pipe on Windows. On Windows, it is necessary to specify distinct pipe names only for those servers that support named-pipe connections.--shared-memory-base-name=nameThis option currently is used only on Windows. It designates the shared-memory name used by a Windows server to allow clients to connect via shared memory. It is necessary to specify distinct shared-memory names only for those servers that support shared-memory connections.
--pid-file=file_nameThis option is used only on Unix. It indicates the pathname of the file in which the server writes its process ID.
If you use the following log file options, they must be different for each server:
--log=file_name--log-bin=file_name--log-update=file_name--log-error=file_name--bdb-logdir=file_name
Section 5.11.5, “Server Log Maintenance”, discusses the log file options further.
For better performance, you can specify the following options differently for each server, to spread the load between several physical disks:
--tmpdir=path--bdb-tmpdir=path
Having different temporary directories is also recommended to make it easier to determine which MySQL server created any given temporary file.
With very limited exceptions, each server should use a different
data directory, which is specified using the
--datadir= option.
path
Warning: Normally, you should
never have two servers that update data in the same databases.
This may lead to unpleasant surprises if your operating system
does not support fault-free system locking. If (despite this
warning) you run multiple servers using the same data directory
and they have logging enabled, you must use the appropriate
options to specify log filenames that are unique to each server.
Otherwise, the servers try to log to the same files. Please note
that this kind of setup only works with MyISAM
and MERGE tables, and not with any of the other
storage engines.
The warning against sharing a data directory among servers also applies in an NFS environment. Allowing multiple MySQL servers to access a common data directory over NFS is a very bad idea.
The primary problem is that NFS is the speed bottleneck. It is not meant for such use.
Another risk with NFS is that you must devise a way to ensure that two or more servers do not interfere with each other. Usually NFS file locking is handled by the
lockddaemon, but at the moment there is no platform that performs locking 100% reliably in every situation.
Make it easy for yourself: Forget about sharing a data directory among servers over NFS. A better solution is to have one computer that contains several CPUs and use an operating system that handles threads efficiently.
If you have multiple MySQL installations in different locations,
you can specify the base installation directory for each server
with the
--basedir= option
to cause each server to use a different data directory, log files,
and PID file. (The defaults for all these values are determined
relative to the base directory). In that case, the only other
options you need to specify are the path--socket and
--port options. For example, suppose that you
install different versions of MySQL using tar
file binary distributions. These install in different locations,
so you can start the server for each installation using the
command bin/mysqld_safe under its corresponding
base directory. mysqld_safe determines the
proper --basedir option to pass to
mysqld, and you need specify only the
--socket and --port options to
mysqld_safe.
As discussed in the following sections, it is possible to start
additional servers by setting environment variables or by
specifying appropriate command-line options. However, if you need
to run multiple servers on a more permanent basis, it is more
convenient to use option files to specify for each server those
option values that must be unique to it. The
--defaults-file option is useful for this
purpose.
You can run multiple servers on Windows by starting them manually from the command line, each with appropriate operating parameters. You also have the option of installing several servers as Windows services and running them that way. General instructions for running MySQL servers from the command line or as services are given in Section 2.4.8, “Installing MySQL on Windows”. This section describes how to make sure that you start each server with different values for those startup options that must be unique per server, such as the data directory. These options are described in Section 5.12, “Running Multiple MySQL Servers on the Same Machine”.
To start multiple servers manually from the command line, you
can specify the appropriate options on the command line or in
an option file. It is more convenient to place the options in
an option file, but it is necessary to make sure that each
server gets its own set of options. To do this, create an
option file for each server and tell the server the filename
with a --defaults-file option when you run
it.
Suppose that you want to run mysqld on port
3307 with a data directory of C:\mydata1,
and mysqld-debug on port 3308 with a data
directory of C:\mydata2. (To do this,
make sure that before you start the servers, each data
directory exists and has its own copy of the
mysql database that contains the grant
tables.) Then create two option files. For example, create one
file named C:\my-opts1.cnf that looks
like this:
[mysqld] datadir = C:/mydata1 port = 3307
Create a second file named
C:\my-opts2.cnf that looks like this:
[mysqld] datadir = C:/mydata2 port = 3308
Then start each server with its own option file:
C:\>C:\mysql\bin\mysqld --defaults-file=C:\my-opts1.cnfC:\>C:\mysql\bin\mysqld-debug --defaults-file=C:\my-opts2.cnf
Each server starts in the foreground (no new prompt appears until the server exits later), so you will need to issue those two commands in separate console windows.
To shut down the servers, you must connect to each using the appropriate port number:
C:\>C:\mysql\bin\mysqladmin --port=3307 shutdownC:\>C:\mysql\bin\mysqladmin --port=3308 shutdown
Servers configured as just described allow clients to connect
over TCP/IP. If your version of Windows supports named pipes
and you also want to allow named-pipe connections, use the
mysqld-nt or
mysqld-debug server and specify options
that enable the named pipe and specify its name. Each server
that supports named-pipe connections must use a unique pipe
name. For example, the C:\my-opts1.cnf
file might be written like this:
[mysqld] datadir = C:/mydata1 port = 3307 enable-named-pipe socket = mypipe1
Then start the server this way:
C:\> C:\mysql\bin\mysqld-nt --defaults-file=C:\my-opts1.cnf
Modify C:\my-opts2.cnf similarly for use
by the second server.
A similar procedure applies for servers that you want to
support shared-memory connections. Enable such connections
with the --shared-memory option and specify a
unique shared-memory name for each server with the
--shared-memory-base-name option.
A MySQL server can run as a Windows service. The procedures for installing, controlling, and removing a single MySQL service are described in Section 2.4.8.11, “Starting MySQL as a Windows Service”.
You can also install multiple MySQL servers as services. In this case, you must make sure that each server uses a different service name in addition to all the other parameters that must be unique for each server.
For the following instructions, assume that you want to run
the mysqld-nt server from two different
versions of MySQL that are installed at
C:\mysql-4.1.8 and
C:\mysql-5.0.42, respectively.
(This might be the case if you're running 4.1.8 as your
production server, but also want to conduct tests using
5.0.42.)
The following principles apply when installing a MySQL service
with the --install or
--install-manual option:
If you specify no service name, the server uses the default service name of
MySQLand the server reads options from the[mysqld]group in the standard option files.If you specify a service name after the
--installoption, the server ignores the[mysqld]option group and instead reads options from the group that has the same name as the service. The server reads options from the standard option files.If you specify a
--defaults-fileoption after the service name, the server ignores the standard option files and reads options only from the[mysqld]group of the named file.
Note: Before MySQL 4.0.17,
only a server installed using the default service name
(MySQL) or one installed explicitly with a
service name of mysqld will read the
[mysqld] group in the standard option
files. As of 4.0.17, all servers read the
[mysqld] group if they read the standard
option files, even if they are installed using another service
name. This allows you to use the [mysqld]
group for options that should be used by all MySQL services,
and an option group named after each service for use by the
server installed with that service name.
Based on the preceding information, you have several ways to set up multiple services. The following instructions describe some examples. Before trying any of them, be sure that you shut down and remove any existing MySQL services first.
Approach 1: Specify the options for all services in one of the standard option files. To do this, use a different service name for each server. Suppose that you want to run the 4.1.8 mysqld-nt using the service name of
mysqld1and the 5.0.42 mysqld-nt using the service namemysqld2. In this case, you can use the[mysqld1]group for 4.1.8 and the[mysqld2]group for 5.0.42. For example, you can set upC:\my.cnflike this:# options for mysqld1 service [mysqld1] basedir = C:/mysql-4.1.8 port = 3307 enable-named-pipe socket = mypipe1 # options for mysqld2 service [mysqld2] basedir = C:/mysql-5.0.42 port = 3308 enable-named-pipe socket = mypipe2
Install the services as follows, using the full server pathnames to ensure that Windows registers the correct executable program for each service:
C:\>
C:\mysql-4.1.8\bin\mysqld-nt --install mysqld1C:\>C:\mysql-5.0.42\bin\mysqld-nt --install mysqld2To start the services, use the services manager, or use NET START with the appropriate service names:
C:\>
NET START mysqld1C:\>NET START mysqld2To stop the services, use the services manager, or use NET STOP with the appropriate service names:
C:\>
NET STOP mysqld1C:\>NET STOP mysqld2Approach 2: Specify options for each server in separate files and use
--defaults-filewhen you install the services to tell each server what file to use. In this case, each file should list options using a[mysqld]group.With this approach, to specify options for the 4.1.8 mysqld-nt, create a file
C:\my-opts1.cnfthat looks like this:[mysqld] basedir = C:/mysql-4.1.8 port = 3307 enable-named-pipe socket = mypipe1
For the 5.0.42 mysqld-nt, create a file
C:\my-opts2.cnfthat looks like this:[mysqld] basedir = C:/mysql-5.0.42 port = 3308 enable-named-pipe socket = mypipe2
Install the services as follows (enter each command on a single line):
C:\>
C:\mysql-4.1.8\bin\mysqld-nt --install mysqld1--defaults-file=C:\my-opts1.cnfC:\>C:\mysql-5.0.42\bin\mysqld-nt --install mysqld2--defaults-file=C:\my-opts2.cnfTo use a
--defaults-fileoption when you install a MySQL server as a service, you must precede the option with the service name.After installing the services, start and stop them the same way as in the preceding example.
To remove multiple services, use mysqld
--remove for each one, specifying a service name
following the --remove option. If the service
name is the default (MySQL), you can omit
it.
The easiest way is to run multiple servers on Unix is to compile them with different TCP/IP ports and Unix socket files so that each one is listening on different network interfaces. Compiling in different base directories for each installation also results automatically in a separate, compiled-in data directory, log file, and PID file location for each server.
Assume that an existing 4.1.8 server is configured for the
default TCP/IP port number (3306) and Unix socket file
(/tmp/mysql.sock). To configure a new
5.0.42 server to have different operating parameters,
use a configure command something like this:
shell>./configure --with-tcp-port=port_number\--with-unix-socket-path=file_name\--prefix=/usr/local/mysql-5.0.42
Here, port_number and
file_name must be different from the
default TCP/IP port number and Unix socket file pathname, and
the --prefix value should specify an
installation directory different from the one under which the
existing MySQL installation is located.
If you have a MySQL server listening on a given port number, you can use the following command to find out what operating parameters it is using for several important configurable variables, including the base directory and Unix socket filename:
shell> mysqladmin --host=host_name --port=port_number variables
With the information displayed by that command, you can tell what option values not to use when configuring an additional server.
Note that if you specify localhost as a
hostname, mysqladmin defaults to using a Unix
socket file connection rather than TCP/IP. From MySQL 4.1
onward, you can explicitly specify the connection protocol to
use by using the
--protocol={TCP|SOCKET|PIPE|MEMORY} option.
You don't have to compile a new MySQL server just to start with a different Unix socket file and TCP/IP port number. It is also possible to use the same server binary and start each invocation of it with different parameter values at runtime. One way to do so is by using command-line options:
shell> mysqld_safe --socket=file_name --port=port_number
To start a second server, provide different
--socket and --port option
values, and pass a
--datadir=
option to mysqld_safe so that the server uses
a different data directory.
path
Another way to achieve a similar effect is to use environment variables to set the Unix socket filename and TCP/IP port number:
shell>MYSQL_UNIX_PORT=/tmp/mysqld-new.sockshell>MYSQL_TCP_PORT=3307shell>export MYSQL_UNIX_PORT MYSQL_TCP_PORTshell>mysql_install_db --user=mysqlshell>mysqld_safe --datadir=/path/to/datadir &
This is a quick way of starting a second server to use for testing. The nice thing about this method is that the environment variable settings apply to any client programs that you invoke from the same shell. Thus, connections for those clients are automatically directed to the second server.
Section 2.4.19, “Environment Variables”, includes a list of other environment variables you can use to affect mysqld.
For automatic server execution, the startup script that is executed at boot time should execute the following command once for each server with an appropriate option file path for each command:
shell> mysqld_safe --defaults-file=file_name
Each option file should contain option values specific to a given server.
On Unix, the mysqld_multi script is another way to start multiple servers. See Section 5.3.3, “mysqld_multi — Manage Multiple MySQL Servers”.
To connect with a client program to a MySQL server that is listening to different network interfaces from those compiled into your client, you can use one of the following methods:
Start the client with
--host=to connect via TCP/IP to a remote server, withhost_name--port=port_number--host=127.0.0.1 --port=to connect via TCP/IP to a local server, or withport_number--host=localhost --socket=to connect to a local server via a Unix socket file or a Windows named pipe.file_nameAs of MySQL 4.1, start the client with
--protocol=tcpto connect via TCP/IP,--protocol=socketto connect via a Unix socket file,--protocol=pipeto connect via a named pipe, or--protocol=memoryto connect via shared memory. For TCP/IP connections, you may also need to specify--hostand--portoptions. For the other types of connections, you may need to specify a--socketoption to specify a Unix socket file or Windows named-pipe name, or a--shared-memory-base-nameoption to specify the shared-memory name. Shared-memory connections are supported only on Windows.On Unix, set the
MYSQL_UNIX_PORTandMYSQL_TCP_PORTenvironment variables to point to the Unix socket file and TCP/IP port number before you start your clients. If you normally use a specific socket file or port number, you can place commands to set these environment variables in your.loginfile so that they apply each time you log in. See Section 2.4.19, “Environment Variables”.Specify the default Unix socket file and TCP/IP port number in the
[client]group of an option file. For example, you can useC:\my.cnfon Windows, or the.my.cnffile in your home directory on Unix. See Section 4.3.2, “Using Option Files”.In a C program, you can specify the socket file or port number arguments in the
mysql_real_connect()call. You can also have the program read option files by callingmysql_options(). See Section 22.2.3, “C API Function Descriptions”.If you are using the Perl
DBD::mysqlmodule, you can read options from MySQL option files. For example:$dsn = "DBI:mysql:test;mysql_read_default_group=client;" . "mysql_read_default_file=/usr/local/mysql/data/my.cnf"; $dbh = DBI->connect($dsn, $user, $password);See Section 22.4, “MySQL Perl API”.
Other programming interfaces may provide similar capabilities for reading option files.
MySQL Enterprise Subscribers to MySQL Enterprise will find additional information on running multiple MySQL servers on one machine in the MySQL Enterprise Knowledge Base article found at https://kb.mysql.com/view.php?id=4926.
The query cache stores the text of a SELECT
statement together with the corresponding result that was sent to
the client. If an identical statement is received later, the
server retrieves the results from the query cache rather than
parsing and executing the statement again.
The query cache is extremely useful in an environment where you have tables that do not change very often and for which the server receives many identical queries. This is a typical situation for many Web servers that generate many dynamic pages based on database content.
Note: The query cache does not return stale data. When tables are modified, any relevant entries in the query cache are flushed.
Note: The query cache does not
work in an environment where you have multiple
mysqld servers updating the same
MyISAM tables.
Note: The query cache is not used for server-side prepared statements. If you're using server-side prepared statements consider that these statement won't be satisfied by the query cache. See Section 22.2.4, “C API Prepared Statements”.
Some performance data for the query cache follows. These results were generated by running the MySQL benchmark suite on a Linux Alpha 2×500MHz system with 2GB RAM and a 64MB query cache.
If all the queries you are performing are simple (such as selecting a row from a table with one row), but still differ so that the queries cannot be cached, the overhead for having the query cache active is 13%. This could be regarded as the worst case scenario. In real life, queries tend to be much more complicated, so the overhead normally is significantly lower.
Searches for a single row in a single-row table are 238% faster with the query cache than without it. This can be regarded as close to the minimum speedup to be expected for a query that is cached.
To disable the query cache at server startup, set the
query_cache_size system variable to 0. By
disabling the query cache code, there is no noticeable overhead.
If you build MySQL from source, query cache capabilities can be
excluded from the server entirely by invoking
configure with the
--without-query-cache option.
This section describes how the query cache works when it is operational. Section 5.13.3, “Query Cache Configuration”, describes how to control whether it is operational.
Incoming queries are compared to those in the query cache before parsing, so the following two queries are regarded as different by the query cache:
SELECT * FROMtbl_nameSelect * fromtbl_name
Queries must be exactly the same (byte for byte) to be seen as identical. In addition, query strings that are identical may be treated as different for other reasons. Queries that use different databases, different protocol versions, or different default character sets are considered different queries and are cached separately.
Because comparison of a query against those in the cache occurs before parsing, the cache is not used for queries of the following types:
Prepared statements
Queries that are a subquery of an outer query
Queries executed within the body of a stored procedure, stored function, or trigger
Before a query result is fetched from the query cache, MySQL
checks that the user has SELECT privilege for
all databases and tables involved. If this is not the case, the
cached result is not used.
If a query result is returned from query cache, the server
increments the Qcache_hits status variable,
not Com_select. See
Section 5.13.4, “Query Cache Status and Maintenance”.
If a table changes, all cached queries that use the table become
invalid and are removed from the cache. This includes queries
that use MERGE tables that map to the changed
table. A table can be changed by many types of statements, such
as INSERT, UPDATE,
DELETE, TRUNCATE,
ALTER TABLE, DROP TABLE,
or DROP DATABASE.
The query cache also works within transactions when using
InnoDB tables.
In MySQL 5.0, queries generated by views are cached.
Before MySQL 5.0, a query that began with a leading comment could be cached, but could not be fetched from the cache. This problem is fixed in MySQL 5.0.
The query cache works for SELECT SQL_CALC_FOUND_ROWS
... queries and stores a value that is returned by a
following SELECT FOUND_ROWS() query.
FOUND_ROWS() returns the correct value even
if the preceding query was fetched from the cache because the
number of found rows is also stored in the cache. The
SELECT FOUND_ROWS() query itself cannot be
cached.
A query cannot be cached if it contains any of the functions shown in the following table:
BENCHMARK() | CONNECTION_ID() | CURDATE() |
CURRENT_DATE() | CURRENT_TIME() | CURRENT_TIMESTAMP() |
CURTIME() | DATABASE() | ENCRYPT() with one parameter |
FOUND_ROWS() | GET_LOCK() | LAST_INSERT_ID() |
LOAD_FILE() | MASTER_POS_WAIT() | NOW() |
RAND() | RELEASE_LOCK() | SYSDATE() |
UNIX_TIMESTAMP() with no parameters | USER() |
A query also is not cached under these conditions:
It refers to user-defined functions (UDFs) or stored functions.
It refers to user variables.
It refers to tables in the
mysqlsystem database.It is of any of the following forms:
SELECT ... IN SHARE MODE SELECT ... FOR UPDATE SELECT ... INTO OUTFILE ... SELECT ... INTO DUMPFILE ... SELECT * FROM ... WHERE autoincrement_col IS NULL
The last form is not cached because it is used as the ODBC workaround for obtaining the last insert ID value. See the MyODBC section of Chapter 23, Connectors.
It was issued as a prepared statement, even if no placeholders were employed. For example, the query used here is not cached:
char *my_sql_stmt = "SELECT a, b FROM table_c"; /* ... */ mysql_stmt_prepare(stmt, my_sql_stmt, strlen(my_sql_stmt));
It uses
TEMPORARYtables.It does not use any tables.
The user has a column-level privilege for any of the involved tables.
Two query cache-related options may be specified in
SELECT statements:
Examples:
SELECT SQL_CACHE id, name FROM customer; SELECT SQL_NO_CACHE id, name FROM customer;
The have_query_cache server system variable
indicates whether the query cache is available:
mysql> SHOW VARIABLES LIKE 'have_query_cache';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| have_query_cache | YES |
+------------------+-------+
When using a standard MySQL binary, this value is always
YES, even if query caching is disabled.
Several other system variables control query cache operation.
These can be set in an option file or on the command line when
starting mysqld. The query cache system
variables all have names that begin with
query_cache_. They are described briefly in
Section 5.2.3, “System Variables”, with additional
configuration information given here.
To set the size of the query cache, set the
query_cache_size system variable. Setting it
to 0 disables the query cache. The default size is 0, so the
query cache is disabled by default.
MySQL Enterprise For expert advice on configuring the query cache subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
Note
When using the Windows Configuration Wizard to install or
configure MySQL, the default value for
query_cache_size will be configured
automatically for you based on the different configuration
types available. When using the Windows Configuration Wizard,
the query cache may be enabled (i.e. set to a non-zero value)
due to the selected configuration. The query cache is also
controlled by the setting of the
query_cache_type variable. You should check
the values of these variables as set in your
my.ini file after configuration has taken
place.
When you set query_cache_size to a non-zero
value, keep in mind that the query cache needs a minimum size of
about 40KB to allocate its structures. (The exact size depends
on system architecture.) If you set the value too small, you'll
get a warning, as in this example:
mysql>SET GLOBAL query_cache_size = 40000;Query OK, 0 rows affected, 1 warning (0.00 sec) mysql>SHOW WARNINGS\G*************************** 1. row *************************** Level: Warning Code: 1282 Message: Query cache failed to set size 39936; new query cache size is 0 mysql>SET GLOBAL query_cache_size = 41984;Query OK, 0 rows affected (0.00 sec) mysql>SHOW VARIABLES LIKE 'query_cache_size';+------------------+-------+ | Variable_name | Value | +------------------+-------+ | query_cache_size | 41984 | +------------------+-------+
For the query cache to actually be able to hold any query results, its size must be set larger:
mysql>SET GLOBAL query_cache_size = 1000000;Query OK, 0 rows affected (0.04 sec) mysql>SHOW VARIABLES LIKE 'query_cache_size';+------------------+--------+ | Variable_name | Value | +------------------+--------+ | query_cache_size | 999424 | +------------------+--------+ 1 row in set (0.00 sec)
The query_cache_size will be aligned to the
nearest 1024 byte block. The value reported may therefore be
different from the value that you set.
If the query cache size is greater than 0, the
query_cache_type variable influences how it
works. This variable can be set to the following values:
A value of
0orOFFprevents caching or retrieval of cached results.A value of
1orONallows caching except of those statements that begin withSELECT SQL_NO_CACHE.A value of
2orDEMANDcauses caching of only those statements that begin withSELECT SQL_CACHE.
Setting the GLOBAL
query_cache_type value determines query cache
behavior for all clients that connect after the change is made.
Individual clients can control cache behavior for their own
connection by setting the SESSION
query_cache_type value. For example, a client
can disable use of the query cache for its own queries like
this:
mysql> SET SESSION query_cache_type = OFF;
To control the maximum size of individual query results that can
be cached, set the query_cache_limit system
variable. The default value is 1MB.
When a query is to be cached, its result (the data sent to the
client) is stored in the query cache during result retrieval.
Therefore the data usually is not handled in one big chunk. The
query cache allocates blocks for storing this data on demand, so
when one block is filled, a new block is allocated. Because
memory allocation operation is costly (timewise), the query
cache allocates blocks with a minimum size given by the
query_cache_min_res_unit system variable.
When a query is executed, the last result block is trimmed to
the actual data size so that unused memory is freed. Depending
on the types of queries your server executes, you might find it
helpful to tune the value of
query_cache_min_res_unit:
The default value of
query_cache_min_res_unitis 4KB. This should be adequate for most cases.If you have a lot of queries with small results, the default block size may lead to memory fragmentation, as indicated by a large number of free blocks. Fragmentation can force the query cache to prune (delete) queries from the cache due to lack of memory. In this case, you should decrease the value of
query_cache_min_res_unit. The number of free blocks and queries removed due to pruning are given by the values of theQcache_free_blocksandQcache_lowmem_prunesstatus variables.If most of your queries have large results (check the
Qcache_total_blocksandQcache_queries_in_cachestatus variables), you can increase performance by increasingquery_cache_min_res_unit. However, be careful to not make it too large (see the previous item).
MySQL Enterprise If the query cache is under-utilized, performance will suffer. Advice on avoiding this problem is provided to subscribers to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
You can check whether the query cache is present in your MySQL server using the following statement:
mysql> SHOW VARIABLES LIKE 'have_query_cache';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| have_query_cache | YES |
+------------------+-------+
You can defragment the query cache to better utilize its memory
with the FLUSH QUERY CACHE statement. The
statement does not remove any queries from the cache.
The RESET QUERY CACHE statement removes all
query results from the query cache. The FLUSH
TABLES statement also does this.
To monitor query cache performance, use SHOW
STATUS to view the cache status variables:
mysql> SHOW STATUS LIKE 'Qcache%';
+-------------------------+--------+
| Variable_name | Value |
+-------------------------+--------+
| Qcache_free_blocks | 36 |
| Qcache_free_memory | 138488 |
| Qcache_hits | 79570 |
| Qcache_inserts | 27087 |
| Qcache_lowmem_prunes | 3114 |
| Qcache_not_cached | 22989 |
| Qcache_queries_in_cache | 415 |
| Qcache_total_blocks | 912 |
+-------------------------+--------+
Descriptions of each of these variables are given in Section 5.2.5, “Status Variables”. Some uses for them are described here.
The total number of SELECT queries is given
by this formula:
Com_select + Qcache_hits + queries with errors found by parser
The Com_select value is given by this
formula:
Qcache_inserts + Qcache_not_cached + queries with errors found during the column-privileges check
The query cache uses variable-length blocks, so
Qcache_total_blocks and
Qcache_free_blocks may indicate query cache
memory fragmentation. After FLUSH QUERY
CACHE, only a single free block remains.
Every cached query requires a minimum of two blocks (one for the query text and one or more for the query results). Also, every table that is used by a query requires one block. However, if two or more queries use the same table, only one table block needs to be allocated.
The information provided by the
Qcache_lowmem_prunes status variable can help
you tune the query cache size. It counts the number of queries
that have been removed from the cache to free up memory for
caching new queries. The query cache uses a least recently used
(LRU) strategy to decide which queries to remove from the cache.
Tuning information is given in
Section 5.13.3, “Query Cache Configuration”.
Table of Contents
- 6.1. Introduction to Replication
- 6.2. Replication Implementation Overview
- 6.3. Replication Implementation Details
- 6.4. How to Set Up Replication
- 6.5. Replication Compatibility Between MySQL Versions
- 6.6. Upgrading a Replication Setup
- 6.7. Replication Features and Known Problems
- 6.8. Replication Startup Options
- 6.9. How Servers Evaluate Replication Rules
- 6.10. Replication FAQ
- 6.11. Troubleshooting Replication
- 6.12. How to Report Replication Bugs or Problems
- 6.13. Auto-Increment in Multiple-Master Replication
This chapter describes the various replication features provided by MySQL. It introduces replication concepts, shows how to set up replication servers, and serves as a reference to the available replication options. It also provides a list of frequently asked questions (with answers), and troubleshooting advice for solving replication problems.
MySQL Enterprise The MySQL Network Monitoring and Advisory Service provides numerous advisors that give immediate feedback about replication-related problems. For more information see http://www.mysql.com/products/enterprise/advisors.html.
For a description of the syntax of replication-related SQL statements, see Section 13.6, “Replication Statements”.
MySQL features support for one-way, asynchronous replication, in which one server acts as the master, while one or more other servers act as slaves. This is in contrast to the synchronous replication which is a characteristic of MySQL Cluster (see Chapter 15, MySQL Cluster).
In single-master replication, the master server writes updates to its binary log files and maintains an index of those files to keep track of log rotation. The binary log files serve as a record of updates to be sent to any slave servers. When a slave connects to its master, it informs the master of the position up to which the slave read the logs at its last successful update. The slave receives any updates that have taken place since that time, and then blocks and waits for the master to notify it of new updates.
A slave server can itself serve as a master if you want to set up chained replication servers.
Multiple-master replication is possible, but raises issues not present in single-master replication. See Section 6.13, “Auto-Increment in Multiple-Master Replication”.
When you are using replication, all updates to the tables that are replicated should be performed on the master server. Otherwise, you must always be careful to avoid conflicts between updates that users make to tables on the master and updates that they make to tables on the slave.
Replication offers benefits for robustness, speed, and system administration:
Robustness is increased with a master/slave setup. In the event of problems with the master, you can switch to the slave as a backup.
Better response time for clients can be achieved by splitting the load for processing client queries between the master and slave servers.
SELECTqueries may be sent to the slave to reduce the query processing load of the master. Statements that modify data should still be sent to the master so that the master and slave do not get out of synchrony. This load-balancing strategy is effective if non-updating queries dominate, but that is the normal case.Another benefit of using replication is that you can perform database backups using a slave server without disturbing the master. The master continues to process updates while the backup is being made. See Section 5.9.1, “Database Backups”.
MySQL replication is based on the master server keeping track of all changes to your databases (updates, deletes, and so on) in its binary logs. Therefore, to use replication, you must enable binary logging on the master server. See Section 5.11.3, “The Binary Log”.
Each slave server receives from the master the saved updates that the master has recorded in its binary log, so that the slave can execute the same updates on its copy of the data.
It is extremely important to realize that the binary log is simply a record starting from the fixed point in time at which you enable binary logging. Any slaves that you set up need copies of the databases on your master as they existed at the moment you enabled binary logging on the master. If you start your slaves with databases that are not in the same state as those on the master when the binary log was started, your slaves are quite likely to fail.
After the slave has been set up with a copy of the master's data,
it connects to the master and waits for updates to process. If the
master fails, or the slave loses connectivity with your master,
the slave keeps trying to connect periodically until it is able to
resume listening for updates. The
--master-connect-retry option controls the retry
interval. The default is 60 seconds.
Each slave keeps track of where it left off when it last read from its master server. The master has no knowledge of how many slaves it has or which ones are up to date at any given time.
MySQL replication capabilities are implemented using three threads
(one on the master server and two on the slave). When a
START SLAVE statement is issued on a slave
server, the slave creates an I/O thread, which connects to the
master and asks it to send the updates recorded in its binary
logs. The master creates a thread to send the binary log contents
to the slave. This thread can be identified as the Binlog
Dump thread in the output of SHOW
PROCESSLIST on the master. The slave I/O thread reads
the updates that the master Binlog Dump thread
sends and copies them to local files, known as relay
logs, in the slave's data directory. The third thread
is the SQL thread, which the slave creates to read the relay logs
and to execute the updates they contain.
MySQL Enterprise For constant monitoring of the status of slaves subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
In the preceding description, there are three threads per master/slave connection. A master that has multiple slaves creates one thread for each currently-connected slave, and each slave has its own I/O and SQL threads.
The slave uses two threads so that reading updates from the master and executing them can be separated into two independent tasks. Thus, the task of reading statements is not slowed down if statement execution is slow. For example, if the slave server has not been running for a while, its I/O thread can quickly fetch all the binary log contents from the master when the slave starts, even if the SQL thread lags far behind. If the slave stops before the SQL thread has executed all the fetched statements, the I/O thread has at least fetched everything so that a safe copy of the statements is stored locally in the slave's relay logs, ready for execution the next time that the slave starts. This enables the master server to purge its binary logs sooner because it no longer needs to wait for the slave to fetch their contents.
The SHOW PROCESSLIST statement provides
information that tells you what is happening on the master and on
the slave regarding replication. The following example illustrates
how the three threads show up in the output from SHOW
PROCESSLIST.
On the master server, the output from SHOW
PROCESSLIST looks like this:
mysql> SHOW PROCESSLIST\G
*************************** 1. row ***************************
Id: 2
User: root
Host: localhost:32931
db: NULL
Command: Binlog Dump
Time: 94
State: Has sent all binlog to slave; waiting for binlog to
be updated
Info: NULL
Here, thread 2 is a Binlog Dump replication
thread for a connected slave. The State
information indicates that all outstanding updates have been sent
to the slave and that the master is waiting for more updates to
occur. If you see no Binlog Dump threads on a
master server, this means that replication is not running —
that is, that no slaves are currently connected.
On the slave server, the output from SHOW
PROCESSLIST looks like this:
mysql> SHOW PROCESSLIST\G
*************************** 1. row ***************************
Id: 10
User: system user
Host:
db: NULL
Command: Connect
Time: 11
State: Waiting for master to send event
Info: NULL
*************************** 2. row ***************************
Id: 11
User: system user
Host:
db: NULL
Command: Connect
Time: 11
State: Has read all relay log; waiting for the slave I/O
thread to update it
Info: NULL
This information indicates that thread 10 is the I/O thread that
is communicating with the master server, and thread 11 is the SQL
thread that is processing the updates stored in the relay logs. At
the time that the SHOW PROCESSLIST was run,
both threads were idle, waiting for further updates.
The value in the Time column can show how late
the slave is compared to the master. See
Section 6.10, “Replication FAQ”.
The following list shows the most common states you may see in
the State column for the master's
Binlog Dump thread. If you see no
Binlog Dump threads on a master server, this
means that replication is not running — that is, that no
slaves are currently connected.
Sending binlog event to slaveBinary logs consist of events, where an event is usually an update plus some other information. The thread has read an event from the binary log and is now sending it to the slave.
Finished reading one binlog; switching to next binlogThe thread has finished reading a binary log file and is opening the next one to send to the slave.
Has sent all binlog to slave; waiting for binlog to be updatedThe thread has read all outstanding updates from the binary logs and sent them to the slave. The thread is now idle, waiting for new events to appear in the binary log resulting from new updates occurring on the master.
Waiting to finalize terminationA very brief state that occurs as the thread is stopping.
The following list shows the most common states you see in the
State column for a slave server I/O thread.
This state also appears in the Slave_IO_State
column displayed by SHOW SLAVE STATUS, so you
can get a good view of what is happening by using that
statement.
Connecting to masterThe thread is attempting to connect to the master.
Checking master versionA state that occurs very briefly, after the connection to the master is established.
Registering slave on masterA state that occurs very briefly after the connection to the master is established.
Requesting binlog dumpA state that occurs very briefly, after the connection to the master is established. The thread sends to the master a request for the contents of its binary logs, starting from the requested binary log filename and position.
Waiting to reconnect after a failed binlog dump requestIf the binary log dump request failed (due to disconnection), the thread goes into this state while it sleeps, then tries to reconnect periodically. The interval between retries can be specified using the
--master-connect-retryoption.Reconnecting after a failed binlog dump requestThe thread is trying to reconnect to the master.
Waiting for master to send eventThe thread has connected to the master and is waiting for binary log events to arrive. This can last for a long time if the master is idle. If the wait lasts for
slave_net_timeoutseconds, a timeout occurs. At that point, the thread considers the connection to be broken and makes an attempt to reconnect.Queueing master event to the relay logThe thread has read an event and is copying it to the relay log so that the SQL thread can process it.
Waiting to reconnect after a failed master event readAn error occurred while reading (due to disconnection). The thread is sleeping for
master-connect-retryseconds before attempting to reconnect.Reconnecting after a failed master event readThe thread is trying to reconnect to the master. When connection is established again, the state becomes
Waiting for master to send event.Waiting for the slave SQL thread to free enough relay log spaceYou are using a non-zero
relay_log_space_limitvalue, and the relay logs have grown large enough that their combined size exceeds this value. The I/O thread is waiting until the SQL thread frees enough space by processing relay log contents so that it can delete some relay log files.Waiting for slave mutex on exitA state that occurs briefly as the thread is stopping.
The following list shows the most common states you may see in
the State column for a slave server SQL
thread:
Reading event from the relay logThe thread has read an event from the relay log so that the event can be processed.
Has read all relay log; waiting for the slave I/O thread to update itThe thread has processed all events in the relay log files, and is now waiting for the I/O thread to write new events to the relay log.
Waiting for slave mutex on exitA very brief state that occurs as the thread is stopping.
The State column for the I/O thread may also
show the text of a statement. This indicates that the thread has
read an event from the relay log, extracted the statement from
it, and is executing it.
By default, relay logs filenames have the form
host_name-relay-bin.nnnnnnhost_name is the name of the
slave server host and nnnnnn is a
sequence number. Successive relay log files are created using
successive sequence numbers, beginning with
000001. The slave uses an index file to track
the relay log files currently in use. The default relay log
index filename is
host_name-relay-bin.index--relay-log and
--relay-log-index server options. See
Section 6.8, “Replication Startup Options”.
Relay logs have the same format as binary logs and can be read
using mysqlbinlog. The SQL thread
automatically deletes each relay log file as soon as it has
executed all events in the file and no longer needs it. There is
no explicit mechanism for deleting relay logs because the SQL
thread takes care of doing so. However, FLUSH
LOGS rotates relay logs, which influences when the SQL
thread deletes them.
A slave server creates a new relay log file under the following conditions:
Each time the I/O thread starts.
When the logs are flushed; for example, with
FLUSH LOGSor mysqladmin flush-logs.When the size of the current relay log file becomes too large. The meaning of “too large” is determined as follows:
If the value of
max_relay_log_sizeis greater than 0, that is the maximum relay log file size.If the value of
max_relay_log_sizeis 0,max_binlog_sizedetermines the maximum relay log file size.
A slave replication server creates two additional small files in
the data directory. These status files are
named master.info and
relay-log.info by default. Their names can
be changed by using the --master-info-file and
--relay-log-info-file options. See
Section 6.8, “Replication Startup Options”.
The two status files contain information like that shown in the
output of the SHOW SLAVE STATUS statement,
which is discussed in Section 13.6.2, “SQL Statements for Controlling Slave Servers”.
Because the status files are stored on disk, they survive a
slave server's shutdown. The next time the slave starts up, it
reads the two files to determine how far it has proceeded in
reading binary logs from the master and in processing its own
relay logs.
The I/O thread updates the master.info
file. The following table shows the correspondence between the
lines in the file and the columns displayed by SHOW
SLAVE STATUS.
| Line | Description |
| 1 | Number of lines in the file |
| 2 | Master_Log_File |
| 3 | Read_Master_Log_Pos |
| 4 | Master_Host |
| 5 | Master_User |
| 6 | Password (not shown by SHOW SLAVE STATUS) |
| 7 | Master_Port |
| 8 | Connect_Retry |
| 9 | Master_SSL_Allowed |
| 10 | Master_SSL_CA_File |
| 11 | Master_SSL_CA_Path |
| 12 | Master_SSL_Cert |
| 13 | Master_SSL_Cipher |
| 14 | Master_SSL_Key |
The SQL thread updates the relay-log.info
file. The following table shows the correspondence between the
lines in the file and the columns displayed by SHOW
SLAVE STATUS.
| Line | Description |
| 1 | Relay_Log_File |
| 2 | Relay_Log_Pos |
| 3 | Relay_Master_Log_File |
| 4 | Exec_Master_Log_Pos |
The contents of the relay-log.info file and
the states shown by the SHOW SLAVE STATES
command may not match if the relay-log.info
file has not been flushed to disk. Ideally, you should only view
relay-log.info on a slave that is offline
(i.e. mysqld is not running). For a running
system, SHOW SLAVE STATUS should be used.
When you back up the slave's data, you should back up these two
status files as well, along with the relay log files. They are
needed to resume replication after you restore the slave's data.
If you lose the relay logs but still have the
relay-log.info file, you can check it to
determine how far the SQL thread has executed in the master
binary logs. Then you can use CHANGE MASTER
TO with the MASTER_LOG_FILE and
MASTER_LOG_POS options to tell the slave to
re-read the binary logs from that point. Of course, this
requires that the binary logs still exist on the master server.
If your slave is subject to replicating LOAD DATA
INFILE statements, you should also back up any
SQL_LOAD-* files that exist in the
directory that the slave uses for this purpose. The slave needs
these files to resume replication of any interrupted
LOAD DATA INFILE operations. The directory
location is specified using the
--slave-load-tmpdir option. If this option is
not specified, the directory location is the value of the
tmpdir system variable.
This section briefly describes how to set up complete replication of a MySQL server. It assumes that you want to replicate all databases on the master and have not previously configured replication. You must shut down your master server briefly to complete the steps outlined here.
This procedure is written in terms of setting up a single slave, but you can repeat it to set up multiple slaves.
Although this method is the most straightforward way to set up a slave, it is not the only one. For example, if you have a snapshot of the master's data, and the master already has its server ID set and binary logging enabled, you can set up a slave without shutting down the master or even blocking updates to it. For more details, please see Section 6.10, “Replication FAQ”.
If you want to administer a MySQL replication setup, we suggest that you read this entire chapter through and try all statements mentioned in Section 13.6.1, “SQL Statements for Controlling Master Servers”, and Section 13.6.2, “SQL Statements for Controlling Slave Servers”. You should also familiarize yourself with the replication startup options described in Section 6.8, “Replication Startup Options”.
Note: This procedure and some of
the replication SQL statements shown in later sections require the
SUPER privilege.
Make sure that the versions of MySQL installed on the master and slave are compatible according to the table shown in Section 6.5, “Replication Compatibility Between MySQL Versions”. Ideally, you should use the most recent version of MySQL on both master and slave.
If you encounter a problem, please do not report it as a bug until you have verified that the problem is present in the latest MySQL release.
Set up an account on the master server that the slave server can use to connect. This account must be given the
REPLICATION SLAVEprivilege. If the account is used only for replication (which is recommended), you don't need to grant any additional privileges.MySQL Enterprise Subscribers to the MySQL Network Monitoring and Advisory Service are quickly notified if there is a replication master and no account with the
REPLICATION SLAVEprivilege. For more information see http://www.mysql.com/products/enterprise/advisors.html.Suppose that your domain is
mydomain.comand that you want to create an account with a username ofreplsuch that slave servers can use the account to access the master server from any host in your domain using a password ofslavepass. To create the account, use thisGRANTstatement:mysql>
GRANT REPLICATION SLAVE ON *.*->TO 'repl'@'%.mydomain.com' IDENTIFIED BY 'slavepass';For additional information about setting up user accounts and privileges, see Section 5.8, “MySQL User Account Management”.
Flush all the tables and block write statements by executing a
FLUSH TABLES WITH READ LOCKstatement:mysql>
FLUSH TABLES WITH READ LOCK;For
InnoDBtables, note thatFLUSH TABLES WITH READ LOCKalso blocksCOMMIToperations. When you have acquired a global read lock, you can start a filesystem snapshot of yourInnoDBtables. Internally (inside theInnoDBstorage engine) the snapshot won't be consistent (because theInnoDBcaches are not flushed), but this is not a cause for concern, becauseInnoDBresolves this at startup and delivers a consistent result. This means thatInnoDBcan perform crash recovery when started on this snapshot, without corruption. However, there is no way to stop the MySQL server while insuring a consistent snapshot of yourInnoDBtables.Leave running the client from which you issue the
FLUSH TABLESstatement so that the read lock remains in effect. (If you exit the client, the lock is released.) Then take a snapshot of the data on your master server.The easiest way to create a snapshot is to use an archiving program to make a binary backup of the databases in your master's data directory. For example, use tar on Unix, or PowerArchiver, WinRAR, WinZip, or any similar software on Windows. To use tar to create an archive that includes all databases, change location into the master server's data directory, then execute this command:
shell>
tar -cvf /tmp/mysql-snapshot.tar .If you want the archive to include only a database called
this_db, use this command instead:shell>
tar -cvf /tmp/mysql-snapshot.tar ./this_dbThen copy the archive file to the
/tmpdirectory on the slave server host. On that machine, change location into the slave's data directory, and unpack the archive file using this command:shell>
tar -xvf /tmp/mysql-snapshot.tarYou may not want to replicate the
mysqldatabase if the slave server has a different set of user accounts from those that exist on the master. In this case, you should exclude it from the archive. You also need not include any log files in the archive, or themaster.infoorrelay-log.infofiles.While the read lock placed by
FLUSH TABLES WITH READ LOCKis in effect, read the value of the current binary log name and offset on the master:mysql >
SHOW MASTER STATUS;+---------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +---------------+----------+--------------+------------------+ | mysql-bin.003 | 73 | test | manual,mysql | +---------------+----------+--------------+------------------+The
Filecolumn shows the name of the log andPositionshows the offset within the file. In this example, the binary log file ismysql-bin.003and the offset is 73. Record these values. You need them later when you are setting up the slave. They represent the replication coordinates at which the slave should begin processing new updates from the master.If the master has been running previously without binary logging enabled, the log name and position values displayed by
SHOW MASTER STATUSor mysqldump --master-data will be empty. In that case, the values that you need to use later when specifying the slave's log file and position are the empty string ('') and4.After you have taken the snapshot and recorded the log name and offset, you can re-enable write activity on the master:
mysql>
UNLOCK TABLES;If you are using
InnoDBtables, ideally you should use theInnoDBHot Backup tool, which takes a consistent snapshot without acquiring any locks on the master server, and records the log name and offset corresponding to the snapshot to be later used on the slave. Hot Backup is an additional non-free (commercial) tool that is not included in the standard MySQL distribution. See theInnoDBHot Backup home page at http://www.innodb.com/manual.php for detailed information.Without the Hot Backup tool, the quickest way to take a binary snapshot of
InnoDBtables is to shut down the master server and copy theInnoDBdata files, log files, and table format files (.frmfiles). To record the current log file name and offset, you should issue the following statements before you shut down the server:mysql>
FLUSH TABLES WITH READ LOCK;mysql>SHOW MASTER STATUS;Then record the log name and the offset from the output of
SHOW MASTER STATUSas was shown earlier. After recording the log name and the offset, shut down the server without unlocking the tables to make sure that the server goes down with the snapshot corresponding to the current log file and offset:shell>
mysqladmin -u root shutdownAn alternative that works for both
MyISAMandInnoDBtables is to take an SQL dump of the master instead of a binary copy as described in the preceding discussion. For this, you can use mysqldump --master-data on your master and later load the SQL dump file into your slave. However, this is slower than doing a binary copy.Make sure that the
[mysqld]section of themy.cnffile on the master host includes alog-binoption. The section should also have aserver-id=option, wheremaster_idmaster_idmust be a positive integer value from 1 to 232 – 1. For example:[mysqld] log-bin=mysql-bin server-id=1
If those options are not present, add them and restart the server. The server cannot act as a replication master unless binary logging is enabled.
Note: For the greatest possible durability and consistency in a replication setup using
InnoDBwith transactions, you should useinnodb_flush_log_at_trx_commit=1,sync_binlog=1, and, before MySQL 5.0.3,innodb_safe_binlog, in the mastermy.cnffile. (innodb_safe_binlogis not needed from 5.0.3 on.)Stop the server that is to be used as a slave and add the following lines to its
my.cnffile:[mysqld] server-id=
slave_idThe
slave_idvalue, like themaster_idvalue, must be a positive integer value from 1 to 232 – 1. In addition, it is necessary that the ID of the slave be different from the ID of the master. For example:[mysqld] server-id=2
If you are setting up multiple slaves, each one must have a unique
server-idvalue that differs from that of the master and from each of the other slaves. Think ofserver-idvalues as something similar to IP addresses: These IDs uniquely identify each server instance in the community of replication partners.If you do not specify a
server-idvalue, it is set to 1 if you have not definedmaster-host; otherwise it is set to 2. Note that in the case ofserver-idomission, a master refuses connections from all slaves, and a slave refuses to connect to a master. Thus, omittingserver-idis good only for backup with a binary log.If you made a binary backup of the master server's data, copy it to the slave server's data directory before starting the slave. Make sure that the privileges on the files and directories are correct. The system account that you use to run the slave server must be able to read and write the files, just as on the master.
If you made a backup using mysqldump, start the slave first. The dump file is loaded in a later step.
Start the slave server. If it has been replicating previously, start the slave server with the
--skip-slave-startoption so that it doesn't immediately try to connect to its master. You also may want to start the slave server with the--log-warningsoption to get more messages in the error log about problems (for example, network or connection problems). The option is enabled by default, but aborted connections are not logged to the error log unless the option value is greater than 1.If you made a backup of the master server's data using mysqldump, load the dump file into the slave server:
shell>
mysql -u root -p < dump_file.sqlExecute the following statement on the slave, replacing the option values with the actual values relevant to your system:
mysql>
CHANGE MASTER TO->MASTER_HOST='->master_host_name',MASTER_USER='->replication_user_name',MASTER_PASSWORD='->replication_password',MASTER_LOG_FILE='->recorded_log_file_name',MASTER_LOG_POS=recorded_log_position;The following table shows the maximum allowable length for the string-valued options:
MASTER_HOST60 MASTER_USER16 MASTER_PASSWORD32 MASTER_LOG_FILE255 Start the slave threads:
mysql>
START SLAVE;
After you have performed this procedure, the slave should connect to the master and catch up on any updates that have occurred since the snapshot was taken.
If you have forgotten to set the server-id
option for the master, slaves cannot connect to it.
If you have forgotten to set the server-id
option for the slave, you get the following error in the slave's
error log:
Warning: You should set server-id to a non-0 value if master_host is set; we will force server id to 2, but this MySQL server will not act as a slave.
You also find error messages in the slave's error log if it is not able to replicate for any other reason.
Once a slave is replicating, you can find in its data directory
one file named master.info and another named
relay-log.info. The slave uses these two
files to keep track of how much of the master's binary log it has
processed. Do not remove or edit these files
unless you know exactly what you are doing and fully understand
the implications. Even in that case, it is preferred that you use
the CHANGE MASTER TO statement to change
replication parameters. The slave will use the values specified in
the statement to update the status files automatically.
Note: The content of
master.info overrides some of the server
options specified on the command line or in
my.cnf. See
Section 6.8, “Replication Startup Options”, for more details.
Once you have a snapshot of the master, you can use it to set up other slaves by following the slave portion of the procedure just described. You do not need to take another snapshot of the master; you can use the same one for each slave.
The binary log format as implemented in MySQL 5.0 is
considerably different from that used in previous versions. Major
changes were made in MySQL 5.0.3 (for improvements to handling of
character sets and LOAD DATA INFILE) and 5.0.4
(for improvements to handling of time zones).
We recommend using the most recent MySQL version available because replication capabilities are continually being improved. We also recommend using the same version for both the master and the slave. We recommend upgrading masters and slaves running alpha or beta versions to new (production) versions. Replication from a 5.0.3 master to a 5.0.2 slave will fail; from a 5.0.4 master to a 5.0.3 slave will also fail. In general, slaves running MySQL 5.0.x may be used with older masters (even those running MySQL 3.23, 4.0, or 4.1), but not the reverse. For more information on potential issues, see Section 6.7, “Replication Features and Known Problems”.
Note: You cannot replicate from a master that uses a newer binary log format to a slave that uses an older format (for example, from MySQL 5.0 to MySQL 4.1.) This has significant implications for upgrading replication servers, as described in Section 6.6, “Upgrading a Replication Setup”.
The preceding information pertains to replication compatibility at the protocol level. However, there can be other constraints, such as SQL-level compatibility issues. For example, a 5.0 master cannot replicate to a 4.1 slave if the replicated statements use SQL features available in 5.0 but not in 4.1. These and other issues are discussed in Section 6.7, “Replication Features and Known Problems”.
When you upgrade servers that participate in a replication setup, the procedure for upgrading depends on the current server versions and the version to which you are upgrading.
This section applies to upgrading replication from MySQL 3.23, 4.0, or 4.1 to MySQL 5.0. A 4.0 server should be 4.0.3 or newer.
When you upgrade a master to 5.0 from an earlier MySQL release series, you should first ensure that all the slaves of this master are using the same 5.0.x release. If this is not the case, you should first upgrade the slaves. To upgrade each slave, shut it down, upgrade it to the appropriate 5.0.x version, restart it, and restart replication. The 5.0 slave is able to read the old relay logs written prior to the upgrade and to execute the statements they contain. Relay logs created by the slave after the upgrade are in 5.0 format.
After the slaves have been upgraded, shut down the master, upgrade it to the same 5.0.x release as the slaves, and restart it. The 5.0 master is able to read the old binary logs written prior to the upgrade and to send them to the 5.0 slaves. The slaves recognize the old format and handle it properly. Binary logs created by the master following the upgrade are in 5.0 format. These too are recognized by the 5.0 slaves.
In other words, there are no measures to take when upgrading to MySQL 5.0, except that the slaves must be MySQL 5.0 before you can upgrade the master to 5.0. Note that downgrading from 5.0 to older versions does not work so simply: You must ensure that any 5.0 binary logs or relay logs have been fully processed, so that you can remove them before proceeding with the downgrade.
In general, replication compatibility at the SQL level requires
that any features used be supported by both the master and the
slave servers. If you use a feature on a master server that is
available only as of a given version of MySQL, you cannot
replicate to a slave that is older than that version. Such
incompatibilities are likely to occur between series, so that, for
example, you cannot replicate from MySQL 5.0 to
4.1. However, these incompatibilities also can occur
for within-series replication. For example, the
SLEEP() function is available in MySQL 5.0.12
and up. If you use this function on the master server, you cannot
replicate to a slave server that is older than MySQL 5.0.12.
If you are planning to use replication between 5.0 and a previous version of MySQL you should consult the edition of the MySQL Reference Manual corresponding to the earlier release series for information regarding the replication characteristics of that series.
The following list provides details about what is supported and
what is not. Additional InnoDB-specific
information about replication is given in
Section 14.2.6.5, “InnoDB and MySQL Replication”.
Replication issues with regard to stored routines and triggers is described in Section 17.4, “Binary Logging of Stored Routines and Triggers”.
Known issue: In MySQL 5.0.17, the syntax for
CREATE TRIGGERchanged to include aDEFINERclause for specifying which access privileges to check at trigger invocation time. (See Section 18.1, “CREATE TRIGGERSyntax”, for more information.) However, if you attempt to replicate from a master server older than MySQL 5.0.17 to a slave running MySQL 5.0.17 through 5.0.19, replication ofCREATE TRIGGERstatements fails on the slave with aDefiner not fully qualifiederror. A workaround is to create triggers on the master using a version-specific comment embedded in eachCREATE TRIGGERstatement:CREATE /*!50017 DEFINER = 'root'@'localhost' */ TRIGGER ... ;
CREATE TRIGGERstatements written this way will replicate to newer slaves, which pick up theDEFINERclause from the comment and execute successfully.This slave problem is fixed as of MySQL 5.0.20.
Replication of
AUTO_INCREMENT,LAST_INSERT_ID(), andTIMESTAMPvalues is done correctly, subject to the following exceptions.INSERT DELAYED ... VALUES(LAST_INSERT_ID())inserts a different value on the master and the slave. (Bug#20819) This is fixed in MySQL 5.1 when using row-based or mixed-format binary logging.Before MySQL 5.0.26, a stored procedure that uses
LAST_INSERT_ID()does not replicate properly.When a statement uses a stored function that inserts into an
AUTO_INCREMENTcolumn, the generatedAUTO_INCREMENTvalue is not written into the binary log, so a different value can in some cases be inserted on the slave.Adding an
AUTO_INCREMENTcolumn to a table withALTER TABLEmight not produce the same ordering of the rows on the slave and the master. This occurs because the order in which the rows are numbered depends on the specific storage engine used for the table and the order in which the rows were inserted. If it is important to have the same order on the master and slave, the rows must be ordered before assigning anAUTO_INCREMENTnumber. Assuming that you want to add anAUTO_INCREMENTcolumn to the tablet1, the following statements produce a new tablet2identical tot1but with anAUTO_INCREMENTcolumn:CREATE TABLE t2 LIKE t1; ALTER TABLE t2 ADD id INT AUTO_INCREMENT PRIMARY KEY; INSERT INTO t2 SELECT * FROM t1 ORDER BY col1, col2;
This assumes that the table
t1has columnscol1andcol2.Important: To guarantee the same ordering on both master and slave, all columns of
t1must be referenced in theORDER BYclause.The instructions just given are subject to the limitations of
CREATE TABLE ... LIKE: Foreign key definitions are ignored, as are theDATA DIRECTORYandINDEX DIRECTORYtable options. If a table definition includes any of those characteristics, createt2using aCREATE TABLEstatement that is identical to the one used to createt1, but with the addition of theAUTO_INCREMENTcolumn.Regardless of the method used to create and populate the copy having the
AUTO_INCREMENTcolumn, the final step is to drop the original table and then rename the copy:DROP t1; ALTER TABLE t2 RENAME t1;
Certain functions do not replicate well under some conditions:
The
USER(),CURRENT_USER(),UUID(),VERSION(), andLOAD_FILE()functions are replicated without change and thus do not work reliably on the slave.As of MySQL 5.0.13, the
SYSDATE()function is no longer equivalent toNOW(). Implications are thatSYSDATE()is not replication-safe because it is not affected bySET TIMESTAMPstatements in the binary log and is non-deterministic. To avoid this, you can start the server with the--sysdate-is-nowoption to causeSYSDATE()to be an alias forNOW().The
GET_LOCK(),RELEASE_LOCK(),IS_FREE_LOCK(), andIS_USED_LOCK()functions that handle user-level locks are replicated without the slave knowing the concurrency context on master. Therefore, these functions should not be used to insert into a master's table because the content on the slave would differ. (For example, do not issue a statement such asINSERT INTO mytable VALUES(GET_LOCK(...)).)
As a workaround for the preceding limitations, you can use the strategy of saving the problematic function result in a user variable and referring to the variable in a later statement. For example, the following single-row
INSERTis problematic due to the reference to theUUID()function:INSERT INTO t VALUES(UUID());
To work around the problem, do this instead:
SET @my_uuid = UUID(); INSERT INTO t VALUES(@my_uuid);
That sequence of statements replicates because the value of
@my_uuidis stored in the binary log as a user-variable event prior to theINSERTstatement and is available for use in theINSERT.The same idea applies to multiple-row inserts, but is more cumbersome to use. For a two-row insert, you can do this:
SET @my_uuid1 = UUID(); @my_uuid2 = UUID(); INSERT INTO t VALUES(@my_uuid1),(@my_uuid2);
However, if the number of rows is large or unknown, the workaround is difficult or impracticable. For example, you cannot convert the following statement to one in which a given individual user variable is associated with each row:
INSERT INTO t2 SELECT UUID(), * FROM t1;
User privileges are replicated only if the
mysqldatabase is replicated. That is, theGRANT,REVOKE,SET PASSWORD,CREATE USER, andDROP USERstatements take effect on the slave only if the replication setup includes themysqldatabase.If you're replicating all databases, but don't want statements that affect user privileges to be replicated, set up the slave to not replicate the
mysqldatabase, using the--replicate-wild-ignore-table=mysql.%option. The slave will recognize that issuing privilege-related SQL statements won't have an effect, and thus not execute those statements.The
FOREIGN_KEY_CHECKS,SQL_MODE,UNIQUE_CHECKS, andSQL_AUTO_IS_NULLvariables are all replicated in MySQL 5.0. Thestorage_enginesystem variable (also known astable_type) is not yet replicated, which is a good thing for replication between different storage engines.Starting from MySQL 5.0.3 (master and slave), replication works even if the master and slave have different global character set variables. Starting from MySQL 5.0.4 (master and slave), replication works even if the master and slave have different global time zone variables.
The following applies to replication between MySQL servers that use different character sets:
If the master uses MySQL 4.1, you must always use the same global character set and collation on the master and the slave, regardless of the MySQL version running on the slave. (These are controlled by the
--character-set-serverand--collation-serveroptions.) Otherwise, you may get duplicate-key errors on the slave, because a key that is unique in the master character set might not be unique in the slave character set. Note that this is not a cause for concern when master and slave are both MySQL 5.0 or later.If the master is older than MySQL 4.1.3, the character set of any client should never be made different from its global value because this character set change is not known to the slave. In other words, clients should not use
SET NAMES,SET CHARACTER SET, and so forth. If both the master and the slave are 4.1.3 or newer, clients can freely set session values for character set variables because these settings are written to the binary log and so are known to the slave. That is, clients can useSET NAMESorSET CHARACTER SETor can set variables such ascollation_clientorcollation_server. However, clients are prevented from changing the global value of these variables; as stated previously, the master and slave must always have identical global character set values.If you have databases on the master with character sets that differ from the global
character_set_servervalue, you should design yourCREATE TABLEstatements so that tables in those databases do not implicitly rely on the database default character set (see Bug#2326). A good workaround is to state the character set and collation explicitly inCREATE TABLEstatements.
If the master uses MySQL 4.1, the same system time zone should be set for both master and slave. Otherwise some statements will not be replicated properly, such as statements that use the
NOW()orFROM_UNIXTIME()functions. You can set the time zone in which MySQL server runs by using the--timezone=option of thetimezone_namemysqld_safescript or by setting theTZenvironment variable. Both master and slave should also have the same default connection time zone setting; that is, the--default-time-zoneparameter should have the same value for both master and slave. Note that this is not necessary when the master is MySQL 5.0 or later.CONVERT_TZ(...,...,@@global.time_zone)is not properly replicated.CONVERT_TZ(...,...,@@session.time_zone)is properly replicated only if the master and slave are from MySQL 5.0.4 or newer.Session variables are not replicated properly when used in statements that update tables. For example,
SET MAX_JOIN_SIZE=1000followed byINSERT INTO mytable VALUES(@@MAX_JOIN_SIZE)will not insert the same data on the master and the slave. This does not apply to the common sequence ofSET TIME_ZONE=...followed byINSERT INTO mytable VALUES(CONVERT_TZ(...,...,@@time_zone)), which replicates correctly as of MySQL 5.0.4.It is possible to replicate transactional tables on the master using non-transactional tables on the slave. For example, you can replicate an
InnoDBmaster table as aMyISAMslave table. However, if you do this, there are problems if the slave is stopped in the middle of aBEGIN/COMMITblock because the slave restarts at the beginning of theBEGINblock.Update statements that refer to user-defined variables (that is, variables of the form
@) are replicated correctly in MySQL 5.0. However, this is not true for versions prior to 4.1. Note that user variable names are case insensitive starting in MySQL 5.0. You should take this into account when setting up replication between MySQL 5.0 and older versions.var_nameNon-delayed
INSERTstatements that refer toRAND()or user-defined variables replicate correctly. However, changing the statements to useINSERT DELAYEDcan result in different results on master and slave.Slaves can connect to masters using SSL.
Views are always replicated to slaves. Views are filtered by their own name, not by the tables they refer to. This means that a view can be replicated to the slave even if the view contains a table that would normally be filtered out by
replication-ignore-tablerules. Care should therefore be taken to ensure that views do not replicate table data that would normally be filtered for security reasons.In MySQL 5.0 (starting from 5.0.3), there is a global system variable
slave_transaction_retries: If the replication slave SQL thread fails to execute a transaction because of anInnoDBdeadlock or because it exceeded theInnoDBinnodb_lock_wait_timeoutor the NDBClusterTransactionDeadlockDetectionTimeoutorTransactionInactiveTimeoutvalue, the transaction automatically retriesslave_transaction_retriestimes before stopping with an error. The default value is 10. Starting from MySQL 5.0.4, the total retry count can be seen in the output ofSHOW STATUS; see Section 5.2.5, “Status Variables”.If a
DATA DIRECTORYorINDEX DIRECTORYtable option is used in aCREATE TABLEstatement on the master server, the table option is also used on the slave. This can cause problems if no corresponding directory exists in the slave host filesystem or if it exists but is not accessible to the slave server. MySQL supports ansql_modeoption calledNO_DIR_IN_CREATE. If the slave server is run with this SQL mode enabled, it ignores theDATA DIRECTORYandINDEX DIRECTORYtable options when replicatingCREATE TABLEstatements. The result is thatMyISAMdata and index files are created in the table's database directory.It is possible for the data on the master and slave to become different if a statement is designed in such a way that the data modification is non-deterministic; that is, left to the will of the query optimizer. (This is in general not a good practice, even outside of replication.) For a detailed explanation of this issue, see Section B.1.8.1, “Open Issues in MySQL”.
Using
LOAD TABLE FROM MASTERwhere the master is running MySQL 4.1 and the slave is running MySQL 5.0 may corrupt the table data, and is not supported. (Bug#16261)The following applies only if either the master or the slave is running MySQL version 5.0.3 or older: If on the master a
LOAD DATA INFILEis interrupted (integrity constraint violation, killed connection, and so on), the slave skips theLOAD DATA INFILEentirely. This means that if this command permanently inserted or updated table records before being interrupted, these modifications are not replicated to the slave.Some forms of the
FLUSHstatement are not logged because they could cause problems if replicated to a slave:FLUSH LOGS,FLUSH MASTER,FLUSH SLAVE, andFLUSH TABLES WITH READ LOCK. For a syntax example, see Section 13.5.5.2, “FLUSHSyntax”. TheFLUSH TABLES,ANALYZE TABLE,OPTIMIZE TABLE, andREPAIR TABLEstatements are written to the binary log and thus replicated to slaves. This is not normally a problem because these statements do not modify table data. However, this can cause difficulties under certain circumstances. If you replicate the privilege tables in themysqldatabase and update those tables directly without usingGRANT, you must issue aFLUSH PRIVILEGESon the slaves to put the new privileges into effect. In addition, if you useFLUSH TABLESwhen renaming aMyISAMtable that is part of aMERGEtable, you must issueFLUSH TABLESmanually on the slaves. These statements are written to the binary log unless you specifyNO_WRITE_TO_BINLOGor its aliasLOCAL.When a server shuts down and restarts, its
MEMORY(HEAP) tables become empty. The master replicates this effect to slaves as follows: The first time that the master uses eachMEMORYtable after startup, it logs an event that notifies the slaves that the table needs to be emptied by writing aDELETEstatement for that table to the binary log. See Section 14.4, “TheMEMORY(HEAP) Storage Engine”, for more information aboutMEMORYtables.Temporary tables are replicated except in the case where you shut down the slave server (not just the slave threads) and you have replicated temporary tables that are used in updates that have not yet been executed on the slave. If you shut down the slave server, the temporary tables needed by those updates are no longer available when the slave is restarted. To avoid this problem, do not shut down the slave while it has temporary tables open. Instead, use the following procedure:
Issue a
STOP SLAVEstatement.Use
SHOW STATUSto check the value of theSlave_open_temp_tablesvariable.If the value is 0, issue a mysqladmin shutdown command to stop the slave.
If the value is not 0, restart the slave threads with
START SLAVE.Repeat the procedure later until the
Slave_open_temp_tablesvariable is 0 and you can stop the slave.
The syntax for multiple-table
DELETEstatements that use table aliases changed between MySQL 4.0 and 4.1. In MySQL 4.0, you should use the true table name to refer to any table from which rows should be deleted:DELETE test FROM test AS t1, test2 WHERE ...
In MySQL 4.1, you must use the alias:
DELETE t1 FROM test AS t1, test2 WHERE ...
If you use such
DELETEstatements, the change in syntax means that a 4.0 master cannot replicate to 4.1 (or higher) slaves.It is safe to connect servers in a circular master/slave relationship if you use the
--log-slave-updatesoption. That means that you can create a setup such as this:A -> B -> C -> A
However, many statements do not work correctly in this kind of setup unless your client code is written to take care of the potential problems that can occur from updates that occur in different sequence on different servers.
Server IDs are encoded in binary log events, so server A knows when an event that it reads was originally created by itself and does not execute the event (unless server A was started with the
--replicate-same-server-idoption, which is meaningful only in rare cases). Thus, there are no infinite loops. This type of circular setup works only if you perform no conflicting updates between the tables. In other words, if you insert data in both A and C, you should never insert a row in A that may have a key that conflicts with a row inserted in C. You should also not update the same rows on two servers if the order in which the updates are applied is significant.If a statement on a slave produces an error, the slave SQL thread terminates, and the slave writes a message to its error log. You should then connect to the slave manually and determine the cause of the problem. (
SHOW SLAVE STATUSis useful for this.) Then fix the problem (for example, you might need to create a non-existent table) and runSTART SLAVE.It is safe to shut down a master server and restart it later. When a slave loses its connection to the master, the slave tries to reconnect immediately and retries periodically if that fails. The default is to retry every 60 seconds. This may be changed with the
--master-connect-retryoption. A slave also is able to deal with network connectivity outages. However, the slave notices the network outage only after receiving no data from the master forslave_net_timeoutseconds. If your outages are short, you may want to decreaseslave_net_timeout. See Section 5.2.3, “System Variables”.Shutting down the slave (cleanly) is also safe because it keeps track of where it left off. Unclean shutdowns might produce problems, especially if the disk cache was not flushed to disk before the system went down. Your system fault tolerance is greatly increased if you have a good uninterruptible power supply. Unclean shutdowns of the master may cause inconsistencies between the content of tables and the binary log in master; this can be avoided by using
InnoDBtables and the--innodb-safe-binlogoption on the master. See Section 5.11.3, “The Binary Log”.Note:
--innodb-safe-binlogis unneeded as of MySQL 5.0.3, having been made obsolete by the introduction of XA transaction support.A crash on the master side can result in the master's binary log having a final position less than the most recent position read by the slave, due to the master's binary log file not being flushed. This can cause the slave not to be able to replicate when the master comes back up. Setting
sync_binlog=1in the mastermy.cnffile helps to minimize this problem because it causes the master to flush its binary log more frequently.Due to the non-transactional nature of
MyISAMtables, it is possible to have a statement that only partially updates a table and returns an error code. This can happen, for example, on a multiple-row insert that has one row violating a key constraint, or if a long update statement is killed after updating some of the rows. If that happens on the master, the slave thread exits and waits for the database administrator to decide what to do about it unless the error code is legitimate and execution of the statement results in the same error code on the slave. If this error code validation behavior is not desirable, some or all errors can be masked out (ignored) with the--slave-skip-errorsoption.If you update transactional tables from non-transactional tables inside a
BEGIN/COMMITsequence, updates to the binary log may be out of synchrony with table states if the non-transactional table is updated before the transaction commits. This occurs because the transaction is written to the binary log only when it is committed.In situations where transactions mix updates to transactional and non-transactional tables, the order of statements in the binary log is correct, and all needed statements are written to the binary log even in case of a
ROLLBACK. However, when a second connection updates the non-transactional table before the first connection's transaction is complete, statements can be logged out of order, because the second connection's update is written immediately after it is performed, regardless of the state of the transaction being performed by the first connection.Caution
You should not use transactions in a replication environment that update both transactional and non-transactional tables.
Floating-point values are approximate, so comparisons involving them are inexact. This is true for operations that use floating-point values explicitly, or values that are converted to floating-point implicitly. Comparisons of floating-point values might yield different results on master and slave servers due to differences in computer architecture, the compiler used to build MySQL, and so forth. See Section 12.2.2, “Type Conversion in Expression Evaluation”, and Section B.1.5.8, “Problems with Floating-Point Comparisons”.
This section describes the options that you can use on slave replication servers. You can specify these options either on the command line or in an option file.
On the master and each slave, you must use the
server-id option to establish a unique
replication ID. For each server, you should pick a unique positive
integer in the range from 1 to 232
– 1, and each ID must be different from every other ID.
Example: server-id=3
Options that you can use on the master server for controlling binary logging are described in Section 5.11.3, “The Binary Log”.
Some slave server replication options are handled in a special
way, in the sense that each is ignored if a
master.info file exists when the slave starts
and contains a value for the option. The following options are
handled this way:
--master-host--master-user--master-password--master-port--master-connect-retry--master-ssl--master-ssl-ca--master-ssl-capath--master-ssl-cert--master-ssl-cipher--master-ssl-key
The master.info file format in MySQL
5.0 includes values corresponding to the SSL options.
In addition, the file format includes as its first line the number
of lines in the file. (See Section 6.3.4, “Replication Relay and Status Files”.) If you
upgrade an older server (before MySQL 4.1.1) to a newer version,
the new server upgrades the master.info file
to the new format automatically when it starts. However, if you
downgrade a newer server to an older version, you should remove
the first line manually before starting the older server for the
first time.
If no master.info file exists when the slave
server starts, it uses the values for those options that are
specified in option files or on the command line. This occurs when
you start the server as a replication slave for the very first
time, or when you have run RESET SLAVE and then
have shut down and restarted the slave.
If the master.info file exists when the slave
server starts, the server uses its contents and ignores any
options that correspond to the values listed in the file. Thus, if
you start the slave server with different values of the startup
options that correspond to values in the
master.info file, the different values have
no effect, because the server continues to use the
master.info file. To use different values,
you must either restart after removing the
master.info file or (preferably) use the
CHANGE MASTER TO statement to reset the values
while the slave is running.
Suppose that you specify this option in your
my.cnf file:
[mysqld]
master-host=some_host
The first time you start the server as a replication slave, it
reads and uses that option from the my.cnf
file. The server then records the value in the
master.info file. The next time you start the
server, it reads the master host value from the
master.info file only and ignores the value
in the option file. If you modify the my.cnf
file to specify a different master host of
some_other_host, the change still has
no effect. You should use CHANGE MASTER TO
instead.
MySQL Enterprise For expert advice regarding slave startup options subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
Because the server gives an existing
master.info file precedence over the startup
options just described, you might prefer not to use startup
options for these values at all, and instead specify them by using
the CHANGE MASTER TO statement. See
Section 13.6.2.1, “CHANGE MASTER TO Syntax”.
This example shows a more extensive use of startup options to configure a slave server:
[mysqld] server-id=2 master-host=db-master.mycompany.com master-port=3306 master-user=pertinax master-password=freitag master-connect-retry=60 report-host=db-slave.mycompany.com
The following list describes startup options for controlling
replication. Many of these options can be reset while the server
is running by using the CHANGE MASTER TO
statement. Others, such as the --replicate-*
options, can be set only when the slave server starts.
Normally, a slave does not log to its own binary log any updates that are received from a master server. This option tells the slave to log the updates performed by its SQL thread to its own binary log. For this option to have any effect, the slave must also be started with the
--log-binoption to enable binary logging.--log-slave-updatesis used when you want to chain replication servers. For example, you might want to set up replication servers using this arrangement:A -> B -> C
Here, A serves as the master for the slave B, and B serves as the master for the slave C. For this to work, B must be both a master and a slave. You must start both A and B with
--log-binto enable binary logging, and B with the--log-slave-updatesoption so that updates received from A are logged by B to its binary log.This option causes a server to print more messages to the error log about what it is doing. With respect to replication, the server generates warnings that it succeeded in reconnecting after a network/connection failure, and informs you as to how each slave thread started. This option is enabled by default; to disable it, use
--skip-log-warnings. Aborted connections are not logged to the error log unless the value is greater than 1.--master-connect-retry=secondsThe number of seconds that the slave thread sleeps before trying to reconnect to the master in case the master goes down or the connection is lost. The value in the
master.infofile takes precedence if it can be read. If not set, the default is 60. Connection retries are not invoked until the slave times out reading data from the master according to the value of--slave-net-timeout. The number of reconnection attempts is limited by the--master-retry-countoption.The hostname or IP number of the master replication server. The value in
master.infotakes precedence if it can be read. If no master host is specified, the slave thread does not start.The name to use for the file in which the slave records information about the master. The default name is
master.infoin the data directory.The password of the account that the slave thread uses for authentication when it connects to the master. The value in the
master.infofile takes precedence if it can be read. If not set, an empty password is assumed.The TCP/IP port number that the master is listening on. The value in the
master.infofile takes precedence if it can be read. If not set, the compiled-in setting is assumed (normally 3306).The number of times that the slave tries to connect to the master before giving up. Reconnects are attempted at intervals set by
--master-connect-retryand reconnects are triggered when data reads by the slave time out according to the--slave-net-timeoutoption. The default value is 86400.--master-ssl,--master-ssl-ca=,file_name--master-ssl-capath=,directory_name--master-ssl-cert=,file_name--master-ssl-cipher=,cipher_list--master-ssl-key=file_nameThese options are used for setting up a secure replication connection to the master server using SSL. Their meanings are the same as the corresponding
--ssl,--ssl-ca,--ssl-capath,--ssl-cert,--ssl-cipher,--ssl-keyoptions that are described in Section 5.8.7.3, “SSL Command Options”. The values in themaster.infofile take precedence if they can be read.The username of the account that the slave thread uses for authentication when it connects to the master. This account must have the
REPLICATION SLAVEprivilege. The value in themaster.infofile takes precedence if it can be read. If the master username is not set, the nametestis assumed.The size at which the server rotates relay log files automatically. For more information, see Section 6.3.4, “Replication Relay and Status Files”. The default size is 1GB.
When this option is given, the server allows no updates except from users that have the
SUPERprivilege or (on a slave server) from updates performed by slave threads. On a slave server, this can be useful to ensure that the slave accepts updates only from its master server and not from clients. As of MySQL 5.0.16, this option does not apply toTEMPORARYtables.The name for the relay log. The default name is
host_name-relay-bin.nnnnnnhost_nameis the name of the slave server host andnnnnnnindicates that relay logs are created in numbered sequence. You can specify the option to create hostname-independent relay log names, or if your relay logs tend to be big (and you don't want to decreasemax_relay_log_size) and you need to put them in some area different from the data directory, or if you want to increase speed by balancing load between disks.The name to use for the relay log index file. The default name is
host_name-relay-bin.indexhost_nameis the name of the slave server.--relay-log-info-file=file_nameThe name to use for the file in which the slave records information about the relay logs. The default name is
relay-log.infoin the data directory.Disable or enable automatic purging of relay logs as soon as they are not needed any more. The default value is 1 (enabled). This is a global variable that can be changed dynamically with
SET GLOBAL relay_log_purge =.NThis option places an upper limit on the total size in bytes of all relay logs on the slave. A value of 0 means “no limit.” This is useful for a slave server host that has limited disk space. When the limit is reached, the I/O thread stops reading binary log events from the master server until the SQL thread has caught up and deleted some unused relay logs. Note that this limit is not absolute: There are cases where the SQL thread needs more events before it can delete relay logs. In that case, the I/O thread exceeds the limit until it becomes possible for the SQL thread to delete some relay logs, because not doing so would cause a deadlock. You should not set
--relay-log-space-limitto less than twice the value of--max-relay-log-size(or--max-binlog-sizeif--max-relay-log-sizeis 0). In that case, there is a chance that the I/O thread waits for free space because--relay-log-space-limitis exceeded, but the SQL thread has no relay log to purge and is unable to satisfy the I/O thread. This forces the I/O thread to temporarily ignore--relay-log-space-limit.Tell the slave to restrict replication to statements where the default database (that is, the one selected by
USE) isdb_name. To specify more than one database, use this option multiple times, once for each database. Note that this does not replicate cross-database statements such asUPDATEwhile having selected a different database or no database.some_db.some_tableSET foo='bar'Warning
To specify multiple databases you must use multiple instances of this option. Because database names can contain commas, if you supply a comma separated list then the list will be treated as the name of a single database.
An example of what does not work as you might expect: If the slave is started with
--replicate-do-db=salesand you issue the following statements on the master, theUPDATEstatement is not replicated:USE prices; UPDATE sales.january SET amount=amount+1000;
The main reason for this “just check the default database” behavior is that it is difficult from the statement alone to know whether it should be replicated (for example, if you are using multiple-table
DELETEstatements or multiple-tableUPDATEstatements that act across multiple databases). It is also faster to check only the default database rather than all databases if there is no need.If you need cross-database updates to work, use
--replicate-wild-do-table=instead. See Section 6.9, “How Servers Evaluate Replication Rules”.db_name.%--replicate-do-table=db_name.tbl_nameTell the slave thread to restrict replication to the specified table. To specify more than one table, use this option multiple times, once for each table. This works for cross-database updates, in contrast to
--replicate-do-db. See Section 6.9, “How Servers Evaluate Replication Rules”.Tells the slave to not replicate any statement where the default database (that is, the one selected by
USE) isdb_name. To specify more than one database to ignore, use this option multiple times, once for each database. You should not use this option if you are using cross-database updates and you do not want these updates to be replicated. See Section 6.9, “How Servers Evaluate Replication Rules”.An example of what does not work as you might expect: If the slave is started with
--replicate-ignore-db=salesand you issue the following statements on the master, theUPDATEstatement is replicated:USE prices; UPDATE sales.january SET amount=amount+1000;
Note
In the preceding example the statement is replicated because
--replicate-ignore-dbonly applies to the default database (set through theUSEstatement). Because thesalesdatabase was specified explicitly in the statement, the statement has not been filtered.If you need cross-database updates to work, use
--replicate-wild-ignore-table=instead. See Section 6.9, “How Servers Evaluate Replication Rules”.db_name.%--replicate-ignore-table=db_name.tbl_nameTells the slave thread to not replicate any statement that updates the specified table, even if any other tables might be updated by the same statement. To specify more than one table to ignore, use this option multiple times, once for each table. This works for cross-database updates, in contrast to
--replicate-ignore-db. See Section 6.9, “How Servers Evaluate Replication Rules”.--replicate-rewrite-db=from_name->to_nameTells the slave to translate the default database (that is, the one selected by
USE) toto_nameif it wasfrom_nameon the master. Only statements involving tables are affected (not statements such asCREATE DATABASE,DROP DATABASE, andALTER DATABASE), and only iffrom_nameis the default database on the master. This does not work for cross-database updates. The database name translation is done before the--replicate-*rules are tested.If you use this option on the command line and the ‘
>’ character is special to your command interpreter, quote the option value. For example:shell>
mysqld --replicate-rewrite-db="olddb->newdb"To be used on slave servers. Usually you should use the default setting of 0, to prevent infinite loops caused by circular replication. If set to 1, the slave does not skip events having its own server ID. Normally, this is useful only in rare configurations. Cannot be set to 1 if
--log-slave-updatesis used. Note that by default the slave I/O thread does not even write binary log events to the relay log if they have the slave's server id (this optimization helps save disk usage). So if you want to use--replicate-same-server-id, be sure to start the slave with this option before you make the slave read its own events that you want the slave SQL thread to execute.--replicate-wild-do-table=db_name.tbl_nameTells the slave thread to restrict replication to statements where any of the updated tables match the specified database and table name patterns. Patterns can contain the ‘
%’ and ‘_’ wildcard characters, which have the same meaning as for theLIKEpattern-matching operator. To specify more than one table, use this option multiple times, once for each table. This works for cross-database updates. See Section 6.9, “How Servers Evaluate Replication Rules”.Example:
--replicate-wild-do-table=foo%.bar%replicates only updates that use a table where the database name starts withfooand the table name starts withbar.If the table name pattern is
%, it matches any table name and the option also applies to database-level statements (CREATE DATABASE,DROP DATABASE, andALTER DATABASE). For example, if you use--replicate-wild-do-table=foo%.%, database-level statements are replicated if the database name matches the patternfoo%.To include literal wildcard characters in the database or table name patterns, escape them with a backslash. For example, to replicate all tables of a database that is named
my_own%db, but not replicate tables from themy1ownAABCdbdatabase, you should escape the ‘_’ and ‘%’ characters like this:--replicate-wild-do-table=my\_own\%db. If you're using the option on the command line, you might need to double the backslashes or quote the option value, depending on your command interpreter. For example, with the bash shell, you would need to type--replicate-wild-do-table=my\\_own\\%db.--replicate-wild-ignore-table=db_name.tbl_nameTells the slave thread not to replicate a statement where any table matches the given wildcard pattern. To specify more than one table to ignore, use this option multiple times, once for each table. This works for cross-database updates. See Section 6.9, “How Servers Evaluate Replication Rules”.
Example:
--replicate-wild-ignore-table=foo%.bar%does not replicate updates that use a table where the database name starts withfooand the table name starts withbar.For information about how matching works, see the description of the
--replicate-wild-do-tableoption. The rules for including literal wildcard characters in the option value are the same as for--replicate-wild-ignore-tableas well.The hostname or IP number of the slave to be reported to the master during slave registration. This value appears in the output of
SHOW SLAVE HOSTSon the master server. Leave the value unset if you do not want the slave to register itself with the master. Note that it is not sufficient for the master to simply read the IP number of the slave from the TCP/IP socket after the slave connects. Due to NAT and other routing issues, that IP may not be valid for connecting to the slave from the master or other hosts.The account password of the slave to be reported to the master during slave registration. This value appears in the output of
SHOW SLAVE HOSTSon the master server if the--show-slave-auth-infooption is given.The TCP/IP port number for connecting to the slave, to be reported to the master during slave registration. Set this only if the slave is listening on a non-default port or if you have a special tunnel from the master or other clients to the slave. If you are not sure, do not use this option.
The account username of the slave to be reported to the master during slave registration. This value appears in the output of
SHOW SLAVE HOSTSon the master server if the--show-slave-auth-infooption is given.id="option_mysqld_slave_compressed_protocol"
--show-slave-auth-infoDisplay slave usernames and passwords in the output of
SHOW SLAVE HOSTSon the master server for slaves started with the--report-userand--report-passwordoptions.Tells the slave server not to start the slave threads when the server starts. To start the threads later, use a
START SLAVEstatement.--slave_compressed_protocol={0|1}If this option is set to 1, use compression for the slave/master protocol if both the slave and the master support it. The default is 0 (no compression).
The name of the directory where the slave creates temporary files. This option is by default equal to the value of the
tmpdirsystem variable. When the slave SQL thread replicates aLOAD DATA INFILEstatement, it extracts the file to be loaded from the relay log into temporary files, and then loads these into the table. If the file loaded on the master is huge, the temporary files on the slave are huge, too. Therefore, it might be advisable to use this option to tell the slave to put temporary files in a directory located in some filesystem that has a lot of available space. In that case, the relay logs are huge as well, so you might also want to use the--relay-logoption to place the relay logs in that filesystem.The directory specified by this option should be located in a disk-based filesystem (not a memory-based filesystem) because the temporary files used to replicate
LOAD DATA INFILEmust survive machine restarts. The directory also should not be one that is cleared by the operating system during the system startup process.The number of seconds to wait for more data from the master before the slave considers the connection broken, aborts the read, and tries to reconnect. The first retry occurs immediately after the timeout. The interval between retries is controlled by the
--master-connect-retryoption and the number of reconnection attempts is limited by the--master-retry-countoption. The default is 3600 seconds (one hour).--slave-skip-errors=[err_code1,err_code2,...|all]Normally, replication stops when an error occurs on the slave. This gives you the opportunity to resolve the inconsistency in the data manually. This option tells the slave SQL thread to continue replication when a statement returns any of the errors listed in the option value.
Do not use this option unless you fully understand why you are getting errors. If there are no bugs in your replication setup and client programs, and no bugs in MySQL itself, an error that stops replication should never occur. Indiscriminate use of this option results in slaves becoming hopelessly out of synchrony with the master, with you having no idea why this has occurred.
For error codes, you should use the numbers provided by the error message in your slave error log and in the output of
SHOW SLAVE STATUS. Appendix B, Errors, Error Codes, and Common Problems, lists server error codes.You can also (but should not) use the very non-recommended value of
allto cause the slave to ignore all error messages and keeps going regardless of what happens. Needless to say, if you useall, there are no guarantees regarding the integrity of your data. Please do not complain (or file bug reports) in this case if the slave's data is not anywhere close to what it is on the master. You have been warned.Examples:
--slave-skip-errors=1062,1053 --slave-skip-errors=all
If a master server does not write a statement to its binary log, the statement is not replicated. If the server does log the statement, the statement is sent to all slaves and each slave determines whether to execute it or ignore it.
On the master side, decisions about which statements to log are
based on the --binlog-do-db and
--binlog-ignore-db options that control binary
logging. For a description of the rules that servers use in
evaluating these options, see Section 5.11.3, “The Binary Log”.
On the slave side, decisions about whether to execute or ignore
statements received from the master are made according to the
--replicate-* options that the slave was started
with. (See Section 6.8, “Replication Startup Options”.) The slave
evaluates these options using the following procedure, which first
checks the database-level options and then the table-level
options.
In the simplest case, when there are no
--replicate-* options, the procedure yields the
result that the slave executes all statements that it receives
from the master. Otherwise, the result depends on the particular
options given. In general, to make it easier to determine what
effect an option set will have, it is recommended that you avoid
mixing “do” and “ignore” options, or
wildcard and non-wildcard options.
Stage 1. Check the database options.
At this stage, the slave checks whether there are any
--replicate-do-db or
--replicate-ignore-db options that specify
database-specific conditions:
No: Permit the statement and proceed to the table-checking stage.
Yes: Test the options using the same rules as for the
--binlog-do-dband--binlog-ignore-dboptions to determine whether to permit or ignore the statement. What is the result of the test?Permit: Do not execute the statement immediately. Defer the decision and proceed to the table-checking stage.
Ignore: Ignore the statement and exit.
This stage can permit a statement for further option-checking, or cause it to be ignored. However, statements that are permitted at this stage are not actually executed yet. Instead, they pass to the following stage that checks the table options.
Stage 2. Check the table options.
First, as a preliminary condition, the slave checks whether the
statement occurs within a stored function or (prior to MySQL
5.0.12) a stored procedure. If so, execute the statement and exit.
(Stored procedures are exempt from this test as of MySQL 5.0.12
because procedure logging occurs at the level of statements that
are executed within the routine rather than at the
CALL level.)
Next, the slave checks for table options and evaluates them. If
the server reaches this point, it executes all statements if there
are no table options. If there are “do” table
options, the statement must match one of them if it is to be
executed; otherwise, it is ignored. If there are any
“ignore” options, all statements are executed except
those that match any ignore option. The
following steps describe how this evaluation occurs in more
detail.
Are there any
--replicate-*-tableoptions?No: There are no table restrictions, so all statements match. Execute the statement and exit.
Yes: There are table restrictions. Evaluate the tables to be updated against them. There might be multiple tables to update, so loop through the following steps for each table looking for a matching option (first the non-wild options, and then the wild options). Only tables that are to be updated are compared to the options. For example, if the statement is
INSERT INTO sales SELECT * FROM prices, onlysalesis compared to the options). If several tables are to be updated (multiple-table statement), the first table that matches “do” or “ignore” wins. That is, the server checks the first table against the options. If no decision could be made, it checks the second table against the options, and so on.
Are there any
--replicate-do-tableoptions?No: Proceed to the next step.
Yes: Does the table match any of them?
No: Proceed to the next step.
Yes: Execute the statement and exit.
Are there any
--replicate-ignore-tableoptions?No: Proceed to the next step.
Yes: Does the table match any of them?
No: Proceed to the next step.
Yes: Ignore the statement and exit.
Are there any
--replicate-wild-do-tableoptions?No: Proceed to the next step.
Yes: Does the table match any of them?
No: Proceed to the next step.
Yes: Execute the statement and exit.
Are there any
--replicate-wild-ignore-tableoptions?No: Proceed to the next step.
Yes: Does the table match any of them?
No: Proceed to the next step.
Yes: Ignore the statement and exit.
No
--replicate-*-tableoption was matched. Is there another table to test against these options?No: We have now tested all tables to be updated and could not match any option. Are there
--replicate-do-tableor--replicate-wild-do-tableoptions?No: There were no “do” table options, so no explicit “do” match is required. Execute the statement and exit.
Yes: There were “do” table options, so the statement is executed only with an explicit match to one of them. Ignore the statement and exit.
Yes: Loop.
Examples:
No
--replicate-*options at allThe slave executes all statements that it receives from the master.
--replicate-*-dboptions, but no table optionsThe slave permits or ignores statements using the database options. Then it executes all statements permitted by those options because there are no table restrictions.
--replicate-*-tableoptions, but no database optionsAll statements are permitted at the database-checking stage because there are no database conditions. The slave executes or ignores statements based on the table options.
A mix of database and table options
The slave permits or ignores statements using the database options. Then it evaluates all statements permitted by those options according to the table options. In some cases, this process can yield what might seem a counterintuitive result. Consider the following set of options:
[mysqld] replicate-do-db = db1 replicate-do-table = db2.mytbl2
Suppose that
db1is the default database and the slave receives this statement:INSERT INTO mytbl1 VALUES(1,2,3);
The database is
db1, which matches the--replicate-do-dboption at the database-checking stage. The algorithm then proceeds to the table-checking stage. If there were no table options, the statement would be executed. However, because the options include a “do” table option, the statement must match if it is to be executed. The statement does not match, so it is ignored. (The same would happen for any table indb1.)
Q: How do I configure a slave if the master is running and I do not want to stop it?
A: There are several
possibilities. If you have taken a snapshot backup of the master
at some point and recorded the binary log filename and offset
(from the output of SHOW MASTER STATUS)
corresponding to the snapshot, use the following procedure:
Make sure that the slave is assigned a unique server ID.
Execute the following statement on the slave, filling in appropriate values for each option:
mysql>
CHANGE MASTER TO->MASTER_HOST='->master_host_name',MASTER_USER='->master_user_name',MASTER_PASSWORD='->master_pass',MASTER_LOG_FILE='->recorded_log_file_name',MASTER_LOG_POS=recorded_log_position;Execute
START SLAVEon the slave.
If you do not have a backup of the master server, here is a quick procedure for creating one. All steps should be performed on the master host.
Issue this statement to acquire a global read lock:
mysql>
FLUSH TABLES WITH READ LOCK;With the lock still in place, execute this command (or a variation of it):
shell>
tar zcf /tmp/backup.tar.gz /var/lib/mysqlIssue this statement and record the output, which you will need later:
mysql>
SHOW MASTER STATUS;Release the lock:
mysql>
UNLOCK TABLES;
An alternative to using the preceding procedure to make a binary copy is to make an SQL dump of the master. To do this, you can use mysqldump --master-data on your master and later load the SQL dump into your slave. However, this is slower than making a binary copy.
Regardless of which of the two methods you use, afterward follow the instructions for the case when you have a snapshot and have recorded the log filename and offset. You can use the same snapshot to set up several slaves. Once you have the snapshot of the master, you can wait to set up a slave as long as the binary logs of the master are left intact. The two practical limitations on the length of time you can wait are the amount of disk space available to retain binary logs on the master and the length of time it takes the slave to catch up.
Q: Does the slave need to be connected to the master all the time?
A: No, it does not. The slave can go down or stay disconnected for hours or even days, and then reconnect and catch up on updates. For example, you can set up a master/slave relationship over a dial-up link where the link is up only sporadically and for short periods of time. The implication of this is that, at any given time, the slave is not guaranteed to be in synchrony with the master unless you take some special measures.
Q: How do I know how late a slave is compared to the master? In other words, how do I know the date of the last statement replicated by the slave?
A: You can read the
Seconds_Behind_Master column in SHOW
SLAVE STATUS. See
Section 6.3, “Replication Implementation Details”.
When the slave SQL thread executes an event read from the master,
it modifies its own time to the event timestamp. (This is why
TIMESTAMP is well replicated.) In the
Time column in the output of SHOW
PROCESSLIST, the number of seconds displayed for the
slave SQL thread is the number of seconds between the timestamp of
the last replicated event and the real time of the slave machine.
You can use this to determine the date of the last replicated
event. Note that if your slave has been disconnected from the
master for one hour, and then reconnects, you may immediately see
Time values like 3600 for the slave SQL thread
in SHOW PROCESSLIST. This is because the slave
is executing statements that are one hour old.
Q: How do I force the master to block updates until the slave catches up?
A: Use the following procedure:
On the master, execute these statements:
mysql>
FLUSH TABLES WITH READ LOCK;mysql>SHOW MASTER STATUS;Record the replication coordinates (the log filename and offset) from the output of the
SHOWstatement.On the slave, issue the following statement, where the arguments to the
MASTER_POS_WAIT()function are the replication coordinate values obtained in the previous step:mysql>
SELECT MASTER_POS_WAIT('log_name',log_offset);The
SELECTstatement blocks until the slave reaches the specified log file and offset. At that point, the slave is in synchrony with the master and the statement returns.On the master, issue the following statement to allow the master to begin processing updates again:
mysql>
UNLOCK TABLES;
Q: What issues should I be aware of when setting up two-way replication?
A: MySQL replication currently does not support any locking protocol between master and slave to guarantee the atomicity of a distributed (cross-server) update. In other words, it is possible for client A to make an update to co-master 1, and in the meantime, before it propagates to co-master 2, client B could make an update to co-master 2 that makes the update of client A work differently than it did on co-master 1. Thus, when the update of client A makes it to co-master 2, it produces tables that are different from what you have on co-master 1, even after all the updates from co-master 2 have also propagated. This means that you should not chain two servers together in a two-way replication relationship unless you are sure that your updates can safely happen in any order, or unless you take care of mis-ordered updates somehow in the client code.
You should also realize that two-way replication actually does not improve performance very much (if at all) as far as updates are concerned. Each server must do the same number of updates, just as you would have a single server do. The only difference is that there is a little less lock contention, because the updates originating on another server are serialized in one slave thread. Even this benefit might be offset by network delays.
Q: How can I use replication to improve performance of my system?
A: You should set up one server
as the master and direct all writes to it. Then configure as many
slaves as you have the budget and rackspace for, and distribute
the reads among the master and the slaves. You can also start the
slaves with the --skip-innodb,
--skip-bdb,
--low-priority-updates, and
--delay-key-write=ALL options to get speed
improvements on the slave end. In this case, the slave uses
non-transactional MyISAM tables instead of
InnoDB and BDB tables to get
more speed by eliminating transactional overhead.
Q: What should I do to prepare client code in my own applications to use performance-enhancing replication?
A: If the part of your code that is responsible for database access has been properly abstracted/modularized, converting it to run with a replicated setup should be very smooth and easy. Change the implementation of your database access to send all writes to the master, and to send reads to either the master or a slave. If your code does not have this level of abstraction, setting up a replicated system gives you the opportunity and motivation to it clean up. Start by creating a wrapper library or module that implements the following functions:
safe_writer_connect()safe_reader_connect()safe_reader_statement()safe_writer_statement()
safe_ in each function name means that the
function takes care of handling all error conditions. You can use
different names for the functions. The important thing is to have
a unified interface for connecting for reads, connecting for
writes, doing a read, and doing a write.
Then convert your client code to use the wrapper library. This may be a painful and scary process at first, but it pays off in the long run. All applications that use the approach just described are able to take advantage of a master/slave configuration, even one involving multiple slaves. The code is much easier to maintain, and adding troubleshooting options is trivial. You need modify only one or two functions; for example, to log how long each statement took, or which statement among those issued gave you an error.
If you have written a lot of code, you may want to automate the conversion task by using the replace utility that comes with standard MySQL distributions, or write your own conversion script. Ideally, your code uses consistent programming style conventions. If not, then you are probably better off rewriting it anyway, or at least going through and manually regularizing it to use a consistent style.
Q: When and how much can MySQL replication improve the performance of my system?
A: MySQL replication is most beneficial for a system that processes frequent reads and infrequent writes. In theory, by using a single-master/multiple-slave setup, you can scale the system by adding more slaves until you either run out of network bandwidth, or your update load grows to the point that the master cannot handle it.
To determine how many slaves you can use before the added benefits
begin to level out, and how much you can improve performance of
your site, you need to know your query patterns, and to determine
empirically by benchmarking the relationship between the
throughput for reads (reads per second, or
reads) and for writes
(writes) on a typical master and a typical
slave. The example here shows a rather simplified calculation of
what you can get with replication for a hypothetical system.
Let's say that system load consists of 10% writes and 90% reads,
and we have determined by benchmarking that
reads is 1200 – 2 ×
writes. In other words, the system can do 1,200
reads per second with no writes, the average write is twice as
slow as the average read, and the relationship is linear. Let us
suppose that the master and each slave have the same capacity, and
that we have one master and N slaves.
Then we have for each server (master or slave):
reads = 1200 – 2 × writes
reads = 9 × writes / ( (reads are split, but writes go to all servers)
N
+ 1)
9 × writes / (
N + 1) + 2
× writes = 1200
writes = 1200 / (2 +
9/(
N+1))
The last equation indicates the maximum number of writes for
N slaves, given a maximum possible read
rate of 1,200 per minute and a ratio of nine reads per write.
This analysis yields the following conclusions:
If
N= 0 (which means we have no replication), our system can handle about 1200/11 = 109 writes per second.If
N= 1, we get up to 184 writes per second.If
N= 8, we get up to 400 writes per second.If
N= 17, we get up to 480 writes per second.Eventually, as
Napproaches infinity (and our budget negative infinity), we can get very close to 600 writes per second, increasing system throughput about 5.5 times. However, with only eight servers, we increase it nearly four times.
Note that these computations assume infinite network bandwidth and
neglect several other factors that could be significant on your
system. In many cases, you may not be able to perform a
computation similar to the one just shown that accurately predicts
what will happen on your system if you add
N replication slaves. However,
answering the following questions should help you decide whether
and by how much replication will improve the performance of your
system:
What is the read/write ratio on your system?
How much more write load can one server handle if you reduce the reads?
For how many slaves do you have bandwidth available on your network?
Q: How can I use replication to provide redundancy or high availability?
A: With the currently available features, you would have to set up a master and a slave (or several slaves), and to write a script that monitors the master to check whether it is up. Then instruct your applications and the slaves to change master in case of failure. Some suggestions:
To tell a slave to change its master, use the
CHANGE MASTER TOstatement.A good way to keep your applications informed as to the location of the master is by having a dynamic DNS entry for the master. With
bindyou can usensupdateto dynamically update your DNS.Run your slaves with the
--log-binoption and without--log-slave-updates. In this way, the slave is ready to become a master as soon as you issueSTOP SLAVE;RESET MASTER, andCHANGE MASTER TOstatement on the other slaves. For example, assume that you have the following setup:WC \ v WC----> M / | \ / | \ v v v S1 S2 S3In this diagram,
Mmeans the master,Sthe slaves,WCthe clients issuing database writes and reads; clients that issue only database reads are not represented, because they need not switch.S1,S2, andS3are slaves running with--log-binand without--log-slave-updates. Because updates received by a slave from the master are not logged in the binary log unless--log-slave-updatesis specified, the binary log on each slave is empty initially. If for some reasonMbecomes unavailable, you can pick one of the slaves to become the new master. For example, if you pickS1, allWCshould be redirected toS1, which will log updates to its binary log.S2andS3should then replicate fromS1.The reason for running the slave without
--log-slave-updatesis to prevent slaves from receiving updates twice in case you cause one of the slaves to become the new master. Suppose thatS1has--log-slave-updatesenabled. Then it will write updates that it receives fromMto its own binary log. WhenS2changes fromMtoS1as its master, it may receive updates fromS1that it has already received fromMMake sure that all slaves have processed any statements in their relay log. On each slave, issue
STOP SLAVE IO_THREAD, then check the output ofSHOW PROCESSLISTuntil you seeHas read all relay log. When this is true for all slaves, they can be reconfigured to the new setup. On the slaveS1being promoted to become the master, issueSTOP SLAVEandRESET MASTER.On the other slaves
S2andS3, useSTOP SLAVEandCHANGE MASTER TO MASTER_HOST='S1'(where'S1'represents the real hostname ofS1). ToCHANGE MASTER, add all information about how to connect toS1fromS2orS3(user,password,port). InCHANGE MASTER, there is no need to specify the name ofS1's binary log or binary log position to read from: We know it is the first binary log and position 4, which are the defaults forCHANGE MASTER. Finally, useSTART SLAVEonS2andS3.Then instruct all
WCto direct their statements toS1. From that point on, all updates statements sent byWCtoS1are written to the binary log ofS1, which then contains every update statement sent toS1sinceMdied.The result is this configuration:
WC / | WC | M(unavailable) \ | \ | v v S1<--S2 S3 ^ | +-------+When
Mis up again, you must issue on it the sameCHANGE MASTERas that issued onS2andS3, so thatMbecomes a slave ofS1and picks up all theWCwrites that it missed while it was down. To makeMa master again (because it is the most powerful machine, for example), use the preceding procedure as ifS1was unavailable andMwas to be the new master. During this procedure, do not forget to runRESET MASTERonMbefore makingS1,S2, andS3slaves ofM. Otherwise, they may pick up oldWCwrites from before the point at whichMbecame unavailable.Note that there is no synchronization between the different slaves to a master. Some slaves might be ahead of others. This means that the concept outlined in the previous example might not work. In practice, however, the relay logs of different slaves will most likely not be far behind the master, so it would work, anyway (but there is no guarantee).
Q: How do I prevent GRANT and REVOKE statements from replicating to slave machines?
A: Start the server with the
--replicate-wild-ignore-table=mysql.% option.
Q: Does replication work on mixed operating systems (for example, the master runs on Linux while slaves run on Mac OS X and Windows)?
A: Yes.
Q: Does replication work on mixed hardware architectures (for example, the master runs on a 64-bit machine while slaves run on 32-bit machines)?
A: Yes.
If you have followed the instructions, and your replication setup is not working, the first thing to do is check the error log for messages. Many users have lost time by not doing this soon enough after encountering problems.
If you cannot tell from the error log what the problem was, try the following techniques:
Verify that the master has binary logging enabled by issuing a
SHOW MASTER STATUSstatement. If logging is enabled,Positionis non-zero. If binary logging is not enabled, verify that you are running the master with the--log-binand--server-idoptions.Verify that the slave is running. Use
SHOW SLAVE STATUSto check whether theSlave_IO_RunningandSlave_SQL_Runningvalues are bothYes. If not, verify the options that were used when starting the slave server. For example,--skip-slave-startprevents the slave threads from starting until you issue aSTART SLAVEstatement.If the slave is running, check whether it established a connection to the master. Use
SHOW PROCESSLIST, find the I/O and SQL threads and check theirStatecolumn to see what they display. See Section 6.3, “Replication Implementation Details”. If the I/O thread state saysConnecting to master, verify the privileges for the replication user on the master, the master hostname, your DNS setup, whether the master is actually running, and whether it is reachable from the slave.If the slave was running previously but has stopped, the reason usually is that some statement that succeeded on the master failed on the slave. This should never happen if you have taken a proper snapshot of the master, and never modified the data on the slave outside of the slave thread. If the slave stops unexpectedly, it is a bug or you have encountered one of the known replication limitations described in Section 6.7, “Replication Features and Known Problems”. If it is a bug, see Section 6.12, “How to Report Replication Bugs or Problems”, for instructions on how to report it.
MySQL Enterprise For immediate notification whenever a slave stops, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
If a statement that succeeded on the master refuses to run on the slave, try the following procedure if it is not feasible to do a full database resynchronization by deleting the slave's databases and copying a new snapshot from the master:
Determine whether the affected table on the slave is different from the master table. Try to understand how this happened. Then make the slave's table identical to the master's and run
START SLAVE.If the preceding step does not work or does not apply, try to understand whether it would be safe to make the update manually (if needed) and then ignore the next statement from the master.
If you decide that you can skip the next statement from the master, issue the following statements:
mysql>
SET GLOBAL SQL_SLAVE_SKIP_COUNTER =mysql>N;START SLAVE;The value of
Nshould be 1 if the next statement from the master does not useAUTO_INCREMENTorLAST_INSERT_ID(). Otherwise, the value should be 2. The reason for using a value of 2 for statements that useAUTO_INCREMENTorLAST_INSERT_ID()is that they take two events in the binary log of the master.If you are sure that the slave started out perfectly synchronized with the master, and that no one has updated the tables involved outside of the slave thread, then presumably the discrepancy is the result of a bug. If you are running the most recent version of MySQL, please report the problem. If you are running an older version, try upgrading to the latest production release to determine whether the problem persists.
When you have determined that there is no user error involved, and replication still either does not work at all or is unstable, it is time to send us a bug report. We need to obtain as much information as possible from you to be able to track down the bug. Please spend some time and effort in preparing a good bug report.
If you have a repeatable test case that demonstrates the bug, please enter it into our bugs database using the instructions given in Section 1.8, “How to Report Bugs or Problems”. If you have a “phantom” problem (one that you cannot duplicate at will), use the following procedure:
Verify that no user error is involved. For example, if you update the slave outside of the slave thread, the data goes out of synchrony, and you can have unique key violations on updates. In this case, the slave thread stops and waits for you to clean up the tables manually to bring them into synchrony. This is not a replication problem. It is a problem of outside interference causing replication to fail.
Run the slave with the
--log-slave-updatesand--log-binoptions. These options cause the slave to log the updates that it receives from the master into its own binary logs.Save all evidence before resetting the replication state. If we have no information or only sketchy information, it becomes difficult or impossible for us to track down the problem. The evidence you should collect is:
All binary logs from the master
All binary logs from the slave
The output of
SHOW MASTER STATUSfrom the master at the time you discovered the problemThe output of
SHOW SLAVE STATUSfrom the slave at the time you discovered the problemError logs from the master and the slave
Use mysqlbinlog to examine the binary logs. The following should be helpful to find the problem statement.
log_posandlog_fileare theMaster_Log_FileandRead_Master_Log_Posvalues fromSHOW SLAVE STATUS.shell>
mysqlbinlog -jlog_poslog_file| head
After you have collected the evidence for the problem, try to isolate it as a separate test case first. Then enter the problem with as much information as possible into our bugs database using the instructions at Section 1.8, “How to Report Bugs or Problems”.
When multiple servers are configured as replication masters,
special steps must be taken to prevent key collisions when using
AUTO_INCREMENT columns, otherwise multiple
masters may attempt to use the same
AUTO_INCREMENT value when inserting rows.
The auto_increment_increment and
auto_increment_offset system variables help to
accommodate multiple-master replication with
AUTO_INCREMENT columns. Each of these variables
has a default and minimum value of 1, and a maximum value of
65,535. They were introduced in MySQL 5.0.2.
These two variables affect AUTO_INCREMENT
column behavior as follows:
auto_increment_incrementcontrols the increment between successiveAUTO_INCREMENTvalues.auto_increment_offsetdetermines the starting point forAUTO_INCREMENTcolumn values.
By choosing non-conflicting values for these variables on
different masters, servers in a multiple-master configuration will
not use conflicting AUTO_INCREMENT values when
inserting new rows into the same table. To set up
N master servers, set the variables
like this:
Set
auto_increment_incrementtoNon each master.Set each of the
Nmasters to have a differentauto_increment_offset, using the values 1, 2, …,N.
For additional information about
auto_increment_increment and
auto_increment_offset, see
Section 5.2.3, “System Variables”.
Table of Contents
- 7.1. Optimization Overview
- 7.2. Optimizing
SELECTand Other Statements - 7.2.1. Optimizing Queries with
EXPLAIN - 7.2.2. Estimating Query Performance
- 7.2.3. Speed of
SELECTQueries - 7.2.4.
WHEREClause Optimization - 7.2.5. Range Optimization
- 7.2.6. Index Merge Optimization
- 7.2.7.
IS NULLOptimization - 7.2.8.
LEFT JOINandRIGHT JOINOptimization - 7.2.9. Nested Join Optimization
- 7.2.10. Outer Join Simplification
- 7.2.11.
ORDER BYOptimization - 7.2.12.
GROUP BYOptimization - 7.2.13.
DISTINCTOptimization - 7.2.14. Optimizing
IN/=ANYSubqueries - 7.2.15.
LIMITOptimization - 7.2.16. How to Avoid Table Scans
- 7.2.17. Speed of
INSERTStatements - 7.2.18. Speed of
UPDATEStatements - 7.2.19. Speed of
DELETEStatements - 7.2.20. Other Optimization Tips
- 7.2.1. Optimizing Queries with
- 7.3. Locking Issues
- 7.4. Optimizing Database Structure
- 7.4.1. Design Choices
- 7.4.2. Make Your Data as Small as Possible
- 7.4.3. Column Indexes
- 7.4.4. Multiple-Column Indexes
- 7.4.5. How MySQL Uses Indexes
- 7.4.6. The
MyISAMKey Cache - 7.4.7.
MyISAMIndex Statistics Collection - 7.4.8. How MySQL Opens and Closes Tables
- 7.4.9. Drawbacks to Creating Many Tables in the Same Database
- 7.5. Optimizing the MySQL Server
- 7.6. Disk Issues
Optimization is a complex task because ultimately it requires understanding of the entire system to be optimized. Although it may be possible to perform some local optimizations with little knowledge of your system or application, the more optimal you want your system to become, the more you must know about it.
This chapter tries to explain and give some examples of different ways to optimize MySQL. Remember, however, that there are always additional ways to make the system even faster, although they may require increasing effort to achieve.
The most important factor in making a system fast is its basic design. You must also know what kinds of processing your system is doing, and what its bottlenecks are. In most cases, system bottlenecks arise from these sources:
Disk seeks. It takes time for the disk to find a piece of data. With modern disks, the mean time for this is usually lower than 10ms, so we can in theory do about 100 seeks a second. This time improves slowly with new disks and is very hard to optimize for a single table. The way to optimize seek time is to distribute the data onto more than one disk.
Disk reading and writing. When the disk is at the correct position, we need to read the data. With modern disks, one disk delivers at least 10–20MB/s throughput. This is easier to optimize than seeks because you can read in parallel from multiple disks.
CPU cycles. When we have the data in main memory, we need to process it to get our result. Having small tables compared to the amount of memory is the most common limiting factor. But with small tables, speed is usually not the problem.
Memory bandwidth. When the CPU needs more data than can fit in the CPU cache, main memory bandwidth becomes a bottleneck. This is an uncommon bottleneck for most systems, but one to be aware of.
MySQL Enterprise For instant notification of system bottlenecks subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
When using the MyISAM storage engine, MySQL
uses extremely fast table locking that allows multiple readers
or a single writer. The biggest problem with this storage engine
occurs when you have a steady stream of mixed updates and slow
selects on a single table. If this is a problem for certain
tables, you can use another storage engine for them. See
Chapter 14, Storage Engines.
MySQL can work with both transactional and non-transactional
tables. To make it easier to work smoothly with
non-transactional tables (which cannot roll back if something
goes wrong), MySQL has the following rules. Note that these
rules apply only when not running in strict
SQL mode or if you use the IGNORE specifier
for INSERT or UPDATE.
All columns have default values.
If you insert an inappropriate or out-of-range value into a column, MySQL sets the column to the “best possible value” instead of reporting an error. For numerical values, this is 0, the smallest possible value or the largest possible value. For strings, this is either the empty string or as much of the string as can be stored in the column.
All calculated expressions return a value that can be used instead of signaling an error condition. For example, 1/0 returns
NULL.
To change the preceding behaviors, you can enable stricter data
handling by setting the server SQL mode appropriately. For more
information about data handling, see
Section 1.9.6, “How MySQL Deals with Constraints”,
Section 5.2.6, “SQL Modes”, and Section 13.2.4, “INSERT Syntax”.
Because all SQL servers implement different parts of standard SQL, it takes work to write portable database applications. It is very easy to achieve portability for very simple selects and inserts, but becomes more difficult the more capabilities you require. If you want an application that is fast with many database systems, it becomes even more difficult.
All database systems have some weak points. That is, they have different design compromises that lead to different behavior.
To make a complex application portable, you need to determine which SQL servers it must work with, and then determine what features those servers support. You can use the MySQL crash-me program to find functions, types, and limits that you can use with a selection of database servers. crash-me does not check for every possible feature, but it is still reasonably comprehensive, performing about 450 tests. An example of the type of information crash-me can provide is that you should not use column names that are longer than 18 characters if you want to be able to use Informix or DB2.
The crash-me program and the MySQL benchmarks
are all very database independent. By taking a look at how they
are written, you can get a feeling for what you must do to make
your own applications database independent. The programs can be
found in the sql-bench directory of MySQL
source distributions. They are written in Perl and use the DBI
database interface. Use of DBI in itself solves part of the
portability problem because it provides database-independent
access methods. See Section 7.1.4, “The MySQL Benchmark Suite”.
If you strive for database independence, you need to get a good
feeling for each SQL server's bottlenecks. For example, MySQL is
very fast in retrieving and updating rows for
MyISAM tables, but has a problem in mixing
slow readers and writers on the same table. Oracle, on the other
hand, has a big problem when you try to access rows that you
have recently updated (until they are flushed to disk).
Transactional database systems in general are not very good at
generating summary tables from log tables, because in this case
row locking is almost useless.
MySQL Enterprise For expert advice on choosing the database engine suitable to your circumstances subscribe to the MySQL Network Monitoring and Advisory Service For more information see http://www.mysql.com/products/enterprise/advisors.html.
To make your application really database independent, you should define an easily extendable interface through which you manipulate your data. For example, C++ is available on most systems, so it makes sense to use a C++ class-based interface to the databases.
If you use some feature that is specific to a given database
system (such as the REPLACE statement, which
is specific to MySQL), you should implement the same feature for
other SQL servers by coding an alternative method. Although the
alternative might be slower, it enables the other servers to
perform the same tasks.
With MySQL, you can use the /*! */ syntax to
add MySQL-specific keywords to a statement. The code inside
/* */ is treated as a comment (and ignored)
by most other SQL servers. For information about writing
comments, see Section 9.5, “Comment Syntax”.
If high performance is more important than exactness, as for some Web applications, it is possible to create an application layer that caches all results to give you even higher performance. By letting old results expire after a while, you can keep the cache reasonably fresh. This provides a method to handle high load spikes, in which case you can dynamically increase the cache size and set the expiration timeout higher until things get back to normal.
In this case, the table creation information should contain information about the initial cache size and how often the table should normally be refreshed.
An attractive alternative to implementing an application cache is to use the MySQL query cache. By enabling the query cache, the server handles the details of determining whether a query result can be reused. This simplifies your application. See Section 5.13, “The MySQL Query Cache”.
This section describes an early application for MySQL.
During MySQL initial development, the features of MySQL were made to fit our largest customer, which handled data warehousing for a couple of the largest retailers in Sweden.
From all stores, we got weekly summaries of all bonus card transactions, and were expected to provide useful information for the store owners to help them find how their advertising campaigns were affecting their own customers.
The volume of data was quite huge (about seven million summary transactions per month), and we had data for 4–10 years that we needed to present to the users. We got weekly requests from our customers, who wanted instant access to new reports from this data.
We solved this problem by storing all information per month in compressed “transaction tables.” We had a set of simple macros that generated summary tables grouped by different criteria (product group, customer id, store, and so on) from the tables in which the transactions were stored. The reports were Web pages that were dynamically generated by a small Perl script. This script parsed a Web page, executed the SQL statements in it, and inserted the results. We would have used PHP or mod_perl instead, but they were not available at the time.
For graphical data, we wrote a simple tool in C that could process SQL query results and produce GIF images based on those results. This tool also was dynamically executed from the Perl script that parses the Web pages.
In most cases, a new report could be created simply by copying an existing script and modifying the SQL query that it used. In some cases, we needed to add more columns to an existing summary table or generate a new one. This also was quite simple because we kept all transaction-storage tables on disk. (This amounted to about 50GB of transaction tables and 200GB of other customer data.)
We also let our customers access the summary tables directly with ODBC so that the advanced users could experiment with the data themselves.
This system worked well and we had no problems handling the data with quite modest Sun Ultra SPARCstation hardware (2×200MHz). Eventually the system was migrated to Linux.
This benchmark suite is meant to tell any user what operations a
given SQL implementation performs well or poorly. You can get a
good idea for how the benchmarks work by looking at the code and
results in the sql-bench directory in any
MySQL source distribution.
Note that this benchmark is single-threaded, so it measures the minimum time for the operations performed. We plan to add multi-threaded tests to the benchmark suite in the future.
To use the benchmark suite, the following requirements must be satisfied:
The benchmark suite is provided with MySQL source distributions. You can either download a released distribution from http://dev.mysql.com/downloads/, or use the current development source tree. (See Section 2.4.14.3, “Installing from the Development Source Tree”.)
The benchmark scripts are written in Perl and use the Perl DBI module to access database servers, so DBI must be installed. You also need the server-specific DBD drivers for each of the servers you want to test. For example, to test MySQL, PostgreSQL, and DB2, you must have the
DBD::mysql,DBD::Pg, andDBD::DB2modules installed. See Section 2.4.20, “Perl Installation Notes”.
After you obtain a MySQL source distribution, you can find the
benchmark suite located in its sql-bench
directory. To run the benchmark tests, build MySQL, and then
change location into the sql-bench
directory and execute the run-all-tests
script:
shell>cd sql-benchshell>perl run-all-tests --server=server_name
server_name should be the name of one
of the supported servers. To get a list of all options and
supported servers, invoke this command:
shell> perl run-all-tests --help
The crash-me script also is located in the
sql-bench directory.
crash-me tries to determine what features a
database system supports and what its capabilities and
limitations are by actually running queries. For example, it
determines:
What data types are supported
How many indexes are supported
What functions are supported
How big a query can be
How big a
VARCHARcolumn can be
You can find the results from crash-me for many different database servers at http://dev.mysql.com/tech-resources/crash-me.php. For more information about benchmark results, visit http://dev.mysql.com/tech-resources/benchmarks/.
You should definitely benchmark your application and database to find out where the bottlenecks are. After fixing one bottleneck (or by replacing it with a “dummy” module), you can proceed to identify the next bottleneck. Even if the overall performance for your application currently is acceptable, you should at least make a plan for each bottleneck and decide how to solve it if someday you really need the extra performance.
For examples of portable benchmark programs, look at those in the MySQL benchmark suite. See Section 7.1.4, “The MySQL Benchmark Suite”. You can take any program from this suite and modify it for your own needs. By doing this, you can try different solutions to your problem and test which really is fastest for you.
Another free benchmark suite is the Open Source Database Benchmark, available at http://osdb.sourceforge.net/.
It is very common for a problem to occur only when the system is very heavily loaded. We have had many customers who contact us when they have a (tested) system in production and have encountered load problems. In most cases, performance problems turn out to be due to issues of basic database design (for example, table scans are not good under high load) or problems with the operating system or libraries. Most of the time, these problems would be much easier to fix if the systems were not already in production.
To avoid problems like this, you should put some effort into benchmarking your whole application under the worst possible load. You can use Super Smack, available at http://jeremy.zawodny.com/mysql/super-smack/. As suggested by its name, it can bring a system to its knees, so make sure to use it only on your development systems.
- 7.2.1. Optimizing Queries with
EXPLAIN - 7.2.2. Estimating Query Performance
- 7.2.3. Speed of
SELECTQueries - 7.2.4.
WHEREClause Optimization - 7.2.5. Range Optimization
- 7.2.6. Index Merge Optimization
- 7.2.7.
IS NULLOptimization - 7.2.8.
LEFT JOINandRIGHT JOINOptimization - 7.2.9. Nested Join Optimization
- 7.2.10. Outer Join Simplification
- 7.2.11.
ORDER BYOptimization - 7.2.12.
GROUP BYOptimization - 7.2.13.
DISTINCTOptimization - 7.2.14. Optimizing
IN/=ANYSubqueries - 7.2.15.
LIMITOptimization - 7.2.16. How to Avoid Table Scans
- 7.2.17. Speed of
INSERTStatements - 7.2.18. Speed of
UPDATEStatements - 7.2.19. Speed of
DELETEStatements - 7.2.20. Other Optimization Tips
First, one factor affects all statements: The more complex your
permissions setup, the more overhead you have. Using simpler
permissions when you issue GRANT statements
enables MySQL to reduce permission-checking overhead when clients
execute statements. For example, if you do not grant any
table-level or column-level privileges, the server need not ever
check the contents of the tables_priv and
columns_priv tables. Similarly, if you place no
resource limits on any accounts, the server does not have to
perform resource counting. If you have a very high
statement-processing load, it may be worth the time to use a
simplified grant structure to reduce permission-checking overhead.
If your problem is with a specific MySQL expression or function,
you can perform a timing test by invoking the
BENCHMARK() function using the
mysql client program. Its syntax is
BENCHMARK(.
The return value is always zero, but mysql
prints a line displaying approximately how long the statement took
to execute. For example:
loop_count,expression)
mysql> SELECT BENCHMARK(1000000,1+1);
+------------------------+
| BENCHMARK(1000000,1+1) |
+------------------------+
| 0 |
+------------------------+
1 row in set (0.32 sec)
This result was obtained on a Pentium II 400MHz system. It shows that MySQL can execute 1,000,000 simple addition expressions in 0.32 seconds on that system.
All MySQL functions should be highly optimized, but there may be
some exceptions. BENCHMARK() is an excellent
tool for finding out if some function is a problem for your
queries.
EXPLAIN tbl_name
Or:
EXPLAIN [EXTENDED] SELECT select_options
The EXPLAIN statement can be used either as a
synonym for DESCRIBE or as a way to obtain
information about how MySQL executes a SELECT
statement:
EXPLAINis synonymous withtbl_nameDESCRIBEortbl_nameSHOW COLUMNS FROM.tbl_nameWhen you precede a
SELECTstatement with the keywordEXPLAIN, MySQL displays information from the optimizer about the query execution plan. That is, MySQL explains how it would process theSELECT, including information about how tables are joined and in which order.
This section describes the second use of
EXPLAIN for obtaining query execution plan
information. For a description of the
DESCRIBE and SHOW COLUMNS
statements, see Section 13.3.1, “DESCRIBE Syntax”, and
Section 13.5.4.3, “SHOW COLUMNS Syntax”.
With the help of EXPLAIN, you can see where
you should add indexes to tables to get a faster
SELECT that uses indexes to find rows. You
can also use EXPLAIN to check whether the
optimizer joins the tables in an optimal order. To force the
optimizer to use a join order corresponding to the order in
which the tables are named in the SELECT
statement, begin the statement with SELECT
STRAIGHT_JOIN rather than just
SELECT.
If you have a problem with indexes not being used when you
believe that they should be, you should run ANALYZE
TABLE to update table statistics such as cardinality
of keys, that can affect the choices the optimizer makes. See
Section 13.5.2.1, “ANALYZE TABLE Syntax”.
EXPLAIN returns a row of information for each
table used in the SELECT statement. The
tables are listed in the output in the order that MySQL would
read them while processing the query. MySQL resolves all joins
using a single-sweep multi-join method.
This means that MySQL reads a row from the first table, and then
finds a matching row in the second table, the third table, and
so on. When all tables are processed, MySQL outputs the selected
columns and backtracks through the table list until a table is
found for which there are more matching rows. The next row is
read from this table and the process continues with the next
table.
When the EXTENDED keyword is used,
EXPLAIN produces extra information that can
be viewed by issuing a SHOW WARNINGS
statement following the EXPLAIN statement.
This information displays how the optimizer qualifies table and
column names in the SELECT statement, what
the SELECT looks like after the application
of rewriting and optimization rules, and possibly other notes
about the optimization process.
Each output row from EXPLAIN provides
information about one table, and each row contains the following
columns:
idThe
SELECTidentifier. This is the sequential number of theSELECTwithin the query.select_typeThe type of
SELECT, which can be any of those shown in the following table:SIMPLESimple SELECT(not usingUNIONor subqueries)PRIMARYOutermost SELECTUNIONSecond or later SELECTstatement in aUNIONDEPENDENT UNIONSecond or later SELECTstatement in aUNION, dependent on outer queryUNION RESULTResult of a UNION.SUBQUERYFirst SELECTin subqueryDEPENDENT SUBQUERYFirst SELECTin subquery, dependent on outer queryDERIVEDDerived table SELECT(subquery inFROMclause)UNCACHEABLE SUBQUERYA subquery for which the result cannot be cached and must be re-evaluated for each row of the outer query DEPENDENTtypically signifies the use of a correlated subquery. See Section 13.2.8.7, “Correlated Subqueries”.“DEPENDENT SUBQUERY” evaluation differs from
UNCACHEABLE SUBQUERYevaluation. For “DEPENDENT SUBQUERY”, the subquery is re-evaluated only once for each set of different values of the variables from its outer context. ForUNCACHEABLE SUBQUERY, the subquery is re-evaluated for each row of the outer context. Cacheability of subqueries is subject to the restrictions detailed in Section 5.13.1, “How the Query Cache Operates”. For example, referring to user variables makes a subquery uncacheable.tableThe table to which the row of output refers.
typeThe join type. The different join types are listed here, ordered from the best type to the worst:
The table has only one row (= system table). This is a special case of the
constjoin type.The table has at most one matching row, which is read at the start of the query. Because there is only one row, values from the column in this row can be regarded as constants by the rest of the optimizer.
consttables are very fast because they are read only once.constis used when you compare all parts of aPRIMARY KEYorUNIQUEindex to constant values. In the following queries,tbl_namecan be used as aconsttable:SELECT * FROM
tbl_nameWHEREprimary_key=1; SELECT * FROMtbl_nameWHEREprimary_key_part1=1 ANDprimary_key_part2=2;eq_refOne row is read from this table for each combination of rows from the previous tables. Other than the
systemandconsttypes, this is the best possible join type. It is used when all parts of an index are used by the join and the index is aPRIMARY KEYorUNIQUEindex.eq_refcan be used for indexed columns that are compared using the=operator. The comparison value can be a constant or an expression that uses columns from tables that are read before this table. In the following examples, MySQL can use aneq_refjoin to processref_table:SELECT * FROM
ref_table,other_tableWHEREref_table.key_column=other_table.column; SELECT * FROMref_table,other_tableWHEREref_table.key_column_part1=other_table.columnANDref_table.key_column_part2=1;refAll rows with matching index values are read from this table for each combination of rows from the previous tables.
refis used if the join uses only a leftmost prefix of the key or if the key is not aPRIMARY KEYorUNIQUEindex (in other words, if the join cannot select a single row based on the key value). If the key that is used matches only a few rows, this is a good join type.refcan be used for indexed columns that are compared using the=or<=>operator. In the following examples, MySQL can use arefjoin to processref_table:SELECT * FROM
ref_tableWHEREkey_column=expr; SELECT * FROMref_table,other_tableWHEREref_table.key_column=other_table.column; SELECT * FROMref_table,other_tableWHEREref_table.key_column_part1=other_table.columnANDref_table.key_column_part2=1;ref_or_nullThis join type is like
ref, but with the addition that MySQL does an extra search for rows that containNULLvalues. This join type optimization is used most often in resolving subqueries. In the following examples, MySQL can use aref_or_nulljoin to processref_table:SELECT * FROM
ref_tableWHEREkey_column=exprORkey_columnIS NULL;index_mergeThis join type indicates that the Index Merge optimization is used. In this case, the
keycolumn in the output row contains a list of indexes used, andkey_lencontains a list of the longest key parts for the indexes used. For more information, see Section 7.2.6, “Index Merge Optimization”.unique_subqueryThis type replaces
reffor someINsubqueries of the following form:valueIN (SELECTprimary_keyFROMsingle_tableWHEREsome_expr)unique_subqueryis just an index lookup function that replaces the subquery completely for better efficiency.index_subqueryThis join type is similar to
unique_subquery. It replacesINsubqueries, but it works for non-unique indexes in subqueries of the following form:valueIN (SELECTkey_columnFROMsingle_tableWHEREsome_expr)rangeOnly rows that are in a given range are retrieved, using an index to select the rows. The
keycolumn in the output row indicates which index is used. Thekey_lencontains the longest key part that was used. Therefcolumn isNULLfor this type.rangecan be used when a key column is compared to a constant using any of the=,<>,>,>=,<,<=,IS NULL,<=>,BETWEEN, orINoperators:SELECT * FROM
tbl_nameWHEREkey_column= 10; SELECT * FROMtbl_nameWHEREkey_columnBETWEEN 10 and 20; SELECT * FROMtbl_nameWHEREkey_columnIN (10,20,30); SELECT * FROMtbl_nameWHEREkey_part1= 10 ANDkey_part2IN (10,20,30);indexThis join type is the same as
ALL, except that only the index tree is scanned. This usually is faster thanALLbecause the index file usually is smaller than the data file.MySQL can use this join type when the query uses only columns that are part of a single index.
ALLA full table scan is done for each combination of rows from the previous tables. This is normally not good if the table is the first table not marked
const, and usually very bad in all other cases. Normally, you can avoidALLby adding indexes that allow row retrieval from the table based on constant values or column values from earlier tables.
possible_keysThe
possible_keyscolumn indicates which indexes MySQL can choose from use to find the rows in this table. Note that this column is totally independent of the order of the tables as displayed in the output fromEXPLAIN. That means that some of the keys inpossible_keysmight not be usable in practice with the generated table order.If this column is
NULL, there are no relevant indexes. In this case, you may be able to improve the performance of your query by examining theWHEREclause to check whether it refers to some column or columns that would be suitable for indexing. If so, create an appropriate index and check the query withEXPLAINagain. See Section 13.1.2, “ALTER TABLESyntax”.To see what indexes a table has, use
SHOW INDEX FROM.tbl_namekeyThe
keycolumn indicates the key (index) that MySQL actually decided to use. If MySQL decides to use one of thepossible_keysindexes to look up rows, that index is listed as the key value.It is possible that
keywill name an index that is not present in thepossible_keysvalue. This can happen if none of thepossible_keysindexes are suitable for looking up rows, but all the columns selected by the query are columns of some other index. That is, the named index covers the selected columns, so although it is not used to determine which rows to retrieve, an index scan is more efficient than a data row scan.For
InnoDB, a secondary index might cover the selected columns even if the query also selects the primary key becauseInnoDBstores the primary key value with each secondary index. IfkeyisNULL, MySQL found no index to use for executing the query more efficiently.To force MySQL to use or ignore an index listed in the
possible_keyscolumn, useFORCE INDEX,USE INDEX, orIGNORE INDEXin your query. See Section 13.2.7.2, “Index Hint Syntax”.For
MyISAMandBDBtables, runningANALYZE TABLEhelps the optimizer choose better indexes. ForMyISAMtables, myisamchk --analyze does the same. See Section 13.5.2.1, “ANALYZE TABLESyntax”, and Section 5.9.4, “Table Maintenance and Crash Recovery”.key_lenThe
key_lencolumn indicates the length of the key that MySQL decided to use. The length isNULLif thekeycolumn saysNULL. Note that the value ofkey_lenenables you to determine how many parts of a multiple-part key MySQL actually uses.refThe
refcolumn shows which columns or constants are compared to the index named in thekeycolumn to select rows from the table.rowsThe
rowscolumn indicates the number of rows MySQL believes it must examine to execute the query.ExtraThis column contains additional information about how MySQL resolves the query. The following list explains the values that can appear in this column. If you want to make your queries as fast as possible, you should look out for
Extravalues ofUsing filesortandUsing temporary.DistinctMySQL is looking for distinct values, so it stops searching for more rows for the current row combination after it has found the first matching row.
Full scan on NULL keyThis occurs for subquery optimization as a fallback strategy when the optimizer cannot use an index-lookup access method.
Impossible WHERE noticed after reading const tablesMySQL has read all
const(andsystem) tables and notice that theWHEREclause is always false.No tablesThe query has no
FROMclause, or has aFROM DUALclause.Not existsMySQL was able to do a
LEFT JOINoptimization on the query and does not examine more rows in this table for the previous row combination after it finds one row that matches theLEFT JOINcriteria. Here is an example of the type of query that can be optimized this way:SELECT * FROM t1 LEFT JOIN t2 ON t1.id=t2.id WHERE t2.id IS NULL;
Assume that
t2.idis defined asNOT NULL. In this case, MySQL scanst1and looks up the rows int2using the values oft1.id. If MySQL finds a matching row int2, it knows thatt2.idcan never beNULL, and does not scan through the rest of the rows int2that have the sameidvalue. In other words, for each row int1, MySQL needs to do only a single lookup int2, regardless of how many rows actually match int2.range checked for each record (index map:N)MySQL found no good index to use, but found that some of indexes might be used after column values from preceding tables are known. For each row combination in the preceding tables, MySQL checks whether it is possible to use a
rangeorindex_mergeaccess method to retrieve rows. This is not very fast, but is faster than performing a join with no index at all. The applicability criteria are as described in Section 7.2.5, “Range Optimization”, and Section 7.2.6, “Index Merge Optimization”, with the exception that all column values for the preceding table are known and considered to be constants.Select tables optimized awayThe query contained only aggregate functions (
MIN(),MAX()) that were all resolved using an index, orCOUNT(*)forMyISAM, and noGROUP BYclause. The optimizer determined that only one row should be returned.Using filesortMySQL must do an extra pass to find out how to retrieve the rows in sorted order. The sort is done by going through all rows according to the join type and storing the sort key and pointer to the row for all rows that match the
WHEREclause. The keys then are sorted and the rows are retrieved in sorted order. See Section 7.2.11, “ORDER BYOptimization”.Using indexThe column information is retrieved from the table using only information in the index tree without having to do an additional seek to read the actual row. This strategy can be used when the query uses only columns that are part of a single index.
Using temporaryTo resolve the query, MySQL needs to create a temporary table to hold the result. This typically happens if the query contains
GROUP BYandORDER BYclauses that list columns differently.Using whereA
WHEREclause is used to restrict which rows to match against the next table or send to the client. Unless you specifically intend to fetch or examine all rows from the table, you may have something wrong in your query if theExtravalue is notUsing whereand the table join type isALLorindex.Using sort_union(...),Using union(...),Using intersect(...)These indicate how index scans are merged for the
index_mergejoin type. See Section 7.2.6, “Index Merge Optimization”, for more information.Using index for group-bySimilar to the
Using indexway of accessing a table,Using index for group-byindicates that MySQL found an index that can be used to retrieve all columns of aGROUP BYorDISTINCTquery without any extra disk access to the actual table. Additionally, the index is used in the most efficient way so that for each group, only a few index entries are read. For details, see Section 7.2.12, “GROUP BYOptimization”.Using where with pushed conditionThis item applies to
NDB Clustertables only. It means that MySQL Cluster is using condition pushdown to improve the efficiency of a direct comparison (=) between a non-indexed column and a constant. In such cases, the condition is “pushed down” to the cluster's data nodes where it is evaluated in all partitions simultaneously. This eliminates the need to send non-matching rows over the network, and can speed up such queries by a factor of 5 to 10 times over cases where condition pushdown could be but is not used.Suppose that you have a Cluster table defined as follows:
CREATE TABLE t1 ( a INT, b INT, KEY(a) ) ENGINE=NDBCLUSTER;In this case, condition pushdown can be used with a query such as this one:
SELECT a,b FROM t1 WHERE b = 10;
This can be seen in the output of
EXPLAIN SELECT, as shown here:mysql>
EXPLAIN SELECT a,b FROM t1 WHERE b = 10\G*************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 10 Extra: Using where with pushed conditionCondition pushdown cannot be used with either of these two queries:
SELECT a,b FROM t1 WHERE a = 10; SELECT a,b FROM t1 WHERE b + 1 = 10;
With regard to the first of these two queries, condition pushdown is not applicable because an index exists on column
a. In the case of the second query, a condition pushdown cannot be employed because the comparison involving the non-indexed columnbis an indirect one. (However, it would apply if you were to reduceb + 1 = 10tob = 9in theWHEREclause.)However, a condition pushdown may also be employed when an indexed column is compared with a constant using a
>or<operator:mysql>
EXPLAIN SELECT a,b FROM t1 WHERE a<2\G*************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 type: range possible_keys: a key: a key_len: 5 ref: NULL rows: 2 Extra: Using where with pushed conditionWith regard to condition pushdown, keep in mind that:
Condition pushdown is relevant to MySQL Cluster only, and does not occur when executing queries against tables using any other storage engine.
Condition pushdown capability is not used by default. To enable it, you can start mysqld with the
--engine-condition-pushdownoption, or execute the following statement:SET engine_condition_pushdown=On;
Note: Condition pushdown is not supported for columns of any of the
BLOBorTEXTtypes.
Condition pushdown,
Using where with pushed condition, andengine_condition_pushdownwere all introduced in MySQL 5.0 Cluster.
You can get a good indication of how good a join is by taking
the product of the values in the rows column
of the EXPLAIN output. This should tell you
roughly how many rows MySQL must examine to execute the query.
If you restrict queries with the
max_join_size system variable, this row
product also is used to determine which multiple-table
SELECT statements to execute and which to
abort. See Section 7.5.2, “Tuning Server Parameters”.
The following example shows how a multiple-table join can be
optimized progressively based on the information provided by
EXPLAIN.
Suppose that you have the SELECT statement
shown here and that you plan to examine it using
EXPLAIN:
EXPLAIN SELECT tt.TicketNumber, tt.TimeIn,
tt.ProjectReference, tt.EstimatedShipDate,
tt.ActualShipDate, tt.ClientID,
tt.ServiceCodes, tt.RepetitiveID,
tt.CurrentProcess, tt.CurrentDPPerson,
tt.RecordVolume, tt.DPPrinted, et.COUNTRY,
et_1.COUNTRY, do.CUSTNAME
FROM tt, et, et AS et_1, do
WHERE tt.SubmitTime IS NULL
AND tt.ActualPC = et.EMPLOYID
AND tt.AssignedPC = et_1.EMPLOYID
AND tt.ClientID = do.CUSTNMBR;
For this example, make the following assumptions:
The columns being compared have been declared as follows:
Table Column Data Type ttActualPCCHAR(10)ttAssignedPCCHAR(10)ttClientIDCHAR(10)etEMPLOYIDCHAR(15)doCUSTNMBRCHAR(15)The tables have the following indexes:
Table Index ttActualPCttAssignedPCttClientIDetEMPLOYID(primary key)doCUSTNMBR(primary key)The
tt.ActualPCvalues are not evenly distributed.
Initially, before any optimizations have been performed, the
EXPLAIN statement produces the following
information:
table type possible_keys key key_len ref rows Extra
et ALL PRIMARY NULL NULL NULL 74
do ALL PRIMARY NULL NULL NULL 2135
et_1 ALL PRIMARY NULL NULL NULL 74
tt ALL AssignedPC, NULL NULL NULL 3872
ClientID,
ActualPC
range checked for each record (key map: 35)
Because type is ALL for
each table, this output indicates that MySQL is generating a
Cartesian product of all the tables; that is, every combination
of rows. This takes quite a long time, because the product of
the number of rows in each table must be examined. For the case
at hand, this product is 74 × 2135 × 74 × 3872
= 45,268,558,720 rows. If the tables were bigger, you can only
imagine how long it would take.
One problem here is that MySQL can use indexes on columns more
efficiently if they are declared as the same type and size. In
this context, VARCHAR and
CHAR are considered the same if they are
declared as the same size. tt.ActualPC is
declared as CHAR(10) and
et.EMPLOYID is CHAR(15),
so there is a length mismatch.
To fix this disparity between column lengths, use ALTER
TABLE to lengthen ActualPC from 10
characters to 15 characters:
mysql> ALTER TABLE tt MODIFY ActualPC VARCHAR(15);
Now tt.ActualPC and
et.EMPLOYID are both
VARCHAR(15). Executing the
EXPLAIN statement again produces this result:
table type possible_keys key key_len ref rows Extra
tt ALL AssignedPC, NULL NULL NULL 3872 Using
ClientID, where
ActualPC
do ALL PRIMARY NULL NULL NULL 2135
range checked for each record (key map: 1)
et_1 ALL PRIMARY NULL NULL NULL 74
range checked for each record (key map: 1)
et eq_ref PRIMARY PRIMARY 15 tt.ActualPC 1
This is not perfect, but is much better: The product of the
rows values is less by a factor of 74. This
version executes in a couple of seconds.
A second alteration can be made to eliminate the column length
mismatches for the tt.AssignedPC =
et_1.EMPLOYID and tt.ClientID =
do.CUSTNMBR comparisons:
mysql>ALTER TABLE tt MODIFY AssignedPC VARCHAR(15),->MODIFY ClientID VARCHAR(15);
After that modification, EXPLAIN produces the
output shown here:
table type possible_keys key key_len ref rows Extra
et ALL PRIMARY NULL NULL NULL 74
tt ref AssignedPC, ActualPC 15 et.EMPLOYID 52 Using
ClientID, where
ActualPC
et_1 eq_ref PRIMARY PRIMARY 15 tt.AssignedPC 1
do eq_ref PRIMARY PRIMARY 15 tt.ClientID 1
At this point, the query is optimized almost as well as
possible. The remaining problem is that, by default, MySQL
assumes that values in the tt.ActualPC column
are evenly distributed, and that is not the case for the
tt table. Fortunately, it is easy to tell
MySQL to analyze the key distribution:
mysql> ANALYZE TABLE tt;
With the additional index information, the join is perfect and
EXPLAIN produces this result:
table type possible_keys key key_len ref rows Extra
tt ALL AssignedPC NULL NULL NULL 3872 Using
ClientID, where
ActualPC
et eq_ref PRIMARY PRIMARY 15 tt.ActualPC 1
et_1 eq_ref PRIMARY PRIMARY 15 tt.AssignedPC 1
do eq_ref PRIMARY PRIMARY 15 tt.ClientID 1
Note that the rows column in the output from
EXPLAIN is an educated guess from the MySQL
join optimizer. You should check whether the numbers are even
close to the truth by comparing the rows
product with the actual number of rows that the query returns.
If the numbers are quite different, you might get better
performance by using STRAIGHT_JOIN in your
SELECT statement and trying to list the
tables in a different order in the FROM
clause.
MySQL Enterprise Subscribers to the MySQL Network Monitoring and Advisory Service regularly receive expert advice on optimization. For more information see http://www.mysql.com/products/enterprise/advisors.html.
In most cases, you can estimate query performance by counting
disk seeks. For small tables, you can usually find a row in one
disk seek (because the index is probably cached). For bigger
tables, you can estimate that, using B-tree indexes, you need
this many seeks to find a row:
log(.
row_count) /
log(index_block_length / 3 × 2
/ (index_length +
data_pointer_length)) + 1
In MySQL, an index block is usually 1,024 bytes and the data
pointer is usually four bytes. For a 500,000-row table with an
index length of three bytes (the size of
MEDIUMINT), the formula indicates
log(500,000)/log(1024/3×2/(3+4)) + 1 =
4 seeks.
This index would require storage of about 500,000 × 7 × 3/2 = 5.2MB (assuming a typical index buffer fill ratio of 2/3), so you probably have much of the index in memory and so need only one or two calls to read data to find the row.
For writes, however, you need four seek requests to find where to place a new index value and normally two seeks to update the index and write the row.
Note that the preceding discussion does not mean that your
application performance slowly degenerates by log
N. As long as everything is cached by
the OS or the MySQL server, things become only marginally slower
as the table gets bigger. After the data gets too big to be
cached, things start to go much slower until your applications
are bound only by disk seeks (which increase by log
N). To avoid this, increase the key
cache size as the data grows. For MyISAM
tables, the key cache size is controlled by the
key_buffer_size system variable. See
Section 7.5.2, “Tuning Server Parameters”.
MySQL Enterprise The MySQL Network Monitoring and Advisory Service provides a number of advisors specifically designed to improve query performance. For more information see http://www.mysql.com/products/enterprise/advisors.html.
In general, when you want to make a slow SELECT ...
WHERE query faster, the first thing to check is
whether you can add an index. All references between different
tables should usually be done with indexes. You can use the
EXPLAIN statement to determine which indexes
are used for a SELECT. See
Section 7.2.1, “Optimizing Queries with EXPLAIN”, and Section 7.4.5, “How MySQL Uses Indexes”.
Some general tips for speeding up queries on
MyISAM tables:
To help MySQL better optimize queries, use
ANALYZE TABLEor run myisamchk --analyze on a table after it has been loaded with data. This updates a value for each index part that indicates the average number of rows that have the same value. (For unique indexes, this is always 1.) MySQL uses this to decide which index to choose when you join two tables based on a non-constant expression. You can check the result from the table analysis by usingSHOW INDEX FROMand examining thetbl_nameCardinalityvalue. myisamchk --description --verbose shows index distribution information.To sort an index and data according to an index, use myisamchk --sort-index --sort-records=1 (assuming that you want to sort on index 1). This is a good way to make queries faster if you have a unique index from which you want to read all rows in order according to the index. The first time you sort a large table this way, it may take a long time.
This section discusses optimizations that can be made for
processing WHERE clauses. The examples use
SELECT statements, but the same optimizations
apply for WHERE clauses in
DELETE and UPDATE
statements.
Work on the MySQL optimizer is ongoing, so this section is incomplete. MySQL performs a great many optimizations, not all of which are documented here.
Some of the optimizations performed by MySQL follow:
Removal of unnecessary parentheses:
((a AND b) AND c OR (((a AND b) AND (c AND d)))) -> (a AND b AND c) OR (a AND b AND c AND d)
Constant folding:
(a<b AND b=c) AND a=5 -> b>5 AND b=c AND a=5
Constant condition removal (needed because of constant folding):
(B>=5 AND B=5) OR (B=6 AND 5=5) OR (B=7 AND 5=6) -> B=5 OR B=6
Constant expressions used by indexes are evaluated only once.
COUNT(*)on a single table without aWHEREis retrieved directly from the table information forMyISAMandMEMORYtables. This is also done for anyNOT NULLexpression when used with only one table.Early detection of invalid constant expressions. MySQL quickly detects that some
SELECTstatements are impossible and returns no rows.HAVINGis merged withWHEREif you do not useGROUP BYor aggregate functions (COUNT(),MIN(), and so on).For each table in a join, a simpler
WHEREis constructed to get a fastWHEREevaluation for the table and also to skip rows as soon as possible.All constant tables are read first before any other tables in the query. A constant table is any of the following:
An empty table or a table with one row.
A table that is used with a
WHEREclause on aPRIMARY KEYor aUNIQUEindex, where all index parts are compared to constant expressions and are defined asNOT NULL.
All of the following tables are used as constant tables:
SELECT * FROM t WHERE
primary_key=1; SELECT * FROM t1,t2 WHERE t1.primary_key=1 AND t2.primary_key=t1.id;The best join combination for joining the tables is found by trying all possibilities. If all columns in
ORDER BYandGROUP BYclauses come from the same table, that table is preferred first when joining.If there is an
ORDER BYclause and a differentGROUP BYclause, or if theORDER BYorGROUP BYcontains columns from tables other than the first table in the join queue, a temporary table is created.If you use the
SQL_SMALL_RESULToption, MySQL uses an in-memory temporary table.Each table index is queried, and the best index is used unless the optimizer believes that it is more efficient to use a table scan. At one time, a scan was used based on whether the best index spanned more than 30% of the table, but a fixed percentage no longer determines the choice between using an index or a scan. The optimizer now is more complex and bases its estimate on additional factors such as table size, number of rows, and I/O block size.
In some cases, MySQL can read rows from the index without even consulting the data file. If all columns used from the index are numeric, only the index tree is used to resolve the query.
Before each row is output, those that do not match the
HAVINGclause are skipped.
Some examples of queries that are very fast:
SELECT COUNT(*) FROMtbl_name; SELECT MIN(key_part1),MAX(key_part1) FROMtbl_name; SELECT MAX(key_part2) FROMtbl_nameWHEREkey_part1=constant; SELECT ... FROMtbl_nameORDER BYkey_part1,key_part2,... LIMIT 10; SELECT ... FROMtbl_nameORDER BYkey_part1DESC,key_part2DESC, ... LIMIT 10;
MySQL resolves the following queries using only the index tree, assuming that the indexed columns are numeric:
SELECTkey_part1,key_part2FROMtbl_nameWHEREkey_part1=val; SELECT COUNT(*) FROMtbl_nameWHEREkey_part1=val1ANDkey_part2=val2; SELECTkey_part2FROMtbl_nameGROUP BYkey_part1;
The following queries use indexing to retrieve the rows in sorted order without a separate sorting pass:
SELECT ... FROMtbl_nameORDER BYkey_part1,key_part2,... ; SELECT ... FROMtbl_nameORDER BYkey_part1DESC,key_part2DESC, ... ;
The range access method uses a single index
to retrieve a subset of table rows that are contained within one
or several index value intervals. It can be used for a
single-part or multiple-part index. The following sections give
a detailed description of how intervals are extracted from the
WHERE clause.
For a single-part index, index value intervals can be
conveniently represented by corresponding conditions in the
WHERE clause, so we speak of
range conditions rather than
“intervals.”
The definition of a range condition for a single-part index is as follows:
For both
BTREEandHASHindexes, comparison of a key part with a constant value is a range condition when using the=,<=>,IN,IS NULL, orIS NOT NULLoperators.For
BTREEindexes, comparison of a key part with a constant value is a range condition when using the>,<,>=,<=,BETWEEN,!=, or<>operators, orLIKE '(wherepattern''does not start with a wildcard).pattern'For all types of indexes, multiple range conditions combined with
ORorANDform a range condition.
“Constant value” in the preceding descriptions means one of the following:
A constant from the query string
A column of a
constorsystemtable from the same joinThe result of an uncorrelated subquery
Any expression composed entirely from subexpressions of the preceding types
Here are some examples of queries with range conditions in the
WHERE clause:
SELECT * FROM t1 WHEREkey_col> 1 ANDkey_col< 10; SELECT * FROM t1 WHEREkey_col= 1 ORkey_colIN (15,18,20); SELECT * FROM t1 WHEREkey_colLIKE 'ab%' ORkey_colBETWEEN 'bar' AND 'foo';
Note that some non-constant values may be converted to constants during the constant propagation phase.
MySQL tries to extract range conditions from the
WHERE clause for each of the possible
indexes. During the extraction process, conditions that cannot
be used for constructing the range condition are dropped,
conditions that produce overlapping ranges are combined, and
conditions that produce empty ranges are removed.
Consider the following statement, where
key1 is an indexed column and
nonkey is not indexed:
SELECT * FROM t1 WHERE (key1 < 'abc' AND (key1 LIKE 'abcde%' OR key1 LIKE '%b')) OR (key1 < 'bar' AND nonkey = 4) OR (key1 < 'uux' AND key1 > 'z');
The extraction process for key key1 is as
follows:
Start with original
WHEREclause:(key1 < 'abc' AND (key1 LIKE 'abcde%' OR key1 LIKE '%b')) OR (key1 < 'bar' AND nonkey = 4) OR (key1 < 'uux' AND key1 > 'z')
Remove
nonkey = 4andkey1 LIKE '%b'because they cannot be used for a range scan. The correct way to remove them is to replace them withTRUE, so that we do not miss any matching rows when doing the range scan. Having replaced them withTRUE, we get:(key1 < 'abc' AND (key1 LIKE 'abcde%' OR TRUE)) OR (key1 < 'bar' AND TRUE) OR (key1 < 'uux' AND key1 > 'z')
Collapse conditions that are always true or false:
(key1 LIKE 'abcde%' OR TRUE)is always true(key1 < 'uux' AND key1 > 'z')is always false
Replacing these conditions with constants, we get:
(key1 < 'abc' AND TRUE) OR (key1 < 'bar' AND TRUE) OR (FALSE)
Removing unnecessary
TRUEandFALSEconstants, we obtain:(key1 < 'abc') OR (key1 < 'bar')
Combining overlapping intervals into one yields the final condition to be used for the range scan:
(key1 < 'bar')
In general (and as demonstrated by the preceding example), the
condition used for a range scan is less restrictive than the
WHERE clause. MySQL performs an additional
check to filter out rows that satisfy the range condition but
not the full WHERE clause.
The range condition extraction algorithm can handle nested
AND/OR constructs of
arbitrary depth, and its output does not depend on the order
in which conditions appear in WHERE clause.
Currently, MySQL does not support merging multiple ranges for
the range access method for spatial
indexes. To work around this limitation, you can use a
UNION with identical
SELECT statements, except that you put each
spatial predicate in a different SELECT.
Range conditions on a multiple-part index are an extension of range conditions for a single-part index. A range condition on a multiple-part index restricts index rows to lie within one or several key tuple intervals. Key tuple intervals are defined over a set of key tuples, using ordering from the index.
For example, consider a multiple-part index defined as
key1(, and the
following set of key tuples listed in key order:
key_part1,
key_part2,
key_part3)
key_part1key_part2key_part3NULL 1 'abc' NULL 1 'xyz' NULL 2 'foo' 1 1 'abc' 1 1 'xyz' 1 2 'abc' 2 1 'aaa'
The condition key_part1 =
1
(1,-inf,-inf) <= (key_part1,key_part2,key_part3) < (1,+inf,+inf)
The interval covers the 4th, 5th, and 6th tuples in the preceding data set and can be used by the range access method.
By contrast, the condition
key_part3 =
'abc'
The following descriptions indicate how range conditions work for multiple-part indexes in greater detail.
For
HASHindexes, each interval containing identical values can be used. This means that the interval can be produced only for conditions in the following form:key_part1cmpconst1ANDkey_part2cmpconst2AND ... ANDkey_partNcmpconstN;Here,
const1,const2, … are constants,cmpis one of the=,<=>, orIS NULLcomparison operators, and the conditions cover all index parts. (That is, there areNconditions, one for each part of anN-part index.) For example, the following is a range condition for a three-partHASHindex:key_part1= 1 ANDkey_part2IS NULL ANDkey_part3= 'foo'For the definition of what is considered to be a constant, see Section 7.2.5.1, “The Range Access Method for Single-Part Indexes”.
For a
BTREEindex, an interval might be usable for conditions combined withAND, where each condition compares a key part with a constant value using=,<=>,IS NULL,>,<,>=,<=,!=,<>,BETWEEN, orLIKE '(wherepattern''does not start with a wildcard). An interval can be used as long as it is possible to determine a single key tuple containing all rows that match the condition (or two intervals ifpattern'<>or!=is used). For example, for this condition:key_part1= 'foo' ANDkey_part2>= 10 ANDkey_part3> 10The single interval is:
('foo',10,10) < (key_part1,key_part2,key_part3) < ('foo',+inf,+inf)It is possible that the created interval contains more rows than the initial condition. For example, the preceding interval includes the value
('foo', 11, 0), which does not satisfy the original condition.If conditions that cover sets of rows contained within intervals are combined with
OR, they form a condition that covers a set of rows contained within the union of their intervals. If the conditions are combined withAND, they form a condition that covers a set of rows contained within the intersection of their intervals. For example, for this condition on a two-part index:(
key_part1= 1 ANDkey_part2< 2) OR (key_part1> 5)The intervals are:
(1,-inf) < (
key_part1,key_part2) < (1,2) (5,-inf) < (key_part1,key_part2)In this example, the interval on the first line uses one key part for the left bound and two key parts for the right bound. The interval on the second line uses only one key part. The
key_lencolumn in theEXPLAINoutput indicates the maximum length of the key prefix used.In some cases,
key_lenmay indicate that a key part was used, but that might be not what you would expect. Suppose thatkey_part1andkey_part2can beNULL. Then thekey_lencolumn displays two key part lengths for the following condition:key_part1>= 1 ANDkey_part2< 2But, in fact, the condition is converted to this:
key_part1>= 1 ANDkey_part2IS NOT NULL
Section 7.2.5.1, “The Range Access Method for Single-Part Indexes”, describes how optimizations are performed to combine or eliminate intervals for range conditions on a single-part index. Analogous steps are performed for range conditions on multiple-part indexes.
The Index Merge method is used to
retrieve rows with several range scans and to
merge their results into one. The merge can produce unions,
intersections, or unions-of-intersections of its underlying
scans.
Note: If you have upgraded from a previous version of MySQL, you should be aware that this type of join optimization is first introduced in MySQL 5.0, and represents a significant change in behavior with regard to indexes. (Formerly, MySQL was able to use at most only one index for each referenced table.)
In EXPLAIN output, the Index Merge method
appears as index_merge in the
type column. In this case, the
key column contains a list of indexes used,
and key_len contains a list of the longest
key parts for those indexes.
Examples:
SELECT * FROMtbl_nameWHEREkey1= 10 ORkey2= 20; SELECT * FROMtbl_nameWHERE (key1= 10 ORkey2= 20) ANDnon_key=30; SELECT * FROM t1, t2 WHERE (t1.key1IN (1,2) OR t1.key2LIKE 'value%') AND t2.key1=t1.some_col; SELECT * FROM t1, t2 WHERE t1.key1=1 AND (t2.key1=t1.some_colOR t2.key2=t1.some_col2);
The Index Merge method has several access algorithms (seen in
the Extra field of EXPLAIN
output):
Using intersect(...)Using union(...)Using sort_union(...)
The following sections describe these methods in greater detail.
Note: The Index Merge optimization algorithm has the following known deficiencies:
If a range scan is possible on some key, an Index Merge is not considered. For example, consider this query:
SELECT * FROM t1 WHERE (goodkey1 < 10 OR goodkey2 < 20) AND badkey < 30;
For this query, two plans are possible:
An Index Merge scan using the
(goodkey1 < 10 OR goodkey2 < 20)condition.A range scan using the
badkey < 30condition.
However, the optimizer considers only the second plan.
If your query has a complex
WHEREclause with deepAND/ORnesting and MySQL doesn't choose the optimal plan, try distributing terms using the following identity laws:(
xANDy) ORz= (xORz) AND (yORz) (xORy) ANDz= (xANDz) OR (yANDz)Index Merge is not applicable to fulltext indexes. We plan to extend it to cover these in a future MySQL release.
The choice between different possible variants of the Index Merge access method and other access methods is based on cost estimates of various available options.
This access algorithm can be employed when a
WHERE clause was converted to several range
conditions on different keys combined with
AND, and each condition is one of the
following:
In this form, where the index has exactly
Nparts (that is, all index parts are covered):key_part1=const1ANDkey_part2=const2... ANDkey_partN=constNAny range condition over a primary key of an
InnoDBorBDBtable.
Examples:
SELECT * FROMinnodb_tableWHEREprimary_key< 10 ANDkey_col1=20; SELECT * FROMtbl_nameWHERE (key1_part1=1 ANDkey1_part2=2) ANDkey2=2;
The Index Merge intersection algorithm performs simultaneous scans on all used indexes and produces the intersection of row sequences that it receives from the merged index scans.
If all columns used in the query are covered by the used
indexes, full table rows are not retrieved
(EXPLAIN output contains Using
index in Extra field in this
case). Here is an example of such a query:
SELECT COUNT(*) FROM t1 WHERE key1=1 AND key2=1;
If the used indexes don't cover all columns used in the query, full rows are retrieved only when the range conditions for all used keys are satisfied.
If one of the merged conditions is a condition over a primary
key of an InnoDB or BDB
table, it is not used for row retrieval, but is used to filter
out rows retrieved using other conditions.
The applicability criteria for this algorithm are similar to
those for the Index Merge method intersection algorithm. The
algorithm can be employed when the table's
WHERE clause was converted to several range
conditions on different keys combined with
OR, and each condition is one of the
following:
In this form, where the index has exactly
Nparts (that is, all index parts are covered):key_part1=const1ANDkey_part2=const2... ANDkey_partN=constNAny range condition over a primary key of an
InnoDBorBDBtable.A condition for which the Index Merge method intersection algorithm is applicable.
Examples:
SELECT * FROM t1 WHEREkey1=1 ORkey2=2 ORkey3=3; SELECT * FROMinnodb_tableWHERE (key1=1 ANDkey2=2) OR (key3='foo' ANDkey4='bar') ANDkey5=5;
This access algorithm is employed when the
WHERE clause was converted to several range
conditions combined by OR, but for which
the Index Merge method union algorithm is not applicable.
Examples:
SELECT * FROMtbl_nameWHEREkey_col1< 10 ORkey_col2< 20; SELECT * FROMtbl_nameWHERE (key_col1> 10 ORkey_col2= 20) ANDnonkey_col=30;
The difference between the sort-union algorithm and the union algorithm is that the sort-union algorithm must first fetch row IDs for all rows and sort them before returning any rows.
MySQL can perform the same optimization on
col_name IS NULL
that it can use for col_name
= constant_value.
For example, MySQL can use indexes and ranges to search for
NULL with IS NULL.
Examples:
SELECT * FROMtbl_nameWHEREkey_colIS NULL; SELECT * FROMtbl_nameWHEREkey_col<=> NULL; SELECT * FROMtbl_nameWHEREkey_col=const1ORkey_col=const2ORkey_colIS NULL;
If a WHERE clause includes a
col_name IS NULL
condition for a column that is declared as NOT
NULL, that expression is optimized away. This
optimization does not occur in cases when the column might
produce NULL anyway; for example, if it comes
from a table on the right side of a LEFT
JOIN.
MySQL can also optimize the combination
col_name =
expr AND
col_name IS NULLEXPLAIN shows ref_or_null
when this optimization is used.
This optimization can handle one IS NULL for
any key part.
Some examples of queries that are optimized, assuming that there
is an index on columns a and
b of table t2:
SELECT * FROM t1 WHERE t1.a=expr OR t1.a IS NULL;
SELECT * FROM t1, t2 WHERE t1.a=t2.a OR t2.a IS NULL;
SELECT * FROM t1, t2
WHERE (t1.a=t2.a OR t2.a IS NULL) AND t2.b=t1.b;
SELECT * FROM t1, t2
WHERE t1.a=t2.a AND (t2.b=t1.b OR t2.b IS NULL);
SELECT * FROM t1, t2
WHERE (t1.a=t2.a AND t2.a IS NULL AND ...)
OR (t1.a=t2.a AND t2.a IS NULL AND ...);
ref_or_null works by first doing a read on
the reference key, and then a separate search for rows with a
NULL key value.
Note that the optimization can handle only one IS
NULL level. In the following query, MySQL uses key
lookups only on the expression (t1.a=t2.a AND t2.a IS
NULL) and is not able to use the key part on
b:
SELECT * FROM t1, t2 WHERE (t1.a=t2.a AND t2.a IS NULL) OR (t1.b=t2.b AND t2.b IS NULL);
MySQL implements an A LEFT
JOIN B join_condition
Table
Bis set to depend on tableAand all tables on whichAdepends.Table
Ais set to depend on all tables (exceptB) that are used in theLEFT JOINcondition.The
LEFT JOINcondition is used to decide how to retrieve rows from tableB. (In other words, any condition in theWHEREclause is not used.)All standard join optimizations are performed, with the exception that a table is always read after all tables on which it depends. If there is a circular dependence, MySQL issues an error.
All standard
WHEREoptimizations are performed.If there is a row in
Athat matches theWHEREclause, but there is no row inBthat matches theONcondition, an extraBrow is generated with all columns set toNULL.If you use
LEFT JOINto find rows that do not exist in some table and you have the following test:col_nameIS NULLWHEREpart, wherecol_nameis a column that is declared asNOT NULL, MySQL stops searching for more rows (for a particular key combination) after it has found one row that matches theLEFT JOINcondition.
The implementation of RIGHT JOIN is analogous
to that of LEFT JOIN with the roles of the
tables reversed.
The join optimizer calculates the order in which tables should
be joined. The table read order forced by LEFT
JOIN or STRAIGHT_JOIN helps the
join optimizer do its work much more quickly, because there are
fewer table permutations to check. Note that this means that if
you do a query of the following type, MySQL does a full scan on
b because the LEFT JOIN
forces it to be read before d:
SELECT * FROM a JOIN b LEFT JOIN c ON (c.key=a.key) LEFT JOIN d ON (d.key=a.key) WHERE b.key=d.key;
The fix in this case is reverse the order in which
a and b are listed in the
FROM clause:
SELECT * FROM b JOIN a LEFT JOIN c ON (c.key=a.key) LEFT JOIN d ON (d.key=a.key) WHERE b.key=d.key;
For a LEFT JOIN, if the
WHERE condition is always false for the
generated NULL row, the LEFT
JOIN is changed to a normal join. For example, the
WHERE clause would be false in the following
query if t2.column1 were
NULL:
SELECT * FROM t1 LEFT JOIN t2 ON (column1) WHERE t2.column2=5;
Therefore, it is safe to convert the query to a normal join:
SELECT * FROM t1, t2 WHERE t2.column2=5 AND t1.column1=t2.column1;
This can be made faster because MySQL can use table
t2 before table t1 if
doing so would result in a better query plan. To force a
specific table order, use STRAIGHT_JOIN.
As of MySQL 5.0.1, the syntax for expressing joins allows nested
joins. The following discussion refers to the join syntax
described in Section 13.2.7.1, “JOIN Syntax”.
The syntax of table_factor is
extended in comparison with the SQL Standard. The latter accepts
only table_reference, not a list of
them inside a pair of parentheses. This is a conservative
extension if we consider each comma in a list of
table_reference items as equivalent
to an inner join. For example:
SELECT * FROM t1 LEFT JOIN (t2, t3, t4)
ON (t2.a=t1.a AND t3.b=t1.b AND t4.c=t1.c)
is equivalent to:
SELECT * FROM t1 LEFT JOIN (t2 CROSS JOIN t3 CROSS JOIN t4)
ON (t2.a=t1.a AND t3.b=t1.b AND t4.c=t1.c)
In MySQL, CROSS JOIN is a syntactic
equivalent to INNER JOIN (they can replace
each other). In standard SQL, they are not equivalent.
INNER JOIN is used with an
ON clause; CROSS JOIN is
used otherwise.
In versions of MySQL prior to 5.0.1, parentheses in
table_references were just omitted
and all join operations were grouped to the left. In general,
parentheses can be ignored in join expressions containing only
inner join operations.
After removing parentheses and grouping operations to the left, the join expression:
t1 LEFT JOIN (t2 LEFT JOIN t3 ON t2.b=t3.b OR t2.b IS NULL) ON t1.a=t2.a
transforms into the expression:
(t1 LEFT JOIN t2 ON t1.a=t2.a) LEFT JOIN t3
ON t2.b=t3.b OR t2.b IS NULL
Yet, the two expressions are not equivalent. To see this,
suppose that the tables t1,
t2, and t3 have the
following state:
Table
t1contains rows(1),(2)Table
t2contains row(1,101)Table
t3contains row(101)
In this case, the first expression returns a result set
including the rows (1,1,101,101),
(2,NULL,NULL,NULL), whereas the second
expression returns the rows (1,1,101,101),
(2,NULL,NULL,101):
mysql>SELECT *->FROM t1->LEFT JOIN->(t2 LEFT JOIN t3 ON t2.b=t3.b OR t2.b IS NULL)->ON t1.a=t2.a;+------+------+------+------+ | a | a | b | b | +------+------+------+------+ | 1 | 1 | 101 | 101 | | 2 | NULL | NULL | NULL | +------+------+------+------+ mysql>SELECT *->FROM (t1 LEFT JOIN t2 ON t1.a=t2.a)->LEFT JOIN t3->ON t2.b=t3.b OR t2.b IS NULL;+------+------+------+------+ | a | a | b | b | +------+------+------+------+ | 1 | 1 | 101 | 101 | | 2 | NULL | NULL | 101 | +------+------+------+------+
In the following example, an outer join operation is used together with an inner join operation:
t1 LEFT JOIN (t2, t3) ON t1.a=t2.a
That expression cannot be transformed into the following expression:
t1 LEFT JOIN t2 ON t1.a=t2.a, t3.
For the given table states, the two expressions return different sets of rows:
mysql>SELECT *->FROM t1 LEFT JOIN (t2, t3) ON t1.a=t2.a;+------+------+------+------+ | a | a | b | b | +------+------+------+------+ | 1 | 1 | 101 | 101 | | 2 | NULL | NULL | NULL | +------+------+------+------+ mysql>SELECT *->FROM t1 LEFT JOIN t2 ON t1.a=t2.a, t3;+------+------+------+------+ | a | a | b | b | +------+------+------+------+ | 1 | 1 | 101 | 101 | | 2 | NULL | NULL | 101 | +------+------+------+------+
Therefore, if we omit parentheses in a join expression with outer join operators, we might change the result set for the original expression.
More exactly, we cannot ignore parentheses in the right operand of the left outer join operation and in the left operand of a right join operation. In other words, we cannot ignore parentheses for the inner table expressions of outer join operations. Parentheses for the other operand (operand for the outer table) can be ignored.
The following expression:
(t1,t2) LEFT JOIN t3 ON P(t2.b,t3.b)
is equivalent to this expression:
t1, t2 LEFT JOIN t3 ON P(t2.b,t3.b)
for any tables t1,t2,t3 and any condition
P over attributes t2.b and
t3.b.
Whenever the order of execution of the join operations in a join
expression (join_table) is not from
left to right, we talk about nested joins. Consider the
following queries:
SELECT * FROM t1 LEFT JOIN (t2 LEFT JOIN t3 ON t2.b=t3.b) ON t1.a=t2.a WHERE t1.a > 1 SELECT * FROM t1 LEFT JOIN (t2, t3) ON t1.a=t2.a WHERE (t2.b=t3.b OR t2.b IS NULL) AND t1.a > 1
Those queries are considered to contain these nested joins:
t2 LEFT JOIN t3 ON t2.b=t3.b t2, t3
The nested join is formed in the first query with a left join operation, whereas in the second query it is formed with an inner join operation.
In the first query, the parentheses can be omitted: The
grammatical structure of the join expression will dictate the
same order of execution for join operations. For the second
query, the parentheses cannot be omitted, although the join
expression here can be interpreted unambiguously without them.
(In our extended syntax the parentheses in (t2,
t3) of the second query are required, although
theoretically the query could be parsed without them: We still
would have unambiguous syntactical structure for the query
because LEFT JOIN and ON
would play the role of the left and right delimiters for the
expression (t2,t3).)
The preceding examples demonstrate these points:
For join expressions involving only inner joins (and not outer joins), parentheses can be removed. You can remove parentheses and evaluate left to right (or, in fact, you can evaluate the tables in any order).
The same is not true, in general, for outer joins or for outer joins mixed with inner joins. Removal of parentheses may change the result.
Queries with nested outer joins are executed in the same
pipeline manner as queries with inner joins. More exactly, a
variation of the nested-loop join algorithm is exploited. Recall
by what algorithmic schema the nested-loop join executes a
query. Suppose that we have a join query over 3 tables
T1,T2,T3 of the form:
SELECT * FROM T1 INNER JOIN T2 ON P1(T1,T2)
INNER JOIN T3 ON P2(T2,T3)
WHERE P(T1,T2,T3).
Here, P1(T1,T2) and
P2(T3,T3) are some join conditions (on
expressions), whereas P(t1,t2,t3) is a
condition over columns of tables T1,T2,T3.
The nested-loop join algorithm would execute this query in the following manner:
FOR each row t1 in T1 {
FOR each row t2 in T2 such that P1(t1,t2) {
FOR each row t3 in T3 such that P2(t2,t3) {
IF P(t1,t2,t3) {
t:=t1||t2||t3; OUTPUT t;
}
}
}
}
The notation t1||t2||t3 means “a row
constructed by concatenating the columns of rows
t1, t2, and
t3.” In some of the following
examples, NULL where a row name appears means
that NULL is used for each column of that
row. For example, t1||t2||NULL means “a
row constructed by concatenating the columns of rows
t1 and t2, and
NULL for each column of
t3.”
Now let's consider a query with nested outer joins:
SELECT * FROM T1 LEFT JOIN
(T2 LEFT JOIN T3 ON P2(T2,T3))
ON P1(T1,T2)
WHERE P(T1,T2,T3).
For this query, we modify the nested-loop pattern to get:
FOR each row t1 in T1 {
BOOL f1:=FALSE;
FOR each row t2 in T2 such that P1(t1,t2) {
BOOL f2:=FALSE;
FOR each row t3 in T3 such that P2(t2,t3) {
IF P(t1,t2,t3) {
t:=t1||t2||t3; OUTPUT t;
}
f2=TRUE;
f1=TRUE;
}
IF (!f2) {
IF P(t1,t2,NULL) {
t:=t1||t2||NULL; OUTPUT t;
}
f1=TRUE;
}
}
IF (!f1) {
IF P(t1,NULL,NULL) {
t:=t1||NULL||NULL; OUTPUT t;
}
}
}
In general, for any nested loop for the first inner table in an
outer join operation, a flag is introduced that is turned off
before the loop and is checked after the loop. The flag is
turned on when for the current row from the outer table a match
from the table representing the inner operand is found. If at
the end of the loop cycle the flag is still off, no match has
been found for the current row of the outer table. In this case,
the row is complemented by NULL values for
the columns of the inner tables. The result row is passed to the
final check for the output or into the next nested loop, but
only if the row satisfies the join condition of all embedded
outer joins.
In our example, the outer join table expressed by the following expression is embedded:
(T2 LEFT JOIN T3 ON P2(T2,T3))
Note that for the query with inner joins, the optimizer could choose a different order of nested loops, such as this one:
FOR each row t3 in T3 {
FOR each row t2 in T2 such that P2(t2,t3) {
FOR each row t1 in T1 such that P1(t1,t2) {
IF P(t1,t2,t3) {
t:=t1||t2||t3; OUTPUT t;
}
}
}
}
For the queries with outer joins, the optimizer can choose only such an order where loops for outer tables precede loops for inner tables. Thus, for our query with outer joins, only one nesting order is possible. For the following query, the optimizer will evaluate two different nestings:
SELECT * T1 LEFT JOIN (T2,T3) ON P1(T1,T2) AND P2(T1,T3) WHERE P(T1,T2,T3)
The nestings are these:
FOR each row t1 in T1 {
BOOL f1:=FALSE;
FOR each row t2 in T2 such that P1(t1,t2) {
FOR each row t3 in T3 such that P2(t1,t3) {
IF P(t1,t2,t3) {
t:=t1||t2||t3; OUTPUT t;
}
f1:=TRUE
}
}
IF (!f1) {
IF P(t1,NULL,NULL) {
t:=t1||NULL||NULL; OUTPUT t;
}
}
}
and:
FOR each row t1 in T1 {
BOOL f1:=FALSE;
FOR each row t3 in T3 such that P2(t1,t3) {
FOR each row t2 in T2 such that P1(t1,t2) {
IF P(t1,t2,t3) {
t:=t1||t2||t3; OUTPUT t;
}
f1:=TRUE
}
}
IF (!f1) {
IF P(t1,NULL,NULL) {
t:=t1||NULL||NULL; OUTPUT t;
}
}
}
In both nestings, T1 must be processed in the
outer loop because it is used in an outer join.
T2 and T3 are used in an
inner join, so that join must be processed in the inner loop.
However, because the join is an inner join,
T2 and T3 can be processed
in either order.
When discussing the nested-loop algorithm for inner joins, we
omitted some details whose impact on the performance of query
execution may be huge. We did not mention so-called
“pushed-down” conditions. Suppose that our
WHERE condition
P(T1,T2,T3) can be represented by a
conjunctive formula:
P(T1,T2,T2) = C1(T1) AND C2(T2) AND C3(T3).
In this case, MySQL actually uses the following nested-loop schema for the execution of the query with inner joins:
FOR each row t1 in T1 such that C1(t1) {
FOR each row t2 in T2 such that P1(t1,t2) AND C2(t2) {
FOR each row t3 in T3 such that P2(t2,t3) AND C3(t3) {
IF P(t1,t2,t3) {
t:=t1||t2||t3; OUTPUT t;
}
}
}
}
You see that each of the conjuncts C1(T1),
C2(T2), C3(T3) are pushed
out of the most inner loop to the most outer loop where it can
be evaluated. If C1(T1) is a very restrictive
condition, this condition pushdown may greatly reduce the number
of rows from table T1 passed to the inner
loops. As a result, the execution time for the query may improve
immensely.
For a query with outer joins, the WHERE
condition is to be checked only after it has been found that the
current row from the outer table has a match in the inner
tables. Thus, the optimization of pushing conditions out of the
inner nested loops cannot be applied directly to queries with
outer joins. Here we have to introduce conditional pushed-down
predicates guarded by the flags that are turned on when a match
has been encountered.
For our example with outer joins with:
P(T1,T2,T3)=C1(T1) AND C(T2) AND C3(T3)
the nested-loop schema using guarded pushed-down conditions looks like this:
FOR each row t1 in T1 such that C1(t1) {
BOOL f1:=FALSE;
FOR each row t2 in T2
such that P1(t1,t2) AND (f1?C2(t2):TRUE) {
BOOL f2:=FALSE;
FOR each row t3 in T3
such that P2(t2,t3) AND (f1&&f2?C3(t3):TRUE) {
IF (f1&&f2?TRUE:(C2(t2) AND C3(t3))) {
t:=t1||t2||t3; OUTPUT t;
}
f2=TRUE;
f1=TRUE;
}
IF (!f2) {
IF (f1?TRUE:C2(t2) && P(t1,t2,NULL)) {
t:=t1||t2||NULL; OUTPUT t;
}
f1=TRUE;
}
}
IF (!f1 && P(t1,NULL,NULL)) {
t:=t1||NULL||NULL; OUTPUT t;
}
}
In general, pushed-down predicates can be extracted from join
conditions such as P1(T1,T2) and
P(T2,T3). In this case, a pushed-down
predicate is guarded also by a flag that prevents checking the
predicate for the NULL-complemented row
generated by the corresponding outer join operation.
Note that access by key from one inner table to another in the
same nested join is prohibited if it is induced by a predicate
from the WHERE condition. (We could use
conditional key access in this case, but this technique is not
employed yet in MySQL 5.0.)
Table expressions in the FROM clause of a
query are simplified in many cases.
At the parser stage, queries with right outer joins operations are converted to equivalent queries containing only left join operations. In the general case, the conversion is performed according to the following rule:
(T1, ...) RIGHT JOIN (T2,...) ON P(T1,...,T2,...) = (T2, ...) LEFT JOIN (T1,...) ON P(T1,...,T2,...)
All inner join expressions of the form T1 INNER JOIN T2
ON P(T1,T2) are replaced by the list
T1,T2, P(T1,T2) being
joined as a conjunct to the WHERE condition
(or to the join condition of the embedding join, if there is
any).
When the optimizer evaluates plans for join queries with outer join operation, it takes into consideration only the plans where, for each such operation, the outer tables are accessed before the inner tables. The optimizer options are limited because only such plans enables us to execute queries with outer joins operations by the nested loop schema.
Suppose that we have a query of the form:
SELECT * T1 LEFT JOIN T2 ON P1(T1,T2) WHERE P(T1,T2) AND R(T2)
with R(T2) narrowing greatly the number of
matching rows from table T2. If we executed
the query as it is, the optimizer would have no other choice
besides to access table T1 before table
T2 that may lead to a very inefficient
execution plan.
Fortunately, MySQL converts such a query into a query without an
outer join operation if the WHERE condition
is null-rejected. A condition is called null-rejected for an
outer join operation if it evaluates to FALSE
or to UNKNOWN for any
NULL-complemented row built for the
operation.
Thus, for this outer join:
T1 LEFT JOIN T2 ON T1.A=T2.A
Conditions such as these are null-rejected:
T2.B IS NOT NULL, T2.B > 3, T2.C <= T1.C, T2.B < 2 OR T2.C > 1
Conditions such as these are not null-rejected:
T2.B IS NULL, T1.B < 3 OR T2.B IS NOT NULL, T1.B < 3 OR T2.B > 3
The general rules for checking whether a condition is null-rejected for an outer join operation are simple. A condition is null-rejected in the following cases:
If it is of the form
A IS NOT NULL, whereAis an attribute of any of the inner tablesIf it is a predicate containing a reference to an inner table that evaluates to
UNKNOWNwhen one of its arguments isNULLIf it is a conjunction containing a null-rejected condition as a conjunct
If it is a disjunction of null-rejected conditions
A condition can be null-rejected for one outer join operation in a query and not null-rejected for another. In the query:
SELECT * FROM T1 LEFT JOIN T2 ON T2.A=T1.A
LEFT JOIN T3 ON T3.B=T1.B
WHERE T3.C > 0
the WHERE condition is null-rejected for the
second outer join operation but is not null-rejected for the
first one.
If the WHERE condition is null-rejected for
an outer join operation in a query, the outer join operation is
replaced by an inner join operation.
For example, the preceding query is replaced with the query:
SELECT * FROM T1 LEFT JOIN T2 ON T2.A=T1.A
INNER JOIN T3 ON T3.B=T1.B
WHERE T3.C > 0
For the original query, the optimizer would evaluate plans
compatible with only one access order
T1,T2,T3. For the replacing query, it
additionally considers the access sequence
T3,T1,T2.
A conversion of one outer join operation may trigger a conversion of another. Thus, the query:
SELECT * FROM T1 LEFT JOIN T2 ON T2.A=T1.A
LEFT JOIN T3 ON T3.B=T2.B
WHERE T3.C > 0
will be first converted to the query:
SELECT * FROM T1 LEFT JOIN T2 ON T2.A=T1.A
INNER JOIN T3 ON T3.B=T2.B
WHERE T3.C > 0
which is equivalent to the query:
SELECT * FROM (T1 LEFT JOIN T2 ON T2.A=T1.A), T3 WHERE T3.C > 0 AND T3.B=T2.B
Now the remaining outer join operation can be replaced by an
inner join, too, because the condition
T3.B=T2.B is null-rejected and we get a query
without outer joins at all:
SELECT * FROM (T1 INNER JOIN T2 ON T2.A=T1.A), T3 WHERE T3.C > 0 AND T3.B=T2.B
Sometimes we succeed in replacing an embedded outer join operation, but cannot convert the embedding outer join. The following query:
SELECT * FROM T1 LEFT JOIN
(T2 LEFT JOIN T3 ON T3.B=T2.B)
ON T2.A=T1.A
WHERE T3.C > 0
is converted to:
SELECT * FROM T1 LEFT JOIN
(T2 INNER JOIN T3 ON T3.B=T2.B)
ON T2.A=T1.A
WHERE T3.C > 0,
That can be rewritten only to the form still containing the embedding outer join operation:
SELECT * FROM T1 LEFT JOIN
(T2,T3)
ON (T2.A=T1.A AND T3.B=T2.B)
WHERE T3.C > 0.
When trying to convert an embedded outer join operation in a
query, we must take into account the join condition for the
embedding outer join together with the WHERE
condition. In the query:
SELECT * FROM T1 LEFT JOIN
(T2 LEFT JOIN T3 ON T3.B=T2.B)
ON T2.A=T1.A AND T3.C=T1.C
WHERE T3.D > 0 OR T1.D > 0
the WHERE condition is not null-rejected for
the embedded outer join, but the join condition of the embedding
outer join T2.A=T1.A AND T3.C=T1.C is
null-rejected. So the query can be converted to:
SELECT * FROM T1 LEFT JOIN
(T2, T3)
ON T2.A=T1.A AND T3.C=T1.C AND T3.B=T2.B
WHERE T3.D > 0 OR T1.D > 0
The algorithm that converts outer join operations into inner joins was implemented in full measure, as it has been described here, in MySQL 5.0.1. MySQL 4.1 performs only some simple conversions.
In some cases, MySQL can use an index to satisfy an
ORDER BY clause without doing any extra
sorting.
The index can also be used even if the ORDER
BY does not match the index exactly, as long as all of
the unused portions of the index and all the extra
ORDER BY columns are constants in the
WHERE clause. The following queries use the
index to resolve the ORDER BY part:
SELECT * FROM t1 ORDER BYkey_part1,key_part2,... ; SELECT * FROM t1 WHEREkey_part1=constantORDER BYkey_part2; SELECT * FROM t1 ORDER BYkey_part1DESC,key_part2DESC; SELECT * FROM t1 WHEREkey_part1=1 ORDER BYkey_part1DESC,key_part2DESC;
In some cases, MySQL cannot use indexes to
resolve the ORDER BY, although it still uses
indexes to find the rows that match the WHERE
clause. These cases include the following:
You use
ORDER BYon different keys:SELECT * FROM t1 ORDER BY
key1,key2;You use
ORDER BYon non-consecutive parts of a key:SELECT * FROM t1 WHERE
key2=constantORDER BYkey_part2;You mix
ASCandDESC:SELECT * FROM t1 ORDER BY
key_part1DESC,key_part2ASC;The key used to fetch the rows is not the same as the one used in the
ORDER BY:SELECT * FROM t1 WHERE
key2=constantORDER BYkey1;You are joining many tables, and the columns in the
ORDER BYare not all from the first non-constant table that is used to retrieve rows. (This is the first table in theEXPLAINoutput that does not have aconstjoin type.)You have different
ORDER BYandGROUP BYexpressions.The type of table index used does not store rows in order. For example, this is true for a
HASHindex in aMEMORYtable.
With EXPLAIN SELECT ... ORDER BY, you can
check whether MySQL can use indexes to resolve the query. It
cannot if you see Using filesort in the
Extra column. See Section 7.2.1, “Optimizing Queries with EXPLAIN”.
MySQL has two filesort algorithms for sorting
and retrieving results. The original method uses only the
ORDER BY columns. The modified method uses
not just the ORDER BY columns, but all the
columns used in the query.
The optimizer selects which filesort
algorithm to use. It normally uses the modified algorithm except
when BLOB or TEXT columns
are involved, in which case it uses the original algorithm.
The original filesort algorithm works as
follows:
Read all rows according to key or by table scanning. Rows that do not match the
WHEREclause are skipped.For each row, store a pair of values in a buffer (the sort key and the row pointer). The size of the buffer is the value of the
sort_buffer_sizesystem variable.When the buffer gets full, run a qsort (quicksort) on it and store the result in a temporary file. Save a pointer to the sorted block. (If all pairs fit into the sort buffer, no temporary file is created.)
Repeat the preceding steps until all rows have been read.
Do a multi-merge of up to
MERGEBUFF(7) regions to one block in another temporary file. Repeat until all blocks from the first file are in the second file.Repeat the following until there are fewer than
MERGEBUFF2(15) blocks left.On the last multi-merge, only the pointer to the row (the last part of the sort key) is written to a result file.
Read the rows in sorted order by using the row pointers in the result file. To optimize this, we read in a big block of row pointers, sort them, and use them to read the rows in sorted order into a row buffer. The size of the buffer is the value of the
read_rnd_buffer_sizesystem variable. The code for this step is in thesql/records.ccsource file.
One problem with this approach is that it reads rows twice: One
time when evaluating the WHERE clause, and
again after sorting the pair values. And even if the rows were
accessed successively the first time (for example, if a table
scan is done), the second time they are accessed randomly. (The
sort keys are ordered, but the row positions are not.)
The modified filesort algorithm incorporates
an optimization such that it records not only the sort key value
and row position, but also the columns required for the query.
This avoids reading the rows twice. The modified
filesort algorithm works like this:
Read the rows that match the
WHEREclause.For each row, record a tuple of values consisting of the sort key value and row position, and also the columns required for the query.
Sort the tuples by sort key value
Retrieve the rows in sorted order, but read the required columns directly from the sorted tuples rather than by accessing the table a second time.
Using the modified filesort algorithm, the
tuples are longer than the pairs used in the original method,
and fewer of them fit in the sort buffer (the size of which is
given by sort_buffer_size). As a result, it
is possible for the extra I/O to make the modified approach
slower, not faster. To avoid a slowdown, the optimization is
used only if the total size of the extra columns in the sort
tuple does not exceed the value of the
max_length_for_sort_data system variable. (A
symptom of setting the value of this variable too high is that
you should see high disk activity and low CPU activity.)
If you want to increase ORDER BY speed, check
whether you can get MySQL to use indexes rather than an extra
sorting phase. If this is not possible, you can try the
following strategies:
Increase the size of the
sort_buffer_sizevariable.Increase the size of the
read_rnd_buffer_sizevariable.Change
tmpdirto point to a dedicated filesystem with large amounts of empty space. This option accepts several paths that are used in round-robin fashion. Paths should be separated by colon characters (‘:’) on Unix and semicolon characters (‘;’) on Windows, NetWare, and OS/2. You can use this feature to spread the load across several directories. Note: The paths should be for directories in filesystems that are located on different physical disks, not different partitions on the same disk.
By default, MySQL sorts all GROUP BY
queries as if you
specified col1,
col2, ...ORDER BY in the query as
well. If you include an col1,
col2, ...ORDER BY clause
explicitly that contains the same column list, MySQL optimizes
it away without any speed penalty, although the sorting still
occurs. If a query includes GROUP BY but you
want to avoid the overhead of sorting the result, you can
suppress sorting by specifying ORDER BY NULL.
For example:
INSERT INTO foo SELECT a, COUNT(*) FROM bar GROUP BY a ORDER BY NULL;
The most general way to satisfy a GROUP BY
clause is to scan the whole table and create a new temporary
table where all rows from each group are consecutive, and then
use this temporary table to discover groups and apply aggregate
functions (if any). In some cases, MySQL is able to do much
better than that and to avoid creation of temporary tables by
using index access.
The most important preconditions for using indexes for
GROUP BY are that all GROUP
BY columns reference attributes from the same index,
and that the index stores its keys in order (for example, this
is a BTREE index and not a
HASH index). Whether use of temporary tables
can be replaced by index access also depends on which parts of
an index are used in a query, the conditions specified for these
parts, and the selected aggregate functions.
There are two ways to execute a GROUP BY
query via index access, as detailed in the following sections.
In the first method, the grouping operation is applied together
with all range predicates (if any). The second method first
performs a range scan, and then groups the resulting tuples.
The most efficient way to process GROUP BY
is when the index is used to directly retrieve the group
fields. With this access method, MySQL uses the property of
some index types that the keys are ordered (for example,
BTREE). This property enables use of lookup
groups in an index without having to consider all keys in the
index that satisfy all WHERE conditions.
This access method considers only a fraction of the keys in an
index, so it is called a loose index
scan. When there is no WHERE
clause, a loose index scan reads as many keys as the number of
groups, which may be a much smaller number than that of all
keys. If the WHERE clause contains range
predicates (see the discussion of the range
join type in Section 7.2.1, “Optimizing Queries with EXPLAIN”), a loose index scan
looks up the first key of each group that satisfies the range
conditions, and again reads the least possible number of keys.
This is possible under the following conditions:
The query is over a single table.
The
GROUP BYincludes the first consecutive parts of the index. (If, instead ofGROUP BY, the query has aDISTINCTclause, all distinct attributes refer to the beginning of the index.)The only aggregate functions used (if any) are
MIN()andMAX(), and all of them refer to the same column.Any other parts of the index than those from the
GROUP BYreferenced in the query must be constants (that is, they must be referenced in equalities with constants), except for the argument ofMIN()orMAX()functions.
The EXPLAIN output for such queries shows
Using index for group-by in the
Extra column.
The following queries fall into this category, assuming that
there is an index idx(c1,c2,c3) on table
t1(c1,c2,c3,c4):
SELECT c1, c2 FROM t1 GROUP BY c1, c2; SELECT DISTINCT c1, c2 FROM t1; SELECT c1, MIN(c2) FROM t1 GROUP BY c1; SELECT c1, c2 FROM t1 WHERE c1 <constGROUP BY c1, c2; SELECT MAX(c3), MIN(c3), c1, c2 FROM t1 WHERE c2 >constGROUP BY c1, c2; SELECT c2 FROM t1 WHERE c1 <constGROUP BY c1, c2; SELECT c1, c2 FROM t1 WHERE c3 =constGROUP BY c1, c2;
The following queries cannot be executed with this quick select method, for the reasons given:
There are aggregate functions other than
MIN()orMAX(), for example:SELECT c1, SUM(c2) FROM t1 GROUP BY c1;
The fields in the
GROUP BYclause do not refer to the beginning of the index, as shown here:SELECT c1,c2 FROM t1 GROUP BY c2, c3;
The query refers to a part of a key that comes after the
GROUP BYpart, and for which there is no equality with a constant, an example being:SELECT c1,c3 FROM t1 GROUP BY c1, c2;
A tight index scan may be either a full index scan or a range index scan, depending on the query conditions.
When the conditions for a loose index scan are not met, it is
still possible to avoid creation of temporary tables for
GROUP BY queries. If there are range
conditions in the WHERE clause, this method
reads only the keys that satisfy these conditions. Otherwise,
it performs an index scan. Because this method reads all keys
in each range defined by the WHERE clause,
or scans the whole index if there are no range conditions, we
term it a tight index scan. Notice that
with a tight index scan, the grouping operation is performed
only after all keys that satisfy the range conditions have
been found.
For this method to work, it is sufficient that there is a
constant equality condition for all columns in a query
referring to parts of the key coming before or in between
parts of the GROUP BY key. The constants
from the equality conditions fill in any “gaps”
in the search keys so that it is possible to form complete
prefixes of the index. These index prefixes then can be used
for index lookups. If we require sorting of the GROUP
BY result, and it is possible to form search keys
that are prefixes of the index, MySQL also avoids extra
sorting operations because searching with prefixes in an
ordered index already retrieves all the keys in order.
The following queries do not work with the loose index scan
access method described earlier, but still work with the tight
index scan access method (assuming that there is an index
idx(c1,c2,c3) on table
t1(c1,c2,c3,c4)).
There is a gap in the
GROUP BY, but it is covered by the conditionc2 = 'a':SELECT c1, c2, c3 FROM t1 WHERE c2 = 'a' GROUP BY c1, c3;
The
GROUP BYdoes not begin with the first part of the key, but there is a condition that provides a constant for that part:SELECT c1, c2, c3 FROM t1 WHERE c1 = 'a' GROUP BY c2, c3;
DISTINCT combined with ORDER
BY needs a temporary table in many cases.
Because DISTINCT may use GROUP
BY, you should be aware of how MySQL works with
columns in ORDER BY or
HAVING clauses that are not part of the
selected columns. See Section 12.11.3, “GROUP BY and HAVING with Hidden
Fields”.
In most cases, a DISTINCT clause can be
considered as a special case of GROUP BY. For
example, the following two queries are equivalent:
SELECT DISTINCT c1, c2, c3 FROM t1 WHERE c1 >const; SELECT c1, c2, c3 FROM t1 WHERE c1 >constGROUP BY c1, c2, c3;
Due to this equivalence, the optimizations applicable to
GROUP BY queries can be also applied to
queries with a DISTINCT clause. Thus, for
more details on the optimization possibilities for
DISTINCT queries, see
Section 7.2.12, “GROUP BY Optimization”.
When combining LIMIT
with
row_countDISTINCT, MySQL stops as soon as it finds
row_count unique rows.
If you do not use columns from all tables named in a query,
MySQL stops scanning any unused tables as soon as it finds the
first match. In the following case, assuming that
t1 is used before t2
(which you can check with EXPLAIN), MySQL
stops reading from t2 (for any particular row
in t1) when it finds the first row in
t2:
SELECT DISTINCT t1.a FROM t1, t2 where t1.a=t2.a;
Certain optimizations are applicable to comparisons that use the
IN operator to test subquery results (or that
use =ANY, which is equivalent). This section
discusses these optimizations, particularly with regard to the
challenges that NULL values present.
Suggestions on what you can do to help the optimizer are given
at the end of the discussion.
Consider the following subquery comparison:
outer_exprIN (SELECTinner_exprFROM ... WHEREsubquery_where)
MySQL evaluates queries “from outside to inside.”
That is, it first obtains the value of the outer expression
outer_expr, and then runs the
subquery and captures the rows that it produces.
A very useful optimization is to “inform” the
subquery that the only rows of interest are those where the
inner expression inner_expr is equal
to outer_expr. This is done by
pushing down an appropriate equality into the subquery's
WHERE clause. That is, the comparison is
converted to this:
EXISTS (SELECT 1 FROM ... WHEREsubquery_whereANDouter_expr=inner_expr)
After the conversion, MySQL can use the pushed-down equality to limit the number of rows that it must examine when evaluating the subquery.
More generally, a comparison of N
values to a subquery that returns
N-value rows is subject to the same
conversion. If oe_i and
ie_i represent corresponding outer
and inner expression values, this subquery comparison:
(oe_1, ...,oe_N) IN (SELECTie_1, ...,ie_NFROM ... WHEREsubquery_where)
Becomes:
EXISTS (SELECT 1 FROM ... WHEREsubquery_whereANDoe_1=ie_1AND ... ANDoe_N=ie_N)
The following discussion assumes a single pair of outer and inner expression values for simplicity.
The conversion just described has its limitations. It is valid
only if we ignore possible NULL values. That
is, the “pushdown” strategy works as long as both
of these two conditions are true:
outer_exprandinner_exprcannot beNULL.You do not need to distinguish
NULLfromFALSEsubquery results. (If the subquery is a part of anORorANDexpression in theWHEREclause, MySQL assumes that you don't care.)
When either or both of those conditions do not hold, optimization is more complex.
Suppose that outer_expr is known to
be a non-NULL value but the subquery does not
produce a row such that outer_expr =
inner_expr. Then
outer_expr IN (SELECT
...)
NULL, if theSELECTproduces any row whereinner_exprisNULLFALSE, if theSELECTproduces only non-NULLvalues or produces nothing
In this situation, the approach of looking for rows with
outer_expr =
inner_exprinner_expr is
NULL. Roughly speaking, the subquery can be
converted to:
EXISTS (SELECT 1 FROM ... WHEREsubquery_whereAND (outer_expr=inner_exprORinner_exprIS NULL))
The need to evaluate the extra IS NULL
condition is why MySQL has the ref_or_null
access method:
mysql>EXPLAIN->SELECT->outer_exprIN (SELECT t2.maybe_null_keyFROM t2, t3 WHERE ...)-> FROM t1; *************************** 1. row *************************** id: 1 select_type: PRIMARY table: t1 ... *************************** 2. row *************************** id: 2 select_type: DEPENDENT SUBQUERY table: t2 type: ref_or_null possible_keys: maybe_null_key key: maybe_null_key key_len: 5 ref: func rows: 2 Extra: Using where; Using index ...
The unique_subquery and
index_subquery subqery-specific access
methods also have or-null variants. However, they are not
visible in EXPLAIN output, so you must use
EXPLAIN EXTENDED followed by SHOW
WARNINGS (note the checking NULL in
the warning message):
mysql>EXPLAIN EXTENDED->SELECT*************************** 1. row *************************** id: 1 select_type: PRIMARY table: t1 ... *************************** 2. row *************************** id: 2 select_type: DEPENDENT SUBQUERY table: t2 type: index_subquery possible_keys: maybe_null_key key: maybe_null_key key_len: 5 ref: func rows: 2 Extra: Using index mysql>outer_exprIN (SELECT maybe_null_key FROM t2) FROM t1\GSHOW WARNINGS\G*************************** 1. row *************************** Level: Note Code: 1003 Message: select (`test`.`t1`.`outer_expr`, (((`test`.`t1`.`outer_expr`) in t2 on maybe_null_key checking NULL))) AS `outer_expr IN (SELECT maybe_null_key FROM t2)` from `test`.`t1`
The additional OR ... IS NULL condition makes
query execution slightly more complicated (and some
optimizations within the subquery become inapplicable), but
generally this is tolerable.
The situation is much worse when
outer_expr can be
NULL. According to the SQL interpretation of
NULL as “unknown value,”
NULL IN (SELECT should evaluate to:
inner_expr
...)
NULL, if theSELECTproduces any rowsFALSE, if theSELECTproduces no rows
For proper evaluation, it is necessary to be able to check
whether the SELECT has produced any rows at
all, so outer_expr =
inner_expr
Essentially, there must be different ways to execute the
subquery depending on the value of
outer_expr. In MySQL 5.0
before 5.0.36, the optimizer chose speed over distinguishing a
NULL from FALSE result, so
for some queries, you might get a FALSE
result rather than NULL.
As of MySQL 5.0.36, the optimizer chooses SQL compliance over
speed, so it accounts for the possibility that
outer_expr might be
NULL.
If outer_expr is
NULL, to evaluate the following expression,
it is necessary to run the SELECT to
determine whether it produces any rows:
NULL IN (SELECTinner_exprFROM ... WHEREsubquery_where)
It is necessary to run the original SELECT
here, without any pushed-down equalities of the kind mentioned
earlier.
On the other hand, when outer_expr is
not NULL, it is absolutely essential that
this comparison:
outer_exprIN (SELECTinner_exprFROM ... WHEREsubquery_where)
be converted to this expression that uses a pushed-down condition:
EXISTS (SELECT 1 FROM ... WHEREsubquery_whereANDouter_expr=inner_expr)
Without this conversion, subqueries will be slow. To solve the dilemma of whether to push down or not push down conditions into the subquery, the conditions are wrapped in “trigger” functions. Thus, an expression of the following form:
outer_exprIN (SELECTinner_exprFROM ... WHEREsubquery_where)
is converted into:
EXISTS (SELECT 1 FROM ... WHEREsubquery_whereAND trigcond(outer_expr=inner_expr))
More generally, if the subquery comparison is based on several pairs of outer and inner expressions, the conversion takes this comparison:
(oe_1, ...,oe_N) IN (SELECTie_1, ...,ie_NFROM ... WHEREsubquery_where)
and converts it to this expression:
EXISTS (SELECT 1 FROM ... WHEREsubquery_whereAND trigcond(oe_1=ie_1) AND ... AND trigcond(oe_N=ie_N) )
Each trigcond(
is a special function that evaluates to the following values:
X)
Xwhen the “linked” outer expressionoe_iis notNULLTRUEwhen the “linked” outer expressionoe_iisNULL
Note that trigger functions are not
triggers of the kind that you create with CREATE
TRIGGER.
Equalities that are wrapped into trigcond()
functions are not first class predicates for the query
optimizer. Most optimizations cannot deal with predicates that
may be turned on and off at query execution time, so they assume
any trigcond( to
be an unknown function and ignore it. At the moment, triggered
equalities can be used by those optimizations:
X)
Reference optimizations:
trigcond(can be used to constructX=Y[ORYIS NULL])ref,eq_ref, orref_or_nulltable accesses.Index lookup-based subquery execution engines:
trigcond(can be used to constructX=Y)unique_subqueryorindex_subqueryaccesses.Table-condition generator: If the subquery is a join of several tables, the triggered condition will be checked as soon as possible.
When the optimizer uses a triggered condition to create some
kind of index lookup-based access (as for the first two items of
the preceding list), it must have a fallback strategy for the
case when the condition is turned off. This fallback strategy is
always the same: Do a full table scan. In
EXPLAIN output, the fallback shows up as
Full scan on NULL key in the
Extra column:
mysql>EXPLAIN SELECT t1.col1,->t1.col1 IN (SELECT t2.key1 FROM t2 WHERE t2.col2=t1.col2) FROM t1\G*************************** 1. row *************************** id: 1 select_type: PRIMARY table: t1 ... *************************** 2. row *************************** id: 2 select_type: DEPENDENT SUBQUERY table: t2 type: index_subquery possible_keys: key1 key: key1 key_len: 5 ref: func rows: 2 Extra: Using where; Full scan on NULL key
If you run EXPLAIN EXTENDED followed by
SHOW WARNINGS, you can see the triggered
condition:
*************************** 1. row ***************************
Level: Note
Code: 1003
Message: select `test`.`t1`.`col1` AS `col1`,
<in_optimizer>(`test`.`t1`.`col1`,
<exists>(<index_lookup>(<cache>(`test`.`t1`.`col1`) in t2
on key1 checking NULL
where (`test`.`t2`.`col2` = `test`.`t1`.`col2`) having
trigcond(<is_not_null_test>(`test`.`t2`.`key1`))))) AS
`t1.col1 IN (select t2.key1 from t2 where t2.col2=t1.col2)`
from `test`.`t1`
The use of triggered conditions has some performance
implications. A NULL IN (SELECT ...)
expression now may cause a full table scan (which is slow) when
it previously did not. This is the price paid for correct
results (the goal of the trigger-condition strategy was to
improve compliance and not speed).
For multiple-table subqueries, execution of NULL IN
(SELECT ...) will be particularly slow because the
join optimizer doesn't optimize for the case where the outer
expression is NULL. It assumes that subquery
evaluations with NULL on the left side are
very rare, even if there are statistics that indicate otherwise.
On the other hand, if the outer expression might be
NULL but never actually is, there is no
performance penalty.
To help the query optimizer better execute your queries, use these tips:
A column must be declared as
NOT NULLif it really is. (This also helps other aspects of the optimizer.)If you don't need to distinguish a
NULLfromFALSEsubquery result, you can easily avoid the slow execution path. Replace a comparison that looks like this:outer_exprIN (SELECTinner_exprFROM ...)with this expression:
(
outer_exprIS NOT NULL) AND (outer_exprIN (SELECTinner_exprFROM ...))Then
NULL IN (SELECT ...)will never be evaluated because MySQL stops evaluatingANDparts as soon as the expression result is clear.
In some cases, MySQL handles a query differently when you are
using LIMIT
and not using
row_countHAVING:
If you are selecting only a few rows with
LIMIT, MySQL uses indexes in some cases when normally it would prefer to do a full table scan.If you use
LIMITwithrow_countORDER BY, MySQL ends the sorting as soon as it has found the firstrow_countrows of the sorted result, rather than sorting the entire result. If ordering is done by using an index, this is very fast. If a filesort must be done, all rows that match the query without theLIMITclause must be selected, and most or all of them must be sorted, before it can be ascertained that the firstrow_countrows have been found. In either case, after the initial rows have been found, there is no need to sort any remainder of the result set, and MySQL does not do so.When combining
LIMITwithrow_countDISTINCT, MySQL stops as soon as it findsrow_countunique rows.In some cases, a
GROUP BYcan be resolved by reading the key in order (or doing a sort on the key) and then calculating summaries until the key value changes. In this case,LIMITdoes not calculate any unnecessaryrow_countGROUP BYvalues.As soon as MySQL has sent the required number of rows to the client, it aborts the query unless you are using
SQL_CALC_FOUND_ROWS.LIMIT 0quickly returns an empty set. This can be useful for checking the validity of a query. When using one of the MySQL APIs, it can also be employed for obtaining the types of the result columns. (This trick does not work in the MySQL Monitor (the mysql program), which merely displaysEmpty setin such cases; you should instead useSHOW COLUMNSorDESCRIBEfor this purpose.)When the server uses temporary tables to resolve the query, it uses the
LIMITclause to calculate how much space is required.row_count
The output from EXPLAIN shows
ALL in the type column
when MySQL uses a table scan to resolve a query. This usually
happens under the following conditions:
The table is so small that it is faster to perform a table scan than to bother with a key lookup. This is common for tables with fewer than 10 rows and a short row length.
There are no usable restrictions in the
ONorWHEREclause for indexed columns.You are comparing indexed columns with constant values and MySQL has calculated (based on the index tree) that the constants cover too large a part of the table and that a table scan would be faster. See Section 7.2.4, “
WHEREClause Optimization”.You are using a key with low cardinality (many rows match the key value) through another column. In this case, MySQL assumes that by using the key it probably will do many key lookups and that a table scan would be faster.
MySQL Enterprise For expert advice on avoiding excessive table scans subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
For small tables, a table scan often is appropriate and the performance impact is negligible. For large tables, try the following techniques to avoid having the optimizer incorrectly choose a table scan:
Use
ANALYZE TABLEto update the key distributions for the scanned table. See Section 13.5.2.1, “tbl_nameANALYZE TABLESyntax”.Use
FORCE INDEXfor the scanned table to tell MySQL that table scans are very expensive compared to using the given index:SELECT * FROM t1, t2 FORCE INDEX (
index_for_column) WHERE t1.col_name=t2.col_name;Start mysqld with the
--max-seeks-for-key=1000option or useSET max_seeks_for_key=1000to tell the optimizer to assume that no key scan causes more than 1,000 key seeks. See Section 5.2.3, “System Variables”.
The time required for inserting a row is determined by the following factors, where the numbers indicate approximate proportions:
Connecting: (3)
Sending query to server: (2)
Parsing query: (2)
Inserting row: (1 × size of row)
Inserting indexes: (1 × number of indexes)
Closing: (1)
This does not take into consideration the initial overhead to open tables, which is done once for each concurrently running query.
The size of the table slows down the insertion of indexes by log
N, assuming B-tree indexes.
You can use the following methods to speed up inserts:
If you are inserting many rows from the same client at the same time, use
INSERTstatements with multipleVALUESlists to insert several rows at a time. This is considerably faster (many times faster in some cases) than using separate single-rowINSERTstatements. If you are adding data to a non-empty table, you can tune thebulk_insert_buffer_sizevariable to make data insertion even faster. See Section 5.2.3, “System Variables”.If multiple clients are inserting a lot of rows, you can get higher speed by using the
INSERT DELAYEDstatement. See Section 13.2.4.2, “INSERT DELAYEDSyntax”.For a
MyISAMtable, you can use concurrent inserts to add rows at the same time thatSELECTstatements are running, if there are no deleted rows in middle of the data file. See Section 7.3.3, “Concurrent Inserts”.When loading a table from a text file, use
LOAD DATA INFILE. This is usually 20 times faster than usingINSERTstatements. See Section 13.2.5, “LOAD DATA INFILESyntax”.With some extra work, it is possible to make
LOAD DATA INFILErun even faster for aMyISAMtable when the table has many indexes. Use the following procedure:Optionally create the table with
CREATE TABLE.Execute a
FLUSH TABLESstatement or a mysqladmin flush-tables command.Use myisamchk --keys-used=0 -rq
/path/to/db/tbl_name. This removes all use of indexes for the table.Insert data into the table with
LOAD DATA INFILE. This does not update any indexes and therefore is very fast.If you intend only to read from the table in the future, use myisampack to compress it. See Section 14.1.3.3, “Compressed Table Characteristics”.
Re-create the indexes with myisamchk -rq
/path/to/db/tbl_name. This creates the index tree in memory before writing it to disk, which is much faster that updating the index duringLOAD DATA INFILEbecause it avoids lots of disk seeks. The resulting index tree is also perfectly balanced.Execute a
FLUSH TABLESstatement or a mysqladmin flush-tables command.
LOAD DATA INFILEperforms the preceding optimization automatically if theMyISAMtable into which you insert data is empty. The main difference between automatic optimization and using the procedure explicitly is that you can let myisamchk allocate much more temporary memory for the index creation than you might want the server to allocate for index re-creation when it executes theLOAD DATA INFILEstatement.You can also disable or enable the indexes for a
MyISAMtable by using the following statements rather than myisamchk. If you use these statements, you can skip theFLUSH TABLEoperations:ALTER TABLE
tbl_nameDISABLE KEYS; ALTER TABLEtbl_nameENABLE KEYS;To speed up
INSERToperations that are performed with multiple statements for non-transactional tables, lock your tables:LOCK TABLES a WRITE; INSERT INTO a VALUES (1,23),(2,34),(4,33); INSERT INTO a VALUES (8,26),(6,29); ... UNLOCK TABLES;
This benefits performance because the index buffer is flushed to disk only once, after all
INSERTstatements have completed. Normally, there would be as many index buffer flushes as there areINSERTstatements. Explicit locking statements are not needed if you can insert all rows with a singleINSERT.To obtain faster insertions for transactional tables, you should use
START TRANSACTIONandCOMMITinstead ofLOCK TABLES.Locking also lowers the total time for multiple-connection tests, although the maximum wait time for individual connections might go up because they wait for locks. Suppose that five clients attempt to perform inserts simultaneously as follows:
Connection 1 does 1000 inserts
Connections 2, 3, and 4 do 1 insert
Connection 5 does 1000 inserts
If you do not use locking, connections 2, 3, and 4 finish before 1 and 5. If you use locking, connections 2, 3, and 4 probably do not finish before 1 or 5, but the total time should be about 40% faster.
INSERT,UPDATE, andDELETEoperations are very fast in MySQL, but you can obtain better overall performance by adding locks around everything that does more than about five successive inserts or updates. If you do very many successive inserts, you could do aLOCK TABLESfollowed by anUNLOCK TABLESonce in a while (each 1,000 rows or so) to allow other threads access to the table. This would still result in a nice performance gain.INSERTis still much slower for loading data thanLOAD DATA INFILE, even when using the strategies just outlined.To increase performance for
MyISAMtables, for bothLOAD DATA INFILEandINSERT, enlarge the key cache by increasing thekey_buffer_sizesystem variable. See Section 7.5.2, “Tuning Server Parameters”.
MySQL Enterprise For more advice on optimizing the performance of your server, subscribe to the MySQL Network Monitoring and Advisory Service. Numerous advisors are dedicated to monitoring performance. For more information see http://www.mysql.com/products/enterprise/advisors.html.
An update statement is optimized like a
SELECT query with the additional overhead of
a write. The speed of the write depends on the amount of data
being updated and the number of indexes that are updated.
Indexes that are not changed do not get updated.
Another way to get fast updates is to delay updates and then do many updates in a row later. Performing multiple updates together is much quicker than doing one at a time if you lock the table.
For a MyISAM table that uses dynamic row
format, updating a row to a longer total length may split the
row. If you do this often, it is very important to use
OPTIMIZE TABLE occasionally. See
Section 13.5.2.5, “OPTIMIZE TABLE Syntax”.
The time required to delete individual rows is exactly
proportional to the number of indexes. To delete rows more
quickly, you can increase the size of the key cache by
increasing the key_buffer_size system
variable. See Section 7.5.2, “Tuning Server Parameters”.
To delete all rows from a table, TRUNCATE TABLE
is faster than
than tbl_nameDELETE FROM Truncate operations are not
transaction-safe; an error occurs when attempting one in the
course of an active transaction or active table lock.
. See
Section 13.2.9, “tbl_nameTRUNCATE Syntax”.
This section lists a number of miscellaneous tips for improving query processing speed:
Use persistent connections to the database to avoid connection overhead. If you cannot use persistent connections and you are initiating many new connections to the database, you may want to change the value of the
thread_cache_sizevariable. See Section 7.5.2, “Tuning Server Parameters”.Always check whether all your queries really use the indexes that you have created in the tables. In MySQL, you can do this with the
EXPLAINstatement. See Section 7.2.1, “Optimizing Queries withEXPLAIN”.Try to avoid complex
SELECTqueries onMyISAMtables that are updated frequently, to avoid problems with table locking that occur due to contention between readers and writers.MyISAMsupports concurrent inserts: If a table has no free blocks in the middle of the data file, you canINSERTnew rows into it at the same time that other threads are reading from the table. If it is important to be able to do this, you should consider using the table in ways that avoid deleting rows. Another possibility is to runOPTIMIZE TABLEto defragment the table after you have deleted a lot of rows from it. This behavior is altered by setting theconcurrent_insertvariable. You can force new rows to be appended (and therefore allow concurrent inserts), even in tables that have deleted rows. See Section 7.3.3, “Concurrent Inserts”.MySQL Enterprise For optimization tips geared to your specific circumstances subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
To fix any compression issues that may have occurred with
ARCHIVEtables, you can useOPTIMIZE TABLE. See Section 14.8, “TheARCHIVEStorage Engine”.Use
ALTER TABLE ... ORDER BYif you usually retrieve rows inexpr1,expr2, ...expr1,expr2, ...In some cases, it may make sense to introduce a column that is “hashed” based on information from other columns. If this column is short, reasonably unique, and indexed, it may be much faster than a “wide” index on many columns. In MySQL, it is very easy to use this extra column:
SELECT * FROM
tbl_nameWHEREhash_col=MD5(CONCAT(col1,col2)) ANDcol1='constant' ANDcol2='constant';For
MyISAMtables that change frequently, you should try to avoid all variable-length columns (VARCHAR,BLOB, andTEXT). The table uses dynamic row format if it includes even a single variable-length column. See Chapter 14, Storage Engines.It is normally not useful to split a table into different tables just because the rows become large. In accessing a row, the biggest performance hit is the disk seek needed to find the first byte of the row. After finding the data, most modern disks can read the entire row fast enough for most applications. The only cases where splitting up a table makes an appreciable difference is if it is a
MyISAMtable using dynamic row format that you can change to a fixed row size, or if you very often need to scan the table but do not need most of the columns. See Chapter 14, Storage Engines.If you often need to calculate results such as counts based on information from a lot of rows, it may be preferable to introduce a new table and update the counter in real time. An update of the following form is very fast:
UPDATE
tbl_nameSETcount_col=count_col+1 WHEREkey_col=constant;This is very important when you use MySQL storage engines such as
MyISAMthat has only table-level locking (multiple readers with single writers). This also gives better performance with most database systems, because the row locking manager in this case has less to do.If you need to collect statistics from large log tables, use summary tables instead of scanning the entire log table. Maintaining the summaries should be much faster than trying to calculate statistics “live.” Regenerating new summary tables from the logs when things change (depending on business decisions) is faster than changing the running application.
If possible, you should classify reports as “live” or as “statistical,” where data needed for statistical reports is created only from summary tables that are generated periodically from the live data.
Take advantage of the fact that columns have default values. Insert values explicitly only when the value to be inserted differs from the default. This reduces the parsing that MySQL must do and improves the insert speed.
In some cases, it is convenient to pack and store data into a
BLOBcolumn. In this case, you must provide code in your application to pack and unpack information, but this may save a lot of accesses at some stage. This is practical when you have data that does not conform well to a rows-and-columns table structure.Normally, you should try to keep all data non-redundant (observing what is referred to in database theory as third normal form). However, there may be situations in which it can be advantageous to duplicate information or create summary tables to gain more speed.
Stored routines or UDFs (user-defined functions) may be a good way to gain performance for some tasks. See Chapter 17, Stored Procedures and Functions, and Section 24.2, “Adding New Functions to MySQL”, for more information.
You can increase performance by caching queries or answers in your application and then executing many inserts or updates together. If your database system supports table locks (as do MySQL and Oracle), this should help to ensure that the index cache is only flushed once after all updates. You can also take advantage of MySQL's query cache to achieve similar results; see Section 5.13, “The MySQL Query Cache”.
Use
INSERT DELAYEDwhen you do not need to know when your data is written. This reduces the overall insertion impact because many rows can be written with a single disk write.Use
INSERT LOW_PRIORITYwhen you want to giveSELECTstatements higher priority than your inserts.Use
SELECT HIGH_PRIORITYto get retrievals that jump the queue. That is, theSELECTis executed even if there is another client waiting to do a write.LOW_PRIORITYandHIGH_PRIORITYhave an effect only for storage engines that use only table-level locking (MyISAM,MEMORY,MERGE).Use multiple-row
INSERTstatements to store many rows with one SQL statement. Many SQL servers support this, including MySQL.Use
LOAD DATA INFILEto load large amounts of data. This is faster than usingINSERTstatements.Use
AUTO_INCREMENTcolumns so that each row in a table can be identified by a single unique value. unique values.Use
OPTIMIZE TABLEonce in a while to avoid fragmentation with dynamic-formatMyISAMtables. See Section 14.1.3, “MyISAMTable Storage Formats”.Use
MEMORY(HEAP) tables when possible to get more speed. See Section 14.4, “TheMEMORY(HEAP) Storage Engine”.MEMORYtables are useful for non-critical data that is accessed often, such as information about the last displayed banner for users who don't have cookies enabled in their Web browser. User sessions are another alternative available in many Web application environments for handling volatile state data.With Web servers, images and other binary assets should normally be stored as files. That is, store only a reference to the file rather than the file itself in the database. Most Web servers are better at caching files than database contents, so using files is generally faster.
Columns with identical information in different tables should be declared to have identical data types so that joins based on the corresponding columns will be faster.
Try to keep column names simple. For example, in a table named
customer, use a column name ofnameinstead ofcustomer_name. To make your names portable to other SQL servers, you should keep them shorter than 18 characters.If you need really high speed, you should take a look at the low-level interfaces for data storage that the different SQL servers support. For example, by accessing the MySQL
MyISAMstorage engine directly, you could get a speed increase of two to five times compared to using the SQL interface. To be able to do this, the data must be on the same server as the application, and usually it should only be accessed by one process (because external file locking is really slow). One could eliminate these problems by introducing low-levelMyISAMcommands in the MySQL server (this could be one easy way to get more performance if needed). By carefully designing the database interface, it should be quite easy to support this type of optimization.If you are using numerical data, it is faster in many cases to access information from a database (using a live connection) than to access a text file. Information in the database is likely to be stored in a more compact format than in the text file, so accessing it involves fewer disk accesses. You also save code in your application because you need not parse your text files to find line and column boundaries.
Replication can provide a performance benefit for some operations. You can distribute client retrievals among replication servers to split up the load. To avoid slowing down the master while making backups, you can make backups using a slave server. See Chapter 6, Replication.
Declaring a
MyISAMtable with theDELAY_KEY_WRITE=1table option makes index updates faster because they are not flushed to disk until the table is closed. The downside is that if something kills the server while such a table is open, you should ensure that the table is okay by running the server with the--myisam-recoveroption, or by running myisamchk before restarting the server. (However, even in this case, you should not lose anything by usingDELAY_KEY_WRITE, because the key information can always be generated from the data rows.)
MySQL manages contention for table contents using locking:
Internal locking; is performed within the MySQL server itself to manage contention for table contents by multiple threads. This type of locking is internal because it is performed entirely by the server and involves no other programs. See Section 7.3.1, “Internal Locking Methods”.
External locking occurs when the server and other programs lock table files to coordinate among themselves which program can access the tables at which time. See Section 7.3.4, “External Locking”. See Section 7.3.4, “External Locking”.
This section discusses internal locking; that is, locking performed within the MySQL server itself to manage contention for table contents by multiple threads. This type of locking is internal because it is performed entirely by the server and involves no other programs. External locking occurs when the server and other programs lock table files to coordinate among themselves which program can access the tables at which time. See Section 7.3.4, “External Locking”.
MySQL uses table-level locking for MyISAM and
MEMORY tables, page-level locking for
BDB tables, and row-level locking for
InnoDB tables.
In many cases, you can make an educated guess about which locking type is best for an application, but generally it is difficult to say that a given lock type is better than another. Everything depends on the application and different parts of an application may require different lock types.
To decide whether you want to use a storage engine with
row-level locking, you should look at what your application does
and what mix of select and update statements it uses. For
example, most Web applications perform many selects, relatively
few deletes, updates based mainly on key values, and inserts
into a few specific tables. The base MySQL
MyISAM setup is very well tuned for this.
MySQL Enterprise The MySQL Network Monitoring and Advisory Service provides expert advice on when to use table-level locking and when to use row-level locking. To subscribe see http://www.mysql.com/products/enterprise/advisors.html.
Table locking in MySQL is deadlock-free for storage engines that use table-level locking. Deadlock avoidance is managed by always requesting all needed locks at once at the beginning of a query and always locking the tables in the same order.
MySQL grants table WRITE locks as follows:
If there are no locks on the table, put a write lock on it.
Otherwise, put the lock request in the write lock queue.
MySQL grants table READ locks as follows:
If there are no write locks on the table, put a read lock on it.
Otherwise, put the lock request in the read lock queue.
When a lock is released, the lock is made available to the
threads in the write lock queue and then to the threads in the
read lock queue. This means that if you have many updates for a
table, SELECT statements wait until there are
no more updates.
You can analyze the table lock contention on your system by
checking the Table_locks_waited and
Table_locks_immediate status variables:
mysql> SHOW STATUS LIKE 'Table%';
+-----------------------+---------+
| Variable_name | Value |
+-----------------------+---------+
| Table_locks_immediate | 1151552 |
| Table_locks_waited | 15324 |
+-----------------------+---------+
The MyISAM storage engine supports concurrent
inserts to reduce contention between readers and writers for a
given table: If a MyISAM table has no free
blocks in the middle of the data file, rows are always inserted
at the end of the data file. In this case, you can freely mix
concurrent INSERT and
SELECT statements for a
MyISAM table without locks. That is, you can
insert rows into a MyISAM table at the same
time other clients are reading from it. Holes can result from
rows having been deleted from or updated in the middle of the
table. If there are holes, concurrent inserts are disabled but
are re-enabled automatically when all holes have been filled
with new data. This behavior is altered by the
concurrent_insert system variable. See
Section 7.3.3, “Concurrent Inserts”.
If you want to perform many INSERT and
SELECT operations on a table
real_table when concurrent inserts are not
possible, you can insert rows into a temporary table
temp_table and update the real table with the
rows from the temporary table periodically. This can be done
with the following code:
mysql>LOCK TABLES real_table WRITE, temp_table WRITE;mysql>INSERT INTO real_table SELECT * FROM temp_table;mysql>DELETE FROM temp_table;mysql>UNLOCK TABLES;
InnoDB uses row locks and
BDB uses page locks. Deadlocks are possible
for these storage engines because they automatically acquire
locks during the processing of SQL statements, not at the start
of the transaction.
Advantages of row-level locking:
Fewer lock conflicts when accessing different rows in many threads
Fewer changes for rollbacks
Possible to lock a single row for a long time
Disadvantages of row-level locking:
Requires more memory than page-level or table-level locks
Slower than page-level or table-level locks when used on a large part of the table because you must acquire many more locks
Definitely much slower than other locks if you often do
GROUP BYoperations on a large part of the data or if you must scan the entire table frequently
Table locks are superior to page-level or row-level locks in the following cases:
Most statements for the table are reads
Statements for the table are a mix of reads and writes, where writes are updates or deletes for a single row that can be fetched with one key read:
UPDATE
tbl_nameSETcolumn=valueWHEREunique_key_col=key_value; DELETE FROMtbl_nameWHEREunique_key_col=key_value;SELECTcombined with concurrentINSERTstatements, and very fewUPDATEorDELETEstatementsMany scans or
GROUP BYoperations on the entire table without any writers
With higher-level locks, you can more easily tune applications by supporting locks of different types, because the lock overhead is less than for row-level locks.
Options other than row-level or page-level locking:
Versioning (such as that used in MySQL for concurrent inserts) where it is possible to have one writer at the same time as many readers. This means that the database or table supports different views for the data depending on when access begins. Other common terms for this are “time travel,” “copy on write,” or “copy on demand.”
Copy on demand is in many cases superior to page-level or row-level locking. However, in the worst case, it can use much more memory than using normal locks.
Instead of using row-level locks, you can employ application-level locks, such as those provided by
GET_LOCK()andRELEASE_LOCK()in MySQL. These are advisory locks, so they work only in well-behaved applications. See Section 12.10.4, “Miscellaneous Functions”.
To achieve a very high lock speed, MySQL uses table locking
(instead of page, row, or column locking) for all storage
engines except InnoDB,
BDB, and NDBCLUSTER.
For InnoDB and BDB tables,
MySQL only uses table locking if you explicitly lock the table
with LOCK TABLES. For these storage engines,
we recommend that you not use LOCK TABLES at
all, because InnoDB uses automatic row-level
locking and BDB uses page-level locking to
ensure transaction isolation.
For large tables, table locking is much better than row locking for most applications, but there are some pitfalls:
Table locking enables many threads to read from a table at the same time, but if a thread wants to write to a table, it must first get exclusive access. During the update, all other threads that want to access this particular table must wait until the update is done.
Table updates normally are considered to be more important than table retrievals, so they are given higher priority. This should ensure that updates to a table are not “starved” even if there is heavy
SELECTactivity for the table.Table locking causes problems in cases such as when a thread is waiting because the disk is full and free space needs to become available before the thread can proceed. In this case, all threads that want to access the problem table are also put in a waiting state until more disk space is made available.
Table locking is also disadvantageous under the following scenario:
A client issues a
SELECTthat takes a long time to run.Another client then issues an
UPDATEon the same table. This client waits until theSELECTis finished.Another client issues another
SELECTstatement on the same table. BecauseUPDATEhas higher priority thanSELECT, thisSELECTwaits for theUPDATEto finish, and for the firstSELECTto finish.
The following items describe some ways to avoid or reduce contention caused by table locking:
Try to get the
SELECTstatements to run faster so that they lock tables for a shorter time. You might have to create some summary tables to do this.Start mysqld with
--low-priority-updates. For storage engines that use only table-level locking (MyISAM,MEMORY,MERGE), this gives all statements that update (modify) a table lower priority thanSELECTstatements. In this case, the secondSELECTstatement in the preceding scenario would execute before theUPDATEstatement, and would not need to wait for the firstSELECTto finish.You can specify that all updates issued in a specific connection should be done with low priority by using the
SET LOW_PRIORITY_UPDATES=1statement. See Section 13.5.3, “SETSyntax”.You can give a specific
INSERT,UPDATE, orDELETEstatement lower priority with theLOW_PRIORITYattribute.You can give a specific
SELECTstatement higher priority with theHIGH_PRIORITYattribute. See Section 13.2.7, “SELECTSyntax”.You can start mysqld with a low value for the
max_write_lock_countsystem variable to force MySQL to temporarily elevate the priority of allSELECTstatements that are waiting for a table after a specific number of inserts to the table occur. This allowsREADlocks after a certain number ofWRITElocks.If you have problems with
INSERTcombined withSELECT, you might want to consider switching toMyISAMtables, which support concurrentSELECTandINSERTstatements. (See Section 7.3.3, “Concurrent Inserts”.)If you mix inserts and deletes on the same table,
INSERT DELAYEDmay be of great help. See Section 13.2.4.2, “INSERT DELAYEDSyntax”.If you have problems with mixed
SELECTandDELETEstatements, theLIMIToption toDELETEmay help. See Section 13.2.1, “DELETESyntax”.Using
SQL_BUFFER_RESULTwithSELECTstatements can help to make the duration of table locks shorter. See Section 13.2.7, “SELECTSyntax”.You could change the locking code in
mysys/thr_lock.cto use a single queue. In this case, write locks and read locks would have the same priority, which might help some applications.
Here are some tips concerning table locks in MySQL:
Concurrent users are not a problem if you do not mix updates with selects that need to examine many rows in the same table.
You can use
LOCK TABLESto increase speed, because many updates within a single lock is much faster than updating without locks. Splitting table contents into separate tables may also help.If you encounter speed problems with table locks in MySQL, you may be able to improve performance by converting some of your tables to
InnoDBorBDBtables. See Section 14.2, “TheInnoDBStorage Engine”, and Section 14.5, “TheBDB(BerkeleyDB) Storage Engine”.MySQL Enterprise Lock contention can seriously degrade performance. The MySQL Network Monitoring and Advisory Service provides expert advice on avoiding this problem. To subscribe see http://www.mysql.com/products/enterprise/advisors.html.
The MyISAM storage engine supports concurrent
inserts to reduce contention between readers and writers for a
given table: If a MyISAM table has no holes
in the data file (deleted rows in the middle), inserts can be
performed to add rows to the end of the table at the same time
that SELECT statements are reading rows from
the table.
The concurrent_insert system variable can be
set to modify the concurrent-insert processing. By default, the
variable is set to 1 and concurrent inserts are handled as just
described. If concurrent_inserts is set to 0,
concurrent inserts are disabled. If the variable is set to 2,
concurrent inserts at the end of the table are allowed even for
tables that have deleted rows. See also the description of the
concurrent_insert
system variable.
Under circumstances where concurrent inserts can be used, there
is seldom any need to use the DELAYED
modifier for INSERT statements. See
Section 13.2.4.2, “INSERT DELAYED Syntax”.
If you are using the binary log, concurrent inserts are
converted to normal inserts for CREATE ...
SELECT or INSERT ... SELECT
statements. This is done to ensure that you can re-create an
exact copy of your tables by applying the log during a backup
operation. See Section 5.11.3, “The Binary Log”.
With LOAD DATA INFILE, if you specify
CONCURRENT with a MyISAM
table that satisfies the condition for concurrent inserts (that
is, it contains no free blocks in the middle), other threads can
retrieve data from the table while LOAD DATA
is executing. Use of the CONCURRENT option
affects the performance of LOAD DATA a bit,
even if no other thread is using the table at the same time.
If you specify HIGH_PRIORITY, it overrides
the effect of the --low-priority-updates option
if the server was started with that option. It also causes
concurrent inserts not to be used.
For LOCK TABLE, the difference between
READ LOCAL and READ is
that READ LOCAL allows non-conflicting
INSERT statements (concurrent inserts) to
execute while the lock is held. However, this cannot be used if
you are going to manipulate the database using processes
external to the server while you hold the lock.
External locking is the use of filesystem locking to manage contention for database tables by multiple processes. External locking is used in situations where a single process such as the MySQL server cannot be assumed to be the only process that requires access to tables. Here are some examples:
If you run multiple servers that use the same database directory (not recommended), each server must have external locking enabled.
If you use myisamchk to perform table maintenance operations on
MyISAMtables, you must either ensure that the server is not running, or that the server has external locking enabled so that it locks table files as necessary to coordinate with myisamchk for access to the tables. The same is true for use of myisampack to packMyISAMtables.
With external locking in effect, each process that requires access to a table acquires a filesystem lock for the table files before proceeding to access the table. If all necessary locks cannot be acquired, the process is blocked from accessing the table until the locks can be obtained (after the process that currently holds the locks releases them).
External locking affects server performance because the server must sometimes wait for other processes before it can access tables.
External locking is unnecessary if you run a single server to access a given data directory (which is the usual case) and if no other programs such as myisamchk need to modify tables while the server is running. If you only read tables with other programs, external locking is not required, although myisamchk might report warnings if the server changes tables while myisamchk is reading them.
With external locking disabled, to use
myisamchk, you must either stop the server
while myisamchk executes or else lock and
flush the tables before running myisamchk.
(See Section 7.5.1, “System Factors and Startup Parameter Tuning”.) To avoid this
requirement, use the CHECK TABLE and
REPAIR TABLE statements to check and repair
MyISAM tables.
For mysqld, external locking is controlled by
the value of the skip_external_locking system
variable. (Before MySQL 4.0.3, this variable is named
skip_locking.) When this variable is enabled,
external locking is disabled, and vice versa. From MySQL 4.0 on,
external locking is disabled by default. Before MySQL 4.0,
external locking is enabled by default on Linux or when MySQL is
configured to use MIT-pthreads.
Use of external locking can be controlled at server startup by
using the --external-locking or
--skip-external-locking option. (Before MySQL
4.0.3, these options are named --enable-locking
and --skip-locking.)
If you do use external locking option to enable updates to
MyISAM tables from many MySQL processes, you
must ensure that the following conditions are satisfied:
You should not use the query cache for queries that use tables that are updated by another process.
You should not start the server with the
--delay-key-write=ALLoption or use theDELAY_KEY_WRITE=1table option for any shared tables. Otherise, index corruption can occur.
The easiest way to satisfy these conditions is to always use
--external-locking together with
--delay-key-write=OFF and
--query-cache-size=0. (This is not done by
default because in many setups it is useful to have a mixture of
the preceding options.)
- 7.4.1. Design Choices
- 7.4.2. Make Your Data as Small as Possible
- 7.4.3. Column Indexes
- 7.4.4. Multiple-Column Indexes
- 7.4.5. How MySQL Uses Indexes
- 7.4.6. The
MyISAMKey Cache - 7.4.7.
MyISAMIndex Statistics Collection - 7.4.8. How MySQL Opens and Closes Tables
- 7.4.9. Drawbacks to Creating Many Tables in the Same Database
MySQL keeps row data and index data in separate files. Many (almost all) other database systems mix row and index data in the same file. We believe that the MySQL choice is better for a very wide range of modern systems.
Another way to store the row data is to keep the information for each column in a separate area (examples are SDBM and Focus). This causes a performance hit for every query that accesses more than one column. Because this degenerates so quickly when more than one column is accessed, we believe that this model is not good for general-purpose databases.
The more common case is that the index and data are stored together (as in Oracle/Sybase, et al). In this case, you find the row information at the leaf page of the index. The good thing with this layout is that it, in many cases, depending on how well the index is cached, saves a disk read. The bad things with this layout are:
Table scanning is much slower because you have to read through the indexes to get at the data.
You cannot use only the index table to retrieve data for a query.
You use more space because you must duplicate indexes from the nodes (you cannot store the row in the nodes).
Deletes degenerate the table over time (because indexes in nodes are usually not updated on delete).
It is more difficult to cache only the index data.
One of the most basic optimizations is to design your tables to take as little space on the disk as possible. This can result in huge improvements because disk reads are faster, and smaller tables normally require less main memory while their contents are being actively processed during query execution. Indexing also is a lesser resource burden if done on smaller columns.
MySQL supports many different storage engines (table types) and row formats. For each table, you can decide which storage and indexing method to use. Choosing the proper table format for your application may give you a big performance gain. See Chapter 14, Storage Engines.
You can get better performance for a table and minimize storage space by using the techniques listed here:
Use the most efficient (smallest) data types possible. MySQL has many specialized types that save disk space and memory. For example, use the smaller integer types if possible to get smaller tables.
MEDIUMINTis often a better choice thanINTbecause aMEDIUMINTcolumn uses 25% less space.Declare columns to be
NOT NULLif possible. It makes everything faster and you save one bit per column. If you really needNULLin your application, you should definitely use it. Just avoid having it on all columns by default.For
MyISAMtables, if you do not have any variable-length columns (VARCHAR,TEXT, orBLOBcolumns), a fixed-size row format is used. This is faster but unfortunately may waste some space. See Section 14.1.3, “MyISAMTable Storage Formats”. You can hint that you want to have fixed length rows even if you haveVARCHARcolumns with theCREATE TABLEoptionROW_FORMAT=FIXED.Starting with MySQL 5.0.3,
InnoDBtables use a more compact storage format. In earlier versions of MySQL,InnoDBrows contain some redundant information, such as the number of columns and the length of each column, even for fixed-size columns. By default, tables are created in the compact format (ROW_FORMAT=COMPACT). If you wish to downgrade to older versions of MySQL, you can request the old format withROW_FORMAT=REDUNDANT.The compact
InnoDBformat also changes howCHARcolumns containing UTF-8 data are stored. WithROW_FORMAT=REDUNDANT, a UTF-8CHAR(occupies 3 ×N)Nbytes, given that the maximum length of a UTF-8 encoded character is three bytes. Many languages can be written primarily using single-byte UTF-8 characters, so a fixed storage length often wastes space. WithROW_FORMAT=COMPACTformat,InnoDBallocates a variable amount of storage in the range fromNto 3 ×Nbytes for these columns by stripping trailing spaces if necessary. The minimum storage length is kept asNbytes to facilitate in-place updates in typical cases.The primary index of a table should be as short as possible. This makes identification of each row easy and efficient.
Create only the indexes that you really need. Indexes are good for retrieval but bad when you need to store data quickly. If you access a table mostly by searching on a combination of columns, create an index on them. The first part of the index should be the column most used. If you always use many columns when selecting from the table, you should use the column with more duplicates first to obtain better compression of the index.
If it is very likely that a string column has a unique prefix on the first number of characters, it's better to index only this prefix, using MySQL's support for creating an index on the leftmost part of the column (see Section 13.1.4, “
CREATE INDEXSyntax”). Shorter indexes are faster, not only because they require less disk space, but because they also give you more hits in the index cache, and thus fewer disk seeks. See Section 7.5.2, “Tuning Server Parameters”.In some circumstances, it can be beneficial to split into two a table that is scanned very often. This is especially true if it is a dynamic-format table and it is possible to use a smaller static format table that can be used to find the relevant rows when scanning the table.
All MySQL data types can be indexed. Use of indexes on the
relevant columns is the best way to improve the performance of
SELECT operations.
The maximum number of indexes per table and the maximum index length is defined per storage engine. See Chapter 14, Storage Engines. All storage engines support at least 16 indexes per table and a total index length of at least 256 bytes. Most storage engines have higher limits.
With
col_name(N)N characters of a
string column. Indexing only a prefix of column values in this
way can make the index file much smaller. When you index a
BLOB or TEXT column, you
must specify a prefix length for the index.
For example:
CREATE TABLE test (blob_col BLOB, INDEX(blob_col(10)));
Prefixes can be up to 1000 bytes long (767 bytes for
InnoDB tables). Note that prefix limits are
measured in bytes, whereas the prefix length in CREATE
TABLE statements is interpreted as number of
characters. Be sure to take this into account when
specifying a prefix length for a column that uses a multi-byte
character set.
You can also create FULLTEXT indexes. These
are used for full-text searches. Only the
MyISAM storage engine supports
FULLTEXT indexes and only for
CHAR, VARCHAR, and
TEXT columns. Indexing always takes place
over the entire column and column prefix indexing is not
supported. For details, see Section 12.8, “Full-Text Search Functions”.
You can also create indexes on spatial data types. Currently,
only MyISAM supports R-tree indexes on
spatial types. As of MySQL 5.0.16, other storage engines use
B-trees for indexing spatial types (except for
ARCHIVE and NDBCLUSTER,
which do not support spatial type indexing).
The MEMORY storage engine uses
HASH indexes by default, but also supports
BTREE indexes.
MySQL can create composite indexes (that is, indexes on multiple columns). An index may consist of up to 15 columns. For certain data types, you can index a prefix of the column (see Section 7.4.3, “Column Indexes”).
A multiple-column index can be considered a sorted array containing values that are created by concatenating the values of the indexed columns.
MySQL uses multiple-column indexes in such a way that queries
are fast when you specify a known quantity for the first column
of the index in a WHERE clause, even if you
do not specify values for the other columns.
Suppose that a table has the following specification:
CREATE TABLE test (
id INT NOT NULL,
last_name CHAR(30) NOT NULL,
first_name CHAR(30) NOT NULL,
PRIMARY KEY (id),
INDEX name (last_name,first_name)
);
The name index is an index over the
last_name and first_name
columns. The index can be used for queries that specify values
in a known range for last_name, or for both
last_name and first_name.
Therefore, the name index is used in the
following queries:
SELECT * FROM test WHERE last_name='Widenius'; SELECT * FROM test WHERE last_name='Widenius' AND first_name='Michael'; SELECT * FROM test WHERE last_name='Widenius' AND (first_name='Michael' OR first_name='Monty'); SELECT * FROM test WHERE last_name='Widenius' AND first_name >='M' AND first_name < 'N';
However, the name index is
not used in the following queries:
SELECT * FROM test WHERE first_name='Michael'; SELECT * FROM test WHERE last_name='Widenius' OR first_name='Michael';
The manner in which MySQL uses indexes to improve query performance is discussed further in Section 7.4.5, “How MySQL Uses Indexes”.
Indexes are used to find rows with specific column values quickly. Without an index, MySQL must begin with the first row and then read through the entire table to find the relevant rows. The larger the table, the more this costs. If the table has an index for the columns in question, MySQL can quickly determine the position to seek to in the middle of the data file without having to look at all the data. If a table has 1,000 rows, this is at least 100 times faster than reading sequentially. If you need to access most of the rows, it is faster to read sequentially, because this minimizes disk seeks.
Most MySQL indexes (PRIMARY KEY,
UNIQUE, INDEX, and
FULLTEXT) are stored in B-trees. Exceptions
are that indexes on spatial data types use R-trees, and that
MEMORY tables also support hash indexes.
Strings are automatically prefix- and end-space compressed. See
Section 13.1.4, “CREATE INDEX Syntax”.
In general, indexes are used as described in the following
discussion. Characteristics specific to hash indexes (as used in
MEMORY tables) are described at the end of
this section.
MySQL uses indexes for these operations:
To find the rows matching a
WHEREclause quickly.To eliminate rows from consideration. If there is a choice between multiple indexes, MySQL normally uses the index that finds the smallest number of rows.
To retrieve rows from other tables when performing joins. MySQL can use indexes on columns more efficiently if they are declared as the same type and size. In this context,
VARCHARandCHARare considered the same if they are declared as the same size. For example,VARCHAR(10)andCHAR(10)are the same size, butVARCHAR(10)andCHAR(15)are not.Comparison of dissimilar columns may prevent use of indexes if values cannot be compared directly without conversion. Suppose that a numeric column is compared to a string column. For a given value such as
1in the numeric column, it might compare equal to any number of values in the string column such as'1',' 1','00001', or'01.e1'. This rules out use of any indexes for the string column.To find the
MIN()orMAX()value for a specific indexed columnkey_col. This is optimized by a preprocessor that checks whether you are usingWHEREon all key parts that occur beforekey_part_N=constantkey_colin the index. In this case, MySQL does a single key lookup for eachMIN()orMAX()expression and replaces it with a constant. If all expressions are replaced with constants, the query returns at once. For example:SELECT MIN(
key_part2),MAX(key_part2) FROMtbl_nameWHEREkey_part1=10;To sort or group a table if the sorting or grouping is done on a leftmost prefix of a usable key (for example,
ORDER BY). If all key parts are followed bykey_part1,key_part2DESC, the key is read in reverse order. See Section 7.2.11, “ORDER BYOptimization”.In some cases, a query can be optimized to retrieve values without consulting the data rows. If a query uses only columns from a table that are numeric and that form a leftmost prefix for some key, the selected values may be retrieved from the index tree for greater speed:
SELECT
key_part3FROMtbl_nameWHEREkey_part1=1
Suppose that you issue the following SELECT
statement:
mysql> SELECT * FROM tbl_name WHERE col1=val1 AND col2=val2;
If a multiple-column index exists on col1 and
col2, the appropriate rows can be fetched
directly. If separate single-column indexes exist on
col1 and col2, the
optimizer tries to find the most restrictive index by deciding
which index finds fewer rows and using that index to fetch the
rows.
If the table has a multiple-column index, any leftmost prefix of
the index can be used by the optimizer to find rows. For
example, if you have a three-column index on (col1,
col2, col3), you have indexed search capabilities on
(col1), (col1, col2), and
(col1, col2, col3).
MySQL cannot use an index if the columns do not form a leftmost
prefix of the index. Suppose that you have the
SELECT statements shown here:
SELECT * FROMtbl_nameWHERE col1=val1; SELECT * FROMtbl_nameWHERE col1=val1AND col2=val2; SELECT * FROMtbl_nameWHERE col2=val2; SELECT * FROMtbl_nameWHERE col2=val2AND col3=val3;
If an index exists on (col1, col2, col3),
only the first two queries use the index. The third and fourth
queries do involve indexed columns, but
(col2) and (col2, col3)
are not leftmost prefixes of (col1, col2,
col3).
A B-tree index can be used for column comparisons in expressions
that use the =, >,
>=, <,
<=, or BETWEEN
operators. The index also can be used for
LIKE comparisons if the argument to
LIKE is a constant string that does not start
with a wildcard character. For example, the following
SELECT statements use indexes:
SELECT * FROMtbl_nameWHEREkey_colLIKE 'Patrick%'; SELECT * FROMtbl_nameWHEREkey_colLIKE 'Pat%_ck%';
In the first statement, only rows with 'Patrick' <=
are
considered. In the second statement, only rows with
key_col < 'Patricl''Pat' <= are considered.
key_col <
'Pau'
The following SELECT statements do not use
indexes:
SELECT * FROMtbl_nameWHEREkey_colLIKE '%Patrick%'; SELECT * FROMtbl_nameWHEREkey_colLIKEother_col;
In the first statement, the LIKE value begins
with a wildcard character. In the second statement, the
LIKE value is not a constant.
If you use ... LIKE
'% and
string%'string is longer than three
characters, MySQL uses the Turbo Boyer-Moore
algorithm to initialize the pattern for the string
and then uses this pattern to perform the search more quickly.
A search using col_name IS
NULLcol_name is indexed.
Any index that does not span all AND levels
in the WHERE clause is not used to optimize
the query. In other words, to be able to use an index, a prefix
of the index must be used in every AND group.
The following WHERE clauses use indexes:
... WHEREindex_part1=1 ANDindex_part2=2 ANDother_column=3 /*index= 1 ORindex= 2 */ ... WHEREindex=1 OR A=10 ANDindex=2 /* optimized like "index_part1='hello'" */ ... WHEREindex_part1='hello' ANDindex_part3=5 /* Can use index onindex1but not onindex2orindex3*/ ... WHEREindex1=1 ANDindex2=2 ORindex1=3 ANDindex3=3;
These WHERE clauses do
not use indexes:
/*index_part1is not used */ ... WHEREindex_part2=1 ANDindex_part3=2 /* Index is not used in both parts of the WHERE clause */ ... WHEREindex=1 OR A=10 /* No index spans all rows */ ... WHEREindex_part1=1 ORindex_part2=10
Sometimes MySQL does not use an index, even if one is available.
One circumstance under which this occurs is when the optimizer
estimates that using the index would require MySQL to access a
very large percentage of the rows in the table. (In this case, a
table scan is likely to be much faster because it requires fewer
seeks.) However, if such a query uses LIMIT
to retrieve only some of the rows, MySQL uses an index anyway,
because it can much more quickly find the few rows to return in
the result.
Hash indexes have somewhat different characteristics from those just discussed:
They are used only for equality comparisons that use the
=or<=>operators (but are very fast). They are not used for comparison operators such as<that find a range of values.The optimizer cannot use a hash index to speed up
ORDER BYoperations. (This type of index cannot be used to search for the next entry in order.)MySQL cannot determine approximately how many rows there are between two values (this is used by the range optimizer to decide which index to use). This may affect some queries if you change a
MyISAMtable to a hash-indexedMEMORYtable.Only whole keys can be used to search for a row. (With a B-tree index, any leftmost prefix of the key can be used to find rows.)
MySQL Enterprise Often, it is not possible to predict exactly what indexes will be required or will be most efficient — actual table usage is the best indicator. The MySQL Network Monitoring and Advisory Service provides expert advice on this topic. For more information see http://www.mysql.com/products/enterprise/advisors.html.
To minimize disk I/O, the MyISAM storage
engine exploits a strategy that is used by many database
management systems. It employs a cache mechanism to keep the
most frequently accessed table blocks in memory:
For index blocks, a special structure called the key cache (or key buffer) is maintained. The structure contains a number of block buffers where the most-used index blocks are placed.
For data blocks, MySQL uses no special cache. Instead it relies on the native operating system filesystem cache.
This section first describes the basic operation of the
MyISAM key cache. Then it discusses features
that improve key cache performance and that enable you to better
control cache operation:
Access to the key cache no longer is serialized among threads. Multiple threads can access the cache concurrently.
You can set up multiple key caches and assign table indexes to specific caches.
To control the size of the key cache, use the
key_buffer_size system variable. If this
variable is set equal to zero, no key cache is used. The key
cache also is not used if the key_buffer_size
value is too small to allocate the minimal number of block
buffers (8).
MySQL Enterprise
For expert advice on identifying the optimum size for
key_buffer_size, subscribe to the MySQL
Network Monitoring and Advisory Service. See
http://www.mysql.com/products/enterprise/advisors.html.
When the key cache is not operational, index files are accessed using only the native filesystem buffering provided by the operating system. (In other words, table index blocks are accessed using the same strategy as that employed for table data blocks.)
An index block is a contiguous unit of access to the
MyISAM index files. Usually the size of an
index block is equal to the size of nodes of the index B-tree.
(Indexes are represented on disk using a B-tree data structure.
Nodes at the bottom of the tree are leaf nodes. Nodes above the
leaf nodes are non-leaf nodes.)
All block buffers in a key cache structure are the same size. This size can be equal to, greater than, or less than the size of a table index block. Usually one these two values is a multiple of the other.
When data from any table index block must be accessed, the server first checks whether it is available in some block buffer of the key cache. If it is, the server accesses data in the key cache rather than on disk. That is, it reads from the cache or writes into it rather than reading from or writing to disk. Otherwise, the server chooses a cache block buffer containing a different table index block (or blocks) and replaces the data there by a copy of required table index block. As soon as the new index block is in the cache, the index data can be accessed.
If it happens that a block selected for replacement has been modified, the block is considered “dirty.” In this case, prior to being replaced, its contents are flushed to the table index from which it came.
Usually the server follows an LRU (Least Recently Used) strategy: When choosing a block for replacement, it selects the least recently used index block. To make this choice easier, the key cache module maintains a special queue (LRU chain) of all used blocks. When a block is accessed, it is placed at the end of the queue. When blocks need to be replaced, blocks at the beginning of the queue are the least recently used and become the first candidates for eviction.
Threads can access key cache buffers simultaneously, subject to the following conditions:
A buffer that is not being updated can be accessed by multiple threads.
A buffer that is being updated causes threads that need to use it to wait until the update is complete.
Multiple threads can initiate requests that result in cache block replacements, as long as they do not interfere with each other (that is, as long as they need different index blocks, and thus cause different cache blocks to be replaced).
Shared access to the key cache enables the server to improve throughput significantly.
Shared access to the key cache improves performance but does not eliminate contention among threads entirely. They still compete for control structures that manage access to the key cache buffers. To reduce key cache access contention further, MySQL also provides multiple key caches. This feature enables you to assign different table indexes to different key caches.
Where there are multiple key caches, the server must know
which cache to use when processing queries for a given
MyISAM table. By default, all
MyISAM table indexes are cached in the
default key cache. To assign table indexes to a specific key
cache, use the CACHE INDEX statement (see
Section 13.5.5.1, “CACHE INDEX Syntax”). For example, the following
statement assigns indexes from the tables
t1, t2, and
t3 to the key cache named
hot_cache:
mysql> CACHE INDEX t1, t2, t3 IN hot_cache;
+---------+--------------------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+---------+--------------------+----------+----------+
| test.t1 | assign_to_keycache | status | OK |
| test.t2 | assign_to_keycache | status | OK |
| test.t3 | assign_to_keycache | status | OK |
+---------+--------------------+----------+----------+
The key cache referred to in a CACHE INDEX
statement can be created by setting its size with a
SET GLOBAL parameter setting statement or
by using server startup options. For example:
mysql> SET GLOBAL keycache1.key_buffer_size=128*1024;
To destroy a key cache, set its size to zero:
mysql> SET GLOBAL keycache1.key_buffer_size=0;
Note that you cannot destroy the default key cache. Any attempt to do this will be ignored:
mysql>SET GLOBAL key_buffer_size = 0;mysql>SHOW VARIABLES LIKE 'key_buffer_size';+-----------------+---------+ | Variable_name | Value | +-----------------+---------+ | key_buffer_size | 8384512 | +-----------------+---------+
Key cache variables are structured system variables that have
a name and components. For
keycache1.key_buffer_size,
keycache1 is the cache variable name and
key_buffer_size is the cache component. See
Section 5.2.4.1, “Structured System Variables”, for a
description of the syntax used for referring to structured key
cache system variables.
By default, table indexes are assigned to the main (default) key cache created at the server startup. When a key cache is destroyed, all indexes assigned to it are reassigned to the default key cache.
For a busy server, we recommend a strategy that uses three key caches:
A “hot” key cache that takes up 20% of the space allocated for all key caches. Use this for tables that are heavily used for searches but that are not updated.
A “cold” key cache that takes up 20% of the space allocated for all key caches. Use this cache for medium-sized, intensively modified tables, such as temporary tables.
A “warm” key cache that takes up 60% of the key cache space. Employ this as the default key cache, to be used by default for all other tables.
One reason the use of three key caches is beneficial is that access to one key cache structure does not block access to the others. Statements that access tables assigned to one cache do not compete with statements that access tables assigned to another cache. Performance gains occur for other reasons as well:
The hot cache is used only for retrieval queries, so its contents are never modified. Consequently, whenever an index block needs to be pulled in from disk, the contents of the cache block chosen for replacement need not be flushed first.
For an index assigned to the hot cache, if there are no queries requiring an index scan, there is a high probability that the index blocks corresponding to non-leaf nodes of the index B-tree remain in the cache.
An update operation most frequently executed for temporary tables is performed much faster when the updated node is in the cache and need not be read in from disk first. If the size of the indexes of the temporary tables are comparable with the size of cold key cache, the probability is very high that the updated node is in the cache.
CACHE INDEX sets up an association between
a table and a key cache, but the association is lost each time
the server restarts. If you want the association to take
effect each time the server starts, one way to accomplish this
is to use an option file: Include variable settings that
configure your key caches, and an init-file
option that names a file containing CACHE
INDEX statements to be executed. For example:
key_buffer_size = 4G hot_cache.key_buffer_size = 2G cold_cache.key_buffer_size = 2G init_file=/path/to/data-directory/mysqld_init.sql
MySQL Enterprise
For advice on how best to configure your
my.cnf/my.ini option file subscribe to
MySQL Network Monitoring and Advisory Service.
Recommendations are based on actual table usage. For more
information see
http://www.mysql.com/products/enterprise/advisors.html.
The statements in mysqld_init.sql are
executed each time the server starts. The file should contain
one SQL statement per line. The following example assigns
several tables each to hot_cache and
cold_cache:
CACHE INDEX db1.t1, db1.t2, db2.t3 IN hot_cache CACHE INDEX db1.t4, db2.t5, db2.t6 IN cold_cache
By default, the key cache management system uses the LRU strategy for choosing key cache blocks to be evicted, but it also supports a more sophisticated method called the midpoint insertion strategy.
When using the midpoint insertion strategy, the LRU chain is
divided into two parts: a hot sub-chain and a warm sub-chain.
The division point between two parts is not fixed, but the key
cache management system takes care that the warm part is not
“too short,” always containing at least
key_cache_division_limit percent of the key
cache blocks. key_cache_division_limit is a
component of structured key cache variables, so its value is a
parameter that can be set per cache.
When an index block is read from a table into the key cache, it is placed at the end of the warm sub-chain. After a certain number of hits (accesses of the block), it is promoted to the hot sub-chain. At present, the number of hits required to promote a block (3) is the same for all index blocks.
A block promoted into the hot sub-chain is placed at the end
of the chain. The block then circulates within this sub-chain.
If the block stays at the beginning of the sub-chain for a
long enough time, it is demoted to the warm chain. This time
is determined by the value of the
key_cache_age_threshold component of the
key cache.
The threshold value prescribes that, for a key cache
containing N blocks, the block at
the beginning of the hot sub-chain not accessed within the
last N ×
key_cache_age_threshold / 100
The midpoint insertion strategy allows you to keep more-valued
blocks always in the cache. If you prefer to use the plain LRU
strategy, leave the
key_cache_division_limit value set to its
default of 100.
The midpoint insertion strategy helps to improve performance
when execution of a query that requires an index scan
effectively pushes out of the cache all the index blocks
corresponding to valuable high-level B-tree nodes. To avoid
this, you must use a midpoint insertion strategy with the
key_cache_division_limit set to much less
than 100. Then valuable frequently hit nodes are preserved in
the hot sub-chain during an index scan operation as well.
If there are enough blocks in a key cache to hold blocks of an entire index, or at least the blocks corresponding to its non-leaf nodes, it makes sense to preload the key cache with index blocks before starting to use it. Preloading allows you to put the table index blocks into a key cache buffer in the most efficient way: by reading the index blocks from disk sequentially.
Without preloading, the blocks are still placed into the key cache as needed by queries. Although the blocks will stay in the cache, because there are enough buffers for all of them, they are fetched from disk in random order, and not sequentially.
To preload an index into a cache, use the LOAD INDEX
INTO CACHE statement. For example, the following
statement preloads nodes (index blocks) of indexes of the
tables t1 and t2:
mysql> LOAD INDEX INTO CACHE t1, t2 IGNORE LEAVES;
+---------+--------------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+---------+--------------+----------+----------+
| test.t1 | preload_keys | status | OK |
| test.t2 | preload_keys | status | OK |
+---------+--------------+----------+----------+
The IGNORE LEAVES modifier causes only
blocks for the non-leaf nodes of the index to be preloaded.
Thus, the statement shown preloads all index blocks from
t1, but only blocks for the non-leaf nodes
from t2.
If an index has been assigned to a key cache using a
CACHE INDEX statement, preloading places
index blocks into that cache. Otherwise, the index is loaded
into the default key cache.
It is possible to specify the size of the block buffers for an
individual key cache using the
key_cache_block_size variable. This permits
tuning of the performance of I/O operations for index files.
The best performance for I/O operations is achieved when the size of read buffers is equal to the size of the native operating system I/O buffers. But setting the size of key nodes equal to the size of the I/O buffer does not always ensure the best overall performance. When reading the big leaf nodes, the server pulls in a lot of unnecessary data, effectively preventing reading other leaf nodes.
Currently, you cannot control the size of the index blocks in
a table. This size is set by the server when the
.MYI index file is created, depending on
the size of the keys in the indexes present in the table
definition. In most cases, it is set equal to the I/O buffer
size.
A key cache can be restructured at any time by updating its parameter values. For example:
mysql> SET GLOBAL cold_cache.key_buffer_size=4*1024*1024;
If you assign to either the key_buffer_size
or key_cache_block_size key cache component
a value that differs from the component's current value, the
server destroys the cache's old structure and creates a new
one based on the new values. If the cache contains any dirty
blocks, the server saves them to disk before destroying and
re-creating the cache. Restructuring does not occur if you
change other key cache parameters.
When restructuring a key cache, the server first flushes the contents of any dirty buffers to disk. After that, the cache contents become unavailable. However, restructuring does not block queries that need to use indexes assigned to the cache. Instead, the server directly accesses the table indexes using native filesystem caching. Filesystem caching is not as efficient as using a key cache, so although queries execute, a slowdown can be anticipated. After the cache has been restructured, it becomes available again for caching indexes assigned to it, and the use of filesystem caching for the indexes ceases.
Storage engines collect statistics about tables for use by the optimizer. Table statistics are based on value groups, where a value group is a set of rows with the same key prefix value. For optimizer purposes, an important statistic is the average value group size.
MySQL uses the average value group size in the following ways:
To estimate how may rows must be read for each
refaccessTo estimate how many row a partial join will produce; that is, the number of rows that an operation of this form will produce:
(...) JOIN
tbl_nameONtbl_name.key=expr
As the average value group size for an index increases, the index is less useful for those two purposes because the average number of rows per lookup increases: For the index to be good for optimization purposes, it is best that each index value target a small number of rows in the table. When a given index value yields a large number of rows, the index is less useful and MySQL is less likely to use it.
The average value group size is related to table cardinality,
which is the number of value groups. The SHOW
INDEX statement displays a cardinality value based on
N/S, where
N is the number of rows in the table
and S is the average value group
size. That ratio yields an approximate number of value groups in
the table.
For a join based on the <=> comparison
operator, NULL is not treated differently
from any other value: NULL <=> NULL,
just as N <=>
NN.
However, for a join based on the = operator,
NULL is different from
non-NULL values:
expr1 =
expr2expr1 or
expr2 (or both) are
NULL. This affects ref
accesses for comparisons of the form
tbl_name.key =
exprexpr is NULL,
because the comparison cannot be true.
For = comparisons, it does not matter how
many NULL values are in the table. For
optimization purposes, the relevant value is the average size of
the non-NULL value groups. However, MySQL
does not currently allow that average size to be collected or
used.
For MyISAM tables, you have some control over
collection of table statistics by means of the
myisam_stats_method system variable. This
variable has two possible values, which differ as follows:
When
myisam_stats_methodisnulls_equal, allNULLvalues are treated as identical (that is, they all form a single value group).If the
NULLvalue group size is much higher than the average non-NULLvalue group size, this method skews the average value group size upward. This makes index appear to the optimizer to be less useful than it really is for joins that look for non-NULLvalues. Consequently, thenulls_equalmethod may cause the optimizer not to use the index forrefaccesses when it should.When
myisam_stats_methodisnulls_unequal,NULLvalues are not considered the same. Instead, eachNULLvalue forms a separate value group of size 1.If you have many
NULLvalues, this method skews the average value group size downward. If the average non-NULLvalue group size is large, countingNULLvalues each as a group of size 1 causes the optimizer to overestimate the value of the index for joins that look for non-NULLvalues. Consequently, thenulls_unequalmethod may cause the optimizer to use this index forreflookups when other methods may be better.
If you tend to use many joins that use
<=> rather than =,
NULL values are not special in comparisons
and one NULL is equal to another. In this
case, nulls_equal is the appropriate
statistics method.
The myisam_stats_method system variable has
global and session values. Setting the global value affects
MyISAM statistics collection for all
MyISAM tables. Setting the session value
affects statistics collection only for the current client
connection. This means that you can force a table's statistics
to be regenerated with a given method without affecting other
clients by setting the session value of
myisam_stats_method.
To regenerate table statistics, you can use any of the following methods:
Set
myisam_stats_method, and then issue aCHECK TABLEstatementExecute myisamchk --stats_method=
method_name--analyzeChange the table to cause its statistics to go out of date (for example, insert a row and then delete it), and then set
myisam_stats_methodand issue anANALYZE TABLEstatement
Some caveats regarding the use of
myisam_stats_method:
You can force table statistics to be collected explicitly, as just described. However, MySQL may also collect statistics automatically. For example, if during the course of executing statements for a table, some of those statements modify the table, MySQL may collect statistics. (This may occur for bulk inserts or deletes, or some
ALTER TABLEstatements, for example.) If this happens, the statistics are collected using whatever valuemyisam_stats_methodhas at the time. Thus, if you collect statistics using one method, butmyisam_stats_methodis set to the other method when a table's statistics are collected automatically later, the other method will be used.There is no way to tell which method was used to generate statistics for a given
MyISAMtable.myisam_stats_methodapplies only toMyISAMtables. Other storage engines have only one method for collecting table statistics. Usually it is closer to thenulls_equalmethod.
When you execute a mysqladmin status command, you should see something like this:
Uptime: 426 Running threads: 1 Questions: 11082 Reloads: 1 Open tables: 12
The Open tables value of 12 can be somewhat
puzzling if you have only six tables.
MySQL is multi-threaded, so there may be many clients issuing
queries for a given table simultaneously. To minimize the
problem with multiple client threads having different states on
the same table, the table is opened independently by each
concurrent thread. This uses additional memory but normally
increases performance. With MyISAM tables,
one extra file descriptor is required for the data file for each
client that has the table open. (By contrast, the index file
descriptor is shared between all threads.)
The table_cache,
max_connections, and
max_tmp_tables system variables affect the
maximum number of files the server keeps open. If you increase
one or more of these values, you may run up against a limit
imposed by your operating system on the per-process number of
open file descriptors. Many operating systems allow you to
increase the open-files limit, although the method varies widely
from system to system. Consult your operating system
documentation to determine whether it is possible to increase
the limit and how to do so.
table_cache is related to
max_connections. For example, for 200
concurrent running connections, you should have a table cache
size of at least 200 ×
, where
NN is the maximum number of tables per
join in any of the queries which you execute. You must also
reserve some extra file descriptors for temporary tables and
files.
Make sure that your operating system can handle the number of
open file descriptors implied by the
table_cache setting. If
table_cache is set too high, MySQL may run
out of file descriptors and refuse connections, fail to perform
queries, and be very unreliable. You also have to take into
account that the MyISAM storage engine needs
two file descriptors for each unique open table. You can
increase the number of file descriptors available to MySQL using
the --open-files-limit startup option to
mysqld. See
Section B.1.2.17, “'File' Not Found and
Similar Errors”.
The cache of open tables is kept at a level of
table_cache entries. The default value is 64;
this can be changed with the --table_cache
option to mysqld. Note that MySQL may
temporarily open more tables than this to execute queries.
MySQL Enterprise
Performance may suffer if table_cache is
set too low. For expert advice on the optimum value for this
variable, subscribe to the MySQL Network Monitoring and
Advisory Service. For more information see
http://www.mysql.com/products/enterprise/advisors.html.
MySQL closes an unused table and removes it from the table cache under the following circumstances:
When the cache is full and a thread tries to open a table that is not in the cache.
When the cache contains more than
table_cacheentries and a table in the cache is no longer being used by any threads.When a table flushing operation occurs. This happens when someone issues a
FLUSH TABLESstatement or executes a mysqladmin flush-tables or mysqladmin refresh command.
When the table cache fills up, the server uses the following procedure to locate a cache entry to use:
Tables that are not currently in use are released, beginning with the table least recently used.
If a new table needs to be opened, but the cache is full and no tables can be released, the cache is temporarily extended as necessary.
When the cache is in a temporarily extended state and a table goes from a used to unused state, the table is closed and released from the cache.
A table is opened for each concurrent access. This means the
table needs to be opened twice if two threads access the same
table or if a thread accesses the table twice in the same query
(for example, by joining the table to itself). Each concurrent
open requires an entry in the table cache. The first open of any
MyISAM table takes two file descriptors: one
for the data file and one for the index file. Each additional
use of the table takes only one file descriptor for the data
file. The index file descriptor is shared among all threads.
If you are opening a table with the HANDLER
statement, a
dedicated table object is allocated for the thread. This table
object is not shared by other threads and is not closed until
the thread calls tbl_name OPENHANDLER
or the
thread terminates. When this happens, the table is put back in
the table cache (if the cache is not full). See
Section 13.2.3, “tbl_name CLOSEHANDLER Syntax”.
You can determine whether your table cache is too small by
checking the mysqld status variable
Opened_tables:
mysql> SHOW GLOBAL STATUS LIKE 'Opened_tables';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Opened_tables | 2741 |
+---------------+-------+
If the value is very large, even when you have not issued many
FLUSH TABLES statements, you should increase
the table cache size. See
Section 5.2.3, “System Variables”, and
Section 5.2.5, “Status Variables”.
If you have many MyISAM tables in the same
database directory, open, close, and create operations are slow.
If you execute SELECT statements on many
different tables, there is a little overhead when the table
cache is full, because for every table that has to be opened,
another must be closed. You can reduce this overhead by making
the table cache larger.
We start with system-level factors, because some of these decisions must be made very early to achieve large performance gains. In other cases, a quick look at this section may suffice. However, it is always nice to have a sense of how much can be gained by changing factors that apply at this level.
The operating system to use is very important. To get the best use of multiple-CPU machines, you should use Solaris (because its threads implementation works well) or Linux (because the 2.4 and later kernels have good SMP support). Note that older Linux kernels have a 2GB filesize limit by default. If you have such a kernel and a need for files larger than 2GB, you should get the Large File Support (LFS) patch for the ext2 filesystem. Other filesystems such as ReiserFS and XFS do not have this 2GB limitation.
Before using MySQL in production, we advise you to test it on your intended platform.
Other tips:
If you have enough RAM, you could remove all swap devices. Some operating systems use a swap device in some contexts even if you have free memory.
Avoid external locking. Since MySQL 4.0, the default has been for external locking to be disabled on all systems. The
--external-lockingand--skip-external-lockingoptions explicitly enable and disable external locking.Note that disabling external locking does not affect MySQL's functionality as long as you run only one server. Just remember to take down the server (or lock and flush the relevant tables) before you run myisamchk. On some systems it is mandatory to disable external locking because it does not work, anyway.
The only case in which you cannot disable external locking is when you run multiple MySQL servers (not clients) on the same data, or if you run myisamchk to check (not repair) a table without telling the server to flush and lock the tables first. Note that using multiple MySQL servers to access the same data concurrently is generally not recommended, except when using MySQL Cluster.
The
LOCK TABLESandUNLOCK TABLESstatements use internal locking, so you can use them even if external locking is disabled.
You can determine the default buffer sizes used by the mysqld server using this command:
shell> mysqld --verbose --help
This command produces a list of all mysqld options and configurable system variables. The output includes the default variable values and looks something like this:
back_log 50 binlog_cache_size 32768 bulk_insert_buffer_size 8388608 connect_timeout 5 date_format (No default value) datetime_format (No default value) default_week_format 0 delayed_insert_limit 100 delayed_insert_timeout 300 delayed_queue_size 1000 expire_logs_days 0 flush_time 1800 ft_max_word_len 84 ft_min_word_len 4 ft_query_expansion_limit 20 ft_stopword_file (No default value) group_concat_max_len 1024 innodb_additional_mem_pool_size 1048576 innodb_autoextend_increment 8 innodb_buffer_pool_awe_mem_mb 0 innodb_buffer_pool_size 8388608 innodb_concurrency_tickets 500 innodb_file_io_threads 4 innodb_force_recovery 0 innodb_lock_wait_timeout 50 innodb_log_buffer_size 1048576 innodb_log_file_size 5242880 innodb_log_files_in_group 2 innodb_mirrored_log_groups 1 innodb_open_files 300 innodb_sync_spin_loops 20 innodb_thread_concurrency 8 innodb_thread_sleep_delay 10000 interactive_timeout 28800 join_buffer_size 131072 key_buffer_size 8388600 key_cache_age_threshold 300 key_cache_block_size 1024 key_cache_division_limit 100 long_query_time 10 lower_case_table_names 1 max_allowed_packet 1048576 max_binlog_cache_size 4294967295 max_binlog_size 1073741824 max_connect_errors 10 max_connections 100 max_delayed_threads 20 max_error_count 64 max_heap_table_size 16777216 max_join_size 4294967295 max_length_for_sort_data 1024 max_relay_log_size 0 max_seeks_for_key 4294967295 max_sort_length 1024 max_tmp_tables 32 max_user_connections 0 max_write_lock_count 4294967295 multi_range_count 256 myisam_block_size 1024 myisam_data_pointer_size 6 myisam_max_extra_sort_file_size 2147483648 myisam_max_sort_file_size 2147483647 myisam_repair_threads 1 myisam_sort_buffer_size 8388608 net_buffer_length 16384 net_read_timeout 30 net_retry_count 10 net_write_timeout 60 open_files_limit 0 optimizer_prune_level 1 optimizer_search_depth 62 preload_buffer_size 32768 query_alloc_block_size 8192 query_cache_limit 1048576 query_cache_min_res_unit 4096 query_cache_size 0 query_cache_type 1 query_cache_wlock_invalidate FALSE query_prealloc_size 8192 range_alloc_block_size 2048 read_buffer_size 131072 read_only FALSE read_rnd_buffer_size 262144 div_precision_increment 4 record_buffer 131072 relay_log_purge TRUE relay_log_space_limit 0 slave_compressed_protocol FALSE slave_net_timeout 3600 slave_transaction_retries 10 slow_launch_time 2 sort_buffer_size 2097144 sync-binlog 0 sync-frm TRUE sync-replication 0 sync-replication-slave-id 0 sync-replication-timeout 10 table_cache 64 thread_cache_size 0 thread_concurrency 10 thread_stack 196608 time_format (No default value) tmp_table_size 33554432 transaction_alloc_block_size 8192 transaction_prealloc_size 4096 updatable_views_with_limit 1 wait_timeout 28800
For a mysqld server that is currently running, you can see the current values of its system variables by connecting to it and issuing this statement:
mysql> SHOW VARIABLES;
You can also see some statistical and status indicators for a running server by issuing this statement:
mysql> SHOW STATUS;
System variable and status information also can be obtained using mysqladmin:
shell>mysqladmin variablesshell>mysqladmin extended-status
For a full description of all system and status variables, see Section 5.2.3, “System Variables”, and Section 5.2.5, “Status Variables”.
MySQL uses algorithms that are very scalable, so you can usually run with very little memory. However, normally you get better performance by giving MySQL more memory.
When tuning a MySQL server, the two most important variables to
configure are key_buffer_size and
table_cache. You should first feel confident
that you have these set appropriately before trying to change
any other variables.
The following examples indicate some typical variable values for different runtime configurations.
If you have at least 256MB of memory and many tables and want maximum performance with a moderate number of clients, you should use something like this:
shell>
mysqld_safe --key_buffer_size=64M --table_cache=256 \--sort_buffer_size=4M --read_buffer_size=1M &If you have only 128MB of memory and only a few tables, but you still do a lot of sorting, you can use something like this:
shell>
mysqld_safe --key_buffer_size=16M --sort_buffer_size=1MIf there are very many simultaneous connections, swapping problems may occur unless mysqld has been configured to use very little memory for each connection. mysqld performs better if you have enough memory for all connections.
With little memory and lots of connections, use something like this:
shell>
mysqld_safe --key_buffer_size=512K --sort_buffer_size=100K \--read_buffer_size=100K &Or even this:
shell>
mysqld_safe --key_buffer_size=512K --sort_buffer_size=16K \--table_cache=32 --read_buffer_size=8K \--net_buffer_length=1K &
If you are performing GROUP BY or
ORDER BY operations on tables that are much
larger than your available memory, you should increase the value
of read_rnd_buffer_size to speed up the
reading of rows following sorting operations.
You can make use of the example option files included with your MySQL distribution; see Section 4.3.2.1, “Preconfigured Option Files”.
If you specify an option on the command line for mysqld or mysqld_safe, it remains in effect only for that invocation of the server. To use the option every time the server runs, put it in an option file.
To see the effects of a parameter change, do something like this:
shell> mysqld --key_buffer_size=32M --verbose --help
The variable values are listed near the end of the output. Make
sure that the --verbose and
--help options are last. Otherwise, the effect
of any options listed after them on the command line are not
reflected in the output.
For information on tuning the InnoDB storage
engine, see Section 14.2.11, “InnoDB Performance Tuning Tips”.
MySQL Enterprise For expert advice on tuning system parameters subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
The task of the query optimizer is to find an optimal plan for executing an SQL query. Because the difference in performance between “good” and “bad” plans can be orders of magnitude (that is, seconds versus hours or even days), most query optimizers, including that of MySQL, perform a more or less exhaustive search for an optimal plan among all possible query evaluation plans. For join queries, the number of possible plans investigated by the MySQL optimizer grows exponentially with the number of tables referenced in a query. For small numbers of tables (typically less than 7–10) this is not a problem. However, when larger queries are submitted, the time spent in query optimization may easily become the major bottleneck in the server's performance.
MySQL 5.0.1 introduces a more flexible method for query optimization that allows the user to control how exhaustive the optimizer is in its search for an optimal query evaluation plan. The general idea is that the fewer plans that are investigated by the optimizer, the less time it spends in compiling a query. On the other hand, because the optimizer skips some plans, it may miss finding an optimal plan.
The behavior of the optimizer with respect to the number of plans it evaluates can be controlled via two system variables:
The
optimizer_prune_levelvariable tells the optimizer to skip certain plans based on estimates of the number of rows accessed for each table. Our experience shows that this kind of “educated guess” rarely misses optimal plans, and may dramatically reduce query compilation times. That is why this option is on (optimizer_prune_level=1) by default. However, if you believe that the optimizer missed a better query plan, this option can be switched off (optimizer_prune_level=0) with the risk that query compilation may take much longer. Note that, even with the use of this heuristic, the optimizer still explores a roughly exponential number of plans.The
optimizer_search_depthvariable tells how far into the “future” of each incomplete plan the optimizer should look to evaluate whether it should be expanded further. Smaller values ofoptimizer_search_depthmay result in orders of magnitude smaller query compilation times. For example, queries with 12, 13, or more tables may easily require hours and even days to compile ifoptimizer_search_depthis close to the number of tables in the query. At the same time, if compiled withoptimizer_search_depthequal to 3 or 4, the optimizer may compile in less than a minute for the same query. If you are unsure of what a reasonable value is foroptimizer_search_depth, this variable can be set to 0 to tell the optimizer to determine the value automatically.
Most of the following tests were performed on Linux with the MySQL benchmarks, but they should give some indication for other operating systems and workloads.
You obtain the fastest executables when you link with
-static.
On Linux, it is best to compile the server with
pgcc and -O3. You need about
200MB memory to compile sql_yacc.cc with
these options, because gcc or
pgcc needs a great deal of memory to make all
functions inline. You should also set CXX=gcc
when configuring MySQL to avoid inclusion of the
libstdc++ library, which is not needed. Note
that with some versions of pgcc, the
resulting binary runs only on true Pentium processors, even if
you use the compiler option indicating that you want the
resulting code to work on all x586-type processors (such as
AMD).
By using a better compiler and compilation options, you can obtain a 10–30% speed increase in applications. This is particularly important if you compile the MySQL server yourself.
When we tested both the Cygnus CodeFusion and Fujitsu compilers, neither was sufficiently bug-free to allow MySQL to be compiled with optimizations enabled.
The standard MySQL binary distributions are compiled with
support for all character sets. When you compile MySQL yourself,
you should include support only for the character sets that you
are going to use. This is controlled by the
--with-charset option to
configure.
Here is a list of some measurements that we have made:
If you use pgcc and compile everything with
-O6, the mysqld server is 1% faster than with gcc 2.95.2.If you link dynamically (without
-static), the result is 13% slower on Linux. Note that you still can use a dynamically linked MySQL library for your client applications. It is the server that is most critical for performance.For a connection from a client to a server running on the same host, if you connect using TCP/IP rather than a Unix socket file, performance is 7.5% slower. (On Unix, if you connect to the hostname
localhost, MySQL uses a socket file by default.)For TCP/IP connections from a client to a server, connecting to a remote server on another host is 8–11% slower than connecting to a server on the same host, even for connections over 100Mb/s Ethernet.
When running our benchmark tests using secure connections (all data encrypted with internal SSL support) performance was 55% slower than with unencrypted connections.
If you compile with
--with-debug=full, most queries are 20% slower. Some queries may take substantially longer; for example, the MySQL benchmarks run 35% slower. If you use--with-debug(without=full), the speed decrease is only 15%. For a version of mysqld that has been compiled with--with-debug=full, you can disable memory checking at runtime by starting it with the--skip-safemallocoption. The execution speed should then be close to that obtained when configuring with--with-debug.On a Sun UltraSPARC-IIe, a server compiled with Forte 5.0 is 4% faster than one compiled with gcc 3.2.
On a Sun UltraSPARC-IIe, a server compiled with Forte 5.0 is 4% faster in 32-bit mode than in 64-bit mode.
Compiling with gcc 2.95.2 for UltraSPARC with the
-mcpu=v8 -Wa,-xarch=v8plusaoptions gives 4% more performance.On Solaris 2.5.1, MIT-pthreads is 8–12% slower than Solaris native threads on a single processor. With greater loads or more CPUs, the difference should be larger.
Compiling on Linux-x86 using gcc without frame pointers (
-fomit-frame-pointeror-fomit-frame-pointer -ffixed-ebp) makes mysqld 1–4% faster.
Binary MySQL distributions for Linux that are provided by MySQL AB used to be compiled with pgcc. We had to go back to regular gcc due to a bug in pgcc that would generate binaries that do not run on AMD. We will continue using gcc until that bug is resolved. In the meantime, if you have a non-AMD machine, you can build a faster binary by compiling with pgcc. The standard MySQL Linux binary is linked statically to make it faster and more portable.
The following list indicates some of the ways that the mysqld server uses memory. Where applicable, the name of the system variable relevant to the memory use is given:
The key buffer is shared by all threads; its size is determined by the
key_buffer_sizevariable. Other buffers used by the server are allocated as needed. See Section 7.5.2, “Tuning Server Parameters”.Each connection uses some thread-specific space. The following list indicates these and which variables control their size:
A stack (default 192KB, variable
thread_stack)A connection buffer (variable
net_buffer_length)A result buffer (variable
net_buffer_length)
The connection buffer and result buffer both begin with a size given by
net_buffer_lengthbut are dynamically enlarged up tomax_allowed_packetbytes as needed. The result buffer shrinks tonet_buffer_lengthafter each SQL statement. While a statement is running, a copy of the current statement string is also allocated.All threads share the same base memory.
When a thread is no longer needed, the memory allocated to it is released and returned to the system unless the thread goes back into the thread cache. In that case, the memory remains allocated.
Only compressed
MyISAMtables are memory mapped. This is because the 32-bit memory space of 4GB is not large enough for most big tables. When systems with a 64-bit address space become more common, we may add general support for memory mapping.Each request that performs a sequential scan of a table allocates a read buffer (variable
read_buffer_size).When reading rows in an arbitrary sequence (for example, following a sort), a random-read buffer (variable
read_rnd_buffer_size) may be allocated in order to avoid disk seeks.All joins are executed in a single pass, and most joins can be done without even using a temporary table. Most temporary tables are memory-based hash tables. Temporary tables with a large row length (calculated as the sum of all column lengths) or that contain
BLOBcolumns are stored on disk.If an internal heap table exceeds the size of
tmp_table_size, MySQL handles this automatically by changing the in-memory heap table to a disk-basedMyISAMtable as necessary. You can also increase the temporary table size by setting thetmp_table_sizeoption to mysqld, or by setting the SQL optionSQL_BIG_TABLESin the client program. See Section 13.5.3, “SETSyntax”.MySQL Enterprise Subscribers to the MySQL Network Monitoring and Advisory Service are alerted when temporary tables exceed
tmp_table_size. Advisors make recommendations for the optimum value oftmp_table_sizebased on actual table usage. For more information about the MySQL Network Monitoring and Advisory Service please see http://www.mysql.com/products/enterprise/advisors.html.Most requests that perform a sort allocate a sort buffer and zero to two temporary files depending on the result set size. See Section B.1.4.4, “Where MySQL Stores Temporary Files”.
Almost all parsing and calculating is done in a local memory store. No memory overhead is needed for small items, so the normal slow memory allocation and freeing is avoided. Memory is allocated only for unexpectedly large strings. This is done with
malloc()andfree().For each
MyISAMtable that is opened, the index file is opened once; the data file is opened once for each concurrently running thread. For each concurrent thread, a table structure, column structures for each column, and a buffer of size3 ×are allocated (whereNNis the maximum row length, not countingBLOBcolumns). ABLOBcolumn requires five to eight bytes plus the length of theBLOBdata. TheMyISAMstorage engine maintains one extra row buffer for internal use.For each table having
BLOBcolumns, a buffer is enlarged dynamically to read in largerBLOBvalues. If you scan a table, a buffer as large as the largestBLOBvalue is allocated.Handler structures for all in-use tables are saved in a cache and managed as a FIFO. By default, the cache has 64 entries. If a table has been used by two running threads at the same time, the cache contains two entries for the table. See Section 7.4.8, “How MySQL Opens and Closes Tables”.
A
FLUSH TABLESstatement or mysqladmin flush-tables command closes all tables that are not in use at once and marks all in-use tables to be closed when the currently executing thread finishes. This effectively frees most in-use memory.FLUSH TABLESdoes not return until all tables have been closed.
ps and other system status programs may
report that mysqld uses a lot of memory. This
may be caused by thread stacks on different memory addresses.
For example, the Solaris version of ps counts
the unused memory between stacks as used memory. You can verify
this by checking available swap with swap -s.
We test mysqld with several memory-leakage
detectors (both commercial and Open Source), so there should be
no memory leaks.
In some cases, the server creates internal temporary tables
while processing queries. A temporary table can be held in
memory and processed by the MEMORY storage
engine, or stored on disk and processed by the
MyISAM storage engine. Temporary tables can
be created under conditions such as these:
If there is an
ORDER BYclause and a differentGROUP BYclause, or if theORDER BYorGROUP BYcontains columns from tables other than the first table in the join queue, a temporary table is created.If you use the
SQL_SMALL_RESULToption, MySQL uses an in-memory temporary table.DISTINCTcombined withORDER BYmay require a temporary table.
You can tell whether a query requires a temporary table by using
EXPLAIN and checking the
Extra column to see whether it says
Using temporary. See
Section 7.2.1, “Optimizing Queries with EXPLAIN”.
Some conditions prevent the use of a MEMORY
temporary table, in which case the server uses a
MyISAM table instead:
Presence of a
TEXTorBLOBcolumn in the tablePresence of any column in a
GROUP BYorDISTINCTclause larger than 512 bytes
A temporary table that is created initially as a
MEMORY table might be converted to a
MyISAM table and stored on disk if it becomes
too large. The max_heap_table_size system
variable determines how large MEMORY tables
are allowed to grow. It applies to all MEMORY
tables, including those created with CREATE
TABLE. However, for internal MEMORY
tables, the actual maximum size is determined by
max_heap_table_size in combination with
tmp_table_size: Whichever value is smaller is
the one that applies. If the size of an internal
MEMORY table exceeds the limit, MySQL
automatically converts it to an on-disk
MyISAM table.
When a new client connects to mysqld, mysqld spawns a new thread to handle the request. This thread first checks whether the hostname is in the hostname cache. If not, the thread attempts to resolve the hostname:
If the operating system supports the thread-safe
gethostbyaddr_r()andgethostbyname_r()calls, the thread uses them to perform hostname resolution.If the operating system does not support the thread-safe calls, the thread locks a mutex and calls
gethostbyaddr()andgethostbyname()instead. In this case, no other thread can resolve hostnames that are not in the hostname cache until the first thread unlocks the mutex.
You can disable DNS hostname lookups by starting
mysqld with the
--skip-name-resolve option. However, in this
case, you can use only IP numbers in the MySQL grant tables.
If you have a very slow DNS and many hosts, you can get more
performance by either disabling DNS lookups with
--skip-name-resolve or by increasing the
HOST_CACHE_SIZE define (default value: 128)
and recompiling mysqld.
You can disable the hostname cache by starting the server with
the --skip-host-cache option. To clear the
hostname cache, issue a FLUSH HOSTS statement
or execute the mysqladmin flush-hosts
command.
To disallow TCP/IP connections entirely, start
mysqld with the
--skip-networking option.
Disk seeks are a huge performance bottleneck. This problem becomes more apparent when the amount of data starts to grow so large that effective caching becomes impossible. For large databases where you access data more or less randomly, you can be sure that you need at least one disk seek to read and a couple of disk seeks to write things. To minimize this problem, use disks with low seek times.
Increase the number of available disk spindles (and thereby reduce the seek overhead) by either symlinking files to different disks or striping the disks:
Using symbolic links
This means that, for
MyISAMtables, you symlink the index file and data files from their usual location in the data directory to another disk (that may also be striped). This makes both the seek and read times better, assuming that the disk is not used for other purposes as well. See Section 7.6.1, “Using Symbolic Links”.Striping means that you have many disks and put the first block on the first disk, the second block on the second disk, and the
N-th block on the (NMODnumber_of_disksThe speed difference for striping is very dependent on the parameters. Depending on how you set the striping parameters and number of disks, you may get differences measured in orders of magnitude. You have to choose to optimize for random or sequential access.
For reliability, you may want to use RAID 0+1 (striping plus mirroring), but in this case, you need 2 ×
Ndrives to holdNdrives of data. This is probably the best option if you have the money for it. However, you may also have to invest in some volume-management software to handle it efficiently.A good option is to vary the RAID level according to how critical a type of data is. For example, store semi-important data that can be regenerated on a RAID 0 disk, but store really important data such as host information and logs on a RAID 0+1 or RAID
Ndisk. RAIDNcan be a problem if you have many writes, due to the time required to update the parity bits.On Linux, you can get much more performance by using
hdparmto configure your disk's interface. (Up to 100% under load is not uncommon.) The followinghdparmoptions should be quite good for MySQL, and probably for many other applications:hdparm -m 16 -d 1
Note that performance and reliability when using this command depend on your hardware, so we strongly suggest that you test your system thoroughly after using
hdparm. Please consult thehdparmmanual page for more information. Ifhdparmis not used wisely, filesystem corruption may result, so back up everything before experimenting!You can also set the parameters for the filesystem that the database uses:
If you do not need to know when files were last accessed (which is not really useful on a database server), you can mount your filesystems with the
-o noatimeoption. That skips updates to the last access time in inodes on the filesystem, which avoids some disk seeks.On many operating systems, you can set a filesystem to be updated asynchronously by mounting it with the
-o asyncoption. If your computer is reasonably stable, this should give you more performance without sacrificing too much reliability. (This flag is on by default on Linux.)
You can move tables and databases from the database directory to other locations and replace them with symbolic links to the new locations. You might want to do this, for example, to move a database to a file system with more free space or increase the speed of your system by spreading your tables to different disk.
The recommended way to do this is simply to symlink databases to a different disk. Symlink tables only as a last resort.
On Unix, the way to symlink a database is first to create a directory on some disk where you have free space and then to create a symlink to it from the MySQL data directory.
shell>mkdir /dr1/databases/testshell>ln -s /dr1/databases/test/path/to/datadir
MySQL does not support linking one directory to multiple
databases. Replacing a database directory with a symbolic link
works as long as you do not make a symbolic link between
databases. Suppose that you have a database
db1 under the MySQL data directory, and
then make a symlink db2 that points to
db1:
shell>cdshell>/path/to/datadirln -s db1 db2
The result is that, or any table tbl_a in
db1, there also appears to be a table
tbl_a in db2. If one
client updates db1.tbl_a and another client
updates db2.tbl_a, problems are likely to
occur.
However, if you really need to do this, it is possible by
altering the source file
mysys/my_symlink.c, in which you should
look for the following statement:
if (!(MyFlags & MY_RESOLVE_LINK) ||
(!lstat(filename,&stat_buff) && S_ISLNK(stat_buff.st_mode)))
Change the statement to this:
if (1)
You should not symlink tables on systems that do not have a
fully operational realpath() call. (Linux
and Solaris support realpath()). You can
check whether your system supports symbolic links by issuing a
SHOW VARIABLES LIKE 'have_symlink'
statement.
Symlinks are fully supported only for
MyISAM tables. For files used by tables for
other storage engines, you may get strange problems if you try
to use symbolic links.
The handling of symbolic links for MyISAM
tables works as follows:
In the data directory, you always have the table format (
.frm) file, the data (.MYD) file, and the index (.MYI) file. The data file and index file can be moved elsewhere and replaced in the data directory by symlinks. The format file cannot.You can symlink the data file and the index file independently to different directories.
You can instruct a running MySQL server to perform the symlinking by using the
DATA DIRECTORYandINDEX DIRECTORYoptions toCREATE TABLE. See Section 13.1.5, “CREATE TABLESyntax”. Alternatively, symlinking can be accomplished manually from the command line usingln -sif mysqld is not running.myisamchk does not replace a symlink with the data file or index file. It works directly on the file to which the symlink points. Any temporary files are created in the directory where the data file or index file is located. The same is true for the
ALTER TABLE,OPTIMIZE TABLE, andREPAIR TABLEstatements.Note: When you drop a table that is using symlinks, both the symlink and the file to which the symlink points are dropped. This is an extremely good reason why you should not run mysqld as the system
rootor allow system users to have write access to MySQL database directories.If you rename a table with
ALTER TABLE ... RENAMEand you do not move the table to another database, the symlinks in the database directory are renamed to the new names and the data file and index file are renamed accordingly.If you use
ALTER TABLE ... RENAMEto move a table to another database, the table is moved to the other database directory. The old symlinks and the files to which they pointed are deleted. In other words, the new table is not symlinked.If you are not using symlinks, you should use the
--skip-symbolic-linksoption to mysqld to ensure that no one can use mysqld to drop or rename a file outside of the data directory.
Table symlink operations that are not yet supported:
ALTER TABLEignores theDATA DIRECTORYandINDEX DIRECTORYtable options.BACKUP TABLEandRESTORE TABLEdo not respect symbolic links.The
.frmfile must never be a symbolic link (as indicated previously, only the data and index files can be symbolic links). Attempting to do this (for example, to make synonyms) produces incorrect results. Suppose that you have a databasedb1under the MySQL data directory, a tabletbl1in this database, and in thedb1directory you make a symlinktbl2that points totbl1:shell>
cdshell>/path/to/datadir/db1ln -s tbl1.frm tbl2.frmshell>ln -s tbl1.MYD tbl2.MYDshell>ln -s tbl1.MYI tbl2.MYIProblems result if one thread reads
db1.tbl1and another thread updatesdb1.tbl2:The query cache is “fooled” (it has no way of knowing that
tbl1has not been updated, so it returns outdated results).ALTERstatements ontbl2fail.
Symbolic links are enabled by default for all Windows servers.
This enables you to put a database directory on a different
disk by setting up a symbolic link to it. This is similar to
the way that database symbolic links work on Unix, although
the procedure for setting up the link is different. If you do
not need symbolic links, you can disable them using the
--skip-symbolic-links option.
On Windows, create a symbolic link to a MySQL database by
creating a file in the data directory that contains the path
to the destination directory. The file should be named
db_name.symdb_name is the database name.
Suppose that the MySQL data directory is
C:\mysql\data and you want to have
database foo located at
D:\data\foo. Set up a symlink using this
procedure
Make sure that the
D:\data\foodirectory exists by creating it if necessary. If you already have a database directory namedfooin the data directory, you should move it toD:\data. Otherwise, the symbolic link will be ineffective. To avoid problems, make sure that the server is not running when you move the database directory.Create a text file
C:\mysql\data\foo.symthat contains the pathnameD:\data\foo\.
After this, all tables created in the database
foo are created in
D:\data\foo. Note that the
symbolic link is not used if a directory with the same name as
the database exists in the MySQL data directory.
Table of Contents
- 8.1. Overview of Client and Utility Programs
- 8.2. innochecksum — Offline InnoDB File Checksum Utility
- 8.3. my_print_defaults — Display Options from Option Files
- 8.4. myisam_ftdump — Display Full-Text Index information
- 8.5. myisamchk — MyISAM Table-Maintenance Utility
- 8.6. myisamlog — Display MyISAM Log File Contents
- 8.7. myisampack — Generate Compressed, Read-Only MyISAM Tables
- 8.8. mysql — The MySQL Command-Line Tool
- 8.9. mysqlaccess — Client for Checking Access Privileges
- 8.10. mysqladmin — Client for Administering a MySQL Server
- 8.11. mysqlbinlog — Utility for Processing Binary Log Files
- 8.12. mysqlcheck — A Table Maintenance and Repair Program
- 8.13. mysqldump — A Database Backup Program
- 8.14. mysqlhotcopy — A Database Backup Program
- 8.15. mysqlimport — A Data Import Program
- 8.16. mysqlmanagerc — Internal Test-Suite Program
- 8.17. mysqlmanager-pwgen — Internal Test-Suite Program
- 8.18. mysqlshow — Display Database, Table, and Column Information
- 8.19. mysql_convert_table_format — Convert Tables to Use a Given Storage Engine
- 8.20. mysql_explain_log — Use EXPLAIN on Statements in Query Log
- 8.21. mysql_find_rows — Extract Queries from Update Log
- 8.22. mysql_fix_extensions — Make Table Filename Extensions Lowercase
- 8.23. mysql_setpermission — Interactively Set Permissions in Grant Tables
- 8.24. mysql_tableinfo — Generate Database Metadata
- 8.25. mysql_waitpid — Kill Process and Wait for Its Termination
- 8.26. mysql_zap — Kill Processes That Match a Pattern
- 8.27. perror — Explain Error Codes
- 8.28. replace — A String-Replacement Utility
- 8.29. resolveip — Resolve Hostname to IP Address or Vice Versa
- 8.30. resolve_stack_dump — Resolve Numeric Stack Trace Dump to Symbols
There are many different MySQL client programs that connect to the server to access databases or perform administrative tasks. Other utilities are available as well. These do not establish a client connection with the server but perform MySQL-related operations.
This chapter provides a brief overview of these programs and then a more detailed description of each one. Each program's description indicates its invocation syntax and the options that it understands. See Chapter 4, Using MySQL Programs, for general information on invoking programs and specifying program options.
The following list briefly describes the MySQL client programs and utilities:
An offline
InnoDBoffline file checksum utility. See Section 8.2, “innochecksum — Offline InnoDB File Checksum Utility”.A utility that are present in option groups of option files. See Section 8.3, “my_print_defaults — Display Options from Option Files”.
A utility that displays information about full-text indexes in
MyISAMtables. See Section 8.4, “myisam_ftdump — Display Full-Text Index information”.A utility to describe, check, optimize, and repair
MyISAMtables. isamchk is a similar program forISAMtables. See Section 8.5, “myisamchk — MyISAM Table-Maintenance Utility”.A utility that processes the contents of a
MyISAMlog file. See Section 8.6, “myisamlog — Display MyISAM Log File Contents”.A utility that compresses
MyISAMtables to produce smaller read-only tables. See Section 8.7, “myisampack — Generate Compressed, Read-Only MyISAM Tables”.The command-line tool for interactively entering SQL statements or executing them from a file in batch mode. See Section 8.8, “mysql — The MySQL Command-Line Tool”.
A script that checks the access privileges for a hostname, username, and database combination. See Section 8.9, “mysqlaccess — Client for Checking Access Privileges”.
A client that performs administrative operations, such as creating or dropping databases, reloading the grant tables, flushing tables to disk, and reopening log files. mysqladmin can also be used to retrieve version, process, and status information from the server. See Section 8.10, “mysqladmin — Client for Administering a MySQL Server”.
A utility for reading statements from a binary log. The log of executed statements contained in the binary log files can be used to help recover from a crash. See Section 8.11, “mysqlbinlog — Utility for Processing Binary Log Files”.
A table-maintenance client that checks, repairs, analyzes, and optimizes tables. See Section 8.12, “mysqlcheck — A Table Maintenance and Repair Program”.
A client that dumps a MySQL database into a file as SQL, text, or XML. See Section 8.13, “mysqldump — A Database Backup Program”.
A utility that quickly makes backups of
MyISAMtables while the server is running. See Section 8.14, “mysqlhotcopy — A Database Backup Program”.A client that imports text files into their respective tables using
LOAD DATA INFILE. See Section 8.15, “mysqlimport — A Data Import Program”.A client that displays information about databases, tables, columns, and indexes. See Section 8.18, “mysqlshow — Display Database, Table, and Column Information”.
A utility that converts tables in a database to use a given storage engine. See Section 8.19, “mysql_convert_table_format — Convert Tables to Use a Given Storage Engine”.
A utility that analyzes queries in the MySQL query log using
EXPLAINSee Section 8.20, “mysql_explain_log — Use EXPLAIN on Statements in Query Log”.A utility that reads update log files and extracts queries that match a given regular expression. See Section 8.21, “mysql_find_rows — Extract Queries from Update Log”.
A utility that converts the extensions for
MyISAM(orISAM) table files to lowercase. This can be useful after transferring the files from a system with case-insensitive filenames to a system with case-sensitive filenames. See Section 8.22, “mysql_fix_extensions — Make Table Filename Extensions Lowercase”.A utility for interactively setting permissions in the MySQL grant tables. See Section 8.23, “mysql_setpermission — Interactively Set Permissions in Grant Tables”.
A utility that generates database metadata. Section 8.24, “mysql_tableinfo — Generate Database Metadata”.
A utility that kills the process with a given process ID. See Section 8.25, “mysql_waitpid — Kill Process and Wait for Its Termination”.
A utility that kills processes that match a pattern. See Section 8.26, “mysql_zap — Kill Processes That Match a Pattern”.
A utility that displays the meaning of system or MySQL error codes. See Section 8.27, “perror — Explain Error Codes”.
A utility program that performs string replacement in the input text. See Section 8.28, “replace — A String-Replacement Utility”.
A utility program that resolves a hostname to an IP address or vice versa. See Section 8.29, “resolveip — Resolve Hostname to IP Address or Vice Versa”.
A utility program that resolves a numeric stack trace dump to symbols. See Section 8.30, “resolve_stack_dump — Resolve Numeric Stack Trace Dump to Symbols”.
MySQL AB also provides a number of GUI tools for administering and otherwise working with MySQL servers. For basic information about these, see Chapter 4, Using MySQL Programs.
Each MySQL program takes many different options. Most programs
provide a --help option that you can use to get a
full description of the program's different options. For example,
try mysql --help.
MySQL client programs that communicate with the server using the MySQL client/server library use the following environment variables:
MYSQL_UNIX_PORT | The default Unix socket file; used for connections to
localhost |
MYSQL_TCP_PORT | The default port number; used for TCP/IP connections |
MYSQL_PWD | The default password |
MYSQL_DEBUG | Debug trace options when debugging |
TMPDIR | The directory where temporary tables and files are created |
Use of MYSQL_PWD is insecure. See
Section 5.8.6, “Keeping Your Password Secure”.
You can override the default option values or values specified in environment variables for all standard programs by specifying options in an option file or on the command line. See Section 4.3, “Specifying Program Options”.
innochecksum prints checksums for
InnoDB files.
Invoke innochecksum like this:
shell> innochecksum [options] file_name
innodchecksum understands the options described in the following list. For options that refer to page numbers, the numbers are zero-based.
my_print_defaults displays the options that
are present in option groups of option files. The output
indicates what options will be used by programs that read the
specified option groups. For example, the
mysqlcheck program reads the
[mysqlcheck] and
[client] option groups. To see what options
are present in those groups in the standard option files,
invoke my_print_defaults like this:
shell> my_print_defaults mysqlcheck client
--user=myusername
--password=secret
--host=localhost
The output consists of options, one per line, in the form that they would be specified on the command line.
my_print_defaults understands the following
options:
Display a help message and exit.
--config-file=,file_name--defaults-file=,file_name-cfile_nameRead only the given option file.
--debug=debug_options, -#debug_optionsWrite a debugging log. The
debug_optionsstring often is'd:t:o,. The default isfile_name''d:t:o,/tmp/my_print_defaults.trace'.--defaults-extra-file=,file_name--extra-file=,file_name-efile_nameRead this option file after the global option file but (on Unix) before the user option file.
--defaults-group-suffix=,suffix-gsuffixIn addition to the groups named on the command line, read groups that have the given suffix.
Return an empty string.
Verbose mode. Print more information about what the program does.
Display version information and exit.
myisam_ftdump displays information about
FULLTEXT indexes in
MyISAM tables. It reads the
MyISAM index file directly, so it must be
run on the server host where the table is located
Invoke myisam_ftdump like this:
shell> myisam_ftdump [options] tbl_name index_num
The tbl_name argument should be the
name of a MyISAM table. You can also
specify a table by naming its index file (the file with the
.MYI suffix). If you do not invoke
myisam_ftdump in the directory where the
table files are located, the table or index file name must be
preceded by the pathname to the table's database directory.
Index numbers begin with 0.
Example: Suppose that the test database
contains a table named mytexttablel that
has the following definition:
CREATE TABLE mytexttable ( id INT NOT NULL, txt TEXT NOT NULL, PRIMARY KEY (id), FULLTEXT (txt) );
The index on id is index 0 and the
FULLTEXT index on txt is
index 1. If your working directory is the
test database directory, invoke
myisam_ftdump as follows:
shell> myisam_ftdump mytexttable 1
If the pathname to the test database
directory is /usr/local/mysql/data/test,
you can also specify the table name argument using that
pathname. This is useful if you do not invoke
myisam_ftdump in the database directory:
shell> myisam_ftdump /usr/local/mysql/data/test/mytexttable 1
myisam_ftdump understands the following options:
Display a help message and exit.
Calculate per-word statistics (counts and global weights).
Dump the index, including data offsets and word weights.
Report the length distribution.
Report global index statistics. This is the default operation if no other operation is specified.
Verbose mode. Print more output about what the program does.
The myisamchk utility gets information
about your database tables or checks, repairs, or optimizes
them. myisamchk works with
MyISAM tables (tables that have
.MYD and .MYI files
for storing data and indexes).
Caution
It is best to make a backup of a table before performing a table repair operation; under some circumstances the operation might cause data loss. Possible causes include but are not limited to filesystem errors.
Invoke myisamchk like this:
shell> myisamchk [options] tbl_name ...
The options specify what you want
myisamchk to do. They are described in the
following sections. You can also get a list of options by
invoking myisamchk --help.
With no options, myisamchk simply checks your table as the default operation. To get more information or to tell myisamchk to take corrective action, specify options as described in the following discussion.
tbl_name is the database table you
want to check or repair. If you run
myisamchk somewhere other than in the
database directory, you must specify the path to the database
directory, because myisamchk has no idea
where the database is located. In fact,
myisamchk doesn't actually care whether the
files you are working on are located in a database directory.
You can copy the files that correspond to a database table
into some other location and perform recovery operations on
them there.
You can name several tables on the
myisamchk command line if you wish. You can
also specify a table by naming its index file (the file with
the .MYI suffix). This allows you to
specify all tables in a directory by using the pattern
*.MYI. For example, if you are in a
database directory, you can check all the
MyISAM tables in that directory like this:
shell> myisamchk *.MYI
If you are not in the database directory, you can check all the tables there by specifying the path to the directory:
shell> myisamchk /path/to/database_dir/*.MYI
You can even check all tables in all databases by specifying a wildcard with the path to the MySQL data directory:
shell> myisamchk /path/to/datadir/*/*.MYI
The recommended way to quickly check all
MyISAM tables is:
shell>myisamchk --silent --fastshell>/path/to/datadir/*/*.MYIisamchk --silent/path/to/datadir/*/*.ISM
If you want to check all MyISAM tables and
repair any that are corrupted, you can use the following
command:
shell>myisamchk --silent --force --fast --update-state \--key_buffer_size=64M --sort_buffer_size=64M \--read_buffer_size=1M --write_buffer_size=1M \shell>/path/to/datadir/*/*.MYIisamchk --silent --force --key_buffer_size=64M \--sort_buffer_size=64M --read_buffer_size=1M --write_buffer_size=1M \/path/to/datadir/*/*.ISM
This command assumes that you have more than 64MB free. For more information about memory allocation with myisamchk, see Section 8.5.5, “myisamchk Memory Usage”.
MySQL Enterprise For expert advice on checking and repairing tables, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
Important
You must ensure that no other program is using the tables while you are running myisamchk. The most effective means of doing so is to shut down the MySQL server while running myisamchk, or to lock all tables that myisamchk is being used on.
Otherwise, when you run myisamchk, it may display the following error message:
warning: clients are using or haven't closed the table properly
This means that you are trying to check a table that has
been updated by another program (such as the
mysqld server) that hasn't yet closed the
file or that has died without closing the file properly,
which can sometimes lead to the corruption of one or more
MyISAM tables.
If mysqld is running, you must force it
to flush any table modifications that are still buffered in
memory by using FLUSH TABLES. You should
then ensure that no one is using the tables while you are
running myisamchk
However, the easiest way to avoid this problem is to use
CHECK TABLE instead of
myisamchk to check tables. See
Section 13.5.2.3, “CHECK TABLE Syntax”.
The options described in this section can be used for any type of table maintenance operation performed by myisamchk. The sections following this one describe options that pertain only to specific operations, such as table checking or repairing.
Display a help message and exit.
--debug=debug_options, -#debug_optionsWrite a debugging log. The
debug_optionsstring often is'd:t:o,.file_name'Silent mode. Write output only when errors occur. You can use
-stwice (-ss) to make myisamchk very silent.Verbose mode. Print more information about what the program does. This can be used with
-dand-e. Use-vmultiple times (-vv,-vvv) for even more output.Display version information and exit.
Instead of terminating with an error if the table is locked, wait until the table is unlocked before continuing. If you are running mysqld with external locking disabled, the table can be locked only by another myisamchk command.
You can also set the following variables by using
--
syntax:
var_name=value
| Variable | Default Value |
decode_bits | 9 |
ft_max_word_len | version-dependent |
ft_min_word_len | 4 |
ft_stopword_file | built-in list |
key_buffer_size | 523264 |
myisam_block_size | 1024 |
read_buffer_size | 262136 |
sort_buffer_size | 2097144 |
sort_key_blocks | 16 |
stats_method | nulls_unequal |
write_buffer_size | 262136 |
It is also possible to set variables by using
--set-variable=
or var_name=value-O
syntax. However, this syntax is deprecated as of MySQL 4.0.
var_name=value
The possible myisamchk variables and their default values can be examined with myisamchk --help:
sort_buffer_size is used when the keys are
repaired by sorting keys, which is the normal case when you
use --recover.
key_buffer_size is used when you are
checking the table with --extend-check or
when the keys are repaired by inserting keys row by row into
the table (like when doing normal inserts). Repairing through
the key buffer is used in the following cases:
You use
--safe-recover.The temporary files needed to sort the keys would be more than twice as big as when creating the key file directly. This is often the case when you have large key values for
CHAR,VARCHAR, orTEXTcolumns, because the sort operation needs to store the complete key values as it proceeds. If you have lots of temporary space and you can force myisamchk to repair by sorting, you can use the--sort-recoveroption.
Repairing through the key buffer takes much less disk space than using sorting, but is also much slower.
If you want a faster repair, set the
key_buffer_size and
sort_buffer_size variables to about 25% of
your available memory. You can set both variables to large
values, because only one of them is used at a time.
myisam_block_size is the size used for
index blocks.
stats_method influences how
NULL values are treated for index
statistics collection when the --analyze
option is given. It acts like the
myisam_stats_method system variable. For
more information, see the description of
myisam_stats_method in
Section 5.2.3, “System Variables”, and
Section 7.4.7, “MyISAM Index Statistics Collection”. For MySQL
5.0, stats_method was added in
MySQL 5.0.14. For older versions, the statistics collection
method is equivalent to nulls_equal.
The ft_min_word_len and
ft_max_word_len variables are available as
of MySQL 4.0.0. ft_stopword_file is
available as of MySQL 4.0.19.
ft_min_word_len and
ft_max_word_len indicate the minimum and
maximum word length for FULLTEXT indexes.
ft_stopword_file names the stopword file.
These need to be set under the following circumstances.
If you use myisamchk to perform an
operation that modifies table indexes (such as repair or
analyze), the FULLTEXT indexes are rebuilt
using the default full-text parameter values for minimum and
maximum word length and the stopword file unless you specify
otherwise. This can result in queries failing.
The problem occurs because these parameters are known only by
the server. They are not stored in MyISAM
index files. To avoid the problem if you have modified the
minimum or maximum word length or the stopword file in the
server, specify the same ft_min_word_len,
ft_max_word_len, and
ft_stopword_file values to
myisamchk that you use for
mysqld. For example, if you have set the
minimum word length to 3, you can repair a table with
myisamchk like this:
shell> myisamchk --recover --ft_min_word_len=3 tbl_name.MYI
To ensure that myisamchk and the server use
the same values for full-text parameters, you can place each
one in both the [mysqld] and
[myisamchk] sections of an option file:
[mysqld] ft_min_word_len=3 [myisamchk] ft_min_word_len=3
An alternative to using myisamchk is to use
the REPAIR TABLE, ANALYZE
TABLE, OPTIMIZE TABLE, or
ALTER TABLE. These statements are performed
by the server, which knows the proper full-text parameter
values to use.
myisamchk supports the following options for table checking operations:
Check the table for errors. This is the default operation if you specify no option that selects an operation type explicitly.
Check only tables that have changed since the last check.
Check the table very thoroughly. This is quite slow if the table has many indexes. This option should only be used in extreme cases. Normally, myisamchk or myisamchk --medium-check should be able to determine whether there are any errors in the table.
If you are using
--extend-checkand have plenty of memory, setting thekey_buffer_sizevariable to a large value helps the repair operation run faster.Check only tables that haven't been closed properly.
Do a repair operation automatically if myisamchk finds any errors in the table. The repair type is the same as that specified with the
--recoveror-roption.Print informational statistics about the table that is checked.
Do a check that is faster than an
--extend-checkoperation. This finds only 99.99% of all errors, which should be good enough in most cases.Don't mark the table as checked. This is useful if you use myisamchk to check a table that is in use by some other application that doesn't use locking, such as mysqld when run with external locking disabled.
Store information in the
.MYIfile to indicate when the table was checked and whether the table crashed. This should be used to get full benefit of the--check-only-changedoption, but you shouldn't use this option if the mysqld server is using the table and you are running it with external locking disabled.
myisamchk supports the following options for table repair operations:
Make a backup of the
.MYDfile asfile_name-time.BAKThe directory where character sets are installed. See Section 5.10.1, “The Character Set Used for Data and Sorting”.
Correct the checksum information for the table.
--data-file-length=len, -DlenMaximum length of the data file (when re-creating data file when it is “full”).
Do a repair that tries to recover every possible row from the data file. Normally, this also finds a lot of garbage rows. Don't use this option unless you are desperate.
Overwrite old intermediate files (files with names like
tbl_name.TMDFor myisamchk, the option value is a bit-value that indicates which indexes to update. Each binary bit of the option value corresponds to a table index, where the first index is bit 0. An option value of 0 disables updates to all indexes, which can be used to get faster inserts. Deactivated indexes can be reactivated by using myisamchk -r.
Do not follow symbolic links. Normally myisamchk repairs the table that a symlink points to. This option does not exist as of MySQL 4.0 because versions from 4.0 on do not remove symlinks during repair operations.
Skip rows larger than the given length if myisamchk cannot allocate memory to hold them.
Uses the same technique as
-rand-n, but creates all the keys in parallel, using different threads. This is beta-quality code. Use at your own risk!Achieve a faster repair by not modifying the data file. You can specify this option twice to force myisamchk to modify the original data file in case of duplicate keys.
Do a repair that can fix almost any problem except unique keys that aren't unique (which is an extremely unlikely error with
MyISAMtables). If you want to recover a table, this is the option to try first. You should try--safe-recoveronly if myisamchk reports that the table can't be recovered using--recover. (In the unlikely case that--recoverfails, the data file remains intact.)If you have lots of memory, you should increase the value of
sort_buffer_size.Do a repair using an old recovery method that reads through all rows in order and updates all index trees based on the rows found. This is an order of magnitude slower than
--recover, but can handle a couple of very unlikely cases that--recovercannot. This recovery method also uses much less disk space than--recover. Normally, you should repair first with--recover, and then with--safe-recoveronly if--recoverfails.If you have lots of memory, you should increase the value of
key_buffer_size.Change the character set used by the table indexes. This option was replaced by
--set-collationin MySQL 5.0.3.Specify the collation to use for sorting table indexes. The character set name is implied by the first part of the collation name. This option was added in MySQL 5.0.3.
Force myisamchk to use sorting to resolve the keys even if the temporary files would be very large.
Path of the directory to be used for storing temporary files. If this is not set, myisamchk uses the value of the
TMPDIRenvironment variable.tmpdircan be set to a list of directory paths that are used successively in round-robin fashion for creating temporary files. The separator character between directory names is the colon (‘:’) on Unix and the semicolon (‘;’) on Windows, NetWare, and OS/2.Unpack a table that was packed with myisampack.
myisamchk supports the following options for actions other than table checks and repairs:
Analyze the distribution of key values. This improves join performance by enabling the join optimizer to better choose the order in which to join the tables and which indexes it should use. To obtain information about the key distribution, use a myisamchk --description --verbose
tbl_namecommand or theSHOW INDEX FROMstatement.tbl_nameMySQL Enterprise For expert advice on optimizing tables, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
--block-search=,offset-boffsetFind the record that a block at the given offset belongs to.
Print some descriptive information about the table.
--set-auto-increment[=,value]-A[value]Force
AUTO_INCREMENTnumbering for new records to start at the given value (or higher, if there are existing records withAUTO_INCREMENTvalues this large). Ifvalueis not specified,AUTO_INCREMENTnumbers for new records begin with the largest value currently in the table, plus one.Sort the index tree blocks in high-low order. This optimizes seeks and makes table scans that use indexes faster.
Sort records according to a particular index. This makes your data much more localized and may speed up range-based
SELECTandORDER BYoperations that use this index. (The first time you use this option to sort a table, it may be very slow.) To determine a table's index numbers, useSHOW INDEX, which displays a table's indexes in the same order that myisamchk sees them. Indexes are numbered beginning with 1.If keys are not packed (
PACK_KEYS=0), they have the same length, so when myisamchk sorts and moves records, it just overwrites record offsets in the index. If keys are packed (PACK_KEYS=1), myisamchk must unpack key blocks first, then re-create indexes and pack the key blocks again. (In this case, re-creating indexes is faster than updating offsets for each index.)
Memory allocation is important when you run myisamchk. myisamchk uses no more memory than its memory-related variables are set to. If you are going to use myisamchk on very large tables, you should first decide how much memory you want it to use. The default is to use only about 3MB to perform repairs. By using larger values, you can get myisamchk to operate faster. For example, if you have more than 32MB RAM, you could use options such as these (in addition to any other options you might specify):
shell>myisamchk --sort_buffer_size=16M --key_buffer_size=16M \--read_buffer_size=1M --write_buffer_size=1M ...
Using --sort_buffer_size=16M should probably
be enough for most cases.
Be aware that myisamchk uses temporary
files in TMPDIR. If
TMPDIR points to a memory filesystem, you
may easily get out of memory errors. If this happens, run
myisamchk with the
--tmpdir=
option to specify some directory located on a filesystem that
has more space.
path
When repairing, myisamchk also needs a lot of disk space:
Double the size of the data file (the original file and a copy). This space is not needed if you do a repair with
--quick; in this case, only the index file is re-created. This space is needed on the same filesystem as the original data file! (The copy is created in the same directory as the original.)Space for the new index file that replaces the old one. The old index file is truncated at the start of the repair operation, so you usually ignore this space. This space is needed on the same filesystem as the original index file!
When using
--recoveror--sort-recover(but not when using--safe-recover), you need space for a sort buffer. The following formula yields the amount of space required:(
largest_key+row_pointer_length) ×number_of_rows× 2You can check the length of the keys and the
row_pointer_lengthwith myisamchk -dvtbl_name. This space is allocated in the temporary directory (specified byTMPDIRor--tmpdir=).path
If you have a problem with disk space during repair, you can
try --safe-recover instead of
--recover.
myisamlog processes the contents of a
MyISAM log file.
Invoke myisamlog like this:
shell>myisamlog [shell>options] [log_file[tbl_name] ...]isamlog [options] [log_file[tbl_name] ...]
The default operation is update (-u). If a
recovery is done (-r), all writes and
possibly updates and deletes are done and errors are only
counted. The default log file name is
myisam.log for
myisamlog and isam.log
for isamlog if no
log_file argument is given, If
tables are named on the command line, only those tables are
updated.
myisamlog understands the following options:
Display a help message and exit.
Execute only
Ncommands.Specify the maximum number of open files.
Display extra information before exiting.
Specify the starting offset.
Remove
Ncomponents from path.Perform a recovery operation.
Specify record position file and record position.
Perform an update operation.
Verbose mode. Print more output about what the program does. This option can be given multiple times to produce more and more output.
Specify the write file.
Display version information.
The myisampack utility compresses
MyISAM tables.
myisampack works by compressing each column
in the table separately. Usually,
myisampack packs the data file 40%-70%.
When the table is used later, the server reads into memory the information needed to decompress columns. This results in much better performance when accessing individual rows, because you only have to uncompress exactly one row.
MySQL uses mmap() when possible to perform
memory mapping on compressed tables. If
mmap() does not work, MySQL falls back to
normal read/write file operations.
A similar utility, pack_isam, compresses
ISAM tables. Because
ISAM tables are deprecated, this section
discusses only myisampack, but the general
procedures for using myisampack are also
true for pack_isam unless otherwise
specified. References to myisamchk should
be read as references to isamchk if you are
using pack_isam.
Please note the following:
If the mysqld server was invoked with external locking disabled, it is not a good idea to invoke myisampack if the table might be updated by the server during the packing process. It is safest to compress tables with the server stopped.
After packing a table, it becomes read-only. This is generally intended (such as when accessing packed tables on a CD). Allowing writes to a packed table is on our TODO list, but with low priority.
myisampack can pack
BLOBorTEXTcolumns. (The older pack_isam program forISAMtables did not have this capability.)
Invoke myisampack like this:
shell> myisampack [options] file_name ...
Each filename argument should be the name of an index
(.MYI) file. If you are not in the
database directory, you should specify the pathname to the
file. It is permissible to omit the .MYI
extension.
After you compress a table with myisampack, you should use myisamchk -rq to rebuild its indexes. Section 8.5, “myisamchk — MyISAM Table-Maintenance Utility”.
myisampack supports the following options:
Display a help message and exit.
Make a backup of each table's data file using the name
tbl_name.OLDThe directory where character sets are installed. See Section 5.10.1, “The Character Set Used for Data and Sorting”.
--debug[=,debug_options]-# [debug_options]Write a debugging log. The
debug_optionsstring often is'd:t:o,.file_name'Produce a packed table even if it becomes larger than the original or if the intermediate file from an earlier invocation of myisampack exists. (myisampack creates an intermediate file named
tbl_name.TMD.TMDfile might not be deleted.) Normally, myisampack exits with an error if it finds thattbl_name.TMD--force, myisampack packs the table anyway.--join=,big_tbl_name-jbig_tbl_nameJoin all tables named on the command line into a single table
big_tbl_name. All tables that are to be combined must have identical structure (same column names and types, same indexes, and so forth).Silent mode. Write output only when errors occur.
Do not actually pack the table, just test packing it.
Use the named directory as the location where myisampack creates temporary files.
Verbose mode. Write information about the progress of the packing operation and its result.
Display version information and exit.
Wait and retry if the table is in use. If the mysqld server was invoked with external locking disabled, it is not a good idea to invoke myisampack if the table might be updated by the server during the packing process.
The following sequence of commands illustrates a typical table compression session:
shell>ls -l station.*-rw-rw-r-- 1 monty my 994128 Apr 17 19:00 station.MYD -rw-rw-r-- 1 monty my 53248 Apr 17 19:00 station.MYI -rw-rw-r-- 1 monty my 5767 Apr 17 19:00 station.frm shell>myisamchk -dvv stationMyISAM file: station Isam-version: 2 Creation time: 1996-03-13 10:08:58 Recover time: 1997-02-02 3:06:43 Data records: 1192 Deleted blocks: 0 Datafile parts: 1192 Deleted data: 0 Datafile pointer (bytes): 2 Keyfile pointer (bytes): 2 Max datafile length: 54657023 Max keyfile length: 33554431 Recordlength: 834 Record format: Fixed length table description: Key Start Len Index Type Root Blocksize Rec/key 1 2 4 unique unsigned long 1024 1024 1 2 32 30 multip. text 10240 1024 1 Field Start Length Type 1 1 1 2 2 4 3 6 4 4 10 1 5 11 20 6 31 1 7 32 30 8 62 35 9 97 35 10 132 35 11 167 4 12 171 16 13 187 35 14 222 4 15 226 16 16 242 20 17 262 20 18 282 20 19 302 30 20 332 4 21 336 4 22 340 1 23 341 8 24 349 8 25 357 8 26 365 2 27 367 2 28 369 4 29 373 4 30 377 1 31 378 2 32 380 8 33 388 4 34 392 4 35 396 4 36 400 4 37 404 1 38 405 4 39 409 4 40 413 4 41 417 4 42 421 4 43 425 4 44 429 20 45 449 30 46 479 1 47 480 1 48 481 79 49 560 79 50 639 79 51 718 79 52 797 8 53 805 1 54 806 1 55 807 20 56 827 4 57 831 4 shell>myisampack station.MYICompressing station.MYI: (1192 records) - Calculating statistics normal: 20 empty-space: 16 empty-zero: 12 empty-fill: 11 pre-space: 0 end-space: 12 table-lookups: 5 zero: 7 Original trees: 57 After join: 17 - Compressing file 87.14% Remember to run myisamchk -rq on compressed tables shell>ls -l station.*-rw-rw-r-- 1 monty my 127874 Apr 17 19:00 station.MYD -rw-rw-r-- 1 monty my 55296 Apr 17 19:04 station.MYI -rw-rw-r-- 1 monty my 5767 Apr 17 19:00 station.frm shell>myisamchk -dvv stationMyISAM file: station Isam-version: 2 Creation time: 1996-03-13 10:08:58 Recover time: 1997-04-17 19:04:26 Data records: 1192 Deleted blocks: 0 Datafile parts: 1192 Deleted data: 0 Datafile pointer (bytes): 3 Keyfile pointer (bytes): 1 Max datafile length: 16777215 Max keyfile length: 131071 Recordlength: 834 Record format: Compressed table description: Key Start Len Index Type Root Blocksize Rec/key 1 2 4 unique unsigned long 10240 1024 1 2 32 30 multip. text 54272 1024 1 Field Start Length Type Huff tree Bits 1 1 1 constant 1 0 2 2 4 zerofill(1) 2 9 3 6 4 no zeros, zerofill(1) 2 9 4 10 1 3 9 5 11 20 table-lookup 4 0 6 31 1 3 9 7 32 30 no endspace, not_always 5 9 8 62 35 no endspace, not_always, no empty 6 9 9 97 35 no empty 7 9 10 132 35 no endspace, not_always, no empty 6 9 11 167 4 zerofill(1) 2 9 12 171 16 no endspace, not_always, no empty 5 9 13 187 35 no endspace, not_always, no empty 6 9 14 222 4 zerofill(1) 2 9 15 226 16 no endspace, not_always, no empty 5 9 16 242 20 no endspace, not_always 8 9 17 262 20 no endspace, no empty 8 9 18 282 20 no endspace, no empty 5 9 19 302 30 no endspace, no empty 6 9 20 332 4 always zero 2 9 21 336 4 always zero 2 9 22 340 1 3 9 23 341 8 table-lookup 9 0 24 349 8 table-lookup 10 0 25 357 8 always zero 2 9 26 365 2 2 9 27 367 2 no zeros, zerofill(1) 2 9 28 369 4 no zeros, zerofill(1) 2 9 29 373 4 table-lookup 11 0 30 377 1 3 9 31 378 2 no zeros, zerofill(1) 2 9 32 380 8 no zeros 2 9 33 388 4 always zero 2 9 34 392 4 table-lookup 12 0 35 396 4 no zeros, zerofill(1) 13 9 36 400 4 no zeros, zerofill(1) 2 9 37 404 1 2 9 38 405 4 no zeros 2 9 39 409 4 always zero 2 9 40 413 4 no zeros 2 9 41 417 4 always zero 2 9 42 421 4 no zeros 2 9 43 425 4 always zero 2 9 44 429 20 no empty 3 9 45 449 30 no empty 3 9 46 479 1 14 4 47 480 1 14 4 48 481 79 no endspace, no empty 15 9 49 560 79 no empty 2 9 50 639 79 no empty 2 9 51 718 79 no endspace 16 9 52 797 8 no empty 2 9 53 805 1 17 1 54 806 1 3 9 55 807 20 no empty 3 9 56 827 4 no zeros, zerofill(2) 2 9 57 831 4 no zeros, zerofill(1) 2 9
myisampack displays the following kinds of information:
normalThe number of columns for which no extra packing is used.
empty-spaceThe number of columns containing values that are only spaces. These occupy one bit.
empty-zeroThe number of columns containing values that are only binary zeros. These occupy one bit.
empty-fillThe number of integer columns that do not occupy the full byte range of their type. These are changed to a smaller type. For example, a
BIGINTcolumn (eight bytes) can be stored as aTINYINTcolumn (one byte) if all its values are in the range from-128to127.pre-spaceThe number of decimal columns that are stored with leading spaces. In this case, each value contains a count for the number of leading spaces.
end-spaceThe number of columns that have a lot of trailing spaces. In this case, each value contains a count for the number of trailing spaces.
table-lookupThe column had only a small number of different values, which were converted to an
ENUMbefore Huffman compression.zeroThe number of columns for which all values are zero.
Original treesThe initial number of Huffman trees.
After joinThe number of distinct Huffman trees left after joining trees to save some header space.
After a table has been compressed, myisamchk -dvv prints additional information about each column:
TypeThe data type. The value may contain any of the following descriptors:
constantAll rows have the same value.
no endspaceDo not store endspace.
no endspace, not_alwaysDo not store endspace and do not do endspace compression for all values.
no endspace, no emptyDo not store endspace. Do not store empty values.
table-lookupThe column was converted to an
ENUM.zerofill(N)The most significant
Nbytes in the value are always 0 and are not stored.no zerosDo not store zeros.
always zeroZero values are stored using one bit.
Huff treeThe number of the Huffman tree associated with the column.
BitsThe number of bits used in the Huffman tree.
After you run myisampack, you must run myisamchk to re-create any indexes. At this time, you can also sort the index blocks and create statistics needed for the MySQL optimizer to work more efficiently:
shell> myisamchk -rq --sort-index --analyze tbl_name.MYI
A similar procedure applies for ISAM
tables. After using pack_isam, use
isamchk to re-create the indexes:
shell> isamchk -rq --sort-index --analyze tbl_name.ISM
After you have installed the packed table into the MySQL database directory, you should execute mysqladmin flush-tables to force mysqld to start using the new table.
To unpack a packed table, use the --unpack
option to myisamchk or
isamchk.
mysql is a simple SQL shell (with GNU
readline capabilities). It supports
interactive and non-interactive use. When used interactively,
query results are presented in an ASCII-table format. When
used non-interactively (for example, as a filter), the result
is presented in tab-separated format. The output format can be
changed using command options.
If you have problems due to insufficient memory for large
result sets, use the --quick option. This
forces mysql to retrieve results from the
server a row at a time rather than retrieving the entire
result set and buffering it in memory before displaying it.
This is done by returning the result set using the
mysql_use_result() C API function in the
client/server library rather than
mysql_store_result().
Using mysql is very easy. Invoke it from the prompt of your command interpreter as follows:
shell> mysql db_name
Or:
shell> mysql --user=user_name --password=your_password db_name
Then type an SQL statement, end it with
‘;’, \g, or
\G and press Enter.
As of MySQL 5.0.25, typing Control-C causes mysql to attempt to kill the current statement. If this cannot be done, or Control-C is typed again before the statement is killed, mysql exits. Previously, Control-C caused mysql to exit in all cases.
You can execute SQL statements in a script file (batch file) like this:
shell> mysql db_name < script.sql > output.tab
mysql supports the following options:
Display a help message and exit.
Enable automatic rehashing. This option is on by default, which enables table and column name completion. Use
--skip-auto-rehashto disable rehashing. That causes mysql to start faster, but you must issue therehashcommand if you want to use table and column name completion.Print results using tab as the column separator, with each row on a new line. With this option, mysql does not use the history file.
The directory where character sets are installed. See Section 5.10.1, “The Character Set Used for Data and Sorting”.
Write column names in results.
Compress all information sent between the client and the server if both support compression.
--database=,db_name-Ddb_nameThe database to use. This is useful primarily in an option file.
--debug[=,debug_options]-# [debug_options]Write a debugging log. The
debug_optionsstring often is'd:t:o,. The default isfile_name''d:t:o,/tmp/mysql.trace'.Print some debugging information when the program exits.
--default-character-set=charset_nameUse
charset_nameas the default character set. See Section 5.10.1, “The Character Set Used for Data and Sorting”.Set the statement delimiter. The default is the semicolon character (‘
;’).--execute=,statement-estatementExecute the statement and quit. The default output format is like that produced with
--batch. See Section 4.3.1, “Using Options on the Command Line”, for some examples.Continue even if an SQL error occurs.
--host=,host_name-hhost_nameConnect to the MySQL server on the given host.
Produce HTML output.
Ignore spaces after function names. The effect of this is described in the discussion for the
IGNORE_SPACESQL mode (see Section 5.2.6, “SQL Modes”).Write line numbers for errors. Disable this with
--skip-line-numbers.Enable or disable
LOCALcapability forLOAD DATA INFILE. With no value, the option enablesLOCAL. The option may be given as--local-infile=0or--local-infile=1to explicitly disable or enableLOCAL. EnablingLOCALhas no effect if the server does not also support it.MySQL Enterprise For expert advice on the security implications of enabling
LOCAL, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.Enable named mysql commands. Long-format commands are allowed, not just short-format commands. For example,
quitand\qboth are recognized. Use--skip-named-commandsto disable named commands. See Section 8.8.2, “mysql Commands”.Deprecated form of
-skip-auto-rehash. See the description for--auto-rehash.Do not beep when errors occur.
Disable named commands. Use the
\*form only, or use named commands only at the beginning of a line ending with a semicolon (‘;’). mysql starts with this option enabled by default. However, even with this option, long-format commands still work from the first line. See Section 8.8.2, “mysql Commands”.Deprecated form of
--skip-pager. See the--pageroption.Do not copy output to a file. Section 8.8.2, “mysql Commands”, discusses tee files further.
Ignore statements except those for the default database named on the command line. This is useful for skipping updates to other databases in the binary log.
Use the given command for paging query output. If the command is omitted, the default pager is the value of your
PAGERenvironment variable. Valid pagers are less, more, cat [> filename], and so forth. This option works only on Unix. It does not work in batch mode. To disable paging, use--skip-pager. Section 8.8.2, “mysql Commands”, discusses output paging further.--password[=,password]-p[password]The password to use when connecting to the server. If you use the short option form (
-p), you cannot have a space between the option and the password. If you omit thepasswordvalue following the--passwordor-poption on the command line, you are prompted for one.Specifying a password on the command line should be considered insecure. See Section 5.8.6, “Keeping Your Password Secure”.
The TCP/IP port number to use for the connection.
Set the prompt to the specified format. The default is
mysql>. The special sequences that the prompt can contain are described in Section 8.8.2, “mysql Commands”.--protocol={TCP|SOCKET|PIPE|MEMORY}The connection protocol to use.
Do not cache each query result, print each row as it is received. This may slow down the server if the output is suspended. With this option, mysql does not use the history file.
Write column values without escape conversion. Often used with the
--batchoption.If the connection to the server is lost, automatically try to reconnect. A single reconnect attempt is made each time the connection is lost. To suppress reconnection behavior, use
--skip-reconnect.--safe-updates,--i-am-a-dummy,-UAllow only those
UPDATEandDELETEstatements that specify which rows to modify by using key values. If you have set this option in an option file, you can override it by using--safe-updateson the command line. See Section 8.8.5, “mysql Tips”, for more information about this option.Do not send passwords to the server in old (pre-4.1.1) format. This prevents connections except for servers that use the newer password format.
MySQL Enterprise For expert advice on database security, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
Cause warnings to be shown after each statement if there are any. This option applies to interactive and batch mode. This option was added in MySQL 5.0.6.
Ignore
SIGINTsignals (typically the result of typing Control-C).Silent mode. Produce less output. This option can be given multiple times to produce less and less output.
Do not write column names in results.
Do not write line numbers for errors. Useful when you want to compare result files that include error messages.
For connections to
localhost, the Unix socket file to use, or, on Windows, the name of the named pipe to use.Options that begin with
--sslspecify whether to connect to the server via SSL and indicate where to find SSL keys and certificates. See Section 5.8.7.3, “SSL Command Options”.Display output in table format. This is the default for interactive use, but can be used to produce table output in batch mode.
Append a copy of output to the given file. This option does not work in batch mode. in Section 8.8.2, “mysql Commands”, discusses tee files further.
Flush the buffer after each query.
--user=,user_name-uuser_nameThe MySQL username to use when connecting to the server.
Verbose mode. Produce more output about what the program does. This option can be given multiple times to produce more and more output. (For example,
-v -v -vproduces table output format even in batch mode.)Display version information and exit.
Print query output rows vertically (one line per column value). Without this option, you can specify vertical output for individual statements by terminating them with
\G.If the connection cannot be established, wait and retry instead of aborting.
Produce XML output.
Note: Prior to MySQL 5.0.26, there was no differentiation in the output when using this option between columns containing the
NULLvalue and columns containing the string literal'NULL'; both were represented as<field name="
column_name">NULL</field>Beginning with MySQL 5.0.26, the output when
--xmlis used with mysql matches that of mysqldump--xml. See the section of the Manual which discusses the--xmloption for mysqldump for details.Beginning with MySQL 5.0.40, the XML output also uses an XML namespace, as shown here:
shell>
mysql --xml -uroot -e "SHOW VARIABLES LIKE 'version%'"<?xml version="1.0"?> <resultset statement="SHOW VARIABLES LIKE 'version%'" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <row> <field name="Variable_name">version</field> <field name="Value">5.0.40-debug</field> </row> <row> <field name="Variable_name">version_comment</field> <field name="Value">Source distribution</field> </row> <row> <field name="Variable_name">version_compile_machine</field> <field name="Value">i686</field> </row> <row> <field name="Variable_name">version_compile_os</field> <field name="Value">suse-linux-gnu</field> </row> </resultset>(See Bug#25946.)
You can also set the following variables by using
--
syntax:
var_name=value
The number of seconds before connection timeout. (Default value is
0.)The maximum packet length to send to or receive from the server. (Default value is 16MB.)
The automatic limit for rows in a join when using
--safe-updates. (Default value is 1,000,000.)The buffer size for TCP/IP and socket communication. (Default value is 16KB.)
The automatic limit for
SELECTstatements when using--safe-updates. (Default value is 1,000.)
It is also possible to set variables by using
--set-variable=
or var_name=value-O
syntax. This syntax is deprecated.
var_name=value
On Unix, the mysql client writes a record
of executed statements to a history file. By default, the
history file is named .mysql_history and
is created in your home directory. To specify a different
file, set the value of the MYSQL_HISTFILE
environment variable.
If you do not want to maintain a history file, first remove
.mysql_history if it exists, and then use
either of the following techniques:
Set the
MYSQL_HISTFILEvariable to/dev/null. To cause this setting to take effect each time you log in, put the setting in one of your shell's startup files.Create
.mysql_historyas a symbolic link to/dev/null:shell>
ln -s /dev/null $HOME/.mysql_historyYou need do this only once.
mysql sends each SQL statement that you
issue to the server to be executed. There is also a set of
commands that mysql itself interprets. For
a list of these commands, type help or
\h at the mysql>
prompt:
mysql> help
List of all MySQL commands:
Note that all text commands must be first on line and end with ';'
? (\?) Synonym for `help'.
charset (\C) Switch to another charset. Might be needed for processing
binlog with multi-byte charsets.
clear (\c) Clear command.
connect (\r) Reconnect to the server. Optional arguments are db and host.
delimiter (\d) Set statement delimiter. NOTE: Takes the rest of the line as
new delimiter.
edit (\e) Edit command with $EDITOR.
ego (\G) Send command to mysql server, display result vertically.
exit (\q) Exit mysql. Same as quit.
go (\g) Send command to mysql server.
help (\h) Display this help.
nopager (\n) Disable pager, print to stdout.
notee (\t) Don't write into outfile.
pager (\P) Set PAGER [to_pager]. Print the query results via PAGER.
print (\p) Print current command.
prompt (\R) Change your mysql prompt.
quit (\q) Quit mysql.
rehash (\#) Rebuild completion hash.
source (\.) Execute an SQL script file. Takes a file name as an argument.
status (\s) Get status information from the server.
system (\!) Execute a system shell command.
tee (\T) Set outfile [to_outfile]. Append everything into given
outfile.
use (\u) Use another database. Takes database name as argument.
warnings (\W) Show warnings after every statement.
nowarning (\w) Don't show warnings after every statement.
For server side help, type 'help contents'
Each command has both a long and short form. The long form is not case sensitive; the short form is. The long form can be followed by an optional semicolon terminator, but the short form should not.
If you provide an argument to the help
command, mysql uses it as a search string
to access server-side help from the contents of the MySQL
Reference Manual. For more information, see
Section 8.8.3, “mysql Server-Side Help”.
The charset command changes the default
character set and issues a SET NAMES
statement. This enables the character set to remain
synchronized on the client and server if
mysql is run with auto-reconnect enabled
(which is not recommended), because the changed character set
is used for reconnects. This command was added in MySQL
5.0.25.
In the delimiter command, you should avoid
the use of the backslash (‘\’)
character because that is the escape character for MySQL.
The edit, nopager, pager, and system commands work only in Unix.
The status command provides some
information about the connection and the server you are using.
If you are running in --safe-updates mode,
status also prints the values for the
mysql variables that affect your queries.
To log queries and their output, use the
tee command. All the data displayed on the
screen is appended into a given file. This can be very useful
for debugging purposes also. You can enable this feature on
the command line with the --tee option, or
interactively with the tee command. The
tee file can be disabled interactively with
the notee command. Executing
tee again re-enables logging. Without a
parameter, the previous file is used. Note that
tee flushes query results to the file after
each statement, just before mysql prints
its next prompt.
By using the --pager option, it is possible
to browse or search query results in interactive mode with
Unix programs such as less,
more, or any other similar program. If you
specify no value for the option, mysql
checks the value of the PAGER environment
variable and sets the pager to that. Output paging can be
enabled interactively with the pager
command and disabled with nopager. The
command takes an optional argument; if given, the paging
program is set to that. With no argument, the pager is set to
the pager that was set on the command line, or
stdout if no pager was specified.
Output paging works only in Unix because it uses the
popen() function, which does not exist on
Windows. For Windows, the tee option can be
used instead to save query output, although this is not as
convenient as pager for browsing output in
some situations.
Here are a few tips about the pager command:
You can use it to write to a file and the results go only to the file:
mysql>
pager cat > /tmp/log.txtYou can also pass any options for the program that you want to use as your pager:
mysql>
pager less -n -i -SIn the preceding example, note the
-Soption. You may find it very useful for browsing wide query results. Sometimes a very wide result set is difficult to read on the screen. The-Soption to less can make the result set much more readable because you can scroll it horizontally using the left-arrow and right-arrow keys. You can also use-Sinteractively within less to switch the horizontal-browse mode on and off. For more information, read the less manual page:shell>
man lessYou can specify very complex pager commands for handling query output:
mysql>
pager cat | tee /dr1/tmp/res.txt \| tee /dr2/tmp/res2.txt | less -n -i -SIn this example, the command would send query results to two files in two different directories on two different filesystems mounted on
/dr1and/dr2, yet still display the results onscreen via less.
You can also combine the tee and pager functions. Have a tee file enabled and pager set to less, and you are able to browse the results using the less program and still have everything appended into a file the same time. The difference between the Unix tee used with the pager command and the mysql built-in tee command is that the built-in tee works even if you do not have the Unix tee available. The built-in tee also logs everything that is printed on the screen, whereas the Unix tee used with pager does not log quite that much. Additionally, tee file logging can be turned on and off interactively from within mysql. This is useful when you want to log some queries to a file, but not others.
The default mysql> prompt can be
reconfigured. The string for defining the prompt can contain
the following special sequences:
| Option | Description |
\v | The server version |
\d | The default database |
\h | The server host |
\p | The current TCP/IP port or socket file |
\u | Your username |
\U | Your full
|
\\ | A literal ‘\’ backslash character |
\n | A newline character |
\t | A tab character |
\ | A space (a space follows the backslash) |
\_ | A space |
\R | The current time, in 24-hour military time (0-23) |
\r | The current time, standard 12-hour time (1-12) |
\m | Minutes of the current time |
\y | The current year, two digits |
\Y | The current year, four digits |
\D | The full current date |
\s | Seconds of the current time |
\w | The current day of the week in three-letter format (Mon, Tue, …) |
\P | am/pm |
\o | The current month in numeric format |
\O | The current month in three-letter format (Jan, Feb, …) |
\c | A counter that increments for each statement you issue |
\l | The current delimiter. (New in 5.0.25) |
\S | Semicolon |
\' | Single quote |
\" | Double quote |
‘\’ followed by any other
letter just becomes that letter.
If you specify the prompt command with no
argument, mysql resets the prompt to the
default of mysql>.
You can set the prompt in several ways:
Use an environment variable. You can set the
MYSQL_PS1environment variable to a prompt string. For example:shell>
export MYSQL_PS1="(\u@\h) [\d]> "Use a command-line option. You can set the
--promptoption on the command line to mysql. For example:shell>
mysql --prompt="(\u@\h) [\d]> "(user@host) [database]>Use an option file. You can set the
promptoption in the[mysql]group of any MySQL option file, such as/etc/my.cnfor the.my.cnffile in your home directory. For example:[mysql] prompt=(\\u@\\h) [\\d]>\\_
In this example, note that the backslashes are doubled. If you set the prompt using the
promptoption in an option file, it is advisable to double the backslashes when using the special prompt options. There is some overlap in the set of allowable prompt options and the set of special escape sequences that are recognized in option files. (These sequences are listed in Section 4.3.2, “Using Option Files”.) The overlap may cause you problems if you use single backslashes. For example,\sis interpreted as a space rather than as the current seconds value. The following example shows how to define a prompt within an option file to include the current time inHH:MM:SS>format:[mysql] prompt="\\r:\\m:\\s> "
Set the prompt interactively. You can change your prompt interactively by using the
prompt(or\R) command. For example:mysql>
prompt (\u@\h) [\d]>\_PROMPT set to '(\u@\h) [\d]>\_' (user@host) [database]> (user@host) [database]> prompt Returning to default PROMPT of mysql> mysql>
mysql> help search_string
If you provide an argument to the help
command, mysql uses it as a search string
to access server-side help from the contents of the MySQL
Reference Manual. The proper operation of this command
requires that the help tables in the mysql
database be initialized with help topic information (see
Section 5.2.8, “Server-Side Help”).
If there is no match for the search string, the search fails:
mysql> help me
Nothing found
Please try to run 'help contents' for a list of all accessible topics
Use help contents to see a list of the help categories:
mysql> help contents
You asked for help about help category: "Contents"
For more information, type 'help <item>', where <item> is one of the
following categories:
Account Management
Administration
Data Definition
Data Manipulation
Data Types
Functions
Functions and Modifiers for Use with GROUP BY
Geographic Features
Language Structure
Storage Engines
Stored Routines
Table Maintenance
Transactions
Triggers
If the search string matches multiple items, mysql shows a list of matching topics:
mysql> help logs
Many help items for your request exist.
To make a more specific request, please type 'help <item>',
where <item> is one of the following topics:
SHOW
SHOW BINARY LOGS
SHOW ENGINE
SHOW LOGS
Use a topic as the search string to see the help entry for that topic:
mysql> help show binary logs
Name: 'SHOW BINARY LOGS'
Description:
Syntax:
SHOW BINARY LOGS
SHOW MASTER LOGS
Lists the binary log files on the server. This statement is used as
part of the procedure described in [purge-master-logs], that shows how
to determine which logs can be purged.
mysql> SHOW BINARY LOGS;
+---------------+-----------+
| Log_name | File_size |
+---------------+-----------+
| binlog.000015 | 724935 |
| binlog.000016 | 733481 |
+---------------+-----------+
The mysql client typically is used interactively, like this:
shell> mysql db_name
However, it is also possible to put your SQL statements in a
file and then tell mysql to read its input
from that file. To do so, create a text file
text_file that contains the
statements you wish to execute. Then invoke
mysql as shown here:
shell> mysql db_name < text_file
If you place a USE
statement as the
first statement in the file, it is unnecessary to specify the
database name on the command line:
db_name
shell> mysql < text_file
If you are already running mysql, you can
execute an SQL script file using the source
command or \. command:
mysql>sourcemysql>file_name\.file_name
Sometimes you may want your script to display progress information to the user. For this you can insert statements like this:
SELECT '<info_to_display>' AS ' ';
The statement shown outputs
<info_to_display>.
For more information about batch mode, see Section 3.5, “Using mysql in Batch Mode”.
This section describes some techniques that can help you use mysql more effectively.
Some query results are much more readable when displayed vertically, instead of in the usual horizontal table format. Queries can be displayed vertically by terminating the query with \G instead of a semicolon. For example, longer text values that include newlines often are much easier to read with vertical output:
mysql> SELECT * FROM mails WHERE LENGTH(txt) < 300 LIMIT 300,1\G
*************************** 1. row ***************************
msg_nro: 3068
date: 2000-03-01 23:29:50
time_zone: +0200
mail_from: Monty
reply: monty@no.spam.com
mail_to: "Thimble Smith" <tim@no.spam.com>
sbj: UTF-8
txt: >>>>> "Thimble" == Thimble Smith writes:
Thimble> Hi. I think this is a good idea. Is anyone familiar
Thimble> with UTF-8 or Unicode? Otherwise, I'll put this on my
Thimble> TODO list and see what happens.
Yes, please do that.
Regards,
Monty
file: inbox-jani-1
hash: 190402944
1 row in set (0.09 sec)
For beginners, a useful startup option is
--safe-updates (or
--i-am-a-dummy, which has the same effect).
It is helpful for cases when you might have issued a
DELETE FROM
statement but
forgotten the tbl_nameWHERE clause. Normally,
such a statement deletes all rows from the table. With
--safe-updates, you can delete rows only by
specifying the key values that identify them. This helps
prevent accidents.
When you use the --safe-updates option,
mysql issues the following statement when
it connects to the MySQL server:
SET SQL_SAFE_UPDATES=1,SQL_SELECT_LIMIT=1000, SQL_MAX_JOIN_SIZE=1000000;
See Section 13.5.3, “SET Syntax”.
The SET statement has the following
effects:
You are not allowed to execute an
UPDATEorDELETEstatement unless you specify a key constraint in theWHEREclause or provide aLIMITclause (or both). For example:UPDATE
tbl_nameSETnot_key_column=valWHEREkey_column=val; UPDATEtbl_nameSETnot_key_column=valLIMIT 1;The server limits all large
SELECTresults to 1,000 rows unless the statement includes aLIMITclause.The server aborts multiple-table
SELECTstatements that probably need to examine more than 1,000,000 row combinations.
To specify limits different from 1,000 and 1,000,000, you
can override the defaults by using the
--select_limit and
--max_join_size options:
shell> mysql --safe-updates --select_limit=500 --max_join_size=10000
If the mysql client loses its connection to the server while sending a statement, it immediately and automatically tries to reconnect once to the server and send the statement again. However, even if mysql succeeds in reconnecting, your first connection has ended and all your previous session objects and settings are lost: temporary tables, the autocommit mode, and user-defined and session variables. Also, any current transaction rolls back. This behavior may be dangerous for you, as in the following example where the server was shut down and restarted between the first and second statements without you knowing it:
mysql>SET @a=1;Query OK, 0 rows affected (0.05 sec) mysql>INSERT INTO t VALUES(@a);ERROR 2006: MySQL server has gone away No connection. Trying to reconnect... Connection id: 1 Current database: test Query OK, 1 row affected (1.30 sec) mysql>SELECT * FROM t;+------+ | a | +------+ | NULL | +------+ 1 row in set (0.05 sec)
The @a user variable has been lost with
the connection, and after the reconnection it is undefined.
If it is important to have mysql
terminate with an error if the connection has been lost, you
can start the mysql client with the
--skip-reconnect option.
For more information about auto-reconnect and its effect on state information when a reconnection occurs, see Section 22.2.13, “Controlling Automatic Reconnect Behavior”.
mysqlaccess is a diagnostic tool that Yves
Carlier has provided for the MySQL distribution. It checks the
access privileges for a hostname, username, and database
combination. Note that mysqlaccess checks
access using only the user,
db, and host tables. It
does not check table, column, or routine privileges specified
in the tables_priv,
columns_priv, or
procs_priv tables.
Invoke mysqlaccess like this:
shell> mysqlaccess [host_name [user_name [db_name]]] [options]
mysqlaccess understands the following options:
Display a help message and exit.
Generate reports in single-line tabular format.
Copy the new access privileges from the temporary tables to the original grant tables. The grant tables must be flushed for the new privileges to take effect. (For example, execute a mysqladmin reload command.)
Reload the temporary grant tables from original ones.
Specify the database name.
Specify the debug level.
Ncan be an integer from 0 to 3.--host=,host_name-hhost_nameThe hostname to use in the access privileges.
Display some examples that show how to use mysqlaccess.
Assume that the server is an old MySQL server (before MySQL 3.21) that does not yet know how to handle full
WHEREclauses.--password[=,password]-p[password]The password to use when connecting to the server. If you omit the
passwordvalue following the--passwordor-poption on the command line, you are prompted for one.Specifying a password on the command line should be considered insecure. See Section 5.8.6, “Keeping Your Password Secure”.
Display suggestions and ideas for future releases.
Show the privilege differences after making changes to the temporary grant tables.
Display the release notes.
--rhost=,host_name-Hhost_nameConnect to the MySQL server on the given host.
Undo the most recent changes to the temporary grant tables.
--spassword[=,password]-P[password]The password to use when connecting to the server as the superuser. If you omit the
passwordvalue following the--passwordor-poption on the command line, you are prompted for one.Specifying a password on the command line should be considered insecure. See Section 5.8.6, “Keeping Your Password Secure”.
--superuser=,user_name-Uuser_nameSpecify the username for connecting as the superuser.
Generate reports in table format.
--user=,user_name-uuser_nameThe username to use in the access privileges.
Display version information and exit.
If your MySQL distribution is installed in some non-standard
location, you must change the location where
mysqlaccess expects to find the
mysql client. Edit the
mysqlaccess script at approximately line
18. Search for a line that looks like this:
$MYSQL = '/usr/local/bin/mysql'; # path to mysql executable
Change the path to reflect the location where
mysql actually is stored on your system. If
you do not do this, a Broken pipe error
will occur when you run mysqlaccess.
mysqladmin is a client for performing administrative operations. You can use it to check the server's configuration and current status, to create and drop databases, and more.
Invoke mysqladmin like this:
shell> mysqladmin [options] command [command-arg] [command [command-arg]] ...
mysqladmin supports the commands described in the following list. Some of the commands take an argument following the command name.
Create a new database named
db_name.Tell the server to write debug information to the error log.
Delete the database named
db_nameand all its tables.Display the server status variables and their values.
MySQL Enterprise For expert advice on using server status variables, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
Flush all information in the host cache.
Flush all logs.
Reload the grant tables (same as
reload).Clear status variables.
Flush all tables.
Flush the thread cache.
Kill server threads. If multiple thread ID values are given, there must be no spaces in the list.
This is like the
passwordcommand but stores the password using the old (pre-4.1) password-hashing format. (See Section 5.7.9, “Password Hashing as of MySQL 4.1”.)MySQL Enterprise For expert advice on the security implications of using the
old-passwordcommand, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.Set a new password. This changes the password to
new-passwordfor the account that you use with mysqladmin for connecting to the server. Thus, the next time you invoke mysqladmin (or any other client program) using the same account, you will need to specify the new password.If the
new-passwordvalue contains spaces or other characters that are special to your command interpreter, you need to enclose it within quotes. On Windows, be sure to use double quotes rather than single quotes; single quotes are not stripped from the password, but rather are interpreted as part of the password. For example:shell>
mysqladmin password "my new password"Check whether the server is alive. The return status from mysqladmin is 0 if the server is running, 1 if it is not. This is 0 even in case of an error such as
Access denied, because this means that the server is running but refused the connection, which is different from the server not running.Show a list of active server threads. This is like the output of the
SHOW PROCESSLISTstatement. If the--verboseoption is given, the output is like that ofSHOW FULL PROCESSLIST. (See Section 13.5.4.21, “SHOW PROCESSLISTSyntax”.)Reload the grant tables.
Flush all tables and close and open log files.
Stop the server.
Start replication on a slave server.
Display a short server status message.
Stop replication on a slave server.
Display the server system variables and their values.
MySQL Enterprise For expert advice on using server system variables, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
Display version information from the server.
All commands can be shortened to any unique prefix. For example:
shell> mysqladmin proc stat
+----+-------+-----------+----+---------+------+-------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-------+-----------+----+---------+------+-------+------------------+
| 51 | monty | localhost | | Query | 0 | | show processlist |
+----+-------+-----------+----+---------+------+-------+------------------+
Uptime: 1473624 Threads: 1 Questions: 39487
Slow queries: 0 Opens: 541 Flush tables: 1
Open tables: 19 Queries per second avg: 0.0268
The mysqladmin status command result displays the following values:
The number of seconds the MySQL server has been running.
The number of active threads (clients).
The number of questions (queries) from clients since the server was started.
The number of queries that have taken more than
long_query_timeseconds. See Section 5.11.4, “The Slow Query Log”.The number of tables the server has opened.
The number of
flush-*,refresh, andreloadcommands the server has executed.The number of tables that currently are open.
The amount of memory allocated directly by mysqld. This value is displayed only when MySQL has been compiled with
--with-debug=full.The maximum amount of memory allocated directly by mysqld. This value is displayed only when MySQL has been compiled with
--with-debug=full.
If you execute mysqladmin shutdown when connecting to a local server using a Unix socket file, mysqladmin waits until the server's process ID file has been removed, to ensure that the server has stopped properly.
mysqladmin supports the following options:
Display a help message and exit.
The directory where character sets are installed. See Section 5.10.1, “The Character Set Used for Data and Sorting”.
Compress all information sent between the client and the server if both support compression.
The number of iterations to make for repeated command execution. This works only with the
--sleepoption.--debug[=,debug_options]-# [debug_options]Write a debugging log. The
debug_optionsstring often is'd:t:o,. The default isfile_name''d:t:o,/tmp/mysqladmin.trace'.--default-character-set=charset_nameUse
charset_nameas the default character set. See Section 5.10.1, “The Character Set Used for Data and Sorting”.Do not ask for confirmation for the
dropcommand. With multiple commands, continue even if an error occurs.db_name--host=,host_name-hhost_nameConnect to the MySQL server on the given host.
--password[=,password]-p[password]The password to use when connecting to the server. If you use the short option form (
-p), you cannot have a space between the option and the password. If you omit thepasswordvalue following the--passwordor-poption on the command line, you are prompted for one.Specifying a password on the command line should be considered insecure. See Section 5.8.6, “Keeping Your Password Secure”.
The TCP/IP port number to use for the connection.
--protocol={TCP|SOCKET|PIPE|MEMORY}The connection protocol to use.
Show the difference between the current and previous values when used with the
--sleepoption. Currently, this option works only with theextended-statuscommand.Exit silently if a connection to the server cannot be established.
Execute commands repeatedly, sleeping for
delayseconds in between. The--countoption determines the number of iterations.For connections to
localhost, the Unix socket file to use, or, on Windows, the name of the named pipe to use.Options that begin with
--sslspecify whether to connect to the server via SSL and indicate where to find SSL keys and certificates. See Section 5.8.7.3, “SSL Command Options”.--user=,user_name-uuser_nameThe MySQL username to use when connecting to the server.
Verbose mode. Print more information about what the program does.
Display version information and exit.
Print output vertically. This is similar to
--relative, but prints output vertically.If the connection cannot be established, wait and retry instead of aborting. If a
countvalue is given, it indicates the number of times to retry. The default is one time.
You can also set the following variables by using
--
syntax:
var_name=value
It is also possible to set variables by using
--set-variable=
or var_name=value-O
syntax. This syntax is deprecated.
var_name=value
The binary log files that the server generates are written in binary format. To examine these files in text format, use the mysqlbinlog utility. You can also use mysqlbinlog to read relay log files written by a slave server in a replication setup. Relay logs have the same format as binary log files.
Invoke mysqlbinlog like this:
shell> mysqlbinlog [options] log_file ...
For example, to display the contents of the binary log file
named binlog.000003, use this command:
shell> mysqlbinlog binlog.0000003
The output includes all events contained in
binlog.000003. Event information includes
the statement executed, the time the statement took, the
thread ID of the client that issued it, the timestamp when it
was executed, and so forth.
The output from mysqlbinlog can be re-executed (for example, by using it as input to mysql) to reapply the statements in the log. This is useful for recovery operations after a server crash. For other usage examples, see the discussion later in this section.
Normally, you use mysqlbinlog to read
binary log files directly and apply them to the local MySQL
server. It is also possible to read binary logs from a remote
server by using the --read-from-remote-server
option. When you read remote binary logs, the connection
parameter options can be given to indicate how to connect to
the server. These options are --host,
--password, --port,
--protocol, --socket, and
--user; they are ignored except when you also
use the --read-from-remote-server option.
Binary logs and relay logs are discussed further in Section 5.11.3, “The Binary Log”, and Section 6.3.4, “Replication Relay and Status Files”.
mysqlbinlog supports the following options:
Display a help message and exit.
The directory where character sets are installed. See Section 5.10.1, “The Character Set Used for Data and Sorting”.
--database=,db_name-ddb_nameList entries for just this database (local log only). You can only specify one database with this option - if you specify multiple
--databaseoptions, only the last one is used. This option forces mysqlbinlog to output entries from the binary log where the default database (that is, the one selected byUSE) isdb_name. Note that this does not replicate cross-database statements such asUPDATEwhile having selected a different database or no database.some_db.some_tableSET foo='bar'--debug[=,debug_options]-# [debug_options]Write a debugging log. A typical
debug_optionsstring is often'd:t:o,.file_name'Disable binary logging. This is useful for avoiding an endless loop if you use the
--to-last-logoption and are sending the output to the same MySQL server. This option also is useful when restoring after a crash to avoid duplication of the statements you have logged.This option requires that you have the
SUPERprivilege. It causes mysqlbinlog to include aSET SQL_LOG_BIN=0statement in its output to disable binary logging of the remaining output. TheSETstatement is ineffective unless you have theSUPERprivilege.With this option, if mysqlbinlog reads a binary log event that it does not recognize, it prints a warning, ignores the event, and continues. Without this option, mysqlbinlog stops if it reads such an event.
Display a hex dump of the log in comments. This output can be helpful for replication debugging. Hex dump format is discussed later in this section. This option was added in MySQL 5.0.16.
--host=,host_name-hhost_nameGet the binary log from the MySQL server on the given host.
Prepare local temporary files for
LOAD DATA INFILEin the specified directory.Skip the first
Nentries in the log.--password[=,password]-p[password]The password to use when connecting to the server. If you use the short option form (
-p), you cannot have a space between the option and the password. If you omit thepasswordvalue following the--passwordor-poption on the command line, you are prompted for one.Specifying a password on the command line should be considered insecure. See Section 5.8.6, “Keeping Your Password Secure”.
The TCP/IP port number to use for connecting to a remote server.
Deprecated. Use
--start-positioninstead.--protocol={TCP|SOCKET|PIPE|MEMORY}The connection protocol to use.
Read the binary log from a MySQL server rather than reading a local log file. Any connection parameter options are ignored unless this option is given as well. These options are
--host,--password,--port,--protocol,--socket, and--user.Direct output to the given file.
Add a
SET NAMESstatement to the output to specify the character set to be used for processing log files. This option was added in MySQL 5.0.23.charset_nameDisplay only the statements contained in the log, without any extra information.
For connections to
localhost, the Unix socket file to use, or, on Windows, the name of the named pipe to use.Start reading the binary log at the first event having a timestamp equal to or later than the
datetimeargument. Thedatetimevalue is relative to the local time zone on the machine where you run mysqlbinlog. The value should be in a format accepted for theDATETIMEorTIMESTAMPdata types. For example:shell>
mysqlbinlog --start-datetime="2005-12-25 11:25:56" binlog.000003This option is useful for point-in-time recovery. See Section 5.9.2, “Example Backup and Recovery Strategy”.
Stop reading the binary log at the first event having a timestamp equal or posterior to the
datetimeargument. This option is useful for point-in-time recovery. See the description of the--start-datetimeoption for information about thedatetimevalue.Start reading the binary log at the first event having a position equal to the
Nargument. This option applies to the first log file named on the command line.Stop reading the binary log at the first event having a position equal or greater than the
Nargument. This option applies to the last log file named on the command line.Do not stop at the end of the requested binary log from a MySQL server, but rather continue printing until the end of the last binary log. If you send the output to the same MySQL server, this may lead to an endless loop. This option requires
--read-from-remote-server.--user=,user_name-uuser_nameThe MySQL username to use when connecting to a remote server.
Display version information and exit.
You can also set the following variable by using
--
syntax:
var_name=value
It is also possible to set variables by using
--set-variable=
or var_name=value-O
syntax. This syntax is deprecated.
var_name=value
You can pipe the output of mysqlbinlog into the mysql client to execute the statements contained in the binary log. This is used to recover from a crash when you have an old backup (see Section 5.9.1, “Database Backups”). For example:
shell> mysqlbinlog binlog.000001 | mysql
Or:
shell> mysqlbinlog binlog.[0-9]* | mysql
You can also redirect the output of mysqlbinlog to a text file instead, if you need to modify the statement log first (for example, to remove statements that you do not want to execute for some reason). After editing the file, execute the statements that it contains by using it as input to the mysql program.
mysqlbinlog has the
--start-position option, which prints only
those statements with an offset in the binary log greater than
or equal to a given position (the given position must match
the start of one event). It also has options to stop and start
when it sees an event with a given date and time. This enables
you to perform point-in-time recovery using the
--stop-datetime option (to be able to say,
for example, “roll forward my databases to how they were
today at 10:30 a.m.”).
If you have more than one binary log to execute on the MySQL server, the safe method is to process them all using a single connection to the server. Here is an example that demonstrates what may be unsafe:
shell>mysqlbinlog binlog.000001 | mysql # DANGER!!shell>mysqlbinlog binlog.000002 | mysql # DANGER!!
Processing binary logs this way using different connections to
the server causes problems if the first log file contains a
CREATE TEMPORARY TABLE statement and the
second log contains a statement that uses the temporary table.
When the first mysql process terminates,
the server drops the temporary table. When the second
mysql process attempts to use the table,
the server reports “unknown table.”
To avoid problems like this, use a single connection to execute the contents of all binary logs that you want to process. Here is one way to do so:
shell> mysqlbinlog binlog.000001 binlog.000002 | mysql
Another approach is to write all the logs to a single file and then process the file:
shell>mysqlbinlog binlog.000001 > /tmp/statements.sqlshell>mysqlbinlog binlog.000002 >> /tmp/statements.sqlshell>mysql -e "source /tmp/statements.sql"
mysqlbinlog can produce output that
reproduces a LOAD DATA INFILE operation
without the original data file. mysqlbinlog
copies the data to a temporary file and writes a LOAD
DATA LOCAL INFILE statement that refers to the file.
The default location of the directory where these files are
written is system-specific. To specify a directory explicitly,
use the --local-load option.
Because mysqlbinlog converts LOAD
DATA INFILE statements to LOAD DATA LOCAL
INFILE statements (that is, it adds
LOCAL), both the client and the server that
you use to process the statements must be configured to allow
LOCAL capability. See
Section 5.6.4, “Security Issues with LOAD DATA LOCAL”.
MySQL Enterprise
For expert advice on the security implications of enabling
LOCAL, subscribe to the MySQL Network
Monitoring and Advisory Service. For more information see
http://www.mysql.com/products/enterprise/advisors.html.
Warning: The temporary files
created for LOAD DATA LOCAL statements are
not automatically deleted because they
are needed until you actually execute those statements. You
should delete the temporary files yourself after you no longer
need the statement log. The files can be found in the
temporary file directory and have names like
original_file_name-#-#.
The --hexdump option produces a hex dump of
the log contents in comments:
shell> mysqlbinlog --hexdump master-bin.000001
With the preceding command, the output might look like this:
/*!40019 SET @@session.max_insert_delayed_threads=0*/; /*!50003 SET @OLD_COMPLETION_TYPE=@@COMPLETION_TYPE,COMPLETION_TYPE=0*/; # at 4 #051024 17:24:13 server id 1 end_log_pos 98 # Position Timestamp Type Master ID Size Master Pos Flags # 00000004 9d fc 5c 43 0f 01 00 00 00 5e 00 00 00 62 00 00 00 00 00 # 00000017 04 00 35 2e 30 2e 31 35 2d 64 65 62 75 67 2d 6c |..5.0.15.debug.l| # 00000027 6f 67 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |og..............| # 00000037 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| # 00000047 00 00 00 00 9d fc 5c 43 13 38 0d 00 08 00 12 00 |.......C.8......| # 00000057 04 04 04 04 12 00 00 4b 00 04 1a |.......K...| # Start: binlog v 4, server v 5.0.15-debug-log created 051024 17:24:13 # at startup ROLLBACK;
Hex dump output currently contains the following elements. This format might change in the future.
Position: The byte position within the log file.Timestamp: The event timestamp. In the example shown,'9d fc 5c 43'is the representation of'051024 17:24:13'in hexadecimal.Type: The type of the log event. In the example shown,'0f'means that the example event is aFORMAT_DESCRIPTION_EVENT. The following table lists the possible types.Type Name Meaning 00UNKNOWN_EVENTThis event should never be present in the log. 01START_EVENT_V3This indicates the start of a log file written by MySQL 4 or earlier. 02QUERY_EVENTThe most common type of events. These contain statements executed on the master. 03STOP_EVENTIndicates that master has stopped. 04ROTATE_EVENTWritten when the master switches to a new log file. 05INTVAR_EVENTUsed mainly for AUTO_INCREMENTvalues and when theLAST_INSERT_ID()function is used in the statement.06LOAD_EVENTUsed for LOAD DATA INFILEin MySQL 3.23.07SLAVE_EVENTReserved for future use. 08CREATE_FILE_EVENTUsed for LOAD DATA INFILEstatements. This indicates the start of execution of such a statement. A temporary file is created on the slave. Used in MySQL 4 only.09APPEND_BLOCK_EVENTContains data for use in a LOAD DATA INFILEstatement. The data is stored in the temporary file on the slave.0aEXEC_LOAD_EVENTUsed for LOAD DATA INFILEstatements. The contents of the temporary file is stored in the table on the slave. Used in MySQL 4 only.0bDELETE_FILE_EVENTRollback of a LOAD DATA INFILEstatement. The temporary file should be deleted on slave.0cNEW_LOAD_EVENTUsed for LOAD DATA INFILEin MySQL 4 and earlier.0dRAND_EVENTUsed to send information about random values if the RAND()function is used in the statement.0eUSER_VAR_EVENTUsed to replicate user variables. 0fFORMAT_DESCRIPTION_EVENTThis indicates the start of a log file written by MySQL 5 or later. 10XID_EVENTEvent indicating commit of an XA transaction. 11BEGIN_LOAD_QUERY_EVENTUsed for LOAD DATA INFILEstatements in MySQL 5 and later.12EXECUTE_LOAD_QUERY_EVENTUsed for LOAD DATA INFILEstatements in MySQL 5 and later.13TABLE_MAP_EVENTReserved for future use. 14WRITE_ROWS_EVENTReserved for future use. 15UPDATE_ROWS_EVENTReserved for future use. 16DELETE_ROWS_EVENTReserved for future use. Master ID: The server id of the master that created the event.Size: The size in bytes of the event.Master Pos: The position of the event in the original master log file.Flags: 16 flags. Currently, the following flags are used. The others are reserved for the future.Flag Name Meaning 01LOG_EVENT_BINLOG_IN_USE_FLog file correctly closed. (Used only in FORMAT_DESCRIPTION_EVENT.) If this flag is set (if the flags are, for example,'01 00') in aFORMAT_DESCRIPTION_EVENT, the log file has not been properly closed. Most probably this is because of a master crash (for example, due to power failure).02Reserved for future use. 04LOG_EVENT_THREAD_SPECIFIC_FSet if the event is dependent on the connection it was executed in (for example, '04 00'), for example, if the event uses temporary tables.08LOG_EVENT_SUPPRESS_USE_FSet in some circumstances when the event is not dependent on the default database. The other flags are reserved for future use.
The mysqlcheck client checks, repairs, optimizes, and analyzes tables.
mysqlcheck is similar in function to myisamchk, but works differently. The main operational difference is that mysqlcheck must be used when the mysqld server is running, whereas myisamchk should be used when it is not. The benefit of using mysqlcheck is that you do not have to stop the server to check or repair your tables.
mysqlcheck uses the SQL statements
CHECK TABLE, REPAIR
TABLE, ANALYZE TABLE, and
OPTIMIZE TABLE in a convenient way for the
user. It determines which statements to use for the operation
you want to perform, and then sends the statements to the
server to be executed. For details about which storage engines
each statement works with, see the descriptions for those
statements in Chapter 13, SQL Statement Syntax.
The MyISAM storage engine supports all four
statements, so mysqlcheck can be used to
perform all four operations on MyISAM
tables. Other storage engines do not necessarily support all
operations. In such cases, an error message is displayed. For
example, if test.t is a
MEMORY table, an attempt to check it
produces this result:
shell> mysqlcheck test t
test.t
note : The storage engine for the table doesn't support check
Caution
It is best to make a backup of a table before performing a table repair operation; under some circumstances the operation might cause data loss. Possible causes include but are not limited to filesystem errors.
There are three general ways to invoke mysqlcheck:
shell>mysqlcheck [shell>options]db_name[tables]mysqlcheck [shell>options] --databasesdb_name1[db_name2db_name3...]mysqlcheck [options] --all-databases
If you do not name any tables following
db_name or if you use the
--databases or
--all-databases option, entire databases are
checked.
mysqlcheck has a special feature compared
to other client programs. The default behavior of checking
tables (--check) can be changed by renaming
the binary. If you want to have a tool that repairs tables by
default, you should just make a copy of
mysqlcheck named
mysqlrepair, or make a symbolic link to
mysqlcheck named
mysqlrepair. If you invoke
mysqlrepair, it repairs tables.
The following names can be used to change mysqlcheck default behavior:
| mysqlrepair | The default option is --repair |
| mysqlanalyze | The default option is --analyze |
| mysqloptimize | The default option is --optimize |
mysqlcheck supports the following options:
Display a help message and exit.
Check all tables in all databases. This is the same as using the
--databasesoption and naming all the databases on the command line.Instead of issuing a statement for each table, execute a single statement for each database that names all the tables from that database to be processed.
Analyze the tables.
MySQL Enterprise For expert advice on optimizing tables, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
If a checked table is corrupted, automatically fix it. Any necessary repairs are done after all tables have been checked.
The directory where character sets are installed. See Section 5.10.1, “The Character Set Used for Data and Sorting”.
Check the tables for errors. This is the default operation.
Check only tables that have changed since the last check or that have not been closed properly.
Invoke
CHECK TABLEwith theFOR UPGRADEoption to check tables for incompatibilities with the current version of the server. This option was added in MySQL 5.0.19.Compress all information sent between the client and the server if both support compression.
Process all tables in the named databases. Normally, mysqlcheck treats the first name argument on the command line as a database name and following names as table names. With this option, it treats all name arguments as database names.
--debug[=,debug_options]-# [debug_options]Write a debugging log. A typical
debug_optionsstring is often'd:t:o,.file_name'--default-character-set=charset_nameUse
charset_nameas the default character set. See Section 5.10.1, “The Character Set Used for Data and Sorting”.If you are using this option to check tables, it ensures that they are 100% consistent but takes a long time.
If you are using this option to repair tables, it runs an extended repair that may not only take a long time to execute, but may produce a lot of garbage rows also!
Check only tables that have not been closed properly.
Continue even if an SQL error occurs.
--host=,host_name-hhost_nameConnect to the MySQL server on the given host.
Do a check that is faster than an
--extendedoperation. This finds only 99.99% of all errors, which should be good enough in most cases.Optimize the tables.
--password[=,password]-p[password]The password to use when connecting to the server. If you use the short option form (
-p), you cannot have a space between the option and the password. If you omit thepasswordvalue following the--passwordor-poption on the command line, you are prompted for one.Specifying a password on the command line should be considered insecure. See Section 5.8.6, “Keeping Your Password Secure”.
The TCP/IP port number to use for the connection.
--protocol={TCP|SOCKET|PIPE|MEMORY}The connection protocol to use.
If you are using this option to check tables, it prevents the check from scanning the rows to check for incorrect links. This is the fastest check method.
If you are using this option to repair tables, it tries to repair only the index tree. This is the fastest repair method.
Perform a repair that can fix almost anything except unique keys that are not unique.
Silent mode. Print only error messages.
For connections to
localhost, the Unix socket file to use, or, on Windows, the name of the named pipe to use.Options that begin with
--sslspecify whether to connect to the server via SSL and indicate where to find SSL keys and certificates. See Section 5.8.7.3, “SSL Command Options”.Overrides the
--databasesor-Boption. All name arguments following the option are regarded as table names.For repair operations on
MyISAMtables, get the table structure from the.frmfile so that the table can be repaired even if the.MYIheader is corrupted.--user=,user_name-uuser_nameThe MySQL username to use when connecting to the server.
Verbose mode. Print information about the various stages of program operation.
Display version information and exit.
The mysqldump client is a backup program originally written by Igor Romanenko. It can be used to dump a database or a collection of databases for backup or transfer to another SQL server (not necessarily a MySQL server). The dump typically contains SQL statements to create the table, populate it, or both. However, mysqldump can also be used to generate files in CSV, other delimited text, or XML format.
If you are doing a backup on the server and your tables all
are MyISAM tables, consider using the
mysqlhotcopy instead because it can
accomplish faster backups and faster restores. See
Section 8.14, “mysqlhotcopy — A Database Backup Program”.
There are three general ways to invoke mysqldump:
shell>mysqldump [shell>options]db_name[tables]mysqldump [shell>options] --databasesdb_name1[db_name2db_name3...]mysqldump [options] --all-databases
If you do not name any tables following
db_name or if you use the
--databases or
--all-databases option, entire databases are
dumped.
To get a list of the options your version of mysqldump supports, execute mysqldump --help.
Some mysqldump options are shorthand for
groups of other options. --opt and
--compact fall into this category. For
example, use of --opt is the same as
specifying --add-drop-table --add-locks
--create-options --disable-keys --extended-insert
--lock-tables --quick --set-charset. Note that all of
the options that --opt stands for also are on
by default because --opt is on by default.
To reverse the effect of a group option, uses its
--skip- form
(xxx--skip-opt or
--skip-compact). It is also possible to
select only part of the effect of a group option by following
it with options that enable or disable specific features. Here
are some examples:
To select the effect of
--optexcept for some features, use the--skipoption for each feature. For example, to disable extended inserts and memory buffering, use--opt --skip-extended-insert --skip-quick. (As of MySQL 5.0,--skip-extended-insert --skip-quickis sufficient because--optis on by default.)To reverse
--optfor all features except index disabling and table locking, use--skip-opt --disable-keys --lock-tables.
When you selectively enable or disable the effect of a group
option, order is important because options are processed first
to last. For example, --disable-keys --lock-tables
--skip-opt would not have the intended effect; it is
the same as --skip-opt by itself.
mysqldump can retrieve and dump table
contents row by row, or it can retrieve the entire content
from a table and buffer it in memory before dumping it.
Buffering in memory can be a problem if you are dumping large
tables. To dump tables row by row, use the
--quick option (or --opt,
which enables --quick).
--opt (and hence --quick) is
enabled by default as of MySQL 5.0 to enable
memory buffering, use --skip-quick.
If you are using a recent version of
mysqldump to generate a dump to be reloaded
into a very old MySQL server, you should not use the
--opt or --extended-insert
option. Use --skip-opt instead.
Before MySQL 4.1.2, out-of-range numeric values such as
-inf and inf, as well as
NaN (not-a-number) values are dumped by
mysqldump as NULL. You
can see this using the following sample table:
mysql>CREATE TABLE t (f DOUBLE);mysql>INSERT INTO t VALUES(1e+111111111111111111111);mysql>INSERT INTO t VALUES(-1e111111111111111111111);mysql>SELECT f FROM t;+------+ | f | +------+ | inf | | -inf | +------+
For this table, mysqldump produces the following data output:
-- -- Dumping data for table `t` -- INSERT INTO t VALUES (NULL); INSERT INTO t VALUES (NULL);
The significance of this behavior is that if you dump and
restore the table, the new table has contents that differ from
the original contents. This problem is fixed as of MySQL
4.1.2; you cannot insert inf in the table,
so this mysqldump behavior is only relevant
when you deal with old servers.
mysqldump supports the following options:
Display a help message and exit.
Add a
DROP DATABASEstatement before eachCREATE DATABASEstatement.Add a
DROP TABLEstatement before eachCREATE TABLEstatement.Surround each table dump with
LOCK TABLESandUNLOCK TABLESstatements. This results in faster inserts when the dump file is reloaded. See Section 7.2.17, “Speed ofINSERTStatements”.Dump all tables in all databases. This is the same as using the
--databasesoption and naming all the databases on the command line.Allow creation of column names that are keywords. This works by prefixing each column name with the table name.
The directory where character sets are installed. See Section 5.10.1, “The Character Set Used for Data and Sorting”.
Write additional information in the dump file such as program version, server version, and host. This option is enabled by default. To suppress this additional information, use
--skip-comments.Produce less verbose output. This option suppresses comments and enables the
--skip-add-drop-table,--skip-set-charset,--skip-disable-keys, and--skip-add-locksoptions.Produce output that is more compatible with other database systems or with older MySQL servers. The value of
namecan beansi,mysql323,mysql40,postgresql,oracle,mssql,db2,maxdb,no_key_options,no_table_options, orno_field_options. To use several values, separate them by commas. These values have the same meaning as the corresponding options for setting the server SQL mode. See Section 5.2.6, “SQL Modes”.This option does not guarantee compatibility with other servers. It only enables those SQL mode values that are currently available for making dump output more compatible. For example,
--compatible=oracledoes not map data types to Oracle types or use Oracle comment syntax.This option requires a server version of 4.1.0 or higher. With older servers, it does nothing.
Use complete
INSERTstatements that include column names.Compress all information sent between the client and the server if both support compression.
Include all MySQL-specific table options in the
CREATE TABLEstatements.Dump several databases. Normally, mysqldump treats the first name argument on the command line as a database name and following names as table names. With this option, it treats all name arguments as database names.
CREATE DATABASEandUSEstatements are included in the output before each new database.--debug[=,debug_options]-# [debug_options]Write a debugging log. The
debug_optionsstring is often'd:t:o,. The default value isfile_name''d:t:o,/tmp/mysqldump.trace'.--default-character-set=charset_nameUse
charset_nameas the default character set. See Section 5.10.1, “The Character Set Used for Data and Sorting”. If no character set is specified, mysqldump usesutf8, and earlier versions uselatin1.Write
INSERT DELAYEDstatements rather thanINSERTstatements.On a master replication server, delete the binary logs after performing the dump operation. This option automatically enables
--master-data.For each table, surround the
INSERTstatements with/*!40000 ALTER TABLEandtbl_nameDISABLE KEYS */;/*!40000 ALTER TABLEstatements. This makes loading the dump file faster because the indexes are created after all rows are inserted. This option is effective only for non-unique indexes oftbl_nameENABLE KEYS */;MyISAMtables.Use multiple-row
INSERTsyntax that include severalVALUESlists. This results in a smaller dump file and speeds up inserts when the file is reloaded.--fields-terminated-by=...,--fields-enclosed-by=...,--fields-optionally-enclosed-by=...,--fields-escaped-by=...These options are used with the
-Toption and have the same meaning as the corresponding clauses forLOAD DATA INFILE. See Section 13.2.5, “LOAD DATA INFILESyntax”.Deprecated. Now renamed to
--lock-all-tables.Flush the MySQL server log files before starting the dump. This option requires the
RELOADprivilege. Note that if you use this option in combination with the--all-databases(or-A) option, the logs are flushed for each database dumped. The exception is when using--lock-all-tablesor--master-data: In this case, the logs are flushed only once, corresponding to the moment that all tables are locked. If you want your dump and the log flush to happen at exactly the same moment, you should use--flush-logstogether with either--lock-all-tablesor--master-data.Emit a
FLUSH PRIVILEGESstatement after dumping themysqldatabase. This option should be used any time the dump contains themysqldatabase and any other database that depends on the data in themysqldatabase for proper restoration. This option was added in MySQL 5.0.26.Continue even if an SQL error occurs during a table dump.
One use for this option is to cause mysqldump to continue executing even when it encounters a view that has become invalid because the defintion refers to a table that has been dropped. Without
--force, mysqldump exits with an error message. With--force, mysqldump prints the error message, but it also writes a SQL comment containing the view definition to the dump output and continues executing.--host=,host_name-hhost_nameDump data from the MySQL server on the given host. The default host is
localhost.Dump binary columns using hexadecimal notation (for example,
'abc'becomes0x616263). The affected data types areBINARY,VARBINARY, andBLOB. As of MySQL 5.0.13,BITcolumns are affected as well.--ignore-table=db_name.tbl_nameDo not dump the given table, which must be specified using both the database and table names. To ignore multiple tables, use this option multiple times.
Write
INSERTstatements with theIGNOREoption.This option is used with the
-Toption and has the same meaning as the corresponding clause forLOAD DATA INFILE. See Section 13.2.5, “LOAD DATA INFILESyntax”.Lock all tables across all databases. This is achieved by acquiring a global read lock for the duration of the whole dump. This option automatically turns off
--single-transactionand--lock-tables.Lock all tables before dumping them. The tables are locked with
READ LOCALto allow concurrent inserts in the case ofMyISAMtables. For transactional tables such asInnoDBandBDB,--single-transactionis a much better option, because it does not need to lock the tables at all.Please note that when dumping multiple databases,
--lock-tableslocks tables for each database separately. Therefore, this option does not guarantee that the tables in the dump file are logically consistent between databases. Tables in different databases may be dumped in completely different states.Write the binary log filename and position to the output. This option requires the
RELOADprivilege and the binary log must be enabled. If the option value is equal to 1, the position and filename are written to the dump output in the form of aCHANGE MASTERstatement. If the dump is from a master server and you use it to set up a slave server, theCHANGE MASTERstatement causes the slave to start from the correct position in the master's binary logs. If the option value is equal to 2, theCHANGE MASTERstatement is written as an SQL comment. (This is the default action ifvalueis omitted.)The
--master-dataoption automatically turns off--lock-tables. It also turns on--lock-all-tables, unless--single-transactionalso is specified (in which case, a global read lock is acquired only for a short time at the beginning of the dump. See also the description for--single-transaction. In all cases, any action on logs happens at the exact moment of the dump.Enclose the
INSERTstatements for each dumped table withinSET AUTOCOMMIT=0andCOMMITstatements.This option suppresses the
CREATE DATABASEstatements that are otherwise included in the output if the--databasesor--all-databasesoption is given.Do not write
CREATE TABLEstatements that re-create each dumped table.Do not write any table row information (that is, do not dump table contents). This is very useful if you want to dump only the
CREATE TABLEstatement for the table.This option is shorthand; it is the same as specifying
--add-drop-table --add-locks --create-options --disable-keys --extended-insert --lock-tables --quick --set-charset. It should give you a fast dump operation and produce a dump file that can be reloaded into a MySQL server quickly.The
--optoption is enabled by default. Use--skip-optto disable it. See the discussion at the beginning of this section for information about selectively enabling or disabling certain of the options affected by--opt.Sorts each table's rows by its primary key, or by its first unique index, if such an index exists. This is useful when dumping a
MyISAMtable to be loaded into anInnoDBtable, but will make the dump itself take considerably longer.--password[=,password]-p[password]The password to use when connecting to the server. If you use the short option form (
-p), you cannot have a space between the option and the password. If you omit thepasswordvalue following the--passwordor-poption on the command line, you are prompted for one.Specifying a password on the command line should be considered insecure. See Section 5.8.6, “Keeping Your Password Secure”.
The TCP/IP port number to use for the connection.
--protocol={TCP|SOCKET|PIPE|MEMORY}The connection protocol to use.
This option is useful for dumping large tables. It forces mysqldump to retrieve rows for a table from the server a row at a time rather than retrieving the entire row set and buffering it in memory before writing it out.
Quote database, table, and column names within ‘
`’ characters. If theANSI_QUOTESSQL mode is enabled, names are quoted within ‘"’ characters. This option is enabled by default. It can be disabled with--skip-quote-names, but this option should be given after any option such as--compatiblethat may enable--quote-names.Direct output to a given file. This option should be used on Windows to prevent newline ‘
\n’ characters from being converted to ‘\r\n’ carriage return/newline sequences. The result file is created and its contents overwritten, even if an error occurs while generating the dump. The previous contents are lost.Dump stored routines (functions and procedures) from the dumped databases. Use of this option requires the
SELECTprivilege for themysql.proctable. The output generated by using--routinescontainsCREATE PROCEDUREandCREATE FUNCTIONstatements to re-create the routines. However, these statements do not include attributes such as the routine creation and modification timestamps. This means that when the routines are reloaded, they will be created with the timestamps equal to the reload time.If you require routines to be re-created with their original timestamp attributes, do not use
--routines. Instead, dump and reload the contents of themysql.proctable directly, using a MySQL account that has appropriate privileges for themysqldatabase.This option was added in MySQL 5.0.13. Before that, stored routines are not dumped. Routine
DEFINERvalues are not dumped until MySQL 5.0.20. This means that before 5.0.20, when routines are reloaded, they will be created with the definer set to the reloading user. If you require routines to be re-created with their original definer, dump and load the contents of themysql.proctable directly as described earlier.Add
SET NAMESto the output. This option is enabled by default. To suppress thedefault_character_setSET NAMESstatement, use--skip-set-charset.This option issues a
BEGINSQL statement before dumping data from the server. It is useful only with transactional tables such asInnoDBandBDB, because then it dumps the consistent state of the database at the time whenBEGINwas issued without blocking any applications.When using this option, you should keep in mind that only
InnoDBtables are dumped in a consistent state. For example, anyMyISAMorMEMORYtables dumped while using this option may still change state.The
--single-transactionoption and the--lock-tablesoption are mutually exclusive, becauseLOCK TABLEScauses any pending transactions to be committed implicitly.This option is not supported for MySQL Cluster tables; the results cannot be guaranteed to be consistent due to the fact that the
NDBClusterstorage engine supports only theREAD_COMMITTEDtransaction isolation level. You should always useNDBbackup and restore instead.To dump large tables, you should combine this option with
--quick.See the description for the
--optoption.For connections to
localhost, the Unix socket file to use, or, on Windows, the name of the named pipe to use.See the description for the
--commentsoption.Options that begin with
--sslspecify whether to connect to the server via SSL and indicate where to find SSL keys and certificates. See Section 5.8.7.3, “SSL Command Options”.Produce tab-separated data files. For each dumped table, mysqldump creates a
tbl_name.sqlCREATE TABLEstatement that creates the table, and atbl_name.txtBy default, the
.txtdata files are formatted using tab characters between column values and a newline at the end of each line. The format can be specified explicitly using the--fields-andxxx--lines-terminated-byoptions.Note: This option should be used only when mysqldump is run on the same machine as the mysqld server. You must have the
FILEprivilege, and the server must have permission to write files in the directory that you specify.Override the
--databasesor-Boption. mysqldump regards all name arguments following the option as table names.Dump triggers for each dumped table. This option is enabled by default; disable it with
--skip-triggers. This option was added in MySQL 5.0.11. Before that, triggers are not dumped.Add
SET TIME_ZONE='+00:00'to the dump file so thatTIMESTAMPcolumns can be dumped and reloaded between servers in different time zones. Without this option,TIMESTAMPcolumns are dumped and reloaded in the time zones local to the source and destination servers, which can cause the values to change.--tz-utcalso protects against changes due to daylight saving time.--tz-utcis enabled by default. To disable it, use--skip-tz-utc. This option was added in MySQL 5.0.15.--user=,user_name-uuser_nameThe MySQL username to use when connecting to the server.
Verbose mode. Print more information about what the program does.
Display version information and exit.
--where=',where_condition'-w 'where_condition'Dump only rows selected by the given
WHEREcondition. Quotes around the condition are mandatory if it contains spaces or other characters that are special to your command interpreter.Examples:
--where="user='jimf'" -w"userid>1" -w"userid<1"
Write dump output as well-formed XML.
NULL,'NULL', and Empty Values: For some column namedcolumn_name, theNULLvalue, an empty string, and the string value'NULL'are distinguished from one another in the output generated by this option as follows:Value: XML Representation: NULL(unknown value)<field name="column_name" xsi:nil="true" />''(empty string)<field name="column_name"></field>'NULL'(string value)<field name="column_name">NULL</field>Beginning with MySQL 5.0.26, the output from the mysql client when run using the
--xmloption also follows these rules. (See Section 8.8.1, “mysql Options”.)Beginning with MySQL 5.0.40, XML output from mysqldump includes the XML namespace, as shown here:
shell>
mysqldump --xml -u root world City<?xml version="1.0"?> <mysqldump xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <database name="world"> <table_structure name="City"> <field Field="ID" Type="int(11)" Null="NO" Key="PRI" Extra="auto_increment" /> <field Field="Name" Type="char(35)" Null="NO" Key="" Default="" Extra="" /> <field Field="CountryCode" Type="char(3)" Null="NO" Key="" Default="" Extra="" /> <field Field="District" Type="char(20)" Null="NO" Key="" Default="" Extra="" /> <field Field="Population" Type="int(11)" Null="NO" Key="" Default="0" Extra="" /> <key Table="City" Non_unique="0" Key_name="PRIMARY" Seq_in_index="1" Column_name="ID" Collation="A" Cardinality="4079" Null="" Index_type="BTREE" Comment="" /> <options Name="City" Engine="MyISAM" Version="10" Row_format="Fixed" Rows="4079" Avg_row_length="67" Data_length="27329 3" Max_data_length="18858823439613951" Index_length="43008" Data_free="0" Auto_increment="4080" Create_time="2007-03-31 01:47:01" Updat e_time="2007-03-31 01:47:02" Collation="latin1_swedish_ci" Create_options="" Comment="" /> </table_structure> <table_data name="City"> <row> <field name="ID">1</field> <field name="Name">Kabul</field> <field name="CountryCode">AFG</field> <field name="District">Kabol</field> <field name="Population">1780000</field> </row>...<row> <field name="ID">4079</field> <field name="Name">Rafah</field> <field name="CountryCode">PSE</field> <field name="District">Rafah</field> <field name="Population">92020</field> </row> </table_data> </database> </mysqldump>
You can also set the following variables by using
--
syntax:
var_name=value
The maximum size of the buffer for client/server communication. The maximum is 1GB.
The initial size of the buffer for client/server communication. When creating multiple-row-insert statements (as with option
--extended-insertor--opt), mysqldump creates rows up tonet_buffer_lengthlength. If you increase this variable, you should also ensure that thenet_buffer_lengthvariable in the MySQL server is at least this large.
It is also possible to set variables by using
--set-variable=
or var_name=value-O
syntax. This syntax is deprecated.
var_name=value
The most common use of mysqldump is probably for making a backup of an entire database:
shell> mysqldump db_name > backup-file.sql
You can read the dump file back into the server like this:
shell> mysql db_name < backup-file.sql
Or like this:
shell> mysql -e "source /path-to-backup/backup-file.sql" db_name
mysqldump is also very useful for populating databases by copying data from one MySQL server to another:
shell> mysqldump --opt db_name | mysql --host=remote_host -C db_name
It is possible to dump several databases with one command:
shell> mysqldump --databases db_name1 [db_name2 ...] > my_databases.sql
To dump all databases, use the
--all-databases option:
shell> mysqldump --all-databases > all_databases.sql
For InnoDB tables,
mysqldump provides a way of making an
online backup:
shell> mysqldump --all-databases --single-transaction > all_databases.sql
This backup just needs to acquire a global read lock on all
tables (using FLUSH TABLES WITH READ LOCK)
at the beginning of the dump. As soon as this lock has been
acquired, the binary log coordinates are read and the lock is
released. If and only if one long updating statement is
running when the FLUSH statement is issued,
the MySQL server may get stalled until that long statement
finishes, and then the dump becomes lock-free. If the update
statements that the MySQL server receives are short (in terms
of execution time), the initial lock period should not be
noticeable, even with many updates.
For point-in-time recovery (also known as “roll-forward,” when you need to restore an old backup and replay the changes that happened since that backup), it is often useful to rotate the binary log (see Section 5.11.3, “The Binary Log”) or at least know the binary log coordinates to which the dump corresponds:
shell> mysqldump --all-databases --master-data=2 > all_databases.sql
Or:
shell>mysqldump --all-databases --flush-logs --master-data=2> all_databases.sql
The --master-data and
--single-transaction options can be used
simultaneously, which provides a convenient way to make an
online backup suitable for point-in-time recovery if tables
are stored using the InnoDB storage engine.
For more information on making backups, see Section 5.9.1, “Database Backups”, and Section 5.9.2, “Example Backup and Recovery Strategy”.
If you encounter problems backing up views, please read the section that covers restrictions on views which describes a workaround for backing up views when this fails due to insufficient privileges. See Section F.4, “Restrictions on Views”.
mysqlhotcopy is a Perl script that was
originally written and contributed by Tim Bunce. It uses
LOCK TABLES, FLUSH
TABLES, and cp or
scp to make a database backup quickly. It
is the fastest way to make a backup of the database or single
tables, but it can be run only on the same machine where the
database directories are located.
mysqlhotcopy works only for backing up
MyISAM and ISAM tables,
and ARCHIVE tables. It runs on Unix and
NetWare.
shell> mysqlhotcopy db_name [/path/to/new_directory]
shell> mysqlhotcopy db_name_1 ... db_name_n /path/to/new_directory
Back up tables in the given database that match a regular expression:
shell> mysqlhotcopy db_name./regex/
The regular expression for the table name can be negated by
prefixing it with a tilde
(‘~’):
shell> mysqlhotcopy db_name./~regex/
mysqlhotcopy supports the following options:
Display a help message and exit.
Do not rename target directory (if it exists); merely add files to it.
Do not abort if a target exists; rename it by adding an
_oldsuffix.Insert checkpoint entries into the specified database
db_nameand tabletbl_name.Base directory of the chroot jail in which mysqld operates. The
pathvalue should match that of the--chrootoption given to mysqld.Enable debug output.
Report actions without performing them.
Flush logs after all tables are locked.
--host=,host_name-hhost_nameThe hostname of the local host to use for making a TCP/IP connection to the local server. By default, the connection is made to
localhostusing a Unix socket file.Do not delete previous (renamed) target when done.
The method for copying files (
cporscp).Do not include full index files in the backup. This makes the backup smaller and faster. The indexes for reloaded tables can be reconstructed later with myisamchk -rq.
--password=,password-ppasswordThe password to use when connecting to the server. Note that the password value is not optional for this option, unlike for other MySQL programs. You can use an option file to avoid giving the password on the command line.
Specifying a password on the command line should be considered insecure. See Section 5.8.6, “Keeping Your Password Secure”.
The TCP/IP port number to use when connecting to the local server.
Be silent except for errors.
--record_log_pos=db_name.tbl_nameRecord master and slave status in the specified database
db_nameand tabletbl_name.Copy all databases with names that match the given regular expression.
Reset the binary log after locking all the tables.
Reset the
master.infofile after locking all the tables.The Unix socket file to use for the connection.
The suffix for names of copied databases.
The temporary directory. The default is
/tmp.--user=,user_name-uuser_nameThe MySQL username to use when connecting to the server.
mysqlhotcopy reads the
[client] and
[mysqlhotcopy] option groups from option
files.
To execute mysqlhotcopy, you must have
access to the files for the tables that you are backing up,
the SELECT privilege for those tables, the
RELOAD privilege (to be able to execute
FLUSH TABLES), and the LOCK
TABLES privilege (to be able to lock the tables).
Use perldoc for additional
mysqlhotcopy documentation, including
information about the structure of the tables needed for the
--checkpoint and
--record_log_pos options:
shell> perldoc mysqlhotcopy
The mysqlimport client provides a
command-line interface to the LOAD DATA
INFILE SQL statement. Most options to
mysqlimport correspond directly to clauses
of LOAD DATA INFILE syntax. See
Section 13.2.5, “LOAD DATA INFILE Syntax”.
Invoke mysqlimport like this:
shell> mysqlimport [options] db_name textfile1 [textfile2 ...]
For each text file named on the command line,
mysqlimport strips any extension from the
filename and uses the result to determine the name of the
table into which to import the file's contents. For example,
files named patient.txt,
patient.text, and
patient all would be imported into a
table named patient.
mysqlimport supports the following options:
Display a help message and exit.
The directory where character sets are installed. See Section 5.10.1, “The Character Set Used for Data and Sorting”.
--columns=,column_list-ccolumn_listThis option takes a comma-separated list of column names as its value. The order of the column names indicates how to match data file columns with table columns.
Compress all information sent between the client and the server if both support compression.
--debug[=,debug_options]-# [debug_options]Write a debugging log. The
debug_optionsstring often is'd:t:o,.file_name'--default-character-set=charset_nameUse
charset_nameas the default character set. See Section 5.10.1, “The Character Set Used for Data and Sorting”.Empty the table before importing the text file.
--fields-terminated-by=...,--fields-enclosed-by=...,--fields-optionally-enclosed-by=...,--fields-escaped-by=...These options have the same meaning as the corresponding clauses for
LOAD DATA INFILE. See Section 13.2.5, “LOAD DATA INFILESyntax”.Ignore errors. For example, if a table for a text file does not exist, continue processing any remaining files. Without
--force, mysqlimport exits if a table does not exist.--host=,host_name-hhost_nameImport data to the MySQL server on the given host. The default host is
localhost.See the description for the
--replaceoption.Ignore the first
Nlines of the data file.This option has the same meaning as the corresponding clause for
LOAD DATA INFILE. For example, to import Windows files that have lines terminated with carriage return/linefeed pairs, use--lines-terminated-by="\r\n". (You might have to double the backslashes, depending on the escaping conventions of your command interpreter.) See Section 13.2.5, “LOAD DATA INFILESyntax”.Read input files locally from the client host.
MySQL Enterprise For expert advice on the security implications of enabling
LOCAL, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.Lock all tables for writing before processing any text files. This ensures that all tables are synchronized on the server.
Use
LOW_PRIORITYwhen loading the table. This affects only storage engines that use only table-level locking (MyISAM,MEMORY,MERGE).--password[=,password]-p[password]The password to use when connecting to the server. If you use the short option form (
-p), you cannot have a space between the option and the password. If you omit thepasswordvalue following the--passwordor-poption on the command line, you are prompted for one.Specifying a password on the command line should be considered insecure. See Section 5.8.6, “Keeping Your Password Secure”.
The TCP/IP port number to use for the connection.
--protocol={TCP|SOCKET|PIPE|MEMORY}The connection protocol to use.
The
--replaceand--ignoreoptions control handling of input rows that duplicate existing rows on unique key values. If you specify--replace, new rows replace existing rows that have the same unique key value. If you specify--ignore, input rows that duplicate an existing row on a unique key value are skipped. If you do not specify either option, an error occurs when a duplicate key value is found, and the rest of the text file is ignored.Silent mode. Produce output only when errors occur.
For connections to
localhost, the Unix socket file to use, or, on Windows, the name of the named pipe to use.Options that begin with
--sslspecify whether to connect to the server via SSL and indicate where to find SSL keys and certificates. See Section 5.8.7.3, “SSL Command Options”.--user=,user_name-uuser_nameThe MySQL username to use when connecting to the server.
Verbose mode. Print more information about what the program does.
Display version information and exit.
Here is a sample session that demonstrates use of mysqlimport:
shell>mysql -e 'CREATE TABLE imptest(id INT, n VARCHAR(30))' testshell>eda 100 Max Sydow 101 Count Dracula . w imptest.txt 32 q shell>od -c imptest.txt0000000 1 0 0 \t M a x S y d o w \n 1 0 0000020 1 \t C o u n t D r a c u l a \n 0000040 shell>mysqlimport --local test imptest.txttest.imptest: Records: 2 Deleted: 0 Skipped: 0 Warnings: 0 shell>mysql -e 'SELECT * FROM imptest' test+------+---------------+ | id | n | +------+---------------+ | 100 | Max Sydow | | 101 | Count Dracula | +------+---------------+
This program was used internally for test purposes. As of MySQL 5.0, it is no longer used.
This program was used internally for test purposes. As of MySQL 5.0, it is no longer used.
The mysqlshow client can be used to quickly see which databases exist, their tables, or a table's columns or indexes.
mysqlshow provides a command-line interface
to several SQL SHOW statements. See
Section 13.5.4, “SHOW Syntax”. The same information can be obtained
by using those statements directly. For example, you can issue
them from the mysql client program.
Invoke mysqlshow like this:
shell> mysqlshow [options] [db_name [tbl_name [col_name]]]
If no database is given, a list of database names is shown.
If no table is given, all matching tables in the database are shown.
If no column is given, all matching columns and column types in the table are shown.
The output displays only the names of those databases, tables, or columns for which you have some privileges.
If the last argument contains shell or SQL wildcard characters
(‘*’,
‘?’,
‘%’, or
‘_’), only those names that are
matched by the wildcard are shown. If a database name contains
any underscores, those should be escaped with a backslash
(some Unix shells require two) to get a list of the proper
tables or columns. ‘*’ and
‘?’ characters are converted
into SQL ‘%’ and
‘_’ wildcard characters. This
might cause some confusion when you try to display the columns
for a table with a ‘_’ in the
name, because in this case, mysqlshow shows
you only the table names that match the pattern. This is
easily fixed by adding an extra
‘%’ last on the command line as
a separate argument.
mysqlshow supports the following options:
Display a help message and exit.
The directory where character sets are installed. See Section 5.10.1, “The Character Set Used for Data and Sorting”.
Compress all information sent between the client and the server if both support compression.
Show the number of rows per table. This can be slow for non-
MyISAMtables. This option was added in MySQL 5.0.6.--debug[=,debug_options]-# [debug_options]Write a debugging log. The
debug_optionsstring often is'd:t:o,.file_name'--default-character-set=charset_nameUse
charset_nameas the default character set. See Section 5.10.1, “The Character Set Used for Data and Sorting”.--host=,host_name-hhost_nameConnect to the MySQL server on the given host.
Show table indexes.
--password[=,password]-p[password]The password to use when connecting to the server. If you use the short option form (
-p), you cannot have a space between the option and the password. If you omit thepasswordvalue following the--passwordor-poption on the command line, you are prompted for one.Specifying a password on the command line should be considered insecure. See Section 5.8.6, “Keeping Your Password Secure”.
Specifying a password on the command line should be considered insecure. See Section 5.8.6, “Keeping Your Password Secure”.
The TCP/IP port number to use for the connection.
--protocol={TCP|SOCKET|PIPE|MEMORY}The connection protocol to use.
Show a column indicating the table type, as in
SHOW FULL TABLES. The type isBASE TABLEorVIEW. This option was added in MySQL 5.0.4.For connections to
localhost, the Unix socket file to use, or, on Windows, the name of the named pipe to use.Options that begin with
--sslspecify whether to connect to the server via SSL and indicate where to find SSL keys and certificates. See Section 5.8.7.3, “SSL Command Options”.Display extra information about each table.
--user=,user_name-uuser_nameThe MySQL username to use when connecting to the server.
Verbose mode. Print more information about what the program does. This option can be used multiple times to increase the amount of information.
Display version information and exit.
mysql_convert_table_format converts the
tables in a database to use a particular storage engine
(MyISAM by default).
mysql_convert_table_format is written in
Perl and requires that the DBI and
DBD::mysql Perl modules be installed (see
Section 2.4.20, “Perl Installation Notes”).
Invoke mysql_convert_table_format like this:
shell> mysql_convert_table_format [options]db_name
The db_name argument indicates the
database containing the tables to be converted.
mysql_convert_table_format understands the options described in the following list.
Display a help message and exit.
Continue even if errors occur.
Connect to the MySQL server on the given host.
The password to use when connecting to the server. Note that the password value is not optional for this option, unlike for other MySQL programs. You can use an option file to avoid giving the password on the command line.
Specifying a password on the command line should be considered insecure. See Section 5.8.6, “Keeping Your Password Secure”.
The TCP/IP port number to use for the connection.
--socket=pathFor connections to
localhost, the Unix socket file to use.Specify the storage engine that the tables should be converted to use. The default is
MyISAMif this option is not given.MySQL Enterprise For expert advice on choosing the optimum storage engine, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
The MySQL username to use when connecting to the server.
Verbose mode. Print more information about what the program does.
Display version information and exit.
mysql_explain_log reads its standard input
for query log contents. It uses EXPLAIN to
analyze SELECT statements found in the
input. UPDATE statements are rewritten to
SELECT statements and also analyzed with
EXPLAIN.
mysql_explain_log then displays a summary
of its results.
The results may assist you in determining which queries result in table scans and where it would be beneficial to add indexes to your tables.
Invoke mysql_explain_log like this, where
log_file contains all or part of a
MySQL query log:
shell> mysql_explain_log [options] < log_file
mysql_explain_log understands the following options:
Display a help message and exit.
Select entries from the log only for the given date.
--host=,host_name-hhost_nameConnect to the MySQL server on the given host.
--password=,password-ppasswordThe password to use when connecting to the server.
Specifying a password on the command line should be considered insecure. See Section 5.8.6, “Keeping Your Password Secure”.
Enable error output.
For connections to
localhost, the Unix socket file to use, or, on Windows, the name of the named pipe to use.--user=,user_name-uuser_nameThe MySQL username to use when connecting to the server.
mysql_find_rows reads update log files and
extracts queries that match a given regular expression or that
contain USE
or
db_nameSET statements.
Invoke mysql_find_rows like this:
shell> mysql_find_rows [options] [file_name ...]
Each file_name argument should be
the name of an updat log file. If no filenames are given,
mysql_find_rows reads the standard input.
Examples:
mysql_find_rows --regexp=problem_table --rows=20 < update.log mysql_find_rows --regexp=problem_table update-log.1 update-log.2
mysql_find_rows supports the following options:
mysql_fix_extensions converts the
extensions for MyISAM (or
ISAM) table files to lowercase. It looks
for files with an extension that that matches any lettercase
variant of .frm,
.myd, .myi,
.isd, and .ism and
renames them to have extensionsn of .frm,
.MYD, .MYI,
.ISD, and .ISM,
respectively. This can be useful after transferring the files
from a system with case-insensitive filenames (such as
Windows) to a system with case-sensitive filenames.
Invoke mysql_fix_extensions like this,
where data_dir is the pathname to
the MySQL data directory.
shell> mysql_fix_extensions data_dir
mysql_setpermission is a Perl script that
was originally written and contributed by Luuk de Boer. It
interactively sets permissions in the MySQL grant tables.
mysql_setpermission is written in Perl and
requires that the DBI and
DBD::mysql Perl modules be installed (see
Section 2.4.20, “Perl Installation Notes”).
Invoke mysql_setpermission like this:
shell> mysql_setpermission [options]
options should be either
--help to display the help message, or
options that indicate how to connect to the MySQL server. The
account used when you connect determines which permissions you
have when attempting to modify existing permissions in the
grant tables.
mysql_setpermissions also reads options
from the [client] and
[perl] groups in the
.my.cnf file in your home directory, if
the file exists.
mysql_setpermission understands the following options:
Display a help message and exit.
Connect to the MySQL server on the given host.
The password to use when connecting to the server. Note that the password value is not optional for this option, unlike for other MySQL programs. You can use an option file to avoid giving the password on the command line.
Specifying a password on the command line should be considered insecure. See Section 5.8.6, “Keeping Your Password Secure”.
The TCP/IP port number to use for the connection.
For connections to
localhost, the Unix socket file to use.The MySQL username to use when connecting to the server.
mysql_tableinfo creates tables and
populates them with database metadata. It uses SHOW
DATABASES, SHOW TABLES,
SHOW TABLE STATUS, SHOW
COLUMNS, and SHOW INDEX to obtain
the metadata.
In MySQL 5.0 and up, the INFORMATION_SCHEMA
database contains the same kind of information in the
SCHEMATA, TABLES,
COLUMNS, and STATISTICS
tables. See Chapter 20, The INFORMATION_SCHEMA Database.
Invoke mysql_tableinfo like this:
shell> mysql_tableinfo [options] db_name [db_like [tbl_like]]
The db_name argument indicates
which database mysql_tableinfo should use
as the location for the metadata tables. The database will be
created if it does not exist. The tables will be named
db, tbl (or
tbl_status), col, and
idx.
If the db_like or
tbl_like arguments are given, they
are used as patterns and metadata is generated only for
databases or tables that match the patterns. These arguments
default to % if not given.
Examples:
mysql_tableinfo info mysql_tableinfo info world mysql_tableinfo info mydb tmp%
Each of the commands stores information into tables in the
info database. The first stores information
for all databases and tables. The second stores information
for all tables in the world database. The
third stores information for tables in the
mydb database that have names matching the
pattern tmp%.
mysql_tableinfo supports the following options:
Display a help message and exit.
Before populating each metadata table, drop it if it exists.
Similar to
--clear, but exits after dropping the metadata tables to be populated.Generate column metadata into the
coltable.--host=,host_name-hhost_nameConnect to the MySQL server on the given host.
Generate index metadata into the
idxtable.--password=,password-ppasswordThe password to use when connecting to the server. Note that the password value is not optional for this option, unlike for other MySQL programs. You can use an option file to avoid giving the password on the command line.
Specifying a password on the command line should be considered insecure. See Section 5.8.6, “Keeping Your Password Secure”.
The TCP/IP port number to use for the connection.
Add
prefix_strat the beginning of each metadata table name.Be silent except for errors.
The Unix socket file to use for the connection.
Use
SHOW TABLE STATUSinstead ofSHOW TABLES. This provides more complete information, but is slower.--user=,user_name-uuser_nameThe MySQL username to use when connecting to the server.
mysql_waitpid signals a process to
terminate and waits for the process to exit. It uses the
kill() system call and Unix signals, so it
runs on Unix and Unix-like systems.
Invoke mysql_waitpid like this:
shell> mysql_waitpid [options] pid wait_time
mysql_waitpid sends signal 0 to the process
identified by pid and waits up to
wait_time seconds for the process
to terminate. pid and
wait_time must be positive
integers.
If process termination occurs within the wait time or the process does not exist, mysql_waitpid returns 0. Otherwise, it returns 1.
If the kill() system call cannot handle
signal 0, mysql_waitpid() uses signal 1
instead.
mysql_waitpid understands the following options:
mysql_zap kills processes that match a pattern. It uses the ps command and Unix signals, so it runs on Unix and Unix-like systems.
Invoke mysql_zap like this:
shell> mysql_zap [-signal] [-?Ift] pattern
A process matches if its output line from the
ps command contains the pattern. By
default, mysql_zap asks for confirmation
for each process. Respond y to kill the
process, or q to exit
mysql_zap. For any other response,
mysql_zap does not attempt to kill the
process.
If the -
option is given, it specifies the name or number of the signal
to send to each process. Otherwise,
mysql_zap tries first with
signalTERM (signal 15) and then with
KILL (signal 9).
mysql_zap understands the following additional options:
For most system errors, MySQL displays, in addition to an internal text message, the system error code in one of the following styles:
message ... (errno: #) message ... (Errcode: #)
You can find out what the error code means by examining the documentation for your system or by using the perror utility.
perror prints a description for a system error code or for a storage engine (table handler) error code.
Invoke perror like this:
shell> perror [options] errorcode ...
Example:
shell> perror 13 64
OS error code 13: Permission denied
OS error code 64: Machine is not on the network
To obtain the error message for a MySQL Cluster error code,
invoke perror with the
--ndb option:
shell> perror --ndb errorcode
Note that the meaning of system error messages may be dependent on your operating system. A given error code may mean different things on different operating systems.
perror supports the following options:
Display a help message and exit.
Print the error message for a MySQL Cluster error code.
Silent mode. Print only the error message.
Verbose mode. Print error code and message. This is the default behavior.
Display version information and exit.
The replace utility program changes strings in place in files or on the standard input.
Invoke replace in one of the following ways:
shell>replaceshell>fromto[fromto] ... --file[file] ...replacefromto[fromto] ... <file
from represents a string to look
for and to represents its
replacement. There can be one or more pairs of strings.
Use the -- option to indicate where the
string-replacement list ends and the filenames begin. In this
case, any file named on the command line is modified in place,
so you may want to make a copy of the original before
converting it. replace prints a
message indicating which of the input files it actually
modifies.
If the -- option is not given,
replace reads the standard input and writes
to the standard output.
replace uses a finite state machine to
match longer strings first. It can be used to swap strings.
For example, the following command swaps a
and b in the given files,
file1 and file2:
shell> replace a b b a -- file1 file2 ...
The replace program is used by msql2mysql. See Section 22.9.1, “msql2mysql — Convert mSQL Programs for Use with MySQL”.
replace supports the following options:
Display a help message and exit.
Write a debugging log. The
debug_options'd:t:o,.file_name'Silent mode. Print less information what the program does.
Verbose mode. Print more information about what the program does.
Display version information and exit.
The resolveip utility resolves hostnames to IP addresses and vice versa.
Invoke resolveip like this:
shell> resolveip [options] {host_name|ip-addr} ...
resolveip understands the options described in the following list.
resolve_stack_dump resolves a numeric stack dump to symbols.
Invoke resolve_stack_dump like this:
shell> resolve_stack_dump [options] symbols_file [numeric_dump_file]
The symbols file should include the output from the nm --numeric-sort mysqld command. The numeric dump file should contain a numeric stack track from mysqld. If no numeric dump file is named on the command line, the stack trace is read from the standard input.
resolve_stack_dump understands the options described in the following list.
Table of Contents
This chapter discusses the rules for writing the following elements of SQL statements when using MySQL:
Literal values such as strings and numbers
Identifiers such as database, table, and column names
Reserved words
User-defined and system variables
Comments
This section describes how to write literal values in MySQL. These
include strings, numbers, hexadecimal values, boolean values, and
NULL. The section also covers the various
nuances and “gotchas” that you may run into when
dealing with these basic types in MySQL.
A string is a sequence of bytes or characters, enclosed within
either single quote (‘'’) or
double quote (‘"’) characters.
Examples:
'a string' "another string"
If the ANSI_QUOTES SQL mode is enabled,
string literals can be quoted only within single quotes because
a string quoted within double quotes is interpreted as an
identifier.
A binary string is a string of bytes that has no character set or collation. A non-binary string is a string of characters that has a character set and collation. For both types of strings, comparisons are based on the numeric values of the string unit. For binary strings, the unit is the byte. For non-binary strings the unit is the character and some character sets allow multi-byte characters. Character value ordering is a function of the string collation.
String literals may have an optional character set introducer
and COLLATE clause:
[_charset_name]'string' [COLLATEcollation_name]
Examples:
SELECT _latin1'string'; SELECT _latin1'string' COLLATE latin1_danish_ci;
For more information about these forms of string syntax, see Section 10.3.5, “Character String Literal Character Set and Collation”.
Within a string, certain sequences have special meaning. Each of
these sequences begins with a backslash
(‘\’), known as the
escape character. MySQL recognizes the
following escape sequences:
For all other escape sequences, backslash is ignored. That is,
the escaped character is interpreted as if it was not escaped.
For example, ‘\x’ is just
‘x’.
These sequences are case sensitive. For example,
‘\b’ is interpreted as a
backspace, but ‘\B’ is
interpreted as ‘B’.
The ASCII 26 character can be encoded as
‘\Z’ to enable you to work around
the problem that ASCII 26 stands for END-OF-FILE on Windows.
ASCII 26 within a file causes problems if you try to use
mysql .
db_name <
file_name
Escape processing is done according to the character set
indicated by the character_set_connection
system variable. This is true even for strings that are preceded
by an introducer that indicates a different character set, as
discussed in Section 10.3.5, “Character String Literal Character Set and Collation”.
The ‘\%’ and
‘\_’ sequences are used to search
for literal instances of ‘%’ and
‘_’ in pattern-matching contexts
where they would otherwise be interpreted as wildcard
characters. See the description of the LIKE
operator in Section 12.4.1, “String Comparison Functions”. If
you use ‘\%’ or
‘\_’ in non-pattern-matching
contexts, they evaluate to the strings
‘\%’ and
‘\_’, not to
‘%’ and
‘_’.
There are several ways to include quote characters within a string:
A ‘
'’ inside a string quoted with ‘'’ may be written as ‘''’.A ‘
"’ inside a string quoted with ‘"’ may be written as ‘""’.Precede the quote character by an escape character (‘
\’).A ‘
'’ inside a string quoted with ‘"’ needs no special treatment and need not be doubled or escaped. In the same way, ‘"’ inside a string quoted with ‘'’ needs no special treatment.
The following SELECT statements demonstrate
how quoting and escaping work:
mysql>SELECT 'hello', '"hello"', '""hello""', 'hel''lo', '\'hello';+-------+---------+-----------+--------+--------+ | hello | "hello" | ""hello"" | hel'lo | 'hello | +-------+---------+-----------+--------+--------+ mysql>SELECT "hello", "'hello'", "''hello''", "hel""lo", "\"hello";+-------+---------+-----------+--------+--------+ | hello | 'hello' | ''hello'' | hel"lo | "hello | +-------+---------+-----------+--------+--------+ mysql>SELECT 'This\nIs\nFour\nLines';+--------------------+ | This Is Four Lines | +--------------------+ mysql>SELECT 'disappearing\ backslash';+------------------------+ | disappearing backslash | +------------------------+
If you want to insert binary data into a string column (such as
a BLOB column), the following characters must
be represented by escape sequences:
NUL | NUL byte (ASCII 0). Represent this character by
‘\0’ (a backslash
followed by an ASCII ‘0’
character). |
\ | Backslash (ASCII 92). Represent this character by
‘\\’. |
' | Single quote (ASCII 39). Represent this character by
‘\'’. |
" | Double quote (ASCII 34). Represent this character by
‘\"’. |
When writing application programs, any string that might contain any of these special characters must be properly escaped before the string is used as a data value in an SQL statement that is sent to the MySQL server. You can do this in two ways:
Process the string with a function that escapes the special characters. In a C program, you can use the
mysql_real_escape_string()C API function to escape characters. See Section 22.2.3.53, “mysql_real_escape_string()”. The Perl DBI interface provides aquotemethod to convert special characters to the proper escape sequences. See Section 22.4, “MySQL Perl API”. Other language interfaces may provide a similar capability.As an alternative to explicitly escaping special characters, many MySQL APIs provide a placeholder capability that enables you to insert special markers into a statement string, and then bind data values to them when you issue the statement. In this case, the API takes care of escaping special characters in the values for you.
Integers are represented as a sequence of digits. Floats use
‘.’ as a decimal separator.
Either type of number may be preceded by
‘-’ or
‘+’ to indicate a negative or
positive value, respectively
Examples of valid integers:
1221 0 -32
Examples of valid floating-point numbers:
294.42 -32032.6809e+10 148.00
An integer may be used in a floating-point context; it is interpreted as the equivalent floating-point number.
MySQL supports hexadecimal values. In numeric contexts, these act like integers (64-bit precision). In string contexts, these act like binary strings, where each pair of hex digits is converted to a character:
mysql>SELECT x'4D7953514C';-> 'MySQL' mysql>SELECT 0xa+0;-> 10 mysql>SELECT 0x5061756c;-> 'Paul'
The default type of a hexadecimal value is a string. If you want
to ensure that the value is treated as a number, you can use
CAST(... AS UNSIGNED):
mysql> SELECT 0x41, CAST(0x41 AS UNSIGNED);
-> 'A', 65
The x'
syntax is based on standard SQL. The hexstring'0x
syntax is based on ODBC. Hexadecimal strings are often used by
ODBC to supply values for BLOB columns.
You can convert a string or a number to a string in hexadecimal
format with the HEX() function:
mysql>SELECT HEX('cat');-> '636174' mysql>SELECT 0x636174;-> 'cat'
The constants TRUE and
FALSE evaluate to 1 and
0, respectively. The constant names can be
written in any lettercase.
mysql> SELECT TRUE, true, FALSE, false;
-> 1, 1, 0, 0
Beginning with MySQL 5.0.3, bit-field values can be written
using b'
notation. value'value is a binary value
written using zeros and ones.
Bit-field notation is convenient for specifying values to be
assigned to BIT columns:
mysql>CREATE TABLE t (b BIT(8));mysql>INSERT INTO t SET b = b'11111111';mysql>INSERT INTO t SET b = b'1010';+------+----------+----------+----------+ | b+0 | BIN(b+0) | OCT(b+0) | HEX(b+0) | +------+----------+----------+----------+ | 255 | 11111111 | 377 | FF | | 10 | 1010 | 12 | A | +------+----------+----------+----------+
The NULL value means “no data.”
NULL can be written in any lettercase.
Be aware that the NULL value is different
from values such as 0 for numeric types or
the empty string for string types. See
Section B.1.5.3, “Problems with NULL Values”.
For text file import or export operations performed with
LOAD DATA INFILE or SELECT ... INTO
OUTFILE, NULL is represented by the
\N sequence. See Section 13.2.5, “LOAD DATA INFILE Syntax”.
Database, table, index, column, and alias names are identifiers. This section describes the allowable syntax for identifiers in MySQL.
The following table describes the maximum length for each type of identifier.
| Identifier | Maximum Length (bytes) |
| Database | 64 |
| Table | 64 |
| Column | 64 |
| Index | 64 |
| Alias | 255 |
There are some restrictions on the characters that may appear in identifiers:
No identifier can contain ASCII 0 (
0x00) or a byte with a value of 255.The use of identifier quote characters in identifiers is permitted, although it is best to avoid doing so if possible.
Database, table, and column names should not end with space characters.
Database names cannot contain ‘
/’, ‘\’, ‘.’, or characters that are not allowed in a directory name.Table names cannot contain ‘
/’, ‘\’, ‘.’, or characters that are not allowed in a filename.The length of the identifier is in bytes, not characters. If you use multi-byte characters in your identifier names, then the maximum length will depend on the byte count of all the characters used.
Identifiers are stored using Unicode (UTF-8). This applies to
identifiers in table definitions that are stored in
.frm files and to identifiers stored in the
grant tables in the mysql database. The sizes
of the string columns in the grant tables (and in any other
tables) in MySQL 5.0 are given as number of
characters. This means that (unlike some earlier versions of
MySQL) you can use multi-byte characters without reducing the
number of characters allowed for values stored in these columns.
An identifier may be quoted or unquoted. If an identifier is a
reserved word or contains special characters, you
must quote it whenever you refer to it.
(Exception: A word that follows a period in a qualified name must
be an identifier, so it need not be quoted even if it is
reserved.) For a list of reserved words, see
Section 9.3, “Reserved Words”. Special characters are those
outside the set of alphanumeric characters from the current
character set, ‘_’, and
‘$’.
The identifier quote character is the backtick
(‘`’):
mysql> SELECT * FROM `select` WHERE `select`.id > 100;
If the ANSI_QUOTES SQL mode is enabled, it is
also allowable to quote identifiers within double quotes:
mysql>CREATE TABLE "test" (col INT);ERROR 1064: You have an error in your SQL syntax. (...) mysql>SET sql_mode='ANSI_QUOTES';mysql>CREATE TABLE "test" (col INT);Query OK, 0 rows affected (0.00 sec)
Note: Because the ANSI_QUOTES mode causes the
server to interpret double-quoted strings as identifiers, string
literals must be enclosed within single quotes when this mode is
enabled. They cannot be enclosed within double quotes.
The server SQL mode is controlled as described in Section 5.2.6, “SQL Modes”.
Identifier quote characters can be included within an identifier
if you quote the identifier. If the character
to be included within the identifier is the same as that used to
quote the identifier itself, then you need to double the
character. The following statement creates a table named
a`b that contains a column named
c"d:
mysql> CREATE TABLE `a``b` (`c"d` INT);
Identifiers may begin with a digit but unless quoted may not consist solely of digits.
It is recommended that you do not use names of the form
MeMeNM and
N are integers. For example, avoid
using 1e or 2e2 as
identifiers, because an expression such as 1e+3
is ambiguous. Depending on context, it might be interpreted as the
expression 1e + 3 or as the number
1e+3.
A user variable cannot be used directly in an SQL statement as an identifier or as part of an identifier. See Section 9.4, “User-Defined Variables”, for more information and examples of workarounds.
Be careful when using MD5() to produce table
names because it can produce names in illegal or ambiguous formats
such as those just described.
MySQL allows names that consist of a single identifier or
multiple identifiers. The components of a multiple-part name
should be separated by period
(‘.’) characters. The initial
parts of a multiple-part name act as qualifiers that affect the
context within which the final identifier is interpreted.
In MySQL you can refer to a column using any of the following forms:
| Column Reference | Meaning |
col_name | The column col_name from whichever table used
in the statement contains a column of that name. |
tbl_name.col_name | The column col_name from table
tbl_name of the default
database. |
db_name.tbl_name.col_name | The column col_name from table
tbl_name of the database
db_name. |
If any components of a multiple-part name require quoting, quote
them individually rather than quoting the name as a whole. For
example, write `my-table`.`my-column`, not
`my-table.my-column`.
You need not specify a tbl_name or
db_name.tbl_name prefix for a column
reference in a statement unless the reference would be
ambiguous. Suppose that tables t1 and
t2 each contain a column
c, and you retrieve c in a
SELECT statement that uses both
t1 and t2. In this case,
c is ambiguous because it is not unique among
the tables used in the statement. You must qualify it with a
table name as t1.c or t2.c
to indicate which table you mean. Similarly, to retrieve from a
table t in database db1
and from a table t in database
db2 in the same statement, you must refer to
columns in those tables as
db1.t. and
col_namedb2.t..
col_name
A word that follows a period in a qualified name must be an identifier, so it is not necessary to quote it, even if it is a reserved word.
The syntax .tbl_name means the table
tbl_name in the default database.
This syntax is accepted for ODBC compatibility because some ODBC
programs prefix table names with a
‘.’ character.
In MySQL, databases correspond to directories within the data
directory. Each table within a database corresponds to at least
one file within the database directory (and possibly more,
depending on the storage engine). Consequently, the case
sensitivity of the underlying operating system determines the
case sensitivity of database and table names. This means
database and table names are case sensitive in most varieties of
Unix, and not case sensitive in Windows. One notable exception
is Mac OS X, which is Unix-based but uses a default filesystem
type (HFS+) that is not case sensitive. However, Mac OS X also
supports UFS volumes, which are case sensitive just as on any
Unix. See Section 1.9.4, “MySQL Extensions to Standard SQL”. The
lower_case_table_names system variable also
affects how the server handles identifier case sensitivity, as
described later in this section.
MySQL Enterprise
lower_case_table_names is just one of the
system variables monitored by the MySQL Network Monitoring and
Advisory Service. For information about subscribing to this
service see,
http://www.mysql.com/products/enterprise/advisors.html.
Note: Although database and
table names are not case sensitive on some platforms, you should
not refer to a given database or table using different cases
within the same statement. The following statement would not
work because it refers to a table both as
my_table and as MY_TABLE:
mysql> SELECT * FROM my_table WHERE MY_TABLE.col=1;
Column, index and stored routine names are not case sensitive on any platform, nor are column aliases. Trigger names are case sensitive.
By default, table aliases are case sensitive on Unix, but not so
on Windows or Mac OS X. The following statement would not work
on Unix, because it refers to the alias both as
a and as A:
mysql>SELECT->col_nameFROMtbl_nameAS aWHERE a.col_name= 1 OR A.col_name= 2;
However, this same statement is permitted on Windows. To avoid problems caused by such differences, it is best to adopt a consistent convention, such as always creating and referring to databases and tables using lowercase names. This convention is recommended for maximum portability and ease of use.
How table and database names are stored on disk and used in
MySQL is affected by the
lower_case_table_names system variable, which
you can set when starting mysqld.
lower_case_table_names can take the values
shown in the following table. On Unix, the default value of
lower_case_table_names is 0. On Windows the
default value is 1. On Mac OS X, the default value is 2.
| Value | Meaning |
0 | Table and database names are stored on disk using the lettercase
specified in the CREATE TABLE or
CREATE DATABASE statement. Name
comparisons are case sensitive. Note that if you force
this variable to 0 with
--lower-case-table-names=0 on a
case-insensitive filesystem and access
MyISAM tablenames using different
lettercases, index corruption may result. |
1 | Table names are stored in lowercase on disk and name comparisons are not case sensitive. MySQL converts all table names to lowercase on storage and lookup. This behavior also applies to database names and table aliases. |
2 | Table and database names are stored on disk using the lettercase
specified in the CREATE TABLE or
CREATE DATABASE statement, but MySQL
converts them to lowercase on lookup. Name comparisons
are not case sensitive.
Note: This works
only on filesystems that are not
case sensitive! InnoDB table names
are stored in lowercase, as for
lower_case_table_names=1. |
If you are using MySQL on only one platform, you don't normally
have to change the lower_case_table_names
variable. However, you may encounter difficulties if you want to
transfer tables between platforms that differ in filesystem case
sensitivity. For example, on Unix, you can have two different
tables named my_table and
MY_TABLE, but on Windows these two names are
considered identical. To avoid data transfer problems stemming
from lettercase of database or table names, you have two
options:
Use
lower_case_table_names=1on all systems. The main disadvantage with this is that when you useSHOW TABLESorSHOW DATABASES, you don't see the names in their original lettercase.Use
lower_case_table_names=0on Unix andlower_case_table_names=2on Windows. This preserves the lettercase of database and table names. The disadvantage of this is that you must ensure that your statements always refer to your database and table names with the correct lettercase on Windows. If you transfer your statements to Unix, where lettercase is significant, they do not work if the lettercase is incorrect.Exception: If you are using
InnoDBtables, you should setlower_case_table_namesto 1 on all platforms to force names to be converted to lowercase.
Note that if you plan to set the
lower_case_table_names system variable to 1
on Unix, you must first convert your old database and table
names to lowercase before restarting mysqld
with the new variable setting.
Object names may be considered duplicates if their uppercase
forms are equal according to a binary collation. That is true
for names of cursors, conditions, functions, procedures,
savepoints, and routine local variables. It is not true for
names of columns, constraints, databases, statements prepared
with PREPARE, tables, triggers, users, and
user-defined variables.
MySQL 5.0 supports built-in (native) functions, user-defined functions (UDFs), and stored functions. This section describes how the server recognizes whether the name of a built-in function is used as a function call or as an identifier, and how the server determines which function to use in cases when functions of different types exist with a given name.
Built-In Function Name Parsing
The parser uses default rules for parsing names of built-in
functions. These rules can be changed by enabling the
IGNORE_SPACE SQL mode.
When the parser encounters a word that is the name of a built-in
function, it must determine whether the name signifies a
function call or is instead a non-expression reference to an
identifier such as a table or column name. For example, in the
following statements, the first reference to
count is a function call, whereas the second
reference is a table name:
SELECT COUNT(*) FROM mytable; CREATE TABLE count (i INT);
The parser should recognize the name of a built-in function as indicating a function call only when parsing what is expected to be an expression. That is, in non-expression context, function names are permitted as identifiers.
However, some built-in functions have special parsing or implementation considerations, so the parser uses the following rules by default to distinguish whether their names are being used as function calls or as identifiers in non-expression context:
To use the name as a function call in an expression, there must be no whitespace between the name and the following ‘
(’ parenthesis character.Conversely, to use the function name as an identifier, it must not be followed immediately by a parenthesis.
The requirement that function calls be written with no
whitespace between the name and the parenthesis applies only to
the built-in functions that have special considerations.
COUNT is one such name. The exact list of
function names for which following whitespace determines their
interpretation are those listed in the
sql_functions[] array of the
sql/lex.h source file. Before MySQL 5.1,
they are rather numerous (about 200), so you may find it easiest
to treat the no-whitespace requirement as applying to all
function calls. In MySQL 5.1, parser improvements reduce to
about 30 the number of affected function names.
For functions not listed in the
sql_functions[]) array, whitespace does not
matter. They are interpreted as function calls only when used in
expression context and may be used freely as identifiers
otherwise. ASCII is one such name. However,
for these non-affected function names, interpretation may vary
in expression context:
func_name ()func_name ()
The IGNORE_SPACE SQL mode can be used to
modify how the parser treats function names that are
whitespace-sensitive:
With
IGNORE_SPACEdisabled, the parser interprets the name as a function call when there is no whitespace between the name and the following parenthesis. This occurs even when the function name is used in non-expression context:mysql>
CREATE TABLE count(i INT);ERROR 1064 (42000): You have an error in your SQL syntax ... near 'count(i INT)'To eliminate the error and cause the name to be treated as an identifier, either use whitespace following the name or write it as a quoted identifier (or both):
CREATE TABLE count (i INT); CREATE TABLE `count`(i INT); CREATE TABLE `count` (i INT);
With
IGNORE_SPACEenabled, the parser loosens the requirement that there be no whitespace between the function name and the following parenthesis. This provides more flexibility in writing function calls. For example, either of the following function calls are legal:SELECT COUNT(*) FROM mytable; SELECT COUNT (*) FROM mytable;
However, enabling
IGNORE_SPACEalso has the side effect that the parser treats the affected function names as reserved words (see Section 9.3, “Reserved Words”). This means that a space following the name no longer signifies its use as an identifier. The name can be used in function calls with or without following whitespace, but causes a syntax error in non-expression context unless it is quoted. For example, withIGNORE_SPACEenabled, both of the following statements fail with a syntax error because the parser interpretscountas a reserved word:CREATE TABLE count(i INT); CREATE TABLE count (i INT);
To use the function name in non-expression context, write it as a quoted identifier:
CREATE TABLE `count`(i INT); CREATE TABLE `count` (i INT);
To enable the IGNORE_SPACE SQL mode, use this
statement:
SET sql_mode = 'IGNORE_SPACE';
IGNORE_SPACE is also enabled by certain other
composite modes such as ANSI that include it
in their value:
SET sql_mode = 'ANSI';
Check Section 5.2.6, “SQL Modes”, to see which composite
modes enable IGNORE_SPACE.
To minimize the dependency of SQL code on the
IGNORE_SPACE setting, use these guidelines:
Avoid creating UDFs or stored functions that have the same name as a built-in function.
Avoid using function names in non-expression context. For example, these statements use
count(one of the affected function names affected byIGNORE_SPACE), so they fail with or without whitespace following the name ifIGNORE_SPACEis enabled:CREATE TABLE count(i INT); CREATE TABLE count (i INT);
If you must use a function name in non-expression context, write it as a quoted identifier:
CREATE TABLE `count`(i INT); CREATE TABLE `count` (i INT);
Function Name Resolution
The following rules describe how the server resolves references to function names for function creation and invocation:
Built-in functions and user-defined functions
A UDF can be created with the same name as a built-in function but the UDF cannot be invoked because the parser resolves invocations of the function to refer to the built-in function. For example, if you create a UDF named
ABS, references toABS()invoke the built-in function.Built-in functions and stored functions
It is possible to create a stored function with the same name as a built-in function, but to invoke the stored function it is necessary to qualify it with a database name. For example, if you create a stored function named
PIin thetestdatabase, you invoke it astest.PI()because the server resolvesPI()as a reference to the built-in function.User-defined functions and stored functions
User-defined functions and stored functions share the same namespace, so you cannot create a UDF and a stored function with the same name.
The preceding function name resolution rules have implications for upgrading to versions of MySQL that implement new built-in functions:
If you have already created a user-defined function with a given name and upgrade MySQL to a version that implements a new built-in function with the same name, the UDF becomes inaccessible. To correct this, use
DROP FUNCTIONto drop the UDF, and then useCREATE FUNCTIONto re-create the UDF with a different non-conflicting name.If a new version of MySQL implements a built-in function with the same name as an existing stored function, you have two choices: Rename the stored function to use a non-conflicting name, or change calls to the function so that they use a schema qualifier (that is, use
schema_name.func_name()
Certain words such as SELECT,
DELETE, or BIGINT are
reserved and require special treatment for use as identifiers such
as table and column names. This may also be true for the names of
built-in functions.
Reserved words are permitted as identifiers if you quote them as described in Section 9.2, “Database, Table, Index, Column, and Alias Names”:
mysql>CREATE TABLE interval (begin INT, end INT);ERROR 1064 (42000): You have an error in your SQL syntax ... near 'interval (begin INT, end INT)' mysql>CREATE TABLE `interval` (begin INT, end INT);Query OK, 0 rows affected (0.01 sec)
Exception: A word that follows a period in a qualified name must be an identifier, so it need not be quoted even if it is reserved:
mysql> CREATE TABLE mydb.interval (begin INT, end INT);
Query OK, 0 rows affected (0.01 sec)
Names of built-in functions are permitted as identifiers but may
require care to be used as such. For example,
COUNT is acceptable as a column name. However,
by default, no whitespace is allowed in function invocations
between the function name and the following
‘(’ character. This requirement
enables the parser to distinguish whether the name is used in a
function call or in non-function context. For further detail on
recognition of function names, see
Section 9.2.3, “Function Name Parsing and Resolution”.
The words in the following table are explicitly reserved in MySQL
5.0. At some point, you might upgrade to a higher
version, so it's a good idea to have a look at future reserved
words, too. You can find these in the manuals that cover higher
versions of MySQL. Most of the words in the table are forbidden by
standard SQL as column or table names (for example,
GROUP). A few are reserved because MySQL needs
them and uses a yacc parser. A reserved word
can be used as an identifier if you quote it.
ADD | ALL | ALTER |
ANALYZE | AND | AS |
ASC | ASENSITIVE | BEFORE |
BETWEEN | BIGINT | BINARY |
BLOB | BOTH | BY |
CALL | CASCADE | CASE |
CHANGE | CHAR | CHARACTER |
CHECK | COLLATE | COLUMN |
CONDITION | CONSTRAINT | CONTINUE |
CONVERT | CREATE | CROSS |
CURRENT_DATE | CURRENT_TIME | CURRENT_TIMESTAMP |
CURRENT_USER | CURSOR | DATABASE |
DATABASES | DAY_HOUR | DAY_MICROSECOND |
DAY_MINUTE | DAY_SECOND | DEC |
DECIMAL | DECLARE | DEFAULT |
DELAYED | DELETE | DESC |
DESCRIBE | DETERMINISTIC | DISTINCT |
DISTINCTROW | DIV | DOUBLE |
DROP | DUAL | EACH |
ELSE | ELSEIF | ENCLOSED |
ESCAPED | EXISTS | EXIT |
EXPLAIN | FALSE | FETCH |
FLOAT | FLOAT4 | FLOAT8 |
FOR | FORCE | FOREIGN |
FROM | FULLTEXT | GRANT |
GROUP | HAVING | HIGH_PRIORITY |
HOUR_MICROSECOND | HOUR_MINUTE | HOUR_SECOND |
IF | IGNORE | IN |
INDEX | INFILE | INNER |
INOUT | INSENSITIVE | INSERT |
INT | INT1 | INT2 |
INT3 | INT4 | INT8 |
INTEGER | INTERVAL | INTO |
IS | ITERATE | JOIN |
KEY | KEYS | KILL |
LEADING | LEAVE | LEFT |
LIKE | LIMIT | LINES |
LOAD | LOCALTIME | LOCALTIMESTAMP |
LOCK | LONG | LONGBLOB |
LONGTEXT | LOOP | LOW_PRIORITY |
MATCH | MEDIUMBLOB | MEDIUMINT |
MEDIUMTEXT | MIDDLEINT | MINUTE_MICROSECOND |
MINUTE_SECOND | MOD | MODIFIES |
NATURAL | NOT | NO_WRITE_TO_BINLOG |
NULL | NUMERIC | ON |
OPTIMIZE | OPTION | OPTIONALLY |
OR | ORDER | OUT |
OUTER | OUTFILE | PRECISION |
PRIMARY | PROCEDURE | PURGE |
RAID0 | READ | READS |
REAL | REFERENCES | REGEXP |
RELEASE | RENAME | REPEAT |
REPLACE | REQUIRE | RESTRICT |
RETURN | REVOKE | RIGHT |
RLIKE | SCHEMA | SCHEMAS |
SECOND_MICROSECOND | SELECT | SENSITIVE |
SEPARATOR | SET | SHOW |
SMALLINT | SONAME | SPATIAL |
SPECIFIC | SQL | SQLEXCEPTION |
SQLSTATE | SQLWARNING | SQL_BIG_RESULT |
SQL_CALC_FOUND_ROWS | SQL_SMALL_RESULT | SSL |
STARTING | STRAIGHT_JOIN | TABLE |
TERMINATED | THEN | TINYBLOB |
TINYINT | TINYTEXT | TO |
TRAILING | TRIGGER | TRUE |
UNDO | UNION | UNIQUE |
UNLOCK | UNSIGNED | UPDATE |
USAGE | USE | USING |
UTC_DATE | UTC_TIME | UTC_TIMESTAMP |
VALUES | VARBINARY | VARCHAR |
VARCHARACTER | VARYING | WHEN |
WHERE | WHILE | WITH |
WRITE | X509 | XOR |
YEAR_MONTH | ZEROFILL |
The following are new reserved words in MySQL 5.0:
ASENSITIVE | CALL | CONDITION |
CONTINUE | CURSOR | DECLARE |
DETERMINISTIC | EACH | ELSEIF |
EXIT | FETCH | INOUT |
INSENSITIVE | ITERATE | LEAVE |
LOOP | MODIFIES | OUT |
READS | RELEASE | REPEAT |
RETURN | SCHEMA | SCHEMAS |
SENSITIVE | SPECIFIC | SQL |
SQLEXCEPTION | SQLSTATE | SQLWARNING |
TRIGGER | UNDO | WHILE |
MySQL allows some keywords to be used as unquoted identifiers because many people previously used them. Examples are those in the following list:
ACTIONBITDATEENUMNOTEXTTIMETIMESTAMP
You can store a value in a user-defined variable and then refer to it later. This enables you to pass values from one statement to another. User-defined variables are connection-specific. That is, a user variable defined by one client cannot be seen or used by other clients. All variables for a given client connection are automatically freed when that client exits.
User variables are written as
@, where the
variable name var_namevar_name may consist of
alphanumeric characters from the current character set,
‘.’,
‘_’, and
‘$’. The default character set is
latin1 (cp1252 West European). This may be
changed with the --default-character-set option
to mysqld. See
Section 5.10.1, “The Character Set Used for Data and Sorting”. A user variable name can contain
other characters if you quote it as a string or identifier (for
example, @'my-var',
@"my-var", or @`my-var`).
Note: User variable names are case sensitive before MySQL 5.0 and not case sensitive in MySQL 5.0 and up.
One way to set a user-defined variable is by issuing a
SET statement:
SET @var_name=expr[, @var_name=expr] ...
For SET, either = or
:= can be used as the assignment operator. The
expr assigned to each variable can
evaluate to an integer, real, string, or NULL
value. However, if the value of the variable is selected in a
result set, it is returned to the client as a string.
You can also assign a value to a user variable in statements other
than SET. In this case, the assignment operator
must be := and not = because
= is treated as a comparison operator in
non-SET statements:
mysql>SET @t1=0, @t2=0, @t3=0;mysql>SELECT @t1:=(@t2:=1)+@t3:=4,@t1,@t2,@t3;+----------------------+------+------+------+ | @t1:=(@t2:=1)+@t3:=4 | @t1 | @t2 | @t3 | +----------------------+------+------+------+ | 5 | 5 | 1 | 4 | +----------------------+------+------+------+
User variables may be used in contexts where expressions are
allowed. This does not currently include contexts that explicitly
require a literal value, such as in the LIMIT
clause of a SELECT statement, or the
IGNORE
clause of a N LINESLOAD DATA statement.
If a user variable is assigned a string value, it has the same character set and collation as the string. The coercibility of user variables is implicit as of MySQL 5.0.3. (This is the same coercibility as for table column values.)
Note: In a
SELECT statement, each expression is evaluated
only when sent to the client. This means that in a
HAVING, GROUP BY, or
ORDER BY clause, you cannot refer to an
expression that involves variables that are set in the
SELECT list. For example, the following
statement does not work as expected:
mysql> SELECT (@aa:=id) AS a, (@aa+3) AS b FROM tbl_name HAVING b=5;
The reference to b in the
HAVING clause refers to an alias for an
expression in the SELECT list that uses
@aa. This does not work as expected:
@aa contains the value of id
from the previous selected row, not from the current row.
The order of evaluation for user variables is undefined and may
change based on the elements contained within a given query. In
SELECT @a, @a := @a+1 ..., you might think that
MySQL will evaluate @a first and then do an
assignment second, but changing the query (for example, by adding
a GROUP BY, HAVING, or
ORDER BY clause) may change the order of
evaluation.
The general rule is never to assign a value to a user variable in one part of a statement and use the same variable in some other part of the same statement. You might get the results you expect, but this is not guaranteed.
Another issue with setting a variable and using it in the same statement is that the default result type of a variable is based on the type of the variable at the start of the statement. The following example illustrates this:
mysql>SET @a='test';mysql>SELECT @a,(@a:=20) FROMtbl_name;
For this SELECT statement, MySQL reports to the
client that column one is a string and converts all accesses of
@a to strings, even though @a is set to a
number for the second row. After the SELECT
statement executes, @a is regarded as a number
for the next statement.
To avoid problems with this behavior, either do not set and use
the same variable within a single statement, or else set the
variable to 0, 0.0, or
'' to define its type before you use it.
A user variable cannot be used directly in an SQL statement as an identifier or as part of an identifier, even if it is set off with backticks. This is shown in the following example:
mysql>SELECT c1 FROM t;+----+ | c1 | +----+ | 0 | +----+ | 1 | +----+ 2 rows in set (0.00 sec) mysql>SET @col = "c1";Query OK, 0 rows affected (0.00 sec) mysql>SELECT @col FROM t;+------+ | @col | +------+ | c1 | +------+ 1 row in set (0.00 sec) mysql>SELECT `@col` FROM t;ERROR 1054 (42S22): Unknown column '@col' in 'field list' mysql> SET @col = "`c1`"; Query OK, 0 rows affected (0.00 sec) mysql>SELECT @col FROM t;+------+ | @col | +------+ | `c1` | +------+ 1 row in set (0.00 sec)
One way to work around this problem is to assemble a string for the query in application code, as shown here using PHP 5:
<?php
$mysqli = new mysqli("localhost", "user", "pass", "test");
if( mysqli_connect_errno() )
die("Connection failed: %s\n", mysqli_connect_error());
$col = "c1";
$query = "SELECT $col FROM t";
$result = $mysqli->query($query);
while($row = $result->fetch_assoc())
{
echo "<p>" . $row["$col"] . "</p>\n";
}
$result->close();
$mysqli->close();
?>
(Assembling an SQL statement in this fashion is sometimes known as “Dynamic SQL”.) It is also possible to perform such operations using prepared statements, without the need to concatenate strings of SQL in client code. This example illustrates how this can be done:
mysql>SET @c = "c1";Query OK, 0 rows affected (0.00 sec) mysql>SET @s = CONCAT("SELECT ", @c, " FROM t");Query OK, 0 rows affected (0.00 sec) mysql>PREPARE stmt FROM @s;Query OK, 0 rows affected (0.04 sec) Statement prepared mysql>EXECUTE stmt;+----+ | c1 | +----+ | 0 | +----+ | 1 | +----+ 2 rows in set (0.00 sec) mysql>DEALLOCATE PREPARE stmt;Query OK, 0 rows affected (0.00 sec)
You cannot use a placeholder for the name of a database, table, or column in an SQL prepared statement. See Section 13.7, “SQL Syntax for Prepared Statements”, for more information.
If you refer to a variable that has not been initialized, it has a
value of NULL and a type of string.
MySQL Server supports three comment styles:
From a ‘
#’ character to the end of the line.From a ‘
--’ sequence to the end of the line. In MySQL, the ‘--’ (double-dash) comment style requires the second dash to be followed by at least one whitespace or control character (such as a space, tab, newline, and so on). This syntax differs slightly from standard SQL comment syntax, as discussed in Section 1.9.5.7, “'--' as the Start of a Comment”.From a
/*sequence to the following*/sequence, as in the C programming language. This syntax allows a comment to extend over multiple lines because the beginning and closing sequences need not be on the same line.
The following example demonstrates all three comment styles:
mysql>SELECT 1+1; # This comment continues to the end of linemysql>SELECT 1+1; -- This comment continues to the end of linemysql>SELECT 1 /* this is an in-line comment */ + 1;mysql>SELECT 1+/*this is amultiple-line comment*/1;
MySQL Server supports some variants of C-style comments. These enable you to write code that includes MySQL extensions, but is still portable, by using comments of the following form:
/*! MySQL-specific code */
In this case, MySQL Server parses and executes the code within the
comment as it would any other SQL statement, but other SQL servers
will ignore the extensions. For example, MySQL Server recognizes
the STRAIGHT_JOIN keyword in the following
statement, but other servers will not:
SELECT /*! STRAIGHT_JOIN */ col1 FROM table1,table2 WHERE ...
If you add a version number after the
‘!’ character, the syntax within
the comment is executed only if the MySQL version is greater than
or equal to the specified version number. The
TEMPORARY keyword in the following comment is
executed only by servers from MySQL 3.23.02 or higher:
CREATE /*!32302 TEMPORARY */ TABLE t (a INT);
The comment syntax just described applies to how the mysqld server parses SQL statements. The mysql client program also performs some parsing of statements before sending them to the server. (It does this to determine statement boundaries within a multiple-statement input line.)
Table of Contents
- 10.1. Character Sets and Collations in General
- 10.2. Character Sets and Collations in MySQL
- 10.3. Specifying Character Sets and Collations
- 10.3.1. Server Character Set and Collation
- 10.3.2. Database Character Set and Collation
- 10.3.3. Table Character Set and Collation
- 10.3.4. Column Character Set and Collation
- 10.3.5. Character String Literal Character Set and Collation
- 10.3.6. National Character Set
- 10.3.7. Examples of Character Set and Collation Assignment
- 10.3.8. Compatibility with Other DBMSs
- 10.4. Connection Character Sets and Collations
- 10.5. Collation Issues
- 10.6. Operations Affected by Character Set Support
- 10.7. Unicode Support
- 10.8. UTF-8 for Metadata
- 10.9. Column Character Set Conversion
- 10.10. Character Sets and Collations That MySQL Supports
MySQL includes character set support that enables you to store data
using a variety of character sets and perform comparisons according
to a variety of collations. You can specify character sets at the
server, database, table, and column level. MySQL supports the use of
character sets for the MyISAM,
MEMORY, NDBCluster, and
InnoDB storage engines.
This chapter discusses the following topics:
What are character sets and collations?
The multiple-level default system for character set assignment
Syntax for specifying character sets and collations
Affected functions and operations
Unicode support
The character sets and collations that are available, with notes
Character set issues affect data storage, but also communication
between client programs and the MySQL server. If you want the client
program to communicate with the server using a character set
different from the default, you'll need to indicate which one. For
example, to use the utf8 Unicode character set,
issue this statement after connecting to the server:
SET NAMES 'utf8';
For more information about character set-related issues in client/server communication, see Section 10.4, “Connection Character Sets and Collations”.
A character set is a set of symbols and encodings. A collation is a set of rules for comparing characters in a character set. Let's make the distinction clear with an example of an imaginary character set.
Suppose that we have an alphabet with four letters:
‘A’,
‘B’,
‘a’,
‘b’. We give each letter a number:
‘A’ = 0,
‘B’ = 1,
‘a’ = 2,
‘b’ = 3. The letter
‘A’ is a symbol, the number 0 is
the encoding for
‘A’, and the combination of all
four letters and their encodings is a
character set.
Suppose that we want to compare two string values,
‘A’ and
‘B’. The simplest way to do this is
to look at the encodings: 0 for ‘A’
and 1 for ‘B’. Because 0 is less
than 1, we say ‘A’ is less than
‘B’. What we've just done is apply
a collation to our character set. The collation is a set of rules
(only one rule in this case): “compare the
encodings.” We call this simplest of all possible
collations a binary collation.
But what if we want to say that the lowercase and uppercase
letters are equivalent? Then we would have at least two rules: (1)
treat the lowercase letters ‘a’ and
‘b’ as equivalent to
‘A’ and
‘B’; (2) then compare the
encodings. We call this a case-insensitive
collation. It's a little more complex than a binary collation.
In real life, most character sets have many characters: not just
‘A’ and
‘B’ but whole alphabets, sometimes
multiple alphabets or eastern writing systems with thousands of
characters, along with many special symbols and punctuation marks.
Also in real life, most collations have many rules, not just for
whether to distinguish lettercase, but also for whether to
distinguish accents (an “accent” is a mark attached
to a character as in German ‘Ö’),
and for multiple-character mappings (such as the rule that
‘Ö’ =
‘OE’ in one of the two German
collations).
MySQL can do these things for you:
Store strings using a variety of character sets
Compare strings using a variety of collations
Mix strings with different character sets or collations in the same server, the same database, or even the same table
Allow specification of character set and collation at any level
In these respects, MySQL is far ahead of most other database management systems. However, to use these features effectively, you need to know what character sets and collations are available, how to change the defaults, and how they affect the behavior of string operators and functions.
The MySQL server can support multiple character sets. To list the
available character sets, use the SHOW CHARACTER
SET statement. A partial listing follows. For more
complete information, see Section 10.10, “Character Sets and Collations That MySQL Supports”.
mysql> SHOW CHARACTER SET;
+----------+-----------------------------+---------------------+--------+
| Charset | Description | Default collation | Maxlen |
+----------+-----------------------------+---------------------+--------+
| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 |
| dec8 | DEC West European | dec8_swedish_ci | 1 |
| cp850 | DOS West European | cp850_general_ci | 1 |
| hp8 | HP West European | hp8_english_ci | 1 |
| koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 |
| latin1 | cp1252 West European | latin1_swedish_ci | 1 |
| latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 |
| swe7 | 7bit Swedish | swe7_swedish_ci | 1 |
| ascii | US ASCII | ascii_general_ci | 1 |
| ujis | EUC-JP Japanese | ujis_japanese_ci | 3 |
| sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 |
| hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 |
| tis620 | TIS620 Thai | tis620_thai_ci | 1 |
| euckr | EUC-KR Korean | euckr_korean_ci | 2 |
| koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 |
| gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 |
| greek | ISO 8859-7 Greek | greek_general_ci | 1 |
| cp1250 | Windows Central European | cp1250_general_ci | 1 |
| gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 |
| latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 |
...
Any given character set always has at least one collation. It may
have several collations. To list the collations for a character
set, use the SHOW COLLATION statement. For
example, to see the collations for the latin1
(cp1252 West European) character set, use this statement to find
those collation names that begin with latin1:
mysql> SHOW COLLATION LIKE 'latin1%';
+---------------------+---------+----+---------+----------+---------+
| Collation | Charset | Id | Default | Compiled | Sortlen |
+---------------------+---------+----+---------+----------+---------+
| latin1_german1_ci | latin1 | 5 | | | 0 |
| latin1_swedish_ci | latin1 | 8 | Yes | Yes | 1 |
| latin1_danish_ci | latin1 | 15 | | | 0 |
| latin1_german2_ci | latin1 | 31 | | Yes | 2 |
| latin1_bin | latin1 | 47 | | Yes | 1 |
| latin1_general_ci | latin1 | 48 | | | 0 |
| latin1_general_cs | latin1 | 49 | | | 0 |
| latin1_spanish_ci | latin1 | 94 | | | 0 |
+---------------------+---------+----+---------+----------+---------+
The latin1 collations have the following
meanings:
| Collation | Meaning |
latin1_german1_ci | German DIN-1 |
latin1_swedish_ci | Swedish/Finnish |
latin1_danish_ci | Danish/Norwegian |
latin1_german2_ci | German DIN-2 |
latin1_bin | Binary according to latin1 encoding |
latin1_general_ci | Multilingual (Western European) |
latin1_general_cs | Multilingual (ISO Western European), case sensitive |
latin1_spanish_ci | Modern Spanish |
Collations have these general characteristics:
Two different character sets cannot have the same collation.
Each character set has one collation that is the default collation. For example, the default collation for
latin1islatin1_swedish_ci. The output forSHOW CHARACTER SETindicates which collation is the default for each displayed character set.There is a convention for collation names: They start with the name of the character set with which they are associated, they usually include a language name, and they end with
_ci(case insensitive),_cs(case sensitive), or_bin(binary).
In cases where a character set has multiple collations, it might not be clear which collation is most suitable for a given application. To avoid choosing the wrong collation, it can be helpful to perform some comparisons with representative data values to make sure that a given collation sorts values the way you expect.
- 10.3.1. Server Character Set and Collation
- 10.3.2. Database Character Set and Collation
- 10.3.3. Table Character Set and Collation
- 10.3.4. Column Character Set and Collation
- 10.3.5. Character String Literal Character Set and Collation
- 10.3.6. National Character Set
- 10.3.7. Examples of Character Set and Collation Assignment
- 10.3.8. Compatibility with Other DBMSs
There are default settings for character sets and collations at four levels: server, database, table, and column. The following description may appear complex, but it has been found in practice that multiple-level defaulting leads to natural and obvious results.
CHARACTER SET is used in clauses that specify a
character set. CHARSET may be used as a synonym
for CHARACTER SET.
MySQL Server has a server character set and a server collation. These can be set at server startup and changed at runtime.
Initially, the server character set and collation depend on the
options that you use when you start mysqld.
You can use --character-set-server for the
character set. Along with it, you can add
--collation-server for the collation. If you
don't specify a character set, that is the same as saying
--character-set-server=latin1. If you specify
only a character set (for example, latin1)
but not a collation, that is the same as saying
--character-set-server=latin1
--collation-server=latin1_swedish_ci because
latin1_swedish_ci is the default collation
for latin1. Therefore, the following three
commands all have the same effect:
shell>mysqldshell>mysqld --character-set-server=latin1shell>mysqld --character-set-server=latin1 \--collation-server=latin1_swedish_ci
One way to change the settings is by recompiling. If you want to
change the default server character set and collation when
building from sources, use: --with-charset and
--with-collation as arguments for
configure. For example:
shell> ./configure --with-charset=latin1
Or:
shell>./configure --with-charset=latin1 \--with-collation=latin1_german1_ci
Both mysqld and configure verify that the character set/collation combination is valid. If not, each program displays an error message and terminates.
The current server character set and collation can be determined
from the values of the character_set_server
and collation_server system variables. These
variables can be changed at runtime.
Every database has a database character set and a database
collation. The CREATE DATABASE and
ALTER DATABASE statements have optional
clauses for specifying the database character set and collation:
CREATE DATABASEdb_name[[DEFAULT] CHARACTER SETcharset_name] [[DEFAULT] COLLATEcollation_name] ALTER DATABASEdb_name[[DEFAULT] CHARACTER SETcharset_name] [[DEFAULT] COLLATEcollation_name]
The keyword SCHEMA can be used instead of
DATABASE.
All database options are stored in a text file named
db.opt that can be found in the database
directory.
The CHARACTER SET and
COLLATE clauses make it possible to create
databases with different character sets and collations on the
same MySQL server.
Example:
CREATE DATABASE db_name CHARACTER SET latin1 COLLATE latin1_swedish_ci;
MySQL chooses the database character set and database collation in the following manner:
If both
CHARACTER SETandXCOLLATEwere specified, then character setYXand collationY.If
CHARACTER SETwas specified withoutXCOLLATE, then character setXand its default collation.If
COLLATEwas specified withoutYCHARACTER SET, then the character set associated withYand collationY.Otherwise, the server character set and server collation.
The database character set and collation are used as default
values if the table character set and collation are not
specified in CREATE TABLE statements. They
have no other purpose.
The character set and collation for the default database can be
determined from the values of the
character_set_database and
collation_database system variables. The
server sets these variables whenever the default database
changes. If there is no default database, the variables have the
same value as the corresponding server-level system variables,
character_set_server and
collation_server.
Every table has a table character set and a table collation. The
CREATE TABLE and ALTER
TABLE statements have optional clauses for specifying
the table character set and collation:
CREATE TABLEtbl_name(column_list) [[DEFAULT] CHARACTER SETcharset_name] [COLLATEcollation_name]] ALTER TABLEtbl_name[[DEFAULT] CHARACTER SETcharset_name] [COLLATEcollation_name]
Example:
CREATE TABLE t1 ( ... ) CHARACTER SET latin1 COLLATE latin1_danish_ci;
MySQL chooses the table character set and collation in the following manner:
If both
CHARACTER SETandXCOLLATEwere specified, then character setYXand collationY.If
CHARACTER SETwas specified withoutXCOLLATE, then character setXand its default collation.If
COLLATEwas specified withoutYCHARACTER SET, then the character set associated withYand collationY.Otherwise, the database character set and collation.
The table character set and collation are used as default values if the column character set and collation are not specified in individual column definitions. The table character set and collation are MySQL extensions; there are no such things in standard SQL.
Every “character” column (that is, a column of type
CHAR, VARCHAR, or
TEXT) has a column character set and a column
collation. Column definition syntax has optional clauses for
specifying the column character set and collation:
col_name{CHAR | VARCHAR | TEXT} (col_length) [CHARACTER SETcharset_name] [COLLATEcollation_name]
Example:
CREATE TABLE Table1
(
column1 VARCHAR(5) CHARACTER SET latin1 COLLATE latin1_german1_ci
);
MySQL chooses the column character set and collation in the following manner:
If both
CHARACTER SETandXCOLLATEwere specified, then character setYXand collationYare used.If
CHARACTER SETwas specified withoutXCOLLATE, then character setXand its default collation are used.If
COLLATEwas specified withoutYCHARACTER SET, then the character set associated withYand collationY.Otherwise, the table character set and collation are used.
The CHARACTER SET and
COLLATE clauses are standard SQL.
Every character string literal has a character set and a collation.
A character string literal may have an optional character set
introducer and COLLATE clause:
[_charset_name]'string' [COLLATEcollation_name]
Examples:
SELECT 'string'; SELECT _latin1'string'; SELECT _latin1'string' COLLATE latin1_danish_ci;
For the simple statement SELECT
', the string has
the character set and collation defined by the
string'character_set_connection and
collation_connection system variables.
The _
expression is formally called an
introducer. It tells the parser, “the
string that is about to follow uses character set
charset_nameX.” Because this has confused
people in the past, we emphasize that an introducer does not
cause any conversion; it is strictly a signal that does not
change the string's value. An introducer is also legal before
standard hex literal and numeric hex literal notation
(x' and
literal'0x)>.
nnnn
Examples:
SELECT _latin1 x'AABBCC'; SELECT _latin1 0xAABBCC;
MySQL determines a literal's character set and collation in the following manner:
If both
_XandCOLLATEwere specified, then character setYXand collationYare used.If
_Xis specified butCOLLATEis not specified, then character setXand its default collation are used.Otherwise, the character set and collation given by the
character_set_connectionandcollation_connectionsystem variables are used.
Examples:
A string with
latin1character set andlatin1_german1_cicollation:SELECT _latin1'Müller' COLLATE latin1_german1_ci;
A string with
latin1character set and its default collation (that is,latin1_swedish_ci):SELECT _latin1'Müller';
A string with the connection default character set and collation:
SELECT 'Müller';
Character set introducers and the COLLATE
clause are implemented according to standard SQL specifications.
An introducer indicates the character set for the following
string, but does not change now how the parser performs escape
processing within the string. Escapes are always interpreted by
the parser according to the character set given by
character_set_connection.
The following examples show that escape processsing occurs using
character_set_connection even in the presence
of an introducer. The examples use SET NAMES
(which changes character_set_connection, as
discussed in Section 10.4, “Connection Character Sets and Collations”), and display
the resulting strings using the HEX()
function so that the exact string contents can be seen.
Example 1:
mysql>SET NAMES latin1;Query OK, 0 rows affected (0.01 sec) mysql>SELECT HEX('à\n'), HEX(_sjis'à\n');+------------+-----------------+ | HEX('à\n') | HEX(_sjis'à\n') | +------------+-----------------+ | E00A | E00A | +------------+-----------------+ 1 row in set (0.00 sec)
Here, ‘à’ (hex value
E0) is followed by
‘\n’, the escape sequence for
newline. The escape sequence is interpreted using the
character_set_connection value of
latin1 to produce a literal newline (hex
value 0A). This happens even for the second
string. That is, the introducer of _sjis does
not affect the parser's escape processing.
Example 2:
mysql>SET NAMES sjis;Query OK, 0 rows affected (0.00 sec) mysql>SELECT HEX('à\n'), HEX(_latin1'à\n');+------------+-------------------+ | HEX('à\n') | HEX(_latin1'à\n') | +------------+-------------------+ | E05C6E | E05C6E | +------------+-------------------+ 1 row in set (0.04 sec)
Here, character_set_connection is
sjis, a character set in which the sequence
of ‘à’ followed by
‘\’ (hex values
05 and 5C) is a valid
multi-byte character. Hence, the first two bytes of the string
are interpreted as a single sjis character,
and the ‘\’ is not intrepreted as
an escape character. The following
‘n’ (hex value
6E) is not interpreted as part of an escape
sequence. This is true even for the second string; the
introducer of _latin1 does not affect escape
processing.
Standard SQL defines NCHAR or
NATIONAL CHAR as a way to indicate that a
CHAR column should use some predefined
character set. MySQL 5.0 uses
utf8 as this predefined character set. For
example, these data type declarations are equivalent:
CHAR(10) CHARACTER SET utf8 NATIONAL CHARACTER(10) NCHAR(10)
As are these:
VARCHAR(10) CHARACTER SET utf8 NATIONAL VARCHAR(10) NCHAR VARCHAR(10) NATIONAL CHARACTER VARYING(10) NATIONAL CHAR VARYING(10)
You can use
N' to
create a string in the national character set. These two
statements are equivalent:
literal'
SELECT N'some text'; SELECT _utf8'some text';
For information on upgrading character sets to MySQL 5.0 from versions prior to 4.1, see the MySQL 3.23, 4.0, 4.1 Reference Manual.
The following examples show how MySQL determines default character set and collation values.
Example 1: Table and Column Definition
CREATE TABLE t1
(
c1 CHAR(10) CHARACTER SET latin1 COLLATE latin1_german1_ci
) DEFAULT CHARACTER SET latin2 COLLATE latin2_bin;
Here we have a column with a latin1 character
set and a latin1_german1_ci collation. The
definition is explicit, so that's straightforward. Notice that
there is no problem with storing a latin1
column in a latin2 table.
Example 2: Table and Column Definition
CREATE TABLE t1
(
c1 CHAR(10) CHARACTER SET latin1
) DEFAULT CHARACTER SET latin1 COLLATE latin1_danish_ci;
This time we have a column with a latin1
character set and a default collation. Although it might seem
natural, the default collation is not taken from the table
level. Instead, because the default collation for
latin1 is always
latin1_swedish_ci, column
c1 has a collation of
latin1_swedish_ci (not
latin1_danish_ci).
Example 3: Table and Column Definition
CREATE TABLE t1
(
c1 CHAR(10)
) DEFAULT CHARACTER SET latin1 COLLATE latin1_danish_ci;
We have a column with a default character set and a default
collation. In this circumstance, MySQL checks the table level to
determine the column character set and collation. Consequently,
the character set for column c1 is
latin1 and its collation is
latin1_danish_ci.
Example 4: Database, Table, and Column Definition
CREATE DATABASE d1
DEFAULT CHARACTER SET latin2 COLLATE latin2_czech_ci;
USE d1;
CREATE TABLE t1
(
c1 CHAR(10)
);
We create a column without specifying its character set and
collation. We're also not specifying a character set and a
collation at the table level. In this circumstance, MySQL checks
the database level to determine the table settings, which
thereafter become the column settings.) Consequently, the
character set for column c1 is
latin2 and its collation is
latin2_czech_ci.
Several character set and collation system variables relate to a client's interaction with the server. Some of these have been mentioned in earlier sections:
The server character set and collation can be determined from the values of the
character_set_serverandcollation_serversystem variables.The character set and collation of the default database can be determined from the values of the
character_set_databaseandcollation_databasesystem variables.
Additional character set and collation system variables are involved in handling traffic for the connection between a client and the server. Every client has connection-related character set and collation system variables.
Consider what a “connection” is: It's what you make when you connect to the server. The client sends SQL statements, such as queries, over the connection to the server. The server sends responses, such as result sets, over the connection back to the client. This leads to several questions about character set and collation handling for client connections, each of which can be answered in terms of system variables:
What character set is the statement in when it leaves the client?
The server takes the
character_set_clientsystem variable to be the character set in which statements are sent by the client.What character set should the server translate a statement to after receiving it?
For this, the server uses the
character_set_connectionandcollation_connectionsystem variables. It converts statements sent by the client fromcharacter_set_clienttocharacter_set_connection(except for string literals that have an introducer such as_latin1or_utf8).collation_connectionis important for comparisons of literal strings. For comparisons of strings with column values,collation_connectiondoes not matter because columns have their own collation, which has a higher collation precedence.What character set should the server translate to before shipping result sets or error messages back to the client?
The
character_set_resultssystem variable indicates the character set in which the server returns query results to the client. This includes result data such as column values, and result metadata such as column names.
You can fine-tune the settings for these variables, or you can depend on the defaults (in which case, you can skip the rest of this section).
There are two statements that affect the connection character sets:
SET NAMES 'charset_name' SET CHARACTER SETcharset_name
SET NAMES indicates what character set the
client will use to send SQL statements to the server. Thus,
SET NAMES 'cp1251' tells the server
“future incoming messages from this client are in character
set cp1251.” It also specifies the
character set that the server should use for sending results back
to the client. (For example, it indicates what character set to
use for column values if you use a SELECT
statement.)
A SET NAMES '
statement is equivalent to these three statements:
x'
SET character_set_client =x; SET character_set_results =x; SET character_set_connection =x;
Setting character_set_connection to
x also sets
collation_connection to the default collation
for x. It is not necessary to set that
collation explicitly. To specify a particular collation for the
character sets, use the optional COLLATE
clause:
SET NAMES 'charset_name' COLLATE 'collation_name'
SET CHARACTER SET is similar to SET
NAMES but sets
character_set_connection and
collation_connection to
character_set_database and
collation_database. A SET CHARACTER
SET statement is equivalent
to these three statements:
x
SET character_set_client =x; SET character_set_results =x; SET collation_connection = @@collation_database;
Setting collation_connection also sets
character_set_connection to the character set
associated with the collation (equivalent to executing
SET character_set_connection =
@@character_set_database). It is not necessary to set
character_set_connection explicitly.
When a client connects, it sends to the server the name of the
character set that it wants to use. The server uses the name to
set the character_set_client,
character_set_results, and
character_set_connection system variables. In
effect, the server performs a SET NAMES
operation using the character set name.
With the mysql client, it is not necessary to
execute SET NAMES every time you start up if
you want to use a character set different from the default. You
can add the --default-character-set option
setting to your mysql statement line, or in
your option file. For example, the following option file setting
changes the three character set variables set to
koi8r each time you invoke
mysql:
[mysql] default-character-set=koi8r
If you are using the mysql client with
auto-reconnect enabled (which is not recommended), it is
preferable to use the charset command rather
than SET NAMES. For example:
mysql> charset utf8
Charset changed
The charset command issues a SET
NAMES statement, and also changes the default character
set that is used if mysql reconnects after the
connection has dropped.
Example: Suppose that column1 is defined as
CHAR(5) CHARACTER SET latin2. If you do not say
SET NAMES or SET CHARACTER
SET, then for SELECT column1 FROM t,
the server sends back all the values for
column1 using the character set that the client
specified when it connected. On the other hand, if you say
SET NAMES 'latin1' or SET CHARACTER
SET latin1 before issuing the SELECT
statement, the server converts the latin2
values to latin1 just before sending results
back. Conversion may be lossy if there are characters that are not
in both character sets.
If you do not want the server to perform any conversion of result
sets, set character_set_results to
NULL:
SET character_set_results = NULL;
Note: Currently, UCS-2 cannot be
used as a client character set, which means that SET
NAMES 'ucs2' does not work.
To see the values of the character set and collation system variables that apply to your connection, use these statements:
SHOW VARIABLES LIKE 'character_set%'; SHOW VARIABLES LIKE 'collation%';
You must also consider the environment within which your MySQL application executes. For example, if you will send statements using UTF-8 test taken from a file that you create in an editor, you should edit the file with the locale of your environment set to UTF-8 so that the file's encoding is correct and so that the operating system handles it correctly. For a script that executes in a Web environment, the script must handle the character encoding properly for its interaction with the MySQL server, and it must generate pages that correctly indicate the encoding so that browsers know now to display the content of the pages.
The following sections discuss various aspects of character set collations.
With the COLLATE clause, you can override
whatever the default collation is for a comparison.
COLLATE may be used in various parts of SQL
statements. Here are some examples:
With
ORDER BY:SELECT k FROM t1 ORDER BY k COLLATE latin1_german2_ci;
With
AS:SELECT k COLLATE latin1_german2_ci AS k1 FROM t1 ORDER BY k1;
With
GROUP BY:SELECT k FROM t1 GROUP BY k COLLATE latin1_german2_ci;
With aggregate functions:
SELECT MAX(k COLLATE latin1_german2_ci) FROM t1;
With
DISTINCT:SELECT DISTINCT k COLLATE latin1_german2_ci FROM t1;
With
WHERE:SELECT * FROM t1 WHERE _latin1 'Müller' COLLATE latin1_german2_ci = k;SELECT * FROM t1 WHERE k LIKE _latin1 'Müller' COLLATE latin1_german2_ci;With
HAVING:SELECT k FROM t1 GROUP BY k HAVING k = _latin1 'Müller' COLLATE latin1_german2_ci;
The COLLATE clause has high precedence
(higher than ||), so the following two
expressions are equivalent:
x || y COLLATE z x || (y COLLATE z)
The BINARY operator casts the string
following it to a binary string. This is an easy way to force a
comparison to be done byte by byte rather than character by
character. BINARY also causes trailing spaces
to be significant.
mysql>SELECT 'a' = 'A';-> 1 mysql>SELECT BINARY 'a' = 'A';-> 0 mysql>SELECT 'a' = 'a ';-> 1 mysql>SELECT BINARY 'a' = 'a ';-> 0
BINARY is
shorthand for strCAST(.
str AS
BINARY)
The BINARY attribute in character column
definitions has a different effect. A character column defined
with the BINARY attribute is assigned the
binary collation of the column's character set. Every character
set has a binary collation. For example, the binary collation
for the latin1 character set is
latin1_bin, so if the table default character
set is latin1, these two column definitions
are equivalent:
CHAR(10) BINARY CHAR(10) CHARACTER SET latin1 COLLATE latin1_bin
The effect of BINARY as a column attribute
differs from its effect prior to MySQL 4.1. Formerly,
BINARY resulted in a column that was treated
as a binary string. A binary string is a string of bytes that
has no character set or collation, which differs from a
non-binary character string that has a binary collation. For
both types of strings, comparisons are based on the numeric
values of the string unit, but for non-binary strings the unit
is the character and some character sets allow multi-byte
characters. Section 11.4.2, “The BINARY and VARBINARY Types”.
The use of CHARACTER SET binary in the
definition of a CHAR,
VARCHAR, or TEXT column
causes the column to be treated as a binary data type. For
example, the following pairs of definitions are equivalent:
CHAR(10) CHARACTER SET binary BINARY(10) VARCHAR(10) CHARACTER SET binary VARBINARY(10) TEXT CHARACTER SET binary BLOB
In the great majority of statements, it is obvious what
collation MySQL uses to resolve a comparison operation. For
example, in the following cases, it should be clear that the
collation is the collation of column x:
SELECT x FROM T ORDER BY x; SELECT x FROM T WHERE x = x; SELECT DISTINCT x FROM T;
However, when multiple operands are involved, there can be ambiguity. For example:
SELECT x FROM T WHERE x = 'Y';
Should this query use the collation of the column
x, or of the string literal
'Y'?
Standard SQL resolves such questions using what used to be
called “coercibility” rules. Basically, this means:
Both x and 'Y' have
collations, so which collation takes precedence? This can be
difficult to resolve, but the following rules cover most
situations:
An explicit
COLLATEclause has a coercibility of 0. (Not coercible at all.)The concatenation of two strings with different collations has a coercibility of 1.
The collation of a column or a stored routine parameter or local variable has a coercibility of 2.
A “system constant” (the string returned by functions such as
USER()orVERSION()) has a coercibility of 3.A literal's collation has a coercibility of 4.
NULLor an expression that is derived fromNULLhas a coercibility of 5.
The preceding coercibility values are current as of MySQL 5.0.3.
In MySQL 5.0 prior to 5.0.3, there is no system
constant or ignorable coercibility. Functions such as
USER() have a coercibility of 2 rather than
3, and literals have a coercibility of 3 rather than 4.
Those rules resolve ambiguities in the following manner:
Use the collation with the lowest coercibility value.
If both sides have the same coercibility, then it is an error if the collations aren't the same.
Examples:
column1 = 'A' | Use collation of column1 |
column1 = 'A' COLLATE x | Use collation of 'A' COLLATE x |
column1 COLLATE x = 'A' COLLATE y | Error |
The COERCIBILITY() function can be used to
determine the coercibility of a string expression:
mysql>SELECT COERCIBILITY('A' COLLATE latin1_swedish_ci);-> 0 mysql>SELECT COERCIBILITY(VERSION());-> 3 mysql>SELECT COERCIBILITY('A');-> 4
Each character set has one or more collations, but each
collation is associated with one and only one character set.
Therefore, the following statement causes an error message
because the latin2_bin collation is not legal
with the latin1 character set:
mysql> SELECT _latin1 'x' COLLATE latin2_bin;
ERROR 1253 (42000): COLLATION 'latin2_bin' is not valid
for CHARACTER SET 'latin1'
Suppose that column X in table
T has these latin1 column
values:
Muffler Müller MX Systems MySQL
Suppose also that the column values are retrieved using the following statement:
SELECT X FROM T ORDER BY X COLLATE collation_name;
The following table shows the resulting order of the values if
we use ORDER BY with different collations:
latin1_swedish_ci | latin1_german1_ci | latin1_german2_ci |
| Muffler | Muffler | Müller |
| MX Systems | Müller | Muffler |
| Müller | MX Systems | MX Systems |
| MySQL | MySQL | MySQL |
The character that causes the different sort orders in this
example is the U with two dots over it
(ü), which the Germans call
“U-umlaut.”
The first column shows the result of the
SELECTusing the Swedish/Finnish collating rule, which says that U-umlaut sorts with Y.The second column shows the result of the
SELECTusing the German DIN-1 rule, which says that U-umlaut sorts with U.The third column shows the result of the
SELECTusing the German DIN-2 rule, which says that U-umlaut sorts with UE.
This section describes operations that take character set information into account.
MySQL has many operators and functions that return a string. This section answers the question: What is the character set and collation of such a string?
For simple functions that take string input and return a string
result as output, the output's character set and collation are
the same as those of the principal input value. For example,
UPPER( returns a
string whose character string and collation are the same as that
of X)X. The same applies for
INSTR(), LCASE(),
LOWER(), LTRIM(),
MID(), REPEAT(),
REPLACE(), REVERSE(),
RIGHT(), RPAD(),
RTRIM(), SOUNDEX(),
SUBSTRING(), TRIM(),
UCASE(), and UPPER().
Note: The REPLACE() function, unlike all
other functions, always ignores the collation of the string
input and performs a case-sensitive comparison.
If a string input or function result is a binary string, the
string has no character set or collation. This can be check by
using the CHARSET() and
COLLATION() functions, both of which return
binary to indicate that their argument is a
binary string:
mysql> SELECT CHARSET(BINARY 'a'), COLLATION(BINARY 'a');
+---------------------+-----------------------+
| CHARSET(BINARY 'a') | COLLATION(BINARY 'a') |
+---------------------+-----------------------+
| binary | binary |
+---------------------+-----------------------+
For operations that combine multiple string inputs and return a single string output, the “aggregation rules” of standard SQL apply for determining the collation of the result:
If an explicit
COLLATEoccurs, useXX.If explicit
COLLATEandXCOLLATEoccur, raise an error.YOtherwise, if all collations are
X, useX.Otherwise, the result has no collation.
For example, with CASE ... WHEN a THEN b WHEN b THEN c
COLLATE , the
resulting collation is X ENDX. The same
applies for UNION, ||,
CONCAT(), ELT(),
GREATEST(), IF(), and
LEAST().
For operations that convert to character data, the character set
and collation of the strings that result from the operations are
defined by the character_set_connection and
collation_connection system variables. This
applies only to CAST(),
CONV(), FORMAT(),
HEX(), SPACE(). Before
MySQL 5.0.15, it also applies to CHAR().
If you are uncertain about the character set or collation of the
result returned by a string function, you can use the
CHARSET() or COLLATE()
function to find out:
mysql> SELECT USER(), CHARSET(USER()), COLLATION(USER());
+----------------+-----------------+-------------------+
| USER() | CHARSET(USER()) | COLLATION(USER()) |
+----------------+-----------------+-------------------+
| test@localhost | utf8 | utf8_general_ci |
+----------------+-----------------+-------------------+
CONVERT() provides a way to convert data
between different character sets. The syntax is:
CONVERT(exprUSINGtranscoding_name)
In MySQL, transcoding names are the same as the corresponding character set names.
Examples:
SELECT CONVERT(_latin1'Müller' USING utf8);
INSERT INTO utf8table (utf8column)
SELECT CONVERT(latin1field USING utf8) FROM latin1table;
CONVERT(... USING ...) is implemented
according to the standard SQL specification.
You may also use CAST() to convert a string
to a different character set. The syntax is:
CAST(character_stringAScharacter_data_typeCHARACTER SETcharset_name)
Example:
SELECT CAST(_latin1'test' AS CHAR CHARACTER SET utf8);
If you use CAST() without specifying
CHARACTER SET, the resulting character set
and collation are defined by the
character_set_connection and
collation_connection system variables. If you
use CAST() with CHARACTER SET
X, the resulting character set and collation are
X and the default collation of
X.
You may not use a COLLATE clause inside a
CAST(), but you may use it outside. That is,
CAST(... COLLATE ...) is illegal, but
CAST(...) COLLATE ... is legal.
Example:
SELECT CAST(_latin1'test' AS CHAR CHARACTER SET utf8) COLLATE utf8_bin;
Several SHOW statements provide additional
character set information. These include SHOW CHARACTER
SET, SHOW COLLATION, SHOW
CREATE DATABASE, SHOW CREATE TABLE
and SHOW COLUMNS. These statements are
described here briefly. For more information, see
Section 13.5.4, “SHOW Syntax”.
INFORMATION_SCHEMA has several tables that
contain information similar to that displayed by the
SHOW statements. For example, the
CHARACTER_SETS and
COLLATIONS tables contain the information
displayed by SHOW CHARACTER SET and
SHOW COLLATION.
Chapter 20, The INFORMATION_SCHEMA Database.
The SHOW CHARACTER SET command shows all
available character sets. It takes an optional
LIKE clause that indicates which character
set names to match. For example:
mysql> SHOW CHARACTER SET LIKE 'latin%';
+---------+-----------------------------+-------------------+--------+
| Charset | Description | Default collation | Maxlen |
+---------+-----------------------------+-------------------+--------+
| latin1 | cp1252 West European | latin1_swedish_ci | 1 |
| latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 |
| latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 |
| latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 |
+---------+-----------------------------+-------------------+--------+
The output from SHOW COLLATION includes all
available character sets. It takes an optional
LIKE clause that indicates which collation
names to match. For example:
mysql> SHOW COLLATION LIKE 'latin1%';
+-------------------+---------+----+---------+----------+---------+
| Collation | Charset | Id | Default | Compiled | Sortlen |
+-------------------+---------+----+---------+----------+---------+
| latin1_german1_ci | latin1 | 5 | | | 0 |
| latin1_swedish_ci | latin1 | 8 | Yes | Yes | 0 |
| latin1_danish_ci | latin1 | 15 | | | 0 |
| latin1_german2_ci | latin1 | 31 | | Yes | 2 |
| latin1_bin | latin1 | 47 | | Yes | 0 |
| latin1_general_ci | latin1 | 48 | | | 0 |
| latin1_general_cs | latin1 | 49 | | | 0 |
| latin1_spanish_ci | latin1 | 94 | | | 0 |
+-------------------+---------+----+---------+----------+---------+
SHOW CREATE DATABASE displays the
CREATE DATABASE statement that creates a
given database:
mysql> SHOW CREATE DATABASE test;
+----------+-----------------------------------------------------------------+
| Database | Create Database |
+----------+-----------------------------------------------------------------+
| test | CREATE DATABASE `test` /*!40100 DEFAULT CHARACTER SET latin1 */ |
+----------+-----------------------------------------------------------------+
If no COLLATE clause is shown, the default
collation for the character set applies.
SHOW CREATE TABLE is similar, but displays
the CREATE TABLE statement to create a given
table. The column definitions indicate any character set
specifications, and the table options include character set
information.
The SHOW COLUMNS statement displays the
collations of a table's columns when invoked as SHOW
FULL COLUMNS. Columns with CHAR,
VARCHAR, or TEXT data
types have collations. Numeric and other non-character types
have no collation (indicated by NULL as the
Collation value). For example:
mysql> SHOW FULL COLUMNS FROM person\G
*************************** 1. row ***************************
Field: id
Type: smallint(5) unsigned
Collation: NULL
Null: NO
Key: PRI
Default: NULL
Extra: auto_increment
Privileges: select,insert,update,references
Comment:
*************************** 2. row ***************************
Field: name
Type: char(60)
Collation: latin1_swedish_ci
Null: NO
Key:
Default:
Extra:
Privileges: select,insert,update,references
Comment:
The character set is not part of the display but is implied by the collation name.
MySQL 5.0 supports two character sets for storing Unicode data:
ucs2, the UCS-2 Unicode character set.utf8, the UTF-8 encoding of the Unicode character set.
In UCS-2 (binary Unicode representation), every character is
represented by a two-byte Unicode code with the most significant
byte first. For example: LATIN CAPITAL LETTER A
has the code 0x0041 and it is stored as a
two-byte sequence: 0x00 0x41. CYRILLIC
SMALL LETTER YERU (Unicode 0x044B) is
stored as a two-byte sequence: 0x04 0x4B. For
Unicode characters and their codes, please refer to the
Unicode Home Page.
The MySQL implementation of UCS-2 stores characters in big-endian byte order and does not use a byte order mark (BOM) at the beginning of UCS-2 values. Other database systems might use little-ending byte order or a BOM, in which case conversion of UCS-2 values will need to be performed when transferring data between those systems and MySQL.
Currently, UCS-2 cannot be used as a client character set, which
means that SET NAMES 'ucs2' does not work.
UTF-8 (Unicode Transform representation) is an alternative way to store Unicode data. It is implemented according to RFC 3629. The idea of UTF-8 is that various Unicode characters are encoded using byte sequences of different lengths:
Basic Latin letters, digits, and punctuation signs use one byte.
Most European and Middle East script letters fit into a two-byte sequence: extended Latin letters (with tilde, macron, acute, grave and other accents), Cyrillic, Greek, Armenian, Hebrew, Arabic, Syriac, and others.
Korean, Chinese, and Japanese ideographs use three-byte sequences.
RFC 3629 describes encoding sequences that take from one to four bytes. Currently, MySQL support for UTF-8 does not include four-byte sequences. (An older standard for UTF-8 encoding is given by RFC 2279, which describes UTF-8 sequences that take from one to six bytes. RFC 3629 renders RFC 2279 obsolete; for this reason, sequences with five and six bytes are no longer used.)
Tip: To save space with UTF-8,
use VARCHAR instead of CHAR.
Otherwise, MySQL must reserve three bytes for each character in a
CHAR CHARACTER SET utf8 column because that is
the maximum possible length. For example, MySQL must reserve 30
bytes for a CHAR(10) CHARACTER SET utf8 column.
Metadata is “the data about the
data.” Anything that describes the
database — as opposed to being the
contents of the database — is metadata.
Thus column names, database names, usernames, version names, and
most of the string results from SHOW are
metadata. This is also true of the contents of tables in
INFORMATION_SCHEMA, because those tables by
definition contain information about database objects.
Representation of metadata must satisfy these requirements:
All metadata must be in the same character set. Otherwise, neither the
SHOWcommands norSELECTstatements for tables inINFORMATION_SCHEMAwould work properly because different rows in the same column of the results of these operations would be in different character sets.Metadata must include all characters in all languages. Otherwise, users would not be able to name columns and tables using their own languages.
To satisfy both requirements, MySQL stores metadata in a Unicode character set, namely UTF-8. This does not cause any disruption if you never use accented or non-Latin characters. But if you do, you should be aware that metadata is in UTF-8.
The metadata requirements mean that the return values of the
USER(), CURRENT_USER(),
SESSION_USER(),
SYSTEM_USER(), DATABASE(),
and VERSION() functions have the UTF-8
character set by default.
The server sets the character_set_system system
variable to the name of the metadata character set:
mysql> SHOW VARIABLES LIKE 'character_set_system';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| character_set_system | utf8 |
+----------------------+-------+
Storage of metadata using Unicode does not
mean that the server returns headers of columns and the results of
DESCRIBE functions in the
character_set_system character set by default.
When you use SELECT column1 FROM t, the name
column1 itself is returned from the server to
the client in the character set determined by the value of the
character_set_results system variable, which
has a default value of latin1. If you want the
server to pass metadata results back in a different character set,
use the SET NAMES statement to force the server
to perform character set conversion. SET NAMES
sets the character_set_results and other
related system variables. (See
Section 10.4, “Connection Character Sets and Collations”.) Alternatively, a client
program can perform the conversion after receiving the result from
the server. It is more efficient for the client perform the
conversion, but this option is not always available for all
clients.
If character_set_results is set to
NULL, no conversion is performed and the server
returns metadata using its original character set (the set
indicated by character_set_system).
Error messages returned from the server to the client are converted to the client character set automatically, as with metadata.
If you are using (for example) the USER()
function for comparison or assignment within a single statement,
don't worry. MySQL performs some automatic conversion for you.
SELECT * FROM Table1 WHERE USER() = latin1_column;
This works because the contents of
latin1_column are automatically converted to
UTF-8 before the comparison.
INSERT INTO Table1 (latin1_column) SELECT USER();
This works because the contents of USER() are
automatically converted to latin1 before the
assignment. Automatic conversion is not fully implemented yet, but
should work correctly in a later version.
Although automatic conversion is not in the SQL standard, the SQL standard document does say that every character set is (in terms of supported characters) a “subset” of Unicode. Because it is a well-known principle that “what applies to a superset can apply to a subset,” we believe that a collation for Unicode can apply for comparisons with non-Unicode strings.
To convert a binary or non-binary string column to use a
particular character set, use ALTER TABLE. For
successful conversion to occur, one of the following conditions
must apply:
If the column has a binary data type (
BINARY,VARBINARY,BLOB), all the values that it contains must be encoded using a single character set (the character set you're converting the column to). If you use a binary column to store information in multiple character sets, MySQL has no way to know which values use which character set and cannot convert the data properly.If the column has a non-binary data type (
CHAR,VARCHAR,TEXT), its contents should be encoded in the column's character set, not some other character set. If the contents are encoded in a different character set, you can convert the column to use a binary data type first, and then to a non-binary column with the desired character set.
Suppose that a table t has a binary column
named col1 defined as
BINARY(50). Assuming that the information in
the column is encoded using a single character set, you can
convert it to a non-binary column that has that character set. For
example, if col1 contains binary data
representing characters in the greek character
set, you can convert it as follows:
ALTER TABLE t MODIFY col1 CHAR(50) CHARACTER SET greek;
Suppose that table t has a non-binary column
named col1 defined as CHAR(50)
CHARACTER SET latin1 but you want to convert it to use
utf8 so that you can store values from many
languages. The following statement accomplishes this:
ALTER TABLE t MODIFY col1 CHAR(50) CHARACTER SET utf8;
Conversion may be lossy if the column contains characters that are not in both character sets.
A special case occurs if you have old tables from MySQL 4.0 or
earlier where a non-binary column contains values that actually
are encoded in a character set different from the server's default
character set. For example, an application might have stored
sjis values in a column, even though MySQL's
default character set was latin1. It is
possible to convert the column to use the proper character set but
an additional step is required. Suppose that the server's default
character set was latin1 and
col1 is defined as CHAR(50)
but its contents are sjis values. The first
step is to convert the column to a binary data type, which removes
the existing character set information without performing any
character conversion:
ALTER TABLE t MODIFY col1 BINARY(50);
The next step is to convert the column to a non-binary data type with the proper character set:
ALTER TABLE t MODIFY col1 CHAR(50) CHARACTER SET sjis;
This procedure requires that the table not have been modified
already with statements such as INSERT or
UPDATE after an upgrade to MySQL 4.1 or later.
In that case, MySQL would store new values in the column using
latin1, and the column will contain a mix of
sjis and latin1 values and
cannot be converted properly.
If you specified attributes when creating a column initially, you
should also specify them when altering the table with
ALTER TABLE. For example, if you specified
NOT NULL and an explicit
DEFAULT value, you should also provide them in
the ALTER TABLE statement. Otherwise, the
resulting column definition will not include those attributes.
MySQL supports 70+ collations for 30+ character sets. This section indicates which character sets MySQL supports. There is one subsection for each group of related character sets. For each character set, the allowable collations are listed.
You can always list the available character sets and their default
collations with the SHOW CHARACTER SET
statement:
mysql> SHOW CHARACTER SET;
+----------+-----------------------------+---------------------+
| Charset | Description | Default collation |
+----------+-----------------------------+---------------------+
| big5 | Big5 Traditional Chinese | big5_chinese_ci |
| dec8 | DEC West European | dec8_swedish_ci |
| cp850 | DOS West European | cp850_general_ci |
| hp8 | HP West European | hp8_english_ci |
| koi8r | KOI8-R Relcom Russian | koi8r_general_ci |
| latin1 | cp1252 West European | latin1_swedish_ci |
| latin2 | ISO 8859-2 Central European | latin2_general_ci |
| swe7 | 7bit Swedish | swe7_swedish_ci |
| ascii | US ASCII | ascii_general_ci |
| ujis | EUC-JP Japanese | ujis_japanese_ci |
| sjis | Shift-JIS Japanese | sjis_japanese_ci |
| hebrew | ISO 8859-8 Hebrew | hebrew_general_ci |
| tis620 | TIS620 Thai | tis620_thai_ci |
| euckr | EUC-KR Korean | euckr_korean_ci |
| koi8u | KOI8-U Ukrainian | koi8u_general_ci |
| gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci |
| greek | ISO 8859-7 Greek | greek_general_ci |
| cp1250 | Windows Central European | cp1250_general_ci |
| gbk | GBK Simplified Chinese | gbk_chinese_ci |
| latin5 | ISO 8859-9 Turkish | latin5_turkish_ci |
| armscii8 | ARMSCII-8 Armenian | armscii8_general_ci |
| utf8 | UTF-8 Unicode | utf8_general_ci |
| ucs2 | UCS-2 Unicode | ucs2_general_ci |
| cp866 | DOS Russian | cp866_general_ci |
| keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci |
| macce | Mac Central European | macce_general_ci |
| macroman | Mac West European | macroman_general_ci |
| cp852 | DOS Central European | cp852_general_ci |
| latin7 | ISO 8859-13 Baltic | latin7_general_ci |
| cp1251 | Windows Cyrillic | cp1251_general_ci |
| cp1256 | Windows Arabic | cp1256_general_ci |
| cp1257 | Windows Baltic | cp1257_general_ci |
| binary | Binary pseudo charset | binary |
| geostd8 | GEOSTD8 Georgian | geostd8_general_ci |
| cp932 | SJIS for Windows Japanese | cp932_japanese_ci |
| eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci |
+----------+-----------------------------+---------------------+
In cases where a character set has multiple collations, it might not be clear which collation is most suitable for a given application. To avoid choosing the wrong collation, it can be helpful to perform some comparisons with representative data values to make sure that a given collation sorts values the way you expect.
MySQL has two Unicode character sets. You can store text in about 650 languages using these character sets.
ucs2(UCS-2 Unicode) collations:ucs2_binucs2_czech_ciucs2_danish_ciucs2_esperanto_ciucs2_estonian_ciucs2_general_ci(default)ucs2_hungarian_ciucs2_icelandic_ciucs2_latvian_ciucs2_lithuanian_ciucs2_persian_ciucs2_polish_ciucs2_roman_ciucs2_romanian_ciucs2_slovak_ciucs2_slovenian_ciucs2_spanish2_ciucs2_spanish_ciucs2_swedish_ciucs2_turkish_ciucs2_unicode_ci
utf8(UTF-8 Unicode) collations:utf8_binutf8_czech_ciutf8_danish_ciutf8_esperanto_ciutf8_estonian_ciutf8_general_ci(default)utf8_hungarian_ciutf8_icelandic_ciutf8_latvian_ciutf8_lithuanian_ciutf8_persian_ciutf8_polish_ciutf8_roman_ciutf8_romanian_ciutf8_slovak_ciutf8_slovenian_ciutf8_spanish2_ciutf8_spanish_ciutf8_swedish_ciutf8_turkish_ciutf8_unicode_ci
The MySQL implementation of UCS-2 stores characters in big-endian byte order and does not use a byte order mark (BOM) at the beginning of UCS-2 values. Other database systems might use little-ending byte order or a BOM, in which case conversion of UCS-2 values will need to be performed when transferring data between those systems and MySQL.
Note that in the ucs2_roman_ci and
utf8_roman_ci collations,
I and J compare as equals,
and U and V compare as
equals.
The ucs2_esperanto_ci and
utf8_esperanto_ci collations were added in
MySQL 5.0.13. The ucs2_hungarian_ci and
utf8_hungarian_ci collations were added in
MySQL 5.0.19.
MySQL implements the utf8_unicode_ci
collation according to the Unicode Collation Algorithm (UCA)
described at
http://www.unicode.org/reports/tr10/. The
collation uses the version-4.0.0 UCA weight keys:
http://www.unicode.org/Public/UCA/4.0.0/allkeys-4.0.0.txt.
The following discussion uses
utf8_unicode_ci, but it is also true for
ucs2_unicode_ci.
Currently, the utf8_unicode_ci collation has
only partial support for the Unicode Collation Algorithm. Some
characters are not supported yet. Also, combining marks are not
fully supported. This affects primarily Vietnamese, Yoruba, and
some smaller languages such as Navajo.
The most significant feature in
utf8_unicode_ci is that it supports
expansions; that is, when one character compares as equal to
combinations of other characters. For example, in German and
some other languages ‘ß’ is
equal to ‘ss’.
utf8_general_ci is a legacy collation that
does not support expansions. It can make only one-to-one
comparisons between characters. This means that comparisons for
the utf8_general_ci collation are faster, but
slightly less correct, than comparisons for
utf8_unicode_ci.
For example, the following equalities hold in both
utf8_general_ci and
utf8_unicode_ci:
Ä = A Ö = O Ü = U
A difference between the collations is that this is true for
utf8_general_ci:
ß = s
Whereas this is true for utf8_unicode_ci:
ß = ss
MySQL implements language-specific collations for the
utf8 character set only if the ordering with
utf8_unicode_ci does not work well for a
language. For example, utf8_unicode_ci works
fine for German and French, so there is no need to create
special utf8 collations for these two
languages.
utf8_general_ci also is satisfactory for both
German and French, except that
‘ß’ is equal to
‘s’, and not to
‘ss’. If this is acceptable for
your application, then you should use
utf8_general_ci because it is faster.
Otherwise, use utf8_unicode_ci because it is
more accurate.
utf8_swedish_ci, like other
utf8 language-specific collations, is derived
from utf8_unicode_ci with additional language
rules. For example, in Swedish, the following relationship
holds, which is not something expected by a German or French
speaker:
Ü = Y < Ö
The utf8_spanish_ci and
utf8_spanish2_ci collations correspond to
modern Spanish and traditional Spanish, respectively. In both
collations, ‘ñ’ (n-tilde) is a
separate letter between ‘n’ and
‘o’. In addition, for traditional
Spanish, ‘ch’ is a separate
letter between ‘c’ and
‘d’, and
‘ll’ is a separate letter between
‘l’ and
‘m’
Western European character sets cover most West European languages, such as French, Spanish, Catalan, Basque, Portuguese, Italian, Albanian, Dutch, German, Danish, Swedish, Norwegian, Finnish, Faroese, Icelandic, Irish, Scottish, and English.
ascii(US ASCII) collations:ascii_binascii_general_ci(default)
cp850(DOS West European) collations:cp850_bincp850_general_ci(default)
dec8(DEC Western European) collations:dec8_bindec8_swedish_ci(default)
hp8(HP Western European) collations:hp8_binhp8_english_ci(default)
latin1(cp1252 West European) collations:latin1_binlatin1_danish_cilatin1_general_cilatin1_general_cslatin1_german1_cilatin1_german2_cilatin1_spanish_cilatin1_swedish_ci(default)
latin1is the default character set. MySQL'slatin1is the same as the Windowscp1252character set. This means it is the same as the officialISO 8859-1or IANA (Internet Assigned Numbers Authority)latin1, except that IANAlatin1treats the code points between0x80and0x9fas “undefined,” whereascp1252, and therefore MySQL'slatin1, assign characters for those positions. For example,0x80is the Euro sign. For the “undefined” entries incp1252, MySQL translates0x81to Unicode0x0081,0x8dto0x008d,0x8fto0x008f,0x90to0x0090, and0x9dto0x009d.The
latin1_swedish_cicollation is the default that probably is used by the majority of MySQL customers. Although it is frequently said that it is based on the Swedish/Finnish collation rules, there are Swedes and Finns who disagree with this statement.The
latin1_german1_ciandlatin1_german2_cicollations are based on the DIN-1 and DIN-2 standards, where DIN stands for Deutsches Institut für Normung (the German equivalent of ANSI). DIN-1 is called the “dictionary collation” and DIN-2 is called the “phone book collation.”latin1_german1_ci(dictionary) rules:Ä = A Ö = O Ü = U ß = s
latin1_german2_ci(phone-book) rules:Ä = AE Ö = OE Ü = UE ß = ss
In the
latin1_spanish_cicollation, ‘ñ’ (n-tilde) is a separate letter between ‘n’ and ‘o’.macroman(Mac West European) collations:macroman_binmacroman_general_ci(default)
swe7(7bit Swedish) collations:swe7_binswe7_swedish_ci(default)
MySQL provides some support for character sets used in the Czech Republic, Slovakia, Hungary, Romania, Slovenia, Croatia, Poland, and Serbia (Latin).
cp1250(Windows Central European) collations:cp1250_bincp1250_croatian_cicp1250_czech_cscp1250_general_ci(default)
cp852(DOS Central European) collations:cp852_bincp852_general_ci(default)
keybcs2(DOS Kamenicky Czech-Slovak) collations:keybcs2_binkeybcs2_general_ci(default)
latin2(ISO 8859-2 Central European) collations:latin2_binlatin2_croatian_cilatin2_czech_cslatin2_general_ci(default)latin2_hungarian_ci
macce(Mac Central European) collations:macce_binmacce_general_ci(default)
South European and Middle Eastern character sets supported by MySQL include Armenian, Arabic, Georgian, Greek, Hebrew, and Turkish.
armscii8(ARMSCII-8 Armenian) collations:armscii8_binarmscii8_general_ci(default)
cp1256(Windows Arabic) collations:cp1256_bincp1256_general_ci(default)
geostd8(GEOSTD8 Georgian) collations:geostd8_bingeostd8_general_ci(default)
greek(ISO 8859-7 Greek) collations:greek_bingreek_general_ci(default)
hebrew(ISO 8859-8 Hebrew) collations:hebrew_binhebrew_general_ci(default)
latin5(ISO 8859-9 Turkish) collations:latin5_binlatin5_turkish_ci(default)
The Baltic character sets cover Estonian, Latvian, and Lithuanian languages.
cp1257(Windows Baltic) collations:cp1257_bincp1257_general_ci(default)cp1257_lithuanian_ci
latin7(ISO 8859-13 Baltic) collations:latin7_binlatin7_estonian_cslatin7_general_ci(default)latin7_general_cs
The Cyrillic character sets and collations are for use with Belarusian, Bulgarian, Russian, Ukrainian, and Serbian (Cyrillic) languages.
cp1251(Windows Cyrillic) collations:cp1251_bincp1251_bulgarian_cicp1251_general_ci(default)cp1251_general_cscp1251_ukrainian_ci
cp866(DOS Russian) collations:cp866_bincp866_general_ci(default)
koi8r(KOI8-R Relcom Russian) collations:koi8r_binkoi8r_general_ci(default)
koi8u(KOI8-U Ukrainian) collations:koi8u_binkoi8u_general_ci(default)
The Asian character sets that we support include Chinese,
Japanese, Korean, and Thai. These can be complicated. For
example, the Chinese sets must allow for thousands of different
characters. See Section 10.10.7.1, “The cp932 Character Set”, for additional
information about the cp932 and
sjis character sets.
For answers to some common questions and problems relating support for Asian character sets in MySQL, see Section A.11, “MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets”.
big5(Big5 Traditional Chinese) collations:big5_binbig5_chinese_ci(default)
cp932(SJIS for Windows Japanese) collations:cp932_bincp932_japanese_ci(default)
eucjpms(UJIS for Windows Japanese) collations:eucjpms_bineucjpms_japanese_ci(default)
euckr(EUC-KR Korean) collations:euckr_bineuckr_korean_ci(default)
gb2312(GB2312 Simplified Chinese) collations:gb2312_bingb2312_chinese_ci(default)
gbk(GBK Simplified Chinese) collations:gbk_bingbk_chinese_ci(default)
sjis(Shift-JIS Japanese) collations:sjis_binsjis_japanese_ci(default)
tis620(TIS620 Thai) collations:tis620_bintis620_thai_ci(default)
ujis(EUC-JP Japanese) collations:ujis_binujis_japanese_ci(default)
Why is cp932
needed?
In MySQL, the sjis character set
corresponds to the Shift_JIS character set
defined by IANA, which supports JIS X0201 and JIS X0208
characters. (See
http://www.iana.org/assignments/character-sets.)
However, the meaning of “SHIFT JIS” as a
descriptive term has become very vague and it often includes
the extensions to Shift_JIS that are
defined by various vendors.
For example, “SHIFT JIS” used in Japanese Windows
environments is a Microsoft extension of
Shift_JIS and its exact name is
Microsoft Windows Codepage : 932 or
cp932. In addition to the characters
supported by Shift_JIS,
cp932 supports extension characters such as
NEC special characters, NEC selected — IBM extended
characters, and IBM extended characters.
Many Japanese users have experienced problems using these extension characters. These problems stem from the following factors:
MySQL automatically converts character sets.
Character sets are converted via Unicode (
ucs2).The
sjischaracter set does not support the conversion of these extension characters.There are several conversion rules from so-called “SHIFT JIS” to Unicode, and some characters are converted to Unicode differently depending on the conversion rule. MySQL supports only one of these rules (described later).
The MySQL cp932 character set is designed
to solve these problems. It is available as of MySQL 5.0.3.
Because MySQL supports character set conversion, it is
important to separate IANA Shift_JIS and
cp932 into two different character sets
because they provide different conversion rules.
How does cp932 differ
from sjis?
The cp932 character set differs from
sjis in the following ways:
cp932supports NEC special characters, NEC selected — IBM extended characters, and IBM selected characters.Some
cp932characters have two different code points, both of which convert to the same Unicode code point. When converting from Unicode back tocp932, one of the code points must be selected. For this “round trip conversion,” the rule recommended by Microsoft is used. (See http://support.microsoft.com/kb/170559/EN-US/.)The conversion rule works like this:
If the character is in both JIS X 0208 and NEC special characters, use the code point of JIS X 0208.
If the character is in both NEC special characters and IBM selected characters, use the code point of NEC special characters.
If the character is in both IBM selected characters and NEC selected — IBM extended characters, use the code point of IBM extended characters.
The table shown at http://www.microsoft.com/globaldev/reference/dbcs/932.htm provides information about the Unicode values of
cp932characters. Forcp932table entries with characters under which a four-digit number appears, the number represents the corresponding Unicode (ucs2) encoding. For table entries with an underlined two-digit value appears, there is a range ofcp932character values that begin with those two digits. Clicking such a table entry takes you to a page that displays the Unicode value for each of thecp932characters that begin with those digits.The following links are of special interest. They correspond to the encodings for the following sets of characters:
NEC special characters:
http://www.microsoft.com/globaldev/reference/dbcs/932/932_87.htm
NEC selected — IBM extended characters:
http://www.microsoft.com/globaldev/reference/dbcs/932/932_ED.htm http://www.microsoft.com/globaldev/reference/dbcs/932/932_EE.htm
IBM selected characters:
http://www.microsoft.com/globaldev/reference/dbcs/932/932_FA.htm http://www.microsoft.com/globaldev/reference/dbcs/932/932_FB.htm http://www.microsoft.com/globaldev/reference/dbcs/932/932_FC.htm
Starting from version 5.0.3,
cp932supports conversion of user-defined characters in combination witheucjpms, and solves the problems withsjis/ujisconversion. For details, please refer to http://www.opengroup.or.jp/jvc/cde/sjis-euc-e.html.
For some characters, conversion to and from
ucs2 is different for
sjis and cp932. The
following tables illustrate these differences.
Conversion to ucs2:
sjis/cp932
Value | sjis ->
ucs2 Conversion | cp932 ->
ucs2 Conversion |
| 5C | 005C | 005C |
| 7E | 007E | 007E |
| 815C | 2015 | 2015 |
| 815F | 005C | FF3C |
| 8160 | 301C | FF5E |
| 8161 | 2016 | 2225 |
| 817C | 2212 | FF0D |
| 8191 | 00A2 | FFE0 |
| 8192 | 00A3 | FFE1 |
| 81CA | 00AC | FFE2 |
Conversion from ucs2:
ucs2 value | ucs2 ->
sjis Conversion | ucs2 ->
cp932 Conversion |
| 005C | 815F | 5C |
| 007E | 7E | 7E |
| 00A2 | 8191 | 3F |
| 00A3 | 8192 | 3F |
| 00AC | 81CA | 3F |
| 2015 | 815C | 815C |
| 2016 | 8161 | 3F |
| 2212 | 817C | 3F |
| 2225 | 3F | 8161 |
| 301C | 8160 | 3F |
| FF0D | 3F | 817C |
| FF3C | 3F | 815F |
| FF5E | 3F | 8160 |
| FFE0 | 3F | 8191 |
| FFE1 | 3F | 8192 |
| FFE2 | 3F | 81CA |
Users of any Japanese character sets should be aware that
using --character-set-client-handshake (or
--skip-character-set-client-handshake) has an
important effect. See Section 5.2.2, “Command Options”.
Table of Contents
MySQL supports a number of data types in several categories: numeric types, date and time types, and string (character) types. This chapter first gives an overview of these data types, and then provides a more detailed description of the properties of the types in each category, and a summary of the data type storage requirements. The initial overview is intentionally brief. The more detailed descriptions later in the chapter should be consulted for additional information about particular data types, such as the allowable formats in which you can specify values.
MySQL also supports extensions for handing spatial data. Chapter 16, Spatial Extensions, provides information about these data types.
Several of the data type descriptions use these conventions:
Mindicates the maximum display width for integer types. For floating-point and fixed-point types,Mis the total number of digits that can be stored. For string types,Mis the maximum length. The maximum allowable value ofMdepends on the data type.Dapplies to floating-point and fixed-point types and indicates the number of digits following the decimal point. The maximum possible value is 30, but should be no greater thanM–2.Square brackets (‘
[’ and ‘]’) indicate optional parts of type definitions.
A summary of the numeric data types follows. For additional information, see Section 11.2, “Numeric Types”. Storage requirements are given in Section 11.5, “Data Type Storage Requirements”.
M indicates the maximum display width
for integer types. The maximum legal display width is 255.
Display width is unrelated to the range of values a type can
contain, as described in Section 11.2, “Numeric Types”. For
floating-point and fixed-point types,
M is the total number of digits that
can be stored.
If you specify ZEROFILL for a numeric column,
MySQL automatically adds the UNSIGNED
attribute to the column.
Numeric data types that allow the UNSIGNED
attribute also allow SIGNED. However, these
data types are signed by default, so the
SIGNED attribute has no effect.
SERIAL is an alias for BIGINT
UNSIGNED NOT NULL AUTO_INCREMENT UNIQUE.
SERIAL DEFAULT VALUE in the definition of an
integer column is an alias for NOT NULL AUTO_INCREMENT
UNIQUE.
Warning: When you use
subtraction between integer values where one is of type
UNSIGNED, the result is unsigned unless the
NO_UNSIGNED_SUBTRACTION SQL mode is enabled.
See Section 12.9, “Cast Functions and Operators”.
A bit-field type.
Mindicates the number of bits per value, from 1 to 64. The default is 1 ifMis omitted.This data type was added in MySQL 5.0.3 for
MyISAM, and extended in 5.0.5 toMEMORY,InnoDB, andBDB. Before 5.0.3,BITis a synonym forTINYINT(1).TINYINT[(M)] [UNSIGNED] [ZEROFILL]A very small integer. The signed range is
-128to127. The unsigned range is0to255.These types are synonyms for
TINYINT(1). A value of zero is considered false. Non-zero values are considered true:mysql>
SELECT IF(0, 'true', 'false');+------------------------+ | IF(0, 'true', 'false') | +------------------------+ | false | +------------------------+ mysql>SELECT IF(1, 'true', 'false');+------------------------+ | IF(1, 'true', 'false') | +------------------------+ | true | +------------------------+ mysql>SELECT IF(2, 'true', 'false');+------------------------+ | IF(2, 'true', 'false') | +------------------------+ | true | +------------------------+However, the values
TRUEandFALSEare merely aliases for1and0, respectively, as shown here:mysql>
SELECT IF(0 = FALSE, 'true', 'false');+--------------------------------+ | IF(0 = FALSE, 'true', 'false') | +--------------------------------+ | true | +--------------------------------+ mysql>SELECT IF(1 = TRUE, 'true', 'false');+-------------------------------+ | IF(1 = TRUE, 'true', 'false') | +-------------------------------+ | true | +-------------------------------+ mysql>SELECT IF(2 = TRUE, 'true', 'false');+-------------------------------+ | IF(2 = TRUE, 'true', 'false') | +-------------------------------+ | false | +-------------------------------+ mysql>SELECT IF(2 = FALSE, 'true', 'false');+--------------------------------+ | IF(2 = FALSE, 'true', 'false') | +--------------------------------+ | false | +--------------------------------+The last two statements display the results shown because
2is equal to neither1nor0.We intend to implement full boolean type handling, in accordance with standard SQL, in a future MySQL release.
SMALLINT[(M)] [UNSIGNED] [ZEROFILL]A small integer. The signed range is
-32768to32767. The unsigned range is0to65535.MEDIUMINT[(M)] [UNSIGNED] [ZEROFILL]A medium-sized integer. The signed range is
-8388608to8388607. The unsigned range is0to16777215.INT[(M)] [UNSIGNED] [ZEROFILL]A normal-size integer. The signed range is
-2147483648to2147483647. The unsigned range is0to4294967295.INTEGER[(M)] [UNSIGNED] [ZEROFILL]This type is a synonym for
INT.BIGINT[(M)] [UNSIGNED] [ZEROFILL]A large integer. The signed range is
-9223372036854775808to9223372036854775807. The unsigned range is0to18446744073709551615.SERIALis an alias forBIGINT UNSIGNED NOT NULL AUTO_INCREMENT UNIQUE.Some things you should be aware of with respect to
BIGINTcolumns:All arithmetic is done using signed
BIGINTorDOUBLEvalues, so you should not use unsigned big integers larger than9223372036854775807(63 bits) except with bit functions! If you do that, some of the last digits in the result may be wrong because of rounding errors when converting aBIGINTvalue to aDOUBLE.MySQL can handle
BIGINTin the following cases:When using integers to store large unsigned values in a
BIGINTcolumn.In
MIN(orcol_name)MAX(, wherecol_name)col_namerefers to aBIGINTcolumn.When using operators (
+,-,*, and so on) where both operands are integers.
You can always store an exact integer value in a
BIGINTcolumn by storing it using a string. In this case, MySQL performs a string-to-number conversion that involves no intermediate double-precision representation.The
-,+, and*operators useBIGINTarithmetic when both operands are integer values. This means that if you multiply two big integers (or results from functions that return integers), you may get unexpected results when the result is larger than9223372036854775807.
FLOAT[(M,D)] [UNSIGNED] [ZEROFILL]A small (single-precision) floating-point number. Allowable values are
-3.402823466E+38to-1.175494351E-38,0, and1.175494351E-38to3.402823466E+38. These are the theoretical limits, based on the IEEE standard. The actual range might be slightly smaller depending on your hardware or operating system.Mis the total number of digits andDis the number of digits following the decimal point. IfMandDare omitted, values are stored to the limits allowed by the hardware. A single-precision floating-point number is accurate to approximately 7 decimal places.UNSIGNED, if specified, disallows negative values.Using
FLOATmight give you some unexpected problems because all calculations in MySQL are done with double precision. See Section B.1.5.7, “Solving Problems with No Matching Rows”.DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL]A normal-size (double-precision) floating-point number. Allowable values are
-1.7976931348623157E+308to-2.2250738585072014E-308,0, and2.2250738585072014E-308to1.7976931348623157E+308. These are the theoretical limits, based on the IEEE standard. The actual range might be slightly smaller depending on your hardware or operating system.Mis the total number of digits andDis the number of digits following the decimal point. IfMandDare omitted, values are stored to the limits allowed by the hardware. A double-precision floating-point number is accurate to approximately 15 decimal places.UNSIGNED, if specified, disallows negative values.DOUBLE PRECISION[(,M,D)] [UNSIGNED] [ZEROFILL]REAL[(M,D)] [UNSIGNED] [ZEROFILL]These types are synonyms for
DOUBLE. Exception: If theREAL_AS_FLOATSQL mode is enabled,REALis a synonym forFLOATrather thanDOUBLE.FLOAT(p) [UNSIGNED] [ZEROFILL]A floating-point number.
prepresents the precision in bits, but MySQL uses this value only to determine whether to useFLOATorDOUBLEfor the resulting data type. Ifpis from 0 to 24, the data type becomesFLOATwith noMorDvalues. Ifpis from 25 to 53, the data type becomesDOUBLEwith noMorDvalues. The range of the resulting column is the same as for the single-precisionFLOATor double-precisionDOUBLEdata types described earlier in this section.DECIMAL[(M[,D])] [UNSIGNED] [ZEROFILL]For MySQL 5.0.3 and above:
A packed “exact” fixed-point number.
Mis the total number of digits (the precision) andDis the number of digits after the decimal point (the scale). The decimal point and (for negative numbers) the ‘-’ sign are not counted inM. IfDis 0, values have no decimal point or fractional part. The maximum number of digits (M) forDECIMALis 65 (64 from 5.0.3 to 5.0.5). The maximum number of supported decimals (D) is 30. IfDis omitted, the default is 0. IfMis omitted, the default is 10.UNSIGNED, if specified, disallows negative values.All basic calculations (
+, -, *, /) withDECIMALcolumns are done with a precision of 65 digits.Before MySQL 5.0.3:
An unpacked fixed-point number. Behaves like a
CHARcolumn; “unpacked” means the number is stored as a string, using one character for each digit of the value.Mis the total number of digits andDis the number of digits after the decimal point. The decimal point and (for negative numbers) the ‘-’ sign are not counted inM, although space for them is reserved. IfDis 0, values have no decimal point or fractional part. The maximum range ofDECIMALvalues is the same as forDOUBLE, but the actual range for a givenDECIMALcolumn may be constrained by the choice ofMandD. IfDis omitted, the default is 0. IfMis omitted, the default is 10.UNSIGNED, if specified, disallows negative values.The behavior used by the server for
DECIMALcolumns in a table depends on the version of MySQL used to create the table. If your server is from MySQL 5.0.3 or higher, but you haveDECIMALcolumns in tables that were created before 5.0.3, the old behavior still applies to those columns. To convert the tables to the newerDECIMALformat, dump them with mysqldump and reload them.DEC[(,M[,D])] [UNSIGNED] [ZEROFILL]NUMERIC[(,M[,D])] [UNSIGNED] [ZEROFILL]FIXED[(M[,D])] [UNSIGNED] [ZEROFILL]These types are synonyms for
DECIMAL. TheFIXEDsynonym is available for compatibility with other database systems.
A summary of the temporal data types follows. For additional information, see Section 11.3, “Date and Time Types”. Storage requirements are given in Section 11.5, “Data Type Storage Requirements”. Functions that operate on temporal values are described at Section 12.6, “Date and Time Functions”.
For the DATETIME and DATE
range descriptions, “supported” means that although
earlier values might work, there is no guarantee.
A date. The supported range is
'1000-01-01'to'9999-12-31'. MySQL displaysDATEvalues in'YYYY-MM-DD'format, but allows assignment of values toDATEcolumns using either strings or numbers.A date and time combination. The supported range is
'1000-01-01 00:00:00'to'9999-12-31 23:59:59'. MySQL displaysDATETIMEvalues in'YYYY-MM-DD HH:MM:SS'format, but allows assignment of values toDATETIMEcolumns using either strings or numbers.A timestamp. The range is
'1970-01-01 00:00:01'UTC to partway through the year2038.TIMESTAMPvalues are stored as the number of seconds since the epoch ('1970-01-01 00:00:00'UTC). ATIMESTAMPcannot represent the value'1970-01-01 00:00:00'because that is equivalent to 0 seconds from the epoch and the value 0 is reserved for representing'0000-00-00 00:00:00', the “zero”TIMESTAMPvalue.A
TIMESTAMPcolumn is useful for recording the date and time of anINSERTorUPDATEoperation. By default, the firstTIMESTAMPcolumn in a table is automatically set to the date and time of the most recent operation if you do not assign it a value yourself. You can also set anyTIMESTAMPcolumn to the current date and time by assigning it aNULLvalue. Variations on automatic initialization and update properties are described in Section 11.3.1.1, “TIMESTAMPProperties as of MySQL 4.1”.A
TIMESTAMPvalue is returned as a string in the format'YYYY-MM-DD HH:MM:SS'with a display width fixed at 19 characters. To obtain the value as a number, you should add+0to the timestamp column.Note: The
TIMESTAMPformat that was used prior to MySQL 4.1 is not supported in MySQL 5.0; see MySQL 3.23, 4.0, 4.1 Reference Manual for information regarding the old format.A time. The range is
'-838:59:59'to'838:59:59'. MySQL displaysTIMEvalues in'HH:MM:SS'format, but allows assignment of values toTIMEcolumns using either strings or numbers.A year in two-digit or four-digit format. The default is four-digit format. In four-digit format, the allowable values are
1901to2155, and0000. In two-digit format, the allowable values are70to69, representing years from 1970 to 2069. MySQL displaysYEARvalues inYYYYformat, but allows you to assign values toYEARcolumns using either strings or numbers.
The SUM() and AVG()
aggregate functions do not work with temporal values. (They
convert the values to numbers, which loses the part after the
first non-numeric character.) To work around this problem, you
can convert to numeric units, perform the aggregate operation,
and convert back to a temporal value. Examples:
SELECT SEC_TO_TIME(SUM(TIME_TO_SEC(time_col))) FROMtbl_name; SELECT FROM_DAYS(SUM(TO_DAYS(date_col))) FROMtbl_name;
A summary of the string data types follows. For additional information, see Section 11.4, “String Types”. Storage requirements are given in Section 11.5, “Data Type Storage Requirements”.
In some cases, MySQL may change a string column to a type
different from that given in a CREATE TABLE
or ALTER TABLE statement. See
Section 13.1.5.1, “Silent Column Specification Changes”.
In MySQL 4.1 and up, string data types include some features that you may not have encountered in working with versions of MySQL prior to 4.1:
MySQL interprets length specifications in character column definitions in character units. (Before MySQL 4.1, column lengths were interpreted in bytes.) This applies to
CHAR,VARCHAR, and theTEXTtypes.Column definitions for many string data types can include attributes that specify the character set or collation of the column. These attributes apply to the
CHAR,VARCHAR, theTEXTtypes,ENUM, andSETdata types:The
CHARACTER SETattribute specifies the character set, and theCOLLATEattribute specifies a collation for the character set. For example:CREATE TABLE t ( c1 VARCHAR(20) CHARACTER SET utf8, c2 TEXT CHARACTER SET latin1 COLLATE latin1_general_cs );This table definition creates a column named
c1that has a character set ofutf8with the default collation for that character set, and a column namedc2that has a character set oflatin1and a case-sensitive collation.CHARSETis a synonym forCHARACTER SET.The
ASCIIattribute is shorthand forCHARACTER SET latin1.The
UNICODEattribute is shorthand forCHARACTER SET ucs2.The
BINARYattribute is shorthand for specifying the binary collation of the column character set. In this case, sorting and comparison are based on numeric character values. (Before MySQL 4.1,BINARYcaused a column to store binary strings and sorting and comparison were based on numeric byte values. This is the same as using character values for single-byte character sets, but not for multi-byte character sets.)
Character column sorting and comparison are based on the character set assigned to the column. (Before MySQL 4.1, sorting and comparison were based on the collation of the server character set.) For the
CHAR,VARCHAR,TEXT,ENUM, andSETdata types, you can declare a column with a binary collation or theBINARYattribute to cause sorting and comparison to use the underlying character code values rather than a lexical ordering.
Chapter 10, Character Set Support, provides additional information about use of character sets in MySQL.
[NATIONAL] CHAR(M) [CHARACTER SETcharset_name] [COLLATEcollation_name]A fixed-length string that is always right-padded with spaces to the specified length when stored.
Mrepresents the column length. The range ofMis 0 to 255 characters.Note: Trailing spaces are removed when
CHARvalues are retrieved.Before MySQL 5.0.3, a
CHARcolumn with a length specification greater than 255 is converted to the smallestTEXTtype that can hold values of the given length. For example,CHAR(500)is converted toTEXT, andCHAR(200000)is converted toMEDIUMTEXT. This is a compatibility feature. However, this conversion causes the column to become a variable-length column, and also affects trailing-space removal.In MySQL 5.0.3 and later, if you attempt to set the length of a
CHARgreater than 255, theCREATE TABLEorALTER TABLEstatement in which this is done fails with an error:mysql>
CREATE TABLE c1 (col1 INT, col2 CHAR(500));ERROR 1074 (42000): Column length too big for column 'col' (max = 255); use BLOB or TEXT instead mysql>SHOW CREATE TABLE c1;ERROR 1146 (42S02): Table 'test.c1' doesn't existCHARis shorthand forCHARACTER.NATIONAL CHAR(or its equivalent short form,NCHAR) is the standard SQL way to define that aCHARcolumn should use some predefined character set. MySQL 4.1 and up usesutf8as this predefined character set. Section 10.3.6, “National Character Set”.The
CHAR BYTEdata type is an alias for theBINARYdata type. This is a compatibility feature.MySQL allows you to create a column of type
CHAR(0). This is useful primarily when you have to be compliant with old applications that depend on the existence of a column but that do not actually use its value.CHAR(0)is also quite nice when you need a column that can take only two values: A column that is defined asCHAR(0) NULLoccupies only one bit and can take only the valuesNULLand''(the empty string).CHAR [CHARACTER SETcharset_name] [COLLATEcollation_name]This type is a synonym for
CHAR(1).[NATIONAL] VARCHAR(M) [CHARACTER SETcharset_name] [COLLATEcollation_name]A variable-length string.
Mrepresents the maximum column length. In MySQL 5.0, the range ofMis 0 to 255 before MySQL 5.0.3, and 0 to 65,535 in MySQL 5.0.3 and later. (The actual maximum length of aVARCHARin MySQL 5.0 is determined by the maximum row size and the character set you use. The maximum effective column length starting with MySQL 5.0.3 is subject to a row size of 65,532 bytes.)Note: Before 5.0.3, trailing spaces were removed when
VARCHARvalues were stored, which differs from the standard SQL specification.Prior to MySQL 5.0.3, a
VARCHARcolumn with a length specification greater than 255 was converted to the smallestTEXTtype that could hold values of the given length. For example,VARCHAR(500)was converted toTEXT, andVARCHAR(200000)was converted toMEDIUMTEXT. This was a compatibility feature. However, this conversion affected trailing-space removal.VARCHARis shorthand forCHARACTER VARYING.VARCHARvalues are stored using as many characters as are needed, plus one byte to record the length (two bytes for columns that are declared with a length longer than 255).The
BINARYtype is similar to theCHARtype, but stores binary byte strings rather than non-binary character strings.The
VARBINARYtype is similar to theVARCHARtype, but stores binary byte strings rather than non-binary character strings.A
BLOBcolumn with a maximum length of 255 (28 – 1) bytes.TINYTEXT [CHARACTER SETcharset_name] [COLLATEcollation_name]A
TEXTcolumn with a maximum length of 255 (28 – 1) characters.A
BLOBcolumn with a maximum length of 65,535 (216 – 1) bytes.An optional length
Mcan be given for this type. If this is done, MySQL creates the column as the smallestBLOBtype large enough to hold valuesMbytes long.TEXT[(M)] [CHARACTER SETcharset_name] [COLLATEcollation_name]A
TEXTcolumn with a maximum length of 65,535 (216 – 1) characters.An optional length
Mcan be given for this type. If this is done, MySQL creates the column as the smallestTEXTtype large enough to hold valuesMcharacters long.A
BLOBcolumn with a maximum length of 16,777,215 (224 – 1) bytes.MEDIUMTEXT [CHARACTER SETcharset_name] [COLLATEcollation_name]A
TEXTcolumn with a maximum length of 16,777,215 (224 – 1) characters.A
BLOBcolumn with a maximum length of 4,294,967,295 or 4GB (232 – 1) bytes. The maximum effective (permitted) length ofLONGBLOBcolumns depends on the configured maximum packet size in the client/server protocol and available memory.LONGTEXT [CHARACTER SETcharset_name] [COLLATEcollation_name]A
TEXTcolumn with a maximum length of 4,294,967,295 or 4GB (232 – 1) characters. The maximum effective (permitted) length ofLONGTEXTcolumns depends on the configured maximum packet size in the client/server protocol and available memory.ENUM('value1','value2',...) [CHARACTER SETcharset_name] [COLLATEcollation_name]An enumeration. A string object that can have only one value, chosen from the list of values
',value1'',value2'...,NULLor the special''error value. AnENUMcolumn can have a maximum of 65,535 distinct values.ENUMvalues are represented internally as integers.SET('value1','value2',...) [CHARACTER SETcharset_name] [COLLATEcollation_name]A set. A string object that can have zero or more values, each of which must be chosen from the list of values
',value1'',value2'...ASETcolumn can have a maximum of 64 members.SETvalues are represented internally as integers.
The DEFAULT
clause in a data type specification indicates a default value
for a column. With one exception, the default value must be a
constant; it cannot be a function or an expression. This means,
for example, that you cannot set the default for a date column
to be the value of a function such as valueNOW()
or CURRENT_DATE. The exception is that you
can specify CURRENT_TIMESTAMP as the default
for a TIMESTAMP column. See
Section 11.3.1.1, “TIMESTAMP Properties as of MySQL 4.1”.
Prior to MySQL 5.0.2, if a column definition includes no
explicit DEFAULT value, MySQL determines the
default value as follows:
If the column can take NULL as a value, the
column is defined with an explicit DEFAULT
NULL clause.
If the column cannot take NULL as the value,
MySQL defines the column with an explicit
DEFAULT clause, using the implicit default
value for the column data type. Implicit defaults are defined as
follows:
For numeric types other than integer types declared with the
AUTO_INCREMENTattribute, the default is0. For anAUTO_INCREMENTcolumn, the default value is the next value in the sequence.For date and time types other than
TIMESTAMP, the default is the appropriate “zero” value for the type. For the firstTIMESTAMPcolumn in a table, the default value is the current date and time. See Section 11.3, “Date and Time Types”.For string types other than
ENUM, the default value is the empty string. ForENUM, the default is the first enumeration value.
BLOB and TEXT columns
cannot be assigned a default value.
As of MySQL 5.0.2, if a column definition includes no explicit
DEFAULT value, MySQL determines the default
value as follows:
If the column can take NULL as a value, the
column is defined with an explicit DEFAULT
NULL clause. This is the same as before 5.0.2.
If the column cannot take NULL as the value,
MySQL defines the column with no explicit
DEFAULT clause. For data entry, if an
INSERT or REPLACE
statement includes no value for the column, MySQL handles the
column according to the SQL mode in effect at the time:
If strict SQL mode is not enabled, MySQL sets the column to the implicit default value for the column data type.
If strict mode is enabled, an error occurs for transactional tables and the statement is rolled back. For non-transactional tables, an error occurs, but if this happens for the second or subsequent row of a multiple-row statement, the preceding rows will have been inserted.
Suppose that a table t is defined as follows:
CREATE TABLE t (i INT NOT NULL);
In this case, i has no explicit default, so
in strict mode each of the following statements produce an error
and no row is inserted. When not using strict mode, only the
third statement produces an error; the implicit default is
inserted for the first two statements, but the third fails
because DEFAULT(i) cannot produce a value:
INSERT INTO t VALUES(); INSERT INTO t VALUES(DEFAULT); INSERT INTO t VALUES(DEFAULT(i));
See Section 5.2.6, “SQL Modes”.
For a given table, you can use the SHOW CREATE
TABLE statement to see which columns have an explicit
DEFAULT clause.
SERIAL DEFAULT VALUE in the definition of an
integer column is an alias for NOT NULL AUTO_INCREMENT
UNIQUE.
MySQL supports all of the standard SQL numeric data types. These
types include the exact numeric data types
(INTEGER, SMALLINT,
DECIMAL, and NUMERIC), as
well as the approximate numeric data types
(FLOAT, REAL, and
DOUBLE PRECISION). The keyword
INT is a synonym for
INTEGER, and the keyword DEC
is a synonym for DECIMAL. For numeric type
storage requirements, see Section 11.5, “Data Type Storage Requirements”.
As of MySQL 5.0.3, a BIT data type is available
for storing bit-field values. (Before 5.0.3, MySQL interprets
BIT as TINYINT(1).) In MySQL
5.0.3, BIT is supported only for
MyISAM. MySQL 5.0.5 extends
BIT support to MEMORY,
InnoDB, and BDB.
As an extension to the SQL standard, MySQL also supports the
integer types TINYINT,
MEDIUMINT, and BIGINT. The
following table shows the required storage and range for each of
the integer types.
| Type | Bytes | Minimum Value | Maximum Value |
| (Signed/Unsigned) | (Signed/Unsigned) | ||
TINYINT | 1 | -128 | 127 |
0 | 255 | ||
SMALLINT | 2 | -32768 | 32767 |
0 | 65535 | ||
MEDIUMINT | 3 | -8388608 | 8388607 |
0 | 16777215 | ||
INT | 4 | -2147483648 | 2147483647 |
0 | 4294967295 | ||
BIGINT | 8 | -9223372036854775808 | 9223372036854775807 |
0 | 18446744073709551615 |
Another extension is supported by MySQL for optionally specifying
the display width of integer data types in parentheses following
the base keyword for the type (for example,
INT(4)). This optional display width is used to
display integer values having a width less than the width
specified for the column by left-padding them with spaces.
The display width does not constrain the
range of values that can be stored in the column, nor the number
of digits that are displayed for values having a width exceeding
that specified for the column. For example, a column specified as
SMALLINT(3) has the usual
SMALLINT range of -32768 to
32767, and values outside the range allowed by
three characters are displayed using more than three characters.
When used in conjunction with the optional extension attribute
ZEROFILL, the default padding of spaces is
replaced with zeros. For example, for a column declared as
INT(5) ZEROFILL, a value of
4 is retrieved as 00004.
Note that if you store larger values than the display width in an
integer column, you may experience problems when MySQL generates
temporary tables for some complicated joins, because in these
cases MySQL assumes that the data fits into the original column
width.
Note: The
ZEROFILL attribute is stripped when a column is
involved in expressions or UNION queries.
All integer types can have an optional (non-standard) attribute
UNSIGNED. Unsigned values can be used when you
want to allow only non-negative numbers in a column and you need a
larger upper numeric range for the column. For example, if an
INT column is UNSIGNED, the
size of the column's range is the same but its endpoints shift
from -2147483648 and
2147483647 up to 0 and
4294967295.
Floating-point and fixed-point types also can be
UNSIGNED. As with integer types, this attribute
prevents negative values from being stored in the column. However,
unlike the integer types, the upper range of column values remains
the same.
If you specify ZEROFILL for a numeric column,
MySQL automatically adds the UNSIGNED attribute
to the column.
For floating-point data types, MySQL uses four bytes for single-precision values and eight bytes for double-precision values.
The FLOAT and DOUBLE data
types are used to represent approximate numeric data values. For
FLOAT the SQL standard allows an optional
specification of the precision (but not the range of the exponent)
in bits following the keyword FLOAT in
parentheses. MySQL also supports this optional precision
specification, but the precision value is used only to determine
storage size. A precision from 0 to 23 results in a four-byte
single-precision FLOAT column. A precision from
24 to 53 results in an eight-byte double-precision
DOUBLE column.
MySQL allows a non-standard syntax:
FLOAT(
or
M,D)REAL(
or M,D)DOUBLE
PRECISION(.
Here,
“M,D)(”
means than values can be stored with up to
M,D)M digits in total, of which
D digits may be after the decimal
point. For example, a column defined as
FLOAT(7,4) will look like
-999.9999 when displayed. MySQL performs
rounding when storing values, so if you insert
999.00009 into a FLOAT(7,4)
column, the approximate result is 999.0001.
MySQL treats DOUBLE as a synonym for
DOUBLE PRECISION (a non-standard extension).
MySQL also treats REAL as a synonym for
DOUBLE PRECISION (a non-standard variation),
unless the REAL_AS_FLOAT SQL mode is enabled.
For maximum portability, code requiring storage of approximate
numeric data values should use FLOAT or
DOUBLE PRECISION with no specification of
precision or number of digits.
The DECIMAL and NUMERIC data
types are used to store exact numeric data values. In MySQL,
NUMERIC is implemented as
DECIMAL. These types are used to store values
for which it is important to preserve exact precision, for example
with monetary data.
As of MySQL 5.0.3, DECIMAL and
NUMERIC values are stored in binary format.
Previously, they were stored as strings, with one character used
for each digit of the value, the decimal point (if the scale is
greater than 0), and the ‘-’ sign
(for negative numbers). See Chapter 21, Precision Math.
When declaring a DECIMAL or
NUMERIC column, the precision and scale can be
(and usually is) specified; for example:
salary DECIMAL(5,2)
In this example, 5 is the precision and
2 is the scale. The precision represents the
number of significant digits that are stored for values, and the
scale represents the number of digits that can be stored following
the decimal point. If the scale is 0, DECIMAL
and NUMERIC values contain no decimal point or
fractional part.
Standard SQL requires that the salary column be
able to store any value with five digits and two decimals. In this
case, therefore, the range of values that can be stored in the
salary column is from
-999.99 to 999.99. MySQL
enforces this limit as of MySQL 5.0.3. Before 5.0.3, on the
positive end of the range, the column could actually store numbers
up to 9999.99. (For positive numbers, MySQL
5.0.2 and earlier used the byte reserved for the sign to extend
the upper end of the range.)
In standard SQL, the syntax
DECIMAL( is
equivalent to
M)DECIMAL(.
Similarly, the syntax M,0)DECIMAL is equivalent to
DECIMAL(, where
the implementation is allowed to decide the value of
M,0)M. MySQL supports both of these variant
forms of the DECIMAL and
NUMERIC syntax. The default value of
M is 10.
The maximum number of digits for DECIMAL or
NUMERIC is 65 (64 from MySQL 5.0.3 to 5.0.5).
Before MySQL 5.0.3, the maximum range of
DECIMAL and NUMERIC values
is the same as for DOUBLE, but the actual range
for a given DECIMAL or
NUMERIC column can be constrained by the
precision or scale for a given column. When such a column is
assigned a value with more digits following the decimal point than
are allowed by the specified scale, the value is converted to that
scale. (The precise behavior is operating system-specific, but
generally the effect is truncation to the allowable number of
digits.)
As of MySQL 5.0.3, the BIT data type is used to
store bit-field values. A type of
BIT( allows for
storage of M)M-bit values.
M can range from 1 to 64.
To specify bit values,
b' notation
can be used. value'value is a binary value
written using zeros and ones. For example,
b'111' and b'10000000'
represent 7 and 128, respectively. See
Section 9.1.5, “Bit-Field Values”.
If you assign a value to a
BIT( column that
is less than M)M bits long, the value is
padded on the left with zeros. For example, assigning a value of
b'101' to a BIT(6) column
is, in effect, the same as assigning b'000101'.
When asked to store a value in a numeric column that is outside
the data type's allowable range, MySQL's behavior depends on the
SQL mode in effect at the time. For example, if no restrictive
modes are enabled, MySQL clips the value to the appropriate
endpoint of the range and stores the resulting value instead.
However, if the mode is set to TRADITIONAL,
MySQL rejects a value that is out of range with an error, and the
insert fails, in accordance with the SQL standard.
In non-strict mode, when an out-of-range value is assigned to an
integer column, MySQL stores the value representing the
corresponding endpoint of the column data type range. If you store
256 into a TINYINT or TINYINT
UNSIGNED column, MySQL stores 127 or 255, respectively.
When a floating-point or fixed-point column is assigned a value
that exceeds the range implied by the specified (or default)
precision and scale, MySQL stores the value representing the
corresponding endpoint of that range.
Conversions that occur due to clipping when MySQL is not operating
in strict mode are reported as warnings for ALTER
TABLE, LOAD DATA INFILE,
UPDATE, and multiple-row
INSERT statements. When MySQL is operating in
strict mode, these statements fail, and some or all of the values
will not be inserted or changed, depending on whether the table is
a transactional table and other factors. For details, see
Section 5.2.6, “SQL Modes”.
The date and time types for representing temporal values are
DATETIME, DATE,
TIMESTAMP, TIME, and
YEAR. Each temporal type has a range of legal
values, as well as a “zero” value that may be used
when you specify an illegal value that MySQL cannot represent. The
TIMESTAMP type has special automatic updating
behavior, described later on. For temporal type storage
requirements, see Section 11.5, “Data Type Storage Requirements”.
Starting from MySQL 5.0.2, MySQL gives warnings or errors if you
try to insert an illegal date. By setting the SQL mode to the
appropriate value, you can specify more exactly what kind of dates
you want MySQL to support. (See
Section 5.2.6, “SQL Modes”.) You can get MySQL to accept
certain dates, such as '1999-11-31', by using
the ALLOW_INVALID_DATES SQL mode. (Before
5.0.2, this mode was the default behavior for MySQL.) This is
useful when you want to store a “possibly wrong”
value which the user has specified (for example, in a web form) in
the database for future processing. Under this mode, MySQL
verifies only that the month is in the range from 0 to 12 and that
the day is in the range from 0 to 31. These ranges are defined to
include zero because MySQL allows you to store dates where the day
or month and day are zero in a DATE or
DATETIME column. This is extremely useful for
applications that need to store a birthdate for which you do not
know the exact date. In this case, you simply store the date as
'1999-00-00' or
'1999-01-00'. If you store dates such as these,
you should not expect to get correct results for functions such as
DATE_SUB() or DATE_ADD that
require complete dates. (If you do not want
to allow zero in dates, you can use the
NO_ZERO_IN_DATE SQL mode).
Prior to MySQL 5.0.42, when DATE
values are compared with DATETIME values
the time portion of the DATETIME value is
ignored. Starting from MySQL 5.0.42 a
DATE value is coerced to the
DATETIME type by adding the time portion
as '00:00:00'. To mimic the old behavior
use the CAST() function in the following way:
SELECT .
date_field =
CAST(NOW() as DATE);
MySQL also allows you to store '0000-00-00' as
a “dummy date” (if you are not using the
NO_ZERO_DATE SQL mode). This is in some cases
is more convenient (and uses less space in data and index) than
using NULL values.
Here are some general considerations to keep in mind when working with date and time types:
MySQL retrieves values for a given date or time type in a standard output format, but it attempts to interpret a variety of formats for input values that you supply (for example, when you specify a value to be assigned to or compared to a date or time type). Only the formats described in the following sections are supported. It is expected that you supply legal values. Unpredictable results may occur if you use values in other formats.
Dates containing two-digit year values are ambiguous because the century is unknown. MySQL interprets two-digit year values using the following rules:
Year values in the range
70-99are converted to1970-1999.Year values in the range
00-69are converted to2000-2069.
Although MySQL tries to interpret values in several formats, dates always must be given in year-month-day order (for example,
'98-09-04'), rather than in the month-day-year or day-month-year orders commonly used elsewhere (for example,'09-04-98','04-09-98').MySQL automatically converts a date or time type value to a number if the value is used in a numeric context and vice versa.
By default, when MySQL encounters a value for a date or time type that is out of range or otherwise illegal for the type (as described at the beginning of this section), it converts the value to the “zero” value for that type. The exception is that out-of-range
TIMEvalues are clipped to the appropriate endpoint of theTIMErange.The following table shows the format of the “zero” value for each type. Note that the use of these values produces warnings if the
NO_ZERO_DATESQL mode is enabled.Data Type “Zero” Value DATETIME'0000-00-00 00:00:00'DATE'0000-00-00'TIMESTAMP'0000-00-00 00:00:00'TIME'00:00:00'YEAR0000The “zero” values are special, but you can store or refer to them explicitly using the values shown in the table. You can also do this using the values
'0'or0, which are easier to write.“Zero” date or time values used through MyODBC are converted automatically to
NULLin MyODBC 2.50.12 and above, because ODBC cannot handle such values.
The DATETIME, DATE, and
TIMESTAMP types are related. This section
describes their characteristics, how they are similar, and how
they differ.
The DATETIME type is used when you need
values that contain both date and time information. MySQL
retrieves and displays DATETIME values in
'YYYY-MM-DD HH:MM:SS' format. The supported
range is '1000-01-01 00:00:00' to
'9999-12-31 23:59:59'.
The DATE type is used when you need only a
date value, without a time part. MySQL retrieves and displays
DATE values in
'YYYY-MM-DD' format. The supported range is
'1000-01-01' to
'9999-12-31'.
For the DATETIME and DATE
range descriptions, “supported” means that although
earlier values might work, there is no guarantee.
The TIMESTAMP data type has varying
properties, depending on the MySQL version and the SQL mode the
server is running in. These properties are described later in
this section.
You can specify DATETIME,
DATE, and TIMESTAMP values
using any of a common set of formats:
As a string in either
'YYYY-MM-DD HH:MM:SS'or'YY-MM-DD HH:MM:SS'format. A “relaxed” syntax is allowed: Any punctuation character may be used as the delimiter between date parts or time parts. For example,'98-12-31 11:30:45','98.12.31 11+30+45','98/12/31 11*30*45', and'98@12@31 11^30^45'are equivalent.As a string in either
'YYYY-MM-DD'or'YY-MM-DD'format. A “relaxed” syntax is allowed here, too. For example,'98-12-31','98.12.31','98/12/31', and'98@12@31'are equivalent.As a string with no delimiters in either
'YYYYMMDDHHMMSS'or'YYMMDDHHMMSS'format, provided that the string makes sense as a date. For example,'19970523091528'and'970523091528'are interpreted as'1997-05-23 09:15:28', but'971122129015'is illegal (it has a nonsensical minute part) and becomes'0000-00-00 00:00:00'.As a string with no delimiters in either
'YYYYMMDD'or'YYMMDD'format, provided that the string makes sense as a date. For example,'19970523'and'970523'are interpreted as'1997-05-23', but'971332'is illegal (it has nonsensical month and day parts) and becomes'0000-00-00'.As a number in either
YYYYMMDDHHMMSSorYYMMDDHHMMSSformat, provided that the number makes sense as a date. For example,19830905132800and830905132800are interpreted as'1983-09-05 13:28:00'.As a number in either
YYYYMMDDorYYMMDDformat, provided that the number makes sense as a date. For example,19830905and830905are interpreted as'1983-09-05'.As the result of a function that returns a value that is acceptable in a
DATETIME,DATE, orTIMESTAMPcontext, such asNOW()orCURRENT_DATE.
A microseconds part is allowable in temporal values in some
contexts, such as in literal values, and in the arguments to or
return values from some temporal functions. Microseconds are
specified as a trailing .uuuuuu part in the
value. Example:
mysql> SELECT MICROSECOND('2010-12-10 14:12:09.019473');
+-------------------------------------------+
| MICROSECOND('2010-12-10 14:12:09.019473') |
+-------------------------------------------+
| 19473 |
+-------------------------------------------+
However, microseconds cannot be stored into a column of any temporal data type. Any microseconds part is discarded.
As of MySQL 5.0.8, conversion of DATETIME
values to numeric form (for example, by adding
+0) results in a double value with a
microseconds part of .000000:
mysql> SELECT NOW(), NOW()+0;
+---------------------+-----------------------+
| NOW() | NOW()+0 |
+---------------------+-----------------------+
| 2007-04-23 14:21:52 | 20070423142152.000000 |
+---------------------+-----------------------+
Before MySQL 5.0.8, the conversion results in an integer value with no microseconds part.
Illegal DATETIME, DATE, or
TIMESTAMP values are converted to the
“zero” value of the appropriate type
('0000-00-00 00:00:00' or
'0000-00-00').
For values specified as strings that include date part
delimiters, it is not necessary to specify two digits for month
or day values that are less than 10.
'1979-6-9' is the same as
'1979-06-09'. Similarly, for values specified
as strings that include time part delimiters, it is not
necessary to specify two digits for hour, minute, or second
values that are less than 10.
'1979-10-30 1:2:3' is the same as
'1979-10-30 01:02:03'.
Values specified as numbers should be 6, 8, 12, or 14 digits
long. If a number is 8 or 14 digits long, it is assumed to be in
YYYYMMDD or YYYYMMDDHHMMSS
format and that the year is given by the first 4 digits. If the
number is 6 or 12 digits long, it is assumed to be in
YYMMDD or YYMMDDHHMMSS
format and that the year is given by the first 2 digits. Numbers
that are not one of these lengths are interpreted as though
padded with leading zeros to the closest length.
Values specified as non-delimited strings are interpreted using
their length as given. If the string is 8 or 14 characters long,
the year is assumed to be given by the first 4 characters.
Otherwise, the year is assumed to be given by the first 2
characters. The string is interpreted from left to right to find
year, month, day, hour, minute, and second values, for as many
parts as are present in the string. This means you should not
use strings that have fewer than 6 characters. For example, if
you specify '9903', thinking that represents
March, 1999, MySQL inserts a “zero” date value into
your table. This occurs because the year and month values are
99 and 03, but the day
part is completely missing, so the value is not a legal date.
However, you can explicitly specify a value of zero to represent
missing month or day parts. For example, you can use
'990300' to insert the value
'1999-03-00'.
You can to some extent assign values of one date type to an object of a different date type. However, there may be some alteration of the value or loss of information:
If you assign a
DATEvalue to aDATETIMEorTIMESTAMPobject, the time part of the resulting value is set to'00:00:00'because theDATEvalue contains no time information.If you assign a
DATETIMEorTIMESTAMPvalue to aDATEobject, the time part of the resulting value is deleted because theDATEtype stores no time information.Remember that although
DATETIME,DATE, andTIMESTAMPvalues all can be specified using the same set of formats, the types do not all have the same range of values. For example,TIMESTAMPvalues cannot be earlier than1970or later than2038. This means that a date such as'1968-01-01', while legal as aDATETIMEorDATEvalue, is not valid as aTIMESTAMPvalue and is converted to0.
Be aware of certain pitfalls when specifying date values:
The relaxed format allowed for values specified as strings can be deceiving. For example, a value such as
'10:11:12'might look like a time value because of the ‘:’ delimiter, but if used in a date context is interpreted as the year'2010-11-12'. The value'10:45:15'is converted to'0000-00-00'because'45'is not a legal month.As of 5.0.2, the server requires that month and day values be legal, and not merely in the range 1 to 12 and 1 to 31, respectively. With strict mode disabled, invalid dates such as
'2004-04-31'are converted to'0000-00-00'and a warning is generated. With strict mode enabled, invalid dates generate an error. To allow such dates, enableALLOW_INVALID_DATES. See Section 5.2.6, “SQL Modes”, for more information.Before MySQL 5.0.2, the MySQL server performs only basic checking on the validity of a date: The ranges for year, month, and day are 1000 to 9999, 00 to 12, and 00 to 31, respectively. Any date containing parts not within these ranges is subject to conversion to
'0000-00-00'. Please note that this still allows you to store invalid dates such as'2002-04-31'. To ensure that a date is valid, you should perform a check in your application.Dates containing two-digit year values are ambiguous because the century is unknown. MySQL interprets two-digit year values using the following rules:
Year values in the range
00-69are converted to2000-2069.Year values in the range
70-99are converted to1970-1999.
Note: In older versions of
MySQL (prior to 4.1), the properties of the
TIMESTAMP data type differed significantly
in many ways from what is described in this section. If you
need to convert older TIMESTAMP data to
work with MySQL 5.0, be sure to see the
MySQL 3.23, 4.0, 4.1 Reference Manual
for details.
TIMESTAMP columns are displayed in the same
format as DATETIME columns. In other words,
the display width is fixed at 19 characters, and the format is
YYYY-MM-DD HH:MM:SS.
The MySQL server can be also be run with the
MAXDB SQL mode enabled. When the server
runs with this mode enabled, TIMESTAMP is
identical with DATETIME. That is, if this
mode is enabled at the time that a table is created,
TIMESTAMP columns are created as
DATETIME columns. As a result, such columns
use DATETIME display format, have the same
range of values, and there is no automatic initialization or
updating to the current date and time.
To enable MAXDB mode, set the server SQL
mode to MAXDB at startup using the
--sql-mode=MAXDB server option or by setting
the global sql_mode variable at runtime:
mysql> SET GLOBAL sql_mode=MAXDB;
A client can cause the server to run in
MAXDB mode for its own connection as
follows:
mysql> SET SESSION sql_mode=MAXDB;
Note that the information in the following discussion applies
to TIMESTAMP columns only for tables not
created with MAXDB mode enabled, because
such columns are created as DATETIME
columns.
As of MySQL 5.0.2, MySQL does not accept timestamp values that
include a zero in the day or month column or values that are
not a valid date. The sole exception to this rule is the
special value '0000-00-00 00:00:00'.
You have considerable flexibility in determining when
automatic TIMESTAMP initialization and
updating occur and which column should have those behaviors:
For one
TIMESTAMPcolumn in a table, you can assign the current timestamp as the default value and the auto-update value. It is possible to have the current timestamp be the default value for initializing the column, for the auto-update value, or both. It is not possible to have the current timestamp be the default value for one column and the auto-update value for another column.You can specify which
TIMESTAMPcolumn to automatically initialize or update to the current date and time. This need not be the firstTIMESTAMPcolumn.
The following rules govern initialization and updating of
TIMESTAMP columns:
If a
DEFAULTvalue is specified for the firstTIMESTAMPcolumn in a table, it is not ignored. The default can beCURRENT_TIMESTAMPor a constant date and time value.DEFAULT NULLis the same asDEFAULT CURRENT_TIMESTAMPfor the firstTIMESTAMPcolumn. For any otherTIMESTAMPcolumn,DEFAULT NULLis treated asDEFAULT 0.Any single
TIMESTAMPcolumn in a table can be used as the one that is initialized to the current timestamp or updated automatically.In a
CREATE TABLEstatement, the firstTIMESTAMPcolumn can be declared in any of the following ways:With both
DEFAULT CURRENT_TIMESTAMPandON UPDATE CURRENT_TIMESTAMPclauses, the column has the current timestamp for its default value, and is automatically updated.With neither
DEFAULTnorON UPDATEclauses, it is the same asDEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP.With a
DEFAULT CURRENT_TIMESTAMPclause and noON UPDATEclause, the column has the current timestamp for its default value but is not automatically updated.With no
DEFAULTclause and with anON UPDATE CURRENT_TIMESTAMPclause, the column has a default of 0 and is automatically updated.With a constant
DEFAULTvalue, the column has the given default. If the column has anON UPDATE CURRENT_TIMESTAMPclause, it is automatically updated, otherwise not.
In other words, you can use the current timestamp for both the initial value and the auto-update value, or either one, or neither. (For example, you can specify
ON UPDATEto enable auto-update without also having the column auto-initialized.)CURRENT_TIMESTAMPor any of its synonyms (CURRENT_TIMESTAMP(),NOW(),LOCALTIME,LOCALTIME(),LOCALTIMESTAMP, orLOCALTIMESTAMP()) can be used in theDEFAULTandON UPDATEclauses. They all mean “the current timestamp.” (UTC_TIMESTAMPis not allowed. Its range of values does not align with those of theTIMESTAMPcolumn anyway unless the current time zone isUTC.)The order of the
DEFAULTandON UPDATEattributes does not matter. If bothDEFAULTandON UPDATEare specified for aTIMESTAMPcolumn, either can precede the other. For example, these statements are equivalent:CREATE TABLE t (ts TIMESTAMP); CREATE TABLE t (ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP); CREATE TABLE t (ts TIMESTAMP ON UPDATE CURRENT_TIMESTAMP DEFAULT CURRENT_TIMESTAMP);To specify automatic default or updating for a
TIMESTAMPcolumn other than the first one, you must suppress the automatic initialization and update behaviors for the firstTIMESTAMPcolumn by explicitly assigning it a constantDEFAULTvalue (for example,DEFAULT 0orDEFAULT '2003-01-01 00:00:00'). Then, for the otherTIMESTAMPcolumn, the rules are the same as for the firstTIMESTAMPcolumn, except that if you omit both of theDEFAULTandON UPDATEclauses, no automatic initialization or updating occurs.Example. These statements are equivalent:
CREATE TABLE t ( ts1 TIMESTAMP DEFAULT 0, ts2 TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP); CREATE TABLE t ( ts1 TIMESTAMP DEFAULT 0, ts2 TIMESTAMP ON UPDATE CURRENT_TIMESTAMP DEFAULT CURRENT_TIMESTAMP);
You can set the current time zone on a per-connection basis,
as described in Section 5.10.8, “MySQL Server Time Zone Support”.
TIMESTAMP values are stored in UTC, being
converted from the current time zone for storage, and
converted back to the current time zone upon retrieval. As
long as the time zone setting remains constant, you get back
the same value you store. If you store a
TIMESTAMP value, and then change the time
zone and retrieve the value, the retrieved value is different
than the value you stored. This occurs because the same time
zone was not used for conversion in both directions. The
current time zone is available as the value of the
time_zone system variable.
You can include the NULL attribute in the
definition of a TIMESTAMP column to allow
the column to contain NULL values. For
example:
CREATE TABLE t ( ts1 TIMESTAMP NULL DEFAULT NULL, ts2 TIMESTAMP NULL DEFAULT 0, ts3 TIMESTAMP NULL DEFAULT CURRENT_TIMESTAMP );
If the NULL attribute is not specified,
setting the column to NULL sets it to the
current timestamp. Note that a TIMESTAMP
column which allows NULL values will
not take on the current timestamp except
under one of the following conditions:
Its default value is defined as
CURRENT_TIMESTAMPNOW()orCURRENT_TIMESTAMPis inserted into the column
In other words, a TIMESTAMP column defined
as NULL will auto-initialize only if it is
created using a definition such as the following:
CREATE TABLE t (ts TIMESTAMP NULL DEFAULT CURRENT_TIMESTAMP);
Otherwise — that is, if the TIMESTAMP
column is defined to allow NULL values but
not using DEFAULT TIMESTAMP, as shown
here…
CREATE TABLE t1 (ts TIMESTAMP NULL DEFAULT NULL); CREATE TABLE t2 (ts TIMESTAMP NULL DEFAULT '0000-00-00 00:00:00');
…then you must explicitly insert a value corresponding to the current date and time. For example:
INSERT INTO t1 VALUES (NOW()); INSERT INTO t2 VALUES (CURRENT_TIMESTAMP);
Note that TIMESTAMP columns are
NOT NULL by default.
MySQL retrieves and displays TIME values in
'HH:MM:SS' format (or
'HHH:MM:SS' format for large hours values).
TIME values may range from
'-838:59:59' to
'838:59:59'. The hours part may be so large
because the TIME type can be used not only to
represent a time of day (which must be less than 24 hours), but
also elapsed time or a time interval between two events (which
may be much greater than 24 hours, or even negative).
You can specify TIME values in a variety of
formats:
As a string in
'D HH:MM:SS.fraction'format. You can also use one of the following “relaxed” syntaxes:'HH:MM:SS.fraction','HH:MM:SS','HH:MM','D HH:MM:SS','D HH:MM','D HH', or'SS'. HereDrepresents days and can have a value from 0 to 34. Note that MySQL does not store the fraction part.As a string with no delimiters in
'HHMMSS'format, provided that it makes sense as a time. For example,'101112'is understood as'10:11:12', but'109712'is illegal (it has a nonsensical minute part) and becomes'00:00:00'.As a number in
HHMMSSformat, provided that it makes sense as a time. For example,101112is understood as'10:11:12'. The following alternative formats are also understood:SS,MMSS,HHMMSS,HHMMSS.fraction. Note that MySQL does not store the fraction part.As the result of a function that returns a value that is acceptable in a
TIMEcontext, such asCURRENT_TIME.
A trailing .uuuuuu microseconds part of
TIME values is allowed under the same
conditions as for other temporal values, as described in
Section 11.3.1, “The DATETIME, DATE, and
TIMESTAMP Types”. This includes the property that any
microseconds part is discarded from values stored into
TIME columns.
For TIME values specified as strings that
include a time part delimiter, it is not necessary to specify
two digits for hours, minutes, or seconds values that are less
than 10. '8:3:2' is the
same as '08:03:02'.
Be careful about assigning abbreviated values to a
TIME column. Without colons, MySQL interprets
values using the assumption that the two rightmost digits
represent seconds. (MySQL interprets TIME
values as elapsed time rather than as time of day.) For example,
you might think of '1112' and
1112 as meaning '11:12:00'
(12 minutes after 11 o'clock), but MySQL interprets them as
'00:11:12' (11 minutes, 12 seconds).
Similarly, '12' and 12 are
interpreted as '00:00:12'.
TIME values with colons, by contrast, are
always treated as time of the day. That is,
'11:12' mean '11:12:00',
not '00:11:12'.
By default, values that lie outside the TIME
range but are otherwise legal are clipped to the closest
endpoint of the range. For example,
'-850:00:00' and
'850:00:00' are converted to
'-838:59:59' and
'838:59:59'. Illegal TIME
values are converted to '00:00:00'. Note that
because '00:00:00' is itself a legal
TIME value, there is no way to tell, from a
value of '00:00:00' stored in a table,
whether the original value was specified as
'00:00:00' or whether it was illegal.
For more restrictive treatment of invalid
TIME values, enable strict SQL mode to cause
errors to occur. See Section 5.2.6, “SQL Modes”.
The YEAR type is a one-byte type used for
representing years.
MySQL retrieves and displays YEAR values in
YYYY format. The range is
1901 to 2155.
You can specify YEAR values in a variety of
formats:
As a four-digit string in the range
'1901'to'2155'.As a four-digit number in the range
1901to2155.As a two-digit string in the range
'00'to'99'. Values in the ranges'00'to'69'and'70'to'99'are converted toYEARvalues in the ranges2000to2069and1970to1999.As a two-digit number in the range
1to99. Values in the ranges1to69and70to99are converted toYEARvalues in the ranges2001to2069and1970to1999. Note that the range for two-digit numbers is slightly different from the range for two-digit strings, because you cannot specify zero directly as a number and have it be interpreted as2000. You must specify it as a string'0'or'00'or it is interpreted as0000.As the result of a function that returns a value that is acceptable in a
YEARcontext, such asNOW().
Illegal YEAR values are converted to
0000.
MySQL Server itself has no problems with Year 2000 (Y2K) compliance:
MySQL Server uses Unix time functions that handle dates into the year
2038forTIMESTAMPvalues. ForDATEandDATETIMEvalues, dates through the year9999are accepted.All MySQL date functions are implemented in one source file,
sql/time.cc, and are coded very carefully to be year 2000-safe.In MySQL, the
YEARdata type can store the years0and1901to2155in one byte and display them using two or four digits. All two-digit years are considered to be in the range1970to2069, which means that if you store01in aYEARcolumn, MySQL Server treats it as2001.
Although MySQL Server itself is Y2K-safe, you may run into
problems if you use it with applications that are not Y2K-safe.
For example, many old applications store or manipulate years
using two-digit values (which are ambiguous) rather than
four-digit values. This problem may be compounded by
applications that use values such as 00 or
99 as “missing” value
indicators. Unfortunately, these problems may be difficult to
fix because different applications may be written by different
programmers, each of whom may use a different set of conventions
and date-handling functions.
Thus, even though MySQL Server has no Y2K problems, it is the application's responsibility to provide unambiguous input. Any value containing a two-digit year is ambiguous, because the century is unknown. Such values must be interpreted into four-digit form because MySQL stores years internally using four digits.
For DATETIME, DATE,
TIMESTAMP, and YEAR types,
MySQL interprets dates with ambiguous year values using the
following rules:
Year values in the range
00-69are converted to2000-2069.Year values in the range
70-99are converted to1970-1999.
Remember that these rules are only heuristics that provide reasonable guesses as to what your data values mean. If the rules used by MySQL do not produce the correct values, you should provide unambiguous input containing four-digit year values.
ORDER BY properly sorts
YEAR values that have two-digit years.
Some functions like MIN() and
MAX() convert a YEAR to a
number. This means that a value with a two-digit year does not
work properly with these functions. The fix in this case is to
convert the TIMESTAMP or
YEAR to four-digit year format.
The string types are CHAR,
VARCHAR, BINARY,
VARBINARY, BLOB,
TEXT, ENUM, and
SET. This section describes how these types
work and how to use them in your queries. For string type storage
requirements, see Section 11.5, “Data Type Storage Requirements”.
The CHAR and VARCHAR types
are similar, but differ in the way they are stored and
retrieved. As of MySQL 5.0.3, they also differ in maximum length
and in whether trailing spaces are retained.
The CHAR and VARCHAR types
are declared with a length that indicates the maximum number of
characters you want to store. For example,
CHAR(30) can hold up to 30 characters.
The length of a CHAR column is fixed to the
length that you declare when you create the table. The length
can be any value from 0 to 255. When CHAR
values are stored, they are right-padded with spaces to the
specified length. When CHAR values are
retrieved, trailing spaces are removed.
Values in VARCHAR columns are variable-length
strings. The length can be specified as a value from 0 to 255
before MySQL 5.0.3, and 0 to 65,535 in 5.0.3 and later versions.
(The maximum effective length of a VARCHAR in
MySQL 5.0.3 and later is determined by the maximum row size and
the character set used. The maximum column length is subject to
a row size of 65,532 bytes.)
In contrast to CHAR,
VARCHAR values are stored using only as many
characters as are needed, plus one byte to record the length
(two bytes for columns that are declared with a length longer
than 255).
VARCHAR values are not padded when they are
stored. Handling of trailing spaces is version-dependent. As of
MySQL 5.0.3, trailing spaces are retained when values are stored
and retrieved, in conformance with standard SQL. Before MySQL
5.0.3, trailing spaces are removed from values when they are
stored into a VARCHAR column; this means that
the spaces also are absent from retrieved values.
If you assign a value to a CHAR or
VARCHAR column that exceeds the column's
maximum length, the value is truncated to fit. If the truncated
characters are not spaces, a warning is generated. For
truncation of non-space characters, you can cause an error to
occur (rather than a warning) and suppress insertion of the
value by using strict SQL mode. See
Section 5.2.6, “SQL Modes”.
Before MySQL 5.0.3, if you need a data type for which trailing
spaces are not removed, consider using a BLOB
or TEXT type. Also, if you want to store
binary values such as results from an encryption or compression
function that might contain arbitrary byte values, use a
BLOB column rather than a
CHAR or VARCHAR column, to
avoid potential problems with trailing space removal that would
change data values.
The following table illustrates the differences between
CHAR and VARCHAR by
showing the result of storing various string values into
CHAR(4) and VARCHAR(4)
columns:
| Value | CHAR(4) | Storage Required | VARCHAR(4) | Storage Required |
'' | ' ' | 4 bytes | '' | 1 byte |
'ab' | 'ab ' | 4 bytes | 'ab' | 3 bytes |
'abcd' | 'abcd' | 4 bytes | 'abcd' | 5 bytes |
'abcdefgh' | 'abcd' | 4 bytes | 'abcd' | 5 bytes |
Note that the values shown as stored in the last row of the table apply only when not using strict mode; if MySQL is running in strict mode, values that exceed the column length are not stored, and an error results.
If a given value is stored into the CHAR(4)
and VARCHAR(4) columns, the values retrieved
from the columns are not always the same because trailing spaces
are removed from CHAR columns upon retrieval.
The following example illustrates this difference:
mysql>CREATE TABLE vc (v VARCHAR(4), c CHAR(4));Query OK, 0 rows affected (0.01 sec) mysql>INSERT INTO vc VALUES ('ab ', 'ab ');Query OK, 1 row affected (0.00 sec) mysql>SELECT CONCAT('(', v, ')'), CONCAT('(', c, ')') FROM vc;+---------------------+---------------------+ | CONCAT('(', v, ')') | CONCAT('(', c, ')') | +---------------------+---------------------+ | (ab ) | (ab) | +---------------------+---------------------+ 1 row in set (0.06 sec)
Values in CHAR and VARCHAR
columns are sorted and compared according to the character set
collation assigned to the column.
Note that all MySQL collations are of type
PADSPACE. This means that all
CHAR and VARCHAR values in
MySQL are compared without regard to any trailing spaces. For
example:
mysql>CREATE TABLE names (myname CHAR(10), yourname VARCHAR(10));Query OK, 0 rows affected (0.09 sec) mysql>INSERT INTO names VALUES ('Monty ', 'Monty ');Query OK, 1 row affected (0.00 sec) mysql>SELECT myname = 'Monty ', yourname = 'Monty ' FROM names;+--------------------+----------------------+ | myname = 'Monty ' | yourname = 'Monty ' | +--------------------+----------------------+ | 1 | 1 | +--------------------+----------------------+ 1 row in set (0.00 sec)
Note that this is true for all MySQL versions, and it makes no
difference whether your version trims trailing spaces from
VARCHAR values before storing them. Nor does
the server SQL mode make any difference in this regard.
For those cases where trailing pad characters are stripped or
comparisons ignore them, if a column has an index that requires
unique values, inserting into the column values that differ only
in number of trailing pad characters will result in a
duplicate-key error. For example, if a table contains
'a', an attempt to store
'a ' causes a duplicate-key error.
The BINARY and VARBINARY
types are similar to CHAR and
VARCHAR, except that they contain binary
strings rather than non-binary strings. That is, they contain
byte strings rather than character strings. This means that they
have no character set, and sorting and comparison are based on
the numeric values of the bytes in the values.
The allowable maximum length is the same for
BINARY and VARBINARY as it
is for CHAR and VARCHAR,
except that the length for BINARY and
VARBINARY is a length in bytes rather than in
characters.
The BINARY and VARBINARY
data types are distinct from the CHAR BINARY
and VARCHAR BINARY data types. For the latter
types, the BINARY attribute does not cause
the column to be treated as a binary string column. Instead, it
causes the binary collation for the column character set to be
used, and the column itself contains non-binary character
strings rather than binary byte strings. For example,
CHAR(5) BINARY is treated as CHAR(5)
CHARACTER SET latin1 COLLATE latin1_bin, assuming that
the default character set is latin1. This
differs from BINARY(5), which stores 5-bytes
binary strings that have no character set or collation.
When BINARY values are stored, they are
right-padded with the pad value to the specified length. The pad
value and how it is handled is version specific:
As of MySQL 5.0.15, the pad value is
0x00(the zero byte). Values are right-padded with0x00on insert, and no trailing bytes are removed on select. All bytes are significant in comparisons, includingORDER BYandDISTINCToperations.0x00bytes and spaces are different in comparisons, with0x00< space.Example: For a
BINARY(3)column,'a 'becomes'a \0'when inserted.'a\0'becomes'a\0\0'when inserted. Both inserted values remain unchanged when selected.Before MySQL 5.0.15, the pad value is space. Values are right-padded with space on insert, and trailing spaces are removed on select. Trailing spaces are ignored in comparisons, including
ORDER BYandDISTINCToperations.0x00bytes and spaces are different in comparisons, with0x00< space.Example: For a
BINARY(3)column,'a 'becomes'a 'when inserted and'a'when selected.'a\0'becomes'a\0 'when inserted and'a\0'when selected.
For VARBINARY, there is no padding on insert
and no bytes are stripped on select. All bytes are significant
in comparisons, including ORDER BY and
DISTINCT operations. 0x00
bytes and spaces are different in comparisons, with
0x00 < space. (Exceptions: Before MySQL
5.0.3, trailing spaces are removed when values are stored.
Before MySQL 5.0.15, trailing 0x00 bytes are removed for
ORDER BY operations.)
Note: The InnoDB storage engine continues to
preserve trailing spaces in BINARY and
VARBINARY column values through MySQL 5.0.18.
Beginning with MySQL 5.0.19, InnoDB uses
trailing space characters in making comparisons as do other
MySQL storage engines.
For those cases where trailing pad bytes are stripped or
comparisons ignore them, if a column has an index that requires
unique values, inserting into the column values that differ only
in number of trailing pad bytes will result in a duplicate-key
error. For example, if a table contains 'a',
an attempt to store 'a\0' causes a
duplicate-key error.
You should consider the preceding padding and stripping
characteristics carefully if you plan to use the
BINARY data type for storing binary data and
you require that the value retrieved be exactly the same as the
value stored. The following example illustrates how
0x00-padding of BINARY
values affects column value comparisons:
mysql>CREATE TABLE t (c BINARY(3));Query OK, 0 rows affected (0.01 sec) mysql>INSERT INTO t SET c = 'a';Query OK, 1 row affected (0.01 sec) mysql>SELECT HEX(c), c = 'a', c = 'a\0\0' from t;+--------+---------+-------------+ | HEX(c) | c = 'a' | c = 'a\0\0' | +--------+---------+-------------+ | 610000 | 0 | 1 | +--------+---------+-------------+ 1 row in set (0.09 sec)
If the value retrieved must be the same as the value specified
for storage with no padding, it might be preferable to use
VARBINARY or one of the
BLOB data types instead.
A BLOB is a binary large object that can hold
a variable amount of data. The four BLOB
types are TINYBLOB, BLOB,
MEDIUMBLOB, and LONGBLOB.
These differ only in the maximum length of the values they can
hold. The four TEXT types are
TINYTEXT, TEXT,
MEDIUMTEXT, and LONGTEXT.
These correspond to the four BLOB types and
have the same maximum lengths and storage requirements. See
Section 11.5, “Data Type Storage Requirements”. No lettercase conversion
for TEXT or BLOB columns
takes place during storage or retrieval.
BLOB columns are treated as binary strings
(byte strings). TEXT columns are treated as
non-binary strings (character strings). BLOB
columns have no character set, and sorting and comparison are
based on the numeric values of the bytes in column values.
TEXT columns have a character set, and values
are sorted and compared based on the collation of the character
set.
If a TEXT column is indexed, index entry
comparisons are space-padded at the end. This means that, if the
index requires unique values, duplicate-key errors will occur
for values that differ only in the number of trailing spaces.
For example, if a table contains 'a', an
attempt to store 'a ' causes a
duplicate-key error. This is not true for
BLOB columns.
When not running in strict mode, if you assign a value to a
BLOB or TEXT column that
exceeds the data type's maximum length, the value is truncated
to fit. If the truncated characters are not spaces, a warning is
generated. You can cause an error to occur and the value to be
rejected rather than to be truncated with a warning by using
strict SQL mode. See Section 5.2.6, “SQL Modes”.
In most respects, you can regard a BLOB
column as a VARBINARY column that can be as
large as you like. Similarly, you can regard a
TEXT column as a VARCHAR
column. BLOB and TEXT
differ from VARBINARY and
VARCHAR in the following ways:
There is no trailing-space removal for
BLOBandTEXTcolumns when values are stored or retrieved. Before MySQL 5.0.3, this differs fromVARBINARYandVARCHAR, for which trailing spaces are removed when values are stored.Note that
TEXTis on comparison space extended to fit the compared object, exactly likeCHARandVARCHAR.For indexes on
BLOBandTEXTcolumns, you must specify an index prefix length. ForCHARandVARCHAR, a prefix length is optional. See Section 7.4.3, “Column Indexes”.
LONG and LONG VARCHAR map
to the MEDIUMTEXT data type. This is a
compatibility feature. If you use the BINARY
attribute with a TEXT data type, the column
is assigned the binary collation of the column character set.
MySQL Connector/ODBC defines BLOB values as
LONGVARBINARY and TEXT
values as LONGVARCHAR.
Because BLOB and TEXT
values can be extremely long, you might encounter some
constraints in using them:
Only the first
max_sort_lengthbytes of the column are used when sorting. The default value ofmax_sort_lengthis 1024. This value can be changed using the--max_sort_length=option when starting the mysqld server. See Section 5.2.3, “System Variables”.NYou can make more bytes significant in sorting or grouping by increasing the value of
max_sort_lengthat runtime. Any client can change the value of its sessionmax_sort_lengthvariable:mysql>
SET max_sort_length = 2000;mysql>SELECT id, comment FROM t->ORDER BY comment;Another way to use
GROUP BYorORDER BYon aBLOBorTEXTcolumn containing long values when you want more thanmax_sort_lengthbytes to be significant is to convert the column value into a fixed-length object. The standard way to do this is with theSUBSTRING()function. For example, the following statement causes 2000 bytes of thecommentcolumn to be taken into account for sorting:mysql>
SELECT id, SUBSTRING(comment,1,2000) FROM t->ORDER BY SUBSTRING(comment,1,2000);The maximum size of a
BLOBorTEXTobject is determined by its type, but the largest value you actually can transmit between the client and server is determined by the amount of available memory and the size of the communications buffers. You can change the message buffer size by changing the value of themax_allowed_packetvariable, but you must do so for both the server and your client program. For example, both mysql and mysqldump allow you to change the client-sidemax_allowed_packetvalue. See Section 7.5.2, “Tuning Server Parameters”, Section 8.8, “mysql — The MySQL Command-Line Tool”, and Section 8.13, “mysqldump — A Database Backup Program”. You may also want to compare the packet sizes and the size of the data objects you are storing with the storage requirements, see Section 11.5, “Data Type Storage Requirements”
Each BLOB or TEXT value is
represented internally by a separately allocated object. This is
in contrast to all other data types, for which storage is
allocated once per column when the table is opened.
In some cases, it may be desirable to store binary data such as
media files in BLOB or
TEXT columns. You may find MySQL's string
handling functions useful for working with such data. See
Section 12.4, “String Functions”. For security and other
reasons, it is usually preferable to do so using application
code rather than allowing application users the
FILE privilege. You can discuss specifics for
various languages and platforms in the MySQL Forums
(http://forums.mysql.com/).
An ENUM is a string object with a value
chosen from a list of allowed values that are enumerated
explicitly in the column specification at table creation time.
An enumeration value must be a quoted string literal; it may not be an expression, even one that evaluates to a string value. This means that you also may not employ a user variable as an enumeration value.
For example, you can create a table with an
ENUM column like this:
CREATE TABLE sizes (
name ENUM('small', 'medium', 'large')
);
However, this version of the previous CREATE
TABLE statement does not work:
CREATE TABLE sizes (
c1 ENUM('small', CONCAT('med','ium'), 'large')
);
You also may not employ a user variable as an enumeration value. This pair of statements do not work:
SET @mysize = 'medium';
CREATE TABLE sizes (
name ENUM('small', @mysize, 'large')
);
If you wish to use a number as an enumeration value, you must enclose it in quotes.
The value may also be the empty string ('')
or NULL under certain circumstances:
If you insert an invalid value into an
ENUM(that is, a string not present in the list of allowed values), the empty string is inserted instead as a special error value. This string can be distinguished from a “normal” empty string by the fact that this string has the numerical value 0. More about this later.If strict SQL mode is enabled, attempts to insert invalid
ENUMvalues result in an error.If an
ENUMcolumn is declared to allowNULL, theNULLvalue is a legal value for the column, and the default value isNULL. If anENUMcolumn is declaredNOT NULL, its default value is the first element of the list of allowed values.
Each enumeration value has an index:
Values from the list of allowable elements in the column specification are numbered beginning with 1.
The index value of the empty string error value is 0. This means that you can use the following
SELECTstatement to find rows into which invalidENUMvalues were assigned:mysql>
SELECT * FROMtbl_nameWHEREenum_col=0;The index of the
NULLvalue isNULL.The term “index” here refers only to position within the list of enumeration values. It has nothing to do with table indexes.
For example, a column specified as ENUM('one', 'two',
'three') can have any of the values shown here. The
index of each value is also shown:
| Value | Index |
NULL | NULL |
'' | 0 |
'one' | 1 |
'two' | 2 |
'three' | 3 |
An enumeration can have a maximum of 65,535 elements.
Trailing spaces are automatically deleted from
ENUM member values in the table definition
when a table is created.
When retrieved, values stored into an ENUM
column are displayed using the lettercase that was used in the
column definition. Note that ENUM columns can
be assigned a character set and collation. For binary or
case-sensitive collations, lettercase is taken into account when
assigning values to the column.
If you retrieve an ENUM value in a numeric
context, the column value's index is returned. For example, you
can retrieve numeric values from an ENUM
column like this:
mysql> SELECT enum_col+0 FROM tbl_name;
If you store a number into an ENUM column,
the number is treated as the index into the possible values, and
the value stored is the enumeration member with that index.
(However, this does not work with
LOAD DATA, which treats all input as
strings.) If the numeric value is quoted, it is still
interpreted as an index if there is no matching string in the
list of enumeration values. For these reasons, it is not
advisable to define an ENUM column with
enumeration values that look like numbers, because this can
easily become confusing. For example, the following column has
enumeration members with string values of
'0', '1', and
'2', but numeric index values of
1, 2, and
3:
numbers ENUM('0','1','2')
If you store 2, it is interpreted as an index
value, and becomes '1' (the value with index
2). If you store '2', it matches an
enumeration value, so it is stored as '2'. If
you store '3', it does not match any
enumeration value, so it is treated as an index and becomes
'2' (the value with index 3).
mysql>INSERT INTO t (numbers) VALUES(2),('2'),('3');mysql>SELECT * FROM t;+---------+ | numbers | +---------+ | 1 | | 2 | | 2 | +---------+
ENUM values are sorted according to the order
in which the enumeration members were listed in the column
specification. (In other words, ENUM values
are sorted according to their index numbers.) For example,
'a' sorts before 'b' for
ENUM('a', 'b'), but 'b'
sorts before 'a' for ENUM('b',
'a'). The empty string sorts before non-empty strings,
and NULL values sort before all other
enumeration values. To prevent unexpected results, specify the
ENUM list in alphabetical order. You can also
use GROUP BY CAST(col AS CHAR) or
GROUP BY CONCAT(col) to make sure that the
column is sorted lexically rather than by index number.
If you want to determine all possible values for an
ENUM column, use SHOW COLUMNS FROM
and parse the
tbl_name LIKE
enum_colENUM definition in the
Type column of the output.
A SET is a string object that can have zero
or more values, each of which must be chosen from a list of
allowed values specified when the table is created.
SET column values that consist of multiple
set members are specified with members separated by commas
(‘,’). A consequence of this is
that SET member values should not themselves
contain commas.
For example, a column specified as SET('one', 'two')
NOT NULL can have any of these values:
'' 'one' 'two' 'one,two'
A SET can have a maximum of 64 different
members.
Trailing spaces are automatically deleted from
SET member values in the table definition
when a table is created.
When retrieved, values stored in a SET column
are displayed using the lettercase that was used in the column
definition. Note that SET columns can be
assigned a character set and collation. For binary or
case-sensitive collations, lettercase is taken into account when
assigning values to the column.
MySQL stores SET values numerically, with the
low-order bit of the stored value corresponding to the first set
member. If you retrieve a SET value in a
numeric context, the value retrieved has bits set corresponding
to the set members that make up the column value. For example,
you can retrieve numeric values from a SET
column like this:
mysql> SELECT set_col+0 FROM tbl_name;
If a number is stored into a SET column, the
bits that are set in the binary representation of the number
determine the set members in the column value. For a column
specified as SET('a','b','c','d'), the
members have the following decimal and binary values:
SET Member | Decimal Value | Binary Value |
'a' | 1 | 0001 |
'b' | 2 | 0010 |
'c' | 4 | 0100 |
'd' | 8 | 1000 |
If you assign a value of 9 to this column,
that is 1001 in binary, so the first and
fourth SET value members
'a' and 'd' are selected
and the resulting value is 'a,d'.
For a value containing more than one SET
element, it does not matter what order the elements are listed
in when you insert the value. It also does not matter how many
times a given element is listed in the value. When the value is
retrieved later, each element in the value appears once, with
elements listed according to the order in which they were
specified at table creation time. For example, suppose that a
column is specified as SET('a','b','c','d'):
mysql> CREATE TABLE myset (col SET('a', 'b', 'c', 'd'));
If you insert the values 'a,d',
'd,a', 'a,d,d',
'a,d,a', and 'd,a,d':
mysql> INSERT INTO myset (col) VALUES
-> ('a,d'), ('d,a'), ('a,d,a'), ('a,d,d'), ('d,a,d');
Query OK, 5 rows affected (0.01 sec)
Records: 5 Duplicates: 0 Warnings: 0
Then all of these values appear as 'a,d' when
retrieved:
mysql> SELECT col FROM myset;
+------+
| col |
+------+
| a,d |
| a,d |
| a,d |
| a,d |
| a,d |
+------+
5 rows in set (0.04 sec)
If you set a SET column to an unsupported
value, the value is ignored and a warning is issued:
mysql>INSERT INTO myset (col) VALUES ('a,d,d,s');Query OK, 1 row affected, 1 warning (0.03 sec) mysql>SHOW WARNINGS;+---------+------+------------------------------------------+ | Level | Code | Message | +---------+------+------------------------------------------+ | Warning | 1265 | Data truncated for column 'col' at row 1 | +---------+------+------------------------------------------+ 1 row in set (0.04 sec) mysql>SELECT col FROM myset;+------+ | col | +------+ | a,d | | a,d | | a,d | | a,d | | a,d | | a,d | +------+ 6 rows in set (0.01 sec)
If strict SQL mode is enabled, attempts to insert invalid
SET values result in an error.
SET values are sorted numerically.
NULL values sort before
non-NULL SET values.
Normally, you search for SET values using the
FIND_IN_SET() function or the
LIKE operator:
mysql>SELECT * FROMmysql>tbl_nameWHERE FIND_IN_SET('value',set_col)>0;SELECT * FROMtbl_nameWHEREset_colLIKE '%value%';
The first statement finds rows where
set_col contains the
value set member. The second is
similar, but not the same: It finds rows where
set_col contains
value anywhere, even as a substring
of another set member.
The following statements also are legal:
mysql>SELECT * FROMmysql>tbl_nameWHEREset_col& 1;SELECT * FROMtbl_nameWHEREset_col= 'val1,val2';
The first of these statements looks for values containing the
first set member. The second looks for an exact match. Be
careful with comparisons of the second type. Comparing set
values to
'
returns different results than comparing values to
val1,val2''.
You should specify the values in the same order they are listed
in the column definition.
val2,val1'
If you want to determine all possible values for a
SET column, use SHOW COLUMNS FROM
and parse the
tbl_name LIKE
set_colSET definition in the Type
column of the output.
The storage requirements for each of the data types supported by MySQL are listed here by category.
The maximum size of a row in a MyISAM table is
65,534 bytes. Each BLOB and
TEXT column accounts for only five to nine
bytes toward this size.
Important: For tables using the
NDBCluster storage engine, there is the factor
of 4-byte alignment to be taken into
account when calculating storage requirements. This means that all
NDB data storage is done in multiples of 4
bytes. Thus, a column value that — in a table using a
storage engine other than NDB — would
take 15 bytes for storage, requires 16 bytes in an
NDB table. This requirement applies in addition
to any other considerations that are discussed in this section.
For example, in NDBCluster tables, the
TINYINT, SMALLINT,
MEDIUMINT, and INTEGER
(INT) column types each require 4 bytes storage
per record.
In addition, when calculating storage requirements for Cluster
tables, you must remember that every table using the
NDBCluster storage engine requires a primary
key; if no primary key is defined by the user, then a
“hidden” primary key will be created by
NDB. This hidden primary key consumes 31-35
bytes per table record.
You may also find the ndb_size.pl utility to
be useful in such cases. This Perl script connects to a current
MySQL (non-Cluster) database and creates a report on how much
space that database would require if it used the
NDBCluster storage engine. See
Section 15.9.14, “ndb_size.pl — NDBCluster Size Requirement Estimator”, for more
information.
Storage Requirements for Numeric Types
| Data Type | Storage Required |
TINYINT | 1 byte |
SMALLINT | 2 bytes |
MEDIUMINT | 3 bytes |
INT, INTEGER | 4 bytes |
BIGINT | 8 bytes |
FLOAT( | 4 bytes if 0 <= p <= 24, 8 bytes if 25
<= p <= 53 |
FLOAT | 4 bytes |
DOUBLE [PRECISION], REAL | 8 bytes |
DECIMAL(,
NUMERIC( | Varies; see following discussion |
BIT( | approximately (M+7)/8 bytes |
The storage requirements for DECIMAL (and
NUMERIC) are version-specific:
As of MySQL 5.0.3, values for DECIMAL columns
are represented using a binary format that packs nine decimal
(base 10) digits into four bytes. Storage for the integer and
fractional parts of each value are determined separately. Each
multiple of nine digits requires four bytes, and the
“leftover” digits require some fraction of four
bytes. The storage required for excess digits is given by the
following table:
| Leftover Digits | Number of Bytes |
| 0 | 0 |
| 1 | 1 |
| 2 | 1 |
| 3 | 2 |
| 4 | 2 |
| 5 | 3 |
| 6 | 3 |
| 7 | 4 |
| 8 | 4 |
Before MySQL 5.0.3, DECIMAL columns are
represented as strings and storage requirements are:
M+2 bytes if
D > 0,
M+1D = 0 (D+2,
if M <
D
Storage Requirements for Date and Time Types
| Data Type | Storage Required |
DATE | 3 bytes |
DATETIME | 8 bytes |
TIMESTAMP | 4 bytes |
TIME | 3 bytes |
YEAR | 1 byte |
Storage Requirements for String Types
| Data Type | Storage Required |
CHAR( | <=
255 |
VARCHAR( | Prior to MySQL 5.0.3: L
+ 1 bytes, where <= 255. MySQL 5.0.3 and
later: L + 1 bytes,
where <= 255 or
L + 2 bytes, where
<= 65535 (see note below). |
BINARY( | <=
255 |
VARBINARY( | Prior to MySQL 5.0.3: L
+ 1 bytes, where <= 255. MySQL 5.0.3 and
later: L + 1 bytes,
where <= 255 or
L + 2 bytes, where
<= 65535 (see note below). |
TINYBLOB, TINYTEXT | L+1 byte, where L
< 28 |
BLOB, TEXT | L+2 bytes, where L
< 216 |
MEDIUMBLOB, MEDIUMTEXT | L+3 bytes, where L
< 224 |
LONGBLOB, LONGTEXT | L+4 bytes, where L
< 232 |
ENUM(' | 1 or 2 bytes, depending on the number of enumeration values (65,535 values maximum) |
SET(' | 1, 2, 3, 4, or 8 bytes, depending on the number of set members (64 members maximum) |
For the CHAR, VARCHAR, and
TEXT types, the values
L and M in
the preceding table should be interpreted as number of characters,
and lengths for these types in column specifications indicate the
number of characters. For example, to store a
TINYTEXT value requires
L characters plus one byte.
VARCHAR, VARBINARY, and the
BLOB and TEXT types are
variable-length types. For each, the storage requirements depend
on these factors:
The actual length of the column value
The column's maximum possible length
The character set used for the column
For example, a VARCHAR(10) column can hold a
string with a maximum length of 10. Assuming that the column uses
the latin1 character set (one byte per
character), the actual storage required is the length of the
string (L), plus one byte to record the
length of the string. For the string 'abcd',
L is 4 and the storage requirement is
five bytes. If the same column was instead declared as
VARCHAR(500), the string
'abcd' requires 4 + 2 = 6 bytes. Two bytes
rather than one are required for the prefix because the length of
the column is greater than 255 characters.
To calculate the number of bytes used to
store a particular CHAR,
VARCHAR, or TEXT column
value, you must take into account the character set used for that
column. In particular, when using the utf8
Unicode character set, you must keep in mind that not all
utf8 characters use the same number of bytes.
For a breakdown of the storage used for different categories of
utf8 characters, see
Section 10.7, “Unicode Support”.
Note: In MySQL 5.0.3 and later,
the effective maximum length for a
VARCHAR or VARBINARY column
is 65,532.
As of MySQL 5.0.3, the NDBCLUSTER engine
supports only fixed-width columns. This means that a
VARCHAR column from a table in a MySQL Cluster
will behave as follows:
If the size of the column is fewer than 256 characters, the column requires one byte extra storage per row.
If the size of the column is 256 characters or more, the column requires two bytes extra storage per row.
Note that the number of bytes required per character varies
according to the character set used. For example, if a
VARCHAR(100) column in a Cluster table uses the
utf8 character set, then each character
requires 3 bytes storage. This means that each record in such a
column takes up 100 × 3 + 1 = 301 bytes for
storage, regardless of the length of the string actually stored in
any given record. For a VARCHAR(1000) column in
a table using the NDBCLUSTER storage engine
with the utf8 character set, each record will
use 1000 × 3 + 2 = 3002 bytes storage; that is,
the column is 1,000 characters wide, each character requires 3
bytes storage, and each record has a 2-byte overhead because 1,000
> 256.
The BLOB and TEXT types
require 1, 2, 3, or 4 bytes to record the length of the column
value, depending on the maximum possible length of the type. See
Section 11.4.3, “The BLOB and TEXT Types”.
TEXT and BLOB columns are
implemented differently in the NDB Cluster storage engine, wherein
each row in a TEXT column is made up of two
separate parts. One of these is of fixed size (256 bytes), and is
actually stored in the original table. The other consists of any
data in excess of 256 bytes, which is stored in a hidden table. The
rows in this second table are always 2,000 bytes long. This means
that the size of a TEXT column is 256 if
size <= 256 (where
size represents the size of the row);
otherwise, the size is 256 + size +
(2000 – (size – 256) %
2000).
The size of an ENUM object is determined by the
number of different enumeration values. One byte is used for
enumerations with up to 255 possible values. Two bytes are used
for enumerations having between 256 and 65,535 possible values.
See Section 11.4.4, “The ENUM Type”.
The size of a SET object is determined by the
number of different set members. If the set size is
N, the object occupies
( bytes,
rounded up to 1, 2, 3, 4, or 8 bytes. A N+7)/8SET can
have a maximum of 64 members. See Section 11.4.5, “The SET Type”.
For optimum storage, you should try to use the most precise type
in all cases. For example, if an integer column is used for values
in the range from 1 to
99999, MEDIUMINT UNSIGNED is
the best type. Of the types that represent all the required
values, this type uses the least amount of storage.
Tables created in MySQL 5.0.3 and above uses a new storage format
for DECIMAL columns. All basic calculation
(+,-,*,/) with DECIMAL
columns are done with precision of 65 decimal (base 10) digits.
See Section 11.1.1, “Overview of Numeric Types”.
Prior to MySQL 5.0.3, calculations on DECIMAL
values are performed using double-precision operations. If
accuracy is not too important or if speed is the highest priority,
the DOUBLE type may be good enough. For high
precision, you can always convert to a fixed-point type stored in
a BIGINT. This allows you to do all
calculations with 64-bit integers and then convert results back to
floating-point values as necessary.
To facilitate the use of code written for SQL implementations from other vendors, MySQL maps data types as shown in the following table. These mappings make it easier to import table definitions from other database systems into MySQL:
| Other Vendor Type | MySQL Type |
BOOL | TINYINT |
BOOLEAN | TINYINT |
CHARACTER VARYING( | VARCHAR( |
FIXED | DECIMAL |
FLOAT4 | FLOAT |
FLOAT8 | DOUBLE |
INT1 | TINYINT |
INT2 | SMALLINT |
INT3 | MEDIUMINT |
INT4 | INT |
INT8 | BIGINT |
LONG VARBINARY | MEDIUMBLOB |
LONG VARCHAR | MEDIUMTEXT |
LONG | MEDIUMTEXT |
MIDDLEINT | MEDIUMINT |
NUMERIC | DECIMAL |
Data type mapping occurs at table creation time, after which the
original type specifications are discarded. If you create a table
with types used by other vendors and then issue a
DESCRIBE
statement, MySQL reports the table structure using the equivalent
MySQL types. For example:
tbl_name
mysql>CREATE TABLE t (a BOOL, b FLOAT8, c LONG VARCHAR, d NUMERIC);Query OK, 0 rows affected (0.00 sec) mysql>DESCRIBE t;+-------+---------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------------+------+-----+---------+-------+ | a | tinyint(1) | YES | | NULL | | | b | double | YES | | NULL | | | c | mediumtext | YES | | NULL | | | d | decimal(10,0) | YES | | NULL | | +-------+---------------+------+-----+---------+-------+ 4 rows in set (0.01 sec)
Table of Contents
- 12.1. Operator and Function Reference
- 12.2. Operators
- 12.3. Control Flow Functions
- 12.4. String Functions
- 12.5. Numeric Functions
- 12.6. Date and Time Functions
- 12.7. What Calendar Is Used By MySQL?
- 12.8. Full-Text Search Functions
- 12.9. Cast Functions and Operators
- 12.10. Other Functions
- 12.11. Functions and Modifiers for Use with
GROUP BYClauses
Expressions can be used at several points in SQL statements, such as
in the ORDER BY or HAVING
clauses of SELECT statements, in the
WHERE clause of a SELECT,
DELETE, or UPDATE statement,
or in SET statements. Expressions can be written
using literal values, column values, NULL,
built-in functions, stored functions, user-defined functions, and
operators. This chapter describes the functions and operators that
are allowed for writing expressions in MySQL. Instructions for
writing stored functions and user-defined functions are given in
Chapter 17, Stored Procedures and Functions, and
Section 24.2, “Adding New Functions to MySQL”. See
Section 9.2.3, “Function Name Parsing and Resolution”, for the rules describing how
the server interprets references to different kinds of functions.
An expression that contains NULL always produces
a NULL value unless otherwise indicated in the
documentation for a particular function or operator.
Note: By default, there must be no whitespace between a function name and the parenthesis following it. This helps the MySQL parser distinguish between function calls and references to tables or columns that happen to have the same name as a function. However, spaces around function arguments are permitted.
You can tell the MySQL server to accept spaces after function names
by starting it with the --sql-mode=IGNORE_SPACE
option. (See Section 5.2.6, “SQL Modes”.) Individual client
programs can request this behavior by using the
CLIENT_IGNORE_SPACE option for
mysql_real_connect(). In either case, all
function names become reserved words.
For the sake of brevity, most examples in this chapter display the output from the mysql program in abbreviated form. Rather than showing examples in this format:
mysql> SELECT MOD(29,9);
+-----------+
| mod(29,9) |
+-----------+
| 2 |
+-----------+
1 rows in set (0.00 sec)
This format is used instead:
mysql> SELECT MOD(29,9);
-> 2
Note
This table is part of an ongoing process to expand and simplify the information provided on these elements. Further improvements to the table, and corresponding descriptions will be applied over the coming months.
| Name | Description |
|---|---|
ABS() | Return the absolute value |
ACOS() | Return the arc cosine |
ADDDATE()(v4.1.1) | Add dates |
ADDTIME()(v4.1.1) | Add time |
AES_DECRYPT() | Decrypt using AES |
AES_ENCRYPT() | Encrypt using AES |
AND, && | Logical AND |
ASCII() | Return numeric value of left-most character |
ASIN() | Return the arc sine |
ATAN2(), ATAN() | Return the arc tangent of the two arguments |
ATAN() | Return the arc tangent |
AVG() | Return the average value of the argument |
BENCHMARK() | Repeatedly execute an expression |
BETWEEN ... AND ... | Check whether a value is within a range of values |
BIN() | Return a string representation of the argument |
BINARY | Cast a string to a binary string |
BIT_AND() | Return bitwise and |
BIT_COUNT() | Return the number of bits that are set |
BIT_LENGTH() | Return length of argument in bits |
BIT_OR() | Return bitwise or |
BIT_XOR()(v4.1.1) | Return bitwise xor |
& | Bitwise AND |
| | Bitwise OR |
^ | Bitwise XOR |
/ | Division operator |
CASE | Case statement |
CAST() | Cast a value as a certain type |
CEILING(), CEIL() | Return the smallest integer value not less than the argument |
CHAR_LENGTH() | Return number of characters in argument |
CHAR() | Return the character for each integer passed |
CHARACTER_LENGTH() | A synonym for CHAR_LENGTH() |
CHARSET()(v4.1.0) | Return the character set of the argument |
COALESCE() | Return the first non-NULL argument |
COERCIBILITY()(v4.1.1) | Return the collation coercibility value of the string argument |
COLLATION()(v4.1.0) | Return the collation of the string argument |
COMPRESS()(v4.1.1) | Return result as a binary string |
CONCAT_WS() | Return concatenate with separator |
CONCAT() | Return concatenated string |
CONNECTION_ID() | Return the connection ID (thread ID) for the connection |
CONV() | Convert numbers between different number bases |
CONVERT_TZ()(v4.1.3) | Convert from one timezone to another |
COS() | Return the cosine |
COT() | Return the cotangent |
COUNT(DISTINCT) | Return the count of a number of different values |
COUNT() | Return a count of the number of rows returned |
CRC32()(v4.1.0) | Compute a cyclic redundancy check value |
CURDATE() | Return the current date |
CURRENT_DATE(), CURRENT_DATE | Synonyms for CURDATE() |
CURRENT_TIME(), CURRENT_TIME | Synonyms for CURTIME() |
CURRENT_TIMESTAMP(), CURRENT_TIMESTAMP | Synonyms for NOW() |
CURRENT_USER(), CURRENT_USER | Return the username and hostname combination |
CURTIME() | Return the current time |
DATABASE() | Return the default (current) database name |
DATE_ADD() | Add two dates |
DATE_FORMAT() | Format date as specified |
DATE_SUB() | Subtract two dates |
DATE()(v4.1.1) | Extract the date part of a date or datetime expression |
DATEDIFF()(v4.1.1) | Subtract two dates |
DAY()(v4.1.1) | Synonym for DAYOFMONTH() |
DAYNAME()(v4.1.21) | Return the name of the weekday |
DAYOFMONTH() | Return the day of the month (1-31) |
DAYOFWEEK() | Return the weekday index of the argument |
DAYOFYEAR() | Return the day of the year (1-366) |
DECODE() | Decodes a string encrypted using ENCODE() |
DEFAULT() | Return the default value for a table column |
DEGREES() | Convert radians to degrees |
DES_DECRYPT() | Decrypt a string |
DES_ENCRYPT() | Decrypt a string |
DIV(v4.1.0) | Integer division |
ELT() | Return string at index number |
ENCODE() | Encode a string |
ENCRYPT() | Encrypt a string |
<=> | NULL-safe equal to operator |
= | Equal operator |
EXP() | Raise to the power of |
EXPORT_SET() | Return a string such that for every bit set in the value bits, you get an on string and for every unset bit, you get an off string |
EXTRACT | Extract part of a date |
FIELD() | Return the index (position) of the first argument in the subsequent arguments |
FIND_IN_SET() | Return the index position of the first argument within the second argument |
FLOOR() | Return the largest integer value not greater than the argument |
FORMAT() | Return a number formatted to specified number of decimal places |
FOUND_ROWS() | For a SELECT with a LIMIT clause, the number of rows that would be returned were there no LIMIT clause |
FROM_DAYS() | Convert a day number to a date |
FROM_UNIXTIME() | Format date as a UNIX timestamp |
GET_FORMAT()(v4.1.1) | Return a date format string |
GET_LOCK() | Get a named lock |
>= | Greater than or equal operator |
> | Greater than operator |
GREATEST() | Return the largest argument |
GROUP_CONCAT()(v4.1) | Return a concatenated string |
HEX() | Return a string representation of a hex value |
HOUR() | Extract the hour |
IF() | If/else construct |
IFNULL() | Null if/else construct |
IN | Check whether a value is within a set of values |
INET_ATON() | Return the numeric value of an IP address |
INET_NTOA() | Return the IP address from a numeric value |
INSERT() | Insert a substring at the specified position up to the specified number of characters |
INSTR() | Return the index of the first occurrence of substring |
INTERVAL() | Return the index of the argument that is less than the first argument |
IS_FREE_LOCK() | Checks whether the named lock is free |
IS NULL | NULL value test |
IS_USED_LOCK()(v4.1.0) | Checks whether the named lock is in use. Return connection identifier if true. |
IS | Test a value against a boolean |
ISNULL() | Test whether the argument is NULL |
LAST_DAY(v4.1.1) | Return the last day of the month for the argument |
LAST_INSERT_ID() | Value of the AUTOINCREMENT column for the last INSERT |
LCASE() | Synonym for LOWER() |
LEAST() | Return the smallest argument |
<< | Left shift |
LEFT() | Return the leftmost number of characters as specified |
LENGTH() | Return the length of a string in bytes |
<= | Less than or equal operator |
< | Less than operator |
LIKE | Simple pattern matching |
LN() | Return the natural logarithm of the argument |
LOAD_FILE() | Load the named file |
LOCALTIME(), LOCALTIME | Synonym for NOW() |
LOCALTIMESTAMP, LOCALTIMESTAMP()(v4.0.6) | Synonym for NOW() |
LOCATE() | Return the position of the first occurrence of substring |
LOG10() | Return the base-10 logarithm of the argument |
LOG2() | Return the base-2 logarithm of the argument |
LOG() | Return the natural logarithm of the first argument |
LOWER() | Return the argument in lowercase |
LPAD() | Return the string argument, left-padded with the specified string |
LTRIM() | Remove leading spaces |
MAKE_SET() | Return a set of comma-separated strings that have the corresponding bit in bits set |
MAKEDATE()(v4.1.1) | Create a date from the year and day of year |
MAKETIME(v4.1.1) | MAKETIME() |
MASTER_POS_WAIT() | Block until the slave has read and applied all updates up to the specified position |
MAX() | Return the maximum value |
MD5() | Calculate MD5 checksum |
MICROSECOND()(v4.1.1) | Return the microseconds from argument |
MID() | Return a substring starting from the specified position |
MIN() | Return the minimum value |
- | Minus operator |
MINUTE() | Return the minute from the argument |
MOD() | Return the remainder |
% | Modulo operator |
MONTH() | Return the month from the date passed |
MONTHNAME()(v4.1.21) | Return the name of the month |
NAME_CONST()(v5.0.12) | Causes the column to have the given name |
NOT BETWEEN ... AND ... | Check whether a value is not within a range of values |
!=, <> | Not equal operator |
NOT IN | Check whether a value is not within a set of values |
NOT LIKE | Negation of simple pattern matching |
NOT REGEXP | Negation of REGEXP |
NOT, ! | Negates value |
NOW() | Return the current date and time |
NULLIF() | Return NULL if expr1 = expr2 |
OCT() | Return a string representation of the octal argument |
OCTET_LENGTH() | A synonym for LENGTH() |
OLD_PASSWORD()(v4.1) | Return the value of the old (pre-4.1) implementation of PASSWORD |
||, OR | Logical OR |
ORD() | If the leftmost character of the argument is a multi-byte character, returns the code for that character |
PASSWORD() | Calculate and return a password string |
PERIOD_ADD() | Add a period to a year-month |
PERIOD_DIFF() | Return the number of months between periods |
PI() | Return the value of pi |
+ | Addition operator |
POSITION() | A synonym for LOCATE() |
POW(), POWER() | Return the argument raised to the specified power |
QUARTER() | Return the quarter from a date argument |
QUOTE() | Escape the argument for use in an SQL statement |
RADIANS() | Return argument converted to radians |
RAND() | Return a random floating-point value |
REGEXP | Pattern matching using regular expressions |
RELEASE_LOCK() | Releases the named lock |
REPEAT() | Repeat a string the specified number of times |
REPLACE() | Replace occurrences of a specified string |
REVERSE() | Reverse the characters in a string |
>> | Right shift |
RIGHT() | Return the specified rightmost number of characters |
RLIKE | Synonym for REGEXP |
ROUND() | Round the argument |
ROW_COUNT()(v5.0.1) | The number of rows updated |
RPAD() | Append string the specified number of times |
RTRIM() | Remove trailing spaces |
SCHEMA()(v5.0.2) | A synonym for DATABASE() |
SEC_TO_TIME() | Converts seconds to 'HH:MM:SS' format |
SECOND() | Return the second (0-59) |
SESSION_USER() | Synonym for USER() |
SHA1(), SHA() | Calculate an SHA-1 160-bit checksum |
SIGN() | Return the sign of the argument |
SIN() | Return the sine of the argument |
SLEEP()(v5.0.12) | Sleep for a number of seconds |
SOUNDEX() | Return a soundex string |
SOUNDS LIKE(v4.1.0) | Compare sounds |
SPACE() | Return a string of the specified number of spaces |
SQRT() | Return the square root of the argument |
STD(), STDDEV() | Return the population standard deviation |
STDDEV_POP()(v5.0.3) | Return the population standard deviation |
STDDEV_SAMP()(v5.0.3) | Return the sample standard deviation |
STR_TO_DATE()(v4.1.1) | Convert a string to a date |
STRCMP() | Compare two strings |
SUBDATE() | When invoked with three arguments a synonym for DATE_SUB() |
SUBSTRING_INDEX() | Return a substring from a string before the specified number of occurrences of the delimiter |
SUBSTRING(), SUBSTR() | Return the substring as specified |
SUBTIME()(v4.1.1) | Subtract times |
SUM() | Return the sum |
SYSDATE() | Return the time at which the function executes |
SYSTEM_USER() | Synonym for USER() |
TAN() | Return the tangent of the argument |
~ | Invert bits |
TIME_FORMAT() | Format as time |
TIME_TO_SEC() | Return the argument converted to seconds |
TIME()(v4.1.1) | Extract the time portion of the expression passed |
TIMEDIFF()(v4.1.1) | Subtract time |
* | Times operator |
TIMESTAMP()(v4.1.1) | With a single argument, this function returns the date or datetime expression. With two arguments, the sum of the arguments |
TIMESTAMPADD()(v5.0.0) | Add an interval to a datetime expression |
TIMESTAMPDIFF()(v5.0.0) | Subtract an interval from a datetime expression |
TO_DAYS() | Return the date argument converted to days |
TRIM() | Remove leading and trailing spaces |
TRUNCATE() | Truncate to specified number of decimal places |
UCASE() | Synonym for UPPER() |
- | Change the sign of the argument |
UNCOMPRESS()(v4.1.1) | Uncompress a string compressed |
UNCOMPRESSED_LENGTH()(v4.1.1) | Return the length of a string before compression |
UNHEX()(v4.1.2) | Convert each pair of hexadecimal digits to a character |
UNIX_TIMESTAMP() | Return a UNIX timestamp |
UPPER() | Convert to uppercase |
USER() | Return the current username and hostname |
UTC_DATE()(v4.1.1) | Return the current UTC date |
UTC_TIME()(v4.1.1) | Return the current UTC time |
UTC_TIMESTAMP()(v4.1.1) | Return the current UTC date and time |
UUID()(v4.1.2) | Return a Universal Unique Identifier (UUID) |
VALUES()(v4.1.1) | Defines the values to be used during an INSERT |
VAR_POP()(v5.0.3) | Return the population standard variance |
VAR_SAMP()(v5.0.3) | Return the sample variance |
VARIANCE()(v4.1) | Return the population standard variance |
WEEK() | Return the week number |
WEEKDAY() | Return the weekday index |
WEEKOFYEAR()(v4.1.1) | Return the calendar week of the date (1-53) |
XOR | Logical XOR |
YEAR() | Return the year |
YEARWEEK() | Return the year and week |
| Name | Description |
|---|---|
AND, && | Logical AND |
BINARY | Cast a string to a binary string |
& | Bitwise AND |
| | Bitwise OR |
^ | Bitwise XOR |
/ | Division operator |
DIV(v4.1.0) | Integer division |
<=> | NULL-safe equal to operator |
= | Equal operator |
>= | Greater than or equal operator |
> | Greater than operator |
IS NULL | NULL value test |
IS | Test a value against a boolean |
<< | Left shift |
<= | Less than or equal operator |
< | Less than operator |
LIKE | Simple pattern matching |
- | Minus operator |
% | Modulo operator |
!=, <> | Not equal operator |
NOT LIKE | Negation of simple pattern matching |
NOT REGEXP | Negation of REGEXP |
NOT, ! | Negates value |
||, OR | Logical OR |
+ | Addition operator |
REGEXP | Pattern matching using regular expressions |
>> | Right shift |
RLIKE | Synonym for REGEXP |
SOUNDS LIKE(v4.1.0) | Compare sounds |
~ | Invert bits |
* | Times operator |
- | Change the sign of the argument |
XOR | Logical XOR |
Operator precedences are shown in the following list, from lowest precedence to the highest. Operators that are shown together on a line have the same precedence.
:= ||, OR, XOR &&, AND NOT BETWEEN, CASE, WHEN, THEN, ELSE =, <=>, >=, >, <=, <, <>, !=, IS, LIKE, REGEXP, IN | & <<, >> -, + *, /, DIV, %, MOD ^ - (unary minus), ~ (unary bit inversion) ! BINARY, COLLATE
The precedence shown for NOT is as of MySQL
5.0.2. For earlier versions, or from 5.0.2 on if the
HIGH_NOT_PRECEDENCE SQL mode is enabled, the
precedence of NOT is the same as that of the
! operator. See
Section 5.2.6, “SQL Modes”.
The precedence of operators determines the order of evaluation of terms in an expression. To override this order and group terms explicitly, use parentheses. For example:
mysql>SELECT 1+2*3;-> 7 mysql>SELECT (1+2)*3;-> 9
When an operator is used with operands of different types, type conversion occurs to make the operands compatible. Some conversions occur implicitly. For example, MySQL automatically converts numbers to strings as necessary, and vice versa.
mysql>SELECT 1+'1';-> 2 mysql>SELECT CONCAT(2,' test');-> '2 test'
It is also possible to perform explicit conversions. If you want
to convert a number to a string explicitly, use the
CAST() or CONCAT()
function (CAST() is preferable):
mysql>SELECT 38.8, CAST(38.8 AS CHAR);-> 38.8, '38.8' mysql>SELECT 38.8, CONCAT(38.8);-> 38.8, '38.8'
The following rules describe how conversion occurs for comparison operations:
If one or both arguments are
NULL, the result of the comparison isNULL, except for theNULL-safe<=>equality comparison operator. ForNULL <=> NULL, the result is true.If both arguments in a comparison operation are strings, they are compared as strings.
If both arguments are integers, they are compared as integers.
Hexadecimal values are treated as binary strings if not compared to a number.
If one of the arguments is a
TIMESTAMPorDATETIMEcolumn and the other argument is a constant, the constant is converted to a timestamp before the comparison is performed. This is done to be more ODBC-friendly. Note that this is not done for the arguments toIN()! To be safe, always use complete datetime, date, or time strings when doing comparisons.In all other cases, the arguments are compared as floating-point (real) numbers.
The following examples illustrate conversion of strings to numbers for comparison operations:
mysql>SELECT 1 > '6x';-> 0 mysql>SELECT 7 > '6x';-> 1 mysql>SELECT 0 > 'x6';-> 0 mysql>SELECT 0 = 'x6';-> 1
Note that when you are comparing a string column with a number,
MySQL cannot use an index on the column to look up the value
quickly. If str_col is an indexed
string column, the index cannot be used when performing the
lookup in the following statement:
SELECT * FROMtbl_nameWHEREstr_col=1;
The reason for this is that there are many different strings
that may convert to the value 1, such as
'1', ' 1', or
'1a'.
Comparisons that use floating-point numbers (or values that are converted to floating-point numbers) are approximate because such numbers are inexact. This might lead to results that appear inconsistent:
mysql>SELECT '18015376320243458' = 18015376320243458;-> 1 mysql>SELECT '18015376320243459' = 18015376320243459;-> 0
Such results can occur because the values are converted to floating-point numbers, which have only 53 bits of precision and are subject to rounding:
mysql> SELECT '18015376320243459'+0.0;
-> 1.8015376320243e+16
Furthermore, the conversion from string to floating-point and from integer to floating-point do not necessarily occur the same way. The integer may be converted to floating-point by the CPU, whereas the string is converted digit by digit in an operation that involves floating-point multiplications.
The results shown will vary on different systems, and can be
affected by factors such as computer architecture or the
compiler version or optimization level. One way to avoid such
problems is to use CAST() so that a value
will not be converted implicitly to a float-point number:
mysql> SELECT CAST('18015376320243459' AS UNSIGNED) = 18015376320243459;
-> 1
For more information about floating-point comparisons, see Section B.1.5.8, “Problems with Floating-Point Comparisons”.
| Name | Description |
|---|---|
BETWEEN ... AND ... | Check whether a value is within a range of values |
COALESCE() | Return the first non-NULL argument |
<=> | NULL-safe equal to operator |
= | Equal operator |
>= | Greater than or equal operator |
> | Greater than operator |
GREATEST() | Return the largest argument |
IN | Check whether a value is within a set of values |
INTERVAL() | Return the index of the argument that is less than the first argument |
IS NULL | NULL value test |
IS | Test a value against a boolean |
ISNULL() | Test whether the argument is NULL |
LEAST() | Return the smallest argument |
<= | Less than or equal operator |
< | Less than operator |
LIKE | Simple pattern matching |
NOT BETWEEN ... AND ... | Check whether a value is not within a range of values |
!=, <> | Not equal operator |
NOT IN | Check whether a value is not within a set of values |
NOT LIKE | Negation of simple pattern matching |
SOUNDS LIKE(v4.1.0) | Compare sounds |
Comparison operations result in a value of 1
(TRUE), 0
(FALSE), or NULL. These
operations work for both numbers and strings. Strings are
automatically converted to numbers and numbers to strings as
necessary.
Some of the functions in this section (such as
LEAST() and GREATEST())
return values other than 1
(TRUE), 0
(FALSE), or NULL. However,
the value they return is based on comparison operations
performed according to the rules described in
Section 12.2.2, “Type Conversion in Expression Evaluation”.
To convert a value to a specific type for comparison purposes,
you can use the CAST() function. String
values can be converted to a different character set using
CONVERT(). See
Section 12.9, “Cast Functions and Operators”.
By default, string comparisons are not case sensitive and use
the current character set. The default is
latin1 (cp1252 West European), which also
works well for English.
Equal:
mysql>
SELECT 1 = 0;-> 0 mysql>SELECT '0' = 0;-> 1 mysql>SELECT '0.0' = 0;-> 1 mysql>SELECT '0.01' = 0;-> 0 mysql>SELECT '.01' = 0.01;-> 1NULL-safe equal. This operator performs an equality comparison like the=operator, but returns1rather thanNULLif both operands areNULL, and0rather thanNULLif one operand isNULL.mysql>
SELECT 1 <=> 1, NULL <=> NULL, 1 <=> NULL;-> 1, 1, 0 mysql>SELECT 1 = 1, NULL = NULL, 1 = NULL;-> 1, NULL, NULLNot equal:
mysql>
SELECT '.01' <> '0.01';-> 1 mysql>SELECT .01 <> '0.01';-> 0 mysql>SELECT 'zapp' <> 'zappp';-> 1Less than or equal:
mysql>
SELECT 0.1 <= 2;-> 1Less than:
mysql>
SELECT 2 < 2;-> 0Greater than or equal:
mysql>
SELECT 2 >= 2;-> 1Greater than:
mysql>
SELECT 2 > 2;-> 0IS,boolean_valueIS NOTboolean_valueTests a value against a boolean value, where
boolean_valuecan beTRUE,FALSE, orUNKNOWN.mysql>
SELECT 1 IS TRUE, 0 IS FALSE, NULL IS UNKNOWN;-> 1, 1, 1 mysql>SELECT 1 IS NOT UNKNOWN, 0 IS NOT UNKNOWN, NULL IS NOT UNKNOWN;-> 1, 1, 0IS [NOT]syntax was added in MySQL 5.0.2.boolean_valueTests whether a value is or is not
NULL.mysql>
SELECT 1 IS NULL, 0 IS NULL, NULL IS NULL;-> 0, 0, 1 mysql>SELECT 1 IS NOT NULL, 0 IS NOT NULL, NULL IS NOT NULL;-> 1, 1, 0To work well with ODBC programs, MySQL supports the following extra features when using
IS NULL:You can find the row that contains the most recent
AUTO_INCREMENTvalue by issuing a statement of the following form immediately after generating the value:SELECT * FROM
tbl_nameWHEREauto_colIS NULLThis behavior can be disabled by setting
SQL_AUTO_IS_NULL=0. See Section 13.5.3, “SETSyntax”.For
DATEandDATETIMEcolumns that are declared asNOT NULL, you can find the special date'0000-00-00'by using a statement like this:SELECT * FROM
tbl_nameWHEREdate_columnIS NULLThis is needed to get some ODBC applications to work because ODBC does not support a
'0000-00-00'date value.
If
expris greater than or equal tominandexpris less than or equal tomax,BETWEENreturns1, otherwise it returns0. This is equivalent to the expression(if all the arguments are of the same type. Otherwise type conversion takes place according to the rules described in Section 12.2.2, “Type Conversion in Expression Evaluation”, but applied to all the three arguments.min<=exprANDexpr<=max)mysql>
SELECT 1 BETWEEN 2 AND 3;-> 0 mysql>SELECT 'b' BETWEEN 'a' AND 'c';-> 1 mysql>SELECT 2 BETWEEN 2 AND '3';-> 1 mysql>SELECT 2 BETWEEN 2 AND 'x-3';-> 0For best results when using
BETWEENwith date or time values, you should useCAST()to explicitly convert the values to the desired data type. Examples: If you compare aDATETIMEto twoDATEvalues, convert theDATEvalues toDATETIMEvalues. If you use a string constant such as'2001-1-1'in a comparison to aDATE, cast the string to aDATE.This is the same as
NOT (.exprBETWEENminANDmax)Returns the first non-
NULLvalue in the list, orNULLif there are no non-NULLvalues.mysql>
SELECT COALESCE(NULL,1);-> 1 mysql>SELECT COALESCE(NULL,NULL,NULL);-> NULLWith two or more arguments, returns the largest (maximum-valued) argument. The arguments are compared using the same rules as for
LEAST().mysql>
SELECT GREATEST(2,0);-> 2 mysql>SELECT GREATEST(34.0,3.0,5.0,767.0);-> 767.0 mysql>SELECT GREATEST('B','A','C');-> 'C'Before MySQL 5.0.13,
GREATEST()returnsNULLonly if all arguments areNULL. As of 5.0.13, it returnsNULLif any argument isNULL.Returns
1ifexpris equal to any of the values in theINlist, else returns0. If all values are constants, they are evaluated according to the type ofexprand sorted. The search for the item then is done using a binary search. This meansINis very quick if theINvalue list consists entirely of constants. Otherwise, type conversion takes place according to the rules described in Section 12.2.2, “Type Conversion in Expression Evaluation”, but applied to all the arguments.mysql>
SELECT 2 IN (0,3,5,7);-> 0 mysql>SELECT 'wefwf' IN ('wee','wefwf','weg');-> 1You should never mix quoted and unquoted values in an
INlist because the comparison rules for quoted values (such as strings) and unquoted values (such as numbers) differ. Mixing types may therefore lead to inconsistent results. For example, do not write anINexpression like this:SELECT val1 FROM tbl1 WHERE val1 IN (1,2,'a');
Instead, write it like this:
SELECT val1 FROM tbl1 WHERE val1 IN ('1','2','a');The number of values in the
INlist is only limited by themax_allowed_packetvalue.To comply with the SQL standard,
INreturnsNULLnot only if the expression on the left hand side isNULL, but also if no match is found in the list and one of the expressions in the list isNULL.IN()syntax can also be used to write certain types of subqueries. See Section 13.2.8.3, “Subqueries withANY,IN, andSOME”.This is the same as
NOT (.exprIN (value,...))If
exprisNULL,ISNULL()returns1, otherwise it returns0.mysql>
SELECT ISNULL(1+1);-> 0 mysql>SELECT ISNULL(1/0);-> 1ISNULL()can be used instead of=to test whether a value isNULL. (Comparing a value toNULLusing=always yields false.)The
ISNULL()function shares some special behaviors with theIS NULLcomparison operator. See the description ofIS NULL.Returns
0ifN<N1,1ifN<N2and so on or-1ifNisNULL. All arguments are treated as integers. It is required thatN1<N2<N3<...<Nnfor this function to work correctly. This is because a binary search is used (very fast).mysql>
SELECT INTERVAL(23, 1, 15, 17, 30, 44, 200);-> 3 mysql>SELECT INTERVAL(10, 1, 10, 100, 1000);-> 2 mysql>SELECT INTERVAL(22, 23, 30, 44, 200);-> 0With two or more arguments, returns the smallest (minimum-valued) argument. The arguments are compared using the following rules:
If the return value is used in an
INTEGERcontext or all arguments are integer-valued, they are compared as integers.If the return value is used in a
REALcontext or all arguments are real-valued, they are compared as reals.If any argument is a case-sensitive string, the arguments are compared as case-sensitive strings.
In all other cases, the arguments are compared as case-insensitive strings.
Before MySQL 5.0.13,
LEAST()returnsNULLonly if all arguments areNULL. As of 5.0.13, it returnsNULLif any argument isNULL.mysql>
SELECT LEAST(2,0);-> 0 mysql>SELECT LEAST(34.0,3.0,5.0,767.0);-> 3.0 mysql>SELECT LEAST('B','A','C');-> 'A'Note that the preceding conversion rules can produce strange results in some borderline cases:
mysql>
SELECT CAST(LEAST(3600, 9223372036854775808.0) as SIGNED);-> -9223372036854775808This happens because MySQL reads
9223372036854775808.0in an integer context. The integer representation is not good enough to hold the value, so it wraps to a signed integer.
In SQL, all logical operators evaluate to
TRUE, FALSE, or
NULL (UNKNOWN). In MySQL,
these are implemented as 1 (TRUE), 0
(FALSE), and NULL. Most of
this is common to different SQL database servers, although some
servers may return any non-zero value for
TRUE.
Logical NOT. Evaluates to
1if the operand is0, to0if the operand is non-zero, andNOT NULLreturnsNULL.mysql>
SELECT NOT 10;-> 0 mysql>SELECT NOT 0;-> 1 mysql>SELECT NOT NULL;-> NULL mysql>SELECT ! (1+1);-> 0 mysql>SELECT ! 1+1;-> 1The last example produces
1because the expression evaluates the same way as(!1)+1.Note that the precedence of the
NOToperator changed in MySQL 5.0.2. See Section 12.2.1, “Operator Precedence”.Logical AND. Evaluates to
1if all operands are non-zero and notNULL, to0if one or more operands are0, otherwiseNULLis returned.mysql>
SELECT 1 && 1;-> 1 mysql>SELECT 1 && 0;-> 0 mysql>SELECT 1 && NULL;-> NULL mysql>SELECT 0 && NULL;-> 0 mysql>SELECT NULL && 0;-> 0Logical OR. When both operands are non-
NULL, the result is1if any operand is non-zero, and0otherwise. With aNULLoperand, the result is1if the other operand is non-zero, andNULLotherwise. If both operands areNULL, the result isNULL.mysql>
SELECT 1 || 1;-> 1 mysql>SELECT 1 || 0;-> 1 mysql>SELECT 0 || 0;-> 0 mysql>SELECT 0 || NULL;-> NULL mysql>SELECT 1 || NULL;-> 1Logical XOR. Returns
NULLif either operand isNULL. For non-NULLoperands, evaluates to1if an odd number of operands is non-zero, otherwise0is returned.mysql>
SELECT 1 XOR 1;-> 0 mysql>SELECT 1 XOR 0;-> 1 mysql>SELECT 1 XOR NULL;-> NULL mysql>SELECT 1 XOR 1 XOR 1;-> 1a XOR bis mathematically equal to(a AND (NOT b)) OR ((NOT a) and b).
| Name | Description |
|---|---|
CASE | Case statement |
IF() | If/else construct |
IFNULL() | Null if/else construct |
NULLIF() | Return NULL if expr1 = expr2 |
CASEvalueWHEN [compare_value] THENresult[WHEN [compare_value] THENresult...] [ELSEresult] ENDCASE WHEN [condition] THENresult[WHEN [condition] THENresult...] [ELSEresult] ENDThe first version returns the
resultwherevalue=compare_valueELSEis returned, orNULLif there is noELSEpart.mysql>
SELECT CASE 1 WHEN 1 THEN 'one'->WHEN 2 THEN 'two' ELSE 'more' END;-> 'one' mysql>SELECT CASE WHEN 1>0 THEN 'true' ELSE 'false' END;-> 'true' mysql>SELECT CASE BINARY 'B'->WHEN 'a' THEN 1 WHEN 'b' THEN 2 END;-> NULLThe default return type of a
CASEexpression is the compatible aggregated type of all return values, but also depends on the context in which it is used. If used in a string context, the result is returned as a string. If used in a numeric context, then the result is returned as a decimal, real, or integer value.Note: The syntax of the
CASEexpression shown here differs slightly from that of the SQLCASEstatement described in Section 17.2.10.2, “CASEStatement”, for use inside stored routines. TheCASEstatement cannot have anELSE NULLclause, and it is terminated withEND CASEinstead ofEND.If
expr1isTRUE(expr1<> 0expr1<> NULLIF()returnsexpr2; otherwise it returnsexpr3.IF()returns a numeric or string value, depending on the context in which it is used.mysql>
SELECT IF(1>2,2,3);-> 3 mysql>SELECT IF(1<2,'yes','no');-> 'yes' mysql>SELECT IF(STRCMP('test','test1'),'no','yes');-> 'no'If only one of
expr2orexpr3is explicitlyNULL, the result type of theIF()function is the type of the non-NULLexpression.expr1is evaluated as an integer value, which means that if you are testing floating-point or string values, you should do so using a comparison operation.mysql>
SELECT IF(0.1,1,0);-> 0 mysql>SELECT IF(0.1<>0,1,0);-> 1In the first case shown,
IF(0.1)returns0because0.1is converted to an integer value, resulting in a test ofIF(0). This may not be what you expect. In the second case, the comparison tests the original floating-point value to see whether it is non-zero. The result of the comparison is used as an integer.The default return type of
IF()(which may matter when it is stored into a temporary table) is calculated as follows:Expression Return Value expr2orexpr3returns a stringstring expr2orexpr3returns a floating-point valuefloating-point expr2orexpr3returns an integerinteger If
expr2andexpr3are both strings, the result is case sensitive if either string is case sensitive.Note: There is also an
IFstatement, which differs from theIF()function described here. See Section 17.2.10.1, “IFStatement”.If
expr1is notNULL,IFNULL()returnsexpr1; otherwise it returnsexpr2.IFNULL()returns a numeric or string value, depending on the context in which it is used.mysql>
SELECT IFNULL(1,0);-> 1 mysql>SELECT IFNULL(NULL,10);-> 10 mysql>SELECT IFNULL(1/0,10);-> 10 mysql>SELECT IFNULL(1/0,'yes');-> 'yes'The default result value of
IFNULL(is the more “general” of the two expressions, in the orderexpr1,expr2)STRING,REAL, orINTEGER. Consider the case of a table based on expressions or where MySQL must internally store a value returned byIFNULL()in a temporary table:mysql>
CREATE TABLE tmp SELECT IFNULL(1,'test') AS test;mysql>DESCRIBE tmp;+-------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+-------+ | test | char(4) | | | | | +-------+---------+------+-----+---------+-------+In this example, the type of the
testcolumn isCHAR(4).Returns
NULLifexpr1=expr2expr1. This is the same asCASE WHEN.expr1=expr2THEN NULL ELSEexpr1ENDmysql>
SELECT NULLIF(1,1);-> NULL mysql>SELECT NULLIF(1,2);-> 1Note that MySQL evaluates
expr1twice if the arguments are not equal.
| Name | Description |
|---|---|
ASCII() | Return numeric value of left-most character |
BIN() | Return a string representation of the argument |
BIT_LENGTH() | Return length of argument in bits |
CHAR_LENGTH() | Return number of characters in argument |
CHAR() | Return the character for each integer passed |
CHARACTER_LENGTH() | A synonym for CHAR_LENGTH() |
CONCAT_WS() | Return concatenate with separator |
CONCAT() | Return concatenated string |
CONV() | Convert numbers between different number bases |
ELT() | Return string at index number |
<=> | NULL-safe equal to operator |
= | Equal operator |
EXPORT_SET() | Return a string such that for every bit set in the value bits, you get an on string and for every unset bit, you get an off string |
FIELD() | Return the index (position) of the first argument in the subsequent arguments |
FIND_IN_SET() | Return the index position of the first argument within the second argument |
FORMAT() | Return a number formatted to specified number of decimal places |
>= | Greater than or equal operator |
> | Greater than operator |
HEX() | Return a string representation of a hex value |
INSERT() | Insert a substring at the specified position up to the specified number of characters |
INSTR() | Return the index of the first occurrence of substring |
IS NULL | NULL value test |
IS | Test a value against a boolean |
LCASE() | Synonym for LOWER() |
LEFT() | Return the leftmost number of characters as specified |
LENGTH() | Return the length of a string in bytes |
<= | Less than or equal operator |
< | Less than operator |
LIKE | Simple pattern matching |
LOAD_FILE() | Load the named file |
LOCATE() | Return the position of the first occurrence of substring |
LOWER() | Return the argument in lowercase |
LPAD() | Return the string argument, left-padded with the specified string |
LTRIM() | Remove leading spaces |
MAKE_SET() | Return a set of comma-separated strings that have the corresponding bit in bits set |
MID() | Return a substring starting from the specified position |
!=, <> | Not equal operator |
NOT LIKE | Negation of simple pattern matching |
NOT REGEXP | Negation of REGEXP |
OCT() | Return a string representation of the octal argument |
OCTET_LENGTH() | A synonym for LENGTH() |
ORD() | If the leftmost character of the argument is a multi-byte character, returns the code for that character |
POSITION() | A synonym for LOCATE() |
QUOTE() | Escape the argument for use in an SQL statement |
REGEXP | Pattern matching using regular expressions |
REPEAT() | Repeat a string the specified number of times |
REPLACE() | Replace occurrences of a specified string |
REVERSE() | Reverse the characters in a string |
RIGHT() | Return the specified rightmost number of characters |
RLIKE | Synonym for REGEXP |
RPAD() | Append string the specified number of times |
RTRIM() | Remove trailing spaces |
SOUNDEX() | Return a soundex string |
SOUNDS LIKE(v4.1.0) | Compare sounds |
SPACE() | Return a string of the specified number of spaces |
STRCMP() | Compare two strings |
SUBSTRING_INDEX() | Return a substring from a string before the specified number of occurrences of the delimiter |
SUBSTRING(), SUBSTR() | Return the substring as specified |
TRIM() | Remove leading and trailing spaces |
UCASE() | Synonym for UPPER() |
UNHEX()(v4.1.2) | Convert each pair of hexadecimal digits to a character |
UPPER() | Convert to uppercase |
String-valued functions return NULL if the
length of the result would be greater than the value of the
max_allowed_packet system variable. See
Section 7.5.2, “Tuning Server Parameters”.
For functions that operate on string positions, the first position is numbered 1.
For functions that take length arguments, non-integer arguments are rounded to the nearest integer.
Returns the numeric value of the leftmost character of the string
str. Returns0ifstris the empty string. ReturnsNULLifstrisNULL.ASCII()works for characters with numeric values from0to255.mysql>
SELECT ASCII('2');-> 50 mysql>SELECT ASCII(2);-> 50 mysql>SELECT ASCII('dx');-> 100See also the
ORD()function.Returns a string representation of the binary value of
N, whereNis a longlong (BIGINT) number. This is equivalent toCONV(. ReturnsN,10,2)NULLifNisNULL.mysql>
SELECT BIN(12);-> '1100'Returns the length of the string
strin bits.mysql>
SELECT BIT_LENGTH('text');-> 32CHAR(N,... [USINGcharset_name])CHAR()interprets each argumentNas an integer and returns a string consisting of the characters given by the code values of those integers.NULLvalues are skipped.mysql>
SELECT CHAR(77,121,83,81,'76');-> 'MySQL' mysql>SELECT CHAR(77,77.3,'77.3');-> 'MMM'As of MySQL 5.0.15,
CHAR()arguments larger than 255 are converted into multiple result bytes. For example,CHAR(256)is equivalent toCHAR(1,0), andCHAR(256*256)is equivalent toCHAR(1,0,0):mysql>
SELECT HEX(CHAR(1,0)), HEX(CHAR(256));+----------------+----------------+ | HEX(CHAR(1,0)) | HEX(CHAR(256)) | +----------------+----------------+ | 0100 | 0100 | +----------------+----------------+ mysql>SELECT HEX(CHAR(1,0,0)), HEX(CHAR(256*256));+------------------+--------------------+ | HEX(CHAR(1,0,0)) | HEX(CHAR(256*256)) | +------------------+--------------------+ | 010000 | 010000 | +------------------+--------------------+By default,
CHAR()returns a binary string. To produce a string in a given character set, use the optionalUSINGclause:mysql>
SELECT CHARSET(CHAR(0x65)), CHARSET(CHAR(0x65 USING utf8));+---------------------+--------------------------------+ | CHARSET(CHAR(0x65)) | CHARSET(CHAR(0x65 USING utf8)) | +---------------------+--------------------------------+ | binary | utf8 | +---------------------+--------------------------------+If
USINGis given and the result string is illegal for the given character set, a warning is issued. Also, if strict SQL mode is enabled, the result fromCHAR()becomesNULL.Before MySQL 5.0.15,
CHAR()returns a string in the connection character set and theUSINGclause is unavailable. In addition, each argument is interpreted modulo 256, soCHAR(256)andCHAR(256*256)both are equivalent toCHAR(0).Returns the length of the string
str, measured in characters. A multi-byte character counts as a single character. This means that for a string containing five two-byte characters,LENGTH()returns10, whereasCHAR_LENGTH()returns5.CHARACTER_LENGTH()is a synonym forCHAR_LENGTH().Returns the string that results from concatenating the arguments. May have one or more arguments. If all arguments are non-binary strings, the result is a non-binary string. If the arguments include any binary strings, the result is a binary string. A numeric argument is converted to its equivalent binary string form; if you want to avoid that, you can use an explicit type cast, as in this example:
SELECT CONCAT(CAST(
int_colAS CHAR),char_col);CONCAT()returnsNULLif any argument isNULL.mysql>
SELECT CONCAT('My', 'S', 'QL');-> 'MySQL' mysql>SELECT CONCAT('My', NULL, 'QL');-> NULL mysql>SELECT CONCAT(14.3);-> '14.3'CONCAT_WS(separator,str1,str2,...)CONCAT_WS()stands for Concatenate With Separator and is a special form ofCONCAT(). The first argument is the separator for the rest of the arguments. The separator is added between the strings to be concatenated. The separator can be a string, as can the rest of the arguments. If the separator isNULL, the result isNULL.mysql>
SELECT CONCAT_WS(',','First name','Second name','Last Name');-> 'First name,Second name,Last Name' mysql>SELECT CONCAT_WS(',','First name',NULL,'Last Name');-> 'First name,Last Name'CONCAT_WS()does not skip empty strings. However, it does skip anyNULLvalues after the separator argument.Converts numbers between different number bases. Returns a string representation of the number
N, converted from basefrom_baseto baseto_base. ReturnsNULLif any argument isNULL. The argumentNis interpreted as an integer, but may be specified as an integer or a string. The minimum base is2and the maximum base is36. Ifto_baseis a negative number,Nis regarded as a signed number. Otherwise,Nis treated as unsigned.CONV()works with 64-bit precision.mysql>
SELECT CONV('a',16,2);-> '1010' mysql>SELECT CONV('6E',18,8);-> '172' mysql>SELECT CONV(-17,10,-18);-> '-H' mysql>SELECT CONV(10+'10'+'10'+0xa,10,10);-> '40'Returns
str1ifN=1,str2ifN=2, and so on. ReturnsNULLifNis less than1or greater than the number of arguments.ELT()is the complement ofFIELD().mysql>
SELECT ELT(1, 'ej', 'Heja', 'hej', 'foo');-> 'ej' mysql>SELECT ELT(4, 'ej', 'Heja', 'hej', 'foo');-> 'foo'EXPORT_SET(bits,on,off[,separator[,number_of_bits]])Returns a string such that for every bit set in the value
bits, you get anonstring and for every bit not set in the value, you get anoffstring. Bits inbitsare examined from right to left (from low-order to high-order bits). Strings are added to the result from left to right, separated by theseparatorstring (the default being the comma character ‘,’). The number of bits examined is given bynumber_of_bits(defaults to 64).mysql>
SELECT EXPORT_SET(5,'Y','N',',',4);-> 'Y,N,Y,N' mysql>SELECT EXPORT_SET(6,'1','0',',',10);-> '0,1,1,0,0,0,0,0,0,0'Returns the index (position) of
strin thestr1,str2,str3,...list. Returns0ifstris not found.If all arguments to
FIELD()are strings, all arguments are compared as strings. If all arguments are numbers, they are compared as numbers. Otherwise, the arguments are compared as double.If
strisNULL, the return value is0becauseNULLfails equality comparison with any value.FIELD()is the complement ofELT().mysql>
SELECT FIELD('ej', 'Hej', 'ej', 'Heja', 'hej', 'foo');-> 2 mysql>SELECT FIELD('fo', 'Hej', 'ej', 'Heja', 'hej', 'foo');-> 0Returns a value in the range of 1 to
Nif the stringstris in the string liststrlistconsisting ofNsubstrings. A string list is a string composed of substrings separated by ‘,’ characters. If the first argument is a constant string and the second is a column of typeSET, theFIND_IN_SET()function is optimized to use bit arithmetic. Returns0ifstris not instrlistor ifstrlistis the empty string. ReturnsNULLif either argument isNULL. This function does not work properly if the first argument contains a comma (‘,’) character.mysql>
SELECT FIND_IN_SET('b','a,b,c,d');-> 2Formats the number
Xto a format like'#,###,###.##', rounded toDdecimal places, and returns the result as a string. IfDis0, the result has no decimal point or fractional part.mysql>
SELECT FORMAT(12332.123456, 4);-> '12,332.1235' mysql>SELECT FORMAT(12332.1,4);-> '12,332.1000' mysql>SELECT FORMAT(12332.2,0);-> '12,332'If
N_or_Sis a number, returns a string representation of the hexadecimal value ofN, whereNis a longlong (BIGINT) number. This is equivalent toCONV(.N,10,16)If
N_or_Sis a string, returns a hexadecimal string representation ofN_or_Swhere each character inN_or_Sis converted to two hexadecimal digits.mysql>
SELECT HEX(255);-> 'FF' mysql>SELECT 0x616263;-> 'abc' mysql>SELECT HEX('abc');-> 616263Returns the string
str, with the substring beginning at positionposandlencharacters long replaced by the stringnewstr. Returns the original string ifposis not within the length of the string. Replaces the rest of the string from positionposiflenis not within the length of the rest of the string. ReturnsNULLif any argument isNULL.mysql>
SELECT INSERT('Quadratic', 3, 4, 'What');-> 'QuWhattic' mysql>SELECT INSERT('Quadratic', -1, 4, 'What');-> 'Quadratic' mysql>SELECT INSERT('Quadratic', 3, 100, 'What');-> 'QuWhat'This function is multi-byte safe.
Returns the position of the first occurrence of substring
substrin stringstr. This is the same as the two-argument form ofLOCATE(), except that the order of the arguments is reversed.mysql>
SELECT INSTR('foobarbar', 'bar');-> 4 mysql>SELECT INSTR('xbar', 'foobar');-> 0This function is multi-byte safe, and is case sensitive only if at least one argument is a binary string.
LCASE()is a synonym forLOWER().Returns the leftmost
lencharacters from the stringstr, orNULLif any argument isNULL.mysql>
SELECT LEFT('foobarbar', 5);-> 'fooba'Returns the length of the string
str, measured in bytes. A multi-byte character counts as multiple bytes. This means that for a string containing five two-byte characters,LENGTH()returns10, whereasCHAR_LENGTH()returns5.mysql>
SELECT LENGTH('text');-> 4Reads the file and returns the file contents as a string. To use this function, the file must be located on the server host, you must specify the full pathname to the file, and you must have the
FILEprivilege. The file must be readable by all and its size less thanmax_allowed_packetbytes.If the file does not exist or cannot be read because one of the preceding conditions is not satisfied, the function returns
NULL.As of MySQL 5.0.19, the
character_set_filesystemsystem variable controls interpretation of filenames that are given as literal strings.mysql>
UPDATE tSET blob_col=LOAD_FILE('/tmp/picture')WHERE id=1;LOCATE(,substr,str)LOCATE(substr,str,pos)The first syntax returns the position of the first occurrence of substring
substrin stringstr. The second syntax returns the position of the first occurrence of substringsubstrin stringstr, starting at positionpos. Returns0ifsubstris not instr.mysql>
SELECT LOCATE('bar', 'foobarbar');-> 4 mysql>SELECT LOCATE('xbar', 'foobar');-> 0 mysql>SELECT LOCATE('bar', 'foobarbar', 5);-> 7This function is multi-byte safe, and is case-sensitive only if at least one argument is a binary string.
Returns the string
strwith all characters changed to lowercase according to the current character set mapping. The default islatin1(cp1252 West European).mysql>
SELECT LOWER('QUADRATICALLY');-> 'quadratically'This function is multi-byte safe.
Returns the string
str, left-padded with the stringpadstrto a length oflencharacters. Ifstris longer thanlen, the return value is shortened tolencharacters.mysql>
SELECT LPAD('hi',4,'??');-> '??hi' mysql>SELECT LPAD('hi',1,'??');-> 'h'Returns the string
strwith leading space characters removed.mysql>
SELECT LTRIM(' barbar');-> 'barbar'This function is multi-byte safe.
Returns a set value (a string containing substrings separated by ‘
,’ characters) consisting of the strings that have the corresponding bit inbitsset.str1corresponds to bit 0,str2to bit 1, and so on.NULLvalues instr1,str2,...are not appended to the result.mysql>
SELECT MAKE_SET(1,'a','b','c');-> 'a' mysql>SELECT MAKE_SET(1 | 4,'hello','nice','world');-> 'hello,world' mysql>SELECT MAKE_SET(1 | 4,'hello','nice',NULL,'world');-> 'hello' mysql>SELECT MAKE_SET(0,'a','b','c');-> ''MID(is a synonym forstr,pos,len)SUBSTRING(.str,pos,len)Returns a string representation of the octal value of
N, whereNis a longlong (BIGINT) number. This is equivalent toCONV(. ReturnsN,10,8)NULLifNisNULL.mysql>
SELECT OCT(12);-> '14'OCTET_LENGTH()is a synonym forLENGTH().If the leftmost character of the string
stris a multi-byte character, returns the code for that character, calculated from the numeric values of its constituent bytes using this formula:(1st byte code) + (2nd byte code × 256) + (3rd byte code × 2562) ...
If the leftmost character is not a multi-byte character,
ORD()returns the same value as theASCII()function.mysql>
SELECT ORD('2');-> 50POSITION(is a synonym forsubstrINstr)LOCATE(.substr,str)Quotes a string to produce a result that can be used as a properly escaped data value in an SQL statement. The string is returned enclosed by single quotes and with each instance of single quote (‘
'’), backslash (‘\’), ASCIINUL, and Control-Z preceded by a backslash. If the argument isNULL, the return value is the word “NULL” without enclosing single quotes.mysql>
SELECT QUOTE('Don\'t!');-> 'Don\'t!' mysql>SELECT QUOTE(NULL);-> NULLReturns a string consisting of the string
strrepeatedcounttimes. Ifcountis less than 1, returns an empty string. ReturnsNULLifstrorcountareNULL.mysql>
SELECT REPEAT('MySQL', 3);-> 'MySQLMySQLMySQL'Returns the string
strwith all occurrences of the stringfrom_strreplaced by the stringto_str.REPLACE()performs a case-sensitive match when searching forfrom_str.mysql>
SELECT REPLACE('www.mysql.com', 'w', 'Ww');-> 'WwWwWw.mysql.com'This function is multi-byte safe.
Returns the string
strwith the order of the characters reversed.mysql>
SELECT REVERSE('abc');-> 'cba'This function is multi-byte safe.
Returns the rightmost
lencharacters from the stringstr, orNULLif any argument isNULL.mysql>
SELECT RIGHT('foobarbar', 4);-> 'rbar'This function is multi-byte safe.
Returns the string
str, right-padded with the stringpadstrto a length oflencharacters. Ifstris longer thanlen, the return value is shortened tolencharacters.mysql>
SELECT RPAD('hi',5,'?');-> 'hi???' mysql>SELECT RPAD('hi',1,'?');-> 'h'This function is multi-byte safe.
Returns the string
strwith trailing space characters removed.mysql>
SELECT RTRIM('barbar ');-> 'barbar'This function is multi-byte safe.
Returns a soundex string from
str. Two strings that sound almost the same should have identical soundex strings. A standard soundex string is four characters long, but theSOUNDEX()function returns an arbitrarily long string. You can useSUBSTRING()on the result to get a standard soundex string. All non-alphabetic characters instrare ignored. All international alphabetic characters outside the A-Z range are treated as vowels.Important: When using
SOUNDEX(), you should be aware of the following limitations:This function, as currently implemented, is intended to work well with strings that are in the English language only. Strings in other languages may not produce reliable results.
This function is not guaranteed to provide consistent results with strings that use multi-byte character sets, including
utf-8.We hope to remove these limitations in a future release. See Bug#22638 for more information.
mysql>
SELECT SOUNDEX('Hello');-> 'H400' mysql>SELECT SOUNDEX('Quadratically');-> 'Q36324'Note: This function implements the original Soundex algorithm, not the more popular enhanced version (also described by D. Knuth). The difference is that original version discards vowels first and duplicates second, whereas the enhanced version discards duplicates first and vowels second.
This is the same as
SOUNDEX(.expr1) = SOUNDEX(expr2)Returns a string consisting of
Nspace characters.mysql>
SELECT SPACE(6);-> ' 'SUBSTRING(,str,pos)SUBSTRING(,strFROMpos)SUBSTRING(,str,pos,len)SUBSTRING(strFROMposFORlen)The forms without a
lenargument return a substring from stringstrstarting at positionpos. The forms with alenargument return a substringlencharacters long from stringstr, starting at positionpos. The forms that useFROMare standard SQL syntax. It is also possible to use a negative value forpos. In this case, the beginning of the substring isposcharacters from the end of the string, rather than the beginning. A negative value may be used forposin any of the forms of this function.For all forms of
SUBSTRING(), the position of the first character in the string from which the substring is to be extracted is reckoned as1.mysql>
SELECT SUBSTRING('Quadratically',5);-> 'ratically' mysql>SELECT SUBSTRING('foobarbar' FROM 4);-> 'barbar' mysql>SELECT SUBSTRING('Quadratically',5,6);-> 'ratica' mysql>SELECT SUBSTRING('Sakila', -3);-> 'ila' mysql>SELECT SUBSTRING('Sakila', -5, 3);-> 'aki' mysql>SELECT SUBSTRING('Sakila' FROM -4 FOR 2);-> 'ki'This function is multi-byte safe.
If
lenis less than 1, the result is the empty string.SUBSTR()is a synonym forSUBSTRING().SUBSTRING_INDEX(str,delim,count)Returns the substring from string
strbeforecountoccurrences of the delimiterdelim. Ifcountis positive, everything to the left of the final delimiter (counting from the left) is returned. Ifcountis negative, everything to the right of the final delimiter (counting from the right) is returned.SUBSTRING_INDEX()performs a case-sensitive match when searching fordelim.mysql>
SELECT SUBSTRING_INDEX('www.mysql.com', '.', 2);-> 'www.mysql' mysql>SELECT SUBSTRING_INDEX('www.mysql.com', '.', -2);-> 'mysql.com'This function is multi-byte safe.
TRIM([{BOTH | LEADING | TRAILING} [,remstr] FROM]str)TRIM([remstrFROM]str)Returns the string
strwith allremstrprefixes or suffixes removed. If none of the specifiersBOTH,LEADING, orTRAILINGis given,BOTHis assumed.remstris optional and, if not specified, spaces are removed.mysql>
SELECT TRIM(' bar ');-> 'bar' mysql>SELECT TRIM(LEADING 'x' FROM 'xxxbarxxx');-> 'barxxx' mysql>SELECT TRIM(BOTH 'x' FROM 'xxxbarxxx');-> 'bar' mysql>SELECT TRIM(TRAILING 'xyz' FROM 'barxxyz');-> 'barx'This function is multi-byte safe.
UCASE()is a synonym forUPPER().Performs the inverse operation of
HEX(. That is, it interprets each pair of hexadecimal digits in the argument as a number and converts it to the character represented by the number. The resulting characters are returned as a binary string.str)mysql>
SELECT UNHEX('4D7953514C');-> 'MySQL' mysql>SELECT 0x4D7953514C;-> 'MySQL' mysql>SELECT UNHEX(HEX('string'));-> 'string' mysql>SELECT HEX(UNHEX('1267'));-> '1267'The characters in the argument string must be legal hexadecimal digits:
'0'..'9','A'..'F','a'..'f'. IfUNHEX()encounters any non-hexadecimal digits in the argument, it returnsNULL:mysql>
SELECT UNHEX('GG');+-------------+ | UNHEX('GG') | +-------------+ | NULL | +-------------+A
NULLresult can occur if the argument toUNHEX()is aBINARYcolumn, because values are padded with 0x00 bytes when stored but those bytes are not stripped on retrieval. For example'aa'is stored into aCHAR(3)column as'aa 'and retrieved as'aa'(with the trailing pad space stripped), soUNHEX()for the column value returns'A'. By contrast'aa'is stored into aBINARY(3)column as'aa\0'and retrieved as'aa\0'(with the trailing pad0x00byte not stripped).'\0'is not a legal hexadecimal digit, soUNHEX()for the column value returnsNULL.Returns the string
strwith all characters changed to uppercase according to the current character set mapping. The default islatin1(cp1252 West European).mysql>
SELECT UPPER('Hej');-> 'HEJ'This function is multi-byte safe.
| Name | Description |
|---|---|
<=> | NULL-safe equal to operator |
= | Equal operator |
>= | Greater than or equal operator |
> | Greater than operator |
IS NULL | NULL value test |
IS | Test a value against a boolean |
<= | Less than or equal operator |
< | Less than operator |
LIKE | Simple pattern matching |
!=, <> | Not equal operator |
NOT LIKE | Negation of simple pattern matching |
SOUNDS LIKE(v4.1.0) | Compare sounds |
If a string function is given a binary string as an argument, the resulting string is also a binary string. A number converted to a string is treated as a binary string. This affects only comparisons.
Normally, if any expression in a string comparison is case sensitive, the comparison is performed in case-sensitive fashion.
exprLIKEpat[ESCAPE 'escape_char']Pattern matching using SQL simple regular expression comparison. Returns
1(TRUE) or0(FALSE). If eitherexprorpatisNULL, the result isNULL.The pattern need not be a literal string. For example, it can be specified as a string expression or table column.
Per the SQL standard,
LIKEperforms matching on a per-character basis, thus it can produce results different from the=comparison operator:mysql>
SELECT 'ä' LIKE 'ae' COLLATE latin1_german2_ci;+-----------------------------------------+ | 'ä' LIKE 'ae' COLLATE latin1_german2_ci | +-----------------------------------------+ | 0 | +-----------------------------------------+ mysql>SELECT 'ä' = 'ae' COLLATE latin1_german2_ci;+--------------------------------------+ | 'ä' = 'ae' COLLATE latin1_german2_ci | +--------------------------------------+ | 1 | +--------------------------------------+With
LIKEyou can use the following two wildcard characters in the pattern:Character Description %Matches any number of characters, even zero characters _Matches exactly one character mysql>
SELECT 'David!' LIKE 'David_';-> 1 mysql>SELECT 'David!' LIKE '%D%v%';-> 1To test for literal instances of a wildcard character, precede it by the escape character. If you do not specify the
ESCAPEcharacter, ‘\’ is assumed.String Description \%Matches one ‘ %’ character\_Matches one ‘ _’ charactermysql>
SELECT 'David!' LIKE 'David\_';-> 0 mysql>SELECT 'David_' LIKE 'David\_';-> 1To specify a different escape character, use the
ESCAPEclause:mysql>
SELECT 'David_' LIKE 'David|_' ESCAPE '|';-> 1The escape sequence should be empty or one character long. As of MySQL 5.0.16, if the
NO_BACKSLASH_ESCAPESSQL mode is enabled, the sequence cannot be empty.The following two statements illustrate that string comparisons are not case sensitive unless one of the operands is a binary string:
mysql>
SELECT 'abc' LIKE 'ABC';-> 1 mysql>SELECT 'abc' LIKE BINARY 'ABC';-> 0In MySQL,
LIKEis allowed on numeric expressions. (This is an extension to the standard SQLLIKE.)mysql>
SELECT 10 LIKE '1%';-> 1Note: Because MySQL uses C escape syntax in strings (for example, ‘
\n’ to represent a newline character), you must double any ‘\’ that you use inLIKEstrings. For example, to search for ‘\n’, specify it as ‘\\n’. To search for ‘\’, specify it as ‘\\\\’; this is because the backslashes are stripped once by the parser and again when the pattern match is made, leaving a single backslash to be matched against. (Exception: At the end of the pattern string, backslash can be specified as ‘\\’. At the end of the string, backslash stands for itself because there is nothing following to escape.)exprNOT LIKEpat[ESCAPE 'escape_char']This is the same as
NOT (.exprLIKEpat[ESCAPE 'escape_char'])Note
Aggregate queries involving
NOT LIKEcomparisons with columns containingNULLmay yield unexpected results. For example, consider the following table and data:CREATE TABLE foo (bar VARCHAR(10)); INSERT INTO foo VALUES (NULL), (NULL);
The query
SELECT COUNT(*) FROM foo WHERE bar LIKE '%baz%';returns0. You might assume thatSELECT COUNT(*) FROM foo WHERE bar NOT LIKE '%baz%';would return2. However, this is not the case: The second query returns0. This is becauseNULL NOT LIKEalways returnsexprNULL, regardless of the value ofexpr. The same is true for aggregate queries involvingNULLand comparisons usingNOT RLIKEorNOT REGEXP. In such cases, you must test explicitly forNOT NULLusingOR(and notAND), as shown here:SELECT COUNT(*) FROM foo WHERE bar NOT LIKE '%baz%' OR bar IS NULL;
exprNOT REGEXPpatexprNOT RLIKEpatThis is the same as
NOT (.exprREGEXPpat)exprREGEXPpatexprRLIKEpatPerforms a pattern match of a string expression
expragainst a patternpat. The pattern can be an extended regular expression. The syntax for regular expressions is discussed in Section 12.4.2, “Regular Expressions”. Returns1ifexprmatchespat; otherwise it returns0. If eitherexprorpatisNULL, the result isNULL.RLIKEis a synonym forREGEXP, provided formSQLcompatibility.The pattern need not be a literal string. For example, it can be specified as a string expression or table column.
Note: Because MySQL uses the C escape syntax in strings (for example, ‘
\n’ to represent the newline character), you must double any ‘\’ that you use in yourREGEXPstrings.REGEXPis not case sensitive, except when used with binary strings.mysql>
SELECT 'Monty!' REGEXP 'm%y%%';-> 0 mysql>SELECT 'Monty!' REGEXP '.*';-> 1 mysql>SELECT 'new*\n*line' REGEXP 'new\\*.\\*line';-> 1 mysql>SELECT 'a' REGEXP 'A', 'a' REGEXP BINARY 'A';-> 1 0 mysql>SELECT 'a' REGEXP '^[a-d]';-> 1REGEXPandRLIKEuse the current character set when deciding the type of a character. The default islatin1(cp1252 West European). Warning: These operators are not multi-byte safe.STRCMP()returns0if the strings are the same,-1if the first argument is smaller than the second according to the current sort order, and1otherwise.mysql>
SELECT STRCMP('text', 'text2');-> -1 mysql>SELECT STRCMP('text2', 'text');-> 1 mysql>SELECT STRCMP('text', 'text');-> 0STRCMP()uses the current character set when performing comparisons. This makes the default comparison behavior case insensitive unless one or both of the operands are binary strings.
| Name | Description |
|---|---|
NOT REGEXP | Negation of REGEXP |
REGEXP | Pattern matching using regular expressions |
RLIKE | Synonym for REGEXP |
A regular expression is a powerful way of specifying a pattern for a complex search.
MySQL uses Henry Spencer's implementation of regular
expressions, which is aimed at conformance with POSIX 1003.2.
See Appendix G, Credits. MySQL uses the extended version
to support pattern-matching operations performed with the
REGEXP operator in SQL statements. See
Section 3.3.4.7, “Pattern Matching”, and
Section 12.4.1, “String Comparison Functions”.
This section is a summary, with examples, of the special
characters and constructs that can be used in MySQL for
REGEXP operations. It does not contain all
the details that can be found in Henry Spencer's
regex(7) manual page. That manual page is
included in MySQL source distributions, in the
regex.7 file under the
regex directory.
A regular expression describes a set of strings. The simplest
regular expression is one that has no special characters in it.
For example, the regular expression hello
matches hello and nothing else.
Non-trivial regular expressions use certain special constructs
so that they can match more than one string. For example, the
regular expression hello|word matches either
the string hello or the string
word.
As a more complex example, the regular expression
B[an]*s matches any of the strings
Bananas, Baaaaas,
Bs, and any other string starting with a
B, ending with an s, and
containing any number of a or
n characters in between.
A regular expression for the REGEXP operator
may use any of the following special characters and constructs:
^Match the beginning of a string.
mysql>
SELECT 'fo\nfo' REGEXP '^fo$';-> 0 mysql>SELECT 'fofo' REGEXP '^fo';-> 1$Match the end of a string.
mysql>
SELECT 'fo\no' REGEXP '^fo\no$';-> 1 mysql>SELECT 'fo\no' REGEXP '^fo$';-> 0.Match any character (including carriage return and newline).
mysql>
SELECT 'fofo' REGEXP '^f.*$';-> 1 mysql>SELECT 'fo\r\nfo' REGEXP '^f.*$';-> 1a*Match any sequence of zero or more
acharacters.mysql>
SELECT 'Ban' REGEXP '^Ba*n';-> 1 mysql>SELECT 'Baaan' REGEXP '^Ba*n';-> 1 mysql>SELECT 'Bn' REGEXP '^Ba*n';-> 1a+Match any sequence of one or more
acharacters.mysql>
SELECT 'Ban' REGEXP '^Ba+n';-> 1 mysql>SELECT 'Bn' REGEXP '^Ba+n';-> 0a?Match either zero or one
acharacter.mysql>
SELECT 'Bn' REGEXP '^Ba?n';-> 1 mysql>SELECT 'Ban' REGEXP '^Ba?n';-> 1 mysql>SELECT 'Baan' REGEXP '^Ba?n';-> 0de|abcMatch either of the sequences
deorabc.mysql>
SELECT 'pi' REGEXP 'pi|apa';-> 1 mysql>SELECT 'axe' REGEXP 'pi|apa';-> 0 mysql>SELECT 'apa' REGEXP 'pi|apa';-> 1 mysql>SELECT 'apa' REGEXP '^(pi|apa)$';-> 1 mysql>SELECT 'pi' REGEXP '^(pi|apa)$';-> 1 mysql>SELECT 'pix' REGEXP '^(pi|apa)$';-> 0(abc)*Match zero or more instances of the sequence
abc.mysql>
SELECT 'pi' REGEXP '^(pi)*$';-> 1 mysql>SELECT 'pip' REGEXP '^(pi)*$';-> 0 mysql>SELECT 'pipi' REGEXP '^(pi)*$';-> 1{1},{2,3}{n}or{m,n}notation provides a more general way of writing regular expressions that match many occurrences of the previous atom (or “piece”) of the pattern.mandnare integers.a*Can be written as
a{0,}.a+Can be written as
a{1,}.a?Can be written as
a{0,1}.
To be more precise,
a{n}matches exactlyninstances ofa.a{n,}matchesnor more instances ofa.a{m,n}matchesmthroughninstances ofa, inclusive.mandnmust be in the range from0toRE_DUP_MAX(default 255), inclusive. If bothmandnare given,mmust be less than or equal ton.mysql>
SELECT 'abcde' REGEXP 'a[bcd]{2}e';-> 0 mysql>SELECT 'abcde' REGEXP 'a[bcd]{3}e';-> 1 mysql>SELECT 'abcde' REGEXP 'a[bcd]{1,10}e';-> 1[a-dX],[^a-dX]Matches any character that is (or is not, if ^ is used) either
a,b,c,dorX. A-character between two other characters forms a range that matches all characters from the first character to the second. For example,[0-9]matches any decimal digit. To include a literal]character, it must immediately follow the opening bracket[. To include a literal-character, it must be written first or last. Any character that does not have a defined special meaning inside a[]pair matches only itself.mysql>
SELECT 'aXbc' REGEXP '[a-dXYZ]';-> 1 mysql>SELECT 'aXbc' REGEXP '^[a-dXYZ]$';-> 0 mysql>SELECT 'aXbc' REGEXP '^[a-dXYZ]+$';-> 1 mysql>SELECT 'aXbc' REGEXP '^[^a-dXYZ]+$';-> 0 mysql>SELECT 'gheis' REGEXP '^[^a-dXYZ]+$';-> 1 mysql>SELECT 'gheisa' REGEXP '^[^a-dXYZ]+$';-> 0[.characters.]Within a bracket expression (written using
[and]), matches the sequence of characters of that collating element.charactersis either a single character or a character name likenewline. The following table lists the allowable character names.The following table shows the allowable character names and the characters that they match. For characters given as numeric values, the values are represented in octal.
Name Character Name Character NUL0SOH001STX002ETX003EOT004ENQ005ACK006BEL007alert007BS010backspace'\b'HT011tab'\t'LF012newline'\n'VT013vertical-tab'\v'FF014form-feed'\f'CR015carriage-return'\r'SO016SI017DLE020DC1021DC2022DC3023DC4024NAK025SYN026ETB027CAN030EM031SUB032ESC033IS4034FS034IS3035GS035IS2036RS036IS1037US037space' 'exclamation-mark'!'quotation-mark'"'number-sign'#'dollar-sign'$'percent-sign'%'ampersand'&'apostrophe'\''left-parenthesis'('right-parenthesis')'asterisk'*'plus-sign'+'comma','hyphen'-'hyphen-minus'-'period'.'full-stop'.'slash'/'solidus'/'zero'0'one'1'two'2'three'3'four'4'five'5'six'6'seven'7'eight'8'nine'9'colon':'semicolon';'less-than-sign'<'equals-sign'='greater-than-sign'>'question-mark'?'commercial-at'@'left-square-bracket'['backslash'\\'reverse-solidus'\\'right-square-bracket']'circumflex'^'circumflex-accent'^'underscore'_'low-line'_'grave-accent'`'left-brace'{'left-curly-bracket'{'vertical-line'|'right-brace'}'right-curly-bracket'}'tilde'~'DEL177mysql>
SELECT '~' REGEXP '[[.~.]]';-> 1 mysql>SELECT '~' REGEXP '[[.tilde.]]';-> 1[=character_class=]Within a bracket expression (written using
[and]),[=character_class=]represents an equivalence class. It matches all characters with the same collation value, including itself. For example, ifoand(+)are the members of an equivalence class, then[[=o=]],[[=(+)=]], and[o(+)]are all synonymous. An equivalence class may not be used as an endpoint of a range.[:character_class:]Within a bracket expression (written using
[and]),[:character_class:]represents a character class that matches all characters belonging to that class. The following table lists the standard class names. These names stand for the character classes defined in thectype(3)manual page. A particular locale may provide other class names. A character class may not be used as an endpoint of a range.alnumAlphanumeric characters alphaAlphabetic characters blankWhitespace characters cntrlControl characters digitDigit characters graphGraphic characters lowerLowercase alphabetic characters printGraphic or space characters punctPunctuation characters spaceSpace, tab, newline, and carriage return upperUppercase alphabetic characters xdigitHexadecimal digit characters mysql>
SELECT 'justalnums' REGEXP '[[:alnum:]]+';-> 1 mysql>SELECT '!!' REGEXP '[[:alnum:]]+';-> 0[[:<:]],[[:>:]]These markers stand for word boundaries. They match the beginning and end of words, respectively. A word is a sequence of word characters that is not preceded by or followed by word characters. A word character is an alphanumeric character in the
alnumclass or an underscore (_).mysql>
SELECT 'a word a' REGEXP '[[:<:]]word[[:>:]]';-> 1 mysql>SELECT 'a xword a' REGEXP '[[:<:]]word[[:>:]]';-> 0
To use a literal instance of a special character in a regular
expression, precede it by two backslash (\) characters. The
MySQL parser interprets one of the backslashes, and the regular
expression library interprets the other. For example, to match
the string 1+2 that contains the special
+ character, only the last of the following
regular expressions is the correct one:
mysql>SELECT '1+2' REGEXP '1+2';-> 0 mysql>SELECT '1+2' REGEXP '1\+2';-> 0 mysql>SELECT '1+2' REGEXP '1\\+2';-> 1
| Name | Description |
|---|---|
ABS() | Return the absolute value |
ACOS() | Return the arc cosine |
ASIN() | Return the arc sine |
ATAN2(), ATAN() | Return the arc tangent of the two arguments |
ATAN() | Return the arc tangent |
/ | Division operator |
CEILING(), CEIL() | Return the smallest integer value not less than the argument |
COS() | Return the cosine |
COT() | Return the cotangent |
CRC32()(v4.1.0) | Compute a cyclic redundancy check value |
DEGREES() | Convert radians to degrees |
DIV(v4.1.0) | Integer division |
EXP() | Raise to the power of |
FLOOR() | Return the largest integer value not greater than the argument |
LN() | Return the natural logarithm of the argument |
LOG10() | Return the base-10 logarithm of the argument |
LOG2() | Return the base-2 logarithm of the argument |
LOG() | Return the natural logarithm of the first argument |
- | Minus operator |
MOD() | Return the remainder |
% | Modulo operator |
PI() | Return the value of pi |
+ | Addition operator |
POW(), POWER() | Return the argument raised to the specified power |
RADIANS() | Return argument converted to radians |
RAND() | Return a random floating-point value |
ROUND() | Round the argument |
SIGN() | Return the sign of the argument |
SIN() | Return the sine of the argument |
SQRT() | Return the square root of the argument |
TAN() | Return the tangent of the argument |
* | Times operator |
TRUNCATE() | Truncate to specified number of decimal places |
- | Change the sign of the argument |
| Name | Description |
|---|---|
/ | Division operator |
DIV(v4.1.0) | Integer division |
- | Minus operator |
% | Modulo operator |
+ | Addition operator |
* | Times operator |
- | Change the sign of the argument |
The usual arithmetic operators are available. The precision of the result is determined according to the following rules:
Note that in the case of
-,+, and*, the result is calculated withBIGINT(64-bit) precision if both arguments are integers.If one of the arguments is an unsigned integer, and the other argument is also an integer, the result is an unsigned integer.
If any of the operands of a
+,-,/,*,%is a real or string value, then the precision of the result is the precision of the argument with the maximum precision.In multiplication and division, the precision of the result when using two exact values is the precision of the first argument + the value of the
div_precision_incrementglobal variable. For example, the expression5.05 / 0.0014would have a precision of six decimal places (3607.142857).
These rules are applied for each operation, such that nested
calculations imply the precision of each component. Hence,
(14620 / 9432456) / (24250 / 9432456), would
resolve first to (0.0014) / (0.0026), with
the final result having 8 decimal places
(0.57692308).
Because of these rules and the method they are applied, care should be taken to ensure that components and sub-components of a calculation use the appropriate level of precision. See Section 12.9, “Cast Functions and Operators”.
Addition:
mysql>
SELECT 3+5;-> 8Subtraction:
mysql>
SELECT 3-5;-> -2Unary minus. This operator changes the sign of the argument.
mysql>
SELECT - 2;-> -2Note: If this operator is used with a
BIGINT, the return value is also aBIGINT. This means that you should avoid using–on integers that may have the value of –263.Multiplication:
mysql>
SELECT 3*5;-> 15 mysql>SELECT 18014398509481984*18014398509481984.0;-> 324518553658426726783156020576256.0 mysql>SELECT 18014398509481984*18014398509481984;-> 0The result of the last expression is incorrect because the result of the integer multiplication exceeds the 64-bit range of
BIGINTcalculations. (See Section 11.2, “Numeric Types”.)Division:
mysql>
SELECT 3/5;-> 0.60Division by zero produces a
NULLresult:mysql>
SELECT 102/(1-1);-> NULLA division is calculated with
BIGINTarithmetic only if performed in a context where its result is converted to an integer.Integer division. Similar to
FLOOR(), but is safe withBIGINTvalues.mysql>
SELECT 5 DIV 2;-> 2Modulo operation. Returns the remainder of
Ndivided byM. For more information, see the description for theMOD()function in Section 12.5.2, “Mathematical Functions”.
| Name | Description |
|---|---|
ABS() | Return the absolute value |
ACOS() | Return the arc cosine |
ASIN() | Return the arc sine |
ATAN2(), ATAN() | Return the arc tangent of the two arguments |
ATAN() | Return the arc tangent |
CEILING(), CEIL() | Return the smallest integer value not less than the argument |
COS() | Return the cosine |
COT() | Return the cotangent |
CRC32()(v4.1.0) | Compute a cyclic redundancy check value |
DEGREES() | Convert radians to degrees |
EXP() | Raise to the power of |
FLOOR() | Return the largest integer value not greater than the argument |
LN() | Return the natural logarithm of the argument |
LOG10() | Return the base-10 logarithm of the argument |
LOG2() | Return the base-2 logarithm of the argument |
LOG() | Return the natural logarithm of the first argument |
MOD() | Return the remainder |
PI() | Return the value of pi |
POW(), POWER() | Return the argument raised to the specified power |
RADIANS() | Return argument converted to radians |
RAND() | Return a random floating-point value |
ROUND() | Round the argument |
SIGN() | Return the sign of the argument |
SIN() | Return the sine of the argument |
SQRT() | Return the square root of the argument |
TAN() | Return the tangent of the argument |
TRUNCATE() | Truncate to specified number of decimal places |
All mathematical functions return NULL in the
event of an error.
Returns the absolute value of
X.mysql>
SELECT ABS(2);-> 2 mysql>SELECT ABS(-32);-> 32This function is safe to use with
BIGINTvalues.Returns the arc cosine of
X, that is, the value whose cosine isX. ReturnsNULLifXis not in the range-1to1.mysql>
SELECT ACOS(1);-> 0 mysql>SELECT ACOS(1.0001);-> NULL mysql>SELECT ACOS(0);-> 1.5707963267949Returns the arc sine of
X, that is, the value whose sine isX. ReturnsNULLifXis not in the range-1to1.mysql>
SELECT ASIN(0.2);-> 0.20135792079033 mysql>SELECT ASIN('foo');+-------------+ | ASIN('foo') | +-------------+ | 0 | +-------------+ 1 row in set, 1 warning (0.00 sec) mysql>SHOW WARNINGS;+---------+------+-----------------------------------------+ | Level | Code | Message | +---------+------+-----------------------------------------+ | Warning | 1292 | Truncated incorrect DOUBLE value: 'foo' | +---------+------+-----------------------------------------+Returns the arc tangent of
X, that is, the value whose tangent isX.mysql>
SELECT ATAN(2);-> 1.1071487177941 mysql>SELECT ATAN(-2);-> -1.1071487177941Returns the arc tangent of the two variables
XandY. It is similar to calculating the arc tangent ofY/Xmysql>
SELECT ATAN(-2,2);-> -0.78539816339745 mysql>SELECT ATAN2(PI(),0);-> 1.5707963267949Returns the smallest integer value not less than
X.CEILING()andCEIL()are synonymous.mysql>
SELECT CEILING(1.23);-> 2 mysql>SELECT CEIL(-1.23);-> -1For exact-value numeric arguments, the return value has an exact-value numeric type. For string or floating-point arguments, the return value has a floating-point type.
Returns the cosine of
X, whereXis given in radians.mysql>
SELECT COS(PI());-> -1Returns the cotangent of
X.mysql>
SELECT COT(12);-> -1.5726734063977 mysql>SELECT COT(0);-> NULLComputes a cyclic redundancy check value and returns a 32-bit unsigned value. The result is
NULLif the argument isNULL. The argument is expected to be a string and (if possible) is treated as one if it is not.mysql>
SELECT CRC32('MySQL');-> 3259397556 mysql>SELECT CRC32('mysql');-> 2501908538Returns the argument
X, converted from radians to degrees.mysql>
SELECT DEGREES(PI());-> 180 mysql>SELECT DEGREES(PI() / 2);-> 90Returns the value of e (the base of natural logarithms) raised to the power of
X.mysql>
SELECT EXP(2);-> 7.3890560989307 mysql>SELECT EXP(-2);-> 0.13533528323661 mysql>SELECT EXP(0);-> 1Returns the largest integer value not greater than
X.mysql>
SELECT FLOOR(1.23);-> 1 mysql>SELECT FLOOR(-1.23);-> -2For exact-value numeric arguments, the return value has an exact-value numeric type. For string or floating-point arguments, the return value has a floating-point type.
FORMAT(X,D)Formats the number
Xto a format like'#,###,###.##', rounded toDdecimal places, and returns the result as a string. For details, see Section 12.4, “String Functions”.Returns the natural logarithm of
X; that is, the base-e logarithm ofX.mysql>
SELECT LN(2);-> 0.69314718055995 mysql>SELECT LN(-2);-> NULLThis function is synonymous with
LOG(.X)If called with one parameter, this function returns the natural logarithm of
X.mysql>
SELECT LOG(2);-> 0.69314718055995 mysql>SELECT LOG(-2);-> NULLIf called with two parameters, this function returns the logarithm of
Xfor an arbitrary baseB.mysql>
SELECT LOG(2,65536);-> 16 mysql>SELECT LOG(10,100);-> 2LOG(is equivalent toB,X)LOG(.X) / LOG(B)Returns the base-2 logarithm of
Xmysql>
SELECT LOG2(65536);-> 16 mysql>SELECT LOG2(-100);-> NULLLOG2()is useful for finding out how many bits a number requires for storage. This function is equivalent to the expressionLOG(.X) / LOG(2)Returns the base-10 logarithm of
X.mysql>
SELECT LOG10(2);-> 0.30102999566398 mysql>SELECT LOG10(100);-> 2 mysql>SELECT LOG10(-100);-> NULLLOG10(is equivalent toX)LOG(10,.X)Modulo operation. Returns the remainder of
Ndivided byM.mysql>
SELECT MOD(234, 10);-> 4 mysql>SELECT 253 % 7;-> 1 mysql>SELECT MOD(29,9);-> 2 mysql>SELECT 29 MOD 9;-> 2This function is safe to use with
BIGINTvalues.MOD()also works on values that have a fractional part and returns the exact remainder after division:mysql>
SELECT MOD(34.5,3);-> 1.5MOD(returnsN,0)NULL.Returns the value of π (pi). The default number of decimal places displayed is seven, but MySQL uses the full double-precision value internally.
mysql>
SELECT PI();-> 3.141593 mysql>SELECT PI()+0.000000000000000000;-> 3.141592653589793116Returns the value of
Xraised to the power ofY.mysql>
SELECT POW(2,2);-> 4 mysql>SELECT POW(2,-2);-> 0.25Returns the argument
X, converted from degrees to radians. (Note that π radians equals 180 degrees.)mysql>
SELECT RADIANS(90);-> 1.5707963267949Returns a random floating-point value
vin the range0<=v<1.0. If a constant integer argumentNis specified, it is used as the seed value, which produces a repeatable sequence of column values.mysql>
SELECT RAND();-> 0.9233482386203 mysql>SELECT RAND(20);-> 0.15888261251047 mysql>SELECT RAND(20);-> 0.15888261251047 mysql>SELECT RAND();-> 0.63553050033332 mysql>SELECT RAND();-> 0.70100469486881 mysql>SELECT RAND(20);-> 0.15888261251047The effect of using a non-constant argument is undefined. As of MySQL 5.0.13, non-constant arguments are disallowed.
To obtain a random integer
Rin the rangei<=R<j, use the expressionFLOOR(. For example, to obtain a random integer in the range the rangei+ RAND() * (j–i))7<=R<12, you could use the following statement:SELECT FLOOR(7 + (RAND() * 5));
You cannot use a column with
RAND()values in anORDER BYclause, becauseORDER BYwould evaluate the column multiple times. However, you can retrieve rows in random order like this:mysql>
SELECT * FROMtbl_nameORDER BY RAND();ORDER BY RAND()combined withLIMITis useful for selecting a random sample from a set of rows:mysql>
SELECT * FROM table1, table2 WHERE a=b AND c<d->ORDER BY RAND() LIMIT 1000;Note that
RAND()in aWHEREclause is re-evaluated every time theWHEREis executed.RAND()is not meant to be a perfect random generator, but instead is a fast way to generate ad hoc random numbers which is portable between platforms for the same MySQL version.Rounds the argument
XtoDdecimal places. The rounding algorithm depends on the data type ofX.Ddefaults to 0 if not specified.Dcan be negative to causeDdigits left of the decimal point of the valueXto become zero.mysql>
SELECT ROUND(-1.23);-> -1 mysql>SELECT ROUND(-1.58);-> -2 mysql>SELECT ROUND(1.58);-> 2 mysql>SELECT ROUND(1.298, 1);-> 1.3 mysql>SELECT ROUND(1.298, 0);-> 1 mysql>SELECT ROUND(23.298, -1);-> 20The return type is the same type as that of the first argument (assuming that it is integer, double, or decimal). This means that for an integer argument, the result is an integer (no decimal places):
mysql>
SELECT ROUND(150.000,2), ROUND(150,2);+------------------+--------------+ | ROUND(150.000,2) | ROUND(150,2) | +------------------+--------------+ | 150.00 | 150 | +------------------+--------------+Before MySQL 5.0.3, the behavior of
ROUND()when the argument is halfway between two integers depends on the C library implementation. Different implementations round to the nearest even number, always up, always down, or always toward zero. If you need one kind of rounding, you should use a well-defined function such asTRUNCATE()orFLOOR()instead.As of MySQL 5.0.3,
ROUND()uses the precision math library for exact-value arguments when the first argument is a decimal value:For exact-value numbers,
ROUND()uses the “round half up” or “round toward nearest” rule: A value with a fractional part of .5 or greater is rounded up to the next integer if positive or down to the next integer if negative. (In other words, it is rounded away from zero.) A value with a fractional part less than .5 is rounded down to the next integer if positive or up to the next integer if negative.For approximate-value numbers, the result depends on the C library. On many systems, this means that
ROUND()uses the "round to nearest even" rule: A value with any fractional part is rounded to the nearest even integer.
The following example shows how rounding differs for exact and approximate values:
mysql>
SELECT ROUND(2.5), ROUND(25E-1);+------------+--------------+ | ROUND(2.5) | ROUND(25E-1) | +------------+--------------+ | 3 | 2 | +------------+--------------+For more information, see Chapter 21, Precision Math.
Returns the sign of the argument as
-1,0, or1, depending on whetherXis negative, zero, or positive.mysql>
SELECT SIGN(-32);-> -1 mysql>SELECT SIGN(0);-> 0 mysql>SELECT SIGN(234);-> 1Returns the sine of
X, whereXis given in radians.mysql>
SELECT SIN(PI());-> 1.2246063538224e-16 mysql>SELECT ROUND(SIN(PI()));-> 0Returns the square root of a non-negative number
X.mysql>
SELECT SQRT(4);-> 2 mysql>SELECT SQRT(20);-> 4.4721359549996 mysql>SELECT SQRT(-16);-> NULLReturns the tangent of
X, whereXis given in radians.mysql>
SELECT TAN(PI());-> -1.2246063538224e-16 mysql>SELECT TAN(PI()+1);-> 1.5574077246549Returns the number
X, truncated toDdecimal places. IfDis0, the result has no decimal point or fractional part.Dcan be negative to causeDdigits left of the decimal point of the valueXto become zero.mysql>
SELECT TRUNCATE(1.223,1);-> 1.2 mysql>SELECT TRUNCATE(1.999,1);-> 1.9 mysql>SELECT TRUNCATE(1.999,0);-> 1 mysql>SELECT TRUNCATE(-1.999,1);-> -1.9 mysql>SELECT TRUNCATE(122,-2);-> 100 mysql>SELECT TRUNCATE(10.28*100,0);-> 1028All numbers are rounded toward zero.
This section describes the functions that can be used to manipulate temporal values. See Section 11.3, “Date and Time Types”, for a description of the range of values each date and time type has and the valid formats in which values may be specified.
| Name | Description |
|---|---|
ADDDATE()(v4.1.1) | Add dates |
ADDTIME()(v4.1.1) | Add time |
CONVERT_TZ()(v4.1.3) | Convert from one timezone to another |
CURDATE() | Return the current date |
CURRENT_DATE(), CURRENT_DATE | Synonyms for CURDATE() |
CURRENT_TIME(), CURRENT_TIME | Synonyms for CURTIME() |
CURRENT_TIMESTAMP(), CURRENT_TIMESTAMP | Synonyms for NOW() |
CURTIME() | Return the current time |
DATE_ADD() | Add two dates |
DATE_FORMAT() | Format date as specified |
DATE_SUB() | Subtract two dates |
DATE()(v4.1.1) | Extract the date part of a date or datetime expression |
DATEDIFF()(v4.1.1) | Subtract two dates |
DAY()(v4.1.1) | Synonym for DAYOFMONTH() |
DAYNAME()(v4.1.21) | Return the name of the weekday |
DAYOFMONTH() | Return the day of the month (1-31) |
DAYOFWEEK() | Return the weekday index of the argument |
DAYOFYEAR() | Return the day of the year (1-366) |
EXTRACT | Extract part of a date |
FROM_DAYS() | Convert a day number to a date |
FROM_UNIXTIME() | Format date as a UNIX timestamp |
GET_FORMAT()(v4.1.1) | Return a date format string |
HOUR() | Extract the hour |
LAST_DAY(v4.1.1) | Return the last day of the month for the argument |
LOCALTIME(), LOCALTIME | Synonym for NOW() |
LOCALTIMESTAMP, LOCALTIMESTAMP()(v4.0.6) | Synonym for NOW() |
MAKEDATE()(v4.1.1) | Create a date from the year and day of year |
MAKETIME(v4.1.1) | MAKETIME() |
MICROSECOND()(v4.1.1) | Return the microseconds from argument |
MINUTE() | Return the minute from the argument |
MONTH() | Return the month from the date passed |
MONTHNAME()(v4.1.21) | Return the name of the month |
NOW() | Return the current date and time |
PERIOD_ADD() | Add a period to a year-month |
PERIOD_DIFF() | Return the number of months between periods |
QUARTER() | Return the quarter from a date argument |
SEC_TO_TIME() | Converts seconds to 'HH:MM:SS' format |
SECOND() | Return the second (0-59) |
STR_TO_DATE()(v4.1.1) | Convert a string to a date |
SUBDATE() | When invoked with three arguments a synonym for DATE_SUB() |
SUBTIME()(v4.1.1) | Subtract times |
SYSDATE() | Return the time at which the function executes |
TIME_FORMAT() | Format as time |
TIME_TO_SEC() | Return the argument converted to seconds |
TIME()(v4.1.1) | Extract the time portion of the expression passed |
TIMEDIFF()(v4.1.1) | Subtract time |
TIMESTAMP()(v4.1.1) | With a single argument, this function returns the date or datetime expression. With two arguments, the sum of the arguments |
TIMESTAMPADD()(v5.0.0) | Add an interval to a datetime expression |
TIMESTAMPDIFF()(v5.0.0) | Subtract an interval from a datetime expression |
TO_DAYS() | Return the date argument converted to days |
UNIX_TIMESTAMP() | Return a UNIX timestamp |
UTC_DATE()(v4.1.1) | Return the current UTC date |
UTC_TIME()(v4.1.1) | Return the current UTC time |
UTC_TIMESTAMP()(v4.1.1) | Return the current UTC date and time |
WEEK() | Return the week number |
WEEKDAY() | Return the weekday index |
WEEKOFYEAR()(v4.1.1) | Return the calendar week of the date (1-53) |
YEAR() | Return the year |
YEARWEEK() | Return the year and week |
Here is an example that uses date functions. The following query
selects all rows with a date_col value
from within the last 30 days:
mysql>SELECT->somethingFROMtbl_nameWHERE DATE_SUB(CURDATE(),INTERVAL 30 DAY) <=date_col;
Note that the query also selects rows with dates that lie in the future.
Functions that expect date values usually accept datetime values and ignore the time part. Functions that expect time values usually accept datetime values and ignore the date part.
Functions that return the current date or time each are evaluated
only once per query at the start of query execution. This means
that multiple references to a function such as
NOW() within a single query always produce the
same result (for our purposes a single query also includes a call
to a stored routine or trigger and all sub-routines called by that
routine/trigger). This principle also applies to
CURDATE(), CURTIME(),
UTC_DATE(), UTC_TIME(),
UTC_TIMESTAMP(), and to any of their synonyms.
The CURRENT_TIMESTAMP(),
CURRENT_TIME(),
CURRENT_DATE(), and
FROM_UNIXTIME() functions return values in the
connection's current time zone, which is available as the value of
the time_zone system variable. In addition,
UNIX_TIMESTAMP() assumes that its argument is a
datetime value in the current time zone. See
Section 5.10.8, “MySQL Server Time Zone Support”.
Some date functions can be used with “zero” dates or
incomplete dates such as '2001-11-00', whereas
others cannot. Functions that extract parts of dates typically
work with incomplete dates. For example:
mysql> SELECT DAYOFMONTH('2001-11-00'), MONTH('2005-00-00');
-> 0, 0
Other functions expect complete dates and return
NULL for incomplete dates. These include
functions that perform date arithmetic or that map parts of dates
to names. For example:
mysql>SELECT DATE_ADD('2006-05-00',INTERVAL 1 DAY);-> NULL mysql>SELECT DAYNAME('2006-05-00');-> NULL
ADDDATE(,date,INTERVALexprunit)ADDDATE(expr,days)When invoked with the
INTERVALform of the second argument,ADDDATE()is a synonym forDATE_ADD(). The related functionSUBDATE()is a synonym forDATE_SUB(). For information on theINTERVALunitargument, see the discussion forDATE_ADD().mysql>
SELECT DATE_ADD('1998-01-02', INTERVAL 31 DAY);-> '1998-02-02' mysql>SELECT ADDDATE('1998-01-02', INTERVAL 31 DAY);-> '1998-02-02'When invoked with the
daysform of the second argument, MySQL treats it as an integer number of days to be added toexpr.mysql>
SELECT ADDDATE('1998-01-02', 31);-> '1998-02-02'ADDTIME()addsexpr2toexpr1and returns the result.expr1is a time or datetime expression, andexpr2is a time expression.mysql>
SELECT ADDTIME('1997-12-31 23:59:59.999999',->'1 1:1:1.000002');-> '1998-01-02 01:01:01.000001' mysql>SELECT ADDTIME('01:00:00.999999', '02:00:00.999998');-> '03:00:01.999997'CONVERT_TZ()converts a datetime valuedtfrom the time zone given byfrom_tzto the time zone given byto_tzand returns the resulting value. Time zones are specified as described in Section 5.10.8, “MySQL Server Time Zone Support”. This function returnsNULLif the arguments are invalid.If the value falls out of the supported range of the
TIMESTAMPtype when converted fromfrom_tzto UTC, no conversion occurs. TheTIMESTAMPrange is described in Section 11.1.2, “Overview of Date and Time Types”.mysql>
SELECT CONVERT_TZ('2004-01-01 12:00:00','GMT','MET');-> '2004-01-01 13:00:00' mysql>SELECT CONVERT_TZ('2004-01-01 12:00:00','+00:00','+10:00');-> '2004-01-01 22:00:00'Note: To use named time zones such as
'MET'or'Europe/Moscow', the time zone tables must be properly set up. See Section 5.10.8, “MySQL Server Time Zone Support”, for instructions.If you intend to use
CONVERT_TZ()while other tables are locked withLOCK TABLES, you must also lock themysql.time_zone_nametable.Returns the current date as a value in
'YYYY-MM-DD'orYYYYMMDDformat, depending on whether the function is used in a string or numeric context.mysql>
SELECT CURDATE();-> '1997-12-15' mysql>SELECT CURDATE() + 0;-> 19971215CURRENT_DATEandCURRENT_DATE()are synonyms forCURDATE().Returns the current time as a value in
'HH:MM:SS'orHHMMSSformat, depending on whether the function is used in a string or numeric context. The value is expressed in the current time zone.mysql>
SELECT CURTIME();-> '23:50:26' mysql>SELECT CURTIME() + 0;-> 235026CURRENT_TIMEandCURRENT_TIME()are synonyms forCURTIME().CURRENT_TIMESTAMP,CURRENT_TIMESTAMP()CURRENT_TIMESTAMPandCURRENT_TIMESTAMP()are synonyms forNOW().Extracts the date part of the date or datetime expression
expr.mysql>
SELECT DATE('2003-12-31 01:02:03');-> '2003-12-31'DATEDIFF()returnsexpr1–expr2expressed as a value in days from one date to the other.expr1andexpr2are date or date-and-time expressions. Only the date parts of the values are used in the calculation.mysql>
SELECT DATEDIFF('1997-12-31 23:59:59','1997-12-30');-> 1 mysql>SELECT DATEDIFF('1997-11-30 23:59:59','1997-12-31');-> -31DATE_ADD(,date,INTERVALexprunit)DATE_SUB(date,INTERVALexprunit)These functions perform date arithmetic.
dateis aDATETIMEorDATEvalue specifying the starting date.expris an expression specifying the interval value to be added or subtracted from the starting date.expris a string; it may start with a ‘-’ for negative intervals.unitis a keyword indicating the units in which the expression should be interpreted.The
INTERVALkeyword and theunitspecifier are not case sensitive.The following table shows the expected form of the
exprargument for eachunitvalue.unitValueExpected exprFormatMICROSECONDMICROSECONDSSECONDSECONDSMINUTEMINUTESHOURHOURSDAYDAYSWEEKWEEKSMONTHMONTHSQUARTERQUARTERSYEARYEARSSECOND_MICROSECOND'SECONDS.MICROSECONDS'MINUTE_MICROSECOND'MINUTES.MICROSECONDS'MINUTE_SECOND'MINUTES:SECONDS'HOUR_MICROSECOND'HOURS.MICROSECONDS'HOUR_SECOND'HOURS:MINUTES:SECONDS'HOUR_MINUTE'HOURS:MINUTES'DAY_MICROSECOND'DAYS.MICROSECONDS'DAY_SECOND'DAYS HOURS:MINUTES:SECONDS'DAY_MINUTE'DAYS HOURS:MINUTES'DAY_HOUR'DAYS HOURS'YEAR_MONTH'YEARS-MONTHS'The values
QUARTERandWEEKare available beginning with MySQL 5.0.0.MySQL allows any punctuation delimiter in the
exprformat. Those shown in the table are the suggested delimiters. If thedateargument is aDATEvalue and your calculations involve onlyYEAR,MONTH, andDAYparts (that is, no time parts), the result is aDATEvalue. Otherwise, the result is aDATETIMEvalue.Date arithmetic also can be performed using
INTERVALtogether with the+or-operator:date+ INTERVALexprunitdate- INTERVALexprunitINTERVALis allowed on either side of theexprunit+operator if the expression on the other side is a date or datetime value. For the-operator,INTERVALis allowed only on the right side, because it makes no sense to subtract a date or datetime value from an interval.exprunitmysql>
SELECT '1997-12-31 23:59:59' + INTERVAL 1 SECOND;-> '1998-01-01 00:00:00' mysql>SELECT INTERVAL 1 DAY + '1997-12-31';-> '1998-01-01' mysql>SELECT '1998-01-01' - INTERVAL 1 SECOND;-> '1997-12-31 23:59:59' mysql>SELECT DATE_ADD('1997-12-31 23:59:59',->INTERVAL 1 SECOND);-> '1998-01-01 00:00:00' mysql>SELECT DATE_ADD('1997-12-31 23:59:59',->INTERVAL 1 DAY);-> '1998-01-01 23:59:59' mysql>SELECT DATE_ADD('1997-12-31 23:59:59',->INTERVAL '1:1' MINUTE_SECOND);-> '1998-01-01 00:01:00' mysql>SELECT DATE_SUB('1998-01-01 00:00:00',->INTERVAL '1 1:1:1' DAY_SECOND);-> '1997-12-30 22:58:59' mysql>SELECT DATE_ADD('1998-01-01 00:00:00',->INTERVAL '-1 10' DAY_HOUR);-> '1997-12-30 14:00:00' mysql>SELECT DATE_SUB('1998-01-02', INTERVAL 31 DAY);-> '1997-12-02' mysql>SELECT DATE_ADD('1992-12-31 23:59:59.000002',->INTERVAL '1.999999' SECOND_MICROSECOND);-> '1993-01-01 00:00:01.000001'If you specify an interval value that is too short (does not include all the interval parts that would be expected from the
unitkeyword), MySQL assumes that you have left out the leftmost parts of the interval value. For example, if you specify aunitofDAY_SECOND, the value ofexpris expected to have days, hours, minutes, and seconds parts. If you specify a value like'1:10', MySQL assumes that the days and hours parts are missing and the value represents minutes and seconds. In other words,'1:10' DAY_SECONDis interpreted in such a way that it is equivalent to'1:10' MINUTE_SECOND. This is analogous to the way that MySQL interpretsTIMEvalues as representing elapsed time rather than as a time of day.If you add to or subtract from a date value something that contains a time part, the result is automatically converted to a datetime value:
mysql>
SELECT DATE_ADD('1999-01-01', INTERVAL 1 DAY);-> '1999-01-02' mysql>SELECT DATE_ADD('1999-01-01', INTERVAL 1 HOUR);-> '1999-01-01 01:00:00'If you add
MONTH,YEAR_MONTH, orYEARand the resulting date has a day that is larger than the maximum day for the new month, the day is adjusted to the maximum days in the new month:mysql>
SELECT DATE_ADD('1998-01-30', INTERVAL 1 MONTH);-> '1998-02-28'Date arithmetic operations require complete dates and do not work with incomplete dates such as
'2006-07-00'or badly malformed dates:mysql>
SELECT DATE_ADD('2006-07-00', INTERVAL 1 DAY);-> NULL mysql>SELECT '2005-03-32' + INTERVAL 1 MONTH;-> NULLFormats the
datevalue according to theformatstring.The following specifiers may be used in the
formatstring. The ‘%’ character is required before format specifier characters.Specifier Description %aAbbreviated weekday name ( Sun..Sat)%bAbbreviated month name ( Jan..Dec)%cMonth, numeric ( 0..12)%DDay of the month with English suffix ( 0th,1st,2nd,3rd, …)%dDay of the month, numeric ( 00..31)%eDay of the month, numeric ( 0..31)%fMicroseconds ( 000000..999999)%HHour ( 00..23)%hHour ( 01..12)%IHour ( 01..12)%iMinutes, numeric ( 00..59)%jDay of year ( 001..366)%kHour ( 0..23)%lHour ( 1..12)%MMonth name ( January..December)%mMonth, numeric ( 00..12)%pAMorPM%rTime, 12-hour ( hh:mm:ssfollowed byAMorPM)%SSeconds ( 00..59)%sSeconds ( 00..59)%TTime, 24-hour ( hh:mm:ss)%UWeek ( 00..53), where Sunday is the first day of the week%uWeek ( 00..53), where Monday is the first day of the week%VWeek ( 01..53), where Sunday is the first day of the week; used with%X%vWeek ( 01..53), where Monday is the first day of the week; used with%x%WWeekday name ( Sunday..Saturday)%wDay of the week ( 0=Sunday..6=Saturday)%XYear for the week where Sunday is the first day of the week, numeric, four digits; used with %V%xYear for the week, where Monday is the first day of the week, numeric, four digits; used with %v%YYear, numeric, four digits %yYear, numeric (two digits) %%A literal ‘ %’ character%xx, for any ‘x’ not listed aboveRanges for the month and day specifiers begin with zero due to the fact that MySQL allows the storing of incomplete dates such as
'2004-00-00'.As of MySQL 5.0.25, the language used for day and month names and abbreviations is controlled by the value of the
lc_time_namessystem variable (Section 5.10.9, “MySQL Server Locale Support”).As of MySQL 5.0.36,
DATE_FORMAT()returns a string with a character set and collation given bycharacter_set_connectionandcollation_connectionso that it can return month and weekday names containing non-ASCII characters. Before 5.0.36, the return value is a binary string.mysql>
SELECT DATE_FORMAT('1997-10-04 22:23:00', '%W %M %Y');-> 'Saturday October 1997' mysql>SELECT DATE_FORMAT('1997-10-04 22:23:00', '%H:%i:%s');-> '22:23:00' mysql>SELECT DATE_FORMAT('1997-10-04 22:23:00','%D %y %a %d %m %b %j'); -> '4th 97 Sat 04 10 Oct 277' mysql>SELECT DATE_FORMAT('1997-10-04 22:23:00','%H %k %I %r %T %S %w'); -> '22 22 10 10:23:00 PM 22:23:00 00 6' mysql>SELECT DATE_FORMAT('1999-01-01', '%X %V');-> '1998 52' mysql>SELECT DATE_FORMAT('2006-06-00', '%d');-> '00'DATE_SUB(date,INTERVALexprunit)See
DATE_ADD().DAY()is a synonym forDAYOFMONTH().Returns the name of the weekday for
date. As of MySQL 5.0.25, the language used for the name is controlled by the value of thelc_time_namessystem variable (Section 5.10.9, “MySQL Server Locale Support”).mysql>
SELECT DAYNAME('1998-02-05');-> 'Thursday'Returns the day of the month for
date, in the range0to31.mysql>
SELECT DAYOFMONTH('1998-02-03');-> 3Returns the weekday index for
date(1= Sunday,2= Monday, …,7= Saturday). These index values correspond to the ODBC standard.mysql>
SELECT DAYOFWEEK('1998-02-03');-> 3Returns the day of the year for
date, in the range1to366.mysql>
SELECT DAYOFYEAR('1998-02-03');-> 34The
EXTRACT()function uses the same kinds of unit specifiers asDATE_ADD()orDATE_SUB(), but extracts parts from the date rather than performing date arithmetic.mysql>
SELECT EXTRACT(YEAR FROM '1999-07-02');-> 1999 mysql>SELECT EXTRACT(YEAR_MONTH FROM '1999-07-02 01:02:03');-> 199907 mysql>SELECT EXTRACT(DAY_MINUTE FROM '1999-07-02 01:02:03');-> 20102 mysql>SELECT EXTRACT(MICROSECOND->FROM '2003-01-02 10:30:00.000123');-> 123Given a day number
N, returns aDATEvalue.mysql>
SELECT FROM_DAYS(729669);-> '1997-10-07'Use
FROM_DAYS()with caution on old dates. It is not intended for use with values that precede the advent of the Gregorian calendar (1582). See Section 12.7, “What Calendar Is Used By MySQL?”.FROM_UNIXTIME(,unix_timestamp)FROM_UNIXTIME(unix_timestamp,format)Returns a representation of the
unix_timestampargument as a value in'YYYY-MM-DD HH:MM:SS'orYYYYMMDDHHMMSSformat, depending on whether the function is used in a string or numeric context. The value is expressed in the current time zone.unix_timestampis an internal timestamp value such as is produced by theUNIX_TIMESTAMP()function.If
formatis given, the result is formatted according to theformatstring, which is used the same way as listed in the entry for theDATE_FORMAT()function.mysql>
SELECT FROM_UNIXTIME(875996580);-> '1997-10-04 22:23:00' mysql>SELECT FROM_UNIXTIME(875996580) + 0;-> 19971004222300 mysql>SELECT FROM_UNIXTIME(UNIX_TIMESTAMP(),->'%Y %D %M %h:%i:%s %x');-> '2003 6th August 06:22:58 2003'Note: If you use
UNIX_TIMESTAMP()andFROM_UNIXTIME()to convert betweenTIMESTAMPvalues and Unix timestamp values, the conversion is lossy because the mapping is not one-to-one in both directions. For details, see the description of theUNIX_TIMESTAMP()function.GET_FORMAT(DATE|TIME|DATETIME, 'EUR'|'USA'|'JIS'|'ISO'|'INTERNAL')Returns a format string. This function is useful in combination with the
DATE_FORMAT()and theSTR_TO_DATE()functions.The possible values for the first and second arguments result in several possible format strings (for the specifiers used, see the table in the
DATE_FORMAT()function description). ISO format refers to ISO 9075, not ISO 8601.Function Call Result GET_FORMAT(DATE,'USA')'%m.%d.%Y'GET_FORMAT(DATE,'JIS')'%Y-%m-%d'GET_FORMAT(DATE,'ISO')'%Y-%m-%d'GET_FORMAT(DATE,'EUR')'%d.%m.%Y'GET_FORMAT(DATE,'INTERNAL')'%Y%m%d'GET_FORMAT(DATETIME,'USA')'%Y-%m-%d %H.%i.%s'GET_FORMAT(DATETIME,'JIS')'%Y-%m-%d %H:%i:%s'GET_FORMAT(DATETIME,'ISO')'%Y-%m-%d %H:%i:%s'GET_FORMAT(DATETIME,'EUR')'%Y-%m-%d %H.%i.%s'GET_FORMAT(DATETIME,'INTERNAL')'%Y%m%d%H%i%s'GET_FORMAT(TIME,'USA')'%h:%i:%s %p'GET_FORMAT(TIME,'JIS')'%H:%i:%s'GET_FORMAT(TIME,'ISO')'%H:%i:%s'GET_FORMAT(TIME,'EUR')'%H.%i.%s'GET_FORMAT(TIME,'INTERNAL')'%H%i%s'TIMESTAMPcan also be used as the first argument toGET_FORMAT(), in which case the function returns the same values as forDATETIME.mysql>
SELECT DATE_FORMAT('2003-10-03',GET_FORMAT(DATE,'EUR'));-> '03.10.2003' mysql>SELECT STR_TO_DATE('10.31.2003',GET_FORMAT(DATE,'USA'));-> '2003-10-31'Returns the hour for
time. The range of the return value is0to23for time-of-day values. However, the range ofTIMEvalues actually is much larger, soHOURcan return values greater than23.mysql>
SELECT HOUR('10:05:03');-> 10 mysql>SELECT HOUR('272:59:59');-> 272Takes a date or datetime value and returns the corresponding value for the last day of the month. Returns
NULLif the argument is invalid.mysql>
SELECT LAST_DAY('2003-02-05');-> '2003-02-28' mysql>SELECT LAST_DAY('2004-02-05');-> '2004-02-29' mysql>SELECT LAST_DAY('2004-01-01 01:01:01');-> '2004-01-31' mysql>SELECT LAST_DAY('2003-03-32');-> NULLLOCALTIMEandLOCALTIME()are synonyms forNOW().LOCALTIMESTAMP,LOCALTIMESTAMP()LOCALTIMESTAMPandLOCALTIMESTAMP()are synonyms forNOW().Returns a date, given year and day-of-year values.
dayofyearmust be greater than 0 or the result isNULL.mysql>
SELECT MAKEDATE(2001,31), MAKEDATE(2001,32);-> '2001-01-31', '2001-02-01' mysql>SELECT MAKEDATE(2001,365), MAKEDATE(2004,365);-> '2001-12-31', '2004-12-30' mysql>SELECT MAKEDATE(2001,0);-> NULLReturns a time value calculated from the
hour,minute, andsecondarguments.mysql>
SELECT MAKETIME(12,15,30);-> '12:15:30'Returns the microseconds from the time or datetime expression
expras a number in the range from0to999999.mysql>
SELECT MICROSECOND('12:00:00.123456');-> 123456 mysql>SELECT MICROSECOND('1997-12-31 23:59:59.000010');-> 10Returns the minute for
time, in the range0to59.mysql>
SELECT MINUTE('98-02-03 10:05:03');-> 5Returns the month for
date, in the range0to12.mysql>
SELECT MONTH('1998-02-03');-> 2Returns the full name of the month for
date. As of MySQL 5.0.25, the language used for the name is controlled by the value of thelc_time_namessystem variable (Section 5.10.9, “MySQL Server Locale Support”).mysql>
SELECT MONTHNAME('1998-02-05');-> 'February'Returns the current date and time as a value in
'YYYY-MM-DD HH:MM:SS'orYYYYMMDDHHMMSSformat, depending on whether the function is used in a string or numeric context. The value is expressed in the current time zone.mysql>
SELECT NOW();-> '1997-12-15 23:50:26' mysql>SELECT NOW() + 0;-> 19971215235026NOW()returns a constant time that indicates the time at which the statement began to execute. (Within a stored routine or trigger,NOW()returns the time at which the routine or triggering statement began to execute.) This differs from the behavior forSYSDATE(), which returns the exact time at which it executes as of MySQL 5.0.13.mysql>
SELECT NOW(), SLEEP(2), NOW();+---------------------+----------+---------------------+ | NOW() | SLEEP(2) | NOW() | +---------------------+----------+---------------------+ | 2006-04-12 13:47:36 | 0 | 2006-04-12 13:47:36 | +---------------------+----------+---------------------+ mysql>SELECT SYSDATE(), SLEEP(2), SYSDATE();+---------------------+----------+---------------------+ | SYSDATE() | SLEEP(2) | SYSDATE() | +---------------------+----------+---------------------+ | 2006-04-12 13:47:44 | 0 | 2006-04-12 13:47:46 | +---------------------+----------+---------------------+See the description for
SYSDATE()for additional information about the differences between the two functions.Adds
Nmonths to periodP(in the formatYYMMorYYYYMM). Returns a value in the formatYYYYMM. Note that the period argumentPis not a date value.mysql>
SELECT PERIOD_ADD(9801,2);-> 199803Returns the number of months between periods
P1andP2.P1andP2should be in the formatYYMMorYYYYMM. Note that the period argumentsP1andP2are not date values.mysql>
SELECT PERIOD_DIFF(9802,199703);-> 11Returns the quarter of the year for
date, in the range1to4.mysql>
SELECT QUARTER('98-04-01');-> 2Returns the second for
time, in the range0to59.mysql>
SELECT SECOND('10:05:03');-> 3Returns the
secondsargument, converted to hours, minutes, and seconds, as a value in'HH:MM:SS'orHHMMSSformat, depending on whether the function is used in a string or numeric context.mysql>
SELECT SEC_TO_TIME(2378);-> '00:39:38' mysql>SELECT SEC_TO_TIME(2378) + 0;-> 3938This is the inverse of the
DATE_FORMAT()function. It takes a stringstrand a format stringformat.STR_TO_DATE()returns aDATETIMEvalue if the format string contains both date and time parts, or aDATEorTIMEvalue if the string contains only date or time parts.The date, time, or datetime values contained in
strshould be given in the format indicated byformat. For the specifiers that can be used informat, see theDATE_FORMAT()function description. Ifstrcontains an illegal date, time, or datetime value,STR_TO_DATE()returnsNULL. Starting from MySQL 5.0.3, an illegal value also produces a warning.Range checking on the parts of date values is as described in Section 11.3.1, “The
DATETIME,DATE, andTIMESTAMPTypes”. This means, for example, that “zero” dates or dates with part values of 0 are allowed unless the SQL mode is set to disallow such values.mysql>
SELECT STR_TO_DATE('00/00/0000', '%m/%d/%Y');-> '0000-00-00' mysql>SELECT STR_TO_DATE('04/31/2004', '%m/%d/%Y');-> '2004-04-31'Note: You cannot use format
"%X%V"to convert a year-week string to a date because the combination of a year and week does not uniquely identify a year and month if the week crosses a month boundary. To convert a year-week to a date, then you should also specify the weekday:mysql>
SELECT STR_TO_DATE('200442 Monday', '%X%V %W');-> '2004-10-18'SUBDATE(,date,INTERVALexprunit)SUBDATE(expr,days)When invoked with the
INTERVALform of the second argument,SUBDATE()is a synonym forDATE_SUB(). For information on theINTERVALunitargument, see the discussion forDATE_ADD().mysql>
SELECT DATE_SUB('1998-01-02', INTERVAL 31 DAY);-> '1997-12-02' mysql>SELECT SUBDATE('1998-01-02', INTERVAL 31 DAY);-> '1997-12-02'The second form allows the use of an integer value for
days. In such cases, it is interpreted as the number of days to be subtracted from the date or datetime expressionexpr.mysql>
SELECT SUBDATE('1998-01-02 12:00:00', 31);-> '1997-12-02 12:00:00'SUBTIME()returnsexpr1–expr2expressed as a value in the same format asexpr1.expr1is a time or datetime expression, andexpr2is a time expression.mysql>
SELECT SUBTIME('1997-12-31 23:59:59.999999','1 1:1:1.000002');-> '1997-12-30 22:58:58.999997' mysql>SELECT SUBTIME('01:00:00.999999', '02:00:00.999998');-> '-00:59:59.999999'Returns the current date and time as a value in
'YYYY-MM-DD HH:MM:SS'orYYYYMMDDHHMMSSformat, depending on whether the function is used in a string or numeric context.As of MySQL 5.0.13,
SYSDATE()returns the time at which it executes. This differs from the behavior forNOW(), which returns a constant time that indicates the time at which the statement began to execute. (Within a stored routine or trigger,NOW()returns the time at which the routine or triggering statement began to execute.)mysql>
SELECT NOW(), SLEEP(2), NOW();+---------------------+----------+---------------------+ | NOW() | SLEEP(2) | NOW() | +---------------------+----------+---------------------+ | 2006-04-12 13:47:36 | 0 | 2006-04-12 13:47:36 | +---------------------+----------+---------------------+ mysql>SELECT SYSDATE(), SLEEP(2), SYSDATE();+---------------------+----------+---------------------+ | SYSDATE() | SLEEP(2) | SYSDATE() | +---------------------+----------+---------------------+ | 2006-04-12 13:47:44 | 0 | 2006-04-12 13:47:46 | +---------------------+----------+---------------------+In addition, the
SET TIMESTAMPstatement affects the value returned byNOW()but not bySYSDATE(). This means that timestamp settings in the binary log have no effect on invocations ofSYSDATE().Because
SYSDATE()can return different values even within the same statement, and is not affected bySET TIMESTAMP, it is non-deterministic and therefore unsafe for replication. If that is a problem, you can start the server with the--sysdate-is-nowoption to causeSYSDATE()to be an alias forNOW().Extracts the time part of the time or datetime expression
exprand returns it as a string.mysql>
SELECT TIME('2003-12-31 01:02:03');-> '01:02:03' mysql>SELECT TIME('2003-12-31 01:02:03.000123');-> '01:02:03.000123'TIMEDIFF()returnsexpr1–expr2expressed as a time value.expr1andexpr2are time or date-and-time expressions, but both must be of the same type.mysql>
SELECT TIMEDIFF('2000:01:01 00:00:00',->'2000:01:01 00:00:00.000001');-> '-00:00:00.000001' mysql>SELECT TIMEDIFF('1997-12-31 23:59:59.000001',->'1997-12-30 01:01:01.000002');-> '46:58:57.999999'TIMESTAMP(,expr)TIMESTAMP(expr1,expr2)With a single argument, this function returns the date or datetime expression
expras a datetime value. With two arguments, it adds the time expressionexpr2to the date or datetime expressionexpr1and returns the result as a datetime value.mysql>
SELECT TIMESTAMP('2003-12-31');-> '2003-12-31 00:00:00' mysql>SELECT TIMESTAMP('2003-12-31 12:00:00','12:00:00');-> '2004-01-01 00:00:00'TIMESTAMPADD(unit,interval,datetime_expr)Adds the integer expression
intervalto the date or datetime expressiondatetime_expr. The unit forintervalis given by theunitargument, which should be one of the following values:FRAC_SECOND,SECOND,MINUTE,HOUR,DAY,WEEK,MONTH,QUARTER, orYEAR.The
unitvalue may be specified using one of keywords as shown, or with a prefix ofSQL_TSI_. For example,DAYandSQL_TSI_DAYboth are legal.mysql>
SELECT TIMESTAMPADD(MINUTE,1,'2003-01-02');-> '2003-01-02 00:01:00' mysql>SELECT TIMESTAMPADD(WEEK,1,'2003-01-02');-> '2003-01-09'TIMESTAMPADD()is available as of MySQL 5.0.0.TIMESTAMPDIFF(unit,datetime_expr1,datetime_expr2)Returns the integer difference between the date or datetime expressions
datetime_expr1anddatetime_expr2. The unit for the result is given by theunitargument. The legal values forunitare the same as those listed in the description of theTIMESTAMPADD()function.mysql>
SELECT TIMESTAMPDIFF(MONTH,'2003-02-01','2003-05-01');-> 3 mysql>SELECT TIMESTAMPDIFF(YEAR,'2002-05-01','2001-01-01');-> -1TIMESTAMPDIFF()is available as of MySQL 5.0.0.This is used like the
DATE_FORMAT()function, but theformatstring may contain format specifiers only for hours, minutes, and seconds. Other specifiers produce aNULLvalue or0.If the
timevalue contains an hour part that is greater than23, the%Hand%khour format specifiers produce a value larger than the usual range of0..23. The other hour format specifiers produce the hour value modulo 12.mysql>
SELECT TIME_FORMAT('100:00:00', '%H %k %h %I %l');-> '100 100 04 04 4'Returns the
timeargument, converted to seconds.mysql>
SELECT TIME_TO_SEC('22:23:00');-> 80580 mysql>SELECT TIME_TO_SEC('00:39:38');-> 2378Given a date
date, returns a day number (the number of days since year 0).mysql>
SELECT TO_DAYS(950501);-> 728779 mysql>SELECT TO_DAYS('1997-10-07');-> 729669TO_DAYS()is not intended for use with values that precede the advent of the Gregorian calendar (1582), because it does not take into account the days that were lost when the calendar was changed. For dates before 1582 (and possibly a later year in other locales), results from this function are not reliable. See Section 12.7, “What Calendar Is Used By MySQL?”, for details.Remember that MySQL converts two-digit year values in dates to four-digit form using the rules in Section 11.3, “Date and Time Types”. For example,
'1997-10-07'and'97-10-07'are seen as identical dates:mysql>
SELECT TO_DAYS('1997-10-07'), TO_DAYS('97-10-07');-> 729669, 729669UNIX_TIMESTAMP(),UNIX_TIMESTAMP(date)If called with no argument, returns a Unix timestamp (seconds since
'1970-01-01 00:00:00'UTC) as an unsigned integer. IfUNIX_TIMESTAMP()is called with adateargument, it returns the value of the argument as seconds since'1970-01-01 00:00:00'UTC.datemay be aDATEstring, aDATETIMEstring, aTIMESTAMP, or a number in the formatYYMMDDorYYYYMMDD. The server interpretsdateas a value in the current time zone and converts it to an internal value in UTC. Clients can set their time zone as described in Section 5.10.8, “MySQL Server Time Zone Support”.mysql>
SELECT UNIX_TIMESTAMP();-> 882226357 mysql>SELECT UNIX_TIMESTAMP('1997-10-04 22:23:00');-> 875996580When
UNIX_TIMESTAMPis used on aTIMESTAMPcolumn, the function returns the internal timestamp value directly, with no implicit “string-to-Unix-timestamp” conversion. If you pass an out-of-range date toUNIX_TIMESTAMP(), it returns0.Note: If you use
UNIX_TIMESTAMP()andFROM_UNIXTIME()to convert betweenTIMESTAMPvalues and Unix timestamp values, the conversion is lossy because the mapping is not one-to-one in both directions. For example, due to conventions for local time zone changes, it is possible for twoUNIX_TIMESTAMP()to map twoTIMESTAMPvalues to the same Unix timestamp value.FROM_UNIXTIME()will map that value back to only one of the originalTIMESTAMPvalues. Here is an example, usingTIMESTAMPvalues in theCETtime zone:mysql>
SELECT UNIX_TIMESTAMP('2005-03-27 03:00:00');+---------------------------------------+ | UNIX_TIMESTAMP('2005-03-27 03:00:00') | +---------------------------------------+ | 1111885200 | +---------------------------------------+ mysql>SELECT UNIX_TIMESTAMP('2005-03-27 02:00:00');+---------------------------------------+ | UNIX_TIMESTAMP('2005-03-27 02:00:00') | +---------------------------------------+ | 1111885200 | +---------------------------------------+ mysql>SELECT FROM_UNIXTIME(1111885200);+---------------------------+ | FROM_UNIXTIME(1111885200) | +---------------------------+ | 2005-03-27 03:00:00 | +---------------------------+If you want to subtract
UNIX_TIMESTAMP()columns, you might want to cast the result to signed integers. See Section 12.9, “Cast Functions and Operators”.Returns the current UTC date as a value in
'YYYY-MM-DD'orYYYYMMDDformat, depending on whether the function is used in a string or numeric context.mysql>
SELECT UTC_DATE(), UTC_DATE() + 0;-> '2003-08-14', 20030814Returns the current UTC time as a value in
'HH:MM:SS'orHHMMSSformat, depending on whether the function is used in a string or numeric context.mysql>
SELECT UTC_TIME(), UTC_TIME() + 0;-> '18:07:53', 180753UTC_TIMESTAMP,UTC_TIMESTAMP()Returns the current UTC date and time as a value in
'YYYY-MM-DD HH:MM:SS'orYYYYMMDDHHMMSSformat, depending on whether the function is used in a string or numeric context.mysql>
SELECT UTC_TIMESTAMP(), UTC_TIMESTAMP() + 0;-> '2003-08-14 18:08:04', 20030814180804This function returns the week number for
date. The two-argument form ofWEEK()allows you to specify whether the week starts on Sunday or Monday and whether the return value should be in the range from0to53or from1to53. If themodeargument is omitted, the value of thedefault_week_formatsystem variable is used. See Section 5.2.3, “System Variables”.The following table describes how the
modeargument works.First day Mode of week Range Week 1 is the first week … 0 Sunday 0-53 with a Sunday in this year 1 Monday 0-53 with more than 3 days this year 2 Sunday 1-53 with a Sunday in this year 3 Monday 1-53 with more than 3 days this year 4 Sunday 0-53 with more than 3 days this year 5 Monday 0-53 with a Monday in this year 6 Sunday 1-53 with more than 3 days this year 7 Monday 1-53 with a Monday in this year mysql>
SELECT WEEK('1998-02-20');-> 7 mysql>SELECT WEEK('1998-02-20',0);-> 7 mysql>SELECT WEEK('1998-02-20',1);-> 8 mysql>SELECT WEEK('1998-12-31',1);-> 53Note that if a date falls in the last week of the previous year, MySQL returns
0if you do not use2,3,6, or7as the optionalmodeargument:mysql>
SELECT YEAR('2000-01-01'), WEEK('2000-01-01',0);-> 2000, 0One might argue that MySQL should return
52for theWEEK()function, because the given date actually occurs in the 52nd week of 1999. We decided to return0instead because we want the function to return “the week number in the given year.” This makes use of theWEEK()function reliable when combined with other functions that extract a date part from a date.If you would prefer the result to be evaluated with respect to the year that contains the first day of the week for the given date, use
0,2,5, or7as the optionalmodeargument.mysql>
SELECT WEEK('2000-01-01',2);-> 52Alternatively, use the
YEARWEEK()function:mysql>
SELECT YEARWEEK('2000-01-01');-> 199952 mysql>SELECT MID(YEARWEEK('2000-01-01'),5,2);-> '52'Returns the weekday index for
date(0= Monday,1= Tuesday, …6= Sunday).mysql>
SELECT WEEKDAY('1998-02-03 22:23:00');-> 1 mysql>SELECT WEEKDAY('1997-11-05');-> 2Returns the calendar week of the date as a number in the range from
1to53.WEEKOFYEAR()is a compatibility function that is equivalent toWEEK(.date,3)mysql>
SELECT WEEKOFYEAR('1998-02-20');-> 8Returns the year for
date, in the range1000to9999, or0for the “zero” date.mysql>
SELECT YEAR('98-02-03');-> 1998YEARWEEK(,date)YEARWEEK(date,mode)Returns year and week for a date. The
modeargument works exactly like themodeargument toWEEK(). The year in the result may be different from the year in the date argument for the first and the last week of the year.mysql>
SELECT YEARWEEK('1987-01-01');-> 198653Note that the week number is different from what the
WEEK()function would return (0) for optional arguments0or1, asWEEK()then returns the week in the context of the given year.
MySQL uses what is known as a proleptic Gregorian calendar.
Every country that has switched from the Julian to the Gregorian calendar has had to discard at least ten days during the switch. To see how this works, consider the month of October 1582, when the first Julian-to-Gregorian switch occurred:
| Monday | Tuesday | Wednesday | Thursday | Friday | Saturday | Sunday |
| 1 | 2 | 3 | 4 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
There are no dates between October 4 and October 15. This discontinuity is called the cutover. Any dates before the cutover are Julian, and any dates following the cutover are Gregorian. Dates during a cutover are non-existent.
A calendar applied to dates when it wasn't actually in use is
called proleptic. Thus, if we assume there
was never a cutover and Gregorian rules always rule, we have a
proleptic Gregorian calendar. This is what is used by MySQL, as is
required by standard SQL. For this reason, dates prior to the
cutover stored as MySQL DATE or
DATETIME values must be adjusted to compensate
for the difference. It is important to realize that the cutover
did not occur at the same time in all countries, and that the
later it happened, the more days were lost. For example, in Great
Britain, it took place in 1752, when Wednesday September 2 was
followed by Thursday September 14. Russia remained on the Julian
calendar until 1918, losing 13 days in the process, and what is
popularly referred to as its “October Revolution”
occurred in November according to the Gregorian calendar.
MATCH (col1,col2,...) AGAINST (expr[search_modifier])search_modifier:{ IN BOOLEAN MODE | WITH QUERY EXPANSION }
MySQL has support for full-text indexing and searching:
A full-text index in MySQL is an index of type
FULLTEXT.Full-text indexes can be used only with
MyISAMtables, and can be created only forCHAR,VARCHAR, orTEXTcolumns.A
FULLTEXTindex definition can be given in theCREATE TABLEstatement when a table is created, or added later usingALTER TABLEorCREATE INDEX.For large datasets, it is much faster to load your data into a table that has no
FULLTEXTindex and then create the index after that, than to load data into a table that has an existingFULLTEXTindex.
Full-text searching is performed using MATCH() ...
AGAINST syntax. MATCH() takes a
comma-separated list that names the columns to be searched.
AGAINST takes a string to search for, and an
optional modifier that indicates what type of search to perform.
The search string must be a literal string, not a variable or a
column name. There are three types of full-text searches:
A boolean search interprets the search string using the rules of a special query language. The string contains the words to search for. It can also contain operators that specify requirements such that a word must be present or absent in matching rows, or that it should be weighted higher or lower than usual. Common words such as “some” or “then” are stopwords and do not match if present in the search string. The
IN BOOLEAN MODEmodifier specifies a boolean search. For more information, see Section 12.8.1, “Boolean Full-Text Searches”.A natural language search interprets the search string as a phrase in natural human language (a phrase in free text). There are no special operators. The stopword list applies. In addition, words that are present in more than 50% of the rows are considered common and do not match. Full-text searches are natural language searches if no modifier is given.
A query expansion search is a modification of a natural language search. The search string is used to perform a natural language search. Then words from the most relevant rows returned by the search are added to the search string and the search is done again. The query returns the rows from the second search. The
WITH QUERY EXPANSIONmodifier specifies a query expansion search. For more information, see Section 12.8.2, “Full-Text Searches with Query Expansion”.
Constraints on full-text searching are listed in Section 12.8.4, “Full-Text Restrictions”.
mysql>CREATE TABLE articles (->id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,->title VARCHAR(200),->body TEXT,->FULLTEXT (title,body)->);Query OK, 0 rows affected (0.00 sec) mysql>INSERT INTO articles (title,body) VALUES->('MySQL Tutorial','DBMS stands for DataBase ...'),->('How To Use MySQL Well','After you went through a ...'),->('Optimizing MySQL','In this tutorial we will show ...'),->('1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),->('MySQL vs. YourSQL','In the following database comparison ...'),->('MySQL Security','When configured properly, MySQL ...');Query OK, 6 rows affected (0.00 sec) Records: 6 Duplicates: 0 Warnings: 0 mysql>SELECT * FROM articles->WHERE MATCH (title,body) AGAINST ('database');+----+-------------------+------------------------------------------+ | id | title | body | +----+-------------------+------------------------------------------+ | 5 | MySQL vs. YourSQL | In the following database comparison ... | | 1 | MySQL Tutorial | DBMS stands for DataBase ... | +----+-------------------+------------------------------------------+ 2 rows in set (0.00 sec)
The MATCH() function performs a natural
language search for a string against a text
collection. A collection is a set of one or more
columns included in a FULLTEXT index. The
search string is given as the argument to
AGAINST(). For each row in the table,
MATCH() returns a relevance value; that is, a
similarity measure between the search string and the text in that
row in the columns named in the MATCH() list.
By default, the search is performed in case-insensitive fashion.
However, you can perform a case-sensitive full-text search by
using a binary collation for the indexed columns. For example, a
column that uses the latin1 character set of
can be assigned a collation of latin1_bin to
make it case sensitive for full-text searches.
When MATCH() is used in a
WHERE clause, as in the example shown earlier,
the rows returned are automatically sorted with the highest
relevance first. Relevance values are non-negative floating-point
numbers. Zero relevance means no similarity. Relevance is computed
based on the number of words in the row, the number of unique
words in that row, the total number of words in the collection,
and the number of documents (rows) that contain a particular word.
To simply count matches, you could use a query like this:
mysql>SELECT COUNT(*) FROM articles->WHERE MATCH (title,body)->AGAINST ('database');+----------+ | COUNT(*) | +----------+ | 2 | +----------+ 1 row in set (0.00 sec)
However, you might find it quicker to rewrite the query as follows:
mysql>SELECT->COUNT(IF(MATCH (title,body) AGAINST ('database'), 1, NULL))->AS count->FROM articles;+-------+ | count | +-------+ | 2 | +-------+ 1 row in set (0.00 sec)
The first query sorts the results by relevance whereas the second does not. However, the second query performs a full table scan and the first does not. The first may be faster if the search matches few rows; otherwise, the second may be faster because it would read many rows anyway.
For natural-language full-text searches, it is a requirement that
the columns named in the MATCH() function be
the same columns included in some FULLTEXT
index in your table. For the preceding query, note that the
columns named in the MATCH() function
(title and body) are the
same as those named in the definition of the
article table's FULLTEXT
index. If you wanted to search the title or
body separately, you would need to create
separate FULLTEXT indexes for each column.
It is also possible to perform a boolean search or a search with query expansion. These search types are described in Section 12.8.1, “Boolean Full-Text Searches”, and Section 12.8.2, “Full-Text Searches with Query Expansion”.
A full-text search that uses an index can name columns only from a
single table in the MATCH() clause because an
index cannot span multiple tables. A boolean search can be done in
the absence of an index (albeit more slowly), in which case it is
possible to name columns from multiple tables.
The preceding example is a basic illustration that shows how to
use the MATCH() function where rows are
returned in order of decreasing relevance. The next example shows
how to retrieve the relevance values explicitly. Returned rows are
not ordered because the SELECT statement
includes neither WHERE nor ORDER
BY clauses:
mysql>SELECT id, MATCH (title,body) AGAINST ('Tutorial')->FROM articles;+----+-----------------------------------------+ | id | MATCH (title,body) AGAINST ('Tutorial') | +----+-----------------------------------------+ | 1 | 0.65545833110809 | | 2 | 0 | | 3 | 0.66266459226608 | | 4 | 0 | | 5 | 0 | | 6 | 0 | +----+-----------------------------------------+ 6 rows in set (0.00 sec)
The following example is more complex. The query returns the
relevance values and it also sorts the rows in order of decreasing
relevance. To achieve this result, you should specify
MATCH() twice: once in the
SELECT list and once in the
WHERE clause. This causes no additional
overhead, because the MySQL optimizer notices that the two
MATCH() calls are identical and invokes the
full-text search code only once.
mysql>SELECT id, body, MATCH (title,body) AGAINST->('Security implications of running MySQL as root') AS score->FROM articles WHERE MATCH (title,body) AGAINST->('Security implications of running MySQL as root');+----+-------------------------------------+-----------------+ | id | body | score | +----+-------------------------------------+-----------------+ | 4 | 1. Never run mysqld as root. 2. ... | 1.5219271183014 | | 6 | When configured properly, MySQL ... | 1.3114095926285 | +----+-------------------------------------+-----------------+ 2 rows in set (0.00 sec)
The MySQL FULLTEXT implementation regards any
sequence of true word characters (letters, digits, and
underscores) as a word. That sequence may also contain apostrophes
(‘'’), but not more than one in a
row. This means that aaa'bbb is regarded as one
word, but aaa''bbb is regarded as two words.
Apostrophes at the beginning or the end of a word are stripped by
the FULLTEXT parser;
'aaa'bbb' would be parsed as
aaa'bbb.
The FULLTEXT parser determines where words
start and end by looking for certain delimiter characters; for
example, ‘ ’ (space),
‘,’ (comma), and
‘.’ (period). If words are not
separated by delimiters (as in, for example, Chinese), the
FULLTEXT parser cannot determine where a word
begins or ends. To be able to add words or other indexed terms in
such languages to a FULLTEXT index, you must
preprocess them so that they are separated by some arbitrary
delimiter such as ‘"’.
Some words are ignored in full-text searches:
Any word that is too short is ignored. The default minimum length of words that are found by full-text searches is four characters.
Words in the stopword list are ignored. A stopword is a word such as “the” or “some” that is so common that it is considered to have zero semantic value. There is a built-in stopword list, but it can be overwritten by a user-defined list.
The default stopword list is given in Section 12.8.3, “Full-Text Stopwords”. The default minimum word length and stopword list can be changed as described in Section 12.8.5, “Fine-Tuning MySQL Full-Text Search”.
Every correct word in the collection and in the query is weighted according to its significance in the collection or query. Consequently, a word that is present in many documents has a lower weight (and may even have a zero weight), because it has lower semantic value in this particular collection. Conversely, if the word is rare, it receives a higher weight. The weights of the words are combined to compute the relevance of the row.
Such a technique works best with large collections (in fact, it
was carefully tuned this way). For very small tables, word
distribution does not adequately reflect their semantic value, and
this model may sometimes produce bizarre results. For example,
although the word “MySQL” is present in every row of
the articles table shown earlier, a search for
the word produces no results:
mysql>SELECT * FROM articles->WHERE MATCH (title,body) AGAINST ('MySQL');Empty set (0.00 sec)
The search result is empty because the word “MySQL” is present in at least 50% of the rows. As such, it is effectively treated as a stopword. For large datasets, this is the most desirable behavior: A natural language query should not return every second row from a 1GB table. For small datasets, it may be less desirable.
A word that matches half of the rows in a table is less likely to locate relevant documents. In fact, it most likely finds plenty of irrelevant documents. We all know this happens far too often when we are trying to find something on the Internet with a search engine. It is with this reasoning that rows containing the word are assigned a low semantic value for the particular dataset in which they occur. A given word may exceed the 50% threshold in one dataset but not another.
The 50% threshold has a significant implication when you first try full-text searching to see how it works: If you create a table and insert only one or two rows of text into it, every word in the text occurs in at least 50% of the rows. As a result, no search returns any results. Be sure to insert at least three rows, and preferably many more. Users who need to bypass the 50% limitation can use the boolean search mode; see Section 12.8.1, “Boolean Full-Text Searches”.
MySQL can perform boolean full-text searches using the
IN BOOLEAN MODE modifier:
mysql>SELECT * FROM articles WHERE MATCH (title,body)->AGAINST ('+MySQL -YourSQL' IN BOOLEAN MODE);+----+-----------------------+-------------------------------------+ | id | title | body | +----+-----------------------+-------------------------------------+ | 1 | MySQL Tutorial | DBMS stands for DataBase ... | | 2 | How To Use MySQL Well | After you went through a ... | | 3 | Optimizing MySQL | In this tutorial we will show ... | | 4 | 1001 MySQL Tricks | 1. Never run mysqld as root. 2. ... | | 6 | MySQL Security | When configured properly, MySQL ... | +----+-----------------------+-------------------------------------+
The + and - operators
indicate that a word is required to be present or absent,
respectively, for a match to occur. Thus, this query retrieves
all the rows that contain the word “MySQL” but that
do not contain the word
“YourSQL”.
Boolean full-text searches have these characteristics:
They do not use the 50% threshold.
They do not automatically sort rows in order of decreasing relevance. You can see this from the preceding query result: The row with the highest relevance is the one that contains “MySQL” twice, but it is listed last, not first.
They can work even without a
FULLTEXTindex, although a search executed in this fashion would be quite slow.The minimum and maximum word length full-text parameters apply.
The stopword list applies.
The boolean full-text search capability supports the following operators:
+A leading plus sign indicates that this word must be present in each row that is returned.
-A leading minus sign indicates that this word must not be present in any of the rows that are returned.
Note: The
-operator acts only to exclude rows that are otherwise matched by other search terms. Thus, a boolean-mode search that contains only terms preceded by-returns an empty result. It does not return “all rows except those containing any of the excluded terms.”(no operator)
By default (when neither
+nor-is specified) the word is optional, but the rows that contain it are rated higher. This mimics the behavior ofMATCH() ... AGAINST()without theIN BOOLEAN MODEmodifier.> <These two operators are used to change a word's contribution to the relevance value that is assigned to a row. The
>operator increases the contribution and the<operator decreases it. See the example following this list.( )Parentheses group words into subexpressions. Parenthesized groups can be nested.
~A leading tilde acts as a negation operator, causing the word's contribution to the row's relevance to be negative. This is useful for marking “noise” words. A row containing such a word is rated lower than others, but is not excluded altogether, as it would be with the
-operator.*The asterisk serves as the truncation (or wildcard) operator. Unlike the other operators, it should be appended to the word to be affected. Words match if they begin with the word preceding the
*operator.If a stopword or too-short word is specified with the truncation operator, it will not be stripped from a boolean query. For example, a search for
'+word +stopword*'will likely return fewer rows than a search for'+word +stopword'because the former query remains as is and requiresstopword*to be present in a document. The latter query is transformed to+word."A phrase that is enclosed within double quote (‘
"’) characters matches only rows that contain the phrase literally, as it was typed. The full-text engine splits the phrase into words, performs a search in theFULLTEXTindex for the words. Prior to MySQL 5.0.3, the engine then performed a substring search for the phrase in the records that were found, so the match must include non-word characters in the phrase. As of MySQL 5.0.3, non-word characters need not be matched exactly: Phrase searching requires only that matches contain exactly the same words as the phrase and in the same order. For example,"test phrase"matches"test, phrase"in MySQL 5.0.3, but not before.If the phrase contains no words that are in the index, the result is empty. For example, if all words are either stopwords or shorter than the minimum length of indexed words, the result is empty.
The following examples demonstrate some search strings that use boolean full-text operators:
'apple banana'Find rows that contain at least one of the two words.
'+apple +juice'Find rows that contain both words.
'+apple macintosh'Find rows that contain the word “apple”, but rank rows higher if they also contain “macintosh”.
'+apple -macintosh'Find rows that contain the word “apple” but not “macintosh”.
'+apple ~macintosh'Find rows that contain the word “apple”, but if the row also contains the word “macintosh”, rate it lower than if row does not. This is “softer” than a search for
'+apple -macintosh', for which the presence of “macintosh” causes the row not to be returned at all.'+apple +(>turnover <strudel)'Find rows that contain the words “apple” and “turnover”, or “apple” and “strudel” (in any order), but rank “apple turnover” higher than “apple strudel”.
'apple*'Find rows that contain words such as “apple”, “apples”, “applesauce”, or “applet”.
'"some words"'Find rows that contain the exact phrase “some words” (for example, rows that contain “some words of wisdom” but not “some noise words”). Note that the ‘
"’ characters that enclose the phrase are operator characters that delimit the phrase. They are not the quotes that enclose the search string itself.
Full-text search supports query expansion (and in particular, its variant “blind query expansion”). This is generally useful when a search phrase is too short, which often means that the user is relying on implied knowledge that the full-text search engine lacks. For example, a user searching for “database” may really mean that “MySQL”, “Oracle”, “DB2”, and “RDBMS” all are phrases that should match “databases” and should be returned, too. This is implied knowledge.
Blind query expansion (also known as automatic relevance
feedback) is enabled by adding WITH QUERY
EXPANSION following the search phrase. It works by
performing the search twice, where the search phrase for the
second search is the original search phrase concatenated with
the few most highly relevant documents from the first search.
Thus, if one of these documents contains the word
“databases” and the word “MySQL”, the
second search finds the documents that contain the word
“MySQL” even if they do not contain the word
“database”. The following example shows this
difference:
mysql>SELECT * FROM articles->WHERE MATCH (title,body) AGAINST ('database');+----+-------------------+------------------------------------------+ | id | title | body | +----+-------------------+------------------------------------------+ | 5 | MySQL vs. YourSQL | In the following database comparison ... | | 1 | MySQL Tutorial | DBMS stands for DataBase ... | +----+-------------------+------------------------------------------+ 2 rows in set (0.00 sec) mysql>SELECT * FROM articles->WHERE MATCH (title,body)->AGAINST ('database' WITH QUERY EXPANSION);+----+-------------------+------------------------------------------+ | id | title | body | +----+-------------------+------------------------------------------+ | 1 | MySQL Tutorial | DBMS stands for DataBase ... | | 5 | MySQL vs. YourSQL | In the following database comparison ... | | 3 | Optimizing MySQL | In this tutorial we will show ... | +----+-------------------+------------------------------------------+ 3 rows in set (0.00 sec)
Another example could be searching for books by Georges Simenon about Maigret, when a user is not sure how to spell “Maigret”. A search for “Megre and the reluctant witnesses” finds only “Maigret and the Reluctant Witnesses” without query expansion. A search with query expansion finds all books with the word “Maigret” on the second pass.
Note: Because blind query expansion tends to increase noise significantly by returning non-relevant documents, it is meaningful to use only when a search phrase is rather short.
The following table shows the default list of full-text stopwords.
| a's | able | about | above | according |
| accordingly | across | actually | after | afterwards |
| again | against | ain't | all | allow |
| allows | almost | alone | along | already |
| also | although | always | am | among |
| amongst | an | and | another | any |
| anybody | anyhow | anyone | anything | anyway |
| anyways | anywhere | apart | appear | appreciate |
| appropriate | are | aren't | around | as |
| aside | ask | asking | associated | at |
| available | away | awfully | be | became |
| because | become | becomes | becoming | been |
| before | beforehand | behind | being | believe |
| below | beside | besides | best | better |
| between | beyond | both | brief | but |
| by | c'mon | c's | came | can |
| can't | cannot | cant | cause | causes |
| certain | certainly | changes | clearly | co |
| com | come | comes | concerning | consequently |
| consider | considering | contain | containing | contains |
| corresponding | could | couldn't | course | currently |
| definitely | described | despite | did | didn't |
| different | do | does | doesn't | doing |
| don't | done | down | downwards | during |
| each | edu | eg | eight | either |
| else | elsewhere | enough | entirely | especially |
| et | etc | even | ever | every |
| everybody | everyone | everything | everywhere | ex |
| exactly | example | except | far | few |
| fifth | first | five | followed | following |
| follows | for | former | formerly | forth |
| four | from | further | furthermore | get |
| gets | getting | given | gives | go |
| goes | going | gone | got | gotten |
| greetings | had | hadn't | happens | hardly |
| has | hasn't | have | haven't | having |
| he | he's | hello | help | hence |
| her | here | here's | hereafter | hereby |
| herein | hereupon | hers | herself | hi |
| him | himself | his | hither | hopefully |
| how | howbeit | however | i'd | i'll |
| i'm | i've | ie | if | ignored |
| immediate | in | inasmuch | inc | indeed |
| indicate | indicated | indicates | inner | insofar |
| instead | into | inward | is | isn't |
| it | it'd | it'll | it's | its |
| itself | just | keep | keeps | kept |
| know | knows | known | last | lately |
| later | latter | latterly | least | less |
| lest | let | let's | like | liked |
| likely | little | look | looking | looks |
| ltd | mainly | many | may | maybe |
| me | mean | meanwhile | merely | might |
| more | moreover | most | mostly | much |
| must | my | myself | name | namely |
| nd | near | nearly | necessary | need |
| needs | neither | never | nevertheless | new |
| next | nine | no | nobody | non |
| none | noone | nor | normally | not |
| nothing | novel | now | nowhere | obviously |
| of | off | often | oh | ok |
| okay | old | on | once | one |
| ones | only | onto | or | other |
| others | otherwise | ought | our | ours |
| ourselves | out | outside | over | overall |
| own | particular | particularly | per | perhaps |
| placed | please | plus | possible | presumably |
| probably | provides | que | quite | qv |
| rather | rd | re | really | reasonably |
| regarding | regardless | regards | relatively | respectively |
| right | said | same | saw | say |
| saying | says | second | secondly | see |
| seeing | seem | seemed | seeming | seems |
| seen | self | selves | sensible | sent |
| serious | seriously | seven | several | shall |
| she | should | shouldn't | since | six |
| so | some | somebody | somehow | someone |
| something | sometime | sometimes | somewhat | somewhere |
| soon | sorry | specified | specify | specifying |
| still | sub | such | sup | sure |
| t's | take | taken | tell | tends |
| th | than | thank | thanks | thanx |
| that | that's | thats | the | their |
| theirs | them | themselves | then | thence |
| there | there's | thereafter | thereby | therefore |
| therein | theres | thereupon | these | they |
| they'd | they'll | they're | they've | think |
| third | this | thorough | thoroughly | those |
| though | three | through | throughout | thru |
| thus | to | together | too | took |
| toward | towards | tried | tries | truly |
| try | trying | twice | two | un |
| under | unfortunately | unless | unlikely | until |
| unto | up | upon | us | use |
| used | useful | uses | using | usually |
| value | various | very | via | viz |
| vs | want | wants | was | wasn't |
| way | we | we'd | we'll | we're |
| we've | welcome | well | went | were |
| weren't | what | what's | whatever | when |
| whence | whenever | where | where's | whereafter |
| whereas | whereby | wherein | whereupon | wherever |
| whether | which | while | whither | who |
| who's | whoever | whole | whom | whose |
| why | will | willing | wish | with |
| within | without | won't | wonder | would |
| would | wouldn't | yes | yet | you |
| you'd | you'll | you're | you've | your |
| yours | yourself | yourselves | zero |
Full-text searches are supported for
MyISAMtables only.Full-text searches can be used with most multi-byte character sets. The exception is that for Unicode, the
utf8character set can be used, but not theucs2character set.Ideographic languages such as Chinese and Japanese do not have word delimiters. Therefore, the
FULLTEXTparser cannot determine where words begin and end in these and other such languages. The implications of this and some workarounds for the problem are described in Section 12.8, “Full-Text Search Functions”.Although the use of multiple character sets within a single table is supported, all columns in a
FULLTEXTindex must use the same character set and collation.The
MATCH()column list must match exactly the column list in someFULLTEXTindex definition for the table, unless thisMATCH()isIN BOOLEAN MODE. Boolean-mode searches can be done on non-indexed columns, although they are likely to be slow.The argument to
AGAINST()must be a constant string.
MySQL's full-text search capability has few user-tunable parameters. You can exert more control over full-text searching behavior if you have a MySQL source distribution because some changes require source code modifications. See Section 2.4.14, “MySQL Installation Using a Source Distribution”.
Note that full-text search is carefully tuned for the most effectiveness. Modifying the default behavior in most cases can actually decrease effectiveness. Do not alter the MySQL sources unless you know what you are doing.
Most full-text variables described in this section must be set at server startup time. A server restart is required to change them; they cannot be modified while the server is running.
Some variable changes require that you rebuild the
FULLTEXT indexes in your tables. Instructions
for doing this are given at the end of this section.
The minimum and maximum lengths of words to be indexed are defined by the
ft_min_word_lenandft_max_word_lensystem variables. (See Section 5.2.3, “System Variables”.) The default minimum value is four characters; the default maximum is version dependent. If you change either value, you must rebuild yourFULLTEXTindexes. For example, if you want three-character words to be searchable, you can set theft_min_word_lenvariable by putting the following lines in an option file:[mysqld] ft_min_word_len=3
Then you must restart the server and rebuild your
FULLTEXTindexes. Note particularly the remarks regarding myisamchk in the instructions following this list.To override the default stopword list, set the
ft_stopword_filesystem variable. (See Section 5.2.3, “System Variables”.) The variable value should be the pathname of the file containing the stopword list, or the empty string to disable stopword filtering. After changing the value of this variable or the contents of the stopword file, restart the server and rebuild yourFULLTEXTindexes.The stopword list is free-form. That is, you may use any non-alphanumeric character such as newline, space, or comma to separate stopwords. Exceptions are the underscore character (‘
_’) and a single apostrophe (‘'’) which are treated as part of a word. The character set of the stopword list is the server's default character set; see Section 10.3.1, “Server Character Set and Collation”.The 50% threshold for natural language searches is determined by the particular weighting scheme chosen. To disable it, look for the following line in
myisam/ftdefs.h:#define GWS_IN_USE GWS_PROB
Change that line to this:
#define GWS_IN_USE GWS_FREQ
Then recompile MySQL. There is no need to rebuild the indexes in this case. Note: By making this change, you severely decrease MySQL's ability to provide adequate relevance values for the
MATCH()function. If you really need to search for such common words, it would be better to search usingIN BOOLEAN MODEinstead, which does not observe the 50% threshold.To change the operators used for boolean full-text searches, set the
ft_boolean_syntaxsystem variable. This variable can be changed while the server is running, but you must have theSUPERprivilege to do so. No rebuilding of indexes is necessary in this case. See Section 5.2.3, “System Variables”, which describes the rules governing how to set this variable.If you want to change the set of characters that are considered word characters, you can do so in two ways. Suppose that you want to treat the hyphen character ('-') as a word character. Use either of these methods:
Modify the MySQL source: In
myisam/ftdefs.h, see thetrue_word_char()andmisc_word_char()macros. Add'-'to one of those macros and recompile MySQL.Modify a character set file: This requires no recompilation. The
true_word_char()macro uses a “character type” table to distinguish letters and numbers from other characters. . You can edit the<ctype><map>contents in one of the character set XML files to specify that'-'is a “letter.” Then use the given character set for yourFULLTEXTindexes.
After making the modification, you must rebuild the indexes for each table that contains any
FULLTEXTindexes.
If you modify full-text variables that affect indexing
(ft_min_word_len,
ft_max_word_len, or
ft_stopword_file), or if you change the
stopword file itself, you must rebuild your
FULLTEXT indexes after making the changes and
restarting the server. To rebuild the indexes in this case, it
is sufficient to do a QUICK repair operation:
mysql> REPAIR TABLE tbl_name QUICK;
Each table that contains any FULLTEXT index
must be repaired as just shown. Otherwise, queries for the table
may yield incorrect results, and modifications to the table will
cause the server to see the table as corrupt and in need of
repair.
Note that if you use myisamchk to perform an
operation that modifies table indexes (such as repair or
analyze), the FULLTEXT indexes are rebuilt
using the default full-text parameter
values for minimum word length, maximum word length, and
stopword file unless you specify otherwise. This can result in
queries failing.
The problem occurs because these parameters are known only by
the server. They are not stored in MyISAM
index files. To avoid the problem if you have modified the
minimum or maximum word length or stopword file values used by
the server, specify the same ft_min_word_len,
ft_max_word_len, and
ft_stopword_file values to
myisamchk that you use for
mysqld. For example, if you have set the
minimum word length to 3, you can repair a table with
myisamchk like this:
shell> myisamchk --recover --ft_min_word_len=3 tbl_name.MYI
To ensure that myisamchk and the server use
the same values for full-text parameters, place each one in both
the [mysqld] and
[myisamchk] sections of an option file:
[mysqld] ft_min_word_len=3 [myisamchk] ft_min_word_len=3
An alternative to using myisamchk is to use
the REPAIR TABLE, ANALYZE
TABLE, OPTIMIZE TABLE, or
ALTER TABLE statements. These statements are
performed by the server, which knows the proper full-text
parameter values to use.
The
BINARYoperator casts the string following it to a binary string. This is an easy way to force a column comparison to be done byte by byte rather than character by character. This causes the comparison to be case sensitive even if the column isn't defined asBINARYorBLOB.BINARYalso causes trailing spaces to be significant.mysql>
SELECT 'a' = 'A';-> 1 mysql>SELECT BINARY 'a' = 'A';-> 0 mysql>SELECT 'a' = 'a ';-> 1 mysql>SELECT BINARY 'a' = 'a ';-> 0In a comparison,
BINARYaffects the entire operation; it can be given before either operand with the same result.BINARYis shorthand forstrCAST(.strAS BINARY)Note that in some contexts, if you cast an indexed column to
BINARY, MySQL is not able to use the index efficiently.CAST(,exprAStype)CONVERT(,expr,type)CONVERT(exprUSINGtranscoding_name)The
CAST()andCONVERT()functions take a value of one type and produce a value of another type.The
typecan be one of the following values:BINARY[(N)]CHAR[(N)]DATEDATETIMEDECIMALSIGNED [INTEGER]TIMEUNSIGNED [INTEGER]
BINARYproduces a string with theBINARYdata type. See Section 11.4.2, “TheBINARYandVARBINARYTypes” for a description of how this affects comparisons. If the optional lengthNis given,BINARY(causes the cast to use no more thanN)Nbytes of the argument. As of MySQL 5.0.17, values shorter thanNbytes are padded with0x00bytes to a length ofN.CHAR(causes the cast to use no more thanN)Ncharacters of the argument.The
DECIMALtype is available as of MySQL 5.0.8.CAST()andCONVERT(... USING ...)are standard SQL syntax. The non-USINGform ofCONVERT()is ODBC syntax.CONVERT()withUSINGis used to convert data between different character sets. In MySQL, transcoding names are the same as the corresponding character set names. For example, this statement converts the string'abc'in the default character set to the corresponding string in theutf8character set:SELECT CONVERT('abc' USING utf8);
Normally, you cannot compare a BLOB value or
other binary string in case-insensitive fashion because binary
strings have no character set, and thus no concept of lettercase.
To perform a case-insensitive comparison, use the
CONVERT() function to convert the value to a
non-binary string. If the character set of the result has a
case-insensitive collation, the LIKE operation
is not case sensitive:
SELECT 'A' LIKE CONVERT(blob_colUSING latin1) FROMtbl_name;
To use a different character set, substitute its name for
latin1 in the preceding statement. To ensure
that a case-insensitive collation is used, specify a
COLLATE clause following the
CONVERT() call.
CONVERT() can be used more generally for
comparing strings that are represented in different character
sets.
The cast functions are useful when you want to create a column
with a specific type in a CREATE ... SELECT
statement:
CREATE TABLE new_table SELECT CAST('2000-01-01' AS DATE);
The functions also can be useful for sorting
ENUM columns in lexical order. Normally,
sorting of ENUM columns occurs using the
internal numeric values. Casting the values to
CHAR results in a lexical sort:
SELECTenum_colFROMtbl_nameORDER BY CAST(enum_colAS CHAR);
CAST(
is the same thing as str AS BINARY)BINARY
.
strCAST(
treats the expression as a string with the default character set.
expr AS CHAR)
CAST() also changes the result if you use it as
part of a more complex expression such as CONCAT('Date:
',CAST(NOW() AS DATE)).
You should not use CAST() to extract data in
different formats but instead use string functions like
LEFT() or EXTRACT(). See
Section 12.6, “Date and Time Functions”.
To cast a string to a numeric value in numeric context, you normally do not have to do anything other than to use the string value as though it were a number:
mysql> SELECT 1+'1';
-> 2
If you use a number in string context, the number automatically is
converted to a BINARY string.
mysql> SELECT CONCAT('hello you ',2);
-> 'hello you 2'
MySQL supports arithmetic with both signed and unsigned 64-bit
values. If you are using numeric operators (such as
+ or -) and one of the
operands is an unsigned integer, the result is unsigned. You can
override this by using the SIGNED and
UNSIGNED cast operators to cast the operation
to a signed or unsigned 64-bit integer, respectively.
mysql>SELECT CAST(1-2 AS UNSIGNED)-> 18446744073709551615 mysql>SELECT CAST(CAST(1-2 AS UNSIGNED) AS SIGNED);-> -1
Note that if either operand is a floating-point value, the result
is a floating-point value and is not affected by the preceding
rule. (In this context, DECIMAL column values
are regarded as floating-point values.)
mysql> SELECT CAST(1 AS UNSIGNED) - 2.0;
-> -1.0
If you are using a string in an arithmetic operation, this is converted to a floating-point number.
If you convert a “zero” date string to a date,
CONVERT() and CAST() return
NULL when the NO_ZERO_DATE
SQL mode is enabled. As of MySQL 5.0.4, they also produce a
warning.
| Name | Description |
|---|---|
AES_DECRYPT() | Decrypt using AES |
AES_ENCRYPT() | Encrypt using AES |
BENCHMARK() | Repeatedly execute an expression |
BIT_COUNT() | Return the number of bits that are set |
& | Bitwise AND |
| | Bitwise OR |
^ | Bitwise XOR |
CHARSET()(v4.1.0) | Return the character set of the argument |
COERCIBILITY()(v4.1.1) | Return the collation coercibility value of the string argument |
COLLATION()(v4.1.0) | Return the collation of the string argument |
COMPRESS()(v4.1.1) | Return result as a binary string |
CONNECTION_ID() | Return the connection ID (thread ID) for the connection |
COUNT() | Return a count of the number of rows returned |
CURRENT_USER(), CURRENT_USER | Return the username and hostname combination |
DATABASE() | Return the default (current) database name |
DECODE() | Decodes a string encrypted using ENCODE() |
DEFAULT() | Return the default value for a table column |
DES_DECRYPT() | Decrypt a string |
DES_ENCRYPT() | Decrypt a string |
ENCODE() | Encode a string |
ENCRYPT() | Encrypt a string |
FOUND_ROWS() | For a SELECT with a LIMIT clause, the number of rows that would be returned were there no LIMIT clause |
GET_LOCK() | Get a named lock |
INET_ATON() | Return the numeric value of an IP address |
INET_NTOA() | Return the IP address from a numeric value |
IS_FREE_LOCK() | Checks whether the named lock is free |
IS_USED_LOCK()(v4.1.0) | Checks whether the named lock is in use. Return connection identifier if true. |
LAST_INSERT_ID() | Value of the AUTOINCREMENT column for the last INSERT |
<< | Left shift |
MASTER_POS_WAIT() | Block until the slave has read and applied all updates up to the specified position |
MD5() | Calculate MD5 checksum |
NAME_CONST()(v5.0.12) | Causes the column to have the given name |
OLD_PASSWORD()(v4.1) | Return the value of the old (pre-4.1) implementation of PASSWORD |
PASSWORD() | Calculate and return a password string |
RELEASE_LOCK() | Releases the named lock |
>> | Right shift |
ROW_COUNT()(v5.0.1) | The number of rows updated |
SCHEMA()(v5.0.2) | A synonym for DATABASE() |
SESSION_USER() | Synonym for USER() |
SHA1(), SHA() | Calculate an SHA-1 160-bit checksum |
SLEEP()(v5.0.12) | Sleep for a number of seconds |
SYSTEM_USER() | Synonym for USER() |
~ | Invert bits |
UNCOMPRESS()(v4.1.1) | Uncompress a string compressed |
UNCOMPRESSED_LENGTH()(v4.1.1) | Return the length of a string before compression |
USER() | Return the current username and hostname |
UUID()(v4.1.2) | Return a Universal Unique Identifier (UUID) |
VALUES()(v4.1.1) | Defines the values to be used during an INSERT |
| Name | Description |
|---|---|
BIT_COUNT() | Return the number of bits that are set |
& | Bitwise AND |
| | Bitwise OR |
^ | Bitwise XOR |
<< | Left shift |
>> | Right shift |
~ | Invert bits |
MySQL uses BIGINT (64-bit) arithmetic for bit
operations, so these operators have a maximum range of 64 bits.
Bitwise OR:
mysql>
SELECT 29 | 15;-> 31The result is an unsigned 64-bit integer.
Bitwise AND:
mysql>
SELECT 29 & 15;-> 13The result is an unsigned 64-bit integer.
Bitwise XOR:
mysql>
SELECT 1 ^ 1;-> 0 mysql>SELECT 1 ^ 0;-> 1 mysql>SELECT 11 ^ 3;-> 8The result is an unsigned 64-bit integer.
Shifts a longlong (
BIGINT) number to the left.mysql>
SELECT 1 << 2;-> 4The result is an unsigned 64-bit integer.
Shifts a longlong (
BIGINT) number to the right.mysql>
SELECT 4 >> 2;-> 1The result is an unsigned 64-bit integer.
Invert all bits.
mysql>
SELECT 5 & ~1;-> 4The result is an unsigned 64-bit integer.
Returns the number of bits that are set in the argument
N.mysql>
SELECT BIT_COUNT(29), BIT_COUNT(b'101010');-> 4, 3
| Name | Description |
|---|---|
AES_DECRYPT() | Decrypt using AES |
AES_ENCRYPT() | Encrypt using AES |
COMPRESS()(v4.1.1) | Return result as a binary string |
DECODE() | Decodes a string encrypted using ENCODE() |
DES_DECRYPT() | Decrypt a string |
DES_ENCRYPT() | Decrypt a string |
ENCODE() | Encode a string |
ENCRYPT() | Encrypt a string |
MD5() | Calculate MD5 checksum |
OLD_PASSWORD()(v4.1) | Return the value of the old (pre-4.1) implementation of PASSWORD |
PASSWORD() | Calculate and return a password string |
SHA1(), SHA() | Calculate an SHA-1 160-bit checksum |
UNCOMPRESS()(v4.1.1) | Uncompress a string compressed |
UNCOMPRESSED_LENGTH()(v4.1.1) | Return the length of a string before compression |
The functions in this section perform encryption and decryption, and compression and uncompression:
| Compression or encryption | Uncompression or decryption |
| AES_ENCRYT() | AES_DECRYPT() |
| COMPRESS() | UNCOMPRESS() |
| ENCODE() | DECODE() |
| DES_ENCRYPT() | DES_DECRYPT() |
| ENCRYPT() | Not available |
| MD5() | Not available |
| OLD_PASSWORD() | Not available |
| PASSWORD() | Not available |
| SHA() or SHA1() | Not available |
| Not available | UNCOMPRESSED_LENGTH() |
Note: The encryption and
compression functions return binary strings. For many of these
functions, the result might contain arbitrary byte values. If
you want to store these results, use a BLOB
column rather than a CHAR or (before MySQL
5.0.3) VARCHAR column to avoid potential
problems with trailing space removal that would change data
values.
Note: Exploits for the MD5 and SHA-1 algorithms have become known. You may wish to consider using one of the other encryption functions described in this section instead.
AES_ENCRYPT(,str,key_str)AES_DECRYPT(crypt_str,key_str)These functions allow encryption and decryption of data using the official AES (Advanced Encryption Standard) algorithm, previously known as “Rijndael.” Encoding with a 128-bit key length is used, but you can extend it up to 256 bits by modifying the source. We chose 128 bits because it is much faster and it is secure enough for most purposes.
AES_ENCRYPT()encrypts a string and returns a binary string.AES_DECRYPT()decrypts the encrypted string and returns the original string. The input arguments may be any length. If either argument isNULL, the result of this function is alsoNULL.Because AES is a block-level algorithm, padding is used to encode uneven length strings and so the result string length may be calculated using this formula:
16 × (trunc(
string_length/ 16) + 1)If
AES_DECRYPT()detects invalid data or incorrect padding, it returnsNULL. However, it is possible forAES_DECRYPT()to return a non-NULLvalue (possibly garbage) if the input data or the key is invalid.You can use the AES functions to store data in an encrypted form by modifying your queries:
INSERT INTO t VALUES (1,AES_ENCRYPT('text','password'));AES_ENCRYPT()andAES_DECRYPT()can be considered the most cryptographically secure encryption functions currently available in MySQL.Compresses a string and returns the result as a binary string. This function requires MySQL to have been compiled with a compression library such as
zlib. Otherwise, the return value is alwaysNULL. The compressed string can be uncompressed withUNCOMPRESS().mysql>
SELECT LENGTH(COMPRESS(REPEAT('a',1000)));-> 21 mysql>SELECT LENGTH(COMPRESS(''));-> 0 mysql>SELECT LENGTH(COMPRESS('a'));-> 13 mysql>SELECT LENGTH(COMPRESS(REPEAT('a',16)));-> 15The compressed string contents are stored the following way:
Empty strings are stored as empty strings.
Non-empty strings are stored as a four-byte length of the uncompressed string (low byte first), followed by the compressed string. If the string ends with space, an extra ‘
.’ character is added to avoid problems with endspace trimming should the result be stored in aCHARorVARCHARcolumn. (Use ofCHARorVARCHARto store compressed strings is not recommended. It is better to use aBLOBcolumn instead.)
Decrypts the encrypted string
crypt_strusingpass_stras the password.crypt_strshould be a string returned fromENCODE().Encrypt
strusingpass_stras the password. To decrypt the result, useDECODE().The result is a binary string of the same length as
str.The strength of the encryption is based on how good the random generator is. It should suffice for short strings.
DES_DECRYPT(crypt_str[,key_str])Decrypts a string encrypted with
DES_ENCRYPT(). If an error occurs, this function returnsNULL.Note that this function works only if MySQL has been configured with SSL support. See Section 5.8.7, “Using Secure Connections”.
If no
key_strargument is given,DES_DECRYPT()examines the first byte of the encrypted string to determine the DES key number that was used to encrypt the original string, and then reads the key from the DES key file to decrypt the message. For this to work, the user must have theSUPERprivilege. The key file can be specified with the--des-key-fileserver option.If you pass this function a
key_strargument, that string is used as the key for decrypting the message.If the
crypt_strargument does not appear to be an encrypted string, MySQL returns the givencrypt_str.DES_ENCRYPT(str[,{key_num|key_str}])Encrypts the string with the given key using the Triple-DES algorithm.
Note that this function works only if MySQL has been configured with SSL support. See Section 5.8.7, “Using Secure Connections”.
The encryption key to use is chosen based on the second argument to
DES_ENCRYPT(), if one was given:Argument Description No argument The first key from the DES key file is used. key_numThe given key number (0-9) from the DES key file is used. key_strThe given key string is used to encrypt str.The key file can be specified with the
--des-key-fileserver option.The return string is a binary string where the first character is
CHAR(128 |. If an error occurs,key_num)DES_ENCRYPT()returnsNULL.The 128 is added to make it easier to recognize an encrypted key. If you use a string key,
key_numis 127.The string length for the result is given by this formula:
new_len=orig_len+ (8 - (orig_len% 8)) + 1Each line in the DES key file has the following format:
key_numdes_key_strEach
key_numvalue must be a number in the range from0to9. Lines in the file may be in any order.des_key_stris the string that is used to encrypt the message. There should be at least one space between the number and the key. The first key is the default key that is used if you do not specify any key argument toDES_ENCRYPT().You can tell MySQL to read new key values from the key file with the
FLUSH DES_KEY_FILEstatement. This requires theRELOADprivilege.One benefit of having a set of default keys is that it gives applications a way to check for the existence of encrypted column values, without giving the end user the right to decrypt those values.
mysql>
SELECT customer_address FROM customer_table>WHERE crypted_credit_card = DES_ENCRYPT('credit_card_number');Encrypts
strusing the Unixcrypt()system call and returns a binary string. Thesaltargument should be a string with at least two characters. If nosaltargument is given, a random value is used.mysql>
SELECT ENCRYPT('hello');-> 'VxuFAJXVARROc'ENCRYPT()ignores all but the first eight characters ofstr, at least on some systems. This behavior is determined by the implementation of the underlyingcrypt()system call.The use of
ENCYPT()with multi-byte character sets other thanutf8is not recommended because the system call expects a string terminated by a zero byte.If
crypt()is not available on your system (as is the case with Windows),ENCRYPT()always returnsNULL.Calculates an MD5 128-bit checksum for the string. The value is returned as a binary string of 32 hex digits, or
NULLif the argument wasNULL. The return value can, for example, be used as a hash key.mysql>
SELECT MD5('testing');-> 'ae2b1fca515949e5d54fb22b8ed95575'This is the “RSA Data Security, Inc. MD5 Message-Digest Algorithm.”
If you want to convert the value to uppercase, see the description of binary string conversion given in the entry for the
BINARYoperator in Section 12.9, “Cast Functions and Operators”.See the note regarding the MD5 algorithm at the beginning this section.
OLD_PASSWORD()was added to MySQL when the implementation ofPASSWORD()was changed to improve security.OLD_PASSWORD()returns the value of the old (pre-4.1) implementation ofPASSWORD()as a binary string, and is intended to permit you to reset passwords for any pre-4.1 clients that need to connect to your version 5.0 MySQL server without locking them out. See Section 5.7.9, “Password Hashing as of MySQL 4.1”.Calculates and returns a password string from the plaintext password
strand returns a binary string, orNULLif the argument wasNULL. This is the function that is used for encrypting MySQL passwords for storage in thePasswordcolumn of theusergrant table.mysql>
SELECT PASSWORD('badpwd');-> '*AAB3E285149C0135D51A520E1940DD3263DC008C'PASSWORD()encryption is one-way (not reversible).PASSWORD()does not perform password encryption in the same way that Unix passwords are encrypted. SeeENCRYPT().Note: The
PASSWORD()function is used by the authentication system in MySQL Server; you should not use it in your own applications. For that purpose, considerMD5()orSHA1()instead. Also see RFC 2195, section 2 (Challenge-Response Authentication Mechanism (CRAM)), for more information about handling passwords and authentication securely in your applications.Calculates an SHA-1 160-bit checksum for the string, as described in RFC 3174 (Secure Hash Algorithm). The value is returned as a binary string of 40 hex digits, or
NULLif the argument wasNULL. One of the possible uses for this function is as a hash key. You can also use it as a cryptographic function for storing passwords.SHA()is synonymous withSHA1().mysql>
SELECT SHA1('abc');-> 'a9993e364706816aba3e25717850c26c9cd0d89d'SHA1()can be considered a cryptographically more secure equivalent ofMD5(). However, see the note regarding the MD5 and SHA-1 algorithms at the beginning this section.UNCOMPRESS(string_to_uncompress)Uncompresses a string compressed by the
COMPRESS()function. If the argument is not a compressed value, the result isNULL. This function requires MySQL to have been compiled with a compression library such aszlib. Otherwise, the return value is alwaysNULL.mysql>
SELECT UNCOMPRESS(COMPRESS('any string'));-> 'any string' mysql>SELECT UNCOMPRESS('any string');-> NULLUNCOMPRESSED_LENGTH(compressed_string)Returns the length that the compressed string had before being compressed.
mysql>
SELECT UNCOMPRESSED_LENGTH(COMPRESS(REPEAT('a',30)));-> 30
| Name | Description |
|---|---|
BENCHMARK() | Repeatedly execute an expression |
CHARSET()(v4.1.0) | Return the character set of the argument |
COERCIBILITY()(v4.1.1) | Return the collation coercibility value of the string argument |
COLLATION()(v4.1.0) | Return the collation of the string argument |
CONNECTION_ID() | Return the connection ID (thread ID) for the connection |
CURRENT_USER(), CURRENT_USER | Return the username and hostname combination |
DATABASE() | Return the default (current) database name |
FOUND_ROWS() | For a SELECT with a LIMIT clause, the number of rows that would be returned were there no LIMIT clause |
LAST_INSERT_ID() | Value of the AUTOINCREMENT column for the last INSERT |
ROW_COUNT()(v5.0.1) | The number of rows updated |
SCHEMA()(v5.0.2) | A synonym for DATABASE() |
SESSION_USER() | Synonym for USER() |
SYSTEM_USER() | Synonym for USER() |
USER() | Return the current username and hostname |
The
BENCHMARK()function executes the expressionexprrepeatedlycounttimes. It may be used to time how quickly MySQL processes the expression. The result value is always0. The intended use is from within the mysql client, which reports query execution times:mysql>
SELECT BENCHMARK(1000000,ENCODE('hello','goodbye'));+----------------------------------------------+ | BENCHMARK(1000000,ENCODE('hello','goodbye')) | +----------------------------------------------+ | 0 | +----------------------------------------------+ 1 row in set (4.74 sec)The time reported is elapsed time on the client end, not CPU time on the server end. It is advisable to execute
BENCHMARK()several times, and to interpret the result with regard to how heavily loaded the server machine is.BENCHMARK()is intended for measuring the runtime performance of scalar expressions, which has some significant implications for the way that you use it and interpret the results:Only scalar expressions can be used. Although the expression can be a subquery, it must return a single column and at most a single row. For example,
BENCHMARK(10, (SELECT * FROM t))will fail if the tablethas more than one column or more than one row.Executing a
SELECTstatementexprNtimes differs from executingSELECT BENCHMARK(in terms of the amount of overhead involved. The two have very different execution profiles and you should not expect them to take the same amount of time. The former involves the parser, optimizer, table locking, and runtime evaluationN,expr)Ntimes each. The latter involves only runtime evaluationNtimes, and all the other components just once. Memory structures already allocated are reused, and runtime optimizations such as local caching of results already evaluated for aggregate functions can alter the results. Use ofBENCHMARK()thus measures performance of the runtime component by giving more weight to that component and removing the “noise” introduced by the network, parser, optimizer, and so forth.
Returns the character set of the string argument.
mysql>
SELECT CHARSET('abc');-> 'latin1' mysql>SELECT CHARSET(CONVERT('abc' USING utf8));-> 'utf8' mysql>SELECT CHARSET(USER());-> 'utf8'Returns the collation coercibility value of the string argument.
mysql>
SELECT COERCIBILITY('abc' COLLATE latin1_swedish_ci);-> 0 mysql>SELECT COERCIBILITY(USER());-> 3 mysql>SELECT COERCIBILITY('abc');-> 4The return values have the meanings shown in the following table. Lower values have higher precedence.
Coercibility Meaning Example 0Explicit collation Value with COLLATEclause1No collation Concatenation of strings with different collations 2Implicit collation Column value 3System constant USER()return value4Coercible Literal string 5Ignorable NULLor an expression derived fromNULLBefore MySQL 5.0.3, the return values are shown as follows, and functions such as
USER()have a coercibility of 2:Coercibility Meaning Example 0Explicit collation Value with COLLATEclause1No collation Concatenation of strings with different collations 2Implicit collation Column value, stored routine parameter or local variable 3Coercible Literal string Returns the collation of the string argument.
mysql>
SELECT COLLATION('abc');-> 'latin1_swedish_ci' mysql>SELECT COLLATION(_utf8'abc');-> 'utf8_general_ci'Returns the connection ID (thread ID) for the connection. Every connection has an ID that is unique among the set of currently connected clients.
mysql>
SELECT CONNECTION_ID();-> 23786Returns the username and hostname combination for the MySQL account that the server used to authenticate the current client. This account determines your access privileges. As of MySQL 5.0.10, within a stored routine that is defined with the
SQL SECURITY DEFINERcharacteristic,CURRENT_USER()returns the creator of the routine. The return value is a string in theutf8character set.The value of
CURRENT_USER()can differ from the value ofUSER().mysql>
SELECT USER();-> 'davida@localhost' mysql>SELECT * FROM mysql.user;ERROR 1044: Access denied for user ''@'localhost' to database 'mysql' mysql>SELECT CURRENT_USER();-> '@localhost'The example illustrates that although the client specified a username of
davida(as indicated by the value of theUSER()function), the server authenticated the client using an anonymous user account (as seen by the empty username part of theCURRENT_USER()value). One way this might occur is that there is no account listed in the grant tables fordavida.Returns the default (current) database name as a string in the
utf8character set. If there is no default database,DATABASE()returnsNULL. Within a stored routine, the default database is the database that the routine is associated with, which is not necessarily the same as the database that is the default in the calling context.mysql>
SELECT DATABASE();-> 'test'A
SELECTstatement may include aLIMITclause to restrict the number of rows the server returns to the client. In some cases, it is desirable to know how many rows the statement would have returned without theLIMIT, but without running the statement again. To obtain this row count, include aSQL_CALC_FOUND_ROWSoption in theSELECTstatement, and then invokeFOUND_ROWS()afterward:mysql>
SELECT SQL_CALC_FOUND_ROWS * FROM->tbl_nameWHERE id > 100 LIMIT 10;mysql>SELECT FOUND_ROWS();The second
SELECTreturns a number indicating how many rows the firstSELECTwould have returned had it been written without theLIMITclause.In the absence of the
SQL_CALC_FOUND_ROWSoption in the most recentSELECTstatement,FOUND_ROWS()returns the number of rows in the result set returned by that statement.The row count available through
FOUND_ROWS()is transient and not intended to be available past the statement following theSELECT SQL_CALC_FOUND_ROWSstatement. If you need to refer to the value later, save it:mysql>
SELECT SQL_CALC_FOUND_ROWS * FROM ... ;mysql>SET @rows = FOUND_ROWS();If you are using
SELECT SQL_CALC_FOUND_ROWS, MySQL must calculate how many rows are in the full result set. However, this is faster than running the query again withoutLIMIT, because the result set need not be sent to the client.SQL_CALC_FOUND_ROWSandFOUND_ROWS()can be useful in situations when you want to restrict the number of rows that a query returns, but also determine the number of rows in the full result set without running the query again. An example is a Web script that presents a paged display containing links to the pages that show other sections of a search result. UsingFOUND_ROWS()allows you to determine how many other pages are needed for the rest of the result.The use of
SQL_CALC_FOUND_ROWSandFOUND_ROWS()is more complex forUNIONstatements than for simpleSELECTstatements, becauseLIMITmay occur at multiple places in aUNION. It may be applied to individualSELECTstatements in theUNION, or global to theUNIONresult as a whole.The intent of
SQL_CALC_FOUND_ROWSforUNIONis that it should return the row count that would be returned without a globalLIMIT. The conditions for use ofSQL_CALC_FOUND_ROWSwithUNIONare:The
SQL_CALC_FOUND_ROWSkeyword must appear in the firstSELECTof theUNION.The value of
FOUND_ROWS()is exact only ifUNION ALLis used. IfUNIONwithoutALLis used, duplicate removal occurs and the value ofFOUND_ROWS()is only approximate.If no
LIMITis present in theUNION,SQL_CALC_FOUND_ROWSis ignored and returns the number of rows in the temporary table that is created to process theUNION.
LAST_INSERT_ID(),LAST_INSERT_ID(expr)LAST_INSERT_ID()(with no argument) returns the first automatically generated value that was set for anAUTO_INCREMENTcolumn by the most recently executedINSERTstatement to affect such a column. For example, after inserting a row that generates anAUTO_INCREMENTvalue, you can get the value like this:mysql>
SELECT LAST_INSERT_ID();-> 195The currently executing statement does not affect the value of
LAST_INSERT_ID(). Suppose that you generate anAUTO_INCREMENTvalue with one statement, and then refer toLAST_INSERT_ID()in a multiple-rowINSERTstatement that inserts rows into a table with its ownAUTO_INCREMENTcolumn. The value ofLAST_INSERT_ID()will remain stable in the second statement; its value for the second and later rows is not affected by the earlier row insertions. (However, if you mix references toLAST_INSERT_ID()andLAST_INSERT_ID(, the effect is undefined.)expr)If the previous statement returned an error, the value of
LAST_INSERT_ID()is undefined. For transactional tables, if the statement is rolled back due to an error, the value ofLAST_INSERT_ID()is left undefined. For manualROLLBACK, the value ofLAST_INSERT_ID()is not restored to that before the transaction; it remains as it was at the point of theROLLBACK.Within the body of a stored routine (procedure or function) or a trigger, the value of
LAST_INSERT_ID()changes the same way as for statements executed outside the body of these kinds of objects. The effect of a stored routine or trigger upon the value ofLAST_INSERT_ID()that is seen by following statements depends on the kind of routine:If a stored procedure executes statements that change the value of
LAST_INSERT_ID(), the changed value will be seen by statements that follow the procedure call.For stored functions and triggers that change the value, the value is restored when the function or trigger ends, so following statements will not see a changed value.
The ID that was generated is maintained in the server on a per-connection basis. This means that the value returned by the function to a given client is the first
AUTO_INCREMENTvalue generated for most recent statement affecting anAUTO_INCREMENTcolumn by that client. This value cannot be affected by other clients, even if they generateAUTO_INCREMENTvalues of their own. This behavior ensures that each client can retrieve its own ID without concern for the activity of other clients, and without the need for locks or transactions.The value of
LAST_INSERT_ID()is not changed if you set theAUTO_INCREMENTcolumn of a row to a non-“magic” value (that is, a value that is notNULLand not0).Important: If you insert multiple rows using a single
INSERTstatement,LAST_INSERT_ID()returns the value generated for the first inserted row only. The reason for this is to make it possible to reproduce easily the sameINSERTstatement against some other server.For example:
mysql>
USE test;Database changed mysql>CREATE TABLE t (->id INT AUTO_INCREMENT NOT NULL PRIMARY KEY,->name VARCHAR(10) NOT NULL->);Query OK, 0 rows affected (0.09 sec) mysql>INSERT INTO t VALUES (NULL, 'Bob');Query OK, 1 row affected (0.01 sec) mysql>SELECT * FROM t;+----+------+ | id | name | +----+------+ | 1 | Bob | +----+------+ 1 row in set (0.01 sec) mysql>SELECT LAST_INSERT_ID();+------------------+ | LAST_INSERT_ID() | +------------------+ | 1 | +------------------+ 1 row in set (0.00 sec) mysql>INSERT INTO t VALUES->(NULL, 'Mary'), (NULL, 'Jane'), (NULL, 'Lisa');Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> SELECT * FROM t; +----+------+ | id | name | +----+------+ | 1 | Bob | | 2 | Mary | | 3 | Jane | | 4 | Lisa | +----+------+ 4 rows in set (0.01 sec) mysql>SELECT LAST_INSERT_ID();+------------------+ | LAST_INSERT_ID() | +------------------+ | 2 | +------------------+ 1 row in set (0.00 sec)Although the second
INSERTstatement inserted three new rows intot, the ID generated for the first of these rows was2, and it is this value that is returned byLAST_INSERT_ID()for the followingSELECTstatement.If you use
INSERT IGNOREand the row is ignored, theAUTO_INCREMENTcounter is not incremented andLAST_INSERT_ID()returns0, which reflects that no row was inserted.If
expris given as an argument toLAST_INSERT_ID(), the value of the argument is returned by the function and is remembered as the next value to be returned byLAST_INSERT_ID(). This can be used to simulate sequences:Create a table to hold the sequence counter and initialize it:
mysql>
CREATE TABLE sequence (id INT NOT NULL);mysql>INSERT INTO sequence VALUES (0);Use the table to generate sequence numbers like this:
mysql>
UPDATE sequence SET id=LAST_INSERT_ID(id+1);mysql>SELECT LAST_INSERT_ID();The
UPDATEstatement increments the sequence counter and causes the next call toLAST_INSERT_ID()to return the updated value. TheSELECTstatement retrieves that value. Themysql_insert_id()C API function can also be used to get the value. See Section 22.2.3.37, “mysql_insert_id()”.
You can generate sequences without calling
LAST_INSERT_ID(), but the utility of using the function this way is that the ID value is maintained in the server as the last automatically generated value. It is multi-user safe because multiple clients can issue theUPDATEstatement and get their own sequence value with theSELECTstatement (ormysql_insert_id()), without affecting or being affected by other clients that generate their own sequence values.Note that
mysql_insert_id()is only updated afterINSERTandUPDATEstatements, so you cannot use the C API function to retrieve the value forLAST_INSERT_ID(after executing other SQL statements likeexpr)SELECTorSET.ROW_COUNT()returns the number of rows updated, inserted, or deleted by the preceding statement. This is the same as the row count that the mysql client displays and the value from themysql_affected_rows()C API function.mysql>
INSERT INTO t VALUES(1),(2),(3);Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql>SELECT ROW_COUNT();+-------------+ | ROW_COUNT() | +-------------+ | 3 | +-------------+ 1 row in set (0.00 sec) mysql>DELETE FROM t WHERE i IN(1,2);Query OK, 2 rows affected (0.00 sec) mysql>SELECT ROW_COUNT();+-------------+ | ROW_COUNT() | +-------------+ | 2 | +-------------+ 1 row in set (0.00 sec)ROW_COUNT()was added in MySQL 5.0.1.This function is a synonym for
DATABASE(). It was added in MySQL 5.0.2.SESSION_USER()is a synonym forUSER().SYSTEM_USER()is a synonym forUSER().Returns the current MySQL username and hostname as a string in the
utf8character set.mysql>
SELECT USER();-> 'davida@localhost'The value indicates the username you specified when connecting to the server, and the client host from which you connected. The value can be different from that of
CURRENT_USER().You can extract only the username part like this:
mysql>
SELECT SUBSTRING_INDEX(USER(),'@',1);-> 'davida'Returns a string that indicates the MySQL server version. The string uses the
utf8character set.mysql>
SELECT VERSION();-> '5.0.42-standard'Note that if your version string ends with
-logthis means that logging is enabled.
| Name | Description |
|---|---|
COUNT() | Return a count of the number of rows returned |
DEFAULT() | Return the default value for a table column |
GET_LOCK() | Get a named lock |
INET_ATON() | Return the numeric value of an IP address |
INET_NTOA() | Return the IP address from a numeric value |
IS_FREE_LOCK() | Checks whether the named lock is free |
IS_USED_LOCK()(v4.1.0) | Checks whether the named lock is in use. Return connection identifier if true. |
MASTER_POS_WAIT() | Block until the slave has read and applied all updates up to the specified position |
NAME_CONST()(v5.0.12) | Causes the column to have the given name |
RELEASE_LOCK() | Releases the named lock |
SLEEP()(v5.0.12) | Sleep for a number of seconds |
UUID()(v4.1.2) | Return a Universal Unique Identifier (UUID) |
VALUES()(v4.1.1) | Defines the values to be used during an INSERT |
Returns the default value for a table column. Starting with MySQL 5.0.2, an error results if the column has no default value.
mysql>
UPDATE t SET i = DEFAULT(i)+1 WHERE id < 100;FORMAT(X,D)Formats the number
Xto a format like'#,###,###.##', rounded toDdecimal places, and returns the result as a string. For details, see Section 12.4, “String Functions”.Tries to obtain a lock with a name given by the string
str, using a timeout oftimeoutseconds. Returns1if the lock was obtained successfully,0if the attempt timed out (for example, because another client has previously locked the name), orNULLif an error occurred (such as running out of memory or the thread was killed with mysqladmin kill). If you have a lock obtained withGET_LOCK(), it is released when you executeRELEASE_LOCK(), execute a newGET_LOCK(), or your connection terminates (either normally or abnormally). Locks obtained withGET_LOCK()do not interact with transactions. That is, committing a transaction does not release any such locks obtained during the transaction.This function can be used to implement application locks or to simulate record locks. Names are locked on a server-wide basis. If a name has been locked by one client,
GET_LOCK()blocks any request by another client for a lock with the same name. This allows clients that agree on a given lock name to use the name to perform cooperative advisory locking. But be aware that it also allows a client that is not among the set of cooperating clients to lock a name, either inadvertently or deliberately, and thus prevent any of the cooperating clients from locking that name. One way to reduce the likelihood of this is to use lock names that are database-specific or application-specific. For example, use lock names of the formdb_name.strorapp_name.str.mysql>
SELECT GET_LOCK('lock1',10);-> 1 mysql>SELECT IS_FREE_LOCK('lock2');-> 1 mysql>SELECT GET_LOCK('lock2',10);-> 1 mysql>SELECT RELEASE_LOCK('lock2');-> 1 mysql>SELECT RELEASE_LOCK('lock1');-> NULLThe second
RELEASE_LOCK()call returnsNULLbecause the lock'lock1'was automatically released by the secondGET_LOCK()call.Note: If a client attempts to acquire a lock that is already held by another client, it blocks according to the
timeoutargument. If the blocked client terminates, its thread does not die until the lock request times out. This is a known bug.Given the dotted-quad representation of a network address as a string, returns an integer that represents the numeric value of the address. Addresses may be 4- or 8-byte addresses.
mysql>
SELECT INET_ATON('209.207.224.40');-> 3520061480The generated number is always in network byte order. For the example just shown, the number is calculated as 209×2563 + 207×2562 + 224×256 + 40.
INET_ATON()also understands short-form IP addresses:mysql>
SELECT INET_ATON('127.0.0.1'), INET_ATON('127.1');-> 2130706433, 2130706433Note: When storing values generated by
INET_ATON(), it is recommended that you use anINT UNSIGNEDcolumn. If you use a (signed)INTcolumn, values corresponding to IP addresses for which the first octet is greater than 127 cannot be stored correctly. See Section 11.2, “Numeric Types”.Given a numeric network address (4 or 8 byte), returns the dotted-quad representation of the address as a string.
mysql>
SELECT INET_NTOA(3520061480);-> '209.207.224.40'Checks whether the lock named
stris free to use (that is, not locked). Returns1if the lock is free (no one is using the lock),0if the lock is in use, andNULLif an error occurs (such as an incorrect argument).Checks whether the lock named
stris in use (that is, locked). If so, it returns the connection identifier of the client that holds the lock. Otherwise, it returnsNULL.MASTER_POS_WAIT(log_name,log_pos[,timeout])This function is useful for control of master/slave synchronization. It blocks until the slave has read and applied all updates up to the specified position in the master log. The return value is the number of log events the slave had to wait for to advance to the specified position. The function returns
NULLif the slave SQL thread is not started, the slave's master information is not initialized, the arguments are incorrect, or an error occurs. It returns-1if the timeout has been exceeded. If the slave SQL thread stops whileMASTER_POS_WAIT()is waiting, the function returnsNULL. If the slave is past the specified position, the function returns immediately.If a
timeoutvalue is specified,MASTER_POS_WAIT()stops waiting whentimeoutseconds have elapsed.timeoutmust be greater than 0; a zero or negativetimeoutmeans no timeout.Returns the given value. When used to produce a result set column,
NAME_CONST()causes the column to have the given name.mysql>
SELECT NAME_CONST('myname', 14);+--------+ | myname | +--------+ | 14 | +--------+This function was added in MySQL 5.0.12. It is for internal use only. The server uses it when writing statements from stored routines that contain references to local routine variables, as described in Section 17.4, “Binary Logging of Stored Routines and Triggers”, You might see this function in the output from mysqlbinlog.
Releases the lock named by the string
strthat was obtained withGET_LOCK(). Returns1if the lock was released,0if the lock was not established by this thread (in which case the lock is not released), andNULLif the named lock did not exist. The lock does not exist if it was never obtained by a call toGET_LOCK()or if it has previously been released.The
DOstatement is convenient to use withRELEASE_LOCK(). See Section 13.2.2, “DOSyntax”.Sleeps (pauses) for the number of seconds given by the
durationargument, then returns 0. IfSLEEP()is interrupted, it returns 1. The duration may have a fractional part given in microseconds. This function was added in MySQL 5.0.12.Returns a Universal Unique Identifier (UUID) generated according to “DCE 1.1: Remote Procedure Call” (Appendix A) CAE (Common Applications Environment) Specifications published by The Open Group in October 1997 (Document Number C706, http://www.opengroup.org/public/pubs/catalog/c706.htm).
A UUID is designed as a number that is globally unique in space and time. Two calls to
UUID()are expected to generate two different values, even if these calls are performed on two separate computers that are not connected to each other.A UUID is a 128-bit number represented by a string of five hexadecimal numbers in
aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeeeformat:The first three numbers are generated from a timestamp.
The fourth number preserves temporal uniqueness in case the timestamp value loses monotonicity (for example, due to daylight saving time).
The fifth number is an IEEE 802 node number that provides spatial uniqueness. A random number is substituted if the latter is not available (for example, because the host computer has no Ethernet card, or we do not know how to find the hardware address of an interface on your operating system). In this case, spatial uniqueness cannot be guaranteed. Nevertheless, a collision should have very low probability.
Currently, the MAC address of an interface is taken into account only on FreeBSD and Linux. On other operating systems, MySQL uses a randomly generated 48-bit number.
mysql>
SELECT UUID();-> '6ccd780c-baba-1026-9564-0040f4311e29'Note that
UUID()does not yet work with replication.In an
INSERT ... ON DUPLICATE KEY UPDATEstatement, you can use theVALUES(function in thecol_name)UPDATEclause to refer to column values from theINSERTportion of the statement. In other words,VALUES(in thecol_name)UPDATEclause refers to the value ofcol_namethat would be inserted, had no duplicate-key conflict occurred. This function is especially useful in multiple-row inserts. TheVALUES()function is meaningful only inINSERT ... ON DUPLICATE KEY UPDATEstatements and returnsNULLotherwise. Section 13.2.4.3, “INSERT ... ON DUPLICATE KEY UPDATESyntax”.mysql>
INSERT INTO table (a,b,c) VALUES (1,2,3),(4,5,6)->ON DUPLICATE KEY UPDATE c=VALUES(a)+VALUES(b);
| Name | Description |
|---|---|
AVG() | Return the average value of the argument |
BIT_AND() | Return bitwise and |
BIT_OR() | Return bitwise or |
BIT_XOR()(v4.1.1) | Return bitwise xor |
COUNT(DISTINCT) | Return the count of a number of different values |
GROUP_CONCAT()(v4.1) | Return a concatenated string |
MAX() | Return the maximum value |
MIN() | Return the minimum value |
STD(), STDDEV() | Return the population standard deviation |
STDDEV_POP()(v5.0.3) | Return the population standard deviation |
STDDEV_SAMP()(v5.0.3) | Return the sample standard deviation |
SUM() | Return the sum |
VAR_POP()(v5.0.3) | Return the population standard variance |
VAR_SAMP()(v5.0.3) | Return the sample variance |
VARIANCE()(v4.1) | Return the population standard variance |
This section describes group (aggregate) functions that operate
on sets of values. Unless otherwise stated, group functions
ignore NULL values.
If you use a group function in a statement containing no
GROUP BY clause, it is equivalent to grouping
on all rows.
For numeric arguments, the variance and standard deviation
functions return a DOUBLE value. The
SUM() and AVG() functions
return a DECIMAL value for exact-value
arguments (integer or DECIMAL), and a
DOUBLE value for approximate-value arguments
(FLOAT or DOUBLE). (Before
MySQL 5.0.3, SUM() and
AVG() return DOUBLE for
all numeric arguments.)
The SUM() and AVG()
aggregate functions do not work with temporal values. (They
convert the values to numbers, losing everything after the first
non-numeric character.) To work around this problem, you can
convert to numeric units, perform the aggregate operation, and
convert back to a temporal value. Examples:
SELECT SEC_TO_TIME(SUM(TIME_TO_SEC(time_col))) FROMtbl_name; SELECT FROM_DAYS(SUM(TO_DAYS(date_col))) FROMtbl_name;
Returns the average value of
exprDISTINCToption can be used as of MySQL 5.0.3 to return the average of the distinct values ofexpr.AVG()returnsNULLif there were no matching rows.mysql>
SELECT student_name, AVG(test_score)->FROM student->GROUP BY student_name;Returns the bitwise
ANDof all bits inexpr. The calculation is performed with 64-bit (BIGINT) precision.This function returns
18446744073709551615if there were no matching rows. (This is the value of an unsignedBIGINTvalue with all bits set to 1.)Returns the bitwise
ORof all bits inexpr. The calculation is performed with 64-bit (BIGINT) precision.This function returns
0if there were no matching rows.Returns the bitwise
XORof all bits inexpr. The calculation is performed with 64-bit (BIGINT) precision.This function returns
0if there were no matching rows.Returns a count of the number of non-
NULLvalues ofexprin the rows retrieved by aSELECTstatement. The result is aBIGINTvalue.COUNT()returns0if there were no matching rows.mysql>
SELECT student.student_name,COUNT(*)->FROM student,course->WHERE student.student_id=course.student_id->GROUP BY student_name;COUNT(*)is somewhat different in that it returns a count of the number of rows retrieved, whether or not they containNULLvalues.COUNT(*)is optimized to return very quickly if theSELECTretrieves from one table, no other columns are retrieved, and there is noWHEREclause. For example:mysql>
SELECT COUNT(*) FROM student;This optimization applies only to
MyISAMtables only, because an exact row count is stored for this storage engine and can be accessed very quickly. For transactional storage engines such asInnoDBandBDB, storing an exact row count is more problematic because multiple transactions may be occurring, each of which may affect the count.COUNT(DISTINCTexpr,[expr...])Returns a count of the number of different non-
NULLvalues.COUNT(DISTINCT)returns0if there were no matching rows.mysql>
SELECT COUNT(DISTINCT results) FROM student;In MySQL, you can obtain the number of distinct expression combinations that do not contain
NULLby giving a list of expressions. In standard SQL, you would have to do a concatenation of all expressions insideCOUNT(DISTINCT ...).This function returns a string result with the concatenated non-
NULLvalues from a group. It returnsNULLif there are no non-NULLvalues. The full syntax is as follows:GROUP_CONCAT([DISTINCT]
expr[,expr...] [ORDER BY {unsigned_integer|col_name|expr} [ASC | DESC] [,col_name...]] [SEPARATORstr_val])mysql>
SELECT student_name,->GROUP_CONCAT(test_score)->FROM student->GROUP BY student_name;Or:
mysql>
SELECT student_name,->GROUP_CONCAT(DISTINCT test_score->ORDER BY test_score DESC SEPARATOR ' ')->FROM student->GROUP BY student_name;In MySQL, you can get the concatenated values of expression combinations. You can eliminate duplicate values by using
DISTINCT. If you want to sort values in the result, you should useORDER BYclause. To sort in reverse order, add theDESC(descending) keyword to the name of the column you are sorting by in theORDER BYclause. The default is ascending order; this may be specified explicitly using theASCkeyword.SEPARATORis followed by the string value that should be inserted between values of result. The default is a comma (‘,’). You can eliminate the separator altogether by specifyingSEPARATOR ''.The result is truncated to the maximum length that is given by the
group_concat_max_lensystem variable, which has a default value of 1024. The value can be set higher, although the maximum effective length of the return value is constrained by the value ofmax_allowed_packet. The syntax to change the value ofgroup_concat_max_lenat runtime is as follows, wherevalis an unsigned integer:SET [SESSION | GLOBAL] group_concat_max_len =
val;Beginning with MySQL 5.0.19, the type returned by
GROUP_CONCAT()is alwaysVARCHARunlessgroup_concat_max_lenis greater than 512, in which case, it returns aBLOB. (Previously, it returned aBLOBwithgroup_concat_max_lengreater than 512 only if the query included anORDER BYclause.)See also
CONCAT()andCONCAT_WS(): Section 12.4, “String Functions”.MIN([DISTINCT],expr)MAX([DISTINCT]expr)Returns the minimum or maximum value of
expr.MIN()andMAX()may take a string argument; in such cases they return the minimum or maximum string value. See Section 7.4.5, “How MySQL Uses Indexes”. TheDISTINCTkeyword can be used to find the minimum or maximum of the distinct values ofexpr, however, this produces the same result as omittingDISTINCT.MIN()andMAX()returnNULLif there were no matching rows.mysql>
SELECT student_name, MIN(test_score), MAX(test_score)->FROM student->GROUP BY student_name;For
MIN(),MAX(), and other aggregate functions, MySQL currently comparesENUMandSETcolumns by their string value rather than by the string's relative position in the set. This differs from howORDER BYcompares them. This is expected to be rectified in a future MySQL release.Returns the population standard deviation of
expr. This is an extension to standard SQL. TheSTDDEV()form of this function is provided for compatibility with Oracle. As of MySQL 5.0.3, the standard SQL functionSTDDEV_POP()can be used instead.These functions return
NULLif there were no matching rows.Returns the population standard deviation of
expr(the square root ofVAR_POP()). This function was added in MySQL 5.0.3. Before 5.0.3, you can useSTD()orSTDDEV(), which are equivalent but not standard SQL.STDDEV_POP()returnsNULLif there were no matching rows.Returns the sample standard deviation of
expr(the square root ofVAR_SAMP(). This function was added in MySQL 5.0.3.STDDEV_SAMP()returnsNULLif there were no matching rows.Returns the sum of
expr. If the return set has no rows,SUM()returnsNULL. TheDISTINCTkeyword can be used in MySQL 5.0 to sum only the distinct values ofexpr.SUM()returnsNULLif there were no matching rows.Returns the population standard variance of
expr. It considers rows as the whole population, not as a sample, so it has the number of rows as the denominator. This function was added in MySQL 5.0.3. Before 5.0.3, you can useVARIANCE(), which is equivalent but is not standard SQL.VAR_POP()returnsNULLif there were no matching rows.Returns the sample variance of
expr. That is, the denominator is the number of rows minus one. This function was added in MySQL 5.0.3.VAR_SAMP()returnsNULLif there were no matching rows.Returns the population standard variance of
expr. This is an extension to standard SQL. As of MySQL 5.0.3, the standard SQL functionVAR_POP()can be used instead.VARIANCE()returnsNULLif there were no matching rows.
The GROUP BY clause allows a WITH
ROLLUP modifier that causes extra rows to be added to
the summary output. These rows represent higher-level (or
super-aggregate) summary operations. ROLLUP
thus allows you to answer questions at multiple levels of
analysis with a single query. It can be used, for example, to
provide support for OLAP (Online Analytical Processing)
operations.
Suppose that a table named sales has
year, country,
product, and profit
columns for recording sales profitability:
CREATE TABLE sales
(
year INT NOT NULL,
country VARCHAR(20) NOT NULL,
product VARCHAR(32) NOT NULL,
profit INT
);
The table's contents can be summarized per year with a simple
GROUP BY like this:
mysql> SELECT year, SUM(profit) FROM sales GROUP BY year;
+------+-------------+
| year | SUM(profit) |
+------+-------------+
| 2000 | 4525 |
| 2001 | 3010 |
+------+-------------+
This output shows the total profit for each year, but if you also want to determine the total profit summed over all years, you must add up the individual values yourself or run an additional query.
Or you can use ROLLUP, which provides both
levels of analysis with a single query. Adding a WITH
ROLLUP modifier to the GROUP BY
clause causes the query to produce another row that shows the
grand total over all year values:
mysql> SELECT year, SUM(profit) FROM sales GROUP BY year WITH ROLLUP;
+------+-------------+
| year | SUM(profit) |
+------+-------------+
| 2000 | 4525 |
| 2001 | 3010 |
| NULL | 7535 |
+------+-------------+
The grand total super-aggregate line is identified by the value
NULL in the year column.
ROLLUP has a more complex effect when there
are multiple GROUP BY columns. In this case,
each time there is a “break” (change in value) in
any but the last grouping column, the query produces an extra
super-aggregate summary row.
For example, without ROLLUP, a summary on the
sales table based on year,
country, and product might
look like this:
mysql>SELECT year, country, product, SUM(profit)->FROM sales->GROUP BY year, country, product;+------+---------+------------+-------------+ | year | country | product | SUM(profit) | +------+---------+------------+-------------+ | 2000 | Finland | Computer | 1500 | | 2000 | Finland | Phone | 100 | | 2000 | India | Calculator | 150 | | 2000 | India | Computer | 1200 | | 2000 | USA | Calculator | 75 | | 2000 | USA | Computer | 1500 | | 2001 | Finland | Phone | 10 | | 2001 | USA | Calculator | 50 | | 2001 | USA | Computer | 2700 | | 2001 | USA | TV | 250 | +------+---------+------------+-------------+
The output indicates summary values only at the
year/country/product level of analysis. When
ROLLUP is added, the query produces several
extra rows:
mysql>SELECT year, country, product, SUM(profit)->FROM sales->GROUP BY year, country, product WITH ROLLUP;+------+---------+------------+-------------+ | year | country | product | SUM(profit) | +------+---------+------------+-------------+ | 2000 | Finland | Computer | 1500 | | 2000 | Finland | Phone | 100 | | 2000 | Finland | NULL | 1600 | | 2000 | India | Calculator | 150 | | 2000 | India | Computer | 1200 | | 2000 | India | NULL | 1350 | | 2000 | USA | Calculator | 75 | | 2000 | USA | Computer | 1500 | | 2000 | USA | NULL | 1575 | | 2000 | NULL | NULL | 4525 | | 2001 | Finland | Phone | 10 | | 2001 | Finland | NULL | 10 | | 2001 | USA | Calculator | 50 | | 2001 | USA | Computer | 2700 | | 2001 | USA | TV | 250 | | 2001 | USA | NULL | 3000 | | 2001 | NULL | NULL | 3010 | | NULL | NULL | NULL | 7535 | +------+---------+------------+-------------+
For this query, adding ROLLUP causes the
output to include summary information at four levels of
analysis, not just one. Here's how to interpret the
ROLLUP output:
Following each set of product rows for a given year and country, an extra summary row is produced showing the total for all products. These rows have the
productcolumn set toNULL.Following each set of rows for a given year, an extra summary row is produced showing the total for all countries and products. These rows have the
countryandproductscolumns set toNULL.Finally, following all other rows, an extra summary row is produced showing the grand total for all years, countries, and products. This row has the
year,country, andproductscolumns set toNULL.
Other Considerations When using
ROLLUP
The following items list some behaviors specific to the MySQL
implementation of ROLLUP:
When you use ROLLUP, you cannot also use an
ORDER BY clause to sort the results. In other
words, ROLLUP and ORDER BY
are mutually exclusive. However, you still have some control
over sort order. GROUP BY in MySQL sorts
results, and you can use explicit ASC and
DESC keywords with columns named in the
GROUP BY list to specify sort order for
individual columns. (The higher-level summary rows added by
ROLLUP still appear after the rows from which
they are calculated, regardless of the sort order.)
LIMIT can be used to restrict the number of
rows returned to the client. LIMIT is applied
after ROLLUP, so the limit applies against
the extra rows added by ROLLUP. For example:
mysql>SELECT year, country, product, SUM(profit)->FROM sales->GROUP BY year, country, product WITH ROLLUP->LIMIT 5;+------+---------+------------+-------------+ | year | country | product | SUM(profit) | +------+---------+------------+-------------+ | 2000 | Finland | Computer | 1500 | | 2000 | Finland | Phone | 100 | | 2000 | Finland | NULL | 1600 | | 2000 | India | Calculator | 150 | | 2000 | India | Computer | 1200 | +------+---------+------------+-------------+
Using LIMIT with ROLLUP
may produce results that are more difficult to interpret,
because you have less context for understanding the
super-aggregate rows.
The NULL indicators in each super-aggregate
row are produced when the row is sent to the client. The server
looks at the columns named in the GROUP BY
clause following the leftmost one that has changed value. For
any column in the result set with a name that is a lexical match
to any of those names, its value is set to
NULL. (If you specify grouping columns by
column number, the server identifies which columns to set to
NULL by number.)
Because the NULL values in the
super-aggregate rows are placed into the result set at such a
late stage in query processing, you cannot test them as
NULL values within the query itself. For
example, you cannot add HAVING product IS
NULL to the query to eliminate from the output all but
the super-aggregate rows.
On the other hand, the NULL values do appear
as NULL on the client side and can be tested
as such using any MySQL client programming interface.
MySQL extends the use of GROUP BY so that you
can use non-aggregated columns or calculations in the
SELECT list that do not appear in the
GROUP BY clause. You can use this feature to
get better performance by avoiding unnecessary column sorting
and grouping. For example, you do not need to group on
customer.name in the following query:
SELECT order.custid, customer.name, MAX(payments) FROM order,customer WHERE order.custid = customer.custid GROUP BY order.custid;
In standard SQL, you would have to add
customer.name to the GROUP
BY clause. In MySQL, the name is redundant.
Do not use this feature if the columns you
omit from the GROUP BY part are not constant
in the group. The server is free to return any value from the
group, so the results are indeterminate unless all values are
the same.
A similar MySQL extension applies to the
HAVING clause. The SQL standard does not
allow the HAVING clause to name any column
that is not found in the GROUP BY clause if
it is not enclosed in an aggregate function. MySQL allows the
use of such columns to simplify calculations. This extension
assumes that the non-grouped columns will have the same
group-wise values. Otherwise, the result is indeterminate.
If the ONLY_FULL_GROUP_BY SQL mode is
enabled, the MySQL extension to GROUP BY does
not apply. That is, columns not named in the GROUP
BY clause cannot be used in the
SELECT list or HAVING
clause if not used in an aggregate function.
The select list extension also applies to ORDER
BY. That is, you can use non-aggregated columns or
calculations in the ORDER BY clause that do
not appear in the GROUP BY clause. This
extension does not apply if the
ONLY_FULL_GROUP_BY SQL mode is enabled.
In some cases, you can use MIN() and
MAX() to obtain a specific column value even
if it isn't unique. The following gives the value of
column from the row containing the smallest
value in the sort column:
SUBSTR(MIN(CONCAT(RPAD(sort,6,' '),column)),7)
See Section 3.6.4, “The Rows Holding the Group-wise Maximum of a Certain Field”.
Note that if you are trying to follow standard SQL, you can't
use expressions in GROUP BY clauses. You can
work around this limitation by using an alias for the
expression:
SELECT id,FLOOR(value/100) AS val
FROM tbl_name
GROUP BY id, val;
MySQL does allow expressions in GROUP BY
clauses. For example:
SELECT id,FLOOR(value/100)
FROM tbl_name
GROUP BY id, FLOOR(value/100);
Table of Contents
This chapter describes the syntax for most of the SQL statements supported by MySQL. Additional statement descriptions can be found in the following chapters:
The
EXPLAINstatement is discussed in Chapter 7, Optimization.Statements for writing stored routines are covered in Chapter 17, Stored Procedures and Functions.
Statements for writing triggers are covered in Chapter 18, Triggers.
View-related statements are covered in Chapter 19, Views.
ALTER {DATABASE | SCHEMA} [db_name]
alter_specification [alter_specification] ...
alter_specification:
[DEFAULT] CHARACTER SET charset_name
| [DEFAULT] COLLATE collation_name
ALTER DATABASE enables you to change the
overall characteristics of a database. These characteristics are
stored in the db.opt file in the database
directory. To use ALTER DATABASE, you need
the ALTER privilege on the database.
ALTER SCHEMA is a synonym for ALTER
DATABASE as of MySQL 5.0.2.
The CHARACTER SET clause changes the default
database character set. The COLLATE clause
changes the default database collation.
Chapter 10, Character Set Support, discusses character set and collation
names.
The database name can be omitted, in which case the statement applies to the default database.
MySQL Enterprise In a production environment, alteration of a database is not a common occurrence and may indicate a security breach. Advisors provided as part of the MySQL Network Monitoring and Advisory Service automatically alert you when data definition statements are issued. For more information see, http://www.mysql.com/products/enterprise/advisors.html.
ALTER [IGNORE] TABLEtbl_namealter_specification[,alter_specification] ...alter_specification:table_option... | ADD [COLUMN]column_definition[FIRST | AFTERcol_name] | ADD [COLUMN] (column_definition,...) | ADD {INDEX|KEY} [index_name] [index_type] (index_col_name,...) | ADD [CONSTRAINT [symbol]] PRIMARY KEY [index_type] (index_col_name,...) | ADD [CONSTRAINT [symbol]] UNIQUE [INDEX|KEY] [index_name] [index_type] (index_col_name,...) | ADD [FULLTEXT|SPATIAL] [INDEX|KEY] [index_name] (index_col_name,...) | ADD [CONSTRAINT [symbol]] FOREIGN KEY [index_name] (index_col_name,...) [reference_definition] | ALTER [COLUMN]col_name{SET DEFAULTliteral| DROP DEFAULT} | CHANGE [COLUMN]old_col_namecolumn_definition[FIRST|AFTERcol_name] | MODIFY [COLUMN]column_definition[FIRST | AFTERcol_name] | DROP [COLUMN]col_name| DROP PRIMARY KEY | DROP {INDEX|KEY}index_name| DROP FOREIGN KEYfk_symbol| DISABLE KEYS | ENABLE KEYS | RENAME [TO]new_tbl_name| ORDER BYcol_name[,col_name] ... | CONVERT TO CHARACTER SETcharset_name[COLLATEcollation_name] | [DEFAULT] CHARACTER SETcharset_name[COLLATEcollation_name] | DISCARD TABLESPACE | IMPORT TABLESPACEindex_col_name:col_name[(length)] [ASC | DESC]index_type: USING {BTREE | HASH}
ALTER TABLE enables you to change the
structure of an existing table. For example, you can add or
delete columns, create or destroy indexes, change the type of
existing columns, or rename columns or the table itself. You can
also change the comment for the table and type of the table.
The syntax for many of the allowable alterations is similar to
clauses of the CREATE TABLE statement. See
Section 13.1.5, “CREATE TABLE Syntax”, for more information.
Some operations may result in warnings if attempted on a table
for which the storage engine does not support the operation.
These warnings can be displayed with SHOW
WARNINGS. See Section 13.5.4.28, “SHOW WARNINGS Syntax”.
If you use ALTER TABLE to change a column
specification but DESCRIBE
indicates that
your column was not changed, it is possible that MySQL ignored
your modification for one of the reasons described in
Section 13.1.5.1, “Silent Column Specification Changes”.
tbl_name
In most cases, ALTER TABLE works by making a
temporary copy of the original table. The alteration is
performed on the copy, and then the original table is deleted
and the new one is renamed. While ALTER TABLE
is executing, the original table is readable by other clients.
Updates and writes to the table are stalled until the new table
is ready, and then are automatically redirected to the new table
without any failed updates.
If you use ALTER TABLE
without any
other options, MySQL simply renames any files that correspond to
the table tbl_name RENAME TO
new_tbl_nametbl_name. (You can also use
the RENAME TABLE statement to rename tables.
See Section 13.1.9, “RENAME TABLE Syntax”.) Any privileges granted
specifically for the renamed table are not migrated to the new
name. They must be changed manually.
If you use any option to ALTER TABLE other
than RENAME, MySQL always creates a temporary
table, even if the data wouldn't strictly need to be copied
(such as when you change the name of a column). For
MyISAM tables, you can speed up the index
re-creation operation (which is the slowest part of the
alteration process) by setting the
myisam_sort_buffer_size system variable to a
high value.
To use
ALTER TABLE, you needALTER,INSERT, andCREATEprivileges for the table.IGNOREis a MySQL extension to standard SQL. It controls howALTER TABLEworks if there are duplicates on unique keys in the new table or if warnings occur when strict mode is enabled. IfIGNOREis not specified, the copy is aborted and rolled back if duplicate-key errors occur. IfIGNOREis specified, only the first row is used of rows with duplicates on a unique key, The other conflicting rows are deleted. Incorrect values are truncated to the closest matching acceptable value.table_optionsignifies a table option of the kind that can be used in theCREATE TABLEstatement. (Section 13.1.5, “CREATE TABLESyntax”, lists all table options.) This includes options such asENGINE,AUTO_INCREMENT, andAVG_ROW_LENGTH. However,ALTER TABLEignores theDATA DIRECTORYandINDEX DIRECTORYtable options.For example, to convert a table to be an
InnoDBtable, use this statement:ALTER TABLE t1 ENGINE = InnoDB;
The outcome of attempting to change a table's storage engine is affected by whether the desired storage engine is available and the setting of the
NO_ENGINE_SUBSTITUTIONSQL mode, as described in Section 5.2.6, “SQL Modes”.As of MySQL 5.0.23, to prevent inadvertent loss of data,
ALTER TABLEcannot be used to change the storage engine of a table toMERGEorBLACKHOLE.To change the value of the
AUTO_INCREMENTcounter to be used for new rows, do this:ALTER TABLE t2 AUTO_INCREMENT =
value;You cannot reset the counter to a value less than or equal to any that have already been used. For
MyISAM, if the value is less than or equal to the maximum value currently in theAUTO_INCREMENTcolumn, the value is reset to the current maximum plus one. ForInnoDB, you can useALTER TABLE ... AUTO_INCREMENT =as of MySQL 5.0.3, but if the value is less than the current maximum value in the column, no error message is given and the current sequence value is not changed.valueYou can issue multiple
ADD,ALTER,DROP, andCHANGEclauses in a singleALTER TABLEstatement, separated by commas. This is a MySQL extension to standard SQL, which allows only one of each clause perALTER TABLEstatement. For example, to drop multiple columns in a single statement, do this:ALTER TABLE t2 DROP COLUMN c, DROP COLUMN d;
CHANGE,col_nameDROP, andcol_nameDROP INDEXare MySQL extensions to standard SQL.MODIFYis an Oracle extension toALTER TABLE.The word
COLUMNis optional and can be omitted.column_definitionclauses use the same syntax forADDandCHANGEas forCREATE TABLE. Note that this syntax includes the column name, not just its data type. See Section 13.1.5, “CREATE TABLESyntax”.You can rename a column using a
CHANGEclause. To do so, specify the old and new column names and the type that the column currently has. For example, to rename anold_col_namecolumn_definitionINTEGERcolumn fromatob, you can do this:ALTER TABLE t1 CHANGE a b INTEGER;
If you want to change a column's type but not the name,
CHANGEsyntax still requires an old and new column name, even if they are the same. For example:ALTER TABLE t1 CHANGE b b BIGINT NOT NULL;
You can also use
MODIFYto change a column's type without renaming it:ALTER TABLE t1 MODIFY b BIGINT NOT NULL;
If you use
CHANGEorMODIFYto shorten a column for which an index exists on the column, and the resulting column length is less than the index length, MySQL shortens the index automatically.When you change a data type using
CHANGEorMODIFY, MySQL tries to convert existing column values to the new type as well as possible.To add a column at a specific position within a table row, use
FIRSTorAFTER. The default is to add the column last. You can also usecol_nameFIRSTandAFTERinCHANGEorMODIFYoperations.ALTER ... SET DEFAULTorALTER ... DROP DEFAULTspecify a new default value for a column or remove the old default value, respectively. If the old default is removed and the column can beNULL, the new default isNULL. If the column cannot beNULL, MySQL assigns a default value, as described in Section 11.1.4, “Data Type Default Values”.DROP INDEXremoves an index. This is a MySQL extension to standard SQL. See Section 13.1.7, “DROP INDEXSyntax”.If columns are dropped from a table, the columns are also removed from any index of which they are a part. If all columns that make up an index are dropped, the index is dropped as well.
If a table contains only one column, the column cannot be dropped. If what you intend is to remove the table, use
DROP TABLEinstead.DROP PRIMARY KEYdrops the primary index. Note: In older versions of MySQL, if no primary index existed,DROP PRIMARY KEYwould drop the firstUNIQUEindex in the table. This is not the case in MySQL 5.0, where trying to useDROP PRIMARY KEYon a table with no primary key results in an error.If you add a
UNIQUE INDEXorPRIMARY KEYto a table, it is stored before any non-unique index so that MySQL can detect duplicate keys as early as possible.Some storage engines allow you to specify an index type when creating an index. The syntax for the
index_typespecifier isUSING. For details abouttype_nameUSING, see Section 13.1.4, “CREATE INDEXSyntax”.After an
ALTER TABLEstatement, it may be necessary to runANALYZE TABLEto update index cardinality information. See Section 13.5.4.13, “SHOW INDEXSyntax”.ORDER BYenables you to create the new table with the rows in a specific order. Note that the table does not remain in this order after inserts and deletes. This option is useful primarily when you know that you are mostly to query the rows in a certain order most of the time. By using this option after major changes to the table, you might be able to get higher performance. In some cases, it might make sorting easier for MySQL if the table is in order by the column that you want to order it by later.ORDER BYsyntax allows for one or more column names to be specified for sorting, each of which optionally can be followed byASCorDESCto indicate ascending or descending sort order, respectively. The default is ascending order. Only column names are allowed as sort criteria; arbitrary expressions are not allowed.If you use
ALTER TABLEon aMyISAMtable, all non-unique indexes are created in a separate batch (as forREPAIR TABLE). This should makeALTER TABLEmuch faster when you have many indexes.This feature can be activated explicitly.
ALTER TABLE ... DISABLE KEYStells MySQL to stop updating non-unique indexes for aMyISAMtable.ALTER TABLE ... ENABLE KEYSthen should be used to re-create missing indexes. MySQL does this with a special algorithm that is much faster than inserting keys one by one, so disabling keys before performing bulk insert operations should give a considerable speedup. UsingALTER TABLE ... DISABLE KEYSrequires theINDEXprivilege in addition to the privileges mentioned earlier.While the non-unique indexes are disabled, they are ignored for statements such as
SELECTandEXPLAINthat otherwise would use them.The
FOREIGN KEYandREFERENCESclauses are supported by theInnoDBstorage engine, which implementsADD [CONSTRAINT [. See Section 14.2.6.4, “symbol]] FOREIGN KEY (...) REFERENCES ... (...)FOREIGN KEYConstraints”. For other storage engines, the clauses are parsed but ignored. TheCHECKclause is parsed but ignored by all storage engines. See Section 13.1.5, “CREATE TABLESyntax”. The reason for accepting but ignoring syntax clauses is for compatibility, to make it easier to port code from other SQL servers, and to run applications that create tables with references. See Section 1.9.5, “MySQL Differences from Standard SQL”.You cannot add a foreign key and drop a foreign key in separate clauses of a single
ALTER TABLEstatement. You must use separate statements.InnoDBsupports the use ofALTER TABLEto drop foreign keys:ALTER TABLE
tbl_nameDROP FOREIGN KEYfk_symbol;You cannot add a foreign key and drop a foreign key in separate clauses of a single
ALTER TABLEstatement. You must use separate statements.For more information, see Section 14.2.6.4, “
FOREIGN KEYConstraints”.Pending
INSERT DELAYEDstatements are lost if a table is write locked andALTER TABLEis used to modify the table structure.If you want to change the table default character set and all character columns (
CHAR,VARCHAR,TEXT) to a new character set, use a statement like this:ALTER TABLE
tbl_nameCONVERT TO CHARACTER SETcharset_name;Warning: The preceding operation converts column values between the character sets. This is not what you want if you have a column in one character set (like
latin1) but the stored values actually use some other, incompatible character set (likeutf8). In this case, you have to do the following for each such column:ALTER TABLE t1 CHANGE c1 c1 BLOB; ALTER TABLE t1 CHANGE c1 c1 TEXT CHARACTER SET utf8;
The reason this works is that there is no conversion when you convert to or from
BLOBcolumns.If you specify
CONVERT TO CHARACTER SET binary, theCHAR,VARCHAR, andTEXTcolumns are converted to their corresponding binary string types (BINARY,VARBINARY,BLOB). This means that the columns no longer will have a character set and a subsequentCONVERT TOoperation will not apply to them.To change only the default character set for a table, use this statement:
ALTER TABLE
tbl_nameDEFAULT CHARACTER SETcharset_name;The word
DEFAULTis optional. The default character set is the character set that is used if you do not specify the character set for a new column which you add to a table (for example, withALTER TABLE ... ADD column).For an
InnoDBtable that is created with its own tablespace in an.ibdfile, that file can be discarded and imported. To discard the.ibdfile, use this statement:ALTER TABLE
tbl_nameDISCARD TABLESPACE;This deletes the current
.ibdfile, so be sure that you have a backup first. Attempting to access the table while the tablespace file is discarded results in an error.To import the backup
.ibdfile back into the table, copy it into the database directory, and then issue this statement:ALTER TABLE
tbl_nameIMPORT TABLESPACE;
With the mysql_info() C API function, you can
find out how many rows were copied, and (when
IGNORE is used) how many rows were deleted
due to duplication of unique key values. See
Section 22.2.3.35, “mysql_info()”.
Here are some examples that show uses of ALTER
TABLE. Begin with a table t1 that
is created as shown here:
CREATE TABLE t1 (a INTEGER,b CHAR(10));
To rename the table from t1 to
t2:
ALTER TABLE t1 RENAME t2;
To change column a from
INTEGER to TINYINT NOT
NULL (leaving the name the same), and to change column
b from CHAR(10) to
CHAR(20) as well as renaming it from
b to c:
ALTER TABLE t2 MODIFY a TINYINT NOT NULL, CHANGE b c CHAR(20);
To add a new TIMESTAMP column named
d:
ALTER TABLE t2 ADD d TIMESTAMP;
To add indexes on column d and on column
a:
ALTER TABLE t2 ADD INDEX (d), ADD INDEX (a);
To remove column c:
ALTER TABLE t2 DROP COLUMN c;
To add a new AUTO_INCREMENT integer column
named c:
ALTER TABLE t2 ADD c INT UNSIGNED NOT NULL AUTO_INCREMENT, ADD PRIMARY KEY (c);
Note that we indexed c (as a PRIMARY
KEY), because AUTO_INCREMENT
columns must be indexed, and also that we declare
c as NOT NULL, because
primary key columns cannot be NULL.
When you add an AUTO_INCREMENT column, column
values are filled in with sequence numbers for you
automatically. For MyISAM tables, you can set
the first sequence number by executing SET
INSERT_ID= before
valueALTER TABLE or by using the
AUTO_INCREMENT=
table option. See Section 13.5.3, “valueSET Syntax”.
With MyISAM tables, if you do not change the
AUTO_INCREMENT column, the sequence number is
not affected. If you drop an AUTO_INCREMENT
column and then add another AUTO_INCREMENT
column, the numbers are resequenced beginning with 1.
When replication is used, adding an
AUTO_INCREMENT column to a table might not
produce the same ordering of the rows on the slave and the
master. This occurs because the order in which the rows are
numbered depends on the specific storage engine used for the
table and the order in which the rows were inserted. If it is
important to have the same order on the master and slave, the
rows must be ordered before assigning an
AUTO_INCREMENT number. Assuming that you want
to add an AUTO_INCREMENT column to the table
t1, the following statements produce a new
table t2 identical to t1
but with an AUTO_INCREMENT column:
CREATE TABLE t2 (id INT AUTO_INCREMENT PRIMARY KEY) SELECT * FROM t1 ORDER BY col1, col2;
This assumes that the table t1 has columns
col1 and col2.
This set of statements will also produce a new table
t2 identical to t1, with
the addition of an AUTO_INCREMENT column:
CREATE TABLE t2 LIKE t1; ALTER TABLE T2 ADD id INT AUTO_INCREMENT PRIMARY KEY; INSERT INTO t2 SELECT * FROM t1 ORDER BY col1, col2;
Important: To guarantee the
same ordering on both master and slave, all
columns of t1 must be referenced in the
ORDER BY clause.
Regardless of the method used to create and populate the copy
having the AUTO_INCREMENT column, the final
step is to drop the original table and then rename the copy:
DROP t1; ALTER TABLE t2 RENAME t1;
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name
[create_specification [create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
| [DEFAULT] COLLATE collation_name
CREATE DATABASE creates a database with the
given name. To use this statement, you need the
CREATE privilege for the database.
CREATE SCHEMA is a synonym for
CREATE DATABASE as of MySQL 5.0.2.
An error occurs if the database exists and you did not specify
IF NOT EXISTS.
create_specification options specify
database characteristics. Database characteristics are stored in
the db.opt file in the database directory.
The CHARACTER SET clause specifies the
default database character set. The COLLATE
clause specifies the default database collation.
Chapter 10, Character Set Support, discusses character set and collation
names.
A database in MySQL is implemented as a directory containing
files that correspond to tables in the database. Because there
are no tables in a database when it is initially created, the
CREATE DATABASE statement creates only a
directory under the MySQL data directory and the
db.opt file. Rules for allowable database
names are given in Section 9.2, “Database, Table, Index, Column, and Alias Names”.
If you manually create a directory under the data directory (for
example, with mkdir), the server considers it
a database directory and it shows up in the output of
SHOW DATABASES.
You can also use the mysqladmin program to create databases. See Section 8.10, “mysqladmin — Client for Administering a MySQL Server”.
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEXindex_name[index_type] ONtbl_name(index_col_name,...)index_col_name:col_name[(length)] [ASC | DESC]index_type: USING {BTREE | HASH}
CREATE INDEX is mapped to an ALTER
TABLE statement to create indexes. See
Section 13.1.2, “ALTER TABLE Syntax”. CREATE INDEX
cannot be used to create a PRIMARY KEY; use
ALTER TABLE instead. For more information
about indexes, see Section 7.4.5, “How MySQL Uses Indexes”.
Normally, you create all indexes on a table at the time the
table itself is created with CREATE TABLE.
See Section 13.1.5, “CREATE TABLE Syntax”. CREATE
INDEX enables you to add indexes to existing tables.
A column list of the form (col1,col2,...)
creates a multiple-column index. Index values are formed by
concatenating the values of the given columns.
Indexes can be created that use only the leading part of column
values, using
col_name(length)
Prefixes can be specified for
CHAR,VARCHAR,BINARY, andVARBINARYcolumns.BLOBandTEXTcolumns also can be indexed, but a prefix length must be given.Prefix lengths are given in characters for non-binary string types and in bytes for binary string types. That is, index entries consist of the first
lengthcharacters of each column value forCHAR,VARCHAR, andTEXTcolumns, and the firstlengthbytes of each column value forBINARY,VARBINARY, andBLOBcolumns.For spatial columns, prefix values can be given as described later in this section.
The statement shown here creates an index using the first 10
characters of the name column:
CREATE INDEX part_of_name ON customer (name(10));
If names in the column usually differ in the first 10
characters, this index should not be much slower than an index
created from the entire name column. Also,
using column prefixes for indexes can make the index file much
smaller, which could save a lot of disk space and might also
speed up INSERT operations.
Prefix lengths are storage engine-dependent (for example, a
prefix can be up to 1000 bytes long for
MyISAM tables, 767 bytes for
InnoDB tables). Note that prefix limits are
measured in bytes, whereas the prefix length in CREATE
INDEX statements is interpreted as number of
characters for non-binary data types (CHAR,
VARCHAR, TEXT). Take this
into account when specifying a prefix length for a column that
uses a multi-byte character set. For example,
utf8 columns require up to three index bytes
per character.
A UNIQUE index creates a constraint such that
all values in the index must be distinct. An error occurs if you
try to add a new row with a key value that matches an existing
row. This constraint does not apply to NULL
values except for the BDB storage engine. For
other engines, a UNIQUE index allows multiple
NULL values for columns that can contain
NULL. If you specify a prefix value for a
column in a UNIQUE index, the column values
must be unique within the prefix.
MySQL Enterprise Lack of proper indexes can greatly reduce performance. Subscribe to the MySQL Network Monitoring and Advisory Service for notification of inefficient use of indexes. For more information see http://www.mysql.com/products/enterprise/advisors.html.
FULLTEXT indexes are supported only for
MyISAM tables and can include only
CHAR, VARCHAR, and
TEXT columns. Indexing always happens over
the entire column; column prefix indexing is not supported and
any prefix length is ignored if specified. See
Section 12.8, “Full-Text Search Functions”, for details of operation.
The MyISAM, InnoDB,
NDB, BDB, and
ARCHIVE storage engines support spatial
columns such as (POINT and
GEOMETRY.
(Chapter 16, Spatial Extensions, describes the spatial
data types.) However, support for spatial column indexing varies
among engines. Spatial and non-spatial indexes are available
according to the following rules.
Spatial indexes (created using SPATIAL
INDEX):
Available only for
MyISAMtables. Specifying aSPATIAL INDEXfor other storage engines results in an error.Indexed columns must be
NOT NULL.In MySQL 5.0, the full width of each column is indexed by default, but column prefix lengths are allowed. However, as of MySQL 5.0.40, the length is not displayed in
SHOW CREATE TABLEoutput. mysqldump uses that statement. As of that version, if a table withSPATIALindexes containing prefixed columns is dumped and reloaded, the index is created with no prefixes. (The full column width of each column is indexed.)
Non-spatial indexes (created with INDEX,
UNIQUE, or PRIMARY KEY):
Allowed for any storage engine that supports spatial columns except
ARCHIVE.Columns can be
NULLunless the index is a primary key.For each spatial column in a non-
SPATIALindex exceptPOINTcolumns, a column prefix length must be specified. (This is the same requirement as for indexedBLOBcolumns.) The prefix length is given in bytes.The index type for a non-
SPATIALindex depends on the storage engine. Currently, B-tree is used.
In MySQL 5.0:
You can add an index on a column that can have
NULLvalues only if you are using theMyISAM,InnoDB,BDB, orMEMORYstorage engine.You can add an index on a
BLOBorTEXTcolumn only if you are using theMyISAM,BDB, orInnoDBstorage engine.
An index_col_name specification can
end with ASC or DESC.
These keywords are allowed for future extensions for specifying
ascending or descending index value storage. Currently, they are
parsed but ignored; index values are always stored in ascending
order.
Some storage engines allow you to specify an index type when creating an index. The allowable index type values supported by different storage engines are shown in the following table. Where multiple index types are listed, the first one is the default when no index type specifier is given.
| Storage Engine | Allowable Index Types |
MyISAM | BTREE |
InnoDB | BTREE |
MEMORY/HEAP | HASH, BTREE |
NDB | HASH |
If you specify an index type that is not legal for a given storage engine, but there is another index type available that the engine can use without affecting query results, the engine uses the available type.
Examples:
CREATE TABLE lookup (id INT) ENGINE = MEMORY; CREATE INDEX id_index USING BTREE ON lookup (id);
For indexes on NDB table columns, the
USING clause can be specified only for a
unique index or primary key. In such cases, the USING
HASH clause prevents the creation of an implicit
ordered index. Without USING HASH, a
statement defining a unique index or primary key automatically
results in the creation of a HASH index in
addition to the ordered index, both of which index the same set
of columns.
TYPE is
recognized as a synonym for type_nameUSING
. However,
type_nameUSING is the preferred form.
CREATE [TEMPORARY] TABLE [IF NOT EXISTS]tbl_name(create_definition,...) [table_option...]
Or:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS]tbl_name[(create_definition,...)] [table_option...]select_statement
Or:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS]tbl_name{ LIKEold_tbl_name| (LIKEold_tbl_name) }create_definition:column_definition| [CONSTRAINT [symbol]] PRIMARY KEY [index_type] (index_col_name,...) | {INDEX|KEY} [index_name] [index_type] (index_col_name,...) | [CONSTRAINT [symbol]] UNIQUE [INDEX|KEY] [index_name] [index_type] (index_col_name,...) | {FULLTEXT|SPATIAL} [INDEX|KEY] [index_name] (index_col_name,...) | [CONSTRAINT [symbol]] FOREIGN KEY [index_name] (index_col_name,...) [reference_definition] | CHECK (expr)column_definition:col_namedata_type[NOT NULL | NULL] [DEFAULTdefault_value] [AUTO_INCREMENT] [UNIQUE [KEY] | [PRIMARY] KEY] [COMMENT 'string'] [reference_definition]data_type: BIT[(length)] | TINYINT[(length)] [UNSIGNED] [ZEROFILL] | SMALLINT[(length)] [UNSIGNED] [ZEROFILL] | MEDIUMINT[(length)] [UNSIGNED] [ZEROFILL] | INT[(length)] [UNSIGNED] [ZEROFILL] | INTEGER[(length)] [UNSIGNED] [ZEROFILL] | BIGINT[(length)] [UNSIGNED] [ZEROFILL] | REAL[(length,decimals)] [UNSIGNED] [ZEROFILL] | DOUBLE[(length,decimals)] [UNSIGNED] [ZEROFILL] | FLOAT[(length,decimals)] [UNSIGNED] [ZEROFILL] | DECIMAL(length,decimals) [UNSIGNED] [ZEROFILL] | NUMERIC(length,decimals) [UNSIGNED] [ZEROFILL] | DATE | TIME | TIMESTAMP | DATETIME | YEAR | CHAR(length) [CHARACTER SETcharset_name] [COLLATEcollation_name] | VARCHAR(length) [CHARACTER SETcharset_name] [COLLATEcollation_name] | BINARY(length) | VARBINARY(length) | TINYBLOB | BLOB | MEDIUMBLOB | LONGBLOB | TINYTEXT [BINARY] [CHARACTER SETcharset_name] [COLLATEcollation_name] | TEXT [BINARY] [CHARACTER SETcharset_name] [COLLATEcollation_name] | MEDIUMTEXT [BINARY] [CHARACTER SETcharset_name] [COLLATEcollation_name] | LONGTEXT [BINARY] [CHARACTER SETcharset_name] [COLLATEcollation_name] | ENUM(value1,value2,value3,...) [CHARACTER SETcharset_name] [COLLATEcollation_name] | SET(value1,value2,value3,...) [CHARACTER SETcharset_name] [COLLATEcollation_name] |spatial_typeindex_col_name:col_name[(length)] [ASC | DESC]index_type: USING {BTREE | HASH}reference_definition: REFERENCEStbl_name[(index_col_name,...)] [MATCH FULL | MATCH PARTIAL | MATCH SIMPLE] [ON DELETEreference_option] [ON UPDATEreference_option]reference_option: RESTRICT | CASCADE | SET NULL | NO ACTIONtable_option: {ENGINE|TYPE} [=]engine_name| AUTO_INCREMENT [=]value| AVG_ROW_LENGTH [=]value| [DEFAULT] CHARACTER SETcharset_name| CHECKSUM [=] {0 | 1} | COLLATEcollation_name| COMMENT [=] 'string' | CONNECTION [=] 'connect_string' | DATA DIRECTORY [=] 'absolute path to directory' | DELAY_KEY_WRITE [=] {0 | 1} | INDEX DIRECTORY [=] 'absolute path to directory' | INSERT_METHOD [=] { NO | FIRST | LAST } | MAX_ROWS [=]value| MIN_ROWS [=]value| PACK_KEYS [=] {0 | 1 | DEFAULT} | PASSWORD [=] 'string' | ROW_FORMAT [=] {DEFAULT|DYNAMIC|FIXED|COMPRESSED|REDUNDANT|COMPACT} | UNION [=] (tbl_name[,tbl_name]...)select_statement:[IGNORE | REPLACE] [AS] SELECT ... (Some legal select statement)
CREATE TABLE creates a table with the given
name. You must have the CREATE privilege for
the table.
Rules for allowable table names are given in Section 9.2, “Database, Table, Index, Column, and Alias Names”. By default, the table is created in the default database. An error occurs if the table exists, if there is no default database, or if the database does not exist.
The table name can be specified as
db_name.tbl_name to create the table
in a specific database. This works regardless of whether there
is a default database, assuming that the database exists. If you
use quoted identifiers, quote the database and table names
separately. For example, write
`mydb`.`mytbl`, not
`mydb.mytbl`.
You can use the TEMPORARY keyword when
creating a table. A TEMPORARY table is
visible only to the current connection, and is dropped
automatically when the connection is closed. This means that two
different connections can use the same temporary table name
without conflicting with each other or with an existing
non-TEMPORARY table of the same name. (The
existing table is hidden until the temporary table is dropped.)
To create temporary tables, you must have the CREATE
TEMPORARY TABLES privilege.
Note: CREATE
TABLE does not automatically commit the current active
transaction if you use the TEMPORARY keyword.
The keywords IF NOT EXISTS prevent an error
from occurring if the table exists. However, there is no
verification that the existing table has a structure identical
to that indicated by the CREATE TABLE
statement. Note: If you use IF NOT
EXISTS in a CREATE TABLE ... SELECT
statement, any rows selected by the SELECT
part are inserted regardless of whether the table already
exists.
MySQL represents each table by an .frm
table format (definition) file in the database directory. The
storage engine for the table might create other files as well.
In the case of MyISAM tables, the storage
engine creates data and index files. Thus, for each
MyISAM table
tbl_name, there are three disk files:
| File | Purpose |
| Table format (definition) file |
| Data file |
| Index file |
Chapter 14, Storage Engines, describes what files each storage engine creates to represent tables.
data_type represents the data type is
a column definition. spatial_type
represents a spatial data type. The data type syntax shown is
representative only. For a full description of the syntax
available for specfiying column data types, as well as
information about the properties of each type, see
Chapter 11, Data Types, and
Chapter 16, Spatial Extensions.
Some attributes do not apply to all data types.
AUTO_INCREMENT applies only to integer types.
DEFAULT does not apply to the
BLOB or TEXT types.
If neither
NULLnorNOT NULLis specified, the column is treated as thoughNULLhad been specified.An integer column can have the additional attribute
AUTO_INCREMENT. When you insert a value ofNULL(recommended) or0into an indexedAUTO_INCREMENTcolumn, the column is set to the next sequence value. Typically this isvalue+1valueis the largest value for the column currently in the table.AUTO_INCREMENTsequences begin with1.To retrieve an
AUTO_INCREMENTvalue after inserting a row, use theLAST_INSERT_ID()SQL function or themysql_insert_id()C API function. See Section 12.10.3, “Information Functions”, and Section 22.2.3.37, “mysql_insert_id()”.If the
NO_AUTO_VALUE_ON_ZEROSQL mode is enabled, you can store0inAUTO_INCREMENTcolumns as0without generating a new sequence value. See Section 5.2.6, “SQL Modes”.Note: There can be only one
AUTO_INCREMENTcolumn per table, it must be indexed, and it cannot have aDEFAULTvalue. AnAUTO_INCREMENTcolumn works properly only if it contains only positive values. Inserting a negative number is regarded as inserting a very large positive number. This is done to avoid precision problems when numbers “wrap” over from positive to negative and also to ensure that you do not accidentally get anAUTO_INCREMENTcolumn that contains0.For
MyISAMandBDBtables, you can specify anAUTO_INCREMENTsecondary column in a multiple-column key. See Section 3.6.9, “UsingAUTO_INCREMENT”.To make MySQL compatible with some ODBC applications, you can find the
AUTO_INCREMENTvalue for the last inserted row with the following query:SELECT * FROM
tbl_nameWHEREauto_colIS NULLFor information about
InnoDBandAUTO_INCREMENT, see Section 14.2.6.3, “HowAUTO_INCREMENTColumns Work inInnoDB”.Character data types (
CHAR,VARCHAR,TEXT) can includeCHARACTER SETandCOLLATEattributes to specify the character set and collation for the column. For details, see Chapter 10, Character Set Support.CHARSETis a synonym forCHARACTER SET. Example:CREATE TABLE t (c CHAR(20) CHARACTER SET utf8 COLLATE utf8_bin);
MySQL 5.0 interprets length specifications in character column definitions in characters. (Versions before MySQL 4.1 interpreted them in bytes.) Lengths for
BINARYandVARBINARYare in bytes.The
DEFAULTclause specifies a default value for a column. With one exception, the default value must be a constant; it cannot be a function or an expression. This means, for example, that you cannot set the default for a date column to be the value of a function such asNOW()orCURRENT_DATE. The exception is that you can specifyCURRENT_TIMESTAMPas the default for aTIMESTAMPcolumn. See Section 11.3.1.1, “TIMESTAMPProperties as of MySQL 4.1”.If a column definition includes no explicit
DEFAULTvalue, MySQL determines the default value as described in Section 11.1.4, “Data Type Default Values”.BLOBandTEXTcolumns cannot be assigned a default value.A comment for a column can be specified with the
COMMENToption, up to 255 characters long. The comment is displayed by theSHOW CREATE TABLEandSHOW FULL COLUMNSstatements.KEYis normally a synonym forINDEX. The key attributePRIMARY KEYcan also be specified as justKEYwhen given in a column definition. This was implemented for compatibility with other database systems.A
UNIQUEindex creates a constraint such that all values in the index must be distinct. An error occurs if you try to add a new row with a key value that matches an existing row. This constraint does not apply toNULLvalues except for theBDBstorage engine. For other engines, aUNIQUEindex allows multipleNULLvalues for columns that can containNULL.A
PRIMARY KEYis a unique index where all key columns must be defined asNOT NULL. If they are not explicitly declared asNOT NULL, MySQL declares them so implicitly (and silently). A table can have only onePRIMARY KEY. If you do not have aPRIMARY KEYand an application asks for thePRIMARY KEYin your tables, MySQL returns the firstUNIQUEindex that has noNULLcolumns as thePRIMARY KEY.In
InnoDBtables, having a longPRIMARY KEYwastes a lot of space. (See Section 14.2.13, “InnoDBTable and Index Structures”.)In the created table, a
PRIMARY KEYis placed first, followed by allUNIQUEindexes, and then the non-unique indexes. This helps the MySQL optimizer to prioritize which index to use and also more quickly to detect duplicatedUNIQUEkeys.A
PRIMARY KEYcan be a multiple-column index. However, you cannot create a multiple-column index using thePRIMARY KEYkey attribute in a column specification. Doing so only marks that single column as primary. You must use a separatePRIMARY KEY(clause.index_col_name, ...)If a
PRIMARY KEYorUNIQUEindex consists of only one column that has an integer type, you can also refer to the column as_rowidinSELECTstatements.In MySQL, the name of a
PRIMARY KEYisPRIMARY. For other indexes, if you do not assign a name, the index is assigned the same name as the first indexed column, with an optional suffix (_2,_3,...) to make it unique. You can see index names for a table usingSHOW INDEX FROM. See Section 13.5.4.13, “tbl_nameSHOW INDEXSyntax”.Some storage engines allow you to specify an index type when creating an index. The syntax for the
index_typespecifier isUSING.type_nameExample:
CREATE TABLE lookup (id INT, INDEX USING BTREE (id)) ENGINE = MEMORY;
For details about
USING, see Section 13.1.4, “CREATE INDEXSyntax”.For more information about indexes, see Section 7.4.5, “How MySQL Uses Indexes”.
In MySQL 5.0, only the
MyISAM,InnoDB,BDB, andMEMORYstorage engines support indexes on columns that can haveNULLvalues. In other cases, you must declare indexed columns asNOT NULLor an error results.For
CHAR,VARCHAR,BINARY, andVARBINARYcolumns, indexes can be created that use only the leading part of column values, usingcol_name(length)BLOBandTEXTcolumns also can be indexed, but a prefix length must be given. Prefix lengths are given in characters for non-binary string types and in bytes for binary string types. That is, index entries consist of the firstlengthcharacters of each column value forCHAR,VARCHAR, andTEXTcolumns, and the firstlengthbytes of each column value forBINARY,VARBINARY, andBLOBcolumns. Indexing only a prefix of column values like this can make the index file much smaller. See Section 7.4.3, “Column Indexes”.Only the
MyISAM,BDB, andInnoDBstorage engines support indexing onBLOBandTEXTcolumns. For example:CREATE TABLE test (blob_col BLOB, INDEX(blob_col(10)));
Prefixes can be up to 1000 bytes long (767 bytes for
InnoDBtables). Note that prefix limits are measured in bytes, whereas the prefix length inCREATE TABLEstatements is interpreted as number of characters for non-binary data types (CHAR,VARCHAR,TEXT). Take this into account when specifying a prefix length for a column that uses a multi-byte character set.An
index_col_namespecification can end withASCorDESC. These keywords are allowed for future extensions for specifying ascending or descending index value storage. Currently, they are parsed but ignored; index values are always stored in ascending order.When you use
ORDER BYorGROUP BYon aTEXTorBLOBcolumn in aSELECT, the server sorts values using only the initial number of bytes indicated by themax_sort_lengthsystem variable. See Section 11.4.3, “TheBLOBandTEXTTypes”.You can create special
FULLTEXTindexes, which are used for full-text searches. Only theMyISAMstorage engine supportsFULLTEXTindexes. They can be created only fromCHAR,VARCHAR, andTEXTcolumns. Indexing always happens over the entire column; column prefix indexing is not supported and any prefix length is ignored if specified. See Section 12.8, “Full-Text Search Functions”, for details of operation.You can create
SPATIALindexes on spatial data types. Spatial types are supported only forMyISAMtables and indexed columns must be declared asNOT NULL. See Chapter 16, Spatial Extensions.InnoDBtables support checking of foreign key constraints. See Section 14.2, “TheInnoDBStorage Engine”. Note that theFOREIGN KEYsyntax inInnoDBis more restrictive than the syntax presented for theCREATE TABLEstatement at the beginning of this section: The columns of the referenced table must always be explicitly named.InnoDBsupports bothON DELETEandON UPDATEactions on foreign keys. For the precise syntax, see Section 14.2.6.4, “FOREIGN KEYConstraints”.For other storage engines, MySQL Server parses and ignores the
FOREIGN KEYandREFERENCESsyntax inCREATE TABLEstatements. TheCHECKclause is parsed but ignored by all storage engines. See Section 1.9.5.5, “Foreign Keys”.For
MyISAMtables, eachNULLcolumn takes one bit extra, rounded up to the nearest byte. The maximum row length in bytes can be calculated as follows:row length = 1 + (sum of column lengths) + (number of NULL columns+delete_flag+ 7)/8 + (number of variable-length columns)delete_flagis 1 for tables with static row format. Static tables use a bit in the row record for a flag that indicates whether the row has been deleted.delete_flagis 0 for dynamic tables because the flag is stored in the dynamic row header.These calculations do not apply for
InnoDBtables, for which storage size is no different forNULLcolumns than forNOT NULLcolumns.
The ENGINE table option specifies the storage
engine for the table. TYPE is a synonym, but
ENGINE is the preferred option name.
The ENGINE table option takes the storage
engine names shown in the following table.
| Storage Engine | Description |
ARCHIVE | The archiving storage engine. See
Section 14.8, “The ARCHIVE Storage Engine”. |
BDB | Transaction-safe tables with page locking. Also known as
BerkeleyDB. See
Section 14.5, “The BDB (BerkeleyDB) Storage
Engine”. |
CSV | Tables that store rows in comma-separated values format. See
Section 14.9, “The CSV Storage Engine”. |
EXAMPLE | An example engine. See Section 14.6, “The EXAMPLE Storage Engine”. |
FEDERATED | Storage engine that accesses remote tables. See
Section 14.7, “The FEDERATED Storage Engine”. |
HEAP | This is a synonym for MEMORY. |
ISAM (OBSOLETE) | Not available in MySQL 5.0. If you are upgrading to MySQL
5.0 from a previous version, you should
convert any existing ISAM tables to
MyISAM before
performing the upgrade. |
InnoDB | Transaction-safe tables with row locking and foreign keys. See
Section 14.2, “The InnoDB Storage Engine”. |
MEMORY | The data for this storage engine is stored only in memory. See
Section 14.4, “The MEMORY (HEAP) Storage Engine”. |
MERGE | A collection of MyISAM tables used as one table. Also
known as MRG_MyISAM. See
Section 14.3, “The MERGE Storage Engine”. |
MyISAM | The binary portable storage engine that is the default storage engine
used by MySQL. See
Section 14.1, “The MyISAM Storage Engine”. |
NDBCLUSTER | Clustered, fault-tolerant, memory-based tables. Also known as
NDB. See
Chapter 15, MySQL Cluster. |
If a storage engine is specified that is not available, MySQL
uses the default engine instead. Normally, this is
MyISAM. For example, if a table definition
includes the ENGINE=BDB option but the MySQL
server does not support BDB tables, the table
is created as a MyISAM table. This makes it
possible to have a replication setup where you have
transactional tables on the master but tables created on the
slave are non-transactional (to get more speed). In MySQL
5.0, a warning occurs if the storage engine
specification is not honored.
Engine substitution can be controlled by the setting of the
NO_ENGINE_SUBSTITUTION SQL mode, as described
in Section 5.2.6, “SQL Modes”.
The other table options are used to optimize the behavior of the
table. In most cases, you do not have to specify any of them.
These options apply to all storage engines unless otherwise
indicated. Options that do not apply to a given storage engine
may be accepted and remembered as part of the table definition.
Such options then apply if you later use ALTER
TABLE to convert the table to use a different storage
engine.
AUTO_INCREMENTThe initial
AUTO_INCREMENTvalue for the table. In MySQL 5.0, this works forMyISAMandMEMORYtables. It is also supported forInnoDBas of MySQL 5.0.3. To set the first auto-increment value for engines that do not support theAUTO_INCREMENTtable option, insert a “dummy” row with a value one less than the desired value after creating the table, and then delete the dummy row.For engines that support the
AUTO_INCREMENTtable option inCREATE TABLEstatements, you can also useALTER TABLEto reset thetbl_nameAUTO_INCREMENT =NAUTO_INCREMENTvalue. The value cannot be set lower than the maximum value currently in the column.AVG_ROW_LENGTHAn approximation of the average row length for your table. You need to set this only for large tables with variable-size rows.
When you create a
MyISAMtable, MySQL uses the product of theMAX_ROWSandAVG_ROW_LENGTHoptions to decide how big the resulting table is. If you don't specify either option, the maximum size for a table is 256TB of data by default (4GB before MySQL 5.0.6). (If your operating system does not support files that large, table sizes are constrained by the file size limit.) If you want to keep down the pointer sizes to make the index smaller and faster and you don't really need big files, you can decrease the default pointer size by setting themyisam_data_pointer_sizesystem variable, which was added in MySQL 4.1.2. (See Section 5.2.3, “System Variables”.) If you want all your tables to be able to grow above the default limit and are willing to have your tables slightly slower and larger than necessary, you can increase the default pointer size by setting this variable.[DEFAULT] CHARACTER SETSpecify a default character set for the table.
CHARSETis a synonym forCHARACTER SET.CHECKSUMSet this to 1 if you want MySQL to maintain a live checksum for all rows (that is, a checksum that MySQL updates automatically as the table changes). This makes the table a little slower to update, but also makes it easier to find corrupted tables. The
CHECKSUM TABLEstatement reports the checksum. (MyISAMonly.)COLLATESpecify a default collation for the table.
COMMENTA comment for the table, up to 60 characters long.
CONNECTIONThe connection string for a
FEDERATEDtable. This option is available as of MySQL 5.0.13; before that, use aCOMMENToption for the connection string.DATA DIRECTORY,INDEX DIRECTORYBy using
DATA DIRECTORY='ordirectory'INDEX DIRECTORY='you can specify where thedirectory'MyISAMstorage engine should put a table's data file and index file. The directory must be the full pathname to the directory, not a relative path.These options work only when you are not using the
--skip-symbolic-linksoption. Your operating system must also have a working, thread-saferealpath()call. See Section 7.6.1.2, “Using Symbolic Links for Tables on Unix”, for more complete information.DELAY_KEY_WRITESet this to 1 if you want to delay key updates for the table until the table is closed. See the description of the
delay_key_writesystem variable in Section 5.2.3, “System Variables”. (MyISAMonly.)INSERT_METHODIf you want to insert data into a
MERGEtable, you must specify withINSERT_METHODthe table into which the row should be inserted.INSERT_METHODis an option useful forMERGEtables only. Use a value ofFIRSTorLASTto have inserts go to the first or last table, or a value ofNOto prevent inserts. See Section 14.3, “TheMERGEStorage Engine”.MAX_ROWSThe maximum number of rows you plan to store in the table. This is not a hard limit, but rather a hint to the storage engine that the table must be able to store at least this many rows.
MIN_ROWSThe minimum number of rows you plan to store in the table.
PACK_KEYSPACK_KEYStakes effect only withMyISAMtables. Set this option to 1 if you want to have smaller indexes. This usually makes updates slower and reads faster. Setting the option to 0 disables all packing of keys. Setting it toDEFAULTtells the storage engine to pack only longCHARorVARCHARcolumns.If you do not use
PACK_KEYS, the default is to pack strings, but not numbers. If you usePACK_KEYS=1, numbers are packed as well.When packing binary number keys, MySQL uses prefix compression:
Every key needs one extra byte to indicate how many bytes of the previous key are the same for the next key.
The pointer to the row is stored in high-byte-first order directly after the key, to improve compression.
This means that if you have many equal keys on two consecutive rows, all following “same” keys usually only take two bytes (including the pointer to the row). Compare this to the ordinary case where the following keys takes
storage_size_for_key + pointer_size(where the pointer size is usually 4). Conversely, you get a significant benefit from prefix compression only if you have many numbers that are the same. If all keys are totally different, you use one byte more per key, if the key is not a key that can haveNULLvalues. (In this case, the packed key length is stored in the same byte that is used to mark if a key isNULL.)PASSWORDThis option is unused. If you have a need to scramble your
.frmfiles and make them unusable to any other MySQL server, please contact our sales department.ROW_FORMATDefines how the rows should be stored. For
MyISAMtables, the option value can beFIXEDorDYNAMICfor static or variable-length row format. myisampack sets the type toCOMPRESSED. See Section 14.1.3, “MyISAMTable Storage Formats”.Starting with MySQL 5.0.3, for
InnoDBtables, rows are stored in compact format (ROW_FORMAT=COMPACT) by default. The non-compact format used in older versions of MySQL can still be requested by specifyingROW_FORMAT=REDUNDANT.RAID_TYPERAIDsupport has been removed as of MySQL 5.0. For information onRAID, see http://dev.mysql.com/doc/refman/4.1/en/create-table.html.UNIONUNIONis used when you want to access a collection of identicalMyISAMtables as one. This works only withMERGEtables. See Section 14.3, “TheMERGEStorage Engine”.You must have
SELECT,UPDATE, andDELETEprivileges for the tables you map to aMERGEtable. (Note: Formerly, all tables used had to be in the same database as theMERGEtable itself. This restriction no longer applies.)
You can create one table from another by adding a
SELECT statement at the end of the
CREATE TABLE statement:
CREATE TABLEnew_tblSELECT * FROMorig_tbl;
MySQL creates new columns for all elements in the
SELECT. For example:
mysql>CREATE TABLE test (a INT NOT NULL AUTO_INCREMENT,->PRIMARY KEY (a), KEY(b))->ENGINE=MyISAM SELECT b,c FROM test2;
This creates a MyISAM table with three
columns, a, b, and
c. Notice that the columns from the
SELECT statement are appended to the right
side of the table, not overlapped onto it. Take the following
example:
mysql>SELECT * FROM foo;+---+ | n | +---+ | 1 | +---+ mysql>CREATE TABLE bar (m INT) SELECT n FROM foo;Query OK, 1 row affected (0.02 sec) Records: 1 Duplicates: 0 Warnings: 0 mysql>SELECT * FROM bar;+------+---+ | m | n | +------+---+ | NULL | 1 | +------+---+ 1 row in set (0.00 sec)
For each row in table foo, a row is inserted
in bar with the values from
foo and default values for the new columns.
In a table resulting from CREATE TABLE ...
SELECT, columns named only in the CREATE
TABLE part come first. Columns named in both parts or
only in the SELECT part come after that. The
data type of SELECT columns can be overridden
by also specifying the column in the CREATE
TABLE part.
If any errors occur while copying the data to the table, it is automatically dropped and not created.
CREATE TABLE ... SELECT does not
automatically create any indexes for you. This is done
intentionally to make the statement as flexible as possible. If
you want to have indexes in the created table, you should
specify these before the SELECT statement:
mysql> CREATE TABLE bar (UNIQUE (n)) SELECT n FROM foo;
Some conversion of data types might occur. For example, the
AUTO_INCREMENT attribute is not preserved,
and VARCHAR columns can become
CHAR columns.
When creating a table with CREATE ... SELECT,
make sure to alias any function calls or expressions in the
query. If you do not, the CREATE statement
might fail or result in undesirable column names.
CREATE TABLE artists_and_works SELECT artist.name, COUNT(work.artist_id) AS number_of_works FROM artist LEFT JOIN work ON artist.id = work.artist_id GROUP BY artist.id;
You can also explicitly specify the data type for a generated column:
CREATE TABLE foo (a TINYINT NOT NULL) SELECT b+1 AS a FROM bar;
Use LIKE to create an empty table based on
the definition of another table, including any column attributes
and indexes defined in the original table:
CREATE TABLEnew_tblLIKEorig_tbl;
The copy is created using the same version of the table storage format as the original table.
CREATE TABLE ... LIKE does not preserve any
DATA DIRECTORY or INDEX
DIRECTORY table options that were specified for the
original table, or any foreign key definitions.
You can precede the SELECT by
IGNORE or REPLACE to
indicate how to handle rows that duplicate unique key values.
With IGNORE, new rows that duplicate an
existing row on a unique key value are discarded. With
REPLACE, new rows replace rows that have the
same unique key value. If neither IGNORE nor
REPLACE is specified, duplicate unique key
values result in an error.
To ensure that the binary log can be used to re-create the
original tables, MySQL does not allow concurrent inserts during
CREATE TABLE ... SELECT.
In some cases, MySQL silently changes column specifications
from those given in a CREATE TABLE or
ALTER TABLE statement. These might be
changes to a data type, to attributes associated with a data
type, or to an index specification.
Some silent column specification changes include modifications to attribute or index specifications:
TIMESTAMPdisplay sizes are discarded.Also note that
TIMESTAMPcolumns areNOT NULLby default.Columns that are part of a
PRIMARY KEYare madeNOT NULLeven if not declared that way.Trailing spaces are automatically deleted from
ENUMandSETmember values when the table is created.MySQL maps certain data types used by other SQL database vendors to MySQL types. See Section 11.7, “Using Data Types from Other Database Engines”.
If you include a
USINGclause to specify an index type that is not legal for a given storage engine, but there is another index type available that the engine can use without affecting query results, the engine uses the available type.
Possible data type changes are given in the following list. These occur only up to the versions listed. After that, an error occurs if a column cannot be created using the specified data type.
Before MySQL 5.0.3,
VARCHARcolumns with a length less than four are changed toCHAR.Before MySQL 5.0.3, if any column in a table has a variable length, the entire row becomes variable-length as a result. Therefore, if a table contains any variable-length columns (
VARCHAR,TEXT, orBLOB), allCHARcolumns longer than three characters are changed toVARCHARcolumns. This does not affect how you use the columns in any way; in MySQL,VARCHARis just a different way to store characters. MySQL performs this conversion because it saves space and makes table operations faster. See Chapter 14, Storage Engines.Before MySQL 5.0.3, a
CHARorVARCHARcolumn with a length specification greater than 255 is converted to the smallestTEXTtype that can hold values of the given length. For example,VARCHAR(500)is converted toTEXT, andVARCHAR(200000)is converted toMEDIUMTEXT. Similar conversions occur forBINARYandVARBINARY, except that they are converted to aBLOBtype.Note that these conversions result in a change in behavior with regard to treatment of trailing spaces.
As of MySQL 5.0.3, a
CHARorBINARYcolumn with a length specification greater than 255 is not silently converted. Instead, an error occurs. From MySQL 5.0.6 on, silent conversion ofVARCHARandVARBINARYcolumns with a length specification greater than 65,535 does not occur if strict SQL mode is enabled. Instead, an error occurs.Before MySQL 5.0.10, for a specification of
DECIMAL(, ifM,D)Mis not larger thanD, it is adjusted upward. For example,DECIMAL(10,10)becomesDECIMAL(11,10). As of MySQL 5.0.10,DECIMAL(10,10)is created as specified.
To see whether MySQL used a data type other than the one you
specified, issue a DESCRIBE or
SHOW CREATE TABLE statement after creating
or altering the table.
Certain other data type changes can occur if you compress a table using myisampack. See Section 14.1.3.3, “Compressed Table Characteristics”.
DROP {DATABASE | SCHEMA} [IF EXISTS] db_name
DROP DATABASE drops all tables in the
database and deletes the database. Be very
careful with this statement! To use DROP
DATABASE, you need the DROP
privilege on the database. DROP SCHEMA is a
synonym for DROP DATABASE as of MySQL 5.0.2.
Important: When a database is
dropped, user privileges on the database are
not automatically dropped. See
Section 13.5.1.3, “GRANT Syntax”.
IF EXISTS is used to prevent an error from
occurring if the database does not exist.
If you use DROP DATABASE on a symbolically
linked database, both the link and the original database are
deleted.
DROP DATABASE returns the number of tables
that were removed. This corresponds to the number of
.frm files removed.
The DROP DATABASE statement removes from the
given database directory those files and directories that MySQL
itself may create during normal operation:
All files with these extensions:
.BAK.DAT.HSH.MRG.MYD.MYI.TRG.TRN.db.frm.ibd.ndbAll subdirectories with names that consist of two hex digits
00-ff. These are subdirectories used forRAIDtables. (These directories are not removed as of MySQL 5.0, when support forRAIDtables was removed. You should convert any existingRAIDtables and remove these directories manually before upgrading to MySQL 5.0. See Section 2.4.16.2, “Upgrading from MySQL 4.1 to 5.0”.)The
db.optfile, if it exists.
If other files or directories remain in the database directory
after MySQL removes those just listed, the database directory
cannot be removed. In this case, you must remove any remaining
files or directories manually and issue the DROP
DATABASE statement again.
You can also drop databases with mysqladmin. See Section 8.10, “mysqladmin — Client for Administering a MySQL Server”.
DROP INDEXindex_nameONtbl_name
DROP INDEX drops the index named
index_name from the table
tbl_name. This statement is mapped to
an ALTER TABLE statement to drop the index.
See Section 13.1.2, “ALTER TABLE Syntax”.
DROP [TEMPORARY] TABLE [IF EXISTS]
tbl_name [, tbl_name] ...
[RESTRICT | CASCADE]
DROP TABLE removes one or more tables. You
must have the DROP privilege for each table.
All table data and the table definition are
removed, so be careful
with this statement! If any of the tables named in the argument
list do not exist, MySQL returns an error indicating by name
which non-existing tables it was unable to drop, but it also
drops all of the tables in the list that do exist.
Important: When a table is
dropped, user privileges on the table are
not automatically dropped. See
Section 13.5.1.3, “GRANT Syntax”.
Use IF EXISTS to prevent an error from
occurring for tables that do not exist. A
NOTE is generated for each non-existent table
when using IF EXISTS. See
Section 13.5.4.28, “SHOW WARNINGS Syntax”.
RESTRICT and CASCADE are
allowed to make porting easier. In MySQL 5.0, they
do nothing.
Note: DROP
TABLE automatically commits the current active
transaction, unless you use the TEMPORARY
keyword.
The TEMPORARY keyword has the following
effects:
The statement drops only
TEMPORARYtables.The statement does not end an ongoing transaction.
No access rights are checked. (A
TEMPORARYtable is visible only to the client that created it, so no check is necessary.)
Using TEMPORARY is a good way to ensure that
you do not accidentally drop a non-TEMPORARY
table.
RENAME TABLEtbl_nameTOnew_tbl_name[,tbl_name2TOnew_tbl_name2] ...
This statement renames one or more tables.
The rename operation is done atomically, which means that no
other thread can access any of the tables while the rename is
running. For example, if you have an existing table
old_table, you can create another table
new_table that has the same structure but is
empty, and then replace the existing table with the empty one as
follows (assuming that backup_table does not
already exist):
CREATE TABLE new_table (...); RENAME TABLE old_table TO backup_table, new_table TO old_table;
If the statement renames more than one table, renaming
operations are done from left to right. If you want to swap two
table names, you can do so like this (assuming that
tmp_table does not already exist):
RENAME TABLE old_table TO tmp_table,
new_table TO old_table,
tmp_table TO new_table;
As long as two databases are on the same filesystem, you can use
RENAME TABLE to move a table from one
database to another:
RENAME TABLEcurrent_db.tbl_nameTOother_db.tbl_name;
Beginning with MySQL 5.0.2, if there are any triggers associated
with a table which is moved to a different database using
RENAME TABLE, then the statement fails with
the error Trigger in wrong schema.
As of MySQL 5.0.14, RENAME TABLE also works
for views, as long as you do not try to rename a view into a
different database.
Any privileges granted specifically for the renamed table or view are not migrated to the new name. They must be changed manually.
When you execute RENAME, you cannot have any
locked tables or active transactions. You must also have the
ALTER and DROP privileges
on the original table, and the CREATE and
INSERT privileges on the new table.
If MySQL encounters any errors in a multiple-table rename, it does a reverse rename for all renamed tables to return everything to its original state.
Single-table syntax:
DELETE [LOW_PRIORITY] [QUICK] [IGNORE] FROMtbl_name[WHEREwhere_condition] [ORDER BY ...] [LIMITrow_count]
Multiple-table syntax:
DELETE [LOW_PRIORITY] [QUICK] [IGNORE]
tbl_name[.*] [, tbl_name[.*]] ...
FROM table_references
[WHERE where_condition]
Or:
DELETE [LOW_PRIORITY] [QUICK] [IGNORE]
FROM tbl_name[.*] [, tbl_name[.*]] ...
USING table_references
[WHERE where_condition]
For the single-table syntax, the DELETE
statement deletes rows from tbl_name
and returns the number of rows deleted. The
WHERE clause, if given, specifies the
conditions that identify which rows to delete. With no
WHERE clause, all rows are deleted. If the
ORDER BY clause is specified, the rows are
deleted in the order that is specified. The
LIMIT clause places a limit on the number of
rows that can be deleted.
For the multiple-table syntax, DELETE deletes
from each tbl_name the rows that
satisfy the conditions. In this case, ORDER
BY and LIMIT cannot be used.
where_condition is an expression that
evaluates to true for each row to be deleted. It is specified as
described in Section 13.2.7, “SELECT Syntax”.
As stated, a DELETE statement with no
WHERE clause deletes all rows. A faster way
to do this, when you do not want to know the number of deleted
rows, is to use TRUNCATE TABLE. See
Section 13.2.9, “TRUNCATE Syntax”.
If you delete the row containing the maximum value for an
AUTO_INCREMENT column, the value is reused
later for a BDB table, but not for a
MyISAM or InnoDB table. If
you delete all rows in the table with DELETE FROM
(without a
tbl_nameWHERE clause) in
AUTOCOMMIT mode, the sequence starts over for
all storage engines except InnoDB and
MyISAM. There are some exceptions to this
behavior for InnoDB tables, as discussed in
Section 14.2.6.3, “How AUTO_INCREMENT Columns Work in
InnoDB”.
For MyISAM and BDB tables,
you can specify an AUTO_INCREMENT secondary
column in a multiple-column key. In this case, reuse of values
deleted from the top of the sequence occurs even for
MyISAM tables. See
Section 3.6.9, “Using AUTO_INCREMENT”.
The DELETE statement supports the following
modifiers:
If you specify
LOW_PRIORITY, the server delays execution of theDELETEuntil no other clients are reading from the table. This affects only storage engines that use only table-level locking (MyISAM,MEMORY,MERGE).For
MyISAMtables, if you use theQUICKkeyword, the storage engine does not merge index leaves during delete, which may speed up some kinds of delete operations.The
IGNOREkeyword causes MySQL to ignore all errors during the process of deleting rows. (Errors encountered during the parsing stage are processed in the usual manner.) Errors that are ignored due to the use ofIGNOREare returned as warnings.
The speed of delete operations may also be affected by factors
discussed in Section 7.2.19, “Speed of DELETE Statements”.
In MyISAM tables, deleted rows are maintained
in a linked list and subsequent INSERT
operations reuse old row positions. To reclaim unused space and
reduce file sizes, use the OPTIMIZE TABLE
statement or the myisamchk utility to
reorganize tables. OPTIMIZE TABLE is easier,
but myisamchk is faster. See
Section 13.5.2.5, “OPTIMIZE TABLE Syntax”, and
Section 8.5, “myisamchk — MyISAM Table-Maintenance Utility”.
The QUICK modifier affects whether index
leaves are merged for delete operations. DELETE
QUICK is most useful for applications where index
values for deleted rows are replaced by similar index values
from rows inserted later. In this case, the holes left by
deleted values are reused.
DELETE QUICK is not useful when deleted
values lead to underfilled index blocks spanning a range of
index values for which new inserts occur again. In this case,
use of QUICK can lead to wasted space in the
index that remains unreclaimed. Here is an example of such a
scenario:
Create a table that contains an indexed
AUTO_INCREMENTcolumn.Insert many rows into the table. Each insert results in an index value that is added to the high end of the index.
Delete a block of rows at the low end of the column range using
DELETE QUICK.
In this scenario, the index blocks associated with the deleted
index values become underfilled but are not merged with other
index blocks due to the use of QUICK. They
remain underfilled when new inserts occur, because new rows do
not have index values in the deleted range. Furthermore, they
remain underfilled even if you later use
DELETE without QUICK,
unless some of the deleted index values happen to lie in index
blocks within or adjacent to the underfilled blocks. To reclaim
unused index space under these circumstances, use
OPTIMIZE TABLE.
If you are going to delete many rows from a table, it might be
faster to use DELETE QUICK followed by
OPTIMIZE TABLE. This rebuilds the index
rather than performing many index block merge operations.
The MySQL-specific LIMIT
option to
row_countDELETE tells the server the maximum number of
rows to be deleted before control is returned to the client.
This can be used to ensure that a given
DELETE statement does not take too much time.
You can simply repeat the DELETE statement
until the number of affected rows is less than the
LIMIT value.
If the DELETE statement includes an
ORDER BY clause, the rows are deleted in the
order specified by the clause. This is really useful only in
conjunction with LIMIT. For example, the
following statement finds rows matching the
WHERE clause, sorts them by
timestamp_column, and deletes the first
(oldest) one:
DELETE FROM somelog WHERE user = 'jcole' ORDER BY timestamp_column LIMIT 1;
You can specify multiple tables in a DELETE
statement to delete rows from one or more tables depending on
the particular condition in the WHERE clause.
However, you cannot use ORDER BY or
LIMIT in a multiple-table
DELETE. The
table_references clause lists the
tables involved in the join. Its syntax is described in
Section 13.2.7.1, “JOIN Syntax”.
For the first multiple-table syntax, only matching rows from the
tables listed before the FROM clause are
deleted. For the second multiple-table syntax, only matching
rows from the tables listed in the FROM
clause (before the USING clause) are deleted.
The effect is that you can delete rows from many tables at the
same time and have additional tables that are used only for
searching:
DELETE t1, t2 FROM t1, t2, t3 WHERE t1.id=t2.id AND t2.id=t3.id;
Or:
DELETE FROM t1, t2 USING t1, t2, t3 WHERE t1.id=t2.id AND t2.id=t3.id;
These statements use all three tables when searching for rows to
delete, but delete matching rows only from tables
t1 and t2.
The preceding examples show inner joins that use the comma
operator, but multiple-table DELETE
statements can use any type of join allowed in
SELECT statements, such as LEFT
JOIN.
The syntax allows .* after the table names
for compatibility with Access.
If you use a multiple-table DELETE statement
involving InnoDB tables for which there are
foreign key constraints, the MySQL optimizer might process
tables in an order that differs from that of their parent/child
relationship. In this case, the statement fails and rolls back.
Instead, you should delete from a single table and rely on the
ON DELETE capabilities that
InnoDB provides to cause the other tables to
be modified accordingly.
Note: If you provide an alias for a table, you must use the alias when referring to the table:
DELETE t1 FROM test AS t1, test2 WHERE ...
Cross-database deletes are supported for multiple-table deletes, but in this case, you must refer to the tables without using aliases. For example:
DELETE test1.tmp1, test2.tmp2 FROM test1.tmp1, test2.tmp2 WHERE ...
Currently, you cannot delete from a table and select from the same table in a subquery.
DOexpr[,expr] ...
DO executes the expressions but does not
return any results. In most respects, DO is
shorthand for SELECT , but has the advantage that it is slightly faster
when you do not care about the result.
expr,
...
DO is useful primarily with functions that
have side effects, such as RELEASE_LOCK().
HANDLERtbl_nameOPEN [ ASalias] HANDLERtbl_nameREADindex_name{ = | >= | <= | < } (value1,value2,...) [ WHEREwhere_condition] [LIMIT ... ] HANDLERtbl_nameREADindex_name{ FIRST | NEXT | PREV | LAST } [ WHEREwhere_condition] [LIMIT ... ] HANDLERtbl_nameREAD { FIRST | NEXT } [ WHEREwhere_condition] [LIMIT ... ] HANDLERtbl_nameCLOSE
The HANDLER statement provides direct access
to table storage engine interfaces. It is available for
MyISAM and InnoDB tables.
The HANDLER ... OPEN statement opens a table,
making it accessible via subsequent HANDLER ...
READ statements. This table object is not shared by
other threads and is not closed until the thread calls
HANDLER ... CLOSE or the thread terminates.
If you open the table using an alias, further references to the
open table with other HANDLER statements must
use the alias rather than the table name.
The first HANDLER ... READ syntax fetches a
row where the index specified satisfies the given values and the
WHERE condition is met. If you have a
multiple-column index, specify the index column values as a
comma-separated list. Either specify values for all the columns
in the index, or specify values for a leftmost prefix of the
index columns. Suppose that an index my_idx
includes three columns named col_a,
col_b, and col_c, in that
order. The HANDLER statement can specify
values for all three columns in the index, or for the columns in
a leftmost prefix. For example:
HANDLER ... READ my_idx = (col_a_val,col_b_val,col_c_val) ... HANDLER ... READ my_idx = (col_a_val,col_b_val) ... HANDLER ... READ my_idx = (col_a_val) ...
To employ the HANDLER interface to refer to a
table's PRIMARY KEY, use the quoted
identifier `PRIMARY`:
HANDLER tbl_name READ `PRIMARY` ...
The second HANDLER ... READ syntax fetches a
row from the table in index order that matches the
WHERE condition.
The third HANDLER ... READ syntax fetches a
row from the table in natural row order that matches the
WHERE condition. It is faster than
HANDLER when a full
table scan is desired. Natural row order is the order in which
rows are stored in a tbl_name READ
index_nameMyISAM table data file.
This statement works for InnoDB tables as
well, but there is no such concept because there is no separate
data file.
Without a LIMIT clause, all forms of
HANDLER ... READ fetch a single row if one is
available. To return a specific number of rows, include a
LIMIT clause. It has the same syntax as for
the SELECT statement. See
Section 13.2.7, “SELECT Syntax”.
HANDLER ... CLOSE closes a table that was
opened with HANDLER ... OPEN.
HANDLER is a somewhat low-level statement.
For example, it does not provide consistency. That is,
HANDLER ... OPEN does
not take a snapshot of the table, and does
not lock the table. This means that after a
HANDLER ... OPEN statement is issued, table
data can be modified (by the current thread or other threads)
and these modifications might be only partially visible to
HANDLER ... NEXT or HANDLER ...
PREV scans.
There are several reasons to use the HANDLER
interface instead of normal SELECT
statements:
HANDLERis faster thanSELECT:A designated storage engine handler object is allocated for the
HANDLER ... OPEN. The object is reused for subsequentHANDLERstatements for that table; it need not be reinitialized for each one.There is less parsing involved.
There is no optimizer or query-checking overhead.
The table does not have to be locked between two handler requests.
The handler interface does not have to provide a consistent look of the data (for example, dirty reads are allowed), so the storage engine can use optimizations that
SELECTdoes not normally allow.
For applications that use a low-level
ISAM-like interface,HANDLERmakes it much easier to port them to MySQL.HANDLERenables you to traverse a database in a manner that is difficult (or even impossible) to accomplish withSELECT. TheHANDLERinterface is a more natural way to look at data when working with applications that provide an interactive user interface to the database.
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name [(col_name,...)]
VALUES ({expr | DEFAULT},...),(...),...
[ ON DUPLICATE KEY UPDATE col_name=expr, ... ]
Or:
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
SET col_name={expr | DEFAULT}, ...
[ ON DUPLICATE KEY UPDATE col_name=expr, ... ]
Or:
INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name [(col_name,...)]
SELECT ...
[ ON DUPLICATE KEY UPDATE col_name=expr, ... ]
INSERT inserts new rows into an existing
table. The INSERT ... VALUES and
INSERT ... SET forms of the statement insert
rows based on explicitly specified values. The INSERT
... SELECT form inserts rows selected from another
table or tables. INSERT ... SELECT is
discussed further in Section 13.2.4.1, “INSERT ... SELECT Syntax”.
You can use REPLACE instead of
INSERT to overwrite old rows.
REPLACE is the counterpart to INSERT
IGNORE in the treatment of new rows that contain
unique key values that duplicate old rows: The new rows are used
to replace the old rows rather than being discarded. See
Section 13.2.6, “REPLACE Syntax”.
tbl_name is the table into which rows
should be inserted. The columns for which the statement provides
values can be specified as follows:
You can provide a comma-separated list of column names following the table name. In this case, a value for each named column must be provided by the
VALUESlist or theSELECTstatement.If you do not specify a list of column names for
INSERT ... VALUESorINSERT ... SELECT, values for every column in the table must be provided by theVALUESlist or theSELECTstatement. If you do not know the order of the columns in the table, useDESCRIBEto find out.tbl_nameThe
SETclause indicates the column names explicitly.
Column values can be given in several ways:
If you are not running in strict SQL mode, any column not explicitly given a value is set to its default (explicit or implicit) value. For example, if you specify a column list that does not name all the columns in the table, unnamed columns are set to their default values. Default value assignment is described in Section 11.1.4, “Data Type Default Values”. See also Section 1.9.6.2, “Constraints on Invalid Data”.
If you want an
INSERTstatement to generate an error unless you explicitly specify values for all columns that do not have a default value, you should use strict mode. See Section 5.2.6, “SQL Modes”.Use the keyword
DEFAULTto set a column explicitly to its default value. This makes it easier to writeINSERTstatements that assign values to all but a few columns, because it enables you to avoid writing an incompleteVALUESlist that does not include a value for each column in the table. Otherwise, you would have to write out the list of column names corresponding to each value in theVALUESlist.You can also use
DEFAULT(as a more general form that can be used in expressions to produce a given column's default value.col_name)If both the column list and the
VALUESlist are empty,INSERTcreates a row with each column set to its default value:INSERT INTO
tbl_name() VALUES();In strict mode, an error occurs if any column doesn't have a default value. Otherwise, MySQL uses the implicit default value for any column that does not have an explicitly defined default.
You can specify an expression
exprto provide a column value. This might involve type conversion if the type of the expression does not match the type of the column, and conversion of a given value can result in different inserted values depending on the data type. For example, inserting the string'1999.0e-2'into anINT,FLOAT,DECIMAL(10,6), orYEARcolumn results in the values1999,19.9921,19.992100, and1999being inserted, respectively. The reason the value stored in theINTandYEARcolumns is1999is that the string-to-integer conversion looks only at as much of the initial part of the string as may be considered a valid integer or year. For the floating-point and fixed-point columns, the string-to-floating-point conversion considers the entire string a valid floating-point value.An expression
exprcan refer to any column that was set earlier in a value list. For example, you can do this because the value forcol2refers tocol1, which has previously been assigned:INSERT INTO
tbl_name(col1,col2) VALUES(15,col1*2);But the following is not legal, because the value for
col1refers tocol2, which is assigned aftercol1:INSERT INTO
tbl_name(col1,col2) VALUES(col2*2,15);One exception involves columns that contain
AUTO_INCREMENTvalues. Because theAUTO_INCREMENTvalue is generated after other value assignments, any reference to anAUTO_INCREMENTcolumn in the assignment returns a0.
INSERT statements that use
VALUES syntax can insert multiple rows. To do
this, include multiple lists of column values, each enclosed
within parentheses and separated by commas. Example:
INSERT INTO tbl_name (a,b,c) VALUES(1,2,3),(4,5,6),(7,8,9);
The values list for each row must be enclosed within parentheses. The following statement is illegal because the number of values in the list does not match the number of column names:
INSERT INTO tbl_name (a,b,c) VALUES(1,2,3,4,5,6,7,8,9);
The rows-affected value for an INSERT can be
obtained using the mysql_affected_rows() C
API function. See Section 22.2.3.1, “mysql_affected_rows()”.
If you use an INSERT ... VALUES statement
with multiple value lists or INSERT ...
SELECT, the statement returns an information string in
this format:
Records: 100 Duplicates: 0 Warnings: 0
Records indicates the number of rows
processed by the statement. (This is not necessarily the number
of rows actually inserted because Duplicates
can be non-zero.) Duplicates indicates the
number of rows that could not be inserted because they would
duplicate some existing unique index value.
Warnings indicates the number of attempts to
insert column values that were problematic in some way. Warnings
can occur under any of the following conditions:
Inserting
NULLinto a column that has been declaredNOT NULL. For multiple-rowINSERTstatements orINSERT INTO ... SELECTstatements, the column is set to the implicit default value for the column data type. This is0for numeric types, the empty string ('') for string types, and the “zero” value for date and time types.INSERT INTO ... SELECTstatements are handled the same way as multiple-row inserts because the server does not examine the result set from theSELECTto see whether it returns a single row. (For a single-rowINSERT, no warning occurs whenNULLis inserted into aNOT NULLcolumn. Instead, the statement fails with an error.)Setting a numeric column to a value that lies outside the column's range. The value is clipped to the closest endpoint of the range.
Assigning a value such as
'10.34 a'to a numeric column. The trailing non-numeric text is stripped off and the remaining numeric part is inserted. If the string value has no leading numeric part, the column is set to0.Inserting a string into a string column (
CHAR,VARCHAR,TEXT, orBLOB) that exceeds the column's maximum length. The value is truncated to the column's maximum length.Inserting a value into a date or time column that is illegal for the data type. The column is set to the appropriate zero value for the type.
If you are using the C API, the information string can be
obtained by invoking the mysql_info()
function. See Section 22.2.3.35, “mysql_info()”.
If INSERT inserts a row into a table that has
an AUTO_INCREMENT column, you can find the
value used for that column by using the SQL
LAST_INSERT_ID() function. From within the C
API, use the mysql_insert_id() function.
However, you should note that the two functions do not always
behave identically. The behavior of INSERT
statements with respect to AUTO_INCREMENT
columns is discussed further in
Section 12.10.3, “Information Functions”, and
Section 22.2.3.37, “mysql_insert_id()”.
The INSERT statement supports the following
modifiers:
If you use the
DELAYEDkeyword, the server puts the row or rows to be inserted into a buffer, and the client issuing theINSERT DELAYEDstatement can then continue immediately. If the table is in use, the server holds the rows. When the table is free, the server begins inserting rows, checking periodically to see whether there are any new read requests for the table. If there are, the delayed row queue is suspended until the table becomes free again. See Section 13.2.4.2, “INSERT DELAYEDSyntax”.DELAYEDis ignored withINSERT ... SELECTorINSERT ... ON DUPLICATE KEY UPDATE.If you use the
LOW_PRIORITYkeyword, execution of theINSERTis delayed until no other clients are reading from the table. This includes other clients that began reading while existing clients are reading, and while theINSERT LOW_PRIORITYstatement is waiting. It is possible, therefore, for a client that issues anINSERT LOW_PRIORITYstatement to wait for a very long time (or even forever) in a read-heavy environment. (This is in contrast toINSERT DELAYED, which lets the client continue at once. Note thatLOW_PRIORITYshould normally not be used withMyISAMtables because doing so disables concurrent inserts. See Section 7.3.3, “Concurrent Inserts”.If you specify
HIGH_PRIORITY, it overrides the effect of the--low-priority-updatesoption if the server was started with that option. It also causes concurrent inserts not to be used. See Section 7.3.3, “Concurrent Inserts”.LOW_PRIORITYandHIGH_PRIORITYaffect only storage engines that use only table-level locking (MyISAM,MEMORY,MERGE).If you use the
IGNOREkeyword, errors that occur while executing theINSERTstatement are treated as warnings instead. For example, withoutIGNORE, a row that duplicates an existingUNIQUEindex orPRIMARY KEYvalue in the table causes a duplicate-key error and the statement is aborted. WithIGNORE, the row still is not inserted, but no error is issued. Data conversions that would trigger errors abort the statement ifIGNOREis not specified. WithIGNORE, invalid values are adjusted to the closest values and inserted; warnings are produced but the statement does not abort. You can determine with themysql_info()C API function how many rows were actually inserted into the table.If you specify
ON DUPLICATE KEY UPDATE, and a row is inserted that would cause a duplicate value in aUNIQUEindex orPRIMARY KEY, anUPDATEof the old row is performed. See Section 13.2.4.3, “INSERT ... ON DUPLICATE KEY UPDATESyntax”.
INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name [(col_name,...)]
SELECT ...
[ ON DUPLICATE KEY UPDATE col_name=expr, ... ]
With INSERT ... SELECT, you can quickly
insert many rows into a table from one or many tables. For
example:
INSERT INTO tbl_temp2 (fld_id) SELECT tbl_temp1.fld_order_id FROM tbl_temp1 WHERE tbl_temp1.fld_order_id > 100;
The following conditions hold for a INSERT ...
SELECT statements:
Specify
IGNOREto ignore rows that would cause duplicate-key violations.DELAYEDis ignored withINSERT ... SELECT.The target table of the
INSERTstatement may appear in theFROMclause of theSELECTpart of the query. (This was not possible in some older versions of MySQL.) In this case, MySQL creates a temporary table to hold the rows from theSELECTand then inserts those rows into the target table.AUTO_INCREMENTcolumns work as usual.To ensure that the binary log can be used to re-create the original tables, MySQL does not allow concurrent inserts for
INSERT ... SELECTstatements.Currently, you cannot insert into a table and select from the same table in a subquery.
To avoid ambigious column reference problems when the
SELECTand theINSERTrefer to the same table, provide a unique alias for each table used in theSELECTpart, and qualify column names in that part with the appropriate alias.
In the values part of ON DUPLICATE KEY
UPDATE, you can refer to columns in other tables, as
long as you do not use GROUP BY in the
SELECT part. One side effect is that you
must qualify non-unique column names in the values part.
INSERT DELAYED ...
The DELAYED option for the
INSERT statement is a MySQL extension to
standard SQL that is very useful if you have clients that
cannot or need not wait for the INSERT to
complete. This is a common situation when you use MySQL for
logging and you also periodically run
SELECT and UPDATE
statements that take a long time to complete.
When a client uses INSERT DELAYED, it gets
an okay from the server at once, and the row is queued to be
inserted when the table is not in use by any other thread.
Another major benefit of using INSERT
DELAYED is that inserts from many clients are
bundled together and written in one block. This is much faster
than performing many separate inserts.
Note that INSERT DELAYED is slower than a
normal INSERT if the table is not otherwise
in use. There is also the additional overhead for the server
to handle a separate thread for each table for which there are
delayed rows. This means that you should use INSERT
DELAYED only when you are really sure that you need
it.
The queued rows are held only in memory until they are
inserted into the table. This means that if you terminate
mysqld forcibly (for example, with
kill -9) or if mysqld
dies unexpectedly, any queued rows that have not
been written to disk are lost.
There are some constraints on the use of
DELAYED:
INSERT DELAYEDworks only withMyISAM,MEMORY, andARCHIVEtables. See Section 14.1, “TheMyISAMStorage Engine”, Section 14.4, “TheMEMORY(HEAP) Storage Engine”, and Section 14.8, “TheARCHIVEStorage Engine”.For
MyISAMtables, if there are no free blocks in the middle of the data file, concurrentSELECTandINSERTstatements are supported. Under these circumstances, you very seldom need to useINSERT DELAYEDwithMyISAM.INSERT DELAYEDshould be used only forINSERTstatements that specify value lists. The server ignoresDELAYEDforINSERT ... SELECTorINSERT ... ON DUPLICATE KEY UPDATEstatements.Because the
INSERT DELAYEDstatement returns immediately, before the rows are inserted, you cannot useLAST_INSERT_ID()to get theAUTO_INCREMENTvalue that the statement might generate.DELAYEDrows are not visible toSELECTstatements until they actually have been inserted.DELAYEDis ignored on slave replication servers because it could cause the slave to have different data than the master.Pending
INSERT DELAYEDstatements are lost if a table is write locked andALTER TABLEis used to modify the table structure.INSERT DELAYEDis not supported for views.
The following describes in detail what happens when you use
the DELAYED option to
INSERT or REPLACE. In
this description, the “thread” is the thread that
received an INSERT DELAYED statement and
“handler” is the thread that handles all
INSERT DELAYED statements for a particular
table.
When a thread executes a
DELAYEDstatement for a table, a handler thread is created to process allDELAYEDstatements for the table, if no such handler already exists.The thread checks whether the handler has previously acquired a
DELAYEDlock; if not, it tells the handler thread to do so. TheDELAYEDlock can be obtained even if other threads have aREADorWRITElock on the table. However, the handler waits for allALTER TABLElocks orFLUSH TABLESstatements to finish, to ensure that the table structure is up to date.The thread executes the
INSERTstatement, but instead of writing the row to the table, it puts a copy of the final row into a queue that is managed by the handler thread. Any syntax errors are noticed by the thread and reported to the client program.The client cannot obtain from the server the number of duplicate rows or the
AUTO_INCREMENTvalue for the resulting row, because theINSERTreturns before the insert operation has been completed. (If you use the C API, themysql_info()function does not return anything meaningful, for the same reason.)The binary log is updated by the handler thread when the row is inserted into the table. In case of multiple-row inserts, the binary log is updated when the first row is inserted.
Each time that
delayed_insert_limitrows are written, the handler checks whether anySELECTstatements are still pending. If so, it allows these to execute before continuing.When the handler has no more rows in its queue, the table is unlocked. If no new
INSERT DELAYEDstatements are received withindelayed_insert_timeoutseconds, the handler terminates.If more than
delayed_queue_sizerows are pending in a specific handler queue, the thread requestingINSERT DELAYEDwaits until there is room in the queue. This is done to ensure that mysqld does not use all memory for the delayed memory queue.The handler thread shows up in the MySQL process list with
delayed_insertin theCommandcolumn. It is killed if you execute aFLUSH TABLESstatement or kill it withKILL. However, before exiting, it first stores all queued rows into the table. During this time it does not accept any newthread_idINSERTstatements from other threads. If you execute anINSERT DELAYEDstatement after this, a new handler thread is created.Note that this means that
INSERT DELAYEDstatements have higher priority than normalINSERTstatements if there is anINSERT DELAYEDhandler running. Other update statements have to wait until theINSERT DELAYEDqueue is empty, someone terminates the handler thread (withKILL), or someone executes athread_idFLUSH TABLES.The following status variables provide information about
INSERT DELAYEDstatements:Status Variable Meaning Delayed_insert_threadsNumber of handler threads Delayed_writesNumber of rows written with INSERT DELAYEDNot_flushed_delayed_rowsNumber of rows waiting to be written You can view these variables by issuing a
SHOW STATUSstatement or by executing a mysqladmin extended-status command.
If you specify ON DUPLICATE KEY UPDATE, and
a row is inserted that would cause a duplicate value in a
UNIQUE index or PRIMARY
KEY, an UPDATE of the old row is
performed. For example, if column a is
declared as UNIQUE and contains the value
1, the following two statements have
identical effect:
INSERT INTO table (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c=c+1; UPDATE table SET c=c+1 WHERE a=1;
The rows-affected value is 1 if the row is inserted as a new record and 2 if an existing record is updated.
If column b is also unique, the
INSERT is equivalent to this
UPDATE statement instead:
UPDATE table SET c=c+1 WHERE a=1 OR b=2 LIMIT 1;
If a=1 OR b=2 matches several rows, only
one row is updated. In general, you
should try to avoid using an ON DUPLICATE
KEY clause on tables with multiple unique indexes.
You can use the
VALUES(
function in the col_name)UPDATE clause to refer to
column values from the INSERT portion of
the INSERT ... UPDATE statement. In other
words,
VALUES(
in the col_name)UPDATE clause refers to the value of
col_name that would be inserted,
had no duplicate-key conflict occurred. This function is
especially useful in multiple-row inserts. The
VALUES() function is meaningful only in
INSERT ... UPDATE statements and returns
NULL otherwise. Example:
INSERT INTO table (a,b,c) VALUES (1,2,3),(4,5,6) ON DUPLICATE KEY UPDATE c=VALUES(a)+VALUES(b);
That statement is identical to the following two statements:
INSERT INTO table (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c=3; INSERT INTO table (a,b,c) VALUES (4,5,6) ON DUPLICATE KEY UPDATE c=9;
If a table contains an AUTO_INCREMENT
column and INSERT ... UPDATE inserts a row,
the LAST_INSERT_ID() function returns the
AUTO_INCREMENT value. If the statement
updates a row instead, LAST_INSERT_ID() is
not meaningful. However, you can work around this by using
LAST_INSERT_ID(.
Suppose that expr)id is the
AUTO_INCREMENT column. To make
LAST_INSERT_ID() meaningful for updates,
insert rows as follows:
INSERT INTO table (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE id=LAST_INSERT_ID(id), c=3;
The DELAYED option is ignored when you use
ON DUPLICATE KEY UPDATE.
LOAD DATA [LOW_PRIORITY | CONCURRENT] [LOCAL] INFILE 'file_name' [REPLACE | IGNORE] INTO TABLEtbl_name[CHARACTER SETcharset_name] [FIELDS [TERMINATED BY 'string'] [[OPTIONALLY] ENCLOSED BY 'char'] [ESCAPED BY 'char'] ] [LINES [STARTING BY 'string'] [TERMINATED BY 'string'] ] [IGNOREnumberLINES] [(col_name_or_user_var,...)] [SETcol_name=expr,...]
The LOAD DATA INFILE statement reads rows
from a text file into a table at a very high speed. The filename
must be given as a literal string.
LOAD DATA INFILE is the complement of
SELECT ... INTO OUTFILE. (See
Section 13.2.7, “SELECT Syntax”.) To write data from a table to a file,
use SELECT ... INTO OUTFILE. To read the file
back into a table, use LOAD DATA INFILE. The
syntax of the FIELDS and
LINES clauses is the same for both
statements. Both clauses are optional, but
FIELDS must precede LINES
if both are specified.
For more information about the efficiency of
INSERT versus LOAD DATA
INFILE and speeding up LOAD DATA
INFILE, see Section 7.2.17, “Speed of INSERT Statements”.
The character set indicated by the
character_set_database system variable is
used to interpret the information in the file. SET
NAMES and the setting of
character_set_client do not affect
interpretation of input. Beginning with MySQL 5.0.38, if the
contents of the input file use a character set that differs from
the default, it is possible (and usually preferable) to use the
CHARACTER SET clause to specify the character
set of the file.
Note that it is currently not possible to load data files that
use the ucs2 character set.
As of MySQL 5.0.19, the
character_set_filesystem system variable
controls the interpretation of the filename.
You can also load data files by using the
mysqlimport utility; it operates by sending a
LOAD DATA INFILE statement to the server. The
--local option causes
mysqlimport to read data files from the
client host. You can specify the --compress
option to get better performance over slow networks if the
client and server support the compressed protocol. See
Section 8.15, “mysqlimport — A Data Import Program”.
If you use LOW_PRIORITY, execution of the
LOAD DATA statement is delayed until no other
clients are reading from the table. This affects only storage
engines that use only table-level locking
(MyISAM, MEMORY,
MERGE).
If you specify CONCURRENT with a
MyISAM table that satisfies the condition for
concurrent inserts (that is, it contains no free blocks in the
middle), other threads can retrieve data from the table while
LOAD DATA is executing. Using this option
affects the performance of LOAD DATA a bit,
even if no other thread is using the table at the same time.
The LOCAL keyword, if specified, is
interpreted with respect to the client end of the connection:
If
LOCALis specified, the file is read by the client program on the client host and sent to the server. The file can be given as a full pathname to specify its exact location. If given as a relative pathname, the name is interpreted relative to the directory in which the client program was started.If
LOCALis not specified, the file must be located on the server host and is read directly by the server. The server uses the following rules to locate the file:If the filename is an absolute pathname, the server uses it as given.
If the filename is a relative pathname with one or more leading components, the server searches for the file relative to the server's data directory.
If a filename with no leading components is given, the server looks for the file in the database directory of the default database.
Note that, in the non-LOCAL case, these rules
mean that a file named as ./myfile.txt is
read from the server's data directory, whereas the file named as
myfile.txt is read from the database
directory of the default database. For example, if
db1 is the default database, the following
LOAD DATA statement reads the file
data.txt from the database directory for
db1, even though the statement explicitly
loads the file into a table in the db2
database:
LOAD DATA INFILE 'data.txt' INTO TABLE db2.my_table;
Windows pathnames are specified using forward slashes rather than backslashes. If you do use backslashes, you must double them.
For security reasons, when reading text files located on the
server, the files must either reside in the database directory
or be readable by all. Also, to use LOAD DATA
INFILE on server files, you must have the
FILE privilege. See
Section 5.7.3, “Privileges Provided by MySQL”.
Using LOCAL is a bit slower than letting the
server access the files directly, because the contents of the
file must be sent over the connection by the client to the
server. On the other hand, you do not need the
FILE privilege to load local files.
LOCAL works only if your server and your
client both have been enabled to allow it. For example, if
mysqld was started with
--local-infile=0, LOCAL does
not work. See Section 5.6.4, “Security Issues with LOAD DATA LOCAL”.
On Unix, if you need LOAD DATA to read from a
pipe, you can use the following technique (here we load the
listing of the / directory into a table):
mkfifo /mysql/db/x/x chmod 666 /mysql/db/x/x find / -ls > /mysql/db/x/x & mysql -e "LOAD DATA INFILE 'x' INTO TABLE x" x
Note that you must run the command that generates the data to be loaded and the mysql commands either on separate terminals, or run the data generation process in the background (as shown in the preceding example). If you do not do this, the pipe will block until data is read by the mysql process.
The REPLACE and IGNORE
keywords control handling of input rows that duplicate existing
rows on unique key values:
If you specify
REPLACE, input rows replace existing rows. In other words, rows that have the same value for a primary key or unique index as an existing row. See Section 13.2.6, “REPLACESyntax”.If you specify
IGNORE, input rows that duplicate an existing row on a unique key value are skipped. If you do not specify either option, the behavior depends on whether theLOCALkeyword is specified. WithoutLOCAL, an error occurs when a duplicate key value is found, and the rest of the text file is ignored. WithLOCAL, the default behavior is the same as ifIGNOREis specified; this is because the server has no way to stop transmission of the file in the middle of the operation.
If you want to ignore foreign key constraints during the load
operation, you can issue a SET
FOREIGN_KEY_CHECKS=0 statement before executing
LOAD DATA.
If you use LOAD DATA INFILE on an empty
MyISAM table, all non-unique indexes are
created in a separate batch (as for REPAIR
TABLE). Normally, this makes LOAD DATA
INFILE much faster when you have many indexes. In some
extreme cases, you can create the indexes even faster by turning
them off with ALTER TABLE ... DISABLE KEYS
before loading the file into the table and using ALTER
TABLE ... ENABLE KEYS to re-create the indexes after
loading the file. See Section 7.2.17, “Speed of INSERT Statements”.
For both the LOAD DATA INFILE and
SELECT ... INTO OUTFILE statements, the
syntax of the FIELDS and
LINES clauses is the same. Both clauses are
optional, but FIELDS must precede
LINES if both are specified.
If you specify a FIELDS clause, each of its
subclauses (TERMINATED BY,
[OPTIONALLY] ENCLOSED BY, and
ESCAPED BY) is also optional, except that you
must specify at least one of them.
If you specify no FIELDS clause, the defaults
are the same as if you had written this:
FIELDS TERMINATED BY '\t' ENCLOSED BY '' ESCAPED BY '\\'
If you specify no LINES clause, the defaults
are the same as if you had written this:
LINES TERMINATED BY '\n' STARTING BY ''
In other words, the defaults cause LOAD DATA
INFILE to act as follows when reading input:
Look for line boundaries at newlines.
Do not skip over any line prefix.
Break lines into fields at tabs.
Do not expect fields to be enclosed within any quoting characters.
Interpret occurrences of tab, newline, or ‘
\’ preceded by ‘\’ as literal characters that are part of field values.
Conversely, the defaults cause SELECT ... INTO
OUTFILE to act as follows when writing output:
Write tabs between fields.
Do not enclose fields within any quoting characters.
Use ‘
\’ to escape instances of tab, newline, or ‘\’ that occur within field values.Write newlines at the ends of lines.
Backslash is the MySQL escape character within strings, so to
write FIELDS ESCAPED BY '\\', you must
specify two backslashes for the value to be interpreted as a
single backslash.
Note: If you have generated the
text file on a Windows system, you might have to use
LINES TERMINATED BY '\r\n' to read the file
properly, because Windows programs typically use two characters
as a line terminator. Some programs, such as
WordPad, might use \r as a
line terminator when writing files. To read such files, use
LINES TERMINATED BY '\r'.
If all the lines you want to read in have a common prefix that
you want to ignore, you can use LINES STARTING BY
' to skip
over the prefix, and anything before it. If
a line does not include the prefix, the entire line is skipped.
Suppose that you issue the following statement:
prefix_string'
LOAD DATA INFILE '/tmp/test.txt' INTO TABLE test FIELDS TERMINATED BY ',' LINES STARTING BY 'xxx';
If the data file looks like this:
xxx"abc",1 something xxx"def",2 "ghi",3
The resulting rows will be ("abc",1) and
("def",2). The third row in the file is
skipped because it does not contain the prefix.
The IGNORE option can be used to ignore lines at the start
of the file. For example, you can use number
LINESIGNORE 1
LINES to skip over an initial header line containing
column names:
LOAD DATA INFILE '/tmp/test.txt' INTO TABLE test IGNORE 1 LINES;
When you use SELECT ... INTO OUTFILE in
tandem with LOAD DATA INFILE to write data
from a database into a file and then read the file back into the
database later, the field- and line-handling options for both
statements must match. Otherwise, LOAD DATA
INFILE will not interpret the contents of the file
properly. Suppose that you use SELECT ... INTO
OUTFILE to write a file with fields delimited by
commas:
SELECT * INTO OUTFILE 'data.txt' FIELDS TERMINATED BY ',' FROM table2;
To read the comma-delimited file back in, the correct statement would be:
LOAD DATA INFILE 'data.txt' INTO TABLE table2 FIELDS TERMINATED BY ',';
If instead you tried to read in the file with the statement
shown following, it wouldn't work because it instructs
LOAD DATA INFILE to look for tabs between
fields:
LOAD DATA INFILE 'data.txt' INTO TABLE table2 FIELDS TERMINATED BY '\t';
The likely result is that each input line would be interpreted as a single field.
LOAD DATA INFILE can be used to read files
obtained from external sources. For example, many programs can
export data in comma-separated values (CSV) format, such that
lines have fields separated by commas and enclosed within double
quotes. If lines in such a file are terminated by newlines, the
statement shown here illustrates the field- and line-handling
options you would use to load the file:
LOAD DATA INFILE 'data.txt' INTO TABLE tbl_name
FIELDS TERMINATED BY ',' ENCLOSED BY '"'
LINES TERMINATED BY '\n';
Any of the field- or line-handling options can specify an empty
string (''). If not empty, the
FIELDS [OPTIONALLY] ENCLOSED BY and
FIELDS ESCAPED BY values must be a single
character. The FIELDS TERMINATED BY,
LINES STARTING BY, and LINES
TERMINATED BY values can be more than one character.
For example, to write lines that are terminated by carriage
return/linefeed pairs, or to read a file containing such lines,
specify a LINES TERMINATED BY '\r\n' clause.
To read a file containing jokes that are separated by lines
consisting of %%, you can do this
CREATE TABLE jokes (a INT NOT NULL AUTO_INCREMENT PRIMARY KEY, joke TEXT NOT NULL); LOAD DATA INFILE '/tmp/jokes.txt' INTO TABLE jokes FIELDS TERMINATED BY '' LINES TERMINATED BY '\n%%\n' (joke);
FIELDS [OPTIONALLY] ENCLOSED BY controls
quoting of fields. For output (SELECT ... INTO
OUTFILE), if you omit the word
OPTIONALLY, all fields are enclosed by the
ENCLOSED BY character. An example of such
output (using a comma as the field delimiter) is shown here:
"1","a string","100.20" "2","a string containing a , comma","102.20" "3","a string containing a \" quote","102.20" "4","a string containing a \", quote and comma","102.20"
If you specify OPTIONALLY, the
ENCLOSED BY character is used only to enclose
values from columns that have a string data type (such as
CHAR, BINARY,
TEXT, or ENUM):
1,"a string",100.20 2,"a string containing a , comma",102.20 3,"a string containing a \" quote",102.20 4,"a string containing a \", quote and comma",102.20
Note that occurrences of the ENCLOSED BY
character within a field value are escaped by prefixing them
with the ESCAPED BY character. Also note that
if you specify an empty ESCAPED BY value, it
is possible to inadvertently generate output that cannot be read
properly by LOAD DATA INFILE. For example,
the preceding output just shown would appear as follows if the
escape character is empty. Observe that the second field in the
fourth line contains a comma following the quote, which
(erroneously) appears to terminate the field:
1,"a string",100.20 2,"a string containing a , comma",102.20 3,"a string containing a " quote",102.20 4,"a string containing a ", quote and comma",102.20
For input, the ENCLOSED BY character, if
present, is stripped from the ends of field values. (This is
true regardless of whether OPTIONALLY is
specified; OPTIONALLY has no effect on input
interpretation.) Occurrences of the ENCLOSED
BY character preceded by the ESCAPED
BY character are interpreted as part of the current
field value.
If the field begins with the ENCLOSED BY
character, instances of that character are recognized as
terminating a field value only if followed by the field or line
TERMINATED BY sequence. To avoid ambiguity,
occurrences of the ENCLOSED BY character
within a field value can be doubled and are interpreted as a
single instance of the character. For example, if
ENCLOSED BY '"' is specified, quotes are
handled as shown here:
"The ""BIG"" boss" -> The "BIG" boss The "BIG" boss -> The "BIG" boss The ""BIG"" boss -> The ""BIG"" boss
FIELDS ESCAPED BY controls how to write or
read special characters. If the FIELDS ESCAPED
BY character is not empty, it is used to prefix the
following characters on output:
The
FIELDS ESCAPED BYcharacterThe
FIELDS [OPTIONALLY] ENCLOSED BYcharacterThe first character of the
FIELDS TERMINATED BYandLINES TERMINATED BYvaluesASCII
0(what is actually written following the escape character is ASCII ‘0’, not a zero-valued byte)
If the FIELDS ESCAPED BY character is empty,
no characters are escaped and NULL is output
as NULL, not \N. It is
probably not a good idea to specify an empty escape character,
particularly if field values in your data contain any of the
characters in the list just given.
For input, if the FIELDS ESCAPED BY character
is not empty, occurrences of that character are stripped and the
following character is taken literally as part of a field value.
The exceptions are an escaped ‘0’
or ‘N’ (for example,
\0 or \N if the escape
character is ‘\’). These
sequences are interpreted as ASCII NUL (a zero-valued byte) and
NULL. The rules for NULL
handling are described later in this section.
For more information about
‘\’-escape syntax, see
Section 9.1, “Literal Values”.
In certain cases, field- and line-handling options interact:
If
LINES TERMINATED BYis an empty string andFIELDS TERMINATED BYis non-empty, lines are also terminated withFIELDS TERMINATED BY.If the
FIELDS TERMINATED BYandFIELDS ENCLOSED BYvalues are both empty (''), a fixed-row (non-delimited) format is used. With fixed-row format, no delimiters are used between fields (but you can still have a line terminator). Instead, column values are read and written using a field width wide enough to hold all values in the field. ForTINYINT,SMALLINT,MEDIUMINT,INT, andBIGINT, the field widths are 4, 6, 8, 11, and 20, respectively, no matter what the declared display width is.LINES TERMINATED BYis still used to separate lines. If a line does not contain all fields, the rest of the columns are set to their default values. If you do not have a line terminator, you should set this to''. In this case, the text file must contain all fields for each row.Fixed-row format also affects handling of
NULLvalues, as described later. Note that fixed-size format does not work if you are using a multi-byte character set.Note: Before MySQL 5.0.6, fixed-row format used the display width of the column. For example,
INT(4)was read or written using a field with a width of 4. However, if the column contained wider values, they were dumped to their full width, leading to the possibility of a “ragged” field holding values of different widths. Using a field wide enough to hold all values in the field prevents this problem. However, data files written before this change was made might not be reloaded correctly withLOAD DATA INFILEfor MySQL 5.0.6 and up. This change also affects data files read by mysqlimport and written by mysqldump --tab, which useLOAD DATA INFILEandSELECT ... INTO OUTFILE.
Handling of NULL values varies according to
the FIELDS and LINES
options in use:
For the default
FIELDSandLINESvalues,NULLis written as a field value of\Nfor output, and a field value of\Nis read asNULLfor input (assuming that theESCAPED BYcharacter is ‘\’).If
FIELDS ENCLOSED BYis not empty, a field containing the literal wordNULLas its value is read as aNULLvalue. This differs from the wordNULLenclosed withinFIELDS ENCLOSED BYcharacters, which is read as the string'NULL'.If
FIELDS ESCAPED BYis empty,NULLis written as the wordNULL.With fixed-row format (which is used when
FIELDS TERMINATED BYandFIELDS ENCLOSED BYare both empty),NULLis written as an empty string. Note that this causes bothNULLvalues and empty strings in the table to be indistinguishable when written to the file because both are written as empty strings. If you need to be able to tell the two apart when reading the file back in, you should not use fixed-row format.
An attempt to load NULL into a NOT
NULL column causes assignment of the implicit default
value for the column's data type and a warning, or an error in
strict SQL mode. Implicit default values are discussed in
Section 11.1.4, “Data Type Default Values”.
Some cases are not supported by LOAD DATA
INFILE:
Fixed-size rows (
FIELDS TERMINATED BYandFIELDS ENCLOSED BYboth empty) andBLOBorTEXTcolumns.If you specify one separator that is the same as or a prefix of another,
LOAD DATA INFILEcannot interpret the input properly. For example, the followingFIELDSclause would cause problems:FIELDS TERMINATED BY '"' ENCLOSED BY '"'
If
FIELDS ESCAPED BYis empty, a field value that contains an occurrence ofFIELDS ENCLOSED BYorLINES TERMINATED BYfollowed by theFIELDS TERMINATED BYvalue causesLOAD DATA INFILEto stop reading a field or line too early. This happens becauseLOAD DATA INFILEcannot properly determine where the field or line value ends.
The following example loads all columns of the
persondata table:
LOAD DATA INFILE 'persondata.txt' INTO TABLE persondata;
By default, when no column list is provided at the end of the
LOAD DATA INFILE statement, input lines are
expected to contain a field for each table column. If you want
to load only some of a table's columns, specify a column list:
LOAD DATA INFILE 'persondata.txt' INTO TABLE persondata (col1,col2,...);
You must also specify a column list if the order of the fields in the input file differs from the order of the columns in the table. Otherwise, MySQL cannot tell how to match input fields with table columns.
Before MySQL 5.0.3, the column list must contain only names of
columns in the table being loaded, and the
SET clause is not supported. As of MySQL
5.0.3, the column list can contain either column names or user
variables. With user variables, the SET
clause enables you to perform transformations on their values
before assigning the result to columns.
User variables in the SET clause can be used
in several ways. The following example uses the first input
column directly for the value of t1.column1,
and assigns the second input column to a user variable that is
subjected to a division operation before being used for the
value of t1.column2:
LOAD DATA INFILE 'file.txt' INTO TABLE t1 (column1, @var1) SET column2 = @var1/100;
The SET clause can be used to supply values
not derived from the input file. The following statement sets
column3 to the current date and time:
LOAD DATA INFILE 'file.txt' INTO TABLE t1 (column1, column2) SET column3 = CURRENT_TIMESTAMP;
You can also discard an input value by assigning it to a user variable and not assigning the variable to a table column:
LOAD DATA INFILE 'file.txt' INTO TABLE t1 (column1, @dummy, column2, @dummy, column3);
Use of the column/variable list and SET
clause is subject to the following restrictions:
Assignments in the
SETclause should have only column names on the left hand side of assignment operators.You can use subqueries in the right hand side of
SETassignments. A subquery that returns a value to be assigned to a column may be a scalar subquery only. Also, you cannot use a subquery to select from the table that is being loaded.Lines ignored by an
IGNOREclause are not processed for the column/variable list orSETclause.User variables cannot be used when loading data with fixed-row format because user variables do not have a display width.
When processing an input line, LOAD DATA
splits it into fields and uses the values according to the
column/variable list and the SET clause, if
they are present. Then the resulting row is inserted into the
table. If there are BEFORE INSERT or
AFTER INSERT triggers for the table, they are
activated before or after inserting the row, respectively.
If an input line has too many fields, the extra fields are ignored and the number of warnings is incremented.
If an input line has too few fields, the table columns for which input fields are missing are set to their default values. Default value assignment is described in Section 11.1.4, “Data Type Default Values”.
An empty field value is interpreted differently than if the field value is missing:
For string types, the column is set to the empty string.
For numeric types, the column is set to
0.For date and time types, the column is set to the appropriate “zero” value for the type. See Section 11.3, “Date and Time Types”.
These are the same values that result if you assign an empty
string explicitly to a string, numeric, or date or time type
explicitly in an INSERT or
UPDATE statement.
TIMESTAMP columns are set to the current date
and time only if there is a NULL value for
the column (that is, \N), or if the
TIMESTAMP column's default value is the
current timestamp and it is omitted from the field list when a
field list is specified.
LOAD DATA INFILE regards all input as
strings, so you cannot use numeric values for
ENUM or SET columns the
way you can with INSERT statements. All
ENUM and SET values must
be specified as strings.
BIT values cannot be loaded using binary
notation (for example, b'011010'). To work
around this, specify the values as regular integers and use the
SET clause to convert them so that MySQL
performs a numeric type conversion and loads them into the
BIT column properly:
shell>cat /tmp/bit_test.txt2 127 shell>mysql testmysql>LOAD DATA INFILE '/tmp/bit_test.txt'->INTO TABLE bit_test (@var1) SET b= CAST(@var1 AS SIGNED);Query OK, 2 rows affected (0.00 sec) Records: 2 Deleted: 0 Skipped: 0 Warnings: 0 mysql>SELECT BIN(b+0) FROM bit_test;+----------+ | bin(b+0) | +----------+ | 10 | | 1111111 | +----------+ 2 rows in set (0.00 sec)
When the LOAD DATA INFILE statement finishes,
it returns an information string in the following format:
Records: 1 Deleted: 0 Skipped: 0 Warnings: 0
If you are using the C API, you can get information about the
statement by calling the mysql_info()
function. See Section 22.2.3.35, “mysql_info()”.
Warnings occur under the same circumstances as when values are
inserted via the INSERT statement (see
Section 13.2.4, “INSERT Syntax”), except that LOAD DATA
INFILE also generates warnings when there are too few
or too many fields in the input row. The warnings are not stored
anywhere; the number of warnings can be used only as an
indication of whether everything went well.
You can use SHOW WARNINGS to get a list of
the first max_error_count warnings as
information about what went wrong. See
Section 13.5.4.28, “SHOW WARNINGS Syntax”.
REPLACE [LOW_PRIORITY | DELAYED]
[INTO] tbl_name [(col_name,...)]
VALUES ({expr | DEFAULT},...),(...),...
Or:
REPLACE [LOW_PRIORITY | DELAYED]
[INTO] tbl_name
SET col_name={expr | DEFAULT}, ...
Or:
REPLACE [LOW_PRIORITY | DELAYED]
[INTO] tbl_name [(col_name,...)]
SELECT ...
REPLACE works exactly like
INSERT, except that if an old row in the
table has the same value as a new row for a PRIMARY
KEY or a UNIQUE index, the old row
is deleted before the new row is inserted. See
Section 13.2.4, “INSERT Syntax”.
REPLACE is a MySQL extension to the SQL
standard. It either inserts, or deletes and
inserts. For another MySQL extension to standard SQL —
that either inserts or updates — see
Section 13.2.4.3, “INSERT ... ON DUPLICATE KEY UPDATE Syntax”.
Note that unless the table has a PRIMARY KEY
or UNIQUE index, using a
REPLACE statement makes no sense. It becomes
equivalent to INSERT, because there is no
index to be used to determine whether a new row duplicates
another.
Values for all columns are taken from the values specified in
the REPLACE statement. Any missing columns
are set to their default values, just as happens for
INSERT. You cannot refer to values from the
current row and use them in the new row. If you use an
assignment such as SET
, the reference
to the column name on the right hand side is treated as
col_name =
col_name + 1DEFAULT(,
so the assignment is equivalent to col_name)SET
.
col_name =
DEFAULT(col_name) + 1
To use REPLACE, you must have both the
INSERT and DELETE
privileges for the table.
The REPLACE statement returns a count to
indicate the number of rows affected. This is the sum of the
rows deleted and inserted. If the count is 1 for a single-row
REPLACE, a row was inserted and no rows were
deleted. If the count is greater than 1, one or more old rows
were deleted before the new row was inserted. It is possible for
a single row to replace more than one old row if the table
contains multiple unique indexes and the new row duplicates
values for different old rows in different unique indexes.
The affected-rows count makes it easy to determine whether
REPLACE only added a row or whether it also
replaced any rows: Check whether the count is 1 (added) or
greater (replaced).
If you are using the C API, the affected-rows count can be
obtained using the mysql_affected_rows()
function.
Currently, you cannot replace into a table and select from the same table in a subquery.
MySQL uses the following algorithm for
REPLACE (and LOAD DATA ...
REPLACE):
Try to insert the new row into the table
While the insertion fails because a duplicate-key error occurs for a primary key or unique index:
Delete from the table the conflicting row that has the duplicate key value
Try again to insert the new row into the table
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr, ...
[FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[PROCEDURE procedure_name(argument_list)]
[INTO OUTFILE 'file_name' export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name]]
[FOR UPDATE | LOCK IN SHARE MODE]]
SELECT is used to retrieve rows selected from
one or more tables, and can include UNION
statements and subqueries. See Section 13.2.7.3, “UNION Syntax”, and
Section 13.2.8, “Subquery Syntax”.
The most commonly used clauses of SELECT
statements are these:
Each
select_exprindicates a column that you want to retrieve. There must be at least oneselect_expr.table_referencesindicates the table or tables from which to retrieve rows. Its syntax is described in Section 13.2.7.1, “JOINSyntax”.The
WHEREclause, if given, indicates the condition or conditions that rows must satisfy to be selected.where_conditionis an expression that evaluates to true for each row to be selected. The statement selects all rows if there is noWHEREclause.In the
WHEREclause, you can use any of the functions and operators that MySQL supports, except for aggregate (summary) functions. See Chapter 12, Functions and Operators.
SELECT can also be used to retrieve rows
computed without reference to any table.
For example:
mysql> SELECT 1 + 1;
-> 2
You are allowed to specify DUAL as a dummy
table name in situations where no tables are referenced:
mysql> SELECT 1 + 1 FROM DUAL;
-> 2
DUAL is purely for the convenience of people
who require that all SELECT statements should
have FROM and possibly other clauses. MySQL
may ignore the clauses. MySQL does not require FROM
DUAL if no tables are referenced.
In general, clauses used must be given in exactly the order
shown in the syntax description. For example, a
HAVING clause must come after any
GROUP BY clause and before any ORDER
BY clause. The exception is that the
INTO clause can appear either as shown in the
syntax description or immediately preceding the
FROM clause.
A
select_exprcan be given an alias usingAS. The alias is used as the expression's column name and can be used inalias_nameGROUP BY,ORDER BY, orHAVINGclauses. For example:SELECT CONCAT(last_name,', ',first_name) AS full_name FROM mytable ORDER BY full_name;
The
ASkeyword is optional when aliasing aselect_expr. The preceding example could have been written like this:SELECT CONCAT(last_name,', ',first_name) full_name FROM mytable ORDER BY full_name;
However, because the
ASis optional, a subtle problem can occur if you forget the comma between twoselect_exprexpressions: MySQL interprets the second as an alias name. For example, in the following statement,columnbis treated as an alias name:SELECT columna columnb FROM mytable;
For this reason, it is good practice to be in the habit of using
ASexplicitly when specifying column aliases.It is not allowable to use a column alias in a
WHEREclause, because the column value might not yet be determined when theWHEREclause is executed. See Section B.1.5.4, “Problems with Column Aliases”.The
FROMclause indicates the table or tables from which to retrieve rows. If you name more than one table, you are performing a join. For information on join syntax, see Section 13.2.7.1, “table_referencesJOINSyntax”. For each table specified, you can optionally specify an alias.tbl_name[[AS]alias] [index_hint)]The use of index hints provides the optimizer with information about how to choose indexes during query processing. For a description of the syntax for specifying these hints, see Section 13.2.7.2, “Index Hint Syntax”.
You can use
SET max_seeks_for_key=as an alternative way to force MySQL to prefer key scans instead of table scans. See Section 5.2.3, “System Variables”.valueYou can refer to a table within the default database as
tbl_name, or asdb_name.tbl_nameto specify a database explicitly. You can refer to a column ascol_name,tbl_name.col_name, ordb_name.tbl_name.col_name. You need not specify atbl_nameordb_name.tbl_nameprefix for a column reference unless the reference would be ambiguous. See Section 9.2.1, “Identifier Qualifiers”, for examples of ambiguity that require the more explicit column reference forms.A table reference can be aliased using
tbl_nameASalias_nametbl_name alias_name:SELECT t1.name, t2.salary FROM employee AS t1, info AS t2 WHERE t1.name = t2.name; SELECT t1.name, t2.salary FROM employee t1, info t2 WHERE t1.name = t2.name;
Columns selected for output can be referred to in
ORDER BYandGROUP BYclauses using column names, column aliases, or column positions. Column positions are integers and begin with 1:SELECT college, region, seed FROM tournament ORDER BY region, seed; SELECT college, region AS r, seed AS s FROM tournament ORDER BY r, s; SELECT college, region, seed FROM tournament ORDER BY 2, 3;
To sort in reverse order, add the
DESC(descending) keyword to the name of the column in theORDER BYclause that you are sorting by. The default is ascending order; this can be specified explicitly using theASCkeyword.Use of column positions is deprecated because the syntax has been removed from the SQL standard.
If you use
GROUP BY, output rows are sorted according to theGROUP BYcolumns as if you had anORDER BYfor the same columns. To avoid the overhead of sorting thatGROUP BYproduces, addORDER BY NULL:SELECT a, COUNT(b) FROM test_table GROUP BY a ORDER BY NULL;
MySQL extends the
GROUP BYclause so that you can also specifyASCandDESCafter columns named in the clause:SELECT a, COUNT(b) FROM test_table GROUP BY a DESC;
MySQL extends the use of
GROUP BYto allow selecting fields that are not mentioned in theGROUP BYclause. If you are not getting the results that you expect from your query, please read the description ofGROUP BYfound in Section 12.11, “Functions and Modifiers for Use withGROUP BYClauses”.GROUP BYallows aWITH ROLLUPmodifier. See Section 12.11.2, “GROUP BYModifiers”.The
HAVINGclause is applied nearly last, just before items are sent to the client, with no optimization. (LIMITis applied afterHAVING.)A
HAVINGclause can refer to any column or alias named in aselect_exprin theSELECTlist or in outer subqueries, and to aggregate functions. However, the SQL standard requires thatHAVINGmust reference only columns in theGROUP BYclause or columns used in aggregate functions. To accommodate both standard SQL and the MySQL-specific behavior of being able to refer columns in theSELECTlist, MySQL 5.0.2 and up allowsHAVINGto refer to columns in theSELECTlist, columns in theGROUP BYclause, columns in outer subqueries, and to aggregate functions.For example, the following statement works in MySQL 5.0.2 but produces an error for earlier versions:
mysql>
SELECT COUNT(*) FROM t GROUP BY col1 HAVING col1 = 2;If the
HAVINGclause refers to a column that is ambiguous, a warning occurs. In the following statement,col2is ambiguous because it is used as both an alias and a column name:SELECT COUNT(col1) AS col2 FROM t GROUP BY col2 HAVING col2 = 2;
Preference is given to standard SQL behavior, so if a
HAVINGcolumn name is used both inGROUP BYand as an aliased column in the output column list, preference is given to the column in theGROUP BYcolumn.Do not use
HAVINGfor items that should be in theWHEREclause. For example, do not write the following:SELECT
col_nameFROMtbl_nameHAVINGcol_name> 0;Write this instead:
SELECT
col_nameFROMtbl_nameWHEREcol_name> 0;The
HAVINGclause can refer to aggregate functions, which theWHEREclause cannot:SELECT user, MAX(salary) FROM users GROUP BY user HAVING MAX(salary) > 10;
(This did not work in some older versions of MySQL.)
MySQL allows duplicate column names. That is, there can be more than one
select_exprwith the same name. This is an extension to standard SQL. Because MySQL also allowsGROUP BYandHAVINGto refer toselect_exprvalues, this can result in an ambiguity:SELECT 12 AS a, a FROM t GROUP BY a;
In that statement, both columns have the name
a. To ensure that the correct column is used for grouping, use different names for eachselect_expr.MySQL resolves unqualified column or alias references in
ORDER BYclauses by searching in theselect_exprvalues, then in the columns of the tables in theFROMclause. ForGROUP BYorHAVINGclauses, it searches theFROMclause before searching in theselect_exprvalues. (ForGROUP BYandHAVING, this differs from the pre-MySQL 5.0 behavior that used the same rules as forORDER BY.)The
LIMITclause can be used to constrain the number of rows returned by theSELECTstatement.LIMITtakes one or two numeric arguments, which must both be non-negative integer constants (except when using prepared statements).With two arguments, the first argument specifies the offset of the first row to return, and the second specifies the maximum number of rows to return. The offset of the initial row is 0 (not 1):
SELECT * FROM tbl LIMIT 5,10; # Retrieve rows 6-15
To retrieve all rows from a certain offset up to the end of the result set, you can use some large number for the second parameter. This statement retrieves all rows from the 96th row to the last:
SELECT * FROM tbl LIMIT 95,18446744073709551615;
With one argument, the value specifies the number of rows to return from the beginning of the result set:
SELECT * FROM tbl LIMIT 5; # Retrieve first 5 rows
In other words,
LIMITis equivalent torow_countLIMIT 0,.row_countFor prepared statements, you can use placeholders (supported as of MySQL version 5.0.7). The following statements will return one row from the
tbltable:SET @a=1; PREPARE STMT FROM 'SELECT * FROM tbl LIMIT ?'; EXECUTE STMT USING @a;
The following statements will return the second to sixth row from the
tbltable:SET @skip=1; SET @numrows=5; PREPARE STMT FROM 'SELECT * FROM tbl LIMIT ?, ?'; EXECUTE STMT USING @skip, @numrows;
For compatibility with PostgreSQL, MySQL also supports the
LIMITsyntax.row_countOFFSEToffsetThe
SELECT ... INTO OUTFILE 'form offile_name'SELECTwrites the selected rows to a file. The file is created on the server host, so you must have theFILEprivilege to use this syntax.file_namecannot be an existing file, which among other things prevents files such as/etc/passwdand database tables from being destroyed. As of MySQL 5.0.19, thecharacter_set_filesystemsystem variable controls the interpretation of the filename.The
SELECT ... INTO OUTFILEstatement is intended primarily to let you very quickly dump a table to a text file on the server machine. If you want to create the resulting file on some client host other than the server host, you cannot useSELECT ... INTO OUTFILE. In that case, you should instead use a command such asmysql -e "SELECT ..." >to generate the file on the client host.file_nameSELECT ... INTO OUTFILEis the complement ofLOAD DATA INFILE; the syntax for theexport_optionspart of the statement consists of the sameFIELDSandLINESclauses that are used with theLOAD DATA INFILEstatement. See Section 13.2.5, “LOAD DATA INFILESyntax”.FIELDS ESCAPED BYcontrols how to write special characters. If theFIELDS ESCAPED BYcharacter is not empty, it is used as a prefix that precedes following characters on output:The
FIELDS ESCAPED BYcharacterThe
FIELDS [OPTIONALLY] ENCLOSED BYcharacterThe first character of the
FIELDS TERMINATED BYandLINES TERMINATED BYvaluesASCII
NUL(the zero-valued byte; what is actually written following the escape character is ASCII ‘0’, not a zero-valued byte)
The
FIELDS TERMINATED BY,ENCLOSED BY,ESCAPED BY, orLINES TERMINATED BYcharacters must be escaped so that you can read the file back in reliably. ASCIINULis escaped to make it easier to view with some pagers.The resulting file does not have to conform to SQL syntax, so nothing else need be escaped.
If the
FIELDS ESCAPED BYcharacter is empty, no characters are escaped andNULLis output asNULL, not\N. It is probably not a good idea to specify an empty escape character, particularly if field values in your data contain any of the characters in the list just given.Here is an example that produces a file in the comma-separated values (CSV) format used by many programs:
SELECT a,b,a+b INTO OUTFILE '/tmp/result.txt' FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY '\n' FROM test_table;
If you use
INTO DUMPFILEinstead ofINTO OUTFILE, MySQL writes only one row into the file, without any column or line termination and without performing any escape processing. This is useful if you want to store aBLOBvalue in a file.The
INTOclause can name a list of one or more variables, which can be user-defined variables, or parameters or local variables within a stored function or procedure body. The selected values are assigned to the variables. The number of variables must match the number of columns.Within a stored routine, the variables can be routine parameters or local variables. See Section 17.2.7.3, “
SELECT ... INTOStatement”.Note: Any file created by
INTO OUTFILEorINTO DUMPFILEis writable by all users on the server host. The reason for this is that the MySQL server cannot create a file that is owned by anyone other than the user under whose account it is running. (You should never run mysqld asrootfor this and other reasons.) The file thus must be world-writable so that you can manipulate its contents.The
SELECTsyntax description at the beginning this section shows theINTOclause near the end of the statement. It is also possible to useINTO OUTFILEorINTO DUMPFILEimmediately preceding theFROMclause.A
PROCEDUREclause names a procedure that should process the data in the result set. For an example, see Section 24.3.1, “Procedure Analyse”.If you use
FOR UPDATEwith a storage engine that uses page or row locks, rows examined by the query are write-locked until the end of the current transaction. UsingLOCK IN SHARE MODEsets a shared lock that allows other transactions to read the examined rows but not to update or delete them. See Section 14.2.10.5, “SELECT ... FOR UPDATEandSELECT ... LOCK IN SHARE MODELocking Reads”.
Following the SELECT keyword, you can use a
number of options that affect the operation of the statement.
The ALL, DISTINCT, and
DISTINCTROW options specify whether duplicate
rows should be returned. If none of these options are given, the
default is ALL (all matching rows are
returned). DISTINCT and
DISTINCTROW are synonyms and specify removal
of duplicate rows from the result set.
HIGH_PRIORITY,
STRAIGHT_JOIN, and options beginning with
SQL_ are MySQL extensions to standard SQL.
HIGH_PRIORITYgives theSELECThigher priority than a statement that updates a table. You should use this only for queries that are very fast and must be done at once. ASELECT HIGH_PRIORITYquery that is issued while the table is locked for reading runs even if there is an update statement waiting for the table to be free. This affects only storage engines that use only table-level locking (MyISAM,MEMORY,MERGE).HIGH_PRIORITYcannot be used withSELECTstatements that are part of aUNION.STRAIGHT_JOINforces the optimizer to join the tables in the order in which they are listed in theFROMclause. You can use this to speed up a query if the optimizer joins the tables in non-optimal order. See Section 7.2.1, “Optimizing Queries withEXPLAIN”.STRAIGHT_JOINalso can be used in thetable_referenceslist. See Section 13.2.7.1, “JOINSyntax”.SQL_BIG_RESULTcan be used withGROUP BYorDISTINCTto tell the optimizer that the result set has many rows. In this case, MySQL directly uses disk-based temporary tables if needed, and prefers sorting to using a temporary table with a key on theGROUP BYelements.SQL_BUFFER_RESULTforces the result to be put into a temporary table. This helps MySQL free the table locks early and helps in cases where it takes a long time to send the result set to the client.SQL_SMALL_RESULTcan be used withGROUP BYorDISTINCTto tell the optimizer that the result set is small. In this case, MySQL uses fast temporary tables to store the resulting table instead of using sorting. This should not normally be needed.SQL_CALC_FOUND_ROWStells MySQL to calculate how many rows there would be in the result set, disregarding anyLIMITclause. The number of rows can then be retrieved withSELECT FOUND_ROWS(). See Section 12.10.3, “Information Functions”.SQL_CACHEtells MySQL to store the query result in the query cache if you are using aquery_cache_typevalue of2orDEMAND. For a query that usesUNIONor subqueries, this option effects anySELECTin the query. See Section 5.13, “The MySQL Query Cache”.SQL_NO_CACHEtells MySQL not to store the query result in the query cache. See Section 5.13, “The MySQL Query Cache”. For a query that usesUNIONor subqueries, this option effects anySELECTin the query.
MySQL supports the following JOIN syntaxes
for the table_references part of
SELECT statements and multiple-table
DELETE and UPDATE
statements:
table_references:table_reference[,table_reference] ...table_reference:table_factor|join_tabletable_factor:tbl_name[[AS]alias] [index_hint)] | (table_references) | { OJtable_referenceLEFT OUTER JOINtable_referenceONconditional_expr}join_table:table_reference[INNER | CROSS] JOINtable_factor[join_condition] |table_referenceSTRAIGHT_JOINtable_factor|table_referenceSTRAIGHT_JOINtable_factorONcondition|table_referenceLEFT [OUTER] JOINtable_referencejoin_condition|table_referenceNATURAL [LEFT [OUTER]] JOINtable_factor|table_referenceRIGHT [OUTER] JOINtable_referencejoin_condition|table_referenceNATURAL [RIGHT [OUTER]] JOINtable_factorjoin_condition: ONconditional_expr| USING (column_list)index_hint: USE {INDEX|KEY} [FOR JOIN] (index_list)] | IGNORE {INDEX|KEY} [FOR JOIN] (index_list)] | FORCE {INDEX|KEY} [FOR JOIN] (index_list)]index_list:index_name[,index_name] ...
A table reference is also known as a join expression.
The syntax of table_factor is
extended in comparison with the SQL Standard. The latter
accepts only table_reference, not a
list of them inside a pair of parentheses.
This is a conservative extension if we consider each comma in
a list of table_reference items as
equivalent to an inner join. For example:
SELECT * FROM t1 LEFT JOIN (t2, t3, t4)
ON (t2.a=t1.a AND t3.b=t1.b AND t4.c=t1.c)
is equivalent to:
SELECT * FROM t1 LEFT JOIN (t2 CROSS JOIN t3 CROSS JOIN t4)
ON (t2.a=t1.a AND t3.b=t1.b AND t4.c=t1.c)
In MySQL, CROSS JOIN is a syntactic
equivalent to INNER JOIN (they can replace
each other). In standard SQL, they are not equivalent.
INNER JOIN is used with an
ON clause, CROSS JOIN is
used otherwise.
In versions of MySQL prior to 5.0.1, parentheses in
table_references were just omitted
and all join operations were grouped to the left. In general,
parentheses can be ignored in join expressions containing only
inner join operations. As of 5.0.1, nested joins are allowed
(see Section 7.2.9, “Nested Join Optimization”).
Further changes in join processing were made in 5.0.12 to make MySQL more compliant with standard SQL. These charges are described later in this section.
Index hints can be specified to affect how the MySQL optimizer makes use of indexes. For more information, see Section 13.2.7.2, “Index Hint Syntax”.
The following list describes general factors to take into account when writing joins.
A table reference can be aliased using
tbl_nameASalias_nametbl_name alias_name:SELECT t1.name, t2.salary FROM employee AS t1 INNER JOIN info AS t2 ON t1.name = t2.name; SELECT t1.name, t2.salary FROM employee t1 INNER JOIN info t2 ON t1.name = t2.name;
INNER JOINand,(comma) are semantically equivalent in the absence of a join condition: both produce a Cartesian product between the specified tables (that is, each and every row in the first table is joined to each and every row in the second table).However, the precedence of the comma operator is less than of
INNER JOIN,CROSS JOIN,LEFT JOIN, and so on. If you mix comma joins with the other join types when there is a join condition, an error of the formUnknown column 'may occur. Information about dealing with this problem is given later in this section.col_name' in 'on clause'The
ONconditional is any conditional expression of the form that can be used in aWHEREclause. Generally, you should use theONclause for conditions that specify how to join tables, and theWHEREclause to restrict which rows you want in the result set.If there is no matching row for the right table in the
ONorUSINGpart in aLEFT JOIN, a row with all columns set toNULLis used for the right table. You can use this fact to find rows in a table that have no counterpart in another table:SELECT table1.* FROM table1 LEFT JOIN table2 ON table1.id=table2.id WHERE table2.id IS NULL;
This example finds all rows in
table1with anidvalue that is not present intable2(that is, all rows intable1with no corresponding row intable2). This assumes thattable2.idis declaredNOT NULL. See Section 7.2.8, “LEFT JOINandRIGHT JOINOptimization”.The
USING(clause names a list of columns that must exist in both tables. If tablescolumn_list)aandbboth contain columnsc1,c2, andc3, the following join compares corresponding columns from the two tables:a LEFT JOIN b USING (c1,c2,c3)
The
NATURAL [LEFT] JOINof two tables is defined to be semantically equivalent to anINNER JOINor aLEFT JOINwith aUSINGclause that names all columns that exist in both tables.RIGHT JOINworks analogously toLEFT JOIN. To keep code portable across databases, it is recommended that you useLEFT JOINinstead ofRIGHT JOIN.The
{ OJ ... LEFT OUTER JOIN ...}syntax shown in the join syntax description exists only for compatibility with ODBC. The curly braces in the syntax should be written literally; they are not metasyntax as used elsewhere in syntax descriptions.STRAIGHT_JOINis identical toJOIN, except that the left table is always read before the right table. This can be used for those (few) cases for which the join optimizer puts the tables in the wrong order.
Some join examples:
SELECT * FROM table1, table2; SELECT * FROM table1 INNER JOIN table2 ON table1.id=table2.id; SELECT * FROM table1 LEFT JOIN table2 ON table1.id=table2.id; SELECT * FROM table1 LEFT JOIN table2 USING (id); SELECT * FROM table1 LEFT JOIN table2 ON table1.id=table2.id LEFT JOIN table3 ON table2.id=table3.id;
Join Processing Changes in MySQL 5.0.12
Beginning with MySQL 5.0.12, natural joins and joins with
USING, including outer join variants, are
processed according to the SQL:2003 standard. The goal was to
align the syntax and semantics of MySQL with respect to
NATURAL JOIN and JOIN ...
USING according to SQL:2003. However, these changes
in join processing can result in different output columns for
some joins. Also, some queries that appeared to work correctly
in older versions must be rewritten to comply with the
standard.
These changes have five main aspects:
The way that MySQL determines the result columns of
NATURALorUSINGjoin operations (and thus the result of the entireFROMclause).Expansion of
SELECT *andSELECTinto a list of selected columns.tbl_name.*Resolution of column names in
NATURALorUSINGjoins.Transformation of
NATURALorUSINGjoins intoJOIN ... ON.Resolution of column names in the
ONcondition of aJOIN ... ON.
The following list provides more detail about several effects of the 5.0.12 change in join processing. The term “previously” means “prior to MySQL 5.0.12.”
The columns of a
NATURALjoin or aUSINGjoin may be different from previously. Specifically, redundant output columns no longer appear, and the order of columns forSELECT *expansion may be different from before.Consider this set of statements:
CREATE TABLE t1 (i INT, j INT); CREATE TABLE t2 (k INT, j INT); INSERT INTO t1 VALUES(1,1); INSERT INTO t2 VALUES(1,1); SELECT * FROM t1 NATURAL JOIN t2; SELECT * FROM t1 JOIN t2 USING (j);
Previously, the statements produced this output:
+------+------+------+------+ | i | j | k | j | +------+------+------+------+ | 1 | 1 | 1 | 1 | +------+------+------+------+ +------+------+------+------+ | i | j | k | j | +------+------+------+------+ | 1 | 1 | 1 | 1 | +------+------+------+------+
In the first
SELECTstatement, columnjappears in both tables and thus becomes a join column, so, according to standard SQL, it should appear only once in the output, not twice. Similarly, in the second SELECT statement, columnjis named in theUSINGclause and should appear only once in the output, not twice. But in both cases, the redundant column is not eliminated. Also, the order of the columns is not correct according to standard SQL.Now the statements produce this output:
+------+------+------+ | j | i | k | +------+------+------+ | 1 | 1 | 1 | +------+------+------+ +------+------+------+ | j | i | k | +------+------+------+ | 1 | 1 | 1 | +------+------+------+
The redundant column is eliminated and the column order is correct according to standard SQL:
First, coalesced common columns of the two joined tables, in the order in which they occur in the first table
Second, columns unique to the first table, in order in which they occur in that table
Third, columns unique to the second table, in order in which they occur in that table
The single result column that replaces two common columns is defined via the coalesce operation. That is, for two
t1.aandt2.athe resulting single join columnais defined asa = COALESCE(t1.a, t2.a), where:COALESCE(x, y) = (CASE WHEN V1 IS NOT NULL THEN V1 ELSE V2 END)
If the join operation is any other join, the result columns of the join consists of the concatenation of all columns of the joined tables. This is the same as previously.
A consequence of the definition of coalesced columns is that, for outer joins, the coalesced column contains the value of the non-
NULLcolumn if one of the two columns is alwaysNULL. If neither or both columns areNULL, both common columns have the same value, so it doesn't matter which one is chosen as the value of the coalesced column. A simple way to interpret this is to consider that a coalesced column of an outer join is represented by the common column of the inner table of aJOIN. Suppose that the tablest1(a,b)andt2(a,c)have the following contents:t1 t2 ---- ---- 1 x 2 z 2 y 3 w
Then:
mysql>
SELECT * FROM t1 NATURAL LEFT JOIN t2;+------+------+------+ | a | b | c | +------+------+------+ | 1 | x | NULL | | 2 | y | z | +------+------+------+Here column
acontains the values oft1.a.mysql>
SELECT * FROM t1 NATURAL RIGHT JOIN t2;+------+------+------+ | a | c | b | +------+------+------+ | 2 | z | y | | 3 | w | NULL | +------+------+------+Here column
acontains the values oft2.a.Compare these results to the otherwise equivalent queries with
JOIN ... ON:mysql>
SELECT * FROM t1 LEFT JOIN t2 ON (t1.a = t2.a);+------+------+------+------+ | a | b | a | c | +------+------+------+------+ | 1 | x | NULL | NULL | | 2 | y | 2 | z | +------+------+------+------+mysql>
SELECT * FROM t1 RIGHT JOIN t2 ON (t1.a = t2.a);+------+------+------+------+ | a | b | a | c | +------+------+------+------+ | 2 | y | 2 | z | | NULL | NULL | 3 | w | +------+------+------+------+Previously, a
USINGclause could be rewritten as anONclause that compares corresponding columns. For example, the following two clauses were semantically identical:a LEFT JOIN b USING (c1,c2,c3) a LEFT JOIN b ON a.c1=b.c1 AND a.c2=b.c2 AND a.c3=b.c3
Now the two clauses no longer are quite the same:
With respect to determining which rows satisfy the join condition, both joins remain semantically identical.
With respect to determining which columns to display for
SELECT *expansion, the two joins are not semantically identical. TheUSINGjoin selects the coalesced value of corresponding columns, whereas theONjoin selects all columns from all tables. For the precedingUSINGjoin,SELECT *selects these values:COALESCE(a.c1,b.c1), COALESCE(a.c2,b.c2), COALESCE(a.c3,b.c3)
For the
ONjoin,SELECT *selects these values:a.c1, a.c2, a.c3, b.c1, b.c2, b.c3
With an inner join,
COALESCE(a.c1,b.c1)is the same as eithera.c1orb.c1because both columns will have the same value. With an outer join (such asLEFT JOIN), one of the two columns can beNULL. That column will be omitted from the result.
The evaluation of multi-way natural joins differs in a very important way that affects the result of
NATURALorUSINGjoins and that can require query rewriting. Suppose that you have three tablest1(a,b),t2(c,b), andt3(a,c)that each have one row:t1(1,2),t2(10,2), andt3(7,10). Suppose also that you have thisNATURAL JOINon the three tables:SELECT ... FROM t1 NATURAL JOIN t2 NATURAL JOIN t3;
Previously, the left operand of the second join was considered to be
t2, whereas it should be the nested join(t1 NATURAL JOIN t2). As a result, the columns oft3are checked for common columns only int2, and, ift3has common columns witht1, these columns are not used as equi-join columns. Thus, previously, the preceding query was transformed to the following equi-join:SELECT ... FROM t1, t2, t3 WHERE t1.b = t2.b AND t2.c = t3.c;
That join is missing one more equi-join predicate
(t1.a = t3.a). As a result, it produces one row, not the empty result that it should. The correct equivalent query is this:SELECT ... FROM t1, t2, t3 WHERE t1.b = t2.b AND t2.c = t3.c AND t1.a = t3.a;
If you require the same query result in current versions of MySQL as in older versions, rewrite the natural join as the first equi-join.
Previously, the comma operator (
,) andJOINboth had the same precedence, so the join expressiont1, t2 JOIN t3was interpreted as((t1, t2) JOIN t3). NowJOINhas higher precedence, so the expression is interpreted as(t1, (t2 JOIN t3)). This change affects statements that use anONclause, because that clause can refer only to columns in the operands of the join, and the change in precedence changes interpretation of what those operands are.Example:
CREATE TABLE t1 (i1 INT, j1 INT); CREATE TABLE t2 (i2 INT, j2 INT); CREATE TABLE t3 (i3 INT, j3 INT); INSERT INTO t1 VALUES(1,1); INSERT INTO t2 VALUES(1,1); INSERT INTO t3 VALUES(1,1); SELECT * FROM t1, t2 JOIN t3 ON (t1.i1 = t3.i3);
Previously, the
SELECTwas legal due to the implicit grouping oft1,t2as(t1,t2). Now theJOINtakes precedence, so the operands for theONclause aret2andt3. Becauset1.i1is not a column in either of the operands, the result is anUnknown column 't1.i1' in 'on clause'error. To allow the join to be processed, group the first two tables explicitly with parentheses so that the operands for theONclause are(t1,t2)andt3:SELECT * FROM (t1, t2) JOIN t3 ON (t1.i1 = t3.i3);
Alternatively, avoid the use of the comma operator and use
JOINinstead:SELECT * FROM t1 JOIN t2 JOIN t3 ON (t1.i1 = t3.i3);
This change also applies to statements that mix the comma operator with
INNER JOIN,CROSS JOIN,LEFT JOIN, andRIGHT JOIN, all of which now have higher precedence than the comma operator.Previously, the
ONclause could refer to columns in tables named to its right. Now anONclause can refer only to its operands.Example:
CREATE TABLE t1 (i1 INT); CREATE TABLE t2 (i2 INT); CREATE TABLE t3 (i3 INT); SELECT * FROM t1 JOIN t2 ON (i1 = i3) JOIN t3;
Previously, the
SELECTstatement was legal. Now the statement fails with anUnknown column 'i3' in 'on clause'error becausei3is a column int3, which is not an operand of theONclause. The statement should be rewritten as follows:SELECT * FROM t1 JOIN t2 JOIN t3 ON (i1 = i3);
Resolution of column names in
NATURALorUSINGjoins is different than previously. For column names that are outside theFROMclause, MySQL now handles a superset of the queries compared to previously. That is, in cases when MySQL formerly issued an error that some column is ambiguous, the query now is handled correctly. This is due to the fact that MySQL now treats the common columns ofNATURALorUSINGjoins as a single column, so when a query refers to such columns, the query compiler does not consider them as ambiguous.Example:
SELECT * FROM t1 NATURAL JOIN t2 WHERE b > 1;
Previously, this query would produce an error
ERROR 1052 (23000): Column 'b' in where clause is ambiguous. Now the query produces the correct result:+------+------+------+ | b | c | y | +------+------+------+ | 4 | 2 | 3 | +------+------+------+
One extension of MySQL compared to the SQL:2003 standard is that MySQL allows you to qualify the common (coalesced) columns of
NATURALorUSINGjoins (just as previously), while the standard disallows that.
You can provide hints to give the optimizer information about
how to choose indexes during query processing.
Section 13.2.7.1, “JOIN Syntax”, describes the general syntax for
specifying tables in a SELECT statement.
The syntax for an individual table, including that for index
hints, looks like this:
tbl_name[[AS]alias] [index_hint)]index_hint: USE {INDEX|KEY} [FOR JOIN] (index_list)] | IGNORE {INDEX|KEY} [FOR JOIN] (index_list)] | FORCE {INDEX|KEY} [FOR JOIN] (index_list)]index_list:index_name[,index_name] ...
By specifying USE INDEX
(, you can
tell MySQL to use only one of the named indexes to find rows
in the table. The alternative syntax index_list)IGNORE INDEX
( can be used
to tell MySQL to not use some particular index or indexes.
These hints are useful if index_list)EXPLAIN shows
that MySQL is using the wrong index from the list of possible
indexes.
You can also use FORCE INDEX, which acts
like USE INDEX
( but with the
addition that a table scan is assumed to be
very expensive. In other words, a table
scan is used only if there is no way to use one of the given
indexes to find rows in the table.
index_list)
USE KEY, IGNORE KEY, and
FORCE KEY are synonyms for USE
INDEX, IGNORE INDEX, and
FORCE INDEX.
Each hint requires the names of indexes,
not the names of columns. The name of a PRIMARY
KEY is PRIMARY. To see the index
names for a table, use SHOW INDEX.
Index hints do not work for FULLTEXT
indexes.
USE INDEX, IGNORE INDEX,
and FORCE INDEX affect only which indexes
are used when MySQL decides how to find rows in the table and
how to do the join. They do not affect whether an index is
used when resolving an ORDER BY or
GROUP BY clause. As of MySQL 5.0.40, the
optional FOR JOIN clause can be added to
make this explicit.
Examples:
SELECT * FROM table1 USE INDEX (col1_index,col2_index) WHERE col1=1 AND col2=2 AND col3=3; SELECT * FROM table1 IGNORE INDEX (col3_index) WHERE col1=1 AND col2=2 AND col3=3;
SELECT ... UNION [ALL | DISTINCT] SELECT ... [UNION [ALL | DISTINCT] SELECT ...]
UNION is used to combine the result from
multiple SELECT statements into a single
result set.
The column names from the first SELECT
statement are used as the column names for the results
returned. Selected columns listed in corresponding positions
of each SELECT statement should have the
same data type. (For example, the first column selected by the
first statement should have the same type as the first column
selected by the other statements.)
If the data types of corresponding SELECT
columns do not match, the types and lengths of the columns in
the UNION result take into account the
values retrieved by all of the SELECT
statements. For example, consider the following:
mysql> SELECT REPEAT('a',1) UNION SELECT REPEAT('b',10);
+---------------+
| REPEAT('a',1) |
+---------------+
| a |
| bbbbbbbbbb |
+---------------+
(In some earlier versions of MySQL, only the type and length
from the first SELECT would have been used
and the second row would have been truncated to a length of
1.)
The SELECT statements are normal select
statements, but with the following restrictions:
Only the last
SELECTstatement can useINTO OUTFILE.HIGH_PRIORITYcannot be used withSELECTstatements that are part of aUNION. If you specify it for the firstSELECT, it has no effect. If you specify it for any subsequentSELECTstatements, a syntax error results.
The default behavior for UNION is that
duplicate rows are removed from the result. The optional
DISTINCT keyword has no effect other than
the default because it also specifies duplicate-row removal.
With the optional ALL keyword,
duplicate-row removal does not occur and the result includes
all matching rows from all the SELECT
statements.
You can mix UNION ALL and UNION
DISTINCT in the same query. Mixed
UNION types are treated such that a
DISTINCT union overrides any
ALL union to its left. A
DISTINCT union can be produced explicitly
by using UNION DISTINCT or implicitly by
using UNION with no following
DISTINCT or ALL keyword.
To use an ORDER BY or
LIMIT clause to sort or limit the entire
UNION result, parenthesize the individual
SELECT statements and place the
ORDER BY or LIMIT after
the last one. The following example uses both clauses:
(SELECT a FROM t1 WHERE a=10 AND B=1) UNION (SELECT a FROM t2 WHERE a=11 AND B=2) ORDER BY a LIMIT 10;
This kind of ORDER BY cannot use column
references that include a table name (that is, names in
tbl_name.col_name
format). Instead, provide a column alias in the first
SELECT statement and refer to the alias in
the ORDER BY. (Alternatively, refer to the
column in the ORDER BY using its column
position. However, use of column positions is deprecated.)
Also, if a column to be sorted is aliased, the ORDER
BY clause must refer to the
alias, not the column name. The first of the following
statements will work, but the second will fail with an
Unknown column 'a' in 'order clause' error:
(SELECT a AS b FROM t) UNION (SELECT ...) ORDER BY b; (SELECT a AS b FROM t) UNION (SELECT ...) ORDER BY a;
To apply ORDER BY or
LIMIT to an individual
SELECT, place the clause inside the
parentheses that enclose the SELECT:
(SELECT a FROM t1 WHERE a=10 AND B=1 ORDER BY a LIMIT 10) UNION (SELECT a FROM t2 WHERE a=11 AND B=2 ORDER BY a LIMIT 10);
Use of ORDER BY for individual
SELECT statements implies nothing about the
order in which the rows appear in the final result because
UNION by default produces an unordered set
of rows. If ORDER BY appears with
LIMIT, it is used to determine the subset
of the selected rows to retrieve for the
SELECT, but does not necessarily affect the
order of those rows in the final UNION
result. If ORDER BY appears without
LIMIT in a SELECT, it is
optimized away because it will have no effect anyway.
To cause rows in a UNION result to consist
of the sets of rows retrieved by each
SELECT one after the other, select an
additional column in each SELECT to use as
a sort column and add an ORDER BY following
the last SELECT:
(SELECT 1 AS sort_col, col1a, col1b, ... FROM t1) UNION (SELECT 2, col2a, col2b, ... FROM t2) ORDER BY sort_col;
To additionally maintain sort order within individual
SELECT results, add a secondary column to
the ORDER BY clause:
(SELECT 1 AS sort_col, col1a, col1b, ... FROM t1) UNION (SELECT 2, col2a, col2b, ... FROM t2) ORDER BY sort_col, col1a;
- 13.2.8.1. The Subquery as Scalar Operand
- 13.2.8.2. Comparisons Using Subqueries
- 13.2.8.3. Subqueries with
ANY,IN, andSOME - 13.2.8.4. Subqueries with
ALL - 13.2.8.5. Row Subqueries
- 13.2.8.6.
EXISTSandNOT EXISTS - 13.2.8.7. Correlated Subqueries
- 13.2.8.8. Subqueries in the
FROMclause - 13.2.8.9. Subquery Errors
- 13.2.8.10. Optimizing Subqueries
- 13.2.8.11. Rewriting Subqueries as Joins for Earlier MySQL Versions
A subquery is a SELECT statement within
another statement.
Starting with MySQL 4.1, all subquery forms and operations that the SQL standard requires are supported, as well as a few features that are MySQL-specific.
Here is an example of a subquery:
SELECT * FROM t1 WHERE column1 = (SELECT column1 FROM t2);
In this example, SELECT * FROM t1 ... is the
outer query (or outer
statement), and (SELECT column1 FROM
t2) is the subquery. We say that
the subquery is nested within the outer
query, and in fact it is possible to nest subqueries within
other subqueries, to a considerable depth. A subquery must
always appear within parentheses.
The main advantages of subqueries are:
They allow queries that are structured so that it is possible to isolate each part of a statement.
They provide alternative ways to perform operations that would otherwise require complex joins and unions.
They are, in many people's opinion, more readable than complex joins or unions. Indeed, it was the innovation of subqueries that gave people the original idea of calling the early SQL “Structured Query Language.”
Here is an example statement that shows the major points about subquery syntax as specified by the SQL standard and supported in MySQL:
DELETE FROM t1 WHERE s11 > ANY (SELECT COUNT(*) /* no hint */ FROM t2 WHERE NOT EXISTS (SELECT * FROM t3 WHERE ROW(5*t2.s1,77)= (SELECT 50,11*s1 FROM t4 UNION SELECT 50,77 FROM (SELECT * FROM t5) AS t5)));
A subquery can return a scalar (a single value), a single row, a single column, or a table (one or more rows of one or more columns). These are called scalar, column, row, and table subqueries. Subqueries that return a particular kind of result often can be used only in certain contexts, as described in the following sections.
There are few restrictions on the type of statements in which
subqueries can be used. A subquery can contain any of the
keywords or clauses that an ordinary SELECT
can contain: DISTINCT, GROUP
BY, ORDER BY,
LIMIT, joins, index hints,
UNION constructs, comments, functions, and so
on.
One restriction is that a subquery's outer statement must be one
of: SELECT, INSERT,
UPDATE, DELETE,
SET, or DO. Another
restriction is that currently you cannot modify a table and
select from the same table in a subquery. This applies to
statements such as DELETE,
INSERT, REPLACE,
UPDATE, and (because subqueries can be used
in the SET clause) LOAD DATA
INFILE.
A more comprehensive discussion of restrictions on subquery use, including performance issues for certain forms of subquery syntax, is given in Section F.3, “Restrictions on Subqueries”.
In its simplest form, a subquery is a scalar subquery that
returns a single value. A scalar subquery is a simple operand,
and you can use it almost anywhere a single column value or
literal is legal, and you can expect it to have those
characteristics that all operands have: a data type, a length,
an indication whether it can be NULL, and
so on. For example:
CREATE TABLE t1 (s1 INT, s2 CHAR(5) NOT NULL); INSERT INTO t1 VALUES(100, 'abcde'); SELECT (SELECT s2 FROM t1);
The subquery in this SELECT returns a
single value ('abcde') that has a data type
of CHAR, a length of 5, a character set and
collation equal to the defaults in effect at CREATE
TABLE time, and an indication that the value in the
column can be NULL. In fact, almost all
subqueries can be NULL. If the table used
in the example were empty, the value of the subquery would be
NULL.
There are a few contexts in which a scalar subquery cannot be
used. If a statement allows only a literal value, you cannot
use a subquery. For example, LIMIT requires
literal integer arguments, and LOAD DATA
INFILE requires a literal string filename. You
cannot use subqueries to supply these values.
When you see examples in the following sections that contain
the rather spartan construct (SELECT column1 FROM
t1), imagine that your own code contains much more
diverse and complex constructions.
Suppose that we make two tables:
CREATE TABLE t1 (s1 INT); INSERT INTO t1 VALUES (1); CREATE TABLE t2 (s1 INT); INSERT INTO t2 VALUES (2);
Then perform a SELECT:
SELECT (SELECT s1 FROM t2) FROM t1;
The result is 2 because there is a row in
t2 containing a column
s1 that has a value of
2.
A scalar subquery can be part of an expression, but remember the parentheses, even if the subquery is an operand that provides an argument for a function. For example:
SELECT UPPER((SELECT s1 FROM t1)) FROM t2;
The most common use of a subquery is in the form:
non_subquery_operandcomparison_operator(subquery)
Where comparison_operator is one of
these operators:
= > < >= <= <>
For example:
... 'a' = (SELECT column1 FROM t1)
At one time the only legal place for a subquery was on the right side of a comparison, and you might still find some old DBMSs that insist on this.
Here is an example of a common-form subquery comparison that
you cannot do with a join. It finds all the values in table
t1 that are equal to a maximum value in
table t2:
SELECT column1 FROM t1 WHERE column1 = (SELECT MAX(column2) FROM t2);
Here is another example, which again is impossible with a join
because it involves aggregating for one of the tables. It
finds all rows in table t1 containing a
value that occurs twice in a given column:
SELECT * FROM t1 AS t WHERE 2 = (SELECT COUNT(*) FROM t1 WHERE t1.id = t.id);
For a comparison performed with one of these operators, the
subquery must return a scalar, with the exception that
= can be used with row subqueries. See
Section 13.2.8.5, “Row Subqueries”.
Syntax:
operandcomparison_operatorANY (subquery)operandIN (subquery)operandcomparison_operatorSOME (subquery)
The ANY keyword, which must follow a
comparison operator, means “return
TRUE if the comparison is
TRUE for ANY of the
values in the column that the subquery returns.” For
example:
SELECT s1 FROM t1 WHERE s1 > ANY (SELECT s1 FROM t2);
Suppose that there is a row in table t1
containing (10). The expression is
TRUE if table t2
contains (21,14,7) because there is a value
7 in t2 that is less
than 10. The expression is
FALSE if table t2
contains (20,10), or if table
t2 is empty. The expression is
unknown if table t2
contains (NULL,NULL,NULL).
When used with a subquery, the word IN is
an alias for = ANY. Thus, these two
statements are the same:
SELECT s1 FROM t1 WHERE s1 = ANY (SELECT s1 FROM t2); SELECT s1 FROM t1 WHERE s1 IN (SELECT s1 FROM t2);
IN and = ANY are not
synonyms when used with an expression list.
IN can take an expression list, but
= ANY cannot. See
Section 12.2.3, “Comparison Functions and Operators”.
NOT IN is not an alias for
<> ANY, but for <>
ALL. See Section 13.2.8.4, “Subqueries with ALL”.
The word SOME is an alias for
ANY. Thus, these two statements are the
same:
SELECT s1 FROM t1 WHERE s1 <> ANY (SELECT s1 FROM t2); SELECT s1 FROM t1 WHERE s1 <> SOME (SELECT s1 FROM t2);
Use of the word SOME is rare, but this
example shows why it might be useful. To most people's ears,
the English phrase “a is not equal to any b”
means “there is no b which is equal to a,” but
that is not what is meant by the SQL syntax. The syntax means
“there is some b to which a is not equal.” Using
<> SOME instead helps ensure that
everyone understands the true meaning of the query.
Syntax:
operandcomparison_operatorALL (subquery)
The word ALL, which must follow a
comparison operator, means “return
TRUE if the comparison is
TRUE for ALL of the
values in the column that the subquery returns.” For
example:
SELECT s1 FROM t1 WHERE s1 > ALL (SELECT s1 FROM t2);
Suppose that there is a row in table t1
containing (10). The expression is
TRUE if table t2
contains (-5,0,+5) because
10 is greater than all three values in
t2. The expression is
FALSE if table t2
contains (12,6,NULL,-100) because there is
a single value 12 in table
t2 that is greater than
10. The expression is
unknown (that is,
NULL) if table t2
contains (0,NULL,1).
Finally, if table t2 is empty, the result
is TRUE. So, the following statement is
TRUE when table t2 is
empty:
SELECT * FROM t1 WHERE 1 > ALL (SELECT s1 FROM t2);
But this statement is NULL when table
t2 is empty:
SELECT * FROM t1 WHERE 1 > (SELECT s1 FROM t2);
In addition, the following statement is
NULL when table t2 is
empty:
SELECT * FROM t1 WHERE 1 > ALL (SELECT MAX(s1) FROM t2);
In general, tables containing
NULL values and empty
tables are “edge cases.” When writing
subquery code, always consider whether you have taken those
two possibilities into account.
NOT IN is an alias for <>
ALL. Thus, these two statements are the same:
SELECT s1 FROM t1 WHERE s1 <> ALL (SELECT s1 FROM t2); SELECT s1 FROM t1 WHERE s1 NOT IN (SELECT s1 FROM t2);
The discussion to this point has been of scalar or column subqueries; that is, subqueries that return a single value or a column of values. A row subquery is a subquery variant that returns a single row and can thus return more than one column value. Here are two examples:
SELECT * FROM t1 WHERE (1,2) = (SELECT column1, column2 FROM t2); SELECT * FROM t1 WHERE ROW(1,2) = (SELECT column1, column2 FROM t2);
The queries here are both TRUE if table
t2 has a row where column1 =
1 and column2 = 2.
The expressions (1,2) and
ROW(1,2) are sometimes called
row constructors. The two are
equivalent. They are legal in other contexts as well. For
example, the following two statements are semantically
equivalent (although the first one cannot be optimized until
MySQL 5.0.26):
SELECT * FROM t1 WHERE (column1,column2) = (1,1); SELECT * FROM t1 WHERE column1 = 1 AND column2 = 1;
The normal use of row constructors is for comparisons with
subqueries that return two or more columns. For example, the
following query answers the request, “find all rows in
table t1 that also exist in table
t2”:
SELECT column1,column2,column3 FROM t1 WHERE (column1,column2,column3) IN (SELECT column1,column2,column3 FROM t2);
If a subquery returns any rows at all, EXISTS
is
subqueryTRUE, and NOT EXISTS
is
subqueryFALSE. For example:
SELECT column1 FROM t1 WHERE EXISTS (SELECT * FROM t2);
Traditionally, an EXISTS subquery starts
with SELECT *, but it could begin with
SELECT 5 or SELECT
column1 or anything at all. MySQL ignores the
SELECT list in such a subquery, so it makes
no difference.
For the preceding example, if t2 contains
any rows, even rows with nothing but NULL
values, the EXISTS condition is
TRUE. This is actually an unlikely example
because a [NOT] EXISTS subquery almost
always contains correlations. Here are some more realistic
examples:
What kind of store is present in one or more cities?
SELECT DISTINCT store_type FROM stores WHERE EXISTS (SELECT * FROM cities_stores WHERE cities_stores.store_type = stores.store_type);What kind of store is present in no cities?
SELECT DISTINCT store_type FROM stores WHERE NOT EXISTS (SELECT * FROM cities_stores WHERE cities_stores.store_type = stores.store_type);What kind of store is present in all cities?
SELECT DISTINCT store_type FROM stores s1 WHERE NOT EXISTS ( SELECT * FROM cities WHERE NOT EXISTS ( SELECT * FROM cities_stores WHERE cities_stores.city = cities.city AND cities_stores.store_type = stores.store_type));
The last example is a double-nested NOT
EXISTS query. That is, it has a NOT
EXISTS clause within a NOT EXISTS
clause. Formally, it answers the question “does a city
exist with a store that is not in
Stores”? But it is easier to say
that a nested NOT EXISTS answers the
question “is x
TRUE for all
y?”
A correlated subquery is a subquery that contains a reference to a table that also appears in the outer query. For example:
SELECT * FROM t1 WHERE column1 = ANY (SELECT column1 FROM t2 WHERE t2.column2 = t1.column2);
Notice that the subquery contains a reference to a column of
t1, even though the subquery's
FROM clause does not mention a table
t1. So, MySQL looks outside the subquery,
and finds t1 in the outer query.
Suppose that table t1 contains a row where
column1 = 5 and column2 =
6; meanwhile, table t2 contains a
row where column1 = 5 and column2
= 7. The simple expression ... WHERE
column1 = ANY (SELECT column1 FROM t2) would be
TRUE, but in this example, the
WHERE clause within the subquery is
FALSE (because (5,6) is
not equal to (5,7)), so the subquery as a
whole is FALSE.
Scoping rule: MySQL evaluates from inside to outside. For example:
SELECT column1 FROM t1 AS x WHERE x.column1 = (SELECT column1 FROM t2 AS x WHERE x.column1 = (SELECT column1 FROM t3 WHERE x.column2 = t3.column1));
In this statement, x.column2 must be a
column in table t2 because SELECT
column1 FROM t2 AS x ... renames
t2. It is not a column in table
t1 because SELECT column1 FROM t1
... is an outer query that is farther
out.
For subqueries in HAVING or ORDER
BY clauses, MySQL also looks for column names in the
outer select list.
For certain cases, a correlated subquery is optimized. For example:
valIN (SELECTkey_valFROMtbl_nameWHEREcorrelated_condition)
Otherwise, they are inefficient and likely to be slow. Rewriting the query as a join might improve performance.
Aggregate functions in correlated subqueries may contain outer references, provided the function contains nothing but outer references, and provided the function is not contained in another function or expression.
Subqueries are legal in a SELECT
statement's FROM clause. The actual syntax
is:
SELECT ... FROM (subquery) [AS]name...
The [AS]
clause is mandatory, because every table in a
nameFROM clause must have a name. Any columns
in the subquery select list must
have unique names. You can find this syntax described
elsewhere in this manual, where the term used is
“derived tables.”
For the sake of illustration, assume that you have this table:
CREATE TABLE t1 (s1 INT, s2 CHAR(5), s3 FLOAT);
Here is how to use a subquery in the FROM
clause, using the example table:
INSERT INTO t1 VALUES (1,'1',1.0); INSERT INTO t1 VALUES (2,'2',2.0); SELECT sb1,sb2,sb3 FROM (SELECT s1 AS sb1, s2 AS sb2, s3*2 AS sb3 FROM t1) AS sb WHERE sb1 > 1;
Result: 2, '2', 4.0.
Here is another example: Suppose that you want to know the average of a set of sums for a grouped table. This does not work:
SELECT AVG(SUM(column1)) FROM t1 GROUP BY column1;
However, this query provides the desired information:
SELECT AVG(sum_column1) FROM (SELECT SUM(column1) AS sum_column1 FROM t1 GROUP BY column1) AS t1;
Notice that the column name used within the subquery
(sum_column1) is recognized in the outer
query.
Subqueries in the FROM clause can return a
scalar, column, row, or table. Subqueries in the
FROM clause cannot be correlated
subqueries, unless used within the ON
clause of a JOIN operation.
Subqueries in the FROM clause are executed
even for the EXPLAIN statement (that is,
derived temporary tables are built). This occurs because
upper-level queries need information about all tables during
the optimization phase, and the table represented by a
subquery in the FROM clause is unavailable
unless the subquery is executed.
There are some errors that apply only to subqueries. This section describes them.
Unsupported subquery syntax:
ERROR 1235 (ER_NOT_SUPPORTED_YET) SQLSTATE = 42000 Message = "This version of MySQL does not yet support 'LIMIT & IN/ALL/ANY/SOME subquery'"
This means that statements of the following form do not work yet:
SELECT * FROM t1 WHERE s1 IN (SELECT s2 FROM t2 ORDER BY s1 LIMIT 1)
Incorrect number of columns from subquery:
ERROR 1241 (ER_OPERAND_COL) SQLSTATE = 21000 Message = "Operand should contain 1 column(s)"
This error occurs in cases like this:
SELECT (SELECT column1, column2 FROM t2) FROM t1;
You may use a subquery that returns multiple columns, if the purpose is comparison. In other contexts, the subquery must be a scalar operand. See Section 13.2.8.5, “Row Subqueries”.
Incorrect number of rows from subquery:
ERROR 1242 (ER_SUBSELECT_NO_1_ROW) SQLSTATE = 21000 Message = "Subquery returns more than 1 row"
This error occurs for statements where the subquery returns more than one row. Consider the following example:
SELECT * FROM t1 WHERE column1 = (SELECT column1 FROM t2);
If
SELECT column1 FROM t2returns just one row, the previous query will work. If the subquery returns more than one row, error 1242 will occur. In that case, the query should be rewritten as:SELECT * FROM t1 WHERE column1 = ANY (SELECT column1 FROM t2);
Incorrectly used table in subquery:
Error 1093 (ER_UPDATE_TABLE_USED) SQLSTATE = HY000 Message = "You can't specify target table 'x' for update in FROM clause"
This error occurs in cases such as the following:
UPDATE t1 SET column2 = (SELECT MAX(column1) FROM t1);
You can use a subquery for assignment within an
UPDATEstatement because subqueries are legal inUPDATEandDELETEstatements as well as inSELECTstatements. However, you cannot use the same table (in this case, tablet1) for both the subquery'sFROMclause and the update target.
For transactional storage engines, the failure of a subquery causes the entire statement to fail. For non-transactional storage engines, data modifications made before the error was encountered are preserved.
Development is ongoing, so no optimization tip is reliable for the long term. The following list provides some interesting tricks that you might want to play with:
Use subquery clauses that affect the number or order of the rows in the subquery. For example:
SELECT * FROM t1 WHERE t1.column1 IN (SELECT column1 FROM t2 ORDER BY column1); SELECT * FROM t1 WHERE t1.column1 IN (SELECT DISTINCT column1 FROM t2); SELECT * FROM t1 WHERE EXISTS (SELECT * FROM t2 LIMIT 1);
Replace a join with a subquery. For example, try this:
SELECT DISTINCT column1 FROM t1 WHERE t1.column1 IN ( SELECT column1 FROM t2);
Instead of this:
SELECT DISTINCT t1.column1 FROM t1, t2 WHERE t1.column1 = t2.column1;
Some subqueries can be transformed to joins for compatibility with older versions of MySQL that do not support subqueries. However, in some cases, converting a subquery to a join may improve performance. See Section 13.2.8.11, “Rewriting Subqueries as Joins for Earlier MySQL Versions”.
Move clauses from outside to inside the subquery. For example, use this query:
SELECT * FROM t1 WHERE s1 IN (SELECT s1 FROM t1 UNION ALL SELECT s1 FROM t2);
Instead of this query:
SELECT * FROM t1 WHERE s1 IN (SELECT s1 FROM t1) OR s1 IN (SELECT s1 FROM t2);
For another example, use this query:
SELECT (SELECT column1 + 5 FROM t1) FROM t2;
Instead of this query:
SELECT (SELECT column1 FROM t1) + 5 FROM t2;
Use a row subquery instead of a correlated subquery. For example, use this query:
SELECT * FROM t1 WHERE (column1,column2) IN (SELECT column1,column2 FROM t2);
Instead of this query:
SELECT * FROM t1 WHERE EXISTS (SELECT * FROM t2 WHERE t2.column1=t1.column1 AND t2.column2=t1.column2);
Use
NOT (a = ANY (...))rather thana <> ALL (...).Use
x = ANY (rather thantable containing (1,2))x=1 OR x=2.Use
= ANYrather thanEXISTS.For uncorrelated subqueries that always return one row,
INis always slower than=. For example, use this query:SELECT * FROM t1 WHERE t1.
col_name= (SELECT a FROM t2 WHERE b =some_const);Instead of this query:
SELECT * FROM t1 WHERE t1.
col_nameIN (SELECT a FROM t2 WHERE b =some_const);
These tricks might cause programs to go faster or slower.
Using MySQL facilities like the BENCHMARK()
function, you can get an idea about what helps in your own
situation. See Section 12.10.3, “Information Functions”.
Some optimizations that MySQL itself makes are:
MySQL executes uncorrelated subqueries only once. Use
EXPLAINto make sure that a given subquery really is uncorrelated.MySQL rewrites
IN,ALL,ANY, andSOMEsubqueries in an attempt to take advantage of the possibility that the select-list columns in the subquery are indexed.MySQL replaces subqueries of the following form with an index-lookup function, which
EXPLAINdescribes as a special join type (unique_subqueryorindex_subquery):... IN (SELECT
indexed_columnFROMsingle_table...)MySQL enhances expressions of the following form with an expression involving
MIN()orMAX(), unlessNULLvalues or empty sets are involved:value{ALL|ANY|SOME} {> | < | >= | <=} (uncorrelated subquery)For example, this
WHEREclause:WHERE 5 > ALL (SELECT x FROM t)
might be treated by the optimizer like this:
WHERE 5 > (SELECT MAX(x) FROM t)
There is a chapter titled “How MySQL Transforms Subqueries” in the MySQL Internals Manual, available at http://dev.mysql.com/doc/.
In previous versions of MySQL (prior to MySQL 4.1), only
nested queries of the form INSERT ... SELECT
... and REPLACE ... SELECT ...
were supported. Although this is not the case in MySQL
5.0, it is still true that there are sometimes
other ways to test membership in a set of values. It is also
true that on some occasions, it is not only possible to
rewrite a query without a subquery, but it can be more
efficient to make use of some of these techniques rather than
to use subqueries. One of these is the IN()
construct:
For example, this query:
SELECT * FROM t1 WHERE id IN (SELECT id FROM t2);
Can be rewritten as:
SELECT DISTINCT t1.* FROM t1, t2 WHERE t1.id=t2.id;
The queries:
SELECT * FROM t1 WHERE id NOT IN (SELECT id FROM t2); SELECT * FROM t1 WHERE NOT EXISTS (SELECT id FROM t2 WHERE t1.id=t2.id);
Can be rewritten using IN():
SELECT table1.* FROM table1 LEFT JOIN table2 ON table1.id=table2.id WHERE table2.id IS NULL;
A LEFT [OUTER] JOIN can be faster than an
equivalent subquery because the server might be able to
optimize it better — a fact that is not specific to
MySQL Server alone. Prior to SQL-92, outer joins did not
exist, so subqueries were the only way to do certain things.
Today, MySQL Server and many other modern database systems
offer a wide range of outer join types.
MySQL Server supports multiple-table DELETE
statements that can be used to efficiently delete rows based
on information from one table or even from many tables at the
same time. Multiple-table UPDATE statements
are also supported. See Section 13.2.1, “DELETE Syntax”, and
Section 13.2.10, “UPDATE Syntax”.
TRUNCATE [TABLE] tbl_name
TRUNCATE TABLE empties a table completely.
Logically, this is equivalent to a DELETE
statement that deletes all rows, but there are practical
differences under some circumstances.
For InnoDB before version 5.0.3,
TRUNCATE TABLE is mapped to
DELETE, so there is no difference. Starting
with MySQL 5.0.3, fast TRUNCATE TABLE is
available. However, the operation is still mapped to
DELETE if there are foreign key constraints
that reference the table. (When fast truncate is used, it resets
any AUTO_INCREMENT counter. From MySQL 5.0.13
on, the AUTO_INCREMENT counter is reset by
TRUNCATE TABLE, regardless of whether there
is a foreign key constraint.)
For other storage engines, TRUNCATE TABLE
differs from DELETE in the following ways in
MySQL 5.0:
Truncate operations drop and re-create the table, which is much faster than deleting rows one by one.
Truncate operations are not transaction-safe; an error occurs when attempting one in the course of an active transaction or active table lock.
The number of deleted rows is not returned.
As long as the table format file
tbl_name.frmTRUNCATE TABLE, even if the data or index files have become corrupted.The table handler does not remember the last used
AUTO_INCREMENTvalue, but starts counting from the beginning. This is true even forMyISAMandInnoDB, which normally do not reuse sequence values.Since truncation of a table does not make any use of
DELETE, theTRUNCATEstatement does not invokeON DELETEtriggers.
Single-table syntax:
UPDATE [LOW_PRIORITY] [IGNORE]tbl_nameSETcol_name1=expr1[,col_name2=expr2...] [WHEREwhere_condition] [ORDER BY ...] [LIMITrow_count]
Multiple-table syntax:
UPDATE [LOW_PRIORITY] [IGNORE]table_referencesSETcol_name1=expr1[,col_name2=expr2...] [WHEREwhere_condition]
For the single-table syntax, the UPDATE
statement updates columns of existing rows in
tbl_name with new values. The
SET clause indicates which columns to modify
and the values they should be given. The
WHERE clause, if given, specifies the
conditions that identify which rows to update. With no
WHERE clause, all rows are updated. If the
ORDER BY clause is specified, the rows are
updated in the order that is specified. The
LIMIT clause places a limit on the number of
rows that can be updated.
For the multiple-table syntax, UPDATE updates
rows in each table named in
table_references that satisfy the
conditions. In this case, ORDER BY and
LIMIT cannot be used.
where_condition is an expression that
evaluates to true for each row to be updated. It is specified as
described in Section 13.2.7, “SELECT Syntax”.
The UPDATE statement supports the following
modifiers:
If you use the
LOW_PRIORITYkeyword, execution of theUPDATEis delayed until no other clients are reading from the table. This affects only storage engines that use only table-level locking (MyISAM,MEMORY,MERGE).If you use the
IGNOREkeyword, the update statement does not abort even if errors occur during the update. Rows for which duplicate-key conflicts occur are not updated. Rows for which columns are updated to values that would cause data conversion errors are updated to the closest valid values instead.
If you access a column from tbl_name
in an expression, UPDATE uses the current
value of the column. For example, the following statement sets
the age column to one more than its current
value:
UPDATE persondata SET age=age+1;
Single-table UPDATE assignments are generally
evaluated from left to right. For multiple-table updates, there
is no guarantee that assignments are carried out in any
particular order.
If you set a column to the value it currently has, MySQL notices this and does not update it.
If you update a column that has been declared NOT
NULL by setting to NULL, the column
is set to the default value appropriate for the data type and
the warning count is incremented. The default value is
0 for numeric types, the empty string
('') for string types, and the
“zero” value for date and time types.
UPDATE returns the number of rows that were
actually changed. The mysql_info() C API
function returns the number of rows that were matched and
updated and the number of warnings that occurred during the
UPDATE.
You can use LIMIT
to restrict the
scope of the row_countUPDATE. A
LIMIT clause is a rows-matched restriction.
The statement stops as soon as it has found
row_count rows that satisfy the
WHERE clause, whether or not they actually
were changed.
If an UPDATE statement includes an
ORDER BY clause, the rows are updated in the
order specified by the clause. This can be useful in certain
situations that might otherwise result in an error. Suppose that
a table t contains a column
id that has a unique index. The following
statement could fail with a duplicate-key error, depending on
the order in which rows are updated:
UPDATE t SET id = id + 1;
For example, if the table contains 1 and 2 in the
id column and 1 is updated to 2 before 2 is
updated to 3, an error occurs. To avoid this problem, add an
ORDER BY clause to cause the rows with larger
id values to be updated before those with
smaller values:
UPDATE t SET id = id + 1 ORDER BY id DESC;
You can also perform UPDATE operations
covering multiple tables. However, you cannot use ORDER
BY or LIMIT with a multiple-table
UPDATE. The
table_references clause lists the
tables involved in the join. Its syntax is described in
Section 13.2.7.1, “JOIN Syntax”. Here is an example:
UPDATE items,month SET items.price=month.price WHERE items.id=month.id;
The preceding example shows an inner join that uses the comma
operator, but multiple-table UPDATE
statements can use any type of join allowed in
SELECT statements, such as LEFT
JOIN.
You need the UPDATE privilege only for
columns referenced in a multiple-table UPDATE
that are actually updated. You need only the
SELECT privilege for any columns that are
read but not modified.
If you use a multiple-table UPDATE statement
involving InnoDB tables for which there are
foreign key constraints, the MySQL optimizer might process
tables in an order that differs from that of their parent/child
relationship. In this case, the statement fails and rolls back.
Instead, update a single table and rely on the ON
UPDATE capabilities that InnoDB
provides to cause the other tables to be modified accordingly.
See Section 14.2.6.4, “FOREIGN KEY Constraints”.
Currently, you cannot update a table and select from the same table in a subquery.
{DESCRIBE | DESC} tbl_name [col_name | wild]
DESCRIBE provides information about the
columns in a table. It is a shortcut for SHOW COLUMNS
FROM. As of MySQL 5.0.1, these statements also display
information for views. (See Section 13.5.4.3, “SHOW COLUMNS Syntax”.)
col_name can be a column name, or a
string containing the SQL ‘%’ and
‘_’ wildcard characters to obtain
output only for the columns with names matching the string.
There is no need to enclose the string within quotes unless it
contains spaces or other special characters.
mysql> DESCRIBE city;
+------------+----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+----------+------+-----+---------+----------------+
| Id | int(11) | NO | PRI | NULL | auto_increment |
| Name | char(35) | NO | | | |
| Country | char(3) | NO | UNI | | |
| District | char(20) | YES | MUL | | |
| Population | int(11) | NO | | 0 | |
+------------+----------+------+-----+---------+----------------+
5 rows in set (0.00 sec)
Field indicates the column name.
The Null field indicates whether
NULL values can be stored in the column.
The Key field indicates whether the column is
indexed. A value of PRI indicates that the
column is part of the table's primary key.
UNI indicates that the column is part of a
UNIQUE index. The MUL
value indicates that multiple occurrences of a given value are
allowed within the column.
One reason for MUL to be displayed on a
UNIQUE index is that several columns form a
composite UNIQUE index; although the
combination of the columns is unique, each column can still hold
multiple occurrences of a given value. Note that in a composite
index, only the leftmost column of the index has an entry in the
Key field.
Before MySQL 5.0.11, if the column allows
NULL values, the Key value
can be MUL even when a
UNIQUE index is used. The rationale was that
multiple rows in a UNIQUE index can hold a
NULL value if the column is not declared
NOT NULL. As of MySQL 5.0.11, the display is
UNI rather than MUL
regardless of whether the column allows NULL;
you can see from the Null field whether or
not the column can contain NULL.
The Default field indicates the default value
that is assigned to the column.
The Extra field contains any additional
information that is available about a given column. In the
example shown, the Extra field indicates that
the Id column was created with the
AUTO_INCREMENT keyword.
If the data types are different from what you expect them to be
based on a CREATE TABLE statement, note that
MySQL sometimes changes data types. See
Section 13.1.5.1, “Silent Column Specification Changes”.
The DESCRIBE statement is provided for
compatibility with Oracle.
The SHOW CREATE TABLE and SHOW TABLE
STATUS statements also provide information about
tables. See Section 13.5.4, “SHOW Syntax”.
HELP 'search_string'
The HELP statement returns online information
from the MySQL Reference manual. Its proper operation requires
that the help tables in the mysql database be
initialized with help topic information (see
Section 5.2.8, “Server-Side Help”).
The HELP statement searches the help tables
for the given search string and displays the result of the
search. The search string is not case sensitive.
The HELP statement understands several types of search strings:
At the most general level, use
contentsto retrieve a list of the top-level help categories:HELP 'contents'
For a list of topics in a given help category, such as
Data Types, use the category name:HELP 'data types'
For help on a specific help topic, such as the
ASCII()function or theCREATE TABLEstatement, use the associated keyword or keywords:HELP 'ascii' HELP 'create table'
In other words, the search string matches a category, many
topics, or a single topic. You cannot necessarily tell in
advance whether a given search string will return a list of
items or the help information for a single help topic. However,
you can tell what kind of response HELP
returned by examining the number of rows and columns in the
result set.
The following descriptions indicate the forms that the result
set can take. Output for the example statements is shown using
the familar “tabular” or “vertical”
format that you see when using the mysql
client, but note that mysql itself reformats
HELP result sets in a different way.
Empty result set
No match could be found for the search string.
Result set containing a single row with three columns
This means that the search string yielded a hit for the help topic. The result has three columns:
name: The topic name.description: Descriptive help text for the topic.example: Usage example or exmples. This column might be blank.
Example:
HELP 'replace'Yields:
name: REPLACE description: Syntax: REPLACE(str,from_str,to_str) Returns the string str with all occurrences of the string from_str replaced by the string to_str. REPLACE() performs a case-sensitive match when searching for from_str. example: mysql> SELECT REPLACE('www.mysql.com', 'w', 'Ww'); -> 'WwWwWw.mysql.com'Result set containing multiple rows with two columns
This means that the search string matched many help topics. The result set indicates the help topic names:
name: The help topic name.is_it_category:Yif the name represents a help category,Nif it does not. If it does not, thenamevalue when specified as the argument to theHELPstatement should yield a single-row result set containing a description for the named item.
Example:
HELP 'status'Yields:
+-----------------------+----------------+ | name | is_it_category | +-----------------------+----------------+ | SHOW | N | | SHOW ENGINE | N | | SHOW INNODB STATUS | N | | SHOW MASTER STATUS | N | | SHOW PROCEDURE STATUS | N | | SHOW SLAVE STATUS | N | | SHOW STATUS | N | | SHOW TABLE STATUS | N | +-----------------------+----------------+
Result set containing multiple rows with three columns
This means the search string matches a category. The result set contains category entries:
source_category_name: The help category name.name: The category or topic nameis_it_category:Yif the name represents a help category,Nif it does not. If it does not, thenamevalue when specified as the argument to theHELPstatement should yield a single-row result set containing a description for the named item.
Example:
HELP 'functions'Yields:
+----------------------+-------------------------+----------------+ | source_category_name | name | is_it_category | +----------------------+-------------------------+----------------+ | Functions | CREATE FUNCTION | N | | Functions | DROP FUNCTION | N | | Functions | Bit Functions | Y | | Functions | Comparison operators | Y | | Functions | Control flow functions | Y | | Functions | Date and Time Functions | Y | | Functions | Encryption Functions | Y | | Functions | Information Functions | Y | | Functions | Logical operators | Y | | Functions | Miscellaneous Functions | Y | | Functions | Numeric Functions | Y | | Functions | String Functions | Y | +----------------------+-------------------------+----------------+
If you intend to use the HELP() statement
while other tables are locked with LOCK
TABLES, you must also lock the required
mysql.help_
tables.
xxx
USE db_name
The USE
statement tells MySQL to use the
db_namedb_name database as the default
(current) database for subsequent statements. The database
remains the default until the end of the session or another
USE statement is issued:
USE db1; SELECT COUNT(*) FROM mytable; # selects from db1.mytable USE db2; SELECT COUNT(*) FROM mytable; # selects from db2.mytable
Making a particular database the default by means of the
USE statement does not preclude you from
accessing tables in other databases. The following example
accesses the author table from the
db1 database and the
editor table from the db2
database:
USE db1; SELECT author_name,editor_name FROM author,db2.editor WHERE author.editor_id = db2.editor.editor_id;
The USE statement is provided for
compatibility with Sybase.
MySQL supports local transactions (within a given client
connection) through statements such as SET
AUTOCOMMIT, START TRANSACTION,
COMMIT, and ROLLBACK. See
Section 13.4.1, “START TRANSACTION, COMMIT, and
ROLLBACK Syntax”. Beginning with MySQL 5.0, XA transaction
support is available, which enables MySQL to participate in
distributed transactions as well. See Section 13.4.7, “XA Transactions”.
START TRANSACTION [WITH CONSISTENT SNAPSHOT] | BEGIN [WORK]
COMMIT [WORK] [AND [NO] CHAIN] [[NO] RELEASE]
ROLLBACK [WORK] [AND [NO] CHAIN] [[NO] RELEASE]
SET AUTOCOMMIT = {0 | 1}
The START TRANSACTION and
BEGIN statement begin a new transaction.
COMMIT commits the current transaction,
making its changes permanent. ROLLBACK rolls
back the current transaction, canceling its changes. The
SET AUTOCOMMIT statement disables or enables
the default autocommit mode for the current connection.
Beginning with MySQL 5.0.3, the optional WORK
keyword is supported for COMMIT and
ROLLBACK, as are the CHAIN
and RELEASE clauses. CHAIN
and RELEASE can be used for additional
control over transaction completion. The value of the
completion_type system variable determines
the default completion behavior. See
Section 5.2.3, “System Variables”.
The AND CHAIN clause causes a new transaction
to begin as soon as the current one ends, and the new
transaction has the same isolation level as the just-terminated
transaction. The RELEASE clause causes the
server to disconnect the current client connection after
terminating the current transaction. Including the
NO keyword suppresses
CHAIN or RELEASE
completion, which can be useful if the
completion_type system variable is set to
cause chaining or release completion by default.
By default, MySQL runs with autocommit mode enabled. This means that as soon as you execute a statement that updates (modifies) a table, MySQL stores the update on disk.
If you are using a transaction-safe storage engine (such as
InnoDB, BDB, or
NDB Cluster), you can disable autocommit mode
with the following statement:
SET AUTOCOMMIT=0;
After disabling autocommit mode by setting the
AUTOCOMMIT variable to zero, you must use
COMMIT to store your changes to disk or
ROLLBACK if you want to ignore the changes
you have made since the beginning of your transaction.
To disable autocommit mode for a single series of statements,
use the START TRANSACTION statement:
START TRANSACTION; SELECT @A:=SUM(salary) FROM table1 WHERE type=1; UPDATE table2 SET summary=@A WHERE type=1; COMMIT;
With START TRANSACTION, autocommit remains
disabled until you end the transaction with
COMMIT or ROLLBACK. The
autocommit mode then reverts to its previous state.
BEGIN and BEGIN WORK are
supported as aliases of START TRANSACTION for
initiating a transaction. START TRANSACTION
is standard SQL syntax and is the recommended way to start an
ad-hoc transaction.
Important: Many APIs used for
writing MySQL client applications (such as JDBC) provide their
own methods for starting transactions that can (and sometimes
should) be used instead of sending a START
TRANSACTION statement from the client. See
Chapter 22, APIs and Libraries, or the documentation for your API, for
more information.
The BEGIN statement differs from the use of
the BEGIN keyword that starts a
BEGIN ... END compound statement. The latter
does not begin a transaction. See Section 17.2.5, “BEGIN ... END Compound Statement Syntax”.
You can also begin a transaction like this:
START TRANSACTION WITH CONSISTENT SNAPSHOT;
The WITH CONSISTENT SNAPSHOT clause starts a
consistent read for storage engines that are capable of it.
Currently, this applies only to InnoDB. The
effect is the same as issuing a START
TRANSACTION followed by a SELECT
from any InnoDB table. See
Section 14.2.10.4, “Consistent Non-Locking Read”.
The WITH CONSISTENT SNAPSHOT clause does not
change the current transaction isolation level, so it provides a
consistent snapshot only if the current isolation level is one
that allows consistent read (REPEATABLE READ
or SERIALIZABLE).
Beginning a transaction causes any pending transaction to be committed. See Section 13.4.3, “Statements That Cause an Implicit Commit”, for more information.
Beginning a transaction also causes table locks acquired with
LOCK TABLES to be released, as though you had
executed UNLOCK TABLES. Beginning a
transaction does not release a global read lock acquired with
FLUSH TABLES WITH READ LOCK.
For best results, transactions should be performed using only tables managed by a single transactional storage engine. Otherwise, the following problems can occur:
If you use tables from more than one transaction-safe storage engine (such as
InnoDBandBDB), and the transaction isolation level is notSERIALIZABLE, it is possible that when one transaction commits, another ongoing transaction that uses the same tables will see only some of the changes made by the first transaction. That is, the atomicity of transactions is not guaranteed with mixed engines and inconsistencies can result. (If mixed-engine transactions are infrequent, you can useSET TRANSACTION ISOLATION LEVELto set the isolation level toSERIALIZABLEon a per-transaction basis as necessary.)If you use non-transaction-safe tables within a transaction, any changes to those tables are stored at once, regardless of the status of autocommit mode.
If you issue a
ROLLBACKstatement after updating a non-transactional table within a transaction, anER_WARNING_NOT_COMPLETE_ROLLBACKwarning occurs. Changes to transaction-safe tables are rolled back, but not changes to non-transaction-safe tables.
Each transaction is stored in the binary log in one chunk, upon
COMMIT. Transactions that are rolled back are
not logged. (Exception:
Modifications to non-transactional tables cannot be rolled back.
If a transaction that is rolled back includes modifications to
non-transactional tables, the entire transaction is logged with
a ROLLBACK statement at the end to ensure
that the modifications to those tables are replicated.) See
Section 5.11.3, “The Binary Log”.
You can change the isolation level for transactions with
SET TRANSACTION ISOLATION LEVEL. See
Section 13.4.6, “SET TRANSACTION Syntax”.
Rolling back can be a slow operation that may occur without the
user having explicitly asked for it (for example, when an error
occurs). Because of this, SHOW PROCESSLIST
displays Rolling back in the
State column for the connection during
implicit and explicit (ROLLBACK SQL
statement) rollbacks.
Some statements cannot be rolled back. In general, these include data definition language (DDL) statements, such as those that create or drop databases, those that create, drop, or alter tables or stored routines.
You should design your transactions not to include such
statements. If you issue a statement early in a transaction that
cannot be rolled back, and then another statement later fails,
the full effect of the transaction cannot be rolled back in such
cases by issuing a ROLLBACK statement.
Each of the following statements (and any synonyms for them)
implicitly end a transaction, as if you had done a
COMMIT before executing the statement:
ALTER TABLE,BEGIN,CREATE INDEX,DROP INDEX,DROP TABLE,LOAD MASTER DATA,LOCK TABLES,LOAD DATA INFILE,RENAME TABLE,SET AUTOCOMMIT=1,START TRANSACTION,UNLOCK TABLES.Beginning with MySQL 5.0.8, The
CREATE TABLE,CREATE DATABASEDROP DATABASE, andTRUNCATE TABLEstatements cause an implicit commit. Beginning with MySQL 5.0.13, theALTER FUNCTION,ALTER PROCEDURE,CREATE FUNCTION,CREATE PROCEDURE,DROP FUNCTION, andDROP PROCEDUREstatements cause an implicit commit. Beginning with MySQL 5.0.15, theALTER VIEW,CREATE TRIGGER,CREATE USER,CREATE VIEW,DROP TRIGGER,DROP USER,DROP VIEW, andRENAME USERstatements cause an implicit commit.UNLOCK TABLEScommits a transaction only if any tables currently have been locked withLOCK TABLES. This does not occur forUNLOCK TABLESfollowingFLUSH TABLES WITH READ LOCKbecause the latter statement does not acquire table-level locks.The
CREATE TABLEstatement inInnoDBis processed as a single transaction. This means that aROLLBACKfrom the user does not undoCREATE TABLEstatements the user made during that transaction.CREATE TABLEandDROP TABLEdo not commit a transaction if theTEMPORARYkeyword is used. (This does not apply to other operations on temporary tables such asCREATE INDEX, which do cause a commit.)In MySQL 5.0.25 and earlier,
LOAD DATA INFILEcaused an implicit commit for all storage engines. Beginning with MySQL 5.0.26, it causes an implicit commit only for tables using theNDBstorage engine. For more information, see Bug#11151.
Transactions cannot be nested. This is a consequence of the
implicit COMMIT performed for any current
transaction when you issue a START
TRANSACTION statement or one of its synonyms.
Statements that cause implicit cannot be used in an XA
transaction while the transaction is in an
ACTIVE state.
The BEGIN statement differs from the use of
the BEGIN keyword that starts a
BEGIN ... END compound statement. The latter
does not cause an implicit commit. See
Section 17.2.5, “BEGIN ... END Compound Statement Syntax”.
SAVEPOINTidentifierROLLBACK [WORK] TO SAVEPOINTidentifierRELEASE SAVEPOINTidentifier
InnoDB supports the SQL statements
SAVEPOINT and ROLLBACK TO
SAVEPOINT. Starting from MySQL 5.0.3, RELEASE
SAVEPOINT and the optional WORK
keyword for ROLLBACK are supported as well.
The SAVEPOINT statement sets a named
transaction savepoint with a name of
identifier. If the current
transaction has a savepoint with the same name, the old
savepoint is deleted and a new one is set.
The ROLLBACK TO SAVEPOINT statement rolls
back a transaction to the named savepoint. Modifications that
the current transaction made to rows after the savepoint was set
are undone in the rollback, but InnoDB does
not release the row locks that were stored
in memory after the savepoint. (Note that for a new inserted
row, the lock information is carried by the transaction ID
stored in the row; the lock is not separately stored in memory.
In this case, the row lock is released in the undo.) Savepoints
that were set at a later time than the named savepoint are
deleted.
If the ROLLBACK TO SAVEPOINT statement
returns the following error, it means that no savepoint with the
specified name exists:
ERROR 1181: Got error 153 during ROLLBACK
The RELEASE SAVEPOINT statement removes the
named savepoint from the set of savepoints of the current
transaction. No commit or rollback occurs. It is an error if the
savepoint does not exist.
All savepoints of the current transaction are deleted if you
execute a COMMIT, or a
ROLLBACK that does not name a savepoint.
Beginning with MySQL 5.0.17, a new savepoint level is created when a stored function is invoked or a trigger is activated. The savepoints on previous levels become unavailable and thus do not conflict with savepoints on the new level. When the function or trigger terminates, any savepoints it created are released and the previous savepoint level is restored.
LOCK TABLES
tbl_name [AS alias]
{READ [LOCAL] | [LOW_PRIORITY] WRITE}
[, tbl_name [AS alias]
{READ [LOCAL] | [LOW_PRIORITY] WRITE}] ...
UNLOCK TABLES
LOCK TABLES locks base tables (but not views)
for the current thread. If any of the tables are locked by other
threads, it blocks until all locks can be acquired.
UNLOCK TABLES explicitly releases any locks
held by the current thread. All tables that are locked by the
current thread are implicitly unlocked when the thread issues
another LOCK TABLES, or when the connection
to the server is closed. UNLOCK TABLES is
also used after acquiring a global read lock with FLUSH
TABLES WITH READ LOCK to release that lock. (You can
lock all tables in all databases with read locks with the
FLUSH TABLES WITH READ LOCK statement. See
Section 13.5.5.2, “FLUSH Syntax”. This is a very convenient way to get
backups if you have a filesystem such as Veritas that can take
snapshots in time.)
To use LOCK TABLES, you must have the
LOCK TABLES privilege and the
SELECT privilege for the involved tables.
The main reasons to use LOCK TABLES are to
emulate transactions or to get more speed when updating tables.
This is explained in more detail later.
A table lock protects only against inappropriate reads or writes
by other clients. The client holding the lock, even a read lock,
can perform table-level operations such as DROP
TABLE. Truncate operations are not transaction-safe,
so an error occurs if the client attempts one during an active
transaction or while holding a table lock.
Note the following regarding the use of LOCK
TABLES with transactional tables:
LOCK TABLESis not transaction-safe and implicitly commits any active transactions before attempting to lock the tables. Also, beginning a transaction (for example, withSTART TRANSACTION) implicitly performs anUNLOCK TABLES. (See Section 13.4.3, “Statements That Cause an Implicit Commit”.)The correct way to use
LOCK TABLESwith transactional tables, such asInnoDBtables, is to setAUTOCOMMIT = 0and not to callUNLOCK TABLESuntil you commit the transaction explicitly. When you callLOCK TABLES,InnoDBinternally takes its own table lock, and MySQL takes its own table lock.InnoDBreleases its table lock at the next commit, but for MySQL to release its table lock, you have to callUNLOCK TABLES. You should not haveAUTOCOMMIT = 1, because thenInnoDBreleases its table lock immediately after the call ofLOCK TABLES, and deadlocks can very easily happen. Note that we do not acquire theInnoDBtable lock at all ifAUTOCOMMIT=1, to help old applications avoid unnecessary deadlocks.ROLLBACKdoes not release MySQL's non-transactional table locks.FLUSH TABLES WITH READ LOCKacquires a global read lock and not table locks, so it is not subject to the same behavior asLOCK TABLESandUNLOCK TABLESwith respect to table locking and implicit commits. See Section 13.5.5.2, “FLUSHSyntax”.
When you use LOCK TABLES, you must lock all
tables that you are going to use in your statements. Because
LOCK TABLES will not lock views, if the
operation that you are performing uses any views, you must also
lock all of the base tables on which those views depend. While
the locks obtained with a LOCK TABLES
statement are in effect, you cannot access any tables that were
not locked by the statement. Also, you cannot use a locked table
multiple times in a single query. Use aliases instead, in which
case you must obtain a lock for each alias separately.
mysql>LOCK TABLE t WRITE, t AS t1 WRITE;mysql>INSERT INTO t SELECT * FROM t;ERROR 1100: Table 't' was not locked with LOCK TABLES mysql>INSERT INTO t SELECT * FROM t AS t1;
If your statements refer to a table by means of an alias, you must lock the table using that same alias. It does not work to lock the table without specifying the alias:
mysql>LOCK TABLE t READ;mysql>SELECT * FROM t AS myalias;ERROR 1100: Table 'myalias' was not locked with LOCK TABLES
Conversely, if you lock a table using an alias, you must refer to it in your statements using that alias:
mysql>LOCK TABLE t AS myalias READ;mysql>SELECT * FROM t;ERROR 1100: Table 't' was not locked with LOCK TABLES mysql>SELECT * FROM t AS myalias;
If a thread obtains a READ lock on a table,
that thread (and all other threads) can only read from the
table. If a thread obtains a WRITE lock on a
table, only the thread holding the lock can write to the table.
Other threads are blocked from reading or writing the table
until the lock has been released.
The difference between READ LOCAL and
READ is that READ LOCAL
allows non-conflicting INSERT statements
(concurrent inserts) to execute while the lock is held. However,
this cannot be used if you are going to manipulate the database
using processes external to the server while you hold the lock.
For InnoDB tables, READ
LOCAL is the same as READ as of
MySQL 5.0.13. (Before that, READ LOCAL
essentially does nothing: It does not lock the table at all, so
for InnoDB tables, the use of READ
LOCAL is deprecated because a plain consistent-read
SELECT does the same thing, and no locks are
needed.)
WRITE locks normally have higher priority
than READ locks to ensure that updates are
processed as soon as possible. This means that if one thread
obtains a READ lock and then another thread
requests a WRITE lock, subsequent
READ lock requests wait until the
WRITE thread has gotten the lock and released
it. You can use LOW_PRIORITY WRITE locks to
allow other threads to obtain READ locks
before the thread that is waiting for the
WRITE lock. You should use
LOW_PRIORITY WRITE locks only if you are sure
that eventually there will be a time when no threads have a
READ lock. (Exception: For
InnoDB tables in transactional mode
(autocommit = 0), a LOW_PRIORITY WRITE lock
acts like a regular WRITE lock and precedes
waiting READ locks.)
LOCK TABLES works as follows:
Sort all tables to be locked in an internally defined order. From the user standpoint, this order is undefined.
If a table is to be locked with a read and a write lock, put the write lock before the read lock.
Lock one table at a time until the thread gets all locks.
This policy ensures that table locking is deadlock free. There
are, however, other things you need to be aware of about this
policy: If you are using a LOW_PRIORITY WRITE
lock for a table, it means only that MySQL waits for this
particular lock until there are no threads that want a
READ lock. When the thread has gotten the
WRITE lock and is waiting to get the lock for
the next table in the lock table list, all other threads wait
for the WRITE lock to be released. If this
becomes a serious problem with your application, you should
consider converting some of your tables to transaction-safe
tables.
You can safely use KILL to terminate a thread
that is waiting for a table lock. See Section 13.5.5.3, “KILL Syntax”.
Note that you should not lock any tables
that you are using with INSERT DELAYED
because in that case the INSERT is performed
by a separate thread.
Normally, you do not need to lock tables, because all single
UPDATE statements are atomic; no other thread
can interfere with any other currently executing SQL statement.
However, there are a few cases when locking tables may provide
an advantage:
If you are going to run many operations on a set of
MyISAMtables, it is much faster to lock the tables you are going to use. LockingMyISAMtables speeds up inserting, updating, or deleting on them because MySQL does not flush the key cache for the locked tables untilUNLOCK TABLESis called. Normally, the key cache is flushed after each SQL statement.The downside to locking the tables is that no thread can update a
READ-locked table (including the one holding the lock) and no thread can access aWRITE-locked table other than the one holding the lock.If you are using tables for a non-transactional storage engine, you must use
LOCK TABLESif you want to ensure that no other thread modifies the tables between aSELECTand anUPDATE. The example shown here requiresLOCK TABLESto execute safely:LOCK TABLES trans READ, customer WRITE; SELECT SUM(value) FROM trans WHERE customer_id=
some_id; UPDATE customer SET total_value=sum_from_previous_statementWHERE customer_id=some_id; UNLOCK TABLES;Without
LOCK TABLES, it is possible that another thread might insert a new row in thetranstable between execution of theSELECTandUPDATEstatements.
You can avoid using LOCK TABLES in many cases
by using relative updates (UPDATE customer SET
)
or the value=value+new_valueLAST_INSERT_ID() function. See
Section 1.9.5.3, “Transactions and Atomic Operations”.
You can also avoid locking tables in some cases by using the
user-level advisory lock functions GET_LOCK()
and RELEASE_LOCK(). These locks are saved in
a hash table in the server and implemented with
pthread_mutex_lock() and
pthread_mutex_unlock() for high speed. See
Section 12.10.4, “Miscellaneous Functions”.
See Section 7.3.1, “Internal Locking Methods”, for more information on locking policy.
Note: If you use ALTER
TABLE on a locked table, it may become unlocked. See
Section B.1.7.1, “Problems with ALTER TABLE”.
SET [GLOBAL | SESSION] TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE }
This statement sets the transaction isolation level for the next transaction, globally, or for the current session.
The default behavior of SET TRANSACTION is to
set the isolation level for the next (not yet started)
transaction. If you use the GLOBAL keyword,
the statement sets the default transaction level globally for
all new connections created from that point on. Existing
connections are unaffected. You need the
SUPER privilege to do this. Using the
SESSION keyword sets the default transaction
level for all future transactions performed on the current
connection.
For descriptions of each InnoDB transaction
isolation level, see
Section 14.2.10.3, “InnoDB and TRANSACTION ISOLATION
LEVEL”.
InnoDB supports each of these levels in MySQL
5.0. The default level is REPEATABLE
READ.
To set the initial default global isolation level for
mysqld, use the
--transaction-isolation option. See
Section 5.2.2, “Command Options”.
MySQL 5.0.3 and up provides server-side support for XA
transactions. Currently, this support is available for the
InnoDB storage engine. The MySQL XA
implementation is based on the X/Open CAE document
Distributed Transaction Processing: The XA
Specification. This document is published by The
Open Group and available at
http://www.opengroup.org/public/pubs/catalog/c193.htm.
Limitations of the current XA implementation are described in
Section F.5, “Restrictions on XA Transactions”.
On the client side, there are no special requirements. The XA
interface to a MySQL server consists of SQL statements that
begin with the XA keyword. MySQL client
programs must be able to send SQL statements and to understand
the semantics of the XA statement interface. They do not need be
linked against a recent client library. Older client libraries
also will work.
Currently, among the MySQL Connectors, MySQL Connector/J 5.0.0 supports XA directly (by means of a class interface that handles the XA SQL statement interface for you).
XA supports distributed transactions; that is, the ability to allow multiple separate transactional resources to participate in a global transaction. Transactional resources often are RDBMSs but may be other kinds of resources.
MySQL Enterprise For expert advice on XA Distributed Transaction Support subscribe to the MySQL Network Monitoring and Advisory Service. For more information see, http://www.mysql.com/products/enterprise/advisors.html.
A global transaction involves several actions that are
transactional in themselves, but that all must either complete
successfully as a group, or all be rolled back as a group. In
essence, this extends ACID properties “up a level”
so that multiple ACID transactions can be executed in concert as
components of a global operation that also has ACID properties.
(However, for a distributed transaction, you must use the
SERIALIZABLE isolation level to achieve ACID
properties. It is enough to use REPEATABLE
READ for a non-distributed transaction, but not for a
distributed transaction.)
Some examples of distributed transactions:
An application may act as an integration tool that combines a messaging service with an RDBMS. The application makes sure that transactions dealing with message sending, retrieval, and processing that also involve a transactional database all happen in a global transaction. You can think of this as “transactional email.”
An application performs actions that involve different database servers, such as a MySQL server and an Oracle server (or multiple MySQL servers), where actions that involve multiple servers must happen as part of a global transaction, rather than as separate transactions local to each server.
A bank keeps account information in an RDBMS and distributes and receives money via automated teller machines (ATMs). It is necessary to ensure that ATM actions are correctly reflected in the accounts, but this cannot be done with the RDBMS alone. A global transaction manager integrates the ATM and database resources to ensure overall consistency of financial transactions.
Applications that use global transactions involve one or more Resource Managers and a Transaction Manager:
A Resource Manager (RM) provides access to transactional resources. A database server is one kind of resource manager. It must be possible to either commit or roll back transactions managed by the RM.
A Transaction Manager (TM) coordinates the transactions that are part of a global transaction. It communicates with the RMs that handle each of these transactions. The individual transactions within a global transaction are “branches” of the global transaction. Global transactions and their branches are identified by a naming scheme described later.
The MySQL implementation of XA MySQL enables a MySQL server to act as a Resource Manager that handles XA transactions within a global transaction. A client program that connects to the MySQL server acts as the Transaction Manager.
To carry out a global transaction, it is necessary to know which components are involved, and bring each component to a point when it can be committed or rolled back. Depending on what each component reports about its ability to succeed, they must all commit or roll back as an atomic group. That is, either all components must commit, or all components musts roll back. To manage a global transaction, it is necessary to take into account that any component or the connecting network might fail.
The process for executing a global transaction uses two-phase commit (2PC). This takes place after the actions performed by the branches of the global transaction have been executed.
In the first phase, all branches are prepared. That is, they are told by the TM to get ready to commit. Typically, this means each RM that manages a branch records the actions for the branch in stable storage. The branches indicate whether they are able to do this, and these results are used for the second phase.
In the second phase, the TM tells the RMs whether to commit or roll back. If all branches indicated when they were prepared that they will be able to commit, all branches are told to commit. If any branch indicated when it was prepared that it will not be able to commit, all branches are told to roll back.
In some cases, a global transaction might use one-phase commit (1PC). For example, when a Transaction Manager finds that a global transaction consists of only one transactional resource (that is, a single branch), that resource can be told to prepare and commit at the same time.
To perform XA transactions in MySQL, use the following statements:
XA {START|BEGIN} xid [JOIN|RESUME]
XA END xid [SUSPEND [FOR MIGRATE]]
XA PREPARE xid
XA COMMIT xid [ONE PHASE]
XA ROLLBACK xid
XA RECOVER
For XA START, the JOIN
and RESUME clauses are not supported.
For XA END the SUSPEND [FOR
MIGRATE] clause is not supported.
Each XA statement begins with the XA
keyword, and most of them require an
xid value. An
xid is an XA transaction
identifier. It indicates which transaction the statement
applies to. xid values are supplied
by the client, or generated by the MySQL server. An
xid value has from one to three
parts:
xid:gtrid[,bqual[,formatID]]
gtrid is a global transaction
identifier, bqual is a branch
qualifier, and formatID is a number
that identifies the format used by the
gtrid and
bqual values. As indicated by the
syntax, bqual and
formatID are optional. The default
bqual value is
'' if not given. The default
formatID value is 1 if not given.
gtrid and
bqual must be string literals, each
up to 64 bytes (not characters) long.
gtrid and
bqual can be specified in several
ways. You can use a quoted string ('ab'),
hex string (0x6162,
X'ab'), or bit value
(b').
nnnn'
formatID is an unsigned integer.
The gtrid and
bqual values are interpreted in
bytes by the MySQL server's underlying XA support routines.
However, while an SQL statement containing an XA statement is
being parsed, the server works with some specific character
set. To be safe, write gtrid and
bqual as hex strings.
xid values typically are generated
by the Transaction Manager. Values generated by one TM must be
different from values generated by other TMs. A given TM must
be able to recognize its own xid
values in a list of values returned by the XA
RECOVER statement.
XA START
starts an XA transaction with the given
xidxid value. Each XA transaction must
have a unique xid value, so the
value must not currently be used by another XA transaction.
Uniqueness is assessed using the
gtrid and
bqual values. All following XA
statements for the XA transaction must be specified using the
same xid value as that given in the
XA START statement. If you use any of those
statements but specify an xid value
that does not correspond to some existing XA transaction, an
error occurs.
One or more XA transactions can be part of the same global
transaction. All XA transactions within a given global
transaction must use the same gtrid
value in the xid value. For this
reason, gtrid values must be
globally unique so that there is no ambiguity about which
global transaction a given XA transaction is part of. The
bqual part of the
xid value must be different for
each XA transaction within a global transaction. (The
requirement that bqual values be
different is a limitation of the current MySQL XA
implementation. It is not part of the XA specification.)
The XA RECOVER statement returns
information for those XA transactions on the MySQL server that
are in the PREPARED state. (See
Section 13.4.7.2, “XA Transaction States”.) The output includes a row for
each such XA transaction on the server, regardless of which
client started it.
XA RECOVER output rows look like this (for
an example xid value consisting of
the parts 'abc', 'def',
and 7):
mysql> XA RECOVER;
+----------+--------------+--------------+--------+
| formatID | gtrid_length | bqual_length | data |
+----------+--------------+--------------+--------+
| 7 | 3 | 3 | abcdef |
+----------+--------------+--------------+--------+
The output columns have the following meanings:
formatIDis theformatIDpart of the transactionxidgtrid_lengthis the length in bytes of thegtridpart of thexidbqual_lengthis the length in bytes of thebqualpart of thexiddatais the concatenation of thegtridandbqualparts of thexid
An XA transaction progresses through the following states:
Use
XA STARTto start an XA transaction and put it in theACTIVEstate.For an
ACTIVEXA transaction, issue the SQL statements that make up the transaction, and then issue anXA ENDstatement.XA ENDputs the transaction in theIDLEstate.For an
IDLEXA transaction, you can issue either anXA PREPAREstatement or anXA COMMIT ... ONE PHASEstatement:XA PREPAREputs the transaction in thePREPAREDstate. AnXA RECOVERstatement at this point will include the transaction'sxidvalue in its output, becauseXA RECOVERlists all XA transactions that are in thePREPAREDstate.XA COMMIT ... ONE PHASEprepares and commits the transaction. Thexidvalue will not be listed byXA RECOVERbecause the transaction terminates.
For a
PREPAREDXA transaction, you can issue anXA COMMITstatement to commit and terminate the transaction, orXA ROLLBACKto roll back and terminate the transaction.
Here is a simple XA transaction that inserts a row into a table as part of a global transaction:
mysql>XA START 'xatest';Query OK, 0 rows affected (0.00 sec) mysql>INSERT INTO mytable (i) VALUES(10);Query OK, 1 row affected (0.04 sec) mysql>XA END 'xatest';Query OK, 0 rows affected (0.00 sec) mysql>XA PREPARE 'xatest';Query OK, 0 rows affected (0.00 sec) mysql>XA COMMIT 'xatest';Query OK, 0 rows affected (0.00 sec)
Within the context of a given client connection, XA
transactions and local (non-XA) transactions are mutually
exclusive. For example, if XA START has
been issued to begin an XA transaction, a local transaction
cannot be started until the XA transaction has been committed
or rolled back. Conversely, if a local transaction has been
started with START TRANSACTION, no XA
statements can be used until the transaction has been
committed or rolled back.
Note that if an XA transaction is in the
ACTIVE state, you cannot issue any
statements that cause an implicit commit. That would violate
the XA contract because you could not roll back the XA
transaction. You will receive the following error if you try
to execute such a statement:
ERROR 1399 (XAE07): XAER_RMFAIL: The command cannot be executed when global transaction is in the ACTIVE state
Statements to which the preceding remark applies are listed at Section 13.4.3, “Statements That Cause an Implicit Commit”.
MySQL account information is stored in the tables of the
mysql database. This database and the access
control system are discussed extensively in
Chapter 5, Database Administration, which you should
consult for additional details.
Important: Some releases of MySQL introduce changes to the structure of the grant tables to add new privileges or features. Whenever you update to a new version of MySQL, you should update your grant tables to make sure that they have the current structure so that you can take advantage of any new capabilities. See Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.
MySQL Enterprise In a production environment it is always prudent to examine any changes to users' accounts. The MySQL Network Monitoring and Advisory Service provides notification whenever users' privileges are altered. For more information see, http://www.mysql.com/products/enterprise/advisors.html.
CREATE USERuser[IDENTIFIED BY [PASSWORD] 'password'] [,user[IDENTIFIED BY [PASSWORD] 'password']] ...
The CREATE USER statement was added in
MySQL 5.0.2. This statement creates new MySQL accounts. To use
it, you must have the global CREATE USER
privilege or the INSERT privilege for the
mysql database. For each account,
CREATE USER creates a new record in the
mysql.user table that has no privileges. An
error occurs if the account already exists. Each account is
named using the same format as for the
GRANT statement; for example,
'jeffrey'@'localhost'. If you specify only
the username part of the account name, a hostname part of
'%' is used. For additional information
about specifying account names, see Section 13.5.1.3, “GRANT Syntax”.
The account can be given a password with the optional
IDENTIFIED BY clause. The
user value and the password are
given the same way as for the GRANT
statement. In particular, to specify the password in plain
text, omit the PASSWORD keyword. To specify
the password as the hashed value as returned by the
PASSWORD() function, include the
PASSWORD keyword. See
Section 13.5.1.3, “GRANT Syntax”.
DROP USERuser[,user] ...
The DROP USER statement removes one or more
MySQL accounts. To use it, you must have the global
CREATE USER privilege or the
DELETE privilege for the
mysql database. Each account is named using
the same format as for the GRANT statement;
for example, 'jeffrey'@'localhost'. If you
specify only the username part of the account name, a hostname
part of '%' is used. For additional
information about specifying account names, see
Section 13.5.1.3, “GRANT Syntax”.
DROP USER as present in MySQL 5.0.0 removes
only accounts that have no privileges. In MySQL 5.0.2, it was
modified to remove account privileges as well. This means that
the procedure for removing an account depends on your version
of MySQL.
As of MySQL 5.0.2, you can remove an account and its privileges as follows:
DROP USER user;
The statement removes privilege rows for the account from all grant tables.
In MySQL 5.0.0 and 5.0.1, DROP USER deletes
only MySQL accounts that have no privileges. In these MySQL
versions, it serves only to remove each account record from
the user table. To remove a MySQL account
completely (including all of its privileges), you should use
the following procedure, performing these steps in the order
shown:
Use
SHOW GRANTSto determine what privileges the account has. See Section 13.5.4.12, “SHOW GRANTSSyntax”.Use
REVOKEto revoke the privileges displayed bySHOW GRANTS. This removes rows for the account from all the grant tables except theusertable, and revokes any global privileges listed in theusertable. See Section 13.5.1.3, “GRANTSyntax”.Delete the account by using
DROP USERto remove theusertable record.
Important: DROP USER
does not automatically close any open user sessions. Rather,
in the event that a user with an open session is dropped, the
statement does not take effect until that user's session is
closed. Once the session is closed, the user is dropped, and
that user's next attempt to log in will fail. This
is by design.
DROP USER does not automatically delete or
invalidate any database objects that the user created. This
applies to tables, views, stored routines, and triggers.
GRANTpriv_type[(column_list)] [,priv_type[(column_list)]] ... ON [object_type] {tbl_name| * | *.* |db_name.*} TOuser[IDENTIFIED BY [PASSWORD] 'password'] [,user[IDENTIFIED BY [PASSWORD] 'password']] ... [REQUIRE NONE | [{SSL| X509}] [CIPHER 'cipher' [AND]] [ISSUER 'issuer' [AND]] [SUBJECT 'subject']] [WITHwith_option[with_option] ...]object_type= TABLE | FUNCTION | PROCEDUREwith_option= GRANT OPTION | MAX_QUERIES_PER_HOURcount| MAX_UPDATES_PER_HOURcount| MAX_CONNECTIONS_PER_HOURcount| MAX_USER_CONNECTIONScount
The GRANT statement enables system
administrators to create MySQL user accounts and to grant
rights to from accounts. To use GRANT, you
must have the GRANT OPTION privilege, and
you must have the privileges that you are granting. The
REVOKE statement is related and enables
administrators to remove account privileges. See
Section 13.5.1.5, “REVOKE Syntax”.
MySQL Enterprise For automated notification of users with inappropriate privileges, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
MySQL account information is stored in the tables of the
mysql database. This database and the
access control system are discussed extensively in
Chapter 5, Database Administration, which you should
consult for additional details.
Important: Some releases of MySQL introduce changes to the structure of the grant tables to add new privileges or features. Whenever you update to a new version of MySQL, you should update your grant tables to make sure that they have the current structure so that you can take advantage of any new capabilities. See Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.
If the grant tables hold privilege rows that contain
mixed-case database or table names and the
lower_case_table_names system variable is
set to a non-zero value, REVOKE cannot be
used to revoke these privileges. It will be necessary to
manipulate the grant tables directly.
(GRANT will not create such rows when
lower_case_table_names is set, but such
rows might have been created prior to setting the variable.)
Privileges can be granted at several levels:
Global level
Global privileges apply to all databases on a given server. These privileges are stored in the
mysql.usertable.GRANT ALL ON *.*andREVOKE ALL ON *.*grant and revoke only global privileges.Database level
Database privileges apply to all objects in a given database. These privileges are stored in the
mysql.dbandmysql.hosttables.GRANT ALL ONanddb_name.*REVOKE ALL ONgrant and revoke only database privileges.db_name.*Table level
Table privileges apply to all columns in a given table. These privileges are stored in the
mysql.tables_privtable.GRANT ALL ONanddb_name.tbl_nameREVOKE ALL ONgrant and revoke only table privileges.db_name.tbl_nameColumn level
Column privileges apply to single columns in a given table. These privileges are stored in the
mysql.columns_privtable. When usingREVOKE, you must specify the same columns that were granted.Routine level
The
CREATE ROUTINE,ALTER ROUTINE,EXECUTE, andGRANTprivileges apply to stored routines (functions and procedures). They can be granted at the global and database levels. Also, except forCREATE ROUTINE, these privileges can be granted at the routine level for individual routines and are stored in themysql.procs_privtable.
The object_type clause was added in
MySQL 5.0.6. It should be specified as
TABLE, FUNCTION, or
PROCEDURE when the following object is a
table, a stored function, or a stored procedure.
For the GRANT and REVOKE
statements, priv_type can be
specified as any of the following:
| Privilege | Meaning |
ALL [PRIVILEGES] | Sets all simple privileges except GRANT OPTION |
ALTER | Enables use of ALTER TABLE |
ALTER ROUTINE | Enables stored routines to be altered or dropped |
CREATE | Enables use of CREATE TABLE |
CREATE ROUTINE | Enables creation of stored routines |
CREATE TEMPORARY TABLES | Enables use of CREATE TEMPORARY TABLE |
CREATE USER | Enables use of CREATE USER, DROP
USER, RENAME USER, and
REVOKE ALL PRIVILEGES. |
CREATE VIEW | Enables use of CREATE VIEW |
DELETE | Enables use of DELETE |
DROP | Enables use of DROP TABLE |
EXECUTE | Enables the user to run stored routines |
FILE | Enables use of SELECT ... INTO OUTFILE and
LOAD DATA INFILE |
INDEX | Enables use of CREATE INDEX and DROP
INDEX |
INSERT | Enables use of INSERT |
LOCK TABLES | Enables use of LOCK TABLES on tables for which you
have the SELECT privilege |
PROCESS | Enables the user to see all processes with SHOW
PROCESSLIST |
REFERENCES | Not implemented |
RELOAD | Enables use of FLUSH |
REPLICATION CLIENT | Enables the user to ask where slave or master servers are |
REPLICATION SLAVE | Needed for replication slaves (to read binary log events from the master) |
SELECT | Enables use of SELECT |
SHOW DATABASES | SHOW DATABASES shows all databases |
SHOW VIEW | Enables use of SHOW CREATE VIEW |
SHUTDOWN | Enables use of mysqladmin shutdown |
SUPER | Enables use of CHANGE MASTER,
KILL, PURGE MASTER
LOGS, and SET GLOBAL
statements, the mysqladmin debug
command; allows you to connect (once) even if
max_connections is reached |
UPDATE | Enables use of UPDATE |
USAGE | Synonym for “no privileges” |
GRANT OPTION | Enables privileges to be granted |
The EXECUTE privilege is not operational
until MySQL 5.0.3. CREATE VIEW and
SHOW VIEW were added in MySQL 5.0.1.
CREATE USER, CREATE
ROUTINE, and ALTER ROUTINE were
added in MySQL 5.0.3.
The REFERENCES privilege currently is
unused.
USAGE can be specified when you want to
create a user that has no privileges.
Use SHOW GRANTS to determine what
privileges an account has. See Section 13.5.4.12, “SHOW GRANTS Syntax”.
You can assign global privileges by using ON
*.* syntax or database-level privileges by using
ON
syntax. If you specify db_name.*ON * and you have
selected a default database, the privileges are granted in
that database. (Warning: If
you specify ON * and you have
not selected a default database, the
privileges granted are global.)
The FILE, PROCESS,
RELOAD, REPLICATION
CLIENT, REPLICATION SLAVE,
SHOW DATABASES,
SHUTDOWN, SUPER, and
CREATE USER privileges are administrative
privileges that can only be granted globally (using
ON *.* syntax).
Other privileges can be granted globally or at more specific levels.
The priv_type values that you can
specify for a table are SELECT,
INSERT, UPDATE,
DELETE, CREATE,
DROP, GRANT OPTION,
INDEX, ALTER,
CREATE VIEW and SHOW
VIEW.
The priv_type values that you can
specify for a column (that is, when you use a
column_list clause) are
SELECT, INSERT, and
UPDATE.
The priv_type values that you can
specify at the routine level are ALTER
ROUTINE, EXECUTE, and
GRANT OPTION. CREATE
ROUTINE is not a routine-level privilege because you
must have this privilege to create a routine in the first
place.
For the global, database, table, and routine levels,
GRANT ALL assigns only the privileges that
exist at the level you are granting. For example,
GRANT ALL ON
is a
database-level statement, so it does not grant any global-only
privileges such as db_name.*FILE.
MySQL allows you to grant privileges even on database objects
that do not exist. In such cases, the privileges to be granted
must include the CREATE privilege.
This behavior is by design, and is
intended to enable the database administrator to prepare user
accounts and privileges for database objects that are to be
created at a later time.
Important: MySQL does not automatically revoke any privileges when you drop a table or database. However, if you drop a routine, any routine-level privileges granted for that routine are revoked.
Note: the
‘_’ and
‘%’ wildcards are allowed when
specifying database names in GRANT
statements that grant privileges at the global or database
levels. This means, for example, that if you want to use a
‘_’ character as part of a
database name, you should specify it as
‘\_’ in the
GRANT statement, to prevent the user from
being able to access additional databases matching the
wildcard pattern; for example, GRANT ... ON
`foo\_bar`.* TO ....
To accommodate granting rights to users from arbitrary hosts,
MySQL supports specifying the user
value in the form
user_name@host_nameuser_name or
host_name value is legal as an
unquoted identifier, you need not quote it. However, quotes
are necessary to specify a
user_name string containing special
characters (such as ‘-’), or a
host_name string containing special
characters or wildcard characters (such as
‘%’); for example,
'test-user'@'test-hostname'. Quote the
username and hostname separately.
You can specify wildcards in the hostname. For example,
user_name@'%.loc.gov'user_name for any host
in the loc.gov domain, and
user_name@'144.155.166.%'user_name for any host
in the 144.155.166 class C subnet.
The simple form user_name is a
synonym for
user_name@'%'
MySQL does not support wildcards in
usernames. Anonymous users are defined by inserting
entries with User='' into the
mysql.user table or by creating a user with
an empty name with the GRANT statement:
GRANT ALL ON test.* TO ''@'localhost' ...
When specifying quoted values, quote database, table, column,
and routine names as identifiers, using backticks
(‘`’). Quote hostnames,
usernames, and passwords as strings, using single quotes
(‘'’).
Warning: If you allow
anonymous users to connect to the MySQL server, you should
also grant privileges to all local users as
user_name@localhostlocalhost in the
mysql.user table (created during MySQL
installation) is used when named users try to log in to the
MySQL server from the local machine. For details, see
Section 5.7.5, “Access Control, Stage 1: Connection Verification”.
You can determine whether this applies to you by executing the following query, which lists any anonymous users:
SELECT Host, User FROM mysql.user WHERE User='';
If you want to delete the local anonymous user account to avoid the problem just described, use these statements:
DELETE FROM mysql.user WHERE Host='localhost' AND User=''; FLUSH PRIVILEGES;
GRANT supports hostnames up to 60
characters long. Database, table, column, and routine names
can be up to 64 characters. Usernames can be up to 16
characters. Note:
The allowable length for usernames cannot be changed
by altering the mysql.user table, and
attempting to do so results in unpredictable behavior which
may even make it impossible for users to log in to the MySQL
server. You should never alter any of the tables in
the mysql database in any manner whatsoever
except by means of the procedure prescribed by MySQL AB that
is described in Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.
The privileges for a table, column, or routine are formed
additively as the logical OR of the
privileges at each of the privilege levels. For example, if
the mysql.user table specifies that a user
has a global SELECT privilege, the
privilege cannot be denied by an entry at the database, table,
or column level.
The privileges for a column can be calculated as follows:
global privileges OR (database privileges AND host privileges) OR table privileges OR column privileges OR routine privileges
In most cases, you grant rights to a user at only one of the privilege levels, so life is not normally this complicated. The details of the privilege-checking procedure are presented in Section 5.7, “The MySQL Access Privilege System”.
If you grant privileges for a username/hostname combination
that does not exist in the mysql.user
table, an entry is added and remains there until deleted with
a DELETE statement. In other words,
GRANT may create user
table entries, but REVOKE does not remove
them; you must do that explicitly using DROP
USER or DELETE.
Warning: If you create a new
user but do not specify an IDENTIFIED BY
clause, the user has no password. This is very insecure. As of
MySQL 5.0.2, you can enable the
NO_AUTO_CREATE_USER SQL mode to prevent
GRANT from creating a new user if it would
otherwise do so, unless IDENTIFIED BY is
given to provide the new user a non-empty password.
MySQL Enterprise The MySQL Network Monitoring and Advisory Service specifically guards against user accounts with no passwords. To find out more see http://www.mysql.com/products/enterprise/advisors.html.
If a new user is created or if you have global grant
privileges, the user's password is set to the password
specified by the IDENTIFIED BY clause, if
one is given. If the user already had a password, this is
replaced by the new one.
Passwords can also be set with the SET
PASSWORD statement. See
Section 13.5.1.6, “SET PASSWORD Syntax”.
In the IDENTIFIED BY clause, the password
should be given as the literal password value. It is
unnecessary to use the PASSWORD() function
as it is for the SET PASSWORD statement.
For example:
GRANT ... IDENTIFIED BY 'mypass';
If you do not want to send the password in clear text and you
know the hashed value that PASSWORD() would
return for the password, you can specify the hashed value
preceded by the keyword PASSWORD:
GRANT ... IDENTIFIED BY PASSWORD '*6C8989366EAF75BB670AD8EA7A7FC1176A95CEF4';
In a C program, you can get the hashed value by using the
make_scrambled_password() C API function.
If you grant privileges for a database, an entry in the
mysql.db table is created if needed. If all
privileges for the database are removed with
REVOKE, this entry is deleted.
The SHOW DATABASES privilege enables the
account to see database names by issuing the SHOW
DATABASE statement. Accounts that do not have this
privilege see only databases for which they have some
privileges, and cannot use the statement at all if the server
was started with the --skip-show-database
option.
MySQL Enterprise
The SHOW DATABASES privilege should be
granted only to users who need to see all the databases on a
MySQL server. Subscribers to the MySQL Network Monitoring
and Advisory Service are alerted when servers are started
without the --skip-show-database option.
For more information see,
http://www.mysql.com/products/enterprise/advisors.html.
If a user has no privileges for a table, the table name is not
displayed when the user requests a list of tables (for
example, with a SHOW TABLES statement).
The WITH GRANT OPTION clause gives the user
the ability to give to other users any privileges the user has
at the specified privilege level. You should be careful to
whom you give the GRANT OPTION privilege,
because two users with different privileges may be able to
join privileges!
You cannot grant another user a privilege which you yourself
do not have; the GRANT OPTION privilege
enables you to assign only those privileges which you yourself
possess.
Be aware that when you grant a user the GRANT
OPTION privilege at a particular privilege level,
any privileges the user possesses (or may be given in the
future) at that level can also be granted by that user to
other users. Suppose that you grant a user the
INSERT privilege on a database. If you then
grant the SELECT privilege on the database
and specify WITH GRANT OPTION, that user
can give to other users not only the SELECT
privilege, but also INSERT. If you then
grant the UPDATE privilege to the user on
the database, the user can grant INSERT,
SELECT, and UPDATE.
For a non-administrative user, you should not grant the
ALTER privilege globally or for the
mysql database. If you do that, the user
can try to subvert the privilege system by renaming tables!
The MAX_QUERIES_PER_HOUR
,
countMAX_UPDATES_PER_HOUR
, and
countMAX_CONNECTIONS_PER_HOUR
options limit the
number of queries, updates, and logins a user can perform
during any given one-hour period. (Queries for which results
are served from the query cache do not count against the
countMAX_QUERIES_PER_HOUR limit.) If
count is 0 (the
default), this means that there is no limitation for that
user.
The MAX_USER_CONNECTIONS
option, implemented
in MySQL 5.0.3, limits the maximum number of simultaneous
connections that the account can make. If
countcount is 0 (the
default), the max_user_connections system
variable determines the number of simultaneous connections for
the account.
Note: To specify any of these resource-limit options for an
existing user without affecting existing privileges, use
GRANT USAGE ON *.* ... WITH MAX_....
See Section 5.8.4, “Limiting Account Resources”.
MySQL can check X509 certificate attributes in addition to the
usual authentication that is based on the username and
password. To specify SSL-related options for a MySQL account,
use the REQUIRE clause of the
GRANT statement. (For background
information on the use of SSL with MySQL, see
Section 5.8.7, “Using Secure Connections”.)
There are a number of different possibilities for limiting connection types for a given account:
REQUIRE NONEindicates that the account has no SSL or X509 requirements. This is the default if no SSL-relatedREQUIREoptions are specified. Unencrypted connections are allowed if the username and password are valid. However, encrypted connections can also be used, at the client's option, if the client has the proper certificate and key files. That is, the client need not specify any SSL commmand options, in which case the connection will be unencrypted. To use an encrypted connection, the client must specify either the--ssl-caoption, or all three of the--ssl-ca,--ssl-key, and--ssl-certoptions.The
REQUIRE SSLoption tells the server to allow only SSL-encrypted connections for the account.GRANT ALL PRIVILEGES ON test.* TO 'root'@'localhost' IDENTIFIED BY 'goodsecret' REQUIRE SSL;
To connect, the client must specify the
--ssl-caoption, and may additionally specify the--ssl-keyand--ssl-certoptions.REQUIRE X509means that the client must have a valid certificate but that the exact certificate, issuer, and subject do not matter. The only requirement is that it should be possible to verify its signature with one of the CA certificates.GRANT ALL PRIVILEGES ON test.* TO 'root'@'localhost' IDENTIFIED BY 'goodsecret' REQUIRE X509;
To connect, the client must specify the
--ssl-ca,--ssl-key, and--ssl-certoptions. This is also true forISSUERandSUBJECTbecause thoseREQUIREoptions implyX509.REQUIRE ISSUER 'places the restriction on connection attempts that the client must present a valid X509 certificate issued by CAissuer''. If the client presents a certificate that is valid but has a different issuer, the server rejects the connection. Use of X509 certificates always implies encryption, so theissuer'SSLoption is unnecessary in this case.GRANT ALL PRIVILEGES ON test.* TO 'root'@'localhost' IDENTIFIED BY 'goodsecret' REQUIRE ISSUER '/C=FI/ST=Some-State/L=Helsinki/ O=MySQL Finland AB/CN=Tonu Samuel/Email=tonu@example.com';Note that the
'value should be entered as a single string.issuer'REQUIRE SUBJECT 'places the restriction on connection attempts that the client must present a valid X509 certificate containing the subjectsubject'subject. If the client presents a certificate that is valid but has a different subject, the server rejects the connection.GRANT ALL PRIVILEGES ON test.* TO 'root'@'localhost' IDENTIFIED BY 'goodsecret' REQUIRE SUBJECT '/C=EE/ST=Some-State/L=Tallinn/ O=MySQL demo client certificate/ CN=Tonu Samuel/Email=tonu@example.com';Note that the
'value should be entered as a single string.subject'REQUIRE CIPHER 'is needed to ensure that ciphers and key lengths of sufficient strength are used. SSL itself can be weak if old algorithms using short encryption keys are used. Using this option, you can ask that a specific cipher method is used to allow a connection.cipher'GRANT ALL PRIVILEGES ON test.* TO 'root'@'localhost' IDENTIFIED BY 'goodsecret' REQUIRE CIPHER 'EDH-RSA-DES-CBC3-SHA';
The SUBJECT, ISSUER, and
CIPHER options can be combined in the
REQUIRE clause like this:
GRANT ALL PRIVILEGES ON test.* TO 'root'@'localhost'
IDENTIFIED BY 'goodsecret'
REQUIRE SUBJECT '/C=EE/ST=Some-State/L=Tallinn/
O=MySQL demo client certificate/
CN=Tonu Samuel/Email=tonu@example.com'
AND ISSUER '/C=FI/ST=Some-State/L=Helsinki/
O=MySQL Finland AB/CN=Tonu Samuel/Email=tonu@example.com'
AND CIPHER 'EDH-RSA-DES-CBC3-SHA';
The AND keyword is optional between
REQUIRE options.
The order of the options does not matter, but no option can be specified twice.
When mysqld starts, all privileges are read into memory. For details, see Section 5.7.7, “When Privilege Changes Take Effect”.
Note that if you are using table, column, or routine privileges for even one user, the server examines table, column, and routine privileges for all users and this slows down MySQL a bit. Similarly, if you limit the number of queries, updates, or connections for any users, the server must monitor these values.
The biggest differences between the standard SQL and MySQL
versions of GRANT are:
In MySQL, privileges are associated with the combination of a hostname and username and not with only a username.
Standard SQL does not have global or database-level privileges, nor does it support all the privilege types that MySQL supports.
MySQL does not support the standard SQL
TRIGGERorUNDERprivileges.Standard SQL privileges are structured in a hierarchical manner. If you remove a user, all privileges the user has been granted are revoked. This is also true in MySQL 5.0.2 and up if you use
DROP USER. Before 5.0.2, the granted privileges are not automatically revoked; you must revoke them yourself. See Section 13.5.1.2, “DROP USERSyntax”.In standard SQL, when you drop a table, all privileges for the table are revoked. In standard SQL, when you revoke a privilege, all privileges that were granted based on that privilege are also revoked. In MySQL, privileges can be dropped only with explicit
REVOKEstatements or by manipulating values stored in the MySQL grant tables.In MySQL, it is possible to have the
INSERTprivilege for only some of the columns in a table. In this case, you can still executeINSERTstatements on the table, provided that you omit those columns for which you do not have theINSERTprivilege. The omitted columns are set to their implicit default values if strict SQL mode is not enabled. In strict mode, the statement is rejected if any of the omitted columns have no default value. (Standard SQL requires you to have theINSERTprivilege on all columns.) Section 5.2.6, “SQL Modes”, discusses strict mode. Section 11.1.4, “Data Type Default Values”, discusses implicit default values.
RENAME USERold_userTOnew_user[,old_userTOnew_user] ...
The RENAME USER statement renames existing
MySQL accounts. To use it, you must have the global
CREATE USER privilege or the
UPDATE privilege for the
mysql database. An error occurs if any old
account does not exist or any new account exists. Each account
is named using the same format as for the
GRANT statement; for example,
'jeffrey'@'localhost'. If you specify only
the username part of the account name, a hostname part of
'%' is used. For additional information
about specifying account names, see Section 13.5.1.3, “GRANT Syntax”.
RENAME USER does not automatically migrate
any database objects that the user created, nor does it
migrate any privileges that the user had prior to the
renaming. This applies to tables, views, stored routines, and
triggers.
The RENAME USER statement was added in
MySQL 5.0.2.
REVOKEpriv_type[(column_list)] [,priv_type[(column_list)]] ... ON [object_type] {tbl_name| * | *.* |db_name.*} FROMuser[,user] ... REVOKE ALL PRIVILEGES, GRANT OPTION FROMuser[,user] ...
The REVOKE statement enables system
administrators to revoke privileges from MySQL accounts. To
use REVOKE, you must have the
GRANT OPTION privilege, and you must have
the privileges that you are revoking.
Each account is named using the same format as for the
GRANT statement; for example,
'jeffrey'@'localhost'. If you specify only
the username part of the account name, a hostname part of
'%' is used. For additional information
about specifying account names, see Section 13.5.1.3, “GRANT Syntax”.
For details on the levels at which privileges exist, the
allowable priv_type values, and the
syntax for specifying users and passwords, see
Section 13.5.1.3, “GRANT Syntax”
If the grant tables hold privilege rows that contain
mixed-case database or table names and the
lower_case_table_names system variable is
set to a non-zero value, REVOKE cannot be
used to revoke these privileges. It will be necessary to
manipulate the grant tables directly.
(GRANT will not create such rows when
lower_case_table_names is set, but such
rows might have been created prior to setting the variable.)
To revoke all privileges, use the following syntax, which drops all global, database-, table-, and column-level privileges for the named user or users:
REVOKE ALL PRIVILEGES, GRANT OPTION FROMuser[,user] ...
To use this REVOKE syntax, you must have
the global CREATE USER privilege or the
UPDATE privilege for the
mysql database.
REVOKE removes privileges, but does not
drop user table entries. You must do that
explicitly using DELETE or DROP
USER (see Section 13.5.1.2, “DROP USER Syntax”).
SET PASSWORD [FORuser] = PASSWORD('some password')
The SET PASSWORD statement assigns a
password to an existing MySQL user account.
With no FOR clause, this statement sets the
password for the current user. Any client that has connected
to the server using a non-anonymous account can change the
password for that account.
With a FOR clause, this statement sets the
password for a specific account on the current server host.
Only clients that have the UPDATE privilege
for the mysql database can do this. The
user value should be given in
user_name@host_nameuser_name and
host_name are exactly as they are
listed in the User and
Host columns of the
mysql.user table entry. For example, if you
had an entry with User and
Host column values of
'bob' and '%.loc.gov',
you would write the statement like this:
SET PASSWORD FOR 'bob'@'%.loc.gov' = PASSWORD('newpass');
That is equivalent to the following statements:
UPDATE mysql.user SET Password=PASSWORD('newpass')
WHERE User='bob' AND Host='%.loc.gov';
FLUSH PRIVILEGES;
Note: If you are connecting
to a MySQL 4.1 or later server using a pre-4.1 client program,
do not use the preceding SET PASSWORD or
UPDATE statement without reading
Section 5.7.9, “Password Hashing as of MySQL 4.1”, first. The password format
changed in MySQL 4.1, and under certain circumstances it is
possible that if you change your password, you might not be
able to connect to the server afterward.
You can see which account the server authenticated you as by
executing SELECT CURRENT_USER().
MySQL Enterprise For automated notification of users without passwords, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLEtbl_name[,tbl_name] ...
ANALYZE TABLE analyzes and stores the key
distribution for a table. During the analysis, the table is
locked with a read lock for MyISAM and
BDB. For InnoDB the
table is locked with a write lock. This statement works with
MyISAM, BDB, and
InnoDB tables. For
MyISAM tables, this statement is equivalent
to using myisamchk --analyze.
For more information on how the analysis works
withinInnoDB, see
Section 14.2.16, “Restrictions on InnoDB Tables”.
MySQL Enterprise For expert advice on optimizing tables subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
MySQL uses the stored key distribution to decide the order in which tables should be joined when you perform a join on something other than a constant.
This statement requires SELECT and
INSERT privileges for the table.
ANALYZE TABLE returns a result set with the
following columns:
| Column | Value |
Table | The table name |
Op | Always analyze |
Msg_type | One of status, error,
info, or warning |
Msg_text | The message |
You can check the stored key distribution with the
SHOW INDEX statement. See
Section 13.5.4.13, “SHOW INDEX Syntax”.
If the table has not changed since the last ANALYZE
TABLE statement, the table is not analyzed again.
By default, ANALYZE TABLE statements are
written to the binary log so that such statements used on a
MySQL server acting as a replication master will be replicated
to replication slaves. Logging can be suppressed with the
optional NO_WRITE_TO_BINLOG keyword or its
alias LOCAL.
BACKUP TABLEtbl_name[,tbl_name] ... TO '/path/to/backup/directory'
Note: This statement is deprecated. We are working on a better replacement for it that will provide online backup capabilities. In the meantime, the mysqlhotcopy script can be used instead.
BACKUP TABLE copies to the backup directory
the minimum number of table files needed to restore the table,
after flushing any buffered changes to disk. The statement
works only for MyISAM tables. It copies the
.frm definition and
.MYD data files. The
.MYI index file can be rebuilt from those
two files. The directory should be specified as a full
pathname. To restore the table, use RESTORE
TABLE.
During the backup, a read lock is held for each table, one at
time, as they are being backed up. If you want to back up
several tables as a snapshot (preventing any of them from
being changed during the backup operation), issue a
LOCK TABLES statement first, to obtain a
read lock for all tables in the group.
BACKUP TABLE returns a result set with the
following columns:
| Column | Value |
Table | The table name |
Op | Always backup |
Msg_type | One of status, error,
info, or warning |
Msg_text | The message |
CHECK TABLEtbl_name[,tbl_name] ... [option] ...option= {FOR UPGRADE | QUICK | FAST | MEDIUM | EXTENDED | CHANGED}
CHECK TABLE checks a table or tables for
errors. CHECK TABLE works for
MyISAM, InnoDB, and (as
of MySQL 5.0.16) ARCHIVE tables. For
MyISAM tables, the key statistics are
updated as well.
As of MySQL 5.0.2, CHECK TABLE can also
check views for problems, such as tables that are referenced
in the view definition that no longer exist.
CHECK TABLE returns a result set with the
following columns:
| Column | Value |
Table | The table name |
Op | Always check |
Msg_type | One of status, error,
info, or warning |
Msg_text | The message |
Note that the statement might produce many rows of information
for each checked table. The last row has a
Msg_type value of status
and the Msg_text normally should be
OK. If you don't get OK,
or Table is already up to date you should
normally run a repair of the table. See
Section 5.9.4, “Table Maintenance and Crash Recovery”. Table is already
up to date means that the storage engine for the
table indicated that there was no need to check the table.
The FOR UPGRADE option checks whether the
named tables are compatible with the current version of MySQL.
This option was added in MySQL 5.0.19. With FOR
UPGRADE, the server checks each table to determine
whether there have been any incompatible changes in any of the
table's data types or indexes since the table was created. If
not, the check succeeds. Otherwise, if there is a possible
incompatibility, the server runs a full check on the table
(which might take some time). If the full check succeeds, the
server marks the table's .frm file with
the current MySQL version number. Marking the
.frm file ensures that further checks for
the table with the same version of the server will be fast.
Incompatibilities might occur because the storage format for a data type has changed or because its sort order has changed. Our aim is to avoid these changes, but occasionally they are necessary to correct problems that would be worse than an incompatibility between releases.
Currently, FOR UPGRADE discovers these
incompatibilities:
The indexing order for end-space in
TEXTcolumns forInnoDBandMyISAMtables changed between MySQL 4.1 and 5.0.The storage method of the new
DECIMALdata type changed between MySQL 5.0.3 and 5.0.5.
The other check options that can be given are shown in the
following table. These options apply only to checking
MyISAM tables and are ignored for
InnoDB tables and views.
| Type | Meaning |
QUICK | Do not scan the rows to check for incorrect links. |
FAST | Check only tables that have not been closed properly. |
CHANGED | Check only tables that have been changed since the last check or that have not been closed properly. |
MEDIUM | Scan rows to verify that deleted links are valid. This also calculates a key checksum for the rows and verifies this with a calculated checksum for the keys. |
EXTENDED | Do a full key lookup for all keys for each row. This ensures that the table is 100% consistent, but takes a long time. |
If none of the options QUICK,
MEDIUM, or EXTENDED are
specified, the default check type for dynamic-format
MyISAM tables is MEDIUM.
This has the same result as running myisamchk
--medium-check tbl_name
on the table. The default check type also is
MEDIUM for static-format
MyISAM tables, unless
CHANGED or FAST is
specified. In that case, the default is
QUICK. The row scan is skipped for
CHANGED and FAST because
the rows are very seldom corrupted.
You can combine check options, as in the following example that does a quick check on the table to determine whether it was closed properly:
CHECK TABLE test_table FAST QUICK;
Note: In some cases,
CHECK TABLE changes the table. This happens
if the table is marked as “corrupted” or
“not closed properly” but CHECK
TABLE does not find any problems in the table. In
this case, CHECK TABLE marks the table as
okay.
If a table is corrupted, it is most likely that the problem is in the indexes and not in the data part. All of the preceding check types check the indexes thoroughly and should thus find most errors.
If you just want to check a table that you assume is okay, you
should use no check options or the QUICK
option. The latter should be used when you are in a hurry and
can take the very small risk that QUICK
does not find an error in the data file. (In most cases, under
normal usage, MySQL should find any error in the data file. If
this happens, the table is marked as “corrupted”
and cannot be used until it is repaired.)
FAST and CHANGED are
mostly intended to be used from a script (for example, to be
executed from cron) if you want to check
tables from time to time. In most cases,
FAST is to be preferred over
CHANGED. (The only case when it is not
preferred is when you suspect that you have found a bug in the
MyISAM code.)
EXTENDED is to be used only after you have
run a normal check but still get strange errors from a table
when MySQL tries to update a row or find a row by key. This is
very unlikely if a normal check has succeeded.
Some problems reported by CHECK TABLE
cannot be corrected automatically:
Found row where the auto_increment column has the value 0.This means that you have a row in the table where the
AUTO_INCREMENTindex column contains the value 0. (It is possible to create a row where theAUTO_INCREMENTcolumn is 0 by explicitly setting the column to 0 with anUPDATEstatement.)This is not an error in itself, but could cause trouble if you decide to dump the table and restore it or do an
ALTER TABLEon the table. In this case, theAUTO_INCREMENTcolumn changes value according to the rules ofAUTO_INCREMENTcolumns, which could cause problems such as a duplicate-key error.To get rid of the warning, simply execute an
UPDATEstatement to set the column to some value other than 0.If
CHECK TABLEfinds a problem for anInnoDBtable, the server shuts down to prevent error propagation. Details of the error will be written to the error log.
CHECKSUM TABLEtbl_name[,tbl_name] ... [ QUICK | EXTENDED ]
CHECKSUM TABLE reports a table checksum.
With QUICK, the live table checksum is
reported if it is available, or NULL
otherwise. This is very fast. A live checksum is enabled by
specifying the CHECKSUM=1 table option when
you create the table; currently, this is supported only for
MyISAM tables. See
Section 13.1.5, “CREATE TABLE Syntax”.
With EXTENDED, the entire table is read row
by row and the checksum is calculated. This can be very slow
for large tables.
If neither QUICK nor
EXTENDED is specified, MySQL returns a live
checksum if the table storage engine supports it and scans the
table otherwise.
For a non-existent table, CHECKSUM TABLE
returns NULL and, as of MySQL 5.0.3,
generates a warning.
The checksum value depends on the table row format. If the row
format changes, the checksum will change. For example, the
storage format for VARCHAR changed between
MySQL 4.1 and 5.0, so if a 4.1 table is upgraded to MySQL 5.0,
the checksum value may change.
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLEtbl_name[,tbl_name] ...
OPTIMIZE TABLE should be used if you have
deleted a large part of a table or if you have made many
changes to a table with variable-length rows (tables that have
VARCHAR, VARBINARY,
BLOB, or TEXT columns).
Deleted rows are maintained in a linked list and subsequent
INSERT operations reuse old row positions.
You can use OPTIMIZE TABLE to reclaim the
unused space and to defragment the data file.
This statement requires SELECT and
INSERT privileges for the table.
In most setups, you need not run OPTIMIZE
TABLE at all. Even if you do a lot of updates to
variable-length rows, it is not likely that you need to do
this more than once a week or month and only on certain
tables.
OPTIMIZE TABLE works
only for MyISAM,
InnoDB, and (as of MySQL 5.0.16)
ARCHIVE tables. It does
not work for tables created using any
other storage engine.
For MyISAM tables, OPTIMIZE
TABLE works as follows:
If the table has deleted or split rows, repair the table.
If the index pages are not sorted, sort them.
If the table's statistics are not up to date (and the repair could not be accomplished by sorting the index), update them.
For BDB tables, OPTIMIZE
TABLE currently is mapped to ANALYZE
TABLE. See Section 13.5.2.1, “ANALYZE TABLE Syntax”.
For InnoDB tables, OPTIMIZE
TABLE is mapped to ALTER TABLE,
which rebuilds the table to update index statistics and free
unused space in the clustered index.
You can make OPTIMIZE TABLE work on other
storage engines by starting mysqld with the
--skip-new or --safe-mode
option. In this case, OPTIMIZE TABLE is
just mapped to ALTER TABLE.
OPTIMIZE TABLE returns a result set with
the following columns:
| Column | Value |
Table | The table name |
Op | Always optimize |
Msg_type | One of status, error,
info, or warning |
Msg_text | The message |
Note that MySQL locks the table during the time
OPTIMIZE TABLE is running.
By default, OPTIMIZE TABLE statements are
written to the binary log so that such statements used on a
MySQL server acting as a replication master will be replicated
to replication slaves. Logging can be suppressed with the
optional NO_WRITE_TO_BINLOG keyword or its
alias LOCAL.
OPTIMIZE TABLE does not sort R-tree
indexes, such as spatial indexes on POINT
columns. (Bug#23578)
REPAIR [LOCAL | NO_WRITE_TO_BINLOG] TABLE
tbl_name [, tbl_name] ... [QUICK] [EXTENDED] [USE_FRM]
REPAIR TABLE repairs a possibly corrupted
table. By default, it has the same effect as
myisamchk --recover
tbl_name. REPAIR
TABLE works for MyISAM and for
ARCHIVE tables. See
Section 14.1, “The MyISAM Storage Engine”, and
Section 14.8, “The ARCHIVE Storage Engine”.
This statement requires SELECT and
INSERT privileges for the table.
Normally, you should never have to run this statement.
However, if disaster strikes, REPAIR TABLE
is very likely to get back all your data from a
MyISAM table. If your tables become
corrupted often, you should try to find the reason for it, to
eliminate the need to use REPAIR TABLE. See
Section B.1.4.2, “What to Do If MySQL Keeps Crashing”, and
Section 14.1.4, “MyISAM Table Problems”.
Caution
It is best to make a backup of a table before performing a table repair operation; under some circumstances the operation might cause data loss. Possible causes include but are not limited to filesystem errors.
Warning
If the server dies during a REPAIR TABLE
operation, it is essential after restarting it that you
immediately execute another REPAIR TABLE
statement for the table before performing any other
operations on it. (It is always a good idea to start by
making a backup.) In the worst case, you might have a new
clean index file without information about the data file,
and then the next operation you perform could overwrite the
data file. This is an unlikely but possible scenario.
REPAIR TABLE returns a result set with the
following columns:
| Column | Value |
Table | The table name |
Op | Always repair |
Msg_type | One of status, error,
info, or warning |
Msg_text | The message |
The REPAIR TABLE statement might produce
many rows of information for each repaired table. The last row
has a Msg_type value of
status and Msg_test
normally should be OK. If you do not get
OK, you should try repairing the table with
myisamchk --safe-recover. (REPAIR
TABLE does not yet implement all the options of
myisamchk.) With myisamchk
--safe-recover, you can also use options that
REPAIR TABLE does not support, such as
--max-record-length.
If QUICK is given, REPAIR
TABLE tries to repair only the index tree. This type
of repair is like that done by myisamchk --recover
--quick.
If you use EXTENDED, MySQL creates the
index row by row instead of creating one index at a time with
sorting. This type of repair is like that done by
myisamchk --safe-recover.
There is also a USE_FRM mode available for
REPAIR TABLE. Use this if the
.MYI index file is missing or if its
header is corrupted. In this mode, MySQL re-creates the
.MYI file using information from the
.frm file. This kind of repair cannot be
done with myisamchk.
Note: Use this mode
only if you cannot use regular
REPAIR modes. The .MYI
header contains important table metadata (in particular,
current AUTO_INCREMENT value and
Delete link) that are lost in
REPAIR ... USE_FRM. Don't use
USE_FRM if the table is compressed because
this information is also stored in the
.MYI file.
Caution
Do not use USE_FRM if your table was
created by a different version of the MySQL server than the
one you are currently running. Doing so risks the loss of
all rows in the table. It is particularly dangerous to use
USE_FRM after the server returns this
message:
Table upgrade required. Please do
"REPAIR TABLE `tbl_name`" to fix it!
By default, REPAIR TABLE statements are
written to the binary log so that such statements used on a
MySQL server acting as a replication master will be replicated
to replication slaves. Logging can be suppressed with the
optional NO_WRITE_TO_BINLOG keyword or its
alias LOCAL.
RESTORE TABLEtbl_name[,tbl_name] ... FROM '/path/to/backup/directory'
RESTORE TABLE restores the table or tables
from a backup that was made with BACKUP
TABLE. The directory should be specified as a full
pathname.
Existing tables are not overwritten; if you try to restore
over an existing table, an error occurs. Just as for
BACKUP TABLE, RESTORE
TABLE currently works only for
MyISAM tables. Restored tables are not
replicated from master to slave.
The backup for each table consists of its
.frm format file and
.MYD data file. The restore operation
restores those files, and then uses them to rebuild the
.MYI index file. Restoring takes longer
than backing up due to the need to rebuild the indexes. The
more indexes the table has, the longer it takes.
RESTORE TABLE returns a result set with the
following columns:
| Column | Value |
Table | The table name |
Op | Always restore |
Msg_type | One of status, error,
info, or warning |
Msg_text | The message |
SETvariable_assignment[,variable_assignment] ...variable_assignment:user_var_name=expr| [GLOBAL | SESSION]system_var_name=expr| [@@global. | @@session. | @@]system_var_name=expr
The SET statement assigns values to different
types of variables that affect the operation of the server or
your client. Older versions of MySQL employed SET
OPTION, but this syntax is deprecated in favor of
SET without OPTION.
This section describes use of SET for
assigning values to system variables or user variables. For
general information about these types of variables, see
Section 5.2.3, “System Variables”, and
Section 9.4, “User-Defined Variables”. System variables also can be
set at server startup, as described in
Section 5.2.4, “Using System Variables”.
Some variants of SET syntax are used in other
contexts:
SET PASSWORDassigns account passwords. See Section 13.5.1.6, “SET PASSWORDSyntax”.SET TRANSACTION ISOLATION LEVELsets the isolation level for transaction processing. See Section 13.4.6, “SET TRANSACTIONSyntax”.SETis used within stored routines to assign values to local routine variables. See Section 17.2.7.2, “VariableSETStatement”.
The following discussion shows the different
SET syntaxes that you can use to set
variables. The examples use the = assignment
operator, but the := operator also is
allowable.
A user variable is written as
@ and can
be set as follows:
var_name
SET @var_name=expr;
Many system variables are dynamic and can be changed while the
server runs by using the SET statement. For a
list, see Section 5.2.4.2, “Dynamic System Variables”. To change
a system variable with SET, refer to it as
var_name, optionally preceded by a
modifier:
To indicate explicitly that a variable is a global variable, precede its name by
GLOBALor@@global.. TheSUPERprivilege is required to set global variables.To indicate explicitly that a variable is a session variable, precede its name by
SESSION,@@session., or@@. Setting a session variable requires no special privilege, but a client can change only its own session variables, not those of any other client.LOCALand@@local.are synonyms forSESSIONand@@session..If no modifier is present,
SETchanges the session variable.
MySQL Enterprise The MySQL Network Monitoring and Advisory Service makes extensive use of system variables to determine the state of your server. For more information see http://www.mysql.com/products/enterprise/advisors.html.
A SET statement can contain multiple variable
assignments, separated by commas. If you set several system
variables, the most recent GLOBAL or
SESSION modifier in the statement is used for
following variables that have no modifier specified.
Examples:
SET sort_buffer_size=10000; SET @@local.sort_buffer_size=10000; SET GLOBAL sort_buffer_size=1000000, SESSION sort_buffer_size=1000000; SET @@sort_buffer_size=1000000; SET @@global.sort_buffer_size=1000000, @@local.sort_buffer_size=1000000;
When you assign a value to a system variable with
SET, you cannot use suffix letters in the
value (as can be done with startup options). However, the value
can take the form of an expression:
SET sort_buffer_size = 10 * 1024 * 1024;
The @@
syntax for system variables is supported for compatibility with
some other database systems.
var_name
If you change a session system variable, the value remains in effect until your session ends or until you change the variable to a different value. The change is not visible to other clients.
If you change a global system variable, the value is remembered
and used for new connections until the server restarts. (To make
a global system variable setting permanent, you should set it in
an option file.) The change is visible to any client that
accesses that global variable. However, the change affects the
corresponding session variable only for clients that connect
after the change. The global variable change does not affect the
session variable for any client that is currently connected (not
even that of the client that issues the SET
GLOBAL statement).
To prevent incorrect usage, MySQL produces an error if you use
SET GLOBAL with a variable that can only be
used with SET SESSION or if you do not
specify GLOBAL (or
@@global.) when setting a global variable.
To set a SESSION variable to the
GLOBAL value or a GLOBAL
value to the compiled-in MySQL default value, use the
DEFAULT keyword. For example, the following
two statements are identical in setting the session value of
max_join_size to the global value:
SET max_join_size=DEFAULT; SET @@session.max_join_size=@@global.max_join_size;
Not all system variables can be set to
DEFAULT. In such cases, use of
DEFAULT results in an error.
You can refer to the values of specific global or sesson system
variables in expressions by using one of the
@@-modifiers. For example, you can retrieve
values in a SELECT statement like this:
SELECT @@global.sql_mode, @@session.sql_mode, @@sql_mode;
When you refer to a system variable in an expression as
@@ (that
is, when you do not specify var_name@@global. or
@@session.), MySQL returns the session value
if it exists and the global value otherwise. (This differs from
SET @@, which always refers
to the session value.)
var_name =
value
To display system variables names and values, use the
SHOW VARIABLES statement. (See
Section 13.5.4.27, “SHOW VARIABLES Syntax”.)
The following list describes options that have non-standard
syntax or that are not described in the list of system variables
found in Section 5.2.3, “System Variables”. Although the
options described here are not displayed by SHOW
VARIABLES, you can obtain their values with
SELECT (with the exception of
CHARACTER SET and SET
NAMES). For example:
mysql> SELECT @@AUTOCOMMIT;
+--------------+
| @@AUTOCOMMIT |
+--------------+
| 1 |
+--------------+
The lettercase of thse options does not matter.
AUTOCOMMIT = {0 | 1}Set the autocommit mode. If set to 1, all changes to a table take effect immediately. If set to 0 you have to use
COMMITto accept a transaction orROLLBACKto cancel it. By default, client connections begin withAUTOCOMMITset to 1. If you changeAUTOCOMMITmode from 0 to 1, MySQL performs an automaticCOMMITof any open transaction. Another way to begin a transaction is to use aSTART TRANSACTIONorBEGINstatement. See Section 13.4.1, “START TRANSACTION,COMMIT, andROLLBACKSyntax”.BIG_TABLES = {0 | 1}If set to 1, all temporary tables are stored on disk rather than in memory. This is a little slower, but the error
The tabledoes not occur fortbl_nameis fullSELECToperations that require a large temporary table. The default value for a new connection is 0 (use in-memory temporary tables). Normally, you should never need to set this variable, because in-memory tables are automatically converted to disk-based tables as required. (Note: This variable was formerly namedSQL_BIG_TABLES.)CHARACTER SET {charset_name| DEFAULT}This maps all strings from and to the client with the given mapping. You can add new mappings by editing
sql/convert.ccin the MySQL source distribution.SET CHARACTER SETsets three session system variables:character_set_clientandcharacter_set_resultsare set to the given character set, andcharacter_set_connectionto the value ofcharacter_set_database. See Section 10.4, “Connection Character Sets and Collations”.The default mapping can be restored by using the value
DEFAULT. The default depends on the server configuration.Note that the syntax for
SET CHARACTER SETdiffers from that for setting most other options.FOREIGN_KEY_CHECKS = {0 | 1}If set to 1 (the default), foreign key constraints for
InnoDBtables are checked. If set to 0, they are ignored. Disabling foreign key checking can be useful for reloadingInnoDBtables in an order different from that required by their parent/child relationships. See Section 14.2.6.4, “FOREIGN KEYConstraints”.Setting
FOREIGN_KEY_CHECKSto 0 also affects data definition statements:DROP DATABASEdrops a database even if it contains tables that have foreign keys that are referred to by tables outside the database, andDROP TABLEdrops tables that have foreign keys that are referred to by other tables.Note
Setting
FOREIGN_KEY_CHECKSto 1 does not trigger a scan of the existing table data. Therefore, rows added to the table whileFOREIGN_KEY_CHECKS=0will not be verified for consistency.IDENTITY =valueThis variable is a synonym for the
LAST_INSERT_IDvariable. It exists for compatibility with other database systems. You can read its value withSELECT @@IDENTITY, and set it usingSET IDENTITY.INSERT_ID =valueSet the value to be used by the following
INSERTorALTER TABLEstatement when inserting anAUTO_INCREMENTvalue. This is mainly used with the binary log.LAST_INSERT_ID =valueSet the value to be returned from
LAST_INSERT_ID(). This is stored in the binary log when you useLAST_INSERT_ID()in a statement that updates a table. Setting this variable does not update the value returned by themysql_insert_id()C API function.NAMES {'charset_name' [COLLATE 'collation_name'} | DEFAULT}SET NAMESsets the three session system variablescharacter_set_client,character_set_connection, andcharacter_set_resultsto the given character set. Settingcharacter_set_connectiontocharset_namealso setscollation_connectionto the default collation forcharset_name. The optionalCOLLATEclause may be used to specify a collation explicitly. See Section 10.4, “Connection Character Sets and Collations”.The default mapping can be restored by using a value of
DEFAULT. The default depends on the server configuration.Note that the syntax for
SET NAMESdiffers from that for setting most other options.ONE_SHOTThis option is a modifier, not a variable. It can be used to influence the effect of variables that set the character set, the collation, and the time zone.
ONE_SHOTis primarily used for replication purposes: mysqlbinlog usesSET ONE_SHOTto modify temporarily the values of character set, collation, and time zone variables to reflect at rollforward what they were originally.ONE_SHOTis for internal use only and is deprecated for MySQL 5.0 and up.You cannot use
ONE_SHOTwith other than the allowed set of variables; if you try, you get an error like this:mysql>
SET ONE_SHOT max_allowed_packet = 1;ERROR 1382 (HY000): The 'SET ONE_SHOT' syntax is reserved for purposes internal to the MySQL serverIf
ONE_SHOTis used with the allowed variables, it changes the variables as requested, but only for the next non-SETstatement. After that, the server resets all character set, collation, and time zone-related system variables to their previous values. Example:mysql>
SET ONE_SHOT character_set_connection = latin5;mysql>SET ONE_SHOT collation_connection = latin5_turkish_ci;mysql>SHOW VARIABLES LIKE '%_connection';+--------------------------+-------------------+ | Variable_name | Value | +--------------------------+-------------------+ | character_set_connection | latin5 | | collation_connection | latin5_turkish_ci | +--------------------------+-------------------+ mysql>SHOW VARIABLES LIKE '%_connection';+--------------------------+-------------------+ | Variable_name | Value | +--------------------------+-------------------+ | character_set_connection | latin1 | | collation_connection | latin1_swedish_ci | +--------------------------+-------------------+PROFILING = {0 | 1}If set to 0 (the default), statement profiling is disabled. If set to 1, statement profiling is enabled and the
SHOW PROFILESandSHOW PROFILEstatements provide access to profiling information. See Section 13.5.4.22, “SHOW PROFILESandSHOW PROFILESyntax”. This variable was added in MySQL 5.0.37.PROFILING_HISTORY_SIZE =valueThe number of statements for which to maintain profiling information if
PROFILINGis enabled. The default value is 15. The maximum value is 100. Setting the value to 0 effectively disables profiling. See Section 13.5.4.22, “SHOW PROFILESandSHOW PROFILESyntax”. This variable was added in MySQL 5.0.37.SQL_AUTO_IS_NULL = {0 | 1}If set to 1 (the default), you can find the last inserted row for a table that contains an
AUTO_INCREMENTcolumn by using the following construct:WHERE
auto_increment_columnIS NULLThis behavior is used by some ODBC programs, such as Access.
SQL_BIG_SELECTS = {0 | 1}If set to 0, MySQL aborts
SELECTstatements that are likely to take a very long time to execute (that is, statements for which the optimizer estimates that the number of examined rows exceeds the value ofmax_join_size). This is useful when an inadvisableWHEREstatement has been issued. The default value for a new connection is 1, which allows allSELECTstatements.If you set the
max_join_sizesystem variable to a value other thanDEFAULT,SQL_BIG_SELECTSis set to 0.SQL_BUFFER_RESULT = {0 | 1}If set to 1,
SQL_BUFFER_RESULTforces results fromSELECTstatements to be put into temporary tables. This helps MySQL free the table locks early and can be beneficial in cases where it takes a long time to send results to the client. The default value is 0.SQL_LOG_BIN = {0 | 1}If set to 0, no logging is done to the binary log for the client. The client must have the
SUPERprivilege to set this option. The default value is 1.SQL_LOG_OFF = {0 | 1}If set to 1, no logging is done to the general query log for this client. The client must have the
SUPERprivilege to set this option. The default value is 0.SQL_LOG_UPDATE = {0 | 1}This variable is deprecated, and is mapped to
SQL_LOG_BIN.SQL_NOTES = {0 | 1}If set to 1 (the default), warnings of
Notelevel are recorded. If set to 0,Notewarnings are suppressed. mysqldump includes output to set this variable to 0 so that reloading the dump file does not produce warnings for events that do not affect the integrity of the reload operation.SQL_NOTESwas added in MySQL 5.0.3.SQL_QUOTE_SHOW_CREATE = {0 | 1}If set to 1 (the default), the server quotes identifiers for
SHOW CREATE TABLEandSHOW CREATE DATABASEstatements. If set to 0, quoting is disabled. This option is enabled by default so that replication works for identifiers that require quoting. See Section 13.5.4.6, “SHOW CREATE TABLESyntax”, and Section 13.5.4.4, “SHOW CREATE DATABASESyntax”.SQL_SAFE_UPDATES = {0 | 1}If set to 1, MySQL aborts
UPDATEorDELETEstatements that do not use a key in theWHEREclause or aLIMITclause. This makes it possible to catchUPDATEorDELETEstatements where keys are not used properly and that would probably change or delete a large number of rows. The default value is 0.SQL_SELECT_LIMIT = {value| DEFAULT}The maximum number of rows to return from
SELECTstatements. The default value for a new connection is “unlimited.” If you have changed the limit, the default value can be restored by using aSQL_SELECT_LIMITvalue ofDEFAULT.If a
SELECThas aLIMITclause, theLIMITtakes precedence over the value ofSQL_SELECT_LIMIT.SQL_SELECT_LIMITdoes not apply toSELECTstatements executed within stored routines. It also does not apply toSELECTstatements that do not produce a result set to be returned to the client. These includeSELECTstatements in subqueries,CREATE TABLE ... SELECT, andINSERT INTO ... SELECT.SQL_WARNINGS = {0 | 1}This variable controls whether single-row
INSERTstatements produce an information string if warnings occur. The default is 0. Set the value to 1 to produce an information string.TIMESTAMP = {timestamp_value| DEFAULT}Set the time for this client. This is used to get the original timestamp if you use the binary log to restore rows.
timestamp_valueshould be a Unix epoch timestamp, not a MySQL timestamp.SET TIMESTAMPaffects the value returned byNOW()but not bySYSDATE(). This means that timestamp settings in the binary log have no effect on invocations ofSYSDATE(). The server can be started with the--sysdate-is-nowoption to causeSYSDATE()to be an alias forNOW(), in which caseSET TIMESTAMPaffects both functions.UNIQUE_CHECKS = {0 | 1}If set to 1 (the default), uniqueness checks for secondary indexes in
InnoDBtables are performed. If set to 0, storage engines are allowed to assume that duplicate keys are not present in input data. If you know for certain that your data does not contain uniqueness violations, you can set this to 0 to speed up large table imports toInnoDB.Note that setting this variable to 0 does not require storage engines to ignore duplicate keys. An engine is still allowed to check for them and issue duplicate-key errors if it detects them.
- 13.5.4.1.
SHOW CHARACTER SETSyntax - 13.5.4.2.
SHOW COLLATIONSyntax - 13.5.4.3.
SHOW COLUMNSSyntax - 13.5.4.4.
SHOW CREATE DATABASESyntax - 13.5.4.5.
SHOW CREATE PROCEDUREandSHOW CREATE FUNCTIONSyntax - 13.5.4.6.
SHOW CREATE TABLESyntax - 13.5.4.7.
SHOW CREATE VIEWSyntax - 13.5.4.8.
SHOW DATABASESSyntax - 13.5.4.9.
SHOW ENGINESyntax - 13.5.4.10.
SHOW ENGINESSyntax - 13.5.4.11.
SHOW ERRORSSyntax - 13.5.4.12.
SHOW GRANTSSyntax - 13.5.4.13.
SHOW INDEXSyntax - 13.5.4.14.
SHOW INNODB STATUSSyntax - 13.5.4.15.
SHOW LOGSSyntax - 13.5.4.16.
SHOW MUTEX STATUSSyntax - 13.5.4.17.
SHOW OPEN TABLESSyntax - 13.5.4.18.
SHOW PRIVILEGESSyntax - 13.5.4.19.
SHOW PROCEDURE CODEandSHOW FUNCTION CODESyntax - 13.5.4.20.
SHOW PROCEDURE STATUSandSHOW FUNCTION STATUSSyntax - 13.5.4.21.
SHOW PROCESSLISTSyntax - 13.5.4.22.
SHOW PROFILESandSHOW PROFILESyntax - 13.5.4.23.
SHOW STATUSSyntax - 13.5.4.24.
SHOW TABLE STATUSSyntax - 13.5.4.25.
SHOW TABLESSyntax - 13.5.4.26.
SHOW TRIGGERSSyntax - 13.5.4.27.
SHOW VARIABLESSyntax - 13.5.4.28.
SHOW WARNINGSSyntax
SHOW has many forms that provide information
about databases, tables, columns, or status information about
the server. This section describes those following:
SHOW [FULL] COLUMNS FROMtbl_name[FROMdb_name] [LIKE 'pattern'] SHOW CREATE DATABASEdb_nameSHOW CREATE FUNCTIONfuncnameSHOW CREATE PROCEDUREprocnameSHOW CREATE TABLEtbl_nameSHOW DATABASES [LIKE 'pattern'] SHOW ENGINEengine_name{LOGS | STATUS } SHOW [STORAGE] ENGINES SHOW ERRORS [LIMIT [offset,]row_count] SHOW FUNCTION CODEsp_nameSHOW FUNCTION STATUS [LIKE 'pattern'] SHOW GRANTS FORuserSHOW INDEX FROMtbl_name[FROMdb_name] SHOW INNODB STATUS SHOW PROCEDURE CODEsp_nameSHOW PROCEDURE STATUS [LIKE 'pattern'] SHOW [BDB] LOGS SHOW MUTEX STATUS SHOW PRIVILEGES SHOW [FULL] PROCESSLIST SHOW PROFILE [types] [FOR QUERYn] [OFFSETn] [LIMITn] SHOW PROFILES SHOW [GLOBAL | SESSION] STATUS [LIKE 'pattern'] SHOW TABLE STATUS [FROMdb_name] [LIKE 'pattern'] SHOW [OPEN] TABLES [FROMdb_name] [LIKE 'pattern'] SHOW TRIGGERS SHOW [GLOBAL | SESSION] VARIABLES [LIKE 'pattern'] SHOW WARNINGS [LIMIT [offset,]row_count]
The SHOW statement also has forms that
provide information about replication master and slave servers
and are described in Section 13.6, “Replication Statements”:
SHOW BINARY LOGS SHOW BINLOG EVENTS SHOW MASTER STATUS SHOW SLAVE HOSTS SHOW SLAVE STATUS
If the syntax for a given SHOW statement
includes a LIKE
' part,
pattern'' is a
string that can contain the SQL
‘pattern'%’ and
‘_’ wildcard characters. The
pattern is useful for restricting statement output to matching
values.
Several SHOW statements also accept a
WHERE clause that provides more flexibility
in specifying which rows to display. See
Section 20.19, “Extensions to SHOW Statements”.
Many MySQL APIs (such as PHP) allow you to treat the result
returned from a SHOW statement as you would a
result set from a SELECT; see
Chapter 22, APIs and Libraries, or your API documentation for more
information. In addition, you can work in SQL with results from
queries on tables in the INFORMATION_SCHEMA
database, which you cannot easily do with results from
SHOW statements. See
Chapter 20, The INFORMATION_SCHEMA Database.
SHOW CHARACTER SET [LIKE 'pattern']
The SHOW CHARACTER SET statement shows all
available character sets. It takes an optional
LIKE clause that indicates which character
set names to match. For example:
mysql> SHOW CHARACTER SET LIKE 'latin%';
+---------+-----------------------------+-------------------+--------+
| Charset | Description | Default collation | Maxlen |
+---------+-----------------------------+-------------------+--------+
| latin1 | cp1252 West European | latin1_swedish_ci | 1 |
| latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 |
| latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 |
| latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 |
+---------+-----------------------------+-------------------+--------+
The Maxlen column shows the maximum number
of bytes required to store one character.
SHOW COLLATION [LIKE 'pattern']
The output from SHOW COLLATION includes all
available character sets. It takes an optional
LIKE clause whose
pattern indicates which collation
names to match. For example:
mysql> SHOW COLLATION LIKE 'latin1%';
+-------------------+---------+----+---------+----------+---------+
| Collation | Charset | Id | Default | Compiled | Sortlen |
+-------------------+---------+----+---------+----------+---------+
| latin1_german1_ci | latin1 | 5 | | | 0 |
| latin1_swedish_ci | latin1 | 8 | Yes | Yes | 0 |
| latin1_danish_ci | latin1 | 15 | | | 0 |
| latin1_german2_ci | latin1 | 31 | | Yes | 2 |
| latin1_bin | latin1 | 47 | | Yes | 0 |
| latin1_general_ci | latin1 | 48 | | | 0 |
| latin1_general_cs | latin1 | 49 | | | 0 |
| latin1_spanish_ci | latin1 | 94 | | | 0 |
+-------------------+---------+----+---------+----------+---------+
The Default column indicates whether a
collation is the default for its character set.
Compiled indicates whether the character
set is compiled into the server. Sortlen is
related to the amount of memory required to sort strings
expressed in the character set.
SHOW [FULL] COLUMNS FROMtbl_name[FROMdb_name] [LIKE 'pattern']
SHOW COLUMNS displays information about the
columns in a given table. It also works for views as of MySQL
5.0.1.
If the data types differ from what you expect them to be based
on your CREATE TABLE statement, note that
MySQL sometimes changes data types when you create or alter a
table. The conditions for which this occurs are described in
Section 13.1.5.1, “Silent Column Specification Changes”.
The FULL keyword causes the output to
include the privileges you have as well as any per-column
comments for each column.
You can use db_name.tbl_name as an
alternative to the
tbl_name FROM
db_name
mysql>SHOW COLUMNS FROM mytable FROM mydb;mysql>SHOW COLUMNS FROM mydb.mytable;
SHOW FIELDS is a synonym for SHOW
COLUMNS. You can also list a table's columns with
the mysqlshow db_name
tbl_name command.
The DESCRIBE statement provides information
similar to SHOW COLUMNS. See
Section 13.3.1, “DESCRIBE Syntax”.
SHOW CREATE {DATABASE | SCHEMA} db_name
Shows the CREATE DATABASE statement that
creates the given database. SHOW CREATE
SCHEMA is a synonym for SHOW CREATE
DATABASE as of MySQL 5.0.2.
mysql>SHOW CREATE DATABASE test\G*************************** 1. row *************************** Database: test Create Database: CREATE DATABASE `test` /*!40100 DEFAULT CHARACTER SET latin1 */ mysql>SHOW CREATE SCHEMA test\G*************************** 1. row *************************** Database: test Create Database: CREATE DATABASE `test` /*!40100 DEFAULT CHARACTER SET latin1 */
SHOW CREATE DATABASE quotes table and
column names according to the value of the
SQL_QUOTE_SHOW_CREATE option. See
Section 13.5.3, “SET Syntax”.
SHOW CREATE {PROCEDURE | FUNCTION} sp_name
These statements are MySQL extensions. Similar to
SHOW CREATE TABLE, they return the exact
string that can be used to re-create the named routine. The
statements require that you be the owner of the routine or
have SELECT access to the
mysql.proc table.
mysql> SHOW CREATE FUNCTION test.hello\G
*************************** 1. row ***************************
Function: hello
sql_mode:
Create Function: CREATE FUNCTION `test`.`hello`(s CHAR(20)) RETURNS CHAR(50)
RETURN CONCAT('Hello, ',s,'!')
SHOW CREATE TABLE tbl_name
Shows the CREATE TABLE statement that
creates the given table. As of MySQL 5.0.1, this statement
also works with views.
mysql> SHOW CREATE TABLE t\G
*************************** 1. row ***************************
Table: t
Create Table: CREATE TABLE t (
id INT(11) default NULL auto_increment,
s char(60) default NULL,
PRIMARY KEY (id)
) ENGINE=MyISAM
SHOW CREATE TABLE quotes table and column
names according to the value of the
SQL_QUOTE_SHOW_CREATE option. See
Section 13.5.3, “SET Syntax”.
SHOW CREATE VIEW view_name
This statement shows a CREATE VIEW
statement that creates the given view.
mysql> SHOW CREATE VIEW v;
+------+----------------------------------------------------+
| View | Create View |
+------+----------------------------------------------------+
| v | CREATE VIEW `test`.`v` AS select 1 AS `a`,2 AS `b` |
+------+----------------------------------------------------+
This statement was added in MySQL 5.0.1.
Prior to MySQL 5.0.11, the output columns from this statement
were shown as Table and Create
Table.
Use of SHOW CREATE VIEW requires the
SHOW VIEW privilege and the
SELECT privilege for the view in question.
You can also obtain information about view objects from
INFORMATION_SCHEMA, which contains a
VIEWS table. See
Section 20.15, “The INFORMATION_SCHEMA VIEWS Table”.
SHOW {DATABASES | SCHEMAS} [LIKE 'pattern']
SHOW DATABASES lists the databases on the
MySQL server host. SHOW SCHEMAS is a
synonym for SHOW DATABASES as of MySQL
5.0.2.
You see only those databases for which you have some kind of
privilege, unless you have the global SHOW
DATABASES privilege. You can also get this list
using the mysqlshow command.
If the server was started with the
--skip-show-database option, you cannot use
this statement at all unless you have the SHOW
DATABASES privilege.
SHOW ENGINE engine_name {LOGS | STATUS }
SHOW ENGINE displays log or status
information about a storage engine. The following statements
currently are supported:
SHOW ENGINE BDB LOGS SHOW ENGINE INNODB STATUS SHOW ENGINE NDB STATUS SHOW ENGINE NDBCLUSTER STATUS
SHOW ENGINE BDB LOGS displays status
information about existing BDB log files.
It returns the following fields:
FileThe full path to the log file.
TypeThe log file type (
BDBfor Berkeley DB log files).StatusThe status of the log file (
FREEif the file can be removed, orIN USEif the file is needed by the transaction subsystem)
SHOW ENGINE INNODB STATUS displays
extensive information about the state of the
InnoDB storage engine.
The InnoDB Monitors provide additional
information about InnoDB processing. See
Section 14.2.11.1, “SHOW ENGINE INNODB STATUS and the
InnoDB Monitors”.
Older (and now deprecated) synonyms for SHOW ENGINE
BDB LOGS and SHOW ENGINE INNODB
STATUS are SHOW [BDB] LOGS and
SHOW INNODB STATUS, respectively.
If the server has the NDBCLUSTER storage
engine enabled, SHOW ENGINE NDB STATUS can
be used to display cluster status information. Sample output
from this statement is shown here:
mysql> SHOW ENGINE NDB STATUS;
+-----------------------+---------+------+--------+
| free_list | created | free | sizeof |
+-----------------------+---------+------+--------+
| NdbTransaction | 5 | 0 | 208 |
| NdbOperation | 4 | 4 | 660 |
| NdbIndexScanOperation | 1 | 1 | 736 |
| NdbIndexOperation | 0 | 0 | 1060 |
| NdbRecAttr | 645 | 645 | 72 |
| NdbApiSignal | 16 | 16 | 136 |
| NdbLabel | 0 | 0 | 196 |
| NdbBranch | 0 | 0 | 24 |
| NdbSubroutine | 0 | 0 | 68 |
| NdbCall | 0 | 0 | 16 |
| NdbBlob | 2 | 2 | 204 |
| NdbReceiver | 2 | 0 | 68 |
+-----------------------+---------+------+--------+
12 rows in set (0.00 sec)
The most useful of the rows from the output of this statement are described in the following list:
NdbTransaction: The number and size ofNdbTransactionobjects that have been created. AnNdbTransactionis created each time a table schema operation (such asCREATE TABLEorALTER TABLE) is performed on anNDBtable.NdbOperation: The number and size ofNdbOperationobjects that have been created.NdbIndexScanOperation: The number and size ofNdbIndexScanOperationobjects that have been created.NdbIndexOperation: The number and size ofNdbIndexOperationobjects that have been created.NdbRecAttr: The number and size ofNdbRecAttrobjects that have been created. In general, one of these is created each time a data manipulation statement is performed by an SQL node.NdbBlob: The number and size ofNdbBlobobjects that have been created. AnNdbBlobis created for each new operation involving aBLOBcolumn in anNDBtable.NdbReceiver: The number and size of anyNdbReceiverobject that have been created. The number in thecreatedcolumn is the same as the number of data nodes in the cluster to which the MySQL server has connected.
Note: SHOW ENGINE
NDB STATUS returns an empty result if no operations
involving NDB tables have been performed by
the MySQL client accessing the SQL node on which this
statement is run.
SHOW ENGINE NDBCLUSTER STATUS is a synonym
for SHOW ENGINE NDB STATUS.
MySQL Enterprise
The SHOW ENGINE
statement provides valuable information about the state of
your server. For expert interpretation of this information,
subscribe to the MySQL Network Monitoring and Advisory
Service. For more information see
http://www.mysql.com/products/enterprise/advisors.html.
engine_name STATUS
SHOW [STORAGE] ENGINES
SHOW ENGINES displays status information
about the server's storage engines. This is particularly
useful for checking whether a storage engine is supported, or
to see what the default engine is. SHOW TABLE
TYPES is a deprecated synonym.
mysql> SHOW ENGINES\G
*************************** 1. row ***************************
Engine: MyISAM
Support: DEFAULT
Comment: Default engine as of MySQL 3.23 with great performance
*************************** 2. row ***************************
Engine: MEMORY
Support: YES
Comment: Hash based, stored in memory, useful for temporary tables
*************************** 3. row ***************************
Engine: HEAP
Support: YES
Comment: Alias for MEMORY
*************************** 4. row ***************************
Engine: MERGE
Support: YES
Comment: Collection of identical MyISAM tables
*************************** 5. row ***************************
Engine: MRG_MYISAM
Support: YES
Comment: Alias for MERGE
*************************** 6. row ***************************
Engine: ISAM
Support: NO
Comment: Obsolete storage engine, now replaced by MyISAM
*************************** 7. row ***************************
Engine: MRG_ISAM
Support: NO
Comment: Obsolete storage engine, now replaced by MERGE
*************************** 8. row ***************************
Engine: InnoDB
Support: YES
Comment: Supports transactions, row-level locking, and foreign keys
*************************** 9. row ***************************
Engine: INNOBASE
Support: YES
Comment: Alias for INNODB
*************************** 10. row ***************************
Engine: BDB
Support: YES
Comment: Supports transactions and page-level locking
*************************** 11. row ***************************
Engine: BERKELEYDB
Support: YES
Comment: Alias for BDB
*************************** 12. row ***************************
Engine: NDBCLUSTER
Support: NO
Comment: Clustered, fault-tolerant, memory-based tables
*************************** 13. row ***************************
Engine: NDB
Support: NO
Comment: Alias for NDBCLUSTER
*************************** 14. row ***************************
Engine: EXAMPLE
Support: NO
Comment: Example storage engine
*************************** 15. row ***************************
Engine: ARCHIVE
Support: YES
Comment: Archive storage engine
*************************** 16. row ***************************
Engine: CSV
Support: NO
Comment: CSV storage engine
*************************** 17. row ***************************
Engine: FEDERATED
Support: YES
Comment: Federated MySQL storage engine
*************************** 18. row ***************************
Engine: BLACKHOLE
Support: YES
Comment: /dev/null storage engine (anything you write to it disappears)
The output from SHOW ENGINES may vary
according to the MySQL version used and other factors. The
values shown in the Support column indicate
the server's level of support for different features, as shown
here:
| Value | Meaning |
YES | The feature is supported and is active. |
NO | The feature is not supported. |
DISABLED | The feature is supported but has been disabled. |
A value of NO means that the server was
compiled without support for the feature, so it cannot be
activated at runtime.
A value of DISABLED occurs either because
the server was started with an option that disables the
feature, or because not all options required to enable it were
given. In the latter case, the error log file should contain a
reason indicating why the option is disabled. See
Section 5.11.1, “The Error Log”.
You might also see DISABLED for a storage
engine if the server was compiled to support it, but was
started with a
--skip-
option. For example, engine--skip-innodb disables
the InnoDB engine. For the NDB
Cluster storage engine, DISABLED
means the server was compiled with support for MySQL Cluster,
but was not started with the --ndb-cluster
option.
All MySQL servers support MyISAM tables,
because MyISAM is the default storage
engine.
SHOW ERRORS [LIMIT [offset,]row_count] SHOW COUNT(*) ERRORS
This statement is similar to SHOW WARNINGS,
except that instead of displaying errors, warnings, and notes,
it displays only errors.
The LIMIT clause has the same syntax as for
the SELECT statement. See
Section 13.2.7, “SELECT Syntax”.
The SHOW COUNT(*) ERRORS statement displays
the number of errors. You can also retrieve this number from
the error_count variable:
SHOW COUNT(*) ERRORS; SELECT @@error_count;
For more information, see Section 13.5.4.28, “SHOW WARNINGS Syntax”.
SHOW GRANTS [FOR user]
This statement lists the GRANT statement or
statements that must be issued to duplicate the privileges
that are granted to a MySQL user account. The account is named
using the same format as for the GRANT
statement; for example,
'jeffrey'@'localhost'. If you specify only
the username part of the account name, a hostname part of
'%' is used. For additional information
about specifying account names, see Section 13.5.1.3, “GRANT Syntax”.
mysql> SHOW GRANTS FOR 'root'@'localhost';
+---------------------------------------------------------------------+
| Grants for root@localhost |
+---------------------------------------------------------------------+
| GRANT ALL PRIVILEGES ON *.* TO 'root'@'localhost' WITH GRANT OPTION |
+---------------------------------------------------------------------+
To list the privileges granted to the account that you are using to connect to the server, you can use any of the following statements:
SHOW GRANTS; SHOW GRANTS FOR CURRENT_USER; SHOW GRANTS FOR CURRENT_USER();
As of MySQL 5.0.24, if SHOW GRANTS FOR
CURRENT_USER (or any of the equivalent syntaxes) is
used in DEFINER context, such as within a
stored procedure that is defined with SQL SECURITY
DEFINER), the grants displayed are those of the
definer and not the invoker.
SHOW GRANTS displays only the privileges
granted explicitly to the named account. Other privileges
might be available to the account, but they are not displayed.
For example, if an anonymous account exists, the named account
might be able to use its privileges, but SHOW
GRANTS will not display them.
SHOW INDEX FROMtbl_name[FROMdb_name]
SHOW INDEX returns table index information.
The format resembles that of the
SQLStatistics call in ODBC.
SHOW INDEX returns the following fields:
TableThe name of the table.
Non_unique0 if the index cannot contain duplicates, 1 if it can.
Key_nameThe name of the index.
Seq_in_indexThe column sequence number in the index, starting with 1.
Column_nameThe column name.
How the column is sorted in the index. In MySQL, this can have values ‘
A’ (Ascending) orNULL(Not sorted).An estimate of the number of unique values in the index. This is updated by running
ANALYZE TABLEor myisamchk -a.Cardinalityis counted based on statistics stored as integers, so the value is not necessarily exact even for small tables. The higher the cardinality, the greater the chance that MySQL uses the index when doing joins.Sub_partThe number of indexed characters if the column is only partly indexed,
NULLif the entire column is indexed.PackedIndicates how the key is packed.
NULLif it is not.NullContains
YESif the column may containNULL. If not, the column containsNOas of MySQL 5.0.3, and''before that.Index_typeThe index method used (
BTREE,FULLTEXT,HASH,RTREE).CommentVarious remarks.
You can use
db_name.tbl_name
as an alternative to the
tbl_name FROM
db_name
SHOW INDEX FROM mytable FROM mydb; SHOW INDEX FROM mydb.mytable;
SHOW KEYS is a synonym for SHOW
INDEX. You can also list a table's indexes with the
mysqlshow -k db_name
tbl_name command.
SHOW INNODB STATUS
In MySQL 5.0, this is a deprecated synonym for
SHOW ENGINE INNODB STATUS. See
Section 13.5.4.9, “SHOW ENGINE Syntax”.
SHOW [BDB] LOGS
In MySQL 5.0, this is a deprecated synonym for
SHOW ENGINE BDB LOGS. See
Section 13.5.4.9, “SHOW ENGINE Syntax”.
SHOW MUTEX STATUS
SHOW MUTEX STATUS displays
InnoDB mutex statistics. The output fields
are:
MutexThe mutex name. The name indicates the mutex purpose. For example, the
log_sysmutex is used by theInnoDBlogging subsystem and indicates how intensive logging activity is. Thebuf_poolmutex protects theInnoDBbuffer pool.ModuleThe source file where the mutex is implemented.
Countindicates how many times the mutex was requested.Spin_waitsindicates how many times the spinlock had to run.Spin_roundsindicates the number of spinlock rounds. (spin_roundsdivided byspin_waitsprovides the average round count.)OS_waitsindicates the number of operating system waits. This occurs when the spinlock did not work (the mutex was not locked during the spinlock and it was necessary to yield to the operating system and wait).OS_yieldsindicates the number of times that a thread trying to lock a mutex gave up its timeslice and yielded to the operating system (on the presumption that allowing other threads to run will free the mutex so that it can be locked).OS_waits_timeos_wait_timesindicates the amount of time (in ms) spent in operating system waits, if thetimed_mutexessystem variable is 1 (ON). Iftimed_mutexesis 0 (OFF), timing is disabled, soOS_waits_timeis 0.timed_mutexesis off by default.
Information from this statement can be used to diagnose system
problems. For example, large values of
spin_waits and
spin_rounds may indicate scalability
problems.
SHOW MUTEX STATUS was added in MySQL 5.0.3.
In MySQL 5.1, SHOW MUTEX STATUS
is renamed to SHOW ENGINE INNODB MUTEX. The
latter statement displays similar information but in a
somewhat different output format.
SHOW OPEN TABLES [FROMdb_name] [LIKE 'pattern']
SHOW OPEN TABLES lists the
non-TEMPORARY tables that are currently
open in the table cache. See Section 7.4.8, “How MySQL Opens and Closes Tables”.
SHOW OPEN TABLES returns the following
fields:
DatabaseThe database containing the table.
TableThe table name.
In_useThe number of table locks or lock requests there are for the table. For example, if one client acquires a lock for a table using
LOCK TABLE t1 WRITE,In_usewill be 1. If another client issuesLOCK TABLE t1 WRITEwhile the table remains locked, the client will block waiting for the lock, but the lock request causesIn_useto be 2. If the count is zero, the table is open but not currently being used.Name_lockedWhether the table name is locked. Name locking is used for operations such as dropping or renaming tables.
The FROM and LIKE
clauses may be used as of MySQL 5.0.12.
SHOW PRIVILEGES
SHOW PRIVILEGES shows the list of system
privileges that the MySQL server supports. The exact list of
privileges depends on the version of your server.
mysql> SHOW PRIVILEGES\G
*************************** 1. row ***************************
Privilege: Alter
Context: Tables
Comment: To alter the table
*************************** 2. row ***************************
Privilege: Alter routine
Context: Functions,Procedures
Comment: To alter or drop stored functions/procedures
*************************** 3. row ***************************
Privilege: Create
Context: Databases,Tables,Indexes
Comment: To create new databases and tables
*************************** 4. row ***************************
Privilege: Create routine
Context: Functions,Procedures
Comment: To use CREATE FUNCTION/PROCEDURE
*************************** 5. row ***************************
Privilege: Create temporary tables
Context: Databases
Comment: To use CREATE TEMPORARY TABLE
...
SHOW {PROCEDURE | FUNCTION} CODE sp_name
These statements are MySQL extensions that are available only
for servers that have been built with debugging support. They
display a representation of the internal implementation of the
named routine. The statements require that you be the owner of
the routine or have SELECT access to the
mysql.proc table.
If the named routine is available, each statement produces a
result set. Each row in the result set corresponds to one
“instruction” in the routine. The first column is
Pos, which is an ordinal number beginning
with 0. The second column is Instruction,
which contains an SQL statement (usually changed from the
original source), or a directive which has meaning only to the
stored-routine handler.
mysql>DELIMITER //mysql>CREATE PROCEDURE p1 ()->BEGIN->DECLARE fanta INT DEFAULT 55;->DROP TABLE t2;->LOOP->INSERT INTO t3 VALUES (fanta);->END LOOP;->END//Query OK, 0 rows affected (0.00 sec) mysql>SHOW PROCEDURE CODE p1//+-----+----------------------------------------+ | Pos | Instruction | +-----+----------------------------------------+ | 0 | set fanta@0 55 | | 1 | stmt 9 "DROP TABLE t2" | | 2 | stmt 5 "INSERT INTO t3 VALUES (fanta)" | | 3 | jump 2 | +-----+----------------------------------------+ 4 rows in set (0.00 sec)
In this example, the non-executable BEGIN
and END statements have disappeared, and
for the DECLARE
statement,
only the executable part appears (the part where the default
is assigned). For each statement that is taken from source,
there is a code word variable_namestmt followed by a
type (9 means DROP, 5 means
INSERT, and so on). The final row contains
an instruction jump 2, meaning
GOTO instruction #2.
These statements were added in MySQL 5.0.17.
SHOW {PROCEDURE | FUNCTION} STATUS [LIKE 'pattern']
These statements are MySQL extensions. They return characteristics of routines, such as the database, name, type, creator, and creation and modification dates. If no pattern is specified, the information for all stored procedures or all stored functions is listed, depending on which statement you use.
mysql> SHOW FUNCTION STATUS LIKE 'hello'\G
*************************** 1. row ***************************
Db: test
Name: hello
Type: FUNCTION
Definer: testuser@localhost
Modified: 2004-08-03 15:29:37
Created: 2004-08-03 15:29:37
Security_type: DEFINER
Comment:
You can also get information about stored routines from the
ROUTINES table in
INFORMATION_SCHEMA. See
Section 20.14, “The INFORMATION_SCHEMA ROUTINES Table”.
SHOW [FULL] PROCESSLIST
SHOW PROCESSLIST shows you which threads
are running. You can also get this information using the
mysqladmin processlist command. If you have
the PROCESS privilege, you can see all
threads. Otherwise, you can see only your own threads (that
is, threads associated with the MySQL account that you are
using). See Section 13.5.5.3, “KILL Syntax”. If you do not use the
FULL keyword, only the first 100 characters
of each statement are shown in the Info
field.
MySQL Enterprise Subscribers to MySQL Network Monitoring and Advisory Service receive instant notification and expert advice on resolution when there are too many concurrent processes. For more information see, http://www.mysql.com/products/enterprise/advisors.html.
This statement is very useful if you get the “too many
connections” error message and want to find out what is
going on. MySQL reserves one extra connection to be used by
accounts that have the SUPER privilege, to
ensure that administrators should always be able to connect
and check the system (assuming that you are not giving this
privilege to all your users).
The output of SHOW PROCESSLIST may look
like this:
mysql> SHOW FULL PROCESSLIST\G *************************** 1. row *************************** Id: 1 User: system user Host: db: NULL Command: Connect Time: 1030455 State: Waiting for master to send event Info: NULL *************************** 2. row *************************** Id: 2 User: system user Host: db: NULL Command: Connect Time: 1004 State: Has read all relay log; waiting for the slave I/O thread to update it Info: NULL *************************** 3. row *************************** Id: 3112 User: replikator Host: artemis:2204 db: NULL Command: Binlog Dump Time: 2144 State: Has sent all binlog to slave; waiting for binlog to be updated Info: NULL *************************** 4. row *************************** Id: 3113 User: replikator Host: iconnect2:45781 db: NULL Command: Binlog Dump Time: 2086 State: Has sent all binlog to slave; waiting for binlog to be updated Info: NULL *************************** 5. row *************************** Id: 3123 User: stefan Host: localhost db: apollon Command: Query Time: 0 State: NULL Info: SHOW FULL PROCESSLIST 5 rows in set (0.00 sec)
The columns have the following meaning:
IdThe connection identifier.
UserThe MySQL user who issued the statement. If this is
system user, it refers to a non-client thread spawned by the server to handle tasks internally. This could be the I/O or SQL thread used on replication slaves or a delayed-row handler. Forsystem user, there is no host specified in theHostcolumn.HostThe hostname of the client issuing the statement (except for
system userwhere there is no host).SHOW PROCESSLISTreports the hostname for TCP/IP connections inhost_name:client_portdbThe default database, if one is selected, otherwise
NULL.CommandThe value of that column corresponds to the
COM_commands of the client/server protocol. See Section 5.2.5, “Status Variables”xxxThe
Commandvalue may be one of the following:Binlog Dump,Change user,Close stmt,Connect,Connect Out,Create DB,Daemon,Debug,Delayed insert,Drop DB,Error,Execute,Fetch,Field List,Init DB,Kill,Long Data,Ping,Prepare,Processlist,Query,Quit,Refresh,Register Slave,Reset stmt,Set option,Shutdown,Sleep,Statistics,Table Dump,TimeTimeThe time in seconds that the thread has been in its current state.
StateAn action, event, or state, which can be one of the following:
After create,Analyzing,Changing master,Checking master version,Checking table,Connecting to master,Copying to group table,Copying to tmp table,Creating delayed handler,Creating index,Creating sort index,Creating table from master dump,Creating tmp table,Execution of init_command,FULLTEXT initialization,Finished reading one binlog; switching to next binlog,Flushing tables,Killed,Killing slave,Locked,Making temp file,Opening master dump table,Opening table,Opening tables,Processing request,Purging old relay logs,Queueing master event to the relay log,Reading event from the relay log,Reading from net,Reading master dump table data,Rebuilding the index on master dump table,Reconnecting after a failed binlog dump request,Reconnecting after a failed master event read,Registering slave on master,Removing duplicates,Reopen tables,Repair by sorting,Repair done,Repair with keycache,Requesting binlog dump,Rolling back,Saving state,Searching rows for update,Sending binlog event to slave,Sending data,Sorting for group,Sorting for order,Sorting index,Sorting result,System lock,Table lock,Thread initialized,Updating,User lock,Waiting for INSERT,Waiting for master to send event,Waiting for master update,Waiting for slave mutex on exit,Waiting for table,Waiting for tables,Waiting for the next event in relay log,Waiting on cond,Waiting to finalize termination,Waiting to reconnect after a failed binlog dump request,Waiting to reconnect after a failed master event read,Writing to net,allocating local table,cleaning up,closing tables,converting HEAP to MyISAM,copy to tmp table,creating table,deleting from main table,deleting from reference tables,discard_or_import_tablespace,end,freeing items,got handler lock,got old table,info,init,insert,logging slow query,login,preparing,purging old relay logs,query end,removing tmp table,rename,rename result table,reschedule,setup,starting slave,statistics,storing row into queue,unauthenticated user,update,updating,updating main table,updating reference tables,upgrading lock,waiting for delay_list,waiting for handler insert,waiting for handler lock,waiting for handler open,Waiting for event from ndbclusterThe most common
Statevalues are described in the rest of this section. Most of the otherStatevalues are useful only for finding bugs in the server. See also Section 6.3, “Replication Implementation Details”, for additional information about process states for replication servers.For the
SHOW PROCESSLISTstatement, the value ofStateisNULL.InfoThe statement that the thread is executing, or
NULLif it is not executing any statement.
Some State values commonly seen in the
output from SHOW PROCESSLIST:
Checking tableThe thread is performing a table check operation.
Closing tablesMeans that the thread is flushing the changed table data to disk and closing the used tables. This should be a fast operation. If not, you should verify that you do not have a full disk and that the disk is not in very heavy use.
Connect OutA replication slave is connecting to its master.
Copying to group tableIf a statement has different
ORDER BYandGROUP BYcriteria, the rows are sorted by group and copied to a temporary table.Copying to tmp tableThe server is copying to a temporary table in memory.
Copying to tmp table on diskThe server is copying to a temporary table on disk. The temporary result set was larger than
tmp_table_sizeand the thread is changing the temporary table from in-memory to disk-based format to save memory.Creating tmp tableThe thread is creating a temporary table to hold a part of the result for the query.
deleting from main tableThe server is executing the first part of a multiple-table delete. It is deleting only from the first table, and saving fields and offsets to be used for deleting from the other (reference) tables.
deleting from reference tablesThe server is executing the second part of a multiple-table delete and deleting the matched rows from the other tables.
Flushing tablesThe thread is executing
FLUSH TABLESand is waiting for all threads to close their tables.FULLTEXT initializationThe server is preparing to perform a natural-language full-text search.
KilledSomeone has sent a
KILLstatement to the thread and it should abort next time it checks the kill flag. The flag is checked in each major loop in MySQL, but in some cases it might still take a short time for the thread to die. If the thread is locked by some other thread, the kill takes effect as soon as the other thread releases its lock.LockedThe query is locked by another query.
Sending dataThe thread is processing rows for a
SELECTstatement and also is sending data to the client.Sorting for groupThe thread is doing a sort to satisfy a
GROUP BY.Sorting for orderThe thread is doing a sort to satisfy a
ORDER BY.Opening tablesThe thread is trying to open a table. This is should be very fast procedure, unless something prevents opening. For example, an
ALTER TABLEor aLOCK TABLEstatement can prevent opening a table until the statement is finished.Reading from netThe server is reading a packet from the network.
Removing duplicatesThe query was using
SELECT DISTINCTin such a way that MySQL could not optimize away the distinct operation at an early stage. Because of this, MySQL requires an extra stage to remove all duplicated rows before sending the result to the client.Reopen tableThe thread got a lock for the table, but noticed after getting the lock that the underlying table structure changed. It has freed the lock, closed the table, and is trying to reopen it.
Repair by sortingThe repair code is using a sort to create indexes.
Repair with keycacheThe repair code is using creating keys one by one through the key cache. This is much slower than
Repair by sorting.Searching rows for updateThe thread is doing a first phase to find all matching rows before updating them. This has to be done if the
UPDATEis changing the index that is used to find the involved rows.SleepingThe thread is waiting for the client to send a new statement to it.
statisticsThe server is calculating statistics to develop a query execution plan.
The thread is waiting to get an external system lock for the table. If you are not using multiple mysqld servers that are accessing the same tables, you can disable system locks with the
--skip-external-lockingoption.unauthenticated userThe state of a thread that has become associated with a client connection but for which authentication of the client user has not yet been done.
Upgrading lockThe
INSERT DELAYEDhandler is trying to get a lock for the table to insert rows.UpdatingThe thread is searching for rows to update and is updating them.
updating main tableThe server is executing the first part of a multiple-table update. It is updating only the first table, and saving fields and offsets to be used for updating the other (reference) tables.
updating reference tablesThe server is executing the second part of a multiple-table update and updating the matched rows from the other tables.
User LockThe thread is waiting on a
GET_LOCK().Waiting for event from ndbclusterThe server is acting as an SQL node in a MySQL Cluster, and is connected to a cluster management node.
Waiting for tablesThe thread got a notification that the underlying structure for a table has changed and it needs to reopen the table to get the new structure. However, to reopen the table, it must wait until all other threads have closed the table in question.
This notification takes place if another thread has used
FLUSH TABLESor one of the following statements on the table in question:FLUSH TABLES,tbl_nameALTER TABLE,RENAME TABLE,REPAIR TABLE,ANALYZE TABLE, orOPTIMIZE TABLE.waiting for handler insertThe
INSERT DELAYEDhandler has processed all pending inserts and is waiting for new ones.Writing to netThe server is writing a packet to the network.
Most states correspond to very quick operations. If a thread stays in any of these states for many seconds, there might be a problem that needs to be investigated.
This section does not apply to MySQL Enterprise Server users.
SHOW PROFILES SHOW PROFILE [type[,type] ... ] [FOR QUERYn] [LIMITn[OFFSETn]]type: ALL | BLOCK IO | CONTEXT SWITCHES | CPU | IPC | MEMORY | PAGE FAULTS | SOURCE | SWAPS
The SHOW PROFILES and SHOW
PROFILE statements display profiling information
that indicates resource usage for statements executed during
the course of the current session.
Profiling is controlled by the profiling
session variable, which has a default value of 0
(OFF). Profiling is enabled by setting
profiling to 1 or ON:
mysql> SET profiling = 1;
SHOW PROFILES displays a list of the most
recent statements sent to the master. The size of the list is
controlled by the profiling_history_size
session variable, which has a default value of 15. The maximum
value is 100. Setting the value to 0 has the practical effect
of disabling profiling.
All statements are profiled except SHOW
PROFILES and SHOW PROFILE, so you
will find neither of those statements in the profile list.
Malformed statements are profiled. For example, SHOW
PROFILING is an illegal statement, and a syntax
error occurs if you try to execute it, but it will show up in
the profiling list.
SHOW PROFILE displays detailed information
about a single statement. Without the FOR QUERY
clause, the output
pertains to the most recently executed statement. If
nFOR QUERY is
included, nSHOW PROFILE displays information
for statement n. The values of
n correspond to the
Query_ID values displayed by SHOW
PROFILES.
The LIMIT
clause may be given to limit the output to
nn rows. If LIMIT
is given, OFFSET
may be added to begin
the output nn rows into the full set
of rows.
By default, SHOW PROFILE displays
Status and Duration
columns. Optional type values may
be specified to display specific additional types of
information:
ALLdisplays all informationBLOCK IOdisplays counts for block input and output operationsCONTEXT SWITCHESdisplays counts for voluntary and involuntary context switchesCPUdisplays user and system CPU usage timesIPCdisplays counts for messages sent and receivedMEMORYis not currently implementedPAGE FAULTSdisplays counts for major and minor page faultsSOURCEdisplays the names of functions from the source code, together with the name and line number of the file in which the function occursSWAPSdisplays swap counts
Profiling is enabled per session. When a session ends, its profiling information is lost.
mysql>SELECT @@profiling;+-------------+ | @@profiling | +-------------+ | 0 | +-------------+ 1 row in set (0.00 sec) mysql>SET profiling = 1;Query OK, 0 rows affected (0.00 sec) mysql>DROP TABLE IF EXISTS t1;Query OK, 0 rows affected, 1 warning (0.00 sec) mysql>CREATE TABLE T1 (id INT);Query OK, 0 rows affected (0.01 sec) mysql>SHOW PROFILES;+----------+----------+--------------------------+ | Query_ID | Duration | Query | +----------+----------+--------------------------+ | 0 | 0.000088 | SET PROFILING = 1 | | 1 | 0.000136 | DROP TABLE IF EXISTS t1 | | 2 | 0.011947 | CREATE TABLE t1 (id INT) | +----------+----------+--------------------------+ 3 rows in set (0.00 sec) mysql>SHOW PROFILE;+----------------------+----------+ | Status | Duration | +----------------------+----------+ | checking permissions | 0.000040 | | creating table | 0.000056 | | After create | 0.011363 | | query end | 0.000375 | | freeing items | 0.000089 | | logging slow query | 0.000019 | | cleaning up | 0.000005 | +----------------------+----------+ 7 rows in set (0.00 sec) mysql>SHOW PROFILE FOR QUERY 1;+--------------------+----------+ | Status | Duration | +--------------------+----------+ | query end | 0.000107 | | freeing items | 0.000008 | | logging slow query | 0.000015 | | cleaning up | 0.000006 | +--------------------+----------+ 4 rows in set (0.00 sec) mysql>SHOW PROFILE CPU FOR QUERY 2;+----------------------+----------+----------+------------+ | Status | Duration | CPU_user | CPU_system | +----------------------+----------+----------+------------+ | checking permissions | 0.000040 | 0.000038 | 0.000002 | | creating table | 0.000056 | 0.000028 | 0.000028 | | After create | 0.011363 | 0.000217 | 0.001571 | | query end | 0.000375 | 0.000013 | 0.000028 | | freeing items | 0.000089 | 0.000010 | 0.000014 | | logging slow query | 0.000019 | 0.000009 | 0.000010 | | cleaning up | 0.000005 | 0.000003 | 0.000002 | +----------------------+----------+----------+------------+ 7 rows in set (0.00 sec)
Profiling is only partially functional on some architectures.
For values that depend on the getrusage()
system call, NULL is returned on systems
that do not support the call.
SHOW PROFILES and SHOW
PROFILE were added in MySQL 5.0.37.
You can also get profiling information from the
PROFILING table in
INFORMATION_SCHEMA. See
Section 20.17, “The INFORMATION_SCHEMA PROFILING Table”. For example, the following
queries produce the same result:
SHOW PROFILE FOR QUERY 2;
SELECT STATE, FORMAT(DURATION, 6) AS DURATION
FROM INFORMATION_SCHEMA.PROFILING
WHERE QUERY_ID = 2 ORDER BY SEQ;
SHOW [GLOBAL | SESSION] STATUS [LIKE 'pattern']
SHOW STATUS provides server status
information. This information also can be obtained using the
mysqladmin extended-status command.
Partial output is shown here. The list of names and values may be different for your server. The meaning of each variable is given in Section 5.2.5, “Status Variables”.
mysql> SHOW STATUS;
+--------------------------+------------+
| Variable_name | Value |
+--------------------------+------------+
| Aborted_clients | 0 |
| Aborted_connects | 0 |
| Bytes_received | 155372598 |
| Bytes_sent | 1176560426 |
| Connections | 30023 |
| Created_tmp_disk_tables | 0 |
| Created_tmp_tables | 8340 |
| Created_tmp_files | 60 |
...
| Open_tables | 1 |
| Open_files | 2 |
| Open_streams | 0 |
| Opened_tables | 44600 |
| Questions | 2026873 |
...
| Table_locks_immediate | 1920382 |
| Table_locks_waited | 0 |
| Threads_cached | 0 |
| Threads_created | 30022 |
| Threads_connected | 1 |
| Threads_running | 1 |
| Uptime | 80380 |
+--------------------------+------------+
With a LIKE clause, the statement displays
only rows for those variables with names that match the
pattern:
mysql> SHOW STATUS LIKE 'Key%';
+--------------------+----------+
| Variable_name | Value |
+--------------------+----------+
| Key_blocks_used | 14955 |
| Key_read_requests | 96854827 |
| Key_reads | 162040 |
| Key_write_requests | 7589728 |
| Key_writes | 3813196 |
+--------------------+----------+
The GLOBAL and SESSION
options are new in MySQL 5.0.2. With the
GLOBAL modifier, SHOW
STATUS displays the status values for all
connections to MySQL. With SESSION, it
displays the status values for the current connection. If no
modifier is present, the default is
SESSION. LOCAL is a
synonym for SESSION.
Some status variables have only a global value. For these, you
get the same value for both GLOBAL and
SESSION.
MySQL Enterprise Status variables provide valuable clues to the state of your servers. For expert interpretation of the information provided by status variables, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
Note: Before MySQL 5.0.2,
SHOW STATUS returned global status values.
Because the default as of 5.0.2 is to return session values,
this is incompatible with previous versions. To issue a
SHOW STATUS statement that will retrieve
global status values for all versions of MySQL, write it like
this:
SHOW /*!50002 GLOBAL */ STATUS;
SHOW TABLE STATUS [FROMdb_name] [LIKE 'pattern']
SHOW TABLE STATUS works likes SHOW
TABLES, but provides a lot of information about each
table. You can also get this list using the mysqlshow
--status db_name command.
As of MySQL 5.0.1, this statement also displays information about views.
SHOW TABLE STATUS returns the following
fields:
NameThe name of the table.
EngineThe storage engine for the table. See Chapter 14, Storage Engines.
VersionThe version number of the table's
.frmfile.Row_formatThe row storage format (
Fixed,Dynamic,Compressed,Redundant,Compact). Starting with MySQL/InnoDB 5.0.3, the format ofInnoDBtables is reported asRedundantorCompact. Prior to 5.0.3,InnoDBtables are always in theRedundantformat.RowsThe number of rows. Some storage engines, such as
MyISAM, store the exact count. For other storage engines, such asInnoDB, this value is an approximation, and may vary from the actual value by as much as 40 to 50%. In such cases, useSELECT COUNT(*)to obtain an accurate count.The
Rowsvalue isNULLfor tables in theINFORMATION_SCHEMAdatabase.Avg_row_lengthThe average row length.
Data_lengthThe length of the data file.
Max_data_lengthThe maximum length of the data file. This is the total number of bytes of data that can be stored in the table, given the data pointer size used.
Index_lengthThe length of the index file.
Data_freeThe number of allocated but unused bytes.
Auto_incrementThe next
AUTO_INCREMENTvalue.Create_timeWhen the table was created.
Update_timeWhen the data file was last updated. For some storage engines, this value is
NULL. For example,InnoDBstores multiple tables in its tablespace and the data file timestamp does not apply.Check_timeWhen the table was last checked. Not all storage engines update this time, in which case the value is always
NULL.CollationThe table's character set and collation.
ChecksumThe live checksum value (if any).
Create_optionsExtra options used with
CREATE TABLE.CommentThe comment used when creating the table (or information as to why MySQL could not access the table information).
In the table comment, InnoDB tables report
the free space of the tablespace to which the table belongs.
For a table located in the shared tablespace, this is the free
space of the shared tablespace. If you are using multiple
tablespaces and the table has its own tablespace, the free
space is for only that table.
For MEMORY tables, the
Data_length,
Max_data_length, and
Index_length values approximate the actual
amount of allocated memory. The allocation algorithm reserves
memory in large amounts to reduce the number of allocation
operations.
Beginning with MySQL 5.0.3, for NDB Cluster
tables, the output of this statement shows appropriate values
for the Avg_row_length and
Data_length columns, with the exception
that BLOB columns are not taken into
account. In addition, the number of replicas is now shown in
the Comment column (as
number_of_replicas).
For views, all the fields displayed by SHOW TABLE
STATUS are NULL except that
Name indicates the view name and
Comment says view.
SHOW [FULL] TABLES [FROMdb_name] [LIKE 'pattern']
SHOW TABLES lists the
non-TEMPORARY tables in a given database.
You can also get this list using the mysqlshow
db_name command.
Before MySQL 5.0.1, the output from SHOW
TABLES contains a single column of table names.
Beginning with MySQL 5.0.1, this statement also lists any
views in the database. As of MySQL 5.0.2, the
FULL modifier is supported such that
SHOW FULL TABLES displays a second output
column. Values for the second column are BASE
TABLE for a table and VIEW for a
view.
Note: If you have no
privileges for a table, the table does not show up in the
output from SHOW TABLES or
mysqlshow db_name.
SHOW TRIGGERS [FROMdb_name] [LIKEexpr]
SHOW TRIGGERS lists the triggers currently
defined on the MySQL server. This statement requires the
SUPER privilege. It was implemented in
MySQL 5.0.10.
For the trigger ins_sum as defined in
Section 18.3, “Using Triggers”, the output of this statement
is as shown here:
mysql> SHOW TRIGGERS LIKE 'acc%'\G
*************************** 1. row ***************************
Trigger: ins_sum
Event: INSERT
Table: account
Statement: SET @sum = @sum + NEW.amount
Timing: BEFORE
Created: NULL
sql_mode:
Definer: myname@localhost
Note: When using a
LIKE clause with SHOW
TRIGGERS, the expression to be matched
(expr) is compared with the name of
the table on which the trigger is declared, and not with the
name of the trigger:
mysql> SHOW TRIGGERS LIKE 'ins%';
Empty set (0.01 sec)
A brief explanation of the columns in the output of this statement is shown here:
TriggerThe name of the trigger.
EventThe event that causes trigger activation: one of
'INSERT','UPDATE', or'DELETE'.TableThe table for which the trigger is defined.
StatementThe statement to be executed when the trigger is activated. This is the same as the text shown in the
ACTION_STATEMENTcolumn ofINFORMATION_SCHEMA.TRIGGERS.TimingOne of the two values
'BEFORE'or'AFTER'.CreatedCurrently, the value of this column is always
NULL.sql_modeThe SQL mode in effect when the trigger executes. This column was added in MySQL 5.0.11.
DefinerThe account that created the trigger. This column was added in MySQL 5.0.17.
You must have the SUPER privilege to
execute SHOW TRIGGERS.
See also Section 20.16, “The INFORMATION_SCHEMA TRIGGERS Table”.
SHOW [GLOBAL | SESSION] VARIABLES [LIKE 'pattern']
SHOW VARIABLES shows the values of MySQL
system variables. This information also can be obtained using
the mysqladmin variables command.
With the GLOBAL modifier, SHOW
VARIABLES displays the values that are used for new
connections to MySQL. With SESSION, it
displays the values that are in effect for the current
connection. If no modifier is present, the default is
SESSION. LOCAL is a
synonym for SESSION.
If the default system variable values are unsuitable, you can
set them using command options when mysqld
starts, and most can be changed at runtime with the
SET statement. See
Section 5.2.4, “Using System Variables”, and
Section 13.5.3, “SET Syntax”.
Partial output is shown here. The list of names and values may be different for your server. Section 5.2.3, “System Variables”, describes the meaning of each variable, and Section 7.5.2, “Tuning Server Parameters”, provides information about tuning them.
mysql> SHOW VARIABLES;
+---------------------------------+-------------------------------------+
| Variable_name | Value |
+---------------------------------+-------------------------------------+
| auto_increment_increment | 1 |
| auto_increment_offset | 1 |
| automatic_sp_privileges | ON |
| back_log | 50 |
| basedir | / |
| bdb_cache_size | 8388600 |
| bdb_home | /var/lib/mysql/ |
| bdb_log_buffer_size | 32768 |
...
| max_connections | 100 |
| max_connect_errors | 10 |
| max_delayed_threads | 20 |
| max_error_count | 64 |
| max_heap_table_size | 16777216 |
| max_join_size | 4294967295 |
| max_relay_log_size | 0 |
| max_sort_length | 1024 |
...
| time_zone | SYSTEM |
| timed_mutexes | OFF |
| tmp_table_size | 33554432 |
| tmpdir | |
| transaction_alloc_block_size | 8192 |
| transaction_prealloc_size | 4096 |
| tx_isolation | REPEATABLE-READ |
| updatable_views_with_limit | YES |
| version | 5.0.19-Max |
| version_comment | MySQL Community Edition - Max (GPL) |
| version_compile_machine | i686 |
| version_compile_os | pc-linux-gnu |
| wait_timeout | 28800 |
+---------------------------------+-------------------------------------+
With a LIKE clause, the statement displays
only rows for those variables with names that match the
pattern. To obtain the row for a specific variable, use a
LIKE clause as shown:
SHOW VARIABLES LIKE 'max_join_size'; SHOW SESSION VARIABLES LIKE 'max_join_size';
To get a list of variables whose name match a pattern, use the
‘%’ wildcard character in a
LIKE clause:
SHOW VARIABLES LIKE '%size%'; SHOW GLOBAL VARIABLES LIKE '%size%';
Wildcard characters can be used in any position within the
pattern to be matched. Strictly speaking, because
‘_’ is a wildcard that matches
any single character, you should escape it as
‘\_’ to match it literally. In
practice, this is rarely necessary.
SHOW WARNINGS [LIMIT [offset,]row_count] SHOW COUNT(*) WARNINGS
SHOW WARNINGS shows the error, warning, and
note messages that resulted from the last statement that
generated messages, or nothing if the last statement that used
a table generated no messages. A related statement,
SHOW ERRORS, shows only the errors. See
Section 13.5.4.11, “SHOW ERRORS Syntax”.
The list of messages is reset for each new statement that uses a table.
The SHOW COUNT(*) WARNINGS statement
displays the total number of errors, warnings, and notes. You
can also retrieve this number from the
warning_count variable:
SHOW COUNT(*) WARNINGS; SELECT @@warning_count;
The value of warning_count might be greater
than the number of messages displayed by SHOW
WARNINGS if the max_error_count
system variable is set so low that not all messages are
stored. An example shown later in this section demonstrates
how this can happen.
The LIMIT clause has the same syntax as for
the SELECT statement. See
Section 13.2.7, “SELECT Syntax”.
The MySQL server sends back the total number of errors,
warnings, and notes resulting from the last statement. If you
are using the C API, this value can be obtained by calling
mysql_warning_count(). See
Section 22.2.3.72, “mysql_warning_count()”.
Warnings are generated for statements such as LOAD
DATA INFILE and DML statements such as
INSERT, UPDATE,
CREATE TABLE, and ALTER
TABLE.
The following DROP TABLE statement results
in a note:
mysql>DROP TABLE IF EXISTS no_such_table;mysql>SHOW WARNINGS;+-------+------+-------------------------------+ | Level | Code | Message | +-------+------+-------------------------------+ | Note | 1051 | Unknown table 'no_such_table' | +-------+------+-------------------------------+
Here is a simple example that shows a syntax warning for
CREATE TABLE and conversion warnings for
INSERT:
mysql>CREATE TABLE t1 (a TINYINT NOT NULL, b CHAR(4)) TYPE=MyISAM;Query OK, 0 rows affected, 1 warning (0.00 sec) mysql>SHOW WARNINGS\G*************************** 1. row *************************** Level: Warning Code: 1287 Message: 'TYPE=storage_engine' is deprecated, use 'ENGINE=storage_engine' instead 1 row in set (0.00 sec) mysql>INSERT INTO t1 VALUES(10,'mysql'),(NULL,'test'),->(300,'Open Source');Query OK, 3 rows affected, 4 warnings (0.01 sec) Records: 3 Duplicates: 0 Warnings: 4 mysql>SHOW WARNINGS\G*************************** 1. row *************************** Level: Warning Code: 1265 Message: Data truncated for column 'b' at row 1 *************************** 2. row *************************** Level: Warning Code: 1263 Message: Data truncated, NULL supplied to NOT NULL column 'a' at row 2 *************************** 3. row *************************** Level: Warning Code: 1264 Message: Data truncated, out of range for column 'a' at row 3 *************************** 4. row *************************** Level: Warning Code: 1265 Message: Data truncated for column 'b' at row 3 4 rows in set (0.00 sec)
The maximum number of error, warning, and note messages to
store is controlled by the max_error_count
system variable. By default, its value is 64. To change the
number of messages you want stored, change the value of
max_error_count. In the following example,
the ALTER TABLE statement produces three
warning messages, but only one is stored because
max_error_count has been set to 1:
mysql>SHOW VARIABLES LIKE 'max_error_count';+-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | max_error_count | 64 | +-----------------+-------+ 1 row in set (0.00 sec) mysql>SET max_error_count=1;Query OK, 0 rows affected (0.00 sec) mysql>ALTER TABLE t1 MODIFY b CHAR;Query OK, 3 rows affected, 3 warnings (0.00 sec) Records: 3 Duplicates: 0 Warnings: 3 mysql>SELECT @@warning_count;+-----------------+ | @@warning_count | +-----------------+ | 3 | +-----------------+ 1 row in set (0.01 sec) mysql>SHOW WARNINGS;+---------+------+----------------------------------------+ | Level | Code | Message | +---------+------+----------------------------------------+ | Warning | 1263 | Data truncated for column 'b' at row 1 | +---------+------+----------------------------------------+ 1 row in set (0.00 sec)
To disable warnings, set max_error_count to
0. In this case, warning_count still
indicates how many warnings have occurred, but none of the
messages are stored.
As of MySQL 5.0.3, you can set the
SQL_NOTES session variable to 0 to cause
Note-level warnings not to be recorded.
CACHE INDEXtbl_index_list[,tbl_index_list] ... INkey_cache_nametbl_index_list:tbl_name[[INDEX|KEY] (index_name[,index_name] ...)]
The CACHE INDEX statement assigns table
indexes to a specific key cache. It is used only for
MyISAM tables.
The following statement assigns indexes from the tables
t1, t2, and
t3 to the key cache named
hot_cache:
mysql> CACHE INDEX t1, t2, t3 IN hot_cache;
+---------+--------------------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+---------+--------------------+----------+----------+
| test.t1 | assign_to_keycache | status | OK |
| test.t2 | assign_to_keycache | status | OK |
| test.t3 | assign_to_keycache | status | OK |
+---------+--------------------+----------+----------+
The syntax of CACHE INDEX enables you to
specify that only particular indexes from a table should be
assigned to the cache. The current implementation assigns all
the table's indexes to the cache, so there is no reason to
specify anything other than the table name.
The key cache referred to in a CACHE INDEX
statement can be created by setting its size with a parameter
setting statement or in the server parameter settings. For
example:
mysql> SET GLOBAL keycache1.key_buffer_size=128*1024;
Key cache parameters can be accessed as members of a structured system variable. See Section 5.2.4.1, “Structured System Variables”.
A key cache must exist before you can assign indexes to it:
mysql> CACHE INDEX t1 IN non_existent_cache;
ERROR 1284 (HY000): Unknown key cache 'non_existent_cache'
By default, table indexes are assigned to the main (default) key cache created at the server startup. When a key cache is destroyed, all indexes assigned to it become assigned to the default key cache again.
Index assignment affects the server globally: If one client assigns an index to a given cache, this cache is used for all queries involving the index, no matter which client issues the queries.
FLUSH [LOCAL | NO_WRITE_TO_BINLOG]
flush_option [, flush_option] ...
The FLUSH statement clears or reloads
various internal caches used by MySQL. To execute
FLUSH, you must have the
RELOAD privilege.
The RESET statement is similar to
FLUSH. See Section 13.5.5.5, “RESET Syntax”.
flush_option can be any of the
following:
HOSTSEmpties the host cache tables. You should flush the host tables if some of your hosts change IP number or if you get the error message
Host '. When more thanhost_name' is blockedmax_connect_errorserrors occur successively for a given host while connecting to the MySQL server, MySQL assumes that something is wrong and blocks the host from further connection requests. Flushing the host tables allows the host to attempt to connect again. See Section B.1.2.5, “Host '”. You can start mysqld withhost_name' is blocked--max_connect_errors=999999999to avoid this error message.DES_KEY_FILEReloads the DES keys from the file that was specified with the
--des-key-fileoption at server startup time.LOGSCloses and reopens all log files. If binary logging is enabled, the sequence number of the binary log file is incremented by one relative to the previous file. On Unix, this is the same thing as sending a
SIGHUPsignal to the mysqld server (except on some Mac OS X 10.3 versions where mysqld ignoresSIGHUPandSIGQUIT).If the server was started with the
--log-erroroption,FLUSH LOGScauses it to rename the current error log file with a suffix of-oldand create a new empty log file. No renaming occurs if the--log-erroroption was not given.MASTER(DEPRECATED). Deletes all binary logs, resets the binary log index file and creates a new binary log.FLUSH MASTERis deprecated in favor ofRESET MASTER, and is supported for backwards compatibility only. See Section 13.6.1.2, “RESET MASTERSyntax”.PRIVILEGESReloads the privileges from the grant tables in the
mysqldatabase.QUERY CACHEDefragment the query cache to better utilize its memory.
FLUSH QUERY CACHEdoes not remove any queries from the cache, unlikeRESET QUERY CACHE.SLAVE(DEPRECATED). Resets all replication slave parameters, including relay log files and replication position in the master's binary logs.FLUSH SLAVEis deprecated in favour ofRESET SLAVE, and is supported for backwards compatibility only. See Section 13.6.2.5, “RESET SLAVESyntax”.STATUSThis option adds the current thread's session status variable values to the global values and resets the session values to zero. It also resets the counters for key caches (default and named) to zero and sets
Max_used_conectionsto the current number of open connections. This is something you should use only when debugging a query. See Section 1.8, “How to Report Bugs or Problems”.{TABLE | TABLES} [tbl_name[,tbl_name] ...]When no tables are named, closes all open tables and forces all tables in use to be closed. This also flushes the query cache. With one or more table names, flushes only the given tables.
FLUSH TABLESalso removes all query results from the query cache, like theRESET QUERY CACHEstatement.TABLES WITH READ LOCKCloses all open tables and locks all tables for all databases with a read lock until you explicitly release the lock by executing
UNLOCK TABLES. This is very convenient way to get backups if you have a filesystem such as Veritas that can take snapshots in time.FLUSH TABLES WITH READ LOCKacquires a global read lock and not table locks, so it is not subject to the same behavior asLOCK TABLESandUNLOCK TABLESwith respect to table locking and implicit commits:UNLOCK TABLEScommits a transaction only if any tables currently have been locked withLOCK TABLES. This does not occur forUNLOCK TABLESfollowingFLUSH TABLES WITH READ LOCKbecause the latter statement does not acquire table-level locks.Beginning a transaction causes table locks acquired with
LOCK TABLESto be released, as though you had executedUNLOCK TABLES. Beginning a transaction does not release a global read lock acquired withFLUSH TABLES WITH READ LOCK.
USER_RESOURCESResets all per-hour user resources to zero. This enables clients that have reached their hourly connection, query, or update limits to resume activity immediately.
FLUSH USER_RESOURCESdoes not apply to the limit on maximum simultaneous connections. See Section 13.5.1.3, “GRANTSyntax”.
By default, FLUSH statements are written to
the binary log so that such statements used on a MySQL server
acting as a replication master will be replicated to
replication slaves. Logging can be suppressed with the
optional NO_WRITE_TO_BINLOG keyword or its
alias LOCAL.
Note: FLUSH
LOGS, FLUSH MASTER,
FLUSH SLAVE, and FLUSH TABLES WITH
READ LOCK are not logged in any case because they
would cause problems if replicated to a slave.
You can also access some of these statements with the
mysqladmin utility, using the
flush-hosts, flush-logs,
flush-privileges,
flush-status, or
flush-tables commands.
Using FLUSH statements within stored
functions or triggers is not supported in MySQL
5.0. However, you may use
FLUSH in stored procedures, so long as
these are not called from stored functions or triggers. See
Section F.1, “Restrictions on Stored Routines and Triggers”.
See also Section 13.5.5.5, “RESET Syntax”, for information about how
the RESET statement is used with
replication.
KILL [CONNECTION | QUERY] thread_id
Each connection to mysqld runs in a
separate thread. You can see which threads are running with
the SHOW PROCESSLIST statement and kill a
thread with the KILL
statement.
thread_id
In MySQL 5.0.0, KILL allows the optional
CONNECTION or QUERY
modifier:
KILL CONNECTIONis the same asKILLwith no modifier: It terminates the connection associated with the giventhread_id.KILL QUERYterminates the statement that the connection is currently executing, but leaves the connection itself intact.
If you have the PROCESS privilege, you can
see all threads. If you have the SUPER
privilege, you can kill all threads and statements. Otherwise,
you can see and kill only your own threads and statements.
You can also use the mysqladmin processlist and mysqladmin kill commands to examine and kill threads.
Note: You cannot use
KILL with the Embedded MySQL Server
library, because the embedded server merely runs inside the
threads of the host application. It does not create any
connection threads of its own.
When you use KILL, a thread-specific kill
flag is set for the thread. In most cases, it might take some
time for the thread to die, because the kill flag is checked
only at specific intervals:
In
SELECT,ORDER BYandGROUP BYloops, the flag is checked after reading a block of rows. If the kill flag is set, the statement is aborted.During
ALTER TABLE, the kill flag is checked before each block of rows are read from the original table. If the kill flag was set, the statement is aborted and the temporary table is deleted.During
UPDATEorDELETEoperations, the kill flag is checked after each block read and after each updated or deleted row. If the kill flag is set, the statement is aborted. Note that if you are not using transactions, the changes are not rolled back.GET_LOCK()aborts and returnsNULL.An
INSERT DELAYEDthread quickly flushes (inserts) all rows it has in memory and then terminates.If the thread is in the table lock handler (state:
Locked), the table lock is quickly aborted.If the thread is waiting for free disk space in a write call, the write is aborted with a “disk full” error message.
Warning: Killing a
REPAIR TABLEorOPTIMIZE TABLEoperation on aMyISAMtable results in a table that is corrupted and unusable. Any reads or writes to such a table fail until you optimize or repair it again (without interruption).
LOAD INDEX INTO CACHEtbl_index_list[,tbl_index_list] ...tbl_index_list:tbl_name[[INDEX|KEY] (index_name[,index_name] ...)] [IGNORE LEAVES]
The LOAD INDEX INTO CACHE statement
preloads a table index into the key cache to which it has been
assigned by an explicit CACHE INDEX
statement, or into the default key cache otherwise.
LOAD INDEX INTO CACHE is used only for
MyISAM tables.
The IGNORE LEAVES modifier causes only
blocks for the non-leaf nodes of the index to be preloaded.
The following statement preloads nodes (index blocks) of
indexes for the tables t1 and
t2:
mysql> LOAD INDEX INTO CACHE t1, t2 IGNORE LEAVES;
+---------+--------------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+---------+--------------+----------+----------+
| test.t1 | preload_keys | status | OK |
| test.t2 | preload_keys | status | OK |
+---------+--------------+----------+----------+
This statement preloads all index blocks from
t1. It preloads only blocks for the
non-leaf nodes from t2.
The syntax of LOAD INDEX INTO CACHE enables
you to specify that only particular indexes from a table
should be preloaded. The current implementation preloads all
the table's indexes into the cache, so there is no reason to
specify anything other than the table name.
LOAD INDEX INTO CACHE fails unless all
indexes in a table have the same block size. You can determine
index block sizes for a table by using myisamchk
-dv and checking the Blocksize
column.
RESETreset_option[,reset_option] ...
The RESET statement is used to clear the
state of various server operations. You must have the
RELOAD privilege to execute
RESET.
RESET acts as a stronger version of the
FLUSH statement. See
Section 13.5.5.2, “FLUSH Syntax”.
reset_option can be any of the
following:
MASTERDeletes all binary logs listed in the index file, resets the binary log index file to be empty, and creates a new binary log file. (Known as
FLUSH MASTERin versions of MySQL before 3.23.26.) See Section 13.6.1, “SQL Statements for Controlling Master Servers”.QUERY CACHERemoves all query results from the query cache.
SLAVEMakes the slave forget its replication position in the master binary logs. Also resets the relay log by deleting any existing relay log files and beginning a new one. (Known as
FLUSH SLAVEin versions of MySQL before 3.23.26.) See Section 13.6.2, “SQL Statements for Controlling Slave Servers”.
This section describes SQL statements related to replication. One group of statements is used for controlling master servers. The other is used for controlling slave servers.
Replication can be controlled through the SQL interface. This section discusses statements for managing master replication servers. Section 13.6.2, “SQL Statements for Controlling Slave Servers”, discusses statements for managing slave servers.
PURGE {MASTER | BINARY} LOGS TO 'log_name'
PURGE {MASTER | BINARY} LOGS BEFORE 'date'
Deletes all the binary logs listed in the log index prior to the specified log or date. The logs also are removed from the list recorded in the log index file, so that the given log becomes the first.
Example:
PURGE MASTER LOGS TO 'mysql-bin.010'; PURGE MASTER LOGS BEFORE '2003-04-02 22:46:26';
The BEFORE variant's
date argument can be in
'YYYY-MM-DD hh:mm:ss' format.
MASTER and BINARY are
synonyms.
This statement is safe to run while slaves are replicating. You do not need to stop them. If you have an active slave that currently is reading one of the logs you are trying to delete, this statement does nothing and fails with an error. However, if a slave is dormant and you happen to purge one of the logs it has yet to read, the slave will be unable to replicate after it comes up.
To safely purge logs, follow this procedure:
On each slave server, use
SHOW SLAVE STATUSto check which log it is reading.Obtain a listing of the binary logs on the master server with
SHOW BINARY LOGS.Determine the earliest log among all the slaves. This is the target log. If all the slaves are up to date, this is the last log on the list.
Make a backup of all the logs you are about to delete. (This step is optional, but always advisable.)
Purge all logs up to but not including the target log.
You can also set the expire_logs_days
system variable to expire binary log files automatically after
a given number of days (see
Section 5.2.3, “System Variables”). If you are using
replication, you should set the variable no lower than the
maximum number of days your slaves might lag behind the
master.
RESET MASTER
Deletes all binary logs listed in the index file, resets the binary log index file to be empty, and creates a new binary log file.
SET SQL_LOG_BIN = {0|1}
Disables or enables binary logging for the current connection
(SQL_LOG_BIN is a session variable) if the
client has the SUPER privilege. The
statement is refused with an error if the client does not have
that privilege.
SHOW BINLOG EVENTS [IN 'log_name'] [FROMpos] [LIMIT [offset,]row_count]
Shows the events in the binary log. If you do not specify
', the
first binary log is displayed.
log_name'
The LIMIT clause has the same syntax as for
the SELECT statement. See
Section 13.2.7, “SELECT Syntax”.
Note: Issuing a SHOW
BINLOG EVENTS with no LIMIT
clause could start a very time- and resource-consuming process
because the server returns to the client the complete contents
of the binary log (which includes all statements executed by
the server that modify data). As an alternative to
SHOW BINLOG EVENTS, use the
mysqlbinlog utility to save the binary log
to a text file for later examination and analysis. See
Section 8.11, “mysqlbinlog — Utility for Processing Binary Log Files”.
SHOW BINARY LOGS SHOW MASTER LOGS
Lists the binary log files on the server. This statement is
used as part of the procedure described in
Section 13.6.1.1, “PURGE MASTER LOGS Syntax”, that shows how to
determine which logs can be purged.
mysql> SHOW BINARY LOGS;
+---------------+-----------+
| Log_name | File_size |
+---------------+-----------+
| binlog.000015 | 724935 |
| binlog.000016 | 733481 |
+---------------+-----------+
SHOW MASTER LOGS is equivalent to
SHOW BINARY LOGS. The
File_size column is displayed as of MySQL
5.0.7.
SHOW MASTER STATUS
Provides status information about the binary log files of the master. Example:
mysql > SHOW MASTER STATUS;
+---------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+---------------+----------+--------------+------------------+
| mysql-bin.003 | 73 | test | manual,mysql |
+---------------+----------+--------------+------------------+
SHOW SLAVE HOSTS
Displays a list of replication slaves currently registered
with the master. Only slaves started with the
--report-host=
option are visible in this list.
slave_name
The list is displayed on any server (not just the master server). The output looks like this:
mysql> SHOW SLAVE HOSTS;
+------------+-----------+------+-----------+
| Server_id | Host | Port | Master_id |
+------------+-----------+------+-----------+
| 192168010 | iconnect2 | 3306 | 192168011 |
| 1921680101 | athena | 3306 | 192168011 |
+------------+-----------+------+-----------+
Server_id: The unique server ID of the slave server, as configured in the server's option file, or on the command line with--server-id=.valueHost: The host name of the slave server, as configured in the server's option file, or on the command line with--report-host=. Note that this can differ from the machine name as configured in the operating system.valuePort: The port the slave server is listening on.Master_id: The unique server ID of the master server that the slave server is replicating from.
Some MySQL versions report another variable,
Rpl_recovery_rank. This variable was never
used, and was eventually removed.
- 13.6.2.1.
CHANGE MASTER TOSyntax - 13.6.2.2.
LOAD DATA FROM MASTERSyntax - 13.6.2.3.
LOAD TABLESyntaxtbl_nameFROM MASTER - 13.6.2.4.
MASTER_POS_WAIT()Syntax - 13.6.2.5.
RESET SLAVESyntax - 13.6.2.6.
SET GLOBAL SQL_SLAVE_SKIP_COUNTERSyntax - 13.6.2.7.
SHOW SLAVE STATUSSyntax - 13.6.2.8.
START SLAVESyntax - 13.6.2.9.
STOP SLAVESyntax
Replication can be controlled through the SQL interface. This section discusses statements for managing slave replication servers. Section 13.6.1, “SQL Statements for Controlling Master Servers”, discusses statements for managing master servers.
CHANGE MASTER TOmaster_def[,master_def] ...master_def: MASTER_HOST = 'host_name' | MASTER_USER = 'user_name' | MASTER_PASSWORD = 'password' | MASTER_PORT =port_num| MASTER_CONNECT_RETRY =count| MASTER_LOG_FILE = 'master_log_name' | MASTER_LOG_POS =master_log_pos| RELAY_LOG_FILE = 'relay_log_name' | RELAY_LOG_POS =relay_log_pos| MASTER_SSL = {0|1} | MASTER_SSL_CA = 'ca_file_name' | MASTER_SSL_CAPATH = 'ca_directory_name' | MASTER_SSL_CERT = 'cert_file_name' | MASTER_SSL_KEY = 'key_file_name' | MASTER_SSL_CIPHER = 'cipher_list'
CHANGE MASTER TO changes the parameters
that the slave server uses for connecting to and communicating
with the master server. It also updates the contents of the
master.info and
relay-log.info files.
MASTER_USER,
MASTER_PASSWORD,
MASTER_SSL,
MASTER_SSL_CA,
MASTER_SSL_CAPATH,
MASTER_SSL_CERT,
MASTER_SSL_KEY, and
MASTER_SSL_CIPHER provide information to
the slave about how to connect to its master.
The SSL options (MASTER_SSL,
MASTER_SSL_CA,
MASTER_SSL_CAPATH,
MASTER_SSL_CERT,
MASTER_SSL_KEY, and
MASTER_SSL_CIPHER) can be changed even on
slaves that are compiled without SSL support. They are saved
to the master.info file, but are ignored
unless you use a server that has SSL support enabled.
If you don't specify a given parameter, it keeps its old value, except as indicated in the following discussion. For example, if the password to connect to your MySQL master has changed, you just need to issue these statements to tell the slave about the new password:
STOP SLAVE; -- if replication was running CHANGE MASTER TO MASTER_PASSWORD='new3cret'; START SLAVE; -- if you want to restart replication
There is no need to specify the parameters that do not change (host, port, user, and so forth).
MASTER_HOST and
MASTER_PORT are the hostname (or IP
address) of the master host and its TCP/IP port. Note that if
MASTER_HOST is equal to
localhost, then, like in other parts of
MySQL, the port number might be ignored (if Unix socket files
can be used, for example).
If you specify MASTER_HOST or
MASTER_PORT, the slave assumes that the
master server is different from before (even if you specify a
host or port value that is the same as the current value.) In
this case, the old values for the master binary log name and
position are considered no longer applicable, so if you do not
specify MASTER_LOG_FILE and
MASTER_LOG_POS in the statement,
MASTER_LOG_FILE='' and
MASTER_LOG_POS=4 are silently appended to
it.
MASTER_LOG_FILE and
MASTER_LOG_POS are the coordinates at which
the slave I/O thread should begin reading from the master the
next time the thread starts. If you specify either of them,
you cannot specify RELAY_LOG_FILE or
RELAY_LOG_POS. If neither of
MASTER_LOG_FILE or
MASTER_LOG_POS are specified, the slave
uses the last coordinates of the slave SQL
thread before CHANGE MASTER was
issued. This ensures that there is no discontinuity in
replication, even if the slave SQL thread was late compared to
the slave I/O thread, when you merely want to change, say, the
password to use.
CHANGE MASTER deletes all relay
log files and starts a new one, unless you specify
RELAY_LOG_FILE or
RELAY_LOG_POS. In that case, relay logs are
kept; the relay_log_purge global variable
is set silently to 0.
CHANGE MASTER is useful for setting up a
slave when you have the snapshot of the master and have
recorded the log and the offset corresponding to it. After
loading the snapshot into the slave, you can run
CHANGE MASTER TO
MASTER_LOG_FILE='
on the slave.
log_name_on_master',
MASTER_LOG_POS=log_offset_on_master
The following example changes the master and master's binary log coordinates. This is used when you want to set up the slave to replicate the master:
CHANGE MASTER TO MASTER_HOST='master2.mycompany.com', MASTER_USER='replication', MASTER_PASSWORD='bigs3cret', MASTER_PORT=3306, MASTER_LOG_FILE='master2-bin.001', MASTER_LOG_POS=4, MASTER_CONNECT_RETRY=10;
The next example shows an operation that is less frequently
employed. It is used when the slave has relay logs that you
want it to execute again for some reason. To do this, the
master need not be reachable. You need only use
CHANGE MASTER TO and start the SQL thread
(START SLAVE SQL_THREAD):
CHANGE MASTER TO RELAY_LOG_FILE='slave-relay-bin.006', RELAY_LOG_POS=4025;
You can even use the second operation in a non-replication
setup with a standalone, non-slave server for recovery
following a crash. Suppose that your server has crashed and
you have restored a backup. You want to replay the server's
own binary logs (not relay logs, but regular binary logs),
named (for example) myhost-bin.*. First,
make a backup copy of these binary logs in some safe place, in
case you don't exactly follow the procedure below and
accidentally have the server purge the binary logs. Use
SET GLOBAL relay_log_purge=0 for additional
safety. Then start the server without the
--log-bin option, Instead, use the
--replicate-same-server-id,
--relay-log=myhost-bin (to make the server
believe that these regular binary logs are relay logs) and
--skip-slave-start options. After the server
starts, issue these statements:
CHANGE MASTER TO RELAY_LOG_FILE='myhost-bin.153', RELAY_LOG_POS=410, MASTER_HOST='some_dummy_string'; START SLAVE SQL_THREAD;
The server reads and executes its own binary logs, thus
achieving crash recovery. Once the recovery is finished, run
STOP SLAVE, shut down the server, delete
the master.info and
relay-log.info files, and restart the
server with its original options.
Specifying the MASTER_HOST option (even
with a dummy value) is required to make the server think it is
a slave.
LOAD DATA FROM MASTER
This feature is deprecated. We recommend not using it anymore. It is subject to removal in a future version of MySQL.
Since the current implementation of LOAD DATA FROM
MASTER and LOAD TABLE FROM MASTER
is very limited, these statements are deprecated in versions
4.1 of MySQL and above. We will introduce a more advanced
technique (called “online backup”) in a future
version. That technique will have the additional advantage of
working with more storage engines.
For MySQL 5.1 and earlier, the recommended alternative
solution to using LOAD DATA FROM MASTER or
LOAD TABLE FROM MASTER is using
mysqldump or
mysqlhotcopy. The latter requires Perl and
two Perl modules (DBI and
DBD:mysql) and works for
MyISAM and ARCHIVE
tables only. With mysqldump, you can create
SQL dumps on the master and pipe (or copy) these to a
mysql client on the slave. This has the
advantage of working for all storage engines, but can be quite
slow, since it works using SELECT.
This statement takes a snapshot of the master and copies it to
the slave. It updates the values of
MASTER_LOG_FILE and
MASTER_LOG_POS so that the slave starts
replicating from the correct position. Any table and database
exclusion rules specified with the
--replicate-*-do-* and
--replicate-*-ignore-* options are honored.
--replicate-rewrite-db is
not taken into account because a user
could use this option to set up a non-unique mapping such as
--replicate-rewrite-db="db1->db3" and
--replicate-rewrite-db="db2->db3", which
would confuse the slave when loading tables from the master.
Use of this statement is subject to the following conditions:
It works only for
MyISAMtables. Attempting to load a non-MyISAMtable results in the following error:ERROR 1189 (08S01): Net error reading from master
It acquires a global read lock on the master while taking the snapshot, which prevents updates on the master during the load operation.
If you are loading large tables, you might have to increase
the values of net_read_timeout and
net_write_timeout on both the master and
slave servers. See Section 5.2.3, “System Variables”.
Note that LOAD DATA FROM MASTER does
not copy any tables from the
mysql database. This makes it easy to have
different users and privileges on the master and the slave.
To use LOAD DATA FROM MASTER, the
replication account that is used to connect to the master must
have the RELOAD and
SUPER privileges on the master and the
SELECT privilege for all master tables you
want to load. All master tables for which the user does not
have the SELECT privilege are ignored by
LOAD DATA FROM MASTER. This is because the
master hides them from the user: LOAD DATA FROM
MASTER calls SHOW DATABASES to
know the master databases to load, but SHOW
DATABASES returns only databases for which the user
has some privilege. See Section 13.5.4.8, “SHOW DATABASES Syntax”. On
the slave side, the user that issues LOAD DATA FROM
MASTER must have privileges for dropping and
creating the databases and tables that are copied.
LOAD TABLE tbl_name FROM MASTER
This feature is deprecated. We recommend not using it anymore. It is subject to removal in a future version of MySQL.
Since the current implementation of LOAD DATA FROM
MASTER and LOAD TABLE FROM MASTER
is very limited, these statements are deprecated in versions
4.1 of MySQL and above. We will introduce a more advanced
technique (called “online backup”) in a future
version. That technique will have the additional advantage of
working with more storage engines.
For MySQL 5.1 and earlier, the recommended alternative
solution to using LOAD DATA FROM MASTER or
LOAD TABLE FROM MASTER is using
mysqldump or
mysqlhotcopy. The latter requires Perl and
two Perl modules (DBI and
DBD:mysql) and works for
MyISAM and ARCHIVE
tables only. With mysqldump, you can create
SQL dumps on the master and pipe (or copy) these to a
mysql client on the slave. This has the
advantage of working for all storage engines, but can be quite
slow, since it works using SELECT.
Transfers a copy of the table from the master to the slave.
This statement is implemented mainly debugging LOAD
DATA FROM MASTER operations. To use LOAD
TABLE, the account used for connecting to the master
server must have the RELOAD and
SUPER privileges on the master and the
SELECT privilege for the master table to
load. On the slave side, the user that issues LOAD
TABLE FROM MASTER must have privileges for dropping
and creating the table.
The conditions for LOAD DATA FROM MASTER
apply here as well. For example, LOAD TABLE FROM
MASTER works only for MyISAM
tables. The timeout notes for LOAD DATA FROM
MASTER apply as well.
SELECT MASTER_POS_WAIT('master_log_file', master_log_pos)
This is actually a function, not a statement. It is used to ensure that the slave has read and executed events up to a given position in the master's binary log. See Section 12.10.4, “Miscellaneous Functions”, for a full description.
RESET SLAVE
RESET SLAVE makes the slave forget its
replication position in the master's binary logs. This
statement is meant to be used for a clean start: It deletes
the master.info and
relay-log.info files, all the relay logs,
and starts a new relay log.
Note: All relay logs are
deleted, even if they have not been completely executed by the
slave SQL thread. (This is a condition likely to exist on a
replication slave if you have issued a STOP
SLAVE statement or if the slave is highly loaded.)
Connection information stored in the
master.info file is immediately reset
using any values specified in the corresponding startup
options. This information includes values such as master host,
master port, master user, and master password. If the slave
SQL thread was in the middle of replicating temporary tables
when it was stopped, and RESET SLAVE is
issued, these replicated temporary tables are deleted on the
slave.
SET GLOBAL SQL_SLAVE_SKIP_COUNTER = N
This statement skips the next N
events from the master. This is useful for recovering from
replication stops caused by a statement.
This statement is valid only when the slave thread is not running. Otherwise, it produces an error.
SHOW SLAVE STATUS
This statement provides status information on essential
parameters of the slave threads. If you issue this statement
using the mysql client, you can use a
\G statement terminator rather than a
semicolon to obtain a more readable vertical layout:
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: localhost
Master_User: root
Master_Port: 3306
Connect_Retry: 3
Master_Log_File: gbichot-bin.005
Read_Master_Log_Pos: 79
Relay_Log_File: gbichot-relay-bin.005
Relay_Log_Pos: 548
Relay_Master_Log_File: gbichot-bin.005
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 79
Relay_Log_Space: 552
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 8
SHOW SLAVE STATUS returns the following
fields:
Slave_IO_StateA copy of the
Statefield of the output ofSHOW PROCESSLISTfor the slave I/O thread. This tells you what the thread is doing: trying to connect to the master, waiting for events from the master, reconnecting to the master, and so on. Possible states are listed in Section 6.3, “Replication Implementation Details”. It is necessary to check this field for older versions of MySQL (prior to 5.0.12) because in these versions the thread could be running while unsuccessfully trying to connect to the master; only this field makes you aware of the connection problem. The state of the SQL thread is not copied because it is simpler. If it is running, there is no problem; if it is not, you can find the error in theLast_Errorfield (described below).Master_HostThe current master host.
Master_UserThe current user used to connect to the master.
Master_PortThe current master port.
Connect_RetryThe current value of the
--master-connect-retryoption.Master_Log_FileThe name of the master binary log file from which the I/O thread is currently reading.
Read_Master_Log_PosThe position up to which the I/O thread has read in the current master binary log.
Relay_Log_FileThe name of the relay log file from which the SQL thread is currently reading and executing.
Relay_Log_PosThe position up to which the SQL thread has read and executed in the current relay log.
Relay_Master_Log_FileThe name of the master binary log file containing the most recent event executed by the SQL thread.
Slave_IO_RunningWhether the I/O thread is started and has connected successfully to the master. For older versions of MySQL (prior to 4.1.14 and 5.0.12)
Slave_IO_RunningisYESif the I/O thread is started, even if the slave hasn't connected to the master yet.Slave_SQL_RunningWhether the SQL thread is started.
Replicate_Do_DB,Replicate_Ignore_DBThe lists of databases that were specified with the
--replicate-do-dband--replicate-ignore-dboptions, if any.Replicate_Do_Table,Replicate_Ignore_Table,Replicate_Wild_Do_Table,Replicate_Wild_Ignore_TableThe lists of tables that were specified with the
--replicate-do-table,--replicate-ignore-table,--replicate-wild-do-table, and--replicate-wild-ignore_tableoptions, if any.Last_Errno,Last_ErrorThe error number and error message returned by the most recently executed query. An error number of 0 and message of the empty string mean “no error.” If the
Last_Errorvalue is not empty, it also appears as a message in the slave's error log. For example:Last_Errno: 1051 Last_Error: error 'Unknown table 'z'' on query 'drop table z'
The message indicates that the table
zexisted on the master and was dropped there, but it did not exist on the slave, soDROP TABLEfailed on the slave. (This might occur, for example, if you forget to copy the table to the slave when setting up replication.)Skip_CounterThe most recently used value for
SQL_SLAVE_SKIP_COUNTER.Exec_Master_Log_PosThe position of the last event executed by the SQL thread from the master's binary log (
Relay_Master_Log_File). (Relay_Master_Log_File,Exec_Master_Log_Pos) in the master's binary log corresponds to (Relay_Log_File,Relay_Log_Pos) in the relay log.Relay_Log_SpaceThe total combined size of all existing relay logs.
Until_Condition,Until_Log_File,Until_Log_PosThe values specified in the
UNTILclause of theSTART SLAVEstatement.Until_Conditionhas these values:Noneif noUNTILclause was specifiedMasterif the slave is reading until a given position in the master's binary logsRelayif the slave is reading until a given position in its relay logs
Until_Log_FileandUntil_Log_Posindicate the log filename and position values that define the point at which the SQL thread stops executing.Master_SSL_Allowed,Master_SSL_CA_File,Master_SSL_CA_Path,Master_SSL_Cert,Master_SSL_Cipher,Master_SSL_KeyThese fields show the SSL parameters used by the slave to connect to the master, if any.
Master_SSL_Allowedhas these values:Yesif an SSL connection to the master is permittedNoif an SSL connection to the master is not permittedIgnoredif an SSL connection is permitted but the slave server does not have SSL support enabled
The values of the other SSL-related fields correspond to the values of the
MASTER_SSL_CA,MASTER_SSL_CAPATH,MASTER_SSL_CERT,MASTER_SSL_CIPHER, andMASTER_SSL_KEYoptions to theCHANGE MASTERstatement. See Section 13.6.2.1, “CHANGE MASTER TOSyntax”.Seconds_Behind_MasterThis field is an indication of how “late” the slave is:
When the slave SQL thread is actively running (processing updates), this field is the number of seconds that have elapsed since the timestamp of the most recent event on the master executed by that thread.
When the SQL thread has caught up to the slave I/O thread and goes idle waiting for more events from the I/O thread, this field is zero.
In essence, this field measures the time difference in seconds between the slave SQL thread and the slave I/O thread.
If the network connection between master and slave is fast, the slave I/O thread is very close to the master, so this field is a good approximation of how late the slave SQL thread is compared to the master. If the network is slow, this is not a good approximation; the slave SQL thread may quite often be caught up with the slow-reading slave I/O thread, so
Seconds_Behind_Masteroften shows a value of 0, even if the I/O thread is late compared to the master. In other words, this column is useful only for fast networks.This time difference computation works even though the master and slave do not have identical clocks (the clock difference is computed when the slave I/O thread starts, and assumed to remain constant from then on).
Seconds_Behind_MasterisNULL(which means “unknown”) if the slave SQL thread is not running, or if the slave I/O thread is not running or not connected to master. For example if the slave I/O thread is sleeping for the number of seconds given by the--master-connect-retryoption before reconnecting,NULLis shown, as the slave cannot know what the master is doing, and so cannot say reliably how late it is.This field has one limitation. The timestamp is preserved through replication, which means that, if a master M1 is itself a slave of M0, any event from M1's binlog which originates in replicating an event from M0's binlog has the timestamp of that event. This enables MySQL to replicate
TIMESTAMPsuccessfully. However, the drawback forSeconds_Behind_Masteris that if M1 also receives direct updates from clients, the value randomly deviates, because sometimes the last M1's event is from M0 and sometimes it is the most recent timestamp from a direct update.
START SLAVE [thread_type[,thread_type] ... ] START SLAVE [SQL_THREAD] UNTIL MASTER_LOG_FILE = 'log_name', MASTER_LOG_POS =log_posSTART SLAVE [SQL_THREAD] UNTIL RELAY_LOG_FILE = 'log_name', RELAY_LOG_POS =log_posthread_type: IO_THREAD | SQL_THREAD
START SLAVE with no
thread_type options starts both of
the slave threads. The I/O thread reads queries from the
master server and stores them in the relay log. The SQL thread
reads the relay log and executes the queries. START
SLAVE requires the SUPER
privilege.
If START SLAVE succeeds in starting the
slave threads, it returns without any error. However, even in
that case, it might be that the slave threads start and then
later stop (for example, because they do not manage to connect
to the master or read its binary logs, or some other problem).
START SLAVE does not warn you about this.
You must check the slave's error log for error messages
generated by the slave threads, or check that they are running
satisfactorily with SHOW SLAVE STATUS.
You can add IO_THREAD and
SQL_THREAD options to the statement to name
which of the threads to start.
An UNTIL clause may be added to specify
that the slave should start and run until the SQL thread
reaches a given point in the master binary logs or in the
slave relay logs. When the SQL thread reaches that point, it
stops. If the SQL_THREAD option is
specified in the statement, it starts only the SQL thread.
Otherwise, it starts both slave threads. If the SQL thread is
running, the UNTIL clause is ignored and a
warning is issued.
For an UNTIL clause, you must specify both
a log filename and position. Do not mix master and relay log
options.
Any UNTIL condition is reset by a
subsequent STOP SLAVE statement, a
START SLAVE statement that includes no
UNTIL clause, or a server restart.
The UNTIL clause can be useful for
debugging replication, or to cause replication to proceed
until just before the point where you want to avoid having the
slave replicate a statement. For example, if an unwise
DROP TABLE statement was executed on the
master, you can use UNTIL to tell the slave
to execute up to that point but no farther. To find what the
event is, use mysqlbinlog with the master
logs or slave relay logs, or by using a SHOW BINLOG
EVENTS statement.
If you are using UNTIL to have the slave
process replicated queries in sections, it is recommended that
you start the slave with the
--skip-slave-start option to prevent the SQL
thread from running when the slave server starts. It is
probably best to use this option in an option file rather than
on the command line, so that an unexpected server restart does
not cause it to be forgotten.
The SHOW SLAVE STATUS statement includes
output fields that display the current values of the
UNTIL condition.
In old versions of MySQL (before 4.0.5), this statement was
called SLAVE START. This usage is still
accepted in MySQL 5.0 for backward compatibility,
but is deprecated.
STOP SLAVE [thread_type[,thread_type] ... ]thread_type: IO_THREAD | SQL_THREAD
Stops the slave threads. STOP SLAVE
requires the SUPER privilege.
Like START SLAVE, this statement may be
used with the IO_THREAD and
SQL_THREAD options to name the thread or
threads to be stopped.
In old versions of MySQL (before 4.0.5), this statement was
called SLAVE STOP. This usage is still
accepted in MySQL 5.0 for backward compatibility,
but is deprecated.
MySQL 5.0 provides support for server-side prepared
statements. This support takes advantage of the efficient
client/server binary protocol implemented in MySQL 4.1, provided
that you use an appropriate client programming interface.
Candidate interfaces include the MySQL C API client library (for C
programs), MySQL Connector/J (for Java programs), and MySQL
Connector/NET. For example, the C API provides a set of function
calls that make up its prepared statement API. See
Section 22.2.4, “C API Prepared Statements”. Other language
interfaces can provide support for prepared statements that use
the binary protocol by linking in the C client library, one
example being the
mysqli
extension, available in PHP 5.0 and later.
An alternative SQL interface to prepared statements is available. This interface is not as efficient as using the binary protocol through a prepared statement API, but requires no programming because it is available directly at the SQL level:
You can use it when no programming interface is available to you.
You can use it from any program that allows you to send SQL statements to the server to be executed, such as the mysql client program.
You can use it even if the client is using an old version of the client library. The only requirement is that you be able to connect to a server that is recent enough to support SQL syntax for prepared statements.
SQL syntax for prepared statements is intended to be used for situations such as these:
You want to test how prepared statements work in your application before coding it.
An application has problems executing prepared statements and you want to determine interactively what the problem is.
You want to create a test case that describes a problem you are having with prepared statements, so that you can file a bug report.
You need to use prepared statements but do not have access to a programming API that supports them.
SQL syntax for prepared statements is based on three SQL statements:
PREPAREstmt_nameFROMpreparable_stmtThe
PREPAREstatement prepares a statement and assigns it a name,stmt_name, by which to refer to the statement later. Statement names are not case sensitive.preparable_stmtis either a string literal or a user variable that contains the text of the statement. The text must represent a single SQL statement, not multiple statements. Within the statement, ‘?’ characters can be used as parameter markers to indicate where data values are to be bound to the query later when you execute it. The ‘?’ characters should not be enclosed within quotes, even if you intend to bind them to string values. Parameter markers can be used only where data values should appear, not for SQL keywords, identifiers, and so forth.If a prepared statement with the given name already exists, it is deallocated implicitly before the new statement is prepared. This means that if the new statement contains an error and cannot be prepared, an error is returned and no statement with the given name exists.
The scope of a prepared statement is the client session within which it is created. Other clients cannot see it.
EXECUTEstmt_name[USING @var_name[, @var_name] ...]After preparing a statement, you execute it with an
EXECUTEstatement that refers to the prepared statement name. If the prepared statement contains any parameter markers, you must supply aUSINGclause that lists user variables containing the values to be bound to the parameters. Parameter values can be supplied only by user variables, and theUSINGclause must name exactly as many variables as the number of parameter markers in the statement.You can execute a given prepared statement multiple times, passing different variables to it or setting the variables to different values before each execution.
{DEALLOCATE | DROP} PREPAREstmt_nameTo deallocate a prepared statement, use the
DEALLOCATE PREPAREstatement. Attempting to execute a prepared statement after deallocating it results in an error.If you terminate a client session without deallocating a previously prepared statement, the server deallocates it automatically.
The following SQL statements can be used in prepared statements:
CREATE TABLE, DELETE,
DO, INSERT,
REPLACE, SELECT,
SET, UPDATE, and most
SHOW statements. supported. ANALYZE
TABLE, OPTIMIZE TABLE, and
REPAIR TABLE are supported as of MySQL 5.0.23.
Other statements are not yet supported.
The following examples show two equivalent ways of preparing a statement that computes the hypotenuse of a triangle given the lengths of the two sides.
The first example shows how to create a prepared statement by using a string literal to supply the text of the statement:
mysql>PREPARE stmt1 FROM 'SELECT SQRT(POW(?,2) + POW(?,2)) AS hypotenuse';mysql>SET @a = 3;mysql>SET @b = 4;mysql>EXECUTE stmt1 USING @a, @b;+------------+ | hypotenuse | +------------+ | 5 | +------------+ mysql>DEALLOCATE PREPARE stmt1;
The second example is similar, but supplies the text of the statement as a user variable:
mysql>SET @s = 'SELECT SQRT(POW(?,2) + POW(?,2)) AS hypotenuse';mysql>PREPARE stmt2 FROM @s;mysql>SET @a = 6;mysql>SET @b = 8;mysql>EXECUTE stmt2 USING @a, @b;+------------+ | hypotenuse | +------------+ | 10 | +------------+ mysql>DEALLOCATE PREPARE stmt2;
As of MySQL 5.0.7, placeholders can be used for the arguments of
the LIMIT clause when using prepared
statements. See Section 13.2.7, “SELECT Syntax”.
SQL syntax for prepared statements cannot be used in nested
fashion. That is, a statement passed to PREPARE
cannot itself be a PREPARE,
EXECUTE, or DEALLOCATE
PREPARE statement.
SQL syntax for prepared statements is distinct from using prepared
statement API calls. For example, you cannot use the
mysql_stmt_prepare() C API function to prepare
a PREPARE, EXECUTE, or
DEALLOCATE PREPARE statement.
SQL syntax for prepared statements cannot be used within stored routines (procedures or functions), or triggers. This restriction is lifted as of MySQL 5.0.13 for stored procedures, but not for stored functions or triggers.
SQL syntax for prepared statements does not support
multi-statements (that is, multiple statements within a single
string separated by ‘;’
characters).
Table of Contents
- 14.1. The
MyISAMStorage Engine - 14.2. The
InnoDBStorage Engine - 14.2.1.
InnoDBOverview - 14.2.2.
InnoDBContact Information - 14.2.3.
InnoDBConfiguration - 14.2.4.
InnoDBStartup Options and System Variables - 14.2.5. Creating the
InnoDBTablespace - 14.2.6. Creating and Using
InnoDBTables - 14.2.7. Adding and Removing
InnoDBData and Log Files - 14.2.8. Backing Up and Recovering an
InnoDBDatabase - 14.2.9. Moving an
InnoDBDatabase to Another Machine - 14.2.10.
InnoDBTransaction Model and Locking - 14.2.11.
InnoDBPerformance Tuning Tips - 14.2.12. Implementation of Multi-Versioning
- 14.2.13.
InnoDBTable and Index Structures - 14.2.14.
InnoDBFile Space Management and Disk I/O - 14.2.15.
InnoDBError Handling - 14.2.16. Restrictions on
InnoDBTables - 14.2.17.
InnoDBTroubleshooting
- 14.2.1.
- 14.3. The
MERGEStorage Engine - 14.4. The
MEMORY(HEAP) Storage Engine - 14.5. The
BDB(BerkeleyDB) Storage Engine - 14.6. The
EXAMPLEStorage Engine - 14.7. The
FEDERATEDStorage Engine - 14.8. The
ARCHIVEStorage Engine - 14.9. The
CSVStorage Engine - 14.10. The
BLACKHOLEStorage Engine
MySQL supports several storage engines that act as handlers for different table types. MySQL storage engines include both those that handle transaction-safe tables and those that handle non-transaction-safe tables:
MyISAMmanages non-transactional tables. It provides high-speed storage and retrieval, as well as fulltext searching capabilities.MyISAMis supported in all MySQL configurations, and is the default storage engine unless you have configured MySQL to use a different one by default.The
MEMORYstorage engine provides in-memory tables. TheMERGEstorage engine allows a collection of identicalMyISAMtables to be handled as a single table. LikeMyISAM, theMEMORYandMERGEstorage engines handle non-transactional tables, and both are also included in MySQL by default.Note: The
MEMORYstorage engine formerly was known as theHEAPengine.The
InnoDBandBDBstorage engines provide transaction-safe tables.InnoDBis included by default in all MySQL 5.0 binary distributions. In source distributions, you can enable or disable either engine by configuring MySQL as you like.The
EXAMPLEstorage engine is a “stub” engine that does nothing. You can create tables with this engine, but no data can be stored in them or retrieved from them. The purpose of this engine is to serve as an example in the MySQL source code that illustrates how to begin writing new storage engines. As such, it is primarily of interest to developers.NDB Clusteris the storage engine used by MySQL Cluster to implement tables that are partitioned over many computers. It is available in MySQL 5.0 binary distributions. This storage engine is currently supported on a number of Unix platforms. We intend to add support for this engine on other platforms, including Windows, in future MySQL releases.MySQL Cluster is covered in a separate chapter of this Manual. See Chapter 15, MySQL Cluster, for more information.
The
ARCHIVEstorage engine is used for storing large amounts of data without indexes with a very small footprint.The
CSVstorage engine stores data in text files using comma-separated values format.The
BLACKHOLEstorage engine accepts but does not store data and retrievals always return an empty set.The
FEDERATEDstorage engine was added in MySQL 5.0.3. This engine stores data in a remote database. Currently, it works with MySQL only, using the MySQL C Client API. In future releases, we intend to enable it to connect to other data sources using other drivers or client connection methods.
This chapter describes each of the MySQL storage engines except for
NDB Cluster, which is covered in
Chapter 15, MySQL Cluster.
For answers to some commonly asked questions about MySQL storage engines, see Section A.2, “MySQL 5.0 FAQ — Storage Engines”.
When you create a new table, you can specify which storage engine to
use by adding an ENGINE or
TYPE table option to the CREATE
TABLE statement:
CREATE TABLE t (i INT) ENGINE = INNODB; CREATE TABLE t (i INT) TYPE = MEMORY;
The older term TYPE is supported as a synonym for
ENGINE for backward compatibility, but
ENGINE is the preferred term and
TYPE is deprecated.
If you omit the ENGINE or TYPE
option, the default storage engine is used. Normally, this is
MyISAM, but you can change it by using the
--default-storage-engine or
--default-table-type server startup option, or by
setting the default-storage-engine or
default-table-type option in the
my.cnf configuration file.
You can set the default storage engine to be used during the current
session by setting the storage_engine or
table_type variable:
SET storage_engine=MYISAM; SET table_type=BDB;
When MySQL is installed on Windows using the MySQL Configuration
Wizard, the InnoDB storage engine can be selected
as the default instead of MyISAM. See
Section 2.3.3.2.5, “The Database Usage Dialog”.
To convert a table from one storage engine to another, use an
ALTER TABLE statement that indicates the new
engine:
ALTER TABLE t ENGINE = MYISAM; ALTER TABLE t TYPE = BDB;
See Section 13.1.5, “CREATE TABLE Syntax”, and
Section 13.1.2, “ALTER TABLE Syntax”.
If you try to use a storage engine that is not compiled in or that
is compiled in but deactivated, MySQL instead creates a table using
the default storage engine, usually MyISAM. This
behavior is convenient when you want to copy tables between MySQL
servers that support different storage engines. (For example, in a
replication setup, perhaps your master server supports transactional
storage engines for increased safety, but the slave servers use only
non-transactional storage engines for greater speed.)
This automatic substitution of the default storage engine for unavailable engines can be confusing for new MySQL users. A warning is generated whenever a storage engine is automatically changed.
For new tables, MySQL always creates an .frm
file to hold the table and column definitions. The table's index and
data may be stored in one or more other files, depending on the
storage engine. The server creates the .frm
file above the storage engine level. Individual storage engines
create any additional files required for the tables that they
manage.
A database may contain tables of different types. That is, tables need not all be created with the same storage engine.
Transaction-safe tables (TSTs) have several advantages over non-transaction-safe tables (NTSTs):
They are safer. Even if MySQL crashes or you get hardware problems, you can get your data back, either by automatic recovery or from a backup plus the transaction log.
You can combine many statements and accept them all at the same time with the
COMMITstatement (if autocommit is disabled).You can execute
ROLLBACKto ignore your changes (if autocommit is disabled).If an update fails, all of your changes are reverted. (With non-transaction-safe tables, all changes that have taken place are permanent.)
Transaction-safe storage engines can provide better concurrency for tables that get many updates concurrently with reads.
You can combine transaction-safe and non-transaction-safe tables in
the same statements to get the best of both worlds. However,
although MySQL supports several transaction-safe storage engines,
for best results, you should not mix different storage engines
within a transaction with autocommit disabled. For example, if you
do this, changes to non-transaction-safe tables still are committed
immediately and cannot be rolled back. For information about this
and other problems that can occur in transactions that use mixed
storage engines, see Section 13.4.1, “START TRANSACTION, COMMIT, and
ROLLBACK Syntax”.
Non-transaction-safe tables have several advantages of their own, all of which occur because there is no transaction overhead:
Much faster
Lower disk space requirements
Less memory required to perform updates
MyISAM is the default storage engine. It is based
on the older ISAM code but has many useful
extensions. (Note that MySQL 5.0 does
not support ISAM.)
Each MyISAM table is stored on disk in three
files. The files have names that begin with the table name and have
an extension to indicate the file type. An .frm
file stores the table format. The data file has an
.MYD (MYData) extension. The
index file has an .MYI
(MYIndex) extension.
To specify explicitly that you want a MyISAM
table, indicate that with an ENGINE table option:
CREATE TABLE t (i INT) ENGINE = MYISAM;
The older term TYPE is supported as a synonym for
ENGINE for backward compatibility, but
ENGINE is the preferred term and
TYPE is deprecated.
Normally, it is unnecesary to use ENGINE to
specify the MyISAM storage engine.
MyISAM is the default engine unless the default
has been changed. To ensure that MyISAM is used
in situations where the default might have been changed, include the
ENGINE option explicitly.
You can check or repair MyISAM tables with the
mysqlcheck client or myisamchk
utility. You can also compress MyISAM tables with
myisampack to take up much less space. See
Section 8.12, “mysqlcheck — A Table Maintenance and Repair Program”, Section 5.9.4.1, “Using myisamchk for Crash Recovery”, and
Section 8.7, “myisampack — Generate Compressed, Read-Only MyISAM Tables”.
MyISAM tables have the following characteristics:
All data values are stored with the low byte first. This makes the data machine and operating system independent. The only requirements for binary portability are that the machine uses two's-complement signed integers and IEEE floating-point format. These requirements are widely used among mainstream machines. Binary compatibility might not be applicable to embedded systems, which sometimes have peculiar processors.
There is no significant speed penalty for storing data low byte first; the bytes in a table row normally are unaligned and it takes little more processing to read an unaligned byte in order than in reverse order. Also, the code in the server that fetches column values is not time critical compared to other code.
All numeric key values are stored with the high byte first to allow better index compression.
Large files (up to 63-bit file length) are supported on filesystems and operating systems that support large files.
There is a limit of 232 (~4.295E+09) rows in a
MyISAMtable. If you build MySQL with the--with-big-tablesoption, the row limitation is increased to (232)2 (1.844E+19) rows. See Section 2.4.14.2, “Typical configure Options”. Binary distributions for Unix and Linux are built with this option.The maximum number of indexes per
MyISAMtable is 64. This can be changed by recompiling. Beginning with MySQL 5.0.18, you can configure the build by invoking configure with the--with-max-indexes=option, whereNNis the maximum number of indexes to permit perMyISAMtable.Nmust be less than or equal to 128. Before MySQL 5.0.18, you must change the source.The maximum number of columns per index is 16.
The maximum key length is 1000 bytes. This can also be changed by changing the source and recompiling. For the case of a key longer than 250 bytes, a larger key block size than the default of 1024 bytes is used.
When rows are inserted in sorted order (as when you are using an
AUTO_INCREMENTcolumn), the index tree is split so that the high node only contains one key. This improves space utilization in the index tree.Internal handling of one
AUTO_INCREMENTcolumn per table is supported.MyISAMautomatically updates this column forINSERTandUPDATEoperations. This makesAUTO_INCREMENTcolumns faster (at least 10%). Values at the top of the sequence are not reused after being deleted. (When anAUTO_INCREMENTcolumn is defined as the last column of a multiple-column index, reuse of values deleted from the top of a sequence does occur.) TheAUTO_INCREMENTvalue can be reset withALTER TABLEor myisamchk.Dynamic-sized rows are much less fragmented when mixing deletes with updates and inserts. This is done by automatically combining adjacent deleted blocks and by extending blocks if the next block is deleted.
MyISAMsupports concurrent inserts: If a table has no free blocks in the middle of the data file, you canINSERTnew rows into it at the same time that other threads are reading from the table. A free block can occur as a result of deleting rows or an update of a dynamic length row with more data than its current contents. When all free blocks are used up (filled in), future inserts become concurrent again. See Section 7.3.3, “Concurrent Inserts”.You can put the data file and index file on different directories to get more speed with the
DATA DIRECTORYandINDEX DIRECTORYtable options toCREATE TABLE. See Section 13.1.5, “CREATE TABLESyntax”.BLOBandTEXTcolumns can be indexed.NULLvalues are allowed in indexed columns. This takes 0–1 bytes per key.Each character column can have a different character set. See Chapter 10, Character Set Support.
There is a flag in the
MyISAMindex file that indicates whether the table was closed correctly. If mysqld is started with the--myisam-recoveroption,MyISAMtables are automatically checked when opened, and are repaired if the table wasn't closed properly.myisamchk marks tables as checked if you run it with the
--update-stateoption. myisamchk --fast checks only those tables that don't have this mark.myisamchk --analyze stores statistics for portions of keys, as well as for entire keys.
myisampack can pack
BLOBandVARCHARcolumns.
MyISAM also supports the following features:
Support for a true
VARCHARtype; aVARCHARcolumn starts with a length stored in one or two bytes.Tables with
VARCHARcolumns may have fixed or dynamic row length.The sum of the lengths of the
VARCHARandCHARcolumns in a table may be up to 64KB.Arbitrary length
UNIQUEconstraints.
Additional resources
A forum dedicated to the
MyISAMstorage engine is available at http://forums.mysql.com/list.php?21.
The following options to mysqld can be used to
change the behavior of MyISAM tables. For
additional information, see Section 5.2.2, “Command Options”.
Set the mode for automatic recovery of crashed
MyISAMtables.Don't flush key buffers between writes for any
MyISAMtable.Note: If you do this, you should not access
MyISAMtables from another program (such as from another MySQL server or with myisamchk) when the tables are in use. Doing so risks index corruption. Using--external-lockingdoes not eliminate this risk.
The following system variables affect the behavior of
MyISAM tables. For additional information, see
Section 5.2.3, “System Variables”.
bulk_insert_buffer_sizeThe size of the tree cache used in bulk insert optimization. Note: This is a limit per thread!
myisam_max_extra_sort_file_sizeUsed to help MySQL to decide when to use the slow but safe key cache index creation method. Note: This parameter was given in bytes before MySQL 5.0.6, when it was removed.
myisam_max_sort_file_sizeThe maximum size of the temporary file that MySQL is allowed to use while re-creating a
MyISAMindex (duringREPAIR TABLE,ALTER TABLE, orLOAD DATA INFILE). If the file size would be larger than this value, the index is created using the key cache instead, which is slower. The value is given in bytes.myisam_sort_buffer_sizeSet the size of the buffer used when recovering tables.
Automatic recovery is activated if you start
mysqld with the
--myisam-recover option. In this case, when the
server opens a MyISAM table, it checks whether
the table is marked as crashed or whether the open count variable
for the table is not 0 and you are running the server with
external locking disabled. If either of these conditions is true,
the following happens:
MySQL Enterprise
Subscribers to MySQL Network Monitoring and Advisory Service
receive notification if the --myisam-recover
option has not been set. For more information see
http://www.mysql.com/products/enterprise/advisors.html.
The server checks the table for errors.
If the server finds an error, it tries to do a fast table repair (with sorting and without re-creating the data file).
If the repair fails because of an error in the data file (for example, a duplicate-key error), the server tries again, this time re-creating the data file.
If the repair still fails, the server tries once more with the old repair option method (write row by row without sorting). This method should be able to repair any type of error and has low disk space requirements.
If the recovery wouldn't be able to recover all rows from
previously completed statements and you didn't specify
FORCE in the value of the
--myisam-recover option, automatic repair aborts
with an error message in the error log:
Error: Couldn't repair table: test.g00pages
If you specify FORCE, a warning like this is
written instead:
Warning: Found 344 of 354 rows when repairing ./test/g00pages
Note that if the automatic recovery value includes
BACKUP, the recovery process creates files with
names of the form
tbl_name-datetime.BAK
MyISAM tables use B-tree indexes. You can
roughly calculate the size for the index file as
(key_length+4)/0.67, summed over all keys. This
is for the worst case when all keys are inserted in sorted order
and the table doesn't have any compressed keys.
String indexes are space compressed. If the first index part is a
string, it is also prefix compressed. Space compression makes the
index file smaller than the worst-case figure if a string column
has a lot of trailing space or is a VARCHAR
column that is not always used to the full length. Prefix
compression is used on keys that start with a string. Prefix
compression helps if there are many strings with an identical
prefix.
In MyISAM tables, you can also prefix compress
numbers by specifying the PACK_KEYS=1 table
option when you create the table. Numbers are stored with the high
byte first, so this helps when you have many integer keys that
have an identical prefix.
MyISAM supports three different storage
formats. Two of them, fixed and dynamic format, are chosen
automatically depending on the type of columns you are using. The
third, compressed format, can be created only with the
myisampack utility.
When you use CREATE TABLE or ALTER
TABLE for a table that has no BLOB or
TEXT columns, you can force the table format to
FIXED or DYNAMIC with the
ROW_FORMAT table option.
You can decompress tables by specifying
ROW_FORMAT=DEFAULT with ALTER
TABLE.
See Section 13.1.5, “CREATE TABLE Syntax”, for information about
ROW_FORMAT.
Static format is the default for MyISAM
tables. It is used when the table contains no variable-length
columns (VARCHAR,
VARBINARY, BLOB, or
TEXT). Each row is stored using a fixed
number of bytes.
Of the three MyISAM storage formats, static
format is the simplest and most secure (least subject to
corruption). It is also the fastest of the on-disk formats due
to the ease with which rows in the data file can be found on
disk: To look up a row based on a row number in the index,
multiply the row number by the row length to calculate the row
position. Also, when scanning a table, it is very easy to read a
constant number of rows with each disk read operation.
The security is evidenced if your computer crashes while the
MySQL server is writing to a fixed-format
MyISAM file. In this case,
myisamchk can easily determine where each row
starts and ends, so it can usually reclaim all rows except the
partially written one. Note that MyISAM table
indexes can always be reconstructed based on the data rows.
Note
Fixed-length row format is only available for tables without
BLOB or TEXT columns.
Creating a table with these columns with an explicit
ROW_FORMAT clause will not raise an error
or warning; the format specification will be ignored.
Static-format tables have these characteristics:
CHARandVARCHARcolumns are space-padded to the specified column width, although the column type is not altered. This is also true forNUMERICandDECIMALcolumns created before MySQL 5.0.3.BINARYandVARBINARYcolumns are space-padded to the column width before MySQL 5.0.15. As of 5.0.15,BINARYandVARBINARYcolumns are padded with0x00bytes.Very quick.
Easy to cache.
Easy to reconstruct after a crash, because rows are located in fixed positions.
Reorganization is unnecessary unless you delete a huge number of rows and want to return free disk space to the operating system. To do this, use
OPTIMIZE TABLEor myisamchk -r.Usually require more disk space than dynamic-format tables.
Dynamic storage format is used if a MyISAM
table contains any variable-length columns
(VARCHAR, VARBINARY,
BLOB, or TEXT), or if the
table was created with the ROW_FORMAT=DYNAMIC
table option.
Dynamic format is a little more complex than static format because each row has a header that indicates how long it is. A row can become fragmented (stored in non-contiguous pieces) when it is made longer as a result of an update.
You can use OPTIMIZE TABLE or
myisamchk -r to defragment a table. If you
have fixed-length columns that you access or change frequently
in a table that also contains some variable-length columns, it
might be a good idea to move the variable-length columns to
other tables just to avoid fragmentation.
Dynamic-format tables have these characteristics:
All string columns are dynamic except those with a length less than four.
Each row is preceded by a bitmap that indicates which columns contain the empty string (for string columns) or zero (for numeric columns). Note that this does not include columns that contain
NULLvalues. If a string column has a length of zero after trailing space removal, or a numeric column has a value of zero, it is marked in the bitmap and not saved to disk. Non-empty strings are saved as a length byte plus the string contents.Much less disk space usually is required than for fixed-length tables.
Each row uses only as much space as is required. However, if a row becomes larger, it is split into as many pieces as are required, resulting in row fragmentation. For example, if you update a row with information that extends the row length, the row becomes fragmented. In this case, you may have to run
OPTIMIZE TABLEor myisamchk -r from time to time to improve performance. Use myisamchk -ei to obtain table statistics.More difficult than static-format tables to reconstruct after a crash, because rows may be fragmented into many pieces and links (fragments) may be missing.
The expected row length for dynamic-sized rows is calculated using the following expression:
3 + (
number of columns+ 7) / 8 + (number of char columns) + (packed size of numeric columns) + (length of strings) + (number of NULL columns+ 7) / 8There is a penalty of 6 bytes for each link. A dynamic row is linked whenever an update causes an enlargement of the row. Each new link is at least 20 bytes, so the next enlargement probably goes in the same link. If not, another link is created. You can find the number of links using myisamchk -ed. All links may be removed with
OPTIMIZE TABLEor myisamchk -r.
Compressed storage format is a read-only format that is generated with the myisampack tool. Compressed tables can be uncompressed with myisamchk.
Compressed tables have the following characteristics:
Compressed tables take very little disk space. This minimizes disk usage, which is helpful when using slow disks (such as CD-ROMs).
Each row is compressed separately, so there is very little access overhead. The header for a row takes up one to three bytes depending on the biggest row in the table. Each column is compressed differently. There is usually a different Huffman tree for each column. Some of the compression types are:
Suffix space compression.
Prefix space compression.
Numbers with a value of zero are stored using one bit.
If values in an integer column have a small range, the column is stored using the smallest possible type. For example, a
BIGINTcolumn (eight bytes) can be stored as aTINYINTcolumn (one byte) if all its values are in the range from-128to127.If a column has only a small set of possible values, the data type is converted to
ENUM.A column may use any combination of the preceding compression types.
Can be used for fixed-length or dynamic-length rows.
Note.
While a compressed table is read-only, and you cannot
therefore update or add rows in the table, DDL (Data
Definition Language) operations are still valid. For example,
you may still use DROP to drop the table,
and TRUNCATE to empty the table.
The file format that MySQL uses to store data has been extensively tested, but there are always circumstances that may cause database tables to become corrupted. The following discussion describes how this can happen and how to handle it.
Even though the MyISAM table format is very
reliable (all changes to a table made by an SQL statement are
written before the statement returns), you can still get
corrupted tables if any of the following events occur:
The mysqld process is killed in the middle of a write.
An unexpected computer shutdown occurs (for example, the computer is turned off).
Hardware failures.
You are using an external program (such as myisamchk) to modify a table that is being modified by the server at the same time.
A software bug in the MySQL or
MyISAMcode.
Typical symptoms of a corrupt table are:
You get the following error while selecting data from the table:
Incorrect key file for table: '...'. Try to repair it
Queries don't find rows in the table or return incomplete results.
You can check the health of a MyISAM table
using the CHECK TABLE statement, and repair a
corrupted MyISAM table with REPAIR
TABLE. When mysqld is not running,
you can also check or repair a table with the
myisamchk command. See
Section 13.5.2.3, “CHECK TABLE Syntax”, Section 13.5.2.6, “REPAIR TABLE Syntax”,
and Section 8.5, “myisamchk — MyISAM Table-Maintenance Utility”.
If your tables become corrupted frequently, you should try to
determine why this is happening. The most important thing to
know is whether the table became corrupted as a result of a
server crash. You can verify this easily by looking for a recent
restarted mysqld message in the error log. If
there is such a message, it is likely that table corruption is a
result of the server dying. Otherwise, corruption may have
occurred during normal operation. This is a bug. You should try
to create a reproducible test case that demonstrates the
problem. See Section B.1.4.2, “What to Do If MySQL Keeps Crashing”, and
MySQL
Internals: Porting.
MySQL Enterprise Find out about problems before they occur. Subscribe to the MySQL Network Monitoring and Advisor Service for expert advice about the state of your servers. For more information see http://www.mysql.com/products/enterprise/advisors.html.
Each MyISAM index file
(.MYI file) has a counter in the header
that can be used to check whether a table has been closed
properly. If you get the following warning from CHECK
TABLE or myisamchk, it means that
this counter has gone out of sync:
clients are using or haven't closed the table properly
This warning doesn't necessarily mean that the table is corrupted, but you should at least check the table.
The counter works as follows:
The first time a table is updated in MySQL, a counter in the header of the index files is incremented.
The counter is not changed during further updates.
When the last instance of a table is closed (because a
FLUSH TABLESoperation was performed or because there is no room in the table cache), the counter is decremented if the table has been updated at any point.When you repair the table or check the table and it is found to be okay, the counter is reset to zero.
To avoid problems with interaction with other processes that might check the table, the counter is not decremented on close if it was zero.
In other words, the counter can become incorrect only under these conditions:
A
MyISAMtable is copied without first issuingLOCK TABLESandFLUSH TABLES.MySQL has crashed between an update and the final close. (Note that the table may still be okay, because MySQL always issues writes for everything between each statement.)
A table was modified by myisamchk --recover or myisamchk --update-state at the same time that it was in use by mysqld.
Multiple mysqld servers are using the table and one server performed a
REPAIR TABLEorCHECK TABLEon the table while it was in use by another server. In this setup, it is safe to useCHECK TABLE, although you might get the warning from other servers. However,REPAIR TABLEshould be avoided because when one server replaces the data file with a new one, this is not known to the other servers.In general, it is a bad idea to share a data directory among multiple servers. See Section 5.12, “Running Multiple MySQL Servers on the Same Machine”, for additional discussion.
- 14.2.1.
InnoDBOverview - 14.2.2.
InnoDBContact Information - 14.2.3.
InnoDBConfiguration - 14.2.4.
InnoDBStartup Options and System Variables - 14.2.5. Creating the
InnoDBTablespace - 14.2.6. Creating and Using
InnoDBTables - 14.2.7. Adding and Removing
InnoDBData and Log Files - 14.2.8. Backing Up and Recovering an
InnoDBDatabase - 14.2.9. Moving an
InnoDBDatabase to Another Machine - 14.2.10.
InnoDBTransaction Model and Locking - 14.2.11.
InnoDBPerformance Tuning Tips - 14.2.12. Implementation of Multi-Versioning
- 14.2.13.
InnoDBTable and Index Structures - 14.2.14.
InnoDBFile Space Management and Disk I/O - 14.2.15.
InnoDBError Handling - 14.2.16. Restrictions on
InnoDBTables - 14.2.17.
InnoDBTroubleshooting
InnoDB provides MySQL with a transaction-safe
(ACID compliant) storage engine that has
commit, rollback, and crash recovery capabilities.
InnoDB does locking on the row level and also
provides an Oracle-style consistent non-locking read in
SELECT statements. These features increase
multi-user concurrency and performance. There is no need for lock
escalation in InnoDB because row-level locks
fit in very little space. InnoDB also supports
FOREIGN KEY constraints. You can freely mix
InnoDB tables with tables from other MySQL
storage engines, even within the same statement.
InnoDB has been designed for maximum
performance when processing large data volumes. Its CPU efficiency
is probably not matched by any other disk-based relational
database engine.
Fully integrated with MySQL Server, the InnoDB
storage engine maintains its own buffer pool for caching data and
indexes in main memory. InnoDB stores its
tables and indexes in a tablespace, which may consist of several
files (or raw disk partitions). This is different from, for
example, MyISAM tables where each table is
stored using separate files. InnoDB tables can
be of any size even on operating systems where file size is
limited to 2GB.
InnoDB is included in binary distributions by
default. The Windows Essentials installer makes
InnoDB the MySQL default storage engine on
Windows.
InnoDB is used in production at numerous large
database sites requiring high performance. The famous Internet
news site Slashdot.org runs on InnoDB. Mytrix,
Inc. stores over 1TB of data in InnoDB, and
another site handles an average load of 800 inserts/updates per
second in InnoDB.
InnoDB is published under the same GNU GPL
License Version 2 (of June 1991) as MySQL. For more information on
MySQL licensing, see
http://www.mysql.com/company/legal/licensing/.
Additional resources
A forum dedicated to the
InnoDBstorage engine is available at http://forums.mysql.com/list.php?22.
Contact information for Innobase Oy, producer of the
InnoDB engine:
Web site: http://www.innodb.com/
Email: <sales@innodb.com>
Phone: +358-9-6969 3250 (office)
+358-40-5617367 (mobile)
Innobase Oy Inc.
World Trade Center Helsinki
Aleksanterinkatu 17
P.O.Box 800
00101 Helsinki
Finland
The InnoDB storage engine is enabled by
default. If you don't want to use InnoDB
tables, you can add the skip-innodb option to
your MySQL option file.
Note: InnoDB
provides MySQL with a transaction-safe (ACID
compliant) storage engine that has commit, rollback, and crash
recovery capabilities. However, it cannot do
so if the underlying operating system or hardware does
not work as advertised. Many operating systems or disk subsystems
may delay or reorder write operations to improve performance. On
some operating systems, the very system call that should wait
until all unwritten data for a file has been flushed —
fsync() — might actually return before
the data has been flushed to stable storage. Because of this, an
operating system crash or a power outage may destroy recently
committed data, or in the worst case, even corrupt the database
because of write operations having been reordered. If data
integrity is important to you, you should perform some
“pull-the-plug” tests before using anything in
production. On Mac OS X 10.3 and up, InnoDB
uses a special fcntl() file flush method. Under
Linux, it is advisable to disable the
write-back cache.
On ATAPI hard disks, a command such hdparm -W0
/dev/hda may work to disable the write-back cache.
Beware that some drives or disk controllers
may be unable to disable the write-back cache.
Two important disk-based resources managed by the
InnoDB storage engine are its tablespace data
files and its log files.
Note: If you specify no
InnoDB configuration options, MySQL creates an
auto-extending 10MB data file named ibdata1
and two 5MB log files named ib_logfile0 and
ib_logfile1 in the MySQL data directory. To
get good performance, you should explicitly provide
InnoDB parameters as discussed in the following
examples. Naturally, you should edit the settings to suit your
hardware and requirements.
Note: If is not a good idea to
configure InnoDB to use datafiles or logfiles
on NFS volumes. Otherwise, the files might be locked by other
processes and become unavailable for use by MySQL.
MySQL Enterprise For advice on settings suitable to your specific circumstances, subscribe to the MySQL Network Monitoring and Advisory Services. For more information see http://www.mysql.com/products/enterprise/advisors.html.
The examples shown here are representative. See
Section 14.2.4, “InnoDB Startup Options and System Variables” for additional information
about InnoDB-related configuration parameters.
To set up the InnoDB tablespace files, use the
innodb_data_file_path option in the
[mysqld] section of the
my.cnf option file. On Windows, you can use
my.ini instead. The value of
innodb_data_file_path should be a list of one
or more data file specifications. If you name more than one data
file, separate them by semicolon
(‘;’) characters:
innodb_data_file_path=datafile_spec1[;datafile_spec2]...
For example, a setting that explicitly creates a tablespace having the same characteristics as the default is as follows:
[mysqld] innodb_data_file_path=ibdata1:10M:autoextend
This setting configures a single 10MB data file named
ibdata1 that is auto-extending. No location
for the file is given, so by default, InnoDB
creates it in the MySQL data directory.
Sizes are specified using M or
G suffix letters to indicate units of MB or GB.
A tablespace containing a fixed-size 50MB data file named
ibdata1 and a 50MB auto-extending file named
ibdata2 in the data directory can be
configured like this:
[mysqld] innodb_data_file_path=ibdata1:50M;ibdata2:50M:autoextend
The full syntax for a data file specification includes the filename, its size, and several optional attributes:
file_name:file_size[:autoextend[:max:max_file_size]]
The autoextend attribute and those following
can be used only for the last data file in the
innodb_data_file_path line.
If you specify the autoextend option for the
last data file, InnoDB extends the data file if
it runs out of free space in the tablespace. The increment is 8MB
at a time by default. It can be modified by changing the
innodb_autoextend_increment system variable.
If the disk becomes full, you might want to add another data file
on another disk. Instructions for reconfiguring an existing
tablespace are given in Section 14.2.7, “Adding and Removing InnoDB Data and Log Files”.
InnoDB is not aware of the filesystem maximum
file size, so be cautious on filesystems where the maximum file
size is a small value such as 2GB. To specify a maximum size for
an auto-extending data file, use the max
attribute. The following configuration allows
ibdata1 to grow up to a limit of 500MB:
[mysqld] innodb_data_file_path=ibdata1:10M:autoextend:max:500M
InnoDB creates tablespace files in the MySQL
data directory by default. To specify a location explicitly, use
the innodb_data_home_dir option. For example,
to use two files named ibdata1 and
ibdata2 but create them in the
/ibdata directory, configure
InnoDB like this:
[mysqld] innodb_data_home_dir = /ibdata innodb_data_file_path=ibdata1:50M;ibdata2:50M:autoextend
Note: InnoDB
does not create directories, so make sure that the
/ibdata directory exists before you start the
server. This is also true of any log file directories that you
configure. Use the Unix or DOS mkdir command to
create any necessary directories.
InnoDB forms the directory path for each data
file by textually concatenating the value of
innodb_data_home_dir to the data file name,
adding a pathname separator (slash or backslash) between values if
necessary. If the innodb_data_home_dir option
is not mentioned in my.cnf at all, the
default value is the “dot” directory
./, which means the MySQL data directory.
(The MySQL server changes its current working directory to its
data directory when it begins executing.)
If you specify innodb_data_home_dir as an empty
string, you can specify absolute paths for the data files listed
in the innodb_data_file_path value. The
following example is equivalent to the preceding one:
[mysqld] innodb_data_home_dir = innodb_data_file_path=/ibdata/ibdata1:50M;/ibdata/ibdata2:50M:autoextend
A simple my.cnf
example. Suppose that you have a computer with 128MB
RAM and one hard disk. The following example shows possible
configuration parameters in my.cnf or
my.ini for InnoDB,
including the autoextend attribute. The example
suits most users, both on Unix and Windows, who do not want to
distribute InnoDB data files and log files onto
several disks. It creates an auto-extending data file
ibdata1 and two InnoDB log
files ib_logfile0 and
ib_logfile1 in the MySQL data directory.
[mysqld] # You can write your other MySQL server options here # ... # Data files must be able to hold your data and indexes. # Make sure that you have enough free disk space. innodb_data_file_path = ibdata1:10M:autoextend # # Set buffer pool size to 50-80% of your computer's memory innodb_buffer_pool_size=70M innodb_additional_mem_pool_size=10M # # Set the log file size to about 25% of the buffer pool size innodb_log_file_size=20M innodb_log_buffer_size=8M # innodb_flush_log_at_trx_commit=1
Make sure that the MySQL server has the proper access rights to create files in the data directory. More generally, the server must have access rights in any directory where it needs to create data files or log files.
Note that data files must be less than 2GB in some filesystems. The combined size of the log files must be less than 4GB. The combined size of data files must be at least 10MB.
When you create an InnoDB tablespace for the
first time, it is best that you start the MySQL server from the
command prompt. InnoDB then prints the
information about the database creation to the screen, so you can
see what is happening. For example, on Windows, if
mysqld is located in C:\Program
Files\MySQL\MySQL Server 5.0\bin, you can
start it like this:
C:\> "C:\Program Files\MySQL\MySQL Server 5.0\bin\mysqld" --console
If you do not send server output to the screen, check the server's
error log to see what InnoDB prints during the
startup process.
See Section 14.2.5, “Creating the InnoDB Tablespace”, for an example of what the
information displayed by InnoDB should look
like.
You can place InnoDB options in the
[mysqld] group of any option file that your
server reads when it starts. The locations for option files are
described in Section 4.3.2, “Using Option Files”.
If you installed MySQL on Windows using the installation and
configuration wizards, the option file will be the
my.ini file located in your MySQL
installation directory. See
Section 2.3.3.2.1.1, “The MySQL Server Configuration Wizard on Windows”.
If your PC uses a boot loader where the C:
drive is not the boot drive, your only option is to use the
my.ini file in your Windows directory
(typically C:\WINDOWS). You can use the
SET command at the command prompt in a console
window to print the value of WINDIR:
C:\> SET WINDIR
windir=C:\WINDOWS
If you want to make sure that mysqld reads
options only from a specific file, you can use the
--defaults-file option as the first option on the
command line when starting the server:
mysqld --defaults-file=your_path_to_my_cnf
An advanced my.cnf
example. Suppose that you have a Linux computer with
2GB RAM and three 60GB hard disks at directory paths
/, /dr2 and
/dr3. The following example shows possible
configuration parameters in my.cnf for
InnoDB.
[mysqld] # You can write your other MySQL server options here # ... innodb_data_home_dir = # # Data files must be able to hold your data and indexes innodb_data_file_path = /ibdata/ibdata1:2000M;/dr2/ibdata/ibdata2:2000M:autoextend # # Set buffer pool size to 50-80% of your computer's memory, # but make sure on Linux x86 total memory usage is < 2GB innodb_buffer_pool_size=1G innodb_additional_mem_pool_size=20M innodb_log_group_home_dir = /dr3/iblogs # innodb_log_files_in_group = 2 # # Set the log file size to about 25% of the buffer pool size innodb_log_file_size=250M innodb_log_buffer_size=8M # innodb_flush_log_at_trx_commit=1 innodb_lock_wait_timeout=50 # # Uncomment the next lines if you want to use them #innodb_thread_concurrency=5
In some cases, database performance improves if all the data is
not placed on the same physical disk. Putting log files on a
different disk from data is very often beneficial for performance.
The example illustrates how to do this. It places the two data
files on different disks and places the log files on the third
disk. InnoDB fills the tablespace beginning
with the first data file. You can also use raw disk partitions
(raw devices) as InnoDB data files, which may
speed up I/O. See Section 14.2.3.2, “Using Raw Devices for the Shared Tablespace”.
Warning: On 32-bit GNU/Linux x86,
you must be careful not to set memory usage too high.
glibc may allow the process heap to grow over
thread stacks, which crashes your server. It is a risk if the
value of the following expression is close to or exceeds 2GB:
innodb_buffer_pool_size + key_buffer_size + max_connections*(sort_buffer_size+read_buffer_size+binlog_cache_size) + max_connections*2MB
Each thread uses a stack (often 2MB, but only 256KB in MySQL AB
binaries) and in the worst case also uses
sort_buffer_size + read_buffer_size additional
memory.
By compiling MySQL yourself, you can use up to 64GB of physical
memory in 32-bit Windows. See the description for
innodb_buffer_pool_awe_mem_mb in
Section 14.2.4, “InnoDB Startup Options and System Variables”.
How to tune other mysqld server parameters? The following values are typical and suit most users:
[mysqld]
skip-external-locking
max_connections=200
read_buffer_size=1M
sort_buffer_size=1M
#
# Set key_buffer to 5 - 50% of your RAM depending on how much
# you use MyISAM tables, but keep key_buffer_size + InnoDB
# buffer pool size < 80% of your RAM
key_buffer_size=value
You can store each InnoDB table and its
indexes in its own file. This feature is called “multiple
tablespaces” because in effect each table has its own
tablespace.
Using multiple tablespaces can be beneficial to users who want
to move specific tables to separate physical disks or who wish
to restore backups of single tables quickly without interrupting
the use of the remaining InnoDB tables.
You can enable multiple tablespaces by adding this line to the
[mysqld] section of
my.cnf:
[mysqld] innodb_file_per_table
After restarting the server, InnoDB stores
each newly created table into its own file
tbl_name.ibdMyISAM storage engine does, but
MyISAM divides the table into a data file
tbl_name.MYDtbl_name.MYIInnoDB, the data and the indexes are
stored together in the .ibd file. The
tbl_name.frm
If you remove the innodb_file_per_table line
from my.cnf and restart the server,
InnoDB creates tables inside the shared
tablespace files again.
innodb_file_per_table affects only table
creation, not access to existing tables. If you start the server
with this option, new tables are created using
.ibd files, but you can still access tables
that exist in the shared tablespace. If you remove the option
and restart the server, new tables are created in the shared
tablespace, but you can still access any tables that were
created using multiple tablespaces.
Note: InnoDB
always needs the shared tablespace because it puts its internal
data dictionary and undo logs there. The
.ibd files are not sufficient for
InnoDB to operate.
Note: You cannot freely move
.ibd files between database directories as
you can with MyISAM table files. This is
because the table definition that is stored in the
InnoDB shared tablespace includes the
database name, and because InnoDB must
preserve the consistency of transaction IDs and log sequence
numbers.
To move an .ibd file and the associated
table from one database to another, use a RENAME
TABLE statement:
RENAME TABLEdb1.tbl_nameTOdb2.tbl_name;
If you have a “clean” backup of an
.ibd file, you can restore it to the MySQL
installation from which it originated as follows:
Issue this
ALTER TABLEstatement:ALTER TABLE
tbl_nameDISCARD TABLESPACE;Caution: This statement deletes the current
.ibdfile.Put the backup
.ibdfile back in the proper database directory.Issue this
ALTER TABLEstatement:ALTER TABLE
tbl_nameIMPORT TABLESPACE;
In this context, a “clean”
.ibd file backup means:
There are no uncommitted modifications by transactions in the
.ibdfile.There are no unmerged insert buffer entries in the
.ibdfile.Purge has removed all delete-marked index records from the
.ibdfile.mysqld has flushed all modified pages of the
.ibdfile from the buffer pool to the file.
You can make a clean backup .ibd file using
the following method:
Stop all activity from the mysqld server and commit all transactions.
Wait until
SHOW ENGINE INNODB STATUSshows that there are no active transactions in the database, and the main thread status ofInnoDBisWaiting for server activity. Then you can make a copy of the.ibdfile.
Another method for making a clean copy of an
.ibd file is to use the commercial
InnoDB Hot Backup tool:
Use InnoDB Hot Backup to back up the
InnoDBinstallation.Start a second mysqld server on the backup and let it clean up the
.ibdfiles in the backup.
You can use raw disk partitions as data files in the shared tablespace. By using a raw disk, you can perform non-buffered I/O on Windows and on some Unix systems without filesystem overhead, which may improve performance.
When you create a new data file, you must put the keyword
newraw immediately after the data file size
in innodb_data_file_path. The partition must
be at least as large as the size that you specify. Note that 1MB
in InnoDB is 1024 × 1024 bytes, whereas
1MB in disk specifications usually means 1,000,000 bytes.
[mysqld] innodb_data_home_dir= innodb_data_file_path=/dev/hdd1:3Gnewraw;/dev/hdd2:2Gnewraw
The next time you start the server, InnoDB
notices the newraw keyword and initializes
the new partition. However, do not create or change any
InnoDB tables yet. Otherwise, when you next
restart the server, InnoDB reinitializes the
partition and your changes are lost. (As a safety measure
InnoDB prevents users from modifying data
when any partition with newraw is specified.)
After InnoDB has initialized the new
partition, stop the server, change newraw in
the data file specification to raw:
[mysqld] innodb_data_home_dir= innodb_data_file_path=/dev/hdd1:5Graw;/dev/hdd2:2Graw
Then restart the server and InnoDB allows
changes to be made.
On Windows, you can allocate a disk partition as a data file like this:
[mysqld] innodb_data_home_dir= innodb_data_file_path=//./D::10Gnewraw
The //./ corresponds to the Windows syntax
of \\.\ for accessing physical drives.
When you use raw disk partitions, be sure that they have permissions that allow read and write access by the account used for running the MySQL server.
This section describes the InnoDB-related
command options and system variables. System variables that are
true or false can be enabled at server startup by naming them, or
disabled by using a skip- prefix. For example,
to enable or disable InnoDB checksums, you can
use --innodb_checksums or
--skip-innodb_checksums on the command line, or
innodb_checksums or
skip-innodb_checksums in an option file. System
variables that take a numeric value can be specified as
--
on the command line or as
var_name=valuevar_name=value
MySQL Enterprise The MySQL Network Monitoring and Advisory Service provides expert advice on InnoDB start-up options and related system variables. For more information see http://www.mysql.com/products/enterprise/advisors.html.
InnoDB command options:
Enables the
InnoDBstorage engine, if the server was compiled withInnoDBsupport. Use--skip-innodbto disableInnoDB.Causes
InnoDBto create a file named<datadir>/innodb_status.<pid>InnoDBperiodically writes the output ofSHOW ENGINE INNODB STATUSto this file.
InnoDB system variables:
innodb_additional_mem_pool_sizeThe size in bytes of a memory pool
InnoDBuses to store data dictionary information and other internal data structures. The more tables you have in your application, the more memory you need to allocate here. IfInnoDBruns out of memory in this pool, it starts to allocate memory from the operating system and writes warning messages to the MySQL error log. The default value is 1MB.The increment size (in MB) for extending the size of an auto-extending tablespace when it becomes full. The default value is 8.
The size of the buffer pool (in MB), if it is placed in the AWE memory. This is relevant only in 32-bit Windows. If your 32-bit Windows operating system supports more than 4GB memory, using so-called “Address Windowing Extensions,” you can allocate the
InnoDBbuffer pool into the AWE physical memory using this variable. The maximum possible value for this variable is 63000. If it is greater than 0,innodb_buffer_pool_sizeis the window in the 32-bit address space of mysqld whereInnoDBmaps that AWE memory. A good value forinnodb_buffer_pool_sizeis 500MB.To take advantage of AWE memory, you will need to recompile MySQL yourself. The current project settings needed for doing this can be found in the
innobase/os/os0proj.csource file.The size in bytes of the memory buffer
InnoDBuses to cache data and indexes of its tables. The larger you set this value, the less disk I/O is needed to access data in tables. On a dedicated database server, you may set this to up to 80% of the machine physical memory size. However, do not set it too large because competition for physical memory might cause paging in the operating system.InnoDBcan use checksum validation on all pages read from the disk to ensure extra fault tolerance against broken hardware or data files. This validation is enabled by default. However, under some rare circumstances (such as when running benchmarks) this extra safety feature is unneeded and can be disabled with--skip-innodb_checksums. This variable was added in MySQL 5.0.3.The number of threads that can commit at the same time. A value of 0 disables concurrency control. This variable was added in MySQL 5.0.12.
The number of threads that can enter
InnoDBconcurrently is determined by theinnodb_thread_concurrencyvariable. A thread is placed in a queue when it tries to enterInnoDBif the number of threads has already reached the concurrency limit. When a thread is allowed to enterInnoDB, it is given a number of “free tickets” equal to the value ofinnodb_concurrency_tickets, and the thread can enter and leaveInnoDBfreely until it has used up its tickets. After that point, the thread again becomes subject to the concurrency check (and possible queuing) the next time it tries to enterInnoDB. This variable was added in MySQL 5.0.3.The paths to individual data files and their sizes. The full directory path to each data file is formed by concatenating
innodb_data_home_dirto each path specified here. The file sizes are specified in MB or GB (1024MB) by appendingMorGto the size value. The sum of the sizes of the files must be at least 10MB. If you do not specifyinnodb_data_file_path, the default behavior is to create a single 10MB auto-extending data file namedibdata1. The size limit of individual files is determined by your operating system. You can set the file size to more than 4GB on those operating systems that support big files. You can also use raw disk partitions as data files. See Section 14.2.3.2, “Using Raw Devices for the Shared Tablespace”.The common part of the directory path for all
InnoDBdata files. If you do not set this value, the default is the MySQL data directory. You can specify the value as an empty string, in which case you can use absolute file paths ininnodb_data_file_path.By default,
InnoDBstores all data twice, first to the doublewrite buffer, and then to the actual data files. This variable is enabled by default. It can be turned off with--skip-innodb_doublewritefor benchmarks or cases when top performance is needed rather than concern for data integrity or possible failures. This variable was added in MySQL 5.0.3.If you set this variable to 0,
InnoDBdoes a full purge and an insert buffer merge before a shutdown. These operations can take minutes, or even hours in extreme cases. If you set this variable to 1,InnoDBskips these operations at shutdown. The default value is 1. If you set it to 2,InnoDBwill just flush its logs and then shut down cold, as if MySQL had crashed; no committed transaction will be lost, but crash recovery will be done at the next startup. The value of 2 can be used as of MySQL 5.0.5, except that it cannot be used on NetWare.The number of file I/O threads in
InnoDB. Normally, this should be left at the default value of 4, but disk I/O on Windows may benefit from a larger number. On Unix, increasing the number has no effect;InnoDBalways uses the default value.If this variable is enabled,
InnoDBcreates each new table using its own.ibdfile for storing data and indexes, rather than in the shared tablespace. The default is to create tables in the shared tablespace. See Section 14.2.3.1, “Using Per-Table Tablespaces”.innodb_flush_log_at_trx_commitWhen
innodb_flush_log_at_trx_commitis set to 0, the log buffer is written out to the log file once per second and the flush to disk operation is performed on the log file, but nothing is done at a transaction commit. When this value is 1 (the default), the log buffer is written out to the log file at each transaction commit and the flush to disk operation is performed on the log file. When set to 2, the log buffer is written out to the file at each commit, but the flush to disk operation is not performed on it. However, the flushing on the log file takes place once per second also when the value is 2. Note that the once-per-second flushing is not 100% guaranteed to happen every second, due to process scheduling issues.The default value of this variable is 1, which is the value that is required for ACID compliance. You can achieve better performance by setting the value different from 1, but then you can lose at most one second worth of transactions in a crash. If you set the value to 0, then any mysqld process crash can erase the last second of transactions. If you set the value to 2, then only an operating system crash or a power outage can erase the last second of transactions. However,
InnoDB's crash recovery is not affected and thus crash recovery does work regardless of the value. Note that many operating systems and some disk hardware fool the flush-to-disk operation. They may tell mysqld that the flush has taken place, even though it has not. Then the durability of transactions is not guaranteed even with the setting 1, and in the worst case a power outage can even corrupt theInnoDBdatabase. Using a battery-backed disk cache in the SCSI disk controller or in the disk itself speeds up file flushes, and makes the operation safer. You can also try using the Unix command hdparm to disable the caching of disk writes in hardware caches, or use some other command specific to the hardware vendor.Note: For the greatest possible durability and consistency in a replication setup using
InnoDBwith transactions, you should useinnodb_flush_log_at_trx_commit=1,sync_binlog=1, and, before MySQL 5.0.3,innodb_safe_binlogin your master servermy.cnffile. (innodb_safe_binlogis not needed from 5.0.3 on.)If set to
fdatasync(the default),InnoDBusesfsync()to flush both the data and log files. If set toO_DSYNC,InnoDBusesO_SYNCto open and flush the log files, but usesfsync()to flush the data files. IfO_DIRECTis specified (available on some GNU/Linux versions, FreeBSD and Solaris),InnoDBusesO_DIRECT(ordirectio()on Solaris) to open the data files, and usesfsync()to flush both the data and log files. Note thatInnoDBusesfsync()instead offdatasync(), and it does not useO_DSYNCby default because there have been problems with it on many varieties of Unix. This variable is relevant only for Unix. On Windows, the flush method is alwaysasync_unbufferedand cannot be changed.Different values of this variable can have a marked effect on
InnoDB performance. For example, on some systems whereInnoDBdata and log files are located on a SAN, it has been found that settinginnodb_flush_methodtoO_DIRECTcan degrade performance of simpleSELECTstatements by a factor of three.The crash recovery mode. Warning: This variable should be set greater than 0 only in an emergency situation when you want to dump your tables from a corrupt database! Possible values are from 1 to 6. The meanings of these values are described in Section 14.2.8.1, “Forcing
InnoDBRecovery”. As a safety measure,InnoDBprevents any changes to its data when this variable is greater than 0.The timeout in seconds an
InnoDBtransaction may wait for a lock before being rolled back.InnoDBautomatically detects transaction deadlocks in its own lock table and rolls back the transaction.InnoDBnotices locks set using theLOCK TABLESstatement. The default is 50 seconds.innodb_locks_unsafe_for_binlogThis variable controls next-key locking in
InnoDBsearches and index scans. By default, this variable is 0 (disabled), which means that next-key locking is enabled.Normally,
InnoDBuses an algorithm called next-key locking.InnoDBperforms row-level locking in such a way that when it searches or scans a table index, it sets shared or exclusive locks on any index records it encounters. Thus, the row-level locks are actually index record locks. The locks thatInnoDBsets on index records also affect the “gap” preceding that index record. If a user has a shared or exclusive lock on record R in an index, another user cannot insert a new index record immediately before R in the order of the index. Enabling this variable causesInnoDBnot to use next-key locking in searches or index scans. Next-key locking is still used to ensure foreign key constraints and duplicate key checking. Note that enabling this variable may cause phantom problems: Suppose that you want to read and lock all children from thechildtable with an identifier value larger than 100, with the intention of updating some column in the selected rows later:SELECT * FROM child WHERE id > 100 FOR UPDATE;
Suppose that there is an index on the
idcolumn. The query scans that index starting from the first record whereidis greater than 100. If the locks set on the index records do not lock out inserts made in the gaps, another client can insert a new row into the table. If you execute the sameSELECTwithin the same transaction, you see a new row in the result set returned by the query. This also means that if new items are added to the database,InnoDBdoes not guarantee serializability. Therefore, if this variable is enabledInnoDBguarantees at most isolation levelREAD COMMITTED. (Conflict serializability is still guaranteed.)Starting from MySQL 5.0.2, this option is even more unsafe.
InnoDBin anUPDATEor aDELETEonly locks rows that it updates or deletes. This greatly reduces the probability of deadlocks, but they can happen. Note that enabling this variable still does not allow operations such asUPDATEto overtake other similar operations (such as anotherUPDATE) even in the case when they affect different rows. Consider the following example, beginning with this table:CREATE TABLE A(A INT NOT NULL, B INT) ENGINE = InnoDB; INSERT INTO A VALUES (1,2),(2,3),(3,2),(4,3),(5,2); COMMIT;
Suppose that one client executes these statements:
SET AUTOCOMMIT = 0; UPDATE A SET B = 5 WHERE B = 3;
Then suppose that another client executes these statements following those of the first client:
SET AUTOCOMMIT = 0; UPDATE A SET B = 4 WHERE B = 2;
In this case, the second
UPDATEmust wait for a commit or rollback of the firstUPDATE. The firstUPDATEhas an exclusive lock on row (2,3), and the secondUPDATEwhile scanning rows also tries to acquire an exclusive lock for the same row, which it cannot have. This is becauseUPDATEtwo first acquires an exclusive lock on a row and then determines whether the row belongs to the result set. If not, it releases the unnecessary lock, when theinnodb_locks_unsafe_for_binlogvariable is enabled.Therefore,
InnoDBexecutesUPDATEone as follows:x-lock(1,2) unlock(1,2) x-lock(2,3) update(2,3) to (2,5) x-lock(3,2) unlock(3,2) x-lock(4,3) update(4,3) to (4,5) x-lock(5,2) unlock(5,2)
InnoDBexecutesUPDATEtwo as follows:x-lock(1,2) update(1,2) to (1,4) x-lock(2,3) - wait for query one to commit or rollback
Whether to log
InnoDBarchive files. This variable is present for historical reasons, but is unused. Recovery from a backup is done by MySQL using its own log files, so there is no need to archiveInnoDBlog files. The default for this variable is 0.The size in bytes of the buffer that
InnoDBuses to write to the log files on disk. Sensible values range from 1MB to 8MB. The default is 1MB. A large log buffer allows large transactions to run without a need to write the log to disk before the transactions commit. Thus, if you have big transactions, making the log buffer larger saves disk I/O.The size in bytes of each log file in a log group. The combined size of log files must be less than 4GB on 32-bit computers. The default is 5MB. Sensible values range from 1MB to 1/
N-th of the size of the buffer pool, whereNis the number of log files in the group. The larger the value, the less checkpoint flush activity is needed in the buffer pool, saving disk I/O. But larger log files also mean that recovery is slower in case of a crash.The number of log files in the log group.
InnoDBwrites to the files in a circular fashion. The default (and recommended) is 2.The directory path to the
InnoDBlog files. If you do not specify anyInnoDBlog variables, the default is to create two 5MB files namesib_logfile0andib_logfile1in the MySQL data directory.This is an integer in the range from 0 to 100. The default is 90. The main thread in
InnoDBtries to write pages from the buffer pool so that the percentage of dirty (not yet written) pages will not exceed this value.This variable controls how to delay
INSERT,UPDATEandDELETEoperations when the purge operations are lagging (see Section 14.2.12, “Implementation of Multi-Versioning”). The default value of this variable is 0, meaning that there are no delays.The
InnoDBtransaction system maintains a list of transactions that have delete-marked index records byUPDATEorDELETEoperations. Let the length of this list bepurge_lag. Whenpurge_lagexceedsinnodb_max_purge_lag, eachINSERT,UPDATEandDELETEoperation is delayed by ((purge_lag/innodb_max_purge_lag)×10)–5 milliseconds. The delay is computed in the beginning of a purge batch, every ten seconds. The operations are not delayed if purge cannot run because of an old consistent read view that could see the rows to be purged.A typical setting for a problematic workload might be 1 million, assuming that our transactions are small, only 100 bytes in size, and we can allow 100MB of unpurged rows in our tables.
The number of identical copies of log groups to keep for the database. Currently, this should be set to 1.
This variable is relevant only if you use multiple tablespaces in
InnoDB. It specifies the maximum number of.ibdfiles thatInnoDBcan keep open at one time. The minimum value is 10. The default is 300.The file descriptors used for
.ibdfiles are forInnoDBonly. They are independent of those specified by the--open-files-limitserver option, and do not affect the operation of the table cache.In MySQL 5.0.13 and up,
InnoDBrolls back only the last statement on a transaction timeout. If this option is given, a transaction timeout causesInnoDBto abort and roll back the entire transaction (the same behavior as before MySQL 5.0.13). This variable was added in MySQL 5.0.32.innodb_safe_binlogAdds consistency guarantees between the content of
InnoDBtables and the binary log. See Section 5.11.3, “The Binary Log”. This variable was removed in MySQL 5.0.3, having been made obsolete by the introduction of XA transaction support.When set to
ONor 1 (the default), this variable enablesInnoDBsupport for two-phase commit in XA transactions. Enablinginnodb_support_xacauses an extra disk flush for transaction preparation. If you don't care about using XA, you can disable this variable by setting it toOFFor 0 to reduce the number of disk flushes and get betterInnoDBperformance. This variable was added in MySQL 5.0.3.The number of times a thread waits for an
InnoDBmutex to be freed before the thread is suspended. This variable was added in MySQL 5.0.3.If
AUTOCOMMIT=0,InnoDBhonorsLOCK TABLES; MySQL does not return fromLOCK TABLE .. WRITEuntil all other threads have released all their locks to the table. The default value ofinnodb_table_locksis 1, which means thatLOCK TABLEScauses InnoDB to lock a table internally ifAUTOCOMMIT=0.InnoDBtries to keep the number of operating system threads concurrently insideInnoDBless than or equal to the limit given by this variable. If you have performance issues, andSHOW ENGINE INNODB STATUSreveals many threads waiting for semaphores, you may have thread “thrashing” and should try setting this variable lower or higher. If you have a computer with many processors and disks, you can try setting the value higher to make better use of your computer's resources. A recommended value is the sum of the number of processors and disks your system has.The range of this variable is 0 to 1000. A value of 20 or higher is interpreted as infinite concurrency before MySQL 5.0.19. From 5.0.19 on, 0 is interpreted as infinite. Infinite means that concurrency checking is disabled and the possibly considerable overhead of acquiring and releasing a mutex is avoided.
The default value has changed several times: 8 before MySQL 5.0.8, 20 (infinite) from 5.0.8 through 5.0.18, 0 (infinite) from 5.0.19 to 5.0.20, and 8 (finite) from 5.0.21 on.
How long
InnoDBthreads sleep before joining theInnoDBqueue, in microseconds. The default value is 10,000. A value of 0 disables sleep. This variable was added in MySQL 5.0.3.sync_binlogIf the value of this variable is positive, the MySQL server synchronizes its binary log to disk (
fdatasync()) after everysync_binlogwrites to this binary log. Note that there is one write to the binary log per statement if in autocommit mode, and otherwise one write per transaction. The default value is 0 which does no synchronizing to disk. A value of 1 is the safest choice, because in the event of a crash you lose at most one statement/transaction from the binary log; however, it is also the slowest choice (unless the disk has a battery-backed cache, which makes synchronization very fast).
Suppose that you have installed MySQL and have edited your option
file so that it contains the necessary InnoDB
configuration parameters. Before starting MySQL, you should verify
that the directories you have specified for
InnoDB data files and log files exist and that
the MySQL server has access rights to those directories.
InnoDB does not create directories, only files.
Check also that you have enough disk space for the data and log
files.
It is best to run the MySQL server mysqld from
the command prompt when you first start the server with
InnoDB enabled, not from the
mysqld_safe wrapper or as a Windows service.
When you run from a command prompt you see what
mysqld prints and what is happening. On Unix,
just invoke mysqld. On Windows, use the
--console option.
When you start the MySQL server after initially configuring
InnoDB in your option file,
InnoDB creates your data files and log files,
and prints something like this:
InnoDB: The first specified datafile /home/heikki/data/ibdata1 did not exist: InnoDB: a new database to be created! InnoDB: Setting file /home/heikki/data/ibdata1 size to 134217728 InnoDB: Database physically writes the file full: wait... InnoDB: datafile /home/heikki/data/ibdata2 did not exist: new to be created InnoDB: Setting file /home/heikki/data/ibdata2 size to 262144000 InnoDB: Database physically writes the file full: wait... InnoDB: Log file /home/heikki/data/logs/ib_logfile0 did not exist: new to be created InnoDB: Setting log file /home/heikki/data/logs/ib_logfile0 size to 5242880 InnoDB: Log file /home/heikki/data/logs/ib_logfile1 did not exist: new to be created InnoDB: Setting log file /home/heikki/data/logs/ib_logfile1 size to 5242880 InnoDB: Doublewrite buffer not found: creating new InnoDB: Doublewrite buffer created InnoDB: Creating foreign key constraint system tables InnoDB: Foreign key constraint system tables created InnoDB: Started mysqld: ready for connections
At this point InnoDB has initialized its
tablespace and log files. You can connect to the MySQL server with
the usual MySQL client programs like mysql.
When you shut down the MySQL server with mysqladmin
shutdown, the output is like this:
010321 18:33:34 mysqld: Normal shutdown 010321 18:33:34 mysqld: Shutdown Complete InnoDB: Starting shutdown... InnoDB: Shutdown completed
You can look at the data file and log directories and you see the files created there. When MySQL is started again, the data files and log files have been created already, so the output is much briefer:
InnoDB: Started mysqld: ready for connections
If you add the innodb_file_per_table option to
my.cnf, InnoDB stores each
table in its own .ibd file in the same MySQL
database directory where the .frm file is
created. See Section 14.2.3.1, “Using Per-Table Tablespaces”.
If InnoDB prints an operating system error
during a file operation, usually the problem has one of the
following causes:
You did not create the
InnoDBdata file directory or theInnoDBlog directory.mysqld does not have access rights to create files in those directories.
mysqld cannot read the proper
my.cnformy.inioption file, and consequently does not see the options that you specified.The disk is full or a disk quota is exceeded.
You have created a subdirectory whose name is equal to a data file that you specified, so the name cannot be used as a filename.
There is a syntax error in the
innodb_data_home_dirorinnodb_data_file_pathvalue.
If something goes wrong when InnoDB attempts
to initialize its tablespace or its log files, you should delete
all files created by InnoDB. This means all
ibdata files and all
ib_logfile files. In case you have already
created some InnoDB tables, delete the
corresponding .frm files for these tables
(and any .ibd files if you are using
multiple tablespaces) from the MySQL database directories as
well. Then you can try the InnoDB database
creation again. It is best to start the MySQL server from a
command prompt so that you see what is happening.
To create an InnoDB table, specify an
ENGINE = InnoDB option in the CREATE
TABLE statement:
CREATE TABLE customers (a INT, b CHAR (20), INDEX (a)) ENGINE=InnoDB;
The older term TYPE is supported as a synonym
for ENGINE for backward compatibility, but
ENGINE is the preferred term and
TYPE is deprecated.
The statement creates a table and an index on column
a in the InnoDB tablespace
that consists of the data files that you specified in
my.cnf. In addition, MySQL creates a file
customers.frm in the
test directory under the MySQL database
directory. Internally, InnoDB adds an entry for
the table to its own data dictionary. The entry includes the
database name. For example, if test is the
database in which the customers table is
created, the entry is for 'test/customers'.
This means you can create a table of the same name
customers in some other database, and the table
names do not collide inside InnoDB.
You can query the amount of free space in the
InnoDB tablespace by issuing a SHOW
TABLE STATUS statement for any InnoDB
table. The amount of free space in the tablespace appears in the
Comment section in the output of SHOW
TABLE STATUS. For example:
SHOW TABLE STATUS FROM test LIKE 'customers'
Note that the statistics SHOW displays for
InnoDB tables are only approximate. They are
used in SQL optimization. Table and index reserved sizes in bytes
are accurate, though.
By default, each client that connects to the MySQL server begins
with autocommit mode enabled, which automatically commits every
SQL statement as you execute it. To use multiple-statement
transactions, you can switch autocommit off with the SQL
statement SET AUTOCOMMIT = 0 and use
COMMIT and ROLLBACK to
commit or roll back your transaction. If you want to leave
autocommit on, you can enclose your transactions within
START TRANSACTION and either
COMMIT or ROLLBACK. The
following example shows two transactions. The first is
committed; the second is rolled back.
shell>mysql testmysql>CREATE TABLE CUSTOMER (A INT, B CHAR (20), INDEX (A))->ENGINE=InnoDB;Query OK, 0 rows affected (0.00 sec) mysql>START TRANSACTION;Query OK, 0 rows affected (0.00 sec) mysql>INSERT INTO CUSTOMER VALUES (10, 'Heikki');Query OK, 1 row affected (0.00 sec) mysql>COMMIT;Query OK, 0 rows affected (0.00 sec) mysql>SET AUTOCOMMIT=0;Query OK, 0 rows affected (0.00 sec) mysql>INSERT INTO CUSTOMER VALUES (15, 'John');Query OK, 1 row affected (0.00 sec) mysql>ROLLBACK;Query OK, 0 rows affected (0.00 sec) mysql>SELECT * FROM CUSTOMER;+------+--------+ | A | B | +------+--------+ | 10 | Heikki | +------+--------+ 1 row in set (0.00 sec) mysql>
In APIs such as PHP, Perl DBI, JDBC, ODBC, or the standard C
call interface of MySQL, you can send transaction control
statements such as COMMIT to the MySQL server
as strings just like any other SQL statements such as
SELECT or INSERT. Some
APIs also offer separate special transaction commit and rollback
functions or methods.
Important: Do not convert MySQL system tables in the
mysql database (such as
user or host) to the
InnoDB type. This is an unsupported
operation. The system tables must always be of the
MyISAM type.
If you want all your (non-system) tables to be created as
InnoDB tables, you can simply add the line
default-storage-engine=innodb to the
[mysqld] section of your server option file.
InnoDB does not have a special optimization
for separate index creation the way the
MyISAM storage engine does. Therefore, it
does not pay to export and import the table and create indexes
afterward. The fastest way to alter a table to
InnoDB is to do the inserts directly to an
InnoDB table. That is, use ALTER
TABLE ... ENGINE=INNODB, or create an empty
InnoDB table with identical definitions and
insert the rows with INSERT INTO ... SELECT * FROM
....
If you have UNIQUE constraints on secondary
keys, you can speed up a table import by turning off the
uniqueness checks temporarily during the import operation:
SET UNIQUE_CHECKS=0;
... import operation ...
SET UNIQUE_CHECKS=1;
For big tables, this saves a lot of disk I/O because
InnoDB can then use its insert buffer to
write secondary index records as a batch. Be certain that the
data contains no duplicate keys.
UNIQUE_CHECKS allows but does not require
storage engines to ignore duplicate keys.
To get better control over the insertion process, it might be good to insert big tables in pieces:
INSERT INTO newtable SELECT * FROM oldtable WHERE yourkey > something AND yourkey <= somethingelse;
After all records have been inserted, you can rename the tables.
During the conversion of big tables, you should increase the
size of the InnoDB buffer pool to reduce disk
I/O. Do not use more than 80% of the physical memory, though.
You can also increase the sizes of the InnoDB
log files.
Make sure that you do not fill up the tablespace:
InnoDB tables require a lot more disk space
than MyISAM tables. If an ALTER
TABLE operation runs out of space, it starts a
rollback, and that can take hours if it is disk-bound. For
inserts, InnoDB uses the insert buffer to
merge secondary index records to indexes in batches. That saves
a lot of disk I/O. For rollback, no such mechanism is used, and
the rollback can take 30 times longer than the insertion.
In the case of a runaway rollback, if you do not have valuable
data in your database, it may be advisable to kill the database
process rather than wait for millions of disk I/O operations to
complete. For the complete procedure, see
Section 14.2.8.1, “Forcing InnoDB Recovery”.
If you specify an AUTO_INCREMENT column for
an InnoDB table, the table handle in the
InnoDB data dictionary contains a special
counter called the auto-increment counter that is used in
assigning new values for the column. This counter is stored only
in main memory, not on disk.
InnoDB uses the following algorithm to
initialize the auto-increment counter for a table
T that contains an
AUTO_INCREMENT column named
ai_col: After a server startup, for the first
insert into a table T,
InnoDB executes the equivalent of this
statement:
SELECT MAX(ai_col) FROM T FOR UPDATE;
InnoDB increments by one the value retrieved
by the statement and assigns it to the column and to the
auto-increment counter for the table. If the table is empty,
InnoDB uses the value 1.
If a user invokes a SHOW TABLE STATUS
statement that displays output for the table
T and the auto-increment counter has not been
initialized, InnoDB initializes but does not
increment the value and stores it for use by later inserts. Note
that this initialization uses a normal exclusive-locking read on
the table and the lock lasts to the end of the transaction.
InnoDB follows the same procedure for
initializing the auto-increment counter for a freshly created
table.
After the auto-increment counter has been initialized, if a user
does not explicitly specify a value for an
AUTO_INCREMENT column,
InnoDB increments the counter by one and
assigns the new value to the column. If the user inserts a row
that explicitly specifies the column value, and the value is
bigger than the current counter value, the counter is set to the
specified column value.
You may see gaps in the sequence of values assigned to the
AUTO_INCREMENT column if you roll back
transactions that have generated numbers using the counter.
If a user specifies NULL or
0 for the AUTO_INCREMENT
column in an INSERT,
InnoDB treats the row as if the value had not
been specified and generates a new value for it.
The behavior of the auto-increment mechanism is not defined if a user assigns a negative value to the column or if the value becomes bigger than the maximum integer that can be stored in the specified integer type.
When accessing the auto-increment counter,
InnoDB uses a special table-level
AUTO-INC lock that it keeps to the end of the
current SQL statement, not to the end of the transaction. The
special lock release strategy was introduced to improve
concurrency for inserts into a table containing an
AUTO_INCREMENT column. Nevertheless, two
transactions cannot have the AUTO-INC lock on
the same table simultaneously, which can have a performance
impact if the AUTO-INC lock is held for a
long time. That might be the case for a statement such as
INSERT INTO t1 ... SELECT ... FROM t2 that
inserts all rows from one table into another.
InnoDB uses the in-memory auto-increment
counter as long as the server runs. When the server is stopped
and restarted, InnoDB reinitializes the
counter for each table for the first INSERT
to the table, as described earlier.
Beginning with MySQL 5.0.3, InnoDB supports
the AUTO_INCREMENT =
table option in
NCREATE TABLE and ALTER
TABLE statements, to set the initial counter value or
alter the current counter value. The effect of this option is
canceled by a server restart, for reasons discussed earlier in
this section.
InnoDB also supports foreign key constraints.
The syntax for a foreign key constraint definition in
InnoDB looks like this:
[CONSTRAINTsymbol] FOREIGN KEY [id] (index_col_name, ...) REFERENCEStbl_name(index_col_name, ...) [ON DELETE {RESTRICT | CASCADE | SET NULL | NO ACTION}] [ON UPDATE {RESTRICT | CASCADE | SET NULL | NO ACTION}]
Foreign keys definitions are subject to the following conditions:
Both tables must be
InnoDBtables and they must not beTEMPORARYtables.Corresponding columns in the foreign key and the referenced key must have similar internal data types inside
InnoDBso that they can be compared without a type conversion. The size and sign of integer types must be the same. The length of string types need not be the same. For non-binary (character) string columns, the character set and collation must be the same.In the referencing table, there must be an index where the foreign key columns are listed as the first columns in the same order. Such an index is created on the referencing table automatically if it does not exist.
In the referenced table, there must be an index where the referenced columns are listed as the first columns in the same order.
Index prefixes on foreign key columns are not supported. One consequence of this is that
BLOBandTEXTcolumns cannot be included in a foreign key, because indexes on those columns must always include a prefix length.If the
CONSTRAINTclause is given, thesymbolsymbolvalue must be unique in the database. If the clause is not given,InnoDBcreates the name automatically.
InnoDB rejects any INSERT
or UPDATE operation that attempts to create a
foreign key value in a child table if there is no a matching
candidate key value in the parent table. The action
InnoDB takes for any
UPDATE or DELETE operation
that attempts to update or delete a candidate key value in the
parent table that has some matching rows in the child table is
dependent on the referential action
specified using ON UPDATE and ON
DELETE subclauses of the FOREIGN
KEY clause. When the user attempts to delete or update
a row from a parent table, and there are one or more matching
rows in the child table, InnoDB supports five
options regarding the action to be taken:
CASCADE: Delete or update the row from the parent table and automatically delete or update the matching rows in the child table. BothON DELETE CASCADEandON UPDATE CASCADEare supported. Between two tables, you should not define severalON UPDATE CASCADEclauses that act on the same column in the parent table or in the child table.SET NULL: Delete or update the row from the parent table and set the foreign key column or columns in the child table toNULL. This is valid only if the foreign key columns do not have theNOT NULLqualifier specified. BothON DELETE SET NULLandON UPDATE SET NULLclauses are supported.If you specify a
SET NULLaction, make sure that you have not declared the columns in the child table asNOT NULL.NO ACTION: In standard SQL,NO ACTIONmeans no action in the sense that an attempt to delete or update a primary key value is not allowed to proceed if there is a related foreign key value in the referenced table.InnoDBrejects the delete or update operation for the parent table.RESTRICT: Rejects the delete or update operation for the parent table.NO ACTIONandRESTRICTare the same as omitting theON DELETEorON UPDATEclause. (Some database systems have deferred checks, andNO ACTIONis a deferred check. In MySQL, foreign key constraints are checked immediately, soNO ACTIONandRESTRICTare the same.)SET DEFAULT: This action is recognized by the parser, butInnoDBrejects table definitions containingON DELETE SET DEFAULTorON UPDATE SET DEFAULTclauses.
Note that InnoDB supports foreign key
references within a table. In these cases, “child table
records” really refers to dependent records within the
same table.
InnoDB requires indexes on foreign keys and
referenced keys so that foreign key checks can be fast and not
require a table scan. The index on the foreign key is created
automatically. This is in contrast to some older versions, in
which indexes had to be created explicitly or the creation of
foreign key constraints would fail.
If MySQL reports an error number 1005 from a CREATE
TABLE statement, and the error message refers to errno
150, table creation failed because a foreign key constraint was
not correctly formed. Similarly, if an ALTER
TABLE fails and it refers to errno 150, that means a
foreign key definition would be incorrectly formed for the
altered table. You can use SHOW ENGINE INNODB
STATUS to display a detailed explanation of the most
recent InnoDB foreign key error in the
server.
Note: InnoDB
does not check foreign key constraints on those foreign key or
referenced key values that contain a NULL
column.
Note: Currently, triggers are not activated by cascaded foreign key actions.
Deviation from SQL standards:
If there are several rows in the parent table that have the same
referenced key value, InnoDB acts in foreign
key checks as if the other parent rows with the same key value
do not exist. For example, if you have defined a
RESTRICT type constraint, and there is a
child row with several parent rows, InnoDB
does not allow the deletion of any of those parent rows.
InnoDB performs cascading operations through
a depth-first algorithm, based on records in the indexes
corresponding to the foreign key constraints.
Deviation from SQL standards: A
FOREIGN KEY constraint that references a
non-UNIQUE key is not standard SQL. It is an
InnoDB extension to standard SQL.
Deviation from SQL standards:
If ON UPDATE CASCADE or ON UPDATE
SET NULL recurses to update the same
table it has previously updated during the cascade,
it acts like RESTRICT. This means that you
cannot use self-referential ON UPDATE CASCADE
or ON UPDATE SET NULL operations. This is to
prevent infinite loops resulting from cascaded updates. A
self-referential ON DELETE SET NULL, on the
other hand, is possible, as is a self-referential ON
DELETE CASCADE. Cascading operations may not be nested
more than 15 levels deep.
Deviation from SQL standards:
Like MySQL in general, in an SQL statement that inserts,
deletes, or updates many rows, InnoDB checks
UNIQUE and FOREIGN KEY
constraints row-by-row. According to the SQL standard, the
default behavior should be deferred checking. That is,
constraints are only checked after the entire SQL
statement has been processed. Until
InnoDB implements deferred constraint
checking, some things will be impossible, such as deleting a
record that refers to itself via a foreign key.
Here is a simple example that relates parent
and child tables through a single-column
foreign key:
CREATE TABLE parent (id INT NOT NULL,
PRIMARY KEY (id)
) ENGINE=INNODB;
CREATE TABLE child (id INT, parent_id INT,
INDEX par_ind (parent_id),
FOREIGN KEY (parent_id) REFERENCES parent(id)
ON DELETE CASCADE
) ENGINE=INNODB;
A more complex example in which a
product_order table has foreign keys for two
other tables. One foreign key references a two-column index in
the product table. The other references a
single-column index in the customer table:
CREATE TABLE product (category INT NOT NULL, id INT NOT NULL,
price DECIMAL,
PRIMARY KEY(category, id)) ENGINE=INNODB;
CREATE TABLE customer (id INT NOT NULL,
PRIMARY KEY (id)) ENGINE=INNODB;
CREATE TABLE product_order (no INT NOT NULL AUTO_INCREMENT,
product_category INT NOT NULL,
product_id INT NOT NULL,
customer_id INT NOT NULL,
PRIMARY KEY(no),
INDEX (product_category, product_id),
FOREIGN KEY (product_category, product_id)
REFERENCES product(category, id)
ON UPDATE CASCADE ON DELETE RESTRICT,
INDEX (customer_id),
FOREIGN KEY (customer_id)
REFERENCES customer(id)) ENGINE=INNODB;
InnoDB allows you to add a new foreign key
constraint to a table by using ALTER TABLE:
ALTER TABLEtbl_nameADD [CONSTRAINTsymbol] FOREIGN KEY [id] (index_col_name, ...) REFERENCEStbl_name(index_col_name, ...) [ON DELETE {RESTRICT | CASCADE | SET NULL | NO ACTION}] [ON UPDATE {RESTRICT | CASCADE | SET NULL | NO ACTION}]
Remember to create the required indexes
first. You can also add a self-referential foreign
key constraint to a table using ALTER TABLE.
InnoDB also supports the use of
ALTER TABLE to drop foreign keys:
ALTER TABLEtbl_nameDROP FOREIGN KEYfk_symbol;
If the FOREIGN KEY clause included a
CONSTRAINT name when you created the foreign
key, you can refer to that name to drop the foreign key.
Otherwise, the fk_symbol value is
internally generated by InnoDB when the
foreign key is created. To find out the symbol value when you
want to drop a foreign key, use the SHOW CREATE
TABLE statement. For example:
mysql>SHOW CREATE TABLE ibtest11c\G*************************** 1. row *************************** Table: ibtest11c Create Table: CREATE TABLE `ibtest11c` ( `A` int(11) NOT NULL auto_increment, `D` int(11) NOT NULL default '0', `B` varchar(200) NOT NULL default '', `C` varchar(175) default NULL, PRIMARY KEY (`A`,`D`,`B`), KEY `B` (`B`,`C`), KEY `C` (`C`), CONSTRAINT `0_38775` FOREIGN KEY (`A`, `D`) REFERENCES `ibtest11a` (`A`, `D`) ON DELETE CASCADE ON UPDATE CASCADE, CONSTRAINT `0_38776` FOREIGN KEY (`B`, `C`) REFERENCES `ibtest11a` (`B`, `C`) ON DELETE CASCADE ON UPDATE CASCADE ) ENGINE=INNODB CHARSET=latin1 1 row in set (0.01 sec) mysql>ALTER TABLE ibtest11c DROP FOREIGN KEY `0_38775`;
You cannot add a foreign key and drop a foreign key in separate
clauses of a single ALTER TABLE statement.
Separate statements are required.
The InnoDB parser allows table and column
identifiers in a FOREIGN KEY ... REFERENCES
... clause to be quoted within backticks.
(Alternatively, double quotes can be used if the
ANSI_QUOTES SQL mode is enabled.) The
InnoDB parser also takes into account the
setting of the lower_case_table_names system
variable.
InnoDB returns a table's foreign key
definitions as part of the output of the SHOW CREATE
TABLE statement:
SHOW CREATE TABLE tbl_name;
mysqldump also produces correct definitions of tables to the dump file, and does not forget about the foreign keys.
You can also display the foreign key constraints for a table like this:
SHOW TABLE STATUS FROMdb_nameLIKE 'tbl_name';
The foreign key constraints are listed in the
Comment column of the output.
When performing foreign key checks, InnoDB
sets shared row-level locks on child or parent records it has to
look at. InnoDB checks foreign key
constraints immediately; the check is not deferred to
transaction commit.
To make it easier to reload dump files for tables that have
foreign key relationships, mysqldump
automatically includes a statement in the dump output to set
FOREIGN_KEY_CHECKS to 0. This avoids problems
with tables having to be reloaded in a particular order when the
dump is reloaded. It is also possible to set this variable
manually:
mysql>SET FOREIGN_KEY_CHECKS = 0;mysql>SOURCEmysql>dump_file_name;SET FOREIGN_KEY_CHECKS = 1;
This allows you to import the tables in any order if the dump
file contains tables that are not correctly ordered for foreign
keys. It also speeds up the import operation. Setting
FOREIGN_KEY_CHECKS to 0 can also be useful
for ignoring foreign key constraints during LOAD
DATA and ALTER TABLE operations.
However, even if FOREIGN_KEY_CHECKS=0, InnoDB
does not allow the creation of a foreign key constraint where a
column references a non-matching column type. Also, if an
InnoDB table has foreign key constraints,
ALTER TABLE cannot be used to change the
table to use another storage engine. To alter the storage
engine, you must drop any foreign key constraints first.
InnoDB does not allow you to drop a table
that is referenced by a FOREIGN KEY
constraint, unless you do SET
FOREIGN_KEY_CHECKS=0. When you drop a table, the
constraints that were defined in its create statement are also
dropped.
If you re-create a table that was dropped, it must have a definition that conforms to the foreign key constraints referencing it. It must have the right column names and types, and it must have indexes on the referenced keys, as stated earlier. If these are not satisfied, MySQL returns error number 1005 and refers to errno 150 in the error message.
MySQL replication works for InnoDB tables as
it does for MyISAM tables. It is also
possible to use replication in a way where the storage engine on
the slave is not the same as the original storage engine on the
master. For example, you can replicate modifications to an
InnoDB table on the master to a
MyISAM table on the slave.
To set up a new slave for a master, you have to make a copy of
the InnoDB tablespace and the log files, as
well as the .frm files of the
InnoDB tables, and move the copies to the
slave. If the innodb_file_per_table variable
is enabled, you must also copy the .ibd
files as well. For the proper procedure to do this, see
Section 14.2.8, “Backing Up and Recovering an InnoDB Database”.
If you can shut down the master or an existing slave, you can
take a cold backup of the InnoDB tablespace
and log files and use that to set up a slave. To make a new
slave without taking down any server you can also use the
non-free (commercial)
InnoDB
Hot Backup tool.
You cannot set up replication for InnoDB
using the LOAD TABLE FROM MASTER statement,
which works only for MyISAM tables. There are
two possible workarounds:
Dump the table on the master and import the dump file into the slave.
Use
ALTER TABLEon the master before setting up replication withtbl_nameENGINE=MyISAMLOAD TABLE, and then usetbl_nameFROM MASTERALTER TABLEto convert the master table back toInnoDBafterward. However, this should not be done for tables that have foreign key definitions because the definitions will be lost.
Transactions that fail on the master do not affect replication
at all. MySQL replication is based on the binary log where MySQL
writes SQL statements that modify data. A transaction that fails
(for example, because of a foreign key violation, or because it
is rolled back) is not written to the binary log, so it is not
sent to slaves. See Section 13.4.1, “START TRANSACTION, COMMIT, and
ROLLBACK Syntax”.
This section describes what you can do when your
InnoDB tablespace runs out of room or when you
want to change the size of the log files.
The easiest way to increase the size of the
InnoDB tablespace is to configure it from the
beginning to be auto-extending. Specify the
autoextend attribute for the last data file in
the tablespace definition. Then InnoDB
increases the size of that file automatically in 8MB increments
when it runs out of space. The increment size can be changed by
setting the value of the
innodb_autoextend_increment system variable,
which is measured in MB.
Alternatively, you can increase the size of your tablespace by
adding another data file. To do this, you have to shut down the
MySQL server, change the tablespace configuration to add a new
data file to the end of innodb_data_file_path,
and start the server again.
If your last data file was defined with the keyword
autoextend, the procedure for reconfiguring the
tablespace must take into account the size to which the last data
file has grown. Obtain the size of the data file, round it down to
the closest multiple of 1024 × 1024 bytes (= 1MB), and
specify the rounded size explicitly in
innodb_data_file_path. Then you can add another
data file. Remember that only the last data file in the
innodb_data_file_path can be specified as
auto-extending.
As an example, assume that the tablespace has just one
auto-extending data file ibdata1:
innodb_data_home_dir = innodb_data_file_path = /ibdata/ibdata1:10M:autoextend
Suppose that this data file, over time, has grown to 988MB. Here is the configuration line after modifying the original data file to not be auto-extending and adding another auto-extending data file:
innodb_data_home_dir = innodb_data_file_path = /ibdata/ibdata1:988M;/disk2/ibdata2:50M:autoextend
When you add a new file to the tablespace configuration, make sure
that it does not exist. InnoDB will create and
initialize the file when you restart the server.
Currently, you cannot remove a data file from the tablespace. To decrease the size of your tablespace, use this procedure:
Use mysqldump to dump all your
InnoDBtables.Stop the server.
Remove all the existing tablespace files.
Configure a new tablespace.
Restart the server.
Import the dump files.
If you want to change the number or the size of your
InnoDB log files, use the following
instructions. The procedure to use depends on the value of
innodb_fast_shutdown:
If
innodb_fast_shutdownis not set to 2: You must stop the MySQL server and make sure that it shuts down without errors (to ensure that there is no information for outstanding transactions in the logs). Then copy the old log files into a safe place just in case something went wrong in the shutdown and you need them to recover the tablespace. Delete the old log files from the log file directory, editmy.cnfto change the log file configuration, and start the MySQL server again. mysqld sees that no log files exist at startup and tells you that it is creating new ones.If
innodb_fast_shutdownis set to 2: You should shut down the server, setinnodb_fast_shutdownto 1, and restart the server. The server should be allowed to recover. Then you should shut down the server again and follow the procedure described in the preceding item to changeInnoDBlog file size. Setinnodb_fast_shutdownback to 2 and restart the server.
The key to safe database management is making regular backups.
InnoDB Hot Backup is an online backup tool you
can use to backup your InnoDB database while it
is running. InnoDB Hot Backup does not require
you to shut down your database and it does not set any locks or
disturb your normal database processing. InnoDB Hot
Backup is a non-free (commercial) add-on tool with an
annual license fee of €390 per computer on which the MySQL
server is run. See the
InnoDB Hot
Backup home page for detailed information and
screenshots.
If you are able to shut down your MySQL server, you can make a
binary backup that consists of all files used by
InnoDB to manage its tables. Use the following
procedure:
Shut down your MySQL server and make sure that it shuts down without errors.
Copy all your data files (
ibdatafiles and.ibdfiles) into a safe place.Copy all your
ib_logfilefiles to a safe place.Copy your
my.cnfconfiguration file or files to a safe place.Copy all the
.frmfiles for yourInnoDBtables to a safe place.
Replication works with InnoDB tables, so you
can use MySQL replication capabilities to keep a copy of your
database at database sites requiring high availability.
In addition to making binary backups as just described, you should
also regularly make dumps of your tables with
mysqldump. The reason for this is that a binary
file might be corrupted without you noticing it. Dumped tables are
stored into text files that are human-readable, so spotting table
corruption becomes easier. Also, because the format is simpler,
the chance for serious data corruption is smaller.
mysqldump also has a
--single-transaction option that you can use to
make a consistent snapshot without locking out other clients.
To be able to recover your InnoDB database to
the present from the binary backup just described, you have to run
your MySQL server with binary logging turned on. Then you can
apply the binary log to the backup database to achieve
point-in-time recovery:
mysqlbinlog yourhostname-bin.123 | mysql
To recover from a crash of your MySQL server, the only requirement
is to restart it. InnoDB automatically checks
the logs and performs a roll-forward of the database to the
present. InnoDB automatically rolls back
uncommitted transactions that were present at the time of the
crash. During recovery, mysqld displays output
something like this:
InnoDB: Database was not shut down normally. InnoDB: Starting recovery from log files... InnoDB: Starting log scan based on checkpoint at InnoDB: log sequence number 0 13674004 InnoDB: Doing recovery: scanned up to log sequence number 0 13739520 InnoDB: Doing recovery: scanned up to log sequence number 0 13805056 InnoDB: Doing recovery: scanned up to log sequence number 0 13870592 InnoDB: Doing recovery: scanned up to log sequence number 0 13936128 ... InnoDB: Doing recovery: scanned up to log sequence number 0 20555264 InnoDB: Doing recovery: scanned up to log sequence number 0 20620800 InnoDB: Doing recovery: scanned up to log sequence number 0 20664692 InnoDB: 1 uncommitted transaction(s) which must be rolled back InnoDB: Starting rollback of uncommitted transactions InnoDB: Rolling back trx no 16745 InnoDB: Rolling back of trx no 16745 completed InnoDB: Rollback of uncommitted transactions completed InnoDB: Starting an apply batch of log records to the database... InnoDB: Apply batch completed InnoDB: Started mysqld: ready for connections
If your database gets corrupted or your disk fails, you have to do the recovery from a backup. In the case of corruption, you should first find a backup that is not corrupted. After restoring the base backup, do the recovery from the binary log files using mysqlbinlog and mysql to restore the changes performed after the backup was made.
In some cases of database corruption it is enough just to dump,
drop, and re-create one or a few corrupt tables. You can use the
CHECK TABLE SQL statement to check whether a
table is corrupt, although CHECK TABLE
naturally cannot detect every possible kind of corruption. You can
use innodb_tablespace_monitor to check the
integrity of the file space management inside the tablespace
files.
In some cases, apparent database page corruption is actually due to the operating system corrupting its own file cache, and the data on disk may be okay. It is best first to try restarting your computer. Doing so may eliminate errors that appeared to be database page corruption.
If there is database page corruption, you may want to dump your
tables from the database with SELECT INTO
OUTFILE. Usually, most of the data obtained in this
way is intact. Even so, the corruption may cause SELECT
* FROM statements
or tbl_nameInnoDB background operations to crash or
assert, or even to cause InnoDB roll-forward
recovery to crash. However, you can force the
InnoDB storage engine to start up while
preventing background operations from running, so that you are
able to dump your tables. For example, you can add the following
line to the [mysqld] section of your option
file before restarting the server:
[mysqld] innodb_force_recovery = 4
The allowable non-zero values for
innodb_force_recovery follow. A larger number
includes all precautions of smaller numbers. If you are able to
dump your tables with an option value of at most 4, then you are
relatively safe that only some data on corrupt individual pages
is lost. A value of 6 is more drastic because database pages are
left in an obsolete state, which in turn may introduce more
corruption into B-trees and other database structures.
1(SRV_FORCE_IGNORE_CORRUPT)Let the server run even if it detects a corrupt page. Try to make
SELECT * FROMjump over corrupt index records and pages, which helps in dumping tables.tbl_name2(SRV_FORCE_NO_BACKGROUND)Prevent the main thread from running. If a crash would occur during the purge operation, this recovery value prevents it.
3(SRV_FORCE_NO_TRX_UNDO)Do not run transaction rollbacks after recovery.
4(SRV_FORCE_NO_IBUF_MERGE)Prevent also insert buffer merge operations. If they would cause a crash, do not do them. Do not calculate table statistics.
5(SRV_FORCE_NO_UNDO_LOG_SCAN)Do not look at undo logs when starting the database:
InnoDBtreats even incomplete transactions as committed.6(SRV_FORCE_NO_LOG_REDO)Do not do the log roll-forward in connection with recovery.
You can SELECT from tables to dump them, or
DROP or CREATE tables even
if forced recovery is used. If you know that a given table is
causing a crash on rollback, you can drop it. You can also use
this to stop a runaway rollback caused by a failing mass import
or ALTER TABLE. You can kill the
mysqld process and set
innodb_force_recovery to 3
to bring the database up without the rollback, then
DROP the table that is causing the runaway
rollback.
The database must not otherwise be used with any
non-zero value of
innodb_force_recovery. As a safety
measure, InnoDB prevents users from
performing INSERT, UPDATE,
or DELETE operations when
innodb_force_recovery is greater than 0.
InnoDB implements a checkpoint mechanism
known as “fuzzy” checkpointing.
InnoDB flushes modified database pages from
the buffer pool in small batches. There is no need to flush the
buffer pool in one single batch, which would in practice stop
processing of user SQL statements during the checkpointing
process.
During crash recovery, InnoDB looks for a
checkpoint label written to the log files. It knows that all
modifications to the database before the label are present in
the disk image of the database. Then InnoDB
scans the log files forward from the checkpoint, applying the
logged modifications to the database.
InnoDB writes to its log files on a rotating
basis. All committed modifications that make the database pages
in the buffer pool different from the images on disk must be
available in the log files in case InnoDB has
to do a recovery. This means that when InnoDB
starts to reuse a log file, it has to make sure that the
database page images on disk contain the modifications logged in
the log file that InnoDB is going to reuse.
In other words, InnoDB must create a
checkpoint and this often involves flushing of modified database
pages to disk.
The preceding description explains why making your log files very large may save disk I/O in checkpointing. It often makes sense to set the total size of the log files as big as the buffer pool or even bigger. The drawback of using large log files is that crash recovery can take longer because there is more logged information to apply to the database.
On Windows, InnoDB always stores database and
table names internally in lowercase. To move databases in a binary
format from Unix to Windows or from Windows to Unix, you should
have all table and database names in lowercase. A convenient way
to accomplish this is to add the following line to the
[mysqld] section of your
my.cnf or my.ini file
before creating any databases or tables:
[mysqld] lower_case_table_names=1
Like MyISAM data files,
InnoDB data and log files are binary-compatible
on all platforms having the same floating-point number format. You
can move an InnoDB database simply by copying
all the relevant files listed in Section 14.2.8, “Backing Up and Recovering an InnoDB Database”.
If the floating-point formats differ but you have not used
FLOAT or DOUBLE data types
in your tables, then the procedure is the same: simply copy the
relevant files. If the formats differ and your tables contain
floating-point data, you must use mysqldump to
dump your tables on one machine and then import the dump files on
the other machine.
One way to increase performance is to switch off autocommit mode when importing data, assuming that the tablespace has enough space for the big rollback segment that the import transactions generate. Do the commit only after importing a whole table or a segment of a table.
- 14.2.10.1.
InnoDBLock Modes - 14.2.10.2.
InnoDBandAUTOCOMMIT - 14.2.10.3.
InnoDBandTRANSACTION ISOLATION LEVEL - 14.2.10.4. Consistent Non-Locking Read
- 14.2.10.5.
SELECT ... FOR UPDATEandSELECT ... LOCK IN SHARE MODELocking Reads - 14.2.10.6. Next-Key Locking: Avoiding the Phantom Problem
- 14.2.10.7. An Example of Consistent Read in
InnoDB - 14.2.10.8. Locks Set by Different SQL Statements in
InnoDB - 14.2.10.9. Implicit Transaction Commit and Rollback
- 14.2.10.10. Deadlock Detection and Rollback
- 14.2.10.11. How to Cope with Deadlocks
In the InnoDB transaction model, the goal is to
combine the best properties of a multi-versioning database with
traditional two-phase locking. InnoDB does
locking on the row level and runs queries as non-locking
consistent reads by default, in the style of Oracle. The lock
table in InnoDB is stored so space-efficiently
that lock escalation is not needed: Typically several users are
allowed to lock every row in the database, or any random subset of
the rows, without InnoDB running out of memory.
InnoDB implements standard row-level locking
where there are two types of locks:
A shared (
S) lock allows a transaction to read a row (tuple).An exclusive (
X) lock allows a transaction to update or delete a row.
If transaction T1 holds a shared
(S) lock on tuple
t, then
A request from some distinct transaction
T2for anSlock ontcan be granted immediately. As a result, bothT1andT2hold anSlock ont.A request from some distinct transaction
T2for anXlock ontcannot be granted immediately.
If a transaction T1 holds an exclusive
(X) lock on tuple
t, then a request from some distinct
transaction T2 for a lock of either type on
t cannot be granted immediately. Instead,
transaction T2 has to wait for transaction
T1 to release its lock on tuple
t.
Additionally, InnoDB supports
multiple granularity locking which allows
coexistence of record locks and locks on entire tables. To make
locking at multiple granularity levels practical, additional
types of locks called intention locks are
used. Intention locks are table locks in
InnoDB. The idea behind intention locks is
for a transaction to indicate which type of lock (shared or
exclusive) it will require later for a row in that table. There
are two types of intention locks used in
InnoDB (assume that transaction
T has requested a lock of the indicated type
on table R):
Intention shared (
IS): TransactionTintends to setSlocks on individual rows in tableR.Intention exclusive (
IX): TransactionTintends to setXlocks on those rows.
The intention locking protocol is as follows:
Before a given transaction can acquire an
Slock on a given row, it must first acquire anISor stronger lock on the table containing that row.Before a given transaction can acquire an
Xlock on a given row, it must first acquire anIXlock on the table containing that row.
These rules can be conveniently summarized by means of a lock type compatibility matrix:
X | IX | S | IS | |
X | Conflict | Conflict | Conflict | Conflict |
IX | Conflict | Compatible | Conflict | Compatible |
S | Conflict | Conflict | Compatible | Compatible |
IS | Conflict | Compatible | Compatible | Compatible |
A lock is granted to a requesting transaction if it is compatible with existing locks. A lock is not granted to a requesting transaction if it conflicts with existing locks. A transaction waits until the conflicting existing lock is released. If a lock request conflicts with an existing lock and cannot be granted because it would cause deadlock, an error occurs.
Thus, intention locks do not block anything except full table
requests (for example, LOCK TABLES ...
WRITE). The main purpose of
IX and IS
locks is to show that someone is locking a row, or going to lock
a row in the table.
The following example illustrates how an error can occur when a lock request would cause a deadlock. The example involves two clients, A and B.
First, client A creates a table containing one row, and then
begins a transaction. Within the transaction, A obtains an
S lock on the row by selecting it in
share mode:
mysql>CREATE TABLE t (i INT) ENGINE = InnoDB;Query OK, 0 rows affected (1.07 sec) mysql>INSERT INTO t (i) VALUES(1);Query OK, 1 row affected (0.09 sec) mysql>START TRANSACTION;Query OK, 0 rows affected (0.00 sec) mysql>SELECT * FROM t WHERE i = 1 LOCK IN SHARE MODE;+------+ | i | +------+ | 1 | +------+ 1 row in set (0.10 sec)
Next, client B begins a transaction and attempts to delete the row from the table:
mysql>START TRANSACTION;Query OK, 0 rows affected (0.00 sec) mysql>DELETE FROM t WHERE i = 1;
The delete operation requires an X
lock. The lock cannot be granted because it is incompatible with
the S lock that client A holds, so
the request goes on the queue of lock requests for the row and
client B blocks.
Finally, client A also attempts to delete the row from the table:
mysql> DELETE FROM t WHERE i = 1;
ERROR 1213 (40001): Deadlock found when trying to get lock;
try restarting transaction
Deadlock occurs here because client A needs an
X lock to delete the row. However,
that lock request cannot be granted because client B already has
a request for an X lock and is
waiting for client A to release its S
lock. Nor can the S lock held by A be
upgraded to an X lock because of the
prior request by B for an X lock. As
a result, InnoDB generates an error for
client A and releases its locks. At that point, the lock request
for client B can be granted and B deletes the row from the
table.
In InnoDB, all user activity occurs inside a
transaction. If the autocommit mode is enabled, each SQL
statement forms a single transaction on its own. By default,
MySQL starts new connections with autocommit enabled.
If the autocommit mode is switched off with SET
AUTOCOMMIT = 0, then we can consider that a user
always has a transaction open. An SQL COMMIT
or ROLLBACK statement ends the current
transaction and a new one starts. A COMMIT
means that the changes made in the current transaction are made
permanent and become visible to other users. A
ROLLBACK statement, on the other hand,
cancels all modifications made by the current transaction. Both
statements release all InnoDB locks that were
set during the current transaction.
If the connection has autocommit enabled, the user can still
perform a multiple-statement transaction by starting it with an
explicit START TRANSACTION or
BEGIN statement and ending it with
COMMIT or ROLLBACK.
In terms of the SQL:1992 transaction isolation levels, the
InnoDB default is REPEATABLE
READ. InnoDB offers all four
transaction isolation levels described by the SQL standard. You
can set the default isolation level for all connections by using
the --transaction-isolation option on the
command line or in an option file. For example, you can set the
option in the [mysqld] section of an option
file like this:
[mysqld]
transaction-isolation = {READ-UNCOMMITTED | READ-COMMITTED
| REPEATABLE-READ | SERIALIZABLE}
A user can change the isolation level for a single session or
for all new incoming connections with the SET
TRANSACTION statement. Its syntax is as follows:
SET [SESSION | GLOBAL] TRANSACTION ISOLATION LEVEL
{READ UNCOMMITTED | READ COMMITTED
| REPEATABLE READ | SERIALIZABLE}
Note that there are hyphens in the level names for the
--transaction-isolation option, but not for the
SET TRANSACTION statement.
The default behavior is to set the isolation level for the next
(not started) transaction. If you use the
GLOBAL keyword, the statement sets the
default transaction level globally for all new connections
created from that point on (but not for existing connections).
You need the SUPER privilege to do this.
Using the SESSION keyword sets the default
transaction level for all future transactions performed on the
current connection.
Any client is free to change the session isolation level (even in the middle of a transaction), or the isolation level for the next transaction.
You can determine the global and session transaction isolation
levels by checking the value of the
tx_isolation system variable with these
statements:
SELECT @@global.tx_isolation; SELECT @@tx_isolation;
In row-level locking, InnoDB uses next-key
locking. That means that besides index records,
InnoDB can also lock the “gap”
preceding an index record to block insertions by other users
immediately before the index record. A next-key lock refers to a
lock that locks an index record and the gap before it. A gap
lock refers to a lock that only locks a gap before some index
record. Next-key locking for searches or index scans can be
disabled by enabling the
innodb_locks_unsafe_for_binlog system
variable.
A detailed description of each isolation level in
InnoDB follows:
READ UNCOMMITTEDSELECTstatements are performed in a non-locking fashion, but a possible earlier version of a record might be used. Thus, using this isolation level, such reads are not consistent. This is also called a “dirty read.” Otherwise, this isolation level works likeREAD COMMITTED.READ COMMITTEDA somewhat Oracle-like isolation level. All
SELECT ... FOR UPDATEandSELECT ... LOCK IN SHARE MODEstatements lock only the index records, not the gaps before them, and thus allow the free insertion of new records next to locked records.UPDATEandDELETEstatements using a unique index with a unique search condition lock only the index record found, not the gap before it. In range-typeUPDATEandDELETEstatements,InnoDBmust set next-key or gap locks and block insertions by other users to the gaps covered by the range. This is necessary because “phantom rows” must be blocked for MySQL replication and recovery to work.Consistent reads behave as in Oracle: Each consistent read, even within the same transaction, sets and reads its own fresh snapshot. See Section 14.2.10.4, “Consistent Non-Locking Read”.
REPEATABLE READThis is the default isolation level of
InnoDB.SELECT ... FOR UPDATE,SELECT ... LOCK IN SHARE MODE,UPDATE, andDELETEstatements that use a unique index with a unique search condition lock only the index record found, not the gap before it. With other search conditions, these operations employ next-key locking, locking the index range scanned with next-key or gap locks, and block new insertions by other users.In consistent reads, there is an important difference from the
READ COMMITTEDisolation level: All consistent reads within the same transaction read the same snapshot established by the first read. This convention means that if you issue several plainSELECTstatements within the same transaction, theseSELECTstatements are consistent also with respect to each other. See Section 14.2.10.4, “Consistent Non-Locking Read”.SERIALIZABLEThis level is like
REPEATABLE READ, butInnoDBimplicitly commits all plainSELECTstatements toSELECT ... LOCK IN SHARE MODE.
A consistent read means that InnoDB uses
multi-versioning to present to a query a snapshot of the
database at a point in time. The query see the changes made by
those transactions that committed before that point of time, and
no changes made by later or uncommitted transactions. The
exception to this rule is that the query sees the changes made
by earlier statements within the same transaction. Note that the
exception to the rule causes the following anomaly: if you
update some rows in a table, a SELECT will
see the latest version of the updated rows, while it sees the
old version of other rows. If other users simultaneously update
the same table, the anomaly means that you may see the table in
a state that never existed in the database.
If you are running with the default REPEATABLE
READ isolation level, all consistent reads within the
same transaction read the snapshot established by the first such
read in that transaction. You can get a fresher snapshot for
your queries by committing the current transaction and after
that issuing new queries.
Consistent read is the default mode in which
InnoDB processes SELECT
statements in READ COMMITTED and
REPEATABLE READ isolation levels. A
consistent read does not set any locks on the tables it
accesses, and therefore other users are free to modify those
tables at the same time a consistent read is being performed on
the table.
Note that consistent read does not work over DROP
TABLE and over ALTER TABLE.
Consistent read does not work over DROP TABLE
because MySQL can't use a table that has been dropped and
InnoDB destroys the table. Consistent read
does not work over ALTER TABLE because
ALTER TABLE works by making a temporary copy
of the original table and deleting the original table when the
temporary copy is built. When you reissue a consistent read
within a transaction, rows in the new table are not visible
because those rows did not exist when the transaction's snapshot
was taken.
In some circumstances, a consistent read is not convenient. For
example, you might want to add a new row into your table
child, and make sure that the child has a
parent in table parent. The following example
shows how to implement referential integrity in your application
code.
Suppose that you use a consistent read to read the table
parent and indeed see the parent of the child
in the table. Can you safely add the child row to table
child? No, because it may happen that
meanwhile some other user deletes the parent row from the table
parent without you being aware of it.
The solution is to perform the SELECT in a
locking mode using LOCK IN SHARE MODE:
SELECT * FROM parent WHERE NAME = 'Jones' LOCK IN SHARE MODE;
Performing a read in share mode means that we read the latest
available data, and set a shared mode lock on the rows we read.
A shared mode lock prevents others from updating or deleting the
row we have read. Also, if the latest data belongs to a yet
uncommitted transaction of another client connection, we wait
until that transaction commits. After we see that the preceding
query returns the parent 'Jones', we can
safely add the child record to the child
table and commit our transaction.
Let us look at another example: We have an integer counter field
in a table child_codes that we use to assign
a unique identifier to each child added to table
child. Obviously, using a consistent read or
a shared mode read to read the present value of the counter is
not a good idea because two users of the database may then see
the same value for the counter, and a duplicate-key error occurs
if two users attempt to add children with the same identifier to
the table.
Here, LOCK IN SHARE MODE is not a good
solution because if two users read the counter at the same time,
at least one of them ends up in deadlock when attempting to
update the counter.
In this case, there are two good ways to implement the reading
and incrementing of the counter: (1) update the counter first by
incrementing it by 1 and only after that read it, or (2) read
the counter first with a lock mode FOR
UPDATE, and increment after that. The latter approach
can be implemented as follows:
SELECT counter_field FROM child_codes FOR UPDATE; UPDATE child_codes SET counter_field = counter_field + 1;
A SELECT ... FOR UPDATE reads the latest
available data, setting exclusive locks on each row it reads.
Thus, it sets the same locks a searched SQL
UPDATE would set on the rows.
The preceding description is merely an example of how
SELECT ... FOR UPDATE works. In MySQL, the
specific task of generating a unique identifier actually can be
accomplished using only a single access to the table:
UPDATE child_codes SET counter_field = LAST_INSERT_ID(counter_field + 1); SELECT LAST_INSERT_ID();
The SELECT statement merely retrieves the
identifier information (specific to the current connection). It
does not access any table.
Locks set by IN SHARE MODE and FOR
UPDATE reads are released when the transaction is
committed or rolled back.
Note
Locking of rows for update using SELECT FOR
UPDATE only applies when
AUTOCOMMIT is switched off. If
AUTOCOMMIT is on, then the rows matching
the specification are not locked.
In row-level locking, InnoDB uses an
algorithm called next-key locking.
InnoDB performs the row-level locking in such
a way that when it searches or scans an index of a table, it
sets shared or exclusive locks on the index records it
encounters. Thus, the row-level locks are actually index record
locks.
The next-key locks that InnoDB sets on index
records also affect the “gap” before that index
record. If a user has a shared or exclusive lock on record
R in an index, another user cannot insert a
new index record immediately before R in the
index order. (A gap lock refers to a lock that only locks a gap
before some index record.)
This next-key locking of gaps is done to prevent the so-called
“phantom problem.” Suppose that you want to read
and lock all children from the child table
having an identifier value greater than 100, with the intention
of updating some column in the selected rows later:
SELECT * FROM child WHERE id > 100 FOR UPDATE;
Suppose that there is an index on the id
column. The query scans that index starting from the first
record where id is bigger than 100. If the
locks set on the index records would not lock out inserts made
in the gaps, a new row might meanwhile be inserted to the table.
If you execute the same SELECT within the
same transaction, you would see a new row in the result set
returned by the query. This is contrary to the isolation
principle of transactions: A transaction should be able to run
so that the data it has read does not change during the
transaction. If we regard a set of rows as a data item, the new
“phantom” child would violate this isolation
principle.
When InnoDB scans an index, it can also lock
the gap after the last record in the index. Just that happens in
the previous example: The locks set by InnoDB
prevent any insert to the table where id
would be bigger than 100.
You can use next-key locking to implement a uniqueness check in your application: If you read your data in share mode and do not see a duplicate for a row you are going to insert, then you can safely insert your row and know that the next-key lock set on the successor of your row during the read prevents anyone meanwhile inserting a duplicate for your row. Thus, the next-key locking allows you to “lock” the non-existence of something in your table.
Suppose that you are running in the default REPEATABLE
READ isolation level. When you issue a consistent read
(that is, an ordinary SELECT statement),
InnoDB gives your transaction a timepoint
according to which your query sees the database. If another
transaction deletes a row and commits after your timepoint was
assigned, you do not see the row as having been deleted. Inserts
and updates are treated similarly.
You can advance your timepoint by committing your transaction
and then doing another SELECT.
This is called multi-versioned concurrency control.
User A User B
SET AUTOCOMMIT=0; SET AUTOCOMMIT=0;
time
| SELECT * FROM t;
| empty set
| INSERT INTO t VALUES (1, 2);
|
v SELECT * FROM t;
empty set
COMMIT;
SELECT * FROM t;
empty set
COMMIT;
SELECT * FROM t;
---------------------
| 1 | 2 |
---------------------
1 row in set
In this example, user A sees the row inserted by B only when B has committed the insert and A has committed as well, so that the timepoint is advanced past the commit of B.
If you want to see the “freshest” state of the
database, you should use either the READ
COMMITTED isolation level or a locking read:
SELECT * FROM t LOCK IN SHARE MODE;
A locking read, an UPDATE, or a
DELETE generally set record locks on every
index record that is scanned in the processing of the SQL
statement. It does not matter if there are
WHERE conditions in the statement that would
exclude the row. InnoDB does not remember the
exact WHERE condition, but only knows which
index ranges were scanned. The record locks are normally
next-key locks that also block inserts to the “gap”
immediately before the record.
If the locks to be set are exclusive, InnoDB
always retrieves also the clustered index record and sets a lock
on it.
If you do not have indexes suitable for your statement and MySQL has to scan the whole table to process the statement, every row of the table becomes locked, which in turn blocks all inserts by other users to the table. It is important to create good indexes so that your queries do not unnecessarily need to scan many rows.
InnoDB sets specific types of locks as
follows:
SELECT ... FROMis a consistent read, reading a snapshot of the database and setting no locks unless the transaction isolation level is set toSERIALIZABLE. ForSERIALIZABLElevel, this sets shared next-key locks on the index records it encounters.SELECT ... FROM ... LOCK IN SHARE MODEsets shared next-key locks on all index records the read encounters.SELECT ... FROM ... FOR UPDATEsets exclusive next-key locks on all index records the read encounters.INSERT INTO ... VALUES (...)sets an exclusive lock on the inserted row. Note that this lock is not a next-key lock and does not prevent other users from inserting to the gap before the inserted row. If a duplicate-key error occurs, a shared lock on the duplicate index record is set.While initializing a previously specified
AUTO_INCREMENTcolumn on a table,InnoDBsets an exclusive lock on the end of the index associated with theAUTO_INCREMENTcolumn. In accessing the auto-increment counter,InnoDBuses a specific table lock modeAUTO-INCwhere the lock lasts only to the end of the current SQL statement, not to the end of the entire transaction. Note that other clients cannot insert into the table while theAUTO-INCtable lock is held; see Section 14.2.10.2, “InnoDBandAUTOCOMMIT”.InnoDBfetches the value of a previously initializedAUTO_INCREMENTcolumn without setting any locks.INSERT INTO T SELECT ... FROM S WHERE ...sets an exclusive (non-next-key) lock on each row inserted intoT.InnoDBsets shared next-key locks onS, unlessinnodb_locks_unsafe_for_binlogis enabled, in which case it does the search onSas a consistent read.InnoDBhas to set locks in the latter case: In roll-forward recovery from a backup, every SQL statement has to be executed in exactly the same way it was done originally.CREATE TABLE ... SELECT ...performs theSELECTas a consistent read or with shared locks, as in the previous item.REPLACEis done like an insert if there is no collision on a unique key. Otherwise, an exclusive next-key lock is placed on the row that has to be updated.UPDATE ... WHERE ...sets an exclusive next-key lock on every record the search encounters.DELETE FROM ... WHERE ...sets an exclusive next-key lock on every record the search encounters.If a
FOREIGN KEYconstraint is defined on a table, any insert, update, or delete that requires the constraint condition to be checked sets shared record-level locks on the records that it looks at to check the constraint.InnoDBalso sets these locks in the case where the constraint fails.LOCK TABLESsets table locks, but it is the higher MySQL layer above theInnoDBlayer that sets these locks.InnoDBis aware of table locks ifinnodb_table_locks=1(the default) andAUTOCOMMIT=0, and the MySQL layer aboveInnoDBknows about row-level locks. Otherwise,InnoDB's automatic deadlock detection cannot detect deadlocks where such table locks are involved. Also, because the higher MySQL layer does not know about row-level locks, it is possible to get a table lock on a table where another user currently has row-level locks. However, this does not endanger transaction integrity, as discussed in Section 14.2.10.10, “Deadlock Detection and Rollback”. See also Section 14.2.16, “Restrictions onInnoDBTables”.
By default, MySQL begins each client connection with autocommit
mode enabled. When autocommit is enabled, MySQL does a commit
after each SQL statement if that statement did not return an
error. If an SQL statement returns an error, the commit or
rollback behavior depends on the error. See
Section 14.2.15, “InnoDB Error Handling”.
If you have the autocommit mode off and close a connection without explicitly committing the final transaction, MySQL rolls back that transaction.
Each of the following statements (and any synonyms for them)
implicitly end a transaction, as if you had done a
COMMIT before executing the statement:
ALTER TABLE,BEGIN,CREATE INDEX,DROP INDEX,DROP TABLE,LOAD MASTER DATA,LOCK TABLES,LOAD DATA INFILE,RENAME TABLE,SET AUTOCOMMIT=1,START TRANSACTION,UNLOCK TABLES.Beginning with MySQL 5.0.8, The
CREATE TABLE,CREATE DATABASEDROP DATABASE, andTRUNCATE TABLEstatements cause an implicit commit. Beginning with MySQL 5.0.13, theALTER FUNCTION,ALTER PROCEDURE,CREATE FUNCTION,CREATE PROCEDURE,DROP FUNCTION, andDROP PROCEDUREstatements cause an implicit commit. Beginning with MySQL 5.0.15, theALTER VIEW,CREATE TRIGGER,CREATE USER,CREATE VIEW,DROP TRIGGER,DROP USER,DROP VIEW, andRENAME USERstatements cause an implicit commit.UNLOCK TABLEScommits a transaction only if any tables currently have been locked withLOCK TABLES. This does not occur forUNLOCK TABLESfollowingFLUSH TABLES WITH READ LOCKbecause the latter statement does not acquire table-level locks.The
CREATE TABLEstatement inInnoDBis processed as a single transaction. This means that aROLLBACKfrom the user does not undoCREATE TABLEstatements the user made during that transaction.CREATE TABLEandDROP TABLEdo not commit a transaction if theTEMPORARYkeyword is used. (This does not apply to other operations on temporary tables such asCREATE INDEX, which do cause a commit.)Prior to MySQL 5.0.26,
LOAD DATA INFILEalso caused an implicit commit forInnoDBtables (as was true for all storage engines).
Transactions cannot be nested. This is a consequence of the
implicit COMMIT performed for any current
transaction when you issue a START
TRANSACTION statement or one of its synonyms.
Statements that cause implicit commit cannot be used in an XA
transaction while the transaction is in an
ACTIVE state.
The BEGIN statement differs from the use of
the BEGIN keyword that starts a
BEGIN ... END compound statement. The latter
does not cause an implicit commit. See
Section 17.2.5, “BEGIN ... END Compound Statement Syntax”.
InnoDB automatically detects a deadlock of
transactions and rolls back a transaction or transactions to
break the deadlock. InnoDB tries to pick
small transactions to roll back, where the size of a transaction
is determined by the number of rows inserted, updated, or
deleted.
InnoDB is aware of table locks if
innodb_table_locks=1 (the default) and
AUTOCOMMIT=0, and the MySQL layer above it
knows about row-level locks. Otherwise,
InnoDB cannot detect deadlocks where a table
lock set by a MySQL LOCK TABLES statement or
a lock set by a storage engine other than
InnoDB is involved. You must resolve these
situations by setting the value of the
innodb_lock_wait_timeout system variable.
When InnoDB performs a complete rollback of a
transaction, all locks set by the transaction are released.
However, if just a single SQL statement is rolled back as a
result of an error, some of the locks set by the statement may
be preserved. This happens because InnoDB
stores row locks in a format such that it cannot know afterward
which lock was set by which statement.
Deadlocks are a classic problem in transactional databases, but they are not dangerous unless they are so frequent that you cannot run certain transactions at all. Normally, you must write your applications so that they are always prepared to re-issue a transaction if it gets rolled back because of a deadlock.
InnoDB uses automatic row-level locking. You
can get deadlocks even in the case of transactions that just
insert or delete a single row. That is because these operations
are not really “atomic”; they automatically set
locks on the (possibly several) index records of the row
inserted or deleted.
You can cope with deadlocks and reduce the likelihood of their occurrence with the following techniques:
Use
SHOW ENGINE INNODB STATUSto determine the cause of the latest deadlock. That can help you to tune your application to avoid deadlocks.Always be prepared to re-issue a transaction if it fails due to deadlock. Deadlocks are not dangerous. Just try again.
Commit your transactions often. Small transactions are less prone to collision.
If you are using locking reads (
SELECT ... FOR UPDATEor... LOCK IN SHARE MODE), try using a lower isolation level such asREAD COMMITTED.Access your tables and rows in a fixed order. Then transactions form well-defined queues and do not deadlock.
Add well-chosen indexes to your tables. Then your queries need to scan fewer index records and consequently set fewer locks. Use
EXPLAIN SELECTto determine which indexes the MySQL server regards as the most appropriate for your queries.Use less locking. If you can afford to allow a
SELECTto return data from an old snapshot, do not add the clauseFOR UPDATEorLOCK IN SHARE MODEto it. Using theREAD COMMITTEDisolation level is good here, because each consistent read within the same transaction reads from its own fresh snapshot.If nothing else helps, serialize your transactions with table-level locks. The correct way to use
LOCK TABLESwith transactional tables, such asInnoDBtables, is to setAUTOCOMMIT = 0and not to callUNLOCK TABLESuntil after you commit the transaction explicitly. For example, if you need to write to tablet1and read from tablet2, you can do this:SET AUTOCOMMIT=0; LOCK TABLES t1 WRITE, t2 READ, ...;
... do something with tables t1 and t2 here ...COMMIT; UNLOCK TABLES;Table-level locks make your transactions queue nicely, and deadlocks are avoided.
Another way to serialize transactions is to create an auxiliary “semaphore” table that contains just a single row. Have each transaction update that row before accessing other tables. In that way, all transactions happen in a serial fashion. Note that the
InnoDBinstant deadlock detection algorithm also works in this case, because the serializing lock is a row-level lock. With MySQL table-level locks, the timeout method must be used to resolve deadlocks.In applications that use the
LOCK TABLEScommand, MySQL does not setInnoDBtable locks ifAUTOCOMMIT=1.
In
InnoDB, having a longPRIMARY KEYwastes a lot of disk space because its value must be stored with every secondary index record. (See Section 14.2.13, “InnoDBTable and Index Structures”.) Create anAUTO_INCREMENTcolumn as the primary key if your primary key is long.If the Unix
toptool or the Windows Task Manager shows that the CPU usage percentage with your workload is less than 70%, your workload is probably disk-bound. Maybe you are making too many transaction commits, or the buffer pool is too small. Making the buffer pool bigger can help, but do not set it equal to more than 80% of physical memory.Wrap several modifications into one transaction.
InnoDBmust flush the log to disk at each transaction commit if that transaction made modifications to the database. The rotation speed of a disk is typically at most 167 revolutions/second, which constrains the number of commits to the same 167th of a second if the disk does not “fool” the operating system.If you can afford the loss of some of the latest committed transactions if a crash occurs, you can set the
innodb_flush_log_at_trx_commitparameter to 0.InnoDBtries to flush the log once per second anyway, although the flush is not guaranteed.Make your log files big, even as big as the buffer pool. When
InnoDBhas written the log files full, it has to write the modified contents of the buffer pool to disk in a checkpoint. Small log files cause many unnecessary disk writes. The drawback of big log files is that the recovery time is longer.Make the log buffer quite large as well (on the order of 8MB).
Use the
VARCHARdata type instead ofCHARif you are storing variable-length strings or if the column may contain manyNULLvalues. ACHAR(column always takesN)Ncharacters to store data, even if the string is shorter or its value isNULL. Smaller tables fit better in the buffer pool and reduce disk I/O.When using
row_format=compact(the defaultInnoDBrecord format in MySQL 5.0) and variable-length character sets, such asutf8orsjis,CHAR(will occupy a variable amount of space, at leastN)Nbytes.In some versions of GNU/Linux and Unix, flushing files to disk with the Unix
fsync()call (whichInnoDBuses by default) and other similar methods is surprisingly slow. If you are dissatisfied with database write performance, you might try setting theinnodb_flush_methodparameter toO_DSYNC. AlthoughO_DSYNCseems to be slower on most systems, yours might not be one of them.When using the
InnoDBstorage engine on Solaris 10 for x86_64 architecture (AMD Opteron), it is important to mount any filesystems used for storingInnoDB-related files using theforcedirectiooption. (The default on Solaris 10/x86_64 is not to use this option.) Failure to useforcedirectiocauses a serious degradation ofInnoDB's speed and performance on this platform.When using the
InnoDBstorage engine with a largeinnodb_buffer_pool_sizevalue on any release of Solaris 2.6 and up and any platform (sparc/x86/x64/amd64), a significant performance gain can be achieved by placingInnoDBdata files and log files on raw devices or on a separate direct I/O UFS filesystem (using mount optionforcedirectio; seemount_ufs(1M)). Users of the Veritas filesystem VxFS should use the mount optionconvosync=direct.Other MySQL data files, such as those for
MyISAMtables, should not be placed on a direct I/O filesystem. Executables or libraries must not be placed on a direct I/O filesystem.When importing data into
InnoDB, make sure that MySQL does not have autocommit mode enabled because that requires a log flush to disk for every insert. To disable autocommit during your import operation, surround it withSET AUTOCOMMITandCOMMITstatements:SET AUTOCOMMIT=0;
... SQL import statements ...COMMIT;If you use the mysqldump option
--opt, you get dump files that are fast to import into anInnoDBtable, even without wrapping them with theSET AUTOCOMMITandCOMMITstatements.Beware of big rollbacks of mass inserts:
InnoDBuses the insert buffer to save disk I/O in inserts, but no such mechanism is used in a corresponding rollback. A disk-bound rollback can take 30 times as long to perform as the corresponding insert. Killing the database process does not help because the rollback starts again on server startup. The only way to get rid of a runaway rollback is to increase the buffer pool so that the rollback becomes CPU-bound and runs fast, or to use a special procedure. See Section 14.2.8.1, “ForcingInnoDBRecovery”.Beware also of other big disk-bound operations. Use
DROP TABLEandCREATE TABLEto empty a table, notDELETE FROM.tbl_nameUse the multiple-row
INSERTsyntax to reduce communication overhead between the client and the server if you need to insert many rows:INSERT INTO yourtable VALUES (1,2), (5,5), ...;
This tip is valid for inserts into any table, not just
InnoDBtables.If you have
UNIQUEconstraints on secondary keys, you can speed up table imports by temporarily turning off the uniqueness checks during the import session:SET UNIQUE_CHECKS=0;
... import operation ...SET UNIQUE_CHECKS=1;For big tables, this saves a lot of disk I/O because
InnoDBcan use its insert buffer to write secondary index records in a batch. Be certain that the data contains no duplicate keys.UNIQUE_CHECKSallows but does not require storage engines to ignore duplicate keys.If you have
FOREIGN KEYconstraints in your tables, you can speed up table imports by turning the foreign key checks off for the duration of the import session:SET FOREIGN_KEY_CHECKS=0;
... import operation ...SET FOREIGN_KEY_CHECKS=1;For big tables, this can save a lot of disk I/O.
If you often have recurring queries for tables that are not updated frequently, use the query cache:
[mysqld] query_cache_type = ON query_cache_size = 10M
Unlike
MyISAM,InnoDBdoes not store an index cardinality value in its tables. Instead,InnoDBcomputes a cardinality for a table the first time it accesses it after startup. With a large number of tables, this might take significant time. It is the initial table open operation that is important, so to “warm up” a table for later use, you might want to use it immediately after start up by issuing a statement such asSELECT 1 FROM.tbl_nameLIMIT 1
MySQL Enterprise For optimization recommendations geared to your specific circumstances subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
InnoDB includes InnoDB
Monitors that print information about the
InnoDB internal state. You can use the
SHOW ENGINE INNODB STATUS SQL statement at
any time to fetch the output of the standard
InnoDB Monitor to your SQL client. This
information is useful in performance tuning. (If you are using
the mysql interactive SQL client, the output
is more readable if you replace the usual semicolon statement
terminator with \G.) For a discussion of
InnoDB lock modes, see
Section 14.2.10.1, “InnoDB Lock Modes”.
mysql> SHOW ENGINE INNODB STATUS\G
Another way to use InnoDB Monitors is to let
them periodically write data to the standard output of the
mysqld server. In this case, no output is
sent to clients. When switched on, InnoDB
Monitors print data about every 15 seconds. Server output
usually is directed to the .err log in the
MySQL data directory. This data is useful in performance tuning.
On Windows, you must start the server from a command prompt in a
console window with the --console option if you
want to direct the output to the window rather than to the error
log.
Monitor output includes the following types of information:
Table and record locks held by each active transaction
Lock waits of a transactions
Semaphore waits of threads
Pending file I/O requests
Buffer pool statistics
Purge and insert buffer merge activity of the main
InnoDBthread
To cause the standard InnoDB Monitor to write
to the standard output of mysqld, use the
following SQL statement:
CREATE TABLE innodb_monitor (a INT) ENGINE=INNODB;
The monitor can be stopped by issuing the following statement:
DROP TABLE innodb_monitor;
The CREATE TABLE syntax is just a way to pass
a command to the InnoDB engine through
MySQL's SQL parser: The only things that matter are the table
name innodb_monitor and that it be an
InnoDB table. The structure of the table is
not relevant at all for the InnoDB Monitor.
If you shut down the server, the monitor does not restart
automatically when you restart the server. You must drop the
monitor table and issue a new CREATE TABLE
statement to start the monitor. (This syntax may change in a
future release.)
You can use innodb_lock_monitor in a similar
fashion. This is the same as innodb_monitor,
except that it also provides a great deal of lock information. A
separate innodb_tablespace_monitor prints a
list of created file segments existing in the tablespace and
validates the tablespace allocation data structures. In
addition, there is innodb_table_monitor with
which you can print the contents of the
InnoDB internal data dictionary.
A sample of InnoDB Monitor output:
mysql> SHOW ENGINE INNODB STATUS\G
*************************** 1. row ***************************
Status:
=====================================
030709 13:00:59 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 18 seconds
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 413452, signal count 378357
--Thread 32782 has waited at btr0sea.c line 1477 for 0.00 seconds the
semaphore: X-lock on RW-latch at 41a28668 created in file btr0sea.c line 135
a writer (thread id 32782) has reserved it in mode wait exclusive
number of readers 1, waiters flag 1
Last time read locked in file btr0sea.c line 731
Last time write locked in file btr0sea.c line 1347
Mutex spin waits 0, rounds 0, OS waits 0
RW-shared spins 108462, OS waits 37964; RW-excl spins 681824, OS waits
375485
------------------------
LATEST FOREIGN KEY ERROR
------------------------
030709 13:00:59 Transaction:
TRANSACTION 0 290328284, ACTIVE 0 sec, process no 3195, OS thread id 34831
inserting
15 lock struct(s), heap size 2496, undo log entries 9
MySQL thread id 25, query id 4668733 localhost heikki update
insert into ibtest11a (D, B, C) values (5, 'khDk' ,'khDk')
Foreign key constraint fails for table test/ibtest11a:
,
CONSTRAINT `0_219242` FOREIGN KEY (`A`, `D`) REFERENCES `ibtest11b` (`A`,
`D`) ON DELETE CASCADE ON UPDATE CASCADE
Trying to add in child table, in index PRIMARY tuple:
0: len 4; hex 80000101; asc ....;; 1: len 4; hex 80000005; asc ....;; 2:
len 4; hex 6b68446b; asc khDk;; 3: len 6; hex 0000114e0edc; asc ...N..;; 4:
len 7; hex 00000000c3e0a7; asc .......;; 5: len 4; hex 6b68446b; asc khDk;;
But in parent table test/ibtest11b, in index PRIMARY,
the closest match we can find is record:
RECORD: info bits 0 0: len 4; hex 8000015b; asc ...[;; 1: len 4; hex
80000005; asc ....;; 2: len 3; hex 6b6864; asc khd;; 3: len 6; hex
0000111ef3eb; asc ......;; 4: len 7; hex 800001001e0084; asc .......;; 5:
len 3; hex 6b6864; asc khd;;
------------------------
LATEST DETECTED DEADLOCK
------------------------
030709 12:59:58
*** (1) TRANSACTION:
TRANSACTION 0 290252780, ACTIVE 1 sec, process no 3185, OS thread id 30733
inserting
LOCK WAIT 3 lock struct(s), heap size 320, undo log entries 146
MySQL thread id 21, query id 4553379 localhost heikki update
INSERT INTO alex1 VALUES(86, 86, 794,'aA35818','bb','c79166','d4766t',
'e187358f','g84586','h794',date_format('2001-04-03 12:54:22','%Y-%m-%d
%H:%i'),7
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 0 page no 48310 n bits 568 table test/alex1 index
symbole trx id 0 290252780 lock mode S waiting
Record lock, heap no 324 RECORD: info bits 0 0: len 7; hex 61613335383138;
asc aa35818;; 1:
*** (2) TRANSACTION:
TRANSACTION 0 290251546, ACTIVE 2 sec, process no 3190, OS thread id 32782
inserting
130 lock struct(s), heap size 11584, undo log entries 437
MySQL thread id 23, query id 4554396 localhost heikki update
REPLACE INTO alex1 VALUES(NULL, 32, NULL,'aa3572','','c3572','d6012t','',
NULL,'h396', NULL, NULL, 7.31,7.31,7.31,200)
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 0 page no 48310 n bits 568 table test/alex1 index
symbole trx id 0 290251546 lock_mode X locks rec but not gap
Record lock, heap no 324 RECORD: info bits 0 0: len 7; hex 61613335383138;
asc aa35818;; 1:
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 0 page no 48310 n bits 568 table test/alex1 index
symbole trx id 0 290251546 lock_mode X locks gap before rec insert intention
waiting
Record lock, heap no 82 RECORD: info bits 0 0: len 7; hex 61613335373230;
asc aa35720;; 1:
*** WE ROLL BACK TRANSACTION (1)
------------
TRANSACTIONS
------------
Trx id counter 0 290328385
Purge done for trx's n:o < 0 290315608 undo n:o < 0 17
Total number of lock structs in row lock hash table 70
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 0 0, not started, process no 3491, OS thread id 42002
MySQL thread id 32, query id 4668737 localhost heikki
show innodb status
---TRANSACTION 0 290328384, ACTIVE 0 sec, process no 3205, OS thread id
38929 inserting
1 lock struct(s), heap size 320
MySQL thread id 29, query id 4668736 localhost heikki update
insert into speedc values (1519229,1, 'hgjhjgghggjgjgjgjgjggjgjgjgjgjgggjgjg
jlhhgghggggghhjhghgggggghjhghghghghghhhhghghghjhhjghjghjkghjghjghjghjfhjfh
---TRANSACTION 0 290328383, ACTIVE 0 sec, process no 3180, OS thread id
28684 committing
1 lock struct(s), heap size 320, undo log entries 1
MySQL thread id 19, query id 4668734 localhost heikki update
insert into speedcm values (1603393,1, 'hgjhjgghggjgjgjgjgjggjgjgjgjgjgggjgj
gjlhhgghggggghhjhghgggggghjhghghghghghhhhghghghjhhjghjghjkghjghjghjghjfhjf
---TRANSACTION 0 290328327, ACTIVE 0 sec, process no 3200, OS thread id
36880 starting index read
LOCK WAIT 2 lock struct(s), heap size 320
MySQL thread id 27, query id 4668644 localhost heikki Searching rows for
update
update ibtest11a set B = 'kHdkkkk' where A = 89572
------- TRX HAS BEEN WAITING 0 SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 0 page no 65556 n bits 232 table test/ibtest11a index
PRIMARY trx id 0 290328327 lock_mode X waiting
Record lock, heap no 1 RECORD: info bits 0 0: len 9; hex 73757072656d756d00;
asc supremum.;;
------------------
---TRANSACTION 0 290328284, ACTIVE 0 sec, process no 3195, OS thread id
34831 rollback of SQL statement
ROLLING BACK 14 lock struct(s), heap size 2496, undo log entries 9
MySQL thread id 25, query id 4668733 localhost heikki update
insert into ibtest11a (D, B, C) values (5, 'khDk' ,'khDk')
---TRANSACTION 0 290327208, ACTIVE 1 sec, process no 3190, OS thread id
32782
58 lock struct(s), heap size 5504, undo log entries 159
MySQL thread id 23, query id 4668732 localhost heikki update
REPLACE INTO alex1 VALUES(86, 46, 538,'aa95666','bb','c95666','d9486t',
'e200498f','g86814','h538',date_format('2001-04-03 12:54:22','%Y-%m-%d
%H:%i'),
---TRANSACTION 0 290323325, ACTIVE 3 sec, process no 3185, OS thread id
30733 inserting
4 lock struct(s), heap size 1024, undo log entries 165
MySQL thread id 21, query id 4668735 localhost heikki update
INSERT INTO alex1 VALUES(NULL, 49, NULL,'aa42837','','c56319','d1719t','',
NULL,'h321', NULL, NULL, 7.31,7.31,7.31,200)
--------
FILE I/O
--------
I/O thread 0 state: waiting for i/o request (insert buffer thread)
I/O thread 1 state: waiting for i/o request (log thread)
I/O thread 2 state: waiting for i/o request (read thread)
I/O thread 3 state: waiting for i/o request (write thread)
Pending normal aio reads: 0, aio writes: 0,
ibuf aio reads: 0, log i/o's: 0, sync i/o's: 0
Pending flushes (fsync) log: 0; buffer pool: 0
151671 OS file reads, 94747 OS file writes, 8750 OS fsyncs
25.44 reads/s, 18494 avg bytes/read, 17.55 writes/s, 2.33 fsyncs/s
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf for space 0: size 1, free list len 19, seg size 21,
85004 inserts, 85004 merged recs, 26669 merges
Hash table size 207619, used cells 14461, node heap has 16 buffer(s)
1877.67 hash searches/s, 5121.10 non-hash searches/s
---
LOG
---
Log sequence number 18 1212842764
Log flushed up to 18 1212665295
Last checkpoint at 18 1135877290
0 pending log writes, 0 pending chkp writes
4341 log i/o's done, 1.22 log i/o's/second
----------------------
BUFFER POOL AND MEMORY
----------------------
Total memory allocated 84966343; in additional pool allocated 1402624
Buffer pool size 3200
Free buffers 110
Database pages 3074
Modified db pages 2674
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages read 171380, created 51968, written 194688
28.72 reads/s, 20.72 creates/s, 47.55 writes/s
Buffer pool hit rate 999 / 1000
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue
Main thread process no. 3004, id 7176, state: purging
Number of rows inserted 3738558, updated 127415, deleted 33707, read 755779
1586.13 inserts/s, 50.89 updates/s, 28.44 deletes/s, 107.88 reads/s
----------------------------
END OF INNODB MONITOR OUTPUT
============================
Some notes on the output:
If the
TRANSACTIONSsection reports lock waits, your applications may have lock contention. The output can also help to trace the reasons for transaction deadlocks.The
SEMAPHORESsection reports threads waiting for a semaphore and statistics on how many times threads have needed a spin or a wait on a mutex or a rw-lock semaphore. A large number of threads waiting for semaphores may be a result of disk I/O, or contention problems insideInnoDB. Contention can be due to heavy parallelism of queries or problems in operating system thread scheduling. Settinginnodb_thread_concurrencysmaller than the default value can help in such situations.The
BUFFER POOL AND MEMORYsection gives you statistics on pages read and written. You can calculate from these numbers how many data file I/O operations your queries currently are doing.The
ROW OPERATIONSsection shows what the main thread is doing.
InnoDB sends diagnostic output to
stderr or to files rather than to
stdout or fixed-size memory buffers, to avoid
potential buffer overflows. As a side effect, the output of
SHOW ENGINE INNODB STATUS is written to a
status file in the MySQL data directory every fifteen seconds.
The name of the file is
innodb_status.,
where pidpid is the server process ID.
InnoDB removes the file for a normal
shutdown. If abnormal shutdowns have occurred, instances of
these status files may be present and must be removed manually.
Before removing them, you might want to examine them to see
whether they contain useful information about the cause of
abnormal shutdowns. The
innodb_status.
file is created only if the configuration option
pidinnodb_status_file=1 is set.
Because InnoDB is a multi-versioned storage
engine, it must keep information about old versions of rows in the
tablespace. This information is stored in a data structure called
a rollback segment (after an analogous data
structure in Oracle).
Internally, InnoDB adds two fields to each row
stored in the database. A 6-byte field indicates the transaction
identifier for the last transaction that inserted or updated the
row. Also, a deletion is treated internally as an update where a
special bit in the row is set to mark it as deleted. Each row also
contains a 7-byte field called the roll pointer. The roll pointer
points to an undo log record written to the rollback segment. If
the row was updated, the undo log record contains the information
necessary to rebuild the content of the row before it was updated.
InnoDB uses the information in the rollback
segment to perform the undo operations needed in a transaction
rollback. It also uses the information to build earlier versions
of a row for a consistent read.
Undo logs in the rollback segment are divided into insert and
update undo logs. Insert undo logs are needed only in transaction
rollback and can be discarded as soon as the transaction commits.
Update undo logs are used also in consistent reads, but they can
be discarded only after there is no transaction present for which
InnoDB has assigned a snapshot that in a
consistent read could need the information in the update undo log
to build an earlier version of a database row.
You must remember to commit your transactions regularly, including
those transactions that issue only consistent reads. Otherwise,
InnoDB cannot discard data from the update undo
logs, and the rollback segment may grow too big, filling up your
tablespace.
The physical size of an undo log record in the rollback segment is typically smaller than the corresponding inserted or updated row. You can use this information to calculate the space need for your rollback segment.
In the InnoDB multi-versioning scheme, a row is
not physically removed from the database immediately when you
delete it with an SQL statement. Only when
InnoDB can discard the update undo log record
written for the deletion can it also physically remove the
corresponding row and its index records from the database. This
removal operation is called a purge, and it is quite fast, usually
taking the same order of time as the SQL statement that did the
deletion.
In a scenario where the user inserts and deletes rows in smallish
batches at about the same rate in the table, it is possible that
the purge thread starts to lag behind, and the table grows bigger
and bigger, making everything disk-bound and very slow. Even if
the table carries just 10MB of useful data, it may grow to occupy
10GB with all the “dead” rows. In such a case, it
would be good to throttle new row operations, and allocate more
resources to the purge thread. The
innodb_max_purge_lag system variable exists for
exactly this purpose. See Section 14.2.4, “InnoDB Startup Options and System Variables”, for
more information.
MySQL stores its data dictionary information for tables in
.frm files in database directories. This is
true for all MySQL storage engines. But every
InnoDB table also has its own entry in the
InnoDB internal data dictionary inside the
tablespace. When MySQL drops a table or a database, it has to
delete both an .frm file or files, and the
corresponding entries inside the InnoDB data
dictionary. This is the reason why you cannot move
InnoDB tables between databases simply by
moving the .frm files.
Every InnoDB table has a special index called
the clustered index where the data for the
rows is stored. If you define a PRIMARY KEY on
your table, the index of the primary key is the clustered index.
If you do not define a PRIMARY KEY for your
table, MySQL picks the first UNIQUE index that
has only NOT NULL columns as the primary key
and InnoDB uses it as the clustered index. If
there is no such index in the table, InnoDB
internally generates a clustered index where the rows are ordered
by the row ID that InnoDB assigns to the rows
in such a table. The row ID is a 6-byte field that increases
monotonically as new rows are inserted. Thus, the rows ordered by
the row ID are physically in insertion order.
Accessing a row through the clustered index is fast because the row data is on the same page where the index search leads. If a table is large, the clustered index architecture often saves a disk I/O when compared to the traditional solution. (In many database systems, data storage uses a different page from the index record.)
In InnoDB, the records in non-clustered indexes
(also called secondary indexes) contain the primary key value for
the row. InnoDB uses this primary key value to
search for the row from the clustered index. Note that if the
primary key is long, the secondary indexes use more space.
InnoDB compares CHAR and
VARCHAR strings of different lengths such that
the remaining length in the shorter string is treated as if padded
with spaces.
All InnoDB indexes are B-trees where the
index records are stored in the leaf pages of the tree. The
default size of an index page is 16KB. When new records are
inserted, InnoDB tries to leave 1/16 of the
page free for future insertions and updates of the index
records.
If index records are inserted in a sequential order (ascending
or descending), the resulting index pages are about 15/16 full.
If records are inserted in a random order, the pages are from
1/2 to 15/16 full. If the fill factor of an index page drops
below 1/2, InnoDB tries to contract the index
tree to free the page.
It is a common situation in database applications that the primary key is a unique identifier and new rows are inserted in the ascending order of the primary key. Thus, the insertions to the clustered index do not require random reads from a disk.
On the other hand, secondary indexes are usually non-unique, and
insertions into secondary indexes happen in a relatively random
order. This would cause a lot of random disk I/O operations
without a special mechanism used in InnoDB.
If an index record should be inserted to a non-unique secondary
index, InnoDB checks whether the secondary
index page is in the buffer pool. If that is the case,
InnoDB does the insertion directly to the
index page. If the index page is not found in the buffer pool,
InnoDB inserts the record to a special insert
buffer structure. The insert buffer is kept so small that it
fits entirely in the buffer pool, and insertions can be done
very fast.
Periodically, the insert buffer is merged into the secondary index trees in the database. Often it is possible to merge several insertions to the same page of the index tree, saving disk I/O operations. It has been measured that the insert buffer can speed up insertions into a table up to 15 times.
The insert buffer merging may continue to happen
after the inserting transaction has been
committed. In fact, it may continue to happen after a server
shutdown and restart (see Section 14.2.8.1, “Forcing InnoDB Recovery”).
The insert buffer merging may take many hours, when many secondary indexes must be updated, and many rows have been inserted. During this time, disk I/O will be increased, which can cause significant slowdown on disk-bound queries. Another significant background I/O operation is the purge thread (see Section 14.2.12, “Implementation of Multi-Versioning”).
If a table fits almost entirely in main memory, the fastest way
to perform queries on it is to use hash indexes.
InnoDB has a mechanism that monitors index
searches made to the indexes defined for a table. If
InnoDB notices that queries could benefit
from building a hash index, it does so automatically.
Note that the hash index is always built based on an existing
B-tree index on the table. InnoDB can build a
hash index on a prefix of any length of the key defined for the
B-tree, depending on the pattern of searches that
InnoDB observes for the B-tree index. A hash
index can be partial: It is not required that the whole B-tree
index is cached in the buffer pool. InnoDB
builds hash indexes on demand for those pages of the index that
are often accessed.
In a sense, InnoDB tailors itself through the
adaptive hash index mechanism to ample main memory, coming
closer to the architecture of main-memory databases.
The physical record structure for InnoDB tables is dependent on
the MySQL version and the optional ROW_FORMAT
option used when the table was created. For InnoDB tables in
MySQL earlier than 5.0.3, only the REDUNDANT
row format was available. For MySQL 5.0.3 and later, the default
is to use the COMPACT row format, but you can
use the REDUNDANT format to retain
compatibility with older versions of InnoDB tables.
Records in InnoDB ROW_FORMAT=REDUNDANT tables
have the following characteristics:
Each index record contains a six-byte header. The header is used to link together consecutive records, and also in row-level locking.
Records in the clustered index contain fields for all user-defined columns. In addition, there is a six-byte field for the transaction ID and a seven-byte field for the roll pointer.
If no primary key was defined for a table, each clustered index record also contains a six-byte row ID field.
Each secondary index record contains also all the fields defined for the clustered index key.
A record contains also a pointer to each field of the record. If the total length of the fields in a record is less than 128 bytes, the pointer is one byte; otherwise, two bytes. The array of these pointers is called the record directory. The area where these pointers point is called the data part of the record.
Internally, InnoDB stores fixed-length character columns such as
CHAR(10)in a fixed-length format. InnoDB truncates trailing spaces fromVARCHARcolumns.An SQL
NULLvalue reserves 1 or 2 bytes in the record directory. Besides that, an SQLNULLvalue reserves zero bytes in the data part of the record if stored in a variable length column. In a fixed-length column, it reserves the fixed length of the column in the data part of the record. The motivation behind reserving the fixed space forNULLvalues is that it enables an update of the column fromNULLto a non-NULLvalue to be done in place without causing fragmentation of the index page.
Records in InnoDB ROW_FORMAT=COMPACT tables
have the following characteristics:
Each index record contains a five-byte header that may be preceded by a variable-length header. The header is used to link together consecutive records, and also in row-level locking.
The record header contains a bit vector for indicating
NULLcolumns. The bit vector occupies (n_nullable+7)/8 bytes. Columns that areNULLwill not occupy other space than the bit in this vector.For each non-
NULLvariable-length field, the record header contains the length of the column in one or two bytes. Two bytes will only be needed if part of the column is stored externally or the maximum length exceeds 255 bytes and the actual length exceeds 127 bytes.The record header is followed by the data contents of the columns. Columns that are
NULLare omitted.Records in the clustered index contain fields for all user-defined columns. In addition, there is a six-byte field for the transaction ID and a seven-byte field for the roll pointer.
If no primary key was defined for a table, each clustered index record also contains a six-byte row ID field.
Each secondary index record contains also all the fields defined for the clustered index key.
Internally, InnoDB stores fixed-length, fixed-width character columns such as
CHAR(10)in a fixed-length format. InnoDB truncates trailing spaces fromVARCHARcolumns.Internally, InnoDB attempts to store UTF-8
CHAR(columns inn)nbytes by trimming trailing spaces. InROW_FORMAT=REDUNDANT, such columns occupy 3*nbytes. The motivation behind reserving the minimum spacenis that it in many cases enables an update of the column to be done in place without causing fragmentation of the index page.
InnoDB uses simulated asynchronous disk I/O:
InnoDB creates a number of threads to take
care of I/O operations, such as read-ahead.
There are two read-ahead heuristics in
InnoDB:
In sequential read-ahead, if
InnoDBnotices that the access pattern to a segment in the tablespace is sequential, it posts in advance a batch of reads of database pages to the I/O system.In random read-ahead, if
InnoDBnotices that some area in a tablespace seems to be in the process of being fully read into the buffer pool, it posts the remaining reads to the I/O system.
InnoDB uses a novel file flush technique
called doublewrite. It adds safety to
recovery following an operating system crash or a power outage,
and improves performance on most varieties of Unix by reducing
the need for fsync() operations.
Doublewrite means that before writing pages to a data file,
InnoDB first writes them to a contiguous
tablespace area called the doublewrite buffer. Only after the
write and the flush to the doublewrite buffer has completed does
InnoDB write the pages to their proper
positions in the data file. If the operating system crashes in
the middle of a page write, InnoDB can later
find a good copy of the page from the doublewrite buffer during
recovery.
The data files that you define in the configuration file form
the tablespace of InnoDB. The files are
simply concatenated to form the tablespace. There is no striping
in use. Currently, you cannot define where within the tablespace
your tables are allocated. However, in a newly created
tablespace, InnoDB allocates space starting
from the first data file.
The tablespace consists of database pages with a default size of
16KB. The pages are grouped into extents of 64 consecutive
pages. The “files” inside a tablespace are called
segments in InnoDB.
The term “rollback segment” is somewhat confusing
because it actually contains many tablespace segments.
Two segments are allocated for each index in
InnoDB. One is for non-leaf nodes of the
B-tree, the other is for the leaf nodes. The idea here is to
achieve better sequentiality for the leaf nodes, which contain
the data.
When a segment grows inside the tablespace,
InnoDB allocates the first 32 pages to it
individually. After that InnoDB starts to
allocate whole extents to the segment. InnoDB
can add to a large segment up to 4 extents at a time to ensure
good sequentiality of data.
Some pages in the tablespace contain bitmaps of other pages, and
therefore a few extents in an InnoDB
tablespace cannot be allocated to segments as a whole, but only
as individual pages.
When you ask for available free space in the tablespace by
issuing a SHOW TABLE STATUS statement,
InnoDB reports the extents that are
definitely free in the tablespace. InnoDB
always reserves some extents for cleanup and other internal
purposes; these reserved extents are not included in the free
space.
When you delete data from a table, InnoDB
contracts the corresponding B-tree indexes. Whether the freed
space becomes available for other users depends on whether the
pattern of deletes frees individual pages or extents to the
tablespace. Dropping a table or deleting all rows from it is
guaranteed to release the space to other users, but remember
that deleted rows are physically removed only in an (automatic)
purge operation after they are no longer needed for transaction
rollbacks or consistent reads. (See
Section 14.2.12, “Implementation of Multi-Versioning”.)
If there are random insertions into or deletions from the indexes of a table, the indexes may become fragmented. Fragmentation means that the physical ordering of the index pages on the disk is not close to the index ordering of the records on the pages, or that there are many unused pages in the 64-page blocks that were allocated to the index.
A symptom of fragmentation is that a table takes more space than
it “should” take. How much that is exactly, is
difficult to determine. All InnoDB data and
indexes are stored in B-trees, and their fill factor may vary
from 50% to 100%. Another symptom of fragmentation is that a
table scan such as this takes more time than it
“should” take:
SELECT COUNT(*) FROM t WHERE a_non_indexed_column <> 12345;
(In the preceding query, we are “fooling” the SQL optimizer into scanning the clustered index, rather than a secondary index.) Most disks can read 10 to 50MB/s, which can be used to estimate how fast a table scan should run.
It can speed up index scans if you periodically perform a
“null” ALTER TABLE operation:
ALTER TABLE tbl_name ENGINE=INNODB
That causes MySQL to rebuild the table. Another way to perform a defragmentation operation is to use mysqldump to dump the table to a text file, drop the table, and reload it from the dump file.
If the insertions to an index are always ascending and records
are deleted only from the end, the InnoDB
filespace management algorithm guarantees that fragmentation in
the index does not occur.
Error handling in InnoDB is not always the same
as specified in the SQL standard. According to the standard, any
error during an SQL statement should cause the rollback of that
statement. InnoDB sometimes rolls back only
part of the statement, or the whole transaction. The following
items describe how InnoDB performs error
handling:
If you run out of file space in the tablespace, a MySQL
Table is fullerror occurs andInnoDBrolls back the SQL statement.A transaction deadlock causes
InnoDBto roll back the entire transaction. In the case of a lock wait timeout,InnoDBalso rolls back the entire transaction before MySQL 5.0.13; as of 5.0.13,InnoDBrolls back only the most recent SQL statement.When a transaction rollback occurs due to a deadlock or lock wait timeout, it cancels the effect of the statements within the transaction. But if the start-transaction statement was
START TRANSACTIONorBEGINstatement, rollback does not cancel that statement. Further SQL statements become part of the transaction until the occurrence ofCOMMIT,ROLLBACK, or some SQL statement that causes an implicit commit.A duplicate-key error rolls back the SQL statement, if you have not specified the
IGNOREoption in your statement.A
row too long errorrolls back the SQL statement.Other errors are mostly detected by the MySQL layer of code (above the
InnoDBstorage engine level), and they roll back the corresponding SQL statement. Locks are not released in a rollback of a single SQL statement.
During implicit rollbacks, as well as during the execution of an
explicit ROLLBACK SQL command, SHOW
PROCESSLIST displays Rolling back in
the State column for the relevant connection.
The following is a non-exhaustive list of common
InnoDB-specific errors that you may
encounter, with information about why each occurs and how to
resolve the problem.
1005 (ER_CANT_CREATE_TABLE)Cannot create table. If the error message refers to
errno150, table creation failed because a foreign key constraint was not correctly formed. If the error message refers toerrno-1, table creation probably failed because the table included a column name that matched the name of an internal InnoDB table.1016 (ER_CANT_OPEN_FILE)Cannot find the
InnoDBtable from theInnoDBdata files, although the.frmfile for the table exists. See Section 14.2.17.1, “TroubleshootingInnoDBData Dictionary Operations”.1114 (ER_RECORD_FILE_FULL)InnoDBhas run out of free space in the tablespace. You should reconfigure the tablespace to add a new data file.1205 (ER_LOCK_WAIT_TIMEOUT)Lock wait timeout expired. Transaction was rolled back.
1213 (ER_LOCK_DEADLOCK)Transaction deadlock. You should rerun the transaction.
1216 (ER_NO_REFERENCED_ROW)You are trying to add a row but there is no parent row, and a foreign key constraint fails. You should add the parent row first.
1217 (ER_ROW_IS_REFERENCED)You are trying to delete a parent row that has children, and a foreign key constraint fails. You should delete the children first.
To print the meaning of an operating system error number, use the perror program that comes with the MySQL distribution.
The following table provides a list of some common Linux system error codes. For a more complete list, see Linux source code.
1 (EPERM)Operation not permitted
2 (ENOENT)No such file or directory
3 (ESRCH)No such process
4 (EINTR)Interrupted system call
5 (EIO)I/O error
6 (ENXIO)No such device or address
7 (E2BIG)Arg list too long
8 (ENOEXEC)Exec format error
9 (EBADF)Bad file number
10 (ECHILD)No child processes
11 (EAGAIN)Try again
12 (ENOMEM)Out of memory
13 (EACCES)Permission denied
14 (EFAULT)Bad address
15 (ENOTBLK)Block device required
16 (EBUSY)Device or resource busy
17 (EEXIST)File exists
18 (EXDEV)Cross-device link
19 (ENODEV)No such device
20 (ENOTDIR)Not a directory
21 (EISDIR)Is a directory
22 (EINVAL)Invalid argument
23 (ENFILE)File table overflow
24 (EMFILE)Too many open files
25 (ENOTTY)Inappropriate ioctl for device
26 (ETXTBSY)Text file busy
27 (EFBIG)File too large
28 (ENOSPC)No space left on device
29 (ESPIPE)Illegal seek
30 (EROFS)Read-only file system
31 (EMLINK)Too many links
The following table provides a list of some common Windows system error codes. For a complete list see the Microsoft Web site.
1 (ERROR_INVALID_FUNCTION)Incorrect function.
2 (ERROR_FILE_NOT_FOUND)The system cannot find the file specified.
3 (ERROR_PATH_NOT_FOUND)The system cannot find the path specified.
4 (ERROR_TOO_MANY_OPEN_FILES)The system cannot open the file.
5 (ERROR_ACCESS_DENIED)Access is denied.
6 (ERROR_INVALID_HANDLE)The handle is invalid.
7 (ERROR_ARENA_TRASHED)The storage control blocks were destroyed.
8 (ERROR_NOT_ENOUGH_MEMORY)Not enough storage is available to process this command.
9 (ERROR_INVALID_BLOCK)The storage control block address is invalid.
10 (ERROR_BAD_ENVIRONMENT)The environment is incorrect.
11 (ERROR_BAD_FORMAT)An attempt was made to load a program with an incorrect format.
12 (ERROR_INVALID_ACCESS)The access code is invalid.
13 (ERROR_INVALID_DATA)The data is invalid.
14 (ERROR_OUTOFMEMORY)Not enough storage is available to complete this operation.
15 (ERROR_INVALID_DRIVE)The system cannot find the drive specified.
16 (ERROR_CURRENT_DIRECTORY)The directory cannot be removed.
17 (ERROR_NOT_SAME_DEVICE)The system cannot move the file to a different disk drive.
18 (ERROR_NO_MORE_FILES)There are no more files.
19 (ERROR_WRITE_PROTECT)The media is write protected.
20 (ERROR_BAD_UNIT)The system cannot find the device specified.
21 (ERROR_NOT_READY)The device is not ready.
22 (ERROR_BAD_COMMAND)The device does not recognize the command.
23 (ERROR_CRC)Data error (cyclic redundancy check).
24 (ERROR_BAD_LENGTH)The program issued a command but the command length is incorrect.
25 (ERROR_SEEK)The drive cannot locate a specific area or track on the disk.
26 (ERROR_NOT_DOS_DISK)The specified disk or diskette cannot be accessed.
27 (ERROR_SECTOR_NOT_FOUND)The drive cannot find the sector requested.
28 (ERROR_OUT_OF_PAPER)The printer is out of paper.
29 (ERROR_WRITE_FAULT)The system cannot write to the specified device.
30 (ERROR_READ_FAULT)The system cannot read from the specified device.
31 (ERROR_GEN_FAILURE)A device attached to the system is not functioning.
32 (ERROR_SHARING_VIOLATION)The process cannot access the file because it is being used by another process.
33 (ERROR_LOCK_VIOLATION)The process cannot access the file because another process has locked a portion of the file.
34 (ERROR_WRONG_DISK)The wrong diskette is in the drive. Insert %2 (Volume Serial Number: %3) into drive %1.
36 (ERROR_SHARING_BUFFER_EXCEEDED)Too many files opened for sharing.
38 (ERROR_HANDLE_EOF)Reached the end of the file.
39 (ERROR_HANDLE_DISK_FULL)The disk is full.
87 (ERROR_INVALID_PARAMETER)The parameter is incorrect. (If this error occurs on Windows and you have enabled
innodb_file_per_tablein a server option file, add the lineinnodb_flush_method=unbufferedto the file as well.)112 (ERROR_DISK_FULL)The disk is full.
123 (ERROR_INVALID_NAME)The filename, directory name, or volume label syntax is incorrect.
1450 (ERROR_NO_SYSTEM_RESOURCES)Insufficient system resources exist to complete the requested service.
Warning: Do not convert MySQL system tables in the
mysqldatabase fromMyISAMtoInnoDBtables! This is an unsupported operation. If you do this, MySQL does not restart until you restore the old system tables from a backup or re-generate them with the mysql_install_db script.Warning: If is not a good idea to configure
InnoDBto use datafiles or logfiles on NFS volumes. Otherwise, the files might be locked by other processes and become unavailable for use by MySQL.A table cannot contain more than 1000 columns.
The internal maximum key length is 3500 bytes, but MySQL itself restricts this to 1024 bytes.
The maximum row length, except for
VARCHAR,BLOBandTEXTcolumns, is slightly less than half of a database page. That is, the maximum row length is about 8000 bytes.LONGBLOBandLONGTEXTcolumns must be less than 4GB, and the total row length, including alsoBLOBandTEXTcolumns, must be less than 4GB.InnoDBstores the first 768 bytes of aVARCHAR,BLOB, orTEXTcolumn in the row, and the rest into separate pages.Although
InnoDBsupports row sizes larger than 65535 internally, you cannot define a row containingVARCHARcolumns with a combined size larger than 65535:mysql>
CREATE TABLE t (a VARCHAR(8000), b VARCHAR(10000),->c VARCHAR(10000), d VARCHAR(10000), e VARCHAR(10000),->f VARCHAR(10000), g VARCHAR(10000)) ENGINE=InnoDB;ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. You have to change some columns to TEXT or BLOBsOn some older operating systems, files must be less than 2GB. This is not a limitation of
InnoDBitself, but if you require a large tablespace, you will need to configure it using several smaller data files rather than one or a file large data files.The combined size of the
InnoDBlog files must be less than 4GB.The minimum tablespace size is 10MB. The maximum tablespace size is four billion database pages (64TB). This is also the maximum size for a table.
InnoDBtables do not supportFULLTEXTindexes.InnoDBtables do not support spatial data types before MySQL 5.0.16. As of 5.0.16,InnoDBsupports spatial types, but not indexes on them.ANALYZE TABLEdetermines index cardinality (as displayed in theCardinalitycolumn ofSHOW INDEXoutput) by doing ten random dives to each of the index trees and updating index cardinality estimates accordingly. Note that because these are only estimates, repeated runs ofANALYZE TABLEmay produce different numbers. This makesANALYZE TABLEfast onInnoDBtables but not 100% accurate as it doesn't take all rows into account.MySQL uses index cardinality estimates only in join optimization. If some join is not optimized in the right way, you can try using
ANALYZE TABLE. In the few cases thatANALYZE TABLEdoesn't produce values good enough for your particular tables, you can useFORCE INDEXwith your queries to force the use of a particular index, or set themax_seeks_for_keysystem variable to ensure that MySQL prefers index lookups over table scans. See Section 5.2.3, “System Variables”, and Section B.1.6, “Optimizer-Related Issues”.SHOW TABLE STATUSdoes not give accurate statistics onInnoDBtables, except for the physical size reserved by the table. The row count is only a rough estimate used in SQL optimization.InnoDBdoes not keep an internal count of rows in a table. (In practice, this would be somewhat complicated due to multi-versioning.) To process aSELECT COUNT(*) FROM tstatement,InnoDBmust scan an index of the table, which takes some time if the index is not entirely in the buffer pool. To get a fast count, you have to use a counter table you create yourself and let your application update it according to the inserts and deletes it does. If your table does not change often, using the MySQL query cache is a good solution.SHOW TABLE STATUSalso can be used if an approximate row count is sufficient. See Section 14.2.11, “InnoDBPerformance Tuning Tips”.On Windows,
InnoDBalways stores database and table names internally in lowercase. To move databases in binary format from Unix to Windows or from Windows to Unix, you should always use explicitly lowercase names when creating databases and tables.For an
AUTO_INCREMENTcolumn, you must always define an index for the table, and that index must contain just theAUTO_INCREMENTcolumn. InMyISAMtables, theAUTO_INCREMENTcolumn may be part of a multi-column index.In MySQL 5.0 before MySQL 5.0.3,
InnoDBdoes not support theAUTO_INCREMENTtable option for setting the initial sequence value in aCREATE TABLEorALTER TABLEstatement. To set the value withInnoDB, insert a dummy row with a value one less and delete that dummy row, or insert the first row with an explicit value specified.While initializing a previously specified
AUTO_INCREMENTcolumn on a table,InnoDBsets an exclusive lock on the end of the index associated with theAUTO_INCREMENTcolumn. In accessing the auto-increment counter,InnoDBuses a specific table lock modeAUTO-INCwhere the lock lasts only to the end of the current SQL statement, not to the end of the entire transaction. Note that other clients cannot insert into the table while theAUTO-INCtable lock is held; see Section 14.2.10.2, “InnoDBandAUTOCOMMIT”.When you restart the MySQL server,
InnoDBmay reuse an old value that was generated for anAUTO_INCREMENTcolumn but never stored (that is, a value that was generated during an old transaction that was rolled back).When an
AUTO_INCREMENTcolumn runs out of values,InnoDBwraps aBIGINTto-9223372036854775808andBIGINT UNSIGNEDto1. However,BIGINTvalues have 64 bits, so do note that if you were to insert one million rows per second, it would still take nearly three hundred thousand years beforeBIGINTreached its upper bound. With all other integer type columns, a duplicate-key error results. This is similar to howMyISAMworks, because it is mostly general MySQL behavior and not about any storage engine in particular.DELETE FROMdoes not regenerate the table but instead deletes all rows, one by one.tbl_nameUnder some conditions,
TRUNCATEfor antbl_nameInnoDBtable is mapped toDELETE FROMand doesn't reset thetbl_nameAUTO_INCREMENTcounter. See Section 13.2.9, “TRUNCATESyntax”.In MySQL 5.0, the MySQL
LOCK TABLESoperation acquires two locks on each table ifinnodb_table_locks=1(the default). In addition to a table lock on the MySQL layer, it also acquires anInnoDBtable lock. Older versions of MySQL did not acquireInnoDBtable locks; the old behavior can be selected by settinginnodb_table_locks=0. If noInnoDBtable lock is acquired,LOCK TABLEScompletes even if some records of the tables are being locked by other transactions.All
InnoDBlocks held by a transaction are released when the transaction is committed or aborted. Thus, it does not make much sense to invokeLOCK TABLESonInnoDBtables inAUTOCOMMIT=1mode, because the acquiredInnoDBtable locks would be released immediately.Sometimes it would be useful to lock further tables in the course of a transaction. Unfortunately,
LOCK TABLESin MySQL performs an implicitCOMMITandUNLOCK TABLES. AnInnoDBvariant ofLOCK TABLEShas been planned that can be executed in the middle of a transaction.The
LOAD TABLE FROM MASTERstatement for setting up replication slave servers does not work forInnoDBtables. A workaround is to alter the table toMyISAMon the master, do then the load, and after that alter the master table back toInnoDB. Do not do this if the tables useInnoDB-specific features such as foreign keys.The default database page size in
InnoDBis 16KB. By recompiling the code, you can set it to values ranging from 8KB to 64KB. You must update the values ofUNIV_PAGE_SIZEandUNIV_PAGE_SIZE_SHIFTin theuniv.isource file.Currently, triggers are not activated by cascaded foreign key actions.
You cannot create a table with a column name that matches the name of an internal InnoDB column (including
DB_ROW_ID,DB_TRX_ID,DB_ROLL_PTRandDB_MIX_ID). In versions of MySQL before 5.0.21 this would cause a crash, since 5.0.21 the server will report error 1005 and refers toerrno-1 in the error message.As of MySQL 5.0.19,
InnoDBdoes not ignore trailing spaces when comparingBINARYorVARBINARYcolumn values. See Section 11.4.2, “TheBINARYandVARBINARYTypes” and Section E.1.11, “Changes in release 5.0.19 (04 March 2006)”.
The following general guidelines apply to troubleshooting
InnoDB problems:
When an operation fails or you suspect a bug, you should look at the MySQL server error log, which is the file in the data directory that has a suffix of
.err.When troubleshooting, it is usually best to run the MySQL server from the command prompt, rather than through the mysqld_safe wrapper or as a Windows service. You can then see what mysqld prints to the console, and so have a better grasp of what is going on. On Windows, you must start the server with the
--consoleoption to direct the output to the console window.Use the
InnoDBMonitors to obtain information about a problem (see Section 14.2.11.1, “SHOW ENGINE INNODB STATUSand theInnoDBMonitors”). If the problem is performance-related, or your server appears to be hung, you should useinnodb_monitorto print information about the internal state ofInnoDB. If the problem is with locks, useinnodb_lock_monitor. If the problem is in creation of tables or other data dictionary operations, useinnodb_table_monitorto print the contents of theInnoDBinternal data dictionary.If you suspect that a table is corrupt, run
CHECK TABLEon that table.
MySQL Enterprise The MySQL Network Monitoring and Advisory Service provides a number of advisors specifically designed for monitoring InnoDB tables. In some cases, these advisors can anticipate potential problems. For more information see http://www.mysql.com/products/enterprise/advisors.html.
A specific issue with tables is that the MySQL server keeps data
dictionary information in .frm files it
stores in the database directories, whereas
InnoDB also stores the information into its
own data dictionary inside the tablespace files. If you move
.frm files around, or if the server crashes
in the middle of a data dictionary operation, the locations of
the .frm files may end up out of synchrony
with the locations recorded in the InnoDB
internal data dictionary.
A symptom of an out-of-sync data dictionary is that a
CREATE TABLE statement fails. If this occurs,
you should look in the server's error log. If the log says that
the table already exists inside the InnoDB
internal data dictionary, you have an orphaned table inside the
InnoDB tablespace files that has no
corresponding .frm file. The error message
looks like this:
InnoDB: Error: table test/parent already exists in InnoDB internal InnoDB: data dictionary. Have you deleted the .frm file InnoDB: and not used DROP TABLE? Have you used DROP DATABASE InnoDB: for InnoDB tables in MySQL version <= 3.23.43? InnoDB: See the Restrictions section of the InnoDB manual. InnoDB: You can drop the orphaned table inside InnoDB by InnoDB: creating an InnoDB table with the same name in another InnoDB: database and moving the .frm file to the current database. InnoDB: Then MySQL thinks the table exists, and DROP TABLE will InnoDB: succeed.
You can drop the orphaned table by following the instructions
given in the error message. If you are still unable to use
DROP TABLE successfully, the problem may be
due to name completion in the mysql client.
To work around this problem, start the mysql
client with the --skip-auto-rehash option and
try DROP TABLE again. (With name completion
on, mysql tries to construct a list of table
names, which fails when a problem such as just described
exists.)
Another symptom of an out-of-sync data dictionary is that MySQL
prints an error that it cannot open a
.InnoDB file:
ERROR 1016: Can't open file: 'child2.InnoDB'. (errno: 1)
In the error log you can find a message like this:
InnoDB: Cannot find table test/child2 from the internal data dictionary InnoDB: of InnoDB though the .frm file for the table exists. Maybe you InnoDB: have deleted and recreated InnoDB data files but have forgotten InnoDB: to delete the corresponding .frm files of InnoDB tables?
This means that there is an orphaned .frm
file without a corresponding table inside
InnoDB. You can drop the orphaned
.frm file by deleting it manually.
If MySQL crashes in the middle of an ALTER
TABLE operation, you may end up with an orphaned
temporary table inside the InnoDB tablespace.
Using innodb_table_monitor you can see listed
a table whose name is #sql-.... You can
perform SQL statements on tables whose name contains the
character ‘#’ if you enclose the
name within backticks. Thus, you can drop such an orphaned table
like any other orphaned table using the method described
earlier. Note that to copy or rename a file in the Unix shell,
you need to put the file name in double quotes if the file name
contains ‘#’.
The MERGE storage engine, also known as the
MRG_MyISAM engine, is a collection of identical
MyISAM tables that can be used as one.
“Identical” means that all tables have identical column
and index information. You cannot merge MyISAM
tables in which the columns are listed in a different order, do not
have exactly the same columns, or have the indexes in different
order. However, any or all of the MyISAM tables
can be compressed with myisampack. See
Section 8.7, “myisampack — Generate Compressed, Read-Only MyISAM Tables”. Differences in table options such as
AVG_ROW_LENGTH, MAX_ROWS, or
PACK_KEYS do not matter.
When you create a MERGE table, MySQL creates two
files on disk. The files have names that begin with the table name
and have an extension to indicate the file type. An
.frm file stores the table format, and an
.MRG file contains the names of the tables that
should be used as one. The tables do not have to be in the same
database as the MERGE table itself.
Starting with MySQL 5.0.36 the underlying table definitions and
indexes must conform more closely to the definition of the
MERGE table. Conformance will be checked when the
merged tables are opened, not when the MERGE
table is created. This means that changes to the definitions of
tables within a MERGE may cause a failure when
the MERGE table is accessed.
You can use SELECT, DELETE,
UPDATE, and INSERT on
MERGE tables. You must have
SELECT, UPDATE, and
DELETE privileges on the
MyISAM tables that you map to a
MERGE table.
Note
The use of MERGE tables entails the following
security issue: If a user has access to MyISAM
table t, that user can create a
MERGE table m that
accesses t. However, if the user's
privileges on t are subsequently
revoked, the user can continue to access
t by doing so through
m. If this behavior is undesirable, you
can start the server with the new --skip-merge
option to disable the MERGE storage engine.
This option is available as of MySQL 5.0.24.
If you DROP the MERGE table,
you are dropping only the MERGE specification.
The underlying tables are not affected.
To create a MERGE table, you must specify a
UNION=(
clause that indicates which list-of-tables)MyISAM tables you
want to use as one. You can optionally specify an
INSERT_METHOD option if you want inserts for the
MERGE table to take place in the first or last
table of the UNION list. Use a value of
FIRST or LAST to cause inserts
to be made in the first or last table, respectively. If you do not
specify an INSERT_METHOD option or if you specify
it with a value of NO, attempts to insert rows
into the MERGE table result in an error.
The following example shows how to create a MERGE
table:
mysql>CREATE TABLE t1 (->a INT NOT NULL AUTO_INCREMENT PRIMARY KEY,->message CHAR(20)) ENGINE=MyISAM;mysql>CREATE TABLE t2 (->a INT NOT NULL AUTO_INCREMENT PRIMARY KEY,->message CHAR(20)) ENGINE=MyISAM;mysql>INSERT INTO t1 (message) VALUES ('Testing'),('table'),('t1');mysql>INSERT INTO t2 (message) VALUES ('Testing'),('table'),('t2');mysql>CREATE TABLE total (->a INT NOT NULL AUTO_INCREMENT,->message CHAR(20), INDEX(a))->ENGINE=MERGE UNION=(t1,t2) INSERT_METHOD=LAST;
The older term TYPE is supported as a synonym for
ENGINE for backward compatibility, but
ENGINE is the preferred term and
TYPE is deprecated.
Note that the a column is indexed as a
PRIMARY KEY in the underlying
MyISAM tables, but not in the
MERGE table. There it is indexed but not as a
PRIMARY KEY because a MERGE
table cannot enforce uniqueness over the set of underlying tables.
In MySQL 5.0.36 and higher, when a table that is part of a
MERGE table is opened, the following checks are
applied before opening each table. If any table fails the
conformance checks, then the operation that triggered the opening of
the table will fail. The conformance checks applied to each table
are:
Table must have exactly the same amount of columns that
MERGEtable has.Column order in the
MERGEtable must match the column order in the underlying tables.Additionally, the specification for each column in the parent
MERGEtable and the underlying table are compared. For each column, MySQL checks:Column type in the underlying table equals the column type of
MERGEtable.Column length in the underlying table equals the column length of
MERGEtable.Column of underlying table and column of
MERGEtable can beNULL.
Underlying table must have at least the same amount of keys that merge table has. The underlying table may have morekeys than the
MERGEtable, but cannot have less.For each key:
Check if the key type of underlying table equals the key type of merge table.
Check if number of key parts (i.e. multiple columns within a compound key) in the underlying table key definition equals the number of key parts in merge table key definition.
For each key part:
Check if key part lengths are equal.
Check if key part types are equal.
Check if key part languages are equal.
Check if key part can be
NULL.
After creating the MERGE table, you can issue
queries that operate on the group of tables as a whole:
mysql> SELECT * FROM total;
+---+---------+
| a | message |
+---+---------+
| 1 | Testing |
| 2 | table |
| 3 | t1 |
| 1 | Testing |
| 2 | table |
| 3 | t2 |
+---+---------+
To remap a MERGE table to a different collection
of MyISAM tables, you can use one of the
following methods:
DROPtheMERGEtable and re-create it.Use
ALTER TABLEto change the list of underlying tables.tbl_nameUNION=(...)
MERGE tables can help you solve the following
problems:
Easily manage a set of log tables. For example, you can put data from different months into separate tables, compress some of them with myisampack, and then create a
MERGEtable to use them as one.Obtain more speed. You can split a big read-only table based on some criteria, and then put individual tables on different disks. A
MERGEtable on this could be much faster than using the big table.Perform more efficient searches. If you know exactly what you are looking for, you can search in just one of the split tables for some queries and use a
MERGEtable for others. You can even have many differentMERGEtables that use overlapping sets of tables.Perform more efficient repairs. It is easier to repair individual tables that are mapped to a
MERGEtable than to repair a single large table.Instantly map many tables as one. A
MERGEtable need not maintain an index of its own because it uses the indexes of the individual tables. As a result,MERGEtable collections are very fast to create or remap. (Note that you must still specify the index definitions when you create aMERGEtable, even though no indexes are created.)If you have a set of tables from which you create a large table on demand, you should instead create a
MERGEtable on them on demand. This is much faster and saves a lot of disk space.Exceed the file size limit for the operating system. Each
MyISAMtable is bound by this limit, but a collection ofMyISAMtables is not.You can create an alias or synonym for a
MyISAMtable by defining aMERGEtable that maps to that single table. There should be no really notable performance impact from doing this (only a couple of indirect calls andmemcpy()calls for each read).
The disadvantages of MERGE tables are:
You can use only identical
MyISAMtables for aMERGEtable.You cannot use a number of
MyISAMfeatures inMERGEtables. For example, you cannot createFULLTEXTindexes onMERGEtables. (You can, of course, createFULLTEXTindexes on the underlyingMyISAMtables, but you cannot search theMERGEtable with a full-text search.)If the
MERGEtable is non-temporary, all underlyingMyISAMtables must be non-temporary, too. If theMERGEtable is temporary, theMyISAMtables can be any mix of temporary and non-temporary.MERGEtables use more file descriptors. If 10 clients are using aMERGEtable that maps to 10 tables, the server uses (10 × 10) + 10 file descriptors. (10 data file descriptors for each of the 10 clients, and 10 index file descriptors shared among the clients.)Key reads are slower. When you read a key, the
MERGEstorage engine needs to issue a read on all underlying tables to check which one most closely matches the given key. To read the next key, theMERGEstorage engine needs to search the read buffers to find the next key. Only when one key buffer is used up does the storage engine need to read the next key block. This makesMERGEkeys much slower oneq_refsearches, but not much slower onrefsearches. See Section 7.2.1, “Optimizing Queries withEXPLAIN”, for more information abouteq_refandref.
Additional resources
A forum dedicated to the
MERGEstorage engine is available at http://forums.mysql.com/list.php?93.
The following are known problems with MERGE
tables:
If you use
ALTER TABLEto change aMERGEtable to another storage engine, the mapping to the underlying tables is lost. Instead, the rows from the underlyingMyISAMtables are copied into the altered table, which then uses the specified storage engine.REPLACEdoes not work.You cannot use
REPAIR TABLE,OPTIMIZE TABLE,DROP TABLE,ALTER TABLE,DELETEwithout aWHEREclause,TRUNCATE TABLE, orANALYZE TABLEon any of the tables that are mapped into an openMERGEtable. If you do so, theMERGEtable may still refer to the original table, which yields unexpected results. The easiest way to work around this deficiency is to ensure that noMERGEtables remain open by issuing aFLUSH TABLESstatement prior to performing any of those operations.The unexpected results include the possibility that the operation on the
MERGEtable will report table corruption. However, if this occurs after operations on the underlyingMyISAMtables such as those listed in the previous paragraph (REPAIR TABLE,OPTIMIZE TABLE, and so forth), the corruption message is spurious. To deal with this, issue aFLUSH TABLESstatement after modifying theMyISAMtables.DROP TABLEon a table that is in use by aMERGEtable does not work on Windows because theMERGEstorage engine's table mapping is hidden from the upper layer of MySQL. Windows does not allow open files to be deleted, so you first must flush allMERGEtables (withFLUSH TABLES) or drop theMERGEtable before dropping the table.A
MERGEtable cannot maintain uniqueness constraints over the entire table. When you perform anINSERT, the data goes into the first or lastMyISAMtable (depending on the value of theINSERT_METHODoption). MySQL ensures that unique key values remain unique within thatMyISAMtable, but not across all the tables in the collection.In MySQL 5.0.36 and later, the definition of the
MyISAMtables and theMERGEtable are checked when the tables are accessed (for example, as part of aSELECTorINSERTstatement). The checks ensure that the definitions of the tables and the parentMERGEtable definition match by comparing column order, types, sizes and associated indexes. If there is a difference between the tables then an error will be returned and the statement will fail.Because these checks take place when the tables are opened, any changes to the definition of a single, including column changes, ocolumn ordering and engine alterations will cause the statement to fail.
In MySQL 5.0.35 and earlier:
When you create or alter
MERGEtable, there is no check to ensure that the underlying tables are existingMyISAMtables and have identical structures. When theMERGEtable is used, MySQL checks that the row length for all mapped tables is equal, but this is not foolproof. If you create aMERGEtable from dissimilarMyISAMtables, you are very likely to run into strange problems.Similarly, if you create a
MERGEtable from non-MyISAMtables, or if you drop an underlying table or alter it to be a non-MyISAMtable, no error for theMERGEtable occurs until later when you attempt to use it.Because the underlying
MyISAMtables need not exist when theMERGEtable is created, you can create the tables in any order, as long as you do not use theMERGEtable until all of its underlying tables are in place. Also, if you can ensure that aMERGEtable will not be used during a given period, you can perform maintenance operations on the underlying tables, such as backing up or restoring them, altering them, or dropping and recreating them. It is not necessary to redefine theMERGEtable temporarily to exclude the underlying tables while you are operating on them.
The order of indexes in the
MERGEtable and its underlying tables should be the same. If you useALTER TABLEto add aUNIQUEindex to a table used in aMERGEtable, and then useALTER TABLEto add a non-unique index on theMERGEtable, the index ordering is different for the tables if there was already a non-unique index in the underlying table. (This happens becauseALTER TABLEputsUNIQUEindexes before non-unique indexes to facilitate rapid detection of duplicate keys.) Consequently, queries on tables with such indexes may return unexpected results.If you encounter an error message similar to
ERROR 1017 (HY000): Can't find file: 'it generally indicates that some of the base tables are not using the MyISAM storage engine. Confirm that all tables are MyISAM.mm.MRG' (errno: 2)There is a limit of 232 (~4.295E+09)) rows to a
MERGEtable, just as there is with aMyISAM, it is therefore not possible to merge multipleMyISAMtables that exceed this limitation. However, you build MySQL with the--with-big-tablesoption then the row limitation is increased to (232)2 (1.844E+19) rows. See Section 2.4.14.2, “Typical configure Options”. Beginning with MySQL 5.0.4 all standard binaries are built with this option.The
MERGEstorage engine does not supportINSERT DELAYEDstatements.
The MEMORY storage engine creates tables with
contents that are stored in memory. Formerly, these were known as
HEAP tables. MEMORY is the
preferred term, although HEAP remains supported
for backward compatibility.
Each MEMORY table is associated with one disk
file. The filename begins with the table name and has an extension
of .frm to indicate that it stores the table
definition.
To specify explicitly that you want to create a
MEMORY table, indicate that with an
ENGINE table option:
CREATE TABLE t (i INT) ENGINE = MEMORY;
The older term TYPE is supported as a synonym for
ENGINE for backward compatibility, but
ENGINE is the preferred term and
TYPE is deprecated.
As indicated by the name, MEMORY tables are
stored in memory. They use hash indexes by default, which makes them
very fast, and very useful for creating temporary tables. However,
when the server shuts down, all rows stored in
MEMORY tables are lost. The tables themselves
continue to exist because their definitions are stored in
.frm files on disk, but they are empty when the
server restarts.
This example shows how you might create, use, and remove a
MEMORY table:
mysql>CREATE TABLE test ENGINE=MEMORY->SELECT ip,SUM(downloads) AS down->FROM log_table GROUP BY ip;mysql>SELECT COUNT(ip),AVG(down) FROM test;mysql>DROP TABLE test;
MEMORY tables have the following characteristics:
Space for
MEMORYtables is allocated in small blocks. Tables use 100% dynamic hashing for inserts. No overflow area or extra key space is needed. No extra space is needed for free lists. Deleted rows are put in a linked list and are reused when you insert new data into the table.MEMORYtables also have none of the problems commonly associated with deletes plus inserts in hashed tables.MEMORYtables can have up to 32 indexes per table, 16 columns per index and a maximum key length of 500 bytes.The
MEMORYstorage engine implements bothHASHandBTREEindexes. You can specify one or the other for a given index by adding aUSINGclause as shown here:CREATE TABLE lookup (id INT, INDEX USING HASH (id)) ENGINE = MEMORY; CREATE TABLE lookup (id INT, INDEX USING BTREE (id)) ENGINE = MEMORY;General characteristics of B-tree and hash indexes are described in Section 7.4.5, “How MySQL Uses Indexes”.
You can have non-unique keys in a
MEMORYtable. (This is an uncommon feature for implementations of hash indexes.)If you have a hash index on a
MEMORYtable that has a high degree of key duplication (many index entries containing the same value), updates to the table that affect key values and all deletes are significantly slower. The degree of this slowdown is proportional to the degree of duplication (or, inversely proportional to the index cardinality). You can use aBTREEindex to avoid this problem.Columns that are indexed can contain
NULLvalues.MEMORYtables use a fixed-length row storage format.MEMORYtables cannot containBLOBorTEXTcolumns.MEMORYincludes support forAUTO_INCREMENTcolumns.You can use
INSERT DELAYEDwithMEMORYtables. See Section 13.2.4.2, “INSERT DELAYEDSyntax”.MEMORYtables are shared among all clients (just like any other non-TEMPORARYtable).MEMORYtable contents are stored in memory, which is a property thatMEMORYtables share with internal tables that the server creates on the fly while processing queries. However, the two types of tables differ in thatMEMORYtables are not subject to storage conversion, whereas internal tables are:If an internal table becomes too large, the server automatically converts it to an on-disk table. The size limit is determined by the value of the
tmp_table_sizesystem variable.MEMORYtables are never converted to disk tables. To ensure that you don't accidentally do anything foolish, you can set themax_heap_table_sizesystem variable to impose a maximum size onMEMORYtables. For individual tables, you can also specify aMAX_ROWStable option in theCREATE TABLEstatement.
The server needs sufficient memory to maintain all
MEMORYtables that are in use at the same time.To free memory used by a
MEMORYtable when you no longer require its contents, you should executeDELETEorTRUNCATE TABLE, or remove the table altogether usingDROP TABLE.If you want to populate a
MEMORYtable when the MySQL server starts, you can use the--init-fileoption. For example, you can put statements such asINSERT INTO ... SELECTorLOAD DATA INFILEinto this file to load the table from a persistent data source. See Section 5.2.2, “Command Options”, and Section 13.2.5, “LOAD DATA INFILESyntax”.If you are using replication, the master server's
MEMORYtables become empty when it is shut down and restarted. However, a slave is not aware that these tables have become empty, so it returns out-of-date content if you select data from them. When aMEMORYtable is used on the master for the first time since the master was started, aDELETEstatement is written to the master's binary log automatically, thus synchronizing the slave to the master again. Note that even with this strategy, the slave still has outdated data in the table during the interval between the master's restart and its first use of the table. However, if you use the--init-fileoption to populate theMEMORYtable on the master at startup, it ensures that this time interval is zero.The memory needed for one row in a
MEMORYtable is calculated using the following expression:SUM_OVER_ALL_BTREE_KEYS(
max_length_of_key+ sizeof(char*) × 4) + SUM_OVER_ALL_HASH_KEYS(sizeof(char*) × 2) + ALIGN(length_of_row+1, sizeof(char*))ALIGN()represents a round-up factor to cause the row length to be an exact multiple of thecharpointer size.sizeof(char*)is 4 on 32-bit machines and 8 on 64-bit machines.
Additional resources
A forum dedicated to the
MEMORYstorage engine is available at http://forums.mysql.com/list.php?92.
Sleepycat Software has provided MySQL with the Berkeley DB
transactional storage engine. This storage engine typically is
called BDB for short. BDB
tables may have a greater chance of surviving crashes and are also
capable of COMMIT and ROLLBACK
operations on transactions.
Support for the BDB storage engine is included in
MySQL source distributions, which come with a BDB
distribution that is patched to make it work with MySQL. You cannot
use a non-patched version of BDB with MySQL.
We at MySQL AB work in close cooperation with Sleepycat to keep the quality of the MySQL/BDB interface high. (Even though Berkeley DB is in itself very tested and reliable, the MySQL interface is still considered gamma quality. We continue to improve and optimize it.)
When it comes to support for any problems involving
BDB tables, we are committed to helping our users
locate the problem and create reproducible test cases. Any such test
case is forwarded to Sleepycat, which in turn helps us find and fix
the problem. As this is a two-stage operation, any problems with
BDB tables may take a little longer for us to fix
than for other storage engines. However, we anticipate no
significant difficulties with this procedure because the Berkeley DB
code itself is used in many applications other than MySQL.
For general information about Berkeley DB, please visit the Sleepycat Web site, http://www.sleepycat.com/.
Currently, we know that the BDB storage engine
works with the following operating systems:
Linux 2.x Intel
Sun Solaris (SPARC and x86)
FreeBSD 4.x/5.x (x86, sparc64)
IBM AIX 4.3.x
SCO OpenServer
SCO UnixWare 7.1.x
Windows
The BDB storage engine does
not work with the following operating
systems:
Linux 2.x Alpha
Linux 2.x AMD64
Linux 2.x IA-64
Linux 2.x s390
Mac OS X
Note: The preceding lists are not complete. We update them as we receive more information.
If you build MySQL from source with support for
BDB tables, but the following error occurs when
you start mysqld, it means that the
BDB storage engine is not supported for your
architecture:
bdb: architecture lacks fast mutexes: applications cannot be threaded Can't init databases
In this case, you must rebuild MySQL without
BDB support or start the server with the
--skip-bdb option.
If you have downloaded a binary version of MySQL that includes support for Berkeley DB, simply follow the usual binary distribution installation instructions.
If you build MySQL from source, you can enable
BDB support by invoking
configure with the
--with-berkeley-db option in addition to any
other options that you normally use. Download a MySQL
5.0 distribution, change location into its top-level
directory, and run this command:
shell> ./configure --with-berkeley-db [other-options]
For more information, Section 2.4.13, “Installing MySQL from tar.gz Packages on Other
Unix-Like Systems”, and
Section 2.4.14, “MySQL Installation Using a Source Distribution”.
The following options to mysqld can be used to
change the behavior of the BDB storage engine.
For more information, see Section 5.2.2, “Command Options”.
The base directory for
BDBtables. This should be the same directory that you use for--datadir.The
BDBlock detection method. The option value should beDEFAULT,OLDEST,RANDOM, orYOUNGEST.The
BDBlog file directory.Do not start Berkeley DB in recover mode.
Don't synchronously flush the
BDBlogs. This option is deprecated; use--skip-sync-bdb-logsinstead (see the description for--sync-bdb-logs).Start Berkeley DB in multi-process mode. (Do not use
DB_PRIVATEwhen initializing Berkeley DB.)The
BDBtemporary file directory.Disable the
BDBstorage engine.Synchronously flush the
BDBlogs. This option is enabled by default. Use--skip-sync-bdb-logsto disable it.
If you use the --skip-bdb option, MySQL does not
initialize the Berkeley DB library and this saves a lot of memory.
However, if you use this option, you cannot use
BDB tables. If you try to create a
BDB table, MySQL uses the default storage
engine instead.
Normally, you should start mysqld without the
--bdb-no-recover option if you intend to use
BDB tables. However, this may cause problems
when you try to start mysqld if the
BDB log files are corrupted. See
Section 2.4.15.2.3, “Starting and Troubleshooting the MySQL Server”.
With the bdb_max_lock variable, you can specify
the maximum number of locks that can be active on a
BDB table. The default is 10,000. You should
increase this if errors such as the following occur when you
perform long transactions or when mysqld has to
examine many rows to execute a query:
bdb: Lock table is out of available locks Got error 12 from ...
You may also want to change the
binlog_cache_size and
max_binlog_cache_size variables if you are
using large multiple-statement transactions. See
Section 5.11.3, “The Binary Log”.
See also Section 5.2.3, “System Variables”.
Each BDB table is stored on disk in two files.
The files have names that begin with the table name and have an
extension to indicate the file type. An .frm
file stores the table format, and a .db file
contains the table data and indexes.
To specify explicitly that you want a BDB
table, indicate that with an ENGINE table
option:
CREATE TABLE t (i INT) ENGINE = BDB;
The older term TYPE is supported as a synonym
for ENGINE for backward compatibility, but
ENGINE is the preferred term and
TYPE is deprecated.
BerkeleyDB is a synonym for
BDB in the ENGINE table
option.
The BDB storage engine provides transactional
tables. The way you use these tables depends on the autocommit
mode:
If you are running with autocommit enabled (which is the default), changes to
BDBtables are committed immediately and cannot be rolled back.If you are running with autocommit disabled, changes do not become permanent until you execute a
COMMITstatement. Instead of committing, you can executeROLLBACKto forget the changes.You can start a transaction with the
START TRANSACTIONorBEGINstatement to suspend autocommit, or withSET AUTOCOMMIT=0to disable autocommit explicitly.
For more information about transactions, see
Section 13.4.1, “START TRANSACTION, COMMIT, and
ROLLBACK Syntax”.
The BDB storage engine has the following
characteristics:
BDBtables can have up to 31 indexes per table, 16 columns per index, and a maximum key size of 1024 bytes.MySQL requires a primary key in each
BDBtable so that each row can be uniquely identified. If you don't create one explicitly by declaring aPRIMARY KEY, MySQL creates and maintains a hidden primary key for you. The hidden key has a length of five bytes and is incremented for each insert attempt. This key does not appear in the output ofSHOW CREATE TABLEorDESCRIBE.The primary key is faster than any other index, because it is stored together with the row data. The other indexes are stored as the key data plus the primary key, so it's important to keep the primary key as short as possible to save disk space and get better speed.
This behavior is similar to that of
InnoDB, where shorter primary keys save space not only in the primary index but in secondary indexes as well.If all columns that you access in a
BDBtable are part of the same index or part of the primary key, MySQL can execute the query without having to access the actual row. In aMyISAMtable, this can be done only if the columns are part of the same index.Sequential scanning is slower for
BDBtables than forMyISAMtables because the data inBDBtables is stored in B-trees and not in a separate data file.Key values are not prefix- or suffix-compressed like key values in
MyISAMtables. In other words, key information takes a little more space inBDBtables compared toMyISAMtables.There are often holes in the
BDBtable to allow you to insert new rows in the middle of the index tree. This makesBDBtables somewhat larger thanMyISAMtables.SELECT COUNT(*) FROMis slow fortbl_nameBDBtables, because no row count is maintained in the table.The optimizer needs to know the approximate number of rows in the table. MySQL solves this by counting inserts and maintaining this in a separate segment in each
BDBtable. If you don't issue a lot ofDELETEorROLLBACKstatements, this number should be accurate enough for the MySQL optimizer. However, MySQL stores the number only on close, so it may be incorrect if the server terminates unexpectedly. It should not be fatal even if this number is not 100% correct. You can update the row count by usingANALYZE TABLEorOPTIMIZE TABLE. See Section 13.5.2.1, “ANALYZE TABLESyntax”, and Section 13.5.2.5, “OPTIMIZE TABLESyntax”.Internal locking in
BDBtables is done at the page level.LOCK TABLESworks onBDBtables as with other tables. If you do not useLOCK TABLES, MySQL issues an internal multiple-write lock on the table (a lock that does not block other writers) to ensure that the table is properly locked if another thread issues a table lock.To support transaction rollback, the
BDBstorage engine maintains log files. For maximum performance, you can use the--bdb-logdiroption to place theBDBlogs on a different disk than the one where your databases are located.MySQL performs a checkpoint each time a new
BDBlog file is started, and removes anyBDBlog files that are not needed for current transactions. You can also useFLUSH LOGSat any time to checkpoint the Berkeley DB tables.For disaster recovery, you should use table backups plus MySQL's binary log. See Section 5.9.1, “Database Backups”.
Warning: If you delete old log files that are still in use,
BDBis not able to do recovery at all and you may lose data if something goes wrong.Applications must always be prepared to handle cases where any change of a
BDBtable may cause an automatic rollback and any read may fail with a deadlock error.If you get a full disk with a
BDBtable, you get an error (probably error 28) and the transaction should roll back. This contrasts withMyISAMtables, for which mysqld waits for sufficient free disk space before continuing.
The following list indicates restrictions that you must observe
when using BDB tables:
Each
BDBtable stores in its.dbfile the path to the file as it was created. This is done to enable detection of locks in a multi-user environment that supports symlinks. As a consequence of this, it is not possible to moveBDBtable files from one database directory to another.When making backups of
BDBtables, you must either use mysqldump or else make a backup that includes the files for eachBDBtable (the.frmand.dbfiles) as well as theBDBlog files. TheBDBstorage engine stores unfinished transactions in its log files and requires them to be present when mysqld starts. TheBDBlogs are the files in the data directory with names of the formlog.(ten digits).NNNNNNNNNNIf a column that allows
NULLvalues has a unique index, only a singleNULLvalue is allowed. This differs from other storage engines, which allow multipleNULLvalues in unique indexes.
If the following error occurs when you start mysqld after upgrading, it means that the current version of
BDBdoesn't support the old log file format:bdb: Ignoring log file: .../log.
NNNNNNNNNN: unsupported log version #In this case, you must delete all
BDBlogs from your data directory (the files that have names of the formlog.) and restart mysqld. We also recommend that you then use mysqldump --opt to dump yourNNNNNNNNNNBDBtables, drop the tables, and restore them from the dump file.If autocommit mode is disabled and you drop a
BDBtable that is referenced in another transaction, you may get error messages of the following form in your MySQL error log:001119 23:43:56 bdb: Missing log fileid entry 001119 23:43:56 bdb: txn_abort: Log undo failed for LSN: 1 3644744: InvalidThis is not fatal, but the fix is not trivial. Until the problem is fixed, we recommend that you not drop
BDBtables except while autocommit mode is enabled.
The EXAMPLE storage engine is a stub engine that
does nothing. Its purpose is to serve as an example in the MySQL
source code that illustrates how to begin writing new storage
engines. As such, it is primarily of interest to developers.
The EXAMPLE storage engine is included in MySQL
binary distributions. To enable this storage engine if you build
MySQL from source, invoke configure with the
--with-example-storage-engine option.
To examine the source for the EXAMPLE engine,
look in the sql/examples directory of a MySQL
source distribution.
When you create an EXAMPLE table, the server
creates a table format file in the database directory. The file
begins with the table name and has an .frm
extension. No other files are created. No data can be stored into
the table. Retrievals return an empty result.
mysql>CREATE TABLE test (i INT) ENGINE = EXAMPLE;Query OK, 0 rows affected (0.78 sec) mysql>INSERT INTO test VALUES(1),(2),(3);ERROR 1031 (HY000): Table storage engine for 'test' doesn't have this option mysql>SELECT * FROM test;Empty set (0.31 sec)
The EXAMPLE storage engine does not support
indexing.
The FEDERATED storage engine is available
beginning with MySQL 5.0.3. It is a storage engine that accesses
data in tables of remote databases rather than in local tables.
The FEDERATED storage engine is included in MySQL
binary distributions. To enable this storage engine if you build
MySQL from source, invoke configure with the
--with-federated-storage-engine option.
To examine the source for the FEDERATED engine,
look in the sql directory of a source
distribution for MySQL 5.0.3 or newer.
Additional resources
A forum dedicated to the
FEDERATEDstorage engine is available at http://forums.mysql.com/list.php?105.
When you create a FEDERATED table, the server
creates a table format file in the database directory. The file
begins with the table name and has an .frm
extension. No other files are created, because the actual data is
in a remote table. This differs from the way that storage engines
for local tables work.
For local database tables, data files are local. For example, if
you create a MyISAM table named
users, the MyISAM handler
creates a data file named users.MYD. A handler
for local tables reads, inserts, deletes, and updates data in
local data files, and rows are stored in a format particular to
the handler. To read rows, the handler must parse data into
columns. To write rows, column values must be converted to the row
format used by the handler and written to the local data file.
With the MySQL FEDERATED storage engine, there
are no local data files for a table (for example, there is no
.MYD file). Instead, a remote database stores
the data that normally would be in the table. The local server
connects to a remote server, and uses the MySQL client API to
read, delete, update, and insert data in the remote table. Data
retrieval is initiated via a SELECT * FROM
SQL statement. To
read the result, rows are fetched one at a time by using the
tbl_namemysql_fetch_row() C API function, and then
converting the columns in the SELECT result set
to the format that the FEDERATED handler
expects.
The flow of information is as follows:
SQL calls issued locally
MySQL handler API (data in handler format)
MySQL client API (data converted to SQL calls)
Remote database -> MySQL client API
Convert result sets (if any) to handler format
Handler API -> Result rows or rows-affected count to local
The procedure for using FEDERATED tables is
very simple. Normally, you have two servers running, either both
on the same host or on different hosts. (It is possible for a
FEDERATED table to use another table that is
managed by the same server, although there is little point in
doing so.)
First, you must have a table on the remote server that you want to
access by using a FEDERATED table. Suppose that
the remote table is in the federated database
and is defined like this:
CREATE TABLE test_table (
id INT(20) NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL DEFAULT '',
other INT(20) NOT NULL DEFAULT '0',
PRIMARY KEY (id),
INDEX name (name),
INDEX other_key (other)
)
ENGINE=MyISAM
DEFAULT CHARSET=latin1;
The example uses a MyISAM table, but the table
could use any storage engine.
Next, create a FEDERATED table on the local
server for accessing the remote table:
CREATE TABLE federated_table (
id INT(20) NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL DEFAULT '',
other INT(20) NOT NULL DEFAULT '0',
PRIMARY KEY (id),
INDEX name (name),
INDEX other_key (other)
)
ENGINE=FEDERATED
DEFAULT CHARSET=latin1
CONNECTION='mysql://root@remote_host:9306/federated/test_table';
(Before MySQL 5.0.13, use COMMENT rather than
CONNECTION.)
The structure of this table must be exactly the same as that of
the remote table, except that the ENGINE table
option should be FEDERATED and the
CONNECTION table option is a connection string
that indicates to the FEDERATED engine how to
connect to the remote server.
The FEDERATED engine creates only the
test_table.frm file in the
federated database.
The remote host information indicates the remote server to which
your local server connects, and the database and table information
indicates which remote table to use as the data source. In this
example, the remote server is indicated to be running as
remote_host on port 9306, so there must be a
MySQL server running on the remote host and listening to port
9306.
The general form of the connection string in the
CONNECTION option is as follows:
scheme://user_name[:password]@host_name[:port_num]/db_name/tbl_name
Only mysql is supported as the
scheme value at this point; the
password and port number are optional.
Here are some example connection strings:
CONNECTION='mysql://username:password@hostname:port/database/tablename' CONNECTION='mysql://username@hostname/database/tablename' CONNECTION='mysql://username:password@hostname/database/tablename'
The use of CONNECTION for specifying the
connection string is non-optimal and is likely to change in
future. Keep this in mind for applications that use
FEDERATED tables. Such applications are likely
to need modification if the format for specifying connection
information changes.
Because any password given in the connection string is stored as
plain text, it can be seen by any user who can use SHOW
CREATE TABLE or SHOW TABLE STATUS for
the FEDERATED table, or query the
TABLES table in the
INFORMATION_SCHEMA database.
The following items indicate features that the
FEDERATED storage engine does and does not
support:
In the first version, the remote server must be a MySQL server. Support by
FEDERATEDfor other database engines may be added in the future.The remote table that a
FEDERATEDtable points to must exist before you try to access the table through theFEDERATEDtable.It is possible for one
FEDERATEDtable to point to another, but you must be careful not to create a loop.There is no support for transactions.
A
FEDERATEDtable does not support indexes per-se, since the access to the table is handled remotely, it is the remote table that supports the indexes. Care should be taken when creating aFEDERATEDtable since the index definition from an equivalentMyISAMor other table may not be supported. For example, creating aFEDERATEDtable with an index prefix onVARCHAR,TEXTorBLOBcolumns will fail. The following definition inMyISAMis valid:CREATE TABLE `T1`(`A` VARCHAR(100),UNIQUE KEY(`A`(30))) ENGINE=MYISAM;
The key prefix in this example is incompatible with the
FEDERATEDengine, and the equivalent statement will fail:CREATE TABLE `T1`(`A` VARCHAR(100),UNIQUE KEY(`A`(30))) ENGINE=FEDERATED CONNECTION='MYSQL://127.0.0.1:3306/TEST/T1';
If possible, you should try to separate the column and index definition when creating tables on both the remote server and the local server to avoid these index issues.
Performance on a
FEDERATEDtable when performing bulk inserts (for example, on aINSERT INTO ... SELECT ...statement) is slower than with other table types because each selected row is treated as an individualINSERTstatement on the federated table.There is no way for the
FEDERATEDengine to know if the remote table has changed. The reason for this is that this table must work like a data file that would never be written to by anything other than the database. The integrity of the data in the local table could be breached if there was any change to the remote database.The
FEDERATEDstorage engine supportsSELECT,INSERT,UPDATE,DELETE, and indexes. It does not supportALTER TABLE, or any Data Definition Language statements other thanDROP TABLE. The current implementation does not use Prepared statements.Any
DROP TABLEstatement issued against aFEDERATEDtable will only drop the local table, not the remote table.The implementation uses
SELECT,INSERT,UPDATE, andDELETE, but notHANDLER.FEDERATEDtables do not work with the query cache.
Some of these limitations may be lifted in future versions of the
FEDERATED handler.
The ARCHIVE storage engine is used for storing
large amounts of data without indexes in a very small footprint.
The ARCHIVE storage engine is included in MySQL
binary distributions. To enable this storage engine if you build
MySQL from source, invoke configure with the
--with-archive-storage-engine option.
To examine the source for the ARCHIVE engine,
look in the sql directory of a MySQL source
distribution.
You can check whether the ARCHIVE storage engine
is available with this statement:
mysql> SHOW VARIABLES LIKE 'have_archive';
When you create an ARCHIVE table, the server
creates a table format file in the database directory. The file
begins with the table name and has an .frm
extension. The storage engine creates other files, all having names
beginning with the table name. The data and metadata files have
extensions of .ARZ and
.ARM, respectively. An
.ARN file may appear during optimization
operations.
The ARCHIVE engine supports
INSERT and SELECT, but not
DELETE, REPLACE, or
UPDATE. It does support ORDER
BY operations, BLOB columns, and
basically all but spatial data types (see
Section 16.4.1, “MySQL Spatial Data Types”). The
ARCHIVE engine uses row-level locking.
Storage: Rows are compressed as
they are inserted. The ARCHIVE engine uses
zlib lossless data compression (see
http://www.zlib.net/). You can use OPTIMIZE
TABLE to analyze the table and pack it into a smaller
format (for a reason to use OPTIMIZE TABLE, see
later in this section). Beginning with MySQL 5.0.15, the engine also
supports CHECK TABLE. There are several types of
insertions that are used:
An
INSERTstatement just pushes rows into a compression buffer, and that buffer flushes as necessary. The insertion into the buffer is protected by a lock. ASELECTforces a flush to occur, unless the only insertions that have come in wereINSERT DELAYED(those flush as necessary). See Section 13.2.4.2, “INSERT DELAYEDSyntax”.A bulk insert is visible only after it completes, unless other inserts occur at the same time, in which case it can be seen partially. A
SELECTnever causes a flush of a bulk insert unless a normal insert occurs while it is loading.
Retrieval: On retrieval, rows are
uncompressed on demand; there is no row cache. A
SELECT operation performs a complete table scan:
When a SELECT occurs, it finds out how many rows
are currently available and reads that number of rows.
SELECT is performed as a consistent read. Note
that lots of SELECT statements during insertion
can deteriorate the compression, unless only bulk or delayed inserts
are used. To achieve better compression, you can use
OPTIMIZE TABLE or REPAIR
TABLE. The number of rows in ARCHIVE
tables reported by SHOW TABLE STATUS is always
accurate. See Section 13.5.2.5, “OPTIMIZE TABLE Syntax”,
Section 13.5.2.6, “REPAIR TABLE Syntax”, and
Section 13.5.4.24, “SHOW TABLE STATUS Syntax”.
Additional resources
A forum dedicated to the
ARCHIVEstorage engine is available at http://forums.mysql.com/list.php?112.
The CSV storage engine stores data in text files
using comma-separated values format. It is unavailable on Windows
until MySQL 5.1.
The CSV storage engine is included in MySQL
binary distributions (except on Windows). To enable this storage
engine if you build MySQL from source, invoke
configure with the
--with-csv-storage-engine option.
To examine the source for the CSV engine, look in
the sql/examples directory of a MySQL source
distribution.
When you create a CSV table, the server creates a
table format file in the database directory. The file begins with
the table name and has an .frm extension. The
storage engine also creates a data file. Its name begins with the
table name and has a .CSV extension. The data
file is a plain text file. When you store data into the table, the
storage engine saves it into the data file in comma-separated values
format.
mysql>CREATE TABLE test(i INT, c CHAR(10)) ENGINE = CSV;Query OK, 0 rows affected (0.12 sec) mysql>INSERT INTO test VALUES(1,'record one'),(2,'record two');Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql>SELECT * FROM test;+------+------------+ | i | c | +------+------------+ | 1 | record one | | 2 | record two | +------+------------+ 2 rows in set (0.00 sec)
If you examine the test.CSV file in the
database directory created by executing the preceding statements,
its contents should look like this:
"1","record one" "2","record two"
This format can be read, and even written, by spreadsheet applications such as Microsoft Excel or StarOffice Calc.
The CSV storage engine does not support indexing.
The BLACKHOLE storage engine acts as a
“black hole” that accepts data but throws it away and
does not store it. Retrievals always return an empty result:
mysql>CREATE TABLE test(i INT, c CHAR(10)) ENGINE = BLACKHOLE;Query OK, 0 rows affected (0.03 sec) mysql>INSERT INTO test VALUES(1,'record one'),(2,'record two');Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql>SELECT * FROM test;Empty set (0.00 sec)
The BLACKHOLE storage engine is included in MySQL
binary distributions. To enable this storage engine if you build
MySQL from source, invoke configure with the
--with-blackhole-storage-engine option.
To examine the source for the BLACKHOLE engine,
look in the sql directory of a MySQL source
distribution.
When you create a BLACKHOLE table, the server
creates a table format file in the database directory. The file
begins with the table name and has an .frm
extension. There are no other files associated with the table.
The BLACKHOLE storage engine supports all kinds
of indexes. That is, you can include index declarations in the table
definition.
You can check whether the BLACKHOLE storage
engine is available with this statement:
mysql> SHOW VARIABLES LIKE 'have_blackhole_engine';
Inserts into a BLACKHOLE table do not store any
data, but if the binary log is enabled, the SQL statements are
logged (and replicated to slave servers). This can be useful as a
repeater or filter mechanism. For example, suppose that your
application requires slave-side filtering rules, but transferring
all binary log data to the slave first results in too much traffic.
In such a case, it is possible to set up on the master host a
“dummy” slave process whose default storage engine is
BLACKHOLE, depicted as follows:
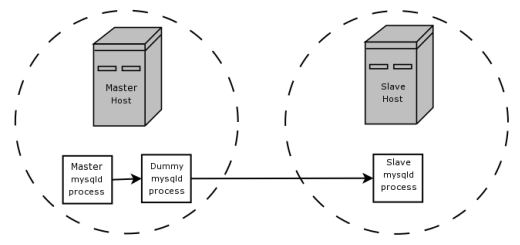
The master writes to its binary log. The “dummy”
mysqld process acts as a slave, applying the
desired combination of replicate-do-* and
replicate-ignore-* rules, and writes a new,
filtered binary log of its own. (See
Section 6.8, “Replication Startup Options”.) This filtered log is
provided to the slave.
The dummy process does not actually store any data, so there is little processing overhead incurred by running the additional mysqld process on the replication master host. This type of setup can be repeated with additional replication slaves.
INSERT triggers for BLACKHOLE
tables work as expected. However, because the
BLACKHOLE table does not actually store any data,
UPDATE and DELETE triggers are
not activated: The FOR EACH ROW clause in the
trigger definition does not apply because there are no rows.
Other possible uses for the BLACKHOLE storage
engine include:
Verification of dump file syntax.
Measurement of the overhead from binary logging, by comparing performance using
BLACKHOLEwith and without binary logging enabled.BLACKHOLEis essentially a “no-op” storage engine, so it could be used for finding performance bottlenecks not related to the storage engine itself.
Table of Contents
- 15.1. MySQL Cluster Overview
- 15.2. Basic MySQL Cluster Concepts
- 15.3. Simple Multi-Computer How-To
- 15.4. MySQL Cluster Configuration
- 15.5. Upgrading and Downgrading MySQL Cluster
- 15.6. Process Management in MySQL Cluster
- 15.7. Management of MySQL Cluster
- 15.8. On-line Backup of MySQL Cluster
- 15.9. Cluster Utility Programs
- 15.9.1. ndb_config — Extract NDB Configuration Information
- 15.9.2. ndb_cpcd — Automate Testing for NDB Development
- 15.9.3. ndb_delete_all — Delete All Rows from NDB Table
- 15.9.4. ndb_desc — Describe NDB Tables
- 15.9.5. ndb_drop_index — Drop Index from NDB Table
- 15.9.6. ndb_drop_table — Drop NDB Table
- 15.9.7. ndb_error_reporter — NDB Error-Reporting Utility
- 15.9.8. ndb_print_backup_file — Print NDB Backup File Contents
- 15.9.9. ndb_print_schema_file — Print NDB Schema File Contents
- 15.9.10. ndb_print_sys_file — Print NDB System File Contents
- 15.9.11. ndb_select_all — Print Rows from NDB Table
- 15.9.12. ndb_select_count — Print Row Counts for NDB Tables
- 15.9.13. ndb_show_tables — Display List of NDB Tables
- 15.9.14. ndb_size.pl — NDBCluster Size Requirement Estimator
- 15.9.15. ndb_waiter — Wait for Cluster to Reach a Given Status
- 15.10. Using High-Speed Interconnects with MySQL Cluster
- 15.11. Known Limitations of MySQL Cluster
- 15.11.1. Non-Compliance In SQL Syntax
- 15.11.2. Limits and Differences from Standard MySQL Limits
- 15.11.3. Limits Relating to Transaction Handling
- 15.11.4. Error Handling
- 15.11.5. Limits Associated with Database Objects
- 15.11.6. Unsupported Or Missing Features
- 15.11.7. Limitations Relating to Performance
- 15.11.8. Issues Exclusive to MySQL Cluster
- 15.11.9. Limitations Relating to Multiple Cluster Nodes
- 15.11.10. Previous MySQL Cluster Issues Resolved in MySQL 5.1
- 15.12. MySQL Cluster Development Roadmap
- 15.13. MySQL Cluster Glossary
MySQL Cluster is a high-availability, high-redundancy version of
MySQL adapted for the distributed computing environment. It uses the
NDB Cluster storage engine to enable running
several MySQL servers in a cluster. This storage engine is available
in MySQL 5.0 binary releases and in RPMs compatible
with most modern Linux distributions.
MySQL 5.0 is currently available and supported on a number of platforms, including Linux, Solaris, Mac OS X, BSD, HP-UX, and many other Unix-style operating systems on a variety of hardware. For exact levels of support available for on specific combinations of operating system versions, operating system distributions, and hardware platforms, please refer to the Cluster Supported Platforms list maintained by the MySQL Support Team on the MySQL AB Web site.
MySQL Cluster is not currently supported on Microsoft Windows. We are working to make Cluster available on all operating systems supported by MySQL, including Windows, and will update the information provided here as this work continues.
This chapter represents a work in progress, and its contents are subject to revision as MySQL Cluster continues to evolve. Additional information regarding MySQL Cluster can be found on the MySQL AB Web site at http://www.mysql.com/products/cluster/.
Additional resources
Answers to some commonly asked questions about Cluster may be found in the Section A.10, “MySQL 5.0 FAQ — MySQL Cluster”.
The MySQL Cluster mailing list: http://lists.mysql.com/cluster.
The MySQL Cluster Forum: http://forums.mysql.com/list.php?25.
Many MySQL Cluster users and some of the MySQL Cluster developers blog about their experiences with Cluster, and make feeds of these available through PlanetMySQL.
If you are new to MySQL Cluster, you may find our Developer Zone article How to set up a MySQL Cluster for two servers to be helpful.
MySQL Cluster is a technology that enables clustering of in-memory databases in a shared-nothing system. The shared-nothing architecture allows the system to work with very inexpensive hardware, and with a minimum of specific requirements for hardware or software.
MySQL Cluster is designed not to have any single point of failure. For this reason, each component is expected to have its own memory and disk, and the use of shared storage mechanisms such as network shares, network filesystems, and SANs is not recommended or supported.
MySQL Cluster integrates the standard MySQL server with an
in-memory clustered storage engine called NDB.
In our documentation, the term NDB refers to
the part of the setup that is specific to the storage engine,
whereas “MySQL Cluster” refers to the combination of
MySQL and the NDB storage engine.
A MySQL Cluster consists of a set of computers, each running a one or more processes which may include a MySQL server, a data node, a management server, and (possibly) a specialized data access programs. The relationship of these components in a cluster is shown here:
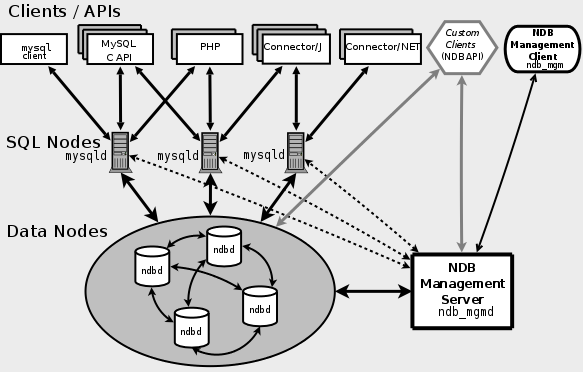
All these programs work together to form a MySQL Cluster. When
data is stored in the NDB Cluster storage
engine, the tables are stored in the data nodes. Such tables are
directly accessible from all other MySQL servers in the cluster.
Thus, in a payroll application storing data in a cluster, if one
application updates the salary of an employee, all other MySQL
servers that query this data can see this change immediately.
The data stored in the data nodes for MySQL Cluster can be mirrored; the cluster can handle failures of individual data nodes with no other impact than that a small number of transactions are aborted due to losing the transaction state. Because transactional applications are expected to handle transaction failure, this should not be a source of problems.
NDB is an in-memory
storage engine offering high-availability and data-persistence
features.
The NDB storage engine can be configured with a
range of failover and load-balancing options, but it is easiest to
start with the storage engine at the cluster level. MySQL
Cluster's NDB storage engine contains a
complete set of data, dependent only on other data within the
cluster itself.
The cluster portion of MySQL Cluster is currently configured independently of the MySQL servers. In a MySQL Cluster, each part of the cluster is considered to be a node.
Note: In many contexts, the term “node” is used to indicate a computer, but when discussing MySQL Cluster it means a process. It is possible to run any number of nodes on a single computer, for which we use the term cluster host.
(However, it should be noted MySQL does not currently support the use of multiple data nodes on a single computer in a production setting. See Section 15.11.9, “Limitations Relating to Multiple Cluster Nodes”.)
There are three types of cluster nodes, and in a minimal MySQL Cluster configuration, there will be at least three nodes, one of each of these types:
Management node (MGM node): The role of this type of node is to manage the other nodes within the MySQL Cluster, performing such functions as providing configuration data, starting and stopping nodes, running backup, and so forth. Because this node type manages the configuration of the other nodes, a node of this type should be started first, before any other node. An MGM node is started with the command ndb_mgmd.
Data node: This type of node stores cluster data. There are as many data nodes as there are replicas, times the number of fragments. For example, with two replicas, each having two fragments, you will need four data nodes. It is not necessary to have more than one replica. A data node is started with the command ndbd.
SQL node: This is a node that accesses the cluster data. In the case of MySQL Cluster, an SQL node is a traditional MySQL server that uses the
NDB Clusterstorage engine. An SQL node is typically started with the command mysqld --ndbcluster or by using mysqld with thendbclusteroption added tomy.cnf.An SQL node is actually just a specialised type of API node, which designates any application which accesses Cluster data. One example of an API node is the ndb_restore utility that is used to restore a cluster backup. It is possible to write such applications using the NDB API.
Important: It is not realistic to expect to employ a three-node setup in a production environment. Such a configuration provides no redundancy; in order to benefit from MySQL Cluster's high-availability features, you must use multiple data and SQL nodes. The use of multiple management nodes is also highly recommended.
For a brief introduction to the relationships between nodes, node groups, replicas, and partitions in MySQL Cluster, see Section 15.2.1, “MySQL Cluster Nodes, Node Groups, Replicas, and Partitions”.
Configuration of a cluster involves configuring each individual node in the cluster and setting up individual communication links between nodes. MySQL Cluster is currently designed with the intention that data nodes are homogeneous in terms of processor power, memory space, and bandwidth. In addition, to provide a single point of configuration, all configuration data for the cluster as a whole is located in one configuration file.
The management server (MGM node) manages the cluster configuration file and the cluster log. Each node in the cluster retrieves the configuration data from the management server, and so requires a way to determine where the management server resides. When interesting events occur in the data nodes, the nodes transfer information about these events to the management server, which then writes the information to the cluster log.
In addition, there can be any number of cluster client processes or applications. These are of two types:
Standard MySQL clients: These are no different for MySQL Cluster than they are for standard (non-Cluster) MySQL. In other words, MySQL Cluster can be accessed from existing MySQL applications written in PHP, Perl, C, C++, Java, Python, Ruby, and so on.
Management clients: These clients connect to the management server and provide commands for starting and stopping nodes gracefully, starting and stopping message tracing (debug versions only), showing node versions and status, starting and stopping backups, and so on.
This section discusses the manner in which MySQL Cluster divides and duplicates data for storage.
Central to an understanding of this topic are the following concepts, listed here with brief definitions:
(Data) Node: An ndbd process, which stores a replica —that is, a copy of the partition (see below) assigned to the node group of which the node is a member.
Each data node should be located on a separate computer. While it is also possible to host multiple ndbd processes on a single computer, such a configuration is not supported.
It is common for the terms “node” and “data node” to be used interchangeably when referring to an ndbd process; where mentioned, management (MGM) nodes (ndb_mgmd processes) and SQL nodes (mysqld processes) are specified as such in this discussion.
Node Group: A node group consists of one or more nodes, and stores partitions, or sets of replicas (see next item).
Note: Currently, all node groups in a cluster must have the same number of nodes.
Partition: This is a portion of the data stored by the cluster. There are as many cluster partitions as nodes participating in the cluster. Each node is responsible for keeping at least one copy of any partitions assigned to it (that is, at least one replica) available to the cluster.
A replica belongs entirely to a single node; a node can (and usually does) store several replicas.
Replica: This is a copy of a cluster partition. Each node in a node group stores a replica. Also sometimes known as a partition replica. The number of replicas is equal to the number of nodes per node group.
The following diagram illustrates a MySQL Cluster with four data nodes, arranged in two node groups of two nodes each; nodes 1 and 2 belong to node group 0, and nodes 3 and 4 belong to node group 1. Note that only data (ndbd) nodes are shown here; although a working cluster requires an ndb_mgm process for cluster management and at least one SQL node to access the data stored by the cluster, these have been omitted in the figure for clarity.
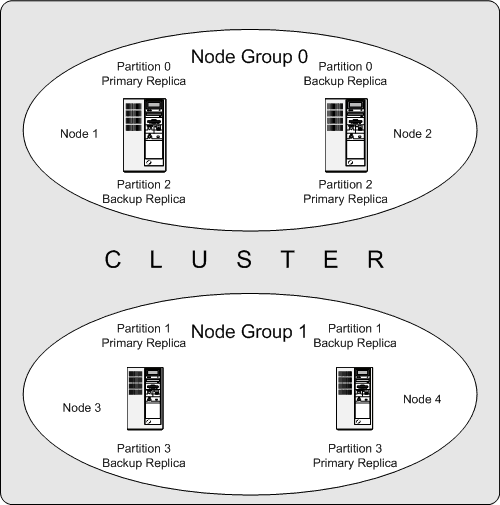
The data stored by the cluster is divided into four partitions, numbered 0, 1, 2, and 3. Each partition is stored — in multiple copies — on the same node group. Partitions are stored on alternate node groups:
Partition 0 is stored on node group 0; a primary replica (primary copy) is stored on node 1, and a backup replica (backup copy of the partition) is stored on node 2.
Partition 1 is stored on the other node group (node group 1); this partition's primary replica is on node 3, and its backup replica is on node 4.
Partition 2 is stored on node group 0. However, the placing of its two replicas is reversed from that of Partition 0; for Partition 2, the primary replica is stored on node 2, and the backup on node 1.
Partition 3 is stored on node group 1, and the placement of its two replicas are reversed from those of partition 1. That is, its primary replica is located on node 4, with the backup on node 3.
What this means regarding the continued operation of a MySQL Cluster is this: so long as each node group participating in the cluster has at least one node operating, the cluster has a complete copy of all data and remains viable. This is illustrated in the next diagram.
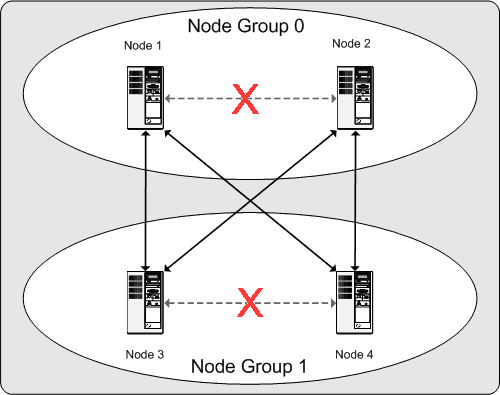
In this example, where the cluster consists of two node groups of two nodes each, any combination of at least one node in node group 0 and at least one node in node group 1 is sufficient to keep the cluster “alive” (indicated by arrows in the diagram). However, if both nodes from either node group fail, the remaining two nodes are not sufficient (shown by the arrows marked out with an X); in either case, the cluster has lost an entire partition and so can no longer provide access to a complete set of all cluster data.
This section is a “How-To” that describes the basics for how to plan, install, configure, and run a MySQL Cluster. Whereas the examples in Section 15.4, “MySQL Cluster Configuration” provide more in-depth information on a variety of clustering options and configuration, the result of following the guidelines and procedures outlined here should be a usable MySQL Cluster which meets the minimum requirements for availability and safeguarding of data.
This section covers hardware and software requirements; networking issues; installation of MySQL Cluster; configuration issues; starting, stopping, and restarting the cluster; loading of a sample database; and performing queries.
Basic Assumptions
This How-To makes the following assumptions:
The cluster setup has four nodes, each on a separate host, and each with a fixed network address on a typical Ethernet as shown here:
Node IP Address Management (MGM) node 192.168.0.10 MySQL server (SQL) node 192.168.0.20 Data (NDBD) node "A" 192.168.0.30 Data (NDBD) node "B" 192.168.0.40 This may be made clearer in the following diagram:
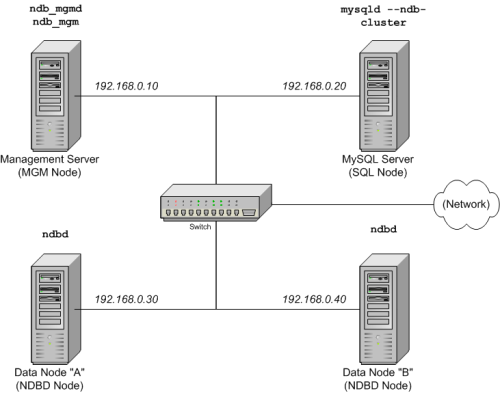
In the interest of simplicity (and reliability), this How-To uses only numeric IP addresses. However, if DNS resolution is available on your network, it is possible to use hostnames in lieu of IP addresses in configuring Cluster. Alternatively, you can use the
/etc/hostsfile or your operating system's equivalent for providing a means to do host lookup if such is available.Note
A common problem when trying to use hostnames for Cluster nodes arises because of the way in which some operating systems (including some Linux distributions) set up the system's own hostname in the
/etc/hostsduring installation. Consider two machines with the hostnamesndb1andndb2, both in theclusternetwork domain. Red Hat Linux (including some derivatives such as CentOS and Fedora) places the following entries in these machines'/etc/hostsfiles:# ndb1
/etc/hosts: 127.0.0.1 ndb1.cluster ndb1 localhost.localdomain localhost# ndb2
/etc/hosts: 127.0.0.1 ndb2.cluster ndb2 localhost.localdomain localhostSuSE Linux (including OpenSuSE) places these entries in the machines'
/etc/hostsfiles:# ndb1
/etc/hosts: 127.0.0.1 localhost 127.0.0.2 ndb1.cluster ndb1# ndb2
/etc/hosts: 127.0.0.1 localhost 127.0.0.2 ndb2.cluster ndb2In both instances,
ndb1routesndb1.clusterto a loopback IP address, but gets a public IP address from DNS forndb2.cluster, whilendb2routesndb2.clusterto a loopback address and obtains a public address forndb1.cluster. The result is that each data node connects to the management server, but cannot tell when any other data nodes have connected, and so the data nodes appear to hang while starting.You should also be aware that you cannot mix
localhostand other hostnames or IP addresses inconfig.ini. For these reasons, the solution in such cases (other than to use IP addresses for allconfig.iniHostNameentries) is to remove the fully qualified hostnames from/etc/hostsand use these inconfig.inifor all cluster hosts.Each host in our scenario is an Intel-based desktop PC running a common, generic Linux distribution installed to disk in a standard configuration, and running no unnecessary services. The core OS with standard TCP/IP networking capabilities should be sufficient. Also for the sake of simplicity, we also assume that the filesystems on all hosts are set up identically. In the event that they are not, you will need to adapt these instructions accordingly.
Standard 100 Mbps or 1 gigabit Ethernet cards are installed on each machine, along with the proper drivers for the cards, and that all four hosts are connected via a standard-issue Ethernet networking appliance such as a switch. (All machines should use network cards with the same throughout. That is, all four machines in the cluster should have 100 Mbps cards or all four machines should have 1 Gbps cards.) MySQL Cluster will work in a 100 Mbps network; however, gigabit Ethernet will provide better performance.
Note that MySQL Cluster is not intended for use in a network for which throughput is less than 100 Mbps. For this reason (among others), attempting to run a MySQL Cluster over a public network such as the Internet is not likely to be successful, and is not recommended.
For our sample data, we will use the
worlddatabase which is available for download from the MySQL AB Web site. As this database takes up a relatively small amount of space, we assume that each machine has 256MB RAM, which should be sufficient for running the operating system, host NDB process, and (for the data nodes) for storing the database.
Although we refer to a Linux operating system in this How-To, the instructions and procedures that we provide here should be easily adaptable to other supported operating systems. We also assume that you already know how to perform a minimal installation and configuration of the operating system with networking capability, or that you are able to obtain assistance in this elsewhere if needed.
We discuss MySQL Cluster hardware, software, and networking requirements in somewhat greater detail in the next section. (See Section 15.3.1, “Hardware, Software, and Networking”.)
One of the strengths of MySQL Cluster is that it can be run on commodity hardware and has no unusual requirements in this regard, other than for large amounts of RAM, due to the fact that all live data storage is done in memory. (Note that this is not the case with Disk Data tables, which are implemented in MySQL 5.1; however, we do not intend to backport this feature to MySQL 5.0.) Naturally, multiple and faster CPUs will enhance performance. Memory requirements for other Cluster processes are relatively small.
The software requirements for Cluster are also modest. Host operating systems do not require any unusual modules, services, applications, or configuration to support MySQL Cluster. For supported operating systems, a standard installation should be sufficient. The MySQL software requirements are simple: all that is needed is a production release of MySQL 5.0 to have Cluster support. It is not necessary to compile MySQL yourself merely to be able to use Cluster. In this How-To, we assume that you are using the server binary appropriate to your operating system, available via the MySQL software downloads page at http://dev.mysql.com/downloads/.
For inter-node communication, Cluster supports TCP/IP networking in any standard topology, and the minimum expected for each host is a standard 100 Mbps Ethernet card, plus a switch, hub, or router to provide network connectivity for the cluster as a whole. We strongly recommend that a MySQL Cluster be run on its own subnet which is not shared with non-Cluster machines for the following reasons:
Security: Communications between Cluster nodes are not encrypted or shielded in any way. The only means of protecting transmissions within a MySQL Cluster is to run your Cluster on a protected network. If you intend to use MySQL Cluster for Web applications, the cluster should definitely reside behind your firewall and not in your network's De-Militarized Zone (DMZ) or elsewhere.
Efficiency: Setting up a MySQL Cluster on a private or protected network allows the cluster to make exclusive use of bandwidth between cluster hosts. Using a separate switch for your MySQL Cluster not only helps protect against unauthorized access to Cluster data, it also ensures that Cluster nodes are shielded from interference caused by transmissions between other computers on the network. For enhanced reliability, you can use dual switches and dual cards to remove the network as a single point of failure; many device drivers support failover for such communication links.
It is also possible to use the high-speed Scalable Coherent Interface (SCI) with MySQL Cluster, but this is not a requirement. See Section 15.10, “Using High-Speed Interconnects with MySQL Cluster”, for more about this protocol and its use with MySQL Cluster.
Each MySQL Cluster host computer running data or SQL nodes must have installed on it a MySQL server binary. For management nodes, it is not necessary to install the MySQL server binary, but you do have to install the MGM server daemon and client binaries (ndb_mgmd and ndb_mgm, respectively). This section covers the steps necessary to install the correct binaries for each type of Cluster node.
MySQL AB provides precompiled binaries that support Cluster, and
there is generally no need to compile these yourself. Therefore,
the first step in the installation process for each cluster host
is to download the file
mysql-5.0.42-pc-linux-gnu-i686.tar.gz
from the MySQL downloads
area. We assume that you have placed it in each
machine's /var/tmp directory. (If you do
require a custom binary, see
Section 2.4.14.3, “Installing from the Development Source Tree”.)
RPMs are also available for both 32-bit and 64-bit Linux platforms. For a MySQL Cluster, three (possibly four) RPMs are required:
The Server RPM (for example,
MySQL-server-5.0.42-0.glibc23.i386.rpm), which supplies the core files needed to run a MySQL Server.The Server/Max RPM (for example,
MySQL-Max-5.0.42-0.glibc23.i386.rpm), which provides a MySQL Server binary with clustering support. In MySQL 5.0, this is needed only through 5.0.37. After that, the regular server RPM provides the server binary with clustering support.The NDB Cluster - Storage engine RPM (for example,
MySQL-ndb-storage-5.0.42-0.glibc23.i386.rpm), which supplies the MySQL Cluster data node binary (ndbd).The NDB Cluster - Storage engine management RPM (for example,
MySQL-ndb-management-5.0.42-0.glibc23.i386.rpm), which provides the MySQL Cluster management server binary (ndb_mgmd).
In addition, you should also obtain the
NDB Cluster - Storage engine basic
tools RPM (for example,
MySQL-ndb-tools-5.0.42-0.glibc23.i386.rpm),
which supplies several useful applications for working with a
MySQL Cluster. The most important of the these is the MySQL
Cluster management client (ndb_mgm). The
NDB Cluster - Storage engine extra
tools RPM (for example,
MySQL-ndb-extra-5.0.42-0.glibc23.i386.rpm)
contains some additional testing and monitoring programs, but is
not required to install a MySQL Cluster. (For more information
about these additional programs, see
Section 15.9, “Cluster Utility Programs”.)
The MySQL version number in the RPM filenames (shown here as
5.0.42) can vary according to the
version which you are actually using. It is very
important that all of the Cluster RPMs to be installed have the
same MySQL version number. The
glibc version number (if present —
shown here as glibc23), and architecture
designation (shown here as i386) should be
appropriate to the machine on which the RPM is to be installed.
See Section 2.4.9, “Installing MySQL from RPM Packages on Linux”, for general information about installing MySQL using RPMs supplied by MySQL AB.
After installing from RPM, you still need to configure the cluster as discussed in Section 15.3.3, “Multi-Computer Configuration”.
Note: After completing the installation, do not yet start any of the binaries. We show you how to do so following the configuration of all nodes.
Data and SQL Node Installation —
.tar.gz Binary
On each of the machines designated to host data or SQL nodes,
perform the following steps as the system
root user:
Check your
/etc/passwdand/etc/groupfiles (or use whatever tools are provided by your operating system for managing users and groups) to see whether there is already amysqlgroup andmysqluser on the system. Some OS distributions create these as part of the operating system installation process. If they are not already present, create a newmysqluser group, and then add amysqluser to this group:shell>
groupadd mysqlshell>useradd -g mysql mysqlThe syntax for useradd and groupadd may differ slightly on different versions of Unix, or they may have different names such as adduser and addgroup.
Change location to the directory containing the downloaded file, unpack the archive, and create a symlink to the
mysqldirectory. Note that the actual file and directory names will vary according to the MySQL version number.shell>
cd /var/tmpshell>tar -C /usr/local -xzvf mysql-5.0.42-pc-linux-gnu-i686.tar.gzshell>ln -s /usr/local/mysql-5.0.42-pc-linux-gnu-i686 /usr/local/mysqlChange location to the
mysqldirectory and run the supplied script for creating the system databases:shell>
cd mysqlshell>scripts/mysql_install_db --user=mysqlSet the necessary permissions for the MySQL server and data directories:
shell>
chown -R root .shell>chown -R mysql datashell>chgrp -R mysql .Note that the data directory on each machine hosting a data node is
/usr/local/mysql/data. We will use this piece of information when we configure the management node. (See Section 15.3.3, “Multi-Computer Configuration”.)Copy the MySQL startup script to the appropriate directory, make it executable, and set it to start when the operating system is booted up:
shell>
cp support-files/mysql.server /etc/rc.d/init.d/shell>chmod +x /etc/rc.d/init.d/mysql.servershell>chkconfig --add mysql.server(The startup scripts directory may vary depending on your operating system and version — for example, in some Linux distributions, it is
/etc/init.d.)Here we use Red Hat's chkconfig for creating links to the startup scripts; use whatever means is appropriate for this purpose on your operating system and distribution, such as update-rc.d on Debian.
Remember that the preceding steps must be performed separately on each machine where a data node or SQL node is to reside.
SQL Node Installation — RPM Files
On each machine to be used for hosting a cluster SQL node, install the MySQL RPM by executing the following command as the system root user, replacing the name shown for the RPM as necessary to match the name of the RPM downloaded from the MySQL AB web site:
shell> rpm -Uhv MySQL-server-5.0.42-0.glibc23.i386.rpm
This installs the MySQL server binary
(mysqld) in the
/usr/sbin directory, as well as all needed
MySQL Server support files. It also installs the
mysql.server and
mysqld_safe startup scripts in
/usr/share/mysql and
/usr/bin, respectively. The RPM installer
should take care of general configuration issues (such as
creating the mysql user and group, if needed)
automatically.
Data Node Installation — RPM Files
On a computer that is to host a cluster data node it is necessary to install only the NDB Cluster - Storage engine RPM. To do so, copy this RPM to the data node host, and run the following command as the system root user, replacing the name shown for the RPM as necessary to match that of the RPM downloaded from the MySQL AB web site:
shell> rpm -Uhv MySQL-ndb-storage-5.0.42-0.glibc23.i386.rpm
The previous command installs the MySQL Cluster data node binary
(ndbd) in the /usr/sbin
directory.
Management Node Installation —
.tar.gz Binary
Installation for the management (MGM) node does not require
installation of the mysqld binary. Only the
binaries for the MGM server and client are required, which can
be found in the downloaded archive. Again, we assume that you
have placed this file in /var/tmp.
As system root (that is, after using
sudo, su root, or your
system's equivalent for temporarily assuming the system
administrator account's privileges), perform the following steps
to install ndb_mgmd and
ndb_mgm on the Cluster management node host:
Change location to the
/var/tmpdirectory, and extract the ndb_mgm and ndb_mgmd from the archive into a suitable directory such as/usr/local/bin:shell>
cd /var/tmpshell>tar -zxvf mysql-5.0.42-pc-linux-gnu-i686.tar.gzshell>cd mysql-5.0.42-pc-linux-gnu-i686shell>cp /bin/ndb_mgm* /usr/local/bin(You can safely delete the directory created by unpacking the downloaded archive, and the files it contains, from
/var/tmponce ndb_mgm and ndb_mgmd have been copied to the executables directory.)Change location to the directory into which you copied the files, and then make both of them executable:
shell>
cd /usr/local/binshell>chmod +x ndb_mgm*
Management Node Installation — RPM File
To install the MySQL Cluster management server, it is necessary only to use the NDB Cluster - Storage engine management RPM. Copy this RPM to the computer intended to host the management node, and then install it by running the following command as the system root user (replace the name shown for the RPM as necessary to match that of the Storage engine management RPM downloaded from the MySQL AB web site):
shell> rpm -Uhv MySQL-ndb-management-5.0.42-0.glibc23.i386.rpm
This installs the management server binary
(ndb_mgmd) to the
/usr/sbin directory.
You should also install the NDB management
client, which is supplied by the Storage
engine basic tools RPM. Copy this RPM to the same
computer as the management node, and then install it by running
the following command as the system root user (again, replace
the name shown for the RPM as necessary to match that of the
Storage engine basic tools RPM
downloaded from the MySQL AB web site):
shell> rpm -Uhv MySQL-ndb-tools-5.0.42-0.glibc23.i386.rpm
The Storage engine basic tools
RPM installs the MySQL Cluster management client
(ndb_mgm) to the
/usr/bin directory.
In Section 15.3.3, “Multi-Computer Configuration”, we create configuration files for all of the nodes in our example Cluster.
For our four-node, four-host MySQL Cluster, it is necessary to write four configuration files, one per node host.
Each data node or SQL node requires a
my.cnffile that provides two pieces of information: a connectstring that tells the node where to find the MGM node, and a line telling the MySQL server on this host (the machine hosting the data node) to run in NDB mode.For more information on connectstrings, see Section 15.4.4.2, “The Cluster Connectstring”.
The management node needs a
config.inifile telling it how many replicas to maintain, how much memory to allocate for data and indexes on each data node, where to find the data nodes, where to save data to disk on each data node, and where to find any SQL nodes.
Configuring the Storage and SQL Nodes
The my.cnf file needed for the data nodes
is fairly simple. The configuration file should be located in
the /etc directory and can be edited using
any text editor. (Create the file if it does not exist.) For
example:
shell> vi /etc/my.cnf
We show vi being used here to create the file, but any text editor should work just as well.
For each data node and SQL node in our example setup,
my.cnf should look like this:
# Options for mysqld process: [MYSQLD] ndbcluster # run NDB storage engine ndb-connectstring=192.168.0.10 # location of management server # Options for ndbd process: [MYSQL_CLUSTER] ndb-connectstring=192.168.0.10 # location of management server
After entering the preceding information, save this file and exit the text editor. Do this for the machines hosting data node “A”, data node “B”, and the SQL node.
Important: Once you have
started a mysqld process with the
ndbcluster and
ndb-connectstring parameters in the
[MYSQLD] in the my.cnf
file as shown previously, you cannot execute any CREATE
TABLE or ALTER TABLE statements
without having actually started the cluster. Otherwise, these
statements will fail with an error. This is by
design.
Configuring the Management Node
The first step in configuring the MGM node is to create the
directory in which the configuration file can be found and then
to create the file itself. For example (running as
root):
shell>mkdir /var/lib/mysql-clustershell>cd /var/lib/mysql-clustershell>vi config.ini
For our representative setup, the
config.ini file should read as follows:
# Options affecting ndbd processes on all data nodes:
[NDBD DEFAULT]
NoOfReplicas=2 # Number of replicas
DataMemory=80M # How much memory to allocate for data storage
IndexMemory=18M # How much memory to allocate for index storage
# For DataMemory and IndexMemory, we have used the
# default values. Since the "world" database takes up
# only about 500KB, this should be more than enough for
# this example Cluster setup.
# TCP/IP options:
[TCP DEFAULT]
portnumber=2202 # This the default; however, you can use any
# port that is free for all the hosts in cluster
# Note: It is recommended beginning with MySQL 5.0 that
# you do not specify the portnumber at all and simply allow
# the default value to be used instead
# Management process options:
[NDB_MGMD]
hostname=192.168.0.10 # Hostname or IP address of MGM node
datadir=/var/lib/mysql-cluster # Directory for MGM node log files
# Options for data node "A":
[NDBD]
# (one [NDBD] section per data node)
hostname=192.168.0.30 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for this data node's data files
# Options for data node "B":
[NDBD]
hostname=192.168.0.40 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for this data node's data files
# SQL node options:
[MYSQLD]
hostname=192.168.0.20 # Hostname or IP address
# (additional mysqld connections can be
# specified for this node for various
# purposes such as running ndb_restore)
(Note: The
world database can be downloaded from
http://dev.mysql.com/doc/, where it can be found listed
under “Examples”.)
After all the configuration files have been created and these minimal options have been specified, you are ready to proceed with starting the cluster and verifying that all processes are running. We discuss how this is done in Section 15.3.4, “Initial Startup”.
For more detailed information about the available MySQL Cluster configuration parameters and their uses, see Section 15.4.4, “Configuration File”, and Section 15.4, “MySQL Cluster Configuration”. For configuration of MySQL Cluster as relates to making backups, see Section 15.8.4, “Configuration for Cluster Backup”.
Note: The default port for Cluster management nodes is 1186; the default port for data nodes is 2202. Beginning with MySQL 5.0.3, this restriction is lifted, and the cluster automatically allocates ports for data nodes from those that are already free.
Starting the cluster is not very difficult after it has been configured. Each cluster node process must be started separately, and on the host where it resides. The management node should be started first, followed by the data nodes, and then finally by any SQL nodes:
On the management host, issue the following command from the system shell to start the MGM node process:
shell>
ndb_mgmd -f /var/lib/mysql-cluster/config.iniNote that ndb_mgmd must be told where to find its configuration file, using the
-for--config-fileoption. (See Section 15.6.3, “ndb_mgmd — The Management Server Process”, for details.)On each of the data node hosts, run this command to start the ndbd process for the first time:
shell>
ndbd --initialNote that it is very important to use the
--initialparameter only when starting ndbd for the first time, or when restarting after a backup/restore operation or a configuration change. This is because the--initialoption causes the node to delete any files created by earlier ndbd instances that are needed for recovery, including the recovery log files.If you used RPM files to install MySQL on the cluster host where the SQL node is to reside, you can (and should) use the supplied startup script to start the MySQL server process on the SQL node.
If all has gone well, and the cluster has been set up correctly, the cluster should now be operational. You can test this by invoking the ndb_mgm management node client. The output should look like that shown here, although you might see some slight differences in the output depending upon the exact version of MySQL that you are using:
shell>ndb_mgm-- NDB Cluster -- Management Client -- ndb_mgm>SHOWConnected to Management Server at: localhost:1186 Cluster Configuration --------------------- [ndbd(NDB)] 2 node(s) id=2 @192.168.0.30 (Version: 5.0.42, Nodegroup: 0, Master) id=3 @192.168.0.40 (Version: 5.0.42, Nodegroup: 0) [ndb_mgmd(MGM)] 1 node(s) id=1 @192.168.0.10 (Version: 5.0.42) [mysqld(SQL)] 1 node(s) id=4 (Version: 5.0.42)
Note: The SQL node is
referenced here as [mysqld(API)]. This is
perfectly normal, and reflects the fact that the
mysqld process is acting as a cluster API
node.
You should now be ready to work with databases, tables, and data in MySQL Cluster. See Section 15.3.5, “Loading Sample Data and Performing Queries”, for a brief discussion.
Working with data in MySQL Cluster is not much different from doing so in MySQL without Cluster. There are two points to keep in mind:
For a table to be replicated in the cluster, it must use the
NDB Clusterstorage engine. To specify this, use theENGINE=NDBorENGINE=NDBCLUSTERtable option. You can add this option when creating the table:CREATE TABLE
tbl_name( ... ) ENGINE=NDBCLUSTER;Alternatively, for an existing table that uses a different storage engine, use
ALTER TABLEto change the table to useNDB Cluster:ALTER TABLE
tbl_nameENGINE=NDBCLUSTER;Each
NDBtable must have a primary key. If no primary key is defined by the user when a table is created, theNDB Clusterstorage engine automatically generates a hidden one. (Note: This hidden key takes up space just as does any other table index. It is not uncommon to encounter problems due to insufficient memory for accommodating these automatically created indexes.)
If you are importing tables from an existing database using the
output of mysqldump, you can open the SQL
script in a text editor and add the ENGINE
option to any table creation statements, or replace any existing
ENGINE (or TYPE) options.
Suppose that you have the world sample
database on another MySQL server that does not support MySQL
Cluster, and you want to export the City
table:
shell> mysqldump --add-drop-table world City > city_table.sql
The resulting city_table.sql file will
contain this table creation statement (and the
INSERT statements necessary to import the
table data):
DROP TABLE IF EXISTS `City`;
CREATE TABLE `City` (
`ID` int(11) NOT NULL auto_increment,
`Name` char(35) NOT NULL default '',
`CountryCode` char(3) NOT NULL default '',
`District` char(20) NOT NULL default '',
`Population` int(11) NOT NULL default '0',
PRIMARY KEY (`ID`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1;
INSERT INTO `City` VALUES (1,'Kabul','AFG','Kabol',1780000);
INSERT INTO `City` VALUES (2,'Qandahar','AFG','Qandahar',237500);
INSERT INTO `City` VALUES (3,'Herat','AFG','Herat',186800);
(remaining INSERT statements omitted)
You will need to make sure that MySQL uses the NDB storage
engine for this table. There are two ways that this can be
accomplished. One of these is to modify the table definition
before importing it into the Cluster
database. Using the City table as an example,
modify the ENGINE option of the definition as
follows:
DROP TABLE IF EXISTS `City`;
CREATE TABLE `City` (
`ID` int(11) NOT NULL auto_increment,
`Name` char(35) NOT NULL default '',
`CountryCode` char(3) NOT NULL default '',
`District` char(20) NOT NULL default '',
`Population` int(11) NOT NULL default '0',
PRIMARY KEY (`ID`)
) ENGINE=NDBCLUSTER DEFAULT CHARSET=latin1;
INSERT INTO `City` VALUES (1,'Kabul','AFG','Kabol',1780000);
INSERT INTO `City` VALUES (2,'Qandahar','AFG','Qandahar',237500);
INSERT INTO `City` VALUES (3,'Herat','AFG','Herat',186800);
(remaining INSERT statements omitted)
This must be done for the definition of each table that is to be
part of the clustered database. The easiest way to accomplish
this is to do a search-and-replace on the file that contains the
definitions and replace all instances of
TYPE=
or
engine_nameENGINE=
with engine_nameENGINE=NDBCLUSTER. If you do not want to
modify the file, you can use the unmodified file to create the
tables, and then use ALTER TABLE to change
their storage engine. The particulars are given later in this
section.
Assuming that you have already created a database named
world on the SQL node of the cluster, you can
then use the mysql command-line client to
read city_table.sql, and create and
populate the corresponding table in the usual manner:
shell> mysql world < city_table.sql
It is very important to keep in mind that the preceding command
must be executed on the host where the SQL node is running (in
this case, on the machine with the IP address
192.168.0.20).
To create a copy of the entire world database
on the SQL node, use mysqldump on the
non-cluster server to export the database to a file named
world.sql; for example, in the
/tmp directory. Then modify the table
definitions as just described and import the file into the SQL
node of the cluster like this:
shell> mysql world < /tmp/world.sql
If you save the file to a different location, adjust the preceding instructions accordingly.
It is important to note that NDB Cluster in
MySQL 5.0 does not support autodiscovery of
databases. (See Section 15.11, “Known Limitations of MySQL Cluster”.)
This means that, once the world database and
its tables have been created on one data node, you need to issue
the CREATE SCHEMA world statement (beginning
with MySQL 5.0.2, you may use CREATE SCHEMA
world instead), followed by FLUSH
TABLES on each SQL node in the cluster. This causes
the node to recognize the database and read its table
definitions.
Running SELECT queries on the SQL node is no
different from running them on any other instance of a MySQL
server. To run queries from the command line, you first need to
log in to the MySQL Monitor in the usual way (specify the
root password at the Enter
password: prompt):
shell> mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1 to server version: 5.0.42
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql>
We simply use the MySQL server's root account
and assume that you have followed the standard security
precautions for installing a MySQL server, including setting a
strong root password. For more information,
see Section 2.4.15.3, “Securing the Initial MySQL Accounts”.
It is worth taking into account that Cluster nodes do not make
use of the MySQL privilege system when accessing one another.
Setting or changing MySQL user accounts (including the
root account) effects only applications that
access the SQL node, not interaction between nodes.
If you did not modify the ENGINE clauses in
the table definitions prior to importing the SQL script, you
should run the following statements at this point:
mysql>USE world;mysql>ALTER TABLE City ENGINE=NDBCLUSTER;mysql>ALTER TABLE Country ENGINE=NDBCLUSTER;mysql>ALTER TABLE CountryLanguage ENGINE=NDBCLUSTER;
Selecting a database and running a SELECT query against a table in that database is also accomplished in the usual manner, as is exiting the MySQL Monitor:
mysql>USE world;mysql>SELECT Name, Population FROM City ORDER BY Population DESC LIMIT 5;+-----------+------------+ | Name | Population | +-----------+------------+ | Bombay | 10500000 | | Seoul | 9981619 | | São Paulo | 9968485 | | Shanghai | 9696300 | | Jakarta | 9604900 | +-----------+------------+ 5 rows in set (0.34 sec) mysql>\qBye shell>
Applications that use MySQL can employ standard APIs to access
NDB tables. It is important to remember that your application
must access the SQL node, and not the MGM or data nodes. This
brief example shows how we might execute the
SELECT statement just shown by using PHP 5's
mysqli extension running on a Web server
elsewhere on the network:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type"
content="text/html; charset=iso-8859-1">
<title>SIMPLE mysqli SELECT</title>
</head>
<body>
<?php
# connect to SQL node:
$link = new mysqli('192.168.0.20', 'root', 'root_password', 'world');
# parameters for mysqli constructor are:
# host, user, password, database
if( mysqli_connect_errno() )
die("Connect failed: " . mysqli_connect_error());
$query = "SELECT Name, Population
FROM City
ORDER BY Population DESC
LIMIT 5";
# if no errors...
if( $result = $link->query($query) )
{
?>
<table border="1" width="40%" cellpadding="4" cellspacing ="1">
<tbody>
<tr>
<th width="10%">City</th>
<th>Population</th>
</tr>
<?
# then display the results...
while($row = $result->fetch_object())
printf(<tr>\n <td align=\"center\">%s</td><td>%d</td>\n</tr>\n",
$row->Name, $row->Population);
?>
</tbody
</table>
<?
# ...and verify the number of rows that were retrieved
printf("<p>Affected rows: %d</p>\n", $link->affected_rows);
}
else
# otherwise, tell us what went wrong
echo mysqli_error();
# free the result set and the mysqli connection object
$result->close();
$link->close();
?>
</body>
</html>
We assume that the process running on the Web server can reach the IP address of the SQL node.
In a similar fashion, you can use the MySQL C API, Perl-DBI, Python-mysql, or MySQL AB's own Connectors to perform the tasks of data definition and manipulation just as you would normally with MySQL.
To shut down the cluster, enter the following command in a shell on the machine hosting the MGM node:
shell> ndb_mgm -e shutdown
The -e option here is used to pass a command to
the ndb_mgm client from the shell. See
Section 4.3.1, “Using Options on the Command Line”. The command causes the
ndb_mgm, ndb_mgmd, and any
ndbd processes to terminate gracefully. Any
SQL nodes can be terminated using mysqladmin
shutdown and other means.
To restart the cluster, run these commands:
On the management host (
192.168.0.10in our example setup):shell>
ndb_mgmd -f /var/lib/mysql-cluster/config.iniOn each of the data node hosts (
192.168.0.30and192.168.0.40):shell>
ndbdRemember not to invoke this command with the
--initialoption when restarting an NDBD node normally.On the SQL host (
192.168.0.20):shell>
mysqld &
For information on making Cluster backups, see Section 15.8.2, “Using The Management Client to Create a Backup”.
To restore the cluster from backup requires the use of the ndb_restore command. This is covered in Section 15.8.3, “ndb_restore — Restore a Cluster Backup”.
More information on configuring MySQL Cluster can be found in Section 15.4, “MySQL Cluster Configuration”.
A MySQL server that is part of a MySQL Cluster differs in only one
respect from a normal (non-clustered) MySQL server, in that it
employs the NDB Cluster storage engine. This
engine is also referred to simply as NDB, and
the two forms of the name are synonymous.
To avoid unnecessary allocation of resources, the server is
configured by default with the NDB storage
engine disabled. To enable NDB, you must modify
the server's my.cnf configuration file, or
start the server with the --ndbcluster option.
The MySQL server is a part of the cluster, so it also must know
how to access an MGM node to obtain the cluster configuration
data. The default behavior is to look for the MGM node on
localhost. However, should you need to specify
that its location is elsewhere, this can be done in
my.cnf or on the MySQL server command line.
Before the NDB storage engine can be used, at
least one MGM node must be operational, as well as any desired
data nodes.
NDB, the Cluster storage engine, is available
in binary distributions for Linux, Mac OS X, and Solaris. We are
working to make Cluster run on all operating systems supported
by MySQL, including Windows.
If you choose to build from a source tarball or the MySQL
5.0 BitKeeper tree, be sure to use the
--with-ndbcluster option when running
configure. You can also use the
BUILD/compile-pentium-max build script. Note
that this script includes OpenSSL, so you must either have or
obtain OpenSSL to build successfully, or else modify
compile-pentium-max to exclude this
requirement. Of course, you can also just follow the standard
instructions for compiling your own binaries, and then perform
the usual tests and installation procedure. See
Section 2.4.14.3, “Installing from the Development Source Tree”.
You should also note that compile-pentium-max
installs MySQL to the directory
/usr/local/mysql, placing all MySQL Cluster
executables, scripts, databases, and support files in
subdirectories under this directory. If this is not what you
desire, be sure to modify the script accordingly.
In the next few sections, we assume that you are already familiar with installing MySQL, and here we cover only the differences between configuring MySQL Cluster and configuring MySQL without clustering. (See Chapter 2, Installing and Upgrading MySQL, if you require more information about the latter.)
You will find Cluster configuration easiest if you have already
have all management and data nodes running first; this is likely
to be the most time-consuming part of the configuration. Editing
the my.cnf file is fairly straightforward,
and this section will cover only any differences from
configuring MySQL without clustering.
To familiarize you with the basics, we will describe the simplest possible configuration for a functional MySQL Cluster. After this, you should be able to design your desired setup from the information provided in the other relevant sections of this chapter.
First, you need to create a configuration directory such as
/var/lib/mysql-cluster, by executing the
following command as the system root user:
shell> mkdir /var/lib/mysql-cluster
In this directory, create a file named
config.ini that contains the following
information. Substitute appropriate values for
HostName and DataDir as
necessary for your system.
# file "config.ini" - showing minimal setup consisting of 1 data node, # 1 management server, and 3 MySQL servers. # The empty default sections are not required, and are shown only for # the sake of completeness. # Data nodes must provide a hostname but MySQL Servers are not required # to do so. # If you don't know the hostname for your machine, use localhost. # The DataDir parameter also has a default value, but it is recommended to # set it explicitly. # Note: DB, API, and MGM are aliases for NDBD, MYSQLD, and NDB_MGMD # respectively. DB and API are deprecated and should not be used in new # installations. [NDBD DEFAULT] NoOfReplicas= 1 [MYSQLD DEFAULT] [NDB_MGMD DEFAULT] [TCP DEFAULT] [NDB_MGMD] HostName= myhost.example.com [NDBD] HostName= myhost.example.com DataDir= /var/lib/mysql-cluster [MYSQLD] [MYSQLD] [MYSQLD]
You can now start the ndb_mgmd management
server. By default, it attempts to read the
config.ini file in its current working
directory, so change location into the directory where the file
is located and then invoke ndb_mgmd:
shell>cd /var/lib/mysql-clustershell>ndb_mgmd
Then start a single data node by running
ndbd. When starting ndbd
for a given data node for the very first time, you should use
the --initial option as shown here:
shell> ndbd --initial
For subsequent ndbd starts, you will
generally want to omit the
--initial option:
shell> ndbd
The reason for omitting --initial on subsequent
restarts is that this option causes ndbd to
delete and re-create all existing data and log files (as well as
all table metadata) for this data node. One exception to this
rule about not using --initial except for the
first ndbd invocation is that you use it when
restarting the cluster and restoring from backup after adding
new data nodes.
By default, ndbd looks for the management
server at localhost on port 1186.
Note: If you have installed
MySQL from a binary tarball, you will need to specify the path
of the ndb_mgmd and ndbd
servers explicitly. (Normally, these will be found in
/usr/local/mysql/bin.)
Finally, change location to the MySQL data directory (usually
/var/lib/mysql or
/usr/local/mysql/data), and make sure that
the my.cnf file contains the option
necessary to enable the NDB storage engine:
[mysqld] ndbcluster
You can now start the MySQL server as usual:
shell> mysqld_safe --user=mysql &
Wait a moment to make sure the MySQL server is running properly.
If you see the notice mysql ended, check the
server's .err file to find out what went
wrong.
If all has gone well so far, you now can start using the
cluster. Connect to the server and verify that the
NDBCLUSTER storage engine is enabled:
shell>mysqlWelcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 1 to server version: 5.0.42 Type 'help;' or '\h' for help. Type '\c' to clear the buffer. mysql>SHOW ENGINES\G... *************************** 12. row *************************** Engine: NDBCLUSTER Support: YES Comment: Clustered, fault-tolerant, memory-based tables *************************** 13. row *************************** Engine: NDB Support: YES Comment: Alias for NDBCLUSTER ...
The row numbers shown in the preceding example output may be different from those shown on your system, depending upon how your server is configured.
Try to create an NDBCLUSTER table:
shell>mysqlmysql>USE test;Database changed mysql>CREATE TABLE ctest (i INT) ENGINE=NDBCLUSTER;Query OK, 0 rows affected (0.09 sec) mysql>SHOW CREATE TABLE ctest \G*************************** 1. row *************************** Table: ctest Create Table: CREATE TABLE `ctest` ( `i` int(11) default NULL ) ENGINE=ndbcluster DEFAULT CHARSET=latin1 1 row in set (0.00 sec)
To check that your nodes were set up properly, start the management client:
shell> ndb_mgm
Use the SHOW command from within the management client to obtain a report on the cluster's status:
NDB> SHOW
Cluster Configuration
---------------------
[ndbd(NDB)] 1 node(s)
id=2 @127.0.0.1 (Version: 3.5.3, Nodegroup: 0, Master)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @127.0.0.1 (Version: 3.5.3)
[mysqld(API)] 3 node(s)
id=3 @127.0.0.1 (Version: 3.5.3)
id=4 (not connected, accepting connect from any host)
id=5 (not connected, accepting connect from any host)
At this point, you have successfully set up a working MySQL
Cluster. You can now store data in the cluster by using any
table created with ENGINE=NDBCLUSTER or its
alias ENGINE=NDB.
- 15.4.4.1. Basic Example Configuration
- 15.4.4.2. The Cluster Connectstring
- 15.4.4.3. Defining Cluster Computers
- 15.4.4.4. Defining the Management Server
- 15.4.4.5. Defining Data Nodes
- 15.4.4.6. Defining SQL and Other API Nodes
- 15.4.4.7. Cluster TCP/IP Connections
- 15.4.4.8. TCP/IP Connections Using Direct Connections
- 15.4.4.9. Shared-Memory Connections
- 15.4.4.10. SCI Transport Connections
Configuring MySQL Cluster requires working with two files:
my.cnf: Specifies options for all MySQL Cluster executables. This file, with which you should be familiar with from previous work with MySQL, must be accessible by each executable running in the cluster.config.ini: This file is read only by the MySQL Cluster management server, which then distributes the information contained therein to all processes participating in the cluster.config.inicontains a description of each node involved in the cluster. This includes configuration parameters for data nodes and configuration parameters for connections between all nodes in the cluster. For a quick reference to the sections that can appear in this file, and what sorts of configuration parameters may be placed in each section, see Sections of theconfig.iniFile.
We are continuously making improvements in Cluster configuration and attempting to simplify this process. Although we strive to maintain backward compatibility, there may be times when introduce an incompatible change. In such cases we will try to let Cluster users know in advance if a change is not backward compatible. If you find such a change and we have not documented it, please report it in the MySQL bugs database using the instructions given in Section 1.8, “How to Report Bugs or Problems”.
To support MySQL Cluster, you will need to update
my.cnf as shown in the following example.
Note that the options shown here should not be confused with
those that are used in config.ini files.
You may also specify these parameters on the command line when
invoking the executables.
# my.cnf # example additions to my.cnf for MySQL Cluster # (valid in MySQL 5.0) # enable ndbcluster storage engine, and provide connectstring for # management server host (default port is 1186) [mysqld] ndbcluster ndb-connectstring=ndb_mgmd.mysql.com # provide connectstring for management server host (default port: 1186) [ndbd] connect-string=ndb_mgmd.mysql.com # provide connectstring for management server host (default port: 1186) [ndb_mgm] connect-string=ndb_mgmd.mysql.com # provide location of cluster configuration file [ndb_mgmd] config-file=/etc/config.ini
(For more information on connectstrings, see Section 15.4.4.2, “The Cluster Connectstring”.)
# my.cnf # example additions to my.cnf for MySQL Cluster # (will work on all versions) # enable ndbcluster storage engine, and provide connectstring for management # server host to the default port 1186 [mysqld] ndbcluster ndb-connectstring=ndb_mgmd.mysql.com:1186
Important: Once you have
started a mysqld process with the
ndbcluster and
ndb-connectstring parameters in the
[MYSQLD] in the my.cnf
file as shown previously, you cannot execute any
CREATE TABLE or ALTER
TABLE statements without having actually started the
cluster. Otherwise, these statements will fail with an error.
This is by design.
You may also use a separate [mysql_cluster]
section in the cluster my.cnf file for
settings to be read and used by all executables:
# cluster-specific settings [mysql_cluster] ndb-connectstring=ndb_mgmd.mysql.com:1186
For additional NDB variables that can be
set in the my.cnf file, see
Section 5.2.3, “System Variables”.
The configuration file is named
config.ini by default. It is read by
ndb_mgmd at startup and can be placed
anywhere. Its location and name are specified by using
--config-file=
on the ndb_mgmd command line. If the
configuration file is not specified,
ndb_mgmd by default tries to read a file
named path_nameconfig.ini located in the current
working directory.
Currently, the configuration file is in INI format, which
consists of sections preceded by section headings (surrounded
by square brackets), followed by the appropriate parameter
names and values. One deviation from the standard INI format
is that the parameter name and value can be separated by a
colon (‘:’) as well as the
equals sign (‘=’). Another
deviation is that sections are not uniquely identified by
section name. Instead, unique sections (such as two different
nodes of the same type) are identified by a unique ID
specified as a parameter within the section.
Default values are defined for most parameters, and can also
be specified in config.ini. To create a
default value section, simply add the word
DEFAULT to the section name. For example,
an [NDBD] section contains parameters that
apply to a particular data node, whereas an [NDBD
DEFAULT] section contains parameters that apply to
all data nodes. Suppose that all data nodes should use the
same data memory size. To configure them all, create an
[NDBD DEFAULT] section that contains a
DataMemory line to specify the data memory
size.
At a minimum, the configuration file must define the computers and nodes involved in the cluster and on which computers these nodes are located. An example of a simple configuration file for a cluster consisting of one management server, two data nodes and two MySQL servers is shown here:
# file "config.ini" - 2 data nodes and 2 SQL nodes # This file is placed in the startup directory of ndb_mgmd (the # management server) # The first MySQL Server can be started from any host. The second # can be started only on the host mysqld_5.mysql.com [NDBD DEFAULT] NoOfReplicas= 2 DataDir= /var/lib/mysql-cluster [NDB_MGMD] Hostname= ndb_mgmd.mysql.com DataDir= /var/lib/mysql-cluster [NDBD] HostName= ndbd_2.mysql.com [NDBD] HostName= ndbd_3.mysql.com [MYSQLD] [MYSQLD] HostName= mysqld_5.mysql.com
Each node has its own section in the
config.ini file. For example, this
cluster has two data nodes, so the preceding configuration
file contains two [NDBD] sections defining
these nodes.
Note
Do not place comments on the same line as a section heading
in the config.ini file; this causes the
management server not to start because it cannot parse the
configuration file in such cases.
Sections of the
config.ini File
There are six different sections that you can use in the
config.ini configuration file, as
described in the following list:
[COMPUTER]: Defines cluster hosts. This is not required to configure a viable MySQL Cluster, but be may used as a convenience when setting up a large cluster. See Section 15.4.4.3, “Defining Cluster Computers”, for more information.[NDBD]: Defines a cluster data node (ndbd process). See Section 15.4.4.5, “Defining Data Nodes”, for details.[MYSQLD]: Defines the cluster's MySQL server nodes (also called SQL or API nodes). For a discussion of SQL node configuration, see Section 15.4.4.6, “Defining SQL and Other API Nodes”.[MGM]or[NDB_MGMD]: Defines a cluster management server (MGM) node. For information concerning the configuration of MGM nodes, see Section 15.4.4.4, “Defining the Management Server”.[TCP]: Defines a TCP/IP connection between cluster nodes, with TCP/IP being the default connection protocol. Normally,[TCP]or[TCP DEFAULT]sections are not required to set up a MySQL Cluster, as the cluster handles this automatically; however, it may be necessary in some situations to override the defaults provided by the cluster. See Section 15.4.4.7, “Cluster TCP/IP Connections”, for information about available TCP/IP configuration parameters and how to use them. (You may also find Section 15.4.4.8, “TCP/IP Connections Using Direct Connections” to be of interest in some cases.)[SHM]: Defines shared-memory connections between nodes. In MySQL 5.0, it is enabled by default, but should still be considered experimental. For a discussion of SHM interconnects, see Section 15.4.4.9, “Shared-Memory Connections”.[SCI]:Defines Scalable Coherent Interface connections between cluster data nodes. Such connections require software which, while freely available, is not part of the MySQL Cluster distribution, as well as specialised hardware. See Section 15.4.4.10, “SCI Transport Connections” for detailed information about SCI interconnects.
You can define DEFAULT values for each
section. All Cluster parameter names are case-insensitive,
which differs from parameters specified in
my.cnf or my.ini
files.
With the exception of the MySQL Cluster management server (ndb_mgmd), each node that is part of a MySQL Cluster requires a connectstring that points to the management server's location. This connectstring is used in establishing a connection to the management server as well as in performing other tasks depending on the node's role in the cluster. The syntax for a connectstring is as follows:
<connectstring> :=
[<nodeid-specification>,]<host-specification>[,<host-specification>]
<nodeid-specification> := node_id
<host-specification> := host_name[:port_num]
node_id is an integer larger than 1 which
identifies a node in config.ini.
host_name is a string representing
a valid Internet host name or IP address.
port_num is an integer referring to
a TCP/IP port number.
example 1 (long): "nodeid=2,myhost1:1100,myhost2:1100,192.168.0.3:1200" example 2 (short): "myhost1"
All nodes will use localhost:1186 as the
default connectstring value if none is provided. If
port_num is omitted from the
connectstring, the default port is 1186. This port should
always be available on the network because it has been
assigned by IANA for this purpose (see
http://www.iana.org/assignments/port-numbers
for details).
By listing multiple
<host-specification> values, it is
possible to designate several redundant management servers. A
cluster node will attempt to contact successive management
servers on each host in the order specified, until a
successful connection has been established.
There are a number of different ways to specify the connectstring:
Each executable has its own command-line option which enables specifying the management server at startup. (See the documentation for the respective executable.)
It is also possible to set the connectstring for all nodes in the cluster at once by placing it in a
[mysql_cluster]section in the management server'smy.cnffile.For backward compatibility, two other options are available, using the same syntax:
Set the
NDB_CONNECTSTRINGenvironment variable to contain the connectstring.Write the connectstring for each executable into a text file named
Ndb.cfgand place this file in the executable's startup directory.
However, these are now deprecated and should not be used for new installations.
The recommended method for specifying the connectstring is to
set it on the command line or in the
my.cnf file for each executable.
The maximum length of a connectstring is 1024 characters.
The [COMPUTER] section has no real
significance other than serving as a way to avoid the need of
defining host names for each node in the system. All
parameters mentioned here are required.
The [NDB_MGMD] section is used to configure
the behavior of the management server.
[MGM] can be used as an alias; the two
section names are equivalent. All parameters in the following
list are optional and assume their default values if omitted.
Note: If neither the
ExecuteOnComputer nor the
HostName parameter is present, the default
value localhost will be assumed for both.
Each node in the cluster has a unique identity, which is represented by an integer value in the range 1 to 63 inclusive. This ID is used by all internal cluster messages for addressing the node.
This refers to the
Idset for one of the computers defined in a[COMPUTER]section of theconfig.inifile.This is the port number on which the management server listens for configuration requests and management commands.
Specifying this parameter defines the hostname of the computer on which the management node is to reside. To specify a hostname other than
localhost, either this parameter orExecuteOnComputeris required.This parameter specifies where to send cluster logging information. There are three options in this regard —
CONSOLE,SYSLOG, andFILE— withFILEbeing the default:CONSOLEoutputs the log tostdout:CONSOLE
SYSLOGsends the log to asyslogfacility, possible values being one ofauth,authpriv,cron,daemon,ftp,kern,lpr,mail,news,syslog,user,uucp,local0,local1,local2,local3,local4,local5,local6, orlocal7.Note: Not every facility is necessarily supported by every operating system.
SYSLOG:facility=syslog
FILEpipes the cluster log output to a regular file on the same machine. The following values can be specified:filename: The name of the log file.maxsize: The maximum size (in bytes) to which the file can grow before logging rolls over to a new file. When this occurs, the old log file is renamed by appending.Nto the filename, whereNis the next number not yet used with this name.maxfiles: The maximum number of log files.
FILE:filename=cluster.log,maxsize=1000000,maxfiles=6
The default value for the
FILEparameter isFILE:filename=ndb_, wherenode_id_cluster.log,maxsize=1000000,maxfiles=6node_idis the ID of the node.
It is possible to specify multiple log destinations separated by semicolons as shown here:
CONSOLE;SYSLOG:facility=local0;FILE:filename=/var/log/mgmd
This parameter is used to define which nodes can act as arbitrators. Only management nodes and SQL nodes can be arbitrators.
ArbitrationRankcan take one of the following values:0: The node will never be used as an arbitrator.1: The node has high priority; that is, it will be preferred as an arbitrator over low-priority nodes.2: Indicates a low-priority node which be used as an arbitrator only if a node with a higher priority is not available for that purpose.
Normally, the management server should be configured as an arbitrator by setting its
ArbitrationRankto 1 (the default value) and that of all SQL nodes to 0.An integer value which causes the management server's responses to arbitration requests to be delayed by that number of milliseconds. By default, this value is 0; it is normally not necessary to change it.
This specifies the directory where output files from the management server will be placed. These files include cluster log files, process output files, and the daemon's process ID (PID) file. (For log files, this location can be overridden by setting the
FILEparameter forLogDestinationas discussed previously in this section.)The default value for this parameter is the directory in which ndb_mgmd is located.
The [NDBD] and [NDBD DEFAULT] sections are
used to configure the behavior of the cluster's data nodes.
There are many parameters which control buffer sizes, pool
sizes, timeouts, and so forth. The only mandatory parameters
are:
Either
ExecuteOnComputerorHostName, which must be defined in the local[NDBD]section.The parameter
NoOfReplicas, which must be defined in the [NDBD DEFAULT] section, as it is common to all Cluster data nodes.
Most data node parameters are set in the [NDBD
DEFAULT] section. Only those parameters explicitly
stated as being able to set local values are allowed to be
changed in the [NDBD] section. Where
present, HostName, Id
and ExecuteOnComputer
must be defined in the local
[NDBD] section, and not in any other
section of config.ini. In other words,
settings for these parameters are specific to one data node.
For those parameters affecting memory usage or buffer sizes,
it is possible to use K,
M, or G as a suffix to
indicate units of 1024, 1024×1024, or
1024×1024×1024. (For example,
100K means 100 × 1024 = 102400.)
Parameter names and values are currently case-sensitive.
The Id value (that is, the data node
identifier) can be allocated on the command line when the node
is started or in the configuration file.
This is the node ID used as the address of the node for all cluster internal messages. This is an integer in the range 1 to 63 inclusive. Each node in the cluster must have a unique identity.
This refers to the
Idset for one of the computers defined in a[COMPUTER]section.Specifying this parameter defines the hostname of the computer on which the data node is to reside. To specify a hostname other than
localhost, either this parameter orExecuteOnComputeris required.Each node in the cluster uses a port to connect to other nodes. This port is used also for non-TCP transporters in the connection setup phase. The default port is allocated dynamically in such a way as to ensure that no two nodes on the same computer receive the same port number, so it should not normally be necessary to specify a value for this parameter.
This global parameter can be set only in the
[NDBD DEFAULT]section, and defines the number of replicas for each table stored in the cluster. This parameter also specifies the size of node groups. A node group is a set of nodes all storing the same information.Node groups are formed implicitly. The first node group is formed by the set of data nodes with the lowest node IDs, the next node group by the set of the next lowest node identities, and so on. By way of example, assume that we have 4 data nodes and that
NoOfReplicasis set to 2. The four data nodes have node IDs 2, 3, 4 and 5. Then the first node group is formed from nodes 2 and 3, and the second node group by nodes 4 and 5. It is important to configure the cluster in such a manner that nodes in the same node groups are not placed on the same computer because a single hardware failure would cause the entire cluster to crash.If no node IDs are provided, the order of the data nodes will be the determining factor for the node group. Whether or not explicit assignments are made, they can be viewed in the output of the management client's
SHOWstatement.There is no default value for
NoOfReplicas; the maximum possible value is 4.Important: The value for this parameter must divide evenly into the number of data nodes in the cluster. For example, if there are two data nodes, then
NoOfReplicasmust be equal to either 1 or 2, since 2/3 and 2/4 both yield fractional values; if there are four data nodes, thenNoOfReplicasmust be equal to 1, 2, or 4.This parameter specifies the directory where trace files, log files, pid files and error logs are placed.
This parameter specifies the directory where all files created for metadata, REDO logs, UNDO logs and data files are placed. The default is the directory specified by
DataDir. Note: This directory must exist before the ndbd process is initiated.The recommended directory hierarchy for MySQL Cluster includes
/var/lib/mysql-cluster, under which a directory for the node's filesystem is created. The name of this subdirectory contains the node ID. For example, if the node ID is 2, this subdirectory is namedndb_2_fs.This parameter specifies the directory in which backups are placed. If omitted, the default backup location is the directory named
BACKUPunder the location specified by theFileSystemPathparameter. (See above.)
Data Memory, Index Memory, and String Memory
DataMemory and
IndexMemory are [NDBD]
parameters specifying the size of memory segments used to
store the actual records and their indexes. In setting values
for these, it is important to understand how
DataMemory and
IndexMemory are used, as they usually need
to be updated to reflect actual usage by the cluster:
This parameter defines the amount of space (in bytes) available for storing database records. The entire amount specified by this value is allocated in memory, so it is extremely important that the machine has sufficient physical memory to accommodate it.
The memory allocated by
DataMemoryis used to store both the actual records and indexes. Each record is currently of fixed size. (EvenVARCHARcolumns are stored as fixed-width columns.) There is a 16-byte overhead on each record; an additional amount for each record is incurred because it is stored in a 32KB page with 128 byte page overhead (see below). There is also a small amount wasted per page due to the fact that each record is stored in only one page. The maximum record size is currently 8052 bytes.The memory space defined by
DataMemoryis also used to store ordered indexes, which use about 10 bytes per record. Each table row is represented in the ordered index. A common error among users is to assume that all indexes are stored in the memory allocated byIndexMemory, but this is not the case: Only primary key and unique hash indexes use this memory; ordered indexes use the memory allocated byDataMemory. However, creating a primary key or unique hash index also creates an ordered index on the same keys, unless you specifyUSING HASHin the index creation statement. This can be verified by running ndb_desc -ddb_nametable_namein the management client.The memory space allocated by
DataMemoryconsists of 32KB pages, which are allocated to table fragments. Each table is normally partitioned into the same number of fragments as there are data nodes in the cluster. Thus, for each node, there are the same number of fragments as are set inNoOfReplicas.Once a page has been allocated, it is currently not possible to return it to the pool of free pages, except by deleting the table. (This also means that
DataMemorypages, once allocated to a given table, cannot be used by other tables.) Performing a node recovery also compresses the partition because all records are inserted into empty partitions from other live nodes.The
DataMemorymemory space also contains UNDO information: For each update, a copy of the unaltered record is allocated in theDataMemory. There is also a reference to each copy in the ordered table indexes. Unique hash indexes are updated only when the unique index columns are updated, in which case a new entry in the index table is inserted and the old entry is deleted upon commit. For this reason, it is also necessary to allocate enough memory to handle the largest transactions performed by applications using the cluster. In any case, performing a few large transactions holds no advantage over using many smaller ones, for the following reasons:Large transactions are not any faster than smaller ones
Large transactions increase the number of operations that are lost and must be repeated in event of transaction failure
Large transactions use more memory
The default value for
DataMemoryis 80MB; the minimum is 1MB. There is no maximum size, but in reality the maximum size has to be adapted so that the process does not start swapping when the limit is reached. This limit is determined by the amount of physical RAM available on the machine and by the amount of memory that the operating system may commit to any one process. 32-bit operating systems are generally limited to 2–4GB per process; 64-bit operating systems can use more. For large databases, it may be preferable to use a 64-bit operating system for this reason.This parameter controls the amount of storage used for hash indexes in MySQL Cluster. Hash indexes are always used for primary key indexes, unique indexes, and unique constraints. Note that when defining a primary key and a unique index, two indexes will be created, one of which is a hash index used for all tuple accesses as well as lock handling. It is also used to enforce unique constraints.
The size of the hash index is 25 bytes per record, plus the size of the primary key. For primary keys larger than 32 bytes another 8 bytes is added.
The default value for
IndexMemoryis 18MB. The minimum is 1MB.This parameter determines how much memory is allocated for strings such as table names, and is specified in an
[NDBD]or[NDBD DEFAULT]section of theconfig.inifile. A value between0and100inclusive is interpreted as a percent of the maxmimum default value, which is calculated based on a number of factors including the number of tables, maximum table name size, maximum size of.FRMfiles,MaxNoOfTriggers, maximum column name size, and maximum default column value. In general it is safe to assume that the maximum default value is approximately 5 MB for a MySQL Cluster having 1000 tables.A value greater than
100is interpreted as a number of bytes.In MySQL 5.0, the default value is
100— that is, 100 percent of the default maximum, or roughly 5 MB. It is possible to reduce this value safely, but it should never be less than 5 percent. If you encounter Error 773 Out of string memory, please modify StringMemory config parameter: Permanent error: Schema error, this means that means that you have set theStringMemoryvalue too low.25(25 percent) is not excessive, and should prevent this error from recurring in all but the most extreme conditions, as when there are hundreds or thousands ofNDBtables with names whose lengths and columns whose number approach their permitted maximums.
The following example illustrates how memory is used for a table. Consider this table definition:
CREATE TABLE example ( a INT NOT NULL, b INT NOT NULL, c INT NOT NULL, PRIMARY KEY(a), UNIQUE(b) ) ENGINE=NDBCLUSTER;
For each record, there are 12 bytes of data plus 12 bytes
overhead. Having no nullable columns saves 4 bytes of
overhead. In addition, we have two ordered indexes on columns
a and b consuming
roughly 10 bytes each per record. There is a primary key hash
index on the base table using roughly 29 bytes per record. The
unique constraint is implemented by a separate table with
b as primary key and a
as a column. This other table consumes an additional 29 bytes
of index memory per record in the example
table as well 8 bytes of record data plus 12 bytes of
overhead.
Thus, for one million records, we need 58MB for index memory to handle the hash indexes for the primary key and the unique constraint. We also need 64MB for the records of the base table and the unique index table, plus the two ordered index tables.
You can see that hash indexes takes up a fair amount of memory space; however, they provide very fast access to the data in return. They are also used in MySQL Cluster to handle uniqueness constraints.
Currently, the only partitioning algorithm is hashing and ordered indexes are local to each node. Thus, ordered indexes cannot be used to handle uniqueness constraints in the general case.
An important point for both IndexMemory and
DataMemory is that the total database size
is the sum of all data memory and all index memory for each
node group. Each node group is used to store replicated
information, so if there are four nodes with two replicas,
there will be two node groups. Thus, the total data memory
available is 2 × DataMemory for each
data node.
It is highly recommended that DataMemory
and IndexMemory be set to the same values
for all nodes. Data distribution is even over all nodes in the
cluster, so the maximum amount of space available for any node
can be no greater than that of the smallest node in the
cluster.
DataMemory and
IndexMemory can be changed, but decreasing
either of these can be risky; doing so can easily lead to a
node or even an entire MySQL Cluster that is unable to restart
due to there being insufficient memory space. Increasing these
values should be acceptable, but it is recommended that such
upgrades are performed in the same manner as a software
upgrade, beginning with an update of the configuration file,
and then restarting the management server followed by
restarting each data node in turn.
Updates do not increase the amount of index memory used. Inserts take effect immediately; however, rows are not actually deleted until the transaction is committed.
The next three [NDBD] parameters that we
discuss are important because they affect the number of
parallel transactions and the sizes of transactions that can
be handled by the system.
MaxNoOfConcurrentTransactions sets the
number of parallel transactions possible in a node.
MaxNoOfConcurrentOperations sets the number
of records that can be in update phase or locked
simultaneously.
Both of these parameters (especially
MaxNoOfConcurrentOperations) are likely
targets for users setting specific values and not using the
default value. The default value is set for systems using
small transactions, to ensure that these do not use excessive
memory.
For each active transaction in the cluster there must be a record in one of the cluster nodes. The task of coordinating transactions is spread among the nodes. The total number of transaction records in the cluster is the number of transactions in any given node times the number of nodes in the cluster.
Transaction records are allocated to individual MySQL servers. Normally, there is at least one transaction record allocated per connection that using any table in the cluster. For this reason, one should ensure that there are more transaction records in the cluster than there are concurrent connections to all MySQL servers in the cluster.
This parameter must be set to the same value for all cluster nodes.
Changing this parameter is never safe and doing so can cause a cluster to crash. When a node crashes, one of the nodes (actually the oldest surviving node) will build up the transaction state of all transactions ongoing in the crashed node at the time of the crash. It is thus important that this node has as many transaction records as the failed node.
The default value is 4096.
It is a good idea to adjust the value of this parameter according to the size and number of transactions. When performing transactions of only a few operations each and not involving a great many records, there is no need to set this parameter very high. When performing large transactions involving many records need to set this parameter higher.
Records are kept for each transaction updating cluster data, both in the transaction coordinator and in the nodes where the actual updates are performed. These records contain state information needed to find UNDO records for rollback, lock queues, and other purposes.
This parameter should be set to the number of records to be updated simultaneously in transactions, divided by the number of cluster data nodes. For example, in a cluster which has four data nodes and which is expected to handle 1,000,000 concurrent updates using transactions, you should set this value to 1000000 / 4 = 250000.
Read queries which set locks also cause operation records to be created. Some extra space is allocated within individual nodes to accommodate cases where the distribution is not perfect over the nodes.
When queries make use of the unique hash index, there are actually two operation records used per record in the transaction. The first record represents the read in the index table and the second handles the operation on the base table.
The default value is 32768.
This parameter actually handles two values that can be configured separately. The first of these specifies how many operation records are to be placed with the transaction coordinator. The second part specifies how many operation records are to be local to the database.
A very large transaction performed on an eight-node cluster requires as many operation records in the transaction coordinator as there are reads, updates, and deletes involved in the transaction. However, the operation records of the are spread over all eight nodes. Thus, if it is necessary to configure the system for one very large transaction, it is a good idea to configure the two parts separately.
MaxNoOfConcurrentOperationswill always be used to calculate the number of operation records in the transaction coordinator portion of the node.It is also important to have an idea of the memory requirements for operation records. These consume about 1KB per record.
By default, this parameter is calculated as 1.1 ×
MaxNoOfConcurrentOperations. This fits systems with many simultaneous transactions, none of them being very large. If there is a need to handle one very large transaction at a time and there are many nodes, it is a good idea to override the default value by explicitly specifying this parameter.
The next set of [NDBD] parameters is used
to determine temporary storage when executing a statement that
is part of a Cluster transaction. All records are released
when the statement is completed and the cluster is waiting for
the commit or rollback.
The default values for these parameters are adequate for most situations. However, users with a need to support transactions involving large numbers of rows or operations may need to increase these values to enable better parallelism in the system, whereas users whose applications require relatively small transactions can decrease the values to save memory.
MaxNoOfConcurrentIndexOperationsFor queries using a unique hash index, another temporary set of operation records is used during a query's execution phase. This parameter sets the size of that pool of records. Thus, this record is allocated only while executing a part of a query. As soon as this part has been executed, the record is released. The state needed to handle aborts and commits is handled by the normal operation records, where the pool size is set by the parameter
MaxNoOfConcurrentOperations.The default value of this parameter is 8192. Only in rare cases of extremely high parallelism using unique hash indexes should it be necessary to increase this value. Using a smaller value is possible and can save memory if the DBA is certain that a high degree of parallelism is not required for the cluster.
The default value of
MaxNoOfFiredTriggersis 4000, which is sufficient for most situations. In some cases it can even be decreased if the DBA feels certain the need for parallelism in the cluster is not high.A record is created when an operation is performed that affects a unique hash index. Inserting or deleting a record in a table with unique hash indexes or updating a column that is part of a unique hash index fires an insert or a delete in the index table. The resulting record is used to represent this index table operation while waiting for the original operation that fired it to complete. This operation is short-lived but can still require a large number of records in its pool for situations with many parallel write operations on a base table containing a set of unique hash indexes.
The memory affected by this parameter is used for tracking operations fired when updating index tables and reading unique indexes. This memory is used to store the key and column information for these operations. It is only very rarely that the value for this parameter needs to be altered from the default.
The default value for
TransactionBufferMemoryis 1MB.Normal read and write operations use a similar buffer, whose usage is even more short-lived. The compile-time parameter
ZATTRBUF_FILESIZE(found inndb/src/kernel/blocks/Dbtc/Dbtc.hpp) set to 4000 × 128 bytes (500KB). A similar buffer for key information,ZDATABUF_FILESIZE(also inDbtc.hpp) contains 4000 × 16 = 62.5KB of buffer space.Dbtcis the module that handles transaction coordination.
There are additional [NDBD] parameters in
the Dblqh module (in
ndb/src/kernel/blocks/Dblqh/Dblqh.hpp)
that affect reads and updates. These include
ZATTRINBUF_FILESIZE, set by default to
10000 × 128 bytes (1250KB) and
ZDATABUF_FILE_SIZE, set by default to
10000*16 bytes (roughly 156KB) of buffer space. To date,
there have been neither any reports from users nor any
results from our own extensive tests suggesting that either
of these compile-time limits should be increased.
This parameter is used to control the number of parallel scans that can be performed in the cluster. Each transaction coordinator can handle the number of parallel scans defined for this parameter. Each scan query is performed by scanning all partitions in parallel. Each partition scan uses a scan record in the node where the partition is located, the number of records being the value of this parameter times the number of nodes. The cluster should be able to sustain
MaxNoOfConcurrentScansscans concurrently from all nodes in the cluster.Scans are actually performed in two cases. The first of these cases occurs when no hash or ordered indexes exists to handle the query, in which case the query is executed by performing a full table scan. The second case is encountered when there is no hash index to support the query but there is an ordered index. Using the ordered index means executing a parallel range scan. The order is kept on the local partitions only, so it is necessary to perform the index scan on all partitions.
The default value of
MaxNoOfConcurrentScansis 256. The maximum value is 500.Specifies the number of local scan records if many scans are not fully parallelized. If the number of local scan records is not provided, it is calculated as the product of
MaxNoOfConcurrentScansand the number of data nodes in the system. The minimum value is 32.This parameter is used to calculate the number of lock records which must be there to handle many concurrent scan operations.
The default value is 64; this value has a strong connection to the
ScanBatchSizedefined in the SQL nodes.This is an internal buffer used for passing messages within individual nodes and between nodes. Although it is highly unlikely that this would need to be changed, it is configurable. By default, it is set to 1MB.
These [NDBD] parameters control log and
checkpoint behavior.
This parameter sets the number of REDO log files for the node, and thus the amount of space allocated to REDO logging. Because the REDO log files are organized in a ring, it is extremely important that the first and last log files in the set (sometimes referred to as the “head” and “tail” log files, respectively) do not meet. When these approach one another too closely, the node begins aborting all transactions encompassing updates due to a lack of room for new log records.
A
REDOlog record is not removed until three local checkpoints have been completed since that log record was inserted. Checkpointing frequency is determined by its own set of configuration parameters discussed elsewhere in this chapter.How these parameters interact and proposals for how to configure them are discussed in Section 15.4.6, “Configuring Parameters for Local Checkpoints”.
The default parameter value is 8, which means 8 sets of 4 16MB files for a total of 512MB. In other words, REDO log space must be allocated in blocks of 64MB. In scenarios requiring a great many updates, the value for
NoOfFragmentLogFilesmay need to be set as high as 300 or even higher to provide sufficient space for REDO logs.If the checkpointing is slow and there are so many writes to the database that the log files are full and the log tail cannot be cut without jeopardizing recovery, all updating transactions are aborted with internal error code 410 (
Out of log file space temporarily). This condition prevails until a checkpoint has completed and the log tail can be moved forward.Important: This parameter cannot be changed “on the fly”; you must restart the node using
--initial. If you wish to change this value for a running cluster, you can do so via a rolling node restart.This parameter sets a ceiling on how many internal threads to allocate for open files. Any situation requiring a change in this parameter should be reported as a bug.
The default value is 40.
This parameter sets the maximum number of trace files that are kept before overwriting old ones. Trace files are generated when, for whatever reason, the node crashes.
The default is 25 trace files.
The next set of [NDBD] parameters defines
pool sizes for metadata objects, used to define the maximum
number of attributes, tables, indexes, and trigger objects
used by indexes, events, and replication between clusters.
Note that these act merely as “suggestions” to
the cluster, and any that are not specified revert to the
default values shown.
Defines the number of attributes that can be defined in the cluster.
The default value is 1000, with the minimum possible value being 32. The maximum is 4294967039. Each attribute consumes around 200 bytes of storage per node due to the fact that all metadata is fully replicated on the servers.
When setting
MaxNoOfAttributes, it is important to prepare in advance for anyALTER TABLEstatements that you might want to perform in the future. This is due to the fact, during the execution ofALTER TABLEon a Cluster table, 3 times the number of attributes as in the original table are used. For example, if a table requires 100 attributes, and you want to be able to alter it later, you need to set the value ofMaxNoOfAttributesto 300. Assuming that you can create all desired tables without any problems, a good rule of thumb is to add two times the number of attributes in the largest table toMaxNoOfAttributesto be sure. You should also verify that this number is sufficient by trying an actualALTER TABLEafter configuring the parameter. If this is not successful, increaseMaxNoOfAttributesby another multiple of the original value and test it again.A table object is allocated for each table, unique hash index, and ordered index. This parameter sets the maximum number of table objects for the cluster as a whole.
For each attribute that has a
BLOBdata type an extra table is used to store most of theBLOBdata. These tables also must be taken into account when defining the total number of tables.The default value of this parameter is 128. The minimum is 8 and the maximum is 1600. Each table object consumes approximately 20KB per node.
For each ordered index in the cluster, an object is allocated describing what is being indexed and its storage segments. By default, each index so defined also defines an ordered index. Each unique index and primary key has both an ordered index and a hash index.
The default value of this parameter is 128. Each object consumes approximately 10KB of data per node.
For each unique index that is not a primary key, a special table is allocated that maps the unique key to the primary key of the indexed table. By default, an ordered index is also defined for each unique index. To prevent this, you must specify the
USING HASHoption when defining the unique index.The default value is 64. Each index consumes approximately 15KB per node.
Internal update, insert, and delete triggers are allocated for each unique hash index. (This means that three triggers are created for each unique hash index.) However, an ordered index requires only a single trigger object. Backups also use three trigger objects for each normal table in the cluster.
This parameter sets the maximum number of trigger objects in the cluster.
The default value is 768.
This parameter is deprecated in MySQL 5.0; you should use
MaxNoOfOrderedIndexesandMaxNoOfUniqueHashIndexesinstead.This parameter is used only by unique hash indexes. There needs to be one record in this pool for each unique hash index defined in the cluster.
The default value of this parameter is 128.
The behavior of data nodes is also affected by a set of
[NDBD] parameters taking on boolean values.
These parameters can each be specified as
TRUE by setting them equal to
1 or Y, and as
FALSE by setting them equal to
0 or N.
For a number of operating systems, including Solaris and Linux, it is possible to lock a process into memory and so avoid any swapping to disk. This can be used to help guarantee the cluster's real-time characteristics.
Beginning with MySQL 5.0.36, this parameter takes one of the integer values
0,1, or2, which act as follows:0: Disables locking. This is the default value.1: Performs the lock after allocating memory for the process.2: Performs the lock before memory for the process is allocated.
Previously, this parameter was a Boolean.
0orfalsewas the default setting, and disabled locking.1ortrueenabled locking of the process after its memory was allocated. Important: Beginning with MySQL 5.0.36, it is no longer possible to usetrueorfalsefor the value of this parameter; when upgrading from a previous version, you must change the value to0,1, or2.This parameter specifies whether an ndbd process should exit or perform an automatic restart when an error condition is encountered.
This feature is enabled by default.
It is possible to specify MySQL Cluster tables as diskless, meaning that tables are not checkpointed to disk and that no logging occurs. Such tables exist only in main memory. A consequence of using diskless tables is that neither the tables nor the records in those tables survive a crash. However, when operating in diskless mode, it is possible to run ndbd on a diskless computer.
Important: This feature causes the entire cluster to operate in diskless mode.
When this feature is enabled, Cluster online backup is disabled. In addition, a partial start of the cluster is not possible.
Disklessis disabled by default.This feature is accessible only when building the debug version where it is possible to insert errors in the execution of individual blocks of code as part of testing.
This feature is disabled by default.
Controlling Timeouts, Intervals, and Disk Paging
There are a number of [NDBD] parameters
specifying timeouts and intervals between various actions in
Cluster data nodes. Most of the timeout values are specified
in milliseconds. Any exceptions to this are mentioned where
applicable.
To prevent the main thread from getting stuck in an endless loop at some point, a “watchdog” thread checks the main thread. This parameter specifies the number of milliseconds between checks. If the process remains in the same state after three checks, the watchdog thread terminates it.
This parameter can easily be changed for purposes of experimentation or to adapt to local conditions. It can be specified on a per-node basis although there seems to be little reason for doing so.
The default timeout is 4000 milliseconds (4 seconds).
This parameter specifies how long the Cluster waits for all data nodes to come up before the cluster initialization routine is invoked. This timeout is used to avoid a partial Cluster startup whenever possible.
The default value is 30000 milliseconds (30 seconds). 0 disables the timeout, in which case the cluster may start only if all nodes are available.
If the cluster is ready to start after waiting for
StartPartialTimeoutmilliseconds but is still possibly in a partitioned state, the cluster waits until this timeout has also passed.The default timeout is 60000 milliseconds (60 seconds).
If a data node has not completed its startup sequence within the time specified by this parameter, the node startup fails. Setting this parameter to 0 (the default value) means that no data node timeout is applied.
For nonzero values, this parameter is measured in milliseconds. For data nodes containing extremely large amounts of data, this parameter should be increased. For example, in the case of a data node containing several gigabytes of data, a period as long as 10–15 minutes (that is, 600000 to 1000000 milliseconds) might be required to perform a node restart.
One of the primary methods of discovering failed nodes is by the use of heartbeats. This parameter states how often heartbeat signals are sent and how often to expect to receive them. After missing three heartbeat intervals in a row, the node is declared dead. Thus, the maximum time for discovering a failure through the heartbeat mechanism is four times the heartbeat interval.
The default heartbeat interval is 1500 milliseconds (1.5 seconds). This parameter must not be changed drastically and should not vary widely between nodes. If one node uses 5000 milliseconds and the node watching it uses 1000 milliseconds, obviously the node will be declared dead very quickly. This parameter can be changed during an online software upgrade, but only in small increments.
Each data node sends heartbeat signals to each MySQL server (SQL node) to ensure that it remains in contact. If a MySQL server fails to send a heartbeat in time it is declared “dead,” in which case all ongoing transactions are completed and all resources released. The SQL node cannot reconnect until all activities initiated by the previous MySQL instance have been completed. The three-heartbeat criteria for this determination are the same as described for
HeartbeatIntervalDbDb.The default interval is 1500 milliseconds (1.5 seconds). This interval can vary between individual data nodes because each data node watches the MySQL servers connected to it, independently of all other data nodes.
This parameter is an exception in that it does not specify a time to wait before starting a new local checkpoint; rather, it is used to ensure that local checkpoints are not performed in a cluster where relatively few updates are taking place. In most clusters with high update rates, it is likely that a new local checkpoint is started immediately after the previous one has been completed.
The size of all write operations executed since the start of the previous local checkpoints is added. This parameter is also exceptional in that it is specified as the base-2 logarithm of the number of 4-byte words, so that the default value 20 means 4MB (4 × 220) of write operations, 21 would mean 8MB, and so on up to a maximum value of 31, which equates to 8GB of write operations.
All the write operations in the cluster are added together. Setting
TimeBetweenLocalCheckpointsto 6 or less means that local checkpoints will be executed continuously without pause, independent of the cluster's workload.When a transaction is committed, it is committed in main memory in all nodes on which the data is mirrored. However, transaction log records are not flushed to disk as part of the commit. The reasoning behind this behavior is that having the transaction safely committed on at least two autonomous host machines should meet reasonable standards for durability.
It is also important to ensure that even the worst of cases — a complete crash of the cluster — is handled properly. To guarantee that this happens, all transactions taking place within a given interval are put into a global checkpoint, which can be thought of as a set of committed transactions that has been flushed to disk. In other words, as part of the commit process, a transaction is placed in a global checkpoint group. Later, this group's log records are flushed to disk, and then the entire group of transactions is safely committed to disk on all computers in the cluster.
This parameter defines the interval between global checkpoints. The default is 2000 milliseconds.
TimeBetweenInactiveTransactionAbortCheckTimeout handling is performed by checking a timer on each transaction once for every interval specified by this parameter. Thus, if this parameter is set to 1000 milliseconds, every transaction will be checked for timing out once per second.
The default value is 1000 milliseconds (1 second).
This parameter states the maximum time that is permitted to lapse between operations in the same transaction before the transaction is aborted.
The default for this parameter is zero (no timeout). For a real-time database that needs to ensure that no transaction keeps locks for too long, this parameter should be set to a much smaller value. The unit is milliseconds.
TransactionDeadlockDetectionTimeoutWhen a node executes a query involving a transaction, the node waits for the other nodes in the cluster to respond before continuing. A failure to respond can occur for any of the following reasons:
The node is “dead”
The operation has entered a lock queue
The node requested to perform the action could be heavily overloaded.
This timeout parameter states how long the transaction coordinator waits for query execution by another node before aborting the transaction, and is important for both node failure handling and deadlock detection. Setting it too high can cause a undesirable behavior in situations involving deadlocks and node failure.
The default timeout value is 1200 milliseconds (1.2 seconds).
NoOfDiskPagesToDiskAfterRestartTUPWhen executing a local checkpoint, the algorithm flushes all data pages to disk. Merely doing so as quickly as possible without any moderation is likely to impose excessive loads on processors, networks, and disks. To control the write speed, this parameter specifies how many pages per 100 milliseconds are to be written. In this context, a “page” is defined as 8KB. This parameter is specified in units of 80KB per second, so , setting
NoOfDiskPagesToDiskAfterRestartTUPto a value of20entails writing 1.6MB in data pages to disk each second during a local checkpoint. This value includes the writing of UNDO log records for data pages. That is, this parameter handles the limitation of writes from data memory. UNDO log records for index pages are handled by the parameterNoOfDiskPagesToDiskAfterRestartACC. (See the entry forIndexMemoryfor information about index pages.)In short, this parameter specifies how quickly to execute local checkpoints. It operates in conjunction with
NoOfFragmentLogFiles,DataMemory, andIndexMemory.For more information about the interaction between these parameters and possible strategies for choosing appropriate values for them, see Section 15.4.6, “Configuring Parameters for Local Checkpoints”.
The default value is 40 (3.2MB of data pages per second).
NoOfDiskPagesToDiskAfterRestartACCThis parameter uses the same units as
NoOfDiskPagesToDiskAfterRestartTUPand acts in a similar fashion, but limits the speed of writing index pages from index memory.The default value of this parameter is 20 (1.6MB of index memory pages per second).
NoOfDiskPagesToDiskDuringRestartTUPThis parameter is used in a fashion similar to
NoOfDiskPagesToDiskAfterRestartTUPandNoOfDiskPagesToDiskAfterRestartACC, only it does so with regard to local checkpoints executed in the node when a node is restarting. A local checkpoint is always performed as part of all node restarts. During a node restart it is possible to write to disk at a higher speed than at other times, because fewer activities are being performed in the node.This parameter covers pages written from data memory.
The default value is 40 (3.2MB per second).
NoOfDiskPagesToDiskDuringRestartACCControls the number of index memory pages that can be written to disk during the local checkpoint phase of a node restart.
As with
NoOfDiskPagesToDiskAfterRestartTUPandNoOfDiskPagesToDiskAfterRestartACC, values for this parameter are expressed in terms of 8KB pages written per 100 milliseconds (80KB/second).The default value is 20 (1.6MB per second).
This parameter specifies how long data nodes wait for a response from the arbitrator to an arbitration message. If this is exceeded, the network is assumed to have split.
The default value is 1000 milliseconds (1 second).
Several [NDBD] configuration parameters
corresponding to former compile-time parameters are also
available. These enable the advanced user to have more control
over the resources used by node processes and to adjust
various buffer sizes at need.
These buffers are used as front ends to the file system when
writing log records to disk. If the node is running in
diskless mode, these parameters can be set to their minimum
values without penalty due to the fact that disk writes are
“faked” by the NDB storage
engine's filesystem abstraction layer.
The UNDO index buffer, whose size is set by this parameter, is used during local checkpoints. The
NDBstorage engine uses a recovery scheme based on checkpoint consistency in conjunction with an operational REDO log. To produce a consistent checkpoint without blocking the entire system for writes, UNDO logging is done while performing the local checkpoint. UNDO logging is activated on a single table fragment at a time. This optimization is possible because tables are stored entirely in main memory.The UNDO index buffer is used for the updates on the primary key hash index. Inserts and deletes rearrange the hash index; the NDB storage engine writes UNDO log records that map all physical changes to an index page so that they can be undone at system restart. It also logs all active insert operations for each fragment at the start of a local checkpoint.
Reads and updates set lock bits and update a header in the hash index entry. These changes are handled by the page-writing algorithm to ensure that these operations need no UNDO logging.
This buffer is 2MB by default. The minimum value is 1MB, which is sufficient for most applications. For applications doing extremely large or numerous inserts and deletes together with large transactions and large primary keys, it may be necessary to increase the size of this buffer. If this buffer is too small, the NDB storage engine issues internal error code 677 (
Index UNDO buffers overloaded).Important: It is not safe to decrease the value of this parameter during a rolling restart.
This parameter sets the size of the UNDO data buffer, which performs a function similar to that of the UNDO index buffer, except the UNDO data buffer is used with regard to data memory rather than index memory. This buffer is used during the local checkpoint phase of a fragment for inserts, deletes, and updates.
Because UNDO log entries tend to grow larger as more operations are logged, this buffer is also larger than its index memory counterpart, with a default value of 16MB.
This amount of memory may be unnecessarily large for some applications. In such cases, it is possible to decrease this size to a minimum of 1MB.
It is rarely necessary to increase the size of this buffer. If there is such a need, it is a good idea to check whether the disks can actually handle the load caused by database update activity. A lack of sufficient disk space cannot be overcome by increasing the size of this buffer.
If this buffer is too small and gets congested, the NDB storage engine issues internal error code 891 (Data UNDO buffers overloaded).
Important: It is not safe to decrease the value of this parameter during a rolling restart.
All update activities also need to be logged. The REDO log makes it possible to replay these updates whenever the system is restarted. The NDB recovery algorithm uses a “fuzzy” checkpoint of the data together with the UNDO log, and then applies the REDO log to play back all changes up to the restoration point.
RedoBuffersets the size of the buffer inwhich the REDO log is written, and is 8MB by default. The minimum value is 1MB.If this buffer is too small, the NDB storage engine issues error code 1221 (
REDO log buffers overloaded).Important: It is not safe to decrease the value of this parameter during a rolling restart.
In managing the cluster, it is very important to be able to
control the number of log messages sent for various event
types to stdout. For each event category,
there are 16 possible event levels (numbered 0 through 15).
Setting event reporting for a given event category to level 15
means all event reports in that category are sent to
stdout; setting it to 0 means that there
will be no event reports made in that category.
By default, only the startup message is sent to
stdout, with the remaining event reporting
level defaults being set to 0. The reason for this is that
these messages are also sent to the management server's
cluster log.
An analogous set of levels can be set for the management client to determine which event levels to record in the cluster log.
The reporting level for events generated during startup of the process.
The default level is 1.
The reporting level for events generated as part of graceful shutdown of a node.
The default level is 0.
The reporting level for statistical events such as number of primary key reads, number of updates, number of inserts, information relating to buffer usage, and so on.
The default level is 0.
The reporting level for events generated by local and global checkpoints.
The default level is 0.
The reporting level for events generated during node restart.
The default level is 0.
The reporting level for events generated by connections between cluster nodes.
The default level is 0.
The reporting level for events generated by errors and warnings by the cluster as a whole. These errors do not cause any node failure but are still considered worth reporting.
The default level is 0.
The reporting level for events generated for information about the general state of the cluster.
The default level is 0.
The [NDBD] parameters discussed in this
section define memory buffers set aside for execution of
online backups.
In creating a backup, there are two buffers used for sending data to the disk. The backup data buffer is used to fill in data recorded by scanning a node's tables. Once this buffer has been filled to the level specified as
BackupWriteSize(see below), the pages are sent to disk. While flushing data to disk, the backup process can continue filling this buffer until it runs out of space. When this happens, the backup process pauses the scan and waits until some disk writes have completed freed up memory so that scanning may continue.The default value is 2MB.
The backup log buffer fulfills a role similar to that played by the backup data buffer, except that it is used for generating a log of all table writes made during execution of the backup. The same principles apply for writing these pages as with the backup data buffer, except that when there is no more space in the backup log buffer, the backup fails. For that reason, the size of the backup log buffer must be large enough to handle the load caused by write activities while the backup is being made. See Section 15.8.4, “Configuration for Cluster Backup”.
The default value for this parameter should be sufficient for most applications. In fact, it is more likely for a backup failure to be caused by insufficient disk write speed than it is for the backup log buffer to become full. If the disk subsystem is not configured for the write load caused by applications, the cluster is unlikely to be able to perform the desired operations.
It is preferable to configure cluster nodes in such a manner that the processor becomes the bottleneck rather than the disks or the network connections.
The default value is 2MB.
This parameter is simply the sum of
BackupDataBufferSizeandBackupLogBufferSize.The default value is 2MB + 2MB = 4MB.
Important: If
BackupDataBufferSizeandBackupLogBufferSizetaken together exceed 4MB, then this parameter must be set explicitly in theconfig.inifile to their sum.This parameter specifies the default size of messages written to disk by the backup log and backup data buffers.
The default value is 32KB.
This parameter specifies the maximum size of messages written to disk by the backup log and backup data buffers.
The default value is 256KB.
Important: When specifying these parameters, the following relationships must hold true. Otherwise, the data node will be unable to start.
BackupDataBufferSize >= BackupWriteSize + 188KBBackupLogBufferSize >= BackupWriteSize + 16KBBackupMaxWriteSize >= BackupWriteSize
The [MYSQLD] and [API]
sections in the config.ini file define
the behavior of the MySQL servers (SQL nodes) and other
applications (API nodes) used to access cluster data. None of
the parameters shown is required. If no computer or host name
is provided, any host can use this SQL or API node.
Generally speaking, a [MYSQLD] section is
used to indicate a MySQL server providing an SQL interface to
the cluster, and an [API] section is used
for applications other than mysqld
processes accessing cluster data, but the two designations are
actually synonomous; you can, for instance, list parameters
for a MySQL server acting as an SQL node in an
[API] section.
The
Idvalue is used to identify the node in all cluster internal messages. It must be an integer in the range 1 to 63 inclusive, and must be unique among all node IDs within the cluster.This refers to the
Idset for one of the computers (hosts) defined in a[COMPUTER]section of the configuration file.Specifying this parameter defines the hostname of the computer on which the SQL node (API node) is to reside. To specify a hostname other than
localhost, either this parameter orExecuteOnComputeris required.This parameter defines which nodes can act as arbitrators. Both MGM nodes and SQL nodes can be arbitrators. A value of 0 means that the given node is never used as an arbitrator, a value of 1 gives the node high priority as an arbitrator, and a value of 2 gives it low priority. A normal configuration uses the management server as arbitrator, setting its
ArbitrationRankto 1 (the default) and those for all SQL nodes to 0.Setting this parameter to any other value than 0 (the default) means that responses by the arbitrator to arbitration requests will be delayed by the stated number of milliseconds. It is usually not necessary to change this value.
For queries that are translated into full table scans or range scans on indexes, it is important for best performance to fetch records in properly sized batches. It is possible to set the proper size both in terms of number of records (
BatchSize) and in terms of bytes (BatchByteSize). The actual batch size is limited by both parameters.The speed at which queries are performed can vary by more than 40% depending upon how this parameter is set. In future releases, MySQL Server will make educated guesses on how to set parameters relating to batch size, based on the query type.
This parameter is measured in bytes and by default is equal to 32KB.
This parameter is measured in number of records and is by default set to 64. The maximum size is 992.
The batch size is the size of each batch sent from each data node. Most scans are performed in parallel to protect the MySQL Server from receiving too much data from many nodes in parallel; this parameter sets a limit to the total batch size over all nodes.
The default value of this parameter is set to 256KB. Its maximum size is 16MB.
You can obtain some information from a MySQL server running as
a Cluster SQL node using SHOW STATUS in the
mysql client, as shown here:
mysql> SHOW STATUS LIKE 'ndb%';
+-----------------------------+---------------+
| Variable_name | Value |
+-----------------------------+---------------+
| Ndb_cluster_node_id | 5 |
| Ndb_config_from_host | 192.168.0.112 |
| Ndb_config_from_port | 1186 |
| Ndb_number_of_storage_nodes | 4 |
+-----------------------------+---------------+
4 rows in set (0.02 sec)
For information about these Cluster system status variables, see Section 5.2.5, “Status Variables”.
TCP/IP is the default transport mechanism for establishing
connections in MySQL Cluster. It is normally not necessary to
define connections because Cluster automatically set ups a
connection between each of the data nodes, between each data
node and all MySQL server nodes, and between each data node
and the management server. (For one exception to this rule,
see Section 15.4.4.8, “TCP/IP Connections Using Direct Connections”.)
[TCP] sections in the
config.ini file explicitly define TCP/IP
connections between nodes in the cluster.
It is necessary to define a connection only to override the
default connection parameters. In that case, it is necessary
to define at least NodeId1,
NodeId2, and the parameters to change.
Important
Any [TCP] sections in the
config.ini file should be listed last,
following any other sections in the file. This is not
required for a [TCP DEFAULT] section.
This is a known issue with the way in which the
config.ini file is read by the cluster
management server.
It is also possible to change the default values for these
parameters by setting them in the [TCP
DEFAULT] section.
To identify a connection between two nodes it is necessary to provide their node IDs in the
[TCP]section of the configuration file. These are the same uniqueIdvalues for each of these nodes as described in Section 15.4.4.6, “Defining SQL and Other API Nodes”.TCP transporters use a buffer to store all messages before performing the send call to the operating system. When this buffer reaches 64KB its contents are sent; these are also sent when a round of messages have been executed. To handle temporary overload situations it is also possible to define a bigger send buffer. The default size of the send buffer is 256KB.
To be able to retrace a distributed message datagram, it is necessary to identify each message. When this parameter is set to
Y, message IDs are transported over the network. This feature is disabled by default in production builds, and enabled in-debugbuilds.This parameter is a boolean parameter (enabled by setting it to
Yor1, disabled by setting it toNor0). It is disabled by default. When it is enabled, checksums for all messages are calculated before they placed in the send buffer. This feature ensures that messages are not corrupted while waiting in the send buffer, or by the transport mechanism.This formerly specified the port number to be used for listening for connections from other nodes. This parameter should no longer be used.
Specifies the size of the buffer used when receiving data from the TCP/IP socket. There is seldom any need to change this parameter from its default value of 64KB, except possibly to save memory.
Setting up a cluster using direct connections between data
nodes requires specifying explicitly the crossover IP
addresses of the data nodes so connected in the
[TCP] section of the cluster
config.ini file.
In the following example, we envision a cluster with at least
four hosts, one each for a management server, an SQL node, and
two data nodes. The cluster as a whole resides on the
172.23.72.* subnet of a LAN. In addition to
the usual network connections, the two data nodes are
connected directly using a standard crossover cable, and
communicate with one another directly using IP addresses in
the 1.1.0.* address range as shown:
# Management Server [NDB_MGMD] Id=1 HostName=172.23.72.20 # SQL Node [MYSQLD] Id=2 HostName=172.23.72.21 # Data Nodes [NDBD] Id=3 HostName=172.23.72.22 [NDBD] Id=4 HostName=172.23.72.23 # TCP/IP Connections [TCP] NodeId1=3 NodeId2=4 HostName1=1.1.0.1 HostName2=1.1.0.2
The HostName
parameter, where NN is an integer,
is used only when specifying direct TCP/IP connections.
The use of direct connections between data nodes can improve the cluster's overall efficiency by allowing the data nodes to bypass an Ethernet device such as a switch, hub, or router, thus cutting down on the cluster's latency. It is important to note that to take the best advantage of direct connections in this fashion with more than two data nodes, you must have a direct connection between each data node and every other data node in the same node group.
MySQL Cluster attempts to use the shared memory transporter
and configure it automatically where possible. (In very early
versions of MySQL Cluster, shared memory segments functioned
only when the server binary was built using
--with-ndb-shm.) [SHM]
sections in the config.ini file
explicitly define shared-memory connections between nodes in
the cluster. When explicitly defining shared memory as the
connection method, it is necessary to define at least
NodeId1, NodeId2 and
ShmKey. All other parameters have default
values that should work well in most cases.
Important: SHM functionality is considered experimental only. It is not officially supported in any MySQL release series up to and including 5.0. This means that you must determine for yourself or by using our free resources (forums, mailing lists) whether it can be made to work correctly in your specific case.
To identify a connection between two nodes it is necessary to provide node identifiers for each of them, as
NodeId1andNodeId2.When setting up shared memory segments, a node ID, expressed as an integer, is used to identify uniquely the shared memory segment to use for the communication. There is no default value.
Each SHM connection has a shared memory segment where messages between nodes are placed by the sender and read by the reader. The size of this segment is defined by
ShmSize. The default value is 1MB.To retrace the path of a distributed message, it is necessary to provide each message with a unique identifier. Setting this parameter to
Ycauses these message IDs to be transported over the network as well. This feature is disabled by default in production builds, and enabled in-debugbuilds.This parameter is a boolean (
Y/N) parameter which is disabled by default. When it is enabled, checksums for all messages are calculated before being placed in the send buffer.This feature prevents messages from being corrupted while waiting in the send buffer. It also serves as a check against data being corrupted during transport.
[SCI] sections in the
config.ini file explicitly define SCI
(Scalable Coherent Interface) connections between cluster
nodes. Using SCI transporters in MySQL Cluster is supported
only when the MySQL binaries are built using
--with-ndb-sci=.
The /your/path/to/SCIpath should point to a
directory that contains at a minimum lib
and include directories containing SISCI
libraries and header files. (See
Section 15.10, “Using High-Speed Interconnects with MySQL Cluster” for more
information about SCI.)
In addition, SCI requires specialized hardware.
It is strongly recommended to use SCI Transporters only for communication between ndbd processes. Note also that using SCI Transporters means that the ndbd processes never sleep. For this reason, SCI Transporters should be used only on machines having at least two CPUs dedicated for use by ndbd processes. There should be at least one CPU per ndbd process, with at least one CPU left in reserve to handle operating system activities.
To identify a connection between two nodes it is necessary to provide node identifiers for each of them, as
NodeId1andNodeId2.This identifies the SCI node ID on the first Cluster node (identified by
NodeId1).It is possible to set up SCI Transporters for failover between two SCI cards which then should use separate networks between the nodes. This identifies the node ID and the second SCI card to be used on the first node.
This identifies the SCI node ID on the second Cluster node (identified by
NodeId2).When using two SCI cards to provide failover, this parameter identifies the second SCI card to be used on the second node.
Each SCI transporter has a shared memory segment used for communication between the two nodes. Setting the size of this segment to the default value of 1MB should be sufficient for most applications. Using a smaller value can lead to problems when performing many parallel inserts; if the shared buffer is too small, this can also result in a crash of the ndbd process.
A small buffer in front of the SCI media stores messages before transmitting them over the SCI network. By default, this is set to 8KB. Our benchmarks show that performance is best at 64KB but 16KB reaches within a few percent of this, and there was little if any advantage to increasing it beyond 8KB.
To trace a distributed message it is necessary to identify each message uniquely. When this parameter is set to
Y, message IDs are transported over the network. This feature is disabled by default in production builds, and enabled in-debugbuilds.This parameter is a boolean value, and is disabled by default. When
Checksumis enabled, checksums are calculated for all messages before they are placed in the send buffer. This feature prevents messages from being corrupted while waiting in the send buffer. It also serves as a check against data being corrupted during transport.
The next three sections provide summary tables of MySQL Cluster
configuration parameters used in the
config.ini file to govern the cluster's
functioning. Each table lists the parameters for one of the
Cluster node process types (ndbd,
ndb_mgmd, and mysqld), and
includes the parameter's type as well as its default, mimimum,
and maximum values as applicable.
It is also stated what type of restart is required (node restart
or system restart) — and whether the restart must be done
with --initial — to change the value of a
given configuration parameter. This information is provided in
each table's Restart Type
column, which contains one of the values shown in this list:
N: Node RestartIN: Initial Node RestartS: System RestartIS: Initial System Restart
When performing a node restart or an initial node restart, all
of the cluster's data nodes must be restarted in turn (also
referred to as a rolling restart). It is
possible to update cluster configuration parameters marked
N or IN online —
that is, without shutting down the cluster — in this
fashion. An initial node restart requires restarting each
ndbd process with the
--initial option.
A system restart requires a complete shutdown and restart of the entire cluster. An initial system restart requires taking a backup of the cluster, wiping the cluster filesystem after shutdown, and then restoring from the backup following the restart.
In any cluster restart, all of the cluster's management servers must be restarted in order for them to read the updated configuration parameter values.
Important: Values for numeric cluster parameters can generally be increased without any problems, although it is advisable to do so progressively, making such adjustments in relatively small increments. However, decreasing the values of such parameters — particularly those relating to memory usage and disk space — is not to be undertaken lightly, and it is recommended that you do so only following careful planning and testing. In addition, it is the generally the case that parameters relating to memory and disk usage which can be raised using a simple node restart require an initial node restart to be lowered.
Because some of these parameters can be used for configuring more than one type of cluster node, they may appear in more than one of the tables.
(Note that 4294967039 — which often
appears as a maximum value in these tables — is equal to
232 –
28 – 1.)
The following table provides information about parameters used
in the [NDBD] or
[NDB_DEFAULT] sections of a
config.ini file for configuring MySQL
Cluster data nodes. For detailed descriptions and other
additional information about each of these parameters, see
Section 15.4.4.5, “Defining Data Nodes”.
Restart Type Column Values
N: Node RestartIN: Initial Node RestartS: System RestartIS: Initial System Restart
See Section 15.4.5, “Overview of Cluster Configuration Parameters”, for additional explanations of these abbreviations.
| Parameter Name | Type/Units | Default Value | Minimum Value | Maximum Value | Restart Type |
ArbitrationTimeout | milliseconds | 1000 | 10 | 4294967039 | N |
BackupDataBufferSize | bytes | 2M | 0 | 4294967039 | N |
BackupDataDir | string | | N/A | N/A | IN |
BackupLogBufferSize | bytes | 2M | 0 | 4294967039 | N |
BackupMemory | bytes | 4M | 0 | 4294967039 | N |
BackupWriteSize | bytes | 32K | 2K | 4294967039 | N |
BackupMaxWriteSize | bytes | 256K | 2K | 4294967039 | N |
BatchSizePerLocalScan | integer | 64 | 1 | 992 | N |
DataDir | string | /var/lib/mysql-cluster | N/A | N/A | IN |
DataMemory | bytes | 80M | 1M | 1024G (subject to available system RAM and size of
IndexMemory) | N |
Diskless | true|false (1|0) | 0 | 0 | 1 | IS |
ExecuteOnComputer | integer | ||||
FileSystemPath | string | value specified for DataDir | N/A | N/A | IN |
HeartbeatIntervalDbApi | milliseconds | 1500 | 100 | 4294967039 | N |
HeartbeatIntervalDbDb | milliseconds | 1500 | 10 | 4294967039 | N |
HostName | string | localhost | N/A | N/A | S |
Id | integer | None | 1 | 63 | N |
IndexMemory | bytes | 18M | 1M | 1024G (subject to available system RAM and size of
DataMemory) | N |
LockPagesInMainMemory | As of MySQL 5.0.36: integer;
previously: true|false
(1|0) | 0 | 0 | 1 | N |
LogLevelCheckpoint | integer | 0 | 0 | 15 | IN |
LogLevelConnection | integer | 0 | 0 | 15 | N |
LogLevelError | integer | 0 | 0 | 15 | N |
LogLevelInfo | integer | 0 | 0 | 15 | N |
LogLevelNodeRestart | integer | 0 | 0 | 15 | N |
LogLevelShutdown | integer | 0 | 0 | 15 | N |
LogLevelStartup | integer | 1 | 0 | 15 | N |
LogLevelStatistic | integer | 0 | 0 | 15 | N |
LongMessageBuffer | bytes | 1M | 512K | 4294967039 | N |
MaxNoOfAttributes | integer | 1000 | 32 | 4294967039 | N |
MaxNoOfConcurrentIndexOperations | integer | 8K | 0 | 4294967039 | N |
MaxNoOfConcurrentOperations | integer | 32768 | 32 | 4294967039 | N |
MaxNoOfConcurrentScans | integer | 256 | 2 | 500 | N |
MaxNoOfConcurrentTransactions | integer | 4096 | 32 | 4294967039 | N |
MaxNoOfFiredTriggers | integer | 4000 | 0 | 4294967039 | N |
MaxNoOfIndexes
(DEPRECATED — use
MaxNoOfOrderedIndexes or
MaxNoOfUniqueHashIndexes instead) | integer | 128 | 0 | 4294967039 | N |
MaxNoOfLocalOperations | integer | UNDEFINED | 32 | 4294967039 | N |
MaxNoOfLocalScans | integer | UNDEFINED (see
description) | 32 | 4294967039 | N |
MaxNoOfOrderedIndexes | integer | 128 | 0 | 4294967039 | N |
MaxNoOfSavedMessages | integer | 25 | 0 | 4294967039 | N |
MaxNoOfTables | integer | 128 | 8 | 4294967039 | N |
MaxNoOfTriggers | integer | 768 | 0 | 4294967039 | N |
MaxNoOfUniqueHashIndexes | integer | 64 | 0 | 4294967039 | N |
NoOfDiskPagesToDiskAfterRestartACC | integer (number of 8KB pages per 100 milliseconds) | 20 (= 20 * 80KB = 1.6MB/second) | 1 | 4294967039 | N |
NoOfDiskPagesToDiskAfterRestartTUP | integer (number of 8KB pages per 100 milliseconds) | 40 (= 40 * 80KB = 3.2MB/second) | 1 | 4294967039 | N |
NoOfDiskPagesToDiskDuringRestartACC | integer (number of 8KB pages per 100 milliseconds) | 20 (= 20 * 80KB = 1.6MB/second) | 1 | 4294967039 | N |
NoOfDiskPagesToDiskDuringRestartTUP | integer (number of 8KB pages per 100 milliseconds) | 40 (= 40 * 80KB = 3.2MB/second) | 1 | 4294967039 | N |
NoOfFragmentLogFiles | integer | 8 | 1 | 4294967039 | IN |
NoOfReplicas | integer | None | 1 | 4 | IS |
RedoBuffer | bytes | 8M | 1M | 4294967039 | N |
RestartOnErrorInsert
(DEBUG BUILDS ONLY) | true|false (1|0) | 0 | 0 | 1 | N |
ServerPort
(OBSOLETE) | integer | 1186 | 0 | 4294967039 | N |
StartFailureTimeout | milliseconds | 0 | 0 | 4294967039 | N |
StartPartialTimeout | milliseconds | 30000 | 0 | 4294967039 | N |
StartPartitionedTimeout | milliseconds | 60000 | 0 | 4294967039 | N |
StopOnError | true|false (1|0) | 1 | 0 | 1 | N |
TimeBetweenGlobalCheckpoints | milliseconds | 2000 | 10 | 32000 | N |
TimeBetweenInactiveTransactionAbortCheck | milliseconds | 1000 | 1000 | 4294967039 | N |
TimeBetweenLocalCheckpoints | integer (number of 4-byte words as a base-2 logarithm) | 20 (= 4 * 220 = 4MB write
operations) | 0 | 31 | N |
TimeBetweenWatchDogCheck | milliseconds | 4000 | 70 | 4294967039 | N |
TransactionBufferMemory | bytes | 1M | 1K | 4294967039 | N |
TransactionDeadlockDetectionTimeout | milliseconds | 1200 | 50 | 4294967039 | N |
TransactionInactiveTimeout | milliseconds | 0 | 0 | 4294967039 | N |
UndoDataBuffer | bytes | 16M | 1M | 4294967039 | N |
UndoIndexBuffer | bytes | 2M | 1M | 4294967039 | N |
The following table provides information about parameters used
in the [NDB_MGMD] or
[MGM] sections of a
config.ini file for configuring MySQL
Cluster management nodes. For detailed descriptions and other
additional information about each of these parameters, see
Section 15.4.4.4, “Defining the Management Server”.
Restart Type Column Values
N: Node RestartIN: Initial Node RestartS: System RestartIS: Initial System Restart
See Section 15.4.5, “Overview of Cluster Configuration Parameters”, for additional explanations of these abbreviations.
| Parameter Name | Type/Units | Default Value | Minimum Value | Maximum Value | Restart Type |
ArbitrationDelay | milliseconds | 0 | 0 | 4294967039 | N |
ArbitrationRank | integer | 1 | 0 | 2 | N |
DataDir | string | ./ (ndb_mgmd directory) | N/A | N/A | IN |
ExecuteOnComputer | integer | ||||
HostName | string | localhost | N/A | N/A | IN |
Id | integer | None | 1 | 63 | IN |
LogDestination | CONSOLE, SYSLOG, or
FILE | FILE (see
Section 15.4.4.4, “Defining the Management Server”) | N/A | N/A | N |
The following table provides information about parameters used
in the [SQL] and [API]
sections of a config.ini file for
configuring MySQL Cluster SQL nodes and API nodes. For
detailed descriptions and other additional information about
each of these parameters, see
Section 15.4.4.6, “Defining SQL and Other API Nodes”.
Restart Type Column Values
N: Node RestartIN: Initial Node RestartS: System RestartIS: Initial System Restart
See Section 15.4.5, “Overview of Cluster Configuration Parameters”, for additional explanations of these abbreviations.
| Parameter Name | Type/Units | Default Value | Minimum Value | Maximum Value | Restart Type |
ArbitrationDelay | milliseconds | 0 | 0 | 4294967039 | N |
ArbitrationRank | integer | 1 | 0 | 2 | N |
BatchByteSize | bytes | 32K | 1K | 1M | N |
BatchSize | integer | 64 | 1 | 992 | N |
ExecuteOnComputer | integer | ||||
HostName | string | localhost | N/A | N/A | IN |
Id | integer | None | 1 | 63 | IN |
MaxScanBatchSize | bytes | 256K | 32K | 16M | N |
The parameters discussed in
Logging
and Checkpointing and in
Data
Memory, Index Memory, and String Memory that are used to
configure local checkpoints for a MySQL Cluster do not exist in
isolation, but rather are very much interdepedent on each other.
In this section, we illustrate how these parameters —
including DataMemory,
IndexMemory,
NoOfDiskPagesToDiskAfterRestartTUP,
NoOfDiskPagesToDiskAfterRestartACC, and
NoOfFragmentLogFiles — relate to one
another in a working Cluster.
In this example, we assume that our application performs the following numbers of types of operations per hour:
50000 selects
15000 inserts
15000 updates
15000 deletes
We also make the following assumptions about the data used in the application:
We are working with a single table having 40 columns.
Each column can hold up to 32 bytes of data.
A typical
UPDATErun by the application affects the values of 5 columns.No
NULLvalues are inserted by the application.
A good starting point is to determine the amount of time that should elapse between local checkpoints (LCPs). It worth noting that, in the event of a system restart, it takes 40-60 percent of this interval to execute the REDO log — for example, if the time between LCPs is 5 minutes (300 seconds), then it should take 2 to 3 minutes (120 to 180 seconds) for the REDO log to be read.
The maximum amount of data per node can be assumed to be the
size of the DataMemory parameter. In this
example, we assume that this is 2 GB. The
NoOfDiskPagesToDiskAfterRestartTUP parameter
represents the amount of data to be checkpointed per unit time
— however, this parameter is actually expressed as the
number of 8K memory pages to be checkpointed per 100
milliseconds. 2 GB per 300 seconds is approximately 6.8 MB per
second, or 700 KB per 100 milliseconds, which works out to
roughly 85 pages per 100 milliseconds.
Similarly, we can calculate
NoOfDiskPagesToDiskAfterRestartACC in terms
of the time for local checkpoints and the amount of memory
required for indexes — that is, the
IndexMemory. Assuming that we allow 512 MB
for indexes, this works out to approximately 20 8-KB pages per
100 milliseconds for this parameter.
Next, we need to determine the number of REDO log files required
— that is, fragment log files — the corresponding
parameter being NoOfFragmentLogFiles. We need
to make sure that there are sufficient REDO log files for
keeping records for at least 3 local checkpoints. In a
production setting, there are always uncertainties — for
instance, we cannot be sure that disks always operate at top
speed or with maximum throughput. For this reason, it is best to
err on the side of caution, so we double our requirement and
calculate a number of fragment log files which should be enough
to keep records covering 6 local checkpoints.
It is also important to remember that the disk also handles
writes to the REDO log and UNDO log, so if you find that the
amount of data being written to disk as detemined by the values
of NoOfDiskPagesToDiskAfterRestartACC and
NoOfDiskPagesToDiskAfterRestartTUP is
approaching the amount of disk bandwidth available, you may wish
to increase the time between local checkpoints.
Given 5 minutes (300 seconds) per local checkpoint, this means that we need to support writing log records at maximum speed for 6 * 300 = 1800 seconds. The size of a REDO log record is 72 bytes plus 4 bytes per updated column value plus the maximum size of the updated column, and there is one REDO log record for each table record updated in a transaction, on each node where the data reside. Using the numbers of operations set out previously in this section, we derive the following:
50000 select operations per hour yields 0 log records (and thus 0 bytes), since
SELECTstatements are not recorded in the REDO log.15000
DELETEstatements per hour is approximately 5 delete operations per second. (Since we wish to be conservative in our estimate, we round up here and in the following calculations.) No columns are updated by deletes, so these statements consume only 5 operations * 72 bytes per operation = 360 bytes per second.15000
UPDATEstatements per hour is roughly the same as 5 updates per second. Each update uses 72 bytes, plus 4 bytes per column * 5 columns updated, plus 32 bytes per column * 5 columns — this works out to 72 + 20 + 160 = 252 bytes per operation, and multiplying this by 5 operation per second yields 1260 bytes per second.15000
INSERTstatements per hour is equivalent to 5 insert operations per second. Each insert requires REDO log space of 72 bytes, plus 4 bytes per record * 40 columns, plus 32 bytes per column * 40 columns, which is 72 + 160 + 1280 = 1512 bytes per operation. This times 5 operations per second yields 7560 bytes per second.
So the total number of REDO log bytes being written per second
is approximately 0 + 360 + 1260 + 7560 = 9180 bytes. Mutiplied
by 1800 seconds, this yields 16524000 bytes required for REDO
logging, or approximately 15.75 MB. The unit used for
NoOfFragmentLogFiles represents a set of 4
16-MB log files — that is, 64 MB. Thus, the minimum value
(3) for this parameter is sufficient for the scenario envisioned
in this example, since 3 times 64 = 192 MB, or about 12 times
what is required; the default value of 8 (or 512 MB) is more
than ample in this case.
A copy of each altered table record is kept in the UNDO log. In the scenario discussed above, the UNDO log would not require any more space than what is provided by the default seetings. However, given the size of disks, it is sensible to allocate at least 1 GB for it.
This portion of the MySQL Cluster chapter covers upgrading and downgrading a MySQL Cluster from one MySQL release to another. It discusses different types of Cluster upgrades and downgrades, and provides a Cluster upgrade/downgrade compatibility matrix (see Section 15.5.2, “Cluster Upgrade and Downgrade Compatibility”). You are expected already to be familiar with installing and configuring a MySQL Cluster prior to attempting an upgrade or downgrade. See Section 15.4, “MySQL Cluster Configuration”.
This section remains in development, and continues to be updated and expanded.
This section discusses how to perform a rolling restart of a MySQL Cluster installation, so called because it involves stopping and starting (or restarting) each node in turn, so that the cluster itself remains operational. This is often done as part of a rolling upgrade or rolling downgrade, where high availability of the cluster is mandatory and no downtime of the cluster as a whole is permissible. Where we refer to upgrades, the information provided here also generally applies to downgrades as well.
There are a number of reasons why a rolling restart might be desirable:
Cluster Configuration Change: To make a change in the cluster's configuration, such as adding an SQL node to the cluster, or setting a configuration parameter to a new value.
Cluster Software Upgrade/Downgrade: To upgrade the cluster to a newer version of the MySQL Cluster software (or to downgrade it to an older version). This is usually referred to as a “rolling upgrade” (or “rolling downgrade”, when reverting to an older version of MySQL Cluster).
Change on Node Host: To make changes in the hardware or operating system on which one or more cluster nodes are running
Cluster Reset: To reset the cluster because it has reached an undesirable state
Freeing of Resources: To allow memory allocated to a table by successive
INSERTandDELETEoperations to be freed for re-use by other Cluster tables
The process for performing a rolling restart may be generalised as follows:
Stop all cluster management nodes (ndb_mgmd processes), reconfigure them, then restart them
Stop, reconfigure, then restart each cluster data node (ndbd process) in turn
Stop, reconfigure, then restart each cluster SQL node (mysqld process) in turn
The specifics for implementing a particular rolling upgrade depend upon the actual changes being made. A more detailed view of the process is presented here:
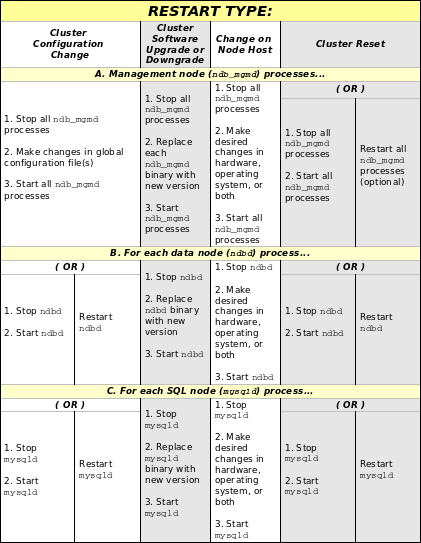
In the previous diagram, Stop
and Start steps indicate that
the process must be stopped completely using a shell command
(such as kill on most Unix systems) or the
management client STOP command, then started
again from a system shell by invoking the
ndbd or ndb_mgmd
executable as appropriate.
Restart indicates the process
may be restarted using the ndb_mgm management
client RESTART command.
Important
When performing an upgrade or downgrade of the cluster software, you must upgrade or downgrade the management nodes first, then the data nodes, and finally the SQL nodes. Doing so in any other order may leave the cluster in an unusable state.
This section provides information regarding Cluster software and table file compatibility between differing versions of the MySQL Server for purposes of performing upgrades and downgrades.
Important: Only compatibility
between MySQL versions with regard to NDB
Cluster is taken into account in this section, and
there are likely other issues to be considered. As
with any other MySQL software upgrade or downgrade, you are
strongly encouraged to review the relevant portions of the MySQL
Manual for the MySQL versions from which and to which you intend
to migrate, before attempting an upgrade or downgrade of the
MySQL Cluster software. See
Section 2.4.16, “Upgrading MySQL”.
The following table shows Cluster upgrade and downgrade compatibility between different versions of the MySQL Server.
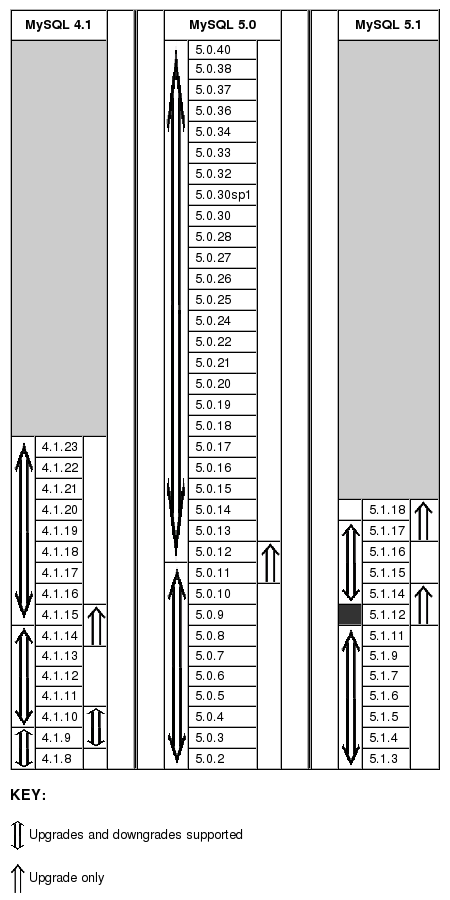
Notes:
4.1 Series:
You cannot upgrade directly from 4.1.8 to 4.1.10 (or newer); you must first upgrade from 4.1.8 to 4.1.9, then upgrade to 4.1.10. Similarly, you cannot downgrade directly from 4.1.10 (or newer) to 4.1.8; you must first downgrade from 4.1.10 to 4.1.9, then downgrade from 4.1.9 to 4.1.8.
If you wish to upgrade a MySQL Cluster to 4.1.15, you must upgrade to 4.1.14 first, and you must upgrade to 4.1.15 before upgrading to 4.1.16 or newer.
Cluster downgrades from 4.1.15 to 4.1.14 (or earlier versions) are not supported.
Cluster upgrades from MySQL Server versions previous to 4.1.8 are not supported; when upgrading from these, you must dump all
NDBtables, install the new version of the software, and then reload the tables from the dump.5.0 Series:
MySQL 5.0.2 was the first public release in this series.
Cluster downgrades from MySQL 5.0 to MySQL 4.1 are not supported.
Cluster downgrades from 5.0.12 to 5.0.11 (or earlier) are not supported.
You cannot restore with ndb_restore to a MySQL 5.0 Cluster using a backup made from a Cluster running MySQL 5.1. You must use mysqldump in such cases.
There was no public release for MySQL 5.0.23.
5.1 Series:
MySQL 5.1.3 was the first public release in this series.
You cannot downgrade a MySQL 5.1.6 or later Cluster using Disk Data tables to MySQL 5.1.5 or earlier unless you convert all such tables to in-memory Cluster tables first.
MySQL 5.1.8, MySQL 5.1.10, and MySQL 5.1.13 were not released.
Online cluster upgrades and downgrades between MySQL 5.1.11 (or an earlier version) and 5.1.12 (or a later version) are not possible due to major changes in the cluster filesystem. In such cases, you must perform a backup or dump, upgrade (or downgrade) the software, start each data node with
--initial, and then restore from the backup or dump. You can useNDBbackup/restore or mysqldump for this purpose.Online downgrades from MySQL 5.1.14 or later to versions previous to 5.1.14 are not supported due to incompatible changes in the cluster system tables.
Online upgrades from MySQL 5.1.17 and earlier to 5.1.18 and later are not supported for clusters using replication due to incompatible changes in the
mysql.ndb_apply_statustable. However, it should not be necessary to shut down the cluster entirely, if you follow this modified rolling restart procedure:Stop the management server, update the
ndb_mgmdbinary, then start it again. For multiple management servers, repeat this step for each management server in turn.For each data node in turn: Stop the data node, replace the
ndbdbinary with the new version, then restart the data node. It is not necessary to use--initialwhen restarting any of the data nodes.Stop all SQL nodes. Replace the mysqld binary with the new version for all SQL nodes, then restart them. It is not necessary to start them one at a time, but they must all be shut down at the same time before starting any of them again using the 5.1.18 (or later) mysqld. Otherwise — due to the fact that
mysql.ndb_apply_statususes theNDBstorage engine and is thus shared between all SQL nodes — there may be conflicts between MySQL servers using the old and new versions of the table.
You can find more information about the changes to
ndb_apply_statusin the MySQL 5.1 Manual.
Understanding how to manage MySQL Cluster requires a knowledge of four essential processes. In the next few sections of this chapter, we cover the roles played by these processes in a cluster, how to use them, and what startup options are available for each of them:
mysqld is the traditional MySQL server
process. To be used with MySQL Cluster,
mysqld needs to be built with support for the
NDB Cluster storage engine, as it is in the
precompiled binaries available from
http://dev.mysql.com/downloads/. If you build MySQL from
source, you must invoke configure with the
--with-ndbcluster option to enable NDB
Cluster storage engine support.
If the mysqld binary has been built with
Cluster support, the NDB Cluster storage
engine is still disabled by default. You can use either of two
possible options to enable this engine:
Use
--ndbclusteras a startup option on the command line when starting mysqld.Insert a line containing
ndbclusterin the[mysqld]section of yourmy.cnffile.
An easy way to verify that your server is running with the
NDB Cluster storage engine enabled is to
issue the SHOW ENGINES statement in the MySQL
Monitor (mysql). You should see the value
YES as the Support value
in the row for NDBCLUSTER. If you see
NO in this row or if there is no such row
displayed in the output, you are not running an
NDB-enabled version of MySQL. If you see
DISABLED in this row, you need to enable it
in either one of the two ways just described.
To read cluster configuration data, the MySQL server requires at a minimum three pieces of information:
The MySQL server's own cluster node ID
The hostname or IP address for the management server (MGM node)
The number of the TCP/IP port on which it can connect to the management server
Node IDs can be allocated dynamically, so it is not strictly necessary to specify them explicitly.
The mysqld parameter
ndb-connectstring is used to specify the
connectstring either on the command line when starting
mysqld or in my.cnf. The
connectstring contains the hostname or IP address where the
management server can be found, as well as the TCP/IP port it
uses.
In the following example, ndb_mgmd.mysql.com
is the host where the management server resides, and the
management server listens for cluster messages on port 1186:
shell> mysqld --ndbcluster --ndb-connectstring=ndb_mgmd.mysql.com:1186
See Section 15.4.4.2, “The Cluster Connectstring”, for more information on connectstrings.
Given this information, the MySQL server will be a full participant in the cluster. (We often refer to a mysqld process running in this manner as an SQL node.) It will be fully aware of all cluster data nodes as well as their status, and will establish connections to all data nodes. In this case, it is able to use any data node as a transaction coordinator and to read and update node data.
You can see in the mysql client whether a
MySQL server is connected to the cluster using SHOW
PROCESSLIST. If the MySQL server is connected to the
cluster, and you have the PROCESS privilege,
then the first row of the output is as shown here:
mysql> SHOW PROCESSLIST \G
*************************** 1. row ***************************
Id: 1
User: system user
Host:
db:
Command: Daemon
Time: 1
State: Waiting for event from ndbcluster
Info: NULL
Important
To participate in a MySQL Cluster, the
mysqld process must be started with
both the options
--ndbcluster and
--ndb-connectstring (or their equivalents in
my.cnf). If mysqld is
started with only the --ndbcluster option, or
if it is unable to contact the cluster, it is not possible to
work with NDB tables, nor is it
possible to create any new tables regardless of storage
engine. The latter restriction is a safety measure
intended to prevent the creation of tables having the same
names as NDB tables while the SQL node is
not connected to the cluster. If you wish to create tables
using a different storage engine while the
mysqld process is not participating in a
MySQL Cluster, you must restart the server
without the --ndbcluster
option.
ndbd is the process that is used to handle all the data in tables using the NDB Cluster storage engine. This is the process that empowers a data node to accomplish distributed transaction handling, node recovery, checkpointing to disk, online backup, and related tasks.
In a MySQL Cluster, a set of ndbd processes cooperate in handling data. These processes can execute on the same computer (host) or on different computers. The correspondences between data nodes and Cluster hosts is completely configurable.
ndbd generates a set of log files which
are placed in the directory specified by
DataDir in the
config.ini configuration file. These
log files are listed below. Note that
node_id represents the node's
unique identifier. For example,
ndb_2_error.log is the error log
generated by the data node whose node ID is
2.
ndb_is a file containing records of all crashes which the referenced ndbd process has encountered. Each record in this file contains a brief error string and a reference to a trace file for this crash. A typical entry in this file might appear as shown here:node_id_error.logDate/Time: Saturday 30 July 2004 - 00:20:01 Type of error: error Message: Internal program error (failed ndbrequire) Fault ID: 2341 Problem data: DbtupFixAlloc.cpp Object of reference: DBTUP (Line: 173) ProgramName: NDB Kernel ProcessID: 14909 TraceFile: ndb_2_trace.log.2 ***EOM***
Listings of possible ndbd exit codes and messages generated when a data node process shuts down prematurely can be found in
ndbdError Messages.Note: It is very important to be aware that the last entry in the error log file is not necessarily the newest one (nor is it likely to be). Entries in the error log are not listed in chronological order; rather, they correspond to the order of the trace files as determined in the
ndb_file (see below). Error log entries are thus overwritten in a cyclical and not sequential fashion.node_id_trace.log.nextndb_is a trace file describing exactly what happened just before the error occurred. This information is useful for analysis by the MySQL Cluster development team.node_id_trace.log.trace_idIt is possible to configure the number of these trace files that will be created before old files are overwritten.
trace_idis a number which is incremented for each successive trace file.ndb_is the file that keeps track of the next trace file number to be assigned.node_id_trace.log.nextndb_is a file containing any data output by the ndbd process. This file is created only if ndbd is started as a daemon, which is the default behavior.node_id_out.logndb_is a file containing the process ID of the ndbd process when started as a daemon. It also functions as a lock file to avoid the starting of nodes with the same identifier.node_id.pidndb_is a file used only in debug versions of ndbd, where it is possible to trace all incoming, outgoing, and internal messages with their data in the ndbd process.node_id_signal.log
It is recommended not to use a directory mounted through NFS
because in some environments this can cause problems whereby
the lock on the .pid file remains in
effect even after the process has terminated.
To start ndbd, it may also be necessary to specify the hostname of the management server and the port on which it is listening. Optionally, one may also specify the node ID that the process is to use.
shell> ndbd --connect-string="nodeid=2;host=ndb_mgmd.mysql.com:1186"
See Section 15.4.4.2, “The Cluster Connectstring”, for additional information about this issue. Section 15.6.5, “Command Options for MySQL Cluster Processes”, describes other options for ndbd.
When ndbd starts, it actually initiates two processes. The first of these is called the “angel process”; its only job is to discover when the execution process has been completed, and then to restart the ndbd process if it is configured to do so. Thus, if you attempt to kill ndbd via the Unix kill command, it is necessary to kill both processes, beginning with the angel process. The preferred method of terminating an ndbd process is to use the management client and stop the process from there.
The execution process uses one thread for reading, writing, and scanning data, as well as all other activities. This thread is implemented asynchronously so that it can easily handle thousands of concurrent activites. In addition, a watch-dog thread supervises the execution thread to make sure that it does not hang in an endless loop. A pool of threads handles file I/O, with each thread able to handle one open file. Threads can also be used for transporter connections by the transporters in the ndbd process. In a multi-processor system performing a large number of operations (including updates), the ndbd process can consume up to 2 CPUs if permitted to do so.
For a machine with many CPUs it is possible to use several ndbd processes which belong to different node groups; however, such a configuration is still considered experimental and is not supported for MySQL 5.0 in a production setting. See Section 15.11, “Known Limitations of MySQL Cluster”.
The management server is the process that reads the cluster configuration file and distributes this information to all nodes in the cluster that request it. It also maintains a log of cluster activities. Management clients can connect to the management server and check the cluster's status.
It is not strictly necessary to specify a connectstring when starting the management server. However, if you are using more than one management server, a connectstring should be provided and each node in the cluster should specify its node ID explicitly.
See Section 15.4.4.2, “The Cluster Connectstring”, for information about using connectstrings. Section 15.6.5, “Command Options for MySQL Cluster Processes”, describes other options for ndb_mgmd.
The following files are created or used by
ndb_mgmd in its starting directory, and
are placed in the DataDir as specified in
the config.ini configuration file. In
the list that follows, node_id is
the unique node identifier.
config.iniis the configuration file for the cluster as a whole. This file is created by the user and read by the management server. Section 15.4, “MySQL Cluster Configuration”, discusses how to set up this file.ndb_is the cluster events log file. Examples of such events include checkpoint startup and completion, node startup events, node failures, and levels of memory usage. A complete listing of cluster events with descriptions may be found in Section 15.7, “Management of MySQL Cluster”.node_id_cluster.logWhen the size of the cluster log reaches one million bytes, the file is renamed to
ndb_, wherenode_id_cluster.log.seq_idseq_idis the sequence number of the cluster log file. (For example: If files with the sequence numbers 1, 2, and 3 already exist, the next log file is named using the number4.)ndb_is the file used fornode_id_out.logstdoutandstderrwhen running the management server as a daemon.ndb_is the process ID file used when running the management server as a daemon.node_id.pid
The ndb_mgm management client process is actually not needed to run the cluster. Its value lies in providing a set of commands for checking the cluster's status, starting backups, and performing other administrative functions. The management client accesses the management server using a C API. Advanced users can also employ this API for programming dedicated management processes to perform tasks similar to those performed by ndb_mgm.
To start the management client, it is necessary to supply the hostname and port number of the management server:
shell> ndb_mgm [host_name [port_num]]
For example:
shell> ndb_mgm ndb_mgmd.mysql.com 1186
The default hostname and port number are
localhost and 1186, respectively.
Additional information about using ndb_mgm can be found in Section 15.6.5.4, “Command Options for ndb_mgm”, and Section 15.7.2, “Commands in the MySQL Cluster Management Client”.
All MySQL Cluster executables (except for
mysqld) take the options described in this
section. Users of earlier MySQL Cluster versions should note
that some of these options have been changed from those in MySQL
4.1 Cluster to make them consistent with one another as well as
with mysqld. You can use the
--help option with any MySQL Cluster executable
to view a list of the options which it supports.
The following options are common to all MySQL Cluster executables:
--help--usage,-?Prints a short list with descriptions of the available command options.
--connect-string=,connect_string-cconnect_stringconnect_stringsets the connectstring to the management server as a command option.shell>
ndbd --connect-string="nodeid=2;host=ndb_mgmd.mysql.com:1186"--debug[=options]This option can be used only for versions compiled with debugging enabled. It is used to enable output from debug calls in the same manner as for the mysqld process.
--execute=,command-ecommandCan be used to send a command to a Cluster executable from the system shell. For example, either of the following:
shell>
ndb_mgm -e "SHOW"or
shell>
ndb_mgm --execute="SHOW"is equivalent to
ndb_mgm>
SHOWThis is analogous to how the
--executeor-eoption works with the mysql command-line client. See Section 4.3.1, “Using Options on the Command Line”.--version,-VPrints the MySQL Cluster version number of the executable. The version number is relevant because not all versions can be used together, and the MySQL Cluster startup process verifies that the versions of the binaries being used can co-exist in the same cluster. This is also important when performing an online (rolling) software upgrade or downgrade of MySQL Cluster. (See Section 15.5.1, “Performing a Rolling Restart of the Cluster”).
The next few sections describe options specific to individual
NDB programs.
--ndb-connectstring=connect_stringWhen using the
NDB Clusterstorage engine, this option specifies the management server that distributes cluster configuration data.--ndbclusterThe
NDB Clusterstorage engine is necessary for using MySQL Cluster. If a mysqld binary includes support for theNDB Clusterstorage engine, the engine is disabled by default. Use the--ndbclusteroption to enable it. Use--skip-ndbclusterto explicitly disable the engine.
For options common to all NDB programs, see
Section 15.6.5, “Command Options for MySQL Cluster Processes”.
--bind-addressCauses ndbd to bind to a specific network interface. This option has no default value.
This option was added in MySQL 5.0.29.
--daemon,-dInstructs ndbd to execute as a daemon process. This is the default behavior.
--nodaemoncan be used to prevent the process from running as a daemon.--initialInstructs ndbd to perform an initial start. An initial start erases any files created for recovery purposes by earlier instances of ndbd. It also re-creates recovery log files. Note that on some operating systems this process can take a substantial amount of time.
An
--initialstart is to be used only the very first time that the ndbd process is started because it removes all files from the Cluster filesystem and re-creates all REDO log files. The exceptions to this rule are:When performing a software upgrade which has changed the contents of any files.
When restarting the node with a new version of ndbd.
As a measure of last resort when for some reason the node restart or system restart repeatedly fails. In this case, be aware that this node can no longer be used to restore data due to the destruction of the data files.
This option does not affect any backup files that have already been created by the affected node.
It is possible to achieve the same effect by deleting by other means (such as using rm -r -f) all files and directories in the data node's
DataDir— with the possible exception of theBACKUPdirectory inDataDir, should you wish to retain any backups that have been created on that data node — and then starting ndbd without having to use the--initialoption. This may be useful when scripting Cluster administrative tasks.--initial-startThis option is used when performing a partial initial start of the cluster. Each node should be started with this option, as well as
--no-wait-nodes.For example, suppose you have a 4-node cluster whose data nodes have the IDs 2, 3, 4, and 5, and you wish to perform a partial initial start using only nodes 2, 4, and 5 — that is, omitting node 3:
ndbd --ndbd-nodeid=2 --no-wait-nodes=3 --initial-start ndbd --ndbd-nodeid=4 --no-wait-nodes=3 --initial-start ndbd --ndbd-nodeid=5 --no-wait-nodes=3 --initial-start
This option was added in MySQL 5.0.21.
--nowait-nodes=node_id_1[,node_id_2[, ...]]This option takes a list of data nodes which for which the cluster will not wait for before starting.
This can be used to start the cluster in a partitioned state. For example, to start the cluster with only half of the data nodes (nodes 2, 3, 4, and 5) running in a 4-node cluster, you can start each ndbd process with
--nowait-nodes=3,5. In this case, the cluster starts as soon as nodes 2 and 4 connect, and does not waitStartPartitionedTimeoutmilliseconds for nodes 3 and 5 to connect as it would otherwise.If you wanted to start up the same cluster as in the previous example without one ndbd — say, for example, that the host machine for node 3 has suffered a hardware failure — then start nodes 2, 4, and 5 with
--no-wait-nodes=3. Then the cluster will start as soon as nodes 2, 4, and 5 connect and will not wait for node 3 to start.This option was added in MySQL 5.0.21.
--nodaemonInstructs ndbd not to start as a daemon process. This is useful when ndbd is being debugged and you want output to be redirected to the screen.
--nostart,-nInstructs ndbd not to start automatically. When this option is used, ndbd connects to the management server, obtains configuration data from it, and initializes communication objects. However, it does not actually start the execution engine until specifically requested to do so by the management server. This can be accomplished by issuing the proper
STARTcommand in the management client (see Section 15.7.2, “Commands in the MySQL Cluster Management Client”).
For options common to NDB programs, see Section 15.6.5, “Command Options for MySQL Cluster Processes”.
--config-file=,filename-ffilenameInstructs the management server as to which file it should use for its configuration file. This option must be specified. The filename defaults to
config.ini.Note: This option also can be given as
-c, but this shortcut is obsolete and should not be used in new installations.file_name--daemon,-dInstructs ndb_mgmd to start as a daemon process. This is the default behavior.
--nodaemonInstructs ndb_mgmd not to start as a daemon process.
For options common to NDB programs, see Section 15.6.5, “Command Options for MySQL Cluster Processes”.
--try-reconnect=numberIf the connection to the management server is broken, the node tries to reconnect to it every 5 seconds until it succeeds. By using this option, it is possible to limit the number of attempts to
numberbefore giving up and reporting an error instead.
Managing a MySQL Cluster involves a number of tasks, the first of which is to configure and start MySQL Cluster. This is covered in Section 15.4, “MySQL Cluster Configuration”, and Section 15.6, “Process Management in MySQL Cluster”.
The following sections cover the management of a running MySQL Cluster.
There are essentially two methods of actively managing a running
MySQL Cluster. The first of these is through the use of commands
entered into the management client whereby cluster status can be
checked, log levels changed, backups started and stopped, and
nodes stopped and started. The second method involves studying the
contents of the cluster log
ndb_;
this is usually found in the management server's
node_id_cluster.logDataDir directory, but this location can be
overridden using the LogDestination option
— see Section 15.4.4.4, “Defining the Management Server”, for
details. (Recall that node_id
represents the unique identifier of the node whose activity is
being logged.) The cluster log contains event reports generated by
ndbd. It is also possible to send cluster log
entries to a Unix system log.
In addition, some aspects of the cluster's operation can be
monitored from an SQL node using the SHOW ENGINE NDB
STATUS statement. See Section 13.5.4.9, “SHOW ENGINE Syntax”, for
more information.
This section describes the steps involved when the cluster is started.
There are several different startup types and modes, as shown here:
Initial Start: The cluster starts with a clean filesystem on all data nodes. This occurs either when the cluster started for the very first time, or when it is restarted using the
--initialoption.System Restart: The cluster starts and reads data stored in the data nodes. This occurs when the cluster has been shut down after having been in use, when it is desired for the cluster to resume operations from the point where it left off.
Node Restart: This is the online restart of a cluster node while the cluster itself is running.
Initial Node Restart: This is the same as a node restart, except that the node is reinitialized and started with a clean filesystem.
Prior to startup, each data node (ndbd
process) must be initialized. Initialization consists of the
following steps:
Obtain a Node ID.
Fetch configuration data.
Allocate ports to be used for inter-node communications.
Allocate memory according to settings obtained from the configuration file.
When a data node or SQL node first connects to the management node, it reserves a cluster node ID. To make sure that no other node allocates the same node ID, this ID is retained until the node has managed to connect to the cluster and at least one ndbd reports that this node is connected. This retention of the node ID is guarded by the connection between the node in question and ndb_mgmd.
Normally, in the event of a problem with the node, the node disconnects from the management server, the socket used for the connection is closed, and the reserved node ID is freed. However, if a node is disconnected abruptly — for example, due to a hardware failure in one of the cluster hosts, or because of network issues — the normal closing of the socket by the operating system may not take place. In this case, the node ID continues to be reserved and not released until a TCP timeout occurs 10 or so minutes later.
To take care of this problem, you can use PURGE STALE
SESSIONS. Running this statement forces all reserved
node IDs to be checked; any that are not being used by nodes
actually connected to the cluster are then freed.
Beginning with MySQL 5.0.22, timeout handling of node ID
assignments is implemented. This performs the ID usage checks
automatically after approximately 20 seconds, so that
PURGE STALE SESSIONS should no longer be
necessary in a normal Cluster start.
After each data node has been initialized, the cluster startup process can proceed. The stages which the cluster goes through during this process are listed here:
Stage 0
Clear the cluster filesystem. This stage occurs only if the cluster was started with the
--initialoption.Stage 1
This stage sets up Cluster connections, establishes inter-node communications, and starts Cluster heartbeats.
Note: When one or more nodes hang in Phase 1 while the remaining node or nodes hang in Phase 2, this often indicates network problems. One possible cause of such issues is one or more cluster hosts having multiple network interfaces. Another common source of problems causing this condition is the blocking of TCP/IP ports needed for communications between cluster nodes. In the latter case, this is often due to a misconfigured firewall.
Stage 2
The arbitrator node is elected. If this is a system restart, the cluster determines the latest restorable global checkpoint.
Stage 3
This stage initializes a number of internal cluster variables.
Stage 4
For an initial start or initial node restart, the redo log files are created. The number of these files is equal to
NoOfFragmentLogFiles.For a system restart:
Read schema or schemas.
Read data from the local checkpoint and undo logs.
Apply all redo information until the latest restorable global checkpoint has been reached.
For a node restart, find the tail of the redo log.
Stage 5
If this is an initial start, create the
SYSTAB_0andNDB$EVENTSinternal system tables.For a node restart or an initial node restart:
The node is included in transaction handling operations.
The node schema is compared with that of the master and synchronized with it.
Synchronize data received in the form of
INSERTfrom the other data nodes in this node's node group.In all cases, wait for complete local checkpoint as determined by the arbitrator.
Stage 6
Update internal variables.
Stage 7
Update internal variables.
Stage 8
In a system restart, rebuild all indexes.
Stage 9
Update internal variables.
Stage 100
At this point in a node restart or initial node restart, APIs may connect to the node and begin to receive events.
Stage 101
At this point in a node restart or initial node restart, event delivery is handed over to the node joining the cluster. The newly-joined node takes over responsibility for delivering its primary data to subscribers.
After this process is completed for an initial start or system restart, transaction handling is enabled. For a node restart or initial node restart, completion of the startup process means that the node may now act as a transaction coordinator.
In addition to the central configuration file, a cluster may also be controlled through a command-line interface available through the management client ndb_mgm. This is the primary administrative interface to a running cluster.
Commands for the event logs are given in Section 15.7.3, “Event Reports Generated in MySQL Cluster”; commands for creating backups and restoring from backup are provided in Section 15.8, “On-line Backup of MySQL Cluster”.
The management client has the following basic commands. In the
listing that follows, node_id denotes
either a database node ID or the keyword ALL,
which indicates that the command should be applied to all of the
cluster's data nodes.
HELPDisplays information on all available commands.
SHOWDisplays information on the cluster's status.
Note: In a cluster where multiple management nodes are in use, this command displays information only for data nodes that are actually connected to the current management server.
node_idSTARTBrings online the data node identified by
node_id(or all data nodes).Beginning with MySQL 5.0.19, this command can also be used to individual management nodes online. Note:
ALL STARTcontinues to affect data nodes only.Important: To use this command to bring a data node online, the data node must have been started using ndbd --nostart or ndbd -n.
node_idSTOPStops the data node identified by
node_id(or all data nodes).Beginning with MySQL 5.0.19, this command can also be used to stop individual management nodes. Note:
ALL STOPcontinues to affect data nodes only.A node affected by this command disconnects from the cluster, and its associated ndbd or ndb_mgmd process terminates.
node_idRESTART [-n] [-i]Restarts the data node identified by
node_id(or all data nodes).Using the
-ioption withRESTARTcauses the data node to perform an initial restart; that is, the node's filesystem is deleted and recreated. The effect is the same as that obtained from stopping the data node process and then starting it again using ndbd --initial from the system shell.Using the
-noption causes the data node process to be restarted, but the data node is not actually brought online until the appropriateSTARTcommand is issued. The effect of this option is the same as that obtained from stopping the data node and then starting it again usingndbd --nostartorndbd -nfrom the system shell.node_idSTATUSDisplays status information for the data node identified by
node_id(or for all data nodes).ENTER SINGLE USER MODEnode_idEnters single user mode, whereby only the MySQL server identified by the node ID
node_idis allowed to access the database.Important: Do not attempt to have data nodes join the cluster while it is running in single user mode. Doing so can cause subsequent multiple node failures. Beginning with MySQL 5.1.12, it is no longer possible to add nodes while in single user mode. (See Bug#20395 for more information.)
EXIT SINGLE USER MODEExits single user mode, allowing all SQL nodes (that is, all running mysqld processes) to access the database.
QUIT,EXITTerminates the management client.
This command does not affect any nodes connected to the cluster.
SHUTDOWNShuts down all cluster data nodes and management nodes. To exit the management client after this has been done, use
EXITorQUIT.This command does not shut down any SQL nodes or API nodes that are connected to the cluster.
In this section, we discuss the types of event logs provided by MySQL Cluster, and the types of events that are logged.
MySQL Cluster provides two types of event log:
The cluster log, which includes events generated by all cluster nodes. The cluster log is the log recommended for most uses because it provides logging information for an entire cluster in a single location.
By default, the cluster log is saved to a file named
ndb_, (wherenode_id_cluster.lognode_idis the node ID of the management server) in the same directory where the ndb_mgm binary resides.Cluster logging information can also be sent to
stdoutor asyslogfacility in addition to or instead of being saved to a file, as determined by the values set for theDataDirandLogDestinationconfiguration parameters. See Section 15.4.4.4, “Defining the Management Server”, for more information about these parameters.Node logs are local to each node.
Output generated by node event logging is written to the file
ndb_(wherenode_id_out.lognode_idis the node's node ID) in the node'sDataDir. Node event logs are generated for both management nodes and data nodes.Node logs are intended to be used only during application development, or for debugging application code.
Both types of event logs can be set to log different subsets of events.
Each reportable event can be distinguished according to three different criteria:
Category: This can be any one of the following values:
STARTUP,SHUTDOWN,STATISTICS,CHECKPOINT,NODERESTART,CONNECTION,ERROR, orINFO.Priority: This is represented by one of the numbers from 1 to 15 inclusive, where 1 indicates “most important” and 15 “least important.”
Severity Level: This can be any one of the following values:
ALERT,CRITICAL,ERROR,WARNING,INFO, orDEBUG.
Both the cluster log and the node log can be filtered on these properties.
The format used in the cluster log is as shown here:
2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 1: Data usage is 2%(60 32K pages of total 2560) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 1: Index usage is 1%(24 8K pages of total 2336) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 1: Resource 0 min: 0 max: 639 curr: 0 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 2: Data usage is 2%(76 32K pages of total 2560) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 2: Index usage is 1%(24 8K pages of total 2336) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 2: Resource 0 min: 0 max: 639 curr: 0 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 3: Data usage is 2%(58 32K pages of total 2560) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 3: Index usage is 1%(25 8K pages of total 2336) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 3: Resource 0 min: 0 max: 639 curr: 0 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 4: Data usage is 2%(74 32K pages of total 2560) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 4: Index usage is 1%(25 8K pages of total 2336) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 4: Resource 0 min: 0 max: 639 curr: 0 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 4: Node 9 Connected 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 1: Node 9 Connected 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 1: Node 9: API version 5.1.15 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 2: Node 9 Connected 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 2: Node 9: API version 5.1.15 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 3: Node 9 Connected 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 3: Node 9: API version 5.1.15 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 4: Node 9: API version 5.1.15 2007-01-26 19:59:22 [MgmSrvr] ALERT -- Node 2: Node 7 Disconnected 2007-01-26 19:59:22 [MgmSrvr] ALERT -- Node 2: Node 7 Disconnected
Each line in the cluster log contains the following information:
A timestamp in
YYYY-MM-DDHH:MM:SSThe type of node which is performing the logging. In the cluster log, this is always
[MgmSrvr].The severity of the event.
The ID of the node reporting the event.
A description of the event. The most common types of events to appear in the log are connections and disconnections between different nodes in the cluster, and when checkpoints occur. In some cases, the description may contain status information.
The following management commands are related to the cluster log:
CLUSTERLOG ONTurns the cluster log on.
CLUSTERLOG OFFTurns the cluster log off.
CLUSTERLOG INFOProvides information about cluster log settings.
node_idCLUSTERLOGcategory=thresholdLogs
categoryevents with priority less than or equal tothresholdin the cluster log.CLUSTERLOG FILTERseverity_levelToggles cluster logging of events of the specified
severity_level.
The following table describes the default setting (for all data nodes) of the cluster log category threshold. If an event has a priority with a value lower than or equal to the priority threshold, it is reported in the cluster log.
Note that events are reported per data node, and that the threshold can be set to different values on different nodes.
| Category | Default threshold (All data nodes) |
STARTUP | 7 |
SHUTDOWN | 7 |
STATISTICS | 7 |
CHECKPOINT | 7 |
NODERESTART | 7 |
CONNECTION | 7 |
ERROR | 15 |
INFO | 7 |
The STATISTICS category can provide a great
deal of useful data. See
Section 15.7.3.3, “Using CLUSTERLOG STATISTICS”, for more
information.
Thresholds are used to filter events within each category. For
example, a STARTUP event with a priority of
3 is not logged unless the threshold for
STARTUP is changed to 3 or lower. Only
events with priority 3 or lower are sent if the threshold is
3.
The following table shows the event severity levels.
(Note: These correspond to
Unix syslog levels, except for
LOG_EMERG and
LOG_NOTICE, which are not used or mapped.)
| 1 | ALERT | A condition that should be corrected immediately, such as a corrupted system database |
| 2 | CRITICAL | Critical conditions, such as device errors or insufficient resources |
| 3 | ERROR | Conditions that should be corrected, such as configuration errors |
| 4 | WARNING | Conditions that are not errors, but that might require special handling |
| 5 | INFO | Informational messages |
| 6 | DEBUG | Debugging messages used for NDB Cluster development |
Event severity levels can be turned on or off (using
CLUSTERLOG FILTER — see above). If a
severity level is turned on, then all events with a priority
less than or equal to the category thresholds are logged. If
the severity level is turned off then no events belonging to
that severity level are logged.
An event report reported in the event logs has the following format:
datetime[string]severity--message
For example:
09:19:30 2005-07-24 [NDB] INFO -- Node 4 Start phase 4 completed
This section discusses all reportable events, ordered by category and severity level within each category.
In the event descriptions, GCP and LCP mean “Global Checkpoint” and “Local Checkpoint,” respectively.
CONNECTION
Events
These events are associated with connections between Cluster nodes.
| Event | Priority | Severity Level | Description |
| data nodes connected | 8 | INFO | Data nodes connected |
| data nodes disconnected | 8 | INFO | Data nodes disconnected |
| Communication closed | 8 | INFO | SQL node or data node connection closed |
| Communication opened | 8 | INFO | SQL node or data node connection opened |
CHECKPOINT
Events
The logging messages shown here are associated with checkpoints.
| Event | Priority | Severity Level | Description |
| LCP stopped in calc keep GCI | 0 | ALERT | LCP stopped |
| Local checkpoint fragment completed | 11 | INFO | LCP on a fragment has been completed |
| Global checkpoint completed | 10 | INFO | GCP finished |
| Global checkpoint started | 9 | INFO | Start of GCP: REDO log is written to disk |
| Local checkpoint completed | 8 | INFO | LCP completed normally |
| Local checkpoint started | 7 | INFO | Start of LCP: data written to disk |
| Report undo log blocked | 7 | INFO | UNDO logging blocked; buffer near overflow |
STARTUP
Events
The following events are generated in response to the startup of a node or of the cluster and of its success or failure. They also provide information relating to the progress of the startup process, including information concerning logging activities.
| Event | Priority | Severity Level | Description |
| Internal start signal received STTORRY | 15 | INFO | Blocks received after completion of restart |
| Undo records executed | 15 | INFO | |
| New REDO log started | 10 | INFO | GCI keep X, newest restorable GCI
Y |
| New log started | 10 | INFO | Log part X, start MB
Y, stop MB
Z |
| Node has been refused for inclusion in the cluster | 8 | INFO | Node cannot be included in cluster due to misconfiguration, inability to establish communication, or other problem |
| data node neighbors | 8 | INFO | Shows neighboring data nodes |
data node start phase X completed | 4 | INFO | A data node start phase has been completed |
| Node has been successfully included into the cluster | 3 | INFO | Displays the node, managing node, and dynamic ID |
| data node start phases initiated | 1 | INFO | NDB Cluster nodes starting |
| data node all start phases completed | 1 | INFO | NDB Cluster nodes started |
| data node shutdown initiated | 1 | INFO | Shutdown of data node has commenced |
| data node shutdown aborted | 1 | INFO | Unable to shut down data node normally |
NODERESTART
Events
The following events are generated when restarting a node and relate to the success or failure of the node restart process.
| Event | Priority | Severity Level | Description |
| Node failure phase completed | 8 | ALERT | Reports completion of node failure phases |
Node has failed, node state was X | 8 | ALERT | Reports that a node has failed |
| Report arbitrator results | 2 | ALERT | There are eight different possible results for arbitration attempts:
|
| Completed copying a fragment | 10 | INFO | |
| Completed copying of dictionary information | 8 | INFO | |
| Completed copying distribution information | 8 | INFO | |
| Starting to copy fragments | 8 | INFO | |
| Completed copying all fragments | 8 | INFO | |
| GCP takeover started | 7 | INFO | |
| GCP takeover completed | 7 | INFO | |
| LCP takeover started | 7 | INFO | |
LCP takeover completed (state = X) | 7 | INFO | |
| Report whether an arbitrator is found or not | 6 | INFO | There are seven different possible outcomes when seeking an arbitrator:
|
STATISTICS
Events
The following events are of a statistical nature. They provide information such as numbers of transactions and other operations, amount of data sent or received by individual nodes, and memory usage.
| Event | Priority | Severity Level | Description |
| Report job scheduling statistics | 9 | INFO | Mean internal job scheduling statistics |
| Sent number of bytes | 9 | INFO | Mean number of bytes sent to node X |
| Received # of bytes | 9 | INFO | Mean number of bytes received from node X |
| Report transaction statistics | 8 | INFO | Numbers of: transactions, commits, reads, simple reads, writes, concurrent operations, attribute information, and aborts |
| Report operations | 8 | INFO | Number of operations |
| Report table create | 7 | INFO | |
| Memory usage | 5 | INFO | Data and index memory usage (80%, 90%, and 100%) |
ERROR
Events
These events relate to Cluster errors and warnings. The presence of one or more of these generally indicates that a major malfunction or failure has occurred.
| Event | Priority | Severity | Description |
| Dead due to missed heartbeat | 8 | ALERT | Node X declared “dead” due to
missed heartbeat |
| Transporter errors | 2 | ERROR | |
| Transporter warnings | 8 | WARNING | |
| Missed heartbeats | 8 | WARNING | Node X missed heartbeat
#Y |
| General warning events | 2 | WARNING |
INFO
Events
These events provide general information about the state of the cluster and activities associated with Cluster maintenance, such as logging and heartbeat transmission.
| Event | Priority | Severity | Description |
| Sent heartbeat | 12 | INFO | Heartbeat sent to node X |
| Create log bytes | 11 | INFO | Log part, log file, MB |
| General information events | 2 | INFO |
The NDB management client's
CLUSTERLOG STATISTICS command can provide a
number of useful statistics in its output. The following
statistics are reported by the transaction coordinator:
| Statistic | Description (Number of...) |
Trans. Count | Transactions attempted with this node as coordinator |
Commit Count | Transactions committed with this node as coordinator |
Read Count | Primary key reads (all) |
Simple Read Count | Primary key reads reading the latest committed value |
Write Count | Primary key writes (includes all INSERT,
UPDATE, and
DELETE operations) |
AttrInfoCount | Data words used to describe all reads and writes received |
Concurrent Operations | All concurrent operations ongoing at the moment the report is taken |
Abort Count | Transactions with this node as coordinator that were aborted |
Scans | Scans (all) |
Range Scans | Index scans |
The ndbd process has a scheduler that runs in an infinite loop. During each loop scheduler performs the following tasks:
Read any incoming messages from sockets into a job buffer.
Check whether there are any timed messages to be executed; if so, put these into the job buffer as well.
Execute (in a loop) any messages in the job buffer.
Send any distributed messages that were generated by executing the messages in the job buffer.
Wait for any new incoming messages.
The number of loops executed in the third step is reported as
the Mean Loop Counter. This statistic
increases in size as the utilisation of the TCP/IP buffer
improves. You can use this to monitor performance as you add
new processes to the cluster.
The Mean send size and Mean
receive size statistics allow you to gauge the
efficiency of writes and reads (respectively) between nodes.
These values are given in bytes. Higher values mean a lower
cost per byte sent or received; the maximum is 64k.
To cause all cluster log statistics to be logged, you can use
the following command in the NDB management
client:
ndb_mgm> ALL CLUSTERLOG STATISTICS=15
Note: Setting the threshold
for STATISTICS to 15 causes the cluster log
to become very verbose, and to gow quite rapidly in size, in
direct proportion to the number of cluster nodes and the
amount of activity on the cluster.
Single user mode allows the database administrator to restrict access to the database system to a single API node, such as a MySQL server (SQL node) or an instance of ndb_restore. When entering single user mode, connections to all other API nodes are closed gracefully and all running transactions are aborted. No new transactions are permitted to start.
Once the cluster has entered single user mode, only the designated API node is granted access to the database.
You can use the ALL STATUS command to see when the cluster has entered single user mode.
Example:
ndb_mgm> ENTER SINGLE USER MODE 5
After this command has executed and the cluster has entered
single user mode, the API node whose node ID is
5 becomes the cluster's only permitted user.
The node specified in the preceding command must be an API node; attempting to specify any other type of node will be rejected.
Note: When the preceding commmand is invoked, all transactions running on the designated node are aborted, the connection is closed, and the server must be restarted.
The command EXIT SINGLE USER MODE changes the state of the cluster's data nodes from single user mode to normal mode. API nodes — such as MySQL Servers — waiting for a connection (that is, waiting for the cluster to become ready and available), are again permitted to connect. The API node denoted as the single-user node continues to run (if still connected) during and after the state change.
Example:
ndb_mgm> EXIT SINGLE USER MODE
There are two recommended ways to handle a node failure when running in single user mode:
Method 1:
Finish all single user mode transactions
Issue the EXIT SINGLE USER MODE command
Restart the cluster's data nodes
Method 2:
Restart database nodes prior to entering single user mode.
This section discusses several SQL statements that can prove useful in managing and monitoring a MySQL server that is connected to a MySQL Cluster, and in some cases provide information about the cluster itself.
SHOW ENGINE NDB STATUS,SHOW ENGINE NDBCLUSTER STATUSThe output of this statement contains information about the server's connection to the cluster, creation and usage of MySQL Cluster objects, and binary logging for MySQL Cluster replication.
See Section 13.5.4.9, “
SHOW ENGINESyntax”, for a usage example and more detailed information.SHOW ENGINES [LIKE 'NDB%']This statement can be used to determine whether or not clustering support is enabled in the MySQL server, and if so, whether it is active.
See Section 13.5.4.10, “
SHOW ENGINESSyntax”, for more detailed information.SHOW VARIABLES LIKE 'NDB%'This statement provides a list of most server system variables relating to the
NDBstorage engine, and their values, as shown here:mysql>
SHOW VARIABLES LIKE 'NDB%';+-------------------------------------+-------+ | Variable_name | Value | +-------------------------------------+-------+ | ndb_autoincrement_prefetch_sz | 32 | | ndb_cache_check_time | 0 | | ndb_extra_logging | 0 | | ndb_force_send | ON | | ndb_index_stat_cache_entries | 32 | | ndb_index_stat_enable | OFF | | ndb_index_stat_update_freq | 20 | | ndb_report_thresh_binlog_epoch_slip | 3 | | ndb_report_thresh_binlog_mem_usage | 10 | | ndb_use_copying_alter_table | OFF | | ndb_use_exact_count | ON | | ndb_use_transactions | ON | +-------------------------------------+-------+See Section 5.2.3, “System Variables”, for more information.
SHOW STATUS LIKE 'NDB%'This statement shows at a glance whether or not the MySQL server is acting as a cluster SQL node, and if so, it provides the MySQL server's cluster node ID, the hostname and port for the cluster management server to which it is connected, and the number of data nodes in the cluster, as shown here:
mysql>
SHOW STATUS LIKE 'NDB%';+--------------------------+---------------+ | Variable_name | Value | +--------------------------+---------------+ | Ndb_cluster_node_id | 10 | | Ndb_config_from_host | 192.168.0.103 | | Ndb_config_from_port | 1186 | | Ndb_number_of_data_nodes | 4 | +--------------------------+---------------+If the MySQL server was built with clustering support, but it is not connected to a cluster, all rows in the output of this statement contain a zero or an empty string:
mysql>
SHOW STATUS LIKE 'NDB%';+--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | Ndb_cluster_node_id | 0 | | Ndb_config_from_host | | | Ndb_config_from_port | 0 | | Ndb_number_of_data_nodes | 0 | +--------------------------+-------+See also Section 13.5.4.23, “
SHOW STATUSSyntax”.
This section describes how to create a backup and how to restore the database from a backup at a later time.
A backup is a snapshot of the database at a given time. The backup consists of three main parts:
Metadata: the names and definitions of all database tables
Table records: the data actually stored in the database tables at the time that the backup was made
Transaction log: a sequential record telling how and when data was stored in the database
Each of these parts is saved on all nodes participating in the backup. During backup, each node saves these three parts into three files on disk:
BACKUP-backup_id.node_id.ctlA control file containing control information and metadata. Each node saves the same table definitions (for all tables in the cluster) to its own version of this file.
BACKUP-backup_id-0.node_id.dataA data file containing the table records, which are saved on a per-fragment basis. That is, different nodes save different fragments during the backup. The file saved by each node starts with a header that states the tables to which the records belong. Following the list of records there is a footer containing a checksum for all records.
BACKUP-backup_id.node_id.logA log file containing records of committed transactions. Only transactions on tables stored in the backup are stored in the log. Nodes involved in the backup save different records because different nodes host different database fragments.
In the listing above, backup_id
stands for the backup identifier and
node_id is the unique identifier for
the node creating the file.
Before starting a backup, make sure that the cluster is properly configured for performing one. (See Section 15.8.4, “Configuration for Cluster Backup”.)
Creating a backup using the management client involves the following steps:
Start the management client (ndb_mgm).
Execute the command
START BACKUP.The management client responds as shown here:
Waiting for completed, this may take several minutes Node 1: Backup
backup_idstarted from nodemanagement_node_idHere,
backup_idis the unique identifier for this particular backup. (This identifier will also be saved in the cluster log, if it has not been configured otherwise.)management_node_idis the node ID of the management to which the management client is connected.This means that the cluster has received and processed the backup request. It does not mean that the backup has been completed.
Note: Backup messages were not recorded in the cluster log in MySQL 5.1.12 or 5.1.13. The logging of backup operations was restored in MySQL 5.1.14 (see Bug#24544).
When the backup is completed, the management client will indicate this as shown here:
Node 1: Backup
backup_idstarted from nodemanagement_node_idcompleted StartGCP: 417599 StopGCP: 417602 #Records: 105957 #LogRecords: 0 Data: 99719356 bytes Log: 0 bytesThe values shown for
StartGCP,StopGCP,#Records,#LogRecords,Data, andLogwill vary according to the specifics of your cluster.
Cluster backups are created by default in the
BACKUP subdirectory of the
DataDir on each data node. This can be
overridden for one or more data nodes individually, or for all
cluster data nodes in the config.ini file
using the BackupDataDir configuration
parameter as discussed in
Identifying
Data Nodes. The backup files created for a backup with a
given backup_id are stored in a
subdirectory named
BACKUP-
in the backup directory.
backup_id
To abort a backup that is already in progress:
Start the management client.
Execute this command:
ndb_mgm>
ABORT BACKUPbackup_idThe number
backup_idis the identifier of the backup that was included in the response of the management client when the backup was started (in the messageBackup).backup_idstarted from nodemanagement_node_idThe management client will acknowledge the abort request with
Abort of backup. Note: At this point, the management client has not yet received a response from the cluster data nodes to this request, and the backup has not yet actually been aborted.backup_idorderedAfter the backup has been aborted, the management client will report this fact in a manner similar to what is shown here:
Node 1: Backup 3 started from 5 has been aborted. Error: 1321 - Backup aborted by user request: Permanent error: User defined error Node 3: Backup 3 started from 5 has been aborted. Error: 1323 - 1323: Permanent error: Internal error Node 2: Backup 3 started from 5 has been aborted. Error: 1323 - 1323: Permanent error: Internal error Node 4: Backup 3 started from 5 has been aborted. Error: 1323 - 1323: Permanent error: Internal error
In this example, we have shown sample output for a cluster with 4 data nodes, where the sequence number of the backup to be aborted is
3, and the management node to which the cluster management client is connected has the node ID5. The first node to complete its part in aborting the backup reports that the reason for the abort was due to a request by the user. (The remaining nodes report that the backup was aborted due to an unspecified internal error.) Note: There is no guarantee that the cluster nodes will respond to anABORT BACKUPcommand in any particular order.The
Backupmessages mean that the backup has been terminated and that all files relating to this backup have been removed from the cluster filesystem.backup_idstarted from nodemanagement_node_idhas been aborted
It is also possible to abort a backup in progress from a system shell using this command:
shell> ndb_mgm -e "ABORT BACKUP backup_id"
Note: If there is no backup
with ID backup_id running when an
ABORT BACKUP is issued, the management client
makes no response, nor is it indicated in the cluster log that
an invalid abort command was sent.
The cluster restoration program is implemented as a separate
command-line utility ndb_restore, which
can normally be found in the MySQL bin
directory. This program reads the files created as a result
of the backup and inserts the stored information into the
database.
ndb_restore must be executed once for
each of the backup files that were created by the
START BACKUP command used to create the
backup (see
Section 15.8.2, “Using The Management Client to Create a Backup”).
This is equal to the number of data nodes in the cluster at
the time that the backup was created.
Note: Before using ndb_restore, it is recommended that the cluster be running in single user mode, unless you are restoring multiple data nodes in parallel. See Section 15.7.4, “Single User Mode”, for more information about single user mode.
Typical options for this utility are shown here:
ndb_restore [-cconnectstring] -nnode_id[-m] -bbackup_id-r [backup_path=]/path/to/backup/files
The -c option is used to specify a
connectstring which tells ndb_restore
where to locate the cluster management server. (See
Section 15.4.4.2, “The Cluster Connectstring”, for
information on connectstrings.) If this option is not used,
then ndb_restore attempts to connect to a
management server on localhost:1186. This
utility acts as a cluster API node, and so requires a free
connection “slot” to connect to the cluster
management server. This means that there must be at least
one [API] or [MYSQLD]
section that can be used by it in the cluster
config.ini file. It is a good idea to
keep at least one empty [API] or
[MYSQLD] section in
config.ini that is not being used for a
MySQL server or other application for this reason (see
Section 15.4.4.6, “Defining SQL and Other API Nodes”).
You can verify that ndb_restore is connected to the cluster by using the SHOW command in the ndb_mgm management client. You can also accomplish this from a system shell, as shown here:
shell> ndb_mgm -e "SHOW"
-n is used to specify the node ID of the
data node on which the backups were taken.
The first time you run the ndb_restore
restoration program, you also need to restore the metadata.
In other words, you must re-create the database tables
— this can be done by running it with the
-m option. Note that the cluster should
have an empty database when starting to restore a backup.
(In other words, you should start ndbd
with --initial prior to performing the
restore.)
The -b option is used to specify the ID or
sequence number of the backup, and is the same number shown
by the management client in the Backup
message displayed upon completion of a backup. (See
Section 15.8.2, “Using The Management Client to Create a Backup”.)
backup_id completed
The path to the backup directory is required, and must
include the subdirectory corresponding to the ID backup of
the backup to be restored. For example, if the data node's
DataDir is
/var/lib/mysql-cluster, then the backup
directory is
/var/lib/mysql-cluster/BACKUP, and the
backup files for the backup with the ID 3 can be found in
/var/lib/mysql-cluster/BACKUP/BACKUP-3.
The path may be absolute or relative to the directory in
which the ndb_restore executable is
located, and may be optionally prefixed with
backup_path=.
Important
When restoring cluster backups, you must be sure to restore all data nodes from backups having the same backup ID. Using files from different backups will at best result in restoring the cluster to an inconsistent state, and may fail altogether.
It is possible to restore a backup to a database with a
different configuration than it was created from. For
example, suppose that a backup with backup ID
12, created in a cluster with two
database nodes having the node IDs 2 and
3, is to be restored to a cluster with
four nodes. Then ndb_restore must be run
twice — once for each database node in the cluster
where the backup was taken. However,
ndb_restore cannot always restore backups
made from a cluster running one version of MySQL to a
cluster running a different MySQL version. See
Section 15.5.2, “Cluster Upgrade and Downgrade Compatibility”,
for more information.
Note
For more rapid restoration, the data may be restored in
parallel, provided that there is a sufficient number of
cluster connections available. That is, when restoring to
multiple nodes in parallel, you must have an
[API] or [MYSQLD]
section in the cluster config.ini
file available for each concurrent
ndb_restore process. However, the data
files must always be applied before the logs.
Most of the options available for this program are shown in the following table:
| Long Form | Short Form | Description | Default Value |
--backup-id | -b | Backup sequence ID | 0 |
--backup_path | None | Path to backup files | ./ |
--character-sets-dir | None | Specify the directory where character set information can be found | None |
--connect, --connectstring, or
--ndb-connectstring | -c or -C | Set the connectstring in
[nodeid=
format | localhost:1186 |
--core-file | None | Write a core file in the event of an error | TRUE |
--debug | -# | Output debug log | d:t:O, |
--help or --usage | -? | Display help message with available options and current values, then exit | [N/A] |
--ndb-mgmd-host | None | Set the host and port in
--connect,
--connectstring, or
--ndb-connectstring, but without a
way to specify the nodeid | None |
--ndb-nodeid | None | Specify a node ID for the ndb_restore process | 0 |
--ndb-optimized-node-selection | None | Optimize selection of nodes for transactions | TRUE |
--ndb-shm | None | Use shared memory connections when available | FALSE |
--nodeid | -n | Use backup files from node with the specified ID | 0 |
--parallelism | -p | Set from 1 to 1024 parallel transactions to be used during the restoration process | 128 |
--print | None | Print metadata and log to stdout | FALSE |
--print_data | None | Print data to stdout | FALSE |
--print_log | None | Print log to stdout | FALSE |
--print_meta | None | Print metadata to stdout | FALSE |
--restore_data | -r | Restore data and logs | FALSE |
--restore_meta | -m | Restore table metadata | FALSE |
--version | -V | Output version information and exit | [N/A] |
Beginning with MySQL 5.0.40, several additional options are
available for use with the --print_data
option in generating data dumps, either to
stdout, or to a file. These are similar
to some of the options used with
mysqldump, and are shown in the following
table:
| Long Form | Short Form | Description | Default Value |
--tab | -T | Creates dumpfiles, one per table, each named
. for the current directory). | None |
--fields-enclosed-by | None | String used to enclose all column values | None |
--fields-optionally-enclosed-by | None | String used to enclose column values containing character data (such as
CHAR,
VARCHAR,
BINARY,
TEXT, or
ENUM) | None |
--fields-terminated-by | None | String used to separate column values | \t (tab character) |
--hex | None | Use hex format for binary values | [N/A] |
--lines-terminated-by | None | String used to terminate each line | \n (linefeed character) |
--appends | None | When used with --tab, causes the data to be appended to
existing files of the same name | [N/A] |
Note
If a table has no explicit primary key, then the output
generated when using the --print includes
the table's hidden primary key.
Beginning with MySQL 5.0.40, it is possible to restore selected databases, or to restore selected tables from a given database using the syntax shown here:
ndb_restoreother_optionsdb_name_1[db_name_2[,db_name_3][, ...] |tbl_name_1[,tbl_name_2][, ...]]
In other words, you can specify either of the following to be restored:
All tables from one or more databases
One or more tables from a single database
Note
ndb_restore reports both temporary and
permanent errors. In the case of temporary errors, it may
able to recover from them. Beginning with MySQL 5.0.29, it
reports Restore successful, but encountered
temporary error, please look at configuration in
such cases.
Five configuration parameters are essential for backup:
BackupDataBufferSizeThe amount of memory used to buffer data before it is written to disk.
BackupLogBufferSizeThe amount of memory used to buffer log records before these are written to disk.
BackupMemoryThe total memory allocated in a database node for backups. This should be the sum of the memory allocated for the backup data buffer and the backup log buffer.
BackupWriteSizeThe default size of blocks written to disk. This applies for both the backup data buffer and the backup log buffer.
BackupMaxWriteSizeThe maximum size of blocks written to disk. This applies for both the backup data buffer and the backup log buffer.
More detailed information about these parameters can be found in Backup Parameters.
If an error code is returned when issuing a backup request, the
most likely cause is insufficient memory or disk space. You
should check that there is enough memory allocated for the
backup. Important: If you have
set BackupDataBufferSize and
BackupLogBufferSize and their sum is greater
than 4MB, then you must also set BackupMemory
as well. See
BackupMemory.
You should also make sure that there is sufficient space on the hard drive partition of the backup target.
NDB does not support repeatable reads, which
can cause problems with the restoration process. Although the
backup process is “hot”, restoring a MySQL Cluster
from backup is not a 100% “hot” process. This is
due to the fact that, for the duration of the restore process,
running transactions get non-repeatable reads from the restored
data. This means that the state of the data is inconsistent
while the restore is in progress.
- 15.9.1. ndb_config — Extract NDB Configuration Information
- 15.9.2. ndb_cpcd — Automate Testing for NDB Development
- 15.9.3. ndb_delete_all — Delete All Rows from NDB Table
- 15.9.4. ndb_desc — Describe NDB Tables
- 15.9.5. ndb_drop_index — Drop Index from NDB Table
- 15.9.6. ndb_drop_table — Drop NDB Table
- 15.9.7. ndb_error_reporter — NDB Error-Reporting Utility
- 15.9.8. ndb_print_backup_file — Print NDB Backup File Contents
- 15.9.9. ndb_print_schema_file — Print NDB Schema File Contents
- 15.9.10. ndb_print_sys_file — Print NDB System File Contents
- 15.9.11. ndb_select_all — Print Rows from NDB Table
- 15.9.12. ndb_select_count — Print Row Counts for NDB Tables
- 15.9.13. ndb_show_tables — Display List of NDB Tables
- 15.9.14. ndb_size.pl — NDBCluster Size Requirement Estimator
- 15.9.15. ndb_waiter — Wait for Cluster to Reach a Given Status
This section discusses the MySQL Cluster utility programs that can
be found in the mysql/bin directory. Each of
these — except for ndb_size.pl and
ndb_error_reporter — is a standalone
binary that can be used from a system shell, and that does not
need to connect to a MySQL server (nor even requires that a MySQL
server be connected to the cluster).
These utilities can also serve as examples for writing your own
applications using the NDB API. The source code
for most of these programs may be found in the
ndb/tools directory of the MySQL
5.0 tree (see Section 2.4.14, “MySQL Installation Using a Source Distribution”).
The NDB API is not covered in this manual;
please refer to the
NDB API
Guide for information about this API.
All of the NDB utilities are listed here with
brief descriptions:
ndb_config: Retrieves Cluster configuration options.
ndb_cpcd: Used in testing and debugging MySQL Cluster.
ndb_delete_all: Deletes all rows from a given table.
ndb_desc: Lists all properties of an
NDBtable.ndb_drop_index: Drops the specified index from an
NDBtable.ndb_drop_table: Drops an
NDBtable.ndb_error_reporter: Can be used to gather information useful for diagnosing problems with the cluster.
ndb_mgm: This is the MySQL Cluster management client, which is discussed in Section 15.7.2, “Commands in the MySQL Cluster Management Client”.
ndb_print_backup_file: Prints diagnostic information obtained from cluster backup files.
ndb_print_schema_file: Prints diagnostic information obtained from cluster schema files.
ndb_print_sys_file: Prints diagnostic information obtained from cluster system files.
ndb_restore: This utility is used to restore a cluster from backup. See Section 15.8.3, “ndb_restore — Restore a Cluster Backup”, for more information.
ndb_select_all: Prints all rows from an
NDBtable.ndb_select_count: Gets the number of rows in one or more
NDBtables.ndb_show_tables: Shows all
NDBtables anywhere in the cluster.ndb_size.pl: Examines all the tables in a given non-Cluster database and calculates the amount of storage each would require if it were converted to use the
NDBstorage engine.ndb_waiter: Reports on the status of cluster data nodes in a manner similar to that of the management client command
ALL STATUS.
Most of these utilities need to connect to a Cluster management
server in order to function. The exceptions are
ndb_size.pl (see below), and the following
utilities which access a cluster data node filesystem and so need
to be run on a data node host:
ndb_print_backup_file
ndb_print_schema_file
ndb_print_sys_file
ndb_size.pl is a Perl script which is also
intended to be used from the shell; however it is a MySQL
application and must be able to connect to a MySQL server. See
Section 15.9.14, “ndb_size.pl — NDBCluster Size Requirement Estimator”, for additional
requirements for using this script.
ndb_error_reporter is also a Perl script. It is used to gather cluster data node and management node logs together into a tarball to submit along with a bug report. It can use ssh or scp to access the node filesystems remotely.
Additional information about each of these utilities (except for ndb_mgm and ndb_restore) can be found in the sections that follow.
Note: All of these utilities (except for ndb_size.pl and ndb_config) can use the options discussed in Section 15.6.5, “Command Options for MySQL Cluster Processes”. Additional options specific to each utility program are discussed in the individual program listings.
The order in which these options are used is generally not important. For example, all of these commands produce exactly the same output:
ndb_desc -c localhost fish -d testndb_desc fish -c localhost -d testndb_desc -d test fish -c localhost
This tool extracts configuration information for data nodes,
SQL nodes, and API nodes from a cluster management node (and
possibly its config.ini file).
Usage:
ndb_config options
The options available for this
utility differ somewhat from those used with the other
utilities, and so are listed in their entirety in the next
section, followed by some examples.
Options:
Causes ndb_config to print a list of available options, and then exit.
Causes ndb_config to print a version information string, and then exit.
--ndb-connectstring=connect_stringSpecifies the connectstring to use in connecting to the management server. The format for the connectstring is the same as described in Section 15.4.4.2, “The Cluster Connectstring”, and defaults to
localhost:1186.The use of
-cas a short version for this option is supported for ndb_config beginning with MySQL 5.0.29.Gives the path to the management server's configuration file (
config.ini). This may be a relative or absolute path. If the management node resides on a different host from the one on which ndb_config is invoked, then an absolute path must be used.--query=,query-options-qquery-optionsThis is a comma-delimited list of query options — that is, a list of one or more node attributes to be returned. These include
id(node ID), type (node type — that is,ndbd,mysqld, orndb_mgmd), and any configuration parameters whose values are to be obtained.For example,
--query=id,type,indexmemory,datamemorywould return the node ID, node type,DataMemory, andIndexMemoryfor each node.Note: If a given parameter is not applicable to a certain type of node, than an empty string is returned for the corresponding value. See the examples later in this section for more information.
Specifies the hostname of the node for which configuration information is to be obtained.
--id=,node_id--nodeid=node_idUsed to specify the node ID of the node for which configuration information is to be obtained.
(Tells ndb_config to print information from parameters defined in
[ndbd]sections only. Currently, using this option has no affect, since these are the only values checked, but it may become possible in future to query parameters set in[tcp]and other sections of cluster configuration files.)Filters results so that only configuration values applying to nodes of the specified
node_type(ndbd,mysqld, orndb_mgmd) are returned.--fields=,delimiter-fdelimiterSpecifies a
delimiterstring used to separate the fields in the result. The default is “,” (the comma character).Note: If the
delimitercontains spaces or escapes (such as\nfor the linefeed character), then it must be quoted.--rows=,separator-rseparatorSpecifies a
separatorstring used to separate the rows in the result. The default is a space character.Note: If the
separatorcontains spaces or escapes (such as\nfor the linefeed character), then it must be quoted.
Examples:
To obtain the node ID and type of each node in the cluster:
shell>
./ndb_config --query=id,type --fields=':' --rows='\n'1:ndbd 2:ndbd 3:ndbd 4:ndbd 5:ndb_mgmd 6:mysqld 7:mysqld 8:mysqld 9:mysqldIn this example, we used the
--fieldsoptions to separate the ID and type of each node with a colon character (:), and the--rowsoptions to place the values for each node on a new line in the output.To produce a connectstring that can be used by data, SQL, and API nodes to connect to the management server:
shell>
./ndb_config --config-file=usr/local/mysql/cluster-data/config.ini --query=hostname,portnumber --fields=: --rows=, --type=ndb_mgmd192.168.0.179:1186This invocation of ndb_config checks only data nodes (using the
--typeoption), and shows the values for each node's ID and hostname, and itsDataMemory,IndexMemory, andDataDirparameters:shell>
./ndb_config --type=ndbd --query=id,host,datamemory,indexmemory,datadir -f ' : ' -r '\n'1 : 192.168.0.193 : 83886080 : 18874368 : /usr/local/mysql/cluster-data 2 : 192.168.0.112 : 83886080 : 18874368 : /usr/local/mysql/cluster-data 3 : 192.168.0.176 : 83886080 : 18874368 : /usr/local/mysql/cluster-data 4 : 192.168.0.119 : 83886080 : 18874368 : /usr/local/mysql/cluster-dataIn this example, we used the short options
-fand-rfor setting the field delimiter and row separator, respectively.To exclude results from any host except one in particular, use the
--hostoption:shell>
./ndb_config --host=192.168.0.176 -f : -r '\n' -q id,type3:ndbd 5:ndb_mgmdIn this example, we also used the short form
-qto determine the attributes to be queried.Similarly, you can limit results to a node with a specific ID using the
--idor--nodeidoption.
This utility is found in the libexec
directory. It is part of an internal automated test
framework used in testing and bedugging MySQL Cluster.
Because it can control processes on remote systems, it is
not advisable to use ndb_cpcd in a
production cluster.
Because some users may be interested in employing the Cluster testing framework for their own development or testing purposes, we intend to make details of this application's usage available in the near future as part of the MySQL Internals Manual.
The source files for ndb_cpcd may be
found in the directory
storage/ndb/src/cw/cpcd, in the MySQL
5.0 source tree.
ndb_delete_all deletes all rows from the
given NDB table. In some cases, this can
be much faster than DELETE or even
TRUNCATE.
Usage:
ndb_delete_all -cconnect_stringtbl_name-ddb_name
This deletes all rows from the table named
tbl_name in the database named
db_name. It is exactly equivalent
to executing TRUNCATE
in MySQL.
db_name.tbl_name
Additional Options:
ndb_desc provides a detailed description
of one or more NDB tables.
Usage:
ndb_desc -cconnect_stringtbl_name-ddb_name
Sample Output:
MySQL table creation and population statements:
USE test;
CREATE TABLE fish (
id INT(11) NOT NULL AUTO_INCREMENT,
name VARCHAR(20),
PRIMARY KEY pk (id),
UNIQUE KEY uk (name)
) ENGINE=NDBCLUSTER;
INSERT INTO fish VALUES
('','guppy'), ('','tuna'), ('','shark'),
('','manta ray'), ('','grouper'), ('','puffer');
Output from ndb_desc:
shell> ./ndb_desc -c localhost fish -d test -p
-- fish --
Version: 16777221
Fragment type: 5
K Value: 6
Min load factor: 78
Max load factor: 80
Temporary table: no
Number of attributes: 2
Number of primary keys: 1
Length of frm data: 268
Row Checksum: 1
Row GCI: 1
TableStatus: Retrieved
-- Attributes --
id Int PRIMARY KEY DISTRIBUTION KEY AT=FIXED ST=MEMORY
name Varchar(20;latin1_swedish_ci) NULL AT=SHORT_VAR ST=MEMORY
-- Indexes --
PRIMARY KEY(id) - UniqueHashIndex
uk(name) - OrderedIndex
PRIMARY(id) - OrderedIndex
uk$unique(name) - UniqueHashIndex
-- Per partition info --
Partition Row count Commit count Frag fixed memory Frag varsized memory
2 2 2 65536 327680
1 2 2 65536 327680
3 2 2 65536 327680
NDBT_ProgramExit: 0 - OK
Additional Options:
ndb_drop_index drops the specified index
from an NDB table. It is
recommended that you use this utility only as an example for
writing NDB API applications — see the
Warning later in this section for details.
Usage:
ndb_drop_index -cconnect_stringtable_nameindex-ddb_name
The statement shown above drops the index named
index from the
table in the
database.
Additional Options: None that are specific to this application.
Warning: Operations performed on Cluster table indexes using the NDB API are not visible to MySQL and make the table unusable by a MySQL server. If you use this program to drop an index, then try to access the table from an SQL node, an error results, as shown here:
shell>./ndb_drop_index -c localhost dogs ix -d ctest1Dropping index dogs/idx...OK NDBT_ProgramExit: 0 - OK shell>./mysql -u jon -p ctest1Enter password: ******* Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 7 to server version: 5.1.12-beta-20060817 Type 'help;' or '\h' for help. Type '\c' to clear the buffer. mysql> SHOW TABLES; +------------------+ | Tables_in_ctest1 | +------------------+ | a | | bt1 | | bt2 | | dogs | | employees | | fish | +------------------+ 6 rows in set (0.00 sec) mysql> SELECT * FROM dogs; ERROR 1296 (HY000): Got error 4243 'Index not found' from NDBCLUSTER
In such a case, your only option for
making the table available to MySQL again is to drop the
table and re-create it. You can use either the SQL
statementDROP TABLE or the
ndb_drop_table utility (see
Section 15.9.6, “ndb_drop_table — Drop NDB Table”) to
drop the table.
ndb_drop_table drops the specified
NDB table. (If you try to use this on a
table created with a storage engine other than NDB, it fails
with the error 723: No such table
exists.) This operation is extremely fast
— in some cases, it can be an order of magnitude
faster than using DROP TABLE on an
NDB table from MySQL.
Usage:
ndb_drop_table -cconnect_stringtbl_name-ddb_name
Additional Options: None.
ndb_error_reporter creates an archive from data node and management node log files that can be used to help diagnose bugs or other problems with a cluster. It is highly recommended that you make use of this utility when filing reports of bugs in MySQL Cluster.
Usage:
ndb_error_reporterpath/to/config-file[username] [--fs]
This utility is intended for use on a management node host,
and requires the path to the management host configuration
file (config.ini). Optionally, you can
supply the name of a user that is able to access the
cluster's data nodes via SSH, in order to copy the data node
log files. ndb_error_reporter then includes all of these
files in archive that is created in the same directory in
which it is run. The archive is named
ndb_error_report_,
where YYYYMMDDHHMMSS.tar.bz2YYYYMMDDHHMMSS is a
datetime string.
If the --fs is used, then the data node
filesystems are also copied to the management host and
included in the archive that is produced by this script. As
data node filesystems can be extremely large even after
being compressed, we ask that you please do
not send archives created using this
option to MySQL AB unless you are specifically requested to
do so.
ndb_print_backup_file obtains diagnostic information from a cluster backup file.
Usage:
ndb_print_backup_file file_name
file_name is the name of a
cluster backup file. This can be any of the files
(.Data, .ctl, or
.log file) found in a cluster backup
directory. These files are found in the data node's backup
directory under the subdirectory
BACKUP-,
where ## is the sequence number
for the backup. For more information about cluster backup
files and their contents, see
Section 15.8.1, “Cluster Backup Concepts”.
Like ndb_print_schema_file and
ndb_print_sys_file (and unlike most of
the other NDB utilities that are intended
to be run on a management server host or to connect to a
management server) ndb_print_backup_file
must be run on a cluster data node, since it accesses the
data node filesystem directly. Because it does not make use
of the management server, this utility can be used when the
management server is not running, and even when the cluster
has been completely shut down.
Additional Options: None.
ndb_print_schema_file obtains diagnostic information from a cluster schema file.
Usage:
ndb_print_schema_file file_name
file_name is the name of a
cluster schema file.
Like ndb_print_backup_file and
ndb_print_sys_file (and unlike most of
the other NDB utilities that are intended
to be run on a management server host or to connect to a
management server) ndb_schema_backup_file
must be run on a cluster data node, since it accesses the
data node filesystem directly. Because it does not make use
of the management server, this utility can be used when the
management server is not running, and even when the cluster
has been completely shut down.
Additional Options: None.
ndb_print_sys_file obtains diagnostic information from a cluster system file.
Usage:
ndb_print_sys_file file_name
file_name is the name of a
cluster system file (sysfile). Cluster system files are
located in a data node's data directory
(DataDir); the path under this directory
to system files matches the pattern
ndb_.
In each case, the #_fs/D#/DBDIH/P#.sysfile# represents a
number (not necessarily the same number).
Like ndb_print_backup_file and
ndb_print_schema_file (and unlike most of
the other NDB utilities that are intended
to be run on a management server host or to connect to a
management server) ndb_print_backup_file
must be run on a cluster data node, since it accesses the
data node filesystem directly. Because it does not make use
of the management server, this utility can be used when the
management server is not running, and even when the cluster
has been completely shut down.
Additional Options: None.
ndb_select_all prints all rows from an
NDB table to stdout.
Usage:
ndb_select_all -cconnect_stringtbl_name-ddb_name[>file_name]
Additional Options:
--lock=,lock_type-llock_typeEmploys a lock when reading the table. Possible values for
lock_typeare:0: Read lock1: Read lock with hold2: Exclusive read lock
There is no default value for this option.
--order=,index_name-oindex_nameOrders the output according to the index named
index_name. Note that this is the name of an index, not of a column, and that the index must have been explicitly named when created.Sorts the output in descending order. This option can be used only in conjunction with the
-o(--order) option.Excludes column headers from the output.
Causes all numeric values to be displayed in hexadecimal format. This does not affect the output of numerals contained in strings or datetime values.
--delimiter=,character-DcharacterCauses the
characterto be used as a column delimiter. Only table data columns are separated by this delimiter.The default delimiter is the tab character.
Adds a
ROWIDcolumn providing information about the fragments in which rows are stored.Adds a column to the output showing the global checkpoint at which each row was last updated. See Section 15.13, “MySQL Cluster Glossary”, and Section 15.7.3.2, “Log Events”, for more information about checkpoints.
Scan the table in the order of the tuples.
Causes any table data to be omitted.
Sample Output:
Output from a MySQL SELECT statement:
mysql> SELECT * FROM ctest1.fish;
+----+-----------+
| id | name |
+----+-----------+
| 3 | shark |
| 6 | puffer |
| 2 | tuna |
| 4 | manta ray |
| 5 | grouper |
| 1 | guppy |
+----+-----------+
6 rows in set (0.04 sec)
Output from the equivalent invocation of ndb_select_all:
shell> ./ndb_select_all -c localhost fish -d ctest1
id name
3 [shark]
6 [puffer]
2 [tuna]
4 [manta ray]
5 [grouper]
1 [guppy]
6 rows returned
NDBT_ProgramExit: 0 - OK
Note that all string values are enclosed by square brackets
(“[...]”)
in the output of ndb_select_all. For a
further example, consider the table created and populated as
shown here:
CREATE TABLE dogs (
id INT(11) NOT NULL AUTO_INCREMENT,
name VARCHAR(25) NOT NULL,
breed VARCHAR(50) NOT NULL,
PRIMARY KEY pk (id),
KEY ix (name)
)
ENGINE=NDB;
INSERT INTO dogs VALUES
('', 'Lassie', 'collie'),
('', 'Scooby-Doo', 'Great Dane'),
('', 'Rin-Tin-Tin', 'German Shepherd'),
('', 'Rosscoe', 'Mutt');
This demonstrates the use of several additional ndb_select_all options:
shell> ./ndb_select_all -d ctest1 dogs -o ix -z --gci
GCI id name breed
834461 2 [Scooby-Doo] [Great Dane]
834878 4 [Rosscoe] [Mutt]
834463 3 [Rin-Tin-Tin] [German Shepherd]
835657 1 [Lassie] [Collie]
4 rows returned
NDBT_ProgramExit: 0 - OK
ndb_select_count prints the number of
rows in one or more NDB tables. With a
single table, the result is equivalent to that obtained by
using the MySQL statement SELECT COUNT(*) FROM
.
tbl_name
Usage:
ndb_select_count [-cconnect_string] -ddb_nametbl_name[,tbl_name2[, ...]]
Additional Options: None that are specific to this application. However, you can obtain row counts from multiple tables in the same database by listing the table names separated by spaces when invoking this command, as shown under Sample Output.
Sample Output:
shell> ./ndb_select_count -c localhost -d ctest1 fish dogs
6 records in table fish
4 records in table dogs
NDBT_ProgramExit: 0 - OK
ndb_show_tables displays a list of all
NDB database objects in the cluster. By
default, this includes not only both user-created tables and
NDB system tables, but
NDB-specific indexes, and internal
triggers, as well.
Usage:
ndb_show_tables [-c connect_string]
Additional Options:
Specifies the number of times the utility should execute. This is 1 when this option is not specified, but if you do use the option, you must supply an integer argument for it.
Using this option causes the output to be in a format suitable for use with
LOAD DATA INFILE.Can be used to restrict the output to one type of object, specified by an integer type code as shown here:
1: System table
2: User-created table
3: Unique hash index
Any other value causes all
NDBdatabase objects to be listed (the default).If specified, this causes unqualified object names to be displayed.
Note: Only user-created
Cluster tables may be accessed from MySQL; system tables
such as SYSTAB_0 are not visible to
mysqld. However, you can examine the
contents of system tables using NDB API
applications such as ndb_select_all (see
Section 15.9.11, “ndb_select_all — Print Rows from NDB Table”).
This is a Perl script that can be used to estimate the
amount of space that would be required by a MySQL database
if it were converted to use the
NDBCluster storage engine. Unlike the
other utilities discussed in this section, it does not
require access to a MySQL Cluster (in fact, there is no
reason for it to do so). However, it does need to access the
MySQL server on which the database to be tested resides.
Requirements:
A running MySQL server. The server instance does not have to provide support for MySQL Cluster.
A working installation of Perl.
The
DBIandHTML::Templatemodules, both of which can be obtained from CPAN if they are not already part of your Perl installation. (Many Linux and other operating system distribution provide their own packages for one or both of these libraries.)The
ndb_size.tmpltemplate file, which you should be able to find in theshare/mysqldirectory of your MySQL installation. This file should be copied or moved into the same directory asndb_size.pl— if it is not there already — before running the script.A MySQL user account having the necessary privileges. If you do not wish to use an existing account, then creating one using
GRANT USAGE ON— wheredb_name.*db_nameis the name of the database to be examined — is sufficient for this purpose.
ndb_size.pl and
ndb_size.tmpl can also be found in the
MySQL sources in storage/ndb/tools. If
these files are not present in your MySQL installation, you
can obtain them from the
MySQLForge
project page.
Usage:
perl ndb_size.pldb_namehostnameusernamepassword>file_name.html
The command shown connects to the MySQL server at
hostname using the account of the
user username having the password
password, analyses all of the
tables in database db_name, and
generates a report in HTML format which is directed to the
file
file_name.htmlstdout.) This figure shows partial sample
output as viewed in a Web browser:
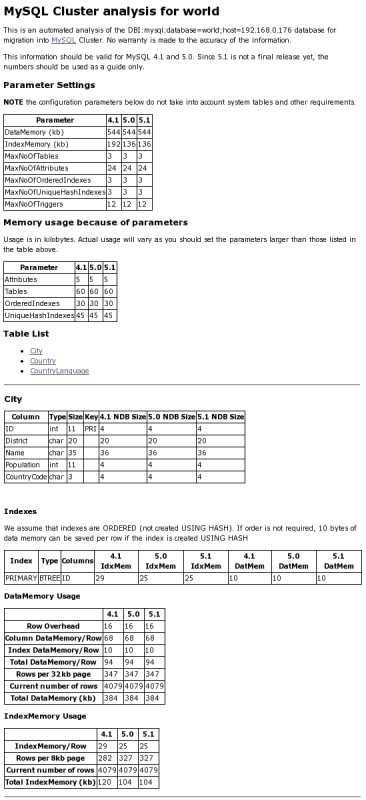
The output from this script includes:
Minimum values for the
DataMemory,IndexMemory,MaxNoOfTables,MaxNoOfAttributes,MaxNoOfOrderedIndexes,MaxNoOfUniqueHashIndexes, andMaxNoOfTriggersconfiguration parameters required to accommodate the tables analysed.Memory requirements for all of the tables, attributes, ordered indexes, and unique hash indexes defined in the database.
The
IndexMemoryandDataMemoryrequired per table and table row.
ndb_waiter repeatedly (each 100
milliseconds) prints out the status of all cluster data
nodes until either the cluster reaches a given status or the
--timeout limit is exceeded, then exits. By
default, it waits for the cluster to achieve
STARTED status, in which all nodes have
started and connected to the cluster. This can be overridden
using the --no-contact and
--not-started options (see
Additional
Options).
The node states reported by this utility are as follows:
NO_CONTACT: The node cannot be contacted.UNKNOWN: The node can be contacted, but its status is not yet known. Usually, this means that the node has received aSTARTorRESTARTcommand from the management server, but has not yet acted on it.NOT_STARTED: The node has stopped, but remains in contact with the cluster. This is seen when restarting the node using the management client'sRESTARTcommand.STARTING: The node's ndbd process has started, but the node has not yet joined the cluster.STARTED: The node is operational, and has joined the cluster.SHUTTING_DOWN: The node is shutting down.SINGLE USER MODE: This is shown for all cluster data nodes when the cluster is in single user mode.
Usage:
ndb_waiter [-c connect_string]
Instead of waiting for the
STARTEDstate, ndb_waiter continues running until the cluster reachesNO_CONTACTstatus before exiting.Instead of waiting for the
STARTEDstate, ndb_waiter continues running until the cluster reachesNOT_STARTEDstatus before exiting.Time to wait. The program exits if the desired state is not achieved within this number of seconds. The default is 120 seconds (1200 reporting cycles).
Sample Output:
Shown here is the output from ndb_waiter
when run against a 4-node cluster in which two nodes have
been shut down and then started again manually. Duplicate
reports (indicated by “...”)
are omitted.
shell> ./ndb_waiter -c localhost
Connecting to mgmsrv at (localhost)
State node 1 STARTED
State node 2 NO_CONTACT
State node 3 STARTED
State node 4 NO_CONTACT
Waiting for cluster enter state STARTED
...
State node 1 STARTED
State node 2 UNKNOWN
State node 3 STARTED
State node 4 NO_CONTACT
Waiting for cluster enter state STARTED
...
State node 1 STARTED
State node 2 STARTING
State node 3 STARTED
State node 4 NO_CONTACT
Waiting for cluster enter state STARTED
...
State node 1 STARTED
State node 2 STARTING
State node 3 STARTED
State node 4 UNKNOWN
Waiting for cluster enter state STARTED
...
State node 1 STARTED
State node 2 STARTING
State node 3 STARTED
State node 4 STARTING
Waiting for cluster enter state STARTED
...
State node 1 STARTED
State node 2 STARTED
State node 3 STARTED
State node 4 STARTING
Waiting for cluster enter state STARTED
...
State node 1 STARTED
State node 2 STARTED
State node 3 STARTED
State node 4 STARTED
Waiting for cluster enter state STARTED
NDBT_ProgramExit: 0 - OK
Note: If no connectstring
is specified, then ndb_waiter tries to
connect to a management on localhost, and
reports Connecting to mgmsrv at (null).
Even before design of NDB Cluster began in
1996, it was evident that one of the major problems to be
encountered in building parallel databases would be communication
between the nodes in the network. For this reason, NDB
Cluster was designed from the very beginning to allow
for the use of a number of different data transport mechanisms. In
this Manual, we use the term transporter
for these.
The MySQL Cluster codebase includes support for four different transporters:
TCP/IP using 100 Mbps or gigabit Ethernet, as discussed in Section 15.4.4.7, “Cluster TCP/IP Connections”.
Direct (machine-to-machine) TCP/IP; although this transporter uses the same TCP/IP protocol as mentioned in the previous item, it requires setting up the hardware differently and is configured differently as well. For this reason, it is considered a separate transport mechanism for MySQL Cluster. See Section 15.4.4.8, “TCP/IP Connections Using Direct Connections”, for details.
Shared memory (SHM). For more information about SHM, see Section 15.4.4.9, “Shared-Memory Connections”.
Scalable Coherent Interface (SCI), as described in the next section of this chapter, Section 15.4.4.10, “SCI Transport Connections”.
Most users today employ TCP/IP over Ethernet because it is ubiquitous. TCP/IP is also by far the best-tested transporter for use with MySQL Cluster.
We are working to make sure that communication with the ndbd process is made in “chunks” that are as large as possible because this benefits all types of data transmission.
For users who desire it, it is also possible to use cluster interconnects to enhance performance even further. There are two ways to achieve this: Either a custom transporter can be designed to handle this case, or you can use socket implementations that bypass the TCP/IP stack to one extent or another. We have experimented with both of these techniques using the SCI (Scalable Coherent Interface) technology developed by Dolphin.
In this section, we show how to adapt a cluster configured for normal TCP/IP communication to use SCI Sockets instead. This documentation is based on SCI Sockets version 2.3.0 as of 01 October 2004.
Prerequisites
Any machines with which you wish to use SCI Sockets must be equipped with SCI cards.
It is possible to use SCI Sockets with any version of MySQL Cluster. No special builds are needed because it uses normal socket calls which are already available in MySQL Cluster. However, SCI Sockets are currently supported only on the Linux 2.4 and 2.6 kernels. SCI Transporters have been tested successfully on additional operating systems although we have verified these only with Linux 2.4 to date.
There are essentially four requirements for SCI Sockets:
Building the SCI Socket libraries.
Installation of the SCI Socket kernel libraries.
Installation of one or two configuration files.
The SCI Socket kernel library must enabled either for the entire machine or for the shell where the MySQL Cluster processes are started.
This process needs to be repeated for each machine in the cluster where you plan to use SCI Sockets for inter-node communication.
Two packages need to be retrieved to get SCI Sockets working:
The source code package containing the DIS support libraries for the SCI Sockets libraries.
The source code package for the SCI Socket libraries themselves.
Currently, these are available only in source code format. The
latest versions of these packages at the time of this writing
were available as (respectively)
DIS_GPL_2_5_0_SEP_10_2004.tar.gz and
SCI_SOCKET_2_3_0_OKT_01_2004.tar.gz. You
should be able to find these (or possibly newer versions) at
http://www.dolphinics.no/support/downloads.html.
Package Installation
Once you have obtained the library packages, the next step is to unpack them into appropriate directories, with the SCI Sockets library unpacked into a directory below the DIS code. Next, you need to build the libraries. This example shows the commands used on Linux/x86 to perform this task:
shell>tar xzf DIS_GPL_2_5_0_SEP_10_2004.tar.gzshell>cd DIS_GPL_2_5_0_SEP_10_2004/src/shell>tar xzf ../../SCI_SOCKET_2_3_0_OKT_01_2004.tar.gzshell>cd ../adm/bin/Linux_pkgsshell>./make_PSB_66_release
It is possible to build these libraries for some 64-bit procesors. To build the libraries for Opteron CPUs using the 64-bit extensions, run make_PSB_66_X86_64_release rather than make_PSB_66_release. If the build is made on an Itanium machine, you should use make_PSB_66_IA64_release. The X86-64 variant should work for Intel EM64T architectures but this has not yet (to our knowledge) been tested.
Once the build process is complete, the compiled libraries will
be found in a zipped tar file with a name along the lines of
DIS-.
It is now time to install the package in the proper place. In
this example we will place the installation in
<operating-system>-time-date/opt/DIS.
(Note: You will most likely
need to run the following as the system root
user.)
shell>cp DIS_Linux_2.4.20-8_181004.tar.gz /opt/shell>cd /optshell>tar xzf DIS_Linux_2.4.20-8_181004.tar.gzshell>mv DIS_Linux_2.4.20-8_181004 DIS
Network Configuration
Now that all the libraries and binaries are in their proper place, we need to ensure that the SCI cards have proper node IDs within the SCI address space.
It is also necessary to decide on the network structure before proceeding. There are three types of network structures which can be used in this context:
A simple one-dimensional ring
One or more SCI switches with one ring per switch port
A two- or three-dimensional torus.
Each of these topologies has its own method for providing node IDs. We discuss each of them in brief.
A simple ring uses node IDs which are non-zero multiples of 4: 4, 8, 12,...
The next possibility uses SCI switches. An SCI switch has 8 ports, each of which can support a ring. It is necessary to make sure that different rings use different node ID spaces. In a typical configuration, the first port uses node IDs below 64 (4 – 60), the next 64 node IDs (68 – 124) are assigned to the next port, and so on, with node IDs 452 – 508 being assigned to the eighth port.
Two- and three-dimensional torus network structures take into account where each node is located in each dimension, incrementing by 4 for each node in the first dimension, by 64 in the second dimension, and (where applicable) by 1024 in the third dimension. See Dolphin's Web site for more thorough documentation.
In our testing we have used switches, although most large cluster installations use 2- or 3-dimensional torus structures. The advantage provided by switches is that, with dual SCI cards and dual switches, it is possible to build with relative ease a redundant network where the average failover time on the SCI network is on the order of 100 microseconds. This is supported by the SCI transporter in MySQL Cluster and is also under development for the SCI Socket implementation.
Failover for the 2D/3D torus is also possible but requires sending out new routing indexes to all nodes. However, this requires only 100 milliseconds or so to complete and should be acceptable for most high-availability cases.
By placing cluster data nodes properly within the switched architecture, it is possible to use 2 switches to build a structure whereby 16 computers can be interconnected and no single failure can hinder more than one of them. With 32 computers and 2 switches it is possible to configure the cluster in such a manner that no single failure can cause the loss of more than two nodes; in this case, it is also possible to know which pair of nodes is affected. Thus, by placing the two nodes in separate node groups, it is possible to build a “safe” MySQL Cluster installation.
To set the node ID for an SCI card use the following command in
the /opt/DIS/sbin directory. In this
example, -c 1 refers to the number of the SCI
card (this is always 1 if there is only 1 card in the machine);
-a 0 refers to adapter 0; and
68 is the node ID:
shell> ./sciconfig -c 1 -a 0 -n 68
If you have multiple SCI cards in the same machine, you can
determine which card has which slot by issuing the following
command (again we assume that the current working directory is
/opt/DIS/sbin):
shell> ./sciconfig -c 1 -gsn
This will give you the SCI card's serial number. Then repeat
this procedure with -c 2, and so on, for each
card in the machine. Once you have matched each card with a
slot, you can set node IDs for all cards.
After the necessary libraries and binaries are installed, and
the SCI node IDs are set, the next step is to set up the mapping
from hostnames (or IP addresses) to SCI node IDs. This is done
in the SCI sockets configuration file, which should be saved as
/etc/sci/scisock.conf. In this file, each
SCI node ID is mapped through the proper SCI card to the
hostname or IP address that it is to communicate with. Here is a
very simple example of such a configuration file:
#host #nodeId alpha 8 beta 12 192.168.10.20 16
It is also possible to limit the configuration so that it
applies only to a subset of the available ports for these hosts.
An additional configuration file
/etc/sci/scisock_opt.conf can be used to
accomplish this, as shown here:
#-key -type -values EnablePortsByDefault yes EnablePort tcp 2200 DisablePort tcp 2201 EnablePortRange tcp 2202 2219 DisablePortRange tcp 2220 2231
Driver Installation
With the configuration files in place, the drivers can be installed.
First, the low-level drivers and then the SCI socket driver need to be installed:
shell>cd DIS/sbin/shell>./drv-install add PSB66shell>./scisocket-install add
If desired, the installation can be checked by invoking a script which verifies that all nodes in the SCI socket configuration files are accessible:
shell>cd /opt/DIS/sbin/shell>./status.sh
If you discover an error and need to change the SCI socket configuration, it is necessary to use ksocketconfig to accomplish this task:
shell>cd /opt/DIS/utilshell>./ksocketconfig -f
Testing the Setup
To ensure that SCI sockets are actually being used, you can
employ the latency_bench test program. Using
this utility's server component, clients can connect to the
server to test the latency of the connection. Determining
whether SCI is enabled should be fairly simple from observing
the latency. (Note: Before
using latency_bench, it is necessary to set
the LD_PRELOAD environment variable as shown
later in this section.)
To set up a server, use the following:
shell>cd /opt/DIS/bin/socketshell>./latency_bench -server
To run a client, use latency_bench again,
except this time with the -client option:
shell>cd /opt/DIS/bin/socketshell>./latency_bench -clientserver_hostname
SCI socket configuration should now be complete and MySQL Cluster ready to use both SCI Sockets and the SCI transporter (see Section 15.4.4.10, “SCI Transport Connections”).
Starting the Cluster
The next step in the process is to start MySQL Cluster. To
enable usage of SCI Sockets it is necessary to set the
environment variable LD_PRELOAD before
starting ndbd, mysqld, and
ndb_mgmd. This variable should point to the
kernel library for SCI Sockets.
To start ndbd in a bash shell, do the following:
bash-shell>export LD_PRELOAD=/opt/DIS/lib/libkscisock.sobash-shell>ndbd
In a tcsh environment the same thing can be accomplished with:
tcsh-shell>setenv LD_PRELOAD=/opt/DIS/lib/libkscisock.sotcsh-shell>ndbd
Note: MySQL Cluster can use only the kernel variant of SCI Sockets.
The ndbd process has a number of simple constructs which are used to access the data in a MySQL Cluster. We have created a very simple benchmark to check the performance of each of these and the effects which various interconnects have on their performance.
There are four access methods:
Primary key access
This is access of a record through its primary key. In the simplest case, only one record is accessed at a time, which means that the full cost of setting up a number of TCP/IP messages and a number of costs for context switching are borne by this single request. In the case where multiple primary key accesses are sent in one batch, those accesses share the cost of setting up the necessary TCP/IP messages and context switches. If the TCP/IP messages are for different destinations, additional TCP/IP messages need to be set up.
Unique key access
Unique key accesses are similar to primary key accesses, except that a unique key access is executed as a read on an index table followed by a primary key access on the table. However, only one request is sent from the MySQL Server, and the read of the index table is handled by ndbd. Such requests also benefit from batching.
Full table scan
When no indexes exist for a lookup on a table, a full table scan is performed. This is sent as a single request to the ndbd process, which then divides the table scan into a set of parallel scans on all cluster ndbd processes. In future versions of MySQL Cluster, an SQL node will be able to filter some of these scans.
Range scan using ordered index
When an ordered index is used, it performs a scan in the same manner as the full table scan, except that it scans only those records which are in the range used by the query transmitted by the MySQL server (SQL node). All partitions are scanned in parallel when all bound index attributes include all attributes in the partitioning key.
To check the base performance of these access methods, we have developed a set of benchmarks. One such benchmark, testReadPerf, tests simple and batched primary and unique key accesses. This benchmark also measures the setup cost of range scans by issuing scans returning a single record. There is also a variant of this benchmark which uses a range scan to fetch a batch of records.
In this way, we can determine the cost of both a single key access and a single record scan access, as well as measure the impact of the communication media used, on base access methods.
In our tests, we ran the base benchmarks for both a normal transporter using TCP/IP sockets and a similar setup using SCI sockets. The figures reported in the following table are for small accesses of 20 records per access. The difference between serial and batched access decreases by a factor of 3 to 4 when using 2KB records instead. SCI Sockets were not tested with 2KB records. Tests were performed on a cluster with 2 data nodes running on 2 dual-CPU machines equipped with AMD MP1900+ processors.
| Access Type | TCP/IP Sockets | SCI Socket |
| Serial pk access | 400 microseconds | 160 microseconds |
| Batched pk access | 28 microseconds | 22 microseconds |
| Serial uk access | 500 microseconds | 250 microseconds |
| Batched uk access | 70 microseconds | 36 microseconds |
| Indexed eq-bound | 1250 microseconds | 750 microseconds |
| Index range | 24 microseconds | 12 microseconds |
We also performed another set of tests to check the performance of SCI Sockets vis-à-vis that of the SCI transporter, and both of these as compared with the TCP/IP transporter. All these tests used primary key accesses either serially and multi-threaded, or multi-threaded and batched.
The tests showed that SCI sockets were about 100% faster than TCP/IP. The SCI transporter was faster in most cases compared to SCI sockets. One notable case occurred with many threads in the test program, which showed that the SCI transporter did not perform very well when used for the mysqld process.
Our overall conclusion was that, for most benchmarks, using SCI sockets improves performance by approximately 100% over TCP/IP, except in rare instances when communication performance is not an issue. This can occur when scan filters make up most of processing time or when very large batches of primary key accesses are achieved. In that case, the CPU processing in the ndbd processes becomes a fairly large part of the overhead.
Using the SCI transporter instead of SCI Sockets is only of interest in communicating between ndbd processes. Using the SCI transporter is also only of interest if a CPU can be dedicated to the ndbd process because the SCI transporter ensures that this process will never go to sleep. It is also important to ensure that the ndbd process priority is set in such a way that the process does not lose priority due to running for an extended period of time, as can be done by locking processes to CPUs in Linux 2.6. If such a configuration is possible, the ndbd process will benefit by 10–70% as compared with using SCI sockets. (The larger figures will be seen when performing updates and probably on parallel scan operations as well.)
There are several other optimized socket implementations for computer clusters, including Myrinet, Gigabit Ethernet, Infiniband and the VIA interface. We have tested MySQL Cluster so far only with SCI sockets. See Section 15.10.1, “Configuring MySQL Cluster to use SCI Sockets” for information on how to set up SCI sockets using ordinary TCP/IP for MySQL Cluster.
- 15.11.1. Non-Compliance In SQL Syntax
- 15.11.2. Limits and Differences from Standard MySQL Limits
- 15.11.3. Limits Relating to Transaction Handling
- 15.11.4. Error Handling
- 15.11.5. Limits Associated with Database Objects
- 15.11.6. Unsupported Or Missing Features
- 15.11.7. Limitations Relating to Performance
- 15.11.8. Issues Exclusive to MySQL Cluster
- 15.11.9. Limitations Relating to Multiple Cluster Nodes
- 15.11.10. Previous MySQL Cluster Issues Resolved in MySQL 5.1
In the sections that follow, we discuss known limitations in MySQL
5.0 Cluster releases as compared with the features
available when using the MyISAM and
InnoDB storage engines. Currently, there are no
plans to address these in coming releases of MySQL
5.0; however, we will attempt to supply fixes for
these issues in subsequent release series. If you check the
“Cluster” category in the MySQL bugs database at
http://bugs.mysql.com, you can find known bugs
which (if marked “5.0”) we intend to
correct in upcoming releases of MySQL 5.0.
This information is intended to be complete with respect to the conditions just set forth. You can report any discrepancies that you encounter to the MySQL bugs database using the instructions given in Section 1.8, “How to Report Bugs or Problems”. If we do not plan to fix the problem in MySQL 5.0, we will add it to the list.
See Section 15.11.10, “Previous MySQL Cluster Issues Resolved in MySQL 5.1” for a list of issues in MySQL Cluster in MySQL 4.1 that have been resolved in the current version.
Some SQL statements relating to certain MySQL features produce
errors when used with NDB tables, as
described in the following list:
Temporary tables. Temporary tables are not supported. Trying either to create a temporary table that uses the
NDBstorage engine or to alter an existing temporary table to useNDBfails with the error Table storage engine 'ndbcluster' does not support the create option 'TEMPORARY'.Indexes and keys in
NDBtables. Keys and indexes on MySQL Cluster tables are subject to the following limitations:TEXTandBLOBcolumns. You cannot create indexes onNDBtable columns that use any of theTEXTorBLOBdata types.FULLTEXTindexes. TheNDBstorage engine does not supportFULLTEXTindexes, which are possible forMyISAMtables only.However, you can create indexes on
VARCHARcolumns ofNDBtables.BITcolumns. ABITcolumn cannot be a primary key, unique key, or index, nor can it be part of a composite primary key, unique key, or index.AUTO_INCREMENTcolumns. Like other MySQL storage engines, theNDBstorage engine can handle a maximum of oneAUTO_INCREMENTcolumn per table. However, in the case of a Cluster table with no explicit primary key, anAUTO_INCREMENTcolumn is automatically defined and used as a “hidden” primary key. For this reason, you cannot define a table that has an explicitAUTO_INCREMENTcolumn unless that column is also declared using thePRIMARY KEYoption. Attempting to create a table with anAUTO_INCREMENTcolumn that is not the table's primary key, and using theNDBstorage engine, fails with an error.
MySQL Cluster and geometry data types. Geometry datatypes (
WKTandWKB) are supported inNDBtables in MySQL 5.0. However, spatial indexes are not supported.auto_increment_incrementandauto_increment_offset. Theauto_increment_incrementandauto_increment_offsetserver system variables are not supported for Cluster replication.
In this section, we list limits found in MySQL Cluster that either differ from limits found in, or that are not found in, standard MySQL.
Memory usage and recovery. Memory comsumed when data is inserted into an
NDBtable is not automatically recovered when deleted, as it is with other storage engines. Instead, the following rules hold true:A
DELETEstatement on anNDBtable makes the memory formerly used by the deleted rows available for re-use by inserts on the same table only. This memory cannot be used by otherNDBtables.A
DROP TABLEorTRUNCATEoperation on anNDBtable frees the memory that was used by this table for re-use by anyNDBtable, either by the same table or by anotherNDBtable.Note
Recall that
TRUNCATEdrops and re-creates the table. See Section 13.2.9, “TRUNCATESyntax”.Memory freed by
DELETEoperations but still allocated to a specific table can also be made available for general re-use by performing a rolling restart of the cluster. See Section 15.5.1, “Performing a Rolling Restart of the Cluster”.Limits imposed by the cluster's configuration. A number of hard limits exist which are configurable, but available main memory in the cluster sets limits. See the complete list of configuration parameters in Section 15.4.4, “Configuration File”. Most configuration parameters can be upgraded online. These hard limits include:
Database memory size and index memory size (
DataMemoryandIndexMemory, respectively).DataMemoryis allocated as 32KB pages. As eachDataMemorypage is used, it is assigned to a specific table; once allocated, this memory cannot be freed except by dropping the table.See Section 15.4.4.5, “Defining Data Nodes”, for further information about
DataMemoryandIndexMemory.The maximum number of operations that can be performed per transaction is set using the configuration parameters
MaxNoOfConcurrentOperationsandMaxNoOfLocalOperations.Note
Bulk loading,
TRUNCATE TABLE, andALTER TABLEare handled as special cases by running multiple transactions, and so are not subject to this limitation.Different limits related to tables and indexes. For example, the maximum number of ordered indexes per table is determined by
MaxNoOfOrderedIndexes.
Memory usage. All Cluster table rows are of fixed length. This means (for example) that if a table has one or more
VARCHARfields containing only relatively small values, more memory and disk space is required when using theNDBstorage engine than would be the case for the same table and data using theMyISAMengine. (In other words, in the case of aVARCHARcolumn, the column requires the same amount of storage as aCHARcolumn of the same size.)Node and data object maximums. The following limits apply to numbers of cluster nodes and metadata objects:
The maximum number of data nodes is 48.
A data node cannot have a node ID greater than 49.
The total maximum number of nodes in a MySQL Cluster is 63. This number includes all SQL nodes (MySQL Servers), API nodes (applications accessing the cluster other than MySQL servers), data nodes, and management servers.
The maximum number of metadata objects in MySQL 5.0 Cluster 20320. This limit is hard-coded.
A number of limitations exist in MySQL Cluster with regard to the handling of transactions. These include the following:
Transaction isolation level. The
NDBCLUSTERstorage engine supports only theREAD COMMITTEDtransaction isolation level. (InnoDB, for example, supportsREAD COMMITTED,READ UNCOMMITTED,REPEATABLE READ, andSERIALIZABLE.) See Section 15.8.5, “Backup Troubleshooting”, for information on how this can affect backing up and restoring Cluster databases.)Important
If a
SELECTfrom a Cluster table includes aBLOBorTEXTcolumn, theREAD COMMITTEDtransaction isolation level is converted to a read with read lock. This is done to guarantee consistency, due to the fact that parts of the values stored in columns of these types are actually read from a separate table.Rollbacks. There is no partial rollback of transactions. A duplicate key or similar error rolls back the entire transaction.
Transactions and memory usage. As noted elsewhere in this chapter, MySQL Cluster does not handle large transactions well; it is better to perform a number of small transactions with a few operations each than to attempt a single large transaction containing a great many operations. Among other considerations, large transactions require very large amounts of memory. Because of this, the transactional behaviour of a number of MySQL statements is effected as described in the following list:
TRUNCATEis not transactional when used onNDBtables. If aTRUNCATEfails to empty the table, then it must be re-run until it is successful.DELETE FROM(even with noWHEREclause) is transactional. For tables containing a great many rows, you may find that performance is improved by using severalDELETE FROM ... LIMIT ...statements to “chunk” the delete operation. If your objective is to empty the table, then you may wish to useTRUNCATEinstead.LOAD DATAstatements.LOAD DATA INFILEis not transactional when used onNDBtables.Important
When executing a
LOAD DATA INFILEstatement, theNDBengine performs commits at irregular intervals that enable better utilization of the communication network. It is not possible to know ahead of time when such commits take place.LOAD DATA FROM MASTERis not supported in MySQL Cluster.ALTER TABLEand transactions. When copying anNDBtable as part of anALTER TABLE, the creation of the copy is non-transactional. (In any case, this operation is rolled back when the copy is deleted.)
Starting, stopping, or restarting a node may give rise to temporary errors causing some transactions to fail. These include the following cases:
Temporary errors. When first starting a node, it is possible that you may see Error 1204 Temporary failure, distribution changed and similar temporary errors.
Errors due to node failure. The stopping or failure of any data node can result in a number of different node failure errors. (However, there should be no aborted transactions when performing a planned shutdown of the cluster.)
In either of these cases, any errors that are generated must be handled within the application. This should be done by retrying the transaction.
See also Section 15.11.2, “Limits and Differences from Standard MySQL Limits”.
Some database objects such as tables and indexes have different
limitations when using the NDBCLUSTER storage
engine:
Identifiers. Database names, table names and attribute names cannot be as long in
NDBtables as when using other table handlers. Attribute names are truncated to 31 characters, and if not unique after truncation give rise to errors. Database names and table names can total a maximum of 122 characters. In other words, the maximum length for anNDBtable name is 122 characters, less the number of characters in the name of the database of which that table is a part.Number of tables. The maximum number of tables in a Cluster database in MySQL 5.0 is limited to 1792.
Attributes per table. The maximum number of attributes (that is, columns and indexes) per table is limited to 128.
Attributes per key. The maximum number of attributes per key is 32.
Row size. The maximum permitted size of any one row is 8KB. Note that each
BLOBorTEXTcolumn contributes 256 + 8 = 264 bytes towards this total.
A number of features supported by other storage engines are not
supported for NDB tables. Trying to use any
of these features in MySQL Cluster does not cause errors in or
of itself; however, errors may occur in applications that
expects the features to be supported or enforced:
Foreign key constraints. The foreign key construct is ignored, just as it is in
MyISAMtables.OPTIMIZEoperations.OPTIMIZEoperations are not supported.LOAD TABLE ... FROM MASTER.LOAD TABLE ... FROM MASTERis not supported.Savepoints and rollbacks. Savepoints and rollbacks to savepoints are ignored as in
MyISAM.Durability of commits. There are no durable commits on disk. Commits are replicated, but there is no guarantee that logs are flushed to disk on commit.
Replication. Replication is not supported.
Note
See Section 15.11.3, “Limits Relating to Transaction Handling”,
for more information relating to limitations on transaction
handling in NDB.
The following performance issues are specific to or especially pronounced in MySQL Cluster:
Range scans. There are query performance issues due to sequential access to the
NDBstorage engine; it is also relatively more expensive to do many range scans than it is with eitherMyISAMorInnoDB.Reliability of
Records in range. TheRecords in rangestatistic is available but is not completely tested or officially supported. This may result in non-optimal query plans in some cases. If necessary, you can employUSE INDEXorFORCE INDEXto alter the execution plan. See Section 13.2.7.2, “Index Hint Syntax”, for more information on how to do this.Unique hash indexes. Unique hash indexes created with
USING HASHcannot be used for accessing a table ifNULLis given as part of the key.
The following are limitations specific to the
NDBCLUSTER storage engine:
Machine architecture. The following issues relate to physical architecture of cluster hosts:
All machines used in the cluster must have the same architecture. That is, all machines hosting nodes must be either big-endian or little-endian, and you cannot use a mixture of both. For example, you cannot have a management node running on a PowerPC which directs a data node that is running on an x86 machine. This restriction does not apply to machines simply running mysql or other clients that may be accessing the cluster's SQL nodes.
Adding and dropping of data nodes. Online adding or dropping of data nodes is not currently possible. In such cases, the entire cluster must be restarted.
Backup and restore between architectures. It is also not possible to perform a Cluster backup and restore between different architectures. For example, you cannot back up a cluster running on a big-endian platform and then restore from that backup to a cluster running on a little-endian system. (Bug#19255)
Online schema changes. It is not possible to make online schema changes such as those accomplished using
ALTER TABLEorCREATE INDEX, as theNDB Clusterengine does not support autodiscovery of such changes. (However, you can import or create a table that uses a different storage engine, and then convert it toNDBusingALTER TABLE. In such a case, you must issue atbl_nameENGINE=NDBCLUSTERFLUSH TABLESstatement to force the cluster to pick up the change.)Binary logging. MySQL Cluster has the following limitations or restrictions with regard to binary logging:
SQL_LOG_BINhas no effect on data operations; however, it is supported for schema operations.MySQL Cluster cannot produce a binlog for tables having
BLOBcolumns but no primary key.Only the following schema operations are logged in a cluster binlog which is not on the mysqld executing the statement:
CREATE TABLEALTER TABLEDROP TABLECREATE DATABASE/CREATE SCHEMADROP DATABASE/DROP SCHEMA
See also Section 15.11.9, “Limitations Relating to Multiple Cluster Nodes”.
Multiple SQL nodes.
The following are issues relating to the use of multiple MySQL
servers as MySQL Cluster SQL nodes, and are specific to the
NDBCLUSTER storage engine:
ALTER TABLEoperations.ALTER TABLEis not fully locking when running multiple MySQL servers (no distributed table lock).Replication. MySQL replication will not work correctly if updates are done on multiple MySQL servers. However, if the database partitioning scheme is done at the application level and no transactions take place across these partitions, replication can be made to work.
Database autodiscovery. Autodiscovery of databases is not supported for multiple MySQL servers accessing the same MySQL Cluster. However, autodiscovery of tables is supported in such cases. What this means is that after a database named
db_nameis created or imported using one MySQL server, you should issue aCREATE DATABASEstatement on each additional MySQL server that accesses the same MySQL Cluster. (As of MySQL 5.0.2, you may also usedb_nameCREATE SCHEMA.) Once this has been done for a given MySQL server, that server should be able to detect the database tables without error.db_nameDDL operations. DDL operations are not node failure safe. If a node fails while trying to peform one of these (such as
CREATE TABLEorALTER TABLE), the data dictionary is locked and no further DDL statements can be executed without restarting the cluster.
Multiple management nodes. When using multiple management servers:
You must give nodes explicit IDs in connectstrings because automatic allocation of node IDs does not work across multiple management servers.
You must take extreme care to have the same configurations for all management servers. No special checks for this are performed by the cluster.
Prior to MySQL 5.0.14, all data nodes had to be restarted after bringing up the cluster in order for the management nodes to be able to see one another.
Multiple data node processes. While it is possible to run multiple cluster processes concurrently on a single host, it is not always advisable to do so for reasons of performance and high availability, as well as other considerations. In particular, in MySQL 5.0, we do not support for production use any MySQL Cluster deployment in which more than one ndbd process is run on a single physical machine.
Note
We may support multiple data nodes per host in a future MySQL release, following additional testing. However, in MySQL 5.0, such configurations can be considered experimental only.
Multiple network addresses. Multiple network addresses per data node are not supported. Use of these is liable to cause problems: In the event of a data node failure, an SQL node waits for confirmation that the data node went down but never receives it because another route to that data node remains open. This can effectively make the cluster inoperable.
Note
It is possible to use multiple network hardware
interfaces (such as Ethernet cards)
for a single data node, but these must be bound to the
same address. This also means that it not possible to use
more than one [TCP] section per
connection in the config.ini file. See
Section 15.4.4.7, “Cluster TCP/IP Connections”, for more
information.
The following Cluster limitations in MySQL 4.1 have been resolved in MySQL 5.0 as shown below:
Character set support. The
NDB Clusterstorage engine supports all character sets and collations available in MySQL 5.0.Character set directory. Beginning with MySQL 5.0.21, it is possible to install MySQL with Cluster support to a non-default location and change the search path for font description files using either the
--basediror--character-sets-diroptions. (Previously, ndbd in MySQL 5.0 searched only the default path — typically/usr/local/mysql/share/mysql/charsets— for character sets.)Metadata objects. Prior to MySQL 5.0.6, the maximum number of metadata objects possible was 1600. Beginning with MySQL 5.0.6, this limit is increased to 20320.
Column indexes using prefixes. MySQL Cluster in MySQL 5.0 supports column indexes that make use of prefixes.
Query cache. Unlike the case in MySQL 4.1, the Cluster storage engine in MySQL 5.0 supports MySQL's query cache. See Section 5.13, “The MySQL Query Cache”.
IGNOREandREPLACEfunctionality. In MySQL 5.0.19 and earlier,INSERT IGNORE,UPDATE IGNORE, andREPLACEwere supported only for primary keys, but not for unique keys. It was possible to work around this issue by removing the constraint, then dropping the unique index, performing any inserts, and then adding the unique index again.This limitation was removed for
INSERT IGNOREandREPLACEin MySQL 5.0.20. (See Bug#17431.)
In this section, we discuss changes in the implementation of MySQL Cluster in MySQL 5.0 as compared to MySQL 4.1. We will also discuss our roadmap for further improvements to MySQL Cluster as currently planned for MySQL 5.1.
There are relatively few changes between the NDB Cluster storage engine implementations in MySQL 4.1 and in 5.0, so the upgrade path should be relatively quick and painless.
All significantly new features being developed for MySQL Cluster are going into the MySQL 5.1 and 5.2 trees. For information on changes in the Cluster implementations in MySQL versions 5.1 and later, see http://dev.mysql.com/doc/refman/5.1/en/ndbcluster.html.
MySQL Cluster in versions 5.0.3-beta and later contains a number of new features that are likely to be of interest:
Push-Down Conditions: Consider the following query:
SELECT * FROM t1 WHERE non_indexed_attribute = 1;
This query will use a full table scan and the condition will be evaluated in the cluster's data nodes. Thus, it is not necessary to send the records across the network for evaluation. (That is, function transport is used, rather than data transport.) Please note that this feature is currently disabled by default (pending more thorough testing), but it should work in most cases. This feature can be enabled through the use of the
SET engine_condition_pushdown = Onstatement. Alternatively, you can run mysqld with the this feature enabled by starting the MySQL server with the--engine-condition-pushdownoption.A major benefit of this change is that queries can be executed in parallel. This means that queries against non-indexed columns can run faster than previously by a factor of as much as 5 to 10 times, times the number of data nodes, because multiple CPUs can work on the query in parallel.
You can use
EXPLAINto determine when condition pushdown is being used. See Section 7.2.1, “Optimizing Queries withEXPLAIN”.Decreased
IndexMemoryUsage: In MySQL 5.0, each record consumes approximately 25 bytes of index memory, and every unique index uses 25 bytes per record of index memory (in addition to some data memory because these are stored in a separate table). This is because the primary key is not stored in the index memory anymore.Query Cache Enabled for MySQL Cluster: See Section 5.13, “The MySQL Query Cache”, for information on configuring and using the query cache.
New Optimizations: One optimization that merits particular attention is that a batched read interface is now used in some queries. For example, consider the following query:
SELECT * FROM t1 WHERE
primary_keyIN (1,2,3,4,5,6,7,8,9,10);This query will be executed 2 to 3 times more quickly than in previous MySQL Cluster versions due to the fact that all 10 key lookups are sent in a single batch rather than one at a time.
Limit On Number of Metadata Objects: Beginning with MySQL 5.0.6, each Cluster database may contain a maximum of 20320 metadata objects — this includes database tables, system tables, indexes and
BLOBvalues. (Previously, this number was 1600.)
What is said here is a status report based on recent commits to the MySQL 5.1 source tree. It should be noted all 5.1 development is subject to change.
There are currently 4 major new features being developed for MySQL 5.1:
Integration of MySQL Cluster into MySQL replication: This will make it possible to update from any MySQL Server in the cluster and still have the MySQL Replication handled by one of the MySQL Servers in the cluster, with the state of the slave side remaining consistent with the cluster acting as the master.
Support for disk-based records: Records on disk will be supported. Indexed fields including the primary key hash index must still be stored in RAM but all other fields can be on disk.
Variable-sized records: A column defined as
VARCHAR(255)currently uses 260 bytes of storage independent of what is stored in any particular record. In MySQL 5.1 Cluster tables, only the portion of the column actually taken up by the record will be stored. This will make possible a reduction in space requirements for such columns by a factor of 5 in many cases.User-defined partitioning: Users will be able to define partitions based on columns that are part of the primary key. The MySQL Server will be able to discover whether it is possible to prune away some of the partitions from the
WHEREclause. Partitioning based onKEY,HASH,RANGE, andLISThandlers will be possible, as well as subpartitioning. This feature should also be available for many other handlers, and not onlyNDB Cluster.
In addition, we are working to increase the 8KB size limit for
rows containing columns of types other than
BLOB or TEXT in Cluster
tables. This is due to the fact that rows are currently fixed in
size and the page size is 32,768 bytes (minus 128 bytes for the
row header). Currently, this means that if we allowed more than
8KB per record, any remaining space (up to approximately 14,000
bytes) would be left empty. In MySQL 5.1, we plan to fix this
limitation so that using more than 8KB in a given row does not
result in the remainder of the page being wasted.
The following terms are useful to an understanding of MySQL Cluster or have specialized meanings when used in relation to it.
Cluster:
In its generic sense, a cluster is a set of computers functioning as a unit and working together to accomplish a single task.
NDB Cluster:This is the storage engine used in MySQL to implement data storage, retrieval, and management distributed among several computers.
MySQL Cluster:
This refers to a group of computers working together using the
NDBstorage engine to support a distributed MySQL database in a shared-nothing architecture using in-memory storage.Configuration files:
Text files containing directives and information regarding the cluster, its hosts, and its nodes. These are read by the cluster's management nodes when the cluster is started. See Section 15.4.4, “Configuration File”, for details.
Backup:
A complete copy of all cluster data, transactions and logs, saved to disk or other long-term storage.
Restore:
Returning the cluster to a previous state, as stored in a backup.
Checkpoint:
Generally speaking, when data is saved to disk, it is said that a checkpoint has been reached. More specific to Cluster, it is a point in time where all committed transactions are stored on disk. With regard to the
NDBstorage engine, there are two types of checkpoints which work together to ensure that a consistent view of the cluster's data is maintained:Local Checkpoint (LCP):
This is a checkpoint that is specific to a single node; however, LCP's take place for all nodes in the cluster more or less concurrently. An LCP involves saving all of a node's data to disk, and so usually occurs every few minutes. The precise interval varies, and depends upon the amount of data stored by the node, the level of cluster activity, and other factors.
Global Checkpoint (GCP):
A GCP occurs every few seconds, when transactions for all nodes are synchronized and the redo-log is flushed to disk.
Cluster host:
A computer making up part of a MySQL Cluster. A cluster has both a physical structure and a logical structure. Physically, the cluster consists of a number of computers, known as cluster hosts (or more simply as hosts. See also Node and Node group below.
Node:
This refers to a logical or functional unit of MySQL Cluster, and is sometimes also referred to as a cluster node. In the context of MySQL Cluster, we use the term “node” to indicate a process rather than a physical component of the cluster. There are three node types required to implement a working MySQL Cluster:
Management (MGM) nodes:
Manages the other nodes within the MySQL Cluster. It provides configuration data to the other nodes; starts and stops nodes; handles network partitioning; creates backups and restores from them, and so forth.
SQL (MySQL server) nodes:
Instances of MySQL Server which serve as front ends to data kept in the cluster's data nodes. Clients desiring to store, retrieve, or update data can access an SQL node just as they would any other MySQL Server, employing the usual authentication methods and API's; the underlying distribution of data between node groups is transparent to users and applications. SQL nodes access the cluster's databases as a whole without regard to the data's distribution across different data nodes or cluster hosts.
Data nodes:
These nodes store the actual data. Table data fragments are stored in a set of node groups; each node group stores a different subset of the table data. Each of the nodes making up a node group stores a replica of the fragment for which that node group is responsible. Currently, a single cluster can support up to 48 data nodes total.
It is possible for more than one node to co-exist on a single machine. (In fact, it is even possible to set up a complete cluster on one machine, although one would almost certainly not want to do this in a production environment.) It may be helpful to remember that, when working with MySQL Cluster, the term host refers to a physical component of the cluster whereas a node is a logical or functional component (that is, a process).
Note Regarding Terms: In older versions of the MySQL Cluster documentation, data nodes were sometimes referred to as “database nodes”. The term “storage nodes” has also been used. In addition, SQL nodes were sometimes known as “client nodes”. This older terminology has been deprecated to minimize confusion, and for this reason should be avoided. They are also often referred to as “API nodes” — an SQL node is actually an API node that provides an SQL interface to the cluster.
Node group:
A set of data nodes. All data nodes in a node group contain the same data (fragments), and all nodes in a single group should reside on different hosts. It is possible to control which nodes belong to which node groups.
For more information, see Section 15.2.1, “MySQL Cluster Nodes, Node Groups, Replicas, and Partitions”.
Node failure:
MySQL Cluster is not solely dependent upon the functioning of any single node making up the cluster; the cluster can continue to run if one or more nodes fail. The precise number of node failures that a given cluster can tolerate depends upon the number of nodes and the cluster's configuration.
Node restart:
The process of restarting a failed cluster node.
Initial node restart:
The process of starting a cluster node with its filesystem removed. This is sometimes used in the course of software upgrades and in other special circumstances.
System crash (or system failure):
This can occur when so many cluster nodes have failed that the cluster's state can no longer be guaranteed.
System restart:
The process of restarting the cluster and reinitializing its state from disk logs and checkpoints. This is required after either a planned or an unplanned shutdown of the cluster.
Fragment:
A portion of a database table; in the
NDBstorage engine, a table is broken up into and stored as a number of fragments. A fragment is sometimes also called a “partition”; however, “fragment” is the preferred term. Tables are fragmented in MySQL Cluster in order to facilitate load balancing between machines and nodes.Replica:
Under the
NDBstorage engine, each table fragment has number of replicas stored on other data nodes in order to provide redundancy. Currently, there may be up four replicas per fragment.Transporter:
A protocol providing data transfer between nodes. MySQL Cluster currently supports four different types of transporter connections:
TCP/IP
This is, of course, the familiar network protocol that underlies HTTP, FTP (and so on) on the Internet. TCP/IP can be used for both local and remote connections.
SCI
Scalable Coherent Interface is a high-speed protocol used in building multiprocessor systems and parallel-processing applications. Use of SCI with MySQL Cluster requires specialized hardware, as discussed in Section 15.10.1, “Configuring MySQL Cluster to use SCI Sockets”. For a basic introduction to SCI, see this essay at dolphinics.com.
SHM
Unix-style shared memory segments. Where supported, SHM is used automatically to connect nodes running on the same host. The Unix man page for
shmop(2)is a good place to begin obtaining additional information about this topic.
Note: The cluster transporter is internal to the cluster. Applications using MySQL Cluster communicate with SQL nodes just as they do with any other version of MySQL Server (via TCP/IP, or through the use of Unix socket files or Windows named pipes). Queries can be sent and results retrieved using the standard MySQL client APIs.
NDB:This stands for Network Database, and refers to the storage engine used to enable MySQL Cluster. The
NDBstorage engine supports all the usual MySQL data types and SQL statements, and is ACID-compliant. This engine also provides full support for transactions (commits and rollbacks).shared-nothing architecture:
The ideal architecture for a MySQL Cluster. In a true shared-nothing setup, each node runs on a separate host. The advantage such an arrangement is that there no single host or node can act as single point of failure or as a performance bottle neck for the system as a whole.
In-memory storage:
All data stored in each data node is kept in memory on the node's host computer. For each data node in the cluster, you must have available an amount of RAM equal to the size of the database times the number of replicas, divided by the number of data nodes. Thus, if the database takes up 1GB of memory, and you want to set up the cluster with four replicas and eight data nodes, a minimum of 500MB memory will be required per node. Note that this is in addition to any requirements for the operating system and any other applications that might be running on the host.
Table:
As is usual in the context of a relational database, the term “table” denotes a set of identically structured records. In MySQL Cluster, a database table is stored in a data node as a set of fragments, each of which is replicated on additional data nodes. The set of data nodes replicating the same fragment or set of fragments is referred to as a node group.
Cluster programs:
These are command-line programs used in running, configuring, and administering MySQL Cluster. They include both server daemons:
ndbd:
The data node daemon (runs a data node process)
ndb_mgmd:
The management server daemon (runs a management server process)
and client programs:
ndb_mgm:
The management client (provides an interface for executing management commands)
ndb_waiter:
Used to verify status of all nodes in a cluster
ndb_restore:
Restores cluster data from backup
For more about these programs and their uses, see Section 15.6, “Process Management in MySQL Cluster”.
Event log:
MySQL Cluster logs events by category (startup, shutdown, errors, checkpoints, and so on), priority, and severity. A complete listing of all reportable events may be found in Section 15.7.3, “Event Reports Generated in MySQL Cluster”. Event logs are of two types:
Cluster log:
Keeps a record of all desired reportable events for the cluster as a whole.
Node log:
A separate log which is also kept for each individual node.
Under normal circumstances, it is necessary and sufficient to keep and examine only the cluster log. The node logs need be consulted only for application development and debugging purposes.
Table of Contents
- 16.1. Introduction to MySQL Spatial Support
- 16.2. The OpenGIS Geometry Model
- 16.2.1. The Geometry Class Hierarchy
- 16.2.2. Class
Geometry - 16.2.3. Class
Point - 16.2.4. Class
Curve - 16.2.5. Class
LineString - 16.2.6. Class
Surface - 16.2.7. Class
Polygon - 16.2.8. Class
GeometryCollection - 16.2.9. Class
MultiPoint - 16.2.10. Class
MultiCurve - 16.2.11. Class
MultiLineString - 16.2.12. Class
MultiSurface - 16.2.13. Class
MultiPolygon
- 16.3. Supported Spatial Data Formats
- 16.4. Creating a Spatially Enabled MySQL Database
- 16.5. Analyzing Spatial Information
- 16.5.1. Geometry Format Conversion Functions
- 16.5.2.
GeometryFunctions - 16.5.3. Functions That Create New Geometries from Existing Ones
- 16.5.4. Functions for Testing Spatial Relations Between Geometric Objects
- 16.5.5. Relations on Geometry Minimal Bounding Rectangles (MBRs)
- 16.5.6. Functions That Test Spatial Relationships Between Geometries
- 16.6. Optimizing Spatial Analysis
- 16.7. MySQL Conformance and Compatibility
MySQL supports spatial extensions to allow the generation, storage,
and analysis of geographic features. Before MySQL 5.0.16, these
features are available for MyISAM tables only. As
of MySQL 5.0.16, InnoDB, NDB,
BDB, and ARCHIVE also support
spatial features.
For spatial columns, MyISAM supports both
SPATIAL and non-SPATIAL
indexes. Other storage engines support
non-SPATIAL indexes, as described in
Section 13.1.4, “CREATE INDEX Syntax”.
This chapter covers the following topics:
The basis of these spatial extensions in the OpenGIS geometry model
Data formats for representing spatial data
How to use spatial data in MySQL
Use of indexing for spatial data
MySQL differences from the OpenGIS specification
Additional resources
The Open Geospatial Consortium publishes the OpenGIS® Simple Features Specifications For SQL, a document that proposes several conceptual ways for extending an SQL RDBMS to support spatial data. This specification is available from the OGC Web site at http://www.opengis.org/docs/99-049.pdf.
If you have questions or concerns about the use of the spatial extensions to MySQL, you can discuss them in the GIS forum: http://forums.mysql.com/list.php?23.
MySQL implements spatial extensions following the specification of the Open Geospatial Consortium (OGC). This is an international consortium of more than 250 companies, agencies, and universities participating in the development of publicly available conceptual solutions that can be useful with all kinds of applications that manage spatial data. The OGC maintains a Web site at http://www.opengis.org/.
In 1997, the Open Geospatial Consortium published the OpenGIS® Simple Features Specifications For SQL, a document that proposes several conceptual ways for extending an SQL RDBMS to support spatial data. This specification is available from the OGC Web site at http://www.opengis.org/docs/99-049.pdf. It contains additional information relevant to this chapter.
MySQL implements a subset of the SQL with Geometry Types environment proposed by OGC. This term refers to an SQL environment that has been extended with a set of geometry types. A geometry-valued SQL column is implemented as a column that has a geometry type. The specification describe a set of SQL geometry types, as well as functions on those types to create and analyze geometry values.
A geographic feature is anything in the world that has a location. A feature can be:
An entity. For example, a mountain, a pond, a city.
A space. For example, a postcode area, the tropics.
A definable location. For example, a crossroad, as a particular place where two streets intersect.
Some documents use the term geospatial feature to refer to geographic features.
Geometry is another word that denotes a geographic feature. Originally the word geometry meant measurement of the earth. Another meaning comes from cartography, referring to the geometric features that cartographers use to map the world.
This chapter uses all of these terms synonymously: geographic feature, geospatial feature, feature, or geometry. Here, the term most commonly used is geometry, defined as a point or an aggregate of points representing anything in the world that has a location.
- 16.2.1. The Geometry Class Hierarchy
- 16.2.2. Class
Geometry - 16.2.3. Class
Point - 16.2.4. Class
Curve - 16.2.5. Class
LineString - 16.2.6. Class
Surface - 16.2.7. Class
Polygon - 16.2.8. Class
GeometryCollection - 16.2.9. Class
MultiPoint - 16.2.10. Class
MultiCurve - 16.2.11. Class
MultiLineString - 16.2.12. Class
MultiSurface - 16.2.13. Class
MultiPolygon
The set of geometry types proposed by OGC's SQL with Geometry Types environment is based on the OpenGIS Geometry Model. In this model, each geometric object has the following general properties:
It is associated with a Spatial Reference System, which describes the coordinate space in which the object is defined.
It belongs to some geometry class.
The geometry classes define a hierarchy as follows:
Geometry(non-instantiable)Point(instantiable)Curve(non-instantiable)LineString(instantiable)LineLinearRing
Surface(non-instantiable)Polygon(instantiable)
GeometryCollection(instantiable)MultiPoint(instantiable)MultiCurve(non-instantiable)MultiLineString(instantiable)
MultiSurface(non-instantiable)MultiPolygon(instantiable)
It is not possible to create objects in non-instantiable classes. It is possible to create objects in instantiable classes. All classes have properties, and instantiable classes may also have assertions (rules that define valid class instances).
Geometry is the base class. It is an abstract
class. The instantiable subclasses of
Geometry are restricted to zero-, one-, and
two-dimensional geometric objects that exist in two-dimensional
coordinate space. All instantiable geometry classes are defined
so that valid instances of a geometry class are topologically
closed (that is, all defined geometries include their boundary).
The base Geometry class has subclasses for
Point, Curve,
Surface, and
GeometryCollection:
Pointrepresents zero-dimensional objects.Curverepresents one-dimensional objects, and has subclassLineString, with sub-subclassesLineandLinearRing.Surfaceis designed for two-dimensional objects and has subclassPolygon.GeometryCollectionhas specialized zero-, one-, and two-dimensional collection classes namedMultiPoint,MultiLineString, andMultiPolygonfor modeling geometries corresponding to collections ofPoints,LineStrings, andPolygons, respectively.MultiCurveandMultiSurfaceare introduced as abstract superclasses that generalize the collection interfaces to handleCurvesandSurfaces.
Geometry, Curve,
Surface, MultiCurve, and
MultiSurface are defined as non-instantiable
classes. They define a common set of methods for their
subclasses and are included for extensibility.
Point, LineString,
Polygon,
GeometryCollection,
MultiPoint,
MultiLineString, and
MultiPolygon are instantiable classes.
Geometry is the root class of the hierarchy.
It is a non-instantiable class but has a number of properties
that are common to all geometry values created from any of the
Geometry subclasses. These properties are
described in the following list. Particular subclasses have
their own specific properties, described later.
Geometry Properties
A geometry value has the following properties:
Its type. Each geometry belongs to one of the instantiable classes in the hierarchy.
Its SRID, or Spatial Reference Identifier. This value identifies the geometry's associated Spatial Reference System that describes the coordinate space in which the geometry object is defined.
In MySQL, the SRID value is just an integer associated with the geometry value. All calculations are done assuming Euclidean (planar) geometry.
Its coordinates in its Spatial Reference System, represented as double-precision (eight-byte) numbers. All non-empty geometries include at least one pair of (X,Y) coordinates. Empty geometries contain no coordinates.
Coordinates are related to the SRID. For example, in different coordinate systems, the distance between two objects may differ even when objects have the same coordinates, because the distance on the planar coordinate system and the distance on the geocentric system (coordinates on the Earth's surface) are different things.
Its interior, boundary, and exterior.
Every geometry occupies some position in space. The exterior of a geometry is all space not occupied by the geometry. The interior is the space occupied by the geometry. The boundary is the interface between the geometry's interior and exterior.
Its MBR (Minimum Bounding Rectangle), or Envelope. This is the bounding geometry, formed by the minimum and maximum (X,Y) coordinates:
((MINX MINY, MAXX MINY, MAXX MAXY, MINX MAXY, MINX MINY))
Whether the value is simple or non-simple. Geometry values of types (
LineString,MultiPoint,MultiLineString) are either simple or non-simple. Each type determines its own assertions for being simple or non-simple.Whether the value is closed or not closed. Geometry values of types (
LineString,MultiString) are either closed or not closed. Each type determines its own assertions for being closed or not closed.Whether the value is empty or non-empty A geometry is empty if it does not have any points. Exterior, interior, and boundary of an empty geometry are not defined (that is, they are represented by a
NULLvalue). An empty geometry is defined to be always simple and has an area of 0.Its dimension. A geometry can have a dimension of –1, 0, 1, or 2:
–1 for an empty geometry.
0 for a geometry with no length and no area.
1 for a geometry with non-zero length and zero area.
2 for a geometry with non-zero area.
Pointobjects have a dimension of zero.LineStringobjects have a dimension of 1.Polygonobjects have a dimension of 2. The dimensions ofMultiPoint,MultiLineString, andMultiPolygonobjects are the same as the dimensions of the elements they consist of.
A Point is a geometry that represents a
single location in coordinate space.
Point
Examples
Imagine a large-scale map of the world with many cities. A
Pointobject could represent each city.On a city map, a
Pointobject could represent a bus stop.
Point
Properties
X-coordinate value.
Y-coordinate value.
Pointis defined as a zero-dimensional geometry.The boundary of a
Pointis the empty set.
A Curve is a one-dimensional geometry,
usually represented by a sequence of points. Particular
subclasses of Curve define the type of
interpolation between points. Curve is a
non-instantiable class.
Curve
Properties
A
Curvehas the coordinates of its points.A
Curveis defined as a one-dimensional geometry.A
Curveis simple if it does not pass through the same point twice.A
Curveis closed if its start point is equal to its endpoint.The boundary of a closed
Curveis empty.The boundary of a non-closed
Curveconsists of its two endpoints.A
Curvethat is simple and closed is aLinearRing.
A LineString is a Curve
with linear interpolation between points.
LineString
Examples
On a world map,
LineStringobjects could represent rivers.In a city map,
LineStringobjects could represent streets.
LineString
Properties
A
LineStringhas coordinates of segments, defined by each consecutive pair of points.A
LineStringis aLineif it consists of exactly two points.A
LineStringis aLinearRingif it is both closed and simple.
A Surface is a two-dimensional geometry. It
is a non-instantiable class. Its only instantiable subclass is
Polygon.
Surface
Properties
A
Surfaceis defined as a two-dimensional geometry.The OpenGIS specification defines a simple
Surfaceas a geometry that consists of a single “patch” that is associated with a single exterior boundary and zero or more interior boundaries.The boundary of a simple
Surfaceis the set of closed curves corresponding to its exterior and interior boundaries.
A Polygon is a planar
Surface representing a multisided geometry.
It is defined by a single exterior boundary and zero or more
interior boundaries, where each interior boundary defines a hole
in the Polygon.
Polygon
Examples
On a region map,
Polygonobjects could represent forests, districts, and so on.
Polygon
Assertions
The boundary of a
Polygonconsists of a set ofLinearRingobjects (that is,LineStringobjects that are both simple and closed) that make up its exterior and interior boundaries.A
Polygonhas no rings that cross. The rings in the boundary of aPolygonmay intersect at aPoint, but only as a tangent.A
Polygonhas no lines, spikes, or punctures.A
Polygonhas an interior that is a connected point set.A
Polygonmay have holes. The exterior of aPolygonwith holes is not connected. Each hole defines a connected component of the exterior.
The preceding assertions make a Polygon a
simple geometry.
A GeometryCollection is a geometry that is a
collection of one or more geometries of any class.
All the elements in a GeometryCollection must
be in the same Spatial Reference System (that is, in the same
coordinate system). There are no other constraints on the
elements of a GeometryCollection, although
the subclasses of GeometryCollection
described in the following sections may restrict membership.
Restrictions may be based on:
Element type (for example, a
MultiPointmay contain onlyPointelements)Dimension
Constraints on the degree of spatial overlap between elements
A MultiPoint is a geometry collection
composed of Point elements. The points are
not connected or ordered in any way.
MultiPoint
Examples
On a world map, a
MultiPointcould represent a chain of small islands.On a city map, a
MultiPointcould represent the outlets for a ticket office.
MultiPoint
Properties
A
MultiPointis a zero-dimensional geometry.A
MultiPointis simple if no two of itsPointvalues are equal (have identical coordinate values).The boundary of a
MultiPointis the empty set.
A MultiCurve is a geometry collection
composed of Curve elements.
MultiCurve is a non-instantiable class.
MultiCurve
Properties
A
MultiCurveis a one-dimensional geometry.A
MultiCurveis simple if and only if all of its elements are simple; the only intersections between any two elements occur at points that are on the boundaries of both elements.A
MultiCurveboundary is obtained by applying the “mod 2 union rule” (also known as the “odd-even rule”): A point is in the boundary of aMultiCurveif it is in the boundaries of an odd number ofMultiCurveelements.A
MultiCurveis closed if all of its elements are closed.The boundary of a closed
MultiCurveis always empty.
A MultiLineString is a
MultiCurve geometry collection composed of
LineString elements.
MultiLineString
Examples
On a region map, a
MultiLineStringcould represent a river system or a highway system.
A MultiSurface is a geometry collection
composed of surface elements. MultiSurface is
a non-instantiable class. Its only instantiable subclass is
MultiPolygon.
MultiSurface
Assertions
Two
MultiSurfacesurfaces have no interiors that intersect.Two
MultiSurfaceelements have boundaries that intersect at most at a finite number of points.
A MultiPolygon is a
MultiSurface object composed of
Polygon elements.
MultiPolygon
Examples
On a region map, a
MultiPolygoncould represent a system of lakes.
MultiPolygon
Assertions
A
MultiPolygonhas no twoPolygonelements with interiors that intersect.A
MultiPolygonhas no twoPolygonelements that cross (crossing is also forbidden by the previous assertion), or that touch at an infinite number of points.A
MultiPolygonmay not have cut lines, spikes, or punctures. AMultiPolygonis a regular, closed point set.A
MultiPolygonthat has more than onePolygonhas an interior that is not connected. The number of connected components of the interior of aMultiPolygonis equal to the number ofPolygonvalues in theMultiPolygon.
MultiPolygon
Properties
A
MultiPolygonis a two-dimensional geometry.A
MultiPolygonboundary is a set of closed curves (LineStringvalues) corresponding to the boundaries of itsPolygonelements.Each
Curvein the boundary of theMultiPolygonis in the boundary of exactly onePolygonelement.Every
Curvein the boundary of anPolygonelement is in the boundary of theMultiPolygon.
This section describes the standard spatial data formats that are used to represent geometry objects in queries. They are:
Well-Known Text (WKT) format
Well-Known Binary (WKB) format
Internally, MySQL stores geometry values in a format that is not identical to either WKT or WKB format.
The Well-Known Text (WKT) representation of Geometry is designed to exchange geometry data in ASCII form.
Examples of WKT representations of geometry objects:
A
Point:POINT(15 20)
Note that point coordinates are specified with no separating comma.
A
LineStringwith four points:LINESTRING(0 0, 10 10, 20 25, 50 60)
Note that point coordinate pairs are separated by commas.
A
Polygonwith one exterior ring and one interior ring:POLYGON((0 0,10 0,10 10,0 10,0 0),(5 5,7 5,7 7,5 7, 5 5))
A
MultiPointwith threePointvalues:MULTIPOINT(0 0, 20 20, 60 60)
A
MultiLineStringwith twoLineStringvalues:MULTILINESTRING((10 10, 20 20), (15 15, 30 15))
A
MultiPolygonwith twoPolygonvalues:MULTIPOLYGON(((0 0,10 0,10 10,0 10,0 0)),((5 5,7 5,7 7,5 7, 5 5)))
A
GeometryCollectionconsisting of twoPointvalues and oneLineString:GEOMETRYCOLLECTION(POINT(10 10), POINT(30 30), LINESTRING(15 15, 20 20))
A Backus-Naur grammar that specifies the formal production rules for writing WKT values can be found in the OpenGIS specification document referenced near the beginning of this chapter.
The Well-Known Binary (WKB) representation for geometric values is defined by the OpenGIS specification. It is also defined in the ISO SQL/MM Part 3: Spatial standard.
WKB is used to exchange geometry data as binary streams
represented by BLOB values containing
geometric WKB information.
WKB uses one-byte unsigned integers, four-byte unsigned integers, and eight-byte double-precision numbers (IEEE 754 format). A byte is eight bits.
For example, a WKB value that corresponds to POINT(1
1) consists of this sequence of 21 bytes (each
represented here by two hex digits):
0101000000000000000000F03F000000000000F03F
The sequence may be broken down into these components:
Byte order : 01 WKB type : 01000000 X : 000000000000F03F Y : 000000000000F03F
Component representation is as follows:
The byte order may be either 0 or 1 to indicate little-endian or big-endian storage. The little-endian and big-endian byte orders are also known as Network Data Representation (NDR) and External Data Representation (XDR), respectively.
The WKB type is a code that indicates the geometry type. Values from 1 through 7 indicate
Point,LineString,Polygon,MultiPoint,MultiLineString,MultiPolygon, andGeometryCollection.A
Pointvalue has X and Y coordinates, each represented as a double-precision value.
WKB values for more complex geometry values are represented by more complex data structures, as detailed in the OpenGIS specification.
This section describes the data types you can use for representing spatial data in MySQL, and the functions available for creating and retrieving spatial values.
MySQL has data types that correspond to OpenGIS classes. Some of these types hold single geometry values:
GEOMETRYPOINTLINESTRINGPOLYGON
GEOMETRY can store geometry values of any
type. The other single-value types (POINT,
LINESTRING, and POLYGON)
restrict their values to a particular geometry type.
The other data types hold collections of values:
MULTIPOINTMULTILINESTRINGMULTIPOLYGONGEOMETRYCOLLECTION
GEOMETRYCOLLECTION can store a collection of
objects of any type. The other collection types
(MULTIPOINT,
MULTILINESTRING,
MULTIPOLYGON, and
GEOMETRYCOLLECTION) restrict collection
members to those having a particular geometry type.
This section describes how to create spatial values using Well-Known Text and Well-Known Binary functions that are defined in the OpenGIS standard, and using MySQL-specific functions.
MySQL provides a number of functions that take as input parameters a Well-Known Text representation and, optionally, a spatial reference system identifier (SRID). They return the corresponding geometry.
GeomFromText() accepts a WKT of any
geometry type as its first argument. An implementation also
provides type-specific construction functions for construction
of geometry values of each geometry type.
GeomCollFromText(,wkt[,srid])GeometryCollectionFromText(wkt[,srid])Constructs a
GEOMETRYCOLLECTIONvalue using its WKT representation and SRID.GeomFromText(,wkt[,srid])GeometryFromText(wkt[,srid])Constructs a geometry value of any type using its WKT representation and SRID.
LineFromText(,wkt[,srid])LineStringFromText(wkt[,srid])Constructs a
LINESTRINGvalue using its WKT representation and SRID.MLineFromText(,wkt[,srid])MultiLineStringFromText(wkt[,srid])Constructs a
MULTILINESTRINGvalue using its WKT representation and SRID.MPointFromText(,wkt[,srid])MultiPointFromText(wkt[,srid])Constructs a
MULTIPOINTvalue using its WKT representation and SRID.MPolyFromText(,wkt[,srid])MultiPolygonFromText(wkt[,srid])Constructs a
MULTIPOLYGONvalue using its WKT representation and SRID.Constructs a
POINTvalue using its WKT representation and SRID.PolyFromText(,wkt[,srid])PolygonFromText(wkt[,srid])Constructs a
POLYGONvalue using its WKT representation and SRID.
The OpenGIS specification also defines the following optional
functions, which MySQL does not implement. These functions
construct Polygon or
MultiPolygon values based on the WKT
representation of a collection of rings or closed
LineString values. These values may
intersect.
Constructs a
MultiPolygonvalue from aMultiLineStringvalue in WKT format containing an arbitrary collection of closedLineStringvalues.Constructs a
Polygonvalue from aMultiLineStringvalue in WKT format containing an arbitrary collection of closedLineStringvalues.
MySQL provides a number of functions that take as input
parameters a BLOB containing a Well-Known
Binary representation and, optionally, a spatial reference
system identifier (SRID). They return the corresponding
geometry.
GeomFromWKB() accepts a WKB of any geometry
type as its first argument. An implementation also provides
type-specific construction functions for construction of
geometry values of each geometry type.
GeomCollFromWKB(,wkb[,srid])GeometryCollectionFromWKB(wkb[,srid])Constructs a
GEOMETRYCOLLECTIONvalue using its WKB representation and SRID.GeomFromWKB(,wkb[,srid])GeometryFromWKB(wkb[,srid])Constructs a geometry value of any type using its WKB representation and SRID.
LineFromWKB(,wkb[,srid])LineStringFromWKB(wkb[,srid])Constructs a
LINESTRINGvalue using its WKB representation and SRID.MLineFromWKB(,wkb[,srid])MultiLineStringFromWKB(wkb[,srid])Constructs a
MULTILINESTRINGvalue using its WKB representation and SRID.MPointFromWKB(,wkb[,srid])MultiPointFromWKB(wkb[,srid])Constructs a
MULTIPOINTvalue using its WKB representation and SRID.MPolyFromWKB(,wkb[,srid])MultiPolygonFromWKB(wkb[,srid])Constructs a
MULTIPOLYGONvalue using its WKB representation and SRID.Constructs a
POINTvalue using its WKB representation and SRID.PolyFromWKB(,wkb[,srid])PolygonFromWKB(wkb[,srid])Constructs a
POLYGONvalue using its WKB representation and SRID.
The OpenGIS specification also describes optional functions
for constructing Polygon or
MultiPolygon values based on the WKB
representation of a collection of rings or closed
LineString values. These values may
intersect. MySQL does not implement these functions:
Constructs a
MultiPolygonvalue from aMultiLineStringvalue in WKB format containing an arbitrary collection of closedLineStringvalues.Constructs a
Polygonvalue from aMultiLineStringvalue in WKB format containing an arbitrary collection of closedLineStringvalues.
MySQL provides a set of useful non-standard functions for
creating geometry WKB representations. The functions described
in this section are MySQL extensions to the OpenGIS
specification. The results of these functions are
BLOB values containing WKB representations
of geometry values with no SRID. The results of these
functions can be substituted as the first argument for any
function in the GeomFromWKB() function
family.
Constructs a WKB
GeometryCollection. If any argument is not a well-formed WKB representation of a geometry, the return value isNULL.Constructs a WKB
LineStringvalue from a number of WKBPointarguments. If any argument is not a WKBPoint, the return value isNULL. If the number ofPointarguments is less than two, the return value isNULL.Constructs a WKB
MultiLineStringvalue using WKBLineStringarguments. If any argument is not a WKBLineString, the return value isNULL.Constructs a WKB
MultiPointvalue using WKBPointarguments. If any argument is not a WKBPoint, the return value isNULL.Constructs a WKB
MultiPolygonvalue from a set of WKBPolygonarguments. If any argument is not a WKBPolygon, the return value isNULL.Constructs a WKB
Pointusing its coordinates.Constructs a WKB
Polygonvalue from a number of WKBLineStringarguments. If any argument does not represent the WKB of aLinearRing(that is, not a closed and simpleLineString) the return value isNULL.
MySQL provides a standard way of creating spatial columns for
geometry types, for example, with CREATE
TABLE or ALTER TABLE. Currently,
spatial columns are supported for MyISAM,
InnoDB, NDB,
BDB, and ARCHIVE tables.
(Support for storage engines other than
MyISAM was added in MySQL 5.0.16.) See also
the annotations about spatial indexes under
Section 16.6.1, “Creating Spatial Indexes”.
Use the
CREATE TABLEstatement to create a table with a spatial column:CREATE TABLE geom (g GEOMETRY);
Use the
ALTER TABLEstatement to add or drop a spatial column to or from an existing table:ALTER TABLE geom ADD pt POINT; ALTER TABLE geom DROP pt;
After you have created spatial columns, you can populate them with spatial data.
Values should be stored in internal geometry format, but you can convert them to that format from either Well-Known Text (WKT) or Well-Known Binary (WKB) format. The following examples demonstrate how to insert geometry values into a table by converting WKT values into internal geometry format:
Perform the conversion directly in the
INSERTstatement:INSERT INTO geom VALUES (GeomFromText('POINT(1 1)')); SET @g = 'POINT(1 1)'; INSERT INTO geom VALUES (GeomFromText(@g));Perform the conversion prior to the
INSERT:SET @g = GeomFromText('POINT(1 1)'); INSERT INTO geom VALUES (@g);
The following examples insert more complex geometries into the table:
SET @g = 'LINESTRING(0 0,1 1,2 2)'; INSERT INTO geom VALUES (GeomFromText(@g)); SET @g = 'POLYGON((0 0,10 0,10 10,0 10,0 0),(5 5,7 5,7 7,5 7, 5 5))'; INSERT INTO geom VALUES (GeomFromText(@g)); SET @g = 'GEOMETRYCOLLECTION(POINT(1 1),LINESTRING(0 0,1 1,2 2,3 3,4 4))'; INSERT INTO geom VALUES (GeomFromText(@g));
The preceding examples all use GeomFromText()
to create geometry values. You can also use type-specific
functions:
SET @g = 'POINT(1 1)'; INSERT INTO geom VALUES (PointFromText(@g)); SET @g = 'LINESTRING(0 0,1 1,2 2)'; INSERT INTO geom VALUES (LineStringFromText(@g)); SET @g = 'POLYGON((0 0,10 0,10 10,0 10,0 0),(5 5,7 5,7 7,5 7, 5 5))'; INSERT INTO geom VALUES (PolygonFromText(@g)); SET @g = 'GEOMETRYCOLLECTION(POINT(1 1),LINESTRING(0 0,1 1,2 2,3 3,4 4))'; INSERT INTO geom VALUES (GeomCollFromText(@g));
Note that if a client application program wants to use WKB representations of geometry values, it is responsible for sending correctly formed WKB in queries to the server. However, there are several ways of satisfying this requirement. For example:
Inserting a
POINT(1 1)value with hex literal syntax:mysql>
INSERT INTO geom VALUES->(GeomFromWKB(0x0101000000000000000000F03F000000000000F03F));An ODBC application can send a WKB representation, binding it to a placeholder using an argument of
BLOBtype:INSERT INTO geom VALUES (GeomFromWKB(?))
Other programming interfaces may support a similar placeholder mechanism.
In a C program, you can escape a binary value using
mysql_real_escape_string()and include the result in a query string that is sent to the server. See Section 22.2.3.53, “mysql_real_escape_string()”.
Geometry values stored in a table can be fetched in internal format. You can also convert them into WKT or WKB format.
Fetching spatial data in internal format:
Fetching geometry values using internal format can be useful in table-to-table transfers:
CREATE TABLE geom2 (g GEOMETRY) SELECT g FROM geom;
Fetching spatial data in WKT format:
The
AsText()function converts a geometry from internal format into a WKT string.SELECT AsText(g) FROM geom;
Fetching spatial data in WKB format:
The
AsBinary()function converts a geometry from internal format into aBLOBcontaining the WKB value.SELECT AsBinary(g) FROM geom;
- 16.5.1. Geometry Format Conversion Functions
- 16.5.2.
GeometryFunctions - 16.5.3. Functions That Create New Geometries from Existing Ones
- 16.5.4. Functions for Testing Spatial Relations Between Geometric Objects
- 16.5.5. Relations on Geometry Minimal Bounding Rectangles (MBRs)
- 16.5.6. Functions That Test Spatial Relationships Between Geometries
After populating spatial columns with values, you are ready to query and analyze them. MySQL provides a set of functions to perform various operations on spatial data. These functions can be grouped into four major categories according to the type of operation they perform:
Functions that convert geometries between various formats
Functions that provide access to qualitative or quantitative properties of a geometry
Functions that describe relations between two geometries
Functions that create new geometries from existing ones
Spatial analysis functions can be used in many contexts, such as:
Any interactive SQL program, such as mysql or MySQL Query Browser
Application programs written in any language that supports a MySQL client API
MySQL supports the following functions for converting geometry values between internal format and either WKT or WKB format:
Converts a value in internal geometry format to its WKB representation and returns the binary result.
SELECT AsBinary(g) FROM geom;
Converts a value in internal geometry format to its WKT representation and returns the string result.
mysql>
SET @g = 'LineString(1 1,2 2,3 3)';mysql>SELECT AsText(GeomFromText(@g));+--------------------------+ | AsText(GeomFromText(@g)) | +--------------------------+ | LINESTRING(1 1,2 2,3 3) | +--------------------------+Converts a string value from its WKT representation into internal geometry format and returns the result. A number of type-specific functions are also supported, such as
PointFromText()andLineFromText(). See Section 16.4.2.1, “Creating Geometry Values Using WKT Functions”.Converts a binary value from its WKB representation into internal geometry format and returns the result. A number of type-specific functions are also supported, such as
PointFromWKB()andLineFromWKB(). See Section 16.4.2.2, “Creating Geometry Values Using WKB Functions”.
Each function that belongs to this group takes a geometry value
as its argument and returns some quantitative or qualitative
property of the geometry. Some functions restrict their argument
type. Such functions return NULL if the
argument is of an incorrect geometry type. For example,
Area() returns NULL if the
object type is neither Polygon nor
MultiPolygon.
The functions listed in this section do not restrict their argument and accept a geometry value of any type.
Returns the inherent dimension of the geometry value
g. The result can be –1, 0, 1, or 2. The meaning of these values is given in Section 16.2.2, “ClassGeometry”.mysql>
SELECT Dimension(GeomFromText('LineString(1 1,2 2)'));+------------------------------------------------+ | Dimension(GeomFromText('LineString(1 1,2 2)')) | +------------------------------------------------+ | 1 | +------------------------------------------------+Returns the Minimum Bounding Rectangle (MBR) for the geometry value
g. The result is returned as aPolygonvalue.The polygon is defined by the corner points of the bounding box:
POLYGON((MINX MINY, MAXX MINY, MAXX MAXY, MINX MAXY, MINX MINY))
mysql>
SELECT AsText(Envelope(GeomFromText('LineString(1 1,2 2)')));+-------------------------------------------------------+ | AsText(Envelope(GeomFromText('LineString(1 1,2 2)'))) | +-------------------------------------------------------+ | POLYGON((1 1,2 1,2 2,1 2,1 1)) | +-------------------------------------------------------+Returns as a string the name of the geometry type of which the geometry instance
gis a member. The name corresponds to one of the instantiableGeometrysubclasses.mysql>
SELECT GeometryType(GeomFromText('POINT(1 1)'));+------------------------------------------+ | GeometryType(GeomFromText('POINT(1 1)')) | +------------------------------------------+ | POINT | +------------------------------------------+Returns an integer indicating the Spatial Reference System ID for the geometry value
g.In MySQL, the SRID value is just an integer associated with the geometry value. All calculations are done assuming Euclidean (planar) geometry.
mysql>
SELECT SRID(GeomFromText('LineString(1 1,2 2)',101));+-----------------------------------------------+ | SRID(GeomFromText('LineString(1 1,2 2)',101)) | +-----------------------------------------------+ | 101 | +-----------------------------------------------+
The OpenGIS specification also defines the following functions, which MySQL does not implement:
Returns a geometry that is the closure of the combinatorial boundary of the geometry value
g.Returns 1 if the geometry value
gis the empty geometry, 0 if it is not empty, and –1 if the argument isNULL. If the geometry is empty, it represents the empty point set.Currently, this function is a placeholder and should not be used. If implemented, its behavior will be as described in the next paragraph.
Returns 1 if the geometry value
ghas no anomalous geometric points, such as self-intersection or self-tangency.IsSimple()returns 0 if the argument is not simple, and –1 if it isNULL.The description of each instantiable geometric class given earlier in the chapter includes the specific conditions that cause an instance of that class to be classified as not simple. (See Section 16.2.1, “The Geometry Class Hierarchy”.)
A Point consists of X and Y coordinates,
which may be obtained using the following functions:
Returns the X-coordinate value for the point
pas a double-precision number.mysql>
SET @pt = 'Point(56.7 53.34)';mysql>SELECT X(GeomFromText(@pt));+----------------------+ | X(GeomFromText(@pt)) | +----------------------+ | 56.7 | +----------------------+Returns the Y-coordinate value for the point
pas a double-precision number.mysql>
SET @pt = 'Point(56.7 53.34)';mysql>SELECT Y(GeomFromText(@pt));+----------------------+ | Y(GeomFromText(@pt)) | +----------------------+ | 53.34 | +----------------------+
A LineString consists of
Point values. You can extract particular
points of a LineString, count the number of
points that it contains, or obtain its length.
Returns the
Pointthat is the endpoint of theLineStringvaluels.mysql>
SET @ls = 'LineString(1 1,2 2,3 3)';mysql>SELECT AsText(EndPoint(GeomFromText(@ls)));+-------------------------------------+ | AsText(EndPoint(GeomFromText(@ls))) | +-------------------------------------+ | POINT(3 3) | +-------------------------------------+Returns as a double-precision number the length of the
LineStringvaluelsin its associated spatial reference.mysql>
SET @ls = 'LineString(1 1,2 2,3 3)';mysql>SELECT GLength(GeomFromText(@ls));+----------------------------+ | GLength(GeomFromText(@ls)) | +----------------------------+ | 2.8284271247462 | +----------------------------+GLength()is a non-standard name. It corresponds to the OpenGISLength()function.Returns the number of
Pointobjects in theLineStringvaluels.mysql>
SET @ls = 'LineString(1 1,2 2,3 3)';mysql>SELECT NumPoints(GeomFromText(@ls));+------------------------------+ | NumPoints(GeomFromText(@ls)) | +------------------------------+ | 3 | +------------------------------+Returns the
N-thPointin theLinestringvaluels. Points are numbered beginning with 1.mysql>
SET @ls = 'LineString(1 1,2 2,3 3)';mysql>SELECT AsText(PointN(GeomFromText(@ls),2));+-------------------------------------+ | AsText(PointN(GeomFromText(@ls),2)) | +-------------------------------------+ | POINT(2 2) | +-------------------------------------+Returns the
Pointthat is the start point of theLineStringvaluels.mysql>
SET @ls = 'LineString(1 1,2 2,3 3)';mysql>SELECT AsText(StartPoint(GeomFromText(@ls)));+---------------------------------------+ | AsText(StartPoint(GeomFromText(@ls))) | +---------------------------------------+ | POINT(1 1) | +---------------------------------------+
The OpenGIS specification also defines the following function, which MySQL does not implement:
Returns as a double-precision number the length of the
MultiLineStringvaluemls. The length ofmlsis equal to the sum of the lengths of its elements.mysql>
SET @mls = 'MultiLineString((1 1,2 2,3 3),(4 4,5 5))';mysql>SELECT GLength(GeomFromText(@mls));+-----------------------------+ | GLength(GeomFromText(@mls)) | +-----------------------------+ | 4.2426406871193 | +-----------------------------+GLength()is a non-standard name. It corresponds to the OpenGISLength()function.Returns 1 if the
MultiLineStringvaluemlsis closed (that is, theStartPoint()andEndPoint()values are the same for eachLineStringinmls). Returns 0 ifmlsis not closed, and –1 if it isNULL.mysql>
SET @mls = 'MultiLineString((1 1,2 2,3 3),(4 4,5 5))';mysql>SELECT IsClosed(GeomFromText(@mls));+------------------------------+ | IsClosed(GeomFromText(@mls)) | +------------------------------+ | 0 | +------------------------------+
Returns as a double-precision number the area of the
Polygonvaluepoly, as measured in its spatial reference system.mysql>
SET @poly = 'Polygon((0 0,0 3,3 0,0 0),(1 1,1 2,2 1,1 1))';mysql>SELECT Area(GeomFromText(@poly));+---------------------------+ | Area(GeomFromText(@poly)) | +---------------------------+ | 4 | +---------------------------+Returns the exterior ring of the
Polygonvaluepolyas aLineString.mysql>
SET @poly =->'Polygon((0 0,0 3,3 3,3 0,0 0),(1 1,1 2,2 2,2 1,1 1))';mysql>SELECT AsText(ExteriorRing(GeomFromText(@poly)));+-------------------------------------------+ | AsText(ExteriorRing(GeomFromText(@poly))) | +-------------------------------------------+ | LINESTRING(0 0,0 3,3 3,3 0,0 0) | +-------------------------------------------+Returns the
N-th interior ring for thePolygonvaluepolyas aLineString. Rings are numbered beginning with 1.mysql>
SET @poly =->'Polygon((0 0,0 3,3 3,3 0,0 0),(1 1,1 2,2 2,2 1,1 1))';mysql>SELECT AsText(InteriorRingN(GeomFromText(@poly),1));+----------------------------------------------+ | AsText(InteriorRingN(GeomFromText(@poly),1)) | +----------------------------------------------+ | LINESTRING(1 1,1 2,2 2,2 1,1 1) | +----------------------------------------------+Returns the number of interior rings in the
Polygonvaluepoly.mysql>
SET @poly =->'Polygon((0 0,0 3,3 3,3 0,0 0),(1 1,1 2,2 2,2 1,1 1))';mysql>SELECT NumInteriorRings(GeomFromText(@poly));+---------------------------------------+ | NumInteriorRings(GeomFromText(@poly)) | +---------------------------------------+ | 1 | +---------------------------------------+
Returns as a double-precision number the area of the
MultiPolygonvaluempoly, as measured in its spatial reference system.mysql>
SET @mpoly =->'MultiPolygon(((0 0,0 3,3 3,3 0,0 0),(1 1,1 2,2 2,2 1,1 1)))';mysql>SELECT Area(GeomFromText(@mpoly));+----------------------------+ | Area(GeomFromText(@mpoly)) | +----------------------------+ | 8 | +----------------------------+
The OpenGIS specification also defines the following functions, which MySQL does not implement:
Returns the
N-th geometry in theGeometryCollectionvaluegc. Geometries are numbered beginning with 1.mysql>
SET @gc = 'GeometryCollection(Point(1 1),LineString(2 2, 3 3))';mysql>SELECT AsText(GeometryN(GeomFromText(@gc),1));+----------------------------------------+ | AsText(GeometryN(GeomFromText(@gc),1)) | +----------------------------------------+ | POINT(1 1) | +----------------------------------------+Returns the number of geometries in the
GeometryCollectionvaluegc.mysql>
SET @gc = 'GeometryCollection(Point(1 1),LineString(2 2, 3 3))';mysql>SELECT NumGeometries(GeomFromText(@gc));+----------------------------------+ | NumGeometries(GeomFromText(@gc)) | +----------------------------------+ | 2 | +----------------------------------+
Section 16.5.2, “Geometry Functions”, discusses
several functions that construct new geometries from existing
ones. See that section for descriptions of these functions:
Envelope(g)StartPoint(ls)EndPoint(ls)PointN(ls,N)ExteriorRing(poly)InteriorRingN(poly,N)GeometryN(gc,N)
OpenGIS proposes a number of other functions that can produce geometries. They are designed to implement spatial operators.
These functions are not implemented in MySQL. They may appear in future releases.
Returns a geometry that represents all points whose distance from the geometry value
gis less than or equal to a distance ofd.Returns a geometry that represents the convex hull of the geometry value
g.Returns a geometry that represents the point set difference of the geometry value
g1withg2.Returns a geometry that represents the point set intersection of the geometry values
g1withg2.Returns a geometry that represents the point set symmetric difference of the geometry value
g1withg2.Returns a geometry that represents the point set union of the geometry values
g1andg2.
The functions described in these sections take two geometries as input parameters and return a qualitative or quantitative relation between them.
MySQL provides several functions that test relations between
minimal bounding rectangles of two geometries
g1 and g2. The return
values 1 and 0 indicate true and false, respectively.
Returns 1 or 0 to indicate whether the Minimum Bounding Rectangle of
g1contains the Minimum Bounding Rectangle ofg2. This tests the opposite relationship asMBRWithin().mysql>
SET @g1 = GeomFromText('Polygon((0 0,0 3,3 3,3 0,0 0))');mysql>SET @g2 = GeomFromText('Point(1 1)');mysql>SELECT MBRContains(@g1,@g2), MBRContains(@g2,@g1);----------------------+----------------------+ | MBRContains(@g1,@g2) | MBRContains(@g2,@g1) | +----------------------+----------------------+ | 1 | 0 | +----------------------+----------------------+Returns 1 or 0 to indicate whether the Minimum Bounding Rectangles of the two geometries
g1andg2are disjoint (do not intersect).Returns 1 or 0 to indicate whether the Minimum Bounding Rectangles of the two geometries
g1andg2are the same.Returns 1 or 0 to indicate whether the Minimum Bounding Rectangles of the two geometries
g1andg2intersect.Returns 1 or 0 to indicate whether the Minimum Bounding Rectangles of the two geometries
g1andg2overlap. The term spatially overlaps is used if two geometries intersect and their intersection results in a geometry of the same dimension but not equal to either of the given geometries.Returns 1 or 0 to indicate whether the Minimum Bounding Rectangles of the two geometries
g1andg2touch. Two geometries spatially touch if the interiors of the geometries do not intersect, but the boundary of one of the geometries intersects either the boundary or the interior of the other.Returns 1 or 0 to indicate whether the Minimum Bounding Rectangle of
g1is within the Minimum Bounding Rectangle ofg2. This tests the opposite relationship asMBRWithin().mysql>
SET @g1 = GeomFromText('Polygon((0 0,0 3,3 3,3 0,0 0))');mysql>SET @g2 = GeomFromText('Polygon((0 0,0 5,5 5,5 0,0 0))');mysql>SELECT MBRWithin(@g1,@g2), MBRWithin(@g2,@g1);+--------------------+--------------------+ | MBRWithin(@g1,@g2) | MBRWithin(@g2,@g1) | +--------------------+--------------------+ | 1 | 0 | +--------------------+--------------------+
The OpenGIS specification defines the following functions. They
test the relationship between two geometry values
g1 and g2.
The return values 1 and 0 indicate true and false, respectively.
Note
Currently, MySQL does not implement these functions according
to the specification. Those that are implemented return the
same result as the corresponding MBR-based functions. This
includes functions in the following list other than
Distance() and
Related().
These functions may be implemented in future releases with full support for spatial analysis, not just MBR-based support.
Returns 1 or 0 to indicate whether
g1completely containsg2. This tests the opposite relationship asWithin().Returns 1 if
g1spatially crossesg2. ReturnsNULLifg1is aPolygonor aMultiPolygon, or ifg2is aPointor aMultiPoint. Otherwise, returns 0.The term spatially crosses denotes a spatial relation between two given geometries that has the following properties:
The two geometries intersect
Their intersection results in a geometry that has a dimension that is one less than the maximum dimension of the two given geometries
Their intersection is not equal to either of the two given geometries
Returns 1 or 0 to indicate whether
g1is spatially disjoint from (does not intersect)g2.Returns as a double-precision number the shortest distance between any two points in the two geometries.
Returns 1 or 0 to indicate whether
g1is spatially equal tog2.Returns 1 or 0 to indicate whether
g1spatially intersectsg2.Returns 1 or 0 to indicate whether
g1spatially overlapsg2. The term spatially overlaps is used if two geometries intersect and their intersection results in a geometry of the same dimension but not equal to either of the given geometries.Returns 1 or 0 to indicate whether the spatial relationship specified by
pattern_matrixexists betweeng1andg2. Returns –1 if the arguments areNULL. The pattern matrix is a string. Its specification will be noted here if this function is implemented.Returns 1 or 0 to indicate whether
g1spatially touchesg2. Two geometries spatially touch if the interiors of the geometries do not intersect, but the boundary of one of the geometries intersects either the boundary or the interior of the other.Returns 1 or 0 to indicate whether
g1is spatially withing2. This tests the opposite relationship asContains().
Search operations in non-spatial databases can be optimized using
SPATIAL indexes. This is true for spatial
databases as well. With the help of a great variety of
multi-dimensional indexing methods that have previously been
designed, it is possible to optimize spatial searches. The most
typical of these are:
Point queries that search for all objects that contain a given point
Region queries that search for all objects that overlap a given region
MySQL uses R-Trees with quadratic
splitting for SPATIAL indexes on
spatial columns. A SPATIAL index is built using
the MBR of a geometry. For most geometries, the MBR is a minimum
rectangle that surrounds the geometries. For a horizontal or a
vertical linestring, the MBR is a rectangle degenerated into the
linestring. For a point, the MBR is a rectangle degenerated into
the point.
It is also possible to create normal indexes on spatial columns.
In a non-SPATIAL index, you must declare a
prefix for any spatial column except for POINT
columns.
MyISAM supports both SPATIAL
and non-SPATIAL indexes. Other storage engines
support non-SPATIAL indexes, as described in
Section 13.1.4, “CREATE INDEX Syntax”.
MySQL can create spatial indexes using syntax similar to that
for creating regular indexes, but extended with the
SPATIAL keyword. Currently, columns in
spatial indexes must be declared NOT NULL.
The following examples demonstrate how to create spatial
indexes:
With
CREATE TABLE:CREATE TABLE geom (g GEOMETRY NOT NULL, SPATIAL INDEX(g));
With
ALTER TABLE:ALTER TABLE geom ADD SPATIAL INDEX(g);
With
CREATE INDEX:CREATE SPATIAL INDEX sp_index ON geom (g);
For MyISAM tables, SPATIAL
INDEX creates an R-tree index. For storage engines
that support non-spatial indexing of spatial columns, the engine
creates a B-tree index. A B-tree index on spatial values will be
useful for exact-value lookups, but not for range scans.
For more information on indexing spatial columns, see
Section 13.1.4, “CREATE INDEX Syntax”.
To drop spatial indexes, use ALTER TABLE or
DROP INDEX:
With
ALTER TABLE:ALTER TABLE geom DROP INDEX g;
With
DROP INDEX:DROP INDEX sp_index ON geom;
Example: Suppose that a table geom contains
more than 32,000 geometries, which are stored in the column
g of type GEOMETRY. The
table also has an AUTO_INCREMENT column
fid for storing object ID values.
mysql>DESCRIBE geom;+-------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+----------------+ | fid | int(11) | | PRI | NULL | auto_increment | | g | geometry | | | | | +-------+----------+------+-----+---------+----------------+ 2 rows in set (0.00 sec) mysql>SELECT COUNT(*) FROM geom;+----------+ | count(*) | +----------+ | 32376 | +----------+ 1 row in set (0.00 sec)
To add a spatial index on the column g, use
this statement:
mysql> ALTER TABLE geom ADD SPATIAL INDEX(g);
Query OK, 32376 rows affected (4.05 sec)
Records: 32376 Duplicates: 0 Warnings: 0
The optimizer investigates whether available spatial indexes can
be involved in the search for queries that use a function such
as MBRContains() or
MBRWithin() in the WHERE
clause. The following query finds all objects that are in the
given rectangle:
mysql>SET @poly =->'Polygon((30000 15000,31000 15000,31000 16000,30000 16000,30000 15000))';mysql>SELECT fid,AsText(g) FROM geom WHERE->MBRContains(GeomFromText(@poly),g);+-----+---------------------------------------------------------------+ | fid | AsText(g) | +-----+---------------------------------------------------------------+ | 21 | LINESTRING(30350.4 15828.8,30350.6 15845,30333.8 15845,30 ... | | 22 | LINESTRING(30350.6 15871.4,30350.6 15887.8,30334 15887.8, ... | | 23 | LINESTRING(30350.6 15914.2,30350.6 15930.4,30334 15930.4, ... | | 24 | LINESTRING(30290.2 15823,30290.2 15839.4,30273.4 15839.4, ... | | 25 | LINESTRING(30291.4 15866.2,30291.6 15882.4,30274.8 15882. ... | | 26 | LINESTRING(30291.6 15918.2,30291.6 15934.4,30275 15934.4, ... | | 249 | LINESTRING(30337.8 15938.6,30337.8 15946.8,30320.4 15946. ... | | 1 | LINESTRING(30250.4 15129.2,30248.8 15138.4,30238.2 15136. ... | | 2 | LINESTRING(30220.2 15122.8,30217.2 15137.8,30207.6 15136, ... | | 3 | LINESTRING(30179 15114.4,30176.6 15129.4,30167 15128,3016 ... | | 4 | LINESTRING(30155.2 15121.4,30140.4 15118.6,30142 15109,30 ... | | 5 | LINESTRING(30192.4 15085,30177.6 15082.2,30179.2 15072.4, ... | | 6 | LINESTRING(30244 15087,30229 15086.2,30229.4 15076.4,3024 ... | | 7 | LINESTRING(30200.6 15059.4,30185.6 15058.6,30186 15048.8, ... | | 10 | LINESTRING(30179.6 15017.8,30181 15002.8,30190.8 15003.6, ... | | 11 | LINESTRING(30154.2 15000.4,30168.6 15004.8,30166 15014.2, ... | | 13 | LINESTRING(30105 15065.8,30108.4 15050.8,30118 15053,3011 ... | | 154 | LINESTRING(30276.2 15143.8,30261.4 15141,30263 15131.4,30 ... | | 155 | LINESTRING(30269.8 15084,30269.4 15093.4,30258.6 15093,30 ... | | 157 | LINESTRING(30128.2 15011,30113.2 15010.2,30113.6 15000.4, ... | +-----+---------------------------------------------------------------+ 20 rows in set (0.00 sec)
Use EXPLAIN to check the way this query is
executed:
mysql>SET @poly =->'Polygon((30000 15000,31000 15000,31000 16000,30000 16000,30000 15000))';mysql>EXPLAIN SELECT fid,AsText(g) FROM geom WHERE->MBRContains(GeomFromText(@poly),g)\G*************************** 1. row *************************** id: 1 select_type: SIMPLE table: geom type: range possible_keys: g key: g key_len: 32 ref: NULL rows: 50 Extra: Using where 1 row in set (0.00 sec)
Check what would happen without a spatial index:
mysql>SET @poly =->'Polygon((30000 15000,31000 15000,31000 16000,30000 16000,30000 15000))';mysql>EXPLAIN SELECT fid,AsText(g) FROM g IGNORE INDEX (g) WHERE->MBRContains(GeomFromText(@poly),g)\G*************************** 1. row *************************** id: 1 select_type: SIMPLE table: geom type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 32376 Extra: Using where 1 row in set (0.00 sec)
Executing the SELECT statement without the
spatial index yields the same result but causes the execution
time to rise from 0.00 seconds to 0.46 seconds:
mysql>SET @poly =->'Polygon((30000 15000,31000 15000,31000 16000,30000 16000,30000 15000))';mysql>SELECT fid,AsText(g) FROM geom IGNORE INDEX (g) WHERE->MBRContains(GeomFromText(@poly),g);+-----+---------------------------------------------------------------+ | fid | AsText(g) | +-----+---------------------------------------------------------------+ | 1 | LINESTRING(30250.4 15129.2,30248.8 15138.4,30238.2 15136. ... | | 2 | LINESTRING(30220.2 15122.8,30217.2 15137.8,30207.6 15136, ... | | 3 | LINESTRING(30179 15114.4,30176.6 15129.4,30167 15128,3016 ... | | 4 | LINESTRING(30155.2 15121.4,30140.4 15118.6,30142 15109,30 ... | | 5 | LINESTRING(30192.4 15085,30177.6 15082.2,30179.2 15072.4, ... | | 6 | LINESTRING(30244 15087,30229 15086.2,30229.4 15076.4,3024 ... | | 7 | LINESTRING(30200.6 15059.4,30185.6 15058.6,30186 15048.8, ... | | 10 | LINESTRING(30179.6 15017.8,30181 15002.8,30190.8 15003.6, ... | | 11 | LINESTRING(30154.2 15000.4,30168.6 15004.8,30166 15014.2, ... | | 13 | LINESTRING(30105 15065.8,30108.4 15050.8,30118 15053,3011 ... | | 21 | LINESTRING(30350.4 15828.8,30350.6 15845,30333.8 15845,30 ... | | 22 | LINESTRING(30350.6 15871.4,30350.6 15887.8,30334 15887.8, ... | | 23 | LINESTRING(30350.6 15914.2,30350.6 15930.4,30334 15930.4, ... | | 24 | LINESTRING(30290.2 15823,30290.2 15839.4,30273.4 15839.4, ... | | 25 | LINESTRING(30291.4 15866.2,30291.6 15882.4,30274.8 15882. ... | | 26 | LINESTRING(30291.6 15918.2,30291.6 15934.4,30275 15934.4, ... | | 154 | LINESTRING(30276.2 15143.8,30261.4 15141,30263 15131.4,30 ... | | 155 | LINESTRING(30269.8 15084,30269.4 15093.4,30258.6 15093,30 ... | | 157 | LINESTRING(30128.2 15011,30113.2 15010.2,30113.6 15000.4, ... | | 249 | LINESTRING(30337.8 15938.6,30337.8 15946.8,30320.4 15946. ... | +-----+---------------------------------------------------------------+ 20 rows in set (0.46 sec)
In future releases, spatial indexes may also be used for optimizing other functions. See Section 16.5.4, “Functions for Testing Spatial Relations Between Geometric Objects”.
MySQL does not yet implement the following GIS features:
Additional Metadata Views
OpenGIS specifications propose several additional metadata views. For example, a system view named
GEOMETRY_COLUMNScontains a description of geometry columns, one row for each geometry column in the database.The OpenGIS function
Length()onLineStringandMultiLineStringcurrently should be called in MySQL asGLength()The problem is that there is an existing SQL function
Length()that calculates the length of string values, and sometimes it is not possible to distinguish whether the function is called in a textual or spatial context. We need either to solve this somehow, or decide on another function name.
Table of Contents
- 17.1. Stored Routines and the Grant Tables
- 17.2. Stored Routine Syntax
- 17.2.1.
CREATE PROCEDUREandCREATE FUNCTIONSyntax - 17.2.2.
ALTER PROCEDUREandALTER FUNCTIONSyntax - 17.2.3.
DROP PROCEDUREandDROP FUNCTIONSyntax - 17.2.4.
CALLStatement Syntax - 17.2.5.
BEGIN ... ENDCompound Statement Syntax - 17.2.6.
DECLAREStatement Syntax - 17.2.7. Variables in Stored Routines
- 17.2.8. Conditions and Handlers
- 17.2.9. Cursors
- 17.2.10. Flow Control Constructs
- 17.2.1.
- 17.3. Stored Procedures, Functions, Triggers, and
LAST_INSERT_ID() - 17.4. Binary Logging of Stored Routines and Triggers
Stored routines (procedures and functions) are supported in MySQL 5.0. A stored procedure is a set of SQL statements that can be stored in the server. Once this has been done, clients don't need to keep reissuing the individual statements but can refer to the stored procedure instead.
Answers to some questions that are commonly asked regarding stored routines in MySQL can be found in Section A.4, “MySQL 5.0 FAQ — Stored Procedures”.
MySQL Enterprise For expert advice on using stored procedures and functions subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
Some situations where stored routines can be particularly useful:
When multiple client applications are written in different languages or work on different platforms, but need to perform the same database operations.
When security is paramount. Banks, for example, use stored procedures and functions for all common operations. This provides a consistent and secure environment, and routines can ensure that each operation is properly logged. In such a setup, applications and users would have no access to the database tables directly, but can only execute specific stored routines.
Stored routines can provide improved performance because less information needs to be sent between the server and the client. The tradeoff is that this does increase the load on the database server because more of the work is done on the server side and less is done on the client (application) side. Consider this if many client machines (such as Web servers) are serviced by only one or a few database servers.
Stored routines also allow you to have libraries of functions in the database server. This is a feature shared by modern application languages that allow such design internally (for example, by using classes). Using these client application language features is beneficial for the programmer even outside the scope of database use.
MySQL follows the SQL:2003 syntax for stored routines, which is also used by IBM's DB2.
The MySQL implementation of stored routines is still in progress. All syntax described in this chapter is supported and any limitations and extensions are documented where appropriate. Further discussion of restrictions on use of stored routines is given in Section F.1, “Restrictions on Stored Routines and Triggers”.
Binary logging for stored routines takes place as described in Section 17.4, “Binary Logging of Stored Routines and Triggers”.
Recursive stored procedures are disabled by default, but can be
enabled on the server by setting the
max_sp_recursion_depth server system variable to
a nonzero value. See Section 5.2.3, “System Variables”, for
more information.
Stored functions cannot be recursive. See Section F.1, “Restrictions on Stored Routines and Triggers”.
Stored routines require the proc table in the
mysql database. This table is created during
the MySQL 5.0 installation procedure. If you are
upgrading to MySQL 5.0 from an earlier version, be
sure to update your grant tables to make sure that the
proc table exists. See
Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.
The server manipulates the mysql.proc table in
response to statements that create, alter, or drop stored
routines. It is not supported that the server will notice manual
manipulation of this table.
Beginning with MySQL 5.0.3, the grant system takes stored routines into account as follows:
The
CREATE ROUTINEprivilege is needed to create stored routines.The
ALTER ROUTINEprivilege is needed to alter or drop stored routines. This privilege is granted automatically to the creator of a routine if necessary, and dropped when the routine creator drops the routine.The
EXECUTEprivilege is required to execute stored routines. However, this privilege is granted automatically to the creator of a routine if necessary (and dropped when the creator drops the routine). Also, the defaultSQL SECURITYcharacteristic for a routine isDEFINER, which enables users who have access to the database with which the routine is associated to execute the routine.If the
automatic_sp_privilegessystem variable is 0, theEXECUTEandALTER ROUTINEprivileges are not automatically granted and dropped.
- 17.2.1.
CREATE PROCEDUREandCREATE FUNCTIONSyntax - 17.2.2.
ALTER PROCEDUREandALTER FUNCTIONSyntax - 17.2.3.
DROP PROCEDUREandDROP FUNCTIONSyntax - 17.2.4.
CALLStatement Syntax - 17.2.5.
BEGIN ... ENDCompound Statement Syntax - 17.2.6.
DECLAREStatement Syntax - 17.2.7. Variables in Stored Routines
- 17.2.8. Conditions and Handlers
- 17.2.9. Cursors
- 17.2.10. Flow Control Constructs
A stored routine is either a procedure or a function. Stored
routines are created with CREATE PROCEDURE and
CREATE FUNCTION statements. A procedure is
invoked using a CALL statement, and can only
pass back values using output variables. A function can be called
from inside a statement just like any other function (that is, by
invoking the function's name), and can return a scalar value.
Stored routines may call other stored routines.
As of MySQL 5.0.1, a stored procedure or function is associated with a particular database. This has several implications:
When the routine is invoked, an implicit
USEis performed (and undone when the routine terminates).db_nameUSEstatements within stored routines are disallowed.You can qualify routine names with the database name. This can be used to refer to a routine that is not in the current database. For example, to invoke a stored procedure
por functionfthat is associated with thetestdatabase, you can sayCALL test.p()ortest.f().When a database is dropped, all stored routines associated with it are dropped as well.
(In MySQL 5.0.0, stored routines are global and not associated
with a database. They inherit the default database from the
caller. If a USE
is executed within
the routine, the original default database is restored upon
routine exit.)
db_name
MySQL supports the very useful extension that allows the use of
regular SELECT statements (that is, without
using cursors or local variables) inside a stored procedure. The
result set of such a query is simply sent directly to the client.
Multiple SELECT statements generate multiple
result sets, so the client must use a MySQL client library that
supports multiple result sets. This means the client must use a
client library from a version of MySQL at least as recent as 4.1.
The client should also specify the
CLIENT_MULTI_RESULTS option when it connects.
For C programs, this can be done with the
mysql_real_connect() C API function. See
Section 22.2.3.52, “mysql_real_connect()”, and
Section 22.2.9, “C API Handling of Multiple Statement Execution”.
The following sections describe the syntax used to create, alter, drop, and invoke stored procedures and functions.
CREATE
[DEFINER = { user | CURRENT_USER }]
PROCEDURE sp_name ([proc_parameter[,...]])
[characteristic ...] routine_body
CREATE
[DEFINER = { user | CURRENT_USER }]
FUNCTION sp_name ([func_parameter[,...]])
RETURNS type
[characteristic ...] routine_body
proc_parameter:
[ IN | OUT | INOUT ] param_name type
func_parameter:
param_name type
type:
Any valid MySQL data type
characteristic:
LANGUAGE SQL
| [NOT] DETERMINISTIC
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT 'string'
routine_body:
Valid SQL procedure statement
These statements create stored routines. As of MySQL 5.0.3, to
use them, it is necessary to have the CREATE
ROUTINE privilege. If binary logging is enabled, these
statements might also require the SUPER
privilege, as described in
Section 17.4, “Binary Logging of Stored Routines and Triggers”. MySQL automatically
grants the ALTER ROUTINE and
EXECUTE privileges to the routine creator.
By default, the routine is associated with the default database.
To associate the routine explicitly with a given database,
specify the name as db_name.sp_name
when you create it.
If the routine name is the same as the name of a built-in SQL function, you must use a space between the name and the following parenthesis when defining the routine, or a syntax error occurs. This is also true when you invoke the routine later. For this reason, we suggest that it is better to avoid re-using the names of existing SQL functions for your own stored routines.
The IGNORE_SPACE SQL mode applies to built-in
functions, not to stored routines. It is always allowable to
have spaces after a routine name, regardless of whether
IGNORE_SPACE is enabled.
The parameter list enclosed within parentheses must always be
present. If there are no parameters, an empty parameter list of
() should be used.
Each parameter can be declared to use any valid data type,
except that the COLLATE attribute cannot be
used.
Each parameter is an IN parameter by default.
To specify otherwise for a parameter, use the keyword
OUT or INOUT before the
parameter name.
Note: Specifying a parameter as
IN, OUT, or
INOUT is valid only for a
PROCEDURE. (FUNCTION
parameters are always regarded as IN
parameters.)
An IN parameter passes a value into a
procedure. The procedure might modify the value, but the
modification is not visible to the caller when the procedure
returns. An OUT parameter passes a value from
the procedure back to the caller. Its initial value is
NULL within the procedure, and its value is
visible to the caller when the procedure returns. An
INOUT parameter is initialized by the caller,
can be modified by the procedure, and any change made by the
procedure is visible to the caller when the procedure returns.
For each OUT or INOUT
parameter, pass a user-defined variable so that you can obtain
its value when the procedure returns. (For an example, see
Section 17.2.4, “CALL Statement Syntax”.) If you are calling the procedure from
within another stored procedure or function, you can also pass a
routine parameter or local routine variable as an
IN or INOUT parameter.
The RETURNS clause may be specified only for
a FUNCTION, for which it is mandatory. It
indicates the return type of the function, and the function body
must contain a RETURN
statement. If the
valueRETURN statement returns a value of a
different type, the value is coerced to the proper type. For
example, if a function specifies an ENUM or
SET value in the RETURNS
clause, but the RETURN statement returns an
integer, the value returned from the function is the string for
the corresponding ENUM member of set of
SET members.
The routine_body consists of a valid
SQL procedure statement. This can be a simple statement such as
SELECT or INSERT, or it
can be a compound statement written using
BEGIN and END. Compound
statement syntax is described in Section 17.2.5, “BEGIN ... END Compound Statement Syntax”.
Compound statements can contain declarations, loops, and other
control structure statements. The syntax for these statements is
described later in this chapter. See, for example,
Section 17.2.6, “DECLARE Statement Syntax”, and
Section 17.2.10, “Flow Control Constructs”. Some statements are
not allowed in stored routines; see
Section F.1, “Restrictions on Stored Routines and Triggers”.
MySQL stores the sql_mode system variable
setting that is in effect at the time a routine is created, and
always executes the routine with this setting in force,
regardless of the current server SQL mode.
The CREATE FUNCTION statement was used in
earlier versions of MySQL to support UDFs (user-defined
functions). See Section 24.2, “Adding New Functions to MySQL”. UDFs
continue to be supported, even with the existence of stored
functions. A UDF can be regarded as an external stored function.
However, do note that stored functions share their namespace
with UDFs. See Section 9.2.3, “Function Name Parsing and Resolution”, for the
rules describing how the server interprets references to
different kinds of functions.
A procedure or function is considered
“deterministic” if it always produces the same
result for the same input parameters, and “not
deterministic” otherwise. If neither
DETERMINISTIC nor NOT
DETERMINISTIC is given in the routine definition, the
default is NOT DETERMINISTIC.
A routine that contains the NOW() function
(or its synonyms) or RAND() is
non-deterministic, but it might still be replication-safe. For
NOW(), the binary log includes the timestamp
and replicates correctly. RAND() also
replicates correctly as long as it is invoked only once within a
routine. (You can consider the routine execution timestamp and
random number seed as implicit inputs that are identical on the
master and slave.)
Currently, the DETERMINISTIC characteristic
is accepted, but not yet used by the optimizer. However, if
binary logging is enabled, this characteristic affects which
routine definitions MySQL accepts. See
Section 17.4, “Binary Logging of Stored Routines and Triggers”.
Several characteristics provide information about the nature of data use by the routine. In MySQL, these characteristics are advisory only. The server does not use them to constrain what kinds of statements a routine will be allowed to execute.
CONTAINS SQLindicates that the routine does not contain statements that read or write data. This is the default if none of these characteristics is given explicitly. Examples of such statements areSET @x = 1orDO RELEASE_LOCK('abc'), which execute but neither read nor write data.NO SQLindicates that the routine contains no SQL statements.READS SQL DATAindicates that the routine contains statements that read data (for example,SELECT), but not statements that write data.MODIFIES SQL DATAindicates that the routine contains statements that may write data (for example,INSERTorDELETE).
The SQL SECURITY characteristic can be used
to specify whether the routine should be executed using the
permissions of the user who creates the routine or the user who
invokes it. The default value is DEFINER.
This feature is new in SQL:2003. The creator or invoker must
have permission to access the database with which the routine is
associated. As of MySQL 5.0.3, it is necessary to have the
EXECUTE privilege to be able to execute the
routine. The user that must have this privilege is either the
definer or invoker, depending on how the SQL
SECURITY characteristic is set.
The optional DEFINER clause specifies the
MySQL account to be used when checking access privileges at
routine execution time for routines that have the SQL
SECURITY DEFINER characteristic. The
DEFINER clause was added in MySQL 5.0.20.
If a user value is given, it should
be a MySQL account in
'
format (the same format used in the user_name'@'host_name'GRANT
statement). The user_name and
host_name values both are required.
CURRENT_USER also can be given as
CURRENT_USER(). The default
DEFINER value is the user who executes the
CREATE PROCEDURE or CREATE
FUNCTION or statement. (This is the same as
DEFINER = CURRENT_USER.)
If you specify the DEFINER clause, you cannot
set the value to any account but your own unless you have the
SUPER privilege. These rules determine the
legal DEFINER user values:
If you do not have the
SUPERprivilege, the only legaluservalue is your own account, either specified literally or by usingCURRENT_USER. You cannot set the definer to some other account.If you have the
SUPERprivilege, you can specify any syntactically legal account name. If the account does not actually exist, a warning is generated.Although it is possible to create routines with a non-existent
DEFINERvalue, an error occurs if the routine executes with definer privileges but the definer does not exist at execution time.
When the routine is invoked, an implicit USE
is performed (and
undone when the routine terminates). db_nameUSE
statements within stored routines are disallowed.
As of MySQL 5.0.18, the server uses the data type of a routine
parameter or function return value as follows. These rules also
apply to local routine variables created with the
DECLARE statement
(Section 17.2.7.1, “DECLARE Local Variables”).
Assignments are checked for data type mismatches and overflow. Conversion and overflow problems result in warnings, or errors in strict mode.
For character data types, if there is a
CHARACTER SETclause in the declaration, the specified character set and its default collation are used. If there is no such clause, the database character set and collation that are in effect at the time the routine is created are used. (These are given by the values of thecharacter_set_databaseandcollation_databasesystem variables.) TheCOLLATEattribute is not supported. (This includes use ofBINARY, because in this contextBINARYspecifies the binary collation of the character set.)Only scalar values can be assigned to parameters or variables. For example, a statement such as
SET x = (SELECT 1, 2)is invalid.
Before MySQL 5.0.18, parameters, return values, and local
variables are treated as items in expressions, and are subject
to automatic (silent) conversion and truncation. Stored
functions ignore the sql_mode setting.
The COMMENT clause is a MySQL extension, and
may be used to describe the stored routine. This information is
displayed by the SHOW CREATE PROCEDURE and
SHOW CREATE FUNCTION statements.
MySQL allows routines to contain DDL statements, such as
CREATE and DROP. MySQL
also allows stored procedures (but not stored functions) to
contain SQL transaction statements such as
COMMIT. Stored functions may not contain
statements that do explicit or implicit commit or rollback.
Support for these statements is not required by the SQL
standard, which states that each DBMS vendor may decide whether
to allow them.
Stored routines cannot use LOAD DATA INFILE.
Statements that return a result set cannot be used within a
stored function. This includes SELECT
statements that do not use INTO to fetch
column values into variables, SHOW
statements, and other statements such as
EXPLAIN. For statements that can be
determined at function definition time to return a result set, a
Not allowed to return a result set from a
function error occurs
(ER_SP_NO_RETSET_IN_FUNC). For statements
that can be determined only at runtime to return a result set, a
PROCEDURE %s can't return a result set in the given
context error occurs
(ER_SP_BADSELECT).
Note: Before MySQL 5.0.10,
stored functions created with CREATE FUNCTION
must not contain references to tables, with limited exceptions.
They may include some SET statements that
contain table references, for example SET a:= (SELECT
MAX(id) FROM t), and SELECT
statements that fetch values directly into variables, for
example SELECT i INTO var1 FROM t.
The following is an example of a simple stored procedure that
uses an OUT parameter. The example uses the
mysql client delimiter
command to change the statement delimiter from
; to // while the
procedure is being defined. This allows the ;
delimiter used in the procedure body to be passed through to the
server rather than being interpreted by mysql
itself.
mysql>delimiter //mysql>CREATE PROCEDURE simpleproc (OUT param1 INT)->BEGIN->SELECT COUNT(*) INTO param1 FROM t;->END;->//Query OK, 0 rows affected (0.00 sec) mysql>delimiter ;mysql>CALL simpleproc(@a);Query OK, 0 rows affected (0.00 sec) mysql>SELECT @a;+------+ | @a | +------+ | 3 | +------+ 1 row in set (0.00 sec)
When using the delimiter command, you should
avoid the use of the backslash
(‘\’) character because that is
the escape character for MySQL.
The following is an example of a function that takes a
parameter, performs an operation using an SQL function, and
returns the result. In this case, it is unnecessary to use
delimiter because the function definition
contains no internal ; statement delimiters:
mysql>CREATE FUNCTION hello (s CHAR(20)) RETURNS CHAR(50)->RETURN CONCAT('Hello, ',s,'!');Query OK, 0 rows affected (0.00 sec) mysql>SELECT hello('world');+----------------+ | hello('world') | +----------------+ | Hello, world! | +----------------+ 1 row in set (0.00 sec)
For information about invoking stored procedures from within
programs written in a language that has a MySQL interface, see
Section 17.2.4, “CALL Statement Syntax”.
ALTER {PROCEDURE | FUNCTION} sp_name [characteristic ...]
characteristic:
{ CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT 'string'
This statement can be used to change the characteristics of a
stored procedure or function. As of MySQL 5.0.3, you must have
the ALTER ROUTINE privilege for the routine.
(That privilege is granted automatically to the routine
creator.) If binary logging is enabled, this statement might
also require the SUPER privilege, as
described in Section 17.4, “Binary Logging of Stored Routines and Triggers”.
More than one change may be specified in an ALTER
PROCEDURE or ALTER FUNCTION
statement.
DROP {PROCEDURE | FUNCTION} [IF EXISTS] sp_name
This statement is used to drop a stored procedure or function.
That is, the specified routine is removed from the server. As of
MySQL 5.0.3, you must have the ALTER ROUTINE
privilege for the routine. (That privilege is granted
automatically to the routine creator.)
The IF EXISTS clause is a MySQL extension. It
prevents an error from occurring if the procedure or function
does not exist. A warning is produced that can be viewed with
SHOW WARNINGS.
CALLsp_name([parameter[,...]]) CALLsp_name[()]
The CALL statement invokes a procedure that
was defined previously with CREATE PROCEDURE.
CALL can pass back values to its caller using
parameters that are declared as OUT or
INOUT parameters. It also
“returns” the number of rows affected, which a
client program can obtain at the SQL level by calling the
ROW_COUNT() function and from C by calling
the mysql_affected_rows() C API function.
As of MySQL 5.1.13, stored procedures that take no arguments now
can be invoked without parentheses. That is, CALL
p() and CALL p are equivalent.
To get back a value from a procedure using an
OUT or INOUT parameter,
pass the parameter by means of a user variable, and then check
the value of the variable after the procedure returns. (If you
are calling the procedure from within another stored procedure
or function, you can also pass a routine parameter or local
routine variable as an IN or
INOUT parameter.) For an
INOUT parameter, initialize its value before
passing it to the procedure. The following procedure has an
OUT parameter that the procedure sets to the
current server version, and an INOUT value
that the procedure increments by one from its current value:
CREATE PROCEDURE p (OUT ver_param VARCHAR(25), INOUT incr_param INT) BEGIN # Set value of OUT parameter SELECT VERSION() INTO ver_param; # Increment value of INOUT parameter SET incr_param = incr_param + 1; END;
Before calling the procedure, initialize the variable to be
passed as the INOUT parameter. After calling
the procedure, the values of the two variables will have been
set or modified:
mysql>SET @increment = 10;mysql>CALL p(@version, @increment);mysql>SELECT @version, @increment;+------------+------------+ | @version | @increment | +------------+------------+ | 5.0.25-log | 11 | +------------+------------+
If you write C programs that use the CALL SQL
statement to execute stored procedures that produce result sets,
you must set the
CLIENT_MULTI_RESULTS flag, either explicitly,
or implicitly by setting
CLIENT_MULTI_STATEMENTS when you call
mysql_real_connect(). This is because each
such stored procedure produces multiple results: the result sets
returned by statements executed within the procedure, as well as
a result to indicate the call status. To process the result of a
CALL statement, use a loop that calls
mysql_next_result() to determine whether
there are more results. For an example, see
Section 22.2.9, “C API Handling of Multiple Statement Execution”.
For programs written in a language that provides a MySQL
interface, there is no native method for directly retrieving the
results of OUT or INOUT
parameters from CALL statements. To get the
parameter values, pass user-defined variables to the procedure
in the CALL statement and then execute a
SELECT statement to produce a result set
containing the variable values. The following example
illustrates the technique (without error checking) for a stored
procedure p1 that has two
OUT parameters.
mysql_query(mysql, "CALL p1(@param1, @param2)"); mysql_query(mysql, "SELECT @param1, @param2"); result = mysql_store_result(mysql); row = mysql_fetch_row(result); mysql_free_result(result);
After the preceding code executes, row[0] and
row[1] contain the values of
@param1 and @param2,
respectively.
To handle INOUT parameters, execute a
statement prior to the CALL that sets the
user variables to the values to be passed to the procedure.
[begin_label:] BEGIN [statement_list] END [end_label]
BEGIN ... END syntax is used for writing
compound statements, which can appear within stored routines and
triggers. A compound statement can contain multiple statements,
enclosed by the BEGIN and
END keywords.
statement_list represents a list of
one or more statements. Each statement within
statement_list must be terminated by
a semicolon (;) statement delimiter. Note
that statement_list is optional,
which means that the empty compound statement (BEGIN
END) is legal.
Use of multiple statements requires that a client is able to
send statement strings containing the ;
statement delimiter. This is handled in the
mysql command-line client with the
delimiter command. Changing the
; end-of-statement delimiter (for example, to
//) allows ; to be used in
a routine body. For an example, see
Section 17.2.1, “CREATE PROCEDURE and CREATE
FUNCTION Syntax”.
A compound statement can be labeled.
end_label cannot be given unless
begin_label also is present. If both
are present, they must be the same.
The optional [NOT] ATOMIC clause is not yet
supported. This means that no transactional savepoint is set at
the start of the instruction block and the
BEGIN clause used in this context has no
effect on the current transaction.
The DECLARE statement is used to define
various items local to a routine:
Local variables. See Section 17.2.7, “Variables in Stored Routines”.
Conditions and handlers. See Section 17.2.8, “Conditions and Handlers”.
Cursors. See Section 17.2.9, “Cursors”.
The SIGNAL and RESIGNAL
statements are not currently supported.
DECLARE is allowed only inside a
BEGIN ... END compound statement and must be
at its start, before any other statements.
Declarations must follow a certain order. Cursors must be declared before declaring handlers, and variables and conditions must be declared before declaring either cursors or handlers.
You may declare and use variables within a routine.
DECLAREvar_name[,...]type[DEFAULTvalue]
This statement is used to declare local variables. To provide
a default value for the variable, include a
DEFAULT clause. The value can be specified
as an expression; it need not be a constant. If the
DEFAULT clause is missing, the initial
value is NULL.
Local variables are treated like routine parameters with
respect to data type and overflow checking. See
Section 17.2.1, “CREATE PROCEDURE and CREATE
FUNCTION Syntax”.
The scope of a local variable is within the BEGIN ...
END block where it is declared. The variable can be
referred to in blocks nested within the declaring block,
except those blocks that declare a variable with the same
name.
SETvar_name=expr[,var_name=expr] ...
The SET statement in stored routines is an
extended version of the general SET
statement. Referenced variables may be ones declared inside a
routine, or global system variables.
The SET statement in stored routines is
implemented as part of the pre-existing SET
syntax. This allows an extended syntax of SET a=x,
b=y, ... where different variable types (locally
declared variables and global and session server variables)
can be mixed. This also allows combinations of local variables
and some options that make sense only for system variables; in
that case, the options are recognized but ignored.
SELECTcol_name[,...] INTOvar_name[,...]table_expr
This SELECT syntax stores selected columns
directly into variables. Therefore, only a single row may be
retrieved.
SELECT id,data INTO x,y FROM test.t1 LIMIT 1;
User variable names are not case sensitive. See Section 9.4, “User-Defined Variables”.
Important: SQL variable names
should not be the same as column names. If an SQL statement,
such as a SELECT ... INTO statement,
contains a reference to a column and a declared local variable
with the same name, MySQL currently interprets the reference
as the name of a variable. For example, in the following
statement, xname is interpreted as a
reference to the xname
variable rather than the
xname column:
CREATE PROCEDURE sp1 (x VARCHAR(5))
BEGIN
DECLARE xname VARCHAR(5) DEFAULT 'bob';
DECLARE newname VARCHAR(5);
DECLARE xid INT;
SELECT xname,id INTO newname,xid
FROM table1 WHERE xname = xname;
SELECT newname;
END;
When this procedure is called, the newname
variable returns the value 'bob' regardless
of the value of the table1.xname column.
See also Section F.1, “Restrictions on Stored Routines and Triggers”.
Certain conditions may require specific handling. These conditions can relate to errors, as well as to general flow control inside a routine.
DECLAREcondition_nameCONDITION FORcondition_valuecondition_value: SQLSTATE [VALUE]sqlstate_value|mysql_error_code
This statement specifies conditions that need specific
handling. It associates a name with a specified error
condition. The name can subsequently be used in a
DECLARE HANDLER statement. See
Section 17.2.8.2, “DECLARE Handlers”.
A condition_value can be an
SQLSTATE value or a MySQL error code.
DECLAREhandler_typeHANDLER FORcondition_value[,...]statementhandler_type: CONTINUE | EXIT | UNDOcondition_value: SQLSTATE [VALUE]sqlstate_value|condition_name| SQLWARNING | NOT FOUND | SQLEXCEPTION |mysql_error_code
The DECLARE ... HANDLER statement specifies
handlers that each may deal with one or more conditions. If
one of these conditions occurs, the specified
statement is executed.
statement can be a simple statement
(for example, SET ), or it can be a
compound statement written using var_name
= valueBEGIN and
END (see Section 17.2.5, “BEGIN ... END Compound Statement Syntax”).
For a CONTINUE handler, execution of the
current routine continues after execution of the handler
statement. For an EXIT handler, execution
terminates for the BEGIN ... END compound
statement in which the handler is declared. (This is true even
if the condition occurs in an inner block.) The
UNDO handler type statement is not yet
supported.
If a condition occurs for which no handler has been declared,
the default action is EXIT.
A condition_value can be any of the
following values:
An SQLSTATE value or a MySQL error code.
A condition name previously specified with
DECLARE ... CONDITION. See Section 17.2.8.1, “DECLAREConditions”.SQLWARNINGis shorthand for all SQLSTATE codes that begin with01.NOT FOUNDis shorthand for all SQLSTATE codes that begin with02.SQLEXCEPTIONis shorthand for all SQLSTATE codes not caught bySQLWARNINGorNOT FOUND.
Example:
mysql>CREATE TABLE test.t (s1 int,primary key (s1));Query OK, 0 rows affected (0.00 sec) mysql>delimiter //mysql>CREATE PROCEDURE handlerdemo ()->BEGIN->DECLARE CONTINUE HANDLER FOR SQLSTATE '23000' SET @x2 = 1;->SET @x = 1;->INSERT INTO test.t VALUES (1);->SET @x = 2;->INSERT INTO test.t VALUES (1);->SET @x = 3;->END;->//Query OK, 0 rows affected (0.00 sec) mysql>CALL handlerdemo()//Query OK, 0 rows affected (0.00 sec) mysql>SELECT @x//+------+ | @x | +------+ | 3 | +------+ 1 row in set (0.00 sec)
The example associates a handler with SQLSTATE 23000, which
occurs for a duplicate-key error. Notice that
@x is 3, which shows
that MySQL executed to the end of the procedure. If the line
DECLARE CONTINUE HANDLER FOR SQLSTATE '23000' SET @x2
= 1; had not been present, MySQL would have taken
the default path (EXIT) after the second
INSERT failed due to the PRIMARY
KEY constraint, and SELECT @x
would have returned 2.
If you want to ignore a condition, you can declare a
CONTINUE handler for it and associate it
with an empty block. For example:
DECLARE CONTINUE HANDLER FOR SQLWARNING BEGIN END;
Cursors are supported inside stored procedures and functions and triggers. The syntax is as in embedded SQL. Cursors are currently asensitive, read-only, and non-scrolling. Asensitive means that the server may or may not make a copy of its result table.
Cursors must be declared before declaring handlers, and variables and conditions must be declared before declaring either cursors or handlers.
Example:
CREATE PROCEDURE curdemo()
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE a CHAR(16);
DECLARE b,c INT;
DECLARE cur1 CURSOR FOR SELECT id,data FROM test.t1;
DECLARE cur2 CURSOR FOR SELECT i FROM test.t2;
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = 1;
OPEN cur1;
OPEN cur2;
REPEAT
FETCH cur1 INTO a, b;
FETCH cur2 INTO c;
IF NOT done THEN
IF b < c THEN
INSERT INTO test.t3 VALUES (a,b);
ELSE
INSERT INTO test.t3 VALUES (a,c);
END IF;
END IF;
UNTIL done END REPEAT;
CLOSE cur1;
CLOSE cur2;
END
DECLAREcursor_nameCURSOR FORselect_statement
This statement declares a cursor. Multiple cursors may be declared in a routine, but each cursor in a given block must have a unique name.
The SELECT statement cannot have an
INTO clause.
FETCHcursor_nameINTOvar_name[,var_name] ...
This statement fetches the next row (if a row exists) using the specified open cursor, and advances the cursor pointer.
If no more rows are available, a No Data condition occurs with SQLSTATE value 02000. To detect this condition, you can set up a handler for it. An example is shown in Section 17.2.9, “Cursors”.
The IF, CASE,
LOOP, WHILE,
REPLACE, ITERATE, and
LEAVE constructs are fully implemented.
Many of these constructs contain other statements, as indicated
by the grammar specifications in the following sections. Such
constructs may be nested. For example, an IF
statement might contain a WHILE loop, which
itself contains a CASE statement.
FOR loops are not currently supported.
IFsearch_conditionTHENstatement_list[ELSEIFsearch_conditionTHENstatement_list] ... [ELSEstatement_list] END IF
IF implements a basic conditional
construct. If the search_condition
evaluates to true, the corresponding SQL statement list is
executed. If no search_condition
matches, the statement list in the ELSE
clause is executed. Each
statement_list consists of one or
more statements.
Note: There is also an
IF() function, which
differs from the IF
statement described here. See
Section 12.3, “Control Flow Functions”.
CASEcase_valueWHENwhen_valueTHENstatement_list[WHENwhen_valueTHENstatement_list] ... [ELSEstatement_list] END CASE
Or:
CASE
WHEN search_condition THEN statement_list
[WHEN search_condition THEN statement_list] ...
[ELSE statement_list]
END CASE
The CASE statement for stored routines
implements a complex conditional construct. If a
search_condition evaluates to true,
the corresponding SQL statement list is executed. If no search
condition matches, the statement list in the
ELSE clause is executed. Each
statement_list consists of one or
more statements.
Note: The syntax of the
CASE statement shown
here for use inside stored routines differs slightly from that
of the SQL CASE
expression described in
Section 12.3, “Control Flow Functions”. The
CASE statement cannot have an ELSE
NULL clause, and it is terminated with END
CASE instead of END.
[begin_label:] LOOPstatement_listEND LOOP [end_label]
LOOP implements a simple loop construct,
enabling repeated execution of the statement list, which
consists of one or more statements. The statements within the
loop are repeated until the loop is exited; usually this is
accomplished with a LEAVE statement.
A LOOP statement can be labeled.
end_label cannot be given unless
begin_label also is present. If
both are present, they must be the same.
LEAVE label
This statement is used to exit any labeled flow control
construct. It can be used within BEGIN ...
END or loop constructs (LOOP,
REPEAT, WHILE).
ITERATE label
ITERATE can appear only within
LOOP, REPEAT, and
WHILE statements.
ITERATE means “do the loop
again.”
Example:
CREATE PROCEDURE doiterate(p1 INT)
BEGIN
label1: LOOP
SET p1 = p1 + 1;
IF p1 < 10 THEN ITERATE label1; END IF;
LEAVE label1;
END LOOP label1;
SET @x = p1;
END
[begin_label:] REPEATstatement_listUNTILsearch_conditionEND REPEAT [end_label]
The statement list within a REPEAT
statement is repeated until the
search_condition is true. Thus, a
REPEAT always enters the loop at least
once. statement_list consists of
one or more statements.
A REPEAT statement can be labeled.
end_label cannot be given unless
begin_label also is present. If
both are present, they must be the same.
Example:
mysql>delimiter //mysql>CREATE PROCEDURE dorepeat(p1 INT)->BEGIN->SET @x = 0;->REPEAT SET @x = @x + 1; UNTIL @x > p1 END REPEAT;->END->//Query OK, 0 rows affected (0.00 sec) mysql>CALL dorepeat(1000)//Query OK, 0 rows affected (0.00 sec) mysql>SELECT @x//+------+ | @x | +------+ | 1001 | +------+ 1 row in set (0.00 sec)
[begin_label:] WHILEsearch_conditionDOstatement_listEND WHILE [end_label]
The statement list within a WHILE statement
is repeated as long as the
search_condition is true.
statement_list consists of one or
more statements.
A WHILE statement can be labeled.
end_label cannot be given unless
begin_label also is present. If
both are present, they must be the same.
Example:
CREATE PROCEDURE dowhile()
BEGIN
DECLARE v1 INT DEFAULT 5;
WHILE v1 > 0 DO
...
SET v1 = v1 - 1;
END WHILE;
END
Within the body of a stored routine (procedure or function) or a
trigger, the value of LAST_INSERT_ID() changes
the same way as for statements executed outside the body of these
kinds of objects (see Section 12.10.3, “Information Functions”).
The effect of a stored routine or trigger upon the value of
LAST_INSERT_ID() that is seen by following
statements depends on the kind of routine:
If a stored procedure executes statements that change the value of
LAST_INSERT_ID(), the changed value will be seen by statements that follow the procedure call.For stored functions and triggers that change the value, the value is restored when the function or trigger ends, so following statements will not see a changed value.
The binary log contains information about SQL statements that modify database contents. This information is stored in the form of “events” that describe the modifications. The binary log has two important purposes:
For replication, the master server sends the events contained in its binary log to its slaves, which execute those events to make the same data changes that were made on the master. See Section 6.2, “Replication Implementation Overview”.
Certain data recovery operations require use of the binary log. After a backup file has been restored, the events in the binary log that were recorded after the backup was made are re-executed. These events bring databases up to date from the point of the backup. See Section 5.9.2.2, “Using Backups for Recovery”.
This section describes the development of binary logging in MySQL 5.0 with respect to stored routines (procedures and functions) and triggers. The discussion first summarizes the changes that have taken place in the logging implementation, and then states the current conditions that the implementation places on the use of stored routines. Finally, implementation details are given that provide information about when and why various changes were made. These details show how several aspects of the current logging behavior were implemented in response to shortcomings identified in earlier versions.
In general, the issues described here result from the fact that binary logging occurs at the SQL statement level. A future MySQL release is expected to implement row-level binary logging, which specifies the changes to make to individual rows as a result of executing SQL statements.
Unless noted otherwise, the remarks here assume that you have
enabled binary logging by starting the server with the
--log-bin option. (See
Section 5.11.3, “The Binary Log”.) If the binary log is not enabled,
replication is not possible, nor is the binary log available for
data recovery.
The development of stored routine logging in MySQL 5.0 can be summarized as follows:
Before MySQL 5.0.6: In the initial implementation of stored routine logging, statements that create stored routines and
CALLstatements are not logged. These omissions can cause problems for replication and data recovery.MySQL 5.0.6: Statements that create stored routines and
CALLstatements are logged. Stored function invocations are logged when they occur in statements that update data (because those statements are logged). However, function invocations are not logged when they occur in statements such asSELECTthat do not change data, even if a data change occurs within a function itself; this can cause problems. Under some circumstances, functions and procedures can have different effects if executed at different times or on different (master and slave) machines, and thus can be unsafe for data recovery or replication. To handle this, measures are implemented to allow identification of safe routines and to prevent creation of unsafe routines except by users with sufficient privileges.MySQL 5.0.12: For stored functions, when a function invocation that changes data occurs within a non-logged statement such as
SELECT, the server logs aDOstatement that invokes the function so that the function gets executed during data recovery or replication to slave servers. For stored procedures, the server does not logfunc_name()CALLstatements. Instead, it logs individual statements within a procedure that are executed as a result of aCALL. This eliminates problems that may occur when a procedure would follow a different execution path on a slave than on the master.MySQL 5.0.16: The procedure logging changes made in 5.0.12 allow the conditions on unsafe routines to be relaxed for stored procedures. Consequently, the user interface for controlling these conditions is revised to apply only to functions. Procedure creators are no longer bound by them.
MySQL 5.0.17: Logging of stored functions as
DOstatements (per the changes made in 5.0.12) are logged asfunc_name()SELECTstatements instead for better control over error checking.func_name()
As a consequence of the preceding changes, the following conditions currently apply to stored function creation when binary logging is enabled. These conditions do not apply to stored procedure creation.
To create or alter a stored function, you must have the
SUPERprivilege, in addition to theCREATE ROUTINEorALTER ROUTINEprivilege that is normally required.When you create a stored function, you must declare either that it is deterministic or that it does not modify data. Otherwise, it may be unsafe for data recovery or replication. Two sets of function characteristics apply here:
The
DETERMINISTICandNOT DETERMINISTICcharacteristics indicate whether a function always produces the same result for given inputs. The default isNOT DETERMINISTICif neither characteristic is given, so you must specifyDETERMINISTICexplicitly to declare that a function is deterministic.Use of the
NOW()function (or its synonyms) orRAND()does not necessarily make a function non-deterministic. ForNOW(), the binary log includes the timestamp and replicates correctly.RAND()also replicates correctly as long as it is invoked only once within a function. (You can consider the function execution timestamp and random number seed as implicit inputs that are identical on the master and slave.)SYSDATE()is not affected by the timestamps in the binary log, so it causes stored routines to be non-deterministic if statement-based logging is used. This does not occur if the server is started with the--sysdate-is-nowoption to causeSYSDATE()to be an alias forNOW().The
CONTAINS SQL,NO SQL,READS SQL DATA, andMODIFIES SQL DATAcharacteristics provide information about whether the function reads or writes data. EitherNO SQLorREADS SQL DATAindicates that a function does not change data, but you must specify one of these explicitly because the default isCONTAINS SQLif no characteristic is given.
By default, for a
CREATE FUNCTIONstatement to be accepted,DETERMINISTICor one ofNO SQLandREADS SQL DATAmust be specified explicitly. Otherwise an error occurs:ERROR 1418 (HY000): This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable)
Assessment of the nature of a function is based on the “honesty” of the creator: MySQL does not check that a function declared
DETERMINISTICis free of statements that produce non-deterministic results.To relax the preceding conditions on function creation (that you must have the
SUPERprivilege and that a function must be declared deterministic or to not modify data), set the globallog_bin_trust_function_creatorssystem variable to 1. By default, this variable has a value of 0, but you can change it like this:mysql>
SET GLOBAL log_bin_trust_function_creators = 1;You can also set this variable by using the
--log-bin-trust-function-creators=1option when starting the server.If binary logging is not enabled,
log_bin_trust_function_creatorsdoes not apply andSUPERis not required for routine creation.
Triggers are similar to stored functions, so the preceding remarks
regarding functions also apply to triggers with the following
exception: CREATE TRIGGER does not have an
optional DETERMINISTIC characteristic, so
triggers are assumed to be always deterministic. However, this
assumption might in some cases be invalid. For example, the
UUID() function is non-deterministic (and does
not replicate). You should be careful about using such functions
in triggers.
Triggers can update tables (as of MySQL 5.0.10), so error messages
similar to those for stored functions occur with CREATE
TRIGGER if you do not have the SUPER
privilege and log_bin_trust_function_creators
is 0.
The rest of this section provides details on the development of stored routine logging. Some of these details give additional background on the rationale for the current logging-related conditions on stored routine use.
Routine logging before MySQL 5.0.6: Statements that create and use stored routines are not written to the binary log, but statements invoked within stored routines are logged. Suppose that you issue the following statements:
CREATE PROCEDURE mysp INSERT INTO t VALUES(1); CALL mysp();
For this example, only the INSERT statement
appears in the binary log. The CREATE PROCEDURE
and CALL statements do not appear. The absence
of routine-related statements in the binary log means that stored
routines are not replicated correctly. It also means that for a
data recovery operation, re-executing events in the binary log
does not recover stored routines.
Routine logging changes in MySQL
5.0.6: To address the absence of logging for stored
routine creation and CALL statements (and the
consequent replication and data recovery concerns), the
characteristics of binary logging for stored routines were changed
as described here. (Some of the items in the following list point
out issues that are dealt with in later versions.)
The server writes
CREATE PROCEDURE,CREATE FUNCTION,ALTER PROCEDURE,ALTER FUNCTION,DROP PROCEDURE, andDROP FUNCTIONstatements to the binary log. Also, the server logsCALLstatements, not the statements executed within procedures. Suppose that you issue the following statements:CREATE PROCEDURE mysp INSERT INTO t VALUES(1); CALL mysp();
For this example, the
CREATE PROCEDUREandCALLstatements appear in the binary log, but theINSERTstatement does not appear. This corrects the problem that occurred before MySQL 5.0.6 such that only theINSERTwas logged.Logging
CALLstatements has a security implication for replication, which arises from two factors:It is possible for a procedure to follow different execution paths on master and slave servers.
Statements executed on a slave are processed by the slave SQL thread which has full privileges.
The implication is that although a user must have the
CREATE ROUTINEprivilege to create a routine, the user can write a routine containing a dangerous statement that will execute only on the slave where the statement is processed by the SQL thread that has full privileges. For example, if the master and slave servers have server ID values of 1 and 2, respectively, a user on the master server could create and invoke an unsafe procedureunsafe_sp()as follows:mysql>
delimiter //mysql>CREATE PROCEDURE unsafe_sp ()->BEGIN->IF @@server_id=2 THEN DROP DATABASE accounting; END IF;->END;->//mysql>delimiter ;mysql>CALL unsafe_sp();The
CREATE PROCEDUREandCALLstatements are written to the binary log, so the slave will execute them. Because the slave SQL thread has full privileges, it will execute theDROP DATABASEstatement that drops theaccountingdatabase. Thus, theCALLstatement has different effects on the master and slave and is not replication-safe.The preceding example uses a stored procedure, but similar problems can occur for stored functions that are invoked within statements that are written to the binary log: Function invocation has different effects on the master and slave.
To guard against this danger for servers that have binary logging enabled, MySQL 5.0.6 introduces the requirement that stored procedure and function creators must have the
SUPERprivilege, in addition to the usualCREATE ROUTINEprivilege that is required. Similarly, to useALTER PROCEDUREorALTER FUNCTION, you must have theSUPERprivilege in addition to theALTER ROUTINEprivilege. Without theSUPERprivilege, an error will occur:ERROR 1419 (HY000): You do not have the SUPER privilege and binary logging is enabled (you *might* want to use the less safe log_bin_trust_routine_creators variable)
If you do not want to require routine creators to have the
SUPERprivilege (for example, if all users with theCREATE ROUTINEprivilege on your system are experienced application developers), set the globallog_bin_trust_routine_creatorssystem variable to 1. You can also set this variable by using the--log-bin-trust-routine-creators=1option when starting the server. If binary logging is not enabled,log_bin_trust_routine_creatorsdoes not apply andSUPERis not required for routine creation.If a routine that performs updates is non-deterministic, it is not repeatable. This can have two undesirable effects:
It will make a slave different from the master.
Restored data will be different from the original data.
To deal with these problems, MySQL enforces the following requirement: On a master server, creation and alteration of a routine is refused unless you declare the routine to be deterministic or to not modify data. Two sets of routine characteristics apply here:
The
DETERMINISTICandNOT DETERMINISTICcharacteristics indicate whether a routine always produces the same result for given inputs. The default isNOT DETERMINISTICif neither characteristic is given. To declare that a routine is deterministic, you must specifyDETERMINISTICexplicitly.The
CONTAINS SQL,NO SQL,READS SQL DATA, andMODIFIES SQL DATAcharacteristics provide information about whether the routine reads or writes data. EitherNO SQLorREADS SQL DATAindicates that a routine does not change data, but you must specify one of these explicitly because the default isCONTAINS SQLif no characteristic is given.
By default, for a
CREATE PROCEDUREorCREATE FUNCTIONstatement to be accepted,DETERMINISTICor one ofNO SQLandREADS SQL DATAmust be specified explicitly. Otherwise an error occurs:ERROR 1418 (HY000): This routine has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you *might* want to use the less safe log_bin_trust_routine_creators variable)
If you set
log_bin_trust_routine_creatorsto 1, the requirement that routines be deterministic or not modify data is dropped.A
CALLstatement is written to the binary log if the routine returns no error, but not otherwise. When a routine that modifies data fails, you get this warning:ERROR 1417 (HY000): A routine failed and has neither NO SQL nor READS SQL DATA in its declaration and binary logging is enabled; if non-transactional tables were updated, the binary log will miss their changes
This logging behavior has the potential to cause problems. If a routine partly modifies a non-transactional table (such as a
MyISAMtable) and returns an error, the binary log will not reflect these changes. To protect against this, you should use transactional tables in the routine and modify the tables within transactions.If you use the
IGNOREkeyword withINSERT,DELETE, orUPDATEto ignore errors within a routine, a partial update might occur but no error will result. Such statements are logged and they replicate normally.Although statements normally are not written to the binary log if they are rolled back,
CALLstatements are logged even when they occur within a rolled-back transaction. This can result in aCALLbeing rolled back on the master but executed on slaves.If a stored function is invoked within a statement such as
SELECTthat does not modify data, execution of the function is not written to the binary log, even if the function itself modifies data. This logging behavior has the potential to cause problems. Suppose that a functionmyfunc()is defined as follows:CREATE FUNCTION myfunc () RETURNS INT DETERMINISTIC BEGIN INSERT INTO t (i) VALUES(1); RETURN 0; END;
Given that definition, the following statement is not written to the binary log because it is a
SELECT. Nevertheless, it modifies the tabletbecausemyfunc()modifiest:SELECT myfunc();
A workaround for this problem is to invoke functions that do updates only within statements that do updates (and which therefore are written to the binary log). Note that although the
DOstatement sometimes is executed for the side effect of evaluating an expression,DOis not a workaround here because it is not written to the binary log.On slave servers,
--replicate-*-tablerules do not apply toCALLstatements or to statements within stored routines. These statements are always replicated. If such statements contain references to tables that do not exist on the slave, they could have undesirable effects when executed on the slave.
Routine logging changes in MySQL 5.0.12: The changes in 5.0.12 address several problems that were present in earlier versions:
Stored function invocations in non-logged statements such as
SELECTwere not being logged, even when a function itself changed data.Stored procedure logging at the
CALLlevel could cause different effects on a master and slave if a procedure took different execution paths on the two machines.CALLstatements were logged even when they occurred within a rolled-back transaction.
To deal with these issues, MySQL 5.0.12 implements the following changes to function and procedure logging:
A stored function invocation is logged as a
DOstatement if the function changes data and occurs within a statement that would not otherwise be logged. This corrects the problem of non-replication of data changes that result from use of stored functions in non-logged statements. For example,SELECTstatements are not written to the binary log, but aSELECTmight invoke a stored function that makes changes. To handle this, aDOstatement is written to the binary log when the given function makes a change. Suppose that the following statements are executed on the master:func_name()CREATE FUNCTION f1(a INT) RETURNS INT BEGIN IF (a < 3) THEN INSERT INTO t2 VALUES (a); END IF; END; CREATE TABLE t1 (a INT); INSERT INTO t1 VALUES (1),(2),(3); SELECT f1(a) FROM t1;When the
SELECTstatement executes, the functionf1()is invoked three times. Two of those invocations insert a row, and MySQL logs aDOstatement for each of them. That is, MySQL writes the following statements to the binary log:DO f1(1); DO f1(2);
The server also logs a
DOstatement for a stored function invocation when the function invokes a stored procedure that causes an error. In this case, the server writes theDOstatement to the log along with the expected error code. On the slave, if the same error occurs, that is the expected result and replication continues. Otherwise, replication stops.Note: See later in this section for changes made in MySQL 5.0.19: These logged
DOstatements are logged asfunc_name()SELECTstatements instead.func_name()Stored procedure calls are logged at the statement level rather than at the
CALLlevel. That is, the server does not log theCALLstatement, it logs those statements within the procedure that actually execute. As a result, the same changes that occur on the master will be observed on slave servers. This eliminates the problems that could result from a procedure having different execution paths on different machines. For example, theDROP DATABASEproblem shown earlier for theunsafe_sp()procedure does not occur and the routine is no longer replication-unsafe because it has the same effect on master and slave servers.In general, statements executed within a stored procedure are written to the binary log using the same rules that would apply were the statements to be executed in standalone fashion. Some special care is taken when logging procedure statements because statement execution within procedures is not quite the same as in non-procedure context:
A statement to be logged might contain references to local procedure variables. These variables do not exist outside of stored procedure context, so a statement that refers to such a variable cannot be logged literally. Instead, each reference to a local variable is replaced by this construct for logging purposes:
NAME_CONST(
var_name,var_value)var_nameis the local variable name, andvar_valueis a constant indicating the value that the variable has at the time the statement is logged.NAME_CONST()has a value ofvar_value, and a “name” ofvar_name. Thus, if you invoke this function directly, you get a result like this:mysql>
SELECT NAME_CONST('myname', 14);+--------+ | myname | +--------+ | 14 | +--------+NAME_CONST()allows a logged standalone statement to be executed on a slave with the same effect as the original statement that was executed on the master within a stored procedure.A statement to be logged might contain references to user-defined variables. To handle this, MySQL writes a
SETstatement to the binary log to make sure that the variable exists on the slave with the same value as on the master. For example, if a statement refers to a variable@my_var, that statement will be preceded in the binary log by the following statement, wherevalueis the value of@my_varon the master:SET @my_var =
value;Procedure calls can occur within a committed or rolled-back transaction. Previously,
CALLstatements were logged even if they occurred within a rolled-back transaction. As of MySQL 5.0.12, transactional context is accounted for so that the transactional aspects of procedure execution are replicated correctly. That is, the server logs those statements within the procedure that actually execute and modify data, and also logsBEGIN,COMMIT, andROLLBACKstatements as necessary. For example, if a procedure updates only transactional tables and is executed within a transaction that is rolled back, those updates are not logged. If the procedure occurs within a committed transaction,BEGINandCOMMITstatements are logged with the updates. For a procedure that executes within a rolled-back transaction, its statements are logged using the same rules that would apply if the statements were executed in standalone fashion:Updates to transactional tables are not logged.
Updates to non-transactional tables are logged because rollback does not cancel them.
Updates to a mix of transactional and non-transactional tables are logged surrounded by
BEGINandROLLBACKso that slaves will make the same changes and rollbacks as on the master.
A stored procedure call is not written to the binary log at the statement level if the procedure is invoked from within a stored function. In that case, the only thing logged is the statement that invokes the function (if it occurs within a statement that is logged) or a
DOstatement (if it occurs within a statement that is not logged). For this reason, care still should be exercised in the use of stored functions that invoke a procedure, even if the procedure is otherwise safe in itself.Because procedure logging occurs at the statement level rather than at the
CALLlevel, interpretation of the--replicate-*-tableoptions is revised to apply only to stored functions. They no longer apply to stored procedures, except those procedures that are invoked from within functions.
Routine logging changes in MySQL
5.0.16: In 5.0.12, a change was introduced to log
stored procedure calls at the statement level rather than at the
CALL level. This change eliminates the
requirement that procedures be identified as safe. The requirement
now exists only for stored functions, because they still appear in
the binary log as function invocations rather than as the
statements executed within the function. To reflect the lifting of
the restriction on stored procedures, the
log_bin_trust_routine_creators system variable
is renamed to log_bin_trust_function_creators
and the --log-bin-trust-routine-creators server
option is renamed to
--log-bin-trust-function-creators. (For backward
compatibility, the old names are recognized but result in a
warning.) Error messages that now apply only to functions and not
to routines in general are re-worded.
Routine logging changes in MySQL
5.0.19: In 5.0.12, a change was introduced to log a
stored function invocation as DO
if the invocation
changes data and occurs within a non-logged statement, or if the
function invokes a stored procedure that produces an error. In
5.0.19, these invocations are logged as func_name()SELECT
instead. The
change to func_name()SELECT was made because use of
DO was found to yield insufficient control over
error code checking.
Support for triggers is included beginning with MySQL 5.0.2. A
trigger is a named database object that is associated with a table
and that is activated when a particular event occurs for the table.
For example, the following statements create a table and an
INSERT trigger. The trigger sums the values
inserted into one of the table's columns:
mysql>CREATE TABLE account (acct_num INT, amount DECIMAL(10,2));Query OK, 0 rows affected (0.03 sec) mysql>CREATE TRIGGER ins_sum BEFORE INSERT ON account->FOR EACH ROW SET @sum = @sum + NEW.amount;Query OK, 0 rows affected (0.06 sec)
This chapter describes the syntax for creating and dropping triggers, and shows some examples of how to use them. Discussion of restrictions on use of triggers is given in Section F.1, “Restrictions on Stored Routines and Triggers”. Remarks regarding binary logging as it applies to triggers are given in Section 17.4, “Binary Logging of Stored Routines and Triggers”.
For answers to some common questions about triggers in MySQL 5.0, see Section A.5, “MySQL 5.0 FAQ — Triggers”.
CREATE
[DEFINER = { user | CURRENT_USER }]
TRIGGER trigger_name trigger_time trigger_event
ON tbl_name FOR EACH ROW trigger_stmt
This statement creates a new trigger. A trigger is a named
database object that is associated with a table, and that
activates when a particular event occurs for the table.
CREATE TRIGGER was added in MySQL 5.0.2.
Currently, its use requires the SUPER
privilege.
MySQL Enterprise For expert advice on creating triggers subscribe to the MySQL Network Monitoring and Advisory Service. For more information see, http://www.mysql.com/products/enterprise/advisors.html.
The trigger becomes associated with the table named
tbl_name, which must refer to a
permanent table. You cannot associate a trigger with a
TEMPORARY table or a view.
When the trigger is activated, the DEFINER
clause determines the privileges that apply, as described later in
this section.
trigger_time is the trigger action
time. It can be BEFORE or
AFTER to indicate that the trigger activates
before or after the statement that activated it.
trigger_event indicates the kind of
statement that activates the trigger. The
trigger_event can be one of the
following:
INSERT: The trigger is activated whenever a new row is inserted into the table; for example, throughINSERT,LOAD DATA, andREPLACEstatements.UPDATE: The trigger is activated whenever a row is modified; for example, throughUPDATEstatements.DELETE: The trigger is activated whenever a row is deleted from the table; for example, throughDELETEandREPLACEstatements. However,DROP TABLEandTRUNCATEstatements on the table do not activate this trigger, because they do not useDELETE. See Section 13.2.9, “TRUNCATESyntax”.
It is important to understand that the
trigger_event does not represent a
literal type of SQL statement that activates the trigger so much
as it represents a type of table operation. For example, an
INSERT trigger is activated by not only
INSERT statements but also LOAD
DATA statements because both statements insert rows into
a table.
A potentially confusing example of this is the INSERT
INTO ... ON DUPLICATE KEY UPDATE ... syntax: a
BEFORE INSERT trigger will activate for every
row, followed by either an AFTER INSERT trigger
or both the BEFORE UPDATE and AFTER
UPDATE triggers, depending on whether there was a
duplicate key for the row.
There cannot be two triggers for a given table that have the same
trigger action time and event. For example, you cannot have two
BEFORE UPDATE triggers for a table. But you can
have a BEFORE UPDATE and a BEFORE
INSERT trigger, or a BEFORE UPDATE
and an AFTER UPDATE trigger.
trigger_stmt is the statement to
execute when the trigger activates. If you want to execute
multiple statements, use the BEGIN ... END
compound statement construct. This also enables you to use the
same statements that are allowable within stored routines. See
Section 17.2.5, “BEGIN ... END Compound Statement Syntax”. Some statements are not allowed in
triggers; see Section F.1, “Restrictions on Stored Routines and Triggers”.
MySQL stores the sql_mode system variable
setting that is in effect at the time a trigger is created, and
always executes the trigger with this setting in force,
regardless of the current server SQL mode.
Note: Currently, triggers are not activated by cascaded foreign key actions. This limitation will be lifted as soon as possible.
Note: Before MySQL 5.0.10,
triggers cannot contain direct references to tables by name.
Beginning with MySQL 5.0.10, you can write triggers such as the
one named testref shown in this example:
CREATE TABLE test1(a1 INT);
CREATE TABLE test2(a2 INT);
CREATE TABLE test3(a3 INT NOT NULL AUTO_INCREMENT PRIMARY KEY);
CREATE TABLE test4(
a4 INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
b4 INT DEFAULT 0
);
DELIMITER |
CREATE TRIGGER testref BEFORE INSERT ON test1
FOR EACH ROW BEGIN
INSERT INTO test2 SET a2 = NEW.a1;
DELETE FROM test3 WHERE a3 = NEW.a1;
UPDATE test4 SET b4 = b4 + 1 WHERE a4 = NEW.a1;
END;
|
DELIMITER ;
INSERT INTO test3 (a3) VALUES
(NULL), (NULL), (NULL), (NULL), (NULL),
(NULL), (NULL), (NULL), (NULL), (NULL);
INSERT INTO test4 (a4) VALUES
(0), (0), (0), (0), (0), (0), (0), (0), (0), (0);
Suppose that you insert the following values into table
test1 as shown here:
mysql>INSERT INTO test1 VALUES->(1), (3), (1), (7), (1), (8), (4), (4);Query OK, 8 rows affected (0.01 sec) Records: 8 Duplicates: 0 Warnings: 0
As a result, the data in the four tables will be as follows:
mysql>SELECT * FROM test1;+------+ | a1 | +------+ | 1 | | 3 | | 1 | | 7 | | 1 | | 8 | | 4 | | 4 | +------+ 8 rows in set (0.00 sec) mysql>SELECT * FROM test2;+------+ | a2 | +------+ | 1 | | 3 | | 1 | | 7 | | 1 | | 8 | | 4 | | 4 | +------+ 8 rows in set (0.00 sec) mysql>SELECT * FROM test3;+----+ | a3 | +----+ | 2 | | 5 | | 6 | | 9 | | 10 | +----+ 5 rows in set (0.00 sec) mysql>SELECT * FROM test4;+----+------+ | a4 | b4 | +----+------+ | 1 | 3 | | 2 | 0 | | 3 | 1 | | 4 | 2 | | 5 | 0 | | 6 | 0 | | 7 | 1 | | 8 | 1 | | 9 | 0 | | 10 | 0 | +----+------+ 10 rows in set (0.00 sec)
You can refer to columns in the subject table (the table
associated with the trigger) by using the aliases
OLD and NEW.
OLD. refers
to a column of an existing row before it is updated or deleted.
col_nameNEW. refers
to the column of a new row to be inserted or an existing row after
it is updated.
col_name
The DEFINER clause specifies the MySQL account
to be used when checking access privileges at trigger activation
time. It was added in MySQL 5.0.17. If a
user value is given, it should be a
MySQL account in
'
format (the same format used in the user_name'@'host_name'GRANT
statement). The user_name and
host_name values both are required.
CURRENT_USER also can be given as
CURRENT_USER(). The default
DEFINER value is the user who executes the
CREATE TRIGGER statement. (This is the same as
DEFINER = CURRENT_USER.)
If you specify the DEFINER clause, you cannot
set the value to any account but your own unless you have the
SUPER privilege. These rules determine the
legal DEFINER user values:
If you do not have the
SUPERprivilege, the only legaluservalue is your own account, either specified literally or by usingCURRENT_USER. You cannot set the definer to some other account.If you have the
SUPERprivilege, you can specify any syntactically legal account name. If the account does not actually exist, a warning is generated.Although it is possible to create triggers with a non-existent
DEFINERvalue, it is not a good idea for such triggers to be activated until the definer actually does exist. Otherwise, the behavior with respect to privilege checking is undefined.
Note: Because MySQL currently requires the
SUPER privilege for the use of CREATE
TRIGGER, only the second of the preceding rules applies.
(MySQL 5.1.6 implements the TRIGGER privilege
and requires that privilege for trigger creation, so at that point
both rules come into play and SUPER is required only for
specifying a DEFINER value other than your own account.)
From MySQL 5.0.17 on, MySQL checks trigger privileges like this:
At
CREATE TRIGGERtime, the user that issues the statement must have theSUPERprivilege.At trigger activation time, privileges are checked against the
DEFINERuser. This user must have these privileges:The
SUPERprivilege.The
SELECTprivilege for the subject table if references to table columns occur viaOLD.orcol_nameNEW.in the trigger definition.col_nameThe
UPDATEprivilege for the subject table if table columns are targets ofSET NEW.assignments in the trigger definition.col_name=valueWhatever other privileges normally are required for the statements executed by the trigger.
Before MySQL 5.0.17, MySQL checks trigger privileges like this:
At
CREATE TRIGGERtime, the user that issues the statement must have theSUPERprivilege.At trigger activation time, privileges are checked against the user whose actions cause the trigger to be activated. This user must have whatever privileges normally are required for the statements executed by the trigger.
Note that the introduction of the DEFINER
clause changes the meaning of CURRENT_USER()
within trigger definitions: The CURRENT_USER()
function evaluates to the trigger DEFINER value
as of MySQL 5.0.17 and to the user whose actions caused the
trigger to be activated before 5.0.17.
DROP TRIGGER [IF EXISTS] [schema_name.]trigger_name
This statement drops a trigger. The schema (database) name is
optional. If the schema is omitted, the trigger is dropped from
the default schema. DROP TRIGGER was added in
MySQL 5.0.2. Its use requires the SUPER
privilege.
Use IF EXISTS to prevent an error from
occurring for a trigger that does not exist. A
NOTE is generated for a non-existent trigger
when using IF EXISTS. See
Section 13.5.4.28, “SHOW WARNINGS Syntax”. The IF EXISTS
clause was added in MySQL 5.0.32.
Note: Prior to MySQL 5.0.10, the
table name was required instead of the schema name
(table_name.trigger_nameDROP TRIGGER does not work after the upgrade.
See Section 2.4.16.2, “Upgrading from MySQL 4.1 to 5.0”, for a suggested upgrade
procedure.
In addition, triggers created in MySQL 5.0.16 or later cannot be dropped following a downgrade to MySQL 5.0.15 or earlier. If you wish to perform such a downgrade, you must also in this case drop all triggers prior to the downgrade, and then re-create them afterwards.
(For more information about these two issues, see Bug#15921 and Bug#18588.)
Support for triggers is included beginning with MySQL 5.0.2. This section discusses how to use triggers and some limitations regarding their use. Additional information about trigger limitations is given in Section F.1, “Restrictions on Stored Routines and Triggers”.
A trigger is a named database object that is associated with a table, and that activates when a particular event occurs for the table. Some uses for triggers are to perform checks of values to be inserted into a table or to perform calculations on values involved in an update.
A trigger is associated with a table and is defined to activate
when an INSERT, DELETE, or
UPDATE statement for the table executes. A
trigger can be set to activate either before or after the
triggering statement. For example, you can have a trigger activate
before each row that is deleted from a table or after each row
that is updated.
To create a trigger or drop a trigger, use the CREATE
TRIGGER or DROP TRIGGER statement.
The syntax for these statements is described in
Section 18.1, “CREATE TRIGGER Syntax”, and
Section 18.2, “DROP TRIGGER Syntax”.
Here is a simple example that associates a trigger with a table
for INSERT statements. It acts as an
accumulator to sum the values inserted into one of the columns of
the table.
The following statements create a table and a trigger for it:
mysql>CREATE TABLE account (acct_num INT, amount DECIMAL(10,2));mysql>CREATE TRIGGER ins_sum BEFORE INSERT ON account->FOR EACH ROW SET @sum = @sum + NEW.amount;
The CREATE TRIGGER statement creates a trigger
named ins_sum that is associated with the
account table. It also includes clauses that
specify the trigger activation time, the triggering event, and
what to do with the trigger activates:
The keyword
BEFOREindicates the trigger action time. In this case, the trigger should activate before each row inserted into the table. The other allowable keyword here isAFTER.The keyword
INSERTindicates the event that activates the trigger. In the example,INSERTstatements cause trigger activation. You can also create triggers forDELETEandUPDATEstatements.The statement following
FOR EACH ROWdefines the statement to execute each time the trigger activates, which occurs once for each row affected by the triggering statement In the example, the triggered statement is a simpleSETthat accumulates the values inserted into theamountcolumn. The statement refers to the column asNEW.amountwhich means “the value of theamountcolumn to be inserted into the new row.”
To use the trigger, set the accumulator variable to zero, execute
an INSERT statement, and then see what value
the variable has afterward:
mysql>SET @sum = 0;mysql>INSERT INTO account VALUES(137,14.98),(141,1937.50),(97,-100.00);mysql>SELECT @sum AS 'Total amount inserted';+-----------------------+ | Total amount inserted | +-----------------------+ | 1852.48 | +-----------------------+
In this case, the value of @sum after the
INSERT statement has executed is 14.98
+ 1937.50 - 100, or 1852.48.
To destroy the trigger, use a DROP TRIGGER
statement. You must specify the schema name if the trigger is not
in the default schema:
mysql> DROP TRIGGER test.ins_sum;
Trigger names exist in the schema namespace, meaning that all triggers must have unique names within a schema. Triggers in different schemas can have the same name.
In addition to the requirement that trigger names be unique for a
schema, there are other limitations on the types of triggers you
can create. In particular, you cannot have two triggers for a
table that have the same activation time and activation event. For
example, you cannot define two BEFORE INSERT
triggers or two AFTER UPDATE triggers for a
table. This should rarely be a significant limitation, because it
is possible to define a trigger that executes multiple statements
by using the BEGIN ... END compound statement
construct after FOR EACH ROW. (An example
appears later in this section.)
The OLD and NEW keywords
enable you to access columns in the rows affected by a trigger.
(OLD and NEW are not case
sensitive.) In an INSERT trigger, only
NEW. can be
used; there is no old row. In a col_nameDELETE trigger,
only OLD.
can be used; there is no new row. In an col_nameUPDATE
trigger, you can use
OLD. to
refer to the columns of a row before it is updated and
col_nameNEW. to
refer to the columns of the row after it is updated.
col_name
A column named with OLD is read-only. You can
refer to it (if you have the SELECT privilege),
but not modify it. A column named with NEW can
be referred to if you have the SELECT privilege
for it. In a BEFORE trigger, you can also
change its value with SET
NEW. if you have the
col_name =
valueUPDATE privilege for it. This means you can use
a trigger to modify the values to be inserted into a new row or
that are used to update a row.
In a BEFORE trigger, the NEW
value for an AUTO_INCREMENT column is 0, not
the automatically generated sequence number that will be generated
when the new record actually is inserted.
OLD and NEW are MySQL
extensions to triggers.
By using the BEGIN ... END construct, you can
define a trigger that executes multiple statements. Within the
BEGIN block, you also can use other syntax that
is allowed within stored routines such as conditionals and loops.
However, just as for stored routines, if you use the
mysql program to define a trigger that executes
multiple statements, it is necessary to redefine the
mysql statement delimiter so that you can use
the ; statement delimiter within the trigger
definition. The following example illustrates these points. It
defines an UPDATE trigger that checks the new
value to be used for updating each row, and modifies the value to
be within the range from 0 to 100. This must be a
BEFORE trigger because the value needs to be
checked before it is used to update the row:
mysql>delimiter //mysql>CREATE TRIGGER upd_check BEFORE UPDATE ON account->FOR EACH ROW->BEGIN->IF NEW.amount < 0 THEN->SET NEW.amount = 0;->ELSEIF NEW.amount > 100 THEN->SET NEW.amount = 100;->END IF;->END;//mysql>delimiter ;
It can be easier to define a stored procedure separately and then
invoke it from the trigger using a simple CALL
statement. This is also advantageous if you want to invoke the
same routine from within several triggers.
There are some limitations on what can appear in statements that a trigger executes when activated:
The trigger cannot use the
CALLstatement to invoke stored procedures that return data to the client or that use dynamic SQL. (Stored procedures are allowed to return data to the trigger throughOUTorINOUTparameters.)The trigger cannot use statements that explicitly or implicitly begin or end a transaction such as
START TRANSACTION,COMMIT, orROLLBACK.Prior to MySQL 5.0.10, triggers cannot contain direct references to tables by name.
MySQL handles errors during trigger execution as follows:
If a
BEFOREtrigger fails, the operation on the corresponding row is not performed.A
BEFOREtrigger is activated by the attempt to insert or modify the row, regardless of whether the attempt subsequently succeeds.An
AFTERtrigger is executed only if theBEFOREtrigger (if any) and the row operation both execute successfully.An error during either a
BEFOREorAFTERtrigger results in failure of the entire statement that caused trigger invocation.For transactional tables, failure of a statement should cause rollback of all changes performed by the statement. Failure of a trigger causes the statement to fail, so trigger failure also causes rollback. For non-transactional tables, such rollback cannot be done, so although the statement fails, any changes performed prior to the point of the error remain in effect.
Views (including updatable views) are implemented in MySQL Server 5.0. Views are available in binary releases from 5.0.1 and up.
Answers to some frequently asked questions concerning views in MySQL 5.0 can be found in Section A.6, “MySQL 5.0 FAQ — Views”.
This chapter discusses the following topics:
Creating or altering views with
CREATE VIEWorALTER VIEWDestroying views with
DROP VIEW
Discussion of restrictions on use of views is given in Section F.4, “Restrictions on Views”.
To use views if you have upgraded to MySQL 5.0.1 from an older release, you should upgrade your grant tables so that they contain the view-related privileges. See Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.
Metadata about views can be obtained from the
INFORMATION_SCHEMA.VIEWS table and by using the
SHOW CREATE VIEW statement. See
Section 20.15, “The INFORMATION_SCHEMA VIEWS Table”, and
Section 13.5.4.7, “SHOW CREATE VIEW Syntax”.
ALTER
[ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
[DEFINER = { user | CURRENT_USER }]
[SQL SECURITY { DEFINER | INVOKER }]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
This statement changes the definition of a view, which must exist.
The syntax is similar to that for CREATE VIEW
and the effect is the same as for CREATE OR REPLACE
VIEW. See Section 19.2, “CREATE VIEW Syntax”. This statement
requires the CREATE VIEW and
DROP privileges for the view, and some
privilege for each column referred to in the
SELECT statement.
This statement was added in MySQL 5.0.1. The
DEFINER and SQL SECURITY
clauses may be used as of MySQL 5.0.16 to specify the security
context to be used when checking access privileges at view
invocation time. For details, see Section 19.2, “CREATE VIEW Syntax”.
CREATE
[OR REPLACE]
[ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
[DEFINER = { user | CURRENT_USER }]
[SQL SECURITY { DEFINER | INVOKER }]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
This statement creates a new view, or replaces an existing one if
the OR REPLACE clause is given. If the view
does not exist, CREATE OR REPLACE VIEW is the
same as CREATE VIEW. If the view does exist,
CREATE OR REPLACE VIEW is the same as
ALTER VIEW. The
select_statement is a
SELECT statement that provides the definition
of the view. The statement can select from base tables or other
views.
This statement requires the CREATE VIEW
privilege for the view, and some privilege for each column
selected by the SELECT statement. For columns
used elsewhere in the SELECT statement you must
have the SELECT privilege. If the OR
REPLACE clause is present, you must also have the
DROP privilege for the view.
A view belongs to a database. By default, a new view is created in
the default database. To create the view explicitly in a given
database, specify the name as
db_name.view_name when you create it.
mysql> CREATE VIEW test.v AS SELECT * FROM t;
Base tables and views share the same namespace within a database, so a database cannot contain a base table and a view that have the same name.
Views must have unique column names with no duplicates, just like
base tables. By default, the names of the columns retrieved by the
SELECT statement are used for the view column
names. To define explicit names for the view columns, the optional
column_list clause can be given as a
list of comma-separated identifiers. The number of names in
column_list must be the same as the
number of columns retrieved by the SELECT
statement.
Columns retrieved by the SELECT statement can
be simple references to table columns. They can also be
expressions that use functions, constant values, operators, and so
forth.
Unqualified table or view names in the SELECT
statement are interpreted with respect to the default database. A
view can refer to tables or views in other databases by qualifying
the table or view name with the proper database name.
A view can be created from many kinds of SELECT
statements. It can refer to base tables or other views. It can use
joins, UNION, and subqueries. The
SELECT need not even refer to any tables. The
following example defines a view that selects two columns from
another table, as well as an expression calculated from those
columns:
mysql>CREATE TABLE t (qty INT, price INT);mysql>INSERT INTO t VALUES(3, 50);mysql>CREATE VIEW v AS SELECT qty, price, qty*price AS value FROM t;mysql>SELECT * FROM v;+------+-------+-------+ | qty | price | value | +------+-------+-------+ | 3 | 50 | 150 | +------+-------+-------+
A view definition is subject to the following restrictions:
The
SELECTstatement cannot contain a subquery in theFROMclause.The
SELECTstatement cannot refer to system or user variables.The
SELECTstatement cannot refer to prepared statement parameters.Within a stored routine, the definition cannot refer to routine parameters or local variables.
Any table or view referred to in the definition must exist. However, after a view has been created, it is possible to drop a table or view that the definition refers to. In this case, use of the view results in an error. To check a view definition for problems of this kind, use the
CHECK TABLEstatement.The definition cannot refer to a
TEMPORARYtable, and you cannot create aTEMPORARYview.The tables named in the view definition must already exist.
You cannot associate a trigger with a view.
ORDER BY is allowed in a view definition, but
it is ignored if you select from a view using a statement that has
its own ORDER BY.
For other options or clauses in the definition, they are added to
the options or clauses of the statement that references the view,
but the effect is undefined. For example, if a view definition
includes a LIMIT clause, and you select from
the view using a statement that has its own
LIMIT clause, it is undefined which limit
applies. This same principle applies to options such as
ALL, DISTINCT, or
SQL_SMALL_RESULT that follow the
SELECT keyword, and to clauses such as
INTO, FOR UPDATE,
LOCK IN SHARE MODE, and
PROCEDURE.
If you create a view and then change the query processing environment by changing system variables, that may affect the results that you get from the view:
mysql>CREATE VIEW v AS SELECT CHARSET(CHAR(65)), COLLATION(CHAR(65));Query OK, 0 rows affected (0.00 sec) mysql>SET NAMES 'latin1';Query OK, 0 rows affected (0.00 sec) mysql>SELECT * FROM v;+-------------------+---------------------+ | CHARSET(CHAR(65)) | COLLATION(CHAR(65)) | +-------------------+---------------------+ | latin1 | latin1_swedish_ci | +-------------------+---------------------+ 1 row in set (0.00 sec) mysql>SET NAMES 'utf8';Query OK, 0 rows affected (0.00 sec) mysql>SELECT * FROM v;+-------------------+---------------------+ | CHARSET(CHAR(65)) | COLLATION(CHAR(65)) | +-------------------+---------------------+ | utf8 | utf8_general_ci | +-------------------+---------------------+ 1 row in set (0.00 sec)
The DEFINER and SQL SECURITY
clauses specify the security context to be used when checking
access privileges at view invocation time. They were addded in
MySQL 5.0.13, but have no effect until MySQL 5.0.16.
CURRENT_USER also can be given as
CURRENT_USER().
Within a stored routine that is defined with the SQL
SECURITY DEFINER characteristic,
CURRENT_USER returns the routine creator. This
also affects a view defined within such a routine, if the view
definition contains a DEFINER value of
CURRENT_USER.
The default DEFINER value is the user who
executes the CREATE VIEW statement. (This is
the same as DEFINER = CURRENT_USER.) If a
user value is given, it should be a
MySQL account in
'
format (the same format used in the user_name'@'host_name'GRANT
statement). The user_name and
host_name values both are required.
If you specify the DEFINER clause, you cannot
set the value to any user but your own unless you have the
SUPER privilege. These rules determine the
legal DEFINER user values:
If you do not have the
SUPERprivilege, the only legaluservalue is your own account, either specified literally or by usingCURRENT_USER. You cannot set the definer to some other account.If you have the
SUPERprivilege, you can specify any syntactically legal account name. If the account does not actually exist, a warning is generated.
The SQL SECURITY characteristic determines
which MySQL account to use when checking access privileges for the
view when the view is executed. The legal characteristic values
are DEFINER and INVOKER.
These indicate that the view must be executable by the user who
defined it or invoked it, respectively. The default SQL
SECURITY value is DEFINER.
As of MySQL 5.0.16 (when the DEFINER and
SQL SECURITY clauses were implemented), view
privileges are checked like this:
At view definition time, the view creator must have the privileges needed to use the top-level objects accessed by the view. For example, if the view definition refers to a stored function, only the privileges needed to invoke the function can be checked. The privileges required when the function runs can be checked only as it executes: For different invocations of the function, different execution paths within the function might be taken.
At view execution time, privileges for objects accessed by the view are checked against the privileges held by the view creator or invoker, depending on whether the
SQL SECURITYcharacteristic isDEFINERorINVOKER, respectively.If view execution causes execution of a stored function, privilege checking for statements executed within the function depend on whether the function is defined with a
SQL SECURITYcharacteristic ofDEFINERorINVOKER. If the security characteristic isDEFINER, the function runs with the privileges of its creator. If the characteristic isINVOKER, the function runs with the privileges determined by the view'sSQL SECURITYcharacteristic.
Prior to MySQL 5.0.16 (before the DEFINER and
SQL SECURITY clauses were implemented),
privileges required for objects used in a view are checked at view
creation time.
Example: A view might depend on a stored function, and that
function might invoke other stored routines. For example, the
following view invokes a stored function f():
CREATE VIEW v AS SELECT * FROM t WHERE t.id = f(t.name);
Suppose that f() contains a statement such as
this:
IF name IS NULL then CALL p1(); ELSE CALL p2(); END IF;
The privileges required for executing statements within
f() need to be checked when
f() executes. This might mean that privileges
are needed for p1() or p2(),
depending on the execution path within f().
Those privileges need to be checked at runtime, and the user who
must possess the privileges is determined by the SQL
SECURITY values of the function f()
and the view v.
The DEFINER and SQL SECURITY
clauses for views are extensions to standard SQL. In standard SQL,
views are handled using the rules for SQL SECURITY
INVOKER.
If you invoke a view that was created before MySQL 5.0.13, it is
treated as though it was created with a SQL SECURITY
DEFINER clause and with a DEFINER
value that is the same as your account. However, because the
actual definer is unknown, MySQL issues a warning. To make the
warning go away, it is sufficient to re-create the view so that
the view definition includes a DEFINER clause.
The optional ALGORITHM clause is a MySQL
extension to standard SQL. ALGORITHM takes
three values: MERGE,
TEMPTABLE, or UNDEFINED. The
default algorithm is UNDEFINED if no
ALGORITHM clause is present. The algorithm
affects how MySQL processes the view.
For MERGE, the text of a statement that refers
to the view and the view definition are merged such that parts of
the view definition replace corresponding parts of the statement.
For TEMPTABLE, the results from the view are
retrieved into a temporary table, which then is used to execute
the statement.
For UNDEFINED, MySQL chooses which algorithm to
use. It prefers MERGE over
TEMPTABLE if possible, because
MERGE is usually more efficient and because a
view cannot be updatable if a temporary table is used.
A reason to choose TEMPTABLE explicitly is that
locks can be released on underlying tables after the temporary
table has been created and before it is used to finish processing
the statement. This might result in quicker lock release than the
MERGE algorithm so that other clients that use
the view are not blocked as long.
A view algorithm can be UNDEFINED for three
reasons:
No
ALGORITHMclause is present in theCREATE VIEWstatement.The
CREATE VIEWstatement has an explicitALGORITHM = UNDEFINEDclause.ALGORITHM = MERGEis specified for a view that can be processed only with a temporary table. In this case, MySQL generates a warning and sets the algorithm toUNDEFINED.
As mentioned earlier, MERGE is handled by
merging corresponding parts of a view definition into the
statement that refers to the view. The following examples briefly
illustrate how the MERGE algorithm works. The
examples assume that there is a view v_merge
that has this definition:
CREATE ALGORITHM = MERGE VIEW v_merge (vc1, vc2) AS SELECT c1, c2 FROM t WHERE c3 > 100;
Example 1: Suppose that we issue this statement:
SELECT * FROM v_merge;
MySQL handles the statement as follows:
v_mergebecomest*becomesvc1, vc2, which corresponds toc1, c2The view
WHEREclause is added
The resulting statement to be executed becomes:
SELECT c1, c2 FROM t WHERE c3 > 100;
Example 2: Suppose that we issue this statement:
SELECT * FROM v_merge WHERE vc1 < 100;
This statement is handled similarly to the previous one, except
that vc1 < 100 becomes c1 <
100 and the view WHERE clause is
added to the statement WHERE clause using an
AND connective (and parentheses are added to
make sure the parts of the clause are executed with correct
precedence). The resulting statement to be executed becomes:
SELECT c1, c2 FROM t WHERE (c3 > 100) AND (c1 < 100);
Effectively, the statement to be executed has a
WHERE clause of this form:
WHERE (select WHERE) AND (view WHERE)
The MERGE algorithm requires a one-to-one
relationship between the rows in the view and the rows in the
underlying table. If this relationship does not hold, a temporary
table must be used instead. Lack of a one-to-one relationship
occurs if the view contains any of a number of constructs:
Aggregate functions (
SUM(),MIN(),MAX(),COUNT(), and so forth)DISTINCTGROUP BYHAVINGUNIONorUNION ALLSubquery in the select list
Refers only to literal values (in this case, there is no underlying table)
Some views are updatable. That is, you can use them in statements
such as UPDATE, DELETE, or
INSERT to update the contents of the underlying
table. For a view to be updatable, there must be a one-to-one
relationship between the rows in the view and the rows in the
underlying table. There are also certain other constructs that
make a view non-updatable. To be more specific, a view is not
updatable if it contains any of the following:
Aggregate functions (
SUM(),MIN(),MAX(),COUNT(), and so forth)DISTINCTGROUP BYHAVINGUNIONorUNION ALLSubquery in the select list
Certain joins (see additional join discussion later in this section)
Non-updatable view in the
FROMclauseA subquery in the
WHEREclause that refers to a table in theFROMclauseRefers only to literal values (in this case, there is no underlying table to update)
ALGORITHM = TEMPTABLE(use of a temporary table always makes a view non-updatable)
With respect to insertability (being updatable with
INSERT statements), an updatable view is
insertable if it also satisfies these additional requirements for
the view columns:
There must be no duplicate view column names.
The view must contain all columns in the base table that do not have a default value.
The view columns must be simple column references and not derived columns. A derived column is one that is not a simple column reference but is derived from an expression. These are examples of derived columns:
3.14159 col1 + 3 UPPER(col2) col3 / col4 (
subquery)
A view that has a mix of simple column references and derived columns is not insertable, but it can be updatable if you update only those columns that are not derived. Consider this view:
CREATE VIEW v AS SELECT col1, 1 AS col2 FROM t;
This view is not insertable because col2 is
derived from an expression. But it is updatable if the update does
not try to update col2. This update is
allowable:
UPDATE v SET col1 = 0;
This update is not allowable because it attempts to update a derived column:
UPDATE v SET col2 = 0;
It is sometimes possible for a multiple-table view to be
updatable, assuming that it can be processed with the
MERGE algorithm. For this to work, the view
must use an inner join (not an outer join or a
UNION). Also, only a single table in the view
definition can be updated, so the SET clause
must name only columns from one of the tables in the view. Views
that use UNION ALL are disallowed even though
they might be theoretically updatable, because the implementation
uses temporary tables to process them.
For a multiple-table updatable view, INSERT can
work if it inserts into a single table. DELETE
is not supported.
INSERT DELAYED is not supported for views.
If a table contains an AUTO_INCREMENT column,
inserting into an insertable view on the table that does not
include the AUTO_INCREMENT column does not
change the value of LAST_INSERT_ID(), because
the side effects of inserting default values into columns not part
of the view should not be visible.
The WITH CHECK OPTION clause can be given for
an updatable view to prevent inserts or updates to rows except
those for which the WHERE clause in the
select_statement is true.
In a WITH CHECK OPTION clause for an updatable
view, the LOCAL and CASCADED
keywords determine the scope of check testing when the view is
defined in terms of another view. The LOCAL
keyword restricts the CHECK OPTION only to the
view being defined. CASCADED causes the checks
for underlying views to be evaluated as well. When neither keyword
is given, the default is CASCADED. Consider the
definitions for the following table and set of views:
mysql>CREATE TABLE t1 (a INT);mysql>CREATE VIEW v1 AS SELECT * FROM t1 WHERE a < 2->WITH CHECK OPTION;mysql>CREATE VIEW v2 AS SELECT * FROM v1 WHERE a > 0->WITH LOCAL CHECK OPTION;mysql>CREATE VIEW v3 AS SELECT * FROM v1 WHERE a > 0->WITH CASCADED CHECK OPTION;
Here the v2 and v3 views are
defined in terms of another view, v1.
v2 has a LOCAL check option,
so inserts are tested only against the v2
check. v3 has a CASCADED
check option, so inserts are tested not only against its own
check, but against those of underlying views. The following
statements illustrate these differences:
mysql>INSERT INTO v2 VALUES (2);Query OK, 1 row affected (0.00 sec) mysql>INSERT INTO v3 VALUES (2);ERROR 1369 (HY000): CHECK OPTION failed 'test.v3'
MySQL sets a flag, called the view updatability flag, at
CREATE VIEW time. The flag is set to
YES (true) if UPDATE and
DELETE (and similar operations) are legal for
the view. Otherwise, the flag is set to NO
(false). The IS_UPDATABLE column in the
INFORMATION_SCHEMA.VIEWS table displays the
status of this flag. It means that the server always knows whether
a view is updatable. If the view is not updatable, statements such
UPDATE, DELETE, and
INSERT are illegal and will be rejected. (Note
that even if a view is updatable, it might not be possible to
insert into it, as described elsewhere in this section.)
The updatability of views may be affected by the value of the
updatable_views_with_limit system variable. See
Section 5.2.3, “System Variables”.
The CREATE VIEW statement was added in MySQL
5.0.1. The WITH CHECK OPTION clause was
implemented in MySQL 5.0.2.
DROP VIEW [IF EXISTS]
view_name [, view_name] ...
[RESTRICT | CASCADE]
DROP VIEW removes one or more views. You must
have the DROP privilege for each view. If any
of the views named in the argument list do not exist, MySQL
returns an error indicating by name which non-existing views it
was unable to drop, but it also drops all of the views in the list
that do exist.
The IF EXISTS clause prevents an error from
occurring for views that don't exist. When this clause is given, a
NOTE is generated for each non-existent view.
See Section 13.5.4.28, “SHOW WARNINGS Syntax”.
RESTRICT and CASCADE, if
given, are parsed and ignored.
This statement was added in MySQL 5.0.1.
Table of Contents
- 20.1. The
INFORMATION_SCHEMA SCHEMATATable - 20.2. The
INFORMATION_SCHEMA TABLESTable - 20.3. The
INFORMATION_SCHEMA COLUMNSTable - 20.4. The
INFORMATION_SCHEMA STATISTICSTable - 20.5. The
INFORMATION_SCHEMA USER_PRIVILEGESTable - 20.6. The
INFORMATION_SCHEMA SCHEMA_PRIVILEGESTable - 20.7. The
INFORMATION_SCHEMA TABLE_PRIVILEGESTable - 20.8. The
INFORMATION_SCHEMA COLUMN_PRIVILEGESTable - 20.9. The
INFORMATION_SCHEMA CHARACTER_SETSTable - 20.10. The
INFORMATION_SCHEMA COLLATIONSTable - 20.11. The
INFORMATION_SCHEMA COLLATION_CHARACTER_SET_APPLICABILITYTable - 20.12. The
INFORMATION_SCHEMA TABLE_CONSTRAINTSTable - 20.13. The
INFORMATION_SCHEMA KEY_COLUMN_USAGETable - 20.14. The
INFORMATION_SCHEMA ROUTINESTable - 20.15. The
INFORMATION_SCHEMA VIEWSTable - 20.16. The
INFORMATION_SCHEMA TRIGGERSTable - 20.17. The
INFORMATION_SCHEMA PROFILINGTable - 20.18. Other
INFORMATION_SCHEMATables - 20.19. Extensions to
SHOWStatements
INFORMATION_SCHEMA provides access to database
metadata.
Metadata is data about the data, such as the name of a database or table, the data type of a column, or access privileges. Other terms that sometimes are used for this information are data dictionary and system catalog.
INFORMATION_SCHEMA is the information database,
the place that stores information about all the other databases that
the MySQL server maintains. Inside
INFORMATION_SCHEMA there are several read-only
tables. They are actually views, not base tables, so there are no
files associated with them.
In effect, we have a database named
INFORMATION_SCHEMA, although the server does not
create a database directory with that name. It is possible to select
INFORMATION_SCHEMA as the default database with a
USE statement, but it is possible only to read
the contents of tables. You cannot insert into them, update them, or
delete from them.
Here is an example of a statement that retrieves information from
INFORMATION_SCHEMA:
mysql>SELECT table_name, table_type, engine->FROM information_schema.tables->WHERE table_schema = 'db5'->ORDER BY table_name DESC;+------------+------------+--------+ | table_name | table_type | engine | +------------+------------+--------+ | v56 | VIEW | NULL | | v3 | VIEW | NULL | | v2 | VIEW | NULL | | v | VIEW | NULL | | tables | BASE TABLE | MyISAM | | t7 | BASE TABLE | MyISAM | | t3 | BASE TABLE | MyISAM | | t2 | BASE TABLE | MyISAM | | t | BASE TABLE | MyISAM | | pk | BASE TABLE | InnoDB | | loop | BASE TABLE | MyISAM | | kurs | BASE TABLE | MyISAM | | k | BASE TABLE | MyISAM | | into | BASE TABLE | MyISAM | | goto | BASE TABLE | MyISAM | | fk2 | BASE TABLE | InnoDB | | fk | BASE TABLE | InnoDB | +------------+------------+--------+ 17 rows in set (0.01 sec)
Explanation: The statement requests a list of all the tables in
database db5, in reverse alphabetical order,
showing just three pieces of information: the name of the table, its
type, and its storage engine.
Each MySQL user has the right to access these tables, but can see
only the rows in the tables that correspond to objects for which the
user has the proper access privileges. In some cases (for example,
the ROUTINE_DEFINITION column in the
INFORMATION_SCHEMA.ROUTINES table), users who
have insufficient privileges will see NULL.
The SELECT ... FROM INFORMATION_SCHEMA statement
is intended as a more consistent way to provide access to the
information provided by the various SHOW
statements that MySQL supports (SHOW DATABASES,
SHOW TABLES, and so forth). Using
SELECT has these advantages, compared to
SHOW:
It conforms to Codd's rules. That is, all access is done on tables.
Nobody needs to learn a new statement syntax. Because they already know how
SELECTworks, they only need to learn the object names.The implementor need not worry about adding keywords.
There are millions of possible output variations, instead of just one. This provides more flexibility for applications that have varying requirements about what metadata they need.
Migration is easier because every other DBMS does it this way.
However, because SHOW is popular with MySQL
employees and users, and because it might be confusing were it to
disappear, the advantages of conventional syntax are not a
sufficient reason to eliminate SHOW. In fact,
along with the implementation of
INFORMATION_SCHEMA, there are enhancements to
SHOW as well. These are described in
Section 20.19, “Extensions to SHOW Statements”.
There is no difference between the privileges required for
SHOW statements and those required to select
information from INFORMATION_SCHEMA. In either
case, you have to have some privilege on an object in order to see
information about it.
The implementation for the INFORMATION_SCHEMA
table structures in MySQL follows the ANSI/ISO SQL:2003 standard
Part 11 Schemata. Our intent is approximate
compliance with SQL:2003 core feature F021 Basic
information schema.
Users of SQL Server 2000 (which also follows the standard) may
notice a strong similarity. However, MySQL has omitted many columns
that are not relevant for our implementation, and added columns that
are MySQL-specific. One such column is the ENGINE
column in the INFORMATION_SCHEMA.TABLES table.
Although other DBMSs use a variety of names, like
syscat or system, the standard
name is INFORMATION_SCHEMA.
The following sections describe each of the tables and columns that
are in INFORMATION_SCHEMA. For each column, there
are three pieces of information:
“
INFORMATION_SCHEMAName” indicates the name for the column in theINFORMATION_SCHEMAtable. This corresponds to the standard SQL name unless the “Remarks” field says “MySQL extension.”“
SHOWName” indicates the equivalent field name in the closestSHOWstatement, if there is one.“Remarks” provides additional information where applicable. If this field is
NULL, it means that the value of the column is alwaysNULL. If this field says “MySQL extension,” the column is a MySQL extension to standard SQL.
To avoid using any name that is reserved in the standard or in DB2,
SQL Server, or Oracle, we changed the names of some columns marked
“MySQL extension”. (For example, we changed
COLLATION to TABLE_COLLATION
in the TABLES table.) See the list of reserved
words near the end of this article:
http://www.dbazine.com/gulutzan5.shtml.
The definition for character columns (for example,
TABLES.TABLE_NAME) is generally
VARCHAR( where N) CHARACTER SET
utf8N is at least 64.
MySQL uses the default collation for this character set
(utf8_general_ci) for all searches, sorts,
comparisons, and other string operations on such columns. If the
default collation is not correct for your needs, you can force a
suitable collation with a COLLATE clause
(Section 10.5.1, “Using COLLATE in SQL Statements”).
Each section indicates what SHOW statement is
equivalent to a SELECT that retrieves information
from INFORMATION_SCHEMA, if there is such a
statement.
Note: At present, there are some missing columns and some columns out of order. We are working on this and updating the documentation as changes are made.
For answers to questions that are often asked concerning the
INFORMATION_SCHEMA database, see
Section A.7, “MySQL 5.0 FAQ — INFORMATION_SCHEMA”.
A schema is a database, so the SCHEMATA table
provides information about databases.
INFORMATION_SCHEMA
Name | SHOW Name | Remarks |
CATALOG_NAME | NULL | |
SCHEMA_NAME | Database | |
DEFAULT_CHARACTER_SET_NAME | ||
DEFAULT_COLLATION_NAME | ||
SQL_PATH | NULL |
Notes:
DEFAULT_COLLATION_NAMEwas added in MySQL 5.0.6.
The following statements are equivalent:
SELECT SCHEMA_NAME AS `Database` FROM INFORMATION_SCHEMA.SCHEMATA [WHERE SCHEMA_NAME LIKE 'wild'] SHOW DATABASES [LIKE 'wild']
The TABLES table provides information about
tables in databases.
INFORMATION_SCHEMA
Name | SHOW Name | Remarks |
TABLE_CATALOG | NULL | |
TABLE_SCHEMA | Table_... | |
TABLE_NAME | Table_... | |
TABLE_TYPE | ||
ENGINE | Engine | MySQL extension |
VERSION | Version | MySQL extension |
ROW_FORMAT | Row_format | MySQL extension |
TABLE_ROWS | Rows | MySQL extension |
AVG_ROW_LENGTH | Avg_row_length | MySQL extension |
DATA_LENGTH | Data_length | MySQL extension |
MAX_DATA_LENGTH | Max_data_length | MySQL extension |
INDEX_LENGTH | Index_length | MySQL extension |
DATA_FREE | Data_free | MySQL extension |
AUTO_INCREMENT | Auto_increment | MySQL extension |
CREATE_TIME | Create_time | MySQL extension |
UPDATE_TIME | Update_time | MySQL extension |
CHECK_TIME | Check_time | MySQL extension |
TABLE_COLLATION | Collation | MySQL extension |
CHECKSUM | Checksum | MySQL extension |
CREATE_OPTIONS | Create_options | MySQL extension |
TABLE_COMMENT | Comment | MySQL extension |
Notes:
TABLE_SCHEMAandTABLE_NAMEare a single field in aSHOWdisplay, for exampleTable_in_db1.TABLE_TYPEshould beBASE TABLEorVIEW. If table is temporary, thenTABLE_TYPE=TEMPORARY. (There are no temporary views, so this is not ambiguous.)The
TABLE_ROWScolumn isNULLif the table is in theINFORMATION_SCHEMAdatabase. ForInnoDBtables, the row count is only a rough estimate used in SQL optimization.We have nothing for the table's default character set.
TABLE_COLLATIONis close, because collation names begin with a character set name.
The following statements are equivalent:
SELECT table_name FROM INFORMATION_SCHEMA.TABLES [WHERE table_schema = 'db_name'] [WHERE|AND table_name LIKE 'wild'] SHOW TABLES [FROMdb_name] [LIKE 'wild']
The COLUMNS table provides information about
columns in tables.
INFORMATION_SCHEMA
Name | SHOW Name | Remarks |
TABLE_CATALOG | NULL | |
TABLE_SCHEMA | ||
TABLE_NAME | ||
COLUMN_NAME | Field | |
ORDINAL_POSITION | see notes | |
COLUMN_DEFAULT | Default | |
IS_NULLABLE | Null | |
DATA_TYPE | Type | |
CHARACTER_MAXIMUM_LENGTH | Type | |
CHARACTER_OCTET_LENGTH | ||
NUMERIC_PRECISION | Type | |
NUMERIC_SCALE | Type | |
CHARACTER_SET_NAME | ||
COLLATION_NAME | Collation | |
COLUMN_TYPE | Type | MySQL extension |
COLUMN_KEY | Key | MySQL extension |
EXTRA | Extra | MySQL extension |
COLUMN_COMMENT | Comment | MySQL extension |
Notes:
In
SHOW, theTypedisplay includes values from several differentCOLUMNScolumns.ORDINAL_POSITIONis necessary because you might want to sayORDER BY ORDINAL_POSITION. UnlikeSHOW,SELECTdoes not have automatic ordering.CHARACTER_OCTET_LENGTHshould be the same asCHARACTER_MAXIMUM_LENGTH, except for multi-byte character sets.CHARACTER_SET_NAMEcan be derived fromCollation. For example, if you saySHOW FULL COLUMNS FROM t, and you see in theCollationcolumn a value oflatin1_swedish_ci, the character set is what's before the first underscore:latin1.
The following statements are nearly equivalent:
SELECT COLUMN_NAME, DATA_TYPE, IS_NULLABLE, COLUMN_DEFAULT FROM INFORMATION_SCHEMA.COLUMNS WHERE table_name = 'tbl_name' [AND table_schema = 'db_name'] [AND column_name LIKE 'wild'] SHOW COLUMNS FROMtbl_name[FROMdb_name] [LIKE 'wild']
The STATISTICS table provides information about
table indexes.
INFORMATION_SCHEMA
Name | SHOW Name | Remarks |
TABLE_CATALOG | NULL | |
TABLE_SCHEMA | = Database | |
TABLE_NAME | Table | |
NON_UNIQUE | Non_unique | |
INDEX_SCHEMA | = Database | |
INDEX_NAME | Key_name | |
SEQ_IN_INDEX | Seq_in_index | |
COLUMN_NAME | Column_name | |
COLLATION | Collation | |
CARDINALITY | Cardinality | |
SUB_PART | Sub_part | MySQL extension |
PACKED | Packed | MySQL extension |
NULLABLE | Null | MySQL extension |
INDEX_TYPE | Index_type | MySQL extension |
COMMENT | Comment | MySQL extension |
Notes:
There is no standard table for indexes. The preceding list is similar to what SQL Server 2000 returns for
sp_statistics, except that we replaced the nameQUALIFIERwithCATALOGand we replaced the nameOWNERwithSCHEMA.Clearly, the preceding table and the output from
SHOW INDEXare derived from the same parent. So the correlation is already close.
The following statements are equivalent:
SELECT * FROM INFORMATION_SCHEMA.STATISTICS WHERE table_name = 'tbl_name' [AND table_schema = 'db_name'] SHOW INDEX FROMtbl_name[FROMdb_name]
The USER_PRIVILEGES table provides information
about global privileges. This information comes from the
mysql.user grant table.
INFORMATION_SCHEMA
Name | SHOW Name | Remarks |
GRANTEE | '
value, MySQL extension | |
TABLE_CATALOG | NULL, MySQL extension | |
PRIVILEGE_TYPE | MySQL extension | |
IS_GRANTABLE | MySQL extension |
Notes:
This is a non-standard table. It takes its values from the
mysql.usertable.
The SCHEMA_PRIVILEGES table provides
information about schema (database) privileges. This information
comes from the mysql.db grant table.
INFORMATION_SCHEMA
Name | SHOW Name | Remarks |
GRANTEE | '
value, MySQL extension | |
TABLE_CATALOG | NULL, MySQL extension | |
TABLE_SCHEMA | MySQL extension | |
PRIVILEGE_TYPE | MySQL extension | |
IS_GRANTABLE | MySQL extension |
Notes:
This is a non-standard table. It takes its values from the
mysql.dbtable.
The TABLE_PRIVILEGES table provides information
about table privileges. This information comes from the
mysql.tables_priv grant table.
INFORMATION_SCHEMA
Name | SHOW Name | Remarks |
GRANTEE | '
value | |
TABLE_CATALOG | NULL | |
TABLE_SCHEMA | ||
TABLE_NAME | ||
PRIVILEGE_TYPE | ||
IS_GRANTABLE |
Notes:
PRIVILEGE_TYPEcan contain one (and only one) of these values:SELECT,INSERT,UPDATE,REFERENCES,ALTER,INDEX,DROP,CREATE VIEW.
The following statements are not equivalent:
SELECT ... FROM INFORMATION_SCHEMA.TABLE_PRIVILEGES SHOW GRANTS ...
The COLUMN_PRIVILEGES table provides
information about column privileges. This information comes from
the mysql.columns_priv grant table.
INFORMATION_SCHEMA
Name | SHOW Name | Remarks |
GRANTEE | '
value | |
TABLE_CATALOG | NULL | |
TABLE_SCHEMA | ||
TABLE_NAME | ||
COLUMN_NAME | ||
PRIVILEGE_TYPE | ||
IS_GRANTABLE |
Notes:
In the output from
SHOW FULL COLUMNS, the privileges are all in one field and in lowercase, for example,select,insert,update,references. InCOLUMN_PRIVILEGES, there is one privilege per row, in uppercase.PRIVILEGE_TYPEcan contain one (and only one) of these values:SELECT,INSERT,UPDATE,REFERENCES.If the user has
GRANT OPTIONprivilege,IS_GRANTABLEshould beYES. Otherwise,IS_GRANTABLEshould beNO. The output does not listGRANT OPTIONas a separate privilege.
The following statements are not equivalent:
SELECT ... FROM INFORMATION_SCHEMA.COLUMN_PRIVILEGES SHOW GRANTS ...
The CHARACTER_SETS table provides information
about available character sets.
INFORMATION_SCHEMA
Name | SHOW Name | Remarks |
CHARACTER_SET_NAME | Charset | |
DEFAULT_COLLATE_NAME | Default collation | |
DESCRIPION | Description | MySQL extension |
MAXLEN | Maxlen | MySQL extension |
The following statements are equivalent:
SELECT * FROM INFORMATION_SCHEMA.CHARACTER_SETS [WHERE name LIKE 'wild'] SHOW CHARACTER SET [LIKE 'wild']
The COLLATIONS table provides information about
collations for each character set.
INFORMATION_SCHEMA
Name | SHOW Name | Remarks |
COLLATION_NAME | Collation | |
CHARACTER_SET_NAME | Charset | MySQL extension |
ID | Id | MySQL extension |
IS_DEFAULT | Default | MySQL extension |
IS_COMPILED | Compiled | MySQL extension |
SORTLEN | Sortlen | MySQL extension |
The following statements are equivalent:
SELECT COLLATION_NAME FROM INFORMATION_SCHEMA.COLLATIONS [WHERE collation_name LIKE 'wild'] SHOW COLLATION [LIKE 'wild']
The COLLATION_CHARACTER_SET_APPLICABILITY table
indicates what character set is applicable for what collation. The
columns are equivalent to the first two display fields that we get
from SHOW COLLATION.
INFORMATION_SCHEMA
Name | SHOW Name | Remarks |
COLLATION_NAME | Collation | |
CHARACTER_SET_NAME | Charset |
The TABLE_CONSTRAINTS table describes which
tables have constraints.
INFORMATION_SCHEMA
Name | SHOW Name | Remarks |
CONSTRAINT_CATALOG | NULL | |
CONSTRAINT_SCHEMA | ||
CONSTRAINT_NAME | ||
TABLE_SCHEMA | ||
TABLE_NAME | ||
CONSTRAINT_TYPE |
Notes:
The
CONSTRAINT_TYPEvalue can beUNIQUE,PRIMARY KEY, orFOREIGN KEY.The
UNIQUEandPRIMARY KEYinformation is about the same as what you get from theKey_namefield in the output fromSHOW INDEXwhen theNon_uniquefield is0.The
CONSTRAINT_TYPEcolumn can contain one of these values:UNIQUE,PRIMARY KEY,FOREIGN KEY,CHECK. This is aCHAR(notENUM) column. TheCHECKvalue is not available until we supportCHECK.
The KEY_COLUMN_USAGE table describes which key
columns have constraints.
INFORMATION_SCHEMA
Name | SHOW Name | Remarks |
CONSTRAINT_CATALOG | NULL | |
CONSTRAINT_SCHEMA | ||
CONSTRAINT_NAME | ||
TABLE_CATALOG | ||
TABLE_SCHEMA | ||
TABLE_NAME | ||
COLUMN_NAME | ||
ORDINAL_POSITION | ||
POSITION_IN_UNIQUE_CONSTRAINT | ||
REFERENCED_TABLE_SCHEMA | ||
REFERENCED_TABLE_NAME | ||
REFERENCED_COLUMN_NAME |
Notes:
If the constraint is a foreign key, then this is the column of the foreign key, not the column that the foreign key references.
The value of
ORDINAL_POSITIONis the column's position within the constraint, not the column's position within the table. Column positions are numbered beginning with 1.The value of
POSITION_IN_UNIQUE_CONSTRAINTisNULLfor unique and primary-key constraints. For foreign-key constraints, it is the ordinal position in key of the table that is being referenced.For example, suppose that there are two tables name
t1andt3that have the following definitions:CREATE TABLE t1 ( s1 INT, s2 INT, s3 INT, PRIMARY KEY(s3) ) ENGINE=InnoDB; CREATE TABLE t3 ( s1 INT, s2 INT, s3 INT, KEY(s1), CONSTRAINT CO FOREIGN KEY (s2) REFERENCES t1(s3) ) ENGINE=InnoDB;For those two tables, the
KEY_COLUMN_USAGEtable has two rows:One row with
CONSTRAINT_NAME='PRIMARY',TABLE_NAME='t1',COLUMN_NAME='s3',ORDINAL_POSITION=1,POSITION_IN_UNIQUE_CONSTRAINT=NULL.One row with
CONSTRAINT_NAME='CO',TABLE_NAME='t3',COLUMN_NAME='s2',ORDINAL_POSITION=1,POSITION_IN_UNIQUE_CONSTRAINT=1.
REFERENCED_TABLE_SCHEMA,REFERENCED_TABLE_NAME, andREFERENCED_COLUMN_NAMEwere added in MySQL 5.0.6.
The ROUTINES table provides information about
stored routines (both procedures and functions). The
ROUTINES table does not include user-defined
functions (UDFs) at this time.
The column named “mysql.proc name”
indicates the mysql.proc table column that
corresponds to the INFORMATION_SCHEMA.ROUTINES
table column, if any.
INFORMATION_SCHEMA
Name | mysql.proc Name | Remarks |
SPECIFIC_NAME | specific_name | |
ROUTINE_CATALOG | NULL | |
ROUTINE_SCHEMA | db | |
ROUTINE_NAME | name | |
ROUTINE_TYPE | type | {PROCEDURE|FUNCTION} |
DTD_IDENTIFIER | (data type descriptor) | |
ROUTINE_BODY | SQL | |
ROUTINE_DEFINITION | body | |
EXTERNAL_NAME | NULL | |
EXTERNAL_LANGUAGE | language | NULL |
PARAMETER_STYLE | SQL | |
IS_DETERMINISTIC | is_deterministic | |
SQL_DATA_ACCESS | sql_data_access | |
SQL_PATH | NULL | |
SECURITY_TYPE | security_type | |
CREATED | created | |
LAST_ALTERED | modified | |
SQL_MODE | sql_mode | MySQL extension |
ROUTINE_COMMENT | comment | MySQL extension |
DEFINER | definer | MySQL extension |
Notes:
MySQL calculates
EXTERNAL_LANGUAGEthus:If
mysql.proc.language='SQL',EXTERNAL_LANGUAGEisNULLOtherwise,
EXTERNAL_LANGUAGEis what is inmysql.proc.language. However, we do not have external languages yet, so it is alwaysNULL.
The VIEWS table provides information about
views in databases. You must have the SHOW VIEW
privilege to access this table.
INFORMATION_SCHEMA
Name | SHOW Name | Remarks |
TABLE_CATALOG | NULL | |
TABLE_SCHEMA | ||
TABLE_NAME | ||
VIEW_DEFINITION | ||
CHECK_OPTION | ||
IS_UPDATABLE | ||
DEFINER | ||
SECURITY_TYPE |
Notes:
The
VIEW_DEFINITIONcolumn has most of what you see in theCreate Tablefield thatSHOW CREATE VIEWproduces. Skip the words beforeSELECTand skip the wordsWITH CHECK OPTION. Suppose that the original statement was:CREATE VIEW v AS SELECT s2,s1 FROM t WHERE s1 > 5 ORDER BY s1 WITH CHECK OPTION;
Then the view definition looks like this:
SELECT s2,s1 FROM t WHERE s1 > 5 ORDER BY s1
The
CHECK_OPTIONcolumn always has a value ofNONE.MySQL sets a flag, called the view updatability flag, at
CREATE VIEWtime. The flag is set toYES(true) ifUPDATEandDELETE(and similar operations) are legal for the view. Otherwise, the flag is set toNO(false). TheIS_UPDATABLEcolumn in theVIEWStable displays the status of this flag. It means that the server always knows whether a view is updatable. If the view is not updatable, statements suchUPDATE,DELETE, andINSERTare illegal and will be rejected. (Note that even if a view is updatable, it might not be possible to insert into it; for details, refer to Section 19.2, “CREATE VIEWSyntax”.)The
DEFINERandSECURITY_TYPEcolumns were added in MySQL 5.0.14.DEFINERindicates who defined the view.SECURITY_TYPEhas a value ofDEFINERorINVOKER.
The TRIGGERS table provides information about
triggers. You must have the SUPER privilege to
access this table.
INFORMATION_SCHEMA
Name | SHOW Name | Remarks |
TRIGGER_CATALOG | NULL | |
TRIGGER_SCHEMA | ||
TRIGGER_NAME | Trigger | |
EVENT_MANIPULATION | Event | |
EVENT_OBJECT_CATALOG | NULL | |
EVENT_OBJECT_SCHEMA | ||
EVENT_OBJECT_TABLE | Table | |
ACTION_ORDER | 0 | |
ACTION_CONDITION | NULL | |
ACTION_STATEMENT | Statement | |
ACTION_ORIENTATION | ROW | |
ACTION_TIMING | Timing | |
ACTION_REFERENCE_OLD_TABLE | NULL | |
ACTION_REFERENCE_NEW_TABLE | NULL | |
ACTION_REFERENCE_OLD_ROW | OLD | |
ACTION_REFERENCE_NEW_ROW | NEW | |
CREATED | NULL (0) | |
SQL_MODE | MySQL extension | |
DEFINER | MySQL extension |
Notes:
The
TRIGGERStable was added in MySQL 5.0.10.The
TRIGGER_SCHEMAandTRIGGER_NAMEcolumns contain the name of the database in which the trigger occurs and the trigger name, respectively.The
EVENT_MANIPULATIONcolumn contains one of the values'INSERT','DELETE', or'UPDATE'.As noted in Chapter 18, Triggers, every trigger is associated with exactly one table. The
EVENT_OBJECT_SCHEMAandEVENT_OBJECT_TABLEcolumns contain the database in which this table occurs, and the table's name.The
ACTION_ORDERstatement contains the ordinal position of the trigger's action within the list of all similar triggers on the same table. Currently, this value is always0, because it is not possible to have more than one trigger with the sameEVENT_MANIPULATIONandACTION_TIMINGon the same table.The
ACTION_STATEMENTcolumn contains the statement to be executed when the trigger is invoked. This is the same as the text displayed in theStatementcolumn of the output fromSHOW TRIGGERS. Note that this text uses UTF-8 encoding.The
ACTION_ORIENTATIONcolumn always contains the value'ROW'.The
ACTION_TIMINGcolumn contains one of the two values'BEFORE'or'AFTER'.The columns
ACTION_REFERENCE_OLD_ROWandACTION_REFERENCE_NEW_ROWcontain the old and new column identifiers, respectively. This means thatACTION_REFERENCE_OLD_ROWalways contains the value'OLD'andACTION_REFERENCE_NEW_ROWalways contains the value'NEW'.The
SQL_MODEcolumn shows the server SQL mode that was in effect at the time when the trigger was created (and thus which remains in effect for this trigger whenever it is invoked, regardless of the current server SQL mode). The possible range of values for this column is the same as that of thesql_modesystem variable. See Section 5.2.6, “SQL Modes”.The
DEFINERcolumn was added in MySQL 5.0.17.DEFINERindicates who defined the trigger.The following columns currently always contain
NULL:TRIGGER_CATALOG,EVENT_OBJECT_CATALOG,ACTION_CONDITION,ACTION_REFERENCE_OLD_TABLE,ACTION_REFERENCE_NEW_TABLE, andCREATED.
Example, using the ins_sum trigger defined in
Section 18.3, “Using Triggers”:
mysql> SELECT * FROM INFORMATION_SCHEMA.TRIGGERS\G
*************************** 1. row ***************************
TRIGGER_CATALOG: NULL
TRIGGER_SCHEMA: test
TRIGGER_NAME: ins_sum
EVENT_MANIPULATION: INSERT
EVENT_OBJECT_CATALOG: NULL
EVENT_OBJECT_SCHEMA: test
EVENT_OBJECT_TABLE: account
ACTION_ORDER: 0
ACTION_CONDITION: NULL
ACTION_STATEMENT: SET @sum = @sum + NEW.amount
ACTION_ORIENTATION: ROW
ACTION_TIMING: BEFORE
ACTION_REFERENCE_OLD_TABLE: NULL
ACTION_REFERENCE_NEW_TABLE: NULL
ACTION_REFERENCE_OLD_ROW: OLD
ACTION_REFERENCE_NEW_ROW: NEW
CREATED: NULL
SQL_MODE:
DEFINER: me@localhost
This section does not apply to MySQL Enterprise Server users.
The PROFILING table provides statement
profiling information. Its contents correspond to the information
produced by the SHOW PROFILES and SHOW
PROFILE statements (see
Section 13.5.4.22, “SHOW PROFILES and SHOW PROFILE
Syntax”). The table is empty unless the
profiling session variable is set to 1.
INFORMATION_SCHEMA
Name | SHOW Name | Remarks |
QUERY_ID | Query_ID | |
SEQ | | |
STATE | Status | |
DURATION | Duration | |
CPU_USER | CPU_user | |
CPU_SYSTEM | CPU_system | |
CONTEXT_VOLUNTARY | Context_voluntary | |
CONTEXT_INVOLUNTARY | Context_involuntary | |
BLOCK_OPS_IN | Block_ops_in | |
BLOCK_OPS_OUT | Block_ops_out | |
MESSAGES_SENT | Messages_sent | |
MESSAGES_RECEIVED | Messages_received | |
PAGE_FAULTS_MAJOR | Page_faults_major | |
PAGE_FAULTS_MINOR | Page_faults_minor | |
SWAPS | Swaps | |
SOURCE_FUNCTION | Source_function | |
SOURCE_FILE | Source_file | |
SOURCE_LINE | Source_line |
Notes:
The
PROFILINGtable was added in MySQL 5.0.37.QUERY_IDis a numeric statement identifier.SEQis a sequence number indicating the display order for rows with the sameQUERY_IDvalue.STATEis the profiling state to which the row measurements apply.DURATIONindicates how long statement execution remained in the given state, in seconds.CPU_USERandCPU_SYSTEMindicate user and system CPU use, in seconds.CONTEXT_VOLUNTARYandCONTEXT_INVOLUNTARYindicate how many voluntary and involuntary context switches occurred.BLOCK_OPS_INandBLOCK_OPS_OUTindicate the number of block input and output operations.MESSAGES_SENTandMESSAGES_RECEIVEDindicate the number of communication messages sent and received.PAGE_FAULTS_MAJORandPAGE_FAULTS_MINORindicate the number of major and minor page faults.SWAPSindicates how many swaps occurred.SOURCE_FUNCTION,SOURCE_FILE, andSOURCE_LINEprovide information indicating where in the source code the profiled state executes.
We intend to implement additional
INFORMATION_SCHEMA tables. In particular, we
acknowledge the need for the PARAMETERS and
REFERENTIAL_CONSTRAINTS tables.
(REFERENTIAL_CONSTRAINTS is implemented in
MySQL 5.1.)
Some extensions to SHOW statements accompany
the implementation of INFORMATION_SCHEMA:
SHOWcan be used to get information about the structure ofINFORMATION_SCHEMAitself.Several
SHOWstatements accept aWHEREclause that provides more flexibility in specifying which rows to display.
These extensions are available beginning with MySQL 5.0.3.
INFORMATION_SCHEMA is an information database,
so its name is included in the output from SHOW
DATABASES. Similarly, SHOW TABLES can
be used with INFORMATION_SCHEMA to obtain a
list of its tables:
mysql> SHOW TABLES FROM INFORMATION_SCHEMA;
+---------------------------------------+
| Tables_in_information_schema |
+---------------------------------------+
| CHARACTER_SETS |
| COLLATIONS |
| COLLATION_CHARACTER_SET_APPLICABILITY |
| COLUMNS |
| COLUMN_PRIVILEGES |
| KEY_COLUMN_USAGE |
| ROUTINES |
| SCHEMATA |
| SCHEMA_PRIVILEGES |
| STATISTICS |
| TABLES |
| TABLE_CONSTRAINTS |
| TABLE_PRIVILEGES |
| TRIGGERS |
| USER_PRIVILEGES |
| VIEWS |
+---------------------------------------+
16 rows in set (0.00 sec)
SHOW COLUMNS and DESCRIBE
can display information about the columns in individual
INFORMATION_SCHEMA tables.
Several SHOW statements have been extended to
allow a WHERE clause:
SHOW CHARACTER SET SHOW COLLATION SHOW COLUMNS SHOW DATABASES SHOW FUNCTION STATUS SHOW KEYS SHOW OPEN TABLES SHOW PROCEDURE STATUS SHOW STATUS SHOW TABLE STATUS SHOW TABLES SHOW VARIABLES
The WHERE clause, if present, is evaluated
against the column names displayed by the SHOW
statement. For example, the SHOW CHARACTER SET
statement produces these output columns:
mysql> SHOW CHARACTER SET;
+----------+-----------------------------+---------------------+--------+
| Charset | Description | Default collation | Maxlen |
+----------+-----------------------------+---------------------+--------+
| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 |
| dec8 | DEC West European | dec8_swedish_ci | 1 |
| cp850 | DOS West European | cp850_general_ci | 1 |
| hp8 | HP West European | hp8_english_ci | 1 |
| koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 |
| latin1 | cp1252 West European | latin1_swedish_ci | 1 |
| latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 |
...
To use a WHERE clause with SHOW
CHARACTER SET, you would refer to those column names. As
an example, the following statement displays information about
character sets for which the default collation contains the string
'japanese':
mysql> SHOW CHARACTER SET WHERE `Default collation` LIKE '%japanese%';
+---------+---------------------------+---------------------+--------+
| Charset | Description | Default collation | Maxlen |
+---------+---------------------------+---------------------+--------+
| ujis | EUC-JP Japanese | ujis_japanese_ci | 3 |
| sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 |
| cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 |
| eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 |
+---------+---------------------------+---------------------+--------+
This statement displays the multi-byte character sets:
mysql> SHOW CHARACTER SET WHERE Maxlen > 1;
+---------+---------------------------+---------------------+--------+
| Charset | Description | Default collation | Maxlen |
+---------+---------------------------+---------------------+--------+
| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 |
| ujis | EUC-JP Japanese | ujis_japanese_ci | 3 |
| sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 |
| euckr | EUC-KR Korean | euckr_korean_ci | 2 |
| gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 |
| gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 |
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 |
| cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 |
| eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 |
+---------+---------------------------+---------------------+--------+
Table of Contents
MySQL 5.0 introduces precision math: numeric value handling that results in more accurate results and more control over invalid values than in earlier versions of MySQL. Precision math is based on two implementation changes:
The introduction of SQL modes in MySQL 5.0 that control how strict the server is about accepting or rejecting invalid data.
The introduction in MySQL 5.0.3 of a library for fixed-point arithmetic.
These changes have several implications for numeric operations:
More precise calculations: For exact-value numbers, calculations do not introduce floating-point errors. Instead, exact precision is used. For example, a number such as
.0001is treated as an exact value rather than as an approximation, and summing it 10,000 times produces a result of exactly1, not a value that merely “close” to 1.Well-defined rounding behavior: For exact-value numbers, the result of
ROUND()depends on its argument, not on environmental factors such as how the underlying C library works.Improved platform independence: Operations on exact numeric values are the same across different platforms such as Windows and Unix.
Control over handling of invalid values: Overflow and division by zero are detectable and can be treated as errors. For example, you can treat a value that is too large for a column as an error rather than having the value truncated to lie within the range of the column's data type. Similarly, you can treat division by zero as an error rather than as an operation that produces a result of
NULL. The choice of which approach to take is determined by the setting of thesql_modesystem variable.
An important result of these changes is that MySQL provides improved compliance with standard SQL.
The following discussion covers several aspects of how precision
math works (including possible incompatibilities with older
applications). At the end, some examples are given that demonstrate
how MySQL 5.0 handles numeric operations precisely. For
information about using the sql_mode system
variable to control the SQL mode, see
Section 5.2.6, “SQL Modes”.
The scope of precision math for exact-value operations includes
the exact-value data types (DECIMAL and integer
types) and exact-value numeric literals. Approximate-value data
types and numeric literals still are handled as floating-point
numbers.
Exact-value numeric literals have an integer part or fractional
part, or both. They may be signed. Examples: 1,
.2, 3.4,
-5, -6.78,
+9.10.
Approximate-value numeric literals are represented in scientific
notation with a mantissa and exponent. Either or both parts may be
signed. Examples: 1.2E3,
1.2E-3, -1.2E3,
-1.2E-3.
Two numbers that look similar need not be both exact-value or both
approximate-value. For example, 2.34 is an
exact-value (fixed-point) number, whereas
2.34E0 is an approximate-value (floating-point)
number.
The DECIMAL data type is a fixed-point type and
calculations are exact. In MySQL, the DECIMAL
type has several synonyms: NUMERIC,
DEC, FIXED. The integer
types also are exact-value types.
The FLOAT and DOUBLE data
types are floating-point types and calculations are approximate.
In MySQL, types that are synonymous with FLOAT
or DOUBLE are DOUBLE
PRECISION and REAL.
This section discusses the characteristics of the
DECIMAL data type (and its synonyms) as of
MySQL 5.0.3, with particular regard to the following topics:
Maximum number of digits
Storage format
Storage requirements
The non-standard MySQL extension to the upper range of
DECIMALcolumns
Some of these changes result in possible incompatibilities for applications that are written for older versions of MySQL. These incompatibilities are noted throughout this section.
The declaration syntax for a DECIMAL column
remains
DECIMAL(,
although the range of values for the arguments has changed
somewhat:
M,D)
Mis the maximum number of digits (the precision). It has a range of 1 to 65. This introduces a possible incompatibility for older applications, because previous versions of MySQL allow a range of 1 to 254.The precision of 65 digits actually applies as of MySQL 5.0.6. From 5.0.3 to 5.0.5, the precision is 64 digits.
Dis the number of digits to the right of the decimal point (the scale). It has a range of 0 to 30 and must be no larger thanM.
The maximum value of 65 for M means
that calculations on DECIMAL values are
accurate up to 65 digits. This limit of 65 digits of precision
also applies to exact-value numeric literals, so the maximum range
of such literals is different from before. (Prior to MySQL 5.0.3,
decimal values could have up to 254 digits. However, calculations
were done using floating-point and thus were approximate, not
exact.) This change in the range of literal values is another
possible source of incompatibility for older applications.
Values for DECIMAL columns no longer are
represented as strings that require one byte per digit or sign
character. Instead, a binary format is used that packs nine
decimal digits into four bytes. This change to
DECIMAL storage format changes the storage
requirements as well. The storage requirements for the integer and
fractional parts of each value are determined separately. Each
multiple of nine digits requires four bytes, and any digits left
over require some fraction of four bytes. For example, a
DECIMAL(18,9) column has nine digits on either
side of the decimal point, so the integer part and the fractional
part each require four bytes. A DECIMAL(20,10)
column has ten digits on either side of the decimal point. Each
part requires four bytes for nine of the digits, and one byte for
the remaining digit.
The storage required for leftover digits is given by the following table:
| Leftover Digits | Number of Bytes |
| 0 | 0 |
| 1 | 1 |
| 2 | 1 |
| 3 | 2 |
| 4 | 2 |
| 5 | 3 |
| 6 | 3 |
| 7 | 4 |
| 8 | 4 |
| 9 | 4 |
As a result of the change from string to numeric format for
DECIMAL storage, DECIMAL
columns no longer store a leading + character
or leading 0 digits. Before MySQL 5.0.3, if you
inserted +0003.1 into a
DECIMAL(5,1) column, it was stored as
+0003.1. As of MySQL 5.0.3, it is stored as
3.1. Applications that rely on the older
behavior must be modified to account for this change.
The change of storage format also means that
DECIMAL columns no longer support the
non-standard extension that allowed values larger than the range
implied by the column definition. Formerly, one byte was allocated
for storing the sign character. For positive values that needed no
sign byte, MySQL allowed an extra digit to be stored instead. For
example, a DECIMAL(3,0) column must support a
range of at least –999 to
999, but MySQL would allow storing values from
1000 to 9999 as well, by
using the sign byte to store an extra digit. This extension to the
upper range of DECIMAL columns no longer is
allowed. In MySQL 5.0.3 and up, a
DECIMAL(
column allows at most
M,D)M−D digits
to the left of the decimal point. This can result in an
incompatibility if an application has a reliance on MySQL allowing
“too-large” values.
The SQL standard requires that the precision of
NUMERIC(
be exactly M,D)M
digits. For
DECIMAL(,
the standard requires a precision of at least
M,D)M digits but allows more. In MySQL,
DECIMAL(
and
M,D)NUMERIC(
are the same, and both have a precision of exactly
M,D)M digits.
Summary of incompatibilities:
The following list summarizes the incompatibilities that result
from changes to DECIMAL column and value
handling. You can use it as guide when porting older applications
for use with MySQL 5.0.3 and up.
For
DECIMAL(, the maximumM,D)Mis 65, not 254.Calculations involving exact-value decimal numbers are accurate to 65 digits. This is fewer than the maximum number of digits allowed before MySQL 5.0.3 (254 digits), but the exact-value precision is greater. Calculations formerly were done with double-precision floating-point, which has a precision of 52 bits (about 15 decimal digits).
The non-standard MySQL extension to the upper range of
DECIMALcolumns no longer is supported.Leading ‘
+’ and ‘0’ characters are not stored.
The behavior used by the server for DECIMAL
columns in a table depends on the version of MySQL used to create
the table. If your server is from MySQL 5.0.3 or higher, but you
have DECIMAL columns in tables that were
created before 5.0.3, the old behavior still applies to those
columns. To convert the tables to the newer
DECIMAL format, dump them with
mysqldump and reload them.
With precision math, exact-value numbers are used as given
whenever possible. For example, numbers in comparisons are used
exactly as given without a change in value. In strict SQL mode,
for INSERT into a column with an exact data
type (DECIMAL or integer), a number is inserted
with its exact value if it is within the column range. When
retrieved, the value should be the same as what was inserted.
(Without strict mode, truncation for INSERT is
allowable.)
Handling of a numeric expression depends on what kind of values the expression contains:
If any approximate values are present, the expression is approximate and is evaluated using floating-point arithmetic.
If no approximate values are present, the expression contains only exact values. If any exact value contains a fractional part (a value following the decimal point), the expression is evaluated using
DECIMALexact arithmetic and has a precision of 65 digits. (The term “exact” is subject to the limits of what can be represented in binary. For example,1.0/3.0can be approximated in decimal notation as.333..., but not written as an exact number, so(1.0/3.0)*3.0does not evaluate to exactly1.0.)Otherwise, the expression contains only integer values. The expression is exact and is evaluated using integer arithmetic and has a precision the same as
BIGINT(64 bits).
If a numeric expression contains any strings, they are converted to double-precision floating-point values and the expression is approximate.
Inserts into numeric columns are affected by the SQL mode, which
is controlled by the sql_mode system variable.
(See Section 5.2.6, “SQL Modes”.) The following discussion
mentions strict mode (selected by the
STRICT_ALL_TABLES or
STRICT_TRANS_TABLES mode values) and
ERROR_FOR_DIVISION_BY_ZERO. To turn on all
restrictions, you can simply use TRADITIONAL
mode, which includes both strict mode values and
ERROR_FOR_DIVISION_BY_ZERO:
mysql> SET sql_mode='TRADITIONAL';
If a number is inserted into an exact type column
(DECIMAL or integer), it is inserted with its
exact value if it is within the column range.
If the value has too many digits in the fractional part, rounding occurs and a warning is generated. Rounding is done as described in Section 21.4, “Rounding Behavior”.
If the value has too many digits in the integer part, it is too large and is handled as follows:
If strict mode is not enabled, the value is truncated to the nearest legal value and a warning is generated.
If strict mode is enabled, an overflow error occurs.
Underflow is not detected, so underflow handing is undefined.
By default, division by zero produces a result of
NULL and no warning. With the
ERROR_FOR_DIVISION_BY_ZERO SQL mode enabled,
MySQL handles division by zero differently:
If strict mode is not enabled, a warning occurs.
If strict mode is enabled, inserts and updates involving division by zero are prohibited, and an error occurs.
In other words, inserts and updates involving expressions that
perform division by zero can be treated as errors, but this
requires ERROR_FOR_DIVISION_BY_ZERO in addition
to strict mode.
Suppose that we have this statement:
INSERT INTO t SET i = 1/0;
This is what happens for combinations of strict and
ERROR_FOR_DIVISION_BY_ZERO modes:
sql_mode Value | Result |
'' (Default) | No warning, no error; i is set to
NULL. |
| strict | No warning, no error; i is set to
NULL. |
ERROR_FOR_DIVISION_BY_ZERO | Warning, no error; i is set to
NULL. |
strict,ERROR_FOR_DIVISION_BY_ZERO | Error condition; no row is inserted. |
For inserts of strings into numeric columns, conversion from string to number is handled as follows if the string has non-numeric contents:
A string that does not begin with a number cannot be used as a number and produces an error in strict mode, or a warning otherwise. This includes the empty string.
A string that begins with a number can be converted, but the trailing non-numeric portion is truncated. If the truncated portion contains anything other than spaces, this produces an error in strict mode, or a warning otherwise.
This section discusses precision math rounding for the
ROUND() function and for inserts into columns
with exact-value types (DECIMAL and integer).
The ROUND() function rounds differently
depending on whether its argument is exact or approximate:
For exact-value numbers,
ROUND()uses the “round half up” rule: A value with a fractional part of .5 or greater is rounded up to the next integer if positive or down to the next integer if negative. (In other words, it is rounded away from zero.) A value with a fractional part less than .5 is rounded down to the next integer if positive or up to the next integer if negative.For approximate-value numbers, the result depends on the C library. On many systems, this means that
ROUND()uses the “round to nearest even” rule: A value with any fractional part is rounded to the nearest even integer.
The following example shows how rounding differs for exact and approximate values:
mysql> SELECT ROUND(2.5), ROUND(25E-1);
+------------+--------------+
| ROUND(2.5) | ROUND(25E-1) |
+------------+--------------+
| 3 | 2 |
+------------+--------------+
For inserts into a DECIMAL or integer column,
the target is an exact data type, so rounding uses “round
half up,” regardless of whether the value to be inserted is
exact or approximate:
mysql>CREATE TABLE t (d DECIMAL(10,0));Query OK, 0 rows affected (0.00 sec) mysql>INSERT INTO t VALUES(2.5),(2.5E0);Query OK, 2 rows affected, 2 warnings (0.00 sec) Records: 2 Duplicates: 0 Warnings: 2 mysql>SELECT d FROM t;+------+ | d | +------+ | 3 | | 3 | +------+
This section provides some examples that show how precision math improves query results in MySQL 5 compared to older versions.
Example 1. Numbers are used with their exact value as given when possible.
Before MySQL 5.0.3, numbers that are treated as floating-point values produce inexact results:
mysql> SELECT .1 + .2 = .3;
+--------------+
| .1 + .2 = .3 |
+--------------+
| 0 |
+--------------+
As of MySQL 5.0.3, numbers are used as given when possible:
mysql> SELECT .1 + .2 = .3;
+--------------+
| .1 + .2 = .3 |
+--------------+
| 1 |
+--------------+
For floating-point values, results are inexact:
mysql> SELECT .1E0 + .2E0 = .3E0;
+--------------------+
| .1E0 + .2E0 = .3E0 |
+--------------------+
| 0 |
+--------------------+
Another way to see the difference in exact and approximate value
handling is to add a small number to a sum many times. Consider
the following stored procedure, which adds
.0001 to a variable 1,000 times.
CREATE PROCEDURE p ()
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE d DECIMAL(10,4) DEFAULT 0;
DECLARE f FLOAT DEFAULT 0;
WHILE i < 10000 DO
SET d = d + .0001;
SET f = f + .0001E0;
SET i = i + 1;
END WHILE;
SELECT d, f;
END;
The sum for both d and f
logically should be 1, but that is true only for the decimal
calculation. The floating-point calculation introduces small
errors:
+--------+------------------+ | d | f | +--------+------------------+ | 1.0000 | 0.99999999999991 | +--------+------------------+
Example 2. Multiplication is
performed with the scale required by standard SQL. That is, for
two numbers X1 and
X2 that have scale
S1 and S2,
the scale of the result is S1
+ S2
Before MySQL 5.0.3, this is what happens:
mysql> SELECT .01 * .01;
+-----------+
| .01 * .01 |
+-----------+
| 0.00 |
+-----------+
The displayed value is incorrect. The value was calculated correctly in this case, but not displayed to the required scale. To see that the calculated value actually was .0001, try this:
mysql> SELECT .01 * .01 + .0000;
+-------------------+
| .01 * .01 + .0000 |
+-------------------+
| 0.0001 |
+-------------------+
As of MySQL 5.0.3, the displayed scale is correct:
mysql> SELECT .01 * .01;
+-----------+
| .01 * .01 |
+-----------+
| 0.0001 |
+-----------+
Example 3. Rounding behavior is well-defined.
Before MySQL 5.0.3, rounding behavior (for example, with the
ROUND() function) is dependent on the
implementation of the underlying C library. This results in
inconsistencies from platform to platform. For example, you might
get a different value on Windows than on Linux, or a different
value on x86 machines than on PowerPC machines.
As of MySQL 5.0.3, rounding happens like this:
Rounding for exact-value columns (DECIMAL and
integer) and exact-valued numbers uses the “round half
up” rule. Values with a fractional part of .5 or greater
are rounded away from zero to the nearest integer, as shown here:
mysql> SELECT ROUND(2.5), ROUND(-2.5);
+------------+-------------+
| ROUND(2.5) | ROUND(-2.5) |
+------------+-------------+
| 3 | -3 |
+------------+-------------+
However, rounding for floating-point values uses the C library, which on many systems uses the “round to nearest even” rule. Values with any fractional part on such systems are rounded to the nearest even integer:
mysql> SELECT ROUND(2.5E0), ROUND(-2.5E0);
+--------------+---------------+
| ROUND(2.5E0) | ROUND(-2.5E0) |
+--------------+---------------+
| 2 | -2 |
+--------------+---------------+
Example 4. In strict mode, inserting a value that is too large results in overflow and causes an error, rather than truncation to a legal value.
Before MySQL 5.0.2 (or in 5.0.2 and later, without strict mode), truncation to a legal value occurs:
mysql>CREATE TABLE t (i TINYINT);Query OK, 0 rows affected (0.01 sec) mysql>INSERT INTO t SET i = 128;Query OK, 1 row affected, 1 warning (0.00 sec) mysql>SELECT i FROM t;+------+ | i | +------+ | 127 | +------+ 1 row in set (0.00 sec)
As of MySQL 5.0.2, overflow occurs if strict mode is in effect:
mysql>SET sql_mode='STRICT_ALL_TABLES';Query OK, 0 rows affected (0.00 sec) mysql>CREATE TABLE t (i TINYINT);Query OK, 0 rows affected (0.00 sec) mysql>INSERT INTO t SET i = 128;ERROR 1264 (22003): Out of range value adjusted for column 'i' at row 1 mysql>SELECT i FROM t;Empty set (0.00 sec)
Example 5: In strict mode and
with ERROR_FOR_DIVISION_BY_ZERO set, division
by zero causes an error, and not a result of
NULL.
Before MySQL 5.0.2 (or when not using strict mode in 5.0.2 or a
later version), division by zero has a result of
NULL:
mysql>CREATE TABLE t (i TINYINT);Query OK, 0 rows affected (0.01 sec) mysql>INSERT INTO t SET i = 1 / 0;Query OK, 1 row affected (0.00 sec) mysql>SELECT i FROM t;+------+ | i | +------+ | NULL | +------+ 1 row in set (0.00 sec)
As of MySQL 5.0.2, division by zero is an error if the proper SQL modes are in effect:
mysql>SET sql_mode='STRICT_ALL_TABLES,ERROR_FOR_DIVISION_BY_ZERO';Query OK, 0 rows affected (0.00 sec) mysql>CREATE TABLE t (i TINYINT);Query OK, 0 rows affected (0.00 sec) mysql>INSERT INTO t SET i = 1 / 0;ERROR 1365 (22012): Division by 0 mysql>SELECT i FROM t;Empty set (0.01 sec)
Example 6. Prior to MySQL 5.0.3 (before precision math was introduced), exact-value and approximate-value literals both are converted to double-precision floating-point values:
mysql>SELECT VERSION();+------------+ | VERSION() | +------------+ | 4.1.18-log | +------------+ 1 row in set (0.01 sec) mysql>CREATE TABLE t SELECT 2.5 AS a, 25E-1 AS b;Query OK, 1 row affected (0.07 sec) Records: 1 Duplicates: 0 Warnings: 0 mysql>DESCRIBE t;+-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | a | double(3,1) | | | 0.0 | | | b | double | | | 0 | | +-------+-------------+------+-----+---------+-------+ 2 rows in set (0.04 sec)
As of MySQL 5.0.3, the approximate-value literal still is
converted to floating-point, but the exact-value literal is
handled as DECIMAL:
mysql>SELECT VERSION();+------------+ | VERSION() | +------------+ | 5.0.19-log | +------------+ 1 row in set (0.17 sec) mysql>CREATE TABLE t SELECT 2.5 AS a, 25E-1 AS b;Query OK, 1 row affected (0.19 sec) Records: 1 Duplicates: 0 Warnings: 0 mysql>DESCRIBE t;+-------+-----------------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-----------------------+------+-----+---------+-------+ | a | decimal(2,1) unsigned | NO | | 0.0 | | | b | double | NO | | 0 | | +-------+-----------------------+------+-----+---------+-------+ 2 rows in set (0.02 sec)
Example 7. If the argument to an aggregate function is an exact numeric type, the result is also an exact numeric type, with a scale at least that of the argument.
Consider these statements:
mysql>CREATE TABLE t (i INT, d DECIMAL, f FLOAT);mysql>INSERT INTO t VALUES(1,1,1);mysql>CREATE TABLE y SELECT AVG(i), AVG(d), AVG(f) FROM t;
Result before MySQL 5.0.3 (prior to the introduction of precision math in MySQL):
mysql> DESCRIBE y;
+--------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+--------------+------+-----+---------+-------+
| AVG(i) | double(17,4) | YES | | NULL | |
| AVG(d) | double(17,4) | YES | | NULL | |
| AVG(f) | double | YES | | NULL | |
+--------+--------------+------+-----+---------+-------+
The result is a double no matter the argument type.
Result as of MySQL 5.0.3:
mysql> DESCRIBE y;
+--------+---------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+---------------+------+-----+---------+-------+
| AVG(i) | decimal(14,4) | YES | | NULL | |
| AVG(d) | decimal(14,4) | YES | | NULL | |
| AVG(f) | double | YES | | NULL | |
+--------+---------------+------+-----+---------+-------+
The result is a double only for the floating-point argument. For
exact type arguments, the result is also an exact type. (From
MySQL 5.0.3 to 5.0.6, the first two columns are
DECIMAL(64,0).)
Table of Contents
- 22.1. libmysqld, the Embedded MySQL Server Library
- 22.2. MySQL C API
- 22.2.1. C API Data types
- 22.2.2. C API Function Overview
- 22.2.3. C API Function Descriptions
- 22.2.4. C API Prepared Statements
- 22.2.5. C API Prepared Statement Data types
- 22.2.6. C API Prepared Statement Function Overview
- 22.2.7. C API Prepared Statement Function Descriptions
- 22.2.8. C API Prepared statement problems
- 22.2.9. C API Handling of Multiple Statement Execution
- 22.2.10. C API Handling of Date and Time Values
- 22.2.11. C API Threaded Function Descriptions
- 22.2.12. C API Embedded Server Function Descriptions
- 22.2.13. Controlling Automatic Reconnect Behavior
- 22.2.14. Common Questions and Problems When Using the C API
- 22.2.15. Building Client Programs
- 22.2.16. How to Make a Threaded Client
- 22.3. MySQL PHP API
- 22.4. MySQL Perl API
- 22.5. MySQL C++ API
- 22.6. MySQL Python API
- 22.7. MySQL Tcl API
- 22.8. MySQL Eiffel Wrapper
- 22.9. MySQL Program Development Utilities
This chapter describes the APIs available for MySQL, where to get them, and how to use them. The C API is the most extensively covered, because it was developed by the MySQL team, and is the basis for most of the other APIs. This chapter also covers some programs that are useful for application developers.
The embedded MySQL server library is NOT part of MySQL 5.0. It is part of previous editions and will be included in future versions, starting with MySQL 5.1. You can find appropriate documentation in the corresponding manuals for these versions. In this manual, only an overview of the embedded library is provided.
The embedded MySQL server library makes it possible to run a full-featured MySQL server inside a client application. The main benefits are increased speed and more simple management for embedded applications.
The embedded server library is based on the client/server version of MySQL, which is written in C/C++. Consequently, the embedded server also is written in C/C++. There is no embedded server available in other languages.
The API is identical for the embedded MySQL version and the client/server version. To change an old threaded application to use the embedded library, you normally only have to add calls to the following functions:
| Function | When to Call |
mysql_library_init() | Should be called before any other MySQL function is called, preferably
early in the main() function. |
mysql_library_end() | Should be called before your program exits. |
mysql_thread_init() | Should be called in each thread you create that accesses MySQL. |
mysql_thread_end() | Should be called before calling pthread_exit() |
Then you must link your code with libmysqld.a
instead of libmysqlclient.a. To ensure binary
compatibility between your application and the server library, be
sure to compile your application against headers for the same
series of MySQL that was used to compile the server library. For
example, if libmysqld was compiled against
MySQL 4.1 headers, do not compile your application against MySQL
5.1 headers, or vice versa.
The
mysql_library_
functions are also included in
xxx()libmysqlclient.a to allow you to change
between the embedded and the client/server version by just linking
your application with the right library. See
Section 22.2.3.40, “mysql_library_init()”.
One difference between the embedded server and the standalone
server is that for the embedded server, authentication for
connections is disabled by default. To use authentication for the
embedded server, specify the
--with-embedded-privilege-control option when you
invoke configure to configure your MySQL
distribution.
- 22.2.1. C API Data types
- 22.2.2. C API Function Overview
- 22.2.3. C API Function Descriptions
- 22.2.4. C API Prepared Statements
- 22.2.5. C API Prepared Statement Data types
- 22.2.6. C API Prepared Statement Function Overview
- 22.2.7. C API Prepared Statement Function Descriptions
- 22.2.8. C API Prepared statement problems
- 22.2.9. C API Handling of Multiple Statement Execution
- 22.2.10. C API Handling of Date and Time Values
- 22.2.11. C API Threaded Function Descriptions
- 22.2.12. C API Embedded Server Function Descriptions
- 22.2.13. Controlling Automatic Reconnect Behavior
- 22.2.14. Common Questions and Problems When Using the C API
- 22.2.15. Building Client Programs
- 22.2.16. How to Make a Threaded Client
The C API code is distributed with MySQL. It is included in the
mysqlclient library and allows C programs to
access a database.
Many of the clients in the MySQL source distribution are written in
C. If you are looking for examples that demonstrate how to use the C
API, take a look at these clients. You can find these in the
clients directory in the MySQL source
distribution.
Most of the other client APIs (all except Connector/J and
Connector/NET) use the mysqlclient library to
communicate with the MySQL server. This means that, for example, you
can take advantage of many of the same environment variables that
are used by other client programs, because they are referenced from
the library. See Chapter 8, Client and Utility Programs, for a
list of these variables.
The client has a maximum communication buffer size. The size of the buffer that is allocated initially (16KB) is automatically increased up to the maximum size (the maximum is 16MB). Because buffer sizes are increased only as demand warrants, simply increasing the default maximum limit does not in itself cause more resources to be used. This size check is mostly a check for erroneous statements and communication packets.
The communication buffer must be large enough to contain a single
SQL statement (for client-to-server traffic) and one row of returned
data (for server-to-client traffic). Each thread's communication
buffer is dynamically enlarged to handle any query or row up to the
maximum limit. For example, if you have BLOB
values that contain up to 16MB of data, you must have a
communication buffer limit of at least 16MB (in both server and
client). The client's default maximum is 16MB, but the default
maximum in the server is 1MB. You can increase this by changing the
value of the max_allowed_packet parameter when
the server is started. See Section 7.5.2, “Tuning Server Parameters”.
The MySQL server shrinks each communication buffer to
net_buffer_length bytes after each query. For
clients, the size of the buffer associated with a connection is not
decreased until the connection is closed, at which time client
memory is reclaimed.
For programming with threads, see Section 22.2.16, “How to Make a Threaded Client”. For creating a standalone application which includes the "server" and "client" in the same program (and does not communicate with an external MySQL server), see Section 22.1, “libmysqld, the Embedded MySQL Server Library”.
This structure represents a handle to one database connection. It is used for almost all MySQL functions. You should not try to make a copy of a
MYSQLstructure. There is no guarantee that such a copy will be usable.This structure represents the result of a query that returns rows (
SELECT,SHOW,DESCRIBE,EXPLAIN). The information returned from a query is called the result set in the remainder of this section.This is a type-safe representation of one row of data. It is currently implemented as an array of counted byte strings. (You cannot treat these as null-terminated strings if field values may contain binary data, because such values may contain null bytes internally.) Rows are obtained by calling
mysql_fetch_row().This structure contains information about a field, such as the field's name, type, and size. Its members are described in more detail here. You may obtain the
MYSQL_FIELDstructures for each field by callingmysql_fetch_field()repeatedly. Field values are not part of this structure; they are contained in aMYSQL_ROWstructure.This is a type-safe representation of an offset into a MySQL field list. (Used by
mysql_field_seek().) Offsets are field numbers within a row, beginning at zero.The type used for the number of rows and for
mysql_affected_rows(),mysql_num_rows(), andmysql_insert_id(). This type provides a range of0to1.84e19.On some systems, attempting to print a value of type
my_ulonglongdoes not work. To print such a value, convert it tounsigned longand use a%luprint format. Example:printf ("Number of rows: %lu\n", (unsigned long) mysql_num_rows(result));A boolean type, for values that are true (non-zero) or false (zero).
The MYSQL_FIELD structure contains the members
listed here:
char * nameThe name of the field, as a null-terminated string. If the field was given an alias with an
ASclause, the value ofnameis the alias.char * org_nameThe name of the field, as a null-terminated string. Aliases are ignored.
char * tableThe name of the table containing this field, if it isn't a calculated field. For calculated fields, the
tablevalue is an empty string. If the column is selected from a view,tablenames the view. If the table or view was given an alias with anASclause, the value oftableis the alias.char * org_tableThe name of the table, as a null-terminated string. Aliases are ignored. If the column is selected from a view,
org_tablenames the underlying table.char * dbThe name of the database that the field comes from, as a null-terminated string. If the field is a calculated field,
dbis an empty string.char * catalogThe catalog name. This value is always
"def".char * defThe default value of this field, as a null-terminated string. This is set only if you use
mysql_list_fields().unsigned long lengthThe width of the field. This corresponds to the display length, in bytes.
unsigned long max_lengthThe maximum width of the field for the result set (the length in bytes of the longest field value for the rows actually in the result set). If you use
mysql_store_result()ormysql_list_fields(), this contains the maximum length for the field. If you usemysql_use_result(), the value of this variable is zero.The value of
max_lengthis the length of the string representation of the values in the result set. For example, if you retrieve aFLOATcolumn and the “widest” value is-12.345,max_lengthis 7 (the length of'-12.345').If you are using the prepared statements,
max_lengthis not set by default because for the binary protocol the lengths of the values depend on the types of the values in the result set. (See Section 22.2.5, “C API Prepared Statement Data types”.) If you want themax_lengthvalues anyway, enable theSTMT_ATTR_UPDATE_MAX_LENGTHoption withmysql_stmt_attr_set()and the lengths will be set when you callmysql_stmt_store_result(). (See Section 22.2.7.3, “mysql_stmt_attr_set()”, and Section 22.2.7.27, “mysql_stmt_store_result()”.)unsigned int name_lengthThe length of
name.unsigned int org_name_lengthThe length of
org_name.unsigned int table_lengthThe length of
table.unsigned int org_table_lengthThe length of
org_table.unsigned int db_lengthThe length of
db.unsigned int catalog_lengthThe length of
catalog.unsigned int def_lengthThe length of
def.unsigned int flagsDifferent bit-flags for the field. The
flagsvalue may have zero or more of the following bits set:Flag Value Flag Description NOT_NULL_FLAGField can't be NULLPRI_KEY_FLAGField is part of a primary key UNIQUE_KEY_FLAGField is part of a unique key MULTIPLE_KEY_FLAGField is part of a non-unique key UNSIGNED_FLAGField has the UNSIGNEDattributeZEROFILL_FLAGField has the ZEROFILLattributeBINARY_FLAGField has the BINARYattributeAUTO_INCREMENT_FLAGField has the AUTO_INCREMENTattributeENUM_FLAGField is an ENUM(deprecated)SET_FLAGField is a SET(deprecated)BLOB_FLAGField is a BLOBorTEXT(deprecated)TIMESTAMP_FLAGField is a TIMESTAMP(deprecated)Use of the
BLOB_FLAG,ENUM_FLAG,SET_FLAG, andTIMESTAMP_FLAGflags is deprecated because they indicate the type of a field rather than an attribute of its type. It is preferable to testfield->typeagainstMYSQL_TYPE_BLOB,MYSQL_TYPE_ENUM,MYSQL_TYPE_SET, orMYSQL_TYPE_TIMESTAMPinstead.The following example illustrates a typical use of the
flagsvalue:if (field->flags & NOT_NULL_FLAG) printf("Field can't be null\n");You may use the following convenience macros to determine the boolean status of the
flagsvalue:Flag Status Description IS_NOT_NULL(flags)True if this field is defined as NOT NULLIS_PRI_KEY(flags)True if this field is a primary key IS_BLOB(flags)True if this field is a BLOBorTEXT(deprecated; testfield->typeinstead)unsigned int decimalsThe number of decimals for numeric fields.
unsigned int charsetnrThe character set number for the field.
enum enum_field_types typeThe type of the field. The
typevalue may be one of theMYSQL_TYPE_symbols shown in the following table.Type Value Type Description MYSQL_TYPE_TINYTINYINTfieldMYSQL_TYPE_SHORTSMALLINTfieldMYSQL_TYPE_LONGINTEGERfieldMYSQL_TYPE_INT24MEDIUMINTfieldMYSQL_TYPE_LONGLONGBIGINTfieldMYSQL_TYPE_DECIMALDECIMALorNUMERICfieldMYSQL_TYPE_NEWDECIMALPrecision math DECIMALorNUMERICfield (MySQL 5.0.3 and up)MYSQL_TYPE_FLOATFLOATfieldMYSQL_TYPE_DOUBLEDOUBLEorREALfieldMYSQL_TYPE_BITBITfield (MySQL 5.0.3 and up)MYSQL_TYPE_TIMESTAMPTIMESTAMPfieldMYSQL_TYPE_DATEDATEfieldMYSQL_TYPE_TIMETIMEfieldMYSQL_TYPE_DATETIMEDATETIMEfieldMYSQL_TYPE_YEARYEARfieldMYSQL_TYPE_STRINGCHARorBINARYfieldMYSQL_TYPE_VAR_STRINGVARCHARorVARBINARYfieldMYSQL_TYPE_BLOBBLOBorTEXTfield (usemax_lengthto determine the maximum length)MYSQL_TYPE_SETSETfieldMYSQL_TYPE_ENUMENUMfieldMYSQL_TYPE_GEOMETRYSpatial field MYSQL_TYPE_NULLNULL-type fieldYou can use the
IS_NUM()macro to test whether a field has a numeric type. Pass thetypevalue toIS_NUM()and it evaluates to TRUE if the field is numeric:if (IS_NUM(field->type)) printf("Field is numeric\n");To distinguish between binary and non-binary data for string data types, check whether the
charsetnrvalue is 63. If so, the character set isbinary, which indicates binary rather than non-binary data. This is how to distinguish betweenBINARYandCHAR,VARBINARYandVARCHAR, andBLOBandTEXT.
The functions available in the C API are summarized here and described in greater detail in a later section. See Section 22.2.3, “C API Function Descriptions”.
| Function | Description |
| my_init() | Initialize global variables, and thread handler in thread-safe programs. |
| mysql_affected_rows() | Returns the number of rows changed/deleted/inserted by the last
UPDATE, DELETE, or
INSERT query. |
| mysql_autocommit() | Toggles autocommit mode on/off. |
| mysql_change_user() | Changes user and database on an open connection. |
| mysql_close() | Closes a server connection. |
| mysql_commit() | Commits the transaction. |
| mysql_connect() | Connects to a MySQL server. This function is deprecated; use
mysql_real_connect() instead. |
| mysql_create_db() | Creates a database. This function is deprecated; use the SQL statement
CREATE DATABASE instead. |
| mysql_data_seek() | Seeks to an arbitrary row number in a query result set. |
| mysql_debug() | Does a DBUG_PUSH with the given string. |
| mysql_drop_db() | Drops a database. This function is deprecated; use the SQL statement
DROP DATABASE instead. |
| mysql_dump_debug_info() | Makes the server write debug information to the log. |
| mysql_eof() | Determines whether the last row of a result set has been read. This
function is deprecated; mysql_errno()
or mysql_error() may be used instead. |
| mysql_errno() | Returns the error number for the most recently invoked MySQL function. |
| mysql_error() | Returns the error message for the most recently invoked MySQL function. |
| mysql_escape_string() | Escapes special characters in a string for use in an SQL statement. |
| mysql_fetch_field() | Returns the type of the next table field. |
| mysql_fetch_field_direct() | Returns the type of a table field, given a field number. |
| mysql_fetch_fields() | Returns an array of all field structures. |
| mysql_fetch_lengths() | Returns the lengths of all columns in the current row. |
| mysql_fetch_row() | Fetches the next row from the result set. |
| mysql_field_seek() | Puts the column cursor on a specified column. |
| mysql_field_count() | Returns the number of result columns for the most recent statement. |
| mysql_field_tell() | Returns the position of the field cursor used for the last
mysql_fetch_field(). |
| mysql_free_result() | Frees memory used by a result set. |
| mysql_get_client_info() | Returns client version information as a string. |
| mysql_get_client_version() | Returns client version information as an integer. |
| mysql_get_host_info() | Returns a string describing the connection. |
| mysql_get_server_version() | Returns version number of server as an integer. |
| mysql_get_proto_info() | Returns the protocol version used by the connection. |
| mysql_get_server_info() | Returns the server version number. |
| mysql_info() | Returns information about the most recently executed query. |
| mysql_init() | Gets or initializes a MYSQL structure. |
| mysql_insert_id() | Returns the ID generated for an AUTO_INCREMENT column
by the previous query. |
| mysql_kill() | Kills a given thread. |
| mysql_library_end() | Finalize the MySQL C API library. |
| mysql_library_init() | Initialize the MySQL C API library. |
| mysql_list_dbs() | Returns database names matching a simple regular expression. |
| mysql_list_fields() | Returns field names matching a simple regular expression. |
| mysql_list_processes() | Returns a list of the current server threads. |
| mysql_list_tables() | Returns table names matching a simple regular expression. |
| mysql_more_results() | Checks whether any more results exist. |
| mysql_next_result() | Returns/initiates the next result in multiple-statement executions. |
| mysql_num_fields() | Returns the number of columns in a result set. |
| mysql_num_rows() | Returns the number of rows in a result set. |
| mysql_options() | Sets connect options for mysql_connect(). |
| mysql_ping() | Checks whether the connection to the server is working, reconnecting as necessary. |
| mysql_query() | Executes an SQL query specified as a null-terminated string. |
| mysql_real_connect() | Connects to a MySQL server. |
| mysql_real_escape_string() | Escapes special characters in a string for use in an SQL statement, taking into account the current character set of the connection. |
| mysql_real_query() | Executes an SQL query specified as a counted string. |
| mysql_refresh() | Flush or reset tables and caches. |
| mysql_reload() | Tells the server to reload the grant tables. |
| mysql_rollback() | Rolls back the transaction. |
| mysql_row_seek() | Seeks to a row offset in a result set, using value returned from
mysql_row_tell(). |
| mysql_row_tell() | Returns the row cursor position. |
| mysql_select_db() | Selects a database. |
| mysql_server_end() | Finalize the MySQL C API library. |
| mysql_server_init() | Initialize the MySQL C API library. |
| mysql_set_local_infile_default() | Set the LOAD DATA LOCAL INFILE handler callbacks to
their default values. |
| mysql_set_local_infile_handler() | Install application-specific LOAD DATA LOCAL INFILE
handler callbacks. |
| mysql_set_server_option() | Sets an option for the connection (like
multi-statements). |
| mysql_sqlstate() | Returns the SQLSTATE error code for the last error. |
| mysql_shutdown() | Shuts down the database server. |
| mysql_stat() | Returns the server status as a string. |
| mysql_store_result() | Retrieves a complete result set to the client. |
| mysql_thread_end() | Finalize thread handler. |
| mysql_thread_id() | Returns the current thread ID. |
| mysql_thread_init() | Initialize thread handler. |
| mysql_thread_safe() | Returns 1 if the clients are compiled as thread-safe. |
| mysql_use_result() | Initiates a row-by-row result set retrieval. |
| mysql_warning_count() | Returns the warning count for the previous SQL statement. |
Application programs should use this general outline for interacting with MySQL:
Initialize the MySQL library by calling
mysql_library_init(). This function exists in both themysqlclientC client library and themysqldembedded server library, so it is used whether you build a regular client program by linking with the-libmysqlclientflag, or an embedded server application by linking with the-libmysqldflag.Initialize a connection handler by calling
mysql_init()and connect to the server by callingmysql_real_connect().Issue SQL statements and process their results. (The following discussion provides more information about how to do this.)
Close the connection to the MySQL server by calling
mysql_close().End use of the MySQL library by calling
mysql_library_end().
The purpose of calling mysql_library_init() and
mysql_library_end() is to provide proper
initialization and finalization of the MySQL library. For
applications that are linked with the client library, they provide
improved memory management. If you don't call
mysql_library_end(), a block of memory remains
allocated. (This does not increase the amount of memory used by
the application, but some memory leak detectors will complain
about it.) For applications that are linked with the embedded
server, these calls start and stop the server.
mysql_library_init() and
mysql_library_end() are available as of MySQL
5.0.3. For older versions of MySQL, you can call
mysql_server_init() and
mysql_server_end() instead.
In a non-multi-threaded environment, the call to
mysql_library_init() may be omitted, because
mysql_init() will invoke it automatically as
necessary. However, mysql_library_init() is not
thread-safe in a multi-threaded environment, and thus neither is
mysql_init(), which calls
mysql_library_init(). You must either call
mysql_library_init() prior to spawning any
threads, or else use a mutex to protect the call, whether you
invoke mysql_library_init() or indirectly via
mysql_init(). This should be done prior to any
other client library call.
To connect to the server, call mysql_init() to
initialize a connection handler, then call
mysql_real_connect() with that handler (along
with other information such as the hostname, username, and
password). Upon connection,
mysql_real_connect() sets the
reconnect flag (part of the
MYSQL structure) to a value of
1 in versions of the API older than 5.0.3, or
0 in newer versions. A value of
1 for this flag indicates that if a statement
cannot be performed because of a lost connection, to try
reconnecting to the server before giving up. As of MySQL 5.0.13,
you can use the MYSQL_OPT_RECONNECT option to
mysql_options() to control reconnection
behavior. When you are done with the connection, call
mysql_close() to terminate it.
While a connection is active, the client may send SQL statements
to the server using mysql_query() or
mysql_real_query(). The difference between the
two is that mysql_query() expects the query to
be specified as a null-terminated string whereas
mysql_real_query() expects a counted string. If
the string contains binary data (which may include null bytes),
you must use mysql_real_query().
For each non-SELECT query (for example,
INSERT, UPDATE,
DELETE), you can find out how many rows were
changed (affected) by calling
mysql_affected_rows().
For SELECT queries, you retrieve the selected
rows as a result set. (Note that some statements are
SELECT-like in that they return rows. These
include SHOW, DESCRIBE, and
EXPLAIN. They should be treated the same way as
SELECT statements.)
There are two ways for a client to process result sets. One way is
to retrieve the entire result set all at once by calling
mysql_store_result(). This function acquires
from the server all the rows returned by the query and stores them
in the client. The second way is for the client to initiate a
row-by-row result set retrieval by calling
mysql_use_result(). This function initializes
the retrieval, but does not actually get any rows from the server.
In both cases, you access rows by calling
mysql_fetch_row(). With
mysql_store_result(),
mysql_fetch_row() accesses rows that have
previously been fetched from the server. With
mysql_use_result(),
mysql_fetch_row() actually retrieves the row
from the server. Information about the size of the data in each
row is available by calling
mysql_fetch_lengths().
After you are done with a result set, call
mysql_free_result() to free the memory used for
it.
The two retrieval mechanisms are complementary. Client programs
should choose the approach that is most appropriate for their
requirements. In practice, clients tend to use
mysql_store_result() more commonly.
An advantage of mysql_store_result() is that
because the rows have all been fetched to the client, you not only
can access rows sequentially, you can move back and forth in the
result set using mysql_data_seek() or
mysql_row_seek() to change the current row
position within the result set. You can also find out how many
rows there are by calling mysql_num_rows(). On
the other hand, the memory requirements for
mysql_store_result() may be very high for large
result sets and you are more likely to encounter out-of-memory
conditions.
An advantage of mysql_use_result() is that the
client requires less memory for the result set because it
maintains only one row at a time (and because there is less
allocation overhead, mysql_use_result() can be
faster). Disadvantages are that you must process each row quickly
to avoid tying up the server, you don't have random access to rows
within the result set (you can only access rows sequentially), and
you don't know how many rows are in the result set until you have
retrieved them all. Furthermore, you
must retrieve all the rows even
if you determine in mid-retrieval that you've found the
information you were looking for.
The API makes it possible for clients to respond appropriately to
statements (retrieving rows only as necessary) without knowing
whether the statement is a SELECT. You can do
this by calling mysql_store_result() after each
mysql_query() (or
mysql_real_query()). If the result set call
succeeds, the statement was a SELECT and you
can read the rows. If the result set call fails, call
mysql_field_count() to determine whether a
result was actually to be expected. If
mysql_field_count() returns zero, the statement
returned no data (indicating that it was an
INSERT, UPDATE,
DELETE, and so forth), and was not expected to
return rows. If mysql_field_count() is
non-zero, the statement should have returned rows, but didn't.
This indicates that the statement was a SELECT
that failed. See the description for
mysql_field_count() for an example of how this
can be done.
Both mysql_store_result() and
mysql_use_result() allow you to obtain
information about the fields that make up the result set (the
number of fields, their names and types, and so forth). You can
access field information sequentially within the row by calling
mysql_fetch_field() repeatedly, or by field
number within the row by calling
mysql_fetch_field_direct(). The current field
cursor position may be changed by calling
mysql_field_seek(). Setting the field cursor
affects subsequent calls to
mysql_fetch_field(). You can also get
information for fields all at once by calling
mysql_fetch_fields().
For detecting and reporting errors, MySQL provides access to error
information by means of the mysql_errno() and
mysql_error() functions. These return the error
code or error message for the most recently invoked function that
can succeed or fail, allowing you to determine when an error
occurred and what it was.
- 22.2.3.1.
mysql_affected_rows() - 22.2.3.2.
mysql_autocommit() - 22.2.3.3.
mysql_change_user() - 22.2.3.4.
mysql_character_set_name() - 22.2.3.5.
mysql_close() - 22.2.3.6.
mysql_commit() - 22.2.3.7.
mysql_connect() - 22.2.3.8.
mysql_create_db() - 22.2.3.9.
mysql_data_seek() - 22.2.3.10.
mysql_debug() - 22.2.3.11.
mysql_drop_db() - 22.2.3.12.
mysql_dump_debug_info() - 22.2.3.13.
mysql_eof() - 22.2.3.14.
mysql_errno() - 22.2.3.15.
mysql_error() - 22.2.3.16.
mysql_escape_string() - 22.2.3.17.
mysql_fetch_field() - 22.2.3.18.
mysql_fetch_field_direct() - 22.2.3.19.
mysql_fetch_fields() - 22.2.3.20.
mysql_fetch_lengths() - 22.2.3.21.
mysql_fetch_row() - 22.2.3.22.
mysql_field_count() - 22.2.3.23.
mysql_field_seek() - 22.2.3.24.
mysql_field_tell() - 22.2.3.25.
mysql_free_result() - 22.2.3.26.
mysql_get_character_set_info() - 22.2.3.27.
mysql_get_client_info() - 22.2.3.28.
mysql_get_client_version() - 22.2.3.29.
mysql_get_host_info() - 22.2.3.30.
mysql_get_proto_info() - 22.2.3.31.
mysql_get_server_info() - 22.2.3.32.
mysql_get_server_version() - 22.2.3.33.
mysql_get_ssl_cipher() - 22.2.3.34.
mysql_hex_string() - 22.2.3.35.
mysql_info() - 22.2.3.36.
mysql_init() - 22.2.3.37.
mysql_insert_id() - 22.2.3.38.
mysql_kill() - 22.2.3.39.
mysql_library_end() - 22.2.3.40.
mysql_library_init() - 22.2.3.41.
mysql_list_dbs() - 22.2.3.42.
mysql_list_fields() - 22.2.3.43.
mysql_list_processes() - 22.2.3.44.
mysql_list_tables() - 22.2.3.45.
mysql_more_results() - 22.2.3.46.
mysql_next_result() - 22.2.3.47.
mysql_num_fields() - 22.2.3.48.
mysql_num_rows() - 22.2.3.49.
mysql_options() - 22.2.3.50.
mysql_ping() - 22.2.3.51.
mysql_query() - 22.2.3.52.
mysql_real_connect() - 22.2.3.53.
mysql_real_escape_string() - 22.2.3.54.
mysql_real_query() - 22.2.3.55.
mysql_refresh() - 22.2.3.56.
mysql_reload() - 22.2.3.57.
mysql_rollback() - 22.2.3.58.
mysql_row_seek() - 22.2.3.59.
mysql_row_tell() - 22.2.3.60.
mysql_select_db() - 22.2.3.61.
mysql_set_character_set() - 22.2.3.62.
mysql_set_local_infile_default() - 22.2.3.63.
mysql_set_local_infile_handler() - 22.2.3.64.
mysql_set_server_option() - 22.2.3.65.
mysql_shutdown() - 22.2.3.66.
mysql_sqlstate() - 22.2.3.67.
mysql_ssl_set() - 22.2.3.68.
mysql_stat() - 22.2.3.69.
mysql_store_result() - 22.2.3.70.
mysql_thread_id() - 22.2.3.71.
mysql_use_result() - 22.2.3.72.
mysql_warning_count()
In the descriptions here, a parameter or return value of
NULL means NULL in the sense
of the C programming language, not a MySQL NULL
value.
Functions that return a value generally return a pointer or an
integer. Unless specified otherwise, functions returning a pointer
return a non-NULL value to indicate success or
a NULL value to indicate an error, and
functions returning an integer return zero to indicate success or
non-zero to indicate an error. Note that “non-zero”
means just that. Unless the function description says otherwise,
do not test against a value other than zero:
if (result) /* correct */
... error ...
if (result < 0) /* incorrect */
... error ...
if (result == -1) /* incorrect */
... error ...
When a function returns an error, the
Errors subsection of the function
description lists the possible types of errors. You can find out
which of these occurred by calling
mysql_errno(). A string representation of the
error may be obtained by calling mysql_error().
my_ulonglong mysql_affected_rows(MYSQL
*mysql)
Description
After executing a statement with
mysql_query() or
mysql_real_query(), returns the number of
rows changed (for) UPDATE), deleted (for
DELETE, or inserted (for
INSERT. For SELECT
statements, mysql_affected_rows() works like
mysql_num_rows().
Return Values
An integer greater than zero indicates the number of rows
affected or retrieved. Zero indicates that no records were
updated for an UPDATE statement, no rows
matched the WHERE clause in the query or that
no query has yet been executed. -1 indicates that the query
returned an error or that, for a SELECT
query, mysql_affected_rows() was called prior
to calling mysql_store_result(). Because
mysql_affected_rows() returns an unsigned
value, you can check for -1 by comparing the return value to
(my_ulonglong)-1 (or to
(my_ulonglong)~0, which is equivalent).
Errors
None.
Example
char *stmt = "UPDATE products SET cost=cost*1.25 WHERE group=10";
mysql_query(&mysql,stmt);
printf("%ld products updated",
(long) mysql_affected_rows(&mysql));
For UPDATE statements, if you specify the
CLIENT_FOUND_ROWS flag when connecting to
mysqld,
mysql_affected_rows() returns the number of
rows matched by the WHERE clause. Otherwise,
the default behavior is to return the number of rows actually
changed.
Note that when you use a REPLACE command,
mysql_affected_rows() returns 2 if the new
row replaced an old row, because in this case, one row was
inserted after the duplicate was deleted.
If you use INSERT ... ON DUPLICATE KEY UPDATE
to insert a row, mysql_affected_rows()
returns 1 if the row is inserted as a new row and 2 if an
existing row is updated.
my_bool mysql_autocommit(MYSQL *mysql, my_bool
mode)
Description
Sets autocommit mode on if mode is 1, off if
mode is 0.
Return Values
Zero if successful. Non-zero if an error occurred.
Errors
None.
my_bool mysql_change_user(MYSQL *mysql, const char
*user, const char *password, const char *db)
Description
Changes the user and causes the database specified by
db to become the default (current) database
on the connection specified by mysql. In
subsequent queries, this database is the default for table
references that do not include an explicit database specifier.
mysql_change_user() fails if the connected
user cannot be authenticated or doesn't have permission to use
the database. In this case, the user and database are not
changed
The db parameter may be set to
NULL if you don't want to have a default
database.
This command resets the state as if one had done a new connect.
(See Section 22.2.13, “Controlling Automatic Reconnect Behavior”.) It always performs a
ROLLBACK of any active transactions, closes
and drops all temporary tables, and unlocks all locked tables.
Session system variables are reset to the values of the
corresponding global system variables. Prepared statements are
released and HANDLER variables are closed.
Locks acquired with GET_LOCK() are released.
These effects occur even if the user didn't change.
Return Values
Zero for success. Non-zero if an error occurred.
Errors
The same that you can get from
mysql_real_connect().
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
ER_UNKNOWN_COM_ERRORThe MySQL server doesn't implement this command (probably an old server).
ER_ACCESS_DENIED_ERRORThe user or password was wrong.
ER_BAD_DB_ERRORThe database didn't exist.
ER_DBACCESS_DENIED_ERRORThe user did not have access rights to the database.
ER_WRONG_DB_NAMEThe database name was too long.
Example
if (mysql_change_user(&mysql, "user", "password", "new_database"))
{
fprintf(stderr, "Failed to change user. Error: %s\n",
mysql_error(&mysql));
}
const char *mysql_character_set_name(MYSQL
*mysql)
Description
Returns the default character set for the current connection.
Return Values
The default character set
Errors
None.
void mysql_close(MYSQL *mysql)
Description
Closes a previously opened connection.
mysql_close() also deallocates the connection
handle pointed to by mysql if the handle was
allocated automatically by mysql_init() or
mysql_connect().
Return Values
None.
Errors
None.
my_bool mysql_commit(MYSQL *mysql)
Description
Commits the current transaction.
As of MySQL 5.0.3, the action of this function is subject to the
value of the completion_type system variable.
In particular, if the value of
completion_type is 2, the server performs a
release after terminating a transaction and closes the client
connection. The client program should call
mysql_close() to close the connection from
the client side.
Return Values
Zero if successful. Non-zero if an error occurred.
Errors
None.
MYSQL *mysql_connect(MYSQL *mysql, const char *host,
const char *user, const char *passwd)
Description
This function is deprecated. It is preferable to use
mysql_real_connect() instead.
mysql_connect() attempts to establish a
connection to a MySQL database engine running on
host. mysql_connect() must
complete successfully before you can execute any of the other
API functions, with the exception of
mysql_get_client_info().
The meanings of the parameters are the same as for the
corresponding parameters for
mysql_real_connect() with the difference that
the connection parameter may be NULL. In this
case, the C API allocates memory for the connection structure
automatically and frees it when you call
mysql_close(). The disadvantage of this
approach is that you can't retrieve an error message if the
connection fails. (To get error information from
mysql_errno() or
mysql_error(), you must provide a valid
MYSQL pointer.)
Return Values
Same as for mysql_real_connect().
Errors
Same as for mysql_real_connect().
int mysql_create_db(MYSQL *mysql, const char
*db)
Description
Creates the database named by the db
parameter.
This function is deprecated. It is preferable to use
mysql_query() to issue an SQL CREATE
DATABASE statement instead.
Return Values
Zero if the database was created successfully. Non-zero if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
Example
if(mysql_create_db(&mysql, "my_database"))
{
fprintf(stderr, "Failed to create new database. Error: %s\n",
mysql_error(&mysql));
}
void mysql_data_seek(MYSQL_RES *result, my_ulonglong
offset)
Description
Seeks to an arbitrary row in a query result set. The
offset value is a row number and should be in
the range from 0 to
mysql_num_rows(result)-1.
This function requires that the result set structure contains
the entire result of the query, so
mysql_data_seek() may be used only in
conjunction with mysql_store_result(), not
with mysql_use_result().
Return Values
None.
Errors
None.
void mysql_debug(const char *debug)
Description
Does a DBUG_PUSH with the given string.
mysql_debug() uses the Fred Fish debug
library. To use this function, you must compile the client
library to support debugging. See
MySQL
Internals: Porting.
Return Values
None.
Errors
None.
Example
The call shown here causes the client library to generate a
trace file in /tmp/client.trace on the
client machine:
mysql_debug("d:t:O,/tmp/client.trace");
int mysql_drop_db(MYSQL *mysql, const char
*db)
Description
Drops the database named by the db parameter.
This function is deprecated. It is preferable to use
mysql_query() to issue an SQL DROP
DATABASE statement instead.
Return Values
Zero if the database was dropped successfully. Non-zero if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
Example
if(mysql_drop_db(&mysql, "my_database"))
fprintf(stderr, "Failed to drop the database: Error: %s\n",
mysql_error(&mysql));
int mysql_dump_debug_info(MYSQL *mysql)
Description
Instructs the server to write some debug information to the log.
For this to work, the connected user must have the
SUPER privilege.
Return Values
Zero if the command was successful. Non-zero if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
my_bool mysql_eof(MYSQL_RES *result)
Description
This function is deprecated. mysql_errno() or
mysql_error() may be used instead.
mysql_eof() determines whether the last row
of a result set has been read.
If you acquire a result set from a successful call to
mysql_store_result(), the client receives the
entire set in one operation. In this case, a
NULL return from
mysql_fetch_row() always means the end of the
result set has been reached and it is unnecessary to call
mysql_eof(). When used with
mysql_store_result(),
mysql_eof() always returns true.
On the other hand, if you use
mysql_use_result() to initiate a result set
retrieval, the rows of the set are obtained from the server one
by one as you call mysql_fetch_row()
repeatedly. Because an error may occur on the connection during
this process, a NULL return value from
mysql_fetch_row() does not necessarily mean
the end of the result set was reached normally. In this case,
you can use mysql_eof() to determine what
happened. mysql_eof() returns a non-zero
value if the end of the result set was reached and zero if an
error occurred.
Historically, mysql_eof() predates the
standard MySQL error functions mysql_errno()
and mysql_error(). Because those error
functions provide the same information, their use is preferred
over mysql_eof(), which is deprecated. (In
fact, they provide more information, because
mysql_eof() returns only a boolean value
whereas the error functions indicate a reason for the error when
one occurs.)
Return Values
Zero if no error occurred. Non-zero if the end of the result set has been reached.
Errors
None.
Example
The following example shows how you might use
mysql_eof():
mysql_query(&mysql,"SELECT * FROM some_table");
result = mysql_use_result(&mysql);
while((row = mysql_fetch_row(result)))
{
// do something with data
}
if(!mysql_eof(result)) // mysql_fetch_row() failed due to an error
{
fprintf(stderr, "Error: %s\n", mysql_error(&mysql));
}
However, you can achieve the same effect with the standard MySQL error functions:
mysql_query(&mysql,"SELECT * FROM some_table");
result = mysql_use_result(&mysql);
while((row = mysql_fetch_row(result)))
{
// do something with data
}
if(mysql_errno(&mysql)) // mysql_fetch_row() failed due to an error
{
fprintf(stderr, "Error: %s\n", mysql_error(&mysql));
}
unsigned int mysql_errno(MYSQL *mysql)
Description
For the connection specified by mysql,
mysql_errno() returns the error code for the
most recently invoked API function that can succeed or fail. A
return value of zero means that no error occurred. Client error
message numbers are listed in the MySQL
errmsg.h header file. Server error message
numbers are listed in mysqld_error.h.
Errors also are listed at Appendix B, Errors, Error Codes, and Common Problems.
Note that some functions like
mysql_fetch_row() don't set
mysql_errno() if they succeed.
A rule of thumb is that all functions that have to ask the
server for information reset mysql_errno() if
they succeed.
MySQL-specific error numbers returned by
mysql_errno() differ from SQLSTATE values
returned by mysql_sqlstate(). For example,
the mysql client program displays errors
using the following format, where 1146 is the
mysql_errno() value and
'42S02' is the corresponding
mysql_sqlstate() value:
shell> SELECT * FROM no_such_table;
ERROR 1146 (42S02): Table 'test.no_such_table' doesn't exist
Return Values
An error code value for the last
mysql_ call,
if it failed. zero means no error occurred.
xxx()
Errors
None.
const char *mysql_error(MYSQL *mysql)
Description
For the connection specified by mysql,
mysql_error() returns a null-terminated
string containing the error message for the most recently
invoked API function that failed. If a function didn't fail, the
return value of mysql_error() may be the
previous error or an empty string to indicate no error.
A rule of thumb is that all functions that have to ask the
server for information reset mysql_error() if
they succeed.
For functions that reset mysql_error(), the
following two tests are equivalent:
if(*mysql_error(&mysql))
{
// an error occurred
}
if(mysql_error(&mysql)[0])
{
// an error occurred
}
The language of the client error messages may be changed by recompiling the MySQL client library. Currently, you can choose error messages in several different languages. See Section 5.10.2, “Setting the Error Message Language”.
Return Values
A null-terminated character string that describes the error. An empty string if no error occurred.
Errors
None.
You should use mysql_real_escape_string()
instead!
This function is identical to
mysql_real_escape_string() except that
mysql_real_escape_string() takes a connection
handler as its first argument and escapes the string according
to the current character set.
mysql_escape_string() does not take a
connection argument and does not respect the current character
set.
MYSQL_FIELD *mysql_fetch_field(MYSQL_RES
*result)
Description
Returns the definition of one column of a result set as a
MYSQL_FIELD structure. Call this function
repeatedly to retrieve information about all columns in the
result set. mysql_fetch_field() returns
NULL when no more fields are left.
mysql_fetch_field() is reset to return
information about the first field each time you execute a new
SELECT query. The field returned by
mysql_fetch_field() is also affected by calls
to mysql_field_seek().
If you've called mysql_query() to perform a
SELECT on a table but have not called
mysql_store_result(), MySQL returns the
default blob length (8KB) if you call
mysql_fetch_field() to ask for the length of
a BLOB field. (The 8KB size is chosen because
MySQL doesn't know the maximum length for the
BLOB. This should be made configurable
sometime.) Once you've retrieved the result set,
field->max_length contains the length of
the largest value for this column in the specific query.
Return Values
The MYSQL_FIELD structure for the current
column. NULL if no columns are left.
Errors
None.
Example
MYSQL_FIELD *field;
while((field = mysql_fetch_field(result)))
{
printf("field name %s\n", field->name);
}
MYSQL_FIELD *mysql_fetch_field_direct(MYSQL_RES
*result, unsigned int fieldnr)
Description
Given a field number fieldnr for a column
within a result set, returns that column's field definition as a
MYSQL_FIELD structure. You may use this
function to retrieve the definition for an arbitrary column. The
value of fieldnr should be in the range from
0 to mysql_num_fields(result)-1.
Return Values
The MYSQL_FIELD structure for the specified
column.
Errors
None.
Example
unsigned int num_fields;
unsigned int i;
MYSQL_FIELD *field;
num_fields = mysql_num_fields(result);
for(i = 0; i < num_fields; i++)
{
field = mysql_fetch_field_direct(result, i);
printf("Field %u is %s\n", i, field->name);
}
MYSQL_FIELD *mysql_fetch_fields(MYSQL_RES
*result)
Description
Returns an array of all MYSQL_FIELD
structures for a result set. Each structure provides the field
definition for one column of the result set.
Return Values
An array of MYSQL_FIELD structures for all
columns of a result set.
Errors
None.
Example
unsigned int num_fields;
unsigned int i;
MYSQL_FIELD *fields;
num_fields = mysql_num_fields(result);
fields = mysql_fetch_fields(result);
for(i = 0; i < num_fields; i++)
{
printf("Field %u is %s\n", i, fields[i].name);
}
unsigned long *mysql_fetch_lengths(MYSQL_RES
*result)
Description
Returns the lengths of the columns of the current row within a
result set. If you plan to copy field values, this length
information is also useful for optimization, because you can
avoid calling strlen(). In addition, if the
result set contains binary data, you
must use this function to
determine the size of the data, because
strlen() returns incorrect results for any
field containing null characters.
The length for empty columns and for columns containing
NULL values is zero. To see how to
distinguish these two cases, see the description for
mysql_fetch_row().
Return Values
An array of unsigned long integers representing the size of each
column (not including any terminating null characters).
NULL if an error occurred.
Errors
mysql_fetch_lengths() is valid only for the
current row of the result set. It returns
NULL if you call it before calling
mysql_fetch_row() or after retrieving all
rows in the result.
Example
MYSQL_ROW row;
unsigned long *lengths;
unsigned int num_fields;
unsigned int i;
row = mysql_fetch_row(result);
if (row)
{
num_fields = mysql_num_fields(result);
lengths = mysql_fetch_lengths(result);
for(i = 0; i < num_fields; i++)
{
printf("Column %u is %lu bytes in length.\n",
i, lengths[i]);
}
}
MYSQL_ROW mysql_fetch_row(MYSQL_RES *result)
Description
Retrieves the next row of a result set. When used after
mysql_store_result(),
mysql_fetch_row() returns
NULL when there are no more rows to retrieve.
When used after mysql_use_result(),
mysql_fetch_row() returns
NULL when there are no more rows to retrieve
or if an error occurred.
The number of values in the row is given by
mysql_num_fields(result). If
row holds the return value from a call to
mysql_fetch_row(), pointers to the values are
accessed as row[0] to
row[mysql_num_fields(result)-1].
NULL values in the row are indicated by
NULL pointers.
The lengths of the field values in the row may be obtained by
calling mysql_fetch_lengths(). Empty fields
and fields containing NULL both have length
0; you can distinguish these by checking the pointer for the
field value. If the pointer is NULL, the
field is NULL; otherwise, the field is empty.
MySQL-specific error numbers returned by
mysql_errno() differ from SQLSTATE values
returned by mysql_sqlstate(). For example,
the mysql client program displays errors
using the following format, where 1146 is the
mysql_errno() value and
'42S02' is the corresponding
mysql_sqlstate() value:
shell> SELECT * FROM no_such_table;
ERROR 1146 (42S02): Table 'test.no_such_table' doesn't exist
Return Values
A MYSQL_ROW structure for the next row.
NULL if there are no more rows to retrieve or
if an error occurred.
Errors
Note that error is not reset between calls to
mysql_fetch_row()
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
Example
MYSQL_ROW row;
unsigned int num_fields;
unsigned int i;
num_fields = mysql_num_fields(result);
while ((row = mysql_fetch_row(result)))
{
unsigned long *lengths;
lengths = mysql_fetch_lengths(result);
for(i = 0; i < num_fields; i++)
{
printf("[%.*s] ", (int) lengths[i],
row[i] ? row[i] : "NULL");
}
printf("\n");
}
unsigned int mysql_field_count(MYSQL *mysql)
Description
Returns the number of columns for the most recent query on the connection.
The normal use of this function is when
mysql_store_result() returned
NULL (and thus you have no result set
pointer). In this case, you can call
mysql_field_count() to determine whether
mysql_store_result() should have produced a
non-empty result. This allows the client program to take proper
action without knowing whether the query was a
SELECT (or SELECT-like)
statement. The example shown here illustrates how this may be
done.
Return Values
An unsigned integer representing the number of columns in a result set.
Errors
None.
Example
MYSQL_RES *result;
unsigned int num_fields;
unsigned int num_rows;
if (mysql_query(&mysql,query_string))
{
// error
}
else // query succeeded, process any data returned by it
{
result = mysql_store_result(&mysql);
if (result) // there are rows
{
num_fields = mysql_num_fields(result);
// retrieve rows, then call mysql_free_result(result)
}
else // mysql_store_result() returned nothing; should it have?
{
if(mysql_field_count(&mysql) == 0)
{
// query does not return data
// (it was not a SELECT)
num_rows = mysql_affected_rows(&mysql);
}
else // mysql_store_result() should have returned data
{
fprintf(stderr, "Error: %s\n", mysql_error(&mysql));
}
}
}
An alternative is to replace the
mysql_field_count(&mysql) call with
mysql_errno(&mysql). In this case, you
are checking directly for an error from
mysql_store_result() rather than inferring
from the value of mysql_field_count() whether
the statement was a SELECT.
MYSQL_FIELD_OFFSET mysql_field_seek(MYSQL_RES *result,
MYSQL_FIELD_OFFSET offset)
Description
Sets the field cursor to the given offset. The next call to
mysql_fetch_field() retrieves the field
definition of the column associated with that offset.
To seek to the beginning of a row, pass an
offset value of zero.
Return Values
The previous value of the field cursor.
Errors
None.
MYSQL_FIELD_OFFSET mysql_field_tell(MYSQL_RES
*result)
Description
Returns the position of the field cursor used for the last
mysql_fetch_field(). This value can be used
as an argument to mysql_field_seek().
Return Values
The current offset of the field cursor.
Errors
None.
void mysql_free_result(MYSQL_RES *result)
Description
Frees the memory allocated for a result set by
mysql_store_result(),
mysql_use_result(),
mysql_list_dbs(), and so forth. When you are
done with a result set, you must free the memory it uses by
calling mysql_free_result().
Do not attempt to access a result set after freeing it.
Return Values
None.
Errors
None.
void mysql_get_character_set_info(MYSQL *mysql,
MY_CHARSET_INFO *cs)
Description
This function provides information about the default client
character set. The default character set may be changed with the
mysql_set_character_set() function.
This function was added in MySQL 5.0.10.
Example
if (!mysql_set_character_set(&mysql, "utf8"))
{
MY_CHARSET_INFO cs;
mysql_get_character_set_info(&mysql, &cs);
printf("character set information:\n");
printf("character set name: %s\n", cs.name);
printf("collation name: %s\n", cs.csname);
printf("comment: %s\n", cs.comment);
printf("directory: %s\n", cs.dir);
printf("multi byte character min. length: %d\n", cs.mbminlen);
printf("multi byte character max. length: %d\n", cs.mbmaxlen);
}
const char *mysql_get_client_info(void)
Description
Returns a string that represents the client library version.
Return Values
A character string that represents the MySQL client library version.
Errors
None.
unsigned long mysql_get_client_version(void)
Description
Returns an integer that represents the client library version.
The value has the format XYYZZ where
X is the major version, YY
is the release level, and ZZ is the version
number within the release level. For example, a value of
40102 represents a client library version of
4.1.2.
Return Values
An integer that represents the MySQL client library version.
Errors
None.
const char *mysql_get_host_info(MYSQL *mysql)
Description
Returns a string describing the type of connection in use, including the server hostname.
Return Values
A character string representing the server hostname and the connection type.
Errors
None.
unsigned int mysql_get_proto_info(MYSQL
*mysql)
Description
Returns the protocol version used by current connection.
Return Values
An unsigned integer representing the protocol version used by the current connection.
Errors
None.
const char *mysql_get_server_info(MYSQL
*mysql)
Description
Returns a string that represents the server version number.
Return Values
A character string that represents the server version number.
Errors
None.
unsigned long mysql_get_server_version(MYSQL
*mysql)
Description
Returns the version number of the server as an integer.
Return Values
A number that represents the MySQL server version in this format:
major_version*10000 + minor_version *100 + sub_version
For example, 5.0.12 is returned as 50012.
This function is useful in client programs for quickly determining whether some version-specific server capability exists.
Errors
None.
const char *mysql_get_ssl_cipher(MYSQL
*mysql)
Description
mysql_get_ssl_cipher() returns the SSL cipher
used for the given connection to the server.
mysql is the connection handler returned from
mysql_init().
This function was added in MySQL 5.1.9.
Return Values
A string naming the SSL cipher used for the connection, or
NULL if no cipher is being used.
unsigned long mysql_hex_string(char *to, const char
*from, unsigned long length)
Description
This function is used to create a legal SQL string that you can use in an SQL statement. See Section 9.1.1, “Strings”.
The string in from is encoded to hexadecimal
format, with each character encoded as two hexadecimal digits.
The result is placed in to and a terminating
null byte is appended.
The string pointed to by from must be
length bytes long. You must allocate the
to buffer to be at least
length*2+1 bytes long. When
mysql_hex_string() returns, the contents of
to is a null-terminated string. The return
value is the length of the encoded string, not including the
terminating null character.
The return value can be placed into an SQL statement using
either 0x or
valueX' format.
However, the return value does not include the
value'0x or X'...'. The caller
must supply whichever of those is desired.
Example
char query[1000],*end;
end = strmov(query,"INSERT INTO test_table values(");
end = strmov(end,"0x");
end += mysql_hex_string(end,"What's this",11);
end = strmov(end,",0x");
end += mysql_hex_string(end,"binary data: \0\r\n",16);
*end++ = ')';
if (mysql_real_query(&mysql,query,(unsigned int) (end - query)))
{
fprintf(stderr, "Failed to insert row, Error: %s\n",
mysql_error(&mysql));
}
The strmov() function used in the example is
included in the mysqlclient library and works
like strcpy() but returns a pointer to the
terminating null of the first parameter.
Return Values
The length of the value placed into to, not
including the terminating null character.
Errors
None.
const char *mysql_info(MYSQL *mysql)
Description
Retrieves a string providing information about the most recently
executed statement, but only for the statements listed here. For
other statements, mysql_info() returns
NULL. The format of the string varies
depending on the type of statement, as described here. The
numbers are illustrative only; the string contains values
appropriate for the statement.
INSERT INTO ... SELECT ...String format:
Records: 100 Duplicates: 0 Warnings: 0INSERT INTO ... VALUES (...),(...),(...)...String format:
Records: 3 Duplicates: 0 Warnings: 0LOAD DATA INFILE ...String format:
Records: 1 Deleted: 0 Skipped: 0 Warnings: 0ALTER TABLEString format:
Records: 3 Duplicates: 0 Warnings: 0UPDATEString format:
Rows matched: 40 Changed: 40 Warnings: 0
Note that mysql_info() returns a
non-NULL value for INSERT ...
VALUES only for the multiple-row form of the statement
(that is, only if multiple value lists are specified).
Return Values
A character string representing additional information about the
most recently executed statement. NULL if no
information is available for the statement.
Errors
None.
MYSQL *mysql_init(MYSQL *mysql)
Description
Allocates or initializes a MYSQL object
suitable for mysql_real_connect(). If
mysql is a NULL pointer,
the function allocates, initializes, and returns a new object.
Otherwise, the object is initialized and the address of the
object is returned. If mysql_init() allocates
a new object, it is freed when mysql_close()
is called to close the connection.
Return Values
An initialized MYSQL* handle.
NULL if there was insufficient memory to
allocate a new object.
Errors
In case of insufficient memory, NULL is
returned.
my_ulonglong mysql_insert_id(MYSQL *mysql)
Description
Returns the value generated for an
AUTO_INCREMENT column by the previous
INSERT or UPDATE
statement. Use this function after you have performed an
INSERT statement into a table that contains
an AUTO_INCREMENT field.
More precisely, mysql_insert_id() is updated
under these conditions:
INSERTstatements that store a value into anAUTO_INCREMENTcolumn. This is true whether the value is automatically generated by storing the special valuesNULLor0into the column, or is an explicit non-special value.In the case of a multiple-row
INSERTstatement,mysql_insert_id()returns the first automatically generatedAUTO_INCREMENTvalue; if no such value is generated, it returns the last last explicit value inserted into theAUTO_INCREMENTcolumn.INSERTstatements that generate anAUTO_INCREMENTvalue by insertingLAST_INSERT_ID(into any column.expr)INSERTstatements that generate anAUTO_INCREMENTvalue by updating any column toLAST_INSERT_ID(.expr)The value of
mysql_insert_id()is not affected by statements such asSELECTthat return a result set.If the previous statement returned an error, the value of
mysql_insert_id()is undefined.
Note that mysql_insert_id() returns
0 if the previous statement does not use an
AUTO_INCREMENT value. If you need to save the
value for later, be sure to call
mysql_insert_id() immediately after the
statement that generates the value.
The value of mysql_insert_id() is affected
only by statements issued within the current client connection.
It is not affected by statements issued by other clients.
See Section 12.10.3, “Information Functions”.
Also note that the value of the SQL
LAST_INSERT_ID() function always contains the
most recently generated AUTO_INCREMENT value,
and is not reset between statements because the value of that
function is maintained in the server. Another difference is that
LAST_INSERT_ID() is not updated if you set an
AUTO_INCREMENT column to a specific
non-special value.
The reason for the difference between
LAST_INSERT_ID() and
mysql_insert_id() is that
LAST_INSERT_ID() is made easy to use in
scripts while mysql_insert_id() tries to
provide a little more exact information of what happens to the
AUTO_INCREMENT column.
Return Values
Described in the preceding discussion.
Errors
None.
int mysql_kill(MYSQL *mysql, unsigned long
pid)
Description
Asks the server to kill the thread specified by
pid.
Return Values
Zero for success. Non-zero if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
void mysql_library_end(void)
Description
This function finalizes the MySQL library. You should call it
when you are done using the library (for example, after
disconnecting from the server). The action taken by the call
depends on whether your application is linked to the MySQL
client library or the MySQL embedded server library. For a
client program linked against the
libmysqlclient library by using the
-lmysqlclient flag,
mysql_library_end() performs some memory
management to clean up. For an embedded server application
linked against the libmysqld library by using
the -lmysqld flag,
mysql_library_end() shuts down the embedded
server and then cleans up.
See Section 22.2.2, “C API Function Overview”, and
Section 22.2.3.40, “mysql_library_init()”, for usage information.
mysql_library_end() was added in MySQL 5.0.3.
For older versions of MySQL, call
mysql_server_end() instead.
int mysql_library_init(int argc, char **argv, char
**groups)
Description
This function should be called to initialize the MySQL library
before you call any other MySQL function. If your application
uses the embedded server, this call starts the server and
initializes any subsystems (mysys,
InnoDB, and so forth) that the server uses.
In a non-multi-threaded environment, the call to
mysql_library_init() may be omitted, because
mysql_init() will invoke it automatically as
necessary. However, mysql_library_init() is
not thread-safe in a multi-threaded environment, and thus
neither is mysql_init(), which calls
mysql_library_init(). You must either call
mysql_library_init() prior to spawning any
threads, or else use a mutex to protect the call, whether you
invoke mysql_library_init() or indirectly via
mysql_init(). This should be done prior to
any other client library call.
After your application is done using the MySQL library, call
mysql_library_end() to clean up. See
Section 22.2.3.39, “mysql_library_end()”.
The argc and argv
arguments are analogous to the arguments to
main(). The first element of
argv is ignored (it typically contains the
program name). For convenience, argc may be
0 (zero) if there are no command-line
arguments for the server.
mysql_library_init() makes a copy of the
arguments so it's safe to destroy argv or
groups after the call.
If you want to connect to an external server without starting
the embedded server, you have to specify a negative value for
argc.
The groups argument should be an array of
strings that indicate the groups in option files from which
options should be read. See Section 4.3.2, “Using Option Files”. The
final entry in the array should be NULL. For
convenience, if the groups argument itself is
NULL, the [server] and
[embedded] groups are used by default.
See Section 22.2.2, “C API Function Overview”, for additional usage information.
mysql_library_init() was added in MySQL
5.0.3. For older versions of MySQL, call
mysql_server_init() instead.
Example
#include <mysql.h>
#include <stdlib.h>
static char *server_args[] = {
"this_program", /* this string is not used */
"--datadir=.",
"--key_buffer_size=32M"
};
static char *server_groups[] = {
"embedded",
"server",
"this_program_SERVER",
(char *)NULL
};
int main(void) {
if (mysql_library_init(sizeof(server_args) / sizeof(char *),
server_args, server_groups)) {
fprintf(stderr, "could not initialize MySQL library\n");
exit(1);
}
/* Use any MySQL API functions here */
mysql_library_end();
return EXIT_SUCCESS;
}
Return Values
Zero if successful. Non-zero if an error occurred.
MYSQL_RES *mysql_list_dbs(MYSQL *mysql, const char
*wild)
Description
Returns a result set consisting of database names on the server
that match the simple regular expression specified by the
wild parameter. wild may
contain the wildcard characters
‘%’ or
‘_’, or may be a
NULL pointer to match all databases. Calling
mysql_list_dbs() is similar to executing the
query SHOW databases [LIKE wild].
You must free the result set with
mysql_free_result().
Return Values
A MYSQL_RES result set for success.
NULL if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_OUT_OF_MEMORYOut of memory.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
MYSQL_RES *mysql_list_fields(MYSQL *mysql, const char
*table, const char *wild)
Description
Returns a result set consisting of field names in the given
table that match the simple regular expression specified by the
wild parameter. wild may
contain the wildcard characters
‘%’ or
‘_’, or may be a
NULL pointer to match all fields. Calling
mysql_list_fields() is similar to executing
the query SHOW COLUMNS FROM
.
tbl_name [LIKE
wild]
Note that it's recommended that you use SHOW COLUMNS
FROM instead of
tbl_namemysql_list_fields().
You must free the result set with
mysql_free_result().
Return Values
A MYSQL_RES result set for success.
NULL if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
MYSQL_RES *mysql_list_processes(MYSQL *mysql)
Description
Returns a result set describing the current server threads. This
is the same kind of information as that reported by
mysqladmin processlist or a SHOW
PROCESSLIST query.
You must free the result set with
mysql_free_result().
Return Values
A MYSQL_RES result set for success.
NULL if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
MYSQL_RES *mysql_list_tables(MYSQL *mysql, const char
*wild)
Description
Returns a result set consisting of table names in the current
database that match the simple regular expression specified by
the wild parameter. wild
may contain the wildcard characters
‘%’ or
‘_’, or may be a
NULL pointer to match all tables. Calling
mysql_list_tables() is similar to executing
the query SHOW tables [LIKE
.
wild]
You must free the result set with
mysql_free_result().
Return Values
A MYSQL_RES result set for success.
NULL if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
my_bool mysql_more_results(MYSQL *mysql)
Description
This function is used when you execute multiple statements
specified as a single statement string, or when you execute
CALL statements, which can return multiple
result sets.
mysql_more_results() true if more results
exist from the currently executed statement, in which case the
application must call mysql_next_result() to
fetch the results.
Return Values
TRUE (1) if more results exist.
FALSE (0) if no more results exist.
In most cases, you can call
mysql_next_result() instead to test whether
more results exist and initiate retrieval if so.
See Section 22.2.9, “C API Handling of Multiple Statement Execution”, and
Section 22.2.3.46, “mysql_next_result()”.
Errors
None.
int mysql_next_result(MYSQL *mysql)
Description
This function is used when you execute multiple statements
specified as a single statement string, or when you execute
CALL statements, which can return multiple
result sets.
If more statement results exist,
mysql_next_result() reads the next statement
result and returns the status back to the application.
Before calling mysql_next_result(), you must
call mysql_free_result() for the preceding
statement if it is a query that returned a result set.
After calling mysql_next_result() the state
of the connection is as if you had called
mysql_real_query() or
mysql_query() for the next statement. This
means that you can call mysql_store_result(),
mysql_warning_count(),
mysql_affected_rows(), and so forth.
If mysql_next_result() returns an error, no
other statements are executed and there are no more results to
fetch.
If your program executes stored procedures with the
CALL SQL statement, you
must set the
CLIENT_MULTI_RESULTS flag explicitly, or
implicitly by setting CLIENT_MULTI_STATEMENTS
when you call mysql_real_connect(). This is
because each CALL returns a result to
indicate the call status, in addition to any results sets that
might be returned by statements executed within the procedure.
In addition, because CALL can return multiple
results, you should process those results using a loop that
calls mysql_next_result() to determine
whether there are more results.
For an example that shows how to use
mysql_next_result(), see
Section 22.2.9, “C API Handling of Multiple Statement Execution”.
Return Values
| Return Value | Description |
| 0 | Successful and there are more results |
| -1 | Successful and there are no more results |
| >0 | An error occurred |
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order. For example if you didn't call
mysql_use_result()for a previous result set.CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
unsigned int mysql_num_fields(MYSQL_RES
*result)
To pass a MYSQL* argument instead, use
unsigned int mysql_field_count(MYSQL *mysql).
Description
Returns the number of columns in a result set.
Note that you can get the number of columns either from a
pointer to a result set or to a connection handle. You would use
the connection handle if mysql_store_result()
or mysql_use_result() returned
NULL (and thus you have no result set
pointer). In this case, you can call
mysql_field_count() to determine whether
mysql_store_result() should have produced a
non-empty result. This allows the client program to take proper
action without knowing whether the query was a
SELECT (or SELECT-like)
statement. The example shown here illustrates how this may be
done.
Return Values
An unsigned integer representing the number of columns in a result set.
Errors
None.
Example
MYSQL_RES *result;
unsigned int num_fields;
unsigned int num_rows;
if (mysql_query(&mysql,query_string))
{
// error
}
else // query succeeded, process any data returned by it
{
result = mysql_store_result(&mysql);
if (result) // there are rows
{
num_fields = mysql_num_fields(result);
// retrieve rows, then call mysql_free_result(result)
}
else // mysql_store_result() returned nothing; should it have?
{
if (mysql_errno(&mysql))
{
fprintf(stderr, "Error: %s\n", mysql_error(&mysql));
}
else if (mysql_field_count(&mysql) == 0)
{
// query does not return data
// (it was not a SELECT)
num_rows = mysql_affected_rows(&mysql);
}
}
}
An alternative (if you know that your query should have returned
a result set) is to replace the
mysql_errno(&mysql) call with a check
whether mysql_field_count(&mysql) returns
0. This happens only if something went wrong.
my_ulonglong mysql_num_rows(MYSQL_RES
*result)
Description
Returns the number of rows in the result set.
The use of mysql_num_rows() depends on
whether you use mysql_store_result() or
mysql_use_result() to return the result set.
If you use mysql_store_result(),
mysql_num_rows() may be called immediately.
If you use mysql_use_result(),
mysql_num_rows() does not return the correct
value until all the rows in the result set have been retrieved.
mysql_num_rows() is intended for use with
statements that return a result set, such as
SELECT. For statements such as
INSERT, UPDATE, or
DELETE, the number of affected rows can be
obtained with mysql_affected_rows().
Return Values
The number of rows in the result set.
Errors
None.
int mysql_options(MYSQL *mysql, enum mysql_option
option, const char *arg)
Description
Can be used to set extra connect options and affect behavior for a connection. This function may be called multiple times to set several options.
mysql_options() should be called after
mysql_init() and before
mysql_connect() or
mysql_real_connect().
The option argument is the option that you
want to set; the arg argument is the value
for the option. If the option is an integer,
arg should point to the value of the integer.
The following list describes the possible options, their effect,
and how arg is used for each option. Several
of the options apply only when the application is linked against
the libmysqld embedded server library and are
unused for applications linked against the
libmysql client library. For option
descriptions that indicate arg is unused, its
value is irrelevant; it is conventional to pass 0.
MYSQL_INIT_COMMAND(argument type:char *)Statement to execute when connecting to the MySQL server. Automatically re-executed if reconnection occurs.
MYSQL_OPT_COMPRESS(argument: not used)Use the compressed client/server protocol.
MYSQL_OPT_CONNECT_TIMEOUT(argument type:unsigned int *)Connect timeout in seconds.
MYSQL_OPT_GUESS_CONNECTION(argument: not used)For an application linked against the
libmysqldembedded server library, this allows the library to guess whether to use the embedded server or a remote server. “Guess” means that if the hostname is set and is notlocalhost, it uses a remote server. This behavior is the default.MYSQL_OPT_USE_EMBEDDED_CONNECTIONandMYSQL_OPT_USE_REMOTE_CONNECTIONcan be used to override it. This option is ignored for applications linked against thelibmysqlclientclient library.MYSQL_OPT_LOCAL_INFILE(argument type: optional pointer tounsigned int)If no pointer is given or if pointer points to an
unsigned intthat has a non-zero value, theLOAD LOCAL INFILEstatement is enabled.MYSQL_OPT_NAMED_PIPE(argument: not used)Use named pipes to connect to a MySQL server on Windows, if the server allows named-pipe connections.
MYSQL_OPT_PROTOCOL(argument type:unsigned int *)Type of protocol to use. Should be one of the enum values of
mysql_protocol_typedefined inmysql.h.MYSQL_OPT_READ_TIMEOUT(argument type:unsigned int *)Timeout for reads from server (works only for TCP/IP connections, and only for Windows prior to MySQL 5.0.25). You can this option so that a lost connection can be detected earlier than the TCP/IP
Close_Wait_Timeoutvalue of 10 minutes.MYSQL_OPT_RECONNECT(argument type:my_bool *)Enable or disable automatic reconnection to the server if the connection is found to have been lost. Reconnect has been off by default since MySQL 5.0.3; this option is new in 5.0.13 and provides a way to set reconnection behavior explicitly.
MYSQL_OPT_SET_CLIENT_IP(argument type:char *)For an application linked against linked against the
libmysqldembedded server library (whenlibmysqldis compiled with authentication support), this means that the user is considered to have connected from the specified IP address (specified as a string) for authentication purposes. This option is ignored for applications linked against thelibmysqlclientclient library.MYSQL_OPT_SSL_VERIFY_SERVER_CERT(argument type:my_bool *)Enable or disable verification of the server's Common Name value in its certificate against the hostname used when connecting to the server. The connection is rejected if there is a mismatch. This feature can be used to prevent man-in-the-middle attacks. Verification is disabled by default. Added in MySQL 5.0.23.
MYSQL_OPT_USE_EMBEDDED_CONNECTION(argument: not used)For an application linked against the
libmysqldembedded server library, this forces the use of the embedded server for the connection. This option is ignored for applications linked against thelibmysqlclientclient library.MYSQL_OPT_USE_REMOTE_CONNECTION(argument: not used)For an application linked against the
libmysqldembedded server library, this forces the use of a remote server for the connection. This option is ignored for applications linked against thelibmysqlclientclient library.MYSQL_OPT_USE_RESULT(argument: not used)This option is unused.
MYSQL_OPT_WRITE_TIMEOUT(argument type:unsigned int *)Timeout for writes to server (works currently only on Windows on TCP/IP connections).
MYSQL_READ_DEFAULT_FILE(argument type:char *)Read options from the named option file instead of from
my.cnf.MYSQL_READ_DEFAULT_GROUP(argument type:char *)Read options from the named group from
my.cnfor the file specified withMYSQL_READ_DEFAULT_FILE.MYSQL_REPORT_DATA_TRUNCATION(argument type:my_bool *)Enable or disable reporting of data truncation errors for prepared statements via
MYSQL_BIND.error. (Default: enabled) Added in 5.0.3.MYSQL_SECURE_AUTH(argument type:my_bool *)Whether to connect to a server that does not support the password hashing used in MySQL 4.1.1 and later.
MYSQL_SET_CHARSET_DIR(argument type:char *)The pathname to the directory that contains character set definition files.
MYSQL_SET_CHARSET_NAME(argument type:char *)The name of the character set to use as the default character set.
MYSQL_SHARED_MEMORY_BASE_NAME(argument type:char *)The name of the shared-memory object for communication to the server on Windows, if the server supports shared-memory connection. Should have the same value as the
--shared-memory-base-nameoption used for the mysqld server you want to connect to.
Note that the client group is always read if
you use MYSQL_READ_DEFAULT_FILE or
MYSQL_READ_DEFAULT_GROUP.
The specified group in the option file may contain the following options:
| Option | Description |
connect-timeout | Connect timeout in seconds. On Linux this timeout is also used for waiting for the first answer from the server. |
compress | Use the compressed client/server protocol. |
database | Connect to this database if no database was specified in the connect command. |
debug | Debug options. |
disable-local-infile | Disable use of LOAD DATA LOCAL. |
host | Default hostname. |
init-command | Statement to execute when connecting to MySQL server. Automatically re-executed if reconnection occurs. |
interactive-timeout | Same as specifying CLIENT_INTERACTIVE to
mysql_real_connect(). See
Section 22.2.3.52, “mysql_real_connect()”. |
local-infile[=(0|1)] | If no argument or argument != 0 then enable use of LOAD DATA
LOCAL. |
max_allowed_packet | Max size of packet client can read from server. |
multi-results | Allow multiple result sets from multiple-statement executions or stored procedures. |
multi-statements | Allow the client to send multiple statements in a single string
(separated by ‘;’). |
password | Default password. |
pipe | Use named pipes to connect to a MySQL server on Windows. |
protocol={TCP|SOCKET|PIPE|MEMORY} | The protocol to use when connecting to the server. |
port | Default port number. |
return-found-rows | Tell mysql_info() to return found rows instead of
updated rows when using UPDATE. |
shared-memory-base-name= | Shared-memory name to use to connect to server (default is "MYSQL"). |
socket | Default socket file. |
user | Default user. |
Note that timeout has been replaced by
connect-timeout, but
timeout is still supported in MySQL
5.0 for backward compatibility.
For more information about option files, see Section 4.3.2, “Using Option Files”.
Return Values
Zero for success. Non-zero if you specify an unknown option.
Example
MYSQL mysql;
mysql_init(&mysql);
mysql_options(&mysql,MYSQL_OPT_COMPRESS,0);
mysql_options(&mysql,MYSQL_READ_DEFAULT_GROUP,"odbc");
if (!mysql_real_connect(&mysql,"host","user","passwd","database",0,NULL,0))
{
fprintf(stderr, "Failed to connect to database: Error: %s\n",
mysql_error(&mysql));
}
This code requests that the client use the compressed
client/server protocol and read the additional options from the
odbc section in the
my.cnf file.
int mysql_ping(MYSQL *mysql)
Description
Checks whether the connection to the server is working. If the connection has gone down, an attempt to reconnect is made unless auto-reconnect is disabled.
This function can be used by clients that remain idle for a long while, to check whether the server has closed the connection and reconnect if necessary.
Return Values
Zero if the connection to the server is alive. Non-zero if an error occurred. A non-zero return does not indicate whether the MySQL server itself is down; the connection might be broken for other reasons such as network problems.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_UNKNOWN_ERRORAn unknown error occurred.
int mysql_query(MYSQL *mysql, const char
*stmt_str)
Description
Executes the SQL statement pointed to by the null-terminated
string stmt_str. Normally, the string must
consist of a single SQL statement and you should not add a
terminating semicolon (‘;’) or
\g to the statement. If multiple-statement
execution has been enabled, the string can contain several
statements separated by semicolons. See
Section 22.2.9, “C API Handling of Multiple Statement Execution”.
mysql_query() cannot be used for statements
that contain binary data; you must use
mysql_real_query() instead. (Binary data may
contain the ‘\0’ character, which
mysql_query() interprets as the end of the
statement string.)
If you want to know whether the statement should return a result
set, you can use mysql_field_count() to check
for this. See Section 22.2.3.22, “mysql_field_count()”.
Return Values
Zero if the statement was successful. Non-zero if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
MYSQL *mysql_real_connect(MYSQL *mysql, const char
*host, const char *user, const char *passwd, const char *db,
unsigned int port, const char *unix_socket, unsigned long
client_flag)
Description
mysql_real_connect() attempts to establish a
connection to a MySQL database engine running on
host. mysql_real_connect()
must complete successfully before you can execute any other API
functions that require a valid MYSQL
connection handle structure.
The parameters are specified as follows:
The first parameter should be the address of an existing
MYSQLstructure. Before callingmysql_real_connect()you must callmysql_init()to initialize theMYSQLstructure. You can change a lot of connect options with themysql_options()call. See Section 22.2.3.49, “mysql_options()”.The value of
hostmay be either a hostname or an IP address. IfhostisNULLor the string"localhost", a connection to the local host is assumed. For Windows, the client connects using a shared-memory connection, if the server has shared-memory connections enabled. Otherwise, TCP/IP is used. For Unix, the client connects using a Unix socket file. For local connections, you can also influence the type of connection to use with theMYSQL_OPT_PROTOCOLorMYSQL_OPT_NAMED_PIPEoptions tomysql_options(). The type of connection must be supported by the server. For ahostvalue of"."on Windows, the client connects using a named pipe, if the server has named-pipe connections enabled. If named-pipe connections are not enabled, an error occurs.The
userparameter contains the user's MySQL login ID. IfuserisNULLor the empty string"", the current user is assumed. Under Unix, this is the current login name. Under Windows ODBC, the current username must be specified explicitly. See the MyODBC section of Chapter 23, Connectors.The
passwdparameter contains the password foruser. IfpasswdisNULL, only entries in theusertable for the user that have a blank (empty) password field are checked for a match. This allows the database administrator to set up the MySQL privilege system in such a way that users get different privileges depending on whether they have specified a password.Note: Do not attempt to encrypt the password before calling
mysql_real_connect(); password encryption is handled automatically by the client API.dbis the database name. Ifdbis notNULL, the connection sets the default database to this value.If
portis not 0, the value is used as the port number for the TCP/IP connection. Note that thehostparameter determines the type of the connection.If
unix_socketis notNULL, the string specifies the socket or named pipe that should be used. Note that thehostparameter determines the type of the connection.The value of
client_flagis usually 0, but can be set to a combination of the following flags to enable certain features:Flag Name Flag Description CLIENT_COMPRESSUse compression protocol. CLIENT_FOUND_ROWSReturn the number of found (matched) rows, not the number of changed rows. CLIENT_IGNORE_SPACEAllow spaces after function names. Makes all functions names reserved words. CLIENT_INTERACTIVEAllow interactive_timeoutseconds (instead ofwait_timeoutseconds) of inactivity before closing the connection. The client's sessionwait_timeoutvariable is set to the value of the sessioninteractive_timeoutvariable.CLIENT_LOCAL_FILESEnable LOAD DATA LOCALhandling.CLIENT_MULTI_RESULTSTell the server that the client can handle multiple result sets from multiple-statement executions or stored procedures. This is automatically set if CLIENT_MULTI_STATEMENTSis set. See the note following this table for more information about this flag.CLIENT_MULTI_STATEMENTSTell the server that the client may send multiple statements in a single string (separated by ‘ ;’). If this flag is not set, multiple-statement execution is disabled. See the note following this table for more information about this flag.CLIENT_NO_SCHEMADon't allow the db_name.tbl_name.col_namesyntax. This is for ODBC. It causes the parser to generate an error if you use that syntax, which is useful for trapping bugs in some ODBC programs.CLIENT_ODBCThe client is an ODBC client. This changes mysqld to be more ODBC-friendly. CLIENT_SSLUse SSL (encrypted protocol). This option should not be set by application programs; it is set internally in the client library. Instead, use mysql_ssl_set()before callingmysql_real_connect().
If your program uses the CALL SQL statement
to execute stored procedures that produce result sets, you
must set the
CLIENT_MULTI_RESULTS flag, either explicitly,
or implicitly by setting
CLIENT_MULTI_STATEMENTS when you call
mysql_real_connect(). This is because each
such stored procedure produces multiple results: the result sets
returned by statements executed within the procedure, as well as
a result to indicate the call status.
If you enable CLIENT_MULTI_STATEMENTS or
CLIENT_MULTI_RESULTS, you should process the
result for every call to mysql_query() or
mysql_real_query() by using a loop that calls
mysql_next_result() to determine whether
there are more results. For an example, see
Section 22.2.9, “C API Handling of Multiple Statement Execution”.
For some parameters, it is possible to have the value taken from
an option file rather than from an explicit value in the
mysql_real_connect() call. To do this, call
mysql_options() with the
MYSQL_READ_DEFAULT_FILE or
MYSQL_READ_DEFAULT_GROUP option before
calling mysql_real_connect(). Then, in the
mysql_real_connect() call, specify the
“no-value” value for each parameter to be read from
an option file:
For
host, specify a value ofNULLor the empty string ("").For
user, specify a value ofNULLor the empty string.For
passwd, specify a value ofNULL. (For the password, a value of the empty string in themysql_real_connect()call cannot be overridden in an option file, because the empty string indicates explicitly that the MySQL account must have an empty password.)For
db, specify a value ofNULLor the empty string.For
port, specify a value of 0.For
unix_socket, specify a value ofNULL.
If no value is found in an option file for a parameter, its default value is used as indicated in the descriptions given earlier in this section.
Return Values
A MYSQL* connection handle if the connection
was successful, NULL if the connection was
unsuccessful. For a successful connection, the return value is
the same as the value of the first parameter.
Errors
CR_CONN_HOST_ERRORFailed to connect to the MySQL server.
CR_CONNECTION_ERRORFailed to connect to the local MySQL server.
CR_IPSOCK_ERRORFailed to create an IP socket.
CR_OUT_OF_MEMORYOut of memory.
CR_SOCKET_CREATE_ERRORFailed to create a Unix socket.
CR_UNKNOWN_HOSTFailed to find the IP address for the hostname.
CR_VERSION_ERRORA protocol mismatch resulted from attempting to connect to a server with a client library that uses a different protocol version. This can happen if you use a very old client library to connect to a new server that wasn't started with the
--old-protocoloption.CR_NAMEDPIPEOPEN_ERRORFailed to create a named pipe on Windows.
CR_NAMEDPIPEWAIT_ERRORFailed to wait for a named pipe on Windows.
CR_NAMEDPIPESETSTATE_ERRORFailed to get a pipe handler on Windows.
CR_SERVER_LOSTIf
connect_timeout> 0 and it took longer thanconnect_timeoutseconds to connect to the server or if the server died while executing theinit-command.
Example
MYSQL mysql;
mysql_init(&mysql);
mysql_options(&mysql,MYSQL_READ_DEFAULT_GROUP,"your_prog_name");
if (!mysql_real_connect(&mysql,"host","user","passwd","database",0,NULL,0))
{
fprintf(stderr, "Failed to connect to database: Error: %s\n",
mysql_error(&mysql));
}
By using mysql_options() the MySQL library
reads the [client] and
[your_prog_name] sections in the
my.cnf file which ensures that your program
works, even if someone has set up MySQL in some non-standard
way.
Note that upon connection,
mysql_real_connect() sets the
reconnect flag (part of the
MYSQL structure) to a value of
1 in versions of the API older than 5.0.3, or
0 in newer versions. A value of
1 for this flag indicates that if a statement
cannot be performed because of a lost connection, to try
reconnecting to the server before giving up. As of MySQL 5.0.13,
you can use the MYSQL_OPT_RECONNECT option to
mysql_options() to control reconnection
behavior.
unsigned long mysql_real_escape_string(MYSQL *mysql,
char *to, const char *from, unsigned long length)
Note that mysql must be a valid, open
connection. This is needed because the escaping depends on the
character set in use by the server.
Description
This function is used to create a legal SQL string that you can use in an SQL statement. See Section 9.1.1, “Strings”.
The string in from is encoded to an escaped
SQL string, taking into account the current character set of the
connection. The result is placed in to and a
terminating null byte is appended. Characters encoded are
NUL (ASCII 0),
‘\n’,
‘\r’,
‘\’,
‘'’,
‘"’, and Control-Z (see
Section 9.1, “Literal Values”). (Strictly speaking, MySQL requires
only that backslash and the quote character used to quote the
string in the query be escaped. This function quotes the other
characters to make them easier to read in log files.)
The string pointed to by from must be
length bytes long. You must allocate the
to buffer to be at least
length*2+1 bytes long. (In the worst case,
each character may need to be encoded as using two bytes, and
you need room for the terminating null byte.) When
mysql_real_escape_string() returns, the
contents of to is a null-terminated string.
The return value is the length of the encoded string, not
including the terminating null character.
If you need to change the character set of the connection, you
should use the mysql_set_character_set()
function rather than executing a SET NAMES
(or SET CHARACTER SET) statement.
mysql_set_character_set() works like
SET NAMES but also affects the character set
used by mysql_real_escape_string(), which
SET NAMES does not.
Example
char query[1000],*end;
end = strmov(query,"INSERT INTO test_table values(");
*end++ = '\'';
end += mysql_real_escape_string(&mysql, end,"What's this",11);
*end++ = '\'';
*end++ = ',';
*end++ = '\'';
end += mysql_real_escape_string(&mysql, end,"binary data: \0\r\n",16);
*end++ = '\'';
*end++ = ')';
if (mysql_real_query(&mysql,query,(unsigned int) (end - query)))
{
fprintf(stderr, "Failed to insert row, Error: %s\n",
mysql_error(&mysql));
}
The strmov() function used in the example is
included in the mysqlclient library and works
like strcpy() but returns a pointer to the
terminating null of the first parameter.
Return Values
The length of the value placed into to, not
including the terminating null character.
Errors
None.
int mysql_real_query(MYSQL *mysql, const char
*stmt_str, unsigned long length)
Description
Executes the SQL statement pointed to by
stmt_str, which should be a string
length bytes long. Normally, the string must
consist of a single SQL statement and you should not add a
terminating semicolon (‘;’) or
\g to the statement. If multiple-statement
execution has been enabled, the string can contain several
statements separated by semicolons. See
Section 22.2.9, “C API Handling of Multiple Statement Execution”.
mysql_query() cannot be used for statements
that contain binary data; you must use
mysql_real_query() instead. (Binary data may
contain the ‘\0’ character, which
mysql_query() interprets as the end of the
statement string.) In addition,
mysql_real_query() is faster than
mysql_query() because it does not call
strlen() on the statement string.
If you want to know whether the statement should return a result
set, you can use mysql_field_count() to check
for this. See Section 22.2.3.22, “mysql_field_count()”.
Return Values
Zero if the statement was successful. Non-zero if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
int mysql_refresh(MYSQL *mysql, unsigned int
options)
Description
This functions flushes tables or caches, or resets replication
server information. The connected user must have the
RELOAD privilege.
The options argument is a bit mask composed
from any combination of the following values. Multiple values
can be OR'ed together to perform multiple operations with a
single call.
REFRESH_GRANTRefresh the grant tables, like
FLUSH PRIVILEGES.REFRESH_LOGFlush the logs, like
FLUSH LOGS.REFRESH_TABLESFlush the table cache, like
FLUSH TABLES.REFRESH_HOSTSFlush the host cache, like
FLUSH HOSTS.REFRESH_STATUSReset status variables, like
FLUSH STATUS.REFRESH_THREADSFlush the thread cache.
REFRESH_SLAVEOn a slave replication server, reset the master server information and restart the slave, like
RESET SLAVE.REFRESH_MASTEROn a master replication server, remove the binary log files listed in the binary log index and truncate the index file, like
RESET MASTER.
Return Values
Zero for success. Non-zero if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
int mysql_reload(MYSQL *mysql)
Description
Asks the MySQL server to reload the grant tables. The connected
user must have the RELOAD privilege.
This function is deprecated. It is preferable to use
mysql_query() to issue an SQL FLUSH
PRIVILEGES statement instead.
Return Values
Zero for success. Non-zero if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
my_bool mysql_rollback(MYSQL *mysql)
Description
Rolls back the current transaction.
As of MySQL 5.0.3, the action of this function is subject to the
value of the completion_type system variable.
In particular, if the value of
completion_type is 2, the server performs a
release after terminating a transaction and closes the client
connection. The client program should call
mysql_close() to close the connection from
the client side.
Return Values
Zero if successful. Non-zero if an error occurred.
Errors
None.
MYSQL_ROW_OFFSET mysql_row_seek(MYSQL_RES *result,
MYSQL_ROW_OFFSET offset)
Description
Sets the row cursor to an arbitrary row in a query result set.
The offset value is a row offset that should
be a value returned from mysql_row_tell() or
from mysql_row_seek(). This value is not a
row number; if you want to seek to a row within a result set by
number, use mysql_data_seek() instead.
This function requires that the result set structure contains
the entire result of the query, so
mysql_row_seek() may be used only in
conjunction with mysql_store_result(), not
with mysql_use_result().
Return Values
The previous value of the row cursor. This value may be passed
to a subsequent call to mysql_row_seek().
Errors
None.
MYSQL_ROW_OFFSET mysql_row_tell(MYSQL_RES
*result)
Description
Returns the current position of the row cursor for the last
mysql_fetch_row(). This value can be used as
an argument to mysql_row_seek().
You should use mysql_row_tell() only after
mysql_store_result(), not after
mysql_use_result().
Return Values
The current offset of the row cursor.
Errors
None.
int mysql_select_db(MYSQL *mysql, const char
*db)
Description
Causes the database specified by db to become
the default (current) database on the connection specified by
mysql. In subsequent queries, this database
is the default for table references that do not include an
explicit database specifier.
mysql_select_db() fails unless the connected
user can be authenticated as having permission to use the
database.
Return Values
Zero for success. Non-zero if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
int mysql_set_character_set(MYSQL *mysql, char
*csname)
Description
This function is used to set the default character set for the
current connection. The string csname
specifies a valid character set name. The connection collation
becomes the default collation of the character set. This
function works like the SET NAMES statement,
but also sets the value of mysql->charset,
and thus affects the character set used by
mysql_real_escape_string()
This function was added in MySQL 5.0.7.
Return Values
Zero for success. Non-zero if an error occurred.
Example
MYSQL mysql;
mysql_init(&mysql);
if (!mysql_real_connect(&mysql,"host","user","passwd","database",0,NULL,0))
{
fprintf(stderr, "Failed to connect to database: Error: %s\n",
mysql_error(&mysql));
}
if (!mysql_set_character_set(&mysql, "utf8"))
{
printf("New client character set: %s\n",
mysql_character_set_name(&mysql));
}
void mysql_set_local_infile_default(MYSQL *mysql);
Description
Sets the LOAD LOCAL DATA INFILE handler
callback functions to the defaults used internally by the C
client library. The library calls this function automatically if
mysql_set_local_infile_handler() has not been
called or does not supply valid functions for each of its
callbacks.
The mysql_set_local_infile_default() function
was added in MySQL 4.1.2.
Return Values
None.
Errors
None.
void
mysql_set_local_infile_handler(MYSQL *mysql,
int (*local_infile_init)(void **, const char *, void *),
int (*local_infile_read)(void *, char *, unsigned int),
void (*local_infile_end)(void *),
int (*local_infile_error)(void *, char*, unsigned int),
void *userdata);
Description
This function installs callbacks to be used during the execution
of LOAD DATA LOCAL INFILE statements. It
enables application programs to exert control over local
(client-side) data file reading. The arguments are the
connection handler, a set of pointers to callback functions, and
a pointer to a data area that the callbacks can use to share
information.
To use mysql_set_local_infile_handler(), you
must write the following callback functions:
int local_infile_init(void **ptr, const char *filename, void *userdata);
The initialization function. This is called once to do any setup
necessary, open the data file, allocate data structures, and so
forth. The first void** argument is a pointer
to a pointer. You can set the pointer (that is,
*ptr) to a value that will be passed to each
of the other callbacks (as a void*). The
callbacks can use this pointed-to value to maintain state
information. The userdata argument is the
same value that is passed to
mysql_set_local_infile_handler().
The initialization function should return zero for success, non-zero for an error.
int local_infile_read(void *ptr, char *buf, unsigned int buf_len);
The data-reading function. This is called repeatedly to read the
data file. buf points to the buffer where the
read data should be stored, and buf_len is
the maximum number of bytes that the callback can read and store
in the buffer. (It can read fewer bytes, but should not read
more.)
The return value is the number of bytes read, or zero when no more data could be read (this indicates EOF). Return a value less than zero if an error occurs.
void local_infile_end(void *ptr)
The termination function. This is called once after
local_infile_read() has returned zero (EOF)
or an error. This function should deallocate any memory
allocated by local_infile_init() and perform
any other cleanup necessary. It is invoked even if the
initalization function returns an error.
int
local_infile_error(void *ptr,
char *error_msg,
unsigned int error_msg_len);
The error-handling function. This is called to get a textual
error message to return to the user in case any of your other
functions returns an error. error_msg points
to the buffer into which the message should be written, and
error_msg_len is the length of the buffer.
The message should be written as a null-terminated string, so
the message can be at most
error_msg_len–1 bytes long.
The return value is the error number.
Typically, the other callbacks store the error message in the
data structure pointed to by ptr, so that
local_infile_error() can copy the message
from there into error_msg.
After calling
mysql_set_local_infile_handler() in your C
code and passing pointers to your callback functions, you can
then issue a LOAD DATA LOCAL INFILE statement
(for example, by using mysql_query()). The
client library automatically invokes your callbacks. The
filename specified in LOAD DATA LOCAL INFILE
will be passed as the second parameter to the
local_infile_init() callback.
The mysql_set_local_infile_handler() function
was added in MySQL 4.1.2.
Return Values
None.
Errors
None.
int mysql_set_server_option(MYSQL *mysql, enum
enum_mysql_set_option option)
Description
Enables or disables an option for the connection.
option can have one of the following values:
| MYSQL_OPTION_MULTI_STATEMENTS_ON | Enable multiple-statement support. |
| MYSQL_OPTION_MULTI_STATEMENTS_OFF | Disable multiple-statement support. |
If you enable multiple-statement support, you should retrieve
results from calls to mysql_query() or
mysql_real_query() by using a loop that calls
mysql_next_result() to determine whether
there are more results. For an example, see
Section 22.2.9, “C API Handling of Multiple Statement Execution”.
Enabling multiple-statement support with
MYSQL_OPTION_MULTI_STATEMENTS_ON does not
have quite the same effect as enabling it by passing the
CLIENT_MULTI_STATEMENTS flag to
mysql_real_connect():
CLIENT_MULTI_STATEMENTS also enables
CLIENT_MULTI_RESULTS. If you are using the
CALL SQL statement in your programs,
multiple-result support must be enabled; this means that
MYSQL_OPTION_MULTI_STATEMENTS_ON by itself is
insufficient to allow the use of CALL.
Return Values
Zero for success. Non-zero if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
ER_UNKNOWN_COM_ERRORThe server didn't support
mysql_set_server_option()(which is the case that the server is older than 4.1.1) or the server didn't support the option one tried to set.
int mysql_shutdown(MYSQL *mysql, enum
mysql_enum_shutdown_level shutdown_level)
Description
Asks the database server to shut down. The connected user must
have SHUTDOWN privileges. The
shutdown_level argument was added in MySQL
5.0.1. MySQL 5.0 servers support only one type of
shutdown; shutdown_level must be equal to
SHUTDOWN_DEFAULT. Additional shutdown levels
are planned to make it possible to choose the desired level.
Dynamically linked executables which have been compiled with
older versions of the libmysqlclient headers
and call mysql_shutdown() need to be used
with the old libmysqlclient dynamic library.
The shutdown process is described in Section 5.2.7, “The Shutdown Process”.
Return Values
Zero for success. Non-zero if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
const char *mysql_sqlstate(MYSQL *mysql)
Description
Returns a null-terminated string containing the SQLSTATE error
code for the most recently executed SQL statement. The error
code consists of five characters. '00000'
means “no error.” The values are specified by ANSI
SQL and ODBC. For a list of possible values, see
Appendix B, Errors, Error Codes, and Common Problems.
SQLSTATE values returned by mysql_sqlstate()
differ from MySQL-specific error numbers returned by
mysql_errno(). For example, the
mysql client program displays errors using
the following format, where 1146 is the
mysql_errno() value and
'42S02' is the corresponding
mysql_sqlstate() value:
shell> SELECT * FROM no_such_table;
ERROR 1146 (42S02): Table 'test.no_such_table' doesn't exist
Not all MySQL error numbers are mapped to SQLSTATE error codes.
The value 'HY000' (general error) is used for
unmapped error numbers.
If you call mysql_sqlstate() after
mysql_real_connect() fails,
mysql_sqlstate() might not return a useful
value. For example, this happens if a host is blocked by the
server and the connection is closed without any SQLSTATE value
being sent to the client.
Return Values
A null-terminated character string containing the SQLSTATE error code.
See Also
See Section 22.2.3.14, “mysql_errno()”,
Section 22.2.3.15, “mysql_error()”, and
Section 22.2.7.26, “mysql_stmt_sqlstate()”.
int mysql_ssl_set(MYSQL *mysql, const char *key, const
char *cert, const char *ca, const char *capath, const char
*cipher)
Description
mysql_ssl_set() is used for establishing
secure connections using SSL. It must be called before
mysql_real_connect().
mysql_ssl_set() does nothing unless OpenSSL
support is enabled in the client library.
mysql is the connection handler returned from
mysql_init(). The other parameters are
specified as follows:
keyis the pathname to the key file.certis the pathname to the certificate file.cais the pathname to the certificate authority file.capathis the pathname to a directory that contains trusted SSL CA certificates in pem format.cipheris a list of allowable ciphers to use for SSL encryption.
Any unused SSL parameters may be given as
NULL.
Return Values
This function always returns 0. If SSL setup
is incorrect, mysql_real_connect() returns an
error when you attempt to connect.
const char *mysql_stat(MYSQL *mysql)
Description
Returns a character string containing information similar to that provided by the mysqladmin status command. This includes uptime in seconds and the number of running threads, questions, reloads, and open tables.
Return Values
A character string describing the server status.
NULL if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
MYSQL_RES *mysql_store_result(MYSQL *mysql)
Description
After invoking mysql_query() or
mysql_real_query(), you must call
mysql_store_result() or
mysql_use_result() for every statement that
successfully retrieves data (SELECT,
SHOW, DESCRIBE,
EXPLAIN, CHECK TABLE, and
so forth). You must also call
mysql_free_result() after you are done with
the result set.
You don't have to call mysql_store_result()
or mysql_use_result() for other statements,
but it does not do any harm or cause any notable performance
degradation if you call mysql_store_result()
in all cases. You can detect whether the statement has a result
set by checking whether mysql_store_result()
returns a non-zero value (more about this later on).
If you enable multiple-statement support, you should retrieve
results from calls to mysql_query() or
mysql_real_query() by using a loop that calls
mysql_next_result() to determine whether
there are more results. For an example, see
Section 22.2.9, “C API Handling of Multiple Statement Execution”.
If you want to know whether a statement should return a result
set, you can use mysql_field_count() to check
for this. See Section 22.2.3.22, “mysql_field_count()”.
mysql_store_result() reads the entire result
of a query to the client, allocates a
MYSQL_RES structure, and places the result
into this structure.
mysql_store_result() returns a null pointer
if the statement didn't return a result set (for example, if it
was an INSERT statement).
mysql_store_result() also returns a null
pointer if reading of the result set failed. You can check
whether an error occurred by checking whether
mysql_error() returns a non-empty string,
mysql_errno() returns non-zero, or
mysql_field_count() returns zero.
An empty result set is returned if there are no rows returned. (An empty result set differs from a null pointer as a return value.)
After you have called mysql_store_result()
and gotten back a result that isn't a null pointer, you can call
mysql_num_rows() to find out how many rows
are in the result set.
You can call mysql_fetch_row() to fetch rows
from the result set, or mysql_row_seek() and
mysql_row_tell() to obtain or set the current
row position within the result set.
Return Values
A MYSQL_RES result structure with the
results. NULL (0) if an error occurred.
Errors
mysql_store_result() resets
mysql_error() and
mysql_errno() if it succeeds.
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_OUT_OF_MEMORYOut of memory.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
unsigned long mysql_thread_id(MYSQL *mysql)
Description
Returns the thread ID of the current connection. This value can
be used as an argument to mysql_kill() to
kill the thread.
If the connection is lost and you reconnect with
mysql_ping(), the thread ID changes. This
means you should not get the thread ID and store it for later.
You should get it when you need it.
Return Values
The thread ID of the current connection.
Errors
None.
MYSQL_RES *mysql_use_result(MYSQL *mysql)
Description
You must call mysql_store_result() or
mysql_use_result() for every query that
successfully retrieves data (SELECT,
SHOW, DESCRIBE,
EXPLAIN).
mysql_use_result() initiates a result set
retrieval but does not actually read the result set into the
client like mysql_store_result() does.
Instead, each row must be retrieved individually by making calls
to mysql_fetch_row(). This reads the result
of a query directly from the server without storing it in a
temporary table or local buffer, which is somewhat faster and
uses much less memory than
mysql_store_result(). The client allocates
memory only for the current row and a communication buffer that
may grow up to max_allowed_packet bytes.
On the other hand, you shouldn't use
mysql_use_result() if you are doing a lot of
processing for each row on the client side, or if the output is
sent to a screen on which the user may type a
^S (stop scroll). This ties up the server and
prevent other threads from updating any tables from which the
data is being fetched.
When using mysql_use_result(), you must
execute mysql_fetch_row() until a
NULL value is returned, otherwise, the
unfetched rows are returned as part of the result set for your
next query. The C API gives the error Commands out of
sync; you can't run this command now if you forget to
do this!
You may not use mysql_data_seek(),
mysql_row_seek(),
mysql_row_tell(),
mysql_num_rows(), or
mysql_affected_rows() with a result returned
from mysql_use_result(), nor may you issue
other queries until mysql_use_result() has
finished. (However, after you have fetched all the rows,
mysql_num_rows() accurately returns the
number of rows fetched.)
You must call mysql_free_result() once you
are done with the result set.
When using the libmysqld embedded server, the
memory benefits are essentially lost because memory usage
incrementally increases with each row retrieved until
mysql_free_result() is called.
Return Values
A MYSQL_RES result structure.
NULL if an error occurred.
Errors
mysql_use_result() resets
mysql_error() and
mysql_errno() if it succeeds.
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_OUT_OF_MEMORYOut of memory.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
The MySQL client/server protocol provides for the use of prepared
statements. This capability uses the MYSQL_STMT
statement handler data structure returned by the
mysql_stmt_init() initialization function.
Prepared execution is an efficient way to execute a statement more
than once. The statement is first parsed to prepare it for
execution. Then it is executed one or more times at a later time,
using the statement handle returned by the initialization
function.
Prepared execution is faster than direct execution for statements executed more than once, primarily because the query is parsed only once. In the case of direct execution, the query is parsed every time it is executed. Prepared execution also can provide a reduction of network traffic because for each execution of the prepared statement, it is necessary only to send the data for the parameters.
Prepared statements might not provide a performance increase in some situations. For best results, test your application both with prepared and non-prepared statements and choose whichever yields best performance.
Another advantage of prepared statements is that it uses a binary protocol that makes data transfer between client and server more efficient.
The following statements can be used as prepared statements:
CREATE TABLE, DELETE,
DO, INSERT,
REPLACE, SELECT,
SET, UPDATE, and most
SHOW statements. Other statements are not
supported in MySQL 5.0.
Prepared statements use several data structures:
To prepare a statement, pass the statement string to
mysql_stmt_init(), which returns a pointer to aMYSQL_STMTdata structure.To provide input parameters for a prepared statement, set up
MYSQL_BINDstructures and pass them tomysql_stmt_bind_param(). To receive output column values, set upMYSQL_BINDstructures and pass them tomysql_stmt_bind_result().The
MYSQL_TIMEstructure is used to transfer temporal data in both directions.
The following discussion describes the prepared statement data types in detail.
This structure represents a prepared statement. A statement is created by calling
mysql_stmt_init(), which returns a statement handle (that is, a pointer to aMYSQL_STMT). The handle is used for all subsequent operations with the statement until you close it withmysql_stmt_close(), at which point the handle becomes invalid.The
MYSQL_STMTstructure has no members that are intended for application use. Also, you should not try to make a copy of aMYSQL_STMTstructure. There is no guarantee that such a copy will be usable.Multiple statement handles can be associated with a single connection. The limit on the number of handles depends on the available system resources.
This structure is used both for statement input (data values sent to the server) and output (result values returned from the server):
For input,
MYSQL_BINDis used withmysql_stmt_bind_param()to bind parameter data values to buffers for use bymysql_stmt_execute().For output,
MYSQL_BINDis used withmysql_stmt_bind_result()to bind result set buffers for use in fetching rows withmysql_stmt_fetch().
To use a
MYSQL_BINDstructure, you should zero its contents to initialize it, and then set its members appropriately. For example, to declare and initialize an array of threeMYSQL_BINDstructures, use this code:MYSQL_BIND bind[3]; memset(bind, 0, sizeof(bind));
The
MYSQL_BINDstructure contains the following members for use by application programs. For several of the members, the manner of use depends on whether the structure is used for input or output.enum enum_field_types buffer_typeThe type of the buffer. This member indicates the data type of the C language variable that you are binding to the statement parameter. The allowable
buffer_typevalues are listed later in this section. For input,buffer_typeindicates the type of the variable containing the value that you will send to the server. For output, it indicates the type of the variable into which you want a value received from the server to be stored.void *bufferA pointer to the buffer to be used for data transfer. This is the address of a variable.
For input,
bufferis a pointer to the variable in which a statement parameter's data value is stored. When you callmysql_stmt_execute(), MySQL takes the value that you have stored in the variable and uses it in place of the corresponding parameter marker in the statement.For output,
bufferis a pointer to the variable in which to return a result set column value. When you callmysql_stmt_fetch(), MySQL returns a column value and stores it in this variable. You can access the value when the call returns.To minimize the need for MySQL to perform type conversions between C language values on the client side and SQL values on the server side, use variables that have types similar to those of the corresponding SQL values. For numeric data types,
buffershould point to a variable of the proper numeric C type. (Forcharor integer variables, you should also indicate whether the variable has theunsignedattribute by setting theis_unsignedmember, described later in this list.) For character (non-binary) and binary string data types,buffershould point to a character buffer. For date and time data types,buffershould point to aMYSQL_TIMEstructure.See the notes about type conversions later in the section.
unsigned long buffer_lengthThe actual size of
*bufferin bytes. This indicates the maximum amount of data that can be stored in the buffer. For character and binary C data, thebuffer_lengthvalue specifies the length of*bufferwhen used withmysql_stmt_bind_param()to specify input values, or the maximum number of output data bytes that can be fetched into the buffer when used withmysql_stmt_bind_result().unsigned long *lengthA pointer to an
unsigned longvariable that indicates the actual number of bytes of data stored in*buffer.lengthis used for character or binary C data.For input parameter data binding,
lengthpoints to anunsigned longvariable that indicates the actual length of the parameter value stored in*buffer; this is used bymysql_stmt_execute().For output value binding, the return value of
mysql_stmt_fetch()determines the interpretation of the length:If
mysql_stmt_fetch()returns 0,*lengthindicates the actual length of the parameter value.If
mysql_stmt_fetch()returnsMYSQL_DATA_TRUNCATED,*lengthindicates the non-truncated length of the parameter value. In this case, the minimum of*lengthandbuffer_lengthindicates the actual length of the value.
lengthis ignored for numeric and temporal data types because the length of the data value is determined by thebuffer_typevalue.my_bool *is_nullThis member points to a
my_boolvariable that is true if a value isNULL, false if it is notNULL. For input, set*is_nullto true to indicate that you are passing aNULLvalue as a statement parameter.The reason that
is_nullis not a boolean scalar but is instead a pointer to a boolean scalar is to provide flexibility in how you specifyNULLvalues:If your data values are always
NULL, useMYSQL_TYPE_NULLas thebuffer_typevalue when you bind the column. The other members do not matter.If your data values are always
NOT NULL, set the other members appropriately for the variable you are binding, and setis_null = (my_bool*) 0.In all other cases, set the other members appriopriately, and set
is_nullto the address of amy_boolvariable. Set that variable's value to true or false appropriately between executions to indicate whether data values areNULLorNOT NULL, respectively.
For output, the value pointed to by
is_nullis set to true after you fetch a row if the result set column value returned from the statement isNULL.my_bool is_unsignedThis member is used for C variables with data types that can be
unsigned(char,short int,int,long long int). Setis_unsignedto true if the variable pointed to bybufferisunsignedand false otherwise. For example, if you bind asigned charvariable tobuffer, specify a type code ofMYSQL_TYPE_TINYand setis_unsignedto false. If you bind anunsigned charinstead, the type code is the same butis_unsignedshould be true. (Forchar, it is not defined whether it is signed or unsigned, so it is best to be explicit about signedness by usingsigned charorunsigned char.)is_unsignedapplies only to the C language variable on the client side. It indicates nothing about the signedness of the corresponding SQL value on the server side. For example, if you use anintvariable to supply a value for aBIGINT UNSIGNEDcolumn,is_unsignedshould be false becauseintis a signed type. If you use anunsigned intvariable to supply a value for aBIGINTcolumn,is_unsignedshould be true becauseunsigned intis an unsigned type. MySQL performs the proper conversion between signed and unsigned values in both directions, although a warning occurs if truncation results.my_bool *errorFor output, set this member to point to a
my_boolvariable to have truncation information for the parameter stored there after a row fetching operation. (Truncation reporting is enabled by default, but can be controlled by callingmysql_options()with theMYSQL_REPORT_DATA_TRUNCATIONoption.) When truncation reporting is enabled,mysql_stmt_fetch()returnsMYSQL_DATA_TRUNCATEDand*erroris true in theMYSQL_BINDstructures for parameters in which truncation occurred. Truncation indicates loss of sign or significant digits, or that a string was too long to fit in a column. Theerrormember was added in MySQL 5.0.3.
This structure is used to send and receive
DATE,TIME,DATETIME, andTIMESTAMPdata directly to and from the server. Set thebuffer_typemember of aMYSQL_BINDstructure to one of the temporal types (MYSQL_TYPE_TIME,MYSQL_TYPE_DATE,MYSQL_TYPE_DATETIME,MYSQL_TYPE_TIMESTAMP), and set thebuffermember to point to aMYSQL_TIMEstructure.The
MYSQL_TIMEstructure contains the members listed in the following table.Member Description unsigned int yearThe year unsigned int monthThe month of the year unsigned int dayThe day of the month unsigned int hourThe hour of the day unsigned int minuteThe minute of the hour unsigned int secondThe second of the minute my_bool negA boolean flag to indicate whether the time is negative unsigned long second_partThe fractional part of the second in microseconds; currently unused Only those parts of a
MYSQL_TIMEstructure that apply to a given type of temporal value are used. Theyear,month, anddayelements are used forDATE,DATETIME, andTIMESTAMPvalues. Thehour,minute, andsecondelements are used forTIME,DATETIME, andTIMESTAMPvalues. See Section 22.2.10, “C API Handling of Date and Time Values”.
The following table shows the allowable values that may be
specified in the buffer_type member of
MYSQL_BIND structures for input values. The
value should be chosen according to the data type of the C
language variable that you are binding. If the variable is
unsigned, you should also set the
is_unsigned member to true. The table shows the
C variable types that you can use, the corresponding type codes,
and the SQL data types for which the supplied value can be used
without conversion.
| Input Variable C Type | buffer_type Value | SQL Type of Destination Value |
signed char | MYSQL_TYPE_TINY | TINYINT |
short int | MYSQL_TYPE_SHORT | SMALLINT |
int | MYSQL_TYPE_LONG | INT |
long long int | MYSQL_TYPE_LONGLONG | BIGINT |
float | MYSQL_TYPE_FLOAT | FLOAT |
double | MYSQL_TYPE_DOUBLE | DOUBLE |
MYSQL_TIME | MYSQL_TYPE_TIME | TIME |
MYSQL_TIME | MYSQL_TYPE_DATE | DATE |
MYSQL_TIME | MYSQL_TYPE_DATETIME | DATETIME |
MYSQL_TIME | MYSQL_TYPE_TIMESTAMP | TIMESTAMP |
char[] | MYSQL_TYPE_STRING (for non-binary data) | TEXT, CHAR, VARCHAR |
char[] | MYSQL_TYPE_BLOB (for binary data) | BLOB, BINARY, VARBINARY |
MYSQL_TYPE_NULL | NULL |
The use of MYSQL_TYPE_NULL is described earlier
in connection with the is_null member.
The following table shows the allowable values that may be
specified in the buffer_type member of
MYSQL_BIND structures for output values. The
value should be chosen according to the data type of the C
language variable that you are binding. If the variable is
unsigned, you should also set the
is_unsigned member to true. The table shows the
SQL types of received values, the corresponding type code that
such values have in result set metadata, and the recommended C
language data types to bind to the MYSQL_BIND
structure to receive the SQL values without conversion.
| SQL Type of Received Value | buffer_type Value | Output Variable C Type |
TINYINT | MYSQL_TYPE_TINY | signed char |
SMALLINT | MYSQL_TYPE_SHORT | short int |
MEDIUMINT | MYSQL_TYPE_INT24 | int |
INT | MYSQL_TYPE_LONG | int |
BIGINT | MYSQL_TYPE_LONGLONG | long long int |
FLOAT | MYSQL_TYPE_FLOAT | float |
DOUBLE | MYSQL_TYPE_DOUBLE | double |
DECIMAL | MYSQL_TYPE_NEWDECIMAL | char[] |
YEAR | MYSQL_TYPE_SHORT | short int |
TIME | MYSQL_TYPE_TIME | MYSQL_TIME |
DATE | MYSQL_TYPE_DATE | MYSQL_TIME |
DATETIME | MYSQL_TYPE_DATETIME | MYSQL_TIME |
TIMESTAMP | MYSQL_TYPE_TIMESTAMP | MYSQL_TIME |
CHAR, BINARY | MYSQL_TYPE_STRING | char[] |
VARCHAR, VARBINARY | MYSQL_TYPE_VAR_STRING | char[] |
TINYBLOB, TINYTEXT | MYSQL_TYPE_TINY_BLOB | char[] |
BLOB, TEXT | MYSQL_TYPE_BLOB | char[] |
MEDIUMBLOB, MEDIUMTEXT | MYSQL_TYPE_MEDIUM_BLOB | char[] |
LONGBLOB, LONGTEXT | MYSQL_TYPE_LONG_BLOB | char[] |
BIT | MYSQL_TYPE_BIT | char[] |
The C language variable types are those recommended if you want to avoid type conversions. If there is a mismatch between the C variable type on the client side and the corresponding SQL value on the server side, MySQL performs implicit type conversions in both directions.
MySQL knows the type code for the SQL value on the server side.
The buffer_type value indicates the MySQL the
type code of the C variable that holds the value on the client
side. The two codes together tell MySQL what conversion must be
performed, if any. Here are some examples:
If you use
MYSQL_TYPE_LONGwith anintvariable to pass an integer value to the server that is to be stored into aFLOATcolumn, MySQL converts the value to floating-point format before storing it.If you fetch a SQL
MEDIUMINTcolumn value, but specify abuffer_typevalue ofMYSQL_TYPE_LONGLONGand use a C variable of typelong long intas the destination buffer, MySQL will convert theMEDIUMINTvalue (which requires less than 8 bytes) for storage into thelong long int(an 8-byte variable).If you fetch a numeric column with a value of 255 into a
char[4]character array and specify abuffer_typevalue ofMYSQL_TYPE_STRING, the resulting value in the array will be a 4-byte string containing'255\0'.DECIMALvalues are returned as strings, which is why the corresponding C type ischar[].DECIMALvalues returned by the server correspond to the string representation of the original server-side value. For example,12.345is returned to the client as'12.345'. If you specifyMYSQL_TYPE_NEWDECIMALand bind a string buffer to theMYSQL_BINDstructure,mysql_stmt_fetch()stores the value in the buffer without conversion. If instead you specify a numeric variable and type code,mysql_stmt_fetch()converts the string-formatDECIMALvalue to numeric form.For the
MYSQL_TYPE_BITtype code,BITvalues are returned into a string buffer (thus, the corresponding C type ischar[]here, too). The value represents a bit string that requires interpretation on the client side. To return the value as a type that is easier to deal with, you can use a query of the following form that uses+ 0to cause the value to be cast to integer:SELECT bit_col + 0 FROM t
To retrieve the value, bind an integer variable large enough to hold the value and specify the appropriate corresponding integer type code.
Before binding variables to the MYSQL_BIND
structures that are to be used for fetching column values, you can
check the type codes for each column of the result set. This might
be desirable if you want to determine which variable types would
be best to use to avoid type conversions. To get the type codes,
call mysql_stmt_result_metadata() after
executing the prepared statement with
mysql_stmt_execute(). The metadata provides
access to the type codes for the result set as described in
Section 22.2.7.22, “mysql_stmt_result_metadata()”, and
Section 22.2.1, “C API Data types”.
If you cause the max_length member of the
MYSQL_FIELD column metadata structures to be
set (by calling mysql_stmt_attr_set()), be
aware that the max_length values for the result
set indicate the lengths of the longest string representation of
the result values, not the lengths of the binary representation.
That is, max_length does not necessarily
correspond to the size of the buffers needed to fetch the values
with the binary protocol used for prepared statements. The size of
the buffers should be chosen according to the types of the
variables into which you fetch the values.
For input character (non-binary) string data (indicated by
MYSQL_TYPE_STRING), the value is assumed to be
in the character set indicated by the
character_set_client system variable. If the
value is stored into a column with a different character set, the
appropriate conversion to that character set occurs. For input
binary string data (indicated by
MYSQL_TYPE_BLOB), the value is treated as
having the binary character set; that is, it is
treated as a byte string and no conversion occurs.
To determine whether output string values in a result set returned
from the server contain binary or non-binary data, check whether
the charsetnr value of the result set metadata
is 63 (see Section 22.2.1, “C API Data types”). If so, the
character set is binary, which indicates binary
rather than non-binary data. This enables you to distinguish
between BINARY and CHAR,
VARBINARY and VARCHAR, and
the BLOB and TEXT types.
The functions available for prepared statement processing are summarized here and described in greater detail in a later section. See Section 22.2.7, “C API Prepared Statement Function Descriptions”.
| Function | Description |
| mysql_stmt_affected_rows() | Returns the number of rows changes, deleted, or inserted by prepared
UPDATE, DELETE, or
INSERT statement. |
| mysql_stmt_attr_get() | Get value of an attribute for a prepared statement. |
| mysql_stmt_attr_set() | Sets an attribute for a prepared statement. |
| mysql_stmt_bind_param() | Associates application data buffers with the parameter markers in a prepared SQL statement. |
| mysql_stmt_bind_result() | Associates application data buffers with columns in the result set. |
| mysql_stmt_close() | Frees memory used by prepared statement. |
| mysql_stmt_data_seek() | Seeks to an arbitrary row number in a statement result set. |
| mysql_stmt_errno() | Returns the error number for the last statement execution. |
| mysql_stmt_error() | Returns the error message for the last statement execution. |
| mysql_stmt_execute() | Executes the prepared statement. |
| mysql_stmt_fetch() | Fetches the next row of data from the result set and returns data for all bound columns. |
| mysql_stmt_fetch_column() | Fetch data for one column of the current row of the result set. |
| mysql_stmt_field_count() | Returns the number of result columns for the most recent statement. |
| mysql_stmt_free_result() | Free the resources allocated to the statement handle. |
| mysql_stmt_init() | Allocates memory for MYSQL_STMT structure and
initializes it. |
| mysql_stmt_insert_id() | Returns the ID generated for an AUTO_INCREMENT column
by prepared statement. |
| mysql_stmt_num_rows() | Returns total rows from the statement buffered result set. |
| mysql_stmt_param_count() | Returns the number of parameters in a prepared SQL statement. |
| mysql_stmt_param_metadata() | (Return parameter metadata in the form of a result set.) Currently, this function does nothing. |
| mysql_stmt_prepare() | Prepares an SQL string for execution. |
| mysql_stmt_reset() | Reset the statement buffers in the server. |
| mysql_stmt_result_metadata() | Returns prepared statement metadata in the form of a result set. |
| mysql_stmt_row_seek() | Seeks to a row offset in a statement result set, using value returned
from mysql_stmt_row_tell(). |
| mysql_stmt_row_tell() | Returns the statement row cursor position. |
| mysql_stmt_send_long_data() | Sends long data in chunks to server. |
| mysql_stmt_sqlstate() | Returns the SQLSTATE error code for the last statement execution. |
| mysql_stmt_store_result() | Retrieves the complete result set to the client. |
Call mysql_stmt_init() to create a statement
handle, then mysql_stmt_prepare to prepare it,
mysql_stmt_bind_param() to supply the parameter
data, and mysql_stmt_execute() to execute the
statement. You can repeat the
mysql_stmt_execute() by changing parameter
values in the respective buffers supplied through
mysql_stmt_bind_param().
If the statement is a SELECT or any other
statement that produces a result set,
mysql_stmt_prepare() also returns the result
set metadata information in the form of a
MYSQL_RES result set through
mysql_stmt_result_metadata().
You can supply the result buffers using
mysql_stmt_bind_result(), so that the
mysql_stmt_fetch() automatically returns data
to these buffers. This is row-by-row fetching.
You can also send the text or binary data in chunks to server
using mysql_stmt_send_long_data(). See
Section 22.2.7.25, “mysql_stmt_send_long_data()”.
When statement execution has been completed, the statement handle
must be closed using mysql_stmt_close() so that
all resources associated with it can be freed.
If you obtained a SELECT statement's result set
metadata by calling
mysql_stmt_result_metadata(), you should also
free the metadata using mysql_free_result().
Execution Steps
To prepare and execute a statement, an application follows these steps:
Create a prepared statement handle with
mysql_stmt_init(). To prepare the statement on the server, callmysql_stmt_prepare()and pass it a string containing the SQL statement.If the statement produces a result set, call
mysql_stmt_result_metadata()to obtain the result set metadata. This metadata is itself in the form of result set, albeit a separate one from the one that contains the rows returned by the query. The metadata result set indicates how many columns are in the result and contains information about each column.Set the values of any parameters using
mysql_stmt_bind_param(). All parameters must be set. Otherwise, statement execution returns an error or produces unexpected results.Call
mysql_stmt_execute()to execute the statement.If the statement produces a result set, bind the data buffers to use for retrieving the row values by calling
mysql_stmt_bind_result().Fetch the data into the buffers row by row by calling
mysql_stmt_fetch()repeatedly until no more rows are found.Repeat steps 3 through 6 as necessary, by changing the parameter values and re-executing the statement.
When mysql_stmt_prepare() is called, the MySQL
client/server protocol performs these actions:
The server parses the statement and sends the okay status back to the client by assigning a statement ID. It also sends total number of parameters, a column count, and its metadata if it is a result set oriented statement. All syntax and semantics of the statement are checked by the server during this call.
The client uses this statement ID for the further operations, so that the server can identify the statement from among its pool of statements.
When mysql_stmt_execute() is called, the MySQL
client/server protocol performs these actions:
The client uses the statement handle and sends the parameter data to the server.
The server identifies the statement using the ID provided by the client, replaces the parameter markers with the newly supplied data, and executes the statement. If the statement produces a result set, the server sends the data back to the client. Otherwise, it sends an okay status and total number of rows changed, deleted, or inserted.
When mysql_stmt_fetch() is called, the MySQL
client/server protocol performs these actions:
The client reads the data from the packet row by row and places it into the application data buffers by doing the necessary conversions. If the application buffer type is same as that of the field type returned from the server, the conversions are straightforward.
If an error occurs, you can get the statement error code, error
message, and SQLSTATE value using
mysql_stmt_errno(),
mysql_stmt_error(), and
mysql_stmt_sqlstate(), respectively.
Prepared Statement Logging
For prepared statements that are executed with the
mysql_stmt_prepare() and
mysql_stmt_execute() C API functions, the
server writes Prepare and
Execute lines to the general query log so that
you can tell when statements are prepared and executed.
Suppose that you prepare and execute a statement as follows:
Call
mysql_stmt_prepare()to prepare the statement string"SELECT ?".Call
mysql_stmt_bind_param()to bind the value3to the parameter in the prepared statement.Call
mysql_stmt_execute()to execute the prepared statement.
As a result of the preceding calls, the server writes the following lines to the general query log:
Prepare [1] SELECT ? Execute [1] SELECT 3
Each Prepare and Execute
line in the log is tagged with a
[ statement
identifier so that you can keep track of which prepared statement
is being logged. N]N is a positive
integer. If there are multiple prepared statements active
simultaneously for the client, N may be
greater than 1. Each Execute lines shows a
prepared statement after substitution of data values for
? parameters.
Version notes: Prepare lines are displayed
without [ before
MySQL 4.1.10. N]Execute lines are not displayed
at all before MySQL 4.1.10.
- 22.2.7.1.
mysql_stmt_affected_rows() - 22.2.7.2.
mysql_stmt_attr_get() - 22.2.7.3.
mysql_stmt_attr_set() - 22.2.7.4.
mysql_stmt_bind_param() - 22.2.7.5.
mysql_stmt_bind_result() - 22.2.7.6.
mysql_stmt_close() - 22.2.7.7.
mysql_stmt_data_seek() - 22.2.7.8.
mysql_stmt_errno() - 22.2.7.9.
mysql_stmt_error() - 22.2.7.10.
mysql_stmt_execute() - 22.2.7.11.
mysql_stmt_fetch() - 22.2.7.12.
mysql_stmt_fetch_column() - 22.2.7.13.
mysql_stmt_field_count() - 22.2.7.14.
mysql_stmt_free_result() - 22.2.7.15.
mysql_stmt_init() - 22.2.7.16.
mysql_stmt_insert_id() - 22.2.7.17.
mysql_stmt_num_rows() - 22.2.7.18.
mysql_stmt_param_count() - 22.2.7.19.
mysql_stmt_param_metadata() - 22.2.7.20.
mysql_stmt_prepare() - 22.2.7.21.
mysql_stmt_reset() - 22.2.7.22.
mysql_stmt_result_metadata() - 22.2.7.23.
mysql_stmt_row_seek() - 22.2.7.24.
mysql_stmt_row_tell() - 22.2.7.25.
mysql_stmt_send_long_data() - 22.2.7.26.
mysql_stmt_sqlstate() - 22.2.7.27.
mysql_stmt_store_result()
To prepare and execute queries, use the functions described in detail in the following sections.
Note that all functions operating with a
MYSQL_STMT structure begin with the prefix
mysql_stmt_.
To create a MYSQL_STMT handle, use the
mysql_stmt_init() function.
my_ulonglong mysql_stmt_affected_rows(MYSQL_STMT
*stmt)
Description
Returns the total number of rows changed, deleted, or inserted
by the last executed statement. May be called immediately after
mysql_stmt_execute() for
UPDATE, DELETE, or
INSERT statements. For
SELECT statements,
mysql_stmt_affected_rows() works like
mysql_num_rows().
Return Values
An integer greater than zero indicates the number of rows
affected or retrieved. Zero indicates that no records were
updated for an UPDATE statement, no rows
matched the WHERE clause in the query, or
that no query has yet been executed. -1 indicates that the query
returned an error or that, for a SELECT
query, mysql_stmt_affected_rows() was called
prior to calling mysql_stmt_store_result().
Because mysql_stmt_affected_rows() returns an
unsigned value, you can check for -1 by comparing the return
value to (my_ulonglong)-1 (or to
(my_ulonglong)~0, which is equivalent).
See Section 22.2.3.1, “mysql_affected_rows()”, for additional
information on the return value.
Errors
None.
Example
For the usage of mysql_stmt_affected_rows(),
refer to the Example from Section 22.2.7.10, “mysql_stmt_execute()”.
int mysql_stmt_attr_get(MYSQL_STMT *stmt, enum
enum_stmt_attr_type option, void *arg)
Description
Can be used to get the current value for a statement attribute.
The option argument is the option that you
want to get; the arg should point to a
variable that should contain the option value. If the option is
an integer, then arg should point to the
value of the integer.
See Section 22.2.7.3, “mysql_stmt_attr_set()”, for a list of options
and option types.
Note: In MySQL
5.0, mysql_stmt_attr_get() uses
unsigned int *, not my_bool
*, for STMT_ATTR_UPDATE_MAX_LENGTH.
This was corrected in MySQL 5.1.7.
Return Values
Zero if successful. Non-zero if option is
unknown.
Errors
None.
int mysql_stmt_attr_set(MYSQL_STMT *stmt, enum
enum_stmt_attr_type option, const void *arg)
Description
Can be used to affect behavior for a prepared statement. This function may be called multiple times to set several options.
The option argument is the option that you
want to set; the arg argument is the value
for the option. If the option is an integer, then
arg should point to the value of the integer.
Possible option values:
| Option | Argument Type | Function |
STMT_ATTR_UPDATE_MAX_LENGTH | my_bool * | If set to 1: Update metadata
MYSQL_FIELD->max_length in
mysql_stmt_store_result(). |
STMT_ATTR_CURSOR_TYPE | unsigned long * | Type of cursor to open for statement when
mysql_stmt_execute() is invoked.
*arg can be
CURSOR_TYPE_NO_CURSOR (the default)
or CURSOR_TYPE_READ_ONLY. |
STMT_ATTR_PREFETCH_ROWS | unsigned long * | Number of rows to fetch from server at a time when using a cursor.
*arg can be in the range from 1 to
the maximum value of unsigned long.
The default is 1. |
Note: In MySQL
5.0, mysql_stmt_attr_get() uses
unsigned int *, not my_bool
*, for STMT_ATTR_UPDATE_MAX_LENGTH.
This is corrected in MySQL 5.1.7.
If you use the STMT_ATTR_CURSOR_TYPE option
with CURSOR_TYPE_READ_ONLY, a cursor is
opened for the statement when you invoke
mysql_stmt_execute(). If there is already an
open cursor from a previous
mysql_stmt_execute() call, it closes the
cursor before opening a new one.
mysql_stmt_reset() also closes any open
cursor before preparing the statement for re-execution.
mysql_stmt_free_result() closes any open
cursor.
If you open a cursor for a prepared statement,
mysql_stmt_store_result() is unnecessary,
because that function causes the result set to be buffered on
the client side.
The STMT_ATTR_CURSOR_TYPE option was added in
MySQL 5.0.2. The STMT_ATTR_PREFETCH_ROWS
option was added in MySQL 5.0.6.
Return Values
Zero if successful. Non-zero if option is
unknown.
Errors
None.
Example
The following example opens a cursor for a prepared statement and sets the number of rows to fetch at a time to 5:
MYSQL_STMT *stmt;
int rc;
unsigned long type;
unsigned long prefetch_rows = 5;
stmt = mysql_stmt_init(mysql);
type = (unsigned long) CURSOR_TYPE_READ_ONLY;
rc = mysql_stmt_attr_set(stmt, STMT_ATTR_CURSOR_TYPE, (void*) &type);
/* ... check return value ... */
rc = mysql_stmt_attr_set(stmt, STMT_ATTR_PREFETCH_ROWS,
(void*) &prefetch_rows);
/* ... check return value ... */
my_bool mysql_stmt_bind_param(MYSQL_STMT *stmt,
MYSQL_BIND *bind)
Description
mysql_stmt_bind_param() is used to bind input
data for the parameter markers in the SQL statement that was
passed to mysql_stmt_prepare(). It uses
MYSQL_BIND structures to supply the data.
bind is the address of an array of
MYSQL_BIND structures. The client library
expects the array to contain one element for each
‘?’ parameter marker that is
present in the query.
Suppose that you prepare the following statement:
INSERT INTO mytbl VALUES(?,?,?)
When you bind the parameters, the array of
MYSQL_BIND structures must contain three
elements, and can be declared like this:
MYSQL_BIND bind[3];
Section 22.2.5, “C API Prepared Statement Data types”, describes
the members of each MYSQL_BIND element and
how they should be set to provide input values.
Return Values
Zero if the bind operation was successful. Non-zero if an error occurred.
Errors
CR_UNSUPPORTED_PARAM_TYPEThe conversion is not supported. Possibly the
buffer_typevalue is illegal or is not one of the supported types.CR_OUT_OF_MEMORYOut of memory.
CR_UNKNOWN_ERRORAn unknown error occurred.
Example
For the usage of mysql_stmt_bind_param(),
refer to the Example from Section 22.2.7.10, “mysql_stmt_execute()”.
my_bool mysql_stmt_bind_result(MYSQL_STMT *stmt,
MYSQL_BIND *bind)
Description
mysql_stmt_bind_result() is used to associate
(that is, bind) output columns in the result set to data buffers
and length buffers. When mysql_stmt_fetch()
is called to fetch data, the MySQL client/server protocol places
the data for the bound columns into the specified buffers.
All columns must be bound to buffers prior to calling
mysql_stmt_fetch(). bind
is the address of an array of MYSQL_BIND
structures. The client library expects the array to contain one
element for each column of the result set. If you do not bind
columns to MYSQL_BIND structures,
mysql_stmt_fetch() simply ignores the data
fetch. The buffers should be large enough to hold the data
values, because the protocol doesn't return data values in
chunks.
A column can be bound or rebound at any time, even after a
result set has been partially retrieved. The new binding takes
effect the next time mysql_stmt_fetch() is
called. Suppose that an application binds the columns in a
result set and calls mysql_stmt_fetch(). The
client/server protocol returns data in the bound buffers. Then
suppose that the application binds the columns to a different
set of buffers. The protocol places data into the newly bound
buffers when the next call to
mysql_stmt_fetch() occurs.
To bind a column, an application calls
mysql_stmt_bind_result() and passes the type,
address, and length of the output buffer into which the value
should be stored.
Section 22.2.5, “C API Prepared Statement Data types”, describes
the members of each MYSQL_BIND element and
how they should be set to receive output values.
Return Values
Zero if the bind operation was successful. Non-zero if an error occurred.
Errors
CR_UNSUPPORTED_PARAM_TYPEThe conversion is not supported. Possibly the
buffer_typevalue is illegal or is not one of the supported types.CR_OUT_OF_MEMORYOut of memory.
CR_UNKNOWN_ERRORAn unknown error occurred.
Example
For the usage of mysql_stmt_bind_result(),
refer to the Example from Section 22.2.7.11, “mysql_stmt_fetch()”.
my_bool mysql_stmt_close(MYSQL_STMT *)
Description
Closes the prepared statement.
mysql_stmt_close() also deallocates the
statement handle pointed to by stmt.
If the current statement has pending or unread results, this function cancels them so that the next query can be executed.
Return Values
Zero if the statement was freed successfully. Non-zero if an error occurred.
Errors
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_UNKNOWN_ERRORAn unknown error occurred.
Example
For the usage of mysql_stmt_close(), refer to
the Example from Section 22.2.7.10, “mysql_stmt_execute()”.
void mysql_stmt_data_seek(MYSQL_STMT *stmt,
my_ulonglong offset)
Description
Seeks to an arbitrary row in a statement result set. The
offset value is a row number and should be in
the range from 0 to
mysql_stmt_num_rows(stmt)-1.
This function requires that the statement result set structure
contains the entire result of the last executed query, so
mysql_stmt_data_seek() may be used only in
conjunction with mysql_stmt_store_result().
Return Values
None.
Errors
None.
unsigned int mysql_stmt_errno(MYSQL_STMT
*stmt)
Description
For the statement specified by stmt,
mysql_stmt_errno() returns the error code for
the most recently invoked statement API function that can
succeed or fail. A return value of zero means that no error
occurred. Client error message numbers are listed in the MySQL
errmsg.h header file. Server error message
numbers are listed in mysqld_error.h.
Errors also are listed at Appendix B, Errors, Error Codes, and Common Problems.
Return Values
An error code value. Zero if no error occurred.
Errors
None.
const char *mysql_stmt_error(MYSQL_STMT
*stmt)
Description
For the statement specified by stmt,
mysql_stmt_error() returns a null-terminated
string containing the error message for the most recently
invoked statement API function that can succeed or fail. An
empty string ("") is returned if no error
occurred. This means the following two tests are equivalent:
if(*mysql_stmt_errno(stmt))
{
// an error occurred
}
if (mysql_stmt_error(stmt)[0])
{
// an error occurred
}
The language of the client error messages may be changed by recompiling the MySQL client library. Currently, you can choose error messages in several different languages.
Return Values
A character string that describes the error. An empty string if no error occurred.
Errors
None.
int mysql_stmt_execute(MYSQL_STMT *stmt)
Description
mysql_stmt_execute() executes the prepared
query associated with the statement handle. The currently bound
parameter marker values are sent to server during this call, and
the server replaces the markers with this newly supplied data.
If the statement is an UPDATE,
DELETE, or INSERT, the
total number of changed, deleted, or inserted rows can be found
by calling mysql_stmt_affected_rows(). If
this is a statement such as SELECT that
generates a result set, you must call
mysql_stmt_fetch() to fetch the data prior to
calling any other functions that result in query processing. For
more information on how to fetch the results, refer to
Section 22.2.7.11, “mysql_stmt_fetch()”.
For statements that generate a result set, you can request that
mysql_stmt_execute() open a cursor for the
statement by calling mysql_stmt_attr_set()
before executing the statement. If you execute a statement
multiple times, mysql_stmt_execute() closes
any open cursor before opening a new one.
Return Values
Zero if execution was successful. Non-zero if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_OUT_OF_MEMORYOut of memory.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
Example
The following example demonstrates how to create and populate a
table using mysql_stmt_init(),
mysql_stmt_prepare(),
mysql_stmt_param_count(),
mysql_stmt_bind_param(),
mysql_stmt_execute(), and
mysql_stmt_affected_rows(). The
mysql variable is assumed to be a valid
connection handle.
#define STRING_SIZE 50
#define DROP_SAMPLE_TABLE "DROP TABLE IF EXISTS test_table"
#define CREATE_SAMPLE_TABLE "CREATE TABLE test_table(col1 INT,\
col2 VARCHAR(40),\
col3 SMALLINT,\
col4 TIMESTAMP)"
#define INSERT_SAMPLE "INSERT INTO \
test_table(col1,col2,col3) \
VALUES(?,?,?)"
MYSQL_STMT *stmt;
MYSQL_BIND bind[3];
my_ulonglong affected_rows;
int param_count;
short small_data;
int int_data;
char str_data[STRING_SIZE];
unsigned long str_length;
my_bool is_null;
if (mysql_query(mysql, DROP_SAMPLE_TABLE))
{
fprintf(stderr, " DROP TABLE failed\n");
fprintf(stderr, " %s\n", mysql_error(mysql));
exit(0);
}
if (mysql_query(mysql, CREATE_SAMPLE_TABLE))
{
fprintf(stderr, " CREATE TABLE failed\n");
fprintf(stderr, " %s\n", mysql_error(mysql));
exit(0);
}
/* Prepare an INSERT query with 3 parameters */
/* (the TIMESTAMP column is not named; the server */
/* sets it to the current date and time) */
stmt = mysql_stmt_init(mysql);
if (!stmt)
{
fprintf(stderr, " mysql_stmt_init(), out of memory\n");
exit(0);
}
if (mysql_stmt_prepare(stmt, INSERT_SAMPLE, strlen(INSERT_SAMPLE)))
{
fprintf(stderr, " mysql_stmt_prepare(), INSERT failed\n");
fprintf(stderr, " %s\n", mysql_stmt_error(stmt));
exit(0);
}
fprintf(stdout, " prepare, INSERT successful\n");
/* Get the parameter count from the statement */
param_count= mysql_stmt_param_count(stmt);
fprintf(stdout, " total parameters in INSERT: %d\n", param_count);
if (param_count != 3) /* validate parameter count */
{
fprintf(stderr, " invalid parameter count returned by MySQL\n");
exit(0);
}
/* Bind the data for all 3 parameters */
memset(bind, 0, sizeof(bind));
/* INTEGER PARAM */
/* This is a number type, so there is no need
to specify buffer_length */
bind[0].buffer_type= MYSQL_TYPE_LONG;
bind[0].buffer= (char *)&int_data;
bind[0].is_null= 0;
bind[0].length= 0;
/* STRING PARAM */
bind[1].buffer_type= MYSQL_TYPE_STRING;
bind[1].buffer= (char *)str_data;
bind[1].buffer_length= STRING_SIZE;
bind[1].is_null= 0;
bind[1].length= &str_length;
/* SMALLINT PARAM */
bind[2].buffer_type= MYSQL_TYPE_SHORT;
bind[2].buffer= (char *)&small_data;
bind[2].is_null= &is_null;
bind[2].length= 0;
/* Bind the buffers */
if (mysql_stmt_bind_param(stmt, bind))
{
fprintf(stderr, " mysql_stmt_bind_param() failed\n");
fprintf(stderr, " %s\n", mysql_stmt_error(stmt));
exit(0);
}
/* Specify the data values for the first row */
int_data= 10; /* integer */
strncpy(str_data, "MySQL", STRING_SIZE); /* string */
str_length= strlen(str_data);
/* INSERT SMALLINT data as NULL */
is_null= 1;
/* Execute the INSERT statement - 1*/
if (mysql_stmt_execute(stmt))
{
fprintf(stderr, " mysql_stmt_execute(), 1 failed\n");
fprintf(stderr, " %s\n", mysql_stmt_error(stmt));
exit(0);
}
/* Get the total number of affected rows */
affected_rows= mysql_stmt_affected_rows(stmt);
fprintf(stdout, " total affected rows(insert 1): %lu\n",
(unsigned long) affected_rows);
if (affected_rows != 1) /* validate affected rows */
{
fprintf(stderr, " invalid affected rows by MySQL\n");
exit(0);
}
/* Specify data values for second row,
then re-execute the statement */
int_data= 1000;
strncpy(str_data, "
The most popular Open Source database",
STRING_SIZE);
str_length= strlen(str_data);
small_data= 1000; /* smallint */
is_null= 0; /* reset */
/* Execute the INSERT statement - 2*/
if (mysql_stmt_execute(stmt))
{
fprintf(stderr, " mysql_stmt_execute, 2 failed\n");
fprintf(stderr, " %s\n", mysql_stmt_error(stmt));
exit(0);
}
/* Get the total rows affected */
affected_rows= mysql_stmt_affected_rows(stmt);
fprintf(stdout, " total affected rows(insert 2): %lu\n",
(unsigned long) affected_rows);
if (affected_rows != 1) /* validate affected rows */
{
fprintf(stderr, " invalid affected rows by MySQL\n");
exit(0);
}
/* Close the statement */
if (mysql_stmt_close(stmt))
{
fprintf(stderr, " failed while closing the statement\n");
fprintf(stderr, " %s\n", mysql_stmt_error(stmt));
exit(0);
}
Note: For complete examples on
the use of prepared statement functions, refer to the file
tests/mysql_client_test.c. This file can be
obtained from a MySQL source distribution or from the BitKeeper
source repository.
int mysql_stmt_fetch(MYSQL_STMT *stmt)
Description
mysql_stmt_fetch() returns the next row in
the result set. It can be called only while the result set
exists; that is, after a call to
mysql_stmt_execute() that creates a result
set or after mysql_stmt_store_result(), which
is called after mysql_stmt_execute() to
buffer the entire result set.
mysql_stmt_fetch() returns row data using the
buffers bound by mysql_stmt_bind_result(). It
returns the data in those buffers for all the columns in the
current row set and the lengths are returned to the
length pointer.
All columns must be bound by the application before calling
mysql_stmt_fetch().
If a fetched data value is a NULL value, the
*is_null value of the corresponding
MYSQL_BIND structure contains TRUE (1).
Otherwise, the data and its length are returned in the
*buffer and *length
elements based on the buffer type specified by the application.
Each numeric and temporal type has a fixed length, as listed in
the following table. The length of the string types depends on
the length of the actual data value, as indicated by
data_length.
| Type | Length |
MYSQL_TYPE_TINY | 1 |
MYSQL_TYPE_SHORT | 2 |
MYSQL_TYPE_LONG | 4 |
MYSQL_TYPE_LONGLONG | 8 |
MYSQL_TYPE_FLOAT | 4 |
MYSQL_TYPE_DOUBLE | 8 |
MYSQL_TYPE_TIME | sizeof(MYSQL_TIME) |
MYSQL_TYPE_DATE | sizeof(MYSQL_TIME) |
MYSQL_TYPE_DATETIME | sizeof(MYSQL_TIME) |
MYSQL_TYPE_STRING | data length |
MYSQL_TYPE_BLOB | data_length |
Return Values
| Return Value | Description |
| 0 | Successful, the data has been fetched to application data buffers. |
| 1 | Error occurred. Error code and message can be obtained by calling
mysql_stmt_errno() and
mysql_stmt_error(). |
MYSQL_NO_DATA | No more rows/data exists |
MYSQL_DATA_TRUNCATED | Data truncation occurred |
MYSQL_DATA_TRUNCATED is returned when
truncation reporting is enabled. (Reporting is enabled by
default, but can be controlled with
mysql_options().) To determine which
parameters were truncated when this value is returned, check the
error members of the
MYSQL_BIND parameter structures.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_OUT_OF_MEMORYOut of memory.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
CR_UNSUPPORTED_PARAM_TYPEThe buffer type is
MYSQL_TYPE_DATE,MYSQL_TYPE_TIME,MYSQL_TYPE_DATETIME, orMYSQL_TYPE_TIMESTAMP, but the data type is notDATE,TIME,DATETIME, orTIMESTAMP.All other unsupported conversion errors are returned from
mysql_stmt_bind_result().
Example
The following example demonstrates how to fetch data from a
table using mysql_stmt_result_metadata(),
mysql_stmt_bind_result(), and
mysql_stmt_fetch(). (This example expects to
retrieve the two rows inserted by the example shown in
Section 22.2.7.10, “mysql_stmt_execute()”.) The
mysql variable is assumed to be a valid
connection handle.
#define STRING_SIZE 50
#define SELECT_SAMPLE "SELECT col1, col2, col3, col4 \
FROM test_table"
MYSQL_STMT *stmt;
MYSQL_BIND bind[4];
MYSQL_RES *prepare_meta_result;
MYSQL_TIME ts;
unsigned long length[4];
int param_count, column_count, row_count;
short small_data;
int int_data;
char str_data[STRING_SIZE];
my_bool is_null[4];
my_bool error[4];
/* Prepare a SELECT query to fetch data from test_table */
stmt = mysql_stmt_init(mysql);
if (!stmt)
{
fprintf(stderr, " mysql_stmt_init(), out of memory\n");
exit(0);
}
if (mysql_stmt_prepare(stmt, SELECT_SAMPLE, strlen(SELECT_SAMPLE)))
{
fprintf(stderr, " mysql_stmt_prepare(), SELECT failed\n");
fprintf(stderr, " %s\n", mysql_stmt_error(stmt));
exit(0);
}
fprintf(stdout, " prepare, SELECT successful\n");
/* Get the parameter count from the statement */
param_count= mysql_stmt_param_count(stmt);
fprintf(stdout, " total parameters in SELECT: %d\n", param_count);
if (param_count != 0) /* validate parameter count */
{
fprintf(stderr, " invalid parameter count returned by MySQL\n");
exit(0);
}
/* Fetch result set meta information */
prepare_meta_result = mysql_stmt_result_metadata(stmt);
if (!prepare_meta_result)
{
fprintf(stderr,
" mysql_stmt_result_metadata(), \
returned no meta information\n");
fprintf(stderr, " %s\n", mysql_stmt_error(stmt));
exit(0);
}
/* Get total columns in the query */
column_count= mysql_num_fields(prepare_meta_result);
fprintf(stdout,
" total columns in SELECT statement: %d\n",
column_count);
if (column_count != 4) /* validate column count */
{
fprintf(stderr, " invalid column count returned by MySQL\n");
exit(0);
}
/* Execute the SELECT query */
if (mysql_stmt_execute(stmt))
{
fprintf(stderr, " mysql_stmt_execute(), failed\n");
fprintf(stderr, " %s\n", mysql_stmt_error(stmt));
exit(0);
}
/* Bind the result buffers for all 4 columns before fetching them */
memset(bind, 0, sizeof(bind));
/* INTEGER COLUMN */
bind[0].buffer_type= MYSQL_TYPE_LONG;
bind[0].buffer= (char *)&int_data;
bind[0].is_null= &is_null[0];
bind[0].length= &length[0];
bind[0].error= &error[0];
/* STRING COLUMN */
bind[1].buffer_type= MYSQL_TYPE_STRING;
bind[1].buffer= (char *)str_data;
bind[1].buffer_length= STRING_SIZE;
bind[1].is_null= &is_null[1];
bind[1].length= &length[1];
bind[1].error= &error[1];
/* SMALLINT COLUMN */
bind[2].buffer_type= MYSQL_TYPE_SHORT;
bind[2].buffer= (char *)&small_data;
bind[2].is_null= &is_null[2];
bind[2].length= &length[2];
bind[2].error= &error[2];
/* TIMESTAMP COLUMN */
bind[3].buffer_type= MYSQL_TYPE_TIMESTAMP;
bind[3].buffer= (char *)&ts;
bind[3].is_null= &is_null[3];
bind[3].length= &length[3];
bind[3].error= &error[3];
/* Bind the result buffers */
if (mysql_stmt_bind_result(stmt, bind))
{
fprintf(stderr, " mysql_stmt_bind_result() failed\n");
fprintf(stderr, " %s\n", mysql_stmt_error(stmt));
exit(0);
}
/* Now buffer all results to client */
if (mysql_stmt_store_result(stmt))
{
fprintf(stderr, " mysql_stmt_store_result() failed\n");
fprintf(stderr, " %s\n", mysql_stmt_error(stmt));
exit(0);
}
/* Fetch all rows */
row_count= 0;
fprintf(stdout, "Fetching results ...\n");
while (!mysql_stmt_fetch(stmt))
{
row_count++;
fprintf(stdout, " row %d\n", row_count);
/* column 1 */
fprintf(stdout, " column1 (integer) : ");
if (is_null[0])
fprintf(stdout, " NULL\n");
else
fprintf(stdout, " %d(%ld)\n", int_data, length[0]);
/* column 2 */
fprintf(stdout, " column2 (string) : ");
if (is_null[1])
fprintf(stdout, " NULL\n");
else
fprintf(stdout, " %s(%ld)\n", str_data, length[1]);
/* column 3 */
fprintf(stdout, " column3 (smallint) : ");
if (is_null[2])
fprintf(stdout, " NULL\n");
else
fprintf(stdout, " %d(%ld)\n", small_data, length[2]);
/* column 4 */
fprintf(stdout, " column4 (timestamp): ");
if (is_null[3])
fprintf(stdout, " NULL\n");
else
fprintf(stdout, " %04d-%02d-%02d %02d:%02d:%02d (%ld)\n",
ts.year, ts.month, ts.day,
ts.hour, ts.minute, ts.second,
length[3]);
fprintf(stdout, "\n");
}
/* Validate rows fetched */
fprintf(stdout, " total rows fetched: %d\n", row_count);
if (row_count != 2)
{
fprintf(stderr, " MySQL failed to return all rows\n");
exit(0);
}
/* Free the prepared result metadata */
mysql_free_result(prepare_meta_result);
/* Close the statement */
if (mysql_stmt_close(stmt))
{
fprintf(stderr, " failed while closing the statement\n");
fprintf(stderr, " %s\n", mysql_stmt_error(stmt));
exit(0);
}
int mysql_stmt_fetch_column(MYSQL_STMT *stmt,
MYSQL_BIND *bind, unsigned int column, unsigned long
offset)
Description
Fetch one column from the current result set row.
bind provides the buffer where data should be
placed. It should be set up the same way as for
mysql_stmt_bind_result().
column indicates which column to fetch. The
first column is numbered 0. offset is the
offset within the data value at which to begin retrieving data.
This can be used for fetching the data value in pieces. The
beginning of the value is offset 0.
Return Values
Zero if the value was fetched successfully. Non-zero if an error occurred.
Errors
CR_INVALID_PARAMETER_NOInvalid column number.
CR_NO_DATAThe end of the result set has already been reached.
unsigned int mysql_stmt_field_count(MYSQL_STMT
*stmt)
Description
Returns the number of columns for the most recent statement for
the statement handler. This value is zero for statements such as
INSERT or DELETE that do
not produce result sets.
mysql_stmt_field_count() can be called after
you have prepared a statement by invoking
mysql_stmt_prepare().
Return Values
An unsigned integer representing the number of columns in a result set.
Errors
None.
my_bool mysql_stmt_free_result(MYSQL_STMT
*stmt)
Description
Releases memory associated with the result set produced by
execution of the prepared statement. If there is a cursor open
for the statement, mysql_stmt_free_result()
closes it.
Return Values
Zero if the result set was freed successfully. Non-zero if an error occurred.
Errors
MYSQL_STMT *mysql_stmt_init(MYSQL *mysql)
Description
Create a MYSQL_STMT handle. The handle should
be freed with mysql_stmt_close(MYSQL_STMT *).
Return values
A pointer to a MYSQL_STMT structure in case
of success. NULL if out of memory.
Errors
CR_OUT_OF_MEMORYOut of memory.
my_ulonglong mysql_stmt_insert_id(MYSQL_STMT
*stmt)
Description
Returns the value generated for an
AUTO_INCREMENT column by the prepared
INSERT or UPDATE
statement. Use this function after you have executed a prepared
INSERT statement on a table which contains an
AUTO_INCREMENT field.
See Section 22.2.3.37, “mysql_insert_id()”, for more information.
Return Values
Value for AUTO_INCREMENT column which was
automatically generated or explicitly set during execution of
prepared statement, or value generated by
LAST_INSERT_ID(
function. Return value is undefined if statement does not set
expr)AUTO_INCREMENT value.
Errors
None.
my_ulonglong mysql_stmt_num_rows(MYSQL_STMT
*stmt)
Description
Returns the number of rows in the result set.
The use of mysql_stmt_num_rows() depends on
whether you used mysql_stmt_store_result() to
buffer the entire result set in the statement handle.
If you use mysql_stmt_store_result(),
mysql_stmt_num_rows() may be called
immediately.
mysql_stmt_num_rows() is intended for use
with statements that return a result set, such as
SELECT. For statements such as
INSERT, UPDATE, or
DELETE, the number of affected rows can be
obtained with mysql_stmt_affected_rows().
Return Values
The number of rows in the result set.
Errors
None.
unsigned long mysql_stmt_param_count(MYSQL_STMT
*stmt)
Description
Returns the number of parameter markers present in the prepared statement.
Return Values
An unsigned long integer representing the number of parameters in a statement.
Errors
None.
Example
For the usage of mysql_stmt_param_count(),
refer to the Example from Section 22.2.7.10, “mysql_stmt_execute()”.
MYSQL_RES *mysql_stmt_param_metadata(MYSQL_STMT
*stmt)
This function currently does nothing.
Description
Return Values
Errors
int mysql_stmt_prepare(MYSQL_STMT *stmt, const char
*stmt_str, unsigned long length)
Description
Given the statement handle returned by
mysql_stmt_init(), prepares the SQL statement
pointed to by the string stmt_str and returns
a status value. The string length should be given by the
length argument. The string must consist of a
single SQL statement. You should not add a terminating semicolon
(‘;’) or \g to
the statement.
The application can include one or more parameter markers in the
SQL statement by embedding question mark
(‘?’) characters into the SQL
string at the appropriate positions.
The markers are legal only in certain places in SQL statements.
For example, they are allowed in the VALUES()
list of an INSERT statement (to specify
column values for a row), or in a comparison with a column in a
WHERE clause to specify a comparison value.
However, they are not allowed for identifiers (such as table or
column names), or to specify both operands of a binary operator
such as the = equal sign. The latter
restriction is necessary because it would be impossible to
determine the parameter type. In general, parameters are legal
only in Data Manipulation Language (DML) statements, and not in
Data Definition Language (DDL) statements.
The parameter markers must be bound to application variables
using mysql_stmt_bind_param() before
executing the statement.
Return Values
Zero if the statement was prepared successfully. Non-zero if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_OUT_OF_MEMORYOut of memory.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query
CR_UNKNOWN_ERRORAn unknown error occurred.
If the prepare operation was unsuccessful (that is,
mysql_stmt_prepare() returns non-zero), the
error message can be obtained by calling
mysql_stmt_error().
Example
For the usage of mysql_stmt_prepare(), refer
to the Example from Section 22.2.7.10, “mysql_stmt_execute()”.
my_bool mysql_stmt_reset(MYSQL_STMT *stmt)
Description
Reset the prepared statement on the client and server to state
after prepare. This is mainly used to reset data sent with
mysql_stmt_send_long_data(). Any open cursor
for the statement is closed.
To re-prepare the statement with another query, use
mysql_stmt_prepare().
Return Values
Zero if the statement was reset successfully. Non-zero if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query
CR_UNKNOWN_ERRORAn unknown error occurred.
MYSQL_RES *mysql_stmt_result_metadata(MYSQL_STMT
*stmt)
Description
If a statement passed to mysql_stmt_prepare()
is one that produces a result set,
mysql_stmt_result_metadata() returns the
result set metadata in the form of a pointer to a
MYSQL_RES structure that can be used to
process the meta information such as total number of fields and
individual field information. This result set pointer can be
passed as an argument to any of the field-based API functions
that process result set metadata, such as:
mysql_num_fields()mysql_fetch_field()mysql_fetch_field_direct()mysql_fetch_fields()mysql_field_count()mysql_field_seek()mysql_field_tell()mysql_free_result()
The result set structure should be freed when you are done with
it, which you can do by passing it to
mysql_free_result(). This is similar to the
way you free a result set obtained from a call to
mysql_store_result().
The result set returned by
mysql_stmt_result_metadata() contains only
metadata. It does not contain any row results. The rows are
obtained by using the statement handle with
mysql_stmt_fetch().
Return Values
A MYSQL_RES result structure.
NULL if no meta information exists for the
prepared query.
Errors
CR_OUT_OF_MEMORYOut of memory.
CR_UNKNOWN_ERRORAn unknown error occurred.
Example
For the usage of
mysql_stmt_result_metadata(), refer to the
Example from Section 22.2.7.11, “mysql_stmt_fetch()”.
MYSQL_ROW_OFFSET mysql_stmt_row_seek(MYSQL_STMT *stmt,
MYSQL_ROW_OFFSET offset)
Description
Sets the row cursor to an arbitrary row in a statement result
set. The offset value is a row offset that
should be a value returned from
mysql_stmt_row_tell() or from
mysql_stmt_row_seek(). This value is not a
row number; if you want to seek to a row within a result set by
number, use mysql_stmt_data_seek() instead.
This function requires that the result set structure contains
the entire result of the query, so
mysql_stmt_row_seek() may be used only in
conjunction with mysql_stmt_store_result().
Return Values
The previous value of the row cursor. This value may be passed
to a subsequent call to
mysql_stmt_row_seek().
Errors
None.
MYSQL_ROW_OFFSET mysql_stmt_row_tell(MYSQL_STMT
*stmt)
Description
Returns the current position of the row cursor for the last
mysql_stmt_fetch(). This value can be used as
an argument to mysql_stmt_row_seek().
You should use mysql_stmt_row_tell() only
after mysql_stmt_store_result().
Return Values
The current offset of the row cursor.
Errors
None.
my_bool mysql_stmt_send_long_data(MYSQL_STMT *stmt,
unsigned int parameter_number, const char *data, unsigned long
length)
Description
Allows an application to send parameter data to the server in
pieces (or “chunks”). Call this function after
mysql_stmt_bind_param() and before
mysql_stmt_execute(). It can be called
multiple times to send the parts of a character or binary data
value for a column, which must be one of the
TEXT or BLOB data types.
parameter_number indicates which parameter to
associate the data with. Parameters are numbered beginning with
0. data is a pointer to a buffer containing
data to be sent, and length indicates the
number of bytes in the buffer.
Note: The next
mysql_stmt_execute() call ignores the bind
buffer for all parameters that have been used with
mysql_stmt_send_long_data() since last
mysql_stmt_execute() or
mysql_stmt_reset().
If you want to reset/forget the sent data, you can do it with
mysql_stmt_reset(). See
Section 22.2.7.21, “mysql_stmt_reset()”.
Return Values
Zero if the data is sent successfully to server. Non-zero if an error occurred.
Errors
CR_INVALID_BUFFER_USEThe parameter does not have a string or binary type.
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_OUT_OF_MEMORYOut of memory.
CR_UNKNOWN_ERRORAn unknown error occurred.
Example
The following example demonstrates how to send the data for a
TEXT column in chunks. It inserts the data
value 'MySQL - The most popular Open Source
database' into the text_column
column. The mysql variable is assumed to be a
valid connection handle.
#define INSERT_QUERY "INSERT INTO \
test_long_data(text_column) VALUES(?)"
MYSQL_BIND bind[1];
long length;
stmt = mysql_stmt_init(mysql);
if (!stmt)
{
fprintf(stderr, " mysql_stmt_init(), out of memory\n");
exit(0);
}
if (mysql_stmt_prepare(stmt, INSERT_QUERY, strlen(INSERT_QUERY)))
{
fprintf(stderr, "\n mysql_stmt_prepare(), INSERT failed");
fprintf(stderr, "\n %s", mysql_stmt_error(stmt));
exit(0);
}
memset(bind, 0, sizeof(bind));
bind[0].buffer_type= MYSQL_TYPE_STRING;
bind[0].length= &length;
bind[0].is_null= 0;
/* Bind the buffers */
if (mysql_stmt_bind_param(stmt, bind))
{
fprintf(stderr, "\n param bind failed");
fprintf(stderr, "\n %s", mysql_stmt_error(stmt));
exit(0);
}
/* Supply data in chunks to server */
if (mysql_stmt_send_long_data(stmt,0,"MySQL",5))
{
fprintf(stderr, "\n send_long_data failed");
fprintf(stderr, "\n %s", mysql_stmt_error(stmt));
exit(0);
}
/* Supply the next piece of data */
if (mysql_stmt_send_long_data(stmt,0,
" - The most popular Open Source database",40))
{
fprintf(stderr, "\n send_long_data failed");
fprintf(stderr, "\n %s", mysql_stmt_error(stmt));
exit(0);
}
/* Now, execute the query */
if (mysql_stmt_execute(stmt))
{
fprintf(stderr, "\n mysql_stmt_execute failed");
fprintf(stderr, "\n %s", mysql_stmt_error(stmt));
exit(0);
}
const char *mysql_stmt_sqlstate(MYSQL_STMT
*stmt)
Description
For the statement specified by stmt,
mysql_stmt_sqlstate() returns a
null-terminated string containing the SQLSTATE error code for
the most recently invoked prepared statement API function that
can succeed or fail. The error code consists of five characters.
"00000" means “no error.” The
values are specified by ANSI SQL and ODBC. For a list of
possible values, see Appendix B, Errors, Error Codes, and Common Problems.
Note that not all MySQL errors are yet mapped to SQLSTATE codes.
The value "HY000" (general error) is used for
unmapped errors.
Return Values
A null-terminated character string containing the SQLSTATE error code.
int mysql_stmt_store_result(MYSQL_STMT *stmt)
Description
You must call mysql_stmt_store_result() for
every statement that successfully produces a result set
(SELECT, SHOW,
DESCRIBE, EXPLAIN), and
only if you want to buffer the complete result set by the
client, so that the subsequent
mysql_stmt_fetch() call returns buffered
data.
It is unnecessary to call
mysql_stmt_store_result() for other
statements, but if you do, it does not harm or cause any notable
performance problem. You can detect whether the statement
produced a result set by checking if
mysql_stmt_result_metadata() returns
NULL. For more information, refer to
Section 22.2.7.22, “mysql_stmt_result_metadata()”.
Note: MySQL doesn't by default
calculate MYSQL_FIELD->max_length for all
columns in mysql_stmt_store_result() because
calculating this would slow down
mysql_stmt_store_result() considerably and
most applications doesn't need max_length. If
you want max_length to be updated, you can
call mysql_stmt_attr_set(MYSQL_STMT,
STMT_ATTR_UPDATE_MAX_LENGTH, &flag) to enable
this. See Section 22.2.7.3, “mysql_stmt_attr_set()”.
Return Values
Zero if the results are buffered successfully. Non-zero if an error occurred.
Errors
CR_COMMANDS_OUT_OF_SYNCCommands were executed in an improper order.
CR_OUT_OF_MEMORYOut of memory.
CR_SERVER_GONE_ERRORThe MySQL server has gone away.
CR_SERVER_LOSTThe connection to the server was lost during the query.
CR_UNKNOWN_ERRORAn unknown error occurred.
Here follows a list of the currently known problems with prepared statements:
TIME,TIMESTAMP, andDATETIMEdo not support parts of seconds (for example fromDATE_FORMAT().When converting an integer to string,
ZEROFILLis honored with prepared statements in some cases where the MySQL server doesn't print the leading zeros. (For example, withMIN().number-with-zerofill)When converting a floating point number to a string in the client, the rightmost digits of the converted value may differ slightly from those of the original value.
Prepared statements do not use the query cache, even in cases where a query does not contain any placeholders. See Section 5.13.1, “How the Query Cache Operates”.
Prepared statements do not support multi-statements (that is, multiple statements within a single string separated by ‘
;’ characters). This also means that prepared statements cannot invoke stored procedures that return result sets, because prepared statements do not support multiple result sets.
By default, mysql_query() and
mysql_real_query() interpret their statement
string argument as a single statement to be executed, and you
process the result according to whether the statement produces a
result set (a set of rows, as for SELECT) or an
affected-rows count (as for INSERT,
UPDATE, and so forth).
MySQL 5.0 also supports the execution of a string
containing multiple statements separated by semicolon
(‘;’) characters. This capability
is enabled by special options that are specified either when you
connect to the server with mysql_real_connect()
or after connecting by calling`
mysql_set_server_option().
Executing a multiple-statement string can produce multiple result
sets or row-count indicators. Processing these results involves a
different approach than for the single-statement case: After
handling the result from the first statement, it is necessary to
check whether more results exist and process them in turn if so.
To support multiple-result processing, the C API includes the
mysql_more_results() and
mysql_next_result() functions. Generally, these
functions are used at the end of a loop that iterates as long as
more results are available. Failure to process the
result this way may result in a dropped connection to the
server.
Multiple-result processing also is required if you execute
CALL statements for stored procedures: A stored
procedure returns a status result when it terminates, but it may
also produce result sets as it runs (for example, if it executes
SELECT statements). For any stored procedure
that produces result sets in addition to the final status, you
must be prepared to retrieve multiple results.
The multiple statement and result capabilities can be used only
with mysql_query() or
mysql_real_query(). They cannot be used with
the prepared statement interface. Prepared statement handles are
defined to work only with strings that contain a single statement.
See Section 22.2.4, “C API Prepared Statements”.
To enable multiple-statement execution and result processing, the following options may be used:
The
mysql_real_connect()function has aflagsargument for which two option values are relevent:CLIENT_MULTI_RESULTSenables the client program to process multiple results. This option must be enabled if you executeCALLstatements for stored procedures that produce result sets. Otherwise, such procedures result in an errorError 1312 (0A000): PROCEDURE.proc_namecan't return a result set in the given contextCLIENT_MULTI_STATEMENTSenablesmysql_query()andmysql_real_query()to execute statement strings containing multiple statements separated by semicolons. This option also enablesCLIENT_MULTI_RESULTSimplicitly, so aflagsargument ofCLIENT_MULTI_STATEMENTStomysql_real_connect()is equivalent to an argument ofCLIENT_MULTI_STATEMENTS | CLIENT_MULTI_RESULTS. That is,CLIENT_MULTI_STATEMENTSis sufficient to enable multiple-statement execution and all multiple-result processing.
After the connection to the server has been established, you can use the
mysql_set_server_option()function to enable or disable multiple-statement execution by passing it an argument ofMYSQL_OPTION_MULTI_STATEMENTS_ONorMYSQL_OPTION_MULTI_STATEMENTS_OFF. Enabling multiple-statement execution with this function also enables processing of “simple” results for a multiple-statement string where each statement produces a single result, but is not sufficient to allow processing of stored procedures that produce result sets.
The following procedure outlines a suggested strategy for handling multiple statements:
Pass
CLIENT_MULTI_STATEMENTStomysql_real_connect(), to fully enable multiple-statement execution and multiple-result processing.After calling
mysql_query()ormysql_real_query()and verifying that it succeeds, enter a loop within which you process statement results.For each iteration of the loop, handle the current statement result, retrieving either a result set or an affected-rows count. If an error occurs, exit the loop.
At the end of the loop, call
mysql_next_result()to check whether another result exists and initiate retrieval for it if so. If no more results are available, exit the loop.
One possible implementation of the preceding strategy is shown following.
/* connect to server with option CLIENT_MULTI_STATEMENTS */
if (mysql_real_connect (mysql, host_name, user_name, password,
db_name, port_num, socket_name, CLIENT_MULTI_STATEMENTS) == NULL)
{
printf("mysql_real_connect() failed\n");
mysql_close(mysql);
exit(1);
}
/* execute multiple statements */
status = mysql_query(mysql,
"DROP TABLE IF EXISTS test_table;\
CREATE TABLE test_table(id INT);\
INSERT INTO test_table VALUES(10);\
UPDATE test_table SET id=20 WHERE id=10;\
SELECT * FROM test_table;\
DROP TABLE test_table");
if (status)
{
printf("Could not execute statement(s)");
mysql_close(mysql);
exit(0);
}
/* process each statement result */
do {
/* did current statement return data? */
result = mysql_store_result(mysql);
if (result)
{
/* yes; process rows and free the result set */
process_result_set(mysql, result);
mysql_free_result(result);
}
else /* no result set or error */
{
if (mysql_field_count(mysql) == 0)
{
printf("%lld rows affected\n",
mysql_affected_rows(mysql));
}
else /* some error occurred */
{
printf("Could not retrieve result set\n");
break;
}
}
/* more results? -1 = no, >0 = error, 0 = yes (keep looping) */
if ((status = mysql_next_result(mysql)) > 0)
printf("Could not execute statement\n");
} while (status == 0);
mysql_close(mysql);
The final part of the loop can be reduced to a simple test of
whether mysql_next_result() returns non-zero.
The code as written distinguishes between no more results and an
error, which allows a message to be printed for the latter
occurrence.
The binary (prepared statement) protocol allows you to send and
receive date and time values (DATE,
TIME, DATETIME, and
TIMESTAMP), using the
MYSQL_TIME structure. The members of this
structure are described in
Section 22.2.5, “C API Prepared Statement Data types”.
To send temporal data values, create a prepared statement using
mysql_stmt_prepare(). Then, before calling
mysql_stmt_execute() to execute the statement,
use the following procedure to set up each temporal parameter:
In the
MYSQL_BINDstructure associated with the data value, set thebuffer_typemember to the type that indicates what kind of temporal value you're sending. ForDATE,TIME,DATETIME, orTIMESTAMPvalues, setbuffer_typetoMYSQL_TYPE_DATE,MYSQL_TYPE_TIME,MYSQL_TYPE_DATETIME, orMYSQL_TYPE_TIMESTAMP, respectively.Set the
buffermember of theMYSQL_BINDstructure to the address of theMYSQL_TIMEstructure in which you pass the temporal value.Fill in the members of the
MYSQL_TIMEstructure that are appropriate for the type of temporal value to be passed.
Use mysql_stmt_bind_param() to bind the
parameter data to the statement. Then you can call
mysql_stmt_execute().
To retrieve temporal values, the procedure is similar, except that
you set the buffer_type member to the type of
value you expect to receive, and the buffer
member to the address of a MYSQL_TIME structure
into which the returned value should be placed. Use
mysql_bind_results() to bind the buffers to the
statement after calling mysql_stmt_execute()
and before fetching the results.
Here is a simple example that inserts DATE,
TIME, and TIMESTAMP data.
The mysql variable is assumed to be a valid
connection handle.
MYSQL_TIME ts;
MYSQL_BIND bind[3];
MYSQL_STMT *stmt;
strmov(query, "INSERT INTO test_table(date_field, time_field, \
timestamp_field) VALUES(?,?,?");
stmt = mysql_stmt_init(mysql);
if (!stmt)
{
fprintf(stderr, " mysql_stmt_init(), out of memory\n");
exit(0);
}
if (mysql_stmt_prepare(mysql, query, strlen(query)))
{
fprintf(stderr, "\n mysql_stmt_prepare(), INSERT failed");
fprintf(stderr, "\n %s", mysql_stmt_error(stmt));
exit(0);
}
/* set up input buffers for all 3 parameters */
bind[0].buffer_type= MYSQL_TYPE_DATE;
bind[0].buffer= (char *)&ts;
bind[0].is_null= 0;
bind[0].length= 0;
...
bind[1]= bind[2]= bind[0];
...
mysql_stmt_bind_param(stmt, bind);
/* supply the data to be sent in the ts structure */
ts.year= 2002;
ts.month= 02;
ts.day= 03;
ts.hour= 10;
ts.minute= 45;
ts.second= 20;
mysql_stmt_execute(stmt);
..
You need to use the following functions when you want to create a threaded client. See Section 22.2.16, “How to Make a Threaded Client”.
void my_init(void)
Description
my_init() initializes some global variables
that MySQL needs. If you are using a thread-safe client library,
it also calls mysql_thread_init() for this
thread.
It is necessary for my_init() to be called
early in the initialization phase of a program's use of the
MySQL library. However, my_init() is
automatically called by mysql_init(),
mysql_library_init(),
mysql_server_init(), and
mysql_connect(). If you ensure that your
program invokes one of those functions before any other MySQL
calls, there is no need to invoke my_init()
explicitly.
To access my_init(), your program must
include the my_sys.h header file:
#include <my_sys.h>
Return Values
None.
my_bool mysql_thread_init(void)
Description
This function must be called early within each created thread to
initialize thread-specific variables. However, you may not
necessarily need to invoke it explicitly:
mysql_thread_init() is automatically called
by my_init(), which itself is automatically
called by mysql_init(),
mysql_library_init(),
mysql_server_init(), and
mysql_connect(). If you invoke any of those
functions, mysql_thread_init() will be called
for you.
Return Values
Zero if successful. Non-zero if an error occurred.
void mysql_thread_end(void)
Description
This function needs to be called before calling
pthread_exit() to free memory allocated by
mysql_thread_init().
Note that this mysql_thread_end()
is not invoked automatically by the client
library. It must be called explicitly to avoid a
memory leak.
Return Values
None.
MySQL applications can be written to use an embedded server. See
Section 22.1, “libmysqld, the Embedded MySQL Server Library”. To write such an application, you
must link it against the libmysqld library by
using the -lmysqld flag rather than linking it
against the libmysqlclient client library by
using the -lmysqlclient flag. However, the calls
to initialize and finalize the library are the same whether you
write a client application or one that uses the embedded server:
Call mysql_library_init() to initialize the
library and mysql_library_end() when you are
done with it. See Section 22.2.2, “C API Function Overview”.
mysql_library_init() and
mysql_library_end() are available as of MySQL
5.0.3. For earlier versions of MySQL 5.0, call
mysql_server_init() and
mysql_server_end() instead, which are
equivalent. (mysql_library_init() and
mysql_library_end() actually are
#define symbols that make them equivalent to
mysql_server_init() and
mysql_server_end(), but the names more clearly
indicate that they should be called when beginning and ending use
of a MySQL C API library no matter whether the application uses
libmysqlclient or
libmysqld.)
int mysql_server_init(int argc, char **argv, char
**groups)
Description
This function initializes the MySQL library, which must be done before you call any other MySQL function.
As of MySQL 5.0.3, mysql_server_init() is
deprecated and you should call
mysql_library_init() instead. See
Section 22.2.3.40, “mysql_library_init()”.
Return Values
Zero if successful. Non-zero if an error occurred.
void mysql_server_end(void)
Description
This function finalizes the MySQL library. You should call it when you are done using the library.
As of MySQL 5.0.3, mysql_server_end() is
deprecated and you should call
mysql_library_end() instead. See
Section 22.2.3.39, “mysql_library_end()”.
Return Values
None.
The MySQL client library can perform an automatic reconnect to the server if it finds that the connection is down when you attempt to send a statement to the server to be executed. In this case, the library tries once to reconnect to the server and send the statement again.
Automatic reconnection can be convenient because you need not implement your own reconnect code, but if a reconnection does occur, several aspects of the connection state are reset and your application will not know about it. The connection-related state is affected as follows:
Any active transactions are rolled back and autocommit mode is reset.
All table locks are released.
All
TEMPORARYtables are closed (and dropped).Session variables are reinitialized to the values of the corresponding variables. This also affects variables that are set implicitly by statements such as
SET NAMES.User variable settings are lost.
Prepared statements are released.
HANDLERvariables are closed.The value of
LAST_INSERT_ID()is reset to 0.Locks acquired with
GET_LOCK()are released.mysql_ping()does not attempt a reconnection if the connection is down. It returns an error instead.
If it is important for your application to know that the
connection has been dropped (so that is can exit or take action to
adjust for the loss of state information), be sure to disable
auto-reconnect. This can be done explicitly by calling
mysql_options() with the
MYSQL_OPT_RECONNECT option:
my_bool reconnect = 0; mysql_options(&mysql, MYSQL_OPT_RECONNECT, &reconnect);
In MySQL 5.0, auto-reconnect was enabled by default
until MySQL 5.0.3, and disabled by default thereafter. The
MYSQL_OPT_RECONNECT option is available as of
MySQL 5.0.13.
It is possible for mysql_store_result() to
return NULL following a successful call to
mysql_query(). When this happens, it means
one of the following conditions occurred:
There was a
malloc()failure (for example, if the result set was too large).The data couldn't be read (an error occurred on the connection).
The query returned no data (for example, it was an
INSERT,UPDATE, orDELETE).
You can always check whether the statement should have produced
a non-empty result by calling
mysql_field_count(). If
mysql_field_count() returns zero, the result
is empty and the last query was a statement that does not return
values (for example, an INSERT or a
DELETE). If
mysql_field_count() returns a non-zero value,
the statement should have produced a non-empty result. See the
description of the mysql_field_count()
function for an example.
You can test for an error by calling
mysql_error() or
mysql_errno().
In addition to the result set returned by a query, you can also get the following information:
mysql_affected_rows()returns the number of rows affected by the last query when doing anINSERT,UPDATE, orDELETE.For a fast re-create, use
TRUNCATE TABLE.mysql_num_rows()returns the number of rows in a result set. Withmysql_store_result(),mysql_num_rows()may be called as soon asmysql_store_result()returns. Withmysql_use_result(),mysql_num_rows()may be called only after you have fetched all the rows withmysql_fetch_row().mysql_insert_id()returns the ID generated by the last query that inserted a row into a table with anAUTO_INCREMENTindex. See Section 22.2.3.37, “mysql_insert_id()”.Some queries (
LOAD DATA INFILE ...,INSERT INTO ... SELECT ...,UPDATE) return additional information. The result is returned bymysql_info(). See the description formysql_info()for the format of the string that it returns.mysql_info()returns aNULLpointer if there is no additional information.
If you insert a record into a table that contains an
AUTO_INCREMENT column, you can obtain the
value stored into that column by calling the
mysql_insert_id() function.
You can check from your C applications whether a value was
stored in an AUTO_INCREMENT column by
executing the following code (which assumes that you've checked
that the statement succeeded). It determines whether the query
was an INSERT with an
AUTO_INCREMENT index:
if ((result = mysql_store_result(&mysql)) == 0 &&
mysql_field_count(&mysql) == 0 &&
mysql_insert_id(&mysql) != 0)
{
used_id = mysql_insert_id(&mysql);
}
When a new AUTO_INCREMENT value has been
generated, you can also obtain it by executing a SELECT
LAST_INSERT_ID() statement with
mysql_query() and retrieving the value from
the result set returned by the statement.
For LAST_INSERT_ID(), the most recently
generated ID is maintained in the server on a per-connection
basis. It is not changed by another client. It is not even
changed if you update another AUTO_INCREMENT
column with a non-magic value (that is, a value that is not
NULL and not 0). Using
LAST_INSERT_ID() and
AUTO_INCREMENT columns simultaneously from
multiple clients is perfectly valid. Each client will receive
the last inserted ID for the last statement
that client executed.
If you want to use the ID that was generated for one table and insert it into a second table, you can use SQL statements like this:
INSERT INTO foo (auto,text)
VALUES(NULL,'text'); # generate ID by inserting NULL
INSERT INTO foo2 (id,text)
VALUES(LAST_INSERT_ID(),'text'); # use ID in second table
Note that mysql_insert_id() returns the value
stored into an AUTO_INCREMENT column, whether
that value is automatically generated by storing
NULL or 0 or was specified
as an explicit value. LAST_INSERT_ID()
returns only automatically generated
AUTO_INCREMENT values. If you store an
explicit value other than NULL or
0, it does not affect the value returned by
LAST_INSERT_ID().
For more information on obtaining the last ID in an
AUTO_INCREMENT column:
For information on
LAST_INSERT_ID(), which can be used within an SQL statement, see ???.For information on
mysql_insert_id(), the function you use from within the C API, see Section 22.2.3.37, “mysql_insert_id()”.For information on obtaining the auto incremented value when using Connector/J see Section 23.4.5, “Connector/J Notes and Tips”.
For information on obtaining the auto incremented value when using Connector/ODBC see Section 23.1.6.1.1, “Obtaining Auto-Increment Values”.
When linking with the C API, the following errors may occur on some systems:
gcc -g -o client test.o -L/usr/local/lib/mysql \
-lmysqlclient -lsocket -lnsl
Undefined first referenced
symbol in file
floor /usr/local/lib/mysql/libmysqlclient.a(password.o)
ld: fatal: Symbol referencing errors. No output written to client
If this happens on your system, you must include the math
library by adding -lm to the end of the
compile/link line.
If you compile MySQL clients that you've written yourself or that
you obtain from a third-party, they must be linked using the
-lmysqlclient -lz options in the link command.
You may also need to specify a -L option to tell
the linker where to find the library. For example, if the library
is installed in /usr/local/mysql/lib, use
-L/usr/local/mysql/lib -lmysqlclient -lz in the
link command.
For clients that use MySQL header files, you may need to specify
an -I option when you compile them (for example,
-I/usr/local/mysql/include), so that the compiler
can find the header files.
To make it simpler to compile MySQL programs on Unix, we have provided the mysql_config script for you. See Section 22.9.2, “mysql_config — Get Compile Options for Compiling Clients”.
You can use it to compile a MySQL client as follows:
CFG=/usr/local/mysql/bin/mysql_config sh -c "gcc -o progname `$CFG --cflags` progname.c `$CFG --libs`"
The sh -c is needed to get the shell not to
treat the output from mysql_config as one word.
The client library is almost thread-safe. The biggest problem is
that the subroutines in net.c that read from
sockets are not interrupt safe. This was done with the thought
that you might want to have your own alarm that can break a long
read to a server. If you install interrupt handlers for the
SIGPIPE interrupt, the socket handling should
be thread-safe.
To avoid aborting the program when a connection terminates, MySQL
blocks SIGPIPE on the first call to
mysql_library_init(),
mysql_init(), or
mysql_connect(). If you want to use your own
SIGPIPE handler, you should first call
mysql_library_init() and then install your
handler.
In the older binaries that we distribute on our Web site (http://www.mysql.com/), client libraries other than those for Windows are not normally compiled with the thread-safe option. Newer binary distributions should have both a normal and a thread-safe client library.
To get a threaded client where you can interrupt the client from
other threads and set timeouts when talking with the MySQL server,
you should use the net_serv.o code that the
server uses and the -lmysys,
-lmystrings, and -ldbug
libraries.
If you don't need interrupts or timeouts, you can just compile a
thread-safe client library (mysqlclient_r) and
use this. See Section 22.2, “MySQL C API”. In this case, you don't have to
worry about the net_serv.o object file or the
other MySQL libraries.
When using a threaded client and you want to use timeouts and
interrupts, you can make great use of the routines in the
thr_alarm.c file. If you are using routines
from the mysys library, the only thing you must
remember is to call my_init() first! See
Section 22.2.11, “C API Threaded Function Descriptions”.
In all cases, be sure to initialize the client library by calling
mysql_library_init() before calling any other
MySQL functions. When you are done with the library, call
mysql_library_end().
mysql_real_connect() is not thread-safe by
default. The following notes describe how to compile a thread-safe
client library and use it in a thread-safe manner. (The notes
below for mysql_real_connect() also apply to
mysql_connect() as well, although
mysql_connect() is deprecated.)
To make mysql_real_connect() thread-safe, you
must configure your MySQL distribution with this command:
shell> ./configure --enable-thread-safe-client
Then recompile the distribution to create a thread-safe client
library, libmysqlclient_r. (Assuming that your
operating system has a thread-safe
gethostbyname_r() function.) This library is
thread-safe per connection. You can let two threads share the same
connection with the following caveats:
Two threads can't send a query to the MySQL server at the same time on the same connection. In particular, you have to ensure that between calls to
mysql_query()andmysql_store_result(), no other thread is using the same connection.Many threads can access different result sets that are retrieved with
mysql_store_result().If you use
mysql_use_result, you must ensure that no other thread is using the same connection until the result set is closed. However, it really is best for threaded clients that share the same connection to usemysql_store_result().If you want to use multiple threads on the same connection, you must have a mutex lock around your pair of
mysql_query()andmysql_store_result()calls. Oncemysql_store_result()is ready, the lock can be released and other threads may query the same connection.If you use POSIX threads, you can use
pthread_mutex_lock()andpthread_mutex_unlock()to establish and release a mutex lock.
You need to know the following if a thread that is calling MySQL functions did not create the connection to the MySQL database:
When you call mysql_init() or
mysql_connect(), MySQL creates a
thread-specific variable for the thread that is used by the debug
library (among other things).
If you call a MySQL function before the thread has called
mysql_init() or
mysql_connect(), the thread does not have the
necessary thread-specific variables in place and you are likely to
end up with a core dump sooner or later.
To get things to work smoothly you have to do the following:
Call
mysql_library_init()before any other MySQL functions. It is not thread-safe, so call it before threads are created, or protect the call with a mutex.Arrange for
mysql_thread_init()to be called early in the thread handler before calling any MySQL function. If you callmysql_init()ormysql_connect(), they will callmysql_thread_init()for you.In the thread, call
mysql_thread_end()before callingpthread_exit(). This frees the memory used by MySQL thread-specific variables.
If “undefined symbol” errors occur when linking your
client with libmysqlclient_r, in most cases
this is because you haven't included the thread libraries on the
link/compile command.
PHP is a server-side, HTML-embedded scripting language that may be used to create dynamic Web pages. It is available for most operating systems and Web servers, and can access most common databases, including MySQL. PHP may be run as a separate program or compiled as a module for use with the Apache Web server.
PHP actually provides two different MySQL API extensions:
mysql: Available for PHP versions 4 and 5, this extension is intended for use with MySQL versions prior to MySQL 4.1. This extension does not support the improved authentication protocol used in MySQL 5.0, nor does it support prepared statements or multiple statements. If you wish to use this extension with MySQL 5.0, you will likely want to configure the MySQL server to use the --old-passwords option (see Section B.1.2.3, “Client does not support authentication protocol”). This extension is documented on the PHP Web site at http://php.net/mysql.mysqli- Stands for “MySQL, Improved”; this extension is available only in PHP 5. It is intended for use with MySQL 4.1.1 and later. This extension fully supports the authentication protocol used in MySQL 5.0, as well as the Prepared Statements and Multiple Statements APIs. In addition, this extension provides an advanced, object-oriented programming interface. You can read the documentation for themysqliextension at http://php.net/mysqli. A helpful article can be found at http://www.zend.com/php5/articles/php5-mysqli.php.
If you're experiencing problems with enabling both the
mysql and the mysqli
extension when building PHP on Linux yourself, see
Section 22.3.2, “Enabling Both mysql and mysqli in
PHP”.
The PHP distribution and documentation are available from the
PHP Web site. MySQL
provides the mysql and
mysqli extensions for the Windows operating
system for MySQL versions as of 5.0.18 on
http://dev.mysql.com/downloads/connector/php/.
You can find information why you should preferably use the
extensions provided by MySQL on that page.
Error: Maximum Execution Time Exceeded: This is a PHP limit; go into thephp.inifile and set the maximum execution time up from 30 seconds to something higher, as needed. It is also not a bad idea to double the RAM allowed per script to 16MB instead of 8MB.Fatal error: Call to unsupported or undefined function mysql_connect() in ...: This means that your PHP version isn't compiled with MySQL support. You can either compile a dynamic MySQL module and load it into PHP or recompile PHP with built-in MySQL support. This process is described in detail in the PHP manual.Error: Undefined reference to 'uncompress': This means that the client library is compiled with support for a compressed client/server protocol. The fix is to add-lzlast when linking with-lmysqlclient.Error: Client does not support authentication protocol: This is most often encountered when trying to use the oldermysqlextension with MySQL 4.1.1 and later. Possible solutions are: downgrade to MySQL 4.0; switch to PHP 5 and the newermysqliextension; or configure the MySQL server with--old-passwords. (See Section B.1.2.3, “Client does not support authentication protocol”, for more information.)
Those with PHP4 legacy code can make use of a compatibility layer for the old and new MySQL libraries, such as this one: http://www.coggeshall.org/oss/mysql2i.
If you're experiencing problems with enabling both the
mysql and the mysqli
extension when building PHP on Linux yourself, you should try
the following procedure.
Configure PHP like this:
./configure --with-mysqli=/usr/bin/mysql_config --with-mysql=/usr
Edit the
Makefileand search for a line that starts withEXTRA_LIBS. It might look like this (all on one line):EXTRA_LIBS = -lcrypt -lcrypt -lmysqlclient -lz -lresolv -lm -ldl -lnsl -lxml2 -lz -lm -lxml2 -lz -lm -lmysqlclient -lz -lcrypt -lnsl -lm -lxml2 -lz -lm -lcrypt -lxml2 -lz -lm -lcrypt
Remove all duplicates, so that the line looks like this (all on one line):
EXTRA_LIBS = -lcrypt -lcrypt -lmysqlclient -lz -lresolv -lm -ldl -lnsl -lxml2
Build and install PHP:
make make install
The Perl DBI module provides a generic
interface for database access. You can write a DBI script that
works with many different database engines without change. To use
DBI, you must install the DBI module, as well
as a DataBase Driver (DBD) module for each type of server you want
to access. For MySQL, this driver is the
DBD::mysql module.
Perl DBI is the recommended Perl interface. It replaces an older
interface called mysqlperl, which should be
considered obsolete.
Installation instructions for Perl DBI support are given in Section 2.4.20, “Perl Installation Notes”.
DBI information is available at the command line, online, or in printed form:
Once you have the
DBIandDBD::mysqlmodules installed, you can get information about them at the command line with theperldoccommand:shell>
perldoc DBIshell>perldoc DBI::FAQshell>perldoc DBD::mysqlYou can also use
pod2man,pod2html, and so forth to translate this information into other formats.For online information about Perl DBI, visit the DBI Web site, http://dbi.perl.org/. That site hosts a general DBI mailing list. MySQL AB hosts a list specifically about
DBD::mysql; see Section 1.7.1, “MySQL Mailing Lists”.For printed information, the official DBI book is Programming the Perl DBI (Alligator Descartes and Tim Bunce, O'Reilly & Associates, 2000). Information about the book is available at the DBI Web site, http://dbi.perl.org/.
For information that focuses specifically on using DBI with MySQL, see MySQL and Perl for the Web (Paul DuBois, New Riders, 2001). This book's Web site is http://www.kitebird.com/mysql-perl/.
MySQL++ is a MySQL API for C++. Warren Young
has taken over this project. More information can be found at
http://tangentsoft.net/mysql++/doc.
MySQLdb provides MySQL support for Python,
compliant with the Python DB API version 2.0. It can be found at
http://sourceforge.net/projects/mysql-python/.
MySQLtcl is a simple API for accessing a MySQL
database server from the Tcl programming language. It can be found
at http://www.xdobry.de/mysqltcl/.
Eiffel MySQL is an interface to the MySQL database server using the Eiffel programming language, written by Michael Ravits. It can be found at http://efsa.sourceforge.net/archive/ravits/mysql.htm.
This section describes some utilities that you may find useful when developing MySQL programs.
msql2mysqlA shell script that converts
mSQLprograms to MySQL. It doesn't handle every case, but it gives a good start when converting.mysql_configA shell script that produces the option values needed when compiling MySQL programs.
Initially, the MySQL C API was developed to be very similar to that for the mSQL database system. Because of this, mSQL programs often can be converted relatively easily for use with MySQL by changing the names of the C API functions.
The msql2mysql utility performs the conversion of mSQL C API function calls to their MySQL equivalents. msql2mysql converts the input file in place, so make a copy of the original before converting it. For example, use msql2mysql like this:
shell>cp client-prog.c client-prog.c.origshell>msql2mysql client-prog.cclient-prog.c converted
Then examine client-prog.c and make any
post-conversion revisions that may be necessary.
msql2mysql uses the replace utility to make the function name substitutions. See Section 8.28, “replace — A String-Replacement Utility”.
mysql_config provides you with useful information for compiling your MySQL client and connecting it to MySQL.
mysql_config supports the following options:
--cflagsCompiler flags to find include files and critical compiler flags and defines used when compiling the
libmysqlclientlibrary.--includeCompiler options to find MySQL include files. (Note that normally you would use
--cflagsinstead of this option.)--libmysqld-libs,--embeddedLibraries and options required to link with the MySQL embedded server.
--libsLibraries and options required to link with the MySQL client library.
--libs_rLibraries and options required to link with the thread-safe MySQL client library.
--portThe default TCP/IP port number, defined when configuring MySQL.
--socketThe default Unix socket file, defined when configuring MySQL.
--versionVersion number for the MySQL distribution.
If you invoke mysql_config with no options, it displays a list of all options that it supports, and their values:
shell> mysql_config
Usage: /usr/local/mysql/bin/mysql_config [options]
Options:
--cflags [-I/usr/local/mysql/include/mysql -mcpu=pentiumpro]
--include [-I/usr/local/mysql/include/mysql]
--libs [-L/usr/local/mysql/lib/mysql -lmysqlclient -lz
-lcrypt -lnsl -lm -L/usr/lib -lssl -lcrypto]
--libs_r [-L/usr/local/mysql/lib/mysql -lmysqlclient_r
-lpthread -lz -lcrypt -lnsl -lm -lpthread]
--socket [/tmp/mysql.sock]
--port [3306]
--version [4.0.16]
--libmysqld-libs [-L/usr/local/mysql/lib/mysql -lmysqld -lpthread -lz
-lcrypt -lnsl -lm -lpthread -lrt]
You can use mysql_config within a command line to include the value that it displays for a particular option. For example, to compile a MySQL client program, use mysql_config as follows:
shell>CFG=/usr/local/mysql/bin/mysql_configshell>sh -c "gcc -o progname `$CFG --cflags` progname.c `$CFG --libs`"
When you use mysql_config this way, be
sure to invoke it within backtick
(‘`’) characters. That tells
the shell to execute it and substitute its output into the
surrounding command.
Table of Contents
This chapter describes MySQL Connectors, drivers that provide connectivity to the MySQL server for client programs. There are currently five MySQL Connectors:
Connector/ODBC provides driver support for connecting to a MySQL server using the Open Database Connectivity (ODBC) API. Support is available for ODBC connectivity from Windows, Unix and Mac OS X platforms.
Connector/NET enables developers to create .NET applications that use data stored in a MySQL database. Connector/NET implements a fully-functional ADO.NET interface and provides support for use with ADO.NET aware tools. Applications that want to use Connector/NET can be written in any of the supported .NET languages.
The MySQL Visual Studio Plugin works with Connector/NET and Visual Studio 2005. The plugin is a MySQL DDEX Provider, which means that you can use the schema and data manipulation tools within Visual Studio to create and edit objects within a MySQL database.
Connector/J provides driver support for connecting to MySQL from a Java application using the standard Java Database Connectivity (JDBC) API.
Connector/MXJ is a tool that enables easy deployment and management of MySQL server and database through your Java application.
Connector/PHP is a Windows-only connector for PHP that provides the
mysqlandmysqliextensions for use with MySQL 5.0.18 and later.
For information on connecting to a MySQL server using other languages and interfaces than those detailed above, including Perl, Python and PHP for other platforms and environments, please refer to the Chapter 22, APIs and Libraries chapter.
The MySQL Connector/ODBC is the name for the family of MySQL ODBC drivers (previously called MyODBC drivers) that provide access to a MySQL database using the industry standard Open Database Connectivity (ODBC) API. This reference covers Connector/ODBC 3.51, a version of the API that provides ODBC 3.5x compliant access to a MySQL database.
The manual for versions of Connector/ODBC older than 3.51 can be located in the corresponding binary or source distribution.
For more information on the ODBC API standard and how to use it, refer to http://www.microsoft.com/data/.
The application development part of this reference assumes a good working knowledge of C, general DBMS knowledge, and finally, but not least, familiarity with MySQL. For more information about MySQL functionality and its syntax, refer to http://dev.mysql.com/doc/.
Typically, you need to install Connector/ODBC only on Windows machines. For Unix and Mac OS X you can use the native MySQL network or named pipe to communicate with your MySQL database. You may need Connector/ODBC for Unix or Mac OS X if you have an application that requires an ODBC interface to communicate with the database. Applications that require ODBC to communicate with MySQL include ColdFusion, Microsoft Office, and Filemaker Pro.
If you want to install the Connector/ODBC connector on a Unix host, then you must also install an ODBC manager.
Key topics:
For help installing Connector/ODBC see Section 23.1.2, “Connector/ODBC Installation”.
For more information on connecting to a MySQL database from a Windows host using Connector/ODBC see Section 23.1.4.2, “Step-by-step Guide to Connecting to a MySQL Database through Connector/ODBC”.
If you want to use Microsoft Access as an interface to a MySQL database using Connector/ODBC see Section 23.1.4.4, “Using Connector/ODBC with Microsoft Access”.
General tips on using Connector/ODBC, including obtaining the last auto increment ID see Section 23.1.6.1, “Connector/ODBC General Functionality”.
For tips and common questions on using Connector/ODBC with specific application see Section 23.1.6.2, “Connector/ODBC Application Specific Tips”.
For a general list of Frequently Asked Questions see Section 23.1.6.3, “Connector/ODBC Errors and Resolutions”.
Additional support when using Connector/ODBC is available, see Section 23.1.7, “Connector/ODBC Support”.
ODBC (Open Database Connectivity) provides a way for client programs to access a wide range of databases or data sources. ODBC is a standardized API that allows connections to SQL database servers. It was developed according to the specifications of the SQL Access Group and defines a set of function calls, error codes, and data types that can be used to develop database-independent applications. ODBC usually is used when database independence or simultaneous access to different data sources is required.
For more information about ODBC, refer to http://www.microsoft.com/data/.
There are currently two version of Connector/ODBC available:
Connector/ODBC 5.0, currently in beta status, has been designed to extend the functionality of the Connector/ODBC 3.51 driver and incorporate full support for the functionality in the MySQL 5.0 server release, including stored procedures and views. Applications using Connector/ODBC 3.51 will be compatible with Connector/ODBC 5.0, while being able to take advantage of the new features. Features and functionality of the Connector/ODBC 5.0 driver are not currently included in this guide.
Connector/ODBC 3.51 is the current release of the 32-bit ODBC driver, also known as the MySQL ODBC 3.51 driver. This version is enhanced compared to the older Connector/ODBC 2.50 driver. It has support for ODBC 3.5x specification level 1 (complete core API + level 2 features) in order to continue to provide all functionality of ODBC for accessing MySQL.
MyODBC 2.50 is the previous version of the 32-bit ODBC driver from MySQL AB that is based on ODBC 2.50 specification level 0 (with level 1 and 2 features). Information about the MyODBC 2.50 driver is included in this guide for the purposes of comparison only.
Note
From this section onward, the primary focus of this guide is the Connector/ODBC 3.51 driver. More information about the MyODBC 2.50 driver in the documentation included in the installation packages for that version. If there is a specific issue (error or known problem) that only affects the 2.50 version, it may be included here for reference.
Note
Version numbers for MySQL products are formatted as X.X.X. However, Windows tools (Control Panel, properties display) may show the version numbers as XX.XX.XX. For example, the official MySQL formatted version number 5.0.9 may be displayed by Windows tools as 5.00.09. The two versions are the same; only the number display format is different.
Open Database Connectivity (ODBC) is a widely accepted application-programming interface (API) for database access. It is based on the Call-Level Interface (CLI) specifications from X/Open and ISO/IEC for database APIs and uses Structured Query Language (SQL) as its database access language.
A survey of ODBC functions supported by Connector/ODBC is given at Section 23.1.5.1, “Connector/ODBC API Reference”. For general information about ODBC, see http://www.microsoft.com/data/.
The Connector/ODBC architecture is based on five components, as shown in the following diagram:
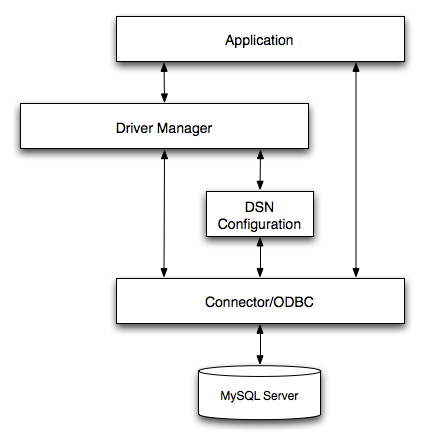
Application:
The Application uses the ODBC API to access the data from the MySQL server. The ODBC API in turn uses the communicates with the Driver Manager. The Application communicates with the Driver Manager using the standard ODBC calls. The Application does not care where the data is stored, how it is stored, or even how the system is configured to access the data. It needs to know only the Data Source Name (DSN).
A number of tasks are common to all applications, no matter how they use ODBC. These tasks are:
Selecting the MySQL server and connecting to it
Submitting SQL statements for execution
Retrieving results (if any)
Processing errors
Committing or rolling back the transaction enclosing the SQL statement
Disconnecting from the MySQL server
Because most data access work is done with SQL, the primary tasks for applications that use ODBC are submitting SQL statements and retrieving any results generated by those statements.
Driver manager:
The Driver Manager is a library that manages communication between application and driver or drivers. It performs the following tasks:
Resolves Data Source Names (DSN). The DSN is a configuration string that identifies a given database driver, database, database host and optionally authentication information that enables an ODBC application to connect to a database using a standardized reference.
Because the database connectivity information is identified by the DSN, any ODBC compliant application can connect to the data source using the same DSN reference. This eliminates the need to separately configure each application that needs access to a given database; instead you instruct the application to use a pre-configured DSN.
Loading and unloading of the driver required to access a specific database as defined within the DSN. For example, if you have configured a DSN that connects to a MySQL database then the driver manager will load the Connector/ODBC driver to enable the ODBC API to communicate with the MySQL host.
Processes ODBC function calls or passes them to the driver for processing.
Connector/ODBC Driver:
The Connector/ODBC driver is a library that implements the functions supported by the ODBC API. It processes ODBC function calls, submits SQL requests to MySQL server, and returns results back to the application. If necessary, the driver modifies an application's request so that the request conforms to syntax supported by MySQL.
DSN Configuration:
The ODBC configuration file stores the driver and database information required to connect to the server. It is used by the Driver Manager to determine which driver to be loaded according to the definition in the DSN. The driver uses this to read connection parameters based on the DSN specified. For more information, Section 23.1.3, “Connector/ODBC Configuration”.
MySQL Server:
The MySQL database where the information is stored. The database is used as the source of the data (during queries) and the destination for data (during inserts and updates).
An ODBC Driver Manager is a library that manages communication between the ODBC-aware application and any drivers. Its main functionality includes:
Resolving Data Source Names (DSN).
Driver loading and unloading.
Processing ODBC function calls or passing them to the driver.
Both Windows and Mac OS X include ODBC driver managers with the operating system. Most ODBC Driver Manager implementations also include an administration application that makes the configuration of DSN and drivers easier. Examples and information on these managers, including Unix ODBC driver managers are listed below:
Microsoft Windows ODBC Driver Manager (
odbc32.dll), http://www.microsoft.com/data/.Mac OS X includes
ODBC Administrator, a GUI application that provides a simpler configuration mechanism for the Unix iODBC Driver Manager. You can configure DSN and driver information either through ODBC Administrator or through the iODBC configuration files. This also means that you can test ODBC Administrator configurations using theiodbctestcommand. http://www.apple.com.unixODBCDriver Manager for Unix (libodbc.so). See http://www.unixodbc.org, for more information. TheunixODBCDriver Manager includes the Connector/ODBC driver 3.51 in the installation package, starting with versionunixODBC2.1.2.iODBCODBC Driver Manager for Unix (libiodbc.so), see http://www.iodbc.org, for more information.
You can install the Connector/ODBC drivers using two different methods, a binary installation and a source installation. The binary installation is the easiest and most straightforward method of installation. Using the source installation methods should only be necessary on platforms where a binary installation package is not available, or in situations where you want to customize or modify the installation process or Connector/ODBC drivers before installation.
MySQL AB distributes all its products under the General Public License (GPL). You can get a copy of the latest version of Connector/ODBC binaries and sources from the MySQL AB Web site http://dev.mysql.com/downloads/.
For more information about Connector/ODBC, visit http://www.mysql.com/products/myodbc/.
For more information about licensing, visit http://www.mysql.com/company/legal/licensing/.
Connector/ODBC can be used on all major platforms supported by MySQL. You can install it on:
Windows 95, 98, Me, NT, 2000, XP, and 2003
All Unix-like Operating Systems, including: AIX, Amiga, BSDI, DEC, FreeBSD, HP-UX 10/11, Linux, NetBSD, OpenBSD, OS/2, SGI Irix, Solaris, SunOS, SCO OpenServer, SCO UnixWare, Tru64 Unix
Mac OS X and Mac OS X Server
If a binary distribution is not available for a particular
platform, see Section 23.1.2.4, “Installing Connector/ODBC from a source distribution”, to
build the driver from the original source code. You can
contribute the binaries you create to MySQL by sending a mail
message to <myodbc@lists.mysql.com>, so that it
becomes available for other users.
Using a binary distribution offers the most straightforward method for installing Connector/ODBC. If you want more control over the driver, the installation location and or to customize elements of the driver you will need to build and install from the source. See the Section 23.1.2.4, “Installing Connector/ODBC from a source distribution”.
Before installing the Connector/ODBC drivers on Windows you should ensure that your Microsoft Data Access Components (MDAC) are up to date. You can obtain the latest version from the Microsoft Data Access and Storage Web site.
There are three available distribution types to use when installing for Windows. The contents in each case are identical, it is only the installation method which is different.
Zipped installer consists of a Zipped package containing a standalone installation application. To install from this package, you must unzip the installer, and then run the installation application. See Section 23.1.2.3.1.1, “Installing the Windows Connector/ODBC Driver using an installer” to complete the installation.
MSI installer, an installation file that can be used with the installer included in Windows 2000, Windows XP and Windows Server 2003. See Section 23.1.2.3.1.1, “Installing the Windows Connector/ODBC Driver using an installer” to complete the installation.
Zipped DLL package, containing the DLL files that need must be manually installed. See Section 23.1.2.3.1.2, “Installing the Windows Connector/ODBC Driver using the Zipped DLL package” to complete the installation.
The installer packages offer a very simple method for installing the Connector/ODBC drivers. If you have downloaded the zipped installer then you must extract the installer application. The basic installation process is identical for both installers.
You should follow these steps to complete the installation:
Double click on the standalone installer that you extracted, or the MSI file you downloaded.
The MySQL Connector/ODBC 3.51 - Setup Wizard will start. Click the button to begin the installation process.
You will need to choose the installation type. The Typical installation provides the standard files you will need to connect to a MySQL database using ODBC. The Complete option installs all the available files, including debug and utility components. It is recommended you choose one of these two options to complete the installation. If choose one of these methods, click and then proceed to step 5.
You may also choose a Custom installation, which enables you to select the individual components that you want to install. You have chosen this method, click and then proceed to step 4.
If you have chosen a custom installation, use the popups to select which components to install and then click to install the necessary files.
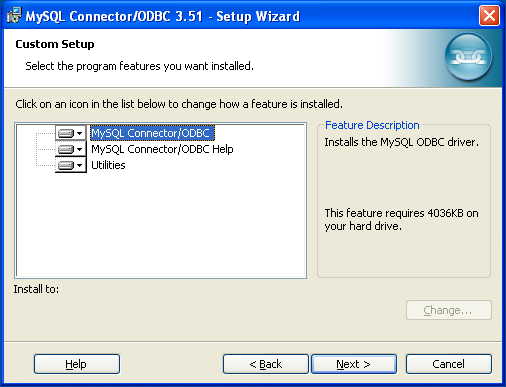
Once the files have copied to your machine, the installation is complete. Click to exit the installer.
Now the installation is complete, you can continue to configure your ODBC connections using Section 23.1.3, “Connector/ODBC Configuration”.
If you have downloaded the Zipped DLL package then you must install the individual files required for Connector/ODBC operation manually. Once you have unzipped the installation files, you can either perform this operation by hand, executing each statement individually, or you can use the included Batch file to perform an installation to the default locations.
To install using the Batch file:
Unzip the Connector/ODBC Zipped DLL package.
Open a Command Prompt.
Change to the directory created when you unzipped the Connector/ODBC Zipped DLL package.
Run
Install.bat:C:\>
Install.batThis will copy the necessary files into the default location, and then register the Connector/ODBC driver with the Windows ODBC manager.
If you want to copy the files to an alternative location - for example, to run or test different versions of the Connector/ODBC driver on the same machine, then you must copy the files by hand. It is however not recommended to install these files in a non-standard location. To copy the files by hand to the default installation location use the following steps:
Unzip the Connector/ODBC Zipped DLL package.
Open a Command Prompt.
Change to the directory created when you unzipped the Connector/ODBC Zipped DLL package.
Copy the library files to a suitable directory. The default is to copy them into the default Windows system directory
\Windows\System32:C:\>
copy lib\myodbc3S.dll \Windows\System32C:\>copy lib\myodbc3S.lib \Windows\System32C:\>copy lib\myodbc3.dll \Windows\System32C:\>copy lib\myodbc3.lib \Windows\System32Copy the Connector/ODBC tools. These must be placed into a directory that is in the system
PATH. The default is to install these into the Windows system directory\Windows\System32:C:\>
copy bin\myodbc3i.exe \Windows\System32C:\>copy bin\myodbc3m.exe \Windows\System32C:\>copy bin\myodbc3c.exe \Windows\System32Optionally copy the help files. For these files to be accessible through the help system, they must be installed in the Windows system directory:
C:\>
copy doc\*.hlp \Windows\System32Finally, you must register the Connector/ODBC driver with the ODBC manager:
C:\>
myodbc3i -a -d -t"MySQL ODBC 3.51 Driver;\ DRIVER=myodbc3.dll;SETUP=myodbc3S.dll"You must change the references to the DLL files and command location in the above statement if you have not installed these files into the default location.
On Windows, you may get the following error when trying to install the older MyODBC 2.50 driver:
An error occurred while copying C:\WINDOWS\SYSTEM\MFC30.DLL. Restart Windows and try installing again (before running any applications which use ODBC)
The reason for the error is that another application is
currently using the ODBC system. Windows may not allow you
to complete the installation. In most cases, you can
continue by pressing Ignore to copy the
rest of the Connector/ODBC files and the final installation
should still work. If it doesn't, the solution is to re-boot
your computer in “safe mode.” Choose safe mode
by pressing F8 just before your machine starts Windows
during re-booting, install the Connector/ODBC drivers, and
re-boot to normal mode.
There are two methods available for installing Connector/ODBC on Unix from a binary distribution. For most Unix environments you will need to use the tarball distribution. For Linux systems, there is also an RPM distribution available.
To install the driver from a tarball distribution
(.tar.gz file), download the latest
version of the driver for your operating system and follow
these steps that demonstrate the process using the Linux
version of the tarball:
shell>su rootshell>gunzip mysql-connector-odbc-3.51.11-i686-pc-linux.tar.gzshell>tar xvf mysql-connector-odbc-3.51.11-i686-pc-linux.tarshell>cd mysql-connector-odbc-3.51.11-i686-pc-linux
Read the installation instructions in the
INSTALL-BINARY file and execute these
commands.
shell>cp libmyodbc* /usr/local/libshell>cp odbc.ini /usr/local/etcshell>export ODBCINI=/usr/local/etc/odbc.ini
Then proceed on to
Section 23.1.3.4, “Configuring a Connector/ODBC DSN on Unix”,
to configure the DSN for Connector/ODBC. For more
information, refer to the
INSTALL-BINARY file that comes with
your distribution.
To install or upgrade Connector/ODBC from an RPM
distribution on Linux, simply download the RPM distribution
of the latest version of Connector/ODBC and follow the
instructions below. Use su root to become
root, then install the RPM file.
If you are installing for the first time:
shell>su rootshell>rpm -ivh mysql-connector-odbc-3.51.12.i386.rpm
If the driver exists, upgrade it like this:
shell>su rootshell>rpm -Uvh mysql-connector-odbc-3.51.12.i386.rpm
If there is any dependency error for MySQL client library,
libmysqlclient, simply ignore it by
supplying the --nodeps option, and then
make sure the MySQL client shared library is in the path or
set through LD_LIBRARY_PATH.
This installs the driver libraries and related documents to
/usr/local/lib and
/usr/share/doc/MyODBC, respectively.
Proceed onto
Section 23.1.3.4, “Configuring a Connector/ODBC DSN on Unix”.
To uninstall the driver,
become root and execute an
rpm command:
shell>su rootshell>rpm -e mysql-connector-odbc
Mac OS X is based on the FreeBSD operating system, and you can normally use the MySQL network port for connecting to MySQL servers on other hosts. Installing the Connector/ODBC driver enables you to connect to MySQL databases on any platform through the ODBC interface. You should only need to install the Connector/ODBC driver when your application requires an ODBC interface. Applications that require or can use ODBC (and therefore the Connector/ODBC driver) include ColdFusion, Filemaker Pro, 4th Dimension and many other applications.
Mac OS X includes its own ODBC manager, based on the
iODBC manager. Mac OS X includes an
administration tool that provides easier administration of
ODBC drivers and configuration, updating the underlying
iODBC configuration files.
You can install Connector/ODBC on a Mac OS X or Mac OS X
Server computer by using the binary distribution. The
package is available as a compressed disk image
(.dmg) file. To install Connector/ODBC
on your computer using this method, follow these steps:
Download the file to your computer and double-click on the downloaded image file.
Within the disk image you will find an installer package (with the
.pkgextension). Double click on this file to start the Mac OS X installer.You will be presented with the installer welcome message. Click the button to begin the installation process.
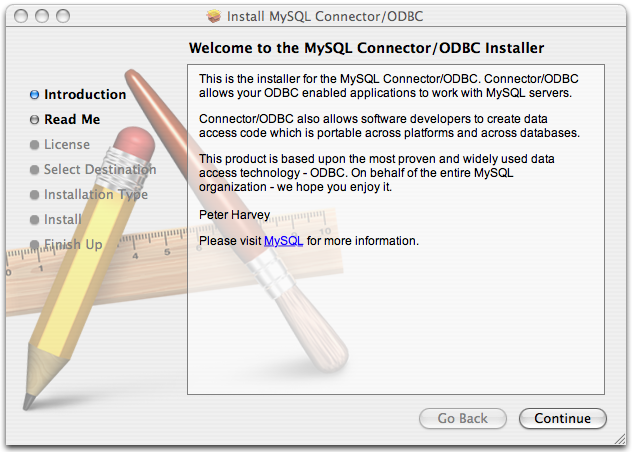
Please take the time to read the Important Information as it contains guidance on how to complete the installation process. Once you have read the notice and collected the necessary information, click .
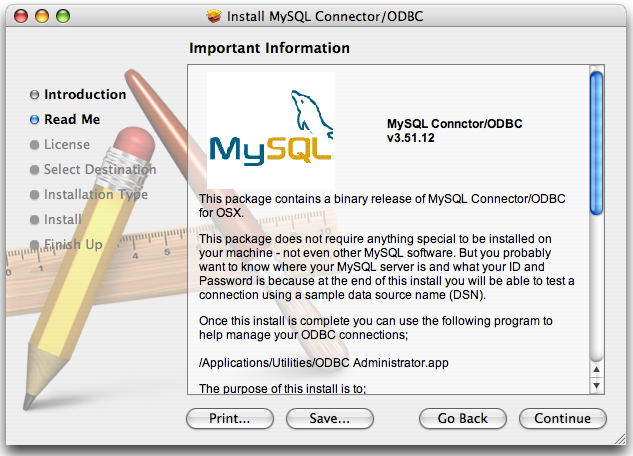
Connector/ODBC drivers are made available under the GNU General Public License. Please read the license if you are not familiar with it before continuing installation. Click to approve the license (you will be asked to confirm that decision) and continue the installation.
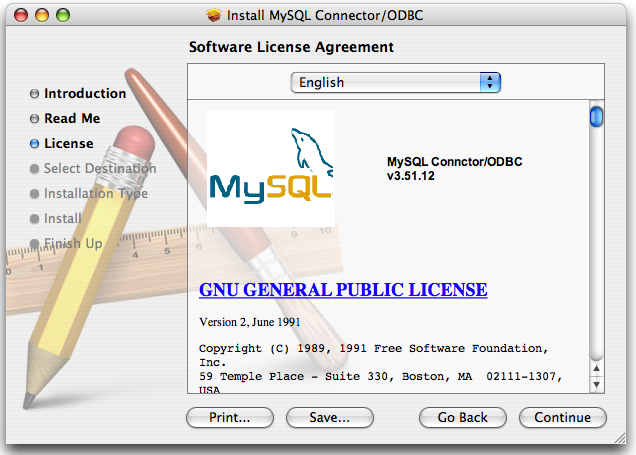
Choose a location to install the Connector/ODBC drivers and the ODBC Administrator application. You must install the files onto a drive with an operating system and you may be limited in the choices available. Select the drive you want to use, and then click .
The installer will automatically select the files that need to be installed on your machine. Click to continue. The installer will copy the necessary files to your machine. A progress bar will be shown indicating the installation progress.
When installation has been completed you will get a window like the one shown below. Click to close and quit the installer.
Installing Connector/ODBC from a source distribution gives you greater flexibility in the contents and installation location of the Connector/ODBC components. It also enables you to build and install Connector/ODBC on platforms where a pre-compiled binary is not available.
Connector/ODBC sources are available either as a downloadable package, or through the revision control system used by the Connector/ODBC developers.
You should only need to install Connector/ODBC from source on Windows if you want to change or modify the source or installation. If you are unsure whether to install from source, please use the binary installation detailed in Section 23.1.2.3.1, “Installing Connector/ODBC from a Binary Distribution on Windows”.
Installing Connector/ODBC from source on Windows requires a number of different tools and packages:
MDAC, Microsoft Data Access SDK from http://www.microsoft.com/data/.
Suitable C compiler, such as Microsoft Visual C++ or the C compiler included with Microsoft Visual Studio.
Compatible
maketool. Microsoft'snmakeis used in the examples in this section.MySQL client libraries and include files from MySQL 4.0.0 or higher. (Preferably MySQL 4.0.16 or higher). This is required because Connector/ODBC uses new calls and structures that exist only starting from this version of the library. To get the client libraries and include files, visit http://dev.mysql.com/downloads/.
Connector/ODBC source distributions include
Makefiles that require the
nmake or other make
utility. In the distribution, you can find
Makefile for building the release
version and Makefile_debug for building
debugging versions of the driver libraries and DLLs.
To build the driver, use this procedure:
Download and extract the sources to a folder, then change directory into that folder. The following command assumes the folder is named
myodbc3-src:C:\>
cd myodbc3-srcEdit
Makefileto specify the correct path for the MySQL client libraries and header files. Then use the following commands to build and install the release version:C:\>
nmake -f MakefileC:\>nmake -f Makefile installnmake -f Makefile builds the release version of the driver and places the binaries in subdirectory called
Release.nmake -f Makefile install installs (copies) the driver DLLs and libraries (
myodbc3.dll,myodbc3.lib) to your system directory.To build the debug version, use
Makefile_Debugrather thanMakefile, as shown below:C:\>
nmake -f Makefile_debugC:\>nmake -f Makefile_debug installYou can clean and rebuild the driver by using:
C:\>
nmake -f Makefile cleanC:\>nmake -f Makefile install
Note:
Make sure to specify the correct MySQL client libraries and header files path in the Makefiles (set the
MYSQL_LIB_PATHandMYSQL_INCLUDE_PATHvariables). The default header file path is assumed to beC:\mysql\include. The default library path is assumed to beC:\mysql\lib\optfor release DLLs andC:\mysql\lib\debugfor debug versions.For the complete usage of nmake, visit http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dv_vcce4/html/evgrfRunningNMAKE.asp.
If you are using the Subversion tree for compiling, all Windows-specific
Makefilesare named asWin_Makefile*.
After the driver libraries are copied/installed to the
system directory, you can test whether the libraries are
properly built by using the samples provided in the
samples subdirectory:
C:\>cd samplesC:\>nmake -f Makefile all
You need the following tools to build MySQL from source on Unix:
A working ANSI C++ compiler. gcc 2.95.2 or later, egcs 1.0.2 or later or egcs 2.91.66, SGI C++, and SunPro C++ are some of the compilers that are known to work.
A good make program. GNU make is always recommended and is sometimes required.
MySQL client libraries and include files from MySQL 4.0.0 or higher. (Preferably MySQL 4.0.16 or higher). This is required because Connector/ODBC uses new calls and structures that exist only starting from this version of the library. To get the client libraries and include files, visit http://dev.mysql.com/downloads/.
If you have built your own MySQL server and/or client libraries from source then you must have used the
--enable-thread-safe-clientoption toconfigurewhen the libraries were built.You should also ensure that the
libmysqlclientlibrary were built and installed as a shared library.A compatible ODBC manager must be installed. Connector/ODBC is known to work with the
iODBCandunixODBCmanagers. See Section 23.1.1.2.2, “ODBC Driver Managers”, for more information.If you are using a character set that isn't compiled into the MySQL client library then you need to install the MySQL character definitions from the
charsetsdirectory intoSHAREDIR(by default,/usr/local/mysql/share/mysql/charsets). These should be in place if you have installed the MySQL server on the same machine. See Chapter 10, Character Set Support, for more information on character set support.
Once you have all the required files, unpack the source files to a separate directory, you then have to run configure and build the library using make.
The configure script gives you a great deal of control over how you configure your Connector/ODBC build. Typically you do this using options on the configure command line. You can also affect configure using certain environment variables. For a list of options and environment variables supported by configure, run this command:
shell> ./configure --help
Some of the more commonly used configure options are described here:
To compile Connector/ODBC, you need to supply the MySQL client include and library files path using the
--with-mysql-path=option, whereDIRDIRis the directory where MySQL is installed.MySQL compile options can be determined by running
DIR/bin/mysql_configSupply the standard header and library files path for your ODBC Driver Manager (
iODBCorunixODBC).If you are using
iODBCandiODBCis not installed in its default location (/usr/local), you might have to use the--with-iodbc=option, whereDIRDIRis the directory whereiODBCis installed.If the
iODBCheaders do not reside inDIR/include--with-iodbc-includes=option to specify their location.INCDIRThe applies to libraries. If they are not in
DIR/lib--with-iodbc-libs=option.LIBDIRIf you are using
unixODBC, use the--with-unixODBC=option (case sensitive) to make configure look forDIRunixODBCinstead ofiODBCby default,DIRis the directory whereunixODBCis installed.If the
unixODBCheaders and libraries aren't located inDIR/includeDIR/lib--with-unixODBC-includes=andINCDIR--with-unixODBC-libs=options.LIBDIR
You might want to specify an installation prefix other than
/usr/local. For example, to install the Connector/ODBC drivers in/usr/local/odbc/lib, use the--prefix=/usr/local/odbcoption.
The final configuration command looks something like this:
shell>./configure --prefix=/usr/local \--with-iodbc=/usr/local \--with-mysql-path=/usr/local/mysql
There are a number of other options that you need, or want, to set when configuring the Connector/ODBC driver before it is built.
To link the driver with MySQL thread safe client libraries
libmysqlclient_r.soorlibmysqlclient_r.a, you must specify the following configure option:--enable-thread-safe
and can be disabled (default) using
--disable-thread-safe
This option enables the building of the driver thread-safe library
libmyodbc3_r.sofrom by linking with MySQL thread-safe client librarylibmysqlclient_r.so(The extensions are OS dependent).If the compilation with the thread-safe option fails, it may be because the correct thread-libraries on the system could not be located. You should set the value of
LIBSto point to the correct thread library for your system.LIBS="-lpthread" ./configure ..
You can enable or disable the shared and static versions of Connector/ODBC using these options:
--enable-shared[=yes/no] --disable-shared --enable-static[=yes/no] --disable-static
By default, all the binary distributions are built as non-debugging versions (configured with
--without-debug).To enable debugging information, build the driver from source distribution and use the
--with-debugoption when you run configure.This option is available only for source trees that have been obtained from the Subversion repository. This option does not apply to the packaged source distributions.
By default, the driver is built with the
--without-docsoption. If you would like the documentation to be built, then execute configure with:--with-docs
To build the driver libraries, you have to just execute make.
shell> make
If any errors occur, correct them and continue the build
process. If you aren't able to build, then send a detailed
email to <myodbc@lists.mysql.com> for further
assistance.
On most platforms, MySQL does not build or support
.so (shared) client libraries by
default. This is based on our experience of problems when
building shared libraries.
In cases like this, you have to download the MySQL distribution and configure it with these options:
--without-server --enable-shared
To build shared driver libraries, you must specify the
--enable-shared option for
configure. By default,
configure does not enable this option.
If you have configured with the
--disable-shared option, you can build the
.so file from the static libraries
using the following commands:
shell>cd mysql-connector-odbc-3.51.01shell>makeshell>cd drivershell>CC=/usr/bin/gcc \$CC -bundle -flat_namespace -undefined error \-o .libs/libmyodbc3-3.51.01.so \catalog.o connect.o cursor.o dll.o error.o execute.o \handle.o info.o misc.o myodbc3.o options.o prepare.o \results.o transact.o utility.o \-L/usr/local/mysql/lib/mysql/ \-L/usr/local/iodbc/lib/ \-lz -lc -lmysqlclient -liodbcinst
Make sure to change -liodbcinst to
-lodbcinst if you are using
unixODBC instead of
iODBC, and configure the library paths
accordingly.
This builds and places the
libmyodbc3-3.51.01.so file in the
.libs directory. Copy this file to the
Connector/ODBC library installation directory
(/usr/local/lib (or the
lib directory under the installation
directory that you supplied with the
--prefix).
shell>cd .libsshell>cp libmyodbc3-3.51.01.so /usr/local/libshell>cd /usr/local/libshell>ln -s libmyodbc3-3.51.01.so libmyodbc3.so
To build the thread-safe driver library:
shell>CC=/usr/bin/gcc \$CC -bundle -flat_namespace -undefined error-o .libs/libmyodbc3_r-3.51.01.socatalog.o connect.o cursor.o dll.o error.o execute.ohandle.o info.o misc.o myodbc3.o options.o prepare.oresults.o transact.o utility.o-L/usr/local/mysql/lib/mysql/-L/usr/local/iodbc/lib/-lz -lc -lmysqlclient_r -liodbcinst
To install the driver libraries, execute the following command:
shell> make install
That command installs one of the following sets of libraries:
For Connector/ODBC 3.51:
libmyodbc3.solibmyodbc3-3.51.01.so, where 3.51.01 is the version of the driverlibmyodbc3.a
For thread-safe Connector/ODBC 3.51:
libmyodbc3_r.solibmyodbc3-3_r.51.01.solibmyodbc3_r.a
For MyODBC 2.5.0:
libmyodbc.solibmyodbc-2.50.39.so, where 2.50.39 is the version of the driverlibmyodbc.a
For more information on build process, refer to the
INSTALL file that comes with the source
distribution. Note that if you are trying to use the
make from Sun, you may end up with
errors. On the other hand, GNU gmake
should work fine on all platforms.
To run the basic samples provided in the distribution with the libraries that you built, use the following command:
shell> make test
Before running the tests, create the DSN 'myodbc3' in
odbc.ini and set the environment
variable ODBCINI to the correct
odbc.ini file; and MySQL server is
running. You can find a sample odbc.ini
with the driver distribution.
You can even modify the
samples/run-samples script to pass the
desired DSN, UID, and PASSWORD values as the command-line
arguments to each sample.
To build the driver on Mac OS X (Darwin), make use of the following configure example:
shell>./configure --prefix=/usr/local--with-unixODBC=/usr/local--with-mysql-path=/usr/local/mysql--disable-shared--enable-gui=no--host=powerpc-apple
The command assumes that the unixODBC and
MySQL are installed in the default locations. If not,
configure accordingly.
On Mac OS X, --enable-shared builds
.dylib files by default. You can build
.so files like this:
shell>makeshell>cd drivershell>CC=/usr/bin/gcc \$CC -bundle -flat_namespace -undefined error-o .libs/libmyodbc3-3.51.01.so *.o-L/usr/local/mysql/lib/-L/usr/local/iodbc/lib-liodbcinst -lmysqlclient -lz -lc
To build the thread-safe driver library:
shell>CC=/usr/bin/gcc \$CC -bundle -flat_namespace -undefined error-o .libs/libmyodbc3-3.51.01.so *.o-L/usr/local/mysql/lib/-L/usr/local/iodbc/lib-liodbcinst -lmysqlclienti_r -lz -lc -lpthread
Make sure to change the -liodbcinst to
-lodbcinst in case of using
unixODBC instead of
iODBC and configure the libraries path
accordingly.
In Apple's version of GCC, both cc and gcc are actually symbolic links to gcc3.
Copy this library to the $prefix/lib
directory and symlink to libmyodbc3.so.
You can cross-check the output shared-library properties using this command:
shell> otool -LD .libs/libmyodbc3-3.51.01.so
To build the driver on HP-UX 10.x or 11.x, make use of the following configure example:
If using cc:
shell>CC="cc" \CFLAGS="+z" \LDFLAGS="-Wl,+b:-Wl,+s" \./configure --prefix=/usr/local--with-unixodbc=/usr/local--with-mysql-path=/usr/local/mysql/lib/mysql--enable-shared--enable-thread-safe
If using gcc:
shell>CC="gcc" \LDFLAGS="-Wl,+b:-Wl,+s" \./configure --prefix=/usr/local--with-unixodbc=/usr/local--with-mysql-path=/usr/local/mysql--enable-shared--enable-thread-safe
Once the driver is built, cross-check its attributes using
chatr .libs/libmyodbc3.sl to determine
whether you need to have set the MySQL client library path
using the SHLIB_PATH environment
variable. For static versions, ignore all shared-library
options and run configure with the
--disable-shared option.
To build the driver on AIX, make use of the following configure example:
shell>./configure --prefix=/usr/local--with-unixodbc=/usr/local--with-mysql-path=/usr/local/mysql--disable-shared--enable-thread-safe
NOTE: For more information about how to build and set up the static and shared libraries across the different platforms refer to ' Using static and shared libraries across platforms'.
Caution: You should read this section only if you are interested in helping us test our new code. If you just want to get MySQL Connector/ODBC up and running on your system, you should use a standard release distribution.
To be able to access the Connector/ODBC source tree, you must have Subversion installed. Subversion is freely available from http://subversion.tigris.org/.
To build from the source trees, you need the following tools:
autoconf 2.52 (or newer)
automake 1.4 (or newer)
libtool 1.4 (or newer)
m4
The most recent development source tree is available from our public Subversion trees at http://dev.mysql.com/tech-resources/sources.html.
To checkout out the Connector/ODBC sources, change to the directory where you want the copy of the Connector/ODBC tree to be stored, then use the following command:
shell> svn co http://svn.mysql.com/svnpublic/connector-odbc3
You should now have a copy of the entire Connector/ODBC source
tree in the directory connector-odbc3. To
build from this source tree on Unix or Linux follow these
steps:
shell>cd connector-odbc3shell>aclocalshell>autoheadershell>autoconfshell>automake;shell>./configure # Add your favorite options hereshell>make
For more information on how to build, refer to the
INSTALL file located in the same
directory. For more information on options to
configure, see
Section 23.1.2.4.2.1, “Typical configure Options”
When the build is done, run make install to install the Connector/ODBC 3.51 driver on your system.
If you have gotten to the make stage and
the distribution does not compile, please report it to
<myodbc@lists.mysql.com>.
On Windows, make use of Windows Makefiles
WIN-Makefile and
WIN-Makefile_debug in building the
driver. For more information, see
Section 23.1.2.4.1, “Installing Connector/ODBC from a Source Distribution on Windows”.
After the initial checkout operation to get the source tree, you should run svn update periodically update your source according to the latest version.
- 23.1.3.1. Data Source Names
- 23.1.3.2. Configuring a Connector/ODBC DSN on Windows
- 23.1.3.3. Configuring a Connector/ODBC DSN on Mac OS X
- 23.1.3.4. Configuring a Connector/ODBC DSN on Unix
- 23.1.3.5. Connector/ODBC Connection Parameters
- 23.1.3.6. Connecting Without a Predefined DSN
- 23.1.3.7. ODBC Connection Pooling
- 23.1.3.8. Getting an ODBC Trace File
Before you connect to a MySQL database using the Connector/ODBC driver you must configure an ODBC Data Source Name. The DSN associates the various configuration parameters required to communicate with a database to a specific name. You use the DSN in an application to communicate with the database, rather than specifying individual parameters within the application itself. DSN information can be user specific, system specific, or provided in a special file. ODBC data source names are configured in different ways, depending on your platform and ODBC driver.
A Data Source Name associates the configuration parameters for communicating with a specific database. Generally a DSN consists of the following parameters:
- Name
- Hostname
- Database Name
- Login
- Password
In addition, different ODBC drivers, including Connector/ODBC, may accept additional driver-specific options and parameters.
There are three types of DSN:
A System DSN is a global DSN definition that is available to any user and application on a particular system. A System DSN can normally only be configured by a systems administrator, or by a user who has specific permissions that let them create System DSNs.
A User DSN is specific to an individual user, and can be used to store database connectivity information that the user regularly uses.
A File DSN uses a simple file to define the DSN configuration. File DSNs can be shared between users and machines and are therefore more practical when installing or deploying DSN information as part of an application across many machines.
DSN information is stored in different locations depending on your platform and environment.
The ODBC Data Source Administrator within
Windows enables you to create DSNs, check driver installation
and configure ODBC systems such as tracing (used for debugging)
and connection pooling.
Different editions and versions of Windows store the
ODBC Data Source Administrator in different
locations depending on the version of Windows that you are
using.
To open the ODBC Data Source Administrator in
Windows Server 2003:
On the
Startmenu, chooseAdministrative Tools, and then clickData Sources (ODBC).
To open the ODBC Data Source Administrator in
Windows 2000 Server or Windows 2000 Professional:
On the
Startmenu, chooseSettings, and then clickControl Panel.In
Control Panel, clickAdministrative Tools.In
Administrative Tools, clickData Sources (ODBC).
To open the ODBC Data Source Administrator on
Windows XP:
On the
Startmenu, clickControl Panel.In the
Control Panelwhen inCategory ViewclickPerformance and Maintenanceand then clickAdministrative Tools.. If you are viewing theControl PanelinClassic View, clickAdministrative Tools.In
Administrative Tools, clickData Sources (ODBC).
Irrespective of your Windows version, you should be presented
the ODBC Data Source Administrator window:
Within Windows XP, you can add the Administrative
Tools folder to your menu
to make it easier to locate the ODBC Data Source Administrator.
To do this:
Right click on the menu.
Select
Properties.Click .
Select the tab.
Within
Start menu items, within theSystem Administrative Toolssection, selectDisplay on the All Programs menu.
Within both Windows Server 2003 and Windows XP you may want to
permanently add the ODBC Data Source
Administrator to your
menu. To do this, locate the Data Sources
(ODBC) icon using the methods shown, then right-click
on the icon and then choose .
To add and configure a new Connector/ODBC data source on
Windows, use the ODBC Data Source
Administrator:
Open the
ODBC Data Source Administrator.To create a System DSN (which will be available to all users) , select the
System DSNtab. To create a User DSN, which will be unique only to the current user, click the button.You will need to select the ODBC driver for this DSN.
Select
MySQL ODBC 3.51 Driver, then clickFinish.You now need to configure the specific fields for the DSN you are creating through the
Add Data Source Namedialog.
In the
Data Source Namebox, enter the name of the data source you want to access. It can be any valid name that you choose.In the
Descriptionbox, enter some text to help identify the connection.In the
Serverfield, enter the name of the MySQL server host that you want to access. By default, it islocalhost.In the
Userfield, enter the user name to use for this connection.In the
Passwordfield, enter the corresponding password for this connection.The
Databasepopup should automatically populate with the list of databases that the user has permissions to access.Click to save the DSN.
A completed DSN configuration may look like this:
You can verify the connection using the parameters you have
entered by clicking the button. If
the connection could be made successfully, you will be
notified with a Success; connection was
made! dialog.
If the connection failed, you can obtain more information on the test and why it may have failed by clicking the button to show additional error messages.
You can configure a number of options for a specific DSN by using either the or tabs in the DSN configuration dialog.
The dialog can be seen below.
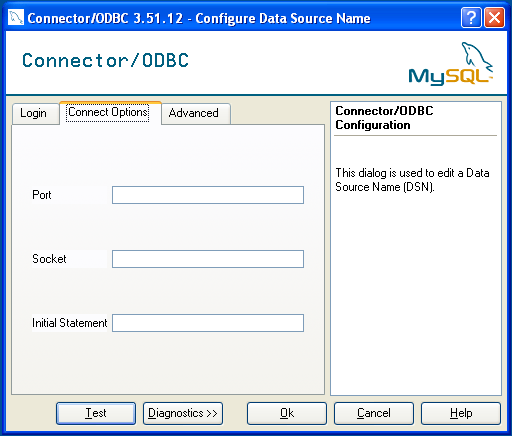
The three options you can configure are:
Portsets the TCP/IP port number to use when communicating with MySQL. Communication with MySQL uses port 3306 by default. If your server is configured to use a different TCP/IP port, you must specify that port number here.Socketsets the name or location of a specific socket or Windows pipe to use when communicating with MySQL.Initial Statementdefines an SQL statement that will be executed when the connection to MySQL is opened. You can use this to set MySQL options for your connection, such as setting the default character set or database to use during your connection.
The tab enables you to configure Connector/ODBC connection parameters. Refer to Section 23.1.3.5, “Connector/ODBC Connection Parameters”, for information about the meaning of these options.
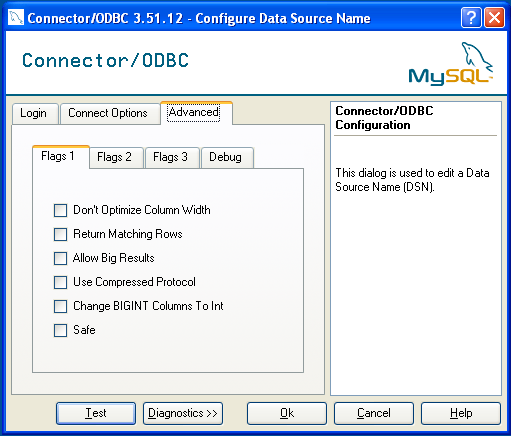
This section answers Connector/ODBC connection-related questions.
While configuring a Connector/ODBC DSN, a
Could Not Load Translator or Setup Libraryerror occursFor more information, refer to MS KnowledgeBase Article(Q260558). Also, make sure you have the latest valid
ctl3d32.dllin your system directory.On Windows, the default
myodbc3.dllis compiled for optimal performance. If you want to debug Connector/ODBC 3.51 (for example, to enable tracing), you should instead usemyodbc3d.dll. To install this file, copymyodbc3d.dllover the installedmyodbc3.dllfile. Make sure to revert back to the release version of the driver DLL once you are done with the debugging because the debug version may cause performance issues. Note that themyodbc3d.dllisn't included in Connector/ODBC 3.51.07 through 3.51.11. If you are using one of these versions, you should copy that DLL from a previous version (for example, 3.51.06).For MyODBC 2.50,
myodbc.dllandmyodbcd.dllare used instead.
To configure a DSN on Mac OS X you should use the ODBC Administrator. If you have Mac OS X 10.2 or earlier, refer to Section 23.1.3.4, “Configuring a Connector/ODBC DSN on Unix”. Select whether you want to create a User DSN or a System DSN. If you want to add a System DSN, you may need to authenticate with the system. You must click the padlock and enter a user and password with administrator privileges.
Open the ODBC Administrator from the
Utilitiesfolder in theApplicationsfolder.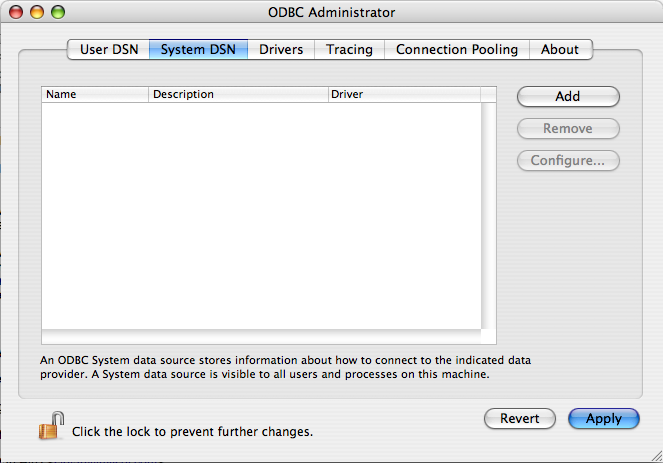
On the User DSN or System DSN panel, click
Select the Connector/ODBC driver and click .
You will be presented with the
Data Source Namedialog. Enter TheData Source Nameand an optionalDescriptionfor the DSN.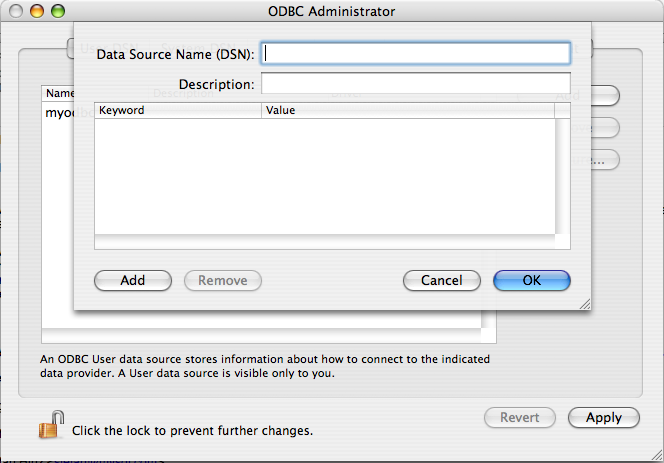
Click to add a new keyword/value pair to the panel. You should configure at least four pairs to specify the
server,username,passwordanddatabaseconnection parameters. See Section 23.1.3.5, “Connector/ODBC Connection Parameters”.Click to add the DSN to the list of configured data source names.
A completed DSN configuration may look like this:
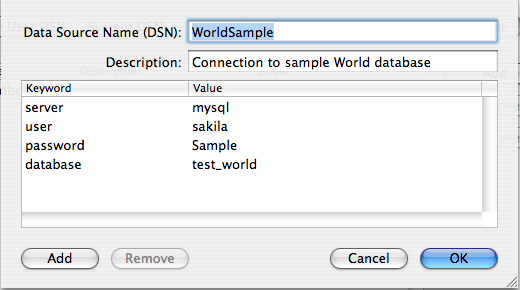
You can configure additional ODBC options to your DSN by adding further keyword/value pairs and setting the corresponding values. See Section 23.1.3.5, “Connector/ODBC Connection Parameters”.
On Unix, you configure DSN entries directly
in the odbc.ini file. Here is a typical
odbc.ini file that configures
myodbc and myodbc3 as the
DSN names for MyODBC 2.50 and Connector/ODBC 3.51, respectively:
; ; odbc.ini configuration for Connector/ODBC and Connector/ODBC 3.51 drivers ; [ODBC Data Sources] myodbc = MyODBC 2.50 Driver DSN myodbc3 = MyODBC 3.51 Driver DSN [myodbc] Driver = /usr/local/lib/libmyodbc.so Description = MyODBC 2.50 Driver DSN SERVER = localhost PORT = USER = root Password = Database = test OPTION = 3 SOCKET = [myodbc3] Driver = /usr/local/lib/libmyodbc3.so Description = Connector/ODBC 3.51 Driver DSN SERVER = localhost PORT = USER = root Password = Database = test OPTION = 3 SOCKET = [Default] Driver = /usr/local/lib/libmyodbc3.so Description = Connector/ODBC 3.51 Driver DSN SERVER = localhost PORT = USER = root Password = Database = test OPTION = 3 SOCKET =
Refer to the Section 23.1.3.5, “Connector/ODBC Connection Parameters”, for the list of connection parameters that can be supplied.
Note: If you are using
unixODBC, you can use the following tools to
set up the DSN:
ODBCConfig GUI tool(HOWTO: ODBCConfig)
odbcinst
In some cases when using unixODBC, you might
get this error:
Data source name not found and no default driver specified
If this happens, make sure the ODBCINI and
ODBCSYSINI environment variables are pointing
to the right odbc.ini file. For example, if
your odbc.ini file is located in
/usr/local/etc, set the environment
variables like this:
export ODBCINI=/usr/local/etc/odbc.ini export ODBCSYSINI=/usr/local/etc
You can specify the parameters in the following tables for
Connector/ODBC when configuring a DSN. Users on Windows can use
the Options and Advanced panels when configuring a DSN to set
these parameters; see the table for information on which options
relate to which fields and checkboxes. On Unix and Mac OS X, use
the parameter name and value as the keyword/value pair in the
DSN configuration. Alternatively, you can set these parameters
within the InConnectionString argument in the
SQLDriverConnect() call.
| Parameter | Default Value | Comment |
user | ODBC (on Windows) | The username used to connect to MySQL. |
server | localhost | The hostname of the MySQL server. |
database | The default database. | |
option | 0 | Options that specify how Connector/ODBC should work. See below. |
port | 3306 | The TCP/IP port to use if server is not
localhost. |
stmt | A statement to execute when connecting to MySQL. | |
password | The password for the user account on
server. | |
socket | The Unix socket file or Windows named pipe to connect to if
server is
localhost. |
The option argument is used to tell
Connector/ODBC that the client isn't 100% ODBC compliant. On
Windows, you normally select options by toggling the checkboxes
in the connection screen, but you can also select them in the
option argument. The following options are
listed in the order in which they appear in the Connector/ODBC
connect screen:
| Value | Windows Checkbox | Description |
| 1 | Don't Optimized Column Width | The client can't handle that Connector/ODBC returns the real width of a column. |
| 2 | Return Matching Rows | The client can't handle that MySQL returns the true value of affected rows. If this flag is set, MySQL returns “found rows” instead. You must have MySQL 3.21.14 or newer to get this to work. |
| 4 | Trace Driver Calls To myodbc.log | Make a debug log in C:\myodbc.log on Windows, or
/tmp/myodbc.log on Unix variants. |
| 8 | Allow Big Results | Don't set any packet limit for results and parameters. |
| 16 | Don't Prompt Upon Connect | Don't prompt for questions even if driver would like to prompt. |
| 32 | Enable Dynamic Cursor | Enable or disable the dynamic cursor support. (Not allowed in Connector/ODBC 2.50.) |
| 64 | Ignore # in Table Name | Ignore use of database name in
db_name.tbl_name.col_name. |
| 128 | User Manager Cursors | Force use of ODBC manager cursors (experimental). |
| 256 | Don't Use Set Locale | Disable the use of extended fetch (experimental). |
| 512 | Pad Char To Full Length | Pad CHAR columns to full column length. |
| 1024 | Return Table Names for SQLDescribeCol | SQLDescribeCol() returns fully qualified column
names. |
| 2048 | Use Compressed Protocol | Use the compressed client/server protocol. |
| 4096 | Ignore Space After Function Names | Tell server to ignore space after function name and before
‘(’ (needed by
PowerBuilder). This makes all function names keywords. |
| 8192 | Force Use of Named Pipes | Connect with named pipes to a mysqld server running on NT. |
| 16384 | Change BIGINT Columns to Int | Change BIGINT columns to INT
columns (some applications can't handle
BIGINT). |
| 32768 | No Catalog (exp) | Return 'user' as Table_qualifier and
Table_owner from
SQLTables (experimental). |
| 65536 | Read Options From my.cnf | Read parameters from the [client] and
[odbc] groups from
my.cnf. |
| 131072 | Safe | Add some extra safety checks (should not be needed but...). |
| 262144 | Disable transaction | Disable transactions. |
| 524288 | Save queries to myodbc.sql | Enable query logging to
c:\myodbc.sql(/tmp/myodbc.sql)
file. (Enabled only in debug mode.) |
| 1048576 | Don't Cache Result (forward only cursors) | Do not cache the results locally in the driver, instead read from server
(mysql_use_result()). This works only
for forward-only cursors. This option is very important
in dealing with large tables when you don't want the
driver to cache the entire result set. |
| 2097152 | Force Use Of Forward Only Cursors | Force the use of Forward-only cursor type. In case of
applications setting the default static/dynamic cursor
type, and one wants the driver to use non-cache result
sets, then this option ensures the forward-only cursor
behavior. |
| 4194304 | Enable auto-reconnect. | Enables auto-reconnection functionality. You should not use this option with transactions, since a auto reconnection during a incomplete transaction may cause corruption. Note that an auto-reconnected connection will not inherit the same settings and environment as the original. This option was enabled in Connector/ODBC 3.5.13. |
| 8388608 | Flag Auto Is Null | When set, this option causes the connection to set the
SQL_AUTO_IS_NULL option to 1. This
disables the standard behavior, but may enable older
applications to correctly identify
AUTO_INCREMENT values. For more
information. See
IS
NULL This option was enabled in
Connector/ODBC 3.5.13. |
To select multiple options, add together their values. For
example, setting option to 12 (4+8) gives you
debugging without packet limits.
The following table shows some recommended
option values for various configurations:
| Configuration | Option Value |
| Microsoft Access, Visual Basic | 3 |
| Driver trace generation (Debug mode) | 4 |
| Microsoft Access (with improved DELETE queries) | 35 |
| Large tables with too many rows | 2049 |
| Sybase PowerBuilder | 135168 |
| Query log generation (Debug mode) | 524288 |
| Generate driver trace as well as query log (Debug mode) | 524292 |
| Large tables with no-cache results | 3145731 |
You can connect to the MySQL server using SQLDriverConnect, by
specifying the DRIVER name field. Here are
the connection strings for Connector/ODBC using DSN-Less
connections:
For MyODBC 2.50:
ConnectionString = "DRIVER={MySQL};\
SERVER=localhost;\
DATABASE=test;\
USER=venu;\
PASSWORD=venu;\
OPTION=3;"For Connector/ODBC 3.51:
ConnectionString = "DRIVER={MySQL ODBC 3.51 Driver};\
SERVER=localhost;\
DATABASE=test;\
USER=venu;\
PASSWORD=venu;\
OPTION=3;"If your programming language converts backslash followed by whitespace to a space, it is preferable to specify the connection string as a single long string, or to use a concatenation of multiple strings that does not add spaces in between. For example:
ConnectionString = "DRIVER={MySQL ODBC 3.51 Driver};"
"SERVER=localhost;"
"DATABASE=test;"
"USER=venu;"
"PASSWORD=venu;"
"OPTION=3;"Note. Note that on Mac OS X you may need to specify the full path to the Connector/ODBC driver library.
Refer to the Section 23.1.3.5, “Connector/ODBC Connection Parameters”, for the list of connection parameters that can be supplied.
Connection pooling enables the ODBC driver to re-use existing connections to a given database from a pool of connections, instead of opening a new connection each time the database is accessed. By enabling connection pooling you can improve the overall performance of your application by lowering the time taken to open a connection to a database in the connection pool.
For more information about connection pooling: http://support.microsoft.com/default.aspx?scid=kb;EN-US;q169470.
If you encounter difficulties or problems with Connector/ODBC,
you should start by making a log file from the ODBC
Manager and Connector/ODBC. This is called
tracing, and is enabled through the ODBC
Manager. The procedure for this differs for Windows, Mac OS X
and Unix.
To enable the trace option on Windows:
The
Tracingtab of the ODBC Data Source Administrator dialog box enables you to configure the way ODBC function calls are traced.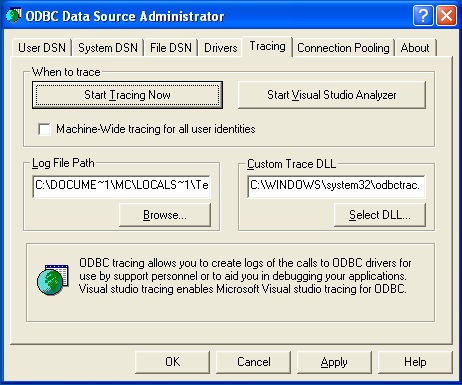
When you activate tracing from the
Tracingtab, theDriver Managerlogs all ODBC function calls for all subsequently run applications.ODBC function calls from applications running before tracing is activated are not logged. ODBC function calls are recorded in a log file you specify.
Tracing ceases only after you click
Stop Tracing Now. Remember that while tracing is on, the log file continues to increase in size and that tracing affects the performance of all your ODBC applications.
To enable the trace option on Mac OS X 10.3 or later you
should use the Tracing tab within
ODBC
Administrator
.
Open the ODBC Administrator.
Select the
Tracingtab.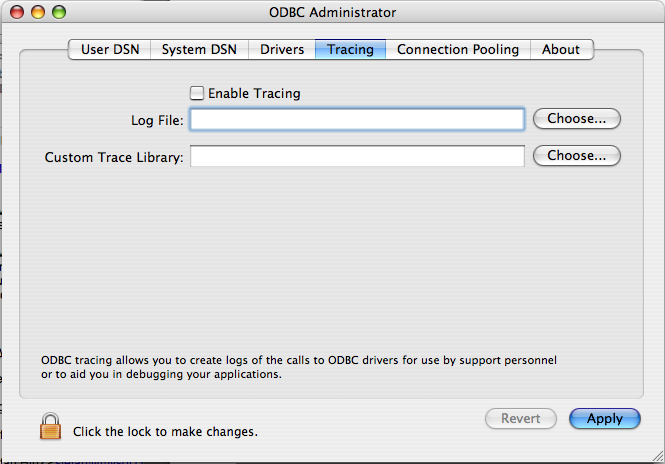
Select the
Enable Tracingcheckbox.Enter the location where you want to save the Tracing log. If you want to append information to an existing log file, click the button.
To enable the trace option on Mac OS X 10.2 (or earlier) or
Unix you must add the trace option to the
ODBC configuration:
On Unix, you need to explicitly set the
Traceoption in theODBC.INIfile.Set the tracing
ONorOFFby usingTraceFileandTraceparameters inodbc.inias shown below:TraceFile = /tmp/odbc.trace Trace = 1
TraceFilespecifies the name and full path of the trace file andTraceis set toONorOFF. You can also use1orYESforONand0orNOforOFF. If you are using ODBCConfig fromunixODBC, then follow the instructions for tracingunixODBCcalls at HOWTO-ODBCConfig.
To generate a Connector/ODBC log, do the following:
Within Windows, enable the
Trace Connector/ODBCoption flag in the Connector/ODBC connect/configure screen. The log is written to fileC:\myodbc.log. If the trace option is not remembered when you are going back to the above screen, it means that you are not using themyodbcd.dlldriver, see Section 23.1.3.2.4, “Errors and Debugging”.On Mac OS X, Unix, or if you are using DSN-Less connection, then you need to supply
OPTION=4in the connection string or set the corresponding keyword/value pair in the DSN.Start your application and try to get it to fail. Then check the Connector/ODBC trace file to find out what could be wrong.
If you need help determining what is wrong, see Section 23.1.7.1, “Connector/ODBC Community Support”.
- 23.1.4.1. Basic Connector/ODBC Application Steps
- 23.1.4.2. Step-by-step Guide to Connecting to a MySQL Database through Connector/ODBC
- 23.1.4.3. Connector/ODBC and Third-Party ODBC Tools
- 23.1.4.4. Using Connector/ODBC with Microsoft Access
- 23.1.4.5. Using Connector/ODBC with Microsoft Word or Excel
- 23.1.4.6. Using Connector/ODBC with Crystal Reports
- 23.1.4.7. Connector/ODBC Programming
Once you have configured a DSN to provide access to a database, how you access and use that connection is dependent on the application or programming language. As ODBC is a standardized interface, any application or language that supports ODBC can use the DSN and connect to the configured database.
Interacting with a MySQL server from an applications using the Connector/ODBC typically involves the following operations:
Configure the Connector/ODBC DSN
Connect to MySQL server
Initialization operations
Execute SQL statements
Retrieve results
Perform Transactions
Disconnect from the server
Most applications use some variation of these steps. The basic application steps are shown in the following diagram:
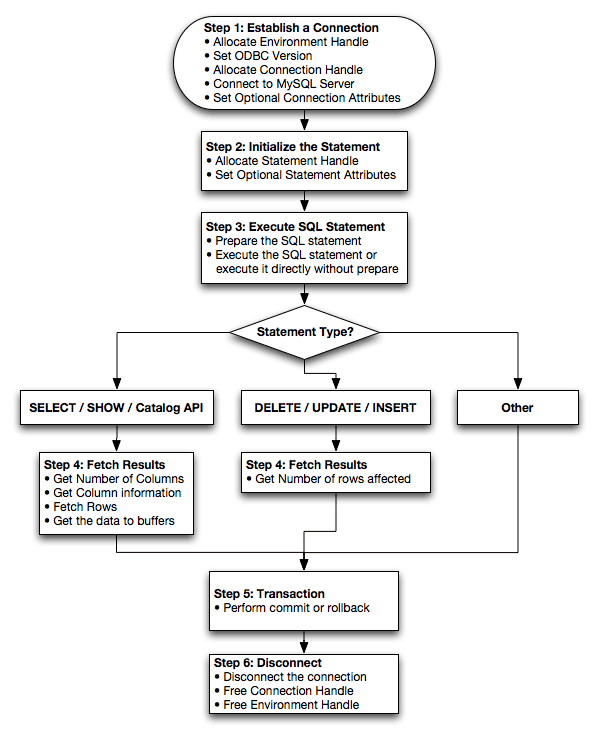
A typical installation situation where you would install Connector/ODBC is when you want to access a database on a Linux or Unix host from a Windows machine.
As an example of the process required to set up access between
two machines, the steps below take you through the basic steps.
These instructions assume that you want to connect to system
ALPHA from system BETA with a username and password of
myuser and mypassword.
On system ALPHA (the MySQL server) follow these steps:
Start the MySQL server.
Use
GRANTto set up an account with a username ofmyuserthat can connect from system BETA using a password ofmyuserto the databasetest:GRANT ALL ON test.* to 'myuser'@'BETA' IDENTIFIED BY 'mypassword';
For more information about MySQL privileges, refer to Section 5.8, “MySQL User Account Management”.
On system BETA (the Connector/ODBC client), follow these steps:
Configure a Connector/ODBC DSN using parameters that match the server, database and authentication information that you have just configured on system ALPHA.
Parameter Value Comment DSN remote_test A name to identify the connection. SERVER ALPHA The address of the remote server. DATABASE test The name of the default database. USER myuser The username configured for access to this database. PASSWORD mypassword The password for myuser.Using an ODBC-capable application, such as Microsoft Office, connect to the MySQL server using the DSN you have just created. If the connection fails, use tracing to examine the connection process. See Section 23.1.3.8, “Getting an ODBC Trace File”, for more information.
Once you have configured your Connector/ODBC DSN, you can access your MySQL database through any application that supports the ODBC interface, including programming languages and third-party applications. This section contains guides and help on using Connector/ODBC with various ODBC-compatible tools and applications, including Microsoft Word, Microsoft Excel and Adobe/Macromedia ColdFusion.
Connector/ODBC has been tested with the following applications:
| Publisher | Application | Notes |
| Adobe | ColdFusion | Formerly Macromedia ColdFusion |
| Borland | C++ Builder | |
| Builder 4 | ||
| Delphi | ||
| Business Objects | Crystal Reports | |
| Claris | Filemaker Pro | |
| Corel | Paradox | |
| Computer Associates | Visual Objects | Also known as CAVO |
| AllFusion ERwin Data Modeler | ||
| Gupta | Team Developer | Previously known as Centura Team Developer; Gupta SQL/Windows |
| Gensym | G2-ODBC Bridge | |
| Inline | iHTML | |
| Lotus | Notes | Versions 4.5 and 4.6 |
| Microsoft | Access | |
| Excel | ||
| Visio Enterprise | ||
| Visual C++ | ||
| Visual Basic | ||
| ODBC.NET | Using C#, Visual Basic, C++ | |
| FoxPro | ||
| Visual Interdev | ||
| OpenOffice.org | OpenOffice.org | |
| Perl | DBD::ODBC | |
| Pervasive Software | DataJunction | |
| Sambar Technologies | Sambar Server | |
| SPSS | SPSS | |
| SoftVelocity | Clarion | |
| SQLExpress | SQLExpress for Xbase++ | |
| Sun | StarOffice | |
| SunSystems | Vision | |
| Sybase | PowerBuilder | |
| PowerDesigner | ||
| theKompany.com | Data Architect |
If you know of any other applications that work with
Connector/ODBC, please send mail to
<myodbc@lists.mysql.com> about them.
You can use MySQL database with Microsoft Access using Connector/ODBC. The MySQL database can be used as an import source, an export source, or as a linked table for direct use within an Access application, so you can use Access as the front-end interface to a MySQL database.
To export a table of data from an Access database to MySQL, follow these instructions:
When you open an Access database or an Access project, a Database window appears. It displays shortcuts for creating new database objects and opening existing objects.
Click the name of the
tableorqueryyou want to export, and then in theFilemenu, selectExport.In the
Export Object Typedialog box, in theObject nameToSave As Typebox, selectODBC Databases ()as shown here:
In the
Exportdialog box, enter a name for the file (or use the suggested name), and then selectOK.The Select Data Source dialog box is displayed; it lists the defined data sources for any ODBC drivers installed on your computer. Click either the File Data Source or Machine Data Source tab, and then double-click the Connector/ODBC or Connector/ODBC 3.51 data source that you want to export to. To define a new data source for Connector/ODBC, please Section 23.1.3.2, “Configuring a Connector/ODBC DSN on Windows”.
Microsoft Access connects to the MySQL Server through this data source and exports new tables and or data.
To import a table or tables from MySQL to Access, follow these instructions:
Open a database, or switch to the Database window for the open database.
To import tables, on the
Filemenu, point toGet External Data, and then clickImport.In the
Importdialog box, in the Files Of Type box, select ODBC Databases (). The Select Data Source dialog box lists the defined data sources The Select Data Source dialog box is displayed; it lists the defined data source names.If the ODBC data source that you selected requires you to log on, enter your login ID and password (additional information might also be required), and then click
OK.Microsoft Access connects to the MySQL server through
ODBC data sourceand displays the list of tables that you canimport.Click each table that you want to
import, and then clickOK.
You can use Microsoft Access as a front end to a MySQL database by linking tables within your Microsoft Access database to tables that exist within your MySQL database. When a query is requested on a table within Access, ODBC is used to execute the queries on the MySQL database instead.
To create a linked table:
Open the Access database that you want to link to MySQL.
From the , choose .
From the browser, choose ODBC Databases () from the Files of type popup.
In the Select Data Source window, choose an existing DSN, either from a File Data Source or Machine Data Source.You can also create a new DSN using the button. For more information on creating a DSN see Section 23.1.3.2, “Configuring a Connector/ODBC DSN on Windows”.
In the Link Tables dialog, select one or more tables from the MySQL database. A link will be created to each table that you select from this list.
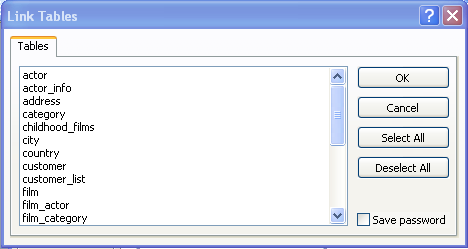
If Microsoft Access is unable to determine the unique record identifier for a table automatically then it may ask you to confirm the column, or combination of columns, to be used to uniquely identify each row from the source table. Select the columns you want to use and click .
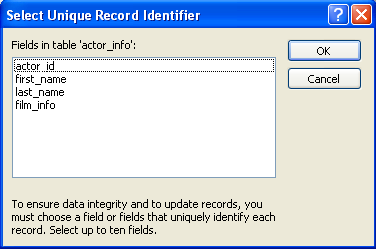
Once the process has been completed, you can now build interfaces and queries to the linked tables just as you would for any Access database.
Use the following procedure to view or to refresh links when the structure or location of a linked table has changed. The Linked Table Manager lists the paths to all currently linked tables.
To view or refresh links:
Open the database that contains links to MySQL tables.
On the
Toolsmenu, point toAdd-ins(Database Utilitiesin Access 2000 or newer), and then clickLinked Table Manager.Select the check box for the tables whose links you want to refresh.
Click OK to refresh the links.
Microsoft Access confirms a successful refresh or, if the
table wasn't found, displays the Select New Location
of <table name> dialog box in which you can
specify its the table's new location. If several selected
tables have moved to the new location that you specify, the
Linked Table Manager searches that location for all selected
tables, and updates all links in one step.
To change the path for a set of linked tables:
Open the database that contains links to tables.
On the
Toolsmenu, point toAdd-ins(Database Utilitiesin Access 2000 or newer), and then clickLinked Table Manager.Select the
Always Prompt For A New Locationcheck box.Select the check box for the tables whose links you want to change, and then click
OK.In the
Select New Location of<table name> dialog box, specify the new location, clickOpen, and then clickOK.
You can use Microsoft Word and Microsoft Excel to access information from a MySQL database using Connector/ODBC. Within Microsoft Word, this facility is most useful when importing data for mailmerge, or for tables and data to be included in reports. Within Microsoft Excel, you can execute queries on your MySQL server and import the data directly into an Excel Worksheet, presenting the data as a series of rows and columns.
With both applications, data is accessed and imported into the application using Microsoft Query , which enables you to execute a query though an ODBC source. You use Microsoft Query to build the SQL statement to be executed, selecting the tables, fields, selection criteria and sort order. For example, to insert information from a table in the World test database into an Excel spreadsheet, using the DSN samples shown in Section 23.1.3, “Connector/ODBC Configuration”:
Create a new Worksheet.
From the
Datamenu, chooseImport External Data, and then selectNew Database Query.Microsoft Query will start. First, you need to choose the data source, by selecting an existing Data Source Name.
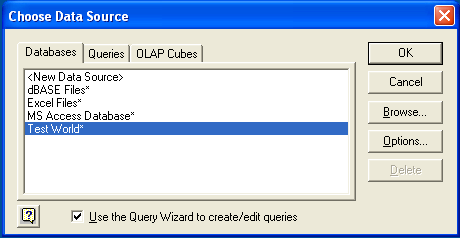
Within the
Query Wizard, you must choose the columns that you want to import. The list of tables available to the user configured through the DSN is shown on the left, the columns that will be added to your query are shown on the right. The columns you choose are equivalent to those in the first section of aSELECTquery. Click to continue.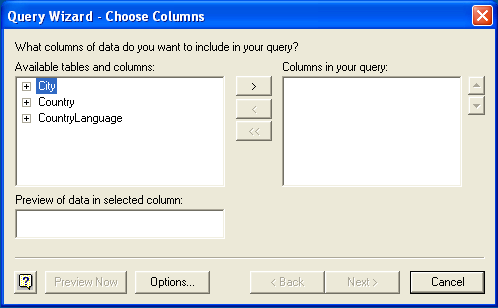
You can filter rows from the query (the equivalent of a
WHEREclause) using theFilter Datadialog. Click to continue.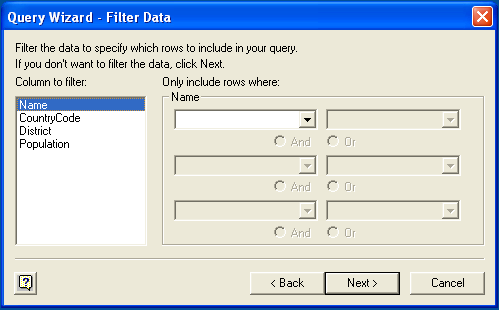
Select an (optional) sort order for the data. This is equivalent to using a
ORDER BYclause in your SQL query. You can select up to three fields for sorting the information returned by the query. Click to continue.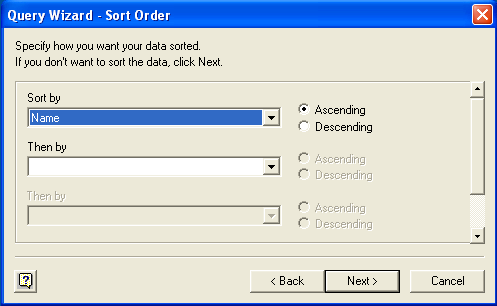
Select the destination for your query. You can select to return the data Microsoft Excel, where you can choose a worksheet and cell where the data will be inserted; you can continue to view the query and results within Microsoft Query, where you can edit the SQL query and further filter and sort the information returned; or you can create an OLAP Cube from the query, which can then be used directly within Microsoft Excel. Click .
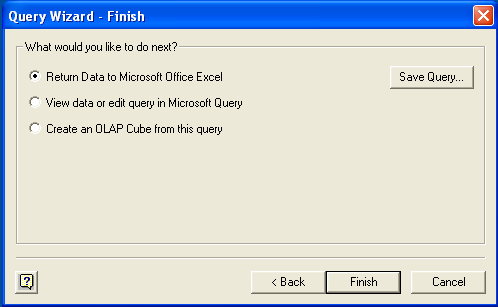
The same process can be used to import data into a Word document, where the data will be inserted as a table. This can be used for mail merge purposes (where the field data is read from a Word table), or where you want to include data and reports within a report or other document.
Crystal Reports can use an ODBC DSN to connect to a database from which you to extract data and information for reporting purposes.
Note
There is a known issue with certain versions of Crystal Reports where the application is unable to open and browse tables and fields through an ODBC connection. Before using Crystal Reports with MySQL, please ensure that you have update to the latest version, including any outstanding service packs and hotfixes. For more information on this issue, see the Business) Objects Knowledgebase for more information.
For example, to create a simple crosstab report within Crystal Reports XI, you should follow these steps:
Create a DSN using the
Data Sources (ODBC)tool. You can either specify a complete database, including username and password, or you can build a basic DSN and use Crystal Reports to set the username and password.For the purposes of this example, a DSN that provides a connection to an instance of the MySQL Sakila sample database has been created.
Open Crystal Reports and create a new project, or an open an existing reporting project into which you want to insert data from your MySQL data source.
Start the Cross-Tab Report Wizard, either by clicking on the option on the Start Page. Expand the Create New Connection folder, then expand the ODBC (RDO) folder to obtain a list of ODBC data sources.
You will be asked to select a data source.
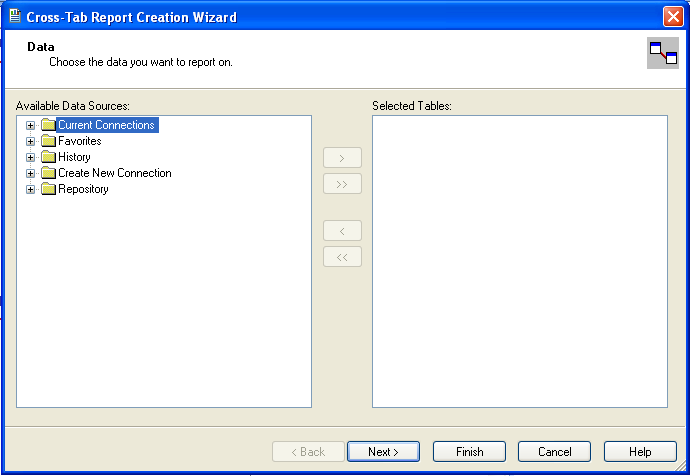
When you first expand the ODBC (RDO) folder you will be presented the Data Source Selection screen. From here you can select either a pre-configured DSN, open a file-based DSN or enter and manual connection string. For this example, the Sakila DSN will be used.
If the DSN contains a username/password combination, or you want to use different authentication credentials, click to enter the username and password that you want to use. Otherwise, click to continue the data source selection wizard.
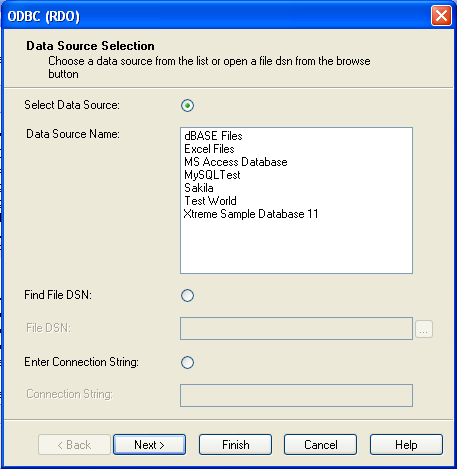
You will be returned the Cross-Tab Report Creation Wizard. You now need to select the database and tables that you want to include in your report. For our example, we will expand the selected Sakila database. Click the
citytable and use the button to add the table to the report. Then repeat the action with thecountrytable. Alternatively you can select multiple tables and add them to the report.Finally, you can select the parent Sakila resource and add of the tables to the report.
Once you have selected the tables you want to include, click to continue.
Crystal Reports will now read the table definitions and automatically identify the links between the tables. The identification of links between tables enables Crystal Reports to automatically lookup and summarize information based on all the tables in the database according to your query. If Crystal Reports is unable to perform the linking itself, you can manually create the links between fields in the tables you have selected.
Click to continue the process.
You can now select the columns and rows that you wish to include within the Cross-Tab report. Drag and drop or use the buttons to add fields to each area of the report. In the example shown, we will report on cities, organized by country, incorporating a count of the number of cities within each country. If you want to browse the data, select a field and click the button.
Click to create a graph of the results. Since we are not creating a graph from this data, click to generate the report.
The finished report will be shown, a sample of the output from the Sakila sample database is shown below.
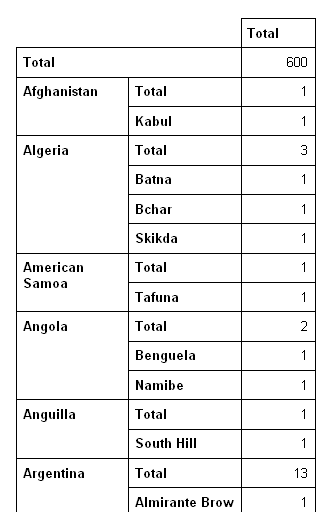
Once the ODBC connection has been opened within Crystal Reports, you can browse and add any fields within the available tables into your reports.
With a suitable ODBC Manager and the Connector/ODBC driver installed, any programming language or environment that can support ODBC should be able to connect to a MySQL database through Connector/ODBC.
This includes, but is certainly not limited to, Microsoft support languages (including Visual Basic, C# and interfaces such as ODBC.NET), Perl (through the DBI module, and the DBD::ODBC driver).
This section contains simple examples of the use of MySQL ODBC 3.51 Driver with ADO, DAO and RDO.
The following ADO (ActiveX Data Objects) example creates a
table my_ado and demonstrates the use of
rs.addNew, rs.delete,
and rs.update.
Private Sub myodbc_ado_Click()
Dim conn As ADODB.Connection
Dim rs As ADODB.Recordset
Dim fld As ADODB.Field
Dim sql As String
'connect to MySQL server using MySQL ODBC 3.51 Driver
Set conn = New ADODB.Connection
conn.ConnectionString = "DRIVER={MySQL ODBC 3.51 Driver};"_
& "SERVER=localhost;"_
& " DATABASE=test;"_
& "UID=venu;PWD=venu; OPTION=3"
conn.Open
'create table
conn.Execute "DROP TABLE IF EXISTS my_ado"
conn.Execute "CREATE TABLE my_ado(id int not null primary key, name varchar(20)," _
& "txt text, dt date, tm time, ts timestamp)"
'direct insert
conn.Execute "INSERT INTO my_ado(id,name,txt) values(1,100,'venu')"
conn.Execute "INSERT INTO my_ado(id,name,txt) values(2,200,'MySQL')"
conn.Execute "INSERT INTO my_ado(id,name,txt) values(3,300,'Delete')"
Set rs = New ADODB.Recordset
rs.CursorLocation = adUseServer
'fetch the initial table ..
rs.Open "SELECT * FROM my_ado", conn
Debug.Print rs.RecordCount
rs.MoveFirst
Debug.Print String(50, "-") & "Initial my_ado Result Set " & String(50, "-")
For Each fld In rs.Fields
Debug.Print fld.Name,
Next
Debug.Print
Do Until rs.EOF
For Each fld In rs.Fields
Debug.Print fld.Value,
Next
rs.MoveNext
Debug.Print
Loop
rs.Close
'rs insert
rs.Open "select * from my_ado", conn, adOpenDynamic, adLockOptimistic
rs.AddNew
rs!Name = "Monty"
rs!txt = "Insert row"
rs.Update
rs.Close
'rs update
rs.Open "SELECT * FROM my_ado"
rs!Name = "update"
rs!txt = "updated-row"
rs.Update
rs.Close
'rs update second time..
rs.Open "SELECT * FROM my_ado"
rs!Name = "update"
rs!txt = "updated-second-time"
rs.Update
rs.Close
'rs delete
rs.Open "SELECT * FROM my_ado"
rs.MoveNext
rs.MoveNext
rs.Delete
rs.Close
'fetch the updated table ..
rs.Open "SELECT * FROM my_ado", conn
Debug.Print rs.RecordCount
rs.MoveFirst
Debug.Print String(50, "-") & "Updated my_ado Result Set " & String(50, "-")
For Each fld In rs.Fields
Debug.Print fld.Name,
Next
Debug.Print
Do Until rs.EOF
For Each fld In rs.Fields
Debug.Print fld.Value,
Next
rs.MoveNext
Debug.Print
Loop
rs.Close
conn.Close
End Sub
The following DAO (Data Access Objects) example creates a
table my_dao and demonstrates the use of
rs.addNew, rs.update,
and result set scrolling.
Private Sub myodbc_dao_Click()
Dim ws As Workspace
Dim conn As Connection
Dim queryDef As queryDef
Dim str As String
'connect to MySQL using MySQL ODBC 3.51 Driver
Set ws = DBEngine.CreateWorkspace("", "venu", "venu", dbUseODBC)
str = "odbc;DRIVER={MySQL ODBC 3.51 Driver};"_
& "SERVER=localhost;"_
& " DATABASE=test;"_
& "UID=venu;PWD=venu; OPTION=3"
Set conn = ws.OpenConnection("test", dbDriverNoPrompt, False, str)
'Create table my_dao
Set queryDef = conn.CreateQueryDef("", "drop table if exists my_dao")
queryDef.Execute
Set queryDef = conn.CreateQueryDef("", "create table my_dao(Id INT AUTO_INCREMENT PRIMARY KEY, " _
& "Ts TIMESTAMP(14) NOT NULL, Name varchar(20), Id2 INT)")
queryDef.Execute
'Insert new records using rs.addNew
Set rs = conn.OpenRecordset("my_dao")
Dim i As Integer
For i = 10 To 15
rs.AddNew
rs!Name = "insert record" & i
rs!Id2 = i
rs.Update
Next i
rs.Close
'rs update..
Set rs = conn.OpenRecordset("my_dao")
rs.Edit
rs!Name = "updated-string"
rs.Update
rs.Close
'fetch the table back...
Set rs = conn.OpenRecordset("my_dao", dbOpenDynamic)
str = "Results:"
rs.MoveFirst
While Not rs.EOF
str = " " & rs!Id & " , " & rs!Name & ", " & rs!Ts & ", " & rs!Id2
Debug.Print "DATA:" & str
rs.MoveNext
Wend
'rs Scrolling
rs.MoveFirst
str = " FIRST ROW: " & rs!Id & " , " & rs!Name & ", " & rs!Ts & ", " & rs!Id2
Debug.Print str
rs.MoveLast
str = " LAST ROW: " & rs!Id & " , " & rs!Name & ", " & rs!Ts & ", " & rs!Id2
Debug.Print str
rs.MovePrevious
str = " LAST-1 ROW: " & rs!Id & " , " & rs!Name & ", " & rs!Ts & ", " & rs!Id2
Debug.Print str
'free all resources
rs.Close
queryDef.Close
conn.Close
ws.Close
End Sub
The following RDO (Remote Data Objects) example creates a
table my_rdo and demonstrates the use of
rs.addNew and
rs.update.
Dim rs As rdoResultset
Dim cn As New rdoConnection
Dim cl As rdoColumn
Dim SQL As String
'cn.Connect = "DSN=test;"
cn.Connect = "DRIVER={MySQL ODBC 3.51 Driver};"_
& "SERVER=localhost;"_
& " DATABASE=test;"_
& "UID=venu;PWD=venu; OPTION=3"
cn.CursorDriver = rdUseOdbc
cn.EstablishConnection rdDriverPrompt
'drop table my_rdo
SQL = "drop table if exists my_rdo"
cn.Execute SQL, rdExecDirect
'create table my_rdo
SQL = "create table my_rdo(id int, name varchar(20))"
cn.Execute SQL, rdExecDirect
'insert - direct
SQL = "insert into my_rdo values (100,'venu')"
cn.Execute SQL, rdExecDirect
SQL = "insert into my_rdo values (200,'MySQL')"
cn.Execute SQL, rdExecDirect
'rs insert
SQL = "select * from my_rdo"
Set rs = cn.OpenResultset(SQL, rdOpenStatic, rdConcurRowVer, rdExecDirect)
rs.AddNew
rs!id = 300
rs!Name = "Insert1"
rs.Update
rs.Close
'rs insert
SQL = "select * from my_rdo"
Set rs = cn.OpenResultset(SQL, rdOpenStatic, rdConcurRowVer, rdExecDirect)
rs.AddNew
rs!id = 400
rs!Name = "Insert 2"
rs.Update
rs.Close
'rs update
SQL = "select * from my_rdo"
Set rs = cn.OpenResultset(SQL, rdOpenStatic, rdConcurRowVer, rdExecDirect)
rs.Edit
rs!id = 999
rs!Name = "updated"
rs.Update
rs.Close
'fetch back...
SQL = "select * from my_rdo"
Set rs = cn.OpenResultset(SQL, rdOpenStatic, rdConcurRowVer, rdExecDirect)
Do Until rs.EOF
For Each cl In rs.rdoColumns
Debug.Print cl.Value,
Next
rs.MoveNext
Debug.Print
Loop
Debug.Print "Row count="; rs.RowCount
'close
rs.Close
cn.Close
End SubThis section contains simple examples that demonstrate the use of Connector/ODBC drivers with ODBC.NET.
The following sample creates a table
my_odbc_net and demonstrates its use in
C#.
/**
* @sample : mycon.cs
* @purpose : Demo sample for ODBC.NET using Connector/ODBC
* @author : Venu, <myodbc@lists.mysql.com>
*
* (C) Copyright MySQL AB, 1995-2006
*
**/
/* build command
*
* csc /t:exe
* /out:mycon.exe mycon.cs
* /r:Microsoft.Data.Odbc.dll
*/
using Console = System.Console;
using Microsoft.Data.Odbc;
namespace myodbc3
{
class mycon
{
static void Main(string[] args)
{
try
{
//Connection string for MyODBC 2.50
/*string MyConString = "DRIVER={MySQL};" +
"SERVER=localhost;" +
"DATABASE=test;" +
"UID=venu;" +
"PASSWORD=venu;" +
"OPTION=3";
*/
//Connection string for Connector/ODBC 3.51
string MyConString = "DRIVER={MySQL ODBC 3.51 Driver};" +
"SERVER=localhost;" +
"DATABASE=test;" +
"UID=venu;" +
"PASSWORD=venu;" +
"OPTION=3";
//Connect to MySQL using Connector/ODBC
OdbcConnection MyConnection = new OdbcConnection(MyConString);
MyConnection.Open();
Console.WriteLine("\n !!! success, connected successfully !!!\n");
//Display connection information
Console.WriteLine("Connection Information:");
Console.WriteLine("\tConnection String:" +
MyConnection.ConnectionString);
Console.WriteLine("\tConnection Timeout:" +
MyConnection.ConnectionTimeout);
Console.WriteLine("\tDatabase:" +
MyConnection.Database);
Console.WriteLine("\tDataSource:" +
MyConnection.DataSource);
Console.WriteLine("\tDriver:" +
MyConnection.Driver);
Console.WriteLine("\tServerVersion:" +
MyConnection.ServerVersion);
//Create a sample table
OdbcCommand MyCommand =
new OdbcCommand("DROP TABLE IF EXISTS my_odbc_net",
MyConnection);
MyCommand.ExecuteNonQuery();
MyCommand.CommandText =
"CREATE TABLE my_odbc_net(id int, name varchar(20), idb bigint)";
MyCommand.ExecuteNonQuery();
//Insert
MyCommand.CommandText =
"INSERT INTO my_odbc_net VALUES(10,'venu', 300)";
Console.WriteLine("INSERT, Total rows affected:" +
MyCommand.ExecuteNonQuery());;
//Insert
MyCommand.CommandText =
"INSERT INTO my_odbc_net VALUES(20,'mysql',400)";
Console.WriteLine("INSERT, Total rows affected:" +
MyCommand.ExecuteNonQuery());
//Insert
MyCommand.CommandText =
"INSERT INTO my_odbc_net VALUES(20,'mysql',500)";
Console.WriteLine("INSERT, Total rows affected:" +
MyCommand.ExecuteNonQuery());
//Update
MyCommand.CommandText =
"UPDATE my_odbc_net SET id=999 WHERE id=20";
Console.WriteLine("Update, Total rows affected:" +
MyCommand.ExecuteNonQuery());
//COUNT(*)
MyCommand.CommandText =
"SELECT COUNT(*) as TRows FROM my_odbc_net";
Console.WriteLine("Total Rows:" +
MyCommand.ExecuteScalar());
//Fetch
MyCommand.CommandText = "SELECT * FROM my_odbc_net";
OdbcDataReader MyDataReader;
MyDataReader = MyCommand.ExecuteReader();
while (MyDataReader.Read())
{
if(string.Compare(MyConnection.Driver,"myodbc3.dll") == 0) {
//Supported only by Connector/ODBC 3.51
Console.WriteLine("Data:" + MyDataReader.GetInt32(0) + " " +
MyDataReader.GetString(1) + " " +
MyDataReader.GetInt64(2));
}
else {
//BIGINTs not supported by Connector/ODBC
Console.WriteLine("Data:" + MyDataReader.GetInt32(0) + " " +
MyDataReader.GetString(1) + " " +
MyDataReader.GetInt32(2));
}
}
//Close all resources
MyDataReader.Close();
MyConnection.Close();
}
catch (OdbcException MyOdbcException) //Catch any ODBC exception ..
{
for (int i=0; i < MyOdbcException.Errors.Count; i++)
{
Console.Write("ERROR #" + i + "\n" +
"Message: " +
MyOdbcException.Errors[i].Message + "\n" +
"Native: " +
MyOdbcException.Errors[i].NativeError.ToString() + "\n" +
"Source: " +
MyOdbcException.Errors[i].Source + "\n" +
"SQL: " +
MyOdbcException.Errors[i].SQLState + "\n");
}
}
}
}
}
The following sample creates a table
my_vb_net and demonstrates the use in VB.
' @sample : myvb.vb
' @purpose : Demo sample for ODBC.NET using Connector/ODBC
' @author : Venu, <myodbc@lists.mysql.com>
'
' (C) Copyright MySQL AB, 1995-2006
'
'
'
' build command
'
' vbc /target:exe
' /out:myvb.exe
' /r:Microsoft.Data.Odbc.dll
' /r:System.dll
' /r:System.Data.dll
'
Imports Microsoft.Data.Odbc
Imports System
Module myvb
Sub Main()
Try
'Connector/ODBC 3.51 connection string
Dim MyConString As String = "DRIVER={MySQL ODBC 3.51 Driver};" & _
"SERVER=localhost;" & _
"DATABASE=test;" & _
"UID=venu;" & _
"PASSWORD=venu;" & _
"OPTION=3;"
'Connection
Dim MyConnection As New OdbcConnection(MyConString)
MyConnection.Open()
Console.WriteLine("Connection State::" & MyConnection.State.ToString)
'Drop
Console.WriteLine("Dropping table")
Dim MyCommand As New OdbcCommand()
MyCommand.Connection = MyConnection
MyCommand.CommandText = "DROP TABLE IF EXISTS my_vb_net"
MyCommand.ExecuteNonQuery()
'Create
Console.WriteLine("Creating....")
MyCommand.CommandText = "CREATE TABLE my_vb_net(id int, name varchar(30))"
MyCommand.ExecuteNonQuery()
'Insert
MyCommand.CommandText = "INSERT INTO my_vb_net VALUES(10,'venu')"
Console.WriteLine("INSERT, Total rows affected:" & _
MyCommand.ExecuteNonQuery())
'Insert
MyCommand.CommandText = "INSERT INTO my_vb_net VALUES(20,'mysql')"
Console.WriteLine("INSERT, Total rows affected:" & _
MyCommand.ExecuteNonQuery())
'Insert
MyCommand.CommandText = "INSERT INTO my_vb_net VALUES(20,'mysql')"
Console.WriteLine("INSERT, Total rows affected:" & _
MyCommand.ExecuteNonQuery())
'Insert
MyCommand.CommandText = "INSERT INTO my_vb_net(id) VALUES(30)"
Console.WriteLine("INSERT, Total rows affected:" & _
MyCommand.ExecuteNonQuery())
'Update
MyCommand.CommandText = "UPDATE my_vb_net SET id=999 WHERE id=20"
Console.WriteLine("Update, Total rows affected:" & _
MyCommand.ExecuteNonQuery())
'COUNT(*)
MyCommand.CommandText = "SELECT COUNT(*) as TRows FROM my_vb_net"
Console.WriteLine("Total Rows:" & MyCommand.ExecuteScalar())
'Select
Console.WriteLine("Select * FROM my_vb_net")
MyCommand.CommandText = "SELECT * FROM my_vb_net"
Dim MyDataReader As OdbcDataReader
MyDataReader = MyCommand.ExecuteReader
While MyDataReader.Read
If MyDataReader("name") Is DBNull.Value Then
Console.WriteLine("id = " & _
CStr(MyDataReader("id")) & " name = " & _
"NULL")
Else
Console.WriteLine("id = " & _
CStr(MyDataReader("id")) & " name = " & _
CStr(MyDataReader("name")))
End If
End While
'Catch ODBC Exception
Catch MyOdbcException As OdbcException
Dim i As Integer
Console.WriteLine(MyOdbcException.ToString)
'Catch program exception
Catch MyException As Exception
Console.WriteLine(MyException.ToString)
End Try
End SubThis section provides reference material for the Connector/ODBC API, showing supported functions and methods, supported MySQL column types and the corresponding native type in Connector/ODBC, and the error codes returned by Connector/ODBC when a fault occurs.
This section summarizes ODBC routines, categorized by functionality.
For the complete ODBC API reference, please refer to the ODBC Programer's Reference at http://msdn.microsoft.com/library/en-us/odbc/htm/odbcabout_this_manual.asp.
An application can call SQLGetInfo function
to obtain conformance information about Connector/ODBC. To
obtain information about support for a specific function in the
driver, an application can call
SQLGetFunctions.
Note
For backward compatibility, the Connector/ODBC 3.51 driver supports all deprecated functions.
The following tables list Connector/ODBC API calls grouped by task:
Connecting to a data source:
| Connector/ODBC | ||||
| Function name | 2.50 | 3.51 | Standard | Purpose |
SQLAllocHandle | No | Yes | ISO 92 | Obtains an environment, connection, statement, or descriptor handle. |
SQLConnect | Yes | Yes | ISO 92 | Connects to a specific driver by data source name, user ID, and password. |
SQLDriverConnect | Yes | Yes | ODBC | Connects to a specific driver by connection string or requests that the Driver Manager and driver display connection dialog boxes for the user. |
SQLAllocEnv | Yes | Yes | Deprecated | Obtains an environment handle allocated from driver. |
SQLAllocConnect | Yes | Yes | Deprecated | Obtains a connection handle |
Obtaining information about a driver and data source:
| Connector/ODBC | ||||
| Function name | 2.50 | 3.51 | Standard | Purpose |
SQLDataSources | No | No | ISO 92 | Returns the list of available data sources, handled by the Driver Manager |
SQLDrivers | No | No | ODBC | Returns the list of installed drivers and their attributes, handles by Driver Manager |
SQLGetInfo | Yes | Yes | ISO 92 | Returns information about a specific driver and data source. |
SQLGetFunctions | Yes | Yes | ISO 92 | Returns supported driver functions. |
SQLGetTypeInfo | Yes | Yes | ISO 92 | Returns information about supported data types. |
Setting and retrieving driver attributes:
| Connector/ODBC | ||||
| Function name | 2.50 | 3.51 | Standard | Purpose |
SQLSetConnectAttr | No | Yes | ISO 92 | Sets a connection attribute. |
SQLGetConnectAttr | No | Yes | ISO 92 | Returns the value of a connection attribute. |
SQLSetConnectOption | Yes | Yes | Deprecated | Sets a connection option |
SQLGetConnectOption | Yes | Yes | Deprecated | Returns the value of a connection option |
SQLSetEnvAttr | No | Yes | ISO 92 | Sets an environment attribute. |
SQLGetEnvAttr | No | Yes | ISO 92 | Returns the value of an environment attribute. |
SQLSetStmtAttr | No | Yes | ISO 92 | Sets a statement attribute. |
SQLGetStmtAttr | No | Yes | ISO 92 | Returns the value of a statement attribute. |
SQLSetStmtOption | Yes | Yes | Deprecated | Sets a statement option |
SQLGetStmtOption | Yes | Yes | Deprecated | Returns the value of a statement option |
Preparing SQL requests:
| Connector/ODBC | ||||
| Function name | 2.50 | 3.51 | Standard | Purpose |
SQLAllocStmt | Yes | Yes | Deprecated | Allocates a statement handle |
SQLPrepare | Yes | Yes | ISO 92 | Prepares an SQL statement for later execution. |
SQLBindParameter | Yes | Yes | ODBC | Assigns storage for a parameter in an SQL statement. |
SQLGetCursorName | Yes | Yes | ISO 92 | Returns the cursor name associated with a statement handle. |
SQLSetCursorName | Yes | Yes | ISO 92 | Specifies a cursor name. |
SQLSetScrollOptions | Yes | Yes | ODBC | Sets options that control cursor behavior. |
Submitting requests:
| Connector/ODBC | ||||
| Function name | 2.50 | 3.51 | Standard | Purpose |
SQLExecute | Yes | Yes | ISO 92 | Executes a prepared statement. |
SQLExecDirect | Yes | Yes | ISO 92 | Executes a statement |
SQLNativeSql | Yes | Yes | ODBC | Returns the text of an SQL statement as translated by the driver. |
SQLDescribeParam | Yes | Yes | ODBC | Returns the description for a specific parameter in a statement. |
SQLNumParams | Yes | Yes | ISO 92 | Returns the number of parameters in a statement. |
SQLParamData | Yes | Yes | ISO 92 | Used in conjunction with SQLPutData to supply
parameter data at execution time. (Useful for long data
values.) |
SQLPutData | Yes | Yes | ISO 92 | Sends part or all of a data value for a parameter. (Useful for long data values.) |
Retrieving results and information about results:
| Connector/ODBC | ||||
| Function name | 2.50 | 3.51 | Standard | Purpose |
SQLRowCount | Yes | Yes | ISO 92 | Returns the number of rows affected by an insert, update, or delete request. |
SQLNumResultCols | Yes | Yes | ISO 92 | Returns the number of columns in the result set. |
SQLDescribeCol | Yes | Yes | ISO 92 | Describes a column in the result set. |
SQLColAttribute | No | Yes | ISO 92 | Describes attributes of a column in the result set. |
SQLColAttributes | Yes | Yes | Deprecated | Describes attributes of a column in the result set. |
SQLFetch | Yes | Yes | ISO 92 | Returns multiple result rows. |
SQLFetchScroll | No | Yes | ISO 92 | Returns scrollable result rows. |
SQLExtendedFetch | Yes | Yes | Deprecated | Returns scrollable result rows. |
SQLSetPos | Yes | Yes | ODBC | Positions a cursor within a fetched block of data and allows an application to refresh data in the rowset or to update or delete data in the result set. |
SQLBulkOperations | No | Yes | ODBC | Performs bulk insertions and bulk bookmark operations, including update, delete, and fetch by bookmark. |
Retrieving error or diagnostic information:
| Connector/ODBC | ||||
| Function name | 2.50 | 3.51 | Standard | Purpose |
SQLError | Yes | Yes | Deprecated | Returns additional error or status information |
SQLGetDiagField | Yes | Yes | ISO 92 | Returns additional diagnostic information (a single field of the diagnostic data structure). |
SQLGetDiagRec | Yes | Yes | ISO 92 | Returns additional diagnostic information (multiple fields of the diagnostic data structure). |
Obtaining information about the data source's system tables (catalog functions) item:
| Connector/ODBC | ||||
| Function name | 2.50 | 3.51 | Standard | Purpose |
SQLColumnPrivileges | Yes | Yes | ODBC | Returns a list of columns and associated privileges for one or more tables. |
SQLColumns | Yes | Yes | X/Open | Returns the list of column names in specified tables. |
SQLForeignKeys | Yes | Yes | ODBC | Returns a list of column names that make up foreign keys, if they exist for a specified table. |
SQLPrimaryKeys | Yes | Yes | ODBC | Returns the list of column names that make up the primary key for a table. |
SQLSpecialColumns | Yes | Yes | X/Open | Returns information about the optimal set of columns that uniquely identifies a row in a specified table, or the columns that are automatically updated when any value in the row is updated by a transaction. |
SQLStatistics | Yes | Yes | ISO 92 | Returns statistics about a single table and the list of indexes associated with the table. |
SQLTablePrivileges | Yes | Yes | ODBC | Returns a list of tables and the privileges associated with each table. |
SQLTables | Yes | Yes | X/Open | Returns the list of table names stored in a specific data source. |
Performing transactions:
| Connector/ODBC | ||||
| Function name | 2.50 | 3.51 | Standard | Purpose |
SQLTransact | Yes | Yes | Deprecated | Commits or rolls back a transaction |
SQLEndTran | No | Yes | ISO 92 | Commits or rolls back a transaction. |
Terminating a statement:
| Connector/ODBC | ||||
| Function name | 2.50 | 3.51 | Standard | Purpose |
SQLFreeStmt | Yes | Yes | ISO 92 | Ends statement processing, discards pending results, and, optionally, frees all resources associated with the statement handle. |
SQLCloseCursor | Yes | Yes | ISO 92 | Closes a cursor that has been opened on a statement handle. |
SQLCancel | Yes | Yes | ISO 92 | Cancels an SQL statement. |
Terminating a connection:
| Connector/ODBC | ||||
| Function name | 2.50 | 3.51 | Standard | Purpose |
SQLDisconnect | Yes | Yes | ISO 92 | Closes the connection. |
SQLFreeHandle | No | Yes | ISO 92 | Releases an environment, connection, statement, or descriptor handle. |
SQLFreeConnect | Yes | Yes | Deprecated | Releases connection handle |
SQLFreeEnv | Yes | Yes | Deprecated | Releases an environment handle |
The following table illustrates how driver maps the server data types to default SQL and C data types:
| Native Value | SQL Type | C Type |
bit | SQL_BIT | SQL_C_BIT |
tinyint | SQL_TINYINT | SQL_C_STINYINT |
tinyint unsigned | SQL_TINYINT | SQL_C_UTINYINT |
bigint | SQL_BIGINT | SQL_C_SBIGINT |
bigint unsigned | SQL_BIGINT | SQL_C_UBIGINT |
long varbinary | SQL_LONGVARBINARY | SQL_C_BINARY |
blob | SQL_LONGVARBINARY | SQL_C_BINARY |
longblob | SQL_LONGVARBINARY | SQL_C_BINARY |
tinyblob | SQL_LONGVARBINARY | SQL_C_BINARY |
mediumblob | SQL_LONGVARBINARY | SQL_C_BINARY |
long varchar | SQL_LONGVARCHAR | SQL_C_CHAR |
text | SQL_LONGVARCHAR | SQL_C_CHAR |
mediumtext | SQL_LONGVARCHAR | SQL_C_CHAR |
char | SQL_CHAR | SQL_C_CHAR |
numeric | SQL_NUMERIC | SQL_C_CHAR |
decimal | SQL_DECIMAL | SQL_C_CHAR |
integer | SQL_INTEGER | SQL_C_SLONG |
integer unsigned | SQL_INTEGER | SQL_C_ULONG |
int | SQL_INTEGER | SQL_C_SLONG |
int unsigned | SQL_INTEGER | SQL_C_ULONG |
mediumint | SQL_INTEGER | SQL_C_SLONG |
mediumint unsigned | SQL_INTEGER | SQL_C_ULONG |
smallint | SQL_SMALLINT | SQL_C_SSHORT |
smallint unsigned | SQL_SMALLINT | SQL_C_USHORT |
real | SQL_FLOAT | SQL_C_DOUBLE |
double | SQL_FLOAT | SQL_C_DOUBLE |
float | SQL_REAL | SQL_C_FLOAT |
double precision | SQL_DOUBLE | SQL_C_DOUBLE |
date | SQL_DATE | SQL_C_DATE |
time | SQL_TIME | SQL_C_TIME |
year | SQL_SMALLINT | SQL_C_SHORT |
datetime | SQL_TIMESTAMP | SQL_C_TIMESTAMP |
timestamp | SQL_TIMESTAMP | SQL_C_TIMESTAMP |
text | SQL_VARCHAR | SQL_C_CHAR |
varchar | SQL_VARCHAR | SQL_C_CHAR |
enum | SQL_VARCHAR | SQL_C_CHAR |
set | SQL_VARCHAR | SQL_C_CHAR |
bit | SQL_CHAR | SQL_C_CHAR |
bool | SQL_CHAR | SQL_C_CHAR |
The following tables lists the error codes returned by the driver apart from the server errors.
| Native Code | SQLSTATE 2 | SQLSTATE 3 | Error Message |
| 500 | 01000 | 01000 | General warning |
| 501 | 01004 | 01004 | String data, right truncated |
| 502 | 01S02 | 01S02 | Option value changed |
| 503 | 01S03 | 01S03 | No rows updated/deleted |
| 504 | 01S04 | 01S04 | More than one row updated/deleted |
| 505 | 01S06 | 01S06 | Attempt to fetch before the result set returned the first row set |
| 506 | 07001 | 07002 | SQLBindParameter not used for all parameters |
| 507 | 07005 | 07005 | Prepared statement not a cursor-specification |
| 508 | 07009 | 07009 | Invalid descriptor index |
| 509 | 08002 | 08002 | Connection name in use |
| 510 | 08003 | 08003 | Connection does not exist |
| 511 | 24000 | 24000 | Invalid cursor state |
| 512 | 25000 | 25000 | Invalid transaction state |
| 513 | 25S01 | 25S01 | Transaction state unknown |
| 514 | 34000 | 34000 | Invalid cursor name |
| 515 | S1000 | HY000 | General driver defined error |
| 516 | S1001 | HY001 | Memory allocation error |
| 517 | S1002 | HY002 | Invalid column number |
| 518 | S1003 | HY003 | Invalid application buffer type |
| 519 | S1004 | HY004 | Invalid SQL data type |
| 520 | S1009 | HY009 | Invalid use of null pointer |
| 521 | S1010 | HY010 | Function sequence error |
| 522 | S1011 | HY011 | Attribute can not be set now |
| 523 | S1012 | HY012 | Invalid transaction operation code |
| 524 | S1013 | HY013 | Memory management error |
| 525 | S1015 | HY015 | No cursor name available |
| 526 | S1024 | HY024 | Invalid attribute value |
| 527 | S1090 | HY090 | Invalid string or buffer length |
| 528 | S1091 | HY091 | Invalid descriptor field identifier |
| 529 | S1092 | HY092 | Invalid attribute/option identifier |
| 530 | S1093 | HY093 | Invalid parameter number |
| 531 | S1095 | HY095 | Function type out of range |
| 532 | S1106 | HY106 | Fetch type out of range |
| 533 | S1117 | HY117 | Row value out of range |
| 534 | S1109 | HY109 | Invalid cursor position |
| 535 | S1C00 | HYC00 | Optional feature not implemented |
| 0 | 21S01 | 21S01 | Column count does not match value count |
| 0 | 23000 | 23000 | Integrity constraint violation |
| 0 | 42000 | 42000 | Syntax error or access violation |
| 0 | 42S02 | 42S02 | Base table or view not found |
| 0 | 42S12 | 42S12 | Index not found |
| 0 | 42S21 | 42S21 | Column already exists |
| 0 | 42S22 | 42S22 | Column not found |
| 0 | 08S01 | 08S01 | Communication link failure |
Here are some common notes and tips for using Connector/ODBC within different environments, applications and tools. The notes provided here are based on the experiences of Connector/ODBC developers and users.
This section provides help with common queries and areas of functionality in MySQL and how to use them with Connector/ODBC.
Obtaining the value of column that uses
AUTO_INCREMENT after an
INSERT statement can be achieved in a
number of different ways. To obtain the value immediately
after an INSERT, use a
SELECT query with the
LAST_INSERT_ID() function.
For example, using Connector/ODBC you would execute two
separate statements, the INSERT statement
and the SELECT query to obtain the
auto-increment value.
INSERT INTO tbl (auto,text) VALUES(NULL,'text'); SELECT LAST_INSERT_ID();
If you do not require the value within your application, but
do require the value as part of another
INSERT, the entire process can be handled
by executing the following statements:
INSERT INTO tbl (auto,text) VALUES(NULL,'text'); INSERT INTO tbl2 (id,text) VALUES(LAST_INSERT_ID(),'text');
Certain ODBC applications (including Delphi and Access) may have trouble obtaining the auto-increment value using the previous examples. In this case, try the following statement as an alternative:
SELECT * FROM tbl WHERE auto IS NULL;
See Section 22.2.14.3, “How to Get the Unique ID for the Last Inserted Row”.
Support for the dynamic cursor is provided
in Connector/ODBC 3.51, but dynamic cursors are not enabled by
default. You can enable this function within Windows by
selecting the Enable Dynamic Cursor
checkbox within the ODBC Data Source Administrator.
On other platforms, you can enable the dynamic cursor by
adding 32 to the OPTION
value when creating the DSN.
The Connector/ODBC driver has been optimized to provide very fast performance. If you experience problems with the performance of Connector/ODBC, or notice a large amount of disk activity for simple queries, there are a number of aspects you should check:
Ensure that
ODBC Tracingis not enabled. With tracing enabled, a lot of information is recorded in the tracing file by the ODBC Manager. You can check, and disable, tracing within Windows using the panel of the ODBC Data Source Administrator. Within Mac OS X, check the panel of ODBC Administrator. See Section 23.1.3.8, “Getting an ODBC Trace File”.Make sure you are using the standard version of the driver, and not the debug version. The debug version includes additional checks and reporting measures.
Disable the Connector/ODBC driver trace and query logs. These options are enabled for each DSN, so make sure to examine only the DSN that you are using in your application. Within Windows, you can disable the Connector/ODBC and query logs by modifying the DSN configuration. Within Mac OS X and Unix, ensure that the driver trace (option value 4) and query logging (option value 524288) are not enabled.
For more information on how to set the query timeout on Microsoft Windows when executing queries through an ODBC connection, read the Microsoft knowledgebase document at http://support.microsoft.com/default.aspx?scid=kb%3Ben-us%3B153756.
Most programs should work with Connector/ODBC, but for each of those listed here, there are specific notes and tips to improve or enhance the way you work with Connector/ODBC and these applications.
With all applications you should ensure that you are using the latest Connector/ODBC drivers, ODBC Manager and any supporting libraries and interfaces used by your application. For example, on Windows, using the latest version of Microsoft Data Access Components (MDAC) will improve the compatibility with ODBC in general, and with the Connector/ODBC driver.
The majority of Microsoft applications have been tested with Connector/ODBC, including Microsoft Office, Microsoft Access and the various programming languages supported within ASP and Microsoft Visual Studio.
To improve the integration between Microsoft Access and MySQL through Connector/ODBC:
For all versions of Access, you should enable the Connector/ODBC
Return matching rowsoption. For Access 2.0, you should additionally enable theSimulate ODBC 1.0option.You should have a
TIMESTAMPcolumn in all tables that you want to be able to update. For maximum portability, don't use a length specification in the column declaration (which is unsupported within MySQL in versions earlier than 4.1).You should have a primary key in each MySQL table you want to use with Access. If not, new or updated rows may show up as
#DELETED#.Use only
DOUBLEfloat fields. Access fails when comparing with single-precision floats. The symptom usually is that new or updated rows may show up as#DELETED#or that you can't find or update rows.If you are using Connector/ODBC to link to a table that has a
BIGINTcolumn, the results are displayed as#DELETED#. The work around solution is:Have one more dummy column with
TIMESTAMPas the data type.Select the
Change BIGINT columns to INToption in the connection dialog in ODBC DSN Administrator.Delete the table link from Access and re-create it.
Old records may still display as
#DELETED#, but newly added/updated records are displayed properly.If you still get the error
Another user has changed your dataafter adding aTIMESTAMPcolumn, the following trick may help you:Don't use a
tabledata sheet view. Instead, create a form with the fields you want, and use thatformdata sheet view. You should set theDefaultValueproperty for theTIMESTAMPcolumn toNOW(). It may be a good idea to hide theTIMESTAMPcolumn from view so your users are not confused.In some cases, Access may generate SQL statements that MySQL can't understand. You can fix this by selecting
"Query|SQLSpecific|Pass-Through"from the Access menu.On Windows NT, Access reports
BLOBcolumns asOLE OBJECTS. If you want to haveMEMOcolumns instead, you should changeBLOBcolumns toTEXTwithALTER TABLE.Access can't always handle the MySQL
DATEcolumn properly. If you have a problem with these, change the columns toDATETIME.If you have in Access a column defined as
BYTE, Access tries to export this asTINYINTinstead ofTINYINT UNSIGNED. This gives you problems if you have values larger than 127 in the column.If you have very large (long) tables in Access, it might take a very long time to open them. Or you might run low on virtual memory and eventually get an
ODBC Query Failederror and the table cannot open. To deal with this, select the following options:Return Matching Rows (2)
Allow BIG Results (8).
These add up to a value of 10 (
OPTION=10).
Some external articles and tips that may be useful when using Access, ODBC and Connector/ODBC:
Optimizing Access ODBC Applications
For a list of tools that can be used with Access and ODBC data sources, refer to converters section for list of available tools.
If you have problems importing data into Microsoft Excel, particularly numerical, date, and time values, this is probably because of a bug in Excel, where the column type of the source data is used to determine the data type when that data is inserted into a cell within the worksheet. The result is that Excel incorrectly identifies the content and this affects both the display format and the data when it is used within calculations.
To address this issue, use the CONCAT()
function in your queries. The use of
CONCAT() forces Excel to treat the value
as a string, which Excel will then parse and usually
correctly identify the embedded information.
However, even with this option, some data may be incorrectly
formatted, even though the source data remains unchanged.
Use the Format Cells option within Excel
to change the format of the displayed information.
To be able to update a table, you must define a primary key for the table.
Visual Basic with ADO can't handle big integers. This means
that some queries like SHOW PROCESSLIST
do not work properly. The fix is to use
OPTION=16384 in the ODBC connect string
or to select the Change BIGINT columns to
INT option in the Connector/ODBC connect screen.
You may also want to select the Return matching
rows option.
If you have a BIGINT in your result, you
may get the error [Microsoft][ODBC Driver Manager]
Driver does not support this parameter. Try
selecting the Change BIGINT columns to
INT option in the Connector/ODBC connect screen.
When you are coding with the ADO API and Connector/ODBC, you
need to pay attention to some default properties that aren't
supported by the MySQL server. For example, using the
CursorLocation Property as
adUseServer returns a result of –1
for the RecordCount Property. To have the
right value, you need to set this property to
adUseClient, as shown in the VB code
here:
Dim myconn As New ADODB.Connection Dim myrs As New Recordset Dim mySQL As String Dim myrows As Long myconn.Open "DSN=MyODBCsample" mySQL = "SELECT * from user" myrs.Source = mySQL Set myrs.ActiveConnection = myconn myrs.CursorLocation = adUseClient myrs.Open myrows = myrs.RecordCount myrs.Close myconn.Close
Another workaround is to use a SELECT
COUNT(*) statement for a similar query to get the
correct row count.
To find the number of rows affected by a specific SQL
statement in ADO, use the RecordsAffected
property in the ADO execute method. For more information on
the usage of execute method, refer to
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/ado270/htm/mdmthcnnexecute.asp.
For information, see ActiveX Data Objects(ADO) Frequently Asked Questions.
You should select the Return matching
rows option in the DSN.
For more information about how to access MySQL via ASP using Connector/ODBC, refer to the following articles:
A Frequently Asked Questions list for ASP can be found at http://support.microsoft.com/default.aspx?scid=/Support/ActiveServer/faq/data/adofaq.asp.
Some articles that may help with Visual Basic and ASP:
MySQL BLOB columns and Visual Basic 6 by Mike Hillyer (
<mike@openwin.org>).How to map Visual basic data type to MySQL types by Mike Hillyer (
<mike@openwin.org>).
With all Borland applications where the Borland Database Engine (BDE) is used, follow these steps to improve compatibility:
Update to BDE 3.2 or newer.
Enable the
Don't optimize column widthsoption in the DSN.Enabled the
Return matching rowsoption in the DSN.
When you start a query, you can use the
Active property or the
Open method. Note that
Active starts by automatically issuing a
SELECT * FROM ... query. That may not be
a good thing if your tables are large.
Also, here is some potentially useful Delphi code that sets
up both an ODBC entry and a BDE entry for Connector/ODBC.
The BDE entry requires a BDE Alias Editor that is free at a
Delphi Super Page near you. (Thanks to Bryan Brunton
<bryan@flesherfab.com> for this):
fReg:= TRegistry.Create;
fReg.OpenKey('\Software\ODBC\ODBC.INI\DocumentsFab', True);
fReg.WriteString('Database', 'Documents');
fReg.WriteString('Description', ' ');
fReg.WriteString('Driver', 'C:\WINNT\System32\myodbc.dll');
fReg.WriteString('Flag', '1');
fReg.WriteString('Password', '');
fReg.WriteString('Port', ' ');
fReg.WriteString('Server', 'xmark');
fReg.WriteString('User', 'winuser');
fReg.OpenKey('\Software\ODBC\ODBC.INI\ODBC Data Sources', True);
fReg.WriteString('DocumentsFab', 'MySQL');
fReg.CloseKey;
fReg.Free;
Memo1.Lines.Add('DATABASE NAME=');
Memo1.Lines.Add('USER NAME=');
Memo1.Lines.Add('ODBC DSN=DocumentsFab');
Memo1.Lines.Add('OPEN MODE=READ/WRITE');
Memo1.Lines.Add('BATCH COUNT=200');
Memo1.Lines.Add('LANGDRIVER=');
Memo1.Lines.Add('MAX ROWS=-1');
Memo1.Lines.Add('SCHEMA CACHE DIR=');
Memo1.Lines.Add('SCHEMA CACHE SIZE=8');
Memo1.Lines.Add('SCHEMA CACHE TIME=-1');
Memo1.Lines.Add('SQLPASSTHRU MODE=SHARED AUTOCOMMIT');
Memo1.Lines.Add('SQLQRYMODE=');
Memo1.Lines.Add('ENABLE SCHEMA CACHE=FALSE');
Memo1.Lines.Add('ENABLE BCD=FALSE');
Memo1.Lines.Add('ROWSET SIZE=20');
Memo1.Lines.Add('BLOBS TO CACHE=64');
Memo1.Lines.Add('BLOB SIZE=32');
AliasEditor.Add('DocumentsFab','MySQL',Memo1.Lines);
The following information is taken from the ColdFusion documentation:
Use the following information to configure ColdFusion Server
for Linux to use the unixODBC driver with
Connector/ODBC for MySQL data sources. Allaire has verified
that MyODBC 2.50.26 works with MySQL 3.22.27 and ColdFusion
for Linux. (Any newer version should also work.) You can
download Connector/ODBC at
http://dev.mysql.com/downloads/connector/odbc/.
ColdFusion version 4.5.1 allows you to us the ColdFusion
Administrator to add the MySQL data source. However, the
driver is not included with ColdFusion version 4.5.1. Before
the MySQL driver appears in the ODBC data sources drop-down
list, you must build and copy the Connector/ODBC driver to
/opt/coldfusion/lib/libmyodbc.so.
The Contrib directory contains the program
mydsn-
which allows you to build and remove the DSN registry file for
the Connector/ODBC driver on ColdFusion applications.
xxx.zip
For more information and guides on using ColdFusion and Connector/ODBC, see the following external sites:
Open Office (http://www.openoffice.org) How-to: MySQL + OpenOffice. How-to: OpenOffice + MyODBC + unixODBC.
Sambar Server (http://www.sambarserver.info) How-to: MyODBC + SambarServer + MySQL.
The following section details some common errors and their suggested fix or alternative solution. If you are still experiencing problems, use the Connector/ODBC mailing list; see Section 23.1.7.1, “Connector/ODBC Community Support”.
Many problems can be resolved by upgrading your Connector/ODBC drivers to the latest available release. On Windows, you should also make sure that you have the latest versions of the Microsoft Data Access Components (MDAC) installed.
Questions
24.1.6.3.1: Are MyODBC 2.50 applications compatible with Connector/ODBC 3.51?
24.1.6.3.2: I have installed Connector/ODBC on Windows XP x64 Edition or Windows Server 2003 R2 x64. The installation completed successfully, but the Connector/ODBC driver does not appear in
ODBC Data Source Administrator.24.1.6.3.3: When connecting or using the button in
ODBC Data Source AdministratorI get error 10061 (Cannot connect to server)24.1.6.3.4: The following error is reported when using transactions:
Transactions are not enabled24.1.6.3.5: The following error is reported when I submit a query:
Cursor not found24.1.6.3.6: Access reports records as
#DELETED#when inserting or updating records in linked tables.24.1.6.3.7: How do I handle Write Conflicts or Row Location errors?
24.1.6.3.8: Exporting data from Access 97 to MySQL reports a
Syntax Error.24.1.6.3.9: Exporting data from Microsoft DTS to MySQL reports a
Syntax Error.24.1.6.3.10: Using ODBC.NET with Connector/ODBC, while fetching empty string (0 length), it starts giving the SQL_NO_DATA exception.
24.1.6.3.11: Using
SELECT COUNT(*) FROMwithin Visual Basic and ASP returns an error.tbl_name24.1.6.3.12: Using the
AppendChunk()orGetChunk()ADO methods, theMultiple-step operation generated errors. Check each status valueerror is returned.24.1.6.3.13: Access Returns
Another user had modified the record that you have modifiedwhile editing records on a Linked Table.24.1.6.3.14: When linking an application directly to the Connector/ODBC library under Unix/Linux, the application crashes.
24.1.6.3.15: Applications in the Microsoft Office suite are unable to update tables that have
DATEorTIMESTAMPcolumns.24.1.6.3.16: When connecting Connector/ODBC 5.x (Beta) to a MySQL 4.x server, the error
1044 Access denied for user 'xxx'@'%' to database 'information_schema'is returned.24.1.6.3.17: When calling
SQLTables, the errorS1T00is returned, but I cannot find this in the list of error numbers for Connector/ODBC.
Questions and Answers
24.1.6.3.1: Are MyODBC 2.50 applications compatible with Connector/ODBC 3.51?
Applications based on MyODBC 2.50 should work fine with Connector/ODBC 3.51 and later versions. If you find something is not working with the latest version of Connector/ODBC which previously worked under an earlier version, please file a bug report. See Section 23.1.7.2, “How to Report Connector/ODBC Problems or Bugs”.
24.1.6.3.2:
I have installed Connector/ODBC on Windows XP x64 Edition
or Windows Server 2003 R2 x64. The installation completed
successfully, but the Connector/ODBC driver does not
appear in ODBC Data Source
Administrator.
This is not a bug, but is related to the way Windows x64
editions operate with the ODBC driver. On Windows x64
editions, the Connector/ODBC driver is installed in the
%SystemRoot%\SysWOW64 folder.
However, the default ODBC Data Source
Administrator that is available through the
Administrative Tools or
Control Panel in Windows x64 Editions
is located in the
%SystemRoot%\system32 folder, and
only searches this folder for ODBC drivers.
On Windowx x64 editions, you should use the ODBC
administration tool located at
%SystemRoot%\SysWOW64\odbcad32.exe,
this will correctly locate the installed Connector/ODBC
drivers and enable you to create a Connector/ODBC DSN.
This issue was originally reported as Bug#20301.
24.1.6.3.3:
When connecting or using the
button in ODBC Data Source
Administrator I get error 10061 (Cannot connect
to server)
This error can be raised by a number of different issues,
including server problems, network problems, and firewall
and port blocking problems. For more information, see
Section B.1.2.2, “Can't connect to [local] MySQL server”.
24.1.6.3.4:
The following error is reported when using transactions:
Transactions are not enabled
This error indicates that you are trying to use
transactions with a MySQL table that does not support
transactions. Transactions are supported within MySQL when
using the InnoDB database engine. In
versions of MySQL before Mysql 5.1 you may also use the
BDB engine.
You should check the following before continuing:
Verify that your MySQL server supports a transactional database engine. Use
SHOW ENGINESto obtain a list of the available engine types.Verify that the tables you are updating use a transaction database engine.
Ensure that you have not enabled the
disable transactionsoption in your DSN.
24.1.6.3.5:
The following error is reported when I submit a query:
Cursor not found
This occurs because the application is using the old MyODBC 2.50 version, and it did not set the cursor name explicitly through SQLSetCursorName. The fix is to upgrade to Connector/ODBC 3.51 version.
24.1.6.3.6:
Access reports records as #DELETED#
when inserting or updating records in linked tables.
If the inserted or updated records are shown as
#DELETED# in the access, then:
If you are using Access 2000, you should get and install the newest (version 2.6 or higher) Microsoft MDAC (
Microsoft Data Access Components) from http://www.microsoft.com/data/. This fixes a bug in Access that when you export data to MySQL, the table and column names aren't specified. Another way to work around this bug is to upgrade to MyODBC 2.50.33 or higher and MySQL 3.23.x or higher, which together provide a workaround for the problem.You should also get and apply the Microsoft Jet 4.0 Service Pack 5 (SP5) which can be found at http://support.microsoft.com/default.aspx?scid=kb;EN-US;q239114. This fixes some cases where columns are marked as
#DELETED#in Access.Note
If you are using MySQL 3.22, you must apply the MDAC patch and use MyODBC 2.50.32 or 2.50.34 and up to work around this problem.
For all versions of Access, you should enable the Connector/ODBC
Return matching rowsoption. For Access 2.0, you should additionally enable theSimulate ODBC 1.0option.You should have a timestamp in all tables that you want to be able to update.
You should have a primary key in the table. If not, new or updated rows may show up as
#DELETED#.Use only
DOUBLEfloat fields. Access fails when comparing with single-precision floats. The symptom usually is that new or updated rows may show up as#DELETED#or that you can't find or update rows.If you are using Connector/ODBC to link to a table that has a
BIGINTcolumn, the results are displayed as#DELETED. The work around solution is:Have one more dummy column with
TIMESTAMPas the data type.Select the
Change BIGINT columns to INToption in the connection dialog in ODBC DSN Administrator.Delete the table link from Access and re-create it.
Old records still display as
#DELETED#, but newly added/updated records are displayed properly.
24.1.6.3.7: How do I handle Write Conflicts or Row Location errors?
If you see the following errors, select the
Return Matching Rows option in the DSN
configuration dialog, or specify
OPTION=2, as the connection parameter:
Write Conflict. Another user has changed your data. Row cannot be located for updating. Some values may have been changed since it was last read.
24.1.6.3.8:
Exporting data from Access 97 to MySQL reports a
Syntax Error.
This error is specific to Access 97 and versions of Connector/ODBC earlier than 3.51.02. Update to the latest version of the Connector/ODBC driver to resolve this problem.
24.1.6.3.9:
Exporting data from Microsoft DTS to MySQL reports a
Syntax Error.
This error occurs only with MySQL tables using the
TEXT or VARCHAR data
types. You can fix this error by upgrading your
Connector/ODBC driver to version 3.51.02 or higher.
24.1.6.3.10: Using ODBC.NET with Connector/ODBC, while fetching empty string (0 length), it starts giving the SQL_NO_DATA exception.
You can get the patch that addresses this problem from http://support.microsoft.com/default.aspx?scid=kb;EN-US;q319243.
24.1.6.3.11:
Using SELECT COUNT(*) FROM
within
Visual Basic and ASP returns an error.
tbl_name
This error occurs because the COUNT(*)
expression is returning a BIGINT, and
ADO can't make sense of a number this big. Select the
Change BIGINT columns to INT option
(option value 16384).
24.1.6.3.12:
Using the AppendChunk() or
GetChunk() ADO methods, the
Multiple-step operation generated errors. Check
each status value error is returned.
The GetChunk() and
AppendChunk() methods from ADO doesn't
work as expected when the cursor location is specified as
adUseServer. On the other hand, you can
overcome this error by using
adUseClient.
A simple example can be found from http://www.dwam.net/iishelp/ado/docs/adomth02_4.htm
24.1.6.3.13:
Access Returns Another user had modified the
record that you have modified while editing
records on a Linked Table.
In most cases, this can be solved by doing one of the following things:
Add a primary key for the table if one doesn't exist.
Add a timestamp column if one doesn't exist.
Only use double-precision float fields. Some programs may fail when they compare single-precision floats.
If these strategies don't help, you should start by making a log file from the ODBC manager (the log you get when requesting logs from ODBCADMIN) and a Connector/ODBC log to help you figure out why things go wrong. For instructions, see Section 23.1.3.8, “Getting an ODBC Trace File”.
24.1.6.3.14: When linking an application directly to the Connector/ODBC library under Unix/Linux, the application crashes.
Connector/ODBC 3.51 under Unix/Linux is not compatible with direct application linking. You must use a driver manager, such as iODBC or unixODBC to connect to an ODBC source.
24.1.6.3.15:
Applications in the Microsoft Office suite are unable to
update tables that have DATE or
TIMESTAMP columns.
This is a known issue with Connector/ODBC. You must ensure
that the field has a default value (rather than
NULL and that the default value is
non-zeo (i.e. the default value is not 0000-00-00
00:00:00).
24.1.6.3.16:
When connecting Connector/ODBC 5.x (Beta) to a MySQL 4.x
server, the error 1044 Access denied for user
'xxx'@'%' to database 'information_schema' is
returned.
Connector/ODBC 5.x is designed to work with MySQL 5.0 or
later, taking advantage of the
INFORMATION_SCHEMA database to
determine data definition information. Support for MySQL
4.1 is planned for the final release.
24.1.6.3.17:
When calling SQLTables, the error
S1T00 is returned, but I cannot find
this in the list of error numbers for Connector/ODBC.
The S1T00 error indicates that a
general timeout has occurred within the ODBC system and is
not a MySQL error. Typically it indicates that the
connection you are using is stale, the server is too busy
to accept your request or that the server has gone away.
There are many different places where you can get support for using Connector/ODBC. You should always try the Connector/ODBC Mailing List or Connector/ODBC Forum. See Section 23.1.7.1, “Connector/ODBC Community Support”, for help before reporting a specific bug or issue to MySQL.
MySQL AB provides assistance to the user community by means of
its mailing lists. For Connector/ODBC-related issues, you can
get help from experienced users by using the
<myodbc@lists.mysql.com> mailing list. Archives are
available online at
http://lists.mysql.com/myodbc.
For information about subscribing to MySQL mailing lists or to browse list archives, visit http://lists.mysql.com/. See Section 1.7.1, “MySQL Mailing Lists”.
Community support from experienced users is also available through the ODBC Forum. You may also find help from other users in the other MySQL Forums, located at http://forums.mysql.com. See Section 1.7.2, “MySQL Community Support at the MySQL Forums”.
If you encounter difficulties or problems with Connector/ODBC,
you should start by making a log file from the ODBC
Manager (the log you get when requesting logs from
ODBC ADMIN) and Connector/ODBC. The procedure
for doing this is described in
Section 23.1.3.8, “Getting an ODBC Trace File”.
Check the Connector/ODBC trace file to find out what could be
wrong. You should be able to determine what statements were
issued by searching for the string
>mysql_real_query in the
myodbc.log file.
You should also try issuing the statements from the
mysql client program or from
admndemo. This helps you determine whether
the error is in Connector/ODBC or MySQL.
If you find out something is wrong, please only send the
relevant rows (maximum 40 rows) to the myodbc
mailing list. See Section 1.7.1, “MySQL Mailing Lists”. Please never
send the whole Connector/ODBC or ODBC log file!
You should ideally include the following information with the email:
Operating system and version
Connector/ODBC version
ODBC Driver Manager type and version
MySQL server version
ODBC trace from Driver Manager
Connector/ODBC log file from Connector/ODBC driver
Simple reproducible sample
Remember that the more information you can supply to us, the more likely it is that we can fix the problem!
Also, before posting the bug, check the MyODBC mailing list archive at http://lists.mysql.com/myodbc.
If you are unable to find out what's wrong, the last option is
to create an archive in tar or Zip format
that contains a Connector/ODBC trace file, the ODBC log file,
and a README file that explains the
problem. You can send this to ftp://ftp.mysql.com/pub/mysql/upload/.
Only MySQL engineers have access to the files you upload, and we
are very discreet with the data.
If you can create a program that also demonstrates the problem, please include it in the archive as well.
If the program works with another SQL server, you should include an ODBC log file where you perform exactly the same SQL statements so that we can compare the results between the two systems.
Remember that the more information you can supply to us, the more likely it is that we can fix the problem.
You can send a patch or suggest a better solution for any
existing code or problems by sending a mail message to
<myodbc@lists.mysql.com>.
The Connector/ODBC Change History (Changelog) is located with the main Changelog for MySQL. See Section E.3, “MySQL Connector/ODBC (MyODBC) Change History”.
Connector/NET enables developers to easily create .NET applications that require secure, high-performance data connectivity with MySQL. It implements the required ADO.NET interfaces and integrates into ADO.NET aware tools. Developers can build applications using their choice of .NET languages. Connector/NET is a fully managed ADO.NET driver written in 100% pure C#.
Connector/NET includes full support for:
MySQL 5.0 features (such as stored procedures)
MySQL 4.1 features (server-side prepared statements, Unicode, and shared memory access, and so forth)
Large-packet support for sending and receiving rows and BLOBs up to 2 gigabytes in size.
Protocol compression which allows for compressing the data stream between the client and server.
Support for connecting using TCP/IP sockets, named pipes, or shared memory on Windows.
Support for connecting using TCP/IP sockets or Unix sockets on Unix.
Support for the Open Source Mono framework developed by Novell.
Fully managed, does not utilize the MySQL client library.
This document is intended as a user's guide to Connector/NET and
includes a full syntax reference. Syntax information is also
included within the Documentation.chm file
included with the Connector/NET distribution.
If you are using MySQL 5.0 or later, and Visual Studio as your development environment, you may want also want to use the MySQL Visual Studio Plugin. The plugin acts as a DDEX (Data Designer Extensibility) provider, enabling you to use the data design tools within Visual Studio to manipulate the schema and objects within a MySQL database. For more information, see Section 23.3, “MySQL Visual Studio Plugin”.
There are currently two versions of Connector/NET available:
Connector/NET 1.0 includes support for MySQL 4.0, and MySQL 5.0 features, and full compatibility with the ADO.NET driver interface.
Connector/NET 5.0 includes support for MySQL 4.0, MySQL 4.1, MySQL 5.0 and MySQL 5.1 features. Connector/NET 5.0 also includes full support for the ADO.Net 2.0 interfaces and subclasses, includes support for the usage advisor and performance monitor (PerfMon) hooks.
Note
Version numbers for MySQL products are formatted as X.X.X. However, Windows tools (Control Panel, properties display) may show the version numbers as XX.XX.XX. For example, the official MySQL formatted version number 5.0.9 may be displayed by Windows tools as 5.00.09. The two versions are the same; only the number display format is different.
Connector/NET runs on any platform that supports the .NET framework. The .NET framework is primarily supported on recent versions of Microsoft Windows, and is supported on Linux through the Open Source Mono framework (see http://www.mono-project.com).
Connector/NET is available for download from http://dev.mysql.com/downloads/connector/net/1.0.html.
On Windows, installation is supported either through a binary installation process or by downloading a Zip file with the Connector/NET components.
Before installing, you should ensure that your system is up to date, including installing the latest version of the .NET Framework.
Using the installer is the most straightforward method of installing Connector/NET on Windows and the installed components include the source code, test code and full reference documentation.
Connector/NET is installed through the use of a Windows
Installer (.msi) installation package,
which can be used to install Connector/NET on all Windows
operating systems. The MSI package in contained within a ZIP
archive named
mysql-connector-net-,
where version.zipversion indicates the
Connector/NET version.
To install Connector/NET:
Double click on the MSI installer file extracted from the Zip you downloaded. Click to start the installation.
You must choose the type of installation that you want to perform.
For most situations, the Typical installation will be suitable. Click the button and proceed to Step 5. A Complete installation installs all the available files. To conduct a Complete installation, click the button and proceed to step 5. If you want to customize your installation, including choosing the components to install and some installation options, click the button and proceed to Step 3.
The Connector/NET installer will register the connector within the Global Assembly Cache (GAC) - this will make the Connector/NET component available to all applications, not just those where you explicitly reference the Connector/NET component. The installer will also create the necessary links in the Start menu to the documentation and release notes.
If you have chosen a custom installation, you can select the individual components that you want to install, including the core interface component, supporting documentation (a CHM file) samples and examples and the source code. Select the items, and their installation level, and then click to continue the installation.
Note
For Connector/NET 1.0.8 or lower and Connector 5.0.4 and lower the installer will attempt to install binaries for both 1.x and 2.x of the .NET Framework. If you only have one version of the framework installed, the connector installation may fail. If this happens, you can choose the framework version to be installed through the custom installation step.
You will be given a final opportunity to confirm the installation. Click to copy and install the files onto your machine.
Once the installation has been completed, click to exit the installer.
Unless you choose otherwise, Connector/NET is installed in
C:\Program Files\MySQL\MySQL Connector Net
, where
X.X.XX.X.X is replaced with the version
of Connector/NET you are installing. New installations do not
overwrite existing versions of Connector/NET.
Depending on your installation type, the installed components will include some or all of the following components:
bin- Connector/NET MySQL libraries for different versions of the .NET environment.docs- contains a CHM of the Connector/NET documentation.samples- sample code and applications that use the Connector/NET component.src- the source code for the Connector/NET component.
You may also use the /quiet or
/q command line option with the
msiexec tool to install the Connector/NET
package automatically (using the default options) with no
notification to the user. Using this option you cannot select
options and no prompts, messages or dialog boxes will be
displayed.
C:\> msiexec /package conector-net.msi /quiet
To provide a progress bar to the user during automatic
installation, but still without presenting the user with a
dialog box of the ability to select options, use the
/passive option.
If you are having problems running the installer, you can
download a .zip file without an installer as an alternative.
That file is called
mysql-connector-net-.
Once downloaded, you can extract the files to a location of
your choice.
version-noinstall.zip
The .zip file contains the following directories:
bin- Connector/NET MySQL libraries for different versions of the .NET environment.doc- contains a CHM of the Connector/NET documentation.Samples- sample code and applications that use the Connector/NET component.mysqlclient- the source code for the Connector/NET component.testsuite- the test suite used to verify the operation of the Connector/NET component.
There is no installer available for installing the Connector/NET component on your Unix installation. However, the installation is very simple. Before installing, please ensure that you have a working Mono project installation.
Note that you should only install the Connector/NET component on Unix environments where you want to connect to a MySQL server through the Mono project. If you are deploying or developing on a different environment such as Java or Perl then you should use a more appropriate connectivity component. See Chapter 23, Connectors, or Chapter 22, APIs and Libraries, for more information.
To install Connector/NET on Unix/Mono:
Download the
mysql-connector-net-and extract the contents.version-noinstall.zipCopy the
MySql.Data.dllfile to your Mono project installation folder.You must register the Connector/NET component in the Global Assembly Cache using the
gacutilcommand:shell> gacutil /i MySql.Data.dll
Once installed, applications that are compiled with the
Connector/NET component need no further changes. However, you
must ensure that when you compile your applications you include
the Connector/NET component using the
-r:MySqlData.dll command line option.
Caution
You should read this section only if you are interested in helping us test our new code. If you just want to get Connector/NET up and running on your system, you should use a standard release distribution.
To be able to access the Connector/NET source tree, you must have Subversion installed. Subversion is freely available from http://subversion.tigris.org/.
The most recent development source tree is available from our public Subversion trees at http://dev.mysql.com/tech-resources/sources.html.
To checkout out the Connector/NET sources, change to the directory where you want the copy of the Connector/NET tree to be stored, then use the following command:
shell> svn co http://svn.mysql.com/svnpublic/connector-net
A Visual Studio project is included in the source which you can use to build Connector/NET.
Connector/NET comprises several classes that are used to connect to the database, execute queries and statements, and manage query results.
The following are the major classes of Connector/NET:
MySqlCommand: Represents an SQL statement to execute against a MySQL database.MySqlCommandBuilder: Automatically generates single-table commands used to reconcile changes made to a DataSet with the associated MySQL database.MySqlConnection: Represents an open connection to a MySQL Server database.MySqlDataAdapter: Represents a set of data commands and a database connection that are used to fill a dataset and update a MySQL database.MySqlDataReader: Provides a means of reading a forward-only stream of rows from a MySQL database.MySqlException: The exception that is thrown when MySQL returns an error.MySqlHelper: Helper class that makes it easier to work with the provider.MySqlTransaction: Represents an SQL transaction to be made in a MySQL database.
This section contains basic information and examples for each of the above classes. For a more detailed reference guide please see Section 23.2.4, “Connector/NET Reference”.
Represents a SQL statement to execute against a MySQL database. This class cannot be inherited.
MySqlCommand features the following methods
for executing commands at a MySQL database:
| Item | Description |
| ExecuteReader | Executes commands that return rows. |
| ExecuteNonQuery | Executes commands such as SQL INSERT, DELETE, and UPDATE statements. |
| ExecuteScalar | Retrieves a single value (for example, an aggregate value) from a database. |
You can reset the CommandText property and
reuse the MySqlCommand object. However, you
must close the
MySqlDataReader
before you can execute a new or previous command.
If a
MySqlException
is generated by the method executing a
MySqlCommand, the
MySqlConnection
remains open. It is the responsibility of the programmer to
close the connection.
Note
Prior versions of the provider used the '@' symbol to mark parameters in SQL. This is incompatible with MySQL user variables, so the provider now uses the '?' symbol to locate parameters in SQL. To support older code, you can set 'old syntax=yes' on your connection string. If you do this, please be aware that an exception will not be throw if you fail to define a parameter that you intended to use in your SQL.
Examples
The following example creates a
MySqlCommand
and a MySqlConnection. The
MySqlConnection is opened and set as the
Connection
for the MySqlCommand. The example then calls
ExecuteNonQuery,
and closes the connection. To accomplish this, the
ExecuteNonQuery is passed a connection string
and a query string that is a SQL INSERT statement.
Visual Basic example:
Public Sub InsertRow(myConnectionString As String)
" If the connection string is null, use a default.
If myConnectionString = "" Then
myConnectionString = "Database=Test;Data Source=localhost;User Id=username;Password=pass"
End If
Dim myConnection As New MySqlConnection(myConnectionString)
Dim myInsertQuery As String = "INSERT INTO Orders (id, customerId, amount) Values(1001, 23, 30.66)"
Dim myCommand As New MySqlCommand(myInsertQuery)
myCommand.Connection = myConnection
myConnection.Open()
myCommand.ExecuteNonQuery()
myCommand.Connection.Close()
End Sub
C# example:
public void InsertRow(string myConnectionString)
{
// If the connection string is null, use a default.
if(myConnectionString == "")
{
myConnectionString = "Database=Test;Data Source=localhost;User Id=username;Password=pass";
}
MySqlConnection myConnection = new MySqlConnection(myConnectionString);
string myInsertQuery = "INSERT INTO Orders (id, customerId, amount) Values(1001, 23, 30.66)";
MySqlCommand myCommand = new MySqlCommand(myInsertQuery);
myCommand.Connection = myConnection;
myConnection.Open();
myCommand.ExecuteNonQuery();
myCommand.Connection.Close();
}
Overload methods for MySqlCommand
Initializes a new instance of the MySqlCommand class.
Examples
The following example creates a MySqlCommand and sets some of its properties.
Note
This example shows how to use one of the overloaded versions
of the MySqlCommand constructor. For
other examples that might be available, see the individual
overload topics.
Visual Basic example:
Public Sub CreateMySqlCommand()
Dim myConnection As New MySqlConnection _
("Persist Security Info=False;database=test;server=myServer")
myConnection.Open()
Dim myTrans As MySqlTransaction = myConnection.BeginTransaction()
Dim mySelectQuery As String = "SELECT * FROM MyTable"
Dim myCommand As New MySqlCommand(mySelectQuery, myConnection, myTrans)
myCommand.CommandTimeout = 20
End Sub
C# example:
public void CreateMySqlCommand()
{
MySqlConnection myConnection = new MySqlConnection("Persist Security Info=False;
database=test;server=myServer");
myConnection.Open();
MySqlTransaction myTrans = myConnection.BeginTransaction();
string mySelectQuery = "SELECT * FROM myTable";
MySqlCommand myCommand = new MySqlCommand(mySelectQuery, myConnection,myTrans);
myCommand.CommandTimeout = 20;
}
C++ example:
public:
void CreateMySqlCommand()
{
MySqlConnection* myConnection = new MySqlConnection(S"Persist Security Info=False;
database=test;server=myServer");
myConnection->Open();
MySqlTransaction* myTrans = myConnection->BeginTransaction();
String* mySelectQuery = S"SELECT * FROM myTable";
MySqlCommand* myCommand = new MySqlCommand(mySelectQuery, myConnection, myTrans);
myCommand->CommandTimeout = 20;
};
Initializes a new instance of the MySqlCommand class.
The base constructor initializes all fields to their default
values. The following table shows initial property values for
an instance of MySqlCommand.
| Properties | Initial Value |
CommandText | empty string ("") |
CommandTimeout | 0 |
CommandType | CommandType.Text |
Connection | Null |
You can change the value for any of these properties through a separate call to the property.
Examples
The following example creates a
MySqlCommand and sets some of its
properties.
Visual Basic example:
Public Sub CreateMySqlCommand()
Dim myCommand As New MySqlCommand()
myCommand.CommandType = CommandType.Text
End Sub
C# example:
public void CreateMySqlCommand()
{
MySqlCommand myCommand = new MySqlCommand();
myCommand.CommandType = CommandType.Text;
}
Initializes a new instance of the
MySqlCommand class with the text of the
query.
Parameters: The text of the query.
When an instance of MySqlCommand is
created, the following read/write properties are set to
initial values.
| Properties | Initial Value |
CommandText | cmdText |
CommandTimeout | 0 |
CommandType | CommandType.Text |
Connection | Null |
You can change the value for any of these properties through a separate call to the property.
Examples
The following example creates a
MySqlCommand and sets some of its
properties.
Visual Basic example:
Public Sub CreateMySqlCommand()
Dim sql as String = "SELECT * FROM mytable"
Dim myCommand As New MySqlCommand(sql)
myCommand.CommandType = CommandType.Text
End Sub
C# example:
public void CreateMySqlCommand()
{
string sql = "SELECT * FROM mytable";
MySqlCommand myCommand = new MySqlCommand(sql);
myCommand.CommandType = CommandType.Text;
}
Initializes a new instance of the
MySqlCommand class with the text of the
query and a MySqlConnection.
Parameters: The text of the query.
Parameters: A
MySqlConnection that represents the
connection to an instance of SQL Server.
When an instance of MySqlCommand is
created, the following read/write properties are set to
initial values.
| Properties | Initial Value |
CommandText | cmdText |
CommandTimeout | 0 |
CommandType | CommandType.Text |
Connection | connection |
You can change the value for any of these properties through a separate call to the property.
Examples
The following example creates a
MySqlCommand and sets some of its
properties.
Visual Basic example:
Public Sub CreateMySqlCommand()
Dim conn as new MySqlConnection("server=myServer")
Dim sql as String = "SELECT * FROM mytable"
Dim myCommand As New MySqlCommand(sql, conn)
myCommand.CommandType = CommandType.Text
End Sub
C# example:
public void CreateMySqlCommand()
{
MySqlConnection conn = new MySqlConnection("server=myserver")
string sql = "SELECT * FROM mytable";
MySqlCommand myCommand = new MySqlCommand(sql, conn);
myCommand.CommandType = CommandType.Text;
}
Initializes a new instance of the
MySqlCommand class with the text of the
query, a MySqlConnection, and the
MySqlTransaction.
Parameters: The text of the query.
Parameters: A
MySqlConnection that represents the
connection to an instance of SQL Server.
Parameters: The
MySqlTransaction in which the
MySqlCommand executes.
When an instance of MySqlCommand is
created, the following read/write properties are set to
initial values.
| Properties | Initial Value |
CommandText | cmdText |
CommandTimeout | 0 |
CommandType | CommandType.Text |
Connection | connection |
You can change the value for any of these properties through a separate call to the property.
Examples
The following example creates a
MySqlCommand and sets some of its
properties.
Visual Basic example:
Public Sub CreateMySqlCommand()
Dim conn as new MySqlConnection("server=myServer")
conn.Open();
Dim txn as MySqlTransaction = conn.BeginTransaction()
Dim sql as String = "SELECT * FROM mytable"
Dim myCommand As New MySqlCommand(sql, conn, txn)
myCommand.CommandType = CommandType.Text
End Sub
C# example:
public void CreateMySqlCommand()
{
MySqlConnection conn = new MySqlConnection("server=myserver")
conn.Open();
MySqlTransaction txn = conn.BeginTransaction();
string sql = "SELECT * FROM mytable";
MySqlCommand myCommand = new MySqlCommand(sql, conn, txn);
myCommand.CommandType = CommandType.Text;
}
Executes a SQL statement against the connection and returns the number of rows affected.
Returns: Number of rows affected
You can use ExecuteNonQuery to perform any type of database operation, however any resultsets returned will not be available. Any output parameters used in calling a stored procedure will be populated with data and can be retrieved after execution is complete. For UPDATE, INSERT, and DELETE statements, the return value is the number of rows affected by the command. For all other types of statements, the return value is -1.
Examples
The following example creates a MySqlCommand and then executes it using ExecuteNonQuery. The example is passed a string that is a SQL statement (such as UPDATE, INSERT, or DELETE) and a string to use to connect to the data source.
Visual Basic example:
Public Sub CreateMySqlCommand(myExecuteQuery As String, myConnection As MySqlConnection)
Dim myCommand As New MySqlCommand(myExecuteQuery, myConnection)
myCommand.Connection.Open()
myCommand.ExecuteNonQuery()
myConnection.Close()
End Sub
C# example:
public void CreateMySqlCommand(string myExecuteQuery, MySqlConnection myConnection)
{
MySqlCommand myCommand = new MySqlCommand(myExecuteQuery, myConnection);
myCommand.Connection.Open();
myCommand.ExecuteNonQuery();
myConnection.Close();
}
Sends the CommandText to the
MySqlConnectionConnection, and builds a
MySqlDataReader using one of the
CommandBehavior values.
Parameters: One of the
CommandBehavior values.
When the CommandType property is set to
StoredProcedure, the
CommandText property should be set to the
name of the stored procedure. The command executes this stored
procedure when you call ExecuteReader.
The MySqlDataReader supports a special mode
that enables large binary values to be read efficiently. For
more information, see the SequentialAccess
setting for CommandBehavior.
While the MySqlDataReader is in use, the
associated MySqlConnection is busy serving
the MySqlDataReader. While in this state,
no other operations can be performed on the
MySqlConnection other than closing it. This
is the case until the MySqlDataReader.Close
method of the MySqlDataReader is called. If
the MySqlDataReader is created with
CommandBehavior set to
CloseConnection, closing the
MySqlDataReader closes the connection
automatically.
Note
When calling ExecuteReader with the
SingleRow behavior, you should be aware
that using a limit clause in your SQL
will cause all rows (up to the limit given) to be retrieved
by the client. The MySqlDataReader.Read
method will still return false after the first row but
pulling all rows of data into the client will have a
performance impact. If the limit clause
is not necessary, it should be avoided.
Returns: A
MySqlDataReader object.
Sends the CommandText to the
MySqlConnectionConnection and builds a
MySqlDataReader.
Returns: A
MySqlDataReader object.
When the CommandType property is set to
StoredProcedure, the
CommandText property should be set to the
name of the stored procedure. The command executes this stored
procedure when you call ExecuteReader.
While the MySqlDataReader is in use, the
associated MySqlConnection is busy serving
the MySqlDataReader. While in this state,
no other operations can be performed on the
MySqlConnection other than closing it. This
is the case until the MySqlDataReader.Close
method of the MySqlDataReader is called.
Examples
The following example creates a
MySqlCommand, then executes it by passing a
string that is a SQL SELECT statement, and
a string to use to connect to the data source.
Visual Basic example:
Public Sub CreateMySqlDataReader(mySelectQuery As String, myConnection As MySqlConnection)
Dim myCommand As New MySqlCommand(mySelectQuery, myConnection)
myConnection.Open()
Dim myReader As MySqlDataReader
myReader = myCommand.ExecuteReader()
Try
While myReader.Read()
Console.WriteLine(myReader.GetString(0))
End While
Finally
myReader.Close
myConnection.Close
End Try
End Sub
C# example:
public void CreateMySqlDataReader(string mySelectQuery, MySqlConnection myConnection)
{
MySqlCommand myCommand = new MySqlCommand(mySelectQuery, myConnection);
myConnection.Open();
MySqlDataReader myReader;
myReader = myCommand.ExecuteReader();
try
{
while(myReader.Read())
{
Console.WriteLine(myReader.GetString(0));
}
}
finally
{
myReader.Close();
myConnection.Close();
}
}
Creates a prepared version of the command on an instance of MySQL Server.
Prepared statements are only supported on MySQL version 4.1 and higher. Calling prepare while connected to earlier versions of MySQL will succeed but will execute the statement in the same way as unprepared.
Examples
The following example demonstrates the use of the
Prepare method.
Visual Basic example:
public sub PrepareExample()
Dim cmd as New MySqlCommand("INSERT INTO mytable VALUES (?val)", myConnection)
cmd.Parameters.Add( "?val", 10 )
cmd.Prepare()
cmd.ExecuteNonQuery()
cmd.Parameters(0).Value = 20
cmd.ExecuteNonQuery()
end sub
C# example:
private void PrepareExample()
{
MySqlCommand cmd = new MySqlCommand("INSERT INTO mytable VALUES (?val)", myConnection);
cmd.Parameters.Add( "?val", 10 );
cmd.Prepare();
cmd.ExecuteNonQuery();
cmd.Parameters[0].Value = 20;
cmd.ExecuteNonQuery();
}
Executes the query, and returns the first column of the first row in the result set returned by the query. Extra columns or rows are ignored.
Returns: The first column of the first row in the result set, or a null reference if the result set is empty
Use the ExecuteScalar method to retrieve a
single value (for example, an aggregate value) from a
database. This requires less code than using the
ExecuteReader method, and then performing
the operations necessary to generate the single value using
the data returned by a MySqlDataReader
A typical ExecuteScalar query can be
formatted as in the following C# example:
C# example:
cmd.CommandText = "select count(*) from region"; Int32 count = (int32) cmd.ExecuteScalar();
Examples
The following example creates a
MySqlCommand and then executes it using
ExecuteScalar. The example is passed a
string that is a SQL statement that returns an aggregate
result, and a string to use to connect to the data source.
Visual Basic example:
Public Sub CreateMySqlCommand(myScalarQuery As String, myConnection As MySqlConnection)
Dim myCommand As New MySqlCommand(myScalarQuery, myConnection)
myCommand.Connection.Open()
myCommand.ExecuteScalar()
myConnection.Close()
End Sub
C# example:
public void CreateMySqlCommand(string myScalarQuery, MySqlConnection myConnection)
{
MySqlCommand myCommand = new MySqlCommand(myScalarQuery, myConnection);
myCommand.Connection.Open();
myCommand.ExecuteScalar();
myConnection.Close();
}
C++ example:
public:
void CreateMySqlCommand(String* myScalarQuery, MySqlConnection* myConnection)
{
MySqlCommand* myCommand = new MySqlCommand(myScalarQuery, myConnection);
myCommand->Connection->Open();
myCommand->ExecuteScalar();
myConnection->Close();
}
Gets or sets the SQL statement to execute at the data source.
Value: The SQL statement or stored procedure to execute. The default is an empty string.
When the CommandType property is set to
StoredProcedure, the
CommandText property should be set to the
name of the stored procedure. The user may be required to use
escape character syntax if the stored procedure name contains
any special characters. The command executes this stored
procedure when you call one of the Execute methods.
Examples
The following example creates a
MySqlCommand and sets some of its
properties.
Visual Basic example:
Public Sub CreateMySqlCommand()
Dim myCommand As New MySqlCommand()
myCommand.CommandText = "SELECT * FROM Mytable ORDER BY id"
myCommand.CommandType = CommandType.Text
End Sub
C# example:
public void CreateMySqlCommand()
{
MySqlCommand myCommand = new MySqlCommand();
myCommand.CommandText = "SELECT * FROM mytable ORDER BY id";
myCommand.CommandType = CommandType.Text;
}
Gets or sets the wait time before terminating the attempt to execute a command and generating an error.
Value: The time (in seconds) to wait for the command to execute. The default is 0 seconds.
MySQL currently does not support any method of canceling a pending or executing operation. All commands issues against a MySQL server will execute until completion or exception occurs.
Gets or sets a value indicating how the
CommandText property is to be interpreted.
Value: One of the
System.Data.CommandType values. The default
is Text.
When you set the CommandType property to
StoredProcedure, you should set the
CommandText property to the name of the
stored procedure. The command executes this stored procedure
when you call one of the Execute methods.
Examples
The following example creates a
MySqlCommand and sets some of its
properties.
Visual Basic example:
Public Sub CreateMySqlCommand()
Dim myCommand As New MySqlCommand()
myCommand.CommandType = CommandType.Text
End Sub
C# example:
public void CreateMySqlCommand()
{
MySqlCommand myCommand = new MySqlCommand();
myCommand.CommandType = CommandType.Text;
}
Gets or sets the MySqlConnection used by
this instance of the MySqlCommand.
Value: The connection to a
data source. The default value is a null reference
(Nothing in Visual Basic).
If you set Connection while a transaction
is in progress and the Transaction property
is not null, an InvalidOperationException
is generated. If the Transaction property
is not null and the transaction has already been committed or
rolled back, Transaction is set to null.
Examples
The following example creates a
MySqlCommand and sets some of its
properties.
Visual Basic example:
Public Sub CreateMySqlCommand()
Dim mySelectQuery As String = "SELECT * FROM mytable ORDER BY id"
Dim myConnectString As String = "Persist Security Info=False;database=test;server=myServer"
Dim myCommand As New MySqlCommand(mySelectQuery)
myCommand.Connection = New MySqlConnection(myConnectString)
myCommand.CommandType = CommandType.Text
End Sub
C# example:
public void CreateMySqlCommand()
{
string mySelectQuery = "SELECT * FROM mytable ORDER BY id";
string myConnectString = "Persist Security Info=False;database=test;server=myServer";
MySqlCommand myCommand = new MySqlCommand(mySelectQuery);
myCommand.Connection = new MySqlConnection(myConnectString);
myCommand.CommandType = CommandType.Text;
}
Get the MySqlParameterCollection
Value: The parameters of the SQL statement or stored procedure. The default is an empty collection.
Connector/Net does not support unnamed parameters. Every parameter added to the collection must have an associated name.
Examples
The following example creates a
MySqlCommand and displays its parameters.
To accomplish this, the method is passed a
MySqlConnection, a query string that is a
SQL SELECT statement, and an array of
MySqlParameter objects.
Visual Basic example:
Public Sub CreateMySqlCommand(myConnection As MySqlConnection, _
mySelectQuery As String, myParamArray() As MySqlParameter)
Dim myCommand As New MySqlCommand(mySelectQuery, myConnection)
myCommand.CommandText = "SELECT id, name FROM mytable WHERE age=?age"
myCommand.UpdatedRowSource = UpdateRowSource.Both
myCommand.Parameters.Add(myParamArray)
Dim j As Integer
For j = 0 To myCommand.Parameters.Count - 1
myCommand.Parameters.Add(myParamArray(j))
Next j
Dim myMessage As String = ""
Dim i As Integer
For i = 0 To myCommand.Parameters.Count - 1
myMessage += myCommand.Parameters(i).ToString() & ControlChars.Cr
Next i
Console.WriteLine(myMessage)
End Sub
C# example:
public void CreateMySqlCommand(MySqlConnection myConnection, string mySelectQuery,
MySqlParameter[] myParamArray)
{
MySqlCommand myCommand = new MySqlCommand(mySelectQuery, myConnection);
myCommand.CommandText = "SELECT id, name FROM mytable WHERE age=?age";
myCommand.Parameters.Add(myParamArray);
for (int j=0; j<myParamArray.Length; j++)
{
myCommand.Parameters.Add(myParamArray[j]) ;
}
string myMessage = "";
for (int i = 0; i < myCommand.Parameters.Count; i++)
{
myMessage += myCommand.Parameters[i].ToString() + "\n";
}
MessageBox.Show(myMessage);
}
Gets or sets the MySqlTransaction within
which the MySqlCommand executes.
Value: The
MySqlTransaction. The default value is a
null reference (Nothing in Visual Basic).
You cannot set the Transaction property if
it is already set to a specific value, and the command is in
the process of executing. If you set the transaction property
to a MySqlTransaction object that is not
connected to the same MySqlConnection as
the MySqlCommand object, an exception will
be thrown the next time you attempt to execute a statement.
Gets or sets how command results are applied to the
DataRow when used by the
System.Data.Common.DbDataAdapter.Update
method of the
System.Data.Common.DbDataAdapter.
Value: One of the
UpdateRowSource values.
The default System.Data.UpdateRowSource
value is Both unless the command is
automatically generated (as in the case of the
MySqlCommandBuilder), in which case the
default is None.
Automatically generates single-table commands used to reconcile changes made to a DataSet with the associated MySQL database. This class cannot be inherited.
The MySqlDataAdapter does not automatically
generate the SQL statements required to reconcile changes made
to a System.Data.DataSetDataSet with the
associated instance of MySQL. However, you can create a
MySqlCommandBuilder object to automatically
generate SQL statements for single-table updates if you set the
MySqlDataAdapter.SelectCommandSelectCommand
property of the MySqlDataAdapter. Then, any
additional SQL statements that you do not set are generated by
the MySqlCommandBuilder.
The MySqlCommandBuilder registers itself as a
listener for
MySqlDataAdapter.OnRowUpdatingRowUpdating
events whenever you set the DataAdapter
property. You can only associate one
MySqlDataAdapter or
MySqlCommandBuilder object with each other at
one time.
To generate INSERT, UPDATE, or DELETE statements, the
MySqlCommandBuilder uses the
SelectCommand property to retrieve a required
set of metadata automatically. If you change the
SelectCommand after the metadata has is
retrieved (for example, after the first update), you should call
the RefreshSchema method to update the
metadata.
The SelectCommand must also return at least
one primary key or unique column. If none are present, an
InvalidOperation exception is generated, and
the commands are not generated.
The MySqlCommandBuilder also uses the
MySqlCommand.ConnectionConnection,
MySqlCommand.CommandTimeoutCommandTimeout,
and MySqlCommand.TransactionTransaction
properties referenced by the SelectCommand.
The user should call RefreshSchema if any of
these properties are modified, or if the
SelectCommand itself is replaced. Otherwise
the
MySqlDataAdapter.InsertCommandInsertCommand,
MySqlDataAdapter.UpdateCommandUpdateCommand,
and
MySqlDataAdapter.DeleteCommandDeleteCommand
properties retain their previous values.
If you call Dispose, the
MySqlCommandBuilder is disassociated from the
MySqlDataAdapter, and the generated commands
are no longer used.
Note
Caution must be used when using
MySqlCommandBuilder on MySql 4.0 systems.
With MySQL 4.0, database/schema information is not provided to
the connector for a query. This means that a query that pulls
columns from two identically named tables in two or more
different databases will not cause an exception to be thrown
but will not work correctly. Even more dangerous is the
situation where your select statement references database X
but is executed in database Y and both databases have tables
with similar layouts. This situation can cause unwanted
changes or deletes. This note does not apply to MySQL versions
4.1 and later.
Examples
The following example uses the MySqlCommand,
along MySqlDataAdapter and
MySqlConnection, to select rows from a data
source. The example is passed an initialized
System.Data.DataSet, a connection string, a
query string that is a SQL SELECT statement,
and a string that is the name of the database table. The example
then creates a MySqlCommandBuilder.
Visual Basic example:
Public Shared Function SelectRows(myConnection As String, mySelectQuery As String, myTableName As String) As DataSet
Dim myConn As New MySqlConnection(myConnection)
Dim myDataAdapter As New MySqlDataAdapter()
myDataAdapter.SelectCommand = New MySqlCommand(mySelectQuery, myConn)
Dim cb As SqlCommandBuilder = New MySqlCommandBuilder(myDataAdapter)
myConn.Open()
Dim ds As DataSet = New DataSet
myDataAdapter.Fill(ds, myTableName)
' Code to modify data in DataSet here
' Without the MySqlCommandBuilder this line would fail.
myDataAdapter.Update(ds, myTableName)
myConn.Close()
End Function 'SelectRows
C# example:
public static DataSet SelectRows(string myConnection, string mySelectQuery, string myTableName)
{
MySqlConnection myConn = new MySqlConnection(myConnection);
MySqlDataAdapter myDataAdapter = new MySqlDataAdapter();
myDataAdapter.SelectCommand = new MySqlCommand(mySelectQuery, myConn);
MySqlCommandBuilder cb = new MySqlCommandBuilder(myDataAdapter);
myConn.Open();
DataSet ds = new DataSet();
myDataAdapter.Fill(ds, myTableName);
//code to modify data in DataSet here
//Without the MySqlCommandBuilder this line would fail
myDataAdapter.Update(ds, myTableName);
myConn.Close();
return ds;
}
Initializes a new instance of the
MySqlCommandBuilder class.
Initializes a new instance of the
MySqlCommandBuilder class and sets the last
one wins property.
Parameters: False to generate change protection code. True otherwise.
The lastOneWins parameter indicates whether
SQL code should be included with the generated DELETE and
UPDATE commands that checks the underlying data for changes.
If lastOneWins is true then this code is
not included and data records could be overwritten in a
multi-user or multi-threaded environments. Setting
lastOneWins to false will include this
check which will cause a concurrency exception to be thrown if
the underlying data record has changed without our knowledge.
Initializes a new instance of the
MySqlCommandBuilder class with the
associated MySqlDataAdapter object.
Parameters: The
MySqlDataAdapter to use.
The MySqlCommandBuilder registers itself as
a listener for MySqlDataAdapter.RowUpdating
events that are generated by the
MySqlDataAdapter specified in this
property.
When you create a new instance
MySqlCommandBuilder, any existing
MySqlCommandBuilder associated with this
MySqlDataAdapter is released.
Initializes a new instance of the
MySqlCommandBuilder class with the
associated MySqlDataAdapter object.
Parameters: The
MySqlDataAdapter to use.
Parameters: False to generate change protection code. True otherwise.
The MySqlCommandBuilder registers itself as
a listener for MySqlDataAdapter.RowUpdating
events that are generated by the
MySqlDataAdapter specified in this
property.
When you create a new instance
MySqlCommandBuilder, any existing
MySqlCommandBuilder associated with this
MySqlDataAdapter is released.
The lastOneWins parameter indicates whether
SQL code should be included with the generated DELETE and
UPDATE commands that checks the underlying data for changes.
If lastOneWins is true then this code is
not included and data records could be overwritten in a
multi-user or multi-threaded environments. Setting
lastOneWins to false will include this
check which will cause a concurrency exception to be thrown if
the underlying data record has changed without our knowledge.
Gets or sets a MySqlDataAdapter object for
which SQL statements are automatically generated.
Value: A
MySqlDataAdapter object.
The MySqlCommandBuilder registers itself as
a listener for MySqlDataAdapter.RowUpdating
events that are generated by the
MySqlDataAdapter specified in this
property.
When you create a new instance
MySqlCommandBuilder, any existing
MySqlCommandBuilder associated with this
MySqlDataAdapter is released.
Gets or sets the beginning character or characters to use when specifying MySQL database objects (for example, tables or columns) whose names contain characters such as spaces or reserved tokens.
Value: The beginning character or characters to use. The default value is `.
Database objects in MySQL can contain special characters such
as spaces that would make normal SQL strings impossible to
correctly parse. Use of the QuotePrefix and
the QuoteSuffix properties allows the
MySqlCommandBuilder to build SQL commands
that handle this situation.
Gets or sets the beginning character or characters to use when specifying MySQL database objects (for example, tables or columns) whose names contain characters such as spaces or reserved tokens.
Value: The beginning character or characters to use. The default value is `.
Database objects in MySQL can contain special characters such
as spaces that would make normal SQL strings impossible to
correctly parse. Use of the QuotePrefix and
the QuoteSuffix properties allows the
MySqlCommandBuilder to build SQL commands
that handle this situation.
Gets the automatically generated
MySqlCommand object required to perform
deletions on the database.
Returns: The
MySqlCommand object generated to handle
delete operations.
An application can use the GetDeleteCommand
method for informational or troubleshooting purposes because
it returns the MySqlCommand object to be
executed.
You can also use GetDeleteCommand as the
basis of a modified command. For example, you might call
GetDeleteCommand and modify the
MySqlCommand.CommandTimeout value, and then
explicitly set that on the
MySqlDataAdapter.
After the SQL statement is first generated, the application
must explicitly call RefreshSchema if it
changes the statement in any way. Otherwise, the
GetDeleteCommand will be still be using
information from the previous statement, which might not be
correct. The SQL statements are first generated either when
the application calls
System.Data.Common.DataAdapter.Update or
GetDeleteCommand.
Gets the automatically generated
MySqlCommand object required to perform
insertions on the database.
Returns: The
MySqlCommand object generated to handle
insert operations.
An application can use the GetInsertCommand
method for informational or troubleshooting purposes because
it returns the MySqlCommand object to be
executed.
You can also use the GetInsertCommand as
the basis of a modified command. For example, you might call
GetInsertCommand and modify the
MySqlCommand.CommandTimeout value, and then
explicitly set that on the
MySqlDataAdapter.
After the SQL statement is first generated, the application
must explicitly call RefreshSchema if it
changes the statement in any way. Otherwise, the
GetInsertCommand will be still be using
information from the previous statement, which might not be
correct. The SQL statements are first generated either when
the application calls
System.Data.Common.DataAdapter.Update or
GetInsertCommand.
Gets the automatically generated
MySqlCommand object required to perform
updates on the database.
Returns: The
MySqlCommand object generated to handle
update operations.
An application can use the GetUpdateCommand
method for informational or troubleshooting purposes because
it returns the MySqlCommand object to be
executed.
You can also use GetUpdateCommand as the
basis of a modified command. For example, you might call
GetUpdateCommand and modify the
MySqlCommand.CommandTimeout value, and then
explicitly set that on the
MySqlDataAdapter.
After the SQL statement is first generated, the application
must explicitly call RefreshSchema if it
changes the statement in any way. Otherwise, the
GetUpdateCommand will be still be using
information from the previous statement, which might not be
correct. The SQL statements are first generated either when
the application calls
System.Data.Common.DataAdapter.Update or
GetUpdateCommand.
Refreshes the database schema information used to generate INSERT, UPDATE, or DELETE statements.
An application should call RefreshSchema
whenever the SELECT statement associated
with the MySqlCommandBuilder changes.
An application should call RefreshSchema
whenever the MySqlDataAdapter.SelectCommand
value of the MySqlDataAdapter changes.
Represents an open connection to a MySQL Server database. This class cannot be inherited.
A MySqlConnection object represents a session
to a MySQL Server data source. When you create an instance of
MySqlConnection, all properties are set to
their initial values. For a list of these values, see the
MySqlConnection constructor.
If the MySqlConnection goes out of scope, it
is not closed. Therefore, you must explicitly close the
connection by calling MySqlConnection.Close
or MySqlConnection.Dispose.
Examples
The following example creates a MySqlCommand
and a MySqlConnection. The
MySqlConnection is opened and set as the
MySqlCommand.Connection for the
MySqlCommand. The example then calls
MySqlCommand.ExecuteNonQuery, and closes the
connection. To accomplish this, the
ExecuteNonQuery is passed a connection string
and a query string that is a SQL INSERT statement.
Visual Basic example:
Public Sub InsertRow(myConnectionString As String)
' If the connection string is null, use a default.
If myConnectionString = "" Then
myConnectionString = "Database=Test;Data Source=localhost;User Id=username;Password=pass"
End If
Dim myConnection As New MySqlConnection(myConnectionString)
Dim myInsertQuery As String = "INSERT INTO Orders (id, customerId, amount) Values(1001, 23, 30.66)"
Dim myCommand As New MySqlCommand(myInsertQuery)
myCommand.Connection = myConnection
myConnection.Open()
myCommand.ExecuteNonQuery()
myCommand.Connection.Close()
End Sub
C# example:
public void InsertRow(string myConnectionString)
{
// If the connection string is null, use a default.
if(myConnectionString == "")
{
myConnectionString = "Database=Test;Data Source=localhost;User Id=username;Password=pass";
}
MySqlConnection myConnection = new MySqlConnection(myConnectionString);
string myInsertQuery = "INSERT INTO Orders (id, customerId, amount) Values(1001, 23, 30.66)";
MySqlCommand myCommand = new MySqlCommand(myInsertQuery);
myCommand.Connection = myConnection;
myConnection.Open();
myCommand.ExecuteNonQuery();
myCommand.Connection.Close();
}
Initializes a new instance of the
MySqlConnection class.
When a new instance of MySqlConnection is
created, the read/write properties are set to the following
initial values unless they are specifically set using their
associated keywords in the ConnectionString
property.
| Properties | Initial Value |
ConnectionString | empty string ("") |
ConnectionTimeout | 15 |
Database | empty string ("") |
DataSource | empty string ("") |
ServerVersion | empty string ("") |
You can change the value for these properties only by using
the ConnectionString property.
Examples
Overload methods for MySqlConnection
Initializes a new instance of the
MySqlConnection class.
Initializes a new instance of the
MySqlConnection class when given a string
containing the connection string.
When a new instance of MySqlConnection is
created, the read/write properties are set to the following
initial values unless they are specifically set using their
associated keywords in the ConnectionString
property.
| Properties | Initial Value |
ConnectionString | empty string ("") |
ConnectionTimeout | 15 |
Database | empty string ("") |
DataSource | empty string ("") |
ServerVersion | empty string ("") |
You can change the value for these properties only by using
the ConnectionString property.
Examples
Parameters: The connection properties used to open the MySQL database.
Opens a database connection with the property settings specified by the ConnectionString.
Exception: Cannot open a connection without specifying a data source or server.
Exception: A connection-level error occurred while opening the connection.
The MySqlConnection draws an open
connection from the connection pool if one is available.
Otherwise, it establishes a new connection to an instance of
MySQL.
Examples
The following example creates a
MySqlConnection, opens it, displays some of
its properties, then closes the connection.
Visual Basic example:
Public Sub CreateMySqlConnection(myConnString As String)
Dim myConnection As New MySqlConnection(myConnString)
myConnection.Open()
MessageBox.Show("ServerVersion: " + myConnection.ServerVersion _
+ ControlChars.Cr + "State: " + myConnection.State.ToString())
myConnection.Close()
End Sub
C# example:
public void CreateMySqlConnection(string myConnString)
{
MySqlConnection myConnection = new MySqlConnection(myConnString);
myConnection.Open();
MessageBox.Show("ServerVersion: " + myConnection.ServerVersion +
"\nState: " + myConnection.State.ToString());
myConnection.Close();
}
Gets the name of the current database or the database to be used after a connection is opened.
Returns: The name of the current database or the name of the database to be used after a connection is opened. The default value is an empty string.
The Database property does not update
dynamically. If you change the current database using a SQL
statement, then this property may reflect the wrong value. If
you change the current database using the
ChangeDatabase method, this property is
updated to reflect the new database.
Examples
The following example creates a
MySqlConnection and displays some of its
read-only properties.
Visual Basic example:
Public Sub CreateMySqlConnection()
Dim myConnString As String = _
"Persist Security Info=False;database=test;server=localhost;user id=joeuser;pwd=pass"
Dim myConnection As New MySqlConnection( myConnString )
myConnection.Open()
MessageBox.Show( "Server Version: " + myConnection.ServerVersion _
+ ControlChars.NewLine + "Database: " + myConnection.Database )
myConnection.ChangeDatabase( "test2" )
MessageBox.Show( "ServerVersion: " + myConnection.ServerVersion _
+ ControlChars.NewLine + "Database: " + myConnection.Database )
myConnection.Close()
End Sub
C# example:
public void CreateMySqlConnection()
{
string myConnString =
"Persist Security Info=False;database=test;server=localhost;user id=joeuser;pwd=pass";
MySqlConnection myConnection = new MySqlConnection( myConnString );
myConnection.Open();
MessageBox.Show( "Server Version: " + myConnection.ServerVersion
+ "\nDatabase: " + myConnection.Database );
myConnection.ChangeDatabase( "test2" );
MessageBox.Show( "ServerVersion: " + myConnection.ServerVersion
+ "\nDatabase: " + myConnection.Database );
myConnection.Close();
}
Gets the current state of the connection.
Returns: A bitwise
combination of the
System.Data.ConnectionState values. The
default is Closed.
The allowed state changes are:
From
ClosedtoOpen, using theOpenmethod of the connection object.From
OpentoClosed, using either theClosemethod or theDisposemethod of the connection object.
Examples
The following example creates a
MySqlConnection, opens it, displays some of
its properties, then closes the connection.
Visual Basic example:
Public Sub CreateMySqlConnection(myConnString As String)
Dim myConnection As New MySqlConnection(myConnString)
myConnection.Open()
MessageBox.Show("ServerVersion: " + myConnection.ServerVersion _
+ ControlChars.Cr + "State: " + myConnection.State.ToString())
myConnection.Close()
End Sub
C# example:
public void CreateMySqlConnection(string myConnString)
{
MySqlConnection myConnection = new MySqlConnection(myConnString);
myConnection.Open();
MessageBox.Show("ServerVersion: " + myConnection.ServerVersion +
"\nState: " + myConnection.State.ToString());
myConnection.Close();
}
Gets a string containing the version of the MySQL server to which the client is connected.
Returns: The version of the instance of MySQL.
Exception: The connection is closed.
Examples
The following example creates a
MySqlConnection, opens it, displays some of
its properties, then closes the connection.
Visual Basic example:
Public Sub CreateMySqlConnection(myConnString As String)
Dim myConnection As New MySqlConnection(myConnString)
myConnection.Open()
MessageBox.Show("ServerVersion: " + myConnection.ServerVersion _
+ ControlChars.Cr + "State: " + myConnection.State.ToString())
myConnection.Close()
End Sub
C# example:
public void CreateMySqlConnection(string myConnString)
{
MySqlConnection myConnection = new MySqlConnection(myConnString);
myConnection.Open();
MessageBox.Show("ServerVersion: " + myConnection.ServerVersion +
"\nState: " + myConnection.State.ToString());
myConnection.Close();
}
Closes the connection to the database. This is the preferred method of closing any open connection.
The Close method rolls back any pending
transactions. It then releases the connection to the
connection pool, or closes the connection if connection
pooling is disabled.
An application can call Close more than one
time. No exception is generated.
Examples
The following example creates a
MySqlConnection, opens it, displays some of
its properties, then closes the connection.
Visual Basic example:
Public Sub CreateMySqlConnection(myConnString As String)
Dim myConnection As New MySqlConnection(myConnString)
myConnection.Open()
MessageBox.Show("ServerVersion: " + myConnection.ServerVersion _
+ ControlChars.Cr + "State: " + myConnection.State.ToString())
myConnection.Close()
End Sub
C# example:
public void CreateMySqlConnection(string myConnString)
{
MySqlConnection myConnection = new MySqlConnection(myConnString);
myConnection.Open();
MessageBox.Show("ServerVersion: " + myConnection.ServerVersion +
"\nState: " + myConnection.State.ToString());
myConnection.Close();
}
Creates and returns a MySqlCommand object
associated with the MySqlConnection.
Returns: A
MySqlCommand object.
Begins a database transaction.
Returns: An object representing the new transaction.
Exception: Parallel transactions are not supported.
This command is equivalent to the MySQL BEGIN TRANSACTION command.
You must explicitly commit or roll back the transaction using
the MySqlTransaction.Commit or
MySqlTransaction.Rollback method.
Note
If you do not specify an isolation level, the default
isolation level is used. To specify an isolation level with
the BeginTransaction method, use the
overload that takes the iso parameter.
Examples
The following example creates a
MySqlConnection and a
MySqlTransaction. It also demonstrates how
to use the BeginTransaction, a
MySqlTransaction.Commit, and
MySqlTransaction.Rollback methods.
Visual Basic example:
Public Sub RunTransaction(myConnString As String)
Dim myConnection As New MySqlConnection(myConnString)
myConnection.Open()
Dim myCommand As MySqlCommand = myConnection.CreateCommand()
Dim myTrans As MySqlTransaction
' Start a local transaction
myTrans = myConnection.BeginTransaction()
' Must assign both transaction object and connection
' to Command object for a pending local transaction
myCommand.Connection = myConnection
myCommand.Transaction = myTrans
Try
myCommand.CommandText = "Insert into Test (id, desc) VALUES (100, 'Description')"
myCommand.ExecuteNonQuery()
myCommand.CommandText = "Insert into Test (id, desc) VALUES (101, 'Description')"
myCommand.ExecuteNonQuery()
myTrans.Commit()
Console.WriteLine("Both records are written to database.")
Catch e As Exception
Try
myTrans.Rollback()
Catch ex As MySqlException
If Not myTrans.Connection Is Nothing Then
Console.WriteLine("An exception of type " + ex.GetType().ToString() + _
" was encountered while attempting to roll back the transaction.")
End If
End Try
Console.WriteLine("An exception of type " + e.GetType().ToString() + _
"was encountered while inserting the data.")
Console.WriteLine("Neither record was written to database.")
Finally
myConnection.Close()
End Try
End Sub
C# example:
public void RunTransaction(string myConnString)
{
MySqlConnection myConnection = new MySqlConnection(myConnString);
myConnection.Open();
MySqlCommand myCommand = myConnection.CreateCommand();
MySqlTransaction myTrans;
// Start a local transaction
myTrans = myConnection.BeginTransaction();
// Must assign both transaction object and connection
// to Command object for a pending local transaction
myCommand.Connection = myConnection;
myCommand.Transaction = myTrans;
try
{
myCommand.CommandText = "insert into Test (id, desc) VALUES (100, 'Description')";
myCommand.ExecuteNonQuery();
myCommand.CommandText = "insert into Test (id, desc) VALUES (101, 'Description')";
myCommand.ExecuteNonQuery();
myTrans.Commit();
Console.WriteLine("Both records are written to database.");
}
catch(Exception e)
{
try
{
myTrans.Rollback();
}
catch (SqlException ex)
{
if (myTrans.Connection != null)
{
Console.WriteLine("An exception of type " + ex.GetType() +
" was encountered while attempting to roll back the transaction.");
}
}
Console.WriteLine("An exception of type " + e.GetType() +
" was encountered while inserting the data.");
Console.WriteLine("Neither record was written to database.");
}
finally
{
myConnection.Close();
}
}
Begins a database transaction with the specified isolation level.
Parameters: The isolation level under which the transaction should run.
Returns: An object representing the new transaction.
Exception: Parallel exceptions are not supported.
This command is equivalent to the MySQL BEGIN TRANSACTION command.
You must explicitly commit or roll back the transaction using
the MySqlTransaction.Commit or
MySqlTransaction.Rollback method.
Note
If you do not specify an isolation level, the default
isolation level is used. To specify an isolation level with
the BeginTransaction method, use the
overload that takes the iso parameter.
Examples
The following example creates a
MySqlConnection and a
MySqlTransaction. It also demonstrates how
to use the BeginTransaction, a
MySqlTransaction.Commit, and
MySqlTransaction.Rollback methods.
Visual Basic example:
Public Sub RunTransaction(myConnString As String)
Dim myConnection As New MySqlConnection(myConnString)
myConnection.Open()
Dim myCommand As MySqlCommand = myConnection.CreateCommand()
Dim myTrans As MySqlTransaction
' Start a local transaction
myTrans = myConnection.BeginTransaction()
' Must assign both transaction object and connection
' to Command object for a pending local transaction
myCommand.Connection = myConnection
myCommand.Transaction = myTrans
Try
myCommand.CommandText = "Insert into Test (id, desc) VALUES (100, 'Description')"
myCommand.ExecuteNonQuery()
myCommand.CommandText = "Insert into Test (id, desc) VALUES (101, 'Description')"
myCommand.ExecuteNonQuery()
myTrans.Commit()
Console.WriteLine("Both records are written to database.")
Catch e As Exception
Try
myTrans.Rollback()
Catch ex As MySqlException
If Not myTrans.Connection Is Nothing Then
Console.WriteLine("An exception of type " + ex.GetType().ToString() + _
" was encountered while attempting to roll back the transaction.")
End If
End Try
Console.WriteLine("An exception of type " + e.GetType().ToString() + _
"was encountered while inserting the data.")
Console.WriteLine("Neither record was written to database.")
Finally
myConnection.Close()
End Try
End Sub
C# example:
public void RunTransaction(string myConnString)
{
MySqlConnection myConnection = new MySqlConnection(myConnString);
myConnection.Open();
MySqlCommand myCommand = myConnection.CreateCommand();
MySqlTransaction myTrans;
// Start a local transaction
myTrans = myConnection.BeginTransaction();
// Must assign both transaction object and connection
// to Command object for a pending local transaction
myCommand.Connection = myConnection;
myCommand.Transaction = myTrans;
try
{
myCommand.CommandText = "insert into Test (id, desc) VALUES (100, 'Description')";
myCommand.ExecuteNonQuery();
myCommand.CommandText = "insert into Test (id, desc) VALUES (101, 'Description')";
myCommand.ExecuteNonQuery();
myTrans.Commit();
Console.WriteLine("Both records are written to database.");
}
catch(Exception e)
{
try
{
myTrans.Rollback();
}
catch (SqlException ex)
{
if (myTrans.Connection != null)
{
Console.WriteLine("An exception of type " + ex.GetType() +
" was encountered while attempting to roll back the transaction.");
}
}
Console.WriteLine("An exception of type " + e.GetType() +
" was encountered while inserting the data.");
Console.WriteLine("Neither record was written to database.");
}
finally
{
myConnection.Close();
}
}
Changes the current database for an open MySqlConnection.
Parameters: The name of the database to use.
The value supplied in the database
parameter must be a valid database name. The
database parameter cannot contain a null
value, an empty string, or a string with only blank
characters.
When you are using connection pooling against MySQL, and you close the connection, it is returned to the connection pool. The next time the connection is retrieved from the pool, the reset connection request executes before the user performs any operations.
Exception: The database name is not valid.
Exception: The connection is not open.
Exception: Cannot change the database.
Examples
The following example creates a
MySqlConnection and displays some of its
read-only properties.
Visual Basic example:
Public Sub CreateMySqlConnection()
Dim myConnString As String = _
"Persist Security Info=False;database=test;server=localhost;user id=joeuser;pwd=pass"
Dim myConnection As New MySqlConnection( myConnString )
myConnection.Open()
MessageBox.Show( "Server Version: " + myConnection.ServerVersion _
+ ControlChars.NewLine + "Database: " + myConnection.Database )
myConnection.ChangeDatabase( "test2" )
MessageBox.Show( "ServerVersion: " + myConnection.ServerVersion _
+ ControlChars.NewLine + "Database: " + myConnection.Database )
myConnection.Close()
End Sub
C# example:
public void CreateMySqlConnection()
{
string myConnString =
"Persist Security Info=False;database=test;server=localhost;user id=joeuser;pwd=pass";
MySqlConnection myConnection = new MySqlConnection( myConnString );
myConnection.Open();
MessageBox.Show( "Server Version: " + myConnection.ServerVersion
+ "\nDatabase: " + myConnection.Database );
myConnection.ChangeDatabase( "test2" );
MessageBox.Show( "ServerVersion: " + myConnection.ServerVersion
+ "\nDatabase: " + myConnection.Database );
myConnection.Close();
}
Occurs when the state of the connection changes.
The StateChange event fires whenever the
State changes from closed to opened, or
from opened to closed. StateChange fires
immediately after the MySqlConnection
transitions.
If an event handler throws an exception from within the
StateChange event, the exception propagates
to the caller of the Open or
Close method.
The StateChange event is not raised unless
you explicitly call Close or
Dispose.
The event handler receives an argument of type
System.Data.StateChangeEventArgs containing
data related to this event. The following
StateChangeEventArgs properties provide
information specific to this event.
| Property | Description |
System.Data.StateChangeEventArgs.CurrentState
| Gets the new state of the connection. The connection object will be in the new state already when the event is fired. |
System.Data.StateChangeEventArgs.OriginalState
| Gets the original state of the connection. |
Occurs when MySQL returns warnings as a result of executing a command or query.
Gets the time to wait while trying to establish a connection before terminating the attempt and generating an error.
Exception: The value set is less than 0.
A value of 0 indicates no limit, and should be avoided in a
MySqlConnection.ConnectionString because an
attempt to connect will wait indefinitely.
Examples
The following example creates a MySqlConnection and sets some of its properties in the connection string.
Visual Basic example:
Public Sub CreateSqlConnection() Dim myConnection As New MySqlConnection() myConnection.ConnectionString = "Persist Security Info=False;Username=user;Password=pass;database=test1;server=localhost;Connect Timeout=30" myConnection.Open() End Sub
C# example:
public void CreateSqlConnection()
{
MySqlConnection myConnection = new MySqlConnection();
myConnection.ConnectionString = "Persist Security Info=False;Username=user;»
Password=pass;database=test1;server=localhost;Connect Timeout=30";
myConnection.Open();
}
Gets or sets the string used to connect to a MySQL Server database.
The ConnectionString returned may not be
exactly like what was originally set but will be indentical in
terms of keyword/value pairs. Security information will not be
included unless the Persist Security Info value is set to
true.
You can use the ConnectionString property
to connect to a database. The following example illustrates a
typical connection string.
"Persist Security Info=False;database=MyDB;»
server=MySqlServer;user id=myUser;Password=myPass"
The ConnectionString property can be set
only when the connection is closed. Many of the connection
string values have corresponding read-only properties. When
the connection string is set, all of these properties are
updated, except when an error is detected. In this case, none
of the properties are updated.
MySqlConnection properties return only
those settings contained in the
ConnectionString.
To connect to a local machine, specify "localhost" for the server. If you do not specify a server, localhost is assumed.
Resetting the ConnectionString on a closed
connection resets all connection string values (and related
properties) including the password. For example, if you set a
connection string that includes "Database= MyDb", and then
reset the connection string to "Data Source=myserver;User
Id=myUser;Password=myPass", the
MySqlConnection.Database property is no
longer set to MyDb.
The connection string is parsed immediately after being set.
If errors in syntax are found when parsing, a runtime
exception, such as ArgumentException, is
generated. Other errors can be found only when an attempt is
made to open the connection.
The basic format of a connection string consists of a series
of keyword/value pairs separated by semicolons. The equal sign
(=) connects each keyword and its value.
Additional notes on setting values for options:
To include values that contain a semicolon, single-quote character, or double-quote character, the value must be enclosed in double quotes. If the value contains both a semicolon and a double-quote character, the value can be enclosed in single quotes. The single quote is also useful if the value begins with a double-quote character. Conversely, the double quote can be used if the value begins with a single quote. If the value contains both single-quote and double-quote characters, the quote character used to enclose the value must be doubled each time it occurs within the value.
To include preceding or trailing spaces in the string value, the value must be enclosed in either single quotes or double quotes. Any leading or trailing spaces around integer, Boolean, or enumerated values are ignored, even if enclosed in quotes. However, spaces within a string literal keyword or value are preserved. Using .NET Framework version 1.1, single or double quotes may be used within a connection string without using delimiters (for example, Data Source= my'Server or Data Source= my"Server), unless a quote character is the first or last character in the value.
To include an equal sign (=) in a keyword or value, it must be preceded by another equal sign. For example, in the hypothetical connection string
"key==word=value"
the keyword is "key=word" and the value is "value".
If a specific keyword in a keyword= value pair occurs multiple times in a connection string, the last occurrence listed is used in the value set.
Keywords are not case sensitive.
The following table lists the valid names for keyword values
within the ConnectionString.
| Name | Default | Description |
Connect Timeout, Connection
Timeout | 15 | The length of time (in seconds) to wait for a connection to the server before terminating the attempt and generating an error. |
Host, Server, Data
Source, DataSource,
Address, Addr,
Network Address | localhost | The name or network address of the instance of MySQL to which to connect. Multiple hosts can be specified separated by &. This can be useful where multiple MySQL servers are configured for replication and you are not concerned about the precise server you are connecting to. No attempt is made by the provider to synchronize writes to the database so care should be taken when using this option. In Unix environment with Mono, this can be a fully qualified path to MySQL socket filename. With this configuration, the Unix socket will be used instead of TCP/IP socket. Currently only a single socket name can be given so accessing MySQL in a replicated environment using Unix sockets is not currently supported. |
Ignore Prepare | true | When true, instructs the provider to ignore any calls to
MySqlCommand.Prepare(). This option
is provided to prevent issues with corruption of the
statements when use with server side prepared
statements. If you want to use server-side prepare
statements, set this option to false. This option was
added in Connector/NET 5.0.3 and Connector/NET 1.0.9. |
Port | 3306 | The port MySQL is using to listen for connections. Specify -1 for this value to use a named pipe connection (Windows only). This value is ignored if Unix socket is used. |
Protocol | socket | Specifies the type of connection to make to the server.Values can be: socket or tcp for a socket connection pipe for a named pipe connection unix for a Unix socket connection memory to use MySQL shared memory |
CharSet, Character Set | Specifies the character set that should be used to encode all queries sent to the server. Resultsets are still returned in the character set of the data returned. | |
Logging | false | When true, various pieces of information is output to any configured TraceListeners. |
Allow Batch | true | When true, multiple SQL statements can be sent with one command execution. -Note- Starting with MySQL 4.1.1, batch statements should be separated by the server-defined seperator character. Commands sent to earlier versions of MySQL should be seperated with ';'. |
Encrypt | false | For Connector/NET 5.0.3 and later, when true, SSL
encryption is used for all data sent between the
client and server if the server has a certificate
installed. Recognized values are
true, false,
yes, and no. In
versions before 5.0.3, this option had no effect. |
Initial Catalog, Database | mysql | The name of the database to use intially |
Password, pwd | The password for the MySQL account being used. | |
Persist Security Info | false | When set to false or no (strongly
recommended), security-sensitive information, such as
the password, is not returned as part of the
connection if the connection is open or has ever been
in an open state. Resetting the connection string
resets all connection string values including the
password. Recognized values are
true, false,
yes, and no. |
User Id, Username,
Uid, User name | The MySQL login account being used. | |
Shared Memory Name | MYSQL | The name of the shared memory object to use for communication if the connection protocol is set to memory. |
Allow Zero Datetime | false | True to have MySqlDataReader.GetValue() return a MySqlDateTime for date
or datetime columns that have illegal values. False
will cause a System.DateTime object
to be returned for legal values and an exception will
be thrown for illegal values. |
Convert Zero Datetime | false | True to have MySqlDataReader.GetValue() and
MySqlDataReader.GetDateTime()
return DateTime.MinValue for date or datetime columns
that have illegal values. |
Old Syntax, OldSyntax | false | Allows use of '@' symbol as a parameter marker. See
MySqlCommand for more info. This is
for compatibility only. All future code should be
written to use the new '?' parameter marker. |
Pipe Name, Pipe | mysql | When set to the name of a named pipe, the
MySqlConnection will attempt to
connect to MySQL on that named pipe.This settings only
applies to the Windows platform. |
Procedure Cache | 25 | Sets the size of the stored procedure cache. By default, Connector/NET will store the metadata (input/output datatypes) about the last 25 stored procedures used. To disable the stored procedure cache, set the value to zero (0). This option was added in Connector/NET 5.0.2 and Connector/NET 1.0.9. |
Use Procedure Bodies | true | Setting this option to false indicates that the user
connecting to the database does not have the
SELECT privileges for the
mysql.proc (stored procedures)
table. When to set to false,
Connector/NET will not rely on this information being
available when the procedure is called. Because
Connector/NET will be unable to determine this
information, you should explicitly set the types of
the all the parameters before the call and the
parameters should be added to the command in the exact
same order as they appear in the procedure definition.
This option was added in Connector/NET 5.0.4 and
Connector/NET 1.0.10. |
The following table lists the valid names for connection
pooling values within the ConnectionString.
For more information about connection pooling, see Connection
Pooling for the MySQL Data Provider.
| Name | Default | Description |
Connection Lifetime | 0 | When a connection is returned to the pool, its creation time is compared
with the current time, and the connection is destroyed
if that time span (in seconds) exceeds the value
specified by Connection Lifetime.
This is useful in clustered configurations to force
load balancing between a running server and a server
just brought online. A value of zero (0) causes pooled
connections to have the maximum connection timeout. |
Max Pool Size | 100 | The maximum number of connections allowed in the pool. |
Min Pool Size | 0 | The minimum number of connections allowed in the pool. |
Pooling | true | When true, the MySqlConnection
object is drawn from the appropriate pool, or if
necessary, is created and added to the appropriate
pool. Recognized values are true,
false, yes, and
no. |
Reset Pooled Connections,
ResetConnections,
ResetPooledConnections | true | Specifies whether a ping and a reset should be sent to the server before a pooled connection is returned. Not resetting will yeild faster connection opens but also will not clear out session items such as temp tables. |
Cache Server Configuration,
CacheServerConfiguration,
CacheServerConfig | false | Specifies whether server variables should be updated when a pooled connection is returned. Turning this one will yeild faster opens but will also not catch any server changes made by other connections. |
When setting keyword or connection pooling values that require a Boolean value, you can use 'yes' instead of 'true', and 'no' instead of 'false'.
Note The MySQL Data Provider uses the
native socket protocol to communicate with MySQL. Therefore,
it does not support the use of an ODBC data source name (DSN)
when connecting to MySQL because it does not add an ODBC
layer.
CAUTION In this release, the application
should use caution when constructing a connection string based
on user input (for example when retrieving user ID and
password information from a dialog box, and appending it to
the connection string). The application should ensure that a
user cannot embed extra connection string parameters in these
values (for example, entering a password as
"validpassword;database=somedb" in an attempt to attach to a
different database).
Examples
The following example creates a
MySqlConnection and sets some of its
properties
Visual Basic example:
Public Sub CreateConnection()
Dim myConnection As New MySqlConnection()
myConnection.ConnectionString = "Persist Security Info=False;database=myDB;server=myHost;Connect Timeout=30;user id=myUser; pwd=myPass"
myConnection.Open()
End Sub 'CreateConnection
C# example:
public void CreateConnection()
{
MySqlConnection myConnection = new MySqlConnection();
myConnection.ConnectionString = "Persist Security Info=False;database=myDB;server=myHost;Connect Timeout=30;user id=myUser; pwd=myPass";
myConnection.Open();
}
Examples
The following example creates a
MySqlConnection in Unix environment with
Mono installed. MySQL socket filename used in this example is
"/var/lib/mysql/mysql.sock". The actual filename depends on
your MySQL configuration.
Visual Basic example:
Public Sub CreateConnection()
Dim myConnection As New MySqlConnection()
myConnection.ConnectionString = "database=myDB;server=/var/lib/mysql/mysql.sock;user id=myUser; pwd=myPass"
myConnection.Open()
End Sub 'CreateConnection
C# example:
public void CreateConnection()
{
MySqlConnection myConnection = new MySqlConnection();
myConnection.ConnectionString = "database=myDB;server=/var/lib/mysql/mysql.sock;user id=myUser; pwd=myPass";
myConnection.Open();
}
Represents a set of data commands and a database connection that are used to fill a dataset and update a MySQL database. This class cannot be inherited.
The MySQLDataAdapter, serves as a bridge
between a System.Data.DataSet and MySQL for
retrieving and saving data. The
MySQLDataAdapter provides this bridge by
mapping DbDataAdapter.Fill, which changes the
data in the DataSet to match the data in the
data source, and DbDataAdapter.Update, which
changes the data in the data source to match the data in the
DataSet, using the appropriate SQL statements
against the data source.
When the MySQLDataAdapter fills a
DataSet, it will create the necessary tables
and columns for the returned data if they do not already exist.
However, primary key information will not be included in the
implicitly created schema unless the
System.Data.MissingSchemaAction property is
set to
System.Data.MissingSchemaAction.AddWithKey.
You may also have the MySQLDataAdapter create
the schema of the DataSet, including primary
key information, before filling it with data using
System.Data.Common.DbDataAdapter.FillSchema.
MySQLDataAdapter is used in conjunction with
MySqlConnection and
MySqlCommand to increase performance when
connecting to a MySQL database.
The MySQLDataAdapter also includes the
MySqlDataAdapter.SelectCommand,
MySqlDataAdapter.InsertCommand,
MySqlDataAdapter.DeleteCommand,
MySqlDataAdapter.UpdateCommand, and
DataAdapter.TableMappings properties to
facilitate the loading and updating of data.
When an instance of MySQLDataAdapter is
created, the read/write properties are set to initial values.
For a list of these values, see the
MySQLDataAdapter constructor.
Note
Please be aware that the DataColumn class
in .NET 1.0 and 1.1 does not allow columns with type of
UInt16, UInt32, or UInt64 to be autoincrement columns. If you
plan to use autoincremement columns with MySQL, you should
consider using signed integer columns.
Examples
The following example creates a MySqlCommand
and a MySqlConnection. The
MySqlConnection is opened and set as the
MySqlCommand.Connection for the
MySqlCommand. The example then calls
MySqlCommand.ExecuteNonQuery, and closes the
connection. To accomplish this, the
ExecuteNonQuery is passed a connection string
and a query string that is a SQL INSERT statement.
Visual Basic example:
Public Function SelectRows(dataSet As DataSet, connection As String, query As String) As DataSet
Dim conn As New MySqlConnection(connection)
Dim adapter As New MySqlDataAdapter()
adapter.SelectCommand = new MySqlCommand(query, conn)
adapter.Fill(dataset)
Return dataset
End Function
C# example:
public DataSet SelectRows(DataSet dataset,string connection,string query)
{
MySqlConnection conn = new MySqlConnection(connection);
MySqlDataAdapter adapter = new MySqlDataAdapter();
adapter.SelectCommand = new MySqlCommand(query, conn);
adapter.Fill(dataset);
return dataset;
}
Overload methods for MySqlDataAdapter
Initializes a new instance of the MySqlDataAdapter class.
When an instance of MySqlDataAdapter is
created, the following read/write properties are set to the
following initial values.
| Properties | Initial Value |
MissingMappingAction
|
MissingMappingAction.Passthrough
|
MissingSchemaAction
| MissingSchemaAction.Add
|
You can change the value of any of these properties through a separate call to the property.
Examples
The following example creates a
MySqlDataAdapter and sets some of its
properties.
Visual Basic example:
Public Sub CreateSqlDataAdapter()
Dim conn As MySqlConnection = New MySqlConnection("Data Source=localhost;" & _
"database=test")
Dim da As MySqlDataAdapter = New MySqlDataAdapter
da.MissingSchemaAction = MissingSchemaAction.AddWithKey
da.SelectCommand = New MySqlCommand("SELECT id, name FROM mytable", conn)
da.InsertCommand = New MySqlCommand("INSERT INTO mytable (id, name) " & _
"VALUES (?id, ?name)", conn)
da.UpdateCommand = New MySqlCommand("UPDATE mytable SET id=?id, name=?name " & _
"WHERE id=?oldId", conn)
da.DeleteCommand = New MySqlCommand("DELETE FROM mytable WHERE id=?id", conn)
da.InsertCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id")
da.InsertCommand.Parameters.Add("?name", MySqlDbType.VarChar, 40, "name")
da.UpdateCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id")
da.UpdateCommand.Parameters.Add("?name", MySqlDbType.VarChar, 40, "name")
da.UpdateCommand.Parameters.Add("?oldId", MySqlDbType.VarChar, 5, "id").SourceVersion = DataRowVersion.Original
da.DeleteCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id").SourceVersion = DataRowVersion.Original
End Sub
C# example:
public static void CreateSqlDataAdapter()
{
MySqlConnection conn = new MySqlConnection("Data Source=localhost;database=test");
MySqlDataAdapter da = new MySqlDataAdapter();
da.MissingSchemaAction = MissingSchemaAction.AddWithKey;
da.SelectCommand = new MySqlCommand("SELECT id, name FROM mytable", conn);
da.InsertCommand = new MySqlCommand("INSERT INTO mytable (id, name) " +
"VALUES (?id, ?name)", conn);
da.UpdateCommand = new MySqlCommand("UPDATE mytable SET id=?id, name=?name " +
"WHERE id=?oldId", conn);
da.DeleteCommand = new MySqlCommand("DELETE FROM mytable WHERE id=?id", conn);
da.InsertCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id");
da.InsertCommand.Parameters.Add("?name", MySqlDbType.VarChar, 40, "name");
da.UpdateCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id");
da.UpdateCommand.Parameters.Add("?name", MySqlDbType.VarChar, 40, "name");
da.UpdateCommand.Parameters.Add("?oldId", MySqlDbType.VarChar, 5, "id").SourceVersion = DataRowVersion.Original;
da.DeleteCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id").SourceVersion = DataRowVersion.Original;
}
Initializes a new instance of the
MySqlDataAdapter class with the specified
MySqlCommand as the
SelectCommand property.
Parameters:
MySqlCommand that is a SQL
SELECT statement or stored procedure and is
set as the SelectCommand property of the
MySqlDataAdapter.
When an instance of MySqlDataAdapter is
created, the following read/write properties are set to the
following initial values.
| Properties | Initial Value |
MissingMappingAction
|
MissingMappingAction.Passthrough
|
MissingSchemaAction
| MissingSchemaAction.Add
|
You can change the value of any of these properties through a separate call to the property.
When SelectCommand (or any of the other
command properties) is assigned to a previously created
MySqlCommand, the
MySqlCommand is not cloned. The
SelectCommand maintains a reference to the
previously created MySqlCommand object.
Examples
The following example creates a
MySqlDataAdapter and sets some of its
properties.
Visual Basic example:
Public Sub CreateSqlDataAdapter()
Dim conn As MySqlConnection = New MySqlConnection("Data Source=localhost;" & _
"database=test")
Dim cmd as new MySqlCommand("SELECT id, name FROM mytable", conn)
Dim da As MySqlDataAdapter = New MySqlDataAdapter(cmd)
da.MissingSchemaAction = MissingSchemaAction.AddWithKey
da.InsertCommand = New MySqlCommand("INSERT INTO mytable (id, name) " & _
"VALUES (?id, ?name)", conn)
da.UpdateCommand = New MySqlCommand("UPDATE mytable SET id=?id, name=?name " & _
"WHERE id=?oldId", conn)
da.DeleteCommand = New MySqlCommand("DELETE FROM mytable WHERE id=?id", conn)
da.InsertCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id")
da.InsertCommand.Parameters.Add("?name", MySqlDbType.VarChar, 40, "name")
da.UpdateCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id")
da.UpdateCommand.Parameters.Add("?name", MySqlDbType.VarChar, 40, "name")
da.UpdateCommand.Parameters.Add("?oldId", MySqlDbType.VarChar, 5, "id").SourceVersion = DataRowVersion.Original
da.DeleteCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id").SourceVersion = DataRowVersion.Original
End Sub
C# example:
public static void CreateSqlDataAdapter()
{
MySqlConnection conn = new MySqlConnection("Data Source=localhost;database=test");
MySqlCommand cmd = new MySqlCommand("SELECT id, name FROM mytable", conn);
MySqlDataAdapter da = new MySqlDataAdapter(cmd);
da.MissingSchemaAction = MissingSchemaAction.AddWithKey;
da.InsertCommand = new MySqlCommand("INSERT INTO mytable (id, name) " +
"VALUES (?id, ?name)", conn);
da.UpdateCommand = new MySqlCommand("UPDATE mytable SET id=?id, name=?name " +
"WHERE id=?oldId", conn);
da.DeleteCommand = new MySqlCommand("DELETE FROM mytable WHERE id=?id", conn);
da.InsertCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id");
da.InsertCommand.Parameters.Add("?name", MySqlDbType.VarChar, 40, "name");
da.UpdateCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id");
da.UpdateCommand.Parameters.Add("?name", MySqlDbType.VarChar, 40, "name");
da.UpdateCommand.Parameters.Add("?oldId", MySqlDbType.VarChar, 5, "id").SourceVersion = DataRowVersion.Original;
da.DeleteCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id").SourceVersion = DataRowVersion.Original;
}
Initializes a new instance of the
MySqlDataAdapter class with a
SelectCommand and a
MySqlConnection object.
Parameters: A
String that is a SQL
SELECT statement or stored procedure to be
used by the SelectCommand property of the
MySqlDataAdapter.
Parameters: A
MySqlConnection that represents the
connection.
This implementation of the MySqlDataAdapter
opens and closes a MySqlConnection if it is
not already open. This can be useful in a an application that
must call the DbDataAdapter.Fill method for
two or more MySqlDataAdapter objects. If
the MySqlConnection is already open, you
must explicitly call MySqlConnection.Close
or MySqlConnection.Dispose to close it.
When an instance of MySqlDataAdapter is
created, the following read/write properties are set to the
following initial values.
| Properties | Initial Value |
MissingMappingAction
|
MissingMappingAction.Passthrough
|
MissingSchemaAction
| MissingSchemaAction.Add
|
You can change the value of any of these properties through a separate call to the property.
Examples
The following example creates a
MySqlDataAdapter and sets some of its
properties.
Visual Basic example:
Public Sub CreateSqlDataAdapter()
Dim conn As MySqlConnection = New MySqlConnection("Data Source=localhost;" & _
"database=test")
Dim da As MySqlDataAdapter = New MySqlDataAdapter("SELECT id, name FROM mytable", conn)
da.MissingSchemaAction = MissingSchemaAction.AddWithKey
da.InsertCommand = New MySqlCommand("INSERT INTO mytable (id, name) " & _
"VALUES (?id, ?name)", conn)
da.UpdateCommand = New MySqlCommand("UPDATE mytable SET id=?id, name=?name " & _
"WHERE id=?oldId", conn)
da.DeleteCommand = New MySqlCommand("DELETE FROM mytable WHERE id=?id", conn)
da.InsertCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id")
da.InsertCommand.Parameters.Add("?name", MySqlDbType.VarChar, 40, "name")
da.UpdateCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id")
da.UpdateCommand.Parameters.Add("?name", MySqlDbType.VarChar, 40, "name")
da.UpdateCommand.Parameters.Add("?oldId", MySqlDbType.VarChar, 5, "id").SourceVersion = DataRowVersion.Original
da.DeleteCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id").SourceVersion = DataRowVersion.Original
End Sub
C# example:
public static void CreateSqlDataAdapter()
{
MySqlConnection conn = new MySqlConnection("Data Source=localhost;database=test");
MySqlDataAdapter da = new MySqlDataAdapter("SELECT id, name FROM mytable", conn);
da.MissingSchemaAction = MissingSchemaAction.AddWithKey;
da.InsertCommand = new MySqlCommand("INSERT INTO mytable (id, name) " +
"VALUES (?id, ?name)", conn);
da.UpdateCommand = new MySqlCommand("UPDATE mytable SET id=?id, name=?name " +
"WHERE id=?oldId", conn);
da.DeleteCommand = new MySqlCommand("DELETE FROM mytable WHERE id=?id", conn);
da.InsertCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id");
da.InsertCommand.Parameters.Add("?name", MySqlDbType.VarChar, 40, "name");
da.UpdateCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id");
da.UpdateCommand.Parameters.Add("?name", MySqlDbType.VarChar, 40, "name");
da.UpdateCommand.Parameters.Add("?oldId", MySqlDbType.VarChar, 5, "id").SourceVersion = DataRowVersion.Original;
da.DeleteCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id").SourceVersion = DataRowVersion.Original;
}
Initializes a new instance of the
MySqlDataAdapter class with a
SelectCommand and a connection string.
Parameters: A
string that is a SQL
SELECT statement or stored procedure to be
used by the SelectCommand property of the
MySqlDataAdapter.
Parameters: The connection string
When an instance of MySqlDataAdapter is
created, the following read/write properties are set to the
following initial values.
| Properties | Initial Value |
MissingMappingAction
|
MissingMappingAction.Passthrough
|
MissingSchemaAction
| MissingSchemaAction.Add
|
You can change the value of any of these properties through a separate call to the property.
Examples
The following example creates a
MySqlDataAdapter and sets some of its
properties.
Visual Basic example:
Public Sub CreateSqlDataAdapter()
Dim da As MySqlDataAdapter = New MySqlDataAdapter("SELECT id, name FROM mytable", "Data Source=localhost;database=test")
Dim conn As MySqlConnection = da.SelectCommand.Connection
da.MissingSchemaAction = MissingSchemaAction.AddWithKey
da.InsertCommand = New MySqlCommand("INSERT INTO mytable (id, name) " & _
"VALUES (?id, ?name)", conn)
da.UpdateCommand = New MySqlCommand("UPDATE mytable SET id=?id, name=?name " & _
"WHERE id=?oldId", conn)
da.DeleteCommand = New MySqlCommand("DELETE FROM mytable WHERE id=?id", conn)
da.InsertCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id")
da.InsertCommand.Parameters.Add("?name", MySqlDbType.VarChar, 40, "name")
da.UpdateCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id")
da.UpdateCommand.Parameters.Add("?name", MySqlDbType.VarChar, 40, "name")
da.UpdateCommand.Parameters.Add("?oldId", MySqlDbType.VarChar, 5, "id").SourceVersion = DataRowVersion.Original
da.DeleteCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id").SourceVersion = DataRowVersion.Original
End Sub
C# example:
public static void CreateSqlDataAdapter()
{
MySqlDataAdapter da = new MySqlDataAdapter("SELECT id, name FROM mytable", "Data Source=localhost;database=test");
MySqlConnection conn = da.SelectCommand.Connection;
da.MissingSchemaAction = MissingSchemaAction.AddWithKey;
da.InsertCommand = new MySqlCommand("INSERT INTO mytable (id, name) " +
"VALUES (?id, ?name)", conn);
da.UpdateCommand = new MySqlCommand("UPDATE mytable SET id=?id, name=?name " +
"WHERE id=?oldId", conn);
da.DeleteCommand = new MySqlCommand("DELETE FROM mytable WHERE id=?id", conn);
da.InsertCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id");
da.InsertCommand.Parameters.Add("?name", MySqlDbType.VarChar, 40, "name");
da.UpdateCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id");
da.UpdateCommand.Parameters.Add("?name", MySqlDbType.VarChar, 40, "name");
da.UpdateCommand.Parameters.Add("?oldId", MySqlDbType.VarChar, 5, "id").SourceVersion = DataRowVersion.Original;
da.DeleteCommand.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id").SourceVersion = DataRowVersion.Original;
}
Gets or sets a SQL statement or stored procedure used to delete records from the data set.
Value: A
MySqlCommand used during
System.Data.Common.DataAdapter.Update to
delete records in the database that correspond to deleted rows
in the DataSet.
During
System.Data.Common.DataAdapter.Update, if
this property is not set and primary key information is
present in the DataSet, the
DeleteCommand can be generated
automatically if you set the SelectCommand
property and use the MySqlCommandBuilder.
Then, any additional commands that you do not set are
generated by the MySqlCommandBuilder. This
generation logic requires key column information to be present
in the DataSet.
When DeleteCommand is assigned to a
previously created MySqlCommand, the
MySqlCommand is not cloned. The
DeleteCommand maintains a reference to the
previously created MySqlCommand object.
Examples
The following example creates a
MySqlDataAdapter and sets the
SelectCommand and
DeleteCommand properties. It assumes you
have already created a MySqlConnection
object.
Visual Basic example:
Public Shared Function CreateCustomerAdapter(conn As MySqlConnection) As MySqlDataAdapter
Dim da As MySqlDataAdapter = New MySqlDataAdapter()
Dim cmd As MySqlCommand
Dim parm As MySqlParameter
' Create the SelectCommand.
cmd = New MySqlCommand("SELECT * FROM mytable WHERE id=?id AND name=?name", conn)
cmd.Parameters.Add("?id", MySqlDbType.VarChar, 15)
cmd.Parameters.Add("?name", MySqlDbType.VarChar, 15)
da.SelectCommand = cmd
' Create the DeleteCommand.
cmd = New MySqlCommand("DELETE FROM mytable WHERE id=?id", conn)
parm = cmd.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id")
parm.SourceVersion = DataRowVersion.Original
da.DeleteCommand = cmd
Return da
End Function
C# example:
public static MySqlDataAdapter CreateCustomerAdapter(MySqlConnection conn)
{
MySqlDataAdapter da = new MySqlDataAdapter();
MySqlCommand cmd;
MySqlParameter parm;
// Create the SelectCommand.
cmd = new MySqlCommand("SELECT * FROM mytable WHERE id=?id AND name=?name", conn);
cmd.Parameters.Add("?id", MySqlDbType.VarChar, 15);
cmd.Parameters.Add("?name", MySqlDbType.VarChar, 15);
da.SelectCommand = cmd;
// Create the DeleteCommand.
cmd = new MySqlCommand("DELETE FROM mytable WHERE id=?id", conn);
parm = cmd.Parameters.Add("?id", MySqlDbType.VarChar, 5, "id");
parm.SourceVersion = DataRowVersion.Original;
da.DeleteCommand = cmd;
return da;
}
Gets or sets a SQL statement or stored procedure used to insert records into the data set.
Value: A
MySqlCommand used during
System.Data.Common.DataAdapter.Update to
insert records into the database that correspond to new rows
in the DataSet.
During
System.Data.Common.DataAdapter.Update, if
this property is not set and primary key information is
present in the DataSet, the
InsertCommand can be generated
automatically if you set the SelectCommand
property and use the MySqlCommandBuilder.
Then, any additional commands that you do not set are
generated by the MySqlCommandBuilder. This
generation logic requires key column information to be present
in the DataSet.
When InsertCommand is assigned to a
previously created MySqlCommand, the
MySqlCommand is not cloned. The
InsertCommand maintains a reference to the
previously created MySqlCommand object.
Note
If execution of this command returns rows, these rows may be
added to the DataSet depending on how you
set the MySqlCommand.UpdatedRowSource
property of the MySqlCommand object.
Examples
The following example creates a
MySqlDataAdapter and sets the
SelectCommand and
InsertCommand properties. It assumes you
have already created a MySqlConnection
object.
Visual Basic example:
Public Shared Function CreateCustomerAdapter(conn As MySqlConnection) As MySqlDataAdapter
Dim da As MySqlDataAdapter = New MySqlDataAdapter()
Dim cmd As MySqlCommand
Dim parm As MySqlParameter
' Create the SelectCommand.
cmd = New MySqlCommand("SELECT * FROM mytable WHERE id=?id AND name=?name", conn)
cmd.Parameters.Add("?id", MySqlDbType.VarChar, 15)
cmd.Parameters.Add("?name", MySqlDbType.VarChar, 15)
da.SelectCommand = cmd
' Create the InsertCommand.
cmd = New MySqlCommand("INSERT INTO mytable (id,name) VALUES (?id, ?name)", conn)
cmd.Parameters.Add( "?id", MySqlDbType.VarChar, 15, "id" )
cmd.Parameters.Add( "?name", MySqlDbType.VarChar, 15, "name" )
da.InsertCommand = cmd
Return da
End Function
C# example:
public static MySqlDataAdapter CreateCustomerAdapter(MySqlConnection conn)
{
MySqlDataAdapter da = new MySqlDataAdapter();
MySqlCommand cmd;
MySqlParameter parm;
// Create the SelectCommand.
cmd = new MySqlCommand("SELECT * FROM mytable WHERE id=?id AND name=?name", conn);
cmd.Parameters.Add("?id", MySqlDbType.VarChar, 15);
cmd.Parameters.Add("?name", MySqlDbType.VarChar, 15);
da.SelectCommand = cmd;
// Create the InsertCommand.
cmd = new MySqlCommand("INSERT INTO mytable (id,name) VALUES (?id,?name)", conn);
cmd.Parameters.Add("?id", MySqlDbType.VarChar, 15, "id" );
cmd.Parameters.Add("?name", MySqlDbType.VarChar, 15, "name" );
da.InsertCommand = cmd;
return da;
}
Gets or sets a SQL statement or stored procedure used to updated records in the data source.
Value: A
MySqlCommand used during
System.Data.Common.DataAdapter.Update to
update records in the database with data from the
DataSet.
During
System.Data.Common.DataAdapter.Update, if
this property is not set and primary key information is
present in the DataSet, the
UpdateCommand can be generated
automatically if you set the SelectCommand
property and use the MySqlCommandBuilder.
Then, any additional commands that you do not set are
generated by the MySqlCommandBuilder. This
generation logic requires key column information to be present
in the DataSet.
When UpdateCommand is assigned to a
previously created MySqlCommand, the
MySqlCommand is not cloned. The
UpdateCommand maintains a reference to the
previously created MySqlCommand object.
Note
If execution of this command returns rows, these rows may be
merged with the DataSet depending on how you set the
MySqlCommand.UpdatedRowSource property of
the MySqlCommand object.
Examples
The following example creates a
MySqlDataAdapter and sets the
SelectCommand and
UpdateCommand properties. It assumes you
have already created a MySqlConnection
object.
Visual Basic example:
Public Shared Function CreateCustomerAdapter(conn As MySqlConnection) As MySqlDataAdapter
Dim da As MySqlDataAdapter = New MySqlDataAdapter()
Dim cmd As MySqlCommand
Dim parm As MySqlParameter
' Create the SelectCommand.
cmd = New MySqlCommand("SELECT * FROM mytable WHERE id=?id AND name=?name", conn)
cmd.Parameters.Add("?id", MySqlDbType.VarChar, 15)
cmd.Parameters.Add("?name", MySqlDbType.VarChar, 15)
da.SelectCommand = cmd
' Create the UpdateCommand.
cmd = New MySqlCommand("UPDATE mytable SET id=?id, name=?name WHERE id=?oldId", conn)
cmd.Parameters.Add( "?id", MySqlDbType.VarChar, 15, "id" )
cmd.Parameters.Add( "?name", MySqlDbType.VarChar, 15, "name" )
parm = cmd.Parameters.Add("?oldId", MySqlDbType.VarChar, 15, "id")
parm.SourceVersion = DataRowVersion.Original
da.UpdateCommand = cmd
Return da
End Function
C# example:
public static MySqlDataAdapter CreateCustomerAdapter(MySqlConnection conn)
{
MySqlDataAdapter da = new MySqlDataAdapter();
MySqlCommand cmd;
MySqlParameter parm;
// Create the SelectCommand.
cmd = new MySqlCommand("SELECT * FROM mytable WHERE id=?id AND name=?name", conn);
cmd.Parameters.Add("?id", MySqlDbType.VarChar, 15);
cmd.Parameters.Add("?name", MySqlDbType.VarChar, 15);
da.SelectCommand = cmd;
// Create the UpdateCommand.
cmd = new MySqlCommand("UPDATE mytable SET id=?id, name=?name WHERE id=?oldId", conn);
cmd.Parameters.Add("?id", MySqlDbType.VarChar, 15, "id" );
cmd.Parameters.Add("?name", MySqlDbType.VarChar, 15, "name" );
parm = cmd.Parameters.Add( "?oldId", MySqlDbType.VarChar, 15, "id" );
parm.SourceVersion = DataRowVersion.Original;
da.UpdateCommand = cmd;
return da;
}
Gets or sets a SQL statement or stored procedure used to select records in the data source.
Value: A
MySqlCommand used during
System.Data.Common.DbDataAdapter.Fill to
select records from the database for placement in the
DataSet.
When SelectCommand is assigned to a
previously created MySqlCommand, the
MySqlCommand is not cloned. The
SelectCommand maintains a reference to the
previously created MySqlCommand object.
If the SelectCommand does not return any
rows, no tables are added to the DataSet,
and no exception is raised.
Examples
The following example creates a
MySqlDataAdapter and sets the
SelectCommand and
InsertCommand properties. It assumes you
have already created a MySqlConnection
object.
Visual Basic example:
Public Shared Function CreateCustomerAdapter(conn As MySqlConnection) As MySqlDataAdapter
Dim da As MySqlDataAdapter = New MySqlDataAdapter()
Dim cmd As MySqlCommand
Dim parm As MySqlParameter
' Create the SelectCommand.
cmd = New MySqlCommand("SELECT * FROM mytable WHERE id=?id AND name=?name", conn)
cmd.Parameters.Add("?id", MySqlDbType.VarChar, 15)
cmd.Parameters.Add("?name", MySqlDbType.VarChar, 15)
da.SelectCommand = cmd
' Create the InsertCommand.
cmd = New MySqlCommand("INSERT INTO mytable (id,name) VALUES (?id, ?name)", conn)
cmd.Parameters.Add( "?id", MySqlDbType.VarChar, 15, "id" )
cmd.Parameters.Add( "?name", MySqlDbType.VarChar, 15, "name" )
da.InsertCommand = cmd
Return da
End Function
C# example:
public static MySqlDataAdapter CreateCustomerAdapter(MySqlConnection conn)
{
MySqlDataAdapter da = new MySqlDataAdapter();
MySqlCommand cmd;
MySqlParameter parm;
// Create the SelectCommand.
cmd = new MySqlCommand("SELECT * FROM mytable WHERE id=?id AND name=?name", conn);
cmd.Parameters.Add("?id", MySqlDbType.VarChar, 15);
cmd.Parameters.Add("?name", MySqlDbType.VarChar, 15);
da.SelectCommand = cmd;
// Create the InsertCommand.
cmd = new MySqlCommand("INSERT INTO mytable (id,name) VALUES (?id,?name)", conn);
cmd.Parameters.Add("?id", MySqlDbType.VarChar, 15, "id" );
cmd.Parameters.Add("?name", MySqlDbType.VarChar, 15, "name" );
da.InsertCommand = cmd;
return da;
}
To create a MySQLDataReader, you must call
the MySqlCommand.ExecuteReader method of the
MySqlCommand object, rather than directly
using a constructor.
While the MySqlDataReader is in use, the
associated MySqlConnection is busy serving
the MySqlDataReader, and no other operations
can be performed on the MySqlConnection other
than closing it. This is the case until the
MySqlDataReader.Close method of the
MySqlDataReader is called.
MySqlDataReader.IsClosed and
MySqlDataReader.RecordsAffected are the only
properties that you can call after the
MySqlDataReader is closed. Though the
RecordsAffected property may be accessed at
any time while the MySqlDataReader exists,
always call Close before returning the value
of RecordsAffected to ensure an accurate
return value.
For optimal performance, MySqlDataReader
avoids creating unnecessary objects or making unnecessary copies
of data. As a result, multiple calls to methods such as
MySqlDataReader.GetValue return a reference
to the same object. Use caution if you are modifying the
underlying value of the objects returned by methods such as
GetValue.
Examples
The following example creates a
MySqlConnection, a
MySqlCommand, and a
MySqlDataReader. The example reads through
the data, writing it out to the console. Finally, the example
closes the MySqlDataReader, then the
MySqlConnection.
Visual Basic example:
Public Sub ReadMyData(myConnString As String)
Dim mySelectQuery As String = "SELECT OrderID, CustomerID FROM Orders"
Dim myConnection As New MySqlConnection(myConnString)
Dim myCommand As New MySqlCommand(mySelectQuery, myConnection)
myConnection.Open()
Dim myReader As MySqlDataReader
myReader = myCommand.ExecuteReader()
' Always call Read before accessing data.
While myReader.Read()
Console.WriteLine((myReader.GetInt32(0) & ", " & myReader.GetString(1)))
End While
' always call Close when done reading.
myReader.Close()
' Close the connection when done with it.
myConnection.Close()
End Sub 'ReadMyData
C# example:
public void ReadMyData(string myConnString) {
string mySelectQuery = "SELECT OrderID, CustomerID FROM Orders";
MySqlConnection myConnection = new MySqlConnection(myConnString);
MySqlCommand myCommand = new MySqlCommand(mySelectQuery,myConnection);
myConnection.Open();
MySqlDataReader myReader;
myReader = myCommand.ExecuteReader();
// Always call Read before accessing data.
while (myReader.Read()) {
Console.WriteLine(myReader.GetInt32(0) + ", " + myReader.GetString(1));
}
// always call Close when done reading.
myReader.Close();
// Close the connection when done with it.
myConnection.Close();
}
GetBytes returns the number of available
bytes in the field. In most cases this is the exact length of
the field. However, the number returned may be less than the
true length of the field if GetBytes has
already been used to obtain bytes from the field. This may be
the case, for example, if the
MySqlDataReader is reading a large data
structure into a buffer. For more information, see the
SequentialAccess setting for
MySqlCommand.CommandBehavior.
If you pass a buffer that is a null reference
(Nothing in Visual Basic),
GetBytes returns the length of the field in
bytes.
No conversions are performed; therefore the data retrieved must already be a byte array.
Gets the value of the specified column as a
TimeSpan object.
Parameters: The zero-based column ordinal.
Returns: The value of the specified column.
Gets the value of the specified column as a
System.DateTime object.
Note
MySQL allows date columns to contain the value '0000-00-00'
and datetime columns to contain the value '0000-00-00
00:00:00'. The DateTime structure cannot contain or
represent these values. To read a datetime value from a
column that might contain zero values, use
GetMySqlDateTime. The behavior of reading
a zero datetime column using this method is defined by the
ZeroDateTimeBehavior connection string
option. For more information on this option, please refer to
MySqlConnection.ConnectionString.
Parameters: The zero-based column ordinal.
Returns: The value of the specified column.
Gets the value of the specified column as a
MySql.Data.Types.MySqlDateTime object.
Parameters: The zero-based column ordinal.
Returns: The value of the specified column.
Gets the value of the specified column as a
String object.
Parameters: The zero-based column ordinal.
Returns: The value of the specified column.
Gets the value of the specified column as a
Decimal object.
Parameters: The zero-based column ordinal.
Returns: The value of the specified column.
Gets the value of the specified column as a double-precision floating point number.
Parameters: The zero-based column ordinal.
Returns: The value of the specified column.
Gets the value of the specified column as a single-precision floating point number.
Parameters: The zero-based column ordinal.
Returns: The value of the specified column.
Gets the value of the specified column as a globally-unique identifier (GUID).
Parameters: The zero-based column ordinal.
Returns: The value of the specified column.
Gets the value of the specified column as a 16-bit signed integer.
Parameters: The zero-based column ordinal.
Returns: The value of the specified column.
Gets the value of the specified column as a 32-bit signed integer.
Parameters: The zero-based column ordinal.
Returns: The value of the specified column.
Gets the value of the specified column as a 64-bit signed integer.
Parameters: The zero-based column ordinal.
Returns: The value of the specified column.
Gets the value of the specified column as a 16-bit unsigned integer.
Parameters: The zero-based column ordinal.
Returns: The value of the specified column.
Gets the value of the specified column as a 32-bit unsigned integer.
Parameters: The zero-based column ordinal.
Returns: The value of the specified column.
This class is created whenever the MySQL Data Provider encounters an error generated from the server.
Any open connections are not automatically closed when an
exception is thrown. If the client application determines that
the exception is fatal, it should close any open
MySqlDataReader objects or
MySqlConnection objects.
Examples
The following example generates a
MySqlException due to a missing server, and
then displays the exception.
Visual Basic example:
Public Sub ShowException()
Dim mySelectQuery As String = "SELECT column1 FROM table1"
Dim myConnection As New MySqlConnection ("Data Source=localhost;Database=Sample;")
Dim myCommand As New MySqlCommand(mySelectQuery, myConnection)
Try
myCommand.Connection.Open()
Catch e As MySqlException
MessageBox.Show( e.Message )
End Try
End Sub
C# example:
public void ShowException()
{
string mySelectQuery = "SELECT column1 FROM table1";
MySqlConnection myConnection =
new MySqlConnection("Data Source=localhost;Database=Sample;");
MySqlCommand myCommand = new MySqlCommand(mySelectQuery,myConnection);
try
{
myCommand.Connection.Open();
}
catch (MySqlException e)
{
MessageBox.Show( e.Message );
}
}
Parameter names are not case sensitive.
Examples
The following example creates multiple instances of
MySqlParameter through the
MySqlParameterCollection collection within
the MySqlDataAdapter. These parameters are
used to select data from the data source and place the data in
the DataSet. This example assumes that a
DataSet and a
MySqlDataAdapter have already been created
with the appropriate schema, commands, and connection.
Visual Basic example:
Public Sub AddSqlParameters()
' ...
' create myDataSet and myDataAdapter
' ...
myDataAdapter.SelectCommand.Parameters.Add("@CategoryName", MySqlDbType.VarChar, 80).Value = "toasters"
myDataAdapter.SelectCommand.Parameters.Add("@SerialNum", MySqlDbType.Long).Value = 239
myDataAdapter.Fill(myDataSet)
End Sub 'AddSqlParameters
C# example:
public void AddSqlParameters()
{
// ...
// create myDataSet and myDataAdapter
// ...
myDataAdapter.SelectCommand.Parameters.Add("@CategoryName", MySqlDbType.VarChar, 80).Value = "toasters";
myDataAdapter.SelectCommand.Parameters.Add("@SerialNum", MySqlDbType.Long).Value = 239;
myDataAdapter.Fill(myDataSet);
}
The number of the parameters in the collection must be equal to the number of parameter placeholders within the command text, or an exception will be generated.
Examples
The following example creates multiple instances of
MySqlParameter through the
MySqlParameterCollection collection within
the MySqlDataAdapter. These parameters are
used to select data within the data source and place the data in
the DataSet. This code assumes that a
DataSet and a
MySqlDataAdapter have already been created
with the appropriate schema, commands, and connection.
Visual Basic example:
Public Sub AddParameters()
' ...
' create myDataSet and myDataAdapter
' ...
myDataAdapter.SelectCommand.Parameters.Add("@CategoryName", MySqlDbType.VarChar, 80).Value = "toasters"
myDataAdapter.SelectCommand.Parameters.Add("@SerialNum", MySqlDbType.Long).Value = 239
myDataAdapter.Fill(myDataSet)
End Sub 'AddSqlParameters
C# example:
public void AddSqlParameters()
{
// ...
// create myDataSet and myDataAdapter
// ...
myDataAdapter.SelectCommand.Parameters.Add("@CategoryName", MySqlDbType.VarChar, 80).Value = "toasters";
myDataAdapter.SelectCommand.Parameters.Add("@SerialNum", MySqlDbType.Long).Value = 239;
myDataAdapter.Fill(myDataSet);
}
Represents a SQL transaction to be made in a MySQL database. This class cannot be inherited.
The application creates a MySqlTransaction
object by calling
MySqlConnection.BeginTransaction on the
MySqlConnection object. All subsequent
operations associated with the transaction (for example,
committing or aborting the transaction), are performed on the
MySqlTransaction object.
Examples
The following example creates a
MySqlConnection and a
MySqlTransaction. It also demonstrates how to
use the MySqlConnection.BeginTransaction,
MySqlTransaction.Commit, and
MySqlTransaction.Rollback methods.
Visual Basic example:
Public Sub RunTransaction(myConnString As String)
Dim myConnection As New MySqlConnection(myConnString)
myConnection.Open()
Dim myCommand As MySqlCommand = myConnection.CreateCommand()
Dim myTrans As MySqlTransaction
' Start a local transaction
myTrans = myConnection.BeginTransaction()
' Must assign both transaction object and connection
' to Command object for a pending local transaction
myCommand.Connection = myConnection
myCommand.Transaction = myTrans
Try
myCommand.CommandText = "Insert into Region (RegionID, RegionDescription) VALUES (100, 'Description')"
myCommand.ExecuteNonQuery()
myCommand.CommandText = "Insert into Region (RegionID, RegionDescription) VALUES (101, 'Description')"
myCommand.ExecuteNonQuery()
myTrans.Commit()
Console.WriteLine("Both records are written to database.")
Catch e As Exception
Try
myTrans.Rollback()
Catch ex As MySqlException
If Not myTrans.Connection Is Nothing Then
Console.WriteLine("An exception of type " & ex.GetType().ToString() & _
" was encountered while attempting to roll back the transaction.")
End If
End Try
Console.WriteLine("An exception of type " & e.GetType().ToString() & _
"was encountered while inserting the data.")
Console.WriteLine("Neither record was written to database.")
Finally
myConnection.Close()
End Try
End Sub 'RunTransaction
C# example:
public void RunTransaction(string myConnString)
{
MySqlConnection myConnection = new MySqlConnection(myConnString);
myConnection.Open();
MySqlCommand myCommand = myConnection.CreateCommand();
MySqlTransaction myTrans;
// Start a local transaction
myTrans = myConnection.BeginTransaction();
// Must assign both transaction object and connection
// to Command object for a pending local transaction
myCommand.Connection = myConnection;
myCommand.Transaction = myTrans;
try
{
myCommand.CommandText = "Insert into Region (RegionID, RegionDescription) VALUES (100, 'Description')";
myCommand.ExecuteNonQuery();
myCommand.CommandText = "Insert into Region (RegionID, RegionDescription) VALUES (101, 'Description')";
myCommand.ExecuteNonQuery();
myTrans.Commit();
Console.WriteLine("Both records are written to database.");
}
catch(Exception e)
{
try
{
myTrans.Rollback();
}
catch (MySqlException ex)
{
if (myTrans.Connection != null)
{
Console.WriteLine("An exception of type " + ex.GetType() +
" was encountered while attempting to roll back the transaction.");
}
}
Console.WriteLine("An exception of type " + e.GetType() +
" was encountered while inserting the data.");
Console.WriteLine("Neither record was written to database.");
}
finally
{
myConnection.Close();
}
}
Rolls back a transaction from a pending state.
The Rollback method is equivalent to the MySQL statement ROLLBACK. The transaction can only be rolled back from a pending state (after BeginTransaction has been called, but before Commit is called).
Examples
The following example creates
MySqlConnection and a
MySqlTransaction. It also demonstrates how
to use the
MySqlConnection.BeginTransaction,
Commit, and Rollback
methods.
Visual Basic example:
Public Sub RunSqlTransaction(myConnString As String)
Dim myConnection As New MySqlConnection(myConnString)
myConnection.Open()
Dim myCommand As MySqlCommand = myConnection.CreateCommand()
Dim myTrans As MySqlTransaction
' Start a local transaction
myTrans = myConnection.BeginTransaction()
' Must assign both transaction object and connection
' to Command object for a pending local transaction
myCommand.Connection = myConnection
myCommand.Transaction = myTrans
Try
myCommand.CommandText = "Insert into mytable (id, desc) VALUES (100, 'Description')"
myCommand.ExecuteNonQuery()
myCommand.CommandText = "Insert into mytable (id, desc) VALUES (101, 'Description')"
myCommand.ExecuteNonQuery()
myTrans.Commit()
Console.WriteLine("Success.")
Catch e As Exception
Try
myTrans.Rollback()
Catch ex As MySqlException
If Not myTrans.Connection Is Nothing Then
Console.WriteLine("An exception of type " & ex.GetType().ToString() & _
" was encountered while attempting to roll back the transaction.")
End If
End Try
Console.WriteLine("An exception of type " & e.GetType().ToString() & _
"was encountered while inserting the data.")
Console.WriteLine("Neither record was written to database.")
Finally
myConnection.Close()
End Try
End Sub
C# example:
public void RunSqlTransaction(string myConnString)
{
MySqlConnection myConnection = new MySqlConnection(myConnString);
myConnection.Open();
MySqlCommand myCommand = myConnection.CreateCommand();
MySqlTransaction myTrans;
// Start a local transaction
myTrans = myConnection.BeginTransaction();
// Must assign both transaction object and connection
// to Command object for a pending local transaction
myCommand.Connection = myConnection;
myCommand.Transaction = myTrans;
try
{
myCommand.CommandText = "Insert into mytable (id, desc) VALUES (100, 'Description')";
myCommand.ExecuteNonQuery();
myCommand.CommandText = "Insert into mytable (id, desc) VALUES (101, 'Description')";
myCommand.ExecuteNonQuery();
myTrans.Commit();
Console.WriteLine("Both records are written to database.");
}
catch(Exception e)
{
try
{
myTrans.Rollback();
}
catch (MySqlException ex)
{
if (myTrans.Connection != null)
{
Console.WriteLine("An exception of type " + ex.GetType() +
" was encountered while attempting to roll back the transaction.");
}
}
Console.WriteLine("An exception of type " + e.GetType() +
" was encountered while inserting the data.");
Console.WriteLine("Neither record was written to database.");
}
finally
{
myConnection.Close();
}
}
Commits the database transaction.
The Commit method is equivalent to the
MySQL SQL statement COMMIT.
Examples
The following example creates
MySqlConnection and a
MySqlTransaction. It also demonstrates how
to use the
MySqlConnection.BeginTransaction,
Commit, and Rollback
methods.
Visual Basic example:
Public Sub RunSqlTransaction(myConnString As String)
Dim myConnection As New MySqlConnection(myConnString)
myConnection.Open()
Dim myCommand As MySqlCommand = myConnection.CreateCommand()
Dim myTrans As MySqlTransaction
' Start a local transaction
myTrans = myConnection.BeginTransaction()
' Must assign both transaction object and connection
' to Command object for a pending local transaction
myCommand.Connection = myConnection
myCommand.Transaction = myTrans
Try
myCommand.CommandText = "Insert into mytable (id, desc) VALUES (100, 'Description')"
myCommand.ExecuteNonQuery()
myCommand.CommandText = "Insert into mytable (id, desc) VALUES (101, 'Description')"
myCommand.ExecuteNonQuery()
myTrans.Commit()
Console.WriteLine("Success.")
Catch e As Exception
Try
myTrans.Rollback()
Catch ex As MySqlException
If Not myTrans.Connection Is Nothing Then
Console.WriteLine("An exception of type " & ex.GetType().ToString() & _
" was encountered while attempting to roll back the transaction.")
End If
End Try
Console.WriteLine("An exception of type " & e.GetType().ToString() & _
"was encountered while inserting the data.")
Console.WriteLine("Neither record was written to database.")
Finally
myConnection.Close()
End Try
End Sub
C# example:
public void RunSqlTransaction(string myConnString)
{
MySqlConnection myConnection = new MySqlConnection(myConnString);
myConnection.Open();
MySqlCommand myCommand = myConnection.CreateCommand();
MySqlTransaction myTrans;
// Start a local transaction
myTrans = myConnection.BeginTransaction();
// Must assign both transaction object and connection
// to Command object for a pending local transaction
myCommand.Connection = myConnection;
myCommand.Transaction = myTrans;
try
{
myCommand.CommandText = "Insert into mytable (id, desc) VALUES (100, 'Description')";
myCommand.ExecuteNonQuery();
myCommand.CommandText = "Insert into mytable (id, desc) VALUES (101, 'Description')";
myCommand.ExecuteNonQuery();
myTrans.Commit();
Console.WriteLine("Both records are written to database.");
}
catch(Exception e)
{
try
{
myTrans.Rollback();
}
catch (MySqlException ex)
{
if (myTrans.Connection != null)
{
Console.WriteLine("An exception of type " + ex.GetType() +
" was encountered while attempting to roll back the transaction.");
}
}
Console.WriteLine("An exception of type " + e.GetType() +
" was encountered while inserting the data.");
Console.WriteLine("Neither record was written to database.");
}
finally
{
myConnection.Close();
}
}
This section of the manual contains a complete reference to the Connector/NET ADO.NET component, automatically generated from the embedded documentation.
Classes
| Class | Description |
| MySqlCommand | |
| MySqlCommandBuilder | |
| MySqlConnection | |
| MySqlDataAdapter | |
| MySqlDataReader | Provides a means of reading a forward-only stream of rows from a MySQL database. This class cannot be inherited. |
| MySqlError | Collection of error codes that can be returned by the server |
| MySqlException | The exception that is thrown when MySQL returns an error. This class cannot be inherited. |
| MySqlHelper | Helper class that makes it easier to work with the provider. |
| MySqlInfoMessageEventArgs | Provides data for the InfoMessage event. This class cannot be inherited. |
| MySqlParameter | Represents a parameter to a MySqlCommand , and optionally, its mapping to DataSetcolumns. This class cannot be inherited. |
| MySqlParameterCollection | Represents a collection of parameters relevant to a MySqlCommand as well as their respective mappings to columns in a DataSet. This class cannot be inherited. |
| MySqlRowUpdatedEventArgs | Provides data for the RowUpdated event. This class cannot be inherited. |
| MySqlRowUpdatingEventArgs | Provides data for the RowUpdating event. This class cannot be inherited. |
| MySqlTransaction |
Delegates
| Delegate | Description |
| MySqlInfoMessageEventHandler | Represents the method that will handle the InfoMessage event of a MySqlConnection. |
| MySqlRowUpdatedEventHandler | Represents the method that will handle the RowUpdatedevent of a MySqlDataAdapter . |
| MySqlRowUpdatingEventHandler | Represents the method that will handle the RowUpdatingevent of a MySqlDataAdapter . |
Enumerations
| Enumeration | Description |
| MySqlDbType | Specifies MySQL specific data type of a field, property, for use in a MySqlParameter . |
| MySqlErrorCode |
For a list of all members of this type, see MySqlCommand Members .
Syntax: Visual Basic
NotInheritable Public Class MySqlCommand_ Inherits Component_ Implements IDbCommand, ICloneable
Syntax: C#
public sealed class MySqlCommand : Component, IDbCommand, ICloneable
Thread Safety
Public static (Shared in Visual Basic) members of this type are safe for multithreaded operations. Instance members are not guaranteed to be thread-safe.
Requirements
Namespace: MySql.Data.MySqlClient
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySqlCommand Members , MySql.Data.MySqlClient Namespace
Public Instance Constructors
| MySqlCommand | Overloaded. Initializes a new instance of the MySqlCommand class. |
Public Instance Properties
| CommandText | |
| CommandTimeout | |
| CommandType | |
| Connection | |
| Container(inherited from Component) | Gets the IContainerthat contains the Component. |
| IsPrepared | |
| Parameters | |
| Site(inherited from Component) | Gets or sets the ISiteof the Component. |
| Transaction | |
| UpdatedRowSource |
Public Instance Methods
| Cancel | Attempts to cancel the execution of a MySqlCommand. This operation is not supported. |
| CreateObjRef(inherited from MarshalByRefObject) | Creates an object that contains all the relevant information required to generate a proxy used to communicate with a remote object. |
| CreateParameter | Creates a new instance of a MySqlParameter object. |
| Dispose(inherited from Component) | Releases all resources used by the Component. |
| Equals(inherited from Object) | Determines whether the specified Objectis equal to the current Object. |
| ExecuteNonQuery | |
| ExecuteReader | Overloaded. |
| ExecuteScalar | |
| GetHashCode(inherited from Object) | Serves as a hash function for a particular type. GetHashCodeis suitable for use in hashing algorithms and data structures like a hash table. |
| GetLifetimeService(inherited from MarshalByRefObject) | Retrieves the current lifetime service object that controls the lifetime policy for this instance. |
| GetType(inherited from Object) | Gets the Typeof the current instance. |
| InitializeLifetimeService(inherited from MarshalByRefObject) | Obtains a lifetime service object to control the lifetime policy for this instance. |
| Prepare | |
| ToString(inherited from Component) | Returns a Stringcontaining the name of the Component, if any. This method should not be overridden. |
Public Instance Events
| Disposed(inherited from Component) | Adds an event handler to listen to the Disposedevent on the component. |
See Also
MySqlCommand Class , MySql.Data.MySqlClient Namespace
Initializes a new instance of the MySqlCommand class.
Overload List
Initializes a new instance of the MySqlCommand class.
See Also
MySqlCommand Class , MySql.Data.MySqlClient Namespace
Initializes a new instance of the MySqlCommand class.
Syntax: Visual Basic
Overloads Public Sub New()
Syntax: C#
public MySqlCommand();
See Also
MySqlCommand Class , MySql.Data.MySqlClient Namespace , MySqlCommand Constructor Overload List
Syntax: Visual Basic
Overloads Public Sub New( _ ByVal cmdText As String _ )
Syntax: C#
public MySqlCommand( stringcmdText );
See Also
MySqlCommand Class , MySql.Data.MySqlClient Namespace , MySqlCommand Constructor Overload List
Syntax: Visual Basic
Overloads Public Sub New( _ ByVal cmdText As String, _ ByVal connection As MySqlConnection _ )
Syntax: C#
public MySqlCommand( stringcmdText, MySqlConnectionconnection );
See Also
MySqlCommand Class , MySql.Data.MySqlClient Namespace , MySqlCommand Constructor Overload List
For a list of all members of this type, see MySqlConnection Members .
Syntax: Visual Basic
NotInheritable Public Class MySqlConnection_ Inherits Component_ Implements IDbConnection, ICloneable
Syntax: C#
public sealed class MySqlConnection : Component, IDbConnection, ICloneable
Thread Safety
Public static (Shared in Visual Basic) members of this type are safe for multithreaded operations. Instance members are not guaranteed to be thread-safe.
Requirements
Namespace: MySql.Data.MySqlClient
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySqlConnection Members , MySql.Data.MySqlClient Namespace
Public Instance Constructors
| MySqlConnection | Overloaded. Initializes a new instance of the MySqlConnection class. |
Public Instance Properties
| ConnectionString | |
| ConnectionTimeout | |
| Container(inherited from Component) | Gets the IContainerthat contains the Component. |
| Database | |
| DataSource | Gets the name of the MySQL server to which to connect. |
| ServerThread | Returns the id of the server thread this connection is executing on |
| ServerVersion | |
| Site(inherited from Component) | Gets or sets the ISiteof the Component. |
| State | |
| UseCompression | Indicates if this connection should use compression when communicating with the server. |
Public Instance Methods
| BeginTransaction | Overloaded. |
| ChangeDatabase | |
| Close | |
| CreateCommand | |
| CreateObjRef(inherited from MarshalByRefObject) | Creates an object that contains all the relevant information required to generate a proxy used to communicate with a remote object. |
| Dispose(inherited from Component) | Releases all resources used by the Component. |
| Equals(inherited from Object) | Determines whether the specified Objectis equal to the current Object. |
| GetHashCode(inherited from Object) | Serves as a hash function for a particular type. GetHashCodeis suitable for use in hashing algorithms and data structures like a hash table. |
| GetLifetimeService(inherited from MarshalByRefObject) | Retrieves the current lifetime service object that controls the lifetime policy for this instance. |
| GetType(inherited from Object) | Gets the Typeof the current instance. |
| InitializeLifetimeService(inherited from MarshalByRefObject) | Obtains a lifetime service object to control the lifetime policy for this instance. |
| Open | |
| Ping | Ping |
| ToString(inherited from Component) | Returns a Stringcontaining the name of the Component, if any. This method should not be overridden. |
Public Instance Events
| Disposed(inherited from Component) | Adds an event handler to listen to the Disposedevent on the component. |
| InfoMessage | |
| StateChange |
See Also
MySqlConnection Class , MySql.Data.MySqlClient Namespace
Initializes a new instance of the MySqlConnection class.
Overload List
Initializes a new instance of the MySqlConnection class.
See Also
MySqlConnection Class , MySql.Data.MySqlClient Namespace
Initializes a new instance of the MySqlConnection class.
Syntax: Visual Basic
Overloads Public Sub New()
Syntax: C#
public MySqlConnection();
See Also
MySqlConnection Class , MySql.Data.MySqlClient Namespace , MySqlConnection Constructor Overload List
Syntax: Visual Basic
Overloads Public Sub New( _ ByVal connectionString As String _ )
Syntax: C#
public MySqlConnection( stringconnectionString );
See Also
MySqlConnection Class , MySql.Data.MySqlClient Namespace , MySqlConnection Constructor Overload List
Syntax: Visual Basic
NotOverridable Public Property ConnectionString As String _ _ Implements IDbConnection.ConnectionString
Syntax: C#
public string ConnectionString {get; set;}
Implements
IDbConnection.ConnectionString
See Also
Syntax: Visual Basic
NotOverridable Public ReadOnly Property ConnectionTimeout As Integer _ _ Implements IDbConnection.ConnectionTimeout
Syntax: C#
public int ConnectionTimeout {get;}
Implements
IDbConnection.ConnectionTimeout
See Also
Syntax: Visual Basic
NotOverridable Public ReadOnly Property Database As String _ _ Implements IDbConnection.Database
Syntax: C#
public string Database {get;}
Implements
IDbConnection.Database
See Also
Gets the name of the MySQL server to which to connect.
Syntax: Visual Basic
Public ReadOnly Property DataSource As String
Syntax: C#
public string DataSource {get;}See Also
Returns the id of the server thread this connection is executing on
Syntax: Visual Basic
Public ReadOnly Property ServerThread As Integer
Syntax: C#
public int ServerThread {get;}See Also
Syntax: Visual Basic
Public ReadOnly Property ServerVersion As String
Syntax: C#
public string ServerVersion {get;}See Also
Syntax: Visual Basic
NotOverridable Public ReadOnly Property State As ConnectionState _ _ Implements IDbConnection.State
Syntax: C#
public System.Data.ConnectionState State {get;}
Implements
IDbConnection.State
See Also
Indicates if this connection should use compression when communicating with the server.
Syntax: Visual Basic
Public ReadOnly Property UseCompression As Boolean
Syntax: C#
public bool UseCompression {get;}See Also
Overload List
See Also
MySqlConnection Class , MySql.Data.MySqlClient Namespace
Syntax: Visual Basic
Overloads Public Function BeginTransaction() As MySqlTransaction
Syntax: C#
public MySqlTransaction BeginTransaction();
See Also
MySqlConnection Class , MySql.Data.MySqlClient Namespace , MySqlConnection.BeginTransaction Overload List
For a list of all members of this type, see MySqlTransaction Members .
Syntax: Visual Basic
NotInheritable Public Class MySqlTransaction_ Implements IDbTransaction, IDisposable
Syntax: C#
public sealed class MySqlTransaction : IDbTransaction, IDisposable
Thread Safety
Public static (Sharedin Visual Basic) members of this type are safe for multithreaded operations. Instance members are notguaranteed to be thread-safe.
Requirements
Namespace: MySql.Data.MySqlClient
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySqlTransaction Members , MySql.Data.MySqlClient Namespace
Public Instance Properties
| Connection | Gets the MySqlConnection object associated with the transaction, or a null reference (Nothing in Visual Basic) if the transaction is no longer valid. |
| IsolationLevel | Specifies the IsolationLevelfor this transaction. |
Public Instance Methods
| Commit | |
| Equals(inherited from Object) | Determines whether the specified Objectis equal to the current Object. |
| GetHashCode(inherited from Object) | Serves as a hash function for a particular type. GetHashCodeis suitable for use in hashing algorithms and data structures like a hash table. |
| GetType(inherited from Object) | Gets the Typeof the current instance. |
| Rollback | |
| ToString(inherited from Object) | Returns a Stringthat represents the current Object. |
See Also
MySqlTransaction Class , MySql.Data.MySqlClient Namespace
Gets the MySqlConnection object associated with the transaction, or a null reference (Nothing in Visual Basic) if the transaction is no longer valid.
Syntax: Visual Basic
Public ReadOnly Property Connection As MySqlConnection
Syntax: C#
public MySqlConnection Connection {get;}Property Value
The MySqlConnection object associated with this transaction.
Remarks
A single application may have multiple database connections, each with zero or more transactions. This property enables you to determine the connection object associated with a particular transaction created by BeginTransaction .
See Also
Specifies the IsolationLevelfor this transaction.
Syntax: Visual Basic
NotOverridable Public ReadOnly Property IsolationLevel As IsolationLevel _ _ Implements IDbTransaction.IsolationLevel
Syntax: C#
public System.Data.IsolationLevel IsolationLevel {get;}
Property Value
The IsolationLevel for this transaction. The default is ReadCommitted.
Implements
IDbTransaction.IsolationLevel
Remarks
Parallel transactions are not supported. Therefore, the IsolationLevel applies to the entire transaction.
See Also
Syntax: Visual Basic
NotOverridable Public Sub Commit() _ _ Implements IDbTransaction.Commit
Syntax: C#
public void Commit();
Implements
IDbTransaction.Commit
See Also
Syntax: Visual Basic
NotOverridable Public Sub Rollback() _ _ Implements IDbTransaction.Rollback
Syntax: C#
public void Rollback();
Implements
IDbTransaction.Rollback
See Also
Syntax: Visual Basic
Overloads Public Function BeginTransaction( _ ByVal iso As IsolationLevel _ ) As MySqlTransaction
Syntax: C#
public MySqlTransaction BeginTransaction( IsolationLeveliso );
See Also
MySqlConnection Class , MySql.Data.MySqlClient Namespace , MySqlConnection.BeginTransaction Overload List
Syntax: Visual Basic
NotOverridable Public Sub ChangeDatabase( _ ByVal databaseName As String _ ) _ _ Implements IDbConnection.ChangeDatabase
Syntax: C#
public void ChangeDatabase( stringdatabaseName );
Implements
IDbConnection.ChangeDatabase
See Also
Syntax: Visual Basic
NotOverridable Public Sub Close() _ _ Implements IDbConnection.Close
Syntax: C#
public void Close();
Implements
IDbConnection.Close
See Also
Syntax: Visual Basic
Public Function CreateCommand() As MySqlCommand
Syntax: C#
public MySqlCommand CreateCommand();
See Also
Syntax: Visual Basic
NotOverridable Public Sub Open() _ _ Implements IDbConnection.Open
Syntax: C#
public void Open();
Implements
IDbConnection.Open
See Also
Ping
Syntax: Visual Basic
Public Function Ping() As Boolean
Syntax: C#
public bool Ping();
Return Value
See Also
Syntax: Visual Basic
Public Event InfoMessage As MySqlInfoMessageEventHandler
Syntax: C#
public event MySqlInfoMessageEventHandler InfoMessage;
See Also
MySqlConnection Class , MySql.Data.MySqlClient Namespace
Represents the method that will handle the InfoMessage event of a MySqlConnection .
Syntax: Visual Basic
Public Delegate Sub MySqlInfoMessageEventHandler( _ ByVal sender As Object, _ ByVal args As MySqlInfoMessageEventArgs _ )
Syntax: C#
public delegate void MySqlInfoMessageEventHandler( objectsender, MySqlInfoMessageEventArgsargs );
Requirements
Namespace: MySql.Data.MySqlClient
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySql.Data.MySqlClient Namespace
Provides data for the InfoMessage event. This class cannot be inherited.
For a list of all members of this type, see MySqlInfoMessageEventArgs Members .
Syntax: Visual Basic
Public Class MySqlInfoMessageEventArgs_ Inherits EventArgs
Syntax: C#
public class MySqlInfoMessageEventArgs : EventArgs
Thread Safety
Public static (Sharedin Visual Basic) members of this type are safe for multithreaded operations. Instance members are notguaranteed to be thread-safe.
Requirements
Namespace: MySql.Data.MySqlClient
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySqlInfoMessageEventArgs Members , MySql.Data.MySqlClient Namespace
MySqlInfoMessageEventArgs overview
Public Instance Constructors
| MySqlInfoMessageEventArgs Constructor | Initializes a new instance of the MySqlInfoMessageEventArgs class. |
Public Instance Fields
Public Instance Methods
| Equals(inherited from Object) | Determines whether the specified Objectis equal to the current Object. |
| GetHashCode(inherited from Object) | Serves as a hash function for a particular type. GetHashCodeis suitable for use in hashing algorithms and data structures like a hash table. |
| GetType(inherited from Object) | Gets the Typeof the current instance. |
| ToString(inherited from Object) | Returns a Stringthat represents the current Object. |
Protected Instance Methods
| Finalize(inherited from Object) | Allows an Objectto attempt to free resources and perform other cleanup operations before the Objectis reclaimed by garbage collection. |
| MemberwiseClone(inherited from Object) | Creates a shallow copy of the current Object. |
See Also
MySqlInfoMessageEventArgs Class , MySql.Data.MySqlClient Namespace
Initializes a new instance of the MySqlInfoMessageEventArgs class.
Syntax: Visual Basic
Public Sub New()
Syntax: C#
public MySqlInfoMessageEventArgs();
See Also
MySqlInfoMessageEventArgs Class , MySql.Data.MySqlClient Namespace
Syntax: Visual Basic
Public errors As MySqlError()
Syntax: C#
public MySqlError[] errors;
See Also
MySqlInfoMessageEventArgs Class , MySql.Data.MySqlClient Namespace
Collection of error codes that can be returned by the server
For a list of all members of this type, see MySqlError Members .
Syntax: Visual Basic
Public Class MySqlError
Syntax: C#
public class MySqlError
Thread Safety
Public static (Shared in Visual Basic) members of this type are safe for multithreaded operations. Instance members are not guaranteed to be thread-safe.
Requirements
Namespace: MySql.Data.MySqlClient
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySqlError Members , MySql.Data.MySqlClient Namespace
Public Instance Constructors
Public Instance Properties
Public Instance Methods
| Equals(inherited from Object) | Determines whether the specified Objectis equal to the current Object. |
| GetHashCode(inherited from Object) | Serves as a hash function for a particular type. GetHashCodeis suitable for use in hashing algorithms and data structures like a hash table. |
| GetType(inherited from Object) | Gets the Typeof the current instance. |
| ToString(inherited from Object) | Returns a Stringthat represents the current Object. |
Protected Instance Methods
| Finalize(inherited from Object) | Allows an Objectto attempt to free resources and perform other cleanup operations before the Objectis reclaimed by garbage collection. |
| MemberwiseClone(inherited from Object) | Creates a shallow copy of the current Object. |
See Also
MySqlError Class , MySql.Data.MySqlClient Namespace
Syntax: Visual Basic
Public Sub New( _ ByVal level As String, _ ByVal code As Integer, _ ByVal message As String _ )
Syntax: C#
public MySqlError( stringlevel, intcode, stringmessage );
Parameters
level:code:message:
See Also
Error code
Syntax: Visual Basic
Public ReadOnly Property Code As Integer
Syntax: C#
public int Code {get;}See Also
Error level
Syntax: Visual Basic
Public ReadOnly Property Level As String
Syntax: C#
public string Level {get;}See Also
Error message
Syntax: Visual Basic
Public ReadOnly Property Message As String
Syntax: C#
public string Message {get;}See Also
Syntax: Visual Basic
Public Event StateChange As StateChangeEventHandler
Syntax: C#
public event StateChangeEventHandler StateChange;
See Also
Syntax: Visual Basic
Overloads Public Sub New( _ ByVal cmdText As String, _ ByVal connection As MySqlConnection, _ ByVal transaction As MySqlTransaction _ )
Syntax: C#
public MySqlCommand( stringcmdText, MySqlConnectionconnection, MySqlTransactiontransaction );
See Also
MySqlCommand Class , MySql.Data.MySqlClient Namespace , MySqlCommand Constructor Overload List
Syntax: Visual Basic
NotOverridable Public Property CommandText As String _ _ Implements IDbCommand.CommandText
Syntax: C#
public string CommandText {get; set;}
Implements
IDbCommand.CommandText
See Also
Syntax: Visual Basic
NotOverridable Public Property CommandTimeout As Integer _ _ Implements IDbCommand.CommandTimeout
Syntax: C#
public int CommandTimeout {get; set;}
Implements
IDbCommand.CommandTimeout
See Also
Syntax: Visual Basic
NotOverridable Public Property CommandType As CommandType _ _ Implements IDbCommand.CommandType
Syntax: C#
public System.Data.CommandType CommandType {get; set;}
Implements
IDbCommand.CommandType
See Also
Syntax: Visual Basic
Public Property Connection As MySqlConnection
Syntax: C#
public MySqlConnection Connection {get; set;}See Also
Syntax: Visual Basic
Public ReadOnly Property IsPrepared As Boolean
Syntax: C#
public bool IsPrepared {get;}See Also
Syntax: Visual Basic
Public ReadOnly Property Parameters As MySqlParameterCollection
Syntax: C#
public MySqlParameterCollection Parameters {get;}See Also
MySqlCommand Class , MySql.Data.MySqlClient Namespace
Represents a collection of parameters relevant to a MySqlCommand as well as their respective mappings to columns in a DataSet. This class cannot be inherited.
For a list of all members of this type, see MySqlParameterCollection Members .
Syntax: Visual Basic
NotInheritable Public Class MySqlParameterCollection_ Inherits MarshalByRefObject_ Implements IDataParameterCollection, IList, ICollection, IEnumerable
Syntax: C#
public sealed class MySqlParameterCollection : MarshalByRefObject, IDataParameterCollection, IList, ICollection, IEnumerable
Thread Safety
Public static (Shared in Visual Basic) members of this type are safe for multithreaded operations. Instance members are not guaranteed to be thread-safe.
Requirements
Namespace: MySql.Data.MySqlClient
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySqlParameterCollection Members , MySql.Data.MySqlClient Namespace
MySqlParameterCollection overview
Public Instance Constructors
| MySqlParameterCollection Constructor | Initializes a new instance of the MySqlParameterCollection class. |
Public Instance Properties
| Count | Gets the number of MySqlParameter objects in the collection. |
| Item | Overloaded. Gets the MySqlParameter with a specified attribute. In C#, this property is the indexer for the MySqlParameterCollection class. |
Public Instance Methods
| Add | Overloaded. Adds the specified MySqlParameter object to the MySqlParameterCollection . |
| Clear | Removes all items from the collection. |
| Contains | Overloaded. Gets a value indicating whether a MySqlParameter exists in the collection. |
| CopyTo | Copies MySqlParameter objects from the MySqlParameterCollection to the specified array. |
| CreateObjRef(inherited from MarshalByRefObject) | Creates an object that contains all the relevant information required to generate a proxy used to communicate with a remote object. |
| Equals(inherited from Object) | Determines whether the specified Objectis equal to the current Object. |
| GetHashCode(inherited from Object) | Serves as a hash function for a particular type. GetHashCodeis suitable for use in hashing algorithms and data structures like a hash table. |
| GetLifetimeService(inherited from MarshalByRefObject) | Retrieves the current lifetime service object that controls the lifetime policy for this instance. |
| GetType(inherited from Object) | Gets the Typeof the current instance. |
| IndexOf | Overloaded. Gets the location of a MySqlParameter in the collection. |
| InitializeLifetimeService(inherited from MarshalByRefObject) | Obtains a lifetime service object to control the lifetime policy for this instance. |
| Insert | Inserts a MySqlParameter into the collection at the specified index. |
| Remove | Removes the specified MySqlParameter from the collection. |
| RemoveAt | Overloaded. Removes the specified MySqlParameter from the collection. |
| ToString(inherited from Object) | Returns a Stringthat represents the current Object. |
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace
Initializes a new instance of the MySqlParameterCollection class.
Syntax: Visual Basic
Public Sub New()
Syntax: C#
public MySqlParameterCollection();
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace
Gets the number of MySqlParameter objects in the collection.
Syntax: Visual Basic
NotOverridable Public ReadOnly Property Count As Integer _ _ Implements ICollection.Count
Syntax: C#
public int Count {get;}
Implements
ICollection.Count
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace
Gets the MySqlParameter with a specified attribute. In C#, this property is the indexer for the MySqlParameterCollection class.
Overload List
Gets the MySqlParameter at the specified index.
Gets the MySqlParameter with the specified name.
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace
Represents a parameter to a MySqlCommand , and optionally, its mapping to DataSetcolumns. This class cannot be inherited.
For a list of all members of this type, see MySqlParameter Members .
Syntax: Visual Basic
NotInheritable Public Class MySqlParameter_ Inherits MarshalByRefObject_ Implements IDataParameter, IDbDataParameter, ICloneable
Syntax: C#
public sealed class MySqlParameter : MarshalByRefObject, IDataParameter, IDbDataParameter, ICloneable
Thread Safety
Public static (Shared in Visual Basic) members of this type are safe for multithreaded operations. Instance members are not guaranteed to be thread-safe.
Requirements
Namespace: MySql.Data.MySqlClient
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySqlParameter Members , MySql.Data.MySqlClient Namespace
Public Instance Constructors
| MySqlParameter | Overloaded. Initializes a new instance of the MySqlParameter class. |
Public Instance Properties
| DbType | Gets or sets the DbTypeof the parameter. |
| Direction | Gets or sets a value indicating whether the parameter is input-only, output-only, bidirectional, or a stored procedure return value parameter. As of MySQL version 4.1 and earlier, input-only is the only valid choice. |
| IsNullable | Gets or sets a value indicating whether the parameter accepts null values. |
| IsUnsigned | |
| MySqlDbType | Gets or sets the MySqlDbType of the parameter. |
| ParameterName | Gets or sets the name of the MySqlParameter. |
| Precision | Gets or sets the maximum number of digits used to represent the Value property. |
| Scale | Gets or sets the number of decimal places to which Value is resolved. |
| Size | Gets or sets the maximum size, in bytes, of the data within the column. |
| SourceColumn | Gets or sets the name of the source column that is mapped to the DataSetand used for loading or returning the Value . |
| SourceVersion | Gets or sets the DataRowVersionto use when loading Value . |
| Value | Gets or sets the value of the parameter. |
Public Instance Methods
| CreateObjRef(inherited from MarshalByRefObject) | Creates an object that contains all the relevant information required to generate a proxy used to communicate with a remote object. |
| Equals(inherited from Object) | Determines whether the specified Objectis equal to the current Object. |
| GetHashCode(inherited from Object) | Serves as a hash function for a particular type. GetHashCodeis suitable for use in hashing algorithms and data structures like a hash table. |
| GetLifetimeService(inherited from MarshalByRefObject) | Retrieves the current lifetime service object that controls the lifetime policy for this instance. |
| GetType(inherited from Object) | Gets the Typeof the current instance. |
| InitializeLifetimeService(inherited from MarshalByRefObject) | Obtains a lifetime service object to control the lifetime policy for this instance. |
| ToString | Overridden. Gets a string containing the ParameterName . |
See Also
MySqlParameter Class , MySql.Data.MySqlClient Namespace
Initializes a new instance of the MySqlParameter class.
Overload List
Initializes a new instance of the MySqlParameter class.
Initializes a new instance of the MySqlParameter class with the parameter name and the data type.
Initializes a new instance of the MySqlParameter class with the parameter name, the MySqlDbType , and the size.
Initializes a new instance of the MySqlParameter class with the parameter name, the type of the parameter, the size of the parameter, a ParameterDirection, the precision of the parameter, the scale of the parameter, the source column, a DataRowVersionto use, and the value of the parameter.
Initializes a new instance of the MySqlParameter class with the parameter name, the MySqlDbType , the size, and the source column name.
Initializes a new instance of the MySqlParameter class with the parameter name and a value of the new MySqlParameter.
See Also
MySqlParameter Class , MySql.Data.MySqlClient Namespace
Initializes a new instance of the MySqlParameter class.
Syntax: Visual Basic
Overloads Public Sub New()
Syntax: C#
public MySqlParameter();
See Also
MySqlParameter Class , MySql.Data.MySqlClient Namespace , MySqlParameter Constructor Overload List
Initializes a new instance of the MySqlParameter class with the parameter name and the data type.
Syntax: Visual Basic
Overloads Public Sub New( _ ByVal parameterName As String, _ ByVal dbType As MySqlDbType _ )
Syntax: C#
public MySqlParameter( stringparameterName, MySqlDbTypedbType );
Parameters
parameterName: The name of the parameter to map.dbType: One of the MySqlDbType values.
See Also
MySqlParameter Class , MySql.Data.MySqlClient Namespace , MySqlParameter Constructor Overload List
Specifies MySQL specific data type of a field, property, for use in a MySqlParameter .
Syntax: Visual Basic
Public Enum MySqlDbType
Syntax: C#
public enum MySqlDbType
Members
| Member Name | Description |
| VarString | A variable-length string containing 0 to 65535 characters |
| Timestamp | A timestamp. The range is '1970-01-01 00:00:01' to sometime in the year 2038 |
| LongBlob | A BLOB or TEXT column with a maximum length of 4294967295 or 4G (2^32 - 1) characters |
| Time | The range is '-838:59:59' to '838:59:59'. |
| TinyBlob | A BLOB or TEXT column with a maximum length of 255 (2^8 - 1) characters |
| Datetime | The supported range is '1000-01-01 00:00:00' to '9999-12-31 23:59:59'. |
| Decimal | A fixed precision and scale numeric value between -1038 -1 and 10 38 -1. |
| UByte | |
| Blob | A BLOB or TEXT column with a maximum length of 65535 (2^16 - 1) characters |
| Double | A normal-size (double-precision) floating-point number. Allowable values are -1.7976931348623157E+308 to -2.2250738585072014E-308, 0, and 2.2250738585072014E-308 to 1.7976931348623157E+308. |
| Newdate | Obsolete Use Datetime or Date type |
| Byte | The signed range is -128 to 127. The unsigned range is 0 to 255. |
| Date | Date The supported range is '1000-01-01' to '9999-12-31'. |
| VarChar | A variable-length string containing 0 to 255 characters |
| UInt16 | |
| UInt24 | |
| Int16 | A 16-bit signed integer. The signed range is -32768 to 32767. The unsigned range is 0 to 65535 |
| NewDecimal | New Decimal |
| Set | A set. A string object that can have zero or more values, each of which must be chosen from the list of values 'value1', 'value2', ... A SET can have a maximum of 64 members. |
| String | Obsolete Use VarChar type |
| Enum | An enumeration. A string object that can have only one value, chosen from the list of values 'value1', 'value2', ..., NULL or the special "" error value. An ENUM can have a maximum of 65535 distinct values |
| Geometry | |
| UInt64 | |
| Int64 | A 64-bit signed integer. |
| UInt32 | |
| Int24 | Specifies a 24 (3 byte) signed or unsigned value. |
| Bit | Bit-field data type |
| Float | A small (single-precision) floating-point number. Allowable values are -3.402823466E+38 to -1.175494351E-38, 0, and 1.175494351E-38 to 3.402823466E+38. |
| Year | A year in 2- or 4-digit format (default is 4-digit). The allowable values are 1901 to 2155, 0000 in the 4-digit year format, and 1970-2069 if you use the 2-digit format (70-69) |
| Int32 | A 32-bit signed integer |
| MediumBlob | A BLOB or TEXT column with a maximum length of 16777215 (2^24 - 1) characters |
Requirements
Namespace: MySql.Data.MySqlClient
Assembly: MySql.Data (in MySql.Data.dll)
See Also
Initializes a new instance of the MySqlParameter class with the parameter name, the MySqlDbType , and the size.
Syntax: Visual Basic
Overloads Public Sub New( _ ByVal parameterName As String, _ ByVal dbType As MySqlDbType, _ ByVal size As Integer _ )
Syntax: C#
public MySqlParameter( stringparameterName, MySqlDbTypedbType, intsize );
Parameters
parameterName: The name of the parameter to map.dbType: One of the MySqlDbType values.size: The length of the parameter.
See Also
MySqlParameter Class , MySql.Data.MySqlClient Namespace , MySqlParameter Constructor Overload List
Initializes a new instance of the MySqlParameter class with the parameter name, the type of the parameter, the size of the parameter, a ParameterDirection, the precision of the parameter, the scale of the parameter, the source column, a DataRowVersionto use, and the value of the parameter.
Syntax: Visual Basic
Overloads Public Sub New( _ ByVal parameterName As String, _ ByVal dbType As MySqlDbType, _ ByVal size As Integer, _ ByVal direction As ParameterDirection, _ ByVal isNullable As Boolean, _ ByVal precision As Byte, _ ByVal scale As Byte, _ ByVal sourceColumn As String, _ ByVal sourceVersion As DataRowVersion, _ ByVal value As Object _ )
Syntax: C#
public MySqlParameter( stringparameterName, MySqlDbTypedbType, intsize, ParameterDirectiondirection, boolisNullable, byteprecision, bytescale, stringsourceColumn, DataRowVersionsourceVersion, objectvalue );
Parameters
parameterName: The name of the parameter to map.dbType: One of the MySqlDbType values.size: The length of the parameter.direction: One of the ParameterDirectionvalues.isNullable: true if the value of the field can be null, otherwise false.precision: The total number of digits to the left and right of the decimal point to which Value is resolved.scale: The total number of decimal places to which Value is resolved.sourceColumn: The name of the source column.sourceVersion: One of the DataRowVersionvalues.value: An Objectthat is the value of the MySqlParameter .
Exceptions
| Exception Type | Condition |
| ArgumentException |
See Also
MySqlParameter Class , MySql.Data.MySqlClient Namespace , MySqlParameter Constructor Overload List
Gets or sets the value of the parameter.
Syntax: Visual Basic
NotOverridable Public Property Value As Object _ _ Implements IDataParameter.Value
Syntax: C#
public object Value {get; set;}
Implements
IDataParameter.Value
See Also
Initializes a new instance of the MySqlParameter class with the parameter name, the MySqlDbType , the size, and the source column name.
Syntax: Visual Basic
Overloads Public Sub New( _ ByVal parameterName As String, _ ByVal dbType As MySqlDbType, _ ByVal size As Integer, _ ByVal sourceColumn As String _ )
Syntax: C#
public MySqlParameter( stringparameterName, MySqlDbTypedbType, intsize, stringsourceColumn );
Parameters
parameterName: The name of the parameter to map.dbType: One of the MySqlDbType values.size: The length of the parameter.sourceColumn: The name of the source column.
See Also
MySqlParameter Class , MySql.Data.MySqlClient Namespace , MySqlParameter Constructor Overload List
Initializes a new instance of the MySqlParameter class with the parameter name and a value of the new MySqlParameter.
Syntax: Visual Basic
Overloads Public Sub New( _ ByVal parameterName As String, _ ByVal value As Object _ )
Syntax: C#
public MySqlParameter( stringparameterName, objectvalue );
Parameters
parameterName: The name of the parameter to map.value: An Objectthat is the value of the MySqlParameter .
See Also
MySqlParameter Class , MySql.Data.MySqlClient Namespace , MySqlParameter Constructor Overload List
Gets or sets the DbTypeof the parameter.
Syntax: Visual Basic
NotOverridable Public Property DbType As DbType _ _ Implements IDataParameter.DbType
Syntax: C#
public System.Data.DbType DbType {get; set;}
Implements
IDataParameter.DbType
See Also
Gets or sets a value indicating whether the parameter is input-only, output-only, bidirectional, or a stored procedure return value parameter. As of MySQL version 4.1 and earlier, input-only is the only valid choice.
Syntax: Visual Basic
NotOverridable Public Property Direction As ParameterDirection _ _ Implements IDataParameter.Direction
Syntax: C#
public System.Data.ParameterDirection Direction {get; set;}
Implements
IDataParameter.Direction
See Also
Gets or sets a value indicating whether the parameter accepts null values.
Syntax: Visual Basic
NotOverridable Public Property IsNullable As Boolean _ _ Implements IDataParameter.IsNullable
Syntax: C#
public bool IsNullable {get; set;}
Implements
IDataParameter.IsNullable
See Also
Syntax: Visual Basic
Public Property IsUnsigned As Boolean
Syntax: C#
public bool IsUnsigned {get; set;}See Also
Gets or sets the MySqlDbType of the parameter.
Syntax: Visual Basic
Public Property MySqlDbType As MySqlDbType
Syntax: C#
public MySqlDbType MySqlDbType {get; set;}See Also
Gets or sets the name of the MySqlParameter.
Syntax: Visual Basic
NotOverridable Public Property ParameterName As String _ _ Implements IDataParameter.ParameterName
Syntax: C#
public string ParameterName {get; set;}
Implements
IDataParameter.ParameterName
See Also
Gets or sets the maximum number of digits used to represent the Value property.
Syntax: Visual Basic
NotOverridable Public Property Precision As Byte _ _ Implements IDbDataParameter.Precision
Syntax: C#
public byte Precision {get; set;}
Implements
IDbDataParameter.Precision
See Also
Gets or sets the number of decimal places to which Value is resolved.
Syntax: Visual Basic
NotOverridable Public Property Scale As Byte _ _ Implements IDbDataParameter.Scale
Syntax: C#
public byte Scale {get; set;}
Implements
IDbDataParameter.Scale
See Also
Gets or sets the maximum size, in bytes, of the data within the column.
Syntax: Visual Basic
NotOverridable Public Property Size As Integer _ _ Implements IDbDataParameter.Size
Syntax: C#
public int Size {get; set;}
Implements
IDbDataParameter.Size
See Also
Gets or sets the name of the source column that is mapped to the DataSetand used for loading or returning the Value .
Syntax: Visual Basic
NotOverridable Public Property SourceColumn As String _ _ Implements IDataParameter.SourceColumn
Syntax: C#
public string SourceColumn {get; set;}
Implements
IDataParameter.SourceColumn
See Also
Gets or sets the DataRowVersionto use when loading Value .
Syntax: Visual Basic
NotOverridable Public Property SourceVersion As DataRowVersion _ _ Implements IDataParameter.SourceVersion
Syntax: C#
public System.Data.DataRowVersion SourceVersion {get; set;}
Implements
IDataParameter.SourceVersion
See Also
Overridden. Gets a string containing the ParameterName .
Syntax: Visual Basic
Overrides Public Function ToString() As String
Syntax: C#
public override string ToString();
Return Value
See Also
Gets the MySqlParameter at the specified index.
Syntax: Visual Basic
Overloads Public Default Property Item( _ ByVal index As Integer _ ) As MySqlParameter
Syntax: C#
public MySqlParameter this[
intindex
] {get; set;}See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace , MySqlParameterCollection.Item Overload List
Gets the MySqlParameter with the specified name.
Syntax: Visual Basic
Overloads Public Default Property Item( _ ByVal name As String _ ) As MySqlParameter
Syntax: C#
public MySqlParameter this[
stringname
] {get; set;}See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace , MySqlParameterCollection.Item Overload List
Adds the specified MySqlParameter object to the MySqlParameterCollection .
Overload List
Adds the specified MySqlParameter object to the MySqlParameterCollection .
Adds the specified MySqlParameter object to the MySqlParameterCollection .
Adds a MySqlParameter to the MySqlParameterCollection given the parameter name and the data type.
Adds a MySqlParameter to the MySqlParameterCollection with the parameter name, the data type, and the column length.
Adds a MySqlParameter to the MySqlParameterCollection with the parameter name, the data type, the column length, and the source column name.
Adds a MySqlParameter to the MySqlParameterCollection given the specified parameter name and value.
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace
Adds the specified MySqlParameter object to the MySqlParameterCollection .
Syntax: Visual Basic
Overloads Public Function Add( _ ByVal value As MySqlParameter _ ) As MySqlParameter
Syntax: C#
public MySqlParameter Add( MySqlParametervalue );
Parameters
value: The MySqlParameter to add to the collection.
Return Value
The newly added MySqlParameter object.
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace , MySqlParameterCollection.Add Overload List
Adds the specified MySqlParameter object to the MySqlParameterCollection .
Syntax: Visual Basic
NotOverridable Overloads Public Function Add( _ ByVal value As Object _ ) As Integer _ _ Implements IList.Add
Syntax: C#
public int Add( objectvalue );
Parameters
value: The MySqlParameter to add to the collection.
Return Value
The index of the new MySqlParameter object.
Implements
IList.Add
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace , MySqlParameterCollection.Add Overload List
Adds a MySqlParameter to the MySqlParameterCollection given the parameter name and the data type.
Syntax: Visual Basic
Overloads Public Function Add( _ ByVal parameterName As String, _ ByVal dbType As MySqlDbType _ ) As MySqlParameter
Syntax: C#
public MySqlParameter Add( stringparameterName, MySqlDbTypedbType );
Parameters
parameterName: The name of the parameter.dbType: One of the MySqlDbType values.
Return Value
The newly added MySqlParameter object.
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace , MySqlParameterCollection.Add Overload List
Adds a MySqlParameter to the MySqlParameterCollection with the parameter name, the data type, and the column length.
Syntax: Visual Basic
Overloads Public Function Add( _ ByVal parameterName As String, _ ByVal dbType As MySqlDbType, _ ByVal size As Integer _ ) As MySqlParameter
Syntax: C#
public MySqlParameter Add( stringparameterName, MySqlDbTypedbType, intsize );
Parameters
parameterName: The name of the parameter.dbType: One of the MySqlDbType values.size: The length of the column.
Return Value
The newly added MySqlParameter object.
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace , MySqlParameterCollection.Add Overload List
Adds a MySqlParameter to the MySqlParameterCollection with the parameter name, the data type, the column length, and the source column name.
Syntax: Visual Basic
Overloads Public Function Add( _ ByVal parameterName As String, _ ByVal dbType As MySqlDbType, _ ByVal size As Integer, _ ByVal sourceColumn As String _ ) As MySqlParameter
Syntax: C#
public MySqlParameter Add( stringparameterName, MySqlDbTypedbType, intsize, stringsourceColumn );
Parameters
parameterName: The name of the parameter.dbType: One of the MySqlDbType values.size: The length of the column.sourceColumn: The name of the source column.
Return Value
The newly added MySqlParameter object.
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace , MySqlParameterCollection.Add Overload List
Adds a MySqlParameter to the MySqlParameterCollection given the specified parameter name and value.
Syntax: Visual Basic
Overloads Public Function Add( _ ByVal parameterName As String, _ ByVal value As Object _ ) As MySqlParameter
Syntax: C#
public MySqlParameter Add( stringparameterName, objectvalue );
Parameters
parameterName: The name of the parameter.value: The Value of the MySqlParameter to add to the collection.
Return Value
The newly added MySqlParameter object.
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace , MySqlParameterCollection.Add Overload List
Removes all items from the collection.
Syntax: Visual Basic
NotOverridable Public Sub Clear() _ _ Implements IList.Clear
Syntax: C#
public void Clear();
Implements
IList.Clear
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace
Gets a value indicating whether a MySqlParameter exists in the collection.
Overload List
Gets a value indicating whether a MySqlParameter exists in the collection.
Gets a value indicating whether a MySqlParameter with the specified parameter name exists in the collection.
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace
Gets a value indicating whether a MySqlParameter exists in the collection.
Syntax: Visual Basic
NotOverridable Overloads Public Function Contains( _ ByVal value As Object _ ) As Boolean _ _ Implements IList.Contains
Syntax: C#
public bool Contains( objectvalue );
Parameters
value: The value of the MySqlParameter object to find.
Return Value
true if the collection contains the MySqlParameter object; otherwise, false.
Implements
IList.Contains
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace , MySqlParameterCollection.Contains Overload List
Gets a value indicating whether a MySqlParameter with the specified parameter name exists in the collection.
Syntax: Visual Basic
NotOverridable Overloads Public Function Contains( _ ByVal name As String _ ) As Boolean _ _ Implements IDataParameterCollection.Contains
Syntax: C#
public bool Contains( stringname );
Parameters
name: The name of the MySqlParameter object to find.
Return Value
true if the collection contains the parameter; otherwise, false.
Implements
IDataParameterCollection.Contains
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace , MySqlParameterCollection.Contains Overload List
Copies MySqlParameter objects from the MySqlParameterCollection to the specified array.
Syntax: Visual Basic
NotOverridable Public Sub CopyTo( _ ByVal array As Array, _ ByVal index As Integer _ ) _ _ Implements ICollection.CopyTo
Syntax: C#
public void CopyTo( Arrayarray, intindex );
Parameters
array:index:
Implements
ICollection.CopyTo
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace
Gets the location of a MySqlParameter in the collection.
Overload List
Gets the location of a MySqlParameter in the collection.
Gets the location of the MySqlParameter in the collection with a specific parameter name.
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace
Gets the location of a MySqlParameter in the collection.
Syntax: Visual Basic
NotOverridable Overloads Public Function IndexOf( _ ByVal value As Object _ ) As Integer _ _ Implements IList.IndexOf
Syntax: C#
public int IndexOf( objectvalue );
Parameters
value: The MySqlParameter object to locate.
Return Value
The zero-based location of the MySqlParameter in the collection.
Implements
IList.IndexOf
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace , MySqlParameterCollection.IndexOf Overload List
Gets the location of the MySqlParameter in the collection with a specific parameter name.
Syntax: Visual Basic
NotOverridable Overloads Public Function IndexOf( _ ByVal parameterName As String _ ) As Integer _ _ Implements IDataParameterCollection.IndexOf
Syntax: C#
public int IndexOf( stringparameterName );
Parameters
parameterName: The name of the MySqlParameter object to retrieve.
Return Value
The zero-based location of the MySqlParameter in the collection.
Implements
IDataParameterCollection.IndexOf
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace , MySqlParameterCollection.IndexOf Overload List
Inserts a MySqlParameter into the collection at the specified index.
Syntax: Visual Basic
NotOverridable Public Sub Insert( _ ByVal index As Integer, _ ByVal value As Object _ ) _ _ Implements IList.Insert
Syntax: C#
public void Insert( intindex, objectvalue );
Parameters
index:value:
Implements
IList.Insert
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace
Removes the specified MySqlParameter from the collection.
Syntax: Visual Basic
NotOverridable Public Sub Remove( _ ByVal value As Object _ ) _ _ Implements IList.Remove
Syntax: C#
public void Remove( objectvalue );
Parameters
value:
Implements
IList.Remove
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace
Removes the specified MySqlParameter from the collection.
Overload List
Removes the specified MySqlParameter from the collection using a specific index.
Removes the specified MySqlParameter from the collection using the parameter name.
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace
Removes the specified MySqlParameter from the collection using a specific index.
Syntax: Visual Basic
NotOverridable Overloads Public Sub RemoveAt( _ ByVal index As Integer _ ) _ _ Implements IList.RemoveAt
Syntax: C#
public void RemoveAt( intindex );
Parameters
index: The zero-based index of the parameter.
Implements
IList.RemoveAt
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace , MySqlParameterCollection.RemoveAt Overload List
Removes the specified MySqlParameter from the collection using the parameter name.
Syntax: Visual Basic
NotOverridable Overloads Public Sub RemoveAt( _ ByVal name As String _ ) _ _ Implements IDataParameterCollection.RemoveAt
Syntax: C#
public void RemoveAt( stringname );
Parameters
name: The name of the MySqlParameter object to retrieve.
Implements
IDataParameterCollection.RemoveAt
See Also
MySqlParameterCollection Class , MySql.Data.MySqlClient Namespace , MySqlParameterCollection.RemoveAt Overload List
Syntax: Visual Basic
Public Property Transaction As MySqlTransaction
Syntax: C#
public MySqlTransaction Transaction {get; set;}See Also
Syntax: Visual Basic
NotOverridable Public Property UpdatedRowSource As UpdateRowSource _ _ Implements IDbCommand.UpdatedRowSource
Syntax: C#
public System.Data.UpdateRowSource UpdatedRowSource {get; set;}
Implements
IDbCommand.UpdatedRowSource
See Also
Attempts to cancel the execution of a MySqlCommand. This operation is not supported.
Syntax: Visual Basic
NotOverridable Public Sub Cancel() _ _ Implements IDbCommand.Cancel
Syntax: C#
public void Cancel();
Implements
IDbCommand.Cancel
Remarks
Cancelling an executing command is currently not supported on any version of MySQL.
Exceptions
| Exception Type | Condition |
| NotSupportedException | This operation is not supported. |
See Also
Creates a new instance of a MySqlParameter object.
Syntax: Visual Basic
Public Function CreateParameter() As MySqlParameter
Syntax: C#
public MySqlParameter CreateParameter();
Return Value
A MySqlParameter object.
Remarks
This method is a strongly-typed version of CreateParameter.
See Also
Syntax: Visual Basic
NotOverridable Public Function ExecuteNonQuery() As Integer _ _ Implements IDbCommand.ExecuteNonQuery
Syntax: C#
public int ExecuteNonQuery();
Implements
IDbCommand.ExecuteNonQuery
See Also
Overload List
See Also
MySqlCommand Class , MySql.Data.MySqlClient Namespace
Syntax: Visual Basic
Overloads Public Function ExecuteReader() As MySqlDataReader
Syntax: C#
public MySqlDataReader ExecuteReader();
See Also
MySqlCommand Class , MySql.Data.MySqlClient Namespace , MySqlCommand.ExecuteReader Overload List
Provides a means of reading a forward-only stream of rows from a MySQL database. This class cannot be inherited.
For a list of all members of this type, see MySqlDataReader Members .
Syntax: Visual Basic
NotInheritable Public Class MySqlDataReader_ Inherits MarshalByRefObject_ Implements IEnumerable, IDataReader, IDisposable, IDataRecord
Syntax: C#
public sealed class MySqlDataReader : MarshalByRefObject, IEnumerable, IDataReader, IDisposable, IDataRecord
Thread Safety
Public static (Shared in Visual Basic) members of this type are safe for multithreaded operations. Instance members are not guaranteed to be thread-safe.
Requirements
Namespace: MySql.Data.MySqlClient
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySqlDataReader Members , MySql.Data.MySqlClient Namespace
Public Instance Properties
| Depth | Gets a value indicating the depth of nesting for the current row. This method is not supported currently and always returns 0. |
| FieldCount | Gets the number of columns in the current row. |
| HasRows | Gets a value indicating whether the MySqlDataReader contains one or more rows. |
| IsClosed | Gets a value indicating whether the data reader is closed. |
| Item | Overloaded. Overloaded. Gets the value of a column in its native format. In C#, this property is the indexer for the MySqlDataReader class. |
| RecordsAffected | Gets the number of rows changed, inserted, or deleted by execution of the SQL statement. |
Public Instance Methods
| Close | Closes the MySqlDataReader object. |
| CreateObjRef(inherited from MarshalByRefObject) | Creates an object that contains all the relevant information required to generate a proxy used to communicate with a remote object. |
| Equals(inherited from Object) | Determines whether the specified Objectis equal to the current Object. |
| GetBoolean | Gets the value of the specified column as a Boolean. |
| GetByte | Gets the value of the specified column as a byte. |
| GetBytes | Reads a stream of bytes from the specified column offset into the buffer an array starting at the given buffer offset. |
| GetChar | Gets the value of the specified column as a single character. |
| GetChars | Reads a stream of characters from the specified column offset into the buffer as an array starting at the given buffer offset. |
| GetDataTypeName | Gets the name of the source data type. |
| GetDateTime | |
| GetDecimal | |
| GetDouble | |
| GetFieldType | Gets the Type that is the data type of the object. |
| GetFloat | |
| GetGuid | |
| GetHashCode(inherited from Object) | Serves as a hash function for a particular type. GetHashCodeis suitable for use in hashing algorithms and data structures like a hash table. |
| GetInt16 | |
| GetInt32 | |
| GetInt64 | |
| GetLifetimeService(inherited from MarshalByRefObject) | Retrieves the current lifetime service object that controls the lifetime policy for this instance. |
| GetMySqlDateTime | |
| GetName | Gets the name of the specified column. |
| GetOrdinal | Gets the column ordinal, given the name of the column. |
| GetSchemaTable | Returns a DataTable that describes the column metadata of the MySqlDataReader. |
| GetString | |
| GetTimeSpan | |
| GetType(inherited from Object) | Gets the Typeof the current instance. |
| GetUInt16 | |
| GetUInt32 | |
| GetUInt64 | |
| GetValue | Gets the value of the specified column in its native format. |
| GetValues | Gets all attribute columns in the collection for the current row. |
| InitializeLifetimeService(inherited from MarshalByRefObject) | Obtains a lifetime service object to control the lifetime policy for this instance. |
| IsDBNull | Gets a value indicating whether the column contains non-existent or missing values. |
| NextResult | Advances the data reader to the next result, when reading the results of batch SQL statements. |
| Read | Advances the MySqlDataReader to the next record. |
| ToString(inherited from Object) | Returns a Stringthat represents the current Object. |
See Also
MySqlDataReader Class , MySql.Data.MySqlClient Namespace
Gets a value indicating the depth of nesting for the current row. This method is not supported currently and always returns 0.
Syntax: Visual Basic
NotOverridable Public ReadOnly Property Depth As Integer _ _ Implements IDataReader.Depth
Syntax: C#
public int Depth {get;}
Implements
IDataReader.Depth
See Also
Gets the number of columns in the current row.
Syntax: Visual Basic
NotOverridable Public ReadOnly Property FieldCount As Integer _ _ Implements IDataRecord.FieldCount
Syntax: C#
public int FieldCount {get;}
Implements
IDataRecord.FieldCount
See Also
Gets a value indicating whether the MySqlDataReader contains one or more rows.
Syntax: Visual Basic
Public ReadOnly Property HasRows As Boolean
Syntax: C#
public bool HasRows {get;}See Also
Gets a value indicating whether the data reader is closed.
Syntax: Visual Basic
NotOverridable Public ReadOnly Property IsClosed As Boolean _ _ Implements IDataReader.IsClosed
Syntax: C#
public bool IsClosed {get;}
Implements
IDataReader.IsClosed
See Also
Overloaded. Gets the value of a column in its native format. In C#, this property is the indexer for the MySqlDataReader class.
Overload List
Overloaded. Gets the value of a column in its native format. In C#, this property is the indexer for the MySqlDataReader class.
Gets the value of a column in its native format. In C#, this property is the indexer for the MySqlDataReader class.
See Also
MySqlDataReader Class , MySql.Data.MySqlClient Namespace
Overloaded. Gets the value of a column in its native format. In C#, this property is the indexer for the MySqlDataReader class.
Syntax: Visual Basic
NotOverridable Overloads Public Default ReadOnly Property Item( _ ByVal i As Integer _ ) _ _ Implements IDataRecord.Item As Object _ _ Implements IDataRecord.Item
Syntax: C#
public object this[
inti
] {get;}Implements
IDataRecord.Item
See Also
MySqlDataReader Class , MySql.Data.MySqlClient Namespace , MySqlDataReader.Item Overload List
Gets the value of a column in its native format. In C#, this property is the indexer for the MySqlDataReader class.
Syntax: Visual Basic
NotOverridable Overloads Public Default ReadOnly Property Item( _ ByVal name As String _ ) _ _ Implements IDataRecord.Item As Object _ _ Implements IDataRecord.Item
Syntax: C#
public object this[
stringname
] {get;}Implements
IDataRecord.Item
See Also
MySqlDataReader Class , MySql.Data.MySqlClient Namespace , MySqlDataReader.Item Overload List
Gets the number of rows changed, inserted, or deleted by execution of the SQL statement.
Syntax: Visual Basic
NotOverridable Public ReadOnly Property RecordsAffected As Integer _ _ Implements IDataReader.RecordsAffected
Syntax: C#
public int RecordsAffected {get;}
Implements
IDataReader.RecordsAffected
See Also
Closes the MySqlDataReader object.
Syntax: Visual Basic
NotOverridable Public Sub Close() _ _ Implements IDataReader.Close
Syntax: C#
public void Close();
Implements
IDataReader.Close
See Also
Gets the value of the specified column as a Boolean.
Syntax: Visual Basic
NotOverridable Public Function GetBoolean( _ ByVal i As Integer _ ) As Boolean _ _ Implements IDataRecord.GetBoolean
Syntax: C#
public bool GetBoolean( inti );
Parameters
i:
Return Value
Implements
IDataRecord.GetBoolean
See Also
Gets the value of the specified column as a byte.
Syntax: Visual Basic
NotOverridable Public Function GetByte( _ ByVal i As Integer _ ) As Byte _ _ Implements IDataRecord.GetByte
Syntax: C#
public byte GetByte( inti );
Parameters
i:
Return Value
Implements
IDataRecord.GetByte
See Also
Reads a stream of bytes from the specified column offset into the buffer an array starting at the given buffer offset.
Syntax: Visual Basic
NotOverridable Public Function GetBytes( _ ByVal i As Integer, _ ByVal dataIndex As Long, _ ByVal buffer As Byte(), _ ByVal bufferIndex As Integer, _ ByVal length As Integer _ ) As Long _ _ Implements IDataRecord.GetBytes
Syntax: C#
public long GetBytes( inti, longdataIndex, byte[]buffer, intbufferIndex, intlength );
Parameters
i: The zero-based column ordinal.dataIndex: The index within the field from which to begin the read operation.buffer: The buffer into which to read the stream of bytes.bufferIndex: The index for buffer to begin the read operation.length: The maximum length to copy into the buffer.
Return Value
The actual number of bytes read.
Implements
IDataRecord.GetBytes
See Also
Gets the value of the specified column as a single character.
Syntax: Visual Basic
NotOverridable Public Function GetChar( _ ByVal i As Integer _ ) As Char _ _ Implements IDataRecord.GetChar
Syntax: C#
public char GetChar( inti );
Parameters
i:
Return Value
Implements
IDataRecord.GetChar
See Also
Reads a stream of characters from the specified column offset into the buffer as an array starting at the given buffer offset.
Syntax: Visual Basic
NotOverridable Public Function GetChars( _ ByVal i As Integer, _ ByVal fieldOffset As Long, _ ByVal buffer As Char(), _ ByVal bufferoffset As Integer, _ ByVal length As Integer _ ) As Long _ _ Implements IDataRecord.GetChars
Syntax: C#
public long GetChars( inti, longfieldOffset, char[]buffer, intbufferoffset, intlength );
Parameters
i:fieldOffset:buffer:bufferoffset:length:
Return Value
Implements
IDataRecord.GetChars
See Also
Gets the name of the source data type.
Syntax: Visual Basic
NotOverridable Public Function GetDataTypeName( _ ByVal i As Integer _ ) As String _ _ Implements IDataRecord.GetDataTypeName
Syntax: C#
public string GetDataTypeName( inti );
Parameters
i:
Return Value
Implements
IDataRecord.GetDataTypeName
See Also
Syntax: Visual Basic
NotOverridable Public Function GetDateTime( _ ByVal index As Integer _ ) As Date _ _ Implements IDataRecord.GetDateTime
Syntax: C#
public DateTime GetDateTime( intindex );
Implements
IDataRecord.GetDateTime
See Also
Syntax: Visual Basic
NotOverridable Public Function GetDecimal( _ ByVal index As Integer _ ) As Decimal _ _ Implements IDataRecord.GetDecimal
Syntax: C#
public decimal GetDecimal( intindex );
Implements
IDataRecord.GetDecimal
See Also
Syntax: Visual Basic
NotOverridable Public Function GetDouble( _ ByVal index As Integer _ ) As Double _ _ Implements IDataRecord.GetDouble
Syntax: C#
public double GetDouble( intindex );
Implements
IDataRecord.GetDouble
See Also
Gets the Type that is the data type of the object.
Syntax: Visual Basic
NotOverridable Public Function GetFieldType( _ ByVal i As Integer _ ) As Type _ _ Implements IDataRecord.GetFieldType
Syntax: C#
public Type GetFieldType( inti );
Parameters
i:
Return Value
Implements
IDataRecord.GetFieldType
See Also
Syntax: Visual Basic
NotOverridable Public Function GetFloat( _ ByVal index As Integer _ ) As Single _ _ Implements IDataRecord.GetFloat
Syntax: C#
public float GetFloat( intindex );
Implements
IDataRecord.GetFloat
See Also
Syntax: Visual Basic
NotOverridable Public Function GetGuid( _ ByVal index As Integer _ ) As Guid _ _ Implements IDataRecord.GetGuid
Syntax: C#
public Guid GetGuid( intindex );
Implements
IDataRecord.GetGuid
See Also
Syntax: Visual Basic
NotOverridable Public Function GetInt16( _ ByVal index As Integer _ ) As Short _ _ Implements IDataRecord.GetInt16
Syntax: C#
public short GetInt16( intindex );
Implements
IDataRecord.GetInt16
See Also
Syntax: Visual Basic
NotOverridable Public Function GetInt32( _ ByVal index As Integer _ ) As Integer _ _ Implements IDataRecord.GetInt32
Syntax: C#
public int GetInt32( intindex );
Implements
IDataRecord.GetInt32
See Also
Syntax: Visual Basic
NotOverridable Public Function GetInt64( _ ByVal index As Integer _ ) As Long _ _ Implements IDataRecord.GetInt64
Syntax: C#
public long GetInt64( intindex );
Implements
IDataRecord.GetInt64
See Also
Syntax: Visual Basic
Public Function GetMySqlDateTime( _ ByVal index As Integer _ ) As MySqlDateTime
Syntax: C#
public MySqlDateTime GetMySqlDateTime( intindex );
See Also
Gets the name of the specified column.
Syntax: Visual Basic
NotOverridable Public Function GetName( _ ByVal i As Integer _ ) As String _ _ Implements IDataRecord.GetName
Syntax: C#
public string GetName( inti );
Parameters
i:
Return Value
Implements
IDataRecord.GetName
See Also
Gets the column ordinal, given the name of the column.
Syntax: Visual Basic
NotOverridable Public Function GetOrdinal( _ ByVal name As String _ ) As Integer _ _ Implements IDataRecord.GetOrdinal
Syntax: C#
public int GetOrdinal( stringname );
Parameters
name:
Return Value
Implements
IDataRecord.GetOrdinal
See Also
Returns a DataTable that describes the column metadata of the MySqlDataReader.
Syntax: Visual Basic
NotOverridable Public Function GetSchemaTable() As DataTable _ _ Implements IDataReader.GetSchemaTable
Syntax: C#
public DataTable GetSchemaTable();
Return Value
Implements
IDataReader.GetSchemaTable
See Also
Syntax: Visual Basic
NotOverridable Public Function GetString( _ ByVal index As Integer _ ) As String _ _ Implements IDataRecord.GetString
Syntax: C#
public string GetString( intindex );
Implements
IDataRecord.GetString
See Also
Syntax: Visual Basic
Public Function GetTimeSpan( _ ByVal index As Integer _ ) As TimeSpan
Syntax: C#
public TimeSpan GetTimeSpan( intindex );
See Also
Syntax: Visual Basic
Public Function GetUInt16( _ ByVal index As Integer _ ) As UInt16
Syntax: C#
public ushort GetUInt16( intindex );
See Also
Syntax: Visual Basic
Public Function GetUInt32( _ ByVal index As Integer _ ) As UInt32
Syntax: C#
public uint GetUInt32( intindex );
See Also
Syntax: Visual Basic
Public Function GetUInt64( _ ByVal index As Integer _ ) As UInt64
Syntax: C#
public ulong GetUInt64( intindex );
See Also
Gets the value of the specified column in its native format.
Syntax: Visual Basic
NotOverridable Public Function GetValue( _ ByVal i As Integer _ ) As Object _ _ Implements IDataRecord.GetValue
Syntax: C#
public object GetValue( inti );
Parameters
i:
Return Value
Implements
IDataRecord.GetValue
See Also
Gets all attribute columns in the collection for the current row.
Syntax: Visual Basic
NotOverridable Public Function GetValues( _ ByVal values As Object() _ ) As Integer _ _ Implements IDataRecord.GetValues
Syntax: C#
public int GetValues( object[]values );
Parameters
values:
Return Value
Implements
IDataRecord.GetValues
See Also
Gets a value indicating whether the column contains non-existent or missing values.
Syntax: Visual Basic
NotOverridable Public Function IsDBNull( _ ByVal i As Integer _ ) As Boolean _ _ Implements IDataRecord.IsDBNull
Syntax: C#
public bool IsDBNull( inti );
Parameters
i:
Return Value
Implements
IDataRecord.IsDBNull
See Also
Advances the data reader to the next result, when reading the results of batch SQL statements.
Syntax: Visual Basic
NotOverridable Public Function NextResult() As Boolean _ _ Implements IDataReader.NextResult
Syntax: C#
public bool NextResult();
Return Value
Implements
IDataReader.NextResult
See Also
Advances the MySqlDataReader to the next record.
Syntax: Visual Basic
NotOverridable Public Function Read() As Boolean _ _ Implements IDataReader.Read
Syntax: C#
public bool Read();
Return Value
Implements
IDataReader.Read
See Also
Syntax: Visual Basic
Overloads Public Function ExecuteReader( _ ByVal behavior As CommandBehavior _ ) As MySqlDataReader
Syntax: C#
public MySqlDataReader ExecuteReader( CommandBehaviorbehavior );
See Also
MySqlCommand Class , MySql.Data.MySqlClient Namespace , MySqlCommand.ExecuteReader Overload List
Syntax: Visual Basic
NotOverridable Public Function ExecuteScalar() As Object _ _ Implements IDbCommand.ExecuteScalar
Syntax: C#
public object ExecuteScalar();
Implements
IDbCommand.ExecuteScalar
See Also
Syntax: Visual Basic
NotOverridable Public Sub Prepare() _ _ Implements IDbCommand.Prepare
Syntax: C#
public void Prepare();
Implements
IDbCommand.Prepare
See Also
For a list of all members of this type, see MySqlCommandBuilder Members .
Syntax: Visual Basic
NotInheritable Public Class MySqlCommandBuilder_ Inherits Component
Syntax: C#
public sealed class MySqlCommandBuilder : Component
Thread Safety
Public static (Sharedin Visual Basic) members of this type are safe for multithreaded operations. Instance members are notguaranteed to be thread-safe.
Requirements
Namespace: MySql.Data.MySqlClient
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySqlCommandBuilder Members , MySql.Data.MySqlClient Namespace
Public Static (Shared) Methods
| DeriveParameters | Overloaded. Retrieves parameter information from the stored procedure specified in the MySqlCommand and populates the Parameters collection of the specified MySqlCommand object. This method is not currently supported since stored procedures are not available in MySql. |
Public Instance Constructors
| MySqlCommandBuilder | Overloaded. Initializes a new instance of the MySqlCommandBuilder class. |
Public Instance Properties
| Container(inherited from Component) | Gets the IContainerthat contains the Component. |
| DataAdapter | |
| QuotePrefix | |
| QuoteSuffix | |
| Site(inherited from Component) | Gets or sets the ISiteof the Component. |
Public Instance Methods
| CreateObjRef(inherited from MarshalByRefObject) | Creates an object that contains all the relevant information required to generate a proxy used to communicate with a remote object. |
| Dispose(inherited from Component) | Releases all resources used by the Component. |
| Equals(inherited from Object) | Determines whether the specified Objectis equal to the current Object. |
| GetDeleteCommand | |
| GetHashCode(inherited from Object) | Serves as a hash function for a particular type. GetHashCodeis suitable for use in hashing algorithms and data structures like a hash table. |
| GetInsertCommand | |
| GetLifetimeService(inherited from MarshalByRefObject) | Retrieves the current lifetime service object that controls the lifetime policy for this instance. |
| GetType(inherited from Object) | Gets the Typeof the current instance. |
| GetUpdateCommand | |
| InitializeLifetimeService(inherited from MarshalByRefObject) | Obtains a lifetime service object to control the lifetime policy for this instance. |
| RefreshSchema | |
| ToString(inherited from Component) | Returns a Stringcontaining the name of the Component, if any. This method should not be overridden. |
Public Instance Events
| Disposed(inherited from Component) | Adds an event handler to listen to the Disposedevent on the component. |
See Also
MySqlCommandBuilder Class , MySql.Data.MySqlClient Namespace
Retrieves parameter information from the stored procedure specified in the MySqlCommand and populates the Parameters collection of the specified MySqlCommand object. This method is not currently supported since stored procedures are not available in MySql.
Overload List
Retrieves parameter information from the stored procedure specified in the MySqlCommand and populates the Parameters collection of the specified MySqlCommand object. This method is not currently supported since stored procedures are not available in MySql.
See Also
MySqlCommandBuilder Class , MySql.Data.MySqlClient Namespace
Retrieves parameter information from the stored procedure specified in the MySqlCommand and populates the Parameters collection of the specified MySqlCommand object. This method is not currently supported since stored procedures are not available in MySql.
Syntax: Visual Basic
Overloads Public Shared Sub DeriveParameters( _ ByVal command As MySqlCommand _ )
Syntax: C#
public static void DeriveParameters( MySqlCommandcommand );
Parameters
command: The MySqlCommand referencing the stored procedure from which the parameter information is to be derived. The derived parameters are added to the Parameters collection of the MySqlCommand.
Exceptions
| Exception Type | Condition |
| InvalidOperationException | The command text is not a valid stored procedure name. |
See Also
MySqlCommandBuilder Class , MySql.Data.MySqlClient Namespace , MySqlCommandBuilder.DeriveParameters Overload List
Syntax: Visual Basic
Overloads Public Shared Sub DeriveParameters( _ ByVal command As MySqlCommand, _ ByVal useProc As Boolean _ )
Syntax: C#
public static void DeriveParameters( MySqlCommandcommand, booluseProc );
See Also
MySqlCommandBuilder Class , MySql.Data.MySqlClient Namespace , MySqlCommandBuilder.DeriveParameters Overload List
Initializes a new instance of the MySqlCommandBuilder class.
Overload List
Initializes a new instance of the MySqlCommandBuilder class.
See Also
MySqlCommandBuilder Class , MySql.Data.MySqlClient Namespace
Initializes a new instance of the MySqlCommandBuilder class.
Syntax: Visual Basic
Overloads Public Sub New()
Syntax: C#
public MySqlCommandBuilder();
See Also
MySqlCommandBuilder Class , MySql.Data.MySqlClient Namespace , MySqlCommandBuilder Constructor Overload List
Syntax: Visual Basic
Overloads Public Sub New( _ ByVal adapter As MySqlDataAdapter _ )
Syntax: C#
public MySqlCommandBuilder( MySqlDataAdapteradapter );
See Also
MySqlCommandBuilder Class , MySql.Data.MySqlClient Namespace , MySqlCommandBuilder Constructor Overload List
For a list of all members of this type, see MySqlDataAdapter Members .
Syntax: Visual Basic
NotInheritable Public Class MySqlDataAdapter_ Inherits DbDataAdapter
Syntax: C#
public sealed class MySqlDataAdapter : DbDataAdapter
Thread Safety
Public static (Sharedin Visual Basic) members of this type are safe for multithreaded operations. Instance members are notguaranteed to be thread-safe.
Requirements
Namespace: MySql.Data.MySqlClient
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySqlDataAdapter Members , MySql.Data.MySqlClient Namespace
Public Instance Constructors
| MySqlDataAdapter | Overloaded. Initializes a new instance of the MySqlDataAdapter class. |
Public Instance Properties
| AcceptChangesDuringFill(inherited from DataAdapter) | Gets or sets a value indicating whether AcceptChangesis called on a DataRowafter it is added to the DataTableduring any of the Fill operations. |
| AcceptChangesDuringUpdate(inherited from DataAdapter) | Gets or sets whether AcceptChangesis called during a Update. |
| Container(inherited from Component) | Gets the IContainerthat contains the Component. |
| ContinueUpdateOnError(inherited from DataAdapter) | Gets or sets a value that specifies whether to generate an exception when an error is encountered during a row update. |
| DeleteCommand | Overloaded. |
| FillLoadOption(inherited from DataAdapter) | Gets or sets the LoadOptionthat determines how the adapter fills the DataTablefrom the DbDataReader. |
| InsertCommand | Overloaded. |
| MissingMappingAction(inherited from DataAdapter) | Determines the action to take when incoming data does not have a matching table or column. |
| MissingSchemaAction(inherited from DataAdapter) | Determines the action to take when existing DataSetschema does not match incoming data. |
| ReturnProviderSpecificTypes(inherited from DataAdapter) | Gets or sets whether the Fillmethod should return provider-specific values or common CLS-compliant values. |
| SelectCommand | Overloaded. |
| Site(inherited from Component) | Gets or sets the ISiteof the Component. |
| TableMappings(inherited from DataAdapter) | Gets a collection that provides the master mapping between a source table and a DataTable. |
| UpdateBatchSize(inherited from DbDataAdapter) | Gets or sets a value that enables or disables batch processing support, and specifies the number of commands that can be executed in a batch. |
| UpdateCommand | Overloaded. |
Public Instance Methods
| CreateObjRef(inherited from MarshalByRefObject) | Creates an object that contains all the relevant information required to generate a proxy used to communicate with a remote object. |
| Dispose(inherited from Component) | Releases all resources used by the Component. |
| Equals(inherited from Object) | Determines whether the specified Objectis equal to the current Object. |
| Fill(inherited from DbDataAdapter) | Overloaded. Adds or refreshes rows in the DataSetto match those in the data source using the DataSetname, and creates a DataTablenamed "Table." |
| FillSchema(inherited from DbDataAdapter) | Overloaded. Configures the schema of the specified DataTablebased on the specified SchemaType. |
| GetFillParameters(inherited from DbDataAdapter) | Gets the parameters set by the user when executing an SQL
SELECT statement. |
| GetHashCode(inherited from Object) | Serves as a hash function for a particular type. GetHashCodeis suitable for use in hashing algorithms and data structures like a hash table. |
| GetLifetimeService(inherited from MarshalByRefObject) | Retrieves the current lifetime service object that controls the lifetime policy for this instance. |
| GetType(inherited from Object) | Gets the Typeof the current instance. |
| InitializeLifetimeService(inherited from MarshalByRefObject) | Obtains a lifetime service object to control the lifetime policy for this instance. |
| ResetFillLoadOption(inherited from DataAdapter) | Resets FillLoadOptionto its default state and causes Fillto honor AcceptChangesDuringFill. |
| ShouldSerializeAcceptChangesDuringFill(inherited from DataAdapter) | Determines whether the AcceptChangesDuringFillproperty should be persisted. |
| ShouldSerializeFillLoadOption(inherited from DataAdapter) | Determines whether the FillLoadOptionproperty should be persisted. |
| ToString(inherited from Component) | Returns a Stringcontaining the name of the Component, if any. This method should not be overridden. |
| Update(inherited from DbDataAdapter) | Overloaded. Calls the respective INSERT, UPDATE, or DELETE statements for each inserted, updated, or deleted row in the specified DataSet. |
Public Instance Events
| Disposed(inherited from Component) | Adds an event handler to listen to the Disposedevent on the component. |
| FillError(inherited from DataAdapter) | Returned when an error occurs during a fill operation. |
| RowUpdated | Occurs during Update after a command is executed against the data source. The attempt to update is made, so the event fires. |
| RowUpdating | Occurs during Update before a command is executed against the data source. The attempt to update is made, so the event fires. |
Protected Internal Instance Properties
| FillCommandBehavior(inherited from DbDataAdapter) | Gets or sets the behavior of the command used to fill the data adapter. |
See Also
MySqlDataAdapter Class , MySql.Data.MySqlClient Namespace
Initializes a new instance of the MySqlDataAdapter class.
Overload List
Initializes a new instance of the MySqlDataAdapter class.
See Also
MySqlDataAdapter Class , MySql.Data.MySqlClient Namespace
Initializes a new instance of the MySqlDataAdapter class.
Syntax: Visual Basic
Overloads Public Sub New()
Syntax: C#
public MySqlDataAdapter();
See Also
MySqlDataAdapter Class , MySql.Data.MySqlClient Namespace , MySqlDataAdapter Constructor Overload List
Syntax: Visual Basic
Overloads Public Sub New( _ ByVal selectCommand As MySqlCommand _ )
Syntax: C#
public MySqlDataAdapter( MySqlCommandselectCommand );
See Also
MySqlDataAdapter Class , MySql.Data.MySqlClient Namespace , MySqlDataAdapter Constructor Overload List
Syntax: Visual Basic
Overloads Public Sub New( _ ByVal selectCommandText As String, _ ByVal connection As MySqlConnection _ )
Syntax: C#
public MySqlDataAdapter( stringselectCommandText, MySqlConnectionconnection );
See Also
MySqlDataAdapter Class , MySql.Data.MySqlClient Namespace , MySqlDataAdapter Constructor Overload List
Syntax: Visual Basic
Overloads Public Sub New( _ ByVal selectCommandText As String, _ ByVal selectConnString As String _ )
Syntax: C#
public MySqlDataAdapter( stringselectCommandText, stringselectConnString );
See Also
MySqlDataAdapter Class , MySql.Data.MySqlClient Namespace , MySqlDataAdapter Constructor Overload List
Syntax: Visual Basic
Overloads Public Property DeleteCommand As MySqlCommand
Syntax: C#
new public MySqlCommand DeleteCommand {get; set;}See Also
Syntax: Visual Basic
Overloads Public Property InsertCommand As MySqlCommand
Syntax: C#
new public MySqlCommand InsertCommand {get; set;}See Also
Syntax: Visual Basic
Overloads Public Property SelectCommand As MySqlCommand
Syntax: C#
new public MySqlCommand SelectCommand {get; set;}See Also
Syntax: Visual Basic
Overloads Public Property UpdateCommand As MySqlCommand
Syntax: C#
new public MySqlCommand UpdateCommand {get; set;}See Also
Occurs during Update after a command is executed against the data source. The attempt to update is made, so the event fires.
Syntax: Visual Basic
Public Event RowUpdated As MySqlRowUpdatedEventHandler
Syntax: C#
public event MySqlRowUpdatedEventHandler RowUpdated;
Event Data
The event handler receives an argument of type MySqlRowUpdatedEventArgs containing data related to this event. The following MySqlRowUpdatedEventArgsproperties provide information specific to this event.
| Property | Description |
| Command | Gets or sets the MySqlCommand executed when Update is called. |
| Errors | Gets any errors generated by the .NET Framework data provider when the Commandwas executed. |
| RecordsAffected | Gets the number of rows changed, inserted, or deleted by execution of the SQL statement. |
| Row | Gets the DataRowsent through an Update. |
| RowCount | Gets the number of rows processed in a batch of updated records. |
| StatementType | Gets the type of SQL statement executed. |
| Status | Gets the UpdateStatusof the Commandproperty. |
| TableMapping | Gets the DataTableMappingsent through an Update. |
See Also
MySqlDataAdapter Class , MySql.Data.MySqlClient Namespace
Represents the method that will handle the RowUpdatedevent of a MySqlDataAdapter .
Syntax: Visual Basic
Public Delegate Sub MySqlRowUpdatedEventHandler( _ ByVal sender As Object, _ ByVal e As MySqlRowUpdatedEventArgs _ )
Syntax: C#
public delegate void MySqlRowUpdatedEventHandler( objectsender, MySqlRowUpdatedEventArgse );
Requirements
Namespace: MySql.Data.MySqlClient
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySql.Data.MySqlClient Namespace
Provides data for the RowUpdated event. This class cannot be inherited.
For a list of all members of this type, see MySqlRowUpdatedEventArgs Members .
Syntax: Visual Basic
NotInheritable Public Class MySqlRowUpdatedEventArgs_ Inherits RowUpdatedEventArgs
Syntax: C#
public sealed class MySqlRowUpdatedEventArgs : RowUpdatedEventArgs
Thread Safety
Public static (Sharedin Visual Basic) members of this type are safe for multithreaded operations. Instance members are notguaranteed to be thread-safe.
Requirements
Namespace: MySql.Data.MySqlClient
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySqlRowUpdatedEventArgs Members , MySql.Data.MySqlClient Namespace
MySqlRowUpdatedEventArgs overview
Public Instance Constructors
| MySqlRowUpdatedEventArgs Constructor | Initializes a new instance of the MySqlRowUpdatedEventArgs class. |
Public Instance Properties
| Command | Overloaded. Gets or sets the MySqlCommand executed when Update is called. |
| Errors(inherited from RowUpdatedEventArgs) | Gets any errors generated by the .NET Framework data provider when the Commandwas executed. |
| RecordsAffected(inherited from RowUpdatedEventArgs) | Gets the number of rows changed, inserted, or deleted by execution of the SQL statement. |
| Row(inherited from RowUpdatedEventArgs) | Gets the DataRowsent through an Update. |
| RowCount(inherited from RowUpdatedEventArgs) | Gets the number of rows processed in a batch of updated records. |
| StatementType(inherited from RowUpdatedEventArgs) | Gets the type of SQL statement executed. |
| Status(inherited from RowUpdatedEventArgs) | Gets the UpdateStatusof the Commandproperty. |
| TableMapping(inherited from RowUpdatedEventArgs) | Gets the DataTableMappingsent through an Update. |
Public Instance Methods
| CopyToRows(inherited from RowUpdatedEventArgs) | Overloaded. Copies references to the modified rows into the provided array. |
| Equals(inherited from Object) | Determines whether the specified Objectis equal to the current Object. |
| GetHashCode(inherited from Object) | Serves as a hash function for a particular type. GetHashCodeis suitable for use in hashing algorithms and data structures like a hash table. |
| GetType(inherited from Object) | Gets the Typeof the current instance. |
| ToString(inherited from Object) | Returns a Stringthat represents the current Object. |
See Also
MySqlRowUpdatedEventArgs Class , MySql.Data.MySqlClient Namespace
Initializes a new instance of the MySqlRowUpdatedEventArgs class.
Syntax: Visual Basic
Public Sub New( _ ByVal row As DataRow, _ ByVal command As IDbCommand, _ ByVal statementType As StatementType, _ ByVal tableMapping As DataTableMapping _ )
Syntax: C#
public MySqlRowUpdatedEventArgs( DataRowrow, IDbCommandcommand, StatementTypestatementType, DataTableMappingtableMapping );
Parameters
row: The DataRowsent through an Update.command: The IDbCommandexecuted when Updateis called.statementType: One of the StatementTypevalues that specifies the type of query executed.tableMapping: The DataTableMappingsent through an Update.
See Also
MySqlRowUpdatedEventArgs Class , MySql.Data.MySqlClient Namespace
Gets or sets the MySqlCommand executed when Update is called.
Syntax: Visual Basic
Overloads Public ReadOnly Property Command As MySqlCommand
Syntax: C#
new public MySqlCommand Command {get;}See Also
MySqlRowUpdatedEventArgs Class , MySql.Data.MySqlClient Namespace
Occurs during Update before a command is executed against the data source. The attempt to update is made, so the event fires.
Syntax: Visual Basic
Public Event RowUpdating As MySqlRowUpdatingEventHandler
Syntax: C#
public event MySqlRowUpdatingEventHandler RowUpdating;
Event Data
The event handler receives an argument of type MySqlRowUpdatingEventArgs containing data related to this event. The following MySqlRowUpdatingEventArgsproperties provide information specific to this event.
| Property | Description |
| Command | Gets or sets the MySqlCommand to execute when performing the Update. |
| Errors | Gets any errors generated by the .NET Framework data provider when the Commandexecutes. |
| Row | Gets the DataRowthat will be sent to the server as part of an insert, update, or delete operation. |
| StatementType | Gets the type of SQL statement to execute. |
| Status | Gets or sets the UpdateStatusof the Commandproperty. |
| TableMapping | Gets the DataTableMappingto send through the Update. |
See Also
MySqlDataAdapter Class , MySql.Data.MySqlClient Namespace
Represents the method that will handle the RowUpdatingevent of a MySqlDataAdapter .
Syntax: Visual Basic
Public Delegate Sub MySqlRowUpdatingEventHandler( _ ByVal sender As Object, _ ByVal e As MySqlRowUpdatingEventArgs _ )
Syntax: C#
public delegate void MySqlRowUpdatingEventHandler( objectsender, MySqlRowUpdatingEventArgse );
Requirements
Namespace: MySql.Data.MySqlClient
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySql.Data.MySqlClient Namespace
Provides data for the RowUpdating event. This class cannot be inherited.
For a list of all members of this type, see MySqlRowUpdatingEventArgs Members .
Syntax: Visual Basic
NotInheritable Public Class MySqlRowUpdatingEventArgs_ Inherits RowUpdatingEventArgs
Syntax: C#
public sealed class MySqlRowUpdatingEventArgs : RowUpdatingEventArgs
Thread Safety
Public static (Sharedin Visual Basic) members of this type are safe for multithreaded operations. Instance members are notguaranteed to be thread-safe.
Requirements
Namespace: MySql.Data.MySqlClient
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySqlRowUpdatingEventArgs Members , MySql.Data.MySqlClient Namespace
MySqlRowUpdatingEventArgs overview
Public Instance Constructors
| MySqlRowUpdatingEventArgs Constructor | Initializes a new instance of the MySqlRowUpdatingEventArgs class. |
Public Instance Properties
| Command | Overloaded. Gets or sets the MySqlCommand to execute when performing the Update. |
| Errors(inherited from RowUpdatingEventArgs) | Gets any errors generated by the .NET Framework data provider when the Commandexecutes. |
| Row(inherited from RowUpdatingEventArgs) | Gets the DataRowthat will be sent to the server as part of an insert, update, or delete operation. |
| StatementType(inherited from RowUpdatingEventArgs) | Gets the type of SQL statement to execute. |
| Status(inherited from RowUpdatingEventArgs) | Gets or sets the UpdateStatusof the Commandproperty. |
| TableMapping(inherited from RowUpdatingEventArgs) | Gets the DataTableMappingto send through the Update. |
Public Instance Methods
| Equals(inherited from Object) | Determines whether the specified Objectis equal to the current Object. |
| GetHashCode(inherited from Object) | Serves as a hash function for a particular type. GetHashCodeis suitable for use in hashing algorithms and data structures like a hash table. |
| GetType(inherited from Object) | Gets the Typeof the current instance. |
| ToString(inherited from Object) | Returns a Stringthat represents the current Object. |
See Also
MySqlRowUpdatingEventArgs Class , MySql.Data.MySqlClient Namespace
Initializes a new instance of the MySqlRowUpdatingEventArgs class.
Syntax: Visual Basic
Public Sub New( _ ByVal row As DataRow, _ ByVal command As IDbCommand, _ ByVal statementType As StatementType, _ ByVal tableMapping As DataTableMapping _ )
Syntax: C#
public MySqlRowUpdatingEventArgs( DataRowrow, IDbCommandcommand, StatementTypestatementType, DataTableMappingtableMapping );
Parameters
row: The DataRowto Update.command: The IDbCommandto execute during Update.statementType: One of the StatementTypevalues that specifies the type of query executed.tableMapping: The DataTableMappingsent through an Update.
See Also
MySqlRowUpdatingEventArgs Class , MySql.Data.MySqlClient Namespace
Gets or sets the MySqlCommand to execute when performing the Update.
Syntax: Visual Basic
Overloads Public Property Command As MySqlCommand
Syntax: C#
new public MySqlCommand Command {get; set;}See Also
MySqlRowUpdatingEventArgs Class , MySql.Data.MySqlClient Namespace
Syntax: Visual Basic
Overloads Public Sub New( _ ByVal adapter As MySqlDataAdapter, _ ByVal lastOneWins As Boolean _ )
Syntax: C#
public MySqlCommandBuilder( MySqlDataAdapteradapter, boollastOneWins );
See Also
MySqlCommandBuilder Class , MySql.Data.MySqlClient Namespace , MySqlCommandBuilder Constructor Overload List
Syntax: Visual Basic
Overloads Public Sub New( _ ByVal lastOneWins As Boolean _ )
Syntax: C#
public MySqlCommandBuilder( boollastOneWins );
See Also
MySqlCommandBuilder Class , MySql.Data.MySqlClient Namespace , MySqlCommandBuilder Constructor Overload List
Syntax: Visual Basic
Public Property DataAdapter As MySqlDataAdapter
Syntax: C#
public MySqlDataAdapter DataAdapter {get; set;}See Also
MySqlCommandBuilder Class , MySql.Data.MySqlClient Namespace
Syntax: Visual Basic
Public Property QuotePrefix As String
Syntax: C#
public string QuotePrefix {get; set;}See Also
MySqlCommandBuilder Class , MySql.Data.MySqlClient Namespace
Syntax: Visual Basic
Public Property QuoteSuffix As String
Syntax: C#
public string QuoteSuffix {get; set;}See Also
MySqlCommandBuilder Class , MySql.Data.MySqlClient Namespace
Syntax: Visual Basic
Public Function GetDeleteCommand() As MySqlCommand
Syntax: C#
public MySqlCommand GetDeleteCommand();
See Also
MySqlCommandBuilder Class , MySql.Data.MySqlClient Namespace
Syntax: Visual Basic
Public Function GetInsertCommand() As MySqlCommand
Syntax: C#
public MySqlCommand GetInsertCommand();
See Also
MySqlCommandBuilder Class , MySql.Data.MySqlClient Namespace
Syntax: Visual Basic
Public Function GetUpdateCommand() As MySqlCommand
Syntax: C#
public MySqlCommand GetUpdateCommand();
See Also
MySqlCommandBuilder Class , MySql.Data.MySqlClient Namespace
Syntax: Visual Basic
Public Sub RefreshSchema()
Syntax: C#
public void RefreshSchema();
See Also
MySqlCommandBuilder Class , MySql.Data.MySqlClient Namespace
The exception that is thrown when MySQL returns an error. This class cannot be inherited.
For a list of all members of this type, see MySqlException Members .
Syntax: Visual Basic
NotInheritable Public Class MySqlException_ Inherits SystemException
Syntax: C#
public sealed class MySqlException : SystemException
Thread Safety
Public static (Sharedin Visual Basic) members of this type are safe for multithreaded operations. Instance members are notguaranteed to be thread-safe.
Requirements
Namespace: MySql.Data.MySqlClient
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySqlException Members , MySql.Data.MySqlClient Namespace
Public Instance Properties
| Data(inherited from Exception) | Gets a collection of key/value pairs that provide additional, user-defined information about the exception. |
| HelpLink(inherited from Exception) | Gets or sets a link to the help file associated with this exception. |
| InnerException(inherited from Exception) | Gets the Exceptioninstance that caused the current exception. |
| Message(inherited from Exception) | Gets a message that describes the current exception. |
| Number | Gets a number that identifies the type of error. |
| Source(inherited from Exception) | Gets or sets the name of the application or the object that causes the error. |
| StackTrace(inherited from Exception) | Gets a string representation of the frames on the call stack at the time the current exception was thrown. |
| TargetSite(inherited from Exception) | Gets the method that throws the current exception. |
Public Instance Methods
| Equals(inherited from Object) | Determines whether the specified Objectis equal to the current Object. |
| GetBaseException(inherited from Exception) | When overridden in a derived class, returns the Exceptionthat is the root cause of one or more subsequent exceptions. |
| GetHashCode(inherited from Object) | Serves as a hash function for a particular type. GetHashCodeis suitable for use in hashing algorithms and data structures like a hash table. |
| GetObjectData(inherited from Exception) | When overridden in a derived class, sets the SerializationInfowith information about the exception. |
| GetType(inherited from Exception) | Gets the runtime type of the current instance. |
| ToString(inherited from Exception) | Creates and returns a string representation of the current exception. |
See Also
MySqlException Class , MySql.Data.MySqlClient Namespace
Gets a number that identifies the type of error.
Syntax: Visual Basic
Public ReadOnly Property Number As Integer
Syntax: C#
public int Number {get;}See Also
Helper class that makes it easier to work with the provider.
For a list of all members of this type, see MySqlHelper Members .
Syntax: Visual Basic
NotInheritable Public Class MySqlHelper
Syntax: C#
public sealed class MySqlHelper
Thread Safety
Public static (Shared in Visual Basic) members of this type are safe for multithreaded operations. Instance members are not guaranteed to be thread-safe.
Requirements
Namespace: MySql.Data.MySqlClient
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySqlHelper Members , MySql.Data.MySqlClient Namespace
Public Static (Shared) Methods
| ExecuteDataRow | Executes a single SQL command and returns the first row of the resultset. A new MySqlConnection object is created, opened, and closed during this method. |
| ExecuteDataset | Overloaded. Executes a single SQL command and returns the resultset in a DataSet. A new MySqlConnection object is created, opened, and closed during this method. |
| ExecuteNonQuery | Overloaded. Executes a single command against a MySQL database. The MySqlConnection is assumed to be open when the method is called and remains open after the method completes. |
| ExecuteReader | Overloaded. Executes a single command against a MySQL database. |
| ExecuteScalar | Overloaded. Execute a single command against a MySQL database. |
| UpdateDataSet | Updates the given table with data from the given DataSet |
Public Instance Methods
| Equals(inherited from Object) | Determines whether the specified Objectis equal to the current Object. |
| GetHashCode(inherited from Object) | Serves as a hash function for a particular type. GetHashCodeis suitable for use in hashing algorithms and data structures like a hash table. |
| GetType(inherited from Object) | Gets the Typeof the current instance. |
| ToString(inherited from Object) | Returns a Stringthat represents the current Object. |
See Also
MySqlHelper Class , MySql.Data.MySqlClient Namespace
Executes a single SQL command and returns the first row of the resultset. A new MySqlConnection object is created, opened, and closed during this method.
Syntax: Visual Basic
Public Shared Function ExecuteDataRow( _ ByVal connectionString As String, _ ByVal commandText As String, _ ParamArray parms As MySqlParameter() _ ) As DataRow
Syntax: C#
public static DataRow ExecuteDataRow( stringconnectionString, stringcommandText, params MySqlParameter[]parms );
Parameters
connectionString: Settings to be used for the connectioncommandText: Command to executeparms: Parameters to use for the command
Return Value
DataRow containing the first row of the resultset
See Also
Executes a single SQL command and returns the resultset in a DataSet. The state of the MySqlConnection object remains unchanged after execution of this method.
Overload List
Executes a single SQL command and returns the resultset in a DataSet. The state of the MySqlConnection object remains unchanged after execution of this method.
Executes a single SQL command and returns the resultset in a DataSet. The state of the MySqlConnection object remains unchanged after execution of this method.
Executes a single SQL command and returns the resultset in a DataSet. A new MySqlConnection object is created, opened, and closed during this method.
Executes a single SQL command and returns the resultset in a DataSet. A new MySqlConnection object is created, opened, and closed during this method.
See Also
MySqlHelper Class , MySql.Data.MySqlClient Namespace
Executes a single SQL command and returns the resultset in a DataSet. The state of the MySqlConnection object remains unchanged after execution of this method.
Syntax: Visual Basic
Overloads Public Shared Function ExecuteDataset( _ ByVal connection As MySqlConnection, _ ByVal commandText As String _ ) As DataSet
Syntax: C#
public static DataSet ExecuteDataset( MySqlConnectionconnection, stringcommandText );
Parameters
connection: MySqlConnection object to usecommandText: Command to execute
Return Value
DataSetcontaining the resultset
See Also
MySqlHelper Class , MySql.Data.MySqlClient Namespace , MySqlHelper.ExecuteDataset Overload List
Executes a single SQL command and returns the resultset in a DataSet. The state of the MySqlConnection object remains unchanged after execution of this method.
Syntax: Visual Basic
Overloads Public Shared Function ExecuteDataset( _ ByVal connection As MySqlConnection, _ ByVal commandText As String, _ ParamArray commandParameters As MySqlParameter() _ ) As DataSet
Syntax: C#
public static DataSet ExecuteDataset( MySqlConnectionconnection, stringcommandText, params MySqlParameter[]commandParameters );
Parameters
connection: MySqlConnection object to usecommandText: Command to executecommandParameters: Parameters to use for the command
Return Value
DataSetcontaining the resultset
See Also
MySqlHelper Class , MySql.Data.MySqlClient Namespace , MySqlHelper.ExecuteDataset Overload List
Executes a single SQL command and returns the resultset in a DataSet. A new MySqlConnection object is created, opened, and closed during this method.
Syntax: Visual Basic
Overloads Public Shared Function ExecuteDataset( _ ByVal connectionString As String, _ ByVal commandText As String _ ) As DataSet
Syntax: C#
public static DataSet ExecuteDataset( stringconnectionString, stringcommandText );
Parameters
connectionString: Settings to be used for the connectioncommandText: Command to execute
Return Value
DataSetcontaining the resultset
See Also
MySqlHelper Class , MySql.Data.MySqlClient Namespace , MySqlHelper.ExecuteDataset Overload List
Executes a single SQL command and returns the resultset in a DataSet. A new MySqlConnection object is created, opened, and closed during this method.
Syntax: Visual Basic
Overloads Public Shared Function ExecuteDataset( _ ByVal connectionString As String, _ ByVal commandText As String, _ ParamArray commandParameters As MySqlParameter() _ ) As DataSet
Syntax: C#
public static DataSet ExecuteDataset( stringconnectionString, stringcommandText, params MySqlParameter[]commandParameters );
Parameters
connectionString: Settings to be used for the connectioncommandText: Command to executecommandParameters: Parameters to use for the command
Return Value
DataSetcontaining the resultset
See Also
MySqlHelper Class , MySql.Data.MySqlClient Namespace , MySqlHelper.ExecuteDataset Overload List
Executes a single command against a MySQL database. The MySqlConnection is assumed to be open when the method is called and remains open after the method completes.
Overload List
Executes a single command against a MySQL database. The MySqlConnection is assumed to be open when the method is called and remains open after the method completes.
Executes a single command against a MySQL database. A new MySqlConnection is created using the ConnectionString given.
See Also
MySqlHelper Class , MySql.Data.MySqlClient Namespace
Executes a single command against a MySQL database. The MySqlConnection is assumed to be open when the method is called and remains open after the method completes.
Syntax: Visual Basic
Overloads Public Shared Function ExecuteNonQuery( _ ByVal connection As MySqlConnection, _ ByVal commandText As String, _ ParamArray commandParameters As MySqlParameter() _ ) As Integer
Syntax: C#
public static int ExecuteNonQuery( MySqlConnectionconnection, stringcommandText, params MySqlParameter[]commandParameters );
Parameters
connection: MySqlConnection object to usecommandText: SQL command to be executedcommandParameters: Array of MySqlParameter objects to use with the command.
Return Value
See Also
MySqlHelper Class , MySql.Data.MySqlClient Namespace , MySqlHelper.ExecuteNonQuery Overload List
Executes a single command against a MySQL database. A new MySqlConnection is created using the ConnectionString given.
Syntax: Visual Basic
Overloads Public Shared Function ExecuteNonQuery( _ ByVal connectionString As String, _ ByVal commandText As String, _ ParamArray parms As MySqlParameter() _ ) As Integer
Syntax: C#
public static int ExecuteNonQuery( stringconnectionString, stringcommandText, params MySqlParameter[]parms );
Parameters
connectionString: ConnectionString to usecommandText: SQL command to be executedparms: Array of MySqlParameter objects to use with the command.
Return Value
See Also
MySqlHelper Class , MySql.Data.MySqlClient Namespace , MySqlHelper.ExecuteNonQuery Overload List
Executes a single command against a MySQL database.
Overload List
Executes a single command against a MySQL database.
Executes a single command against a MySQL database.
See Also
MySqlHelper Class , MySql.Data.MySqlClient Namespace
Executes a single command against a MySQL database.
Syntax: Visual Basic
Overloads Public Shared Function ExecuteReader( _ ByVal connectionString As String, _ ByVal commandText As String _ ) As MySqlDataReader
Syntax: C#
public static MySqlDataReader ExecuteReader( stringconnectionString, stringcommandText );
Parameters
connectionString: Settings to use for this commandcommandText: Command text to use
Return Value
MySqlDataReader object ready to read the results of the command
See Also
MySqlHelper Class , MySql.Data.MySqlClient Namespace , MySqlHelper.ExecuteReader Overload List
Executes a single command against a MySQL database.
Syntax: Visual Basic
Overloads Public Shared Function ExecuteReader( _ ByVal connectionString As String, _ ByVal commandText As String, _ ParamArray commandParameters As MySqlParameter() _ ) As MySqlDataReader
Syntax: C#
public static MySqlDataReader ExecuteReader( stringconnectionString, stringcommandText, params MySqlParameter[]commandParameters );
Parameters
connectionString: Settings to use for this commandcommandText: Command text to usecommandParameters: Array of MySqlParameter objects to use with the command
Return Value
MySqlDataReader object ready to read the results of the command
See Also
MySqlHelper Class , MySql.Data.MySqlClient Namespace , MySqlHelper.ExecuteReader Overload List
Execute a single command against a MySQL database.
Overload List
Execute a single command against a MySQL database.
Execute a single command against a MySQL database.
Execute a single command against a MySQL database.
Execute a single command against a MySQL database.
See Also
MySqlHelper Class , MySql.Data.MySqlClient Namespace
Execute a single command against a MySQL database.
Syntax: Visual Basic
Overloads Public Shared Function ExecuteScalar( _ ByVal connection As MySqlConnection, _ ByVal commandText As String _ ) As Object
Syntax: C#
public static object ExecuteScalar( MySqlConnectionconnection, stringcommandText );
Parameters
connection: MySqlConnection object to usecommandText: Command text to use for the command
Return Value
The first column of the first row in the result set, or a null reference if the result set is empty.
See Also
MySqlHelper Class , MySql.Data.MySqlClient Namespace , MySqlHelper.ExecuteScalar Overload List
Execute a single command against a MySQL database.
Syntax: Visual Basic
Overloads Public Shared Function ExecuteScalar( _ ByVal connection As MySqlConnection, _ ByVal commandText As String, _ ParamArray commandParameters As MySqlParameter() _ ) As Object
Syntax: C#
public static object ExecuteScalar( MySqlConnectionconnection, stringcommandText, params MySqlParameter[]commandParameters );
Parameters
connection: MySqlConnection object to usecommandText: Command text to use for the commandcommandParameters: Parameters to use for the command
Return Value
The first column of the first row in the result set, or a null reference if the result set is empty.
See Also
MySqlHelper Class , MySql.Data.MySqlClient Namespace , MySqlHelper.ExecuteScalar Overload List
Execute a single command against a MySQL database.
Syntax: Visual Basic
Overloads Public Shared Function ExecuteScalar( _ ByVal connectionString As String, _ ByVal commandText As String _ ) As Object
Syntax: C#
public static object ExecuteScalar( stringconnectionString, stringcommandText );
Parameters
connectionString: Settings to use for the updatecommandText: Command text to use for the update
Return Value
The first column of the first row in the result set, or a null reference if the result set is empty.
See Also
MySqlHelper Class , MySql.Data.MySqlClient Namespace , MySqlHelper.ExecuteScalar Overload List
Execute a single command against a MySQL database.
Syntax: Visual Basic
Overloads Public Shared Function ExecuteScalar( _ ByVal connectionString As String, _ ByVal commandText As String, _ ParamArray commandParameters As MySqlParameter() _ ) As Object
Syntax: C#
public static object ExecuteScalar( stringconnectionString, stringcommandText, params MySqlParameter[]commandParameters );
Parameters
connectionString: Settings to use for the commandcommandText: Command text to use for the commandcommandParameters: Parameters to use for the command
Return Value
The first column of the first row in the result set, or a null reference if the result set is empty.
See Also
MySqlHelper Class , MySql.Data.MySqlClient Namespace , MySqlHelper.ExecuteScalar Overload List
Updates the given table with data from the given DataSet
Syntax: Visual Basic
Public Shared Sub UpdateDataSet( _ ByVal connectionString As String, _ ByVal commandText As String, _ ByVal ds As DataSet, _ ByVal tablename As String _ )
Syntax: C#
public static void UpdateDataSet( stringconnectionString, stringcommandText, DataSetds, stringtablename );
Parameters
connectionString: Settings to use for the updatecommandText: Command text to use for the updateds: DataSetcontaining the new data to use in the updatetablename: Tablename in the dataset to update
See Also
Syntax: Visual Basic
Public Enum MySqlErrorCode
Syntax: C#
public enum MySqlErrorCode
Members
| Member Name | Description |
| PacketTooLarge | |
| PasswordNotAllowed | |
| DuplicateKeyEntry | |
| HostNotPrivileged | |
| PasswordNoMatch | |
| AnonymousUser | |
| DuplicateKey | |
| KeyNotFound | |
| DuplicateKeyName |
Requirements
Namespace: MySql.Data.MySqlClient
Assembly: MySql.Data (in MySql.Data.dll)
See Also
Classes
| Class | Description |
| MySqlConversionException | Summary description for MySqlConversionException. |
| MySqlDateTime | Summary description for MySqlDateTime. |
| MySqlValue |
Summary description for MySqlConversionException.
For a list of all members of this type, see MySqlConversionException Members .
Syntax: Visual Basic
Public Class MySqlConversionException_ Inherits ApplicationException
Syntax: C#
public class MySqlConversionException : ApplicationException
Thread Safety
Public static (Sharedin Visual Basic) members of this type are safe for multithreaded operations. Instance members are notguaranteed to be thread-safe.
Requirements
Namespace: MySql.Data.Types
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySqlConversionException Members , MySql.Data.Types Namespace
MySqlConversionException overview
Public Instance Constructors
Public Instance Properties
| Data(inherited from Exception) | Gets a collection of key/value pairs that provide additional, user-defined information about the exception. |
| HelpLink(inherited from Exception) | Gets or sets a link to the help file associated with this exception. |
| InnerException(inherited from Exception) | Gets the Exceptioninstance that caused the current exception. |
| Message(inherited from Exception) | Gets a message that describes the current exception. |
| Source(inherited from Exception) | Gets or sets the name of the application or the object that causes the error. |
| StackTrace(inherited from Exception) | Gets a string representation of the frames on the call stack at the time the current exception was thrown. |
| TargetSite(inherited from Exception) | Gets the method that throws the current exception. |
Public Instance Methods
| Equals(inherited from Object) | Determines whether the specified Objectis equal to the current Object. |
| GetBaseException(inherited from Exception) | When overridden in a derived class, returns the Exceptionthat is the root cause of one or more subsequent exceptions. |
| GetHashCode(inherited from Object) | Serves as a hash function for a particular type. GetHashCodeis suitable for use in hashing algorithms and data structures like a hash table. |
| GetObjectData(inherited from Exception) | When overridden in a derived class, sets the SerializationInfowith information about the exception. |
| GetType(inherited from Exception) | Gets the runtime type of the current instance. |
| ToString(inherited from Exception) | Creates and returns a string representation of the current exception. |
Protected Instance Properties
| HResult(inherited from Exception) | Gets or sets HRESULT, a coded numerical value that is assigned to a specific exception. |
Protected Instance Methods
| Finalize(inherited from Object) | Allows an Objectto attempt to free resources and perform other cleanup operations before the Objectis reclaimed by garbage collection. |
| MemberwiseClone(inherited from Object) | Creates a shallow copy of the current Object. |
See Also
MySqlConversionException Class , MySql.Data.Types Namespace
Syntax: Visual Basic
Public Sub New( _ ByVal msg As String _ )
Syntax: C#
public MySqlConversionException( stringmsg );
See Also
Summary description for MySqlDateTime.
For a list of all members of this type, see MySqlDateTime Members .
Syntax: Visual Basic
Public Class MySqlDateTime_ Inherits MySqlValue_ Implements IConvertible, IComparable
Syntax: C#
public class MySqlDateTime : MySqlValue, IConvertible, IComparable
Thread Safety
Public static (Shared in Visual Basic) members of this type are safe for multithreaded operations. Instance members are not guaranteed to be thread-safe.
Requirements
Namespace: MySql.Data.Types
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySqlDateTime Members , MySql.Data.Types Namespace
Public Static (Shared) Type Conversions
Public Instance Properties
| Day | Returns the day portion of this datetime |
| Hour | Returns the hour portion of this datetime |
| IsNull (inherited from MySqlValue) | |
| IsValidDateTime | Indicates if this object contains a value that can be represented as a DateTime |
| Minute | Returns the minute portion of this datetime |
| Month | Returns the month portion of this datetime |
| Second | Returns the second portion of this datetime |
| ValueAsObject (inherited from MySqlValue) | Returns the value of this field as an object |
| Year | Returns the year portion of this datetime |
Public Instance Methods
| Equals(inherited from Object) | Determines whether the specified Objectis equal to the current Object. |
| GetDateTime | Returns this value as a DateTime |
| GetHashCode(inherited from Object) | Serves as a hash function for a particular type. GetHashCodeis suitable for use in hashing algorithms and data structures like a hash table. |
| GetType(inherited from Object) | Gets the Typeof the current instance. |
| ToString | Returns a MySQL specific string representation of this value |
Protected Instance Fields
| classType (inherited from MySqlValue) | The system type represented by this value |
| dbType (inherited from MySqlValue) | The generic dbtype of this value |
| isNull (inherited from MySqlValue) | Is this value null |
| mySqlDbType (inherited from MySqlValue) | The specific MySQL db type |
| mySqlTypeName (inherited from MySqlValue) | The MySQL specific typename of this value |
| objectValue (inherited from MySqlValue) |
Protected Instance Methods
| Finalize(inherited from Object) | Allows an Objectto attempt to free resources and perform other cleanup operations before the Objectis reclaimed by garbage collection. |
| MemberwiseClone(inherited from Object) | Creates a shallow copy of the current Object. |
See Also
MySqlDateTime Class , MySql.Data.Types Namespace
Syntax: Visual Basic
MySqlDateTime.op_Explicit(val)
Syntax: C#
public static explicit operator DateTime( MySqlDateTimeval );
Parameters
val:
Return Value
See Also
Returns the day portion of this datetime
Syntax: Visual Basic
Public Property Day As Integer
Syntax: C#
public int Day {get; set;}See Also
Returns the hour portion of this datetime
Syntax: Visual Basic
Public Property Hour As Integer
Syntax: C#
public int Hour {get; set;}See Also
Syntax: Visual Basic
Public Property IsNull As Boolean
Syntax: C#
public bool IsNull {get; set;}See Also
MySqlValue Class , MySql.Data.Types Namespace
For a list of all members of this type, see MySqlValue Members .
Syntax: Visual Basic
MustInherit Public Class MySqlValue
Syntax: C#
public abstract class MySqlValue
Thread Safety
Public static (Shared in Visual Basic) members of this type are safe for multithreaded operations. Instance members are not guaranteed to be thread-safe.
Requirements
Namespace: MySql.Data.Types
Assembly: MySql.Data (in MySql.Data.dll)
See Also
MySqlValue Members , MySql.Data.Types Namespace
Protected Static (Shared) Fields
Public Instance Constructors
| MySqlValue Constructor | Initializes a new instance of the MySqlValue class. |
Public Instance Properties
| IsNull | |
| ValueAsObject | Returns the value of this field as an object |
Public Instance Methods
| Equals(inherited from Object) | Determines whether the specified Objectis equal to the current Object. |
| GetHashCode(inherited from Object) | Serves as a hash function for a particular type. GetHashCodeis suitable for use in hashing algorithms and data structures like a hash table. |
| GetType(inherited from Object) | Gets the Typeof the current instance. |
| ToString | Returns a string representation of this value |
Protected Instance Fields
| classType | The system type represented by this value |
| dbType | The generic dbtype of this value |
| isNull | Is this value null |
| mySqlDbType | The specific MySQL db type |
| mySqlTypeName | The MySQL specific typename of this value |
| objectValue |
Protected Instance Methods
| Finalize(inherited from Object) | Allows an Objectto attempt to free resources and perform other cleanup operations before the Objectis reclaimed by garbage collection. |
| MemberwiseClone(inherited from Object) | Creates a shallow copy of the current Object. |
See Also
MySqlValue Class , MySql.Data.Types Namespace
Syntax: Visual Basic
Protected Shared numberFormat As NumberFormatInfo
Syntax: C#
protected static NumberFormatInfo numberFormat;
See Also
Initializes a new instance of the MySqlValue class.
Syntax: Visual Basic
Public Sub New()
Syntax: C#
public MySqlValue();
See Also
Returns the value of this field as an object
Syntax: Visual Basic
Public ReadOnly Property ValueAsObject As Object
Syntax: C#
public object ValueAsObject {get;}See Also
Returns a string representation of this value
Syntax: Visual Basic
Overrides Public Function ToString() As String
Syntax: C#
public override string ToString();
See Also
The system type represented by this value
Syntax: Visual Basic
Protected classType As Type
Syntax: C#
protected Type classType;
See Also
The generic dbtype of this value
Syntax: Visual Basic
Protected dbType As DbType
Syntax: C#
protected DbType dbType;
See Also
The specific MySQL db type
Syntax: Visual Basic
Protected mySqlDbType As MySqlDbType
Syntax: C#
protected MySqlDbType mySqlDbType;
See Also
The MySQL specific typename of this value
Syntax: Visual Basic
Protected mySqlTypeName As String
Syntax: C#
protected string mySqlTypeName;
See Also
Syntax: Visual Basic
Protected objectValue As Object
Syntax: C#
protected object objectValue;
See Also
Indicates if this object contains a value that can be represented as a DateTime
Syntax: Visual Basic
Public ReadOnly Property IsValidDateTime As Boolean
Syntax: C#
public bool IsValidDateTime {get;}See Also
Returns the minute portion of this datetime
Syntax: Visual Basic
Public Property Minute As Integer
Syntax: C#
public int Minute {get; set;}See Also
Returns the month portion of this datetime
Syntax: Visual Basic
Public Property Month As Integer
Syntax: C#
public int Month {get; set;}See Also
Returns the second portion of this datetime
Syntax: Visual Basic
Public Property Second As Integer
Syntax: C#
public int Second {get; set;}See Also
Returns the year portion of this datetime
Syntax: Visual Basic
Public Property Year As Integer
Syntax: C#
public int Year {get; set;}See Also
Returns this value as a DateTime
Syntax: Visual Basic
Public Function GetDateTime() As Date
Syntax: C#
public DateTime GetDateTime();
See Also
Returns a MySQL specific string representation of this value
Syntax: Visual Basic
Overrides Public Function ToString() As String
Syntax: C#
public override string ToString();
See Also
- 23.2.5.1. Connecting to MySQL Using Connector/NET
- 23.2.5.2. Using the Connector/NET with Prepared Statements
- 23.2.5.3. Accessing Stored Procedures with Connector/NET
- 23.2.5.4. Handling BLOB Data With Connector/NET
- 23.2.5.5. Using Connector/NET with Crystal Reports
- 23.2.5.6. Handling Date and Time Information in Connector/NET
In this section we will cover some of the more common use cases for Connector/NET, including BLOB handling, date handling, and using Connector/NET with common tools such as Crystal Reports.
All interaction between a .NET application and the MySQL
server is routed through a MySqlConnection
object. Before your application can interact with the server,
a MySqlConnection object must be instanced,
configured, and opened.
Even when using the MySqlHelper class, a
MySqlConnection object is created by the
helper class.
In this section, we will describe how to connect to MySQL
using the MySqlConnection object.
The MySqlConnection object is configured
using a connection string. A connection string contains sever
key/value pairs, separated by semicolons. Each key/value pair
is joined with an equals sign.
The following is a sample connection string:
Server=127.0.0.1;Uid=root;Pwd=12345;Database=test;
In this example, the MySqlConnection object
is configured to connect to a MySQL server at
127.0.0.1, with a username of
root and a password of
12345. The default database for all
statements will be the test database.
The following options are typically used (a full list of options is available in the API documentation for Section 23.2.3.3.15, “ConnectionString”):
Server: The name or network address of the instance of MySQL to which to connect. The default islocalhost. Aliases includehost,Data Source,DataSource,Address,AddrandNetwork Address.Uid: The MySQL user account to use when connecting. Aliases includeUser Id,UsernameandUser name.Pwd: The password for the MySQL account being used. AliasPasswordcan also be used.Database: The default database that all statements are applied to. Default ismysql. AliasInitial Catalogcan also be used.Port: The port MySQL is using to listen for connections. Default is3306. Specify-1for this value to use a named-pipe connection.
Once you have created a connection string it can be used to open a connection to the MySQL server.
The following code is used to create a
MySqlConnection object, assign the
connection string, and open the connection.
Visual Basic Example
Dim conn As New MySql.Data.MySqlClient.MySqlConnection
Dim myConnectionString as String
myConnectionString = "server=127.0.0.1;" _
& "uid=root;" _
& "pwd=12345;" _
& "database=test;"
Try
conn.ConnectionString = myConnectionString
conn.Open()
Catch ex As MySql.Data.MySqlClient.MySqlException
MessageBox.Show(ex.Message)
End Try
C# Example
MySql.Data.MySqlClient.MySqlConnection conn;
string myConnectionString;
myConnectionString = "server=127.0.0.1;uid=root;" +
"pwd=12345;database=test;";
try
{
conn = new MySql.Data.MySqlClient.MySqlConnection();
conn.ConnectionString = myConnectionString;
conn.Open();
}
catch (MySql.Data.MySqlClient.MySqlException ex)
{
MessageBox.Show(ex.Message);
}
You can also pass the connection string to the constructor of
the MySqlConnection class:
Visual Basic Example
Dim myConnectionString as String
myConnectionString = "server=127.0.0.1;" _
& "uid=root;" _
& "pwd=12345;" _
& "database=test;"
Try
Dim conn As New MySql.Data.MySqlClient.MySqlConnection(myConnectionString)
conn.Open()
Catch ex As MySql.Data.MySqlClient.MySqlException
MessageBox.Show(ex.Message)
End Try
C# Example
MySql.Data.MySqlClient.MySqlConnection conn;
string myConnectionString;
myConnectionString = "server=127.0.0.1;uid=root;" +
"pwd=12345;database=test;";
try
{
conn = new MySql.Data.MySqlClient.MySqlConnection(myConnectionString);
conn.Open();
}
catch (MySql.Data.MySqlClient.MySqlException ex)
{
MessageBox.Show(ex.Message);
}
Once the connection is open it can be used by the other Connector/NET classes to communicate with the MySQL server.
Because connecting to an external server is unpredictable, it
is important to add error handling to your .NET application.
When there is an error connecting, the
MySqlConnection class will return a
MySqlException object. This object has two
properties that are of interest when handling errors:
Message: A message that describes the current exception.Number: The MySQL error number.
When handling errors, you can your application's response based on the error number. The two most common error numbers when connecting are as follows:
0: Cannot connect to server.1045: Invalid username and/or password.
The following code shows how to adapt the application's response based on the actual error:
Visual Basic Example
Dim myConnectionString as String
myConnectionString = "server=127.0.0.1;" _
& "uid=root;" _
& "pwd=12345;" _
& "database=test;"
Try
Dim conn As New MySql.Data.MySqlClient.MySqlConnection(myConnectionString)
conn.Open()
Catch ex As MySql.Data.MySqlClient.MySqlException
Select Case ex.Number
Case 0
MessageBox.Show("Cannot connect to server. Contact administrator")
Case 1045
MessageBox.Show("Invalid username/password, please try again")
End Select
End Try
C# Example
MySql.Data.MySqlClient.MySqlConnection conn;
string myConnectionString;
myConnectionString = "server=127.0.0.1;uid=root;" +
"pwd=12345;database=test;";
try
{
conn = new MySql.Data.MySqlClient.MySqlConnection(myConnectionString);
conn.Open();
}
catch (MySql.Data.MySqlClient.MySqlException ex)
{
switch (ex.Number)
{
case 0:
MessageBox.Show("Cannot connect to server. Contact administrator");
case 1045:
MessageBox.Show("Invalid username/password, please try again");
}
}
Important: Note that if you
are using multilanguage databases you must specify the
character set in the connection string. If you do not specify
the character set, the connection defaults to the
latin1 charset. You can specify the
character set as part of the connection string, for example:
MySqlConnection myConnection = new MySqlConnection("server=127.0.0.1;uid=root;" +
"pwd=12345;database=test;Charset=latin1;");
As of MySQL 4.1, it is possible to use prepared statements with Connector/NET. Use of prepared statements can provide significant performance improvements on queries that are executed more than once.
Prepared execution is faster than direct execution for statements executed more than once, primarily because the query is parsed only once. In the case of direct execution, the query is parsed every time it is executed. Prepared execution also can provide a reduction of network traffic because for each execution of the prepared statement, it is necessary only to send the data for the parameters.
Another advantage of prepared statements is that it uses a binary protocol that makes data transfer between client and server more efficient.
To prepare a statement, create a command object and set the
.CommandText property to your query.
After entering your statement, call the
.Prepare method of the
MySqlCommand object. After the statement is
prepared, add parameters for each of the dynamic elements in
the query.
After you enter your query and enter parameters, execute the
statement using the .ExecuteNonQuery(),
.ExecuteScalar(), or
.ExecuteReader methods.
For subsequent executions, you need only modify the values of
the parameters and call the execute method again, there is no
need to set the .CommandText property or
redefine the parameters.
Visual Basic Example
Dim conn As New MySqlConnection
Dim cmd As New MySqlCommand
conn.ConnectionString = strConnection
Try
conn.Open()
cmd.Connection = conn
cmd.CommandText = "INSERT INTO myTable VALUES(NULL, ?number, ?text)"
cmd.Prepare()
cmd.Parameters.Add("?number", 1)
cmd.Parameters.Add("?text", "One")
For i = 1 To 1000
cmd.Parameters["?number"].Value = i
cmd.Parameters["?text"].Value = "A string value"
cmd.ExecuteNonQuery()
Next
Catch ex As MySqlException
MessageBox.Show("Error " & ex.Number & " has occurred: " & ex.Message, "Error", MessageBoxButtons.OK, MessageBoxIcon.Error)
End Try
C# Example
MySql.Data.MySqlClient.MySqlConnection conn;
MySql.Data.MySqlClient.MySqlCommand cmd;
conn = new MySql.Data.MySqlClient.MySqlConnection();
cmd = new MySql.Data.MySqlClient.MySqlCommand();
conn.ConnectionString = strConnection;
try
{
conn.Open();
cmd.Connection = conn;
cmd.CommandText = "INSERT INTO myTable VALUES(NULL, ?number, ?text)";
cmd.Prepare();
cmd.Parameters.Add("?number", 1);
cmd.Parameters.Add("?text", "One");
for (int i=1; i <= 1000; i++)
{
cmd.Parameters["?number"].Value = i;
cmd.Parameters["?text"].Value = "A string value";
cmd.ExecuteNonQuery();
}
}
catch (MySql.Data.MySqlClient.MySqlException ex)
{
MessageBox.Show("Error " + ex.Number + " has occurred: " + ex.Message,
"Error", MessageBoxButtons.OK, MessageBoxIcon.Error);
}
With the release of MySQL version 5 the MySQL server now supports stored procedures with the SQL 2003 stored procedure syntax.
A stored procedure is a set of SQL statements that can be stored in the server. Once this has been done, clients don't need to keep reissuing the individual statements but can refer to the stored procedure instead.
Stored procedures can be particularly useful in situations such as the following:
When multiple client applications are written in different languages or work on different platforms, but need to perform the same database operations.
When security is paramount. Banks, for example, use stored procedures for all common operations. This provides a consistent and secure environment, and procedures can ensure that each operation is properly logged. In such a setup, applications and users would not get any access to the database tables directly, but can only execute specific stored procedures.
Connector/NET supports the calling of stored procedures
through the MySqlCommand object. Data can
be passed in and our of a MySQL stored procedure through use
of the MySqlCommand.Parameters collection.
Note
When you call a stored procedure, the command object makes
an additional SELECT call to determine
the parameters of the stored procedure. You must ensure that
the user calling the procedure has the
SELECT privilege on the
mysql.proc table to enable them to verify
the parameters. Failure to do this will result in an error
when calling the procedure.
This section will not provide in-depth information on creating Stored Procedures. For such information, please refer to http://dev.mysql.com/doc/mysql/en/stored-procedures.html.
A sample application demonstrating how to use stored
procedures with Connector/NET can be found in the
Samples directory of your Connector/NET
installation.
Stored procedures in MySQL can be created using a variety of
tools. First, stored procedures can be created using the
mysql command-line client. Second, stored
procedures can be created using the MySQL Query
Browser GUI client. Finally, stored procedures can
be created using the .ExecuteNonQuery
method of the MySqlCommand object:
Visual Basic Example
Dim conn As New MySqlConnection
Dim cmd As New MySqlCommand
conn.ConnectionString = "server=127.0.0.1;" _
& "uid=root;" _
& "pwd=12345;" _
& "database=test"
Try
conn.Open()
cmd.Connection = conn
cmd.CommandText = "CREATE PROCEDURE add_emp(" _
& "IN fname VARCHAR(20), IN lname VARCHAR(20), IN bday DATETIME, OUT empno INT) " _
& "BEGIN INSERT INTO emp(first_name, last_name, birthdate) " _
& "VALUES(fname, lname, DATE(bday)); SET empno = LAST_INSERT_ID(); END"
cmd.ExecuteNonQuery()
Catch ex As MySqlException
MessageBox.Show("Error " & ex.Number & " has occurred: " & ex.Message, "Error", MessageBoxButtons.OK, MessageBoxIcon.Error)
End Try
C# Example
MySql.Data.MySqlClient.MySqlConnection conn;
MySql.Data.MySqlClient.MySqlCommand cmd;
conn = new MySql.Data.MySqlClient.MySqlConnection();
cmd = new MySql.Data.MySqlClient.MySqlCommand();
conn.ConnectionString = "server=127.0.0.1;uid=root;" +
"pwd=12345;database=test;";
try
{
conn.Open();
cmd.Connection = conn;
cmd.CommandText = "CREATE PROCEDURE add_emp(" +
"IN fname VARCHAR(20), IN lname VARCHAR(20), IN bday DATETIME, OUT empno INT) " +
"BEGIN INSERT INTO emp(first_name, last_name, birthdate) " +
"VALUES(fname, lname, DATE(bday)); SET empno = LAST_INSERT_ID(); END";
cmd.ExecuteNonQuery();
}
catch (MySql.Data.MySqlClient.MySqlException ex)
{
MessageBox.Show("Error " + ex.Number + " has occurred: " + ex.Message,
"Error", MessageBoxButtons.OK, MessageBoxIcon.Error);
}
It should be noted that, unlike the command-line and GUI clients, you are not required to specify a special delimiter when creating stored procedures in Connector/NET.
To call a stored procedure using Connector/NET, create a
MySqlCommand object and pass the stored
procedure name as the .CommandText
property. Set the .CommandType property to
CommandType.StoredProcedure.
After the stored procedure is named, create one
MySqlCommand parameter for every parameter
in the stored procedure. IN parameters are
defined with the parameter name and the object containing the
value, OUT parameters are defined with the
parameter name and the datatype that is expected to be
returned. All parameters need the parameter direction defined.
After defining parameters, call the stored procedure by using
the MySqlCommand.ExecuteNonQuery() method:
Visual Basic Example
Dim conn As New MySqlConnection
Dim cmd As New MySqlCommand
conn.ConnectionString = "server=127.0.0.1;" _
& "uid=root;" _
& "pwd=12345;" _
& "database=test"
Try
conn.Open()
cmd.Connection = conn
cmd.CommandText = "add_emp"
cmd.CommandType = CommandType.StoredProcedure
cmd.Parameters.Add("?lname", 'Jones')
cmd.Parameters["?lname"].Direction = ParameterDirection.Input
cmd.Parameters.Add("?fname", 'Tom')
cmd.Parameters["?fname"].Direction = ParameterDirection.Input
cmd.Parameters.Add("?bday", #12/13/1977 2:17:36 PM#)
cmd.Parameters["?bday"].Direction = ParameterDirection.Input
cmd.Parameters.Add("?empno", MySqlDbType.Int32)
cmd.Parameters["?empno"].Direction = ParameterDirection.Output
cmd.ExecuteNonQuery()
MessageBox.Show(cmd.Parameters["?empno"].Value)
Catch ex As MySqlException
MessageBox.Show("Error " & ex.Number & " has occurred: " & ex.Message, "Error", MessageBoxButtons.OK, MessageBoxIcon.Error)
End Try
C# Example
MySql.Data.MySqlClient.MySqlConnection conn;
MySql.Data.MySqlClient.MySqlCommand cmd;
conn = new MySql.Data.MySqlClient.MySqlConnection();
cmd = new MySql.Data.MySqlClient.MySqlCommand();
conn.ConnectionString = "server=127.0.0.1;uid=root;" +
"pwd=12345;database=test;";
try
{
conn.Open();
cmd.Connection = conn;
cmd.CommandText = "add_emp";
cmd.CommandType = CommandType.StoredProcedure;
cmd.Parameters.Add("?lname", "Jones");
cmd.Parameters["?lname"].Direction = ParameterDirection.Input;
cmd.Parameters.Add("?fname", "Tom");
cmd.Parameters["?fname"].Direction = ParameterDirection.Input;
cmd.Parameters.Add("?bday", DateTime.Parse("12/13/1977 2:17:36 PM"));
cmd.Parameters["?bday"].Direction = ParameterDirection.Input;
cmd.Parameters.Add("?empno", MySqlDbType.Int32);
cmd.Parameters["?empno"].Direction = ParameterDirection.Output;
cmd.ExecuteNonQuery();
MessageBox.Show(cmd.Parameters["?empno"].Value);
}
catch (MySql.Data.MySqlClient.MySqlException ex)
{
MessageBox.Show("Error " + ex.Number + " has occurred: " + ex.Message,
"Error", MessageBoxButtons.OK, MessageBoxIcon.Error);
}
Once the stored procedure is called, the values of output
parameters can be retrieved by using the
.Value property of the
MySqlConnector.Parameters collection.
One common use for MySQL is the storage of binary data in
BLOB columns. MySQL supports four different
BLOB datatypes: TINYBLOB,
BLOB, MEDIUMBLOB, and
LONGBLOB.
Data stored in a BLOB column can be accessed using Connector/NET and manipulated using client-side code. There are no special requirements for using Connector/NET with BLOB data.
Simple code examples will be presented within this section,
and a full sample application can be found in the
Samples directory of the Connector/NET
installation.
The first step is using MySQL with BLOB data is to configure the server. Let's start by creating a table to be accessed. In my file tables, I usually have four columns: an AUTO_INCREMENT column of appropriate size (UNSIGNED SMALLINT) to serve as a primary key to identify the file, a VARCHAR column that stores the filename, an UNSIGNED MEDIUMINT column that stores the size of the file, and a MEDIUMBLOB column that stores the file itself. For this example, I will use the following table definition:
CREATE TABLE file( file_id SMALLINT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY, file_name VARCHAR(64) NOT NULL, file_size MEDIUMINT UNSIGNED NOT NULL, file MEDIUMBLOB NOT NULL);
After creating a table, you may need to modify the max_allowed_packet system variable. This variable determines how large of a packet (i.e. a single row) can be sent to the MySQL server. By default, the server will only accept a maximum size of 1 meg from our client application. If you do not intend to exceed 1 meg, this should be fine. If you do intend to exceed 1 meg in your file transfers, this number has to be increased.
The max_allowed_packet option can be modified using MySQL
Administrator's Startup Variables screen. Adjust the Maximum
allowed option in the Memory section of the Networking tab to
an appropriate setting. After adjusting the value, click the
button and restart the
server using the Service Control screen of
MySQL Administrator. You can also adjust this value directly
in the my.cnf file (add a line that reads
max_allowed_packet=xxM), or use the SET
max_allowed_packet=xxM; syntax from within MySQL.
Try to be conservative when setting max_allowed_packet, as transfers of BLOB data can take some time to complete. Try to set a value that will be adequate for your intended use and increase the value if necessary.
To write a file to a database we need to convert the file to a
byte array, then use the byte array as a parameter to an
INSERT query.
The following code opens a file using a FileStream object,
reads it into a byte array, and inserts it into the
file table:
Visual Basic Example
Dim conn As New MySqlConnection
Dim cmd As New MySqlCommand
Dim SQL As String
Dim FileSize As UInt32
Dim rawData() As Byte
Dim fs As FileStream
conn.ConnectionString = "server=127.0.0.1;" _
& "uid=root;" _
& "pwd=12345;" _
& "database=test"
Try
fs = New FileStream("c:\image.png", FileMode.Open, FileAccess.Read)
FileSize = fs.Length
rawData = New Byte(FileSize) {}
fs.Read(rawData, 0, FileSize)
fs.Close()
conn.Open()
SQL = "INSERT INTO file VALUES(NULL, ?FileName, ?FileSize, ?File)"
cmd.Connection = conn
cmd.CommandText = SQL
cmd.Parameters.Add("?FileName", strFileName)
cmd.Parameters.Add("?FileSize", FileSize)
cmd.Parameters.Add("?File", rawData)
cmd.ExecuteNonQuery()
MessageBox.Show("File Inserted into database successfully!", _
"Success!", MessageBoxButtons.OK, MessageBoxIcon.Asterisk)
conn.Close()
Catch ex As Exception
MessageBox.Show("There was an error: " & ex.Message, "Error", _
MessageBoxButtons.OK, MessageBoxIcon.Error)
End Try
C# Example
MySql.Data.MySqlClient.MySqlConnection conn;
MySql.Data.MySqlClient.MySqlCommand cmd;
conn = new MySql.Data.MySqlClient.MySqlConnection();
cmd = new MySql.Data.MySqlClient.MySqlCommand();
string SQL;
UInt32 FileSize;
byte[] rawData;
FileStream fs;
conn.ConnectionString = "server=127.0.0.1;uid=root;" +
"pwd=12345;database=test;";
try
{
fs = new FileStream(@"c:\image.png", FileMode.Open, FileAccess.Read);
FileSize = fs.Length;
rawData = new byte[FileSize];
fs.Read(rawData, 0, FileSize);
fs.Close();
conn.Open();
SQL = "INSERT INTO file VALUES(NULL, ?FileName, ?FileSize, ?File)";
cmd.Connection = conn;
cmd.CommandText = SQL;
cmd.Parameters.Add("?FileName", strFileName);
cmd.Parameters.Add("?FileSize", FileSize);
cmd.Parameters.Add("?File", rawData);
cmd.ExecuteNonQuery();
MessageBox.Show("File Inserted into database successfully!",
"Success!", MessageBoxButtons.OK, MessageBoxIcon.Asterisk);
conn.Close();
}
catch (MySql.Data.MySqlClient.MySqlException ex)
{
MessageBox.Show("Error " + ex.Number + " has occurred: " + ex.Message,
"Error", MessageBoxButtons.OK, MessageBoxIcon.Error);
}
The Read method of the
FileStream object is used to load the file
into a byte array which is sized according to the
Length property of the FileStream object.
After assigning the byte array as a parameter of the
MySqlCommand object, the
ExecuteNonQuery method is called and the
BLOB is inserted into the file table.
Once a file is loaded into the file table,
we can use the MySqlDataReader class to
retrieve it.
The following code retrieves a row from the
file table, then loads the data into a
FileStream object to be written to disk:
Visual Basic Example
Dim conn As New MySqlConnection
Dim cmd As New MySqlCommand
Dim myData As MySqlDataReader
Dim SQL As String
Dim rawData() As Byte
Dim FileSize As UInt32
Dim fs As FileStream
conn.ConnectionString = "server=127.0.0.1;" _
& "uid=root;" _
& "pwd=12345;" _
& "database=test"
SQL = "SELECT file_name, file_size, file FROM file"
Try
conn.Open()
cmd.Connection = conn
cmd.CommandText = SQL
myData = cmd.ExecuteReader
If Not myData.HasRows Then Throw New Exception("There are no BLOBs to save")
myData.Read()
FileSize = myData.GetUInt32(myData.GetOrdinal("file_size"))
rawData = New Byte(FileSize) {}
myData.GetBytes(myData.GetOrdinal("file"), 0, rawData, 0, FileSize)
fs = New FileStream("C:\newfile.png", FileMode.OpenOrCreate, FileAccess.Write)
fs.Write(rawData, 0, FileSize)
fs.Close()
MessageBox.Show("File successfully written to disk!", "Success!", MessageBoxButtons.OK, MessageBoxIcon.Asterisk)
myData.Close()
conn.Close()
Catch ex As Exception
MessageBox.Show("There was an error: " & ex.Message, "Error", MessageBoxButtons.OK, MessageBoxIcon.Error)
End Try
C# Example
MySql.Data.MySqlClient.MySqlConnection conn;
MySql.Data.MySqlClient.MySqlCommand cmd;
MySql.Data.MySqlClient.MySqlDataReader myData;
conn = new MySql.Data.MySqlClient.MySqlConnection();
cmd = new MySql.Data.MySqlClient.MySqlCommand();
string SQL;
UInt32 FileSize;
byte[] rawData;
FileStream fs;
conn.ConnectionString = "server=127.0.0.1;uid=root;" +
"pwd=12345;database=test;";
SQL = "SELECT file_name, file_size, file FROM file";
try
{
conn.Open();
cmd.Connection = conn;
cmd.CommandText = SQL;
myData = cmd.ExecuteReader();
if (! myData.HasRows)
throw new Exception("There are no BLOBs to save");
myData.Read();
FileSize = myData.GetUInt32(myData.GetOrdinal("file_size"));
rawData = new byte[FileSize];
myData.GetBytes(myData.GetOrdinal("file"), 0, rawData, 0, FileSize);
fs = new FileStream(@"C:\newfile.png", FileMode.OpenOrCreate, FileAccess.Write);
fs.Write(rawData, 0, FileSize);
fs.Close();
MessageBox.Show("File successfully written to disk!",
"Success!", MessageBoxButtons.OK, MessageBoxIcon.Asterisk);
myData.Close();
conn.Close();
}
catch (MySql.Data.MySqlClient.MySqlException ex)
{
MessageBox.Show("Error " + ex.Number + " has occurred: " + ex.Message,
"Error", MessageBoxButtons.OK, MessageBoxIcon.Error);
}
After connecting, the contents of the file
table are loaded into a MySqlDataReader
object. The GetBytes method of the
MySqlDataReader is used to load the BLOB into a byte array,
which is then written to disk using a FileStream object.
The GetOrdinal method of the
MySqlDataReader can be used to determine the integer index of
a named column. Use of the GetOrdinal method prevents errors
if the column order of the SELECT query is
changed.
Crystal Reports is a common tool used by Windows application developers to perform reporting and document generation. In this section we will show how to use Crystal Reports XI with MySQL and Connector/NET.
When creating a report in Crystal Reports there are two options for accessing the MySQL data while designing your report.
The first option is to use Connector/ODBC as an ADO data source when designing your report. You will be able to browse your database and choose tables and fields using drag and drop to build your report. The disadvantage of this approach is that additional work must be performed within your application to produce a dataset that matches the one expected by your report.
The second option is to create a dataset in VB.NET and save it as XML. This XML file can then be used to design a report. This works quite well when displaying the report in your application, but is less versatile at design time because you must choose all relevant columns when creating the dataset. If you forget a column you must re-create the dataset before the column can be added to the report.
The following code can be used to create a dataset from a query and write it to disk:
Visual Basic Example
Dim myData As New DataSet
Dim conn As New MySqlConnection
Dim cmd As New MySqlCommand
Dim myAdapter As New MySqlDataAdapter
conn.ConnectionString = "server=127.0.0.1;" _
& "uid=root;" _
& "pwd=12345;" _
& "database=world"
Try
conn.Open()
cmd.CommandText = "SELECT city.name AS cityName, city.population AS CityPopulation, " _
& "country.name, country.population, country.continent " _
& "FROM country, city ORDER BY country.continent, country.name"
cmd.Connection = conn
myAdapter.SelectCommand = cmd
myAdapter.Fill(myData)
myData.WriteXml("C:\dataset.xml", XmlWriteMode.WriteSchema)
Catch ex As Exception
MessageBox.Show(ex.Message, "Report could not be created", MessageBoxButtons.OK, MessageBoxIcon.Error)
End Try
C# Example
DataSet myData = new DataSet();
MySql.Data.MySqlClient.MySqlConnection conn;
MySql.Data.MySqlClient.MySqlCommand cmd;
MySql.Data.MySqlClient.MySqlDataAdapter myAdapter;
conn = new MySql.Data.MySqlClient.MySqlConnection();
cmd = new MySql.Data.MySqlClient.MySqlCommand();
myAdapter = new MySql.Data.MySqlClient.MySqlDataAdapter();
conn.ConnectionString = "server=127.0.0.1;uid=root;" +
"pwd=12345;database=test;";
try
{
cmd.CommandText = "SELECT city.name AS cityName, city.population AS CityPopulation, " +
"country.name, country.population, country.continent " +
"FROM country, city ORDER BY country.continent, country.name";
cmd.Connection = conn;
myAdapter.SelectCommand = cmd;
myAdapter.Fill(myData);
myData.WriteXml(@"C:\dataset.xml", XmlWriteMode.WriteSchema);
}
catch (MySql.Data.MySqlClient.MySqlException ex)
{
MessageBox.Show(ex.Message, "Report could not be created",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
The resulting XML file can be used as an ADO.NET XML datasource when designing your report.
If you choose to design your reports using Connector/ODBC, it can be downloaded from dev.mysql.com.
For most purposes the Standard Report wizard should help with the initial creation of a report. To start the wizard, open Crystal Reports and choose the New > Standard Report option from the File menu.
The wizard will first prompt you for a data source. If you are using Connector/ODBC as your data source, use the OLEDB provider for ODBC option from the OLE DB (ADO) tree instead of the ODBC (RDO) tree when choosing a data source. If using a saved dataset, choose the ADO.NET (XML) option and browse to your saved dataset.
The remainder of the report creation process is done automatically by the wizard.
After the report is created, choose the Report Options... entry of the File menu. Un-check the Save Data With Report option. This prevents saved data from interfering with the loading of data within our application.
To display a report we first populate a dataset with the data needed for the report, then load the report and bind it to the dataset. Finally we pass the report to the crViewer control for display to the user.
The following references are needed in a project that displays a report:
CrytalDecisions.CrystalReports.Engine
CrystalDecisions.ReportSource
CrystalDecisions.Shared
CrystalDecisions.Windows.Forms
The following code assumes that you created your report using
a dataset saved using the code shown in
Section 23.2.5.5.2, “Creating a Data Source”,
and have a crViewer control on your form named
myViewer.
Visual Basic Example
Imports CrystalDecisions.CrystalReports.Engine
Imports System.Data
Imports MySql.Data.MySqlClient
Dim myReport As New ReportDocument
Dim myData As New DataSet
Dim conn As New MySqlConnection
Dim cmd As New MySqlCommand
Dim myAdapter As New MySqlDataAdapter
conn.ConnectionString = _
"server=127.0.0.1;" _
& "uid=root;" _
& "pwd=12345;" _
& "database=test"
Try
conn.Open()
cmd.CommandText = "SELECT city.name AS cityName, city.population AS CityPopulation, " _
& "country.name, country.population, country.continent " _
& "FROM country, city ORDER BY country.continent, country.name"
cmd.Connection = conn
myAdapter.SelectCommand = cmd
myAdapter.Fill(myData)
myReport.Load(".\world_report.rpt")
myReport.SetDataSource(myData)
myViewer.ReportSource = myReport
Catch ex As Exception
MessageBox.Show(ex.Message, "Report could not be created", MessageBoxButtons.OK, MessageBoxIcon.Error)
End Try
C# Example
using CrystalDecisions.CrystalReports.Engine;
using System.Data;
using MySql.Data.MySqlClient;
ReportDocument myReport = new ReportDocument();
DataSet myData = new DataSet();
MySql.Data.MySqlClient.MySqlConnection conn;
MySql.Data.MySqlClient.MySqlCommand cmd;
MySql.Data.MySqlClient.MySqlDataAdapter myAdapter;
conn = new MySql.Data.MySqlClient.MySqlConnection();
cmd = new MySql.Data.MySqlClient.MySqlCommand();
myAdapter = new MySql.Data.MySqlClient.MySqlDataAdapter();
conn.ConnectionString = "server=127.0.0.1;uid=root;" +
"pwd=12345;database=test;";
try
{
cmd.CommandText = "SELECT city.name AS cityName, city.population AS CityPopulation, " +
"country.name, country.population, country.continent " +
"FROM country, city ORDER BY country.continent, country.name";
cmd.Connection = conn;
myAdapter.SelectCommand = cmd;
myAdapter.Fill(myData);
myReport.Load(@".\world_report.rpt");
myReport.SetDataSource(myData);
myViewer.ReportSource = myReport;
}
catch (MySql.Data.MySqlClient.MySqlException ex)
{
MessageBox.Show(ex.Message, "Report could not be created",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
A new dataset it generated using the same query used to generate the previously saved dataset. Once the dataset is filled, a ReportDocument is used to load the report file and bind it to the dataset. The ReportDocument is the passed as the ReportSource of the crViewer.
This same approach is taken when a report is created from a single table using Connector/ODBC. The dataset replaces the table used in the report and the report is displayed properly.
When a report is created from multiple tables using Connector/ODBC, a dataset with multiple tables must be created in our application. This allows each table in the report data source to be replaced with a report in the dataset.
We populate a dataset with multiple tables by providing
multiple SELECT statements in our
MySqlCommand object. These SELECT
statements are based on the SQL query shown in Crystal Reports
in the Database menu's Show SQL Query option. Assume the
following query:
SELECT `country`.`Name`, `country`.`Continent`, `country`.`Population`, `city`.`Name`, `city`.`Population` FROM `world`.`country` `country` LEFT OUTER JOIN `world`.`city` `city` ON `country`.`Code`=`city`.`CountryCode` ORDER BY `country`.`Continent`, `country`.`Name`, `city`.`Name`
This query is converted to two SELECT
queries and displayed with the following code:
Visual Basic Example
Imports CrystalDecisions.CrystalReports.Engine
Imports System.Data
Imports MySql.Data.MySqlClient
Dim myReport As New ReportDocument
Dim myData As New DataSet
Dim conn As New MySqlConnection
Dim cmd As New MySqlCommand
Dim myAdapter As New MySqlDataAdapter
conn.ConnectionString = "server=127.0.0.1;" _
& "uid=root;" _
& "pwd=12345;" _
& "database=world"
Try
conn.Open()
cmd.CommandText = "SELECT name, population, countrycode FROM city ORDER BY countrycode, name; " _
& "SELECT name, population, code, continent FROM country ORDER BY continent, name"
cmd.Connection = conn
myAdapter.SelectCommand = cmd
myAdapter.Fill(myData)
myReport.Load(".\world_report.rpt")
myReport.Database.Tables(0).SetDataSource(myData.Tables(0))
myReport.Database.Tables(1).SetDataSource(myData.Tables(1))
myViewer.ReportSource = myReport
Catch ex As Exception
MessageBox.Show(ex.Message, "Report could not be created", MessageBoxButtons.OK, MessageBoxIcon.Error)
End Try
C# Example
using CrystalDecisions.CrystalReports.Engine;
using System.Data;
using MySql.Data.MySqlClient;
ReportDocument myReport = new ReportDocument();
DataSet myData = new DataSet();
MySql.Data.MySqlClient.MySqlConnection conn;
MySql.Data.MySqlClient.MySqlCommand cmd;
MySql.Data.MySqlClient.MySqlDataAdapter myAdapter;
conn = new MySql.Data.MySqlClient.MySqlConnection();
cmd = new MySql.Data.MySqlClient.MySqlCommand();
myAdapter = new MySql.Data.MySqlClient.MySqlDataAdapter();
conn.ConnectionString = "server=127.0.0.1;uid=root;" +
"pwd=12345;database=test;";
try
{
cmd.CommandText = "SELECT name, population, countrycode FROM city ORDER " +
"BY countrycode, name; SELECT name, population, code, continent FROM " +
"country ORDER BY continent, name";
cmd.Connection = conn;
myAdapter.SelectCommand = cmd;
myAdapter.Fill(myData);
myReport.Load(@".\world_report.rpt");
myReport.Database.Tables(0).SetDataSource(myData.Tables(0));
myReport.Database.Tables(1).SetDataSource(myData.Tables(1));
myViewer.ReportSource = myReport;
}
catch (MySql.Data.MySqlClient.MySqlException ex)
{
MessageBox.Show(ex.Message, "Report could not be created",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
It is important to order the SELECT queries
in alphabetical order, as this is the order the report will
expect its source tables to be in. One SetDataSource statement
is needed for each table in the report.
This approach can cause performance problems because Crystal Reports must bind the tables together on the client-side, which will be slower than using a pre-saved dataset.
MySQL and the .NET languages handle date and time information
differently, with MySQL allowing dates that cannot be
represented by a .NET data type, such as '0000-00-00
00:00:00'. These differences can cause problems if
not properly handled.
In this section we will demonstrate how to properly handle date and time information when using Connector/NET.
The differences in date handling can cause problems for
developers who use invalid dates. Invalid MySQL dates cannot
be loaded into native .NET DateTime
objects, including NULL dates.
Because of this issue, .NET DataSet objects
cannot be populated by the Fill method of
the MySqlDataAdapter class as invalid dates
will cause a
System.ArgumentOutOfRangeException
exception to occur.
The best solution to the date problem is to restrict users from entering invalid dates. This can be done on either the client or the server side.
Restricting invalid dates on the client side is as simple as
always using the .NET DateTime class to
handle dates. The DateTime class will only
allow valid dates, ensuring that the values in your database
are also valid. The disadvantage of this is that it is not
useful in a mixed environment where .NET and non .NET code are
used to manipulate the database, as each application must
perform its own date validation.
Users of MySQL 5.0.2 and higher can use the new
traditional SQL mode to restrict invalid
date values. For information on using the
traditional SQL mode, see
Section 5.2.6, “SQL Modes”.
Although it is strongly recommended that you avoid the use of
invalid dates within your .NET application, it is possible to
use invalid dates by means of the
MySqlDateTime datatype.
The MySqlDateTime datatype supports the
same date values that are supported by the MySQL server. The
default behavior of Connector/NET is to return a .NET DateTime
object for valid date values, and return an error for invalid
dates. This default can be modified to cause Connector/NET to
return MySqlDateTime objects for invalid
dates.
To instruct Connector/NET to return a
MySqlDateTime object for invalid dates, add
the following line to your connection string:
Allow Zero Datetime=True
Please note that the use of the
MySqlDateTime class can still be
problematic. The following are some known issues:
Data binding for invalid dates can still cause errors (zero dates like 0000-00-00 do not seem to have this problem).
The
ToStringmethod return a date formatted in the standard MySQL format (for example,2005-02-23 08:50:25). This differs from theToStringbehavior of the .NET DateTime class.The
MySqlDateTimeclass supports NULL dates, while the .NET DateTime class does not. This can cause errors when trying to convert a MySQLDateTime to a DateTime if you do not check for NULL first.
Because of the known issues, the best recommendation is still to use only valid dates in your application.
The .NET DateTime datatype cannot handle
NULL values. As such, when assigning values
from a query to a DateTime variable, you
must first check whether the value is in fact
NULL.
When using a MySqlDataReader, use the
.IsDBNull method to check whether a value
is NULL before making the assignment:
Visual Basic Example
If Not myReader.IsDBNull(myReader.GetOrdinal("mytime")) Then
myTime = myReader.GetDateTime(myReader.GetOrdinal("mytime"))
Else
myTime = DateTime.MinValue
End If
C# Example
if (! myReader.IsDBNull(myReader.GetOrdinal("mytime")))
myTime = myReader.GetDateTime(myReader.GetOrdinal("mytime"));
else
myTime = DateTime.MinValue;
NULL values will work in a dataset and can
be bound to form controls without special handling.
The developers of Connector/NET greatly value the input of our users in the software development process. If you find Connector/NET lacking some feature important to you, or if you discover a bug and need to file a bug report, please use the instructions in Section 1.8, “How to Report Bugs or Problems”.
Community support for Connector/NET can be found through the forums at http://forums.mysql.com.
Community support for Connector/NET can also be found through the mailing lists at http://lists.mysql.com.
Paid support is available from MySQL AB. Additional information is available at http://www.mysql.com/support/.
If you encounter difficulties or problems with Connector/NET, contact the Connector/NET community Section 23.2.6.1, “Connector/NET Community Support”.
You should first try to execute the same SQL statements and
commands from the mysql client program or
from admndemo. This helps you determine
whether the error is in Connector/NET or MySQL.
If reporting a problem, you should ideally include the following information with the email:
Operating system and version
Connector/NET version
MySQL server version
Copies of error messages or other unexpected output
Simple reproducible sample
Remember that the more information you can supply to us, the more likely it is that we can fix the problem.
If you believe the problem to be a bug, then you must report the bug through http://bugs.mysql.com/.
The Connector/NET Change History (Changelog) is located with the main Changelog for MySQL. See Section E.4, “Connector/NET Change History”.
The MySQL Visual Studio Plugin is a DDEX provider; a plug-in for Visual Studio 2005 that allows developers to maintain database structures, and supports built-in data-driven application development tools.
The current version of the MySQL Visual Studio Plugin includes only database maintenance tools. Data-driven application development tools are not supported.
The MySQL DDEX Provider operates as a standard extension to the Visual Studio Data Designer functionality available through the Server Explorer menu of Visual Studio 2005, and enables developers to create database objects and data within a MySQL database.
The MySQL Visual Studio Plugin is designed to work with MySQL version 5.0, but is also compatible with MySQL 4.1.1 and provides limited compatibility with MySQL 5.1.
The MySQL Visual Studio Plugin requires one of Visual Studio 2005 Standard, Professional or Team Developer Edition to be installed. Other editions of Visual Studio 2005 are not supported.
Here is the list of components that should already be installed before starting the installation of the MySQL Visual Studio Plugin:
Visual Studio 2005 Standard, Professional or Team Developer Edition.
MySQL Server 4.1.1 or later (either installed on the same machine, or a separate server).
MySQL Connector/NET 5.0.
Note
When installing Connector/NET you must ensure that the connector is installed into the Global Assembly Cache (GAC). The Connector/NET installer handles this for you automatically, but in a custom installation the option may have been disabled.
The user used to connect to the MySQL server must have the following privileges to use the functionality provided by the MySQL Visual Studio Plugin:
The
SELECTprivilege for theINFORMATION_SCHEMAdatabase.The
EXECUTEprivilege for theSHOW CREATE TABLEstatement.The
SELECTprivilege for themysql.proctable (required for operations with stored procedures and functions).The
SELECTprivilege for themysql.functable (required for operations with User Defined Functions (UDF)).The
EXECUTEprivilege for theSHOW ENGINE STATUSstatement (required for retrieving extended error information).Appropriate privileges for performed operations (e.g. the
SELECTprivilege is required to browse data from a table etc.).
The MySQL Visual Studio Plugin is delivered as a MSI package that can be used to install, uninstall or reinstall the Provider. If you are not using Windows XP or Windows Server 2003 you upgrade the Windows Installer system to the latest version (see http://support.microsoft.com/default.aspx?scid=kb;EN-US;292539 for details).
The MSI-package is named
MySQL.VisualStudio.msi. To install the MySQL
Visual Studio Plugin, right click on the MSI file and select
. The installation process is as follow:
The standard Welcome dialog is opened. Click Next to continue installation.
The License agreement (GNU GPL) window is opened. Accept the agreement and click to continue.
The destination folder choice dialog is opened. Here you can point out the folder where the MySQL Visual Studio Plugin will be installed. The default destination folder is
%ProgramFilesDir%\MySQL\MySQL DDEX Data Provider, where%ProgramFilesDir%is the Program Files folder of the installation machine. After choosing the destination folder, click to continue.The installer will ask to confirm that installation. Click Install to start installation process.
The installation will now take place. At the end of this step the Visual Studio command table is rebuilt (this process may take several minutes).
Once installation is complete, click to end the installation process.
To uninstall the MySQL Visual Studio Plugin, you can use either Add/Remove Programs component of the Control Panel or the same MSI-package. Choose the Remove option, and the Provider will be uninstalled automatically.
To repair the Provider, right click the MSI-package and choose the option. The MySQL Visual Studio Plugin will be repaired automatically.
The installation package includes the following files:
MySQL.VisualStudio.dll— the MySQL DDEX Provider assembly.MySQL.Data.dll— the assembly containing the MySQL Connector .NET which is used by the Provider.MySql.VisualStudio.dll.config— the configuration file for the MySQL Visual Studio Plugin. This file contains default values for the provider GUI layout.Note
Do not remove this file before the first use of the Provider.
Register.reg— the file with registry entries that can be used to register the MySQL DDEX Provider in the case of the manual installation.Install.js— the script used to register the Connector .NET as an ADO.NET data provider in the machine.config file.Release notes.doc— the document with release notes.
To install the Provider manually, copy all files of the installation package in a desired folder, then set the full path to the Provider assembly as a value of the CodeBase entry. For example:
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\VisualStudio\8.0\Packages\{79A115C9-B133-4891-9E7B-242509DAD272}]@="MySql.Data.VisualStudio.MySqlDataProviderPackage"
"InprocServer32"="C:\\WINNT\\system32\\mscoree.dll"
"Class"="MySql.Data.VisualStudio.MySqlDataProviderPackage"
"CodeBase"="C:\\MySqlDdexProvider\\MySql.VisualStudio.dll"
Then import information from the Register.reg file to the registry by clicking of the file. At the confirmation dialog choose Yes. Next you must run the command devenv.exe /setup within a Command Prompt to rebuild the Visual Studio command table.
Once the MySQL Visual Studio Plugin is installed, you can use it to create, modify and delete connections to MySQL databases. To create a connection with a MySQL database, perform the following steps:
Start Visual Studio 2005 and open Server Explorer window by choosing the option from the menu.
Right click on the Data Connections node and choose the button.
The Add Connection dialog is opened. Press the button to choose MySQL Database as a data source.
Change Data Source dialog is opened. Choose MySQL Database in the list of data sources (or the
otheroption, if MySQL Database is absent), and then choose .NET Framework Data Provider for MySQL in the combo box of data providers.
Press to confirm your choice.
Enter the connection settings: the server host name (for example, localhost if the MySQL server is installed on the local machine), the user name, the password, and the default database schema. Note that you must specify the default schema name to open the connection.
You can also set the port to connect with the MySQL server by pressing the button. To test a connection with the MySQL server, ser the server host name, the user name, and the password, and press the button. If the test fails, check the connection values that you have supplied are correct and that the corresponding user and privileges have been configured on the MySQL server.
After you set all settings and test the connection, press . The newly created connection is displayed in Server Explorer. Now you can work with the MySQL server through standard Server Explorer interface.
After a connection is successfully established, all the connection settings are saved. When you next open Visual Studio, the connection to the MySQL server will appear within Server Explorer so that you can re-establish a connection to the MySQL server.
To modify and delete a connection, use the context menu for the corresponding node. You can modify any of the settings just by overwriting the existing values with new ones. Note that a connection should be modified or deleted only if no active editor for it's objects is opened. Otherwise your data could be lost.
To work with a MySQL server using the MySQL Visual Studio Plugin, open the Visual Studio 2005, open the Server Explorer, and select the required connection. The working area of the MySQL Visual Studio Plugin consists of three parts.
Database objects (tables, views, stored routines, triggers, and user defined functions) are displayed in the Server Explorer tree. Here you can choose an object and edit its properties and definition.
Properties of a selected database object are displayed in the Properties panel. Certain properties can be edited directly within this window.
The editor panel provides direct access to the SQL statement and definition of specific objects. Fore example, the SQL statements within a stored procedure definition are shown and edited within this panel.
The Table Editor can be accessed through a mouse action on table-type node of Server Explorer. To create a new table, right click on the Tables node (under the connection node) and choose the command from a context menu. To modify an existing table, double click on a node of the table you wish to modify, or right click on this node and choose the command from a context menu. Either of the commands opens the Table Editor.
The MySQL Visual Studio Plugin Table Editor is implemented in a similar fashion to the standard Query Browser Table Editor, but with minor differences.
The Table Editor consists of the following parts:
Columns Editor — for column creation, modification and deletion.
Indexes tab — for table/column index management.
Foreign Keys tab — for configuration of foreign keys.
Column Details tab — used to set advanced column options.
Properties window — used to set table properties.
To save changes you have made in the Table Editor, use either Save or Save All buttons of the Visual Studio main toolbar, or just press Ctrl+S. Before changes are saved, a confirmation dialog will be displayed to confirm that you want to update the corresponding object within the MySQL database.
You can use the Column Editor to set or change the name, data type, default value and other properties of a table column. To set the properties of an individual column, select the column using the mouse. Alternatively, you can move through the grid using Tab and Shift+Tab keys.
To set or change the name, data type, default value and comment of a column, select the appropriate cell and edit the desired value.
To set or unset flag-type column properties (i.e., primary key,
NOT NULL, auto incremented, flags), check or uncheck the corresponding checkboxes. Note that the available column flags will depend on the columns data type.To reorder columns, index columns or foreign key columns in the Column Editor, select the whole column you wish to reorder by clicking on the selector column at the left of the column grid. Then move the column by using Ctrl+Up (to move the column up) and Ctrl+Down (to move the column down) keys.
To delete a column, select it by clicking on the selector column at the left of the column grid, then press the Delete button on a keyboard.
Index management is performed via the Indexes tab.
To add an index, press the button and set the properties in the Index Settings groupbox at the right. You can set the index name, index kind, index type and a set of index columns.
To remove an index, select the index from the list and press the button.
To change index settings, select the index from the list; detailed information about the index is displayed in the Index Settings panel.
You cannot change a table column to an index column using drag and drop. Instead, you can add new index columns to a table and set their table columns by using the embedded editor within the Indexes tab
Foreign Key management is performed via the Foreign Keys tab.
To add a foreign key, press the button and set properties in the Foreign Keys Settings panel. You can set the foreign key name, referenced table name, foreign key columns and actions on update and delete.
To remove a foreign key, select the foreign key and press the button.
To change foreign key settings, select the foreign key and use the Foreign Keys Settings panel to edit the properties.
When a foreign key is changed, the MySQL Visual Studio Plugin generates two queries: the first query drops the changed keys and the second one recreates the new values. The reason for such a behavior is to avoid the Bug#8377 and Bug#8919.
Note
If changed values are for some reason inconsistent and cause the second query to fail, all affected foreign keys will be dropped. If this is the case, the MySQL Visual Studio Plugin will mark them as new in the Table Editor, and you will have to recreate them later. But if you close the Table Editor without saving, these foreign keys will be lost.
The Column Details tab can be used to set column options. Besides the main column properties that are presented in the Column Editor, in the Column Details tab you can set two additional properties options: the character set and the collation sequence.
There is no separate tab for table options and advanced options. All table options can be browsed and changed using the Properties window of Visual Studio 2005.
The following table properties can be set:
Auto Increment
Average Row Length
Character Set
Checksum for Rows
Collation
Comment
Connection
Data Directory
Delay Key Updates
Engine
Index Directory
Insert Method
Maximum Rows
Minimum Rows
Name
Pack Keys
Password
Row Format
Union
Some of these properties can have arbitrary text values, others accept values from a predefined set.
The properties Schema and Server are read only.
The Table Data Editor, allows a user to browse, create and edit data of tables. The Table Data Editor is implemented as a simple data grid with auto generated columns.
To access the Table Data Editor, right click on a node representing the table or view in Server Explorer. From the nodes context menu, choose the or command. For tables and updatable views, this command opens the Table Data Editor in edit mode. For non-updatable views, this command opens the Table Data Editor in read-only mode.
When in the edit mode, you can modify table data by modifying the displayed table contents directly. To add a row, set desired values in the last row of the grid. To modify values, set new values in appropriate cells. To delete a row, select it by clicking on the selector column at the left of the grid, then press the button.
To save changes you have made in the Table Data Editor, use either or buttons of the Visual Studio main toolbar, or just press Ctrl+S. A confirmation dialog will confirm whether you want the changes saved to the database.
To create a new view, right click the Views node under the connection node in Server Explorer. From the nodes context menu, choose the command. This command opens the SQL Editor.
To modify an existing view, double click on a node of the view you wish to modify, or right click on this node and choose the command from a context menu. Either of the commands opens the SQL Editor.
To create or alter the view definition using SQL Editor, type the appropriate SQL statement in the SQL Editor.
Note
You should enter only the defining statement itself, without
the CREATE VIEW AS preface.
All other view properties can be set in the Properties window. These properties are:
Algorithm
Check Option
Definer
Name
Security Type
Some of these properties can have arbitrary text values, others accept values from a predefined set.
The properties Is Updatable, Schema and Server are readonly.
To save changes you have made, use either or buttons of the Visual Studio main toolbar, or just press Ctrl+S. A confirmation dialog will confirm whether you want the changes saved to the database.
To create a new stored procedure, right click the Stored Procedures node under the connection node in Server Explorer. From the nodes context menu, choose the command. This command opens the SQL Editor.
To create a new stored function, right click the Functions node under the connection node in Server Explorer. From the node's context menu, choose the command.
To modify an existing stored routine (procedure or function), double click on a node of the routine you wish to modify, or right click on this node and choose the command from a context menu. Either of the commands opens the SQL Editor.
To create or alter the routine definition using SQL Editor, type this definition in the SQL Editor using standard SQL.
All other routine properties can be set in the Properties window. These properties are:
Comment
Data Access
Definer
Is Deterministic
Security Type
Some of these properties can have arbitrary text values, others accept values only from a predefined set.
Also you can set all the options directly in the SQL Editor,
using the standard CREATE PROCEDURE or
CREATE FUNCTION statement. However, it is
recommended to use the Properties window
instead.
Note
You should never add the CREATE preface to
the routine definition.
The properties Name, Schema and Server in the Properties window are read-only. Set or change the procedure name in the SQL editor.
To save changes you have made, use either or buttons of the Visual Studio main toolbar, or just press Ctrl+S. A confirmation dialog will confirm whether you want the changes saved to the database..
To create a new trigger, right click on a node of a table for which you wish to add a trigger. From the node's context menu, choose the command. This command opens the SQL Editor.
To modify an existing trigger, double click on a node of the trigger you wish to modify, or right click on this node and choose the command from a context menu. Either of the commands opens the SQL Editor.
To create or alter the trigger definition using SQL Editor, type the trigger statement in the SQL Editor using standard SQL.
Note
You should enter only the trigger statement, that is the part
of the CREATE TRIGGER query that is placed
after the FOR EACH ROW clause.
All other trigger properties are set in the Properties window. These properties are:
Definer
Event Manipulation
Name
Timing
Some of these properties can have arbitrary text values, others accept values only from a predefined set.
The properties Event Table, Schema and Server in the Properties window are read-only.
To save changes you have made, use either or buttons of the Visual Studio main toolbar, or just press Ctrl+S. A confirmation dialog will confirm whether you want the changes saved to the database.
To create a new User Defined Function (UDF), right click the UDFs node under the connection node in Server Explorer. From the node's context menu, choose the command. This command opens the UDF Editor.
To modify an existing UDF, double click on a node of the UDF you wish to modify, or right click on this node and choose the Alter UDF command from a context menu. Either of the commands opens the UDF Editor.
The UDF editor allows you to set the following properties through the properties panel:
Name
So-name (DLL name)
Return type
Is Aggregate
The property Server in the Properties window is read-only.
To save changes you have made, use either or buttons of the Visual Studio main toolbar, or just press Ctrl+S. A confirmation dialog will confirm whether you want the changes saved to the database.
Tables, views, stored routines, triggers, an UDFs can be dropped with the appropriate command from its context menu: , , , , .
You will be asked to confirm the execution of the corresponding drop query in a confirmation dialog.
Dropping of multiple objects is not supported.
Tables, views, stored procedures and functions can be cloned with the appropriate command from its context menu: , , . The clone commands open the corresponding editor for a new object: the Table Editor for cloning a table and the SQL Editor for cloning a view or a routine.
To save the cloned object, use either or buttons of the Visual Studio main toolbar, or just press Ctrl+S. A confirmation dialog will confirm whether you want the changes saved to the database.
If you have a comment, or if you discover a bug, please, use our MySQL bug tracking system (http://bugs.mysql.com) to report problem or add your suggestion.
Questions
24.3.4.1.1: When creating a connection, typing the connection details causes the connection window to immediately close.
Questions and Answers
24.3.4.1.1: When creating a connection, typing the connection details causes the connection window to immediately close.
There are known issues with versions of Connector/NET earlier than 5.0.2. Connector/NET 1.0.x is known not to work. If you have any of these versions installed, or have previously upgraded from an earlier version, uninstall Connector/NET completely and then install Connector/NET 5.0.2.
MySQL provides connectivity for client applications developed in the Java programming language via a JDBC driver, which is called MySQL Connector/J.
MySQL Connector/J is a JDBC-3.0 Type 4 driver, which means that is pure Java, implements version 3.0 of the JDBC specification, and communicates directly with the MySQL server using the MySQL protocol.
Although JDBC is useful by itself, we would hope that if you are not familiar with JDBC that after reading the first few sections of this manual, that you would avoid using naked JDBC for all but the most trivial problems and consider using one of the popular persistence frameworks such as Hibernate, Spring's JDBC templates or Ibatis SQL Maps to do the majority of repetitive work and heavier lifting that is sometimes required with JDBC.
This section is not designed to be a complete JDBC tutorial. If you need more information about using JDBC you might be interested in the following online tutorials that are more in-depth than the information presented here:
JDBC Basics — A tutorial from Sun covering beginner topics in JDBC
JDBC Short Course — A more in-depth tutorial from Sun and JGuru
Key topics:
For help with connection strings, connection options setting up your connection through JDBC, see Section 23.4.4.1, “Driver/Datasource Class Names, URL Syntax and Configuration Properties for Connector/J”.
For tips on using Connector/J and JDBC with generic J2EE toolkits, see Section 23.4.5.2, “Using Connector/J with J2EE and Other Java Frameworks”.
Developers using the Tomcat server platform, see Section 23.4.5.2.2, “Using Connector/J with Tomcat”.
Developers using JBoss, see Section 23.4.5.2.3, “Using Connector/J with JBoss”.
Developers using Spring, see Section 23.4.5.2.4, “Using Connector/J with Spring”.
There are currently four versions of MySQL Connector/J available:
Connector/J 5.1 is current in alpha status. It provides compatibility with all the functionality of MySQL, including 4.1, 5.0, 5.1 and the 6.0 alpha release featuring the new Falcon storage engine. Connector/J 5.1 provides ease of development features, including auto-registration with the Driver Manager, standardized validity checks, categorized SQLExceptions, support for the JDBC-4.0 XML processing, per connection client information,
NCHAR,NVARCHARandNCLOBtypes. This release also includes all bug fixes up to and including Connector/J 5.0.6.Connector/J 5.0 provides support for all the functionality offered by Connector/J 3.1 and includes distributed transaction (XA) support.
Connector/J 3.1 was designed for connectivity to MySQL 4.1 and MySQL 5.0 servers and provides support for all the functionality in MySQL 5.0 except distributed transaction (XA) support.
Connector/J 3.0 provides core functionality and was designed with connectivity to MySQL 3.x or MySQL 4.1 servers, although it will provide basic compatibility with later versions of MySQL. Connector/J 3.0 does not support server-side prepared statements, and does not support any of the features in versions of MySQL later than 4.1.
The current recommended version for Connector/J is 5.0. This guide covers all three connector versions, with specific notes given where a setting applies to a specific option.
MySQL Connector/J supports Java-2 JVMs, including:
JDK 1.2.x (only for Connector/J 3.1.x or earlier)
JDK 1.3.x
JDK 1.4.x
JDK 1.5.x
If you are building Connector/J from source using the source distribution (see Section 23.4.2.4, “Installing from the Development Source Tree”) then you must use JDK 1.4.x or newer to compiler the Connector package.
MySQL Connector/J does not support JDK-1.1.x or JDK-1.0.x.
Because of the implementation of
java.sql.Savepoint, Connector/J 3.1.0 and
newer will not run on JDKs older than 1.4 unless the class
verifier is turned off (by setting the
-Xverify:none option to the Java runtime). This
is because the class verifier will try to load the class
definition for java.sql.Savepoint even
though it is not accessed by the driver unless you actually use
savepoint functionality.
Caching functionality provided by Connector/J 3.1.0 or newer is
also not available on JVMs older than 1.4.x, as it relies on
java.util.LinkedHashMap which was first
available in JDK-1.4.0.
You can install the Connector/J package using two methods, using
either the binary or source distribution. The binary distribution
provides the easiest methods for installation; the source
distribution enables you to customize your installation further.
With either solution, you must manually add the Connector/J
location to your Java CLASSPATH.
The easiest method of installation is to use the binary
distribution of the Connector/J package. The binary distribution
is available either as a Tar/Gzip or Zip file which you must
extract to a suitable location and then optionally make the
information about the package available by changing your
CLASSPATH (see
Section 23.4.2.2, “Installing the Driver and Configuring the CLASSPATH”).
MySQL Connector/J is distributed as a .zip or .tar.gz archive
containing the sources, the class files, and the JAR archive
named
mysql-connector-java-,
and starting with Connector/J 3.1.8 a debug build of the driver
in a file named
[version]-bin.jarmysql-connector-java-.
[version]-bin-g.jar
Starting with Connector/J 3.1.9, the .class
files that constitute the JAR files are only included as part of
the driver JAR file.
You should not use the debug build of the driver unless
instructed to do so when reporting a problem ors bug to MySQL
AB, as it is not designed to be run in production environments,
and will have adverse performance impact when used. The debug
binary also depends on the Aspect/J runtime library, which is
located in the src/lib/aspectjrt.jar file
that comes with the Connector/J distribution.
You will need to use the appropriate graphical or command-line utility to extract the distribution (for example, WinZip for the .zip archive, and tar for the .tar.gz archive). Because there are potentially long filenames in the distribution, we use the GNU tar archive format. You will need to use GNU tar (or an application that understands the GNU tar archive format) to unpack the .tar.gz variant of the distribution.
Once you have extracted the distribution archive, you can
install the driver by placing
mysql-connector-java-[version]-bin.jar in
your classpath, either by adding the full path to it to your
CLASSPATH environment variable, or by
directly specifying it with the command line switch -cp when
starting your JVM.
If you are going to use the driver with the JDBC DriverManager,
you would use com.mysql.jdbc.Driver as the
class that implements java.sql.Driver.
You can set the CLASSPATH environment
variable under UNIX, Linux or Mac OS X either locally for a user
within their .profile,
.login or other login file. You can also set
it globally by editing the global
/etc/profile file.
For example, under a C shell (csh, tcsh) you would add the
Connector/J driver to your CLASSPATH using
the following:
shell> setenv CLASSPATH /path/mysql-connector-java-[ver]-bin.jar:$CLASSPATH
Or with a Bourne-compatible shell (sh, ksh, bash):
export set CLASSPATH=/path/mysql-connector-java-[ver]-bin.jar:$CLASSPATH
Within Windows 2000, Windows XP and Windows Server 2003, you must set the environment variable through the System control panel.
If you want to use MySQL Connector/J with an application server
such as Tomcat or JBoss, you will have to read your vendor's
documentation for more information on how to configure
third-party class libraries, as most application servers ignore
the CLASSPATH environment variable. For
configuration examples for some J2EE application servers, see
Section 23.4.5.2, “Using Connector/J with J2EE and Other Java Frameworks”. However, the
authoritative source for JDBC connection pool configuration
information for your particular application server is the
documentation for that application server.
If you are developing servlets or JSPs, and your application server is J2EE-compliant, you can put the driver's .jar file in the WEB-INF/lib subdirectory of your webapp, as this is a standard location for third party class libraries in J2EE web applications.
You can also use the MysqlDataSource or
MysqlConnectionPoolDataSource classes in the
com.mysql.jdbc.jdbc2.optional package, if
your J2EE application server supports or requires them. Starting
with Connector/J 5.0.0, the
javax.sql.XADataSource interface is
implemented via the
com.mysql.jdbc.jdbc2.optional.MysqlXADataSource
class, which supports XA distributed transactions when used in
combination with MySQL server version 5.0.
The various MysqlDataSource classes support the following parameters (through standard set mutators):
user
password
serverName (see the previous section about fail-over hosts)
databaseName
port
MySQL AB tries to keep the upgrade process as easy as possible, however as is the case with any software, sometimes changes need to be made in new versions to support new features, improve existing functionality, or comply with new standards.
This section has information about what users who are upgrading from one version of Connector/J to another (or to a new version of the MySQL server, with respect to JDBC functionality) should be aware of.
Connector/J 3.1 is designed to be backward-compatible with Connector/J 3.0 as much as possible. Major changes are isolated to new functionality exposed in MySQL-4.1 and newer, which includes Unicode character sets, server-side prepared statements, SQLState codes returned in error messages by the server and various performance enhancements that can be enabled or disabled via configuration properties.
Unicode Character Sets — See the next section, as well as Chapter 10, Character Set Support, for information on this new feature of MySQL. If you have something misconfigured, it will usually show up as an error with a message similar to
Illegal mix of collations.Server-side Prepared Statements — Connector/J 3.1 will automatically detect and use server-side prepared statements when they are available (MySQL server version 4.1.0 and newer).
Starting with version 3.1.7, the driver scans SQL you are preparing via all variants of
Connection.prepareStatement()to determine if it is a supported type of statement to prepare on the server side, and if it is not supported by the server, it instead prepares it as a client-side emulated prepared statement. You can disable this feature by passing emulateUnsupportedPstmts=false in your JDBC URL.If your application encounters issues with server-side prepared statements, you can revert to the older client-side emulated prepared statement code that is still presently used for MySQL servers older than 4.1.0 with the connection property useServerPrepStmts=false
Datetimes with all-zero components (
0000-00-00 ...) — These values can not be represented reliably in Java. Connector/J 3.0.x always converted them to NULL when being read from a ResultSet.Connector/J 3.1 throws an exception by default when these values are encountered as this is the most correct behavior according to the JDBC and SQL standards. This behavior can be modified using the zeroDateTimeBehavior configuration property. The allowable values are:
exception(the default), which throws an SQLException with an SQLState ofS1009.convertToNull, which returnsNULLinstead of the date.round, which rounds the date to the nearest closest value which is0001-01-01.
Starting with Connector/J 3.1.7,
ResultSet.getString()can be decoupled from this behavior via noDatetimeStringSync=true (the default value isfalse) so that you can get retrieve the unaltered all-zero value as a String. It should be noted that this also precludes using any time zone conversions, therefore the driver will not allow you to enable noDatetimeStringSync and useTimezone at the same time.New SQLState Codes — Connector/J 3.1 uses SQL:1999 SQLState codes returned by the MySQL server (if supported), which are different from the legacy X/Open state codes that Connector/J 3.0 uses. If connected to a MySQL server older than MySQL-4.1.0 (the oldest version to return SQLStates as part of the error code), the driver will use a built-in mapping. You can revert to the old mapping by using the configuration property useSqlStateCodes=false.
ResultSet.getString()— CallingResultSet.getString()on a BLOB column will now return the address of the byte[] array that represents it, instead of a String representation of the BLOB. BLOBs have no character set, so they can't be converted to java.lang.Strings without data loss or corruption.To store strings in MySQL with LOB behavior, use one of the TEXT types, which the driver will treat as a java.sql.Clob.
Debug builds — Starting with Connector/J 3.1.8 a debug build of the driver in a file named
mysql-connector-java-is shipped alongside the normal binary jar file that is named[version]-bin-g.jarmysql-connector-java-.[version]-bin.jarStarting with Connector/J 3.1.9, we don't ship the .class files unbundled, they are only available in the JAR archives that ship with the driver.
You should not use the debug build of the driver unless instructed to do so when reporting a problem or bug to MySQL AB, as it is not designed to be run in production environments, and will have adverse performance impact when used. The debug binary also depends on the Aspect/J runtime library, which is located in the
src/lib/aspectjrt.jarfile that comes with the Connector/J distribution.
Using the UTF-8 Character Encoding - Prior to MySQL server version 4.1, the UTF-8 character encoding was not supported by the server, however the JDBC driver could use it, allowing storage of multiple character sets in latin1 tables on the server.
Starting with MySQL-4.1, this functionality is deprecated. If you have applications that rely on this functionality, and can not upgrade them to use the official Unicode character support in MySQL server version 4.1 or newer, you should add the following property to your connection URL:
useOldUTF8Behavior=trueServer-side Prepared Statements - Connector/J 3.1 will automatically detect and use server-side prepared statements when they are available (MySQL server version 4.1.0 and newer). If your application encounters issues with server-side prepared statements, you can revert to the older client-side emulated prepared statement code that is still presently used for MySQL servers older than 4.1.0 with the following connection property:
useServerPrepStmts=false
Caution
You should read this section only if you are interested in helping us test our new code. If you just want to get MySQL Connector/J up and running on your system, you should use a standard release distribution.
To install MySQL Connector/J from the development source tree, make sure that you have the following prerequisites:
Subversion, to check out the sources from our repository (available from http://subversion.tigris.org/).
Apache Ant version 1.6 or newer (available from http://ant.apache.org/).
JDK-1.4.2 or later. Although MySQL Connector/J can be installed on older JDKs, to compile it from source you must have at least JDK-1.4.2.
The Subversion source code repository for MySQL Connector/J is located at http://svn.mysql.com/svnpublic/connector-j. In general, you should not check out the entire repository because it contains every branch and tag for MySQL Connector/J and is quite large.
To check out and compile a specific branch of MySQL Connector/J, follow these steps:
At the time of this writing, there are three active branches of Connector/J:
branch_3_0,branch_3_1andbranch_5_0. Check out the latest code from the branch that you want with the following command (replacing[major]and[minor]with appropriate version numbers):shell>
svn co » http://svn.mysql.com/svnpublic/connector-j/branches/branch_[major]_[minor]/connector-jThis creates a
connector-jsubdirectory in the current directory that contains the latest sources for the requested branch.Change location to the
connector-jdirectory to make it your current working directory:shell>
cd connector-jIssue the following command to compile the driver and create a
.jarfile suitable for installation:shell>
ant distThis creates a
builddirectory in the current directory, where all build output will go. A directory is created in thebuilddirectory that includes the version number of the sources you are building from. This directory contains the sources, compiled.classfiles, and a.jarfile suitable for deployment. For other possible targets, including ones that will create a fully packaged distribution, issue the following command:shell>
ant --projecthelpA newly created
.jarfile containing the JDBC driver will be placed in the directorybuild/mysql-connector-java-.[version]Install the newly created JDBC driver as you would a binary
.jarfile that you download from MySQL by following the instructions in Section 23.4.2.2, “Installing the Driver and Configuring theCLASSPATH”.
Examples of using Connector/J are located throughout this document, this section provides a summary and links to these examples.
Example 23.1, “Obtaining a connection from the
DriverManager”Example 23.2, “Using java.sql.Statement to execute a
SELECTquery”Example 23.7, “Retrieving results and output parameter values”
Example 23.8, “Retrieving
AUTO_INCREMENTcolumn values usingStatement.getGeneratedKeys()”Example 23.9, “Retrieving
AUTO_INCREMENTcolumn values usingSELECT LAST_INSERT_ID()”Example 23.10, “Retrieving
AUTO_INCREMENTcolumn values inUpdatable ResultSets”Example 23.11, “Using a connection pool with a J2EE application server”
- 23.4.4.1. Driver/Datasource Class Names, URL Syntax and Configuration Properties for Connector/J
- 23.4.4.2. JDBC API Implementation Notes
- 23.4.4.3. Java, JDBC and MySQL Types
- 23.4.4.4. Using Character Sets and Unicode
- 23.4.4.5. Connecting Securely Using SSL
- 23.4.4.6. Using Master/Slave Replication with ReplicationConnection
- 23.4.4.7. Mapping MySQL Error Numbers to SQLStates
This section of the manual contains reference material for MySQL Connector/J, some of which is automatically generated during the Connector/J build process.
The name of the class that implements java.sql.Driver in MySQL
Connector/J is com.mysql.jdbc.Driver. The
org.gjt.mm.mysql.Driver class name is also
usable to remain backward-compatible with MM.MySQL. You should
use this class name when registering the driver, or when
otherwise configuring software to use MySQL Connector/J.
The JDBC URL format for MySQL Connector/J is as follows, with items in square brackets ([, ]) being optional:
jdbc:mysql://[host][,failoverhost...][:port]/[database] » [?propertyName1][=propertyValue1][&propertyName2][=propertyValue2]...
If the hostname is not specified, it defaults to 127.0.0.1. If the port is not specified, it defaults to 3306, the default port number for MySQL servers.
jdbc:mysql://[host:port],[host:port].../[database] » [?propertyName1][=propertyValue1][&propertyName2][=propertyValue2]...
If the database is not specified, the connection will be made
with no default database. In this case, you will need to either
call the setCatalog() method on the
Connection instance or fully-specify table names using the
database name (i.e. SELECT dbname.tablename.colname
FROM dbname.tablename...) in your SQL. Not specifying
the database to use upon connection is generally only useful
when building tools that work with multiple databases, such as
GUI database managers.
MySQL Connector/J has fail-over support. This allows the driver
to fail-over to any number of slave hosts and still perform
read-only queries. Fail-over only happens when the connection is
in an autoCommit(true) state, because
fail-over can not happen reliably when a transaction is in
progress. Most application servers and connection pools set
autoCommit to true at the
end of every transaction/connection use.
The fail-over functionality has the following behavior:
If the URL property autoReconnect is false: Failover only happens at connection initialization, and failback occurs when the driver determines that the first host has become available again.
If the URL property autoReconnect is true: Failover happens when the driver determines that the connection has failed (before every query), and falls back to the first host when it determines that the host has become available again (after
queriesBeforeRetryMasterqueries have been issued).
In either case, whenever you are connected to a "failed-over" server, the connection will be set to read-only state, so queries that would modify data will have exceptions thrown (the query will never be processed by the MySQL server).
Configuration properties define how Connector/J will make a connection to a MySQL server. Unless otherwise noted, properties can be set for a DataSource object or for a Connection object.
Configuration Properties can be set in one of the following ways:
Using the set*() methods on MySQL implementations of java.sql.DataSource (which is the preferred method when using implementations of java.sql.DataSource):
com.mysql.jdbc.jdbc2.optional.MysqlDataSource
com.mysql.jdbc.jdbc2.optional.MysqlConnectionPoolDataSource
As a key/value pair in the java.util.Properties instance passed to
DriverManager.getConnection()orDriver.connect()As a JDBC URL parameter in the URL given to
java.sql.DriverManager.getConnection(),java.sql.Driver.connect()or the MySQL implementations of thejavax.sql.DataSourcesetURL()method.Note
If the mechanism you use to configure a JDBC URL is XML-based, you will need to use the XML character literal & to separate configuration parameters, as the ampersand is a reserved character for XML.
The properties are listed in the following tables.
Connection/Authentication.
| Property Name | Definition | Default Value | Since Version |
| user | The user to connect as | all versions | |
| password | The password to use when connecting | all versions | |
| socketFactory | The name of the class that the driver should use for creating socket connections to the server. This class must implement the interface 'com.mysql.jdbc.SocketFactory' and have public no-args constructor. | com.mysql.jdbc.StandardSocketFactory | 3.0.3 |
| connectTimeout | Timeout for socket connect (in milliseconds), with 0 being no timeout. Only works on JDK-1.4 or newer. Defaults to '0'. | 0 | 3.0.1 |
| socketTimeout | Timeout on network socket operations (0, the default means no timeout). | 0 | 3.0.1 |
| useConfigs | Load the comma-delimited list of configuration properties before parsing the URL or applying user-specified properties. These configurations are explained in the 'Configurations' of the documentation. | 3.1.5 | |
| interactiveClient | Set the CLIENT_INTERACTIVE flag, which tells MySQL to timeout connections based on INTERACTIVE_TIMEOUT instead of WAIT_TIMEOUT | false | 3.1.0 |
| localSocketAddress | Hostname or IP address given to explicitly configure the interface that the driver will bind the client side of the TCP/IP connection to when connecting. | 5.0.5 | |
| propertiesTransform | An implementation of com.mysql.jdbc.ConnectionPropertiesTransform that the driver will use to modify URL properties passed to the driver before attempting a connection | 3.1.4 | |
| useCompression | Use zlib compression when communicating with the server (true/false)? Defaults to 'false'. | false | 3.0.17 |
Networking.
| Property Name | Definition | Default Value | Since Version |
| tcpKeepAlive | If connecting using TCP/IP, should the driver set SO_KEEPALIVE? | true | 5.0.7 |
| tcpNoDelay | If connecting using TCP/IP, should the driver set SO_TCP_NODELAY (disabling the Nagle Algorithm)? | true | 5.0.7 |
| tcpRcvBuf | If connecting using TCP/IP, should the driver set SO_RCV_BUF to the given value? The default value of '0', means use the platform default value for this property) | 0 | 5.0.7 |
| tcpSndBuf | If connecting using TCP/IP, shuold the driver set SO_SND_BUF to the given value? The default value of '0', means use the platform default value for this property) | 0 | 5.0.7 |
| tcpTrafficClass | If connecting using TCP/IP, should the driver set traffic class or type-of-service fields ?See the documentation for java.net.Socket.setTrafficClass() for more information. | 0 | 5.0.7 |
High Availability and Clustering.
| Property Name | Definition | Default Value | Since Version |
| autoReconnect | Should the driver try to re-establish stale and/or dead connections? If enabled the driver will throw an exception for a queries issued on a stale or dead connection, which belong to the current transaction, but will attempt reconnect before the next query issued on the connection in a new transaction. The use of this feature is not recommended, because it has side effects related to session state and data consistency when applications don't handle SQLExceptions properly, and is only designed to be used when you are unable to configure your application to handle SQLExceptions resulting from dead and stale connections properly. Alternatively, investigate setting the MySQL server variable "wait_timeout" to some high value rather than the default of 8 hours. | false | 1.1 |
| autoReconnectForPools | Use a reconnection strategy appropriate for connection pools (defaults to 'false') | false | 3.1.3 |
| failOverReadOnly | When failing over in autoReconnect mode, should the connection be set to 'read-only'? | true | 3.0.12 |
| maxReconnects | Maximum number of reconnects to attempt if autoReconnect is true, default is '3'. | 3 | 1.1 |
| reconnectAtTxEnd | If autoReconnect is set to true, should the driver attempt reconnections at the end of every transaction? | false | 3.0.10 |
| initialTimeout | If autoReconnect is enabled, the initial time to wait between re-connect attempts (in seconds, defaults to '2'). | 2 | 1.1 |
| roundRobinLoadBalance | When autoReconnect is enabled, and failoverReadonly is false, should we pick hosts to connect to on a round-robin basis? | false | 3.1.2 |
| queriesBeforeRetryMaster | Number of queries to issue before falling back to master when failed over (when using multi-host failover). Whichever condition is met first, 'queriesBeforeRetryMaster' or 'secondsBeforeRetryMaster' will cause an attempt to be made to reconnect to the master. Defaults to 50. | 50 | 3.0.2 |
| secondsBeforeRetryMaster | How long should the driver wait, when failed over, before attempting | 30 | 3.0.2 |
| resourceId | A globally unique name that identifies the resource that this datasource or connection is connected to, used for XAResource.isSameRM() when the driver can't determine this value based on hostnames used in the URL | 5.0.1 |
Security.
| Property Name | Definition | Default Value | Since Version |
| allowMultiQueries | Allow the use of ';' to delimit multiple queries during one statement (true/false), defaults to 'false' | false | 3.1.1 |
| useSSL | Use SSL when communicating with the server (true/false), defaults to 'false' | false | 3.0.2 |
| requireSSL | Require SSL connection if useSSL=true? (defaults to 'false'). | false | 3.1.0 |
| allowLoadLocalInfile | Should the driver allow use of 'LOAD DATA LOCAL INFILE...' (defaults to 'true'). | true | 3.0.3 |
| allowUrlInLocalInfile | Should the driver allow URLs in 'LOAD DATA LOCAL INFILE' statements? | false | 3.1.4 |
| clientCertificateKeyStorePassword | Password for the client certificates KeyStore | 5.1.0 | |
| clientCertificateKeyStoreType | KeyStore type for client certificates (NULL or empty means use default, standard keystore types supported by the JVM are "JKS" and "PKCS12", your environment may have more available depending on what security products are installed and available to the JVM. | 5.1.0 | |
| clientCertificateKeyStoreUrl | URL to the client certificate KeyStore (if not specified, use defaults) | 5.1.0 | |
| trustCertificateKeyStorePassword | Password for the trusted root certificates KeyStore | 5.1.0 | |
| trustCertificateKeyStoreType | KeyStore type for trusted root certificates (NULL or empty means use default, standard keystore types supported by the JVM are "JKS" and "PKCS12", your environment may have more available depending on what security products are installed and available to the JVM. | 5.1.0 | |
| trustCertificateKeyStoreUrl | URL to the trusted root certificate KeyStore (if not specified, use defaults) | 5.1.0 | |
| paranoid | Take measures to prevent exposure sensitive information in error messages and clear data structures holding sensitive data when possible? (defaults to 'false') | false | 3.0.1 |
Performance Extensions.
| Property Name | Definition | Default Value | Since Version |
| callableStmtCacheSize | If 'cacheCallableStmts' is enabled, how many callable statements should be cached? | 100 | 3.1.2 |
| metadataCacheSize | The number of queries to cache ResultSetMetadata for if cacheResultSetMetaData is set to 'true' (default 50) | 50 | 3.1.1 |
| prepStmtCacheSize | If prepared statement caching is enabled, how many prepared statements should be cached? | 25 | 3.0.10 |
| prepStmtCacheSqlLimit | If prepared statement caching is enabled, what's the largest SQL the driver will cache the parsing for? | 256 | 3.0.10 |
| alwaysSendSetIsolation | Should the driver always communicate with the database when Connection.setTransactionIsolation() is called? If set to false, the driver will only communicate with the database when the requested transaction isolation is different than the whichever is newer, the last value that was set via Connection.setTransactionIsolation(), or the value that was read from the server when the connection was established. | true | 3.1.7 |
| maintainTimeStats | Should the driver maintain various internal timers to enable idle time calculations as well as more verbose error messages when the connection to the server fails? Setting this property to false removes at least two calls to System.getCurrentTimeMillis() per query. | true | 3.1.9 |
| useCursorFetch | If connected to MySQL > 5.0.2, and setFetchSize() > 0 on a statement, should that statement use cursor-based fetching to retrieve rows? | false | 5.0.0 |
| blobSendChunkSize | Chunk to use when sending BLOB/CLOBs via ServerPreparedStatements | 1048576 | 3.1.9 |
| cacheCallableStmts | Should the driver cache the parsing stage of CallableStatements | false | 3.1.2 |
| cachePrepStmts | Should the driver cache the parsing stage of PreparedStatements of client-side prepared statements, the "check" for suitability of server-side prepared and server-side prepared statements themselves? | false | 3.0.10 |
| cacheResultSetMetadata | Should the driver cache ResultSetMetaData for Statements and PreparedStatements? (Req. JDK-1.4+, true/false, default 'false') | false | 3.1.1 |
| cacheServerConfiguration | Should the driver cache the results of 'SHOW VARIABLES' and 'SHOW COLLATION' on a per-URL basis? | false | 3.1.5 |
| defaultFetchSize | The driver will call setFetchSize(n) with this value on all newly-created Statements | 0 | 3.1.9 |
| dontTrackOpenResources | The JDBC specification requires the driver to automatically track and close resources, however if your application doesn't do a good job of explicitly calling close() on statements or result sets, this can cause memory leakage. Setting this property to true relaxes this constraint, and can be more memory efficient for some applications. | false | 3.1.7 |
| dynamicCalendars | Should the driver retrieve the default calendar when required, or cache it per connection/session? | false | 3.1.5 |
| elideSetAutoCommits | If using MySQL-4.1 or newer, should the driver only issue 'set autocommit=n' queries when the server's state doesn't match the requested state by Connection.setAutoCommit(boolean)? | false | 3.1.3 |
| enableQueryTimeouts | When enabled, query timeouts set via Statement.setQueryTimeout() use a shared java.util.Timer instance for scheduling. Even if the timeout doesn't expire before the query is processed, there will be memory used by the TimerTask for the given timeout which won't be reclaimed until the time the timeout would have expired if it hadn't been cancelled by the driver. High-load environments might want to consider disabling this functionality. | true | 5.0.6 |
| holdResultsOpenOverStatementClose | Should the driver close result sets on Statement.close() as required by the JDBC specification? | false | 3.1.7 |
| loadBalanceStrategy | If using a load-balanced connection to connect to SQL nodes in a MySQL Cluster/NDB configuration (by using the URL prefix "jdbc:mysql:loadbalance://"), which load balancin algorithm should the driver use: (1) "random" - the driver will pick a random host for each request. This tends to work better than round-robin, as the randomness will somewhat account for spreading loads where requests vary in response time, while round-robin can sometimes lead to overloaded nodes if there are variations in response times across the workload. (2) "bestResponseTime" - the driver will route the request to the host that had the best response time for the previous transaction. | random | 5.0.6 |
| locatorFetchBufferSize | If 'emulateLocators' is configured to 'true', what size buffer should be used when fetching BLOB data for getBinaryInputStream? | 1048576 | 3.2.1 |
| rewriteBatchedStatements | Should the driver use multiqueries (irregardless of the setting of "allowMultiQueries") as well as rewriting of prepared statements for INSERT into multi-value inserts when executeBatch() is called? Notice that this has the potential for SQL injection if using plain java.sql.Statements and your code doesn't sanitize input correctly. Notice that for prepared statements, server-side prepared statements can not currently take advantage of this rewrite option, and that if you don't specify stream lengths when using PreparedStatement.set*Stream(), the driver won't be able to determine the optimium number of parameters per batch and you might receive an error from the driver that the resultant packet is too large. Statement.getGeneratedKeys() for these rewritten statements only works when the entire batch includes INSERT statements. | false | 3.1.13 |
| useDynamicCharsetInfo | Should the driver use a per-connection cache of character set information queried from the server when necessary, or use a built-in static mapping that is more efficient, but isn't aware of custom character sets or character sets implemented after the release of the JDBC driver? | true | 5.0.6 |
| useFastDateParsing | Use internal String->Date/Time/Teimstamp conversion routines to avoid excessive object creation? | true | 5.0.5 |
| useFastIntParsing | Use internal String->Integer conversion routines to avoid excessive object creation? | true | 3.1.4 |
| useJvmCharsetConverters | Always use the character encoding routines built into the JVM, rather than using lookup tables for single-byte character sets? | false | 5.0.1 |
| useLocalSessionState | Should the driver refer to the internal values of autocommit and transaction isolation that are set by Connection.setAutoCommit() and Connection.setTransactionIsolation() and transaction state as maintained by the protocol, rather than querying the database or blindly sending commands to the database for commit() or rollback() method calls? | false | 3.1.7 |
| useReadAheadInput | Use newer, optimized non-blocking, buffered input stream when reading from the server? | true | 3.1.5 |
Debugging/Profiling.
| Property Name | Definition | Default Value | Since Version |
| logger | The name of a class that implements ${0} that will be used to log messages to. (default is ${1}, which logs to STDERR) | com.mysql.jdbc.log.StandardLogger | 3.1.1 |
| gatherPerfMetrics | Should the driver gather performance metrics, and report them via the configured logger every 'reportMetricsIntervalMillis' milliseconds? | false | 3.1.2 |
| profileSQL | Trace queries and their execution/fetch times to the configured logger (true/false) defaults to 'false' | false | 3.1.0 |
| profileSql | Deprecated, use 'profileSQL' instead. Trace queries and their execution/fetch times on STDERR (true/false) defaults to 'false' | 2.0.14 | |
| reportMetricsIntervalMillis | If 'gatherPerfMetrics' is enabled, how often should they be logged (in ms)? | 30000 | 3.1.2 |
| maxQuerySizeToLog | Controls the maximum length/size of a query that will get logged when profiling or tracing | 2048 | 3.1.3 |
| packetDebugBufferSize | The maximum number of packets to retain when 'enablePacketDebug' is true | 20 | 3.1.3 |
| slowQueryThresholdMillis | If 'logSlowQueries' is enabled, how long should a query (in ms) before it is logged as 'slow'? | 2000 | 3.1.2 |
| slowQueryThresholdNanos | If 'useNanosForElapsedTime' is set to true, and this property is set to a non-zero value, the driver will use this threshold (in nanosecond units) to determine if a query was slow. | 0 | 5.0.7 |
| useUsageAdvisor | Should the driver issue 'usage' warnings advising proper and efficient usage of JDBC and MySQL Connector/J to the log (true/false, defaults to 'false')? | false | 3.1.1 |
| autoGenerateTestcaseScript | Should the driver dump the SQL it is executing, including server-side prepared statements to STDERR? | false | 3.1.9 |
| clientInfoProvider | The name of a class that implements the com.mysql.jdbc.JDBC4ClientInfoProvider interface in order to support JDBC-4.0's Connection.get/setClientInfo() methods | com.mysql.jdbc.JDBC4CommentClientInfoProvider | 5.1.0 |
| dumpMetadataOnColumnNotFound | Should the driver dump the field-level metadata of a result set into the exception message when ResultSet.findColumn() fails? | false | 3.1.13 |
| dumpQueriesOnException | Should the driver dump the contents of the query sent to the server in the message for SQLExceptions? | false | 3.1.3 |
| enablePacketDebug | When enabled, a ring-buffer of 'packetDebugBufferSize' packets will be kept, and dumped when exceptions are thrown in key areas in the driver's code | false | 3.1.3 |
| explainSlowQueries | If 'logSlowQueries' is enabled, should the driver automatically issue an 'EXPLAIN' on the server and send the results to the configured log at a WARN level? | false | 3.1.2 |
| logSlowQueries | Should queries that take longer than 'slowQueryThresholdMillis' be logged? | false | 3.1.2 |
| logXaCommands | Should the driver log XA commands sent by MysqlXaConnection to the server, at the DEBUG level of logging? | false | 5.0.5 |
| resultSetSizeThreshold | If the usage advisor is enabled, how many rows should a result set contain before the driver warns that it is suspiciously large? | 100 | 5.0.5 |
| traceProtocol | Should trace-level network protocol be logged? | false | 3.1.2 |
| useNanosForElapsedTime | For profiling/debugging functionality that measures elapsed time, should the driver try to use nanoseconds resolution if available (JDK >= 1.5)? | false | 5.0.7 |
Miscellaneous.
| Property Name | Definition | Default Value | Since Version |
| useUnicode | Should the driver use Unicode character encodings when handling strings? Should only be used when the driver can't determine the character set mapping, or you are trying to 'force' the driver to use a character set that MySQL either doesn't natively support (such as UTF-8), true/false, defaults to 'true' | true | 1.1g |
| characterEncoding | If 'useUnicode' is set to true, what character encoding should the driver use when dealing with strings? (defaults is to 'autodetect') | 1.1g | |
| characterSetResults | Character set to tell the server to return results as. | 3.0.13 | |
| connectionCollation | If set, tells the server to use this collation via 'set collation_connection' | 3.0.13 | |
| sessionVariables | A comma-separated list of name/value pairs to be sent as SET SESSION ... to the server when the driver connects. | 3.1.8 | |
| allowNanAndInf | Should the driver allow NaN or +/- INF values in PreparedStatement.setDouble()? | false | 3.1.5 |
| autoClosePStmtStreams | Should the driver automatically call .close() on streams/readers passed as arguments via set*() methods? | false | 3.1.12 |
| autoDeserialize | Should the driver automatically detect and de-serialize objects stored in BLOB fields? | false | 3.1.5 |
| capitalizeTypeNames | Capitalize type names in DatabaseMetaData? (usually only useful when using WebObjects, true/false, defaults to 'false') | false | 2.0.7 |
| clobCharacterEncoding | The character encoding to use for sending and retrieving TEXT, MEDIUMTEXT and LONGTEXT values instead of the configured connection characterEncoding | 5.0.0 | |
| clobberStreamingResults | This will cause a 'streaming' ResultSet to be automatically closed, and any outstanding data still streaming from the server to be discarded if another query is executed before all the data has been read from the server. | false | 3.0.9 |
| continueBatchOnError | Should the driver continue processing batch commands if one statement fails. The JDBC spec allows either way (defaults to 'true'). | true | 3.0.3 |
| createDatabaseIfNotExist | Creates the database given in the URL if it doesn't yet exist. Assumes the configured user has permissions to create databases. | false | 3.1.9 |
| emptyStringsConvertToZero | Should the driver allow conversions from empty string fields to numeric values of '0'? | true | 3.1.8 |
| emulateLocators | Should the driver emulate java.sql.Blobs with locators? With this feature enabled, the driver will delay loading the actual Blob data until the one of the retrieval methods (getInputStream(), getBytes(), and so forth) on the blob data stream has been accessed. For this to work, you must use a column alias with the value of the column to the actual name of the Blob. The feature also has the following restrictions: The SELECT that created the result set must reference only one table, the table must have a primary key; the SELECT must alias the original blob column name, specified as a string, to an alternate name; the SELECT must cover all columns that make up the primary key. | false | 3.1.0 |
| emulateUnsupportedPstmts | Should the driver detect prepared statements that are not supported by the server, and replace them with client-side emulated versions? | true | 3.1.7 |
| generateSimpleParameterMetadata | Should the driver generate simplified parameter metadata for PreparedStatements when no metadata is available either because the server couldn't support preparing the statement, or server-side prepared statements are disabled? | false | 5.0.5 |
| ignoreNonTxTables | Ignore non-transactional table warning for rollback? (defaults to 'false'). | false | 3.0.9 |
| jdbcCompliantTruncation | Should the driver throw java.sql.DataTruncation exceptions when data is truncated as is required by the JDBC specification when connected to a server that supports warnings (MySQL 4.1.0 and newer)? | true | 3.1.2 |
| maxRows | The maximum number of rows to return (0, the default means return all rows). | -1 | all versions |
| netTimeoutForStreamingResults | What value should the driver automatically set the server setting 'net_write_timeout' to when the streaming result sets feature is in use? (value has unit of seconds, the value '0' means the driver will not try and adjust this value) | 600 | 5.1.0 |
| noAccessToProcedureBodies | When determining procedure parameter types for CallableStatements, and the connected user can't access procedure bodies through "SHOW CREATE PROCEDURE" or select on mysql.proc should the driver instead create basic metadata (all parameters reported as INOUT VARCHARs) instead of throwing an exception? | false | 5.0.3 |
| noDatetimeStringSync | Don't ensure that ResultSet.getDatetimeType().toString().equals(ResultSet.getString()) | false | 3.1.7 |
| noTimezoneConversionForTimeType | Don't convert TIME values using the server timezone if 'useTimezone'='true' | false | 5.0.0 |
| nullCatalogMeansCurrent | When DatabaseMetadataMethods ask for a 'catalog' parameter, does the value null mean use the current catalog? (this is not JDBC-compliant, but follows legacy behavior from earlier versions of the driver) | true | 3.1.8 |
| nullNamePatternMatchesAll | Should DatabaseMetaData methods that accept *pattern parameters treat null the same as '%' (this is not JDBC-compliant, however older versions of the driver accepted this departure from the specification) | true | 3.1.8 |
| overrideSupportsIntegrityEnhancementFacility | Should the driver return "true" for DatabaseMetaData.supportsIntegrityEnhancementFacility() even if the database doesn't support it to workaround applications that require this method to return "true" to signal support of foreign keys, even though the SQL specification states that this facility contains much more than just foreign key support (one such application being OpenOffice)? | false | 3.1.12 |
| padCharsWithSpace | If a result set column has the CHAR type and the value does not fill the amount of characters specified in the DDL for the column, should the driver pad the remaining characters with space (for ANSI compliance)? | false | 5.0.6 |
| pedantic | Follow the JDBC spec to the letter. | false | 3.0.0 |
| pinGlobalTxToPhysicalConnection | When using XAConnections, should the driver ensure that operations on a given XID are always routed to the same physical connection? This allows the XAConnection to support "XA START ... JOIN" after "XA END" has been called | false | 5.0.1 |
| populateInsertRowWithDefaultValues | When using ResultSets that are CONCUR_UPDATABLE, should the driver pre-poulate the "insert" row with default values from the DDL for the table used in the query so those values are immediately available for ResultSet accessors? This functionality requires a call to the database for metadata each time a result set of this type is created. If disabled (the default), the default values will be populated by the an internal call to refreshRow() which pulls back default values and/or values changed by triggers. | false | 5.0.5 |
| processEscapeCodesForPrepStmts | Should the driver process escape codes in queries that are prepared? | true | 3.1.12 |
| relaxAutoCommit | If the version of MySQL the driver connects to does not support transactions, still allow calls to commit(), rollback() and setAutoCommit() (true/false, defaults to 'false')? | false | 2.0.13 |
| retainStatementAfterResultSetClose | Should the driver retain the Statement reference in a ResultSet after ResultSet.close() has been called. This is not JDBC-compliant after JDBC-4.0. | false | 3.1.11 |
| rollbackOnPooledClose | Should the driver issue a rollback() when the logical connection in a pool is closed? | true | 3.0.15 |
| runningCTS13 | Enables workarounds for bugs in Sun's JDBC compliance testsuite version 1.3 | false | 3.1.7 |
| serverTimezone | Override detection/mapping of timezone. Used when timezone from server doesn't map to Java timezone | 3.0.2 | |
| statementInterceptors | A comma-delimited list of classes that implement "" that should be placed "in between" query execution to influence the results. StatementInterceptors are "chainable", the results returned by the "current" interceptor will be passed on to the next in in the chain, from left-to-right order, as specified in this property. | 5.1.1 | |
| strictFloatingPoint | Used only in older versions of compliance test | false | 3.0.0 |
| strictUpdates | Should the driver do strict checking (all primary keys selected) of updatable result sets (true, false, defaults to 'true')? | true | 3.0.4 |
| tinyInt1isBit | Should the driver treat the datatype TINYINT(1) as the BIT type (because the server silently converts BIT -> TINYINT(1) when creating tables)? | true | 3.0.16 |
| transformedBitIsBoolean | If the driver converts TINYINT(1) to a different type, should it use BOOLEAN instead of BIT for future compatibility with MySQL-5.0, as MySQL-5.0 has a BIT type? | false | 3.1.9 |
| treatUtilDateAsTimestamp | Should the driver treat java.util.Date as a TIMESTAMP for the purposes of PreparedStatement.setObject()? | true | 5.0.5 |
| ultraDevHack | Create PreparedStatements for prepareCall() when required, because UltraDev is broken and issues a prepareCall() for _all_ statements? (true/false, defaults to 'false') | false | 2.0.3 |
| useGmtMillisForDatetimes | Convert between session timezone and GMT before creating Date and Timestamp instances (value of "false" is legacy behavior, "true" leads to more JDBC-compliant behavior. | false | 3.1.12 |
| useHostsInPrivileges | Add '@hostname' to users in DatabaseMetaData.getColumn/TablePrivileges() (true/false), defaults to 'true'. | true | 3.0.2 |
| useInformationSchema | When connected to MySQL-5.0.7 or newer, should the driver use the INFORMATION_SCHEMA to derive information used by DatabaseMetaData? | false | 5.0.0 |
| useJDBCCompliantTimezoneShift | Should the driver use JDBC-compliant rules when converting TIME/TIMESTAMP/DATETIME values' timezone information for those JDBC arguments which take a java.util.Calendar argument? (Notice that this option is exclusive of the "useTimezone=true" configuration option.) | false | 5.0.0 |
| useOldAliasMetadataBehavior | Should the driver use the legacy behavior for "AS" clauses on columns and tables, and only return aliases (if any) for ResultSetMetaData.getColumnName() or ResultSetMetaData.getTableName() rather than the original column/table name? | false | 5.0.4 |
| useOldUTF8Behavior | Use the UTF-8 behavior the driver did when communicating with 4.0 and older servers | false | 3.1.6 |
| useOnlyServerErrorMessages | Don't prepend 'standard' SQLState error messages to error messages returned by the server. | true | 3.0.15 |
| useSSPSCompatibleTimezoneShift | If migrating from an environment that was using server-side prepared statements, and the configuration property "useJDBCCompliantTimeZoneShift" set to "true", use compatible behavior when not using server-side prepared statements when sending TIMESTAMP values to the MySQL server. | false | 5.0.5 |
| useServerPrepStmts | Use server-side prepared statements if the server supports them? | false | 3.1.0 |
| useSqlStateCodes | Use SQL Standard state codes instead of 'legacy' X/Open/SQL state codes (true/false), default is 'true' | true | 3.1.3 |
| useStreamLengthsInPrepStmts | Honor stream length parameter in PreparedStatement/ResultSet.setXXXStream() method calls (true/false, defaults to 'true')? | true | 3.0.2 |
| useTimezone | Convert time/date types between client and server timezones (true/false, defaults to 'false')? | false | 3.0.2 |
| useUnbufferedInput | Don't use BufferedInputStream for reading data from the server | true | 3.0.11 |
| yearIsDateType | Should the JDBC driver treat the MySQL type "YEAR" as a java.sql.Date, or as a SHORT? | true | 3.1.9 |
| zeroDateTimeBehavior | What should happen when the driver encounters DATETIME values that are composed entirely of zeroes (used by MySQL to represent invalid dates)? Valid values are ${0}, ${1} and ${2}. | exception | 3.1.4 |
Connector/J also supports access to MySQL via named pipes on
Windows NT/2000/XP using the
NamedPipeSocketFactory as a plugin-socket
factory via the socketFactory property. If
you don't use a namedPipePath property, the
default of '\\.\pipe\MySQL' will be used. If you use the
NamedPipeSocketFactory, the hostname and port
number values in the JDBC url will be ignored. You can enable
this feature using:
socketFactory=com.mysql.jdbc.NamedPipeSocketFactory
Named pipes only work when connecting to a MySQL server on the same physical machine as the one the JDBC driver is being used on. In simple performance tests, it appears that named pipe access is between 30%-50% faster than the standard TCP/IP access.
You can create your own socket factories by following the
example code in
com.mysql.jdbc.NamedPipeSocketFactory, or
com.mysql.jdbc.StandardSocketFactory.
MySQL Connector/J passes all of the tests in the publicly-available version of Sun's JDBC compliance test suite. However, in many places the JDBC specification is vague about how certain functionality should be implemented, or the specification allows leeway in implementation.
This section gives details on a interface-by-interface level about how certain implementation decisions may affect how you use MySQL Connector/J.
Blob
Starting with Connector/J version 3.1.0, you can emulate Blobs with locators by adding the property 'emulateLocators=true' to your JDBC URL. Using this method, the driver will delay loading the actual Blob data until you retrieve the other data and then use retrieval methods (
getInputStream(),getBytes(), and so forth) on the blob data stream.For this to work, you must use a column alias with the value of the column to the actual name of the Blob, for example:
SELECT id, 'data' as blob_data from blobtable
For this to work, you must also follow follow these rules:
The
SELECTmust also reference only one table, the table must have a primary key.The
SELECTmust alias the original blob column name, specified as a string, to an alternate name.The
SELECTmust cover all columns that make up the primary key.
The Blob implementation does not allow in-place modification (they are copies, as reported by the
DatabaseMetaData.locatorsUpdateCopies()method). Because of this, you should use the correspondingPreparedStatement.setBlob()orResultSet.updateBlob()(in the case of updatable result sets) methods to save changes back to the database.CallableStatement
Starting with Connector/J 3.1.1, stored procedures are supported when connecting to MySQL version 5.0 or newer via the
CallableStatementinterface. Currently, thegetParameterMetaData()method ofCallableStatementis not supported.Clob
The Clob implementation does not allow in-place modification (they are copies, as reported by the
DatabaseMetaData.locatorsUpdateCopies()method). Because of this, you should use thePreparedStatement.setClob()method to save changes back to the database. The JDBC API does not have aResultSet.updateClob()method.Connection
Unlike older versions of MM.MySQL the
isClosed()method does not ping the server to determine if it is alive. In accordance with the JDBC specification, it only returns true ifclosed()has been called on the connection. If you need to determine if the connection is still valid, you should issue a simple query, such asSELECT 1. The driver will throw an exception if the connection is no longer valid.DatabaseMetaData
Foreign Key information (
getImportedKeys()/getExportedKeys()andgetCrossReference()) is only available from InnoDB tables. However, the driver usesSHOW CREATE TABLEto retrieve this information, so when other storage engines support foreign keys, the driver will transparently support them as well.PreparedStatement
PreparedStatements are implemented by the driver, as MySQL does not have a prepared statement feature. Because of this, the driver does not implement
getParameterMetaData()orgetMetaData()as it would require the driver to have a complete SQL parser in the client.Starting with version 3.1.0 MySQL Connector/J, server-side prepared statements and binary-encoded result sets are used when the server supports them.
Take care when using a server-side prepared statement with large parameters that are set via
setBinaryStream(),setAsciiStream(),setUnicodeStream(),setBlob(), orsetClob(). If you want to re-execute the statement with any large parameter changed to a non-large parameter, it is necessary to callclearParameters()and set all parameters again. The reason for this is as follows:During both server-side prepared statements and client-side emulation, large data is exchanged only when
PreparedStatement.execute()is called.
Once that has been done, the stream used to read the data on the client side is closed (as per the JDBC spec), and can't be read from again.
If a parameter changes from large to non-large, the driver must reset the server-side state of the prepared statement to allow the parameter that is being changed to take the place of the prior large value. This removes all of the large data that has already been sent to the server, thus requiring the data to be re-sent, via the
setBinaryStream(),setAsciiStream(),setUnicodeStream(),setBlob()orsetClob()methods.
Consequently, if you want to change the type of a parameter to a non-large one, you must call
clearParameters()and set all parameters of the prepared statement again before it can be re-executed.ResultSet
By default, ResultSets are completely retrieved and stored in memory. In most cases this is the most efficient way to operate, and due to the design of the MySQL network protocol is easier to implement. If you are working with ResultSets that have a large number of rows or large values, and can not allocate heap space in your JVM for the memory required, you can tell the driver to stream the results back one row at a time.
To enable this functionality, you need to create a Statement instance in the following manner:
stmt = conn.createStatement(java.sql.ResultSet.TYPE_FORWARD_ONLY, java.sql.ResultSet.CONCUR_READ_ONLY); stmt.setFetchSize(Integer.MIN_VALUE);The combination of a forward-only, read-only result set, with a fetch size of
Integer.MIN_VALUEserves as a signal to the driver to stream result sets row-by-row. After this any result sets created with the statement will be retrieved row-by-row.There are some caveats with this approach. You will have to read all of the rows in the result set (or close it) before you can issue any other queries on the connection, or an exception will be thrown.
The earliest the locks these statements hold can be released (whether they be
MyISAMtable-level locks or row-level locks in some other storage engine such asInnoDB) is when the statement completes.If the statement is within scope of a transaction, then locks are released when the transaction completes (which implies that the statement needs to complete first). As with most other databases, statements are not complete until all the results pending on the statement are read or the active result set for the statement is closed.
Therefore, if using streaming results, you should process them as quickly as possible if you want to maintain concurrent access to the tables referenced by the statement producing the result set.
ResultSetMetaData
The
isAutoIncrement()method only works when using MySQL servers 4.0 and newer.Statement
When using versions of the JDBC driver earlier than 3.2.1, and connected to server versions earlier than 5.0.3, the
setFetchSize()method has no effect, other than to toggle result set streaming as described above.Connector/J 5.0.0 and later include support for both
Statement.cancel()andStatement.setQueryTimeout(). Both require MySQL 5.0.0 or newer server, and require a separate connection to issue theKILL QUERYstatement. In the case ofsetQueryTimeout(), the implementation creates an additional thread to handle the timeout functionality.Note
Failures to cancel the statement for
setQueryTimeout()may manifest themselves asRuntimeExceptionrather than failing silently, as there is currently no way to unblock the thread that is executing the query being cancelled due to timeout expiration and have it throw the exception instead.MySQL does not support SQL cursors, and the JDBC driver doesn't emulate them, so "setCursorName()" has no effect.
MySQL Connector/J is flexible in the way it handles conversions between MySQL data types and Java data types.
In general, any MySQL data type can be converted to a java.lang.String, and any numerical type can be converted to any of the Java numerical types, although round-off, overflow, or loss of precision may occur.
Starting with Connector/J 3.1.0, the JDBC driver will issue
warnings or throw DataTruncation exceptions as is required by
the JDBC specification unless the connection was configured not
to do so by using the property
jdbcCompliantTruncation and setting it to
false.
The conversions that are always guaranteed to work are listed in the following table:
Connection Properties - Miscellaneous.
| These MySQL Data Types | Can always be converted to these Java types |
CHAR, VARCHAR, BLOB, TEXT, ENUM, and SET | java.lang.String, java.io.InputStream, java.io.Reader,
java.sql.Blob, java.sql.Clob |
FLOAT, REAL, DOUBLE PRECISION, NUMERIC, DECIMAL, TINYINT,
SMALLINT, MEDIUMINT, INTEGER, BIGINT | java.lang.String, java.lang.Short, java.lang.Integer,
java.lang.Long, java.lang.Double,
java.math.BigDecimal |
DATE, TIME, DATETIME, TIMESTAMP | java.lang.String, java.sql.Date, java.sql.Timestamp |
Note
Round-off, overflow or loss of precision may occur if you choose a Java numeric data type that has less precision or capacity than the MySQL data type you are converting to/from.
The ResultSet.getObject() method uses the
type conversions between MySQL and Java types, following the
JDBC specification where appropriate. The value returned by
ResultSetMetaData.GetColumnClassName() is
also shown below. For more information on the
java.sql.Types classes see
Java
2 Platform Types.
MySQL Types to Java Types for ResultSet.getObject().
| MySQL Type Name | Return value of
GetColumnClassName | Returned as Java Class |
| BIT(1) (new in MySQL-5.0) | BIT | java.lang.Boolean |
| BIT( > 1) (new in MySQL-5.0) | BIT | byte[] |
| TINYINT | TINYINT | java.lang.Boolean if the configuration property
tinyInt1isBit is set to
true (the default) and the
storage size is 1, or
java.lang.Integer if not. |
| BOOL, BOOLEAN | TINYINT | See TINYINT, above as these are aliases for TINYINT(1), currently. |
| SMALLINT[(M)] [UNSIGNED] | SMALLINT [UNSIGNED] | java.lang.Integer (regardless if UNSIGNED or not) |
| MEDIUMINT[(M)] [UNSIGNED] | MEDIUMINT [UNSIGNED] | java.lang.Integer, if UNSIGNED
java.lang.Long |
| INT,INTEGER[(M)] [UNSIGNED] | INTEGER [UNSIGNED] | java.lang.Integer, if UNSIGNED
java.lang.Long |
| BIGINT[(M)] [UNSIGNED] | BIGINT [UNSIGNED] | java.lang.Long, if UNSIGNED
java.math.BigInteger |
| FLOAT[(M,D)] | FLOAT | java.lang.Float |
| DOUBLE[(M,B)] | DOUBLE | java.lang.Double |
| DECIMAL[(M[,D])] | DECIMAL | java.math.BigDecimal |
| DATE | DATE | java.sql.Date |
| DATETIME | DATETIME | java.sql.Timestamp |
| TIMESTAMP[(M)] | TIMESTAMP | java.sql.Timestamp |
| TIME | TIME | java.sql.Time |
| YEAR[(2|4)] | YEAR | If yearIsDateType configuration property is set to
false, then the returned object type is
java.sql.Short. If set to
true (the default) then an object of type
java.sql.Date (with the date
set to January 1st, at midnight). |
| CHAR(M) | CHAR | java.lang.String (unless the character set for
the column is BINARY, then
byte[] is returned. |
| VARCHAR(M) [BINARY] | VARCHAR | java.lang.String (unless the character set for
the column is BINARY, then
byte[] is returned. |
| BINARY(M) | BINARY | byte[] |
| VARBINARY(M) | VARBINARY | byte[] |
| TINYBLOB | TINYBLOB | byte[] |
| TINYTEXT | VARCHAR | java.lang.String |
| BLOB | BLOB | byte[] |
| TEXT | VARCHAR | java.lang.String |
| MEDIUMBLOB | MEDIUMBLOB | byte[] |
| MEDIUMTEXT | VARCHAR | java.lang.String |
| LONGBLOB | LONGBLOB | byte[] |
| LONGTEXT | VARCHAR | java.lang.String |
| ENUM('value1','value2',...) | CHAR | java.lang.String |
| SET('value1','value2',...) | CHAR | java.lang.String |
All strings sent from the JDBC driver to the server are
converted automatically from native Java Unicode form to the
client character encoding, including all queries sent via
Statement.execute(),
Statement.executeUpdate(),
Statement.executeQuery() as well as all
PreparedStatement
and
CallableStatement
parameters with the exclusion of parameters set using
setBytes(),
setBinaryStream(),
setAsciiStream(),
setUnicodeStream() and
setBlob() .
Prior to MySQL Server 4.1, Connector/J supported a single
character encoding per connection, which could either be
automatically detected from the server configuration, or could
be configured by the user through the
useUnicode and
characterEncoding properties.
Starting with MySQL Server 4.1, Connector/J supports a single
character encoding between client and server, and any number of
character encodings for data returned by the server to the
client in ResultSets.
The character encoding between client and server is
automatically detected upon connection. The encoding used by the
driver is specified on the server via the
character_set system variable for server
versions older than 4.1.0 and
character_set_server for server versions
4.1.0 and newer. For more information, see
Section 10.3.1, “Server Character Set and Collation”.
To override the automatically-detected encoding on the client
side, use the characterEncoding property
in the URL used to connect to the server.
When specifying character encodings on the client side, Java-style names should be used. The following table lists Java-style names for MySQL character sets:
MySQL to Java Encoding Name Translations.
| MySQL Character Set Name | Java-Style Character Encoding Name |
| ascii | US-ASCII |
| big5 | Big5 |
| gbk | GBK |
| sjis | SJIS (or Cp932 or MS932 for MySQL Server < 4.1.11) |
| cp932 | Cp932 or MS932 (MySQL Server > 4.1.11) |
| gb2312 | EUC_CN |
| ujis | EUC_JP |
| euckr | EUC_KR |
| latin1 | ISO8859_1 |
| latin2 | ISO8859_2 |
| greek | ISO8859_7 |
| hebrew | ISO8859_8 |
| cp866 | Cp866 |
| tis620 | TIS620 |
| cp1250 | Cp1250 |
| cp1251 | Cp1251 |
| cp1257 | Cp1257 |
| macroman | MacRoman |
| macce | MacCentralEurope |
| utf8 | UTF-8 |
| ucs2 | UnicodeBig |
Warning
Do not issue the query 'set names' with Connector/J, as the driver will not detect that the character set has changed, and will continue to use the character set detected during the initial connection setup.
To allow multiple character sets to be sent from the client, the
UTF-8 encoding should be used, either by configuring
utf8 as the default server character set, or
by configuring the JDBC driver to use UTF-8 through the
characterEncoding property.
SSL in MySQL Connector/J encrypts all data (other than the initial handshake) between the JDBC driver and the server. The performance penalty for enabling SSL is an increase in query processing time between 35% and 50%, depending on the size of the query, and the amount of data it returns.
For SSL Support to work, you must have the following:
A JDK that includes JSSE (Java Secure Sockets Extension), like JDK-1.4.1 or newer. SSL does not currently work with a JDK that you can add JSSE to, like JDK-1.2.x or JDK-1.3.x due to the following JSSE bug: http://developer.java.sun.com/developer/bugParade/bugs/4273544.html
A MySQL server that supports SSL and has been compiled and configured to do so, which is MySQL-4.0.4 or later, see Section 5.8.7, “Using Secure Connections”, for more information.
A client certificate (covered later in this section)
You will first need to import the MySQL server CA Certificate
into a Java truststore. A sample MySQL server CA Certificate is
located in the SSL subdirectory of the
MySQL source distribution. This is what SSL will use to
determine if you are communicating with a secure MySQL server.
To use Java's keytool to create a truststore
in the current directory , and import the server's CA
certificate (cacert.pem), you can do the
following (assuming that keytool is in your
path. The keytool should be located in the
bin subdirectory of your JDK or JRE):
shell> keytool -import -alias mysqlServerCACert \
-file cacert.pem -keystore truststoreKeytool will respond with the following information:
Enter keystore password: *********
Owner: EMAILADDRESS=walrus@example.com, CN=Walrus,
O=MySQL AB, L=Orenburg, ST=Some-State, C=RU
Issuer: EMAILADDRESS=walrus@example.com, CN=Walrus,
O=MySQL AB, L=Orenburg, ST=Some-State, C=RU
Serial number: 0
Valid from:
Fri Aug 02 16:55:53 CDT 2002 until: Sat Aug 02 16:55:53 CDT 2003
Certificate fingerprints:
MD5: 61:91:A0:F2:03:07:61:7A:81:38:66:DA:19:C4:8D:AB
SHA1: 25:77:41:05:D5:AD:99:8C:14:8C:CA:68:9C:2F:B8:89:C3:34:4D:6C
Trust this certificate? [no]: yes
Certificate was added to keystoreYou will then need to generate a client certificate, so that the MySQL server knows that it is talking to a secure client:
shell> keytool -genkey -keyalg rsa \
-alias mysqlClientCertificate -keystore keystore
Keytool will prompt you for the following information, and
create a keystore named keystore in the
current directory.
You should respond with information that is appropriate for your situation:
Enter keystore password: *********
What is your first and last name?
[Unknown]: Matthews
What is the name of your organizational unit?
[Unknown]: Software Development
What is the name of your organization?
[Unknown]: MySQL AB
What is the name of your City or Locality?
[Unknown]: Flossmoor
What is the name of your State or Province?
[Unknown]: IL
What is the two-letter country code for this unit?
[Unknown]: US
Is <CN=Matthews, OU=Software Development, O=MySQL AB,
L=Flossmoor, ST=IL, C=US> correct?
[no]: y
Enter key password for <mysqlClientCertificate>
(RETURN if same as keystore password):Finally, to get JSSE to use the keystore and truststore that you have generated, you need to set the following system properties when you start your JVM, replacing path_to_keystore_file with the full path to the keystore file you created, path_to_truststore_file with the path to the truststore file you created, and using the appropriate password values for each property. You can do this either on the command line:
-Djavax.net.ssl.keyStore=path_to_keystore_file -Djavax.net.ssl.keyStorePassword=password -Djavax.net.ssl.trustStore=path_to_truststore_file -Djavax.net.ssl.trustStorePassword=password
Or you can set the values directly within the application:
System.setProperty("javax.net.ssl.keyStore","path_to_keystore_file");
System.setProperty("javax.net.ssl.keyStorePassword","password");
System.setProperty("javax.net.ssl.trustStore","path_to_truststore_file");
System.setProperty("javax.net.ssl.trustStorePassword","password");
You will also need to set useSSL to
true in your connection parameters for MySQL
Connector/J, either by adding useSSL=true to
your URL, or by setting the property useSSL
to true in the
java.util.Properties instance you pass to
DriverManager.getConnection().
You can test that SSL is working by turning on JSSE debugging (as detailed below), and look for the following key events:
...
*** ClientHello, v3.1
RandomCookie: GMT: 1018531834 bytes = { 199, 148, 180, 215, 74, 12, »
54, 244, 0, 168, 55, 103, 215, 64, 16, 138, 225, 190, 132, 153, 2, »
217, 219, 239, 202, 19, 121, 78 }
Session ID: {}
Cipher Suites: { 0, 5, 0, 4, 0, 9, 0, 10, 0, 18, 0, 19, 0, 3, 0, 17 }
Compression Methods: { 0 }
***
[write] MD5 and SHA1 hashes: len = 59
0000: 01 00 00 37 03 01 3D B6 90 FA C7 94 B4 D7 4A 0C ...7..=.......J.
0010: 36 F4 00 A8 37 67 D7 40 10 8A E1 BE 84 99 02 D9 6...7g.@........
0020: DB EF CA 13 79 4E 00 00 10 00 05 00 04 00 09 00 ....yN..........
0030: 0A 00 12 00 13 00 03 00 11 01 00 ...........
main, WRITE: SSL v3.1 Handshake, length = 59
main, READ: SSL v3.1 Handshake, length = 74
*** ServerHello, v3.1
RandomCookie: GMT: 1018577560 bytes = { 116, 50, 4, 103, 25, 100, 58, »
202, 79, 185, 178, 100, 215, 66, 254, 21, 83, 187, 190, 42, 170, 3, »
132, 110, 82, 148, 160, 92 }
Session ID: {163, 227, 84, 53, 81, 127, 252, 254, 178, 179, 68, 63, »
182, 158, 30, 11, 150, 79, 170, 76, 255, 92, 15, 226, 24, 17, 177, »
219, 158, 177, 187, 143}
Cipher Suite: { 0, 5 }
Compression Method: 0
***
%% Created: [Session-1, SSL_RSA_WITH_RC4_128_SHA]
** SSL_RSA_WITH_RC4_128_SHA
[read] MD5 and SHA1 hashes: len = 74
0000: 02 00 00 46 03 01 3D B6 43 98 74 32 04 67 19 64 ...F..=.C.t2.g.d
0010: 3A CA 4F B9 B2 64 D7 42 FE 15 53 BB BE 2A AA 03 :.O..d.B..S..*..
0020: 84 6E 52 94 A0 5C 20 A3 E3 54 35 51 7F FC FE B2 .nR..\ ..T5Q....
0030: B3 44 3F B6 9E 1E 0B 96 4F AA 4C FF 5C 0F E2 18 .D?.....O.L.\...
0040: 11 B1 DB 9E B1 BB 8F 00 05 00 ..........
main, READ: SSL v3.1 Handshake, length = 1712
...
JSSE provides debugging (to STDOUT) when you set the following
system property: -Djavax.net.debug=all This
will tell you what keystores and truststores are being used, as
well as what is going on during the SSL handshake and
certificate exchange. It will be helpful when trying to
determine what is not working when trying to get an SSL
connection to happen.
Starting with Connector/J 3.1.7, we've made available a variant
of the driver that will automatically send queries to a
read/write master, or a failover or round-robin loadbalanced set
of slaves based on the state of
Connection.getReadOnly() .
An application signals that it wants a transaction to be
read-only by calling
Connection.setReadOnly(true), this
replication-aware connection will use one of the slave
connections, which are load-balanced per-vm using a round-robin
scheme (a given connection is sticky to a slave unless that
slave is removed from service). If you have a write transaction,
or if you have a read that is time-sensitive (remember,
replication in MySQL is asynchronous), set the connection to be
not read-only, by calling
Connection.setReadOnly(false) and the driver
will ensure that further calls are sent to the master MySQL
server. The driver takes care of propagating the current state
of autocommit, isolation level, and catalog between all of the
connections that it uses to accomplish this load balancing
functionality.
To enable this functionality, use the "
com.mysql.jdbc.ReplicationDriver " class when
configuring your application server's connection pool or when
creating an instance of a JDBC driver for your standalone
application. Because it accepts the same URL format as the
standard MySQL JDBC driver, ReplicationDriver
does not currently work with
java.sql.DriverManager -based connection
creation unless it is the only MySQL JDBC driver registered with
the DriverManager .
Here is a short, simple example of how ReplicationDriver might be used in a standalone application.
import java.sql.Connection;
import java.sql.ResultSet;
import java.util.Properties;
import com.mysql.jdbc.ReplicationDriver;
public class ReplicationDriverDemo {
public static void main(String[] args) throws Exception {
ReplicationDriver driver = new ReplicationDriver();
Properties props = new Properties();
// We want this for failover on the slaves
props.put("autoReconnect", "true");
// We want to load balance between the slaves
props.put("roundRobinLoadBalance", "true");
props.put("user", "foo");
props.put("password", "bar");
//
// Looks like a normal MySQL JDBC url, with a
// comma-separated list of hosts, the first
// being the 'master', the rest being any number
// of slaves that the driver will load balance against
//
Connection conn =
driver.connect("jdbc:mysql://master,slave1,slave2,slave3/test",
props);
//
// Perform read/write work on the master
// by setting the read-only flag to "false"
//
conn.setReadOnly(false);
conn.setAutoCommit(false);
conn.createStatement().executeUpdate("UPDATE some_table ....");
conn.commit();
//
// Now, do a query from a slave, the driver automatically picks one
// from the list
//
conn.setReadOnly(true);
ResultSet rs =
conn.createStatement().executeQuery("SELECT a,b FROM alt_table");
.......
}
}
The table below provides a mapping of the MySQL Error Numbers to
SQL States
Table 23.1. Mapping of MySQL Error Numbers to SQLStates
| MySQL Error Number | MySQL Error Name | Legacy (X/Open) SQLState | SQL Standard SQLState |
|---|---|---|---|
| 1022 | ER_DUP_KEY | S1000 | 23000 |
| 1037 | ER_OUTOFMEMORY | S1001 | HY001 |
| 1038 | ER_OUT_OF_SORTMEMORY | S1001 | HY001 |
| 1040 | ER_CON_COUNT_ERROR | 08004 | 08004 |
| 1042 | ER_BAD_HOST_ERROR | 08004 | 08S01 |
| 1043 | ER_HANDSHAKE_ERROR | 08004 | 08S01 |
| 1044 | ER_DBACCESS_DENIED_ERROR | S1000 | 42000 |
| 1045 | ER_ACCESS_DENIED_ERROR | 28000 | 28000 |
| 1047 | ER_UNKNOWN_COM_ERROR | 08S01 | HY000 |
| 1050 | ER_TABLE_EXISTS_ERROR | S1000 | 42S01 |
| 1051 | ER_BAD_TABLE_ERROR | 42S02 | 42S02 |
| 1052 | ER_NON_UNIQ_ERROR | S1000 | 23000 |
| 1053 | ER_SERVER_SHUTDOWN | S1000 | 08S01 |
| 1054 | ER_BAD_FIELD_ERROR | S0022 | 42S22 |
| 1055 | ER_WRONG_FIELD_WITH_GROUP | S1009 | 42000 |
| 1056 | ER_WRONG_GROUP_FIELD | S1009 | 42000 |
| 1057 | ER_WRONG_SUM_SELECT | S1009 | 42000 |
| 1058 | ER_WRONG_VALUE_COUNT | 21S01 | 21S01 |
| 1059 | ER_TOO_LONG_IDENT | S1009 | 42000 |
| 1060 | ER_DUP_FIELDNAME | S1009 | 42S21 |
| 1061 | ER_DUP_KEYNAME | S1009 | 42000 |
| 1062 | ER_DUP_ENTRY | S1009 | 23000 |
| 1063 | ER_WRONG_FIELD_SPEC | S1009 | 42000 |
| 1064 | ER_PARSE_ERROR | 42000 | 42000 |
| 1065 | ER_EMPTY_QUERY | 42000 | 42000 |
| 1066 | ER_NONUNIQ_TABLE | S1009 | 42000 |
| 1067 | ER_INVALID_DEFAULT | S1009 | 42000 |
| 1068 | ER_MULTIPLE_PRI_KEY | S1009 | 42000 |
| 1069 | ER_TOO_MANY_KEYS | S1009 | 42000 |
| 1070 | ER_TOO_MANY_KEY_PARTS | S1009 | 42000 |
| 1071 | ER_TOO_LONG_KEY | S1009 | 42000 |
| 1072 | ER_KEY_COLUMN_DOES_NOT_EXITS | S1009 | 42000 |
| 1073 | ER_BLOB_USED_AS_KEY | S1009 | 42000 |
| 1074 | ER_TOO_BIG_FIELDLENGTH | S1009 | 42000 |
| 1075 | ER_WRONG_AUTO_KEY | S1009 | 42000 |
| 1080 | ER_FORCING_CLOSE | S1000 | 08S01 |
| 1081 | ER_IPSOCK_ERROR | 08S01 | 08S01 |
| 1082 | ER_NO_SUCH_INDEX | S1009 | 42S12 |
| 1083 | ER_WRONG_FIELD_TERMINATORS | S1009 | 42000 |
| 1084 | ER_BLOBS_AND_NO_TERMINATED | S1009 | 42000 |
| 1090 | ER_CANT_REMOVE_ALL_FIELDS | S1000 | 42000 |
| 1091 | ER_CANT_DROP_FIELD_OR_KEY | S1000 | 42000 |
| 1101 | ER_BLOB_CANT_HAVE_DEFAULT | S1000 | 42000 |
| 1102 | ER_WRONG_DB_NAME | S1000 | 42000 |
| 1103 | ER_WRONG_TABLE_NAME | S1000 | 42000 |
| 1104 | ER_TOO_BIG_SELECT | S1000 | 42000 |
| 1106 | ER_UNKNOWN_PROCEDURE | S1000 | 42000 |
| 1107 | ER_WRONG_PARAMCOUNT_TO_PROCEDURE | S1000 | 42000 |
| 1109 | ER_UNKNOWN_TABLE | S1000 | 42S02 |
| 1110 | ER_FIELD_SPECIFIED_TWICE | S1000 | 42000 |
| 1112 | ER_UNSUPPORTED_EXTENSION | S1000 | 42000 |
| 1113 | ER_TABLE_MUST_HAVE_COLUMNS | S1000 | 42000 |
| 1115 | ER_UNKNOWN_CHARACTER_SET | S1000 | 42000 |
| 1118 | ER_TOO_BIG_ROWSIZE | S1000 | 42000 |
| 1120 | ER_WRONG_OUTER_JOIN | S1000 | 42000 |
| 1121 | ER_NULL_COLUMN_IN_INDEX | S1000 | 42000 |
| 1129 | ER_HOST_IS_BLOCKED | 08004 | HY000 |
| 1130 | ER_HOST_NOT_PRIVILEGED | 08004 | HY000 |
| 1131 | ER_PASSWORD_ANONYMOUS_USER | S1000 | 42000 |
| 1132 | ER_PASSWORD_NOT_ALLOWED | S1000 | 42000 |
| 1133 | ER_PASSWORD_NO_MATCH | S1000 | 42000 |
| 1136 | ER_WRONG_VALUE_COUNT_ON_ROW | S1000 | 21S01 |
| 1138 | ER_INVALID_USE_OF_NULL | S1000 | 42000 |
| 1139 | ER_REGEXP_ERROR | S1000 | 42000 |
| 1140 | ER_MIX_OF_GROUP_FUNC_AND_FIELDS | S1000 | 42000 |
| 1141 | ER_NONEXISTING_GRANT | S1000 | 42000 |
| 1142 | ER_TABLEACCESS_DENIED_ERROR | S1000 | 42000 |
| 1143 | ER_COLUMNACCESS_DENIED_ERROR | S1000 | 42000 |
| 1144 | ER_ILLEGAL_GRANT_FOR_TABLE | S1000 | 42000 |
| 1145 | ER_GRANT_WRONG_HOST_OR_USER | S1000 | 42000 |
| 1146 | ER_NO_SUCH_TABLE | S1000 | 42S02 |
| 1147 | ER_NONEXISTING_TABLE_GRANT | S1000 | 42000 |
| 1148 | ER_NOT_ALLOWED_COMMAND | S1000 | 42000 |
| 1149 | ER_SYNTAX_ERROR | S1000 | 42000 |
| 1152 | ER_ABORTING_CONNECTION | S1000 | 08S01 |
| 1153 | ER_NET_PACKET_TOO_LARGE | S1000 | 08S01 |
| 1154 | ER_NET_READ_ERROR_FROM_PIPE | S1000 | 08S01 |
| 1155 | ER_NET_FCNTL_ERROR | S1000 | 08S01 |
| 1156 | ER_NET_PACKETS_OUT_OF_ORDER | S1000 | 08S01 |
| 1157 | ER_NET_UNCOMPRESS_ERROR | S1000 | 08S01 |
| 1158 | ER_NET_READ_ERROR | S1000 | 08S01 |
| 1159 | ER_NET_READ_INTERRUPTED | S1000 | 08S01 |
| 1160 | ER_NET_ERROR_ON_WRITE | S1000 | 08S01 |
| 1161 | ER_NET_WRITE_INTERRUPTED | S1000 | 08S01 |
| 1162 | ER_TOO_LONG_STRING | S1000 | 42000 |
| 1163 | ER_TABLE_CANT_HANDLE_BLOB | S1000 | 42000 |
| 1164 | ER_TABLE_CANT_HANDLE_AUTO_INCREMENT | S1000 | 42000 |
| 1166 | ER_WRONG_COLUMN_NAME | S1000 | 42000 |
| 1167 | ER_WRONG_KEY_COLUMN | S1000 | 42000 |
| 1169 | ER_DUP_UNIQUE | S1000 | 23000 |
| 1170 | ER_BLOB_KEY_WITHOUT_LENGTH | S1000 | 42000 |
| 1171 | ER_PRIMARY_CANT_HAVE_NULL | S1000 | 42000 |
| 1172 | ER_TOO_MANY_ROWS | S1000 | 42000 |
| 1173 | ER_REQUIRES_PRIMARY_KEY | S1000 | 42000 |
| 1177 | ER_CHECK_NO_SUCH_TABLE | S1000 | 42000 |
| 1178 | ER_CHECK_NOT_IMPLEMENTED | S1000 | 42000 |
| 1179 | ER_CANT_DO_THIS_DURING_AN_TRANSACTION | S1000 | 25000 |
| 1184 | ER_NEW_ABORTING_CONNECTION | S1000 | 08S01 |
| 1189 | ER_MASTER_NET_READ | S1000 | 08S01 |
| 1190 | ER_MASTER_NET_WRITE | S1000 | 08S01 |
| 1203 | ER_TOO_MANY_USER_CONNECTIONS | S1000 | 42000 |
| 1205 | ER_LOCK_WAIT_TIMEOUT | 41000 | 41000 |
| 1207 | ER_READ_ONLY_TRANSACTION | S1000 | 25000 |
| 1211 | ER_NO_PERMISSION_TO_CREATE_USER | S1000 | 42000 |
| 1213 | ER_LOCK_DEADLOCK | 41000 | 40001 |
| 1216 | ER_NO_REFERENCED_ROW | S1000 | 23000 |
| 1217 | ER_ROW_IS_REFERENCED | S1000 | 23000 |
| 1218 | ER_CONNECT_TO_MASTER | S1000 | 08S01 |
| 1222 | ER_WRONG_NUMBER_OF_COLUMNS_IN_SELECT | S1000 | 21000 |
| 1226 | ER_USER_LIMIT_REACHED | S1000 | 42000 |
| 1230 | ER_NO_DEFAULT | S1000 | 42000 |
| 1231 | ER_WRONG_VALUE_FOR_VAR | S1000 | 42000 |
| 1232 | ER_WRONG_TYPE_FOR_VAR | S1000 | 42000 |
| 1234 | ER_CANT_USE_OPTION_HERE | S1000 | 42000 |
| 1235 | ER_NOT_SUPPORTED_YET | S1000 | 42000 |
| 1239 | ER_WRONG_FK_DEF | S1000 | 42000 |
| 1241 | ER_OPERAND_COLUMNS | S1000 | 21000 |
| 1242 | ER_SUBQUERY_NO_1_ROW | S1000 | 21000 |
| 1247 | ER_ILLEGAL_REFERENCE | S1000 | 42S22 |
| 1248 | ER_DERIVED_MUST_HAVE_ALIAS | S1000 | 42000 |
| 1249 | ER_SELECT_REDUCED | S1000 | 01000 |
| 1250 | ER_TABLENAME_NOT_ALLOWED_HERE | S1000 | 42000 |
| 1251 | ER_NOT_SUPPORTED_AUTH_MODE | S1000 | 08004 |
| 1252 | ER_SPATIAL_CANT_HAVE_NULL | S1000 | 42000 |
| 1253 | ER_COLLATION_CHARSET_MISMATCH | S1000 | 42000 |
| 1261 | ER_WARN_TOO_FEW_RECORDS | S1000 | 01000 |
| 1262 | ER_WARN_TOO_MANY_RECORDS | S1000 | 01000 |
| 1263 | ER_WARN_NULL_TO_NOTNULL | S1000 | 01000 |
| 1264 | ER_WARN_DATA_OUT_OF_RANGE | S1000 | 01000 |
| 1265 | ER_WARN_DATA_TRUNCATED | S1000 | 01000 |
| 1280 | ER_WRONG_NAME_FOR_INDEX | S1000 | 42000 |
| 1281 | ER_WRONG_NAME_FOR_CATALOG | S1000 | 42000 |
| 1286 | ER_UNKNOWN_STORAGE_ENGINE | S1000 | 42000 |
This section provides some general JDBC background.
When you are using JDBC outside of an application server, the
DriverManager class manages the
establishment of Connections.
The DriverManager needs to be told which
JDBC drivers it should try to make Connections with. The
easiest way to do this is to use
Class.forName() on the class that
implements the java.sql.Driver interface.
With MySQL Connector/J, the name of this class is
com.mysql.jdbc.Driver. With this method,
you could use an external configuration file to supply the
driver class name and driver parameters to use when connecting
to a database.
The following section of Java code shows how you might
register MySQL Connector/J from the main()
method of your application:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
// Notice, do not import com.mysql.jdbc.*
// or you will have problems!
public class LoadDriver {
public static void main(String[] args) {
try {
// The newInstance() call is a work around for some
// broken Java implementations
Class.forName("com.mysql.jdbc.Driver").newInstance();
} catch (Exception ex) {
// handle the error
}
}
After the driver has been registered with the
DriverManager, you can obtain a
Connection instance that is connected to a
particular database by calling
DriverManager.getConnection():
Example 23.1. Obtaining a connection from the DriverManager
This example shows how you can obtain a
Connection instance from the
DriverManager. There are a few different
signatures for the getConnection()
method. You should see the API documentation that comes with
your JDK for more specific information on how to use them.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
...
try {
Connection conn =
DriverManager.getConnection("jdbc:mysql://localhost/test?" +
"user=monty&password=greatsqldb");
// Do something with the Connection
...
} catch (SQLException ex) {
// handle any errors
System.out.println("SQLException: " + ex.getMessage());
System.out.println("SQLState: " + ex.getSQLState());
System.out.println("VendorError: " + ex.getErrorCode());
}
Once a Connection is established, it
can be used to create Statement and
PreparedStatement objects, as well as
retrieve metadata about the database. This is explained in
the following sections.
Statement objects allow you to execute
basic SQL queries and retrieve the results through the
ResultSet class which is described later.
To create a Statement instance, you
call the createStatement() method on the
Connection object you have retrieved via
one of the DriverManager.getConnection() or
DataSource.getConnection() methods
described earlier.
Once you have a Statement instance, you
can execute a SELECT query by calling the
executeQuery(String) method with the SQL
you want to use.
To update data in the database, use the
executeUpdate(String SQL) method. This
method returns the number of rows affected by the update
statement.
If you don't know ahead of time whether the SQL statement will
be a SELECT or an
UPDATE/INSERT, then you
can use the execute(String SQL) method.
This method will return true if the SQL query was a
SELECT, or false if it was an
UPDATE, INSERT, or
DELETE statement. If the statement was a
SELECT query, you can retrieve the results
by calling the getResultSet() method. If
the statement was an UPDATE,
INSERT, or DELETE
statement, you can retrieve the affected rows count by calling
getUpdateCount() on the
Statement instance.
Example 23.2. Using java.sql.Statement to execute a SELECT query
// assume that conn is an already created JDBC connection
Statement stmt = null;
ResultSet rs = null;
try {
stmt = conn.createStatement();
rs = stmt.executeQuery("SELECT foo FROM bar");
// or alternatively, if you don't know ahead of time that
// the query will be a SELECT...
if (stmt.execute("SELECT foo FROM bar")) {
rs = stmt.getResultSet();
}
// Now do something with the ResultSet ....
} finally {
// it is a good idea to release
// resources in a finally{} block
// in reverse-order of their creation
// if they are no-longer needed
if (rs != null) {
try {
rs.close();
} catch (SQLException sqlEx) { // ignore }
rs = null;
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException sqlEx) { // ignore }
stmt = null;
}
}
Starting with MySQL server version 5.0 when used with
Connector/J 3.1.1 or newer, the
java.sql.CallableStatement interface is
fully implemented with the exception of the
getParameterMetaData() method.
See Chapter 17, Stored Procedures and Functions, for more information on MySQL stored procedures.
Connector/J exposes stored procedure functionality through
JDBC's CallableStatement interface.
Note
Current versions of MySQL server do not return enough
information for the JDBC driver to provide result set
metadata for callable statements. This means that when using
CallableStatement,
ResultSetMetaData may return
NULL.
The following example shows a stored procedure that returns
the value of inOutParam incremented by 1,
and the string passed in via inputParam as
a ResultSet:
Example 23.3. Stored Procedures
CREATE PROCEDURE demoSp(IN inputParam VARCHAR(255), \
INOUT inOutParam INT)
BEGIN
DECLARE z INT;
SET z = inOutParam + 1;
SET inOutParam = z;
SELECT inputParam;
SELECT CONCAT('zyxw', inputParam);
END
To use the demoSp procedure with
Connector/J, follow these steps:
Prepare the callable statement by using
Connection.prepareCall().Notice that you have to use JDBC escape syntax, and that the parentheses surrounding the parameter placeholders are not optional:
Example 23.4. Using
Connection.prepareCall()import java.sql.CallableStatement; ... // // Prepare a call to the stored procedure 'demoSp' // with two parameters // // Notice the use of JDBC-escape syntax ({call ...}) // CallableStatement cStmt = conn.prepareCall("{call demoSp(?, ?)}"); cStmt.setString(1, "abcdefg");Note
Connection.prepareCall()is an expensive method, due to the metadata retrieval that the driver performs to support output parameters. For performance reasons, you should try to minimize unnecessary calls toConnection.prepareCall()by reusingCallableStatementinstances in your code.Register the output parameters (if any exist)
To retrieve the values of output parameters (parameters specified as
OUTorINOUTwhen you created the stored procedure), JDBC requires that they be specified before statement execution using the variousregisterOutputParameter()methods in theCallableStatementinterface:Example 23.5. Registering output parameters
import java.sql.Types; ... // // Connector/J supports both named and indexed // output parameters. You can register output // parameters using either method, as well // as retrieve output parameters using either // method, regardless of what method was // used to register them. // // The following examples show how to use // the various methods of registering // output parameters (you should of course // use only one registration per parameter). // // // Registers the second parameter as output, and // uses the type 'INTEGER' for values returned from // getObject() // cStmt.registerOutParameter(2, Types.INTEGER); // // Registers the named parameter 'inOutParam', and // uses the type 'INTEGER' for values returned from // getObject() // cStmt.registerOutParameter("inOutParam", Types.INTEGER); ...Set the input parameters (if any exist)
Input and in/out parameters are set as for
PreparedStatementobjects. However,CallableStatementalso supports setting parameters by name:Example 23.6. Setting
CallableStatementinput parameters... // // Set a parameter by index // cStmt.setString(1, "abcdefg"); // // Alternatively, set a parameter using // the parameter name // cStmt.setString("inputParameter", "abcdefg"); // // Set the 'in/out' parameter using an index // cStmt.setInt(2, 1); // // Alternatively, set the 'in/out' parameter // by name // cStmt.setInt("inOutParam", 1); ...Execute the
CallableStatement, and retrieve any result sets or output parameters.Although
CallableStatementsupports calling any of theStatementexecute methods (executeUpdate(),executeQuery()orexecute()), the most flexible method to call isexecute(), as you do not need to know ahead of time if the stored procedure returns result sets:Example 23.7. Retrieving results and output parameter values
... boolean hadResults = cStmt.execute(); // // Process all returned result sets // while (hadResults) { ResultSet rs = cStmt.getResultSet(); // process result set ... hadResults = rs.getMoreResults(); } // // Retrieve output parameters // // Connector/J supports both index-based and // name-based retrieval // int outputValue = cStmt.getInt(2); // index-based outputValue = cStmt.getInt("inOutParam"); // name-based ...
Before version 3.0 of the JDBC API, there was no standard way
of retrieving key values from databases that supported auto
increment or identity columns. With older JDBC drivers for
MySQL, you could always use a MySQL-specific method on the
Statement interface, or issue the query
SELECT LAST_INSERT_ID() after issuing an
INSERT to a table that had an
AUTO_INCREMENT key. Using the
MySQL-specific method call isn't portable, and issuing a
SELECT to get the
AUTO_INCREMENT key's value requires another
round-trip to the database, which isn't as efficient as
possible. The following code snippets demonstrate the three
different ways to retrieve AUTO_INCREMENT
values. First, we demonstrate the use of the new JDBC-3.0
method getGeneratedKeys() which is now the
preferred method to use if you need to retrieve
AUTO_INCREMENT keys and have access to
JDBC-3.0. The second example shows how you can retrieve the
same value using a standard SELECT
LAST_INSERT_ID() query. The final example shows how
updatable result sets can retrieve the
AUTO_INCREMENT value when using the
insertRow() method.
Example 23.8. Retrieving AUTO_INCREMENT column values using
Statement.getGeneratedKeys()
Statement stmt = null;
ResultSet rs = null;
try {
//
// Create a Statement instance that we can use for
// 'normal' result sets assuming you have a
// Connection 'conn' to a MySQL database already
// available
stmt = conn.createStatement(java.sql.ResultSet.TYPE_FORWARD_ONLY,
java.sql.ResultSet.CONCUR_UPDATABLE);
//
// Issue the DDL queries for the table for this example
//
stmt.executeUpdate("DROP TABLE IF EXISTS autoIncTutorial");
stmt.executeUpdate(
"CREATE TABLE autoIncTutorial ("
+ "priKey INT NOT NULL AUTO_INCREMENT, "
+ "dataField VARCHAR(64), PRIMARY KEY (priKey))");
//
// Insert one row that will generate an AUTO INCREMENT
// key in the 'priKey' field
//
stmt.executeUpdate(
"INSERT INTO autoIncTutorial (dataField) "
+ "values ('Can I Get the Auto Increment Field?')",
Statement.RETURN_GENERATED_KEYS);
//
// Example of using Statement.getGeneratedKeys()
// to retrieve the value of an auto-increment
// value
//
int autoIncKeyFromApi = -1;
rs = stmt.getGeneratedKeys();
if (rs.next()) {
autoIncKeyFromApi = rs.getInt(1);
} else {
// throw an exception from here
}
rs.close();
rs = null;
System.out.println("Key returned from getGeneratedKeys():"
+ autoIncKeyFromApi);
} finally {
if (rs != null) {
try {
rs.close();
} catch (SQLException ex) {
// ignore
}
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException ex) {
// ignore
}
}
}
Example 23.9. Retrieving AUTO_INCREMENT column values using
SELECT LAST_INSERT_ID()
Statement stmt = null;
ResultSet rs = null;
try {
//
// Create a Statement instance that we can use for
// 'normal' result sets.
stmt = conn.createStatement();
//
// Issue the DDL queries for the table for this example
//
stmt.executeUpdate("DROP TABLE IF EXISTS autoIncTutorial");
stmt.executeUpdate(
"CREATE TABLE autoIncTutorial ("
+ "priKey INT NOT NULL AUTO_INCREMENT, "
+ "dataField VARCHAR(64), PRIMARY KEY (priKey))");
//
// Insert one row that will generate an AUTO INCREMENT
// key in the 'priKey' field
//
stmt.executeUpdate(
"INSERT INTO autoIncTutorial (dataField) "
+ "values ('Can I Get the Auto Increment Field?')");
//
// Use the MySQL LAST_INSERT_ID()
// function to do the same thing as getGeneratedKeys()
//
int autoIncKeyFromFunc = -1;
rs = stmt.executeQuery("SELECT LAST_INSERT_ID()");
if (rs.next()) {
autoIncKeyFromFunc = rs.getInt(1);
} else {
// throw an exception from here
}
rs.close();
System.out.println("Key returned from " +
"'SELECT LAST_INSERT_ID()': " +
autoIncKeyFromFunc);
} finally {
if (rs != null) {
try {
rs.close();
} catch (SQLException ex) {
// ignore
}
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException ex) {
// ignore
}
}
}
Example 23.10. Retrieving AUTO_INCREMENT column values in
Updatable ResultSets
Statement stmt = null;
ResultSet rs = null;
try {
//
// Create a Statement instance that we can use for
// 'normal' result sets as well as an 'updatable'
// one, assuming you have a Connection 'conn' to
// a MySQL database already available
//
stmt = conn.createStatement(java.sql.ResultSet.TYPE_FORWARD_ONLY,
java.sql.ResultSet.CONCUR_UPDATABLE);
//
// Issue the DDL queries for the table for this example
//
stmt.executeUpdate("DROP TABLE IF EXISTS autoIncTutorial");
stmt.executeUpdate(
"CREATE TABLE autoIncTutorial ("
+ "priKey INT NOT NULL AUTO_INCREMENT, "
+ "dataField VARCHAR(64), PRIMARY KEY (priKey))");
//
// Example of retrieving an AUTO INCREMENT key
// from an updatable result set
//
rs = stmt.executeQuery("SELECT priKey, dataField "
+ "FROM autoIncTutorial");
rs.moveToInsertRow();
rs.updateString("dataField", "AUTO INCREMENT here?");
rs.insertRow();
//
// the driver adds rows at the end
//
rs.last();
//
// We should now be on the row we just inserted
//
int autoIncKeyFromRS = rs.getInt("priKey");
rs.close();
rs = null;
System.out.println("Key returned for inserted row: "
+ autoIncKeyFromRS);
} finally {
if (rs != null) {
try {
rs.close();
} catch (SQLException ex) {
// ignore
}
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException ex) {
// ignore
}
}
}
When you run the preceding example code, you should get the
following output: Key returned from
getGeneratedKeys(): 1 Key returned from
SELECT LAST_INSERT_ID(): 1 Key returned for
inserted row: 2 You should be aware, that at times, it can be
tricky to use the SELECT LAST_INSERT_ID()
query, as that function's value is scoped to a connection. So,
if some other query happens on the same connection, the value
will be overwritten. On the other hand, the
getGeneratedKeys() method is scoped by the
Statement instance, so it can be used
even if other queries happen on the same connection, but not
on the same Statement instance.
This section describes how to use Connector/J in several contexts.
This section provides general background on J2EE concepts that pertain to use of Connector/J.
Connection pooling is a technique of creating and managing a pool of connections that are ready for use by any thread that needs them.
This technique of pooling connections is based on the fact that most applications only need a thread to have access to a JDBC connection when they are actively processing a transaction, which usually take only milliseconds to complete. When not processing a transaction, the connection would otherwise sit idle. Instead, connection pooling allows the idle connection to be used by some other thread to do useful work.
In practice, when a thread needs to do work against a MySQL or other database with JDBC, it requests a connection from the pool. When the thread is finished using the connection, it returns it to the pool, so that it may be used by any other threads that want to use it.
When the connection is loaned out from the pool, it is used
exclusively by the thread that requested it. From a
programming point of view, it is the same as if your thread
called DriverManager.getConnection()
every time it needed a JDBC connection, however with
connection pooling, your thread may end up using either a
new, or already-existing connection.
Connection pooling can greatly increase the performance of your Java application, while reducing overall resource usage. The main benefits to connection pooling are:
Reduced connection creation time
Although this is not usually an issue with the quick connection setup that MySQL offers compared to other databases, creating new JDBC connections still incurs networking and JDBC driver overhead that will be avoided if connections are recycled.
Simplified programming model
When using connection pooling, each individual thread can act as though it has created its own JDBC connection, allowing you to use straight-forward JDBC programming techniques.
Controlled resource usage
If you don't use connection pooling, and instead create a new connection every time a thread needs one, your application's resource usage can be quite wasteful and lead to unpredictable behavior under load.
Remember that each connection to MySQL has overhead (memory, CPU, context switches, and so forth) on both the client and server side. Every connection limits how many resources there are available to your application as well as the MySQL server. Many of these resources will be used whether or not the connection is actually doing any useful work!
Connection pools can be tuned to maximize performance, while keeping resource utilization below the point where your application will start to fail rather than just run slower.
Luckily, Sun has standardized the concept of connection pooling in JDBC through the JDBC-2.0 Optional interfaces, and all major application servers have implementations of these APIs that work fine with MySQL Connector/J.
Generally, you configure a connection pool in your application server configuration files, and access it via the Java Naming and Directory Interface (JNDI). The following code shows how you might use a connection pool from an application deployed in a J2EE application server:
Example 23.11. Using a connection pool with a J2EE application server
import java.sql.Connection;
import java.sql.SQLException;
import java.sql.Statement;
import javax.naming.InitialContext;
import javax.sql.DataSource;
public class MyServletJspOrEjb {
public void doSomething() throws Exception {
/*
* Create a JNDI Initial context to be able to
* lookup the DataSource
*
* In production-level code, this should be cached as
* an instance or static variable, as it can
* be quite expensive to create a JNDI context.
*
* Note: This code only works when you are using servlets
* or EJBs in a J2EE application server. If you are
* using connection pooling in standalone Java code, you
* will have to create/configure datasources using whatever
* mechanisms your particular connection pooling library
* provides.
*/
InitialContext ctx = new InitialContext();
/*
* Lookup the DataSource, which will be backed by a pool
* that the application server provides. DataSource instances
* are also a good candidate for caching as an instance
* variable, as JNDI lookups can be expensive as well.
*/
DataSource ds =
(DataSource)ctx.lookup("java:comp/env/jdbc/MySQLDB");
/*
* The following code is what would actually be in your
* Servlet, JSP or EJB 'service' method...where you need
* to work with a JDBC connection.
*/
Connection conn = null;
Statement stmt = null;
try {
conn = ds.getConnection();
/*
* Now, use normal JDBC programming to work with
* MySQL, making sure to close each resource when you're
* finished with it, which allows the connection pool
* resources to be recovered as quickly as possible
*/
stmt = conn.createStatement();
stmt.execute("SOME SQL QUERY");
stmt.close();
stmt = null;
conn.close();
conn = null;
} finally {
/*
* close any jdbc instances here that weren't
* explicitly closed during normal code path, so
* that we don't 'leak' resources...
*/
if (stmt != null) {
try {
stmt.close();
} catch (sqlexception sqlex) {
// ignore -- as we can't do anything about it here
}
stmt = null;
}
if (conn != null) {
try {
conn.close();
} catch (sqlexception sqlex) {
// ignore -- as we can't do anything about it here
}
conn = null;
}
}
}
}As shown in the example above, after obtaining the JNDI InitialContext, and looking up the DataSource, the rest of the code should look familiar to anyone who has done JDBC programming in the past.
The most important thing to remember when using connection pooling is to make sure that no matter what happens in your code (exceptions, flow-of-control, and so forth), connections, and anything created by them (such as statements or result sets) are closed, so that they may be re-used, otherwise they will be stranded, which in the best case means that the MySQL server resources they represent (such as buffers, locks, or sockets) may be tied up for some time, or worst case, may be tied up forever.
What's the Best Size for my Connection Pool?
As with all other configuration rules-of-thumb, the answer is: it depends. Although the optimal size depends on anticipated load and average database transaction time, the optimum connection pool size is smaller than you might expect. If you take Sun's Java Petstore blueprint application for example, a connection pool of 15-20 connections can serve a relatively moderate load (600 concurrent users) using MySQL and Tomcat with response times that are acceptable.
To correctly size a connection pool for your application, you should create load test scripts with tools such as Apache JMeter or The Grinder, and load test your application.
An easy way to determine a starting point is to configure your connection pool's maximum number of connections to be unbounded, run a load test, and measure the largest amount of concurrently used connections. You can then work backward from there to determine what values of minimum and maximum pooled connections give the best performance for your particular application.
The following instructions are based on the instructions for Tomcat-5.x, available at http://jakarta.apache.org/tomcat/tomcat-5.0-doc/jndi-datasource-examples-howto.html which is current at the time this document was written.
First, install the .jar file that comes with Connector/J in
$CATALINA_HOME/common/lib so that it is
available to all applications installed in the container.
Next, Configure the JNDI DataSource by adding a declaration
resource to
$CATALINA_HOME/conf/server.xml in the
context that defines your web application:
<Context ....>
...
<Resource name="jdbc/MySQLDB"
auth="Container"
type="javax.sql.DataSource"/>
<!-- The name you used above, must match _exactly_ here!
The connection pool will be bound into JNDI with the name
"java:/comp/env/jdbc/MySQLDB"
-->
<ResourceParams name="jdbc/MySQLDB">
<parameter>
<name>factory</name>
<value>org.apache.commons.dbcp.BasicDataSourceFactory</value>
</parameter>
<!-- Don't set this any higher than max_connections on your
MySQL server, usually this should be a 10 or a few 10's
of connections, not hundreds or thousands -->
<parameter>
<name>maxActive</name>
<value>10</value>
</parameter>
<!-- You don't want to many idle connections hanging around
if you can avoid it, only enough to soak up a spike in
the load -->
<parameter>
<name>maxIdle</name>
<value>5</value>
</parameter>
<!-- Don't use autoReconnect=true, it's going away eventually
and it's a crutch for older connection pools that couldn't
test connections. You need to decide whether your application
is supposed to deal with SQLExceptions (hint, it should), and
how much of a performance penalty you're willing to pay
to ensure 'freshness' of the connection -->
<parameter>
<name>validationQuery</name>
<value>SELECT 1</value>
</parameter>
<!-- The most conservative approach is to test connections
before they're given to your application. For most applications
this is okay, the query used above is very small and takes
no real server resources to process, other than the time used
to traverse the network.
If you have a high-load application you'll need to rely on
something else. -->
<parameter>
<name>testOnBorrow</name>
<value>true</value>
</parameter>
<!-- Otherwise, or in addition to testOnBorrow, you can test
while connections are sitting idle -->
<parameter>
<name>testWhileIdle</name>
<value>true</value>
</parameter>
<!-- You have to set this value, otherwise even though
you've asked connections to be tested while idle,
the idle evicter thread will never run -->
<parameter>
<name>timeBetweenEvictionRunsMillis</name>
<value>10000</value>
</parameter>
<!-- Don't allow connections to hang out idle too long,
never longer than what wait_timeout is set to on the
server...A few minutes or even fraction of a minute
is sometimes okay here, it depends on your application
and how much spikey load it will see -->
<parameter>
<name>minEvictableIdleTimeMillis</name>
<value>60000</value>
</parameter>
<!-- Username and password used when connecting to MySQL -->
<parameter>
<name>username</name>
<value>someuser</value>
</parameter>
<parameter>
<name>password</name>
<value>somepass</value>
</parameter>
<!-- Class name for the Connector/J driver -->
<parameter>
<name>driverClassName</name>
<value>com.mysql.jdbc.Driver</value>
</parameter>
<!-- The JDBC connection url for connecting to MySQL, notice
that if you want to pass any other MySQL-specific parameters
you should pass them here in the URL, setting them using the
parameter tags above will have no effect, you will also
need to use & to separate parameter values as the
ampersand is a reserved character in XML -->
<parameter>
<name>url</name>
<value>jdbc:mysql://localhost:3306/test</value>
</parameter>
</ResourceParams>
</Context>In general, you should follow the installation instructions that come with your version of Tomcat, as the way you configure datasources in Tomcat changes from time-to-time, and unfortunately if you use the wrong syntax in your XML file, you will most likely end up with an exception similar to the following:
Error: java.sql.SQLException: Cannot load JDBC driver class 'null ' SQL state: null
These instructions cover JBoss-4.x. To make the JDBC driver
classes available to the application server, copy the .jar
file that comes with Connector/J to the
lib directory for your server
configuration (which is usually called
default). Then, in the same configuration
directory, in the subdirectory named deploy, create a
datasource configuration file that ends with "-ds.xml", which
tells JBoss to deploy this file as a JDBC Datasource. The file
should have the following contents:
<datasources>
<local-tx-datasource>
<!-- This connection pool will be bound into JNDI with the name
"java:/MySQLDB" -->
<jndi-name>MySQLDB</jndi-name>
<connection-url>jdbc:mysql://localhost:3306/dbname</connection-url>
<driver-class>com.mysql.jdbc.Driver</driver-class>
<user-name>user</user-name>
<password>pass</password>
<min-pool-size>5</min-pool-size>
<!-- Don't set this any higher than max_connections on your
MySQL server, usually this should be a 10 or a few 10's
of connections, not hundreds or thousands -->
<max-pool-size>20</max-pool-size>
<!-- Don't allow connections to hang out idle too long,
never longer than what wait_timeout is set to on the
server...A few minutes is usually okay here,
it depends on your application
and how much spikey load it will see -->
<idle-timeout-minutes>5</idle-timeout-minutes>
<!-- If you're using Connector/J 3.1.8 or newer, you can use
our implementation of these to increase the robustness
of the connection pool. -->
<exception-sorter-class-name>
com.mysql.jdbc.integration.jboss.ExtendedMysqlExceptionSorter
</exception-sorter-class-name>
<valid-connection-checker-class-name>
com.mysql.jdbc.integration.jboss.MysqlValidConnectionChecker
</valid-connection-checker-class-name>
</local-tx-datasource>
</datasources> The Spring Framework is a Java-based application framework designed for assisting in application design by providing a way to configure components. The technique used by Spring is a well known design pattern called Dependency Injection (see Inversion of Control Containers and the Dependency Injection pattern). This article will focus on Java-oriented access to MySQL databases with Spring 2.0. For those wondering, there is a .NET port of Spring appropriately named Spring.NET.
Spring is not only a system for configuring components, but also includes support for aspect oriented programming (AOP). This is one of the main benefits and the foundation for Spring's resource and transaction management. Spring also provides utilities for integrating resource management with JDBC and Hibernate.
For the examples in this section the MySQL world sample database will be used. The first task is to setup a MySQL data source through Spring. Components within Spring use the "bean" terminology. For example, to configure a connection to a MySQL server supporting the world sample database you might use:
<util:map id="dbProps">
<entry key="db.driver" value="com.mysql.jdbc.Driver"/>
<entry key="db.jdbcurl" value="jdbc:mysql://localhost/world"/>
<entry key="db.username" value="myuser"/>
<entry key="db.password" value="mypass"/>
</util:map>
In the above example we are assigning values to properties that will be used in the configuration. For the datasource configuration:
<bean id="dataSource"
class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="${db.driver}"/>
<property name="url" value="${db.jdbcurl}"/>
<property name="username" value="${db.username}"/>
<property name="password" value="${db.password}"/>
</bean>
The placeholders are used to provide values for properties of this bean. This means that you can specify all the properties of the configuration in one place instead of entering the values for each property on each bean. We do, however, need one more bean to pull this all together. The last bean is responsible for actually replacing the placeholders with the property values.
<bean
class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="properties" ref="dbProps"/>
</bean>
Now that we have our MySQL data source configured and ready to go, we write some Java code to access it. The example below will retrieve three random cities and their corresponding country using the data source we configured with Spring.
// Create a new application context. this processes the Spring config
ApplicationContext ctx =
new ClassPathXmlApplicationContext("ex1appContext.xml");
// Retrieve the data source from the application context
DataSource ds = (DataSource) ctx.getBean("dataSource");
// Open a database connection using Spring's DataSourceUtils
Connection c = DataSourceUtils.getConnection(ds);
try {
// retrieve a list of three random cities
PreparedStatement ps = c.prepareStatement(
"select City.Name as 'City', Country.Name as 'Country' " +
"from City inner join Country on City.CountryCode = Country.Code " +
"order by rand() limit 3");
ResultSet rs = ps.executeQuery();
while(rs.next()) {
String city = rs.getString("City");
String country = rs.getString("Country");
System.out.printf("The city %s is in %s%n", city, country);
}
} catch (SQLException ex) {
// something has failed and we print a stack trace to analyse the error
ex.printStackTrace();
// ignore failure closing connection
try { c.close(); } catch (SQLException e) { }
} finally {
// properly release our connection
DataSourceUtils.releaseConnection(c, ds);
}This is very similar to normal JDBC access to MySQL with the main difference being that we are using DataSourceUtils instead of the DriverManager to create the connection.
While it may seem like a small difference, the implications are somewhat far reaching. Spring manages this resource in a way similar to a container managed data source in a J2EE application server. When a connection is opened, it can be subsequently accessed in other parts of the code if it is synchronized with a transaction. This makes it possible to treat different parts of your application as transactional instead of passing around a database connection.
Spring makes extensive use of the Template method design
pattern (see
Template
Method Pattern). Our immediate focus will be on the
JdbcTemplate and related classes,
specifically NamedParameterJdbcTemplate.
The template classes handle obtaining and releasing a
connection for data access when one is needed.
The next example shows how to use
NamedParameterJdbcTemplate inside of a
DAO (Data Access Object) class to retrieve a random city
given a country code.
public class Ex2JdbcDao {
/**
* Data source reference which will be provided by Spring.
*/
private DataSource dataSource;
/**
* Our query to find a random city given a country code. Notice
* the ":country" parameter towards the end. This is called a
* named parameter.
*/
private String queryString = "select Name from City " +
"where CountryCode = :country order by rand() limit 1";
/**
* Retrieve a random city using Spring JDBC access classes.
*/
public String getRandomCityByCountryCode(String cntryCode) {
// A template that allows using queries with named parameters
NamedParameterJdbcTemplate template =
new NamedParameterJdbcTemplate(dataSource);
// A java.util.Map is used to provide values for the parameters
Map params = new HashMap();
params.put("country", cntryCode);
// We query for an Object and specify what class we are expecting
return (String)template.queryForObject(queryString, params, String.class);
}
/**
* A JavaBean setter-style method to allow Spring to inject the data source.
* @param dataSource
*/
public void setDataSource(DataSource dataSource) {
this.dataSource = dataSource;
}
}
The focus in the above code is on the
getRandomCityByCountryCode() method. We
pass a country code and use the
NamedParameterJdbcTemplate to query for a
city. The country code is placed in a Map with the key
"country", which is the parameter is named in the SQL query.
To access this code, you need to configure it with Spring by providing a reference to the data source.
<bean id="dao" class="code.Ex2JdbcDao">
<property name="dataSource" ref="dataSource"/>
</bean>
At this point, we can just grab a reference to the DAO from
Spring and call
getRandomCityByCountryCode().
// Create the application context
ApplicationContext ctx =
new ClassPathXmlApplicationContext("ex2appContext.xml");
// Obtain a reference to our DAO
Ex2JdbcDao dao = (Ex2JdbcDao) ctx.getBean("dao");
String countryCode = "USA";
// Find a few random cities in the US
for(int i = 0; i < 4; ++i)
System.out.printf("A random city in %s is %s%n", countryCode,
dao.getRandomCityByCountryCode(countryCode));
This example shows how to use Spring's JDBC classes to
completely abstract away the use of traditional JDBC classes
including Connection and
PreparedStatement.
You might be wondering how we can add transactions into our code if we don't deal directly with the JDBC classes. Spring provides a transaction management package that not only replaces JDBC transaction management, but also allows declarative transaction management (configuration instead of code).
In order to use transactional database access, we will need to change the storage engine of the tables in the world database. The downloaded script explicitly creates MyISAM tables which do not support transactional semantics. The InnoDB storage engine does support transactions and this is what we will be using. We can change the storage engine with the following statements.
ALTER TABLE City ENGINE=InnoDB; ALTER TABLE Country ENGINE=InnoDB; ALTER TABLE CountryLanguage ENGINE=InnoDB;
A good programming practice emphasized by Spring is separating interfaces and implementations. What this means is that we can create a Java interface and only use the operations on this interface without any internal knowledge of what the actual implementation is. We will let Spring manage the implementation and with this it will manage the transactions for our implementation.
First you create a simple interface:
public interface Ex3Dao {
Integer createCity(String name, String countryCode,
String district, Integer population);
}
This interface contains one method that will create a new city record in the database and return the id of the new record. Next you need to create an implementation of this interface.
public class Ex3DaoImpl implements Ex3Dao {
protected DataSource dataSource;
protected SqlUpdate updateQuery;
protected SqlFunction idQuery;
public Integer createCity(String name, String countryCode,
String district, Integer population) {
updateQuery.update(new Object[] { name, countryCode,
district, population });
return getLastId();
}
protected Integer getLastId() {
return idQuery.run();
}
}
You can see that we only operate on abstract query objects here and don't deal directly with the JDBC API. Also, this is the complete implementation. All of our transaction management will be dealt with in the configuration. To get the configuration started, we need to create the DAO.
<bean id="dao" class="code.Ex3DaoImpl">
<property name="dataSource" ref="dataSource"/>
<property name="updateQuery">...</property>
<property name="idQuery">...</property>
</bean>
Now you need to setup the transaction configuration. The
first thing you must do is create transaction manager to
manage the data source and a specification of what
transaction properties are required for for the
dao methods.
<bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="*"/>
</tx:attributes>
</tx:advice>
The preceding code creates a transaction manager that
handles transactions for the data source provided to it. The
txAdvice uses this transaction manager
and the attributes specify to create a transaction for all
methods. Finally you need to apply this advice with an AOP
pointcut.
<aop:config>
<aop:pointcut id="daoMethods"
expression="execution(* code.Ex3Dao.*(..))"/>
<aop:advisor advice-ref="txAdvice" pointcut-ref="daoMethods"/>
</aop:config>
This basically says that all methods called on the
Ex3Dao interface will be wrapped in a
transaction. To make use of this, you only have to retrieve
the dao from the application context and
call a method on the dao instance.
Ex3Dao dao = (Ex3Dao) ctx.getBean("dao");
Integer id = dao.createCity(name, countryCode, district, pop);
We can verify from this that there is no transaction management happening in our Java code and it's all configured with Spring. This is a very powerful notion and regarded as one of the most beneficial features of Spring.
In many sitations, such as web applications, there will be a
large number of small database transactions. When this is
the case, it usually makes sense to create a pool of
database connections available for web requests as needed.
Although MySQL does not spawn an extra process when a
connection is made, there is still a small amount of
overhead to create and setup the connection. Pooling of
connections also alleviates problems such as collecting
large amounts of sockets in the TIME_WAIT
state.
Setting up pooling of MySQL connections with Spring is as
simple as changing the data source configuration in the
application context. There are a number of configurations
that we can use. The first example is based on the
Jakarta
Commons DBCP library. The example below replaces the
source configuration that was based on
DriverManagerDataSource with DBCP's
BasicDataSource.
<bean id="dataSource" destroy-method="close"
class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName" value="${db.driver}"/>
<property name="url" value="${db.jdbcurl}"/>
<property name="username" value="${db.username}"/>
<property name="password" value="${db.password}"/>
<property name="initialSize" value="3"/>
</bean>
The configuration of the two solutions is very similar. The
difference is that DBCP will pool connections to the
database instead of creating a new connection every time one
is requested. We have also set a parameter here called
initialSize. This tells DBCP that we want
three connections in the pool when it is created.
Another way to configure connection pooling is to configure
a data source in our J2EE application server. Using JBoss as
an example, you can set up the MySQL connection pool by
creating a file called
mysql-local-ds.xml and placing it in
the server/default/deploy directory in JBoss. Once we have
this setup, we can use JNDI to look it up. With Spring, this
lookup is very simple. The data source configuration looks
like this.
<jee:jndi-lookup id="dataSource" jndi-name="java:MySQL_DS"/>
There are a few issues that seem to be commonly encountered often by users of MySQL Connector/J. This section deals with their symptoms, and their resolutions.
Questions
24.4.5.3.1: When I try to connect to the database with MySQL Connector/J, I get the following exception:
SQLException: Server configuration denies access to data source SQLState: 08001 VendorError: 0
What's going on? I can connect just fine with the MySQL command-line client.
24.4.5.3.2: My application throws an SQLException 'No Suitable Driver'. Why is this happening?
24.4.5.3.3: I'm trying to use MySQL Connector/J in an applet or application and I get an exception similar to:
SQLException: Cannot connect to MySQL server on host:3306. Is there a MySQL server running on the machine/port you are trying to connect to? (java.security.AccessControlException) SQLState: 08S01 VendorError: 0
24.4.5.3.4: I have a servlet/application that works fine for a day, and then stops working overnight
24.4.5.3.5: I'm trying to use JDBC-2.0 updatable result sets, and I get an exception saying my result set is not updatable.
24.4.5.3.6: I cannot connect to the MySQL server using Connector/J, and I'm sure the connection paramters are correct.
24.4.5.3.7: I am trying to connect to my MySQL server within my application, but I get the following error and stack trace:
java.net.SocketException MESSAGE: Software caused connection abort: recv failed STACKTRACE: java.net.SocketException: Software caused connection abort: recv failed at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.read(Unknown Source) at com.mysql.jdbc.MysqlIO.readFully(MysqlIO.java:1392) at com.mysql.jdbc.MysqlIO.readPacket(MysqlIO.java:1414) at com.mysql.jdbc.MysqlIO.doHandshake(MysqlIO.java:625) at com.mysql.jdbc.Connection.createNewIO(Connection.java:1926) at com.mysql.jdbc.Connection.<init>(Connection.java:452) at com.mysql.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:411)
24.4.5.3.8: My application is deployed through JBoss and I am using transactions to handle the statements on the MySQL database. Under heavy loads I am getting a error and stack trace, but these only occur after a fixed period of heavy activity.
Questions and Answers
24.4.5.3.1: When I try to connect to the database with MySQL Connector/J, I get the following exception:
SQLException: Server configuration denies access to data source SQLState: 08001 VendorError: 0
What's going on? I can connect just fine with the MySQL command-line client.
MySQL Connector/J must use TCP/IP sockets to connect to MySQL, as Java does not support Unix Domain Sockets. Therefore, when MySQL Connector/J connects to MySQL, the security manager in MySQL server will use its grant tables to determine whether the connection should be allowed.
You must add the necessary security credentials to the
MySQL server for this to happen, using the
GRANT statement to your MySQL Server.
See Section 13.5.1.3, “GRANT Syntax”, for more information.
Note
Testing your connectivity with the
mysql command-line client will not
work unless you add the --host flag,
and use something other than
localhost for the host. The
mysql command-line client will use
Unix domain sockets if you use the special hostname
localhost. If you are testing
connectivity to localhost, use
127.0.0.1 as the hostname instead.
Warning
Changing privileges and permissions improperly in MySQL can potentially cause your server installation to not have optimal security properties.
24.4.5.3.2: My application throws an SQLException 'No Suitable Driver'. Why is this happening?
There are three possible causes for this error:
The Connector/J driver is not in your
CLASSPATH, see Section 23.4.2, “Connector/J Installation”.The format of your connection URL is incorrect, or you are referencing the wrong JDBC driver.
When using DriverManager, the
jdbc.driverssystem property has not been populated with the location of the Connector/J driver.
24.4.5.3.3: I'm trying to use MySQL Connector/J in an applet or application and I get an exception similar to:
SQLException: Cannot connect to MySQL server on host:3306. Is there a MySQL server running on the machine/port you are trying to connect to? (java.security.AccessControlException) SQLState: 08S01 VendorError: 0
Either you're running an Applet, your MySQL server has been installed with the "--skip-networking" option set, or your MySQL server has a firewall sitting in front of it.
Applets can only make network connections back to the machine that runs the web server that served the .class files for the applet. This means that MySQL must run on the same machine (or you must have some sort of port re-direction) for this to work. This also means that you will not be able to test applets from your local file system, you must always deploy them to a web server.
MySQL Connector/J can only communicate with MySQL using TCP/IP, as Java does not support Unix domain sockets. TCP/IP communication with MySQL might be affected if MySQL was started with the "--skip-networking" flag, or if it is firewalled.
If MySQL has been started with the "--skip-networking"
option set (the Debian Linux package of MySQL server does
this for example), you need to comment it out in the file
/etc/mysql/my.cnf or /etc/my.cnf. Of course your my.cnf
file might also exist in the data
directory of your MySQL server, or anywhere else
(depending on how MySQL was compiled for your system).
Binaries created by MySQL AB always look in /etc/my.cnf
and [datadir]/my.cnf. If your MySQL server has been
firewalled, you will need to have the firewall configured
to allow TCP/IP connections from the host where your Java
code is running to the MySQL server on the port that MySQL
is listening to (by default, 3306).
24.4.5.3.4: I have a servlet/application that works fine for a day, and then stops working overnight
MySQL closes connections after 8 hours of inactivity. You either need to use a connection pool that handles stale connections or use the "autoReconnect" parameter (see Section 23.4.4.1, “Driver/Datasource Class Names, URL Syntax and Configuration Properties for Connector/J”).
Also, you should be catching SQLExceptions in your
application and dealing with them, rather than propagating
them all the way until your application exits, this is
just good programming practice. MySQL Connector/J will set
the SQLState (see
java.sql.SQLException.getSQLState() in
your APIDOCS) to "08S01" when it encounters
network-connectivity issues during the processing of a
query. Your application code should then attempt to
re-connect to MySQL at this point.
The following (simplistic) example shows what code that can handle these exceptions might look like:
Example 23.12. Example of transaction with retry logic
public void doBusinessOp() throws SQLException {
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
//
// How many times do you want to retry the transaction
// (or at least _getting_ a connection)?
//
int retryCount = 5;
boolean transactionCompleted = false;
do {
try {
conn = getConnection(); // assume getting this from a
// javax.sql.DataSource, or the
// java.sql.DriverManager
conn.setAutoCommit(false);
//
// Okay, at this point, the 'retry-ability' of the
// transaction really depends on your application logic,
// whether or not you're using autocommit (in this case
// not), and whether you're using transacational storage
// engines
//
// For this example, we'll assume that it's _not_ safe
// to retry the entire transaction, so we set retry
// count to 0 at this point
//
// If you were using exclusively transaction-safe tables,
// or your application could recover from a connection going
// bad in the middle of an operation, then you would not
// touch 'retryCount' here, and just let the loop repeat
// until retryCount == 0.
//
retryCount = 0;
stmt = conn.createStatement();
String query = "SELECT foo FROM bar ORDER BY baz";
rs = stmt.executeQuery(query);
while (rs.next()) {
}
rs.close();
rs = null;
stmt.close();
stmt = null;
conn.commit();
conn.close();
conn = null;
transactionCompleted = true;
} catch (SQLException sqlEx) {
//
// The two SQL states that are 'retry-able' are 08S01
// for a communications error, and 40001 for deadlock.
//
// Only retry if the error was due to a stale connection,
// communications problem or deadlock
//
String sqlState = sqlEx.getSQLState();
if ("08S01".equals(sqlState) || "40001".equals(sqlState)) {
retryCount--;
} else {
retryCount = 0;
}
} finally {
if (rs != null) {
try {
rs.close();
} catch (SQLException sqlEx) {
// You'd probably want to log this . . .
}
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException sqlEx) {
// You'd probably want to log this as well . . .
}
}
if (conn != null) {
try {
//
// If we got here, and conn is not null, the
// transaction should be rolled back, as not
// all work has been done
try {
conn.rollback();
} finally {
conn.close();
}
} catch (SQLException sqlEx) {
//
// If we got an exception here, something
// pretty serious is going on, so we better
// pass it up the stack, rather than just
// logging it. . .
throw sqlEx;
}
}
}
} while (!transactionCompleted && (retryCount > 0));
}
Note
Use of the autoReconnect option is not
recommended because there is no safe method of
reconnecting to the MySQL server without risking some
corruption of the connection state or database state
information. Instead, you should use a connection pool
which will enable your application to connect to the
MySQL server using an available connection from the
pool. The autoReconnect facility is
deprecated, and may be removed in a future release.
24.4.5.3.5: I'm trying to use JDBC-2.0 updatable result sets, and I get an exception saying my result set is not updatable.
Because MySQL does not have row identifiers, MySQL Connector/J can only update result sets that have come from queries on tables that have at least one primary key, the query must select every primary key and the query can only span one table (that is, no joins). This is outlined in the JDBC specification.
Note that this issue only occurs when using updatable
result sets, and is caused because Connector/J is unable
to guarantee that it can identify the correct rows within
the result set to be updated without having a unique
reference to each row. There is no requirement to have a
unique field on a table if you are using
UPDATE or DELETE
statements on a table where you can individually specify
the criteria to be matched using a
WHERE clause.
24.4.5.3.6: I cannot connect to the MySQL server using Connector/J, and I'm sure the connection paramters are correct.
Make sure that the skip-networking
option has not been enabled on your server. Connector/J
must be able to communicate with your server over TCP/IP,
named sockets are not supported. Also ensure that you are
not filtering connections through a Firewall or other
network security system. For more informaiton, see
Section B.1.2.2, “Can't connect to [local] MySQL server”.
24.4.5.3.7: I am trying to connect to my MySQL server within my application, but I get the following error and stack trace:
java.net.SocketException MESSAGE: Software caused connection abort: recv failed STACKTRACE: java.net.SocketException: Software caused connection abort: recv failed at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.read(Unknown Source) at com.mysql.jdbc.MysqlIO.readFully(MysqlIO.java:1392) at com.mysql.jdbc.MysqlIO.readPacket(MysqlIO.java:1414) at com.mysql.jdbc.MysqlIO.doHandshake(MysqlIO.java:625) at com.mysql.jdbc.Connection.createNewIO(Connection.java:1926) at com.mysql.jdbc.Connection.<init>(Connection.java:452) at com.mysql.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:411)
The error probably indicates that you are using a older version of the Connector/J JDBC driver (2.0.14 or 3.0.x) and you are trying to connect to a MySQL server with version 4.1x or newer. The older drivers are not compatible with 4.1 or newer of MySQL as they do not support the newer authentication mechanisms.
It is likely that the older version of the Connector/J
driver exists within your application directory or your
CLASSPATH includes the older
Connector/J package.
24.4.5.3.8: My application is deployed through JBoss and I am using transactions to handle the statements on the MySQL database. Under heavy loads I am getting a error and stack trace, but these only occur after a fixed period of heavy activity.
This is a JBoss, not Connector/J, issue and is connected to the use of transactions. Under heavy loads the time taken for transactions to complete can increase, and the error is caused because you have exceeded the predefined timeout.
You can increase the timeout value by setting the
TransactionTimeout attribute to the
TransactionManagerService within the
/conf/jboss-service.xml file
(pre-4.0.3) or
/deploy/jta-service.xml for JBoss
4.0.3 or later. See
TransactionTimeoute
within the JBoss wiki for more information.
MySQL AB provides assistance to the user community by means of its mailing lists. For Connector/J related issues, you can get help from experienced users by using the MySQL and Java mailing list. Archives and subscription information is available online at http://lists.mysql.com/java.
For information about subscribing to MySQL mailing lists or to browse list archives, visit http://lists.mysql.com/. See Section 1.7.1, “MySQL Mailing Lists”.
Community support from experienced users is also available through the JDBC Forum. You may also find help from other users in the other MySQL Forums, located at http://forums.mysql.com. See Section 1.7.2, “MySQL Community Support at the MySQL Forums”.
The normal place to report bugs is http://bugs.mysql.com/, which is the address for our bugs database. This database is public, and can be browsed and searched by anyone. If you log in to the system, you will also be able to enter new reports.
If you have found a sensitive security bug in MySQL, you can send email to security_at_mysql.com.
Writing a good bug report takes patience, but doing it right the first time saves time both for us and for yourself. A good bug report, containing a full test case for the bug, makes it very likely that we will fix the bug in the next release.
This section will help you write your report correctly so that you don't waste your time doing things that may not help us much or at all.
If you have a repeatable bug report, please report it to the bugs database at http://bugs.mysql.com/. Any bug that we are able to repeat has a high chance of being fixed in the next MySQL release.
To report other problems, you can use one of the MySQL mailing lists.
Remember that it is possible for us to respond to a message containing too much information, but not to one containing too little. People often omit facts because they think they know the cause of a problem and assume that some details don't matter.
A good principle is this: If you are in doubt about stating something, state it. It is faster and less troublesome to write a couple more lines in your report than to wait longer for the answer if we must ask you to provide information that was missing from the initial report.
The most common errors made in bug reports are (a) not including the version number of Connector/J or MySQL used, and (b) not fully describing the platform on which Connector/J is installed (including the JVM version, and the platform type and version number that MySQL itself is installed on).
This is highly relevant information, and in 99 cases out of 100, the bug report is useless without it. Very often we get questions like, “Why doesn't this work for me?” Then we find that the feature requested wasn't implemented in that MySQL version, or that a bug described in a report has already been fixed in newer MySQL versions.
Sometimes the error is platform-dependent; in such cases, it is next to impossible for us to fix anything without knowing the operating system and the version number of the platform.
If at all possible, you should create a repeatable, stanalone testcase that doesn't involve any third-party classes.
To streamline this process, we ship a base class for testcases
with Connector/J, named
'com.mysql.jdbc.util.BaseBugReport'. To
create a testcase for Connector/J using this class, create your
own class that inherits from
com.mysql.jdbc.util.BaseBugReport and
override the methods setUp(),
tearDown() and runTest().
In the setUp() method, create code that
creates your tables, and populates them with any data needed to
demonstrate the bug.
In the runTest() method, create code that
demonstrates the bug using the tables and data you created in
the setUp method.
In the tearDown() method, drop any tables you
created in the setUp() method.
In any of the above three methods, you should use one of the
variants of the getConnection() method to
create a JDBC connection to MySQL:
getConnection()- Provides a connection to the JDBC URL specified ingetUrl(). If a connection already exists, that connection is returned, otherwise a new connection is created.getNewConnection()- Use this if you need to get a new connection for your bug report (i.e. there's more than one connection involved).getConnection(String url)- Returns a connection using the given URL.getConnection(String url, Properties props)- Returns a connection using the given URL and properties.
If you need to use a JDBC URL that is different from
'jdbc:mysql:///test', override the method
getUrl() as well.
Use the assertTrue(boolean expression) and
assertTrue(String failureMessage, boolean
expression) methods to create conditions that must be
met in your testcase demonstrating the behavior you are
expecting (vs. the behavior you are observing, which is why you
are most likely filing a bug report).
Finally, create a main() method that creates
a new instance of your testcase, and calls the
run method:
public static void main(String[] args) throws Exception {
new MyBugReport().run();
}Once you have finished your testcase, and have verified that it demonstrates the bug you are reporting, upload it with your bug report to http://bugs.mysql.com/.
The Connector/J Change History (Changelog) is located with the main Changelog for MySQL. See Section E.6, “MySQL Connector/J Change History”.
MySQL Connector/MXJ is a solution for deploying the MySQL database
engine (mysqld) intelligently from within a Java
package.
MySQL Connector/MXJ is a Java Utility package for deploying and managing a MySQL database. Deploying and using MySQL can be as easy as adding an additional parameter to the JDBC connection url, which will result in the database being started when the first connection is made. This makes it easy for Java developers to deploy applications which require a database by reducing installation barriers for their end-users.
MySQL Connector/MXJ makes the MySQL database appear to be a java-based component. It does this by determining what platform the system is running on, selecting the appropriate binary, and launching the executable. It will also optionally deploy an initial database, with any specified parameters.
Included are instructions for use with a JDBC driver and deploying as a JMX MBean to JBoss.
You can download sources and binaries from: http://dev.mysql.com/downloads/connector/mxj/
This a beta release and feedback is welcome and encouraged.
Please send questions or comments to the MySQL and Java mailing list.
Connector/MX
Connector/MXJ 5.x, currently in beta status, includes
mysqldversion 5.x and includes binaries for Linux x86, Mac OS X PPC, Windows XP/NT/2000 x86 and Solaris SPARC. Connector/MXJ 5.x requires the Connector/J 5.x package.The exact version of
mysqldincluded depends on the version of Connector/MXJConnector/MXJ v5.0.3 included MySQL v5.0.22
Connector/MXJ v5.0.4 includes MySQL v5.0.27 (Community) or MySQL v5.0.32 (Enterprise)
Connector/MXJ v5.0.6 includes MySQL 5.0.37 (Community)
Connector/MXJ 1.x includes
mysqldversion 4.1.13 and includes binaries for Linux x86, Windows XP/NT/2000 x86 and Solaris SPARC. Connector/MXJ 1.x requires the Connector/J 3.x package.
A summary of the different MySQL versions supplied with each Connector/MXJ release are shown in the table.
| Connector/MXJ Version | MySQL Version(s) | ||
|---|---|---|---|
| 5.0.6 | 5.0.37 (CS), 5.0.40 (ES) | ||
| 5.0.5 | 5.0.37 (CS), 5.0.36 (ES) | ||
| 5.0.4 | 5.0.27 (CS), 5.0.32 (ES) | ||
| 5.0.3 | 5.0.22 | ||
| 5.0.2 | 5.0.19 |
This guide provides information on the Connector/MXJ 5.x release. For information on using the older releases, please see the documentation included with the appropriate distribution.
Connector/MXJ consists of a Java class, a copy of the
mysqld binary for a specific list of
platforms, and associated files and support utilities. The Java
class controls the initialization of an instance of the embedded
mysqld binary, and the ongoing management of
the mysqld process. The entire sequence and
management can be controlled entirely from within Java using the
Connector/MXJ Java classes. You can see an overview of the
contents of the Connector/MXJ package in the figure below.
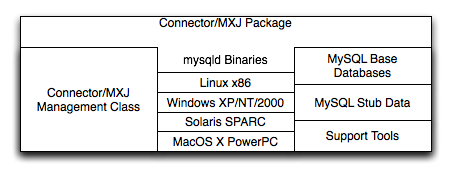
It is important to note that Connector/MXJ is not an embedded
version of MySQL, or a version of MySQL written as part of a
Java class. Connector/MXJ works through the use of an embedded,
compiled binary of mysqld as would normally
be used when deploying a standard MySQL installation.
It is the Connector/MXJ wrapper, support classes and tools, that enable Connector/MXJ to appear as a MySQL instance.
When Connector/MXJ is initialized, the corresponding
mysqld binary for the current platform is
extracted, along with a pre-configured data directed. Both are
contained within the Connector/MXJ JAR file. The
mysqld instance is then started, with any
additional options as specified during the initialization, and
the MySQL database becomes accessible.
Because Connector/MXJ works in combination with Connector/J, you can access and integrate with the MySQL instance through a JDBC connection. When you have finished with the server, the instance is terminated, and, by default, any data created during the session is retained within the temporary directory created when the instance was started.
Connector/MXJ and the embedded mysqld
instance can be deployed in a number of environments where
relying on an existing database, or installing a MySQL instance
would be impossible, including CD-ROM embedded database
applications and temporary database requirements within a
Java-based application environment.
Connector/MXJ does not have a installation application or process, but there are some steps you can follow to make the installation and deployment of Connector/MXJ easier.
Before you start, there are some baseline requirements for
Java Runtime Environment (v1.4.0 or newer) if you are only going to deploy the package.
Java Development Kit (v1.4.0 or newer) if you want to build Connector/MXJ from source.
Connector/J 5.0 or newer.
Depending on your target installation/deployment environment you may also require:
JBoss - 4.0rc1 or newer
Apache Tomcat - 5.0 or newer
Sun's JMX reference implementation version 1.2.1 (from http://java.sun.com/products/JavaManagement/)
Connector/MXJ is compatible with any platform supporting Java
and MySQL. By default, Connector/MXJ incorporates the
mysqld binary for a select number of
platforms, as outlined below.
Linux, i386
Windows NT, Windows 2000, Windows XP, x86
Solaris 8, SPARC 32 (compatible with Solaris 8, Solaris 9 and Solaris 10 on SPARC 32-bit and 64-bit platforms)
Mac OS X, PowerPC
For more information on packaging your own Connector/MXJ with the platforms you require, see Section 23.5.5.1, “Creating your own Connector/MXJ Package”
Because there is no formal installation process, the method, installation directory, and access methods you use for Connector/MXJ are entirely up to your individual requirements.
To perform a basic installation, choose a target directory for
the files included in the Connector/MXJ package. On Unix/Linux
systems you may opt to use a directory such as
/usr/local/connector-mxj; On Windows, you
may want to install the files in the base directory,
C:\Connector-MXJ, or within the
Program Files directory.
To install the files, for a Connector/MXJ 5.0.4 installation:
Download the Connector/MXJ package, either in Tar/Gzip format (ideal for Unix/Linux systems) or Zip format (Windows).
Extract the files from the package. This will create a directory
connector-mxj. Copy and optionally rename this directory to your desired location.For best results, you should update your global
CLASSPATHvariable with the location of the requiredjarfiles.Within Unix/Linux you can do this globally by editing the global shell profile, or on a user by user basis by editing their individual shell profile.
On Windows 2000, Windows NT and Windows XP, you can edit the global
CLASSPATHby editing theEnvironment Variablesconfigured through theSystemcontrol panel.
For Connector/MXJ 5.0.4 and later you need the following JAR
files in your CLASSPATH
connector-mxj.jar— contains the main Connector/MXJ classes.connector-mxj-db-files.jar— contains the embeddedmysqldand database files.aspectjrt.jar— the AspectJ runtime library, located inlib/aspectjrt.jarin the Connector/MXJ package.connector-j.jar— Connector/J, see Section 23.4, “MySQL Connector/J”.
For Connector/MXJ 5.0.3 and earlier, you need the following JAR files:
connector-mxj.jaraspectjrt.jar— the AspectJ runtime library, located inlib/aspectjrt.jarin the Connector/MXJ package.connector-j.jar— Connector/J, see Section 23.4, “MySQL Connector/J”.
Once you have extracted the Connector/MXJ and Connector/J
components you can run one of the sample applications that
initiates a MySQL instance. You can test the installation by
running the ConnectorMXJUrlTestExample:
java ConnectorMXJUrlTestExample jdbc:mysql:mxj://localhost:3336/test?server.basedir=/var/tmp/test-mxj [MysqldResource] launching mysqld (getOptions) [/var/tmp/test-mxj/bin/mysqld][--no-defaults] » [--pid-file=/var/tmp/test-mxj/data/MysqldResource.pid] » [--socket=mysql.sock][--datadir=/var/tmp/test-mxj/data] » [--port=3336][--basedir=/var/tmp/test-mxj] [MysqldResource] launching mysqld (driver_launched_mysqld_1) InnoDB: The first specified data file ./ibdata1 did not exist: InnoDB: a new database to be created! 060726 15:40:42 InnoDB: Setting file ./ibdata1 size to 10 MB InnoDB: Database physically writes the file full: wait... 060726 15:40:43 InnoDB: Log file ./ib_logfile0 did not exist: new to be created InnoDB: Setting log file ./ib_logfile0 size to 5 MB InnoDB: Database physically writes the file full: wait... 060726 15:40:43 InnoDB: Log file ./ib_logfile1 did not exist: new to be created InnoDB: Setting log file ./ib_logfile1 size to 5 MB InnoDB: Database physically writes the file full: wait... InnoDB: Doublewrite buffer not found: creating new InnoDB: Doublewrite buffer created InnoDB: Creating foreign key constraint system tables InnoDB: Foreign key constraint system tables created 060726 15:40:44 InnoDB: Started; log sequence number 0 0 060726 15:40:44 [Note] /var/tmp/test-mxj/bin/mysqld: ready for connections. Version: '5.0.22-max' socket: 'mysql.sock' port: 3336 MySQL Community Edition - Experimental (GPL) [MysqldResource] mysqld running as process: 1210 ------------------------ 5.0.22-max ------------------------ [MysqldResource] stopping mysqld (process: 1210) 060726 15:40:44 [Note] /var/tmp/test-mxj/bin/mysqld: Normal shutdown 060726 15:40:45 InnoDB: Starting shutdown... 060726 15:40:48 InnoDB: Shutdown completed; log sequence number 0 43655 060726 15:40:48 [Note] /var/tmp/test-mxj/bin/mysqld: Shutdown complete [MysqldResource] clearing options [MysqldResource] shutdown complete
The above output shows an instance of MySQL starting, the necessary files being created (log files, InnoDB data files) and the MySQL database entering the running state. The instance is then shutdown by Connector/MXJ before the example terminates.
Connector/MXJ and Connector/J work together to enable you to
launch an instance of the mysqld server
through the use of a keyword in the JDBC connection string.
Deploying Connector/MXJ within a Java application can be
automated through this method, making the deployment of
Connector/MXJ a simple process:
Download and unzip Connector/MXJ, add
connector-mxj.jarto theCLASSPATH.If you are using Connector/MXJ v5.0.4 or later you will also need to add the
connector-mxj-db-files.jarfile to yourCLASSPATH.To the JDBC connection string, embed the
mxjkeyword, for example:jdbc:mysql:mxj://localhost:.PORT/DBNAME
For more details, see Section 23.5.3, “Connector/MXJ Configuration”.
For deployment within a JBoss environment, you must configure the JBoss environment to use the Connector/MXJ component within the JDBC parameters:
Download Connector/MXJ and copy the
connector-mxj.jarfile to the$JBOSS_HOME/server/default/libdirectory.If you are using Connector/MXJ v5.0.4 or later you will also need to copy the
connector-mxj-db-files.jarfile to$JBOSS_HOME/server/default/lib.Download Connector/J and copy the
mysql-connector-java-file to the5.0.4-bin.jar$JBOSS_HOME/server/default/libdirectory.Create an MBean service xml file in the
$JBOSS_HOME/server/default/deploydirectory with any attributes set, for instance thedatadirandautostart.Set the JDBC parameters of your web application to use:
String driver = "com.mysql.jdbc.Driver"; String url = "jdbc:mysql:///test?propertiesTransform="+ "com.mysql.management.jmx.ConnectorMXJPropertiesTransform"; String user = "root"; String password = ""; Class.forName(driver); Connection conn = DriverManager.getConnection(url, user, password);
You may wish to create a separate users and database table spaces for each application, rather than using "root and test".
We highly suggest having a routine backup procedure for backing
up the database files in the datadir.
The best way to ensure that your platform is supported is to run the JUnit tests. These will test the Connector/MXJ classes and the associated components.
The first thing to do is make sure that the components will
work on the platform. The
MysqldResource class is really a
wrapper for a native version of MySQL, so not all platforms
are supported. At the time of this writing, Linux on the i386
architecture has been tested and seems to work quite well, as
does OS X v10.3. There has been limited testing on Windows and
Solaris.
Requirements:
JDK-1.4 or newer (or the JRE if you aren't going to be compiling the source or JSPs).
MySQL Connector/J version 5.0 or newer (from http://dev.mysql.com/downloads/connector/j/) installed and available via your CLASSPATH.
The
javax.managementclasses for JMX version 1.2.1, these are present in the following application servers:JBoss - 4.0rc1 or newer.
Apache Tomcat - 5.0 or newer.
Sun's JMX reference implementation version 1.2.1 (from http://java.sun.com/products/JavaManagement/).
JUnit 3.8.1 (from http://www.junit.org/).
If building from source, All of the requirements from above, plus:
Ant version 1.5 or newer (download from http://ant.apache.org/).
The tests attempt to launch MySQL on the port 3336. If you have a MySQL running, it may conflict, but this isn't very likely because the default port for MySQL is 3306. However, You may set the "c-mxj_test_port" Java property to a port of your choosing. Alternatively, you may wish to start by shutting down any instances of MySQL you have running on the target machine.
The tests suppress output to the console by default. For verbose output, you may set the "c-mxj_test_silent" Java property to "false".
To run the JUnit test suite, the $CLASSPATH must include the following:
JUnit
JMX
Connector/J
MySQL Connector/MXJ
If
connector-mxj.jaris not present in your download, unzip MySQL Connector/MXJ source archive.cd mysqldjmx ant distThen add
$TEMP/cmxj/stage/connector-mxj/connector-mxj.jarto the CLASSPATH.if you have
junit, execute the unit tests. From the command line, type:java junit.textui.TestRunner com.mysql.management.AllTestsSuiteThe output should look something like this:
......................................... ......................................... .......... Time: 259.438 OK (101 tests)
Note that the tests are a bit slow near the end, so please be patient.
A feature of the MySQL Connector/J JDBC driver is the ability to specify a connection to an embedded Connector/MXJ instance through the use of the mxj keyword in the JDBC connection string.
In the following example, we have a program which creates a connection, executes a query, and prints the result to the System.out. The MySQL database will be deployed and started as part of the connection process, and shutdown as part of the finally block.
You can find this file in the Connector/MXJ package as
src/ConnectorMXJUrlTestExample.java.
import java.io.File;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import com.mysql.management.driverlaunched.ServerLauncherSocketFactory;
public class ConnectorMXJUrlTestExample {
public static String DRIVER = "com.mysql.jdbc.Driver";
public static String JAVA_IO_TMPDIR = "java.io.tmpdir";
public static void main(String[] args) throws Exception {
File ourAppDir = new File(System.getProperty(JAVA_IO_TMPDIR));
File databaseDir = new File(ourAppDir, "test-mxj");
int port = 3336;
String url = "jdbc:mysql:mxj://localhost:" + port + "/test" + "?"
+ "server.basedir=" + databaseDir;
System.out.println(url);
String userName = "root";
String password = "";
Class.forName(DRIVER);
Connection conn = null;
try {
conn = DriverManager.getConnection(url, userName, password);
printQueryResults(conn, "SELECT VERSION()");
} finally {
try {
if (conn != null)
conn.close();
} catch (Exception e) {
e.printStackTrace();
}
ServerLauncherSocketFactory.shutdown(databaseDir, null);
}
}
public static void printQueryResults(Connection conn, String SQLquery)
throws Exception {
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(SQLquery);
int columns = rs.getMetaData().getColumnCount();
System.out.println("------------------------");
System.out.println();
while (rs.next()) {
for (int i = 1; i <= columns; i++) {
System.out.println(rs.getString(i));
}
System.out.println();
}
rs.close();
stmt.close();
System.out.println("------------------------");
System.out.flush();
Thread.sleep(100); // wait for System.out to finish flush
}
}To run the above program, be sure to have connector-mxj.jar and Connector/J in the CLASSPATH. Then type:
java ConnectorMXJTestExample
If you have a java application and wish to “embed” a MySQL database, make use of the com.mysql.management.MysqldResource class directly. This class may be instantiated with the default (no argument) constructor, or by passing in a java.io.File object representing the directory you wish the server to be "unzipped" into. It may also be instantiated with printstreams for "stdout" and "stderr" for logging.
Once instantiated, a java.util.Map, the object will be able to provide a java.util.Map of server options appropriate for the platform and version of MySQL which you will be using.
The MysqldResource enables you to "start" MySQL with a java.util.Map of server options which you provide, as well as "shutdown" the database. The following example shows a simplistic way to embed MySQL in an application using plain java objects.
You can find this file in the Connector/MXJ package as
src/ConnectorMXJObjectTestExample.java.
import java.io.File;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.HashMap;
import java.util.Map;
import com.mysql.management.MysqldResource;
public class ConnectorMXJObjectTestExample {
public static String DRIVER = "com.mysql.jdbc.Driver";
public static String JAVA_IO_TMPDIR = "java.io.tmpdir";
public static void main(String[] args) throws Exception {
File ourAppDir = new File(System.getProperty(JAVA_IO_TMPDIR));
File databaseDir = new File(ourAppDir, "mysql-mxj");
int port = 3336;
MysqldResource mysqldResource = startDatabase(databaseDir, port);
String userName = "root";
String password = "";
Class.forName(DRIVER);
Connection conn = null;
try {
String url = "jdbc:mysql://localhost:" + port + "/test";
conn = DriverManager.getConnection(url, userName, password);
printQueryResults(conn, "SELECT VERSION()");
} finally {
try {
if (conn != null) {
conn.close();
}
} catch (Exception e) {
e.printStackTrace();
}
try {
mysqldResource.shutdown();
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static MysqldResource startDatabase(File databaseDir, int port) {
MysqldResource mysqldResource = new MysqldResource(databaseDir);
Map database_options = new HashMap();
database_options.put("port", Integer.toString(port));
mysqldResource.start("test-mysqld-thread", database_options);
if (!mysqldResource.isRunning()) {
throw new RuntimeException("MySQL did not start.");
}
System.out.println("MySQL is running.");
return mysqldResource;
}
public static void printQueryResults(Connection conn, String SQLquery)
throws Exception {
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(SQLquery);
int columns = rs.getMetaData().getColumnCount();
System.out.println("------------------------");
System.out.println();
while (rs.next()) {
for (int i = 1; i <= columns; i++) {
System.out.println(rs.getString(i));
}
System.out.println();
}
rs.close();
stmt.close();
System.out.println("------------------------");
System.out.flush();
Thread.sleep(100); // wait for System.out to finish flush
}
}
Of course there are many options we may wish to set for a MySQL database. These options may be specified as part of the JDBC connection string simply by prefixing each server option with ''server.''. In the following example we set two driver parameters and two server parameters:
String url = "jdbc:mysql://" + hostColonPort + "/"
+ "?"
+ "cacheServerConfiguration=true"
+ "&"
+ "useLocalSessionState=true"
+ "&"
+ "server.basedir=/opt/myapp/db"
+ "&"
+ "server.datadir=/mnt/bigdisk/myapp/data";
The MysqldResource class supports three
different constructor forms:
public MysqldResource(File baseDir, File dataDir, String mysqlVersionString, PrintStream out, PrintStream err, Utils util)The most detailed constructor, enables you to set the base directory, data directory, select a server by its version string, standard out and standard error and MySQL utilities class.
public MysqldResource(File baseDir, File dataDir, String mysqlVersionString, PrintStream out, PrintStream err)Enables you to set the base directory, data directory, select a server by its version string, standard out and standard error.
public MysqldResource(File baseDir, File dataDir, String mysqlVersionString)Enables you to set the base directory, data directory and select a server by its version string. Output for standard out and standard err are directed to System.out and System.err.
public MysqldResource(File baseDir, File dataDir)Enables you to set the base directory and data directory. The default MySQL version is selected, and output for standard out and standard err are directed to System.out and System.err.
public MysqldResource(File baseDir);Allows the setting of the "basedir" to deploy the MySQL files to. Output for standard out and standard err are directed to System.out and System.err.
public MysqldResource();The basedir is defaulted to a subdirectory of the java.io.tempdir. Output for standard out and standard err are directed to System.out and System.err;
MysqldResource API includes the following methods:
void start(String threadName, Map mysqldArgs);Deploys and starts MySQL. The "threadName" string is used to name the thread which actually performs the execution of the MySQL command line. The map is the set of arguments and their values to be passed to the command line.
void shutdown();Shuts down the MySQL instance managed by the MysqldResource object.
Map getServerOptions();Returns a map of all the options and their current (or default, if not running) options available for the MySQL database.
boolean isRunning();Returns true if the MySQL database is running.
boolean isReadyForConnections();Returns true once the database reports that is ready for connections.
void setKillDelay(int millis);The default “Kill Delay” is 30 seconds. This represents the amount of time to wait between the initial request to shutdown and issuing a “force kill” if the database has not shutdown by itself.
void addCompletionListenser(Runnable listener);Allows for applications to be notified when the server process completes. Each ''listener'' will be fired off in its own thread.
String getVersion();Returns the version of MySQL.
void setVersion(int MajorVersion, int minorVersion, int patchLevel);The standard distribution comes with only one version of MySQL packaged. However, it is possible to package multiple versions, and specify which version to use.
This section contains notes and tips on using the Connector/MXJ component within your applications.
If you want to create a custom Connector/MXJ package that
includes a specific mysqld version or
platform then you must extract and rebuild the
connector-mxj.jar (Connector/MXJ v5.0.3 or
earlier) or connector-mxj-db-files.jar
(Connector/MXJ v5.0.4 or later) file.
First, you should create a new directory into which you can
extract the current connector-mxj.jar:
shell> mkdir custom-mxj shell> cd custom-mxj shell> jar -xf connector-mxj.jar shell> ls 5-0-22/ ConnectorMXJObjectTestExample.class ConnectorMXJUrlTestExample.class META-INF/ TestDb.class com/ kill.exe
If you are using Connector/MXJ v5.0.4 or later, you should
unpack the connector-mxj-db-files.jar:
shell> mkdir custom-mxj shell> cd custom-mxj shell> jar -xf connector-mxj-db-files.jar shell> ls 5-0-27/ META-INF/ connector-mxj.properties
The MySQL version directory, 5-0-22 or
5-0-27 in the preceding examples, contains
all of the files used to create an instance of MySQL when
Connector/MXJ is executed. All of the files in this directory
are required for each version of MySQL that you want to embed.
Note as well the format of the version number, which uses
hyphens instead of periods to separate the version number
components.
Within the version specific directory are the platform specific
directories, and archives of the data and
share directory required by MySQL for the
various platforms. For example, here is the listing for the
default Connector/MXJ package:
shell>> ls Linux-i386/ META-INF/ Mac_OS_X-ppc/ SunOS-sparc/ Win-x86/ com/ data_dir.jar share_dir.jar win_share_dir.jar
Platform specific directories are listed by their OS and
platform - for example the mysqld for Mac OS
X PowerPC is located within the
Mac_OS_X-ppc directory. You can delete
directories from this location that you do not require, and add
new directories for additional platforms that you want to
support.
To add a platform specific mysqld, create a
new directory with the corresponding name for your operating
system/platform. For example, you could add a directory for Mac
OS X/Intel using the directory
Mac_OS_X-i386.
On Unix systems, you can determine the platform using
uname:
shell> uname -p i386
Now you need to download or compile mysqld
for the MySQL version and platform you want to include in your
custom connector-mxj.jar package into the
new directory.
Create a file called version.txt in the
OS/platform directory you have just created that contains the
version string/path of the mysqld binary. For example:
mysql-5.0.22-osx10.3-i386/bin/mysqld
You can now recreate the connector-mxj.jar
file with the added mysqld:
shell> cd custom-mxj shell> jar -cf ../connector-mxj.jar *
For Connector/MXJ v5.0.4 and later, you should repackage to the
connector-mxj-db-files.jar:
shell> cd custom-mxj shell> jar -cf ../connector-mxj-db-files.jar *
You should test this package using the steps outlined in Section 23.5.2.3, “Connector/MXJ Quick Start Guide”.
Note
Because the connector-mxj-db-files.jar
file is separate from the main Connector/MXJ classes you can
distribute different
connector-mxj-db-files.jar files to
different hotsts or for different projects without having to
create a completely new main
connector-mxj.jar file for each one.
To include a pre-configured/populated database within your
Connector/MXJ JAR file you must create a custom
data_dir.jar file, as included within the
main connector-mxj.jar (Connector/MXJ 5.0.3
or earlier) or connector-mxj-db-files.jar
(Connector/MXJ 5.0.4 or later) file:
First extract the
connector-mxj.jarfile, as outlined in the previous section (see Section 23.5.5.1, “Creating your own Connector/MXJ Package”).First, create your database and populate the database with the information you require in an existing instance of MySQL - including Connector/MXJ instances. Data file formats are compatible across platforms.
Shutdown the instance of MySQL.
Create a JAR file of the data directory and databases that you want to include your Connector/MXJ package. You should include the
mysqldatabase, which includes user authentication information, in addition to the specific databases you want to include. For example, to create a JAR of themysqlandmxjtestdatabases:shell> jar -cf ../data_dir.jar mysql mxjtest
For Connector/MXJ 5.0.3 or earlier, copy the
data_dir.jarfile into the extractedconnector-mxj.jardirectory, and then create an archive forconnector-mxj.jar.For Connector/MXJ 5.0.4 or later, copy the
data_dir.jarfile into the extractedconnector-mxj-db-files.jardirectory, and then create an archive forconnector-mxj-db-files.jar.
Note that if you are create databases using the InnoDB engine,
you must include the ibdata.* and
ib_logfile* files within the
data_dir.jar archive.
As a JMX MBean, MySQL Connector/MXJ requires a JMX v1.2 compliant MBean container, such as JBoss version 4. The MBean will uses the standard JMX management APIs to present (and allow the setting of) parameters which are appropriate for that platform.
If you are not using the SUN Reference implementation of the JMX libraries, you should skip this section. Or, if you are deploying to JBoss, you also may wish to skip to the next section.
We want to see the MysqldDynamicMBean in action inside of a JMX
agent. In the com.mysql.management.jmx.sunri
package is a custom JMX agent with two MBeans:
the MysqldDynamicMBean, and
a com.sun.jdmk.comm.HtmlAdaptorServer, which provides a web interface for manipulating the beans inside of a JMX agent.
When this very simple agent is started, it will allow a MySQL database to be started and stopped with a web browser.
Complete the testing of the platform as above.
current JDK, JUnit, Connector/J, MySQL Connector/MXJ
this section requires the SUN reference implementation of JMX
PATH,JAVA_HOME,ANT_HOME,CLASSPATH
If not building from source, skip to next step
rebuild with the "sunri.present"
ant -Dsunri.present=true dist re-run tests: java junit.textui.TestRunner com.mysql.management.AllTestsSuite
launch the test agent from the command line:
java com.mysql.management.jmx.sunri.MysqldTestAgentSunHtmlAdaptor &from a browser:
http://localhost:9092/under MysqldAgent,
select "name=mysqld"Observe the MBean View
scroll to the bottom of the screen press the button
click
Back to MBean Viewscroll to the bottom of the screen press button
kill the java process running the Test Agent (jmx server)
Once there is confidence that the MBean will function on the platform, deploying the MBean inside of a standard JMX Agent is the next step. Included are instructions for deploying to JBoss.
Ensure a current version of java development kit (v1.4.x), see above.
Ensure
JAVA_HOMEis set (JBoss requiresJAVA_HOME)Ensure
JAVA_HOME/binis in thePATH(You will NOT need to set your CLASSPATH, nor will you need any of the jars used in the previous tests).
Ensure a current version of JBoss (v4.0RC1 or better)
http://www.jboss.org/index.html select "Downloads" select "jboss-4.0.zip" pick a mirror unzip ~/dload/jboss-4.0.zip create a JBOSS_HOME environment variable set to the unzipped directory unix only: cd $JBOSS_HOME/bin chmod +x *.sh
Deploy (copy) the
connector-mxj.jarto$JBOSS_HOME/server/default/lib.Deploy (copy)
mysql-connector-java-3.1.4-beta-bin.jarto$JBOSS_HOME/server/default/lib.Create a
mxjtest.wardirectory in$JBOSS_HOME/server/default/deploy.Deploy (copy)
index.jspto$JBOSS_HOME/server/default/deploy/mxjtest.war.Create a
mysqld-service.xmlfile in$JBOSS_HOME/server/default/deploy.<?xml version="1.0" encoding="UTF-8"?> <server> <mbean code="com.mysql.management.jmx.jboss.JBossMysqldDynamicMBean" name="mysql:type=service,name=mysqld"> <attribute name="datadir">/tmp/xxx_data_xxx</attribute> <attribute name="autostart">true</attribute> </mbean> </server>Start jboss:
on unix: $JBOSS_HOME/bin/run.sh
on windows: %JBOSS_HOME%\bin\run.bat
Be ready: JBoss sends a lot of output to the screen.
When JBoss seems to have stopped sending output to the screen, open a web browser to:
http://localhost:8080/jmx-consoleScroll down to the bottom of the page in the
mysqlsection, select the bulletedmysqldlink.Observe the JMX MBean View page. MySQL should already be running.
(If "autostart=true" was set, you may skip this step.) Scroll to the bottom of the screen. You may press the button to stop (or start) MySQL observe
Operation completed successfully without a return value.ClickBack to MBean ViewTo confirm MySQL is running, open a web browser to
http://localhost:8080/mxjtest/and you should see thatSELECT 1
returned with a result of
1
Guided by the
$JBOSS_HOME/server/default/deploy/mxjtest.war/index.jspyou will be able to use MySQL in your Web Application. There is atestdatabase and arootuser (no password) ready to experiment with. Try creating a table, inserting some rows, and doing some selects.Shut down MySQL. MySQL will be stopped automatically when JBoss is stopped, or: from the browser, scroll down to the bottom of the MBean View press the stop service button to halt the service. Observe
Operation completed successfully without a return value.Usingpsortask managersee that MySQL is no longer running
As of 1.0.6-beta version is the ability to have the MBean start the MySQL database upon start up. Also, we've taken advantage of the JBoss life-cycle extension methods so that the database will gracefully shut down when JBoss is shutdown.
There are a wide variety of options available for obtaining support for using Connector/MXJ. You should contact the Connector/MXJ community for help before reporting a potential bug or problem. See Section 23.5.6.1, “Connector/MXJ Community Support”.
MySQL AB provides assistance to the user community by means of a number of mailing lists and web based forums.
You can find help and support through the MySQL and Java mailing list.
For information about subscribing to MySQL mailing lists or to browse list archives, visit http://lists.mysql.com/. See Section 1.7.1, “MySQL Mailing Lists”.
Community support from experienced users is also available through the MyODBC Forum. You may also find help from other users in the other MySQL Forums, located at http://forums.mysql.com. See Section 1.7.2, “MySQL Community Support at the MySQL Forums”.
If you encounter difficulties or problems with Connector/MXJ, contact the Connector/MXJ community Section 23.5.6.1, “Connector/MXJ Community Support”.
If reporting a problem, you should ideally include the following information with the email:
Operating system and version
Connector/MXJ version
MySQL server version
Copies of error messages or other unexpected output
Simple reproducible sample
Remember that the more information you can supply to us, the more likely it is that we can fix the problem.
If you believe the problem to be a bug, then you must report the bug through http://bugs.mysql.com/.
The Connector/MXJ Change History (Changelog) is located with the main Changelog for MySQL. See Section E.7, “MySQL Connector/MXJ Change History”.
The PHP distribution and documentation are available from the PHP
Web site. MySQL provides the mysql and
mysqli extensions for the Windows operating
system on
http://dev.mysql.com/downloads/connector/php/ for
MySQL version 4.1.16 and higher, MySQL 5.0.18, and MySQL 5.1. You
can find information why you should preferably use the extensions
provided by MySQL on that page. For platforms other than Windows,
you should use the mysql or
mysqli extensions shipped with the PHP sources.
See Section 22.3, “MySQL PHP API”.
Table of Contents
This chapter describes a lot of things that you need to know when
working on the MySQL code. If you plan to contribute to MySQL
development, want to have access to the bleeding-edge versions of
the code, or just want to keep track of development, follow the
instructions in Section 2.4.14.3, “Installing from the Development Source Tree”. If you
are interested in MySQL internals, you should also subscribe to
our internals mailing list. This list has
relatively low traffic. For details on how to subscribe, please
see Section 1.7.1, “MySQL Mailing Lists”. All developers at MySQL AB
are on the internals list and we help other
people who are working on the MySQL code. Feel free to use this
list both to ask questions about the code and to send patches that
you would like to contribute to the MySQL project!
The MySQL server creates the following threads:
One thread manages TCP/IP file connection requests and creates a new dedicated thread to handle the authentication and SQL statement processing for each connection. (On Unix, this thread also manages Unix socket file connection requests.) On Windows, a similar thread manages shared-memory connection requests, and a thread manages named-pipe connection requests. Every client connection has its own thread, although the manager threads try to avoid creating threads by consulting the thread cache first to see whether a cached thread can be used for a new connection.
On a master replication server, slave server connections are like client connections: There is one thread per connected slave.
On a slave replication server, an I/O thread is started to connect to the master server and read updates from it. An SQL thread is started to apply updates read from the master. These two threads run independently and can be started and stopped independently.
The signal thread handles all signals. This thread also normally handles alarms and calls
process_alarm()to force timeouts on connections that have been idle too long.If
InnoDBis used, there will be 4 additional threads by default. Those are file I/O threads, controlled by theinnodb_file_io_threadsparameter. See Section 14.2.4, “InnoDBStartup Options and System Variables”.If mysqld is compiled with
-DUSE_ALARM_THREAD, a dedicated thread that handles alarms is created. This is only used on some systems where there are problems withsigwait()or if you want to use thethr_alarm()code in your application without a dedicated signal handling thread.If the server is started with the
--flush_time=option, a dedicated thread is created to flush all tables everyvalvalseconds.Each table for which
INSERT DELAYEDstatements are issued gets its own thread.
mysqladmin processlist only shows the
connection, INSERT DELAYED, and replication
threads.
MySQL Enterprise For expert advice on thread management subscribe to the MySQL Network Monitoring and Advisory Service. For more information see, http://www.mysql.com/products/enterprise/advisors.html.
The test system that is included in Unix source and binary distributions makes it possible for users and developers to perform regression tests on the MySQL code. These tests can be run on Unix.
The current set of test cases doesn't test everything in MySQL, but it should catch most obvious bugs in the SQL processing code, operating system or library issues, and is quite thorough in testing replication. Our goal is to have the tests cover 100% of the code. We welcome contributions to our test suite. You may especially want to contribute tests that examine the functionality critical to your system because this ensures that all future MySQL releases work well with your applications.
The test system consists of a test language interpreter
(mysqltest), a shell script to run all tests
(mysql-test-run), the actual test cases
written in a special test language, and their expected results.
To run the test suite on your system after a build, type
make test from the source root directory, or
change location to the mysql-test directory
and type ./mysql-test-run. If you have
installed a binary distribution, change location to the
mysql-test directory under the installation
root directory (for example,
/usr/local/mysql/mysql-test), and run
./mysql-test-run. All tests should succeed.
If any do not, you should try to find out why and report the
problem if it indicates a bug in MySQL. See
Section 1.8, “How to Report Bugs or Problems”.
If one test fails, you should run
mysql-test-run with the
--force option to check whether any other tests
fail.
If you have a copy of mysqld running on the
machine where you want to run the test suite, you do not have to
stop it, as long as it is not using ports
9306 or 9307. If either of
those ports is taken, you should edit
mysql-test-run and change the values of the
master or slave port to one that is available.
In the mysql-test directory, you can run an
individual test case with ./mysql-test-run
test_name.
You can use the mysqltest language to write your own test cases. This is documented in the MySQL Test Framework manual, available at http://dev.mysql.com/doc/.
If you have a question about the test suite, or have a test case
to contribute, send an email message to the MySQL
internals mailing list. See
Section 1.7.1, “MySQL Mailing Lists”. This list does not accept
attachments, so you should FTP all the relevant files to:
ftp://ftp.mysql.com/pub/mysql/upload/
There are two ways to add new functions to MySQL:
You can add functions through the user-defined function (UDF) interface. User-defined functions are compiled as object files and then added to and removed from the server dynamically using the
CREATE FUNCTIONandDROP FUNCTIONstatements. See Section 24.2.2, “CREATE FUNCTIONSyntax”.You can add functions as native (built-in) MySQL functions. Native functions are compiled into the mysqld server and become available on a permanent basis.
Each method has advantages and disadvantages:
If you write user-defined functions, you must install object files in addition to the server itself. If you compile your function into the server, you don't need to do that.
Native functions require you to modify a source distribution. UDFs do not. You can add UDFs to a binary MySQL distribution. No access to MySQL source is necessary.
If you upgrade your MySQL distribution, you can continue to use your previously installed UDFs, unless you upgrade to a newer version for which the UDF interface changes. For native functions, you must repeat your modifications each time you upgrade.
Whichever method you use to add new functions, they can be invoked
in SQL statements just like native functions such as
ABS() or SOUNDEX().
Another way to add functions is by creating stored functions. These are written using SQL statements rather than by compiling object code. The syntax for writing stored functions is described in Chapter 17, Stored Procedures and Functions.
See Section 9.2.3, “Function Name Parsing and Resolution”, for the rules describing how the server interprets references to different kinds of functions.
The following sections describe features of the UDF interface, provide instructions for writing UDFs, discuss security precautions that MySQL takes to prevent UDF misuse, and describe how to add native mySQL functions.
For example source code that illustrates how to write UDFs, take a
look at the sql/udf_example.c file that is
provided in MySQL source distributions.
The MySQL interface for user-defined functions provides the following features and capabilities:
Functions can return string, integer, or real values.
You can define simple functions that operate on a single row at a time, or aggregate functions that operate on groups of rows.
Information is provided to functions that enables them to check the number and types of the arguments passed to them.
You can tell MySQL to coerce arguments to a given type before passing them to a function.
You can indicate that a function returns
NULLor that an error occurred.
CREATE [AGGREGATE] FUNCTIONfunction_nameRETURNS {STRING|INTEGER|REAL|DECIMAL} SONAMEshared_library_name
A user-defined function (UDF) is a way to extend MySQL with a
new function that works like a native (built-in) MySQL function
such as ABS() or CONCAT().
function_name is the name that should
be used in SQL statements to invoke the function. The
RETURNS clause indicates the type of the
function's return value. As of MySQL 5.0.3,
DECIMAL is a legal value after
RETURNS, but currently
DECIMAL functions return string values and
should be written like STRING functions.
shared_library_name is the basename
of the shared object file that contains the code that implements
the function. The file must be located in a directory that is
searched by your system's dynamic linker.
To create a function, you must have the
INSERT and privilege for the
mysql database. This is necessary because
CREATE FUNCTION adds a row to the
mysql.func system table that records the
function's name, type, and shared library name. If you do not
have this table, you should run the
mysql_upgrade command to create it. See
Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.
An active function is one that has been loaded with
CREATE FUNCTION and not removed with
DROP FUNCTION. All active functions are
reloaded each time the server starts, unless you start
mysqld with the
--skip-grant-tables option. In this case, UDF
initialization is skipped and UDFs are unavailable.
For instructions on writing user-defined functions, see Section 24.2.4, “Adding a New User-Defined Function”. For the UDF mechanism to work, functions must be written in C or C++ (or another language that can use C calling conventions), your operating system must support dynamic loading and you must have compiled mysqld dynamically (not statically).
An AGGREGATE function works exactly like a
native MySQL aggregate (summary) function such as
SUM or COUNT(). For
AGGREGATE to work, your
mysql.func table must contain a
type column. If your
mysql.func table does not have this column,
you should run the mysql_upgrade program to
create it (see Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”).
DROP FUNCTION function_name
This statement drops the user-defined function (UDF) named
function_name.
To drop a function, you must have the DELETE
privilege for the mysql database. This is
because DROP FUNCTION removes a row from the
mysql.func system table that records the
function's name, type, and shared library name.
For the UDF mechanism to work, functions must be written in C or
C++ (or another language that can use C calling conventions),
and your operating system must support dynamic loading. The
MySQL source distribution includes a file
sql/udf_example.c that defines 5 new
functions. Consult this file to see how UDF calling conventions
work. UDF-related symbols and data structures are defined in the
include/mysql_com.h header file. (You need
not include this header file directly because it is included by
mysql.h.)
A UDF contains code that becomes part of the running server, so
when you write a UDF, you are bound by any and all constraints
that otherwise apply to writing server code. For example, you
may have problems if you attempt to use functions from the
libstdc++ library. Note that these
constraints may change in future versions of the server, so it
is possible that server upgrades will require revisions to UDFs
that were originally written for older servers. For information
about these constraints, see
Section 2.4.14.2, “Typical configure Options”, and
Section 2.4.14.4, “Dealing with Problems Compiling MySQL”.
To be able to use UDFs, you need to link
mysqld dynamically. Don't configure MySQL
using --with-mysqld-ldflags=-all-static. If you
want to use a UDF that needs to access symbols from
mysqld (for example, the
metaphone function in
sql/udf_example.c that uses
default_charset_info), you must link the
program with -rdynamic (see man
dlopen). If you plan to use UDFs, the rule of thumb is
to configure MySQL with
--with-mysqld-ldflags=-rdynamic unless you have
a very good reason not to.
For each function that you want to use in SQL statements, you
should define corresponding C (or C++) functions. In the
following discussion, the name “xxx” is used for an
example function name. To distinguish between SQL and C/C++
usage, XXX() (uppercase) indicates an SQL
function call, and xxx() (lowercase)
indicates a C/C++ function call.
The C/C++ functions that you write to implement the interface
for XXX() are:
xxx()(required)The main function. This is where the function result is computed. The correspondence between the SQL function data type and the return type of your C/C++ function is shown here:
SQL Type C/C++ Type STRINGchar *INTEGERlong longREALdoubleIt is also possible to declare a
DECIMALfunction, but currently the value is returned as a string, so you should write the UDF as though it were aSTRINGfunction.ROWfunctions are not implemented.xxx_init()(optional)The initialization function for
xxx(). It can be used for the following purposes:To check the number of arguments to
XXX().To check that the arguments are of a required type or, alternatively, to tell MySQL to coerce arguments to the types you want when the main function is called.
To allocate any memory required by the main function.
To specify the maximum length of the result.
To specify (for
REALfunctions) the maximum number of decimal places in the result.To specify whether the result can be
NULL.
xxx_deinit()(optional)The deinitialization function for
xxx(). It should deallocate any memory allocated by the initialization function.
When an SQL statement invokes XXX(), MySQL
calls the initialization function xxx_init()
to let it perform any required setup, such as argument checking
or memory allocation. If xxx_init() returns
an error, MySQL aborts the SQL statement with an error message
and does not call the main or deinitialization functions.
Otherwise, MySQL calls the main function
xxx() once for each row. After all rows have
been processed, MySQL calls the deinitialization function
xxx_deinit() so that it can perform any
required cleanup.
For aggregate functions that work like SUM(),
you must also provide the following functions:
xxx_clear()(required in 5.0)Reset the current aggregate value but do not insert the argument as the initial aggregate value for a new group.
xxx_add()(required)Add the argument to the current aggregate value.
MySQL handles aggregate UDFs as follows:
Call
xxx_init()to let the aggregate function allocate any memory it needs for storing results.Sort the table according to the
GROUP BYexpression.Call
xxx_clear()for the first row in each new group.Call
xxx_add()for each new row that belongs in the same group.Call
xxx()to get the result for the aggregate when the group changes or after the last row has been processed.Repeat 3-5 until all rows has been processed
Call
xxx_deinit()to let the UDF free any memory it has allocated.
All functions must be thread-safe. This includes not just the
main function, but the initialization and deinitialization
functions as well, and also the additional functions required by
aggregate functions. A consequence of this requirement is that
you are not allowed to allocate any global or static variables
that change! If you need memory, you should allocate it in
xxx_init() and free it in
xxx_deinit().
This section describes the different functions that you need to define when you create a simple UDF. Section 24.2.4, “Adding a New User-Defined Function”, describes the order in which MySQL calls these functions.
The main xxx() function should be declared
as shown in this section. Note that the return type and
parameters differ, depending on whether you declare the SQL
function XXX() to return
STRING, INTEGER, or
REAL in the CREATE
FUNCTION statement:
For STRING functions:
char *xxx(UDF_INIT *initid, UDF_ARGS *args,
char *result, unsigned long *length,
char *is_null, char *error);
For INTEGER functions:
long long xxx(UDF_INIT *initid, UDF_ARGS *args,
char *is_null, char *error);
For REAL functions:
double xxx(UDF_INIT *initid, UDF_ARGS *args,
char *is_null, char *error);
DECIMAL functions return string values and
should be declared the same way as STRING
functions. ROW functions are not
implemented.
The initialization and deinitialization functions are declared like this:
my_bool xxx_init(UDF_INIT *initid, UDF_ARGS *args, char *message); void xxx_deinit(UDF_INIT *initid);
The initid parameter is passed to all three
functions. It points to a UDF_INIT
structure that is used to communicate information between
functions. The UDF_INIT structure members
follow. The initialization function should fill in any members
that it wishes to change. (To use the default for a member,
leave it unchanged.)
my_bool maybe_nullxxx_init()should setmaybe_nullto1ifxxx()can returnNULL. The default value is1if any of the arguments are declaredmaybe_null.unsigned int decimalsThe number of decimal digits to the right of the decimal point. The default value is the maximum number of decimal digits in the arguments passed to the main function. (For example, if the function is passed
1.34,1.345, and1.3, the default would be 3, because1.345has 3 decimal digits.unsigned int max_lengthThe maximum length of the result. The default
max_lengthvalue differs depending on the result type of the function. For string functions, the default is the length of the longest argument. For integer functions, the default is 21 digits. For real functions, the default is 13 plus the number of decimal digits indicated byinitid->decimals. (For numeric functions, the length includes any sign or decimal point characters.)If you want to return a blob value, you can set
max_lengthto 65KB or 16MB. This memory is not allocated, but the value is used to decide which data type to use if there is a need to temporarily store the data.char *ptrA pointer that the function can use for its own purposes. For example, functions can use
initid->ptrto communicate allocated memory among themselves.xxx_init()should allocate the memory and assign it to this pointer:initid->ptr = allocated_memory;
In
xxx()andxxx_deinit(), refer toinitid->ptrto use or deallocate the memory.my_bool const_itemxxx_init()should setconst_itemto1ifxxx()always returns the same value and to0otherwise.
This section describes the different functions that you need to define when you create an aggregate UDF. Section 24.2.4, “Adding a New User-Defined Function”, describes the order in which MySQL calls these functions.
xxx_reset()This function is called when MySQL finds the first row in a new group. It should reset any internal summary variables and then use the given
UDF_ARGSargument as the first value in your internal summary value for the group. Declarexxx_reset()as follows:char *xxx_reset(UDF_INIT *initid, UDF_ARGS *args, char *is_null, char *error);xxx_reset()is not needed or used in MySQL 5.0, in which the UDF interface usesxxx_clear()instead. However, you can define bothxxx_reset()andxxx_clear()if you want to have your UDF work with older versions of the server. (If you do include both functions, thexxx_reset()function in many cases can be implemented internally by callingxxx_clear()to reset all variables, and then callingxxx_add()to add theUDF_ARGSargument as the first value in the group.)xxx_clear()This function is called when MySQL needs to reset the summary results. It is called at the beginning for each new group but can also be called to reset the values for a query where there were no matching rows. Declare
xxx_clear()as follows:char *xxx_clear(UDF_INIT *initid, char *is_null, char *error);
is_nullis set to point toCHAR(0)before callingxxx_clear().If something went wrong, you can store a value in the variable to which the
errorargument points.errorpoints to a single-byte variable, not to a string buffer.xxx_clear()is required by MySQL 5.0.xxx_add()This function is called for all rows that belong to the same group, except for the first row. You should use it to add the value in the
UDF_ARGSargument to your internal summary variable.char *xxx_add(UDF_INIT *initid, UDF_ARGS *args, char *is_null, char *error);
The xxx() function for an aggregate UDF
should be declared the same way as for a non-aggregate UDF.
See Section 24.2.4.1, “UDF Calling Sequences for Simple Functions”.
For an aggregate UDF, MySQL calls the xxx()
function after all rows in the group have been processed. You
should normally never access its UDF_ARGS
argument here but instead return a value based on your
internal summary variables.
Return value handling in xxx() should be
done the same way as for a non-aggregate UDF. See
Section 24.2.4.4, “UDF Return Values and Error Handling”.
The xxx_reset() and
xxx_add() functions handle their
UDF_ARGS argument the same way as functions
for non-aggregate UDFs. See Section 24.2.4.3, “UDF Argument Processing”.
The pointer arguments to is_null and
error are the same for all calls to
xxx_reset(),
xxx_clear(), xxx_add()
and xxx(). You can use this to remember
that you got an error or whether the xxx()
function should return NULL. You should not
store a string into *error!
error points to a single-byte variable, not
to a string buffer.
*is_null is reset for each group (before
calling xxx_clear()).
*error is never reset.
If *is_null or *error
are set when xxx() returns, MySQL returns
NULL as the result for the group function.
The args parameter points to a
UDF_ARGS structure that has the members
listed here:
unsigned int arg_countThe number of arguments. Check this value in the initialization function if you require your function to be called with a particular number of arguments. For example:
if (args->arg_count != 2) { strcpy(message,"XXX() requires two arguments"); return 1; }enum Item_result *arg_typeA pointer to an array containing the types for each argument. The possible type values are
STRING_RESULT,INT_RESULT,REAL_RESULT, andDECIMAL_RESULT.To make sure that arguments are of a given type and return an error if they are not, check the
arg_typearray in the initialization function. For example:if (args->arg_type[0] != STRING_RESULT || args->arg_type[1] != INT_RESULT) { strcpy(message,"XXX() requires a string and an integer"); return 1; }Arguments of type
DECIMAL_RESULTare passed as strings, so you should handle them likeSTRING_RESULTvalues.As an alternative to requiring your function's arguments to be of particular types, you can use the initialization function to set the
arg_typeelements to the types you want. This causes MySQL to coerce arguments to those types for each call toxxx(). For example, to specify that the first two arguments should be coerced to string and integer, respectively, do this inxxx_init():args->arg_type[0] = STRING_RESULT; args->arg_type[1] = INT_RESULT;
Exact-value decimal arguments such as
1.3orDECIMALcolumn values are passed with a type ofDECIMAL_RESULT. However, the values are passed as strings. If you want to receive a number, use the initialization function to specify that the argument should be coerced to aREAL_RESULTvalue:args->arg_type[2] = REAL_RESULT;
Note: Prior to MySQL 5.0.3, decimal arguments were passed as
REAL_RESULTvalues. If you upgrade to a newer version and find that your UDF now receives string values, use the initialization function to coerce the arguments to numbers as just described.char **argsargs->argscommunicates information to the initialization function about the general nature of the arguments passed to your function. For a constant argumenti,args->args[i]points to the argument value. (See below for instructions on how to access the value properly.) For a non-constant argument,args->args[i]is0. A constant argument is an expression that uses only constants, such as3or4*7-2orSIN(3.14). A non-constant argument is an expression that refers to values that may change from row to row, such as column names or functions that are called with non-constant arguments.For each invocation of the main function,
args->argscontains the actual arguments that are passed for the row currently being processed.If argument
irepresentsNULL,args->args[i]is a null pointer (0). If the argument is notNULL, functions can refer to it as follows:An argument of type
STRING_RESULTis given as a string pointer plus a length, to allow handling of binary data or data of arbitrary length. The string contents are available asargs->args[i]and the string length isargs->lengths[i]. You should not assume that strings are null-terminated.For an argument of type
INT_RESULT, you must castargs->args[i]to along longvalue:long long int_val; int_val = *((long long*) args->args[i]);
For an argument of type
REAL_RESULT, you must castargs->args[i]to adoublevalue:double real_val; real_val = *((double*) args->args[i]);
For an argument of type
DECIMAL_RESULT, the value is passed as a string and should be handled like aSTRING_RESULTvalue.ROW_RESULTarguments are not implemented.
unsigned long *lengthsFor the initialization function, the
lengthsarray indicates the maximum string length for each argument. You should not change these. For each invocation of the main function,lengthscontains the actual lengths of any string arguments that are passed for the row currently being processed. For arguments of typesINT_RESULTorREAL_RESULT,lengthsstill contains the maximum length of the argument (as for the initialization function).
The initialization function should return 0
if no error occurred and 1 otherwise. If an
error occurs, xxx_init() should store a
null-terminated error message in the
message parameter. The message is returned
to the client. The message buffer is
MYSQL_ERRMSG_SIZE characters long, but you
should try to keep the message to less than 80 characters so
that it fits the width of a standard terminal screen.
The return value of the main function xxx()
is the function value, for long long and
double functions. A string function should
return a pointer to the result and set
*result and *length to
the contents and length of the return value. For example:
memcpy(result, "result string", 13); *length = 13;
The result buffer that is passed to the
xxx() function is 255 bytes long. If your
result fits in this, you don't have to worry about memory
allocation for results.
If your string function needs to return a string longer than
255 bytes, you must allocate the space for it with
malloc() in your
xxx_init() function or your
xxx() function and free it in your
xxx_deinit() function. You can store the
allocated memory in the ptr slot in the
UDF_INIT structure for reuse by future
xxx() calls. See
Section 24.2.4.1, “UDF Calling Sequences for Simple Functions”.
To indicate a return value of NULL in the
main function, set *is_null to
1:
*is_null = 1;
To indicate an error return in the main function, set
*error to 1:
*error = 1;
If xxx() sets *error to
1 for any row, the function value is
NULL for the current row and for any
subsequent rows processed by the statement in which
XXX() was invoked.
(xxx() is not even called for subsequent
rows.)
Files implementing UDFs must be compiled and installed on the
host where the server runs. This process is described below
for the example UDF file
sql/udf_example.c that is included in the
MySQL source distribution.
The immediately following instructions are for Unix. Instructions for Windows are given later in this section.
The udf_example.c file contains the
following functions:
metaphon()returns a metaphon string of the string argument. This is something like a soundex string, but it's more tuned for English.myfunc_double()returns the sum of the ASCII values of the characters in its arguments, divided by the sum of the length of its arguments.myfunc_int()returns the sum of the length of its arguments.sequence([const int])returns a sequence starting from the given number or 1 if no number has been given.lookup()returns the IP number for a hostname.reverse_lookup()returns the hostname for an IP number. The function may be called either with a single string argument of the form'xxx.xxx.xxx.xxx'or with four numbers.
A dynamically loadable file should be compiled as a sharable object file, using a command something like this:
shell> gcc -shared -o udf_example.so udf_example.c
If you are using gcc with
configure and libtool
(which is how MySQL is configured), you should be able to
create udf_example.so with a simpler
command:
shell> make udf_example.la
After you compile a shared object containing UDFs, you must
install it and tell MySQL about it. Compiling a shared object
from udf_example.c using
gcc directly produces a file named
udf_example.so. Compiling the shared
object using make produces a file named
something like udf_example.so.0.0.0 in
the .libs directory (the exact name may
vary from platform to platform). Copy the shared object to
some directory such as /usr/lib that is
searched by your system's dynamic (runtime) linker, or add the
directory in which you placed the shared object to the linker
configuration file (for example,
/etc/ld.so.conf).
The dynamic linker name is system-specific (for example, ld-elf.so.1 on FreeBSD, ld.so on Linux, or dyld on Mac OS X). Consult your system documentation for information about the linker name and how to configure it.
On many systems, you can also set the
LD_LIBRARY or
LD_LIBRARY_PATH environment variable to
point at the directory where you have the files for your UDF.
The dlopen manual page tells you which
variable you should use on your system. You should set this in
mysql.server or
mysqld_safe startup scripts and restart
mysqld.
On some systems, the ldconfig program that
configures the dynamic linker does not recognize a shared
object unless its name begins with lib. In
this case you should rename a file such as
udf_example.so to
libudf_example.so.
On Windows, you can compile user-defined functions by using the following procedure:
You need to obtain the BitKeeper source repository for MySQL 5.0. See Section 2.4.14.3, “Installing from the Development Source Tree”.
You must obtain the CMake build utility from http://www.cmake.org. (Version 2.4.2 or later is required).
In the source repository, look in the
sqldirectory. There are files namedudf_example.defudf_example.cthere. Copy both files from this directory to your working directory.Create a CMake
makefilewith these contents:PROJECT(udf_example) # Path for MySQL include directory INCLUDE_DIRECTORIES("c:/mysql/include") ADD_DEFINITIONS("-DHAVE_DLOPEN") ADD_LIBRARY(udf_example MODULE udf_example.c udf_example.def) TARGET_LINK_LIBRARIES(udf_example wsock32)Create the VC project and solution files:
cmake -G "<Generator>"
Invoking cmake --help shows you a list of valid Generators.
Create
udf_example.dll:devenv udf_example.sln /build Release
After the shared object file has been installed, notify mysqld about the new functions with these statements:
mysql>CREATE FUNCTION metaphon RETURNS STRING SONAME 'udf_example.so';mysql>CREATE FUNCTION myfunc_double RETURNS REAL SONAME 'udf_example.so';mysql>CREATE FUNCTION myfunc_int RETURNS INTEGER SONAME 'udf_example.so';mysql>CREATE FUNCTION lookup RETURNS STRING SONAME 'udf_example.so';mysql>CREATE FUNCTION reverse_lookup->RETURNS STRING SONAME 'udf_example.so';mysql>CREATE AGGREGATE FUNCTION avgcost->RETURNS REAL SONAME 'udf_example.so';
Functions can be deleted using DROP
FUNCTION:
mysql>DROP FUNCTION metaphon;mysql>DROP FUNCTION myfunc_double;mysql>DROP FUNCTION myfunc_int;mysql>DROP FUNCTION lookup;mysql>DROP FUNCTION reverse_lookup;mysql>DROP FUNCTION avgcost;
The CREATE FUNCTION and DROP
FUNCTION statements update the
func system table in the
mysql database. The function's name, type
and shared library name are saved in the table. You must have
the INSERT and DELETE
privileges for the mysql database to create
and drop functions.
You should not use CREATE FUNCTION to add a
function that has previously been created. If you need to
reinstall a function, you should remove it with DROP
FUNCTION and then reinstall it with CREATE
FUNCTION. You would need to do this, for example, if
you recompile a new version of your function, so that
mysqld gets the new version. Otherwise, the
server continues to use the old version.
An active function is one that has been loaded with
CREATE FUNCTION and not removed with
DROP FUNCTION. All active functions are
reloaded each time the server starts, unless you start
mysqld with the
--skip-grant-tables option. In this case, UDF
initialization is skipped and UDFs are unavailable.
If the new function will be referred to in statements that will be replicated to slave servers, you must ensure that every slave server also has the function available. Otherwise, replication will fail on the slaves when they attempt to invoke the function.
MySQL takes the following measures to prevent misuse of user-defined functions.
You must have the INSERT privilege to be
able to use CREATE FUNCTION and the
DELETE privilege to be able to use
DROP FUNCTION. This is necessary because
these statements add and delete rows from the
mysql.func table.
UDFs should have at least one symbol defined in addition to
the xxx symbol that corresponds to the main
xxx() function. These auxiliary symbols
correspond to the xxx_init(),
xxx_deinit(),
xxx_reset(),
xxx_clear(), and
xxx_add() functions. As of MySQL 5.0.3,
mysqld supports an
--allow-suspicious-udfs option that controls
whether UDFs that have only an xxx symbol
can be loaded. By default, the option is off, to prevent
attempts at loading functions from shared object files other
than those containing legitimate UDFs. If you have older UDFs
that contain only the xxx symbol and that
cannot be recompiled to include an auxiliary symbol, it may be
necessary to specify the
--allow-suspicious-udfs option. Otherwise,
you should avoid enabling this capability.
UDF object files cannot be placed in arbitrary directories.
They must be located in some system directory that the dynamic
linker is configured to search. To enforce this restriction
and prevent attempts at specifying pathnames outside of
directories searched by the dynamic linker, MySQL checks the
shared object file name specified in CREATE
FUNCTION statements for pathname delimiter
characters. As of MySQL 5.0.3, MySQL also checks for pathname
delimiters in filenames stored in the
mysql.func table when it loads functions.
This prevents attempts at specifying illegitimate pathnames
through direct manipulation of the
mysql.func table. For information about
UDFs and the runtime linker, see
Section 24.2.4.5, “Compiling and Installing User-Defined Functions”.
The procedure for adding a new native function is described here. Note that you cannot add native functions to a binary distribution because the procedure involves modifying MySQL source code. You must compile MySQL yourself from a source distribution. Also note that if you migrate to another version of MySQL (for example, when a new version is released), you need to repeat the procedure with the new version.
To add a new native MySQL function, follow these steps:
Add one line to
lex.hthat defines the function name in thesql_functions[]array.If the function prototype is simple (just takes zero, one, two or three arguments), you should in
lex.hspecifySYM(FUNC_ARG(whereN)Nis the number of arguments) as the second argument in thesql_functions[]array and add a function that creates a function object initem_create.cc. Take a look at"ABS"andcreate_funcs_abs()for an example of this.If the function prototype is complicated (for example, if it takes a variable number of arguments), you should add two lines to
sql_yacc.yy. One indicates the preprocessor symbol that yacc should define (this should be added at the beginning of the file). Then define the function parameters and add an “item” with these parameters to thesimple_exprparsing rule. For an example, check all occurrences ofATANinsql_yacc.yyto see how this is done.In
item_func.h, declare a class inheriting fromItem_num_funcorItem_str_func, depending on whether your function returns a number or a string.In
item_func.cc, add one of the following declarations, depending on whether you are defining a numeric or string function:double Item_func_newname::val() longlong Item_func_newname::val_int() String *Item_func_newname::Str(String *str)
If you inherit your object from any of the standard items (like
Item_num_func), you probably only have to define one of these functions and let the parent object take care of the other functions. For example, theItem_str_funcclass defines aval()function that executesatof()on the value returned by::str().If the function is non-deterministic, you should include the following statement in the item constructor to indicate that function results should not be cached:
current_thd->lex->safe_to_cache_query=0;
A function is non-deterministic if, given fixed values for its arguments, it can return different results for different invocations.
You should probably also define the following object function:
void Item_func_newname::fix_length_and_dec()
This function should at least calculate
max_lengthbased on the given arguments.max_lengthis the maximum number of characters the function may return. This function should also setmaybe_null = 0if the main function can't return aNULLvalue. The function can check whether any of the function arguments can returnNULLby checking the arguments'maybe_nullvariable. You can take a look atItem_func_mod::fix_length_and_decfor a typical example of how to do this.
All functions must be thread-safe. In other words, don't use any global or static variables in the functions without protecting them with mutexes)
If you want to return NULL, from
::val(), ::val_int() or
::str() you should set
null_value to 1 and return 0.
For ::str() object functions, there are some
additional considerations to be aware of:
The
String *strargument provides a string buffer that may be used to hold the result. (For more information about theStringtype, take a look at thesql_string.hfile.)The
::str()function should return the string that holds the result or(char*) 0if the result isNULL.All current string functions try to avoid allocating any memory unless absolutely necessary!
If the new native function will be referred to in statements that will be replicated to slave servers, you must ensure that every slave server also has the function available. Otherwise, replication will fail on the slaves when they attempt to invoke the function.
In MySQL, you can define a procedure in C++ that can access and
modify the data in a query before it is sent to the client. The
modification can be done on a row-by-row or GROUP
BY level.
We have created an example procedure to show you what can be done.
Additionally, we recommend that you take a look at
mylua. With this you can use the LUA language
to load a procedure at runtime into mysqld.
analyse([
max_elements[,max_memory]])
This procedure is defined in the
sql/sql_analyse.cc file. It examines the
result from a query and returns an analysis of the results that
suggests optimal data types for each column. To obtain this
analysis, append PROCEDURE ANALYSE to the end
of a SELECT statement:
SELECT ... FROM ... WHERE ... PROCEDURE ANALYSE([max_elements,[max_memory]])
For example:
SELECT col1, col2 FROM table1 PROCEDURE ANALYSE(10, 2000);
The results show some statistics for the values returned by the
query, and propose an optimal data type for the columns. This
can be helpful for checking your existing tables, or after
importing new data. You may need to try different settings for
the arguments so that PROCEDURE ANALYSE()
does not suggest the ENUM data type when it
is not appropriate.
The arguments are optional and are used as follows:
max_elements(default 256) is the maximum number of distinct values thatanalysenotices per column. This is used byanalyseto check whether the optimal data type should be of typeENUM.max_memory(default 8192) is the maximum amount of memory thatanalyseshould allocate per column while trying to find all distinct values.
Table of Contents
- A.1. MySQL 5.0 FAQ — General
- A.2. MySQL 5.0 FAQ — Storage Engines
- A.3. MySQL 5.0 FAQ — Server SQL Mode
- A.4. MySQL 5.0 FAQ — Stored Procedures
- A.5. MySQL 5.0 FAQ — Triggers
- A.6. MySQL 5.0 FAQ — Views
- A.7. MySQL 5.0 FAQ —
INFORMATION_SCHEMA - A.8. MySQL 5.0 FAQ — Migration
- A.9. MySQL 5.0 FAQ — Security
- A.10. MySQL 5.0 FAQ — MySQL Cluster
- A.11. MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- A.12. MySQL 5.0 FAQ — Connectors & APIs
- A.13. MySQL 5.0 FAQ — Replication
- A.14. MySQL 5.0 FAQ — MySQL, DRBD, and Heartbeat
- A.14.1. Distributed Replicated Block Device
- A.14.2. Linux Heartbeat
- A.14.3. DRBD Architecture
- A.14.4. DRBD and MySQL Replication
- A.14.5. DRBD and File Systems
- A.14.6. DRBD and LVM
- A.14.7. DRBD and Virtualization
- A.14.8. DRBD and Security
- A.14.9. DRBD and System Requirements
- A.14.10. DBRD and Support and Consulting
Questions
26.1.1: When did MySQL 5.0 become production-ready (GA)?
26.1.2: Can MySQL 5.0 do subqueries?
26.1.3: Can MySQL 5.0 peform multiple-table inserts, updates, and deletes?
26.1.4: Does MySQL 5.0 have a Query Cache? Does it work on Server, Instance or Database?
26.1.5: Does MySQL 5.0 have Sequences?
26.1.6: Does MySQL 5.0 have a
NOW()function with fractions of seconds?26.1.7: Does MySQL 5.0 work with multi-core processors?
26.1.8: Is there a hot backup tool for MyISAM like InnoDB Hot Backup?
26.1.9: Have there been there any improvements in error reporting when foreign keys fail? Does MySQL now report which column and reference failed?
26.1.10: Can MySQL 5.0 perform ACID transactions?
Questions and Answers
26.1.1: When did MySQL 5.0 become production-ready (GA)?
MySQL 5.0.15 was released for production use on 19 October 2005. We are now working on MySQL 5.1, which is currently in beta.
26.1.2: Can MySQL 5.0 do subqueries?
Yes. See Section 13.2.8, “Subquery Syntax”.
26.1.3: Can MySQL 5.0 peform multiple-table inserts, updates, and deletes?
Yes. For the syntax required to perform multiple-table
updates, see Section 13.2.10, “UPDATE Syntax”; for that required to
perform multiple-table deletes, see
Section 13.2.1, “DELETE Syntax”.
A multiple-table insert can be accomplished using a trigger
whose FOR EACH ROW clause contains
multiple INSERT statements within a
BEGIN ... END block. See
Section 18.3, “Using Triggers”.
26.1.4: Does MySQL 5.0 have a Query Cache? Does it work on Server, Instance or Database?
Yes. The query cache operates on the server level, caching complete result sets matched with the original query string. If an exactly identical query is made (which often happens, particularly in web applications), no parsing or execution is necessary; the result is sent directly from the cache. Various tuning options are available. See Section 5.13, “The MySQL Query Cache”.
26.1.5: Does MySQL 5.0 have Sequences?
No. However, MySQL has an AUTO_INCREMENT
system, which in MySQL 5.0 can also handle
inserts in a multi-master replication setup. With the
--auto-increment-increment and
--auto-increment-offset startup options,
you can set each server to generate auto-increment values
that don't conflict with other servers. The
--auto-increment-increment value should be
greater than the number of servers, and each server should
have a unique offset.
26.1.6:
Does MySQL 5.0 have a NOW()
function with fractions of seconds?
No. This is on the MySQL roadmap as a “rolling feature”. This means that it is not a flagship feature, but will be implemented, development time permitting. Specific customer demand may change this scheduling.
However, MySQL does parse time strings with a fractional
component. See Section 11.3.2, “The TIME Type”.
26.1.7: Does MySQL 5.0 work with multi-core processors?
Yes. MySQL is fully multi-threaded, and will make use of multiple CPUs, provided that the operating system supports them.
26.1.8: Is there a hot backup tool for MyISAM like InnoDB Hot Backup?
This is currently under development for a future MySQL release.
26.1.9: Have there been there any improvements in error reporting when foreign keys fail? Does MySQL now report which column and reference failed?
The foreign key support in InnoDB has
seen improvements in each major version of MySQL. Foreign
key support generic to all storage engines is scheduled for
MySQL 5.2; this should resolve any inadequacies in the
current storage engine specific implementation.
26.1.10: Can MySQL 5.0 perform ACID transactions?
Yes. All current MySQL versions support transactions. The
InnoDB storage engine offers full ACID
transactions with row-level locking, multi-versioning,
non-locking repeatable reads, and all four SQL standard
isolation levels.
The NDB storage engine supports the
READ COMMITTED transaction isolation
level only.
Questions
26.2.1: Where can I obtain complete documentation for MySQL storage engines?
26.2.2: Are there any new storage engines in MySQL 5.0?
26.2.3: Have any storage engines been removed in MySQL 5.0?
26.2.4: What are the unique benefits of the
ARCHIVEstorage engine?26.2.5: Do the new features in MySQL 5.0 apply to all storage engines?
Questions and Answers
26.2.1: Where can I obtain complete documentation for MySQL storage engines?
See Chapter 14, Storage Engines. That chapter contains
information about all MySQL storage engines except for the
NDB storage engine used for MySQL
Cluster; NDB is covered in
Chapter 15, MySQL Cluster.
26.2.2: Are there any new storage engines in MySQL 5.0?
Yes. The FEDERATED storage engine, new in
MySQL 5.0, allows the server to access tables
on other (remote) servers. See
Section 14.7, “The FEDERATED Storage Engine”.
26.2.3: Have any storage engines been removed in MySQL 5.0?
Yes. MySQL 5.0 no longer supports the
ISAM storage engine. If you have any
existing ISAM tables from previous
versions of MySQL, you should convert these to
MyISAM before upgrading to MySQL
5.0.
26.2.4:
What are the unique benefits of the
ARCHIVE storage engine?
The ARCHIVE storage engine is ideally
suited for storing large amounts of data without indexes; it
has a very small footprint, and performs selects using table
scans. See Section 14.8, “The ARCHIVE Storage Engine”, for
details.
26.2.5: Do the new features in MySQL 5.0 apply to all storage engines?
The general new features such as views, stored procedures,
triggers, INFORMATION_SCHEMA, precision
math (DECIMAL column type), and the
BIT column type, apply to all storage
engines. There are also additions and changes for specific
storage engines.
Questions
26.3.1: What are server SQL modes?
26.3.2: How many server SQL modes are there?
26.3.3: How do you determine the server SQL mode?
26.3.4: Is the mode dependent on the database or connection?
26.3.5: Can the rules for strict mode be extended?
26.3.6: Does strict mode impact performance?
26.3.7: What is the default server SQL mode when My SQL 5.0 is installed?
Questions and Answers
26.3.1: What are server SQL modes?
Server SQL modes define what SQL syntax MySQL should support and what kind of data validation checks it should perform. This makes it easier to use MySQL in different environments and to use MySQL together with other database servers. The MySQL Server apply these modes individually to different clients. For more information, see Section 5.2.6, “SQL Modes”.
26.3.2: How many server SQL modes are there?
Each mode can be independently switched on and off. See Section 5.2.6, “SQL Modes”, for a complete list of available modes.
26.3.3: How do you determine the server SQL mode?
You can set the default SQL mode (for
mysqld startup) with the
--sql-mode option. Using the statement
SET [SESSION|GLOBAL]
sql_mode=', you
can change the settings from within a connection, either
locally to the connection, or to take effect globally. You
can retrieve the current mode by issuing a modes'SELECT
@@sql_mode statement.
26.3.4: Is the mode dependent on the database or connection?
A mode is not linked to a particular database. Modes can be
set locally to the session (connection), or globally for the
server. you can change these settings using SET
[SESSION|GLOBAL]
sql_mode='.
modes'
26.3.5: Can the rules for strict mode be extended?
When we refer to strict mode, we mean a
mode where at least one of the modes
TRADITIONAL,
STRICT_TRANS_TABLES, or
STRICT_ALL_TABLES is enabled. Options can
be combined, so you can add additional restrictions to a
mode. See Section 5.2.6, “SQL Modes”, for more
information.
26.3.6: Does strict mode impact performance?
The intensive validation of input data that some settings requires more time than if the validation is not done. While the performance impact is not that great, if you do not require such validation (perhaps your application already handles all of this), then MySQL gives you the option of leaving strict mode disabled. However — if you do require it — strict mode can provide such validation.
26.3.7: What is the default server SQL mode when My SQL 5.0 is installed?
By default, no special modes are enabled. See Section 5.2.6, “SQL Modes”, for information about all available modes and MySQL's default behavior.
Questions
26.4.1: Does MySQL 5.0 support stored procedures?
26.4.2: Where can I find documentation for MySQL stored procedures and stored functions?
26.4.3: Is there a discussion forum for MySQL stored procedures?
26.4.4: Where can I find the ANSI SQL 2003 specification for stored procedures?
26.4.5: How do you manage stored routines?
26.4.6: Is there a way to view all stored procedures and stored functions in a given database?
26.4.7: Where are stored procedures stored?
26.4.8: Is it possible to group stored procedures or stored functions into packages?
26.4.9: Can a stored procedure call another stored procedure?
26.4.10: Can a stored procedure call a trigger?
26.4.11: Can a stored procedure access tables?
26.4.12: Do stored procedures have a statement for raising application errors?
26.4.13: Do stored procedures provide exception handling?
26.4.14: Can MySQL 5.0 stored routines return result sets?
26.4.15: Is
WITH RECOMPILEsupported for stored procedures?26.4.16: Is there a MySQL equivalent to using
mod_plsqlas a gateway on Apache to talk directly to a stored procedure in the database?26.4.17: Can I pass an array as input to a stored procedure?
26.4.18: Can I pass a cursor as an
INparameter to a stored procedure?26.4.19: Can I return a cursor as an
OUTparameter from a stored procedure?26.4.20: Can I print out a variable's value within a stored routine for debugging purposes?
26.4.21: Can I commit or roll back transactions inside a stored procedure?
26.4.22: Do MySQL 5.0 stored procedures and functions work with replication?
26.4.23: Are stored procedures and functions created on a master server replicated to a slave?
26.4.24: How are actions that take place inside stored procedures and functions replicated?
26.4.25: Are there special security requirements for using stored procedures and functions together with replication?
26.4.26: What limitations exist for replicating stored procedure and function actions?
26.4.27: Do the preceding limitations affect MySQL's ability to do point-in-time recovery?
26.4.28: What is being done to correct the aforementioned limitations?
Questions and Answers
26.4.1: Does MySQL 5.0 support stored procedures?
Yes. MySQL 5.0 supports two types of stored routines — stored procedures and stored functions.
26.4.2: Where can I find documentation for MySQL stored procedures and stored functions?
See Chapter 17, Stored Procedures and Functions.
26.4.3: Is there a discussion forum for MySQL stored procedures?
Yes. See http://forums.mysql.com/list.php?98.
26.4.4: Where can I find the ANSI SQL 2003 specification for stored procedures?
Unfortunately, the official specifications are not freely available (ANSI makes them available for purchase). However, there are books — such as SQL-99 Complete, Really by Peter Gulutzan and Trudy Pelzer — which give a comprehensive overview of the standard, including coverage of stored procedures.
26.4.5: How do you manage stored routines?
It is always good practice to use a clear naming scheme for
your stored routines. You can manage stored procedures with
CREATE [FUNCTION|PROCEDURE],
ALTER [FUNCTION|PROCEDURE], DROP
[FUNCTION|PROCEDURE], and SHOW CREATE
[FUNCTION|PROCEDURE]. You can obtain information
about existing stored procedures using the
ROUTINES table in the
INFORMATION_SCHEMA database (see
Section 20.14, “The INFORMATION_SCHEMA ROUTINES Table”).
26.4.6: Is there a way to view all stored procedures and stored functions in a given database?
Yes. For a database named dbname,
use this query on the
INFORMATION_SCHEMA.ROUTINES table:
SELECT ROUTINE_TYPE, ROUTINE_NAME
FROM INFORMATION_SCHEMA.ROUTINES
WHERE ROUTINE_SCHEMA='dbname';
For more information, see
Section 20.14, “The INFORMATION_SCHEMA ROUTINES Table”.
The body of a stored routine can be viewed using
SHOW CREATE FUNCTION (for a stored
function) or SHOW CREATE PROCEDURE (for a
stored procedure). See
Section 13.5.4.5, “SHOW CREATE PROCEDURE and SHOW CREATE
FUNCTION Syntax”, for
more information.
26.4.7: Where are stored procedures stored?
In the proc table of the
mysql system database. However, you
should not access the tables in the system database
directly. Instead, use SHOW CREATE
FUNCTION to obtain information about stored
functions, and SHOW CREATE PROCEDURE to
obtain information about stored procedures. See
Section 13.5.4.5, “SHOW CREATE PROCEDURE and SHOW CREATE
FUNCTION Syntax”, for
more information about these statements.
You can also query the ROUTINES table in
the INFORMATION_SCHEMA database —
see Section 20.14, “The INFORMATION_SCHEMA ROUTINES Table”, for information about
this table.
26.4.8: Is it possible to group stored procedures or stored functions into packages?
No. This is not supported in MySQL 5.0.
26.4.9: Can a stored procedure call another stored procedure?
Yes.
26.4.10: Can a stored procedure call a trigger?
A stored procedure can execute an SQL statement, such as an
UPDATE, that causes a trigger to fire.
26.4.11: Can a stored procedure access tables?
Yes. A stored procedure can access one or more tables as required.
26.4.12: Do stored procedures have a statement for raising application errors?
Not in MySQL 5.0. We intend to implement the
SQL standard SIGNAL and
RESIGNAL statements in a future MySQL
release.
26.4.13: Do stored procedures provide exception handling?
MySQL implements HANDLER definitions
according to the SQL standard. See
Section 17.2.8.2, “DECLARE Handlers”, for
details.
26.4.14: Can MySQL 5.0 stored routines return result sets?
Stored procedures can, but stored
functions cannot. If you perform an ordinary
SELECT inside a stored procedure, the
result set is returned directly to the client. You need to
use the MySQL 4.1 (or above) client-server protocol for this
to work. This means that — for instance — in
PHP, you need to use the mysqli extension
rather than the old mysql extension.
26.4.15:
Is WITH RECOMPILE supported for stored
procedures?
Not in MySQL 5.0.
26.4.16:
Is there a MySQL equivalent to using
mod_plsql as a gateway on Apache to talk
directly to a stored procedure in the database?
There is no equivalent in MySQL 5.0.
26.4.17: Can I pass an array as input to a stored procedure?
Not in MySQL 5.0.
26.4.18:
Can I pass a cursor as an IN parameter to
a stored procedure?
In MySQL 5.0, cursors are available inside stored procedures only.
26.4.19:
Can I return a cursor as an OUT parameter
from a stored procedure?
In MySQL 5.0, cursors are available inside
stored procedures only. However, if you do not open a cursor
on a SELECT, the result will be sent
directly to the client. You can also SELECT
INTO variables. See Section 13.2.7, “SELECT Syntax”.
26.4.20: Can I print out a variable's value within a stored routine for debugging purposes?
Yes, you can do this in a stored
procedure, but not in a stored function. If you
perform an ordinary SELECT inside a
stored procedure, the result set is returned directly to the
client. You will need to use the MySQL 4.1 (or above)
client-server protocol for this to work. This means that
— for instance — in PHP, you need to use the
mysqli extension rather than the old
mysql extension.
26.4.21: Can I commit or roll back transactions inside a stored procedure?
Yes. However, you cannot perform transactional operations within a stored function.
26.4.22: Do MySQL 5.0 stored procedures and functions work with replication?
Yes, standard actions carried out in stored procedures and functions are replicated from a master MySQL server to a slave server. There are a few limitations that are described in detail in Section 17.4, “Binary Logging of Stored Routines and Triggers”.
26.4.23: Are stored procedures and functions created on a master server replicated to a slave?
Yes, creation of stored procedures and functions carried out
through normal DDL statements on a master server are
replicated to a slave, so the objects will exist on both
servers. ALTER and
DROP statements for stored procedures and
functions are also replicated.
26.4.24: How are actions that take place inside stored procedures and functions replicated?
MySQL records each DML event that occurs in a stored procedure and replicates those individual actions to a slave server. The actual calls made to execute stored procedures are not replicated.
Stored functions that change data are logged as function invocations, not as the DML events that occur inside each function.
26.4.25: Are there special security requirements for using stored procedures and functions together with replication?
Yes. Because a slave server has authority to execute any statement read from a master's binary log, special security constraints exist for using stored functions with replication. If replication or binary logging in general (for the purpose of point-in-time recovery) is active, then MySQL DBAs have two security options open to them:
Any user wishing to create stored functions must be granted the
SUPERprivilege.Alternatively, a DBA can set the
log_bin_trust_function_creatorssystem variable to 1, which enables anyone with the standardCREATE ROUTINEprivilege to create stored functions.
26.4.26: What limitations exist for replicating stored procedure and function actions?
Non-deterministic (random) or time-based actions embedded in
stored procedures may not replicate properly. By their very
nature, randomly produced results are not predictable and
cannot be exactly reproduced, and therefore, random actions
replicated to a slave will not mirror those performed on a
master. Note that declaring stored functions to be
DETERMINISTIC or setting the
log_bin_trust_function_creators system
variable to 0 will not allow random-valued operations to be
invoked.
In addition, time-based actions cannot be reproduced on a slave because the timing of such actions in a stored procedure is not reproducible through the binary log used for replication. It records only DML events and does not factor in timing constraints.
Finally, non-transactional tables for which errors occur
during large DML actions (such as bulk inserts) may
experience replication issues in that a master may be
partially updated from DML activity, but no updates are done
to the slave because of the errors that occurred. A
workaround is for a function's DML actions to be carried out
with the IGNORE keyword so that updates
on the master that cause errors are ignored and updates that
do not cause errors are replicated to the slave.
26.4.27: Do the preceding limitations affect MySQL's ability to do point-in-time recovery?
The same limitations that affect replication do affect point-in-time recovery.
26.4.28: What is being done to correct the aforementioned limitations?
MySQL 5.1 implements row-based replication, which resolves the limitations mentioned earlier.
We do not plan to backport row-based replication to MySQL 5.0. For additional information, see Row-Based Replication, in the MySQL 5.1 Manual.
Questions
26.5.1: Where can I find the documentation for MySQL 5.0 triggers?
26.5.2: Is there a discussion forum for MySQL Triggers?
26.5.3: Does MySQL 5.0 have statement-level or row-level triggers?
26.5.4: Are there any default triggers?
26.5.5: How are triggers managed in MySQL?
26.5.6: Is there a way to view all triggers in a given database?
26.5.7: Where are triggers stored?
26.5.8: Can a trigger call a stored procedure?
26.5.9: Can triggers access tables?
26.5.10: Can triggers call an external application through a UDF?
26.5.11: Is possible for a trigger to update tables on a remote server?
26.5.12: Do triggers work with replication?
26.5.13: How are actions carried out through triggers on a master replicated to a slave?
Questions and Answers
26.5.1: Where can I find the documentation for MySQL 5.0 triggers?
See Chapter 18, Triggers.
26.5.2: Is there a discussion forum for MySQL Triggers?
Yes. It is available at http://forums.mysql.com/list.php?99.
26.5.3: Does MySQL 5.0 have statement-level or row-level triggers?
In MySQL 5.0, all triggers are FOR
EACH ROW — that is, the trigger is activated
for each row that is inserted, updated, or deleted. MySQL
5.0 does not support triggers using
FOR EACH STATEMENT.
26.5.4: Are there any default triggers?
Not explicitly. MySQL does have specific special behavior
for some TIMESTAMP columns, as well as
for columns which are defined using
AUTO_INCREMENT.
26.5.5: How are triggers managed in MySQL?
In MySQL 5.0, triggers can be created using the
CREATE TRIGGER statement, and dropped
using DROP TRIGGER. See
Section 18.1, “CREATE TRIGGER Syntax”, and
Section 18.2, “DROP TRIGGER Syntax”, for more about
these statements.
Information about triggers can be obtained by querying the
INFORMATION_SCHEMA.TRIGGERS table. See
Section 20.16, “The INFORMATION_SCHEMA TRIGGERS Table”.
26.5.6: Is there a way to view all triggers in a given database?
Yes. You can obtain a listing of all triggers defined on
database dbname using a query on the
INFORMATION_SCHEMA.TRIGGERS table such as the one shown
here:
SELECT TRIGGER_NAME, EVENT_MANIPULATION, EVENT_OBJECT_TABLE, ACTION_STATEMENT
FROM INFORMATION_SCHEMA.TRIGGERS
WHERE TRIGGER_SCHEMA='dbname';
For more information about this table, see
Section 20.16, “The INFORMATION_SCHEMA TRIGGERS Table”.
You can also use the SHOW TRIGGERS
statement, which is specific to MySQL. See
Section 13.5.4.26, “SHOW TRIGGERS Syntax”.
26.5.7: Where are triggers stored?
Triggers are currently stored in .TRG
files, with one such file one per table. In other words, a
trigger belongs to a table.
In the future, we plan to change this so that trigger
information will be included in the
.FRM file that defines the structure of
the table. We also plan to make triggers database-level
objects — rather than table-level objects as they are
now — to bring them into compliance with the SQL
standard.
26.5.8: Can a trigger call a stored procedure?
Yes.
26.5.9: Can triggers access tables?
A trigger can access both old and new data in its own table. Through a stored procedure, or a multiple-table update or delete statement, a trigger can also affect other tables.
26.5.10: Can triggers call an external application through a UDF?
No, not at present.
26.5.11: Is possible for a trigger to update tables on a remote server?
Yes. A table on a remote server could be updated using the
FEDERATED storage engine. (See
Section 14.7, “The FEDERATED Storage Engine”).
26.5.12: Do triggers work with replication?
Triggers and replication in MySQL 5.0 work in the same wasy as in most other database engines: Actions carried out through triggers on a master are not replicated to a slave server. Instead, triggers that exist on tables that reside on a MySQL master server need to be created on the corresponding tables on any MySQL slave servers so that the triggers activate on the slaves as well as the master.
26.5.13: How are actions carried out through triggers on a master replicated to a slave?
First, the triggers that exist on a master must be
re-created on the slave server. Once this is done, the
replication flow works as any other standard DML statement
that participates in replication. For example, consider a
table EMP that has an
AFTER insert trigger, which exists on a
master MySQL server. The same EMP table
and AFTER insert trigger exist on the
slave server as well. The replication flow would be:
An
INSERTstatement is made toEMP.The
AFTERtrigger onEMPactivates.The
INSERTstatement is written to the binary log.The replication slave picks up the
INSERTstatement toEMPand executes it.The
AFTERtrigger onEMPthat exists on the slave activates.
Questions
26.6.1: Where can I find documentation for MySQL Views?
26.6.2: Is there a discussion forum for MySQL Views?
26.6.3: What happens to a view if an underlying table is dropped or renamed?
26.6.4: Does MySQL 5.0 have table snapshots?
26.6.5: Does MySQL 5.0 have materialized views?
26.6.6: Can you insert into views that are based on joins?
Questions and Answers
26.6.1: Where can I find documentation for MySQL Views?
See Chapter 19, Views.
26.6.2: Is there a discussion forum for MySQL Views?
Yes. See http://forums.mysql.com/list.php?100
26.6.3: What happens to a view if an underlying table is dropped or renamed?
After a view has been created, it is possible to drop or
alter a table or view to which the definition refers. To
check a view definition for problems of this kind, use the
CHECK TABLE statement. (See
Section 13.5.2.3, “CHECK TABLE Syntax”.)
26.6.4: Does MySQL 5.0 have table snapshots?
No.
26.6.5: Does MySQL 5.0 have materialized views?
No.
26.6.6: Can you insert into views that are based on joins?
It is possible, provided that your INSERT
statement has a column list that makes it clear there's only
one table involved.
You cannot insert into multiple tables with a single insert on a view.
Questions
26.7.1: Where can I find documentation for the MySQL
INFORMATION_SCHEMAdatabase?26.7.2: Is there a discussion forum for
INFORMATION_SCHEMA?26.7.3: Where can I find the ANSI SQL 2003 specification for
INFORMATION_SCHEMA?26.7.4: What is the difference between the Oracle Data Dictionary and MySQL's
INFORMATION_SCHEMA?26.7.5: Can I add to or otherwise modify the tables found in the
INFORMATION_SCHEMAdatabase?
Questions and Answers
26.7.1:
Where can I find documentation for the MySQL
INFORMATION_SCHEMA database?
See Chapter 20, The INFORMATION_SCHEMA Database
26.7.2:
Is there a discussion forum for
INFORMATION_SCHEMA?
See http://forums.mysql.com/list.php?101.
26.7.3:
Where can I find the ANSI SQL 2003 specification for
INFORMATION_SCHEMA?
Unfortunately, the official specifications are not freely
available. (ANSI makes them available for purchase.)
However, there are books available — such as
SQL-99 Complete, Really by Peter
Gulutzan and Trudy Pelzer — which give a comprehensive
overview of the standard, including
INFORMATION_SCHEMA.
26.7.4:
What is the difference between the Oracle Data Dictionary
and MySQL's INFORMATION_SCHEMA?
Both Oracle and MySQL provide metadata in tables. However,
Oracle and MySQL use different table names and column names.
MySQL's implementation is more similar to those found in DB2
and SQL Server, which also support
INFORMATION_SCHEMA as defined in the SQL
standard.
26.7.5:
Can I add to or otherwise modify the tables found in the
INFORMATION_SCHEMA database?
No. Since applications may rely on a certain standard
structure, this should not be modified. For this reason,
MySQL AB cannot support bugs or other issues which
result from modifying INFORMATION_SCHEMA
tables or data.
Questions
Questions and Answers
26.8.1: Where can I find information on how to migrate from MySQL 4.1 to MySQL 5.0?
For detailed upgrade information, see Section 2.4.16, “Upgrading MySQL”. We recommend that you do not skip a major version when upgrading, but rather complete the process in steps, upgrading from one major version to the next in each step. This may seem more complicated, but it will you save time and trouble — if you encounter problems during the upgrade, their origin will be easier to identify, either by you or — if you have a MySQL Network subscription — by MySQL support.
26.8.2: How has storage engine (table type) support changed in MySQL 5.0 from previous versions?
Storage engine support has changed as follows:
Support for
ISAMtables was removed in MySQL 5.0 and you should now use theMyISAMstorage engine in place ofISAM. To convert a tabletblnamefromISAMtoMyISAM, simply issue a statement such as this one:ALTER TABLE
tblnameENGINE=MYISAM;Internal
RAIDforMyISAMtables was also removed in MySQL 5.0. This was formerly used to allow large tables in file systems that did not support file sizes greater than 2GB. All modern file systems allow for larger tables; in addition, there are now other solutions such asMERGEtables and views.The
VARCHARcolumn type now retains trailing spaces in all storage engines.MEMORYtables (formerly known asHEAPtables) can also containVARCHARcolumns.
Questions
26.9.1: Where can I find documentation that addresses security issues for MySQL?
26.9.2: Does MySQL 5.0 have native support for SSL?
26.9.3: Is SSL support be built into MySQL binaries, or must I recompile the binary myself to enable it?
26.9.4: Does MySQL 5.0 have built-in authentication against LDAP directories?
26.9.5: Does MySQL 5.0 include support for Roles Based Access Control (RBAC)?
Questions and Answers
26.9.1: Where can I find documentation that addresses security issues for MySQL?
The best place to start is Section 5.6, “General Security Issues”.
Other portions of the MySQL Documentation which you may find useful with regard to specific security concerns include the following:
MySQL Enterprise The MySQL Network Monitoring and Advisory Service enforces best practices for maximizing the security of your servers. For more information see http://www.mysql.com/products/enterprise/advisors.html.
26.9.2: Does MySQL 5.0 have native support for SSL?
Most 5.0 binaries have support for SSL connections between the client and server. We can't currently build with the new YaSSL library everywhere, as it's still quite new and does not compile on all platforms yet. See Section 5.8.7, “Using Secure Connections”.
You can also tunnel a connection via SSH, if (for instance) if the client application doesn't support SSL connections. For an example, see Section 5.8.7.5, “Connecting to MySQL Remotely from Windows with SSH”.
26.9.3: Is SSL support be built into MySQL binaries, or must I recompile the binary myself to enable it?
Most 5.0 binaries have SSL enabled for client-server connections that are secured, authenticated, or both. However, the YaSSL library currently does not compile on all platforms. See Section 5.8.7, “Using Secure Connections”, for a complete listing of supported and unsupported platforms.
26.9.4: Does MySQL 5.0 have built-in authentication against LDAP directories?
No. Support for external authentication methods is on the MySQL roadmap as a “rolling feature”, which means that we plan to implement it in the future, but we have not yet determined when this will be done.
26.9.5: Does MySQL 5.0 include support for Roles Based Access Control (RBAC)?
No. Support for roles is on the MySQL roadmap as a “rolling feature”, which means that we plan to implement it in the future, but we have not yet determined when this will be done.
In the following section, we provide answers to questions that are
most frequently asked about MySQL Cluster and the
NDB storage engine.
Questions
26.10.1: What does “NDB” mean?
26.10.2: What's the difference in using Cluster vs using replication?
26.10.3: Do I need to do any special networking to run Cluster? How do computers in a cluster communicate?
26.10.4: How many computers do I need to run a cluster, and why?
26.10.5: What do the different computers do in a MySQL Cluster?
26.10.6: With which operating systems can I use Cluster?
26.10.7: What are the hardware requirements for running MySQL Cluster?
26.10.8: How much RAM do I need? Is it possible to use disk memory at all?
26.10.9: What filesystems can I use with MySQL Cluster? What about network filesystems or network shares?
26.10.10: Can I run MySQL Cluster nodes inside virtual machines (such as those created by VMWare, Parallels, or Xen)?
26.10.11: I'm trying to populate a Cluster database. The loading process terminates prematurely and I get an error message like this one:
ERROR 1114: The table 'my_cluster_table' is fullWhy is this happening?
26.10.12: MySQL Cluster uses TCP/IP. Does this mean that I can run it over the Internet, with one or more nodes in remote locations?
26.10.13: Do I have to learn a new programming or query language to use MySQL Cluster?
26.10.14: How do I find out what an error or warning message means when using MySQL Cluster?
26.10.15: Is MySQL Cluster transaction-safe? What isolation levels are supported?
26.10.16: What storage engines are supported by MySQL Cluster?
26.10.17: Which versions of the MySQL software support Cluster? Do I have to compile from source?
26.10.18: In the event of a catastrophic failure — say, for instance, the whole city loses power and my UPS fails — would I lose all my data?
26.10.19: Is it possible to use
FULLTEXTindexes with Cluster?26.10.20: Can I run multiple nodes on a single computer?
26.10.21: Can I add nodes to a cluster without restarting it?
26.10.22: Are there any limitations that I should be aware of when using MySQL Cluster?
26.10.23: How do I import an existing MySQL database into a cluster?
26.10.24: How do cluster nodes communicate with one another?
26.10.25: What is an arbitrator?
26.10.26: What data types are supported by MySQL Cluster?
26.10.27: How do I start and stop MySQL Cluster?
26.10.28: What happens to cluster data when the cluster is shut down?
26.10.29: Is it helpful to have more than one management node for a cluster?
26.10.30: Can I mix different kinds of hardware and operating systems in one MySQL Cluster?
26.10.31: Can I run two data nodes on a single host? Two SQL nodes?
26.10.32: Can I use hostnames with MySQL Cluster?
26.10.33: How do I handle MySQL users in a Cluster having multiple MySQL servers?
Questions and Answers
26.10.1: What does “NDB” mean?
This stands for
“Network
Database”.
NDB (also known as NDB
Cluster or NDBCLUSTER) is the
storage engine that enables clustering in MySQL.
26.10.2: What's the difference in using Cluster vs using replication?
In a replication setup, a master MySQL server updates one or
more slaves. Transactions are committed sequentially, and a
slow transaction can cause the slave to lag behind the
master. This means that if the master fails, it is possible
that the slave might not have recorded the last few
transactions. If a transaction-safe engine such as
InnoDB is being used, a transaction will
either be complete on the slave or not applied at all, but
replication does not guarantee that all data on the master
and the slave will be consistent at all times. In MySQL
Cluster, all data nodes are kept in synchrony, and a
transaction committed by any one data node is committed for
all data nodes. In the event of a data node failure, all
remaining data nodes remain in a consistent state.
In short, whereas standard MySQL replication is asynchronous, MySQL Cluster is synchronous.
We have implemented (asynchronous) replication for Cluster in MySQL 5.1. This includes the capability to replicate both between two clusters, and from a MySQL cluster to a non-Cluster MySQL server. However, we do not plan to backport this functionality to MySQL 5.0.
26.10.3: Do I need to do any special networking to run Cluster? How do computers in a cluster communicate?
MySQL Cluster is intended to be used in a high-bandwidth environment, with computers connecting via TCP/IP. Its performance depends directly upon the connection speed between the cluster's computers. The minimum connectivity requirements for Cluster include a typical 100-megabit Ethernet network or the equivalent. We recommend you use gigabit Ethernet whenever available.
The faster SCI protocol is also supported, but requires special hardware. See Section 15.10, “Using High-Speed Interconnects with MySQL Cluster”, for more information about SCI.
26.10.4: How many computers do I need to run a cluster, and why?
A minimum of three computers is required to run a viable cluster. However, the minimum recommended number of computers in a MySQL Cluster is four: one each to run the management and SQL nodes, and two computers to serve as data nodes. The purpose of the two data nodes is to provide redundancy; the management node must run on a separate machine to guarantee continued arbitration services in the event that one of the data nodes fails.
To provide increased throughput and high availability, you should use multiple SQL nodes (MySQL Servers connected to the cluster). It is also possible (although not strictly necessary) to run multiple management servers.
26.10.5: What do the different computers do in a MySQL Cluster?
A MySQL Cluster has both a physical and logical organization, with computers being the physical elements. The logical or functional elements of a cluster are referred to as nodes, and a computer housing a cluster node is sometimes referred to as a cluster host. There are three types of nodes, each corresponding to a specific role within the cluster. These are:
Management node (MGM node): Provides management services for the cluster as a whole, including startup, shutdown, backups, and configuration data for the other nodes. The management node server is implemented as the application ndb_mgmd; the management client used to control MySQL Cluster via the MGM node is ndb_mgm.
Data node: Stores and replicates data. Data node functionality is handled by an instance of the NDB data node process ndbd.
SQL node: This is simply an instance of MySQL Server (mysqld) that is built with support for the
NDB Clusterstorage engine and started with the --ndb-cluster option to enable the engine.
26.10.6: With which operating systems can I use Cluster?
MySQL Cluster is supported on most Unix-like operating systems, including Linux, Mac OS X, Solaris, BSD, HP-UX, AIX, and IRIX, among others, as well as Novell Netware. Cluster is not supported for Windows at this time. However, we are working to add Cluster support for other platforms, including Windows, and our goal is to offer MySQL Cluster on all platforms for which MySQL itself is supported.
For more detailed information concerning the level of support which is offered for MySQL Cluster on various operating system versions, OS distributions, and hardware platforms, please refer to http://www.mysql.com/support/supportedplatforms/cluster.html.
26.10.7: What are the hardware requirements for running MySQL Cluster?
Cluster should run on any platform for which NDB-enabled binaries are available. Naturally, faster CPUs and more memory will improve performance, and 64-bit CPUs will likely be more effective than 32-bit processors. There must be sufficient memory on machines used for data nodes to hold each node's share of the database (see How much RAM do I Need? for more information). Nodes can communicate via a standard TCP/IP network and hardware. For SCI support, special networking hardware is required.
26.10.8: How much RAM do I need? Is it possible to use disk memory at all?
In MySQL-5.0, Cluster is in-memory only. This means that all table data (including indexes) is stored in RAM. Therefore, if your data takes up 1GB of space and you want to replicate it once in the cluster, you need 2GB of memory to do so (1 GB per replica). This is in addition to the memory required by the operating system and any applications running on the cluster computers.
If a data node's memory usage exceeds what is available in
RAM, then the system will attempt to use swap space up to
the limit set for DataMemory. However,
this will at best result in severely degraded performance,
and may cause the node to be dropped due to slow response
time (missed heartbeats). We do not recommend on relying on
disk swapping in a production environment for this reason.
In any case, once the DataMemory limit is
reached, any operations requiring additional memory (such as
inserts) will fail.
(We have implemented disk data storage for MySQL Cluster in MySQL 5.1, but we have no plans to add this capability in MySQL 5.0.)
You can use the following formula for obtaining a rough estimate of how much RAM is needed for each data node in the cluster:
(SizeofDatabase × NumberOfReplicas × 1.1 ) / NumberOfDataNodes
To calculate the memory requirements more exactly requires determining, for each table in the cluster database, the storage space required per row (see Section 11.5, “Data Type Storage Requirements”, for details), and multiplying this by the number of rows. You must also remember to account for any column indexes as follows:
Each primary key or hash index created for an
NDBClustertable requires 21–25 bytes per record. These indexes useIndexMemory.Each ordered index requires 10 bytes storage per record, using
DataMemory.Creating a primary key or unique index also creates an ordered index, unless this index is created with
USING HASH. In other words:A primary key or unique index on a Cluster table normally takes up 31 to 35 bytes per record.
However, if the primary key or unique index is created with
USING HASH, then it requires only 21 to 25 bytes per record.
Note that creating MySQL Cluster tables with USING
HASH for all primary keys and unique indexes will
generally cause table updates to run more quickly — in
some cases by a much as 20 to 30 percent faster than updates
on tables where USING HASH was not used
in creating primary and unique keys. This is due to the fact
that less memory is required (because no ordered indexes are
created), and that less CPU must be utilized (because fewer
indexes must be read and possibly updated). However, it also
means that queries that could otherwise use range scans must
be satisfied by other means, which can result in slower
selects.
When calculating Cluster memory requirements, you may find
useful the ndb_size.pl utility which is
available in recent MySQL 5.0 releases. This
Perl script connects to a current (non-Cluster) MySQL
database and creates a report on how much space that
database would require if it used the
NDBCluster storage engine. For more
information, see
Section 15.9.14, “ndb_size.pl — NDBCluster Size Requirement Estimator”.
It is especially important to keep in mind that
every MySQL Cluster table must have a primary
key. The NDB storage engine
creates a primary key automatically if none is defined, and
this primary key is created without USING
HASH.
There is no easy way to determine exactly how much memory is
being used for storage of Cluster indexes at any given time;
however, warnings are written to the Cluster log when 80% of
available DataMemory or
IndexMemory is in use, and again when use
reaches 85%, 90%, and so on.
26.10.9: What filesystems can I use with MySQL Cluster? What about network filesystems or network shares?
Generally, any filesystem that is native to the host operating system should work well with MySQL Cluster. If you find that a given filesystem works particularly well (or not so especially well) with MySQL Cluster, we invite you to discuss your findings in the MySQL Cluster Forums.
We do not test MySQL Cluster with FAT or
VFAT filesystems on Linux. Because of
this, and due to the fact that these are not very useful for
any purpose other than sharing disk partitions between Linux
and Windows operating systems on multi-boot computers, we do
not recommend their use with MySQL Cluster.
MySQL Cluster is implemented as a shared-nothing solution; the idea behind this is that the failure of a single piece of hardware should not cause the failure of multiple cluster nodes, or possibly even the failure of the cluster as a whole. For this reason, the use of network shares or network filesystems is not supported for MySQL Cluster. This also applies to shared storage devices such as SANs.
26.10.10: Can I run MySQL Cluster nodes inside virtual machines (such as those created by VMWare, Parallels, or Xen)?
This is possible but not recommended for a production environment.
We have found that running MySQL Cluster processes inside a virtual machine can give rise to issues with timing and disk subsystems that have a strong negative impact on the operation of the cluster. The behavior of the cluster is often unpredictable in these cases.
If the issue can be reproduced outside the virtual environment, then we may be able to provide assistance. Otherwise, we cannot support it at this time.
26.10.11:
I'm trying to populate a Cluster database. The loading
process terminates prematurely and I get an error message
like this one:
ERROR 1114: The table 'my_cluster_table' is full
Why is this happening?
The cause is very likely to be that your setup does not
provide sufficient RAM for all table data and all indexes,
including the primary key required by the
NDB storage engine and automatically
created in the event that the table definition does not
include the definition of a primary key.
It is also worth noting that all data nodes should have the same amount of RAM, since no data node in a cluster can use more memory than the least amount available to any individual data node. In other words, if there are four computers hosting Cluster data nodes, and three of these have 3GB of RAM available to store Cluster data while the remaining data node has only 1GB RAM, then each data node can devote only 1GB to clustering.
26.10.12: MySQL Cluster uses TCP/IP. Does this mean that I can run it over the Internet, with one or more nodes in remote locations?
It is very unlikely that a cluster would perform reliably under such conditions, as MySQL Cluster was designed and implemented with the assumption that it would be run under conditions guaranteeing dedicated high-speed connectivity such as that found in a LAN setting using 100 Mbps or gigabit Ethernet — preferably the latter. We neither test nor warrant its performance using anything slower than this.
Also, it is extremely important to keep in mind that communications between the nodes in a MySQL Cluster are not secure; they are neither encrypted nor safeguarded by any other protective mechanism. The most secure configuration for a cluster is in a private network behind a firewall, with no direct access to any Cluster data or management nodes from outside. (For SQL nodes, you should take the same precautions as you would with any other instance of the MySQL server.)
26.10.13: Do I have to learn a new programming or query language to use MySQL Cluster?
No. Although some specialized commands are used to manage and configure the cluster itself, only standard (My)SQL queries and commands are required for the following operations:
Creating, altering, and dropping tables
Inserting, updating, and deleting table data
Creating, changing, and dropping primary and unique indexes
Some specialized configuration parameters and files are required to set up a MySQL Cluster — see Section 15.4.4, “Configuration File”, for information about these.
A few simple commands are used in the MySQL Cluster management client for tasks such as starting and stopping cluster nodes. See Section 15.7.2, “Commands in the MySQL Cluster Management Client”.
26.10.14: How do I find out what an error or warning message means when using MySQL Cluster?
There are two ways in which this can be done:
26.10.15: Is MySQL Cluster transaction-safe? What isolation levels are supported?
Yes: For tables created with the
NDB storage engine, transactions are
supported. In MySQL 5.0, Cluster supports only
the READ COMMITTED transaction isolation
level.
26.10.16: What storage engines are supported by MySQL Cluster?
Clustering in MySQL is supported only by the
NDB storage engine. That is, in order for
a table to be shared between nodes in a cluster, it must be
created using ENGINE=NDB (or
ENGINE=NDBCLUSTER, which is equivalent).
It is possible to create tables using other storage engines
(such as MyISAM or
InnoDB) on a MySQL server being used for
clustering, but these non-NDB tables will
not participate in the
cluster; they are local to the individual MySQL server
instance on which they are created.
26.10.17: Which versions of the MySQL software support Cluster? Do I have to compile from source?
Cluster is supported in all server binaries in the
5.0 release series for operating systems on
which MySQL Cluster is available. See
Section 5.2, “mysqld — The MySQL Server”. You can determine whether your
server has NDB support using either the SHOW
VARIABLES LIKE 'have_%' or SHOW
ENGINES statement.
Linux users, please note that NDB is
not included in the standard MySQL
server RPMs. Beginning with MySQL 5.0.4, there are separate
RPM packages for the NDB storage engine and accompanying
management and other tools; see the NDB RPM Downloads
section of the MySQL 5.0 Downloads page for
these. (Prior to 5.0.4, you had to use the
-max binaries supplied as
.tar.gz archives. This is still
possible, but is not required, so you can use your Linux
distribution's RPM manager if you prefer.)
You can also obtain NDB support by compiling MySQL from source, but it is not necessary to do so simply to use MySQL Cluster. To download the latest binary, RPM, or source distribution in the MySQL 5.0 series, visit http://dev.mysql.com/downloads/mysql/5.0.html.
26.10.18: In the event of a catastrophic failure — say, for instance, the whole city loses power and my UPS fails — would I lose all my data?
All committed transactions are logged. Therefore, although it is possible that some data could be lost in the event of a catastrophe, this should be quite limited. Data loss can be further reduced by minimizing the number of operations per transaction. (It is not a good idea to perform large numbers of operations per transaction in any case.)
26.10.19:
Is it possible to use FULLTEXT indexes
with Cluster?
FULLTEXT indexing is not supported by the
NDB storage engine in MySQL
5.0, or by any storage engine other than
MyISAM. We are working to add this
capability in a future release.
26.10.20: Can I run multiple nodes on a single computer?
It is possible but not advisable. One of the chief reasons to run a cluster is to provide redundancy. To enjoy the full benefits of this redundancy, each node should reside on a separate machine. If you place multiple nodes on a single machine and that machine fails, you lose all of those nodes. Given that MySQL Cluster can be run on commodity hardware loaded with a low-cost (or even no-cost) operating system, the expense of an extra machine or two is well worth it to safeguard mission-critical data. It also worth noting that the requirements for a cluster host running a management node are minimal. This task can be accomplished with a 200 MHz Pentium CPU and sufficient RAM for the operating system plus a small amount of overhead for the ndb_mgmd and ndb_mgm processes.
It is acceptable to run multiple cluster data nodes on a single host for learning about MySQL Cluster, or for testing purposes; however, this is not supported for production use.
26.10.21: Can I add nodes to a cluster without restarting it?
Not at present. A simple restart is all that is required for adding new MGM or SQL nodes to a Cluster. When adding data nodes the process is more complex, and requires the following steps:
Make a complete backup of all Cluster data.
Completely shut down the cluster and all cluster node processes.
Restart the cluster, using the
--initialstartup option.Restore all cluster data from the backup.
In a future MySQL Cluster release series, we hope to implement a “hot” reconfiguration capability for MySQL Cluster to minimize (if not eliminate) the requirement for restarting the cluster when adding new nodes. However, this is not planned for MySQL 5.0.
26.10.22: Are there any limitations that I should be aware of when using MySQL Cluster?
Limitations on NDB tables in MySQL
5.0 include:
Temporary tables are not supported; a
CREATE TEMPORARY TABLEstatement usingENGINE=NDBorENGINE=NDBCLUSTERfails with an error.FULLTEXTindexes and index prefixes are not supported. Only complete columns may be indexed.Spatial data types are not supported. See Chapter 16, Spatial Extensions.
Only complete rollbacks for transactions are supported. Partial rollbacks and rollbacks to save points are not supported.
The maximum number of attributes allowed per table is 128, and attribute names cannot be any longer than 31 characters. For each table, the maximum combined length of the table and database names is 122 characters.
The maximum size for a table row is 8 kilobytes, not counting
BLOBvalues. There is no set limit for the number of rows per table. Table size limits depend on a number of factors, in particular on the amount of RAM available to each data node.The
NDBengine does not support foreign key constraints. As withMyISAMtables, these are ignored.
For a complete listing of limitations in MySQL Cluster, see Section 15.11, “Known Limitations of MySQL Cluster”.
26.10.23: How do I import an existing MySQL database into a cluster?
You can import databases into MySQL Cluster much as you
would with any other version of MySQL. Other than the
limitations mentioned elsewhere in this FAQ and in
Section 15.11, “Known Limitations of MySQL Cluster”, the only other
special requirement is that any tables to be included in the
cluster must use the NDB storage engine.
This means that the tables must be created with
ENGINE=NDB or
ENGINE=NDBCLUSTER.
It is also possible to convert existing tables using other
storage engines to NDB Cluster using one
or more ALTER TABLE statement, but this
requires an additional workaround. See
Section 15.11, “Known Limitations of MySQL Cluster”, for details.
26.10.24: How do cluster nodes communicate with one another?
Cluster nodes can communicate via any of three different protocols: TCP/IP, SHM (shared memory), and SCI (Scalable Coherent Interface). Where available, SHM is used by default between nodes residing on the same cluster host; however, this is considered experimental in MySQL 5.0. SCI is a high-speed (1 gigabit per second and higher), high-availability protocol used in building scalable multi-processor systems; it requires special hardware and drivers. See Section 15.10, “Using High-Speed Interconnects with MySQL Cluster”, for more about using SCI as a transport mechanism in MySQL Cluster.
26.10.25: What is an arbitrator?
If one or more nodes in a cluster fail, it is possible that not all cluster nodes will be able to “see” one another. In fact, it is possible that two sets of nodes might become isolated from one another in a network partitioning, also known as a “split brain” scenario. This type of situation is undesirable because each set of nodes tries to behave as though it is the entire cluster.
When cluster nodes go down, there are two possibilities. If more than 50% of the remaining nodes can communicate with each other, we have what is sometimes called a “majority rules” situation, and this set of nodes is considered to be the cluster. The arbitrator comes into play when there is an even number of nodes: in such cases, the set of nodes to which the arbitrator belongs is considered to be the cluster, and nodes not belonging to this set are shut down.
The preceding information is somewhat simplified. A more complete explanation taking into account node groups follows:
When all nodes in at least one node group are alive, network
partitioning is not an issue, because no one portion of the
cluster can form a functional cluster. The real problem
arises when no single node group has all its nodes alive, in
which case network partitioning (the
“split-brain” scenario) becomes possible. Then
an arbitrator is required. All cluster nodes recognize the
same node as the arbitrator, which is normally the
management server; however, it is possible to configure any
of the MySQL Servers in the cluster to act as the arbitrator
instead. The arbitrator accepts the first set of cluster
nodes to contact it, and tells the remaining set to shut
down. Arbitrator selection is controlled by the
ArbitrationRank configuration parameter
for MySQL Server and management server nodes. (See
Section 15.4.4.4, “Defining the Management Server”, for
details.) It should also be noted that the role of
arbitrator does not in and of itself impose any heavy
demands upon the host so designated, and thus the arbitrator
host does not need to be particularly fast or to have extra
memory especially for this purpose.
26.10.26: What data types are supported by MySQL Cluster?
MySQL Cluster supports all of the usual MySQL data types,
with the exception of those associated with MySQL's spatial
extensions. (See Chapter 16, Spatial Extensions.) In
addition, there are some differences with regard to indexes
when used with NDB tables.
Note: MySQL Cluster tables
(that is, tables created with
ENGINE=NDBCLUSTER) have only fixed-width
rows. This means that (for example) each record containing a
VARCHAR(255) column will require space
for 255 characters (as required for the character set and
collation being used for the table), regardless of the
actual number of characters stored therein. This issue is
expected to be fixed in a future MySQL release series.
See Section 15.11, “Known Limitations of MySQL Cluster”, for more information about these issues.
26.10.27: How do I start and stop MySQL Cluster?
It is necessary to start each node in the cluster separately, in the following order:
Start the management node with the ndb_mgmd command.
Start each data node with the ndbd command.
Start each MySQL server (SQL node) using mysqld_safe --user=mysql &.
Each of these commands must be run from a system shell on
the machine housing the affected node. (You do not have to
be physically present at the machine — a remote login
shell can be used for this purpose.) You can verify that the
cluster is running by starting the MGM management client
ndb_mgm on the machine housing the MGM
node and issuing the SHOW or ALL
STATUS command.
To shut down a running cluster, issue the command
SHUTDOWN in the MGM client.
Alternatively, you may enter the following command in a
system shell on the machine hosting the MGM node:
shell> ndb_mgm -e "SHUTDOWN"
(Note that the quotation marks are optional here; the
SHUTDOWN command itself is not
case-sensitive.)
Either of these commands causes the ndb_mgm, ndb_mgm, and any ndbd processes to terminate gracefully. MySQL servers running as Cluster SQL nodes can be stopped using mysqladmin shutdown.
For more information, see Section 15.7.2, “Commands in the MySQL Cluster Management Client”, and Section 15.3.6, “Safe Shutdown and Restart”.
26.10.28: What happens to cluster data when the cluster is shut down?
The data that was held in memory by the cluster's data nodes is written to disk, and is reloaded into memory the next time that the cluster is started.
26.10.29: Is it helpful to have more than one management node for a cluster?
It can be helpful as a fail-safe. Only one MGM node controls the cluster at any given time, but it is possible to configure one MGM as primary, and one or more additional management nodes to take over in the event that the primary MGM node fails.
See Section 15.4.4, “Configuration File”, for information on how to configure MySQL Cluster management nodes.
26.10.30: Can I mix different kinds of hardware and operating systems in one MySQL Cluster?
Yes, so long as all machines and operating systems have the same “endianness” (all big-endian or all little-endian). It is also possible to use different MySQL Cluster releases on different nodes. However, we recommend this be done only as part of a rolling upgrade procedure (see Section 15.5.1, “Performing a Rolling Restart of the Cluster”).
26.10.31: Can I run two data nodes on a single host? Two SQL nodes?
Yes, it is possible to do this. In the case of multiple data nodes, it is advisable (but not required) for each node to use a different data directory. If you want to run multiple SQL nodes on one machine, each instance of mysqld must use a different TCP/IP port. However, running more than one cluster node of a given type per machine is not supported for production use.
26.10.32: Can I use hostnames with MySQL Cluster?
Yes, it is possible to use DNS and DHCP for cluster hosts. However, if your application requires “five nines” availability, we recommend using fixed IP addresses. Making communication between Cluster hosts dependent on services such as DNS and DHCP introduces additional points of failure, and the fewer of these, the better.
26.10.33: How do I handle MySQL users in a Cluster having multiple MySQL servers?
MySQL user accounts and privileges are not automatically propagated between different MySQL servers accessing the same MySQL Cluster. Therefore, you must make sure that these are copied between the SQL nodes yourself.
This set of Frequently Asked Questions derives from the experience of MySQL's Support and Development groups in handling many inquiries about CJK (Chinese-Japanese-Korean) issues.
Questions
26.11.1: I have inserted CJK characters into my table. Why does
SELECTdisplay them as “?” characters?26.11.2: What GB (Chinese) character sets does MySQL support?
26.11.3: What problems should I be aware of when working with the Big5 Chinese character set?
26.11.4: Why do Japanese character set conversions fail?
26.11.5: What should I do if I want to convert SJIS
81CAtocp932?26.11.6: How does MySQL represent the Yen (
¥) sign?26.11.7: Do MySQL plan to make a separate character set where
5Cis the Yen sign, as at least one other major DBMS does?26.11.8: Of what issues should I be aware when working with Korean character sets in MySQL?
26.11.9: Why do I get Data truncated error messages?
26.11.10: Why does my GUI front end or browser not display CJK characters correctly in my application using Access, PHP, or another API?
26.11.11: I've upgraded to MySQL 5.0. How can I revert to behavior like that in MySQL 4.0 with regard to character sets?
26.11.12: Why do some
LIKEandFULLTEXTsearches with CJK characters fail?26.11.13: What CJK character sets are available in MySQL?
26.11.14: How do I know whether character
Xis available in all character sets?26.11.15: Why don't CJK strings sort correctly in Unicode? (I)
26.11.16: Why don't CJK strings sort correctly in Unicode? (II)
26.11.17: Why are my supplementary characters rejected by MySQL?
26.11.18: Shouldn't it be “CJKV”?
26.11.19: Does MySQL allow CJK characters to be used in database and table names?
26.11.20: Where can I find translations of the MySQL Manual into Chinese, Japanese, and Korean?
26.11.21: Where can I get help with CJK and related issues in MySQL?
Questions and Answers
26.11.1:
I have inserted CJK characters into my table. Why does
SELECT display them as “?”
characters?
This problem is usually due to a setting in MySQL that doesn't match the settings for the application program or the operating system. Here are some common steps for correcting these types of issues:
Be certain of what MySQL version you are using.
Use the statement
SELECT VERSION();to determine this.Make sure that the database is actually using the desired character set.
People often think that the client character set is always the same as either the server character set or the character set used for display purposes. However, both of these are false assumptions. You can make sure by checking the result of
SHOW CREATE TABLEor — better — yet by using this statement:tablenameSELECT character_set_name, collation_name FROM information_schema.columns WHERE table_schema = your_database_name AND table_name = your_table_name AND column_name = your_column_name;Determine the hexadecimal value of the character or characters that are not being displayed correctly.
You can obtain this information for a column
column_namein the tabletable_nameusing the following query:SELECT HEX(
column_name) FROMtable_name;3Fis the encoding for the?character; this means that?is the character actually stored in the column. This most often happens because of a problem converting a particular character from your client character set to the target character set.Make sure that a round trip possible — that is, when you select
literal(or_introducer hexadecimal-value), you obtainliteralas a result.For example, the Japanese Katakana character Pe (
ペ') exists in all CJK character sets, and has the code point value (hexadecimal coding)0x30da. To test a round trip for this character, use this query:SELECT 'ペ' AS `ペ`; /* or SELECT _ucs2 0x30da; */
If the result is not also
ペ, then the round trip has failed.For bug reports regarding such failures, we might ask you to follow up with
SELECT HEX('ペ');. Then we can determine whether the client encoding is correct.Make sure that the problem is not with the browser or other application, rather than with MySQL.
Use the mysql client program (on Windows: mysql.exe) to accomplish this task. If mysql displays correctly but your application doesn't, then your problem is probably due to system settings.
To find out what your settings are, use the
SHOW VARIABLESstatement, whose output should resemble what is shown here:mysql>
SHOW VARIABLES LIKE 'char%';+--------------------------+----------------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /usr/local/mysql/share/mysql/charsets/ | +--------------------------+----------------------------------------+ 8 rows in set (0.03 sec)These are typical character-set settings for an international-oriented client (notice the use of
utf8Unicode) connected to a server in the West (latin1is a West Europe character set and a default for MySQL).Although Unicode (usually the
utf8variant on Unix, and theucs2variant on Windows) is preferable to Latin, it's often not what your operating system utilities support best. Many Windows users find that a Microsoft character set, such ascp932for Japanese Windows, is what's suitable.If you cannot control the server settings, and you have no idea what your underlying computer is, then try changing to a common character set for the country that you're in (
euckr= Korea;gb2312orgbk= People's Republic of China;big5= Taiwan;sjis,ujis,cp932, oreucjpms= Japan;ucs2orutf8= anywhere). Usually it is necessary to change only the client and connection and results settings. There is a simple statement which changes all three at once:SET NAMES. For example:SET NAMES 'big5';
Once the setting is correct, you can make it permanent by editing
my.cnformy.ini. For example you might add lines looking like these:[mysqld] character-set-server=big5 [client] default-character-set=big5
It is also possible that there are issues with the API configuration setting being used in your application; see Why does my GUI front end or browser not display CJK characters correctly...? for more information.
26.11.2: What GB (Chinese) character sets does MySQL support?
MySQL supports the two common variants of the
GB (Guojia
Biaozhun, or National
Standard) character sets which are official in
the People's Republic of China: gb2312
and gbk. Sometimes people try to insert
gbk characters into
gb2312, and it works most of the time
because gbk is a superset of
gb2312 — but eventually they try to
insert a rarer Chinese character and it doesn't work. (See
Bug#16072 for an example).
Here, we try to clarify exactly what characters are
legitimate in gb2312 or
gbk, with reference to the official
documents. Please check these references before reporting
gb2312 or gbk bugs.
For a complete listing of the
gb2312characters, ordered according to thegb2312_chinese_cicollation: http://d.udm.net/bar/~bar/charts/gb2312_chinese_ci.html.MySQL's
gbkis in reality “Microsoft code page 936”. This differs from the officialgbkfor charactersA1A4(middle dot),A1AA(em dash),A6E0-A6F5, andA8BB-A8C0. For a listing of the differences, see http://recode.progiciels-bpi.ca/showfile.html?name=dist/libiconv/gbk.h.For a listing of
gbk/Unicode mappings, see http://www.unicode.org/Public/MAPPINGS/VENDORS/MICSFT/WINDOWS/CP936.TXT.For MySQL's listing of
gbkcharacters, see http://d.udm.net/bar/~bar/charts/gbk_chinese_ci.html.
26.11.3: What problems should I be aware of when working with the Big5 Chinese character set?
MySQL supports the Big5 character set which is common in
Hong Kong and Taiwan (Republic of China). MySQL's
big5 is in reality Microsoft code page
950, which is very similar to the original
big5 character set. We changed to this
character set starting with MySQL version 4.1.16 / 5.0.16
(as a result of Bug#12476). For example, the following
statements work in current versions of MySQL, but not in old
versions:
mysql>CREATE TABLE big5 (BIG5 CHAR(1) CHARACTER SET BIG5);Query OK, 0 rows affected (0.13 sec) mysql>INSERT INTO big5 VALUES (0xf9dc);Query OK, 1 row affected (0.00 sec) mysql>SELECT * FROM big5;+------+ | big5 | +------+ | 嫺 | +------+ 1 row in set (0.02 sec)
A feature request for adding HKSCS
extensions has been filed. People who need this extension
may find the suggested patch for Bug#13577 to be of
interest.
26.11.4: Why do Japanese character set conversions fail?
MySQL supports the sjis,
ujis, cp932, and
eucjpms character sets, as well as
Unicode. A common need is to convert between character sets.
For example, there might be a Unix server (typically with
sjis or ujis) and a
Windows client (typically with cp932).
In the following conversion table, the
ucs2 column represents the source, and
the sjis, cp932,
ujis, and eucjpms
columns represent the destinations — that is, the last
4 columns provide the hexadecimal result when we use
CONVERT(ucs2) or we assign a
ucs2 column containing the value to an
sjis, cp932,
ujis, or eucjpms
column.
| Character Name | ucs2 | sjis | cp932 | ujis | eucjpms |
|---|---|---|---|---|---|
| BROKEN BAR | 00A6 | 3F | 3F | 8FA2C3 | 3F |
| FULLWIDTH BROKEN BAR | FFE4 | 3F | FA55 | 3F | 8FA2 |
| YEN SIGN | 00A5 | 3F | 3F | 20 | 3F |
| FULLWIDTH YEN SIGN | FFE5 | 818F | 818F | A1EF | 3F |
| TILDE | 007E | 7E | 7E | 7E | 7E |
| OVERLINE | 203E | 3F | 3F | 20 | 3F |
| HORIZONTAL BAR | 2015 | 815C | 815C | A1BD | A1BD |
| EM DASH | 2014 | 3F | 3F | 3F | 3F |
| REVERSE SOLIDUS | 005C | 815F | 5C | 5C | 5C |
| FULLWIDTH "" | FF3C | 3F | 815F | 3F | A1C0 |
| WAVE DASH | 301C | 8160 | 3F | A1C1 | 3F |
| FULLWIDTH TILDE | FF5E | 3F | 8160 | 3F | A1C1 |
| DOUBLE VERTICAL LINE | 2016 | 8161 | 3F | A1C2 | 3F |
| PARALLEL TO | 2225 | 3F | 8161 | 3F | A1C2 |
| MINUS SIGN | 2212 | 817C | 3F | A1DD | 3F |
| FULLWIDTH HYPHEN-MINUS | FF0D | 3F | 817C | 3F | A1DD |
| CENT SIGN | 00A2 | 8191 | 3F | A1F1 | 3F |
| FULLWIDTH CENT SIGN | FFE0 | 3F | 8191 | 3F | A1F1 |
| POUND SIGN | 00A3 | 8192 | 3F | A1F2 | 3F |
| FULLWIDTH POUND SIGN | FFE1 | 3F | 8192 | 3F | A1F2 |
| NOT SIGN | 00AC | 81CA | 3F | A2CC | 3F |
| FULLWIDTH NOT SIGN | FFE2 | 3F | 81CA | 3F | A2CC |
Now consider this portion of the table:
| ucs2 | sjis | cp932 | |
|---|---|---|---|
| NOT SIGN | 00AC | 81CA | 3F |
| FULLWIDTH NOT SIGN | FFE2 | 3F | 81CA |
This means that MySQL converts the NOT
SIGN (Unicode U+00AC) to
sjis code point 0x81CA
and to cp932 code point
3F. (3F is the
question mark (“?”) — this is what is
always used when the conversion cannot be performed.
26.11.5:
What should I do if I want to convert SJIS
81CA to cp932?
Our answer is: “?”. There are serious
complaints about this: many people would prefer a
“loose” conversion, so that 81CA (NOT
SIGN) in sjis becomes
81CA (FULLWIDTH NOT SIGN) in
cp932. We are considering a change to
this behavior.
26.11.6:
How does MySQL represent the Yen (¥)
sign?
A problem arises because some versions of Japanese character
sets (both sjis and
euc) treat 5C as a
reverse solidus (\
— also known as a backslash), and others treat it as a
yen sign (¥).
MySQL follows only one version of the JIS (Japanese
Industrial Standards) standard description. In MySQL,
5C is always the reverse
solidus (\).
26.11.7:
Do MySQL plan to make a separate character set where
5C is the Yen sign, as at least one other
major DBMS does?
This is one possible solution to the Yen sign issue; however, this will not happen in MySQL 5.1 or 5.2.
26.11.8: Of what issues should I be aware when working with Korean character sets in MySQL?
In theory, while there have been several versions of the
euckr (Extended Unix Code
Korea) character set, only one problem has been
noted.
We use the “ASCII” variant of EUC-KR, in which
the code point 0x5c is REVERSE SOLIDUS,
that is \, instead of the
“KS-Roman” variant of EUC-KR, in which the code
point 0x5c is WON
SIGN(₩). This means that you
cannot convert Unicode U+20A9 to
euckr:
mysql>SELECT->CONVERT('₩' USING euckr) AS euckr,->HEX(CONVERT('₩' USING euckr)) AS hexeuckr;+-------+----------+ | euckr | hexeuckr | +-------+----------+ | ? | 3F | +-------+----------+ 1 row in set (0.00 sec)
MySQL's graphic Korean chart is here: http://d.udm.net/bar/~bar/charts/euckr_korean_ci.html.
26.11.9: Why do I get Data truncated error messages?
For illustration, we'll create a table with one Unicode
(ucs2) column and one Chinese
(gb2312) column.
mysql>CREATE TABLE ch->(ucs2 CHAR(3) CHARACTER SET ucs2,->gb2312 CHAR(3) CHARACTER SET gb2312);Query OK, 0 rows affected (0.05 sec)
We'll try to place the rare character 汌
in both columns.
mysql> INSERT INTO ch VALUES ('A汌B','A汌B');
Query OK, 1 row affected, 1 warning (0.00 sec)
Ah, there's a warning. Let's see what it is.
mysql> SHOW WARNINGS;
+---------+------+---------------------------------------------+
| Level | Code | Message |
+---------+------+---------------------------------------------+
| Warning | 1265 | Data truncated for column 'gb2312' at row 1 |
+---------+------+---------------------------------------------+
1 row in set (0.00 sec)
So it's a warning about the gb2312 column
only.
mysql> SELECT ucs2,HEX(ucs2),gb2312,HEX(gb2312) FROM ch; +-------+--------------+--------+-------------+ | ucs2 | HEX(ucs2) | gb2312 | HEX(gb2312) | +-------+--------------+--------+-------------+ | A汌B | 00416C4C0042 | A?B | 413F42 | +-------+--------------+--------+-------------+ 1 row in set (0.00 sec)
There are several things that need explanation here.
The fact that it's a “warning” rather than an “error” is characteristic of MySQL. We like to try to do what we can, to get the best fit, rather than give up.
The
汌character isn't in thegb2312character set. We described that problem earlier.Admittedly the message is misleading. We didn't “truncate” in this case, we replaced with a question mark. We've had a complaint about this message (See Bug#9337). But until we come up with something better, just accept that error/warning code 2165 can mean a variety of things.
With
SQL_MODE=TRADITIONAL, there would be an error message, but instead of error 2165 you would see:ERROR 1406 (22001): Data too long for column 'gb2312' at row 1.
26.11.10: Why does my GUI front end or browser not display CJK characters correctly in my application using Access, PHP, or another API?
Obtain a direct connection to the server using the
mysql client (Windows:
mysql.exe), and try the same query there.
If mysql responds correctly, then the
trouble may be that your application interface requires
initialization. Use mysql to tell you
what character set or sets it uses with the statement
SHOW VARIABLES LIKE 'char%';. If you are
using Access, then you are most likely connecting with
MyODBC. In this case, you should check
Section 23.1.3, “Connector/ODBC Configuration”. If, for instance,
you use big5, you would enter
SET NAMES 'big5'. (Note that no
; is required in this case). If you are
using ASP, you might need to add SET
NAMES in the code. Here is an example that has
worked in the past:
<%
Session.CodePage=0
Dim strConnection
Dim Conn
strConnection="driver={MySQL ODBC 3.51 Driver};server=server;uid=username;" \
& "pwd=password;database=database;stmt=SET NAMES 'big5';"
Set Conn = Server.CreateObject("ADODB.Connection")
Conn.Open strConnection
%>
In much the same way, if you are using any character set
other than latin1 with Connector/NET,
then you must specify the character set in the connection
string. See
Section 23.2.5.1, “Connecting to MySQL Using Connector/NET”, for more
information.
If you are using PHP, try this:
<?php
$link = mysql_connect($host, $usr, $pwd);
mysql_select_db($db);
if( mysql_error() ) { print "Database ERROR: " . mysql_error(); }
mysql_query("SET NAMES 'utf8'", $link);
?>
In this case, we used SET NAMES to change
character_set_client and
character_set_connection and
character_set_results.
We encourage the use of the newer mysqli
extension, rather than mysql. Using
mysqli, the previous example could be
rewritten as shown here:
<?php
$link = new mysqli($host, $usr, $pwd, $db);
if( mysqli_connect_errno() )
{
printf("Connect failed: %s\n", mysqli_connect_error());
exit();
}
$link->query("SET NAMES 'utf8'");
?>
Another issue often encountered in PHP applications has to
do with assumptions made by the browser. Sometimes adding or
changing a <meta> tag suffices to
correct the problem: for example, to insure that the user
agent interprets page content as UTF-8,
you should include <meta
http-equiv="Content-Type" content="text/html;
charset=utf-8"> in the
<head> of the HTML page.
If you are using Connector/J, see Section 23.4.4.4, “Using Character Sets and Unicode”.
26.11.11: I've upgraded to MySQL 5.0. How can I revert to behavior like that in MySQL 4.0 with regard to character sets?
In MySQL Version 4.0, there was a single “global” character set for both server and client, and the decision as to which character to use was made by the server administrator. This changed starting with MySQL Version 4.1. What happens now is a “handshake”, as described in Section 10.4, “Connection Character Sets and Collations”:
When a client connects, it sends to the server the name of the character set that it wants to use. The server uses the name to set the
character_set_client,character_set_results, andcharacter_set_connectionsystem variables. In effect, the server performs aSET NAMESoperation using the character set name.
The effect of this is that you cannot control the client
character set by starting mysqld with
--character-set-server=utf8. However, some
of our Asian customers have said that prefer the MySQL 4.0
behavior. To make it possible to retain this behavior, we
added a mysqld switch,
--character-set-client-handshake, which can
be turned off with
--skip-character-set-client-handshake. If
you start mysqld with
--skip-character-set-client-handshake,
then, when a client connects, it sends to the server the
name of the character set that it wants to use —
however, the server ignores this request from the
client.
By way of example, suppose that your favorite server
character set is latin1 (unlikely in a
CJK area, but this is the default value). Suppose further
that the client uses utf8 because this is
what the client's operating system supports. Now, start the
server with latin1 as its default
character set:
mysqld --character-set-server=latin1
And then start the client with the default character set
utf8:
mysql --default-character-set=utf8
The current settings can be seen by viewing the output of
SHOW VARIABLES:
mysql> SHOW VARIABLES LIKE 'char%';
+--------------------------+----------------------------------------+
| Variable_name | Value |
+--------------------------+----------------------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/local/mysql/share/mysql/charsets/ |
+--------------------------+----------------------------------------+
8 rows in set (0.01 sec)
Now stop the client, and then stop the server using mysqladmin. Then start the server again, but this time tell it to skip the handshake like so:
mysqld --character-set-server=utf8 --skip-character-set-client-handshake
Start the client with utf8 once again as
the default character set, then display the current
settings:
mysql> SHOW VARIABLES LIKE 'char%';
+--------------------------+----------------------------------------+
| Variable_name | Value |
+--------------------------+----------------------------------------+
| character_set_client | latin1 |
| character_set_connection | latin1 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | latin1 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/local/mysql/share/mysql/charsets/ |
+--------------------------+----------------------------------------+
8 rows in set (0.01 sec)
As you can see by comparing the differing results from
SHOW VARIABLES, the server ignores the
client's initial settings if the
--skip-character-set-client-handshake is
used.
26.11.12:
Why do some LIKE and
FULLTEXT searches with CJK characters
fail?
There is a very simple problem with LIKE
searches on BINARY and
BLOB columns: we need to know the end of
a character. With multi-byte character sets, different
characters might have different octet lengths. For example,
in utf8, A requires
one byte but ペ requires three bytes, as
shown here:
+-------------------------+---------------------------+ | OCTET_LENGTH(_utf8 'A') | OCTET_LENGTH(_utf8 'ペ') | +-------------------------+---------------------------+ | 1 | 3 | +-------------------------+---------------------------+ 1 row in set (0.00 sec)
If we don't know where the first character ends, then we
don't know where the second character begins, in which case
even very simple searches such as LIKE
'_A%' fail. The solution is to use a regular CJK
character set in the first place, or to convert to a CJK
character set before comparing.
This is one reason why MySQL cannot allow encodings of nonexistent characters. If it is not strict about rejecting bad input, then it has no way of knowing where characters end.
For FULLTEXT searches, we need to know
where words begin and end. With Western languages, this is
rarely a problem because most (if not all) of these use an
easy-to-identify word boundary — the space character.
However, this is not usually the case with Asian writing. We
could use arbitrary halfway measures, like assuming that all
Han characters represent words, or (for Japanese) depending
on changes from Katakana to Hiragana due to grammatical
endings. However, the only sure solution requires a
comprehensive word list, which means that we would have to
include a dictionary in the server for each Asian language
supported. This is simply not feasible.
26.11.13: What CJK character sets are available in MySQL?
The list of CJK character sets may vary depending on your
MySQL version. For example, the eucjpms
character set was not supported prior to MySQL 5.0.3 (see
Section E.1.27, “Changes in release 5.0.3 (23 March 2005: Beta)”). However, since the name of
the applicable language appears in the
DESCRIPTION column for every entry in the
INFORMATION_SCHEMA.CHARACTER_SETS table,
you can obtain a current list of all the non-Unicode CJK
character sets using this query:
mysql>SELECT CHARACTER_SET_NAME, DESCRIPTION->FROM INFORMATION_SCHEMA.CHARACTER_SETS->WHERE DESCRIPTION LIKE '%Chinese%'->OR DESCRIPTION LIKE '%Japanese%'->OR DESCRIPTION LIKE '%Korean%'->ORDER BY CHARACTER_SET_NAME;+--------------------+---------------------------+ | CHARACTER_SET_NAME | DESCRIPTION | +--------------------+---------------------------+ | big5 | Big5 Traditional Chinese | | cp932 | SJIS for Windows Japanese | | eucjpms | UJIS for Windows Japanese | | euckr | EUC-KR Korean | | gb2312 | GB2312 Simplified Chinese | | gbk | GBK Simplified Chinese | | sjis | Shift-JIS Japanese | | ujis | EUC-JP Japanese | +--------------------+---------------------------+ 8 rows in set (0.01 sec)
(See Section 20.9, “The INFORMATION_SCHEMA CHARACTER_SETS Table”, for more
information.)
26.11.14:
How do I know whether character X
is available in all character sets?
The majority of simplified Chinese and basic non-halfwidth
Japanese Kana characters
appear in all CJK character sets. This stored procedure
accepts a UCS-2 Unicode character,
converts it to all other character sets, and displays the
results in hexadecimal.
DELIMITER //
CREATE PROCEDURE p_convert(ucs2_char CHAR(1) CHARACTER SET ucs2)
BEGIN
CREATE TABLE tj
(ucs2 CHAR(1) character set ucs2,
utf8 CHAR(1) character set utf8,
big5 CHAR(1) character set big5,
cp932 CHAR(1) character set cp932,
eucjpms CHAR(1) character set eucjpms,
euckr CHAR(1) character set euckr,
gb2312 CHAR(1) character set gb2312,
gbk CHAR(1) character set gbk,
sjis CHAR(1) character set sjis,
ujis CHAR(1) character set ujis);
INSERT INTO tj (ucs2) VALUES (ucs2_char);
UPDATE tj SET utf8=ucs2,
big5=ucs2,
cp932=ucs2,
eucjpms=ucs2,
euckr=ucs2,
gb2312=ucs2,
gbk=ucs2,
sjis=ucs2,
ujis=ucs2;
/* If there's a conversion problem, UPDATE will produce a warning. */
SELECT hex(ucs2) AS ucs2,
hex(utf8) AS utf8,
hex(big5) AS big5,
hex(cp932) AS cp932,
hex(eucjpms) AS eucjpms,
hex(euckr) AS euckr,
hex(gb2312) AS gb2312,
hex(gbk) AS gbk,
hex(sjis) AS sjis,
hex(ujis) AS ujis
FROM tj;
DROP TABLE tj;
END//
The input can be any single ucs2
character, or it can be the code point value (hexadecimal
representation) of that character. For example, from
Unicode's list of ucs2 encodings and
names
(http://www.unicode.org/Public/UNIDATA/UnicodeData.txt),
we know that the Katakana
character Pe appears in all
CJK character sets, and that its code point value is
0x30da. If we use this value as the
argument to p_convert(), the result is as
shown here:
mysql> CALL p_convert(0x30da)//
+------+--------+------+-------+---------+-------+--------+------+------+------+
| ucs2 | utf8 | big5 | cp932 | eucjpms | euckr | gb2312 | gbk | sjis | ujis |
+------+--------+------+-------+---------+-------+--------+------+------+------+
| 30DA | E3839A | C772 | 8379 | A5DA | ABDA | A5DA | A5DA | 8379 | A5DA |
+------+--------+------+-------+---------+-------+--------+------+------+------+
1 row in set (0.04 sec)
Since none of the column values is 3F
— that is, the question mark character
(?) — we know that every conversion
worked.
26.11.15: Why don't CJK strings sort correctly in Unicode? (I)
Sometimes people observe that the result of a
utf8_unicode_ci or
ucs2_unicode_ci search, or of an
ORDER BY sort is not what they think a
native would expect. Although we never rule out the
possibility that there is a bug, we have found in the past
that many people do not read correctly the standard table of
weights for the Unicode Collation Algorithm. MySQL uses the
table found at
http://www.unicode.org/Public/UCA/4.0.0/allkeys-4.0.0.txt.
This is not the first table you will find by navigating from
the unicode.org home page, because MySQL
uses the older 4.0.0 “allkeys” table, rather
than the more recent 4.1.0 table. This is because we are
very wary about changing ordering which affects indexes,
lest we bring about situations such as that reported in Bug#16526, illustrated as follows:
mysql<CREATE TABLE tj (s1 CHAR(1) CHARACTER SET utf8 COLLATE utf8_unicode_ci);Query OK, 0 rows affected (0.05 sec) mysql>INSERT INTO tj VALUES ('が'),('か');Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql>SELECT * FROM tj WHERE s1 = 'か';+------+ | s1 | +------+ | が | | か | +------+ 2 rows in set (0.00 sec)
The character in the first result row is not the one that we
searched for. Why did MySQL retrieve it? First we look for
the Unicode code point value, which is possible by reading
the hexadecimal number for the ucs2
version of the characters:
mysql> SELECT s1, HEX(CONVERT(s1 USING ucs2)) FROM tj;
+------+-----------------------------+
| s1 | HEX(CONVERT(s1 USING ucs2)) |
+------+-----------------------------+
| が | 304C |
| か | 304B |
+------+-----------------------------+
2 rows in set (0.03 sec)
Now we search for 304B and
304C in the 4.0.0
allkeys table, and find these lines:
304B ; [.1E57.0020.000E.304B] # HIRAGANA LETTER KA 304C ; [.1E57.0020.000E.304B][.0000.0140.0002.3099] # HIRAGANA LETTER GA; QQCM
The official Unicode names (following the “#”
mark) tell us the Japanese syllabary (Hiragana), the
informal classification (letter, digit, or punctuation
mark), and the Western identifier (KA or
GA, which happen to be voiced and
unvoiced components of the same letter pair). More
importantly, the primary weight (the
first hexadecimal number inside the square brackets) is
1E57 on both lines. For comparisons in
both searching and sorting, MySQL pays attention to the
primary weight only, ignoring all the other numbers. This
means that we are sorting が and
か correctly according to the Unicode
specification. If we wanted to distinguish them, we'd have
to use a non-UCA (Unicode Collation Algorithm) collation
(utf8_unicode_bin or
utf8_general_ci), or to compare the
HEX() values, or use ORDER BY
CONVERT(s1 USING sjis). Being correct
“according to Unicode” isn't enough, of course:
the person who submitted the bug was equally correct. We
plan to add another collation for Japanese according to the
JIS X 4061 standard, in which voiced/unvoiced letter pairs
like KA/GA are
distinguishable for ordering purposes.
26.11.16: Why don't CJK strings sort correctly in Unicode? (II)
If you are using Unicode (ucs2 or
utf8), and you know what the Unicode sort
order is (see Section A.11, “MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean
Character Sets”), but MySQL still
seems to sort your table incorrectly, then you should first
verify the table character set:
mysql> SHOW CREATE TABLE t\G
******************** 1. row ******************
Table: t
Create Table: CREATE TABLE `t` (
`s1` char(1) CHARACTER SET ucs2 DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
Since the character set appears to be correct, let's see
what information the
INFORMATION_SCHEMA.COLUMNS table can
provide about this column:
mysql>SELECT COLUMN_NAME, CHARACTER_SET_NAME, COLLATION_NAME->FROM INFORMATION_SCHEMA.COLUMNS->WHERE COLUMN_NAME = 's1'->AND TABLE_NAME = 't';+-------------+--------------------+-----------------+ | COLUMN_NAME | CHARACTER_SET_NAME | COLLATION_NAME | +-------------+--------------------+-----------------+ | s1 | ucs2 | ucs2_general_ci | +-------------+--------------------+-----------------+ 1 row in set (0.01 sec)
(See Section 20.3, “The INFORMATION_SCHEMA COLUMNS Table”, for more information.)
You can see that the collation is
ucs2_general_ci instead of
ucs2_unicode_ci. The reason why this is
so can be found using SHOW CHARSET, as
shown here:
mysql> SHOW CHARSET LIKE 'ucs2%';
+---------+---------------+-------------------+--------+
| Charset | Description | Default collation | Maxlen |
+---------+---------------+-------------------+--------+
| ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 |
+---------+---------------+-------------------+--------+
1 row in set (0.00 sec)
For ucs2 and utf8, the
default collation is “general”. To specify a
Unicode collation, use COLLATE
ucs2_unicode_ci.
26.11.17: Why are my supplementary characters rejected by MySQL?
MySQL does not support supplementary characters — that
is, characters which need more than 3 bytes — for
UTF-8. We support only what Unicode calls
the Basic Multilingual Plane / Plane 0.
Only a few very rare Han characters are supplementary;
support for them is uncommon. This has led to reports such
as that found in Bug#12600, which we rejected as “not
a bug”. With utf8, we must
truncate an input string when we encounter bytes that we
don't understand. Otherwise, we wouldn't know how long the
bad multi-byte character is.
One possible workaround is to use ucs2
instead of utf8, in which case the
“bad” characters are changed to question marks;
however, no truncation takes place. You can also change the
data type to BLOB or
BINARY, which perform no validity
checking.
We intend at some point in the future to add support for
UTF-16, which would solve such issues by
allowing 4-byte characters. However, we have as yet set no
definite timetable for doing so.
26.11.18: Shouldn't it be “CJKV”?
No. The term “CJKV” (Chinese Japanese Korean Vietnamese) refers to Vietnamese character sets which contain Han (originally Chinese) characters. MySQL has no plan to support the old Vietnamese script using Han characters. MySQL does of course support the modern Vietnamese script with Western characters.
Bug#4745 is a request for a specialized Vietnamese collation, which we might add in the future if there is sufficient demand for it.
26.11.19: Does MySQL allow CJK characters to be used in database and table names?
This issue is fixed in MySQL 5.1, by automatically rewriting the names of the corresponding directories and files.
For example, if you create a database named
楮 on a server whose operating system
does not support CJK in directory names, MySQL creates a
directory named @0w@00a5@00ae. which is
just a fancy way of encoding E6A5AE
— that is, the Unicode hexadecimal representation for
the 楮 character. However, if you run a
SHOW DATABASES statement, you can see
that the database is listed as 楮.
26.11.20: Where can I find translations of the MySQL Manual into Chinese, Japanese, and Korean?
A Simplified Chinese version of the Manual, current for MySQL 5.1.12, can be found at http://dev.mysql.com/doc/#chinese-5.1. The Japanese translation of the MySQL 4.1 manual can be downloaded from http://dev.mysql.com/doc/#japanese-4.1.
26.11.21: Where can I get help with CJK and related issues in MySQL?
The following resources are available:
A listing of MySQL user groups can be found at http://dev.mysql.com/user-groups/.
You can contact a sales engineer at the MySQL KK Japan office using any of the following:
Tel: +81(0)3-5326-3133 Fax: +81(0)3-5326-3001 Email: dsaito@mysql.com
View feature requests relating to character set issues at http://tinyurl.com/y6xcuf.
Visit the MySQL Character Sets, Collation, Unicode Forum. We are also in the process of adding foreign-language forums at http://forums.mysql.com/.
For common questions, issues, and answers relating to the MySQL Connectors and other APIs, see the following areas of the Manual:
For answers to common queries and question regarding Replication within MySQL, see Section 6.10, “Replication FAQ”.
- A.14.1. Distributed Replicated Block Device
- A.14.2. Linux Heartbeat
- A.14.3. DRBD Architecture
- A.14.4. DRBD and MySQL Replication
- A.14.5. DRBD and File Systems
- A.14.6. DRBD and LVM
- A.14.7. DRBD and Virtualization
- A.14.8. DRBD and Security
- A.14.9. DRBD and System Requirements
- A.14.10. DBRD and Support and Consulting
In the following section, we provide answers to questions that are most frequently asked about Distributed Replicated Block Device (DRBD).
Questions
26.14.1.1: What is DRBD?
26.14.1.2: What are “Block Devices”?
26.14.1.3: How is DRBD licensed?
26.14.1.4: Where can I download DRBD?
26.14.1.5: If I find a bug in DRBD, to whom do I submit the issue?
26.14.1.6: Where can I get more technical and business information concerning MySQL and DRBD?
Questions and Answers
DRBD is an acronym for Distributed Replicated Block Device. DRBD is an open source Linux kernel block device which leverages synchronous replication to achieve a consistent view of data between two systems, typically an Active and Passive system. DRBD currently supports all the major flavors of Linux and comes bundled in several major Linux distributions. The DRBD project is maintained by LINBIT.
26.14.1.2: What are “Block Devices”?
Block devices are the type of device used to represent storage in the Linux Kernel. All physical disk devices present a “block device” interface. Additionally, virtual disk systems like LVM or DRBD present a “block device” interface. In this way, the file system or other software that might want to access a disk device can be used with any number of real or virtual devices without having to know anything about their underlying implementation details.
26.14.1.3: How is DRBD licensed?
DRBD is licensed under the GPL.
26.14.1.4: Where can I download DRBD?
Please see http://www.drbd.org/download.html
26.14.1.5: If I find a bug in DRBD, to whom do I submit the issue?
Bug reports should be submitted to the DRBD mailing list. Please see: http://lists.linbit.com/ .
26.14.1.6: Where can I get more technical and business information concerning MySQL and DRBD?
Please visit: http://mysql.com/drbd/
In the following section, we provide answers to questions that are most frequently asked about Linux Heartbeat.
Questions
26.14.2.1: What is Linux Heartbeat?
26.14.2.2: How is Linux Heartbeat licensed?
26.14.2.3: Where can I download Linux Heartbeat?
26.14.2.4: If I find a bug with Linux Heartbeat, to whom do I submit the issue?
Questions and Answers
26.14.2.1: What is Linux Heartbeat?
The Linux-HA project (http://www.linux-ha.org/) offers a high availability solution commonly referred to as Linux Heartbeat. Linux Heartbeat ships as part of several Linux distributions, as well as within several embedded high availability systems. This solution can also be used for other applications besides databases servers, such as mail servers, web servers, file servers, and DNS servers.
Linux Heartbeat implements a heartbeat-protocol. A heartbeat-protocol means that messages are sent at regular intervals between two or more nodes. If a message is not received from a node within a given interval, then it is assumed the node has failed and some type of failover or recovery action is required. Linux Heartbeat is typically configured to send these heartbeat messages over standard Ethernet interfaces, but it does also support other methods, such as serial-line links.
26.14.2.2: How is Linux Heartbeat licensed?
Linux Heartbeat is licensed under the GPL.
26.14.2.3: Where can I download Linux Heartbeat?
Please see http://linux-ha.org/download/index.html.
26.14.2.4: If I find a bug with Linux Heartbeat, to whom do I submit the issue?
Bug reports should be submitted to http://www.linux-ha.org/ClusterResourceManager/BugReports.
In the following section, we provide answers to questions that are most frequently asked about DRBD Architecture.
Questions
26.14.3.1: Is an Active/Active option available for MySQL with DRBD?
26.14.3.2: What MySQL storage engines are supported with DRBD?
26.14.3.3: How long does a failover take?
26.14.3.4: How long does it take to resynchronize data after a failure?
Questions and Answers
26.14.3.1: Is an Active/Active option available for MySQL with DRBD?
Currently, MySQL does not support Active/Active configurations using DRBD “out of the box”.
26.14.3.2: What MySQL storage engines are supported with DRBD?
All of the MySQL transactional storage engines are supported by DRBD, including InnoDB and Falcon. For archived or read-only data, MyISAM or Archive can also be used.
26.14.3.3: How long does a failover take?
Failover time is dependent on many things, some of which are configurable. After activating the passive host, MySQL will have to start and run a normal recovery process. If the InnoDB log files have been configured to a large size and there was heavy write traffic, this may take a reasonably long period of time. However, under normal circumstances, failover tends to take less than a minute.
26.14.3.4: How long does it take to resynchronize data after a failure?
Resynchronization time depends on how long the two machines are out of communication and how much data was written during that period of time. Resynchronization time is a function of data to be synced, network speed and disk speed. DRBD maintains a bitmap of changed blocks on the primary machine, so only those blocks that have changed will need to be transferred.
In the following section, we provide answers to questions that are most frequently asked about MySQL Replication Scale-out.
Questions
26.14.4.1: What is the difference between MySQL Cluster and DRBD?
26.14.4.2: What is the difference between MySQL Replication and DRBD?
26.14.4.3: How can I combine MySQL Replication scale-out with DRBD?
Questions and Answers
26.14.4.1: What is the difference between MySQL Cluster and DRBD?
Both MySQL Cluster and DRBD replicate data synchronously. MySQL Cluster leverages a shared-nothing storage architecture in which the cluster can be architected beyond an Active/Passive configuration. DRBD operates at a much lower level within the “stack”, at the disk I/O level. For a comparison of various high availability features between these two options, please refer to Figure A.1, “Availability comparison”.
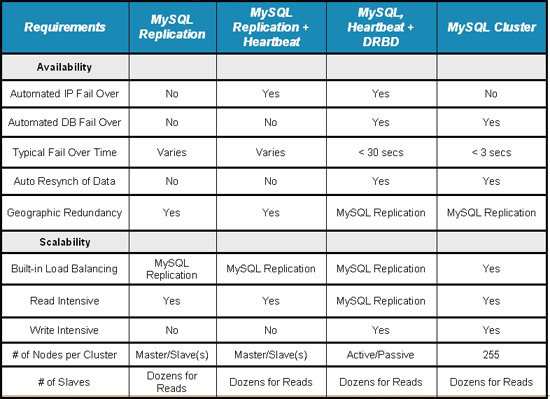
26.14.4.2: What is the difference between MySQL Replication and DRBD?
MySQL Replication replicates data asynchronously while DRBD replicates data synchronously. For a comparison of various high availability features between these two options, please refer to the high availability comparison grid, Figure A.1, “Availability comparison”.
26.14.4.3: How can I combine MySQL Replication scale-out with DRBD?
MySQL Replication is typically deployed in a Master to many Slaves configuration. In this configuration, having many Slaves provides read scalability. DRBD is used to provide high-availability for the Master MySQL Server in an Active/Passive configuration. This provides for automatic failover, safeguards against data loss, and automatically synchronizes the failed MySQL Master after a failover.
The most likely scenario in which MySQL Replication scale-out can be leveraged with DRBD is in the form of attaching replicated MySQL “read-slaves” off of the Active-Master MySQL Server, shown in Figure A.2, “Active-Master MySQL server”. Since DRBD replicates an entire block device, master information such as the binary logs are also replicated. In this way, all of the slaves can attach to the Virtual IP Address managed by Linux Heartbeat. In the event of a failure, the asynchronous nature of MySQL Replication allows the slaves to continue with the new Active machine as their master with no intervention needed.
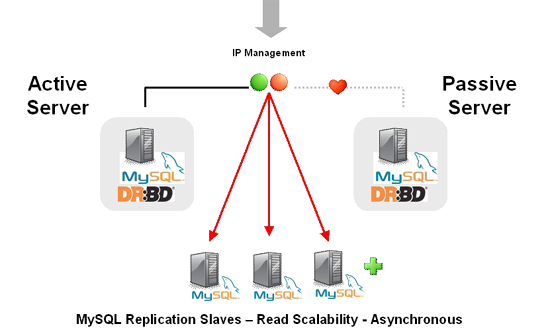
In the following section, we provide answers to questions that are most frequently asked about DRBD and file systems.
Questions
26.14.5.1: Can XFS be used with DRBD?
Questions and Answers
26.14.5.1: Can XFS be used with DRBD?
Yes. XFS uses dynamic block size, thus DRBD 0.7 or later is needed.
In the following section, we provide answers to questions that are most frequently asked about DRBD and LVM.
Questions
26.14.6.1: Can I use DRBD on top of LVM?
26.14.6.2: Can I use LVM on top of DRBD?
26.14.6.3: Can I use DRBD on top of LVM while at the same time running LVM on top of that DRBD?
Questions and Answers
26.14.6.1: Can I use DRBD on top of LVM?
Yes, DRBD supports on-line resizing. If you enlarge your logical volume that acts as a backing device for DRBD, you can enlarge DRBD itself too, and of course your file system if it supports resizing.
26.14.6.2: Can I use LVM on top of DRBD?
Yes, you can use DRBD as a Physical Volume (PV) for LVM.
Depending on the default LVM configuration shipped with
your distribution, you may need to add the
/dev/drbd* device files to the
filter option in your
lvm.conf so LVM scans your DRBDs for
PV signatures.
26.14.6.3: Can I use DRBD on top of LVM while at the same time running LVM on top of that DRBD?
This requires careful tuning of your LVM configuration to avoid duplicate PV scans, but yes, it is possible.
In the following section, we provide answers to questions that are most frequently asked about DRBD and virtualization.
Questions
26.14.7.1: Can I use DRBD with OpenVZ?
26.14.7.2: Can I use DRBD with Xen and/or KVM?
Questions and Answers
26.14.7.1: Can I use DRBD with OpenVZ?
See http://wiki.openvz.org/HA_cluster_with_DRBD_and_Heartbeat.
26.14.7.2: Can I use DRBD with Xen and/or KVM?
Yes. If you are looking for professional consultancy or expert commercial support for Xen- or KVM-based virtualization clusters with DRBD, contact LINBIT (http://www.linbit.com).
In the following section, we provide answers to questions that are most frequently asked about DRBD and security.
Questions
26.14.8.1: Can I encrypt/compress the exchanged data?
26.14.8.2: Does DRBD do mutual node authentication?
Questions and Answers
26.14.8.1: Can I encrypt/compress the exchanged data?
Yes. But there is no option within DRBD to allow for this. You’ll need to leverage a VPN and the network layer should do the rest.
26.14.8.2: Does DRBD do mutual node authentication?
Yes, starting with DRBD 8 shared-secret mutual node authentication is supported.
In the following section, we provide answers to questions that are most frequently asked about DRBD and System Requirements.
Questions
26.14.9.1: What other packages besides DRBD are required?
26.14.9.2: How many machines are required to set up DRBD?
26.14.9.3: Does DRBD only run on Linux?
Questions and Answers
26.14.9.1: What other packages besides DRBD are required?
When using pre-built binary packages, none except a
matching kernel, plus packages for
glibc and your favorite shell. When
compiling DRBD from source additional prerequisite
packages may be required. They include but are not limited
to:
glib-devel
openssl
devel
libgcrypt-devel
glib2-devel
pkgconfig
ncurses-devel
rpm-build
rpm-devel
redhat-rpm-config
gcc
gcc-c++
bison
flex
gnutls-devel
lm_sensors-devel
net-snmp-devel
python-devel
bzip2-devel
libselinux-devel
perl-DBI
libnet
Pre-built x86 and x86_64 packages for specific kernel versions are available with a support subscription from LINBIT. Please note that if the kernel is upgraded, DRBD must be as well.
26.14.9.2: How many machines are required to set up DRBD?
Two machines are required to achieve the minimum degree of high availability. Although at any one given point in time one will be primary and one will be secondary, it is better to consider the machines as part of a mirrored pair without a “natural” primary machine.
26.14.9.3: Does DRBD only run on Linux?
DRBD is a Linux Kernel Module, and can work with many popular Linux distributions. DRBD is currently not available for non-Linux operating systems.
In the following section, we provide answers to questions that are most frequently asked about DRBD and resources.
Questions
26.14.10.1: Does MySQL offer professional consulting to help with designing a DRBD system?
26.14.10.2: Does MySQL offer support for DRBD and Linux Heartbeat from MySQL?
26.14.10.3: Are pre-built binaries or RPMs available?
26.14.10.4: Does MySQL have documentation to help me with the installation and configuration of DRBD and Linux Heartbeat?
26.14.10.5: Is there a dedicated discussion forum for MySQL High-Availability?
26.14.10.6: Where can I get more information about MySQL for DRBD?
Questions and Answers
26.14.10.1: Does MySQL offer professional consulting to help with designing a DRBD system?
Yes. MySQL offers consulting for the design, installation, configuration, and monitoring of high availability DRBD. For more information concerning a High Availability Jumpstart, please see: http://www.mysql.com/consulting/packaged/scaleout.html.
26.14.10.2: Does MySQL offer support for DRBD and Linux Heartbeat from MySQL?
Yes. Support for DRBD is available with an add-on subscription to MySQL Enterprise called “DRBD for MySQL”. For more information about support options for DRBD see: http://mysql.com/products/enterprise/features.html.
For the list of supported Linux distributions, please see: http://www.mysql.com/support/supportedplatforms/enterprise.html.
NOTE: DRBD is only available on Linux. DRBD is not available on Windows, MacOS, Solaris, HPUX, AIX, FreeBSD, or other non-Linux platforms.
26.14.10.3: Are pre-built binaries or RPMs available?
Yes. “DRBD for MySQL” is an add-on subscription to MySQL Enterprise, which provides pre-built binaries for DRBD. For more information see: http://mysql.com/products/enterprise/features.html.
26.14.10.4: Does MySQL have documentation to help me with the installation and configuration of DRBD and Linux Heartbeat?
Coming soon.
26.14.10.5: Is there a dedicated discussion forum for MySQL High-Availability?
Yes, http://forums.mysql.com/list.php?144.
26.14.10.6: Where can I get more information about MySQL for DRBD?
For more information about MySQL for DRBD, including a technical white paper please see: DRBD for MySQL High Availability.
Table of Contents
This appendix lists common problems and errors that may occur and potential resolutions, in addition to listing the errors that may appear when you call MySQL from any host language. The first section covers problems and resolutions. Detailed information on errors is provided; The first list displays server error messages. The second list displays client program messages.
MySQL Enterprise The MySQL Network Monitoring and Advisory Service provides a “Virtual DBA” to assist with problem solving. For more information see http://www.mysql.com/products/enterprise/advisors.html.
This section lists some common problems and error messages that you may encounter. It describes how to determine the causes of the problems and what to do to solve them.
When you run into a problem, the first thing you should do is to find out which program or piece of equipment is causing it:
If you have one of the following symptoms, then it is probably a hardware problems (such as memory, motherboard, CPU, or hard disk) or kernel problem:
The keyboard doesn't work. This can normally be checked by pressing the Caps Lock key. If the Caps Lock light doesn't change, you have to replace your keyboard. (Before doing this, you should try to restart your computer and check all cables to the keyboard.)
The mouse pointer doesn't move.
The machine doesn't answer to a remote machine's pings.
Other programs that are not related to MySQL don't behave correctly.
Your system restarted unexpectedly. (A faulty user-level program should never be able to take down your system.)
In this case, you should start by checking all your cables and run some diagnostic tool to check your hardware! You should also check whether there are any patches, updates, or service packs for your operating system that could likely solve your problem. Check also that all your libraries (such as
glibc) are up to date.It's always good to use a machine with ECC memory to discover memory problems early.
If your keyboard is locked up, you may be able to recover by logging in to your machine from another machine and executing
kbd_mode -a.Please examine your system log file (
/var/log/messagesor similar) for reasons for your problem. If you think the problem is in MySQL, you should also examine MySQL's log files. See Section 5.11, “MySQL Server Logs”.If you don't think you have hardware problems, you should try to find out which program is causing problems. Try using top, ps, Task Manager, or some similar program, to check which program is taking all CPU or is locking the machine.
Use top, df, or a similar program to check whether you are out of memory, disk space, file descriptors, or some other critical resource.
If the problem is some runaway process, you can always try to kill it. If it doesn't want to die, there is probably a bug in the operating system.
If after you have examined all other possibilities and you have concluded that the MySQL server or a MySQL client is causing the problem, it's time to create a bug report for our mailing list or our support team. In the bug report, try to give a very detailed description of how the system is behaving and what you think is happening. You should also state why you think that MySQL is causing the problem. Take into consideration all the situations in this chapter. State any problems exactly how they appear when you examine your system. Use the “copy and paste” method for any output and error messages from programs and log files.
Try to describe in detail which program is not working and all symptoms you see. We have in the past received many bug reports that state only “the system doesn't work.” This doesn't provide us with any information about what could be the problem.
If a program fails, it's always useful to know the following information:
Has the program in question made a segmentation fault (did it dump core)?
Is the program taking up all available CPU time? Check with top. Let the program run for a while, it may simply be evaluating something computationally intensive.
If the mysqld server is causing problems, can you get any response from it with mysqladmin -u root ping or mysqladmin -u root processlist?
What does a client program say when you try to connect to the MySQL server? (Try with mysql, for example.) Does the client jam? Do you get any output from the program?
When sending a bug report, you should follow the outline described in Section 1.8, “How to Report Bugs or Problems”.
- B.1.2.1.
Access denied - B.1.2.2.
Can't connect to [local] MySQL server - B.1.2.3.
Client does not support authentication protocol - B.1.2.4. Password Fails When Entered Interactively
- B.1.2.5.
Host 'host_name' is blocked - B.1.2.6.
Too many connections - B.1.2.7.
Out of memory - B.1.2.8.
MySQL server has gone away - B.1.2.9.
Packet too large - B.1.2.10. Communication Errors and Aborted Connections
- B.1.2.11.
The table is full - B.1.2.12.
Can't create/write to file - B.1.2.13.
Commands out of sync - B.1.2.14.
Ignoring user - B.1.2.15.
Table 'tbl_name' doesn't exist - B.1.2.16.
Can't initialize character set - B.1.2.17. '
File' Not Found and Similar Errors
This section lists some errors that users frequently encounter when running MySQL programs. Although the problems show up when you try to run client programs, the solutions to many of the problems involves changing the configuration of the MySQL server.
An Access denied error can have many
causes. Often the problem is related to the MySQL accounts
that the server allows client programs to use when connecting.
See Section 5.7.8, “Causes of Access denied Errors”, and
Section 5.7.2, “How the Privilege System Works”.
A MySQL client on Unix can connect to the
mysqld server in two different ways: By
using a Unix socket file to connect through a file in the
filesystem (default /tmp/mysql.sock), or
by using TCP/IP, which connects through a port number. A Unix
socket file connection is faster than TCP/IP, but can be used
only when connecting to a server on the same computer. A Unix
socket file is used if you don't specify a hostname or if you
specify the special hostname localhost.
If the MySQL server is running on Windows, you can connect via
TCP/IP. If the server is started with the
--enable-named-pipe option, you can also
connect with named pipes if you run the client on the host
where the server is running. The name of the named pipe is
MySQL by default. If you don't give a
hostname when connecting to mysqld, a MySQL
client first tries to connect to the named pipe. If that
doesn't work, it connects to the TCP/IP port. You can force
the use of named pipes on Windows by using
. as the hostname.
The error (2002) Can't connect to ...
normally means that there is no MySQL server running on the
system or that you are using an incorrect Unix socket filename
or TCP/IP port number when trying to connect to the server.
The error (2003) Can't connect to MySQL server on
'
indicates that the network connection has been refused. You
should check that there is a MySQL server running, that it has
network connections enabled, the network port you specified is
the one configured on the server, and that the TCP/IP port you
are using has not been blocked by a firewall or port blocking
service.
server' (10061)
Start by checking whether there is a process named mysqld running on your server host. (Use ps xa | grep mysqld on Unix or the Task Manager on Windows.) If there is no such process, you should start the server. See Section 2.4.15.2.3, “Starting and Troubleshooting the MySQL Server”.
If a mysqld process is running, you can
check it by trying the following commands. The port number or
Unix socket filename might be different in your setup.
host_ip represents the IP number of the
machine where the server is running.
shell>mysqladmin versionshell>mysqladmin variablesshell>mysqladmin -h `hostname` version variablesshell>mysqladmin -h `hostname` --port=3306 versionshell>mysqladmin -h host_ip versionshell>mysqladmin --protocol=socket --socket=/tmp/mysql.sock version
Note the use of backticks rather than forward quotes with the
hostname command; these cause the output of
hostname (that is, the current hostname) to
be substituted into the mysqladmin command.
If you have no hostname command or are
running on Windows, you can manually type the hostname of your
machine (without backticks) following the
-h option. You can also try -h
127.0.0.1 to connect with TCP/IP to the local host.
Here are some reasons the Can't connect to local
MySQL server error might occur:
mysqld is not running. Check your operating system's process list to ensure the mysqld process is present.
You're running a MySQL server on Windows with many TCP/IP connections to it. If you're experiencing that quite often your clients get that error, you can find a workaround here: Section B.1.2.2.1, “
Connection to MySQL Server Failing on Windows”.You are running on a system that uses MIT-pthreads. If you are running on a system that doesn't have native threads, mysqld uses the MIT-pthreads package. See Section 2.4.2, “Operating Systems Supported by MySQL Community Server”. However, not all MIT-pthreads versions support Unix socket files. On a system without socket file support, you must always specify the hostname explicitly when connecting to the server. Try using this command to check the connection to the server:
shell>
mysqladmin -h `hostname` versionSomeone has removed the Unix socket file that mysqld uses (
/tmp/mysql.sockby default). For example, you might have a cron job that removes old files from the/tmpdirectory. You can always run mysqladmin version to check whether the Unix socket file that mysqladmin is trying to use really exists. The fix in this case is to change the cron job to not removemysql.sockor to place the socket file somewhere else. See Section B.1.4.5, “How to Protect or Change the MySQL Unix Socket File”.You have started the mysqld server with the
--socket=/path/to/socketoption, but forgotten to tell client programs the new name of the socket file. If you change the socket pathname for the server, you must also notify the MySQL clients. You can do this by providing the same--socketoption when you run client programs. You also need to ensure that clients have permission to access themysql.sockfile. To find out where the socket file is, you can do:shell>
netstat -ln | grep mysqlSee Section B.1.4.5, “How to Protect or Change the MySQL Unix Socket File”.
You are using Linux and one server thread has died (dumped core). In this case, you must kill the other mysqld threads (for example, with
killor with themysql_zapscript) before you can restart the MySQL server. See Section B.1.4.2, “What to Do If MySQL Keeps Crashing”.The server or client program might not have the proper access privileges for the directory that holds the Unix socket file or the socket file itself. In this case, you must either change the access privileges for the directory or socket file so that the server and clients can access them, or restart mysqld with a
--socketoption that specifies a socket filename in a directory where the server can create it and where client programs can access it.
If you get the error message Can't connect to MySQL
server on some_host, you can try the following
things to find out what the problem is:
Check whether the server is running on that host by executing
telnet some_host 3306and pressing the Enter key a couple of times. (3306 is the default MySQL port number. Change the value if your server is listening to a different port.) If there is a MySQL server running and listening to the port, you should get a response that includes the server's version number. If you get an error such astelnet: Unable to connect to remote host: Connection refused, then there is no server running on the given port.If the server is running on the local host, try using mysqladmin -h localhost variables to connect using the Unix socket file. Verify the TCP/IP port number that the server is configured to listen to (it is the value of the
portvariable.)Make sure that your mysqld server was not started with the
--skip-networkingoption. If it was, you cannot connect to it using TCP/IP.Check to make sure that there is no firewall blocking access to MySQL. Your firewall may be configured on the basis of the application being executed, or the post number used by MySQL for communication (3306 by default).
Under Linux or Unix, check your IP tables (or similar) configuration to ensure that the port has not been blocked.
Under Windows, applications such as ZoneAlarm and the Windows XP personal firewall may need to be configured to allow external access to a MySQL server.
If you are running under Linux and Security-Enhanced Linux (SELinux) is enabled, make sure you have disabled SELinux protection for the
mysqldprocess.
When you're running a MySQL server on Windows with many
TCP/IP connections to it, and you're experiencing that quite
often your clients get a Can't connect to MySQL
server error, the reason might be that Windows
doesn't allow for enough ephemeral (short-lived) ports to
serve those connections.
By default, Windows allows 5000 ephemeral (short-lived) TCP
ports to the user. After any port is closed it will remain
in a TIME_WAIT status for 120 seconds.
This status allows the connection to be reused at a much
lower cost than reinitializing a brand new connection.
However, the port will not be available again until this
time expires.
With a small stack of available TCP ports (5000) and a high
number of TCP ports being open and closed over a short
period of time along with the TIME_WAIT
status you have a good chance for running out of ports.
There are two ways to address this problem:
Reduce the number of TCP ports consumed quickly by investigating connection pooling or persistent connections where possible
Tune some settings in the Windows registry (see below)
IMPORTANT: The following procedure involves modifying the Windows registry. Before you modify the registry, make sure to back it up and make sure that you understand how to restore the registry if a problem occurs. For information about how to back up, restore, and edit the registry, view the following article in the Microsoft Knowledge Base: http://support.microsoft.com/kb/256986/EN-US/.
Start Registry Editor (
Regedt32.exe).Locate the following key in the registry:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters
On the
Editmenu, clickAdd Value, and then add the following registry value:Value Name: MaxUserPort Data Type: REG_DWORD Value: 65534
This sets the number of ephemeral ports available to any user. The valid range is between 5000 and 65534 (decimal). The default value is 0x1388 (5000 decimal).
On the
Editmenu, clickAdd Value, and then add the following registry value:Value Name: TcpTimedWaitDelay Data Type: REG_DWORD Value: 30
This sets the number of seconds to hold a TCP port connection in
TIME_WAITstate before closing. The valid range is between 0 (zero) and 300 (decimal). The default value is 0x78 (120 decimal).Quit Registry Editor.
Reboot the machine.
Note: Undoing the above should be as simple as deleting the registry entries you've created.
MySQL 5.0 uses an authentication protocol based on a password hashing algorithm that is incompatible with that used by older (pre-4.1) clients. If you upgrade the server from 4.0, attempts to connect to it with an older client may fail with the following message:
shell> mysql
Client does not support authentication protocol requested
by server; consider upgrading MySQL client
To solve this problem, you should use one of the following approaches:
Upgrade all client programs to use a 4.1.1 or newer client library.
When connecting to the server with a pre-4.1 client program, use an account that still has a pre-4.1-style password.
Reset the password to pre-4.1 style for each user that needs to use a pre-4.1 client program. This can be done using the
SET PASSWORDstatement and theOLD_PASSWORD()function:mysql>
SET PASSWORD FOR->'some_user'@'some_host' = OLD_PASSWORD('newpwd');Alternatively, use
UPDATEandFLUSH PRIVILEGES:mysql>
UPDATE mysql.user SET Password = OLD_PASSWORD('->newpwd')WHERE Host = 'mysql>some_host' AND User = 'some_user';FLUSH PRIVILEGES;Substitute the password you want to use for “
newpwd” in the preceding examples. MySQL cannot tell you what the original password was, so you'll need to pick a new one.Tell the server to use the older password hashing algorithm:
Start mysqld with the
--old-passwordsoption.Assign an old-format password to each account that has had its password updated to the longer 4.1 format. You can identify these accounts with the following query:
mysql>
SELECT Host, User, Password FROM mysql.user->WHERE LENGTH(Password) > 16;For each account record displayed by the query, use the
HostandUservalues and assign a password using theOLD_PASSWORD()function and eitherSET PASSWORDorUPDATE, as described earlier.
Note: In older versions of
PHP, the mysql extension does not support
the authentication protocol in MySQL 4.1.1 and higher. This is
true regardless of the PHP version being used. If you wish to
use the mysql extension with MySQL 4.1 or
newer, you may need to follow one of the options discussed
above for configuring MySQL to work with old clients. The
mysqli extension (stands for "MySQL,
Improved"; added in PHP 5) is compatible with the improved
password hashing employed in MySQL 4.1 and higher, and no
special configuration of MySQL need be done to use this MySQL
client library. For more information about the
mysqli extension, see
http://php.net/mysqli.
It may also be possible to compile the older
mysql extension against the new MySQL
client library. This is beyond the scope of this Manual;
consult the PHP documentation for more information. You also
be able to obtain assistance with these issues in our
MySQL with PHP
forum.
For additional background on password hashing and authentication, see Section 5.7.9, “Password Hashing as of MySQL 4.1”.
MySQL client programs prompt for a password when invoked with
a --password or -p option
that has no following password value:
shell> mysql -u user_name -p
Enter password:
On some systems, you may find that your password works when
specified in an option file or on the command line, but not
when you enter it interactively at the Enter
password: prompt. This occurs when the library
provided by the system to read passwords limits password
values to a small number of characters (typically eight). That
is a problem with the system library, not with MySQL. To work
around it, change your MySQL password to a value that is eight
or fewer characters long, or put your password in an option
file.
If you get the following error, it means that
mysqld has received many connect requests
from the host
' that
have been interrupted in the middle:
host_name'
Host 'host_name' is blocked because of many connection errors.
Unblock with 'mysqladmin flush-hosts'
The number of interrupted connect requests allowed is
determined by the value of the
max_connect_errors system variable. After
max_connect_errors failed requests,
mysqld assumes that something is wrong (for
example, that someone is trying to break in), and blocks the
host from further connections until you execute a
mysqladmin flush-hosts command or issue a
FLUSH HOSTS statement. See
Section 5.2.3, “System Variables”.
By default, mysqld blocks a host after 10 connection errors. You can adjust the value by starting the server like this:
shell> mysqld_safe --max_connect_errors=10000 &
If you get this error message for a given host, you should
first verify that there isn't anything wrong with TCP/IP
connections from that host. If you are having network
problems, it does you no good to increase the value of the
max_connect_errors variable.
If you get a Too many connections error
when you try to connect to the mysqld
server, this means that all available connections are in use
by other clients.
The number of connections allowed is controlled by the
max_connections system variable. Its
default value is 100. If you need to support more connections,
you should restart mysqld with a larger
value for this variable.
MySQL Enterprise
Subscribers to the MySQL Network Monitoring and Advisory
Service receive advice on dynamically configuring the
max_connections variable — avoiding
failed connection attempts. For more information see
http://www.mysql.com/products/enterprise/advisors.html.
mysqld actually allows
max_connections+1 clients to connect. The
extra connection is reserved for use by accounts that have the
SUPER privilege. By granting the
SUPER privilege to administrators and not
to normal users (who should not need it), an administrator can
connect to the server and use SHOW
PROCESSLIST to diagnose problems even if the maximum
number of unprivileged clients are connected. See
Section 13.5.4.21, “SHOW PROCESSLIST Syntax”.
The maximum number of connections MySQL can support depends on the quality of the thread library on a given platform. Linux or Solaris should be able to support 500-1000 simultaneous connections, depending on how much RAM you have and what your clients are doing. Static Linux binaries provided by MySQL AB can support up to 4000 connections.
If you issue a query using the mysql client program and receive an error like the following one, it means that mysql does not have enough memory to store the entire query result:
mysql: Out of memory at line 42, 'malloc.c' mysql: needed 8136 byte (8k), memory in use: 12481367 bytes (12189k) ERROR 2008: MySQL client ran out of memory
To remedy the problem, first check whether your query is
correct. Is it reasonable that it should return so many rows?
If not, correct the query and try again. Otherwise, you can
invoke mysql with the
--quick option. This causes it to use the
mysql_use_result() C API function to
retrieve the result set, which places less of a load on the
client (but more on the server).
This section also covers the related Lost connection
to server during query error.
The most common reason for the MySQL server has gone
away error is that the server timed out and closed
the connection. In this case, you normally get one of the
following error codes (which one you get is operating
system-dependent):
| Error Code | Description |
CR_SERVER_GONE_ERROR | The client couldn't send a question to the server. |
CR_SERVER_LOST | The client didn't get an error when writing to the server, but it didn't get a full answer (or any answer) to the question. |
By default, the server closes the connection after eight hours
if nothing has happened. You can change the time limit by
setting the wait_timeout variable when you
start mysqld. See
Section 5.2.3, “System Variables”.
If you have a script, you just have to issue the query again
for the client to do an automatic reconnection. This assumes
that you have automatic reconnection in the client enabled
(which is the default for the mysql
command-line client).
Some other common reasons for the MySQL server has
gone away error are:
You (or the db administrator) has killed the running thread with a
KILLstatement or a mysqladmin kill command.You tried to run a query after closing the connection to the server. This indicates a logic error in the application that should be corrected.
A client application running on a different host does not have the necessary privileges to connect to the MySQL server from that host.
You got a timeout from the TCP/IP connection on the client side. This may happen if you have been using the commands:
mysql_options(..., MYSQL_OPT_READ_TIMEOUT,...)ormysql_options(..., MYSQL_OPT_WRITE_TIMEOUT,...). In this case increasing the timeout may help solve the problem.You have encountered a timeout on the server side and the automatic reconnection in the client is disabled (the
reconnectflag in theMYSQLstructure is equal to 0).You are using a Windows client and the server had dropped the connection (probably because
wait_timeoutexpired) before the command was issued.The problem on Windows is that in some cases MySQL doesn't get an error from the OS when writing to the TCP/IP connection to the server, but instead gets the error when trying to read the answer from the connection.
Prior to MySQL 5.0.19, even if the
reconnectflag in theMYSQLstructure is equal to 1, MySQL does not automatically reconnect and re-issue the query as it doesn't know if the server did get the original query or not.The solution to this is to either do a
mysql_pingon the connection if there has been a long time since the last query (this is whatMyODBCdoes) or setwait_timeouton the mysqld server so high that it in practice never times out.You can also get these errors if you send a query to the server that is incorrect or too large. If mysqld receives a packet that is too large or out of order, it assumes that something has gone wrong with the client and closes the connection. If you need big queries (for example, if you are working with big
BLOBcolumns), you can increase the query limit by setting the server'smax_allowed_packetvariable, which has a default value of 1MB. You may also need to increase the maximum packet size on the client end. More information on setting the packet size is given in Section B.1.2.9, “Packet too large”.An
INSERTorREPLACEstatement that inserts a great many rows can also cause these sorts of errors. Either one of these statements sends a single request to the server irrespective of the number of rows to be inserted; thus, you can often avoid the error by reducing the number of rows sent perINSERTorREPLACE.You also get a lost connection if you are sending a packet 16MB or larger if your client is older than 4.0.8 and your server is 4.0.8 and above, or the other way around.
It is also possible to see this error if hostname lookups fail (for example, if the DNS server on which your server or network relies goes down). This is because MySQL is dependent on the host system for name resolution, but has no way of knowing whether it is working — from MySQL's point of view the problem is indistinguishable from any other network timeout.
You may also see the
MySQL server has gone awayerror if MySQL is started with the--skip-networkingoption.You can also encounter this error with applications that fork child processes, all of which try to use the same connection to the MySQL server. This can be avoided by using a separate connection for each child process.
Another networking issue that can cause this error occurs if the MySQL port (default 3306) is blocked by your firewall, thus preventing any connections at all to the MySQL server.
You have encountered a bug where the server died while executing the query.
You can check whether the MySQL server died and restarted by executing mysqladmin version and examining the server's uptime. If the client connection was broken because mysqld crashed and restarted, you should concentrate on finding the reason for the crash. Start by checking whether issuing the query again kills the server again. See Section B.1.4.2, “What to Do If MySQL Keeps Crashing”.
You can get more information about the lost connections by
starting mysqld with the --log-warnings=2
option. This logs some of the disconnected errors in the
hostname.err file. See
Section 5.11.1, “The Error Log”.
If you want to create a bug report regarding this problem, be sure that you include the following information:
Indicate whether the MySQL server died. You can find information about this in the server error log. See Section B.1.4.2, “What to Do If MySQL Keeps Crashing”.
If a specific query kills mysqld and the tables involved were checked with
CHECK TABLEbefore you ran the query, can you provide a reproducible test case? See MySQL Internals: Porting.What is the value of the
wait_timeoutsystem variable in the MySQL server? (mysqladmin variables gives you the value of this variable.)Have you tried to run mysqld with the
--logoption to determine whether the problem query appears in the log?
See also Section B.1.2.10, “Communication Errors and Aborted Connections”, and Section 1.8, “How to Report Bugs or Problems”.
A communication packet is a single SQL statement sent to the MySQL server, a single row that is sent to the client, or a binary log event sent from a master replication server to a slave.
The largest possible packet that can be transmitted to or from a MySQL 5.0 server or client is 1GB.
When a MySQL client or the mysqld server
receives a packet bigger than
max_allowed_packet bytes, it issues a
Packet too large error and closes the
connection. With some clients, you may also get a
Lost connection to MySQL server during
query error if the communication packet is too
large.
Both the client and the server have their own
max_allowed_packet variable, so if you want
to handle big packets, you must increase this variable both in
the client and in the server.
If you are using the mysql client program,
its default max_allowed_packet variable is
16MB. To set a larger value, start mysql
like this:
shell> mysql --max_allowed_packet=32M
That sets the packet size to 32MB.
The server's default max_allowed_packet
value is 1MB. You can increase this if the server needs to
handle big queries (for example, if you are working with big
BLOB columns). For example, to set the
variable to 16MB, start the server like this:
shell> mysqld --max_allowed_packet=16M
You can also use an option file to set
max_allowed_packet. For example, to set the
size for the server to 16MB, add the following lines in an
option file:
[mysqld] max_allowed_packet=16M
It is safe to increase the value of this variable because the extra memory is allocated only when needed. For example, mysqld allocates more memory only when you issue a long query or when mysqld must return a large result row. The small default value of the variable is a precaution to catch incorrect packets between the client and server and also to ensure that you do not run out of memory by using large packets accidentally.
You can also get strange problems with large packets if you
are using large BLOB values but have not
given mysqld access to enough memory to
handle the query. If you suspect this is the case, try adding
ulimit -d 256000 to the beginning of the
mysqld_safe script and restarting
mysqld.
The server error log can be a useful source of information
about connection problems. See Section 5.11.1, “The Error Log”. If
you start the server with the --log-warnings
option, you might find messages like this in your error log:
010301 14:38:23 Aborted connection 854 to db: 'users' user: 'josh'
If Aborted connections messages appear in
the error log, the cause can be any of the following:
The client program did not call
mysql_close()before exiting.The client had been sleeping more than
wait_timeoutorinteractive_timeoutseconds without issuing any requests to the server. See Section 5.2.3, “System Variables”.The client program ended abruptly in the middle of a data transfer.
When any of these things happen, the server increments the
Aborted_clients status variable.
The server increments the Aborted_connects
status variable when the following things happen:
A client doesn't have privileges to connect to a database.
A client uses an incorrect password.
A connection packet doesn't contain the right information.
It takes more than
connect_timeoutseconds to get a connect packet. See Section 5.2.3, “System Variables”.
If these kinds of things happen, it might indicate that someone is trying to break into your server!
MySQL Enterprise
For reasons of security and performance the advisors
provided by the MySQL Network Monitoring and Advisory
Service pay special attention to the
Aborted_connections status variable. For
more information see
http://www.mysql.com/products/enterprise/advisors.html.
Other reasons for problems with aborted clients or aborted connections:
Use of Ethernet protocol with Linux, both half and full duplex. Many Linux Ethernet drivers have this bug. You should test for this bug by transferring a huge file via FTP between the client and server machines. If a transfer goes in burst-pause-burst-pause mode, you are experiencing a Linux duplex syndrome. The only solution is switching the duplex mode for both your network card and hub/switch to either full duplex or to half duplex and testing the results to determine the best setting.
Some problem with the thread library that causes interrupts on reads.
Badly configured TCP/IP.
Faulty Ethernets, hubs, switches, cables, and so forth. This can be diagnosed properly only by replacing hardware.
The
max_allowed_packetvariable value is too small or queries require more memory than you have allocated for mysqld. See Section B.1.2.9, “Packet too large”.
The maximum effective table size for MySQL databases is usually determined by operating system constraints on file sizes, not by MySQL internal limits. The following table lists some examples of operating system file-size limits. This is only a rough guide and is not intended to be definitive. For the most up-to-date information, be sure to check the documentation specific to your operating system.
| Operating System | File-size Limit |
| Win32 w/ FAT/FAT32 | 2GB/4GB |
| Win32 w/ NTFS | 2TB (possibly larger) |
| Linux 2.2-Intel 32-bit | 2GB (LFS: 4GB) |
| Linux 2.4+ | (using ext3 filesystem) 4TB |
| Solaris 9/10 | 16TB |
| MacOS X w/ HFS+ | 2TB |
| NetWare w/NSS filesystem | 8TB |
Windows users, please note that FAT and VFAT (FAT32) are not considered suitable for production use with MySQL. Use NTFS instead.
On Linux 2.2, you can get MyISAM tables
larger than 2GB in size by using the Large File Support (LFS)
patch for the ext2 filesystem. Most current Linux
distributions are based on kernel 2.4 or higher and include
all the required LFS patches. On Linux 2.4, patches also exist
for ReiserFS to get support for big files (up to 2TB). With
JFS and XFS, petabyte and larger files are possible on Linux.
For a detailed overview about LFS in Linux, have a look at Andreas Jaeger's Large File Support in Linux page at http://www.suse.de/~aj/linux_lfs.html.
If you do encounter a full-table error, there are several reasons why it might have occurred:
The
InnoDBstorage engine maintainsInnoDBtables within a tablespace that can be created from several files. This allows a table to exceed the maximum individual file size. The tablespace can include raw disk partitions, which allows extremely large tables. The maximum tablespace size is 64TB.If you are using
InnoDBtables and run out of room in theInnoDBtablespace. In this case, the solution is to extend theInnoDBtablespace. See Section 14.2.7, “Adding and RemovingInnoDBData and Log Files”.You are using
ISAMorMyISAMtables on an operating system that supports files only up to 2GB in size and you have hit this limit for the data file or index file.You are using a
MyISAMtable and the space required for the table exceeds what is allowed by the internal pointer size.MyISAMcreates tables to allow up to 4GB by default (256TB as of MySQL 5.0.6), but this limit can be changed up to the maximum allowable size of 65,536TB (2567 – 1 bytes).If you need a
MyISAMtable that is larger than the default limit and your operating system supports large files, theCREATE TABLEstatement supportsAVG_ROW_LENGTHandMAX_ROWSoptions. See Section 13.1.5, “CREATE TABLESyntax”. The server uses these options to determine how large a table to allow.If the pointer size is too small for an existing table, you can change the options with
ALTER TABLEto increase a table's maximum allowable size. See Section 13.1.2, “ALTER TABLESyntax”.ALTER TABLE
tbl_nameMAX_ROWS=1000000000 AVG_ROW_LENGTH=nnn;You have to specify
AVG_ROW_LENGTHonly for tables withBLOBorTEXTcolumns; in this case, MySQL can't optimize the space required based only on the number of rows.To change the default size limit for
MyISAMtables, set themyisam_data_pointer_size, which sets the number of bytes used for internal row pointers. The value is used to set the pointer size for new tables if you do not specify theMAX_ROWSoption. The value ofmyisam_data_pointer_sizecan be from 2 to 7. A value of 4 allows tables up to 4GB; a value of 6 allows tables up to 256TB.You can check the maximum data and index sizes by using this statement:
SHOW TABLE STATUS FROM
db_nameLIKE 'tbl_name';You also can use myisamchk -dv /path/to/table-index-file. See Section 13.5.4, “
SHOWSyntax”, or Section 8.5, “myisamchk — MyISAM Table-Maintenance Utility”.Other ways to work around file-size limits for
MyISAMtables are as follows:If your large table is read-only, you can use myisampack to compress it. myisampack usually compresses a table by at least 50%, so you can have, in effect, much bigger tables. myisampack also can merge multiple tables into a single table. See Section 8.7, “myisampack — Generate Compressed, Read-Only MyISAM Tables”.
MySQL includes a
MERGElibrary that allows you to handle a collection ofMyISAMtables that have identical structure as a singleMERGEtable. See Section 14.3, “TheMERGEStorage Engine”.
You are using the
NDBstorage engine, in which case you need to increase the values for theDataMemoryandIndexMemoryconfiguration parameters in yourconfig.inifile. See Section 15.4.5.1, “Data Node Configuration Parameters”.You are using the
MEMORY(HEAP) storage engine; in this case you need to increase the value of themax_heap_table_sizesystem variable. See Section 5.2.3, “System Variables”.
If you get an error of the following type for some queries, it means that MySQL cannot create a temporary file for the result set in the temporary directory:
Can't create/write to file '\\sqla3fe_0.ism'.
The preceding error is a typical message for Windows; the Unix message is similar.
One fix is to start mysqld with the
--tmpdir option or to add the option to the
[mysqld] section of your option file. For
example, to specify a directory of
C:\temp, use these lines:
[mysqld] tmpdir=C:/temp
The C:\temp directory must exist and have
sufficient space for the MySQL server to write to. See
Section 4.3.2, “Using Option Files”.
Another cause of this error can be permissions issues. Make
sure that the MySQL server can write to the
tmpdir directory.
Check also the error code that you get with perror. One reason the server cannot write to a table is that the filesystem is full:
shell> perror 28
OS error code 28: No space left on device
If you get Commands out of sync; you can't run this
command now in your client code, you are calling
client functions in the wrong order.
This can happen, for example, if you are using
mysql_use_result() and try to execute a new
query before you have called
mysql_free_result(). It can also happen if
you try to execute two queries that return data without
calling mysql_use_result() or
mysql_store_result() in between.
If you get the following error, it means that when
mysqld was started or when it reloaded the
grant tables, it found an account in the
user table that had an invalid password.
Found wrong password for user
'
some_user'@'some_host';
ignoring user
As a result, the account is simply ignored by the permission system.
The following list indicates possible causes of and fixes for this problem:
You may be running a new version of mysqld with an old
usertable. You can check this by executing mysqlshow mysql user to see whether thePasswordcolumn is shorter than 16 characters. If so, you can correct this condition by running thescripts/add_long_passwordscript.The account has an old password (eight characters long) and you didn't start mysqld with the
--old-protocoloption. Update the account in theusertable to have a new password or restart mysqld with the--old-protocoloption.You have specified a password in the
usertable without using thePASSWORD()function. Use mysql to update the account in theusertable with a new password, making sure to use thePASSWORD()function:mysql>
UPDATE user SET Password=PASSWORD('->newpwd')WHERE User='some_user' AND Host='some_host';
If you get either of the following errors, it usually means that no table exists in the default database with the given name:
Table 'tbl_name' doesn't exist Can't find file: 'tbl_name' (errno: 2)
In some cases, it may be that the table does exist but that you are referring to it incorrectly:
Because MySQL uses directories and files to store databases and tables, database and table names are case sensitive if they are located on a filesystem that has case-sensitive filenames.
Even for filesystems that are not case sensitive, such as on Windows, all references to a given table within a query must use the same lettercase.
You can check which tables are in the default database with
SHOW TABLES. See Section 13.5.4, “SHOW Syntax”.
You might see an error like this if you have character set problems:
MySQL Connection Failed: Can't initialize character set charset_name
This error can have any of the following causes:
The character set is a multi-byte character set and you have no support for the character set in the client. In this case, you need to recompile the client by running configure with the
--with-charset=orcharset_name--with-extra-charsets=option. See Section 2.4.14.2, “Typical configure Options”.charset_nameAll standard MySQL binaries are compiled with
--with-extra-character-sets=complex, which enables support for all multi-byte character sets. See Section 5.10.1, “The Character Set Used for Data and Sorting”.The character set is a simple character set that is not compiled into mysqld, and the character set definition files are not in the place where the client expects to find them.
In this case, you need to use one of the following methods to solve the problem:
Recompile the client with support for the character set. See Section 2.4.14.2, “Typical configure Options”.
Specify to the client the directory where the character set definition files are located. For many clients, you can do this with the
--character-sets-diroption.Copy the character definition files to the path where the client expects them to be.
If you get ERROR '...' not found (errno:
23), Can't open file: ... (errno:
24), or any other error with errno
23 or errno 24 from MySQL, it
means that you haven't allocated enough file descriptors for
the MySQL server. You can use the perror
utility to get a description of what the error number means:
shell>perror 23OS error code 23: File table overflow shell>perror 24OS error code 24: Too many open files shell>perror 11OS error code 11: Resource temporarily unavailable
The problem here is that mysqld is trying to keep open too many files simultaneously. You can either tell mysqld not to open so many files at once or increase the number of file descriptors available to mysqld.
To tell mysqld to keep open fewer files at
a time, you can make the table cache smaller by reducing the
value of the table_cache system variable
(the default value is 64). Reducing the value of
max_connections also reduces the number of
open files (the default value is 100).
To change the number of file descriptors available to
mysqld, you can use the
--open-files-limit option to
mysqld_safe or (as of MySQL 3.23.30) set
the open_files_limit system variable. See
Section 5.2.3, “System Variables”. The easiest way to
set these values is to add an option to your option file. See
Section 4.3.2, “Using Option Files”. If you have an old version of
mysqld that doesn't support setting the
open files limit, you can edit the
mysqld_safe script. There is a
commented-out line ulimit -n 256 in the
script. You can remove the ‘#’
character to uncomment this line, and change the number
256 to set the number of file descriptors
to be made available to mysqld.
--open-files-limit and
ulimit can increase the number of file
descriptors, but only up to the limit imposed by the operating
system. There is also a “hard” limit that can be
overridden only if you start mysqld_safe or
mysqld as root (just
remember that you also need to start the server with the
--user option in this case so that it does
not continue to run as root after it starts
up). If you need to increase the operating system limit on the
number of file descriptors available to each process, consult
the documentation for your system.
Note: If you run the tcsh shell, ulimit does not work! tcsh also reports incorrect values when you ask for the current limits. In this case, you should start mysqld_safe using sh.
When you are linking an application program to use the MySQL
client library, you might get undefined reference errors for
symbols that start with mysql_, such as
those shown here:
/tmp/ccFKsdPa.o: In function `main': /tmp/ccFKsdPa.o(.text+0xb): undefined reference to `mysql_init' /tmp/ccFKsdPa.o(.text+0x31): undefined reference to `mysql_real_connect' /tmp/ccFKsdPa.o(.text+0x57): undefined reference to `mysql_real_connect' /tmp/ccFKsdPa.o(.text+0x69): undefined reference to `mysql_error' /tmp/ccFKsdPa.o(.text+0x9a): undefined reference to `mysql_close'
You should be able to solve this problem by adding
-Ldir_path -lmysqlclient at the end of your
link command, where dir_path represents the
pathname of the directory where the client library is located.
To determine the correct directory, try this command:
shell> mysql_config --libs
The output from mysql_config might indicate other libraries that should be specified on the link command as well.
If you get undefined reference errors for
the uncompress or
compress function, add
-lz to the end of your link command and try
again.
If you get undefined reference errors for a
function that should exist on your system, such as
connect, check the manual page for the
function in question to determine which libraries you should
add to the link command.
You might get undefined reference errors
such as the following for functions that don't exist on your
system:
mf_format.o(.text+0x201): undefined reference to `__lxstat'
This usually means that your MySQL client library was compiled on a system that is not 100% compatible with yours. In this case, you should download the latest MySQL source distribution and compile MySQL yourself. See Section 2.4.14, “MySQL Installation Using a Source Distribution”.
You might get undefined reference errors at runtime when you
try to execute a MySQL program. If these errors specify
symbols that start with mysql_ or indicate
that the mysqlclient library can't be
found, it means that your system can't find the shared
libmysqlclient.so library. The fix for
this is to tell your system to search for shared libraries
where the library is located. Use whichever of the following
methods is appropriate for your system:
Add the path to the directory where
libmysqlclient.sois located to theLD_LIBRARY_PATHenvironment variable.Add the path to the directory where
libmysqlclient.sois located to theLD_LIBRARYenvironment variable.Copy
libmysqlclient.soto some directory that is searched by your system, such as/lib, and update the shared library information by executingldconfig.
Another way to solve this problem is by linking your program
statically with the -static option, or by
removing the dynamic MySQL libraries before linking your code.
Before trying the second method, you should be sure that no
other programs are using the dynamic libraries.
If you have problems with file permissions, the
UMASK environment variable might be set
incorrectly when mysqld starts. For
example, MySQL might issue the following error message when
you create a table:
ERROR: Can't find file: 'path/with/filename.frm' (Errcode: 13)
The default UMASK value is
0660. You can change this behavior by
starting mysqld_safe as follows:
shell>UMASK=384 # = 600 in octalshell>export UMASKshell>mysqld_safe &
By default, MySQL creates database and RAID
directories with an access permission value of
0700. You can modify this behavior by
setting the UMASK_DIR variable. If you set
its value, new directories are created with the combined
UMASK and UMASK_DIR
values. For example, if you want to give group access to all
new directories, you can do this:
shell>UMASK_DIR=504 # = 770 in octalshell>export UMASK_DIRshell>mysqld_safe &
In MySQL 3.23.25 and above, MySQL assumes that the value for
UMASK and UMASK_DIR is
in octal if it starts with a zero.
If you have never set a root password for
MySQL, the server does not require a password at all for
connecting as root. However, it is
recommended to set a password for each account. See
Section 5.6.1, “General Security Guidelines”.
If you set a root password previously, but
have forgotten what it was, you can set a new password. The
following procedure is for Windows systems. The procedure for
Unix systems is given later in this section.
The procedure under Windows:
Log on to your system as Administrator.
Stop the MySQL server if it is running. For a server that is running as a Windows service, go to the Services manager:
Start Menu -> Control Panel -> Administrative Tools -> Services
Then find the MySQL service in the list, and stop it.
If your server is not running as a service, you may need to use the Task Manager to force it to stop.
Create a text file and place the following command within it on a single line:
SET PASSWORD FOR 'root'@'localhost' = PASSWORD('MyNewPassword');Save the file with any name. For this example the file will be
C:\mysql-init.txt.Open a console window to get to the DOS command prompt:
Start Menu -> Run -> cmd
We are assuming that you installed MySQL to
C:\mysql. If you installed MySQL to another location, adjust the following commands accordingly.At the DOS command prompt, execute this command:
C:\>
C:\mysql\bin\mysqld-nt --init-file=C:\mysql-init.txtThe contents of the file named by the
--init-fileoption are executed at server startup, changing therootpassword. After the server has started successfully, you should deleteC:\mysql-init.txt.If you install MySQL using the MySQL Installation Wizard, you may need to specify a
--defaults-fileoption:C:\>
"C:\Program Files\MySQL\MySQL Server 5.0\bin\mysqld-nt.exe"--defaults-file="C:\Program Files\MySQL\MySQL Server 5.0\my.ini"--init-file=C:\mysql-init.txtThe appropriate
--defaults-filesetting can be found using the Services Manager:Start Menu -> Control Panel -> Administrative Tools -> Services
Find the MySQL service in the list, right-click on it, and choose the
Propertiesoption. ThePath to executablefield contains the--defaults-filesetting.Stop the MySQL server, then restart it in normal mode again. If you run the server as a service, start it from the Windows Services window. If you start the server manually, use whatever command you normally use.
You should be able to connect using the new password.
In a Unix environment, the procedure for resetting the
root password is as follows:
MySQL Enterprise For expert advice on security-related issues, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
Log on to your system as either the Unix
rootuser or as the same user that the mysqld server runs as.Locate the
.pidfile that contains the server's process ID. The exact location and name of this file depend on your distribution, hostname, and configuration. Common locations are/var/lib/mysql/,/var/run/mysqld/, and/usr/local/mysql/data/. Generally, the filename has the extension of.pidand begins with eithermysqldor your system's hostname.You can stop the MySQL server by sending a normal
kill(notkill -9) to the mysqld process, using the pathname of the.pidfile in the following command:shell>
kill `cat /mysql-data-directory/host_name.pid`Note the use of backticks rather than forward quotes with the
catcommand; these cause the output ofcatto be substituted into thekillcommand.Create a text file and place the following command within it on a single line:
SET PASSWORD FOR 'root'@'localhost' = PASSWORD('MyNewPassword');Save the file with any name. For this example the file will be
~/mysql-init.Restart the MySQL server with the special
--init-file=~/mysql-initoption:shell>
mysqld_safe --init-file=~/mysql-init &The contents of the init-file are executed at server startup, changing the root password. After the server has started successfully you should delete
~/mysql-init.You should be able to connect using the new password.
Alternatively, on any platform, you can set the new password using the mysql client(but this approach is less secure):
Stop mysqld and restart it with the
--skip-grant-tables --user=rootoptions (Windows users omit the--user=rootportion).Connect to the mysqld server with this command:
shell>
mysql -u rootIssue the following statements in the mysql client:
mysql>
UPDATE mysql.user SET Password=PASSWORD('->newpwd')WHERE User='root';mysql>FLUSH PRIVILEGES;Replace “
newpwd” with the actualrootpassword that you want to use.You should be able to connect using the new password.
Each MySQL version is tested on many platforms before it is released. This doesn't mean that there are no bugs in MySQL, but if there are bugs, they should be very few and can be hard to find. If you have a problem, it always helps if you try to find out exactly what crashes your system, because you have a much better chance of getting the problem fixed quickly.
First, you should try to find out whether the problem is that the mysqld server dies or whether your problem has to do with your client. You can check how long your mysqld server has been up by executing mysqladmin version. If mysqld has died and restarted, you may find the reason by looking in the server's error log. See Section 5.11.1, “The Error Log”.
On some systems, you can find in the error log a stack trace
of where mysqld died that you can resolve
with the resolve_stack_dump program. See
MySQL
Internals: Porting. Note that the variable values
written in the error log may not always be 100% correct.
Many server crashes are caused by corrupted data files or
index files. MySQL updates the files on disk with the
write() system call after every SQL
statement and before the client is notified about the result.
(This is not true if you are running with
--delay-key-write, in which case data files
are written but not index files.) This means that data file
contents are safe even if mysqld crashes,
because the operating system ensures that the unflushed data
is written to disk. You can force MySQL to flush everything to
disk after every SQL statement by starting
mysqld with the --flush
option.
The preceding means that normally you should not get corrupted tables unless one of the following happens:
The MySQL server or the server host was killed in the middle of an update.
You have found a bug in mysqld that caused it to die in the middle of an update.
Some external program is manipulating data files or index files at the same time as mysqld without locking the table properly.
You are running many mysqld servers using the same data directory on a system that doesn't support good filesystem locks (normally handled by the
lockdlock manager), or you are running multiple servers with external locking disabled.You have a crashed data file or index file that contains very corrupt data that confused mysqld.
You have found a bug in the data storage code. This isn't likely, but it's at least possible. In this case, you can try to change the storage engine to another engine by using
ALTER TABLEon a repaired copy of the table.
Because it is very difficult to know why something is crashing, first try to check whether things that work for others crash for you. Please try the following things:
Stop the mysqld server with mysqladmin shutdown, run myisamchk --silent --force */*.MYI from the data directory to check all
MyISAMtables, and restart mysqld. This ensures that you are running from a clean state. See Chapter 5, Database Administration.Start mysqld with the
--logoption and try to determine from the information written to the log whether some specific query kills the server. About 95% of all bugs are related to a particular query. Normally, this is one of the last queries in the log file just before the server restarts. See Section 5.11.2, “The General Query Log”. If you can repeatedly kill MySQL with a specific query, even when you have checked all tables just before issuing it, then you have been able to locate the bug and should submit a bug report for it. See Section 1.8, “How to Report Bugs or Problems”.Try to make a test case that we can use to repeat the problem. See MySQL Internals: Porting.
Try running the tests in the
mysql-testdirectory and the MySQL benchmarks. See Section 24.1.2, “MySQL Test Suite”. They should test MySQL rather well. You can also add code to the benchmarks that simulates your application. The benchmarks can be found in thesql-benchdirectory in a source distribution or, for a binary distribution, in thesql-benchdirectory under your MySQL installation directory.Try the
fork_big.plscript. (It is located in thetestsdirectory of source distributions.)If you configure MySQL for debugging, it is much easier to gather information about possible errors if something goes wrong. Configuring MySQL for debugging causes a safe memory allocator to be included that can find some errors. It also provides a lot of output about what is happening. Reconfigure MySQL with the
--with-debugor--with-debug=fulloption to configure and then recompile. See MySQL Internals: Porting.Make sure that you have applied the latest patches for your operating system.
Use the
--skip-external-lockingoption to mysqld. On some systems, thelockdlock manager does not work properly; the--skip-external-lockingoption tells mysqld not to use external locking. (This means that you cannot run two mysqld servers on the same data directory and that you must be careful if you use myisamchk. Nevertheless, it may be instructive to try the option as a test.)Have you tried mysqladmin -u root processlist when mysqld appears to be running but not responding? Sometimes mysqld is not comatose even though you might think so. The problem may be that all connections are in use, or there may be some internal lock problem. mysqladmin -u root processlist usually is able to make a connection even in these cases, and can provide useful information about the current number of connections and their status.
Run the command mysqladmin -i 5 status or mysqladmin -i 5 -r status in a separate window to produce statistics while you run your other queries.
Try the following:
Start mysqld from gdb (or another debugger). See MySQL Internals: Porting.
Run your test scripts.
Print the backtrace and the local variables at the three lowest levels. In gdb, you can do this with the following commands when mysqld has crashed inside gdb:
backtrace info local up info local up info local
With gdb, you can also examine which threads exist with
info threadsand switch to a specific thread withthread, whereNNis the thread ID.
Try to simulate your application with a Perl script to force MySQL to crash or misbehave.
Send a normal bug report. See Section 1.8, “How to Report Bugs or Problems”. Be even more detailed than usual. Because MySQL works for many people, it may be that the crash results from something that exists only on your computer (for example, an error that is related to your particular system libraries).
If you have a problem with tables containing dynamic-length rows and you are using only
VARCHARcolumns (notBLOBorTEXTcolumns), you can try to change allVARCHARtoCHARwithALTER TABLE. This forces MySQL to use fixed-size rows. Fixed-size rows take a little extra space, but are much more tolerant to corruption.The current dynamic row code has been in use at MySQL AB for several years with very few problems, but dynamic-length rows are by nature more prone to errors, so it may be a good idea to try this strategy to see whether it helps.
Do not rule out your server hardware when diagnosing problems. Defective hardware can be the cause of data corruption. Particular attention should be paid to both RAMS and hard-drives when troubleshooting hardware.
This section describes how MySQL responds to disk-full errors (such as “no space left on device”), and to quota-exceeded errors (such as “write failed” or “user block limit reached”).
This section is relevant for writes to
MyISAM tables. It also applies for writes
to binary log files and binary log index file, except that
references to “row” and “record”
should be understood to mean “event.”
When a disk-full condition occurs, MySQL does the following:
It checks once every minute to see whether there is enough space to write the current row. If there is enough space, it continues as if nothing had happened.
Every 10 minutes it writes an entry to the log file, warning about the disk-full condition.
To alleviate the problem, you can take the following actions:
To continue, you only have to free enough disk space to insert all records.
To abort the thread, you must use mysqladmin kill. The thread is aborted the next time it checks the disk (in one minute).
Other threads might be waiting for the table that caused the disk-full condition. If you have several “locked” threads, killing the one thread that is waiting on the disk-full condition allows the other threads to continue.
Exceptions to the preceding behavior are when you use
REPAIR TABLE or OPTIMIZE
TABLE or when the indexes are created in a batch
after LOAD DATA INFILE or after an
ALTER TABLE statement. All of these
statements may create large temporary files that, if left to
themselves, would cause big problems for the rest of the
system. If the disk becomes full while MySQL is doing any of
these operations, it removes the big temporary files and mark
the table as crashed. The exception is that for ALTER
TABLE, the old table is left unchanged.
MySQL Enterprise For early notification of possible problems with your MySQL configuration subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
MySQL uses the value of the TMPDIR
environment variable as the pathname of the directory in which
to store temporary files. If you don't have
TMPDIR set, MySQL uses the system default,
which is normally /tmp,
/var/tmp, or
/usr/tmp. If the filesystem containing
your temporary file directory is too small, you can use the
--tmpdir option to mysqld
to specify a directory in a filesystem where you have enough
space.
In MySQL 5.0, the --tmpdir
option can be set to a list of several paths that are used in
round-robin fashion. Paths should be separated by colon
characters (‘:’) on Unix and
semicolon characters (‘;’) on
Windows, NetWare, and OS/2.
Note: To spread the load
effectively, these paths should be located on different
physical disks, not different partitions
of the same disk.
If the MySQL server is acting as a replication slave, you
should not set --tmpdir to point to a
directory on a memory-based filesystem or to a directory that
is cleared when the server host restarts. A replication slave
needs some of its temporary files to survive a machine restart
so that it can replicate temporary tables or LOAD
DATA INFILE operations. If files in the temporary
file directory are lost when the server restarts, replication
fails.
MySQL creates all temporary files as hidden files. This ensures that the temporary files are removed if mysqld is terminated. The disadvantage of using hidden files is that you do not see a big temporary file that fills up the filesystem in which the temporary file directory is located.
MySQL Enterprise Advisors provided by the MySQL Network Monitoring and Advisory Service automatically detect excessive temporary table storage to disk. For more information see http://www.mysql.com/products/enterprise/advisors.html.
When sorting (ORDER BY or GROUP
BY), MySQL normally uses one or two temporary files.
The maximum disk space required is determined by the following
expression:
(length of what is sorted + sizeof(row pointer)) * number of matched rows * 2
The row pointer size is usually four bytes, but may grow in the future for really big tables.
For some SELECT queries, MySQL also creates
temporary SQL tables. These are not hidden and have names of
the form SQL_*.
ALTER TABLE creates a temporary table in
the same directory as the original table.
The default location for the Unix socket file that the server
uses for communication with local clients is
/tmp/mysql.sock. (For some distribution
formats, the directory might be different, such as
/var/lib/mysql for RPMs.)
On some versions of Unix, anyone can delete files in the
/tmp directory or other similar
directories used for temporary files. If the socket file is
located in such a directory on your system, this might cause
problems.
On most versions of Unix, you can protect your
/tmp directory so that files can be
deleted only by their owners or the superuser
(root). To do this, set the
sticky bit on the /tmp
directory by logging in as root and using
the following command:
shell> chmod +t /tmp
You can check whether the sticky bit is set
by executing ls -ld /tmp. If the last
permission character is t, the bit is set.
Another approach is to change the place where the server creates the Unix socket file. If you do this, you should also let client programs know the new location of the file. You can specify the file location in several ways:
Specify the path in a global or local option file. For example, put the following lines in
/etc/my.cnf:[mysqld] socket=/path/to/socket [client] socket=/path/to/socket
Specify a
--socketoption on the command line to mysqld_safe and when you run client programs.Set the
MYSQL_UNIX_PORTenvironment variable to the path of the Unix socket file.Recompile MySQL from source to use a different default Unix socket file location. Define the path to the file with the
--with-unix-socket-pathoption when you run configure. See Section 2.4.14.2, “Typical configure Options”.
You can test whether the new socket location works by attempting to connect to the server with this command:
shell> mysqladmin --socket=/path/to/socket version
If you have a problem with SELECT NOW()
returning values in UTC and not your local time, you have to
tell the server your current time zone. The same applies if
UNIX_TIMESTAMP() returns the wrong value.
This should be done for the environment in which the server
runs; for example, in mysqld_safe or
mysql.server. See
Section 2.4.19, “Environment Variables”.
You can set the time zone for the server with the
--timezone=
option to mysqld_safe. You can also set it
by setting the timezone_nameTZ environment variable
before you start mysqld.
The allowable values for --timezone or
TZ are system-dependent. Consult your
operating system documentation to see what values are
acceptable.
- B.1.5.1. Case Sensitivity in Searches
- B.1.5.2. Problems Using
DATEColumns - B.1.5.3. Problems with
NULLValues - B.1.5.4. Problems with Column Aliases
- B.1.5.5. Rollback Failure for Non-Transactional Tables
- B.1.5.6. Deleting Rows from Related Tables
- B.1.5.7. Solving Problems with No Matching Rows
- B.1.5.8. Problems with Floating-Point Comparisons
By default, MySQL searches are not case sensitive (although
there are some character sets that are never case insensitive,
such as czech). This means that if you
search with col_name LIKE
'a%'A or a. If you want to
make this search case sensitive, make sure that one of the
operands has a case sensitive or binary collation. For
example, if you are comparing a column and a string that both
have the latin1 character set, you can use
the COLLATE operator to cause either
operand to have the latin1_general_cs or
latin1_bin collation. For example:
col_nameCOLLATE latin1_general_cs LIKE 'a%'col_nameLIKE 'a%' COLLATE latin1_general_cscol_nameCOLLATE latin1_bin LIKE 'a%'col_nameLIKE 'a%' COLLATE latin1_bin
If you want a column always to be treated in case-sensitive
fashion, declare it with a case sensitive or binary collation.
See Section 13.1.5, “CREATE TABLE Syntax”.
Simple comparison operations (>=, >, =, <,
<=, sorting, and grouping) are based on each
character's “sort value.” Characters with the
same sort value (such as ‘E’,
‘e’, and
‘é’) are treated as the
same character.
The format of a DATE value is
'YYYY-MM-DD'. According to standard SQL, no
other format is allowed. You should use this format in
UPDATE expressions and in the
WHERE clause of SELECT
statements. For example:
mysql> SELECT * FROM tbl_name WHERE date >= '2003-05-05';
As a convenience, MySQL automatically converts a date to a
number if the date is used in a numeric context (and vice
versa). It is also smart enough to allow a
“relaxed” string form when updating and in a
WHERE clause that compares a date to a
TIMESTAMP, DATE, or
DATETIME column. (“Relaxed
form” means that any punctuation character may be used
as the separator between parts. For example,
'2004-08-15' and
'2004#08#15' are equivalent.) MySQL can
also convert a string containing no separators (such as
'20040815'), provided it makes sense as a
date.
When you compare a DATE,
TIME, DATETIME, or
TIMESTAMP to a constant string with the
<, <=,
=, >=,
>, or BETWEEN
operators, MySQL normally converts the string to an internal
long integer for faster comparison (and also for a bit more
“relaxed” string checking). However, this
conversion is subject to the following exceptions:
When you compare two columns
When you compare a
DATE,TIME,DATETIME, orTIMESTAMPcolumn to an expressionWhen you use any other comparison method than those just listed, such as
INorSTRCMP().
For these exceptional cases, the comparison is done by converting the objects to strings and performing a string comparison.
To keep things safe, assume that strings are compared as strings and use the appropriate string functions if you want to compare a temporal value to a string.
The special date '0000-00-00' can be stored
and retrieved as '0000-00-00'. When using a
'0000-00-00' date through MyODBC, it is
automatically converted to NULL in MyODBC
2.50.12 and above, because ODBC can't handle this kind of
date.
Because MySQL performs the conversions described above, the following statements work:
mysql>INSERT INTOmysql>tbl_name(idate) VALUES (19970505);INSERT INTOmysql>tbl_name(idate) VALUES ('19970505');INSERT INTOmysql>tbl_name(idate) VALUES ('97-05-05');INSERT INTOmysql>tbl_name(idate) VALUES ('1997.05.05');INSERT INTOmysql>tbl_name(idate) VALUES ('1997 05 05');INSERT INTOmysql>tbl_name(idate) VALUES ('0000-00-00');SELECT idate FROMmysql>tbl_nameWHERE idate >= '1997-05-05';SELECT idate FROMmysql>tbl_nameWHERE idate >= 19970505;SELECT MOD(idate,100) FROMmysql>tbl_nameWHERE idate >= 19970505;SELECT idate FROMtbl_nameWHERE idate >= '19970505';
However, the following does not work:
mysql> SELECT idate FROM tbl_name WHERE STRCMP(idate,'20030505')=0;
STRCMP() is a string function, so it
converts idate to a string in
'YYYY-MM-DD' format and performs a string
comparison. It does not convert '20030505'
to the date '2003-05-05' and perform a date
comparison.
If you are using the ALLOW_INVALID_DATES
SQL mode, MySQL allows you to store dates that are given only
limited checking: MySQL requires only that the day is in the
range from 1 to 31 and the month is in the range from 1 to 12.
This makes MySQL very convenient for Web applications where you obtain year, month, and day in three different fields and you want to store exactly what the user inserted (without date validation).
If you are not using the NO_ZERO_IN_DATE
SQL mode, the day or month part can be zero. This is
convenient if you want to store a birthdate in a
DATE column and you know only part of the
date.
If you are not using the NO_ZERO_DATE SQL
mode, MySQL also allows you to store
'0000-00-00' as a “dummy
date.” This is in some cases more convenient than using
NULL values.
If the date cannot be converted to any reasonable value, a
0 is stored in the DATE
column, which is retrieved as '0000-00-00'.
This is both a speed and a convenience issue. We believe that
the database server's responsibility is to retrieve the same
date you stored (even if the data was not logically correct in
all cases). We think it is up to the application and not the
server to check the dates.
If you want MySQL to check all dates and accept only legal
dates (unless overridden by IGNORE), you should set
sql_mode to
"NO_ZERO_IN_DATE,NO_ZERO_DATE".
Date handling in MySQL 5.0.1 and earlier works like MySQL
5.0.2 with the ALLOW_INVALID_DATES SQL mode
enabled.
The concept of the NULL value is a common
source of confusion for newcomers to SQL, who often think that
NULL is the same thing as an empty string
''. This is not the case. For example, the
following statements are completely different:
mysql>INSERT INTO my_table (phone) VALUES (NULL);mysql>INSERT INTO my_table (phone) VALUES ('');
Both statements insert a value into the
phone column, but the first inserts a
NULL value and the second inserts an empty
string. The meaning of the first can be regarded as
“phone number is not known” and the meaning of
the second can be regarded as “the person is known to
have no phone, and thus no phone number.”
To help with NULL handling, you can use the
IS NULL and IS NOT NULL
operators and the IFNULL() function.
In SQL, the NULL value is never true in
comparison to any other value, even NULL.
An expression that contains NULL always
produces a NULL value unless otherwise
indicated in the documentation for the operators and functions
involved in the expression. All columns in the following
example return NULL:
mysql> SELECT NULL, 1+NULL, CONCAT('Invisible',NULL);
If you want to search for column values that are
NULL, you cannot use an expr =
NULL test. The following statement returns no rows,
because expr = NULL is never true for any
expression:
mysql> SELECT * FROM my_table WHERE phone = NULL;
To look for NULL values, you must use the
IS NULL test. The following statements show
how to find the NULL phone number and the
empty phone number:
mysql>SELECT * FROM my_table WHERE phone IS NULL;mysql>SELECT * FROM my_table WHERE phone = '';
See Section 3.3.4.6, “Working with NULL Values”, for additional
information and examples.
You can add an index on a column that can have
NULL values if you are using the
MyISAM, InnoDB, or
BDB, or MEMORY storage
engine. Otherwise, you must declare an indexed column
NOT NULL, and you cannot insert
NULL into the column.
When reading data with LOAD DATA INFILE,
empty or missing columns are updated with
''. If you want a NULL
value in a column, you should use \N in the
data file. The literal word
“NULL” may also be used under
some circumstances. See Section 13.2.5, “LOAD DATA INFILE Syntax”.
When using DISTINCT, GROUP
BY, or ORDER BY, all
NULL values are regarded as equal.
When using ORDER BY,
NULL values are presented first, or last if
you specify DESC to sort in descending
order.
Aggregate (summary) functions such as
COUNT(), MIN(), and
SUM() ignore NULL
values. The exception to this is COUNT(*),
which counts rows and not individual column values. For
example, the following statement produces two counts. The
first is a count of the number of rows in the table, and the
second is a count of the number of non-NULL
values in the age column:
mysql> SELECT COUNT(*), COUNT(age) FROM person;
For some data types, MySQL handles NULL
values specially. If you insert NULL into a
TIMESTAMP column, the current date and time
is inserted. If you insert NULL into an
integer column that has the AUTO_INCREMENT
attribute, the next number in the sequence is inserted.
You can use an alias to refer to a column in GROUP
BY, ORDER BY, or
HAVING clauses. Aliases can also be used to
give columns better names:
SELECT SQRT(a*b) AS root FROMtbl_nameGROUP BY root HAVING root > 0; SELECT id, COUNT(*) AS cnt FROMtbl_nameGROUP BY id HAVING cnt > 0; SELECT id AS 'Customer identity' FROMtbl_name;
Standard SQL doesn't allow you to refer to a column alias in a
WHERE clause. This restriction is imposed
because when the WHERE code is executed,
the column value may not yet be determined. For example, the
following query is illegal:
SELECT id, COUNT(*) AS cnt FROM tbl_name WHERE cnt > 0 GROUP BY id;
The WHERE statement is executed to
determine which rows should be included in the GROUP
BY part, whereas HAVING is used
to decide which rows from the result set should be used.
If you receive the following message when trying to perform a
ROLLBACK, it means that one or more of the
tables you used in the transaction do not support
transactions:
Warning: Some non-transactional changed tables couldn't be rolled back
These non-transactional tables are not affected by the
ROLLBACK statement.
If you were not deliberately mixing transactional and
non-transactional tables within the transaction, the most
likely cause for this message is that a table you thought was
transactional actually is not. This can happen if you try to
create a table using a transactional storage engine that is
not supported by your mysqld server (or
that was disabled with a startup option). If
mysqld doesn't support a storage engine, it
instead creates the table as a MyISAM
table, which is non-transactional.
You can check the storage engine for a table by using either of these statements:
SHOW TABLE STATUS LIKE 'tbl_name'; SHOW CREATE TABLEtbl_name;
See Section 13.5.4.24, “SHOW TABLE STATUS Syntax”, and
Section 13.5.4.6, “SHOW CREATE TABLE Syntax”.
You can check which storage engines your mysqld server supports by using this statement:
SHOW ENGINES;
You can also use the following statement, and check the value of the variable that is associated with the storage engine in which you are interested:
SHOW VARIABLES LIKE 'have_%';
For example, to determine whether the
InnoDB storage engine is available, check
the value of the have_innodb variable.
See Section 13.5.4.10, “SHOW ENGINES Syntax”, and
Section 13.5.4.27, “SHOW VARIABLES Syntax”.
MySQL Enterprise Ensure that your data is adequately protected by subscribing to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
If the total length of the DELETE statement
for related_table is more than 1MB (the
default value of the max_allowed_packet
system variable), you should split it into smaller parts and
execute multiple DELETE statements. You
probably get the fastest DELETE by
specifying only 100 to 1,000 related_column
values per statement if the related_column
is indexed. If the related_column isn't
indexed, the speed is independent of the number of arguments
in the IN clause.
If you have a complicated query that uses many tables but that doesn't return any rows, you should use the following procedure to find out what is wrong:
Test the query with
EXPLAINto check whether you can find something that is obviously wrong. See Section 7.2.1, “Optimizing Queries withEXPLAIN”.Select only those columns that are used in the
WHEREclause.Remove one table at a time from the query until it returns some rows. If the tables are large, it's a good idea to use
LIMIT 10with the query.Issue a
SELECTfor the column that should have matched a row against the table that was last removed from the query.If you are comparing
FLOATorDOUBLEcolumns with numbers that have decimals, you can't use equality (=) comparisons. This problem is common in most computer languages because not all floating-point values can be stored with exact precision. In some cases, changing theFLOATto aDOUBLEfixes this. See Section B.1.5.8, “Problems with Floating-Point Comparisons”.Similar problems may be encountered when comparing
DECIMALvalues prior to MySQL 5.0.3.If you still can't figure out what's wrong, create a minimal test that can be run with
mysql test < query.sqlthat shows your problems. You can create a test file by dumping the tables with mysqldump --quick db_nametbl_name_1...tbl_name_n> query.sql. Open the file in an editor, remove some insert lines (if there are more than needed to demonstrate the problem), and add yourSELECTstatement at the end of the file.Verify that the test file demonstrates the problem by executing these commands:
shell>
mysqladmin create test2shell>mysql test2 < query.sqlAttach the test file to a bug report, which you can file using the instructions in Section 1.8, “How to Report Bugs or Problems”.
Floating-point numbers sometimes cause confusion because they
are approximate. That is, they are not stored as exact values
inside computer architecture. What you can see on the screen
usually is not the exact value of the number. The
FLOAT and DOUBLE data
types are such, and DECIMAL operations
before MySQL 5.0.3 are approximate as well.
Prior to MySQL 5.0.3, DECIMAL columns store
values with exact precision because they are represented as
strings, but calculations on DECIMAL values
are done using floating-point operations. As of 5.0.3, MySQL
performs DECIMAL operations with a
precision of 64 decimal digits, which should solve most common
inaccuracy problems when it comes to
DECIMAL columns. (If your server is from
MySQL 5.0.3 or higher, but you have DECIMAL
columns in tables that were created before 5.0.3, the old
behavior still applies to those columns. To convert the tables
to the newer DECIMAL format, dump them with
mysqldump and reload them.)
The following example (for versions of MySQL older than 5.0.3)
demonstrates the problem. It shows that even for older
DECIMAL columns, calculations that are done
using floating-point operations are subject to floating-point
error. (Were you to replace the DECIMAL
columns with FLOAT, similar problems would
occur for all versions of MySQL.)
mysql>CREATE TABLE t1 (i INT, d1 DECIMAL(9,2), d2 DECIMAL(9,2));mysql>INSERT INTO t1 VALUES (1, 101.40, 21.40), (1, -80.00, 0.00),->(2, 0.00, 0.00), (2, -13.20, 0.00), (2, 59.60, 46.40),->(2, 30.40, 30.40), (3, 37.00, 7.40), (3, -29.60, 0.00),->(4, 60.00, 15.40), (4, -10.60, 0.00), (4, -34.00, 0.00),->(5, 33.00, 0.00), (5, -25.80, 0.00), (5, 0.00, 7.20),->(6, 0.00, 0.00), (6, -51.40, 0.00);mysql>SELECT i, SUM(d1) AS a, SUM(d2) AS b->FROM t1 GROUP BY i HAVING a <> b;+------+--------+-------+ | i | a | b | +------+--------+-------+ | 1 | 21.40 | 21.40 | | 2 | 76.80 | 76.80 | | 3 | 7.40 | 7.40 | | 4 | 15.40 | 15.40 | | 5 | 7.20 | 7.20 | | 6 | -51.40 | 0.00 | +------+--------+-------+
The result is correct. Although the first five records look
like they should not satisfy the comparison (the values of
a and b do not appear to
be different), they may do so because the difference between
the numbers shows up around the tenth decimal or so, depending
on factors such as computer architecture or the compiler
version or optimization level. For example, different CPUs may
evaluate floating-point numbers differently.
As of MySQL 5.0.3, you will get only the last row in the above result.
The problem cannot be solved by using
ROUND() or similar functions, because the
result is still a floating-point number:
mysql>SELECT i, ROUND(SUM(d1), 2) AS a, ROUND(SUM(d2), 2) AS b->FROM t1 GROUP BY i HAVING a <> b;+------+--------+-------+ | i | a | b | +------+--------+-------+ | 1 | 21.40 | 21.40 | | 2 | 76.80 | 76.80 | | 3 | 7.40 | 7.40 | | 4 | 15.40 | 15.40 | | 5 | 7.20 | 7.20 | | 6 | -51.40 | 0.00 | +------+--------+-------+
This is what the numbers in column a look
like when displayed with more decimal places:
mysql>SELECT i, ROUND(SUM(d1), 2)*1.0000000000000000 AS a,->ROUND(SUM(d2), 2) AS b FROM t1 GROUP BY i HAVING a <> b;+------+----------------------+-------+ | i | a | b | +------+----------------------+-------+ | 1 | 21.3999999999999986 | 21.40 | | 2 | 76.7999999999999972 | 76.80 | | 3 | 7.4000000000000004 | 7.40 | | 4 | 15.4000000000000004 | 15.40 | | 5 | 7.2000000000000002 | 7.20 | | 6 | -51.3999999999999986 | 0.00 | +------+----------------------+-------+
Depending on your computer architecture, you may or may not see similar results. For example, on some machines you may get the “correct” results by multiplying both arguments by 1, as the following example shows.
Warning: Never use this method in your applications. It is not an example of a trustworthy method!
mysql>SELECT i, ROUND(SUM(d1), 2)*1 AS a, ROUND(SUM(d2), 2)*1 AS b->FROM t1 GROUP BY i HAVING a <> b;+------+--------+------+ | i | a | b | +------+--------+------+ | 6 | -51.40 | 0.00 | +------+--------+------+
The reason that the preceding example seems to work is that on the particular machine where the test was done, CPU floating-point arithmetic happens to round the numbers to the same value. However, there is no rule that any CPU should do so, so this method cannot be trusted.
The correct way to do floating-point number comparison is to first decide on an acceptable tolerance for differences between the numbers and then do the comparison against the tolerance value. For example, if we agree that floating-point numbers should be regarded the same if they are same within a precision of one in ten thousand (0.0001), the comparison should be written to find differences larger than the tolerance value:
mysql>SELECT i, SUM(d1) AS a, SUM(d2) AS b FROM t1->GROUP BY i HAVING ABS(a - b) > 0.0001;+------+--------+------+ | i | a | b | +------+--------+------+ | 6 | -51.40 | 0.00 | +------+--------+------+ 1 row in set (0.00 sec)
Conversely, to get rows where the numbers are the same, the test should find differences within the tolerance value:
mysql>SELECT i, SUM(d1) AS a, SUM(d2) AS b FROM t1->GROUP BY i HAVING ABS(a - b) <= 0.0001;+------+-------+-------+ | i | a | b | +------+-------+-------+ | 1 | 21.40 | 21.40 | | 2 | 76.80 | 76.80 | | 3 | 7.40 | 7.40 | | 4 | 15.40 | 15.40 | | 5 | 7.20 | 7.20 | +------+-------+-------+
MySQL uses a cost-based optimizer to determine the best way to resolve a query. In many cases, MySQL can calculate the best possible query plan, but sometimes MySQL doesn't have enough information about the data at hand and has to make “educated” guesses about the data.
For the cases when MySQL does not do the "right" thing, tools that you have available to help MySQL are:
Use the
EXPLAINstatement to get information about how MySQL processes a query. To use it, just add the keywordEXPLAINto the front of yourSELECTstatement:mysql>
EXPLAIN SELECT * FROM t1, t2 WHERE t1.i = t2.i;EXPLAINis discussed in more detail in Section 7.2.1, “Optimizing Queries withEXPLAIN”.Use
ANALYZE TABLEto update the key distributions for the scanned table. See Section 13.5.2.1, “tbl_nameANALYZE TABLESyntax”.Use
FORCE INDEXfor the scanned table to tell MySQL that table scans are very expensive compared to using the given index:SELECT * FROM t1, t2 FORCE INDEX (index_for_column) WHERE t1.col_name=t2.col_name;
USE INDEXandIGNORE INDEXmay also be useful. See Section 13.2.7.2, “Index Hint Syntax”.Global and table-level
STRAIGHT_JOIN. See Section 13.2.7, “SELECTSyntax”.You can tune global or thread-specific system variables. For example, Start mysqld with the
--max-seeks-for-key=1000option or useSET max_seeks_for_key=1000to tell the optimizer to assume that no key scan causes more than 1,000 key seeks. See Section 5.2.3, “System Variables”.
MySQL Enterprise For expert advice on configuring MySQL servers for optimal performance, subscribe to the MySQL Network Monitoring and Advisory Service. For more information see http://www.mysql.com/products/enterprise/advisors.html.
ALTER TABLE changes a table to the current
character set. If you get a duplicate-key error during
ALTER TABLE, the cause is either that the
new character sets maps two keys to the same value or that the
table is corrupted. In the latter case, you should run
REPAIR TABLE on the table.
If ALTER TABLE dies with the following
error, the problem may be that MySQL crashed during an earlier
ALTER TABLE operation and there is an old
table named
A- or
xxxB- lying
around:
xxx
Error on rename of './database/name.frm'
to './database/B-xxx.frm' (Errcode: 17)
In this case, go to the MySQL data directory and delete all
files that have names starting with A- or
B-. (You may want to move them elsewhere
instead of deleting them.)
ALTER TABLE works in the following way:
Create a new table named
A-with the requested structural changes.xxxCopy all rows from the original table to
A-.xxxRename the original table to
B-.xxxRename
A-to your original table name.xxxDelete
B-.xxx
If something goes wrong with the renaming operation, MySQL
tries to undo the changes. If something goes seriously wrong
(although this shouldn't happen), MySQL may leave the old
table as
B-. A
simple rename of the table files at the system level should
get your data back.
xxx
If you use ALTER TABLE on a transactional
table or if you are using Windows or OS/2, ALTER
TABLE unlocks the table if you had done a
LOCK TABLE on it. This is done because
InnoDB and these operating systems cannot
drop a table that is in use.
First, consider whether you really need to change the column
order in a table. The whole point of SQL is to abstract the
application from the data storage format. You should always
specify the order in which you wish to retrieve your data. The
first of the following statements returns columns in the order
col_name1,
col_name2,
col_name3, whereas the second
returns them in the order
col_name1,
col_name3,
col_name2:
mysql>SELECTmysql>col_name1,col_name2,col_name3FROMtbl_name;SELECTcol_name1,col_name3,col_name2FROMtbl_name;
If you decide to change the order of table columns anyway, you can do so as follows:
Create a new table with the columns in the new order.
Execute this statement:
mysql>
INSERT INTO new_table->SELECT columns-in-new-order FROM old_table;Drop or rename
old_table.Rename the new table to the original name:
mysql>
ALTER TABLE new_table RENAME old_table;
SELECT * is quite suitable for testing
queries. However, in an application, you should
never rely on using SELECT
* and retrieving the columns based on their
position. The order and position in which columns are returned
does not remain the same if you add, move, or delete columns.
A simple change to your table structure could cause your
application to fail.
The following list indicates limitations on the use of
TEMPORARY tables:
A
TEMPORARYtable can only be of typeMEMORY,ISAM,MyISAM,MERGE, orInnoDB.Temporary tables are not supported for MySQL Cluster.
You cannot refer to a
TEMPORARYtable more than once in the same query. For example, the following does not work:mysql>
SELECT * FROM temp_table, temp_table AS t2;ERROR 1137: Can't reopen table: 'temp_table'The
SHOW TABLESstatement does not listTEMPORARYtables.You cannot use
RENAMEto rename aTEMPORARYtable. However, you can useALTER TABLEinstead:mysql>
ALTER TABLE orig_name RENAME new_name;There are known issues in using temporary tables with replication. See Section 6.7, “Replication Features and Known Problems”, for more information.
This section is a list of the known issues in recent versions of MySQL.
For information about platform-specific issues, see the installation and porting instructions in Section 2.4.18, “Operating System-Specific Notes”, and MySQL Internals: Porting.
The following problems are known and fixing them is a high priority:
If you compare a
NULLvalue to a subquery usingALL/ANY/SOMEand the subquery returns an empty result, the comparison might evaluate to the non-standard result ofNULLrather than toTRUEorFALSE. This will be fixed in MySQL 5.1.Subquery optimization for
INis not as effective as for=.Even if you use
lower_case_table_names=2(which enables MySQL to remember the case used for databases and table names), MySQL does not remember the case used for database names for the functionDATABASE()or within the various logs (on case-insensitive systems).Dropping a
FOREIGN KEYconstraint doesn't work in replication because the constraint may have another name on the slave.REPLACE(andLOAD DATAwith theREPLACEoption) does not triggerON DELETE CASCADE.DISTINCTwithORDER BYdoesn't work insideGROUP_CONCAT()if you don't use all and only those columns that are in theDISTINCTlist.If one user has a long-running transaction and another user drops a table that is updated in the transaction, there is small chance that the binary log may contain the
DROP TABLEcommand before the table is used in the transaction itself. We plan to fix this by having theDROP TABLEcommand wait until the table is not being used in any transaction.When inserting a big integer value (between 263 and 264–1) into a decimal or string column, it is inserted as a negative value because the number is evaluated in a signed integer context.
FLUSH TABLES WITH READ LOCKdoes not blockCOMMITif the server is running without binary logging, which may cause a problem (of consistency between tables) when doing a full backup.ANALYZE TABLEon aBDBtable may in some cases make the table unusable until you restart mysqld. If this happens, look for errors of the following form in the MySQL error file:001207 22:07:56 bdb: log_flush: LSN past current end-of-log
Don't execute
ALTER TABLEon aBDBtable on which you are running multiple-statement transactions until all those transactions complete. (The transaction might be ignored.)ANALYZE TABLE,OPTIMIZE TABLE, andREPAIR TABLEmay cause problems on tables for which you are usingINSERT DELAYED.Performing
LOCK TABLE ...andFLUSH TABLES ...doesn't guarantee that there isn't a half-finished transaction in progress on the table.BDBtables are relatively slow to open. If you have manyBDBtables in a database, it takes a long time to use the mysql client on the database if you are not using the-Aoption or if you are usingrehash. This is especially noticeable when you have a large table cache.Replication uses query-level logging: The master writes the executed queries to the binary log. This is a very fast, compact, and efficient logging method that works perfectly in most cases.
It is possible for the data on the master and slave to become different if a query is designed in such a way that the data modification is non-deterministic (generally not a recommended practice, even outside of replication).
For example:
CREATE ... SELECTorINSERT ... SELECTstatements that insert zero orNULLvalues into anAUTO_INCREMENTcolumn.DELETEif you are deleting rows from a table that has foreign keys withON DELETE CASCADEproperties.REPLACE ... SELECT,INSERT IGNORE ... SELECTif you have duplicate key values in the inserted data.
If and only if the preceding queries have no
ORDER BYclause guaranteeing a deterministic order.For example, for
INSERT ... SELECTwith noORDER BY, theSELECTmay return rows in a different order (which results in a row having different ranks, hence getting a different number in theAUTO_INCREMENTcolumn), depending on the choices made by the optimizers on the master and slave.A query is optimized differently on the master and slave only if:
The table is stored using a different storage engine on the master than on the slave. (It is possible to use different storage engines on the master and slave. For example, you can use
InnoDBon the master, butMyISAMon the slave if the slave has less available disk space.)MySQL buffer sizes (
key_buffer_size, and so on) are different on the master and slave.The master and slave run different MySQL versions, and the optimizer code differs between these versions.
This problem may also affect database restoration using mysqlbinlog|mysql.
The easiest way to avoid this problem is to add an
ORDER BYclause to the aforementioned non-deterministic queries to ensure that the rows are always stored or modified in the same order.In future MySQL versions, we will automatically add an
ORDER BYclause when needed.
The following issues are known and will be fixed in due time:
Log filenames are based on the server hostname (if you don't specify a filename with the startup option). You have to use options such as
--log-bin=if you change your hostname to something else. Another option is to rename the old files to reflect your hostname change (if these are binary logs, you need to edit the binary log index file and fix the binlog names there as well). See Section 5.2.2, “Command Options”.old_host_name-binmysqlbinlog does not delete temporary files left after a
LOAD DATA INFILEcommand. See Section 8.11, “mysqlbinlog — Utility for Processing Binary Log Files”.RENAMEdoesn't work withTEMPORARYtables or tables used in aMERGEtable.Due to the way table format (
.frm) files are stored, you cannot use character 255 (CHAR(255)) in table names, column names, or enumerations. This is scheduled to be fixed in version 5.1 when we implement new table definition format files.When using
SET CHARACTER SET, you can't use translated characters in database, table, and column names.You can't use ‘
_’ or ‘%’ withESCAPEinLIKE ... ESCAPE.If you have a
DECIMALcolumn in which the same number is stored in different formats (for example,+01.00,1.00,01.00),GROUP BYmay regard each value as a different value.You cannot build the server in another directory when using MIT-pthreads. Because this requires changes to MIT-pthreads, we are not likely to fix this. See Section 2.4.14.5, “MIT-pthreads Notes”.
BLOBandTEXTvalues can't reliably be used inGROUP BY,ORDER BYorDISTINCT. Only the firstmax_sort_lengthbytes are used when comparingBLOBvalues in these cases. The default value ofmax_sort_lengthis 1024 and can be changed at server startup time or at runtime.Numeric calculations are done with
BIGINTorDOUBLE(both are normally 64 bits long). Which precision you get depends on the function. The general rule is that bit functions are performed withBIGINTprecision,IFandELT()withBIGINTorDOUBLEprecision, and the rest withDOUBLEprecision. You should try to avoid using unsigned long long values if they resolve to be larger than 63 bits (9223372036854775807) for anything other than bit fields.You can have up to 255
ENUMandSETcolumns in one table.In
MIN(),MAX(), and other aggregate functions, MySQL currently comparesENUMandSETcolumns by their string value rather than by the string's relative position in the set.mysqld_safe redirects all messages from mysqld to the mysqld log. One problem with this is that if you execute mysqladmin refresh to close and reopen the log,
stdoutandstderrare still redirected to the old log. If you use--logextensively, you should edit mysqld_safe to log tohost_name.errhost_name.logIn an
UPDATEstatement, columns are updated from left to right. If you refer to an updated column, you get the updated value instead of the original value. For example, the following statement incrementsKEYby2, not1:mysql>
UPDATEtbl_nameSET KEY=KEY+1,KEY=KEY+1;You can refer to multiple temporary tables in the same query, but you cannot refer to any given temporary table more than once. For example, the following doesn't work:
mysql>
SELECT * FROM temp_table, temp_table AS t2;ERROR 1137: Can't reopen table: 'temp_table'The optimizer may handle
DISTINCTdifferently when you are using “hidden” columns in a join than when you are not. In a join, hidden columns are counted as part of the result (even if they are not shown), whereas in normal queries, hidden columns don't participate in theDISTINCTcomparison. We will probably change this in the future to never compare the hidden columns when executingDISTINCT.An example of this is:
SELECT DISTINCT mp3id FROM band_downloads WHERE userid = 9 ORDER BY id DESC;and
SELECT DISTINCT band_downloads.mp3id FROM band_downloads,band_mp3 WHERE band_downloads.userid = 9 AND band_mp3.id = band_downloads.mp3id ORDER BY band_downloads.id DESC;In the second case, using MySQL Server 3.23.x, you may get two identical rows in the result set (because the values in the hidden
idcolumn may differ).Note that this happens only for queries where that do not have the
ORDER BYcolumns in the result.If you execute a
PROCEDUREon a query that returns an empty set, in some cases thePROCEDUREdoes not transform the columns.Creation of a table of type
MERGEdoesn't check whether the underlying tables are compatible types.If you use
ALTER TABLEto add aUNIQUEindex to a table used in aMERGEtable and then add a normal index on theMERGEtable, the key order is different for the tables if there was an old, non-UNIQUEkey in the table. This is becauseALTER TABLEputsUNIQUEindexes before normal indexes to be able to detect duplicate keys as early as possible.
MySQL programs have access to several types of error information when the server returns an error. For example, the mysql client program displays errors using the following format:
shell> SELECT * FROM no_such_table;
ERROR 1146 (42S02): Table 'test.no_such_table' doesn't exist
The message displayed contains three types of information:
A numeric error value (
1146). This number is MySQL-specific and is not portable to other database systems.A five-character SQLSTATE value (
'42S02'). The values are specified by ANSI SQL and ODBC and are more standardized. Not all MySQL error numbers are mapped to SQLSTATE error codes. The value'HY000'(general error) is used for unmapped errors.A string that provides a textual description of the error.
Server error information comes from the following source files. For details about the way that error information is defined, see the MySQL Internals manual, available at http://dev.mysql.com/doc/.
Error message information is listed in the
share/errmsg.txtfile.%dand%srepresent numbers and strings, respectively, that are substituted into the Message values when they are displayed.The Error values listed in
share/errmsg.txtare used to generate the definitions in theinclude/mysqld_error.handinclude/mysqld_ername.hMySQL source files.The SQLSTATE values listed in
share/errmsg.txtare used to generate the definitions in theinclude/sql_state.hMySQL source file.
Because updates are frequent, it is possible that those files will contain additional error information not listed here.
Error:
1000SQLSTATE:HY000(ER_HASHCHK)Message: hashchk
Error:
1001SQLSTATE:HY000(ER_NISAMCHK)Message: isamchk
Error:
1002SQLSTATE:HY000(ER_NO)Message: NO
Error:
1003SQLSTATE:HY000(ER_YES)Message: YES
Error:
1004SQLSTATE:HY000(ER_CANT_CREATE_FILE)Message: Can't create file '%s' (errno: %d)
Error:
1005SQLSTATE:HY000(ER_CANT_CREATE_TABLE)Message: Can't create table '%s' (errno: %d)
Error:
1006SQLSTATE:HY000(ER_CANT_CREATE_DB)Message: Can't create database '%s' (errno: %d)
Error:
1007SQLSTATE:HY000(ER_DB_CREATE_EXISTS)Message: Can't create database '%s'; database exists
Error:
1008SQLSTATE:HY000(ER_DB_DROP_EXISTS)Message: Can't drop database '%s'; database doesn't exist
Error:
1009SQLSTATE:HY000(ER_DB_DROP_DELETE)Message: Error dropping database (can't delete '%s', errno: %d)
Error:
1010SQLSTATE:HY000(ER_DB_DROP_RMDIR)Message: Error dropping database (can't rmdir '%s', errno: %d)
Error:
1011SQLSTATE:HY000(ER_CANT_DELETE_FILE)Message: Error on delete of '%s' (errno: %d)
Error:
1012SQLSTATE:HY000(ER_CANT_FIND_SYSTEM_REC)Message: Can't read record in system table
Error:
1013SQLSTATE:HY000(ER_CANT_GET_STAT)Message: Can't get status of '%s' (errno: %d)
Error:
1014SQLSTATE:HY000(ER_CANT_GET_WD)Message: Can't get working directory (errno: %d)
Error:
1015SQLSTATE:HY000(ER_CANT_LOCK)Message: Can't lock file (errno: %d)
Error:
1016SQLSTATE:HY000(ER_CANT_OPEN_FILE)Message: Can't open file: '%s' (errno: %d)
Error:
1017SQLSTATE:HY000(ER_FILE_NOT_FOUND)Message: Can't find file: '%s' (errno: %d)
Error:
1018SQLSTATE:HY000(ER_CANT_READ_DIR)Message: Can't read dir of '%s' (errno: %d)
Error:
1019SQLSTATE:HY000(ER_CANT_SET_WD)Message: Can't change dir to '%s' (errno: %d)
Error:
1020SQLSTATE:HY000(ER_CHECKREAD)Message: Record has changed since last read in table '%s'
Error:
1021SQLSTATE:HY000(ER_DISK_FULL)Message: Disk full (%s); waiting for someone to free some space...
Error:
1022SQLSTATE:23000(ER_DUP_KEY)Message: Can't write; duplicate key in table '%s'
Error:
1023SQLSTATE:HY000(ER_ERROR_ON_CLOSE)Message: Error on close of '%s' (errno: %d)
Error:
1024SQLSTATE:HY000(ER_ERROR_ON_READ)Message: Error reading file '%s' (errno: %d)
Error:
1025SQLSTATE:HY000(ER_ERROR_ON_RENAME)Message: Error on rename of '%s' to '%s' (errno: %d)
Error:
1026SQLSTATE:HY000(ER_ERROR_ON_WRITE)Message: Error writing file '%s' (errno: %d)
Error:
1027SQLSTATE:HY000(ER_FILE_USED)Message: '%s' is locked against change
Error:
1028SQLSTATE:HY000(ER_FILSORT_ABORT)Message: Sort aborted
Error:
1029SQLSTATE:HY000(ER_FORM_NOT_FOUND)Message: View '%s' doesn't exist for '%s'
Error:
1030SQLSTATE:HY000(ER_GET_ERRNO)Message: Got error %d from storage engine
Error:
1031SQLSTATE:HY000(ER_ILLEGAL_HA)Message: Table storage engine for '%s' doesn't have this option
Error:
1032SQLSTATE:HY000(ER_KEY_NOT_FOUND)Message: Can't find record in '%s'
Error:
1033SQLSTATE:HY000(ER_NOT_FORM_FILE)Message: Incorrect information in file: '%s'
Error:
1034SQLSTATE:HY000(ER_NOT_KEYFILE)Message: Incorrect key file for table '%s'; try to repair it
Error:
1035SQLSTATE:HY000(ER_OLD_KEYFILE)Message: Old key file for table '%s'; repair it!
Error:
1036SQLSTATE:HY000(ER_OPEN_AS_READONLY)Message: Table '%s' is read only
Error:
1037SQLSTATE:HY001(ER_OUTOFMEMORY)Message: Out of memory; restart server and try again (needed %d bytes)
Error:
1038SQLSTATE:HY001(ER_OUT_OF_SORTMEMORY)Message: Out of sort memory; increase server sort buffer size
Error:
1039SQLSTATE:HY000(ER_UNEXPECTED_EOF)Message: Unexpected EOF found when reading file '%s' (errno: %d)
Error:
1040SQLSTATE:08004(ER_CON_COUNT_ERROR)Message: Too many connections
Error:
1041SQLSTATE:HY000(ER_OUT_OF_RESOURCES)Message: Out of memory; check if mysqld or some other process uses all available memory; if not, you may have to use 'ulimit' to allow mysqld to use more memory or you can add more swap space
Error:
1042SQLSTATE:08S01(ER_BAD_HOST_ERROR)Message: Can't get hostname for your address
Error:
1043SQLSTATE:08S01(ER_HANDSHAKE_ERROR)Message: Bad handshake
Error:
1044SQLSTATE:42000(ER_DBACCESS_DENIED_ERROR)Message: Access denied for user '%s'@'%s' to database '%s'
Error:
1045SQLSTATE:28000(ER_ACCESS_DENIED_ERROR)Message: Access denied for user '%s'@'%s' (using password: %s)
Error:
1046SQLSTATE:3D000(ER_NO_DB_ERROR)Message: No database selected
Error:
1047SQLSTATE:08S01(ER_UNKNOWN_COM_ERROR)Message: Unknown command
Error:
1048SQLSTATE:23000(ER_BAD_NULL_ERROR)Message: Column '%s' cannot be null
Error:
1049SQLSTATE:42000(ER_BAD_DB_ERROR)Message: Unknown database '%s'
Error:
1050SQLSTATE:42S01(ER_TABLE_EXISTS_ERROR)Message: Table '%s' already exists
Error:
1051SQLSTATE:42S02(ER_BAD_TABLE_ERROR)Message: Unknown table '%s'
Error:
1052SQLSTATE:23000(ER_NON_UNIQ_ERROR)Message: Column '%s' in %s is ambiguous
Error:
1053SQLSTATE:08S01(ER_SERVER_SHUTDOWN)Message: Server shutdown in progress
Error:
1054SQLSTATE:42S22(ER_BAD_FIELD_ERROR)Message: Unknown column '%s' in '%s'
Error:
1055SQLSTATE:42000(ER_WRONG_FIELD_WITH_GROUP)Message: '%s' isn't in GROUP BY
Error:
1056SQLSTATE:42000(ER_WRONG_GROUP_FIELD)Message: Can't group on '%s'
Error:
1057SQLSTATE:42000(ER_WRONG_SUM_SELECT)Message: Statement has sum functions and columns in same statement
Error:
1058SQLSTATE:21S01(ER_WRONG_VALUE_COUNT)Message: Column count doesn't match value count
Error:
1059SQLSTATE:42000(ER_TOO_LONG_IDENT)Message: Identifier name '%s' is too long
Error:
1060SQLSTATE:42S21(ER_DUP_FIELDNAME)Message: Duplicate column name '%s'
Error:
1061SQLSTATE:42000(ER_DUP_KEYNAME)Message: Duplicate key name '%s'
Error:
1062SQLSTATE:23000(ER_DUP_ENTRY)Message: Duplicate entry '%s' for key %d
Error:
1063SQLSTATE:42000(ER_WRONG_FIELD_SPEC)Message: Incorrect column specifier for column '%s'
Error:
1064SQLSTATE:42000(ER_PARSE_ERROR)Message: %s near '%s' at line %d
Error:
1065SQLSTATE:42000(ER_EMPTY_QUERY)Message: Query was empty
Error:
1066SQLSTATE:42000(ER_NONUNIQ_TABLE)Message: Not unique table/alias: '%s'
Error:
1067SQLSTATE:42000(ER_INVALID_DEFAULT)Message: Invalid default value for '%s'
Error:
1068SQLSTATE:42000(ER_MULTIPLE_PRI_KEY)Message: Multiple primary key defined
Error:
1069SQLSTATE:42000(ER_TOO_MANY_KEYS)Message: Too many keys specified; max %d keys allowed
Error:
1070SQLSTATE:42000(ER_TOO_MANY_KEY_PARTS)Message: Too many key parts specified; max %d parts allowed
Error:
1071SQLSTATE:42000(ER_TOO_LONG_KEY)Message: Specified key was too long; max key length is %d bytes
Error:
1072SQLSTATE:42000(ER_KEY_COLUMN_DOES_NOT_EXITS)Message: Key column '%s' doesn't exist in table
Error:
1073SQLSTATE:42000(ER_BLOB_USED_AS_KEY)Message: BLOB column '%s' can't be used in key specification with the used table type
Error:
1074SQLSTATE:42000(ER_TOO_BIG_FIELDLENGTH)Message: Column length too big for column '%s' (max = %d); use BLOB or TEXT instead
Error:
1075SQLSTATE:42000(ER_WRONG_AUTO_KEY)Message: Incorrect table definition; there can be only one auto column and it must be defined as a key
Error:
1076SQLSTATE:HY000(ER_READY)Message: %s: ready for connections. Version: '%s' socket: '%s' port: %d
Error:
1077SQLSTATE:HY000(ER_NORMAL_SHUTDOWN)Message: %s: Normal shutdown
Error:
1078SQLSTATE:HY000(ER_GOT_SIGNAL)Message: %s: Got signal %d. Aborting!
Error:
1079SQLSTATE:HY000(ER_SHUTDOWN_COMPLETE)Message: %s: Shutdown complete
Error:
1080SQLSTATE:08S01(ER_FORCING_CLOSE)Message: %s: Forcing close of thread %ld user: '%s'
Error:
1081SQLSTATE:08S01(ER_IPSOCK_ERROR)Message: Can't create IP socket
Error:
1082SQLSTATE:42S12(ER_NO_SUCH_INDEX)Message: Table '%s' has no index like the one used in CREATE INDEX; recreate the table
Error:
1083SQLSTATE:42000(ER_WRONG_FIELD_TERMINATORS)Message: Field separator argument is not what is expected; check the manual
Error:
1084SQLSTATE:42000(ER_BLOBS_AND_NO_TERMINATED)Message: You can't use fixed rowlength with BLOBs; please use 'fields terminated by'
Error:
1085SQLSTATE:HY000(ER_TEXTFILE_NOT_READABLE)Message: The file '%s' must be in the database directory or be readable by all
Error:
1086SQLSTATE:HY000(ER_FILE_EXISTS_ERROR)Message: File '%s' already exists
Error:
1087SQLSTATE:HY000(ER_LOAD_INFO)Message: Records: %ld Deleted: %ld Skipped: %ld Warnings: %ld
Error:
1088SQLSTATE:HY000(ER_ALTER_INFO)Message: Records: %ld Duplicates: %ld
Error:
1089SQLSTATE:HY000(ER_WRONG_SUB_KEY)Message: Incorrect sub part key; the used key part isn't a string, the used length is longer than the key part, or the storage engine doesn't support unique sub keys
Error:
1090SQLSTATE:42000(ER_CANT_REMOVE_ALL_FIELDS)Message: You can't delete all columns with ALTER TABLE; use DROP TABLE instead
Error:
1091SQLSTATE:42000(ER_CANT_DROP_FIELD_OR_KEY)Message: Can't DROP '%s'; check that column/key exists
Error:
1092SQLSTATE:HY000(ER_INSERT_INFO)Message: Records: %ld Duplicates: %ld Warnings: %ld
Error:
1093SQLSTATE:HY000(ER_UPDATE_TABLE_USED)Message: You can't specify target table '%s' for update in FROM clause
Error:
1094SQLSTATE:HY000(ER_NO_SUCH_THREAD)Message: Unknown thread id: %lu
Error:
1095SQLSTATE:HY000(ER_KILL_DENIED_ERROR)Message: You are not owner of thread %lu
Error:
1096SQLSTATE:HY000(ER_NO_TABLES_USED)Message: No tables used
Error:
1097SQLSTATE:HY000(ER_TOO_BIG_SET)Message: Too many strings for column %s and SET
Error:
1098SQLSTATE:HY000(ER_NO_UNIQUE_LOGFILE)Message: Can't generate a unique log-filename %s.(1-999)
Error:
1099SQLSTATE:HY000(ER_TABLE_NOT_LOCKED_FOR_WRITE)Message: Table '%s' was locked with a READ lock and can't be updated
Error:
1100SQLSTATE:HY000(ER_TABLE_NOT_LOCKED)Message: Table '%s' was not locked with LOCK TABLES
Error:
1101SQLSTATE:42000(ER_BLOB_CANT_HAVE_DEFAULT)Message: BLOB/TEXT column '%s' can't have a default value
Error:
1102SQLSTATE:42000(ER_WRONG_DB_NAME)Message: Incorrect database name '%s'
Error:
1103SQLSTATE:42000(ER_WRONG_TABLE_NAME)Message: Incorrect table name '%s'
Error:
1104SQLSTATE:42000(ER_TOO_BIG_SELECT)Message: The SELECT would examine more than MAX_JOIN_SIZE rows; check your WHERE and use SET SQL_BIG_SELECTS=1 or SET SQL_MAX_JOIN_SIZE=# if the SELECT is okay
Error:
1105SQLSTATE:HY000(ER_UNKNOWN_ERROR)Message: Unknown error
Error:
1106SQLSTATE:42000(ER_UNKNOWN_PROCEDURE)Message: Unknown procedure '%s'
Error:
1107SQLSTATE:42000(ER_WRONG_PARAMCOUNT_TO_PROCEDURE)Message: Incorrect parameter count to procedure '%s'
Error:
1108SQLSTATE:HY000(ER_WRONG_PARAMETERS_TO_PROCEDURE)Message: Incorrect parameters to procedure '%s'
Error:
1109SQLSTATE:42S02(ER_UNKNOWN_TABLE)Message: Unknown table '%s' in %s
Error:
1110SQLSTATE:42000(ER_FIELD_SPECIFIED_TWICE)Message: Column '%s' specified twice
Error:
1111SQLSTATE:HY000(ER_INVALID_GROUP_FUNC_USE)Message: Invalid use of group function
Error:
1112SQLSTATE:42000(ER_UNSUPPORTED_EXTENSION)Message: Table '%s' uses an extension that doesn't exist in this MySQL version
Error:
1113SQLSTATE:42000(ER_TABLE_MUST_HAVE_COLUMNS)Message: A table must have at least 1 column
Error:
1114SQLSTATE:HY000(ER_RECORD_FILE_FULL)Message: The table '%s' is full
Error:
1115SQLSTATE:42000(ER_UNKNOWN_CHARACTER_SET)Message: Unknown character set: '%s'
Error:
1116SQLSTATE:HY000(ER_TOO_MANY_TABLES)Message: Too many tables; MySQL can only use %d tables in a join
Error:
1117SQLSTATE:HY000(ER_TOO_MANY_FIELDS)Message: Too many columns
Error:
1118SQLSTATE:42000(ER_TOO_BIG_ROWSIZE)Message: Row size too large. The maximum row size for the used table type, not counting BLOBs, is %ld. You have to change some columns to TEXT or BLOBs
Error:
1119SQLSTATE:HY000(ER_STACK_OVERRUN)Message: Thread stack overrun: Used: %ld of a %ld stack. Use 'mysqld -O thread_stack=#' to specify a bigger stack if needed
Error:
1120SQLSTATE:42000(ER_WRONG_OUTER_JOIN)Message: Cross dependency found in OUTER JOIN; examine your ON conditions
Error:
1121SQLSTATE:42000(ER_NULL_COLUMN_IN_INDEX)Message: Column '%s' is used with UNIQUE or INDEX but is not defined as NOT NULL
Error:
1122SQLSTATE:HY000(ER_CANT_FIND_UDF)Message: Can't load function '%s'
Error:
1123SQLSTATE:HY000(ER_CANT_INITIALIZE_UDF)Message: Can't initialize function '%s'; %s
Error:
1124SQLSTATE:HY000(ER_UDF_NO_PATHS)Message: No paths allowed for shared library
Error:
1125SQLSTATE:HY000(ER_UDF_EXISTS)Message: Function '%s' already exists
Error:
1126SQLSTATE:HY000(ER_CANT_OPEN_LIBRARY)Message: Can't open shared library '%s' (errno: %d %s)
Error:
1127SQLSTATE:HY000(ER_CANT_FIND_DL_ENTRY)Message: Can't find function '%s' in library
Error:
1128SQLSTATE:HY000(ER_FUNCTION_NOT_DEFINED)Message: Function '%s' is not defined
Error:
1129SQLSTATE:HY000(ER_HOST_IS_BLOCKED)Message: Host '%s' is blocked because of many connection errors; unblock with 'mysqladmin flush-hosts'
Error:
1130SQLSTATE:HY000(ER_HOST_NOT_PRIVILEGED)Message: Host '%s' is not allowed to connect to this MySQL server
Error:
1131SQLSTATE:42000(ER_PASSWORD_ANONYMOUS_USER)Message: You are using MySQL as an anonymous user and anonymous users are not allowed to change passwords
Error:
1132SQLSTATE:42000(ER_PASSWORD_NOT_ALLOWED)Message: You must have privileges to update tables in the mysql database to be able to change passwords for others
Error:
1133SQLSTATE:42000(ER_PASSWORD_NO_MATCH)Message: Can't find any matching row in the user table
Error:
1134SQLSTATE:HY000(ER_UPDATE_INFO)Message: Rows matched: %ld Changed: %ld Warnings: %ld
Error:
1135SQLSTATE:HY000(ER_CANT_CREATE_THREAD)Message: Can't create a new thread (errno %d); if you are not out of available memory, you can consult the manual for a possible OS-dependent bug
Error:
1136SQLSTATE:21S01(ER_WRONG_VALUE_COUNT_ON_ROW)Message: Column count doesn't match value count at row %ld
Error:
1137SQLSTATE:HY000(ER_CANT_REOPEN_TABLE)Message: Can't reopen table: '%s'
Error:
1138SQLSTATE:22004(ER_INVALID_USE_OF_NULL)Message: Invalid use of NULL value
Error:
1139SQLSTATE:42000(ER_REGEXP_ERROR)Message: Got error '%s' from regexp
Error:
1140SQLSTATE:42000(ER_MIX_OF_GROUP_FUNC_AND_FIELDS)Message: Mixing of GROUP columns (MIN(),MAX(),COUNT(),...) with no GROUP columns is illegal if there is no GROUP BY clause
Error:
1141SQLSTATE:42000(ER_NONEXISTING_GRANT)Message: There is no such grant defined for user '%s' on host '%s'
Error:
1142SQLSTATE:42000(ER_TABLEACCESS_DENIED_ERROR)Message: %s command denied to user '%s'@'%s' for table '%s'
Error:
1143SQLSTATE:42000(ER_COLUMNACCESS_DENIED_ERROR)Message: %s command denied to user '%s'@'%s' for column '%s' in table '%s'
Error:
1144SQLSTATE:42000(ER_ILLEGAL_GRANT_FOR_TABLE)Message: Illegal GRANT/REVOKE command; please consult the manual to see which privileges can be used
Error:
1145SQLSTATE:42000(ER_GRANT_WRONG_HOST_OR_USER)Message: The host or user argument to GRANT is too long
Error:
1146SQLSTATE:42S02(ER_NO_SUCH_TABLE)Message: Table '%s.%s' doesn't exist
Error:
1147SQLSTATE:42000(ER_NONEXISTING_TABLE_GRANT)Message: There is no such grant defined for user '%s' on host '%s' on table '%s'
Error:
1148SQLSTATE:42000(ER_NOT_ALLOWED_COMMAND)Message: The used command is not allowed with this MySQL version
Error:
1149SQLSTATE:42000(ER_SYNTAX_ERROR)Message: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use
Error:
1150SQLSTATE:HY000(ER_DELAYED_CANT_CHANGE_LOCK)Message: Delayed insert thread couldn't get requested lock for table %s
Error:
1151SQLSTATE:HY000(ER_TOO_MANY_DELAYED_THREADS)Message: Too many delayed threads in use
Error:
1152SQLSTATE:08S01(ER_ABORTING_CONNECTION)Message: Aborted connection %ld to db: '%s' user: '%s' (%s)
Error:
1153SQLSTATE:08S01(ER_NET_PACKET_TOO_LARGE)Message: Got a packet bigger than 'max_allowed_packet' bytes
Error:
1154SQLSTATE:08S01(ER_NET_READ_ERROR_FROM_PIPE)Message: Got a read error from the connection pipe
Error:
1155SQLSTATE:08S01(ER_NET_FCNTL_ERROR)Message: Got an error from fcntl()
Error:
1156SQLSTATE:08S01(ER_NET_PACKETS_OUT_OF_ORDER)Message: Got packets out of order
Error:
1157SQLSTATE:08S01(ER_NET_UNCOMPRESS_ERROR)Message: Couldn't uncompress communication packet
Error:
1158SQLSTATE:08S01(ER_NET_READ_ERROR)Message: Got an error reading communication packets
Error:
1159SQLSTATE:08S01(ER_NET_READ_INTERRUPTED)Message: Got timeout reading communication packets
Error:
1160SQLSTATE:08S01(ER_NET_ERROR_ON_WRITE)Message: Got an error writing communication packets
Error:
1161SQLSTATE:08S01(ER_NET_WRITE_INTERRUPTED)Message: Got timeout writing communication packets
Error:
1162SQLSTATE:42000(ER_TOO_LONG_STRING)Message: Result string is longer than 'max_allowed_packet' bytes
Error:
1163SQLSTATE:42000(ER_TABLE_CANT_HANDLE_BLOB)Message: The used table type doesn't support BLOB/TEXT columns
Error:
1164SQLSTATE:42000(ER_TABLE_CANT_HANDLE_AUTO_INCREMENT)Message: The used table type doesn't support AUTO_INCREMENT columns
Error:
1165SQLSTATE:HY000(ER_DELAYED_INSERT_TABLE_LOCKED)Message: INSERT DELAYED can't be used with table '%s' because it is locked with LOCK TABLES
Error:
1166SQLSTATE:42000(ER_WRONG_COLUMN_NAME)Message: Incorrect column name '%s'
Error:
1167SQLSTATE:42000(ER_WRONG_KEY_COLUMN)Message: The used storage engine can't index column '%s'
Error:
1168SQLSTATE:HY000(ER_WRONG_MRG_TABLE)Message: Unable to open underlying table which is differently defined or of non-MyISAM type or doesn't exist
Error:
1169SQLSTATE:23000(ER_DUP_UNIQUE)Message: Can't write, because of unique constraint, to table '%s'
Error:
1170SQLSTATE:42000(ER_BLOB_KEY_WITHOUT_LENGTH)Message: BLOB/TEXT column '%s' used in key specification without a key length
Error:
1171SQLSTATE:42000(ER_PRIMARY_CANT_HAVE_NULL)Message: All parts of a PRIMARY KEY must be NOT NULL; if you need NULL in a key, use UNIQUE instead
Error:
1172SQLSTATE:42000(ER_TOO_MANY_ROWS)Message: Result consisted of more than one row
Error:
1173SQLSTATE:42000(ER_REQUIRES_PRIMARY_KEY)Message: This table type requires a primary key
Error:
1174SQLSTATE:HY000(ER_NO_RAID_COMPILED)Message: This version of MySQL is not compiled with RAID support
Error:
1175SQLSTATE:HY000(ER_UPDATE_WITHOUT_KEY_IN_SAFE_MODE)Message: You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column
Error:
1176SQLSTATE:HY000(ER_KEY_DOES_NOT_EXITS)Message: Key '%s' doesn't exist in table '%s'
Error:
1177SQLSTATE:42000(ER_CHECK_NO_SUCH_TABLE)Message: Can't open table
Error:
1178SQLSTATE:42000(ER_CHECK_NOT_IMPLEMENTED)Message: The storage engine for the table doesn't support %s
Error:
1179SQLSTATE:25000(ER_CANT_DO_THIS_DURING_AN_TRANSACTION)Message: You are not allowed to execute this command in a transaction
Error:
1180SQLSTATE:HY000(ER_ERROR_DURING_COMMIT)Message: Got error %d during COMMIT
Error:
1181SQLSTATE:HY000(ER_ERROR_DURING_ROLLBACK)Message: Got error %d during ROLLBACK
Error:
1182SQLSTATE:HY000(ER_ERROR_DURING_FLUSH_LOGS)Message: Got error %d during FLUSH_LOGS
Error:
1183SQLSTATE:HY000(ER_ERROR_DURING_CHECKPOINT)Message: Got error %d during CHECKPOINT
Error:
1184SQLSTATE:08S01(ER_NEW_ABORTING_CONNECTION)Message: Aborted connection %ld to db: '%s' user: '%s' host: '%s' (%s)
Error:
1185SQLSTATE:HY000(ER_DUMP_NOT_IMPLEMENTED)Message: The storage engine for the table does not support binary table dump
Error:
1186SQLSTATE:HY000(ER_FLUSH_MASTER_BINLOG_CLOSED)Message: Binlog closed, cannot RESET MASTER
Error:
1187SQLSTATE:HY000(ER_INDEX_REBUILD)Message: Failed rebuilding the index of dumped table '%s'
Error:
1188SQLSTATE:HY000(ER_MASTER)Message: Error from master: '%s'
Error:
1189SQLSTATE:08S01(ER_MASTER_NET_READ)Message: Net error reading from master
Error:
1190SQLSTATE:08S01(ER_MASTER_NET_WRITE)Message: Net error writing to master
Error:
1191SQLSTATE:HY000(ER_FT_MATCHING_KEY_NOT_FOUND)Message: Can't find FULLTEXT index matching the column list
Error:
1192SQLSTATE:HY000(ER_LOCK_OR_ACTIVE_TRANSACTION)Message: Can't execute the given command because you have active locked tables or an active transaction
Error:
1193SQLSTATE:HY000(ER_UNKNOWN_SYSTEM_VARIABLE)Message: Unknown system variable '%s'
Error:
1194SQLSTATE:HY000(ER_CRASHED_ON_USAGE)Message: Table '%s' is marked as crashed and should be repaired
Error:
1195SQLSTATE:HY000(ER_CRASHED_ON_REPAIR)Message: Table '%s' is marked as crashed and last (automatic?) repair failed
Error:
1196SQLSTATE:HY000(ER_WARNING_NOT_COMPLETE_ROLLBACK)Message: Some non-transactional changed tables couldn't be rolled back
Error:
1197SQLSTATE:HY000(ER_TRANS_CACHE_FULL)Message: Multi-statement transaction required more than 'max_binlog_cache_size' bytes of storage; increase this mysqld variable and try again
Error:
1198SQLSTATE:HY000(ER_SLAVE_MUST_STOP)Message: This operation cannot be performed with a running slave; run STOP SLAVE first
Error:
1199SQLSTATE:HY000(ER_SLAVE_NOT_RUNNING)Message: This operation requires a running slave; configure slave and do START SLAVE
Error:
1200SQLSTATE:HY000(ER_BAD_SLAVE)Message: The server is not configured as slave; fix in config file or with CHANGE MASTER TO
Error:
1201SQLSTATE:HY000(ER_MASTER_INFO)Message: Could not initialize master info structure; more error messages can be found in the MySQL error log
Error:
1202SQLSTATE:HY000(ER_SLAVE_THREAD)Message: Could not create slave thread; check system resources
Error:
1203SQLSTATE:42000(ER_TOO_MANY_USER_CONNECTIONS)Message: User %s already has more than 'max_user_connections' active connections
Error:
1204SQLSTATE:HY000(ER_SET_CONSTANTS_ONLY)Message: You may only use constant expressions with SET
Error:
1205SQLSTATE:HY000(ER_LOCK_WAIT_TIMEOUT)Message: Lock wait timeout exceeded; try restarting transaction
Error:
1206SQLSTATE:HY000(ER_LOCK_TABLE_FULL)Message: The total number of locks exceeds the lock table size
Error:
1207SQLSTATE:25000(ER_READ_ONLY_TRANSACTION)Message: Update locks cannot be acquired during a READ UNCOMMITTED transaction
Error:
1208SQLSTATE:HY000(ER_DROP_DB_WITH_READ_LOCK)Message: DROP DATABASE not allowed while thread is holding global read lock
Error:
1209SQLSTATE:HY000(ER_CREATE_DB_WITH_READ_LOCK)Message: CREATE DATABASE not allowed while thread is holding global read lock
Error:
1210SQLSTATE:HY000(ER_WRONG_ARGUMENTS)Message: Incorrect arguments to %s
Error:
1211SQLSTATE:42000(ER_NO_PERMISSION_TO_CREATE_USER)Message: '%s'@'%s' is not allowed to create new users
Error:
1212SQLSTATE:HY000(ER_UNION_TABLES_IN_DIFFERENT_DIR)Message: Incorrect table definition; all MERGE tables must be in the same database
Error:
1213SQLSTATE:40001(ER_LOCK_DEADLOCK)Message: Deadlock found when trying to get lock; try restarting transaction
Error:
1214SQLSTATE:HY000(ER_TABLE_CANT_HANDLE_FT)Message: The used table type doesn't support FULLTEXT indexes
Error:
1215SQLSTATE:HY000(ER_CANNOT_ADD_FOREIGN)Message: Cannot add foreign key constraint
Error:
1216SQLSTATE:23000(ER_NO_REFERENCED_ROW)Message: Cannot add or update a child row: a foreign key constraint fails
Error:
1217SQLSTATE:23000(ER_ROW_IS_REFERENCED)Message: Cannot delete or update a parent row: a foreign key constraint fails
Error:
1218SQLSTATE:08S01(ER_CONNECT_TO_MASTER)Message: Error connecting to master: %s
Error:
1219SQLSTATE:HY000(ER_QUERY_ON_MASTER)Message: Error running query on master: %s
Error:
1220SQLSTATE:HY000(ER_ERROR_WHEN_EXECUTING_COMMAND)Message: Error when executing command %s: %s
Error:
1221SQLSTATE:HY000(ER_WRONG_USAGE)Message: Incorrect usage of %s and %s
Error:
1222SQLSTATE:21000(ER_WRONG_NUMBER_OF_COLUMNS_IN_SELECT)Message: The used SELECT statements have a different number of columns
Error:
1223SQLSTATE:HY000(ER_CANT_UPDATE_WITH_READLOCK)Message: Can't execute the query because you have a conflicting read lock
Error:
1224SQLSTATE:HY000(ER_MIXING_NOT_ALLOWED)Message: Mixing of transactional and non-transactional tables is disabled
Error:
1225SQLSTATE:HY000(ER_DUP_ARGUMENT)Message: Option '%s' used twice in statement
Error:
1226SQLSTATE:42000(ER_USER_LIMIT_REACHED)Message: User '%s' has exceeded the '%s' resource (current value: %ld)
Error:
1227SQLSTATE:42000(ER_SPECIFIC_ACCESS_DENIED_ERROR)Message: Access denied; you need the %s privilege for this operation
Error:
1228SQLSTATE:HY000(ER_LOCAL_VARIABLE)Message: Variable '%s' is a SESSION variable and can't be used with SET GLOBAL
Error:
1229SQLSTATE:HY000(ER_GLOBAL_VARIABLE)Message: Variable '%s' is a GLOBAL variable and should be set with SET GLOBAL
Error:
1230SQLSTATE:42000(ER_NO_DEFAULT)Message: Variable '%s' doesn't have a default value
Error:
1231SQLSTATE:42000(ER_WRONG_VALUE_FOR_VAR)Message: Variable '%s' can't be set to the value of '%s'
Error:
1232SQLSTATE:42000(ER_WRONG_TYPE_FOR_VAR)Message: Incorrect argument type to variable '%s'
Error:
1233SQLSTATE:HY000(ER_VAR_CANT_BE_READ)Message: Variable '%s' can only be set, not read
Error:
1234SQLSTATE:42000(ER_CANT_USE_OPTION_HERE)Message: Incorrect usage/placement of '%s'
Error:
1235SQLSTATE:42000(ER_NOT_SUPPORTED_YET)Message: This version of MySQL doesn't yet support '%s'
Error:
1236SQLSTATE:HY000(ER_MASTER_FATAL_ERROR_READING_BINLOG)Message: Got fatal error %d: '%s' from master when reading data from binary log
Error:
1237SQLSTATE:HY000(ER_SLAVE_IGNORED_TABLE)Message: Slave SQL thread ignored the query because of replicate-*-table rules
Error:
1238SQLSTATE:HY000(ER_INCORRECT_GLOBAL_LOCAL_VAR)Message: Variable '%s' is a %s variable
Error:
1239SQLSTATE:42000(ER_WRONG_FK_DEF)Message: Incorrect foreign key definition for '%s': %s
Error:
1240SQLSTATE:HY000(ER_KEY_REF_DO_NOT_MATCH_TABLE_REF)Message: Key reference and table reference don't match
Error:
1241SQLSTATE:21000(ER_OPERAND_COLUMNS)Message: Operand should contain %d column(s)
Error:
1242SQLSTATE:21000(ER_SUBQUERY_NO_1_ROW)Message: Subquery returns more than 1 row
Error:
1243SQLSTATE:HY000(ER_UNKNOWN_STMT_HANDLER)Message: Unknown prepared statement handler (%.*s) given to %s
Error:
1244SQLSTATE:HY000(ER_CORRUPT_HELP_DB)Message: Help database is corrupt or does not exist
Error:
1245SQLSTATE:HY000(ER_CYCLIC_REFERENCE)Message: Cyclic reference on subqueries
Error:
1246SQLSTATE:HY000(ER_AUTO_CONVERT)Message: Converting column '%s' from %s to %s
Error:
1247SQLSTATE:42S22(ER_ILLEGAL_REFERENCE)Message: Reference '%s' not supported (%s)
Error:
1248SQLSTATE:42000(ER_DERIVED_MUST_HAVE_ALIAS)Message: Every derived table must have its own alias
Error:
1249SQLSTATE:01000(ER_SELECT_REDUCED)Message: Select %u was reduced during optimization
Error:
1250SQLSTATE:42000(ER_TABLENAME_NOT_ALLOWED_HERE)Message: Table '%s' from one of the SELECTs cannot be used in %s
Error:
1251SQLSTATE:08004(ER_NOT_SUPPORTED_AUTH_MODE)Message: Client does not support authentication protocol requested by server; consider upgrading MySQL client
Error:
1252SQLSTATE:42000(ER_SPATIAL_CANT_HAVE_NULL)Message: All parts of a SPATIAL index must be NOT NULL
Error:
1253SQLSTATE:42000(ER_COLLATION_CHARSET_MISMATCH)Message: COLLATION '%s' is not valid for CHARACTER SET '%s'
Error:
1254SQLSTATE:HY000(ER_SLAVE_WAS_RUNNING)Message: Slave is already running
Error:
1255SQLSTATE:HY000(ER_SLAVE_WAS_NOT_RUNNING)Message: Slave already has been stopped
Error:
1256SQLSTATE:HY000(ER_TOO_BIG_FOR_UNCOMPRESS)Message: Uncompressed data size too large; the maximum size is %d (probably, length of uncompressed data was corrupted)
Error:
1257SQLSTATE:HY000(ER_ZLIB_Z_MEM_ERROR)Message: ZLIB: Not enough memory
Error:
1258SQLSTATE:HY000(ER_ZLIB_Z_BUF_ERROR)Message: ZLIB: Not enough room in the output buffer (probably, length of uncompressed data was corrupted)
Error:
1259SQLSTATE:HY000(ER_ZLIB_Z_DATA_ERROR)Message: ZLIB: Input data corrupted
Error:
1260SQLSTATE:HY000(ER_CUT_VALUE_GROUP_CONCAT)Message: %d line(s) were cut by GROUP_CONCAT()
Error:
1261SQLSTATE:01000(ER_WARN_TOO_FEW_RECORDS)Message: Row %ld doesn't contain data for all columns
Error:
1262SQLSTATE:01000(ER_WARN_TOO_MANY_RECORDS)Message: Row %ld was truncated; it contained more data than there were input columns
Error:
1263SQLSTATE:22004(ER_WARN_NULL_TO_NOTNULL)Message: Column was set to data type implicit default; NULL supplied for NOT NULL column '%s' at row %ld
Error:
1264SQLSTATE:22003(ER_WARN_DATA_OUT_OF_RANGE)Message: Out of range value adjusted for column '%s' at row %ld
Error:
1265SQLSTATE:01000(WARN_DATA_TRUNCATED)Message: Data truncated for column '%s' at row %ld
Error:
1266SQLSTATE:HY000(ER_WARN_USING_OTHER_HANDLER)Message: Using storage engine %s for table '%s'
Error:
1267SQLSTATE:HY000(ER_CANT_AGGREGATE_2COLLATIONS)Message: Illegal mix of collations (%s,%s) and (%s,%s) for operation '%s'
Error:
1268SQLSTATE:HY000(ER_DROP_USER)Message: Cannot drop one or more of the requested users
Error:
1269SQLSTATE:HY000(ER_REVOKE_GRANTS)Message: Can't revoke all privileges for one or more of the requested users
Error:
1270SQLSTATE:HY000(ER_CANT_AGGREGATE_3COLLATIONS)Message: Illegal mix of collations (%s,%s), (%s,%s), (%s,%s) for operation '%s'
Error:
1271SQLSTATE:HY000(ER_CANT_AGGREGATE_NCOLLATIONS)Message: Illegal mix of collations for operation '%s'
Error:
1272SQLSTATE:HY000(ER_VARIABLE_IS_NOT_STRUCT)Message: Variable '%s' is not a variable component (can't be used as XXXX.variable_name)
Error:
1273SQLSTATE:HY000(ER_UNKNOWN_COLLATION)Message: Unknown collation: '%s'
Error:
1274SQLSTATE:HY000(ER_SLAVE_IGNORED_SSL_PARAMS)Message: SSL parameters in CHANGE MASTER are ignored because this MySQL slave was compiled without SSL support; they can be used later if MySQL slave with SSL is started
Error:
1275SQLSTATE:HY000(ER_SERVER_IS_IN_SECURE_AUTH_MODE)Message: Server is running in --secure-auth mode, but '%s'@'%s' has a password in the old format; please change the password to the new format
Error:
1276SQLSTATE:HY000(ER_WARN_FIELD_RESOLVED)Message: Field or reference '%s%s%s%s%s' of SELECT #%d was resolved in SELECT #%d
Error:
1277SQLSTATE:HY000(ER_BAD_SLAVE_UNTIL_COND)Message: Incorrect parameter or combination of parameters for START SLAVE UNTIL
Error:
1278SQLSTATE:HY000(ER_MISSING_SKIP_SLAVE)Message: It is recommended to use --skip-slave-start when doing step-by-step replication with START SLAVE UNTIL; otherwise, you will get problems if you get an unexpected slave's mysqld restart
Error:
1279SQLSTATE:HY000(ER_UNTIL_COND_IGNORED)Message: SQL thread is not to be started so UNTIL options are ignored
Error:
1280SQLSTATE:42000(ER_WRONG_NAME_FOR_INDEX)Message: Incorrect index name '%s'
Error:
1281SQLSTATE:42000(ER_WRONG_NAME_FOR_CATALOG)Message: Incorrect catalog name '%s'
Error:
1282SQLSTATE:HY000(ER_WARN_QC_RESIZE)Message: Query cache failed to set size %lu; new query cache size is %lu
Error:
1283SQLSTATE:HY000(ER_BAD_FT_COLUMN)Message: Column '%s' cannot be part of FULLTEXT index
Error:
1284SQLSTATE:HY000(ER_UNKNOWN_KEY_CACHE)Message: Unknown key cache '%s'
Error:
1285SQLSTATE:HY000(ER_WARN_HOSTNAME_WONT_WORK)Message: MySQL is started in --skip-name-resolve mode; you must restart it without this switch for this grant to work
Error:
1286SQLSTATE:42000(ER_UNKNOWN_STORAGE_ENGINE)Message: Unknown table engine '%s'
Error:
1287SQLSTATE:HY000(ER_WARN_DEPRECATED_SYNTAX)Message: '%s' is deprecated; use '%s' instead
Error:
1288SQLSTATE:HY000(ER_NON_UPDATABLE_TABLE)Message: The target table %s of the %s is not updatable
Error:
1289SQLSTATE:HY000(ER_FEATURE_DISABLED)Message: The '%s' feature is disabled; you need MySQL built with '%s' to have it working
Error:
1290SQLSTATE:HY000(ER_OPTION_PREVENTS_STATEMENT)Message: The MySQL server is running with the %s option so it cannot execute this statement
Error:
1291SQLSTATE:HY000(ER_DUPLICATED_VALUE_IN_TYPE)Message: Column '%s' has duplicated value '%s' in %s
Error:
1292SQLSTATE:22007(ER_TRUNCATED_WRONG_VALUE)Message: Truncated incorrect %s value: '%s'
Error:
1293SQLSTATE:HY000(ER_TOO_MUCH_AUTO_TIMESTAMP_COLS)Message: Incorrect table definition; there can be only one TIMESTAMP column with CURRENT_TIMESTAMP in DEFAULT or ON UPDATE clause
Error:
1294SQLSTATE:HY000(ER_INVALID_ON_UPDATE)Message: Invalid ON UPDATE clause for '%s' column
Error:
1295SQLSTATE:HY000(ER_UNSUPPORTED_PS)Message: This command is not supported in the prepared statement protocol yet
Error:
1296SQLSTATE:HY000(ER_GET_ERRMSG)Message: Got error %d '%s' from %s
Error:
1297SQLSTATE:HY000(ER_GET_TEMPORARY_ERRMSG)Message: Got temporary error %d '%s' from %s
Error:
1298SQLSTATE:HY000(ER_UNKNOWN_TIME_ZONE)Message: Unknown or incorrect time zone: '%s'
Error:
1299SQLSTATE:HY000(ER_WARN_INVALID_TIMESTAMP)Message: Invalid TIMESTAMP value in column '%s' at row %ld
Error:
1300SQLSTATE:HY000(ER_INVALID_CHARACTER_STRING)Message: Invalid %s character string: '%s'
Error:
1301SQLSTATE:HY000(ER_WARN_ALLOWED_PACKET_OVERFLOWED)Message: Result of %s() was larger than max_allowed_packet (%ld) - truncated
Error:
1302SQLSTATE:HY000(ER_CONFLICTING_DECLARATIONS)Message: Conflicting declarations: '%s%s' and '%s%s'
Error:
1303SQLSTATE:2F003(ER_SP_NO_RECURSIVE_CREATE)Message: Can't create a %s from within another stored routine
Error:
1304SQLSTATE:42000(ER_SP_ALREADY_EXISTS)Message: %s %s already exists
Error:
1305SQLSTATE:42000(ER_SP_DOES_NOT_EXIST)Message: %s %s does not exist
Error:
1306SQLSTATE:HY000(ER_SP_DROP_FAILED)Message: Failed to DROP %s %s
Error:
1307SQLSTATE:HY000(ER_SP_STORE_FAILED)Message: Failed to CREATE %s %s
Error:
1308SQLSTATE:42000(ER_SP_LILABEL_MISMATCH)Message: %s with no matching label: %s
Error:
1309SQLSTATE:42000(ER_SP_LABEL_REDEFINE)Message: Redefining label %s
Error:
1310SQLSTATE:42000(ER_SP_LABEL_MISMATCH)Message: End-label %s without match
Error:
1311SQLSTATE:01000(ER_SP_UNINIT_VAR)Message: Referring to uninitialized variable %s
Error:
1312SQLSTATE:0A000(ER_SP_BADSELECT)Message: PROCEDURE %s can't return a result set in the given context
Error:
1313SQLSTATE:42000(ER_SP_BADRETURN)Message: RETURN is only allowed in a FUNCTION
Error:
1314SQLSTATE:0A000(ER_SP_BADSTATEMENT)Message: %s is not allowed in stored procedures
Error:
1315SQLSTATE:42000(ER_UPDATE_LOG_DEPRECATED_IGNORED)Message: The update log is deprecated and replaced by the binary log; SET SQL_LOG_UPDATE has been ignored
Error:
1316SQLSTATE:42000(ER_UPDATE_LOG_DEPRECATED_TRANSLATED)Message: The update log is deprecated and replaced by the binary log; SET SQL_LOG_UPDATE has been translated to SET SQL_LOG_BIN
Error:
1317SQLSTATE:70100(ER_QUERY_INTERRUPTED)Message: Query execution was interrupted
Error:
1318SQLSTATE:42000(ER_SP_WRONG_NO_OF_ARGS)Message: Incorrect number of arguments for %s %s; expected %u, got %u
Error:
1319SQLSTATE:42000(ER_SP_COND_MISMATCH)Message: Undefined CONDITION: %s
Error:
1320SQLSTATE:42000(ER_SP_NORETURN)Message: No RETURN found in FUNCTION %s
Error:
1321SQLSTATE:2F005(ER_SP_NORETURNEND)Message: FUNCTION %s ended without RETURN
Error:
1322SQLSTATE:42000(ER_SP_BAD_CURSOR_QUERY)Message: Cursor statement must be a SELECT
Error:
1323SQLSTATE:42000(ER_SP_BAD_CURSOR_SELECT)Message: Cursor SELECT must not have INTO
Error:
1324SQLSTATE:42000(ER_SP_CURSOR_MISMATCH)Message: Undefined CURSOR: %s
Error:
1325SQLSTATE:24000(ER_SP_CURSOR_ALREADY_OPEN)Message: Cursor is already open
Error:
1326SQLSTATE:24000(ER_SP_CURSOR_NOT_OPEN)Message: Cursor is not open
Error:
1327SQLSTATE:42000(ER_SP_UNDECLARED_VAR)Message: Undeclared variable: %s
Error:
1328SQLSTATE:HY000(ER_SP_WRONG_NO_OF_FETCH_ARGS)Message: Incorrect number of FETCH variables
Error:
1329SQLSTATE:02000(ER_SP_FETCH_NO_DATA)Message: No data - zero rows fetched, selected, or processed
Error:
1330SQLSTATE:42000(ER_SP_DUP_PARAM)Message: Duplicate parameter: %s
Error:
1331SQLSTATE:42000(ER_SP_DUP_VAR)Message: Duplicate variable: %s
Error:
1332SQLSTATE:42000(ER_SP_DUP_COND)Message: Duplicate condition: %s
Error:
1333SQLSTATE:42000(ER_SP_DUP_CURS)Message: Duplicate cursor: %s
Error:
1334SQLSTATE:HY000(ER_SP_CANT_ALTER)Message: Failed to ALTER %s %s
Error:
1335SQLSTATE:0A000(ER_SP_SUBSELECT_NYI)Message: Subselect value not supported
Error:
1336SQLSTATE:0A000(ER_STMT_NOT_ALLOWED_IN_SF_OR_TRG)Message: %s is not allowed in stored function or trigger
Error:
1337SQLSTATE:42000(ER_SP_VARCOND_AFTER_CURSHNDLR)Message: Variable or condition declaration after cursor or handler declaration
Error:
1338SQLSTATE:42000(ER_SP_CURSOR_AFTER_HANDLER)Message: Cursor declaration after handler declaration
Error:
1339SQLSTATE:20000(ER_SP_CASE_NOT_FOUND)Message: Case not found for CASE statement
Error:
1340SQLSTATE:HY000(ER_FPARSER_TOO_BIG_FILE)Message: Configuration file '%s' is too big
Error:
1341SQLSTATE:HY000(ER_FPARSER_BAD_HEADER)Message: Malformed file type header in file '%s'
Error:
1342SQLSTATE:HY000(ER_FPARSER_EOF_IN_COMMENT)Message: Unexpected end of file while parsing comment '%s'
Error:
1343SQLSTATE:HY000(ER_FPARSER_ERROR_IN_PARAMETER)Message: Error while parsing parameter '%s' (line: '%s')
Error:
1344SQLSTATE:HY000(ER_FPARSER_EOF_IN_UNKNOWN_PARAMETER)Message: Unexpected end of file while skipping unknown parameter '%s'
Error:
1345SQLSTATE:HY000(ER_VIEW_NO_EXPLAIN)Message: EXPLAIN/SHOW can not be issued; lacking privileges for underlying table
Error:
1346SQLSTATE:HY000(ER_FRM_UNKNOWN_TYPE)Message: File '%s' has unknown type '%s' in its header
Error:
1347SQLSTATE:HY000(ER_WRONG_OBJECT)Message: '%s.%s' is not %s
Error:
1348SQLSTATE:HY000(ER_NONUPDATEABLE_COLUMN)Message: Column '%s' is not updatable
Error:
1349SQLSTATE:HY000(ER_VIEW_SELECT_DERIVED)Message: View's SELECT contains a subquery in the FROM clause
Error:
1350SQLSTATE:HY000(ER_VIEW_SELECT_CLAUSE)Message: View's SELECT contains a '%s' clause
Error:
1351SQLSTATE:HY000(ER_VIEW_SELECT_VARIABLE)Message: View's SELECT contains a variable or parameter
Error:
1352SQLSTATE:HY000(ER_VIEW_SELECT_TMPTABLE)Message: View's SELECT refers to a temporary table '%s'
Error:
1353SQLSTATE:HY000(ER_VIEW_WRONG_LIST)Message: View's SELECT and view's field list have different column counts
Error:
1354SQLSTATE:HY000(ER_WARN_VIEW_MERGE)Message: View merge algorithm can't be used here for now (assumed undefined algorithm)
Error:
1355SQLSTATE:HY000(ER_WARN_VIEW_WITHOUT_KEY)Message: View being updated does not have complete key of underlying table in it
Error:
1356SQLSTATE:HY000(ER_VIEW_INVALID)Message: View '%s.%s' references invalid table(s) or column(s) or function(s) or definer/invoker of view lack rights to use them
Error:
1357SQLSTATE:HY000(ER_SP_NO_DROP_SP)Message: Can't drop or alter a %s from within another stored routine
Error:
1358SQLSTATE:HY000(ER_SP_GOTO_IN_HNDLR)Message: GOTO is not allowed in a stored procedure handler
Error:
1359SQLSTATE:HY000(ER_TRG_ALREADY_EXISTS)Message: Trigger already exists
Error:
1360SQLSTATE:HY000(ER_TRG_DOES_NOT_EXIST)Message: Trigger does not exist
Error:
1361SQLSTATE:HY000(ER_TRG_ON_VIEW_OR_TEMP_TABLE)Message: Trigger's '%s' is view or temporary table
Error:
1362SQLSTATE:HY000(ER_TRG_CANT_CHANGE_ROW)Message: Updating of %s row is not allowed in %strigger
Error:
1363SQLSTATE:HY000(ER_TRG_NO_SUCH_ROW_IN_TRG)Message: There is no %s row in %s trigger
Error:
1364SQLSTATE:HY000(ER_NO_DEFAULT_FOR_FIELD)Message: Field '%s' doesn't have a default value
Error:
1365SQLSTATE:22012(ER_DIVISION_BY_ZERO)Message: Division by 0
Error:
1366SQLSTATE:HY000(ER_TRUNCATED_WRONG_VALUE_FOR_FIELD)Message: Incorrect %s value: '%s' for column '%s' at row %ld
Error:
1367SQLSTATE:22007(ER_ILLEGAL_VALUE_FOR_TYPE)Message: Illegal %s '%s' value found during parsing
Error:
1368SQLSTATE:HY000(ER_VIEW_NONUPD_CHECK)Message: CHECK OPTION on non-updatable view '%s.%s'
Error:
1369SQLSTATE:HY000(ER_VIEW_CHECK_FAILED)Message: CHECK OPTION failed '%s.%s'
Error:
1370SQLSTATE:42000(ER_PROCACCESS_DENIED_ERROR)Message: %s command denied to user '%s'@'%s' for routine '%s'
Error:
1371SQLSTATE:HY000(ER_RELAY_LOG_FAIL)Message: Failed purging old relay logs: %s
Error:
1372SQLSTATE:HY000(ER_PASSWD_LENGTH)Message: Password hash should be a %d-digit hexadecimal number
Error:
1373SQLSTATE:HY000(ER_UNKNOWN_TARGET_BINLOG)Message: Target log not found in binlog index
Error:
1374SQLSTATE:HY000(ER_IO_ERR_LOG_INDEX_READ)Message: I/O error reading log index file
Error:
1375SQLSTATE:HY000(ER_BINLOG_PURGE_PROHIBITED)Message: Server configuration does not permit binlog purge
Error:
1376SQLSTATE:HY000(ER_FSEEK_FAIL)Message: Failed on fseek()
Error:
1377SQLSTATE:HY000(ER_BINLOG_PURGE_FATAL_ERR)Message: Fatal error during log purge
Error:
1378SQLSTATE:HY000(ER_LOG_IN_USE)Message: A purgeable log is in use, will not purge
Error:
1379SQLSTATE:HY000(ER_LOG_PURGE_UNKNOWN_ERR)Message: Unknown error during log purge
Error:
1380SQLSTATE:HY000(ER_RELAY_LOG_INIT)Message: Failed initializing relay log position: %s
Error:
1381SQLSTATE:HY000(ER_NO_BINARY_LOGGING)Message: You are not using binary logging
Error:
1382SQLSTATE:HY000(ER_RESERVED_SYNTAX)Message: The '%s' syntax is reserved for purposes internal to the MySQL server
Error:
1383SQLSTATE:HY000(ER_WSAS_FAILED)Message: WSAStartup Failed
Error:
1384SQLSTATE:HY000(ER_DIFF_GROUPS_PROC)Message: Can't handle procedures with different groups yet
Error:
1385SQLSTATE:HY000(ER_NO_GROUP_FOR_PROC)Message: Select must have a group with this procedure
Error:
1386SQLSTATE:HY000(ER_ORDER_WITH_PROC)Message: Can't use ORDER clause with this procedure
Error:
1387SQLSTATE:HY000(ER_LOGGING_PROHIBIT_CHANGING_OF)Message: Binary logging and replication forbid changing the global server %s
Error:
1388SQLSTATE:HY000(ER_NO_FILE_MAPPING)Message: Can't map file: %s, errno: %d
Error:
1389SQLSTATE:HY000(ER_WRONG_MAGIC)Message: Wrong magic in %s
Error:
1390SQLSTATE:HY000(ER_PS_MANY_PARAM)Message: Prepared statement contains too many placeholders
Error:
1391SQLSTATE:HY000(ER_KEY_PART_0)Message: Key part '%s' length cannot be 0
Error:
1392SQLSTATE:HY000(ER_VIEW_CHECKSUM)Message: View text checksum failed
Error:
1393SQLSTATE:HY000(ER_VIEW_MULTIUPDATE)Message: Can not modify more than one base table through a join view '%s.%s'
Error:
1394SQLSTATE:HY000(ER_VIEW_NO_INSERT_FIELD_LIST)Message: Can not insert into join view '%s.%s' without fields list
Error:
1395SQLSTATE:HY000(ER_VIEW_DELETE_MERGE_VIEW)Message: Can not delete from join view '%s.%s'
Error:
1396SQLSTATE:HY000(ER_CANNOT_USER)Message: Operation %s failed for %s
Error:
1397SQLSTATE:XAE04(ER_XAER_NOTA)Message: XAER_NOTA: Unknown XID
Error:
1398SQLSTATE:XAE05(ER_XAER_INVAL)Message: XAER_INVAL: Invalid arguments (or unsupported command)
Error:
1399SQLSTATE:XAE07(ER_XAER_RMFAIL)Message: XAER_RMFAIL: The command cannot be executed when global transaction is in the %s state
Error:
1400SQLSTATE:XAE09(ER_XAER_OUTSIDE)Message: XAER_OUTSIDE: Some work is done outside global transaction
Error:
1401SQLSTATE:XAE03(ER_XAER_RMERR)Message: XAER_RMERR: Fatal error occurred in the transaction branch - check your data for consistency
Error:
1402SQLSTATE:XA100(ER_XA_RBROLLBACK)Message: XA_RBROLLBACK: Transaction branch was rolled back
Error:
1403SQLSTATE:42000(ER_NONEXISTING_PROC_GRANT)Message: There is no such grant defined for user '%s' on host '%s' on routine '%s'
Error:
1404SQLSTATE:HY000(ER_PROC_AUTO_GRANT_FAIL)Message: Failed to grant EXECUTE and ALTER ROUTINE privileges
Error:
1405SQLSTATE:HY000(ER_PROC_AUTO_REVOKE_FAIL)Message: Failed to revoke all privileges to dropped routine
Error:
1406SQLSTATE:22001(ER_DATA_TOO_LONG)Message: Data too long for column '%s' at row %ld
Error:
1407SQLSTATE:42000(ER_SP_BAD_SQLSTATE)Message: Bad SQLSTATE: '%s'
Error:
1408SQLSTATE:HY000(ER_STARTUP)Message: %s: ready for connections. Version: '%s' socket: '%s' port: %d %s
Error:
1409SQLSTATE:HY000(ER_LOAD_FROM_FIXED_SIZE_ROWS_TO_VAR)Message: Can't load value from file with fixed size rows to variable
Error:
1410SQLSTATE:42000(ER_CANT_CREATE_USER_WITH_GRANT)Message: You are not allowed to create a user with GRANT
Error:
1411SQLSTATE:HY000(ER_WRONG_VALUE_FOR_TYPE)Message: Incorrect %s value: '%s' for function %s
Error:
1412SQLSTATE:HY000(ER_TABLE_DEF_CHANGED)Message: Table definition has changed, please retry transaction
Error:
1413SQLSTATE:42000(ER_SP_DUP_HANDLER)Message: Duplicate handler declared in the same block
Error:
1414SQLSTATE:42000(ER_SP_NOT_VAR_ARG)Message: OUT or INOUT argument %d for routine %s is not a variable or NEW pseudo-variable in BEFORE trigger
Error:
1415SQLSTATE:0A000(ER_SP_NO_RETSET)Message: Not allowed to return a result set from a %s
Error:
1416SQLSTATE:22003(ER_CANT_CREATE_GEOMETRY_OBJECT)Message: Cannot get geometry object from data you send to the GEOMETRY field
Error:
1417SQLSTATE:HY000(ER_FAILED_ROUTINE_BREAK_BINLOG)Message: A routine failed and has neither NO SQL nor READS SQL DATA in its declaration and binary logging is enabled; if non-transactional tables were updated, the binary log will miss their changes
Error:
1418SQLSTATE:HY000(ER_BINLOG_UNSAFE_ROUTINE)Message: This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable)
Error:
1419SQLSTATE:HY000(ER_BINLOG_CREATE_ROUTINE_NEED_SUPER)Message: You do not have the SUPER privilege and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable)
Error:
1420SQLSTATE:HY000(ER_EXEC_STMT_WITH_OPEN_CURSOR)Message: You can't execute a prepared statement which has an open cursor associated with it. Reset the statement to re-execute it.
Error:
1421SQLSTATE:HY000(ER_STMT_HAS_NO_OPEN_CURSOR)Message: The statement (%lu) has no open cursor.
Error:
1422SQLSTATE:HY000(ER_COMMIT_NOT_ALLOWED_IN_SF_OR_TRG)Message: Explicit or implicit commit is not allowed in stored function or trigger.
Error:
1423SQLSTATE:HY000(ER_NO_DEFAULT_FOR_VIEW_FIELD)Message: Field of view '%s.%s' underlying table doesn't have a default value
Error:
1424SQLSTATE:HY000(ER_SP_NO_RECURSION)Message: Recursive stored functions and triggers are not allowed.
Error:
1425SQLSTATE:42000(ER_TOO_BIG_SCALE)Message: Too big scale %d specified for column '%s'. Maximum is %d.
Error:
1426SQLSTATE:42000(ER_TOO_BIG_PRECISION)Message: Too big precision %d specified for column '%s'. Maximum is %d.
Error:
1427SQLSTATE:42000(ER_M_BIGGER_THAN_D)Message: For float(M,D), double(M,D) or decimal(M,D), M must be >= D (column '%s').
Error:
1428SQLSTATE:HY000(ER_WRONG_LOCK_OF_SYSTEM_TABLE)Message: You can't combine write-locking of system '%s.%s' table with other tables
Error:
1429SQLSTATE:HY000(ER_CONNECT_TO_FOREIGN_DATA_SOURCE)Message: Unable to connect to foreign data source: %s
Error:
1430SQLSTATE:HY000(ER_QUERY_ON_FOREIGN_DATA_SOURCE)Message: There was a problem processing the query on the foreign data source. Data source error: %s
Error:
1431SQLSTATE:HY000(ER_FOREIGN_DATA_SOURCE_DOESNT_EXIST)Message: The foreign data source you are trying to reference does not exist. Data source error: %s
Error:
1432SQLSTATE:HY000(ER_FOREIGN_DATA_STRING_INVALID_CANT_CREATE)Message: Can't create federated table. The data source connection string '%s' is not in the correct format
Error:
1433SQLSTATE:HY000(ER_FOREIGN_DATA_STRING_INVALID)Message: The data source connection string '%s' is not in the correct format
Error:
1434SQLSTATE:HY000(ER_CANT_CREATE_FEDERATED_TABLE)Message: Can't create federated table. Foreign data src error: %s
Error:
1435SQLSTATE:HY000(ER_TRG_IN_WRONG_SCHEMA)Message: Trigger in wrong schema
Error:
1436SQLSTATE:HY000(ER_STACK_OVERRUN_NEED_MORE)Message: Thread stack overrun: %ld bytes used of a %ld byte stack, and %ld bytes needed. Use 'mysqld -O thread_stack=#' to specify a bigger stack.
Error:
1437SQLSTATE:42000(ER_TOO_LONG_BODY)Message: Routine body for '%s' is too long
Error:
1438SQLSTATE:HY000(ER_WARN_CANT_DROP_DEFAULT_KEYCACHE)Message: Cannot drop default keycache
Error:
1439SQLSTATE:42000(ER_TOO_BIG_DISPLAYWIDTH)Message: Display width out of range for column '%s' (max = %d)
Error:
1440SQLSTATE:XAE08(ER_XAER_DUPID)Message: XAER_DUPID: The XID already exists
Error:
1441SQLSTATE:22008(ER_DATETIME_FUNCTION_OVERFLOW)Message: Datetime function: %s field overflow
Error:
1442SQLSTATE:HY000(ER_CANT_UPDATE_USED_TABLE_IN_SF_OR_TRG)Message: Can't update table '%s' in stored function/trigger because it is already used by statement which invoked this stored function/trigger.
Error:
1443SQLSTATE:HY000(ER_VIEW_PREVENT_UPDATE)Message: The definition of table '%s' prevents operation %s on table '%s'.
Error:
1444SQLSTATE:HY000(ER_PS_NO_RECURSION)Message: The prepared statement contains a stored routine call that refers to that same statement. It's not allowed to execute a prepared statement in such a recursive manner
Error:
1445SQLSTATE:HY000(ER_SP_CANT_SET_AUTOCOMMIT)Message: Not allowed to set autocommit from a stored function or trigger
Error:
1446SQLSTATE:HY000(ER_MALFORMED_DEFINER)Message: Definer is not fully qualified
Error:
1447SQLSTATE:HY000(ER_VIEW_FRM_NO_USER)Message: View '%s'.'%s' has no definer information (old table format). Current user is used as definer. Please recreate the view!
Error:
1448SQLSTATE:HY000(ER_VIEW_OTHER_USER)Message: You need the SUPER privilege for creation view with '%s'@'%s' definer
Error:
1449SQLSTATE:HY000(ER_NO_SUCH_USER)Message: There is no '%s'@'%s' registered
Error:
1450SQLSTATE:HY000(ER_FORBID_SCHEMA_CHANGE)Message: Changing schema from '%s' to '%s' is not allowed.
Error:
1451SQLSTATE:23000(ER_ROW_IS_REFERENCED_2)Message: Cannot delete or update a parent row: a foreign key constraint fails (%s)
Error:
1452SQLSTATE:23000(ER_NO_REFERENCED_ROW_2)Message: Cannot add or update a child row: a foreign key constraint fails (%s)
Error:
1453SQLSTATE:42000(ER_SP_BAD_VAR_SHADOW)Message: Variable '%s' must be quoted with `...`, or renamed
Error:
1454SQLSTATE:HY000(ER_TRG_NO_DEFINER)Message: No definer attribute for trigger '%s'.'%s'. The trigger will be activated under the authorization of the invoker, which may have insufficient privileges. Please recreate the trigger.
Error:
1455SQLSTATE:HY000(ER_OLD_FILE_FORMAT)Message: '%s' has an old format, you should re-create the '%s' object(s)
Error:
1456SQLSTATE:HY000(ER_SP_RECURSION_LIMIT)Message: Recursive limit %d (as set by the max_sp_recursion_depth variable) was exceeded for routine %s
Error:
1457SQLSTATE:HY000(ER_SP_PROC_TABLE_CORRUPT)Message: Failed to load routine %s. The table mysql.proc is missing, corrupt, or contains bad data (internal code %d)
Error:
1458SQLSTATE:42000(ER_SP_WRONG_NAME)Message: Incorrect routine name '%s'
Error:
1459SQLSTATE:HY000(ER_TABLE_NEEDS_UPGRADE)Message: Table upgrade required. Please do "REPAIR TABLE `%s`" to fix it!
Error:
1460SQLSTATE:42000(ER_SP_NO_AGGREGATE)Message: AGGREGATE is not supported for stored functions
Error:
1461SQLSTATE:42000(ER_MAX_PREPARED_STMT_COUNT_REACHED)Message: Can't create more than max_prepared_stmt_count statements (current value: %lu)
Error:
1462SQLSTATE:HY000(ER_VIEW_RECURSIVE)Message: `%s`.`%s` contains view recursion
Error:
1463SQLSTATE:42000(ER_NON_GROUPING_FIELD_USED)Message: non-grouping field '%s' is used in %s clause
Error:
1464SQLSTATE:HY000(ER_TABLE_CANT_HANDLE_SPKEYS)Message: The used table type doesn't support SPATIAL indexes
Error:
1465SQLSTATE:HY000(ER_NO_TRIGGERS_ON_SYSTEM_SCHEMA)Message: Triggers can not be created on system tables
Error:
1466SQLSTATE:HY000(ER_REMOVED_SPACES)Message: Leading spaces are removed from name '%s'
Error:
1467SQLSTATE:HY000(ER_AUTOINC_READ_FAILED)Message: Failed to read auto-increment value from storage engine
Error:
1468SQLSTATE:HY000(ER_USERNAME)Message: user name
Error:
1469SQLSTATE:HY000(ER_HOSTNAME)Message: host name
Error:
1470SQLSTATE:HY000(ER_WRONG_STRING_LENGTH)Message: String '%s' is too long for %s (should be no longer than %d)
Error:
1471SQLSTATE:HY000(ER_NON_INSERTABLE_TABLE)Message: The target table %s of the %s is not insertable-into
Client error information comes from the following source files:
The Error values and the symbols in parentheses correspond to definitions in the
include/errmsg.hMySQL source file.The Message values correspond to the error messages that are listed in the
libmysql/errmsg.cfile.%dand%srepresent numbers and strings, respectively, that are substituted into the messages when they are displayed.
Because updates are frequent, it is possible that those files will contain additional error information not listed here.
Error:
2000(CR_UNKNOWN_ERROR)Message: Unknown MySQL error
Error:
2001(CR_SOCKET_CREATE_ERROR)Message: Can't create UNIX socket (%d)
Error:
2002(CR_CONNECTION_ERROR)Message: Can't connect to local MySQL server through socket '%s' (%d)
Error:
2003(CR_CONN_HOST_ERROR)Message: Can't connect to MySQL server on '%s' (%d)
Error:
2004(CR_IPSOCK_ERROR)Message: Can't create TCP/IP socket (%d)
Error:
2005(CR_UNKNOWN_HOST)Message: Unknown MySQL server host '%s' (%d)
Error:
2006(CR_SERVER_GONE_ERROR)Message: MySQL server has gone away
Error:
2007(CR_VERSION_ERROR)Message: Protocol mismatch; server version = %d, client version = %d
Error:
2008(CR_OUT_OF_MEMORY)Message: MySQL client ran out of memory
Error:
2009(CR_WRONG_HOST_INFO)Message: Wrong host info
Error:
2010(CR_LOCALHOST_CONNECTION)Message: Localhost via UNIX socket
Error:
2011(CR_TCP_CONNECTION)Message: %s via TCP/IP
Error:
2012(CR_SERVER_HANDSHAKE_ERR)Message: Error in server handshake
Error:
2013(CR_SERVER_LOST)Message: Lost connection to MySQL server during query
Error:
2014(CR_COMMANDS_OUT_OF_SYNC)Message: Commands out of sync; you can't run this command now
Error:
2015(CR_NAMEDPIPE_CONNECTION)Message: Named pipe: %s
Error:
2016(CR_NAMEDPIPEWAIT_ERROR)Message: Can't wait for named pipe to host: %s pipe: %s (%lu)
Error:
2017(CR_NAMEDPIPEOPEN_ERROR)Message: Can't open named pipe to host: %s pipe: %s (%lu)
Error:
2018(CR_NAMEDPIPESETSTATE_ERROR)Message: Can't set state of named pipe to host: %s pipe: %s (%lu)
Error:
2019(CR_CANT_READ_CHARSET)Message: Can't initialize character set %s (path: %s)
Error:
2020(CR_NET_PACKET_TOO_LARGE)Message: Got packet bigger than 'max_allowed_packet' bytes
Error:
2021(CR_EMBEDDED_CONNECTION)Message: Embedded server
Error:
2022(CR_PROBE_SLAVE_STATUS)Message: Error on SHOW SLAVE STATUS:
Error:
2023(CR_PROBE_SLAVE_HOSTS)Message: Error on SHOW SLAVE HOSTS:
Error:
2024(CR_PROBE_SLAVE_CONNECT)Message: Error connecting to slave:
Error:
2025(CR_PROBE_MASTER_CONNECT)Message: Error connecting to master:
Error:
2026(CR_SSL_CONNECTION_ERROR)Message: SSL connection error
Error:
2027(CR_MALFORMED_PACKET)Message: Malformed packet
Error:
2028(CR_WRONG_LICENSE)Message: This client library is licensed only for use with MySQL servers having '%s' license
Error:
2029(CR_NULL_POINTER)Message: Invalid use of null pointer
Error:
2030(CR_NO_PREPARE_STMT)Message: Statement not prepared
Error:
2031(CR_PARAMS_NOT_BOUND)Message: No data supplied for parameters in prepared statement
Error:
2032(CR_DATA_TRUNCATED)Message: Data truncated
Error:
2033(CR_NO_PARAMETERS_EXISTS)Message: No parameters exist in the statement
Error:
2034(CR_INVALID_PARAMETER_NO)Message: Invalid parameter number
Error:
2035(CR_INVALID_BUFFER_USE)Message: Can't send long data for non-string/non-binary data types (parameter: %d)
Error:
2036(CR_UNSUPPORTED_PARAM_TYPE)Message: Using unsupported buffer type: %d (parameter: %d)
Error:
2037(CR_SHARED_MEMORY_CONNECTION)Message: Shared memory: %s
Error:
2038(CR_SHARED_MEMORY_CONNECT_REQUEST_ERROR)Message: Can't open shared memory; client could not create request event (%lu)
Error:
2039(CR_SHARED_MEMORY_CONNECT_ANSWER_ERROR)Message: Can't open shared memory; no answer event received from server (%lu)
Error:
2040(CR_SHARED_MEMORY_CONNECT_FILE_MAP_ERROR)Message: Can't open shared memory; server could not allocate file mapping (%lu)
Error:
2041(CR_SHARED_MEMORY_CONNECT_MAP_ERROR)Message: Can't open shared memory; server could not get pointer to file mapping (%lu)
Error:
2042(CR_SHARED_MEMORY_FILE_MAP_ERROR)Message: Can't open shared memory; client could not allocate file mapping (%lu)
Error:
2043(CR_SHARED_MEMORY_MAP_ERROR)Message: Can't open shared memory; client could not get pointer to file mapping (%lu)
Error:
2044(CR_SHARED_MEMORY_EVENT_ERROR)Message: Can't open shared memory; client could not create %s event (%lu)
Error:
2045(CR_SHARED_MEMORY_CONNECT_ABANDONED_ERROR)Message: Can't open shared memory; no answer from server (%lu)
Error:
2046(CR_SHARED_MEMORY_CONNECT_SET_ERROR)Message: Can't open shared memory; cannot send request event to server (%lu)
Error:
2047(CR_CONN_UNKNOW_PROTOCOL)Message: Wrong or unknown protocol
Error:
2048(CR_INVALID_CONN_HANDLE)Message: Invalid connection handle
Error:
2049(CR_SECURE_AUTH)Message: Connection using old (pre-4.1.1) authentication protocol refused (client option 'secure_auth' enabled)
Error:
2050(CR_FETCH_CANCELED)Message: Row retrieval was canceled by mysql_stmt_close() call
Error:
2051(CR_NO_DATA)Message: Attempt to read column without prior row fetch
Error:
2052(CR_NO_STMT_METADATA)Message: Prepared statement contains no metadata
Error:
2053(CR_NO_RESULT_SET)Message: Attempt to read a row while there is no result set associated with the statement
Error:
2054(CR_NOT_IMPLEMENTED)Message: This feature is not implemented yet
Error:
2055(CR_SERVER_LOST_EXTENDED)Message: Lost connection to MySQL server at '%s', system error: %d
Table of Contents
- C.1. MySQL Enterprise 5.0 Release Notes
- C.1.1. Changes in MySQL Enterprise 5.0.44 (Not yet released)
- C.1.2. Release Notes for MySQL Enterprise 5.0.42 (23 May 2007)
- C.1.3. Release Notes for MySQL Enterprise 5.0.40 (17 April 2007)
- C.1.4. Release Notes for MySQL Enterprise 5.0.38 (20 March 2007 released)
- C.1.5. Release Notes for MySQL Enterprise 5.0.36sp1 (12 April 2007)
- C.1.6. Release Notes for MySQL Enterprise 5.0.36 (20 February 2007)
- C.1.7. Release Notes for MySQL Enterprise 5.0.34 (17 January 2007)
- C.1.8. Release Notes for MySQL Enterprise 5.0.32 (20 December 2006)
- C.1.9. Release Notes for MySQL Enterprise 5.0.30sp1 (19 January 2007)
- C.1.10. Release Notes for MySQL Enterprise 5.0.30 (14 November 2006)
- C.1.11. Release Notes for MySQL Enterprise 5.0.28 (24 October 2006)
This appendix lists the changes from version to version in MySQL Enterprise, including MySQL Enterprise Server. Releases in MySQL Enterprise Server are divided into the following release packs:
Rapid Update Service Packs are issued once a month and incorporate all the bug fixes and security updates introduced since the previous MySQL Enterprise Server release. A single Service Pack can be used to update MySQL Enterprise Server; it is not necessary to install intervening service packs to bring your system up to date.
Quarterly Service Packs are issued each quarter and incorporate all the bug fixes and security updates introduced since the previous MySQL Enterprise Server release. A single Service Pack can be used to update MySQL Enterprise Server; it is not necessary to install intervening service packs to bring your system up to date.
Hot-fix releases incorporate fixes for bugs that caused significant issues that are not released as part of a Service Pack.
The Release Notes are updated as bugs are fixed and features are incorporated, so that everybody can follow the development process.
Note that we tend to update the manual at the same time we make changes to MySQL. If you find a recent version of MySQL listed here that you can't find on our download page (http://dev.mysql.com/downloads/), it means that the version has not yet been released (and will normally be marked so in the appropriate Release Note section).
The date mentioned with a release version is the date of the last change done internally at MySQL AB (the BitKeeper ChangeSet) on which the release was based, not the date when the packages were made available. The binaries are usually made available a few days after the date of the tagged ChangeSet, because building and testing all packages takes some time.
For information on how to determine your current version and release type, see Section 2.2, “Determining your current MySQL version”.
- C.1.1. Changes in MySQL Enterprise 5.0.44 (Not yet released)
- C.1.2. Release Notes for MySQL Enterprise 5.0.42 (23 May 2007)
- C.1.3. Release Notes for MySQL Enterprise 5.0.40 (17 April 2007)
- C.1.4. Release Notes for MySQL Enterprise 5.0.38 (20 March 2007 released)
- C.1.5. Release Notes for MySQL Enterprise 5.0.36sp1 (12 April 2007)
- C.1.6. Release Notes for MySQL Enterprise 5.0.36 (20 February 2007)
- C.1.7. Release Notes for MySQL Enterprise 5.0.34 (17 January 2007)
- C.1.8. Release Notes for MySQL Enterprise 5.0.32 (20 December 2006)
- C.1.9. Release Notes for MySQL Enterprise 5.0.30sp1 (19 January 2007)
- C.1.10. Release Notes for MySQL Enterprise 5.0.30 (14 November 2006)
- C.1.11. Release Notes for MySQL Enterprise 5.0.28 (24 October 2006)
This section documents all changes and bug fixes, beginning with the first MySQL Enterprise Server release (5.0.28), that are made available through hot-fixes, and through service packs.
For a full list of changes, please refer to the changelog sections for each individual 5.0.x release.
This is a Service Pack release of the MySQL Enterprise Server 5.0.
This section documents all changes and bug fixes that have been applied since the last MySQL Enterprise Server release (5.0.42).
Functionality added or changed:
Bugs fixed:
Security Fix:
CREATE TABLE LIKEdid not require any privileges on the source table. (Bug#25578)In addition,
CREATE TABLE LIKEwas not isolated from alteration by other connections, which resulted in various errors and incorrect binary log order when trying to execute concurrently aCREATE TABLE LIKEstatement and either DDL statements on the source table or DML or DDL statements on the target table. (Bug#23667)NDB Cluster: The actual value ofMaxNoOfOpenFilesas used by the cluster was offset by 1 from the value set inconfig.ini. This meant that settingInitialNoOpenFilesto the same value always caused an error. (Bug#28749)NDB Cluster: A fast global checkpoint under high load with a high usage of the redo buffer caused data nodes to fail. (Bug#28653)NDB Cluster:UPDATE IGNOREstatements involving the primary keys of multiple tables could result in data corruption. (Bug#28719)NDB Cluster: A corrupt schema file could cause a File already open error. (Bug#28770)NDB Cluster: When an API node sent more than 1024 signals in a single batch,NDBwould process only the first 1024 of these, and then hang. (Bug#28443)NDB Cluster: A failure to release internal resources following an error could lead to problems with single user mode. (Bug#25818)NDB Cluster: A delay in obtainingAUTO_INCREMENTIDs could lead to excess temporary errors. (Bug#28410)On some Linux distributions where LinuxThreads and NPTL
glibcversions both are available, statically built binaries can crash because the linker defaults to LinuxThreads when linking statically, but calls to external libraries (such aslibnss) are resolved to NPTL versions. This cannot be worked around in the code, so instead if a crash occurs on such a binary/OS combination, print an error message that provides advice about how to fix the problem. (Bug#24611)Stack overflow caused server crashes. (Bug#21476)
The test case for mysqldump failed with
bin-logdisabled. (Bug#28372)Comparing a
DATETIMEcolumn value with a user variable yielded incorrect results. (Bug# 28261)Comparison of the string value of a date showed as unequal to
CURTIME(). Similar behavior was exhibited forDATETIMEvalues. (Bug# 28208)Implicit conversion of
9912101toDATEdid not matchCAST(9912101 AS DATE). (Bug#23093)The check-cpu script failed to detect AMD64 Turion processors correctly. (Bug#17707)
After an upgrade, the names of stored routines referenced by views were no longer displayed by
SHOW CREATE VIEW. This was a regression introduced by the fix for Bug#23191. (Bug#28605)Killing from one connection a long-running
EXPLAIN QUERYstarted from another connection caused mysqld to crash. (Bug#28598)Subselects returning
LONGvalues in MySQL versions later than 5.0.24a returnedLONGLONGprior to this. The previous behavior was restored. This issue was introduced by the fix for Bug#19714. (Bug#28492)A buffer overflow could occur when using
DECIMALcolumns on Windows operating systems. (Bug#28361)Executing
EXPLAIN EXTENDEDon a query using a derived table over a grouping subselect could lead to a server crash. This occurred only when materialization of the derived tables required creation of an auxiliary temporary table, an example being when a grouping operation was carried out with usage of a temporary table. (Bug#28728)Binary logging of prepared statements could produce syntactically incorrect queries in the binary log, replacing some parameters with variable names rather than variable values. This could lead to incorrect results on replication slaves. (Bug#12826, Bug#26842)
Selecting
MIN()on an indexed column that contained onlyNULLvalues causedNULLto be returned for other result columns. (Bug#27573)mysql_upgrade failed if certain SQL modes were set. Now it sets the mode itself to avoid this problem. (Bug#28401)
Some test suite files were missing from some MySQL-test packages. (Bug#26609)
When dumping procedures, mysqldump
--compactgenerated output that restored the session variableSQL_MODEwithout first capturing it. When dumping routines, mysqldump--compactneither set nor retrieved the value ofSQL_MODE. (Bug#28223)Attempting to
LOAD_FILEfrom an empty floppy drive under Windows, caused the server to hang. For example, if you opened a connection to the server and then issued the command SELECT LOAD_FILE('a:test');, with no floppy in the drive, the server was inaccessible until the modal pop-up dialog box was dismissed. (Bug#28366)mysqldump calculated the required memory for a hex-blob string incorrectly causing a buffer overrun. This in turn caused mysqldump to crash silently and produce incomplete output. (Bug#28522)
The query
SELECT '2007-01-01' + INTERVALcaused mysqld to fail. (Bug#28450)column_nameDAY FROMtable_nameThe result of executing of a prepared statement created with
PREPARE s FROM "SELECT 1 LIMIT ?"was not replicated correctly. (Bug#28464)The second execution of a prepared statement from a
UNIONquery withORDER BY RAND()caused the server to crash. This problem could also occur when invoking a stored procedure containing such a query. (Bug#27937)Trying to shut down the server following a failed
LOAD DATA INFILEcaused mysqld to crash. (Bug#17233)The use of an
ORDER BYorDISTINCTclause with a query containing a call to theGROUP_CONCAT()function caused results from previous queries to be redisplayed in the current result. The fix for this includes replacing aBLOBvalue used internally for sorting with aVARCHAR; in some instances, truncation is possible, in which case, an appropriate warning is issued. (Bug#23856, Bug#28273)Running
CHECK TABLEconcurrently with aSELECT,INSERTor other statement on Windows could corrupt a MyISAM table. (Bug#25712)The error message for error number
137did not report which database/table combination reported the problem. (Bug#27173)Forcing the use of an index on a
SELECTquery when the index had been disabled would raise an error without running the query. The query now executes, with a warning generated noting that the use of a disabled index has been ignored. (Bug#28476)Using
CREATE TABLE LIKE ...would raise an assertion when replicated to a slave. (Bug#18950)When using transactions and replication, shutting down the master in the middle of a transaction would cause all slaves to stop replicating. (Bug#22725)
Recreating a view that already exists on the master would cause a replicating slave to terminate replication with a 'different error message on slave and master' error. (Bug#28244)
CURDATE()is less thanNOW(), either when comparingCURDATE()directly (CURDATE() < NOW()is true) or when castingCURDATE()toDATE(CAST(CURDATE() AS DATE) < NOW()is true). However, storingCURDATE()in aDATEcolumn and comparingcol_name< NOW()DATEcolumn asDATETIMEfor comparisons to aDATETIMEconstant. (Bug#21103)For dates with 4-digit year parts less than 200, an incorrect implicit conversion to add a century was applied for date arithmetic performed with
DATE_ADD(),DATE_SUB(),+ INTERVAL, and- INTERVAL. (For example,DATE_ADD('0050-01-01 00:00:00', INTERVAL 0 SECOND)became'2050-01-01 00:00:00'.) (Bug#18997)The result for
CAST()when casting a value toUNSIGNEDwas limited to the maximum signedBIGINTvalue, not the maximum unsigned value. (Bug#8663)A stored program that uses a variable name containing multibyte characters could fail to execute. (Bug#27876)
The
BLACKHOLEstorage engine does not supportINSERT DELAYEDstatements, but they were not being rejected. (Bug#27998)EXPLAINfor a query on an empty table immediately after its creation could result in a server crash. (Bug#28272)Grouping queries with correlated subqueries in
WHEREconditions could produce incorrect results. (Bug#28337)libmysql.dllcould not be dynamically loaded on Windows. (Bug#28358)Portability problems caused by use of
isinf()were corrected. (Bug#28239)Using a
TEXTlocal variable in a stored routine in an expression such asSETproduced an incorrect result. (Bug#27415)var= SUBSTRING(var, 3)A large filesort could result in a division by zero error and a server crash. (Bug#27119)
This is a Monthly Rapid Update release of the MySQL Enterprise Server 5.0.
This section documents all changes and bug fixes that have been applied since the last MySQL Enterprise Server release (5.0.40).
Functionality added or changed:
Prior to this release, when
DATEvalues were compared withDATETIMEvalues the time portion of theDATETIMEvalue was ignored. Now aDATEvalue is coerced to theDATETIMEtype by adding the time portion as “00:00:00”. To mimic the old behavior use the CAST() function in the following way:SELECT. (Bug# 28929)date_field= CAST(NOW() as DATE);
Bugs fixed:
Security fix: Use of a view could allow a user to gain update privileges for tables in other databases. (Bug#27878)
Security fix: If a stored routine was declared using
SQL SECURITY INVOKER, a user who invoked the routine could gain privileges. (Bug#27337)Security fix: The requirement of the
DROPprivilege forRENAME TABLEwas not being enforced. (Bug#27515)NDB Cluster: Repeated insertion of data generated by mysqldump intoNDBtables could eventually lead to failure of the cluster. (Bug#27437)NDB Cluster:ndb_connectstringdid not appear in the output ofSHOW VARIABLES. (Bug#26675)NDB Cluster:INSERT IGNOREwrongly ignoredNULLvalues in unique indexes. (Bug#27980)NDB Cluster: The name of the month “March” was given incorrectly in the cluster error log. (Bug#27926)NDB Cluster(APIs): ForBLOBreads on operations with lock modeLM_CommittedRead, the lock mode was not upgraded toLM_Readbefore the state of theBLOBhad already been calculated. TheNDBAPI methods affected by this problem included the following:NdbOperation::readTuple()NdbScanOperation::readTuples()NdbIndexScanOperation::readTuples()
NDB Cluster: The cluster waited 30 seconds instead of 30 milliseconds before reading table statistics. (Bug#28093)NDB Cluster: It was not possible to add a unique index to anNDBtable while in single user mode. (Bug#27710)The server could abort or deadlock for
INSERT DELAYEDstatements for which another insert was performed implicitly (for example, via a stored function that inserted a row). (Bug#21483)The server could hang for
INSERT IGNORE ... ON DUPLICATE KEY UPDATEif an update failed. (Bug#28000)Quoted labels in stored routines were mishandled, rendering the routines unusable. (Bug#21513)
Changes to some system variables should invalidate statements in the query cache, but invalidation did not happen. (Bug#27792)
Flow control optimization in stored routines could cause exception handlers to never return or execute incorrect logic. (Bug#26977)
An attempt to execute
CREATE TABLE ... SELECTwhen a temporary table with the same name already existed led to the insertion of data into the temporary table and creation of an empty non-temporary table. (Bug#24508)Concurrent execution of
CREATE TABLE ... SELECTand other statements involving the target table suffered from various race conditions, some of which might have led to deadlocks. (Bug#24738)CREATE TABLE IF NOT EXISTS ... SELECTcaused a server crash if the target table already existed and had aBEFORE INSERTtrigger. (Bug#20903)Deadlock occurred for attempts to execute
CREATE TABLE IF NOT EXISTS ... SELECTwhenLOCK TABLEShad been used to acquire a read lock on the target table. (Bug#20662)CAST()toDECIMALdid not check for overflow. (Bug#27957)Views ignored precision for
CAST()operations. (Bug#27921)For
InnoDB, in some rare cases the optimizer preferred a more expensiverefaccess to a less expensive range access. (Bug#28189)A query with a
NOT INsubquery predicate could cause a crash when the left operand of the predicate evaluated toNULL. (Bug#28375)The fix for Bug#17212 provided correct sort order for misordered output of certain queries, but caused significant overall query performance degradation. (Results were correct (good), but returned much more slowly (bad).) The fix also affected performance of queries for which results were correct. The performance degradation has been addressed. (Bug#27531)
For
INSERT ... ON DUPLICATE KEY UPDATEstatements that affected many rows, updates could be applied to the wrong rows. (Bug#27954)Comparisons of
DATEorDATETIMEvalues for theIN()function could yield incorrect results. (Bug#28133)LOAD DATAdid not useCURRENT_TIMESTAMPas the default value for aTIMESTAMPcolumn for which no value was provided. (Bug#27670)On Windows, connection handlers did not properly decrement the server's thread count when exiting. (Bug#25621)
SELECT COUNT(*)from a table containing aDATETIME NOT NULLcolumn could produce spurious warnings with theNO_ZERO_DATESQL mode enabled. (Bug#22824)Nested aggregate functions could be improperly evaluated. (Bug#27363)
Using
CAST()to convertDATETIMEvalues to numeric values did not work. (Bug#23656)Early
NULL-filtering optimization did not work foreq_reftable access. (Bug#27939)Non-grouped columns were allowed by
*inONLY_FULL_GROUP_BYSQL mode. (Bug#27874)Debug builds on Windows generated false alarms about uninitialized variables with some Visual Studio runtime libraries. (Bug#27811)
mysqld did not check the length of option values and could crash with a buffer overflow for long values. (Bug#27715)
Index hints (
USE INDEX,IGNORE INDEX,FORCE INDEX) cannot be used withFULLTEXTindexes, but were not being ignored. (Bug#25951)mysql_upgrade did not detect failure of external commands that it runs. (Bug#26639)
mysql_upgrade did not pass a password to mysqlcheck if one was given. (Bug#25452)
On Windows, mysql_upgrade was sensitive to lettercase of the names of some required components. (Bug#25405)
The result set of a query that used
WITH ROLLUPandDISTINCTcould lack some rollup rows (rows withNULLvalues for grouping attributes) if theGROUP BYlist contained constant expressions. (Bug#24856)Some upgrade problems are detected and better error messages suggesting that mysql_upgrade be run are produced. (Bug#24248)
A performance degradation was observed for outer join queries to which a not-exists optimization was applied. (Bug#28188)
SELECT * INTO OUTFILE ... FROM INFORMATION_SCHEMA.schematafailed with anAccess deniederror, even for a user who has theFILEprivilege. (Bug#28181)Certain queries that used uncorrelated scalar subqueries caused
EXPLAINto to crash. (Bug#27807)INSERT...ON DUPLICATE KEY UPDATEcould causeError 1032: Can't find record in ...for inserts into anInnoDBtable unique index using key column prefixes with an underlyingutf8string column. (Bug#13191)On Linux, the server could not create temporary tables if
lower_case_table_nameswas set to 1 and the value oftmpdirwas a directory name containing any uppercase letters. (Bug#27653)A slave that used
--master-ssl-ciphercould not connect to the master. (Bug#21611)mysqldump crashed if it got no data from
SHOW CREATE PROCEDURE(for example, when trying to dump a routine defined by a different user and for which the current user had no privileges). Now it prints a comment to indicate the problem. It also returns an error, or continues if the--forceoption is given. (Bug#27293)Several math functions produced incorrect results for large unsigned values.
ROUND()produced incorrect results or a crash for a large number-of-decimals argument. (Bug#24912)For storage engines that allow the current auto-increment value to be set, using
ALTER TABLE ... ENGINEto convert a table from one such storage engine to another caused loss of the current value. (For storage engines that do not support setting the value, it cannot be retained anyway when changing the storage engine.) (Bug#25262)Comparison of a
DATEwith aDATETIMEdid not treat theDATEas having a time part of00:00:00. (Bug#27590)A multiple-table
UPDATEcould return an incorrect rows-matched value if, during insertion of rows into a temporary table, the table had to be converted from aMEMORYtable to aMyISAMtable. (Bug#22364)The omission of leading zeros in dates could lead to erroneous results when these were compared with the output of certain date and time functions. (Bug#16377)
If
CREATE TABLE t1 LIKE t2failed due to a full disk, an emptyt2.frmfile could be created but not removed. This file then caused subsequent attempts to create a table namedt2to fail. This is easily corrected at the filesystem level by removing thet2.frmfile manually, but now the server removes the file if the create operation does not complete successfully. (Bug#25761)The
MERGEstorage engine could return incorrect results when several index values that compare equality were present in an index (for example,'gross'and'gross ', which are considered equal but have different lengths). (Bug#24342)For
InnoDBtables, a multiple-rowINSERTof the formINSERT INTO t (id...) VALUES (NULL...) ON DUPLICATE KEY UPDATE id=VALUES(id), whereidis anAUTO_INCREMENTcolumn, could causeERROR 1062 (23000): Duplicate entry...errors or lost rows. (Bug#27650)mysql_install_db is supposed to detect existing system tables and create only those that do not exist. Instead, it was exiting with an error if tables already existed. (Bug#27783)
Failure to allocate memory associated with
transaction_prealloc_sizecould cause a server crash. (Bug#27322)Aborting a statement on the master that applied to a non-transactional statement broke replication. The statement was written to the binary log but not completely executed on the master. Slaves receiving the statement executed it completely, resulting in loss of data synchrony. Now an error code is written to the error log so that the slaves stop without executing the aborted statement. (That is, replication stops, but synchrony to the point of the stop is preserved and you can investigate the problem.) (Bug#26551)
The
AUTO_INCREMENTvalue would not be correctly reported for InnoDB tables when usingSHOW CREATE TABLEstatement or mysqldump command. (Bug#23313)Creating a temporary table with InnoDB when using the one-file-per-table setting, when the host filesystem for temporary tables is
tmpfswould cause an assertion withinmysqld. This was due to the use ofO_DIRECTwhen opening the temporary table file. (Bug#26662)An interaction between
SHOW TABLE STATUSand other concurrent statements that modify the table could result in a divide-by-zero error and a server crash. (Bug#27516)mysqldump could not connect using SSL. (Bug#27669)
yaSSL crashed on pre-Pentium Intel CPUs. (Bug#21765)
Comparisons using row constructors could fail for rows containing
NULLvalues. (Bug#27704)Performing a
UNIONon two views that had hadORDER BYclauses resulted in anUnknown columnerror. (Bug#27786)The
CRC32()function returns an unsigned integer, but the metadata was signed, which could cause certain queries to return incorrect results. (For example, queries that selected aCRC32()value and used that value in theGROUP BYclause.) (Bug#27530)A race condition between
DROP TABLEandSHOW TABLE STATUScould cause the latter to display incorrect information. (Bug#27499)mysqldump would not dump a view for which the
DEFINERno longer exists. (Bug#26817)Changing a
utf8column in anInnoDBtable to a shorter length did not shorten the data values. (Bug#20095)Using
SET GLOBALto change thelc_time_namessystem variable had no effect on new connections. (Bug#22648)The XML output representing an empty result was an empty string rather than an empty
<resultset/>element. (Bug#27608)mysqlbinlog produced different output with the
-Roption than without it. (Bug#27171)A stored function invocation in the
WHEREclause was treated as a constant. (Bug#27354)For queries that used
ORDER BYwithInnoDBtables, if the optimizer chose an index for accessing the table but found a covering index that enabled theORDER BYto be skipped, no results were returned. (Bug#24778)Having the
EXECUTEprivilege for a routine in a database should make it possible toUSEthat database, but the server returned an error instead. This has been corrected. As a result of the change,SHOW TABLESfor a database in which you have only theEXECUTEprivilege returns an empty set rather than an error. (Bug#9504)Some views could not be created even when the user had the requisite privileges. (Bug#24040)
Restoration of the default database after stored routine or trigger execution on a slave could cause replication to stop if the database no longer existed. (Bug#25082)
This is a Monthly Rapid Update release of the MySQL Enterprise Server 5.0.
This section documents all changes and bug fixes that have been applied since the last MySQL Enterprise Server release (5.0.38).
Functionality added or changed:
If you use SSL for a client connection, you can tell the client not to authenticate the server certificate by specifying neither
--ssl-canor--ssl-capath. The server still verifies the client according to any applicable requirements established viaGRANTstatements for the client, and it still uses any--ssl-ca/--ssl-capathvalues that were passed to server at startup time. (Bug#25309)Prefix lengths for columns in
SPATIALindexes are no longer displayed inSHOW CREATE TABLEoutput. mysqldump uses that statement, so if a table withSPATIALindexes containing prefixed columns is dumped and reloaded, the index is created with no prefixes. (The full column width of each column is indexed.) (Bug#26794)The output of mysql
--xmland mysqldump--xmlnow includes a valid XML namespace. (Bug#25946)The mysql_create_system_tables script was removed because mysql_install_db no longer uses it in MySQL 5.0.
The syntax for index hints has been extended to enable explicit specification that the hint applies only to join processing. See Section 13.2.7.2, “Index Hint Syntax”. (Bug#21174)
Binary distributions for some platforms did not include shared libraries; now shared libraries are shipped for all platforms except AIX 5.2 64-bit. (Bug#13450, Bug#16520, Bug#26767)
NDB Cluster: It is now possible to restore selected databases or tables using ndb_restore. (Bug#26899)NDB Cluster: Several options have been added for use with ndb_restore--print_datato facilitate the creation of data dump files. (Bug#26900)If a set function
Swith an outer referenceS(outer_ref)S(outer_ref)S(const)ANSISQL mode is enabled. (Bug#27348)
Bugs fixed:
The server did not shut down cleanly. (Bug#27310)
NDB Cluster:NDBtables havingMEDIUMINT AUTO_INCREMENTcolumns were not restored correctly by ndb_restore, causing spurious duplicate key errors. This issue did not affectTINYINT,INT, orBIGINTcolumns withAUTO_INCREMENT. (Bug#27775)NDB Cluster:NDBtables with indexes whose names contained space characters were not restored correctly by ndb_restore (the index names were truncated). (Bug#27758)NDB Cluster: Some queries that updated multiple tables were not backed up correctly. (Bug#27748)NDB Cluster: Joins on multiple tables containingBLOBcolumns could cause data nodes run out of memory, and to crash with the error NdbObjectIdMap::expand unable to expand. (Bug#26176)NDB Cluster(APIs): UsingNdbBlob::writeData()to write data in the middle of an existing blob value (that is, updating the value) could overwrite some data past the end of the data to be changed. (Bug#27018)NDB Cluster: Under certain rare circumstances,DROP TABLEorTRUNCATEof anNDBtable could cause a node failure or forced cluster shutdown. (Bug#27581)NDB Cluster: Memory usage of a mysqld process grew even while idle. (Bug#27560)NDB Cluster: In some cases,AFTER UPDATEandAFTER DELETEtriggers onNDBtables that referenced subject table did not see the results of operation which caused invocation of the trigger, but rather saw the row as it was prior to the update or delete operation.This was most noticeable when an update operation used a subquery to obtain the rows to be updated. An example would be
UPDATE tbl1 SET col2 = val1 WHERE tbl1.col1 IN (SELECT col3 FROM tbl2 WHERE c4 = val2)where there was anAFTER UPDATEtrigger on tabletbl1. In such cases, the trigger would fail to execute.The problem occurred because the actual update or delete operations were deferred to be able to perform them later as one batch. The fix for this bug solves the problem by disabling this optimization for a given update or delete if the table has an
AFTERtrigger defined for this operation. (Bug#26242)NDB Cluster: Condition pushdown did not work with prepared statements. (Bug#26225)NDB Cluster: When trying to create tables on an SQL node not connected to the cluster, a misleading error message Table 'tbl_name' already exists was generated. The error now generated is Could not connect to storage engine. (Bug#18676)NDB Cluster: Error messages displayed when running in single user mode were inconsistent. (Bug#27021)NDB Cluster: On Solaris, the value of anNDBtable column declared asBIT(33)was always displayed as0. (Bug#26986)NDB Cluster: The output from ndb_restore--print_datawas incorrect for a backup made of a database containing tables withTINYINTorSMALLINTcolumns. (Bug#26740)NDB Cluster: After entering single user mode it was not possible to alter non-NDBtables on any SQL nodes other than the one having sole access to the cluster. (Bug#25275)NDB Cluster: The failure of a data node while restarting could cause other data nodes to hang or crash. (Bug#27003)NDB Cluster: The management client commandnode_idSTATUSNodewhennode_id: not connectednode_idwas not the node ID of a data node. (Bug#21715)Note
The
ALL STATUScommand in the cluster management client still displays status information for data nodes only. This is by design. See Section 15.7.2, “Commands in the MySQL Cluster Management Client”, for more information.NDB Cluster: It was not possible to setLockPagesInMainMemoryequal to0. (Bug#27291)NDB Cluster: A race condition could sometimes occur if the node acting as master failed while node IDs were still being allocated during startup. (Bug#27286)NDB Cluster: When a data node was taking over as the master node, a race condition could sometimes occur as the node was assuming responsibility for handling of global checkpoints. (Bug#27283)NDB Cluster: mysqld processes would sometimes crash under high load. (Bug#26825)NDB Cluster: Some values ofMaxNoOfTablescaused the error Job buffer congestion to occur. (Bug#19378)Some equi-joins containing a
WHEREclause that included aNOT INsubquery caused a server crash. (Bug#27870)Windows binaries contained no debug symbol file. Now
.mapand.pdbfiles are included in 32-bit builds for mysqld-nt.exe, mysqld-debug.exe, and mysqlmanager.exe. (Bug#26893)The test for the
MYSQL_OPT_SSL_VERIFY_SERVER_CERToption formysql_options()was performed incorrectly. Also changed as a result of this bugfix: Theargoption for themysql_options()C API function was changed fromchar *tovoid *. (Bug#24121)The range optimizer could consume a combinatorial amount of memory for certain classes of
WHEREclauses. (Bug#26624)Conversion of
DATETIMEvalues in numeric contexts sometimes did not produce a double (YYYYMMDDHHMMSS.uuuuuu) value. (Bug#16546)Passing nested row expressions with different structures to an
INpredicate caused a server crash. (Bug#27484)SELECT DISTINCTcould return incorrect results if the select list contained duplicated columns. (Bug#27659)A subquery could get incorrect values for references to outer query columns when it contained aggregate functions that were aggregated in outer context. (Bug#27321)
In some cases, the optimizer preferred a range or full index scan access method over lookup access methods when the latter were much cheaper. (Bug#19372)
Duplicates were not properly identified among (potentially) long strings used as arguments for
GROUP_CONCAT(DISTINCT). (Bug#26815)For
InnoDB, fixed consistent-read behavior of the first read statement, if the read was served from the query cache, for theREAD COMMITTEDisolation level. (Bug#21409)The
decimal.hheader file was incorrectly omitted from binary distributions. (Bug#27456)Duplicate members in
SETdefinitions were not detected. Now they result in a warning; if strict SQL mode is enabled, an error occurs instead. (Bug#27069)For
INSERT INTO ... SELECTwhere index searches used column prefixes, insert errors could occur when key value type conversion was done. (Bug#26207)For
SHOW ENGINE INNODB STATUS, theLATEST DEADLOCK INFORMATIONwas not always cleared properly. (Bug#25494)mysqldumpcould crash or exhibit incorrect behavior when some options were given very long values, such as--fields-terminated-by=". The code has been cleaned up to remove a number of fixed-sized buffers and to be more careful about error conditions in memory allocation. (Bug#26346)some very long string"Setting a column to
NOT NULLwith anON DELETE SET NULLclause foreign key crashes the server. (Bug#25927)The values displayed for the
Innodb_row_lock_time,Innodb_row_lock_time_avg, andInnodb_row_lock_time_maxstatus variables were incorrect. (Bug#23666)COUNT(sometimes generated a spurious truncation warning. (Bug#21976)decimal_expr)With
NO_AUTO_VALUE_ON_ZEROSQL mode enabled,LOAD DATAoperations could assign incorrectAUTO_INCREMENTvalues. (Bug#27586)Incorrect results could be returned for some queries that contained a select list expression with
INorBETWEENtogether with anORDER BYorGROUP BYon the same expression usingNOT INorNOT BETWEEN. (Bug#27532)Queries containing subqueries with
COUNT(*)aggregated in an outer context returned incorrect results. This happened only if the subquery did not contain any references to outer columns. (Bug#27257)Use of an aggregate function from an outer context as an argument to
GROUP_CONCAT()caused a server crash. (Bug#27229)REPAIR TABLE ... USE_FRMwith anARCHIVEtable deleted all records from the table. (Bug#26138)On Windows, debug builds of mysqld could fail with heap assertions. (Bug#25765)
On Windows, debug builds of mysqlbinlog could fail with a memory error. (Bug#23736)
String truncation upon insertion into an integer or year column did not generate a warning (or an error in strict mode). (Bug#26359, Bug#27176)
In out-of-memory conditions, the server might crash or otherwise not report an error to the Windows event log. (Bug#27490)
The temporary file-creation code was cleaned up on Windows to improve server stability. (Bug#26233)
Out-of-memory errors for slave I/O threads were not reported. Now they are written to the error log. (Bug#26844)
mysqldump crashed for
MERGEtables if the--complete-insert(-c) option was given. (Bug#25993)In certain situations,
MATCH ... AGAINSTreturned false hits forNULLvalues produced byLEFT JOINwhen no full-text index was available. (Bug#25729)OPTIMIZE TABLEmight fail on Windows when it attempts to rename a temporary file to the original name if the original file had been opened, resulting in loss of the.MYDfile. (Bug#25521)GRANTstatements were not replicated if the server was started with the--replicate-ignore-tableor--replicate-wild-ignore-tableoption. (Bug#25482)A problem in handling of aggregate functions in subqueries caused predicates containing aggregate functions to be ignored during query execution. (Bug#24484)
Improved out-of-memory detection when sending logs from a master server to slaves, and log a message when allocation fails. (Bug#26837)
MBROverlaps()returned incorrect values in some cases. (Bug#24563)SHOW CREATE VIEWqualified references to stored functions in the view definition with the function's database name, even when the database was the default database. This affected mysqldump (which usesSHOW CREATE VIEWto dump views) because the resulting dump file could not be used to reload the database into a different database.SHOW CREATE VIEWnow suppresses the database name for references to functions in the default database. (Bug#23491)With
innodb_file_per_tableenabled, attempting to rename anInnoDBtable to a non-existent database caused the server to exit. (Bug#27381)mysql_install_db could terminate with an error after failing to determine that a system table already existed. (Bug#27022)
For
InnoDBtables having a clustered index that began with aCHARorVARCHARcolumn, deleting a record and then inserting another before the deleted record was purged could result in table corruption. (Bug#26835)Selecting the result of
AVG()within aUNIONcould produce incorrect values. (Bug#24791)An
INTO OUTFILEclause is allowed only for the finalSELECTof aUNION, but this restriction was not being enforced correctly. (Bug#23345)Duplicate entries were not assessed correctly in a
MEMORYtable with aBTREEprimary key on autf8ENUMcolumn. (Bug#24985)For
MyISAMtables,COUNT(*)could return an incorrect value if theWHEREclause compared an indexedTEXTcolumn to the empty string (''). This happened if the column contained empty strings and also strings starting with control characters such as tab or newline. (Bug#26231)For
DELETE FROM(with notbl_nameORDER BYcol_nameWHEREorLIMITclause), the server did not check whethercol_namewas a valid column in the table. (Bug#26186)ALTER VIEWrequires theCREATE VIEWandDROPprivileges for the view. However, if the view was created by another user, the server erroneously required theSUPERprivilege. (Bug#26813)In a view, a column that was defined using a
GEOMETRYfunction was treated as having theLONGBLOBdata type rather than theGEOMETRYtype. (Bug#27300)With the
NO_AUTO_VALUE_ON_ZEROSQL mode enabled,LAST_INSERT_ID()could return 0 afterINSERT ... ON DUPLICATE KEY UPDATE. Additionally, the next rows inserted (by the sameINSERT, or the followingINSERTwith or withoutON DUPLICATE KEY UPDATE), would insert 0 for the auto-generated value if the value for theAUTO_INCREMENTcolumn wasNULLor missing. (Bug#23233)For a stored procedure containing a
SELECTstatement that used a complicated join with anONexpression, the expression could be ignored during re-execution of the procedure, yielding an incorrect result. (Bug#20492)When RAND() was called multiple times inside a stored procedure, the server did not write the correct random seed values to the binary log, resulting in incorrect replication. (Bug#25543)
SOUNDEX()returned an invalid string for international characters in multi-byte character sets. (Bug#22638)Row equalities in
WHEREclauses could cause memory corruption. (Bug#27154)GROUP BYon aucs2column caused a server crash when there was at least one empty string in the column. (Bug#27079)Evaluation of an
IN()predicate containing a decimal-valued argument caused a server crash. (Bug#27362)Storing
NULLvalues in spatial fields caused excessive memory allocation and crashes on some systems. (Bug#27164)mysql_stmt_fetch()did an invalid memory deallocation when used with the embedded server. (Bug#25492)In a
MEMORYtable, using aBTREEindex to scan for updatable rows could lead to an infinite loop. (Bug#26996)The range optimizer could cause the server to run out of memory. (Bug#26625)
The parser accepted illegal code in SQL exception handlers, leading to a crash at runtime when executing the code. (Bug#26503)
Difficult repair or optimization operations could cause an assertion failure, resulting in a server crash. (Bug#25289)
Increasing the width of a
DECIMALcolumn could cause column values to be changed. (Bug#24558)Replication between master and slave would infinitely retry binary log transmission where the
max_allowed_packeton the master was larger than that on the slave if the size of the transfer was between these two values. (Bug#23775)Invalid optimization of pushdown conditions for queries where an outer join was guaranteed to read only one row from the outer table led to results with too few rows. (Bug#26963)
For
INSERT ... ON DUPLICATE KEY UPDATEstatements on tables containingAUTO_INCREMENTcolumns,LAST_INSERT_ID()was reset to 0 if no rows were successfully inserted or changed. “Not changed” includes the case where a row was updated to its current values, but in that case,LAST_INSERT_ID()should not be reset to 0. NowLAST_INSERT_ID()is reset to 0 only if no rows were successfully inserted or touched, whether or not touched rows were changed. (Bug#27033)This bug was introduced by the fix for Bug#19978.
For an
INSERTstatement that should fail due to a column with no default value not being assigned a value, the statement succeeded with no error if the column was assigned a value in anON DUPLICATE KEY UPDATEclause, even if that clause was not used. (Bug#26261)A result set column formed by concatention of string literals was incomplete when the column was produced by a subquery in the
FROMclause. (Bug#26738)When using the result of
SEC_TO_TIME()for time value greater than 24 hours in anORDER BYclause, either directly or through a column alias, the rows were sorted incorrectly as strings. (Bug#26672)If the server was started with
--skip-grant-tables, Selecting fromINFORMATION_SCHEMAtables causes a server crash. (Bug#26285)
This is a Monthly Rapid Update release of the MySQL Enterprise Server 5.0.
This section documents all changes and bug fixes that have been applied since the last MySQL Enterprise Server release (5.0.36).
Functionality added or changed:
To satisfy different user requirements, we provide several servers. mysqld is an optimized server that is a smaller, faster binary. Each package now also includes mysqld-debug, which is compiled with debugging support but is otherwise configured identically to the non-debug server.
Added the
--secure-file-privoption for mysqld, which limits the effect of theLOAD_FILE()function and theLOAD DATAandSELECT ... INTO OUTFILEstatements to work only with files in a given directory. (Bug#18628)Added the
hostnamesystem variable, which the server sets at startup to the server hostname.The server now includes a timestamp in error messages that are logged as a result of unhandled signals (such as
mysqld got signal 11messages). (Bug#24878)
Bugs fixed:
Incompatible change:
INSERT DELAYEDstatements are not supported forMERGEtables, but theMERGEstorage engine was not rejecting such statements, resulting in table corruption. Applications previously usingINSERT DELAYEDintoMERGEtable will break when upgrading to versions with this fix. To avoid the problem, removeDELAYEDfrom such statements. (Bug#26464)NDB Cluster: An invalid pointer was returned following aFSCLOSECONFsignal when accessing the REDO logs during a node restart or system restart. (Bug#26515)NDB Cluster: An inadvertent use of unaligned data caused ndb_restore to fail on some 64-bit platforms, including Sparc and Itanium-2. (Bug#26739)NDB Cluster: An infinite loop in an internal logging function could cause trace logs to fill up with Unknown Signal type error messages and thus grow to unreasonable sizes. (Bug#26720)NDB Cluster: The failure of a data node when restarting it with--initialcould lead to failures of subsequent data node restarts. (Bug#26481)NDB Cluster: Takeover for local checkpointing due to multiple failures of master nodes was sometimes incorrect handled. (Bug#26457)NDB Cluster: TheLockPagesInMemoryparameter was not read until after distributed communication had already started between cluster nodes. When the value of this parameter was1, this could sometimes result in data node failure due to missed heartbeats. (Bug#26454)NDB Cluster: Under some circumstances, following the restart of a management, all cluster data nodes would connect to it normally, but some of them subsequently failed to log any events to the management node. (Bug#26293)NDB Cluster: An error was produced whenSHOW TABLE STATUSwas used on anNDBtable that had noAUTO_INCREMENTcolumn. (Bug#21033)SELECT ... INTO OUTFILEwith a longFIELDS ENCLOSED BYvalue could crash the server. (Bug#27231)DOUBLEvalues such as20070202191048.000000were being treated as illegal arguments byWEEK(). (Bug#23616)AFTER UPDATEtriggers were not activated by the update part ofINSERT ... ON DUPLICATE KEY UPDATEstatements. (Bug#27006, Bug#27210)This bug was introduced by the fix for Bug#19978.
For
INSERT ... ON DUPLICATE KEY UPDATEstatements where someAUTO_INCREMENTvalues were generated automatically for inserts and some rows were updated, one auto-generated value was lost per updated row, leading to faster exhaustion of the range of theAUTO_INCREMENTcolumn. (Bug#24432)Because the original problem can affect replication (different values on master and slave), it is recommended that the master and its slaves be upgraded to the current version.
IN ((,subquery))IN (((, and so forth, are equivalent tosubquery)))IN (, which is always interpreted as a table subquery (so that it is allowed to return more than one row). MySQL was treating the “over-parenthesized” subquery as a single-row subquery and rejecting it if it returned more than one row. This bug primarily affected automatically generated code (such as queries generated by Hibernate), because humans rarely write the over-parenthesized forms. (Bug#21904)subquery)For
MERGEtables defined on underlying tables that contained a shortVARCHARcolumn (shorter than four characters), usingALTER TABLEon at least one but not all of the underlying tables caused the table definitions to be considered different from that of theMERGEtable, even if theALTER TABLEdid not change the definition. (Bug#26881)If a thread previously serviced a connection that was killed, excessive memory and CPU use by the thread occurred if it later serviced a connection that had to wait for a table lock. (Bug#25966)
A view on a join is insertable for
INSERTstatements that store values into only one table of the join. However, inserts were being rejected if the inserted-into table was used in a self-join because MySQL incorrectly was considering the insert to modify multiple tables of the view. (Bug#25122)Expressions involving
SUM(), when used in anORDER BYclause, could lead to out-of-order results. (Bug#25376)LOAD DATA INFILEsent an okay to the client before writing the binary log and committing the changes to the table had finished, thus violating ACID requirements. (Bug#26050)Views that used a scalar correlated subquery returned incorrect results. (Bug#26560)
IF(
expr,unsigned_expr,unsigned_expr) was evaluated to a signed result, not unsigned. This has been corrected. The fix also affects constructs of the formIS [NOT] {TRUE|FALSE}, which were transformed internally intoIF()expressions that evaluated to a signed result. (Bug#24532)For existing views that were defined using
IS [NOT] {TRUE|FALSE}constructs, there is a related implication. The definitions of such views were stored using theIF()expression, not the original construct. This is manifest in thatSHOW CREATE VIEWshows the transformedIF()expression, not the original one. Existing views will evaluate correctly after the fix, but if you wantSHOW CREATE VIEWto display the original construct, you must drop the view and re-create it using its original definition. New views will retain the construct in their definition.BENCHMARK()did not work correctly for expressions that produced aDECIMALresult. (Bug#26093)For some values of the position argument, the
INSERT()function could insert a NUL byte into the result. (Bug#26281)Inserting
utf8data into aTEXTcolumn that used a single-byte character set could result in spurious warnings about truncated data. (Bug#25815)EXPLAIN EXTENDEDdid not showWHEREconditions that were optimized away. (Bug#22331)INSERT DELAYEDstatements inserted incorrect values intoBITcolumns. (Bug#26238)For
exprIN(value_list)BIGINT UNSIGNEDvalues were used forexpror in the value list. (Bug#19342)When a
TIME_FORMAT()expression was used as a column in aGROUP BYclause, the expression result was truncated. (Bug#20293)For
SUBSTRING()evaluation using a temporary table, whenSUBSTRING()was used on a LONGTEXT column, themax_lengthmetadata value of the result was incorrectly calculated and set to 0. Consequently, an empty string was returned instead of the correct result. (Bug#15757)Use of a
GROUP BYclause that referred to a stored function result together withWITH ROLLUPcaused incorrect results. (Bug#25373)Use of a subquery containing
GROUP BYandWITH ROLLUPcaused a server crash. (Bug#26830)Use of a subquery containing a
UNIONwith an invalidORDER BYclause caused a server crash. (Bug#26661)In certain cases it could happen that deleting a row corrupted an
RTREEindex. This affected indexes on spatial columns. (Bug#25673)SSL connections failed on Windows. (Bug#26678)
Added support for
--debugger=dbxfor mysql-test-run.pl and fixed support for--debugger=devenv,--debugger=DevEnv, and--debugger=. (Bug#26792)/path/to/devenvX() IS NULLandY() IS NULLcomparisons failed whenX()andY()returnedNULL. (Bug#26038)UNHEX() IS NULLcomparisons failed whenUNHEX()returnedNULL. (Bug#26537)The
REPEAT()function did not allow a column name as thecountparameter. (Bug#25197)On 64-bit Windows, large timestamp values could be handled incorrectly. (Bug#26536)
In some error messages, inconsistent format specifiers were used for the translations in different languages. comp_err (the error message compiler) now checks for mismatches. (Bug#26571)
On Windows, the server exhibited a file-handle leak after reaching the limit on the number of open file descriptors. (Bug#25222)
A reference to a non-existent column in the
ORDER BYclause of anUPDATE ... ORDER BYstatement could cause a server crash. (Bug#25126)A multiple-row delayed insert with an auto increment column could cause duplicate entries to be created on the slave in a replication environment. (Bug#25507, Bug#26116)
Duplicating the usage of a user variable in a stored procedure or trigger would not be replicated correctly to the slave. (Bug#25167)
User defined variables used within stored procedures and triggers are not replicated correctly when operating in statement-based replication mode. (Bug#20141, Bug#14914)
Loading data using
LOAD DATA INFILEmay not replicate correctly (due to character set incompatibilities) if thecharacter_set_databasevariable is set before the data is loaded. (Bug#15126)DROP TRIGGERstatements would not be filtered on the slave when using thereplication-wild-do-tableoption. (Bug#24478)MySQL would not compile when configured using
--without-query-cache. (Bug#25075)When using certain server SQL modes, the
mysql.proctable was not created by mysql_install_db. In addition, the creation of this and other MySQL system tables was not checked for by mysql-test-run.pl. (Bug#23669, Bug#20166)VIEWrestrictions were applied toSELECTstatements after aCREATE VIEWstatement failed, as though theCREATEhad succeeded. (Bug#25897)An
INSERTtrigger invoking a stored routine that inserted into a table other than the one on which the trigger was defined would fail with a Table '...' doesn't exist referring to the second table when attempting to delete records from the first table. (Bug#21825)A stored procedure that made use of cursors failed when the procedure was invoked from a stored function. (Bug#25345)
When nesting stored procedures within a trigger on a table, a false dependency error was thrown when one of the nested procedures contained a
DROP TABLEstatement. (Bug#22580)When attempting to call a stored procedure creating a table from a trigger on a table
tblin a databasedb, the trigger failed with ERROR 1146 (42S02): Table 'db.tbl' doesn't exist. However, the actual reason that such a trigger fails is due to the fact thatCREATE TABLEcauses an implicitCOMMIT, and so a trigger cannot invoke a stored routine containing this statement. A trigger which does so now fails with ERROR 1422 (HY000): Explicit or implicit commit is not allowed in stored function or trigger, which makes clear the reason for the trigger's failure. (Bug#18914)Local variables in stored routines or triggers, when declared as the
BITtype, were interpreted as strings. (Bug#12976)When a stored routine attempted to execute a statement accessing a nonexistent table, the error was not caught by the routine's exception handler. (Bug#8407, Bug#20713)
NOW()returned the wrong value in statements executed at server startup with the--init-fileoption. (Bug#23240)Instance Manager did not remove the angel PID file on a clean shutdown. (Bug#22511)
The server could crash if two or more threads initiated query cache resize operation at moments very close in time. (Bug#23527)
The conditions checked by the optimizer to allow use of indexes in
INpredicate calculations were unnecessarily tight and were relaxed. (Bug#20420)Several deficiencies in resolution of column names for
INSERT ... SELECTstatements were corrected. (Bug#25831)Indexes on
TEXTcolumns were ignored whenrefaccesses were evaluated. (Bug#25971)The update columns for
INSERT ... SELECT ... ON DUPLICATE KEY UPDATEcould be assigned incorrect values if a temporary table was used to evaluate theSELECT. (Bug#16630)CONNECTIONis no longer treated as a reserved word. (Bug#12204)A user-defined variable could be assigned an incorrect value if a temporary table was employed in obtaining the result of the query used to determine its value. (Bug#24010)
Queries that used a temporary table for the outer query when evaluating a correlated subquery could return incorrect results. (Bug#23800)
For index reads, the
BLACKHOLEengine did not return end-of-file (which it must becauseBLACKHOLEtables contain no rows), causing some queries to crash. (Bug#19717)
This is a Service Pack release of the MySQL Enterprise Server 5.0.
This section documents all changes and bug fixes that have been applied since the last MySQL Enterprise Server release (5.0.36).
Bugs fixed:
For
MERGEtables defined on underlying tables that contained a shortVARCHARcolumn (shorter than four characters), usingALTER TABLEon at least one but not all of the underlying tables caused the table definitions to be considered different from that of theMERGEtable, even if theALTER TABLEdid not change the definition. (Bug#26881)SELECT ... INTO OUTFILEwith a longFIELDS ENCLOSED BYvalue could crash the server. (Bug#27231)
This is a Monthly Rapid Update release of the MySQL Enterprise Server 5.0.
This section documents all changes and bug fixes that have been applied since the last MySQL Enterprise Server release (5.0.34).
Note
After release, a trigger failure problem was found to have been introduced. (Bug#27006) Users affected by this issue should upgrade to MySQL 5.0.38, which corrects the problem.
Functionality added or changed:
Incompatible change: Previously, the
DATE_FORMAT()function returned a binary string. Now it returns a string with a character set and collation given bycharacter_set_connectionandcollation_connectionso that it can return month and weekday names containing non-ASCII characters. (Bug#22646)NDB Cluster: TheLockPagesInMainMemoryconfiguration parameter has changed its type and possible values. For more information, seeLockPagesInMainMemory. (Bug#25686)Important: The values
trueandfalseare no longer accepted for this parameter. If you were using this parameter and had it set tofalsein a previous release, you must change it to0. If you had this parameter set totrue, you should instead use1to obtain the same behavior as previously, or2to take advantage of new functionality introduced with this release described in the section cited above.Important: When using
MERGEtables the definition of theMERGEtable and theMyISAMtables are checked each time the tables are opened for access (including anySELECTorINSERTstatement. Each table is compared for column order, types, sizes and associated. If there is a difference in any one of the tables then the statement will fail.The
localhostanonymous user account created during MySQL installation on Windows now has no global privileges. Formerly this account had all global privileges. For operations that require global privileges, therootaccount can be used instead. (Bug#24496)The bundled yaSSL library was upgraded to version 1.5.8.
Bugs fixed:
Security fix: Using an
INFORMATION_SCHEMAtable withORDER BYin a subquery could cause a server crash. (CVE-2007-1420, Bug#24630, Bug#26556) We would like to thank Oren Isacson from Flowgate Security Consulting as well as well as Stefan Streichsbier from SEC Consult for informing us about this problem.Incompatible change: For
ENUMcolumns that had enumeration values containing commas, the commas were mapped to 0xff internally. However, this rendered the commas indistinguishable from true 0xff characters in the values. This no longer occurs. However, the fix requires that you dump and reload any tables that haveENUMcolumns containing true 0xff in their values: Dump the tables using mysqldump with the current server before upgrading from a version of MySQL 5.0 older than 5.0.36 to version 5.0.36 or newer. (Bug#24660)On Windows, if the server was installed as a service, it did not auto-detect the location of the data directory. (Bug#20376)
If the duplicate key value was present in the table,
INSERT ... ON DUPLICATE KEY UPDATEreported a row count indicating that a record was updated, even when no record actually changed due to the old and new values being the same. Now it reports a row count of zero. (Bug#19978)Some
UPDATEstatements were slower than in previous versions when the search key could not be converted to a valid value for the type of the search column. (Bug#24035)The
WITH CHECK OPTIONclause for views was ignored for updates of multiple-table views when the updates could not be performed on fly and the rows to update had to be put into temporary tables first. (Bug#25931)Using
ORDER BYorGROUP BYcould yield different results when selecting from a view and selecting from the underlying table. (Bug#26209)LAST_INSERT_ID()was not reset to 0 ifINSERT ... SELECTinserted no rows. (Bug#23170)Storing values specified as hexadecimal values 64 or more bits long into
BIT(64),BIGINT, orBIGINT UNSIGNEDcolumns did not raise any warning or error if the value was out of range. (Bug#22533)Inserting
DEFAULTinto a column with no default value could result in garbage in the column. Now the same result occurs as when insertingNULLinto aNOT NULLcolumn. (Bug#20691)The presence of
ORDER BYin a view definition prevented theMERGEalgorithm from being used to resolve the view even if nothing else in the definition required theTEMPTABLEalgorithm. (Bug#12122)ISNULL(DATE(NULL))andISNULL(CAST(NULL AS DATE))erroneously returned false. (Bug#23938)If a slave server closed its relay log (for example, due to an error during log rotation), the I/O thread did not recognize this and still tried to write to the log, causing a server crash. (Bug#10798)
Collation for
LEFT JOINcomparisons could be evaluated incorrectly, leading to improper query results. (Bug#26017)For the
IF()andCOALESCE()function andCASEexpressions, large unsigned integer values could be mishandled and result in warnings. (Bug#22026)The number of
setsockopt()calls performed for reads and writes to the network socket was reduced to decrease system call overhead. (Bug#22943)A
WHEREclause that usedBETWEENforDATETIMEvalues could be treated differently for aSELECTand a view defined as thatSELECT. (Bug#26124)ORDER BYonDOUBLEvalues could change the set of rows returned by a query. (Bug#19690)The code for generating
USEstatements for binary logging ofCREATE PROCEDUREstatements resulted in confusing output from mysqlbinlog forDROP PROCEDUREstatements. (Bug#22043)LOAD DATA INFILEdid not work with pipes. (Bug#25807)DISTINCTqueries that were executed using a loose scan for anInnoDBtable that had been emptied caused a server crash. (Bug#26159)The
InnoDBparser sometimes did not account for null bytes, causing spurious failure of some queries. (Bug#25596)Type conversion errors during formation of index search conditions were not correctly checked, leading to incorrect query results. (Bug#22344)
Within a stored routine, accessing a declared routine variable with
PROCEDURE ANALYSE()caused a server crash. (Bug#23782)Use of already freed memory caused SSL connections to hang forever. (Bug#19209)
mysql.server stop timed out too quickly (35 seconds) waiting for the server to exit. Now it waits up to 15 minutes, to ensure that the server exits. (Bug#25341)
A yaSSL program named test was installed, causing conflicts with the test system utility. It is no longer installed. (Bug#25417)
perror crashed on some platforms due to failure to handle a
NULLpointer. (Bug#25344)mysql_kill()caused a server crash when used on an SSL connection. (Bug#25203)The
readlinelibrary wrote to uninitialized memory, causing mysql to crash. (Bug#19474)yaSSL was sensitive to the presence of whitespace at the ends of lines in PEM-encoded certificates, causing a server crash. (Bug#25189)
mysqld_multi and mysqlaccess looked for option files in
/etceven if the--sysconfdiroption for configure had been given to specify a different directory. (Bug#24780)The
SEC_TO_TIME()andQUARTER()functions sometimes did not handleNULLvalues correctly. (Bug#25643)With
ONLY_FULL_GROUP_BYenables, the server was too strict: Some expressions involving only aggregate values were rejected as non-aggregate (for example,MAX(a) - MIN(a)). (Bug#23417)The arguments of the
ENCODE()and theDECODE()functions were not printed correctly, causing problems in the output ofEXPLAIN EXTENDEDand in view definitions. (Bug#23409)An error in the name resolution of nested
JOIN ... USINGconstructs was corrected. (Bug#25575)A return value of
-1from user-defined handlers was not handled well and could result in conflicts with server code. (Bug#24987)The server might fail to use an appropriate index for
DELETEwhenORDER BY,LIMIT, and a non-restrictingWHEREare present. (Bug#17711)Use of
ON DUPLICATE KEY UPDATEdefeated the usual restriction against inserting into a join-based view unless only one of the underlying tables is used. (Bug#25123)Some queries against
INFORMATION_SCHEMAthat used subqueries failed. (Bug#23299).SHOW COLUMNSreported someNOT NULLcolumns asNULL. (Bug#22377)View definitions that used the
!operator were treated as containing theNOToperator, which has a different precedence and can produce different results. (Bug#25580).For a
UNIQUEindex containing manyNULLvalues, the optimizer would prefer the index forcolIS NULLGROUP BYandDISTINCTdid not groupNULLvalues for columns that have aUNIQUEindex. (Bug#25551).ALTER TABLE ... ENABLE KEYSacquired a global lock, preventing concurrent execution of other statements that use tables. (Bug#25044).For an
InnoDBtable with anyON DELETEtrigger,TRUNCATE TABLEmapped toDELETEand activated triggers. Now a fast truncation occurs and triggers are not activated. (Bug#23556).For
ALTER TABLE, usingORDER BYcould cause a server crash. Now theexpressionORDER BYclause allows only column names to be specified as sort criteria (which was the only documented syntax, anyway). (Bug#24562)readlinedetection did not work correctly on NetBSD. (Bug#23293)The
--with-readlineoption for configure does not work for commercial source packages, but no error message was printed to that effect. Now a message is printed. (Bug#25530)If an
ORDER BYorGROUP BYlist included a constant expression being optimized away and, at the same time, containing single-row subselects that return more that one row, no error was reported. If a query requires sorting by expressions containing single-row subselects that return more than one row, execution of the query may cause a server crash. (Bug#24653)Attempts to access a
MyISAMtable with a corrupt column definition caused a server crash. (Bug#24401)To enable installation of MySQL RPMs on Linux systems running RHEL 4 (which includes SE-Linux) additional information was provided to specify some actions that are allowed to the MySQL binaries. (Bug#12676)
When
SET PASSWORDwas written to the binary log double quotes were included in the statement. If the slave was running in with thesql_modeset toANSI_QUOTESthe event would fail and halt the replication process. (Bug#24158)Accessing a fixed record format table with a crashed key definition results in server/myisamchk segmentation fault. (Bug#24855)
When opening a corrupted
.frmfile during a query, the server crashes. (Bug#24358)If there was insufficient memory to store or update a blob record in a
MyISAMtable then the table will marked as crashed. (Bug#23196)When updating a table that used a
JOINof the table itself (for example, when building trees) and the table was modified on one side of the expression, the table would either be reported as crashed or the wrong rows in the table would be updated. (Bug#21310)Queries that evaluate
NULL IN (SELECT ... UNION SELECT ...)could produce an incorrect result (FALSEinstead ofNULL). (Bug#24085)When reading from the standard input on Windows, mysqlbinlog opened the input in text mode rather than binary mode and consequently misinterpreted some characters such as Control-Z. (Bug#23735)
Within stored routines or prepared statements, inconsistent results occurred with multiple use of
INSERT ... SELECT ... ON DUPLICATE KEY UPDATEwhen theON DUPLICATE KEY UPDATEclause erroneously tried to assign a value to a column mentioned only in itsSELECTpart. (Bug#24491)Expressions of the form
(a, b) IN (SELECT a, MIN(b) FROM t GROUP BY a)could produce incorrect results when columnaof tabletcontainedNULLvalues while columnbdid not. (Bug#24420)Expressions of the form
(a, b) IN (SELECT c, d ...)could produce incorrect results ifa,b, or both wereNULL. (Bug#24127)No warning was issued for use of the
DATA DIRECTORYorINDEX DIRECTORYtable options on a platform that does not support them. (Bug#17498)When a prepared statement failed during the prepare operation, the error code was not cleared when it was reused, even if the subsequent use was successful. (Bug#15518)
mysql_upgrade failed when called with a
basedirpathname containing spaces. (Bug#22801)Hebrew-to-Unicode conversion failed for some characters. Definitions for the following Hebrew characters (as specified by the ISO/IEC 8859-8:1999) were added: LEFT-TO-RIGHT MARK (LRM), RIGHT-TO-LEFT MARK (RLM) (Bug#24037)
An
AFTER UPDATEtrigger on anInnoDBtable with a composite primary key caused the server to crash. (Bug#25398)A query that contained an
EXISTsubquery with aUNIONover correlated and uncorrelatedSELECTqueries could cause the server to crash. (Bug#25219)A query with
ORDER BYandGROUP BYclauses where theORDER BYclause had more elements than theGROUP BYclause caused a memory overrun leading to a crash of the server. (Bug#25172)If there was insufficient memory available to mysqld, this could sometimes cause the server to hang during startup. (Bug#24751)
If a prepared statement accessed a view, access to the tables listed in the query after that view was checked in the security context of the view. (Bug#24404)
A query using
WHEREcould cause the server to crash. (Bug#24261)unsigned_columnNOT IN ('negative_value')A
FETCHstatement using a cursor on a table which was not in the table cache could sometimes cause the server to crash. (Bug#24117)SSL connections could hang at connection shutdown. (Bug#24148, Bug#21781)
The
STDDEV()function returned a positive value for data sets consisting of a single value. (Bug#22555)mysqltest incorrectly tried to retrieve result sets for some queries where no result set was available. (Bug#19410)
mysqltest crashed with a stack overflow. (Bug#24498)
Passing a
NULLvalue to a user-defined function from within a stored procedure crashes the server. (Bug#25382)The row count for
MyISAMtables was not updated properly, causingSHOW TABLE STATUSto report incorrect values. (Bug#23526)The BUILD/check-cpu script did not recognize Celeron processors. (Bug#20061)
On Windows, the
SLEEP()function could sleep too long, especially after a change to the system clock. (Bug#14094, Bug#17635, Bug#24686)A stored routine containing semicolon in its body could not be reloaded from a dump of a binary log. (Bug#20396)
For
SET,SELECT, andDOstatements that invoked a stored function from a database other than the default database, the function invocation could fail to be replicated. (Bug#19725)SET lc_time_names =allowed only exact literal values, not expression values. (Bug#22647)valueChanges to the
lc_time_namessystem variable were not replicated. (Bug#22645)SELECT ... FOR UPDATE,SELECT ... LOCK IN SHARE MODE,DELETE, andUPDATEstatements executed using a full table scan were not releasing locks on rows that did not satisfy theWHEREcondition. (Bug#20390)A stored procedure, executed from a connection using a binary character set, and which wrote multibyte data, would write incorrectly escaped entries to the binary log. This caused syntax errors, and caused replication to fail. (Bug#23619, Bug#24492)
mysqldump --order-by-primary failed if the primary key name was an identifier that required quoting. (Bug#13926)
Re-execution of
CREATE DATABASE,CREATE TABLE, andALTER TABLEstatements in stored routines or as prepared statements caused incorrect results or crashes. (Bug#22060)The internal functions for table preparation, creation, and alteration were not re-execution friendly, causing problems in code that: repeatedly altered a table; repeatedly created and dropped a table; opened and closed a cursor on a table, altered the table, and then reopened the cursor. (Bug#4968, Bug#6895, Bug#19182, Bug#19733)
A workaround was implemented to avoid a race condition in the NPTL
pthread_exit()implementation. (Bug#24507)NDB Cluster(Cluster APIs):libndbclient.sowas not versioned. (Bug#13522)NDB Cluster: Thendb_size.tmplfile (necessary for using thendb_size.plscript) was missing from binary distributions. (Bug#24191)NDB Cluster: A query with anINclause against anNDBtable employing explicit user-defined partitioning did not always return all matching rows. (Bug#25821)NDB Cluster: AnUPDATEusing anINclause on anNDBtable on which there was a trigger caused mysqld to crash. (Bug#25522)NDB Cluster(Cluster APIs): Deletion of anNdb_cluster_connectionobject took a very long time. (Bug#25487)NDB Cluster: It was not possible to create anNDBtable with a key on twoVARCHARcolumns where both columns had a storage length in excess of 256. (Bug#25746)NDB Cluster: In some circumstances, shutting down the cluster could cause connected mysqld processes to crash. (Bug#25668)NDB Cluster: Memory allocations forTEXTcolumns were calculated incorrectly, resulting in space being wasted and other issues. (Bug#25562)NDB Cluster: The failure of a master node during a node restart could lead to a resource leak, causing later node failures. (Bug#25554)NDB Cluster: The management server did not handle logging of node shutdown events correctly in certain cases. (Bug#22013)NDB Cluster: A node shutdown occurred if the master failed during a commit. (Bug#25364)NDB Cluster: Creating a non-unique index with theUSING HASHclause silently created an ordered index instead of issuing a warning. (Bug#24820)NDB Cluster:SELECTstatements with aBLOBorTEXTcolumn in the selected column list and aWHEREcondition including a primary key lookup on aVARCHARprimary key produced empty result sets. (Bug#19956)
This is a Monthly Rapid Update release of the MySQL Enterprise Server 5.0.
This section documents all changes and bug fixes that have been applied since the last MySQL Enterprise Server release (5.0.32).
Functionality added or changed:
The
--skip-thread-priorityoption now is enabled by default for binary Mac OS X distributions. Use of thread priorities degrades performance on Mac OS X. (Bug#18526)Added the
--disable-grant-optionsoption to configure. If configure is run with this option, the--bootstrap,--skip-grant-tables, and--init-fileoptions for mysqld are disabled and cannot be used. For Windows, the configure.js script recognizes theDISABLE_GRANT_OPTIONSflag, which has the same effect.
Bugs fixed:
Optimizations that are legal only for subqueries without tables and
WHEREconditions were applied for any subquery without tables. (Bug#24670)The server was built even when configure was run with the
--without-serveroption. (Bug#23973)mysqld_error.hwas not installed when only the client libraries were built. (Bug#21265)Using a view in combination with a
USINGclause caused column aliases to be ignored. (Bug#25106)A view was not handled correctly if the
SELECTpart contained ‘\Z’. (Bug#24293)Inserting a row into a table without specifying a value for a
BINARY(column caused the column to be set to spaces, not zeroes. (Bug#14171)N) NOT NULLAn assertion failed incorrectly for prepared statements that contained a single-row uncorrelated subquery that was used as an argument of the IS NULL predicate. (Bug#25027)
A table created with the
ROW_FORMAT = FIXEDtable option loses the option if an index is added or dropped withCREATE INDEXorDROP INDEX. (Bug#23404)Dropping a user-defined function sometimes did not remove the UDF entry from the
mysql.proctable. (Bug#15439)Changing the value of
MI_KEY_BLOCK_LENGTHinmyisam.hand recompiling MySQL resulted in a myisamchk that saw existingMyISAMtables as corrupt. (Bug#22119)Instance Manager could crash during shutdown. (Bug#19044)
A deadlock could occur, with the server hanging on
Closing tables, with a sufficient number of concurrentINSERT DELAYED,FLUSH TABLES, andALTER TABLEoperations. (Bug#23312)A user-defined variable could be assigned an incorrect value if a temporary table was employed in obtaining the result of the query used to determine its value. (Bug#16861)
The optimizer removes expressions from
GROUP BYandDISTINCTclauses if they happen to participate inexpression=constantWHEREclause, the idea being that, if the expression is equal to a constant, then it cannot take on multiple values. However, for predicates where the expression and the constant item are of different result types (for example, when a string column is compared to 0), this is not valid, and can lead to invalid results in such cases. The optimizer now performs an additional check of the result types of the expression and the constant; if their types differ, then the expression is not removed from theGROUP BYlist. (Bug#15881)Referencing an ambiguous column alias in an expression in the
ORDER BYclause of a query caused the server to crash. (Bug#25427)Some
CASEstatements inside stored routines could lead to excessive resource usage or a crash of the server. (Bug#24854, Bug#19194)Some joins in which one of the joined tables was a view could return erroneous results or crash the server. (Bug#24345)
OPTIMIZE TABLEtried to sort R-tree indexes such as spatial indexes, although this is not possible (see Section 13.5.2.5, “OPTIMIZE TABLESyntax”). (Bug#23578)User-defined variables could consume excess memory, leading to a crash caused by the exhaustion of resources available to the
MEMORYstorage engine, due to the fact that this engine is used by MySQL for variable storage and intermediate results ofGROUP BYqueries. WhereSEThad been used, such a condition could instead give rise to the misleading error message You may only use constant expressions with SET, rather than Out of memory (Needed NNNNNN bytes). (Bug#23443)InnoDB: During a restart of the MySQL Server that followed the creation of a temporary table using theInnoDBstorage engine, MySQL failed to clean up in such a way thatInnoDBstill attempted to find the files associated with such tables. (Bug#20867)A multiple-table
DELETE QUICKcould sometimes cause one of the affected tables to become corrupted. (Bug#25048)A compressed
MyISAMtable that became corrupted could crash myisamchk and possibly the MySQL Server. (Bug#23139)A crash of the MySQL Server could occur when unpacking a
BLOBcolumn from a row in a corrupted MyISAM table. This could happen when trying to repair a table using eitherREPAIR TABLEor myisamchk; it could also happen when trying to access such a “broken” row using statements likeSELECTif the table was not marked as crashed. (Bug#22053)The
FEDERATEDstorage engine did not support theeuckrcharacter set. (Bug#21556)The
FEDERATEDstorage engine did not support theutf8character set. (Bug#17044)NDB Cluster: Hosts in clusters with a large number of nodes could experience excessive CPU usage while obtaining configuration data. (Bug#25711)NDB Cluster(NDB API): Invoking theNdbTransaction::execute()method using execution typeCommitand abort optionAO_IgnoreErrorcould lead to a crash of the transaction coordinator (DBTC). (Bug#25090)NDB Cluster(NDB API): A unique index lookup on a non-existent tuple could lead to a data node timeout (error 4012). (Bug#25059)NDB Cluster: When a data node was shut down using the management clientSTOPcommand, a connection event (NDB_LE_Connected) was logged instead of a disconnection event (NDB_LE_Disconnected). (Bug#22773)
This is a Monthly Rapid Update release of the MySQL Enterprise Server 5.0.
This section documents all changes and bug fixes that have been applied since the last MySQL Enterprise Server release (5.0.30).
Functionality added or changed:
Incompatible change: The
prepared_stmt_countsystem variable has been converted to thePrepared_stmt_countglobal status variable (viewable with theSHOW GLOBAL STATUSstatement). (Bug#23159)NDB Cluster: Setting the configuration parameterLockPagesInMainMemoryhad no effect. (Bug#24461)NDB Cluster: It is now possible to create a unique hashed index on a column that is not defined asNOT NULL. Note that this change applies only to tables using theNDBstorage engine.Unique indexes on columns in
NDBtables do not store null values because they are mapped to primary keys in an internal index table (and primary keys cannot contain nulls).Normally, an additional ordered index is created when one creates unique indexes on
NDBtable columns; this can be used to search forNULLvalues. However, ifUSING HASHis specified when such an index is created, no ordered index is created.The reason for permitting unique hash indexes with null values is that, in some cases, the user wants to save space if a large number of records are pre-allocated but not fully initialized. This also assumes that the user will not try to search for null values. Since MySQL does not support indexes that are not allowed to be searched in some cases, the
NDBstorage engine uses a full table scan with pushed conditions for the referenced index columns to return the correct result.Note that a warning is returned if one creates a unique nullable hash index, since the query optimizer should be provided a hint not to use it with
NULLvalues if this can be avoided.In MySQL 5.0.13 and up,
InnoDBrolls back only the last statement on a transaction timeout. A new option,--innodb_rollback_on_timeout, causesInnoDBto abort and roll back the entire transaction if a transaction timeout occurs (the same behavior as before MySQL 5.0.13). (Bug#24200)DROP TRIGGERnow supports anIF EXISTSclause. (Bug#23703)The
Com_create_userstatus variable was added (for countingCREATE USERstatements). (Bug#22958)The
--memlockoption relies on system calls that are unreliable on some operating systems. If a crash occurs, the server now checks whether--memlockwas specified and if so issues some information about possible workarounds. (Bug#22860)The bundled yaSSL library was upgraded to version 1.5.0.
Bugs fixed:
NDB Cluster: If the value set forMaxNoOfAttributesis excessive, a suitable error message is now returned. (Bug#19352)NDB Cluster: Sudden disconnection of an SQL or data node could lead to shutdown of data nodes with the error failed ndbrequire. (Bug#24447)NDB Cluster: ndb_config failed when trying to use 2 management servers and node IDs. (Bug#23887)NDB Cluster(Cluster APIs): UsingBITvalues with any of the comparison methods of theNdbScanFilterclass caused the cluster's data nodes to fail. (Bug#24503)NDB Cluster: The failure of a data node failure during a schema operation could lead to additional node failures. (Bug#24752)NDB Cluster: A committed read could be attempted before a data node had time to connect, causing a timeout error. (Bug#24717)NDB Cluster(Cluster APIs): Some MGM API function calls could yield incorrect return values in certain cases where the cluster was operating under a very high load, or experienced timeouts in inter-node communications. (Bug#24011)NDB Cluster: A unique constraint violation was not ignored by anUPDATE IGNOREstatement when the constraint violation occurred on a non-primary key. (Bug#18487, Bug#24303)mysql_fix_privilege_tables did not handle a password containing embedded space or apostrophe characters. (Bug#17700)
Foreign key identifiers for
InnoDBtables could not contain certain characters. (Bug#24299)In some cases, the parser failed to distinguish a user-defined function from a stored function. (Bug#21809)
With
innodb_file_per_tableenabled,InnoDBdisplayed incorrect file times in the output fromSHOW TABLE STATUS. (Bug#24712)The stack size for NetWare binaries was increased to 128KB to prevent problems caused by insufficient stack size. (Bug#23504)
Attempting to use a view containing
DEFINERinformation for a non-existent user resulted in an error message that revealed the definer account. Now the definer is revealed only to superusers. Other users receive only anaccess deniedmessage. (Bug#17254)mysql_upgrade failed if the
--password(or-p) option was given. (Bug#24896)For a nonexistent table,
DROP TEMPORARY TABLEfailed with an incorrect error message ifread_onlywas enabled. (Bug#22077)The
InnoDBmutex structure was simplified to reduce memory load. (Bug#24386)The
REPEAT()function could returnNULLwhen passed a column for the count argument. (Bug#24947)Accuracy was improved for comparisons between
DECIMALcolumns and numbers represented as strings. (Bug#23260)InnoDBcrashed while performing XA recovery of prepared transactions. (Bug#21468)ROW_COUNT()did not work properly as an argument to a stored procedure. (Bug#23760)The size of
MEMORYtables and internal temporary tables was limited to 4GB on 64-bit Windows systems. (Bug#24052)For queries that select from a view, the server was returning
MYSQL_FIELDmetadata inconsistently for view names and table names. For view columns, the server now returns the view name in thetablefield and, if the column selects from an underlying table, the table name in theorg_tablefield. (Bug#20191)It was possible to use
DATETIMEvalues whose year, month, and day parts were all zeroes but whose hour, minute, and second parts contained nonzero values, an example of such an illegalDATETIMEbeing'0000-00-00 11:23:45'. (Bug#21789)It was possible to set the backslash character (“
\”) as the delimiter character usingDELIMITER, but not actually possible to use it as the delimiter. (Bug#21412)The loose index scan optimization for
GROUP BYwithMINorMAXwas not applied within other queries, such asCREATE TABLE ... SELECT ...,INSERT ... SELECT ..., or in theFROMclauses of subqueries. (Bug#24156)ALTER ENABLE KEYSorALTER TABLE DISABLE KEYScombined with anotherALTER TABLEoption other thanRENAME TOdid nothing. In addition, if ALTER TABLE was used on a table having disabled keys, the keys of the resulting table were enabled. (Bug#24395)Queries using a column alias in an expression as part of an
ORDER BYclause failed, an example of such a query beingSELECT mycol + 1 AS mynum FROM mytable ORDER BY 30 - mynum. (Bug#22457)Trailing spaces were not removed from Unicode
CHARcolumn values when used in indexes. This resulted in excessive usage of storage space, and could affect the results of someORDER BYqueries that made use of such indexes.Note: When upgrading, it is necessary to re-create any existing indexes on Unicode
CHARcolumns in order to take advantage of the fix. This can be done by using aREPAIR TABLEstatement on each affected table.Warnings were generated when explicitly casting a character to a number (for example,
CAST('x' AS SIGNED)), but not for implicit conversions in simple arithmetic operations (such as'x' + 0). Now warnings are generated in all cases. (Bug#11927)STR_TO_DATE()returnedNULLif the format string contained a space following a non-format character. (Bug#22029)yaSSL crashed on pre-Pentium Intel CPUs. (Bug#21765)
Selecting into variables sometimes returned incorrect wrong results. (Bug#20836)
mysql_fix_privilege_tables.sqlaltered thetable_privs.table_privcolumn to contain too few privileges, causing loss of theCREATE VIEWandSHOW VIEWprivileges. (Bug#20589)A query with a subquery that references columns of a view from the outer
SELECTcould return an incorrect result if used from a prepared statement. (Bug#20327)A server crash occurred when using
LOAD DATAto load a table containing aNOT NULLspatial column, when the statement did not load the spatial column. Now aNULL supplied to NOT NULL columnerror occurs. (Bug#22372)Unsigned
BIGINTvalues treated as signed values by theMOD()function. (Bug#19955)Compiling PHP 5.1 with the MySQL static libraries failed on some versions of Linux. (Bug#19817)
The
DELIMITERstatement did not work correctly when used in an SQL file run using theSOURCEstatement. (Bug#19799)VARBINARYcolumn values inserted on a MySQL 4.1 server had trailing zeroes following upgrade to MySQL 5.0 or later. (Bug#19371)Constant expressions and some numeric constants used as input parameters to user-defined functions were not treated as constants. (Bug#18761)
Subqueries of the form
NULL IN (SELECT ...)returned invalid results. (Bug#8804, Bug#23485)The
--externoption for mysql-test-run.pl did not function correctly. (Bug#24354)INET_ATON()returned a signedBIGINTvalue, not an unsigned value. (Bug#21466)ALTER TABLEstatements that performed bothRENAME TOand{ENABLE|DISABLE} KEYSoperations caused a server crash. (Bug#24089)myisampack wrote to unallocated memory, causing a crash. (Bug#17951)
Some small double precision numbers (such as
1.00000001e-300) that should have been accepted were truncated to zero. (Bug#22129)The mysql.server script used the source command, which is less portable than the . command; it now uses . instead. (Bug#24294)
DATE_ADD()requires complete dates with no “zero” parts, but sometimes did not returnNULLwhen given such a date. (Bug#22229)Using
FLUSH TABLESin one connection while another connection is usingHANDLERstatements caused a server crash. (Bug#21587)FLUSH LOGSor mysqladmin flush-logs caused a server crash if the binary log was not open. (Bug#17733)Subqueries for which a pushed-down condition did not produce exactly one key field could cause a server crash. (Bug#24056)
LAST_DAY('0000-00-00')could cause a server crash. (Bug#23653)Through the C API, the member strings in
MYSQL_FIELDfor a query that contains expressions may return incorrect results. (Bug#21635)mysql_affected_rows()could return values different frommysql_stmt_affected_rows()for the same sequence of statements. (Bug#23383)IN()andCHAR()can returnNULL, but did not signal that to the query processor, causing incorrect results forIS NULLoperations. (Bug#17047)A trigger that invoked a stored function could cause a server crash when activated by different client connections. (Bug#23651)
CONCURRENTdid not work correctly forLOAD DATA INFILE. (Bug#20637)Inserting a default or invalid value into a spatial column could fail with
Unknown errorrather than a more appropriate error. (Bug#21790)The server could send incorrect column count information to the client for queries that produce a larger number of columns than can fit in a two-byte number. (Bug#19216)
Evaluation of subqueries that require the filesort algorithm were allocating and freeing the
sort_buffer_sizebuffer many times, resulting in slow performance. Now the buffer is allocated once and reused. (Bug#21727)SQL statements close to the size of
max_allowed_packetcould produce binary log events larger thanmax_allowed_packetthat could not be read by slave servers. (Bug#19402)View columns were always handled as having implicit derivation, leading to
illegal mix of collation errorsfor some views inUNIONoperations. Now view column derivation comes from the original expression given in the view definition. (Bug#21505)If elements in a non-top-level
INsubquery were accessed by an index and the subquery result set included aNULLvalue, the quantified predicate that contained the subquery was evaluated toNULLwhen it should return a non-NULLvalue. (Bug#23478)Calculation of
COUNT(DISTINCT),AVG(DISTINCT), orSUM(DISTINCT)when they are referenced more than once in a single query withGROUP BYcould cause a server crash. (Bug#23184)For a cast of a
DATETIMEvalue containing microseconds toDECIMAL, the microseconds part was truncated without generating a warning. Now the microseconds part is preserved. (Bug#19491)Metadata for columns calculated from scalar subqueries was limited to integer, double, or string, even if the actual type of the column was different. (Bug#11032)
Using
EXPLAINcaused a server crash for queries that selected fromINFORMATION_SCHEMAin a subquery in theFROMclause. (Bug#22413)Invalidating the query cache caused a server crash for
INSERT INTO ... SELECTstatements that selected from a view. (Bug#20045)Slave servers would retry the execution of a SQL statement an infinite number of times, ignoring the value
SLAVE_TRANSACTION_RETRIESwhen using the NDB engine. (Bug#16228)On slave servers, transactions that exceeded the lock wait timeout failed to roll back properly. (Bug#20697)
Changes to character set variables prior to an action on a replication-ignored table were forgotten by slave servers. (Bug#22877)
With
lower_case_table_namesset to 1,SHOW CREATE TABLEprinted incorrect output for table names containing Turkish I (LATIN CAPITAL LETTER I WITH DOT ABOVE). (Bug#20404)When applying the
group_concat_max_lenlimit,GROUP_CONCAT()could truncate multi-byte characters in the middle. (Bug#23451)For some problems relating to character set conversion or incorrect string values for
INSERTorUPDATE, the server was reporting truncation or length errors instead. (Bug#18908)
This is a Service Pack release of the MySQL Enterprise Server 5.0.
This section documents all changes and bug fixes that have been applied since the last MySQL Enterprise Server release (5.0.30).
Functionality added or changed:
In MySQL 5.0.13 and up,
InnoDBrolls back only the last statement on a transaction timeout. A new option,--innodb_rollback_on_timeout, causesInnoDBto abort and roll back the entire transaction if a transaction timeout occurs (the same behavior as before MySQL 5.0.13). (Bug#24200)
Bugs fixed:
Several string functions could return incorrect results when given very large length arguments. (Bug#10963)
Certain malformed
INSERTstatements could crash the mysql client. (Bug#21142)Evaluation of subqueries that require the filesort algorithm were allocating and freeing the
sort_buffer_sizebuffer many times, resulting in slow performance. Now the buffer is allocated once and reused. (Bug#21727)The loose index scan optimization for
GROUP BYwithMINorMAXwas not applied within other queries, such asCREATE TABLE ... SELECT ...,INSERT ... SELECT ..., or in theFROMclauses of subqueries. (Bug#24156)The size of
MEMORYtables and internal temporary tables was limited to 4GB on 64-bit Windows systems. (Bug#24052)Accuracy was improved for comparisons between
DECIMALcolumns and numbers represented as strings. (Bug#23260)Calculation of
COUNT(DISTINCT),AVG(DISTINCT), orSUM(DISTINCT)when they are referenced more than once in a single query withGROUP BYcould cause a server crash. (Bug#23184)A stored procedure, executed from a connection using a binary character set, and which wrote multibyte data, would write incorrectly escaped entries to the binary log. This caused syntax errors, and caused replication to fail. (Bug#23619, Bug#24492)
CONCURRENTdid not work correctly forLOAD DATA INFILE. (Bug#20637)Evaluation of subqueries that require the filesort algorithm were allocating and freeing the
sort_buffer_sizebuffer many times, resulting in slow performance. Now the buffer is allocated once and reused. (Bug#21727)InnoDBcrashed while performing XA recovery of prepared transactions. (Bug#21468)
This is a Monthly Rapid Update release of the MySQL Enterprise Server 5.0.
This section documents all changes and bug fixes that have been applied since the last MySQL Enterprise Server release (5.0.28).
Functionality added or changed:
If the user specified the server options
--max-connections=orN--table-open-cache=, a warning would be given in some cases that some values were recalculated, with the result thatM--table-open-cachecould be assigned greater value.It should be noted that, in such cases, both the warning and the increase in the
--table-open-cachevalue were completely harmless. Note also that it is not possible for the MySQL Server to predict or to control limitations on the maximum number of open files, since this is determined by the operating system.The recalculation code has now been fixed to ensure that the value of
--table-open-cacheis no longer increased automatically, and that a warning is now given only if some values had to be decreased due to operating system limits.NDB Cluster: A potential memory leak in theNDBstorage engine's handling of file operations was uncovered. (Bug#21858)NDB Cluster: TheHELPcommand in the Cluster management client now provides command-specific help. For example,HELP RESTARTin ndb_mgm provides detailed information about theSTARTcommand. (Bug#19620)NDB Cluster: Added the --bind-address option for ndbd. This allows a data node process to be bound to a specific network interface. (Bug#22195)NDB Cluster: TheNdb_number_of_storage_nodessystem variable was renamed toNdb_number_of_data_nodes. (Bug#20848)NDB Cluster: The ndb_config utility now accepts-cas a short form of the--ndb-connectstringoption. (Bug#22295)SHOW STATUSis no longer logged to the slow query log. (Bug#19764)mysqldump --single-transaction now uses
START TRANSACTION /*!40100 WITH CONSISTENT SNAPSHOT */rather thanBEGINto start a transaction, so that a consistent snapshot will be used on those servers that support it. (Bug#19660)mysql_upgradenow passes all the parameters specified on the command line to bothmysqlcheckandmysqlusing theupgrade_defaultsfile. (Bug#20100)For the
CALLstatement, stored procedures that take no arguments now can be invoked without parentheses. That is,CALL p()andCALL pare equivalent. (Bug#21462)
Bugs fixed:
NDB Cluster: Data nodes added while the cluster was running in single user mode were all assigned node ID 0, which could later cause multiple node failures. Adding of nodes in single user mode is no longer possible. (Bug#20395)NDB Cluster: Attempting to create anNDBtable on a MySQL with an existing non-Cluster table with the same name in the same database could result in data loss or corruption. MySQL now issues a warning when aSHOW TABLESor other statement causing table discovery finds such a table. (Bug#21378)NDB Cluster(NDB API): Inacivity timeouts for scans were not correctly handled. (Bug#23107)NDB Cluster(NDB API): Attempting to read a nonexistent tuple usingCommitmode forNdbTransaction::execute()caused node failures. (Bug#22672)NDB Cluster(NDB API): Scans closed before being executed were still placed in the send queue. (Bug#21941)NDB Cluster(NDB API): TheNdbOperation::getBlobHandle()method, when called with the name of a nonexistent column, caused a segmentation fault. (Bug#21036)NDB Cluster: A problem with takeover during a system restart caused ordered indexes to be rebuilt incorrectly. (Bug#15303)NDB Cluster: The ndb_config utility did not perform host lookups correctly when using the--hostoption. (Bug#17582)NDB Cluster: The ndb_config utility did not perform host lookups correctly when using the--hostoption (Bug#17582)NDB Cluster: The error returned by the cluster when too many nodes were defined did not make clear the nature of the problem. (Bug#19045)NDB Cluster: ndb_mgm -e show | head would hang after displaying the first 10 lines of output. (Bug#19047)NDB Cluster: In rare situations with resource shortages, a crash could result from insufficientIndexScanOperations. (Bug#19198)NDB Cluster: ndb_restore did not always make clear that it had recovered successfully from temporary errors while restoring a cluster backup. (Bug#19651)NDB Cluster: Error messages given when trying to make online changes parameters such asNoOfReplicasthast can only be changed via a complete shutdown and restart of the cluster did not indicate the true nature of the problem. (Bug#19787)NDB Cluster: Following the restart of an MGM node, the Cluster management client did not automatically reconnect. (Bug#19873)NDB Cluster: In some cases whereSELECT COUNT(*)from anNDBtable should have yielded an error,MAX_INTwas returned instead. (Bug#19914)NDB Cluster(NDB API): When multiple processes or threads in parallel performed the same ordered scan with exclusive lock and updating the retrieved records, the scan could skip some records, which were not updated as a result. (Bug#20446)NDB Cluster: Using an invalid node ID with the management clientSTOPcommand could cause ndb_mgm to hang. (Bug#20575)NDB Cluster: Under some circumstances, local checkpointing would hang, keeping any unstarted nodes from being started. (Bug#20895)NDB Cluster: Condition pushdown did not work correctly withDATETIMEcolumns. (Bug#21056)NDB Cluster: When inserting a row into anNDBtable with a duplicate value for a non-primary unique key, the error issued would reference the wrong key. (Bug#21072)NDB Cluster: Cluster logs were not rotated following the first rotation cycle. (Bug#21345)NDB Cluster: The ndb_mgm management client did not set the exit status on errors, always returning 0 instead. (Bug#21530)NDB Cluster: Partition distribution keys were updated only for the primary and starting replicas during node recovery. This could lead to node failure recovery for clusters having an odd number of replicas. (Bug#21535)Note: We recommend values for
NumberOfReplicasthat are even powers of 2, for best results.NDB Cluster: The output for the--helpoption used withNDBexecutable programs (ndbd, ndb_mgm, ndb_restore, ndb_config, and so on) referred to theNdb.cfgfile, instead ofmy.cnf. (Bug#21585)NDB Cluster: The node recovery algorithm was missing a version check for tables in theALTER_TABLE_COMMITTEDstate (as opposed to theTABLE_ADD_COMMITTEDstate, which has the version check). This could cause inconsistent schemas across nodes following node recovery. (Bug#21756)NDB Cluster: A scan timeout returned Error 4028 (Node failure caused abort of transaction) instead of Error 4008 (Node failure caused abort of transaction...). (Bug#21799)NDB Cluster: The--helpoutput fromNDBbinaries did not include file-related options. (Bug#21994)NDB Cluster: Multiple node restarts in rapid succession could cause a system restart to fail (Bug#22892), or induce a race condition (Bug#23210).NDB Cluster: If a node restart could not be performed from the REDO log, no node takeover took place. This could cause partitions to be left empty during a system restart. (Bug#22893)NDB Cluster:INSERT ... ON DUPLICATE KEY UPDATEon anNDBtable could lead to deadlocks and memory leaks. (Bug#23200)NDB Cluster: The management client commandALL DUMP 1000would cause the cluster to crash if data nodes were connected to the cluster but not yret fully started. (Bug#23203)NDB Cluster: Cluster backups would fail when there were more than 2048 schema objects in the cluster. (Bug#23499)NDB Cluster: Restoring a cluster failed if there were any tables with 128 or more columns. (Bug#23502)If an
init_connectSQL statement produced an error, the connection was silently terminated with no error message. Now the server writes a warning to the error log. (Bug#22158)The internal SQL interpreter of
InnoDBplaced an unnecessary lock on the supremum record wheninnodb_locks_unsafe_for_binlog=1. This caused an assertion failure whenInnoDBwas built with debugging enabled. (Bug#23769)If a table contains an
AUTO_INCREMENTcolumn, inserting into an insertable view on the table that does not include theAUTO_INCREMENTcolumn should not change the value ofLAST_INSERT_ID(), because the side effects of inserting default values into columns not part of the view should not be visible. MySQL was incorrectly settingLAST_INSERT_ID()to zero. (Bug#22584)M% 0NULL, but (M% 0) IS NULLWithin a stored routine, a view definition cannot refer to routine parameters or local variables. However, an error did not occur until the routine was called. Now it occurs during parsing of the routine creation statement. (Bug#20953)
Note: A side effect of this fix is that if you have already created such routines, and error will occur if you execute
SHOW CREATE PROCEDUREorSHOW CREATE FUNCTION. You should drop these routines because they are erroneous.A client library crash was caused by executing a statement such as
SELECT * FROM t1 PROCEDURE ANALYSE()using a server side cursor on a tablet1that does not have the same number of columns as the output fromPROCEDURE ANALYSE(). (Bug#17039)mysql did not check for errors when fetching data during result set printing. (Bug#22913)
Adding a day, month, or year interval to a
DATEvalue produced aDATE, but adding a week interval produced aDATETIMEvalue. Now all produce aDATEvalue. (Bug#21811)The column default value in the output from
SHOW COLUMNSorSELECT FROM INFORMATION_SCHEMA.COLUMNSwas truncated to 64 characters. (Bug#23037)For not-yet-authenticated connections, the
Timecolumn inSHOW PROCESSLISTwas a random value rather thanNULL. (Bug#23379)The
Hostcolumn inSHOW PROCESSLISToutput was blank when the server was started with the--skip-grant-tablesoption. (Bug#22728)The
Handler_rollbackstatus variable sometimes was incremented when no rollback had taken place. (Bug#22728)Within a prepared statement,
SELECT (COUNT(*) = 1)(or similar use of other aggregate functions) did not return the correct result for statement re-execution. (Bug#21354)Lack of validation for input and output
TIMEvalues resulted in several problems:SEC_TO_TIME()within subqueries incorrectly clipped large values;SEC_TO_TIME()treatedBIGINT UNSIGNEDvalues as signed; only truncation warnings were produced when both truncation and out-of-rangeTIMEvalues occurred. (Bug#11655, Bug#20927)Range searches on columns with an index prefix could miss records. (Bug#20732)
With
SQL_MODE=TRADITIONAL, MySQL incorrectly aborted on warnings within stored routines and triggers. (Bug#20028)In mysql, invoking
connector\rwith very longdb_nameorhost_nameparameters caused buffer overflow. (Bug#20894)mysqldump --xml produced invalid XML for
BLOBdata. (Bug#19745)For a debug server, a reference to an undefined user variable in a prepared statment executed with
EXECUTEcaused an assertion failure. (Bug#19356)Within a trigger for a base table, selecting from a view on that base table failed. (Bug#19111)
DELETE IGNOREcould hang for foreign key parent deletes. (Bug#18819)Transient errors in replication from master to slave may trigger multiple
Got fatal error 1236: 'binlog truncated in the middle of event'errors on the slave. (Bug#4053)The value of the
warning_countsystem variable was not being calculated correctly (also affectingSHOW COUNT(*) WARNINGS). (Bug#19024)InnoDBexhibited thread thrashing with more than 50 concurrent connections under an update-intensive workload. (Bug#22868)InnoDBshowed substandard performance with multiple queries running concurrently. (Bug#15815)There was a race condition in the
InnoDBfil_flush_file_spaces()function. (Bug#24089)FROM_UNIXTIME()did not accept arguments up toPOWER(2,31)-1, which it had previously. (Bug#9191)Some yaSSL-related memory leaks detected by Valgrind were fixed. (Bug#23981)
If
COMPRESS()returnedNULL, subsequent invocations ofCOMPRESS()within a result set or within a trigger also returnedNULL. (Bug#23254)mysql would lose its connection to the server if its standard output was not writable. (Bug#17583)
mysql-test-run did not work correctly for RPM-based installations. (Bug#17194)
The return value from
my_seek()was ignored. (Bug#22828)Use of
PREPAREwith aCREATE PROCEDUREstatement that contained a syntax error caused a server crash. (Bug#21868)Use of a DES-encrypted SSL certificate file caused a server crash. (Bug#21868)
Column names were not quoted properly for replicated views. (Bug#19736)
InnoDBused table locks (not row locks) within stored functions. (Bug#18077)Statements such as
DROP PROCEDUREandDROP VIEWwere written to the binary log too late due to a race condition. (Bug#14262)MySQL would fail to build on the Alpha platform. (Bug#23256)
The optimizer failed to use equality propagation for
BETWEENandINpredicates with string arguments. (Bug#22753)The optimizer used the
refjoin type rather thaneq_reffor a simple join on strings. (Bug#22367)The
WITH CHECK OPTIONfor a view failed to prevent storing invalid column values forUPDATEstatements. (Bug#16813)A literal string in a
GROUP BYclause could be interpreted as a column name. (Bug#14019)Some queries that used
MAX()andGROUP BYcould incorrectly return an empty result. (Bug#22342)WITH ROLLUPcould group unequal values. (Bug#20825)Use of a subquery that invoked a function in the column list of the outer query resulted in a memory leak. (Bug#21798)
LIKEsearches failed for indexedutf8character columns. (Bug#20471)FLUSH INSTANCESin Instance Manager triggered an assertion failure. (Bug#19368)ALTER TABLEwas not able to rename a view. (Bug#14959)Entries in the slow query log could have an incorrect
Rows_examinedvalue. (Bug#12240)Insufficient memory (
myisam_sort_buffer_size) could cause a server crash for several operations onMyISAMtables: repair table, create index by sort, repair by sort, parallel repair, bulk insert. (Bug#23175)OPTIMIZE TABLEwithmyisam_repair_threads> 1 could result inMyISAMtable corruption. (Bug#8283)Selecting from a
MERGEtable could result in a server crash if the underlying tables had fewer indexes than theMERGEtable itself. (Bug#22937)A locking safety check in
InnoDBreported a spurious errorstored_select_lock_type is 0 inside ::start_stmt()forINSERT ... SELECTstatements ininnodb_locks_unsafe_for_binlogmode. The safety check was removed. (Bug#10746)For multiple-table
UPDATEstatements, storage engines were not notified of duplicate-key errors. (Bug#21381)Incorrect results could be obtained from re-execution of a parametrized prepared statement or a stored routine with a
SELECTthat usesLEFT JOINwith a second table having only one row. (Bug#21081)An
UPDATEthat referred to a key column in theWHEREclause and activated a trigger that modified the column resulted in a loop. (Bug#20670)Creating a
TEMPORARYtable with the same name as an existing table that was locked by another client could result in a lock conflict forDROP TEMPORARY TABLEbecause the server unnecessarily tried to acquire a name lock. (Bug#21096)After
FLUSH TABLES WITH READ LOCKfollowed byUNLOCK TABLES, attempts to drop or alter a stored routine failed with an error that the routine did not exist, and attempts to execute the routine failed with a lock conflict error. (Bug#21414)SHOW VARIABLEStruncated theValuefield to 256 characters. (Bug#20862)Instance Manager didn't close the client socket file when starting a new mysqld instance. mysqld inherited the socket, causing clients connected to Instance Manager to hang. (Bug#12751)
Instance Manager had a race condition involving mysqld PID file removal. (Bug#22379)
It was possible for a stored routine with a non-
latin1name to cause a stack overrun. (Bug#21311)
This is the first MySQL Enterprise Server release, following the last Community Server release (5.0.27).
Functionality added or changed:
Binary MySQL distributions no longer include a mysqld-max server, except for RPM distributions. Instead, distributions contain a mysqld binary that includes the features previously included in the mysqld-max binary.
Bugs fixed:
Table of Contents
This appendix lists the enhancements and changes from version to version in MySQL Community Server. This information is updated as bugs are fixed and features are incorporated, so that everybody can follow the development process.
Note that we tend to update the manual at the same time we make changes to MySQL. If you find a recent version of MySQL listed here that you can't find on our download page (http://dev.mysql.com/downloads/), it means that the version has not yet been released (and will normally be marked so in the appropriate Release Note section).
The date mentioned with a release version is the date of the last change done internally at MySQL AB (the BitKeeper ChangeSet) on which the release was based, not the date when the packages were made available. The binaries are usually made available a few days after the date of the tagged ChangeSet, because building and testing all packages takes some time.
For information on how to determine your current version and release type, see Section 2.2, “Determining your current MySQL version”.
This section documents all enhancements, changes, and bug fixes made to MySQL Community Server from 5.0.27 on. For changes and bug fixes to earlier versions, see Appendix E, MySQL Change History.
This is a bugfix release for the current production release family. It replaces MySQL 5.0.37.
Functionality added or changed:
If you use SSL for a client connection, you can tell the client not to authenticate the server certificate by specifying neither
--ssl-canor--ssl-capath. The server still verifies the client according to any applicable requirements established viaGRANTstatements for the client, and it still uses any--ssl-ca/--ssl-capathvalues that were passed to server at startup time. (Bug#25309)Prefix lengths for columns in
SPATIALindexes are no longer displayed inSHOW CREATE TABLEoutput. mysqldump uses that statement, so if a table withSPATIALindexes containing prefixed columns is dumped and reloaded, the index is created with no prefixes. (The full column width of each column is indexed.) (Bug#26794)The output of mysql
--xmland mysqldump--xmlnow includes a valid XML namespace. (Bug#25946)The mysql_create_system_tables script was removed because mysql_install_db no longer uses it in MySQL 5.0.
The syntax for index hints has been extended to enable explicit specification that the hint applies only to join processing. See Section 13.2.7.2, “Index Hint Syntax”. (Bug#21174)
Binary distributions for some platforms did not include shared libraries; now shared libraries are shipped for all platforms except AIX 5.2 64-bit. (Bug#13450, Bug#16520, Bug#26767)
NDB Cluster: It is now possible to restore selected databases or tables using ndb_restore. (Bug#26899)NDB Cluster: Several options have been added for use with ndb_restore--print_datato facilitate the creation of data dump files. (Bug#26900)If a set function
Swith an outer referenceS(outer_ref)S(outer_ref)S(const)ANSISQL mode is enabled. (Bug#27348)To satisfy different user requirements, we provide several servers. mysqld is an optimized server that is a smaller, faster binary. Each package now also includes mysqld-debug, which is compiled with debugging support but is otherwise configured identically to the non-debug server.
Added the
--secure-file-privoption for mysql-test-run.pl, which limits the effect of theload_filecommand for mysqltest and for theLOAD DATAandSELECT ... INTO OUTFILEstatements to work with files in a given directory. (Bug#18628)Added the
hostnamesystem variable, which the server sets at startup to the server hostname.The server now includes a timestamp in error messages that are logged as a result of unhandled signals (such as
mysqld got signal 11messages). (Bug#24878)
Bugs fixed:
NDB Cluster:NDBtables havingMEDIUMINT AUTO_INCREMENTcolumns were not restored correctly by ndb_restore, causing spurious duplicate key errors. This issue did not affectTINYINT,INT, orBIGINTcolumns withAUTO_INCREMENT. (Bug#27775)NDB Cluster:NDBtables with indexes whose names contained space characters were not restored correctly by ndb_restore (the index names were truncated). (Bug#27758)NDB Cluster: Some queries that updated multiple tables were not backed up correctly. (Bug#27748)NDB Cluster: Joins on multiple tables containingBLOBcolumns could cause data nodes run out of memory, and to crash with the error NdbObjectIdMap::expand unable to expand. (Bug#26176)NDB Cluster(APIs): UsingNdbBlob::writeData()to write data in the middle of an existing blob value (that is, updating the value) could overwrite some data past the end of the data to be changed. (Bug#27018)NDB Cluster: Under certain rare circumstances,DROP TABLEorTRUNCATEof anNDBtable could cause a node failure or forced cluster shutdown. (Bug#27581)NDB Cluster: Memory usage of a mysqld process grew even while idle. (Bug#27560)NDB Cluster: In some cases,AFTER UPDATEandAFTER DELETEtriggers onNDBtables that referenced subject table did not see the results of operation which caused invocation of the trigger, but rather saw the row as it was prior to the update or delete operation.This was most noticeable when an update operation used a subquery to obtain the rows to be updated. An example would be
UPDATE tbl1 SET col2 = val1 WHERE tbl1.col1 IN (SELECT col3 FROM tbl2 WHERE c4 = val2)where there was anAFTER UPDATEtrigger on tabletbl1. In such cases, the trigger would fail to execute.The problem occurred because the actual update or delete operations were deferred to be able to perform them later as one batch. The fix for this bug solves the problem by disabling this optimization for a given update or delete if the table has an
AFTERtrigger defined for this operation. (Bug#26242)NDB Cluster: Condition pushdown did not work with prepared statements. (Bug#26225)NDB Cluster: When trying to create tables on an SQL node not connected to the cluster, a misleading error message Table 'tbl_name' already exists was generated. The error now generated is Could not connect to storage engine. (Bug#18676)NDB Cluster: Error messages displayed when running in single user mode were inconsistent. (Bug#27021)NDB Cluster: On Solaris, the value of anNDBtable column declared asBIT(33)was always displayed as0. (Bug#26986)NDB Cluster: The output from ndb_restore--print_datawas incorrect for a backup made of a database containing tables withTINYINTorSMALLINTcolumns. (Bug#26740)NDB Cluster: After entering single user mode it was not possible to alter non-NDBtables on any SQL nodes other than the one having sole access to the cluster. (Bug#25275)NDB Cluster: The failure of a data node while restarting could cause other data nodes to hang or crash. (Bug#27003)NDB Cluster: The management client commandnode_idSTATUSNodewhennode_id: not connectednode_idwas not the node ID of a data node. (Bug#21715)Note
The
ALL STATUScommand in the cluster management client still displays status information for data nodes only. This is by design. See Section 15.7.2, “Commands in the MySQL Cluster Management Client”, for more information.NDB Cluster: It was not possible to setLockPagesInMainMemoryequal to0. (Bug#27291)NDB Cluster: A race condition could sometimes occur if the node acting as master failed while node IDs were still being allocated during startup. (Bug#27286)NDB Cluster: When a data node was taking over as the master node, a race condition could sometimes occur as the node was assuming responsibility for handling of global checkpoints. (Bug#27283)NDB Cluster: mysqld processes would sometimes crash under high load. (Bug#26825)NDB Cluster: Some values ofMaxNoOfTablescaused the error Job buffer congestion to occur. (Bug#19378)Some equi-joins containing a
WHEREclause that included aNOT INsubquery caused a server crash. (Bug#27870)Windows binaries contained no debug symbol file. Now
.mapand.pdbfiles are included in 32-bit builds for mysqld-nt.exe, mysqld-debug.exe, and mysqlmanager.exe. (Bug#26893)The test for the
MYSQL_OPT_SSL_VERIFY_SERVER_CERToption formysql_options()was performed incorrectly. Also changed as a result of this bugfix: Theargoption for themysql_options()C API function was changed fromchar *tovoid *. (Bug#24121)The range optimizer could consume a combinatorial amount of memory for certain classes of
WHEREclauses. (Bug#26624)Conversion of
DATETIMEvalues in numeric contexts sometimes did not produce a double (YYYYMMDDHHMMSS.uuuuuu) value. (Bug#16546)Passing nested row expressions with different structures to an
INpredicate caused a server crash. (Bug#27484)SELECT DISTINCTcould return incorrect results if the select list contained duplicated columns. (Bug#27659)A subquery could get incorrect values for references to outer query columns when it contained aggregate functions that were aggregated in outer context. (Bug#27321)
In some cases, the optimizer preferred a range or full index scan access method over lookup access methods when the latter were much cheaper. (Bug#19372)
Duplicates were not properly identified among (potentially) long strings used as arguments for
GROUP_CONCAT(DISTINCT). (Bug#26815)For
InnoDB, fixed consistent-read behavior of the first read statement, if the read was served from the query cache, for theREAD COMMITTEDisolation level. (Bug#21409)The
decimal.hheader file was incorrectly omitted from binary distributions. (Bug#27456)Duplicate members in
SETdefinitions were not detected. Now they result in a warning; if strict SQL mode is enabled, an error occurs instead. (Bug#27069)For
INSERT INTO ... SELECTwhere index searches used column prefixes, insert errors could occur when key value type conversion was done. (Bug#26207)For
SHOW ENGINE INNODB STATUS, theLATEST DEADLOCK INFORMATIONwas not always cleared properly. (Bug#25494)mysqldumpcould crash or exhibit incorrect behavior when some options were given very long values, such as--fields-terminated-by=". The code has been cleaned up to remove a number of fixed-sized buffers and to be more careful about error conditions in memory allocation. (Bug#26346)some very long string"Setting a column to
NOT NULLwith anON DELETE SET NULLclause foreign key crashes the server. (Bug#25927)The values displayed for the
Innodb_row_lock_time,Innodb_row_lock_time_avg, andInnodb_row_lock_time_maxstatus variables were incorrect. (Bug#23666)COUNT(sometimes generated a spurious truncation warning. (Bug#21976)decimal_expr)With
NO_AUTO_VALUE_ON_ZEROSQL mode enabled,LOAD DATAoperations could assign incorrectAUTO_INCREMENTvalues. (Bug#27586)Incorrect results could be returned for some queries that contained a select list expression with
INorBETWEENtogether with anORDER BYorGROUP BYon the same expression usingNOT INorNOT BETWEEN. (Bug#27532)Queries containing subqueries with
COUNT(*)aggregated in an outer context returned incorrect results. This happened only if the subquery did not contain any references to outer columns. (Bug#27257)Use of an aggregate function from an outer context as an argument to
GROUP_CONCAT()caused a server crash. (Bug#27229)REPAIR TABLE ... USE_FRMwith anARCHIVEtable deleted all records from the table. (Bug#26138)On Windows, debug builds of mysqld could fail with heap assertions. (Bug#25765)
On Windows, debug builds of mysqlbinlog could fail with a memory error. (Bug#23736)
String truncation upon insertion into an integer or year column did not generate a warning (or an error in strict mode). (Bug#26359, Bug#27176)
In out-of-memory conditions, the server might crash or otherwise not report an error to the Windows event log. (Bug#27490)
The temporary file-creation code was cleaned up on Windows to improve server stability. (Bug#26233)
Out-of-memory errors for slave I/O threads were not reported. Now they are written to the error log. (Bug#26844)
mysqldump crashed for
MERGEtables if the--complete-insert(-c) option was given. (Bug#25993)In certain situations,
MATCH ... AGAINSTreturned false hits forNULLvalues produced byLEFT JOINwhen no full-text index was available. (Bug#25729)OPTIMIZE TABLEmight fail on Windows when it attempts to rename a temporary file to the original name if the original file had been opened, resulting in loss of the.MYDfile. (Bug#25521)GRANTstatements were not replicated if the server was started with the--replicate-ignore-tableor--replicate-wild-ignore-tableoption. (Bug#25482)A problem in handling of aggregate functions in subqueries caused predicates containing aggregate functions to be ignored during query execution. (Bug#24484)
Improved out-of-memory detection when sending logs from a master server to slaves, and log a message when allocation fails. (Bug#26837)
MBROverlaps()returned incorrect values in some cases. (Bug#24563)SHOW CREATE VIEWqualified references to stored functions in the view definition with the function's database name, even when the database was the default database. This affected mysqldump (which usesSHOW CREATE VIEWto dump views) because the resulting dump file could not be used to reload the database into a different database.SHOW CREATE VIEWnow suppresses the database name for references to functions in the default database. (Bug#23491)With
innodb_file_per_tableenabled, attempting to rename anInnoDBtable to a non-existent database caused the server to exit. (Bug#27381)mysql_install_db could terminate with an error after failing to determine that a system table already existed. (Bug#27022)
For
InnoDBtables having a clustered index that began with aCHARorVARCHARcolumn, deleting a record and then inserting another before the deleted record was purged could result in table corruption. (Bug#26835)Selecting the result of
AVG()within aUNIONcould produce incorrect values. (Bug#24791)An
INTO OUTFILEclause is allowed only for the finalSELECTof aUNION, but this restriction was not being enforced correctly. (Bug#23345)Duplicate entries were not assessed correctly in a
MEMORYtable with aBTREEprimary key on autf8ENUMcolumn. (Bug#24985)For
MyISAMtables,COUNT(*)could return an incorrect value if theWHEREclause compared an indexedTEXTcolumn to the empty string (''). This happened if the column contained empty strings and also strings starting with control characters such as tab or newline. (Bug#26231)For
DELETE FROM(with notbl_nameORDER BYcol_nameWHEREorLIMITclause), the server did not check whethercol_namewas a valid column in the table. (Bug#26186)ALTER VIEWrequires theCREATE VIEWandDROPprivileges for the view. However, if the view was created by another user, the server erroneously required theSUPERprivilege. (Bug#26813)In a view, a column that was defined using a
GEOMETRYfunction was treated as having theLONGBLOBdata type rather than theGEOMETRYtype. (Bug#27300)With the
NO_AUTO_VALUE_ON_ZEROSQL mode enabled,LAST_INSERT_ID()could return 0 afterINSERT ... ON DUPLICATE KEY UPDATE. Additionally, the next rows inserted (by the sameINSERT, or the followingINSERTwith or withoutON DUPLICATE KEY UPDATE), would insert 0 for the auto-generated value if the value for theAUTO_INCREMENTcolumn wasNULLor missing. (Bug#23233)For a stored procedure containing a
SELECTstatement that used a complicated join with anONexpression, the expression could be ignored during re-execution of the procedure, yielding an incorrect result. (Bug#20492)When RAND() was called multiple times inside a stored procedure, the server did not write the correct random seed values to the binary log, resulting in incorrect replication. (Bug#25543)
SOUNDEX()returned an invalid string for international characters in multi-byte character sets. (Bug#22638)Row equalities in
WHEREclauses could cause memory corruption. (Bug#27154)GROUP BYon aucs2column caused a server crash when there was at least one empty string in the column. (Bug#27079)Evaluation of an
IN()predicate containing a decimal-valued argument caused a server crash. (Bug#27362)Storing
NULLvalues in spatial fields caused excessive memory allocation and crashes on some systems. (Bug#27164)mysql_stmt_fetch()did an invalid memory deallocation when used with the embedded server. (Bug#25492)In a
MEMORYtable, using aBTREEindex to scan for updatable rows could lead to an infinite loop. (Bug#26996)The range optimizer could cause the server to run out of memory. (Bug#26625)
The parser accepted illegal code in SQL exception handlers, leading to a crash at runtime when executing the code. (Bug#26503)
Difficult repair or optimization operations could cause an assertion failure, resulting in a server crash. (Bug#25289)
Increasing the width of a
DECIMALcolumn could cause column values to be changed. (Bug#24558)Replication between master and slave would infinitely retry binary log transmission where the
max_allowed_packeton the master was larger than that on the slave if the size of the transfer was between these two values. (Bug#23775)Invalid optimization of pushdown conditions for queries where an outer join was guaranteed to read only one row from the outer table led to results with too few rows. (Bug#26963)
For
INSERT ... ON DUPLICATE KEY UPDATEstatements on tables containingAUTO_INCREMENTcolumns,LAST_INSERT_ID()was reset to 0 if no rows were successfully inserted or changed. “Not changed” includes the case where a row was updated to its current values, but in that case,LAST_INSERT_ID()should not be reset to 0. NowLAST_INSERT_ID()is reset to 0 only if no rows were successfully inserted or touched, whether or not touched rows were changed. (Bug#27033)This bug was introduced by the fix for Bug#19978.
For an
INSERTstatement that should fail due to a column with no default value not being assigned a value, the statement succeeded with no error if the column was assigned a value in anON DUPLICATE KEY UPDATEclause, even if that clause was not used. (Bug#26261)A result set column formed by concatention of string literals was incomplete when the column was produced by a subquery in the
FROMclause. (Bug#26738)When using the result of
SEC_TO_TIME()for time value greater than 24 hours in anORDER BYclause, either directly or through a column alias, the rows were sorted incorrectly as strings. (Bug#26672)If the server was started with
--skip-grant-tables, Selecting fromINFORMATION_SCHEMAtables causes a server crash. (Bug#26285)Incompatible change:
INSERT DELAYEDstatements are not supported forMERGEtables, but theMERGEstorage engine was not rejecting such statements, resulting in table corruption. Applications previously usingINSERT DELAYEDintoMERGEtable will break when upgrading to versions with this fix. To avoid the problem, removeDELAYEDfrom such statements. (Bug#26464)NDB Cluster: An invalid pointer was returned following aFSCLOSECONFsignal when accessing the REDO logs during a node restart or system restart. (Bug#26515)NDB Cluster: An inadvertent use of unaligned data caused ndb_restore to fail on some 64-bit platforms, including Sparc and Itanium-2. (Bug#26739)NDB Cluster: An infinite loop in an internal logging function could cause trace logs to fill up with Unknown Signal type error messages and thus grow to unreasonable sizes. (Bug#26720)NDB Cluster: The failure of a data node when restarting it with--initialcould lead to failures of subsequent data node restarts. (Bug#26481)NDB Cluster: Takeover for local checkpointing due to multiple failures of master nodes was sometimes incorrect handled. (Bug#26457)NDB Cluster: TheLockPagesInMemoryparameter was not read until after distributed communication had already started between cluster nodes. When the value of this parameter was1, this could sometimes result in data node failure due to missed heartbeats. (Bug#26454)NDB Cluster: Under some circumstances, following the restart of a management, all cluster data nodes would connect to it normally, but some of them subsequently failed to log any events to the management node. (Bug#26293)NDB Cluster: An error was produced whenSHOW TABLE STATUSwas used on anNDBtable that had noAUTO_INCREMENTcolumn. (Bug#21033)SELECT ... INTO OUTFILEwith a longFIELDS ENCLOSED BYvalue could crash the server. (Bug#27231)DOUBLEvalues such as20070202191048.000000were being treated as illegal arguments byWEEK(). (Bug#23616)AFTER UPDATEtriggers were not activated by the update part ofINSERT ... ON DUPLICATE KEY UPDATEstatements. (Bug#27006, Bug#27210)This bug was introduced by the fix for Bug#19978.
For
INSERT ... ON DUPLICATE KEY UPDATEstatements where someAUTO_INCREMENTvalues were generated automatically for inserts and some rows were updated, one auto-generated value was lost per updated row, leading to faster exhaustion of the range of theAUTO_INCREMENTcolumn. (Bug#24432)Because the original problem can affect replication (different values on master and slave), it is recommended that the master and its slaves be upgraded to the current version.
IN ((,subquery))IN (((, and so forth, are equivalent tosubquery)))IN (, which is always interpreted as a table subquery (so that it is allowed to return more than one row). MySQL was treating the “over-parenthesized” subquery as a single-row subquery and rejecting it if it returned more than one row. This bug primarily affected automatically generated code (such as queries generated by Hibernate), because humans rarely write the over-parenthesized forms. (Bug#21904)subquery)For
MERGEtables defined on underlying tables that contained a shortVARCHARcolumn (shorter than four characters), usingALTER TABLEon at least one but not all of the underlying tables caused the table definitions to be considered different from that of theMERGEtable, even if theALTER TABLEdid not change the definition. (Bug#26881)If a thread previously serviced a connection that was killed, excessive memory and CPU use by the thread occurred if it later serviced a connection that had to wait for a table lock. (Bug#25966)
CURDATE()is less thanNOW(), either when comparingCURDATE()directly (CURDATE() < NOW()is true) or when castingCURDATE()toDATE(CAST(CURDATE() AS DATE) < NOW()is true). However, storingCURDATE()in aDATEcolumn and comparingcol_name< NOW()DATEcolumn asDATETIMEfor comparisons to aDATETIMEconstant. (Bug#21103)A view on a join is insertable for
INSERTstatements that store values into only one table of the join. However, inserts were being rejected if the inserted-into table was used in a self-join because MySQL incorrectly was considering the insert to modify multiple tables of the view. (Bug#25122)Expressions involving
SUM(), when used in anORDER BYclause, could lead to out-of-order results. (Bug#25376)LOAD DATA INFILEsent an okay to the client before writing the binary log and committing the changes to the table had finished, thus violating ACID requirements. (Bug#26050)Views that used a scalar correlated subquery returned incorrect results. (Bug#26560)
IF(
expr,unsigned_expr,unsigned_expr) was evaluated to a signed result, not unsigned. This has been corrected. The fix also affects constructs of the formIS [NOT] {TRUE|FALSE}, which were transformed internally intoIF()expressions that evaluated to a signed result. (Bug#24532)For existing views that were defined using
IS [NOT] {TRUE|FALSE}constructs, there is a related implication. The definitions of such views were stored using theIF()expression, not the original construct. This is manifest in thatSHOW CREATE VIEWshows the transformedIF()expression, not the original one. Existing views will evaluate correctly after the fix, but if you wantSHOW CREATE VIEWto display the original construct, you must drop the view and re-create it using its original definition. New views will retain the construct in their definition.BENCHMARK()did not work correctly for expressions that produced aDECIMALresult. (Bug#26093)For some values of the position argument, the
INSERT()function could insert a NUL byte into the result. (Bug#26281)Inserting
utf8data into aTEXTcolumn that used a single-byte character set could result in spurious warnings about truncated data. (Bug#25815)EXPLAIN EXTENDEDdid not showWHEREconditions that were optimized away. (Bug#22331)INSERT DELAYEDstatements inserted incorrect values intoBITcolumns. (Bug#26238)For
exprIN(value_list)BIGINT UNSIGNEDvalues were used forexpror in the value list. (Bug#19342)When a
TIME_FORMAT()expression was used as a column in aGROUP BYclause, the expression result was truncated. (Bug#20293)For
SUBSTRING()evaluation using a temporary table, whenSUBSTRING()was used on a LONGTEXT column, themax_lengthmetadata value of the result was incorrectly calculated and set to 0. Consequently, an empty string was returned instead of the correct result. (Bug#15757)Use of a
GROUP BYclause that referred to a stored function result together withWITH ROLLUPcaused incorrect results. (Bug#25373)Use of a subquery containing
GROUP BYandWITH ROLLUPcaused a server crash. (Bug#26830)Use of a subquery containing a
UNIONwith an invalidORDER BYclause caused a server crash. (Bug#26661)In certain cases it could happen that deleting a row corrupted an
RTREEindex. This affected indexes on spatial columns. (Bug#25673)SSL connections failed on Windows. (Bug#26678)
Added support for
--debugger=dbxfor mysql-test-run.pl and fixed support for--debugger=devenv,--debugger=DevEnv, and--debugger=. (Bug#26792)/path/to/devenvX() IS NULLandY() IS NULLcomparisons failed whenX()andY()returnedNULL. (Bug#26038)UNHEX() IS NULLcomparisons failed whenUNHEX()returnedNULL. (Bug#26537)The
REPEAT()function did not allow a column name as thecountparameter. (Bug#25197)On 64-bit Windows, large timestamp values could be handled incorrectly. (Bug#26536)
In some error messages, inconsistent format specifiers were used for the translations in different languages. comp_err (the error message compiler) now checks for mismatches. (Bug#26571)
On Windows, the server exhibited a file-handle leak after reaching the limit on the number of open file descriptors. (Bug#25222)
A reference to a non-existent column in the
ORDER BYclause of anUPDATE ... ORDER BYstatement could cause a server crash. (Bug#25126)A multiple-row delayed insert with an auto increment column could cause duplicate entries to be created on the slave in a replication environment. (Bug#25507, Bug#26116)
Duplicating the usage of a user variable in a stored procedure or trigger would not be replicated correctly to the slave. (Bug#25167)
User defined variables used within stored procedures and triggers are not replicated correctly when operating in statement-based replication mode. (Bug#20141, Bug#14914)
Loading data using
LOAD DATA INFILEmay not replicate correctly (due to character set incompatibilities) if thecharacter_set_databasevariable is set before the data is loaded. (Bug#15126)DROP TRIGGERstatements would not be filtered on the slave when using thereplication-wild-do-tableoption. (Bug#24478)MySQL would not compile when configured using
--without-query-cache. (Bug#25075)When using certain server SQL modes, the
mysql.proctable was not created by mysql_install_db. In addition, the creation of this and other MySQL system tables was not checked for by mysql-test-run.pl. (Bug#23669, Bug#20166)VIEWrestrictions were applied toSELECTstatements after aCREATE VIEWstatement failed, as though theCREATEhad succeeded. (Bug#25897)An
INSERTtrigger invoking a stored routine that inserted into a table other than the one on which the trigger was defined would fail with a Table '...' doesn't exist referring to the second table when attempting to delete records from the first table. (Bug#21825)A stored procedure that made use of cursors failed when the procedure was invoked from a stored function. (Bug#25345)
When nesting stored procedures within a trigger on a table, a false dependency error was thrown when one of the nested procedures contained a
DROP TABLEstatement. (Bug#22580)When attempting to call a stored procedure creating a table from a trigger on a table
tblin a databasedb, the trigger failed with ERROR 1146 (42S02): Table 'db.tbl' doesn't exist. However, the actual reason that such a trigger fails is due to the fact thatCREATE TABLEcauses an implicitCOMMIT, and so a trigger cannot invoke a stored routine containing this statement. A trigger which does so now fails with ERROR 1422 (HY000): Explicit or implicit commit is not allowed in stored function or trigger, which makes clear the reason for the trigger's failure. (Bug#18914)Local variables in stored routines or triggers, when declared as the
BITtype, were interpreted as strings. (Bug#12976)When a stored routine attempted to execute a statement accessing a nonexistent table, the error was not caught by the routine's exception handler. (Bug#8407, Bug#20713)
NOW()returned the wrong value in statements executed at server startup with the--init-fileoption. (Bug#23240)Instance Manager did not remove the angel PID file on a clean shutdown. (Bug#22511)
The server could crash if two or more threads initiated query cache resize operation at moments very close in time. (Bug#23527)
The conditions checked by the optimizer to allow use of indexes in
INpredicate calculations were unnecessarily tight and were relaxed. (Bug#20420)Several deficiencies in resolution of column names for
INSERT ... SELECTstatements were corrected. (Bug#25831)Indexes on
TEXTcolumns were ignored whenrefaccesses were evaluated. (Bug#25971)The update columns for
INSERT ... SELECT ... ON DUPLICATE KEY UPDATEcould be assigned incorrect values if a temporary table was used to evaluate theSELECT. (Bug#16630)CONNECTIONis no longer treated as a reserved word. (Bug#12204)A user-defined variable could be assigned an incorrect value if a temporary table was employed in obtaining the result of the query used to determine its value. (Bug#24010)
Queries that used a temporary table for the outer query when evaluating a correlated subquery could return incorrect results. (Bug#23800)
For index reads, the
BLACKHOLEengine did not return end-of-file (which it must becauseBLACKHOLEtables contain no rows), causing some queries to crash. (Bug#19717)
This is a bugfix release for the current production release family. It replaces MySQL 5.0.33.
Functionality added or changed:
This is the last version for which MySQL-Max RPM distributions are available. (This change was already made for non-RPM binary distributions in 5.0.27.)
Added the
SHOW PROFILESandSHOW PROFILEstatements to display statement profile data, and the accompanyingINFORMATION_SCHEMA.PROFILINGtable. Profiling is controlled via theprofilingandprofiling_history_sizesession variables. see Section 13.5.4.22, “SHOW PROFILESandSHOW PROFILESyntax”, and Section 20.17, “TheINFORMATION_SCHEMA PROFILINGTable”. (From Jeremy Cole) (Bug#24795)Added the
Uptime_since_flush_statusstatus variable, which indicates the number of seconds since the most recentFLUSH STATUSstatement. (From Jeremy Cole) (Bug#24822)Incompatible change: Previously, the
DATE_FORMAT()function returned a binary string. Now it returns a string with a character set and collation given bycharacter_set_connectionandcollation_connectionso that it can return month and weekday names containing non-ASCII characters. (Bug#22646)NDB Cluster: TheLockPagesInMainMemoryconfiguration parameter has changed its type and possible values. For more information, seeLockPagesInMainMemory. (Bug#25686)Important: The values
trueandfalseare no longer accepted for this parameter. If you were using this parameter and had it set tofalsein a previous release, you must change it to0. If you had this parameter set totrue, you should instead use1to obtain the same behavior as previously, or2to take advantage of new functionality introduced with this release described in the section cited above.Important: When using
MERGEtables the definition of theMERGEtable and theMyISAMtables are checked each time the tables are opened for access (including anySELECTorINSERTstatement. Each table is compared for column order, types, sizes and associated. If there is a difference in any one of the tables then the statement will fail.The
localhostanonymous user account created during MySQL installation on Windows now has no global privileges. Formerly this account had all global privileges. For operations that require global privileges, therootaccount can be used instead. (Bug#24496)The bundled yaSSL library was upgraded to version 1.5.8.
The
--skip-thread-priorityoption now is enabled by default for binary Mac OS X distributions. Use of thread priorities degrades performance on Mac OS X. (Bug#18526)Added the
--disable-grant-optionsoption to configure. If configure is run with this option, the--bootstrap,--skip-grant-tables, and--init-fileoptions for mysqld are disabled and cannot be used. For Windows, the configure.js script recognizes theDISABLE_GRANT_OPTIONSflag, which has the same effect.
Bugs fixed:
Incompatible change: For
ENUMcolumns that had enumeration values containing commas, the commas were mapped to 0xff internally. However, this rendered the commas indistinguishable from true 0xff characters in the values. This no longer occurs. However, the fix requires that you dump and reload any tables that haveENUMcolumns containing true 0xff in their values: Dump the tables using mysqldump with the current server before upgrading from a version of MySQL 5.0 older than 5.0.36 to version 5.0.36 or newer. (Bug#24660)On Windows, if the server was installed as a service, it did not auto-detect the location of the data directory. (Bug#20376)
If the duplicate key value was present in the table,
INSERT ... ON DUPLICATE KEY UPDATEreported a row count indicating that a record was updated, even when no record actually changed due to the old and new values being the same. Now it reports a row count of zero. (Bug#19978)Some
UPDATEstatements were slower than in previous versions when the search key could not be converted to a valid value for the type of the search column. (Bug#24035)The
WITH CHECK OPTIONclause for views was ignored for updates of multiple-table views when the updates could not be performed on fly and the rows to update had to be put into temporary tables first. (Bug#25931)Using
ORDER BYorGROUP BYcould yield different results when selecting from a view and selecting from the underlying table. (Bug#26209)LAST_INSERT_ID()was not reset to 0 ifINSERT ... SELECTinserted no rows. (Bug#23170)Storing values specified as hexadecimal values 64 or more bits long into
BIT(64),BIGINT, orBIGINT UNSIGNEDcolumns did not raise any warning or error if the value was out of range. (Bug#22533)Inserting
DEFAULTinto a column with no default value could result in garbage in the column. Now the same result occurs as when insertingNULLinto aNOT NULLcolumn. (Bug#20691)The presence of
ORDER BYin a view definition prevented theMERGEalgorithm from being used to resolve the view even if nothing else in the definition required theTEMPTABLEalgorithm. (Bug#12122)ISNULL(DATE(NULL))andISNULL(CAST(NULL AS DATE))erroneously returned false. (Bug#23938)If a slave server closed its relay log (for example, due to an error during log rotation), the I/O thread did not recognize this and still tried to write to the log, causing a server crash. (Bug#10798)
Using an
INFORMATION_SCHEMAtable withORDER BYin a subquery could cause a server crash. (Bug#24630, Bug#26556)Collation for
LEFT JOINcomparisons could be evaluated incorrectly, leading to improper query results. (Bug#26017)For the
IF()andCOALESCE()function andCASEexpressions, large unsigned integer values could be mishandled and result in warnings. (Bug#22026)The number of
setsockopt()calls performed for reads and writes to the network socket was reduced to decrease system call overhead. (Bug#22943)A
WHEREclause that usedBETWEENforDATETIMEvalues could be treated differently for aSELECTand a view defined as thatSELECT. (Bug#26124)ORDER BYonDOUBLEvalues could change the set of rows returned by a query. (Bug#19690)The code for generating
USEstatements for binary logging ofCREATE PROCEDUREstatements resulted in confusing output from mysqlbinlog forDROP PROCEDUREstatements. (Bug#22043)LOAD DATA INFILEdid not work with pipes. (Bug#25807)DISTINCTqueries that were executed using a loose scan for anInnoDBtable that had been emptied caused a server crash. (Bug#26159)The
InnoDBparser sometimes did not account for null bytes, causing spurious failure of some queries. (Bug#25596)Type conversion errors during formation of index search conditions were not correctly checked, leading to incorrect query results. (Bug#22344)
Within a stored routine, accessing a declared routine variable with
PROCEDURE ANALYSE()caused a server crash. (Bug#23782)Use of already freed memory caused SSL connections to hang forever. (Bug#19209)
mysql.server stop timed out too quickly (35 seconds) waiting for the server to exit. Now it waits up to 15 minutes, to ensure that the server exits. (Bug#25341)
A yaSSL program named test was installed, causing conflicts with the test system utility. It is no longer installed. (Bug#25417)
perror crashed on some platforms due to failure to handle a
NULLpointer. (Bug#25344)mysql_stmt_fetch()did an invalid memory deallocation when used with the embedded server. (Bug#25492)mysql_kill()caused a server crash when used on an SSL connection. (Bug#25203)The
readlinelibrary wrote to uninitialized memory, causing mysql to crash. (Bug#19474)yaSSL was sensitive to the presence of whitespace at the ends of lines in PEM-encoded certificates, causing a server crash. (Bug#25189)
mysqld_multi and mysqlaccess looked for option files in
/etceven if the--sysconfdiroption for configure had been given to specify a different directory. (Bug#24780)The
SEC_TO_TIME()andQUARTER()functions sometimes did not handleNULLvalues correctly. (Bug#25643)With
ONLY_FULL_GROUP_BYenables, the server was too strict: Some expressions involving only aggregate values were rejected as non-aggregate (for example,MAX(a) - MIN(a)). (Bug#23417)The arguments of the
ENCODE()and theDECODE()functions were not printed correctly, causing problems in the output ofEXPLAIN EXTENDEDand in view definitions. (Bug#23409)An error in the name resolution of nested
JOIN ... USINGconstructs was corrected. (Bug#25575)A return value of
-1from user-defined handlers was not handled well and could result in conflicts with server code. (Bug#24987)The server might fail to use an appropriate index for
DELETEwhenORDER BY,LIMIT, and a non-restrictingWHEREare present. (Bug#17711)Use of
ON DUPLICATE KEY UPDATEdefeated the usual restriction against inserting into a join-based view unless only one of the underlying tables is used. (Bug#25123)Some queries against
INFORMATION_SCHEMAthat used subqueries failed. (Bug#23299).SHOW COLUMNSreported someNOT NULLcolumns asNULL. (Bug#22377)View definitions that used the
!operator were treated as containing theNOToperator, which has a different precedence and can produce different results. (Bug#25580).For a
UNIQUEindex containing manyNULLvalues, the optimizer would prefer the index forcolIS NULLGROUP BYandDISTINCTdid not groupNULLvalues for columns that have aUNIQUEindex. (Bug#25551).ALTER TABLE ... ENABLE KEYSacquired a global lock, preventing concurrent execution of other statements that use tables. (Bug#25044).For an
InnoDBtable with anyON DELETEtrigger,TRUNCATE TABLEmapped toDELETEand activated triggers. Now a fast truncation occurs and triggers are not activated. (Bug#23556).For
ALTER TABLE, usingORDER BYcould cause a server crash. Now theexpressionORDER BYclause allows only column names to be specified as sort criteria (which was the only documented syntax, anyway). (Bug#24562)readlinedetection did not work correctly on NetBSD. (Bug#23293)The
--with-readlineoption for configure does not work for commercial source packages, but no error message was printed to that effect. Now a message is printed. (Bug#25530)If an
ORDER BYorGROUP BYlist included a constant expression being optimized away and, at the same time, containing single-row subselects that return more that one row, no error was reported. If a query requires sorting by expressions containing single-row subselects that return more than one row, execution of the query may cause a server crash. (Bug#24653)Attempts to access a
MyISAMtable with a corrupt column definition caused a server crash. (Bug#24401)To enable installation of MySQL RPMs on Linux systems running RHEL 4 (which includes SE-Linux) additional information was provided to specify some actions that are allowed to the MySQL binaries. (Bug#12676)
When
SET PASSWORDwas written to the binary log double quotes were included in the statement. If the slave was running in with thesql_modeset toANSI_QUOTESthe event would fail and halt the replication process. (Bug#24158)Accessing a fixed record format table with a crashed key definition results in server/myisamchk segmentation fault. (Bug#24855)
When opening a corrupted
.frmfile during a query, the server crashes. (Bug#24358)If there was insufficient memory to store or update a blob record in a
MyISAMtable then the table will marked as crashed. (Bug#23196)When updating a table that used a
JOINof the table itself (for example, when building trees) and the table was modified on one side of the expression, the table would either be reported as crashed or the wrong rows in the table would be updated. (Bug#21310)Queries that evaluate
NULL IN (SELECT ... UNION SELECT ...)could produce an incorrect result (FALSEinstead ofNULL). (Bug#24085)When reading from the standard input on Windows, mysqlbinlog opened the input in text mode rather than binary mode and consequently misinterpreted some characters such as Control-Z. (Bug#23735)
Within stored routines or prepared statements, inconsistent results occurred with multiple use of
INSERT ... SELECT ... ON DUPLICATE KEY UPDATEwhen theON DUPLICATE KEY UPDATEclause erroneously tried to assign a value to a column mentioned only in itsSELECTpart. (Bug#24491)Expressions of the form
(a, b) IN (SELECT a, MIN(b) FROM t GROUP BY a)could produce incorrect results when columnaof tabletcontainedNULLvalues while columnbdid not. (Bug#24420)Expressions of the form
(a, b) IN (SELECT c, d ...)could produce incorrect results ifa,b, or both wereNULL. (Bug#24127)No warning was issued for use of the
DATA DIRECTORYorINDEX DIRECTORYtable options on a platform that does not support them. (Bug#17498)When a prepared statement failed during the prepare operation, the error code was not cleared when it was reused, even if the subsequent use was successful. (Bug#15518)
mysql_upgrade failed when called with a
basedirpathname containing spaces. (Bug#22801)Hebrew-to-Unicode conversion failed for some characters. Definitions for the following Hebrew characters (as specified by the ISO/IEC 8859-8:1999) were added: LEFT-TO-RIGHT MARK (LRM), RIGHT-TO-LEFT MARK (RLM) (Bug#24037)
An
AFTER UPDATEtrigger on anInnoDBtable with a composite primary key caused the server to crash. (Bug#25398)A query that contained an
EXISTsubquery with aUNIONover correlated and uncorrelatedSELECTqueries could cause the server to crash. (Bug#25219)A query with
ORDER BYandGROUP BYclauses where theORDER BYclause had more elements than theGROUP BYclause caused a memory overrun leading to a crash of the server. (Bug#25172)If there was insufficient memory available to mysqld, this could sometimes cause the server to hang during startup. (Bug#24751)
If a prepared statement accessed a view, access to the tables listed in the query after that view was checked in the security context of the view. (Bug#24404)
A query using
WHEREcould cause the server to crash. (Bug#24261)unsigned_columnNOT IN ('negative_value')A
FETCHstatement using a cursor on a table which was not in the table cache could sometimes cause the server to crash. (Bug#24117)SSL connections could hang at connection shutdown. (Bug#24148)
The
STDDEV()function returned a positive value for data sets consisting of a single value. (Bug#22555)mysqltest incorrectly tried to retrieve result sets for some queries where no result set was available. (Bug#19410)
mysqltest crashed with a stack overflow. (Bug#24498)
Passing a
NULLvalue to a user-defined function from within a stored procedure crashes the server. (Bug#25382)The row count for
MyISAMtables was not updated properly, causingSHOW TABLE STATUSto report incorrect values. (Bug#23526)The BUILD/check-cpu script did not recognize Celeron processors. (Bug#20061)
On Windows, the
SLEEP()function could sleep too long, especially after a change to the system clock. (Bug#14094, Bug#17635, Bug#24686)A stored routine containing semicolon in its body could not be reloaded from a dump of a binary log. (Bug#20396)
For
SET,SELECT, andDOstatements that invoked a stored function from a database other than the default database, the function invocation could fail to be replicated. (Bug#19725)SET lc_time_names =allowed only exact literal values, not expression values. (Bug#22647)valueChanges to the
lc_time_namessystem variable were not replicated. (Bug#22645)SELECT ... FOR UPDATE,SELECT ... LOCK IN SHARE MODE,DELETE, andUPDATEstatements executed using a full table scan were not releasing locks on rows that did not satisfy theWHEREcondition. (Bug#20390)A stored procedure, executed from a connection using a binary character set, and which wrote multibyte data, would write incorrectly escaped entries to the binary log. This caused syntax errors, and caused replication to fail. (Bug#23619, Bug#24492)
mysqldump --order-by-primary failed if the primary key name was an identifier that required quoting. (Bug#13926)
Re-execution of
CREATE DATABASE,CREATE TABLE, andALTER TABLEstatements in stored routines or as prepared statements caused incorrect results or crashes. (Bug#22060)The internal functions for table preparation, creation, and alteration were not re-execution friendly, causing problems in code that: repeatedly altered a table; repeatedly created and dropped a table; opened and closed a cursor on a table, altered the table, and then reopened the cursor. (Bug#4968, Bug#6895, Bug#19182, Bug#19733)
A workaround was implemented to avoid a race condition in the NPTL
pthread_exit()implementation. (Bug#24507)NDB Cluster(Cluster APIs):libndbclient.sowas not versioned. (Bug#13522)NDB Cluster: Thendb_size.tmplfile (necessary for using thendb_size.plscript) was missing from binary distributions. (Bug#24191)NDB Cluster: A query with anINclause against anNDBtable employing explicit user-defined partitioning did not always return all matching rows. (Bug#25821)NDB Cluster: AnUPDATEusing anINclause on anNDBtable on which there was a trigger caused mysqld to crash. (Bug#25522)NDB Cluster(Cluster APIs): Deletion of anNdb_cluster_connectionobject took a very long time. (Bug#25487)NDB Cluster: It was not possible to create anNDBtable with a key on twoVARCHARcolumns where both columns had a storage length in excess of 256. (Bug#25746)NDB Cluster: In some circumstances, shutting down the cluster could cause connected mysqld processes to crash. (Bug#25668)NDB Cluster: Memory allocations forTEXTcolumns were calculated incorrectly, resulting in space being wasted and other issues. (Bug#25562)NDB Cluster: The failure of a master node during a node restart could lead to a resource leak, causing later node failures. (Bug#25554)NDB Cluster: The management server did not handle logging of node shutdown events correctly in certain cases. (Bug#22013)NDB Cluster: A node shutdown occurred if the master failed during a commit. (Bug#25364)NDB Cluster: Creating a non-unique index with theUSING HASHclause silently created an ordered index instead of issuing a warning. (Bug#24820)NDB Cluster:SELECTstatements with aBLOBorTEXTcolumn in the selected column list and aWHEREcondition including a primary key lookup on aVARCHARprimary key produced empty result sets. (Bug#19956)Optimizations that are legal only for subqueries without tables and
WHEREconditions were applied for any subquery without tables. (Bug#24670)The server was built even when configure was run with the
--without-serveroption. (Bug#23973)mysqld_error.hwas not installed when only the client libraries were built. (Bug#21265)Using a view in combination with a
USINGclause caused column aliases to be ignored. (Bug#25106)A view was not handled correctly if the
SELECTpart contained ‘\Z’. (Bug#24293)Inserting a row into a table without specifying a value for a
BINARY(column caused the column to be set to spaces, not zeroes. (Bug#14171)N) NOT NULLAn assertion failed incorrectly for prepared statements that contained a single-row uncorrelated subquery that was used as an argument of the IS NULL predicate. (Bug#25027)
A table created with the
ROW_FORMAT = FIXEDtable option loses the option if an index is added or dropped withCREATE INDEXorDROP INDEX. (Bug#23404)Dropping a user-defined function sometimes did not remove the UDF entry from the
mysql.proctable. (Bug#15439)Changing the value of
MI_KEY_BLOCK_LENGTHinmyisam.hand recompiling MySQL resulted in a myisamchk that saw existingMyISAMtables as corrupt. (Bug#22119)Instance Manager could crash during shutdown. (Bug#19044)
A deadlock could occur, with the server hanging on
Closing tables, with a sufficient number of concurrentINSERT DELAYED,FLUSH TABLES, andALTER TABLEoperations. (Bug#23312)A user-defined variable could be assigned an incorrect value if a temporary table was employed in obtaining the result of the query used to determine its value. (Bug#16861)
The optimizer removes expressions from
GROUP BYandDISTINCTclauses if they happen to participate inexpression=constantWHEREclause, the idea being that, if the expression is equal to a constant, then it cannot take on multiple values. However, for predicates where the expression and the constant item are of different result types (for example, when a string column is compared to 0), this is not valid, and can lead to invalid results in such cases. The optimizer now performs an additional check of the result types of the expression and the constant; if their types differ, then the expression is not removed from theGROUP BYlist. (Bug#15881)Referencing an ambiguous column alias in an expression in the
ORDER BYclause of a query caused the server to crash. (Bug#25427)Some
CASEstatements inside stored routines could lead to excessive resource usage or a crash of the server. (Bug#24854, Bug#19194)Some joins in which one of the joined tables was a view could return erroneous results or crash the server. (Bug#24345)
OPTIMIZE TABLEtried to sort R-tree indexes such as spatial indexes, although this is not possible (see Section 13.5.2.5, “OPTIMIZE TABLESyntax”). (Bug#23578)User-defined variables could consume excess memory, leading to a crash caused by the exhaustion of resources available to the
MEMORYstorage engine, due to the fact that this engine is used by MySQL for variable storage and intermediate results ofGROUP BYqueries. WhereSEThad been used, such a condition could instead give rise to the misleading error message You may only use constant expressions with SET, rather than Out of memory (Needed NNNNNN bytes). (Bug#23443)InnoDB: During a restart of the MySQL Server that followed the creation of a temporary table using theInnoDBstorage engine, MySQL failed to clean up in such a way thatInnoDBstill attempted to find the files associated with such tables. (Bug#20867)A multiple-table
DELETE QUICKcould sometimes cause one of the affected tables to become corrupted. (Bug#25048)A compressed
MyISAMtable that became corrupted could crash myisamchk and possibly the MySQL Server. (Bug#23139)A crash of the MySQL Server could occur when unpacking a
BLOBcolumn from a row in a corrupted MyISAM table. This could happen when trying to repair a table using eitherREPAIR TABLEor myisamchk; it could also happen when trying to access such a “broken” row using statements likeSELECTif the table was not marked as crashed. (Bug#22053)The
FEDERATEDstorage engine did not support theeuckrcharacter set. (Bug#21556)The
FEDERATEDstorage engine did not support theutf8character set. (Bug#17044)NDB Cluster: Hosts in clusters with a large number of nodes could experience excessive CPU usage while obtaining configuration data. (Bug#25711)NDB Cluster(NDB API): Invoking theNdbTransaction::execute()method using execution typeCommitand abort optionAO_IgnoreErrorcould lead to a crash of the transaction coordinator (DBTC). (Bug#25090)NDB Cluster(NDB API): A unique index lookup on a non-existent tuple could lead to a data node timeout (error 4012). (Bug#25059)NDB Cluster: When a data node was shut down using the management clientSTOPcommand, a connection event (NDB_LE_Connected) was logged instead of a disconnection event (NDB_LE_Disconnected). (Bug#22773)
This is a bugfix release for the current production release family. It replaces MySQL 5.0.27.
Note
This version of MySQL Community Server has been released as a source tarball only; there are no binaries built by MySQL.
Functionality added or changed:
Incompatible change: The
prepared_stmt_countsystem variable has been converted to thePrepared_stmt_countglobal status variable (viewable with theSHOW GLOBAL STATUSstatement). (Bug#23159)NDB Cluster: Setting the configuration parameterLockPagesInMainMemoryhad no effect. (Bug#24461)NDB Cluster: It is now possible to create a unique hashed index on a column that is not defined asNOT NULL. Note that this change applies only to tables using theNDBstorage engine.Unique indexes on columns in
NDBtables do not store null values because they are mapped to primary keys in an internal index table (and primary keys cannot contain nulls).Normally, an additional ordered index is created when one creates unique indexes on
NDBtable columns; this can be used to search forNULLvalues. However, ifUSING HASHis specified when such an index is created, no ordered index is created.The reason for permitting unique hash indexes with null values is that, in some cases, the user wants to save space if a large number of records are pre-allocated but not fully initialized. This also assumes that the user will not try to search for null values. Since MySQL does not support indexes that are not allowed to be searched in some cases, the
NDBstorage engine uses a full table scan with pushed conditions for the referenced index columns to return the correct result.Note that a warning is returned if one creates a unique nullable hash index, since the query optimizer should be provided a hint not to use it with
NULLvalues if this can be avoided.In MySQL 5.0.13 and up,
InnoDBrolls back only the last statement on a transaction timeout. A new option,--innodb_rollback_on_timeout, causesInnoDBto abort and roll back the entire transaction if a transaction timeout occurs (the same behavior as before MySQL 5.0.13). (Bug#24200)DROP TRIGGERnow supports anIF EXISTSclause. (Bug#23703)The
Com_create_userstatus variable was added (for countingCREATE USERstatements). (Bug#22958)The
--memlockoption relies on system calls that are unreliable on some operating systems. If a crash occurs, the server now checks whether--memlockwas specified and if so issues some information about possible workarounds. (Bug#22860)The bundled yaSSL library was upgraded to version 1.5.0.
In MySQL 5.0.13 and up,
InnoDBrolls back only the last statement on a transaction timeout. A new option,--innodb_rollback_on_timeout, causesInnoDBto abort and roll back the entire transaction if a transaction timeout occurs (the same behavior as before MySQL 5.0.13). (Bug#24200)If the user specified the server options
--max-connections=orN--table-open-cache=, a warning would be given in some cases that some values were recalculated, with the result thatM--table-open-cachecould be assigned greater value.It should be noted that, in such cases, both the warning and the increase in the
--table-open-cachevalue were completely harmless. Note also that it is not possible for the MySQL Server to predict or to control limitations on the maximum number of open files, since this is determined by the operating system.The recalculation code has now been fixed to ensure that the value of
--table-open-cacheis no longer increased automatically, and that a warning is now given only if some values had to be decreased due to operating system limits.NDB Cluster: TheHELPcommand in the Cluster management client now provides command-specific help. For example,HELP RESTARTin ndb_mgm provides detailed information about theSTARTcommand. (Bug#19620)NDB Cluster: Added the --bind-address option for ndbd. This allows a data node process to be bound to a specific network interface. (Bug#22195)NDB Cluster: TheNdb_number_of_storage_nodessystem variable was renamed toNdb_number_of_data_nodes. (Bug#20848)NDB Cluster: The ndb_config utility now accepts-cas a short form of the--ndb-connectstringoption. (Bug#22295)SHOW STATUSis no longer logged to the slow query log. (Bug#19764)mysqldump --single-transaction now uses
START TRANSACTION /*!40100 WITH CONSISTENT SNAPSHOT */rather thanBEGINto start a transaction, so that a consistent snapshot will be used on those servers that support it. (Bug#19660)mysql_upgradenow passes all the parameters specified on the command line to bothmysqlcheckandmysqlusing theupgrade_defaultsfile. (Bug#20100)For the
CALLstatement, stored procedures that take no arguments now can be invoked without parentheses. That is,CALL p()andCALL pare equivalent. (Bug#21462)
Bugs fixed:
NDB Cluster: Sudden disconnection of an SQL or data node could lead to shutdown of data nodes with the error failed ndbrequire. (Bug#24447)NDB Cluster: ndb_config failed when trying to use 2 management servers and node IDs. (Bug#23887)NDB Cluster(Cluster APIs): UsingBITvalues with any of the comparison methods of theNdbScanFilterclass caused the cluster's data nodes to fail. (Bug#24503)NDB Cluster: The failure of a data node failure during a schema operation could lead to additional node failures. (Bug#24752)NDB Cluster: A committed read could be attempted before a data node had time to connect, causing a timeout error. (Bug#24717)NDB Cluster(Cluster APIs): Some MGM API function calls could yield incorrect return values in certain cases where the cluster was operating under a very high load, or experienced timeouts in inter-node communications. (Bug#24011)NDB Cluster: A unique constraint violation was not ignored by anUPDATE IGNOREstatement when the constraint violation occurred on a non-primary key. (Bug#18487, Bug#24303)mysql_fix_privilege_tables did not handle a password containing embedded space or apostrophe characters. (Bug#17700)
Foreign key identifiers for
InnoDBtables could not contain certain characters. (Bug#24299)In some cases, the parser failed to distinguish a user-defined function from a stored function. (Bug#21809)
With
innodb_file_per_tableenabled,InnoDBdisplayed incorrect file times in the output fromSHOW TABLE STATUS. (Bug#24712)The stack size for NetWare binaries was increased to 128KB to prevent problems caused by insufficient stack size. (Bug#23504)
Attempting to use a view containing
DEFINERinformation for a non-existent user resulted in an error message that revealed the definer account. Now the definer is revealed only to superusers. Other users receive only anaccess deniedmessage. (Bug#17254)mysql_upgrade failed if the
--password(or-p) option was given. (Bug#24896)For a nonexistent table,
DROP TEMPORARY TABLEfailed with an incorrect error message ifread_onlywas enabled. (Bug#22077)The code for generating
USEstatements for binary logging ofCREATE PROCEDUREstatements resulted in confusing output from mysqlbinlog forDROP PROCEDUREstatements. (Bug#22043)The
InnoDBmutex structure was simplified to reduce memory load. (Bug#24386)The
REPEAT()function could returnNULLwhen passed a column for the count argument. (Bug#24947)Accuracy was improved for comparisons between
DECIMALcolumns and numbers represented as strings. (Bug#23260)InnoDBcrashed while performing XA recovery of prepared transactions. (Bug#21468)ROW_COUNT()did not work properly as an argument to a stored procedure. (Bug#23760)The size of
MEMORYtables and internal temporary tables was limited to 4GB on 64-bit Windows systems. (Bug#24052)For queries that select from a view, the server was returning
MYSQL_FIELDmetadata inconsistently for view names and table names. For view columns, the server now returns the view name in thetablefield and, if the column selects from an underlying table, the table name in theorg_tablefield. (Bug#20191)It was possible to use
DATETIMEvalues whose year, month, and day parts were all zeroes but whose hour, minute, and second parts contained nonzero values, an example of such an illegalDATETIMEbeing'0000-00-00 11:23:45'. (Bug#21789)It was possible to set the backslash character (“
\”) as the delimiter character usingDELIMITER, but not actually possible to use it as the delimiter. (Bug#21412)The loose index scan optimization for
GROUP BYwithMINorMAXwas not applied within other queries, such asCREATE TABLE ... SELECT ...,INSERT ... SELECT ..., or in theFROMclauses of subqueries. (Bug#24156)ALTER ENABLE KEYSorALTER TABLE DISABLE KEYScombined with anotherALTER TABLEoption other thanRENAME TOdid nothing. In addition, if ALTER TABLE was used on a table having disabled keys, the keys of the resulting table were enabled. (Bug#24395)Queries using a column alias in an expression as part of an
ORDER BYclause failed, an example of such a query beingSELECT mycol + 1 AS mynum FROM mytable ORDER BY 30 - mynum. (Bug#22457)Trailing spaces were not removed from Unicode
CHARcolumn values when used in indexes. This resulted in excessive usage of storage space, and could affect the results of someORDER BYqueries that made use of such indexes.Note: When upgrading, it is necessary to re-create any existing indexes on Unicode
CHARcolumns in order to take advantage of the fix. This can be done by using aREPAIR TABLEstatement on each affected table.Warnings were generated when explicitly casting a character to a number (for example,
CAST('x' AS SIGNED)), but not for implicit conversions in simple arithmetic operations (such as'x' + 0). Now warnings are generated in all cases. (Bug#11927)STR_TO_DATE()returnedNULLif the format string contained a space following a non-format character. (Bug#22029)yaSSL crashed on pre-Pentium Intel CPUs. (Bug#21765)
Selecting into variables sometimes returned incorrect wrong results. (Bug#20836)
Inserting
DEFAULTinto a column with no default value could result in garbage in the column. Now the same result occurs as when insertingNULLinto aNOT NULLcolumn. (Bug#20691)mysql_fix_privilege_tables.sqlaltered thetable_privs.table_privcolumn to contain too few privileges, causing loss of theCREATE VIEWandSHOW VIEWprivileges. (Bug#20589)A query with a subquery that references columns of a view from the outer
SELECTcould return an incorrect result if used from a prepared statement. (Bug#20327)A server crash occurred when using
LOAD DATAto load a table containing aNOT NULLspatial column, when the statement did not load the spatial column. Now aNULL supplied to NOT NULL columnerror occurs. (Bug#22372)Unsigned
BIGINTvalues treated as signed values by theMOD()function. (Bug#19955)Compiling PHP 5.1 with the MySQL static libraries failed on some versions of Linux. (Bug#19817)
The
DELIMITERstatement did not work correctly when used in an SQL file run using theSOURCEstatement. (Bug#19799)VARBINARYcolumn values inserted on a MySQL 4.1 server had trailing zeroes following upgrade to MySQL 5.0 or later. (Bug#19371)Constant expressions and some numeric constants used as input parameters to user-defined functions were not treated as constants. (Bug#18761)
Subqueries of the form
NULL IN (SELECT ...)returned invalid results. (Bug#8804, Bug#23485)The
--externoption for mysql-test-run.pl did not function correctly. (Bug#24354)INET_ATON()returned a signedBIGINTvalue, not an unsigned value. (Bug#21466)ALTER TABLEstatements that performed bothRENAME TOand{ENABLE|DISABLE} KEYSoperations caused a server crash. (Bug#24089)myisampack wrote to unallocated memory, causing a crash. (Bug#17951)
Some small double precision numbers (such as
1.00000001e-300) that should have been accepted were truncated to zero. (Bug#22129)The mysql.server script used the source command, which is less portable than the . command; it now uses . instead. (Bug#24294)
DATE_ADD()requires complete dates with no “zero” parts, but sometimes did not returnNULLwhen given such a date. (Bug#22229)Using
FLUSH TABLESin one connection while another connection is usingHANDLERstatements caused a server crash. (Bug#21587)FLUSH LOGSor mysqladmin flush-logs caused a server crash if the binary log was not open. (Bug#17733)Subqueries for which a pushed-down condition did not produce exactly one key field could cause a server crash. (Bug#24056)
LAST_DAY('0000-00-00')could cause a server crash. (Bug#23653)Through the C API, the member strings in
MYSQL_FIELDfor a query that contains expressions may return incorrect results. (Bug#21635)mysql_affected_rows()could return values different frommysql_stmt_affected_rows()for the same sequence of statements. (Bug#23383)IN()andCHAR()can returnNULL, but did not signal that to the query processor, causing incorrect results forIS NULLoperations. (Bug#17047)A trigger that invoked a stored function could cause a server crash when activated by different client connections. (Bug#23651)
CONCURRENTdid not work correctly forLOAD DATA INFILE. (Bug#20637)Inserting a default or invalid value into a spatial column could fail with
Unknown errorrather than a more appropriate error. (Bug#21790)The server could send incorrect column count information to the client for queries that produce a larger number of columns than can fit in a two-byte number. (Bug#19216)
Evaluation of subqueries that require the filesort algorithm were allocating and freeing the
sort_buffer_sizebuffer many times, resulting in slow performance. Now the buffer is allocated once and reused. (Bug#21727)SQL statements close to the size of
max_allowed_packetcould produce binary log events larger thanmax_allowed_packetthat could not be read by slave servers. (Bug#19402)View columns were always handled as having implicit derivation, leading to
illegal mix of collation errorsfor some views inUNIONoperations. Now view column derivation comes from the original expression given in the view definition. (Bug#21505)If elements in a non-top-level
INsubquery were accessed by an index and the subquery result set included aNULLvalue, the quantified predicate that contained the subquery was evaluated toNULLwhen it should return a non-NULLvalue. (Bug#23478)Calculation of
COUNT(DISTINCT),AVG(DISTINCT), orSUM(DISTINCT)when they are referenced more than once in a single query withGROUP BYcould cause a server crash. (Bug#23184)For a cast of a
DATETIMEvalue containing microseconds toDECIMAL, the microseconds part was truncated without generating a warning. Now the microseconds part is preserved. (Bug#19491)Metadata for columns calculated from scalar subqueries was limited to integer, double, or string, even if the actual type of the column was different. (Bug#11032)
Using
EXPLAINcaused a server crash for queries that selected fromINFORMATION_SCHEMAin a subquery in theFROMclause. (Bug#22413)Invalidating the query cache caused a server crash for
INSERT INTO ... SELECTstatements that selected from a view. (Bug#20045)Slave servers would retry the execution of a SQL statement an infinite number of times, ignoring the value
SLAVE_TRANSACTION_RETRIESwhen using the NDB engine. (Bug#16228)On slave servers, transactions that exceeded the lock wait timeout failed to roll back properly. (Bug#20697)
Changes to character set variables prior to an action on a replication-ignored table were forgotten by slave servers. (Bug#22877)
With
lower_case_table_namesset to 1,SHOW CREATE TABLEprinted incorrect output for table names containing Turkish I (LATIN CAPITAL LETTER I WITH DOT ABOVE). (Bug#20404)When applying the
group_concat_max_lenlimit,GROUP_CONCAT()could truncate multi-byte characters in the middle. (Bug#23451)For some problems relating to character set conversion or incorrect string values for
INSERTorUPDATE, the server was reporting truncation or length errors instead. (Bug#18908)Several string functions could return incorrect results when given very large length arguments. (Bug#10963)
Certain malformed
INSERTstatements could crash the mysql client. (Bug#21142)NDB Cluster: Data nodes added while the cluster was running in single user mode were all assigned node ID 0, which could later cause multiple node failures. Adding of nodes in single user mode is no longer possible. (Bug#20395)NDB Cluster: Attempting to create anNDBtable on a MySQL with an existing non-Cluster table with the same name in the same database could result in data loss or corruption. MySQL now issues a warning when aSHOW TABLESor other statement causing table discovery finds such a table. (Bug#21378)NDB Cluster(NDB API): Inacivity timeouts for scans were not correctly handled. (Bug#23107)NDB Cluster(NDB API): Attempting to read a nonexistent tuple usingCommitmode forNdbTransaction::execute()caused node failures. (Bug#22672)NDB Cluster(NDB API): Scans closed before being executed were still placed in the send queue. (Bug#21941)NDB Cluster(NDB API): TheNdbOperation::getBlobHandle()method, when called with the name of a nonexistent column, caused a segmentation fault. (Bug#21036)NDB Cluster: A problem with takeover during a system restart caused ordered indexes to be rebuilt incorrectly. (Bug#15303)NDB Cluster: The ndb_config utility did not perform host lookups correctly when using the--hostoption. (Bug#17582)NDB Cluster: The ndb_config utility did not perform host lookups correctly when using the--hostoption (Bug#17582)NDB Cluster: The error returned by the cluster when too many nodes were defined did not make clear the nature of the problem. (Bug#19045)NDB Cluster: ndb_mgm -e show | head would hang after displaying the first 10 lines of output. (Bug#19047)NDB Cluster: In rare situations with resource shortages, a crash could result from insufficientIndexScanOperations. (Bug#19198)NDB Cluster: ndb_restore did not always make clear that it had recovered successfully from temporary errors while restoring a cluster backup. (Bug#19651)NDB Cluster: Error messages given when trying to make online changes parameters such asNoOfReplicasthast can only be changed via a complete shutdown and restart of the cluster did not indicate the true nature of the problem. (Bug#19787)NDB Cluster: Following the restart of an MGM node, the Cluster management client did not automatically reconnect. (Bug#19873)NDB Cluster: In some cases whereSELECT COUNT(*)from anNDBtable should have yielded an error,MAX_INTwas returned instead. (Bug#19914)NDB Cluster(NDB API): When multiple processes or threads in parallel performed the same ordered scan with exclusive lock and updating the retrieved records, the scan could skip some records, which were not updated as a result. (Bug#20446)NDB Cluster: Using an invalid node ID with the management clientSTOPcommand could cause ndb_mgm to hang. (Bug#20575)NDB Cluster: Under some circumstances, local checkpointing would hang, keeping any unstarted nodes from being started. (Bug#20895)NDB Cluster: Condition pushdown did not work correctly withDATETIMEcolumns. (Bug#21056)NDB Cluster: When inserting a row into anNDBtable with a duplicate value for a non-primary unique key, the error issued would reference the wrong key. (Bug#21072)NDB Cluster: Cluster logs were not rotated following the first rotation cycle. (Bug#21345)NDB Cluster: The ndb_mgm management client did not set the exit status on errors, always returning 0 instead. (Bug#21530)NDB Cluster: Partition distribution keys were updated only for the primary and starting replicas during node recovery. This could lead to node failure recovery for clusters having an odd number of replicas. (Bug#21535)Note: We recommend values for
NumberOfReplicasthat are even powers of 2, for best results.NDB Cluster: The output for the--helpoption used withNDBexecutable programs (ndbd, ndb_mgm, ndb_restore, ndb_config, and so on) referred to theNdb.cfgfile, instead ofmy.cnf. (Bug#21585)NDB Cluster: The node recovery algorithm was missing a version check for tables in theALTER_TABLE_COMMITTEDstate (as opposed to theTABLE_ADD_COMMITTEDstate, which has the version check). This could cause inconsistent schemas across nodes following node recovery. (Bug#21756)NDB Cluster: A scan timeout returned Error 4028 (Node failure caused abort of transaction) instead of Error 4008 (Node failure caused abort of transaction...). (Bug#21799)NDB Cluster: The--helpoutput fromNDBbinaries did not include file-related options. (Bug#21994)NDB Cluster: Multiple node restarts in rapid succession could cause a system restart to fail (Bug#22892), or induce a race condition (Bug#23210).NDB Cluster: If a node restart could not be performed from the REDO log, no node takeover took place. This could cause partitions to be left empty during a system restart. (Bug#22893)NDB Cluster:INSERT ... ON DUPLICATE KEY UPDATEon anNDBtable could lead to deadlocks and memory leaks. (Bug#23200)NDB Cluster: The management client commandALL DUMP 1000would cause the cluster to crash if data nodes were connected to the cluster but not yret fully started. (Bug#23203)NDB Cluster: Cluster backups would fail when there were more than 2048 schema objects in the cluster. (Bug#23499)NDB Cluster: Restoring a cluster failed if there were any tables with 128 or more columns. (Bug#23502)If an
init_connectSQL statement produced an error, the connection was silently terminated with no error message. Now the server writes a warning to the error log. (Bug#22158)The internal SQL interpreter of
InnoDBplaced an unnecessary lock on the supremum record wheninnodb_locks_unsafe_for_binlog=1. This caused an assertion failure whenInnoDBwas built with debugging enabled. (Bug#23769)If a table contains an
AUTO_INCREMENTcolumn, inserting into an insertable view on the table that does not include theAUTO_INCREMENTcolumn should not change the value ofLAST_INSERT_ID(), because the side effects of inserting default values into columns not part of the view should not be visible. MySQL was incorrectly settingLAST_INSERT_ID()to zero. (Bug#22584)M% 0NULL, but (M% 0) IS NULLWithin a stored routine, a view definition cannot refer to routine parameters or local variables. However, an error did not occur until the routine was called. Now it occurs during parsing of the routine creation statement. (Bug#20953)
Note: A side effect of this fix is that if you have already created such routines, and error will occur if you execute
SHOW CREATE PROCEDUREorSHOW CREATE FUNCTION. You should drop these routines because they are erroneous.A client library crash was caused by executing a statement such as
SELECT * FROM t1 PROCEDURE ANALYSE()using a server side cursor on a tablet1that does not have the same number of columns as the output fromPROCEDURE ANALYSE(). (Bug#17039)mysql did not check for errors when fetching data during result set printing. (Bug#22913)
Adding a day, month, or year interval to a
DATEvalue produced aDATE, but adding a week interval produced aDATETIMEvalue. Now all produce aDATEvalue. (Bug#21811)The column default value in the output from
SHOW COLUMNSorSELECT FROM INFORMATION_SCHEMA.COLUMNSwas truncated to 64 characters. (Bug#23037)For not-yet-authenticated connections, the
Timecolumn inSHOW PROCESSLISTwas a random value rather thanNULL. (Bug#23379)The
Hostcolumn inSHOW PROCESSLISToutput was blank when the server was started with the--skip-grant-tablesoption. (Bug#22728)The
Handler_rollbackstatus variable sometimes was incremented when no rollback had taken place. (Bug#22728)Within a prepared statement,
SELECT (COUNT(*) = 1)(or similar use of other aggregate functions) did not return the correct result for statement re-execution. (Bug#21354)Lack of validation for input and output
TIMEvalues resulted in several problems:SEC_TO_TIME()within subqueries incorrectly clipped large values;SEC_TO_TIME()treatedBIGINT UNSIGNEDvalues as signed; only truncation warnings were produced when both truncation and out-of-rangeTIMEvalues occurred. (Bug#11655, Bug#20927)Range searches on columns with an index prefix could miss records. (Bug#20732)
With
SQL_MODE=TRADITIONAL, MySQL incorrectly aborted on warnings within stored routines and triggers. (Bug#20028)In mysql, invoking
connector\rwith very longdb_nameorhost_nameparameters caused buffer overflow. (Bug#20894)mysqldump --xml produced invalid XML for
BLOBdata. (Bug#19745)For a debug server, a reference to an undefined user variable in a prepared statment executed with
EXECUTEcaused an assertion failure. (Bug#19356)Within a trigger for a base table, selecting from a view on that base table failed. (Bug#19111)
DELETE IGNOREcould hang for foreign key parent deletes. (Bug#18819)Transient errors in replication from master to slave may trigger multiple
Got fatal error 1236: 'binlog truncated in the middle of event'errors on the slave. (Bug#4053)The value of the
warning_countsystem variable was not being calculated correctly (also affectingSHOW COUNT(*) WARNINGS). (Bug#19024)InnoDBexhibited thread thrashing with more than 50 concurrent connections under an update-intensive workload. (Bug#22868)InnoDBshowed substandard performance with multiple queries running concurrently. (Bug#15815)There was a race condition in the
InnoDBfil_flush_file_spaces()function. (Bug#24089)FROM_UNIXTIME()did not accept arguments up toPOWER(2,31)-1, which it had previously. (Bug#9191)Some yaSSL-related memory leaks detected by Valgrind were fixed. (Bug#23981)
If
COMPRESS()returnedNULL, subsequent invocations ofCOMPRESS()within a result set or within a trigger also returnedNULL. (Bug#23254)mysql would lose its connection to the server if its standard output was not writable. (Bug#17583)
mysql-test-run did not work correctly for RPM-based installations. (Bug#17194)
The return value from
my_seek()was ignored. (Bug#22828)Use of
PREPAREwith aCREATE PROCEDUREstatement that contained a syntax error caused a server crash. (Bug#21868)Use of a DES-encrypted SSL certificate file caused a server crash. (Bug#21868)
Column names were not quoted properly for replicated views. (Bug#19736)
InnoDBused table locks (not row locks) within stored functions. (Bug#18077)Statements such as
DROP PROCEDUREandDROP VIEWwere written to the binary log too late due to a race condition. (Bug#14262)MySQL would fail to build on the Alpha platform. (Bug#23256)
The optimizer failed to use equality propagation for
BETWEENandINpredicates with string arguments. (Bug#22753)The optimizer used the
refjoin type rather thaneq_reffor a simple join on strings. (Bug#22367)The
WITH CHECK OPTIONfor a view failed to prevent storing invalid column values forUPDATEstatements. (Bug#16813)A literal string in a
GROUP BYclause could be interpreted as a column name. (Bug#14019)Some queries that used
MAX()andGROUP BYcould incorrectly return an empty result. (Bug#22342)WITH ROLLUPcould group unequal values. (Bug#20825)Use of a subquery that invoked a function in the column list of the outer query resulted in a memory leak. (Bug#21798)
LIKEsearches failed for indexedutf8character columns. (Bug#20471)FLUSH INSTANCESin Instance Manager triggered an assertion failure. (Bug#19368)ALTER TABLEwas not able to rename a view. (Bug#14959)Entries in the slow query log could have an incorrect
Rows_examinedvalue. (Bug#12240)Insufficient memory (
myisam_sort_buffer_size) could cause a server crash for several operations onMyISAMtables: repair table, create index by sort, repair by sort, parallel repair, bulk insert. (Bug#23175)OPTIMIZE TABLEwithmyisam_repair_threads> 1 could result inMyISAMtable corruption. (Bug#8283)Selecting from a
MERGEtable could result in a server crash if the underlying tables had fewer indexes than theMERGEtable itself. (Bug#22937)A locking safety check in
InnoDBreported a spurious errorstored_select_lock_type is 0 inside ::start_stmt()forINSERT ... SELECTstatements ininnodb_locks_unsafe_for_binlogmode. The safety check was removed. (Bug#10746)For multiple-table
UPDATEstatements, storage engines were not notified of duplicate-key errors. (Bug#21381)Incorrect results could be obtained from re-execution of a parametrized prepared statement or a stored routine with a
SELECTthat usesLEFT JOINwith a second table having only one row. (Bug#21081)An
UPDATEthat referred to a key column in theWHEREclause and activated a trigger that modified the column resulted in a loop. (Bug#20670)Creating a
TEMPORARYtable with the same name as an existing table that was locked by another client could result in a lock conflict forDROP TEMPORARY TABLEbecause the server unnecessarily tried to acquire a name lock. (Bug#21096)After
FLUSH TABLES WITH READ LOCKfollowed byUNLOCK TABLES, attempts to drop or alter a stored routine failed with an error that the routine did not exist, and attempts to execute the routine failed with a lock conflict error. (Bug#21414)SHOW VARIABLEStruncated theValuefield to 256 characters. (Bug#20862)Instance Manager didn't close the client socket file when starting a new mysqld instance. mysqld inherited the socket, causing clients connected to Instance Manager to hang. (Bug#12751)
Instance Manager had a race condition involving mysqld PID file removal. (Bug#22379)
It was possible for a stored routine with a non-
latin1name to cause a stack overrun. (Bug#21311)MySQL 5.0.26 introduced an ABI incompatibility, which this release reverts. Programs compiled against 5.0.26 are not compatible with any other version and must be recompiled. (Bug#23427)
InnoDB: Reduced optimization level for Windows 64 builds to handle possible memory overrun. (Bug#19424)
This is a bugfix release for the current production release family. It replaces MySQL 5.0.26.
Functionality added or changed:
This is the last version for which binary MySQL-Max distributions are available, except for RPM distributions. (For RPM distributions, the last version is 5.0.37.)
Bugs fixed:
MySQL 5.0.26 introduced an ABI incompatibility, which this release reverts. Programs compiled against 5.0.26 are not compatible with any other version and must be recompiled. (Bug#23427)
Table of Contents
- E.1. Changes in release 5.0.x (Production)
- E.1.1. Changes for release 5.0.27 and up
- E.1.2. Changes in release 5.0.26 (03 October 2006)
- E.1.3. Changes in release 5.0.25 (15 September 2006)
- E.1.4. Changes in release 5.0.24a (25 August 2006)
- E.1.5. Changes in release 5.0.24 (27 July 2006)
- E.1.6. Changes in release 5.0.23 (Not released)
- E.1.7. Changes in release 5.0.22 (24 May 2006)
- E.1.8. Changes in release 5.0.21 (02 May 2006)
- E.1.9. Changes in release 5.0.20a (18 April 2006)
- E.1.10. Changes in release 5.0.20 (31 March 2006)
- E.1.11. Changes in release 5.0.19 (04 March 2006)
- E.1.12. Changes in release 5.0.18 (21 December 2005)
- E.1.13. Changes in release 5.0.17 (14 December 2005)
- E.1.14. Changes in release 5.0.16 (10 November 2005)
- E.1.15. Changes in release 5.0.15 (19 October 2005: Production)
- E.1.16. Changes in release 5.0.14 (Not released)
- E.1.17. Changes in release 5.0.13 (22 September 2005: Release Candidate)
- E.1.18. Changes in release 5.0.12 (02 September 2005)
- E.1.19. Changes in release 5.0.11 (06 August 2005)
- E.1.20. Changes in release 5.0.10 (27 July 2005)
- E.1.21. Changes in release 5.0.9 (15 July 2005)
- E.1.22. Changes in release 5.0.8 (Not released)
- E.1.23. Changes in release 5.0.7 (10 June 2005)
- E.1.24. Changes in release 5.0.6 (26 May 2005)
- E.1.25. Changes in release 5.0.5 (Not released)
- E.1.26. Changes in release 5.0.4 (16 April 2005)
- E.1.27. Changes in release 5.0.3 (23 March 2005: Beta)
- E.1.28. Changes in release 5.0.2 (01 December 2004)
- E.1.29. Changes in release 5.0.1 (27 July 2004)
- E.1.30. Changes in release 5.0.0 (22 December 2003: Alpha)
- E.2. Changes in MySQL Cluster
- E.2.1. Changes in MySQL Cluster-5.0.7 (10 June 2005)
- E.2.2. Changes in MySQL Cluster-5.0.6 (26 May 2005)
- E.2.3. Changes in MySQL Cluster-5.0.5 (Not released)
- E.2.4. Changes in MySQL Cluster-5.0.4 (16 April 2005)
- E.2.5. Changes in MySQL Cluster-5.0.3 (23 March 2005: Beta)
- E.2.6. Changes in MySQL Cluster-5.0.1 (27 July 2004)
- E.2.7. Changes in MySQL Cluster-4.1.13 (15 July 2005)
- E.2.8. Changes in MySQL Cluster-4.1.12 (13 May 2005)
- E.2.9. Changes in MySQL Cluster-4.1.11 (01 April 2005)
- E.2.10. Changes in MySQL Cluster-4.1.10 (12 February 2005)
- E.2.11. Changes in MySQL Cluster-4.1.9 (13 January 2005)
- E.2.12. Changes in MySQL Cluster-4.1.8 (14 December 2004)
- E.2.13. Changes in MySQL Cluster-4.1.7 (23 October 2004)
- E.2.14. Changes in MySQL Cluster-4.1.6 (10 October 2004)
- E.2.15. Changes in MySQL Cluster-4.1.5 (16 September 2004)
- E.2.16. Changes in MySQL Cluster-4.1.4 (31 August 2004)
- E.2.17. Changes in MySQL Cluster-4.1.3 (28 June 2004)
- E.3. MySQL Connector/ODBC (MyODBC) Change History
- E.3.1. Changes in Connector/ODBC 5.0.12 (Not yet released)
- E.3.2. Changes in Connector/ODBC 5.0.11 (31 January 2007)
- E.3.3. Changes in Connector/ODBC 5.0.10 (14 December 2006)
- E.3.4. Changes in Connector/ODBC 5.0.9 (22 November 2006)
- E.3.5. Changes in Connector/ODBC 5.0.8 (17 November 2006)
- E.3.6. Changes in Connector/ODBC 5.0.7 (08 November 2006)
- E.3.7. Changes in Connector/ODBC 5.0.6 (03 November 2006)
- E.3.8. Changes in Connector/ODBC 5.0.5 (17 October 2006)
- E.3.9. Changes in Connector/ODBC 5.0.3 (Connector/ODBC 5.0 Alpha 3) (20 June 2006)
- E.3.10. Changes in Connector/ODBC 5.0.2 (Never released)
- E.3.11. Changes in Connector/ODBC 5.0.1 (Connector/ODBC 5.0 Alpha 2) (05 June 2006)
- E.3.12. Changes in Connector/ODBC 3.51.16 (Not yet released)
- E.3.13. Changes in Connector/ODBC 3.51.15 (7 May 2007)
- E.3.14. Changes in Connector/ODBC 3.51.14 (08 March 2007)
- E.3.15. Changes in Connector/ODBC 3.51.13 (Never released)
- E.3.16. Changes in Connector/ODBC 3.51.12
- E.3.17. Changes in Connector/ODBC 3.51.11
- E.4. Connector/NET Change History
- E.4.1. Changes in MySQL Connector/NET Version 5.1.2 (Not yet released)
- E.4.2. Changes in MySQL Connector/NET Version 5.1.1 (23 May 2007)
- E.4.3. Changes in MySQL Connector/NET Version 5.1.0 (01 May 2007)
- E.4.4. Changes in MySQL Connector/NET Version 5.0.8 (Not yet released)
- E.4.5. Changes in MySQL Connector/NET Version 5.0.7 (18 May 2007)
- E.4.6. Changes in MySQL Connector/NET Version 5.0.6 (22 March 2007)
- E.4.7. Changes in MySQL Connector/NET Version 5.0.5 (07 March 2007)
- E.4.8. Changes in MySQL Connector/NET Version 5.0.4 (Not released)
- E.4.9. Changes in MySQL Connector/NET Version 5.0.3 (05 January 2007)
- E.4.10. Changes in MySQL Connector/NET Version 5.0.2 (06 November 2006)
- E.4.11. Changes in MySQL Connector/NET Version 5.0.1 (01 October 2006)
- E.4.12. Changes in MySQL Connector/NET Version 5.0.0 (08 August 2006)
- E.4.13. Changes in MySQL Connector/NET Version 1.0.10 (Not yet released)
- E.4.14. Changes in MySQL Connector/NET Version 1.0.9 (02 February 2007
- E.4.15. Changes in MySQL Connector/NET Version 1.0.8 (20 October 2006)
- E.4.16. Changes in MySQL Connector/NET Version 1.0.7 (21 November 2005)
- E.4.17. Changes in MySQL Connector/NET Version 1.0.6 (03 October 2005)
- E.4.18. Changes in MySQL Connector/NET Version 1.0.5 (29 August 2005)
- E.4.19. Changes in MySQL Connector/NET Version 1.0.4 (20 January 2005)
- E.4.20. Changes in MySQL Connector/NET Version 1.0.3-gamma (12 October 2004)
- E.4.21. Changes in MySQL Connector/NET Version 1.0.2-gamma (15 November 2004)
- E.4.22. Changes in MySQL Connector/NET Version 1.0.1-beta2 (27 October 2004)
- E.4.23. Changes in MySQL Connector/NET Version 1.0.0 (01 September 2004)
- E.4.24. Changes in MySQL Connector/NET Version 0.9.0 (30 August 2004)
- E.4.25. Changes in MySQL Connector/NET Version 0.76
- E.4.26. Changes in MySQL Connector/NET Version 0.75
- E.4.27. Changes in MySQL Connector/NET Version 0.74
- E.4.28. Changes in MySQL Connector/NET Version 0.71
- E.4.29. Changes in MySQL Connector/NET Version 0.70
- E.4.30. Changes in MySQL Connector/NET Version 0.68
- E.4.31. Changes in MySQL Connector/NET Version 0.65
- E.4.32. Changes in MySQL Connector/NET Version 0.60
- E.4.33. Changes in MySQL Connector/NET Version 0.50
- E.5. MySQL Visual Studio Plugin Change History
- E.6. MySQL Connector/J Change History
- E.6.1. Changes in MySQL Connector/J 5.1.x
- E.6.2. Changes in MySQL Connector/J 5.0.x
- E.6.3. Changes in MySQL Connector/J 3.1.x
- E.6.4. Changes in MySQL Connector/J 3.0.x
- E.6.5. Changes in MySQL Connector/J 2.0.x
- E.6.6. Changes in MySQL Connector/J 1.2b (04 July 1999)
- E.6.7. Changes in MySQL Connector/J 1.2.x and lower
- E.7. MySQL Connector/MXJ Change History
- E.7.1. Changes in MySQL Connector/MXJ 5.0.6 (04 May 2007)
- E.7.2. Changes in MySQL Connector/MXJ 5.0.5 (14 March 2007)
- E.7.3. Changes in MySQL Connector/MXJ 5.0.4 (28 January 2007)
- E.7.4. Changes in MySQL Connector/MXJ 5.0.3 (24 June 2006)
- E.7.5. Changes in MySQL Connector/MXJ 5.0.2 (15 June 2006)
- E.7.6. Changes in MySQL Connector/MXJ 5.0.1 (Never released)
- E.7.7. Changes in MySQL Connector/MXJ 5.0.0 (09 December 2005)
Note
This appendix lists the changes from version to version in the MySQL 5.0 source code through MySQL 5.0.26. For changes made to versions following 5.0.26, see Appendix C, MySQL Enterprise Release Notes, and Appendix D, MySQL Community Server Enhancements and Release Notes.
Starting with MySQL 5.0, we began offering a new version of the Manual for each new series of MySQL releases (5.0, 5.1, and so on). For information about changes in previous release series of the MySQL database software, see the corresponding version of this Manual. For information about legacy versions of the MySQL software through the 4.1 series, see MySQL 3.23, 4.0, 4.1 Reference Manual.
We update this section as we add new features in the 5.0 series, so that everybody can follow the development process.
Note that we tend to update the manual at the same time we make changes to MySQL. If you find a recent version of MySQL listed here that you can't find on our download page (http://dev.mysql.com/downloads/), it means that the version has not yet been released.
The date mentioned with a release version is the date of the last BitKeeper ChangeSet on which the release was based, not the date when the packages were made available. The binaries are usually made available a few days after the date of the tagged ChangeSet, because building and testing all packages takes some time.
The manual included in the source and binary distributions may not be fully accurate when it comes to the release changelog entries, because the integration of the manual happens at build time. For the most up-to-date release changelog, please refer to the online version instead.
- E.1.1. Changes for release 5.0.27 and up
- E.1.2. Changes in release 5.0.26 (03 October 2006)
- E.1.3. Changes in release 5.0.25 (15 September 2006)
- E.1.4. Changes in release 5.0.24a (25 August 2006)
- E.1.5. Changes in release 5.0.24 (27 July 2006)
- E.1.6. Changes in release 5.0.23 (Not released)
- E.1.7. Changes in release 5.0.22 (24 May 2006)
- E.1.8. Changes in release 5.0.21 (02 May 2006)
- E.1.9. Changes in release 5.0.20a (18 April 2006)
- E.1.10. Changes in release 5.0.20 (31 March 2006)
- E.1.11. Changes in release 5.0.19 (04 March 2006)
- E.1.12. Changes in release 5.0.18 (21 December 2005)
- E.1.13. Changes in release 5.0.17 (14 December 2005)
- E.1.14. Changes in release 5.0.16 (10 November 2005)
- E.1.15. Changes in release 5.0.15 (19 October 2005: Production)
- E.1.16. Changes in release 5.0.14 (Not released)
- E.1.17. Changes in release 5.0.13 (22 September 2005: Release Candidate)
- E.1.18. Changes in release 5.0.12 (02 September 2005)
- E.1.19. Changes in release 5.0.11 (06 August 2005)
- E.1.20. Changes in release 5.0.10 (27 July 2005)
- E.1.21. Changes in release 5.0.9 (15 July 2005)
- E.1.22. Changes in release 5.0.8 (Not released)
- E.1.23. Changes in release 5.0.7 (10 June 2005)
- E.1.24. Changes in release 5.0.6 (26 May 2005)
- E.1.25. Changes in release 5.0.5 (Not released)
- E.1.26. Changes in release 5.0.4 (16 April 2005)
- E.1.27. Changes in release 5.0.3 (23 March 2005: Beta)
- E.1.28. Changes in release 5.0.2 (01 December 2004)
- E.1.29. Changes in release 5.0.1 (27 July 2004)
- E.1.30. Changes in release 5.0.0 (22 December 2003: Alpha)
The following changelog shows what has been done in the 5.0 tree:
Basic support for read-only server side cursors. For information about using cursors within stored routines, see Section 17.2.9, “Cursors”. For information about using cursors from within the C API, see Section 22.2.7.3, “
mysql_stmt_attr_set()”.Basic support for (updatable) views. See, for example, Section 19.2, “
CREATE VIEWSyntax”.Basic support for stored procedures and functions (SQL:2003 style). See Chapter 17, Stored Procedures and Functions.
Initial support for rudimentary triggers.
Added
SELECT INTO, which can be of mixed (that is, global and local) types. See Section 17.2.7.3, “list_of_varsSELECT ... INTOStatement”.Removed the update log. It is fully replaced by the binary log. If the MySQL server is started with
--log-update, it is translated to--log-bin(or ignored if the server is explicitly started with--log-bin), and a warning message is written to the error log. SettingSQL_LOG_UPDATEsilently setsSQL_LOG_BINinstead (or do nothing if the server is explicitly started with--log-bin).Support for the
ISAMstorage engine has been removed. If you haveISAMtables, you should convert them before upgrading. See Section 2.4.16.2, “Upgrading from MySQL 4.1 to 5.0”.Support for
RAIDoptions inMyISAMtables has been removed. If you have tables that use these options, you should convert them before upgrading. See Section 2.4.16.2, “Upgrading from MySQL 4.1 to 5.0”.User variable names are now case insensitive: If you do
SET @a=10;thenSELECT @A;now returns10. Case sensitivity of a variable's value depends on the collation of the value.Strict mode, which in essence means that you get an error instead of a warning when inserting an incorrect value into a column. See Section 5.2.6, “SQL Modes”.
VARCHARandVARBINARYcolumns remember end space. AVARCHAR()orVARBINARYcolumn can contain up to 65,535 characters or bytes, respectively.MEMORY(HEAP) tables can haveVARCHARcolumns.When using a constant string or a function that generates a string result in
CREATE ... SELECT, MySQL creates the result column based on the maximum length of the string or expression:Maximum Length Data type = 0 CHAR(0)< 512 VARCHAR(max_length)>= 512 TEXTA fixed-point math library is introduced that supports precision math, resulting in more accurate results when working with the
DECIMALandNUMERICdata types. For details, see Chapter 21, Precision Math.
For a full list of changes, please refer to the changelog sections for each individual 5.0.x release.
Beginning with MySQL 5.0.27, change notes are listed separately for MySQL Enterprise and MySQL Community Server. See Appendix C, MySQL Enterprise Release Notes, and Appendix D, MySQL Community Server Enhancements and Release Notes.
This is a bugfix release for the current production release family.
This section documents all changes and bug fixes that have been applied since the last official MySQL release. If you would like to receive more fine-grained and personalized update alerts about fixes that are relevant to the version and features you use, please consider subscribing to MySQL Enterprise (a commercial MySQL offering). For more details please see http://www.mysql.com/products/enterprise.
Functionality added or changed:
The output generated by the server when using the
--xmloption has changed with regard to null values. It now matches the output from mysqldump--xml. That is, a column containing aNULLvalue is now reported as<field name="
column_name" xsi:nil="true" />whereas a column containing the string value
'NULL'is reported as<field name="
column_name">NULL</field>and a column containing an empty string is reported as
<field name="
column_name">>/field>The source distribution has been updated so that the UDF example can be compiled under Windows with CMake. See Section 24.2.4.5, “Compiling and Installing User-Defined Functions”. (Bug#19121)
The
LOAD DATA FROM MASTERandLOAD TABLE FROM MASTERstatements are deprecated. See Section 13.6.2.2, “LOAD DATA FROM MASTERSyntax”, for recommended alternatives. (Bug#18822, Bug#9125, Bug#12187, Bug#14399, Bug#15025, Bug#20596)LOAD DATA INFILEno longer causes an implicit commit for all storage engines. It now causes an implicit commit only for tables using theNDBstorage engine. (Bug#11151)mysqldump now has a
--flush-privilegesoption. It causes mysqldump to emit aFLUSH PRIVILEGESstatement after dumping themysqldatabase. This option should be used any time the dump contains themysqldatabase and any other database that depends on the data in themysqldatabase for proper restoration. (Bug#21424)The number of
InnoDBthreads is no longer limited to 1,000 on Windows. (Bug#22268)
Bugs fixed:
Deleting entries from a large
MyISAMindex could cause index corruption when it needed to shrink. Deletes from an index can happen when a record is deleted, when a key changes and must be moved, and when a key must be un-inserted because of a duplicate key. This can also happen inREPAIR TABLEwhen a duplicate key is found and in myisamchk when sorting the records by an index. (Bug#22384)mysql_config --libmysqld-libs did not produce any SSL options necessary for linking
libmysqldwith SSL support enabled. (Bug#21239)The parser rejected queries that selected from a table twice using a
UNIONwithin a subquery. The parser now supports arbitrary subquery, join, and parenthesis operations withinEXISTSsubqueries. A limitation still exists for scalar subqueries: If the subquery containsUNION, the firstSELECTof theUNIONcannot be within parentheses. For example,SELECT (SELECT a FROM t1 UNION SELECT b FROM t2)will work, butSELECT ((SELECT a FROM t1) UNION (SELECT b FROM t2))will not. (Bug#14654)Subqueries with aggregate functions but no
FROMclause could return incorrect results. (Bug#21540)The presence of a subquery in the
ONclause of a join in a view definition prevented theMERGEalgorithm from being used for the view in cases where it should be allowed. (Bug#21646)Conversion of values inserted into a
BITcolumn could affect adjacent columns. (Bug#22271)The URL into the online manual that is printed in the stack trace message by the server was out of date. (Bug#21449)
PROCEDURE ANALYSE()returned incorrect values ofMFLOAT(andM,D)DOUBLE(. (Bug#20305)M,D)Join conditions using index prefixes on
utf8columns ofInnoDBtables incorrectly ignored rows where the length of the actual value was greater than the length of the index prefix. (Bug#19960)On an
INSERTinto an updatable but non-insertable view, an error message was issued stating that the view was not updatable. Now the message says the view is not insertable-into. (Bug#5505)INSERT DELAYEDdid not honorSET INSERT_IDor theauto_increment_*system variables. (Bug#20627, Bug#20830)For character sets having a
mbmaxlenvalue of 2, anyALTER TABLEstatement changedTEXTcolumns toMEDIUMTEXT. (Bug#21620)A query that used
GROUP BYand anALLorANYquantified subquery in aHAVINGclause could trigger an assertion failure. (Bug#21853)For an
ENUMcolumn that used theucs2character set, usingALTER TABLEto modify the column definition caused the default value to be lost. (Bug#20108)mysql_com.hunnecessarily referred to theulongtype. (Bug#22227)Incorporated some portability fixes into the definition of
__attribute__inmy_global.h. (Bug#2717)Linking the
pthreadslibrary to single-threaded MySQL libraries causeddlopen()to fail at runtime on HP-UX. (Bug#18267)In the package of pre-built time zone tables that is available for download at http://dev.mysql.com/downloads/timezones.html, the tables now explicitly use the
utf8character set so that they work the same way regardless of the system character set value. (Bug#21208)The build process incorrectly tried to overwrite
sql/lex_hash.h. This caused the build to fail when using a shadow link tree pointing to original sources that were owned by another account. (Bug#18888)mysql_ftdump produced bad counts for common words. (Bug#22326)
yaSSL had a conflicting definition for
socklen_ton hurd-i386 systems. (Bug#22326)When records are merged from the insert buffer and the page needs to be reorganized,
InnoDBused incorrect column length information when interpreting the records of the page. This caused a server crash due to apparent corruption of secondary indexes inROW_FORMAT=COMPACTthat contain prefix indexes of fixed-length columns. Data files should not be corrupted, but the crash was likely to repeat every time the server was restarted. (Bug#21638)Using
GROUP_CONCAT()on the result of a subquery in theFROMclause that itself usedGROUP_CONCAT()could cause a server crash. (Bug#22015)Execution of a prepared statement that uses an
INsubquery with aggregate functions in theHAVINGclause could cause a server crash. (Bug#22085)The value of
LAST_INSERT_ID()was not always updated correctly within stored routines. (Bug#21726)If
mysqldwas linked against a system-installedzliblibrary compiled without large-file support, it would likely exit with aSIGXFSZ(file size exceeded) signal if anARCHIVEtable reached 2GB. The server now checks for space before writing. (Bug#21675)Selecting from a
MERGEtable could result in a server crash if the underlying tables had fewer indexes than theMERGEtable itself. (Bug#21617, Bug#22937)make install tried to build files that should already have been built by make all, causing a failure if installation was performed using a different account than the one used for the initial build. (Bug#19738)
The source distribution would not build on Windows due to a spurious dependency on
ib_config.h. (Bug#22224)The server returns a more informative error message when it attempts to open a
MERGEtable that has been defined to use non-MyISAMtables. (Bug#10974)Within stored routines, some error messages were printed incorrectly. A non-null-terminated string was passed to a message-printing routine that expected a null-terminated string. (Bug#20778)
SUBSTR()results sometimes were stored improperly into a temporary table when multi-byte character sets were used. (Bug#20204)On Windows, inserting into a
MERGEtable after renaming an underlyingMyISAMtable caused a server crash. (Bug#20789)On Mac OS X, zero-byte
read()orwrite()calls to an SMB-mounted filesystem could return a non-standard return value, leading to data corruption. Now such calls are avoided. (Bug#12620)With
TRADITIONALSQL mode, assignment of out-of-bound values and rounding of assigned values was done correctly, but assignment of the same numbers represented as strings sometimes was handled differently. (Bug#6147)The source distribution failed to compile when configured with the
--without-geometryoption. (Bug#12991)The source distribution failed to compile when configured with the
--with-libwrapoption. (Bug#18246)For
INSERT ... ON DUPLICATE KEY UPDATE, use ofVALUES(within thecol_name)UPDATEclause sometimes was handled incorrectly. (Bug#21555)Row equalities (such as
WHERE (a,b) = (c,d)were not taken into account by the optimizer, resulting in slow query execution. Now they are treated as conjunctions of equalities between row elements. (Bug#16081)Column names supplied for a view created on a master server could be lost on a slave server. (Bug#19419)
For a
MyISAMtable locked withLOCK TABLES ...WRITE, queries optimized using theindex_mergemethod did not show rows inserted with the lock in place. (Bug#20256)Table aliases in multiple-table
DELETEstatements sometimes were not resolved. (Bug#21392)A function result in a comparison was replaced with a constant by the optimizer under some circumstances when this optimization was invalid. (Bug#21698)
A subquery that uses an index for both the
WHEREandORDER BYclauses produced an empty result. (Bug#21180)If the
auto_increment_offsetsetting causes MySQL to generate a value larger than the column's maximum possible value, theINSERTstatement is accepted in strict SQL mode, whereas but should fail with an error. (Bug#20573)Queries containing a subquery that used aggregate functions could return incorrect results. (Bug#16792)
EXPLAINsometimes returned an incorrectselect_typefor aSELECTfrom a view, compared to theselect_typefor the equivalentSELECTfrom the base table. (Bug#5500)For a
MyISAMtable with aFULLTEXTindex, compression with myisampack or a check with myisamchk after compression resulted in table corruption. (Bug#19702)BIN(),OCT(), andCONV()did not work with BIT values. (Bug#15583)The server could crash for the second execution of a function containing a
SELECTstatement that uses an aggregatingINsubquery. (Bug#21493)UPGRADEwas treated as a reserved word, although it is not. (Bug#21772)mysql_upgrade produced a malformed
upgrade_defaultsfile by overwriting the[client]group header with apasswordoption. This prevented mysqlcheck from running successfully when invoked by mysql_upgrade. (Bug#21011)Usernames have a maximum length of 16 characters (even if they contain multi-byte characters), but were being truncated to 16 bytes. (Bug#20393)
mysql displayed an empty string for
NULLvalues. (Bug#21618)
This is a bugfix release for the current production release family. This version was released as MySQL Classic 5.0.25 to commercial customers only.
This section documents all changes and bug fixes that have been applied since the last official MySQL release. If you would like to receive more fine-grained and personalized update alerts about fixes that are relevant to the version and features you use, please consider subscribing to MySQL Enterprise (a commercial MySQL offering). For more details please see http://www.mysql.com/products/enterprise.
Functionality added or changed:
For the mysql client, typing Control-C causes mysql to attempt to kill the current statement. If this cannot be done, or Control-C is typed again before the statement is killed, mysql exits. Previously, Control-C caused mysql to exit in all cases. (Bug#17926; see also Bug#1989)
For mysqlshow, if a database name argument contains wildcard characters (such as ‘
_’) but matches a single database name exactly, treat the name as a literal name. This allows a command such as mysqlshow information_schema work without having to escape the wildcard character. (Bug#19147)If a
DROP VIEWstatement named multiple views, it stopped with an error if a non-existent view was named and did not drop the remaining views. Now it continues on and reports an error at the end, similar toDROP TABLE. (Bug#16614)Table comments longer than 60 characters and column comments longer than 255 characters were truncated silently. Now a warning is issued, or an error in strict mode. (Bug#13934)
The bundled yaSSL library was upgraded to version 1.3.7.
The bundled yaSSL library licensing has added a FLOSS exception similar to MySQL to resolve licensing incompatibilities with MySQL. (See the
extra/yassl/FLOSS-EXCEPTIONSfile in a MySQL source distribution for details.) (Bug#16755)The server now issues a warning if it removes leading spaces from an alias. (Bug#10977)
The
VIEW_DEFINITIONcolumn of theINFORMATION_SCHEMAVIEWStable now contains information about the view algorithm. (Bug#16832)For a successful dump, mysqldump now writes a SQL comment to the end of the dump file in the following format:
-- Dump completed on YYYY-MM-DD hh:mm:ss
The mysqld and mysqlmanager manpages have been reclassified from volume 1 to volume 8. (Bug#21220)
configure now defines the symbol
DBUG_ONinconfig.hto indicate whether the source tree is configured to be compiled with debugging support. (Bug#19517)The MySQL distribution now compiles on UnixWare 7.13. (Bug#20190)
The mysql client used the default character set if it automatically reconnected to the server, which is incorrect if the character set had been changed. To enable the character set to remain synchronized on the client and server, the mysql command
charset(or\C) that changes the default character set and now also issues aSET NAMESstatement. The changed character set is used for reconnects. (Bug#11972)mysql_upgrade no longer reads the
[client]option file group because it is not a client and did not understand client options such ashost. Now it reads only the[mysql_upgrade]group. (Bug#19452)MySQL now can do stack dumps on
x86_64andi386/NPTLsystems. (Bug#21250)TIMESTAMPcolumns that areNOT NULLnow are reported that way bySHOW COLUMNSandINFORMATION_SCHEMA. (Bug#20910)Using
--with-debugto configure MySQL with debugging support enables you to use the--debug="d,parser_debug"option when you start the server. This causes the Bison parser that is used to process SQL statements to dump a parser trace to the server's standard error output. Typically, this output is written to the error log.A new system variable,
lc_time_names, specifies the locale that controls the language used to display day and month names and abbreviations. This variable affects the output from theDATE_FORMAT(),DAYNAME()andMONTHNAME()functions. See Section 5.10.9, “MySQL Server Locale Support”.
Bugs fixed:
Security fix: On Linux, and possibly other platforms using case-sensitive filesystems, it was possible for a user granted rights on a database to create or access a database whose name differed only from that of the first by the case of one or more letters. (CVE-2006-4226, Bug#17647)
Security fix: A stored routine created by one user and then made accessible to a different user using
GRANT EXECUTEcould be executed by that user with the privileges of the routine's definer. (CVE-2006-4227, Bug#18630)Setting
myisam_repair_threadscaused any repair operation on aMyISAMtable to fail to update the cardinality of indexes, instead making them always equal to 1. (Bug#18874)The optimizer did not take advantage of indexes on columns used for the second or third arguments of
BETWEEN. (Bug#18165)Successive invocations of a
COUNT(*)query containing a join on twoMyISAMtables and aWHEREclause of the formWHERE (yielded different results. (Bug#21019)table1.column1=table2.column2) ORtable2.column2IS NULLCREATE TABLE ... SELECTstatements that selectedGEOMETRYvalues resulted in a table that containedBLOBcolumns, notGEOMETRYcolumns. (Bug#14807)A
DATEcan be represented as an integer (such as20060101) or as a string (such as'2006.01.01'). When aDATE(orTIME) column is compared in oneSELECTagainst both representations, constant propagation by the optimizer led to comparison ofDATEas a string againstDATEas an integer. This could result in integer comparisons such as2006against20060101, erroneously producing a false result. (Bug#21475)A query result could be sorted improperly when using
ORDER BYfor the second table in a join. (Bug#21302)EXPORT_SET()did not accept arguments with coercible character sets. (Bug#21531)The
--collation-serverserver option was being ignored. With the fix for this problem, if you choose a non-default character set with--character-set-server, you should also use--collation-serverto specify the collation. (Bug#15276)The
index_merge/Intersectionoptimizer could have a memory overrrun when the number of table columns covered by an index is sufficiently large, possibly resulting in a server crash. (Bug#16201)With
max_sp_recursionset to 0, a stored procedure that executed aSHOW CREATE PROCEDUREstatement for itself triggered a recursion limit exceeded error, though the statement involves no recursion. (Bug#21416)The optimizer could produce an incorrect result after
ANDwith collations such aslatin1_german2_ci,utf8_czech_ci, andutf8_lithianian_ci. (Bug#9509)Database and table names have a maximum length of 64 characters (even if they contain multi-byte characters), but were being truncated to 64 bytes. (Bug#21432) This patch was reverted in MySQL 5.0.26.
character_set_resultscan beNULLto signify “no conversion,” but some code did not check forNULL, resulting in a server crash. (Bug#21913)InnoDBwas slow with more than 100,000.idbfiles. (Bug#21112)SHOW INNODB STATUScontained some duplicate output. (Bug#21113)Using cursors with
READ COMMITTEDisolation level could causeInnoDBto crash. (Bug#19834)The ndb_mgm program was included in both the
MySQL-ndb-toolsandMySQL-ndb-managementRPM packages, resulting in a conflict if both were installed. Now ndb_mgm is included only inMySQL-ndb-tools. (Bug#21058)A query could produce different results with and without and index, if the
WHEREclause contained a range condition that used an invalidDATETIMEconstant. (Bug#16249)libmysqldproduced some warnings tostderrwhich could not be silenced. These warnings now are suppressed. (Bug#13717)If a query had a condition of the form
tableX.key=tableY.keyrefaccess, then earlyref-accessNULLfiltering was not peformed for the condition. This could make query execution slower. (Bug#19649)The optimizer sometimes produced an incorrect row-count estimate after elimination of
consttables. This resulted in choosing extremely inefficient execution plans in same cases when distribution of data in joins were skewed. (Bug#21390)Query results could be incorrect if the
WHEREclause containedt., wherekey_partNOT IN (val_list)val_listis a list of more than 1000 constants. (Bug#21282)STR_TO_DATE()sometimes would returnNULLif the%Dformat specifier was not the last specifier in the format string. (Bug#20987)The
myisam_stats_methodvariable was mishandled when set from an option file or on the command line. (Bug#21054)The optimizer assumed that if
(a=x AND b=x)is true,(a=x AND b=x) AND a=bis also true. But that is not always so ifaandbhave different data types. (Bug#21159)InnoDBdid not honorIGNORE INDEX, which prevented usingIGNORE INDEXin cases where an index sort would be slower than a filesort. (Bug#21174) This patch was reverted in MySQL 5.0.26. Hint operation was revised further in MySQL 5.0.40.If a column definition contained a character set declaration, but a
DEFAULTvalue began with an introducer, the introducer character set was used as the column character set. (Bug#20695)The
MD5(),SHA1(), andENCRYPT()functions should return a binary string, but the result sometimes was converted to the character set of the argument.MAKE_SET()andEXPORT_SET()now use the correct character set for their default separators, resulting in consistent result strings which can be coerced according to normal character set rules. (Bug#20536)For connections that required a
SUBJECTvalue, a check was performed to verify that the value was correct, but the connection was not refused if not. (Bug#20411)Some Linux-x86_64-icc packages (of previous releases) mistakenly contained 32-bit binaries. Only ICC builds are affected, not gcc builds. Solaris and FreeBSD x86_64 builds are not affected. (Bug#22238)
INSERT ... SELECTsometimes generated a spuriousColumn count doesn't match value counterror. (Bug#21774)For
TIME_FORMAT(), the%Hand%kformat specifiers can return values larger than two digits (if the hour is greater than 99), but for some query results that contained three-character hours, column values were truncated. (Bug#19844)For table-format output, mysql did not always calculate columns widths correctly for columns containing multi-byte characters in the column name or contents. (Bug#17939)
Views could not be updated within a stored function or trigger. (Bug#17591)
Some user-level errors were being written to the server's error log, which is for server errors. (Bug#20402)
When using tables created under MySQL 4.1 with a 5.0 server, if the tables contained
VARCHARcolumns, for some queries the metadata sent to the client could have an empty column name. (Bug#14897)On 64-bit systems, use of the
cp1250character set with a primary key column in aLIKEclause caused a server crash for patterns having letters in the range 128..255. (Bug#19741)N'xxx'and_utf8'xxx'were not treated as equivalent becauseN'xxx'failed to unescape backslashes (\) and doubled apostrophe/single quote characters (''). (Bug#17313)ORDER BY RAND() LIMIT 1always set a user variable to the last possible value from the table. (Bug#16861)A subquery in the
WHEREclause of the outer query and usingINandGROUP BYreturned an incorrect result. (Bug#16255)When
NOW()was used in aBETWEENclause of the definition for a view, it was replaced with a constant in the view. (Bug#15950)A stored procedure with a
CONTINUEhandler that encountered an error continued to execute a statement that caused an error, rather with the next statement following the one that caused the error. (Bug#8153)libmysqlclientdefined a symbolBN_bin2bnwhich belongs to OpenSSL. This could break applications that also linked against OpenSSL'slibcryptolibrary. The fix required correcting an error in a build script that was failing to add rename macros for some functions. (Bug#21930)COUNT(*)queries withORDER BYandLIMITcould return the wrong result. (Bug#21787)Note: This problem was introduced by the fix for Bug#9676, which limited the rows stored in a temporary table to the
LIMITclause. This optimization is not applicable to non-group queries with aggregate functions. The current fix disables the optimization in such cases.Memory overruns could occur for certain kinds of subqueries. (Bug#21477)
The
SELECTprivilege was required for an insert on a view, instead of theINSERTprivilege. (Bug#21261)Note: This fixes a regression that was introduced by the fix for Bug#20989.
Running
SHOW MASTER LOGSat the same time as binary log files were being switched would causemysqldto hang. (Bug#21965)A server or network failure with an open client connection would cause the client to hang even though the server was no longer available. (Bug#9678)
Inserts into
BITcolumns ofFEDERATEDtables did not work. (Bug#14532)The yaSSL library bundled with
libmysqlclienthad some conflicts with OpenSSL. Now macros are used to rename the conflicting symbols to have a prefix ofya. (Bug#19810)It is possible to create
MERGEtables into which data cannot be inserted (by not specifying aUNIONclause. However, when an insert was attempted, the error message was confusing. Now an error occurs indicating that the table is read-only. (Bug#17766)A
NULbyte within a prepared statement string caused the rest of the string not to be written to the query log, allowing logging to be bypassed. (Bug#21813)mysql_upgrade created temporary files in a possibly insecure way. (Bug#21224)
Some prepared statements caused a server crash when executed a second time. (Bug#21166)
With
query_cache_typeset to 0,RESET QUERY CACHEwas very slow and other threads were blocked during the operation. Now a cache reset is faster and non-blocking. (Bug#21051)NDB Cluster: SettingTransactionDeadlockDetectionTimeoutto a value greater than 12000 would cause scans to deadlock, time out, fail to release scan records, until the cluster ran out of scan records and stopped processing. (Bug#21800)NDB Cluster: The server provided a non-descriptive error message when encountering a fatally corrupted REDO log. (Bug#21615)NDB Cluster: A partial rollback could lead to node restart failures. (Bug#21536)NDB Cluster: The failure of a unique index read due to an invalid schema version could be handled incorrectly in some cases, leading to unpredictable results. (Bug#21384)NDB Cluster: In a cluster with more than 2 replicas, a manual restart of one of the data nodes could fail and cause the other nodes in its nodegroup to shut down. (Bug#21213)NDB Cluster: When the redo buffer ran out of space, a Pointer too large error was raised and the cluster could become unusable until restarted with--initial. (Bug#20892)NDB Cluster: In some situations with a high disk-load, writing of the redo log could hang, causing a crash with the error message GCP STOP detected. (Bug#20904)NDB Cluster: A vague error message was returned when reading of both schema files occurred during a restart of the cluster. (Bug#20860)NDB Cluster: The server did not honor the value set forndb_cache_check_timein themy.cnffile. (Bug#20708)NDB Cluster: The server failed with a non-descriptive error message when out of data memory. (Bug#18475)NDB Cluster: ndb_size.pl and ndb_error_reporter were missing from RPM packages. (Bug#20426)When
DROP DATABASEorSHOW OPEN TABLESwas issued while concurrently issuingDROP TABLE(orRENAME TABLE,CREATE TABLE LIKEor any other statement that required a name lock) in another connection, the server crashed. (Bug#21216)Use of zero-length variable names caused a server crash. (Bug#20908)
Prepared statements caused general log and server memory corruption. (Bug#14346)
mysqldump incorrectly tried to use
LOCK TABLESfor tables in theINFORMATION_SCHEMAdatabase. (Bug#21527)Adding
ORDER BYto aSELECT DISTINCT(query could produce incorrect results. (Bug#21456)expr)For
InnoDBtables, the server could crash when executingNOT IN ()subqueries. (Bug#21077)Use of the
--promptoption orpromptcommand caused mysql to be unable to connect to the Instance Manager. (Bug#17485)The server crashed if it tried to access a
CSVtable for which the data file had been removed. (Bug#15205)CREATE USERdid not respect the 16-character username limit. (Bug#10668)On Windows, a definition for
mysql_set_server_option()was missing from the C client library. (Bug#16513)For the
CSVstorage engine, memory-mapped pages of the data file were not invalidated when new data was appended to the file via traditional (file descriptor-based) I/O primitives. (Bug#15669)In debugging mode, mysqld printed
server_initrather thannetwork_initduring network initialization. (Bug#20968)For user-defined functions created with
CREATE FUNCTION, theDEFINERclause is not legal, but no error was generated. (Bug#21269)mysqld --flush failed to flush
MyISAMtable changes to disk following anUPDATEstatement for which no updated column had an index. (Bug#20060)When not running in strict mode, the server failed to convert the invalid years portion of a
DATEorDATETIMEvalue to'0000'when inserting it into a table. (Bug#19370)This patch was reverted in MySQL 5.0.42.
The
--with-collationoption was not honored for client connections. (Bug#7192)Users who had the
SHOW VIEWprivilege for a view and privileges on one of the view's base table could not see records inINFORMATION_SCHEMAtables relating to the base table. (Bug#20543)An issue with yaSSL prevented Connector/J clients from connecting to the server using a certificate. (Bug#19705)
Some server errors were not reported to the client, causing both to try to read from the connection until a hang or crash resulted. (Bug#16581)
When setting a column to its implicit default value as the result of inserting a
NULLinto aNOT NULLcolumn as part of a multi-row insert orLOAD DATAoperation, the server returned a misleading warning message. (Bug#14770)DECIMALcolumns were handled incorrectly in two respects (Bug#16172):When the precision of the column was too small for the value. In this case, the original value was returned instead of an error.
When the scale of the column was set to 0. In this case, the value. In this case, the value was treated as though the scale had been defined as 2.
Tables created with the
FEDERATEDstorage engine did not permit indexes usingNULLcolumns. (Bug#15133)The Instance Manager allowed
STOP INSTANCEto be used on a server instance that was not running. (Bug#12673)On Windows, mysql_upgrade.exe could not find mysqlcheck.exe. (Bug#20950)
FEDERATEDtables raised invalid duplicate key errors when attempting on one server to insert rows having the same primary key values as rows that had been deleted from the linked table on the other server. (Bug#18764)The C API failed to return a status message when invoking a stored procedure. (Bug#15752)
A stored procedure that created and invoked a prepared statement was not executed when called in a mysqld init-file. (Bug#17843)
Stored procedures did not use the character set defined for the database in which they were created. (Bug#16676)
CREATE PROCEDURE,CREATE FUNTION,CREATE TRIGGER, andCREATE VIEWstatements containing multi-line comments (/* ... */) could not be replicated. (Bug#20438)The final parenthesis of a
CREATE INDEXstatement occurring in a stored procedure was omitted from the binary log when the stored procedure was called. (Bug#19207)Attempting to insert a string of greater than 4096 bytes into a
FEDERATEDtable resulted in the error ERROR 1296 (HY000) at line 2: Got error 10000 'Error on remote system: 1054: Unknown column 'string-value' from FEDERATED. This error was raised regardless of the type of column involved (VARCHAR,TEXT, and so on.) (Bug#17608)Performance during an import on a table with a trigger that called a stored procedure was severely degraded. This issue first arose in MySQL 5.0.18. (Bug#21013)
Repeated
DROP TABLEstatements in a stored procedure could sometimes cause the server to crash. (Bug#19399)The value returned by a stored function returning a string value was not of the declared character set. (Bug#16211)
For mysql, escaping with backslash sometimes did not work. (Bug#20103)
Under certain circumstances,
AVG(returned a value butkey_val)MAX(returned an empty set due to incorrect application ofkey_val)MIN()/MAX()optimization. (Bug#20954)Using aggregate functions in subqueries yielded incorrect results under certain circumstances due to incorrect application of
MIN()/MAX()optimization. (Bug#20792)A query using
WHEREdid not return consistent results on successive invocations. Thecolumn=constantORcolumnIS NULLcolumnin each part of theWHEREclause could be either the same column, or two different columns, for the effect to be observed. (Bug#21019)The
PASSWORD()function returned invalid results when used in someUNIONqueries. (Bug#16881)USEdid not refresh database privileges when employed to re-select the current database. (Bug#10979)A query using
WHERE NOT (yielded a different result from the same query using the samecolumn< ANY (subquery))columnandsubquerywithWHERE (. (Bug#20975)column> ANY (subquery))A user variable set to a value selected from an unsigned column was stored as a signed value. (Bug#7498)
SELECTstatements usingGROUP BYagainst a view could have missing columns in the output when there was a trigger defined on one of the base tables for the view. (Bug#20466)A
SELECTwith a subquery that was bound to the outer query over multiple columns returned different results when a constant was used instead of one of the dependant columns. (Bug#18925)When performing a
GROUP_CONCAT(), the server transformedBLOBcolumnsVARCHARcolumns, which could cause erroneous results when using Connector/J and possibly other MySQL APIs. (Bug#16712)The type of the value returned by the
VARIANCE()function varied according to the type of the input value. The function should always return aDOUBLEvalue. (Bug#10966)Performing an
INSERTon a view that was defined using aSELECTthat specified a collation and a column alias caused the server to crash (Bug#21086).A query of the form shown here caused the server to crash:
SELECT * FROM t1 NATURAL JOIN ( t2 JOIN ( t3 NATURAL JOIN t4, t5 NATURAL JOIN t6 ) ON (t3.id3 = t2.id3 AND t5.id5 = t2.id5) );NDB Cluster(Direct APIs): Invoking the MGM API functionndb_mgm_listen_event()caused a memory leak. (Bug#21671)NDB Cluster(Direct APIs): The MGM API functionndb_logevent_get_fd()was not actually implemented. (Bug#21129)A memory leak was found when running
ndb_mgm -e "SHOW". (Bug#21670)NDB Cluster: Restarting a data node while DDL operations were in progress on the cluster could cause other data nodes to fail. This could also lead to mysqld hanging or crashing under some circumstances. (Bug#21017, Bug#21050)NDB Cluster: An issue that arose from a patch for Bug#19852 made in MySQL 5.0.23 was corrected. (See Section E.1.6, “Changes in release 5.0.23 (Not released)”.)NDB Cluster: The management clientALL STATUScommand could sometimes report the status of some data nodes incorrectly. (Bug#13985)NDB Cluster: Some queries involving joins on very largeNDBtables could crash the MySQL server. (Bug#21059)NDB Cluster:SELECT ... FOR UPDATEfailed to lock the selected rows. (Bug#18184)NDB Cluster: A Cluster whose storage nodes were installed from theMySQL-ndb-storage-RPMs could not perform*CREATEorALTERoperations that made use of non-default character sets or collations. (Bug#14918)NDB Cluster:REPLACEstatements did not work correctly on anNDBtable having both a primary key and a unique key. In such cases, proper values were not set for columns which were not explicitly referenced in the statement. (Bug#20728)NDB Cluster: Trying to create or drop a table while a node was restarting caused the node to crash. This is now handled by raising an error. (Bug#18781)NDB Cluster: Running ndbd--nowait-nodes=whereididwas the node ID of a node that was already running would fail with an invalid error message. (Bug#20419)NDB Cluster: Incorrect values were inserted intoAUTO_INCREMENTcolumns of tables restored from a cluster backup. (Bug#20820)NDB Cluster: When attempting to restart the cluster following a data import, the cluster would fail during Phase 4 of the restart with Error 2334: Job buffer congestion. (Bug#20774)NDB Cluster: A node failure during a scan could sometime cause the node to crash when restarting too quickly following the failure. (Bug#20197)NDB Cluster: It was possible to use port numbers greater than 65535 forServerPortin theconfig.inifile. (Bug#19164)NDB Cluster: Under certain circumstances, a node that was shut down then restarted could hang during the restart. (Bug#18863)NDB Cluster(Replication): In some cases, a large number of MySQL servers sending requests to the cluster simultaneously could cause the cluster to crash. This could also be triggered by many NDB API clients making simultaneous event subscriptions or unsubscriptions. (Bug#20683)NDB Cluster(Direct APIs):NdbScanOperation::readTuples()andNdbIndexScanOperation::readTuples()ignored thebatchparameter. (Bug#20252)The implementation for
UNCOMPRESS()did not indicate that it could returnNULL, causing the optimizer to do the wrong thing. (Bug#18539)TIMESTAMPDIFF()examined only the date and ignored the time when the requested difference unit was months or quarters. (Bug#16226)perror did not properly report NDB error codes. (Bug#16561)
mysqlimport sends a
set @@character_set_database=binarystatement to the server, but this is not understood by pre-4.1 servers. Now mysqlimport encloses the statement within a/*!40101 ... */comment so that old servers will ignore it. (Bug#15690)The character set was not being properly initialized for
CAST()with a type likeCHAR(2) BINARY, which resulted in incorrect results or even a server crash. (Bug#17903)For ODBC compatibility, MySQL supports use of
WHEREforcol_nameIS NULLDATEorDATETIMEcolumns that areNOT NULL, to allow column values of'0000-00-00'or'0000-00-00 00:00:00'to be selected. However, this was not working forWHEREclauses inDELETEstatements. (Bug#8143)The
--master-dataoption for mysqldump requires certain privileges, but mysqldump generated a truncated dump file without producing an appropriate error message or exit status if the invoking user did not have those privileges. (Bug#21215)ALTER VIEWdid not retain existing values of attributes that had been originally specified but were not changed in theALTER VIEWstatement. (Bug#21080)mysql crashed for very long arguments to the
connectcommand. (Bug#21042)perror crashed on Solaris due to
NULLreturn value ofstrerror()system call. (Bug#20145)The
querycommand for mysqltest did not work. (Bug#19890)For certain queries, the server incorrectly resolved a reference to an aggregate function and crashed. (Bug#20868)
When executing a
SELECTwithORDER BYon a view that is constructed from aSELECTstatement containing a stored function, the stored function was evaluated too many times. (Bug#19862)Subqueries on
INFORMATION_SCHEMAtables could erroneously return an empty result. (Bug#21231)On 64-bit Windows, a missing table generated error 1017, not the correct value of 1146. (Bug#21396)
The same trigger error message was produced under two conditions: The trigger duplicated an existing trigger name, or the trigger duplicated an existing combination of action and event. Now different messages are produced for the two conditions so as to be more informative. (Bug#10946)
Multiplication of
DECIMALvalues could produce incorrect fractional part and trailing garbage caused by signed overflow. (Bug#20569)A subquery that contained
LIMITcould return more than one row. (Bug#20519)N,1DESCRIBEreturned the typeBIGINTfor a column of a view if the column was specified by an expression over values of the typeINT. (Bug#19714)Multiple invocations of the
REVERSE()function could return different results. (Bug#18243)Using
> ALLwith subqueries that return no rows yielded incorrect results under certain circumstances due to incorrect application ofMIN()/MAX()optimization. (Bug#18503)Using
ANYwith “non-table” subqueries such asSELECT 1yielded incorrect results under certain circumstances due to incorrect application ofMIN()/MAX()optimization. (Bug#16302)When a row was inserted through a view but did not specify a value for a column that had no default value in the base table, no warning or error occurred. Now a warning occurs, or an error in strict SQL mode. (Bug#16110)
The use of
WHEREincol_nameIS NULLSELECTstatements reset the value ofLAST_INSERT_ID()to zero. (Bug#14553)The server crashed when using the range access method to execut a subquery with a
ORDER BY DESCclause. (Bug#20869)Use of the join cache in favor of an index for
ORDER BYoperations could cause incorrect result sorting. (Bug#17212)A user-defined function that is called on each row of a returned result set, could receive an
in_nullstate that is set, if it was set previously. Now, theis_nullstate is reset to false before each invocation of a UDF. (Bug#19904)Referring to a stored function qualified with the name of one database and tables in another database caused a “table doesn't exist” error. (Bug#18444)
For
NDBand possiblyInnoDBtables, aBEFORE UPDATEtrigger could insert incorrect values. (Bug#18437)Triggers on tables in the
mysqldatabase caused a server crash. Triggers for tables in this database now are disallowed. (Bug#18361)The length of the pattern string prefix for
LIKEoperations was calculated incorrectly for multi-byte character sets. As a result, the scanned range was wider than necessary if the prefix contained any multi-byte characters, and rows could be missing from the result set. (Bug#16674, Bug#18359)For very complex
SELECTstatements could create temporary tables that were too big, but for which the temporary files did not get removed, causing subsequent queries to fail. (Bug#11824)For spatial data types, the server formerly returned these as
VARSTRINGvalues with a binary collation. Now the server returns spatial values asBLOBvalues. (Bug#10166)Using
SELECTand a table join while running a concurrentINSERToperation would join incorrect rows. (Bug#14400)Using
SELECTon a corruptMyISAMtable using the dynamic record format could cause a server crash. (Bug#19835)Using tables from MySQL 4.x in MySQL 5.x, in particular those with
VARCHARfields and usingINSERT DELAYEDto update data in the table would result in either data corruption or a server crash. (Bug#16611, Bug#16218, Bug#17294)Checking a
MyISAMtable (usingCHECK TABLE) having a spatial index and only one row would wrongly indicate that the table was corrupted. (Bug#17877)SHOW GRANTS FOR CURRENT_USERdid not return definer grants when executed inDEFINERcontext (such as within a stored prodedure defined withSQL SECURITY DEFINER), it returned the invoker grants. (Bug#15298)For
SELECT ... FOR UPDATEstatements that usedDISTINCTorGROUP BYover all key parts of a unique index (or primary key), the optimizer unnecessarily created a temporary table, thus losing the linkage to the underlying unique index values. This caused aResult set not updatableerror. (The temporary table is unnecessary because under these circumstances the distinct or grouped columns must also be unique.) (Bug#16458)The first time a user who had been granted the
CREATE ROUTINEprivilege used that privilege to create a stored function or procedure, thePasswordcolumn in that user's row in themysql.usertable was set toNULL. (Bug#19857)Creation of a view as a join of views or tables could fail if the views or tables are in different databases. (Bug#20482)
Use of
MIN()orMAX()withGROUP BYon aucs2column could cause a server crash. (Bug#20076)INSERT INTO ... SELECT ... LIMIT 1could be slow because theLIMITwas ignored when selecting candidate rows. (Bug#9676)Certain queries having a
WHEREclause that included conditions on multi-part keys with more than 2 key parts could produce incorrect results and send [Note] Use_count: Wrong count for key at... messages toSTDERR. (Bug#16168)The
mysql_list_fields()C API function returned the incorrect table name for views. (Bug#19671)A cast problem caused incorrect results for prepared statements that returned float values when MySQL was compiled with gcc 4.0. (Bug#19694)
Updating a column of a
FEDERATEDtable toNULLsometimes failed. (Bug#16494)
This is a bugfix release for the current production release family. It replaces MySQL 5.0.24.
Changes from 5.0.24 to 5.0.24a:
MySQL 5.0.24 introduced an ABI incompatibility, which this release reverts. Programs compiled against 5.0.24 are not compatible with any other version and must be recompiled. (Bug#21543)
Closing of temporary tables failed if binary logging was not enabled. (Bug#20919)
For statements that have a
DEFINERclause such asCREATE TRIGGERorCREATE VIEW, long usernames or hostnames could cause a buffer overflow. (Bug#16899)Pathname separator and device characters were not correctly parameterized for NetWare, causing mysqld startup errors. (Bug#21537)
mysqld could crash when closing temporary tables. (Bug#21582)
In addition, the following problem affected the initial build of 5.0.24a, but has been corrected in the RPM files now available:
The shared compatibility RPM files were missing some files. (Bug#22251)
This is a bugfix release for the current production release family.
This section documents all changes and bug fixes that have been applied since the last official MySQL release. If you would like to receive more fine-grained and personalized update alerts about fixes that are relevant to the version and features you use, please consider subscribing to MySQL Enterprise (a commercial MySQL offering). For more details please see http://www.mysql.com/products/enterprise.
Functionality added or changed:
The
LEFT()andRIGHT()functions returnNULLif any argument isNULL. (Bug#11728)In the
INFORMATION_SCHEMA.ROUTINEStable theROUTINE_DEFINITIONcolumn now is defined asNULLrather thanNOT NULL. Also,NULLrather than the empty string is returned as the column value if the user does not have sufficient privileges to see the routine definition. (Bug#20230)
Bugs fixed:
Security fix: If a user has access to
MyISAMtablet, that user can create aMERGEtablemthat accessest. However, if the user's privileges ontare subsequently revoked, the user can continue to accesstby doing so throughm. If this behavior is undesirable, you can start the server with the new--skip-mergeoption to disable theMERGEstorage engine. (Bug#15195)Using the extended syntax for
TRIM()— that is,TRIM(... FROM ...)— in aSELECTstatement defining a view caused an invalid syntax error when selecting from the view. (Bug#17526)Assignments of values to variables of type
TEXTwere handled incorrectly in stored routines. (Bug#17225)NDB Cluster: The ndb_size.pl script did not account forTEXTandBLOBcolumn values correctly. (Bug#21204)NDB Cluster: The repeated creating and dropping of a table would eventually lead toNDBError 826, Too many tables and attributes ... Insufficient space. (Bug#20847)Issuing a
SHOW CREATE FUNCTIONorSHOW CREATE PROCEDUREstatement without sufficient privileges could crash the mysql client. (Bug#20664)In a view defined with
SQL SECURITY DEFINER, theCURRENT_USER()function returned the invoker, not the definer. (Bug#20570)DATE_ADD()andDATE_SUB()returnedNULLwhen the result date was on the day'9999-12-31'. (Bug#12356)For a
DATEparameter sent via aMYSQL_TIMEdata structure,mysql_stmt_execute()zeroed the hour, minute, and second members of the structure rather than treating them as read-only. (Bug#20152)The
DATA DIRECTORYtable option did not work forTEMPORARYtables. (Bug#8706)With the
auto_increment_incrementsystem variable set larger than 1, if the next generatedAUTO_INCREMENTvalue would be larger than the column's maximum value, the value would be clipped down to that maximum value and inserted, even if the resulting value would not be in the generated sequence. This could cause problems for master-master replication. Now the server clips the value down to the previous value in the sequence, which correctly produces a duplicate-key error if that value already exists in the column. (Bug#20524)If a table on a slave server had a higher
AUTO_INCREMENTcounter than the corresponding master table (even though all rows of the two tables were identical), in some casesREPLACEorINSERT ... ON DUPLICATE KEY UPDATEwould not replicate properly using statement-based logging. (Different values would be inserted on the master and slave.) (Bug#20188)Under heavy load (executing more than 1024 simultaneous complex queries), a problem in the code that handles internal temporary tables could lead to writing beyond allocated space and memory corruption. Use of more than 1024 simultaneous cursors server wide also could lead to memory corruption. (This applies both to stored procedure and C API cursors.) (Bug#21206)
A race condition during slave server shutdown caused an assert failure. (Bug#20850)
mysqldump produced a malformed dump file when dumping multiple databases that contained views. (Bug#20221)
SELECT @@INSERT_IDdisplayed a value unrelated to a precedingSET INSERT_ID. (It was returningLAST_INSERT_IDinstead.) (Bug#20392)Performing
INSERT ... SELECT ... JOIN ... USINGwithout qualifying the column names causedERROR 1052 "column 'x' in field list is ambiguous"even in cases where the column references were unambiguous. (Bug#18080)Bug#10952 may cause inadvertent data loss. A fix for this bug was included in MySQL 5.0.23, but the approach used caused a loss of intended functionality. Because of this, that fix has been reverted in MySQL 5.0.24. As a consequence, the risk of inadvertent data loss still exists (see Bug#10952).
A
SELECTthat used a subquery in theFROMclause that did not select from a table failed when the subquery was used in a join. (Bug#21002)REPLACE ... SELECTfor a view required theINSERTprivilege for tables other than the table being modified. (Bug#20989)The mysql client did not understand
helpcommands that had spaces at the end. (Bug#20328)Failure to account for a
NULLtable pointer on big-endian machines could cause a server crash during type conversion. (Bug#21135)mysqldump sometimes did not select the correct database before trying to dump views from it, resulting in an empty result set that caused mysqldump to die with a segmentation fault. (Bug#21014)
MySQL 5.0.23 was never officially released.
This section documents all changes and bug fixes that have been applied since the last official MySQL release. If you would like to receive more fine-grained and personalized update alerts about fixes that are relevant to the version and features you use, please consider subscribing to MySQL Enterprise (a commercial MySQL offering). For more details please see http://www.mysql.com/products/enterprise.
Functionality added or changed:
NDB Cluster: The limit of 2048 ordered indexes per cluster has been lifted. There is now no upper limit on the number of ordered indexes (includingAUTO_INCREMENTcolumns) that may be used. (Bug#14509)NDB Cluster: The status variablesNdb_connected_hostandNdb_connected_portwere renamed toNdb_config_from_hostandNdb_config_from_port, respectively.The mysql_upgrade command has been converted from a shell script to a C program, so it is available on non-Unix systems such as Windows. This program should be run for each MySQL upgrade. See Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.
Binary distributions that include SSL support now are built using yaSSL when possible.
Added the
--ssl-verify-server-certoption to MySQL client programs. This option causes the server's Common Name value in its certificate to be verified against the hostname used when connecting to the server, and the connection is rejected if there is a mismatch. AddedMYSQL_OPT_SSL_VERIFY_SERVER_CERToption for themysql_options()C API function to enable this verification. This feature can be used to prevent man-in-the-middle attacks. Verification is disabled by default. (Bug#17208)Added the
ssl_ca,ssl_capath,ssl_cert,ssl_cipher, andssl_keysystem variables, which display the values given via the corresponding command options. See Section 5.8.7.3, “SSL Command Options”. (Bug#19606)Added the
log_queries_not_using_indexessystem variable. (Bug#19616)Added the
--angel-pid-fileoption to mysqlmanager for specifying the file in which the angel process records its process ID when mysqlmanager runs in daemon mode. (Bug#14106)The
ONLY_FULL_GROUP_BYSQL mode now also applies to theHAVINGclause. That is, columns not named in theGROUP BYclause cannot be used in theHAVINGclause if not used in an aggregate function. (Bug#18739)SQL syntax for prepared statements now supports
ANALYZE TABLE,OPTIMIZE TABLE, andREPAIR TABLE. (Bug#19308)The bundled yaSSL library was upgraded to version 1.3.5. This improves handling of certain problems with SSL-related command options. (Bug#17737)
Added the
--set-charsetoption to mysqlbinlog to allow the character set to be specified for processing binary log files. (Bug#18351)For a table with an
AUTO_INCREMENTcolumn,SHOW CREATE TABLEnow shows the nextAUTO_INCREMENTvalue to be generated. (Bug#19025)It is now possible to use
NEW.values within triggers asvar_nameINOUTparameters to stored procedures. (Bug#14635)The mysqldumpslow script has been moved from client RPM packages to server RPM packages. This corrects a problem where mysqldumpslow could not be used with a client-only RPM install, because it depends on my_print_defaults which is in the server RPM. (Bug#20216)
The
mysql_get_ssl_cipher()C API function was added.
Bugs fixed:
An invalid
GRANTstatement for whichOkwas returned on a replication master caused an error on the slave and replication to fail. (Bug#6774)Use of the
--no-pageroption caused mysql to crash. (Bug#19363)mysqlcheck tried to check views instead of ignoring them. (Bug#16502)
Long multiple-row
INSERTstatements could take a very long time for some multi-byte character sets. (Bug#15811)Re-executing a stored procedure with a complex stored procedure cursor query could lead to a server crash. (Bug#15217)
Views created from prepared statements inside of stored procedures were created with a definition that included both
SQL_CACHEandSQL_NO_CACHE. (Bug#17203)mysqldump did not dump the table name correctly for some table identifiers that contained unusual characters such as ‘
:’. (Bug#19479)mysqldump would not dump views that had become invalid because a table named in the view definition had been dropped. Instead, it quit with an error message. Now you can specify the
--forceoption to cause mysqldump to keep going and write a SQL comment containing the view definition to the dump output. (Bug#17371)The
WITH CHECK OPTIONwas not enforced when aREPLACEstatement was executed against a view. (Bug#19789)The use of
MIN()andMAX()on columns with an index prefix produced incorrect results in some queries. (Bug#18206)Concatenating the results of multiple constant subselects produced incorrect results. (Bug#16716)
A Table ... doesn't exist error could occur for statements that called a function defined in another database. (Bug#17199)
A buffer overwrite error in Instance Manager caused a crash. (Bug#20622)
Re-execution of a prepared multiple-table
DELETEstatement that involves a trigger or stored function can result in a server crash. (Bug#19634)On Windows, corrected a crash stemming from differences in Visual C runtime library routines from POSIX behavior regarding invalid file descriptors. (Bug#18275)
Multiple-table updates with
FEDERATEDtables could cause a server crash. (Bug#19773)On Windows, terminating mysqld with Control-C could result in a crash during shutdown. (Bug#18235)
On Windows, removal of binary log files would fail if the files were already open. (Bug#19208)
mysqldump produced garbled output for view definitions. (Bug#18462)
The omission of leading zeros in dates could lead to erroneous results when these were compared with the output of certain date and time functions. (Bug#16377)
An invalid comparison between keys with index prefixes over multi-byte character fields could lead to incorrect result sets if the selected query execution plan used a range scan by an index prefix over a
UTF8character field. This also caused incorrect results under similar circumstances with many other character sets. (Bug#14896)NDB Cluster: Cluster system status variables were not updated. (Bug#11459)NDB Cluster: The cluster's data nodes would fail while trying to load data whenNoOfFrangmentLogFileswas equal to 1. (Bug#19894)NDB Cluster: A problem with error handling whenndb_use_exact_countwas enabled could lead to incorrect values returned from queries usingCOUNT(). A warning is now returned in such cases. (Bug#19202)NDB Cluster: Restoring a backup made using ndb_restore failed when the backup had been taken from a cluster whose data memory was full. (Bug#19852)NDB Cluster:TEXTcolumns in Cluster tables having both an explicit primary key and a unique key were not correctly updated byREPLACEstatements. (Bug#19906)NDB Cluster: An internal formatting error caused some management client error messages to be unreadable. (Bug#20016)NDB Cluster: Running management client commands while mgmd was in the process of disconnecting could cause the management server to fail. (Bug#19932)NDB Cluster(NDBAPI): Update operations on blobs were not checked for illegal operations.Note: Read locks with blob update operations are now upgraded from read committed to read shared.
NDB Cluster: The management clientALL STOPcommand shut down mgmd processes (as well as ndbd processes). (Bug#18966)NDB Cluster:LOAD DATA LOCALfailed to ignore duplicate keys in Cluster tables. (Bug#19496)NDB Cluster: RepeatedCREATE-INSERT-DROPoperations tables could in some circumstances cause the MySQL table definition cache to become corrupt, so that some mysqld processes could access table information but others could not. (Bug#18595)NDB Cluster: The mgm client commandALL CLUSTERLOG STATISTICS=15;had no effect. (Bug#20336)NDB Cluster:TRUNCATE TABLEfailed to reset theAUTO_INCREMENTcounter. (Bug#18864)NDB Cluster: The failure of a data node when preparing to commit a transaction (that is, while the node's status wasCS_PREPARE_TO_COMMIT) could cause the failure of other cluster data nodes. (Bug#20185)NDB Cluster: Renaming a table in such a way as to move it to a different database failed to move the table's indexes. (Bug#19967)NDB Cluster: Resources for unique indexes on Cluster table columns were incorrectly allocated, so that only one-fourth as many unique indexes as indicated by the value ofUniqueHashIndexescould be created. (Bug#19623)NDB Cluster: RunningALL STARTin theNDBmanagement client or restarting multiple nodes simultaneously could under some circumstances cause the cluster to crash. (Bug#19930)NDB Cluster(NDBAPI): On big-endian platforms,NdbOperation::write_attr()did not update 32-bit fields correctly. (Bug#19537)NDB Cluster: Some queries having aWHEREclause of the formc1=val1 OR c2 LIKE 'val2'were not evaluated correctly. (Bug # 17421)NDB Cluster: Using “stale” mysqld.FRMfiles could cause a newly-restored cluster to fail. This situation could arise when restarting a MySQL Cluster using the--intialoption while leaving connected mysqld processes running. (Bug#16875)NDB Cluster: Repeated use of theSHOWandALL STATUScommands in the ndb_mgm client could cause the mgmd process to crash. (Bug#18591)NDB Cluster: An issue with ndb_mgmd prevented more than 27mysqldprocesses from connecting to a single cluster at one time. (Bug#17150)NDB Cluster: Data node failures could cause excessive CPU usage by ndb_mgmd. (Bug#13987)NDB Cluster:TRUNCATEfailed on tables havingBLOBorTEXTcolumns with the error Lock wait timeout exceeded. (Bug#19201)NDB Cluster: Stopping multiple nodes could cause node failure handling not to be completed. (Bug#19039)NDB Cluster: ndbd could sometimes fail to start with the error Node failure handling not completed following a graceful restart. (Bug#18550)NDB Cluster: Backups could fail for large clusters with many tables, where the number of tables approachedMaxNoOfTables. (Bug#17607)On Windows, temporary tables containing ‘
:’ in the name could not be created. (Bug#20616)The
--core-file-sizeoption for mysqld_safe was effective only forroot. (Bug#17353)Some queries that used
ORDER BYandLIMITperformed quickly in MySQL 3.23, but slowly in MySQL 4.x/5.x due to an optimizer problem. (Bug#4981)mysql_upgrade was missing from binary MySQL distributions. (Bug#18516, Bug#20403)
Queries using an indexed column as the argument for the
MIN()andMAX()functions following anALTER TABLE .. DISABLE KEYSstatement returned Got error 124 from storage engine untilALTER TABLE ... ENABLE KEYSwas run on the table. (Bug#20357)A number of dependency issues in the RPM
benchandtestpackages caused installation of these packages to fail. (Bug#20078)Nested natural joins worked executed correctly when executed as a non-prepared statement could fail with an
Unknown column 'error when executed as a prepared statement, due to a name resolution problem. (Bug#15355)col_name' in 'field list'GROUP BYon an expression that contained a cast toDECIMALproduced an incorrect result. (Bug#19667)The
max_lengthmetadata value for columns created fromCONCAT()could be incorrect when the collation of an argument differed from the collation of theCONCAT()itself. In some contexts such asUNION, this could lead to truncation of the column contents. (Bug#15962)The MD5() and SHA() functions treat their arguments as case-sensitive strings. But when they are compared, their arguments were compared as case-insensitive strings, which leads to two function calls with different arguments (and thus different results) compared as being identical. This can lead to a wrong decision made in the range optimizer and thus to an incorrect result set. (Bug#15351)
For
BOOLEANmode full-text searches on non-indexed columns,NULLrows generated by aLEFT JOINcaused incorrect query results. (Bug#14708)BITcolumns in a table could cause joins that use the table to fail. (Bug#18895)A
UNIONover more than 128SELECTstatements that use an aggregate function failed. (Bug#18175)InnoDBunlocked its data directory before committing a transaction, potentially resulting in non-recoverable tables if a server crash occurred before the commit. (Bug#19727)Multiple-table
DELETEstatements containing a subquery that selected from one of the tables being modified caused a server crash. (Bug#19225)With settings of
read_buffer_size>= 2G andread_rnd_buffer_size>=2G,LOAD DATA INFILEfailed with no error message or caused a server crash for files larger than 2GB. (Bug#12982)REPLACEstatements caused activation ofUPDATEtriggers, notDELETEandINSERTtriggers. (Bug#13479)The thread for
INSERT DELAYEDrows was maintaining a separateAUTO_INCREMENTcounter, resulting in incorrect values being assigned ifDELAYEDand non-DELAYEDinserts were mixed. (Bug#20195)mysqldump wrote an extra pair of
DROP DATABASEandCREATE DATABASEstatements if run with the--add-drop-databaseoption and the database contained views. (Bug#17201)On 64-bit Windows systems,
REGEXPfor regular expressions with exactly 31 characters did not work. (Bug#19407)For mysqld, Valgrind revealed problems that were corrected: A dangling stack pointer being overwritten (Bug#20769); possible uninitialized data in a string comparison (Bug#20783); memory corruption in replication slaves when switching databases (Bug#19022); syscall write parameter pointing to uninitialized byte (Bug#20579).
For ndb_mgmd, Valgrind revealed problems that were corrected: A memory leak (Bug#19318); a dependency on an uninitialized variable (Bug#20333).
An update that used a join of a table to itself and modified the table on both sides of the join reported the table as crashed. (Bug#18036)
SSL connections using yaSSL on OpenBSD could fail. (Bug#19191)
On Windows, multiple clients simultaneously attempting to perform
ALTER TABLEoperations on anInnoDBtable could deadlock. (Bug#17264)The
fill_help_tables.sqlfile did not load properly if theANSI_QUOTESSQL mode was enabled. (Bug#20542)The
fill_help_tables.sqlfile did not contain aSET NAMES 'utf8'statement to indicate its encoding. This caused problems for some settings of the MySQL character set such asbig5. (Bug#20551)The MySQL server startup script /etc/init.d/mysql (created from mysql.server) is now marked to ensure that the system services ypbind, nscd, ldap, and NTP are started first (if these are configured on the machine). (Bug#18810)
MERGEtables did not work reliably withBITcolumns. (Bug#19648)For a reference to a non-existent index in
FORCE INDEX, the error message referred to a column, not an index. (Bug#17873)Some yaSSL public function names conflicted with those from OpenSSL, causing conflicts for applications that linked against both OpenSSL and a version of
libmysqlclientthat was built with yaSSL support. The yaSSL public functions now are renamed to avoid this conflict. (Bug#19575)CHECK TABLEon aMyISAMtable briefly cleared itsAUTO_INCREMENTvalue, while holding only a read lock. Concurrent inserts to that table could use the wrongAUTO_INCREMENTvalue.CHECK TABLEno longer modifies theAUTO_INCREMENTvalue. (Bug#19604)If there is a global read lock,
CREATE DATABASE,RENAME DATABASE, andDROP DATABASEcould deadlock. (Bug#19815)On Linux,
libmysqlclientwhen compiled with yaSSL using the icc compiler had a spurious dependency on C++ libraries. (Bug#20119)Using
CONCAT(@, whereuser_var,col_name)col_nameis a column in anINFORMATION_SCHEMAtable, could cause erroneous duplication of data in the query result. (Bug#19599)Results from
INFORMATION_SCHEMA.SCHEMATAcould contain uppercase information whenlower_case_table_nameswas not 0. (Bug#17661)Grant table modifications sometimes did not refresh the in-memory tables if the hostname was
''or not specified. (Bug#16297)Invalid escape sequences in option files caused MySQL programs that read them to abort. (Bug#15328)
InnoDB did not increment the
handler_read_prevcounter. (Bug#19542)Race conditions on certain platforms could cause the Instance Manager to fail to initialize. (Bug#19391)
ALTER TABLEon a table created prior to 5.0.3 would cause table corruption if theALTER TABLEdid one of the following:Change the default value of a column.
Change the table comment.
Change the table password.
An
ALTER TABLEoperation that does not need to copy data, when executed on a table created prior to MySQL 4.0.25, could result in a server crash for subsequent accesses to the table. (Bug#19192)The binary log lacked character set information for table name when dropping temporary tables. (Bug#14157)
A
B-TREEindex on aMEMORYtable erroneously reported duplicate entry error for multipleNULLvalues. (Bug#12873)Race conditions on certain platforms could cause the Instance Manager to try to restart the same instance multiple times. (Bug#18023)
A
CREATE TABLEstatement that created a table from a materialized view did not inherit default values from the underlying table. (Bug#19089)The
COM_STATISTICScommand was changed in 5.0.3 to display session status variable values rather than global values. This causes mysqladmin status information not to be useful for theSlow queriesandOpensvalues. NowCOM_STATISTICSdisplays the global values forSlow queriesandOpens. (Bug#18669)INFORMATION_SCHEMA.TABLESprovided inconsistent info about invalid views. This could cause server crashes or result in incorrect data being returned for queries that attempt to obtain information fromINFORMATION_SCHEMAtables about views using stored functions. (Bug#18282)Multiple calls to a stored procedure that selects from
INFORMATION_SCHEMAcould cause a server crash. (Bug#17204)Premature optimization of nested subqueries in the
FROMclause that refer to aggregate functions could lead to incorrect results. (Bug#19077)A view definition that referred to an alias in the
HAVINGclause could be saved in the.frmfile with the alias replaced by the expression that it referred to, causing failure of subsequentSELECT * FROMstatements. (Bug#19573)view_nameSeveral aspects of view privileges were being checked incorrectly. (Bug#18681, Bug#20363)
A view with a non-existent account in the
DEFINERclause causedSHOW CREATE VIEWto fail. NowSHOW CREATE VIEWissues a warning instead. (Bug#14875)A compatibility issue with NPTL (Native POSIX Thread Library) on Linux could result in a deadlock with
FLUSH TABLES WITH READ LOCKunder some conditions. (Bug#20048)MyISAMtable deadlock was possible if one thread issued aLOCK TABLESrequest for write locks and then an administrative statement such asOPTIMIZE TABLE, if between the two statements another client meanwhile issued a multiple-tableSELECTfor some of the locked tables. (Bug#16986)Subqueries that produced a
BIGINT UNSIGNEDvalue were being treated as returning a signed value. (Bug#19700)The patch for Bug#17164 introduced the problem that some outer joins were incorrectly converted to inner joins. (Bug#19816)
BLOBorTEXTarguments to or values returned from stored functions were not copied properly if too long and could become garbled. (Bug#18587)Selecting data from a
MEMORYtable with aVARCHARcolumn and aHASHindex over it returned only the first row matched. (Bug#18233)CREATE TABLE ... SELECTdid not always produce the proper column default value inTRADITIONALSQL mode. (Bug#17626)Privilege checking on the contents of the
INFORMATION_SCHEMA.VIEWStable was insufficiently restrictive. (Bug#16681)The result from
CONV()is a string, but was not always treated the same way as a string when converted to a real value for an arithmetic operation. (Bug#13975)CREATE TABLE ... SELECT ...statements that used a stored function explicitly or implicitly (through a view) resulted in aTable not lockederror. (Bug#12472, Bug#15137)Within a trigger,
SETused the SQL mode of the invoking statement, not the mode in effect at trigger creation time. (Bug#6951)The server no longer uses a signal handler for signal 0 because it could cause a crash on some platforms. (Bug#15869)
Revised memory allocation for local objects within stored functions and triggers to avoid memory leak for repeated function or trigger invocation. (Bug#17260)
EXPLAIN ... SELECT INTOcaused the client to hang. (Bug#15463)Symlinking
.mysql_historyto/dev/nullto suppress statement history saving by mysql did not work. (mysql deleted the symlink and recreated.mysql_historyas a regular file, and then wrote history to it.) (Bug#16803)The
basedirandtmpdirsystem variables could not be accessed via@@syntax. (Bug#1039)var_nameFor certain
CREATE VIEWstatements, the server did not detect invalid subqueries within theSELECTpart. (Bug#7549)The range operator failed and caused a server crash for clauses of the form
tbl_name.unsigned_keypartNOT IN (negative_const, ...)Returning the value of a system variable from a stored function caused a server crash. (Bug#18037)
Updates to a
MEMORYtable caused the size ofBTREEindexes for the table to increase. (Bug#18160)REPAIR TABLEdid not restore the length for packed keys in tables created under MySQL 4.x, which caused them to appear corrupt toCHECK TABLEbut not toREPAIR TABLE. (Bug#17810)Selecting from a view that used
GROUP BYon a non-constant temporal interval (such asDATE(could cause a server crash. (Bug#19490)col) + INTERVAL TIME_TO_SEC(col) SECONDAn outer join of two views that was written using
{ OJ ... }syntax could cause a server crash. (Bug#19396)LOAD_FILE()returned an error if the file did not exist, rather thanNULLas it should according to the manual. (Bug#10418)For certain
CREATE TABLE ... SELECTstatements, the selected values were truncated when inserted into the new table. (Bug#17048)Use of uninitialized user variables in a subquery in the
FROMclause results in bad entries in the binary log. (Bug#19136)In the
INFORMATION_SCHEMA.COLUMNStable, the values for theCHARACTER_MAXIMUM_LENGTHandCHARACTER_OCTET_LENGTHcolumns were incorrect for multi-byte character sets. (Bug#19236)An entry in the
mysql.proctable with an empty routine name caused access to theINFORMATION_SCHEMA.ROUTINEStable to crash the server. (Bug#18177)A range access optimizer heuristic was invalid, causing some queries to be much slower in MySQL 5.0 than in 4.0. (Bug#17379, Bug#18940)
IS_USED_LOCK()could return an incorrect connection identifier. (Bug#16501)mysql displayed
NULLfor strings that are empty or contain only spaces. (Bug#19564)Concurrent reading and writing of privilege structures could crash the server. (Bug#16372)
A
NULbyte within a comment in a statement string caused the rest of the string not to be written to the query log, allowing logging to be bypassed. (CVE-2006-0903, Bug#17667)mysql-test-run.pl started
NDBeven for test cases that didn't need it. (Bug#19083)SELECT DISTINCTqueries sometimes returned only the last row. (Bug#18068)Use of
CONVERT_TZ()in a stored function or trigger (or in a stored procedure called from a stored function or trigger) caused an error. (Bug#11081)Some queries were slower in 5.0 than in 4.1 because some 4.1 cost-evaluation code had not been merged into 5.0. (Bug#14292)
Index prefixes for
utf8VARCHARcolumns did not work forUPDATEstatements. (Bug#19080)InnoDBdoes not supportSPATIALindexes, but did not prevent creation of such an index. (Bug#15860)The configuration information for building the embedded server on Windows was missing a file. (Bug#18455)
The parser leaked memory when its stack needed to be extended. (Bug#18930)
When myisamchk needed to rebuild a table,
AUTO_INCREMENTinformation was lost. (Bug#10405)LOAD DATA FROM MASTERwould fail when trying to load theINFORMATION_SCHEMAdatabase from the master, because theINFORMATION_SCHEMAsystem database would already exist on the slave. (Bug#18607)The binary log would create an incorrect
DROPquery when creating temporary tables during replication. (Bug#17263)The
IN-to-EXISTStransformation was making a reference to a parse tree fragment that was left out of the parse tree. This caused problems with prepared statements. (Bug#18492)In mysqltest,
--sleep=0had no effect. Now it correctly causessleepcommands in test case files to sleep for 0 seconds. (Bug#18312)Attempting to set the default value of an
ENUMorSETcolumn toNULLcaused a server crash. (Bug#19145)The
sql_notesandsql_warningssystem variables were not always displayed correctly bySHOW VARIABLES(for example, they were displayed asONafter being set toOFF). (Bug#16195)The
sql_big_selectssystem variable was not displayed bySHOW VARIABLES. (Bug#17849)The
system_time_zoneandversion_*system variables could not be accessed viaSELECT @@syntax. (Bug#12792, Bug#15684)var_nameFlushing the compression buffer (via
FLUSH TABLE) no longer increases the size of an unmodifiedARCHIVEtable. (Bug#19204)RPM packages had spurious dependencies on Perl modules and other programs. (Bug#13634)
SHOW CREATE TABLEdid not display theAUTO_INCREMENTcolumn attribute if the SQL mode wasMYSQL323orMYSQL40. This also affected mysqldump, which usesSHOW CREATE TABLEto get table definitions. (Bug#14515)
This is a security fix release for the previous production release family.
This section documents all changes and bug fixes that have been applied since the last official MySQL release. If you would like to receive more fine-grained and personalized update alerts about fixes that are relevant to the version and features you use, please consider subscribing to MySQL Enterprise (a commercial MySQL offering). For more details please see http://www.mysql.com/products/enterprise.
Bugs fixed:
Security fix: An SQL-injection security hole has been found in multi-byte encoding processing. The bug was in the server, incorrectly parsing the string escaped with the
mysql_real_escape_string()C API function. (CVE-2006-2753, Bug#8378)This vulnerability was discovered and reported by Josh Berkus
<josh@postgresql.org>and Tom Lane<tgl@sss.pgh.pa.us>as part of the inter-project security collaboration of the OSDB consortium. For more information about SQL injection, please see the following text.Discussion: An SQL-injection security hole has been found in multi-byte encoding processing. An SQL-injection security hole can include a situation whereby when a user supplied data to be inserted into a database, the user might inject SQL statements into the data that the server will execute. With regards to this vulnerability, when character set unaware-escaping is used (for example,
addslashes()in PHP), it is possible to bypass the escaping in some multi-byte character sets (for example, SJIS, BIG5 and GBK). As a result, a function such asaddslashes()is not able to prevent SQL-injection attacks. It is impossible to fix this on the server side. The best solution is for applications to use character set-aware escaping offered by a function suchmysql_real_escape_string().However, a bug was detected in how the MySQL server parses the output of
mysql_real_escape_string(). As a result, even when the character set-aware functionmysql_real_escape_string()was used, SQL injection was possible. This bug has been fixed.Workarounds: If you are unable to upgrade MySQL to a version that includes the fix for the bug in
mysql_real_escape_string()parsing, but run MySQL 5.0.1 or higher, you can use theNO_BACKSLASH_ESCAPESSQL mode as a workaround. (This mode was introduced in MySQL 5.0.1.)NO_BACKSLASH_ESCAPESenables an SQL standard compatibility mode, where backslash is not considered a special character. The result will be that queries will fail.To set this mode for the current connection, enter the following SQL statement:
SET sql_mode='NO_BACKSLASH_ESCAPES';
You can also set the mode globally for all clients:
SET GLOBAL sql_mode='NO_BACKSLASH_ESCAPES';
This SQL mode also can be enabled automatically when the server starts by using the command-line option
--sql-mode=NO_BACKSLASH_ESCAPESor by settingsql-mode=NO_BACKSLASH_ESCAPESin the server option file (for example,my.cnformy.ini, depending on your system).The dropping of a temporary table whose name contained a backtick ('
`') character was not correctly written to the binary log, which also caused it not to be replicated correctly. (Bug#19188)The patch for Bug#8303 broke the fix for Bug#8378 and was undone. (In string literals with an escape character (
\) followed by a multi-byte character that has a second byte of (\), the literal was not interpreted correctly. The next byte now is escaped, not the entire multi-byte character. This means it a strict reverse of themysql_real_escape_string()function.)The client libraries had not been compiled for position-indpendent code on Solaris-SPARC and AMD x86_64 platforms. (Bug#13159, Bug#14202, Bug#18091)
Running myisampack followed by myisamchk with the
--unpackoption would corrupt theauto_incrementkey. (Bug#12633)
This is a bugfix release for the current production release family.
This MySQL 5.0.21 release includes the patches for recently
reported security vulnerabilites in the MySQL client-server
protocol. We would like to thank Stefano Di Paola
<stefano.dipaola@wisec.it> for finding and reporting
these to us.
This section documents all changes and bug fixes that have been applied since the last official MySQL release. If you would like to receive more fine-grained and personalized update alerts about fixes that are relevant to the version and features you use, please consider subscribing to MySQL Enterprise (a commercial MySQL offering). For more details please see http://www.mysql.com/products/enterprise.
Functionality added or changed:
Security enhancement: Added the global
max_prepared_stmt_countsystem variable to limit the total number of prepared statements in the server. This limits the potential for denial-of-service attacks based on running the server out of memory by preparing huge numbers of statements. The current number of prepared statements is available through theprepared_stmt_countsystem variable. (Bug#16365)The
MySQL-shared-compat-5.0.shared compatibility RPMs no longer contain libraries for MySQL 5.1. This avoids a conflict because the 5.0 and 5.1 libraries share the same soname number. It contains libraries for 3.23, 4.0, 4.1, and 5.0. (Bug#19288)X-.i386.rpmCreating a table in an InnoDB database with a column name that matched the name of an internal InnoDB column (including
DB_ROW_ID,DB_TRX_ID,DB_ROLL_PTRandDB_MIX_ID) would cause a crash. MySQL now returns error 1005 (cannot create table) witherrnoset to -1. (Bug#18934)NDB Cluster: It is now possible to perform a partial start of a cluster. That is, it is now possible to bring up the cluster without running ndbd --initial on all configured data nodes first. (Bug#18606)NDB Cluster: A new--nowait-nodesstartup option for ndbd makes it possible to “skip” specific nodes without waiting for them to start when starting the cluster. See Section 15.6.5.2, “Command Options for ndbd”.NDB Cluster: It is now possible to install MySQL with Cluster support to a non-default location and change the search path for font description files using either the--basediror--character-sets-diroptions. (Previously in MySQL 5.0, ndbd searched only the default path for character sets.)In result set metadata, the
MYSQL_FIELD.lengthvalue forBITcolumns now is reported in number of bits. For example, the value for aBIT(9)column is 9. (Formerly, the value was related to number of bytes.) (Bug#13601)The default for the
innodb_thread_concurrencysystem variable was changed to8. (Bug#15868)
Bugs fixed:
Security fix: A malicious client, using specially crafted invalid login or
COM_TABLE_DUMPpackets was able to read uninitialized memory, which potentially, though unlikely in MySQL, could have led to an information disclosure. (CVE-2006-1516, CVE-2006-1517) Thanks to Stefano Di Paola<stefano.dipaola@wisec.it>for finding and reporting this bug.Security fix: A malicious client, using specially crafted invalid
COM_TABLE_DUMPpackets was able to trigger an exploitable buffer overflow on the server. (CVE-2006-1518) Thanks to Stefano Di Paola<stefano.dipaola@wisec.it>for finding and reporting this bug.Security fix: Invalid arguments to
DATE_FORMAT()caused a server crash. (CVE-2006-3469, Bug#20729) Thanks to Jean-David Maillefer for discovering and reporting this problem to the Debian project and to Christian Hammers from the Debian Team for notifying us of it.NDB Cluster: A simultaneousDROP TABLEand table update operation utilising a table scan could trigger a node failure. (Bug#18597)mysql-test-run could not be run as
root. (Bug#17002)MySQL-shared-compat-5.0.13-0.i386.rpm,MySQL-shared-compat-5.0.15-0.i386.rpm,MySQL-shared-compat-5.0.18-0.i386.rpm,MySQL-shared-compat-5.0.19-0.i386.rpm,MySQL-shared-compat-5.0.20-0.i386.rpm, andMySQL-shared-compat-5.0.20a-0.i386.rpmincorrectly depended onglibc2.3 and could not be installed on aglibc2.2 system. (Bug#16539)IA-64 RPM packages for Red Hat and SuSE Linux that were built with the icc compiler incorrectly depended on icc runtime libraries. (Bug#16662)
After calling
FLUSH STATUS, themax_used_connectionsvariable did not increment for existing connections and connections which use the thread cache. (Bug#15933)MySQL would not compile on Linux distributions that use the tinfo library. (Bug#18912)
Within a trigger,
CONNECTION_ID()did not return the connection ID of the thread that caused the trigger to be activated. (Bug#16461)The yaSSL library returned a cipher list in a manner incompatible with OpenSSL. (Bug#18399)
For single-
SELECTunion constructs of the form (SELECT ... ORDER BYorder_list1[LIMITn]) ORDER BYorder_list2, theORDER BYlists were concatenated and theLIMITclause was ignored. (Bug#18767)CREATE VIEWstatements would not be replicated to the slave if the--replicate-wild-ignore-tablerule was enabled. (Bug#18715)Index corruption could occur in cases when
key_cache_block_sizewas not a multiple ofmyisam_block_size(for example, withkey_cache_block_size=1536andmyisam_block_size=1024). (Bug#19079)LAST_INSERT_ID()in a stored function or trigger returned zero. . (Bug#15728)Use of
CONVERT_TZ()in a view definition could result in spurious syntax or access errors. (Bug#15153)UNCOMPRESS(NULL)could cause subsequentUNCOMPRESS()calls to returnNULLfor legal non-NULLarguments. (Bug#18643)Conversion of a number to a
CHAR UNICODEstring returned an invalid result. (Bug#18691)DELETEandUPDATEstatements that used largeNOT IN (clauses could use large amounts of memory. (Bug#15872)value_list)Prevent recursive views caused by using
RENAME TABLEon a view after creating it. (Bug#14308)A
LOCK TABLESstatement that failed could causeMyISAMnot to update table statistics properly, causing a subsequentCHECK TABLEto report table corruption. (Bug#18544)For a reference to a non-existent stored function in a stored routine that had a
CONTINUEhandler, the server continued as though a useful result had been returned, possibly resulting in a server crash. (Bug#18787)InnoDBdid not use a consistent read forCREATE ... SELECTwheninnodb_locks_unsafe_for_binlogwas set. (Bug#18350)InnoDBcould read a delete mark from its system tables incorrectly. (Bug#19217)Corrected a syntax error in mysql-test-run.sh. (Bug#19190)
A missing
DBUG_RETURN()caused the server to emit a spurious error message:missing DBUG_RETURN or DBUG_VOID_RETURN macro in function "open_table". (Bug#18964)DROP DATABASEdid not drop stored routines associated with the database if the database name was longer than 21 characters. (Bug#18344)Avoid trying to include
<asm/atomic.h>when it doesn't work in C++ code. (Bug#13621)Executing
SELECTon a large table that had been compressed within myisampack could cause a crash. (Bug#17917)NDB Cluster: When attempting to create an index on aBITorBLOBcolumn, Error 743: Unsupported character set in table or index was returned instead of Error 906: Unsupported attribute type in index.Within stored routines, usernames were parsed incorrectly if they were enclosed within quotes. (Bug#13310)
Casting a string to
DECIMALworked, but casting a trimmed string (usingLTRIM()orRTRIM()) resulted in loss of decimal digits. (Bug#17043)NDB Cluster: On slow networks or CPUs, the management clientSHOWcommand could sometimes erroneously show all data nodes as being master nodes belonging to nodegroup 0. (Bug#15530)If the second or third argument to
BETWEENwas a constant expression such as'2005-09-01 - INTERVAL 6 MONTHand the other two arguments were columns,BETWEENwas evaluated incorrectly. (Bug#18618)If the first argument to
BETWEENwas aDATEorTIMEcolumn of a view and the other arguments were constants,BETWEENdid not perform conversion of the constants to the appropriate temporary type, resulting in incorrect evaluation. (Bug#16069)Server and clients ignored the
--sysconfdiroption that was passed to configure. (Bug#15069)NDB Cluster: In a 2-node cluster with a node failure, restarting the node with a low value forStartPartialTimeoutcould cause the cluster to come up partitioned (“split-brain” issue). (Bug#16447)A similar issue could occur when the cluster was first started with a sufficiently low value for this parameter. (Bug#18612)
NDB Cluster: On systems with multiple network interfaces, data nodes would get “stuck” in startup phase 2 if the interface connecting them to the management server was working on node startup while the interface interconnecting the data nodes experienced a temporary outage. (Bug#15695)NDB Cluster: Unused open handlers for tables in which the metadata had changed were not properly closed. This could result in stale results from Cluster tables following anALTER TABLE. (Bug#13228)NDB Cluster: Uninitialized internal variables could lead to unexpected results. (Bug#11033, Bug#11034)For
InnoDBtables, an expression of the formcol_nameBETWEENcol_name2- INTERVALxDAY ANDcol_name2+ INTERVALxDAYINSERT DELAYEDinto a view caused an infinite loop. (Bug#13683)Lettercase in database name qualifiers was not consistently handled properly in queries when
lower_case_table_nameswas set to 1. (Bug#15917)The optimizer could cause a server crash or use a non-optimal subset of indexes when evaluating whether to use
Index Merge/Intersectionvariant ofindex_mergeoptimization. (Bug#19021)The presence of multiple equalities in a condition after reading a constant table could cause the optimizer not to use an index. This resulted in certain queries being much slower than in MySQL 4.1. (Bug#16504)
A recent change caused the mysql client not to display
NULLvalues correctly and to display numeric columns left-justified rather than right-justified. The problems have been corrected. (Bug#18265)mysql_reconnect()sent aSET NAMESstatement to the server, even for pre-4.1 servers that do not understand the statement. (Bug#18830)COUNT(*)on aMyISAMtable could return different results for the base table and a view on the base table. (Bug#18237)DELETEwithLEFT JOINforInnoDBtables could crash the server ifinnodb_locks_unsafe_for_binlogwas enabled. (Bug#15650)InnoDBfailure to release an adaptive hash index latch could cause a server crash if the query cache was enabled. (Bug#15758)For mysql.server, if the
basediroption was specified afterdatadirin an option file, the setting fordatadirwas ignored and assumed to be located underbasedir. (Bug#16240)The euro sign (
€) was not stored correctly in columns using thelatin1_german1_ciorlatin1_general_cicollation. (Bug#18321)EXTRACT(QUARTER FROMreturned unexpected results. (Bug#18100)date)TRUNCATEdid not reset theAUTO_INCREMENTcounter forMyISAMtables when issued inside a stored procedure. (Bug#14945)Note: This bug did not affect
InnoDBtables. Also,TRUNCATEdoes not reset theAUTO_INCREMENTcounter forNDBClustertables regardless of when it is called (see Bug#18864).The server was always built as though
--with-extra-charsets=complexhad been specified. (Bug#12076)A query using WHERE (
column_1,column_2) IN ((value_1,value_2)[, (..., ...), ...]) would return incorrect results. (Bug#16248)Queries of the form
SELECT DISTINCTdid not return all matching rows. (Bug#16710)timestamp_columnWHEREdate_function(timestamp_col) =constantWhen running a query that contained a
GROUP_CONCAT( SELECT GROUP_CONCAT(...) ), the result wasNULLexcept in theROLLUPpart of the result, if there was one. (Bug#15560)For tables created in a MySQL 4.1 installation upgraded to MySQL 5.0 and up, multiple-table updates could update only the first matching row. (Bug#16281)
NDB Cluster: When multiple node restarts were attempted without allowing each restart to complete, the error message returned was Array index out of bounds rather than Too many crashed replicas. (Bug#18349)CAST(for largedoubleAS SIGNED INT)doublevalues outside the signed integer range truncates the result to be within range, but the result sometimes had the wrong sign, and no warning was generated. (Bug#15098)Updating a field value when also requesting a lock with
GET_LOCK()would cause slave servers in a replication environment to terminate. (Bug#17284)
This is a bugfix release for the current production release family. It replaces MySQL 5.0.20.
Changes from 5.0.20 to 5.0.20a:
The fix for “Command line options are ignored for mysql client” (Bug#16855) has been revoked because it introduced an incompatible change in the way the mysql command-line client selects the server to connect to. In the worst case, this might have led to a client issuing commands to a server for which they were not intended, and this must not happen. To help all users in understanding this subject, Section 4.2, “Invoking MySQL Programs” now includes additional explanation of how command options with regard to host selection.
The code of the
yaSSLlibrary has been improved to avoid the dependency on a C++ runtime library, so a link with pure C applications is now possible on additional (but not yet all) platforms. We are working on fixing the remaining issues.
Additional information about SSL support:
With version 5.0.20a, SSL support is contained in all binaries for all Unix (including Linux) and Windows platforms except AIX, HP-UX, OpenServer 6, and the RPMs specific for RHAS3/RHAS4/SLES9 on Itanium CPUs (
ia64); It is also not contained in those for Novell Netware. We are trying to add these platforms in future versions.Please note that the original 5.0.20 announcement included inexact wording: SSL support is “included” in both server and client, but by default not “enabled”. SSL can be enabled by passing the SSL-related options (
--ssl,--ssl-key=...,--ssl-cert=...,--ssl-ca=...) when starting the server and the client or by specifying these options in an option file. For more information, see Section 5.8.7, “Using Secure Connections”.
Functionality added or changed:
Added the
--sysdate-is-nowoption to mysqld to enableSYSDATE()to be treated as an alias forNOW(). See Section 12.6, “Date and Time Functions”. (Bug#15101)InnoDB: TheInnoDBstorage engine now provides a descriptive error message ifibdatafile information is omitted frommy.cnf. (Bug#16827)The
NDBClusterstorage engine now supportsINSERT IGNOREandREPLACEstatements. Previously, these statements failed with an error. (Bug#17431)Builds for Windows, Linux, and Unix (except AIX) platforms now have SSL support enabled, in the server as well as in the client libraries. Because part of the SSL code is written in C++, this does introduce dependencies on the system's C++ runtime libraries in several cases, depending on compiler specifics. (Bug#18195)
The syntax for
CREATE PROCEDUREandCREATE FUNCTIONstatements now includes aDEFINERclause. TheDEFINERvalue specifies the security context to be used when checking access privileges at routine invocation time if the routine has theSQL SECURITY DEFINERcharacteristic. See Section 17.2.1, “CREATE PROCEDUREandCREATE FUNCTIONSyntax”, for more information.When mysqldump is invoked with the
--routinesoption, it now dumps theDEFINERvalue for stored routines.Large file support added to build for
QNXplatform. (Bug#17336)Large file support was re-enabled for the MySQL server binary for the AIX 5.2 platform. (Bug#13571)
Bugs fixed:
If the
WHEREcondition of a query contained anOR-edFALSEterm, the set of tables whose rows cannot serve for null-complements in outer joins was determined incorrectly. This resulted in blocking possible conversions of outer joins into joins by the optimizer for such queries. (Bug#17164)mysql_config returned incorrect libraries on
x86_64systems. (Bug#13158)Stored routine names longer than 64 characters were silently truncated. Now the limit is properly enforced and an error occurs. (Bug#17015)
During conversion from one character set to
ucs2, multi-byte characters with noucs2equivalent were converted to multiple characters, rather than to0x003F QUESTION MARK. (Bug#15375)The
mysql_close()C API function leaked handles for shared-memory connections on Windows. (Bug#15846)Checks for permissions on database operations could be performed in a case-insensitive manner (a user with permissions on database
MYDATABASEcould by accident get permissions on databasemyDataBase), if the privilege data were still cached from a previous check. (Bug#17279)If
InnoDBran out of buffer space for row locks and adaptive hashes, the server would crash. NowInnoDBrolls back the transaction. (Bug#18238)InnoDBtables with an adaptive hash blocked other queries duringCHECK TABLEstatements while the entire hash was checked. This could be a long time for a large hash. (Bug#17126)For
InnoDBtables created in MySQL 4.1 or earlier, or created in 5.0 or later with compact format, updating a row so that a long column is updated or the length of some column changes,InnoDBlater would fail to reclaim theBLOBstorage space if the row was deleted. (Bug#18252)InnoDBhad a memory leak for duplicate-key errors with tables having 90 columns or more. (Bug#18384)InnoDB: TheLATEST FOREIGN KEY ERRORsection in the output ofSHOW INNODB STATUSwas sometimes formatted incorrectly, causing problems with scripts that parsed the output of this statement. (Bug#16814)When using
ORDER BYwith a non-string column insideGROUP_CONCAT()the result's character set was converted to binary. (Bug#18281)See also Bug#14169.
SELECT ... WHERE, whencolumnLIKE 'A%'columnhad a key and used thelatin2_czech_cscollation, caused the wrong number of rows to be returned. (Bug#17374)Complex queries with nested joins could cause a server crash. (Bug#18279)
The server could deadlock under heavy load while writing to the binary log. (Bug#18116)
A
SELECT ... ORDER BY ...from a view defined using a function could crash the server. An example of such a view might beCREATE VIEW AS SELECT SQRT(c1) FROM t1. (Bug#18386)A
DELETEusing a subquery could crash the server. (Bug#18306)REPAIR TABLE,OPTIMIZE TABLE, andALTER TABLEoperations on transactional tables (or on tables of any type on Windows) could corrupt triggers associated with those tables. (Bug#18153)MyISAM: Performing a bulk insert on a table referenced by a trigger would crash the table. (Bug#17764)MyISAM: Keys for which the first part of the key was aCHARorVARCHARcolumn using the UTF-8 character set and longer than 254 bytes could become corrupted. (Bug#17705)Using
ORDER BYwithin a stored procedure (whereintvarintvaris an integer variable or expression) would crash the server. (Bug#16474)Note: The use of an integer
iin anORDER BYclause for sorting the result by theiith column is deprecated (and non-standard). It should not be used in new applications. See Section 13.2.7, “SELECTSyntax”.Triggers created in MySQL 5.0.16 and earlier could not be dropped after upgrading the server to 5.0.17 or later. (Bug#15921)
A
SELECTusing a function against a nested view would crash the server. (Bug#15683)NDB Cluster: Certain queries usingORDER BY ... ASCin theWHEREclause could return incorrect results. (Bug#17729)NDB Cluster: A timeout in the handling of anABORTcondition with more that 32 operations could yield a node failure. (Bug#18414)NDB Cluster: A node restart immediately following aCREATE TABLEwould fail. Important: This fix supports 2-node Clusters only. (Bug#18385)NDB Cluster: In event of a node failure during a rollback, a “false” lock could be established on the backup for that node, which lock could not be removed without restarting the node. (Bug#18352)NDB Cluster: The cluster created a crashed replica of a table having an ordered index — or when logging was not enabled, of a table having a table or unique index — leading to a crash of the cluster following 8 successibe restarts. (Bug#18298)NDB Cluster: When replacing a failed master node, the replacement node could cause the cluster to crash from a buffer overflow if it had an excessively large amount of data to write to the cluster log. (Bug#18118)NDB Cluster: If a mysql or other client could not parse the result set returned from a mysqld process acting as an SQL node in a cluster, the client would crash instead of returning the appropriate error. For example, this could happen when the client attempted to use a character set was not available to the mysqld. (Bug#17380)NDB Cluster: Restarting nodes were allowed to start and join the cluster too early. (Bug#16772)If a row was inserted inside a stored procedure using the parameters passed to the procedure in the INSERT statement, the resulting binlog entry was not escaped properly. (Bug#18293)
If InnoDB encountered a
HA_ERR_LOCK_TABLE_FULLerror and rolled-back a transaction, the transaction was still written to the binary log. (Bug#18283)Stored procedures that call UDFs and pass local string variables caused server crashes. (Bug#17261)
Connecting to a server with a UCS2 default character set with a client using a non-UCS2 character set crashed the server. (Bug#18004)
Loading of UDFs in a statically linked MySQL caused a server crash. UDF loading is now blocked if the MySQL server is statically linked. (Bug#11835)
Views that incorporated tables from the
INFORMATION_SCHEMAdatabase resulted in a server crash when queried. (Bug#18224)A
SELECT *query on anINFORMATION_SCHEMAtable by a user with limited privileges resulted in a server crash. (Bug#18113)Attempting to access an
InnoDBtable after starting the server with--skip-innodbcaused a server crash. (Bug#14575)Replication slaves could not replicate triggers from older servers that included no
DEFINERclause in the trigger definition. Now the trigger executes with the privileges of the invoker (which on the slave is the slave SQL thread). (Bug#16266)Character set conversion of string constants for
UNIONof constant and table column was not done when it was safe to do so. (Bug#15949)The
DEFINERvalue for stored routines was not replicated. (Bug#15963)Use of stored functions with
DISTINCTorGROUP BYcan produce incorrect results whenORDER BYis also used. (Bug#13575)Use of
TRUNCATE TABLEfor aTEMPORARYtable on a master server was propagated to slaves properly, but slaves did not decrement theSlave_open_temp_tablescounter properly. (Bug#17137)SELECT COUNT(*)for aMyISAMtable could return different results depending on whether an index was used. (Bug#14980)A
LEFT JOINwith aUNIONthat selects literal values could crash the server. (Bug#17366)Large file support did not work in AIX server binaries. (Bug#10776)
Updating a view that filters certain rows to set a filtered out row to be included in the table caused infinite loop. For example, if the view has a WHERE clause of
salary > 100then issuing an UPDATE statement ofSET salary = 200 WHERE id = 10, caused an infinite loop. (Bug#17726)Certain combinations of joins with mixed
ONandUSINGclauses caused unknown column errors. (Bug#15229)NDB Cluster: Inserting and deletingBLOBcolumn values while a backup was in process could cause the loss of an ndbd node. (Bug#14028)If the server was started with the
--skip-grant-tablesoption, it was impossible to create a trigger or a view without explicitly specifying aDEFINERclause. (Bug#16777)COUNT(DISTINCTandcol1,col2)COUNT(DISTINCT CONCAT(operations produced different results if one of the columns was an indexedcol1,col2))DECIMALcolumn. (Bug#15745)The server displayed garbage in the error message warning about bad assignments to
DECIMALcolumns or routine variables. (Bug#15480)The server would execute stored routines that had a non-existent definer. (Bug#13198)
For
FEDERATEDtables, aSELECTstatement with anORDER BYclause did not return rows in the proper order. (Bug#17377)The
FORMAT()function returned an incorrect result when the client'scharacter_set_connectionvalue wasutf8. (Bug#16678)NDB Cluster: Some query cache statistics were not always correctly reported for Cluster tables. (Bug#16795)Updating the value of a Unicode
VARCHARcolumn with the result returned by a stored function would cause the insertion of ASCII characters into the column instead of Unicode, even where the function's return type was also declared as Unicode. (Bug#17615)
Functionality added or changed:
Incompatible change: The
InnoDBstorage engine no longer ignores trailing spaces when comparingBINARYorVARBINARYcolumn values. This means that (for example) the binary values'a'and'a 'are now regarded as unequal any time they are compared, as they are inMyISAMtables. (Bug#14189)See Section 11.4.2, “The
BINARYandVARBINARYTypes” for more information about theBINARYandVARBINARYtypes.Several changes were made to make upgrades easier:
Added the mysql_upgrade program that checks all tables for incompatibilities with the current version of MySQL Server and repairs them if necessary. This program should be run for each MySQL upgrade (rather than mysql_fix_privilege_tables). See Section 5.5.8, “mysql_upgrade — Check Tables for MySQL Upgrade”.
Added the
FOR UPGRADEoption for theCHECK TABLEstatement. This option checks whether tables are incompatible with the current version of MySQL Server.Added the
--check-upgradeto mysqlcheck that invokesCHECK TABLEwith theFOR UPGRADEoption.
NDB Cluster: The ndb_mgm client commandsnode_idSTARTnode_idSTOPALLfor thenode_idcontinues to affect all data nodes only.)When using the
GROUP_CONCAT()function where thegroup_concat_max_lensystem variable was greater than 512, the type of the result wasBLOBonly if the query included anORDER BYclause; otherwise the result was aVARCHAR.The result type of the
GROUP_CONCAT()function is nowVARCHARonly if the value of thegroup_concat_max_lensystem variable is less than or equal to 512. Otherwise, this function returns aBLOB. (Bug#14169)mysql no longer terminates data value display when it encounters a NUL byte. Instead, it displays NUL bytes as spaces. (Bug#16859)
Added the
--wait-timeoutoption to mysqlmanager to allow configuration of the timeout for dropping an inactive connection, and increased the default timeout from 30 seconds to 28,800 seconds (8 hours). (Bug#12674, Bug#15980)A number of performance issues were resolved that had previously been encountered when using statements that repeatedly invoked stored functions. For example, calling
BENCHMARK()using a stored function executed much more slowly than when invoking it with inline code that accomplished the same task. In most cases the two should now execute with approximately the same speed. (Bug#15014, Bug#14946)libmysqlclientnow uses versioned symbols with GNU ld. (Bug#3074)NDB Cluster: More descriptive warnings are now issued when inappropriate logging parameters are set inconfig.ini. (Formerly, the warning issued was simply Could not add logfile destination.) (Bug#11331)Added the
--port-open-timeoutoption to mysqld to control how many seconds the server should wait for the TCP/IP port to become free if it cannot be opened. (Bug#15591)Repeated invocation of
my_init()andmy_end()caused corruption of character set data and connection failure. (Bug#6536)Two new Hungarian collations are included:
utf8_hungarian_cianducs2_hungarian_ci. These support the correct sort order for Hungarian vowels. However, they do not support the correct order for sorting Hungarian consonant contractions; this issue will be fixed in a future release.Wording of error 1329 changed to No data - zero rows fetched, selected, or processed. (Bug#15206)
The
INFORMATION_SCHEMAnow skips data contained in unlistable/unreadable directories rather than returning an error. (Bug#15851)InnoDB now caches a list of unflushed files instead of scanning for unflushed files during a table flush operation. This improves performance when
--innodb-file-per-tableis set on a system with a large number of InnoDB tables. (Bug#15653)The message for error 1109 changed from Unknown table ... in order clause to Unknown table ... in field list. (Bug#15091)
The
mysqltestutility now converts allCR/LFcombinations toLFto allow test cases intended for Windows to work properly on UNIX-like systems. (Bug#13809)The
mysql_pingfunction will now retry if thereconnectflag is set and errorCR_SERVER_LOSTis encountered during the first attempt to ping the server. (Bug#14057)mysqldumpnow surrounds theDEFINER,SQL SECURITY DEFINERandWITH CHECK OPTIONclauses of aCREATE VIEWstatement with "not in version" comments to prevent errors in earlier versions of MySQL. (Bug#14871)New
charsetcommand added to mysql command-line client. By typingcharsetorname\C(such asname\C UTF8), the client character set can be changed without reconnecting. (Bug#16217)Client API will now attempt reconnect on TCP/IP if the
reconnectflag is set, as is the case with sockets. (Bug#2845)
Bugs fixed:
Generating an
AUTO_INCREMENTvalue through aFEDERATEDtable did not set the value returned byLAST_INSERT_ID(). (Bug#14768)Cursors in stored routines could cause a server crash. (Bug#16887)
Setting the
myisam_repair_threadssystem variable to a value larger than 1 could cause corruption of largeMyISAMtables. (Bug#11527)The length of a
VARCHAR()column that used theutf8character set would increase each time the table was re-created in a stored procedure or prepared statement, eventually causing theCREATE TABLEstatement to fail. (Bug#13134)type_decimalfailed with the prepared statement protocol. (Bug#17826)The MySQL server could crash with out of memory errors when performing aggregate functions on a
DECIMALcolumn. (Bug#17602)A stored procedure failed to return data the first time it was called per connection. (Bug#17476)
Using
DROP FUNCTION IF EXISTSto drop a user-defined function caused a server crash if the server was running with thefunc_name--skip-grant-tablesoption. (Bug#17595)Using
ALTER TABLEto increase the length of aBINARY(column caused column values to be padded with spaces rather thanM)0x00bytes. (Bug#16857)A large
BIGINTvalue specified in aWHEREclause could be treated differently depending on whether it is specified as a quoted string. (For example,WHERE bigint_col = 17666000000000000000versusWHERE bigint_col = '17666000000000000000'). (Bug#9088)A natural join between
INFORMATION_SCHEMAtables failed. (Bug#17523)A memory leak caused warnings on slaves for certain statements that executed without warning on the master. (Bug#16175)
The embedded server did not allow binding of columns to the
MYSQL_TYPE_VAR_STRINGdata type in prepared statements. (Bug#12070)The embedded server failed various tests in the automated test suite. (Bug#9630, Bug#9631, Bug#9633, Bug#10801, Bug#10911, Bug#10924, Bug#10925, Bug#10926, Bug#10930, Bug#15433)
Instance Manager erroneously accepted a list of instance identifiers for the
START INSTANCEandSTOP INSTANCEcommands (should accept only a single identifier). (Bug#12813)For a transaction that used
MyISAMandInnoDBtables, interruption of the transaction due to a dropped connection on a master server caused slaves to lose synchrony. (Bug#16559)SELECTwithGROUP BYon a view can cause a server crash. (Bug#16382)If the query optimizer transformed a
GROUP BYclause in a subquery, it did not also transform theHAVINGclause if there was one, producing incorrect results. (Bug#16603)SUBSTRING_INDEX()could yield inconsistent results when applied with the same arguments to consecutive rows in a query. (Bug#14676)The parser allowed
CREATE AGGREGATE FUNCTIONfor creating stored functions, even thoughAGGREGATEdoes not apply. (It is used only forCREATE FUNCTIONonly when creating user-defined functions.) (Bug#16896)Data truncations on non-UNIQUE indexes could crash InnoDB when using multi-byte character sets. (Bug#17530)
Triggers created without
BEGINandENDclauses resulted in “You have an error in your SQL syntax” errors when dumping and replaying a binary log. (Bug#16878)The
RENAME TABLEstatement did not move triggers to the new table. (Bug#13525)Clients compiled from source with the
--without-readlinedid not save command history from session to session. (Bug#16557)Stored routines that contained only a single statement were not written properly to the dumpfile when using
mysqldump. (Bug#14857)For certain
MERGEtables, the optimizer wrongly assumed that usingindex_merge/intersectionwas too expensive. (Bug#17314)Executing a
SHOW CREATE VIEWquery of an invalid view caused themysql_next_resultfunction oflibMySQL.dllto hang. (Bug#15943)BITfields were not properly handled when using row-based replication. (Bug#13418)Issuing
GRANT EXECUTEon a procedure would display any warnings related to the creation of the procedure. (Bug#7787)NDB Cluster: ndb_delete_all would run out of memory on tables containingBLOBcolumns. (Bug#16693)NDB Cluster:UNIQUEkeys in Cluster tables were limited to 225 bytes in length. (Bug#15918)In a highly concurrent environment, a server crash or deadlock could result from execution of a statement that used stored functions or activated triggers coincident with alteration of the tables used by these functions or triggers. (Bug#16593)
Previously, a stored function invocation was written to the binary log as
DOif the invocation changes data and occurs within a non-logged statement, or if the function invokes a stored procedure that produces an error. These invocations now are logged asfunc_name()SELECTinstead for better control over error code checking (slave servers could stop due to detecting a different error than occurred on the master). (Bug#14769)func_name()CHECKSUM TABLEreturned different values on MyISAM table depending on whether theQUICKorEXTENDEDoptions were used. (Bug#8841)MySQL server dropped client connection for certain SELECT statements against views defined that used
MERGEalgorithm. (Bug#16260)A call to the
IF()function using decimal arguments could return incorrect results. (Bug#16272)A statement containing
GROUP BYandHAVINGclauses could return incorrect results when theHAVINGclause contained logic that returnedFALSEfor every row. (Bug#14927)Using
GROUP BYon column used inWHEREclause could cause empty set to be returned. (Bug#16203)For a MySQL 5.0 server, using MySQL 4.1 tables in queries with a
GROUP BYclause could result in buffer overrun or a server crash. (Bug#16752)SET sql_mode =, whereNN> 31, did not work properly. (Bug#13897)NDB Cluster: Cluster log file paths were truncated to 128 characters. They may now be as long asMAX_PATH(the maximum path length permitted by the operating system). (Bug#17411)The
mysql_stmt_store_result()C API function could not be used for a prepared statement if a cursor had been opened for the statement. (Bug#14013)The
mysql_stmt_sqlstate()C API function incorrectly returned an empty string rather than'00000'when no error occurred. (Bug#16143)Using the
TRUNCATE()function with a negative number for the second argument on aBIGINTcolumn returned incorrect results. (Bug#8461)Instance Manager searched wrong location for password file on some platforms. (Bug#16499)
NDB Cluster: Following multiple forced shutdowns and restarts of data nodes,DROP DATABASEcould fail. (Bug#17325)NDB Cluster: AnUPDATEwith an inner join failed to match any records if both tables in the join did not have a primary key. (Bug#17257)NDB Cluster: ADELETEwith a join in theWHEREclause failed to retrieve any records if both tables in the join did not have a primary key. (Bug#17249)The error message returned by
perrorwas prefixed with OS error code: instead of NDB error code:. (Bug#17235)--ndbNDB Cluster: In some cases,LOAD DATA INFILEdid not load all data intoNDBtables. (Bug#17081)NDB Cluster: TheREDOlog would become corrupted (and thus unreadable) in some circumstances, due to a failure in the query handler. (Bug#17295)NDB Cluster: No error message was generated for settingNoOfFragmentLogFilestoo low. (Bug#13966)NDB Cluster: No error message was generated for settingMaxNoOfAttributestoo low. (Bug#13965)Binary distributions for Solaris contained files with group ownership set to the non-existing
wheelgroup. Now thebingroup is used. (Bug#15562)The
DECIMALdata type was not being handled correctly with prepared statements. (Bug#16511)The
SELECTprivilege was required for triggers that performed no selects. (Bug#15196)The
UPDATEprivilege was required for triggers that performed no updates. (Bug#15166)CAST(... AS TIME)operations returned different results when using versus not using prepared-statement protocol. (Bug#15805)Improper memory handling for stored routine variables could cause memory overruns and binary log corruption. (Bug#15588)
Killing a long-running query containing a subquery could cause a server crash. (Bug#14851)
A
FULLTEXTquery in a prepared statement could result in unexpected behavior. (Bug#14496)A
RETURNstatement within a trigger caused a server crash.RETURNnow is disallowed within triggers. To exit immediately, useLEAVE. (Bug#16829)STR_TO_DATE(1,NULL)caused a server crash. (CVE-2006-3081, Bug#15828)An invalid stored routine could not be dropped. (Bug#16303)
When evaluation of the test in a
CASEfailed in a stored procedure that contained aCONTINUEhandler, execution resumed at the beginning of the CASE statement instead of at the end. (Bug#16568)An
INSERTstatement in a stored procedure corrupted the binary log. (Bug#16621)When MyODBC or any other client called
my_init()/my_end()several times, it caused corruption of charset data stored inonce_mem_pool. (Bug#11892)When multiple handlers are created for the same MySQL error number within nested blocks, the outermost handler took precedence. (Bug#15011)
Certain
LEAVEstatements in stored procedures were not properly optimized. (Bug#15737)Setting InnoDB path settings to an empty string caused InnoDB storage engine to crash upon server startup. (Bug#16157)
InnoDB used full explicit table locks in trigger processing. (Bug#16229)
Server crash when dropping InnoDB constraints named
TABLENAME_ibfk_0Corrected race condition when dropping the adaptive hash index for a B-tree page in InnoDB. (Bug#16582)
The
mysql_real_connect()C API function incorrectly reset theMYSQL_OPT_RECONNECToption to its default value. (Bug#15719)InnoDB: After upgrading anInnoDBtable having aVARCHAR BINARYcolumn created in MySQL 4.0 to MySQL 5.0, update operations on the table would cause the server to crash. (Bug#16298)Trying to compile the server on Windows generated a stack overflow warning due to a recursive definition of the internal
Field_date::store()method. (Bug#15634)The use of
LOAD INDEXwithin a stored routine was permitted and caused the server to crash. Note:LOAD INDEXstatements within stored routines are not supported, and now yield an error if attempted. This behavior is intended. (Bug#14270)The mysqlbinlog utility did not output
DELIMITERstatements, causing syntax errors for stored routine creation statements. (Bug#11312)NDB Cluster returned incorrect
Can't find fileerror for OS error 24, changed toToo many open files. (Bug#15020)Performing a
RENAME TABLEon an InnoDB table when the server is started with the--innodb-file-per-tableoption and the data directory is a symlink caused a server crash. (Bug#15991)Multi-byte path names for
LOAD DATAandSELECT ... INTO OUTFILEcaused errors. Added thecharacter_set_filesystemsystem variable, which controls the interpretation of string literals that refer to filenames. (Bug#12448)Certain subqueries where the inner query is the result of a aggregate function would return different results on MySQL 5.0 than on MySQL 4.1. (Bug#15347)
Attempts to create FULLTEXT indexes on VARCHAR columns larger than 1000 bytes resulted in error. (Bug#13835)
Characters in the
gb2312andeuckrcharacter sets which did not have Unicode mappings were truncated. (Bug#15377)Certain nested LEFT JOIN operations were not properly optimized. (Bug#16393)
GRANTstatements specifying schema names that included underscore characters (i.e.my_schema) did not match if the underscore was escaped in theGRANTstatement (i.e.GRANT ALL ON `my\_schema` ...). (Bug#14834)Running out of diskspace in the location specified by the
tmpdiroption resulted in incorrect error message. (Bug#14634)Test suite
sptest left behind tables when the test failed that could cause future tests to fail. (Bug#15866)UPDATEstatement crashed multi-byte character setFULLTEXTindex if update value was almost identical to initial value only differing in some spaces being changed to . (Bug#16489)A
SELECTquery which contained aGROUP_CONCAT()and anORDER BYclause against theINFORMATION_SCHEMAresulted in an empty result set. (Bug#15307)The
--replicate-doand--replicate-ignoreoptions were not being enforced on multiple-table statements. (Bug#15699, Bug#16487)A prepared statement created from a
SELECT ... LIKEquery (such asPREPARE stmt1 FROM 'SELECT col_1 FROM tedd_test WHERE col_1 LIKE ?';) would begin to produce erratic results after being executed repeatedly numerous (thousands) of times. (Bug#12734)The server would crash when the size of an
ARCHIVEtable grew beyond 2GB. (Bug#15787)Created a user function with an empty string (that is,
CREATE FUNCTION ''()), was accepted by the server. Following this, callingSHOW FUNCTION STATUSwould cause the server to crash. (Bug#15658)In some cases the query optimizer did not properly perform multiple joins where inner joins followed left joins, resulting in corrupted result sets. (Bug#15633)
The absence of a table in the left part of a left or right join was not checked prior to name resolution, which resulted in a server crash. (Bug#15538)
NDBCluster: A bitfield whose offset and length totaled 32 would crash the cluster. (Bug#16125)NDBCluster: Upon the completion of a scan where a key request remained outstanding on the primary replica and a starting node died, the scan did not terminate. This caused incompleted error handling of the failed node. (Bug#15908)NDBCluster: Thendb_autodiscovertest failed sporadically due to a node not being permitted to connect to the cluster. (Bug#15619)NDBCluster: When running more than one management process in a cluster:ndb_mgm -c
host:port-e "node_idstop" would stop a management process running only on the same system on which the command was issued.ndb_mgm -e "shutdown" failed to shut down any management processes at all.
The contents of
fill_help_tables.sqlcould not be loaded in strict SQL mode. (Bug#15760)fill_help_tables.sqlwas not included in binary distributions for several platforms. (Bug#15759)An
INSERT ... SELECTstatement between tables in aMERGEset can return errors when statement involves insert into child table from merge table or vice-versa. (Bug#5390)Certain permission management statements could create a
NULLhostname for a user, resulting in a server crash. (Bug#15598)A
COMMITstatement followed by aALTER TABLEstatement on a BDB table caused server crash. (Bug#14212)A
DELETEstatement involving aLEFT JOINand anIS NULLtest on the right-hand table of the join crashed the server when theinnodb_locks_unsafe_for_binlogoption was enabled. (Bug#15650)Performing an
ORDER BYon an indexedENUMcolumn returned error. (Bug#15308)The
NOT FOUNDcondition handler for stored procedures did not distinguish between aNOT FOUNDcondition and an exception or warning. (Bug#15231)A stored procedure with an undefined variable and an exception handler would hang the client when called. (Bug#14498)
Subselect could return wrong results when records cache and grouping was involved. (Bug#15347)
Temporary table aliasing did not work inside stored functions. (Bug#12198)
MIN()andMAX()operations were not optimized for views. (Bug#16016)Using an aggregate function as the argument for a HAVING clause would result in the aggregate function always returning
FALSE. (Bug#14274)Parallel builds occasionally failed on Solaris. (Bug#16282)
The
FORCE INDEXkeyword in a query would prevent an index merge from being used where an index merge would normally be chosen by the optimizer. (Bug#16166)The
COALESCE()function truncated data in aTINYTEXTcolumn. (Bug#15581)InnoDB: Comparison of indexedVARCHAR CHARACTER SET ucs2 COLLATE ucs2_bincolumns usingLIKEcould fail. (Bug#14583)An attempt to open a table that requires a disabled storage engine could cause a server crash. (Bug#15185)
Issuing a
DROP USERcommand could cause some users to encounter ahostnameis not allowed to connect to this MySQL serverSetting
innodb_log_file_sizeto a value greater than 4G crashed the server. (Bug#15108)A
SELECTof a stored function that references theINFORMATION_SCHEMAcould crash the server. (Bug#15533)Tarball install package was missing a proper
fill_help_tables.sqlfile. (Bug#15151)
Functionality added or changed:
It is now possible to build the server such that
MyISAMtables can support up to 128 keys rather than the standard 64. This can be done by configuring the build using the option--with-max-indexes=, whereNN≤128 is the maximum number of indexes to permit per table. (Bug#10932)The server treats stored routine parameters and local variables (and stored function return values) according to standard SQL. Previously, parameters, variables, and return values were treated as items in expressions and were subject to automatic (silent) conversion and truncation. Now the data type is observed. Data type conversion and overflow problems that occur in assignments result in warnings, or errors in strict mode. The
CHARACTER SETclause for character data type declarations is used. Parameters, variables, and return values must be scalars; it is no longer possible to assign a row value. Also, stored functions execute using thesql_modevalue in force at function creation time rather than ignoring it. For more information, see Section 17.2.1, “CREATE PROCEDUREandCREATE FUNCTIONSyntax”. (Bug#8702, Bug#8768, Bug#8769, Bug#9078, Bug#9572, Bug#12903, Bug#13705, Bug#13808, Bug#13909, Bug#14161, Bug#15148)
Bugs fixed:
API functionmysql_stmt_preparereturned wrong field length for TEXT columns. (Bug#15613)The output of mysqldump --triggers did not contain the
DEFINERclause in dumped trigger definitions. (Bug#15110)The output of
SHOW TRIGGERScontained extraneous whitespace. (Bug#15103)Creating a trigger caused a server crash if the table or trigger database was not known because no default database had been selected. (Bug#14863)
SHOW [FULL] COLUMNSandSHOW INDEX FROMdid not function with temporary tables. (Bug#14271, Bug#14387, Bug#15224)The INFORMATION_SCHEMA.COLUMNS table did not report the size of BINARY or VARBINARY columns. (Bug#14271)
The server would not compile under Cygwin. (Bug#13640)
DESCRIBEdid not function with temporary tables. (Bug#12770)Reversing the order of operands in a
WHEREclause testing a simple equality (such asWHERE t1.col1 = t2.col2) would produce different output fromEXPLAIN. (Bug#15106)Column aliases were displayed incorrectly in a
SELECTfrom a view following an update to a base table of the view. (Bug#14861)Set functions could not be aggregated in outer subqueries. (Bug#12762)
When a connection using yaSSL was aborted, the server would continue to try to read the closed socket, and the thread continued to appear in the output of
SHOW PROCESSLIST. Note that this issue did not affect secure connection attempts using OpenSSL. (Bug#15772)InnoDB: Having two tables in a parent-child relationship enforced by a foreign key where one table usedROW_FORMAT=COMPACTand the other usedROW_FORMAT=REDUNDANTcould result in a MySQL server crash. Note that this problem did not exist prior to MySQL 5.0.3, when the compact row format forInnoDBwas introduced. (Bug#15550)BDB: ADELETE,INSERT, orUPDATEof aBDBtable could cause the server to crash where the query contained a subquery using an index read. (Bug#15536)A left join on a column that having a
NULLvalue could cause the server to crash. (Bug#15268)A replication slave server could sometimes crash on a
BEFORE UPDATEtrigger if theUPDATEquery was not executed in the same database as the table with the trigger. (Bug#14614)A race condition when creating temporary files caused a deadlock on Windows with threads in
Opening tablesorWaiting for tablestates. (Bug#12071)InnoDB: IfFOREIGN_KEY_CHECKSwas 0,InnoDBallowed inconsistent foreign keys to be created. (Bug#13778)NDB Cluster: Under some circumstances, it was possible for a restarting node to undergo a forced shutdown. (Bug#15632)NDB Cluster: If an abort by the Transaction Coordinator timed out, the abort condition was incorrectly handled, causing the transaction record to be released prematurely. (Bug#15685)NDB Cluster: Thendb_read_multi_range.testscript failed to drop a table, causing the test to fail. (Bug#15675) (See also Bug#15401.)NDB Cluster: A node which failed during cluster startup was sometimes not removed from the internal list of active nodes. (Bug#15587)Resolution of the argument to the
VALUES()function to a variable inside a stored routine caused a server crash. The argument must be a table column. (Bug#15441)
Functionality added or changed:
The original Linux RPM packages (5.0.17-0) had an issue with a
zlibdependency that would result in an error during an install or upgrade. They were replaced by new binaries, 5.0.17-1. (Bug#15223) Here is a list of the new RPM binaries:MySQL-{Max,client,devel,server,shared,ndb*}-5.0.17-1.i386.rpm
MySQL-*-standard-5.0.17-1.rhel3.i386.rpm, MySQL-*-standard-5.0.17-1.rhel3.ia64.rpm, MySQL-*-standard-5.0.17-1.rhel3.x86_64.rpm
MySQL-*-pro-5.0.17-1.rhel3.i386.rpm, MySQL-*-pro-5.0.17-1.rhel3.ia64.rpm, MySQL-*-pro-5.0.17-1.rhel3.x86_64.rpm
MySQL-*-pro-gpl-5.0.17-1.rhel3.i386.rpm, MySQL-*-pro-gpl-5.0.17-1.rhel3.ia64.rpm, MySQL-*-pro-gpl-5.0.17-1.rhel3.x86_64.rpm
The syntax for
CREATE TRIGGERnow includes aDEFINERclause for specifying which access privileges to check at trigger invocation time. See Section 18.1, “CREATE TRIGGERSyntax”, for more information.Known issue: If you attempt to replicate from a master server older than MySQL 5.0.17 to a slave running MySQL 5.0.17 through 5.0.19, replication of
CREATE TRIGGERstatements fails on the slave with aDefiner not fully qualifiederror. A workaround is to create triggers on the master using a version-specific comment embedded in eachCREATE TRIGGERstatement:CREATE /*!50017 DEFINER = 'root'@'localhost' */ TRIGGER ... ;
CREATE TRIGGERstatements written this way will replicate to newer slaves, which pick up theDEFINERclause from the comment and execute successfully. (Bug#16266)Added a
DEFINERcolumn to theINFORMATION_SCHEMA.TRIGGERStable.Invoking a stored function or trigger creates a new savepoint level. When the function or trigger finishes, the previous savepoint level is restored. (See Bug#13825 for more information.)
Recursion is allowed in stored procedures. Recursive stored functions and triggers still are disallowed. (Bug#10100)
In the
latin5_turkish_cicollation, the order of the charactersA WITH CIRCUMFLEX,I WITH CIRCUMLEX, andU WITH CIRCUMFLEXwas changed. If you have used these characters in any indexed columns, you should rebuild those indexes. (Bug#13421)Support files for compiling with Visual Studio 6 have been removed. (Bug#15094)
Added the
SHOW FUNCTION CODEandSHOW PROCEDURE CODEstatements (available only for servers that have been built with debugging support). See Section 13.5.4.19, “SHOW PROCEDURE CODEandSHOW FUNCTION CODESyntax”.
Bugs fixed:
RPM packages had an incorrect
zlibdependency. (Bug#15223)NDB Cluster:REPLACEfailed when attempting to update a primary key value in a Cluster table. (Bug#14007)make failed when attempting to build MySQL in different directory than source. (Bug#11827)
Corrected an error-handling problem within stored routines on 64-bit platforms. (Bug#15630)
Slave SQL thread cleanup was not handled properly on Mac OS X when a statement was killed, resulting in a slave crash. (Bug#15623, Bug#15668)
Symbolic links did not function properly on Windows platforms. (Bug#14960, Bug#14310)
mysqld would not start on Windows 9X operating systems including Windows Me. (Bug#15209)
InnoDB: During replication, There was a failure to record events in the binary log that still occurred even in the event of aROLLBACK. For example, this sequence of commands:BEGIN; CREATE TEMPORARY TABLE t1 (a INT) ENGINE=INNODB; ROLLBACK; INSERT INTO t1 VALUES (1);
would succeed on the replication master as expected. However, the
INSERTwould fail on the slave because theROLLBACKwould (erroneously) cause theCREATE TEMPORARY TABLEstatement not to be written to the binlog. (Bug#7947)A bug in
mysql-test/t/mysqltest.testcaused that test to fail. (Bug#15605)The
CREATEtest case in mysql-test-run.pl failed on AIX and SCO. (Bug#15607)NDB Cluster: Creating a table with packed keys failed silently.NDBnow supports thePACK_KEYSoption toCREATE TABLEcorrectly. (Bug#14514)NDB Cluster: UsingORDER BYwhen selecting from a table having the primary key on aprimary_key_columnVARCHARcolumn caused a forced shutdown of the cluster. (Bug#14828, Bug#15240, Bug#15682, Bug#15517)NDB Cluster: Under certain circumstances, when mysqld connects to a cluster management server, the connection would fail before a node ID could be allocated. (Bug#15215)NDB Cluster: There was a small window for a node failure to occur during a backup without an error being reported. (Bug#15425)mysql --help was missing a newline after the version string when the bundled
readlinelibrary was not used. (Bug#15097)Implicit versus explicit conversion of float to integer (such as inserting a float value into an integer column versus using
CAST(... AS UNSIGNEDbefore inserting the value) could produce different results. Implicit and explicit typecasts now are done the same way, with a value equal to the nearest integer according to the prevailing rounding mode. (Bug#12956)GROUP BYon a view column did not correctly account for the possibility that the column could containNULLvalues. (Bug#14850)ANALYZE TABLEdid not properly update table statistics for aMyISAMtable with aFULLTEXTindex containing stopwords, so a subsequentANALYZE TABLEwould not recognize the table as having already been analyzed. (Bug#14902)The maximum value of
MAX_ROWSwas handled incorrectly on 64-bit systems. (Bug#14155)NDB Cluster: A forced cluster shutdown occurred when the management daemon was restarted with a changedconfig.inifile that added an API/SQL node. (Bug#15512)Multiple-table update operations were counting updates and not updated rows. As a result, if a row had several updates it was counted several times for the “rows matched” value but updated only once. (Bug#15028)
A statement that produced a warning, when fetched via
mysql_stmt_fetch(), did not produce a warning count according tomysql_warning_count(). (Bug#15510)Manual manipulation of the
mysql.proctable could cause a server crash. This should not happen, but it is also not supported that the server will notice such changes. (Bug#14233)Revised table locking to allow proper assessment of view security. (Bug#11555)
Within a stored procedure, inserting with
INSERT ... SELECTinto a table with anAUTO_INCREMENTcolumn did not generate the correct sequence number. (Bug#14304)SELECTqueries that began with an opening parenthesis were not being placed in the query cache. (Bug#14652)Space truncation was being ignored when inserting into
BINARYorVARBINARYcolumns. Now space truncation results in a warning, or an error in strict mode. (Bug#14299)The database-changing code for stored routine handling caused an error-handling problem resulting in a server crash. (Bug#15392)
Selecting from a view processed with the temptable algorithm caused a server crash if the query cache was enabled. (Bug#15119)
REPAIR TABLES,BACKUP TABLES,RESTORE TABLESwithin a stored procedure caused a server crash. (Bug#13012)Creating a view that referenced a stored function that selected from a view caused a crash upon selection from the view. (Bug#15096)
ALTER TABLE ... SET DEFAULThad no effect. (Bug#14693)Creating a view within a stored procedure could result in an out of memory error or a server crash. (Bug#14885)
InnoDB: A race condition allowed two threads to drop a hash index simultaneously. (Bug#14747)mysqlhotcopy tried to copy
INFORMATION_SCHEMAtables. (Bug#14610)CHAR(... USING ...)andCONVERT(CHAR(...) USING ...), though logically equivalent, could produce different results. (Bug#14146)The value of
INFORMATION_SCHEMA.TABLES.TABLE_TYPEsometimes was reported as empty. (Bug#14476)InnoDB: Activity on anInnoDBtable caused execution time forSHOW CREATE TABLEfor the table to increase. (Bug#13762)DELETEfromCSVtables reported an incorrect rows-affected value. (Bug#13406)The server crashed if compiled without any transactional storage engines. (Bug#15047)
Declaring a stored routine variable to have a
DEFAULTvalue that referred to a variable of the same name caused a server crash. (For example:DECLARE x INT DEFAULT x) Now theDEFAULTvariable is interpreted as referring to a variable in an outer scope, if there is one. (Bug#14376)Perform character set conversion of constant values whenever possible without data loss. (Bug#10446)
mysql ignored the
MYSQL_TCP_PORTenvironment variable. (Bug#5792)ROW_COUNT()returned an incorrect result afterEXECUTEof a prepared statement. (Bug#14956)A
UNIONofDECIMALcolumns could produce incorrect results. (Bug#14216)Queries that select records based on comparisons to a set of column could crash the server if there was one index covering the columns, and a set of other non-covering indexes that taken together cover the columns. (Bug#15204)
When using an aggregate function to select from a table that has a multiple-column primary key, adding
ORDER BYto the query could produce an incorrect result. (Bug#14920)SHOW CREATE TABLEfor a view could fail if the client had locked the view. (Bug#14726)For binary string data types, mysqldump --hex-blob produced an illegal output value of
0xrather than''. (Bug#13318)Some comparisons for the
IN()operator were inconsistent with equivalent comparisons for the=operator. (Bug#12612)In a stored procedure, continuing (via a condition handler) after a failed variable initialization caused a server crash. (Bug#14643)
Within a stored procedure, exception handling for
UPDATEstatements that caused a duplicate-key error caused aPackets out of ordererror for the following statement. (Bug#13729)Creating a table containing an
ENUMorSETcolumn from within a stored procedure or prepared statement caused a server crash later when executing the procedure or statement. (Bug#14410)Selecting from a view used
filesortretrieval when faster retrieval was possible. (Bug#14816)Warnings from a previous command were not being reset when fetching from a cursor. (Bug#13524)
RESET MASTERfailed to delete log files on Windows. (Bug#13377)Using
ORDER BYon a column from a view, when also selecting the column normally, and via an alias, caused a mistakenColumn 'x' in order clause is ambiguouserror. (Bug#14662)Invoking a stored procedure within another stored procedure caused the server to crash. (Bug#13549)
Stored functions making use of cursors were not replicated. (Bug#14077)
CAST() did not pad with 0x00 to a length ofexprAS BINARY(N)Nbytes. (Bug#14255)Casting a
FLOATorDOUBLEwhose value was less than1.0E-06toDECIMALwould yield an inappropriate value. (Bug#14268)In some cases, a left outer join could yield an invalid result or cause the server to crash, due to a
MYSQL_DATA_TRUNCATEDerror. (Bug#13488)For a invalid view definition, selecting from the
INFORMATION_SCHEMA.VIEWStable or usingSHOW CREATE VIEWfailed, making it difficult to determine what part of the definition was invalid. Now the server returns the definition and issues a warning. (Bug#13818)The server could misinterpret old trigger definition files created before MySQL 5.0.17. Now they are interpreted correctly, but this takes more time and the server issues a warning that the trigger should be re-created. (Bug#14090)
mysqldump --triggers did not account for the SQL mode and could dump trigger definitions with missing whitespace if the
IGNORE_SPACEmode was enabled. (Bug#14554)Within a trigger definition the
CURRENT_USER()function evaluated to the user whose actions caused the trigger to be activated. Now that triggers have aDEFINERvalue,CURRENT_USER()evaluates to the trigger definer. (Bug#5861)CREATE TABLEcould crash the server and write invalid data into thetbl_name(...) SELECT ....frmfile if theCREATE TABLEandSELECTboth contained a column with the same name. Also, if a default value is specified in the column definition, it is now actually used. (Bug#14480)A newline character in a column alias in a view definition caused an error when selecting from the view later. (Bug#13622)
mysql_fix_privilege_tables.sqlcontained an erroneous comment that resulted in an error when the file contents were processed. (Bug#14469)On Windows, the server could crash during shutdown if both replication threads and normal client connection threads were active. (Re-fix of Bug#11796)
The grammar for supporting the
DEFINER = CURRENT_USERclause inCREATE VIEWandALTER VIEWwas incorrect. (Bug#14719)Queries on
ARCHIVEtables that used thefilesortsorting method could result in a server crash. (Bug#14433)The
mysql_stmt_fetch()C APP function could returnMYSQL_NO_DATAfor aSELECT COUNT(*) FROMstatement, which should return 1 row. (Bug#14845)tbl_nameWHERE 1 = 0A
LIMIT-related optimization failed to take into account thatMyISAMtable indexes can be disabled, causing Error 124 when it tried to use such an index. (Bug#14616)A server crash resulted from the following sequence of events: 1) With no default database selected, create a stored procedure with the procedure name explicitly qualified with a database name (
CREATE PROCEDURE). 2) Create another stored procedure with no database name qualifier. 3) Executedb_name.proc_name...SHOW PROCEDURE STATUS. (Bug#14569)Complex subqueries could cause improper internal query execution environment initialization and crash the server. (Bug#14342)
For a table that had been opened with
HANDLER OPEN, issuingOPTIMIZE TABLE,ALTER TABLE, orREPAIR TABLEcaused a server crash. (Bug#14397)A server crash could occur if a prepared statement invoked a stored procedure that existed when the statement was prepared but had been dropped and re-created prior to statement execution. (Bug#12329)
A server crash could occur if a prepared statement updated a table for which a trigger existed when the statement was prepared but had been dropped prior to statement execution. (Bug#13399)
Statements that implicitly commit a transaction are prohibited in stored functions and triggers. An attempt to create a function or trigger containing such a statement produces an error. (Bug#13627) (The originally reported symptom was that a trigger that dropped another trigger could cause a server crash. That problem was fixed by the patch for Bug#13343.)
Functionality added or changed:
When trying to run the server with yaSSL enabled, MySQL now tries to open
/dev/randomautomatically if/dev/urandomis not available. (Bug#13164)The
read_onlysystem variable no longer applies toTEMPORARYtables. (Bug#4544)Due to changes in binary logging, the restrictions on which stored routine creators can be trusted not to create unsafe routines have been lifted for stored procedures (but not stored functions). Consequently, the
log_bin_trust_routine_creatorssystem variable and the corresponding--log-bin-trust-routine-creatorsserver option were renamed tolog_bin_trust_function_creatorsand--log-bin-trust-function-creators. For backward compatibility, the old names are recognized but result in a warning. See Section 17.4, “Binary Logging of Stored Routines and Triggers”.Added the
Compressionstatus variable, which indicates whether the client connection uses compression in the client/server protocol.In MySQL 5.0.13, syntax for
DEFINERandSQL SECURITYclauses was added to theCREATE VIEWandALTER VIEWstatements, but the clauses had no effect. They now are enabled. They specify the security context to be used when checking access privileges at view invocation time. See Section 19.2, “CREATE VIEWSyntax”, for more information.The
InnoDB,NDB,BDB, andARCHIVEstorage engines now support spatial columns. See Chapter 16, Spatial Extensions.The
CHECK TABLEstatement now works forARCHIVEtables.You must now declare a prefix for an index on any column of any
Geometryclass, the only exception being when the column is aPOINT. (Bug#12267)Added a
--hexdumpoption to mysqlbinlog that displays a hex dump of the log in comments. This output can be helpful for replication debugging.MySQL 5.0 now supports character set conversion for seven additional
cp950characters into thebig5character set:0xF9D6,0xF9D7,0xF9D8,0xF9D9,0xF9DA,0xF9DB, and0xF9DC. Note: If you move data containing these additional characters to an older MySQL installation which does not support them, you may encounter errors. (Bug#12476)When a date column is set
NOT NULLand contains0000-00-00, it will be updated for UPDATE statements that containscolumnnameIS NULL
Bugs fixed:
When the
DATE_FORMAT()function appeared in both theSELECTandORDER BYclauses of a query but with arguments that differ by case (i.e. %m and %M), incorrect sorting may have occurred. (Bug#14016)For
InnoDBtables, using a column prefix for autf8column in a primary key causedCannot find recorderrors when attempting to locate records. (Bug#14056)NDB Cluster: A memory leak occurred when performing ordered index scans using indexes a columns larger than 32 bytes, which would eventually lead to the forced shutdown of all mysqld server processes used with the cluster. (Bug#13078)InnoDB: Largeinnobase_buffer_pool_sizeandinnobase_log_file_sizevalues were displayed incorrectly on 64-bit systems. (Bug#12701)InnoDB: When dropping and adding aPRIMARY KEY, if a loose index scan using only the second part of multiple-part index was chosen, incorrect keys were created and an endless loop resulted. (Bug#13293)NDB Cluster: Repeated transactions using unique index lookups could cause a memory leak leading to error 288,Out of index operations in transaction coordinator. (Bug#14199)Selecting from a table in both an outer query and a subquery could cause a server crash. (Bug#14482)
SHOW CREATE TABLEdid not display theCONNECTIONstring forFEDERATEDtables. (Bug#13724)For some stored functions dumped by mysqldump --routines, the function definition could not be reloaded later due to a parsing error. (Bug#14723)
For a
MyISAMtable originally created in MySQL 4.1,INSERT DELAYEDcould cause a server crash. (Bug#13707)The
--exit-info=65536option conflicted with--temp-pooland caused problems with the server's use of temporary files. Now--temp-poolis ignored if--exit-info=65536is specified. (Bug#9551)ORDER BY DESCwithin theGROUP_CONCAT()function was not honored when used in a view. (Bug#14466)A comparison with an invalid date (such as
WHERE) caused any index oncol_name> '2005-09-31'col_namenot to be used and a string comparison for each row, resulting in slow performance. (Bug#14093)Within stored routines,
REPLACE()could return an empty string (rather than the original string) when no replacement was done, andIFNULL()could return garbage results. (Bug#13941)Inserts of too-large
DECIMALvalues were handled inconsistently (sometimes set to the maximumDECIMALvalue, sometimes set to 0). (Bug#13573)Executing
REPAIR TABLE,ANALYZE TABLE, orOPTIMIZE TABLEon a view for which an underlying table had been dropped caused a server crash. (Bug#14540)A prepared statement that selected from a view processed using the merge algorithm could crash on the second execution. (Bug#14026)
Deletes from a
CSVtable could cause table corruption. (Bug#14672)An update of a
CSVtable could cause a server crash. (Bug#13894)For queries with nested outer joins, the optimizer could choose join orders that query execution could not handle. The fix is that now the optimizer avoids choosing such join orders. (Bug#13126)
Starting mysqld with the
--skip-innodband--default-storage-engine=innodb(or--default-table-type=innodbcaused a server crash. (Bug#9815, re-fix of bug from 5.0.5)mysqlmanager did not start up correctly on Windows 2003. (Bug#14537)
The parser did not correctly recognize wildcards in the host part of the
DEFINERuser inCREATE VIEWstatements. (Bug#14256)Memory corruption and a server crash could be caused by statements that used a cursor and generated a result set larger than
max_heap_table_size. (Bug#14210)mysqld_safe did not correctly start the
-maxversion of the server (if it was present) if the--lediroption was given. (Bug#13774)The mysql parser did not properly strip the delimiter from input lines less than nine characters long. For example, this could cause
USE abc;to result in anUnknown database: abc;error. (Bug#14358)Statements of the form
CREATE TABLE ... SELECT ...that created a column with a multi-byte character set could incorrectly calculate the maximum length of the column, resulting in aSpecified key was too longerror. (Bug#14139)Some updatable views could not be updated. (Bug#14027)
Running
OPTIMIZE TABLEand other data-updating statements concurrently on anInnoDBtable could cause a crash or the following warnings in the error log:Warning: Found locks from different threads in write: enter write_lock,Warning: Found locks from different threads in write: start of release lock. (Bug#11704)Indexes for
BDBtables were being limited incorrectly to 255 bytes. (Bug#14381)Use of
col_name= VALUES(col_name)ON DUPLICATE KEY UPDATEclause of anINSERTstatement failed with anColumn 'error. (Bug#13392)col_name' in field list is ambiguousOn Windows, the server was not ignoring hidden or system directories that Windows may have created in the data directory, and would treat them as available databases. (Bug#4375)
mysqldump could not dump views if the
-xoption was given. (Bug#12838)mysqlimport now issues a
SET @@character_set_database = binarystatement before loading data so that a file containing mixed character sets (columns with different character sets) can be loaded properly. (Bug#12123)Use of the deprecated
--sql-bin-update-sameoption caused a server crash. (Bug#12974)Maximum values were handled incorrectly for command-line options of type
GET_LL. (Bug#12925)For a user that has the
SELECTprivilege on a view, the server erroneously was also requiring the user to have theEXECUTEprivilege at view execution time for stored functions used in the view definition. (Bug#9505)Use of
WITH ROLLUP PROCEDURE ANALYSE()could hang the server. (Bug#14138)TIMEDIFF(),ADDTIME(), andSTR_TO_DATE()were not reporting that they could returnNULL, so functions that invoked them might misinterpret their results. (Bug#14009)The example configuration files supplied with MySQL distributions listed the
thread_cache_sizevariable asthread_cache. (Bug#13811)Using
ALTER TABLEto add an index could fail if the operation ran out of temporary file space. Now it automatically makes a second attempt that uses a slower method but no temporary file. In this case, problems that occurred during the first attempt can be displayed withSHOW WARNINGS. (Bug#12166)The input polling loop for Instance Manager did not sleep properly. Instance Manager used up too much CPU as a result. (Bug#14388)
Trying to take the logarithm of a negative value is now handled in the same fashion as division by zero. That is, it produces a warning when
ERROR_FOR_DIVISION_BY_ZEROis set, and an error in strict mode. (Bug#13820)LOAD DATA INFILEwould not accept the same character for both theESCAPED BYand theENCLOSED BYclauses. (Bug#11203)The value of
Last_query_costwas not updated for queries served from the query cache. (Bug#10303)TIMESTAMPDIFF()returned an incorrect result if one argument but not the other was a leap year and a date was from March or later. (Bug#13534)The server incorrectly accepted column definitions of the form
DECIMAL(0,forD)Dless than 11. (Bug#13667)The displayed value for the
CHARACTER_MAXIMUM_LENGTHcolumn in theINFORMATION_SCHEMA.COLUMNStable was not adjusted for multi-byte character sets. (Bug#14290)A bugfix in MySQL 5.0.15 caused the displayed values for the
CHARACTER_MAXIMUM_LENGTHandCHARACTER_OCTET_LENGTHcolumns in theINFORMATION_SCHEMA.COLUMNStable to be reversed. (Bug#14207)On Windows, the value of
character_sets_dirinSHOW VARIABLESoutput was displayed inconsistently (using both ‘/’ and ‘\’ as pathname component separators). (Bug#14137)Subqueries in the
FROMclause failed if the current database wasINFORMATION_SCHEMA. (Bug#14089)Corrected a parser precedence problem that resulted in an
Unknown column ... in 'on clause'error for some joins. (Bug#13832)For
LIKE ... ESCAPE, an escape sequence longer than one character was accepted as valid. Now the sequence must be empty or one character long. If theNO_BACKSLASH_ESCAPESSQL mode is enabled, the sequence must be one character long. (Bug#12595)SELECT DISTINCT CHAR(returned incorrect results aftercol_name)SET NAMES utf8. (Bug#13233)A prepared statement failed with
Illegal mix of collationsif the client character set wasutf8and the statement used a table that had a character set oflatin1. (Bug#12371)Inserting a new row into an
InnoDBtable could causeDATETIMEvalues already stored in the table to change. (Bug#13900)The default value of
query_prealloc_sizewas set to 8192, lower than its minimum of 16384. The minimum has been lowered to 8192. (Bug#13334)The server did not take character set into account in checking the width of the
mysql.user.Passwordcolumn. As a result, it could incorrectly generate long password hashes even if the column was not long enough to hold them. (Bug#13064)Inserting
cp932strings into aVARCHARcolumn caused a server crash rather than string truncation if the string was longer than the column definition. (Bug#12547)Two threads that were creating triggers on an
InnoDBtable at the same time could deadlock. (Bug#12739)mysqladmin and mysqldump would hang on SCO OpenServer. (Bug#13238)
Where one stored procedure called another stored procedure: If the second stored procedure generated an exception, the exception was not caught by the calling stored procedure. For example, if stored procedure
Aused anEXITstatement to handle an exception, subsequent statements inAwould be executed regardless whenAwas called by another stored procedureB, even if an exception that should have been handled by theEXITwas generated inA. (Bug#7049)Trying to create a stored routine with no database selected would crash the server. (Bug#13514, Bug#13587)
Specifying
--default-character-set=cp-932for mysqld would cause SQL scripts containing comments written using that character set to fail with a syntax error. (Bug#13487)Trying to compile the server using the
--without-geometryoption caused the build to fail. (Bug#12991)
Functionality added or changed:
Warning: Incompatible change. For
BINARYcolumns, the pad value and how it is handled has changed. The pad value for inserts now is0x00rather than space, and there is no stripping of the pad value for selects. For details, see Section 11.4.2, “TheBINARYandVARBINARYTypes”.Warning: Incompatible change. The
CHAR()function now returns a binary string rather than a string in the connection character set. An optionalUSINGclause may be used to produce a result in a specific character set instead. Also, arguments larger than 256 produce multiple characters. They are no longer interpreted modulo 256 to produce a single character each. These changes may cause some incompatibilities, as noted in Section 2.4.16.2, “Upgrading from MySQL 4.1 to 5.0”.charsetNDB Cluster: The perror utility included with theMySQL-ServerRPM now provides support for the--ndboption, and so can be used to obtain error message text for MySQL Cluster error codes. (Bug#13740)NDB Cluster: The ndb_mgm client now reports node startup phases automatically. (Bug#16197)When executing single-table
UPDATEorDELETEqueries containing anORDER BY ... LIMITclause, but not having anyNWHEREclause, MySQL can now take advantage of an index to read the firstNrows in the ordering specified in the query. If an index is used, only the firstNrecords will be read, as opposed to scanning the entire table. (Bug#12915)The
MySQL-serverRPM now explicitly assigns themysqlsystem user to themysqluser group during the postinstallation process. This corrects an issue with upgrading the server on some Linux distributions whereby a previously existingmysqluser was not changed to themysqlgroup, resulting in wrong groups for files created following the installation. (Bug#12823)Added the
--tz-utcoption to mysqldump. This option addsSET TIME_ZONE='+00:00'to the dump file so thatTIMESTAMPcolumns can be dumped and reloaded between servers in different time zones and protected from changes due to daylight saving time. (Bug#13052)When declaring a local variable (or parameter) named
passwordorname, and setting it withSET(for example,SET password = ''), the new error messageERROR 42000: Variable 'nnn' must be quoted with `...`, or renamedis returned (where 'nnn' is 'password' or 'names'). This means there is a syntax conflict with special sentences likeSET PASSWORD = PASSWORD(...)(for setting a user's password) andset names default(for setting charset and collation).This must be resolved either by quoting the variable name:
SET `password` = ..., which will set the local variable`password`, or by renaming the variable to something else (if setting the user's password is the desired effect).The following statements now cause an implicit
COMMIT:CREATE VIEWALTER VIEWDROP VIEWCREATE TRIGGERDROP TRIGGERCREATE USERRENAME USERDROP USER
NDBCluster: A number of new or improved error messages have been implemented in this release in order to provide better and more accurate diagnostic information regarding cluster configuration issues and problems. (Bug#11739, Bug#11749, Bug#12044, Bug#12786, Bug#13197)NDBCluster: A new “smart” node allocation algorithm means that it is no longer necessary to use sequential IDs for cluster nodes, and that nodes not explicitly assigned IDs should now have IDs allocated automatically in most cases. In practical terms, this means that it is now possible to assign a set of node IDs such as1,2,4,5without an error being generated due to the missing3. (Bug#13009)
Bugs fixed:
Issuing
STOP SLAVEafter having acquired a global read lock withFLUSH TABLES WITH READ LOCKcaused a deadlock. NowSTOP SLAVEis generates an error in such circumstances. (Bug#10942)An expression in an
ORDER BYclause failed withUnknown column 'if the expression referred to a column alias. (Bug#11694)col_name' in 'order clause'mysqldump could not dump views. (Bug#14061)
Using an undefined variable in an
IForSETclause inside a stored routine produced an incorrectunknown column ... in 'order clause'error message. (Bug#13037)Trying to create a view dynamically using a prepared statement within a stored procedure failed with error 1295. (Bug#13095)
mysqldump --triggers did not quote identifiers properly if the
--compatibleoption was given, so the dump output could not be reloaded. (Bug#13146)Character set conversion was not being done for
FIND_IN_SET(). (Bug#13751)CAST(1E+300 TO SIGNED INT)produced an incorrect result on little-endian machines. (Bug#13344)Corrected a memory-copying problem for
big5values when using icc compiler on Linux IA-64 systems. (Bug#10836)On BSD systems, the system
crypt()call could return an error for some salt values. The error was not handled, resulting in a server crash. (Bug#13619)Character set file parsing during
mysql_real_connect()read past the end of a memory buffer. (Bug#6413)InnoDB: Queries that were executed using anindex_mergeunion or intersection could produce incorrect results if the underlying table used theInnoDBstorage engine and had a primary key containingVARCHARmembers. (Bug#13484)CREATE DEFINER=... VIEW ...caused the server to crash when run with--skip-grant-tables. (Bug#13504)The
--interactive-timeoutand--slave-net-timeoutoptions for mysqld were not being obeyed on Mac OS X and other BSD-based platforms. (Bug#8731)Queries of the form
(SELECT ...) ORDER BY ...were being treated as aUNION. This improperly resulted in only distinct values being returned (becauseUNIONby default eliminates duplicate results). Also, references to column aliases inORDER BYclauses following parenthesizedSELECTstatements were not resolved properly. (Bug#7672)If special characters such as
'_','%', or the escape character were included within the prefix of a column index,LIKEpattern matching on the indexed column did not return the correct result. (Bug#13046, Bug#13919)An
UPDATEquery using a join would be executed incorrectly on a replication slave. (Bug#12618)Server crashed during a
SELECTstatement, writing a message like this to the error log:InnoDB: Error: MySQL is trying to perform a SELECT InnoDB: but it has not locked any tables in ::external_lock()!
NDBCluster: ndb_mgmd would allow a node to be stopped or restarted while another node was still starting up, which could crash the cluster. It should now not be possible to issue a node stop or restart while a different node is still restarting, and the cluster management client issues an error if an attempt is made to do so. (Bug#13461)NDBCluster: Placing multiple[TCP DEFAULT]sections in the clusterconfig.inifile crashed ndb_mgmd. (The ndb_mgmd process now exits gracefully with an appropriate error message instead.) (Bug#13611)NDBCluster: Trying to run ndbd as systemrootwhen connecting to a mysqld process running as themysqlsystem user via SHM caused the ndbd process to crash. (ndbd should now exit gracefully with an appropriate error message instead.) (Bug#9249)Server may over-allocate memory when performing a
FULLTEXTsearch for stopwords only. (Bug#13582)Queries that use indexes in normal
SELECTstatements may cause range scans inVIEWs. (Bug#13327)When calling a stored procedure with the syntax
CALLand no default schema selected,schema.procedurenameERROR 1046was displayed after the procedure returned. (Bug#13616)With
--log-slave-updatesExec_master_log_posof SQL thread lagged IO (Bug#13023)SHOW CREATE TABLEdid not display anyFOREIGN KEYclauses if a temporary file could not be created. NowSHOW CREATE TABLEdisplays an error message in an SQL comment if this occurs. (Bug#13002)A column in the
ONcondition of a join that referenced a table in a nested join could not be resolved if the nested join was a right join. (Bug#13597)A qualified reference to a view column in the
HAVINGclause could not be resolved. (Bug#13410)comp_err did not detect when multiple error messages for a language were given for an error symbol. (Bug#13071)
For XA transaction IDs (
gtrid.bqual.formatIDgtridandbqual. MySQL was also includingformatIDin the uniqueness check. (Bug#13143)Local (non-XA) and XA transactions are supposed to be mutually exclusive within a given client connection, but this prohibition was not always enforced. (Bug#12935)
mysqlcheck
--all-databases--analyze--optimizefailed because it also tried to analyze and optimize theINFORMATION_SCHEMAtables which it can't. (Bug#13783)SELECT * INTO OUTFILE ... FROM INFORMATION_SCHEMA.schematafailed with anAccess deniederror. (Bug#13202)A table or view named Ç (C-cedilla) couldn't be dropped. (Bug#13145)
Tests containing
SHOW TABLE STATUSorINFORMATION_SCHEMAfailed on opnsrv6c. (Bug, #14064, Bug#14065)
Functionality added or changed:
The limit of 255 characters on the input buffer for mysql on Windows has been lifted. The exact limit depends on what the system allows, but can be up to 64K characters. A typical limit is 16K characters. (Bug#12929)
Re-enabled the
--delayed-insertsoption for mysqldump, which now checks for each table dumped whether its storage engine supportsDELAYEDinserts. (Bug#7815)Added the
myisam_stats_method, which controls whetherNULLvalues in indexes are considered the same or different when collecting statistics forMyISAMtables. This influences the query optimizer as described in Section 7.4.7, “MyISAMIndex Statistics Collection”. (Bug#12232)When an
InnoDBforeign key constraint is violated, the error message now indicates which table, column, and constraint names are involved. (Bug#3443)Configure-time checking for the availability of multi-byte macros and functions in the bundled
readlinelibrary. This improves handling of multi-byte character sets in the mysql client. (Bug#3982)The
CHAR()function now takes into account the character set and collation given by thecharacter_set_connectionandcollation_connectionsystem variables. For an argumentntoCHAR(), the result isnmod 256 for single-byte character sets. For multi-byte character sets,nmust be a valid code point in the character set. Also, the result string fromCHAR()is checked for well-formedness. For invalid arguments, or a result that is not well-formed, MySQL generates a warning (or, in strict SQL mode, an error). (Bug#10504)RENAME TABLEnow works for views as well, as long as you do not try to rename a view into a different database. (Bug#5508)Multiple-table
UPDATEandDELETEstatements that do not affect any rows are now written to the binary log and will replicate. (Bug#13348, Bug#12844)Range scans can now be performed for queries on VIEWs such as
column IN (<constants>)andcolumn BETWEEN ConstantA AND ConstantB. (Bug#13317)
Bugs fixed:
Certain joins using
Range checked for each recordin the query execution plan could cause the server to crash. (Bug#24776)NDBCluster: A trigger updating the value of anAUTO_INCREMENTcolumn in a Cluster table would insert an error code rather than the expected value into the column. (Bug#13961)NDBCluster: When performing a delete of a great many (tens of thousands of) rows at once from a Cluster table, an improperly dereferenced pointer could cause the mysqld process to crash. (Bug#9282)CHECKSUM TABLElockedInnoDBtables and did not use a consistent read. (Bug#12669)The
--skip-innodb-doublewriteoption disables use of theInnoDBdoublewrite buffer. However, having this option in effect when creating a new MySQL installation prevented the buffer from even being created, resulting in a server crash later. (Bug#13367)MySQL programs in binary distributions for Solaris 8/9/10 x86 systems would not run on Pentium III machines. (Bug#6772)
When
SELECT ... FOR UPDATEorSELECT ... LOCK IN SHARE MODEfor anInnoDBtable were executed from within a stored function or a trigger, they were converted to a non-locking consistent read. (Bug#11238)NDB Cluster: If ndb_restore could not find a free mysqld process, it crashed. (Bug#13512)NDB Cluster: Receipt of severalenter single user modecommands by multiple ndb_mgmd processes within a short period of time resulted in cluster shutdown. (Bug#13053)NDB Cluster: Multiple ndb_mgmd processes in a cluster would not know each other's IP addresses. (Bug#12037)NDB Cluster: With two mgmd processes in a cluster, ndb_mgmd output forSHOWwould display the same IP address for both processes, even when they were on different hosts. (Bug#11595)NDB Cluster: Queries onNDBtables that are executed usingindex_merge/union orindex_merge/intersection could produce incorrect results. (Bug#13081)The
--replicate-rewrite-dband--replicate-do-tableoptions did not work for statements in which tables were aliased to names other than those listed by the options. (Bug#11139)After running configure with the
--with-embedded-privilege-controloption, the embedded server failed to build. (Bug#13501)Nested handlers within stored procedures didn't work. (Bug#6127)
The optimizer chose a less efficient execution plan for
col_nameBETWEENconstANDconstcol_name=constrefaccess method for both expressions. (Bug#13455)Incorrect creation of
DECIMALlocal variables in a stored procedure could cause a server crash. (Bug#12589)Queries against a
MERGEtable that has a composite index could produce incorrect results. (Bug#9112)The server was not rejecting
FLOAT(orM,D)DOUBLE(columns specifications whenM,D)Mwas less thanD. (Bug#12694)After running configure with the
--without-serveroption, the distribution failed to build. (Bug#11680, Bug#13550)Joins nested under
NATURALorUSINGjoins were sometimes not initialized properly, causing a server crash. (Bug#13545)Locking a view with the query cache enabled and
query_cache_wlock_invalidateenabled could cause a server crash. (Bug#13424)A
HAVINGclause that references an unqualified view column name could crash the server. (Bug#13411)Comparisons involving row constructors containing constants could cause a server crash. (Bug#13356)
NDB Cluster:LOAD DATA INFILEwith a large data file failed. (Bug#10694)NDB Cluster: Adding an index to a table with a large number of columns (more then 100) crashed the storage node. (Bug#13316)Calling the
FORMAT()function with aDECIMALcolumn value caused a server crash when the value wasNULL. (Bug#13361)Aggregate functions sometimes incorrectly were allowed in the
WHEREclause ofUPDATEandDELETEstatements. (Bug#13180)It was possible to create a view that executed a stored function for which you did not have the
EXECUTEprivilege. (Bug#12812)BITcolumns and following columns inNDBtables were corrupt when dumped by mysqldump. (Bug#13152)NATURALjoins and joins withUSINGagainst a view could returnNULLrather than the correct value. (Bug#13127)Use of a user-defined function within the
HAVINGclause of a query resulted in anUnknown columnerror. (Bug#11553)For queries for which the optimizer determined a join type of “Range checked for each record” (as shown by
EXPLAIN, the query sometimes could cause a server crash, depending on the data distribution. (Bug#12291)For queries with
DISTINCTandWITH ROLLUP, theDISTINCTshould be applied after the rollup operation, but was not always. (Bug#12887)The server crashed when processing a view that invoked the
CONVERT_TZ()function. (Bug#11416)Shared-memory connections were not working on Windows. (Bug#12723)
Functionality added or changed:
The syntax for
CREATE VIEWandALTER VIEWstatements now includesDEFINERandSQL SECURITYclauses for specifying the security context to be used when checking access privileges at view invocation time. (The syntax is present in 5.0.13, but these clauses have no effect until 5.0.16.) See Section 19.2, “CREATE VIEWSyntax”, for more information.The
--hex-dumpoption for mysqldump now also applies toBITcolumns.Added a
--routinesoption for mysqldump that enables dumping of stored routines. (Bug#9056)The connection string for
FEDERATEDtables now is specified using aCONNECTIONtable option rather than aCOMMENTtable option.Better detection of connection timeout for replication servers on Windows allows elimination of extraneous
Lost connectionerrors in the error log. (Bug#5588)The counters for the
Key_read_requests,Key_reads,Key_write_requests, andKey_writesstatus variables were changed fromunsigned longtounsigned longlongto accommodate larger values before the variables roll over and restart from 0. (Bug#12920)The restriction on the use of
PREPARE,EXECUTE, andDEALLOCATE PREPAREwithin stored procedures was lifted. The restriction still applies to stored functions and triggers. (Bug#10975, Bug#7115, Bug#10605)A new command line argument was added to mysqld to ignore client character set information sent during handshake, and use server side settings instead, to reproduce 4.0 behavior (Bug#9948):
mysqld --skip-character-set-client-handshake
OPTIMIZE TABLEandHANDLERnow are prohibited in stored procedures and functions and in triggers. (Bug#12953, Bug#12995)InnoDB: TheTRUNCATE TABLEstatement forInnoDBtables always resets the counter for anAUTO_INCREMENTcolumn now, regardless of whether there is a foreign key constraint on the table. (Beginning with 5.0.3,TRUNCATE TABLEreset the counter, but only if there was no such constraint.) (Bug#11946)The
LEAST()andGREATEST()functions used to returnNULLonly if all arguments wereNULL. Now they returnNULLif any argument isNULL, the same as Oracle. (Bug#12791)Two new collations have been added for Esperanto:
utf8_esperanto_cianducs2_esperanto_ci.Reorder network startup to come after all other initialization, particularly storage engine startup which can take a long time. This also prevents MySQL from being run on a privileged port (any port under 1024) unless run as the root user. (Bug#11707)
The Windows binary packages are now compiled with the Microsoft Visual Studio 2003 compiler instead of Microsoft Visual C++ 6.0.
The binaries compiled with the Intel icc compiler are now built using icc 9.0 instead of icc 8.1. You will have to install new versions of the Intel icc runtime libraries, which are available from here: ( http://dev.mysql.com/downloads/os-linux.html)
RAND()no longer allows non-constant initializers. (Prior to MySQL 5.0.13, the effect of non-constant initializers is undefined.) (Bug#6172)
Bugs fixed:
Incompatible change: A lock wait timeout caused
InnoDBto roll back the entire current transaction. Now it rolls back only the most recent SQL statement. (Bug#12308)The
FEDERATEDstorage engine does not supportALTER TABLE, but no appropriate error message was issued. (Bug#13108)mysqldump did not dump triggers properly. (Bug#12597)
NDBCluster: The average row size for Cluster tables was being calculated incorrectly. This affected the values shown for theData_lengthandAvg_row_lengthcolumns in the output generated bySHOW TABLE STATUSas well as the values for thedata_lengthanddata_length/table_rowscolumns shown in theTABLEStable of theINFORMATION_SCHEMAdatabase with respect to Cluster tables (tables using other storage engines were not affected by this bug). (Bug#9896)Within a stored procedure, fetching a large number of rows in a loop using a cursor could result in a server crash or an out of memory error. Also, values inserted within a stored procedure using a cursor were interpreted as
latin1even if character set variables had been set to a different character set. (Bug#6513, Bug#9819)For a server compiled with yaSSL, clients that used MySQL Connector/J were not able to establish SSH connections. (Bug#13029)
When used in view definitions,
DAYNAME(,expr)DAYOFWEEK(,expr)WEEKDAY(were incorrectly treated as though the expression wasexpr)TO_DAYS(orexpr)TO_DAYS(TO_DAYS(. (Bug#13000)expr))Incorrect implicit nesting of joins caused the parser to fail on queries of the form
SELECT ... FROM t1 JOIN t2 JOIN t3 ON t1.t1col = t3.t3colwith anUnknown column 't1.t1col' in 'on clause'error. (Bug#12943)NDB: A cluster shutdown following the crash of a data node would fail to terminate the remaining node processes, even though ndb_mgm showed the shutdown request as having been completed. (Bug#10938, Bug#9996, Bug#11623)A column that can be
NULLwas not handled properly forWITH ROLLUPin a subquery or view. (Bug#12885)Within a transaction, the following statements now cause an implicit commit:
CREATE FUNCTION,DROP FUNCTION,DROP PROCEDURE,ALTER FUNCTION,ALTER PROCEDURE,CREATE PROCEDURE. This corrects a problem where these statements followed byROLLBACKmight not be replicated properly. (Bug#12870)Simultaneous execution of DML statements and
CREATE TRIGGERorDROP TRIGGERstatements on the same table could cause server crashes or errors. (Bug#12704)If a stored function invoked from a
SELECTfailed with an error, it could cause the client connection to be dropped. Now such errors generate warnings instead so as not to interrupt theSELECT. (Bug#12379)A concurrency problem for
CREATE ... SELECTcould cause a server crash. (Bug#12845)The server incorrectly generated an
Unknown tableerror message when for attempts to drop tables in theINFORMATION_SCHEMAdatabase. Now it issues anAccess deniedmessage. (Bug#9846)The server allowed privileges to be granted explicitly for the
INFORMATION_SCHEMAdatabase. Such privileges are always implicit and should not be grantable. (Bug#10734)The server allowed
TEMPORARYtables and stored procedures to be created in theINFORMATION_SCHEMAdatabase. (Bug#9683, Bug#10708)The server failed to disallow
SET AUTOCOMMITin stored functions and triggers. It is allowed to change the value ofAUTOCOMMITin stored procedures, but a runtime error might occur if the procedure is invoked from a stored function or trigger. (Bug#12712)Using an
INOUTparameter with aDECIMALdata type in a stored procedure caused a server crash. (Bug#12979)Performing an
IS NULLcheck on theMIN()orMAX()of an indexed column in a complex query could produce incorrect results. (Bug#12695)The
mysql.serverscript contained incorrect path for thelibexecdirectory. (Bug#12550)The NDB
START BACKUPcommand could be interrupted by aSHOWcommand. (Bug#13054)The
LIKE ... ESCAPEsyntax produced invalid results when escape character was larger than one byte. (Bug#12611)A client connection thread cleanup problem caused the server to crash when closing the connection if the binary log was enabled. (Bug#12517)
Using
ASto rename a column selected from a view in a subquery made it not possible to refer to that column in the outer query. (Bug#12993)The
character_set_systemsystem variable could not be selected withSELECT @@character_set_system. (Bug#11775)A view-creation statement of the form
CREATE VIEWfailed with anameAS SELECT ... FROMtbl_nameASnameNot unique table/alias: 'error. (Bug#6808)name'UNION [DISTINCT]was not removing all duplicates for multi-byte character values. (Bug#12891)Multiplying a
DECIMALvalue within a loop in a stored routine could incorrectly result in a value ofNULL. (Bug#12938)mysql and mysqldump were ignoring the
--defaults-extra-fileoption. (Bug#12917)Columns named in the
USING()clause ofJOIN ... USING()were incorrectly resolved in case-sensitive fashion. (Bug#13067)Local variables in stored routines were not always initialized correctly. (Bug#13133)
SHOW FIELDS FROMcaused error 1046 when no default schema was set. (Bug#12905)schemaname.viewnameThe value of
character_set_resultscould be set toNULL, but returned the string"NULL"when retrieved. (Bug#12363)InnoDB: Limit recursion depth to 200 in deadlock detection to avoid running out of stack space. (Bug#12588)GROUP_CONCAT()ignored an empty string if it was the first value to occur in the result. (Bug#12863)Outer join elimination was erroneously applied for some queries that used a
NOT BETWEENcondition, anIN(condition, or anvalue_list)IF()condition. (Bug#12101, Bug#12102)SHOW FIELDStruncated theTYPEcolumn to 40 characters. (Bug#7142)Use of
PREPAREandEXECUTEwith a statement that selected from a view in a subquery could cause a server crash. (Bug#12651)On HP-UX 11.x (PA-RISC), the
-Loption caused mysqlimport to crash. (Bug#12958)If the binary log is enabled, execution of a stored procedure that modifies table data and uses user variables could cause a server crash or incorrect information to be written to the binary log. (Bug#12637)
Queries with subqueries, where the inner subquery uses the
rangeorindex_mergeaccess method, could return incorrect results. (Bug#12720)After changing the character set with
SET CHARACTER SET, the result of theGROUP_CONCAT()function was not converted to the proper character set. (Bug#12829)A bug introduced in MySQL 5.0.12 caused
SHOW TABLE STATUSto display anAuto_incrementvalue of 0 forInnoDBtables. (Bug#12973)Foreign keys were not properly enforced in
TEMPORARYtables. Foreign keys now are disallowed inTEMPORARYtables. (Bug#12084)Replication of
LOAD DATA INFILEfailed between systems using different pathname syntax (such as delimiter characters). (Bug#11815)Within a stored procedure, a server crash was caused by assigning to a
VARCHAR INOUTparameter the value of an expression that included the variable itself. (For example,SET c = c.) (Bug#12849)SELECT ... JOIN ... ON ... JOIN ... USINGcaused a server crash. (Bug#12977)Using
GROUP BYwhen selecting from a view in some cases could cause incorrect results to be returned. (Bug#12922)myisampack did not properly pack
BLOBvalues larger than 224 bytes. (Bug#4214)Incorrect results could be returned from a view processed using a temporary table. (Bug#12941)
The server crashed when one thread resized the query cache while another thread was using it. (Bug#12848)
mysqld_multi now quotes arguments on command lines that it constructs to avoid problems with arguments that contain shell metacharacters. (Bug#11280)
InnoDB: A consistent read could return inconsistent results due to a bug introduced in MySQL 5.0.5. (Bug#12947)Deadlock occurred when several account management statements were run (particularly between
FLUSH PRIVILEGES/SET PASSWORDandGRANT/REVOKEstatements). (Bug#12423)The Windows installer made a change to one of the
mysql.proctable files, causing stored routine functionality to be compromised. The Windows installer now never overwrites files in the MySQL data directory. During an upgrade from one version to another, a file in the data directory will not be overwritten even if it has not been modified since it was put there by an older installer.If you have already lost access to stored routines because of this problem, you can get them back using the following procedure:
Stop the server.
In the
mysql\datadirectory under your MySQL installation directory, and replace theproc.frmfile with corresponding file from the version of MySQL that you were using before you upgraded.Start the server
Start the mysql command-line client (use the
rootaccount or another account that has full database privileges) and execute themysql_fix_privilege_tables.sqlscript that upgrades the grant tables to the current structure. Instructions for doing this are given in Section 5.5.4, “mysql_fix_privilege_tables — Upgrade MySQL System Tables”.
After this, all stored routine functionality should work. (Bug#12820)
On Windows, the server was preventing tables from being created if the table name was a prefix of a forbidden name. For example,
nulis a forbidden name because it's the same as a Windows device name, but a table with the name ofnornuwas being forbidden as well. (Bug#12325)InnoDBwas too permissive withLOCK TABLE ... READ LOCALand allowed new inserts into the table. NowREAD LOCALis equivalent toREADforInnoDB. This will cause slightly more locking in mysqldump, but makesInnoDBtable dumps consistent withMyISAMtable dumps. (Bug#12410)Use of the mysql client
HELPcommand from within a stored routine caused a “packets out of order” error and a lost connection. NowHELPis detected and disallowed within stored routines. (Bug#12490)Use of yaSSL for a secure client connection caused
LOAD DATA LOCAL INFILEto fail. (Bug#11286)SHOW CREATE PROCEDUREandSHOW CREATE FUNCTIONno longer qualify the routine name with the database name, for consistency with the behavior ofSHOW CREATE TABLE. (Bug#10362)A
UNIONof longutf8VARCHARcolumns was sometimes returned as a column with aLONGTEXTdata type rather thanVARCHAR. This could prevent such queries from working at all if selected into aMEMORYtable because theMEMORYstorage engine does not support theTEXTdata types. (Bug#12537)If a client has opened an
InnoDBtable for which the.ibdfile is missing,InnoDBwould not honor aDROP TABLEstatement for the table. (Bug#12852)ALTER TABLE ... DISCARD TABLESPACEfor non-InnoDBtable caused the client to lose the connection. (The server was not returning the error properly.) (Bug#12207)DO IFNULL(NULL, NULL)andSELECT CAST(IFNULL(NULL, NULL) AS DECIMAL)caused a server crash. (Bug#12841)When using a cursor, a
SELECTstatement that uses aGROUP BYclause could return incorrect results. (Bug#11904)The
SYSDATE()function now returns the time at which it was invoked. In particular, within a stored routine or trigger,SYSDATE()returns the time at which it executes, not the time at which the stored routine or triggering statement began to execute. (Bug#12480)CREATE VIEWinside a stored procedure caused a server crash if the table underlying the view had been deleted. (Bug#12468)A memory leak resulting from repeated
SELECT ... INTOstatements inside a stored procedure could cause the server to crash. (Bug#11333)
Functionality added or changed:
Incompatible change: Beginning with MySQL 5.0.12, natural joins and joins with
USING, including outer join variants, are processed according to the SQL:2003 standard. The changes include elimination of redundant output columns forNATURALjoins and joins specified with aUSINGclause and proper ordering of output columns. (Bug#6136, Bug#6276, Bug#6489, Bug#6495, Bug#6558, Bug#9067, Bug#9978, Bug#10428, Bug#10646, Bug#10972.) The precedence of the comma operator also now is lower compared toJOIN. (Bug#4789, Bug#12065, Bug#13551.)These changes make MySQL more compliant with standard SQL. However, they can result in different output columns for some joins. Also, some queries that appeared to work correctly prior to 5.0.12 must be rewritten to comply with the standard. For details about the scope of the changes and examples that show what query rewrites are necessary, see Section 13.2.7.1, “
JOINSyntax”.Recursive triggers are detected and disallowed. Also, within a stored function or trigger, it is not allowable to modify a table that is already being used (for reading or writing) by the statement that invoked the function or trigger. (Bug#11896, Bug#12644)
SHOW TABLE STATUSfor a view now showsVIEWin uppercase, consistent withSHOW TABLESandINFORMATION_SCHEMA. (Bug#5501)An optimizer estimate of zero rows for a non-empty
InnoDBtable used in a left or right join could cause incomplete rollback for the table. (Bug#12779)Calls to stored procedures were written to the binary log even within transactions that were rolled back, causing them to be executed on replication slaves. (Bug#12334)
Interleaved execution of stored procedures and functions could be written to the binary log incorrectly, causing replication slaves to get out of sync. (Bug#12335)
A query of the form
SHOW TABLE STATUS FROMwould crash the server. (Bug#12636)db_nameWHERE name IN (select_query)Users created using an IP address or other alias rather than a hostname listed in
/etc/hostscould not set their own passwords. (Bug#12302)Using
DESCRIBEon a view after renaming a column in one of the view's base tables caused the server to crash. (Bug#12533)SHOW OPEN TABLESnow supportsFROMandLIKEclauses. (Bug#12183)SHOW TABLE STATUS FROM INFORMATION_SCHEMAnow sorts output by table name the same as it does for other databases. (Bug#12315)SHOW ENGINE INNODB STATUSnow can display longer query strings. (Bug#7819)Added the
SLEEP()function, which pauses for the number of seconds given by its argument. (Bug#6760)Trying to drop the default keycache by setting
@@global.key_buffer_sizeto zero now returns a warning that the default keycache cannot be dropped. (Bug#10473)The stability of cursors when used with
InnoDBtables was greatly improved. (Bug#11832, Bug#12243, Bug#11309)It is no longer possible to issue
FLUSHcommands from within stored functions or triggers. See Section F.1, “Restrictions on Stored Routines and Triggers”, for details. (Bug#12280, Bug#12307)INFORMATION_SCHEMAobjects are now reported as aSYSTEM VIEWtable type. (Bug#11711)
Bugs fixed:
CHECKSUM TABLEcommand returned incorrect results for tables with deleted rows. After upgrading, users who used stored checksum information to detect table changes should rebuild their checksum data. (Bug#12296)A data type of
CHAR BINARYwas not recognized as valid for stored routine parameters. (Bug#9048)SET GLOBAL TRANSACTION ISOLATION LEVELwas not working. (Bug#11207)NDB Cluster: Corrected the parsing of theCLUSTERLOGcommand by ndb_mgm to allow multiple items. (Bug#12833)NDB Cluster: Improved error messages related to filesystem issues. (Bug#11218)NDB Cluster: When a schema was detected to be corrupt, ndb neglected to close it, resulting in a “file already open” error if the schema was opened again later. written. (Bug#12027)NDB Cluster: When it could not copy a fragment, ndbd exited without printing a message about the condition to the error log. Now the message is written. (Bug#12900)NDB Cluster: When a disk full condition occurred, ndbd exited without printing a message about the condition to the error log. Now the message is written. (Bug#12716)mysql_fix_privilege_tables.sqlwas missing a comma, causing a syntax error when executed. (Bug#12705)STRCMP()was not handled correctly in views. (Bug#12489)NDB Cluster: Bad values inconfig.inicaused ndb_mdmd to crash. (Bug#12043)TRUNCATE TABLEdid not work withTEMPORARYInnoDBtables. (Bug#11816)Built-in commands for the mysql client, such as
delimiterand\dare now always parsed within files that are read using the\.andsourcecommands. (Bug#11523)ALTER TABLEdid not move the table to default database unless the new name was qualified with the database name. (Bug#11493)db_name.tRENAMEtIt was not possible to create a stored function with a spatial return value data type. (Bug#10499)
The only valid values for the
PACK_KEYStable option are 0 and 1, but other values were being accepted. (Bug#10056)If a
DROP DATABASEfails on a master server due to the presence of a non-database file in the database directory, the master have the database tables deleted, but not the slaves. To deal with failed database drops, we now writeDROP TABLEstatements to the binary log for the tables so that they are dropped on slaves. (Bug#4680)Improper use of loose index scan in
InnoDBsometimes caused incorrect query results. (Bug#12672)DELETEorUPDATEfor an indexedMyISAMtable could fail. This was due to a change in end-space comparison behavior from 4.0 to 4.1. (Bug#12565)Joins on
VARCHARcolumns of different lengths could produce incorrect results. (Bug#11398)A “Duplicate column name” error no longer occurs when selecting from a view defined as
SELECT *from a join that uses aUSINGclause on tables that have a common column name. (Bug#6558)Invocations of the
SLEEP()function incorrectly could get optimized away for statements in which it occurs. Statements containingSLEEP()incorrectly could be stored in the query cache. (Bug#12689)NDB Cluster: AnALTER TABLEcommand caused loss of data stored prior to the issuing of the command. (Bug#12118)Query cache is switched off if a thread (connection) has tables locked. This prevents invalid results where the locking thread inserts values between a second thread connecting and selecting from the table. (Bug#12385)
NOW(),CURRENT_TIMEand values generated by timestamp columns are now constant for the duration of a stored function or trigger. This prevents the breaking of statements-based replication. (Bug#12480, Bug#12481)Some statements executed on a master server caused the SQL thread on a slave to run out of memory. (Bug#12532)
A
SELECT DISTINCTquery with a constant value for one of the columns would return only a single row. (Bug#12625)NDB Cluster: Cluster failed to take character set data into account when recomputing hashes (and thus could not locate records for updating or deletion) following a configuration change and node restart. (Bug#12220)NDB Cluster: Wrong error message displayed when cluster management server closed port while mysqld was connecting. (Bug#10950)A view was allowed to depend on a function that referred to a temporary table. (Bug#10970)
Prepared statement parameters could cause errors in the binary log if the character set was
cp932. (Bug#11338)The
CREATE_OPTIONScolumn ofINFORMATION_SCHEMA.TABLESshowed incorrect options for tables inINFORMATION_SCHEMA. (Bug#12397)MEMORYtables usingB-Treeindex on 64-bit platforms could produce false table is full errors. (Bug#12460)Issuing
FLUSH INSTANCESfollowed bySTOP INSTANCEcaused instance manager to crash. (Bug#10957)Duplicate instructions in stored procedures resulted in incorrect execution when the optimizer optimized the duplicate code away. (Bug#12168)
SHOW TABLES FROMreturned wrong error message if the schema specified did not exist. (Bug#12591)The
ROW()function returned an incorrect result when comparison involvedNULLvalues. (Bug#12509)Views with multiple
UNIONandUNION ALLproduced incorrect results. (Bug#10624)Stored procedures with particularly long loops could crash server due to memory leak. (Bug#12297, Bug#11247)
Trigger and stored procedure execution could break replication. (Bug#12482)
A server crash could result from an update of a view defined as a join, even though the update updated only a single table. (Bug#12569)
On Windows when the
--innodb_buffer_pool_awe_mem_mboption has been given, the server detects whether AWE support is available and has been compiled into the server, and displays an appropriate error message if not. (Bug#6581)The
NUMERIC_SCALEcolumn of theINFORMATION_SCHEMA.COLUMNStable should be returned as0for integer columns. It was being returned asNULL. (Bug#12301)The
COLUMN_DEFAULTcolumn of theINFORMATION_SCHEMA.COLUMNStable should be returned asNULLif a column has no default value. An empty string was being returned if the column was defined asNOT NULL. (Bug#12518)Slave I/O threads were considered to be in the running state when launched (rather than after successfully connecting to the master server), resulting in incorrect
SHOW SLAVE STATUSoutput. (Bug#10780)Column names in subqueries must be unique, but were not being checked for uniqueness. (Bug#11864)
On Windows, the server could crash during shutdown if both replication threads and normal client connection threads were active. (Bug#11796)
Some subqueries of the form
SELECT ... WHERE ROW(...) IN (were being handled incorrectly. (Bug#11867)subquery)Selecting from a view after
INSERTstatements for the view's underlying table yielded different results than subsequent selects. (Bug#12382)The
mysql_info()C API function could return incorrect data when executed as part of a multi-statement that included a mix of statements that do and do not return information. (Bug#11688)When restoring
INFORMATION_SCHEMAas the default database after failing to execute a stored procedure in an inaccessible database, the server returned a spuriousERROR 42000: Unknown database 'information_schema'message. (Bug#12318)Renamed the
rest()macro inmy_list.htolist_rest()to avoid name clashes with user code. (Bug#12327)DATE_ADD()andDATE_SUB()were converting invalid dates toNULLinTRADITIONALSQL mode rather than rejecting them with an error. (Bug#10627)A trigger that included a
SELECTstatement could cause a server crash. (Bug#11587)An incorrect conversion from
doubletoulonglongcaused indexes not to be used forBDBtables on HP-UX. (Bug#10802)myisampack failed to delete
.TMDtemporary files when run with-Toption. (Bug#12235)Added portability check for Intel compiler to address a problem compiling
InnoDBcode. (Bug#11510)XAallowed two active transactions to be started with the same XID. (Bug#12162)Concatenating
USER()orDATEBASE()with a column produced invalid results. (Bug#12351)Creating a view that included the
TIMESTAMPDIFF()function resulted in a invalid view. (Bug#12298)Comparison of
InnoDBmulti-part primary keys that includeVARCHARcolumns can result in incorrect results. (Bug#12340)For PKG installs on Mac OS X, the preinstallation and postinstallation scripts were being run only for new installations and not for upgrade installations, resulting in an incomplete installation process. (Bug#11380)
Using cursors and nested queries for the same table, corrupted results were returned for the outer query. (Bug#11909)
User variables were not automatically cast for comparisons, causing queries to fail if the column and connection character sets differed. Now when mixing strings with different character sets but the same coercibility, allow conversion if one character set is a superset of the other. (Bug#10892)
Selecting from a view defined as a join over many tables could result in a server crash due to miscalculation of the number of conditions in the
WHEREclause. (Bug#12470)Pathame values for options such as
---basediror--datadirdidn't work on Japanese Windows machines for directory names containing multi-byte characters having a second byte of0x5C(‘\’). (Bug#5439)A race condition between server threads could cause a crash if one thread deleted a stored routine while another thread was executing a stored routine. (Bug#12228)
Mishandling of comparison for rows containing
NULLvalues against rows produced by anINsubquery could cause a server crash. (Bug#12392)Inserting
NULLinto aGEOMETRYcolumn for a table that has a trigger could result in a server crash if the table was subsequently dropped. (Bug#12281)A failure to obtain a lock for an
IN SHARE MODEquery could result in a server crash. (Bug#12082)SELECT ... INTOwithin a trigger could cause a server crash. (Bug#11973)var_nameINSERT ... SELECT ... ON DUPLICATE KEY UPDATEcould fail with an erroneous “Column 'col_name' specified twice” error. (Bug#10109)SHOW TABLE STATUSsometimes reported aRow_formatvalue ofDynamicforMEMORYtables, though such tables always have a format ofFixed. (Bug#3094)A query using a
LEFT JOIN, anINsubquery on the outer table, and anORDER BYclause, caused the server to crash when cursors were enabled. (Bug#11901)Using a stored procedure that referenced tables in the
INFORMATION_SCHEMAdatabase would return an empty result set. (Bug#10055, Bug#12278)Columns defined as
TINYINT(1)were redefined asTINYINT(4)when incorporated into aVIEW. (Bug#11335)ISO-8601formatted dates were not being parsed correctly. (Bug#7308)FLUSH TABLES WITH READ LOCKcombined withLOCK TABLE .. WRITEcaused deadlock. (Bug#9459)NULLcolumn definitions read incorrectly for inner tables of nested outer joins. (Bug#12154)GROUP_CONCATignores theDISTINCTmodifier when used in a query joining multiple tables where one of the tables has a single row. (Bug#12095)UNIONquery withFULLTEXTcould cause server crash. (Bug#11869)
Functionality added or changed:
Security improvement: Applied a patch that addresses a potential
zlibdata vulnerability that could result in an application crash. (CVE-2005-1849) This only affects the binaries for platforms that are linked statically against the bundled zlib (most notably Microsoft Windows and HP-UX).SHOW CHARACTER SETandINFORMATION_SCHEMAnow properly report theLatin1character set ascp1252. (Bug#11216)mysqldump now dumps triggers for each dumped table. This can be suppressed with the
--skip-triggersoption. (Bug#10431)Added new
ER_STACK_OVERRUN_NEED_MOREerror message to indicate that, while the stack is not completely full, more stack space is required. (Bug#11213)NDB: Improved handling of the configuration variablesNoOfPagesToDiskDuringRestartACC,NoOfPagesToDiskAfterRestartACC,NoOfPagesToDiskDuringRestartTUP, andNoOfPagesToDiskAfterRestartTUPshould result in noticeably faster startup times for MySQL Cluster. (Bug#12149)Added support of where clause for queries with
FROM DUAL. (Bug#11745)Added an optimization that avoids key access with
NULLkeys for therefmethod when used in outer joins. (Bug#12144)Maximum size of stored procedures increased from 64k to 4Gb. (Bug#11602)
Added error message for users who attempt
CREATE TABLE ... LIKEand specify a non-table in theLIKEclause. (Bug#6859)
Bugs fixed:
DDL statements now are allowed in stored procedures if the procedure is not invoked from a stored function or a trigger. Also fixed problems where a
TEMPORARYstatement created by one stored routine was inaccessible to another routine invoked during the same connection. (Bug#11126)Creation of the
mysqlgroup account failed during the RPM installation. (Bug#12348)big5strings were not being stored inFULLTEXTindex. (Bug#12075)When
DROP DATABASEwas called concurrently with aDROP TABLEof any table, the MySQL Server crashed. (Bug#12212)max_connections_per_hoursetting was being capped by unrelatedmax_user_connectionssetting. (Bug#9947)SELECT @@local...returned@@session...in the column header. (Bug#10724)Multiplying
ABS()output by a negative number would return incorrect results. (Bug#11402)Updated dependency list for RPM builds to include missing dependencies such as
useraddandgroupadd. (Bug#12233)mysql_install_dbused staticlocalhostvalue inGRANTtables even when server hostname is notlocalhost, such aslocalhost.localdomain. This change is applied to version 5.0.10b on Windows. (Bug#11822)Multiple
SELECT SQL_CACHEqueries in a stored procedure causes error and client hang. (Bug#6897)Added checks to prevent error when allocating memory when there was insufficient memory available. (Bug#7003)
Character data truncated when GBK characters
0xA3A0and0xA1are present. (Bug#11987)Comparisons like
SELECT "A\\" LIKE "A\\";fail when usingSET NAMES utf8;. (Bug#11754)When used in a
SELECTquery against a view, theGROUP_CONCAT()function returned only a single row. (Bug#11412)Calling the C API function
mysql_stmt_fetch()after all rows of a result set were exhausted would return an error instead ofMYSQL_NO_DATA. (Bug#11037)Information about a trigger was not displayed in the output of
SELECT ... FROM INFORMATION_SCHEMA.TRIGGERSwhen the selected database wasINFORMATION_SCHEMA, prior to the trigger's first invocation. (Bug#12127)Issuing successive
FLUSH TABLES WITH READ LOCKwould cause themysqlclient to hang. (Bug#11934)In stored procedures, a cursor that fetched an empty string into a variable would set the variable to
NULLinstead. (Bug#8692)A trigger dependent on a feature of one
SQL_MODEsetting would cause an error when invoked after theSQL_MODEwas changed. (Bug#5891)A delayed insert that would duplicate an existing record crashed the server instead. (Bug#12226)
ALTER TABLEwhenSQL_MODE = 'TRADITIONAL'gave rise to an invalid error message. (Bug#11964)Attempting to repair a table having a fulltext index on a column containing words whose length exceeded 21 characters and where
myisam_repair_threadswas greater than 1 would crash the server. (Bug#11684)The MySQL Cluster backup log was invalid where the number of Cluster nodes was not equal to a power of 2. (Bug#11675)
GROUP_CONCAT()sometimes returned a result with a different collation from that of its arguments. (Bug#10201)The
LPAD()andRPAD()functions returned the wrong length tomysql_fetch_fields(). (Bug#11311)A
UNIQUE VARCHARcolumn would be mis-identified asMULin table descriptions. (Bug#11227)Incorrect error message displayed if user attempted to create a table in a non-existing database using
CREATEsyntax. (Bug#10407)database_name.table_nameInnoDB: Do not flush after each write, not even before setting up the doublewrite buffer. Flushing can be extremely slow on some systems. (Bug#12125)InnoDB: TrueVARCHAR: ReturnNULLcolumns in the format expected by MySQL. (Bug#12186)Two threads could potentially initialize different characters sets and overwrite each other. (Bug#12109)
Unsigned
LONGsystem variables may return incorrect value when retrieved with aSELECTfor certain values. (Bug#10351)Prepared statements were not being written to the Slow Query log. (Bug#9968)
Functionality added or changed:
Security improvement: Applied a patch that addresses a
zlibdata vulnerability that could result in a buffer overflow and code execution. (CVE-2005-2096) (Bug#11844)Incompatible change: The namespace for triggers has changed. Previously, trigger names had to be unique per table. Now they must be unique within the schema (database). An implication of this change is that
DROP TRIGGERsyntax now uses a schema name instead of a table name (schema name is optional and, if omitted, the current schema will be used). (Bug#5892)Note: When upgrading from a previous version of MySQL 5 to MySQL 5.0.10 or newer, you must drop all triggers and re-create them or
DROP TRIGGERwill not work after the upgrade. A suggested procedure for doing this is given in Section 2.4.16.2, “Upgrading from MySQL 4.1 to 5.0”.The viewing of triggers and trigger metadata has been enhanced as follows:
An extension to the
SHOWcommand has been added:SHOW TRIGGERScan be used to view a listing of triggers. See Section 13.5.4.26, “SHOW TRIGGERSSyntax”, for details.The
INFORMATION_SCHEMAdatabase now includes aTRIGGERStable. See Section 20.16, “TheINFORMATION_SCHEMA TRIGGERSTable”, for details. (Bug#9586)
Triggers can now reference tables by name. See Section 18.1, “
CREATE TRIGGERSyntax”, for more information.The output of
perror --helpnow displays the--ndboption. (Bug#11999)On Windows, the search path used by MySQL applications for
my.ininow includes..\my.ini(that is, the application's parent directory, and hence, the installation directory). (Bug#10419)Add the
--defaults-group-suffixoption. See Section 4.3.2, “Using Option Files”.Added
mysql_get_character_set_info()C API function for obtaining information about the default character set of the current connection.The bundled version of the
readlinelibrary was upgraded to version 5.0.It is no longer necessary to issue an explicit
LOCK TABLESfor any tables accessed by a trigger prior to executing any statements that might invoke the trigger. (Bug#9581, Bug#8406)MySQL Cluster: A new-Poption is available for use with the ndb_mgmd client. When called with this option, ndb_mgmd prints all configuration data tostdout, then exits.Add
table_lock_wait_timeoutglobal server system variable.
Bugs fixed:
NDB: Trying to use a greater number of tables then specified by the value ofMaxNoOfTablescaused table corruption such that data nodes could not be restarted. (Bug#9994)NDB: Attempting to create or drop tables during a backup would cause the cluster to shut down. (Bug#11942)When attempting to drop a table with a broken unique index,
NDBfailed to drop the table and erroneously report that the table was unknown. (Bug#11355)SELECT ... NOT IN()gave unexpected results when only static value present between the(). (Bug#11885)Fixed compile error when using GCC4 on AMD64. (Bug#12040)
NDBignored theHostnameoption in theNDBD DEFAULTsection of the Cluster configuration file. (Bug#12028)SHOW PROCEDURE/FUNCTION STATUSdidn't work for users with limited access. (Bug#11577)MySQL server would crash is a fetch was performed after a
ROLLBACKwhen cursors were involved. (Bug#10760)The temporary tables created by an
ALTER TABLEon a cluster table were visible to all MySQL servers. (Bug#12055)NDB_MGMDwas leaking file descriptors. (Bug#11898)IP addresses not shown in
ndb_mgm SHOWcommand on second ndb_mgmd (or on ndb_mgmd restart). (Bug#11596)Functions that evaluate to constants (such as
NOW()andCURRENT_USER()were being evaluated in the definition of aVIEWrather than included verbatim. (Bug#4663)Execution of
SHOW TABLESfailed to increment theCom_show_tablesstatus variable. (Bug#11685)For execution of a stored procedure that refers to a view, changes to the view definition were not seen. The procedure continued to see the old contents of the view. (Bug#6120)
For prepared statements, the SQL parser did not disallow ‘
?’ parameter markers immediately adjacent to other tokens, which could result in malformed statements in the binary log. (For example,SELECT * FROM t WHERE? = 1could becomeSELECT * FROM t WHERE0 = 1.) (Bug#11299)When two threads compete for the same table, a deadlock could occur if one thread has also a lock on another table through
LOCK TABLESand the thread is attempting to remove the table in some manner and the other thread want locks on both tables. (Bug#10600)Aliasing the column names in a
VIEWdid not work when executing aSELECTquery on theVIEW. (Bug#11399)Performing an
ORDER BYon aSELECTfrom aVIEWproduced unexpected results whenVIEWand underlying table had the same column name on different columns. Bug#11709)The C API function
mysql_statement_reset()did not clear error information. (Bug#11183)When used within a subquery,
SUBSTRING()returned an empty string. (Bug#10269)Multiple-table
UPDATEqueries usingCONVERT_TZ()would fail with an error. (Bug#9979)mysql_fetch_fields()returned incorrect length information forMEDIUMandLONGTEXTandBLOBcolumns. (Bug#9735)mysqlbinlogwas failing the test suite on Windows due toBOOLbeing incorrectly cast toINT. (Bug#11567)NDBCLuster: Server left core files following shutdown if data nodes had failed. (Bug#11516)Creating a trigger in one database that references a table in another database was being allowed without generating errors. (Bug#8751)
Duplicate trigger names were allowed within a single schema. (Bug#6182)
Server did not accept some fully-qualified trigger names. (Bug#8758)
The
traditionalSQL mode accepted invalid dates if the date value provided was the result of an implicit type conversion. (Bug#5906)The MySQL server had issues with certain combinations of basedir and datadir. (Bug#7249)
INFORMATION_SCHEMA.COLUMNShad some inaccurate values for some data types. (Bug#11057)LIKE pattern matching using prefix index didn't return correct result. (Bug#11650)
For several character sets, MySQL incorrectly converted the character code for the division sign to the
eucjpmscharacter set. (Bug#11717)When invoked within a view,
SUBTIME()returned incorrect values. (Bug#11760)SHOW BINARY LOGSdisplayed a file size of 0 for all log files but the current one if the files were not located in the data directory. (Bug#12004)Server-side prepared statements failed for columns with a character set of
ucs2. (Bug#9442)References to system variables in an SQL statement prepared with
PREPAREwere evaluated duringEXECUTEto their values at prepare time, not to their values at execution time. (Bug#9359)For server shutdown on Windows, error messages of the form
Forcing close of threadwere being written to the error log. Now connections are closed more gracefully without generating error messages. (Bug#7403)nuser: 'name'Increased the version number of the
libmysqlclientshared library from 14 to 15 because it is binary incompatible with the MySQL 4.1 client library. (Bug#11893)A recent optimizer change caused
DELETE ... WHERE ... NOT LIKEandDELETE ... WHERE ... NOT BETWEENto not properly identify the rows to be deleted. (Bug#11853)Within a stored procedure that selects from a table, invoking another procedure that requires a write lock for the table caused that procedure to fail with a message that the table was read-locked. (Bug#9565)
Within a stored procedure, selecting from a table through a view caused subsequent updates to the table to fail with a message that the table was read-locked. (Bug#9597)
For a stored procedure defined with
SQL SECURITY DEFINERcharacteristic,CURRENT_USER()incorrectly reported the use invoking the procedure, not the user who defined it. (Bug#7291)Creating a table with a
SETorENUMcolumn with theDEFAULT 0clause caused a server crash if the table's character set wasutf8. (Bug#11819)With strict SQL mode enabled,
ALTER TABLEreported spurious “Invalid default value” messages for columns that had noDEFAULTclause. (Bug#9881)In SQL prepared statements, comparisons could fail for values not equally space-padded. For example,
SELECT 'a' = 'a ';returns 1, butPREPARE s FROM 'SELECT ?=?'; SET @a = 'a', @b = 'a '; PREPARE s FROM 'SELECT ?=?'; EXECUTE s USING @a, @b;incorrectly returned 0. (Bug#9379)Labels in stored routines did not work if the character set was not
latin1. (Bug#7088)Invoking the
DES_ENCRYPT()function could cause a server crash if the server was started without the--des-key-fileoption. (Bug#11643)The server crashed upon execution of a statement that used a stored function indirectly (via a view) if the function was not yet in the connection-specific stored routine cache and the statement would update a
Handler_status variable. This fix allows the use of stored routines underxxxLOCK TABLESwithout explicitly locking themysql.locktable. However, you cannot usemysql.procin statements that will combine locking of it with modifications for other tables. (Bug#11554)The server crashed when dropping a trigger that invoked a stored procedure, if the procedure was not yet in the connection-specific stored routine cache. (Bug#11889)
Selecting the result of an aggregate function for an
ENUMorSETcolumn within a subquery could result in a server crash. (Bug#11821)Incorrect column values could be retrieved from views defined using statements of the form
SELECT * FROM. (Bug#11771)tbl_nameThe
mysql.proctable was not being created properly with the properutf8character set and collation, causing server crashes for stored procedure operations if the server was using a multi-byte character set. To take advantage of the bug fix, mysql_fix_privilege_tables should be run to correct the structure of themysql.proctable. (Bug#11365)Note that it is necessary to run mysql_fix_privileges_tables when upgrading from a previous installation that contains the
mysql.proctable (that is, from a previous 5.0 installation). Otherwise, creating stored procedures might not work.Execution of a prepared statement that invoked a non-existent or dropped stored routine would crash the server. (Bug#11834)
Executing a statement that invoked a trigger would cause problems unless a
LOCK TABLESwas first issued for any tables accessed by the trigger. Note: The exact nature of the problem depended upon the MySQL 5.0 release being used: prior to 5.0.3, this resulted in a crash; from 5.0.3 to 5.0.7, MySQL would issue a warning; in 5.0.9, the server would issue an error. (Bug#8406)The same issue caused
LOCK TABLESto fail followingUNLOCK TABLESif triggers were involved. (Bug#9581)In a shared Windows environment, MySQL could not find its configuration file unless the file was in the
C:\directory. (Bug#5354)
Functionality added or changed:
An attempt to create a
TIMESTAMPcolumn with a display width (for example,TIMESTAMP(6)) now results in a warning. Display widths have not been supported forTIMESTAMPsince MySQL 4.1. (Bug#10466)InnoDB: When creating or extending an InnoDB data file, at most one megabyte at a time is allocated for initializing the file. Previously, InnoDB allocated and initialized 1 or 8 megabytes of memory, even if only a few 16-kilobyte pages were to be written. This improves the performance ofCREATE TABLEininnodb_file_per_tablemode.InnoDB: Various optimizations. Removed unreachable debug code from non-debug builds. Added hints for the branch predictor in gcc. Made assertions occupy less space.InnoDB: Makeinnodb_thread_concurrency=20by default. Bypass the concurrency checking if the setting is greater than or equal to 20.InnoDB: MakeCHECK TABLEkillable. (Bug#9730)Recursion in stored routines is now disabled because it was crashing the server. We plan to modify stored routines to allow this to operate safely in a future release. (Bug#11394)
The handling of
BITcolumns has been improved, and should now be much more reliable in a number of cases. (Bug#10617, Bug#11091, Bug#11572)mysql_real_escape_string()API function now respectsNO_BACKSLASH_ESCAPESSQL mode. (Bug#10214)
Bugs fixed:
SHOW CREATE VIEWdid not take theANSI MODEinto account when quoting identifiers. (Bug#6903)The
mysql_configscript did not handle symbolic linking properly. (Bug#10986)Incorrect results when using
GROUP BY ... WITH ROLLUPon aVIEW. (Bug#11639)Instances of the
VAR_SAMP()function in view definitions were converted toVARIANCE(). This is incorrect becauseVARIANCE()is the same asVAR_POP(), notVAR_SAMP(). (Bug#10651)mysqldump failed when reloading a view if the view was defined in terms of a different view that had not yet been reloaded. mysqldump now creates a dummy table to handle this case. (Bug#10927)
mysqldump could crash for illegal or non-existent table names. (Bug#9358)
The
--no-dataoption for mysqldump was being ignored if table names were given after the database name. (Bug#9558)The
--master-dataoption for mysqldump resulted in no error if the binary log was not enabled. Now an error occurs unless the--forceoption is given. (Bug#11678)DES_ENCRYPT()andDES_DECRYPT()require SSL support to be enabled, but were not checking for it. Checking for incorrect arguments or resource exhaustion was also improved for these functions. (Bug#10589)When used in joins,
SUBSTRING()failed to truncate to zero any string values that could not be converted to numbers. (Bug#10124)mysqldump --xmldid not formatNULLcolumn values correctly. (Bug#9657)There was a compression algorithm issue with
myisampackfor very large datasets (where the total size of all records in a single column was on the order of 3 GB or more) on 64-bit platforms. (A fix for other platforms was made in MySQL 5.0.6.) (Bug#8321)Temporary tables were created in the data directory instead of
tmpdir. (Bug#11440)MySQL would not compile correctly on QNX due to missing
rint()function. (Bug#11544)A
SELECT DISTINCTwould work correctly with acol_nameMyISAMtable only when there was an index oncol_name. (Bug#11484)The server would lose table-level
CREATE VIEWandSHOW VIEWprivileges following aFLUSH PRIVILEGESor server restart. (Bug#9795)In strict mode, an
INSERTinto a view that did not include a value for aNOT NULLcolumn but that did include aWHEREtest on the same column would succeed, This happened even though theINSERTshould have been prevented due to the failure to supply a value for theNOT NULLcolumn. (Bug#6443)Running a
CHECK TABLESon multiple views crashed the server. (Bug#11337)When a table had a primary key containing a
BLOBcolumn, creation of another index failed with the errorBLOB/TEXT column used in key specification without keylength, even when the new index did not contain aBLOBcolumn. (Bug#11657)NDB Cluster: When trying to open a table that could not be discovered or unpacked, cluster would return error codes which the MySQL server falsely interpreted as operating system errors. (Bug#103651)
Manually inserting a row with
host=''intomysql.tables_privand performing aFLUSH PRIVILEGESwould cause the server to crash. (Bug#11330)A cursor using a query with a filter on a
DATEorDATETIMEcolumn would cause the server to crash server after the data was fetched. (Bug#11172)Closing a cursor that was already closed would cause MySQL to hang. (Bug#9814)
Using
CONCAT_WSon a column setNOT NULLcaused incorrect results when used in aLEFT JOIN. (Bug#11469)Signed
BIGINTwould not accept-9223372036854775808as aDEFAULTvalue. (Bug#11215)Views did not use indexes on all appropriate queries. (Bug#10031)
For
MEMORYtables, it was possible for updates to be performed using outdated key statistics when the updates involved only very small changes in a very few rows. This resulted in the random failures of queries such asUPDATE t SET col = col + 1 WHERE col_key = 2;where the same query with noWHEREclause would succeed. (Bug#10178)Optimizer performed range check when comparing unsigned integers to negative constants, could cause errors. (Bug#11185)
Wrong comparison method used in
VIEWwhen relaxed date syntax used (for example,2005.06.10). (Bug#11325)The
ENCRYPT()andSUBSTRING_INDEX()functions would cause errors when used with aVIEW. (Bug#7024)Clients would hang following some errors with stored procedures. (Bug#9503)
Combining cursors and subqueries could cause server crash or memory leaks. (Bug#10736)
If a prepared statement cursor is opened but not completely fetched, attempting to open a cursor for a second prepared statement will fail. (Bug#10794)
Note: Starting with version 5.0.8, changes for MySQL Cluster can be found in the combined Change History.
Functionality added or changed:
Warning: Incompatible change: Previously, conversion of
DATETIMEvalues to numeric form by adding zero produced a result inYYYYMMDDHHMMSSformat. The result ofDATETIME+0is now inYYYYMMDDHHMMSS.000000format. (Bug#12268)MEMORYtables now support indexes of up to 500 bytes. See Section 14.4, “TheMEMORY(HEAP) Storage Engine”. (Bug#10566)New
SQL_MODE-NO_ENGINE_SUBSTITUTIONPrevents automatic substitution of storage engine when the requested storage engine is disabled or not compiled in. (Bug#6877)The statements
CREATE TABLE,TRUNCATE TABLE,DROP DATABASE, andCREATE DATABASEcause an implicit commit. (Bug#6883)Expanded on information provided in general log and slow query log for prepared statements. (Bug#8367, Bug#9334)
Where a
GROUP BYquery uses a grouping column from the query'sSELECTclause, MySQL now issues a warning. This is done because the SQL standard states that any grouping column must unambiguously reference a column of the table resulting from the query'sFROMclause, and allowing columns from theSELECTclause to be used as grouping columns is a MySQL extension to the standard.By way of example, consider the following table:
CREATE TABLE users ( userid INT NOT NULL PRIMARY KEY, username VARCHAR(25), usergroupid INT NOT NULL );
MySQL allows you to use the alias in this query:
SELECT usergroupid AS id, COUNT(userid) AS number_of_users FROM users GROUP BY id;
However, the SQL standard requires that the column name be used, as shown here:
SELECT usergroupid AS id, COUNT(userid) AS number_of_users FROM users GROUP BY usergroupid;
Queries such as the first of the two shown above will continue to be supported in MySQL; however, beginning with MySQL 5.0.8, using a column alias in this fashion will generate a warning. Note that in the event of a collision between column names and/or aliases used in joins, MySQL attempts to resolve the conflict by giving preference to columns arising from tables named in the query's
FROMclause. (Bug#11211)The granting or revocation of privileges on a stored routine is no longer performed when running the server with
--skip-grant-tableseven after the statementSET @@global.automatic_sp_privileges=1;has been executed. (Bug#9993)Added support for
B'10'syntax for bit literal. (Bug#10650)
Bugs fixed:
Security fix: On Windows systems, a user with any of the following privileges
REFERENCESCREATE TEMPORARY TABLESGRANT OPTIONCREATESELECT
on
*.*could crash mysqld by issuing aUSE LPT1;orUSE PRN;command. In addition, any of the commandsUSE NUL;,USE CON;,USE COM1;, orUSE AUX;would report success even though the database was not in fact changed. Note: Although this bug was thought to be fixed previously, it was later discovered to be present in the MySQL 5.0.7-beta release for Windows. (Bug#9148, CVE-2005-0799A
CREATE TABLEstatement would crash the server when no database was selected. (Bug#11028)db_name.tbl_nameLIKE ...SELECT DISTINCTqueries orGROUP BYqueries withoutMIN()orMAX()could return inconsistent results for indexed columns. (Bug#11044)The
SHOW INSTANCE OPTIONScommand in MySQL Instance Manager displayed option values incorrectly for options for which no value had been given. (Bug#11200)An outer join with an empty derived table (a result from a subquery) returned no result. (Bug#11284)
An outer join with an
ONcondition that evaluated to false could return an incorrect result. (Bug#11285)mysqld_safewould sometimes fail to remove the pid file for the oldmysqlprocess after a crash. As a result, the server would fail to start due to a falseA mysqld process already exists...error. (Bug#11122)CAST( ... AS DECIMAL) didn't work for strings. (Bug#11283)NULLIF()function could produce incorrect results if first argument isNULL. (Bug#11142)Setting
@@SQL_MODE = NULLcaused an erroneous error message. (Bug#10732)Converting a
VARCHARcolumn having an index to a different type (such asTINYTEXT) gave rise to an incorrect error message. (Bug#10543)Note that this bugfix induces a slight change in the behavior of indexes: If an index is defined to be the same length as a field (or is left to default to that field's length), and the length of the field is later changed, then the index will adopt the new length of the field. Previously, the size of the index did not change for some field types (such as
VARCHAR) when the field type was changed.sql_data_accesscolumn ofroutinestable ofINFORMATION_SCHEMAwas empty. (Bug#11055)A
CAST()value could not be included in aVIEW. (Bug#11387)Server crashed when using
GROUP BYon the result of aDIVoperation on aDATETIMEvalue. (Bug#11385)Possible
NULLvalues inBLOBcolumns could crash the server when aBLOBwas used in aGROUP BYquery. (Bug#11295)Fixed 64 bit compiler warning for packet length in replication. (Bug#11064)
Multiple range accesses in a subquery cause server crash. (Bug#11487)
An issue with index merging could cause suboptimal index merge plans to be chosen when searching by indexes created on
DATEcolumns. The same issue caused the InnoDB storage engine to issue the warningusing a partial-field key prefix in search. (Bug#8441)The
mysqlhotcopyscript was not parsing the output ofSHOW SLAVE STATUScorrectly when called with the--record_log_posoption. (Bug#7967)SELECT * FROMreturned incorrect results when called from a stored procedure, wheretabletablehad a primary key. (Bug#10136)When used in defining a view, the
TIME_FORMAT()function failed with calculated values, for example, when passed the value returned bySEC_TO_TIME(). (Bug#7521)SELECT DISTINCT ... GROUP BYreturned multiple rows (it should return a single row). (Bug#8614)constantINSERT INTO SELECT FROMproduced incorrect result when usingviewORDER BY. (Bug#11298)Fixed hang/crash with Boolean full-text search where a query contained more query terms that one-third of the query length (it could be achieved with truncation operator: 'a*b*c*d*'). (Bug#7858)
Fixed column name generation in
VIEWcreation to ensure there are no duplicate column names. (Bug#7448)An
ORDER BYclause sometimes had no effect on the ordering of a result when selecting specific columns (as opposed to usingSELECT *) from a view. (Bug#7422)Some data definition statements (
CREATE TABLEwhere the table was not a temporary table,TRUNCATE TABLE,DROP DATABASE, andCREATE DATABASE) were not being written to the binary log after aROLLBACK. This also caused problems with replication. (Bug#6883)Calling a stored procedure that made use of an
INSERT ... SELECT ... UNION SELECT ...query caused a server crash. (Bug#11060)Selecting from a view defined using
SELECT SUM(DISTINCT ...)caused an error; attempting to execute aSELECT * FROM INFORMATION_SCHEMA.TABLESquery after defining such a view crashed the server. (Bug#7015)The mysql client would output a prompt twice following input of very long strings, because it incorrectly assumed that a call to the _cgets() function would clear the input buffer. (Bug#10840)
A three byte buffer overflow in the client functions caused improper exiting of the client when reading a command from the user. (Bug#10841)
Fixed a problem where a stored procedure caused a server crash if the query cache was enabled. (Bug#9715)
SHOW CREATE DATABASE INFORMATION_SCHEMAreturned an “unknown database” error. (Bug#9434)Corrected a problem with
IFNULL()returning an incorrect result on 64-bit systems. (Bug#11235)Fixed a problem resolving table names with
lower_case_table_names=2when the table name lettercase differed in theFROMandWHEREclauses. (Bug#9500)Fixed server crash due to some internal functions not taking into account that for multi-byte character sets,
CHARcolumns could exceed 255 bytes andVARCHARcolumns could exceed 65,535 bytes. (Bug#11167)Fixed locking problems for multiple-statement
DELETEstatements performed within a stored routine, such as incorrectly locking a to-be-modified table with a read lock rather than a write lock. (Bug#11158)Fixed a portability problem testing for
crypt()support that caused compilation problems when using OpenSSL/yaSSL on HP-UX and Mac OS X. (Bug#10675, Bug#11150)The hostname cache was not working. (Bug#10931)
On Windows,
mysqlshowdid not interpret wildcard characters properly if they were given in the table name argument. (Bug#10947)The default hostname for MySQL server was always
mysql. (Bug#11174)Using
PREPAREto prepare a statement that invoked a stored routine that deallocated the prepared statement caused a server crash. This is prevented by disabling dynamic SQL within stored routines. (Bug#10975) (Note: This restriction was lifted in 5.0.13 for stored procedures, but not stored functions or triggers.)Using
PREPAREto prepare a statement that invoked a stored routine that executed the prepared statement caused aPackets out of ordererror the second time the routine was invoked. This is prevented by disabling dynamic SQL within stored routines. (Bug#7115) (Note: This restriction was lifted in 5.0.13 for stored procedures, but not stored functions or triggers.)Using prepared statements within a stored routine (
PREPARE,EXECUTE,DEALLOCATE) could cause the client connection to be dropped after the routine returned. This is prevented by disabling dynamic SQL within stored routines. (Bug#10605) (Note: This restriction was lifted in 5.0.13 for stored procedures, but not stored functions or triggers.)When using a cursor with a prepared statement, the first execution returned the correct result but was not cleaned up properly, causing subsequent executions to return incorrect results. (Bug#10729)
MySQL Cluster: Connections between data nodes and management nodes were not being closed following shutdown of
ndb_mgmd. (Bug#11132)MySQL Cluster: mysqld processes would not reconnect to cluster following restart of
ndb_mgmd. (Bug#11221)MySQL Cluster: Fixed problem whereby data nodes would fail to restart on 64-bit Solaris (Bug#9025)
MySQL Cluster: Calling
ndb_select_count()crashed the cluster when running on Red Hat Enterprise 4/64-bit/Opteron. (Bug#10058)MySQL Cluster: Insert records were incorrectly applied by
ndb_restore, thus making restoration from backup inconsistent if the binlog contained inserts. (Bug#11166)MySQL Cluster: Cluster would time out and crash after first query on 64-bit Solaris 9. (Bug#8918)
MySQL Cluster:
ndb_mgmclientshowcommand displayed incorrect output after master data node failure. (Bug#11050)MySQL Cluster: A delete performed as part of a transaction caused an erroneous result. (Bug#11133)
MySQL Cluster: Not allowing sufficient parallelism in cluster configuration (for example,
NoOfTransactionstoo small) causedndb_restoreto fail without providing any error messages. (Bug#10294)MySQL Cluster: When using dynamically allocated ports on Linux, cluster would hang on initial startup. (Bug#10893)
MySQL Cluster: Setting TransactionInactiveTimeout= 0 did not result in an infinite timeout. (Bug#11290)
InnoDB: Enforce maximumCHAR_LENGTH()of UTF-8 data inON UPDATE CASCADE. (Bug#10409)InnoDB: Pad UTF-8VARCHARcolumns with0x20. Pad UCS2CHARcolumns with0x0020. (Bug#10511)
Functionality added or changed:
Security improvement: Applied a patch to fix a UDF library-loading vulnerability that could result in a buffer overflow and code execution. (http://www.appsecinc.com/resources/alerts/mysql/2005-002.html)
Added
mysql_set_character_set()C API function for setting the default character set of the current connection. This allows clients to affect the character set used bymysql_real_escape_string(). (Bug#8317)The behavior of the
Last_query_costsystem variable has been changed. The default value is now 0 (rather than -1) and it now has session-level scope (rather than being global). See Section 5.2.5, “Status Variables”, for additional information.All characters occurring on the same line following the
DELIMITERkeyword will be set as delimiter. For example,DELIMITER :;will set:;as the delimiter. This behavior is now consistent between MySQL 5.1 and MySQL 5.0. (Bug#9879)The
table,type, androwscolumns ofEXPLAINoutput can now beNULL. This is required for usingEXPLAINonSELECTqueries that use no tables (for example,EXPLAIN SELECT 1). (Bug#9899)Placeholders now can be used for
LIMITin prepared statements. (Bug#7306)SHOW BINARY LOGSnow displays aFile_sizecolumn that indicates the size of each file.The
--delayed-insertoption for mysqldump has been disabled to avoid causing problems with storage engines that do not supportINSERT DELAYED. (Bug#7815)Improved the optimizer to be able to use indexes for expressions of the form
indexed_colNOT IN (val1,val2, ...)indexed_colNOT BETWEENval1ANDval2Removed
mysqlshutdown.exeandmysqlwatch.exefrom the Windows “No Installer” distribution (they had already been removed from the “With Installer” distribution before). Removed those programs from the source distribution.Removed
WinMySQLAdminfrom the source distribution and from the “No Installer” Windows distribution (it had already been removed from the “With Installer” distribution before).InnoDB: In stored procedures and functions,InnoDBno longer takes full explicit table locks for every involved table. Only `intention' locks are taken, similar to those in the execution of an ordinary SQL statement. This greatly reduces the number of deadlocks.
Bugs fixed:
Security update: A user with limited privileges could obtain information about the privileges of other users by querying objects in the
INFORMATION_SCHEMAdatabase for which that user did not have the requisite privileges. (Bug#10964)Triggers with dropped functions caused crashes. (Bug#5893)
Failure of a
BEFOREtrigger did not prevent the triggering statement from performing its operation on the row for which the trigger error occurred. Now the triggering statement fails as described in Section 18.3, “Using Triggers”. (Bug#10902)Issuing a write lock for a table from one client prevented other clients from accessing the table's metadata. For example, if one client issued a
LOCK TABLES, then a second client attempting to execute amydb.mytableWRITEUSEwould hang. (Bug#9998)mydb;The
LAST_DAY()failed to returnNULLwhen supplied with an invalid argument. See Section 12.6, “Date and Time Functions”. (Bug#10568)The functions
COALESCE(),IF(), andIFNULL()performed incorrect conversions of their arguments. (Bug#9939)The
TIME_FORMAT()function returned incorrect results with some format specifiers. See Section 12.6, “Date and Time Functions”. (Bug#10590)Dropping stored routines when the MySQL server had been started with
--skip-grant-tablesgenerated extraneous warnings. (Bug#9993)A problem with the
my_global.hfile caused compilation of MySQL to fail on single-processor Linux systems running 2.6 kernels. (Bug#10364)The ucs2_turkish_ci collation failed with upper('i'). UPPER/LOWER now can return a string with different length. (Bug#8610)
OPTIMIZE of InnoDB table does not return 'Table is full' if out of tablespace. (Bug#8135)
GROUP BY queries with ROLLUP returned wrong results for expressions containing group by columns. (Bug#7894)
Fixed bug in
FIELD()function where value list containsNULL. (Bug#10944)Corrected a problem where an incorrect data type was returned in the result set metadata when using a prepared
SELECT DISTINCTstatement to select from a view. (Bug#11111)Fixed bug in the MySQL Instance manager that caused the version to always be
unknownwhenSHOW INSTANCE STATUSwas issued. (Bug#10229)Using
ORDER BYto sort the results of anIF()that contained aFROM_UNIXTIME()expression returned incorrect results due to integer overflow. (Bug#9669)Fixed a server crash resulting from accessing
InnoDBtables within stored functions. This is handled by prohibiting statements that do an implicit or explicit commit or rollback within stored functions or triggers. (Bug#10015)Fixed a server crash resulting from the second invocation of a stored procedure that selected from a view defined as a join that used
ONin the join conditions. (Bug#6866)Using
ALTER TABLEfor a table that had a trigger caused a crash when executing a statement that activated the trigger, and also a crash later withUSEfor the database containing the table. (Bug#5894)db_nameFixed a server crash resulting from an attempt to allocate too much memory when
GROUP BYandblob_colCOUNT(DISTINCT)were used. (Bug#11088)Fixed a portability problem for compiling on Windows with Visual Studio 6. (Bug#11153)
The incorrect sequence of statements
HANDLERwithout a precedingtbl_nameREADindex_nameNEXTHANDLERfor antbl_nameREADindex_name= (value_list)InnoDBtable resulted in a server crash rather than an error. (Bug#5373)On Windows, with
lower_case_table_namesset to 2, usingALTER TABLEto alter aMEMORYorInnoDBtable that had a mixed-case name also improperly changed the name to lowercase. (Bug#9660)The server timed out SSL connections too quickly on Windows. (Bug#8572)
Executing
LOAD INDEX INTO CACHEfor a table while other threads where selecting from the table caused a deadlock. (Bug#10602)Fixed a server crash resulting from
CREATE TABLE ... SELECTthat selected from a table being altered byALTER TABLE. (Bug#10224)The
FEDERATEDstorage engine properly handled outer joins, but not inner joins. (Bug#10848)Consistently report
INFORMATION_SCHEMAtable names in uppercase inSHOW TABLE STATUSoutput. (Bug#10059)Fixed a failure of
WITH ROLLUPto sum values properly. (Bug#10982)Triggers were not being activated for multiple-table
UPDATEorDELETEstatements. (Bug#5860)INSERT BEFOREtriggers were not being activated forINSERT ... SELECTstatements. (Bug#6812)INSERT BEFOREtriggers were not being activated for implicit inserts (LOAD DATA). (Bug#8755)If a stored function contained a
FLUSHstatement, the function crashed when invoked.FLUSHnow is disallowed within stored functions. (Bug#8409)Multiple-row
REPLACEcould fail on a duplicate-key error when having oneAUTO_INCREMENTkey and one unique key. (Bug#11080)Fixed a server crash resulting from invalid string pointer when inserting into the
mysql.hosttable. (Bug#10181)Multiple-table
DELETEdid always delete on the fly from the first table that was to be deleted from. In some cases, when using many tables and it was necessary to access the same row twice in the first table, we could miss some rows-to-be-deleted from other tables. This is now fixed.The
mysql_next_result()function could hang if you were executing many statements in amysql_real_query()call and one of those statements raised an error. (Bug#9992)The combination of
COUNT(),DISTINCT, andCONCAT()sometimes triggered a memory deallocation bug on Windows resulting in a server crash. (Bug#9593)InnoDB: Do very fast shutdown only ifinnodb_fast_shutdown=2, but wait for threads to exit and release allocated memory ifinnodb_fast_shutdown=1. Starting with MySQL/InnoDB 5.0.5, InnoDB would do brutal shutdown also wheninnodb_fast_shutdown=1. (Bug#9673)InnoDB: FixedInnoDB: Error: stored_select_lock_type is 0 inside ::start_stmt()!in a stored procedure call ifinnodb_locks_unsafe_for_binlogwas set inmy.cnf. (Bug#10746)InnoDB: Fixed a duplicate key error that occurred withREPLACEin a table with anAUTO-INCcolumn. (Bug#11005)MySQL would pass an incorrect key length to storage engines for
MIN(). This could cause warningsInnoDB: Warning: using a partial-field key prefix in search.in the.errlog. (Bug#11039, same as Bug#13218 in MySQL 4.1.15)Fixed a server crash for
INSERTorUPDATEwhen theWHEREclause contained a correlated subquery that referred to a column of the table being modified. (Bug#6384)Fixed a problem causing an incorrect result for columns that include an aggregate function as part of an expression when
WITH ROLLUPis added toGROUP BY. (Bug#7914)Fixed a problem with returning an incorrect result from a view that selected a
COALESCE()expression from the result of an outer join. (Bug#9938)MySQL was adding a
DEFAULTclause toENUMcolumns that included no explicitDEFAULTand were defined asNOT NULL. (This is supposed to happen only for columns that areNULL.) (Bug#6267)Corrected inappropriate error messages that were displayed when attempting to set the read-only
warning_countanderror_countsystem variables. (Bug#10339)
Functionality added or changed:
Incompatible change:
MyISAMandInnoDBtables created withDECIMALcolumns in MySQL 5.0.3 to 5.0.5 will appear corrupt after an upgrade to MySQL 5.0.6. Dump such tables with mysqldump before upgrading, and then reload them after upgrading. (The same incompatibility will occur for these tables created in MySQL 5.0.6 after a downgrade to MySQL 5.0.3 to 5.0.5.) (Bug#10465, Bug#10625)Incompatible change: The behavior of
LOAD DATA INFILEandSELECT ... INTO OUTFILEhas changed when theFIELDS TERMINATED BYandFIELDS ENCLOSED BYvalues both are empty. Formerly, a column was read or written the display width of the column. For example,INT(4)was read or written using a field with a width of 4. Now columns are read and written using a field width wide enough to hold all values in the field. However, data files written before this change was made might not be reloaded correctly withLOAD DATA INFILEfor MySQL 4.1.12 and up. This change also affects data files read by mysqlimport and written by mysqldump --tab, which useLOAD DATA INFILEandSELECT ... INTO OUTFILE. For more information, see Section 13.2.5, “LOAD DATA INFILESyntax”. (Bug#12564)The precision of the
DECIMALdata type has been increased from 64 to 65 decimal digits.Added the
div_precision_incrementsystem variable, which indicates the number of digits of precision by which to increase the result of division operations performed with the/operator.Added the
log_bin_trust_routine_creatorssystem variable, which applies when binary logging is enabled. It controls whether stored routine creators can be trusted not to create stored routines that will cause unsafe events to be written to the binary log.Added the
--log-bin-trust-routine-creatorsserver option for setting thelog_bin_trust_routine_creatorssystem variable from the command line.Implemented the
STMT_ATTR_PREFETCH_ROWSoption for themysql_stmt_attr_set()C API function. This sets how many rows to fetch at a time when using cursors with prepared statements.The
GRANTandREVOKEstatements now support anobject_typeclause to be used for disambiguating whether the grant object is a table, a stored function, or a stored procedure. Use of this clause requires that you upgrade your grant tables. See Section 5.5.4, “mysql_fix_privilege_tables — Upgrade MySQL System Tables”. (Bug#10246)Added
REFERENCED_TABLE_SCHEMA,REFERENCED_TABLE_NAME, andREFERENCED_COLUMN_NAMEcolumns to theKEY_COLUMN_USAGEtable ofINFORMATION_SCHEMA. (Bug#9587)Added a
--show-warningsoption to mysql to cause warnings to be shown after each statement if there are any. This option applies to interactive and batch mode. In interactive mode,\wand\Wmay be used to enable and disable warning display. (Bug#8684)Removed a limitation that prevented use of FIFOs as logging targets (such as for the general query log). This modification does not apply to the binary log and the relay log. (Bug#8271)
Added a
--debugoption to my_print_defaults.When the server cannot read a table because it cannot read the
.frmfile, print a message that the table was created with a different version of MySQL. (This can happen if you create tables that use new features and then downgrade to an older version of MySQL.) (Bug#10435)SHOW VARIABLESnow shows theslave_compressed_protocol,slave_load_tmpdirandslave_skip_errorssystem variables. (Bug#7800)Removed unused system variable
myisam_max_extra_sort_file_size.Changed default value of
myisam_data_pointer_sizefrom 4 to 6. This allows us to avoidtable is fullerrors for most cases.The variable
concurrent_insertnow takes 3 values. Setting this to 2 changesMyISAMto do concurrent inserts to end of table if table is in use by another thread.New
/*>prompt for mysql. This prompt indicates that a/* ... */comment was begun on an earlier line and the closing*/sequence has not yet been seen. (Bug#9186)If strict SQL mode is enabled,
VARCHARandVARBINARYcolumns with a length greater than 65,535 no longer are silently converted toTEXTorBLOBcolumns. Instead, an error occurs. (Bug#8295, Bug#8296)The
INFORMATION_SCHEMA.SCHEMATAtable now has aDEFAULT_COLLATION_NAMEcolumn. (Bug#8998)InnoDB: When the maximum length ofSHOW INNODB STATUSoutput would be exceeded, truncate the beginning of the list of active transactions, instead of truncating the end of the output. (Bug#5436)InnoDB: Ifinnodb_locks_unsafe_for_binlogoption is set and the isolation level of the transaction is not set to serializable thenInnoDBuses a consistent read for select in clauses likeINSERT INTO ... SELECTandUPDATE ... (SELECT)that do not specifyFOR UPDATEorIN SHARE MODE. Thus no locks are set to rows read from selected table.Updated version of
libeditto 2.9. (Bug#2596)Removed
mysqlshutdown.exeandmysqlwatch.exefrom the Windows “With Installer” distribution.
Bugs fixed:
An error in the implementation of the
MyISAMcompression algorithm causedmyisampackto fail with very large sets of data (total size of all the records in a single column needed to be >= 3 GB in order to trigger this issue). (Bug#8321)Statements that create and use stored routines were not being written to the binary log, which affects replication and data recovery options. (Bug#2610) Stored routine-related statements now are logged, subject to the issues and limitations discussed in Section 17.4, “Binary Logging of Stored Routines and Triggers”.
Disabled binary logging within stored routines to avoid writing spurious extra statements to the binary log. For example, if a routine
p()executes anINSERTstatement, then forCALL p(), theCALLstatement appears in the binary log, but not theINSERTstatement. (Bug#9100)Statements that create and drop triggers were not being written to the binary log, which affects replication and data recovery options. (Bug#10417) Trigger-related statements now are logged, subject to the issues and limitations discussed in Section 17.4, “Binary Logging of Stored Routines and Triggers”.
The
mysql_stmt_execute()andmysql_stmt_reset()C API functions now close any cursor that is open for the statement, which prevents a server crash. (Bug#9478)The
mysql_stmt_attr_set()C API function now returns an error for option values that are defined inmysql.hbut not yet implemented, such asCURSOR_TYPE_SCROLLABLE. (Bug#9643)MERGEtables could fail on Windows due to incorrect interpretation of pathname separator characters for filenames in the.MRGfile. (Bug#10687)Fixed a server crash for
INSERT ... ON DUPLICATE KEY UPDATEwithMERGEtables, which do not have unique indexes. (Bug#10400)Fix
FORMAT()to do better rounding for double values (for example,FORMAT(4.55,1)returns4.6, not4.5). (Bug#9060)Disallow use of
SESSIONorGLOBALfor user variables or local variables in stored routines. (Bug#9286)Fixed a server crash when using
GROUP BY ... WITH ROLLUPon an indexed column in anInnoDBtable. (Bug#9798)In strict SQL mode, some assignments to numeric columns that should have been rejected were not (such as the result of an arithmetic expression or an explicit
CAST()operation). (Bug#6961)CREATE TABLE t AS SELECT UUID()created aVARCHAR(12)column, which is too small to hold the 36-character result fromUUID(). (Bug#9535)Fixed a server crash in the
BLACKHOLEstorage engine. (Bug#10175)Fixed a server crash resulting from repeated calls to
ABS()when the argument evaluated toNULL. (Bug#10599)For a user-defined function invoked from within a prepared statement, the UDF's initialization routine was invoked for each execution of the statement, but the deinitialization routine was not. (It was invoked only when the statement was closed.) Similarly, when invoking a UDF from within a trigger, the initialization routine was invoked but the deinitialization routine was not. For UDFs that have an expensive deinit function (such as
myperl, this bugfix will have negative performance consequences. (Bug#9913)Portability fix for Cygwin: Don't use
#pragma interfacein source files. (Bug#10241)Fix
CREATE TABLE ... LIKEto work whenlower_case_table_namesis set on a case-sensitive filesystem and the source table name is not given in lowercase. (Bug#9761)Fixed a server crash resulting from a
CHECK TABLEstatement where the arguments were a view name followed by a table name. (Bug#9897)Within a stored procedure, attempting to update a view defined as an inner join failed with a
Table 'error. (Bug#9481)tbl_name' was locked with a READ lock and can't be updatedFixed a problem with
INFORMATION_SCHEMAtables being inaccessible depending on lettercase used to refer to them. (Bug#10018)my_print_defaults was ignoring the
--defaults-extra-fileoption or crashing when the option was given. (Bug#9136, Bug#9851)The
INFORMATION_SCHEMA.COLUMNStable was missing columns of views for which the user has access. (Bug#9838)Fixed a mysqldump crash that occurred with the
--complete-insertoption when dumping tables with a large number of long column names. (Bug#10286)Corrected a problem where
DEFAULTvalues were not assigned properly toBIT(1)orCHAR(1)columns if certain other columns preceded them in the table definition. (Bug#10179)For
MERGEtables, avoid writing absolute pathnames in the.MRGfile for the names of the constituentMyISAMtables so that if the data directory is moved,MERGEtables will not break. For mysqld, write just theMyISAMtable name if it is in the same database as theMERGEtable, and a path relative to the data directory otherwise. For the embedded servers, absolute pathnames may still be used. (Bug#5964)Corrected a problem resolving outer column references in correlated subqueries when using the prepared statements. (Bug#10041)
Corrected the error message for exceeding the
MAX_CONNECTIONS_PER_HOURlimit to saymax_connections_per_hourinstead ofmax_connections. (Bug#9947)Fixed incorrect memory block allocation for the query cache in the embedded server. (Bug#9549)
Corrected an inability to select from a view within a stored procedure. (Bug#9758)
Fixed a server crash resulting from use of
AVG(DISTINCT)withGROUP BY ... WITH ROLLUP. (Bug#9799)Fixed a server crash resulting from use of
DISTINCT AVG()withGROUP BY ... WITH ROLLUP. (Bug#9800)Fixed a server crash resulting from use of a
CHARorVARCHARcolumn withMIN()orMAX()andGROUP BY ... WITH ROLLUP. (Bug#9820)Fixed a server crash resulting from use of
SELECT DISTINCTwith a prepared statement that uses a cursor. (Bug#9520)Fixed server crash resulting from multiple calls to a stored procedure that assigned the result of a subquery to a variable or compared it to a value with
IN. (Bug#5963)Selecting from a single-table view defined on multiple-table views caused a server crash. (Bug#8528)
If the file named by a
--defaults-extra-fileoption does not exist or is otherwise inaccessible, an error now occurs. (Bug#5056)net_read_timeoutandnet_write_timeoutwere not being respected on Windows. (Bug#9721)SELECTfromINFORMATION_SCHEMAtables failed if the statement has aGROUP BYclause and an aggregate function in the select list. (Bug#9404)Corrected some failures of prepared statements for SQL (
PREPAREplusEXECUTE) to return all rows for someSELECTstatements. (Bug#9096, Bug#9777)Remove extra slashes in
--tmpdirvalue (for example, convert/var//tmpto/var/tmp, because they caused various errors. (Bug#8497)Added
Create_routine_priv,Alter_routine_priv, andExecute_privprivileges to themysql.hostprivilege table. (They had been added tomysql.dbin MySQL 5.0.3 but not to thehosttable.) (Bug#8166)Fixed configure to properly recognize whether NPTL is available on Linux. (Bug#2173)
Incomplete results were returned from
INFORMATION_SCHEMA.COLUMNSforINFORMATION_SCHEMAtables for non-rootusers. (Bug#10261)Fixed a portability problem in compiling
mysql.ccwith VC++ on Windows. (Bug#10245)SELECT 0/0returned0rather thanNULL. (Bug#10404)MAX()for anINT UNSIGNED(unsigned 4-byte integer) column could return negative values if the column contained values larger than 231. (Bug#9298)SHOW CREATE VIEWgot confused and could not find the view if there was a temporary table with the same name as the view. (Bug#8921)Fixed a deadlock resulting from use of
FLUSH TABLES WITH READ LOCKwhile anINSERT DELAYEDstatement is in progress. (Bug#7823)The optimizer was choosing suboptimal execution plans for certain outer joins where the right table of a left join (or left table of a right join) had both
ONandWHEREconditions. (Bug#10162)RENAME TABLEfor anARCHIVEtable failed if the.arnfile was not present. (Bug#9911)Invoking a stored function that executed a
SHOWstatement resulted in a server crash. (Bug#8408)Fixed problems with static variables and do not link with
libsupc++to allow building on FreeBSD 5.3. (Bug#9714)Fixed some awk script portability problems in cmd-line-utils/libedit/makelist.sh. (Bug#9954)
Fixed a problem with mishandling of
NULLkey parts in hash indexes onVARCHARcolumns, resulting in incorrect query results. (Bug#9489, Bug#10176)InnoDB: Fixed a critical bug in InnoDBAUTO_INCREMENT: it could assign the same value for several rows. (Bug#10359)InnoDB: All InnoDB bug fixes from 4.1.12 and earlier versions, and also the fixes to bugs #10335 and #10607 listed in the 4.1.13 change notes.
No public release of MySQL 5.0.5 was made. The changes described in this section are available in MySQL 5.0.6.
Functionality added or changed:
Added support for the
BITdata type to theMEMORY,InnoDB, andBDBstorage engines.SHOW VARIABLESno longer displays the deprecatedlog_updatesystem variable. (Bug#9738)The behavior controlled by the
--innodb-fast-shutdownoption now can be changed at runtime by setting the value of the globalinnodb_fast_shutdownsystem variable. It now accepts values 0, 1 and 2 (except on Netware where 2 is disabled). If set to 2, then when the MySQL server shuts down,InnoDBwill just flush its logs and shut down brutally (and quickly) as if a MySQL crash had occurred; no committed transaction will be lost, but a crash recovery will be done at next startup.
Bugs fixed:
Security fix: If mysqld was started with
--user=, it would run using the privileges of the account it was invoked from, even if that wasnon_existent_userroot. (Bug#9833)Corrected a failure to resolve a column reference correctly for a
LEFT JOINthat compared a join column to anINsubquery. (Bug#9338)Fixed a problem where, after an internal temporary table in memory became too large and had to be converted to an on-disk table, the error indicator was not cleared and the query failed with error 1023 (
Can't find record in ''). (Bug#9703)Multiple-table updates could produce spurious data-truncation warnings if they used a join across columns that are indexed using a column prefix. (Bug#9103)
Fixed a string-length comparison problem that caused mysql to fail loading dump files containing certain ‘
\’-sequences. (Bug#9756)Fixed a failure to resolve a column reference properly when an outer join involving a view contained a subquery and the column was used in the subquery and the outer query. (Bug#6106, Bug#6107)
Use of a subquery that used
WITH ROLLUPin theFROMclause of the main query sometimes resulted in aColumn cannot be nullerror. (Bug#9681)Fixed a memory leak that occurred when selecting from a view that contained a subquery. (Bug#10107)
Fixed an optimizer bug in computing the union of two ranges for the
ORoperator. (Bug#9348)Fixed a segmentation fault in mysqlcheck that occurred when the last table checked in
--auto-repairmode returned an error (such as the table being aMERGEtable). (Bug#9492)SET @var= CAST(NULL AS [INTEGER|CHAR])now sets the result type of the variable toINTEGER/CHAR. (Bug#6598)Incorrect results were returned for queries of the form
SELECT ... LEFT JOIN ... WHERE EXISTS (, where the subquery selected rows based on ansubquery)IS NULLcondition. (Bug#9516)Executing
LOCK TABLESand then calling a stored procedure caused an error and resulting in the server thinking that no stored procedures exist. (Bug#9566)Selecting from a view containing a subquery caused the server to hang. (Bug#8490)
Within a stored procedure, attempting to execute a multiple-table
UPDATEfailed with aTable 'error. (Bug#9486)tbl_name' was locked with a READ lock and can't be updatedStarting mysqld with the
--skip-innodband--default-storage-engine=innodb(or--default-table-type=innodbcaused a server crash. (Bug#9815)Queries containing
CURRENT_USER()incorrectly were registered in the query cache. (Bug#9796)Setting the
storage_enginesystem variable toMEMORYsucceeded, but retrieving the variable resulted in a value ofHEAP(the old name for theMEMORYstorage engine) rather thanMEMORY. (Bug#10039)mysqlshow displayed an incorrect row count for tables. (Bug#9391)
The server died with signal 11 if a non-existent location was specified for the location of the binary log. Now the server exits after printing an appropriate error message. (Bug#9542)
Fixed a problem in the client/server protocol where the server closed the connection before sending the final error message. The problem could show up as a
Lost connection to MySQL server during querywhen attempting to connect to access a non-existent database. (Bug#6387, Bug#9455)Fixed a
readline-related crash in mysql when the user pressed Control-R. (Bug#9568)For stored functions that should return a
YEARvalue, corrected a failure of the value to be inYEARformat. (Bug#8861)Fixed a server crash resulting from invocation of a stored function that returned a value having an
ENUMorSETdata type. (Bug#9775)Fixed a server crash resulting from invocation of a stored function that returned a value having a
BLOBdata type. (Bug#9102)Fixed a server crash resulting from invocation of a stored function that returned a value having a
BITdata type. (Bug#7648)TIMEDIFF()with a negative time first argument and positive time second argument produced incorrect results. (Bug#8068)Fixed a problem with
OPTIMIZE TABLEforInnoDBtables being written twice to the binary log. (Bug#9149)InnoDB: PreventALTER TABLEfrom changing the storage engine if there are foreign key constraints on the table. (Bug#5574, Bug#5670)InnoDB: Fixed a bug where next-key locking doesn't allow the insert which does not produce a phantom. (Bug#9354) If the range is of type'a' <= uniquecolumn,InnoDBlock only the RECORD, if the record with the column value'a'exists in a CLUSTERED index. This allows inserts before a range.InnoDB: WhenFOREIGN_KEY_CHECKS=0,ALTER TABLEandRENAME TABLEwill ignore any type incompatibilities between referencing and referenced columns. Thus, it will be possible to convert the character sets of columns that participate in a foreign key. Be sure to convert all tables before modifying any data! (Bug#9802)Provide more informative error messages in clustered setting when a query is issued against a table that has been modified by another mysqld server. (Bug#6762)
Functionality added or changed:
Added
ENGINE=MyISAMtable option when creatingmysql.proctable in mysql_create_system_tables script to make sure the table is created as aMyISAMtable even if the default storage engine has been changed. (Bug#9496)SHOW CREATE TABLEfor anINFORMATION_SCHEMAtable no longer prints aMAX_ROWSvalue because the value has no meaning. (Bug#8941)Invalid
DEFAULTvalues forCREATE TABLEnow generate errors. (Bug#5902)Added
--show-table-typeoption to mysqlshow, to display a column indicating the table type, as inSHOW FULL TABLES. (Bug#5036)The way the time zone information is stored in the binary log was changed, so that it is now possible to have a replication master and slave running with different global time zones. A drawback is that replication from 5.0.4 masters to pre-5.0.4 slaves is impossible.
Added
--with-big-tablescompilation option to configure. (Previously it was necessary to pass-DBIG_TABLESto the compiler manually in order to enable large table support.) See Section 2.4.14.2, “Typical configure Options”, for details.New configuration directives
!includeand!includedirimplemented for including option files and searching directories for option files. See Section 4.3.2, “Using Option Files”, for usage.
Bugs fixed:
The use of
XORtogether withNOT ISNULL()erroneously resulted in some outer joins being converted to inner joins by the optimizer. (Bug#9017)Fixed an optimizer problem where extraneous comparisons between
NULLvalues in indexed columns were being done for operators such as=that are never true forNULL. (Bug#8877)Fixed the client/server protocol for prepared statements so that reconnection works properly when the connection is killed while reconnect is enabled. (Bug#8866)
A server installed as a Windows service and started with
--shared-memorycould not be stopped. (Bug#9665)Fixed a server crash resulting from multiple executions of a prepared statement involving a join of an
INFORMATION_SCHEMAtable with another table. (Bug#9383)Fixed
utf8_spanish2_cianducs2_spanish2_cicollations to not consider ‘r’ equal to ‘rr’. If you upgrade to this version from an earlier version, you should rebuild the indexes of affected tables. (Bug#9269)mysqldump dumped core when invoked with
--tmpand--single-transactionoptions and a non-existent table name. (Bug#9175)Allow extra HKSCS and cp950 characters (
big5extension characters) to be accepted inbig5columns. (Bug#9357)mysql.server no longer uses non-portable alias command or LSB functions. (Bug#9852)
Fixed a server crash resulting from
GROUP BYon a decimal expression. (Bug#9210)In prepared statements, subqueries containing parameters were erroneously treated as
consttables during preparation, resulting in a server crash. (Bug#8807)InnoDB:
ENUMandSETcolumns were treated incorrectly as character strings. This bug did not manifest itself withlatin1collations if there were less than about 100 elements in anENUM, but it caused malfunction withUTF-8. Old tables will continue to work. In new tables,ENUMandSETwill be internally stored as unsigned integers. (Bug#9526)InnoDB: Avoid test suite failures caused by a locking conflict between two server instances at server shutdown/startup. This conflict on advisory locks appears to be the result of a bug in the operating system; these locks should be released when the files are closed, but somehow that does not always happen immediately in Linux. (Bug#9381)
InnoDB: True
VARCHAR: InnoDB stored the 'position' of a row wrong in a column prefix primary key index; this could cause MySQL to complainERROR 1032: Can't find record …in an update of the primary key, and also someORDER BYorDISTINCTqueries. (Bug#9314)InnoDB: Fix bug in MySQL/InnoDB 5.0.3: SQL statements were not rolled back on error. (Bug#8650)
Fixed a
Commands out of syncerror when two prepared statements for single-row result sets were open simultaneously. (Bug#8880)Fixed a server crash after a call to
mysql_stmt_close()for single-row result set. (Bug#9159)Fixed server crashes for
CREATE TABLE ... SELECTorINSERT INTO ... SELECTwhen selecting from multiple-table view. (Bug#8703, Bug#9398)TRADITIONALSQL mode should prevent inserts where a column with no default value is omitted or set to a value ofDEFAULT. Fixed cases where this restriction was not enforced. (Bug#5986)Fixed a server crash when creating a
PRIMARY KEYfor a table, if the table contained aBITcolumn. (Bug#9571)Warning message from
GROUP_CONCAT()did not always indicate correct number of lines. (Bug#8681)The commit count cache for
NDBwas not properly invalidated when deleting a record using a cursor. (Bug#8585)Fixed option-parsing code for the embedded server to understand
K,M, andGsuffixes for thenet_buffer_lengthandmax_allowed_packetoptions. (Bug#9472)Selecting a
BITcolumn failed if the binary client/server protocol was used. (Bug#9608)Fixed a permissions problem whereby information in
INFORMATION_SCHEMAcould be exposed to a user with insufficient privileges. (Bug#7214)An error now occurs if you try to insert an invalid value via a stored procedure in
STRICTmode. (Bug#5907)Link with
libsupc++on Fedora Core 3 to get language support functions. (Bug#6554)The value of the
CHARACTER_MAXIMUM_LENGTHandCHARACTER_OCTET_LENGTHcolumns of theINFORMATION_SCHEMA.COLUMNStable must beNULLfor numeric columns, but were not. (Bug#9344)DROP TABLEdid not drop triggers that were defined for the table.DROP DATABASEdid not drop triggers in the database. (Bug#5859, Bug#6559)CREATE OR REPLACE VIEWandALTER VIEWnow require theCREATE VIEWandDROPprivileges, notCREATE VIEWandDELETE. (DELETEis a row-level privilege, not a table-level privilege.) (Bug#9260)Some user variables were not being handled with “implicit” coercibility. (Bug#9425)
Setting the
max_error_countsystem variable to 0 resulted in a setting of 1. (Bug#9072)Fixed a collation coercibility problem that caused a union between binary and non-binary columns to fail. (Bug#6519)
Fixed a bug in division of floating point numbers. It could cause nine zeros (
000000000) to be inserted in the middle of the quotient. (Bug#9501)INFORMATION_SCHEMAtables had an implicit upper limit for the number of rows. As a result, not all data could be returned for some queries. (Bug#9317)Fixed a problem with the
teecommand in mysql that resulted in mysql crashing. (Bug#8499)CAST()now produces warnings when casting incorrectINTEGERandCHARvalues. This also applies to implicitstringtonumbercasts. (Bug#5912)ALTER TABLEnow fails inSTRICTmode if the alteration generates warnings.Using
CONVERT('0000-00-00',date)orCAST('0000-00-00' as date)with theNO_ZERO_DATESQL mode enabled now produces a warning. (Bug#6145)Inserting a zero date in a
DATE,DATETIMEorTIMESTAMPcolumn duringTRADITIONALmode now produces an error. (Bug#5933)Inserting a zero date into a
DATETIMEcolumn inTRADITIONALmode now produces an error.STR_TO_DATE()now produces errors in strict mode (and warnings otherwise) when given an illegal argument. (Bug#5902)Fixed a problem with
ORDER BYthat sometimes caused incorrect sorting ofutf8data. (Bug#9309)Fixed server crash resulting from queries that combined
SELECT DISTINCT,SUM(), andROLLUP. (Bug#8615)Incorrect results were returned from queries that combined
SELECT DISTINCT,GROUP BY, andROLLUP. (Bug#8616)Too many rows were returned from queries that combined
ROLLUPandLIMITifSQL_CALC_FOUND_ROWSwas given. (Bug#8617)If, on a replication master a
LOAD DATA INFILEoperation was interrupted (by, for example, an integrity constraint violation or killed connection), the slave skipped theLOAD DATA INFILEentirely, thus missing changes if this command permanently inserted or updated table records before being interrupted. (Bug#3247)
Note: This Beta release, as any other pre-production release, should not be installed on “production” level systems or systems with critical data. It is good practice to back up your data before installing any new version of software. Although MySQL worked very hard to ensure a high level of quality, protect your data by making a backup as you would for any software beta release.
Functionality added or changed:
Security improvement: The server creates
.frm,.MYD,.MYI,.MRG,.ISD, and.ISMtable files only if a file with the same name does not already exist. Thanks to Stefano Di Paola<stefano.dipaola@wisec.it>for finding and informing us about this issue. (CVE-2005-0711)Security improvement: User-defined functions should have at least one symbol defined in addition to the
xxxsymbol that corresponds to the mainxxx()function. These auxiliary symbols correspond to thexxx_init(),xxx_deinit(),xxx_reset(),xxx_clear(), andxxx_add()functions. mysqld by default no longer loads UDFs unless they have at least one auxiliary symbol defined in addition to the main symbol. The--allow-suspicious-udfsoption controls whether UDFs that have only anxxxsymbol can be loaded. By default, the option is off. mysqld also checks UDF filenames when it reads them from themysql.functable and rejects those that contain directory pathname separator characters. (It already checked names as given inCREATE FUNCTIONstatements.) See Section 24.2.4.1, “UDF Calling Sequences for Simple Functions”, Section 24.2.4.2, “UDF Calling Sequences for Aggregate Functions”, and Section 24.2.4.6, “User-Defined Function Security Precautions”. Thanks to Stefano Di Paola<stefano.dipaola@wisec.it>for finding and informing us about this issue. (CVE-2005-0709, CVE-2005-0710)The
DECIMALandNUMERICdata types now are handled with a fixed-point library that allows for precision math handling that results in more accurate results. See Chapter 21, Precision Math.Warning: Incompatible change: A consequence of the change in handling of the
DECIMALandNUMERICfixed-point data types is that the server is more strict to follow standard SQL. For example, a data type ofDECIMAL(3,1)stores a maximum value of 99.9. Previously, the server allowed larger numbers to be stored. That is, it stored a value such as 100.0 as 100.0. Now the server clips 100.0 to the maximum allowable value of 99.9. If you have tables that were created before MySQL 5.0.3 and that contain floating-point data not strictly legal for the data type, you should alter the data types of those columns. For example:ALTER TABLE
tbl_nameMODIFYcol_nameDECIMAL(4,1);Warning: Incompatible change: For user-defined functions, exact-value decimal arguments such as
1.3orDECIMALcolumn values were passed asREAL_RESULTvalues prior to MySQL 5.0.3. As of 5.0.3, they are passed as strings with a type ofDECIMAL_RESULT. If you upgrade to 5.0.3 and find that your UDF now receives string values, use the initialization function to coerce the arguments to numbers as described in Section 24.2.4.3, “UDF Argument Processing”.For the
FLOOR()andCEILING()functions, the return type is no longer alwaysBIGINT. For exact-value numeric arguments, the return value has an exact-value numeric type. For string or floating-point arguments, the return value has a floating-point type.Incompatible change: The C API
ER_WARN_DATA_TRUNCATEDwarning symbol was renamed toWARN_DATA_TRUNCATED.InnoDB: Upgrading from 4.1: The sorting order for end-space in
TEXTcolumns for InnoDB tables has changed. Starting from 5.0.3, InnoDB comparesTEXTcolumns as space-padded at the end. If you have a non-unique index on aTEXTcolumn, you should runCHECK TABLEon it, and runOPTIMIZE TABLEif the check reports errors. If you have aUNIQUE INDEXon aTEXTcolumn, you should rebuild the table withOPTIMIZE TABLE.Implemented support for XA transactions. See Section 13.4.7, “XA Transactions”. The implementation make the
innodb_safe_binlogsystem variable obsolete, so it has been removed.mysqlbinlog now prints a
ROLLBACKstatement at the end of its output, in case the server crashed while it was in the process of writing the final entry into the last binary log named on the command line. This causes any half-written transaction to be rolled back when the output is executed. TheROLLBACKis harmless if the binary log file was written and closed normally.Added the
engine_condition_pushdownsystem variable. For NDB, setting this variable to 1 allows processing of someWHEREclause conditions to be processed in NDB nodes before rows are sent to the MySQL server, rather than having rows sent to the server for evaluation.Additional control over transaction completion was implemented. The
COMMITandROLLBACKstatements supportAND [NO] CHAINandRELEASEclauses. There is a newRELEASE SAVEPOINTstatement. Thecompletion_typesystem variable was added for setting the global and session default completion type.A new
CREATE USERprivilege was added.my.cnfin the compile-time datadir (usually/usr/local/mysql/data/in the binary tarball distributions) is not being read anymore. The value of the environment variableMYSQL_HOMEis used instead of the hard-coded path.Support for the
ISAMstorage engine has been removed. If you haveISAMtables, you should convert them before upgrading. See Section 2.4.16.2, “Upgrading from MySQL 4.1 to 5.0”.Support for
RAIDoptions inMyISAMtables has been removed. If you have tables that use these options, you should convert them before upgrading. See Section 2.4.16.2, “Upgrading from MySQL 4.1 to 5.0”.Added support for
AVG(DISTINCT).ONLY_FULL_GROUP_BYno longer is included in theANSIcomposite SQL mode. (Bug#8510)mysqld_safe will create the directory where the UNIX socket file is to be located if the directory does not exist. This applies only to the last component of the directory pathname. (Bug#8513)
The coercibility for the return value of functions such as
USER()orVERSION()now is “system constant” rather than “implicit.” This makes these functions more coercible than column values so that comparisons of the two do not result inIllegal mix of collationserrors.COERCIBILITY()was modified to accommodate this new coercibility value. See Section 12.10.3, “Information Functions”.User variable coercibility has been changed from “coercible” to “implicit.” That is, user variables have the same coercibility as column values.
Boolean full-text phrase searching now requires only that matches contain exactly the same words as the phrase and in the same order. Non-word characters no longer need match exactly.
CHECKSUM TABLEreturns a warning for non-existing tables. The checksum value remainsNULLas before. (Bug#8256)The server now includes a timestamp in the
Ready for connectionsmessage that is written to the error log at startup. (Bug#8444)Added
SQL_NOTESsession variable to causeNote-level warnings not to be recorded. (Bug#6662)Allowed the service-installation command for Windows servers to specify a single option other than
--defaults-filefollowing the service name. This is for compatibility with MySQL 4.1. (Bug#7856)InnoDB: Commit after every 10,000 copied rows when executingALTER TABLE,CREATE INDEX,DROP INDEXorOPTIMIZE TABLE. This makes it much faster to recover from an aborted operation.Added
VAR_POP()andSTDDEV_POP()as standard SQL aliases for theVARIANCE()andSTDDEV()functions that compute population variance and standard deviation. Added newVAR_SAMP()andSTDDEV_SAMP()functions to compute sample variance and standard deviation. (Bug#3190)Fixed a problem with out-of-order packets being sent (
ERRORafterOKorEOF) following aKILL QUERYstatement. (Bug#6804)Retrieving from a view defined as a
SELECTthat mixedUNION ALLandUNION DISTINCTresulted in a different result than retrieving from the originalSELECT. (Bug#6565)Fixed a problem with non-optimal
index_mergequery execution plans being chosen on IRIX. (Bug#8578)BITin column definitions now is a distinct data type; it no longer is treated as a synonym forTINYINT(1).Bit-field values can be written using
b'notation.value'valueis a binary value written using 0s and 1s.From the Windows distribution, predefined accounts without passwords for remote users ("root@%", "@%") were removed (other distributions never had them).
Added
mysql_library_init()andmysql_library_end()as synonyms for themysql_server_init()andmysql_server_end()C API functions.mysql_library_init()andmysql_library_end()are#definesymbols, but the names more clearly indicate that they should be called when beginning and ending use of a MySQL C API library no matter whether the application useslibmysqlclientorlibmysqld. (Bug#6149)SHOW COLUMNSnow displaysNOrather than blank in theNulloutput column if the corresponding table column cannot beNULL.Changed XML format for mysql from
<tocol_name>col_value</col_name><field name="to allow for proper encoding of column names that are not legal as element names. (Bug#7811)col_name">col_value</field>Added
--innodb-checksumsand--innodb-doublewriteoptions for mysqld.Added
--large-pagesoption for mysqld.Added
multi_read_rangesystem variable.SHOW DATABASES,SHOW TABLES,SHOW COLUMNS, and so forth display information about theINFORMATION_SCHEMAdatabase. Also, severalSHOWstatements now accept aWHEREclause specifying which output rows to display. See Chapter 20, TheINFORMATION_SCHEMADatabase.Added the
CREATE ROUTINEandALTER ROUTINEprivileges, and made theEXECUTEprivilege operational.InnoDB: Corrected a bug in the crash recovery of
ROW_FORMAT=COMPACTtables that caused corruption. (Bug#7973) There may still be bugs in the crash recovery, especially inCOMPACTtables.When the
MyISAMstorage engine detects corruption of aMyISAMtable, a message describing the problem now is written to the error log.InnoDB: When MySQL/InnoDB is compiled on Mac OS X 10.2 or earlier, detect the operating system version at run time and use the
fcntl()file flush method on Mac OS X versions 10.3 and later. In Mac OS X,fsync()does not flush the write cache in the disk drive, but the specialfcntl()does; however, the flush request is ignored by some external devices. Failure to flush the buffers may cause severe database corruption at power outages.InnoDB: Implemented fast
TRUNCATE TABLE. The old approach (deleting rows one by one) may be used if the table is being referenced by foreign keys. (Bug#7150)Added
cp932(SJIS for Windows Japanese) andeucjpms(UJIS for Windows Japanese) character sets.Added several
InnoDBstatus variables. See Section 5.2.5, “Status Variables”.Added the
FEDERATEDstorage engine. See Section 14.7, “TheFEDERATEDStorage Engine”.SHOW CREATE TABLEnow usesUSINGrather thanindex_typeTYPEto specify an index type. (Bug#7233)index_typeInnoDB now supports a fast
TRUNCATE TABLE. One visible change from this is that auto-increment values for this table are reset onTRUNCATE.Added an
errormember to theMYSQL_BINDdata structure that is used in the C API for prepared statements. This member is used for reporting data truncation errors. Truncation reporting is enabled via the newMYSQL_REPORT_DATA_TRUNCATIONoption for themysql_options()C API function.API change: the
reconnectflag in theMYSQLstructure is now set to 0 bymysql_real_connect(). Only those client programs which didn't explicitly set this flag to 0 or 1 aftermysql_real_connect()experience a change. Having automatic reconnection enabled by default was considered too dangerous (after reconnection, table locks, temporary tables, user and session variables are lost).FLUSH TABLES WITH READ LOCKis now killable while it's waiting for runningCOMMITstatements to finish.MEMORY(HEAP) can haveVARCHAR()fields.VARCHARcolumns now remember end space. AVARCHAR()column can now contain up to 65535 bytes. For more details, see Section E.1, “Changes in release 5.0.x (Production)”. If the table handler doesn't support the newVARCHARtype, then it's converted to aCHARcolumn. Currently this happens forNDBtables.InnoDB: Introduced a compact record format that does not store the number of columns or the lengths of fixed-size columns. The old format can be requested by specifyingROW_FORMAT=REDUNDANT. The new format (ROW_FORMAT=COMPACT) is the default. The new format typically saves 20 % of disk space and memory.InnoDB: Setting the initialAUTO_INCREMENTvalue for anInnoDBtable usingCREATE TABLE ... AUTO_INCREMENT =now works, andnALTER TABLE ... AUTO_INCREMENT =resets the current value.nSeconds_Behind_MasterisNULL(which means “unknown”) if the slave SQL thread is not running, or if the slave I/O thread is not running or not connected to master. It is zero if the SQL thread has caught up to the I/O thread. It no longer grows indefinitely if the master is idle.The MySQL server aborts immediately instead of simply issuing a warning if it is started with the
--log-binoption but cannot initialize the binary log at startup (that is, an error occurs when writing to the binary log file or binary log index file).The binary log file and binary log index file now are handled the same way as
MyISAMtables when there is a “disk full” or “quota exceeded” error. See Section B.1.4.3, “How MySQL Handles a Full Disk”.The MySQL server now aborts when started with the option
--log-bin-indexand without--log-bin, and when started with--log-slave-updatesand without--log-bin.If the MySQL server is started without an argument to
--log-binand without--log-bin-index, thus not providing a name for the binary log index file, a warning is issued because MySQL falls back to using the hostname for that name, and this is prone to replication issues if the server's hostname's gets changed later. See Section B.1.8.1, “Open Issues in MySQL”.Added account-specific
MAX_USER_CONNECTIONSlimit, which allows you to specify the maximum number of concurrent connections for the account. Also, all limited resources now are counted per account (instead of being counted per user + host pair as it was before). Use the--old-style-user-limitsoption to get the old behavior.InnoDB: A shared record lock (
LOCK_REC_NOT_GAP) is now taken for a matching record in the foreign key check because inserts can be allowed into gaps.InnoDB: Relaxed locking in
INSERT…SELECT, single tableUPDATE…SELECTand single tableDELETE…SELECTclauses wheninnodb_locks_unsafe_for_binlogis used and isolation level of the transaction is not serializable.InnoDBuses consistent read in these cases for a selected table.Added a new global system variable
slave_transaction_retries: if the replication slave SQL thread fails to execute a transaction because of anInnoDBdeadlock or exceeded InnoDB'sinnodb_lock_wait_timeoutor NDBCluster'sTransactionDeadlockDetectionTimeoutorTransactionInactiveTimeout, it automatically retriesslave_transaction_retriestimes before stopping with an error. The default is 10. (Bug#8325)When a client releases a user-level lock,
DO RELEASE_LOCK()will not be written to the binary log anymore (this makes the binary log smaller); as a counterpart, the slave does not actually take the lock when it executesGET_LOCK(). This is mainly an optimization and should not affect existing setups. (Bug#7998)The way the character set information is stored into the binary log was changed, so that it's now possible to have a replication master and slave running with different global character sets. A drawback is that replication from 5.0.3 masters to pre-5.0.3 slaves is impossible.
The
LOAD DATAstatement was extended to support user variables in the target column list, and an optionalSETclause. Now one can perform some transformations on data after they have been read and before they are inserted into the table. For example:LOAD DATA INFILE 'file.txt' INTO TABLE t1 (column1, @var1) SET column2 = @var1/100;
Also, replication of
LOAD DATAwas changed, so you can't replicate such statements from a 5.0.3 master to pre-5.0.3 slaves.NDB Cluster: When using this storage engine, the output ofSHOW TABLE STATUSnow displays properly-calculated values in theAvg_row_lengthandData_lengthcolumns. (Note thatBLOBcolumns are not yet taken into account.) In addition, the number of replicas is now shown in theCommentcolumn (asnumber_of_replicas).
Bugs fixed:
If a
MyISAMtable on Windows hadINDEX DIRECTORYorDATA DIRECTORYtable options, mysqldump dumped the directory pathnames with single-backslash pathname separators. This would cause syntax errors when importing the dump file. mysqldump now changes ‘\’ to ‘/’ in the pathnames on Windows. (Bug#6660)mysql_fix_privilege_tablesnow fixes that themysqlprivilege tables can be used in MySQL 4.1. This allows one to easily downgrade to 4.1 or run MySQL 5.0 and 4.1 with the same privilege files for testing purposes.Fixed bug creating user with GRANT fails with password but works without, (Bug#7905)
mysqldump misinterpreted ‘
_’ and ‘%’ characters in the names of tables to be dumped as wildcard characters. (Bug#9123)The definition of the enumeration-valued
sql_modecolumn of themysql.proctable was missing some of the current allowable SQL modes, so stored routines would not necessarily execute with the SQL mode in effect at the time of routine definition. (Bug#8902)REPAIR TABLEdid not invalidate query results in the query cache that were generated from the table. (Bug#8480)In strict or traditional SQL mode, too-long string values assigned to string columns (
CHAR,VARCHAR,BINARY,VARBINARY,TEXT, orBLOB) were correctly truncated, but the server returned an SQLSTATE value of01000(should be22001). (Bug#6999, Bug#9029)Stored functions that used cursors could return incorrect results. (Bug#8386)
AES_DECRYPT(could fail to returncol_name,key)NULLfor invalid values incol_name, ifcol_namewas declared asNOT NULL. (Bug#8669)Ordering by unsigned expression (more complex than a column reference) was treating the value as signed, producing incorrectly sorted results. (Bug#7425)
HAVINGwas treating unsigned columns as signed. (Bug#7425)Fixed a problem with boolean full-text searches on
utf8columns where a double quote in the search string caused a server crash. (Bug#8351)For a query with both
GROUP BYandCOUNT(DISTINCT)clauses and aFROMclause with a subquery,NULLwas returned for anyVARCHARcolumn selected by the subquery. (Bug#8218)Fixed a bug in
TRUNCATE, which did not work within stored procedures. A workaround has been made so that within stored procedures,TRUNCATEis executed likeDELETE. This was necessary becauseTRUNCATEis implicitly locking tables. (Bug#8850)Fixed an optimizer bug that caused incorrectly ordered result from a query that used a
FULLTEXTindex to retrieve rows and there was another index that was usable forORDER BY. For such a query,EXPLAINshowedfulltextjoin type, but regular (notFULLTEXT) index in theKeycolumn. (Bug#6635)If
SELECT DISTINCTnamed an index column multiple times in the select list, the server tried to access different key fields for each instance of the column, which could result in a crash. (Bug#8532)For a stored function that refers to a given table, invoking the function while selecting from the same table resulted in a server crash. (Bug#8405)
Comparison of a
DECIMALcolumn containingNULLto a subquery that producedDECIMALvalues resulted in a server crash. (Bug#8397)The
--set-character-setoption for myisamchk was changed to--set-collation. The value needed for specifying how to sort indexes is a collation name, not a character set name. (Bug#8349)Hostname matching didn't work if a netmask was specified for table-specific privileges. (Bug#3309)
Corruption of
MyISAMtable indexes could occur withTRUNCATE TABLEif the table had already been opened. For example, this was possible if the table had been opened implicitly by selecting from aMERGEtable that mapped to theMyISAMtable. The server now issues an error message forTRUNCATE TABLEunder these conditions. (Bug#8306)Setting the connection collation to a value different from the server collation followed by a
CREATE TABLEstatement that included a quoted default value resulted in a server crash. (Bug#8235)Fixed handling of table-name matching in mysqlhotcopy to accommodate
DBD::mysql2.9003 and up (which implement identifier quoting). (Bug#8136)Selecting from a view defined as a join caused a server crash if the query cache was enabled. (Bug#8054)
Results in the query cache generated from a view were not properly invalidated after
ALTER VIEWorDROP VIEWon that view. (Bug#8050)FOUND_ROWS()returned an incorrect value after aSELECT SQL_CALC_FOUND_ROWS DISTINCTstatement that selected constants and includedGROUP BYandLIMITclauses. (Bug#7945)Selecting from an
INFORMATION_SCHEMAtable combined with a subquery on anINFORMATION_SCHEMAtable caused an error with the messageTable. (Bug#8164)tbl_nameis corruptedFixed a problem with equality propagation optimization for prepared statements and stored procedures that caused a server crash upon re-execution of the prepared statement or stored procedure. (Bug#8115, Bug#8849)
LEFT OUTER JOINbetween an empty base table and a view on an empty base table caused a server crash. (Bug#7433)Use of
GROUP_CONCAT()in the select list when selecting from a view caused a server crash. (Bug#7116)Use of a view in a correlated subquery that contains
HAVINGbut noGROUP BYcaused a server crash. (Bug#6894)Handling by
mysql_list_fields()of references to stored functions within views was incorrect and could result in a server crash. (Bug#6814)mysqldump now avoids writing
SET NAMESto the dump output if the server is older than version 4.1 and would not understand that statement. (Bug#7997)Fixed problems when selecting from a view that had an
EXISTSorNOT EXISTSsubquery. Selecting columns by name caused a server crash. WithSELECT *, a crash did not occur, but columns in outer query were not resolved properly. (Bug#6394)DDL statements for views were not being written to the binary log (and thus not subject to replication). (Bug#4838)
The
CHAR()function was not ignoringNULLarguments, contrary to the documentation. (Bug#6317)Creating a table using a name containing a character that is illegal in
character_set_clientresulted in the character being stripped from the name and no error. The character now is considered an error. (Bug#8041)Fixed a problem with the Cyrillic letters I and SHORT I being treated the same by the
utf8_general_cicollation. (Bug#8385)Some
INFORMATION_SCHEMAcolumns that contained catalog identifiers were of typeLONGTEXT. These were changed toVARCHAR(, whereNNis the appropriate maximum identifier length. (Bug#7215)Some
INFORMATION_SCHEMAcolumns that contained timestamp values were of typeVARBINARY. These were changed toTIMESTAMP. (Bug#7217)An expression that tested a case-insensitive character column against string constants that differed in lettercase could fail because the constants were treated as having a binary collation. (For example,
WHERE city='London' AND city='london'could fail.) (Bug#7098, Bug#8690)The output of the
STATUS(\s) command in mysql had the values for the server and client character sets reversed. (Bug#7571)If the slave was running with
--replicate-*-tableoptions which excluded one temporary table and included another, and the two tables were used in a singleDROP TEMPORARY TABLE IF EXISTSstatement, as the ones the master automatically writes to its binary log upon client's disconnection when client has not explicitly dropped these, the slave could forget to delete the included replicated temporary table. Only the slave needs to be upgraded. (Bug#8055)When setting integer system variables to a negative value with
SET VARIABLES, the value was treated as a positive value modulo 232. (Bug#6958)Corrected a problem with references to
DUALwhere statements such asSELECT 1 AS a FROM DUALwould succeed but statements such asSELECT 1 AS a FROM DUAL LIMIT 1would fail. (Bug#8023)Fixed a server crash caused by
DELETE FROMwhen thetbl_name... WHERE ... ORDER BYtbl_name.col_nameORDER BYcolumn was qualified with the table name. (Bug#8392)Fixed a bug in
MATCH ... AGAINSTin natural language mode that could cause a server crash if theFULLTEXTindex was not used in a join (EXPLAINdid not showfulltextjoin mode) and the search query matched no rows in the table (Bug#8522).InnoDB: Honor the--tmpdirstartup option when creating temporary files. Previously,InnoDBtemporary files were always created in the temporary directory of the operating system. On Netware,InnoDBwill continue to ignore--tmpdir. (Bug#5822)Platform and architecture information in version information produced for
--versionoption on Windows was alwaysWin95/Win98 (i32). More accurately determine platform asWin32orWin64for 32-bit or 64-bit Windows, and architecture asia32for x86,ia64for Itanium, andaxpfor Alpha. (Bug#4445)If multiple semicolon-separated statements were received in a single packet, they were written to the binary log as a single event rather than as separate per-statement events. For a server serving as a replication master, this caused replication to fail when the event was sent to slave servers. (Bug#8436)
Fixed
LOAD INDEXstatement to actually load index in memory. (Bug#8452)Fixed a failure of multiple-table updates to replicate properly on slave servers when
--replicate-*-tableoptions had been specified. (Bug#7011)Fixed failure of
CREATE TABLE ... LIKEWindows when the source or destination table was located in a symlinked database directory. (Bug#6607)With
lower_case_table_namesset to 1, mysqldump on Windows could write the same table name in different lettercase for different SQL statements. Fixed so that consistent lettercase is used. (Bug#5185)mysqld_safe now understands the
--helpoption. Previously, it ignored the option and attempted to start the server anyway. (Bug#7931)Fixed problem in
NO_BACKSLASH_ESCAPESSQL mode for strings that contained both the string quoting character and backslash. (Bug#6368)Fixed some portability issues with overflow in floating point values.
Prepared statements now gives warnings on prepare.
Fixed bug in prepared statements with
SUM(DISTINCT...).Fixed bug in prepared statements with
OUTER JOIN.Fixed a bug in
CONV()function returning unsignedBIGINTnumber (third argument is positive, and return value does not fit in 32 bits). (Bug#7751)Fixed a failure of the
IN()operator to return correct result if all values in the list were constants and some of them were using substring functions, for example,LEFT(),RIGHT(), orMID(). (Bug#7716)Fixed a crash in
CONVERT_TZ()function when its second or third argument was from aconsttable (see Section 7.2.1, “Optimizing Queries withEXPLAIN”). (Bug#7705)Fixed a problem with calculation of number of columns in row comparison against subquery. (Bug#8020)
Fixed erroneous output resulting from
SELECT DISTINCTcombined with a subquery andGROUP BY. (Bug#7946)Fixed server crash in comparing a nested row expression (for example
row(1,(2,3))) with a subquery. (Bug#8022)Fixed server crash resulting from certain correlated subqueries with forward references (references to an alias defined later in the outer query). (Bug#8025)
Fixed server crash resulting from re-execution of prepared statements containing subqueries. (Bug#8125)
Fixed a bug where
ALTER TABLEimproperly would accept an index on aTIMESTAMPcolumn thatCREATE TABLEwould reject. (Bug#7884)SHOW CREATE TABLEnow reportsENGINE=MEMORYrather thanENGINE=HEAPfor aMEMORYtable (unless theMYSQL323SQL mode is enabled). (Bug#6659)Fixed a bug where the use of
GROUP_CONCAT()withHAVINGcaused a server crash. (Bug#7769)Fixed a bug where comparing the result of a subquery to a non-existent column caused a server crash on Windows. (Bug#7885)
Fixed a bug in a combination of
-notandtrunc*operators of full-text search. Using more than one truncated negative search term, was causing empty result set.InnoDB: Corrected the handling of trailing spaces in the
ucs2character set. (Bug#7350, Bug#8771)InnoDB: Use native
tmpfile()function on Netware. All InnoDB temporary files are created undersys:\tmp. Previously, InnoDB temporary files were never deleted on Netware.Fixed a bug in
max_heap_table_sizehandling, that resulted inTable is fullerror when the table was still smaller than the limit. (Bug#7791).Fixed a symlink vulnerability in the mysqlaccess script. Reported by Javier Fernandez-Sanguino Pena and Debian Security Audit Team. (CVE-2005-0004)
Fixed a bug that caused server crash if some error occurred during filling of temporary table created for derived table or view handling. (Bug#7413)
Fixed a bug which caused server crash if query containing
CONVERT_TZ()function with constant arguments was prepared. (Bug#6849)Prevent adding
CREATE TABLE .. SELECTquery to the binary log when the insertion of new records partially failed. (Bug#6682)Fixed a bug which caused a crash when only the slave I/O thread was stopped and started. (Bug#6148)
Giving mysqld a
SIGHUPcaused it to crash.Changed semantics of
CREATE/ALTER/DROP DATABASEstatements so that replication ofCREATE DATABASEis possible when using--binlog-do-dband--binlog-ignore-db. (Bug#6391)A sequence of
BEGIN(orSET AUTOCOMMIT=0),FLUSH TABLES WITH READ LOCK, transactional update,COMMIT,FLUSH TABLES WITH READ LOCKcould hang the connection forever and possibly the MySQL server itself. This happened for example when running theinnobackupscript several times. (Bug#6732)mysqlbinlog did not print
SET PSEUDO_THREAD_IDstatements in front ofLOAD DATA INFILEstatements inserting into temporary tables, thus causing potential problems when rolling forward these statements after restoring a backup. (Bug#6671)InnoDB: Fixed a bug no error message for ALTER with InnoDB and AUTO_INCREMENT (Bug#7061).
InnoDBnow supportsALTER TABLE...AUTO_INCREMENT = xquery to set auto increment value for a table.Made the MySQL server accept executing
SHOW CREATE DATABASEeven if the connection has an open transaction or locked tables; refusing it made mysqldump --single-transaction sometimes fail to print a completeCREATE DATABASEstatement for some dumped databases. (Bug#7358)Fixed that, when encountering a “disk full” or “quota exceeded” write error,
MyISAMsometimes didn't sleep and retry the write, thus resulting in a corrupted table. (Bug#7714)Fixed that
--expire-log-dayswas not honored if using only transactions. (Bug#7236)Fixed that a slave could crash after replicating many
ANALYZE TABLE,OPTIMIZE TABLE, orREPAIR TABLEstatements from the master. (Bug#6461, Bug#7658)mysqlbinlog forgot to add backquotes around the collation of user variables (causing later parsing problems as
BINARYis a reserved word). (Bug#7793)Ensured that mysqldump --single-transaction sets its transaction isolation level to
REPEATABLE READbefore proceeding (otherwise if the MySQL server was configured to run with a default isolation level lower thanREPEATABLE READit could give an inconsistent dump). (Bug#7850)Fixed that when using the
RPAD()function (or any function adding spaces to the right) in a query that had to be resolved by using a temporary table, all resulting strings had rightmost spaces removed (that is,RPAD()did not work) (Bug#4048)Fixed that a 5.0.3 slave can connect to a master < 3.23.50 without hanging (the reason for the hang is a bug in these quite old masters --
SELECT @@unknown_varhangs them -- which was fixed in MySQL 3.23.50). (Bug#7965)InnoDB: Fixed a deadlock without any locking, simple select and update (Bug#7975).
InnoDBnow takes an exclusive lock whenINSERT ON DUPLICATE KEY UPDATEis checking duplicate keys.Fixed a bug where MySQL was allowing concurrent updates (inserts, deletes) to a table if binary logging is enabled. Changed to ensure that all updates are executed in a serialized fashion, because they are executed serialized when binlog is replayed. (Bug#7879)
Fixed a rare race condition which could lead to
FLUSH TABLES WITH READ LOCKhanging. (Bug#8682)Fixed a bug in replication that caused the master to stamp generated statements (such as
SETcommands) with anerror_codeintended only for another statement. This could happen, for example, when a statements generates a duplicate key error on the master but must be replicated. (Bug#8412)
Functionality added or changed:
Warning: Incompatible change! The precedence of
NOToperator has changed so that expressions such asNOT a BETWEEN b AND care parsed correctly asNOT (a BETWEEN b AND c)rather than as(NOT a) BETWEEN b AND c. The pre-5.0 higher-precedence behavior can be obtained by enabling the newHIGH_NOT_PRECEDENCESQL mode.Warning: Incompatible change!
SHOW STATUSnow shows the session (thread-specific) status variables andSHOW GLOBAL STATUSshows the status variables for the whole server.Before MySQL 5.0.2,
SHOW STATUSreturned global status values. Because the default as of 5.0.2 is to return session values, this is incompatible with previous versions. To issue aSHOW STATUSstatement that will retrieve global status values for all versions of MySQL, write it like this:SHOW /*!50002 GLOBAL */ STATUS;
Added support for the
INFORMATION_SCHEMA“information database” that provides database metadata. See Chapter 20, TheINFORMATION_SCHEMADatabase.A
HAVINGclause in aSELECTstatement now can refer to columns in theGROUP BYclause, as required by standard SQL.Added the
CREATE USERandRENAME USERstatements.Modify
DROP USERso that it drops the account, including all its privileges. Formerly, it removed the account record only for an account that had all privileges revoked.Added
IS [NOT]syntax, whereboolean_valueboolean_valueisTRUE,FALSE, orUNKNOWN.Added several
InnoDBstatus variables. See Section 5.2.5, “Status Variables”.Implemented the
WITH CHECK OPTIONclause forCREATE VIEW.CHECK TABLEnow works for views.The
SCHEMAandSCHEMASkeywords are now accepted as synonyms forDATABASEandDATABASES.Added initial support for rudimentary triggers (the
CREATE TRIGGERandDROP TRIGGERstatements).Added basic support for read-only server side cursors.
mysqldump --single-transaction --master-data is now able to take an online (non-blocking) dump of InnoDB and report the corresponding binary log coordinates, which makes a backup suitable for point-in-time recovery, roll-forward or replication slave creation. See Section 8.13, “mysqldump — A Database Backup Program”.
Added
--start-datetime,--stop-datetime,--start-position,--stop-positionoptions to mysqlbinlog (makes point-in-time recovery easier).Made the MySQL server not react to signals
SIGHUPandSIGQUITon Mac OS X 10.3. This is needed because under this OS, the MySQL server receives lots of these signals (reported as Bug#2030).New
--auto-increment-incrementand--auto-increment-offsetstartup options. These allow you to set up a server to generate auto-increment values that don't conflict with another server.MySQL now by default checks dates and in strict mode allows only fully correct dates. If you want MySQL to behave as before, you should enable the new
ALLOW_INVALID_DATESSQL mode.Added
STRICT_TRANS_TABLES,STRICT_ALL_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO, andTRADITIONALSQL modes. TheTRADITIONALmode is shorthand for all the preceding modes. When using modeTRADITIONAL, MySQL generates an error if you try to insert a wrong value in a column. It does not adjust the value to the closest possible legal value.MySQL now remembers which columns were declared to have default values. In
STRICT_TRANS_TABLES/STRICT_ALL_TABLESmode, you now get an error if you do anINSERTwithout specifying all columns that don't have a default value. A side effect of this is that when you doSHOW CREATEfor a new table, you no longer see aDEFAULTvalue for a column for which you didn't specify a default value.The compilation flag
DONT_USE_DEFAULT_FIELDSwas removed because you can get the same behavior by setting thesql_modesystem variable toSTRICT_TRANS_TABLES.Added
NO_AUTO_CREATE_USERSQL mode to preventGRANTfrom automatically creating new users if it would otherwise do so, unless a password also is specified.We now detect too-large floating point numbers during statement parsing and generate an error messages for them.
Renamed the
sql_updatable_view_keysystem variable toupdatable_views_with_limit. This variable now can have only two values:1orYES: Don't issue an error message (warning only) if a VIEW without presence of a key in the underlying table is used in queries with aLIMITclause for updating. (This is the default value.)0orNO: Prohibit update of a VIEW, which does not contain a key in the underlying table and the query uses aLIMITclause (usually get from GUI tools).
Reverted output format of
SHOW TABLESto old pre-5.0.1 format that did not include a table type column. To get the additional column that lists the table type, useSHOW FULL TABLESnow.The mysql_fix_privilege_tables script now initializes the global
CREATE VIEWandSHOW VIEWprivileges in theusertable to the value of theCREATEprivilege in that table.If the server finds that the
usertable has not been upgraded to include the view-related privilege columns, it treats each account as having view privileges that are the same as itsCREATEprivilege.InnoDB: If you specify the option
innodb_locks_unsafe_for_binloginmy.cnf, InnoDB in anUPDATEor aDELETEonly locks the rows that it updates or deletes. This greatly reduces the probability of deadlocks.A connection doing a rollback now displays "Rolling back" in the
Statecolumn ofSHOW PROCESSLIST.mysqlbinlog now prints an informative commented line (thread id, timestamp, server id, and so forth) before each
LOAD DATA INFILE, like it does for other queries; unless--short-formis used.Two new server system variables were introduced.
auto_increment_incrementandauto_increment_offsetcan be set locally or globally, and are intended for use in controlling the behavior ofAUTO_INCREMENTcolumns in master-to-master replication. Note that these variables are not intended to take the place of sequences. See Section 5.2.3, “System Variables”.
Bugs fixed:
Fixed that mysqlbinlog --read-from-remote-server sometimes couldn't accept two binary log files on the command line. (Bug#4507)
Fixed that mysqlbinlog --position --read-from-remote-server had incorrect
# atlines. (Bug#4506)Fixed that
CREATE TABLE ... TYPE=HEAP ... AS SELECT...caused replication slave to stop. (Bug#4971)Fixed that
mysql_options(...,MYSQL_OPT_LOCAL_INFILE,...)failed to disableLOAD DATA LOCAL INFILE. (Bug#5038)Fixed that
disable-local-infileoption had no effect if client read it from a configuration file usingmysql_options(...,MYSQL_READ_DEFAULT,...). (Bug#5073)Fixed that
SET GLOBAL SYNC_BINLOGdid not work on some platforms (Mac OS X). (Bug#5064)Fixed that mysql-test-run failed on the
rpl_trunc_binlogtest if running test from the installed (the target of 'make install') directory. (Bug#5050)Fixed that mysql-test-run failed on the
grant_cachetest when run as Unix user 'root'. (Bug#4678)Fixed an unlikely deadlock which could happen when using
KILL. (Bug#4810)Fixed a crash when one connection got
KILLed while it was doingSTART SLAVE. (Bug#4827)Made
FLUSH TABLES WITH READ LOCKblockCOMMITif server is running with binary logging; this ensures that the binary log position can be trusted when doing a full backup of tables and the binary log. (Bug#4953)Fixed that the counter of an
auto_incrementcolumn was not reset byTRUNCATE TABLEis the table was a temporary one. (Bug#5033)Fixed slave SQL thread so that the
SET COLLATION_SERVER...statements it replicates don't advance its position (so that if it gets interrupted before the actual update query, it later redoes theSET). (Bug#5705)Fixed that if the slave SQL thread found a syntax error in a query (which should be rare, as the master parsed it successfully), it stops. (Bug#5711)
Fixed that if a write to a
MyISAMtable fails because of a full disk or an exceeded disk quota, it prints a message to the error log every 10 minutes, and waits until disk becomes free. (Bug#3248)Fixed problem introduced in 4.0.21 where a connection starting a transaction, doing updates, then
FLUSH TABLES WITH READ LOCK, thenCOMMIT, would cause replication slaves to stop (complaining about error 1223). Bug surfaced when using the InnoDBinnobackupscript. (Bug#5949)OPTIMIZE TABLE,REPAIR TABLE, andANALYZE TABLEare now replicated without any error code in the binary log. (Bug#5551)If a connection had an open transaction but had done no updates to transactional tables (for example if had just done a
SELECT FOR UPDATEthen executed a non-transactional update, that update automatically committed the transaction (thus releasing InnoDB's row-level locks etc). (Bug#5714)If a connection was interrupted by a network error and did a rollback, the network error code got stored into the
BEGINandROLLBACKbinary log events; that caused superfluous slave stops. (Bug#6522)Fixed a bug which prevented mysqlbinlog from being able to read from
stdin, for example, when piping the output from zcat to mysqlbinlog. (Bug#7853)
Note: This build passes our test suite and fixes a lot of reported bugs found in the previous 5.0.0 release. However, please be aware that this is not a “standard MySQL build” in the sense that there are still some open critical bugs in our bugs database at http://bugs.mysql.com/ that affect this release as well. We are actively fixing these and will make a new release where these are fixed as soon as possible. However, this binary should be a good candidate for testing new MySQL 5.0 features for future products.
Functionality added or changed:
Warning: Incompatible change! C API change:
mysql_shutdown()now requires a second argument. This is a source-level incompatibility that affects how you compile client programs; it does not affect the ability of compiled clients to communicate with older servers. See Section 22.2.3.65, “mysql_shutdown()”.When installing a MySQL server as a Windows service, the installation command can include a
--local-serviceoption following the service name to cause the server to run using theLocalServiceWindows account that has limited privileges. This is in addition to the--defaults-fileoption that also can be given following the service name.Added support for read-only and updatable views based on a single table or other updatable views. View use requires that you upgrade your grant tables to add the view-related privileges. See Section 5.5.4, “mysql_fix_privilege_tables — Upgrade MySQL System Tables”.
Implemented a new “greedy search” optimizer that can significantly reduce the time spent on query optimization for some many-table joins. (You are affected if not only some particular
SELECTis slow, but even usingEXPLAINfor it takes a noticeable amount of time.) Two new system variables,optimizer_search_depthandoptimizer_prune_level, can be used to fine-tune optimizer behavior.A stored procedure is no longer “global.” That is, it now belongs to a specific database:
When a database is dropped, all routines belonging to that database are also dropped.
Procedure names may be qualified, for example,
db.p()When executed from another database, an implicit
USEis in effect.db_nameExplicit
USEstatements no longer are allowed in a stored procedure.db_name
Fixed
SHOW TABLESoutput field name and values according to standard. Field name changed fromTypetotable_type, values areBASE TABLE,VIEWandERROR. (Bug#4603)Added the
sql_updatable_view_keysystem variable.Added the
--replicate-same-server-idserver option.Added
Last_query_coststatus variable that reports optimizer cost for last compiled query.Added the
--to-last-logoption to mysqlbinlog, for use in conjunction with--read-from-remote-server.Added the
--innodb-safe-binlogserver option, which adds consistency guarantees between the content ofInnoDBtables and the binary log. See Section 5.11.3, “The Binary Log”.OPTIMIZE TABLEforInnoDBtables is now mapped toALTER TABLEinstead ofANALYZE TABLE. This rebuilds the table, which updates index statistics and frees space in the clustered index.sync_frmis now a settable global variable (not only a startup option).For replication of
MEMORY(HEAP) tables: Made the master automatically write aDELETE FROMstatement to its binary log when aMEMORYtable is opened for the first time since master's startup. This is for the case where the slave has replicated a non-emptyMEMORYtable, then the master is shut down and restarted: the table is now empty on master; theDELETE FROMempties it on slave too. Note that even with this fix, between the master's restart and the first use of the table on master, the slave still has out-of-date data in the table. But if you use the--init-fileoption to populate theMEMORYtable on the master at startup, it ensures that the failing time interval is zero. (Bug#2477)When a session having open temporary tables terminates, the statement automatically written to the binary log is now
DROP TEMPORARY TABLE IF EXISTSinstead ofDROP TEMPORARY TABLE, for more robustness.The MySQL server now returns an error if
SET SQL_LOG_BINis issued by a user without theSUPERprivilege (in previous versions it just silently ignored the statement in this case).Changed that when the MySQL server has binary logging disabled (that is, no
--log-binoption was used), then no transaction binary log cache is allocated for connections. This should savebinlog_cache_sizebytes of memory (32KB by default) for every connection.Added the
sync_binlog=Nglobal variable and startup option, which makes the MySQL server synchronize its binary log to disk (fdatasync()) after every Nth write to the binary log.Changed the slave SQL thread to print less useless error messages (no more message duplication; no more messages when an error is skipped because of
slave-skip-errors).DROP DATABASE IF EXISTS,DROP TABLE IF EXISTS, single-tableDELETE, and single-tableUPDATEnow are written to the binary log even if they changed nothing on the master (for example, even if aDELETEmatched no rows). The old behavior sometimes caused bad surprises in replication setups.Replication and mysqlbinlog now have better support for the case that the session character set and collation variables are changed within a given session. See Section 6.7, “Replication Features and Known Problems”.
Killing a
CHECK TABLEstatement does not result in the table being marked as “corrupted” any more; the table remains as ifCHECK TABLEhad not even started. See Section 13.5.5.3, “KILLSyntax”.
Bugs fixed:
Strange results with index (x, y) ...
WHERE x=(Bug#3155)val_1AND y>=val_2ORDER BYpk;Adding
ORDER BYto a query that uses a subquery can cause incorrect results. (Bug#3118)ALTER DATABASEcaused the client to hang if the database did not exist. (Bug#2333)SLAVE START(which is a deprecated syntax,START SLAVEshould be used instead) could crash the slave. (Bug#2516)Multiple-table
DELETEstatements were never replicated by the slave if there were any--replicate-*-tableoptions. (Bug#2527)The MySQL server did not report any error if a statement (submitted through
mysql_real_query()ormysql_stmt_prepare()) was terminated by garbage characters. This can happen if you pass a wronglengthparameter to these functions. The result was that the garbage characters were written into the binary log. (Bug#2703)Replication: If a client connects to a slave server and issues an administrative statement for a table (for example,
OPTIMIZE TABLEorREPAIR TABLE), this could sometimes stop the slave SQL thread. This does not lead to any corruption, but you must useSTART SLAVEto get replication going again. (Bug#1858)Made clearer the error message that one gets when an update is refused because of the
--read-onlyoption. (Bug#2757)Fixed that
--replicate-wild-*-tablerules apply toALTER DATABASEwhen the table pattern is%, as is the case forCREATE DATABASEandDROP DATABASE. (Bug#3000)Fixed that when a
Rotateevent is found by the slave SQL thread in the middle of a transaction, the value ofRelay_Log_PosinSHOW SLAVE STATUSremains correct. (Bug#3017)Corrected the master's binary log position that
InnoDBreports when it is doing a crash recovery on a slave server. (Bug#3015)Changed the column
Seconds_Behind_MasterinSHOW SLAVE STATUSto never show a value of -1. (Bug#2826)Changed that when a
DROP TEMPORARY TABLEstatement is automatically written to the binary log when a session ends, the statement is recorded with an error code of value zero (this ensures that killing aSELECTon the master does not result in a superfluous error on the slave). (Bug#3063)Changed that when a thread handling
INSERT DELAYED(also known as adelayed_insertthread) is killed, its statements are recorded with an error code of value zero (killing such a thread does not endanger replication, so we thus avoid a superfluous error on the slave). (Bug#3081)Fixed deadlock when two
START SLAVEcommands were run at the same time. (Bug#2921)Fixed that a statement never triggers a superfluous error on the slave, if it must be excluded given the
--replicate-*options. The bug was that if the statement had been killed on the master, the slave would stop. (Bug#2983)The
--local-loadoption of mysqlbinlog now requires an argument.Fixed a segmentation fault when running
LOAD DATA FROM MASTERafterRESET SLAVE. (Bug#2922)mysqlbinlog --read-from-remote-server read all binary logs following the one that was requested. It now stops at the end of the requested file, the same as it does when reading a local binary log. There is an option
--to-last-logto get the old behavior. (Bug#3204)Fixed mysqlbinlog --read-from-remote-server to print the exact positions of events in the "at #" lines. (Bug#3214)
Fixed a rare error condition that caused the slave SQL thread spuriously to print the message
Binlog has bad magic numberand stop when it was not necessary to do so. (Bug#3401)mysqlbinlog failed to print a
USEstatement under rare circumstances where the binary log contained aLOAD DATA INFILEstatement. (Bug#3415)Fixed memory corruption occurring when replicating a
LOAD DATA INFILEfrom a master running MySQL version 3.23. (Bug#3422)Multiple-table
DELETEstatements were always replicated by the slave if there were some--replicate-*-ignore-tableoptions and no--replicate-*-do-tableoptions. (Bug#3461)Fixed a crash of the MySQL slave server when it was built with
--with-debugand replicating itself. (Bug#3568)Fixed that in some replication error messages, a very long query caused the rest of the message to be invisible (truncated), by putting the query last in the message. (Bug#3357)
If
server-idwas not set using startup options but withSET GLOBAL, the replication slave still complained that it was not set. (Bug#3829)mysql_fix_privilege_tables didn't correctly handle the argument of its
--password=option. (Bug#4240)password_valFixed potential memory overrun in
mysql_real_connect()(which required a compromised DNS server and certain operating systems). (Bug#4017, CVE-2004-0836)During the installation process of the server RPM on Linux, mysqld was run as the
rootsystem user, and if you had--log-bin=it created binary log files owned bysomewhere_out_of_var_lib_mysqlrootin this directory, which remained owned byrootafter the installation. This is now fixed by starting mysqld as themysqlsystem user instead. (Bug#4038)Made
DROP DATABASEhonor the value oflower_case_table_names. (Bug#4066)The slave SQL thread refused to replicate
INSERT ... SELECTif it examined more than 4 billion rows. (Bug#3871)mysqlbinlog didn't escape the string content of user variables, and did not deal well when these variables were in non-ASCII character sets; this is now fixed by always printing the string content of user variables in hexadecimal. The character set and collation of the string is now also printed. (Bug#3875)
Fixed incorrect destruction of expression that led to a server crash on complex
AND/ORexpressions if query was ignored (either by a replication server because of--replicate-*-tablerules, or by any MySQL server because of a syntax error). (Bug#3969, Bug#4494)If
CREATE TEMPORARY TABLE t SELECTfailed while loading the data, the temporary table was not dropped. (Bug#4551)Fixed that when a multiple-table
DROP TABLEfailed to drop a table on the master server, the error code was not written to the binary log. (Bug#4553)When the slave SQL thread was replicating a
LOAD DATA INFILEstatement, it didn't show the statement in the output ofSHOW PROCESSLIST. (Bug#4326)
Functionality added or changed:
The output of the
SHOW BINLOG EVENTSstatement has been modified. TheOrig_log_poscolumn has been renamed toEnd_log_posand now represents the offset of the last byte of the event, plus one.Important note: If you upgrade to MySQL 4.1.1 or higher, it is difficult to downgrade back to 4.0 or 4.1.0! That is because, for earlier versions,
InnoDBis not aware of multiple tablespaces.Added support for
SUM(DISTINCT),MIN(DISTINCT), andMAX(DISTINCT).The
KILLstatement now takesCONNECTIONandQUERYmodifiers. The first is the same asKILLwith no modifier (it kills a given connection thread). The second kills only the statement currently being executed by the connection.Added
TIMESTAMPADD()andTIMESTAMPDIFF()functions.Added
WEEKandQUARTERvalues asINTERVALarguments for theDATE_ADD()andDATE_SUB()functions.New binary log format that enables replication of these session variables:
sql_mode,SQL_AUTO_IS_NULL,FOREIGN_KEY_CHECKS(which was replicated since 4.0.14, but here it's done more efficiently and takes less space in the binary logs),UNIQUE_CHECKS. Other variables (like character sets,SQL_SELECT_LIMIT, ...) will be replicated in upcoming 5.0.x releases.Implemented Index Merge optimization for
ORclauses. See Section 7.2.6, “Index Merge Optimization”.Basic support for stored procedures (SQL:2003 style). See Chapter 17, Stored Procedures and Functions.
Added
SELECT INTO, which can be of mixed (that is, global and local) types. See Section 17.2.7.3, “list_of_varsSELECT ... INTOStatement”.Easier replication upgrade (5.0.0 masters can read older binary logs and 5.0.0 slaves can read older relay logs). See Section 6.5, “Replication Compatibility Between MySQL Versions”, for more details). The format of the binary log and relay log is changed compared to that of MySQL 4.1 and older.
LOAD DATA INFILEcauses an implicit commit. Important: The behaviour ofLOAD DATA INFILEin this regard was changed again in MySQL 5.0.26. See Section E.1.2, “Changes in release 5.0.26 (03 October 2006)”.
Bugs fixed:
- E.2.1. Changes in MySQL Cluster-5.0.7 (10 June 2005)
- E.2.2. Changes in MySQL Cluster-5.0.6 (26 May 2005)
- E.2.3. Changes in MySQL Cluster-5.0.5 (Not released)
- E.2.4. Changes in MySQL Cluster-5.0.4 (16 April 2005)
- E.2.5. Changes in MySQL Cluster-5.0.3 (23 March 2005: Beta)
- E.2.6. Changes in MySQL Cluster-5.0.1 (27 July 2004)
- E.2.7. Changes in MySQL Cluster-4.1.13 (15 July 2005)
- E.2.8. Changes in MySQL Cluster-4.1.12 (13 May 2005)
- E.2.9. Changes in MySQL Cluster-4.1.11 (01 April 2005)
- E.2.10. Changes in MySQL Cluster-4.1.10 (12 February 2005)
- E.2.11. Changes in MySQL Cluster-4.1.9 (13 January 2005)
- E.2.12. Changes in MySQL Cluster-4.1.8 (14 December 2004)
- E.2.13. Changes in MySQL Cluster-4.1.7 (23 October 2004)
- E.2.14. Changes in MySQL Cluster-4.1.6 (10 October 2004)
- E.2.15. Changes in MySQL Cluster-4.1.5 (16 September 2004)
- E.2.16. Changes in MySQL Cluster-4.1.4 (31 August 2004)
- E.2.17. Changes in MySQL Cluster-4.1.3 (28 June 2004)
Starting from 4.1.13 and 5.0.7, all Cluster changes are included in the MySQL Change History, and this manual section is no longer separately maintained.
Note: Starting with version 5.0.8, changes for MySQL Cluster can be found in the combined MySQL Change History.
Functionality added or changed:
Bugs fixed:
(Bug#11019) mgmapi start backup in some cases returns wrong backupid
(Bug#10190) Backup from cluster wih NoOfReplica=1 is corrupt
(Bug#9246) Condition pushdown and left join, wrong result
(Bug#10956) More than 7 node restarts with
--initialcaused cluster to fail.(Bug#9945)
ALTER TABLEcaused server crash. (Linux/390)(Bug#9826) (Bug#10948) Schema change (
DROP TABLE,ALTER TABLE) crashed HPUX and PPC32.(Bug#10711) (Bug#9363) (Bug#8918) (Bug#10058) (Bug#9025) Cluster would time out and crash after first query; setting DataMemory to more than 2GB prevented cluster from starting; calling
ndb_select_count()crashed the cluster. (64-bit Unix OSes)
Functionality added or changed:
Limit on number of metadata objects (number of tables, indexes and BLOBs) now increased to 20,320
Bugs fixed:
Functionality added or changed:
Decreased IndexMemory Usage
Parallel key lookup (read-multi-range) for queries like
SELECT * FROM t1 WHERE primary_key IN (1,2,3,4,5,6,7,8,9,10);
Bugs fixed:
Patches merged from versions 4.1.11 and 4.1.12
(Bug#8315) NdbScanFilter cmp method only works for strings of exact word boundary length
(Bug#8103) Configuration handling error
(Bug#8035) mysqld signal 10 when ndbd is shutdown
(Bug#7631) NDB$EVENT contains unreadable event and table names
(Bug#7628) Filtered event types are ignored
(Bug#7627) Drop Event operation fails
(Bug#7424) create index on datetime fails
Functionality added or changed:
Condition pushdown to storage engine now works for update and delete as well
Bugs fixed:
(Bug#9675) Auto-increment not working with INSERT..SELECT and NDB storage
(Bug#9517) Condition pushdown to storage engine does not work for update/delete
(Bug#9282) API Node Crashes/Reloads on 'DELETE FROM'
(Bug#9280) Memory leak in cluster when dependent sub-queries are used
(Bug#8585) ndb_cache2 fails on aix52
Functionality added or changed:
Condition pushdown to storage engine
Query cache enabled for cluster
Bugs fixed:
Patches merged from version 4.1.10
Functionality added or changed:
This was the first MySQL Cluster release in the 5.0 series. As nearly all attention was still focused on getting 4.1 stable, it is not recommended to use MySQL 5.0.1 for MySQL Cluster.
Bugs fixed:
N/A
Functionality added or changed:
Bugs fixed:
(Bug#11132) Connections between data nodes and management nodes were not being closed following shutdown of
ndb_mgmd.(Bug#11050)
ndb_mgm> showprinted incorrectly after master data node failure.(Bug#10956) More than 7 node restarts with
--initialcaused cluster to fail.(Bug#9826) (Bug#10948) Schema change (
DROP TABLE,ALTER TABLE) crashed HPUX and PPC32.(Bug#9025) Data nodes failed to restart on 64-bit Solaris.
(Bug#11166) Insert records were incorrectly applied by
ndb_restore, thus making restoration from backup inconsistent if the binlog contained inserts.(Bug#8918) (Bug#9363) (Bug#10711) (Bug#10058) (Bug#9025) Cluster would time out and crash after first query; setting DataMemory to more than 2GB prevented cluster from starting; calling
ndb_select_count()crashed the cluster. (64-bit Unix OSes)(Bug#10190) When making a backup of a cluster where
NumberOfReplicaswas equal to 1, the backup's metadata was corrupted. (Linux)(Bug#9945)
ALTER TABLEcaused server crash. (Linux/390)(Bug#11133) A delete operation performed as part of a transaction caused an erroneous result.
(Bug#10294) Not allowing sufficient parallelism in cluster configuration (for example,
NoOfTransactionstoo small) causedndb_restoreto fail without generating any error messages.(Bug#11290) Setting TransactionInactiveTimeout= 0 did not result in an infinite timeout.
Functionality added or changed:
Bugs fixed:
(Bug#10471) Backup can become inconsistent with certain combinations of multiple-row updates
(Bug#10287) ndb_select_all "delimiter" option non functional
(Bug#10142) Unhandled resource shortage in UNIQUE index code
(Bug#10029) crash in ordered index scan after db full
(Bug#10001) 2 NDB nodes get signal 6 (abort) in DBTC
(Bug#9969) 4012 - has misleading error message
(Bug#9960) START BACKUP reports failure albeit succeeding
(Bug#9924) ABORT BACKUP 1 crashes 4 node cluster
(Bug#9892) Index activation file during node recovery
(Bug#9891) Crash in DBACC (line 7004) during commit
(Bug#9865) SELECT does not function properly
(Bug#9839) Column with AUTOINC contains -1 Value on node stop
(Bug#9757) Uncompleted node failure after gracefully stopping node
(Bug#9749) Transactions causes deadlock in ACC
(Bug#9724) Node fails to start: Message: File has already been opened
(Bug#9691) UPDATE fails on attempt to update primary key
(Bug#9675) Auto-increment not working with INSERT..SELECT and NDB storage
(Bug#9318) drop database does not drop ndb tables
(Bug#9280) Memory leak in cluster when dependent sub-queries are used
(Bug#8928) create table with keys will shutdown the cluster
Creating a table did not work for a cluster with 6 nodes. (Bug#8928) Databases with 1, 2, 4, 8, ... (2
nnodes) did not have the problem. After a rolling upgrade, restart each node manually by restarting it with the--initialoption. Otherwise, use dump and restore after an upgrade.
Functionality added or changed:
Bugs fixed:
(Bug#9916) DbaccMain.cpp / DBACC (Line: 4876) / Pointer too large
(Bug#9435) TIMESTAMP columns don't update
(Bug#9052) Uninitialized data during unique index build, potential cluster crash
(Bug#8876) Timeout when committing aborted transaction after node failure
(Bug#8786) ndb_autodiscover, drop index can fail, wait 2 minutes timeout
(Bug#8853) Transaction aborted after long time during node failure (4012)
(Bug#8753) Invalid schema object version after dropping index (crash fixed, currently retry required)
(Bug#8645) Assertion failure with multiple management servers
(Bug#8557) ndbd does not get same nodeid on restart
(Bug#8556) corrupt ndb_mgm show printout for certain configurations
(Bug#8167) cluster shared memory and mysqld signal usage clash
Bugs fixed:
(Bug#8284) Out of fragment memory in DBACC
(Bug#8262) Node crash due to bug in DBLQH
(Bug#8208) node restart fails on Aix 5.2
(Bug#8167) cluster shared memory and mysqld signal usage clash
(Bug#8101) unique index and error 4209 while selecting
(Bug#8070) (Bug#7937) (Bug#6716) various ndb_restore core dumps on HP-UX
(Bug#8010) 4006 forces MySQL Node Restart
(Bug#7928) out of connection objects
(Bug#7898) mysqld crash with ndb (solaris)
(Bug#7864) Not possible to have more than 4.5G data memory
Functionality added or changed:
New implementation of shared memory transporter.
Cluster automatically configures shared memory transporter if possible.
Cluster prioritizes usage of transporters with shared memory and localhost TCP
Added switches to control the above functions,
ndb-shmandndb-optimized-node-selection.
Bugs fixed:
(Bug#7805) config.ini parsing error
(Bug#7798) Running range scan after alter table in different thread causes node failure
(Bug#7761) Alter table does not autocommit
(Bug#7725) Indexed DATETIME Columns Return Random Results
(Bug#7660) START BACKUP does not increment BACKUP-ID (Big Endian machines)
(Bug#7593) Cannot Create A Large NDB Data Warehouse
(Bug#7480) Mysqld crash in ha_ndbcluster using Query Browser
(Bug#7470) shared memory transporter does not connect
(Bug#7396) Primary Key not working in NDB Mysql Clustered table (solaris)
(Bug#7379) ndb restore fails to handle blobs and multiple databases
(Bug#7346) ndb_restore enters infinite loop
(Bug#7340) Problem for inserting data into the Text field on utf8
(Bug#7124) ndb_mgmd is aborted on startup when using SHM connection
Functionality added or changed:
Default port for ndb_mgmd was changed to 1186 (from 2200) as this port number was officially assigned to MySQL Cluster by IANA.
New command in ndb_mgm, PURGE STALE SESSIONS, as a workaround for cases where nodes fail to allocate a node id even if it is free to use.
New command in ndb_mgm, CONNECT.
The ndb executables have been changed to make use of the regular MySQL command line option parsing features. See Section 15.6.5, “Command Options for MySQL Cluster Processes”, for notes on changes.
As bonus of the above you can now specify all command line options in
my.cnfusing the executable names as sections, that is,[ndbd],[ndb_mgmd],[ndb_mgm],[ndb_restore], and so forth.[ndbd] ndb-connectstring=myhost.domain.com:1234 [ndb_mgm] ndb-connectstring=myhost.domain.com:1234Added use of section
[mysql_cluster]inmy.cnf. All cluster executables, including mysqld, parse this section. For example, this is a convenient place to putndb-connectstringso that it need be specified only once.Added cluster log info events on allocation and deallocation of nodeid's.
Added cluster log info events on connection refuse as a result of version mismatch.
Extended connectstring syntax to allow for leaving the port number out. For example,
ndb-connectstring|connect-string=myhost1,myhost2,myhost3is a valid connectstring and connect occurs on default port 1186.Clear text ndb error messages provided also for error codes that are mapped to corresponding mysql error codes, by executing
SHOW WARNINGSafter an error has occurred which relates to the ndb storage engine.Significant performance improvements done for read performance, especially for blobs.
Added some variables for performance tuning,
ndb_force_sendandndb_use_exact_count. Doshow variables like 'ndb%';in mysql client for listing. Usesetcommand to alter variables.Added variables to set some options,
ndb_use_transactionsandndb_autoincrement_prefetch_sz.
Bugs fixed:
(Bug#7303) ndb_mgm: Trying to set CLUSTERLOG for a specific node id core dumps
(Bug#7193) start backup gives false error printout
(Bug#7153) Cluster nodes don't report error on endianness mismatch
(Bug#7152) ndb_mgmd segmentation fault on incorrect HostName in configuration
(Bug#7104) clusterlog filtering and level setting broken
(Bug#6995) ndb_recover on varchar fields results in changing case of data
(Bug#6919) all status only shows 2 nodes on a 8-node cluster
(Bug#6871) DBD execute failed: Got error 897 'Unknown error code' from ndbcluster
(Bug#6794) Wrong outcome of update operation of ndb table
(Bug#6791) Segmentation fault when config.ini is not correctly set
(Bug#6775) failure in acc when running many mysql clients
(Bug#6696) ndb_mgm command line options inconsistent with behavior
(Bug#6684) ndb_restore doesn't give error messages if improper command given
(Bug#6677) ndb_mgm can crash on "ALL CLUSTERLOG"
(Bug#6538) Error code returned when select max() on empty table with index
(Bug#6451) failing create table givers "ghost" tables which are impossible to remove
(Bug#6435) strange behavior of left join
(Bug#6426) update with long pk fails
(Bug#6398) update of primary key fails
(Bug#6354) mysql does not complain about --ndbcluster option when NDB is not compiled in
(Bug#6331) INSERT IGNORE .. SELECT breaks subsequent inserts
(Bug#6288) cluster nodes crash on data import
(Bug#6031) To drop database you have to execute DROP DATABASE command twice
(Bug#6020) LOCK TABLE + delete returns error 208
(Bug#6018) REPLACE does not work for BLOBs + NDB
(Bug#6016) Strange crash with blobs + different DATABASES
(Bug#5973) ndb table belonging to different database shows up in show tables
(Bug#5872) ALTER TABLE with blob from ndb table to myisam fails
(Bug#5844) Failing mysql-test-run leaves stray NDB processes behind
(Bug#5824) HELP text messed up in ndb_mgm
(Bug#5786) Duplicate key error after restore
(Bug#5785) lock timeout during concurrent update
(Bug#5782) Unknown error when using LIMIT with ndb table
(Bug#5756) RESTART node from ndb_mgm fails
A few more not reported bugs fixed
Functionality added or changed:
Optimization 1: Improved performance on index scans. Measured 30% performance increase on query which do large amounts of index scans.
Optimization 2: Improved performance on primary key lookups. Around double performance for autocommitted primary key lookups.
Optimization 3: Improved performance when using blobs by avoiding usage of exclusive locks for blobs.
Bugs fixed:
A few bugs fixed.
Functionality added or changed:
Limited character set support for storage engine NDBCLUSTER:
Char set Collation big5 big5_chinese_ci big5_bin binary binary euckr euckr_korean_ci euckr_bin gb2312 gb2312_chinese_ci gb2312_bin gbk gbk_chinese_ci gbk_bin latin1 latin1_swedish_ci latin1_bin sjis sjis_japanese_ci sjis_bin tis620 tis620_bin ucs2 ucs2_general_ci ucs2_bin ujis ujis_japanese_ci ujis_bin utf8 utf8_general_ci utf8_bin The SCI Transporter has been brought up-to-date with all changes and now works and has been documented as well.
Optimizations when several clients to a MySQL Server access ndb tables.
Added more checks and warnings for erroneous and inappropriate cluster configurations.
SHOW TABLESnow directly shows ndb tables created on a different MySQL server, that is, without a prior table access.Enhanced support for starting MySQL Server independently of ndbd and ndb_mgmd.
Clear text ndb error messages provided by executing
SHOW WARNINGSafter an error has occurred which relates to the ndb storage engine.
Bugs fixed:
Quite a few bugs fixed.
Functionality added or changed:
Many queries in MySQL Cluster are executed as range scans or full table scans. All queries that don't use a unique hash index or the primary hash index use this access method. In a distributed system it is crucial that batching is properly performed.
In previous versions, the batch size was fixed to 16 per data node. In this version it is configurable per MySQL Server. So for queries using lots of large scans it is appropriate to set this parameter rather large and for queries using many small scans only fetching a small amount of records it is appropriate to set it low.
The performance of queries can easily change as much as 40% based on how this variable is set.
In future versions more logic will be implemented for assessing the batch size on a per-query basis. Thus, the semantics of the new configuration variable
ScanBatchSizeare likely to change.The fixed size overhead of the ndbd process has been greatly decreased. This is also true for the overhead per operation record as well as overhead per table and index.
A number of new configuration variables have been introduced to enable configuration of system buffers. Configuration variables for specifying the numbers of tables, unique hash indexes, and ordered indexes have also been introduced.
New configuration variables:
MaxNoOfOrderedIndexes,MaxNoOfUniqueHashIndexesConfiguration variables no longer used:
MaxNoOfIndexes(split into the two above).In previous versions
ALTER TABLE,TRUNCATE TABLE, andLOAD DATAwere performed as one big transaction. In this version, all of these statements are automatically separated into several distinct transactions.This removes the limitation that one could not change very large tables due to the
MaxNoOfConcurrentOperationsparameter.MySQL CLuster's online backup feature now backs up indexes so that both data and indexes are restored.
In previous versions it was not possible to use
NULLin indexes. This is now possible for all supported index types.Much work has been put onto making
AUTO_INCREMENTfeatures work as for other table handlers. Autoincrements as a partial key is still only supported byMyISAM.In earlier versions, mysqld would crash if the cluster wasn't started with the
--ndbclusteroption. Now mysqld handles cluster crashes and starts without crashing.The
-ioption for initial startup of ndbd has been removed. Initial startup still can be specified by using the--initialoption. The reason for this is to ensure that it is clear what takes place when using--initial: this option completely removes all data from the disk and should only be used at initial start, in certain software upgrade cases, and in some cases as a workaround when nodes cannot be restarted successfully.The management client (ndb_mgm) now has additional commands and more information is printed for some commands such as
show.In previous versions, the files were called
ndb_0..when it wasn't possible to allocate a node ID when starting the node. To ensure that files are not so easily overwritten, these files are now namedndb_pid.., where pid is the process ID assigned by the OS.The default parameters have changed for ndb_mgmd and ndbd. In particular, they are now started as daemons by default. The
-noption has been removed since it could cause confusion as to its meaning (nostart or nodaemon).In the configuration file, you can now use
[NDBD]as an alias for[DB],[MYSQLD]as an alias for[API], and[NDB_MGMD]as an alias for[MGM]. Note: In fact,[NDBD],[MYSQLD], and[NDB_MGMD]are now the preferred designations, although the older ones will continue to be supported for some time to come in order to maintain backward compatibility.Many more checks for consistency in configuration have been introduced to in order to provide quicker feedback on configuration errors.
In the connect string, it is now possible to use both ‘
;’ and ‘,’ as the separator between entries. Thus, "nodeid=2,host=localhost:2200" is equivalent to "nodeid=2;host=localhost:2200".In the configuration file, it is also possible to use ‘
:’ or ‘=’ for assignment values. For example,MaxNoOfOrderedIndexes : 128andMaxNoOfOrderedIndexes = 128are equivalent expressions.The configuration variable names are now case insensitive, so
MaxNoOfOrderedIndexes: 128is equivalent toMAXNOOFORDEREDINDEXES = 128.It is possible now to set the backup directory separately from the
FileSystemPathby using theBackupDirconfiguration variable.Log files and trace files can now be placed in any directory by setting the
DataDirconfiguration variable.FileSystemPathis no longer mandatory and defaults toDataDir.Queries involving tables from different databases are now supported.
It is now possible to update the primary key.
The performance of ordered indexes has been greatly improved, particularly the maintenance of indexes on updates, inserts and deletes.
Bugs fixed:
Quite a few bugs fixed.
Functionality added or changed:
The names of the log files and trace files created by the ndbd and ndb_mgmd processes have changed.
Support for the many
BLOBdata types was introduced in this version.
Bugs fixed:
Quite a few bugs were fixed in the 4.1.4 release.
- E.3.1. Changes in Connector/ODBC 5.0.12 (Not yet released)
- E.3.2. Changes in Connector/ODBC 5.0.11 (31 January 2007)
- E.3.3. Changes in Connector/ODBC 5.0.10 (14 December 2006)
- E.3.4. Changes in Connector/ODBC 5.0.9 (22 November 2006)
- E.3.5. Changes in Connector/ODBC 5.0.8 (17 November 2006)
- E.3.6. Changes in Connector/ODBC 5.0.7 (08 November 2006)
- E.3.7. Changes in Connector/ODBC 5.0.6 (03 November 2006)
- E.3.8. Changes in Connector/ODBC 5.0.5 (17 October 2006)
- E.3.9. Changes in Connector/ODBC 5.0.3 (Connector/ODBC 5.0 Alpha 3) (20 June 2006)
- E.3.10. Changes in Connector/ODBC 5.0.2 (Never released)
- E.3.11. Changes in Connector/ODBC 5.0.1 (Connector/ODBC 5.0 Alpha 2) (05 June 2006)
- E.3.12. Changes in Connector/ODBC 3.51.16 (Not yet released)
- E.3.13. Changes in Connector/ODBC 3.51.15 (7 May 2007)
- E.3.14. Changes in Connector/ODBC 3.51.14 (08 March 2007)
- E.3.15. Changes in Connector/ODBC 3.51.13 (Never released)
- E.3.16. Changes in Connector/ODBC 3.51.12
- E.3.17. Changes in Connector/ODBC 3.51.11
Bugs fixed:
Functionality added or changed:
Driver now builds and is partially tested under Linux with the iODBC driver manager.
Added support for ODBC v2 statement options using attributes.
Bugs fixed:
Internal function,
my_setpos_delete_ignore()could cause a crash. (Bug#22796)Updates of
MEMOorTEXTcolumns from within Microsoft Access would fail. (Bug#25263)Transaction support has been added and tested. (Bug#25045)
Connection string parsing for DSN-less connections could fail to identify some parameters. (Bug#25316)
Fixed occasional mis-handling of the
SQL_NUMERIC_Ctype.Fixed the binding of certain integer types.
Connector/ODBC 5.0.10 is the sixth BETA release.
Functionality added or changed:
Added wide-string type info for
SQLGetTypeInfo().Added loose handling of retrieving some diagnostic data. (Bug#15782)
Added initial support for removing braces when calling stored procedures and retrieving result sets from procedure calls. (Bug#24485)
Added initial unicode support in data and metadata. (Bug#24837)
Significant performance improvement when retrieving large text fields in pieces using
SQLGetData()with a buffer smaller than the whole data. Mainly used in Access when fetching very large text fields. (Bug#24876)
Bugs fixed:
Connector/ODBC 5.0.9 is the fifth BETA release.
This is an implementation and testing release, and is not designed for use within a production environment.
Functionality added or changed:
Added recognition of
SQL_C_SHORTandSQL_C_TINYINTas C types.Added support for column binding as SQL_NUMBERIC_STRUCT.
Bugs fixed:
Fixed wildcard handling of and listing of catalogs and tables in
SQLTables.Catch use of
SQL_ATTR_PARAMSET_SIZEand report error until we fully support.Corrected retrieval multiple field types bit and blob/text.
Fixed buffer length return for SQLDriverConnect.
Added limit of display size when requested via
SQLColAttribute/SQL_DESC_DISPLAY_SIZE.Fixed statistics to fail if it couldn't be completed.
Fixed SQLGetData to clear the NULL indicator correctly during multiple calls.
ODBC v2 behaviour in driver now supports ODBC v3 date/time types (since DriverManager maps them).
Connector/ODBC 5.0.8 is the fourth BETA release.
This is an implementation and testing release, and is not designed for use within a production environment.
Functionality added or changed:
Made distinction between
CHAR/BINARY(and VAR versions).Wildcards now support escaped chars and underscore matching (needed to link tables with underscores in access).
Also made
SQL_DESC_NAMEonly fill in the name if there was a data pointer given, otherwise just the length.Fixed display size to be length if max length isn’t available.
Bugs fixed:
Length now used when handling bind parameter (needed in particular for
SQL_WCHAR) - this enables updating char data in MS Access.Fixed string length to chars, not bytes, returned by SQLGetDiagRec.
Fixed using wrong pointer for
SQL_MAX_DRIVER_CONNECTIONSinSQLGetInfo.Fixed binding using
SQL_C_LONG.Allow SQLDescribeCol to be called to retrieve the length of the column name, but not the name itself.
Fix size return from
SQLDescribeCol.Fixed hanlding of numeric pointers in SQLColAttribute.
Fixed type returned for
MYSQL_TYPE_LONGtoSQL_INTEGERinstead ofSQL_TINYINT.Fixed MDiagnostic to use correct v2/v3 error codes.
Set default return to
SQL_SUCCESSif nothing is done forSQLSpecialColumns.Updated retrieval of descriptor fields to use the right pointer types.
Connector/ODBC 5.0.7 is the third BETA release.
This is an implementation and testing release, and is not designed for use within a production environment.
Functionality added or changed:
Improved trace/log.
Added support for
SQLStatisticstoMYODBCShell.
Bugs fixed:
Fixed
SQLDescribeColreturning column name length in bytes rather than chars.SQLBindParameter now handles
SQL_C_DEFAULT.Corrected incorrect column index within
SQLStatistics. Many more tables can now be linked into MS Access.
Connector/ODBC 5.0.6 is the second BETA release.
This is an implementation and testing release, and is not designed for use within a production environment.
Features, limitations and notes on this release:
You no longer have to have Connector/ODBC 3.51 installed before installing this version.
Installation is provided in the form of a standard Microsoft System Installer (MSI).
Connector/ODBC supports both
UserandSystemDSNs.
Connector/ODBC 5.0.5 is the first BETA release.
This is an implementation and testing release, and is not designed for use within a production environment.
Features, limitations and notes on this release:
You no longer have to have Connector/ODBC 3.51 installed before installing this version.
This is an implementation and testing release, and is not designed for use within a production environment.
Features, limitations and notes on this release:
The following ODBC API functions have been added in this release:
SQLBindParameterSQLBindCol
Connector/ODBC 5.0.2 was an internal implementation and testing release.
Features, limitations and notes on this release:
Connector/ODBC 5.0 is Unicode aware.
Connector/ODBC is currently limited to basic applications. ADO applications and Microsoft Office are not supported.
Connector/ODBC must be used with a Driver Manager.
The following ODBC API functions are implemented:
SQLAllocHandleSQLCloseCursorSQLColAttributeSQLColumnsSQLConnectSQLCopyDescSQLDisconnectSQLExecDirectSQLExecuteSQLFetchSQLFreeHandleSQLFreeStmtSQLGetConnectAttrSQLGetDataSQLGetDescFieldSQLGetDescRecSQLGetDiagFieldSQLGetDiagRecSQLGetEnvAttrSQLGetFunctionsSQLGetStmtAttrSQLGetTypeInfoSQLNumResultColsSQLPrepareSQLRowcountSQLTables
The following ODBC API function are implemented, but not yet support all the available attributes/options:
SQLSetConnectAttrSQLSetDescFieldSQLSetDescRecSQLSetEnvAttrSQLSetStmtAttr
Functionality added or changed:
Connector/ODBC now supports using SSL for communication. (Bug#12918)
Bugs fixed:
When using stored procedures, making a
SELECTor second stored procedure call after an initial stored procedure call, the second statement will fail. (Bug#27544)Using curors on results sets with multi-column keys could select the wrong value. (Bug#28255)
Using
BETWEENwith date values, the wrong results could be returned. (Bug#15773)Specifying strings as parameters using the
adBSTRoradVarWChartypes, (SQL_WVARCHARandSQL_WLONGVARCHAR) would be incorrectly quoted. (Bug#16235)Return values from
SQLTables()may be truncated. (Bugs #22797)Data in
TEXTcolumns would fail to be read correctly. (Bug#16917)SQLForeignKeysdoes not escape_and%in the table name arguments. (Bug#27723)When using the
Don't Cache Results(option value1048576) with Microsoft Access, the connection will fail using DAO/VisualBasic. (Bug#4657)
Bugs fixed:
Adding a new DSN with the
myodbc3iutility under AIX would fail. (Bug#27220)Connector/ODBC would incorrectly claim to support
SQLProcedureColumns(by returning true when queried aboutSQLPROCEDURECOLUMNSwithSQLGetFunctions), but this functionality is not supported. (Bug#27591)Using
SQLDriverConnectinstead ofSQLConnectcould cause later operations to fail. (Bug#7912)An incorrect transaction isolation level may not be returned when accessing the connection attributes. (Bug#27589)
When inserting data using bulk statements (through
SQLBulkOperations), the indicators for all rows within the insert would not updated correctly. (Bug#24306)Using
SQLProceduresdoes not return the database name within the returned resultset. (Bug#23033)Connector/ODBC would return too many foreign key results when accessing tables with similar names. (Bug#4518)
When using blobs and parameter replacement in a statement with
WHERE CURSOR OF, the SQL is truncated. (Bug#5853)The
SQLTransact()function did not support an empty connection handle. (Bug#21588)
Functionality added or changed:
Use of
SQL_ATTR_CONNECTION_TIMEOUTon the server has now been disabled. If you attempt to set this attribute on your connection theSQL_SUCCESS_WITH_INFOwill be returned, with an error number/string ofHYC00: Optional feature not supported. (Bug#19823)Added support for the
HENVhandlers inSQLEndTran().Added auto-reconnect option to Connector/ODBC option parameters.
Added auto is null option to Connector/ODBC option parameters. (Bug#10910)
Bugs fixed:
The ODBC driver name and version number were incorrectly reported by the driver. (Bug#19740)
A string format exception would be raised when using iODBC, Connector/ODBC and the embedded MySQL server. (Bug#16535)
When retrieving data from columns that have been compressed using
COMPRESS(), the retrived data would be truncated to 8KB. (Bug#20208)When retrieving
TIMEcolumns, C/ODBC would incorrectly interpret the type of the string and could interpret it as aDATEtype instead. (Bug#25846)On 64-bit systems, some types would be incorrectly returned. (Bug#26024)
Using
DataAdapter, Connector/ODBC may continually consume memory when reading the same records within a loop (Windows Server 2003 SP1/SP2 only). (Bug#20459)Connector/ODBC may insert the wrong parameter values when using prepared statements under 64-bit Linux. (Bug#22446)
Using Connector/ODBC, with
SQLBindColand binding the length to the return value fromSQL_LEN_DATA_AT_EXECfails with a memory allocation error. (Bug#20547)The
SQLDriverConnect()ODBC method did not work with recent Connector/ODBC releases. (Bug#12393)
Connector/ODBC 3.51.13 was an internal implementation and testing release.
Functionality added or changed:
N/A
Bugs fixed:
Functionality added or changed: No changes.
Bugs fixed:
mysql_list_dbcolumns()andinsert_fields()were retrieving all rows from a table. Fixed the queries generated by these functions to return no rows. (Bug#8198)SQLGetTypoInfo()returnedtinyblobforSQL_VARBINARYand nothing forSQL_BINARY. Fixed to returnvarbinaryforSQL_VARBINARY,binaryforSQL_BINARY, andlongblobforSQL_LONGVARBINARY. (Bug#8138)
- E.4.1. Changes in MySQL Connector/NET Version 5.1.2 (Not yet released)
- E.4.2. Changes in MySQL Connector/NET Version 5.1.1 (23 May 2007)
- E.4.3. Changes in MySQL Connector/NET Version 5.1.0 (01 May 2007)
- E.4.4. Changes in MySQL Connector/NET Version 5.0.8 (Not yet released)
- E.4.5. Changes in MySQL Connector/NET Version 5.0.7 (18 May 2007)
- E.4.6. Changes in MySQL Connector/NET Version 5.0.6 (22 March 2007)
- E.4.7. Changes in MySQL Connector/NET Version 5.0.5 (07 March 2007)
- E.4.8. Changes in MySQL Connector/NET Version 5.0.4 (Not released)
- E.4.9. Changes in MySQL Connector/NET Version 5.0.3 (05 January 2007)
- E.4.10. Changes in MySQL Connector/NET Version 5.0.2 (06 November 2006)
- E.4.11. Changes in MySQL Connector/NET Version 5.0.1 (01 October 2006)
- E.4.12. Changes in MySQL Connector/NET Version 5.0.0 (08 August 2006)
- E.4.13. Changes in MySQL Connector/NET Version 1.0.10 (Not yet released)
- E.4.14. Changes in MySQL Connector/NET Version 1.0.9 (02 February 2007
- E.4.15. Changes in MySQL Connector/NET Version 1.0.8 (20 October 2006)
- E.4.16. Changes in MySQL Connector/NET Version 1.0.7 (21 November 2005)
- E.4.17. Changes in MySQL Connector/NET Version 1.0.6 (03 October 2005)
- E.4.18. Changes in MySQL Connector/NET Version 1.0.5 (29 August 2005)
- E.4.19. Changes in MySQL Connector/NET Version 1.0.4 (20 January 2005)
- E.4.20. Changes in MySQL Connector/NET Version 1.0.3-gamma (12 October 2004)
- E.4.21. Changes in MySQL Connector/NET Version 1.0.2-gamma (15 November 2004)
- E.4.22. Changes in MySQL Connector/NET Version 1.0.1-beta2 (27 October 2004)
- E.4.23. Changes in MySQL Connector/NET Version 1.0.0 (01 September 2004)
- E.4.24. Changes in MySQL Connector/NET Version 0.9.0 (30 August 2004)
- E.4.25. Changes in MySQL Connector/NET Version 0.76
- E.4.26. Changes in MySQL Connector/NET Version 0.75
- E.4.27. Changes in MySQL Connector/NET Version 0.74
- E.4.28. Changes in MySQL Connector/NET Version 0.71
- E.4.29. Changes in MySQL Connector/NET Version 0.70
- E.4.30. Changes in MySQL Connector/NET Version 0.68
- E.4.31. Changes in MySQL Connector/NET Version 0.65
- E.4.32. Changes in MySQL Connector/NET Version 0.60
- E.4.33. Changes in MySQL Connector/NET Version 0.50
Bugs fixed:
Bugs fixed:
Running the statement
SHOW PROCESSLISTwould return columns as byte arrays instead of native columns. (Bug#28448)Connector/NET would look for the wrong table when executing
User.IsRole().(Bug#28251)DATETIMEfields from versions of MySQL bgefore 4.1 would be incorrectly parsed, resulting in a exception. (Bug#23342)Installation of the Connector/NET on Windows would fail if VisualStudio had not already been installed. (Bug#28260)
Using
MySQLDataAdapter.FillSchema()on a stored procedure would raise an exception:Invalid attempt to access a field before calling Read(). (Bug#27668)Building a connection string within a tight loop would show slow peformance. (Bug#28167)
The
UNSIGNEDflag for parameters in a stored procedure would be ignored when usingMySqlCommandBuilderto obtain the parameter information. (Bug#27679)Fixed password property on
MySqlConnectionStringBuilderto usePasswordPropertyTextattribute. This causes dots to show instead of actual password text.
Other changes:
Added Membership and Role provider contributed by Sean Wright (thanks!).
Now compiles for .NET CF 2.0.
Rewrote stored procedure parsing code using a new SQL tokenizer. Really nasty procedures including nested comments are now supported.
GetSchema will now report objects relative to the currently selected database. What this means is that passing in null as a database restriction will report objects on the currently selected database only.
Bugs fixed:
Bugs fixed:
Running the statement
SHOW PROCESSLISTwould return columns as byte arrays instead of native columns. (Bug#28448)Enlisting a null transaction would affect the current connection object, such that further enlistment operations to the transaction are not possible. (Bug#26754)
Attempting to change the the
Connection Protocolproperty within aPropertyGridcontrol would raise an exception. (Bug#26472)DATETIMEfields from versions of MySQL bgefore 4.1 would be incorrectly parsed, resulting in a exception. (Bug#23342)Using
MySQLDataAdapter.FillSchema()on a stored procedure would raise an exception:Invalid attempt to access a field before calling Read(). (Bug#27668)Building a connection string within a tight loop would show slow peformance. (Bug#28167)
The
UNSIGNEDflag for parameters in a stored procedure would be ignored when usingMySqlCommandBuilderto obtain the parameter information. (Bug#27679)Using logging (with the
logging=trueparameter to the connection string) would not generate a log file. (Bug#27765)The
CreateFormatcolumn of theDataTypescollection did not contain a format specification for creating a new column type. (Bug#25947)The
charactersetproperty would not be identified during a connection (also affected Visual Studion Plugin). (Bug#27240, Bug#26147)When cloning an open
MySqlClient.MySqlConnectionwith thePersist Security Info=Falseoption set, the cloned connection is not usable because the security information has not been cloned. (Bug#27269)If you close an open connection with an active transaction, the transaction is not automatically rolled back. (Bug#27289)
Bugs fixed:
MySqlParameterCollectionand parameters added withInsertmethod can not be retrieved later usingParameterName. (Bug#27135)Publisher listed in "Add/Remove Programs" is not consistent with other MySQL products. (Bug#27253)
cmd.Parameters.RemoveAt("Id")will cause an error if the last item is requested. (Bug#27187)Exception thrown when using large values in
UInt64parameters. (Bug#27093)DESCRIBE ....SQL command returns byte arrays rather than data on MySQL versions older than 4.1.15. (Bug#27221)MySQL Visual Studio Plugin 1.1.2 does not work with Connector/Net 5.0.5. (Bug#26960)
Functionality added or changed:
Return parameters created with DeriveParameters now have the name
RETURN_VALUE.Fixed problem with parameter name hashing where the hashes were not getting updated when parameters were removed from the collection.
Fixed problem with calling stored functions when a return parameter was not given.
Fixed problem that prevented use of
SchemaOnlyorSingleRowcommand behaviors with stored procedures or prepared statements.Assembly now properly appears in the Visual Studio 2005 Add/Remove Reference dialog.
Added
MySqlParameterCollection.AddWithValueand marked theAdd(name, value)method as obsolete.Added
Use Procedure Bodiesconnection string option to allow calling procedures without using procedure metadata.Reverted behavior that required parameter names to start with the parameter marker. We apologize for this back and forth but we mistakenly changed the behavior to not match what
SqlClientsupports. We now support using either syntax for adding parameters however we also respond exactly likeSqlClientin that if you ask for the index of a parameter using a syntax different than you added the parameter, the result will be -1.
Bugs fixed:
The
UpdateRowSource.FirstReturnedRecordmethod does not work. (Bug#25569)A critical
ConnectionPoolerror would result in repeatedSystem.NullReferenceException. (Bug#25603)Applications would crash when calling with
CommandTypeset toStoredProcedure.BINARYandVARBINARYcolumns would be returned as a string, not binary, datatype. (Bug#25605)MySqlConnection.GetSchemafails withNullReferenceExceptionfor Foreign Keys. (Bug#26660)When a
MySqlConversionExceptionis raised on a remote object, the client application would receive aSerializationExceptioninstead. (Bug#24957)High CPU utilization would be experienced when there is no idle connection waiting when using pooled connections through
MySqlPool.GetConnection. (Bug#24373)Connector/NET would not compile properly when used with Mono 1.2. (Bug#24263)
Opening a connection would be slow due to hostname lookup. (Bug#26152).
Connector/NET would fail to install under Windows Vista. (Bug#26430)
Incorrect values/formats would be applied when the
OldSyntaxconnection string option was used. (Bug#25950)Registry would be incorrectly populated with installation locations. (Bug#25928)
Filling a table schema through a stored procedure triggers a runtime error. (Bug#25609)
MySqlConnectionthrows an exception when connecting to MySQL v4.1.7. (Bug#25726)Returned data types of a
DataTypescollection do not contain the right correctl CLR Datatype. (Bug#25907)GetSchemaandDataTypeswould throw an exception due to an incorrect table name. (Bug#25906)Times with negative values would be returned incorrectly. (Bug#25912)
SELECTdid not work correctly when using aWHEREclause containing a UTF-8 string. (Bug#25651)When closing and then re-opening a connection to a database, the character set specification is lost. (Bug#25614)
When connecting to a MySQL Server earlier than version 4.1, the connection would hang when reading data. (Bug#25458)
When connecting to a server, the return code from the connection could be zero, even though the hostname was incorrect. (Bug#24802)
Using
ExecuteScalar()with more than one query, where one query fails, will hang the connection. (Bug#25443)
Connector/NET Version 5.0.4 was not released due to an incomplete bug fix.
Functionality added or changed:
SSL support has been updated.
The
ViewColumnsGetSchemacollection has been updated.The
CommandBuilder.DeriveParametersfunction has been updated to the procedure cache.Improved speed and performance by re-architecting certain sections of the code.
Usage Advisor has been implemented. The Usage Advisor checks your queries and will report if you are usiing the connection inefficiently.
The
MySqlCommandobject now supports asynchronous query methods. This is implemented useg theBeginExecuteNonQueryandEndExecuteNonQuerymethods.Metadata from storaed procedures and stored function execution are cached.
PerfMon hooks have been added to monitor the stored procedure cache hits and misses.
The ShapZipLib library has been replaced with the deflate support provided within .NET 2.0.
Support for the embedded server and client library have been removed from this release. Support will be added back to a later release.
Bugs fixed:
An exception would be raised, or the process would hang, if
SELECTprivileges on a database were not granted and a stored procedure was used. (Bug#25033)Nested transactions (which are unsupported)do not raise an error or warning. (Bug#22400)
When adding parameter objects to a command object, if the parameter direction is set to
ReturnValuebefore the parameter is added to the command object then when the command is executed it throws an error. (Bug#25013)Additional text added to error message (Bug#25178)
Stored procedure executions are not thread safe. (Bug#23905)
Using
Driver.IsTooOld()would return the wrong value. (Bug#24661)Deleting a connection to a disconnected server when using the Visual Studio Plugin would cause an assertion failure. (Bug#23687)
When using a
DbNull.Valueas the value for a parameter value, and then later setting a specific value type, the command would fail with an exception because the wrong type was implied from theDbNull.Value. (Bug#24565)
Functionality added or changed:
Important change: Due to a number of issues with the use of server-side prepared statements, Connector/NET 5.0.2 has disabled their use by default. The disabling of server-side prepared statements does not affect the operation of the connector in any way.
To enable server-side prepared statements you must add the following configuration property to your connector string properties:
ignore prepare=false
The default value of this property is true.
Implemented a stored procedure cache. By default, the connector caches the metadata for the last 25 procedures that are seen. You can change the numbver of procedures that are cacheds by using the
procedure cacheconnection string.An
Ignore Prepareoption has been added to the connection string options. If enabled, prepared statements will be disabled application-wide. The default for this option is true.
Bugs fixed:
Creating a connection through the Server Explorer when using the Visual Studio Plugin would fail. The installer for the Visual Studio Plugin has been updated to ensure that Connector/NET 5.0.2 must be installed. (Bug#23071)
Within Mono, using the
PreparedStatementinterface could result in an error due to aBitArraycopying error. (Bug#18186)Using Windows Vista (RC2) as a non-privileged user would raise a
Registry key 'Global' access denied. (Bug#22882)One system where IPv6 was enabled, Connector/NET would incorrectly resolve hostnames. (Bug#23758)
Column names with accented characters were not parsed properly causing malformed column names in result sets. (Bug#23657)
Connector/NET did not work as a data source for the
SqlDataSourceobject used by ASP.NET 2.0. (Bug#16126)A
System.FormatExceptionexception would be raised when invoking a stored procedure with anENUMinput parameter. (Bug#23268)During installation, an antivirus error message would be raised (indicating a malicious script problem). (Bug#23245)
An exception would be thrown when calling
GetSchemaTableandfieldswas null. (Bug#23538)
Bugs fixed:
Using
ExecuteScalarwith a datetime field, where the value of the field is "0000-00-00 00:00:00", aMySqlConversionExceptionexception would be raised. (Bug#11991)An
MySql.Data.Types.MySqlConversionExceptionwould be raised when trying to update a row that contained a date field, where the date field contained a zero value (0000-00-00 00:00:00). (Bug#9619)Incorrect field/data lengths could be returned for
VARCHARUTF8 columns. Bug (#14592)Submitting an empty string to a command object through
prepareraises anSystem.IndexOutOfRangeException, rather than a Connector/Net exception. (Bug#18391)Starting a transaction on a connection created by
MySql.Data.MySqlClient.MySqlClientFactory, usingBeginTransactionwithout specifying an isolation level, causes the SQL statement to fail with a syntax error. (Bug#22042)Connector/NET on a Tukish operating system, may fail to execute certain SQL statements correctly. (Bug#22452)
You can now install the Connector/NET MSI package from the command line using the
/passive,/quiet,/qoptions. (Bug#19994)The
MySqlexceptionclass is now derived from theDbExceptionclass. (Bug#21874)Executing multiple queries as part of a transaction returns
There is already an openDataReader associated with this Connection which must be closed first. (Bug#7248)The
#would not be accepted within column/table names, even though it was valid. (Bug#21521)
This is a new Alpha development release, fixing recently discovered bugs.
NOTE: This Alpha release, as any other pre-production release, should not be installed on production level systems or systems with critical data. It is good practice to back up your data before installing any new version of software. Although MySQL has worked very hard to ensure a high level of quality, protect your data by making a backup as you would for any software beta release. Please refer to our bug database at http://bugs.mysql.com/ for more details about the individual bugs fixed in this version.
Bugs fixed:
CommandText: Question mark in comment line is being parsed as a parameter. (Bug#6214)
Functionality added or changed:
Implemented Usage Advisor.
Added Async query methods.
Reimplemented PacketReader/PacketWriter support into
MySqlStreamclass.Added internal implemention of SHA1 so we don't have to distribute the OpenNetCF on mobile devices.
Added usage advisor warnings for requesting column values by the wrong type.
Reworked connection string classes to be simpler and faster.
Added procedure metadata caching.
Added perfmon hooks for stored procedure cache hits and misses.
Implemented
MySqlConnectionBuilderclass.Implemented
MySqlClientFactoryclass.Implemented classes and interfaces for ADO.Net 2.0 support.
Replaced use of ICSharpCode with .NET 2.0 internal deflate support.
Refactored test suite to test all protocols in a single pass.
Completely refactored how column values are handled to avoid boxing in some cases.
Bugs fixed:
Publisher listed in "Add/Remove Programs" is not consistent with other MySQL products. (Bug#27253)
MySqlParameterCollectionand parameters added withInsertmethod can not be retrieved later usingParameterName. (Bug#27135)A critical
ConnectionPoolerror would result in repeatedSystem.NullReferenceException. (Bug#25603)When a
MySqlConversionExceptionis raised on a remote object, the client application would receive aSerializationExceptioninstead. (Bug#24957)High CPU utilization would be experienced when there is no idle connection waiting when using pooled connections through
MySqlPool.GetConnection. (Bug#24373)BINARYandVARBINARYcolumns would be returned as a string, not binary, datatype. (Bug#25605)
Functionality added or changed:
Important change: Due to a number of issues with the use of server-side prepared statements, Connector/NET 5.0.2 has disabled their use by default. The disabling of server-side prepared statements does not affect the operation of the connector in any way.
To enable server-side prepared statements you must add the following configuration property to your connector string properties:
ignore prepare=false
The default value of this property is true.
Important change: Binaries for .NET 1.0 are no longer supplied with this release. If you need support for .NET 1.0, you must build from source.
Implemented a stored procedure cache. By default, the connector caches the metadata for the last 25 procedures that are seen. You can change the numbver of procedures that are cacheds by using the
procedure cacheconnection string.An
Ignore Prepareoption has been added to the connection string options. If enabled, prepared statements will be disabled application-wide. The default for this option is true.The ICSharpCode ZipLib is no longer used by the Connector, and is no longer distributed with it.
Improved
CommandBuilder.DeriveParametersto first try and use the procedure cache before querying for the stored procedure metadata. Return parameters created withDeriveParametersnow have the nameRETURN_VALUE.
Bugs fixed:
Trying to fill a table schema through a stored procedure triggers a runtime error. (Bug#25609)
MySqlConnectionthrows aNullReferenceExceptionandArgumentNullExceptionwhen connecting to MySQL v4.1.7. (Bug#25726)SELECTdid not work correctly when using aWHEREclause containing a UTF-8 string. (Bug#25651)Times with negative values would be returned incorrectly. (Bug#25912)
When closing and then re-opening a connection to a database, the character set specification is lost. (Bug#25614)
When connecting to a server, the return code from the connection could be zero, even though the hostname was incorrect. (Bug#24802)
Using
ExecuteScalar()with more than one query, where one query fails, will hang the connection. (Bug#25443)Nested transactions do not raise an error or warning. (Bug#22400)
When adding parameter objects to a command object, if the parameter direction is set to
ReturnValuebefore the parameter is added to the command object then when the command is executed it throws an error. (Bug#25013)Additional text added to error message. (Bug#25178)
The
CommandBuilderwould mistakenly add insert parameters for a table column with auto incrementation enabled. (Bug#23862)Stored procedure executions are not thread safe. (Bug#23905)
Using
Driver.IsTooOld()would return the wrong value. (Bug#24661)When using a
DbNull.Valueas the value for a parameter value, and then later setting a specific value type, the command would fail with an exception because the wrong type was implied from theDbNull.Value. (Bug#24565)Within Mono, using the
PreparedStatementinterface could result in an error due to aBitArraycopying error. (Bug 18186)One system where IPv6 was enabled, Connector/NET would incorrectly resolve hostnames. (Bug#23758)
An
System.OverflowExceptionwould be raised when accessing a varchar field over 255 bytes. Bug (#23749)
Bugs fixed:
Using
ExecuteScalarwith a datetime field, where the value of the field is "0000-00-00 00:00:00", aMySqlConversionExceptionexception would be raised. (Bug#11991)The
MySqlDateTimeclass did not contain constructors. (Bug#15112)DataReaderwould show the value of the previous row (or last row with non-null data) if the current row contained adatetimefield with a null value. (Bug#16884)An
MySql.Data.Types.MySqlConversionExceptionwould be raised when trying to update a row that contained a date field, where the date field contained a zero value (0000-00-00 00:00:00). (Bug#9619)When using
MySqlDataAdapter, connections to a MySQL server may remain open and active, even though the use of the connection has been completed and the data received. (Bug#8131)Incorrect field/data lengths could be returned for
VARCHARUTF8 columns. Bug (#14592)Submitting an empty string to a command object through
prepareraises anSystem.IndexOutOfRangeException, rather than a Connector/Net exception. (Bug#18391)Connector/NET on a Tukish operating system, may fail to execute certain SQL statements correctly. (Bug#22452)
You can now install the Connector/NET MSI package from the command line using the
/passive,/quiet,/qoptions. (Bug#19994)Executing multiple queries as part of a transaction returns
There is already an openDataReader associated with this Connection which must be closed first. (Bug#7248)Called
MySqlCommandBuilder.DeriveParametersfor a stored procedure that has no paramers would cause an application crash. (Bug#15077)A
SELECTquery on a table with a date with a value of'0000-00-00'would hang the application. (Bug#17736)The
#would not be accepted within column/table names, even though it was valid. (Bug#21521)Calling
Closeon a connection after calling a stored procedure would trigger aNullReferenceException. (Bug#20581)IDataRecord.GetStringwould raiseNullPointerExceptionfor null values in returned rows. Method now throwsSqlNullValueException. (Bug#19294)An exception would be raised when using an output parameter to a
System.Stringvalue. (Bug#17814)The DiscoverParameters function would fail when a stored procedure used a
NUMERICparameter type. (Bug#19515)When running a query that included a date comparison, a DateReader error would be raised. (Bug#19481)
Parameter substitution in queries where the order of parameters and table fields did not match would substitute incorrect values. (Bug#19261)
When working with multiple threads, character set initialization would generate errors. (Bug#17106)
When using an unsigned 64-bit integer in a stored procedure, the unsigned bit would be lost stored. (Bug#16934)
The connection string parser did not allow single or double quotes in the password. (Bug#16659)
The CommandBuilder ignored Unsigned flag at Parameter creation. (Bug#17375)
CHAR type added to MySqlDbType. (Bug#17749)
Unsigned data types were not properly supported. (Bug#16788)
Functionality added or changed:
Stored procedures are now cached.
The method for retrieving stored procedured metadata has been changed so that users without
SELECTprivileges on themysql.proctable can use a stored procedure.
Unsigned
tinyint(NET byte) would lead to and incorrectly determined parameter type from the parameter value. (Bug#18570)The parameter collection object's
Add()method added parameters to the list without first checking to see whether they already existed. Now it updates the value of the existing parameter object if it exists. (Bug#13927)A
#42000Query was emptyexception occurred when executing a query built withMySqlCommandBuilder, if the query string ended with a semicolon. (Bug#14631)Implemented the
MySqlCommandBuilder.DeriveParametersmethod that is used to discover the parameters for a stored procedure. (Bug#13632)Added support for the
cp932character set. (Bug#13806)Calling a stored procedure where a parameter contained special characters (such as
'@') would produce an exception. Note thatANSI_QUOTEShad to be enabled to make this possible. (Bug#13753)A statement that contained multiple references to the same parameter could not be prepared. (Bug#13541)
The
Ping()method did not update theStateproperty of theConnectionobject. (Bug#13658)
The
nantbuild sequence had problems. (Bug#12978)Serializing a parameter failed if the first value passed in was
NULL. (Bug#13276)Field names that contained the following characters caused errors:
()%<>/(Bug#13036)The Connector/NET 1.0.5 installer would not install alongside Connector/NET 1.0.4. (Bug#12835)
Connector/NET 1.0.5 could not connect on Mono. (Bug#13345)
With multiple hosts in the connection string, Connector/NET would not connect to the last host in the list. (Bug#12628)
Connector/NET interpreted the new decimal data type as a byte array. (Bug#11294)
The
cp1250character set was not supported. (Bug#11621)Connection could fail when .NET thread pool had no available worker threads. (Bug#10637)
Decimal parameters caused syntax errors. (Bug#11550, Bug#10486, Bug#10152)
A call to a stored procedure caused an exception if the stored procedure had no parameters. (Bug#11542)
Certain malformed queries would trigger a
Connection must be valid and openerror message. (Bug#11490)The
MySqlCommandBuilderclass could not handle queries that referenced tables in a database other than the default database. (Bug#8382)Connector/NET could not work properly with certain regional settings. (WL#8228)
Trying to use a stored procedure when
Connection.Databasewas not populated generated an exception. (Bug#11450)Trying to read a
TIMESTAMPcolumn generated an exception. (Bug#7951)Parameters were not recognized when they were separated by linefeeds. (Bug#9722)
Calling
MySqlConnection.clonewhen a connection string had not yet been set on the original connection would generate an error. (Bug#10281)Added support to call a stored function from Connector/NET. (Bug#10644)
Connector/NET could not connect to MySQL 4.1.14. (Bug#12771)
The
ConnectionStringproperty could not be set when aMySqlConnectionobject was added with the designer. (Bug#12551, Bug#8724)
Calling prepare causing exception. (Bug#7243)
Fixed another small problem with prepared statements.
MySqlCommand.Connectionreturns an IDbConnection. (Bug#7258)MySqlAdapter.Fillmethod throws error messageNon-negative number required. (Bug#7345)Clone method bug in
MySqlCommand. (Bug#7478)MySqlDataReader.GetString(index)returns non-Null value when field isNull. (Bug#7612)MySqlReader.GetInt32throws exception if column is unsigned. (Bug#7755)GetBytes is working no more. (Bug#7704).
Quote character \222 not quoted in
EscapeString. (Bug#7724)Fixed problem that causes named pipes to not work with some blob functionality.
Fixed problem with shared memory connections.
Problem with Multiple resultsets. (Bug#7436)
Added or filled out several more topics in the API reference documentation.
Made MySQL the default named pipe name.
Now
SHOW COLLATIONis used upon connection to retrieve the full list of charset ids.Fixed Invalid character set index: 200. (Bug#6547)
Installer now includes options to install into GAC and create items.
Int64 Support in
MySqlCommandParameters. (Bug#6863)Connections now do not have to give a database on the connection string.
MySqlDataReader.GetChar(int i)throwsIndexOutOfRangeexception. (Bug#6770)Fixed problem where multiple resultsets having different numbers of columns would cause a problem.
Exception stack trace lost when re-throwing exceptions. (Bug#6983)
Fixed major problem with detecting null values when using prepared statements.
Errors in parsing stored procedure parameters. (Bug#6902)
Integer "out" parameter from stored procedure returned as string. (Bug#6668)
MySqlDateTimein Datatables sorting by Text, not Date. (Bug#7032)Invalid query string when using inout parameters (Bug#7133)
Test suite fails with MySQL 4.0 because of case sensitivity of table names. (Bug#6831)
Inserting
DateTimecausesSystem.InvalidCastExceptionto be thrown. (Bug#7132)InvalidCast when using
DATE_ADD-function. (Bug#6879)An Open Connection has been Closed by the Host System. (Bug#6634)
Added
ServerThreadproperty toMySqlConnectionto expose server thread id.Added Ping method to
MySqlConnection.Changed the name of the test suite to
MySql.Data.Tests.dll.
Fixed problem with MySqlBinary where string values could not be used to update extended text columns
Fixed Installation directory ignored using custom installation (Bug#6329)
Fixed problem where setting command text leaves the command in a prepared state
Fixed double type handling in MySqlParameter(string parameterName, object value) (Bug#6428)
Fixed Zero date "0000-00-00" is returned wrong when filling Dataset (Bug#6429)
Fixed problem where calling stored procedures might cause an "Illegal mix of collations" problem.
Added charset connection string option
Fixed #HY000 Illegal mix of collations (latin1_swedish_ci,IMPLICIT) and (utf8_general_ (Bug#6322)
Added the TableEditor CS and VB sample
Fixed Charset-map for UCS-2 (Bug#6541)
Updated the installer to include the new samples
Fixed Long inserts take very long time (Bu #5453)
Fixed Objects not being disposed (Bug#6649)
Provider is now using character set specified by server as default
Fixed Bug#5602 Possible bug in MySqlParameter(string, object) constructor
Fixed Bug#5458 Calling GetChars on a longtext column throws an exception
Fixed Bug#5474 cannot run a stored procedure populating mysqlcommand.parameters
Fixed Bug#5469 Setting DbType throws NullReferenceException
Fixed problem where connector was not issuing a CMD_QUIT before closing the socket
Fixed Bug#5392 MySqlCommand sees "?" as parameters in string literals
Fixed problem with ConnectionInternal where a key might be added more than once
CP1252 is now used for Latin1 only when the server is 4.1.2 and later
Fixed Bug#5388 DataReader reports all rows as NULL if one row is NULL
Virtualized driver subsystem so future releases could easily support client or embedded server support
Field buffers being reused to decrease memory allocations and increase speed
Fixed problem where using old syntax while using the interfaces caused problems
Using PacketWriter instead of Packet for writing to streams
Refactored compression code into CompressedStream to clean up NativeDriver
Added test case for resetting the command text on a prepared command
Fixed problem where MySqlParameterCollection.Add() would throw unclear exception when given a null value (Bug#5621)
Fixed construtor initialize problems in MySqlCommand() (Bug#5613)
Fixed Parsing the ';' char (Bug#5876)
Fixed missing Reference in DbType setter (Bug#5897)
Fixed System.OverflowException when using YEAR datatype (Bug#6036)
Added Aggregate function test (wasn't really a bug)
Fixed serializing of floating point parameters (double, numeric, single, decimal) (Bug#5900)
IsNullable error (Bug#5796)
Fixed problem where connection lifetime on the connect string was not being respected
Fixed problem where Min Pool Size was not being respected
Fixed MySqlDataReader and 'show tables from ...' behavior (Bug#5256)
Implemented SequentialAccess
Fixed MySqlDateTime sets IsZero property on all subseq.records after first zero found (Bug#6006)
Fixed Can't display Chinese correctly (Bug#5288)
Fixed Russian character support as well
Fixed Method TokenizeSql() uses only a limited set of valid characters for parameters (Bug#6217)
Fixed NET Connector source missing resx files (Bug#6216)
Fixed DBNull Values causing problems with retrieving/updating queries. (Bug#5798)
Fixed Yet Another "object reference not set to an instance of an object" (Bug#5496)
Fixed problem in PacketReader where it could try to allocate the wrong buffer size in EnsureCapacity
Fixed GetBoolean returns wrong values (Bug#6227)
Fixed IndexOutOfBounds when reading BLOB with DataReader with GetString(index) (Bug#6230)
Thai encoding not correctly supported. (Bug#3889)
Updated many of the test cases.
Fixed problem with using compression.
Bumped version number to 1.0.0 for beta 1 release.
Added
COPYING.rtffile for use in installer.Removed all of the XML comment warnings.
Removed some last references to ByteFX.
Added test fixture for prepared statements.
All type classes now implement a
SerializeBinarymethod for sending their data to aPacketWriter.Added
PacketWriterclass that will enable future low-memory large object handling.Fixed many small bugs in running prepared statements and stored procedures.
Changed command so that an exception will not be throw in executing a stored procedure with parameters in old syntax mode.
SingleRowbehavior now working right even with limit.GetBytesnow only works on binary columns.Logger now truncates long sql commands so blob columns don't blow out our log.
host and database now have a default value of "" unless otherwise set.
Connection Timeout seems to be ignored. (Bug#5214)
Added test case for bug# 5051: GetSchema not working correctly.
Fixed problem where
GetSchemawould return false forIsUniquewhen the column is key.MySqlDataReader GetXXXmethods now using the field levelMySqlValueobject and not performing conversions.DataReaderreturningNULLfor time column. (Bug#5097)Added test case for
LOAD DATA LOCAL INFILE.Added replacetext custom nant task.
Added
CommandBuilderTestfixture.Added Last One Wins feature to
CommandBuilder.Fixed persist security info case problem.
Fixed
GetBoolso that 1, true, "true", and "yes" all count as true.Make parameter mark configurable.
Added the "old syntax" connection string parameter to allow use of @ parameter marker.
MySqlCommandBuilder. (Bug#4658)ByteFX.MySqlClientcaches passwords ifPersist Security Infois false. (Bug#4864)Updated license banner in all source files to include FLOSS exception.
Added new .Types namespace and implementations for most current MySql types.
Added
MySqlField41as a subclass ofMySqlField.Changed many classes to now use the new .Types types.
Changed type
enum inttoInt32,shorttoInt16, andbiginttoInt64.Added dummy types
UInt16,UInt32, andUInt64to allow an unsigned parameter to be made.Connections are now reset when they are pulled from the connection pool.
Refactored auth code in driver so it can be used for both auth and reset.
Added
UserResettest inPoolingTests.cs.Connections are now reset using
COM_CHANGE_USERwhen pulled from the pool.Implemented
SingleResultSetbehavior.Implemented support of unicode.
Added char set mappings for utf-8 and ucs-2.
Time fields overflow using bytefx .net mysql driver (Bug#4520)
Modified time test in data type test fixture to check for time spans where hours > 24.
Wrong string with backslash escaping in
ByteFx.Data.MySqlClient.MySqlParameter. (Bug#4505)Added code to Parameter test case TestQuoting to test for backslashes.
MySqlCommandBuilderfails with multi-word column names. (Bug#4486)Fixed bug in
TokenizeSqlwhere underscore would terminate character capture in parameter name.Added test case for spaces in column names.
MySqlDataReader.GetBytesdon't works correctly. (Bug#4324)Added
GetBytes()test case toDataReadertest fixture.Now reading all server variables in
InternalConnection.ConfigureintoHashtable.Now using
string[]for index map inCharSetMap.Added CRInSQL test case for carriage returns in SQL.
Setting maxPacketSize to default value in
Driver.ctor.Setting
MySqlDbTypeon a parameter doesn't set generic type. (Bug#4442)Removed obsolete data types
LongandLongLong.Overflow exception thrown when using "use pipe" on connection string. (Bug#4071)
Changed "use pipe" keyword to "pipe name" or just "pipe".
Allow reading multiple resultsets from a single query.
Added flags attribute to
ServerStatusFlagsenum.Changed name of
ServerStatusenum toServerStatusFlags.Inserted data row doesn't update properly.
Error processing show create table. (Bug#4074)
Change
Packet.ReadLenIntegertoReadPackedLongand addedpacket.ReadPackedIntegerthat alwasy reads integers packed with 2,3,4.Added
syntax.cstest fixture to test various SQL syntax bugs.Improper handling of time values. Now time value of 00:00:00 is not treated as null. (Bug#4149)
Moved all test suite files into
TestSuitefolder.Fixed bug where null column would move the result packet pointer backward.
Added new nant build script.
Clear tablename so it will be regen'ed properly during the next
GenerateSchema. (Bug#3917)GetValueswas always returning zero and was also always trying to copy all fields rather than respecting the size of the array passed in. (Bug#3915)Implemented shared memory access protocol.
Implemented prepared statements for MySQL 4.1.
Implemented stored procedures for MySQL 5.0.
Renamed
MySqlInternalConnectiontoInternalConnection.SQL is now parsed as chars, fixes problems with other languages.
Added logging and allow batch connection string options.
RowUpdatingevent not set when setting theDataAdapterproperty. (Bug#3888)Fixed bug in char set mapping.
Implemented 4.1 authentication.
Improved open/auth code in driver.
Improved how connection bits are set during connection.
Database name is now passed to server during initial handshake.
Changed namespace for client to
MySql.Data.MySqlClient.Changed assembly name of client to
MySql.Data.dll.Changed license text in all source files to GPL.
Added the
MySqlClient.buildNant file.Removed the mono batch files.
Moved some of the unused files into notused folder so nant build file can use wildcards.
Implemented shared memory accesss.
Major revamp in code structure.
Prepared statements now working for MySql 4.1.1 and later.
Finished implementing auth for 4.0, 4.1.0, and 4.1.1.
Changed namespace from
MySQL.Data.MySQLClientback toMySql.Data.MySqlClient.Fixed bug in
CharSetMappingwhere it was trying to use text names as ints.Changed namespace to
MySQL.Data.MySQLClient.Integrated auth changes from UC2004.
Fixed bug where calling any of the GetXXX methods on a datareader before or after reading data would not throw the appropriate exception (thanks Luca Morelli).
Added
TimeSpancode in parameter.cs to properly serialize a timespan object to mysql time format (thanks Gianluca Colombo).Added
TimeStampto parameter serialization code. PreventedDataAdatperupdates from working right (thanks Michael King).Fixed a misspelling in
MySqlHelper.cs(thanks Patrick Kristiansen).
Driver now using charset number given in handshake to create encoding.
Changed command editor to point to
MySqlClient.Design.Fixed bug in
Version.isAtLeast.Changed
DBConnectionStringto support changes done toMySqlConnectionString.Removed
SqlCommandEditorandDataAdapterPreviewDialog.Using new long return values in many places.
Integrated new
CompressedStreamclass.Changed
ConnectionStringand added attributes to allow it to be used inMySqlClient.Design.Changed
packet.csto support newer lengths inReadLenInteger.Changed other classes to use new properties and fields of
MySqlConnectionString.ConnectionInternalis now using PING to see whether the server is alive.Moved toolbox bitmaps into resource folder.
Changed
field.csto allow values to come directly from row buffer.Changed to use the new driver.Send syntax.
Using a new packet queueing system.
Started work handling the "broken" compression packet handling.
Fixed bug in
StreamCreatorwhere failure to connect to a host would continue to loop infinitly (thanks Kevin Casella).Improved connectstring handling.
Moved designers into Pro product.
Removed some old commented out code from
command.cs.Fixed a problem with compression.
Fixed connection object where an exception throw prior to the connection opening would not leave the connection in the connecting state (thanks Chris Cline).
Added GUID support.
Fixed sequence out of order bug (thanks Mark Reay).
Enum values now supported as parameter values (thanks Philipp Sumi).
Year datatype now supported.
Fixed compression.
Fixed bug where a parameter with a
TimeSpanas the value would not serialize properly.Fixed bug where default constructor would not set default connection string values.
Added some XML comments to some members.
Work to fix/improve compression handling.
Improved
ConnectionStringhandling so that it better matches the standard set bySqlClient.A
MySqlExceptionis now thrown if a username is not included in the connection string.Localhost is now used as the default if not specified on the connection string.
An exception is now thrown if an attempt is made to set the connection string while the connection is open.
Small changes to
ConnectionStringdocs.Removed
MultiHostStreamandMySqlStream. Replaced it withCommon/StreamCreator.Added support for Use Pipe connection string value.
Added Platform class for easier access to platform utility functions.
Fixed small pooling bug where new connection was not getting created after
IsAlivefails.Added
Platform.csandStreamCreator.cs.Fixed
Field.csto properly handle 4.1 style timestamps.Changed
Common.VersiontoCommon.DBVersionto avoid name conflict.Fixed
field.csso that text columns return the right field type.Added
MySqlErrorclass to provide some reference for error codes (thanks Geert Veenstra).
Added Unix socket support (thanks Mohammad DAMT).
Only calling
Thread.Sleepwhen no data is available.Improved escaping of quote characters in parameter data.
Removed misleading comments from
parameter.cs.Fixed pooling bug.
Fixed
ConnectionStringeditor dialog (thanks marco p (pomarc)).UserIdnow supported in connection strings (thanks Jeff Neeley).Attempting to create a parameter that is not input throws an exception (thanks Ryan Gregg).
Added much documentation.
Checked in new
MultiHostStreamcapability. Big thanks to Dan Guisinger for this. he originally submitted the code and idea of supporting multiple machines on the connect string.Added a lot of documentation.
Fixed speed issue with 0.73.
Changed to Thread.Sleep(0) in MySqlDataStream to help optimize the case where it doesn't need to wait (thanks Todd German).
Prepopulating the idlepools to
MinPoolSize.Fixed
MySqlPooldeadlock condition as well as stupid bug where CreateNewPooledConnection was not ever adding new connections to the pool. Also fixedMySqlStream.ReadBytesandReadByteto not useTicksPerSecondwhich does not appear to always be right. (thanks Matthew J. Peddlesden)Fix for precision and scale (thanks Matthew J. Peddlesden).
Added
Thread.Sleep(1)to stream reading methods to be more cpu friendly (thanks Sean McGinnis).Fixed problem where
ExecuteReaderwould sometime return null (thanks Lloyd Dupont).Fixed major bug with null field handling (thanks Naucki).
Enclosed queries for
max_allowed_packetandcharactersetinside try catch (and set defaults).Fixed problem where socket was not getting closed properly (thanks Steve!).
Fixed problem where
ExecuteNonQuerywas not always returning the right value.Fixed
InternalConnectionto not use@@session.max_allowed_packetbut use@@max_allowed_packet. (Thanks Miguel)Added many new XML doc lines.
Fixed sql parsing to not send empty queries (thanks Rory).
Fixed problem where the reader was not unpeeking the packet on close.
Fixed problem where user variables were not being handled (thanks Sami Vaaraniemi).
Fixed loop checking in the MySqlPool (thanks Steve M. Brown)
Fixed
ParameterCollection.Addmethod to matchSqlClient(thanks Joshua Mouch).Fixed
ConnectionStringparsing to handle no and yes for boolean and not lowercase values (thanks Naucki).Added
InternalConnectionclass, changes to pooling.Implemented Persist Security Info.
Added
security.csandversion.csto projectFixed
DateTimehandling inParameter.cs(thanks Burkhard Perkens-Golomb).Fixed parameter serialization where some types would throw a cast exception.
Fixed
DataReaderto convert all returned values to prevent casting errors (thanks Keith Murray).Added code to
Command.ExecuteReaderto return null if the initial SQL command throws an exception (thanks Burkhard Perkens-Golomb).Fixed
ExecuteScalarbug introduced with restructure.Restructure to allow for
LOCAL DATA INFILEand better sequencing of packets.Fixed several bugs related to restructure.
Early work done to support more secure passwords in Mysql 4.1. Old passwords in 4.1 not supported yet.
Parameters appearing after system parameters are now handled correctly (Adam M. (adammil)).
Strings can now be assigned directly to blob fields (Adam M.).
Fixed float parameters (thanks Pent).
Improved Parameter constructor and
ParameterCollection.Addmethods to better match SqlClient (thanks Joshua Mouch).Corrected
Connection.CreateCommandto return aMySqlCommandtype.Fixed connection string designer dialog box problem (thanks Abraham Guyt).
Fixed problem with sending commands not always reading the response packet (thanks Joshua Mouch).
Fixed parameter serialization where some blobs types were not being handled (thanks Sean McGinnis).
Removed spurious
MessageBox.showfromDataReadercode (thanks Joshua Mouch).Fixed a nasty bug in the split sql code (thanks everyone!).
Fixed bug in
MySqlStreamwhere too much data could attempt to be read (thanks Peter Belbin)Implemented
HasRows(thanks Nash Pherson).Fixed bug where tables with more than 252 columns cause an exception (thanks Joshua Kessler).
Fixed bug where SQL statements ending in ; would cause a problem (thanks Shane Krueger).
Fixed bug in driver where error messages were getting truncated by 1 character (thanks Shane Krueger).
Made
MySqlExceptionserializable (thanks Mathias Hasselmann).
Updated some of the character code pages to be more accurate.
Fixed problem where readers could be opened on connections that had readers open.
Moved test to separate assembly
MySqlClientTests.Fixed stupid problem in driver with sequence out of order (Thanks Peter Belbin).
Added some pipe tests.
Increased default max pool size to 50.
Compiles with Mono 0-24.
Fixed connection and data reader dispose problems.
Added
Stringdatatype handling to parameter serialization.Fixed sequence problem in driver that occurred after thrown exception (thanks Burkhard Perkens-Golomb).
Added support for
CommandBehavior.SingleRowtoDataReader.Fixed command sql processing so quotes are better handled (thanks Theo Spears).
Fixed parsing of double, single, and decimal values to account for non-English separators. You still have to use the right syntax if you using hard coded sql, but if you use parameters the code will convert floating point types to use '.' appropriately internal both into the server and out.
Added
MySqlStreamclass to simplify timeouts and driver coding.Fixed
DataReaderso that it is closed properly when the associated connection is closed. [thanks smishra]Made client more SqlClient compliant so that DataReaders have to be closed before the connection can be used to run another command.
Improved
DBNull.Valuehandling in the fields.Added several unit tests.
Fixed
MySqlExceptionbase class.Improved driver coding
Fixed bug where NextResult was returning false on the last resultset.
Added more tests for MySQL.
Improved casting problems by equating unsigned 32bit values to Int64 and usigned 16bit values to Int32, and so forth.
Added new constructor for
MySqlParameterfor (name, type, size, srccol)Fixed bug in
MySqlDataReaderwhere it didn't check for null fieldlist before returning field count.Started adding
MySqlClientunit tests (addedMySqlClient/Testsfolder and some test cases).Fixed some things in Connection String handling.
Moved
INIT_DBtoMySqlPool. I may move it again, this is in preparation of the conference.Fixed bug inside
CommandBuilderthat prevented inserts from happening properly.Reworked some of the internals so that all three execute methods of Command worked properly.
Fixed many small bugs found during benchmarking.
The first cut of
CoonectionPoolingis working. "min pool size" and "max pool size" are respected.Work to enable multiple resultsets to be returned.
Character sets are handled much more intelligently now. The driver queries MySQL at startup for the default character set. That character set is then used for conversions if that code page can be loaded. If not, then the default code page for the current OS is used.
Added code to save the inferred type in the name,value constructor of
Parameter.Also, inferred type if value of null parameter is changed using
Valueproperty.Converted all files to use proper Camel case. MySQL is now MySql in all files. PgSQL is now PgSql.
Added attribute to PgSql code to prevent designer from trying to show.
Added
MySQLDbTypeproperty to Parameter object and added proper conversion code to convert fromDbTypetoMySQLDbType).Removed unused
ObjectToStringmethod fromMySQLParameter.cs.Fixed
Add(..)method inParameterCollectionso that it doesn't useAdd(name, value)instead.Fixed
IndexOfandContainsinParameterCollectionto be aware that parameter names are now stored without @.Fixed
Command.ConvertSQLToBytesso it only allows characters that can be in MySQL variable names.Fixed
DataReaderandFieldso that blob fields read their data fromField.csandGetBytesworks right.Added simple query builder editor to
CommandTextproperty ofMySQLCommand.Fixed
CommandBuilderandParameterserialization to account for Parameters not storing @ in their names.Removed
MySQLFieldTypeenum from Field.cs. Now usingMySQLDbTypeenum.Added
Designerattribute to several classes to prevent designer view when using VS.Net.Fixed Initial catalog typo in
ConnectionStringdesigner.Removed 3 parameter constructor for
MySQLParameterthat conflicted with (name, type, value).Changed
MySQLParametersoparamNameis now stored without leading @ (this fixed null inserts when using designer).Changed
TypeConverterforMySQLParameterto use the constructor with all properties.
Fixed sequence issue in driver.
Added
DbParametersEditorto make parameter editing more likeSqlClient.Fixed
Commandclass so that parameters can be edited using the designerUpdate connection string designer to support
Use Compressionflag.Fixed string encoding so that European characters like ä will work correctly.
Creating base classes to aid in building new data providers.
Added support for UID key in connection string.
Field, parameter, command now using DBNull.Value instead of null.
CommandBuilderusingDBNull.Value.CommandBuildernow builds insert command correctly when an auto_insert field is not present.Field now uses typeof keyword to return
System.Types(performance).
MySQLCommandBuildernow implemented.Transaction support now implemented (not all table types support this).
GetSchemaTablefixed to not use xsd (for Mono).Driver is now Mono-compatible.
TIME data type now supported.
More work to improve Timestamp data type handling.
Changed signatures of all classes to match corresponding
SqlClientclasses.
Protocol compression using SharpZipLib (www.icsharpcode.net).
Named pipes on Windows now working properly.
Work done to improve
Timestampdata type handling.Implemented
IEnumerableonDataReadersoDataGridwould work.
Bugs fixed:
Running queries based on a stored procedure would cause the dataset designer to terminate. (Bugs #26364)
DataSet wizard would show all tables instead of only the tables available within the selected database. (Bugs #26348)
Bugs fixed:
Creating a connection through the Server Explorer when using the Visual Studio Plugin would fail. The installer for the Visual Studio Plugin has been updated to ensure that Connector/NET 5.0.2 must be installed. (Bug#23071)
The Add Connection dialog of the Server Explorer would freeze when accessing databases with capitalized characters in their name. (Bug#24875)
This is a bug fix release to resolve an incompatibility issue with Connector/NET 5.0.1.
It is critical that this release only be used with Connector/NET
5.0.1. After installing Connector/NET 5.0.1, you will need to make
a small change in your machine.config file. This file should be
located at
%win%\Microsoft.Net\Framework\v2.0.50727\CONFIG\machine.config
(%win% should be the location of your Windows
folder). Near the bottom of the file you will see a line like
this:
<add name="MySQL Data Provider" invariant="MySql.Data.MySqlClient" description=".Net Framework Data Provider for MySQL" type="MySql.Data.MySqlClient.MySqlClientFactory, MySql.Data"/>
It needs to be changed to be like this:
<add name="MySQL Data Provider" invariant="MySql.Data.MySqlClient" description=".Net Framework Data Provider for MySQL" type="MySql.Data.MySqlClient.MySqlClientFactory, MySql.Data, Version=5.0.1.0, Culture=neutral, PublicKeyToken=c5687fc88969c44d"/>
- E.6.1. Changes in MySQL Connector/J 5.1.x
- E.6.2. Changes in MySQL Connector/J 5.0.x
- E.6.3. Changes in MySQL Connector/J 3.1.x
- E.6.4. Changes in MySQL Connector/J 3.0.x
- E.6.5. Changes in MySQL Connector/J 2.0.x
- E.6.6. Changes in MySQL Connector/J 1.2b (04 July 1999)
- E.6.7. Changes in MySQL Connector/J 1.2.x and lower
Important change: Due to a number of issues with the use of server-side prepared statements, Connector/J 5.0.5 has disabled their use by default. The disabling of server-side prepared statements does not affect the operation of the connector in any way.
To enable server-side prepared statements you must add the following configuration property to your connector string:
useServerPrepStmts=true
The default value of this property is false
(that is, Connector/J does not use server-side prepared
statements).
Note
The disabling of server-side prepared statements does not
affect the operation of the connector. However, if you use the
useTimezone=true connection option and use
client-side prepared statements (instead of server-side
prepared statements) you should also set
useSSPSCompatibleTimezoneShift=true.
Functionality added or changed:
Re-worked Ant buildfile to build JDBC-4.0 classes separately, as well as support building under Eclipse (since Eclipse can't mix/match JDKs).
To build, you must set
JAVA_HOMEto J2SDK-1.4.2 or Java-5, and set the following properties on your Ant command line:com.mysql.jdbc.java6.javac— full path to your Java-6 javac executablecom.mysql.jdbc.java6.rtjar— full path to your Java-6rt.jarfile
New feature — driver will automatically adjust session variable
net_write_timeoutwhen it determines it has been asked for a "streaming" result, and resets it to the previous value when the result set has been consumed. (configuration property is namednetTimeoutForStreamingResultsvalue and has a unit of seconds, the value0means the driver will not try and adjust this value).Added support for JDBC-4.0 categorized
SQLExceptions.Refactored
CommunicationsExceptioninto a JDBC-3.0 version, and a JDBC-4.0 version (which extendsSQLRecoverableException, now that it exists).Note
This change means that if you were catching
com.mysql.jdbc.CommunicationsExceptionin your applications instead of looking at the SQLState class of08, and are moving to Java 6 (or newer), you need to change your imports to that exception to becom.mysql.jdbc.exceptions.jdbc4.CommunicationsException, as the old class will not be instantiated for communications link-related errors under Java 6.Added support for JDBC-4.0's client information. The backend storage of information provided via
Connection.setClientInfo()and retrieved byConnection.getClientInfo()is pluggable by any class that implements thecom.mysql.jdbc.JDBC4ClientInfoProviderinterface and has a no-args constructor.The implementation used by the driver is configured using the
clientInfoProviderconfiguration property (with a default of value ofcom.mysql.jdbc.JDBC4CommentClientInfoProvider, an implementation which lists the client information as a comment prepended to every query sent to the server).This functionality is only available when using Java-6 or newer.
Added support for JDBC-4.0's SQLXML interfaces.
Added support for JDBC-4.0's
Wrapperinterface.Added support for JDBC-4.0's
NCLOB, andNCHAR/NVARCHARtypes.
- E.6.2.1. Changes in MySQL Connector/J 5.0.6 (Not yet released)
- E.6.2.2. Changes in MySQL Connector/J 5.0.5 (02 March 2007)
- E.6.2.3. Changes in MySQL Connector/J 5.0.4 (20 October 2006)
- E.6.2.4. Changes in MySQL Connector/J 5.0.3 (26 July 2006)
- E.6.2.5. Changes in MySQL Connector/J 5.0.2-beta (11 July 2006)
- E.6.2.6. Changes in MySQL Connector/J 5.0.1-beta (Not Released)
- E.6.2.7. Changes in MySQL Connector/J 5.0.0-beta (22 December 2005)
Functionality added or changed:
Fixed issue where a failed-over connection would let an application call
setReadOnly(false), when that call should be ignored until the connection is reconnected to a writable master unlessfailoverReadOnlyhad been set tofalse.Driver will now use
INSERT INTO ... VALUES (DEFAULT)form of statement for updatable result sets forResultSet.insertRow(), rather than pre-populating the insert row with values fromDatabaseMetaData.getColumns()(which results in aSHOW FULL COLUMNSon the server for every result set). If an application requires access to the default values beforeinsertRow()has been called, the JDBC URL should be configured withpopulateInsertRowWithDefaultValuesset totrue.This fix specifically targets performance issues with ColdFusion and the fact that it seems to ask for updatable result sets no matter what the application does with them.
com.mysql.jdbc.[NonRegistering]Drivernow understands URLs of the formatjdbc:mysql:replication://andjdbc:mysql:loadbalance://which will create a ReplicationConnection (exactly like when using[NonRegistering]ReplicationDriver) and an experimental load-balanced connection designed for use with SQL nodes in a MySQL Cluster/NDB environment, respectively.In an effort to simplify things, we're working on deprecating multiple drivers, and instead specifying different core behavior based upon JDBC URL prefixes, so watch for
[NonRegistering]ReplicationDriverto eventually disappear, to be replaced withcom.mysql.jdbc[NonRegistering]Driverwith the new URL prefix.Added an experimental load-balanced connection designed for use with SQL nodes in a MySQL Cluster/NDB environment (This is not for master-slave replication. For that, we suggest you look at
ReplicationConnectionorlbpool).If the JDBC URL starts with
jdbc:mysql:loadbalance://host-1,host-2,...host-n, the driver will create an implementation ofjava.sql.Connectionthat load balances requests across a series of MySQL JDBC connections to the given hosts, where the balancing takes place after transaction commit.Therefore, for this to work (at all), you must use transactions, even if only reading data.
Physical connections to the given hosts will not be created until needed.
The driver will invalidate connections that it detects have had communication errors when processing a request. A new connection to the problematic host will be attempted the next time it is selected by the load balancing algorithm.
There are two choices for load balancing algorithms, which may be specified by the
loadBalanceStrategyJDBC URL configuration property:random— the driver will pick a random host for each request. This tends to work better than round-robin, as the randomness will somewhat account for spreading loads where requests vary in response time, while round-robin can sometimes lead to overloaded nodes if there are variations in response times across the workload.bestResponseTime— the driver will route the request to the host that had the best response time for the previous transaction.
When
useLocalSessionStateis set totrueand connected to a MySQL-5.0 or later server, the JDBC driver will now determine whether an actualcommitorrollbackstatement needs to be sent to the database whenConnection.commit()orConnection.rollback()is called.This is especially helpful for high-load situations with connection pools that always call
Connection.rollback()on connection check-in/check-out because it avoids a round-trip to the server.Give better error message when "streaming" result sets, and the connection gets clobbered because of exceeding
net_write_timeouton the server.New configuration property,
enableQueryTimeouts(defaulttrue).When enabled, query timeouts set via
Statement.setQueryTimeout()use a sharedjava.util.Timerinstance for scheduling. Even if the timeout doesn't expire before the query is processed, there will be memory used by theTimerTaskfor the given timeout which won't be reclaimed until the time the timeout would have expired if it hadn't been cancelled by the driver. High-load environments might want to consider disabling this functionality. (this configuration property is part of themaxPerformanceconfiguration bundle).Added configuration property
padCharsWithSpace(defaults tofalse). If set totrue, and a result set column has theCHARtype and the value does not fill the amount of characters specified in the DDL for the column, the driver will pad the remaining characters with space (for ANSI compliance).Added configuration property
useDynamicCharsetInfo. If set tofalse(the default), the driver will use a per-connection cache of character set information queried from the server when necessary, or when set totrue, use a built-in static mapping that is more efficient, but isn't aware of custom character sets or character sets implemented after the release of the JDBC driver.Note
This only affects the
padCharsWithSpaceconfiguration property and theResultSetMetaData.getColumnDisplayWidth()method.More intelligent initial packet sizes for the "shared" packets are used (512 bytes, rather than 16K), and initial packets used during handshake are now sized appropriately as to not require reallocation.
Bugs fixed:
More useful error messages are generated when the driver thinks a result set is not updatable. (Thanks to Ashley Martens for the patch). (Bug#28085)
Using
ResultSet.get*()with a column index less than 1 returns a misleading error message. (Bug#27317)Client options not sent correctly when using SSL, leading to stored procedures not being able to return results. Thanks to Don Cohen for the bug report, testcase and patch. (Bug#25545)
PreparedStatementis not closed inBlobFromLocator.getBytes(). (Bug#26592)Whitespace surrounding storage/size specifiers in stored procedure parameters declaration causes
NumberFormatExceptionto be thrown when calling stored procedure on JDK-1.5 or newer, as the Number classes in JDK-1.5+ are whitespace intolerant. (Bug#25624)When the configuration property
useCursorFetchwas set totrue, sometimes server would return new, more exact metadata during the execution of the server-side prepared statement that enables this functionality, which the driver ignored (using the original metadata returned duringprepare()), causing corrupt reading of data due to type mismatch when the actual rows were returned. (Bug#26173)Comments in DDL of stored procedures/functions confuse procedure parser, and thus metadata about them can not be created, leading to inability to retrieve said metadata, or execute procedures that have certain comments in them. (Bug#26959)
Fast date/time parsing doesn't take into account
00:00:00as a legal value. (Bug#26789)ResultSet.get*()with a column index < 1 returns misleading error message. (Bug#27317)Statement.setMaxRows()is not effective on result sets materialized from cursors. (Bug#25517)CALL /* ... */doesn't work. As a side effect of this fix, you can now usesome_proc()/* */and#comments when preparing statements using client-side prepared statement emulation. (Bug#27400)If the comments happen to contain parameter markers (
?), they will be treated as belonging to the comment (that is, not recognized) rather than being a parameter of the statement.Note
The statement when sent to the server will contain the comments as-is, they're not stripped during the process of preparing the
PreparedStatementorCallableStatement.BIT(> 1)is returned asjava.lang.StringfromResultSet.getObject()rather thanbyte[]. (Bug#25328)CallableStatementswithOUT/INOUTparameters that are "binary" (BLOB,BIT,(VAR)BINARY,JAVA_OBJECT) have extra 7 bytes. (Bug#25715)Connection.getTransactionIsolation()uses "SHOW VARIABLES LIKE" which is very inefficient on MySQL-5.0+ servers. (Bug#27655)Fixed issue where calling
getGeneratedKeys()on a prepared statement after callingexecute()didn't always return the generated keys (executeUpdate()worked fine however).
Functionality added or changed:
Important change: Due to a number of issues with the use of server-side prepared statements, Connector/J 5.0.5 has disabled their use by default. The disabling of server-side prepared statements does not affect the operation of the connector in any way.
To enable server-side prepared statements you must add the following configuration property to your connector string:
useServerPrepStmts=true
The default value of this property is
false(that is, Connector/J does not use server-side prepared statements).Improved speed of
datetimeparsing for ResultSets that come from plain or non-server-side prepared statements. You can enable old implementation withuseFastDateParsing=falseas a configuration parameter.Added configuration property
localSocketAddress,which is the hostname or IP address given to explicitly configure the interface that the driver will bind the client side of the TCP/IP connection to when connecting.The
rewriteBatchedStatementsfeature can now be used with server-side prepared statements.We've added a new configuration option
treatUtilDateAsTimestamp, which isfalseby default, as (1) We already had specific behavior to treat java.util.Date as a java.sql.Timestamp because it's useful to many folks, and (2) that behavior will very likely be required for drivers JDBC-post-4.0.Fixed logging of XA commands sent to server, it's now configurable via
logXaCommandsproperty (defaults tofalse).Usage Advisor now detects empty results sets and does not report on columns not referenced in those empty sets.
Usage Advisor will now issue warnings for result sets with large numbers of rows. You can configure the trigger value by using the
resultSetSizeThresholdparameter, which has a default value of 100.
Bugs fixed:
Fixed an issue where
XADataSourcescouldn't be bound into JNDI, as theDataSourceFactorydidn't know how to create instances of them.Calling
Statement.cancel()could result in a Null Pointer Exception (NPE). (Bug#24721)Calendars and timezones are now lazily instantiated when required. (Bug#24351)
Client-side prepared statement parser gets confused by in-line comments
/*...*/and therefore cannot rewrite batch statements or reliably detect the type of statements when they are used. (Bug#25025)When using a JDBC connection URL that is malformed, the
NonRegisteringDriver.getPropertyInfomethod will throw a Null Pointer Exception (NPE). (Bug#22628)Using
DatabaseMetaData.getSQLKeywords()does not return a all of the of the reserved keywords for the current MySQL version. Current implementation returns the list of reserved words for MySQL 5.1, and does not distinguish between versions. (Bug#24794)Specifying
US-ASCIIas the character set in a connection to a MySQL 4.1 or newer server does not map correctly. (Bug#24840)Storing a
java.util.Dateobject in aBLOBcolumn would not be serialized correctly duringsetObject. (Bug#25787)A query execution which timed out did not always throw a
MySQLTimeoutException. (Bug#25836)A connection error would occur when connecting to a MySQL server with certain character sets. Some collations/character sets reported as "unknown" (specifically
ciasvariants of existing character sets), and inability to override the detected server character set. (Bug#23645)Using
setFetchSize()breaks preparedSHOWand other commands. (Bug#24360)Using
DATETIMEcolumns would result in time shifts whenuseServerPrepStmtswas true. The reason was due to different behavior when using client-side compared to server-side prepared statements and theuseJDBCCompliantTimezoneShiftoption. This is now fixed if moving from server-side prepared statements to client-side prepared statements by settinguseSSPSCompatibleTimezoneShifttotrue, as the driver can't tell if this is a new deployment that never used server-side prepared statements, or if it is an existing deployment that is switching to client-side prepared statements from server-side prepared statements. (Bug#24344)Inconsistency between
getSchemasandINFORMATION_SCHEMA. (Bug#23304)When using the
rewriteBatchedStatementsconnection option withPreparedState.executeBatch()an internal memory leak would occur. (Bug#25073)Fixed issue where field-level for metadata from
DatabaseMetaDatawhen usingINFORMATION_SCHEMAdidn't have references to current connections, sometimes leading to Null Pointer Exceptions (NPEs) when introspecting them viaResultSetMetaData.Connector/J now returns a better error message when server doesn't return enough information to determine stored procedure/function parameter types. (Bug#24065)
When using server-side prepared statements and timestamp columns, value would be incorrectly populated (with nanoseconds, not microseconds). (Bug#21438)
Timer instance used for
Statement.setQueryTimeout()created per-connection, rather than per-VM, causing memory leak. (Bug#25514)Results sets from
UPDATEstatements that are part of multi-statement queries would cause anSQLExceptionerror, "Result is from UPDATE". (Bug#25009)StringUtils.indexOfIgnoreCaseRespectQuotes()isn't case-insensitive on the first character of the target. This bug also affectedrewriteBatchedStatementsfunctionality when prepared statements did not use uppercase for theVALUESclause. (Bug#25047)Some exceptions thrown out of
StandardSocketFactorywere needlessly wrapped, obscuring their true cause, especially when using socket timeouts. (Bug#21480)DatabaseMetaData.getSchemas()doesn't return aTABLE_CATALOGcolumn. (Bug#23303)EscapeProcessorgets confused by multiple backslashes. We now push the responsibility of syntax errors back on to the server for most escape sequences. (Bug#25399)INOUTparameters inCallableStatementsget doubly-escaped. (Bug#25379)Connection property
socketFactorywasn't exposed via correctly named mutator/accessor, causing data source implementations that use JavaBean naming conventions to set properties to fail to set the property (and in the case of SJAS, fail silently when trying to set this parameter). (Bug#26326)ParameterMetaDatathrowsNullPointerExceptionwhen prepared SQL has a syntax error. AddedgenerateSimpleParameterMetadataconfiguration property, which when set totruewill generate metadata reflectingVARCHARfor every parameter (the default isfalse, which will cause an exception to be thrown if no parameter metadata for the statement is actually available). (Bug#21267)
Other changes:
Performance enhancement of initial character set configuration, driver will only send commands required to configure connection character set session variables if the current values on the server do not match what is required.
Re-worked stored procedure parameter parser to be more robust. Driver no longer requires
BEGINin stored procedure definition, but does have requirement that if a stored function begins with a label directly after the "returns" clause, that the label is not a quoted identifier.Reverted back to internal character conversion routines for single-byte character sets, as the ones internal to the JVM are using much more CPU time than our internal implementation.
Changed cached result set metadata (when using
cacheResultSetMetadata=true) to be cached per-connection rather than per-statement as previously implemented.Use a
java.util.TreeMapto map column names to ordinal indexes forResultSet.findColumn()instead of a HashMap. This allows us to have case-insensitive lookups (required by the JDBC specification) without resorting to the many transient object instances needed to support this requirement with a normalHashMapwith either case-adjusted keys, or case-insensitive keys. (In the worst case scenario for lookups of a 1000 column result set, TreeMaps are about half as fast wall-clock time as a HashMap, however in normal applications their use gives many orders of magnitude reduction in transient object instance creation which pays off later for CPU usage in garbage collection).Avoid static synchronized code in JVM class libraries for dealing with default timezones.
Fixed cases where
ServerPreparedStatementsweren't using cached metadata whencacheResultSetMetadata=truewas used.When using cached metadata, skip field-level metadata packets coming from the server, rather than reading them and discarding them without creating
com.mysql.jdbc.Fieldinstances.Throw exceptions encountered during timeout to thread calling
Statement.execute*(), rather thanRuntimeException.Take
localSocketAddressproperty into account when creating instances ofCommunicationsExceptionwhen the underyling exception is ajava.net.BindException, so that a friendlier error message is given with a little internal diagnostics.Fixed some Null Pointer Exceptions (NPEs) when cached metadata was used with
UpdatableResultSets.When extracting foreign key information from
SHOW CREATE TABLEinDatabaseMetaData, ignore exceptions relating to tables being missing (which could happen for cross-reference or imported-key requests, as the list of tables is generated first, then iterated).
Bugs fixed:
Column names don't match metadata in cases where server doesn't return original column names (column functions) thus breaking compatibility with applications that expect 1-1 mappings between findColumn() and rsmd.getColumnName(), usually manifests itself as "Can't find column ('')" exceptions. (Bug#21379)
When using information_schema for metadata, COLUMN_SIZE for getColumns() is not clamped to range of java.lang.Integer as is the case when not using information_schema, thus leading to a truncation exception that isn't present when not using information_schema. (Bug#21544)
Newlines causing whitespace to span confuse procedure parser when getting parameter metadata for stored procedures. (Bug#22024)
Driver was using milliseconds for Statement.setQueryTimeout() when specification says argument is to be in seconds. (Bug#22359)
Workaround for server crash when calling stored procedures via a server-side prepared statement (driver now detects prepare(stored procedure) and substitutes client-side prepared statement). (Bug#22297)
Added new _ci collations to CharsetMapping - utf8_unicode_ci not working. (Bug#22456)
Driver issues truncation on write exception when it shouldn't (due to sending big decimal incorrectly to server with server-side prepared statement). (Bug#22290)
DBMD.getColumns() does not return expected COLUMN_SIZE for the SET type, now returns length of largest possible set disregarding whitespace or the "," delimitters to be consistent with the ODBC driver. (Bug#22613)
Other changes:
Fixed configuration property
jdbcCompliantTruncationwas not being used for reads of result set values.Driver now supports
{call sp}(without "()" if procedure has no arguments).Driver now sends numeric 1 or 0 for client-prepared statement
setBoolean()calls instead of '1' or '0'.DatabaseMetaData correctly reports
trueforsupportsCatalog*()methods.
Fixed
Statement.cancel()causesNullPointerExceptionif underlying connection has been closed due to server failure. (Bug#20650)Added configuration option
noAccessToProcedureBodieswhich will cause the driver to create basic parameter metadata forCallableStatementswhen the user does not have access to procedure bodies viaSHOW CREATE PROCEDUREor selecting frommysql.procinstead of throwing an exception. The default value for this option isfalse
Bugs fixed:
If the connection to the server has been closed due to a server failure, then the cleanup process will call
Statement.cancel(), triggering aNullPointerException, even though there is no active connection. (Bug#20650)
Fixed can't use
XAConnectionfor local transactions when no global transaction is in progress. (Bug#17401)Fixed driver fails on non-ASCII platforms. The driver was assuming that the platform character set would be a superset of MySQL's
latin1when doing the handshake for authentication, and when reading error messages. We now use Cp1252 for all strings sent to the server during the handshake phase, and a hard-coded mapping of thelanguagesysttem variable to the character set that is used for error messages. (Bug#18086)Fixed
ConnectionProperties(and thus some subclasses) are not serializable, even though some J2EE containers expect them to be. (Bug#19169)Fixed
MysqlValidConnectionCheckerfor JBoss doesn't work withMySQLXADataSources. (Bug#20242)Better caching of character set converters (per-connection) to remove a bottleneck for multibyte character sets.
Added connection/datasource property
pinGlobalTxToPhysicalConnection(defaults tofalse). When set totrue, when usingXAConnections, the driver ensures that operations on a given XID are always routed to the same physical connection. This allows theXAConnectionto supportXA START ... JOINafterXA ENDhas been called, and is also a workaround for transaction managers that don't maintain thread affinity for a global transaction (most either always maintain thread affinity, or have it as a configuration option).MysqlXaConnection.recover(int flags)now allows combinations ofXAResource.TMSTARTRSCANandTMENDRSCAN. To simulate the “scanning” nature of the interface, we return all prepared XIDs forTMSTARTRSCAN, and no new XIDs for calls withTMNOFLAGS, orTMENDRSCANwhen not in combination withTMSTARTRSCAN. This change was made for API compliance, as well as integration with IBM WebSphere's transaction manager.
Not released due to a packaging error
XADataSourceimplemented (ported from 3.2 branch which won't be released as a product). Usecom.mysql.jdbc.jdbc2.optional.MysqlXADataSourceas your datasource class name in your application server to utilize XA transactions in MySQL-5.0.10 and newer.PreparedStatement.setString()didn't work correctly whensql_modeon server containedNO_BACKSLASH_ESCAPESand no characters that needed escaping were present in the string.Attempt detection of the MySQL type
BINARY(it's an alias, so this isn't always reliable), and use thejava.sql.Types.BINARYtype mapping for it.Moved
-bin-g.jarfile into separatedebugsubdirectory to avoid confusion.Don't allow
.setAutoCommit(true), or.commit()or.rollback()on an XA-managed connection as per the JDBC specification.If the connection
useTimezoneis set totrue, then also respect time zone conversions in escape-processed string literals (for example,"{ts ...}"and"{t ...}").Return original column name for
RSMD.getColumnName()if the column was aliased, alias name for.getColumnLabel()(if aliased), and original table name for.getTableName(). Note this only works for MySQL-4.1 and newer, as older servers don't make this information available to clients.Setting
useJDBCCompliantTimezoneShift=true(it's not the default) causes the driver to use GMT for allTIMESTAMP/DATETIMEtime zones, and the current VM time zone for any other type that refers to time zones. This feature can not be used whenuseTimezone=trueto convert between server and client time zones.Add one level of indirection of internal representation of
CallableStatementparameter metadata to avoid class not found issues on JDK-1.3 forParameterMetadatainterface (which doesn't exist prior to JDBC-3.0).Added unit tests for
XADatasource, as well as friendlier exceptions for XA failures compared to the "stock"XAException(which has no messages).Idle timeouts cause
XAConnectionsto whine about rolling themselves back. (Bug#14729)Added support for Connector/MXJ integration via url subprotocol
jdbc:mysql:mxj://....Moved all
SQLExceptionconstructor usage to a factory inSQLError(ground-work for JDBC-4.0SQLState-based exception classes).Removed Java5-specific calls to
BigDecimalconstructor (when result set value is'',(int)0was being used as an argument indirectly via method return value. This signature doesn't exist prior to Java5.)Added service-provider entry to
META-INF/services/java.sql.Driverfor JDBC-4.0 support.Return "[VAR]BINARY" for
RSMD.getColumnTypeName()when that is actually the type, and it can be distinguished (MySQL-4.1 and newer).When fix for Bug#14562 was merged from 3.1.12, added functionality for
CallableStatement's parameter metadata to return correct information for.getParameterClassName().Fuller synchronization of
Connectionto avoid deadlocks when using multithreaded frameworks that multithread a single connection (usually not recommended, but the JDBC spec allows it anyways), part of fix to Bug#14972).Implementation of
Statement.cancel()andStatement.setQueryTimeout(). Both require MySQL-5.0.0 or newer server, require a separate connection to issue theKILL QUERYstatement, and in the case ofsetQueryTimeout()creates an additional thread to handle the timeout functionality.Note: Failures to cancel the statement for
setQueryTimeout()may manifest themselves asRuntimeExceptionsrather than failing silently, as there is currently no way to unblock the thread that is executing the query being cancelled due to timeout expiration and have it throw the exception instead.
- E.6.3.1. Changes in MySQL Connector/J 3.1.15 (Not yet released)
- E.6.3.2. Changes in MySQL Connector/J 3.1.14 (10-19-2006)
- E.6.3.3. Changes in MySQL Connector/J 3.1.13 (26 May 2006)
- E.6.3.4. Changes in MySQL Connector/J 3.1.12 (30 November 2005)
- E.6.3.5. Changes in MySQL Connector/J 3.1.11-stable (07 October 2005)
- E.6.3.6. Changes in MySQL Connector/J 3.1.10-stable (23 June 2005)
- E.6.3.7. Changes in MySQL Connector/J 3.1.9-stable (22 June 2005)
- E.6.3.8. Changes in MySQL Connector/J 3.1.8-stable (14 April 2005)
- E.6.3.9. Changes in MySQL Connector/J 3.1.7-stable (18 February 2005)
- E.6.3.10. Changes in MySQL Connector/J 3.1.6-stable (23 December 2004)
- E.6.3.11. Changes in MySQL Connector/J 3.1.5-gamma (02 December 2004)
- E.6.3.12. Changes in MySQL Connector/J 3.1.4-beta (04 September 2004)
- E.6.3.13. Changes in MySQL Connector/J 3.1.3-beta (07 July 2004)
- E.6.3.14. Changes in MySQL Connector/J 3.1.2-alpha (09 June 2004)
- E.6.3.15. Changes in MySQL Connector/J 3.1.1-alpha (14 February 2004)
- E.6.3.16. Changes in MySQL Connector/J 3.1.0-alpha (18 February 2003)
Important change: Due to a number of issues with the use of server-side prepared statements, Connector/J 5.0.5 has disabled their use by default. The disabling of server-side prepared statements does not affect the operation of the connector in any way.
To enable server-side prepared statements you must add the following configuration property to your connector string:
useServerPrepStmts=true
The default value of this property is false
(that is, Connector/J does not use server-side prepared
statements).
Bugs fixed:
Specifying
US-ASCIIas the character set in a connection to a MySQL 4.1 or newer server does not map correctly. (Bug#24840)
Fixed updatable result set throws ClassCastException when there is row data and moveToInsertRow() is called. (Bug#20479)
Fixed Updatable result set that contains a BIT column fails when server-side prepared statements are used. (Bug#20485)
Fixed memory leak with profileSQL=true. (Bug#16987)
Connection fails to localhost when using timeout and IPv6 is configured. (Bug#19726)
Fixed NullPointerException in MysqlDataSourceFactory due to Reference containing RefAddrs with null content. (Bug#16791)
Fixed ResultSet.getShort() for UNSIGNED TINYINT returns incorrect values when using server-side prepared statements. (Bug#20306)
Fixed can't pool server-side prepared statements, exception raised when re-using them. (Bug#20687)
ResultSet.getSomeInteger() doesn't work for BIT(>1). (Bug#21062)
ResultSet.getFloatFromString() can't retrieve values near Float.MIN/MAX_VALUE. (Bug#18880)
Escape of quotes in client-side prepared statements parsing not respected. Patch covers more than bug report, including NO_BACKSLASH_ESCAPES being set, and stacked quote characters forms of escaping (that is, '' or ""). (Bug#20888)
ReplicationDriver does not always round-robin load balance depending on URL used for slaves list. (Bug#19993)
Fixed calling toString() on ResultSetMetaData for driver-generated (that is, from DatabaseMetaData method calls, or from getGeneratedKeys()) result sets would raise a NullPointerException.
DDriver throws NPE when tracing prepared statements that have been closed (in asSQL()). (Bug#21207)
Removed logger autodetection altogether, must now specify logger explicitly if you want to use a logger other than one that logs to STDERR.
Driver issues truncation on write exception when it shouldn't (due to sending big decimal incorrectly to server with server-side prepared statement). (Bug#22290)
Driver now sends numeric 1 or 0 for client-prepared statement setBoolean() calls instead of '1' or '0'.
Fixed bug where driver would not advance to next host if roundRobinLoadBalance=true and the last host in the list is down.
Fixed Bug#18258 - DatabaseMetaData.getTables(), columns() with bad catalog parameter threw exception rather than return empty result set (as required by spec).
Check and store value for continueBatchOnError property in constructor of Statements, rather than when executing batches, so that Connections closed out from underneath statements don't cause NullPointerExceptions when it's required to check this property.
Fixed bug when calling stored functions, where parameters weren't numbered correctly (first parameter is now the return value, subsequent parameters if specified start at index "2").
INOUTparameter does not storeINvalue. (Bug#15464)Exception thrown for new decimal type when using updatable result sets. (Bug#14609)
No "dos" character set in MySQL > 4.1.0. (Bug#15544)
PreparedStatement.setObject()serializesBigIntegeras object, rather than sending as numeric value (and is thus not complementary to.getObject()on anUNSIGNED LONGtype). (Bug#15383)ResultSet.getShort()forUNSIGNED TINYINTreturned wrong values. (Bug#11874)lib-nodistdirectory missing from package breaks out-of-box build. (Bug#15676)DBMD.getColumns()returns wrong type forBIT. (Bug#15854)Fixed issue where driver was unable to initialize character set mapping tables. Removed reliance on
.propertiesfiles to hold this information, as it turns out to be too problematic to code around class loader hierarchies that change depending on how an application is deployed. Moved information back into theCharsetMappingclass. (Bug#14938)Fixed updatable result set doesn't return
AUTO_INCREMENTvalues forinsertRow()when multiple column primary keys are used. (the driver was checking for the existence of single-column primary keys and an autoincrement value > 0 instead of a straightforwardisAutoIncrement()check). (Bug#16841)Fixed
Statement.getGeneratedKeys()throwsNullPointerExceptionwhen no query has been processed. (Bug#17099)Fixed driver trying to call methods that don't exist on older and newer versions of Log4j. The fix is not trying to auto-detect presence of log4j, too many different incompatible versions out there in the wild to do this reliably. (Bug#13469)
If you relied on autodetection before, you will need to add "logger=com.mysql.jdbc.log.Log4JLogger" to your JDBC URL to enable Log4J usage, or alternatively use the new "CommonsLogger" class to take care of this.
Added support for Apache Commons logging, use "com.mysql.jdbc.log.CommonsLogger" as the value for the "logger" configuration property.
LogFactory now prepends "com.mysql.jdbc.log" to log class name if it can't be found as-specified. This allows you to use "short names" for the built-in log factories, for example "logger=CommonsLogger" instead of "logger=com.mysql.jdbc.log.CommonsLogger".
Fixed issue with
ReplicationConnectionincorrectly copying state, doesn't transfer connection context correctly when transitioning between the same read-only states. (Bug#15570)Fixed issue where server-side prepared statements don't cause truncation exceptions to be thrown when truncation happens. (Bug#18041)
Added performance feature, re-writing of batched executes for
Statement.executeBatch()(for all DML statements) andPreparedStatement.executeBatch()(for INSERTs with VALUE clauses only). Enable by using "rewriteBatchedStatements=true" in your JDBC URL.Fixed
CallableStatement.registerOutParameter()not working when some parameters pre-populated. Still waiting for feedback from JDBC experts group to determine what correct parameter count fromgetMetaData()should be, however. (Bug#17898)Fixed calling
clearParameters()on a closed prepared statement causes NPE. (Bug#17587)Map "latin1" on MySQL server to CP1252 for MySQL > 4.1.0.
Added additional accessor and mutator methods on ConnectionProperties so that DataSource users can use same naming as regular URL properties.
Fixed data truncation and
getWarnings()only returns last warning in set. (Bug#18740)Improved performance of retrieving
BigDecimal,Time,TimestampandDatevalues from server-side prepared statements by creating fewer short-lived instances ofStringswhen the native type is not an exact match for the requested type. (Bug#18496)Fixed aliased column names where length of name > 251 are corrupted. (Bug#18554)
Fixed
ResultSet.wasNull()not always reset correctly for booleans when done via conversion for server-side prepared statements. (Bug#17450)Fixed invalid classname returned for
ResultSetMetaData.getColumnClassName()forBIGINT type. (Bug#19282)Fixed case where driver wasn't reading server status correctly when fetching server-side prepared statement rows, which in some cases could cause warning counts to be off, or multiple result sets to not be read off the wire.
Driver now aware of fix for
BITtype metadata that went into MySQL-5.0.21 for server not reporting length consistently (Bug#13601).Fixed PreparedStatement.setObject(int, Object, int)doesn't respect scale of BigDecimals. (Bug#19615)Fixed
ResultSet.wasNull()returns incorrect value when extracting native string from server-side prepared statement generated result set. (Bug#19282)
Fixed client-side prepared statement bug with embedded
?characters inside quoted identifiers (it was recognized as a placeholder, when it was not).Don't allow
executeBatch()forCallableStatementswith registeredOUT/INOUTparameters (JDBC compliance).Fall back to platform-encoding for
URLDecoder.decode()when parsing driver URL properties if the platform doesn't have a two-argument version of this method.Java type conversion may be incorrect for
MEDIUMINT. (Bug#14562)Added configuration property
useGmtMillisForDatetimeswhich when set totruecausesResultSet.getDate(),.getTimestamp()to return correct millis-since GMT when.getTime()is called on the return value (currently default isfalsefor legacy behavior).Fixed
DatabaseMetaData.stores*Identifiers():If
lower_case_table_names=0(on server):storesLowerCaseIdentifiers()returnsfalsestoresLowerCaseQuotedIdentifiers()returnsfalsestoresMixedCaseIdentifiers()returnstruestoresMixedCaseQuotedIdentifiers()returnstruestoresUpperCaseIdentifiers()returnsfalsestoresUpperCaseQuotedIdentifiers()returnstrue
If
lower_case_table_names=1(on server):storesLowerCaseIdentifiers()returnstruestoresLowerCaseQuotedIdentifiers()returnstruestoresMixedCaseIdentifiers()returnsfalsestoresMixedCaseQuotedIdentifiers()returnsfalsestoresUpperCaseIdentifiers()returnsfalsestoresUpperCaseQuotedIdentifiers()returnstrue
DatabaseMetaData.getColumns()doesn't returnTABLE_NAMEcorrectly. (Bug#14815)Escape processor replaces quote character in quoted string with string delimiter. (Bug#14909)
OpenOffice expects
DBMD.supportsIntegrityEnhancementFacility()to returntrueif foreign keys are supported by the datasource, even though this method also covers support for check constraints, which MySQL doesn't have. Setting the configuration propertyoverrideSupportsIntegrityEnhancementFacilitytotruecauses the driver to returntruefor this method. (Bug#12975)Added
com.mysql.jdbc.testsuite.url.defaultsystem property to set default JDBC url for testsuite (to speed up bug resolution when I'm working in Eclipse).Unable to initialize character set mapping tables (due to J2EE classloader differences). (Bug#14938)
Deadlock while closing server-side prepared statements from multiple threads sharing one connection. (Bug#14972)
logSlowQueriesshould give better info. (Bug#12230)Extraneous sleep on
autoReconnect. (Bug#13775)Driver incorrectly closes streams passed as arguments to
PreparedStatements. Reverts to legacy behavior by setting the JDBC configuration propertyautoClosePStmtStreamstotrue(also included in the 3-0-Compat configuration “bundle”). (Bug#15024)maxQuerySizeToLogis not respected. Added logging of bound values forexecute()phase of server-side prepared statements whenprofileSQL=trueas well. (Bug#13048)Usage advisor complains about unreferenced columns, even though they've been referenced. (Bug#15065)
Don't increase timeout for failover/reconnect. (Bug#6577)
Process escape tokens in
Connection.prepareStatement(...). (Bug#15141) You can disable this behavior by setting the JDBC URL configuration propertyprocessEscapeCodesForPrepStmtstofalse.Reconnect during middle of
executeBatch()should not occur ifautoReconnectis enabled. (Bug#13255)
Spurious
!on console when character encoding isutf8. (Bug#11629)Fixed statements generated for testcases missing
;for “plain” statements.Incorrect generation of testcase scripts for server-side prepared statements. (Bug#11663)
Fixed regression caused by fix for Bug#11552 that caused driver to return incorrect values for unsigned integers when those integers where within the range of the positive signed type.
Moved source code to Subversion repository.
Escape tokenizer doesn't respect stacked single quotes for escapes. (Bug#11797)
GEOMETRYtype not recognized when using server-side prepared statements.ReplicationConnectionwon't switch to slave, throws “Catalog can't be null” exception. (Bug#11879)Properties shared between master and slave with replication connection. (Bug#12218)
Statement.getWarnings()fails with NPE if statement has been closed. (Bug#10630)Only get
char[]from SQL inPreparedStatement.ParseInfo()when needed.Geometry types not handled with server-side prepared statements. (Bug#12104)
StringUtils.getBytes()doesn't work when using multi-byte character encodings and a length in characters is specified. (Bug#11614)Pstmt.setObject(...., Types.BOOLEAN)throws exception. (Bug#11798)maxPerformance.propertiesmis-spells “elideSetAutoCommits”. (Bug#11976)DBMD.storesLower/Mixed/UpperIdentifiers()reports incorrect values for servers deployed on Windows. (Bug#11575)ResultSet.moveToCurrentRow()fails to work when preceded by a call toResultSet.moveToInsertRow(). (Bug#11190)VARBINARYdata corrupted when using server-side prepared statements and.setBytes(). (Bug#11115)explainSlowQuerieshangs with server-side prepared statements. (Bug#12229)Escape processor didn't honor strings demarcated with double quotes. (Bug#11498)
Lifted restriction of changing streaming parameters with server-side prepared statements. As long as
allstreaming parameters were set before execution,.clearParameters()does not have to be called. (due to limitation of client/server protocol, prepared statements can not reset individual stream data on the server side).Reworked
Fieldclass,*Buffer, andMysqlIOto be aware of field lengths >Integer.MAX_VALUE.Updated
DBMD.supportsCorrelatedQueries()to returntruefor versions > 4.1,supportsGroupByUnrelated()to returntrueandgetResultSetHoldability()to returnHOLD_CURSORS_OVER_COMMIT.Handling of catalog argument in
DatabaseMetaData.getIndexInfo(), which also means changes to the following methods inDatabaseMetaData: (Bug#12541)getBestRowIdentifier()getColumns()getCrossReference()getExportedKeys()getImportedKeys()getIndexInfo()getPrimaryKeys()getProcedures()(and thus indirectlygetProcedureColumns())getTables()
The
catalogargument in all of these methods now behaves in the following way:Specifying
NULLmeans that catalog will not be used to filter the results (thus all databases will be searched), unless you've setnullCatalogMeansCurrent=truein your JDBC URL properties.Specifying
""means “current” catalog, even though this isn't quite JDBC spec compliant, it's there for legacy users.Specifying a catalog works as stated in the API docs.
Made
Connection.clientPrepare()available from “wrapped” connections in thejdbc2.optionalpackage (connections built byConnectionPoolDataSourceinstances).
Added
Connection.isMasterConnection()for clients to be able to determine if a multi-host master/slave connection is connected to the first host in the list.Tokenizer for
=in URL properties was causingsessionVariables=....to be parameterized incorrectly. (Bug#12753)Foreign key information that is quoted is parsed incorrectly when
DatabaseMetaDatamethods use that information. (Bug#11781)The
sendBlobChunkSizeproperty is now clamped tomax_allowed_packetwith consideration of stream buffer size and packet headers to avoidPacketTooBigExceptionswhenmax_allowed_packetis similar in size to the defaultsendBlobChunkSizewhich is 1M.CallableStatement.clearParameters()now clears resources associated withINOUT/OUTPUTparameters as well asINPUTparameters.Connection.prepareCall()is database name case-sensitive (on Windows systems). (Bug#12417)cp1251incorrectly mapped towin1251for servers newer than 4.0.x. (Bug#12752)java.sql.Types.OTHERreturned forBINARYandVARBINARYcolumns when usingDatabaseMetaData.getColumns(). (Bug#12970)ServerPreparedStatement.getBinding()now checks if the statement is closed before attempting to reference the list of parameter bindings, to avoid throwing aNullPointerException.ResultSetMetaDatafromStatement.getGeneratedKeys()caused aNullPointerExceptionto be thrown whenever a method that required a connection reference was called. (Bug#13277)Backport of
Fieldclass,ResultSetMetaData.getColumnClassName(), andResultSet.getObject(int)changes from 5.0 branch to fix behavior surroundingVARCHAR BINARY/VARBINARYand related types.Fixed
NullPointerExceptionwhen convertingcatalogparameter in manyDatabaseMetaDataMethodstobyte[]s (for the result set) when the parameter isnull. (nullisn't technically allowed by the JDBC specification, but we've historically allowed it).Backport of
VAR[BINARY|CHAR] [BINARY]types detection from 5.0 branch.Read response in
MysqlIO.sendFileToServer(), even if the local file can't be opened, otherwise next query issued will fail, because it's reading the response to the emptyLOAD DATA INFILEpacket sent to the server.Workaround for Bug#13374:
ResultSet.getStatement()on closed result set returnsNULL(as per JDBC 4.0 spec, but not backward-compatible). Set the connection propertyretainStatementAfterResultSetClosetotrueto be able to retrieve aResultSet's statement after theResultSethas been closed via.getStatement()(the default isfalse, to be JDBC-compliant and to reduce the chance that code using JDBC leaksStatementinstances).URL configuration parameters don't allow ‘
&’ or ‘=’ in their values. The JDBC driver now parses configuration parameters as if they are encoded using the application/x-www-form-urlencoded format as specified byjava.net.URLDecoder(http://java.sun.com/j2se/1.5.0/docs/api/java/net/URLDecoder.html). (Bug#13453)If the ‘
%’ character is present in a configuration property, it must now be represented as%25, which is the encoded form of ‘%’ when using application/x-www-form-urlencoded encoding.The configuration property
sessionVariablesnow allows you to specify variables that start with the ‘@’ sign.When
gatherPerfMetricsis enabled for servers older than 4.1.0, aNullPointerExceptionis thrown from the constructor ofResultSetif the query doesn't use any tables. (Bug#13043)
Fixed connecting without a database specified raised an exception in
MysqlIO.changeDatabaseTo().Initial implemention of
ParameterMetadataforPreparedStatement.getParameterMetadata(). Only works fully forCallableStatements, as current server-side prepared statements return every parameter as aVARCHARtype.
Overhaul of character set configuration, everything now lives in a properties file.
Driver now correctly uses CP932 if available on the server for Windows-31J, CP932 and MS932 java encoding names, otherwise it resorts to SJIS, which is only a close approximation. Currently only MySQL-5.0.3 and newer (and MySQL-4.1.12 or .13, depending on when the character set gets backported) can reliably support any variant of CP932.
com.mysql.jdbc.PreparedStatement.ParseInfodoes unnecessary call totoCharArray(). (Bug#9064)Memory leak in
ServerPreparedStatementifserverPrepare()fails. (Bug#10144)Actually write manifest file to correct place so it ends up in the binary jar file.
Added
createDatabaseIfNotExistproperty (default isfalse), which will cause the driver to ask the server to create the database specified in the URL if it doesn't exist. You must have the appropriate privileges for database creation for this to work.Unsigned
SMALLINTtreated as signed forResultSet.getInt(), fixed all cases forUNSIGNEDinteger values and server-side prepared statements, as well asResultSet.getObject()forUNSIGNED TINYINT. (Bug#10156)Double quotes not recognized when parsing client-side prepared statements. (Bug#10155)
Made
enableStreamingResults()visible oncom.mysql.jdbc.jdbc2.optional.StatementWrapper.Made
ServerPreparedStatement.asSql()work correctly so auto-explain functionality would work with server-side prepared statements.Made JDBC2-compliant wrappers public in order to allow access to vendor extensions.
Cleaned up logging of profiler events, moved code to dump a profiler event as a string to
com.mysql.jdbc.log.LogUtilsso that third parties can use it.DatabaseMetaData.supportsMultipleOpenResults()now returnstrue. The driver has supported this for some time, DBMD just missed that fact.Driver doesn't support
{?=CALL(...)}for calling stored functions. This involved adding support for function retrieval toDatabaseMetaData.getProcedures()andgetProcedureColumns()as well. (Bug#10310)SQLExceptionthrown when retrievingYEAR(2)withResultSet.getString(). The driver will now always treatYEARtypes asjava.sql.Datesand return the correct values forgetString(). Alternatively, theyearIsDateTypeconnection property can be set tofalseand the values will be treated asSHORTs. (Bug#10485)The datatype returned for
TINYINT(1)columns whentinyInt1isBit=true(the default) can be switched betweenTypes.BOOLEANandTypes.BITusing the new configuration propertytransformedBitIsBoolean, which defaults tofalse. If set tofalse(the default),DatabaseMetaData.getColumns()andResultSetMetaData.getColumnType()will returnTypes.BOOLEANforTINYINT(1)columns. Iftrue,Types.BOOLEANwill be returned instead. Regardless of this configuration property, iftinyInt1isBitis enabled, columns with the typeTINYINT(1)will be returned asjava.lang.Booleaninstances fromResultSet.getObject(...), andResultSetMetaData.getColumnClassName()will returnjava.lang.Boolean.SQLExceptionis thrown when using propertycharacterSetResultswithcp932oreucjpms. (Bug#10496)Reorganized directory layout. Sources now are in
srcfolder. Don't pollute parent directory when building, now output goes to./build, distribution goes to./dist.Added support/bug hunting feature that generates
.sqltest scripts toSTDERRwhenautoGenerateTestcaseScriptis set totrue.0-length streams not sent to server when using server-side prepared statements. (Bug#10850)
Setting
cachePrepStmts=truenow causes theConnectionto also cache the check the driver performs to determine if a prepared statement can be server-side or not, as well as caches server-side prepared statements for the lifetime of a connection. As before, theprepStmtCacheSizeparameter controls the size of these caches.Try to handle
OutOfMemoryErrorsmore gracefully. Although not much can be done, they will in most cases close the connection they happened on so that further operations don't run into a connection in some unknown state. When an OOM has happened, any further operations on the connection will fail with a “Connection closed” exception that will also list the OOM exception as the reason for the implicit connection close event.Don't send
COM_RESET_STMTfor each execution of a server-side prepared statement if it isn't required.Driver detects if you're running MySQL-5.0.7 or later, and does not scan for
LIMIT ?[,?]in statements being prepared, as the server supports those types of queries now.VARBINARYdata corrupted when using server-side prepared statements andResultSet.getBytes(). (Bug#11115)Connection.setCatalog()is now aware of theuseLocalSessionStateconfiguration property, which when set totruewill prevent the driver from sendingUSE ...to the server if the requested catalog is the same as the current catalog.Added the following configuration bundles, use one or many via the
useConfigsconfiguration property:maxPerformance— maximum performance without being recklesssolarisMaxPerformance— maximum performance for Solaris, avoids syscalls where it can3-0-Compat— Compatibility with Connector/J 3.0.x functionality
Added
maintainTimeStatsconfiguration property (defaults totrue), which tells the driver whether or not to keep track of the last query time and the last successful packet sent to the server's time. If set tofalse, removes two syscalls per query.autoReconnectping causes exception on connection startup. (Bug#11259)Connector/J dumping query into
SQLExceptiontwice. (Bug#11360)Fixed
PreparedStatement.setClob()not acceptingnullas a parameter.Production package doesn't include JBoss integration classes. (Bug#11411)
Removed nonsensical “costly type conversion” warnings when using usage advisor.
Fixed
DatabaseMetaData.getTables()returning views when they were not asked for as one of the requested table types.Added support for new precision-math
DECIMALtype in MySQL 5.0.3 and up.Fixed
ResultSet.getTime()on aNULLvalue for server-side prepared statements throws NPE.Made
Connection.ping()a public method.DATE_FORMAT()queries returned asBLOBs fromgetObject(). (Bug#8868)ServerPreparedStatementsnow correctly “stream”BLOB/CLOBdata to the server. You can configure the threshold chunk size using the JDBC URL propertyblobSendChunkSize(the default is 1MB).BlobFromLocatornow uses correct identifier quoting when generating prepared statements.Server-side session variables can be preset at connection time by passing them as a comma-delimited list for the connection property
sessionVariables.Fixed regression in
ping()for users usingautoReconnect=true.PreparedStatement.addBatch()doesn't work with server-side prepared statements and streamingBINARYdata. (Bug#9040)DBMD.supportsMixedCase*Identifiers()returns wrong value on servers running on case-sensitive filesystems. (Bug#8800)Cannot use
UTF-8for characterSetResults configuration property. (Bug#9206)A continuation of Bug#8868, where functions used in queries that should return non-string types when resolved by temporary tables suddenly become opaque binary strings (work-around for server limitation). Also fixed fields with type of
CHAR(n) CHARACTER SET BINARYto return correct/matching classes forRSMD.getColumnClassName()andResultSet.getObject(). (Bug#9236)DBMD.supportsResultSetConcurrency()not returningtruefor forward-only/read-only result sets (we obviously support this). (Bug#8792)DATA_TYPEcolumn fromDBMD.getBestRowIdentifier()causesArrayIndexOutOfBoundsExceptionwhen accessed (and in fact, didn't return any value). (Bug#8803)Check for empty strings (
'') when convertingCHAR/VARCHARcolumn data to numbers, throw exception ifemptyStringsConvertToZeroconfiguration property is set tofalse(for backward-compatibility with 3.0, it is now set totrueby default, but will most likely default tofalsein 3.2).PreparedStatement.getMetaData()inserts blank row in database under certain conditions when not using server-side prepared statements. (Bug#9320)Connection.canHandleAsPreparedStatement()now makes “best effort” to distinguishLIMITclauses with placeholders in them from ones without in order to have fewer false positives when generating work-arounds for statements the server cannot currently handle as server-side prepared statements.Fixed
build.xmlto not compilelog4jlogging iflog4jnot available.Added support for the c3p0 connection pool's (http://c3p0.sf.net/) validation/connection checker interface which uses the lightweight
COM_PINGcall to the server if available. To use it, configure your c3p0 connection pool'sconnectionTesterClassNameproperty to usecom.mysql.jdbc.integration.c3p0.MysqlConnectionTester.Better detection of
LIMITinside/outside of quoted strings so that the driver can more correctly determine whether a prepared statement can be prepared on the server or not.Stored procedures with same name in different databases confuse the driver when it tries to determine parameter counts/types. (Bug#9319)
Added finalizers to
ResultSetandStatementimplementations to be JDBC spec-compliant, which requires that if not explicitly closed, these resources should be closed upon garbage collection.Stored procedures with
DECIMALparameters with storage specifications that contained ‘,’ in them would fail. (Bug#9682)PreparedStatement.setObject(int, Object, int type, int scale)now uses scale value forBigDecimalinstances.Statement.getMoreResults()could throw NPE when existing result set was.close()d. (Bug#9704)The performance metrics feature now gathers information about number of tables referenced in a SELECT.
The logging system is now automatically configured. If the value has been set by the user, via the URL property
loggeror the system propertycom.mysql.jdbc.logger, then use that, otherwise, autodetect it using the following steps:Log4j, if it's available,
Then JDK1.4 logging,
Then fallback to our
STDERRlogging.
DBMD.getTables()shouldn't return tables if views are asked for, even if the database version doesn't support views. (Bug#9778)Fixed driver not returning
truefor-1whenResultSet.getBoolean()was called on result sets returned from server-side prepared statements.Added a
Manifest.MFfile with implementation information to the.jarfile.More tests in
Field.isOpaqueBinary()to distinguish opaque binary (that is, fields with typeCHAR(n)andCHARACTER SET BINARY) from output of various scalar and aggregate functions that return strings.Should accept
nullfor catalog (meaning use current) in DBMD methods, even though it's not JDBC-compliant for legacy's sake. Disable by setting connection propertynullCatalogMeansCurrenttofalse(which will be the default value in C/J 3.2.x). (Bug#9917)Should accept
nullfor name patterns in DBMD (meaning ‘%’), even though it isn't JDBC compliant, for legacy's sake. Disable by setting connection propertynullNamePatternMatchesAlltofalse(which will be the default value in C/J 3.2.x). (Bug#9769)
Timestamp key column data needed
_binarystripped forUpdatableResultSet.refreshRow(). (Bug#7686)Timestamps converted incorrectly to strings with server-side prepared statements and updatable result sets. (Bug#7715)
Detect new
sql_modevariable in string form (it used to be integer) and adjust quoting method for strings appropriately.Added
holdResultsOpenOverStatementCloseproperty (default isfalse), that keeps result sets open over statement.close() or new execution on same statement (suggested by Kevin Burton).Infinite recursion when “falling back” to master in failover configuration. (Bug#7952)
Disable multi-statements (if enabled) for MySQL-4.1 versions prior to version 4.1.10 if the query cache is enabled, as the server returns wrong results in this configuration.
Fixed duplicated code in
configureClientCharset()that preventeduseOldUTF8Behavior=truefrom working properly.Removed
dontUnpackBinaryResultsfunctionality, the driver now always stores results from server-side prepared statements as is from the server and unpacks them on demand.Emulated locators corrupt binary data when using server-side prepared statements. (Bug#8096)
Fixed synchronization issue with
ServerPreparedStatement.serverPrepare()that could cause deadlocks/crashes if connection was shared between threads.By default, the driver now scans SQL you are preparing via all variants of
Connection.prepareStatement()to determine if it is a supported type of statement to prepare on the server side, and if it is not supported by the server, it instead prepares it as a client-side emulated prepared statement. You can disable this by passingemulateUnsupportedPstmts=falsein your JDBC URL. (Bug#4718)Remove
_binaryintroducer from parameters used as in/out parameters inCallableStatement.Always return
byte[]s for output parameters registered as*BINARY.Send correct value for “boolean”
trueto server forPreparedStatement.setObject(n, "true", Types.BIT).Fixed bug with Connection not caching statements from
prepareStatement()when the statement wasn't a server-side prepared statement.Choose correct “direction” to apply time adjustments when both client and server are in GMT time zone when using
ResultSet.get(..., cal)andPreparedStatement.set(...., cal).Added
dontTrackOpenResourcesoption (default isfalse, to be JDBC compliant), which helps with memory use for non-well-behaved apps (that is, applications that don't closeStatementobjects when they should).ResultSet.getString()doesn't maintain format stored on server, bug fix only enabled whennoDatetimeStringSyncproperty is set totrue(the default isfalse). (Bug#8428)Fixed NPE in
ResultSet.realClose()when using usage advisor and result set was already closed.PreparedStatementsnot creating streaming result sets. (Bug#8487)Don't pass
NULLtoString.valueOf()inResultSet.getNativeConvertToString(), as it stringifies it (that is, returnsnull), which is not correct for the method in question.ResultSet.getBigDecimal()throws exception when rounding would need to occur to set scale. The driver now chooses a rounding mode of “half up” if non-roundingBigDecimal.setScale()fails. (Bug#8424)Added
useLocalSessionStateconfiguration property, when set totruethe JDBC driver trusts that the application is well-behaved and only sets autocommit and transaction isolation levels using the methods provided onjava.sql.Connection, and therefore can manipulate these values in many cases without incurring round-trips to the database server.Added
enableStreamingResults()toStatementfor connection pool implementations that checkStatement.setFetchSize()for specification-compliant values. CallStatement.setFetchSize(>=0)to disable the streaming results for that statement.Added support for
BITtype in MySQL-5.0.3. The driver will treatBIT(1-8)as the JDBC standardBITtype (which maps tojava.lang.Boolean), as the server does not currently send enough information to determine the size of a bitfield when < 9 bits are declared.BIT(>9)will be treated asVARBINARY, and will returnbyte[]whengetObject()is called.
Fixed hang on
SocketInputStream.read()withStatement.setMaxRows()and multiple result sets when driver has to truncate result set directly, rather than tacking aLIMITon the end of it.nDBMD.getProcedures()doesn't respect catalog parameter. (Bug#7026)
Fix comparisons made between string constants and dynamic strings that are converted with either
toUpperCase()ortoLowerCase()to useLocale.ENGLISH, as some locales “override” case rules for English. Also useStringUtils.indexOfIgnoreCase()instead of.toUpperCase().indexOf(), avoids creating a very short-lived transientStringinstance.Server-side prepared statements did not honor
zeroDateTimeBehaviorproperty, and would cause class-cast exceptions when usingResultSet.getObject(), as the all-zero string was always returned. (Bug#5235)Fixed batched updates with server prepared statements weren't looking if the types had changed for a given batched set of parameters compared to the previous set, causing the server to return the error “Wrong arguments to mysql_stmt_execute()”.
Handle case when string representation of timestamp contains trailing ‘
.’ with no numbers following it.Inefficient detection of pre-existing string instances in
ResultSet.getNativeString(). (Bug#5706)Don't throw exceptions for
Connection.releaseSavepoint().Use a per-session
Calendarinstance by default when decoding dates fromServerPreparedStatements(set to old, less performant behavior by setting propertydynamicCalendars=true).Added experimental configuration property
dontUnpackBinaryResults, which delays unpacking binary result set values until they're asked for, and only creates object instances for non-numerical values (it is set tofalseby default). For some usecase/jvm combinations, this is friendlier on the garbage collector.UNSIGNED BIGINTunpacked incorrectly from server-side prepared statement result sets. (Bug#5729)ServerSidePreparedStatementallocating short-lived objects unnecessarily. (Bug#6225)Removed unwanted new
Throwable()inResultSetconstructor due to bad merge (caused a new object instance that was never used for every result set created). Found while profiling for Bug#6359.Fixed too-early creation of
StringBufferinEscapeProcessor.escapeSQL(), also returnStringwhen escaping not needed (to avoid unnecessary object allocations). Found while profiling for Bug#6359.Use null-safe-equals for key comparisons in updatable result sets.
SUM()onDECIMALwith server-side prepared statement ignores scale if zero-padding is needed (this ends up being due to conversion toDOUBLEby server, which when converted to a string to parse intoBigDecimal, loses all “padding” zeros). (Bug#6537)Use
DatabaseMetaData.getIdentifierQuoteString()when building DBMD queries.Use 1MB packet for sending file for
LOAD DATA LOCAL INFILEif that is <max_allowed_packeton server.ResultSetMetaData.getColumnDisplaySize()returns incorrect values for multi-byte charsets. (Bug#6399)Make auto-deserialization of
java.lang.Objectsstored inBLOBcolumns configurable viaautoDeserializeproperty (defaults tofalse).Re-work
Field.isOpaqueBinary()to detectCHAR(to support fixed-length binary fields forn) CHARACTER SET BINARYResultSet.getObject().Use our own implementation of buffered input streams to get around blocking behavior of
java.io.BufferedInputStream. Disable this withuseReadAheadInput=false.Failing to connect to the server when one of the addresses for the given host name is IPV6 (which the server does not yet bind on). The driver now loops through all IP addresses for a given host, and stops on the first one that
accepts()asocket.connect(). (Bug#6348)
Connector/J 3.1.3 beta does not handle integers correctly (caused by changes to support unsigned reads in
Buffer.readInt()->Buffer.readShort()). (Bug#4510)Added support in
DatabaseMetaData.getTables()andgetTableTypes()for views, which are now available in MySQL server 5.0.x.ServerPreparedStatement.execute*()sometimes threwArrayIndexOutOfBoundsExceptionwhen unpacking field metadata. (Bug#4642)Optimized integer number parsing, enable “old” slower integer parsing using JDK classes via
useFastIntParsing=falseproperty.Added
useOnlyServerErrorMessagesproperty, which causes message text in exceptions generated by the server to only contain the text sent by the server (as opposed to the SQLState's “standard” description, followed by the server's error message). This property is set totrueby default.ResultSet.wasNull()does not work for primatives if a previousnullwas returned. (Bug#4689)Track packet sequence numbers if
enablePacketDebug=true, and throw an exception if packets received out-of-order.ResultSet.getObject()returns wrong type for strings when using prepared statements. (Bug#4482)Calling
MysqlPooledConnection.close()twice (even though an application error), caused NPE. Fixed.ServerPreparedStatementsdealing with return ofDECIMALtype don't work. (Bug#5012)ResultSet.getObject()doesn't return typeBooleanfor pseudo-bit types from prepared statements on 4.1.x (shortcut for avoiding extra type conversion when using binary-encoded result sets obscured test ingetObject()for “pseudo” bit type). (Bug#5032)You can now use URLs in
LOAD DATA LOCAL INFILEstatements, and the driver will use Java's built-in handlers for retreiving the data and sending it to the server. This feature is not enabled by default, you must set theallowUrlInLocalInfileconnection property totrue.The driver is more strict about truncation of numerics on
ResultSet.get*(), and will throw anSQLExceptionwhen truncation is detected. You can disable this by settingjdbcCompliantTruncationtofalse(it is enabled by default, as this functionality is required for JDBC compliance).Added three ways to deal with all-zero datetimes when reading them from a
ResultSet:exception(the default), which throws anSQLExceptionwith an SQLState ofS1009;convertToNull, which returnsNULLinstead of the date; andround, which rounds the date to the nearest closest value which is'0001-01-01'.Fixed
ServerPreparedStatementto read prepared statement metadata off the wire, even though it's currently a placeholder instead of usingMysqlIO.clearInputStream()which didn't work at various times because data wasn't available to read from the server yet. This fixes sporadic errors users were having withServerPreparedStatementsthrowingArrayIndexOutOfBoundExceptions.Use
com.mysql.jdbc.Message's classloader when loading resource bundle, should fix sporadic issues when the caller's classloader can't locate the resource bundle.
Mangle output parameter names for
CallableStatementsso they will not clash with user variable names.Added support for
INOUTparameters inCallableStatements.Null bitmask sent for server-side prepared statements was incorrect. (Bug#4119)
Use SQL Standard SQL states by default, unless
useSqlStateCodesproperty is set tofalse.Added packet debuging code (see the
enablePacketDebugproperty documentation).Added constants for MySQL error numbers (publicly accessible, see
com.mysql.jdbc.MysqlErrorNumbers), and the ability to generate the mappings of vendor error codes to SQLStates that the driver uses (for documentation purposes).Externalized more messages (on-going effort).
Error in retrieval of
mediumintcolumn with prepared statements and binary protocol. (Bug#4311)Support new time zone variables in MySQL-4.1.3 when
useTimezone=true.Support for unsigned numerics as return types from prepared statements. This also causes a change in
ResultSet.getObject()for thebigint unsignedtype, which used to returnBigDecimalinstances, it now returns instances ofjava.lang.BigInteger.
Fixed stored procedure parameter parsing info when size was specified for a parameter (for example,
char(),varchar()).Enabled callable statement caching via
cacheCallableStmtsproperty.Fixed case when no output parameters specified for a stored procedure caused a bogus query to be issued to retrieve out parameters, leading to a syntax error from the server.
Fixed case when no parameters could cause a
NullPointerExceptioninCallableStatement.setOutputParameters().Removed wrapping of exceptions in
MysqlIO.changeUser().Fixed sending of split packets for large queries, enabled nio ability to send large packets as well.
Added
.toString()functionality toServerPreparedStatement, which should help if you're trying to debug a query that is a prepared statement (it shows SQL as the server would process).Added
gatherPerformanceMetricsproperty, along with properties to control when/where this info gets logged (see docs for more info).ServerPreparedStatementsweren't actually de-allocating server-side resources when.close()was called.Added
logSlowQueriesproperty, along withslowQueriesThresholdMillisproperty to control when a query should be considered “slow.”Correctly map output parameters to position given in
prepareCall()versus. order implied duringregisterOutParameter(). (Bug#3146)Correctly detect initial character set for servers >= 4.1.0.
Cleaned up detection of server properties.
Support placeholder for parameter metadata for server >= 4.1.2.
getProcedures()does not return any procedures in result set. (Bug#3539)getProcedureColumns()doesn't work with wildcards for procedure name. (Bug#3540)DBMD.getSQLStateType()returns incorrect value. (Bug#3520)Added
connectionCollationproperty to cause driver to issueset collation_connection=...query on connection init if default collation for given charset is not appropriate.Fixed
DatabaseMetaData.getProcedures()when run on MySQL-5.0.0 (output ofSHOW PROCEDURE STATUSchanged between 5.0.0 and 5.0.1.getWarnings()returnsSQLWarninginstead ofDataTruncation. (Bug#3804)Don't enable server-side prepared statements for server version 5.0.0 or 5.0.1, as they aren't compatible with the '4.1.2+' style that the driver uses (the driver expects information to come back that isn't there, so it hangs).
Fixed bug with
UpdatableResultSetsnot using client-side prepared statements.Fixed character encoding issues when converting bytes to ASCII when MySQL doesn't provide the character set, and the JVM is set to a multi-byte encoding (usually affecting retrieval of numeric values).
Unpack “unknown” data types from server prepared statements as
Strings.Implemented long data (Blobs, Clobs, InputStreams, Readers) for server prepared statements.
Implemented
Statement.getWarnings()for MySQL-4.1 and newer (usingSHOW WARNINGS).Default result set type changed to
TYPE_FORWARD_ONLY(JDBC compliance).Centralized setting of result set type and concurrency.
Refactored how connection properties are set and exposed as
DriverPropertyInfoas well asConnectionandDataSourceproperties.Support for NIO. Use
useNIO=trueon platforms that support NIO.Support for transaction savepoints (MySQL >= 4.0.14 or 4.1.1).
Support for
mysql_change_user(). See thechangeUser()method incom.mysql.jdbc.Connection.Reduced number of methods called in average query to be more efficient.
Prepared
Statementswill be re-prepared on auto-reconnect. Any errors encountered are postponed until first attempt to re-execute the re-prepared statement.Ensure that warnings are cleared before executing queries on prepared statements, as-per JDBC spec (now that we support warnings).
Support “old”
profileSqlcapitalization inConnectionProperties. This property is deprecated, you should useprofileSQLif possible.Optimized
Buffer.readLenByteArray()to return shared empty byte array when length is 0.Allow contents of
PreparedStatement.setBlob()to be retained between calls to.execute*().Deal with 0-length tokens in
EscapeProcessor(caused by callable statement escape syntax).Check for closed connection on delete/update/insert row operations in
UpdatableResultSet.Fix support for table aliases when checking for all primary keys in
UpdatableResultSet.Removed
useFastDatesconnection property.Correctly initialize datasource properties from JNDI Refs, including explicitly specified URLs.
DatabaseMetaDatanow reportssupportsStoredProcedures()for MySQL versions >= 5.0.0Fixed stack overflow in
Connection.prepareCall()(bad merge).Fixed
IllegalAccessErrortoCalendar.getTimeInMillis()inDateTimeValue(for JDK < 1.4).DatabaseMetaData.getColumns()is not returning correct column ordinal info for non-'%'column name patterns. (Bug#1673)Merged fix of datatype mapping from MySQL type
FLOATtojava.sql.Types.REALfrom 3.0 branch.Detect collation of column for
RSMD.isCaseSensitive().Fixed sending of queries larger than 16M.
Added named and indexed input/output parameter support to
CallableStatement. MySQL-5.0.x or newer.Fixed
NullPointerExceptioninServerPreparedStatement.setTimestamp(), as well as year and month descrepencies inServerPreparedStatement.setTimestamp(),setDate().Added ability to have multiple database/JVM targets for compliance and regression/unit tests in
build.xml.Fixed NPE and year/month bad conversions when accessing some datetime functionality in
ServerPreparedStatementsand their resultant result sets.Display where/why a connection was implicitly closed (to aid debugging).
CommunicationsExceptionimplemented, that tries to determine why communications was lost with a server, and displays possible reasons when.getMessage()is called.NULLvalues for numeric types in binary encoded result sets causingNullPointerExceptions. (Bug#2359)Implemented
Connection.prepareCall(), andDatabaseMetaData.getProcedures()andgetProcedureColumns().Reset
long binaryparameters inServerPreparedStatementwhenclearParameters()is called, by sendingCOM_RESET_STMTto the server.Merged prepared statement caching, and
.getMetaData()support from 3.0 branch.Fixed off-by-1900 error in some cases for years in
TimeUtil.fastDate/TimeCreate()when unpacking results from server-side prepared statements.Fixed charset conversion issue in
getTables(). (Bug#2502)Implemented multiple result sets returned from a statement or stored procedure.
Server-side prepared statements were not returning datatype
YEARcorrectly. (Bug#2606)Enabled streaming of result sets from server-side prepared statements.
Class-cast exception when using scrolling result sets and server-side prepared statements. (Bug#2623)
Merged unbuffered input code from 3.0.
Fixed
ConnectionPropertiesthat weren't properly exposed via accessors, cleaned upConnectionPropertiescode.NULLfields were not being encoded correctly in all cases in server-side prepared statements. (Bug#2671)Fixed rare buffer underflow when writing numbers into buffers for sending prepared statement execution requests.
Use DocBook version of docs for shipped versions of drivers.
Added
requireSSLproperty.Added
useServerPrepStmtsproperty (defaultfalse). The driver will use server-side prepared statements when the server version supports them (4.1 and newer) when this property is set totrue. It is currently set tofalseby default until all bind/fetch functionality has been implemented. Currently only DML prepared statements are implemented for 4.1 server-side prepared statements.Track open
Statements, close all whenConnection.close()is called (JDBC compliance).
- E.6.4.1. Changes in MySQL Connector/J 3.0.17-ga (23 June 2005)
- E.6.4.2. Changes in MySQL Connector/J 3.0.16-ga (15 November 2004)
- E.6.4.3. Changes in MySQL Connector/J 3.0.15-production (04 September 2004)
- E.6.4.4. Changes in MySQL Connector/J 3.0.14-production (28 May 2004)
- E.6.4.5. Changes in MySQL Connector/J 3.0.13-production (27 May 2004)
- E.6.4.6. Changes in MySQL Connector/J 3.0.12-production (18 May 2004)
- E.6.4.7. Changes in MySQL Connector/J 3.0.11-stable (19 February 2004)
- E.6.4.8. Changes in MySQL Connector/J 3.0.10-stable (13 January 2004)
- E.6.4.9. Changes in MySQL Connector/J 3.0.9-stable (07 October 2003)
- E.6.4.10. Changes in MySQL Connector/J 3.0.8-stable (23 May 2003)
- E.6.4.11. Changes in MySQL Connector/J 3.0.7-stable (08 April 2003)
- E.6.4.12. Changes in MySQL Connector/J 3.0.6-stable (18 February 2003)
- E.6.4.13. Changes in MySQL Connector/J 3.0.5-gamma (22 January 2003)
- E.6.4.14. Changes in MySQL Connector/J 3.0.4-gamma (06 January 2003)
- E.6.4.15. Changes in MySQL Connector/J 3.0.3-dev (17 December 2002)
- E.6.4.16. Changes in MySQL Connector/J 3.0.2-dev (08 November 2002)
- E.6.4.17. Changes in MySQL Connector/J 3.0.1-dev (21 September 2002)
- E.6.4.18. Changes in MySQL Connector/J 3.0.0-dev (31 July 2002)
Timestamp/Timeconversion goes in the wrong “direction” whenuseTimeZone=trueand server time zone differs from client time zone. (Bug#5874)DatabaseMetaData.getIndexInfo()ignoreduniqueparameter. (Bug#7081)Support new protocol type
MYSQL_TYPE_VARCHAR.Added
useOldUTF8Behavior' configuration property, which causes JDBC driver to act like it did with MySQL-4.0.x and earlier when the character encoding isutf-8when connected to MySQL-4.1 or newer.Statements created from a pooled connection were returning physical connection instead of logical connection when
getConnection()was called. (Bug#7316)PreparedStatementsdon't encode Big5 (and other multi-byte) character sets correctly in static SQL strings. (Bug#7033)Connections starting up failed-over (due to down master) never retry master. (Bug#6966)
PreparedStatement.fixDecimalExponent()adding extra+, making number unparseable by MySQL server. (Bug#7061)Timestamp key column data needed
_binarystripped forUpdatableResultSet.refreshRow(). (Bug#7686)Backported SQLState codes mapping from Connector/J 3.1, enable with
useSqlStateCodes=trueas a connection property, it defaults tofalsein this release, so that we don't break legacy applications (it defaults totruestarting with Connector/J 3.1).PreparedStatement.fixDecimalExponent()adding extra+, making number unparseable by MySQL server. (Bug#7601)Escape sequence {fn convert(..., type)} now supports ODBC-style types that are prepended by
SQL_.Fixed duplicated code in
configureClientCharset()that preventeduseOldUTF8Behavior=truefrom working properly.Handle streaming result sets with more than 2 billion rows properly by fixing wraparound of row number counter.
MS932,SHIFT_JIS, andWindows_31Jnot recognized as aliases forsjis. (Bug#7607)Adding
CP943to aliases forsjis. (Bug#6549, fixed while fixing Bug#7607)Which requires hex escaping of binary data when using multi-byte charsets with prepared statements. (Bug#8064)
NON_UNIQUEcolumn fromDBMD.getIndexInfo()returned inverted value. (Bug#8812)Workaround for server Bug#9098: Default values of
CURRENT_*forDATE,TIME,DATETIME, andTIMESTAMPcolumns can't be distinguished fromstringvalues, soUpdatableResultSet.moveToInsertRow()generates bad SQL for inserting default values.EUCKRcharset is sent asSET NAMES euc_krwhich MySQL-4.1 and newer doesn't understand. (Bug#8629)DatabaseMetaData.supportsSelectForUpdate()returns correct value based on server version.Use hex escapes for
PreparedStatement.setBytes()for double-byte charsets including “aliases”Windows-31J,CP934,MS932.Added support for the
EUC_JP_Solarischaracter encoding, which maps to a MySQL encoding ofeucjpms(backported from 3.1 branch). This only works on servers that supporteucjpms, namely 5.0.3 or later.
Re-issue character set configuration commands when re-using pooled connections and/or
Connection.changeUser()when connected to MySQL-4.1 or newer.Fixed
ResultSetMetaData.isReadOnly()to detect non-writable columns when connected to MySQL-4.1 or newer, based on existence of “original” table and column names.ResultSet.updateByte()when on insert row throwsArrayOutOfBoundsException. (Bug#5664)Fixed
DatabaseMetaData.getTypes()returning incorrect (this is, non-negative) scale for theNUMERICtype.Off-by-one bug in
Buffer.readString(. (Bug#5664)string)Made
TINYINT(1)->BIT/Booleanconversion configurable viatinyInt1isBitproperty (defaulttrueto be JDBC compliant out of the box).Only set
character_set_resultsduring connection establishment if server version >= 4.1.1.Fixed regression where
useUnbufferedInputwas defaulting tofalse.ResultSet.getTimestamp()on a column withTIMEin it fails. (Bug#5664)
StringUtils.escapeEasternUnicodeByteStreamwas still broken for GBK. (Bug#4010)Failover for
autoReconnectnot using port numbers for any hosts, and not retrying all hosts. (Warning: This required a change to theSocketFactoryconnect()method signature, which is nowpublic Socket connect(String host, int portNumber, Properties props); therefore, any third-party socket factories will have to be changed to support this signature. (Bug#4334)Logical connections created by
MysqlConnectionPoolDataSourcewill now issue arollback()when they are closed and sent back to the pool. If your application server/connection pool already does this for you, you can set therollbackOnPooledCloseproperty tofalseto avoid the overhead of an extrarollback().Removed redundant calls to
checkRowPos()inResultSet.DOUBLEmapped twice inDBMD.getTypeInfo(). (Bug#4742)Added FLOSS license exemption.
Calling
.close()twice on aPooledConnectioncauses NPE. (Bug#4808)DBMD.getColumns()returns incorrect JDBC type for unsigned columns. This affects type mappings for all numeric types in theRSMD.getColumnType()andRSMD.getColumnTypeNames()methods as well, to ensure that “like” types fromDBMD.getColumns()match up with whatRSMD.getColumnType()andgetColumnTypeNames()return. (Bug#4138, Bug#4860)“Production” is now “GA” (General Availability) in naming scheme of distributions.
RSMD.getPrecision()returning 0 for non-numeric types (should return max length in chars for non-binary types, max length in bytes for binary types). This fix also fixes mapping ofRSMD.getColumnType()andRSMD.getColumnTypeName()for theBLOBtypes based on the length sent from the server (the server doesn't distinguish betweenTINYBLOB,BLOB,MEDIUMBLOBorLONGBLOBat the network protocol level). (Bug#4880)ResultSetshould releaseField[]instance in.close(). (Bug#5022)ResultSet.getMetaData()should not return incorrectly initialized metadata if the result set has been closed, but should instead throw anSQLException. Also fixed forgetRow()andgetWarnings()and traversal methods by callingcheckClosed()before operating on instance-level fields that are nullified during.close(). (Bug#5069)Parse new time zone variables from 4.1.x servers.
Use
_binaryintroducer forPreparedStatement.setBytes()andset*Stream()when connected to MySQL-4.1.x or newer to avoid misinterpretation during character conversion.
Add unsigned attribute to
DatabaseMetaData.getColumns()output in theTYPE_NAMEcolumn.Added
failOverReadOnlyproperty, to allow end-user to configure state of connection (read-only/writable) when failed over.Backported “change user” and “reset server state” functionality from 3.1 branch, to allow clients of
MysqlConnectionPoolDataSourceto reset server state ongetConnection()on a pooled connection.Don't escape SJIS/GBK/BIG5 when using MySQL-4.1 or newer.
Allow
urlparameter forMysqlDataSourceandMysqlConnectionPoolDataSourceso that passing of other properties is possible from inside appservers.Map duplicate key and foreign key errors to SQLState of
23000.Backport documentation tooling from 3.1 branch.
Return creating statement for
ResultSetscreated bygetGeneratedKeys(). (Bug#2957)Allow
java.util.Dateto be sent in as parameter toPreparedStatement.setObject(), converting it to aTimestampto maintain full precision. (Bug#103).Don't truncate
BLOBorCLOBvalues when usingsetBytes()and/orsetBinary/CharacterStream(). (Bug#2670).Dynamically configure character set mappings for field-level character sets on MySQL-4.1.0 and newer using
SHOW COLLATIONwhen connecting.Map
binarycharacter set toUS-ASCIIto supportDATETIMEcharset recognition for servers >= 4.1.2.Use
SET character_set_resultsduring initialization to allow any charset to be returned to the driver for result sets.Use
charsetnrreturned during connect to encode queries before issuingSET NAMESon MySQL >= 4.1.0.Add helper methods to
ResultSetMetaData(getColumnCharacterEncoding()andgetColumnCharacterSet()) to allow end-users to see what charset the driver thinks it should be using for the column.Only set
character_set_resultsfor MySQL >= 4.1.0.StringUtils.escapeSJISByteStream()not covering all eastern double-byte charsets correctly. (Bug#3511)Renamed
StringUtils.escapeSJISByteStream()to more appropriateescapeEasternUnicodeByteStream().Not specifying database in URL caused
MalformedURLexception. (Bug#3554)Auto-convert MySQL encoding names to Java encoding names if used for
characterEncodingproperty.Added encoding names that are recognized on some JVMs to fix case where they were reverse-mapped to MySQL encoding names incorrectly.
Use
junit.textui.TestRunnerfor all unit tests (to allow them to be run from the command line outside of Ant or Eclipse).UpdatableResultSetnot picking up default values formoveToInsertRow(). (Bug#3557)Inconsistent reporting of data type. The server still doesn't return all types for *BLOBs *TEXT correctly, so the driver won't return those correctly. (Bug#3570)
DBMD.getSQLStateType()returns incorrect value. (Bug#3520)Fixed regression in
PreparedStatement.setString()and eastern character encodings.Made
StringRegressionTest4.1-unicode aware.
Trigger a
SET NAMES utf8when encoding is forced toutf8orutf-8via thecharacterEncodingproperty. Previously, only the Java-style encoding name ofutf-8would trigger this.AutoReconnecttime was growing faster than exponentially. (Bug#2447)Fixed failover always going to last host in list. (Bug#2578)
Added
useUnbufferedInputparameter, and now use it by default (due to JVM issue http://developer.java.sun.com/developer/bugParade/bugs/4401235.html)Detect
on/offor1,2,3form oflower_case_table_namesvalue on server.Return
java.lang.IntegerforTINYINTandSMALLINTtypes fromResultSetMetaData.getColumnClassName(). (Bug#2852)Return
java.lang.DoubleforFLOATtype fromResultSetMetaData.getColumnClassName(). (Bug#2855)Return
[Binstead ofjava.lang.ObjectforBINARY,VARBINARYandLONGVARBINARYtypes fromResultSetMetaData.getColumnClassName()(JDBC compliance).Issue connection events on all instances created from a
ConnectionPoolDataSource.
Don't count quoted IDs when inside a 'string' in
PreparedStatementparsing. (Bug#1511)“Friendlier” exception message for
PacketTooLargeException. (Bug#1534)Backported fix for aliased tables and
UpdatableResultSetsincheckUpdatability()method from 3.1 branch.Fix for
ArrayIndexOutOfBoundsexception when usingStatement.setMaxRows(). (Bug#1695)Barge blobs and split packets not being read correctly. (Bug#1576)
Fixed regression of
Statement.getGeneratedKeys()andREPLACEstatements.Subsequent call to
ResultSet.updateFoo()causes NPE if result set is not updatable. (Bug#1630)Fix for 4.1.1-style authentication with no password.
Foreign Keys column sequence is not consistent in
DatabaseMetaData.getImported/Exported/CrossReference(). (Bug#1731)DatabaseMetaData.getSystemFunction()returning bad functionVResultsSion. (Bug#1775)Cross-database updatable result sets are not checked for updatability correctly. (Bug#1592)
DatabaseMetaData.getColumns()should returnTypes.LONGVARCHARfor MySQLLONGTEXTtype.ResultSet.getObject()onTINYINTandSMALLINTcolumns should return Java typeInteger. (Bug#1913)Added
alwaysClearStreamconnection property, which causes the driver to always empty any remaining data on the input stream before each query.Added more descriptive error message
Server Configuration Denies Access to DataSource, as well as retrieval of message from server.Autoreconnect code didn't set catalog upon reconnect if it had been changed.
Implement
ResultSet.updateClob().ResultSetMetaData.isCaseSensitive()returned wrong value forCHAR/VARCHARcolumns.Connection property
maxRowsnot honored. (Bug#1933)Statements being created too many times in
DBMD.extractForeignKeyFromCreateTable(). (Bug#1925)Support escape sequence {fn convert ... }. (Bug#1914)
ArrayIndexOutOfBoundswhen parameter number == number of parameters + 1. (Bug#1958)ResultSet.findColumn()should use first matching column name when there are duplicate column names inSELECTquery (JDBC-compliance). (Bug#2006)Removed static synchronization bottleneck from
PreparedStatement.setTimestamp().Removed static synchronization bottleneck from instance factory method of
SingleByteCharsetConverter.Enable caching of the parsing stage of prepared statements via the
cachePrepStmts,prepStmtCacheSize, andprepStmtCacheSqlLimitproperties (disabled by default).Speed up parsing of
PreparedStatements, try to use one-pass whenever possible.Fixed security exception when used in Applets (applets can't read the system property
file.encodingwhich is needed forLOAD DATA LOCAL INFILE).Use constants for SQLStates.
Map charset
ko18_rutoko18rwhen connected to MySQL-4.1.0 or newer.Ensure that
Buffer.writeString()saves room for the\0.Fixed exception
Unknown character set 'danish'on connect with JDK-1.4.0Fixed mappings in SQLError to report deadlocks with SQLStates of
41000.maxRowsproperty would affect internal statements, so check it for all statement creation internal to the driver, and set to 0 when it is not.
Faster date handling code in
ResultSetandPreparedStatement(no longer usesDatemethods that synchronize on static calendars).Fixed test for end of buffer in
Buffer.readString().Fixed
ResultSet.previous()behavior to move current position to before result set when on first row of result set. (Bug#496)Fixed
StatementandPreparedStatementissuing bogus queries whensetMaxRows()had been used and aLIMITclause was present in the query.refreshRowdidn't work when primary key values contained values that needed to be escaped (they ended up being doubly escaped). (Bug#661)Support
InnoDBcontraint names when extracting foreign key information inDatabaseMetaData(implementing ideas from Parwinder Sekhon). (Bug#517, Bug#664)Backported 4.1 protocol changes from 3.1 branch (server-side SQL states, new field information, larger client capability flags, connect-with-database, and so forth).
Fix
UpdatableResultSetto return values forgetwhen on insert row. (Bug#675)XXX()The
insertRowin anUpdatableResultSetis now loaded with the default column values whenmoveToInsertRow()is called. (Bug#688)DatabaseMetaData.getColumns()wasn't returningNULLfor default values that are specified asNULL.Change default statement type/concurrency to
TYPE_FORWARD_ONLYandCONCUR_READ_ONLY(spec compliance).Don't try and reset isolation level on reconnect if MySQL doesn't support them.
Don't wrap
SQLExceptionsinRowDataDynamic.Don't change timestamp TZ twice if
useTimezone==true. (Bug#774)Fixed regression in large split-packet handling. (Bug#848)
Better diagnostic error messages in exceptions for “streaming” result sets.
Issue exception on
ResultSet.geton empty result set (wasn't caught in some cases).XXX()Don't hide messages from exceptions thrown in I/O layers.
Don't fire connection closed events when closing pooled connections, or on
PooledConnection.getConnection()with already open connections. (Bug#884)Clip +/- INF (to smallest and largest representative values for the type in MySQL) and NaN (to 0) for
setDouble/setFloat(), and issue a warning on the statement when the server does not support +/- INF or NaN.Double-escaping of
'\'when charset is SJIS or GBK and'\'appears in non-escaped input. (Bug#879)When emptying input stream of unused rows for “streaming” result sets, have the current thread
yield()every 100 rows in order to not monopolize CPU time.DatabaseMetaData.getColumns()getting confused about the keyword “set” in character columns. (Bug#1099)Fixed deadlock issue with
Statement.setMaxRows().Fixed
CLOB.truncate(). (Bug#1130)Optimized
CLOB.setChracterStream(). (Bug#1131)Made
databaseName,portNumber, andserverNameoptional parameters forMysqlDataSourceFactory. (Bug#1246)ResultSet.get/setStringmashing char 127. (Bug#1247)Backported authentication changes for 4.1.1 and newer from 3.1 branch.
Added
com.mysql.jdbc.util.BaseBugReportto help creation of testcases for bug reports.Added property to “clobber” streaming results, by setting the
clobberStreamingResultsproperty totrue(the default isfalse). This will cause a “streaming”ResultSetto be automatically closed, and any oustanding data still streaming from the server to be discarded if another query is executed before all the data has been read from the server.
Allow bogus URLs in
Driver.getPropertyInfo().Return list of generated keys when using multi-value
INSERTSwithStatement.getGeneratedKeys().Use JVM charset with filenames and
LOAD DATA [LOCAL] INFILE.Fix infinite loop with
Connection.cleanup().Changed Ant target
compile-coretocompile-driver, and made testsuite compilation a separate target.Fixed result set not getting set for
Statement.executeUpdate(), which affectedgetGeneratedKeys()andgetUpdateCount()in some cases.Unicode character 0xFFFF in a string would cause the driver to throw an
ArrayOutOfBoundsException. (Bug#378).Return correct number of generated keys when using
REPLACEstatements.Fix problem detecting server character set in some cases.
Fix row data decoding error when using very large packets.
Optimized row data decoding.
Issue exception when operating on an already closed prepared statement.
Fixed SJIS encoding bug, thanks to Naoto Sato.
Optimized usage of
EscapeProcessor.Allow multiple calls to
Statement.close().
Fixed
MysqlPooledConnection.close()calling wrong event type.Fixed
StringIndexOutOfBoundsExceptioninPreparedStatement.setClob().4.1 Column Metadata fixes.
Remove synchronization from
Driver.connect()andDriver.acceptsUrl().IOExceptionsduring a transaction now cause theConnectionto be closed.Fixed missing conversion for
YEARtype inResultSetMetaData.getColumnTypeName().Don't pick up indexes that start with
prias primary keys forDBMD.getPrimaryKeys().Throw
SQLExceptionswhen trying to do operations on a forcefully closedConnection(that is, when a communication link failure occurs).You can now toggle profiling on/off using
Connection.setProfileSql(boolean).Fixed charset issues with database metadata (charset was not getting set correctly).
Updatable
ResultSetscan now be created for aliased tables/columns when connected to MySQL-4.1 or newer.Fixed
LOAD DATA LOCAL INFILEbug when file >max_allowed_packet.Fixed escaping of 0x5c (
'\') character for GBK and Big5 charsets.Fixed
ResultSet.getTimestamp()when underlying field is of typeDATE.Ensure that packet size from
alignPacketSize()does not exceedmax_allowed_packet(JVM bug)Don't reset
Connection.isReadOnly()when autoReconnecting.
Fixed
ResultSetMetaDatato return""when catalog not known. FixesNullPointerExceptionswith Sun'sCachedRowSet.Fixed
DBMD.getTypeInfo()andDBMD.getColumns()returning different value for precision inTEXTandBLOBtypes.Allow ignoring of warning for “non transactional tables” during rollback (compliance/usability) by setting
ignoreNonTxTablesproperty totrue.Fixed
SQLExceptionsgetting swallowed on initial connect.Fixed
Statement.setMaxRows()to stop sendingLIMITtype queries when not needed (performance).Clean up
Statementquery/method mismatch tests (that is,INSERTnot allowed with.executeQuery()).More checks added in
ResultSettraversal method to catch when in closed state.Fixed
ResultSetMetaData.isWritable()to return correct value.Add “window” of different
NULLsorting behavior toDBMD.nullsAreSortedAtStart(4.0.2 to 4.0.10, true; otherwise, no).Implemented
Blob.setBytes(). You still need to pass the resultantBlobback into an updatableResultSetorPreparedStatementto persist the changes, because MySQL does not support “locators”.Backported 4.1 charset field info changes from Connector/J 3.1.
Fixed
Buffer.fastSkipLenString()causingArrayIndexOutOfBoundsexceptions with some queries when unpacking fields.Implemented an empty
TypeMapforConnection.getTypeMap()so that some third-party apps work with MySQL (IBM WebSphere 5.0 Connection pool).Added missing
LONGTEXTtype toDBMD.getColumns().Retrieve
TX_ISOLATIONfrom database forConnection.getTransactionIsolation()when the MySQL version supports it, instead of an instance variable.Quote table names in
DatabaseMetaData.getColumns(),getPrimaryKeys(),getIndexInfo(),getBestRowIdentifier().Greatly reduce memory required for
setBinaryStream()inPreparedStatements.Fixed
ResultSet.isBeforeFirst()for empty result sets.Added update options for foreign key metadata.
Added quoted identifiers to database names for
Connection.setCatalog.Added support for quoted identifiers in
PreparedStatementparser.Streamlined character conversion and
byte[]handling inPreparedStatementsforsetByte().Reduce memory footprint of
PreparedStatementsby sharing outbound packet withMysqlIO.Added
strictUpdatesproperty to allow control of amount of checking for “correctness” of updatable result sets. Set this tofalseif you want faster updatable result sets and you know that you create them fromSELECTstatements on tables with primary keys and that you have selected all primary keys in your query.Added support for 4.0.8-style large packets.
Fixed
PreparedStatement.executeBatch()parameter overwriting.
Changed
charsToByteinSingleByteCharConverterto be non-static.Changed
SingleByteCharConverterto use lazy initialization of each converter.Fixed charset handling in
Fields.java.Implemented
Connection.nativeSQL().More robust escape tokenizer: Recognize
--comments, and allow nested escape sequences (seetestsuite.EscapeProcessingTest).DBMD.getImported/ExportedKeys()now handles multiple foreign keys per table.Fixed
ResultSetMetaData.getPrecision()returning incorrect values for some floating-point types.Fixed
ResultSetMetaData.getColumnTypeName()returningBLOBforTEXTandTEXTforBLOBtypes.Fixed
Buffer.isLastDataPacket()for 4.1 and newer servers.Added
CLIENT_LONG_FLAGto be able to get more column flags (isAutoIncrement()being the most important).Because of above, implemented
ResultSetMetaData.isAutoIncrement()to useField.isAutoIncrement().Honor
lower_case_table_nameswhen enabled in the server when doing table name comparisons inDatabaseMetaDatamethods.Some MySQL-4.1 protocol support (extended field info from selects).
Use non-aliased table/column names and database names to fullly qualify tables and columns in
UpdatableResultSet(requires MySQL-4.1 or newer).Allow user to alter behavior of
Statement/PreparedStatement.executeBatch()viacontinueBatchOnErrorproperty (defaults totrue).Check for connection closed in more
Connectionmethods (createStatement,prepareStatement,setTransactionIsolation,setAutoCommit).More robust implementation of updatable result sets. Checks that all primary keys of the table have been selected.
LOAD DATA LOCAL INFILE ...now works, if your server is configured to allow it. Can be turned off with theallowLoadLocalInfileproperty (see theREADME).Substitute
'?'for unknown character conversions in single-byte character sets instead of'\0'.NamedPipeSocketFactorynow works (only intended for Windows), seeREADMEfor instructions.
Fixed issue with updatable result sets and
PreparedStatementsnot working.Fixed
ResultSet.setFetchDirection(FETCH_UNKNOWN).Fixed issue when calling
Statement.setFetchSize()when using arbitrary values.Fixed incorrect conversion in
ResultSet.getLong().Implemented
ResultSet.updateBlob().Removed duplicate code from
UpdatableResultSet(it can be inherited fromResultSet, the extra code for each method to handle updatability I thought might someday be necessary has not been needed).Fixed
UnsupportedEncodingExceptionthrown when “forcing” a character encoding via properties.Fixed various non-ASCII character encoding issues.
Added driver property
useHostsInPrivileges. Defaults totrue. Affects whether or not@hostnamewill be used inDBMD.getColumn/TablePrivileges.All
DBMDresult set columns describing schemas now returnNULLto be more compliant with the behavior of other JDBC drivers for other database systems (MySQL does not support schemas).Added SSL support. See
READMEfor information on how to use it.Properly restore connection properties when autoReconnecting or failing-over, including
autoCommitstate, and isolation level.Use
SHOW CREATE TABLEwhen possible for determining foreign key information forDatabaseMetaData. Also allows cascade options forDELETEinformation to be returned.Escape
0x5ccharacter in strings for the SJIS charset.Fixed start position off-by-1 error in
Clob.getSubString().Implemented
Clob.truncate().Implemented
Clob.setString().Implemented
Clob.setAsciiStream().Implemented
Clob.setCharacterStream().Added
com.mysql.jdbc.MiniAdminclass, which allows you to sendshutdowncommand to MySQL server. This is intended to be used when “embedding” Java and MySQL server together in an end-user application.Added
connectTimeoutparameter that allows users of JDK-1.4 and newer to specify a maxium time to wait to establish a connection.Failover and
autoReconnectwork only when the connection is in anautoCommit(false)state, in order to stay transaction-safe.Added
queriesBeforeRetryMasterproperty that specifies how many queries to issue when failed over before attempting to reconnect to the master (defaults to 50).Fixed
DBMD.supportsResultSetConcurrency()so that it returnstrueforResultSet.TYPE_SCROLL_INSENSITIVEandResultSet.CONCUR_READ_ONLYorResultSet.CONCUR_UPDATABLE.Fixed
ResultSet.isLast()for empty result sets (should returnfalse).PreparedStatementnow honors stream lengths in setBinary/Ascii/Character Stream() unless you set the connection propertyuseStreamLengthsInPrepStmtstofalse.Removed some not-needed temporary object creation by smarter use of
StringsinEscapeProcessor,ConnectionandDatabaseMetaDataclasses.
Fixed
ResultSet.getRow()off-by-one bug.Fixed
RowDataStatic.getAt()off-by-one bug.Added limited
Clobfunctionality (ResultSet.getClob(),PreparedStatemtent.setClob(),PreparedStatement.setObject(Clob).Added
socketTimeoutparameter to URL.Connection.isClosed()no longer “pings” the server.Connection.close()issuesrollback()whengetAutoCommit()isfalse.Added
paranoidparameter, which sanitizes error messages by removing “sensitive” information from them (such as hostnames, ports, or usernames), as well as clearing “sensitive” data structures when possible.Fixed
ResultSetMetaData.isSigned()forTINYINTandBIGINT.Charsets now automatically detected. Optimized code for single-byte character set conversion.
Implemented
ResultSet.getCharacterStream().Added
LOCAL TEMPORARYto table types inDatabaseMetaData.getTableTypes().Massive code clean-up to follow Java coding conventions (the time had come).
!!! LICENSE CHANGE !!! The driver is now GPL. If you need non-GPL licenses, please contact me
<mark@mysql.com>.JDBC-3.0 functionality including
Statement/PreparedStatement.getGeneratedKeys()andResultSet.getURL().Performance enchancements: Driver is now 50–100% faster in most situations, and creates fewer temporary objects.
Repackaging: New driver name is
com.mysql.jdbc.Driver, old name still works, though (the driver is now provided by MySQL-AB).Better checking for closed connections in
StatementandPreparedStatement.Support for streaming (row-by-row) result sets (see
README) Thanks to Doron.Support for large packets (new addition to MySQL-4.0 protocol), see
READMEfor more information.JDBC Compliance: Passes all tests besides stored procedure tests.
Fix and sort primary key names in
DBMetaData(SF bugs 582086 and 582086).Float types now reported as
java.sql.Types.FLOAT(SF bug 579573).ResultSet.getTimestamp()now works forDATEtypes (SF bug 559134).ResultSet.getDate/Time/Timestampnow recognizes all forms of invalid values that have been set to all zeros by MySQL (SF bug 586058).Testsuite now uses Junit (which you can get from http://www.junit.org.
The driver now only works with JDK-1.2 or newer.
Added multi-host failover support (see
README).General source-code cleanup.
Overall speed improvements via controlling transient object creation in
MysqlIOclass when reading packets.Performance improvements in string handling and field metadata creation (lazily instantiated) contributed by Alex Twisleton-Wykeham-Fiennes.
- E.6.5.1. Changes in MySQL Connector/J 2.0.14 (16 May 2002)
- E.6.5.2. Changes in MySQL Connector/J 2.0.13 (24 April 2002)
- E.6.5.3. Changes in MySQL Connector/J 2.0.12 (07 April 2002)
- E.6.5.4. Changes in MySQL Connector/J 2.0.11 (27 January 2002)
- E.6.5.5. Changes in MySQL Connector/J 2.0.10 (24 January 2002)
- E.6.5.6. Changes in MySQL Connector/J 2.0.9 (13 January 2002)
- E.6.5.7. Changes in MySQL Connector/J 2.0.8 (25 November 2001)
- E.6.5.8. Changes in MySQL Connector/J 2.0.7 (24 October 2001)
- E.6.5.9. Changes in MySQL Connector/J 2.0.6 (16 June 2001)
- E.6.5.10. Changes in MySQL Connector/J 2.0.5 (13 June 2001)
- E.6.5.11. Changes in MySQL Connector/J 2.0.3 (03 December 2000)
- E.6.5.12. Changes in MySQL Connector/J 2.0.1 (06 April 2000)
- E.6.5.13. Changes in MySQL Connector/J 2.0.0pre5 (21 February 2000)
- E.6.5.14. Changes in MySQL Connector/J 2.0.0pre4 (10 January 2000)
- E.6.5.15. Changes in MySQL Connector/J 2.0.0pre (17 August 1999)
More code cleanup.
PreparedStatementnow releases resources on.close(). (SF bug 553268)Quoted identifiers not used if server version does not support them. Also, if server started with
--ansior--sql-mode=ANSI_QUOTES, ‘"’ will be used as an identifier quote character, otherwise ‘'’ will be used.ResultSet.getDouble()now uses code built into JDK to be more precise (but slower).LogicalHandle.isClosed()calls through to physical connection.Added SQL profiling (to
STDERR). SetprofileSql=truein your JDBC URL. SeeREADMEfor more information.Fixed typo for
relaxAutoCommitparameter.
More code cleanup.
Fixed unicode chars being read incorrectly. (SF bug 541088)
Faster blob escaping for
PrepStmt.Added
set/getPortNumber()toDataSource(s). (SF bug 548167)Added
setURL()toMySQLXADataSource. (SF bug 546019)PreparedStatement.toString()fixed. (SF bug 534026)ResultSetMetaData.getColumnClassName()now implemented.Rudimentary version of
Statement.getGeneratedKeys()from JDBC-3.0 now implemented (you need to be using JDK-1.4 for this to work, I believe).DBMetaData.getIndexInfo()- bad PAGES fixed. (SF BUG 542201)
General code cleanup.
Added
getIdleFor()method toConnectionandMysqlLogicalHandle.Relaxed synchronization in all classes, should fix 520615 and 520393.
Added
getTable/ColumnPrivileges()to DBMD (fixes 484502).Added new types to
getTypeInfo(), fixed existing types thanks to Al Davis and Kid Kalanon.Added support for
BITtypes (51870) toPreparedStatement.Fixed
getRow()bug (527165) inResultSet.Fixes for
ResultSetupdatability inPreparedStatement.Fixed time zone off-by-1-hour bug in
PreparedStatement(538286, 528785).ResultSet: Fixed updatability (values being set tonullif not updated).DataSources- fixedsetUrlbug (511614, 525565), wrong datasource class name (532816, 528767).Added identifier quoting to all
DatabaseMetaDatamethods that need them (should fix 518108).Added support for
YEARtype (533556).ResultSet.insertRow()should now detect auto_increment fields in most cases and use that value in the new row. This detection will not work in multi-valued keys, however, due to the fact that the MySQL protocol does not return this information.ResultSet.refreshRow()implemented.Fixed
testsuite.TraversalafterLast()bug, thanks to Igor Lastric.
Fixed missing
DELETE_RULEvalue inDBMD.getImported/ExportedKeys()andgetCrossReference().Full synchronization of
Statement.java.More changes to fix
Unexpected end of input streamerrors when readingBLOBvalues. This should be the last fix.
Fixed spurious
Unexpected end of input streamerrors inMysqlIO(bug 507456).Fixed null-pointer-exceptions when using
MysqlConnectionPoolDataSourcewith Websphere 4 (bug 505839).
Ant build was corrupting included
jarfiles, fixed (bug 487669).Fixed extra memory allocation in
MysqlIO.readPacket()(bug 488663).Implementation of
DatabaseMetaData.getExported/ImportedKeys()andgetCrossReference().Full synchronization on methods modifying instance and class-shared references, driver should be entirely thread-safe now (please let me know if you have problems).
DataSourceimplementations moved toorg.gjt.mm.mysql.jdbc2.optionalpackage, and (initial) implementations ofPooledConnectionDataSourceandXADataSourceare in place (thanks to Todd Wolff for the implementation and testing ofPooledConnectionDataSourcewith IBM WebSphere 4).Added detection of network connection being closed when reading packets (thanks to Todd Lizambri).
Fixed quoting error with escape processor (bug 486265).
Report batch update support through
DatabaseMetaData(bug 495101).Fixed off-by-one-hour error in
PreparedStatement.setTimestamp()(bug 491577).Removed concatenation support from driver (the
||operator), as older versions of VisualAge seem to be the only thing that use it, and it conflicts with the logical||operator. You will need to start mysqld with the--ansiflag to use the||operator as concatenation (bug 491680).Fixed casting bug in
PreparedStatement(bug 488663).
Batch updates now supported (thanks to some inspiration from Daniel Rall).
XADataSource/ConnectionPoolDataSourcecode (experimental)PreparedStatement.setAnyNumericType()now handles positive exponents correctly (adds+so MySQL can understand it).DatabaseMetaData.getPrimaryKeys()andgetBestRowIdentifier()are now more robust in identifying primary keys (matches regardless of case or abbreviation/full spelling ofPrimary KeyinKey_typecolumn).
PreparedStatement.setCharacterStream()now implementedFixed dangling socket problem when in high availability (
autoReconnect=true) mode, and finalizer forConnectionwill close any dangling sockets on GC.Fixed
ResultSetMetaData.getPrecision()returning one less than actual on newer versions of MySQL.ResultSet.getBlob()now returnsnullif column value wasnull.Character sets read from database if
useUnicode=trueandcharacterEncodingis not set. (thanks to Dmitry Vereshchagin)Initial transaction isolation level read from database (if avaialable). (thanks to Dmitry Vereshchagin)
Fixed
DatabaseMetaData.supportsTransactions(), andsupportsTransactionIsolationLevel()andgetTypeInfo()SQL_DATETIME_SUBandSQL_DATA_TYPEfields not being readable.Fixed
PreparedStatementgenerating SQL that would end up with syntax errors for some queries.Fixed
ResultSet.isAfterLast()always returningfalse.Fixed time zone issue in
PreparedStatement.setTimestamp(). (thanks to Erik Olofsson)Captialize type names when
captializeTypeNames=trueis passed in URL or properties (for WebObjects. (thanks to Anjo Krank)Updatable result sets now correctly handle
NULLvalues in fields.PreparedStatement.setDouble() now uses full-precision doubles (reverting a fix made earlier to truncate them).
PreparedStatement.setBoolean() will use 1/0 for values if your MySQL version is 3.21.23 or higher.
Fixed
PreparedStatementparameter checking.Fixed case-sensitive column names in
ResultSet.java.
Fixed
ResultSet.getBlob()ArrayIndexout-of-bounds.Fixed
ResultSetMetaData.getColumnTypeNameforTEXT/BLOB.Fixed
ArrayIndexOutOfBoundswhen sending largeBLOBqueries. (Max size packet was not being set)Added
ISOLATIONlevel support toConnection.setIsolationLevel()Fixed NPE on
PreparedStatement.executeUpdate()when all columns have not been set.Fixed data parsing of
TIMESTAMPvalues with 2-digit years.Added
BytetoPreparedStatement.setObject().ResultSet.getBoolean()now recognizes-1astrue.ResultSethas +/-Inf/inf support.ResultSet.insertRow()works now, even if not all columns are set (they will be set toNULL).DataBaseMetaData.getCrossReference()no longerArrayIndexOOB.getObject()onResultSetcorrectly doesTINYINT->ByteandSMALLINT->Short.
Implemented
getBigDecimal()without scale component for JDBC2.Fixed composite key problem with updatable result sets.
Added detection of -/+INF for doubles.
Faster ASCII string operations.
Fixed incorrect detection of
MAX_ALLOWED_PACKET, so sending large blobs should work now.Fixed off-by-one error in
java.sql.Blobimplementation code.Added
ultraDevHackURL parameter, set totrueto allow (broken) Macromedia UltraDev to use the driver.
Fixed
RSMD.isWritable()returning wrong value. Thanks to Moritz Maass.Cleaned up exception handling when driver connects.
Columns that are of type
TEXTnow return asStringswhen you usegetObject().DatabaseMetaData.getPrimaryKeys()now works correctly with respect tokey_seq. Thanks to Brian Slesinsky.No escape processing is done on
PreparedStatementsanymore per JDBC spec.Fixed many JDBC-2.0 traversal, positioning bugs, especially with respect to empty result sets. Thanks to Ron Smits, Nick Brook, Cessar Garcia and Carlos Martinez.
Fixed some issues with updatability support in
ResultSetwhen using multiple primary keys.
Fixes to ResultSet for insertRow() - Thanks to Cesar Garcia
Fix to Driver to recognize JDBC-2.0 by loading a JDBC-2.0 class, instead of relying on JDK version numbers. Thanks to John Baker.
Fixed ResultSet to return correct row numbers
Statement.getUpdateCount() now returns rows matched, instead of rows actually updated, which is more SQL-92 like.
10-29-99
Statement/PreparedStatement.getMoreResults() bug fixed. Thanks to Noel J. Bergman.
Added Short as a type to PreparedStatement.setObject(). Thanks to Jeff Crowder
Driver now automagically configures maximum/preferred packet sizes by querying server.
Autoreconnect code uses fast ping command if server supports it.
Fixed various bugs with respect to packet sizing when reading from the server and when alloc'ing to write to the server.
Now compiles under JDK-1.2. The driver supports both JDK-1.1 and JDK-1.2 at the same time through a core set of classes. The driver will load the appropriate interface classes at runtime by figuring out which JVM version you are using.
Fixes for result sets with all nulls in the first row. (Pointed out by Tim Endres)
Fixes to column numbers in SQLExceptions in ResultSet (Thanks to Blas Rodriguez Somoza)
The database no longer needs to specified to connect. (Thanks to Christian Motschke)
Better Documentation (in progress), in doc/mm.doc/book1.html
DBMD now allows null for a column name pattern (not in spec), which it changes to '%'.
DBMD now has correct types/lengths for getXXX().
ResultSet.getDate(), getTime(), and getTimestamp() fixes. (contributed by Alan Wilken)
EscapeProcessor now handles \{ \} and { or } inside quotes correctly. (thanks to Alik for some ideas on how to fix it)
Fixes to properties handling in Connection. (contributed by Juho Tikkala)
ResultSet.getObject() now returns null for NULL columns in the table, rather than bombing out. (thanks to Ben Grosman)
ResultSet.getObject() now returns Strings for types from MySQL that it doesn't know about. (Suggested by Chris Perdue)
Removed DataInput/Output streams, not needed, 1/2 number of method calls per IO operation.
Use default character encoding if one is not specified. This is a work-around for broken JVMs, because according to spec, EVERY JVM must support "ISO8859_1", but they don't.
Fixed Connection to use the platform character encoding instead of "ISO8859_1" if one isn't explicitly set. This fixes problems people were having loading the character- converter classes that didn't always exist (JVM bug). (thanks to Fritz Elfert for pointing out this problem)
Changed MysqlIO to re-use packets where possible to reduce memory usage.
Fixed escape-processor bugs pertaining to {} inside quotes.
- E.6.7.1. Changes in MySQL Connector/J 1.2a (14 April 1999)
- E.6.7.2. Changes in MySQL Connector/J 1.1i (24 March 1999)
- E.6.7.3. Changes in MySQL Connector/J 1.1h (08 March 1999)
- E.6.7.4. Changes in MySQL Connector/J 1.1g (19 February 1999)
- E.6.7.5. Changes in MySQL Connector/J 1.1f (31 December 1998)
- E.6.7.6. Changes in MySQL Connector/J 1.1b (03 November 1998)
- E.6.7.7. Changes in MySQL Connector/J 1.1 (02 September 1998)
- E.6.7.8. Changes in MySQL Connector/J 1.0 (24 August 1998)
- E.6.7.9. Changes in MySQL Connector/J 0.9d (04 August 1998)
- E.6.7.10. Changes in MySQL Connector/J 0.9 (28 July 1998)
- E.6.7.11. Changes in MySQL Connector/J 0.8 (06 July 1998)
- E.6.7.12. Changes in MySQL Connector/J 0.7 (01 July 1998)
- E.6.7.13. Changes in MySQL Connector/J 0.6 (21 May 1998)
Fixed character-set support for non-Javasoft JVMs (thanks to many people for pointing it out)
Fixed ResultSet.getBoolean() to recognize 'y' & 'n' as well as '1' & '0' as boolean flags. (thanks to Tim Pizey)
Fixed ResultSet.getTimestamp() to give better performance. (thanks to Richard Swift)
Fixed getByte() for numeric types. (thanks to Ray Bellis)
Fixed DatabaseMetaData.getTypeInfo() for DATE type. (thanks to Paul Johnston)
Fixed EscapeProcessor for "fn" calls. (thanks to Piyush Shah at locomotive.org)
Fixed EscapeProcessor to not do extraneous work if there are no escape codes. (thanks to Ryan Gustafson)
Fixed Driver to parse URLs of the form "jdbc:mysql://host:port" (thanks to Richard Lobb)
Fixed Timestamps for PreparedStatements
Fixed null pointer exceptions in RSMD and RS
Re-compiled with jikes for valid class files (thanks ms!)
Fixed escape processor to deal with unmatched { and } (thanks to Craig Coles)
Fixed escape processor to create more portable (between DATETIME and TIMESTAMP types) representations so that it will work with BETWEEN clauses. (thanks to Craig Longman)
MysqlIO.quit() now closes the socket connection. Before, after many failed connections some OS's would run out of file descriptors. (thanks to Michael Brinkman)
Fixed NullPointerException in Driver.getPropertyInfo. (thanks to Dave Potts)
Fixes to MysqlDefs to allow all *text fields to be retrieved as Strings. (thanks to Chris at Leverage)
Fixed setDouble in PreparedStatement for large numbers to avoid sending scientific notation to the database. (thanks to J.S. Ferguson)
Fixed getScale() and getPrecision() in RSMD. (contrib'd by James Klicman)
Fixed getObject() when field was DECIMAL or NUMERIC (thanks to Bert Hobbs)
DBMD.getTables() bombed when passed a null table-name pattern. Fixed. (thanks to Richard Lobb)
Added check for "client not authorized" errors during connect. (thanks to Hannes Wallnoefer)
Result set rows are now byte arrays. Blobs and Unicode work bidriectonally now. The useUnicode and encoding options are implemented now.
Fixes to PreparedStatement to send binary set by setXXXStream to be sent untouched to the MySQL server.
Fixes to getDriverPropertyInfo().
Changed all ResultSet fields to Strings, this should allow Unicode to work, but your JVM must be able to convert between the character sets. This should also make reading data from the server be a bit quicker, because there is now no conversion from StringBuffer to String.
Changed PreparedStatement.streamToString() to be more efficient (code from Uwe Schaefer).
URL parsing is more robust (throws SQL exceptions on errors rather than NullPointerExceptions)
PreparedStatement now can convert Strings to Time/Date values via setObject() (code from Robert Currey).
IO no longer hangs in Buffer.readInt(), that bug was introduced in 1.1d when changing to all byte-arrays for result sets. (Pointed out by Samo Login)
Fixes to DatabaseMetaData to allow both IBM VA and J-Builder to work. Let me know how it goes. (thanks to Jac Kersing)
Fix to ResultSet.getBoolean() for NULL strings (thanks to Barry Lagerweij)
Beginning of code cleanup, and formatting. Getting ready to branch this off to a parallel JDBC-2.0 source tree.
Added "final" modifier to critical sections in MysqlIO and Buffer to allow compiler to inline methods for speed.
9-29-98
If object references passed to setXXX() in PreparedStatement are null, setNull() is automatically called for you. (Thanks for the suggestion goes to Erik Ostrom)
setObject() in PreparedStatement will now attempt to write a serialized representation of the object to the database for objects of Types.OTHER and objects of unknown type.
Util now has a static method readObject() which given a ResultSet and a column index will re-instantiate an object serialized in the above manner.
Got rid of "ugly hack" in MysqlIO.nextRow(). Rather than catch an exception, Buffer.isLastDataPacket() was fixed.
Connection.getCatalog() and Connection.setCatalog() should work now.
Statement.setMaxRows() works, as well as setting by property maxRows. Statement.setMaxRows() overrides maxRows set via properties or url parameters.
Automatic re-connection is available. Because it has to "ping" the database before each query, it is turned off by default. To use it, pass in "autoReconnect=true" in the connection URL. You may also change the number of reconnect tries, and the initial timeout value via "maxReconnects=n" (default 3) and "initialTimeout=n" (seconds, default 2) parameters. The timeout is an exponential backoff type of timeout; for example, if you have initial timeout of 2 seconds, and maxReconnects of 3, then the driver will timeout 2 seconds, 4 seconds, then 16 seconds between each re-connection attempt.
Fixed handling of blob data in Buffer.java
Fixed bug with authentication packet being sized too small.
The JDBC Driver is now under the LPGL
8-14-98
Fixed Buffer.readLenString() to correctly read data for BLOBS.
Fixed PreparedStatement.stringToStream to correctly read data for BLOBS.
Fixed PreparedStatement.setDate() to not add a day. (above fixes thanks to Vincent Partington)
Added URL parameter parsing (?user=... and so forth).
Big news! New package name. Tim Endres from ICE Engineering is starting a new source tree for GNU GPL'd Java software. He's graciously given me the org.gjt.mm package directory to use, so now the driver is in the org.gjt.mm.mysql package scheme. I'm "legal" now. Look for more information on Tim's project soon.
Now using dynamically sized packets to reduce memory usage when sending commands to the DB.
Small fixes to getTypeInfo() for parameters, and so forth.
DatabaseMetaData is now fully implemented. Let me know if these drivers work with the various IDEs out there. I've heard that they're working with JBuilder right now.
Added JavaDoc documentation to the package.
Package now available in .zip or .tar.gz.
Implemented getTypeInfo(). Connection.rollback() now throws an SQLException per the JDBC spec.
Added PreparedStatement that supports all JDBC API methods for PreparedStatement including InputStreams. Please check this out and let me know if anything is broken.
Fixed a bug in ResultSet that would break some queries that only returned 1 row.
Fixed bugs in DatabaseMetaData.getTables(), DatabaseMetaData.getColumns() and DatabaseMetaData.getCatalogs().
Added functionality to Statement that allows executeUpdate() to store values for IDs that are automatically generated for AUTO_INCREMENT fields. Basically, after an executeUpdate(), look at the SQLWarnings for warnings like "LAST_INSERTED_ID = 'some number', COMMAND = 'your SQL query'". If you are using AUTO_INCREMENT fields in your tables and are executing a lot of executeUpdate()s on one Statement, be sure to clearWarnings() every so often to save memory.
Split MysqlIO and Buffer to separate classes. Some ClassLoaders gave an IllegalAccess error for some fields in those two classes. Now mm.mysql works in applets and all classloaders. Thanks to Joe Ennis <jce@mail.boone.com> for pointing out the problem and working on a fix with me.
Fixed DatabaseMetadata problems in getColumns() and bug in switch statement in the Field constructor. Thanks to Costin Manolache <costin@tdiinc.com> for pointing these out.
Incorporated efficiency changes from Richard Swift <Richard.Swift@kanatek.ca> in
MysqlIO.javaandResultSet.java:We're now 15% faster than gwe's driver.
Started working on
DatabaseMetaData.The following methods are implemented:
getTables()getTableTypes()getColumnsgetCatalogs()
- E.7.1. Changes in MySQL Connector/MXJ 5.0.6 (04 May 2007)
- E.7.2. Changes in MySQL Connector/MXJ 5.0.5 (14 March 2007)
- E.7.3. Changes in MySQL Connector/MXJ 5.0.4 (28 January 2007)
- E.7.4. Changes in MySQL Connector/MXJ 5.0.3 (24 June 2006)
- E.7.5. Changes in MySQL Connector/MXJ 5.0.2 (15 June 2006)
- E.7.6. Changes in MySQL Connector/MXJ 5.0.1 (Never released)
- E.7.7. Changes in MySQL Connector/MXJ 5.0.0 (09 December 2005)
Removed
use-default-architectureproperty replaced.Moved
platform-map.propertiesintodb-files.jar.Updated
build.xmlin preperation for next beta build.Clarified the startup max wait numbers.
Changed tests to shutdown mysqld prior to deleting files.
Delete
portFileon shutdown.Swapped out commercial binaries for v5.0.40.
Fixed port file to always be writen to datadir.
Added os.name-os.arch to resource directory mapping properties file.
Changes in this release:
Updated
build.xmlin prep for next release.Swapped out gpl binaries for v5.0.37.
Swapped out commercial binaries for v5.0.36.
Found and removed dynamic linking in mysql_kill; updated solution.
Changed
connector-mxj.propertiesdefault mysql version to 5.0.37.Replaced
Boolean.parseBooleanwith JDK 1.4 compliantvalueOf.Added Patched
StandardSocketFactoryfrom Connector/J 5-0 HEAD.build.xml:usagenow slightly more verbose; some reformatting.Replaced windows kill.exe resource with re-written version specific to mysqld.
SIGHUPis replaced withMySQLShutdown<PID>event.Now incoporates Reggie Bernett's
SafeTerminateProcessand only calls the unsafe TerminateProcess as a final last resort.New windows
kill.exefixes bug where mysqld was being force terminated. Issue reported by bruno haleblian and others, see: MySQL Forums.In testing so far mysqld reliably shuts down cleanly much faster.
Changed protected constructor of
SimpleMysqldDynamicMBeanfrom taking aMysqldResourceto taking aMysqldFactory, in order to lay groundwork for addressing BUG discovered by Andrew Rubinger. See: MySQL Forums (Actual testing with JBoss, and filing a bug, is still required.)Changed
SimpleMysqldDynamicMBeanto createMysqldResourceon demand in order to allow setting ofdatadir. (Rubinger bug groundwork).Added
getDataDir()to interfaceMysqldResourceI.Added testcase to
com.mysql.management.jmx.AcceptanceTestwhich demonstrats thatdataDiris a mutable MBean property.Moved
MysqldFactoryto main package.Reformatting: Added newlines some files which did not end in them.
Added 5.1.15 binaries to the repository.
Removed 5.1.14 binaries from the repository.
Clarified the synchronization of
MysqldResourcemethods.Clarified the immutability of
baseDir,dataDir,pidFile,portFile.Removed 5.0.22 binaries from the repository.
Added 5.1.14 binaries to repository.
Ensured 5.1.14 compatibility.
Swapped out gpl binaries for v5.0.27.
Swapped out commercial binaries for v5.0.32.
Updated
build.xmlto build to handle with different gpl and commercial mysld version numbers.Moved mysqld binary resourced into separate jar file NOTICE:
CLASSPATHwill now need toconnector-mxj-db-files.jar.Minor test robustness improvements.
Moved default version string out of java class into a text editable properties file (
connector-mxj.properties) in the resources directory.Introduced property for Linux & WinXX to default to 32bit versions.
Allow multiple calls to start server from URL connection on non-3306 port. (Bug#24004)
Only populate the options map from the help text if specifically requested or in the MBean case.
Fixed test to be tollerant of
/tmpbeing a symlink to/foo/tmp.
Swapped out the mysqld binaries for MySQL v5.0.22.
Removed "TeeOutputStream" - no longer needed.
Removed unused imports, formatted code, made minor edits to tests.
Changes in this release:
Replaced string parsing with JDBC connection attempt for determining if a mysqld is "ready for connections"
CLASSPATHwill now need to include Connector/J jar.Extended timeout for help string parsing, to avoid cases where the help text was getting prematurely flushed, and thus truncated.
Changes made on 11 May 2006:
Added trace level logging with Aspect/J.
CLASSPATHwill now need to includelib/aspectjrt.jar
Changes made on 11 May 2006:
Swapped out the mysqld binaries for MySQL v5.0.21
Changes made on 04 May 2006:
ServerLauncherSocketFactory now treats URL parameters in the form of
&server.foo=nullasserverOptionMap.put("foo", null)
Changes made on 26 April 2006:
MysqldResource now tied to dataDir as well as basedir (API CHANGE)
moved PID file into datadir
ServerLauncherSocketFactory.shutdown API change: now takes 2 File parameters (basedir, datadir)
insulated users from problems with "." in basedir
Changes made on 25 April 2006:
Made tests more robust be deleting the /tmp/test-c.mxj directory before running tests.
socket is now "mysql.sock" in datadir
ServerLauncherSocketFactory.shutdown now works across JVMs.
ServerLauncherSocketFactory.shutdown API change: now takes File parameter (basedir) instead of port.
altered to be "basedir" rather than "port" oriented.
Changes made on 18 April 2006:
ServerLauncherSocketFactory.shutdown(port) no longer throws, only reports to System.err
Changes made on 16 March 2006:
swapped out the mysqld binaries for MySQL v5.0.19
added ability to specify "mysql-version" as an url parameter
extracted splitLines(String) to Str utility class
extracted array and list printing to ListToString utility class
reformatted code
Changes made on 16 January 2006:
swapped out the mysqld binaries for MySQL v5.0.18
"platform" directories replace spaces with underscores
help parsing test reflects current help options
Changes made on 16 January 2006:
Swapped out the mysqld binaries for MySQL v5.0.16.
Changes made on 25 October 2005:
Altered examples and tests to use new Connector/J 5.0 URL syntax for for launching Connector/MXJ ("jdbc:mysql:mxj://")
Minor refactorings for type casting and exception handling.
Changes made on 30 August 2005:
Reorganized utils into a single "Utils" collaborator.
Ditched "ClassUtil" (merged with Str).
Removed HelpOptionsParser's need to reference a MysqldResource.
Changes made on 29 August 2005:
Minor test tweaks
Table of Contents
The discussion here describes restrictions that apply to the use of MySQL features such as subqueries or views.
Some of the restrictions noted here apply to all stored routines; that is, both to stored procedures and stored functions. Some of restrictions apply only to stored functions, and not to stored procedures.
All of the restrictions for stored functions also apply to triggers.
Stored routines cannot contain arbitrary SQL statements. The following statements are disallowed:
The table-maintenance statements
CHECK TABLESandOPTIMIZE TABLES. Note: This restriction is lifted beginning with MySQL 5.0.17.The locking statements
LOCK TABLES,UNLOCK TABLES.LOAD DATAandLOAD TABLE.SQL prepared statements (
PREPARE,EXECUTE,DEALLOCATE PREPARE). Implication: You cannot use dynamic SQL within stored routines (where you construct dynamically statements as strings and then execute them). This restriction is lifted as of MySQL 5.0.13 for stored procedures; it still applies to stored functions and triggers.
For stored functions (but not stored procedures), the following additional statements or operations are disallowed:
Statements that do explicit or implicit commit or rollback.
Statements that return a result set. This includes
SELECTstatements that do not have anINTOclause andvar_listSHOWstatements. A function can process a result set either withSELECT ... INTOor by using a cursor andvar_listFETCHstatements. See Section 17.2.7.3, “SELECT ... INTOStatement”.FLUSHstatements.Note: Before MySQL 5.0.10, stored functions created with
CREATE FUNCTIONmust not contain references to tables, with limited exceptions. They may include someSETstatements that contain table references, for exampleSET a:= (SELECT MAX(id) FROM t), andSELECTstatements that fetch values directly into variables, for exampleSELECT i INTO var1 FROM t.Recursive statements. That is, stored functions cannot be used recursively.
Within a stored function or trigger, it is not permitted to modify a table that is already being used (for reading or writing) by the statement that invoked the function or trigger.
Note that although some restrictions normally apply to stored
functions and triggers but not to stored procedures, those
restrictions do apply to stored procedures if they are invoked
from within a stored function or trigger. For example, although
you can use FLUSH in a stored procedure, such a
stored procedure cannot be called from a stored function or
trigger.
It is possible for the same identifier to be used for a routine parameter, a local variable, and a table column. Also, the same local variable name can be used in nested blocks. For example:
CREATE PROCEDURE p (i INT)
BEGIN
DECLARE i INT DEFAULT 0;
SELECT i FROM t;
BEGIN
DECLARE i INT DEFAULT 1;
SELECT i FROM t;
END;
END;
In such cases the identifier is ambiguous and the following precedence rules apply:
A local variable takes precedence over a routine parameter or table column
A routine parameter takes precedence over a table column
A local variable in an inner block takes precedence over a local variable in an outer block
The behavior that table columns do not take precedence over variables is non-standard.
Use of stored routines can cause replication problems. This issue is discussed further in Section 17.4, “Binary Logging of Stored Routines and Triggers”.
INFORMATION_SCHEMA does not yet have a
PARAMETERS table, so applications that need to
acquire routine parameter information at runtime must use
workarounds such as parsing the output of SHOW
CREATE statements.
There are no stored routine debugging facilities.
CALL statements cannot be prepared. This true
both for server-side prepared statements and for SQL prepared
statements.
UNDO handlers are not supported.
FOR loops are not supported.
To prevent problems of interaction between server threads, when a client issues a statement, the server uses a snapshot of routines and triggers available for execution of the statement. That is, the server calculates a list of procedures, functions, and triggers that may be used during execution of the statement, loads them, and then proceeds to execute the statement. This means that while the statement executes, it will not see changes to routines performed by other threads.
For triggers, the following additional statements or operations are disallowed:
Triggers currently are not activated by foreign key actions.
The
RETURNstatement is disallowed in triggers, which cannot return a value. To exit a trigger immediately, use theLEAVEstatement.Triggers are not allowed on tables in the
mysqldatabase.
Server-side cursors are implemented beginning with the C API in
MySQL 5.0.2 via the mysql_stmt_attr_set()
function. A server-side cursor allows a result set to be generated
on the server side, but not transferred to the client except for
those rows that the client requests. For example, if a client
executes a query but is only interested in the first row, the
remaining rows are not transferred.
In MySQL, a server-side cursor is materialized into a temporary
table. Initially, this is a MEMORY table, but
is converted to a MyISAM table if its size
reaches the value of the max_heap_table_size
system variable. (Beginning with MySQL 5.0.14, the same
temporary-table implementation also is used for cursors in stored
routines.) One limitation of the implementation is that for a
large result set, retrieving its rows through a cursor might be
slow.
Cursors are read-only; you cannot use a cursor to update rows.
UPDATE WHERE CURRENT OF and DELETE
WHERE CURRENT OF are not implemented, because updatable
cursors are not supported.
Cursors are non-holdable (not held open after a commit).
Cursors are asensitive.
Cursors are non-scrollable.
Cursors are not named. The statement handler acts as the cursor ID.
You can have open only a single cursor per prepared statement. If you need several cursors, you must prepare several statements.
You cannot use a cursor for a statement that generates a result
set if the statement is not supported in prepared mode. This
includes statements such as CHECK TABLES,
HANDLER READ, and SHOW BINLOG
EVENTS.
In MySQL 5.0 before 5.0.36, if you compare a
NULLvalue to a subquery usingALL,ANY, orSOME, and the subquery returns an empty result, the comparison might evaluate to the non-standard result ofNULLrather than toTRUEorFALSE.A subquery's outer statement can be any one of:
SELECT,INSERT,UPDATE,DELETE,SET, orDO.Subquery optimization for
INis not as effective as for the=operator or forIN(constructs.value_list)A typical case for poor
INsubquery performance is when the subquery returns a small number of rows but the outer query returns a large number of rows to be compared to the subquery result.The problem is that, for a statement that uses an
INsubquery, the optimizer rewrites it as a correlated subquery. Consider the following statement that uses an uncorrelated subquery:SELECT ... FROM t1 WHERE t1.a IN (SELECT b FROM t2);
The optimizer rewrites the statement to a correlated subquery:
SELECT ... FROM t1 WHERE EXISTS (SELECT 1 FROM t2 WHERE t2.b = t1.a);
If the inner and outer queries return
MandNrows, respectively, the execution time becomes on the order ofO(, rather thanM×N)O(as it would be for an uncorrelated subquery.M+N)An implication is that an
INsubquery can be much slower than a query written using anIN(construct that lists the same values that the subquery would return.value_list)In general, you cannot modify a table and select from the same table in a subquery. For example, this limitation applies to statements of the following forms:
DELETE FROM t WHERE ... (SELECT ... FROM t ...); UPDATE t ... WHERE col = (SELECT ... FROM t ...); {INSERT|REPLACE} INTO t (SELECT ... FROM t ...);Exception: The preceding prohibition does not apply if you are using a subquery for the modified table in the
FROMclause. Example:UPDATE t ... WHERE col = (SELECT (SELECT ... FROM t...) AS _t ...);
Here the prohibition does not apply because the result from a subquery in the
FROMclause is stored as a temporary table, so the relevant rows inthave already been selected by the time the update tottakes place.Row comparison operations are only partially supported:
For
exprIN (subquery)exprcan be ann-tuple (specified via row constructor syntax) and the subquery can return rows ofn-tuples.For
exprop{ALL|ANY|SOME} (subquery)exprmust be a scalar value and the subquery must be a column subquery; it cannot return multiple-column rows.
In other words, for a subquery that returns rows of
n-tuples, this is supported:(
val_1, ...,val_n) IN (subquery)But this is not supported:
(
val_1, ...,val_n)op{ALL|ANY|SOME} (subquery)The reason for supporting row comparisons for
INbut not for the others is thatINis implemented by rewriting it as a sequence of=comparisons andANDoperations. This approach cannot be used forALL,ANY, orSOME.Row constructors are not well optimized. The following two expressions are equivalent, but only the second can be optimized:
(col1, col2, ...) = (val1, val2, ...) col1 = val1 AND col2 = val2 AND ...
Subqueries in the
FROMclause cannot be correlated subqueries. They are materialized (executed to produce a result set) before evaluating the outer query, so they cannot be evaluated per row of the outer query.The optimizer is more mature for joins than for subqueries, so in many cases a statement that uses a subquery can be executed more efficiently if you rewrite it as a join.
An exception occurs for the case where an
INsubquery can be rewritten as aSELECT DISTINCTjoin. Example:SELECT col FROM t1 WHERE id_col IN (SELECT id_col2 FROM t2 WHERE
condition);That statement can be rewritten as follows:
SELECT DISTINCT col FROM t1, t2 WHERE t1.id_col = t2.id_col AND
condition;But in this case, the join requires an extra
DISTINCToperation and is not more efficient than the subquery.Possible future optimization: MySQL does not rewrite the join order for subquery evaluation. In some cases, a subquery could be executed more efficiently if MySQL rewrote it as a join. This would give the optimizer a chance to choose between more execution plans. For example, it could decide whether to read one table or the other first.
Example:
SELECT a FROM outer_table AS ot WHERE a IN (SELECT a FROM inner_table AS it WHERE ot.b = it.b);
For that query, MySQL always scans
outer_tablefirst and then executes the subquery oninner_tablefor each row. Ifouter_tablehas a lot of rows andinner_tablehas few rows, the query probably will not be as fast as it could be.The preceding query could be rewritten like this:
SELECT a FROM outer_table AS ot, inner_table AS it WHERE ot.a = it.a AND ot.b = it.b;
In this case, we can scan the small table (
inner_table) and look up rows inouter_table, which will be fast if there is an index on(ot.a,ot.b).Possible future optimization: A correlated subquery is evaluated for each row of the outer query. A better approach is that if the outer row values do not change from the previous row, do not evaluate the subquery again. Instead, use its previous result.
Possible future optimization: A subquery in the
FROMclause is evaluated by materializing the result into a temporary table, and this table does not use indexes. This does not allow the use of indexes in comparison with other tables in the query, although that might be useful.Possible future optimization: If a subquery in the
FROMclause resembles a view to which the merge algorithm can be applied, rewrite the query and apply the merge algorithm so that indexes can be used. The following statement contains such a subquery:SELECT * FROM (SELECT * FROM t1 WHERE t1.t1_col) AS _t1, t2 WHERE t2.t2_col;
The statement can be rewritten as a join like this:
SELECT * FROM t1, t2 WHERE t1.t1_col AND t2.t2_col;
This type of rewriting would provide two benefits:
It avoids the use of a temporary table for which no indexes can be used. In the rewritten query, the optimizer can use indexes on
t1.It gives the optimizer more freedom to choose between different execution plans. For example, rewriting the query as a join allows the optimizer to use
t1ort2first.
Possible future optimization: For
IN,= ANY,<> ANY,= ALL, and<> ALLwith uncorrelated subqueries, use an in-memory hash for a result or a temporary table with an index for larger results. Example:SELECT a FROM big_table AS bt WHERE non_key_field IN (SELECT non_key_field FROM
tableWHEREcondition)In this case, we could create a temporary table:
CREATE TABLE t (key (non_key_field)) (SELECT non_key_field FROM
tableWHEREcondition)Then, for each row in
big_table, do a key lookup intbased onbt.non_key_field.
View processing is not optimized:
It is not possible to create an index on a view.
Indexes can be used for views processed using the merge algorithm. However, a view that is processed with the temptable algorithm is unable to take advantage of indexes on its underlying tables (although indexes can be used during generation of the temporary tables).
Subqueries cannot be used in the FROM clause of
a view. This limitation will be lifted in the future.
There is a general principle that you cannot modify a table and select from the same table in a subquery. See Section F.3, “Restrictions on Subqueries”.
The same principle also applies if you select from a view that selects from the table, if the view selects from the table in a subquery and the view is evaluated using the merge algorithm. Example:
CREATE VIEW v1 AS SELECT * FROM t2 WHERE EXISTS (SELECT 1 FROM t1 WHERE t1.a = t2.a); UPDATE t1, v2 SET t1.a = 1 WHERE t1.b = v2.b;
If the view is evaluated using a temporary table, you
can select from the table in the view
subquery and still modify that table in the outer query. In this
case the view will be stored in a temporary table and thus you are
not really selecting from the table in a subquery and modifying it
“at the same time.” (This is another reason you might
wish to force MySQL to use the temptable algorithm by specifying
ALGORITHM = TEMPTABLE in the view definition.)
You can use DROP TABLE or ALTER
TABLE to drop or alter a table that is used in a view
definition (which invalidates the view) and no warning results
from the drop or alter operation. An error occurs later when the
view is used.
A view definition is “frozen” by certain statements:
If a statement prepared by
PREPARErefers to a view, the view contents seen each time the statement is executed later will be the contents of the view at the time it was prepared. This is true even if the view definition is changed after the statement is prepared and before it is executed. Example:CREATE VIEW v AS SELECT 1; PREPARE s FROM 'SELECT * FROM v'; ALTER VIEW v AS SELECT 2; EXECUTE s;
The result returned by the
EXECUTEstatement is 1, not 2.If a statement in a stored routine refers to a view, the view contents seen by the statement are its contents the first time that statement is executed. For example, this means that if the statement is executed in a loop, further iterations of the statement see the same view contents, even if the view definition is changed later in the loop. Example:
CREATE VIEW v AS SELECT 1; delimiter // CREATE PROCEDURE p () BEGIN DECLARE i INT DEFAULT 0; WHILE i < 5 DO SELECT * FROM v; SET i = i + 1; ALTER VIEW v AS SELECT 2; END WHILE; END; // delimiter ; CALL p();When the procedure
p()is called, theSELECTreturns 1 each time through the loop, even though the view definition is changed within the loop.
With regard to view updatability, the overall goal for views is
that if any view is theoretically updatable, it should be
updatable in practice. This includes views that have
UNION in their definition. Currently, not all
views that are theoretically updatable can be updated. The initial
view implementation was deliberately written this way to get
usable, updatable views into MySQL as quickly as possible. Many
theoretically updatable views can be updated now, but limitations
still exist:
Updatable views with subqueries anywhere other than in the
WHEREclause. Some views that have subqueries in theSELECTlist may be updatable.You cannot use
UPDATEto update more than one underlying table of a view that is defined as a join.You cannot use
DELETEto update a view that is defined as a join.
There exists a shortcoming with the current implementation of
views. If a user is granted the basic privileges necessary to
create a view (the CREATE VIEW and
SELECT privileges), that user will be unable to
call SHOW CREATE VIEW on that object unless the
user is also granted the SHOW VIEW privilege.
That shortcoming can lead to problems backing up a database with mysqldump, which may fail due to insufficient privileges. This problem is described in Bug#22062.
The workaround to the problem is for the administrator to manually
grant the SHOW VIEW privilege to users who are
granted CREATE VIEW, since MySQL doesn't grant
it implicitly when views are created.
XA transaction support is limited to the InnoDB
storage engine.
The MySQL XA implementation is for “external XA,”
where a MySQL server acts as a Resource Manager and client
programs act as Transaction Managers. “Internal XA”
is not implemented. This would allow individual storage engines
within a MySQL server to act as RMs, and the server itself to act
as a TM. Internal XA is required for handling XA transactions that
involve more than one storage engine. The implementation of
internal XA is incomplete because it requires that a storage
engine support two-phase commit at the table handler level, and
currently this is true only for InnoDB.
For XA START, the JOIN and
RESUME clauses are not supported.
For XA END, the SUSPEND [FOR
MIGRATE] clause is not supported.
The requirement that the bqual part of
the xid value be different for each XA
transaction within a global transaction is a limitation of the
current MySQL XA implementation. It is not part of the XA
specification.
If an XA transaction has reached the PREPARED
state and the MySQL server is killed (for example, with
kill -9 on Unix) or shuts down abnormally, the
transaction can be continued after the server restarts. However,
if the client reconnects and commits the transaction, the
transaction will be absent from the binary log even though it has
been committed. This means the data and the binary log have gone
out of synchrony. An implication is that XA cannot be used safely
together with replication.
It is possible that the server will roll back a pending XA
transaction, even one that has reached the
PREPARED state. This happens if a client
connection terminates and the server continues to run, or if
clients are connected and the server shuts down gracefully. (In
the latter case, the server marks each connection to be
terminated, and then rolls back the PREPARED XA
transaction associated with it.) It should be possible to commit
or roll back a PREPARED XA transaction, but
this cannot be done without changes to the binary logging
mechanism.
Table of Contents
This appendix lists the developers, contributors, and supporters that have helped to make MySQL what it is today.
These are the developers that are or have been employed by MySQL
AB to work on the MySQL database software,
roughly in the order they started to work with us. Following each
developer is a small list of the tasks that the developer is
responsible for, or the accomplishments they have made. All
developers are involved in support.
Michael (Monty) Widenius
Lead developer and main author of the MySQL server (mysqld).
New functions for the string library.
Most of the
mysyslibrary.The
ISAMandMyISAMlibraries (B-tree index file handlers with index compression and different record formats).The
HEAPlibrary. A memory table system with our superior full dynamic hashing. In use since 1981 and published around 1984.The replace program (take a look at it, it's COOL!).
Connector/ODBC (MyODBC), the ODBC driver for Windows.
Fixing bugs in MIT-pthreads to get it to work for MySQL Server. And also Unireg, a curses-based application tool with many utilities.
Porting of
mSQLtools likemsqlperl,DBD/DBI, andDB2mysql.Most of
crash-meand the foundation for the MySQL benchmarks.
David Axmark
Initial main writer of the Reference Manual, including enhancements to texi2html.
Automatic Web site updating from the manual.
Initial Autoconf, Automake, and Libtool support.
Licensing.
Parts of all the text files. (Nowadays only the
READMEis left. The rest ended up in the manual.)Lots of testing of new features.
Our in-house Free Software legal expert.
Mailing list maintainer (who never has the time to do it right...).
Our original portability code (now more than 10 years old). Nowadays only some parts of
mysysare left.Someone for Monty to call in the middle of the night when he just got that new feature to work.
Chief "Open Sourcerer" (MySQL community relations).
Jani Tolonen
mysqlimport
A lot of extensions to the command-line clients.
PROCEDURE ANALYSE()
Sinisa Milivojevic (now in support)
Compression (with
zlib) in the client/server protocol.Perfect hashing for the lexical analyzer phase.
Multi-row
INSERTmysqldump -e option
LOAD DATA LOCAL INFILESQL_CALC_FOUND_ROWSSELECToption--max-user-connections=...optionnet_readandnet_write_timeoutGRANT/REVOKEandSHOW GRANTS FORNew client/server protocol for 4.0
UNIONin 4.0Multiple-table
DELETE/UPDATESubqueries in the
FROMclause (4.1).User resources management
Initial developer of the
MySQL++C++ API and theMySQLGUIclient.
Tonu Samuel (past developer)
VIO interface (the foundation for the encrypted client/server protocol).
MySQL Filesystem (a way to use MySQL databases as files and directories).
The
CASEexpression.The
MD5()andCOALESCE()functions.RAIDsupport forMyISAMtables.
Sasha Pachev (past developer)
Initial implementation of replication (up to version 4.0).
SHOW CREATE TABLE.mysql-bench
Matt Wagner
MySQL test suite.
Webmaster (until 2002).
Miguel Solorzano (now in support)
Win32 development and release builds.
Windows NT server code.
WinMySQLAdmin
Timothy Smith (now in development)
Dynamic character sets support.
configure, RPMs and other parts of the build system.
Initial developer of
libmysqld, the embedded server.
Sergei Golubchik
Full-text search.
Added keys to the
MERGElibrary.Precision math.
Jeremy Cole (past developer)
Proofreading and editing this fine manual.
ALTER TABLE ... ORDER BY ....UPDATE ... ORDER BY ....DELETE ... ORDER BY ....
Indrek Siitan
Designing/programming of our Web interface.
Author of our newsletter management system.
Jorge del Conde (past developer)
MySQLCC (MySQL Control Center)
Win32 development
Initial implementation of the Web site portals.
Venu Anuganti (past developer)
MyODBC 3.51
New client/server protocol for 4.1 (for prepared statements).
Arjen Lentz (also handled community, 2004-2006; now works in Support)
Maintainer of the MySQL Reference Manual (2001-2004).
Preparing the O'Reilly printed edition of the manual (2002).
Alexander (Bar) Barkov, Alexey (Holyfoot) Botchkov, and Ramil Kalimullin
Spatial data (GIS) and R-Trees implementation for 4.1
Unicode and character sets for 4.1; documentation for same
Oleksandr (Sanja) Byelkin
Query cache in 4.0
Implementation of subqueries (4.1).
Implementation of views (5.0).
Aleksey (Walrus) Kishkin and Alexey (Ranger) Stroganov
Benchmarks design and analysis.
Maintenance of the MySQL test suite.
Zak Greant (past employee)
Open Source advocate, MySQL community relations.
Carsten Pedersen
The MySQL Certification program.
Lenz Grimmer
Production (build and release) engineering.
Peter Zaitsev
SHA1(),AES_ENCRYPT()andAES_DECRYPT()functions.Debugging, cleaning up various features.
Alexander (Salle) Keremidarski
Support.
Debugging.
Per-Erik Martin
Lead developer for stored procedures (5.0).
Jim Winstead
Former lead Web developer.
Improving server, fixing bugs.
Mark Matthews
Connector/J driver (Java).
Peter Gulutzan
SQL standards compliance.
Documentation of existing MySQL code/algorithms.
Character set documentation.
Guilhem Bichot
Replication, from
MySQLversion 4.0.Fixed handling of exponents for
DECIMAL.Author of
mysql_tableinfo.Backup (in 5.1).
Antony T. Curtis
Porting of the MySQL Database software to OS/2.
Mikael Ronstrom
Much of the initial work on NDB Cluster until 2000. Roughly half the code base at that time. Transaction protocol, node recovery, system restart and restart code and parts of the API functionality.
Lead Architect, developer, debugger of NDB Cluster 1994-2004
Lots of optimizations
Jonas Oreland
On-line Backup
The automatic test environment of MySQL Cluster
Portability Library for NDB Cluster
Lots of other things
Pekka Nouisiainen
Ordered index implementation of MySQL Cluster
BLOB support in MySQL Cluster
Charset support in MySQL Cluster
Martin Skold
Unique index implementation of MySQL Cluster
Integration of NDB Cluster into MySQL
Magnus Svensson
The test framework for MySQL Cluster
Integration of NDB Cluster into MySQL
Tomas Ulin
Lots of work on configuration changes for simple installation and use of MySQL Cluster
Konstantin Osipov
Prepared statements.
Cursors.
Dmitri Lenev
Time zone support.
Triggers (in 5.0).
Although MySQL AB owns all copyrights in the MySQL
server and the MySQL manual, we wish
to recognize those who have made contributions of one kind or
another to the MySQL distribution. Contributors
are listed here, in somewhat random order:
Gianmassimo Vigazzola
<qwerg@mbox.vol.it>or<qwerg@tin.it>The initial port to Win32/NT.
Per Eric Olsson
For more or less constructive criticism and real testing of the dynamic record format.
Irena Pancirov
<irena@mail.yacc.it>Win32 port with Borland compiler.
mysqlshutdown.exeandmysqlwatch.exeDavid J. Hughes
For the effort to make a shareware SQL database. At TcX, the predecessor of MySQL AB, we started with
mSQL, but found that it couldn't satisfy our purposes so instead we wrote an SQL interface to our application builder Unireg. mysqladmin and mysql client are programs that were largely influenced by theirmSQLcounterparts. We have put a lot of effort into making the MySQL syntax a superset ofmSQL. Many of the API's ideas are borrowed frommSQLto make it easy to port freemSQLprograms to the MySQL API. The MySQL software doesn't contain any code frommSQL. Two files in the distribution (client/insert_test.candclient/select_test.c) are based on the corresponding (non-copyrighted) files in themSQLdistribution, but are modified as examples showing the changes necessary to convert code frommSQLto MySQL Server. (mSQLis copyrighted David J. Hughes.)Patrick Lynch
For helping us acquire http://www.mysql.com/.
Fred Lindberg
For setting up qmail to handle the MySQL mailing list and for the incredible help we got in managing the MySQL mailing lists.
Igor Romanenko
<igor@frog.kiev.ua>mysqldump (previously
msqldump, but ported and enhanced by Monty).Yuri Dario
For keeping up and extending the MySQL OS/2 port.
Tim Bunce
Author of mysqlhotcopy.
Zarko Mocnik
<zarko.mocnik@dem.si>Sorting for Slovenian language.
"TAMITO"
<tommy@valley.ne.jp>The
_MBcharacter set macros and the ujis and sjis character sets.Joshua Chamas
<joshua@chamas.com>Base for concurrent insert, extended date syntax, debugging on NT, and answering on the MySQL mailing list.
Yves Carlier
<Yves.Carlier@rug.ac.be>mysqlaccess, a program to show the access rights for a user.
Rhys Jones
<rhys@wales.com>(And GWE Technologies Limited)For one of the early JDBC drivers.
Dr Xiaokun Kelvin ZHU
<X.Zhu@brad.ac.uk>Further development of one of the early JDBC drivers and other MySQL-related Java tools.
James Cooper
<pixel@organic.com>For setting up a searchable mailing list archive at his site.
Rick Mehalick
<Rick_Mehalick@i-o.com>For
xmysql, a graphical X client for MySQL Server.Doug Sisk
<sisk@wix.com>For providing RPM packages of MySQL for Red Hat Linux.
Diemand Alexander V.
<axeld@vial.ethz.ch>For providing RPM packages of MySQL for Red Hat Linux-Alpha.
Antoni Pamies Olive
<toni@readysoft.es>For providing RPM versions of a lot of MySQL clients for Intel and SPARC.
Jay Bloodworth
<jay@pathways.sde.state.sc.us>For providing RPM versions for MySQL 3.21.
David Sacerdote
<davids@secnet.com>Ideas for secure checking of DNS hostnames.
Wei-Jou Chen
<jou@nematic.ieo.nctu.edu.tw>Some support for Chinese(BIG5) characters.
Wei He
<hewei@mail.ied.ac.cn>A lot of functionality for the Chinese(GBK) character set.
Jan Pazdziora
<adelton@fi.muni.cz>Czech sorting order.
Zeev Suraski
<bourbon@netvision.net.il>FROM_UNIXTIME()time formatting,ENCRYPT()functions, and bison advisor. Active mailing list member.Luuk de Boer
<luuk@wxs.nl>Ported (and extended) the benchmark suite to
DBI/DBD. Have been of great help withcrash-meand running benchmarks. Some new date functions. The mysql_setpermission script.Alexis Mikhailov
<root@medinf.chuvashia.su>User-defined functions (UDFs);
CREATE FUNCTIONandDROP FUNCTION.Andreas F. Bobak
<bobak@relog.ch>The
AGGREGATEextension to user-defined functions.Ross Wakelin
<R.Wakelin@march.co.uk>Help to set up InstallShield for MySQL-Win32.
Jethro Wright III
<jetman@li.net>The
libmysql.dlllibrary.James Pereria
<jpereira@iafrica.com>Mysqlmanager, a Win32 GUI tool for administering MySQL Servers.
Curt Sampson
<cjs@portal.ca>Porting of MIT-pthreads to NetBSD/Alpha and NetBSD 1.3/i386.
Martin Ramsch
<m.ramsch@computer.org>Examples in the MySQL Tutorial.
Steve Harvey
For making mysqlaccess more secure.
Konark IA-64 Centre of Persistent Systems Private Limited
http://www.pspl.co.in/konark/. Help with the Win64 port of the MySQL server.
Albert Chin-A-Young.
Configure updates for Tru64, large file support and better TCP wrappers support.
John Birrell
Emulation of
pthread_mutex()for OS/2.Benjamin Pflugmann
Extended
MERGEtables to handleINSERTS. Active member on the MySQL mailing lists.Jocelyn Fournier
Excellent spotting and reporting innumerable bugs (especially in the MySQL 4.1 subquery code).
Marc Liyanage
Maintaining the Mac OS X packages and providing invaluable feedback on how to create Mac OS X PKGs.
Robert Rutherford
Providing invaluable information and feedback about the QNX port.
Previous developers of NDB Cluster
Lots of people were involved in various ways summer students, master thesis students, employees. In total more than 100 people so too many to mention here. Notable name is Ataullah Dabaghi who up until 1999 contributed around a third of the code base. A special thanks also to developers of the AXE system which provided much of the architectural foundations for NDB Cluster with blocks, signals and crash tracing functionality. Also credit should be given to those who believed in the ideas enough to allocate of their budgets for its development from 1992 to present time.
Other contributors, bugfinders, and testers: James H. Thompson,
Maurizio Menghini, Wojciech Tryc, Luca Berra, Zarko Mocnik, Wim
Bonis, Elmar Haneke, <jehamby@lightside>,
<psmith@BayNetworks.com>,
<duane@connect.com.au>, Ted Deppner
<ted@psyber.com>, Mike Simons, Jaakko Hyvatti.
And lots of bug report/patches from the folks on the mailing list.
A big tribute goes to those that help us answer questions on the MySQL mailing lists:
Daniel Koch
<dkoch@amcity.com>Irix setup.
Luuk de Boer
<luuk@wxs.nl>Benchmark questions.
Tim Sailer
<tps@users.buoy.com>DBD::mysqlquestions.Boyd Lynn Gerber
<gerberb@zenez.com>SCO-related questions.
Richard Mehalick
<RM186061@shellus.com>xmysql-related questions and basic installation questions.Zeev Suraski
<bourbon@netvision.net.il>Apache module configuration questions (log & auth), PHP-related questions, SQL syntax-related questions and other general questions.
Francesc Guasch
<frankie@citel.upc.es>General questions.
Jonathan J Smith
<jsmith@wtp.net>Questions pertaining to OS-specifics with Linux, SQL syntax, and other things that might need some work.
David Sklar
<sklar@student.net>Using MySQL from PHP and Perl.
Alistair MacDonald
<A.MacDonald@uel.ac.uk>Is flexible and can handle Linux and perhaps HP-UX. Tries to get users to use mysqlbug.
John Lyon
<jlyon@imag.net>Questions about installing MySQL on Linux systems, using either
.rpmfiles or compiling from source.Lorvid Ltd.
<lorvid@WOLFENET.com>Simple billing/license/support/copyright issues.
Patrick Sherrill
<patrick@coconet.com>ODBC and VisualC++ interface questions.
Randy Harmon
<rjharmon@uptimecomputers.com>DBD, Linux, some SQL syntax questions.
The following people have helped us with writing the MySQL documentation and translating the documentation or error messages in MySQL.
Paul DuBois
Ongoing help with making this manual correct and understandable. That includes rewriting Monty's and David's attempts at English into English as other people know it.
Kim Aldale
Helped to rewrite Monty's and David's early attempts at English into English.
Michael J. Miller Jr.
<mke@terrapin.turbolift.com>For the first MySQL manual. And a lot of spelling/language fixes for the FAQ (that turned into the MySQL manual a long time ago).
Yan Cailin
First translator of the MySQL Reference Manual into simplified Chinese in early 2000 on which the Big5 and HK coded (http://mysql.hitstar.com/) versions were based. Personal home page at linuxdb.yeah.net.
Jay Flaherty
<fty@mediapulse.com>Big parts of the Perl
DBI/DBDsection in the manual.Paul Southworth
<pauls@etext.org>, Ray Loyzaga<yar@cs.su.oz.au>Proof-reading of the Reference Manual.
Therrien Gilbert
<gilbert@ican.net>, Jean-Marc Pouyot<jmp@scalaire.fr>French error messages.
Petr Snajdr,
<snajdr@pvt.net>Czech error messages.
Jaroslaw Lewandowski
<jotel@itnet.com.pl>Polish error messages.
Miguel Angel Fernandez Roiz
Spanish error messages.
Roy-Magne Mo
<rmo@www.hivolda.no>Norwegian error messages and testing of MySQL 3.21.xx.
Timur I. Bakeyev
<root@timur.tatarstan.ru>Russian error messages.
<brenno@dewinter.com>& Filippo Grassilli<phil@hyppo.com>Italian error messages.
Dirk Munzinger
<dirk@trinity.saar.de>German error messages.
Billik Stefan
<billik@sun.uniag.sk>Slovak error messages.
Stefan Saroiu
<tzoompy@cs.washington.edu>Romanian error messages.
Peter Feher
Hungarian error messages.
Roberto M. Serqueira
Portuguese error messages.
Carsten H. Pedersen
Danish error messages.
Arjen Lentz
Dutch error messages, completing earlier partial translation (also work on consistency and spelling).
The following is a list of the creators of the libraries we have included with the MySQL server source to make it easy to compile and install MySQL. We are very thankfully to all individuals that have created these and it has made our life much easier.
Fred Fish
For his excellent C debugging and trace library. Monty has made a number of smaller improvements to the library (speed and additional options).
Richard A. O'Keefe
For his public domain string library.
Henry Spencer
For his regex library, used in
WHERE column REGEXP regexp.Chris Provenzano
Portable user level pthreads. From the copyright: This product includes software developed by Chris Provenzano, the University of California, Berkeley, and contributors. We are currently using version 1_60_beta6 patched by Monty (see
mit-pthreads/Changes-mysql).Jean-loup Gailly and Mark Adler
For the zlib library (used on MySQL on Windows).
Bjorn Benson
For his safe_malloc (memory checker) package which is used in when you configure MySQL with
--debug.Free Software Foundation
The
readlinelibrary (used by the mysql command-line client).The NetBSD foundation
The
libeditpackage (optionally used by the mysql command-line client).
The following is a list of creators/maintainers of some of the most important API/packages/applications that a lot of people use with MySQL.
We can't list every possible package here because the list would then be way to hard to maintain. For other packages, please refer to the software portal at http://solutions.mysql.com/software/.
Tim Bunce, Alligator Descartes
For the
DBD(Perl) interface.Andreas Koenig
<a.koenig@mind.de>For the Perl interface for MySQL Server.
Jochen Wiedmann
<wiedmann@neckar-alb.de>For maintaining the Perl
DBD::mysqlmodule.Eugene Chan
<eugene@acenet.com.sg>For porting PHP for MySQL Server.
Georg Richter
MySQL 4.1 testing and bug hunting. New PHP 5.0
mysqliextension (API) for use with MySQL 4.1 and up.Giovanni Maruzzelli
<maruzz@matrice.it>For porting iODBC (Unix ODBC).
Xavier Leroy
<Xavier.Leroy@inria.fr>The author of LinuxThreads (used by the MySQL Server on Linux).
The following is a list of some of the tools we have used to create MySQL. We use this to express our thanks to those that has created them as without these we could not have made MySQL what it is today.
Free Software Foundation
From whom we got an excellent compiler (gcc), an excellent debugger (gdb and the
libclibrary (from which we have borrowedstrto.cto get some code working in Linux).Free Software Foundation & The XEmacs development team
For a really great editor/environment used by almost everybody at MySQL AB.
Julian Seward
Author of
valgrind, an excellent memory checker tool that has helped us find a lot of otherwise hard to find bugs in MySQL.Dorothea Lütkehaus and Andreas Zeller
For
DDD(The Data Display Debugger) which is an excellent graphical front end to gdb).
Although MySQL AB owns all copyrights in the MySQL
server and the MySQL manual, we wish
to recognize the following companies, which helped us finance the
development of the MySQL server, such as by
paying us for developing a new feature or giving us hardware for
development of the MySQL server.
VA Linux / Andover.net
Funded replication.
NuSphere
Editing of the MySQL manual.
Stork Design studio
The MySQL Web site in use between 1998-2000.
Intel
Contributed to development on Windows and Linux platforms.
Compaq
Contributed to Development on Linux/Alpha.
SWSoft
Development on the embedded mysqld version.
FutureQuest
--skip-show-database
Symbols
- ! (logical NOT), Logical Operators
- != (not equal), Comparison Functions and Operators
- ", Database, Table, Index, Column, and Alias Names
- %, Arithmetic Operators
- % (modulo), Mathematical Functions
- % (wildcard character), Strings
- & (bitwise AND), Bit Functions
- && (logical AND), Logical Operators
- () (parentheses), Operator Precedence
- (Control-Z) \Z, Strings
- * (multiplication), Arithmetic Operators
- + (addition), Arithmetic Operators
- - (subtraction), Arithmetic Operators
- - (unary minus), Arithmetic Operators
- --config-file option (ndb_mgmd), Command Options for ndb_mgmd
- --connect-string option (MySQL Cluster), Command Options for MySQL Cluster Processes
- --debug option (MySQL Cluster), Command Options for MySQL Cluster Processes
- --execute option (MySQL Cluster), Command Options for MySQL Cluster Processes
- --help option
- MySQL Cluster programs, Command Options for MySQL Cluster Processes
- --initial option (ndbd), Command Options for ndbd
- --initial-start option (ndbd), Command Options for ndbd
- --ndb-connectstring option (MySQL Cluster), MySQL Cluster-Related Command Options for mysqld
- --ndbcluster option (MySQL Cluster), MySQL Cluster-Related Command Options for mysqld
- --nodaemon option (ndbd), Command Options for ndbd
- --nostart option (ndbd), Command Options for ndbd
- --nowait-nodes option (ndbd), Command Options for ndbd
- --password option, Keeping Your Password Secure
- --usage option
- MySQL Cluster programs, Command Options for MySQL Cluster Processes
- --version option (MySQL Cluster), Command Options for MySQL Cluster Processes
- -? option
- MySQL Cluster programs, Command Options for MySQL Cluster Processes
- -c option (MySQL Cluster), Command Options for MySQL Cluster Processes
- -c option (ndb_mgmd) (OBSOLETE), Command Options for ndb_mgmd
- -e option (MySQL Cluster), Command Options for MySQL Cluster Processes
- -f option (ndb_mgmd), Command Options for ndb_mgmd
- -n option (ndbd), Command Options for ndbd
- -p option, Keeping Your Password Secure
- -V option (MySQL Cluster), Command Options for MySQL Cluster Processes
- .my.cnf file, Using Option Files, Connecting to the MySQL Server, Causes of Access denied Errors, Keeping Your Password Secure, Using Client Programs in a Multiple-Server Environment
- .mysql_history file, mysql Options
- .pid (process ID) file, Setting Up a Table Maintenance Schedule
- / (division), Arithmetic Operators
- /etc/passwd, Making MySQL Secure Against Attackers, SELECT Syntax
- := (assignment), User-Defined Variables
- < (less than), Comparison Functions and Operators
- <<, Calculating Visits Per Day
- << (left shift), Bit Functions
- <= (less than or equal), Comparison Functions and Operators
- <=> (equal to), Comparison Functions and Operators
- <> (not equal), Comparison Functions and Operators
- = (assignment), User-Defined Variables
- = (equal), Comparison Functions and Operators
- > (greater than), Comparison Functions and Operators
- >= (greater than or equal), Comparison Functions and Operators
- >> (right shift), Bit Functions
- [API] (MySQL Cluster), SQL Node and API Node Configuration Parameters
- [MGM] (MySQL Cluster), Management Node Configuration Parameters
- [NDBD] (MySQL Cluster), Data Node Configuration Parameters
- [NDBD_DEFAULT] (MySQL Cluster), Data Node Configuration Parameters
- [NDB_MGMD] (MySQL Cluster), Management Node Configuration Parameters
- [SQL] (MySQL Cluster), SQL Node and API Node Configuration Parameters
- \" (double quote), Strings
- \' (single quote), Strings
- \. (mysql client command), Using mysql in Batch Mode, Executing SQL Statements from a Text File
- \0 (ASCII 0), Strings
- \b (backspace), Strings
- \n (linefeed), Strings
- \n (newline), Strings
- \r (carriage return), Strings
- \t (tab), Strings
- \Z (Control-Z) ASCII 26, Strings
- \\ (escape), Strings
- ^ (bitwise XOR), Bit Functions
- _ (wildcard character), Strings
- _rowid, CREATE TABLE Syntax
- `, Database, Table, Index, Column, and Alias Names
- | (bitwise OR), Bit Functions
- || (logical OR), Logical Operators
- ~, Bit Functions
A
- abort-slave-event-count option
- mysqld, Command Options
- aborted clients, Communication Errors and Aborted Connections
- aborted connection, Communication Errors and Aborted Connections
- ABS(), Mathematical Functions
- access control, Access Control, Stage 1: Connection Verification
- access denied errors, Access denied
- access privileges, The MySQL Access Privilege System
- account privileges
- accounts
- anonymous user, Securing the Initial MySQL Accounts
- root, Securing the Initial MySQL Accounts
- ACID, Transactions and Atomic Operations, InnoDB Overview
- ACLs, The MySQL Access Privilege System
- ACOS(), Mathematical Functions
- Active Server Pages (ASP), Using Connector/ODBC with Active Server Pages (ASP)
- ActiveState Perl, Installing ActiveState Perl on Windows
- add-drop-database option
- mysqldump, mysqldump — A Database Backup Program
- add-drop-table option
- mysqldump, mysqldump — A Database Backup Program
- add-locks option
- mysqldump, mysqldump — A Database Backup Program
- ADDDATE(), Date and Time Functions
- adding
- character sets, Adding a New Character Set
- native functions, Adding a New Native Function
- new account privileges, Adding New User Accounts to MySQL
- new functions, Adding New Functions to MySQL
- new user privileges, Adding New User Accounts to MySQL
- new users, Installing MySQL from tar.gz Packages on Other Unix-Like Systems, Source Installation Overview
- procedures, Adding New Procedures to MySQL
- user-defined functions, Adding a New User-Defined Function
- addition (+), Arithmetic Operators
- ADDTIME(), Date and Time Functions
- addtodest option
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- AES_DECRYPT(), Encryption and Compression Functions
- AES_ENCRYPT(), Encryption and Compression Functions
- age
- calculating, Date Calculations
- alias, Problems with Column Aliases
- alias names
- case sensitivity, Identifier Case Sensitivity
- aliases
- for expressions, GROUP BY and HAVING with Hidden Fields
- for tables, SELECT Syntax
- in GROUP BY clauses, GROUP BY and HAVING with Hidden Fields
- names, Database, Table, Index, Column, and Alias Names
- on expressions, SELECT Syntax
- ALL, SELECT Syntax, Subqueries with ALL
- all-databases option
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqldump, mysqldump — A Database Backup Program
- all-in-1 option
- allow-keywords option
- mysqldump, mysqldump — A Database Backup Program
- allow-suspicious-udfs option
- allowold option
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- ALLOW_INVALID_DATES SQL mode, SQL Modes
- ALTER COLUMN, ALTER TABLE Syntax
- ALTER DATABASE, ALTER DATABASE Syntax
- ALTER FUNCTION, ALTER PROCEDURE and ALTER FUNCTION Syntax
- ALTER PROCEDURE, ALTER PROCEDURE and ALTER FUNCTION Syntax
- ALTER SCHEMA, ALTER DATABASE Syntax
- ALTER TABLE, ALTER TABLE Syntax, Problems with ALTER TABLE
- ALTER VIEW, ALTER VIEW Syntax
- altering
- database, ALTER DATABASE Syntax
- schema, ALTER DATABASE Syntax
- analyze option
- myisamchk, Other myisamchk Options
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- ANALYZE TABLE, ANALYZE TABLE Syntax
- AND
- bitwise, Bit Functions
- logical, Logical Operators
- angel-pid-file option
- mysqlmanager, MySQL Instance Manager Command Options
- anonymous user, Securing the Initial MySQL Accounts, Access Control, Stage 1: Connection Verification, Access Control, Stage 2: Request Verification
- ANSI mode
- running, Running MySQL in ANSI Mode
- ansi option
- mysqld, Command Options
- ANSI SQL mode, SQL Modes
- ANSI_QUOTES SQL mode, SQL Modes
- answering questions
- etiquette, Guidelines for Using the Mailing Lists
- ANY, Subqueries with ANY, IN, and SOME
- Apache, Using MySQL with Apache
- API node (MySQL Cluster)
- defined, Basic MySQL Cluster Concepts
- API nodes, MySQL Server Process Usage for MySQL Cluster
- API's
- list of, Packages that support MySQL
- APIs, APIs and Libraries
- Perl, MySQL Perl API
- approximate-value literals, Precision Math
- ArbitrationDelay, Defining the Management Server, Defining SQL and Other API Nodes
- ArbitrationRank, Defining the Management Server, Defining SQL and Other API Nodes
- ArbitrationTimeout (MySQL Cluster configuration parameter), Defining Data Nodes
- arbitrator, MySQL 5.0 FAQ — MySQL Cluster
- ARCHIVE storage engine, Storage Engines, The ARCHIVE Storage Engine
- Area(), Polygon Functions, MultiPolygon Functions
- argument processing, UDF Argument Processing
- arithmetic expressions, Arithmetic Operators
- arithmetic functions, Bit Functions
- AS, SELECT Syntax, JOIN Syntax
- AsBinary(), Geometry Format Conversion Functions
- ASCII(), String Functions
- ASIN(), Mathematical Functions
- AsText(), Geometry Format Conversion Functions
- ATAN(), Mathematical Functions
- ATAN2(), Mathematical Functions
- attackers
- security against, Making MySQL Secure Against Attackers
- AUTO-INCREMENT
- auto-rehash option
- mysql, mysql Options
- auto-repair option
- autoclose option
- mysqld_safe, mysqld_safe — MySQL Server Startup Script
- AUTO_INCREMENT, Using AUTO_INCREMENT
- and NULL values, Problems with NULL Values
- AVG(), GROUP BY (Aggregate) Functions
- AVG(DISTINCT), GROUP BY (Aggregate) Functions
B
- backslash
- escape character, Literal Values
- backspace (\b), Strings
- backup option
- myisamchk, myisamchk Repair Options
- myisampack, myisampack — Generate Compressed, Read-Only MyISAM Tables
- BACKUP TABLE, BACKUP TABLE Syntax
- BackupDataBufferSize, Configuration for Cluster Backup
- BackupDataBufferSize (MySQL Cluster configuration parameter), Defining Data Nodes
- BackupDataDir, Defining Data Nodes
- BackupLogBufferSize, Defining Data Nodes, Configuration for Cluster Backup
- BackupMaxWriteSize, Defining Data Nodes, Configuration for Cluster Backup
- BackupMemory, Defining Data Nodes, Configuration for Cluster Backup
- backups, Database Backups
- backups, troubleshooting
- in MySQL Cluster, Backup Troubleshooting
- BackupWriteSize, Defining Data Nodes, Configuration for Cluster Backup
- basedir option
- mysqld, Command Options
- mysqld_safe, mysqld_safe — MySQL Server Startup Script
- mysql_upgrade, mysql_upgrade — Check Tables for MySQL Upgrade
- batch mode, Using mysql in Batch Mode
- batch option
- mysql, mysql Options
- BatchByteSize, Defining SQL and Other API Nodes
- BatchSize, Defining SQL and Other API Nodes
- BatchSizePerLocalScan, Defining Data Nodes
- BDB storage engine, Storage Engines, The BDB (BerkeleyDB) Storage Engine
- BDB tables, Transactions and Atomic Operations
- bdb-home option
- mysqld, BDB Startup Options
- bdb-lock-detect option
- mysqld, BDB Startup Options
- bdb-logdir option
- mysqld, BDB Startup Options
- bdb-no-recover option
- mysqld, BDB Startup Options
- bdb-no-sync option
- mysqld, BDB Startup Options
- bdb-shared-data option
- mysqld, BDB Startup Options
- bdb-tmpdir option
- mysqld, BDB Startup Options
- BdMPolyFromText(), Creating Geometry Values Using WKT Functions
- BdMPolyFromWKB(), Creating Geometry Values Using WKB Functions
- BdPolyFromText(), Creating Geometry Values Using WKT Functions
- BdPolyFromWKB(), Creating Geometry Values Using WKB Functions
- BEGIN, START TRANSACTION, COMMIT, and ROLLBACK Syntax, BEGIN ... END Compound Statement Syntax
- XA transactions, XA Transaction SQL Syntax
- benchmark suite, The MySQL Benchmark Suite
- BENCHMARK(), Information Functions
- benchmarks, Using Your Own Benchmarks
- BerkeleyDB storage engine, Storage Engines, The BDB (BerkeleyDB) Storage Engine
- BETWEEN ... AND, Comparison Functions and Operators
- big5, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- Big5 Chinese character encoding, Case Sensitivity in Searches
- BIGINT data type, Overview of Numeric Types
- BIN(), String Functions
- BINARY, Cast Functions and Operators
- BINARY data type, Overview of String Types, The BINARY and VARBINARY Types
- binary distributions, MySQL Binaries Compiled by MySQL AB
- binary log, The Binary Log
- binary logging
- and MySQL Cluster, Issues Exclusive to MySQL Cluster
- bind-address option
- mysqld, Command Options
- mysqlmanager, MySQL Instance Manager Command Options
- binlog-do-db option
- mysqld, The Binary Log
- binlog-ignore-db option
- mysqld, The Binary Log
- BIT data type, Overview of Numeric Types
- BitKeeper tree, Installing from the Development Source Tree
- BIT_AND(), GROUP BY (Aggregate) Functions
- BIT_COUNT, Calculating Visits Per Day
- BIT_COUNT(), Bit Functions
- bit_functions
- example, Calculating Visits Per Day
- BIT_LENGTH(), String Functions
- BIT_OR, Calculating Visits Per Day
- BIT_OR(), GROUP BY (Aggregate) Functions
- BIT_XOR(), GROUP BY (Aggregate) Functions
- BLACKHOLE storage engine, Storage Engines, The BLACKHOLE Storage Engine
- BLOB
- inserting binary data, Strings
- size, Data Type Storage Requirements
- BLOB columns
- default values, The BLOB and TEXT Types
- indexing, Column Indexes, CREATE TABLE Syntax
- BLOB data type, Overview of String Types, The BLOB and TEXT Types
- block-search option
- myisamchk, Other myisamchk Options
- BOOL data type, Overview of Numeric Types
- BOOLEAN data type, Overview of Numeric Types
- bootstrap option
- mysqld, Command Options
- Borland Builder 4, Using Connector/ODBC with Borland Builder 4
- Borland C++ compiler, Building MySQL from Source Using Borland C++
- Boundary(), General Geometry Functions
- brackets
- square, Data Types
- brief option
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- buffer sizes
- client, APIs and Libraries
- mysqld server, Tuning Server Parameters
- Buffer(), Spatial Operators
- bug reports
- criteria for, How to Report Bugs or Problems
- bugs
- known, Known Issues in MySQL
- reporting, How to Report Bugs or Problems
- bugs database, How to Report Bugs or Problems
- bugs.mysql.com, How to Report Bugs or Problems
- building
- client programs, Building Client Programs
C
- C API
- data types, MySQL C API
- functions, C API Function Overview
- linking problems, Problems Linking with the C API
- C Prepared statement API
- functions, C API Prepared Statement Function Overview
- C++ APIs, MySQL C++ API
- C++ Builder, Using Connector/ODBC with C++ Builder
- C++ compiler
- C++ compiler cannot create executables, Dealing with Problems Compiling MySQL
- C:\my.cnf file, Using Client Programs in a Multiple-Server Environment
- CACHE INDEX, CACHE INDEX Syntax
- caches
- clearing, FLUSH Syntax
- calculating
- dates, Date Calculations
- calendar, What Calendar Is Used By MySQL?
- CALL, CALL Statement Syntax
- calling sequences for aggregate functions
- calling sequences for simple functions
- can't create/write to file, Can't create/write to file
- carriage return (\r), Strings
- CASE, Control Flow Functions, CASE Statement
- case sensitivity
- in access checking, How the Privilege System Works
- in identifiers, Identifier Case Sensitivity
- in names, Identifier Case Sensitivity
- in searches, Case Sensitivity in Searches
- in string comparisons, String Comparison Functions
- case-sensitivity
- of database names, MySQL Extensions to Standard SQL
- of table names, MySQL Extensions to Standard SQL
- CAST, Cast Functions and Operators
- cast functions, Cast Functions and Operators
- cast operators, Cast Functions and Operators
- casts, Type Conversion in Expression Evaluation, Comparison Functions and Operators, Cast Functions and Operators
- CC environment variable, Typical configure Options, Dealing with Problems Compiling MySQL, Environment Variables
- cc1plus problems, Dealing with Problems Compiling MySQL
- CEILING(), Mathematical Functions
- Centroid(), MultiPolygon Functions
- CFLAGS environment variable, Typical configure Options, Dealing with Problems Compiling MySQL, Environment Variables
- CHANGE MASTER TO, CHANGE MASTER TO Syntax
- ChangeLog, MySQL Change History
- changes
- Cluster, Changes in MySQL Cluster
- log, MySQL Change History
- MySQL 5.0, Changes in release 5.0.x (Production)
- MySQL Community Server, MySQL Community Server Enhancements and Release Notes
- MySQL Enterprise, MySQL Enterprise Release Notes
- changes to privileges, Access Control, Stage 2: Request Verification
- changing
- column, ALTER TABLE Syntax
- column order, How to Change the Order of Columns in a Table
- field, ALTER TABLE Syntax
- table, ALTER TABLE Syntax, Problems with ALTER TABLE
- changing socket location, Typical configure Options, Starting and Stopping MySQL Automatically, How to Protect or Change the MySQL Unix Socket File
- CHAR data type, Overview of String Types, String Types
- CHAR VARYING data type, Overview of String Types
- CHAR(), String Functions
- CHARACTER data type, Overview of String Types
- character sets, Typical configure Options, The Character Set Used for Data and Sorting
- adding, Adding a New Character Set
- Character sets, Character Set Support
- CHARACTER VARYING data type, Overview of String Types
- character-set-client-handshake option
- mysqld, Command Options
- character-set-filesystem option
- mysqld, Command Options
- character-set-server option
- mysqld, Command Options
- character-sets-dir option
- myisamchk, myisamchk Repair Options
- myisampack, myisampack — Generate Compressed, Read-Only MyISAM Tables
- mysql, mysql Options
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- mysqlbinlog, mysqlbinlog — Utility for Processing Binary Log Files
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqld, Command Options
- mysqldump, mysqldump — A Database Backup Program
- mysqlimport, mysqlimport — A Data Import Program
- mysqlshow, mysqlshow — Display Database, Table, and Column Information
- characters
- multi-byte, Multi-Byte Character Support
- CHARACTER_LENGTH(), String Functions
- CHARACTER_SETS
- INFORMATION_SCHEMA table, The INFORMATION_SCHEMA CHARACTER_SETS Table
- charset option
- CHARSET(), Information Functions
- CHAR_LENGTH(), String Functions
- check option
- myisamchk, myisamchk Check Options
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- check options
- myisamchk, myisamchk Check Options
- CHECK TABLE, CHECK TABLE Syntax
- check-only-changed option
- myisamchk, myisamchk Check Options
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- check-upgrade option
- checking
- tables for errors, How to Check MyISAM Tables for Errors
- CHECKPOINT Events (MySQL Cluster), Log Events
- checkpoint option
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- Checksum, Cluster TCP/IP Connections
- Checksum (MySQL Cluster), Shared-Memory Connections, SCI Transport Connections
- checksum errors, Solaris Notes
- CHECKSUM TABLE, CHECKSUM TABLE Syntax
- Chinese, Case Sensitivity in Searches
- Chinese, Japanese, Korean character sets
- frequently asked questions, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- choosing
- a MySQL version, Choosing Which MySQL Distribution to Install
- choosing types, Choosing the Right Type for a Column
- chroot option
- mysqld, Command Options
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- CJK
- CJK (Chinese, Japanese, Korean)
- Access, PHP, etc., MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- availability of specific characters, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- available character sets, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- big5, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- character sets available, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- characters displayed as question marks, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- CJKV, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- collations, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- conversion problems with Japanese character sets, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- data truncation, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- Database and table names, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- documentation in Chinese, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- documentation in Japanese, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- documentation in Korean, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- gb2312, gbk, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- Japanese character sets, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- Korean character set, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- LIKE and FULLTEXT, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- MySQL 4.0 behavior, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- ORDER BY treatment, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- problems with Access, PHP, etc., MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- problems with Big5 character sets (Chinese), MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- problems with data truncation, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- problems with euckr character set (Korean), MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- problems with GB character sets (Chinese), MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- problems with LIKE and FULLTEXT, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- problems with Yen sign (Japanese), MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- rejected characters, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- sort order problems, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- sorting problems, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- testing availability of characters, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- Unicode collations, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- Vietnamese, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- Yen sign, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- clear option
- mysql_tableinfo, mysql_tableinfo — Generate Database Metadata
- clear-only option
- mysql_tableinfo, mysql_tableinfo — Generate Database Metadata
- clearing
- caches, FLUSH Syntax
- client programs, Overview of Client and Utility Programs
- building, Building Client Programs
- client tools, APIs and Libraries
- clients
- threaded, How to Make a Threaded Client
- CLOSE, Cursor CLOSE Statement
- closing
- cluster logs, Event Reports Generated in MySQL Cluster, Logging Management Commands
- Clustering, MySQL Cluster
- CLUSTERLOG commands (MySQL Cluster), Logging Management Commands
- CLUSTERLOG STATISTICS command (MySQL Cluster), Using CLUSTERLOG STATISTICS
- CMake, Building MySQL from Source Using CMake and Visual Studio
- COALESCE(), Comparison Functions and Operators
- COERCIBILITY(), Information Functions
- col option
- mysql_tableinfo, mysql_tableinfo — Generate Database Metadata
- ColdFusion, Using Connector/ODBC with ColdFusion
- collating
- strings, String Collating Support
- COLLATION(), Information Functions
- collation-server option
- mysqld, Command Options
- COLLATIONS
- INFORMATION_SCHEMA table, The INFORMATION_SCHEMA COLLATIONS Table
- COLLATION_CHARACTER_SET_APPLICABILITY
- INFORMATION_SCHEMA table, The INFORMATION_SCHEMA COLLATION_CHARACTER_SET_APPLICABILITY Table
- column
- changing, ALTER TABLE Syntax
- types, Data Types
- column comments, CREATE TABLE Syntax
- column names
- case sensitivity, Identifier Case Sensitivity
- column-names option
- mysql, mysql Options
- columns
- changing, How to Change the Order of Columns in a Table
- indexes, Column Indexes
- names, Database, Table, Index, Column, and Alias Names
- other types, Using Data Types from Other Database Engines
- selecting, Selecting Particular Columns
- storage requirements, Data Type Storage Requirements
- COLUMNS
- INFORMATION_SCHEMA table, The INFORMATION_SCHEMA COLUMNS Table
- columns option
- mysqlimport, mysqlimport — A Data Import Program
- COLUMN_PRIVILEGES
- INFORMATION_SCHEMA table, The INFORMATION_SCHEMA COLUMN_PRIVILEGES Table
- comma-separated values data, reading, LOAD DATA INFILE Syntax, SELECT Syntax
- command options
- mysql, mysql Options
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- mysqld, Command Options
- command options (MySQL Cluster), Command Options for MySQL Cluster Processes
- mysqld, MySQL Cluster-Related Command Options for mysqld
- ndbd, Command Options for ndbd
- ndb_mgm, Command Options for ndb_mgm
- ndb_mgmd, Command Options for ndb_mgmd
- command syntax, Conventions Used in This Manual
- command-line history
- mysql, mysql Options
- commands
- for binary distribution, Installing MySQL from tar.gz Packages on Other Unix-Like Systems
- commands out of sync, Commands out of sync
- Comment syntax, Comment Syntax
- comments
- adding, Comment Syntax
- starting, '--' as the Start of a Comment
- comments option
- mysqldump, mysqldump — A Database Backup Program
- COMMIT, Transactions and Atomic Operations, START TRANSACTION, COMMIT, and ROLLBACK Syntax
- XA transactions, XA Transaction SQL Syntax
- commit option
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- compact option
- mysqldump, mysqldump — A Database Backup Program
- comparison operators, Comparison Functions and Operators
- compatibility
- between MySQL versions, Upgrading from MySQL 4.1 to 5.0
- with mSQL, String Comparison Functions
- with ODBC, Identifier Qualifiers, Overview of Numeric Types, Type Conversion in Expression Evaluation, Comparison Functions and Operators, CREATE TABLE Syntax, JOIN Syntax
- with Oracle, MySQL Extensions to Standard SQL, GROUP BY (Aggregate) Functions, DESCRIBE Syntax
- with PostgreSQL, MySQL Extensions to Standard SQL
- with standard SQL, MySQL Standards Compliance
- with Sybase, USE Syntax
- compatible option
- mysqldump, mysqldump — A Database Backup Program
- compiler
- C++ gcc, Typical configure Options
- compiling
- on Windows, Compiling MySQL Clients on Windows
- optimizing, System Factors and Startup Parameter Tuning
- problems, Dealing with Problems Compiling MySQL
- speed, How Compiling and Linking Affects the Speed of MySQL
- statically, Typical configure Options
- user-defined functions, Compiling and Installing User-Defined Functions
- complete-insert option
- mysqldump, mysqldump — A Database Backup Program
- compliance
- compress option
- mysql, mysql Options
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqldump, mysqldump — A Database Backup Program
- mysqlimport, mysqlimport — A Data Import Program
- mysqlshow, mysqlshow — Display Database, Table, and Column Information
- COMPRESS(), Encryption and Compression Functions
- compressed tables, Compressed Table Characteristics
- comp_err, Overview of Server-Side Programs
- charset option, comp_err — Compile MySQL Error Message File
- debug option, comp_err — Compile MySQL Error Message File
- debug-info option, comp_err — Compile MySQL Error Message File
- header_file option, comp_err — Compile MySQL Error Message File
- help option, comp_err — Compile MySQL Error Message File
- in_file option, comp_err — Compile MySQL Error Message File
- name_file option, comp_err — Compile MySQL Error Message File
- out_dir option, comp_err — Compile MySQL Error Message File
- out_file option, comp_err — Compile MySQL Error Message File
- statefile option, comp_err — Compile MySQL Error Message File
- version option, comp_err — Compile MySQL Error Message File
- CONCAT(), String Functions
- CONCAT_WS(), String Functions
- concurrent inserts, Internal Locking Methods, Concurrent Inserts
- Conditions, DECLARE Conditions
- config-file option
- mysqld_multi, mysqld_multi — Manage Multiple MySQL Servers
- my_print_defaults, my_print_defaults — Display Options from Option Files
- ndb_config, ndb_config — Extract NDB Configuration Information
- config.cache, Dealing with Problems Compiling MySQL
- config.cache file, Dealing with Problems Compiling MySQL
- config.ini (MySQL Cluster), Multi-Computer Configuration, Configuration File, Basic Example Configuration, ndb_mgmd — The Management Server Process
- configuration
- MySQL Cluster, Overview of Cluster Configuration Parameters
- configuration files, Causes of Access denied Errors
- configuration options, Typical configure Options
- configure
- disable-grant-options option, Typical configure Options
- enable-thread-safe-client option, Typical configure Options
- localstatedir option, Typical configure Options
- previx option, Typical configure Options
- running after prior invocation, Dealing with Problems Compiling MySQL
- with-big-tables option, Typical configure Options
- with-charset option, Typical configure Options
- with-collation option, Typical configure Options
- with-debug option, Typical configure Options
- with-embedded-server option, Typical configure Options
- with-extra-charsets option, Typical configure Options
- with-unix-socket-path option, Typical configure Options
- without-server option, Typical configure Options
- configure option
- --with-low-memory, Dealing with Problems Compiling MySQL
- configure script, Typical configure Options
- configuring backups
- in MySQL Cluster, Configuration for Cluster Backup
- configuring MySQL Cluster, Simple Multi-Computer How-To, MySQL Cluster Configuration, MySQL Server Process Usage for MySQL Cluster, ndb_mgmd — The Management Server Process
- Configuring MySQL Cluster (concepts), Basic MySQL Cluster Concepts
- connecting
- remotely with SSH, Connecting to MySQL Remotely from Windows with SSH
- to the server, Connecting to and Disconnecting from the Server, Connecting to the MySQL Server
- verification, Access Control, Stage 1: Connection Verification
- connection
- CONNECTION Events (MySQL Cluster), Log Events
- CONNECTION_ID(), Information Functions
- Connector/JDBC, Connectors
- Connector/MXJ, Connectors
- Connector/NET, Connectors, MySQL Connector/NET
- reporting problems, Connector/NET Support
- Connector/ODBC, Connectors, MySQL Connector/ODBC
- Borland, Using Connector/ODBC with Borland Applications
- Borland Database Engine, Using Connector/ODBC with Borland Applications
- reporting problems, Connector/ODBC Support
- Connectors
- MySQL, Connectors
- connectstring, The Cluster Connectstring
- connect_timeout variable, mysql Options, mysqladmin — Client for Administering a MySQL Server
- console option
- mysqld, Command Options
- constant table, Optimizing Queries with EXPLAIN, WHERE Clause Optimization
- constraints, How MySQL Deals with Constraints
- CONSTRAINTS
- INFORMATION_SCHEMA table, The INFORMATION_SCHEMA TABLE_CONSTRAINTS Table
- Contains(), Functions That Test Spatial Relationships Between Geometries
- contributing companies
- list of, Supporters of MySQL
- contributors
- list of, Contributors to MySQL
- control access, Access Control, Stage 1: Connection Verification
- control flow functions, Control Flow Functions
- CONV(), String Functions
- conventions
- typographical, Conventions Used in This Manual
- CONVERT, Cast Functions and Operators
- CONVERT TO, ALTER TABLE Syntax
- CONVERT_TZ(), Date and Time Functions
- ConvexHull(), Spatial Operators
- copy option
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- copying databases, Copying MySQL Databases to Another Machine
- copying tables, CREATE TABLE Syntax
- core-file option
- mysqld, Command Options
- core-file-size option
- mysqld_safe, mysqld_safe — MySQL Server Startup Script
- correct-checksum option
- myisamchk, myisamchk Repair Options
- correlated subqueries, Correlated Subqueries
- COS(), Mathematical Functions
- COT(), Mathematical Functions
- count option
- COUNT(), GROUP BY (Aggregate) Functions
- COUNT(DISTINCT), GROUP BY (Aggregate) Functions
- counting
- table rows, Counting Rows
- crash
- recovery, Using myisamchk for Crash Recovery
- repeated, What to Do If MySQL Keeps Crashing
- crash-me, The MySQL Benchmark Suite
- crash-me program, Designing Applications for Portability, The MySQL Benchmark Suite
- CRC32(), Mathematical Functions
- CREATE DATABASE, CREATE DATABASE Syntax
- CREATE FUNCTION, CREATE PROCEDURE and CREATE FUNCTION Syntax, CREATE FUNCTION Syntax
- CREATE INDEX, CREATE INDEX Syntax
- CREATE PROCEDURE, CREATE PROCEDURE and CREATE FUNCTION Syntax
- CREATE SCHEMA, CREATE DATABASE Syntax
- CREATE TABLE, CREATE TABLE Syntax
- CREATE TRIGGER, CREATE TRIGGER Syntax
- CREATE USER, CREATE USER Syntax
- CREATE VIEW, CREATE VIEW Syntax
- create-options option
- mysqldump, mysqldump — A Database Backup Program
- creating
- bug reports, How to Report Bugs or Problems
- database, CREATE DATABASE Syntax
- databases, Creating and Using a Database
- default startup options, Using Option Files
- function, CREATE FUNCTION Syntax
- schema, CREATE DATABASE Syntax
- tables, Creating a Table
- creating user accounts, CREATE USER Syntax
- CROSS JOIN, JOIN Syntax
- Crosses(), Functions That Test Spatial Relationships Between Geometries
- CR_SERVER_GONE_ERROR, MySQL server has gone away
- CR_SERVER_LOST_ERROR, MySQL server has gone away
- CSV data, reading, LOAD DATA INFILE Syntax, SELECT Syntax
- CSV storage engine, Storage Engines, The CSV Storage Engine
- CURDATE(), Date and Time Functions
- CURRENT_DATE, Date and Time Functions
- CURRENT_TIME, Date and Time Functions
- CURRENT_TIMESTAMP, Date and Time Functions
- CURRENT_USER(), Information Functions
- Cursors, Cursors
- CURTIME(), Date and Time Functions
- customers
- of MySQL, What We Have Used MySQL For
- CXX environment variable, Typical configure Options, Dealing with Problems Compiling MySQL, Environment Variables
- CXXFLAGS environment variable, Typical configure Options, Dealing with Problems Compiling MySQL, Environment Variables
D
- data
- character sets, The Character Set Used for Data and Sorting
- importing, Executing SQL Statements from a Text File
- loading into tables, Loading Data into a Table
- retrieving, Retrieving Information from a Table
- size, Make Your Data as Small as Possible
- data node (MySQL Cluster)
- defined, Basic MySQL Cluster Concepts
- Data truncation with CJK characters, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- data type
- BIGINT, Overview of Numeric Types
- BINARY, Overview of String Types, The BINARY and VARBINARY Types
- BIT, Overview of Numeric Types
- BLOB, Overview of String Types, The BLOB and TEXT Types
- BOOL, Overview of Numeric Types, Using Data Types from Other Database Engines
- BOOLEAN, Overview of Numeric Types, Using Data Types from Other Database Engines
- CHAR, Overview of String Types, String Types
- CHAR VARYING, Overview of String Types
- CHARACTER, Overview of String Types
- CHARACTER VARYING, Overview of String Types
- DATE, Overview of Date and Time Types, The DATETIME, DATE, and TIMESTAMP Types
- DATETIME, Overview of Date and Time Types, The DATETIME, DATE, and TIMESTAMP Types
- DEC, Overview of Numeric Types
- DECIMAL, Overview of Numeric Types, Precision Math
- DOUBLE, Overview of Numeric Types
- DOUBLE PRECISION, Overview of Numeric Types
- ENUM, Overview of String Types, The ENUM Type
- FIXED, Overview of Numeric Types
- FLOAT, Overview of Numeric Types
- GEOMETRY, MySQL Spatial Data Types
- GEOMETRYCOLLECTION, MySQL Spatial Data Types
- INT, Overview of Numeric Types
- INTEGER, Overview of Numeric Types
- LINESTRING, MySQL Spatial Data Types
- LONG, The BLOB and TEXT Types
- LONGBLOB, Overview of String Types
- LONGTEXT, Overview of String Types
- MEDIUMBLOB, Overview of String Types
- MEDIUMINT, Overview of Numeric Types
- MEDIUMTEXT, Overview of String Types
- MULTILINESTRING, MySQL Spatial Data Types
- MULTIPOINT, MySQL Spatial Data Types
- MULTIPOLYGON, MySQL Spatial Data Types
- NATIONAL CHAR, Overview of String Types
- NCHAR, Overview of String Types
- NUMERIC, Overview of Numeric Types
- POINT, MySQL Spatial Data Types
- POLYGON, MySQL Spatial Data Types
- REAL, Overview of Numeric Types
- SET, Overview of String Types, The SET Type
- SMALLINT, Overview of Numeric Types
- TEXT, Overview of String Types, The BLOB and TEXT Types
- TIME, Overview of Date and Time Types, The TIME Type
- TIMESTAMP, Overview of Date and Time Types, The DATETIME, DATE, and TIMESTAMP Types
- TINYBLOB, Overview of String Types
- TINYINT, Overview of Numeric Types
- TINYTEXT, Overview of String Types
- VARBINARY, Overview of String Types, The BINARY and VARBINARY Types
- VARCHAR, Overview of String Types, String Types
- VARCHARACTER, Overview of String Types
- YEAR, Overview of Date and Time Types, The YEAR Type
- data types, Data Types
- C API, MySQL C API
- overview, Data Type Overview
- data-file-length option
- myisamchk, myisamchk Repair Options
- database
- altering, ALTER DATABASE Syntax
- creating, CREATE DATABASE Syntax
- deleting, DROP DATABASE Syntax
- database design, Design Choices
- Database information
- obtaining, SHOW Syntax
- database metadata, The INFORMATION_SCHEMA Database
- database names
- case sensitivity, Identifier Case Sensitivity
- case-sensitivity, MySQL Extensions to Standard SQL
- database option
- mysql, mysql Options
- mysqlbinlog, mysqlbinlog — Utility for Processing Binary Log Files
- DATABASE(), Information Functions
- databases
- backups, Database Backups
- copying, Copying MySQL Databases to Another Machine
- creating, Creating and Using a Database
- defined, What is MySQL?
- information about, Getting Information About Databases and Tables
- names, Database, Table, Index, Column, and Alias Names
- replicating, Replication
- selecting, Creating and Selecting a Database
- symbolic links, Using Symbolic Links for Databases on Unix
- using, Creating and Using a Database
- databases option
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqldump, mysqldump — A Database Backup Program
- DataDir, Defining the Management Server, Defining Data Nodes
- datadir option
- mysqld, Command Options
- mysqld_safe, mysqld_safe — MySQL Server Startup Script
- mysql_upgrade, mysql_upgrade — Check Tables for MySQL Upgrade
- DataJunction, Using Connector/ODBC with Pervasive Software DataJunction
- DataMemory, Defining Data Nodes, Configuring Parameters for Local Checkpoints
- DATE, Problems Using DATE Columns
- date and time functions, Date and Time Functions
- Date and Time types, Date and Time Types
- date calculations, Date Calculations
- DATE columns
- problems, Problems Using DATE Columns
- DATE data type, Overview of Date and Time Types, The DATETIME, DATE, and TIMESTAMP Types
- date functions
- Y2K compliance, Year 2000 Issues and Date Types
- date option
- mysql_explain_log, mysql_explain_log — Use EXPLAIN on Statements in Query Log
- date types, Data Type Storage Requirements
- Y2K issues, Year 2000 Issues and Date Types
- date values
- problems, The DATETIME, DATE, and TIMESTAMP Types
- DATE(), Date and Time Functions
- DATEDIFF(), Date and Time Functions
- DATETIME data type, Overview of Date and Time Types, The DATETIME, DATE, and TIMESTAMP Types
- DATE_ADD(), Date and Time Functions
- DATE_FORMAT(), Date and Time Functions
- DATE_SUB(), Date and Time Functions
- DAY(), Date and Time Functions
- DAYNAME(), Date and Time Functions
- DAYOFMONTH(), Date and Time Functions
- DAYOFWEEK(), Date and Time Functions
- DAYOFYEAR(), Date and Time Functions
- db option
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- db table
- DB2 SQL mode, SQL Modes
- DBI interface, MySQL Perl API
- DBI->quote, Strings
- DBI/DBD interface, MySQL Perl API
- DBI_TRACE environment variable, Environment Variables
- DBI_USER environment variable, Environment Variables
- DEALLOCATE PREPARE, SQL Syntax for Prepared Statements
- debug option
- comp_err, comp_err — Compile MySQL Error Message File
- make_win_bin_dist, make_win_bin_dist — Package MySQL Distribution as ZIP Archive
- myisamchk, myisamchk General Options
- myisampack, myisampack — Generate Compressed, Read-Only MyISAM Tables
- mysql, mysql Options
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- mysqlbinlog, mysqlbinlog — Utility for Processing Binary Log Files
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqld, Command Options
- mysqldump, mysqldump — A Database Backup Program
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- mysqlimport, mysqlimport — A Data Import Program
- mysqlshow, mysqlshow — Display Database, Table, and Column Information
- my_print_defaults, my_print_defaults — Display Options from Option Files
- debug-info option
- comp_err, comp_err — Compile MySQL Error Message File
- mysql, mysql Options
- debugging support, Typical configure Options
- DEC data type, Overview of Numeric Types
- decimal arithmetic, Precision Math
- DECIMAL data type, Overview of Numeric Types, Precision Math
- decimal point, Data Types
- DECLARE, DECLARE Statement Syntax
- DECODE(), Encryption and Compression Functions
- decode_bits myisamchk variable, myisamchk General Options
- DEFAULT
- constraint, Constraints on Invalid Data
- default
- privileges, Securing the Initial MySQL Accounts
- default hostname, Connecting to the MySQL Server
- default installation location, Installation Layouts
- default options, Using Option Files
- DEFAULT value clause, Data Type Default Values, CREATE TABLE Syntax
- default values, MySQL Design Limitations and Tradeoffs, Data Type Default Values, CREATE TABLE Syntax, INSERT Syntax
- BLOB and TEXT columns, The BLOB and TEXT Types
- explicit, Data Type Default Values
- implicit, Data Type Default Values
- suppression, Constraints on Invalid Data
- DEFAULT(), Miscellaneous Functions
- default-character-set option
- mysql, mysql Options
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqld, Command Options
- mysqldump, mysqldump — A Database Backup Program
- mysqlimport, mysqlimport — A Data Import Program
- mysqlshow, mysqlshow — Display Database, Table, and Column Information
- default-collation option
- mysqld, Command Options
- default-mysqld-path option
- mysqlmanager, MySQL Instance Manager Command Options
- default-storage-engine option
- mysqld, Command Options
- default-table-type option
- mysqld, Command Options
- default-time-zone option
- mysqld, Command Options
- defaults-extra-file option, Using Option Files
- mysqld_safe, mysqld_safe — MySQL Server Startup Script
- my_print_defaults, my_print_defaults — Display Options from Option Files
- defaults-file option, Using Option Files
- mysqld_safe, mysqld_safe — MySQL Server Startup Script
- mysqlmanager, MySQL Instance Manager Command Options
- my_print_defaults, my_print_defaults — Display Options from Option Files
- defaults-group-suffix option, Using Option Files
- my_print_defaults, my_print_defaults — Display Options from Option Files
- DEGREES(), Mathematical Functions
- delay-key-write option
- mysqld, Command Options, MyISAM Startup Options
- DELAYED, INSERT DELAYED Syntax
- delayed-insert option
- mysqldump, mysqldump — A Database Backup Program
- delayed_insert_limit, INSERT DELAYED Syntax
- DELETE, DELETE Syntax
- and MySQL Cluster, Limits and Differences from Standard MySQL Limits
- delete option
- mysqlimport, mysqlimport — A Data Import Program
- delete-master-logs option
- mysqldump, mysqldump — A Database Backup Program
- deleting
- database, DROP DATABASE Syntax
- foreign key, ALTER TABLE Syntax, FOREIGN KEY Constraints
- function, DROP FUNCTION Syntax
- index, ALTER TABLE Syntax, DROP INDEX Syntax
- primary key, ALTER TABLE Syntax
- rows, Deleting Rows from Related Tables
- schema, DROP DATABASE Syntax
- table, DROP TABLE Syntax
- user, Removing User Accounts from MySQL, DROP USER Syntax
- users, Removing User Accounts from MySQL, DROP USER Syntax
- deletion
- delimiter option
- mysql, mysql Options
- ndb_select_all, ndb_select_all — Print Rows from NDB Table
- Delphi, Using Connector/ODBC with Delphi
- derived tables, Subqueries in the FROM clause
- des-key-file option
- mysqld, Command Options
- DESC, DESCRIBE Syntax
- descending option
- ndb_select_all, ndb_select_all — Print Rows from NDB Table
- DESCRIBE, Getting Information About Databases and Tables, DESCRIBE Syntax
- description option
- myisamchk, Other myisamchk Options
- design
- choices, Design Choices
- issues, Known Issues in MySQL
- limitations, MySQL Design Limitations and Tradeoffs
- DES_DECRYPT(), Encryption and Compression Functions
- DES_ENCRYPT(), Encryption and Compression Functions
- developers
- list of, Credits
- development source tree, Installing from the Development Source Tree
- Difference(), Spatial Operators
- digits, Data Types
- Dimension(), General Geometry Functions
- directory structure
- default, Installation Layouts
- disable-grant-options option
- configure, Typical configure Options
- disable-keys option
- mysqldump, mysqldump — A Database Backup Program
- disable-log-bin option
- DISCARD TABLESPACE, ALTER TABLE Syntax, Using Per-Table Tablespaces
- disconnect-slave-event-count option
- mysqld, Command Options
- disconnecting
- from the server, Connecting to and Disconnecting from the Server
- Disjoint(), Functions That Test Spatial Relationships Between Geometries
- disk full, How MySQL Handles a Full Disk
- disk issues, Disk Issues
- Diskless, Defining Data Nodes
- disks
- splitting data across, Using Symbolic Links for Databases on Windows
- display size, Data Types
- display triggers, SHOW TRIGGERS Syntax
- display width, Data Types
- displaying
- information
- Cardinality, SHOW INDEX Syntax
- Collation, SHOW INDEX Syntax
- SHOW, SHOW Syntax, SHOW COLUMNS Syntax, SHOW INDEX Syntax, SHOW OPEN TABLES Syntax, SHOW TABLES Syntax
- table status, SHOW TABLE STATUS Syntax
- Distance(), Functions That Test Spatial Relationships Between Geometries
- DISTINCT, Selecting Particular Columns, DISTINCT Optimization, SELECT Syntax
- DISTINCTROW, SELECT Syntax
- DIV, Arithmetic Operators
- division (/), Arithmetic Operators
- DNS, How MySQL Uses DNS
- DO, DO Syntax
- DocBook XML
- documentation source format, About This Manual
- Documentation
- Documenters
- list of, Documenters and translators
- DOUBLE data type, Overview of Numeric Types
- DOUBLE PRECISION data type, Overview of Numeric Types
- double quote (\"), Strings
- downgrades
- downgrading, Downgrading MySQL
- downloading, How to Get MySQL
- drbd
- DRBD, Distributed Replicated Block Device
- DRBD licence, Distributed Replicated Block Device
- DROP DATABASE, DROP DATABASE Syntax
- DROP FOREIGN KEY, ALTER TABLE Syntax, FOREIGN KEY Constraints
- DROP FUNCTION, DROP PROCEDURE and DROP FUNCTION Syntax, DROP FUNCTION Syntax
- DROP INDEX, ALTER TABLE Syntax, DROP INDEX Syntax
- DROP PREPARE, SQL Syntax for Prepared Statements
- DROP PRIMARY KEY, ALTER TABLE Syntax
- DROP PROCEDURE, DROP PROCEDURE and DROP FUNCTION Syntax
- DROP SCHEMA, DROP DATABASE Syntax
- DROP TABLE, DROP TABLE Syntax
- and MySQL Cluster, Limits and Differences from Standard MySQL Limits
- DROP TRIGGER, DROP TRIGGER Syntax
- DROP USER, DROP USER Syntax
- DROP VIEW, DROP VIEW Syntax
- dropping
- dryrun option
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- DUAL, SELECT Syntax
- dump option
- myisam_ftdump, myisam_ftdump — Display Full-Text Index information
- DUMPFILE, SELECT Syntax
- dynamic table characteristics, Dynamic Table Characteristics
E
- Eiffel Wrapper, MySQL Eiffel Wrapper
- ELT(), String Functions
- email lists, MySQL Mailing Lists
- embedded MySQL server library, libmysqld, the Embedded MySQL Server Library
- embedded option
- make_win_bin_dist, make_win_bin_dist — Package MySQL Distribution as ZIP Archive
- enable-named-pipe option
- mysqld, Command Options
- enable-pstack option
- mysqld, Command Options
- enable-thread-safe-client option
- configure, Typical configure Options
- ENCODE(), Encryption and Compression Functions
- ENCRYPT(), Encryption and Compression Functions
- encryption, Basic SSL Concepts
- encryption functions, Encryption and Compression Functions
- END, BEGIN ... END Compound Statement Syntax
- EndPoint(), LineString Functions
- enhancements
- MySQL Community Server, MySQL Community Server Enhancements and Release Notes
- Enhancements
- MySQL Community Server, MySQL Community Server 5.0 Enhancements and Release Notes
- ENTER SINGLE USER MODE command (MySQL Cluster), Commands in the MySQL Cluster Management Client
- entering
- queries, Entering Queries
- ENUM
- ENUM data type, Overview of String Types, The ENUM Type
- Envelope(), General Geometry Functions
- environment variable
- CC, Typical configure Options, Dealing with Problems Compiling MySQL
- CFLAGS, Typical configure Options, Dealing with Problems Compiling MySQL
- CXX, Typical configure Options, Dealing with Problems Compiling MySQL
- CXXFLAGS, Typical configure Options, Dealing with Problems Compiling MySQL
- HOME, mysql Options
- LD_RUN_PATH, Linux Source Distribution Notes, Solaris Notes
- MYSQL_DEBUG, Overview of Client and Utility Programs
- MYSQL_HISTFILE, mysql Options
- MYSQL_HOST, Connecting to the MySQL Server
- MYSQL_PWD, Connecting to the MySQL Server, Overview of Client and Utility Programs
- MYSQL_TCP_PORT, Running Multiple Servers on Unix, Using Client Programs in a Multiple-Server Environment, Overview of Client and Utility Programs
- MYSQL_UNIX_PORT, Running Multiple Servers on Unix, Using Client Programs in a Multiple-Server Environment, Overview of Client and Utility Programs
- PATH, Installing MySQL from tar.gz Packages on Other Unix-Like Systems, Invoking MySQL Programs
- USER, Connecting to the MySQL Server
- Environment variable
- CC, Environment Variables
- CFLAGS, Environment Variables
- CXX, Dealing with Problems Compiling MySQL, Environment Variables
- CXXFLAGS, Environment Variables
- DBI_TRACE, Environment Variables
- DBI_USER, Environment Variables
- HOME, Environment Variables
- LD_LIBRARY_PATH, Problems Using the Perl DBI/DBD Interface
- LD_RUN_PATH, Environment Variables, Problems Using the Perl DBI/DBD Interface
- MYSQL_DEBUG, Environment Variables
- MYSQL_GROUP_SUFFIX, Environment Variables
- MYSQL_HISTFILE, Environment Variables
- MYSQL_HOME, Environment Variables
- MYSQL_HOST, Environment Variables
- MYSQL_PS1, Environment Variables
- MYSQL_PWD, Environment Variables
- MYSQL_TCP_PORT, Environment Variables
- MYSQL_UNIX_PORT, Problems Running mysql_install_db, Environment Variables
- PATH, Environment Variables
- TMPDIR, Problems Running mysql_install_db, Environment Variables
- TZ, Environment Variables, Time Zone Problems
- UMASK, Environment Variables, Problems with File Permissions
- UMASK_DIR, Environment Variables, Problems with File Permissions
- USER, Environment Variables
- Environment variables
- environment variables, Using Environment Variables to Specify Options, Causes of Access denied Errors, Overview of Client and Utility Programs
- list of, Environment Variables
- equal (=), Comparison Functions and Operators
- Equals(), Functions That Test Spatial Relationships Between Geometries
- ERROR Events (MySQL Cluster), Log Events
- error logs (MySQL Cluster), ndbd — The Storage Engine Node Process
- error messages
- can't find file, Problems with File Permissions
- languages, Setting the Error Message Language
- errors
- access denied, Access denied
- checking tables for, How to Check MyISAM Tables for Errors
- common, Problems and Common Errors
- directory checksum, Solaris Notes
- handling for UDFs, UDF Return Values and Error Handling
- in subqueries, Subquery Errors
- known, Known Issues in MySQL
- linking, Problems Linking to the MySQL Client Library
- list of, Common Errors When Using MySQL Programs
- reporting, General Information, How to Report Bugs or Problems
- ERROR_FOR_DIVISION_BY_ZERO SQL mode, SQL Modes
- escape (\\), Strings
- escape characters, Literal Values
- estimating
- query performance, Estimating Query Performance
- event log format (MySQL Cluster), Log Events
- event logs (MySQL Cluster), Event Reports Generated in MySQL Cluster, Logging Management Commands
- event severity levels (MySQL Cluster), Logging Management Commands
- event types (MySQL Cluster), Event Reports Generated in MySQL Cluster, Log Events
- exact-value literals, Precision Math
- example option
- mysqld_multi, mysqld_multi — Manage Multiple MySQL Servers
- EXAMPLE storage engine, Storage Engines, The EXAMPLE Storage Engine
- examples
- compressed tables, myisampack — Generate Compressed, Read-Only MyISAM Tables
- myisamchk output, Getting Information About a Table
- queries, Examples of Common Queries
- exe-suffix option
- make_win_bin_dist, make_win_bin_dist — Package MySQL Distribution as ZIP Archive
- EXECUTE, SQL Syntax for Prepared Statements
- execute option
- mysql, mysql Options
- EXECUTE statement, SQL Syntax for Prepared Statements
- ExecuteOnComputer, Defining the Management Server, Defining Data Nodes, Defining SQL and Other API Nodes
- executing SQL statements from text files, Using mysql in Batch Mode, Executing SQL Statements from a Text File
- EXISTS
- with subqueries, EXISTS and NOT EXISTS
- EXIT command (MySQL Cluster), Commands in the MySQL Cluster Management Client
- EXIT SINGLE USER MODE command (MySQL Cluster), Commands in the MySQL Cluster Management Client
- exit-info option
- mysqld, Command Options
- EXP(), Mathematical Functions
- EXPLAIN, Optimizing Queries with EXPLAIN
- explicit default values, Data Type Default Values
- EXPORT_SET(), String Functions
- expression aliases, GROUP BY and HAVING with Hidden Fields, SELECT Syntax
- expressions
- extended, Pattern Matching
- extend-check option
- myisamchk, myisamchk Check Options, myisamchk Repair Options
- extended option
- extended-insert option
- mysqldump, mysqldump — A Database Backup Program
- extensions
- to standard SQL, MySQL Standards Compliance
- ExteriorRing(), Polygon Functions
- external locking, Command Options, System Variables, Using myisamchk for Crash Recovery, External Locking, SHOW PROCESSLIST Syntax
- external-locking option
- mysqld, Command Options
- extra-file option
- my_print_defaults, my_print_defaults — Display Options from Option Files
- extra-partition-info option
- ndb_desc, ndb_desc — Describe NDB Tables
- EXTRACT(), Date and Time Functions
- extracting
- dates, Date Calculations
F
- FALSE, Numbers, Boolean Values
- testing for, Comparison Functions and Operators
- fast option
- myisamchk, myisamchk Check Options
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- fatal signal 11, Dealing with Problems Compiling MySQL
- features of MySQL, The Main Features of MySQL
- FEDERATED storage engine, Storage Engines, The FEDERATED Storage Engine
- FETCH, Cursor FETCH Statement
- field
- changing, ALTER TABLE Syntax
- FIELD(), String Functions
- fields option
- fields-enclosed-by option
- fields-escaped-by option
- fields-optionally-enclosed-by option
- fields-terminated-by option
- FILE, String Functions
- files
- binary log, The Binary Log
- config.cache, Dealing with Problems Compiling MySQL
- error messages, Setting the Error Message Language
- general query log, The General Query Log
- log, Typical configure Options, Server Log Maintenance
- my.cnf, Replication Features and Known Problems
- not found message, Problems with File Permissions
- permissions, Problems with File Permissions
- repairing, myisamchk Repair Options
- script, Using mysql in Batch Mode
- size limits, The table is full
- slow query log, The Slow Query Log
- text, Executing SQL Statements from a Text File
- tmp, Problems Running mysql_install_db
- update log (obsolete), The Binary Log
- filesort optimization, ORDER BY Optimization
- FileSystemPath, Defining Data Nodes
- FIND_IN_SET(), String Functions
- first-slave option
- mysqldump, mysqldump — A Database Backup Program
- FIXED data type, Overview of Numeric Types
- fixed-point arithmetic, Precision Math
- FLOAT data type, Overview of Numeric Types
- floating-point number, Overview of Numeric Types
- floats, Numbers
- FLOOR(), Mathematical Functions
- FLUSH, FLUSH Syntax
- flush option
- mysqld, Command Options
- flush tables, mysqladmin — Client for Administering a MySQL Server
- flush-logs option
- mysqldump, mysqldump — A Database Backup Program
- flush-privileges option
- mysqldump, mysqldump — A Database Backup Program
- flushlog option
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- FOR UPDATE, SELECT Syntax
- FORCE INDEX, Index Hint Syntax, Optimizer-Related Issues
- FORCE KEY, Index Hint Syntax
- force option
- myisamchk, myisamchk Check Options, myisamchk Repair Options
- myisampack, myisampack — Generate Compressed, Read-Only MyISAM Tables
- mysql, mysql Options
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqldump, mysqldump — A Database Backup Program
- mysqlimport, mysqlimport — A Data Import Program
- mysql_upgrade, mysql_upgrade — Check Tables for MySQL Upgrade
- force-read option
- foreign key
- constraint, PRIMARY KEY and UNIQUE Index Constraints
- deleting, ALTER TABLE Syntax, FOREIGN KEY Constraints
- foreign keys, Foreign Keys, Using Foreign Keys, ALTER TABLE Syntax
- FORMAT(), String Functions
- Forums, MySQL Community Support at the MySQL Forums
- FOUND_ROWS(), Information Functions
- FreeBSD troubleshooting, Dealing with Problems Compiling MySQL
- frequently-asked questions about DRBD, MySQL 5.0 FAQ — MySQL, DRBD, and Heartbeat
- frequently-asked questions about MySQL Cluster, MySQL 5.0 FAQ — MySQL Cluster
- FROM, SELECT Syntax
- FROM_DAYS(), Date and Time Functions
- FROM_UNIXTIME(), Date and Time Functions
- ft_max_word_len myisamchk variable, myisamchk General Options
- ft_min_word_len myisamchk variable, myisamchk General Options
- ft_stopword_file myisamchk variable, myisamchk General Options
- full disk, How MySQL Handles a Full Disk
- full-text search, Full-Text Search Functions
- FULLTEXT, Full-Text Search Functions
- fulltext
- stopword list, Fine-Tuning MySQL Full-Text Search
- function
- creating, CREATE FUNCTION Syntax
- deleting, DROP FUNCTION Syntax
- function names
- parsing, Function Name Parsing and Resolution
- resolving ambiguity, Function Name Parsing and Resolution
- functions, Functions and Operators
- arithmetic, Bit Functions
- bit, Bit Functions
- C API, C API Function Overview
- C Prepared statement API, C API Prepared Statement Function Overview
- cast, Cast Functions and Operators
- control flow, Control Flow Functions
- date and time, Date and Time Functions
- encryption, Encryption and Compression Functions
- GROUP BY, GROUP BY (Aggregate) Functions
- grouping, Operator Precedence
- information, Information Functions
- mathematical, Mathematical Functions
- miscellaneous, Miscellaneous Functions
- native
- adding, Adding a New Native Function
- new, Adding New Functions to MySQL
- string, String Functions
- string comparison, String Comparison Functions
- user-defined, Adding New Functions to MySQL
- Functions
- user-defined, CREATE FUNCTION Syntax, DROP FUNCTION Syntax
- functions for SELECT and WHERE clauses, Functions and Operators
- Future development of MySQL Cluster, MySQL Cluster Development Roadmap
G
- gap lock, InnoDB Startup Options and System Variables, InnoDB and TRANSACTION ISOLATION LEVEL, Next-Key Locking: Avoiding the Phantom Problem
- gb2312, gbk, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- gcc, Typical configure Options
- gci option
- ndb_select_all, ndb_select_all — Print Rows from NDB Table
- gdb option
- mysqld, Command Options
- general information, General Information
- General Public License, What is MySQL?
- general query log, The General Query Log
- geographic feature, Introduction to MySQL Spatial Support
- GeomCollFromText(), Creating Geometry Values Using WKT Functions
- GeomCollFromWKB(), Creating Geometry Values Using WKB Functions
- geometry, Introduction to MySQL Spatial Support
- GEOMETRY data type, MySQL Spatial Data Types
- GEOMETRYCOLLECTION data type, MySQL Spatial Data Types
- GeometryCollection(), Creating Geometry Values Using MySQL-Specific Functions
- GeometryCollectionFromText(), Creating Geometry Values Using WKT Functions
- GeometryCollectionFromWKB(), Creating Geometry Values Using WKB Functions
- GeometryFromText(), Creating Geometry Values Using WKT Functions
- GeometryFromWKB(), Creating Geometry Values Using WKB Functions
- GeometryN(), GeometryCollection Functions
- GeometryType(), General Geometry Functions
- GeomFromText(), Creating Geometry Values Using WKT Functions, Geometry Format Conversion Functions
- GeomFromWKB(), Creating Geometry Values Using WKB Functions, Geometry Format Conversion Functions
- geospatial feature, Introduction to MySQL Spatial Support
- getting MySQL, How to Get MySQL
- GET_FORMAT(), Date and Time Functions
- GET_LOCK(), Miscellaneous Functions
- GIS, Spatial Extensions, Introduction to MySQL Spatial Support
- GLength(), LineString Functions, MultiLineString Functions
- global privileges, GRANT Syntax, REVOKE Syntax
- goals of MySQL, What is MySQL?
- GRANT, GRANT Syntax
- GRANT statement, Adding New User Accounts to MySQL
- grant tables, Access Control, Stage 2: Request Verification
- granting
- privileges, GRANT Syntax
- GRANTS, SHOW GRANTS Syntax
- greater than (>), Comparison Functions and Operators
- greater than or equal (>=), Comparison Functions and Operators
- GREATEST(), Comparison Functions and Operators
- GROUP BY, GROUP BY Optimization
- aliases in, GROUP BY and HAVING with Hidden Fields
- extensions to standard SQL, GROUP BY and HAVING with Hidden Fields, SELECT Syntax
- GROUP BY functions, GROUP BY (Aggregate) Functions
- grouping
- expressions, Operator Precedence
- GROUP_CONCAT(), GROUP BY (Aggregate) Functions
H
- HANDLER, HANDLER Syntax
- Handlers, DECLARE Handlers
- handling
- HAVING, SELECT Syntax
- header option
- ndb_select_all, ndb_select_all — Print Rows from NDB Table
- header_file option
- HEAP storage engine, Storage Engines, The MEMORY (HEAP) Storage Engine
- HeartbeatIntervalDbApi (MySQL Cluster configuration parameter), Defining Data Nodes
- HeartbeatIntervalDbDb (MySQL Cluster configuration parameter), Defining Data Nodes
- HELP command (MySQL Cluster), Commands in the MySQL Cluster Management Client
- help option
- comp_err, comp_err — Compile MySQL Error Message File
- myisamchk, myisamchk General Options
- myisampack, myisampack — Generate Compressed, Read-Only MyISAM Tables
- myisam_ftdump, myisam_ftdump — Display Full-Text Index information
- mysql, mysql Options
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- mysqlbinlog, mysqlbinlog — Utility for Processing Binary Log Files
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqld, Command Options
- mysqldump, mysqldump — A Database Backup Program
- mysqld_multi, mysqld_multi — Manage Multiple MySQL Servers
- mysqld_safe, mysqld_safe — MySQL Server Startup Script
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- mysqlimport, mysqlimport — A Data Import Program
- mysqlmanager, MySQL Instance Manager Command Options
- mysqlshow, mysqlshow — Display Database, Table, and Column Information
- mysql_explain_log, mysql_explain_log — Use EXPLAIN on Statements in Query Log
- mysql_find_rows, mysql_find_rows — Extract Queries from Update Log
- mysql_setpermission, mysql_setpermission — Interactively Set Permissions in Grant Tables
- mysql_tableinfo, mysql_tableinfo — Generate Database Metadata
- mysql_upgrade, mysql_upgrade — Check Tables for MySQL Upgrade
- mysql_waitpid, mysql_waitpid — Kill Process and Wait for Its Termination
- my_print_defaults, my_print_defaults — Display Options from Option Files
- perror, perror — Explain Error Codes
- resolveip, resolveip — Resolve Hostname to IP Address or Vice Versa
- resolve_stack_dump, resolve_stack_dump — Resolve Numeric Stack Trace Dump to Symbols
- HELP statement, HELP Syntax
- HEX(), String Functions
- hex-blob option
- mysqldump, mysqldump — A Database Backup Program
- hexadecimal values, Hexadecimal Values
- hexdump option
- HIGH_NOT_PRECEDENCE SQL mode, SQL Modes
- HIGH_PRIORITY, SELECT Syntax
- hints, MySQL Extensions to Standard SQL
- index, SELECT Syntax, Index Hint Syntax
- history of MySQL, History of MySQL
- HOME environment variable, Environment Variables, mysql Options
- host option
- mysql, mysql Options
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- mysqlbinlog, mysqlbinlog — Utility for Processing Binary Log Files
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqldump, mysqldump — A Database Backup Program
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- mysqlimport, mysqlimport — A Data Import Program
- mysqlshow, mysqlshow — Display Database, Table, and Column Information
- mysql_explain_log, mysql_explain_log — Use EXPLAIN on Statements in Query Log
- mysql_setpermission, mysql_setpermission — Interactively Set Permissions in Grant Tables
- mysql_tableinfo, mysql_tableinfo — Generate Database Metadata
- ndb_config, ndb_config — Extract NDB Configuration Information
- host table, Access Control, Stage 2: Request Verification
- Host*SciId* parameters, SCI Transport Connections
- host.frm
- problems finding, Unix Post-Installation Procedures
- hostname
- default, Connecting to the MySQL Server
- HostName, Defining the Management Server, Defining Data Nodes, Defining SQL and Other API Nodes
- hostname caching, How MySQL Uses DNS
- HOUR(), Date and Time Functions
- howto option
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- html option
- mysql, mysql Options
I
- i-am-a-dummy option
- mysql, mysql Options
- Id, Defining the Management Server, Defining Data Nodes, Defining SQL and Other API Nodes
- ID
- id option
- identifiers, Database, Table, Index, Column, and Alias Names
- case sensitivity, Identifier Case Sensitivity
- quoting, Database, Table, Index, Column, and Alias Names
- idx option
- mysql_tableinfo, mysql_tableinfo — Generate Database Metadata
- IF, IF Statement
- IF(), Control Flow Functions
- IFNULL(), Control Flow Functions
- IGNORE INDEX, Index Hint Syntax
- IGNORE KEY, Index Hint Syntax
- ignore option
- mysqlimport, mysqlimport — A Data Import Program
- ignore-lines option
- mysqlimport, mysqlimport — A Data Import Program
- ignore-spaces option
- mysql, mysql Options
- ignore-table option
- mysqldump, mysqldump — A Database Backup Program
- IGNORE_SPACE SQL mode, SQL Modes
- implicit default values, Data Type Default Values
- IMPORT TABLESPACE, ALTER TABLE Syntax, Using Per-Table Tablespaces
- importing
- IN, Comparison Functions and Operators, Subqueries with ANY, IN, and SOME
- increasing
- performance, Replication FAQ
- increasing with replication
- speed, Replication
- index
- deleting, ALTER TABLE Syntax, DROP INDEX Syntax
- index hints, SELECT Syntax, Index Hint Syntax
- indexes, CREATE INDEX Syntax
- and BLOB columns, Column Indexes, CREATE TABLE Syntax
- and IS NULL, How MySQL Uses Indexes
- and LIKE, How MySQL Uses Indexes
- and NULL values, CREATE TABLE Syntax
- and TEXT columns, Column Indexes, CREATE TABLE Syntax
- assigning to key cache, CACHE INDEX Syntax
- block size, System Variables
- columns, Column Indexes
- leftmost prefix of, How MySQL Uses Indexes
- multi-column, Multiple-Column Indexes
- multiple-part, CREATE INDEX Syntax
- names, Database, Table, Index, Column, and Alias Names
- use of, How MySQL Uses Indexes
- IndexMemory, Defining Data Nodes, Configuring Parameters for Local Checkpoints
- INET_ATON(), Miscellaneous Functions
- INET_NTOA(), Miscellaneous Functions
- INFO Events (MySQL Cluster), Log Events
- information functions, Information Functions
- information option
- myisamchk, myisamchk Check Options
- INFORMATION_SCHEMA, The INFORMATION_SCHEMA Database
- init-file option
- mysqld, Command Options
- INNER JOIN, JOIN Syntax
- innochecksum, Overview of Client and Utility Programs
- InnoDB, InnoDB Overview
- NFS, InnoDB Configuration, Restrictions on InnoDB Tables
- Solaris 10 x86_64 issues, Solaris Notes
- innodb option
- InnoDB storage engine, Storage Engines, The InnoDB Storage Engine
- InnoDB tables, Transactions and Atomic Operations
- innodb-safe-binlog option
- mysqld, Command Options
- innodb_status_file option
- INSERT, Speed of INSERT Statements, INSERT Syntax
- INSERT ... SELECT, INSERT ... SELECT Syntax
- INSERT DELAYED, INSERT DELAYED Syntax
- INSERT statement
- grant privileges, Adding New User Accounts to MySQL
- INSERT(), String Functions
- insert-ignore option
- mysqldump, mysqldump — A Database Backup Program
- inserting
- speed of, Speed of INSERT Statements
- inserts
- concurrent, Internal Locking Methods, Concurrent Inserts
- install option
- mysqlmanager, MySQL Instance Manager Command Options
- installation layouts, Installation Layouts
- installation overview, MySQL Installation Using a Source Distribution
- installing
- binary distribution, Installing MySQL from tar.gz Packages on Other Unix-Like Systems
- Linux RPM packages, Installing MySQL from RPM Packages on Linux
- Mac OS X PKG packages, Installing MySQL on Mac OS X
- MySQL Community Server, Installing MySQL Community Server
- MySQL Enterprise, Installing MySQL Enterprise
- overview, Installing and Upgrading MySQL, MySQL Installation Overview
- Perl, Perl Installation Notes
- Perl on Windows, Installing ActiveState Perl on Windows
- Solaris PKG packages, Installing MySQL on Solaris
- source distribution, MySQL Installation Using a Source Distribution
- user-defined functions, Compiling and Installing User-Defined Functions
- installing MySQL Cluster, Simple Multi-Computer How-To, Multi-Computer Installation, Installing the Cluster Software
- INSTR(), String Functions
- INT data type, Overview of Numeric Types
- integer arithmetic, Precision Math
- INTEGER data type, Overview of Numeric Types
- integers, Numbers
- InteriorRingN(), Polygon Functions
- internal compiler errors, Dealing with Problems Compiling MySQL
- internal locking, Internal Locking Methods
- internals, MySQL Internals
- Internet Relay Chat, MySQL Community Support on Internet Relay Chat (IRC)
- Intersection(), Spatial Operators
- Intersects(), Functions That Test Spatial Relationships Between Geometries
- INTERVAL(), Comparison Functions and Operators
- introducer
- string literal, Strings, Character String Literal Character Set and Collation
- invalid data
- constraint, Constraints on Invalid Data
- in_file option
- IRC, MySQL Community Support on Internet Relay Chat (IRC)
- IS boolean_value, Comparison Functions and Operators
- IS NOT boolean_value, Comparison Functions and Operators
- IS NOT NULL, Comparison Functions and Operators
- IS NULL, IS NULL Optimization, Comparison Functions and Operators
- and indexes, How MySQL Uses Indexes
- isamchk, Overview of Client and Utility Programs
- isamlog, Overview of Client and Utility Programs
- IsClosed(), MultiLineString Functions
- IsEmpty(), General Geometry Functions
- ISNULL(), Comparison Functions and Operators
- ISOLATION LEVEL, SET TRANSACTION Syntax
- IsRing(), LineString Functions
- IsSimple(), General Geometry Functions
- IS_FREE_LOCK(), Miscellaneous Functions
- IS_USED_LOCK(), Miscellaneous Functions
- ITERATE, ITERATE Statement
J
- Japanese character sets
- Japanese, Korean, Chinese character sets
- frequently asked questions, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- JOIN, JOIN Syntax
- join option
K
- keepold option
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- Key cache
- MyISAM, The MyISAM Key Cache
- key cache
- assigning indexes to, CACHE INDEX Syntax
- key space
- MyISAM, Space Needed for Keys
- keys, Column Indexes
- foreign, Foreign Keys, Using Foreign Keys
- multi-column, Multiple-Column Indexes
- searching on two, Searching on Two Keys
- keys option
- keys-used option
- myisamchk, myisamchk Repair Options
- keywords, Reserved Words
- key_buffer_size myisamchk variable, myisamchk General Options
- KEY_COLUMN_USAGE
- INFORMATION_SCHEMA table, The INFORMATION_SCHEMA KEY_COLUMN_USAGE Table
- KILL, KILL Syntax
- known errors, Known Issues in MySQL
- Korean, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- Korean, Chinese, Japanese character sets
- frequently asked questions, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
L
- language option
- mysqld, Command Options
- language support
- error messages, Setting the Error Message Language
- large-pages option
- mysqld, Command Options
- last row
- LAST_DAY(), Date and Time Functions
- LAST_INSERT_ID(), Transactions and Atomic Operations, INSERT Syntax
- LAST_INSERT_ID() and stored routines, Stored Procedures, Functions, Triggers, and LAST_INSERT_ID()
- LAST_INSERT_ID() and triggers, Stored Procedures, Functions, Triggers, and LAST_INSERT_ID()
- LAST_INSERT_ID([expr]), Information Functions
- layout of installation, Installation Layouts
- LCASE(), String Functions
- LD_LIBRARY_PATH environment variable, Problems Using the Perl DBI/DBD Interface
- LD_RUN_PATH environment variable, Linux Source Distribution Notes, Solaris Notes, Environment Variables, Problems Using the Perl DBI/DBD Interface
- LEAST(), Comparison Functions and Operators
- LEAVE, LEAVE Statement
- ledir option
- mysqld_safe, mysqld_safe — MySQL Server Startup Script
- LEFT JOIN, LEFT JOIN and RIGHT JOIN Optimization, JOIN Syntax
- LEFT OUTER JOIN, JOIN Syntax
- LEFT(), String Functions
- leftmost prefix of indexes, How MySQL Uses Indexes
- legal names, Database, Table, Index, Column, and Alias Names
- length option
- myisam_ftdump, myisam_ftdump — Display Full-Text Index information
- LENGTH(), String Functions
- less than (<), Comparison Functions and Operators
- less than or equal (<=), Comparison Functions and Operators
- libmysqld, libmysqld, the Embedded MySQL Server Library
- libraries
- library
- mysqlclient, APIs and Libraries
- mysqld, APIs and Libraries
- LIKE, String Comparison Functions
- and indexes, How MySQL Uses Indexes
- and wildcards, How MySQL Uses Indexes
- LIMIT, LIMIT Optimization, Information Functions, SELECT Syntax
- limitations
- design, MySQL Design Limitations and Tradeoffs
- MySQL Limitations, Limits in MySQL
- replication, Replication Features and Known Problems
- limitations of MySQL Cluster, Known Limitations of MySQL Cluster
- limits
- file-size, The table is full
- MySQL Limits, limits in MySQL, Limits in MySQL
- line-numbers option
- mysql, mysql Options
- linefeed (\n), Strings
- LineFromText(), Creating Geometry Values Using WKT Functions
- LineFromWKB(), Creating Geometry Values Using WKB Functions
- lines-terminated-by option
- LINESTRING data type, MySQL Spatial Data Types
- LineString(), Creating Geometry Values Using MySQL-Specific Functions
- LineStringFromText(), Creating Geometry Values Using WKT Functions
- LineStringFromWKB(), Creating Geometry Values Using WKB Functions
- linking, Building Client Programs
- links
- symbolic, Using Symbolic Links
- Linux
- binary distribution, Linux Binary Distribution Notes
- source distribution, Linux Source Distribution Notes
- literals, Literal Values
- LN(), Mathematical Functions
- LOAD DATA FROM MASTER, LOAD DATA FROM MASTER Syntax
- LOAD DATA INFILE, LOAD DATA INFILE Syntax, Problems with NULL Values
- LOAD TABLE FROM MASTER, LOAD TABLE tbl_name FROM MASTER Syntax
- loading
- tables, Loading Data into a Table
- LOAD_FILE(), String Functions
- local checkpoints (MySQL Cluster), Configuring Parameters for Local Checkpoints
- local option
- mysqlimport, mysqlimport — A Data Import Program
- local-infile option
- mysql, mysql Options
- mysqld, Security-Related mysqld Options
- local-load option
- localstatedir option
- configure, Typical configure Options
- LOCALTIME, Date and Time Functions
- LOCALTIMESTAMP, Date and Time Functions
- LOCATE(), String Functions
- LOCK IN SHARE MODE, SELECT Syntax
- lock option
- ndb_select_all, ndb_select_all — Print Rows from NDB Table
- LOCK TABLES, LOCK TABLES and UNLOCK TABLES Syntax
- lock-all-tables option
- mysqldump, mysqldump — A Database Backup Program
- lock-tables option
- mysqldump, mysqldump — A Database Backup Program
- mysqlimport, mysqlimport — A Data Import Program
- locking, System Factors and Startup Parameter Tuning
- external, Command Options, System Variables, Using myisamchk for Crash Recovery, External Locking, SHOW PROCESSLIST Syntax
- internal, Internal Locking Methods
- page-level, Internal Locking Methods
- row-level, Transactions and Atomic Operations, Internal Locking Methods
- table-level, Internal Locking Methods
- locking methods, Internal Locking Methods
- LockPagesInMainMemory, Defining Data Nodes
- log
- changes, MySQL Change History
- log files, Typical configure Options, MySQL Server Logs
- maintaining, Server Log Maintenance
- names, Database Backups
- log files (MySQL Cluster), ndbd — The Storage Engine Node Process
- log option
- mysqld, Command Options
- mysqld_multi, mysqld_multi — Manage Multiple MySQL Servers
- mysqlmanager, MySQL Instance Manager Command Options
- LOG(), Mathematical Functions
- log-bin option
- mysqld, Command Options
- log-bin-index option
- mysqld, Command Options
- log-bin-trust-function-creators option
- mysqld, Command Options
- log-bin-trust-routine-creators option
- mysqld, Command Options
- log-error option
- mysqld, Command Options
- mysqld_safe, mysqld_safe — MySQL Server Startup Script
- log-isam option
- mysqld, Command Options
- log-long-format option
- mysqld, Command Options
- log-queries-not-using-indexes option
- mysqld, Command Options
- log-short-format option
- mysqld, Command Options
- log-slave-updates option
- mysqld, Replication Startup Options
- log-slow-admin-statements option
- mysqld, Command Options
- log-slow-queries option
- mysqld, Command Options
- log-tc option
- mysqld, Command Options
- log-tc-size option
- mysqld, Command Options
- log-warnings option
- LOG10(), Mathematical Functions
- LOG2(), Mathematical Functions
- LogDestination, Defining the Management Server
- logging commands (MySQL Cluster), Logging Management Commands
- logical operators, Logical Operators
- LogLevelCheckpoint (MySQL Cluster configuration parameter), Defining Data Nodes
- LogLevelConnection (MySQL Cluster configuration parameter), Defining Data Nodes
- LogLevelError, Defining Data Nodes
- LogLevelInfo, Defining Data Nodes
- LogLevelNodeRestart (MySQL Cluster configuration parameter), Defining Data Nodes
- LogLevelShutdown (MySQL Cluster configuration parameter), Defining Data Nodes
- LogLevelStartup (MySQL Cluster configuration parameter), Defining Data Nodes
- LogLevelStatistic (MySQL Cluster configuration parameter), Defining Data Nodes
- LONG data type, The BLOB and TEXT Types
- LONGBLOB data type, Overview of String Types
- LongMessageBuffer, Defining Data Nodes
- LONGTEXT data type, Overview of String Types
- LOOP, LOOP Statement
- loops option
- ndb_show_tables, ndb_show_tables — Display List of NDB Tables
- low-priority option
- mysqlimport, mysqlimport — A Data Import Program
- low-priority-updates option
- mysqld, Command Options
- LOWER(), String Functions
- LPAD(), String Functions
- LTRIM(), String Functions
M
- Mac OS X, MySQL Connector/ODBC
- installation, Installing MySQL on Mac OS X
- mailing list address, General Information
- mailing lists, MySQL Mailing Lists
- archive location, MySQL Mailing Lists
- guidelines, Guidelines for Using the Mailing Lists
- main features of MySQL, The Main Features of MySQL
- maintaining
- log files, Server Log Maintenance
- tables, Setting Up a Table Maintenance Schedule
- MAKEDATE(), Date and Time Functions
- MAKETIME(), Date and Time Functions
- make_binary_distribution, Overview of Server-Side Programs
- MAKE_SET(), String Functions
- make_win_bin_dist, Overview of Server-Side Programs
- debug option, make_win_bin_dist — Package MySQL Distribution as ZIP Archive
- embedded option, make_win_bin_dist — Package MySQL Distribution as ZIP Archive
- exe-suffix option, make_win_bin_dist — Package MySQL Distribution as ZIP Archive
- no-debug option, make_win_bin_dist — Package MySQL Distribution as ZIP Archive
- no-embedded option, make_win_bin_dist — Package MySQL Distribution as ZIP Archive
- only-debug option, make_win_bin_dist — Package MySQL Distribution as ZIP Archive
- make_win_src_distribution, Creating a Windows Source Package from the Latest Development Source, Overview of Server-Side Programs
- management node (MySQL Cluster)
- defined, Basic MySQL Cluster Concepts
- managing MySQL Cluster, Management of MySQL Cluster
- managing MySQL Cluster processes, Process Management in MySQL Cluster
- manual
- available formats, About This Manual
- online location, About This Manual
- typographical conventions, Conventions Used in This Manual
- master-connect-retry option
- mysqld, Replication Startup Options
- master-data option
- mysqldump, mysqldump — A Database Backup Program
- master-host option
- mysqld, Replication Startup Options
- master-info-file option
- mysqld, Replication Startup Options
- master-password option
- mysqld, Replication Startup Options
- master-port option
- mysqld, Replication Startup Options
- master-retry-count option
- mysqld, Replication Startup Options
- master-ssl option
- mysqld, Replication Startup Options
- master-ssl-ca option
- mysqld, Replication Startup Options
- master-ssl-capath option
- mysqld, Replication Startup Options
- master-ssl-cert option
- mysqld, Replication Startup Options
- master-ssl-cipher option
- mysqld, Replication Startup Options
- master-ssl-key option
- mysqld, Replication Startup Options
- master-user option
- mysqld, Replication Startup Options
- master/slave setup, Replication Implementation Overview
- MASTER_POS_WAIT(), Miscellaneous Functions, MASTER_POS_WAIT() Syntax
- MATCH ... AGAINST(), Full-Text Search Functions
- matching
- patterns, Pattern Matching
- math, Precision Math
- mathematical functions, Mathematical Functions
- MAX(), GROUP BY (Aggregate) Functions
- MAX(DISTINCT), GROUP BY (Aggregate) Functions
- max-binlog-dump-events option
- mysqld, Command Options
- max-record-length option
- myisamchk, myisamchk Repair Options
- max-relay-log-size option
- mysqld, Replication Startup Options
- MAXDB SQL mode, SQL Modes
- maximum memory used, mysqladmin — Client for Administering a MySQL Server
- maximums
- maximum tables per join, Limits of Joins
- MaxNoOfAttributes, Defining Data Nodes
- MaxNoOfConcurrentIndexOperations, Defining Data Nodes
- MaxNoOfConcurrentOperations, Defining Data Nodes
- MaxNoOfConcurrentScans, Defining Data Nodes
- MaxNoOfConcurrentTransactions, Defining Data Nodes
- MaxNoOfFiredTriggers, Defining Data Nodes
- MaxNoOfIndexes, Defining Data Nodes
- MaxNoOfLocalOperations, Defining Data Nodes
- MaxNoOfLocalScans, Defining Data Nodes
- MaxNoOfOpenFiles, Defining Data Nodes
- MaxNoOfOrderedIndexes, Defining Data Nodes
- MaxNoOfSavedMessages, Defining Data Nodes
- MaxNoOfTables, Defining Data Nodes
- MaxNoOfTriggers, Defining Data Nodes
- MaxNoOfUniqueHashIndexes, Defining Data Nodes
- MaxScanBatchSize, Defining SQL and Other API Nodes
- max_allowed_packet variable, mysql Options
- MAX_CONNECTIONS_PER_HOUR, Limiting Account Resources
- max_join_size variable, mysql Options
- MAX_QUERIES_PER_HOUR, Limiting Account Resources
- MAX_UPDATES_PER_HOUR, Limiting Account Resources
- MAX_USER_CONNECTIONS, Limiting Account Resources
- MBR, Relations on Geometry Minimal Bounding Rectangles (MBRs)
- MBRContains(), Relations on Geometry Minimal Bounding Rectangles (MBRs)
- MBRDisjoint(), Relations on Geometry Minimal Bounding Rectangles (MBRs)
- MBREqual(), Relations on Geometry Minimal Bounding Rectangles (MBRs)
- MBRIntersects(), Relations on Geometry Minimal Bounding Rectangles (MBRs)
- MBROverlaps(), Relations on Geometry Minimal Bounding Rectangles (MBRs)
- MBRTouches(), Relations on Geometry Minimal Bounding Rectangles (MBRs)
- MBRWithin(), Relations on Geometry Minimal Bounding Rectangles (MBRs)
- MD5(), Encryption and Compression Functions
- medium-check option
- myisamchk, myisamchk Check Options
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- MEDIUMBLOB data type, Overview of String Types
- MEDIUMINT data type, Overview of Numeric Types
- MEDIUMTEXT data type, Overview of String Types
- memlock option
- mysqld, Command Options
- MEMORY storage engine, Storage Engines, The MEMORY (HEAP) Storage Engine
- memory usage
- myisamchk, myisamchk Memory Usage
- memory use, How MySQL Uses Memory, mysqladmin — Client for Administering a MySQL Server
- in MySQL Cluster, Limits and Differences from Standard MySQL Limits
- MERGE storage engine, Storage Engines, The MERGE Storage Engine
- MERGE tables
- defined, The MERGE Storage Engine
- metadata
- database, The INFORMATION_SCHEMA Database
- method option
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- methods
- locking, Internal Locking Methods
- mgmd (MySQL Cluster)
- defined, Basic MySQL Cluster Concepts
- MICROSECOND(), Date and Time Functions
- Microsoft Access, Microsoft Access
- Microsoft ADO, Microsoft ADO
- Microsoft Excel, Microsoft Excel and Column Types
- Microsoft Visual Basic, Microsoft Visual Basic
- Microsoft Visual InterDev, Microsoft Visual InterDev
- MID(), String Functions
- MIN(), GROUP BY (Aggregate) Functions
- MIN(DISTINCT), GROUP BY (Aggregate) Functions
- Minimum Bounding Rectangle, Relations on Geometry Minimal Bounding Rectangles (MBRs)
- minus
- unary (-), Arithmetic Operators
- MINUTE(), Date and Time Functions
- mirror sites, How to Get MySQL
- miscellaneous functions, Miscellaneous Functions
- MIT-pthreads, MIT-pthreads Notes
- MLineFromText(), Creating Geometry Values Using WKT Functions
- MLineFromWKB(), Creating Geometry Values Using WKB Functions
- MOD (modulo), Mathematical Functions
- MOD(), Mathematical Functions
- modes
- batch, Using mysql in Batch Mode
- modulo (%), Mathematical Functions
- modulo (MOD), Mathematical Functions
- monitor
- terminal, Tutorial
- monitoring-interval option
- mysqlmanager, MySQL Instance Manager Command Options
- Mono, MySQL Connector/NET
- MONTH(), Date and Time Functions
- MONTHNAME(), Date and Time Functions
- MPointFromText(), Creating Geometry Values Using WKT Functions
- MPointFromWKB(), Creating Geometry Values Using WKB Functions
- MPolyFromText(), Creating Geometry Values Using WKT Functions
- MPolyFromWKB(), Creating Geometry Values Using WKB Functions
- mSQL compatibility, String Comparison Functions
- MSSQL SQL mode, SQL Modes
- multi-byte character sets, Can't initialize character set
- multi-byte characters, Multi-Byte Character Support
- multi-column indexes, Multiple-Column Indexes
- MULTILINESTRING data type, MySQL Spatial Data Types
- MultiLineString(), Creating Geometry Values Using MySQL-Specific Functions
- MultiLineStringFromText(), Creating Geometry Values Using WKT Functions
- MultiLineStringFromWKB(), Creating Geometry Values Using WKB Functions
- multiple servers, Running Multiple MySQL Servers on the Same Machine
- multiple-part index, CREATE INDEX Syntax
- multiplication (*), Arithmetic Operators
- MULTIPOINT data type, MySQL Spatial Data Types
- MultiPoint(), Creating Geometry Values Using MySQL-Specific Functions
- MultiPointFromText(), Creating Geometry Values Using WKT Functions
- MultiPointFromWKB(), Creating Geometry Values Using WKB Functions
- MULTIPOLYGON data type, MySQL Spatial Data Types
- MultiPolygon(), Creating Geometry Values Using MySQL-Specific Functions
- MultiPolygonFromText(), Creating Geometry Values Using WKT Functions
- MultiPolygonFromWKB(), Creating Geometry Values Using WKB Functions
- My
- derivation, History of MySQL
- my.cnf
- and MySQL Cluster, Multi-Computer Configuration, Configuration File, Basic Example Configuration
- in MySQL Cluster, MySQL Server Process Usage for MySQL Cluster
- my.cnf file, Replication Features and Known Problems
- MyISAM
- compressed tables, Compressed Table Characteristics
- size, Data Type Storage Requirements
- MyISAM key cache, The MyISAM Key Cache
- MyISAM storage engine, Storage Engines, The MyISAM Storage Engine
- myisam-recover option
- mysqld, Command Options, MyISAM Startup Options
- myisamchk, Typical configure Options, Overview of Client and Utility Programs
- analyze option, Other myisamchk Options
- backup option, myisamchk Repair Options
- block-search option, Other myisamchk Options
- character-sets-dir option, myisamchk Repair Options
- check option, myisamchk Check Options
- check-only-changed option, myisamchk Check Options
- correct-checksum option, myisamchk Repair Options
- data-file-length option, myisamchk Repair Options
- debug option, myisamchk General Options
- description option, Other myisamchk Options
- example output, Getting Information About a Table
- extend-check option, myisamchk Check Options, myisamchk Repair Options
- fast option, myisamchk Check Options
- force option, myisamchk Check Options, myisamchk Repair Options
- help option, myisamchk General Options
- information option, myisamchk Check Options
- keys-used option, myisamchk Repair Options
- max-record-length option, myisamchk Repair Options
- medium-check option, myisamchk Check Options
- no-symlinks option, myisamchk Repair Options
- options, myisamchk General Options
- parallel-recover option, myisamchk Repair Options
- quick option, myisamchk Repair Options
- read-only option, myisamchk Check Options
- recover option, myisamchk Repair Options
- safe-recover option, myisamchk Repair Options
- set-auto-increment[ option, Other myisamchk Options
- set-character-set option, myisamchk Repair Options
- set-collation option, myisamchk Repair Options
- silent option, myisamchk General Options
- sort-index option, Other myisamchk Options
- sort-records option, Other myisamchk Options
- sort-recover option, myisamchk Repair Options
- tmpdir option, myisamchk Repair Options
- unpack option, myisamchk Repair Options
- update-state option, myisamchk Check Options
- verbose option, myisamchk General Options
- version option, myisamchk General Options
- wait option, myisamchk General Options
- myisamlog, Overview of Client and Utility Programs
- myisampack, Overview of Client and Utility Programs, Silent Column Specification Changes, Compressed Table Characteristics
- backup option, myisampack — Generate Compressed, Read-Only MyISAM Tables
- character-sets-dir option, myisampack — Generate Compressed, Read-Only MyISAM Tables
- debug option, myisampack — Generate Compressed, Read-Only MyISAM Tables
- force option, myisampack — Generate Compressed, Read-Only MyISAM Tables
- help option, myisampack — Generate Compressed, Read-Only MyISAM Tables
- join option, myisampack — Generate Compressed, Read-Only MyISAM Tables
- silent option, myisampack — Generate Compressed, Read-Only MyISAM Tables
- test option, myisampack — Generate Compressed, Read-Only MyISAM Tables
- tmpdir option, myisampack — Generate Compressed, Read-Only MyISAM Tables
- verbose option, myisampack — Generate Compressed, Read-Only MyISAM Tables
- version option, myisampack — Generate Compressed, Read-Only MyISAM Tables
- wait option, myisampack — Generate Compressed, Read-Only MyISAM Tables
- myisam_block_size myisamchk variable, myisamchk General Options
- myisam_ftdump, Overview of Client and Utility Programs
- count option, myisam_ftdump — Display Full-Text Index information
- dump option, myisam_ftdump — Display Full-Text Index information
- help option, myisam_ftdump — Display Full-Text Index information
- length option, myisam_ftdump — Display Full-Text Index information
- stats option, myisam_ftdump — Display Full-Text Index information
- verbose option, myisam_ftdump — Display Full-Text Index information
- MyODBC, MySQL Connector/ODBC
- MySQL
- defined, What is MySQL?
- introduction, What is MySQL?
- pronunciation, What is MySQL?
- mysql, Overview of Client and Utility Programs
- auto-rehash option, mysql Options
- batch option, mysql Options
- character-sets-dir option, mysql Options
- column-names option, mysql Options
- compress option, mysql Options
- database option, mysql Options
- debug option, mysql Options
- debug-info option, mysql Options
- default-character-set option, mysql Options
- delimiter option, mysql Options
- execute option, mysql Options
- force option, mysql Options
- help option, mysql Options
- host option, mysql Options
- html option, mysql Options
- i-am-a-dummy option, mysql Options
- ignore-spaces option, mysql Options
- line-numbers option, mysql Options
- local-infile option, mysql Options
- named-commands option, mysql Options
- no-auto-rehash option, mysql Options
- no-beep option, mysql Options
- no-named-commands option, mysql Options
- no-pager option, mysql Options
- no-tee option, mysql Options
- one-database option, mysql Options
- pager option, mysql Options
- password option, mysql Options
- port option, mysql Options
- prompt option, mysql Options
- protocol option, mysql Options
- quick option, mysql Options
- raw option, mysql Options
- reconnect option, mysql Options
- safe-updates option, mysql Options
- secure-auth option, mysql Options
- show-warnings option, mysql Options
- sigint-ignore option, mysql Options
- silent option, mysql Options
- skip-column-names option, mysql Options
- skip-line-numbers option, mysql Options
- socket option, mysql Options
- SSL options, mysql Options
- table option, mysql Options
- tee option, mysql Options
- unbuffered option, mysql Options
- user option, mysql Options
- verbose option, mysql Options
- version option, mysql Options
- vertical option, mysql Options
- wait option, mysql Options
- xml option, mysql Options
- MySQL AB
- defined, Overview of MySQL AB
- MySQL binary distribution, Choosing Which MySQL Distribution to Install
- MYSQL C type, C API Data types
- MySQL Cluster, MySQL Cluster
- administration, Command Options for MySQL Cluster Processes, MySQL Cluster-Related Command Options for mysqld, Command Options for ndbd, Command Options for ndb_mgmd, Command Options for ndb_mgm, Commands in the MySQL Cluster Management Client, Using CLUSTERLOG STATISTICS
- and DNS, Simple Multi-Computer How-To
- and IP addressing, Simple Multi-Computer How-To
- and networking, Hardware, Software, and Networking
- and transactions, MySQL 5.0 FAQ — MySQL Cluster
- API node, Basic MySQL Cluster Concepts, Defining SQL and Other API Nodes
- arbitrator, MySQL 5.0 FAQ — MySQL Cluster
- available platforms, MySQL Cluster
- backups, On-line Backup of MySQL Cluster, Cluster Backup Concepts, Using The Management Client to Create a Backup, Configuration for Cluster Backup, Backup Troubleshooting
- benchmarks, Understanding the Impact of Cluster Interconnects
- CHECKPOINT Events, Log Events
- cluster logs, Event Reports Generated in MySQL Cluster, Logging Management Commands
- CLUSTERLOG commands, Logging Management Commands
- CLUSTERLOG STATISTICS command, Using CLUSTERLOG STATISTICS
- commands, Command Options for MySQL Cluster Processes, MySQL Cluster-Related Command Options for mysqld, Command Options for ndbd, Command Options for ndb_mgmd, Command Options for ndb_mgm, Commands in the MySQL Cluster Management Client
- compiling from source, Building MySQL Cluster from Source Code
- concepts, Basic MySQL Cluster Concepts
- configuration, Simple Multi-Computer How-To, MySQL Cluster Configuration, Quick Test Setup of MySQL Cluster, Defining Cluster Computers, Defining the Management Server, Defining Data Nodes, Defining SQL and Other API Nodes, Configuring Parameters for Local Checkpoints, MySQL Server Process Usage for MySQL Cluster, ndb_mgmd — The Management Server Process
- configuration (example), Basic Example Configuration
- configuration changes, Performing a Rolling Restart of the Cluster
- configuration files, Multi-Computer Configuration, Configuration File
- configuration parameters, Overview of Cluster Configuration Parameters, Data Node Configuration Parameters, Management Node Configuration Parameters, SQL Node and API Node Configuration Parameters
- configuring, Configuration for Cluster Backup
- CONNECTION Events, Log Events
- connectstring, The Cluster Connectstring
- data node, Basic MySQL Cluster Concepts, Defining Data Nodes
- data types supported, MySQL 5.0 FAQ — MySQL Cluster
- defining node hosts, Defining Cluster Computers
- direct connections between nodes, TCP/IP Connections Using Direct Connections
- ENTER SINGLE USER MODE command, Commands in the MySQL Cluster Management Client
- ERROR Events, Log Events
- error logs, ndbd — The Storage Engine Node Process
- error messages, MySQL 5.0 FAQ — MySQL Cluster
- event log format, Log Events
- event logging thresholds, Logging Management Commands
- event logs, Event Reports Generated in MySQL Cluster, Logging Management Commands
- event severity levels, Logging Management Commands
- event types, Event Reports Generated in MySQL Cluster, Log Events
- EXIT command, Commands in the MySQL Cluster Management Client
- EXIT SINGLE USER MODE command, Commands in the MySQL Cluster Management Client
- FAQ, MySQL 5.0 FAQ — MySQL Cluster
- general description, MySQL Cluster Overview
- hardware requirements, MySQL 5.0 FAQ — MySQL Cluster
- HELP command, Commands in the MySQL Cluster Management Client
- how to obtain, MySQL 5.0 FAQ — MySQL Cluster
- importing existing tables, MySQL 5.0 FAQ — MySQL Cluster
- INFO Events, Log Events
- information sources, MySQL Cluster
- installation, Simple Multi-Computer How-To, Multi-Computer Installation, Installing the Cluster Software
- interconnects, Using High-Speed Interconnects with MySQL Cluster
- log files, ndbd — The Storage Engine Node Process
- logging commands, Logging Management Commands
- management commands, Using CLUSTERLOG STATISTICS
- management node, Basic MySQL Cluster Concepts, Defining the Management Server
- managing, Management of MySQL Cluster
- memory requirements, MySQL 5.0 FAQ — MySQL Cluster
- memory usage and recovery, Performing a Rolling Restart of the Cluster, Limits and Differences from Standard MySQL Limits
- mgm, Command Options for MySQL Cluster Processes
- mgm client, Commands in the MySQL Cluster Management Client
- mgm management client, Using CLUSTERLOG STATISTICS
- mgm process, Command Options for ndb_mgm
- mgmd, Command Options for MySQL Cluster Processes
- mgmd process, Command Options for ndb_mgmd
- mysqld process, MySQL Server Process Usage for MySQL Cluster, MySQL Cluster-Related Command Options for mysqld
- ndbd, Command Options for MySQL Cluster Processes
- ndbd process, Command Options for ndbd, Using CLUSTERLOG STATISTICS
- ndb_mgm, Initial Startup
- ndb_size.pl (utility), MySQL 5.0 FAQ — MySQL Cluster
- network configuration (SCI), Configuring MySQL Cluster to use SCI Sockets
- network transporters, Using High-Speed Interconnects with MySQL Cluster, Configuring MySQL Cluster to use SCI Sockets
- networking, TCP/IP Connections Using Direct Connections, Shared-Memory Connections, SCI Transport Connections
- networking requirements, MySQL 5.0 FAQ — MySQL Cluster
- node failure (single user mode), Single User Mode
- node identifiers, Shared-Memory Connections, SCI Transport Connections
- node logs, Event Reports Generated in MySQL Cluster
- node types, MySQL 5.0 FAQ — MySQL Cluster
- NODERESTART Events, Log Events
- nodes and node groups, MySQL Cluster Nodes, Node Groups, Replicas, and Partitions
- nodes and types, Basic MySQL Cluster Concepts
- number of computers required, MySQL 5.0 FAQ — MySQL Cluster
- obtaining, Multi-Computer Installation
- partitions, MySQL Cluster Nodes, Node Groups, Replicas, and Partitions
- performance, Understanding the Impact of Cluster Interconnects
- performing queries, Loading Sample Data and Performing Queries
- platforms supported, MySQL 5.0 FAQ — MySQL Cluster
- process management, Process Management in MySQL Cluster
- quick configuration, Quick Test Setup of MySQL Cluster
- QUIT command, Commands in the MySQL Cluster Management Client
- replicas, MySQL Cluster Nodes, Node Groups, Replicas, and Partitions
- requirements, Hardware, Software, and Networking
- resetting, Performing a Rolling Restart of the Cluster
- RESTART command, Commands in the MySQL Cluster Management Client
- restarting, Safe Shutdown and Restart
- roles of computers, MySQL 5.0 FAQ — MySQL Cluster
- runtime statistics, Using CLUSTERLOG STATISTICS
- SCI (Scalable Coherent Interface), SCI Transport Connections, Configuring MySQL Cluster to use SCI Sockets
- SCI drivers, Configuring MySQL Cluster to use SCI Sockets
- SCI network configuration, Configuring MySQL Cluster to use SCI Sockets
- SCI software installation, Configuring MySQL Cluster to use SCI Sockets
- SCI software requirements, Configuring MySQL Cluster to use SCI Sockets
- SCI, performance vs TCP/IP, Understanding the Impact of Cluster Interconnects
- security, MySQL 5.0 FAQ — MySQL Cluster
- shared memory transport, Shared-Memory Connections
- SHOW command, Commands in the MySQL Cluster Management Client
- SHUTDOWN command, Commands in the MySQL Cluster Management Client
- shutting down, Safe Shutdown and Restart
- single user mode, Commands in the MySQL Cluster Management Client, Single User Mode
- SQL node, Basic MySQL Cluster Concepts, Defining SQL and Other API Nodes
- SQL nodes, MySQL Server Process Usage for MySQL Cluster
- SQL statements, MySQL 5.0 FAQ — MySQL Cluster
- SQL statements for monitoring, Quick Reference: MySQL Cluster SQL Statements
- START BACKUP command, Using The Management Client to Create a Backup
- START command, Commands in the MySQL Cluster Management Client
- starting and stopping, MySQL 5.0 FAQ — MySQL Cluster
- starting nodes, Initial Startup
- starting or restarting, MySQL Cluster Startup Phases
- starting with --initial, Quick Test Setup of MySQL Cluster
- STARTUP Events, Log Events
- STATISTICS Events, Log Events
- STATUS command, Commands in the MySQL Cluster Management Client
- STOP command, Commands in the MySQL Cluster Management Client
- storage requirements, Data Type Storage Requirements
- Table is full error, MySQL 5.0 FAQ — MySQL Cluster
- terminology, MySQL Cluster Glossary
- trace files, ndbd — The Storage Engine Node Process
- transaction handling, Limits Relating to Transaction Handling
- transactions, Defining Data Nodes
- transporters
- Scalable Coherent Interface (SCI), SCI Transport Connections
- shared memory (SHM), Shared-Memory Connections
- TCP/IP, TCP/IP Connections Using Direct Connections
- troubleshooting backups, Backup Troubleshooting
- upgrades and downgrades, Upgrading and Downgrading MySQL Cluster, Performing a Rolling Restart of the Cluster, Cluster Upgrade and Downgrade Compatibility
- using in a virtual machine, MySQL 5.0 FAQ — MySQL Cluster
- using tables and data, Loading Sample Data and Performing Queries
- vs replication, MySQL 5.0 FAQ — MySQL Cluster
- MySQL Cluster Glossary, MySQL Cluster Glossary
- MySQL Cluster How-To, Simple Multi-Computer How-To
- MySQL Cluster in MySQL 5.0 and 5.1, MySQL Cluster Development Roadmap
- MySQL Cluster limitations, Known Limitations of MySQL Cluster
- and differences from standard MySQL limits, Limits and Differences from Standard MySQL Limits
- binary logging, Issues Exclusive to MySQL Cluster
- database objects, Limits Associated with Database Objects
- error handling and reporting, Error Handling
- geometry data types, Non-Compliance In SQL Syntax
- implementation, Issues Exclusive to MySQL Cluster
- imposed by configuration, Limits and Differences from Standard MySQL Limits
- INSERT IGNORE, UPDATE IGNORE, and REPLACE statements, Previous MySQL Cluster Issues Resolved in MySQL 5.1
- memory usage and transaction handling, Limits Relating to Transaction Handling
- multiple management servers, Limitations Relating to Multiple Cluster Nodes
- multiple MySQL servers, Limitations Relating to Multiple Cluster Nodes
- performance, Limitations Relating to Performance
- resolved in current version from previous versions, Previous MySQL Cluster Issues Resolved in MySQL 5.1
- syntax, Non-Compliance In SQL Syntax
- transactions, Limits Relating to Transaction Handling
- unsupported features, Unsupported Or Missing Features
- MySQL Cluster processes (types), Process Management in MySQL Cluster
- MySQL Cluster utilities, Cluster Utility Programs
- mysql command options, mysql Options
- mysql commands
- list of, mysql Commands
- MySQL Community Server
- MySQL Dolphin name, History of MySQL
- MySQL Enterprise
- changes, MySQL Enterprise Release Notes
- MySQL history, History of MySQL
- mysql history file, mysql Options
- MySQL mailing lists, MySQL Mailing Lists
- MySQL name, History of MySQL
- mysql prompt command, mysql Commands
- mysql source (command for reading from text files), Using mysql in Batch Mode, Executing SQL Statements from a Text File
- MySQL source distribution, Choosing Which MySQL Distribution to Install
- mysql status command, mysql Commands
- MySQL storage engines, Storage Engines
- MySQL version, How to Get MySQL
- mysql \. (command for reading from text files), Using mysql in Batch Mode, Executing SQL Statements from a Text File
- MySQL++, MySQL C++ API
- mysql.server, Overview of Server-Side Programs
- mysql.sock
- changing location of, Typical configure Options
- protection, How to Protect or Change the MySQL Unix Socket File
- MYSQL323 SQL mode, SQL Modes
- MYSQL40 SQL mode, SQL Modes
- mysqlaccess, Overview of Client and Utility Programs
- brief option, mysqlaccess — Client for Checking Access Privileges
- commit option, mysqlaccess — Client for Checking Access Privileges
- copy option, mysqlaccess — Client for Checking Access Privileges
- db option, mysqlaccess — Client for Checking Access Privileges
- debug option, mysqlaccess — Client for Checking Access Privileges
- help option, mysqlaccess — Client for Checking Access Privileges
- host option, mysqlaccess — Client for Checking Access Privileges
- howto option, mysqlaccess — Client for Checking Access Privileges
- old_server option, mysqlaccess — Client for Checking Access Privileges
- password option, mysqlaccess — Client for Checking Access Privileges
- plan option, mysqlaccess — Client for Checking Access Privileges
- preview option, mysqlaccess — Client for Checking Access Privileges
- relnotes option, mysqlaccess — Client for Checking Access Privileges
- rhost option, mysqlaccess — Client for Checking Access Privileges
- rollback option, mysqlaccess — Client for Checking Access Privileges
- spassword option, mysqlaccess — Client for Checking Access Privileges
- superuser option, mysqlaccess — Client for Checking Access Privileges
- table option, mysqlaccess — Client for Checking Access Privileges
- user option, mysqlaccess — Client for Checking Access Privileges
- version option, mysqlaccess — Client for Checking Access Privileges
- mysqladmin, Overview of Client and Utility Programs, CREATE DATABASE Syntax, DROP DATABASE Syntax, SHOW STATUS Syntax, SHOW VARIABLES Syntax, FLUSH Syntax, KILL Syntax
- character-sets-dir option, mysqladmin — Client for Administering a MySQL Server
- compress option, mysqladmin — Client for Administering a MySQL Server
- count option, mysqladmin — Client for Administering a MySQL Server
- debug option, mysqladmin — Client for Administering a MySQL Server
- default-character-set option, mysqladmin — Client for Administering a MySQL Server
- force option, mysqladmin — Client for Administering a MySQL Server
- help option, mysqladmin — Client for Administering a MySQL Server
- host option, mysqladmin — Client for Administering a MySQL Server
- password option, mysqladmin — Client for Administering a MySQL Server
- port option, mysqladmin — Client for Administering a MySQL Server
- protocol option, mysqladmin — Client for Administering a MySQL Server
- relative option, mysqladmin — Client for Administering a MySQL Server
- silent option, mysqladmin — Client for Administering a MySQL Server
- sleep option, mysqladmin — Client for Administering a MySQL Server
- socket option, mysqladmin — Client for Administering a MySQL Server
- SSL options, mysqladmin — Client for Administering a MySQL Server
- user option, mysqladmin — Client for Administering a MySQL Server
- verbose option, mysqladmin — Client for Administering a MySQL Server
- version option, mysqladmin — Client for Administering a MySQL Server
- vertical option, mysqladmin — Client for Administering a MySQL Server
- wait option, mysqladmin — Client for Administering a MySQL Server
- mysqladmin command options, mysqladmin — Client for Administering a MySQL Server
- mysqladmin option
- mysqld_multi, mysqld_multi — Manage Multiple MySQL Servers
- mysqlbinlog, Overview of Client and Utility Programs
- character-sets-dir option, mysqlbinlog — Utility for Processing Binary Log Files
- database option, mysqlbinlog — Utility for Processing Binary Log Files
- debug option, mysqlbinlog — Utility for Processing Binary Log Files
- disable-log-bin option, mysqlbinlog — Utility for Processing Binary Log Files
- force-read option, mysqlbinlog — Utility for Processing Binary Log Files
- help option, mysqlbinlog — Utility for Processing Binary Log Files
- hexdump option, mysqlbinlog — Utility for Processing Binary Log Files
- host option, mysqlbinlog — Utility for Processing Binary Log Files
- local-load option, mysqlbinlog — Utility for Processing Binary Log Files
- offset option, mysqlbinlog — Utility for Processing Binary Log Files
- password option, mysqlbinlog — Utility for Processing Binary Log Files
- port option, mysqlbinlog — Utility for Processing Binary Log Files
- position option, mysqlbinlog — Utility for Processing Binary Log Files
- protocol option, mysqlbinlog — Utility for Processing Binary Log Files
- read-from-remote-server option, mysqlbinlog — Utility for Processing Binary Log Files
- result-file option, mysqlbinlog — Utility for Processing Binary Log Files
- set-charset option, mysqlbinlog — Utility for Processing Binary Log Files
- short-form option, mysqlbinlog — Utility for Processing Binary Log Files
- socket option, mysqlbinlog — Utility for Processing Binary Log Files
- start-datetime option, mysqlbinlog — Utility for Processing Binary Log Files
- start-position option, mysqlbinlog — Utility for Processing Binary Log Files
- stop-datetime option, mysqlbinlog — Utility for Processing Binary Log Files
- stop-position option, mysqlbinlog — Utility for Processing Binary Log Files
- to-last-log option, mysqlbinlog — Utility for Processing Binary Log Files
- user option, mysqlbinlog — Utility for Processing Binary Log Files
- version option, mysqlbinlog — Utility for Processing Binary Log Files
- mysqlbug script, How to Report Bugs or Problems
- mysqlcheck, Overview of Client and Utility Programs
- all-databases option, mysqlcheck — A Table Maintenance and Repair Program
- all-in-1 option, mysqlcheck — A Table Maintenance and Repair Program
- analyze option, mysqlcheck — A Table Maintenance and Repair Program
- auto-repair option, mysqlcheck — A Table Maintenance and Repair Program
- character-sets-dir option, mysqlcheck — A Table Maintenance and Repair Program
- check option, mysqlcheck — A Table Maintenance and Repair Program
- check-only-changed option, mysqlcheck — A Table Maintenance and Repair Program
- check-upgrade option, mysqlcheck — A Table Maintenance and Repair Program
- compress option, mysqlcheck — A Table Maintenance and Repair Program
- databases option, mysqlcheck — A Table Maintenance and Repair Program
- debug option, mysqlcheck — A Table Maintenance and Repair Program
- default-character-set option, mysqlcheck — A Table Maintenance and Repair Program
- extended option, mysqlcheck — A Table Maintenance and Repair Program
- fast option, mysqlcheck — A Table Maintenance and Repair Program
- force option, mysqlcheck — A Table Maintenance and Repair Program
- help option, mysqlcheck — A Table Maintenance and Repair Program
- host option, mysqlcheck — A Table Maintenance and Repair Program
- medium-check option, mysqlcheck — A Table Maintenance and Repair Program
- optimize option, mysqlcheck — A Table Maintenance and Repair Program
- password option, mysqlcheck — A Table Maintenance and Repair Program
- port option, mysqlcheck — A Table Maintenance and Repair Program
- protocol option, mysqlcheck — A Table Maintenance and Repair Program
- quick option, mysqlcheck — A Table Maintenance and Repair Program
- repair option, mysqlcheck — A Table Maintenance and Repair Program
- silent option, mysqlcheck — A Table Maintenance and Repair Program
- socket option, mysqlcheck — A Table Maintenance and Repair Program
- SSL options, mysqlcheck — A Table Maintenance and Repair Program
- tables option, mysqlcheck — A Table Maintenance and Repair Program
- use-frm option, mysqlcheck — A Table Maintenance and Repair Program
- user option, mysqlcheck — A Table Maintenance and Repair Program
- verbose option, mysqlcheck — A Table Maintenance and Repair Program
- version option, mysqlcheck — A Table Maintenance and Repair Program
- mysqlclient library, APIs and Libraries
- mysqld, Overview of Server-Side Programs
- abort-slave-event-count option, Command Options
- allow-suspicious-udfs option, Command Options, Security-Related mysqld Options
- ansi option, Command Options
- as MySQL Cluster process, MySQL Server Process Usage for MySQL Cluster, MySQL Cluster-Related Command Options for mysqld
- basedir option, Command Options
- bdb-home option, BDB Startup Options
- bdb-lock-detect option, BDB Startup Options
- bdb-logdir option, BDB Startup Options
- bdb-no-recover option, BDB Startup Options
- bdb-no-sync option, BDB Startup Options
- bdb-shared-data option, BDB Startup Options
- bdb-tmpdir option, BDB Startup Options
- bind-address option, Command Options
- binlog-do-db option, The Binary Log
- binlog-ignore-db option, The Binary Log
- bootstrap option, Command Options
- character-set-client-handshake option, Command Options
- character-set-filesystem option, Command Options
- character-set-server option, Command Options
- character-sets-dir option, Command Options
- chroot option, Command Options
- collation-server option, Command Options
- command options, Command Options
- console option, Command Options
- core-file option, Command Options
- datadir option, Command Options
- debug option, Command Options
- default-character-set option, Command Options
- default-collation option, Command Options
- default-storage-engine option, Command Options
- default-table-type option, Command Options
- default-time-zone option, Command Options
- delay-key-write option, Command Options, MyISAM Startup Options
- des-key-file option, Command Options
- disconnect-slave-event-count option, Command Options
- enable-named-pipe option, Command Options
- enable-pstack option, Command Options
- exit-info option, Command Options
- external-locking option, Command Options
- flush option, Command Options
- gdb option, Command Options
- help option, Command Options
- init-file option, Command Options
- innodb option, InnoDB Startup Options and System Variables
- innodb-safe-binlog option, Command Options
- innodb_status_file option, InnoDB Startup Options and System Variables
- language option, Command Options
- large-pages option, Command Options
- local-infile option, Security-Related mysqld Options
- log option, Command Options
- log-bin option, Command Options
- log-bin-index option, Command Options
- log-bin-trust-function-creators option, Command Options
- log-bin-trust-routine-creators option, Command Options
- log-error option, Command Options
- log-isam option, Command Options
- log-long-format option, Command Options
- log-queries-not-using-indexes option, Command Options
- log-short-format option, Command Options
- log-slave-updates option, Replication Startup Options
- log-slow-admin-statements option, Command Options
- log-slow-queries option, Command Options
- log-tc option, Command Options
- log-tc-size option, Command Options
- log-warnings option, Command Options, Replication Startup Options
- low-priority-updates option, Command Options
- master-connect-retry option, Replication Startup Options
- master-host option, Replication Startup Options
- master-info-file option, Replication Startup Options
- master-password option, Replication Startup Options
- master-port option, Replication Startup Options
- master-retry-count option, Replication Startup Options
- master-ssl option, Replication Startup Options
- master-ssl-ca option, Replication Startup Options
- master-ssl-capath option, Replication Startup Options
- master-ssl-cert option, Replication Startup Options
- master-ssl-cipher option, Replication Startup Options
- master-ssl-key option, Replication Startup Options
- master-user option, Replication Startup Options
- max-binlog-dump-events option, Command Options
- max-relay-log-size option, Replication Startup Options
- memlock option, Command Options
- myisam-recover option, Command Options, MyISAM Startup Options
- ndb-connectstring option, Command Options
- ndbcluster option, Command Options
- old-passwords option, Command Options, Security-Related mysqld Options
- one-thread option, Command Options
- open-files-limit option, Command Options
- pid-file option, Command Options
- port option, Command Options
- port-open-timeout option, Command Options
- read-only option, Replication Startup Options
- relay-log option, Replication Startup Options
- relay-log-index option, Replication Startup Options
- relay-log-info-file option, Replication Startup Options
- relay-log-purge option, Replication Startup Options
- relay-log-space-limit option, Replication Startup Options
- replicate-do-db option, Replication Startup Options
- replicate-do-table option, Replication Startup Options
- replicate-ignore-db option, Replication Startup Options
- replicate-ignore-table option, Replication Startup Options
- replicate-rewrite-db option, Replication Startup Options
- replicate-same-server-id option, Replication Startup Options
- replicate-wild-do-table option, Replication Startup Options
- replicate-wild-ignore-table option, Replication Startup Options
- report-host option, Replication Startup Options
- report-password option, Replication Startup Options
- report-port option, Replication Startup Options
- report-user option, Replication Startup Options
- role in MySQL Cluster, Basic MySQL Cluster Concepts
- safe-mode option, Command Options
- safe-show-database option, Command Options, Security-Related mysqld Options
- safe-user-create option, Command Options, Security-Related mysqld Options
- secure-auth option, Command Options, Security-Related mysqld Options
- secure-file-priv option, Command Options, Security-Related mysqld Options
- shared-memory option, Command Options
- shared-memory-base-name option, Command Options
- show-slave-auth-info option, Replication Startup Options
- skip-bdb option, Command Options, BDB Startup Options
- skip-concurrent-insert option, Command Options
- skip-external-locking option, Command Options
- skip-grant-tables option, Command Options, Security-Related mysqld Options
- skip-host-cache option, Command Options
- skip-innodb option, Command Options
- skip-merge option, Command Options
- skip-name-resolve option, Command Options, Security-Related mysqld Options
- skip-ndbcluster option, Command Options
- skip-networking option, Command Options, Security-Related mysqld Options
- skip-safemalloc option, Command Options
- skip-show-database option, Command Options, Security-Related mysqld Options
- skip-slave-start option, Replication Startup Options
- skip-stack-trace option, Command Options
- skip-symbolic-links option, Command Options
- skip-thread-priority option, Command Options
- slave-load-tmpdir option, Replication Startup Options
- slave-net-timeout option, Replication Startup Options
- slave-skip-errors option, Replication Startup Options
- slave_compressed_protocol option, Replication Startup Options
- socket option, Command Options
- sporadic-binlog-dump-fail option, Command Options
- sql-mode option, Command Options
- SSL options, Command Options, Making MySQL Secure Against Attackers
- standalone option, Command Options
- starting, How to Run MySQL as a Normal User
- symbolic-links option, Command Options
- sync-bdb-logs option, BDB Startup Options
- sysdate-is-now option, Command Options
- tc-heuristic-recover option, Command Options
- temp-pool option, Command Options
- tmpdir option, Command Options
- transaction-isolation option, Command Options
- user option, Command Options
- version option, Command Options
- mysqld library, APIs and Libraries
- mysqld option
- mysqld_multi, mysqld_multi — Manage Multiple MySQL Servers
- mysqld_safe, mysqld_safe — MySQL Server Startup Script
- mysqld options, Tuning Server Parameters
- mysqld server
- buffer sizes, Tuning Server Parameters
- mysqld-version option
- mysqld_safe, mysqld_safe — MySQL Server Startup Script
- mysqldump, Copying MySQL Databases to Another Machine, Overview of Client and Utility Programs
- add-drop-database option, mysqldump — A Database Backup Program
- add-drop-table option, mysqldump — A Database Backup Program
- add-locks option, mysqldump — A Database Backup Program
- all-databases option, mysqldump — A Database Backup Program
- allow-keywords option, mysqldump — A Database Backup Program
- character-sets-dir option, mysqldump — A Database Backup Program
- comments option, mysqldump — A Database Backup Program
- compact option, mysqldump — A Database Backup Program
- compatible option, mysqldump — A Database Backup Program
- complete-insert option, mysqldump — A Database Backup Program
- compress option, mysqldump — A Database Backup Program
- create-options option, mysqldump — A Database Backup Program
- databases option, mysqldump — A Database Backup Program
- debug option, mysqldump — A Database Backup Program
- default-character-set option, mysqldump — A Database Backup Program
- delayed-insert option, mysqldump — A Database Backup Program
- delete-master-logs option, mysqldump — A Database Backup Program
- disable-keys option, mysqldump — A Database Backup Program
- extended-insert option, mysqldump — A Database Backup Program
- fields-enclosed-by option, mysqldump — A Database Backup Program, mysqlimport — A Data Import Program
- fields-escaped-by option, mysqldump — A Database Backup Program, mysqlimport — A Data Import Program
- fields-optionally-enclosed-by option, mysqldump — A Database Backup Program, mysqlimport — A Data Import Program
- fields-terminated-by option, mysqldump — A Database Backup Program, mysqlimport — A Data Import Program
- first-slave option, mysqldump — A Database Backup Program
- flush-logs option, mysqldump — A Database Backup Program
- flush-privileges option, mysqldump — A Database Backup Program
- force option, mysqldump — A Database Backup Program
- help option, mysqldump — A Database Backup Program
- hex-blob option, mysqldump — A Database Backup Program
- host option, mysqldump — A Database Backup Program
- ignore-table option, mysqldump — A Database Backup Program
- insert-ignore option, mysqldump — A Database Backup Program
- lines-terminated-by option, mysqldump — A Database Backup Program, mysqlimport — A Data Import Program
- lock-all-tables option, mysqldump — A Database Backup Program
- lock-tables option, mysqldump — A Database Backup Program
- master-data option, mysqldump — A Database Backup Program
- no-autocommit option, mysqldump — A Database Backup Program
- no-create-db option, mysqldump — A Database Backup Program
- no-create-info option, mysqldump — A Database Backup Program
- no-data option, mysqldump — A Database Backup Program
- opt option, mysqldump — A Database Backup Program
- order-by-primary option, mysqldump — A Database Backup Program
- password option, mysqldump — A Database Backup Program
- port option, mysqldump — A Database Backup Program
- problems, mysqldump — A Database Backup Program, Restrictions on Views
- protocol option, mysqldump — A Database Backup Program
- quick option, mysqldump — A Database Backup Program
- quote-names option, mysqldump — A Database Backup Program
- result-file option, mysqldump — A Database Backup Program
- routines option, mysqldump — A Database Backup Program
- set-charset option, mysqldump — A Database Backup Program
- single-transaction option, mysqldump — A Database Backup Program
- skip-comments option, mysqldump — A Database Backup Program
- skip-opt option, mysqldump — A Database Backup Program
- socket option, mysqldump — A Database Backup Program
- SSL options, mysqldump — A Database Backup Program
- tab option, mysqldump — A Database Backup Program
- tables option, mysqldump — A Database Backup Program
- triggers option, mysqldump — A Database Backup Program
- tz-utc option, mysqldump — A Database Backup Program
- user option, mysqldump — A Database Backup Program
- verbose option, mysqldump — A Database Backup Program
- version option, mysqldump — A Database Backup Program
- views, mysqldump — A Database Backup Program, Restrictions on Views
- where option, mysqldump — A Database Backup Program
- workarounds, mysqldump — A Database Backup Program, Restrictions on Views
- xml option, mysqldump — A Database Backup Program
- mysqld_multi, Overview of Server-Side Programs
- config-file option, mysqld_multi — Manage Multiple MySQL Servers
- example option, mysqld_multi — Manage Multiple MySQL Servers
- help option, mysqld_multi — Manage Multiple MySQL Servers
- log option, mysqld_multi — Manage Multiple MySQL Servers
- mysqladmin option, mysqld_multi — Manage Multiple MySQL Servers
- mysqld option, mysqld_multi — Manage Multiple MySQL Servers
- no-log option, mysqld_multi — Manage Multiple MySQL Servers
- password option, mysqld_multi — Manage Multiple MySQL Servers
- silent option, mysqld_multi — Manage Multiple MySQL Servers
- tcp-ip option, mysqld_multi — Manage Multiple MySQL Servers
- user option, mysqld_multi — Manage Multiple MySQL Servers
- verbose option, mysqld_multi — Manage Multiple MySQL Servers
- version option, mysqld_multi — Manage Multiple MySQL Servers
- mysqld_safe, Overview of Server-Side Programs
- autoclose option, mysqld_safe — MySQL Server Startup Script
- basedir option, mysqld_safe — MySQL Server Startup Script
- core-file-size option, mysqld_safe — MySQL Server Startup Script
- datadir option, mysqld_safe — MySQL Server Startup Script
- defaults-extra-file option, mysqld_safe — MySQL Server Startup Script
- defaults-file option, mysqld_safe — MySQL Server Startup Script
- help option, mysqld_safe — MySQL Server Startup Script
- ledir option, mysqld_safe — MySQL Server Startup Script
- log-error option, mysqld_safe — MySQL Server Startup Script
- mysqld option, mysqld_safe — MySQL Server Startup Script
- mysqld-version option, mysqld_safe — MySQL Server Startup Script
- nice option, mysqld_safe — MySQL Server Startup Script
- no-defaults option, mysqld_safe — MySQL Server Startup Script
- open-files-limit option, mysqld_safe — MySQL Server Startup Script
- pid-file option, mysqld_safe — MySQL Server Startup Script
- port option, mysqld_safe — MySQL Server Startup Script
- socket option, mysqld_safe — MySQL Server Startup Script
- timezone option, mysqld_safe — MySQL Server Startup Script
- user option, mysqld_safe — MySQL Server Startup Script
- mysqlhotcopy, Overview of Client and Utility Programs
- addtodest option, mysqlhotcopy — A Database Backup Program
- allowold option, mysqlhotcopy — A Database Backup Program
- checkpoint option, mysqlhotcopy — A Database Backup Program
- chroot option, mysqlhotcopy — A Database Backup Program
- debug option, mysqlhotcopy — A Database Backup Program
- dryrun option, mysqlhotcopy — A Database Backup Program
- flushlog option, mysqlhotcopy — A Database Backup Program
- help option, mysqlhotcopy — A Database Backup Program
- host option, mysqlhotcopy — A Database Backup Program
- keepold option, mysqlhotcopy — A Database Backup Program
- method option, mysqlhotcopy — A Database Backup Program
- noindices option, mysqlhotcopy — A Database Backup Program
- password option, mysqlhotcopy — A Database Backup Program
- port option, mysqlhotcopy — A Database Backup Program
- quiet option, mysqlhotcopy — A Database Backup Program
- record_log_pos option, mysqlhotcopy — A Database Backup Program
- regexp option, mysqlhotcopy — A Database Backup Program
- resetmaster option, mysqlhotcopy — A Database Backup Program
- resetslave option, mysqlhotcopy — A Database Backup Program
- socket option, mysqlhotcopy — A Database Backup Program
- suffix option, mysqlhotcopy — A Database Backup Program
- tmpdir option, mysqlhotcopy — A Database Backup Program
- user option, mysqlhotcopy — A Database Backup Program
- mysqlimport, Copying MySQL Databases to Another Machine, Overview of Client and Utility Programs, LOAD DATA INFILE Syntax
- character-sets-dir option, mysqlimport — A Data Import Program
- columns option, mysqlimport — A Data Import Program
- compress option, mysqlimport — A Data Import Program
- debug option, mysqlimport — A Data Import Program
- default-character-set option, mysqlimport — A Data Import Program
- delete option, mysqlimport — A Data Import Program
- force option, mysqlimport — A Data Import Program
- help option, mysqlimport — A Data Import Program
- host option, mysqlimport — A Data Import Program
- ignore option, mysqlimport — A Data Import Program
- ignore-lines option, mysqlimport — A Data Import Program
- local option, mysqlimport — A Data Import Program
- lock-tables option, mysqlimport — A Data Import Program
- low-priority option, mysqlimport — A Data Import Program
- password option, mysqlimport — A Data Import Program
- port option, mysqlimport — A Data Import Program
- protocol option, mysqlimport — A Data Import Program
- replace option, mysqlimport — A Data Import Program
- silent option, mysqlimport — A Data Import Program
- socket option, mysqlimport — A Data Import Program
- SSL options, mysqlimport — A Data Import Program
- user option, mysqlimport — A Data Import Program
- verbose option, mysqlimport — A Data Import Program
- version option, mysqlimport — A Data Import Program
- mysqlmanager, Overview of Server-Side Programs
- angel-pid-file option, MySQL Instance Manager Command Options
- bind-address option, MySQL Instance Manager Command Options
- default-mysqld-path option, MySQL Instance Manager Command Options
- defaults-file option, MySQL Instance Manager Command Options
- help option, MySQL Instance Manager Command Options
- install option, MySQL Instance Manager Command Options
- log option, MySQL Instance Manager Command Options
- monitoring-interval option, MySQL Instance Manager Command Options
- password-file option, MySQL Instance Manager Command Options
- pid-file option, MySQL Instance Manager Command Options
- port option, MySQL Instance Manager Command Options
- print-defaults option, MySQL Instance Manager Command Options
- print-password-line option, MySQL Instance Manager Command Options
- remove option, MySQL Instance Manager Command Options
- run-as-service option, MySQL Instance Manager Command Options
- socket option, MySQL Instance Manager Command Options
- standalone option, MySQL Instance Manager Command Options
- user option, MySQL Instance Manager Command Options
- version option, MySQL Instance Manager Command Options
- wait-timeout option, MySQL Instance Manager Command Options
- mysqlshow, Overview of Client and Utility Programs
- character-sets-dir option, mysqlshow — Display Database, Table, and Column Information
- compress option, mysqlshow — Display Database, Table, and Column Information
- count option, mysqlshow — Display Database, Table, and Column Information
- debug option, mysqlshow — Display Database, Table, and Column Information
- default-character-set option, mysqlshow — Display Database, Table, and Column Information
- help option, mysqlshow — Display Database, Table, and Column Information
- host option, mysqlshow — Display Database, Table, and Column Information
- keys option, mysqlshow — Display Database, Table, and Column Information
- password option, mysqlshow — Display Database, Table, and Column Information
- port option, mysqlshow — Display Database, Table, and Column Information
- protocol option, mysqlshow — Display Database, Table, and Column Information
- show-table-type option, mysqlshow — Display Database, Table, and Column Information
- socket option, mysqlshow — Display Database, Table, and Column Information
- SSL options, mysqlshow — Display Database, Table, and Column Information
- status option, mysqlshow — Display Database, Table, and Column Information
- user option, mysqlshow — Display Database, Table, and Column Information
- verbose option, mysqlshow — Display Database, Table, and Column Information
- version option, mysqlshow — Display Database, Table, and Column Information
- mysqltest
- MySQL Test Suite, MySQL Test Suite
- mysql_affected_rows(), mysql_affected_rows()
- mysql_autocommit(), mysql_autocommit()
- MYSQL_BIND C type, C API Prepared Statement Data types
- mysql_change_user(), mysql_change_user()
- mysql_character_set_name(), mysql_character_set_name()
- mysql_close(), mysql_close()
- mysql_commit(), mysql_commit()
- mysql_connect(), mysql_connect()
- mysql_convert_table_format, Overview of Client and Utility Programs
- mysql_create_db(), mysql_create_db()
- mysql_data_seek(), mysql_data_seek()
- MYSQL_DEBUG environment variable, Environment Variables, Overview of Client and Utility Programs
- mysql_debug(), mysql_debug()
- mysql_drop_db(), mysql_drop_db()
- mysql_dump_debug_info(), mysql_dump_debug_info()
- mysql_eof(), mysql_eof()
- mysql_errno(), mysql_errno()
- mysql_error(), mysql_error()
- mysql_escape_string(), mysql_escape_string()
- mysql_explain_log, Overview of Client and Utility Programs
- date option, mysql_explain_log — Use EXPLAIN on Statements in Query Log
- help option, mysql_explain_log — Use EXPLAIN on Statements in Query Log
- host option, mysql_explain_log — Use EXPLAIN on Statements in Query Log
- password option, mysql_explain_log — Use EXPLAIN on Statements in Query Log
- printerror option, mysql_explain_log — Use EXPLAIN on Statements in Query Log
- socket option, mysql_explain_log — Use EXPLAIN on Statements in Query Log
- user option, mysql_explain_log — Use EXPLAIN on Statements in Query Log
- mysql_fetch_field(), mysql_fetch_field()
- mysql_fetch_fields(), mysql_fetch_fields()
- mysql_fetch_field_direct(), mysql_fetch_field_direct()
- mysql_fetch_lengths(), mysql_fetch_lengths()
- mysql_fetch_row(), mysql_fetch_row()
- MYSQL_FIELD C type, C API Data types
- mysql_field_count(), mysql_field_count(), mysql_num_fields()
- MYSQL_FIELD_OFFSET C type, C API Data types
- mysql_field_seek(), mysql_field_seek()
- mysql_field_tell(), mysql_field_tell()
- mysql_find_rows, Overview of Client and Utility Programs
- help option, mysql_find_rows — Extract Queries from Update Log
- regexp option, mysql_find_rows — Extract Queries from Update Log
- rows option, mysql_find_rows — Extract Queries from Update Log
- skip-use-db option, mysql_find_rows — Extract Queries from Update Log
- start_row option, mysql_find_rows — Extract Queries from Update Log
- mysql_fix_extensions, Overview of Client and Utility Programs
- mysql_fix_privilege_tables, Overview of Server-Side Programs
- mysql_free_result(), mysql_free_result()
- mysql_get_character_set_info(), mysql_get_character_set_info()
- mysql_get_client_info(), mysql_get_client_info()
- mysql_get_client_version(), mysql_get_client_version()
- mysql_get_host_info(), mysql_get_host_info()
- mysql_get_proto_info(), mysql_get_proto_info()
- mysql_get_server_info(), mysql_get_server_info()
- mysql_get_server_version(), mysql_get_server_version()
- mysql_get_ssl_cipher(), mysql_get_ssl_cipher()
- MYSQL_GROUP_SUFFIX environment variable, Environment Variables
- mysql_hex_string(), mysql_hex_string()
- MYSQL_HISTFILE environment variable, Environment Variables, mysql Options
- MYSQL_HOME environment variable, Environment Variables
- MYSQL_HOST environment variable, Environment Variables, Connecting to the MySQL Server
- mysql_info(), ALTER TABLE Syntax, INSERT Syntax, LOAD DATA INFILE Syntax, UPDATE Syntax, mysql_info()
- mysql_init(), mysql_init()
- mysql_insert_id(), Transactions and Atomic Operations, INSERT Syntax, mysql_insert_id()
- mysql_install_db, Overview of Server-Side Programs
- mysql_install_db script, Problems Running mysql_install_db
- mysql_kill(), mysql_kill()
- mysql_library_end(), mysql_library_end()
- mysql_library_init(), mysql_library_init()
- mysql_list_dbs(), mysql_list_dbs()
- mysql_list_fields(), mysql_list_fields()
- mysql_list_processes(), mysql_list_processes()
- mysql_list_tables(), mysql_list_tables()
- mysql_more_results(), mysql_more_results()
- mysql_next_result(), mysql_next_result()
- mysql_num_fields(), mysql_num_fields()
- mysql_num_rows(), mysql_num_rows()
- mysql_options(), mysql_options()
- mysql_ping(), mysql_ping()
- MYSQL_PS1 environment variable, Environment Variables
- MYSQL_PWD environment variable, Environment Variables, Connecting to the MySQL Server, Overview of Client and Utility Programs
- mysql_query(), mysql_query(), Common Questions and Problems When Using the C API
- mysql_real_connect(), mysql_real_connect()
- mysql_real_escape_string(), Strings, mysql_real_escape_string()
- mysql_real_query(), mysql_real_query()
- mysql_refresh(), mysql_refresh()
- mysql_reload(), mysql_reload()
- MYSQL_RES C type, C API Data types
- mysql_rollback(), mysql_rollback()
- MYSQL_ROW C type, C API Data types
- mysql_row_seek(), mysql_row_seek()
- mysql_row_tell(), mysql_row_tell()
- mysql_secure_installation, Overview of Server-Side Programs
- mysql_select_db(), mysql_select_db()
- mysql_server_end(), mysql_server_end()
- mysql_server_init(), mysql_server_init()
- mysql_setpermission, Overview of Client and Utility Programs
- help option, mysql_setpermission — Interactively Set Permissions in Grant Tables
- host option, mysql_setpermission — Interactively Set Permissions in Grant Tables
- password option, mysql_setpermission — Interactively Set Permissions in Grant Tables
- port option, mysql_setpermission — Interactively Set Permissions in Grant Tables
- socket option, mysql_setpermission — Interactively Set Permissions in Grant Tables
- user option, mysql_setpermission — Interactively Set Permissions in Grant Tables
- mysql_set_character_set(), mysql_set_character_set()
- mysql_set_local_infile_default(), mysql_set_local_infile_default()
- mysql_set_server_option(), mysql_set_server_option()
- mysql_shutdown(), mysql_shutdown()
- mysql_sqlstate(), mysql_sqlstate()
- mysql_ssl_set(), mysql_ssl_set()
- mysql_stat(), mysql_stat()
- MYSQL_STMT C type, C API Prepared Statement Data types
- mysql_stmt_affected_rows(), mysql_stmt_affected_rows()
- mysql_stmt_attr_get(), mysql_stmt_attr_get()
- mysql_stmt_attr_set(), mysql_stmt_attr_set()
- mysql_stmt_bind_param(), mysql_stmt_bind_param()
- mysql_stmt_bind_result(), mysql_stmt_bind_result()
- mysql_stmt_close(), mysql_stmt_close()
- mysql_stmt_data_seek(), mysql_stmt_data_seek()
- mysql_stmt_errno(), mysql_stmt_errno()
- mysql_stmt_error(), mysql_stmt_error()
- mysql_stmt_execute(), mysql_stmt_execute()
- mysql_stmt_fetch(), mysql_stmt_fetch()
- mysql_stmt_fetch_column(), mysql_stmt_fetch_column()
- mysql_stmt_field_count(), mysql_stmt_field_count()
- mysql_stmt_free_result(), mysql_stmt_free_result()
- mysql_stmt_init(), mysql_stmt_init()
- mysql_stmt_insert_id(), mysql_stmt_insert_id()
- mysql_stmt_num_rows(), mysql_stmt_num_rows()
- mysql_stmt_param_count(), mysql_stmt_param_count()
- mysql_stmt_param_metadata(), mysql_stmt_param_metadata()
- mysql_stmt_prepare(), mysql_stmt_prepare()
- mysql_stmt_reset(), mysql_stmt_reset()
- mysql_stmt_result_metadata, mysql_stmt_result_metadata()
- mysql_stmt_row_seek(), mysql_stmt_row_seek()
- mysql_stmt_row_tell(), mysql_stmt_row_tell()
- mysql_stmt_send_long_data(), mysql_stmt_send_long_data()
- mysql_stmt_sqlstate(), mysql_stmt_sqlstate()
- mysql_stmt_store_result(), mysql_stmt_store_result()
- mysql_store_result(), mysql_store_result(), Common Questions and Problems When Using the C API
- mysql_tableinfo, Overview of Client and Utility Programs
- clear option, mysql_tableinfo — Generate Database Metadata
- clear-only option, mysql_tableinfo — Generate Database Metadata
- col option, mysql_tableinfo — Generate Database Metadata
- help option, mysql_tableinfo — Generate Database Metadata
- host option, mysql_tableinfo — Generate Database Metadata
- idx option, mysql_tableinfo — Generate Database Metadata
- password option, mysql_tableinfo — Generate Database Metadata
- port option, mysql_tableinfo — Generate Database Metadata
- prefix option, mysql_tableinfo — Generate Database Metadata
- quiet option, mysql_tableinfo — Generate Database Metadata
- socket option, mysql_tableinfo — Generate Database Metadata
- tbl-status option, mysql_tableinfo — Generate Database Metadata
- user option, mysql_tableinfo — Generate Database Metadata
- MYSQL_TCP_PORT environment variable, Environment Variables, Running Multiple Servers on Unix, Using Client Programs in a Multiple-Server Environment, Overview of Client and Utility Programs
- mysql_thread_end(), mysql_thread_end()
- mysql_thread_id(), mysql_thread_id()
- mysql_thread_init(), mysql_thread_init()
- mysql_thread_safe(), mysql_thread_safe()
- MYSQL_TIME C type, C API Prepared Statement Data types
- mysql_tzinfo_to_sql, Overview of Server-Side Programs
- MYSQL_UNIX_PORT environment variable, Problems Running mysql_install_db, Environment Variables, Running Multiple Servers on Unix, Using Client Programs in a Multiple-Server Environment, Overview of Client and Utility Programs
- mysql_upgrade, Overview of Server-Side Programs, Causes of Access denied Errors
- basedir option, mysql_upgrade — Check Tables for MySQL Upgrade
- datadir option, mysql_upgrade — Check Tables for MySQL Upgrade
- force option, mysql_upgrade — Check Tables for MySQL Upgrade
- help option, mysql_upgrade — Check Tables for MySQL Upgrade
- user option, mysql_upgrade — Check Tables for MySQL Upgrade
- verbose option, mysql_upgrade — Check Tables for MySQL Upgrade
- mysql_use_result(), mysql_use_result()
- mysql_waitpid, Overview of Client and Utility Programs
- help option, mysql_waitpid — Kill Process and Wait for Its Termination
- verbose option, mysql_waitpid — Kill Process and Wait for Its Termination
- version option, mysql_waitpid — Kill Process and Wait for Its Termination
- mysql_warning_count(), mysql_warning_count()
- mysql_zap, Overview of Client and Utility Programs
- my_bool C type, C API Data types
- my_bool values
- printing, C API Data types
- my_init(), my_init()
- my_print_defaults, Overview of Client and Utility Programs
- config-file option, my_print_defaults — Display Options from Option Files
- debug option, my_print_defaults — Display Options from Option Files
- defaults-extra-file option, my_print_defaults — Display Options from Option Files
- defaults-file option, my_print_defaults — Display Options from Option Files
- defaults-group-suffix option, my_print_defaults — Display Options from Option Files
- extra-file option, my_print_defaults — Display Options from Option Files
- help option, my_print_defaults — Display Options from Option Files
- no-defaults option, my_print_defaults — Display Options from Option Files
- verbose option, my_print_defaults — Display Options from Option Files
- version option, my_print_defaults — Display Options from Option Files
- my_ulonglong C type, C API Data types
- my_ulonglong values
- printing, C API Data types
N
- named pipes, Selecting a MySQL Server Type, Testing The MySQL Installation
- named-commands option
- mysql, mysql Options
- names, Database, Table, Index, Column, and Alias Names
- case sensitivity, Identifier Case Sensitivity
- variables, User-Defined Variables
- NAME_CONST(), Miscellaneous Functions
- name_file option
- naming
- releases of MySQL, Choosing Which Version of MySQL to Install
- NATIONAL CHAR data type, Overview of String Types
- native functions
- adding, Adding a New Native Function
- native thread support, Operating Systems Supported by MySQL Community Server
- NATURAL LEFT JOIN, JOIN Syntax
- NATURAL LEFT OUTER JOIN, JOIN Syntax
- NATURAL RIGHT JOIN, JOIN Syntax
- NATURAL RIGHT OUTER JOIN, JOIN Syntax
- NCHAR data type, Overview of String Types
- NDB, MySQL 5.0 FAQ — MySQL Cluster
- ndb option
- perror, perror — Explain Error Codes
- NDB storage engine, MySQL Cluster
- ndb-connectstring option
- mysqld, Command Options
- ndb_config, ndb_config — Extract NDB Configuration Information
- ndbcluster option
- mysqld, Command Options
- ndbd (MySQL Cluster)
- defined, Basic MySQL Cluster Concepts
- ndb_config, Cluster Utility Programs
- config-file option, ndb_config — Extract NDB Configuration Information
- fields option, ndb_config — Extract NDB Configuration Information
- host option, ndb_config — Extract NDB Configuration Information
- id option, ndb_config — Extract NDB Configuration Information
- ndb-connectstring option, ndb_config — Extract NDB Configuration Information
- nodeid option, ndb_config — Extract NDB Configuration Information
- nodes option, ndb_config — Extract NDB Configuration Information
- query option, ndb_config — Extract NDB Configuration Information
- rows option, ndb_config — Extract NDB Configuration Information
- type option, ndb_config — Extract NDB Configuration Information
- usage option, ndb_config — Extract NDB Configuration Information
- version option, ndb_config — Extract NDB Configuration Information
- ndb_cpcd, Cluster Utility Programs
- ndb_delete_all, Cluster Utility Programs
- transactional option, ndb_delete_all — Delete All Rows from NDB Table
- ndb_desc, Cluster Utility Programs
- extra-partition-info option, ndb_desc — Describe NDB Tables
- ndb_drop_index, Cluster Utility Programs
- ndb_drop_table, Cluster Utility Programs
- ndb_error_reporter, Cluster Utility Programs
- ndb_mgm (MySQL Cluster management node client), Initial Startup
- ndb_mgmd (MySQL Cluster)
- defined, Basic MySQL Cluster Concepts
- ndb_print_backup_file, Cluster Utility Programs
- ndb_print_schema_file, Cluster Utility Programs
- ndb_print_sys_file, Cluster Utility Programs
- ndb_restore
- ndb_select_all, Cluster Utility Programs
- delimiter option, ndb_select_all — Print Rows from NDB Table
- descending option, ndb_select_all — Print Rows from NDB Table
- gci option, ndb_select_all — Print Rows from NDB Table
- header option, ndb_select_all — Print Rows from NDB Table
- lock option, ndb_select_all — Print Rows from NDB Table
- nodata option, ndb_select_all — Print Rows from NDB Table
- order option, ndb_select_all — Print Rows from NDB Table
- rowid option, ndb_select_all — Print Rows from NDB Table
- tupscan option, ndb_select_all — Print Rows from NDB Table
- useHexFormat option, ndb_select_all — Print Rows from NDB Table
- ndb_select_count, Cluster Utility Programs
- ndb_show_tables, Cluster Utility Programs
- loops option, ndb_show_tables — Display List of NDB Tables
- parsable option, ndb_show_tables — Display List of NDB Tables
- type option, ndb_show_tables — Display List of NDB Tables
- unqualified option, ndb_show_tables — Display List of NDB Tables
- ndb_size.pl, Cluster Utility Programs
- ndb_size.pl (utility), MySQL 5.0 FAQ — MySQL Cluster
- ndb_waiter, Cluster Utility Programs
- no-contact option, ndb_waiter — Wait for Cluster to Reach a Given Status
- not-started option, ndb_waiter — Wait for Cluster to Reach a Given Status
- timeout option, ndb_waiter — Wait for Cluster to Reach a Given Status
- negative values, Numbers
- nested queries, Subquery Syntax
- net etiquette, Guidelines for Using the Mailing Lists
- netmask notation
- in mysql.user table, Access Control, Stage 1: Connection Verification
- NetWare, Installing MySQL on NetWare
- net_buffer_length variable, mysql Options
- New features in MySQL Cluster, MySQL Cluster Development Roadmap
- new procedures
- adding, Adding New Procedures to MySQL
- new users
- newline (\n), Strings
- next-key lock, InnoDB Startup Options and System Variables, InnoDB and TRANSACTION ISOLATION LEVEL, Next-Key Locking: Avoiding the Phantom Problem
- NFS
- nice option
- mysqld_safe, mysqld_safe — MySQL Server Startup Script
- no matching rows, Solving Problems with No Matching Rows
- no-auto-rehash option
- mysql, mysql Options
- no-autocommit option
- mysqldump, mysqldump — A Database Backup Program
- no-beep option
- mysql, mysql Options
- no-contact option
- no-create-db option
- mysqldump, mysqldump — A Database Backup Program
- no-create-info option
- mysqldump, mysqldump — A Database Backup Program
- no-data option
- mysqldump, mysqldump — A Database Backup Program
- no-debug option
- make_win_bin_dist, make_win_bin_dist — Package MySQL Distribution as ZIP Archive
- no-defaults option, Using Option Files
- mysqld_safe, mysqld_safe — MySQL Server Startup Script
- my_print_defaults, my_print_defaults — Display Options from Option Files
- no-embedded option
- make_win_bin_dist, make_win_bin_dist — Package MySQL Distribution as ZIP Archive
- no-log option
- mysqld_multi, mysqld_multi — Manage Multiple MySQL Servers
- no-named-commands option
- mysql, mysql Options
- no-pager option
- mysql, mysql Options
- no-symlinks option
- myisamchk, myisamchk Repair Options
- no-tee option
- mysql, mysql Options
- nodata option
- ndb_select_all, ndb_select_all — Print Rows from NDB Table
- node groups (MySQL Cluster), MySQL Cluster Nodes, Node Groups, Replicas, and Partitions
- node identifiers (MySQL Cluster), Shared-Memory Connections, SCI Transport Connections
- node logs (MySQL Cluster), Event Reports Generated in MySQL Cluster
- nodeid option
- NODERESTART Events (MySQL Cluster), Log Events
- nodes option
- noindices option
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- non-delimited strings, The DATETIME, DATE, and TIMESTAMP Types
- Non-transactional tables, Rollback Failure for Non-Transactional Tables
- NoOfDiskPagesToDiskAfterRestartACC
- calculating, Configuring Parameters for Local Checkpoints
- NoOfDiskPagesToDiskAfterRestartACC (MySQL Cluster configuration parameter), Defining Data Nodes
- NoOfDiskPagesToDiskAfterRestartTUP
- calculating, Configuring Parameters for Local Checkpoints
- NoOfDiskPagesToDiskAfterRestartTUP (MySQL Cluster configuration parameter), Defining Data Nodes
- NoOfDiskPagesToDiskDuringRestartACC (MySQL Cluster configuration parameter), Defining Data Nodes
- NoOfDiskPagesToDiskDuringRestartTUP (MySQL Cluster configuration parameter), Defining Data Nodes
- NoOfFragmentLogFiles, Defining Data Nodes
- calculating, Configuring Parameters for Local Checkpoints
- NoOfReplicas, Defining Data Nodes
- NOT
- logical, Logical Operators
- NOT BETWEEN, Comparison Functions and Operators
- not equal (!=), Comparison Functions and Operators
- not equal (<>), Comparison Functions and Operators
- NOT EXISTS
- with subqueries, EXISTS and NOT EXISTS
- NOT IN, Comparison Functions and Operators
- NOT LIKE, String Comparison Functions
- NOT NULL
- constraint, Constraints on Invalid Data
- NOT REGEXP, String Comparison Functions
- not-started option
- Novell NetWare, Installing MySQL on NetWare
- NOW(), Date and Time Functions
- NO_AUTO_CREATE_USER SQL mode, SQL Modes
- NO_AUTO_VALUE_ON_ZERO SQL mode, SQL Modes
- NO_BACKSLASH_ESCAPES SQL mode, SQL Modes
- NO_DIR_IN_CREATE SQL mode, SQL Modes
- NO_FIELD_OPTIONS SQL mode, SQL Modes
- NO_KEY_OPTIONS SQL mode, SQL Modes
- NO_TABLE_OPTIONS SQL mode, SQL Modes
- NO_UNSIGNED_SUBTRACTION SQL mode, SQL Modes
- NO_ZERO_DATE SQL mode, SQL Modes
- NO_ZERO_IN_DATE SQL mode, SQL Modes
- NUL, Strings
- NULL, Working with NULL Values, Problems with NULL Values
- ORDER BY, ORDER BY Optimization, SELECT Syntax
- testing for null, Comparison Functions and Operators, Control Flow Functions
- NULL value, Working with NULL Values, NULL Values
- NULL values
- and AUTO_INCREMENT columns, Problems with NULL Values
- and indexes, CREATE TABLE Syntax
- and TIMESTAMP columns, Problems with NULL Values
- vs. empty values, Problems with NULL Values
- NULLIF(), Control Flow Functions
- numbers, Numbers
- NUMERIC data type, Overview of Numeric Types
- numeric types, Data Type Storage Requirements
- numeric-dump-file option
- resolve_stack_dump, resolve_stack_dump — Resolve Numeric Stack Trace Dump to Symbols
- NumGeometries(), GeometryCollection Functions
- NumInteriorRings(), Polygon Functions
- NumPoints(), LineString Functions
O
- Obtaining MySQL Cluster, Multi-Computer Installation
- OCT(), String Functions
- OCTET_LENGTH(), String Functions
- ODBC, MySQL Connector/ODBC
- ODBC compatibility, Identifier Qualifiers, Overview of Numeric Types, Type Conversion in Expression Evaluation, Comparison Functions and Operators, CREATE TABLE Syntax, JOIN Syntax
- offset option
- OLAP, GROUP BY Modifiers
- old-passwords option
- OLD_PASSWORD(), Encryption and Compression Functions
- old_server option
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- ON DUPLICATE KEY, INSERT Syntax
- one-database option
- mysql, mysql Options
- one-thread option
- mysqld, Command Options
- online location of manual, About This Manual
- only-debug option
- make_win_bin_dist, make_win_bin_dist — Package MySQL Distribution as ZIP Archive
- ONLY_FULL_GROUP_BY
- SQL mode, GROUP BY and HAVING with Hidden Fields
- ONLY_FULL_GROUP_BY SQL mode, SQL Modes
- OPEN, Cursor OPEN Statement
- Open Source
- defined, What is MySQL?
- open tables, How MySQL Opens and Closes Tables, mysqladmin — Client for Administering a MySQL Server
- open-files-limit option
- mysqld, Command Options
- mysqld_safe, mysqld_safe — MySQL Server Startup Script
- OpenGIS, Introduction to MySQL Spatial Support
- opening
- opens, mysqladmin — Client for Administering a MySQL Server
- OpenSSL, Using Secure Connections, Using SSL Connections
- open_files_limit variable, mysqlbinlog — Utility for Processing Binary Log Files
- operating systems
- file-size limits, The table is full
- supported, Operating Systems Supported by MySQL Community Server
- Windows versus Unix, MySQL on Windows Compared to MySQL on Unix
- operations
- arithmetic, Arithmetic Operators
- operators, Functions and Operators
- assignment, User-Defined Variables
- cast, Arithmetic Operators, Cast Functions and Operators
- logical, Logical Operators
- precedence, Operator Precedence
- opt option
- mysqldump, mysqldump — A Database Backup Program
- optimization
- subquery, Optimizing IN/=ANY Subqueries
- tips, Other Optimization Tips
- optimizations, WHERE Clause Optimization, Index Merge Optimization
- optimize option
- OPTIMIZE TABLE, OPTIMIZE TABLE Syntax
- optimizer
- controlling, Controlling Query Optimizer Performance
- optimizing
- DISTINCT, DISTINCT Optimization
- filesort, ORDER BY Optimization
- GROUP BY, GROUP BY Optimization
- LEFT JOIN, LEFT JOIN and RIGHT JOIN Optimization
- LIMIT, LIMIT Optimization
- tables, Table Optimization
- option files, Using Option Files, Causes of Access denied Errors
- options
- command-line
- mysql, mysql Options
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- configure, Typical configure Options
- myisamchk, myisamchk General Options
- provided by MySQL, Tutorial
- replication, Replication Features and Known Problems
- OR, Searching on Two Keys, Index Merge Optimization
- bitwise, Bit Functions
- logical, Logical Operators
- OR Index Merge optimization, Index Merge Optimization
- Oracle compatibility, MySQL Extensions to Standard SQL, GROUP BY (Aggregate) Functions, DESCRIBE Syntax
- ORACLE SQL mode, SQL Modes
- ORD(), String Functions
- ORDER BY, Sorting Rows, ALTER TABLE Syntax, SELECT Syntax
- order option
- ndb_select_all, ndb_select_all — Print Rows from NDB Table
- order-by-primary option
- mysqldump, mysqldump — A Database Backup Program
- OUTFILE, SELECT Syntax
- out_dir option
- out_file option
- Overlaps(), Functions That Test Spatial Relationships Between Geometries
- overview, General Information
P
- packages
- list of, Packages that support MySQL
- pack_isam, Overview of Client and Utility Programs
- page-level locking, Internal Locking Methods
- pager option
- mysql, mysql Options
- parallel-recover option
- myisamchk, myisamchk Repair Options
- parameters
- server, Tuning Server Parameters
- parentheses ( and ), Operator Precedence
- parsable option
- ndb_show_tables, ndb_show_tables — Display List of NDB Tables
- partitions (MySQL Cluster), MySQL Cluster Nodes, Node Groups, Replicas, and Partitions
- password
- root user, Securing the Initial MySQL Accounts
- password encryption
- reversibility of, Encryption and Compression Functions
- password option
- mysql, mysql Options
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- mysqlbinlog, mysqlbinlog — Utility for Processing Binary Log Files
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqldump, mysqldump — A Database Backup Program
- mysqld_multi, mysqld_multi — Manage Multiple MySQL Servers
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- mysqlimport, mysqlimport — A Data Import Program
- mysqlshow, mysqlshow — Display Database, Table, and Column Information
- mysql_explain_log, mysql_explain_log — Use EXPLAIN on Statements in Query Log
- mysql_setpermission, mysql_setpermission — Interactively Set Permissions in Grant Tables
- mysql_tableinfo, mysql_tableinfo — Generate Database Metadata
- PASSWORD(), Access Control, Stage 1: Connection Verification, Assigning Account Passwords, Encryption and Compression Functions, Ignoring user
- password-file option
- mysqlmanager, MySQL Instance Manager Command Options
- passwords
- for users, MySQL Usernames and Passwords
- forgotten, How to Reset the Root Password
- lost, How to Reset the Root Password
- resetting, How to Reset the Root Password
- security, What the Privilege System Does
- setting, Assigning Account Passwords, GRANT Syntax, SET PASSWORD Syntax
- PATH environment variable, Installing MySQL from tar.gz Packages on Other Unix-Like Systems, Environment Variables, Invoking MySQL Programs
- pattern matching, Pattern Matching, Regular Expressions
- performance
- benchmarks, Using Your Own Benchmarks
- disk issues, Disk Issues
- estimating, Estimating Query Performance
- improving, Replication FAQ, Make Your Data as Small as Possible
- PERIOD_ADD(), Date and Time Functions
- PERIOD_DIFF(), Date and Time Functions
- Perl
- installing, Perl Installation Notes
- installing on Windows, Installing ActiveState Perl on Windows
- Perl API, MySQL Perl API
- Perl DBI/DBD
- installation problems, Problems Using the Perl DBI/DBD Interface
- permission checks
- effect on speed, Optimizing SELECT and Other Statements
- perror, Overview of Client and Utility Programs
- --ndb option, MySQL 5.0 FAQ — MySQL Cluster
- help option, perror — Explain Error Codes
- ndb option, perror — Explain Error Codes
- silent option, perror — Explain Error Codes
- verbose option, perror — Explain Error Codes
- version option, perror — Explain Error Codes
- PHP API, MySQL PHP API
- PI(), Mathematical Functions
- pid-file option
- mysqld, Command Options
- mysqld_safe, mysqld_safe — MySQL Server Startup Script
- mysqlmanager, MySQL Instance Manager Command Options
- PIPES_AS_CONCAT SQL mode, SQL Modes
- plan option
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- POINT data type, MySQL Spatial Data Types
- point in time recovery, Point-in-Time Recovery
- Point(), Creating Geometry Values Using MySQL-Specific Functions
- PointFromText(), Creating Geometry Values Using WKT Functions
- PointFromWKB(), Creating Geometry Values Using WKB Functions
- PointN(), LineString Functions
- PointOnSurface(), MultiPolygon Functions
- PolyFromText(), Creating Geometry Values Using WKT Functions
- PolyFromWKB(), Creating Geometry Values Using WKB Functions
- POLYGON data type, MySQL Spatial Data Types
- Polygon(), Creating Geometry Values Using MySQL-Specific Functions
- PolygonFromText(), Creating Geometry Values Using WKT Functions
- PolygonFromWKB(), Creating Geometry Values Using WKB Functions
- port option
- mysql, mysql Options
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- mysqlbinlog, mysqlbinlog — Utility for Processing Binary Log Files
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqld, Command Options
- mysqldump, mysqldump — A Database Backup Program
- mysqld_safe, mysqld_safe — MySQL Server Startup Script
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- mysqlimport, mysqlimport — A Data Import Program
- mysqlmanager, MySQL Instance Manager Command Options
- mysqlshow, mysqlshow — Display Database, Table, and Column Information
- mysql_setpermission, mysql_setpermission — Interactively Set Permissions in Grant Tables
- mysql_tableinfo, mysql_tableinfo — Generate Database Metadata
- port-open-timeout option
- mysqld, Command Options
- portability, Designing Applications for Portability
- PortNumber, Defining the Management Server, Cluster TCP/IP Connections
- position option
- POSITION(), String Functions
- post-install
- multiple servers, Running Multiple MySQL Servers on the Same Machine
- post-installation
- setup and testing, Post-Installation Setup and Testing
- PostgreSQL compatibility, MySQL Extensions to Standard SQL
- POSTGRESQL SQL mode, SQL Modes
- POW(), Mathematical Functions
- POWER(), Mathematical Functions
- precedence
- operator, Operator Precedence
- precision
- arithmetic, Precision Math
- precision math, Precision Math
- prefix option
- mysql_tableinfo, mysql_tableinfo — Generate Database Metadata
- PREPARE, SQL Syntax for Prepared Statements
- XA transactions, XA Transaction SQL Syntax
- preview option
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- previx option
- configure, Typical configure Options
- PRIMARY KEY, ALTER TABLE Syntax, CREATE TABLE Syntax
- constraint, PRIMARY KEY and UNIQUE Index Constraints
- primary key
- deleting, ALTER TABLE Syntax
- print-defaults option, Using Option Files
- mysqlmanager, MySQL Instance Manager Command Options
- print-password-line option
- mysqlmanager, MySQL Instance Manager Command Options
- printerror option
- mysql_explain_log, mysql_explain_log — Use EXPLAIN on Statements in Query Log
- privilege
- privilege information
- location, Privileges Provided by MySQL
- privilege system, What the Privilege System Does
- described, How the Privilege System Works
- privileges
- access, The MySQL Access Privilege System
- adding, Adding New User Accounts to MySQL
- default, Securing the Initial MySQL Accounts
- deleting, Removing User Accounts from MySQL, DROP USER Syntax
- display, SHOW GRANTS Syntax
- dropping, Removing User Accounts from MySQL, DROP USER Syntax
- granting, GRANT Syntax
- revoking, REVOKE Syntax
- problems
- access denied errors, Access denied
- common errors, Problems and Common Errors
- compiling, Dealing with Problems Compiling MySQL
- DATE columns, Problems Using DATE Columns
- date values, The DATETIME, DATE, and TIMESTAMP Types
- installing on IBM-AIX, IBM-AIX notes
- installing on Solaris, Solaris Notes
- installing Perl, Problems Using the Perl DBI/DBD Interface
- linking, Problems Linking to the MySQL Client Library
- ODBC, Connector/ODBC Support
- reporting, How to Report Bugs or Problems
- starting the server, Starting and Troubleshooting the MySQL Server
- table locking, Table Locking Issues
- time zone, Time Zone Problems
- PROCEDURE, SELECT Syntax
- procedures
- process management (MySQL Cluster), Process Management in MySQL Cluster
- process support, Operating Systems Supported by MySQL Community Server
- processes
- display, SHOW PROCESSLIST Syntax
- processing
- arguments, UDF Argument Processing
- PROCESSLIST, SHOW PROCESSLIST Syntax
- PROFILING
- INFORMATION_SCHEMA table, The INFORMATION_SCHEMA PROFILING Table
- program variables
- programs
- prompt option
- mysql, mysql Options
- prompts
- meanings, Entering Queries
- pronunciation
- MySQL, What is MySQL?
- protocol option
- mysql, mysql Options
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- mysqlbinlog, mysqlbinlog — Utility for Processing Binary Log Files
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqldump, mysqldump — A Database Backup Program
- mysqlimport, mysqlimport — A Data Import Program
- mysqlshow, mysqlshow — Display Database, Table, and Column Information
- PURGE MASTER LOGS, PURGE MASTER LOGS Syntax
- PURGE STALE SESSIONS, MySQL Cluster Startup Phases
- Python API, MySQL Python API
Q
- QUARTER(), Date and Time Functions
- queries
- entering, Entering Queries
- estimating performance, Estimating Query Performance
- examples, Examples of Common Queries
- speed of, Optimizing SELECT and Other Statements
- Twin Studies project, Queries from the Twin Project
- Query Cache, The MySQL Query Cache
- query option
- questions, mysqladmin — Client for Administering a MySQL Server
- answering, Guidelines for Using the Mailing Lists
- quick option
- myisamchk, myisamchk Repair Options
- mysql, mysql Options
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqldump, mysqldump — A Database Backup Program
- quiet option
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- mysql_tableinfo, mysql_tableinfo — Generate Database Metadata
- QUIT command (MySQL Cluster), Commands in the MySQL Cluster Management Client
- QUOTE(), String Functions
- quote-names option
- mysqldump, mysqldump — A Database Backup Program
- quotes
- in strings, Strings
- quoting, Strings
- quoting binary data, Strings
- quoting of identifiers, Database, Table, Index, Column, and Alias Names
R
- RADIANS(), Mathematical Functions
- RAND(), Mathematical Functions
- raw option
- mysql, mysql Options
- re-creating
- grant tables, Problems Running mysql_install_db
- read-from-remote-server option
- read-only option
- myisamchk, myisamchk Check Options
- mysqld, Replication Startup Options
- read_buffer_size myisamchk variable, myisamchk General Options
- REAL data type, Overview of Numeric Types
- REAL_AS_FLOAT SQL mode, SQL Modes
- ReceiveBufferMemory, Cluster TCP/IP Connections
- reconfiguring, Dealing with Problems Compiling MySQL
- reconnect option
- mysql, mysql Options
- record_log_pos option
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- RECOVER
- XA transactions, XA Transaction SQL Syntax
- recover option
- myisamchk, myisamchk Repair Options
- recovery
- from crash, Using myisamchk for Crash Recovery
- point in time, Point-in-Time Recovery
- RedoBuffer, Defining Data Nodes
- reducing
- data size, Make Your Data as Small as Possible
- references, ALTER TABLE Syntax
- ref_or_null, IS NULL Optimization
- REGEXP, String Comparison Functions
- REGEXP operator, Regular Expressions
- regexp option
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- mysql_find_rows, mysql_find_rows — Extract Queries from Update Log
- regular expression syntax, Regular Expressions
- Related(), Functions That Test Spatial Relationships Between Geometries
- relational databases
- defined, What is MySQL?
- relative option
- relay-log option
- mysqld, Replication Startup Options
- relay-log-index option
- mysqld, Replication Startup Options
- relay-log-info-file option
- mysqld, Replication Startup Options
- relay-log-purge option
- mysqld, Replication Startup Options
- relay-log-space-limit option
- mysqld, Replication Startup Options
- release notes, MySQL Enterprise Release Notes, MySQL Community Server Enhancements and Release Notes
- MySQL Community Server, MySQL Community Server Enhancements and Release Notes
- MySQL Enterprise, MySQL Enterprise Release Notes
- Release Notes
- MySQL Community Server, MySQL Community Server 5.0 Enhancements and Release Notes
- MySQL Enterprise, MySQL Enterprise 5.0 Release Notes
- release numbers, Choosing Which MySQL Distribution to Install
- RELEASE SAVEPOINT, SAVEPOINT and ROLLBACK TO SAVEPOINT Syntax
- releases
- naming scheme, Choosing Which Version of MySQL to Install
- testing, Choosing Which Version of MySQL to Install
- updating, How and When Updates Are Released
- RELEASE_LOCK(), Miscellaneous Functions
- relnotes option
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- remove option
- mysqlmanager, MySQL Instance Manager Command Options
- RENAME TABLE, RENAME TABLE Syntax
- RENAME USER, RENAME USER Syntax
- renaming user accounts, RENAME USER Syntax
- reordering
- repair option
- repair options
- myisamchk, myisamchk Repair Options
- REPAIR TABLE, REPAIR TABLE Syntax
- repairing
- tables, How to Repair Tables
- REPEAT, REPEAT Statement
- REPEAT(), String Functions
- replace, Overview of Client and Utility Programs
- REPLACE, REPLACE Syntax
- replace option
- mysqlimport, mysqlimport — A Data Import Program
- REPLACE(), String Functions
- replicas (MySQL Cluster), MySQL Cluster Nodes, Node Groups, Replicas, and Partitions
- replicate-do-db option
- mysqld, Replication Startup Options
- replicate-do-table option
- mysqld, Replication Startup Options
- replicate-ignore-db option
- mysqld, Replication Startup Options
- replicate-ignore-table option
- mysqld, Replication Startup Options
- replicate-rewrite-db option
- mysqld, Replication Startup Options
- replicate-same-server-id option
- mysqld, Replication Startup Options
- replicate-wild-do-table option
- mysqld, Replication Startup Options
- replicate-wild-ignore-table option
- mysqld, Replication Startup Options
- replication, Replication
- replication limitations, Replication Features and Known Problems
- replication masters
- statements, SQL Statements for Controlling Master Servers
- replication options, Replication Features and Known Problems
- replication slaves
- statements, SQL Statements for Controlling Slave Servers
- report-host option
- mysqld, Replication Startup Options
- report-password option
- mysqld, Replication Startup Options
- report-port option
- mysqld, Replication Startup Options
- report-user option
- mysqld, Replication Startup Options
- reporting
- bugs, How to Report Bugs or Problems
- Connector/NET problems, Connector/NET Support
- Connector/ODBC problems, Connector/ODBC Support
- errors, General Information, How to Report Bugs or Problems
- REQUIRE GRANT option, GRANT Syntax
- reserved words, Reserved Words
- RESET MASTER, RESET MASTER Syntax
- RESET SLAVE, RESET SLAVE Syntax
- resetmaster option
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- resetslave option
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- resolveip, Overview of Client and Utility Programs
- help option, resolveip — Resolve Hostname to IP Address or Vice Versa
- silent option, resolveip — Resolve Hostname to IP Address or Vice Versa
- version option, resolveip — Resolve Hostname to IP Address or Vice Versa
- resolve_stack_dump, Overview of Client and Utility Programs
- help option, resolve_stack_dump — Resolve Numeric Stack Trace Dump to Symbols
- numeric-dump-file option, resolve_stack_dump — Resolve Numeric Stack Trace Dump to Symbols
- symbols-file option, resolve_stack_dump — Resolve Numeric Stack Trace Dump to Symbols
- version option, resolve_stack_dump — Resolve Numeric Stack Trace Dump to Symbols
- RESTART command (MySQL Cluster), Commands in the MySQL Cluster Management Client
- restarting
- the server, Unix Post-Installation Procedures
- RestartOnErrorInsert, Defining Data Nodes
- RESTORE TABLE, RESTORE TABLE Syntax
- restrictions
- server-side cursors, Restrictions on Server-Side Cursors
- stored routines, Restrictions on Stored Routines and Triggers
- subqueries, Restrictions on Subqueries
- triggers, Restrictions on Stored Routines and Triggers
- views, Restrictions on Views
- result-file option
- mysqlbinlog, mysqlbinlog — Utility for Processing Binary Log Files
- mysqldump, mysqldump — A Database Backup Program
- retrieving
- data from tables, Retrieving Information from a Table
- return (\r), Strings
- return values
- REVERSE(), String Functions
- REVOKE, REVOKE Syntax
- revoking
- privileges, REVOKE Syntax
- rhost option
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- RIGHT JOIN, JOIN Syntax
- RIGHT OUTER JOIN, JOIN Syntax
- RIGHT(), String Functions
- RLIKE, String Comparison Functions
- ROLLBACK, Transactions and Atomic Operations, START TRANSACTION, COMMIT, and ROLLBACK Syntax
- XA transactions, XA Transaction SQL Syntax
- rollback option
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- ROLLBACK TO SAVEPOINT, SAVEPOINT and ROLLBACK TO SAVEPOINT Syntax
- rolling restart (MySQL Cluster), Performing a Rolling Restart of the Cluster
- rolling upgrades and downgrades (MySQL Cluster), Performing a Rolling Restart of the Cluster
- ROLLUP, GROUP BY Modifiers
- root password, Securing the Initial MySQL Accounts
- root user
- password resetting, How to Reset the Root Password
- ROUND(), Mathematical Functions
- rounding, Precision Math
- rounding errors, Overview of Numeric Types
- ROUTINES
- INFORMATION_SCHEMA table, The INFORMATION_SCHEMA ROUTINES Table
- routines option
- mysqldump, mysqldump — A Database Backup Program
- ROW, Row Subqueries
- row subqueries, Row Subqueries
- row-level locking, Internal Locking Methods
- rowid option
- ndb_select_all, ndb_select_all — Print Rows from NDB Table
- rows
- counting, Counting Rows
- deleting, Deleting Rows from Related Tables
- locking, Transactions and Atomic Operations
- matching problems, Solving Problems with No Matching Rows
- selecting, Selecting Particular Rows
- sorting, Sorting Rows
- rows option
- mysql_find_rows, mysql_find_rows — Extract Queries from Update Log
- ndb_config, ndb_config — Extract NDB Configuration Information
- ROW_COUNT(), Information Functions
- RPAD(), String Functions
- RPM file, Installing MySQL from RPM Packages on Linux
- RPM Package Manager, Installing MySQL from RPM Packages on Linux
- RTRIM(), String Functions
- run-as-service option
- mysqlmanager, MySQL Instance Manager Command Options
- running
- ANSI mode, Running MySQL in ANSI Mode
- batch mode, Using mysql in Batch Mode
- multiple servers, Running Multiple MySQL Servers on the Same Machine
- queries, Entering Queries
- running configure after prior invocation, Dealing with Problems Compiling MySQL
S
- safe-mode option
- mysqld, Command Options
- safe-recover option
- myisamchk, myisamchk Repair Options
- safe-show-database option
- safe-updates option, Using the --safe-updates Option
- mysql, mysql Options
- safe-user-create option
- Sakila, History of MySQL
- SAVEPOINT, SAVEPOINT and ROLLBACK TO SAVEPOINT Syntax
- scale
- arithmetic, Precision Math
- schema
- altering, ALTER DATABASE Syntax
- creating, CREATE DATABASE Syntax
- deleting, DROP DATABASE Syntax
- SCHEMA(), Information Functions
- SCHEMATA
- INFORMATION_SCHEMA table, The INFORMATION_SCHEMA SCHEMATA Table
- SCHEMA_PRIVILEGES
- INFORMATION_SCHEMA table, The INFORMATION_SCHEMA SCHEMA_PRIVILEGES Table
- SCI (Scalable Coherent Interface), SCI Transport Connections, Configuring MySQL Cluster to use SCI Sockets
- script files, Using mysql in Batch Mode
- scripts
- mysqlbug, How to Report Bugs or Problems
- mysql_install_db, Problems Running mysql_install_db
- searching
- and case sensitivity, Case Sensitivity in Searches
- full-text, Full-Text Search Functions
- MySQL Web pages, How to Report Bugs or Problems
- two keys, Searching on Two Keys
- SECOND(), Date and Time Functions
- secure-auth option
- mysql, mysql Options
- mysqld, Command Options, Security-Related mysqld Options
- secure-file-priv option
- security
- against attackers, Making MySQL Secure Against Attackers
- security system, The MySQL Access Privilege System
- SEC_TO_TIME(), Date and Time Functions
- SELECT
- LIMIT, SELECT Syntax
- optimizing, Optimizing Queries with EXPLAIN
- Query Cache, The MySQL Query Cache
- SELECT INTO, SELECT ... INTO Statement
- SELECT INTO TABLE, SELECT INTO TABLE
- SELECT speed, Speed of SELECT Queries
- selecting
- databases, Creating and Selecting a Database
- select_limit variable, mysql Options
- SendBufferMemory, Cluster TCP/IP Connections
- SendLimit, SCI Transport Connections
- SendSignalId, Cluster TCP/IP Connections, Shared-Memory Connections, SCI Transport Connections
- SEQUENCE, Using AUTO_INCREMENT
- sequence emulation, Information Functions
- sequences, Using AUTO_INCREMENT
- SERIAL, Overview of Numeric Types
- SERIAL DEFAULT VALUE, Data Type Default Values
- server
- connecting, Connecting to and Disconnecting from the Server, Connecting to the MySQL Server
- disconnecting, Connecting to and Disconnecting from the Server
- restart, Unix Post-Installation Procedures
- shutdown, Unix Post-Installation Procedures
- starting, Unix Post-Installation Procedures
- starting and stopping, Starting and Stopping MySQL Automatically
- starting problems, Starting and Troubleshooting the MySQL Server
- server variables, System Variables, SHOW VARIABLES Syntax
- server-side cursor restrictions, Restrictions on Server-Side Cursors
- server-side programs, Overview of Server-Side Programs
- ServerPort, Defining Data Nodes
- servers
- SESSION_USER(), Information Functions
- SET, SET Syntax, Variable SET Statement
- AUTOCOMMIT, SET Syntax
- BIG_TABLES, SET Syntax
- CHARACTER SET, Connection Character Sets and Collations, SET Syntax
- FOREIGN_KEY_CHECKS, SET Syntax
- IDENTITY, SET Syntax
- INSERT_ID, SET Syntax
- LAST_INSERT_ID, SET Syntax
- NAMES, Connection Character Sets and Collations, SET Syntax
- ONE_SHOT, SET Syntax
- PROFILING, SET Syntax
- PROFILING_HISTORY_SIZE, SET Syntax
- size, Data Type Storage Requirements
- SQL_AUTO_IS_NULL, SET Syntax
- SQL_BIG_SELECTS, SET Syntax
- SQL_BUFFER_SELECT, SET Syntax
- SQL_LOG_BIN, SET Syntax
- SQL_LOG_OFF, SET Syntax
- SQL_LOG_UPDATE, SET Syntax
- SQL_NOTES, SET Syntax
- SQL_QUOTE_SHOW_CREATE, SET Syntax
- SQL_SAFE_UPDATES, SET Syntax
- SQL_SELECT_LIMIT, SET Syntax
- SQL_WARNINGS, SET Syntax
- TIMESTAMP, SET Syntax
- UNIQUE_CHECKS, SET Syntax
- SET data type, Overview of String Types, The SET Type
- SET GLOBAL SQL_SLAVE_SKIP_COUNTER, SET GLOBAL SQL_SLAVE_SKIP_COUNTER Syntax
- SET OPTION, SET Syntax
- SET PASSWORD, SET PASSWORD Syntax
- SET PASSWORD statement, Assigning Account Passwords
- SET SQL_LOG_BIN, SET SQL_LOG_BIN Syntax
- SET TRANSACTION, SET TRANSACTION Syntax
- set-auto-increment[ option
- myisamchk, Other myisamchk Options
- set-character-set option
- myisamchk, myisamchk Repair Options
- set-charset option
- mysqlbinlog, mysqlbinlog — Utility for Processing Binary Log Files
- mysqldump, mysqldump — A Database Backup Program
- set-collation option
- myisamchk, myisamchk Repair Options
- setting
- passwords, Assigning Account Passwords
- setting passwords, SET PASSWORD Syntax
- setting program variables, Using Options to Set Program Variables
- setup
- post-installation, Post-Installation Setup and Testing
- SHA(), Encryption and Compression Functions
- SHA1(), Encryption and Compression Functions
- shared memory transporter, Shared-Memory Connections
- shared-memory option
- mysqld, Command Options
- shared-memory-base-name option
- mysqld, Command Options
- SharedBufferSize, SCI Transport Connections
- shell syntax, Conventions Used in This Manual
- ShmKey, Shared-Memory Connections
- ShmSize, Shared-Memory Connections
- short-form option
- SHOW
- in MySQL Cluster management client, Quick Test Setup of MySQL Cluster
- SHOW BINARY LOGS, SHOW BINARY LOGS Syntax
- SHOW BINLOG EVENTS, SHOW Syntax, SHOW BINLOG EVENTS Syntax
- SHOW CHARACTER SET, SHOW CHARACTER SET Syntax
- SHOW COLLATION, SHOW COLLATION Syntax
- SHOW COLUMNS, SHOW Syntax, SHOW COLUMNS Syntax
- SHOW command (MySQL Cluster), Commands in the MySQL Cluster Management Client
- SHOW CREATE DATABASE, SHOW Syntax, SHOW CREATE DATABASE Syntax
- SHOW CREATE FUNCTION, SHOW Syntax, SHOW CREATE PROCEDURE and SHOW CREATE FUNCTION Syntax
- SHOW CREATE PROCEDURE, SHOW Syntax, SHOW CREATE PROCEDURE and SHOW CREATE FUNCTION Syntax
- SHOW CREATE SCHEMA, SHOW Syntax, SHOW CREATE DATABASE Syntax
- SHOW CREATE TABLE, SHOW Syntax, SHOW CREATE TABLE Syntax
- SHOW CREATE VIEW, SHOW Syntax, SHOW CREATE VIEW Syntax
- SHOW DATABASES, SHOW Syntax, SHOW DATABASES Syntax
- SHOW ENGINE, SHOW Syntax, SHOW ENGINE Syntax
- used with MySQL Cluster, Quick Reference: MySQL Cluster SQL Statements
- SHOW ENGINE BDB LOGS, SHOW ENGINE Syntax
- SHOW ENGINE INNODB STATUS, SHOW ENGINE Syntax
- SHOW ENGINE NDB STATUS, SHOW ENGINE Syntax, Quick Reference: MySQL Cluster SQL Statements
- SHOW ENGINE NDBCLUSTER STATUS, Quick Reference: MySQL Cluster SQL Statements
- SHOW ENGINES, SHOW Syntax, SHOW ENGINES Syntax
- used with MySQL Cluster, Quick Reference: MySQL Cluster SQL Statements
- SHOW ERRORS, SHOW Syntax, SHOW ERRORS Syntax
- and MySQL Cluster, MySQL 5.0 FAQ — MySQL Cluster
- SHOW extensions, Extensions to SHOW Statements
- SHOW FIELDS, SHOW Syntax
- SHOW FUNCTION CODE, SHOW Syntax, SHOW PROCEDURE CODE and SHOW FUNCTION CODE Syntax
- SHOW FUNCTION STATUS, SHOW Syntax, SHOW PROCEDURE STATUS and SHOW FUNCTION STATUS Syntax
- SHOW GRANTS, SHOW Syntax, SHOW GRANTS Syntax
- SHOW INDEX, SHOW Syntax, SHOW INDEX Syntax
- SHOW INNODB STATUS, SHOW Syntax
- SHOW KEYS, SHOW Syntax, SHOW INDEX Syntax
- SHOW MASTER LOGS, SHOW Syntax, SHOW BINARY LOGS Syntax
- SHOW MASTER STATUS, SHOW Syntax, SHOW MASTER STATUS Syntax
- SHOW MUTEX STATUS, SHOW Syntax
- SHOW OPEN TABLES, SHOW Syntax, SHOW OPEN TABLES Syntax
- SHOW PRIVILEGES, SHOW Syntax, SHOW PRIVILEGES Syntax
- SHOW PROCEDURE CODE, SHOW Syntax, SHOW PROCEDURE CODE and SHOW FUNCTION CODE Syntax
- SHOW PROCEDURE STATUS, SHOW Syntax, SHOW PROCEDURE STATUS and SHOW FUNCTION STATUS Syntax
- SHOW PROCESSLIST, SHOW Syntax, SHOW PROCESSLIST Syntax
- SHOW PROFILE, SHOW Syntax, SHOW PROFILES and SHOW PROFILE Syntax
- SHOW PROFILES, SHOW Syntax, SHOW PROFILES and SHOW PROFILE Syntax
- SHOW SCHEMAS, SHOW Syntax, SHOW DATABASES Syntax
- SHOW SLAVE HOSTS, SHOW Syntax, SHOW SLAVE HOSTS Syntax
- SHOW SLAVE STATUS, SHOW Syntax, SHOW SLAVE STATUS Syntax
- SHOW STATUS, SHOW Syntax
- used with MySQL Cluster, Quick Reference: MySQL Cluster SQL Statements
- SHOW STORAGE ENGINES, SHOW ENGINES Syntax
- SHOW TABLE STATUS, SHOW Syntax
- SHOW TABLE TYPES, SHOW Syntax, SHOW ENGINES Syntax
- SHOW TABLES, SHOW Syntax, SHOW TABLES Syntax
- SHOW TRIGGERS, SHOW Syntax, SHOW TRIGGERS Syntax
- SHOW VARIABLES, SHOW Syntax
- used with MySQL Cluster, Quick Reference: MySQL Cluster SQL Statements
- SHOW WARNINGS, SHOW Syntax, SHOW WARNINGS Syntax
- and MySQL Cluster, MySQL 5.0 FAQ — MySQL Cluster
- SHOW with WHERE, The INFORMATION_SCHEMA Database, Extensions to SHOW Statements
- show-slave-auth-info option
- mysqld, Replication Startup Options
- show-table-type option
- show-warnings option
- mysql, mysql Options
- SHUTDOWN command (MySQL Cluster), Commands in the MySQL Cluster Management Client
- shutdown_timeout variable, mysqladmin — Client for Administering a MySQL Server
- shutting down
- the server, Unix Post-Installation Procedures
- sigint-ignore option
- mysql, mysql Options
- SIGN(), Mathematical Functions
- silent column changes, Silent Column Specification Changes
- silent option
- myisamchk, myisamchk General Options
- myisampack, myisampack — Generate Compressed, Read-Only MyISAM Tables
- mysql, mysql Options
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqld_multi, mysqld_multi — Manage Multiple MySQL Servers
- mysqlimport, mysqlimport — A Data Import Program
- perror, perror — Explain Error Codes
- resolveip, resolveip — Resolve Hostname to IP Address or Vice Versa
- SIN(), Mathematical Functions
- single quote (\'), Strings
- single user mode (MySQL Cluster), Commands in the MySQL Cluster Management Client, Single User Mode
- and ndb_restore, ndb_restore — Restore a Cluster Backup
- single-transaction option
- mysqldump, mysqldump — A Database Backup Program
- size of tables, The table is full
- sizes
- display, Data Types
- skip-bdb option
- mysqld, Command Options, BDB Startup Options
- skip-column-names option
- mysql, mysql Options
- skip-comments option
- mysqldump, mysqldump — A Database Backup Program
- skip-concurrent-insert option
- mysqld, Command Options
- skip-external-locking option
- mysqld, Command Options
- skip-grant-tables option
- skip-host-cache option
- mysqld, Command Options
- skip-innodb option
- mysqld, Command Options
- skip-line-numbers option
- mysql, mysql Options
- skip-merge option
- mysqld, Command Options
- skip-name-resolve option
- skip-ndbcluster option
- mysqld, Command Options
- skip-networking option
- skip-opt option
- mysqldump, mysqldump — A Database Backup Program
- skip-safemalloc option
- mysqld, Command Options
- skip-show-database option
- skip-slave-start option
- mysqld, Replication Startup Options
- skip-stack-trace option
- mysqld, Command Options
- skip-symbolic-links option
- mysqld, Command Options
- skip-thread-priority option
- mysqld, Command Options
- skip-use-db option
- mysql_find_rows, mysql_find_rows — Extract Queries from Update Log
- slave-load-tmpdir option
- mysqld, Replication Startup Options
- slave-net-timeout option
- mysqld, Replication Startup Options
- slave-skip-errors option
- mysqld, Replication Startup Options
- slave_compressed_protocol option
- mysqld, Replication Startup Options
- sleep option
- SLEEP(), Miscellaneous Functions
- slow queries, mysqladmin — Client for Administering a MySQL Server
- slow query log, The Slow Query Log
- SMALLINT data type, Overview of Numeric Types
- socket location
- changing, Typical configure Options
- socket option
- mysql, mysql Options
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- mysqlbinlog, mysqlbinlog — Utility for Processing Binary Log Files
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqld, Command Options
- mysqldump, mysqldump — A Database Backup Program
- mysqld_safe, mysqld_safe — MySQL Server Startup Script
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- mysqlimport, mysqlimport — A Data Import Program
- mysqlmanager, MySQL Instance Manager Command Options
- mysqlshow, mysqlshow — Display Database, Table, and Column Information
- mysql_explain_log, mysql_explain_log — Use EXPLAIN on Statements in Query Log
- mysql_setpermission, mysql_setpermission — Interactively Set Permissions in Grant Tables
- mysql_tableinfo, mysql_tableinfo — Generate Database Metadata
- Solaris
- installation, Installing MySQL on Solaris
- Solaris installation problems, Solaris Notes
- Solaris troubleshooting, Dealing with Problems Compiling MySQL
- Solaris x86_64 issues, InnoDB Performance Tuning Tips
- SOME, Subqueries with ANY, IN, and SOME
- sort-index option
- myisamchk, Other myisamchk Options
- sort-records option
- myisamchk, Other myisamchk Options
- sort-recover option
- myisamchk, myisamchk Repair Options
- sorting
- character sets, The Character Set Used for Data and Sorting
- data, Sorting Rows
- grant tables, Access Control, Stage 1: Connection Verification, Access Control, Stage 2: Request Verification
- table rows, Sorting Rows
- sort_buffer_size myisamchk variable, myisamchk General Options
- sort_key_blocks myisamchk variable, myisamchk General Options
- SOUNDEX(), String Functions
- SOUNDS LIKE, String Functions
- source (mysql client command), Using mysql in Batch Mode, Executing SQL Statements from a Text File
- source distribution
- installing, MySQL Installation Using a Source Distribution
- source distributions
- on Linux, Linux Source Distribution Notes
- SPACE(), String Functions
- spassword option
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- Spatial Extensions in MySQL, Introduction to MySQL Spatial Support
- speed
- compiling, How Compiling and Linking Affects the Speed of MySQL
- increasing with replication, Replication
- inserting, Speed of INSERT Statements
- linking, How Compiling and Linking Affects the Speed of MySQL
- of queries, Optimizing SELECT and Other Statements, Speed of SELECT Queries
- sporadic-binlog-dump-fail option
- mysqld, Command Options
- SQL
- defined, What is MySQL?
- SQL mode
- ONLY_FULL_GROUP_BY, GROUP BY and HAVING with Hidden Fields
- SQL node (MySQL Cluster)
- defined, Basic MySQL Cluster Concepts
- SQL nodes (MySQL Cluster), MySQL Server Process Usage for MySQL Cluster
- SQL statements
- replication masters, SQL Statements for Controlling Master Servers
- replication slaves, SQL Statements for Controlling Slave Servers
- SQL statements relating to MySQL Cluster, Quick Reference: MySQL Cluster SQL Statements
- SQL-92
- extensions to, MySQL Standards Compliance
- sql-mode option
- mysqld, Command Options
- SQL_BIG_RESULT, SELECT Syntax
- SQL_BUFFER_RESULT, SELECT Syntax
- SQL_CACHE, Query Cache SELECT Options, SELECT Syntax
- SQL_CALC_FOUND_ROWS, SELECT Syntax
- SQL_NO_CACHE, Query Cache SELECT Options, SELECT Syntax
- SQL_SMALL_RESULT, SELECT Syntax
- sql_yacc.cc problems, Dealing with Problems Compiling MySQL
- SQRT(), Mathematical Functions
- square brackets, Data Types
- SRID(), General Geometry Functions
- SSH, Connecting to MySQL Remotely from Windows with SSH
- SSL, Using SSL Connections
- SSL and X509 Basics, Using Secure Connections
- SSL command options, SSL Command Options
- ssl option, SSL Command Options
- SSL options
- mysql, mysql Options
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqld, Command Options, Making MySQL Secure Against Attackers
- mysqldump, mysqldump — A Database Backup Program
- mysqlimport, mysqlimport — A Data Import Program
- mysqlshow, mysqlshow — Display Database, Table, and Column Information
- SSL related options, GRANT Syntax
- ssl-ca option, SSL Command Options
- ssl-capath option, SSL Command Options
- ssl-cert option, SSL Command Options
- ssl-cipher option, SSL Command Options
- ssl-key option, SSL Command Options
- ssl-verify-server-cert option, SSL Command Options
- standalone option
- mysqld, Command Options
- mysqlmanager, MySQL Instance Manager Command Options
- Standard SQL
- differences from, MySQL Differences from Standard SQL, GRANT Syntax
- extensions to, MySQL Standards Compliance, MySQL Extensions to Standard SQL
- standards compatibility, MySQL Standards Compliance
- START
- XA transactions, XA Transaction SQL Syntax
- START BACKUP command (MySQL Cluster), Using The Management Client to Create a Backup
- START command (MySQL Cluster), Commands in the MySQL Cluster Management Client
- START SLAVE, START SLAVE Syntax
- START TRANSACTION, START TRANSACTION, COMMIT, and ROLLBACK Syntax
- start-datetime option
- start-position option
- StartFailureTimeout (MySQL Cluster configuration parameter), Defining Data Nodes
- starting
- comments, '--' as the Start of a Comment
- mysqld, How to Run MySQL as a Normal User
- the server, Unix Post-Installation Procedures
- the server automatically, Starting and Stopping MySQL Automatically
- Starting many servers, Running Multiple MySQL Servers on the Same Machine
- StartPartialTimeout, Defining Data Nodes
- StartPartitionedTimeout (MySQL Cluster configuration parameter), Defining Data Nodes
- StartPoint(), LineString Functions
- STARTUP Events (MySQL Cluster), Log Events
- startup options
- default, Using Option Files
- startup parameters, Tuning Server Parameters
- mysql, mysql Options
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- tuning, System Factors and Startup Parameter Tuning
- start_row option
- mysql_find_rows, mysql_find_rows — Extract Queries from Update Log
- statefile option
- statements
- GRANT, Adding New User Accounts to MySQL
- INSERT, Adding New User Accounts to MySQL
- replication masters, SQL Statements for Controlling Master Servers
- replication slaves, SQL Statements for Controlling Slave Servers
- statically
- compiling, Typical configure Options
- STATISTICS
- INFORMATION_SCHEMA table, The INFORMATION_SCHEMA STATISTICS Table
- STATISTICS Events (MySQL Cluster), Log Events
- stats option
- myisam_ftdump, myisam_ftdump — Display Full-Text Index information
- stats_method myisamchk variable, myisamchk General Options
- status
- tables, SHOW TABLE STATUS Syntax
- status command
- STATUS command (MySQL Cluster), Commands in the MySQL Cluster Management Client
- status option
- status variables, Status Variables, SHOW STATUS Syntax
- STD(), GROUP BY (Aggregate) Functions
- STDDEV(), GROUP BY (Aggregate) Functions
- STDDEV_POP(), GROUP BY (Aggregate) Functions
- STDDEV_SAMP(), GROUP BY (Aggregate) Functions
- STOP command (MySQL Cluster), Commands in the MySQL Cluster Management Client
- STOP SLAVE, STOP SLAVE Syntax
- stop-datetime option
- stop-position option
- StopOnError, Defining Data Nodes
- stopping
- the server, Starting and Stopping MySQL Automatically
- stopword list
- user-defined, Fine-Tuning MySQL Full-Text Search
- storage engine
- ARCHIVE, The ARCHIVE Storage Engine
- storage engines
- choosing, Storage Engines
- storage of data, Design Choices
- storage requirements
- data type, Data Type Storage Requirements
- storage space
- minimizing, Make Your Data as Small as Possible
- stored procedures, Stored Procedures and Functions
- stored procedures and triggers
- defined, Stored Routines and Triggers
- stored routine restrictions, Restrictions on Stored Routines and Triggers
- stored routines
- LAST_INSERT_ID(), Stored Procedures, Functions, Triggers, and LAST_INSERT_ID()
- STRAIGHT_JOIN, SELECT Syntax, JOIN Syntax
- STRCMP(), String Comparison Functions
- STRICT SQL mode, SQL Modes
- STRICT_ALL_TABLES SQL mode, SQL Modes
- STRICT_TRANS_TABLES SQL mode, SQL Modes
- string collating, String Collating Support
- string comparison functions, String Comparison Functions
- string comparisons
- case sensitivity, String Comparison Functions
- string functions, String Functions
- string literal introducer, Strings, Character String Literal Character Set and Collation
- string types, String Types
- StringMemory, Defining Data Nodes
- strings
- defined, Literal Values
- escaping characters, Literal Values
- non-delimited, The DATETIME, DATE, and TIMESTAMP Types
- striping
- defined, Disk Issues
- STR_TO_DATE(), Date and Time Functions
- SUBDATE(), Date and Time Functions
- subqueries, Subquery Syntax
- correlated, Correlated Subqueries
- errors, Subquery Errors
- rewriting as joins, Rewriting Subqueries as Joins for Earlier MySQL Versions
- with ALL, Subqueries with ALL
- with ANY, IN, SOME, Subqueries with ANY, IN, and SOME
- with EXISTS, EXISTS and NOT EXISTS
- with NOT EXISTS, EXISTS and NOT EXISTS
- with ROW, Row Subqueries
- subquery, Subquery Syntax
- subquery optimization, Optimizing IN/=ANY Subqueries
- subquery restrictions, Restrictions on Subqueries
- subselects, Subquery Syntax
- SUBSTR(), String Functions
- SUBSTRING(), String Functions
- SUBSTRING_INDEX(), String Functions
- SUBTIME(), Date and Time Functions
- subtraction (-), Arithmetic Operators
- suffix option
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- SUM(), GROUP BY (Aggregate) Functions
- SUM(DISTINCT), GROUP BY (Aggregate) Functions
- superuser, Securing the Initial MySQL Accounts
- superuser option
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- support
- for operating systems, Operating Systems Supported by MySQL Community Server
- suppression
- default values, Constraints on Invalid Data
- Sybase compatibility, USE Syntax
- symbolic links, Using Symbolic Links, Using Symbolic Links for Databases on Windows
- symbolic-links option
- mysqld, Command Options
- symbols-file option
- resolve_stack_dump, resolve_stack_dump — Resolve Numeric Stack Trace Dump to Symbols
- SymDifference(), Spatial Operators
- sync-bdb-logs option
- mysqld, BDB Startup Options
- syntax
- regular expression, Regular Expressions
- SYSDATE(), Date and Time Functions
- sysdate-is-now option
- mysqld, Command Options
- system
- privilege, What the Privilege System Does
- security, General Security Issues
- system optimization, System Factors and Startup Parameter Tuning
- system table, Optimizing Queries with EXPLAIN
- system variables, System Variables, Using System Variables, SHOW VARIABLES Syntax
- SYSTEM_USER(), Information Functions
T
- tab (\t), Strings
- tab option
- mysqldump, mysqldump — A Database Backup Program
- table
- changing, ALTER TABLE Syntax, Problems with ALTER TABLE
- deleting, DROP TABLE Syntax
- table aliases, SELECT Syntax
- table cache, How MySQL Opens and Closes Tables
- table is full, SET Syntax, The table is full
- Table is full error
- MySQL Cluster, MySQL 5.0 FAQ — MySQL Cluster
- table names
- case sensitivity, Identifier Case Sensitivity
- case-sensitivity, MySQL Extensions to Standard SQL
- table option
- mysql, mysql Options
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- table scans
- avoiding, How to Avoid Table Scans
- table types
- choosing, Storage Engines
- table-level locking, Internal Locking Methods
- tables
- BDB, The BDB (BerkeleyDB) Storage Engine
- Berkeley DB, The BDB (BerkeleyDB) Storage Engine
- BLACKHOLE, The BLACKHOLE Storage Engine
- changing column order, How to Change the Order of Columns in a Table
- checking, myisamchk Check Options
- closing, How MySQL Opens and Closes Tables
- compressed format, Compressed Table Characteristics
- constant, Optimizing Queries with EXPLAIN, WHERE Clause Optimization
- copying, CREATE TABLE Syntax
- counting rows, Counting Rows
- creating, Creating a Table
- CSV, The CSV Storage Engine
- defragment, Dynamic Table Characteristics
- defragmenting, Setting Up a Table Maintenance Schedule, OPTIMIZE TABLE Syntax
- deleting rows, Deleting Rows from Related Tables
- displaying status, SHOW TABLE STATUS Syntax
- dynamic, Dynamic Table Characteristics
- error checking, How to Check MyISAM Tables for Errors
- EXAMPLE, The EXAMPLE Storage Engine
- FEDERATED, The FEDERATED Storage Engine
- flush, mysqladmin — Client for Administering a MySQL Server
- fragmentation, OPTIMIZE TABLE Syntax
- grant, Access Control, Stage 2: Request Verification
- HEAP, The MEMORY (HEAP) Storage Engine
- host, Access Control, Stage 2: Request Verification
- improving performance, Make Your Data as Small as Possible
- information, Getting Information About a Table
- information about, Getting Information About Databases and Tables
- InnoDB, The InnoDB Storage Engine
- loading data, Loading Data into a Table
- maintenance schedule, Setting Up a Table Maintenance Schedule
- maximum size, The table is full
- MEMORY, The MEMORY (HEAP) Storage Engine
- MERGE, The MERGE Storage Engine
- merging, The MERGE Storage Engine
- multiple, Using More Than one Table
- MyISAM, The MyISAM Storage Engine
- names, Database, Table, Index, Column, and Alias Names
- open, How MySQL Opens and Closes Tables
- opening, How MySQL Opens and Closes Tables
- optimizing, Table Optimization
- partitioning, The MERGE Storage Engine
- repairing, How to Repair Tables
- retrieving data, Retrieving Information from a Table
- selecting columns, Selecting Particular Columns
- selecting rows, Selecting Particular Rows
- sorting rows, Sorting Rows
- symbolic links, Using Symbolic Links for Tables on Unix
- system, Optimizing Queries with EXPLAIN
- too many, Drawbacks to Creating Many Tables in the Same Database
- unique ID for last row, How to Get the Unique ID for the Last Inserted Row
- updating, Transactions and Atomic Operations
- TABLES
- INFORMATION_SCHEMA table, The INFORMATION_SCHEMA TABLES Table
- tables option
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqldump, mysqldump — A Database Backup Program
- table_cache, How MySQL Opens and Closes Tables
- TABLE_PRIVILEGES
- INFORMATION_SCHEMA table, The INFORMATION_SCHEMA TABLE_PRIVILEGES Table
- TAN(), Mathematical Functions
- tar
- problems on Solaris, Installing MySQL on Solaris, Solaris Notes
- tbl-status option
- mysql_tableinfo, mysql_tableinfo — Generate Database Metadata
- tc-heuristic-recover option
- mysqld, Command Options
- Tcl API, MySQL Tcl API
- tcp-ip option
- mysqld_multi, mysqld_multi — Manage Multiple MySQL Servers
- TCP/IP, Selecting a MySQL Server Type, Testing The MySQL Installation
- tee option
- mysql, mysql Options
- temp-pool option
- mysqld, Command Options
- temporary file
- write access, Problems Running mysql_install_db
- temporary tables
- internal, How MySQL Uses Internal Temporary Tables
- problems, TEMPORARY TABLE Problems
- terminal monitor
- defined, Tutorial
- test option
- testing
- connection to the server, Access Control, Stage 1: Connection Verification
- installation, Unix Post-Installation Procedures
- of MySQL releases, Choosing Which Version of MySQL to Install
- post-installation, Post-Installation Setup and Testing
- testing mysqld
- mysqltest, MySQL Test Suite
- TEXT
- TEXT columns
- default values, The BLOB and TEXT Types
- indexing, Column Indexes, CREATE TABLE Syntax
- TEXT data type, Overview of String Types, The BLOB and TEXT Types
- text files
- importing, Executing SQL Statements from a Text File
- thread support, Operating Systems Supported by MySQL Community Server
- non-native, MIT-pthreads Notes
- threaded clients, How to Make a Threaded Client
- threads, mysqladmin — Client for Administering a MySQL Server, SHOW PROCESSLIST Syntax, MySQL Internals
- display, SHOW PROCESSLIST Syntax
- TIME data type, Overview of Date and Time Types, The TIME Type
- time types, Data Type Storage Requirements
- time zone problems, Time Zone Problems
- TIME(), Date and Time Functions
- TimeBetweenGlobalCheckpoints (MySQL Cluster configuration parameter), Defining Data Nodes
- TimeBetweenInactiveTransactionAbortCheck (MySQL Cluster configuration parameter), Defining Data Nodes
- TimeBetweenLocalCheckpoints (MySQL Cluster configuration parameter), Defining Data Nodes
- TimeBetweenWatchDogCheck, Defining Data Nodes
- TIMEDIFF(), Date and Time Functions
- timeout, System Variables, Miscellaneous Functions, INSERT DELAYED Syntax
- connect_timeout variable, mysql Options, mysqladmin — Client for Administering a MySQL Server
- shutdown_timeout variable, mysqladmin — Client for Administering a MySQL Server
- timeout option
- TIMESTAMP
- and NULL values, Problems with NULL Values
- TIMESTAMP data type, Overview of Date and Time Types, The DATETIME, DATE, and TIMESTAMP Types
- TIMESTAMP(), Date and Time Functions
- TIMESTAMPADD(), Date and Time Functions
- TIMESTAMPDIFF(), Date and Time Functions
- timezone option
- mysqld_safe, mysqld_safe — MySQL Server Startup Script
- TIME_FORMAT(), Date and Time Functions
- TIME_TO_SEC(), Date and Time Functions
- TINYBLOB data type, Overview of String Types
- TINYINT data type, Overview of Numeric Types
- TINYTEXT data type, Overview of String Types
- tips
- optimization, Other Optimization Tips
- TMPDIR environment variable, Problems Running mysql_install_db, Environment Variables
- tmpdir option
- myisamchk, myisamchk Repair Options
- myisampack, myisampack — Generate Compressed, Read-Only MyISAM Tables
- mysqld, Command Options
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- to-last-log option
- TODO
- symlinks, Using Symbolic Links for Tables on Unix
- tools
- list of, Tools that were used to create MySQL
- Touches(), Functions That Test Spatial Relationships Between Geometries
- TO_DAYS(), Date and Time Functions
- trace files (MySQL Cluster), ndbd — The Storage Engine Node Process
- TRADITIONAL SQL mode, SQL Modes
- transaction-isolation option
- mysqld, Command Options
- transaction-safe tables, Transactions and Atomic Operations, InnoDB Overview
- transactional option
- ndb_delete_all, ndb_delete_all — Delete All Rows from NDB Table
- TransactionBufferMemory, Defining Data Nodes
- TransactionDeadlockDetectionTimeout (MySQL Cluster configuration parameter), Defining Data Nodes
- TransactionInactiveTimeout (MySQL Cluster configuration parameter), Defining Data Nodes
- transactions
- Translators
- list of, Documenters and translators
- trigger restrictions, Restrictions on Stored Routines and Triggers
- trigger, creating, CREATE TRIGGER Syntax
- trigger, dropping, DROP TRIGGER Syntax
- triggers, Stored Routines and Triggers, SHOW TRIGGERS Syntax, Triggers
- LAST_INSERT_ID(), Stored Procedures, Functions, Triggers, and LAST_INSERT_ID()
- TRIGGERS
- INFORMATION_SCHEMA table, The INFORMATION_SCHEMA TRIGGERS Table
- triggers option
- mysqldump, mysqldump — A Database Backup Program
- TRIM(), String Functions
- troubleshooting
- TRUE, Numbers, Boolean Values
- testing for, Comparison Functions and Operators
- TRUNCATE, TRUNCATE Syntax
- and MySQL Cluster, Limits and Differences from Standard MySQL Limits
- TRUNCATE(), Mathematical Functions
- tupscan option
- ndb_select_all, ndb_select_all — Print Rows from NDB Table
- tutorial, Tutorial
- Twin Studies
- queries, Queries from the Twin Project
- type conversions, Type Conversion in Expression Evaluation, Comparison Functions and Operators
- type option
- ndb_config, ndb_config — Extract NDB Configuration Information
- ndb_show_tables, ndb_show_tables — Display List of NDB Tables
- types
- column, Data Types
- columns, Choosing the Right Type for a Column
- data, Data Types
- date, Data Type Storage Requirements
- Date and Time, Date and Time Types
- numeric, Data Type Storage Requirements
- of tables, Storage Engines
- portability, Using Data Types from Other Database Engines
- strings, String Types
- time, Data Type Storage Requirements
- typographical conventions, Conventions Used in This Manual
- TZ environment variable, Environment Variables, Time Zone Problems
- tz-utc option
- mysqldump, mysqldump — A Database Backup Program
U
- UCASE(), String Functions
- UCS-2, Character Set Support
- UDFs, CREATE FUNCTION Syntax, DROP FUNCTION Syntax
- compiling, Compiling and Installing User-Defined Functions
- defined, Adding New Functions to MySQL
- return values, UDF Return Values and Error Handling
- ulimit, 'File' Not Found and Similar Errors
- UMASK environment variable, Environment Variables, Problems with File Permissions
- UMASK_DIR environment variable, Environment Variables, Problems with File Permissions
- unary minus (-), Arithmetic Operators
- unbuffered option
- mysql, mysql Options
- UNCOMPRESS(), Encryption and Compression Functions
- UNCOMPRESSED_LENGTH(), Encryption and Compression Functions
- UndoDataBuffer, Defining Data Nodes
- UndoIndexBuffer, Defining Data Nodes
- UNHEX(), String Functions
- Unicode, Character Set Support
- Unicode Collation Algorithm, Unicode Character Sets
- UNION, Searching on Two Keys, UNION Syntax
- Union(), Spatial Operators
- UNIQUE, ALTER TABLE Syntax
- constraint, PRIMARY KEY and UNIQUE Index Constraints
- unique ID, How to Get the Unique ID for the Last Inserted Row
- Unix, MySQL Connector/ODBC, MySQL Connector/NET
- UNIX_TIMESTAMP(), Date and Time Functions
- UNKNOWN
- testing for, Comparison Functions and Operators
- unloading
- UNLOCK TABLES, LOCK TABLES and UNLOCK TABLES Syntax
- unnamed views, Subqueries in the FROM clause
- unpack option
- myisamchk, myisamchk Repair Options
- unqualified option
- ndb_show_tables, ndb_show_tables — Display List of NDB Tables
- UNTIL, REPEAT Statement
- UPDATE, UPDATE Syntax
- update-state option
- myisamchk, myisamchk Check Options
- updating
- releases of MySQL, How and When Updates Are Released
- tables, Transactions and Atomic Operations
- upgrades
- upgrades and downgrades (MySQL Cluster)
- compatibility between versions, Cluster Upgrade and Downgrade Compatibility
- upgrading, Upgrading MySQL
- different architecture, Copying MySQL Databases to Another Machine
- to 5.0, Upgrading from MySQL 4.1 to 5.0
- upgrading tables
- UPPER(), String Functions
- uptime, mysqladmin — Client for Administering a MySQL Server
- URLs for downloading MySQL, How to Get MySQL
- usage option
- USE, USE Syntax
- USE INDEX, Index Hint Syntax
- USE KEY, Index Hint Syntax
- use-frm option
- useHexFormat option
- ndb_select_all, ndb_select_all — Print Rows from NDB Table
- user accounts
- creating, CREATE USER Syntax
- renaming, RENAME USER Syntax
- USER environment variable, Environment Variables, Connecting to the MySQL Server
- user option
- mysql, mysql Options
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- mysqlbinlog, mysqlbinlog — Utility for Processing Binary Log Files
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqld, Command Options
- mysqldump, mysqldump — A Database Backup Program
- mysqld_multi, mysqld_multi — Manage Multiple MySQL Servers
- mysqld_safe, mysqld_safe — MySQL Server Startup Script
- mysqlhotcopy, mysqlhotcopy — A Database Backup Program
- mysqlimport, mysqlimport — A Data Import Program
- mysqlmanager, MySQL Instance Manager Command Options
- mysqlshow, mysqlshow — Display Database, Table, and Column Information
- mysql_explain_log, mysql_explain_log — Use EXPLAIN on Statements in Query Log
- mysql_setpermission, mysql_setpermission — Interactively Set Permissions in Grant Tables
- mysql_tableinfo, mysql_tableinfo — Generate Database Metadata
- mysql_upgrade, mysql_upgrade — Check Tables for MySQL Upgrade
- user privileges
- user table
- user variables, User-Defined Variables
- USER(), Information Functions
- user-defined functions
- User-defined functions, CREATE FUNCTION Syntax, DROP FUNCTION Syntax
- usernames
- and passwords, MySQL Usernames and Passwords
- users
- USER_PRIVILEGES
- INFORMATION_SCHEMA table, The INFORMATION_SCHEMA USER_PRIVILEGES Table
- uses
- of MySQL, What We Have Used MySQL For
- using multiple disks to start data, Using Symbolic Links for Databases on Windows
- UTC_DATE(), Date and Time Functions
- UTC_TIME(), Date and Time Functions
- UTC_TIMESTAMP(), Date and Time Functions
- UTF-8, Character Set Support
- utility programs, Overview of Client and Utility Programs
- UUID(), Miscellaneous Functions
V
- valid numbers
- examples, Numbers
- VALUES(), Miscellaneous Functions
- VARBINARY data type, Overview of String Types, The BINARY and VARBINARY Types
- VARCHAR
- VARCHAR data type, Overview of String Types, String Types
- VARCHARACTER data type, Overview of String Types
- variables
- mysqld, Tuning Server Parameters
- server, System Variables, SHOW VARIABLES Syntax
- status, Status Variables, SHOW STATUS Syntax
- system, System Variables, Using System Variables, SHOW VARIABLES Syntax
- user, User-Defined Variables
- VARIANCE(), GROUP BY (Aggregate) Functions
- VAR_POP(), GROUP BY (Aggregate) Functions
- VAR_SAMP(), GROUP BY (Aggregate) Functions
- verbose option
- myisamchk, myisamchk General Options
- myisampack, myisampack — Generate Compressed, Read-Only MyISAM Tables
- myisam_ftdump, myisam_ftdump — Display Full-Text Index information
- mysql, mysql Options
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqldump, mysqldump — A Database Backup Program
- mysqld_multi, mysqld_multi — Manage Multiple MySQL Servers
- mysqlimport, mysqlimport — A Data Import Program
- mysqlshow, mysqlshow — Display Database, Table, and Column Information
- mysql_upgrade, mysql_upgrade — Check Tables for MySQL Upgrade
- mysql_waitpid, mysql_waitpid — Kill Process and Wait for Its Termination
- my_print_defaults, my_print_defaults — Display Options from Option Files
- perror, perror — Explain Error Codes
- version
- choosing, Choosing Which MySQL Distribution to Install
- latest, How to Get MySQL
- version option
- comp_err, comp_err — Compile MySQL Error Message File
- myisamchk, myisamchk General Options
- myisampack, myisampack — Generate Compressed, Read-Only MyISAM Tables
- mysql, mysql Options
- mysqlaccess, mysqlaccess — Client for Checking Access Privileges
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- mysqlbinlog, mysqlbinlog — Utility for Processing Binary Log Files
- mysqlcheck, mysqlcheck — A Table Maintenance and Repair Program
- mysqld, Command Options
- mysqldump, mysqldump — A Database Backup Program
- mysqld_multi, mysqld_multi — Manage Multiple MySQL Servers
- mysqlimport, mysqlimport — A Data Import Program
- mysqlmanager, MySQL Instance Manager Command Options
- mysqlshow, mysqlshow — Display Database, Table, and Column Information
- mysql_waitpid, mysql_waitpid — Kill Process and Wait for Its Termination
- my_print_defaults, my_print_defaults — Display Options from Option Files
- ndb_config, ndb_config — Extract NDB Configuration Information
- perror, perror — Explain Error Codes
- resolveip, resolveip — Resolve Hostname to IP Address or Vice Versa
- resolve_stack_dump, resolve_stack_dump — Resolve Numeric Stack Trace Dump to Symbols
- VERSION(), Information Functions
- vertical option
- mysql, mysql Options
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- Vietnamese, MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets
- view restrictions, Restrictions on Views
- views, Views, Views, CREATE VIEW Syntax
- updatable, Views, CREATE VIEW Syntax
- VIEWS
- INFORMATION_SCHEMA table, The INFORMATION_SCHEMA VIEWS Table
- Views
- limitations, Restrictions on Views
- privileges, Restrictions on Views
- problems, Restrictions on Views
- virtual memory
- problems while compiling, Dealing with Problems Compiling MySQL
- Vision, Using Connector/ODBC with SunSystems Vision
- Visual Objects, Visual Objects
- Visual Studio, Building MySQL from Source Using CMake and Visual Studio
- Visual Studio Plugin, Connectors
W
- wait option
- myisamchk, myisamchk General Options
- myisampack, myisampack — Generate Compressed, Read-Only MyISAM Tables
- mysql, mysql Options
- mysqladmin, mysqladmin — Client for Administering a MySQL Server
- wait-timeout option
- mysqlmanager, MySQL Instance Manager Command Options
- WEEK(), Date and Time Functions
- WEEKDAY(), Date and Time Functions
- WEEKOFYEAR(), Date and Time Functions
- Well-Known Binary format, Well-Known Binary (WKB) Format
- Well-Known Text format, Well-Known Text (WKT) Format
- WHERE, WHERE Clause Optimization
- where option
- mysqldump, mysqldump — A Database Backup Program
- WHILE, WHILE Statement
- widths
- display, Data Types
- Wildcard character (%), Strings
- Wildcard character (_), Strings
- wildcards
- and LIKE, How MySQL Uses Indexes
- in mysql.columns_priv table, Access Control, Stage 2: Request Verification
- in mysql.db table, Access Control, Stage 2: Request Verification
- in mysql.host table, Access Control, Stage 2: Request Verification
- in mysql.procs_priv table, Access Control, Stage 2: Request Verification
- in mysql.tables_priv table, Access Control, Stage 2: Request Verification
- in mysql.user table, Access Control, Stage 1: Connection Verification
- Windows, MySQL Connector/ODBC, MySQL Connector/NET
- compiling on, Compiling MySQL Clients on Windows
- open issues, MySQL on Windows Compared to MySQL on Unix
- upgrading, Upgrading MySQL on Windows
- versus Unix, MySQL on Windows Compared to MySQL on Unix
- with-big-tables option, Typical configure Options
- configure, Typical configure Options
- with-debug option
- configure, Typical configure Options
- with-embedded-server option
- configure, Typical configure Options
- with-extra-charsets option
- configure, Typical configure Options
- with-unix-socket-path option
- configure, Typical configure Options
- Within(), Functions That Test Spatial Relationships Between Geometries
- without-server option, Typical configure Options
- configure, Typical configure Options
- WKB format, Well-Known Binary (WKB) Format
- WKT format, Well-Known Text (WKT) Format
- wrappers
- Eiffel, MySQL Eiffel Wrapper
- write access
- write_buffer_size myisamchk variable, myisamchk General Options
X
- X(), Point Functions
- X509/Certificate, Basic SSL Concepts
- XA BEGIN, XA Transaction SQL Syntax
- XA COMMIT, XA Transaction SQL Syntax
- XA PREPARE, XA Transaction SQL Syntax
- XA RECOVER, XA Transaction SQL Syntax
- XA ROLLBACK, XA Transaction SQL Syntax
- XA START, XA Transaction SQL Syntax
- XA transactions, XA Transactions
- transaction identifiers, XA Transaction SQL Syntax
- xid
- XA transaction identifier, XA Transaction SQL Syntax
- xml option
- mysql, mysql Options
- mysqldump, mysqldump — A Database Backup Program
- XOR
- bitwise, Bit Functions
- logical, Logical Operators
Y
- Y(), Point Functions
- yaSSL, Using Secure Connections, Using SSL Connections
- Year 2000 compliance, Year 2000 Issues and Date Types
- Year 2000 issues, Year 2000 Issues and Date Types
- YEAR data type, Overview of Date and Time Types, The YEAR Type
- YEAR(), Date and Time Functions
- YEARWEEK(), Date and Time Functions
- Yen sign (Japanese), MySQL 5.0 FAQ — MySQL Chinese, Japanese, and Korean Character Sets